CN111459994A - A method and system for analyzing big data for disabled people - Google Patents
A method and system for analyzing big data for disabled people Download PDFInfo
- Publication number
- CN111459994A CN111459994A CN202010149602.9A CN202010149602A CN111459994A CN 111459994 A CN111459994 A CN 111459994A CN 202010149602 A CN202010149602 A CN 202010149602A CN 111459994 A CN111459994 A CN 111459994A
- Authority
- CN
- China
- Prior art keywords
- attribute
- data
- matrix
- attributes
- judgment
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2458—Special types of queries, e.g. statistical queries, fuzzy queries or distributed queries
- G06F16/2465—Query processing support for facilitating data mining operations in structured databases
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/248—Presentation of query results
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2216/00—Indexing scheme relating to additional aspects of information retrieval not explicitly covered by G06F16/00 and subgroups
- G06F2216/03—Data mining
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Computational Linguistics (AREA)
- Fuzzy Systems (AREA)
- Mathematical Physics (AREA)
- Probability & Statistics with Applications (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明提供一种面向残疾人大数据的分析方法,包括:对残疾人大数据对应数据集进行属性分解,将所有选择属性按照其选项分解为多个断属性,并将连续属性离散化;然后基于分解后的判断属性采用独热编码表示每一条数据,在每条编码中每个判断属性对应一个属性值,其中,判断属性对应的选项被选中的属性值为1,反之为0,将数据集中所有数据转换成独热编码形成数据集矩阵;基于数据集矩阵,为数据集矩阵中属性值为1的判断属性生成规则集合;对数据集矩阵进行回归分析,依次以一个判断属性作为目标属性,基于关联规则集合,计算数据集中其他属性对该目标属性影响力的权重,所有其他属性对目标属性影响力的权重形成该目标属性的权重集合。

The invention provides an analysis method for disabled big data, which includes: decomposing attributes of a dataset corresponding to the disabled big data, decomposing all selected attributes into a plurality of broken attributes according to their options, and discretizing continuous attributes; and then based on the decomposition The latter judgment attribute uses one-hot encoding to represent each piece of data. In each code, each judgment attribute corresponds to an attribute value. Among them, the selected attribute value of the option corresponding to the judgment attribute is 1. Otherwise, it is 0. The data is converted into one-hot encoding to form a data set matrix; based on the data set matrix, a rule set is generated for the judgment attribute whose attribute value is 1 in the data set matrix; A set of association rules, which calculates the weight of the influence of other attributes in the dataset on the target attribute, and the weights of the influence of all other attributes on the target attribute form the weight set of the target attribute.
Description
技术领域technical field
本发明涉及数据挖掘领域,具体来说涉及大数据智能回归分析领域,更具体地说,涉及一种面向残疾人大数据的分析方法及系统。The invention relates to the field of data mining, in particular to the field of intelligent regression analysis of big data, and more particularly, to a method and system for analyzing big data for disabled persons.
背景技术Background technique
残疾人基础大数据是一种政府资助的调查统计数据集,旨在调查和登记全国残疾人当前的经济状况、就业扶贫情况、无障碍社区服务和教育情况以及个人主体的基本信息,这些登记信息每年由非营利专业机构(如残联)进行更新。实施登记调查的过程包括:设计带有一系列系统问题的残疾人登记或调查表格;将表格分发给基层社区;基层社区组织残疾人填报;将调查反馈验证并整合为表格数据集;将数据集发布。由于残疾人基础大数据通常具有很大的行业效应,并且由政府资助,因此被认为是政府和社会组织从业者制定数据驱动政策的权威来源之一。也就是说,通过对残疾人数据集的分析,政府和社会组织的从业人员可以更好地了解残疾人群体的现状和需求,从而制定相应的合理政策。The Basic Big Data of Disabled Persons is a government-funded survey and statistical data set, which aims to investigate and register the current economic status, employment and poverty alleviation, accessible community services and education of disabled persons across the country, as well as basic information on individual subjects. These registered information It is updated annually by non-profit professional organizations (such as the Disabled Persons' Federation). The process of implementing a registration survey includes: designing a disability registration or survey form with a series of systematic questions; distributing the form to grass-roots communities; grass-roots communities organizing disability reporting; validating and integrating survey feedback into a data set of forms; publishing the data set . Because the basic big data of disabled people usually has great industry effect and is funded by the government, it is considered as one of the authoritative sources for government and social organization practitioners to formulate data-driven policies. That is to say, through the analysis of the disabled data set, the practitioners of the government and social organizations can better understand the current situation and needs of the disabled group, so as to formulate corresponding reasonable policies.
数据回归分析旨在发现影响目标属性值变化的一系列其他属性,并对这些属性的影响力进行量化。通过属性值对演变性进行针对性描述,数据回归分析可以得知哪些属性会对目标属性产生正向或负向影响,且这些属性中哪些属性具有更大的影响力。Data regression analysis aims to discover a range of other attributes that influence changes in the value of the target attribute, and to quantify the impact of these attributes. Through the attribute value to describe the evolution in a targeted manner, data regression analysis can know which attributes will have a positive or negative impact on the target attribute, and which of these attributes have a greater influence.
对残疾人大数据的回归分析研究包括经典的社会学研究方法和目前流行的数据挖掘分析方法:Regression analysis research on disabled big data includes classic sociological research methods and currently popular data mining analysis methods:
经典方法将专家知识与统计学相结合。一般来说,这些方法根据专家知识和随机推断来确定每次分析的变量输入,然后使用统计算法进行分析。经典方法都有一些固有的缺陷,一方面经典方法的研究是费时费力的,需要很多专家帮助研究人员基于其知识和推论创建模型,另一方面经典方法生成的结果简单且有限,对大规模数据很难取得良好的分析结果。Classical methods combine expert knowledge with statistics. In general, these methods determine the variable inputs for each analysis based on expert knowledge and random inference, which are then analyzed using statistical algorithms. Classical methods have some inherent defects. On the one hand, the research of classical methods is time-consuming and labor-intensive, requiring many experts to help researchers create models based on their knowledge and inferences. On the other hand, the results generated by classical methods are simple and limited. It is difficult to obtain good analytical results.
数据挖掘方法普遍采用基于模型的算法。对于回归分析,大多数模型(如神经网络)是黑盒子模式,结果可解释性不强,出现问题时无法追溯。对于可解释的模型(如线性回归),分析精度一般无法保证,例如线性回归模型假设目标值y和属性x=(x1,x2,...,xn)之间的关系是线性的,目标值计算为y=α0+α1x1+α2x2+…+αnxn,其中,α0是除属性x以外影响变量y的所有其他因素的误差项。线性回归模型假设属性之间是相互独立的,不考虑属性之间的相互关联和作用,且要求属性尽量为连续值。然而残疾人大数据是一种基于调查问卷的数据集,往往会出现一些被调查者漏填的属性项,数据属性一般包含有判断题和选择题两种形式,这两种属性均是离散的,且部分属性相互关联、相互作用。此外,对于具有M个选项的选择属性,数据挖掘中普遍采用独热(one-hot)编码模式将选择属性分解为M个判断属性,每个判断属性对应选择属性的某个选项,显然这M个判断属性也是相互关联的(M个判断属性有且只有一个为1)。因次,残疾人大数据包含大量相互关联的离散数据属性,不适合采用线性回归模型进行回归分析。Data mining methods generally use model-based algorithms. For regression analysis, most models (such as neural networks) are black box models, and the results are not very interpretable and cannot be traced back when something goes wrong. For interpretable models (such as linear regression), the analytical accuracy is generally not guaranteed. For example, linear regression models assume that the relationship between the target value y and the attribute x = (x 1 , x 2 , ..., x n ) is linear , the target value is calculated as y = α 0 +α 1 x 1 +α 2 x 2 +...+α n x n , where α 0 is the error term for all other factors affecting variable y except attribute x. The linear regression model assumes that the attributes are independent of each other, does not consider the correlation and role between the attributes, and requires the attributes to be as continuous as possible. However, the disabled big data is a data set based on a questionnaire, and there are often some attribute items that are missed by the respondents. The data attributes generally include two forms of true and false questions and multiple choice questions, both of which are discrete. And some attributes are interrelated and interact with each other. In addition, for the selection attribute with M options, the one-hot encoding mode is generally used in data mining to decompose the selection attribute into M judgment attributes, each judgment attribute corresponds to an option of the selection attribute, obviously this M The judgment attributes are also interrelated (M judgment attributes have and only one is 1). Therefore, the big data of disabled persons contains a large number of interrelated discrete data attributes, which is not suitable for regression analysis by using a linear regression model.
发明内容SUMMARY OF THE INVENTION
因此,本发明的目的在于克服上述现有技术的缺陷,提供一种新的残疾人大数据分析方法,实现数据关联性分析和回归分析,挖掘数据内在联系。Therefore, the purpose of the present invention is to overcome the above-mentioned defects of the prior art, and to provide a new method for analyzing big data of disabled persons, to realize data correlation analysis and regression analysis, and to mine the internal connection of data.
根据本发明的第一方面,本发明提供一种面向残疾人大数据的数据分析方法,包括如下步骤:According to a first aspect of the present invention, the present invention provides a data analysis method for disabled big data, comprising the following steps:
S1、对残疾人大数据对应数据集进行属性分解,将所有选择属性按照其选项分解为多个判断属性,并将连续属性离散化;然后基于分解后的判断属性采用独热编码表示每一条数据,在每条编码中每个判断属性对应一个属性值,其中,判断属性对应的选项被选中的属性值为1,反之为0,将数据集中所有数据转换成独热编码形成数据集矩阵;其中,采用数据分段的方式将连续属性离散化。S1. Decompose the attributes of the dataset corresponding to the disabled big data, decompose all selected attributes into multiple judgment attributes according to their options, and discretize the continuous attributes; then use one-hot encoding to represent each piece of data based on the decomposed judgment attributes. In each code, each judgment attribute corresponds to an attribute value, wherein the attribute value of the selected option corresponding to the judgment attribute is 1, otherwise it is 0, and all data in the data set is converted into one-hot encoding to form a data set matrix; among them, The continuous attributes are discretized by means of data segmentation.
S2、基于数据集矩阵,为数据集矩阵中属性值为1的判断属性生成规则集合,其中,每个判断属性与其他属性之间生成一条规则,优选的,包括:S2. Based on the data set matrix, a rule set is generated for the judgment attribute with the attribute value of 1 in the data set matrix, wherein a rule is generated between each judgment attribute and other attributes, preferably, including:
S21、以一个判断属性为分析对象,以数据集中该判断属性的属性值为1的所有数据组成该分析对象的数据样本矩阵;S21, take a judgment attribute as an analysis object, and form a data sample matrix of the analysis object with all the data in the data set whose attribute value of the judgment attribute is 1;
S22、对数据样本矩阵中属性值为1的判断属性按照出现频率进行排序,并通过支持度进行量化,其中,分别计算数据样本中分析对象以外的每个判断属性在该数据样本矩阵中的支持度以及在数据集矩阵中的支持度,并计算每个判断属性在该数据样本矩阵中的支持度与其在数据集矩阵中的支持度的比值以获得每个判断属性与分析对象之间规则的置信度,将支持度小于支持度阈值或置信度小于置信度阈值的属性值从数据样本矩阵中移除,所述支持度阈值和置信度阈值基于历史数据分析结果预先设置;在本发明的一些实施例中,采用如下方式计算属性值xik=1的支持度:S22. Sort the judgment attributes with the attribute value of 1 in the data sample matrix according to the frequency of occurrence, and quantify by the support degree, wherein the support of each judgment attribute other than the analysis object in the data sample in the data sample matrix is calculated respectively. degree and the support degree in the data set matrix, and calculate the ratio of the support degree of each judgment attribute in the data sample matrix to its support degree in the data set matrix to obtain the regular relationship between each judgment attribute and the analysis object. Confidence, the attribute value whose support is less than the support threshold or the confidence is less than the confidence threshold is removed from the data sample matrix, and the support threshold and the confidence threshold are preset based on historical data analysis results; in some of the present invention In the embodiment, the support degree of the attribute value xik=1 is calculated in the following manner:

采用如下方式计算属性值xjk=1的置信度:The confidence level of the attribute value x jk =1 is calculated as follows:


其中,T是数据集矩阵,X是由T中所有包含属性值xuv=1的数据组成的数据样本矩阵,x是矩阵X内的一行,|x∈X,xjk∈x|是矩阵X中包含属性值xjk=1的行数,|X|是矩阵X的行数,N是数据集矩阵的行数,
S23、根据步骤S22中数据集样本剩余数据构建分析对象的频繁模式树,以分析对象以及分析对象的属性值为1的数据样本矩阵作为树的顶层,以分析对象的数据样本矩阵中的其他属性及其在数据样本矩阵中属性值为1的数据组成的数据矩阵作为树的第二层,每一个其他属性对应一个节点;以本次分析对象的数据样本作为新的数据集矩阵,以第二层节点对应的属性作为新的分析对象,构建频繁模式树的第三层,然后以第三层节点对应的数据矩阵作为新的数据集矩阵构建频繁模式树的第四层,依此类推,直到满足以下任一条件时停止构建频繁模式树:频繁模式树的高度达到预设要求、所有属性值为1的属性都存储到树中、在某一层属性值的支持度低于支持度阈值或置信度低于置信度阈值;S23, construct a frequent pattern tree of the analysis object according to the remaining data of the dataset samples in step S22, take the analysis object and the data sample matrix with the attribute value of the analysis object as 1 as the top layer of the tree, and use other attributes in the data sample matrix of the analysis object and the data matrix composed of the data whose attribute value is 1 in the data sample matrix is used as the second layer of the tree, and each other attribute corresponds to a node; the data sample of this analysis object is used as the new data set matrix, and the second The attribute corresponding to the layer node is used as a new analysis object, and the third layer of the frequent pattern tree is constructed, and then the data matrix corresponding to the third layer node is used as the new data set matrix to construct the fourth layer of the frequent pattern tree, and so on, until Stop building the frequent pattern tree when any of the following conditions are met: the height of the frequent pattern tree meets the preset requirements, all attributes with an attribute value of 1 are stored in the tree, the support of attribute values at a certain level is lower than the support threshold or The confidence level is below the confidence level threshold;
S24、基于步骤S23构建的频繁模式树,进行规则合并,使每个判断属性对应一条规则。S24, combining the rules based on the frequent pattern tree constructed in step S23, so that each judgment attribute corresponds to a rule.
S3、对数据集矩阵进行回归分析,依次以一个判断属性作为目标属性,基于关联规则集合,计算数据集中其他属性对该目标属性影响力的权重,所有其他属性对目标属性影响力的权重形成该目标属性的权重集合。每次以一个判断属性为目标属性,将数据集矩阵中目标属性对应的列作为自变量集合,数据集矩阵中其他判断属性作为一系列因变量集合、以及所有判断属性的规则集合作为因变量,其中,自变量集合中的属性值是目标属性在数据集矩阵中每一行对应的属性值集合,对目标属性进行回归分析。在本发明的一些实施例中,通过如下方式进行回归分析获得目标属性的权重值集合:S3. Perform regression analysis on the matrix of the data set, take a judgment attribute as the target attribute in turn, and calculate the weight of the influence of other attributes in the data set on the target attribute based on the association rule set, and the weight of the influence of all other attributes on the target attribute forms the A collection of weights for the target attribute. Each time a judgment attribute is used as the target attribute, the column corresponding to the target attribute in the data set matrix is used as the independent variable set, the other judgment attributes in the data set matrix are used as a series of dependent variable sets, and the rule set of all judgment attributes is used as the dependent variable. The attribute value in the independent variable set is the attribute value set corresponding to each row of the target attribute in the data set matrix, and the target attribute is subjected to regression analysis. In some embodiments of the present invention, the weight value set of the target attribute is obtained by performing regression analysis in the following manner:
数据集矩阵:TN×(M+1);Data set matrix: T N×(M+1) ;
自变量集合:y=(y1,y2,...,yn),其中,n=N;Set of independent variables: y=(y 1 , y 2 , ..., y n ), where n=N;
因变量集合:

规则集合:rT,其中rT是M+1维的规则;Rule set: r T , where r T is a rule of dimension M+1;
自变量与因变量的关系表示为回归方程:The relationship between the independent variable and the dependent variable is expressed as a regression equation:
yi=α0+α1xi1+…+αMxiM+β1r1(xi)+β2r2(xi)+…+βMrM(xi)-β0r0(yi)y i =α 0 +α 1 x i1 +...+α M x iM +β 1 r 1 (x i )+β 2 r 2 (x i )+...+β M r M (x i )-β 0 r 0 (y i )
其中,θ=(α0...αM,β0...βM)是自变量集合的归一化权重;包括目标属性本身的权重以及基于规则的权重;Among them, θ=(α 0 ... α M , β 0 ... β M ) is the normalized weight of the independent variable set; including the weight of the target attribute itself and the weight based on the rule;
基于给定的评估函数,对回归方程求解,获得目标属性的权重值集合:γ=(γ0=α0-β0,γ1=α1+β1…γM=αM+βM)。Based on the given evaluation function, the regression equation is solved to obtain the weight value set of the target attribute: γ=(γ 0 =α 0 -β 0 , γ 1 =α 1 +β 1 …γ M =α M +β M ) .
优选的,采用梯度下降法逐渐逼近权重参数对回归方程求解得到权重值。Preferably, the weight value is obtained by gradually approximating the weight parameter by using the gradient descent method to solve the regression equation.
S4、将步骤S3中的权重集合进行可视化图形操作。S4. Perform a visual graph operation on the weight set in step S3.
根据本发明的第二方面,提供一种面向残疾人大数据的分析系统,包括:属性分解模块,用于对待分析数据集进行属性分解,将连续属性离散化,并采用独热编码表示每一条数据以将数据集转换成数据集矩阵,该矩阵的行数是数据集的数据条数,该矩阵的列数是分解后的离散属性的个数;数据关联分析模块,用于对经属性分解模块分解处理后的数据集进行分析,输出每个属性对应的规则集合;数据回归分析模块,用于对经属性分解模块分解后的数据集基于规则集合进行回归分析,输出每个属性的权重集合;结果可视化模块,用于将数据回归分析模块输出的属性的权重集合进行可视化显示。According to a second aspect of the present invention, an analysis system for disabled big data is provided, including: an attribute decomposition module, which is used to decompose the attributes of the data set to be analyzed, discretize continuous attributes, and use one-hot encoding to represent each piece of data To convert the data set into a data set matrix, the number of rows of the matrix is the number of data pieces of the data set, and the number of columns of the matrix is the number of discrete attributes after decomposition; the data association analysis module is used to analyze the attribute decomposition module. Analyze the decomposed data set, and output the rule set corresponding to each attribute; the data regression analysis module is used to perform regression analysis on the data set decomposed by the attribute decomposition module based on the rule set, and output the weight set of each attribute; The result visualization module is used to visualize the weight set of attributes output by the data regression analysis module.
与现有技术相比,本发明的优点在于:(1)在宏观应用层面,本发明可以加强残疾人数据资源统筹规划管理、提高科学决策能力、提高残疾人事业管理服务。因此,本发明可为精准助残的政策制定提供辅助,具有重要的工程应用价值。(2)本发明所产出回归分析数学模型具有可解释性,并对影响目标属性值变化的其他属性进行影响力评估。(3)通过挖掘出哪些属性值经常在一条数据中同时出现,本发明以规则的形式描述不同属性的内在关联性,将规则应用于回归方程,充分考虑属性之间的关联特性。(4)数据关联性的实现需要数据集满足一大要求,即数据集中的指定属性的类型需要为离散值而不是连续值。残疾人大数据绝大部分都是离散数据(即数据值是代表对于一个问题的回答选项的选择结果),这使得将数据关联性应用于回归分析变得尤为可行。(5)通过生成描述目标属性的变化趋势的回归方程,并在方程中将属性和规则的权重作为其影响因子加以输出,本发明可以挖掘出影响数据集各类重要指标变化的一系列因素,同时每一个因素都附有描述其影响力的权重因子。该权重因子不仅包含属性本身对目标属性的影响,还包含多个关联规则对目标属性的联合影响,此外,回归方程中未出现的属性对目标属性并无显性影响力。Compared with the prior art, the present invention has the following advantages: (1) At the macro-application level, the present invention can strengthen the overall planning and management of disabled persons' data resources, improve scientific decision-making ability, and improve career management services for disabled persons. Therefore, the present invention can provide assistance for policy formulation of precise disability assistance, and has important engineering application value. (2) The mathematical model of regression analysis produced by the present invention is interpretable, and the influence evaluation is performed on other attributes that affect the change of the target attribute value. (3) By digging out which attribute values often appear in a piece of data, the present invention describes the internal correlation of different attributes in the form of rules, applies the rules to regression equations, and fully considers the correlation characteristics between attributes. (4) The realization of data association requires the data set to meet a major requirement, that is, the type of the specified attribute in the data set needs to be a discrete value rather than a continuous value. The vast majority of disabled big data is discrete data (that is, the data values represent the selection results of answering options to a question), which makes it particularly feasible to apply data correlation to regression analysis. (5) By generating a regression equation describing the change trend of the target attribute, and outputting the weight of the attribute and the rule as its influencing factor in the equation, the present invention can mine a series of factors that affect the changes of various important indicators of the data set, At the same time, each factor is accompanied by a weighting factor describing its influence. The weight factor includes not only the influence of the attribute itself on the target attribute, but also the joint influence of multiple association rules on the target attribute. In addition, the attributes that do not appear in the regression equation have no dominant influence on the target attribute.
附图说明Description of drawings
以下参照附图对本发明实施例作进一步说明,其中:The embodiments of the present invention will be further described below with reference to the accompanying drawings, wherein:
图1为根据本发明示例的频繁模式树示意图;1 is a schematic diagram of a frequent pattern tree according to an example of the present invention;
图2为根据本发明示例的三个省A、B、C的残疾人大数据分析结果示意图;Fig. 2 is a schematic diagram of the analysis results of the disabled big data of three provinces A, B, and C according to an example of the present invention;
图3为根据本发明示例的省份A的残疾人大数据分析结果示意图;3 is a schematic diagram of the analysis results of the disabled big data in province A according to an example of the present invention;
图4为根据本发明示例的省份B的残疾人大数据分析结果示意图;FIG. 4 is a schematic diagram of the analysis results of the disabled big data in province B according to an example of the present invention;
图5为根据本发明示例的省份C的残疾人大数据分析结果示意图;5 is a schematic diagram of the analysis results of the disabled big data in province C according to an example of the present invention;
图6为根据本发明实施例的面向残疾人大数据的分析系统示意图。FIG. 6 is a schematic diagram of an analysis system for disabled big data according to an embodiment of the present invention.
具体实施方式Detailed ways
为了使本发明的目的,技术方案及优点更加清楚明白,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。In order to make the objectives, technical solutions and advantages of the present invention clearer, the present invention will be further described in detail below with reference to the accompanying drawings through specific embodiments. It should be understood that the specific embodiments described herein are only used to explain the present invention, but not to limit the present invention.
由于残疾人大数据是一种政府资助的调查统计数据集,相对于其他大数据具有特殊性,充分了解和分析残疾人大数据有利于制定更加合理的政策,保障残疾人民生。As the disabled big data is a government-funded survey and statistical data set, it is unique compared to other big data. Fully understanding and analyzing the disabled big data will help to formulate more reasonable policies and protect the livelihood of the disabled.
根据本发明的一个实施例,本发明提供一种面向残疾人大数据的分析方法,包括步骤S1、S2、S3和S4,下面详细说明每个步骤。According to an embodiment of the present invention, the present invention provides an analysis method for disabled big data, including steps S1, S2, S3 and S4, each step will be described in detail below.
在步骤S1中,对残疾人大数据对应数据集进行属性分解:In step S1, attribute decomposition is performed on the dataset corresponding to the disabled big data:
首先,对于数据集中存在的连续属性,先将连续属性离散化再进行属性分解,例如对于连续属性“年龄”,可以离散为四个年龄段:少年(0-18)、青年(19-35)、中年(36-55)、老年(56-)。First of all, for the continuous attributes existing in the data set, the continuous attributes are first discretized and then the attributes are decomposed. For example, for the continuous attribute "age", it can be discretized into four age groups: teenagers (0-18), youth (19-35) , middle-aged (36-55), old (56-).
其次,对于数据集中的每个选择属性,采用独热编码表示每一个选项,例如,假设第j个属性Xj所对应的是被调查者对一个有Mj个选项的勾选结果,那么选择属性Xj将被分解为Mj个判断属性:
根据本发明的一个示例,一份残疾人大数据集中的每条数据调查统计表均包含如下选择属性,即可选项:According to an example of the present invention, each data survey statistical table in a large dataset of disabled persons includes the following selection attributes, that is, options:
贫困与建档立卡状况:国家建档立卡贫困人口、其他贫困人口、其他;Poverty and status of file and card establishment: poverty population, other poor population, and others;
家庭住房状况:状况良好、经鉴定属危房、非鉴定危房、租赁房、借住或无固定住所;Household housing status: in good condition, identified as dangerous, not identified as dangerous, rented, rented or without fixed residence;
受教育程度:从未上过学、小学、初中、高中(含中专)、大学专科、大学本科、研究生;Education level: never attended school, primary school, junior high school, high school (including technical secondary school), college junior college, college undergraduate, graduate student;
目前就业扶贫需求:职业技能培训、职业介绍、农村实用技术培训、资金信贷扶持、其他帮扶、无需求;Current employment and poverty alleviation needs: vocational skills training, job introduction, rural practical technical training, capital and credit support, other assistance, no demand;
社会救助及住房改善情况:最低生活保障、特困人员救助供养、医疗救助、其他救助(教育救助、住房救助、就业救助和其他临时救助)、享受住建部门农村危房改造政策(仅农业户口可选)、无。Social assistance and housing improvement: minimum living guarantee, assistance and support for the extremely poor, medical assistance, other assistance (education assistance, housing assistance, employment assistance and other temporary assistance), enjoyment of the housing and construction sector’s rural dilapidated house renovation policy (only agricultural household registration is optional ),none.
对该数据集中的数据进行属性分解,第一个选择属性包含3个选项,分解为3个判断属性;第二个选择属性包含5个选项,分解为5个判断属性;第3个选择属性包含7个选项,分解为7个判断属性;第4个选择属性包含6个选项,分解为6个判断属性;第5个选择属性包含6个选项,分解为6个判断属性,因此,数据集中的选择属性经过属性分解后得到3+5+7+6+6=27个单选问题的判断属性,每一条数据由独热编码表示为一条包含27个属性值的编码,此条数据中被调查者选择了某一个选项,其对应的判断属性的属性值为1,其他则为0。Attribute decomposition is performed on the data in this dataset. The first selection attribute contains 3 options and is decomposed into 3 judgment attributes; the second selection attribute contains 5 options and is decomposed into 5 judgment attributes; the third selection attribute contains 7 options, decomposed into 7 judgment attributes; the fourth selection attribute contains 6 options, decomposed into 6 judgment attributes; the fifth selection attribute contains 6 options, decomposed into 6 judgment attributes, therefore, in the data set After the selection attribute is decomposed, the judgment attributes of 3+5+7+6+6=27 single-choice questions are obtained. Each piece of data is represented by one-hot encoding as a code containing 27 attribute values. If the user selects an option, the attribute value of the corresponding judgment attribute is 1, and the other is 0.
在步骤S2中,基于步骤S1的数据集矩阵,为数据集中属性值为1的判断属性生成规则集合,其中,每个判断属性与其他属性之间生成一条规则,包括:In step S2, based on the data set matrix of step S1, a rule set is generated for the judgment attribute whose attribute value is 1 in the data set, wherein a rule is generated between each judgment attribute and other attributes, including:
S21、以一个判断属性为分析对象,以数据集中该判断属性的属性值为1的所有数据组成该分析对象的数据样本矩阵;S21, take a judgment attribute as an analysis object, and form a data sample matrix of the analysis object with all the data in the data set whose attribute value of the judgment attribute is 1;
S22、对数据样本矩阵中属性值为1的其他属性按照出现频率进行排序,并通过支持度进行量化,其中,分别计算数据样本中分析对象以外的每个判断属性在该数据样本矩阵中的支持度以及在数据集矩阵中的支持度,并计算每个判断属性在该数据样本矩阵中的支持度与其在数据集矩阵中的支持度的比值以获得每个判断属性与分析对象之间规则的置信度,将支持度小于支持度阈值或置信度小于置信度阈值的属性值从数据样本矩阵中移除;S22. Rank other attributes with the attribute value of 1 in the data sample matrix according to the frequency of occurrence, and quantify by the support degree, wherein the support of each judgment attribute other than the analysis object in the data sample in the data sample matrix is calculated respectively. degree and the support degree in the data set matrix, and calculate the ratio of the support degree of each judgment attribute in the data sample matrix to its support degree in the data set matrix to obtain the regular relationship between each judgment attribute and the analysis object. Confidence, remove the attribute values whose support is less than the support threshold or whose confidence is less than the confidence threshold from the data sample matrix;
S23、根据步骤S22中数据集样本剩余数据构建分析对象的频繁模式树,以分析对象以及分析对象的属性值为1的数据样本矩阵作为树的顶层,以分析对象的数据样本矩阵中的其他属性及其在数据样本矩阵中属性值为1的数据组成的数据矩阵作为树的第二层,每一个其他属性对应一个节点;以本次分析对象的数据样本作为新的数据集矩阵,以第二层节点对应的属性作为新的分析对象,构建频繁模式树的第三层,然后以第三层节点对应的数据矩阵作为新的数据集矩阵构建频繁模式树的第四层,依此类推递归构建频繁模式树,直到满足以下任一条件时停止构建频繁模式树:频繁模式树的高度达到预设要求、所有属性值为1的属性都存储到树中、在某一层属性值的支持度低于支持度阈值或置信度低于置信度阈值;S23, construct a frequent pattern tree of the analysis object according to the remaining data of the dataset samples in step S22, take the analysis object and the data sample matrix with the attribute value of the analysis object as 1 as the top layer of the tree, and use other attributes in the data sample matrix of the analysis object and the data matrix composed of the data whose attribute value is 1 in the data sample matrix is used as the second layer of the tree, and each other attribute corresponds to a node; the data sample of this analysis object is used as the new data set matrix, and the second The attribute corresponding to the layer node is used as a new analysis object, and the third layer of the frequent pattern tree is constructed, and then the data matrix corresponding to the third layer node is used as the new data set matrix to construct the fourth layer of the frequent pattern tree, and so on. Frequent pattern tree, stop building the frequent pattern tree until any of the following conditions are met: the height of the frequent pattern tree meets the preset requirements, all attributes with an attribute value of 1 are stored in the tree, and the support of attribute values at a certain layer is low at the support threshold or the confidence is lower than the confidence threshold;
S24、基于步骤S23构建的频繁模式树,进行规则合并,使每个判断属性对应一条规则;S24, based on the frequent pattern tree constructed in step S23, merge the rules so that each judgment attribute corresponds to a rule;
S25、以另一个判断属性为分析对象,重复步骤S21至S24,直到生成所有判断属性的规则集合。S25. Taking another judgment attribute as the analysis object, repeat steps S21 to S24 until a rule set of all judgment attributes is generated.
需要说明的是,规则是指从一个条件推导出另一个条件,例如由X推导出Y就是一条规则,表示为X=>Y,数学公式可以表示为:r(x)=if x1∈{1,2,3}and x2<4 then 1else 0,在针对Y的频繁模式树中,树的顶层就是Y,第二层以及相关的更下层就是X。It should be noted that a rule refers to deriving another condition from one condition. For example, deriving Y from X is a rule, which is expressed as X=>Y, and the mathematical formula can be expressed as: r(x)=if x 1 ∈ { 1, 2, 3} and x 2 <4 then 1else 0, in a frequent pattern tree for Y, the top level of the tree is Y, and the second and related lower levels are X.
根据本发明的一个实施例,数据集矩阵为TN×(M+1),其中数据集矩阵由N个条目组成,每个条目包含M+1个已属性分解的离散属性。基于每个判断属性的每个选项值(独热编码为0的除外)生成规则集合,即基于每个判断属性的属性值为1的数据生成判断属性的规则集合:According to an embodiment of the present invention, the data set matrix is T N×(M+1) , wherein the data set matrix consists of N entries, and each entry contains M+1 discrete attributes that have been attribute decomposed. A rule set is generated based on each option value of each judgment attribute (except for the one-hot encoding of 0), that is, a rule set of judgment attributes is generated based on the data whose attribute value of each judgment attribute is 1:
P1、以一个判断属性xuv为分析对象,从数据集TN×(M+1)中选择包含属性值xuv=1的所有数据,形成数据样本矩阵X。P1. Taking a judgment attribute x uv as the analysis object, select all data including the attribute value x uv =1 from the data set T N×(M+1) to form a data sample matrix X.
P2、根据判断属性的属性值1出现的频率对数据样本矩阵X中经常出现的属性值进行排序,并根据其支持度进行量化,数据样本中每个属性值xjk=1的支持度计算如下:P2. Sort the frequently occurring attribute values in the data sample matrix X according to the frequency of occurrence of attribute value 1 of the judgment attribute, and quantify according to their support degrees. The support degree of each attribute value x jk =1 in the data sample is calculated as follows :


其中x是数据样本矩阵X内的一行,而|x∈X,xjk∈x|是数据样本矩阵中包含属性值xjk=1的行数,|X|是矩阵X的行数,Mj表示xjk所属的第j个选择属性所包含的选项个数即第j个选择属性经过属性分解后包含的判断属性的个数,Mu表示xuv所属的第u个选择属性所包含的选项个数即第u个选择属性经过属性分解后包含的判断属性的个数,规则

在数据样本矩阵中的支持度越高,该属性值在数据样本中出现的频率越高;置信度越高,其对应规则的可信度越高。通过设置预定义的支持度阈值和置信度阈值,支持度或置信度低于阈值的所有属性值都将被视为不经常出现,并将其从相应的数据样本中移除。支持度阈值和置信度阈值可通过历史数据分析结果预先设置。The higher the support in the data sample matrix, the higher the frequency of the attribute value in the data sample; the higher the confidence, the higher the credibility of the corresponding rule. By setting predefined support threshold and confidence threshold, all attribute values with support or confidence below the threshold will be considered infrequent and removed from the corresponding data samples. Support threshold and confidence threshold can be preset through historical data analysis results.
P3、根据步骤P2处理后的数据样本,构建分析对象的频繁模式树。树的顶层是支持度最高的属性值(独热编码为1)以及包含该属性值的数据样本,显然,数据样本矩阵中支持度最高的属性值为分析对象xuv,即supp(xuv)=Mu,其对应数据样本矩阵为X。树的第二层依次为高于支持度阈值和置信度阈值的属性值以及包含该属性值的数据样本。将模式树第二层的每个节点包含的数据集作为新的数据样本矩阵X,计算每个属性值的支持度和置信度作为第三层节点,递归构建频繁模式树,直到满足规则长度(树的高度)或者所有属性值(独热编码为1)都存储到树中或者属性值的支持度或置信度低于阈值。P3. According to the data samples processed in step P2, a frequent pattern tree of the analysis object is constructed. The top level of the tree is the attribute value with the highest support (one-hot encoding is 1) and the data sample containing the attribute value. Obviously, the attribute value with the highest support in the data sample matrix is the analysis object x uv , that is, supp(x uv ) =M u , the corresponding data sample matrix is X. The second level of the tree is the attribute value above the support threshold and confidence threshold in order, and the data samples containing the attribute value. Take the data set contained in each node of the second layer of the pattern tree as a new data sample matrix X, calculate the support and confidence of each attribute value as the third layer node, and recursively construct the frequent pattern tree until the rule length ( The height of the tree) or all attribute values (one-hot encoded as 1) are stored into the tree or the support or confidence of the attribute value is below a threshold.
P4、将分析对象的频繁模式树中的规则,基于树的下层节点对应的后继属性进行合并,使频繁模式树所有底层节点到顶层根节点的路径对应的规则合并为该分析对象对应的一条规则rj(x)。P4. Merge the rules in the frequent pattern tree of the analysis object based on the subsequent attributes corresponding to the lower nodes of the tree, so that the rules corresponding to the paths from all the bottom nodes of the frequent pattern tree to the top root node are merged into a rule corresponding to the analysis object r j (x).
下面结合一个示例进一步对本发明进行说明。The present invention will be further described below with reference to an example.
一份残疾人大数据集中的每条数据调查统计表均包含如下选择属性即可选项:Each data survey statistical table in a large data set of disabled persons contains the following selection attributes:
贫困与建档立卡状况:国家建档立卡贫困人口、其他贫困人口、其他;Poverty and status of file and card establishment: poverty population, other poor population, and others;
家庭住房状况:状况良好、经鉴定属危房、非鉴定危房、租赁房、借住或无固定住所;Household housing status: in good condition, identified as dangerous, not identified as dangerous, rented, rented or without fixed residence;
受教育程度:从未上过学、小学、初中、高中(含中专)、大学专科、大学本科、研究生;Education level: never attended school, primary school, junior high school, high school (including technical secondary school), college junior college, college undergraduate, graduate student;
目前就业扶贫需求:职业技能培训、职业介绍、农村实用技术培训、资金信贷扶持、其他帮扶、无需求;Current employment and poverty alleviation needs: vocational skills training, job introduction, rural practical technical training, capital and credit support, other assistance, no demand;
社会救助及住房改善情况:最低生活保障、特困人员救助供养、医疗救助、其他救助(教育救助、住房救助、就业救助和其他临时救助)、享受住建部门农村危房改造政策(仅农业户口可选)、无。Social assistance and housing improvement: minimum living guarantee, assistance and support for the extremely poor, medical assistance, other assistance (education assistance, housing assistance, employment assistance and other temporary assistance), enjoyment of the housing and construction sector’s rural dilapidated house renovation policy (only agricultural household registration is optional ),none.
数据集中有100条数据(即N=100,这100条数据的独热编码形成数据集矩阵T100x(26+1)),M1=3,M2=5,M3=7,M4=6,M5=6,数据集矩阵中的第j行数据可表示为:xj={xj1,xj2,…xj27},本示例中用xuv代表“贫困与建档立卡状况:国家建档立卡贫困人口”作为分析对象,在100条数据中,有70条选择了xuv(这70条数据就是数据样本矩阵X),为xuv建立关联规则:There are 100 pieces of data in the data set (that is, N=100, the one-hot encoding of these 100 pieces of data forms a data set matrix T 100x(26+1) ), M 1 =3, M 2 =5, M 3 =7, M 4 =6, M 5 =6, the data of the jth row in the data set matrix can be expressed as: x j ={x j1 , x j2 ,...x j27 }, in this example, x uv is used to represent "poverty and documentation Situation: "The poor population with national files and cards" is used as the analysis object. Among the 100 pieces of data, 70 pieces of data have selected x uv (these 70 pieces of data are the data sample matrix X), and establish an association rule for x uv :
首先,假设xjk代表“家庭住房状况:经鉴定属危房”,在数据样本的70条数据中,有30条数据选择了xjk,而在数据集的100条数据中,有50条数据选择了xjk,那么First, assuming that x jk represents "family housing status: it is identified as a dilapidated house", among the 70 pieces of data in the data sample, 30 pieces of data have selected x jk , and among the 100 pieces of data in the data set, 50 pieces of data have been chosen x jk , then



其次,假设xjk代表“受教育程度:从未上过学”,在数据样本的70条数据中,有20条数据选择了xjk,而在数据集的100条数据中,有40条数据选择了xjk,那么Secondly, assuming that x jk represents "educational level: never attended school", among the 70 pieces of data in the data sample, 20 pieces of data have selected x jk , and among the 100 pieces of data in the dataset, there are 40 pieces of data x jk is chosen, then
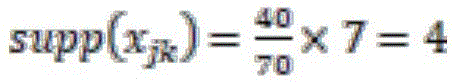


如此构建了频繁模式树的第一和第二层,第一层(根节点)是“贫困与建档立卡状况:国家建档立卡贫困人口”,第二层(叶节点)有2个节点,分别是“家庭住房状况:经鉴定属危房”和“受教育程度:从未上过学”(目前树的长度为2)。In this way, the first and second layers of the frequent pattern tree are constructed. The first layer (root node) is "Poverty and Filed Card Status: National Filed and Registered Poor Population", and the second layer (leaf node) has 2 The nodes are "family housing status: identified as dangerous" and "educational level: never attended school" (current tree length is 2).
然后,以数据样本中的70条数据作为新的数据集矩阵T,“家庭住房状况:经鉴定属危房”作为新的分析对象xuv,从而继续构建树的第三层,假设第三层(叶节点)有1个节点,是“目前就业扶贫需求:职业技能培训”,那么这个规则可以简单表述为“目前就业扶贫需求:职业技能培训and家庭住房状况:经鉴定属危房=>贫困与建档立卡状况:国家建档立卡贫困人口”,依此类推,递归构建如图1所示的基于“贫困与建档立卡状况:国家建档立卡贫困人口”的频繁模式树,其中,树的顶层是“贫困与建档立卡状况:国家建档立卡贫困人口”,树的第二层是“家庭住房状况:经鉴定属危房”、“受教育程度:从未上过学”等,每个判断属性对应一条规则,每条规则对应树中所有底层节点到根节点的路径,一个频繁模式树对应的规则即为一个分析对象的规则,所有分析对象的规则组成规则集合。如果某一规则有悖于常识,可以方便回溯这条路径,查找哪个节点有疑惑(例如置信度或支持度不合适,数据集某些字段填报的质量较差)。Then, take the 70 pieces of data in the data sample as a new data set matrix T, and "family housing status: identified as a dilapidated house" as a new analysis object x uv , so as to continue to build the third layer of the tree, assuming that the third layer ( Leaf node) has 1 node, which is "current employment poverty alleviation needs: vocational skills training", then this rule can be simply expressed as "current employment poverty alleviation needs: vocational skills training and family housing status: identified as dilapidated buildings => poverty and construction File status: the poor population on file with the national file”, and so on, recursively construct the frequent pattern tree based on “Poverty and file status: the poor population on file with the national file” as shown in Figure 1, in which , the top layer of the tree is "Poverty and the status of filing and setting up a card: the poverty-stricken population registered by the state", and the second layer of the tree is "the status of the family housing: it has been identified as a dilapidated house", "education level: never went to school"", etc., each judgment attribute corresponds to a rule, each rule corresponds to the path from all the bottom nodes in the tree to the root node, a rule corresponding to a frequent pattern tree is the rule of an analysis object, and all the rules of the analysis object form a rule set. If a rule is contrary to common sense, it is convenient to backtrack this path and find out which node has doubts (for example, the confidence or support is inappropriate, and the quality of some fields in the data set is poor).
在步骤S3中,对数据集矩阵进行回归分析,依次以一个判断属性作为目标属性,基于关联规则集合,计算数据集中其他属性对该目标属性影响力的权重,所有其他属性对目标属性影响力的权重形成该目标属性的权重集合。In step S3, a regression analysis is performed on the data set matrix, one judgment attribute is used as the target attribute in turn, and based on the association rule set, the weight of the influence of other attributes in the data set on the target attribute is calculated, and the influence of all other attributes on the target attribute is calculated. The weights form the set of weights for this target attribute.
根据本发明的一个实施例,单次分析中,首先以一个判断属性为目标属性,将数据集矩阵中该目标属性对应的列作为自变量集合y=(y1,y2,...,yn),数据集矩阵中其他属性作为一系列因变量形成因变量集合

其次,通过线性方程来描述自变量与因变量集合之间的关联性:Second, the correlation between the independent variable and the set of dependent variables is described by a linear equation:
yi=α0+α1xi1+…+αMxiM+β1r1(xi)+β2r2(xi)+…+βMrM(xi)-β0r0(yi)y i =α 0 +α 1 x i1 +...+α M x iM +β 1 r 1 (x i )+β 2 r 2 (x i )+...+β M r M (x i )-β 0 r 0 (y i )
其中θ=(α0...αM,β0…βM)是自变量集合的归一化权重,通过将因变量集合和规则结果统一用矩阵X表示,自变量集合用矩阵Y表示,回归方程可以被简化为:Y=hθ(X)=θTX。where θ=(α 0 ... α M , β 0 ... β M ) is the normalized weight of the set of independent variables, by unifying the set of dependent variables and the rule results with matrix X, and the set of independent variables with matrix Y, The regression equation can be simplified as: Y=h θ (X)=θ T X.
根据预设的评估函数,对回归方程求解,可以得到权重集合。根据本发明的一个实施例,可以采用梯度下降法逐渐逼近权重参数,也可以直接计算
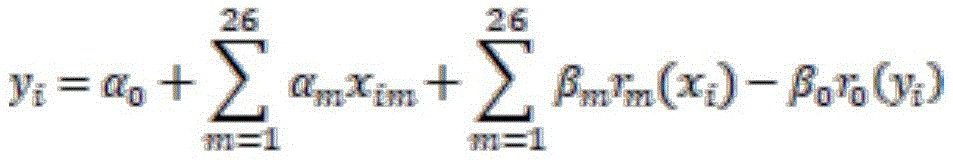
对于最小二乘法,其评估函数为:For the least squares method, the evaluation function is:

评估函数对θ求偏导数:The evaluation function takes the partial derivative with respect to θ:

通过解方程组,数据回归分析确定权重值集合过程可以用以下公式来表示:By solving the system of equations, the process of determining the weight value set by data regression analysis can be expressed by the following formula:
θ=(XTX)-1XTYθ=(X T X) -1 X T Y
最终,γ=(γ0=α0-β0,γ1=α1+β1...γM=αM+βM)就是描述其他判断属性(包含属性本身以及相互关系)对目标属性影响力的权重值集合。根据本发明前述示例,可能本身选择了“贫困与建档立卡状况:国家建档立卡贫困人口”,它有一个权重α1,如果这条数据同时选择了“目前就业扶贫需求:职业技能培训”和“家庭住房状况:经鉴定属危房”,那么根据规则,可以推导出“贫困与建档立卡状况:国家建档立卡贫困人口”,它也有一个权重β1,而γ1=α1+β1才是“贫困与建档立卡状况:国家建档立卡贫困人口”的最终权重值。Finally, γ=(γ 0 =α 0 -β 0 , γ 1 =α 1 +β 1 ...γ M =α M +β M ) is to describe the relationship between other judgment attributes (including the attributes themselves and their relationship) to the target attribute A collection of weight values for influence. According to the aforementioned example of the present invention, it is possible to select “Poverty and status of filing and setting up cards: the poverty-stricken population registered by the state”, which has a weight α 1 . training” and “family housing status: identified as a dilapidated house”, then according to the rules, it can be deduced that “poor and file status: the state file and file the poor”, it also has a weight β 1 , and γ 1 = α 1 + β 1 is the final weight value of "Poverty and the status of file registration: the poor population with national file and registration".
S4、将步骤S3中的权重集合进行可视化图形操作,以便直观分析其他属性对目标属性的影响力,数据回归分析的结果可以通过柱状图的形式可视化,其中幅值大的表示该属性对目标属性的影响较大。S4. Perform a visual graphic operation on the weight set in step S3, so as to intuitively analyze the influence of other attributes on the target attribute. The result of the data regression analysis can be visualized in the form of a histogram, where a large amplitude value indicates that the attribute has an impact on the target attribute. greater impact.
为了说明本发明的效果,发明人从全国残疾人基础数据库中选取三省A、B、C共3798462条数据进行分析实验,每条数据包含28个非隐私属性,覆盖个人基础信息、经济及住房、教育、就业扶贫、社会保障、基本医疗与康复、无障碍、文化体育共8个方面。采用本发明的分析方法,以“贫困与建档立卡状况:国家建档立卡贫困人口”为目标属性对这3798462条数据进行整体分析,通过对影响力进行排序,所得回归分析可视化结果如图2所示,对三省数据分别进行分析,得到回归分析可视化结果如图3至5所示,其中,图3是对A省数据的可视化结果,图4是对B省数据的可视化结果,图5是C省数据的可视化结果,从数据中本发明可以得到有效信息范例如下:In order to illustrate the effect of the present invention, the inventor selects a total of 3,798,462 pieces of data from three provinces A, B, and C from the national basic database of disabled persons for analysis experiments. Each piece of data contains 28 non-privacy attributes, covering basic personal information, economy, housing, Education, employment and poverty alleviation, social security, basic medical care and rehabilitation, barrier-free, culture and sports. Using the analysis method of the present invention, the 3,798,462 pieces of data are analyzed as a whole with the target attribute of "poverty and the status of file and card registration: the poor population with national file and card". As shown in Figure 2, the data of the three provinces are analyzed respectively, and the visualization results of regression analysis are obtained as shown in Figures 3 to 5, wherein Figure 3 is the visualization result of the data in Province A, and Figure 4 is the visualization result of the data in Province B. 5 is the visualization result of the data in Province C, from which the present invention can obtain valid information examples as follows:
(1)就三省整体而言,相对非贫困残疾人,贫困残疾人的影响因素中排名前三位的是最低生活保障、享受住建部门危房改造政策和经鉴定属危房。(1) For the three provinces as a whole, compared with the non-poor disabled persons, the top three influencing factors of the poor disabled persons are the minimum living security, the enjoyment of the dilapidated house renovation policy of the housing construction department, and the certified dilapidated house.
(2)各省份之间的影响因素差异较为显著。(2) There are significant differences in influencing factors among provinces.
(3)省份A的贫困人口显著特性如下:经鉴定属危房;住建部门危房改造政策;属危房未鉴定。(3) The salient characteristics of the poor population in province A are as follows: it has been identified as a dilapidated house; the housing and construction department has a policy of renovating dilapidated houses; it has not been identified as a dangerous house.
(4)省份B的贫困人口显著特性如下:经鉴定属危房;最低生活保障;属危房未鉴定。(4) The salient characteristics of the impoverished population in province B are as follows: it has been identified as a dilapidated house;
(5)省份C的贫困人口显著特性如下:最低生活保障;特困人员救助供养;享受危房改造政策。(5) The salient characteristics of the poor population in province C are as follows: minimum living guarantee; assistance and support for the extremely poor; enjoying the dilapidated house renovation policy.
根据本发明的一个实施例,如图6所示,本发明提供一种面向残疾人大数据的分析系统,包括:属性分解模块,用于对待分析数据集进行属性分解,将连续属性离散化,并采用独热编码表示每一条数据以将数据集转换成数据集矩阵,该矩阵的行数是数据集的数据条数,该矩阵的列数是分解后的离散属性的个数;数据关联分析模块,用于对经属性分解模块分解处理后的数据集进行分析,输出每个属性对应的规则集合;数据回归分析模块,用于对经属性分解模块分解后的数据集基于规则集合进行回归分析,输出每个属性的权重集合;结果可视化模块,用于将数据回归分析模块输出的属性的权重集合进行可视化显示。According to an embodiment of the present invention, as shown in FIG. 6 , the present invention provides an analysis system for disabled big data, including: an attribute decomposition module, which is used to decompose the attributes of the data set to be analyzed, discretize the continuous attributes, and One-hot encoding is used to represent each piece of data to convert the data set into a data set matrix. The number of rows of the matrix is the number of data pieces of the data set, and the number of columns of the matrix is the number of discrete attributes after decomposition; data association analysis module , used to analyze the data set decomposed by the attribute decomposition module, and output the rule set corresponding to each attribute; the data regression analysis module is used to perform regression analysis on the data set decomposed by the attribute decomposition module based on the rule set, Output the weight set of each attribute; the result visualization module is used to visualize the weight set of attributes output by the data regression analysis module.
本发明的有益效果在于:(1)在宏观应用层面,本发明可以加强残疾人数据资源统筹规划管理、提高科学决策能力、提高残疾人事业管理服务。因此,本发明可为精准助残的政策制定提供辅助,具有重要的工程应用价值。(2)本发明所产出回归分析数学模型具有可解释性,并对影响目标属性值变化的其他属性进行影响力评估。(3)通过挖掘出哪些属性值经常在一条数据中同时出现,本发明以规则的形式描述不同属性的内在关联性,将规则应用于回归方程,充分考虑属性之间的关联特性。(4)数据关联性的实现需要数据集满足一大要求,即数据集中的指定属性的类型需要为离散值而不是连续值。残疾人大数据绝大部分都是离散数据(即数据值是代表对于一个问题的回答选项的选择结果),这使得将数据关联性应用于回归分析变得尤为可行。(5)通过生成描述目标属性的变化趋势的回归方程,并在方程中将属性和规则的权重作为其影响因子加以输出,本发明可以挖掘出影响数据集各类重要指标变化的一系列因素,同时每一个因素都附有描述其影响力的权重因子。该权重因子不仅包含属性本身对目标属性的影响,还包含多个关联规则对目标属性的联合影响。此外,回归方程中未出现的属性对目标属性并无显性影响力。The beneficial effects of the present invention are as follows: (1) At the macro-application level, the present invention can strengthen the overall planning and management of disabled persons' data resources, improve scientific decision-making ability, and improve career management services for disabled persons. Therefore, the present invention can provide assistance for policy formulation of precise disability assistance, and has important engineering application value. (2) The mathematical model of regression analysis produced by the present invention is interpretable, and the influence evaluation is performed on other attributes that affect the change of the target attribute value. (3) By digging out which attribute values often appear in a piece of data, the present invention describes the internal correlation of different attributes in the form of rules, applies the rules to regression equations, and fully considers the correlation characteristics between attributes. (4) The realization of data association requires the data set to meet a major requirement, that is, the type of the specified attribute in the data set needs to be a discrete value rather than a continuous value. The vast majority of disabled big data is discrete data (that is, the data values represent the selection results of answering options to a question), which makes it particularly feasible to apply data correlation to regression analysis. (5) By generating a regression equation describing the change trend of the target attribute, and outputting the weight of the attribute and the rule as its influencing factor in the equation, the present invention can mine a series of factors that affect the changes of various important indicators of the data set, At the same time, each factor is accompanied by a weighting factor describing its influence. The weight factor includes not only the influence of the attribute itself on the target attribute, but also the joint influence of multiple association rules on the target attribute. In addition, attributes that do not appear in the regression equation have no dominant influence on the target attribute.
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。It should be noted that although the steps are described above in a specific order, it does not mean that the steps must be executed in the above-mentioned specific order. In fact, some of these steps can be executed concurrently, or even change the order, as long as it can be achieved The required function can be.
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。The present invention may be a system, method and/or computer program product. The computer program product may include a computer-readable storage medium having computer-readable program instructions loaded thereon for causing a processor to implement various aspects of the present invention.
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、静态随机存取存储器(SRAM)、便携式压缩盘只读存储器(CD-ROM)、数字多功能盘(DVD)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。A computer-readable storage medium may be a tangible device that retains and stores instructions for use by the instruction execution device. Computer-readable storage media may include, but are not limited to, electrical storage devices, magnetic storage devices, optical storage devices, electromagnetic storage devices, semiconductor storage devices, or any suitable combination of the foregoing, for example. More specific examples (non-exhaustive list) of computer readable storage media include: portable computer disks, hard disks, random access memory (RAM), read only memory (ROM), erasable programmable read only memory (EPROM) or flash memory), static random access memory (SRAM), portable compact disk read only memory (CD-ROM), digital versatile disk (DVD), memory sticks, floppy disks, mechanically coded devices, such as printers with instructions stored thereon Hole cards or raised structures in grooves, and any suitable combination of the above.
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。Various embodiments of the present invention have been described above, and the foregoing descriptions are exemplary, not exhaustive, and not limiting of the disclosed embodiments. Numerous modifications and variations will be apparent to those of ordinary skill in the art without departing from the scope and spirit of the described embodiments. The terminology used herein was chosen to best explain the principles of the embodiments, the practical application or technical improvement in the marketplace, or to enable others of ordinary skill in the art to understand the embodiments disclosed herein.
Claims (10)






Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010149602.9A CN111459994A (en) | 2020-03-06 | 2020-03-06 | A method and system for analyzing big data for disabled people |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010149602.9A CN111459994A (en) | 2020-03-06 | 2020-03-06 | A method and system for analyzing big data for disabled people |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN111459994A true CN111459994A (en) | 2020-07-28 |
Family
ID=71680944
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010149602.9A Pending CN111459994A (en) | 2020-03-06 | 2020-03-06 | A method and system for analyzing big data for disabled people |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111459994A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114116923A (en) * | 2021-12-01 | 2022-03-01 | 厦门市易联众易惠科技有限公司 | Marking system based on prejudgment, method and device thereof and readable storage medium |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180308010A1 (en) * | 2017-04-25 | 2018-10-25 | Xaxis, Inc. | Double Blind Machine Learning Insight Interface Apparatuses, Methods and Systems |
| CN108717786A (en) * | 2018-07-17 | 2018-10-30 | 南京航空航天大学 | A kind of traffic accident causation method for digging based on universality meta-rule |
| CN109740680A (en) * | 2019-01-07 | 2019-05-10 | 深圳中创华安科技有限公司 | A kind of classification method and system of mixing value attribute examination & approval data |
| CN110334796A (en) * | 2019-06-28 | 2019-10-15 | 北京科技大学 | A method and device for mining association rules of social security events |
| CN110443353A (en) * | 2019-07-16 | 2019-11-12 | 天津大学 | The neural network of implication relation between a kind of excavation feature based on short connection |
-
2020
- 2020-03-06 CN CN202010149602.9A patent/CN111459994A/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180308010A1 (en) * | 2017-04-25 | 2018-10-25 | Xaxis, Inc. | Double Blind Machine Learning Insight Interface Apparatuses, Methods and Systems |
| CN108717786A (en) * | 2018-07-17 | 2018-10-30 | 南京航空航天大学 | A kind of traffic accident causation method for digging based on universality meta-rule |
| CN109740680A (en) * | 2019-01-07 | 2019-05-10 | 深圳中创华安科技有限公司 | A kind of classification method and system of mixing value attribute examination & approval data |
| CN110334796A (en) * | 2019-06-28 | 2019-10-15 | 北京科技大学 | A method and device for mining association rules of social security events |
| CN110443353A (en) * | 2019-07-16 | 2019-11-12 | 天津大学 | The neural network of implication relation between a kind of excavation feature based on short connection |
Non-Patent Citations (2)
| Title |
|---|
| 孔斌等: "数据驱动的网络安全风险事件预测技术研究", 《信息安全研究》 * |
| 杜韬等: "多值属性的数据处理与关联规则挖掘方法研究", 《计算机应用研究》 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114116923A (en) * | 2021-12-01 | 2022-03-01 | 厦门市易联众易惠科技有限公司 | Marking system based on prejudgment, method and device thereof and readable storage medium |
| CN114116923B (en) * | 2021-12-01 | 2025-10-14 | 厦门市腾云易惠科技有限公司 | A marking system based on prediction and its method, device and readable storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Ayyub et al. | Uncertainty modeling and analysis in engineering and the sciences | |
| Asanbe et al. | Teachers’ performance evaluation in higher educational institution using data mining technique | |
| Rockwood et al. | Multilevel mediation analysis | |
| Fernandez et al. | Core: A decision support system for regional competitiveness analysis based on multi-criteria sorting | |
| Zhang et al. | Predicting academic performance using tree-based machine learning models: A case study of bachelor students in an engineering department in China | |
| CN118428348B (en) | A method and system for generating learning situation reports based on large language model | |
| JP7720579B1 (en) | Knowledge graph construction method and search system for major recommendation based on large-scale language model | |
| Wang | Intelligent employment rate prediction model based on a neural computing framework and human–computer interaction platform | |
| CN118966858A (en) | A learning recommendation method, device and storage medium for career development | |
| Feng et al. | Testing for balance in social networks | |
| CN115827968A (en) | Individualized knowledge tracking method based on knowledge graph recommendation | |
| Wang | Fuzzy comprehensive evaluation of physical education based on high dimensional data mining | |
| CN108172047A (en) | A personalized real-time recommendation method for online learning resources | |
| Gómez et al. | Accuracy statistics for judging soft classification | |
| Wu et al. | Using apriori algorithm on students’ performance data for Association Rules Mining | |
| Wan et al. | [Retracted] Career Recommendation for College Students Based on Deep Learning and Machine Learning | |
| Kondor et al. | Complex systems perspective in assessing risks in artificial intelligence | |
| Nguyen et al. | An approach to constructing a graph data repository for course recommendation based on IT career goals in the context of big data | |
| Ringland et al. | Beyond the p-value: Bayesian statistics and causation | |
| CN111459994A (en) | A method and system for analyzing big data for disabled people | |
| Hu et al. | Advancing Microdata Privacy Protection: A Review of Synthetic Data | |
| Lan et al. | [Retracted] Evaluation System of Music Art Instructional Quality Based on Convolutional Neural Networks and Big Data Analysis | |
| Zou et al. | Construction of Student Innovation and Entrepreneurship Experience System Integrating K‐Means Clustering Algorithm | |
| CN117877533A (en) | Method and device for predicting mental health level based on situational voice question design | |
| Yan et al. | Cultural ties in American sociology |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |