CN110069969B - An Authentication Fingerprint Recognition Method Based on Pseudo-Random Integration - Google Patents
An Authentication Fingerprint Recognition Method Based on Pseudo-Random Integration Download PDFInfo
- Publication number
- CN110069969B CN110069969B CN201810718434.3A CN201810718434A CN110069969B CN 110069969 B CN110069969 B CN 110069969B CN 201810718434 A CN201810718434 A CN 201810718434A CN 110069969 B CN110069969 B CN 110069969B
- Authority
- CN
- China
- Prior art keywords
- signal
- sample
- samples
- pseudo
- signal samples
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/12—Fingerprints or palmprints
- G06V40/1347—Preprocessing; Feature extraction
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/12—Fingerprints or palmprints
- G06V40/1365—Matching; Classification
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Human Computer Interaction (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Medical Informatics (AREA)
- Data Mining & Analysis (AREA)
- Artificial Intelligence (AREA)
- Image Analysis (AREA)
- Measurement Of The Respiration, Hearing Ability, Form, And Blood Characteristics Of Living Organisms (AREA)
Abstract
Description
技术领域technical field
本发明涉及无线设备物理层接入认证领域,尤其涉及一种基于伪随机整合的认证指纹识别方法。The invention relates to the field of wireless device physical layer access authentication, in particular to an authentication fingerprint identification method based on pseudo-random integration.
背景技术Background technique
终端节点的接入认证是物联网安全的一个重要而具有挑战性的问题。射频指纹识别是该问题的一种很有前途的解决方案,通过提取由于硬件制造缺陷引起的信号变化来提取指纹以执行终端节点访问认证。机器学习可以通过大量数据的训练很好的完成射频指纹识别。Access authentication of end nodes is an important and challenging issue for IoT security. Radio frequency fingerprinting is a promising solution to this problem, extracting fingerprints to perform end node access authentication by extracting signal changes due to hardware manufacturing defects. Machine learning can complete radio frequency fingerprinting very well through the training of a large amount of data.
射频指纹的机器学习性能受训练数据量的影响很大,需要大量的射频指纹数据才能得到较好的训练和识别结果。在某些情况下,数据十分珍贵,其获取并不容易。数据增强是使用有限的数据获得更好结果的最常用方法。数据增强对系统的最终分类性能和泛化能力有很大的影响,其通过应用“标签不变量”变换来训练实例来生成附加伪实例。目前的研究提供了多种不同的数据增强策略,它们大多在图像识别领域工作。常用的图像增强策略简要概括如下:The machine learning performance of RF fingerprints is greatly affected by the amount of training data, and a large amount of RF fingerprint data is required to obtain better training and recognition results. In some cases, data is so precious that it is not easy to obtain. Data augmentation is the most common way to get better results with limited data. Data augmentation has a large impact on the final classification performance and generalization ability of the system, which generates additional pseudo-instances by applying a "label-invariant" transformation to the training instances. Current research provides a variety of different data augmentation strategies, and most of them work in the field of image recognition. Commonly used image enhancement strategies are briefly summarized as follows:
1、尺度变换:修改图像的大小或缩放图像到一定的比例。1. Scale transformation: Modify the size of the image or scale the image to a certain ratio.
2、位置变换:翻转、旋转和平移,即在水平方向或垂直方向上翻转图像。以一定的角度旋转图像。把图像移到一定的距离。2. Position transformation: flip, rotate and translate, that is, flip the image in the horizontal or vertical direction. Rotate the image by an angle. Move the image to a certain distance.
3、截取或删减。剪掉图像的一部分,删除或保留这部分。3. Intercept or delete. Cut out part of the image, delete or keep this part.
4、颜色抖动。改变图像的亮度、饱和度或对比度。4. Color jitter. Change the brightness, saturation or contrast of the image.
5、PCA抖动。通过主成分分析提取图像的主成分,然后添加一个(0,0.1)的高斯扰动。5. PCA jitter. Extract the principal components of the image by principal component analysis, and then add a (0,0.1) Gaussian perturbation.
6、噪声。随机获得像素点,然后将其设置为高亮度和低灰度级,以模拟加性噪声。6. Noise. Pixel points are randomly obtained and then set to high brightness and low gray level to simulate additive noise.
策略1到4适合于图像增强,其不能直接用作于一维序列,如声音或信号。策略5和6可以用于信号分类,但它们在高信噪比的信号样本中加入额外的噪声会降低最终的分类精度。已有的研究表明,当信噪比降低时,射频指纹识别准确率会迅速下降。因此,目前主流的数据增强方法在主信号处理中并不完全可行,无法直接用于射频指纹识别。Strategies 1 to 4 are suitable for image enhancement, which cannot be used directly for one-dimensional sequences such as sound or signals.
Salamon与Bello在2017年的研究提供了一系列用于声音分类的数据增强策略,它与信号密切相关,如下所述:时间延长:保持频率不变,提高或降低样本的速率;频率改变:保持速率不变,提高或降低样本的频率;动态范围压缩:某些小信号根据需求放大,而大信号保持不变。这些策略确实可以用于信号处理。然而,在射频指纹识别中信号的近似度非常高。同一类型的信号与其被变换后信号的差异将大于该信号与另一种信号的差异。数据增强的一个关键概念是应用于数据的变形不能改变标签的含义,因此这些策略也不适用于射频指纹识别。Salamon and Bello's 2017 study provides a series of data augmentation strategies for sound classification, which are closely related to the signal, as follows: time extension: keep frequency constant, increase or decrease the rate of samples; frequency change: keep The rate remains the same, increasing or decreasing the frequency of the samples; dynamic range compression: some small signals are amplified as needed, while large signals remain unchanged. These strategies can indeed be used for signal processing. However, the approximation of the signals in RFID fingerprinting is very high. A signal of the same type will differ from its transformed signal more than that signal differs from another signal. A key concept of data augmentation is that deformations applied to the data cannot change the meaning of the labels, so these strategies are also not suitable for RFID fingerprinting.
发明内容SUMMARY OF THE INVENTION
本发明的目的在于克服现有技术的不足,提供一种基于伪随机整合的认证指纹识别方法,利用基于伪随机整合的数据增强方式,增加了可供机器学习的训练数据量;同时,结合机器学习,降低了基于随机整合与机器学习的射频指纹识别技术在识别率上的不稳定性。The purpose of the present invention is to overcome the deficiencies of the prior art and provide an authentication fingerprint identification method based on pseudo-random integration, which increases the amount of training data available for machine learning by using the data enhancement method based on pseudo-random integration; Learning reduces the instability of the recognition rate of the radio frequency fingerprint recognition technology based on random integration and machine learning.
本发明的目的是通过以下技术方案来实现的:一种基于伪随机整合的认证指纹识别方法,包括以下步骤:The object of the present invention is to be achieved through the following technical solutions: a kind of authentication fingerprint identification method based on pseudo-random integration, comprising the following steps:
S1.接收设备对发送设备进行信号采集和存储,得到N个信号样本存放在样本库中;S1. The receiving device collects and stores signals from the sending device, and obtains N signal samples and stores them in the sample library;
S2.采用伪随机整合将样本库中N个信号样本增强为K个信号样本;S2. Use pseudo-random integration to enhance the N signal samples in the sample library into K signal samples;
S3.对生成的信号样本进行特征提取;S3. Feature extraction is performed on the generated signal samples;
S4.对于多个不同的发射设备,重复以上S1~S3操作,以设备编号为反馈;并利用机器学习算法中的分类算法对每一个发送设备处理后的信号进行训练,得到分类器;S4. For a plurality of different transmitting devices, repeat the above operations S1 to S3, and use the device number as feedback; and use the classification algorithm in the machine learning algorithm to train the signals processed by each transmitting device to obtain a classifier;
S5.利用训练得到的分类器对待检测波形进行分类,判定其所属设备。S5. Use the classifier obtained by training to classify the waveform to be detected, and determine the equipment to which it belongs.
具体地,所述的步骤S1包括:Specifically, the step S1 includes:
S101.接收设备检测接收到的开机瞬态信号起始点位置;S101. The receiving device detects the position of the starting point of the received power-on transient signal;
S102.从起始点位置开始,采集一个发送设备的M个开机瞬态信号样本点,作为一个信号样本;S102. Starting from the starting point, collect M power-on transient signal sample points of a sending device as a signal sample;
S103.在信号样本中,编号开机瞬态信号样本点,以每个开机瞬态信号样本点对应的幅值定义开机瞬态信号样本点幅值函数fi:S103. In the signal samples, number the power-on transient signal sample points, and define the power-on transient signal sample point amplitude function f i with the amplitude corresponding to each power-on transient signal sample point:
fi={amp:(1,2,……,M)}f i ={amp:(1,2,...,M)}
={amp1,amp2,……,ampM};={amp 1 ,amp 2 ,...,amp M };
S104.按照步骤S101~S103采集N个信号样本存放到样本库中。S104. Collect N signal samples according to steps S101-S103 and store them in the sample library.
具体地,所述步骤S2通过伪随机选择将同一发送设备的多个开机瞬态信号样本点幅值函数进行相参或非相参积累,利用有限的信号样本生成大量的可供机器学习的训练数据,包括:Specifically, the step S2 performs coherent or non-coherent accumulation of the amplitude functions of multiple power-on transient signal sample points of the same sending device by pseudo-random selection, and uses limited signal samples to generate a large number of training machines for machine learning. data, including:
S201.从样本库中随机选取n个信号样本,n<N;S201. Randomly select n signal samples from the sample library, n<N;
S202.从第二次选择信号样本开始,检测选择的n个样本是否与之前的选择完全相同:若是,跳转至步骤S204;若否,进入步骤S203;S202. Starting from the second selection of signal samples, check whether the selected n samples are exactly the same as the previous selection: if so, go to step S204; if not, go to step S203;
S203.将该n个样本相参积累或非相参积累,并存入数据库中:S203. The n samples are accumulated coherently or non-coherently, and stored in the database:
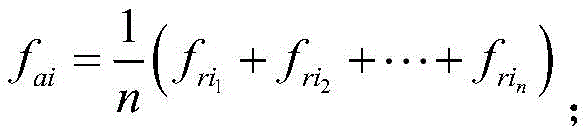
其中fr是库中原始信号样本,fa为生成的信号样本;where fr is the original signal sample in the library, and f a is the generated signal sample;
S204.将参与整合的信号样本从样本库中移除;S204. Remove the signal samples participating in the integration from the sample library;
S205.重复执行步骤S201~S204直到信号库中的样本数量少于n;S205. Repeat steps S201 to S204 until the number of samples in the signal library is less than n;
S206.初始化信号库,将其重置为原始状态;S206. Initialize the signal library and reset it to the original state;
S207.重复执行S201至S206,直到数据库中的信号样本数量达到K个;S207. Repeat S201 to S206 until the number of signal samples in the database reaches K;
S208.输出数据库中的信号样本。S208. Output the signal samples in the database.
具体地,所述步骤S3包括:Specifically, the step S3 includes:
S301.对于数据库中的每一个信号样本,首先进行翻折处理,即对幅度值取绝对值:S301. For each signal sample in the database, firstly perform the folding process, that is, take the absolute value of the amplitude value:
favi=|fi|;f avi = | f i |;
S302.对翻折后的信号样本进行归一化处理:S302. Normalize the folded signal samples:
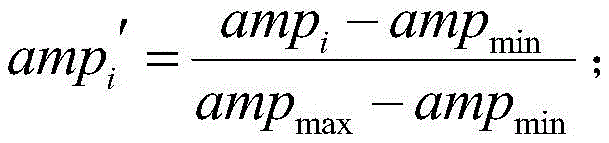
式中,ampi表示信号样本中的第i个样本点幅值,i=1,2,...,M,ampmax表示信号样本中最大的样本点幅值,ampmin表示信号样本中最小的样本点幅值;In the formula, amp i represents the amplitude of the i-th sample point in the signal sample, i=1,2,...,M, amp max represents the amplitude of the largest sample point in the signal sample, and amp min represents the smallest sample point in the signal sample. The sample point amplitude of ;
S303.对归一化处理后的信号样本进行特征提取;S303. Perform feature extraction on the normalized signal samples;
S304.重复步骤S301~S303,直至对数据库中的K个信号样本处理完成,得到K个信号样本的特征数据。S304. Repeat steps S301 to S303 until the processing of the K signal samples in the database is completed, and the characteristic data of the K signal samples is obtained.
优选地,步骤S1中,可以通过向量化的方式提高后续的运行速率,即采用矩阵的形式统一存放所采集到的信号样本:Preferably, in step S1, the subsequent running rate can be improved by means of vectorization, that is, the collected signal samples are uniformly stored in the form of a matrix:

优选地,所述步骤S4中,为提高运行速率,反馈值也可以向量化,即:Preferably, in the step S4, in order to improve the running rate, the feedback value can also be vectorized, that is:
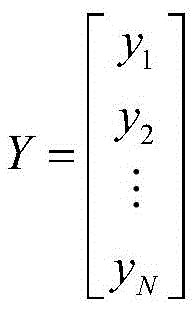
其中,yi为样本fi对应的反馈值,Y为反馈存放矩阵。Among them, yi is the feedback value corresponding to the sample f i , and Y is the feedback storage matrix.
优选地,进一步地,所述步骤S4中,为便于机器学习,可以将特征数据与反馈值对应统一存放,即:Preferably, further, in the step S4, in order to facilitate machine learning, the characteristic data and the feedback value can be stored correspondingly in a unified manner, that is:
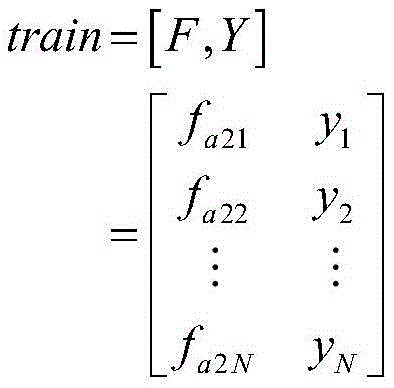
其中,train为机器学习训练矩阵。Among them, train is the machine learning training matrix.
优选地,所述机器学习算法中的分类算法包括k-近邻算法、朴素贝叶斯算法、SVM算法和决策树算法。Preferably, the classification algorithm in the machine learning algorithm includes k-nearest neighbor algorithm, naive Bayes algorithm, SVM algorithm and decision tree algorithm.
优选地,所述步骤S101中,起始点位置检测的方法包括绝对幅度值检测和斜率检测。Preferably, in the step S101, the method for detecting the position of the starting point includes absolute amplitude value detection and slope detection.
优选地,所述步骤S3中的特征提取方法包括基于幅度的特征提取、基于幅度和相位联合的特征提取、基于频率的特征提取、基于相位偏移的特征提取、基于小波变换的特征提取,以及基于多分辨率分析的特征提取;其中所述多分辨率分析中母小波的选择包括Preferably, the feature extraction method in the step S3 includes feature extraction based on amplitude, feature extraction based on amplitude and phase combination, feature extraction based on frequency, feature extraction based on phase shift, feature extraction based on wavelet transform, and Feature extraction based on multi-resolution analysis; wherein the selection of mother wavelets in the multi-resolution analysis includes
haar、dB2、bior和morl。haar, dB2, bior and morl.
本发明的有益效果是:(1)本发明利用随机整合的方法来做射频指纹的数据增强,利用有限的信号样本生成了大量的信号样本,从而提高机器学习可用的训练数据,降低过拟合,一定程度提高了识别准确率。(2)本发明使用伪随机的选择方法,降低了射频指纹样本选取的随机性,减少了识别准确率的不稳定性。(3)本发明对多个发射设备进行数据采集和特征提取,并以设备编号为反馈,以实现分类器的训练和待检波形判断,使每个设备均能保持一个较高的识别准确率,提高了识别结果的可信度。The beneficial effects of the present invention are as follows: (1) The present invention utilizes the method of random integration to enhance the data of the radio frequency fingerprint, and utilizes limited signal samples to generate a large number of signal samples, thereby improving the training data available for machine learning and reducing overfitting. , which improves the recognition accuracy to a certain extent. (2) The present invention uses a pseudo-random selection method, which reduces the randomness of the RF fingerprint sample selection and reduces the instability of the recognition accuracy. (3) The present invention performs data collection and feature extraction on multiple transmitting devices, and uses the device number as feedback to realize the training of the classifier and the judgment of the waveform to be detected, so that each device can maintain a high recognition accuracy rate , which improves the reliability of the recognition results.
附图说明Description of drawings
图1为本发明的方法流程图;Fig. 1 is the method flow chart of the present invention;
图2为基于伪随机整合的数据增强的流程图;2 is a flowchart of data augmentation based on pseudo-random integration;
图3为本发明中的伪随机整合、随机整合与未进行数据增强的信号在各信噪比下的识别率对比图;3 is a comparison diagram of the recognition rates of pseudo-random integration, random integration and signals without data enhancement under each signal-to-noise ratio in the present invention;
图4为本发明中的伪随机整合、随机整合与未进行数据增强的信号对单个设备的识别率对比图。FIG. 4 is a comparison diagram of the recognition rate of a single device by pseudo-random integration, random integration, and signals without data enhancement in the present invention.
具体实施方式Detailed ways
下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。The technical solutions of the present invention are further described in detail below with reference to the accompanying drawings, but the protection scope of the present invention is not limited to the following.
如图1所示,一种基于伪随机整合的认证指纹识别方法,包括以下步骤:As shown in Figure 1, an authentication fingerprint identification method based on pseudo-random integration includes the following steps:
S1.接收设备对发送设备进行信号采集和存储,得到N个信号样本存放在样本库中;S1. The receiving device collects and stores signals from the sending device, and obtains N signal samples and stores them in the sample library;
S2.采用伪随机整合将样本库中N个信号样本增强为K个信号样本;S2. Use pseudo-random integration to enhance the N signal samples in the sample library into K signal samples;
S3.对生成的信号样本进行特征提取;S3. Feature extraction is performed on the generated signal samples;
S4.对于多个不同的发射设备,重复以上S1~S3操作,以设备编号为反馈;并利用机器学习算法中的分类算法对每一个发送设备处理后的信号进行训练,得到分类器;S4. For a plurality of different transmitting devices, repeat the above operations S1 to S3, and use the device number as feedback; and use the classification algorithm in the machine learning algorithm to train the signals processed by each transmitting device to obtain a classifier;
S5.利用训练得到的分类器对待检测波形进行分类,判定其所属设备。S5. Use the classifier obtained by training to classify the waveform to be detected, and determine the equipment to which it belongs.
具体地,所述的步骤S1包括:Specifically, the step S1 includes:
S101.接收设备检测接收到的开机瞬态信号起始点位置;S101. The receiving device detects the position of the starting point of the received power-on transient signal;
S102.从起始点位置开始,采集一个发送设备的M个开机瞬态信号样本点,作为一个信号样本;S102. Starting from the starting point, collect M power-on transient signal sample points of a sending device as a signal sample;
例如,当M为800时,可以从起始点位置采集800个开机瞬态信号样本点,作为一个信号样本;在另外一些实施例中,也可以从起始点前100个位置开始,采集起始点位置前100个开机瞬态信号样本点和起始点后700个开机瞬态信号样本点,作为一个信号样本。For example, when M is 800, 800 power-on transient signal sample points can be collected from the starting point as one signal sample; in other embodiments, the starting point can also be collected starting from 100 positions before the starting point The first 100 power-on transient signal sample points and the 700 power-on transient signal sample points after the starting point are taken as a signal sample.
S103.在信号样本中,编号开机瞬态信号样本点,以每个开机瞬态信号样本点对应的幅值定义开机瞬态信号样本点幅值函数fi:S103. In the signal samples, number the power-on transient signal sample points, and define the power-on transient signal sample point amplitude function f i with the amplitude corresponding to each power-on transient signal sample point:
fi={amp:(1,2,……,M)}f i ={amp:(1,2,...,M)}
={amp1,amp2,……,ampM};={amp 1 ,amp 2 ,...,amp M };
S104.按照步骤S101~S103采集N个信号样本存放到样本库中。S104. Collect N signal samples according to steps S101-S103 and store them in the sample library.
如图2所示,所述步骤S2通过伪随机选择将同一发送设备的多个开机瞬态信号样本点幅值函数进行相参或非相参积累,利用有限的信号样本生成大量的可供机器学习的训练数据,包括:As shown in FIG. 2 , the step S2 performs coherent or non-coherent accumulation of the amplitude functions of multiple power-on transient signal sample points of the same sending device through pseudo-random selection, and uses limited signal samples to generate a large number of available machines. Learned training data, including:
S201.从样本库中随机选取n个信号样本,n<N;S201. Randomly select n signal samples from the sample library, n<N;
S202.从第二次选择信号样本开始,检测选择的n个样本是否与之前的选择完全相同:若是,跳转至步骤S204;若否,进入步骤S203;S202. Starting from the second selection of signal samples, check whether the selected n samples are exactly the same as the previous selection: if so, go to step S204; if not, go to step S203;
S203.将该n个样本相参积累或非相参积累,并存入数据库中:S203. The n samples are accumulated coherently or non-coherently, and stored in the database:

其中fr是库中原始信号样本,fa为生成的信号样本;where fr is the original signal sample in the library, and f a is the generated signal sample;
S204.将参与整合的信号样本从样本库中移除;S204. Remove the signal samples participating in the integration from the sample library;
S205.重复执行步骤S201~S204直到信号库中的样本数量少于n;S205. Repeat steps S201 to S204 until the number of samples in the signal library is less than n;
S206.初始化信号库,将其重置为原始状态;S206. Initialize the signal library and reset it to the original state;
S207.重复执行S201至S206,直到数据库中的信号样本数量达到K个;S207. Repeat S201 to S206 until the number of signal samples in the database reaches K;
S208.输出数据库中的信号样本。S208. Output the signal samples in the database.
具体地,所述步骤S3包括:Specifically, the step S3 includes:
S301.对于数据库中的每一个信号样本,首先进行翻折处理,即对幅度值取绝对值:S301. For each signal sample in the database, firstly perform the folding process, that is, take the absolute value of the amplitude value:
favi=|fi|;f avi = | f i |;
S302.对翻折后的信号样本进行归一化处理:S302. Normalize the folded signal samples:

式中,ampi表示信号样本中的第i个样本点幅值,i=1,2,...,M,ampmax表示信号样本中最大的样本点幅值,ampmin表示信号样本中最小的样本点幅值;In the formula, amp i represents the amplitude of the i-th sample point in the signal sample, i=1,2,...,M, amp max represents the amplitude of the largest sample point in the signal sample, and amp min represents the smallest sample point in the signal sample. The sample point amplitude of ;
S303.对归一化处理后的信号样本进行特征提取;S303. Perform feature extraction on the normalized signal samples;
S304.重复步骤S301~S303,直至对数据库中的K个信号样本处理完成,得到K个信号样本的特征数据。S304. Repeat steps S301 to S303 until the processing of the K signal samples in the database is completed, and the characteristic data of the K signal samples is obtained.
所述步骤S101中,起始点位置检测的方法包括绝对幅度值检测和斜率检测;在本申请的实施例中,采用绝对幅度值检测:阈值设为0.003,当信号幅度的绝对值大于0.003时,分别采样该点之前800和之后2200共3000个样本点(M=3000)。该实施例中,可以通过向量化的方式提高后续的运行速率,即采用矩阵的形式统一存放所采集到的信号样本:In the step S101, the method for detecting the starting point position includes absolute amplitude value detection and slope detection; in the embodiment of the present application, absolute amplitude value detection is adopted: the threshold value is set to 0.003, and when the absolute value of the signal amplitude is greater than 0.003, A total of 3000 sample points (M=3000) are sampled respectively 800 before and 2200 after the point. In this embodiment, the subsequent running rate can be improved by means of vectorization, that is, the collected signal samples are stored uniformly in the form of a matrix:
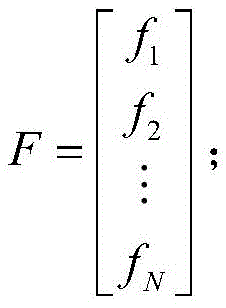
所述步骤S3中的特征提取方法包括基于幅度的特征提取、基于幅度和相位联合的特征提取、基于频率的特征提取、基于相位偏移的特征提取、基于小波变换的特征提取,以及基于多分辨率分析的特征提取;其中所述多分辨率分析中母小波的选择包括haar、dB2、bior和morl。The feature extraction methods in the step S3 include amplitude-based feature extraction, amplitude- and phase-based feature extraction, frequency-based feature extraction, phase-shift-based feature extraction, wavelet transform-based feature extraction, and multiresolution-based feature extraction. Feature extraction of rate analysis; wherein the choice of mother wavelet in the multi-resolution analysis includes haar, dB2, bior and morl.
在本专利的实施例中,采用二级多分辨率分析,以dB2波形函数为母小波,对信号波形依次做两次离散小波变换:In the embodiment of this patent, two-level multi-resolution analysis is adopted, and the dB2 waveform function is used as the mother wavelet, and two discrete wavelet transforms are sequentially performed on the signal waveform:
fa1i=DWT(favi,dB2)f a1i =DWT(f avi ,dB2)
fa2i=DWT(fa1i,dB2)f a2i =DWT(f a1i ,dB2)
具体地,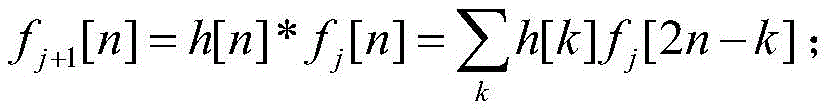
在本申请的实施例中为提高运行速率,所述步骤S4的反馈值也可以向量化,即:In the embodiment of the present application, in order to improve the running rate, the feedback value of the step S4 can also be vectorized, that is:
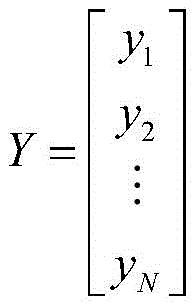
其中,yi为样本fi对应的反馈值,Y为反馈存放矩阵;进一步地,为便于机器学习,可以将特征数据与反馈值对应统一存放,即:Among them, y i is the feedback value corresponding to the sample f i , and Y is the feedback storage matrix; further, in order to facilitate machine learning, the feature data and the feedback value can be stored in a unified manner, that is:

其中,train为机器学习训练矩阵。Among them, train is the machine learning training matrix.
所述机器学习算法中的分类算法包括k-近邻算法、朴素贝叶斯算法、SVM算法和决策树算法。The classification algorithms in the machine learning algorithm include k-nearest neighbor algorithm, naive Bayes algorithm, SVM algorithm and decision tree algorithm.
在本专利的实施例中,步骤S4采用高斯核SVM生成分类器,具体地:第一步,输入带有反馈值的训练矩阵In the embodiment of this patent, step S4 adopts Gaussian kernel SVM to generate a classifier, specifically: the first step is to input a training matrix with feedback values
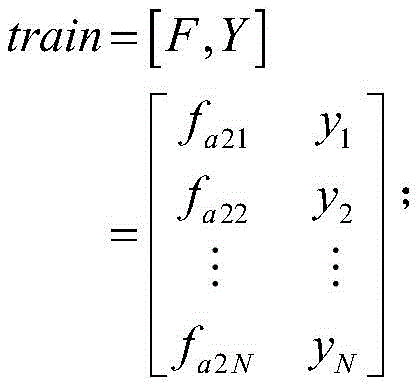
第二步,以train矩阵每行前ltrain个元素为特征,每行最后一个元素为反馈值,使用高斯核SVM进行训练,具体地:In the second step, the first l train elements of each row of the train matrix are characterized, and the last element of each row is the feedback value, and the Gaussian kernel SVM is used for training, specifically:
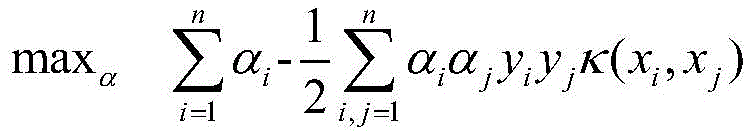
s.t.,αi≥0,i=1,...,nst,α i ≥0,i=1,...,n
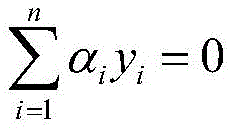
其中,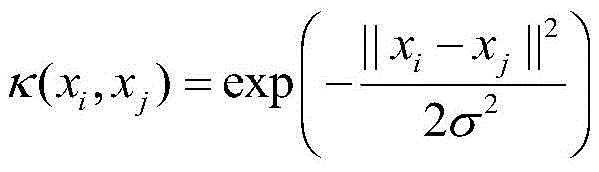
为验证本发明的伪随机整合与传统随机整合的差异性,生成如下四组样本进行射频指纹识别实验:In order to verify the difference between the pseudo-random integration of the present invention and the traditional random integration, the following four groups of samples were generated to carry out radio frequency fingerprint identification experiments:
(a)每个发送设备采集20个样本(N=20),每次选择3个样本进行整合(n=3),使用随机整合生成500个样本(K=500);(a) Each sending device collects 20 samples (N=20), selects 3 samples each time for integration (n=3), and uses random integration to generate 500 samples (K=500);
(b)每个发送设备采集20个样本(N=20),每次选择3个样本进行整合(n=3),使用伪随机整合生成500个样本(K=500);(b) Each sending device collects 20 samples (N=20), selects 3 samples each time for integration (n=3), and uses pseudo-random integration to generate 500 samples (K=500);
(c)每个发送设备采集20个样本,作为比对。为了保证实验的可靠性,对比样本采用有序相参积累(n=3)。这是因为相参积累具有降噪功能,上述做法将在相同程度上提高信噪比;(c) 20 samples were collected from each sending device for comparison. In order to ensure the reliability of the experiment, the comparison sample adopts ordered coherent accumulation (n=3). This is because coherent accumulation has a noise reduction function, and the above approach will improve the signal-to-noise ratio to the same extent;
(d)每个发送设备采集100个样本,采用有序相参积累(n=3)生成100个样本作为比对。(d) Each sending device collects 100 samples, and uses ordered coherent accumulation (n=3) to generate 100 samples for comparison.
实验结果如图3、图4所示,具体地:The experimental results are shown in Figure 3 and Figure 4, specifically:
1)在低信噪比下,随机整合(a)的识别结果优于20个样本的有序相参积累(c),类似于100个样本的有序相参积累(d);1) At low SNR, the recognition result of random integration (a) is better than the ordered coherent accumulation of 20 samples (c), similar to the ordered coherent accumulation of 100 samples (d);
2)在高信噪比下,随机整合(a)的分类精度变得不稳定,并不能达到整合有序的准确性(c)(d);2) Under high signal-to-noise ratio, the classification accuracy of random integration (a) becomes unstable, and cannot achieve the accuracy of orderly integration (c) (d);
3)虽然伪随机整合(b)在分类精度曲线中出现抖动,但效果更好。在高信噪比下,其分类精度稳定在99%以上;3) Although pseudo-random integration (b) appears jittery in the classification accuracy curve, it works better. Under high signal-to-noise ratio, its classification accuracy is stable above 99%;
4)对于单个设备,伪随机整合(b)对于10个设备的识别率均达到了98%以上,稳定性优于其余3种方法(a)(c)(d)。4) For a single device, the pseudo-random integration (b) has a recognition rate of more than 98% for 10 devices, and the stability is better than the other three methods (a) (c) (d).
综上,本发明发送设备的信号进行采集,利用采集到的少量信号样本生成大量训练数据。使用生成的训练数据基于机器学习中的分类算法进行训练,得到分类器,再利用测试集对该分类器的性能进行测试。适用于训练数据不足的射频指纹识别场景,具有识别准确率高、稳定可靠的优势。To sum up, the present invention collects the signals of the sending device, and generates a large amount of training data by using a small number of collected signal samples. Use the generated training data to train based on the classification algorithm in machine learning to obtain a classifier, and then use the test set to test the performance of the classifier. It is suitable for RF fingerprint recognition scenarios with insufficient training data, and has the advantages of high recognition accuracy, stability and reliability.
以上所述是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应该看作是对其他实施例的排除,而可用于其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。The above are preferred embodiments of the present invention, and it should be understood that the present invention is not limited to the form disclosed herein, should not be regarded as an exclusion of other embodiments, but can be used in other combinations, modifications and environments, and can be used herein. Within the scope of the stated concept, modifications can be made through the above teachings or skill or knowledge in the relevant field. However, modifications and changes made by those skilled in the art do not depart from the spirit and scope of the present invention, and should all fall within the protection scope of the appended claims of the present invention.
Claims (7)
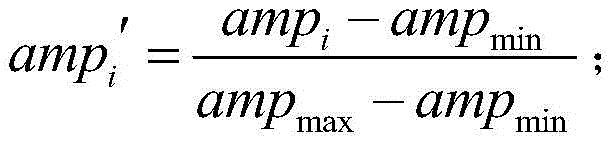
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810718434.3A CN110069969B (en) | 2018-07-03 | 2018-07-03 | An Authentication Fingerprint Recognition Method Based on Pseudo-Random Integration |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810718434.3A CN110069969B (en) | 2018-07-03 | 2018-07-03 | An Authentication Fingerprint Recognition Method Based on Pseudo-Random Integration |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110069969A CN110069969A (en) | 2019-07-30 |
| CN110069969B true CN110069969B (en) | 2021-10-19 |
Family
ID=67365740
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810718434.3A Active CN110069969B (en) | 2018-07-03 | 2018-07-03 | An Authentication Fingerprint Recognition Method Based on Pseudo-Random Integration |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110069969B (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111027623A (en) * | 2019-12-10 | 2020-04-17 | 深圳供电局有限公司 | Data-enhanced intelligent terminal security level classification method and system |
| CN111586689B (en) * | 2020-04-28 | 2023-04-18 | 福建师范大学 | Multi-attribute lightweight physical layer authentication method based on principal component analysis algorithm |
| CN112434714B (en) * | 2020-12-03 | 2025-04-04 | 北京小米松果电子有限公司 | Multimedia recognition method, device, storage medium and electronic device |
| CN113347637B (en) * | 2021-04-19 | 2023-07-18 | 厦门大学 | Embedded wireless device RF fingerprint recognition method and device |
| CN115795371A (en) * | 2022-11-10 | 2023-03-14 | 中国船舶重工集团公司七五0试验场 | A Broadband Transient Signal Detection Method Based on Nonlinear Support Vector Machine |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9443298B2 (en) * | 2012-03-02 | 2016-09-13 | Authentect, Inc. | Digital fingerprinting object authentication and anti-counterfeiting system |
| US9235748B2 (en) * | 2013-11-14 | 2016-01-12 | Wacom Co., Ltd. | Dynamic handwriting verification and handwriting-based user authentication |
| US10289822B2 (en) * | 2016-07-22 | 2019-05-14 | Nec Corporation | Liveness detection for antispoof face recognition |
| CN108230233A (en) * | 2017-05-16 | 2018-06-29 | 北京市商汤科技开发有限公司 | Data enhancing, treating method and apparatus, electronic equipment and computer storage media |
| CN107392123B (en) * | 2017-07-10 | 2021-02-05 | 电子科技大学 | Radio frequency fingerprint feature extraction and identification method based on coherent accumulation noise elimination |
-
2018
- 2018-07-03 CN CN201810718434.3A patent/CN110069969B/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN110069969A (en) | 2019-07-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110069969B (en) | An Authentication Fingerprint Recognition Method Based on Pseudo-Random Integration | |
| Zhao et al. | Towards more accurate iris recognition using deeply learned spatially corresponding features | |
| Raja et al. | Smartphone based visible iris recognition using deep sparse filtering | |
| CN114677556B (en) | Adversarial sample generation method and related equipment for neural network model | |
| CN109165678A (en) | Emitter Recognition and device based on bispectrum 3-D image textural characteristics | |
| US12014569B2 (en) | Synthetic human fingerprints | |
| Ali Khan et al. | Kruskal‐Wallis‐Based Computationally Efficient Feature Selection for Face Recognition | |
| CN106663195A (en) | Improved method for fingerprint matching and camera identification, device and system | |
| CN107451562B (en) | Wave band selection method based on chaotic binary gravity search algorithm | |
| Hu | Illumination invariant face recognition based on dual‐tree complex wavelet transform | |
| Hamadouche et al. | A comparative study of perceptual hashing algorithms: Application on fingerprint images | |
| CN108268837A (en) | Emitter Fingerprint feature extracting method based on Wavelet Entropy and chaotic characteristic | |
| CN107392123B (en) | Radio frequency fingerprint feature extraction and identification method based on coherent accumulation noise elimination | |
| Yuan et al. | Fingerprint liveness detection using multiscale difference co-occurrence matrix | |
| Phan et al. | Action recognition based on motion of oriented magnitude patterns and feature selection | |
| Zhang et al. | Multi-weather classification using evolutionary algorithm on EfficientNet | |
| Melek et al. | Fast matching pursuit for sparse representation‐based face recognition | |
| Sutthiwan et al. | Rake transform and edge statistics for image forgery detection. | |
| Birouk et al. | Robust perceptual fingerprint image hashing: A comparative study | |
| Liu et al. | A wavelet-based memory autoencoder for noncontact fingerprint presentation attack detection | |
| Zhang et al. | Global contrast enhancement detection via deep multi-path network | |
| Chavan | Handwritten online signature verification and forgery detection using hybrid wavelet transform-2 with HMM classifier | |
| CN107341519B (en) | Support vector machine identification optimization method based on multi-resolution analysis | |
| Vazquez‐Fernandez et al. | Improved average of synthetic exact filters for precise eye localisation under realistic conditions | |
| Szymkowski et al. | A novel approach to fingerprint identification using method of sectorization |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |