CN111314156B - Overlay network snapshot acquisition method and evaluation method for peer-to-peer network streaming media - Google Patents
Overlay network snapshot acquisition method and evaluation method for peer-to-peer network streaming media Download PDFInfo
- Publication number
- CN111314156B CN111314156B CN202010134288.7A CN202010134288A CN111314156B CN 111314156 B CN111314156 B CN 111314156B CN 202010134288 A CN202010134288 A CN 202010134288A CN 111314156 B CN111314156 B CN 111314156B
- Authority
- CN
- China
- Prior art keywords
- node
- crawler
- peer
- nodes
- snapshot
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/12—Discovery or management of network topologies
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/951—Indexing; Web crawling techniques
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/104—Peer-to-peer [P2P] networks
- H04L67/1042—Peer-to-peer [P2P] networks using topology management mechanisms
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/104—Peer-to-peer [P2P] networks
- H04L67/1061—Peer-to-peer [P2P] networks using node-based peer discovery mechanisms
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Business, Economics & Management (AREA)
- General Business, Economics & Management (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
- Computer And Data Communications (AREA)
Abstract
本发明公开了一种面向对等网络流媒体的覆盖网络快照获取方法及评价方法,该快照获取方法包括构建面向对等网络流媒体系统的分布式爬虫系统,采用基于节点度排序和节点快照信息反馈机制的预设爬行算法采集目标频道覆盖网络的节点快照,并利用节点快照拓扑微观形变指数、节点快照拓扑宏观稳定指数和覆盖可控节点发现率对网络快照的完整性进行评价。本发明能够避免现有爬虫系统采用单个爬虫终端来采集覆盖网络快照信息带来的爬行效率低下的问题,有效提高爬虫系统的爬行效率,并且保证了爬行结果的完整性和准确性。

The invention discloses an overlay network snapshot acquisition method and evaluation method oriented to peer-to-peer network streaming media. The snapshot acquisition method includes constructing a distributed crawler system oriented to peer-to-peer network streaming media system. The preset crawling algorithm of the feedback mechanism collects the node snapshots of the target channel coverage network, and evaluates the integrity of the network snapshots by using the node snapshot topology microscopic deformation index, the node snapshot topology macroscopic stability index and the coverage controllable node discovery rate. The invention can avoid the problem of low crawling efficiency caused by the existing crawler system using a single crawler terminal to collect snapshot information of the overlay network, effectively improve the crawling efficiency of the crawler system, and ensure the integrity and accuracy of the crawling results.
Description
技术领域technical field
本发明属于计算机科学与技术中的网络通信技术领域,具体涉及一种面向对等网络流媒体的覆盖网络快照获取方法及评价方法。The invention belongs to the technical field of network communication in computer science and technology, and in particular relates to a method for obtaining and evaluating a snapshot of an overlay network for peer-to-peer network streaming media.
背景技术Background technique
近年来,针对对等网络流媒体系统的测量研究受到了来自全球学术界的广泛关注,研究内容已经涵盖了用户行为研究、拓扑结构研究、流量特征研究、安全机制研究等方面。这些研究工作为深入理解大规模对等网络流媒体系统工作原理、系统架构、拓扑属性、流量特征、安全问题等提供了重要的研究思路。其中,基于爬虫技术的主动测量方法通过协议分析技术或逆向工程技术对特定对等网络流媒体系统通信协议进行研究,在此基础上设计爬虫程序伪装成正常的客户端软件加入特定覆盖网络以主动采集相关信息。由于基于爬虫技术的主动测量方法可以准确和直接地获取对等网络流媒体系统的用户信息,该方法被大量用于研究对等网络覆盖网的拓扑结构、用户行为、地理分布、用户规模、安全问题等内容,是目前针对对等网络流媒体系统研究最为有效和主流的测量方法。在主动测量方法中,覆盖网络快照信息是最为重要的一类信息,它包含了某一时刻目标节目覆盖网络中单个节点的IP地址、端口号等基本信息,在线节点的规模和节点间的连接关系等。采集准确的覆盖网节点快照是研究对等网络流媒体系统中用户动态行为特征和拓扑结构演化特征的基础和前提。In recent years, the measurement research on peer-to-peer network streaming media system has received extensive attention from the global academic community, and the research content has covered user behavior research, topology structure research, traffic characteristics research, security mechanism research and so on. These research works provide important research ideas for in-depth understanding of the working principle, system architecture, topology properties, traffic characteristics, and security issues of large-scale peer-to-peer network streaming media systems. Among them, the active measurement method based on crawler technology studies the communication protocol of a specific peer-to-peer network streaming media system through protocol analysis technology or reverse engineering technology. Collect relevant information. Since the active measurement method based on crawler technology can accurately and directly obtain the user information of the peer-to-peer network streaming media system, this method is widely used to study the topology, user behavior, geographical distribution, user scale, security, and security of the peer-to-peer network overlay network. It is the most effective and mainstream measurement method for peer-to-peer network streaming media system research. In the active measurement method, the overlay network snapshot information is the most important kind of information. It includes the basic information such as the IP address and port number of a single node in the overlay network of the target program at a certain moment, the scale of online nodes and the connections between nodes. relationship, etc. Collecting accurate snapshots of overlay network nodes is the basis and premise to study the dynamic behavior characteristics of users and the evolution characteristics of topology structure in peer-to-peer network streaming media systems.
由于对等网络流媒体系统自身具有的大规模、自组织、高度动态等特性使得针对其的主动测量工作面临巨大的挑战:(1)对等网络流媒体覆盖网络具有极强的动态特性,这要求采集节点信息的爬虫程序快速地访问对等网络流媒体覆盖网络中的节点,但爬虫程序的访问速度不仅受限于自身的网络访问能力,还与其爬行过程中交互节点的网络访问速度有关,在爬虫程序采集信息过程中,覆盖网络节点信息总会发生一定程度的变化;(2)对等网络流媒体系统中存在一些不可达节点,节点可能在防火墙或者在NAT(Network AddressTranslator,网络地址转换)之后,这些节点本属于对等网络流媒体系统,但它们并不会对爬虫程序发出的节点列表请求做任何响应并返回其邻居节点信息,可能导致获取覆盖网络节点信息数据并不完整。Due to the large-scale, self-organized, and highly dynamic characteristics of the peer-to-peer network streaming media system itself, the active measurement work for it faces huge challenges: (1) The peer-to-peer network streaming media overlay network has strong dynamic characteristics, which The crawler program that collects node information is required to quickly access the nodes in the peer-to-peer streaming media overlay network, but the access speed of the crawler program is not only limited by its own network access capability, but also related to the network access speed of the interactive nodes during its crawling process. In the process of collecting information by the crawler, the information of the overlay network nodes will always change to a certain extent; (2) There are some unreachable nodes in the peer-to-peer network streaming media system, and the nodes may be in the firewall or in the NAT (Network Address Translator, Network Address Translator). ), these nodes belong to the peer-to-peer network streaming media system, but they do not respond to the node list request sent by the crawler and return their neighbor node information, which may result in incomplete data acquisition of overlay network node information.
目前,在面向对等网络流媒体系统的主动测量研究中,绝大部分的爬虫采用单个爬虫终端来采集覆盖网络快照信息,在评价覆盖网络节点快照采集结果的准确性和完整性方面缺乏系统的指标体系。At present, in the active measurement research for peer-to-peer network streaming media systems, most crawlers use a single crawler terminal to collect overlay network snapshot information, and there is a lack of systematic evaluation of the accuracy and integrity of overlay network node snapshot collection results. indicator system.
发明内容SUMMARY OF THE INVENTION
针对现有技术中存在的以上问题,本发明提供了一种提高爬虫系统爬行效率及爬行结果完整性和准确性的面向对等网络流媒体的覆盖网络快照获取方法及评价方法。Aiming at the above problems existing in the prior art, the present invention provides a method for obtaining and evaluating an overlay network snapshot for a peer-to-peer network streaming media, which improves the crawling efficiency of the crawler system and the integrity and accuracy of the crawling result.
为了达到上述发明目的,本发明采用的技术方案为:In order to achieve the above-mentioned purpose of the invention, the technical scheme adopted in the present invention is:
一种面向对等网络流媒体的覆盖网络快照获取方法,包括以下步骤:A method for obtaining a snapshot of an overlay network for peer-to-peer network streaming media, comprising the following steps:
构建面向对等网络流媒体系统的分布式爬虫系统;Build a distributed crawler system for peer-to-peer streaming media systems;
利用分布式爬虫系统采用预设爬行算法采集目标频道覆盖网络的节点快照。The distributed crawler system uses a preset crawling algorithm to collect node snapshots of the target channel coverage network.
进一步地,所述面向对等网络流媒体系统的分布式爬虫系统具体包括分别与对等网络流媒体系统覆盖网络进行通信的多个节点列表服务器爬虫模块和多个普通节点信息爬虫模块,以及分别与节点列表服务器爬虫模块和普通节点信息爬虫模块进行网络通信的爬虫控制器模块。Further, the distributed crawler system oriented to the peer-to-peer network streaming media system specifically includes multiple node list server crawler modules and multiple common node information crawler modules that communicate with the peer-to-peer network streaming media system overlay network respectively, and respectively. The crawler controller module for network communication with the node list server crawler module and the common node information crawler module.
进一步地,所述爬虫控制器模块具体采用自适应调度算法将爬行任务动态分发给各个爬虫模块,动态调整爬行任务在各个爬虫模块的均衡运行,接收和处理各个爬虫模块反馈的爬行结果并将其保存到数据库中;Further, the crawler controller module specifically adopts an adaptive scheduling algorithm to dynamically distribute the crawling tasks to each crawler module, dynamically adjust the balanced operation of the crawler tasks in each crawler module, receive and process the crawling results fed back by each crawler module and send them back to the crawler module. save to the database;
所述节点列表服务器爬虫模块首先解析频道播放链接获取该频道的节点列表服务器地址和服务端口号,然后利用逆向工程方法获得的对等网络流媒体系统通信协议知识构造与普通客户端相同的节点列表请求报文,不断向节点列表服务器发送节点列表请求报文,采集目标频道覆盖网节点信息;The node list server crawler module first parses the channel play link to obtain the node list server address and service port number of the channel, and then uses the knowledge of the communication protocol of the peer-to-peer network streaming media system obtained by the reverse engineering method to construct the same node list as the ordinary client. Request message, continuously send node list request message to the node list server, and collect target channel overlay network node information;
所述普通节点信息爬虫模块在节点列表服务器爬虫模块完成对目标频道的采集后,对所有节点发送节点列表请求以获得目标节点维护的节点列表信息,最后将所有采集的节点信息进行去重,获得目标频道的最终节点信息并形成节点快照存入到数据库中。The common node information crawler module sends a node list request to all nodes to obtain node list information maintained by the target node after the node list server crawler module completes the collection of the target channel, and finally deduplicates all the collected node information to obtain The final node information of the target channel and form a node snapshot and store it in the database.
进一步地,所述分布式爬虫系统采用预设爬行算法采集目标频道覆盖网络的节点快照具体包括以下分步骤:Further, the distributed crawler system adopts the preset crawling algorithm to collect the node snapshots of the target channel coverage network, which specifically includes the following sub-steps:
(1)利用节点列表服务器爬虫模块首先向频道播放链接解析模块提供的节点列表服务器发送节点列表请求,获得爬行所需的种子节点;(1) Utilize the node list server crawler module to first send a node list request to the node list server provided by the channel play link analysis module to obtain the seed nodes required for crawling;
(2)利用普通节点信息爬虫模块将采集的种子节点存入已发现节点队列中,并将其标记为尚未访问的节点,然后依次向尚未访问的节点发送节点列表请求,最后将已请求过节点列表的节点标记为已访问节点同时存储到已访问节点队列;(2) Use the common node information crawler module to store the collected seed nodes in the discovered node queue, mark them as unvisited nodes, and then send node list requests to the unvisited nodes in turn, and finally request the nodes that have been requested. The nodes in the list are marked as visited nodes and stored in the visited node queue;
(3)当目标节点返回其拥有的节点列表后,利用普通节点信息爬虫模块将收到节点列表中不重复的新节点加入已发现节点队列的队尾;(3) After the target node returns the list of nodes it owns, use the common node information crawler module to add the new nodes that are not repeated in the received node list to the tail of the found node queue;
(4)利用普通节点信息爬虫模块不断向已发现节点队列中尚未访问的节点发送节点列表请求以获取其拥有的伙伴节点信息,直至当前请求的节点为已发现节点队列的最后一个节点时整个爬行过程结束。(4) Use the common node information crawler module to continuously send node list requests to the nodes that have not been visited in the discovered node queue to obtain the partner node information it has, until the currently requested node is the last node of the discovered node queue. The entire crawling Process ends.
进一步地,在爬行过程中,向目标节点发送节点列表请求后,如果该节点超过设定时间阈值或爬行结束时仍未返回其响应报文,则认定该节点为不可达节点,并将该节点保存到不可达节点队列。Further, in the crawling process, after sending a node list request to the target node, if the node exceeds the set time threshold or does not return its response message at the end of the crawling, the node is determined to be an unreachable node, and the node is set as an unreachable node. Save to unreachable node queue.
进一步地,在节点快照采集过程中,上一轮爬行到的节点快照信息在反馈到下一轮之前,首先去除掉不可达的节点和服务器节点,然后根据节点度的大小对节点快照中的节点进行排序,最后将排序后节点度较大的设定比例节点和从节点列表服务器反馈的节点共同作为种子节点成为下一轮爬行的输入。Further, during the node snapshot collection process, before the node snapshot information crawled in the previous round is fed back to the next round, the unreachable nodes and server nodes are first removed, and then the nodes in the node snapshot are analyzed according to the size of the node degree. Sorting is performed, and finally, the set proportion node with larger node degree after sorting and the node fed back from the node list server are jointly used as the seed node and become the input of the next round of crawling.
本发明还提出了一种面向对等网络流媒体的覆盖网络快照采集结果评价方法,包括以下步骤:The present invention also proposes a method for evaluating results of snapshot collection of overlay network oriented to peer-to-peer network streaming media, comprising the following steps:
应用上述的覆盖网络快照获取方法得到覆盖网络快照采集结果;Applying the above-mentioned overlay network snapshot acquisition method to obtain an overlay network snapshot acquisition result;
基于节点快照拓扑形变指数、节点快照拓扑稳定指数和覆盖网络可控节点发现率对覆盖网络快照采集效率和采集结果完整性进行评价。Based on the node snapshot topology deformation index, the node snapshot topology stability index and the overlay network controllable node discovery rate, the collection efficiency of the overlay network snapshot and the integrity of the collection results are evaluated.
进一步地,所述分布式爬虫系统的爬行效率表示为:Further, the crawling efficiency of the distributed crawler system is expressed as:
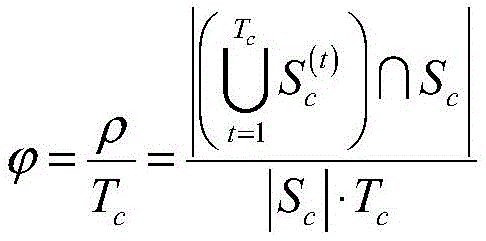
其中,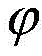
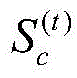
进一步地,设定位于位置A和B的分布式爬虫系统各自在第i轮采集两个节点快照
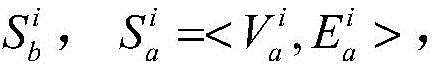
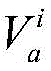
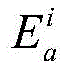

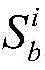
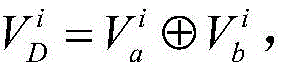


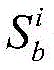
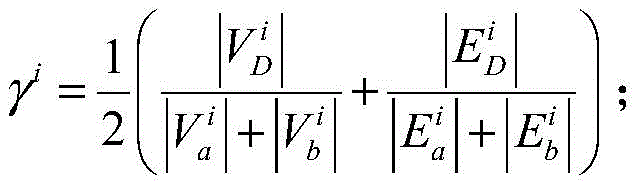
对节点快照

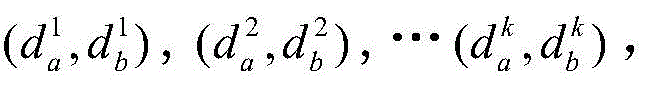
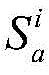
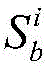

其中,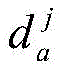
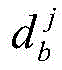
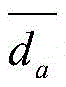

分别在爬虫模块所在地各部署n个可控节点,所述可控节点设置有不同的独立IP地址和端口号,令C=Ca∪Cb∪Cc,Ca、Cb和Cc分别表示三个不同地理位置部署的可控节点集合,则分布式爬虫系统采集N个节点快照的可控节点发现率ψ表示为:Deploy n controllable nodes at the location of the crawler module respectively , and the controllable nodes are provided with different independent IP addresses and port numbers. Represents a set of controllable nodes deployed in three different geographical locations, then the controllable node discovery rate ψ that the distributed crawler system collects snapshots of N nodes is expressed as:
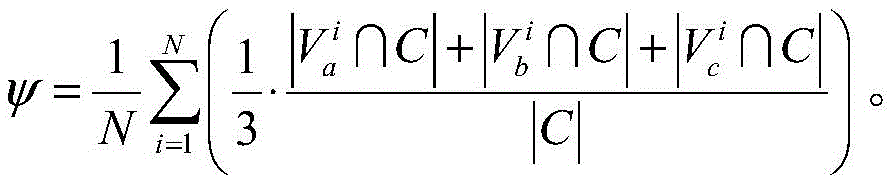
本发明具有以下有益效果:The present invention has the following beneficial effects:
(1)本发明采用分布式架构、节点度排序和节点快照反馈机制构建了一种面向对等网络流媒体系统的高性能爬虫系统,采用预设爬行算法采集目标频道覆盖网络的节点快照,能够避免现有爬虫系统采用单个爬虫终端来采集覆盖网络快照信息带来的爬行效率低下的问题,有效提高爬虫系统的爬行效率;(1) The present invention constructs a high-performance crawler system oriented to a peer-to-peer network streaming media system by adopting a distributed architecture, node degree sorting and node snapshot feedback mechanism, and adopts a preset crawling algorithm to collect node snapshots of the target channel coverage network, which can Avoid the problem of low crawling efficiency caused by the existing crawler system using a single crawler terminal to collect snapshot information of the overlay network, and effectively improve the crawling efficiency of the crawler system;
(2)本发明在分布式爬虫系统的系统架构、爬行算法、爬行速度、爬行结果完整性基础上,形成了一定的测量数据可靠性、完整性和准确性的评价指标和方法,从而保证了爬行结果的完整性和准确性。(2) On the basis of the system architecture, crawling algorithm, crawling speed, and integrity of crawling results of the distributed crawler system, the present invention forms certain evaluation indicators and methods for measuring the reliability, integrity and accuracy of data, thereby ensuring that Completeness and accuracy of crawl results.
附图说明Description of drawings
图1是本发明面向对等网络流媒体的覆盖网络快照获取方法流程示意图;1 is a schematic flowchart of a method for obtaining a snapshot of an overlay network for peer-to-peer network streaming media according to the present invention;
图2是本发明实施例中面向对等网络流媒体的覆盖网络快照获取方法及评价方法框架示意图;2 is a schematic diagram of a framework for obtaining a snapshot of an overlay network and an evaluation method for peer-to-peer network streaming media according to an embodiment of the present invention;
图3是本发明实施例中面向对等网络流媒体系统的分布式爬虫系统框架示意图;3 is a schematic diagram of a distributed crawler system framework for a peer-to-peer network streaming media system in an embodiment of the present invention;
图4是本发明实施例中节点信息存储队列示意图;4 is a schematic diagram of a node information storage queue in an embodiment of the present invention;
图5是本发明实施例中节点快照采集流程示意图。FIG. 5 is a schematic diagram of a flowchart of node snapshot collection in an embodiment of the present invention.
具体实施方式Detailed ways
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。In order to make the objectives, technical solutions and advantages of the present invention clearer, the present invention will be further described in detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the present invention, but not to limit the present invention.
实施例1Example 1
如图1和图2所示,本发明实施例提供了一种面向对等网络流媒体的覆盖网络快照获取方法,包括以下步骤:As shown in FIG. 1 and FIG. 2 , an embodiment of the present invention provides a method for obtaining a snapshot of an overlay network oriented to peer-to-peer network streaming media, including the following steps:
A1、构建面向对等网络流媒体系统的分布式爬虫系统;A1. Build a distributed crawler system for peer-to-peer streaming media systems;
在本发明的一个可选实施例中,对等网络流媒体系统具有的大规模和高度动态的特性使得针对它们的主动测量工作面临了巨大的挑战。已有的研究表明,对等网络系统的覆盖网络具有极强的动态特性,这要求采集节点信息的爬虫程序快速爬行以获得准确的节点快照。否则,由于对等网络流媒体系统覆盖网络中节点的频繁加入和离开,节点快照可能会在爬虫程序爬行过程中发生形变,从而导致采集到不准确的节点快照。更重要的是,已有的研究表明,利用不准确的节点快照来研究对等网络系统覆盖网络的拓扑结构属性很可能会得出完全错误的结论。因此,本发明提出的高性能的分布式爬虫系统对于实施针对对等网络流媒体系统的主动测量研究具有非常重要的意义。In an optional embodiment of the present invention, the large-scale and highly dynamic nature of peer-to-peer streaming media systems makes active measurement work against them a great challenge. Existing research shows that the overlay network of the peer-to-peer network system has strong dynamic characteristics, which requires the crawler program that collects node information to crawl quickly to obtain accurate node snapshots. Otherwise, due to the frequent joining and leaving of nodes in the overlay network of the peer-to-peer streaming media system, the node snapshot may be deformed during the crawling process of the crawler, resulting in inaccurate node snapshots being collected. More importantly, existing studies have shown that using inaccurate node snapshots to study the topological properties of the overlay network of peer-to-peer systems is likely to draw completely wrong conclusions. Therefore, the high-performance distributed crawler system proposed by the present invention is of great significance for implementing active measurement research for the peer-to-peer network streaming media system.
上述的面向对等网络流媒体系统的分布式爬虫系统具体包括分别与对等网络流媒体系统覆盖网络进行通信的多个节点列表服务器爬虫模块和多个普通节点信息爬虫模块,以及分别与节点列表服务器爬虫模块和普通节点信息爬虫模块进行网络通信的爬虫控制器模块,如图3所示。The above-mentioned distributed crawler system for the peer-to-peer network streaming media system specifically includes a plurality of node list server crawler modules and a plurality of common node information crawler modules that communicate with the peer-to-peer network streaming media system overlay network respectively, and respectively communicate with the node list. The crawler controller module for network communication between the server crawler module and the common node information crawler module is shown in Figure 3.
其中爬虫控制器模块是分布式爬虫系统的核心,其具体用于将爬行任务根据需要动态分发给各个爬虫模块,动态调整爬行任务在各个爬虫模块的均衡运行,接收和处理各个爬虫模块反馈的爬行结果并将其保存到数据库中。为了充分利用各个爬虫模块的节点信息采集能力,爬虫控制器模块与各个爬虫终端进行实时的任务进度交互以掌握它们的任务执行情况,并采用自适应调度算法对爬行任务进行动态分配。The crawler controller module is the core of the distributed crawler system, which is specifically used to dynamically distribute crawling tasks to each crawler module as needed, dynamically adjust the balanced operation of crawling tasks in each crawler module, and receive and process the crawling feedback from each crawler module. result and save it to the database. In order to make full use of the node information collection capability of each crawler module, the crawler controller module interacts with each crawler terminal in real-time task progress to master their task execution status, and uses an adaptive scheduling algorithm to dynamically allocate crawling tasks.
节点列表服务器爬虫模块首先解析频道播放链接获取该频道的节点列表服务器地址和服务端口号,然后利用逆向工程方法获得的对等网络流媒体系统通信协议知识构造与普通客户端相同的节点列表请求报文,不断向节点列表服务器发送节点列表请求报文,采集目标频道覆盖网节点信息。由于节点列表服务器无法区分正常的对等网络流媒体客户端和节点列表服务器爬虫系统,因此爬虫程序可以采用这种方式不断地采集目标频道种子节点信息。The node list server crawler module first parses the channel play link to obtain the node list server address and service port number of the channel, and then uses the peer-to-peer network streaming media system communication protocol knowledge obtained by reverse engineering to construct the same node list request report as the ordinary client. It continuously sends node list request messages to the node list server, and collects the target channel overlay network node information. Since the node list server cannot distinguish between the normal peer-to-peer network streaming media client and the node list server crawler system, the crawler program can continuously collect the target channel seed node information in this way.
当节点列表服务器爬虫模块完成对目标频道的采集后,对采集的来自不同节点列表服务器的节点信息进行去重处理,并将去重后的节点信息发送给普通节点信息爬虫模块并启动普通节点信息爬虫模块。普通节点信息爬虫模块对所有节点发送节点列表请求以获得目标节点维护的节点列表信息,最后将所有采集的节点信息进行去重,获得目标频道的最终节点信息并形成节点快照存入到数据库中。When the node list server crawler module completes the collection of the target channel, it deduplicates the collected node information from different node list servers, and sends the deduplicated node information to the common node information crawler module and starts the common node information crawler module. The common node information crawler module sends a node list request to all nodes to obtain the node list information maintained by the target node, and finally deduplicates all the collected node information, obtains the final node information of the target channel, and forms a node snapshot and stores it in the database.
A2、利用分布式爬虫系统采用预设爬行算法采集目标频道覆盖网络的节点快照。A2. Use a distributed crawler system to collect node snapshots of the target channel coverage network by using a preset crawling algorithm.
在本发明的一个可选实施例中,上述分布式爬虫系统采用预设爬行算法采集目标频道覆盖网络的节点快照具体包括以下分步骤:In an optional embodiment of the present invention, the above-mentioned distributed crawler system adopts a preset crawling algorithm to collect node snapshots of the target channel coverage network, which specifically includes the following sub-steps:
(1)利用节点列表服务器爬虫模块首先向频道播放链接解析模块提供的节点列表服务器发送节点列表请求,获得爬行所需的种子节点;这里发送的请求次数可以设置为10次;(1) Using the node list server crawler module to first send a node list request to the node list server provided by the channel play link analysis module to obtain the seed nodes required for crawling; the number of requests sent here can be set to 10 times;
(2)利用普通节点信息爬虫模块将采集的种子节点存入已发现节点队列(Queenof Discovered Peers,Queen-D)中,并将其标记为尚未访问的节点(Unvisited Peers);然后依次向尚未访问的节点发送节点列表请求,这里发送的请求次数可以设置为3次;最后将已请求过节点列表的节点标记为已访问节点(Visited Peers)同时存储到已访问节点队列(Queen of Visited Peers,Queen-V);(2) Use the common node information crawler module to store the collected seed nodes in the queue of discovered nodes (Queen of Discovered Peers, Queen-D), and mark them as unvisited peers (Unvisited Peers); The number of requests sent here can be set to 3 times; finally, the nodes that have requested the node list are marked as visited nodes (Visited Peers) and stored in the visited node queue (Queen of Visited Peers, Queen of Visited Peers, Queen of Visited Peers) -V);
(3)当目标节点返回其拥有的节点列表后,利用普通节点信息爬虫模块将收到节点列表中不重复的新节点加入已发现节点队列Queen-D的队尾;(3) After the target node returns the list of nodes it owns, use the common node information crawler module to add the new nodes that are not repeated in the received node list to the tail of the found node queue Queen-D;
(4)利用普通节点信息爬虫模块不断向已发现节点队列Queen-D中尚未访问的节点发送节点列表请求以获取其拥有的伙伴节点信息,直至当前请求的节点(Current Peer)为已发现节点队列Queen-D的最后一个节点(Last peer)时整个爬行过程结束。(4) The common node information crawler module is used to continuously send node list requests to the nodes that have not been visited in the found node queue Queen-D to obtain the partner node information it has, until the currently requested node (Current Peer) is the found node queue. The whole crawling process ends when Queen-D is the last node (Last peer).
本发明的分布式爬虫系统采用了类似广度优先遍历的爬行策略,但与已有研究工作中判定爬行过程终止条件采用固定的爬行周期和评估新增节点的数量不同。本发明的分布式爬虫系统的爬行终止条件依赖于节点列表请求报文发送时间间隔Δt的设置。The distributed crawler system of the present invention adopts a crawling strategy similar to breadth-first traversal, but is different from the existing research work, which adopts a fixed crawling period and evaluates the number of newly added nodes for determining the termination condition of the crawling process. The crawling termination condition of the distributed crawler system of the present invention depends on the setting of the node list request message sending time interval Δt.
在爬行过程中,向目标节点发送节点列表请求后,如果该节点超过设定时间阈值Tu或爬行结束时仍未返回其响应报文,则认定该节点为不可达节点(Unreachable peers),并将该节点保存到不可达节点队列Queen-U。节点信息存储队列结构如图4所示。During the crawling process, after sending a node list request to the target node, if the node exceeds the set time threshold T u or does not return its response message at the end of the crawling, the node is considered as unreachable peers (Unreachable peers), and Save the node to the unreachable node queue Queen-U. The structure of the node information storage queue is shown in Figure 4.
为了进一步提高分布式爬虫系统的爬行性能,本发明通过增加节点度排序机制和节点快照信息反馈机制,即将每一轮的爬行结果经过重要度排序算法处理后作为输入反馈到下一轮的爬行中,以减少爬虫系统在爬行初始阶段获取种子节点的时间消耗,如图5所示。具体来说,上一轮爬行到的节点快照信息在反馈到下一轮之前,需要先去除掉那些不可达的节点和服务器节点(包括节点列表服务器和流媒体分发服务器节点);然后根据节点度的大小对节点快照中的节点进行排序;最后将排序后节点度最大的前30%的节点和从节点列表服务器反馈的节点一同作为种子节点成为下一轮爬行的输入。In order to further improve the crawling performance of the distributed crawler system, the present invention adds a node degree sorting mechanism and a node snapshot information feedback mechanism, that is, the crawling results of each round are processed by the importance sorting algorithm and fed back to the next round of crawling as an input , in order to reduce the time consumption of the crawler system to obtain seed nodes in the initial stage of crawling, as shown in Figure 5. Specifically, before the node snapshot information crawled in the previous round is fed back to the next round, it is necessary to remove those unreachable nodes and server nodes (including node list server and streaming media distribution server nodes); The nodes in the node snapshot are sorted by the size of the node snapshot; finally, the top 30% nodes with the largest node degree after sorting and the nodes fed back from the node list server are used as the seed nodes as the input of the next round of crawling.
其中,频道覆盖网络节点快照采集时间间隔(Crawling interval)的取值可根据爬虫系统的爬行速度和观测拓扑快照变化频率的需要进行调整。The value of the time interval (Crawling interval) for channel coverage network node snapshot collection can be adjusted according to the crawling speed of the crawler system and the need to observe the change frequency of topology snapshots.
实施例2Example 2
基于上述面向对等网络流媒体的覆盖网络快照获取方法,本发明还提出了一种面向对等网络流媒体的覆盖网络快照采集结果评价方法,如图2所示,包括以下步骤:Based on the above-mentioned method for obtaining an overlay network snapshot for peer-to-peer network streaming media, the present invention also proposes a method for evaluating a result of overlay network snapshot collection for peer-to-peer network streaming media, as shown in FIG. 2 , including the following steps:
B1、应用上述的覆盖网络快照获取方法得到覆盖网络快照采集结果;B1. Apply the above-mentioned overlay network snapshot acquisition method to obtain an overlay network snapshot acquisition result;
B2、基于节点快照拓扑形变指数、节点快照拓扑稳定指数和覆盖网络可控节点发现率对覆盖网络快照采集效率和采集结果完整性进行评价。B2. Based on the node snapshot topology deformation index, the node snapshot topology stability index and the overlay network controllable node discovery rate, the collection efficiency of the overlay network snapshot and the integrity of the collection result are evaluated.
本发明的分布式爬虫系统采用UDP协议来发送伪造的通信协议报文,并与节点列表服务器和普通节点进行交互。所以,在不考虑网络不稳定因素对爬行过程影响的情况下,爬行过程的终止条件将取决于爬虫发送节点列表请求的速度(即单位时间里消耗图3的Queen-D中尚未访问节点的数量)和目标节点返回其伙伴节点信息的速度。其中,后者直接影响到单位时间里图3中队列Queen-D新增节点的数量。而伙伴节点信息的反馈速度主要受爬虫和目标节点的网络带宽、目标节点反馈的邻居节点数量、爬虫发送节点列表的速度等因素影响。如果爬虫发送节点列表请求的速度过快,将可能导致反馈回的节点列表信息尚未到达爬虫终端,爬行过程就已结束,这将导致爬虫系统无法采集到准确的节点快照。相反,如果发送节点列表请求速度过慢,虽然可以获得较为完整的节点信息,但这将增加整个爬行过程的耗时。同时,过长的爬行时间很可能导致采集的节点快照在爬行期间发生形变,从而影响网络拓扑结构测量结果的准确性。因此,设置爬虫终端模块合适的节点列表请求速度至关重要。The distributed crawler system of the present invention uses the UDP protocol to send forged communication protocol messages, and interacts with the node list server and common nodes. Therefore, without considering the influence of network instability factors on the crawling process, the termination condition of the crawling process will depend on the speed at which the crawler sends the node list request (that is, the number of nodes that have not been visited in the Queen-D of Figure 3 consumed per unit time). ) and the speed at which the target node returns information about its partner nodes. Among them, the latter directly affects the number of new nodes in the queue Queen-D in Figure 3 per unit time. The feedback speed of partner node information is mainly affected by the network bandwidth of the crawler and the target node, the number of neighbor nodes fed back by the target node, and the speed at which the crawler sends the node list. If the crawler sends the node list request too fast, the feedback node list information may not reach the crawler terminal, and the crawling process has ended, which will cause the crawler system to fail to collect accurate node snapshots. On the contrary, if the sending speed of the node list request is too slow, although relatively complete node information can be obtained, it will increase the time-consuming of the whole crawling process. At the same time, too long crawling time is likely to cause the node snapshots collected to be deformed during the crawling, thus affecting the accuracy of the network topology measurement results. Therefore, it is very important to set the appropriate node list request speed of the crawler terminal module.
为了便于分析爬虫终端的爬行性能,评估其爬行效率,本发明假设分布式爬虫系统在一轮爬行中,第t秒钟采集到的目标频道覆盖网络节点快照为
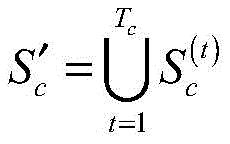
假设Sc为此时目标频道c覆盖网络中的真实节点快照,那么爬虫终端采集频道c覆盖网络节点快照的完整度ρ表示为:Assuming that S c is the real node snapshot in the coverage network of the target channel c at this time, then the integrity ρ of the node snapshot of the coverage network node of the channel c collected by the crawler terminal is expressed as:
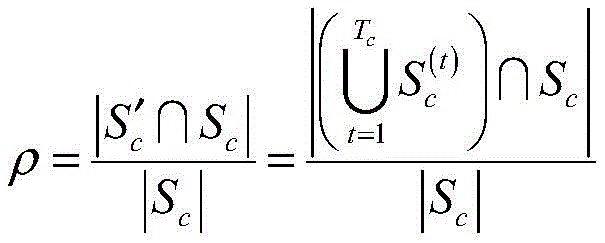
完整度ρ可用于衡量爬虫终端采集节点快照的准确性,但由于对等网络流媒体系统的分布式特性和高度动态特性,使得研究人员很难获得准确的节点快照Sc。因此,计算爬虫终端系统采集的节点快照的完整度ρ面临巨大的挑战。The integrity ρ can be used to measure the accuracy of node snapshots collected by crawler terminals, but due to the distributed and highly dynamic characteristics of peer-to-peer streaming media systems, it is difficult for researchers to obtain accurate node snapshots S c . Therefore, computing the integrity ρ of the node snapshots collected by the crawler terminal system faces a huge challenge.
在高度动态的对等网络流媒体系统中,节点每时每刻都在频繁加入和离开系统,爬虫系统在爬行过程中总会伴随着节点的加入或者离开。节点的这些行为会导致爬虫系统无法获得准确的节点快照Sc,爬行采集获得的节点可能比真实的节点多。此外,有研究表明,即使系统自身的管理平台也无法提供完全精确的实时在线节点信息,更新已经离开系统的节点状态时存在一定滞后性。当节点已经离开了目标频道的覆盖网络,但是节点列表服务器并未立即将其删除,这将导致爬虫终端仍然可以从节点列表服务器中采集到该节点。因此,本文在定义爬虫系统采集的节点快照完整度时使用了Sc和Sc′的交集来表示爬虫采集到的真实节点集合,同时假设爬虫在低于时间阈值Ts里完成爬行过程则节点快照Sc′不发生形变。In a highly dynamic peer-to-peer streaming media system, nodes join and leave the system frequently at all times, and the crawler system always accompanies the joining or leaving of nodes during the crawling process. These behaviors of nodes will cause the crawler system to fail to obtain an accurate node snapshot S c , and the crawler collection may acquire more nodes than real nodes. In addition, studies have shown that even the system's own management platform cannot provide completely accurate real-time online node information, and there is a certain lag in updating the status of nodes that have left the system. When the node has left the overlay network of the target channel, but the node list server does not delete it immediately, this will cause the crawler terminal to still collect the node from the node list server. Therefore, this paper uses the intersection of S c and S c ′ to represent the real node set collected by the crawler when defining the completeness of the node snapshots collected by the crawler system. At the same time, it is assumed that the crawler completes the crawling process within the time threshold T s Snapshot S c ' is not deformed.
在已知爬虫终端采集目标频道覆盖网络的节点快照完整度ρ和爬行过程的总共耗时Tc后,本文定义爬虫系统的爬行效率表示为:After it is known that the crawler terminal collects the node snapshot integrity ρ of the target channel coverage network and the total time-consuming T c of the crawling process, this paper defines the crawling efficiency of the crawler system as:

其中,
根据爬行效率的定义,爬虫终端在爬行过程中的耗时Tc越短则爬行效率越高,爬虫终端采集的节点快照越完整则爬行效率越高。爬行效率表征了爬虫系统采集节点快照的准确性和爬行速度。根据上面的分析可知,爬虫终端爬行过程的终止条件主要取决于爬虫发送节点列表请求的速度。在测量过程中,本文通过对实验中爬虫终端发送节点列表请求的时间间隔Δt和爬行耗时Tc之间关系的测量数据进行曲线拟合发现,Δt与爬行时间Tc存在一定的线性关系。爬行耗时Tc是关于Δt的单调递增函数。因此,当节点快照Sc′在爬行过程中不发生形变(0<Tc≤Ts),那么爬虫系统的爬行效率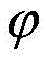
根据对爬虫终端采集节点快照完整度ρ的定义和对其的分析可知,目标频道的节点快照Sc仅理论上存在。由于对等网络流媒体系统高度动态性使得爬虫系统和对等网络流媒体系统运营平台本身均很难获得精确的节点快照Sc,因此节点快照完整度ρ无法进行精确的量化计算。验证爬虫系统采集的节点快照是否完整的一个可靠方法是向节点快照Sc′中所有节点发送会话连接请求,通过评估目标节点对会话连接请求的响应情况来判断当前节点的在线状态。但是,已有表明由于大量的节点位于防火墙或者NAT设备后面,大量的节点并不对爬虫程序发出的会话建立请求做出响应。因此,本发明采用让可控节点加入目标频道覆盖网络,然后通过评估爬虫系统是否能捕获到该可控节点的加入和离开行为来验证爬虫采集快照的准确性。本发明基于节点快照拓扑形变指数、节点快照拓扑稳定指数和覆盖网络可控节点发现率这3个测量指标来详细评估本发明的分布式爬虫系统采集结果的完整性。According to the definition and analysis of the completeness ρ of node snapshots collected by the crawler terminal, the node snapshot S c of the target channel only exists in theory. Due to the highly dynamic nature of the peer-to-peer streaming media system, it is difficult for the crawler system and the operating platform of the peer-to-peer streaming media system to obtain an accurate node snapshot S c , so the node snapshot integrity ρ cannot be accurately quantified. A reliable method to verify whether the node snapshot collected by the crawler system is complete is to send a session connection request to all nodes in the node snapshot S c ′, and judge the online status of the current node by evaluating the response of the target node to the session connection request. However, it has been shown that a large number of nodes do not respond to session establishment requests issued by the crawler due to the large number of nodes located behind firewalls or NAT devices. Therefore, the present invention adopts the controllable node to join the target channel coverage network, and then verifies the accuracy of the crawler's snapshot collection by evaluating whether the crawler system can capture the join and leave behavior of the controllable node. The present invention evaluates the integrity of the collection results of the distributed crawler system of the present invention in detail based on the three measurement indexes of the node snapshot topology deformation index, the node snapshot topology stability index and the coverage network controllable node discovery rate.
定义位于地理位置A的分布式爬虫系统采集的时间连续的在线节点快照集合为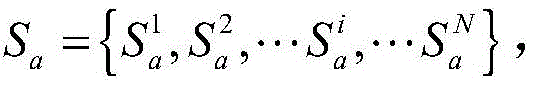
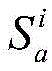
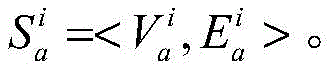
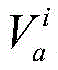
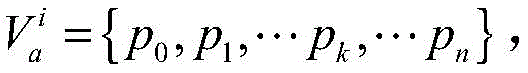

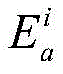
对于位于位置A和B的爬虫系统各自在第i轮采集两个节点快照
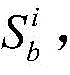
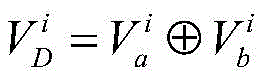
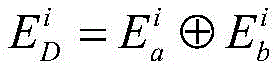
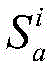
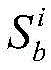
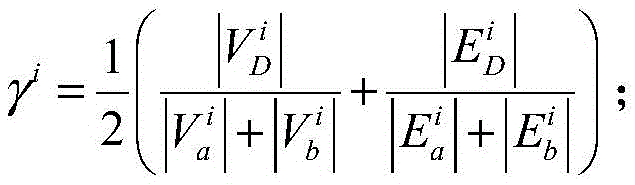
同理,可以计算任意两个节点快照的拓扑形变指数。当两个节点快照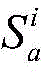
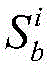
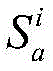
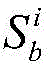
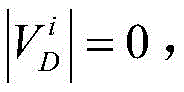
对于节点快照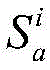
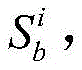
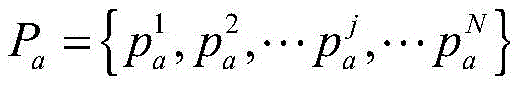
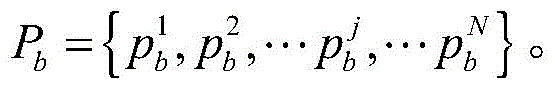
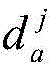
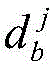

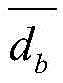
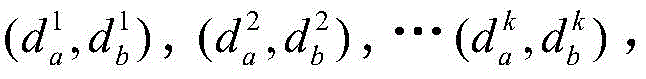
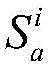
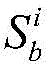
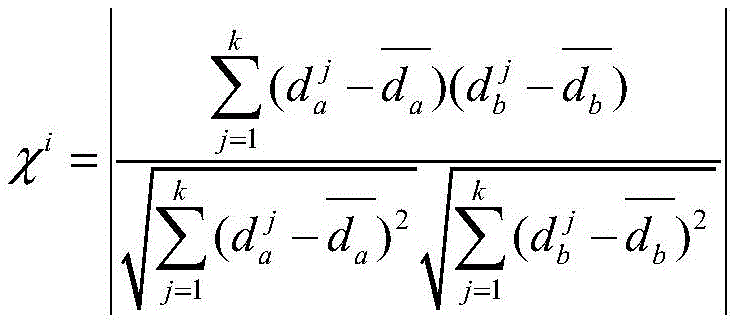
同理,可以计算任意两个节点快照的拓扑稳定指数。它反映了两个拓扑快照宏观的相似程度,其值越大,则对应的两个节点快照拓扑相似程度越高,反之则越低,稳定性指数χ的取值范围同样在[0,1]。Similarly, the topological stability index of snapshots of any two nodes can be calculated. It reflects the macroscopic similarity of two topological snapshots. The larger the value, the higher the topological similarity of the corresponding two node snapshots, and vice versa. The value range of the stability index χ is also in [0,1] .
为了表征本发明的分布式爬虫系统发现频道覆盖网络中可控节点的能力,分别在爬虫所在地各部署了n个可控节点,这些可控节点拥有不同的独立IP地址和端口号,并在分布式爬虫系统启动前加入目标频道覆盖网络。由Ca,Cb和Cc分别表示三个不同地理位置部署的可控节点集合,其中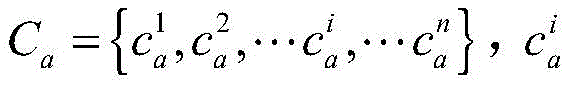

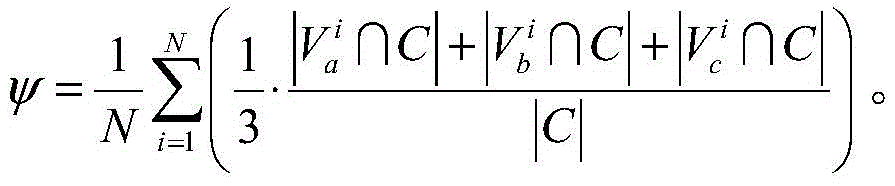
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。Those of ordinary skill in the art will appreciate that the embodiments described herein are intended to assist readers in understanding the principles of the present invention, and it should be understood that the scope of protection of the present invention is not limited to such specific statements and embodiments. Those skilled in the art can make various other specific modifications and combinations without departing from the essence of the present invention according to the technical teaching disclosed in the present invention, and these modifications and combinations still fall within the protection scope of the present invention.
Claims (5)
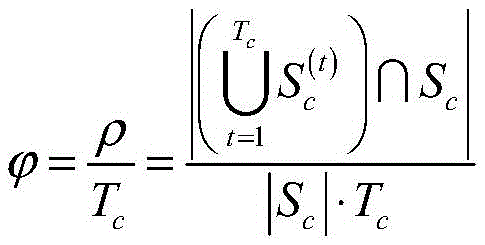
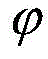
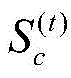
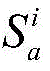



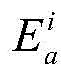
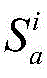
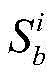
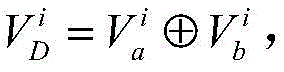


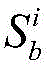
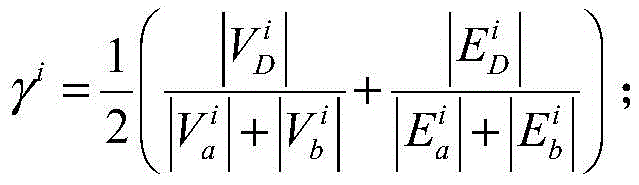



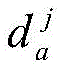
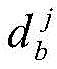
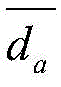
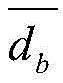
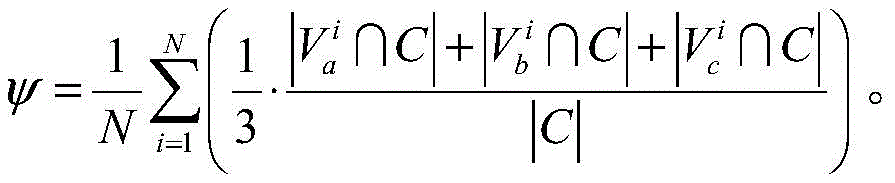
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010134288.7A CN111314156B (en) | 2020-03-02 | 2020-03-02 | Overlay network snapshot acquisition method and evaluation method for peer-to-peer network streaming media |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010134288.7A CN111314156B (en) | 2020-03-02 | 2020-03-02 | Overlay network snapshot acquisition method and evaluation method for peer-to-peer network streaming media |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111314156A CN111314156A (en) | 2020-06-19 |
| CN111314156B true CN111314156B (en) | 2020-12-01 |
Family
ID=71147882
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010134288.7A Active CN111314156B (en) | 2020-03-02 | 2020-03-02 | Overlay network snapshot acquisition method and evaluation method for peer-to-peer network streaming media |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111314156B (en) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105307050A (en) * | 2015-10-26 | 2016-02-03 | 何震宇 | HEVC-based network streaming media application system and method |
| CN106133774A (en) * | 2014-03-28 | 2016-11-16 | 谷歌公司 | Automatic Verification of Advertiser Identifiers in Advertisements |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040088301A1 (en) * | 2002-10-31 | 2004-05-06 | Mallik Mahalingam | Snapshot of a file system |
| US9100362B2 (en) * | 2012-07-06 | 2015-08-04 | Yahoo! Inc. | Peer-to-peer architecture for web traffic management |
| CN107888436A (en) * | 2016-09-30 | 2018-04-06 | 郑州云海信息技术有限公司 | A kind of P2P network routing tables acquisition method, flow and equipment |
-
2020
- 2020-03-02 CN CN202010134288.7A patent/CN111314156B/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106133774A (en) * | 2014-03-28 | 2016-11-16 | 谷歌公司 | Automatic Verification of Advertiser Identifiers in Advertisements |
| CN105307050A (en) * | 2015-10-26 | 2016-02-03 | 何震宇 | HEVC-based network streaming media application system and method |
Non-Patent Citations (2)
| Title |
|---|
| 基于度排序的P2P IPTV分布式爬虫系统设计与实现;王海舟,陈兴蜀,王文贤;《四川大学学报》;20170118;第46卷(第3期);109-115 * |
| 对等网络拓扑测量与特征分析;王勇,云晓春,李奕飞;《软件学报》;20080526;第19卷(第4期);981-992 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111314156A (en) | 2020-06-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN102724063B (en) | Log acquisition server and packet delivery, Log Clustering method and network | |
| Rasti et al. | Respondent-driven sampling for characterizing unstructured overlays | |
| CN107181724B (en) | Identification method and system of cooperative flow and server using method | |
| Voulgaris et al. | A robust and scalable peer-to-peer gossiping protocol | |
| CN109359385A (en) | A training method and device for a service quality assessment model | |
| CN112187710B (en) | Method and device for sensing threat intelligence data, electronic device and storage medium | |
| CN101795214B (en) | Behavior-based P2P detection method under large traffic environment | |
| CN105245362B (en) | Important node information collecting method in a kind of SDN environment | |
| Erman et al. | Bittorrent session characteristics and models | |
| Stutzbach et al. | Characterizing churn in peer-to-peer networks | |
| WO2020187295A1 (en) | Monitoring of abnormal host | |
| Rasti et al. | Evaluating sampling techniques for large dynamic graphs | |
| CN111314156B (en) | Overlay network snapshot acquisition method and evaluation method for peer-to-peer network streaming media | |
| CN104639351A (en) | Processing system and method for constructing network structure deployment diagram | |
| Bolla et al. | A measurement study supporting p2p file-sharing community models | |
| CN118827314B (en) | Computing resource discovery method and system based on double-layer planning model | |
| Maia et al. | Dataflasks: epidemic store for massive scale systems | |
| Psaltoulis et al. | Practical algorithms for size estimation in large and dynamic groups | |
| CN101883030B (en) | Detection method of P2P nodes based on random measure of IP addresses | |
| CN118869511A (en) | Network energy consumption assessment method, device, equipment, storage medium and program product | |
| Wu et al. | Optimization design and realization of ceph storage system based on software defined network | |
| CN110543496A (en) | Data processing method and device for time series database cluster | |
| Salah et al. | Characterizing Graph-theoretic Properties of a large-scale DHT: Measurements vs. Simulations | |
| CN112860378B (en) | A method, system, device and storage medium for calculating minimum virtual resources required for playback traffic | |
| Zhang et al. | Exploiting proximity in cooperative download of large files in peer-to-peer networks |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |