CN110569355B - Viewpoint target extraction and target emotion classification combined method and system based on word blocks - Google Patents
Viewpoint target extraction and target emotion classification combined method and system based on word blocks Download PDFInfo
- Publication number
- CN110569355B CN110569355B CN201910671527.XA CN201910671527A CN110569355B CN 110569355 B CN110569355 B CN 110569355B CN 201910671527 A CN201910671527 A CN 201910671527A CN 110569355 B CN110569355 B CN 110569355B
- Authority
- CN
- China
- Prior art keywords
- word
- block
- target
- word block
- sentence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000605 extraction Methods 0.000 title claims abstract description 38
- 238000000034 method Methods 0.000 title claims abstract description 30
- 230000008451 emotion Effects 0.000 title claims description 8
- 230000002996 emotional effect Effects 0.000 claims abstract description 19
- 239000013598 vector Substances 0.000 claims description 58
- 238000012549 training Methods 0.000 claims description 27
- 230000007246 mechanism Effects 0.000 claims description 10
- 230000006870 function Effects 0.000 claims description 9
- 239000011159 matrix material Substances 0.000 claims description 8
- 238000013528 artificial neural network Methods 0.000 claims description 7
- 230000002457 bidirectional effect Effects 0.000 claims description 7
- 238000010276 construction Methods 0.000 claims description 7
- 230000008569 process Effects 0.000 claims description 6
- 238000004364 calculation method Methods 0.000 claims description 4
- 230000007935 neutral effect Effects 0.000 claims description 4
- 238000007781 pre-processing Methods 0.000 claims description 4
- 230000006403 short-term memory Effects 0.000 claims description 4
- 238000007476 Maximum Likelihood Methods 0.000 claims description 3
- 230000015654 memory Effects 0.000 claims description 3
- 238000004458 analytical method Methods 0.000 description 10
- 238000005516 engineering process Methods 0.000 description 4
- 238000013145 classification model Methods 0.000 description 3
- 238000003062 neural network model Methods 0.000 description 3
- 230000008901 benefit Effects 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000013459 approach Methods 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000003203 everyday effect Effects 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- 230000006855 networking Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3344—Query execution using natural language analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Machine Translation (AREA)
Abstract
本发明提出一种基于词块的观点目标抽取和目标情感分类联合方法及系统,具体为:对于每个连续词块,设计词块级别的特征以此来充分利用多个词之间的整体信息;计算每个词块的情感信息而非单独计算每一个词的情感信息,这样保证词块里多个词的情感倾向的一致性。本发明一是通过有效利用多个词整体信息,二是通过为多个词组成的词块计算一个情感信息表示来避免情感不一致的问题,来提升抽取和分类的准确率,具有良好的实用性。

The present invention proposes a combined method and system for word-block-based opinion target extraction and target sentiment classification. Specifically, for each continuous word block, a word-block-level feature is designed to make full use of the overall information among multiple words. ; Calculate the emotional information of each word block instead of calculating the emotional information of each word separately, so as to ensure the consistency of the emotional tendencies of multiple words in the word block. The present invention improves the accuracy of extraction and classification by effectively utilizing the overall information of multiple words, and by calculating an emotional information representation for word blocks composed of multiple words to avoid the problem of emotional inconsistency, thereby improving the accuracy of extraction and classification, and has good practicability. .
Description
技术领域:Technical field:
本发明涉及深度学习与自然语言处理技术,具体涉及一种基于词块的观点目标抽取和目标情感分类联合方法及系统。The invention relates to deep learning and natural language processing technologies, in particular to a combined method and system for word-block-based opinion target extraction and target emotion classification.
背景技术:Background technique:
近年来,互联网信息技术高速发展,新闻、社交等网站每天有海量的新数据产生出来,这些数据中包含着各种各样表达观点或者情感的信息。对这些数据进行观点、立场、态度等的分析,可以帮助人们更好的做出判断以及决策,比如:对商品的评论进行分析,可以了解用户对商品的满意度,从而制定更加合理的营销策略。但是由于互联网上的数据量以几何倍数增长,如何从这些海量的信息中查找出对自己有用的数据并进行正确的分析,已经成为了一项非常用意义的研究课题。In recent years, with the rapid development of Internet information technology, a large amount of new data is generated every day on news, social networking and other websites, and these data contain various information expressing opinions or emotions. Analysis of opinions, positions, attitudes, etc. on these data can help people make better judgments and decisions. For example, by analyzing product reviews, you can understand users' satisfaction with products, so as to formulate more reasonable marketing strategies. . However, since the amount of data on the Internet has grown exponentially, how to find useful data from these massive amounts of information and conduct correct analysis has become a very useful research topic.
情感分析技术就是一项针对用户产生的信息进行情感倾向进行分析研究的技术。根据情感分析的粒度主要分为:篇章级情感分析,句子级情感分析以及目标级别情感分析。其中针对目标的情感分析主要包括两个子任务,一个是找出句子中的观点目标,另外一个是判断对该目标的情感倾向。传统的基于目标的情感分析分别研究其中一个子任务,但是在实际应用中往往不仅仅需要完成其中一个子任务,而是既需要抽取出其中的观点目标同时又要对目标的情感倾向进行分类。一种比较直观的做法是把两个子任务以流水线的方式串联起来执行,但是这样无法利用两个子任务之间的相互联系。为了充分利用这两个子任务之间的联系,一些基于词级别序列标注的联合方法被提了出来。很多观点目标是由多个词组成的而非单个词,比如“鼠标左键”是由“鼠标”和“左键”两个词构成,所以基于词级别序列标注的联合方法处理这类观点目标的时候仍然存在一些局限性,一是很难利用观点目标级别的特征,二是预测出的同一个观点目标的多个词之间的情感倾向有可能存在不一致,比如对于“鼠标左键”这个情感目标,可能对“鼠标”这个词给出的标签情感分类是正向的,但是“左键”这个词给出的情感分类是负向的。Sentiment analysis technology is a technology that analyzes and studies the sentiment tendency of information generated by users. According to the granularity of sentiment analysis, it is mainly divided into: text-level sentiment analysis, sentence-level sentiment analysis and target-level sentiment analysis. The sentiment analysis for the target mainly includes two sub-tasks, one is to find the opinion target in the sentence, and the other is to judge the emotional tendency of the target. The traditional target-based sentiment analysis studies one of the sub-tasks separately, but in practical applications, it is often not only necessary to complete one of the sub-tasks, but also needs to extract the opinion target and classify the target's emotional tendency. A more intuitive approach is to execute the two subtasks in series in a pipelined manner, but this cannot take advantage of the mutual connection between the two subtasks. To fully exploit the connection between these two subtasks, some joint methods based on word-level sequence tagging are proposed. Many opinion targets are composed of multiple words rather than a single word. For example, "left mouse button" is composed of two words "mouse" and "left button", so the joint method based on word-level sequence tagging deals with such opinion targets. However, there are still some limitations when it comes to the analysis. First, it is difficult to use the features of the opinion target level. Second, there may be inconsistencies in the emotional tendencies between the predicted words of the same opinion target. For example, for the "left mouse button" Sentiment target, maybe the label sentiment classification given to the word "mouse" is positive, but the sentiment classification given to the word "left button" is negative.
发明内容:Invention content:
针对上述技术问题,本发明提出一种基于词块的观点目标抽取和目标情感分类联合方法及系统,来利用情感目标级别的特征同时避免情感分类不一致的问题。In view of the above technical problems, the present invention proposes a combined method and system for opinion target extraction and target sentiment classification based on word blocks, to utilize the features of sentiment target levels while avoiding the problem of inconsistency in sentiment classification.
为了解决上述技术问题,本发明的技术方案如下:In order to solve the above-mentioned technical problems, the technical scheme of the present invention is as follows:
一种基于词块的观点目标抽取和目标情感分类联合方法,包括如下步骤:A joint method of opinion target extraction and target sentiment classification based on word chunks, comprising the following steps:
把需要进行观点目标抽取和目标情感分类的句子进行处理,得到每个句子中所有的连续词块;Process the sentences that need to extract opinions and target sentiment classification, and get all the continuous word blocks in each sentence;
把得到的句子信息以及词块信息输入到观点目标抽取和目标情感分类的联合模型中,对词块进行分类预测;Input the obtained sentence information and word block information into the joint model of opinion target extraction and target sentiment classification, and classify and predict the word block;
根据词块的类别获取句子中的观点目标及其对应的情感类别;其中,所述观点目标抽取和目标情感分类的联合模型的构建方法,包括:According to the category of the word block, the opinion target in the sentence and its corresponding sentiment category are obtained; wherein, the construction method of the joint model of the opinion target extraction and target sentiment classification includes:
(1)将训练数据中句子以及其中标注的观点目标以及目标情感转化为对应的词块以及词块对应的类别;同时通过大规模的非标注语料,训练得到具有语义信息的词向量;(1) Convert the sentences in the training data and the viewpoint targets and target sentiments marked therein into corresponding word blocks and the categories corresponding to the word blocks; at the same time, through large-scale unlabeled corpus, word vectors with semantic information are obtained by training;
(2)将训练数据的句子中的每个词映射成对应的词向量,输入基于词块的目标抽取和目标情感分类联合神经网络模型,并通过反向传播算法进行训练;(2) Map each word in the sentence of the training data into a corresponding word vector, input a joint neural network model based on word block target extraction and target sentiment classification, and train through a back-propagation algorithm;
(3)将需进行观点目标抽取和目标情感分类的句子输入训练完成的联合预测模型,预测出每个词块对应的类别,根据词块的类别得到句子中的观点目标以及对该目标的情感类别。(3) Input the sentences that need to extract the opinion target and classify the target sentiment into the trained joint prediction model, predict the category corresponding to each word block, and obtain the opinion target in the sentence and the sentiment of the target according to the category of the word block. category.
进一步地,所述联合模型的构建方法步骤(1)具体方法包括:Further, the specific method of the construction method step (1) of the joint model includes:
(1-1)设定词块的最大长度值,枚举训练数据输入句子中不超过所设定的最大长度的所有连续文本词块;(1-1) Set the maximum length value of the word block, and enumerate all continuous text word blocks that do not exceed the set maximum length in the input sentence of the training data;
(1-2)根据标注语料中句子标注的观点目标以及目标情感分类,为所有的词块标记类别;(1-2) Mark the categories for all word chunks according to the viewpoint target and target sentiment classification of sentences in the marked corpus;
(1-3)利用传统的词向量以及基于上下文的词向量来表示输入句子中的每一个词:通过word2vec在大规模的非标注语料上训练获取到传统词向量,把句子输入到预训练好的ELMo(Embeddings from Language Models)模型中得到基于上下文的词向量。(1-3) Use traditional word vectors and context-based word vectors to represent each word in the input sentence: obtain traditional word vectors through word2vec training on a large-scale unlabeled corpus, and input the sentence into the pre-trained Context-based word vectors are obtained from the ELMo (Embeddings from Language Models) model.
更进一步地,步骤(1-1)中最大长度值N的设定范围为1≤N≤L,其中,N为整数,L为输入句子的最大长度,优选的长度为4。Further, the setting range of the maximum length value N in step (1-1) is 1≤N≤L, where N is an integer, L is the maximum length of the input sentence, and the preferred length is 4.
更进一步地,步骤(1-2)中定义词块的类别集合为4个类别{TPOS,TNEG,TNEU,O},这4个类别代表的含义分别为:TPOS表示词块是观点目标且其情感倾向是积极的,TNEG表示词块是观点目标且其情感倾向是消极的,TNEU表示词块是观点目标且其情感倾向是中性的,O表示词块不是情感目标。Further, in step (1-2), the category set of the word block is defined as 4 categories {TPOS, TNEG, TNEU, O}, and the meanings of these 4 categories are: TPOS indicates that the word block is an opinion target and its Sentiment orientation is positive, TNEG means that the chunk is an opinion target and its sentiment orientation is negative, TNEU means that the chunk is an opinion target and its sentiment orientation is neutral, and O means that the chunk is not an sentiment target.
进一步地,所述联合模型的构建方法步骤(2)中所述模型输入为:Further, the model input described in the construction method step (2) of the joint model is:
包含T个词的句子X={w1,w2,…,wT},其中wt表示输入句子中的第t个词,模型的目标是预测词块集合中每个词块的类别Y={(i,j,l)|1≤i≤j≤T;j-i+1≤L;l∈C},其中i,j表示词块在句子中的起始位置和终止位置,l表示词块对应的标签,C表示类别集合。A sentence X={w 1 ,w 2 ,...,w T }, which contains T words, where w t represents the t-th word in the input sentence, and the goal of the model is to predict the category Y of each word block in the word block set ={(i,j,l)|1≤i≤j≤T; j-i+1≤L; l∈C}, where i, j represent the starting position and ending position of the word block in the sentence, l Represents the label corresponding to the word chunk, and C represents the category set.
进一步地,所述联合模型的构建方法步骤(2)中所述模型训练过程包括:Further, the model training process described in step (2) of the construction method of the joint model includes:
2-1)将上述输入句子传统的词向量以及基于上下文的词向量进行拼接,作为下一层的输入;2-1) splicing the traditional word vector of the above-mentioned input sentence and the word vector based on the context, as the input of the next layer;
2-2)在上下文表示层,把句子中每个词对应的词向量作为输入,采用多层双向长短记忆神经网络(stacked Bi-LSTM)学习句子中每个词的上下文表示向量;2-2) In the context representation layer, the word vector corresponding to each word in the sentence is used as input, and a multi-layer bidirectional long short-term memory neural network (stacked Bi-LSTM) is used to learn the context representation vector of each word in the sentence;
2-3)每个词块采用两种词块级别的信息来对其进行表示:一种是词块的边界信息,一种是词块的整体信息;2-3) Each word chunk is represented by two chunk-level information: one is the boundary information of the word chunk, and the other is the overall information of the word chunk;
2-4)基于词块的注意力机制用来计算输入句子中和每个词块相关联的上下文中的情感信息;2-4) A word chunk-based attention mechanism is used to calculate the sentiment information in the context associated with each word chunk in the input sentence;
2-5)在输出层把每个词块的向量表示以及基于词块注意力机制的上下文情感信息表示拼接在一起,用于预测词块的类别;2-5) At the output layer, the vector representation of each word block and the contextual emotion information representation based on the word block attention mechanism are spliced together to predict the category of the word block;
2-6)选取交叉熵为模型训练的损失函数;2-6) Select cross entropy as the loss function of model training;
2-7)通过反向传播算法训练模型,更新模型中所有的参数,最终得到词块分类模型。2-7) Train the model through the back-propagation algorithm, update all the parameters in the model, and finally obtain the word block classification model.
更进一步地,步骤2-2)中所述的上下文表示为:Further, the context described in step 2-2) is represented as:

其中,

更进一步地,步骤2-3)中所述边界信息用边界词对应的stack BiLSTM层的输出来进行表示;所述整体信息采用词块中所有词的上下文信息和进行表示;任意一个词块(i,j)词块表示为:Further, the boundary information described in step 2-3) is represented by the output of the stack BiLSTM layer corresponding to the boundary word; the overall information is represented by the context information and of all words in the word block; any word block ( i,j) chunks are represented as:

其中,
更进一步地,步骤2-4)中由于任务不仅需要识别出词块是否是观点目标,还需要判断出这个词块对应的情感信息,而这些情感信息往往是在上下文中,所以采用基于连续词块的注意力机制来计算文本中和目标相关的情感信息。直观上来说,离一个连续词块越近的词,对这个连续的词块的影响可能越大,采用基于距离权重的上下文信息来表示这种影响,对于离词块越近的词设置的权重越大,离其越远的词设置的权重越小。Further, in step 2-4), since the task not only needs to identify whether the word block is a viewpoint target, but also needs to determine the emotional information corresponding to the word block, and these emotional information are often in the context, so the use of continuous word based block attention mechanism to calculate the sentiment information related to the target in the text. Intuitively, words that are closer to a continuous word block may have a greater impact on the continuous word block. The context information based on distance weights is used to represent this impact, and the weights set for words that are closer to the word block are set. The larger the value, the less weight is set for words farther away from it.
步骤2-4)具体方法包括:Step 2-4) The specific method includes:
2-4-1)每个词和词块(i,j)的距离,来定义这个词的权重w′t:2-4-1) The distance between each word and the word block (i, j) to define the weight w' t of the word:

其中lt表示第t个词到词块(i,j)的距离;对于词块中的词,设置距离lt的值为0;对于词块左边的词,距离lt为到词块最左边词的距离;对于词块右边的词,距离lt为到词块最右边词的距离;where lt represents the distance from the t -th word to the word block (i, j ); for the words in the word block, set the value of the distance lt to 0; for the words on the left side of the word block, the distance lt is the distance to the most word block. The distance of the left word; for the word on the right side of the word block, the distance lt is the distance to the rightmost word of the word block;
2-4-2)根据上面获取的权重值,模型计算每个词块(i,j)基于位置权重的上下文表示:2-4-2) According to the weight value obtained above, the model calculates the context representation of each word block (i, j) based on the position weight:

其中et为第t个词对应的基于距离权重的表示,w′t表示第t个词的权重值,
2-4-3)利用基于词块的注意力机制来计算和词块相关的上下文信息,包括:2-4-3) Use the chunk-based attention mechanism to calculate the context information related to the chunk, including:
a)对于词块(i,j),计算每个上下文词et和它的相关性权重,计算公式为:a) For word block (i, j ), calculate each context word et and its relevance weight, the calculation formula is:

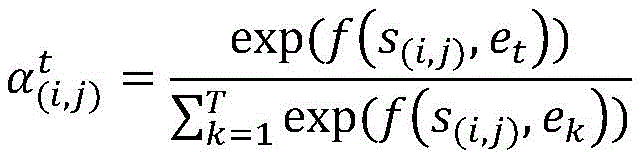
其中s(i,j)为词块(i,j)的向量表示,et为第t个词对应的基于距离权重的表示,Wa为权重矩阵,ba为偏移向量,
b)把这些权重和这些词上下文表示向量相乘并进行加权,即可得到和词块(i,j)相关的上下文信息表示c(i,j):b) Multiply these weights with these word context representation vectors and weight them to obtain the context information representation c (i, j) related to the word block (i, j) :

更进一步地,步骤2-5)中把上述得到的词块(i,j)的向量表示以及与它相关的上下文表示拼接在一起,用来预测词块(i,j)的类别:Further, in step 2-5), the vector representation of the word block (i, j) obtained above and its related context representation are spliced together to predict the category of the word block (i, j):
r(i,j)=[s(i,j);c(i,j)]r (i,j) =[s (i,j) ;c (i,j) ]
y=softmax(Wyr(i,j)+by) y =softmax(W y r (i,j) +by )
其中y为词块对应到各类别的概率分布,Wy为权重矩阵,by为偏移向量。Among them, y is the probability distribution of the word block corresponding to each category, W y is the weight matrix, and b y is the offset vector.
对词块的分类进行处理,在类别O里的认为不是观点目标,在类别TPOS里的即为句子中情感倾向为正向的观点目标,在类别TNEG中的即为句子中情感倾向为负向的观点目标,在类别TNEU中的即为句子中情感倾向为中性的观点目标。The classification of word blocks is processed. Those in category O are considered not to be opinion targets, those in category TPOS are those with positive sentiment in the sentence, and those in category TNEG are those with negative sentiment in sentences. The opinion target of , in the category TNEU is the opinion target whose sentiment tendency is neutral in the sentence.
更进一步地,步骤2-6)中对所有训练样本,通过最大化样本的最大似然函数来训练模型,更新模型中的参数,训练的目标函数loss定义如下:Further, for all training samples in step 2-6), the model is trained by maximizing the maximum likelihood function of the sample, and the parameters in the model are updated, and the training objective function loss is defined as follows:

其中gi是词块对应的真实分类的向量表示,yi为预测得到的概率分布,H代表所有的训练的句子,Sh表示第h个句子中所有的词块。where gi is the vector representation of the true classification corresponding to the word block, yi is the predicted probability distribution, H represents all the training sentences, and Sh represents all the word blocks in the hth sentence.
一种基于词块的观点目标抽取和目标情感分类联合系统,包括:A joint system of opinion target extraction and target sentiment classification based on word chunks, including:
待测数据预处理模块:把需要进行观点目标抽取和目标情感分类的句子进行处理,得到每个句子中所有的连续词块;Data preprocessing module to be tested: process the sentences that need to be extracted and classified to target sentiment, and get all the continuous word blocks in each sentence;
词块分类预测模块:把得到的句子信息以及词块信息输入到观点目标抽取和目标情感分类的联合模型中,对词块进行分类预测;所述联合模型通过把输入句子映射为词向量作为网络输入,搭建基于词块序列的联合神经网络模型,利用反向传播算法进行训练所得;Word block classification prediction module: input the obtained sentence information and word block information into the joint model of opinion target extraction and target sentiment classification, and classify and predict the word block; the joint model maps the input sentence to a word vector as a network Input, build a joint neural network model based on the word block sequence, and use the back propagation algorithm to train the result;
结果获取模块:根据词块的类别获取句子中的观点目标及其对应的情感类别。Result acquisition module: According to the category of the word block, the opinion target in the sentence and its corresponding sentiment category are obtained.
本发明的有益效果在于:针对基于词级别序列标注的观点目标抽取和目标情感倾向分类方法中的两个问题:一是,很难利用多个词组成的观点目标整体信息,二是,多个词组成的观点目标之间可能存在情感不一致;提出了基于连续词块的联合模型来同时进行观点目标抽取以及目标情感倾向分类,具体为:对于每个连续词块,设计词块级别的特征以此来充分利用多个词之间的整体信息;计算每个词块的情感信息而非单独计算每一个词的情感信息,这样保证词块里多个词的情感倾向的一致性。这样,本发明一是通过有效利用多个词整体信息,二是通过为多个词组成的词块计算一个情感信息表示来避免情感不一致的问题,来提升抽取和分类的准确率,具有良好的实用性。The beneficial effects of the present invention are: for the two problems in the method of opinion target extraction and target sentiment tendency classification based on word-level sequence labeling: first, it is difficult to use the overall information of opinion targets composed of multiple words; There may be emotional inconsistencies among opinion targets composed of words; a joint model based on continuous word blocks is proposed to simultaneously extract opinion targets and classify target sentiment tendency. Specifically, for each continuous word block, the block-level features are designed to In this way, the overall information between multiple words can be fully utilized; the sentiment information of each word block is calculated instead of separately calculating the sentiment information of each word, so as to ensure the consistency of the emotional tendencies of multiple words in the word block. In this way, the present invention improves the accuracy of extraction and classification by effectively utilizing the overall information of multiple words, and by calculating an emotional information representation for word blocks composed of multiple words to avoid the problem of emotional inconsistency, thereby improving the accuracy of extraction and classification. practicality.
附图说明:Description of drawings:
图1为本发明实施例提供的基于词块级别的观点目标抽取和目标情感分类流程图;FIG. 1 is a flowchart of opinion target extraction and target sentiment classification based on word block level provided by an embodiment of the present invention;
图2为本发明实施例的神经网络模型结构图。FIG. 2 is a structural diagram of a neural network model according to an embodiment of the present invention.
具体实施方式:Detailed ways:
为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实施案例并结合附图,对本发明做进一步详细说明。In order to make the above objects, features and advantages of the present invention more obvious and easy to understand, the present invention will be further described in detail below through specific implementation cases and in conjunction with the accompanying drawings.
图1为本实施例中基于词块级别的观点目标抽取和目标情感分类流程图方法的流程图,如图所示,该方法主要包括三个阶段,分别是:数据预处理阶段,基于词块级别的观点目标抽取和目标情感分类联合模型训练阶段,对预测得到的分类进行匹配获取到句子中的观点目标以及其情感倾向类别阶段。Fig. 1 is a flowchart of the method for the flow chart of opinion target extraction and target sentiment classification based on the word block level in this embodiment. As shown in the figure, the method mainly includes three stages, which are: a data preprocessing stage, based on the word block In the training stage of the joint model training stage of high-level opinion target extraction and target sentiment classification, the predicted classification is matched to obtain the opinion target in the sentence and its sentiment tendency category stage.
(一)数据预处理阶段(1) Data preprocessing stage
步骤1对于每个句子,穷举其中所有的连续词块(词块长度设定上限)。根据标注语料中给出的观点目标和目标情感分类数据,得到所有词块所在的分类。分类的类别包含4种:TPOS表示词块是观点目标且对该目标的情感类别是正向的,TNEG表示词块是观点目标且对该目标的情感类别是负向的,TNEU表示词块是观点目标且对该目标的情感类别是中性的,O表示词块不是观点目标。比如对于句子“硬盘坏了”,长度上限设置为2,则所有的连续词块及其对应的标签为“(硬,O),(盘,O),(坏,O),(了,O),(硬盘,TNEG),(盘坏,O),(坏了,O)”。Step 1: For each sentence, exhaust all consecutive word blocks in it (the length of the word block sets an upper limit). According to the opinion target and target sentiment classification data given in the annotated corpus, the classification of all word blocks is obtained. There are 4 categories of classification: TPOS indicates that the word chunk is an opinion target and the sentiment category of the target is positive, TNEG indicates that the word chunk is an opinion target and the sentiment category of the target is negative, TNEU indicates that the word chunk is an opinion target and the sentiment category for that target is neutral, O indicates that the chunk is not an opinion target. For example, for the sentence "hard disk is broken", the upper limit of the length is set to 2, then all consecutive word blocks and their corresponding labels are "(hard, O), (disk, O), (bad, O), (now, O ), (hard disk, TNEG), (disk bad, O), (bad, O)".
步骤2,用无标注的语料,通过word2vec训练得到具有语义信息的词向量表示,提供给模型使用。Step 2: Using unlabeled corpus, the word vector representation with semantic information is obtained through word2vec training and provided to the model for use.
(二)模型训练阶段(2) Model training stage
结合图2,基于词块级别的观点目标抽取和目标情感分类联合模型包括以下具体步骤:Combined with Figure 2, the joint model of opinion target extraction and target sentiment classification based on word block level includes the following specific steps:
步骤1,形式化输出和输出,输入为包含T个词的句子X={w1,w2,…,wT},其中wt表示输入句子中的第t个词,目标是预测词块集合中每个词块的类别Y={(i,j,l)|1≤i≤j≤T;j-i+1≤L;l∈C},其中i,j表示词块在句子中的起始位置和终止位置,l表示词块对应的标签,C表示类别集合;Step 1, formalize the output and output, the input is a sentence containing T words X={w 1 ,w 2 ,...,w T }, where w t represents the t-th word in the input sentence, and the goal is to predict the word block The category of each chunk in the set Y = {(i,j,l)|1≤i≤j≤T; j-i+1≤L; l∈C}, where i, j represent the chunk in the sentence The starting position and ending position of , l represents the label corresponding to the word block, and C represents the category set;
步骤2,利用通过word2vec训练得到的词向量表示以及预训练好的语言模型,分别将输入句子中的每个词映射成对应的词向量两类词向量,并且把这两种类别的词向量进行拼接;Step 2, using the word vector representation obtained by word2vec training and the pre-trained language model, map each word in the input sentence into the corresponding word vector two types of word vectors, and the word vectors of these two categories are processed. splicing;
步骤3,上下文表示层,把句子中每个词对应的词向量作为输入,采用M层的双向长短记忆神经网络(stackedBi-LSTM)学习输入句子中每个词的上下文信息,其中第m(m∈{1,…,M})层的隐藏层状态计算公式如下:Step 3, the context representation layer, takes the word vector corresponding to each word in the sentence as the input, and uses the M-layer bidirectional long short-term memory neural network (stackedBi-LSTM) to learn the context information of each word in the input sentence, where the mth (m The calculation formula of the hidden layer state of the ∈{1,…,M}) layer is as follows:

其中,

步骤3词块的表示层,对于任意一个词块(i,j),用两种词块级别的信息来对其进行表示:一种是词块的边界信息,一种是词块的整体信息。其中边界信息直接用上一层得到的边界词的向量表示来获取,整体信息则是上一层得到的词块中所有词的表示的加和:Step 3: The representation layer of the word block, for any word block (i, j), it is represented by two kinds of word block level information: one is the boundary information of the word block, and the other is the overall information of the word block . The boundary information is directly obtained by the vector representation of the boundary words obtained by the previous layer, and the overall information is the sum of the representations of all words in the word block obtained by the previous layer:

其中,
步骤4基于词块的注意力机制,由于模型不仅需要预测一个词块是否是情感目标还需要预测句中对于该目标的情感倾向,而这些情感信息往往存在于词块的上下文中,为了获取和词块相关的情感信息,提出了基于词块的注意力机制来学习这些相关信息;Step 4 is based on the attention mechanism of word blocks, because the model not only needs to predict whether a word block is an emotional target, but also needs to predict the emotional tendency of the target in the sentence, and these emotional information often exist in the context of the word block, in order to obtain and The emotional information related to word chunks, and a word chunk-based attention mechanism is proposed to learn these relevant information;
步骤4-1,直观上来说,离一个词块越近的上下文词,对该词块的影响越大。模型来用了基于位置权重的上下文来模拟这种影响。首先根据每个词和词块(i,j)的距离,来定义这个词的权重w′t:Step 4-1, intuitively speaking, the closer the context word is to a word block, the greater the influence on the word block. The model uses a context based on location weights to simulate this effect. First, according to the distance between each word and the word block (i, j), the weight w' t of the word is defined:

其中lt表示第t个词到词块(i,j)的距离。对于词块中的词,设置距离lt的值为0;对于词块左边的词,距离lt为到词块最左边词的距离;对于词块右边的词,距离lt为到词块最右边词的距离。where l t represents the distance from the t-th word to the word block (i, j). For the words in the word block, set the value of the distance lt to 0; for the words on the left side of the word block, the distance lt is the distance to the leftmost word of the word block; for the words on the right side of the word block, the distance lt is the distance to the word block The distance of the rightmost word.
步骤4-2根据上面获取的权重值,模型计算每个词块(i,j)基于位置权重的上下文表示:Step 4-2 According to the weight value obtained above, the model calculates the context representation of each word block (i, j) based on the position weight:

其中et为第t个词对应的基于距离权重的表示,w′t表示第t个词的权重值,
步骤4-3获取到基于位置权重的上下文表示之后,利用基于词块的注意力机制来计算和词块相关的上下文信息。首先对于词块(i,j),计算每个上下文词et和它的相关性权重,计算公式为:In step 4-3, after obtaining the context representation based on the position weight, the word block-based attention mechanism is used to calculate the context information related to the word block. First, for the word block (i, j ), calculate each context word et and its relevance weight, the calculation formula is:


其中s(i,j)为词块(i,j)的向量表示,et为第t个词对应的基于距离权重的表示,Wa为权重矩阵,ba为偏移向量,

步骤5,输出层,把上面得到的词块(i,j)的向量表示以及与它相关的上下文表示拼接在一起,用来预测词块(i,j)的类别:Step 5, the output layer, concatenates the vector representation of the word block (i, j) obtained above and its related context representation to predict the category of the word block (i, j):
r(i,j)=[s(i,j);c(i,j)]r (i,j) =[s (i,j) ;c (i,j) ]
y=softmax(Wyr(i,j)+by) y =softmax(W y r (i,j) +by )
其中y为词块对应到各类别的概率分布,Wy为权重矩阵,by为偏移向量。Among them, y is the probability distribution of the word block corresponding to each category, W y is the weight matrix, and b y is the offset vector.
步骤6,对所有训练样本,通过最大化样本的最大似然函数来训练模型,更新模型中的参数,训练的目标函数loss定义如下:Step 6: For all training samples, the model is trained by maximizing the maximum likelihood function of the samples, and the parameters in the model are updated. The training objective function loss is defined as follows:

其中gi是词块对应的真实分类的向量表示,yi为预测得到的概率分布,H代表所有的训练的句子,Sh表示第h个句子中所有的词块。where gi is the vector representation of the true classification corresponding to the word block, yi is the predicted probability distribution, H represents all the training sentences, and Sh represents all the word blocks in the hth sentence.
(三)结果处理阶段(3) Result processing stage
步骤1,把需要进行观点目标抽取和目标情感分类的句子进行处理,得到每个句子中所有的连续词块;Step 1: Process the sentences that need to extract the viewpoint target and classify the target sentiment, and obtain all the continuous word blocks in each sentence;
步骤2,把得到的句子信息以及词块信息输入到上面得到的观点目标抽取和目标情感分类的联合模型中,对词块进行分类预测;Step 2, input the obtained sentence information and word block information into the joint model of opinion target extraction and target sentiment classification obtained above, and classify and predict the word block;
步骤3,根据词块的类别获取到句子中的观点目标以及其对应的情感类别Step 3, according to the category of the word block, the viewpoint target in the sentence and its corresponding sentiment category are obtained
由上述方案可以看出,本方案针对基于单个词级别序列标注的联合目标抽取和目标情感分类模型中两个问题:一时无法利用组成目标的多个词的整体信息,二是多个词之间可能存在情感分类不一致的问题,提出基于词块的联合抽取和分类模型,可以提高模型预测的性能,具有良好的实用性。It can be seen from the above scheme that this scheme addresses two problems in the joint target extraction and target sentiment classification model based on single-word-level sequence labeling: firstly, the overall information of multiple words that make up the target cannot be used; There may be inconsistencies in sentiment classification. A joint extraction and classification model based on word blocks is proposed, which can improve the performance of model prediction and has good practicability.
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明构思的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明保护范围内。The above are only the preferred embodiments of the present invention. It should be pointed out that for those skilled in the art, without departing from the concept of the present invention, several improvements and modifications can also be made, and these improvements and modifications should also be regarded as are within the protection scope of the present invention.
Claims (10)













Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910671527.XA CN110569355B (en) | 2019-07-24 | 2019-07-24 | Viewpoint target extraction and target emotion classification combined method and system based on word blocks |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910671527.XA CN110569355B (en) | 2019-07-24 | 2019-07-24 | Viewpoint target extraction and target emotion classification combined method and system based on word blocks |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110569355A CN110569355A (en) | 2019-12-13 |
| CN110569355B true CN110569355B (en) | 2022-05-03 |
Family
ID=68773109
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910671527.XA Active CN110569355B (en) | 2019-07-24 | 2019-07-24 | Viewpoint target extraction and target emotion classification combined method and system based on word blocks |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110569355B (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111160035B (en) * | 2019-12-31 | 2023-06-20 | 北京明朝万达科技股份有限公司 | Text corpus processing method and device |
| CN111079447B (en) * | 2020-03-23 | 2020-07-14 | 深圳智能思创科技有限公司 | Chinese-oriented pre-training method and system |
| CN112148878A (en) * | 2020-09-23 | 2020-12-29 | 网易(杭州)网络有限公司 | Emotional data processing method and device |
| CN112732915A (en) * | 2020-12-31 | 2021-04-30 | 平安科技(深圳)有限公司 | Emotion classification method and device, electronic equipment and storage medium |
| CN115905536B (en) * | 2022-11-30 | 2024-12-03 | 北京智慧星光信息技术股份有限公司 | Industry early warning method and device based on multi-task joint learning |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104731770A (en) * | 2015-03-23 | 2015-06-24 | 中国科学技术大学苏州研究院 | Chinese microblog emotion analysis method based on rules and statistical model |
| CN108470061A (en) * | 2018-03-26 | 2018-08-31 | 福州大学 | A kind of emotional semantic classification system for visual angle grade text |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20120064563A (en) * | 2010-12-09 | 2012-06-19 | 한국전자통신연구원 | Apparatus for controlling facial expression of virtual human using heterogeneous data |
-
2019
- 2019-07-24 CN CN201910671527.XA patent/CN110569355B/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104731770A (en) * | 2015-03-23 | 2015-06-24 | 中国科学技术大学苏州研究院 | Chinese microblog emotion analysis method based on rules and statistical model |
| CN108470061A (en) * | 2018-03-26 | 2018-08-31 | 福州大学 | A kind of emotional semantic classification system for visual angle grade text |
Non-Patent Citations (2)
| Title |
|---|
| Conditional BERT Contextual Augmentation;Xing Wu, Shangwen Lv, Liangjun Zang, Jizhong Han, Songlin Hu;《ICCS 2019》;20190614;全文 * |
| Recurrent attention network on memory for aspect sentiment analysis;Peng Chen,Zhongqian Sun,Lidong;《EMNLP2017》;20170909;全文 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110569355A (en) | 2019-12-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110569355B (en) | Viewpoint target extraction and target emotion classification combined method and system based on word blocks | |
| CN109902145B (en) | Attention mechanism-based entity relationship joint extraction method and system | |
| CN113591483B (en) | A document-level event argument extraction method based on sequence labeling | |
| CN111563164B (en) | A Target-Specific Sentiment Classification Method Based on Graph Neural Network | |
| CN108763326B (en) | Emotion analysis model construction method of convolutional neural network based on feature diversification | |
| CN104834747B (en) | Short text classification method based on convolutional neural networks | |
| CN110427623A (en) | Semi-structured document Knowledge Extraction Method, device, electronic equipment and storage medium | |
| CN108984526A (en) | A kind of document subject matter vector abstracting method based on deep learning | |
| CN110287323B (en) | Target-oriented emotion classification method | |
| CN110377903A (en) | A kind of Sentence-level entity and relationship combine abstracting method | |
| CN113392209B (en) | Text clustering method based on artificial intelligence, related equipment and storage medium | |
| CN107688870B (en) | A method and device for visual analysis of hierarchical factors of deep neural network based on text stream input | |
| CN113095415A (en) | Cross-modal hashing method and system based on multi-modal attention mechanism | |
| CN108647191B (en) | A Sentiment Dictionary Construction Method Based on Supervised Sentiment Text and Word Vectors | |
| CN112256866B (en) | Text fine-grained emotion analysis algorithm based on deep learning | |
| CN113673254A (en) | Knowledge distillation position detection method based on similarity maintenance | |
| CN113761890A (en) | A Multi-level Semantic Information Retrieval Method Based on BERT Context Awareness | |
| CN111666376B (en) | An answer generation method and device based on paragraph boundary scan prediction and word shift distance clustering matching | |
| Shen et al. | Dual memory network model for sentiment analysis of review text | |
| CN110263165A (en) | A kind of user comment sentiment analysis method based on semi-supervised learning | |
| CN116049406A (en) | Cross-domain emotion classification method based on contrast learning | |
| CN110851593B (en) | Complex value word vector construction method based on position and semantics | |
| Wan et al. | A deep neural network model for coreference resolution in geological domain | |
| CN110826315B (en) | Method for identifying timeliness of short text by using neural network system | |
| CN113934835B (en) | Retrieval type reply dialogue method and system combining keywords and semantic understanding representation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |