CN111163056A - Data confidentiality method and system aiming at MapReduce calculation - Google Patents
Data confidentiality method and system aiming at MapReduce calculation Download PDFInfo
- Publication number
- CN111163056A CN111163056A CN201911244325.3A CN201911244325A CN111163056A CN 111163056 A CN111163056 A CN 111163056A CN 201911244325 A CN201911244325 A CN 201911244325A CN 111163056 A CN111163056 A CN 111163056A
- Authority
- CN
- China
- Prior art keywords
- key
- reduce
- task
- stage
- value
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims abstract description 48
- 238000004364 calculation method Methods 0.000 title claims description 18
- 238000012545 processing Methods 0.000 claims abstract description 45
- 238000007781 pre-processing Methods 0.000 claims abstract description 11
- 238000005192 partition Methods 0.000 claims description 81
- 238000003860 storage Methods 0.000 claims description 17
- 238000013507 mapping Methods 0.000 claims description 15
- 230000008569 process Effects 0.000 claims description 15
- 230000006870 function Effects 0.000 description 96
- 238000005315 distribution function Methods 0.000 description 12
- 238000009826 distribution Methods 0.000 description 9
- 238000004458 analytical method Methods 0.000 description 4
- 230000005540 biological transmission Effects 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 239000003638 chemical reducing agent Substances 0.000 description 3
- 230000000717 retained effect Effects 0.000 description 3
- 238000003491 array Methods 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000012634 fragment Substances 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000008092 positive effect Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images





Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L63/00—Network architectures or network communication protocols for network security
- H04L63/04—Network architectures or network communication protocols for network security for providing a confidential data exchange among entities communicating through data packet networks
- H04L63/0428—Network architectures or network communication protocols for network security for providing a confidential data exchange among entities communicating through data packet networks wherein the data content is protected, e.g. by encrypting or encapsulating the payload
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L63/00—Network architectures or network communication protocols for network security
- H04L63/14—Network architectures or network communication protocols for network security for detecting or protecting against malicious traffic
- H04L63/1408—Network architectures or network communication protocols for network security for detecting or protecting against malicious traffic by monitoring network traffic
- H04L63/1416—Event detection, e.g. attack signature detection
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L63/00—Network architectures or network communication protocols for network security
- H04L63/14—Network architectures or network communication protocols for network security for detecting or protecting against malicious traffic
- H04L63/1441—Countermeasures against malicious traffic
Landscapes
- Engineering & Computer Science (AREA)
- Computer Security & Cryptography (AREA)
- Computer Hardware Design (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Storage Device Security (AREA)
Abstract
The invention belongs to the technical field of cloud computing data confidentiality, and discloses a data confidentiality method and system aiming at MapReduce computing, wherein Full Shuffle and Safe Shuffle are provided under a standard MapReduce computing framework; input data is sorted into a key-value key value pair form for preprocessing; merging the key values in each Map task of the Map sub-stage according to the key values; distributing the merged key value pair to each reduce task of a Reducing stage layer respectively; processing the data received by each Reduce task in the Reduce sub-stage; and enabling the output data size of each reduce task to be equal. The method and the device protect data and privacy based on the MapReduce framework in a remote execution environment scene, and avoid the data privacy of the application program from being obtained by a malicious observer through side channel attack.
Description
Technical Field
The invention belongs to the technical field of cloud computing data confidentiality, and particularly relates to a data confidentiality method and system for MapReduce computing.
Background
Currently, the closest prior art: MapReduce is a parallel programming model, is used for the parallel computation of large-scale data set, has the characteristics of functional programming language and vector programming language, and has the functions of data division, computation task scheduling, system optimization, error detection and recovery, so that MapReduce is suitable for application programs such as log analysis, machine learning, distribution sequencing and the like. A MapReduce job is a unit of work that a user wishes to be performed: it includes input data, a MapReduce program and configuration information. MapReduce runs a job by dividing it into tasks. Tasks are divided into a map task (map task) and a reduce task (reduce task). The standard MapReduce data flow of the multi-Reduce task is composed of stages such as fragments, Map and Reduce. Each map task in MapReduce can be subdivided into 4 phases: recordread (for data splitting), map, combine (for data aggregation, this stage may be omitted), partition (for data splitting). Each reduce task in Hadoop can be subdivided into 4 stages: shuffle, sort, reduce, and output format.
Hadoop is an implementation of the MapReduce framework. The software platform is a software platform for developing and operating large-scale data, is an open source software framework realized by Apache in java language, and realizes distributed calculation of mass data by a cluster consisting of a large number of computers. Hadoop has the advantages of high efficiency, low cost, strong capacity expansion capability and reliability. The most core design of the Hadoop framework is as follows: HDFS and MapReduce. HDFS provides storage for massive data, while MapReduce provides computation for massive data.
SGX, fully known as Intel Software Guard Extensions, is a set of x86-64ISA Extensions that can set up a protected execution environment (called Enclave) without requiring any trust other than the code that the processor and user place in its Enclave. Once the software and data are in the Enclave, even the operating system or vmm (hypervisor) cannot affect the code and data inside the Enclave. The security boundary for Enclave contains only the CPU and itself. Enclave is protected by the processor: the processor controls access to the Enclave memory. An instruction attempting to read from or write to the memory of the executing Enclave from outside the Enclave will fail. The Enclave cache line is encrypted and integrity protected before being written to memory (RAM). Enclave code may be called from untrusted code through a callgate calling mechanism similar to the Intel x86 architecture, which transfers control to a user-defined entry point within the Enclave. SGX supports remote authentication, which enables a remote system to cryptographically verify whether particular software has been loaded in secure zone Enclave and establish end-to-end encrypted channel shared secrets.
Cloud computing is the development of grid computing, distributed processing and parallel processing, can be regarded as the realization of business service modes on the computer science concepts, and is a server cluster which is used for computing and can provide super-large-scale computing resources. As a business service mode based on network computing, a cloud computing user can acquire storage space, computing capacity, software service and the like according to the needs of the user, and computing tasks are distributed in a resource pool formed by a large number of computers, so that the computing capacity of the user is not limited by the resources of the user, and the computing tasks with large loads are outsourced to the cloud to complete high-cost computing.
Although cloud computing has many advantages such as virtualization, on-demand service, high extensibility, and the like, a user puts applications, data, and the like on a cloud server, and certain risks are inevitably encountered, and it can be expected that a risk of privacy disclosure will be brought by relying on a cloud computing provider to process sensitive data. The credibility problem of the cloud service provider will seriously affect the effective use of the cloud service by the user.
The use of a public cloud infrastructure to store and process large datasets raises new security issues. Current solutions suggest encrypting all data and accessing it only in the clear within the secure hardware. Such as the VC3 system developed by microsoft corporation, which relies on SGX to protect the operation of local map tasks and reduce tasks, can leverage the popular Hadoop framework to ensure integrity and confidentiality. All data is encrypted by the system AES-GCM.
Even in VC3 systems protected with a secure environment, the distributed processing of large amounts of data still involves intensive encrypted communication between different processing and network storage units, and these modes of communication may leak sensitive information. Protecting only the individual elements of the distributed computation (e.g., the map and reduce elements) inevitably exposes the attacker to several leakage paths of important information. The data volume of the map and reduce jobs, which is visible to the cloud provider and to a lesser extent to other users, observes and associates a series of intermediate key-value pairs exchanged between each map and each reduce, sensitive information being learnt by the data volume size.
IN view of THE above problems, two schemes, SHUFFLE-IN-THE-MIDDLE, were proposed IN Microsoft's research paper Observing and preventingleakage IN MapReduce to prevent intermediate traffic analysis of jobs by safely shuffling all key-value pairs that give all map generation to all Reduce uses. However, the attacker still observes the number of records generated by each map task, the number of records received by the reduce task and the association distribution condition among the records, and the efficiency is low. The SHUFFLE & BALANCE scheme divides the preprocessing into an off-line stage and an on-line stage, and the off-line stage randomizes the sequence of input records to ensure that all map tasks generate the same key-value pair distribution. And sampling input data in an online stage, collecting statistical information of key value pairs generated by maps for balancing between the reduce, and estimating the upper limit of the number of the key value pairs sent to each reduce by each mapper according to probability, so that the intermediate flow sent by each map task is uniformly distributed to each reduce task to meet higher safety definition. But actually, the off-line phase of the scheme randomizes the sequence of input records, so that the maximum key value distribution values of two groups of input data sets with the same size are equal in the running process. This process of randomizing records is time consuming and results in offline inefficiencies and still suffers from insufficient security, such as the scheme may reveal relevant data set information (maximum key values).
In summary, the problems of the prior art are as follows:
1. the existing scheme has a strict requirement on the operation record of an experimental data set, which also causes the problem solving applicability of the prior art to be low.
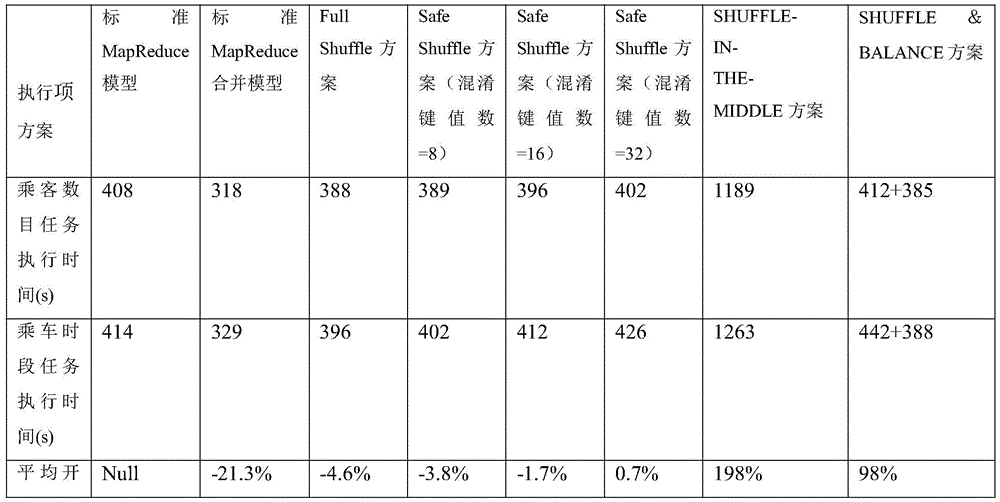
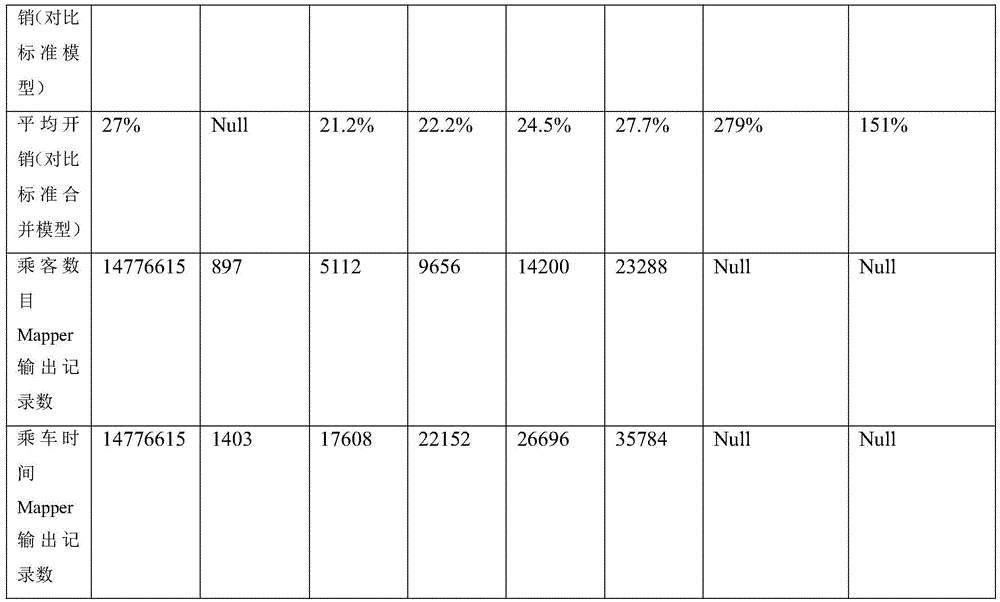
2. Compared with a standard MapReduce framework, THE existing scheme has higher performance overhead, for example, THE SHUFFLE-IN-THE-MIDDLE scheme causes 191 to 205 percent of performance overhead, and THE SHUFFLE & BALANCE scheme causes 95 to 101 percent of performance overhead IN an online stage.
3. The existing scheme only supports the default Partition function and does not support the user-defined shuffle function.
4. The existing scheme has the precondition of accurate probability estimation of input data, and once the estimation is inaccurate, the scheme fails and unnecessary high-performance overhead is caused.
The difficulty of solving the technical problems is as follows: on the premise of ensuring safe and reliable operation of MapReduce, leakage of sensitive information of a data set is avoided to the maximum extent, the applicability of a scheme is improved, and meanwhile, good performance improvement is achieved. The optimal relationship between security and performance must be balanced to achieve the optimal effect of the solution, which is also a difficult point and challenge in design.
The significance of solving the technical problems is as follows: by solving the technical problem of complaint, the intermediate data stream privacy can be better protected under the original MapReduce framework, the side channel attack based on the intermediate data stream in the MapReduce framework in the untrusted public cloud is resisted, the performance overhead is optimized on the premise, and the novel system method is provided with the characteristic of not influencing the high efficiency of distributed computing in the cloud environment.
Disclosure of Invention
Aiming at the problems in the prior art, the invention provides a data security method and system aiming at MapReduce calculation.
The invention is realized in such a way that a data security method aiming at MapReduce calculation comprises the following steps:
in the first step, two novel data shuffling schemes are proposed under the standard MapReduce calculation framework: full Shuffle and Safe Shuffle; three novel sub-phases are defined at Mapping phase level: a Map stage, a Combine stage and a Partition stage, wherein a Reduce sub-stage is defined in a Reducing stage layer;
secondly, in the Map sub-stage of the Mapping stage layer of the MapReduce, the system arranges the input data into a key-value key value pair form for preprocessing;
thirdly, merging the key value pairs in each Map task of the Map sub-stage according to the key value through the combination stage, and adding a false key value pair to the value through the number of key value types of the data set in advance so as to enable the size of the data output by each Map task to be equal, or adding a confusion key value pair on the basis of the previous step so as to enable the number of key value types of the real data set to be hidden;
fourthly, the Partition function of the Partition sub-stage distributes the merged key value pair to each Reduce task of the Reducing stage layer respectively so as to enable the size of data input by each Reduce task of the Reducing sub-stage to be equal;
fifthly, processing the data received by each Reduce task in the Reduce sub-stage, and discarding all the false key value pairs, the confusion key value pairs and the key value pair data which do not belong to the combination of each Reduce task in the Reduce sub-stage;
and sixthly, at the final output storage DFS stage (clearUp function) of each Reduce task in the Reduce sub-stage, adding the confusion key value pair again according to the number of the key value types of the data set so as to enable the data output by each Reduce task to be equal in size.
Further, the second step specifically includes: in a Map sub-phase of a Mapping phase layer of MapReduce, a Map main function arranges input data into a format of a (t.key, t.value) key value pair for preprocessing; the input data is uniformly distributed to each Map task, namely, each Map task has data input with the size of | D |/M, the input data is decrypted and then read into the form of an intermediate key value pair < K, V > by rows through Map _ function; the input data set is represented by | D |, | represents the size of the data after encryption processing, M represents the number of Map tasks, and Map _ function is a Map main function in each Map task.
Further, the third step specifically includes: deploying Combiner _ function in each Map task, and when the Map _ function generates an output encryption key value pair | t |, the Combiner _ function firstly decrypts and then merges key value pairs with the same key value by using Reduce _ function; wherein, the Reduce _ function is a Reduce main function in each Reduce task, and the Combiner _ function is a main function of the combination sub-stage; as a result, a merged key-value pair group is generated in each map task, where the key value of each key-value pair is unique, in the key-value pair format (K)authentic,Vauthentic) The key value pair group is called as a credible key value pair group;
a map task mapiGenerates a trusted keyValue pair group Tm={<K1,V1>,…,<K|Tm|,V|Tm|>When | Tm<K, m will generate Dm=K-|TmL false key value pairs<Kd1,Vd1>,…,<KdDm,VdDm>(ii) a Wherein mapi∈{map1,…,mapMThe task subscript mU (1, M), K is the type number of keys in the original data set, | TmL is the number of key value pairs in the group of the credible key values; the generated pseudo-key value pair has the format of (K)dummy,Vdummy) In which K isdummyAnd VdummyThe virtual false value is a preset virtual false value with a mark; finally, in the Partition sub-phase, there will be | T's in each map taskmI trusted key-value pairs and DmThe number of the false-key-value pairs,<K1,V1>,…,<KK,VK>encrypted and distributed to each Reduce task of the Reduce sub-stage; adding a certain number of obfuscated key-value pairs<Kf1,Vf1>,…,<KfK’,VfK’>So as to hide the number K of key value types of the real data set; wherein the number of obfuscated key-value pairs is denoted by K', and the key-value pair format also uses dummy values with special labels (K)fake,Vfake) Represents; finally, in the Partition sub-phase, there will be | T's in each map taskmI trusted key-value pairs, DmA dummy key-value pair and K' obfuscated key-value pairs,<K1,V1>,…,<KK+K’,VK+K’>each Reduce task distributed to the Reduce sub-phase is encrypted.
Further, the fourth step specifically includes: the Partition function of the Partition sub-stage distributes the merged key value pair to each Reduce task of the Reduce sub-stage respectively so as to enable the size of data input by each Reduce task of the Reduce sub-stage to be equal; in the Partition function of the Partition sub-stage, each encryption key value pair | t | >, is first defined<t.key,t.value>Decrypting, and then fully distributing the key value pair t through a Full distribution function Full _ Partition _ function; wherein the Full _ Partition _ function is performed R times for each key-value pair t,thereby sequentially generating an allocation rule of Full _ Partition _ function (t.key) ═ R (1, 2.., R); let the Reduce task in the Reduce sub-phase be Reducej∈{reduce1,…,reduceRFor the Full Shuffle scheme, each task reducejWill receive K ═ Dm+|TmI encryption key value pairs including a trusted key value pair group (K)authentic,Vauthentic) And a false key value pair (K)dummy,Vdummy) Or K + K' encryption key value pairs including a trusted key value pair group (K) are received for the Safe Shuffle schemeauthentic,Vauthentic) False key value pair (K)dummy,Vdummy) And obfuscating key-value pairs (K)fake,Vfake)。
Further, the fifth step specifically includes: each Reduce of the Reduce sub-phases is performed by a Partition function of the Partition sub-phasejThe task will receive each mapiEncryption key value pair { | t { (a) that task transmitsiDecrypting the key value pair | t |, and judging each obtained key value pair t ═ t.key, t.value); if t.key ═ KdummyOr KfakeThen task reducejThese key-value pairs will be discarded, at each task reducejProcessing the credible key value pair by referring to a User-defined distribution function User _ Partition _ function in the main function Reduce _ function; if User _ Partition _ function (t.key) ═ j, then the key-value pair is retained, otherwise the key-value pair is discarded; wherein for reducejDetermining the cut of a key value pair by judging the value of R and the current reduce task j; then the reserved key value pairs are processed by the Reduce task main function Reduce _ function in sequence, the key value pairs with the same key value are grouped and combined, and each Reduce is used as a resultjA set of key value pairs with unique key value is generated in the task and is called as a set T of credible key value pairsmMarked as (K)authentic,Vauthentic)。
Further, the sixth step specifically includes: for the Full Shuffle protocol, each reducejCredible key value pair group T generated by taskmWhen its number | Tm|<At K, r will generate Dr=K-|TmL false key value pairs<Kd1,Vd1>,…,<KdDr,VdDr>(ii) a Wherein the subscripts of the tasks are rU (1, R), K is the number of types of keys in the original data set, | TmL is the number of key value pairs in the group of the credible key values; the generated pseudo-key value pair has the format of (K)dummy,Vdummy) In which K isdummyAnd VdummyThe virtual false value is a preset virtual false value with a mark; finally, in the stage of storing DFS, there will be | T in each reduce taskmI trusted key-value pairs and DrA false key value pair, i.e.<K1,V1>,…,<KK,VK>Encrypted for storage in the DFS;
for the Safe Shuffle scheme, each reducejCredible key value pair group T generated by taskmWhen its number | Tm|<At K, r will generate Dr=K+K’-|TmL false key value pairs<Kd1,Vd1>,…,<KdDr,VdDr>(ii) a Wherein the subscripts of the tasks are rU (1, R), K is the number of types of keys in the original data set, | TmL is the number of key value pairs in the group of the credible key values; the generated pseudo-key value pair has the format of (K)dummy,Vdummy) In which K isdummyAnd VdummyThe virtual false value is a preset virtual false value with a mark; finally, in the stage of storing DFS, there will be | T in each reduce taskmI trusted key-value pairs and DrThe number of the false-key-value pairs,<K1,V1>,…,<KK+K’,VK+K’>encrypted for storage in the DFS.
Another object of the present invention is to provide a data privacy system for MapReduce computing implementing the method for MapReduce computing, including:
the Map sub-phase processing module is used for preprocessing input data in a form of key-value key value pairs in the Map sub-phase of the Mapping phase layer of MapReduce by the system;
the combination sub-stage processing module is used for merging the key value pairs in each Map task of the Map sub-stage according to the key value, adding the false key value pairs to the key value according to the number of the key value types of the data set in advance so as to enable the size of the data output by each Map task to be equal, or adding the confusion key value pairs on the basis of the above to enable the number of the key value types of the real data set to be hidden;
the Partition sub-stage processing module is used for distributing the merged key value pairs to each Reduce task of the Reducing stage layer by the Partition function of the Partition sub-stage so as to enable the size of data input by each Reduce task of the Reducing sub-stage to be equal;
the Reduce sub-stage processing module 4is used for processing the data received by each Reduce task of the Reduce sub-stage, and discarding all the false key value pairs, the confusion key value pairs and the key value pair data which do not belong to the combination of each Reduce task of the Reduce sub-stage;
and the Reduce sub-stage end processing module is used for outputting and storing a DFS (clean Up function) stage at the last of each Reduce task in the Reduce sub-stage, and adding the confusion key value pair again according to the number of the key value types of the data set so as to enable the data output by each Reduce task to be equal in size.
Another object of the present invention is to provide an information data processing terminal implementing the data privacy method for MapReduce calculation.
Another object of the present invention is to provide a computer-readable storage medium, comprising instructions, which when executed on a computer, cause the computer to perform the data security method for MapReduce computation.
The invention further aims to provide a cloud computing data security system applying the data security method for MapReduce computing.
In summary, the advantages and positive effects of the invention are: the invention provides two novel data shuffling schemes under a standard MapReduce calculation framework: full Shuffle and Safe Shuffle; three novel sub-phases are defined at Mapping phase level: a Map stage, a Combine stage and a Partition stage, wherein a Reduce sub-stage is defined in a Reducing stage layer; in the Map sub-stage of the Mapping stage layer of the MapReduce, the system arranges input data into a key-value key value pair form for preprocessing; merging the key value pairs in each Map task of the Map sub-stage according to the key value through a combination stage, and adding a false key value pair to the value through the number of the key value types of the data set in advance so as to enable the size of the data volume output by each Map task to be equal, or adding a confusion key value pair on the basis of the above to enable the key value types of the real data set to be hidden; the Partition function in the Partition stage distributes the merged key value pairs to each Reduce task of the Reducing stage layer respectively so as to enable the size of data input by each Reduce task in the Reducing sub-stage to be equal; processing the data received by each Reduce task in the Reduce sub-stage, and discarding all the false key value pairs, confusion key value pairs and key value pair data which do not belong to the combination of each Reduce task in the Reduce sub-stage; and in the final output storage DFS stage (clearUp function) of each Reduce task in the Reduce sub-stage, adding the confusion key value pair again according to the number of the key value types of the data set so as to enable the data output by each Reduce task to be equal in size. The data security method and the data security system can carry out data security on data in the operation process of the user operation in the cloud computing platform.
Compared with the prior art, the invention has the following beneficial effects:
(1) the invention relates to a data security method and a system aiming at MapReduce calculation.A specific full distribution function is written in a partition function, the distribution fully distributes data in a map task to reduce tasks, the quantity and the size of data output by all the map tasks are equal, and the quantity is mixed by containing false data, so that the statistical distribution relation between the quantity of the data and input data is not clear, an attacker cannot speculate the data by tracking the flow from each map task to the reduce task, namely, the attacker cannot distinguish the output corresponding relation of the input with the same data size by observing the input, thereby realizing the indistinguishability of map output.
(2) According to the data security method and system for MapReduce calculation, the data volume of receiving, outputting and storing of each reduce task is equal, the data volume does not have the speculation significance after statistics, an attacker is prevented from using different data for tracking the corresponding relation between the map task and the reduce task for multiple times, and therefore the indistinguishability of reduce input is achieved.
The method and the device protect data and privacy based on the MapReduce framework in a remote execution environment scene, and avoid the data privacy of the application program from being acquired by a malicious observer through side channel attack.
Drawings
FIG. 1 is a flowchart of a data security method for MapReduce computation according to an embodiment of the present invention.
FIG. 2 is a schematic structural diagram of a data security system for MapReduce computation according to an embodiment of the present invention;
in the figure: 1. a Map sub-stage processing module; 2. a combination sub-phase processing module; 3. a Partition sub-stage processing module; 4. a Reduce sub-stage processing module; 5. reduce sub-phase end processing module.
FIG. 3 is a diagram of an original MapReduce framework provided by an embodiment of the invention.
FIG. 4is a diagram of a Full Shuffle protocol, which is a protocol provided by an embodiment of the present invention.
FIG. 5 is a diagram of a second Safe Shuffle protocol provided in an embodiment of the present invention.
Detailed Description
In order to make the objects, technical solutions and advantages of the present invention more apparent, the present invention is further described in detail with reference to the following embodiments. It should be understood that the specific embodiments described herein are merely illustrative of the invention and are not intended to limit the invention.
Aiming at the problems in the prior art, the invention provides a data security method and a data security system for MapReduce calculation, and the invention is described in detail with reference to the attached drawings.
As shown in fig. 1, the data security method for MapReduce computation provided by the embodiment of the present invention includes the following steps:
s101, a sub-stage adding step, wherein two novel data shuffling schemes are proposed under a standard MapReduce calculation framework: full Shuffle and Safe Shuffle; three novel sub-phases are defined at Mapping phase level: a Map stage, a Combine stage and a Partition stage, wherein a Reduce sub-stage is defined in a Reducing stage layer;
s102, Map sub-phase processing, namely, in a Map sub-phase of a Mapping phase layer of the MapReduce, preprocessing input data in a key-value key value pair mode by a system;
s103, a combination sub-stage processing step, namely merging the key value pair in each Map task of the Map sub-stage according to the key value through the combination stage, and adding a false key value pair to the value through the number of key value types of the data set in advance so as to enable the size of the data volume output by each Map task to be equal, or adding a confusion key value pair on the basis of the above, so as to enable the number of key value types of the real data set to be hidden;
s104, a Partition sub-stage processing step, wherein a Partition function of the Partition sub-stage distributes the merged key value pairs to each Reduce task of a Reducing stage layer respectively so as to enable the size of data input by each Reduce task of the Reducing sub-stage to be equal;
s105, a Reduce sub-stage processing step, namely processing the data received by each Reduce task in the Reduce sub-stage, and discarding all false key value pairs, confusion key value pairs and key value pair data which do not belong to the combination of each Reduce task in the Reduce sub-stage;
s106, a Reduce sub-stage end processing step, namely, a DFS stage (clearUp function) is output and stored at the last of each Reduce task in the Reduce sub-stage, and the confusion key value pairs are added again according to the number of the key value types of the data sets, so that the data output by each Reduce task are equal in size.
As shown in fig. 2, the data security system for MapReduce computation provided by the embodiment of the present invention includes:
the Map sub-phase processing module 1 is used for preprocessing input data in a form of key-value key value pairs in the Map sub-phase of the Mapping phase layer of the MapReduce by a system;
the combination sub-stage processing module 2 is used for merging the key value pairs in each Map task of the Map sub-stage according to the key value, and adding a false key value pair to the key value according to the number of key value types of the data set in advance so as to enable the size of the data volume output by each Map task to be equal, or adding a confusion key value pair on the basis of the above, so as to enable the number of key value types of the real data set to be hidden;
the Partition sub-stage processing module 3 is used for the Partition function of the Partition sub-stage to distribute the merged key value pair to each Reduce task of the Reducing stage layer so as to enable the size of data input by each Reduce task of the Reducing sub-stage to be equal;
the Reduce sub-stage processing module 4is used for processing the data received by each Reduce task of the Reduce sub-stage, and discarding all the false key value pairs, the confusion key value pairs and the key value pair data which do not belong to the combination of each Reduce task of the Reduce sub-stage;
and the Reduce sub-stage end processing module 5 is used for outputting and storing a DFS (clean Up function) stage at the last of each Reduce task in the Reduce sub-stage, and adding the confusion key value pair again according to the number of the key value types of the data set so as to enable the data output by each Reduce task to be equal in size.
The technical solution of the present invention is further described below with reference to the accompanying drawings.
When the method is specifically implemented, before the MapReduce calculation data is kept secret, the encryption operation needs to be carried out on the MapReduce data. Specifically, data encryption is established on the basis that the MapReduce framework runs in a safe execution environment. The secure execution Environment may be implemented using Trusted Execution Environment (TEE) technology, such as Intel SGX. MapReduce generally decomposes job into tasks, which are divided into a map task and a reduce task, and the tasks are respectively executed by nodes in a cluster. According to the invention, each task is deployed in the trusted execution environment for execution, so that the task is kept secret during operation, but data still needs to be protected during transmission among different tasks. The invention carries out encryption transmission on the data between tasks.
Because the secure execution environment only contains codes of each task processing data in the MapReduce, such as a map task and a reduce task of the standard MapReduce, and the rest Hadoop distributed infrastructure does not need trust, the plaintext of the encrypted data cannot be directly obtained by an attacker in the operation stage.
Although the encryption operation is carried out on the data, the clear text of the data can be ensured not to be directly obtained and modified by an attacker in the running stage. However, after the above processing, the malicious observer may still record the exchange of encrypted data, such as data exchange between each node in the MapReduce system (network traffic analysis) or data exchange between each node and the storage (storage traffic analysis), where the exchanged data amount includes bytes, pages, packets, or records. An observer obtains the statistical distribution of input data on the basis of prior statistical knowledge, and therefore sensitive information in the data is obtained by observing the flow between the map task and the reduce task to analyze, and privacy is leaked.
The data security method of the invention keeps the data secret from the aspects of the indistinguishability of map task input and output and the indistinguishability of reduce task input and output: indistinguishability of map task input: in the preprocessing stage of the job task, the size of an original data set is averagely divided into M sample data sets with the same size, the sample data sets are respectively sent to M different map tasks to be processed, the input data volume and the size of each map task are the same, and an attacker is prevented from observing the corresponding relation from the storage unit DFS to each map task.
Indistinguishability of map task output: and writing a specific full distribution function in the partition function, wherein the distribution averagely distributes the data in the map tasks to the reduce tasks, the quantity and the size of the data output by all the map tasks are equal, so that the statistical distribution relation between the quantity of the data and the input data is not clear, an attacker cannot speculate the data by tracking the flow from each map task to the reduce task, namely, the attacker cannot distinguish the output corresponding relation of the inputs with the same data size by observing the inputs.
Indistinguishability of reduce task input: the data volume received by each reduce task is equal in size and does not have the speculation significance after statistics, and an attacker is prevented from using different data for tracking the corresponding relation between the map task and the reduce task for multiple times.
Indistinguishability of reduce task output: and writing a storage function of a specific rule in the CleanUp function of each reduce task, wherein the rule unifies the output quantity and the size of each reduce task and the output quantity and the size of each map task, so that an attacker cannot guess the inherent characteristics of the data by tracking the flow of each reduce task to the DFS.
Specifically, in order to implement data security from the aspects of the indistinguishability of map task input and output and the indistinguishability of reduce task input and output, the present invention is implemented by the following two embodiments.
Example 1
As shown in fig. 4, compared to the standard MapReduce process (as shown in fig. 3, the standard MapReduce framework), the present embodiment mainly defines three new sub-phases at the Mapping phase level: the Map phase, the combination phase and the Partition phase, wherein the Reduce sub-phase is defined at the Reducing phase layer. The scheme conforms to the indistinguishability of input and output of map tasks, and the sizes of the data volume received and stored by each reduce task which conforms to the indistinguishability of input and output of the reduce end are equal.
The data set input used by a User to submit a job is set as D, | D | represents the size of input data, | represents the size after data encryption processing, M represents the number of Map tasks, R represents the number of Reduce tasks, Map _ function is a Map master function in each Map task, Reduce _ function is a User master function in each Reduce task, a User-defined distribution function er _ Partition _ function and a Full distribution function Full _ Partition _ function are set, and Combiner _ function is a master function of a combination sub-phase. The following describes the processing of Map sub-phase, combination sub-phase, Partition own phase and Reduce sub-phase, respectively.
Map sub-phase: the Map main function Map _ function preprocesses input data into a format of t ═ key value pairs, wherein the input data are uniformly distributed to each Map task, namely, each Map task has data input with the size of | D |/M, the input data are decrypted and then read into a form of intermediate key value pairs < K, V > by lines through the Map _ function
Combination sub-phase: deploying Combiner _ function in each Map task, when the Map _ function generates output encryption key value pair | t |, the Combiner _ function firstly decrypts, then uses Reduce _ function to combine key value pairs with the same key value, as a result, a combined key value pair group is generated in each Map task, wherein the key value of each key value pair is unique, the invention uses key value pair format (K)authentic,Vauthentic) The key value pair group is called as a credible key value pair group. Suppose a map task mapiGenerating credible key value pair group Tm={<K1,V1>,…,<K|Tm|,V|Tm|>When | Tm<K, m will generate Dm=K-|TmL false key value pairs<Kd1,Vd1>,…,<KdDm,VdDm>(ii) a Wherein mapi∈{map1,…,mapMThe task subscript mU (1, M), K is the type number of keys in the original data set, | TmL is the number of key value pairs in the group of the credible key values; the generated pseudo-key value pair has the format of (K)dummy,Vdummy) In which K isdummyAnd VdummyThe virtual false value is a preset virtual false value with a mark; finally, in the Partition sub-phase, there will be | T's in each map taskmI trusted key-value pairs and DmA false key value pair, i.e.<K1,V1>,…,<KK,VK>And each Reduce task encrypted and distributed to the Reduce sub-phase is called Full Shuffle in the scheme.
Partition sub-stage: the partition function distributes the merged key value pair to each Reduce task of the Reduce sub-stage respectively so as to enable the size of data input by each Reduce task of the Reduce sub-stage to be equal; in the Partition function of the Partition sub-stage, each encryption key value pair | t | >, is first defined<t.key,t.value>Decrypting, and then fully distributing the key value pair t through a Full distribution function Full _ Partition _ function; wherein each key-value pair t is executedRow R times Full _ Partition _ function, thereby sequentially generating an allocation rule of Full _ Partition _ function (t.key) ═ R (1, 2.., R); let the Reduce task in the Reduce sub-phase be Reducej∈{reduce1,…,reduceRFor this scheme, each task reducejWill receive K ═ Dm+|TmI encryption key value pairs including a trusted key value pair group (K)authentic,Vauthentic) And a false key value pair (K)dummy,Vdummy)。
Reduce sub-phase: each Reduce of the Reduce sub-phases is performed by a Partition function of the Partition sub-phasejThe task will receive each mapiEncryption key value pair { | t { (a) that task transmitsiDecrypting the key value pair | t |, and judging each obtained key value pair t ═ t.key, t.value); if t.key ═ KfakeThen task reducejThese key-value pairs will be discarded, at each task reducejIn the main function Reduce _ function, the invention processes the credible key value pair by referring to a User-defined distribution function User _ Partition _ function; if User _ Partition _ function (t.key) ═ j, then the key-value pair is retained, otherwise the key-value pair is discarded; wherein for reducejDetermining the cut of a key value pair by judging the value of R and the current reduce task j; then the reserved key value pairs are processed by the Reduce task main function Reduce _ function in sequence, the key value pairs with the same key value are grouped and combined, and each Reduce is used as a resultjA group of key value pair sets with unique key values are generated in the task, and the key value pair sets are also called as credible key value pair groups T in the inventionmMarked as (K)authentic,Vauthentic)。
End of Reduce sub-phase: for this scheme, each reducejCredible key value pair group T generated by taskmWhen its number | Tm|<At K, r will generate Dr=K-|TmL false key value pairs<Kd1,Vd1>,…,<KdDr,VdDr>(ii) a Wherein the task subscripts rU (1, R), K are originalNumber of types, | T, of keys in a datasetmL is the number of key value pairs in the group of the credible key values; the generated pseudo-key value pair has the format of (K)dummy,Vdummy) In which K isdummyAnd VdummyThe virtual false value is a preset virtual false value with a mark; finally, in the stage of storing DFS, there will be | T in each reduce taskmI trusted key-value pairs and DrA false key value pair, i.e.<K1,V1>,…,<KK,VK>Encrypted for storage in the DFS.
Specifically, the present embodiment may be implemented as a standard jobe (one mapreduce task is called jobe) in practice. The present embodiment utilizes a uniform transmission to secure data. When two different data sets with known K types and the same size run on the scheme, the input and output of the map task and the input and output of the reduce task are equal in flow in the process monitored by an observer.
Example 2
The embodiment realizes data confidentiality by adding the false data and protects the number K of the key values. The embodiment accords with the indistinguishability of input and output of map tasks after the MapReduce is rewritten, and the size of the data volume received by each Reduce task which accords with the indistinguishability of input and output of the Reduce end is equal.
As shown in fig. 5, compared to the standard MapReduce process (as shown in fig. 3, the standard MapReduce framework), the present embodiment mainly defines three new sub-phases at the Mapping phase level: the Map phase, the combination phase and the Partition phase, wherein the Reduce sub-phase is defined at the Reducing phase layer. The scheme conforms to the indistinguishability of input and output of map tasks, and the sizes of the data volume received and stored by each reduce task which conforms to the indistinguishability of input and output of the reduce end are equal.
The data set input used by a User to submit a job is set as D, | D | represents the size of input data, | represents the size after data encryption processing, M represents the number of Map tasks, R represents the number of Reduce tasks, Map _ function is a Map master function in each Map task, Reduce _ function is a User master function in each Reduce task, a User-defined distribution function er _ Partition _ function and a Full distribution function Full _ Partition _ function are set, and Combiner _ function is a master function of a combination sub-phase. The following describes the processing of Map sub-phase, combination sub-phase, Partition own phase and Reduce sub-phase, respectively.
Map sub-phase: the Map main function Map _ function preprocesses input data into a format of t ═ key value pairs, wherein the input data are uniformly distributed to each Map task, namely, each Map task has data input with the size of | D |/M, the input data are decrypted and then read into a form of intermediate key value pairs < K, V > by lines through the Map _ function
Combination sub-phase: deploying Combiner _ function in each Map task, when the Map _ function generates output encryption key value pair | t |, the Combiner _ function firstly decrypts, then uses Reduce _ function to combine key value pairs with the same key value, as a result, a combined key value pair group is generated in each Map task, wherein the key value of each key value pair is unique, the invention uses key value pair format (K)authentic,Vauthentic) The key value pair group is called as a credible key value pair group. In particular, for safety, the scheme can add a certain number of confusion key-value pairs on the basis of the Full Shuffle scheme<Kf1,Vf1>,…,<KfK’,VfK’>So as to hide the number K of key value types of the real data set; wherein the number of obfuscated key-value pairs is denoted by K', and the key-value pair format also uses dummy values with special labels (K)fake,Vfake) Represents; finally, in the Partition sub-phase, there will be | T's in each map taskmI trusted key-value pairs, DmA false key-value pair and K' obfuscated key-value pairs, i.e.<K1,V1>,…,<KK+K’,VK+K’>And each Reduce task encrypted and distributed to the Reduce sub-phase is called Safe Shuffle in the scheme.
Partition sub-stage: the partition function distributes the merged key-value pairs to Reduce sub-orders respectivelyEach Reduce task of the segment, so that the size of data input by each Reduce task of the Reduce sub-stage is equal; in the Partition function of the Partition sub-stage, each encryption key value pair | t | >, is first defined<t.key,t.value>Decrypting, and then fully distributing the key value pair t through a Full distribution function Full _ Partition _ function; wherein for each key-value pair t, Full _ Partition _ function is performed R times, thereby generating an allocation rule of Full _ Partition _ function (t.key) ═ R (1, 2., R) in turn; let the Reduce task in the Reduce sub-phase be Reducej∈{reduce1,…,reduceRFor this scheme, each task reducejWill receive K + K' (K ═ D)m+|Tm|) encryption key-value pairs, including pairs of trusted key-value pairs (K)authentic,Vauthentic) False key value pair (K)dummy,Vdummy) And obfuscating key-value pairs (K)fake,Vfake)。
Reduce sub-phase: each Reduce of the Reduce sub-phases is performed by a Partition function of the Partition sub-phasejThe task will receive each mapiEncryption key value pair { | t { (a) that task transmitsiDecrypting the key value pair | t |, and judging each obtained key value pair t ═ t.key, t.value); if t.key ═ KdummyOr KfakeThen task reducejThese key-value pairs will be discarded, at each task reducejIn the main function Reduce _ function, the invention processes the credible key value pair by referring to a User-defined distribution function User _ Partition _ function; if User _ Partition _ function (t.key) ═ j, then the key-value pair is retained, otherwise the key-value pair is discarded; wherein for reducejDetermining the cut of a key value pair by judging the value of R and the current reduce task j; then the reserved key value pairs are processed by the Reduce task main function Reduce _ function in sequence, the key value pairs with the same key value are grouped and combined, and each Reduce is used as a resultjA group of key value pair sets with unique key values are generated in the task, and the key value pair sets are also called as credible key value pair groups T in the inventionmMarked as (K)authentic,Vauthentic)。
End of Reduce sub-phase: for this scheme, when the number | Tm|<At K, r will generate Dr=K+K’-|TmL false key value pairs<Kd1,Vd1>,…,<KdDr,VdDr>(ii) a Wherein the subscripts of the tasks are rU (1, R), K is the number of types of keys in the original data set, | TmL is the number of key value pairs in the group of the credible key values; the generated pseudo-key value pair has the format of (K)dummy,Vdummy) In which K isdummyAnd VdummyThe virtual false value is a preset virtual false value with a mark; finally, in the stage of storing DFS, there will be | T in each reduce taskmI trusted key-value pairs and DrA false key value pair, i.e.<K1,V1>,…,<KK+K’,VK+K’>Encrypted for storage in the DFS.
This embodiment is also implemented as a standard joba. The jobs reserves a complete mapreduce process, the maps of the jobs 2 are only simple copy processes, and the scheme realizes data confidentiality by adding false data in the transmission process of map tasks and reduce tasks, so that different key quantities are protected from being leaked. When two different data sets with the same size run on the scheme, the input and output of the map task and the input and output of the reduce task are still completely equal. In the embodiment, the aliasing false data is added as a constant K', and the aliasing false data and the original real data can be well distributed in the customized Partition function, so that the flow from the map task to each path of the reduce task is equal.
The technical effects of the present invention will be described in detail with reference to experiments.
Experimental results show that the scheme of the invention generates limited performance overhead, sometimes even faster than standard MapReduce runs, that for all experimental tasks the Full Shuffle scheme is 2.5% faster than the standard MapReduce scheme, and that when the number of confusion key pairs added is 8,16,32, the Safe Shuffle scheme is 0.8% faster, 4.9% slower and 11.6% slower than the standard MapReduce scheme, respectively. Compared with THE SHUFFLE-IN-THE-MIDDLE scheme and THE SHUFFLE & BALANCE scheme, THE performance is improved by 212.7 percent and 107.5 percent respectively.
It should be noted that the embodiments of the present invention can be realized by hardware, software, or a combination of software and hardware. The hardware portion may be implemented using dedicated logic; the software portions may be stored in a memory and executed by a suitable instruction execution system, such as a microprocessor or specially designed hardware. Those skilled in the art will appreciate that the apparatus and methods described above may be implemented using computer executable instructions and/or embodied in processor control code, such code being provided on a carrier medium such as a disk, CD-or DVD-ROM, programmable memory such as read only memory (firmware), or a data carrier such as an optical or electronic signal carrier, for example. The apparatus and its modules of the present invention may be implemented by hardware circuits such as very large scale integrated circuits or gate arrays, semiconductors such as logic chips, transistors, or programmable hardware devices such as field programmable gate arrays, programmable logic devices, etc., or by software executed by various types of processors, or by a combination of hardware circuits and software, e.g., firmware.
The above description is only for the purpose of illustrating the preferred embodiments of the present invention and is not to be construed as limiting the invention, and any modifications, equivalents and improvements made within the spirit and principle of the present invention are intended to be included within the scope of the present invention.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911244325.3A CN111163056B (en) | 2019-12-06 | 2019-12-06 | A data security method and system for MapReduce computing |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911244325.3A CN111163056B (en) | 2019-12-06 | 2019-12-06 | A data security method and system for MapReduce computing |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111163056A true CN111163056A (en) | 2020-05-15 |
| CN111163056B CN111163056B (en) | 2021-08-31 |
Family
ID=70555723
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201911244325.3A Active CN111163056B (en) | 2019-12-06 | 2019-12-06 | A data security method and system for MapReduce computing |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111163056B (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111865909A (en) * | 2020-06-08 | 2020-10-30 | 西安电子科技大学 | SGX side channel attack defense method, system, medium, program and application |
| CN113934723A (en) * | 2020-07-13 | 2022-01-14 | 华为技术有限公司 | Key value pair processing method and data processing device |
| CN115794740A (en) * | 2022-11-23 | 2023-03-14 | 中国农业银行股份有限公司 | Data analysis method, system and server |
| CN119697173A (en) * | 2024-12-10 | 2025-03-25 | 中国工商银行股份有限公司 | Data transmission method, device, equipment and storage medium |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105117286A (en) * | 2015-09-22 | 2015-12-02 | 北京大学 | Task scheduling and pipelining executing method in MapReduce |
| CN107025409A (en) * | 2017-06-27 | 2017-08-08 | 中经汇通电子商务有限公司 | A kind of data safety storaging platform |
| CN108595268A (en) * | 2018-04-24 | 2018-09-28 | 咪咕文化科技有限公司 | Data distribution method and device based on MapReduce and computer-readable storage medium |
| CN109145624A (en) * | 2018-08-29 | 2019-01-04 | 广东工业大学 | A kind of more chaos text encryption algorithms based on Hadoop platform |
| CN109684856A (en) * | 2018-12-18 | 2019-04-26 | 西安电子科技大学 | A kind of data encryption method and system for MapReduce calculating |
| US20190266195A1 (en) * | 2010-12-28 | 2019-08-29 | Microsoft Technology Licensing, Llc | Filtering queried data on data stores |
-
2019
- 2019-12-06 CN CN201911244325.3A patent/CN111163056B/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190266195A1 (en) * | 2010-12-28 | 2019-08-29 | Microsoft Technology Licensing, Llc | Filtering queried data on data stores |
| CN105117286A (en) * | 2015-09-22 | 2015-12-02 | 北京大学 | Task scheduling and pipelining executing method in MapReduce |
| CN107025409A (en) * | 2017-06-27 | 2017-08-08 | 中经汇通电子商务有限公司 | A kind of data safety storaging platform |
| CN108595268A (en) * | 2018-04-24 | 2018-09-28 | 咪咕文化科技有限公司 | Data distribution method and device based on MapReduce and computer-readable storage medium |
| CN109145624A (en) * | 2018-08-29 | 2019-01-04 | 广东工业大学 | A kind of more chaos text encryption algorithms based on Hadoop platform |
| CN109684856A (en) * | 2018-12-18 | 2019-04-26 | 西安电子科技大学 | A kind of data encryption method and system for MapReduce calculating |
Non-Patent Citations (1)
| Title |
|---|
| YONGZHI WANG等: ""MtMR: Ensuring MapReduce Computation Integrity with Merkle Tree-Based Verifications"", 《IEEE TRANSACTIONS ON BIG DATA》 * |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111865909A (en) * | 2020-06-08 | 2020-10-30 | 西安电子科技大学 | SGX side channel attack defense method, system, medium, program and application |
| CN113934723A (en) * | 2020-07-13 | 2022-01-14 | 华为技术有限公司 | Key value pair processing method and data processing device |
| CN115794740A (en) * | 2022-11-23 | 2023-03-14 | 中国农业银行股份有限公司 | Data analysis method, system and server |
| CN119697173A (en) * | 2024-12-10 | 2025-03-25 | 中国工商银行股份有限公司 | Data transmission method, device, equipment and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111163056B (en) | 2021-08-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12292994B2 (en) | Encrypting data records and processing encrypted records without exposing plaintext | |
| US10171432B2 (en) | Systems to implement security in computer systems | |
| CN112005237B (en) | Secure collaboration between processors and processing accelerators in a secure enclave | |
| US10148442B2 (en) | End-to-end security for hardware running verified software | |
| US20230319023A1 (en) | Network bound encryption for orchestrating workloads with sensitive data | |
| CN111163056B (en) | A data security method and system for MapReduce computing | |
| Akram et al. | Performance analysis of scientific computing workloads on general purpose tees | |
| Park et al. | Secure hadoop with encrypted HDFS | |
| US11755753B2 (en) | Mechanism to enable secure memory sharing between enclaves and I/O adapters | |
| Wang et al. | Toward scalable fully homomorphic encryption through light trusted computing assistance | |
| US20220171883A1 (en) | Efficient launching of trusted execution environments | |
| GB2532415A (en) | Processing a guest event in a hypervisor-controlled system | |
| WO2020258727A1 (en) | Data encryption method, apparatus and device, and medium | |
| US20250335576A1 (en) | Efficient launching of trusted execution environment | |
| Wu et al. | Exploring dynamic task loading in SGX-based distributed computing | |
| Ashalatha et al. | Network virtualization system for security in cloud computing | |
| CN109684856B (en) | A data security method and system for MapReduce computing | |
| CN103885725A (en) | Virtual machine access control system and method based on cloud computing environment | |
| Yao et al. | CryptVMI: A flexible and encrypted virtual machine introspection system in the cloud | |
| CN114528545B (en) | A data protection method, apparatus, device, and storage medium | |
| Sathya Narayana et al. | Trusted model for virtual machine security in cloud computing | |
| Chu et al. | Secure cryptography infrastructures in the cloud | |
| Fan et al. | SECCEG: A secure and efficient cryptographic co-processor based on embedded GPU system | |
| Rashid et al. | Randomly encrypted key generation algorithm against side channel attack in cloud computing | |
| Cheng et al. | Building your private cloud storage on public cloud service using embedded GPUs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |