CN110083637B - Bridge disease rating data-oriented denoising method - Google Patents
Bridge disease rating data-oriented denoising method Download PDFInfo
- Publication number
- CN110083637B CN110083637B CN201910327313.0A CN201910327313A CN110083637B CN 110083637 B CN110083637 B CN 110083637B CN 201910327313 A CN201910327313 A CN 201910327313A CN 110083637 B CN110083637 B CN 110083637B
- Authority
- CN
- China
- Prior art keywords
- samples
- sample
- data set
- conflict
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2458—Special types of queries, e.g. statistical queries, fuzzy queries or distributed queries
- G06F16/2462—Approximate or statistical queries
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Probability & Statistics with Applications (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Fuzzy Systems (AREA)
- Computational Linguistics (AREA)
- Databases & Information Systems (AREA)
- Complex Calculations (AREA)
- Medical Treatment And Welfare Office Work (AREA)
Abstract
Description
技术领域Technical Field
本发明属于数据处理技术领域,旨在设计一种面向桥梁病害评级数据的去噪方法。The invention belongs to the technical field of data processing and aims to design a denoising method for bridge disease rating data.
背景技术Background Art
改革开放以来,我国公路桥梁迎来大建设大发展时期。目前,我国公路桥梁总数接近80万座,桥梁数量和规模均位居世界之首。然而,我国步入维修期的在役桥梁日渐增多。据不完全统计,我国在役桥梁约40%服役超过20年,技术等级为三、四类的带病桥梁高达30%,甚至有超过10万座桥梁为危桥,安全隐患不容忽视。桥梁病害状况评级是路桥管理和养护的基础。传统的人工评级方法不仅耗时耗力,而且准确度不高,迫切需要运用机器学习技术对在役桥梁病害进行自动评级。现有桥梁数据集中往往包含着大量的标签噪音数据,为了有效提高机器学习方法进行桥梁病害评级的预测性能,需要过滤掉原始数据集中的标签噪音数据。目前主流的标签噪音过滤方法有两种形式:(1)直接改编分类算法来降低标签噪音对算法性能的影响;(2)采用预分类器对数据进行分类投票,然后过滤掉部分疑似噪音数据。然而,上述两种方法在过滤桥梁病害标签噪音数据上的效果并不理想。Since the reform and opening up, my country's highway bridges have ushered in a period of great construction and development. At present, the total number of highway bridges in my country is close to 800,000, ranking first in the world in terms of the number and scale of bridges. However, the number of bridges in service in my country that are entering the maintenance period is increasing. According to incomplete statistics, about 40% of my country's in-service bridges have been in service for more than 20 years, and the number of bridges with technical grades of three or four is as high as 30%. There are even more than 100,000 bridges that are dangerous bridges, and the safety hazards cannot be ignored. The rating of bridge disease conditions is the basis of road and bridge management and maintenance. The traditional manual rating method is not only time-consuming and labor-intensive, but also has low accuracy. It is urgent to use machine learning technology to automatically rate the diseases of in-service bridges. The existing bridge datasets often contain a large amount of labeled noise data. In order to effectively improve the prediction performance of machine learning methods for bridge disease rating, it is necessary to filter out the labeled noise data in the original dataset. At present, there are two mainstream label noise filtering methods: (1) directly adapting the classification algorithm to reduce the impact of label noise on algorithm performance; (2) using a pre-classifier to classify and vote on the data, and then filter out some suspected noise data. However, the above two methods are not ideal in filtering bridge disease label noise data.
综上所述,本交叉领域亟需设计一种新的标签噪音过滤方法来解决上述问题。In summary, this interdisciplinary field urgently needs to design a new label noise filtering method to solve the above problems.
发明内容Summary of the invention
有鉴于此,本发明公开了一种桥梁病害评级数据的去噪方法,有效地提高了基于机器学习的桥梁病害评级方法的预测性能。第一、通过删除原始数据集中难以区分出特征值次序关系的特征得到新的数据集,该数据集中每一特征的特征值皆有次序关系,其中,所述原始数据集中包括有各个桥梁的基本信息,各个种类的桥梁病害信息及对应的桥梁病害等级标签;第二、对数据集中所有样本进行两两比较,并将互相冲突的两个样本组成一个冲突对,而数据集中所有的冲突对构造成一个冲突对集合;第三、统计冲突对集合中样本的出现次数,并对样本的出现次数进行排序;第四、依据样本的轮廓系数和样本频次依次由高到低剔除掉一定比例的样本获得新的数据集;最后,使用stacking方法分别对原始数据集和新数据集进行训练获得两个模型,并对两个模型的桥梁病害等级预测性能进行评估验证,以验证本去噪方法的有效性,若确认有效,便得到了一个相对干净的数据集。In view of this, the present invention discloses a denoising method for bridge disease rating data, which effectively improves the prediction performance of the bridge disease rating method based on machine learning. First, a new data set is obtained by deleting the features whose eigenvalue order relationship is difficult to distinguish in the original data set, and the eigenvalues of each feature in the data set have an order relationship, wherein the original data set includes the basic information of each bridge, each type of bridge disease information and the corresponding bridge disease grade label; second, all samples in the data set are compared in pairs, and the two conflicting samples are formed into a conflict pair, and all conflict pairs in the data set are constructed into a conflict pair set; third, the number of occurrences of samples in the conflict pair set is counted, and the number of occurrences of samples is sorted; fourth, a certain proportion of samples are eliminated from high to low according to the sample silhouette coefficient and sample frequency to obtain a new data set; finally, the stacking method is used to train the original data set and the new data set to obtain two models, and the bridge disease grade prediction performance of the two models is evaluated and verified to verify the effectiveness of the denoising method. If it is confirmed to be effective, a relatively clean data set is obtained.
本发明的技术方案实现形式为:一种面向桥梁病害评级数据的去噪方法,首先通过样本的两两比对获得冲突对集合,然后根据样本在冲突对集合中出现的次数,结合样本的轮廓系数进行噪音数据剔除,得到过滤后的数据集,接着使用同一种机器学习方法分别在原始数据集和过滤后的新数据集上对模型进行训练,最后比较两模型的预测性能,具体步骤为:The technical solution of the present invention is implemented in the form of: a denoising method for bridge disease rating data, firstly, a conflict pair set is obtained by pairwise comparison of samples, then noise data is removed according to the number of times the sample appears in the conflict pair set and the silhouette coefficient of the sample to obtain a filtered data set, then the same machine learning method is used to train the model on the original data set and the filtered new data set respectively, and finally the prediction performance of the two models is compared. The specific steps are:
S1、将原始数据集中的数据进行预处理获得数据集W1,通过对W1中无全序关系的特征进行去除得到新的数据集W2;S1, preprocessing the data in the original data set to obtain data set W 1 , and removing the features without total order relationship in W 1 to obtain a new data set W 2 ;
S2、基于数据集W2,根据特征ai的特征值ai,j对具有不同标签的样本进行两两比较,构造冲突对ci;S2. Based on the data set W 2 , samples with different labels are compared pairwise according to the feature values a i,j of the feature a i , and conflict pairs c i are constructed;
S3、基于冲突对ci构造冲突集合C={c1,c2,...,cN},其中N是冲突集C中包含的冲突对总数;S3. Construct a conflict set C = {c 1 , c 2 , ..., c N } based on the conflict pairs c i , where N is the total number of conflict pairs included in the conflict set C;
S4、通过统计冲突集合C中样本sk出现的频次fk,获得词典D={sk:fk}。S4. Obtain a dictionary D = {s k :f k } by counting the frequency f k of occurrence of the sample s k in the conflict set C.
S5、将词典D中的样本按频次由高到低进行排序;S5, sorting the samples in the dictionary D from high to low according to frequency;
S6、针对排序后前t%的样本,在数据集W2中计算轮廓系数s(k),删除s(k)小于ε的样本sk,获得过滤后的新数据集W3,与此同时删除冲突对集合C中包含疑似噪音样本sk的冲突对;S6. For the first t% of samples after sorting, calculate the silhouette coefficient s(k) in the data set W 2 , delete the samples sk whose s(k) is less than ε, obtain the filtered new data set W 3 , and at the same time delete the conflicting pairs containing the suspected noise samples sk in the conflicting pair set C;
S7、重复S4,S5,S6,直至步骤S62中无s(i)小于ε的样本;S7, repeat S4, S5, S6 until there is no sample with s(i) less than ε in step S62;
S8、使用相同机器学习方法,基于数据集W1和W3分别训练出模型M1和M3,评估并比较模型M3的预测性能。S8. Using the same machine learning method, train models M 1 and M 3 based on data sets W 1 and W 3, respectively, and evaluate and compare the prediction performance of model M 3 .
进一步地,步骤S1包括:Further, step S1 comprises:
S11、基于数据集W1,使用热卡填充方法,利用最相似样本的值补足缺失特征值,最相似样本的度量方法为
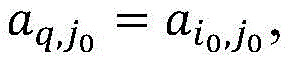

S12、删除对标签值无影响的无用特征;S12, delete useless features that have no effect on the label value;
S13、删除数据集W1中特征值无全序关系的特征,获得数据集W2。S13. Delete the features whose feature values have no total order relationship in the data set W 1 to obtain the data set W 2 .
进一步地,步骤S2包括:Further, step S2 includes:
S21、数据集W2的特征集合为A={a1,a2,...,aNi},Ni是数据集W2的特征总数;S21, the feature set of the data set W 2 is A={a 1 , a 2 , ..., a Ni }, where Ni is the total number of features of the data set W 2 ;
S22、数据集特征ai的特征值集合为
S23、首先判断两个样本的标签,若相同,则跳过比较这两个样本,若标签不同,则对两个样本所有特征下的特征值一一对应地比较大小,其计算公式:S23. First, determine the labels of the two samples. If they are the same, skip comparing the two samples. If the labels are different, compare the feature values of all features of the two samples one by one. The calculation formula is:

S24、选定第一个样本,依次将后面的所有样本按照步骤S23的方式与第一个样本进行比较,构造冲突对,依次进行下去,直至迭代到最后一个样本,然后选定第二个样本,依次将后面的所有样本按照步骤S23的方式与第一个样本进行比较,构造冲突对,依次进行下去,直至迭代到最后一个样本;同样地,直到选定倒数第二个样本比较完后停止迭代。S24, select the first sample, and compare all subsequent samples with the first sample in the manner of step S23, construct conflict pairs, and continue to iterate until the last sample is reached, then select the second sample, and compare all subsequent samples with the first sample in the manner of step S23, construct conflict pairs, and continue to iterate until the last sample is reached; similarly, stop iterating after the second to last sample is selected and compared.
进一步地,步骤S3包括:Further, step S3 includes:
S31、将步骤S23构造的所有冲突对,构造成一个冲突集合C={c1,c2,...,cN},N是冲突集C的冲突对总数。S31 . Construct all conflict pairs constructed in step S23 into a conflict set C={c 1 , c 2 , . . . , c N }, where N is the total number of conflict pairs in the conflict set C.
进一步地,步骤S4包括:Further, step S4 includes:
S41、统计冲突对左边元素中样本sk出现的次数flk;S41, counting the number of occurrences f lk of the sample sk in the left element of the conflict pair;
S42、统计冲突对右边元素中样本sk出现的次数frk;S42, counting the number of occurrences f rk of the sample sk in the right element of the conflicting pair;
S43、计算总频次fk=flk+frk;S43, calculating the total frequency f k =f lk +f rk ;
S44、将样本sk和其出现的频次fk之间的一一映射关系,构造一个词典D={sk:fk},k=1,2,...,Na。S44. Construct a dictionary D = {s k :f k }, k = 1, 2, ..., Na, by mapping the one-to-one relationship between the sample sk and its occurrence frequency f k.
进一步地,步骤S5包括:Further, step S5 includes:
S51、将词典D中的样本按照频次fk由高到低进行排序。S51. Sort the samples in the dictionary D according to the frequency f k from high to low.
进一步地,步骤S6包括:Further, step S6 includes:
S61、根据公式
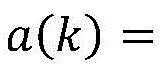


S62、若样本sk的轮廓系数s(k)<ε,则记录下该样本sk的编号,并将其视为疑似噪音样本,在数据集W2中删除掉样本sk,得到新的数据集W3。S62. If the silhouette coefficient s(k) of the sample sk is less than ε, the serial number of the sample sk is recorded and regarded as a suspected noise sample. The sample sk is deleted from the data set W2 to obtain a new data set W3 .
S63、在冲突对集合C中删除包含步骤S62中疑似噪音样本sk的冲突对。S63. Delete the conflicting pair including the suspected noise sample sk in step S62 from the conflicting pair set C.
进一步地,步骤S7包括:Further, step S7 includes:
S71、重复S4,S5,S6,直至步骤S62中无s(i)小于ε的样本(在本专利中,ε被设定为0)。S71. Repeat S4, S5, and S6 until there is no sample with s(i) less than ε in step S62 (in this patent, ε is set to 0).
进一步地,步骤S8包括:Further, step S8 includes:
S81、分别将数据集W1和新数据集W3按照同样的比例分为三部分,分别是训练集、验证集和测试集;S81, respectively divide the data set W1 and the new data set W3 into three parts according to the same proportion, namely, a training set, a validation set and a test set;
S82、运用使用stacking方法分别在W1和W3训练出模型M1和M3;S82, using the stacking method to train models M 1 and M 3 on W 1 and W 3 respectively;
S83、比较评估模型M3的预测性能。S83. Compare and evaluate the prediction performance of model M 3 .
采用上述方法策略后,本发明的积极效果是:After adopting the above method strategy, the positive effects of the present invention are:
(1)本发明针对桥梁病害数据集中出现的标签噪音数据,设计了一种截然不同的噪音消除算法,利用样本与样本之间的标签冲突,依据样本冲突次数找到了不同样本作为噪音数据概率大小的差异,增加了标签噪音过滤的准确性,提高了数据集的数据质量。(1) This paper designs a completely different noise elimination algorithm for the labeled noise data appearing in the bridge disease dataset. It uses the label conflicts between samples and finds the difference in the probability of different samples being noise data based on the number of sample conflicts, thereby increasing the accuracy of label noise filtering and improving the data quality of the dataset.
(2)相较于传统的使用分类算法进行标签噪音过滤的方法,本发明借助了数据集本身内在结构的特异性,提高了最终训练出机器学习模型的预测性能。(2) Compared with the traditional method of using classification algorithms to filter label noise, the present invention takes advantage of the specificity of the intrinsic structure of the data set itself to improve the predictive performance of the machine learning model finally trained.
附图说明BRIEF DESCRIPTION OF THE DRAWINGS
读者在参照附图阅读了本发明的具体实施方式以后,将会更清楚地了解本发明的各个方面,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提之下,还可以根据这些附图获得其他附图。After reading the specific implementation methods of the present invention with reference to the accompanying drawings, the reader will have a clearer understanding of various aspects of the present invention. The accompanying drawings described below are some embodiments of the present invention. For ordinary technicians in this field, other accompanying drawings can be obtained based on these accompanying drawings without paying any creative work.
图1为本发明的面向桥梁病害评级数据的噪音去除方法实施例的流程示意图。FIG1 is a flow chart of an embodiment of a method for removing noise from bridge defect rating data according to the present invention.
图2为本发明的面向桥梁病害评级数据的噪音去除方法实施例中步骤S2的具体流程示意图。FIG. 2 is a schematic diagram of a specific flow chart of step S2 in an embodiment of the method for removing noise from bridge defect rating data of the present invention.
图3为本发明的面向桥梁病害评级数据的噪音去除方法实施例中步骤S4的具体流程示意图。FIG3 is a schematic diagram of a specific flow chart of step S4 in an embodiment of the method for removing noise from bridge defect rating data of the present invention.
图4为本发明的面向桥梁病害评级数据的噪音去除方法实施例中步骤S6的具体流程示意图。FIG. 4 is a schematic diagram of a specific flow chart of step S6 in an embodiment of the method for removing noise from bridge defect rating data of the present invention.
图5为本发明的面向桥梁病害评级数据的噪音去除方法实施例中步骤S8的具体流程示意图。FIG. 5 is a schematic diagram of a specific flow chart of step S8 in an embodiment of the method for removing noise from bridge defect rating data of the present invention.
具体实施方式DETAILED DESCRIPTION
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。In order to make the purpose, technical solution and advantages of the present invention more clearly understood, the present invention is further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the present invention and are not used to limit the present invention.
S1、将原始数据集中的数据进行数据预处理得到数据集W1,对W1中无全序关系的特征进行去除,得到数据集W2。S1. Preprocess the data in the original data set to obtain data set W 1 , remove the features without total order relationship in W 1 , and obtain data set W 2 .
S11、使用热卡填充方法,利用最相似样本的值补足缺失特征值,最相似样本的度量方法为


S12、删除对标签值无影响的无用特征;S12, delete useless features that have no effect on the label value;
S13、删除数据集W1中特征值无全序关系的特征,得到数据集W2。S13. Delete the features whose feature values have no total order relationship in the data set W 1 to obtain the data set W 2 .
S2、根据数据集W2,基于特征ai的特征值ai,j对不同标签的样本进行两两比较,构造冲突对ci。S2. According to the data set W 2 , samples with different labels are compared pairwise based on the feature values a i,j of the feature a i , and conflict pairs c i are constructed.
S21、数据集W2的特征集合为A={a1,a2,...,aNi},Ni是数据集W2的特征总数;S21, the feature set of the data set W 2 is A={a 1 , a 2 , ..., a Ni }, where Ni is the total number of features of the data set W 2 ;
S22、数据集特征ai的特征值集合为D={ai,1,ai,2,...,ai,Na},Na是数据集W2的总样本数,也是特征ai的特征值总数;S22, the feature value set of the feature ai of the data set is D = { ai, 1 , ai, 2, ..., ai, Na }, where Na is the total number of samples in the data set W2 and also the total number of feature values of the feature ai ;
S23、首先判断两个样本的标签,若相同,则跳过比较这两个样本,若标签不同,则对两个样本所有特征下的特征值一一对应地比较大小,其计算公式:S23. First, determine the labels of the two samples. If they are the same, skip comparing the two samples. If the labels are different, compare the feature values of all features of the two samples one by one. The calculation formula is:

S24、选定第一个样本,依次将后面的所有样本按照步骤S23的方式与第一个样本进行比较,构造冲突对,依次进行下去,直至迭代到最后一个样本,然后选定第二个样本,依次将后面的所有样本按照步骤S23的方式与第一个样本进行比较,构造冲突对,依次进行下去,直至迭代到最后一个样本;同样地,直到选定倒数第二个样本比较完后停止迭代。S24, select the first sample, and compare all subsequent samples with the first sample in the manner of step S23, construct conflict pairs, and continue to iterate until the last sample is reached, then select the second sample, and compare all subsequent samples with the first sample in the manner of step S23, construct conflict pairs, and continue to iterate until the last sample is reached; similarly, stop iterating after the second to last sample is selected and compared.
S3、根据冲突对ci构造冲突集合C={c1,c2,...,cN},其中N是冲突集C的冲突对总数。S3. Construct a conflict set C = {c 1 , c 2 , ..., c N } according to the conflict pairs c i , where N is the total number of conflict pairs in the conflict set C.
S31、将步骤S23构造的所有冲突对组成一个冲突集合C={c1,c2,...,cN},其中N是冲突集C的冲突对总数。S31 . All conflict pairs constructed in step S23 are combined into a conflict set C={c 1 , c 2 , . . . , c N }, where N is the total number of conflict pairs in the conflict set C.
S4、通过统计冲突集合C中样本sk出现的频次fk,得到词典D={sk:fk}。S4. By counting the frequency f k of occurrence of sample sk in the conflict set C, a dictionary D = { sk : fk } is obtained.
S41、统计冲突对左边元素中样本sk出现的次数flk;S41, counting the number of occurrences f lk of the sample sk in the left element of the conflict pair;
S42、统计冲突对右边元素中样本sk出现的次数frk;S42, counting the number of occurrences f rk of the sample sk in the right element of the conflicting pair;
S43、计算频次fk=flk+frk;S43, calculating the frequency f k =f lk +f rk ;
S44、将样本sk和其出现的频次fk之间的一一映射关系,构造一个词典D={sk:fk},k=1,2,...,Na。S44. Construct a dictionary D = {s k :f k }, k = 1, 2, ..., Na, by mapping the one-to-one relationship between the sample sk and its occurrence frequency f k.
S5、将词典D中的样本按频次由高到低进行排序。S5. Sort the samples in dictionary D by frequency from high to low.
S51、将词典D中的样本按照频次fk由高到低进行排序。S51. Sort the samples in the dictionary D according to the frequency f k from high to low.
S6、针对排序后前t%的样本在数据集W2中计算轮廓系数s(k),删除s(k小于ε的样本sk,得到过滤后的新数据集W3,同时删除冲突对集合C中包含疑似噪音样本sk的冲突对。S6. Calculate the silhouette coefficient s(k) in the data set W2 for the first t% of the samples after sorting, delete the samples sk whose s(k) is less than ε, obtain the filtered new data set W3 , and delete the conflicting pairs in the conflicting pair set C that contain the suspected noise samples sk .
S61、根据公式



S62、若样本sk的轮廓系数s(k)<ε,则记录下该样本sk的编号,并将其视为疑似噪音样本,在数据集W2中删除掉样本sk,得到新的数据集W3;S62, if the silhouette coefficient s(k) of the sample sk is less than ε, the serial number of the sample sk is recorded and regarded as a suspected noise sample, and the sample sk is deleted from the data set W2 to obtain a new data set W3 ;
S63、在冲突对集合C中删除包含步骤S62中疑似噪音样本sk的冲突对。S63. Delete the conflicting pair including the suspected noise sample sk in step S62 from the conflicting pair set C.
S7、重复S4,S5,S6,直至步骤S62中无s(i)小于ε的样本。S7. Repeat S4, S5, and S6 until there is no sample with s(i) less than ε in step S62.
S71、重复S4,S5,S6,直至步骤S62中无s(i)小于ε的样本(在本专利中,ε被设定为0)。S71. Repeat S4, S5, and S6 until there is no sample with s(i) less than ε in step S62 (in this patent, ε is set to 0).
S8、基于数据集W1和W3运用stacking方法分别训练出模型M1和M3,评估并比较模型M3的预测性能。S8. Based on data sets W1 and W3, use the stacking method to train models M1 and M3 respectively, and evaluate and compare the prediction performance of model M3 .
S81、分别将数据集W1和新数据集W3按照同样的比例分割成三部分,分别作为训练集、验证集和测试集;S81, divide the data set W1 and the new data set W3 into three parts according to the same ratio, as a training set, a validation set and a test set respectively;
S82、运用相同的机器学习算法分别基于W1和W3数据集训练出模型M1和M3;S82, using the same machine learning algorithm to train models M1 and M3 based on the W1 and W3 data sets respectively;
S83、评估并比较模型M3的预测性能。S83. Evaluate and compare the prediction performance of model M 3 .
上文中,参照附图描述了本发明的具体实施方式。但是,本领域中的普通技术人员能够理解,在不偏离本发明的精神和范围的情况下,还可以对本发明的具体实施方式作各种变更和替换。这些变更和替换都落在本发明权利要求书所限定的范围内。In the above, the specific embodiments of the present invention are described with reference to the accompanying drawings. However, those skilled in the art will appreciate that various changes and substitutions may be made to the specific embodiments of the present invention without departing from the spirit and scope of the present invention. These changes and substitutions are all within the scope defined by the claims of the present invention.
Claims (8)

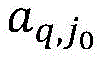

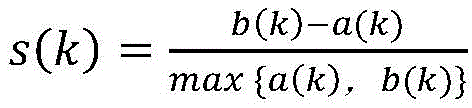

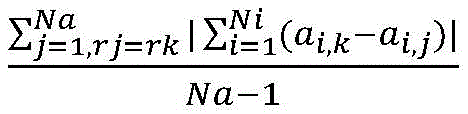
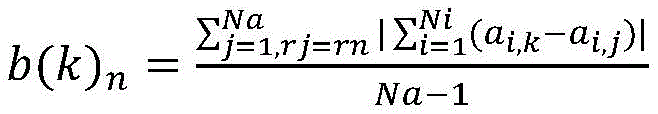
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910327313.0A CN110083637B (en) | 2019-04-23 | 2019-04-23 | Bridge disease rating data-oriented denoising method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910327313.0A CN110083637B (en) | 2019-04-23 | 2019-04-23 | Bridge disease rating data-oriented denoising method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110083637A CN110083637A (en) | 2019-08-02 |
| CN110083637B true CN110083637B (en) | 2023-04-18 |
Family
ID=67416114
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910327313.0A Active CN110083637B (en) | 2019-04-23 | 2019-04-23 | Bridge disease rating data-oriented denoising method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110083637B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111352966A (en) * | 2020-02-24 | 2020-06-30 | 交通运输部水运科学研究所 | A Data Label Calibration Method in Autonomous Navigation |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5341142A (en) * | 1987-07-24 | 1994-08-23 | Northrop Grumman Corporation | Target acquisition and tracking system |
| CN201023495Y (en) * | 2007-04-29 | 2008-02-20 | 余亚莉 | Vehicle mounted railway traffic passenger transport capacity and operation safety intelligence monitoring and prewarning system |
| CN101639934A (en) * | 2009-09-04 | 2010-02-03 | 西安电子科技大学 | SAR image denoising method based on contour wave domain block hidden Markov model |
| CN102340884A (en) * | 2010-07-26 | 2012-02-01 | 中兴通讯股份有限公司 | Base station and method for preventing random access conflicts |
| CN102509083A (en) * | 2011-11-19 | 2012-06-20 | 广州大学 | Detection method for body conflict event |
| CN103150409A (en) * | 2013-04-08 | 2013-06-12 | 深圳市宜搜科技发展有限公司 | Method and system for recommending user search word |
| CN104077749A (en) * | 2014-06-17 | 2014-10-01 | 长江大学 | Seismic data denoising method based on contourlet transformation |
| CN104966090A (en) * | 2015-07-21 | 2015-10-07 | 公安部第三研究所 | Visual word generation and evaluation system and method for realizing image comprehension |
| CN105551028A (en) * | 2015-12-09 | 2016-05-04 | 中山大学 | Method and system for dynamically updating geographic space data based on remote sensing image |
| CN108073940A (en) * | 2016-11-18 | 2018-05-25 | 北京航空航天大学 | A kind of method of 3D object instance object detections in unstructured moving grids |
| CN108549904A (en) * | 2018-03-28 | 2018-09-18 | 西安理工大学 | Difference secret protection K-means clustering methods based on silhouette coefficient |
| CN109389143A (en) * | 2018-06-19 | 2019-02-26 | 北京九章云极科技有限公司 | A data analysis and processing system and automatic modeling method |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7508990B2 (en) * | 2004-07-30 | 2009-03-24 | Euclid Discoveries, Llc | Apparatus and method for processing video data |
| EP3083979B1 (en) * | 2013-12-19 | 2019-02-20 | Axon DX, LLC | Cell detection, capture and isolation methods and apparatus |
-
2019
- 2019-04-23 CN CN201910327313.0A patent/CN110083637B/en active Active
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5341142A (en) * | 1987-07-24 | 1994-08-23 | Northrop Grumman Corporation | Target acquisition and tracking system |
| CN201023495Y (en) * | 2007-04-29 | 2008-02-20 | 余亚莉 | Vehicle mounted railway traffic passenger transport capacity and operation safety intelligence monitoring and prewarning system |
| CN101639934A (en) * | 2009-09-04 | 2010-02-03 | 西安电子科技大学 | SAR image denoising method based on contour wave domain block hidden Markov model |
| CN102340884A (en) * | 2010-07-26 | 2012-02-01 | 中兴通讯股份有限公司 | Base station and method for preventing random access conflicts |
| CN102509083A (en) * | 2011-11-19 | 2012-06-20 | 广州大学 | Detection method for body conflict event |
| CN103150409A (en) * | 2013-04-08 | 2013-06-12 | 深圳市宜搜科技发展有限公司 | Method and system for recommending user search word |
| CN104077749A (en) * | 2014-06-17 | 2014-10-01 | 长江大学 | Seismic data denoising method based on contourlet transformation |
| CN104966090A (en) * | 2015-07-21 | 2015-10-07 | 公安部第三研究所 | Visual word generation and evaluation system and method for realizing image comprehension |
| CN105551028A (en) * | 2015-12-09 | 2016-05-04 | 中山大学 | Method and system for dynamically updating geographic space data based on remote sensing image |
| CN108073940A (en) * | 2016-11-18 | 2018-05-25 | 北京航空航天大学 | A kind of method of 3D object instance object detections in unstructured moving grids |
| CN108549904A (en) * | 2018-03-28 | 2018-09-18 | 西安理工大学 | Difference secret protection K-means clustering methods based on silhouette coefficient |
| CN109389143A (en) * | 2018-06-19 | 2019-02-26 | 北京九章云极科技有限公司 | A data analysis and processing system and automatic modeling method |
Non-Patent Citations (2)
| Title |
|---|
| "De-noising and event extraction for silicon pore sensors using matrix decomposition";P. Sattigeri 等;《 Sensor Signal Processing for Defence》;20130708;第1-4页 * |
| "我国网络舆情热点话题发现研究综述";游丹丹 等;《现代情报》;20170315;第165-171页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110083637A (en) | 2019-08-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110197588B (en) | Method and device for evaluating driving behavior of large truck based on GPS track data | |
| CN110097755B (en) | State recognition method of expressway traffic flow based on deep neural network | |
| CN114444986B (en) | Product analysis method, system, device and medium | |
| TW201732662A (en) | Method and device for establishing data identification model | |
| CN114926299B (en) | A method for predicting vehicle accident risks based on big data analysis | |
| CN111767398A (en) | Classification method of short text data of secondary equipment fault based on convolutional neural network | |
| CN112687349A (en) | Construction method of model for reducing octane number loss | |
| CN111177010B (en) | A method for identifying software defect severity | |
| CN108665093B (en) | Prediction method of highway traffic accident severity based on deep learning | |
| CN116049668A (en) | A Machine Learning-Based Method for Predicting the Severity of Autonomous Driving Accidents | |
| CN110458204A (en) | Vehicle Fault Prediction Method Based on Information Gain and LightGBM Model | |
| CN115130519B (en) | Hull structure fault prediction method using convolutional neural network | |
| CN113112067A (en) | Method for establishing TFRI weight calculation model | |
| CN109859199A (en) | A kind of method of the fresh water pipless pearl quality testing of SD-OCT image | |
| CN116340746A (en) | Feature selection method based on random forest improvement | |
| CN110083637B (en) | Bridge disease rating data-oriented denoising method | |
| CN119541701A (en) | A method for food safety risk assessment based on small sample learning | |
| CN114722960A (en) | Method and system for detecting incomplete track of event log in business process | |
| CN111523562A (en) | A commuter mode vehicle recognition method based on license plate recognition data | |
| CN110807601B (en) | Park road degradation analysis method based on tail cutting data | |
| CN108090635B (en) | A road performance prediction method based on cluster classification | |
| CN115457966B (en) | Pig cough sound identification method based on improved DS evidence theory multi-classifier fusion | |
| CN111143425A (en) | An adaptive feature selection method for high-dimensional datasets based on XGBoost | |
| CN113704073A (en) | Method for detecting abnormal data of automobile maintenance record library | |
| CN119669869A (en) | Multi-level track defect identification system based on vehicle body vibration data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |