CN109977324B - A method and system for mining points of interest - Google Patents
A method and system for mining points of interest Download PDFInfo
- Publication number
- CN109977324B CN109977324B CN201910241403.8A CN201910241403A CN109977324B CN 109977324 B CN109977324 B CN 109977324B CN 201910241403 A CN201910241403 A CN 201910241403A CN 109977324 B CN109977324 B CN 109977324B
- Authority
- CN
- China
- Prior art keywords
- user
- recommendation list
- interest
- data set
- location
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明公开了一种兴趣点挖掘方法及系统,根据原始轨迹数据集构建聚类兴趣点,根据聚类兴趣点获取用户‑位置二分图,然后转换为对应的关联矩阵,通过在隐私阈值范围内调节表征用户隐私安全性大小的隐私预算



The invention discloses a method and system for mining interest points. Clustering interest points are constructed according to an original trajectory data set, a user-location bipartite graph is obtained according to the clustered interest points, and then converted into a corresponding association matrix. Adjust the privacy budget that characterizes the size of user privacy security
Description
技术领域technical field
本发明涉及一种兴趣点挖掘方法及系统,属于数据挖掘技术领域。The invention relates to a point of interest mining method and system, belonging to the technical field of data mining.
背景技术Background technique
随着移动定位设备的快速增长和高速无线网络的广泛使用,基于位置的服务(LBS),包括基于位置的社交网络、基于位置的广告、基于位置的信息共享等被广泛应用。轨迹由一系列<经度,纬度,时间戳>三元组表示的位置信息构成,其蕴含着用户的移动目的地、移动路径以及移动模式等信息。服务后端通过收集大规模不同移动用户的历史轨迹数据,并加以处理与挖掘,可以提供给用户准确且有用的兴趣点推荐服务,例如,某个城市的前10个兴趣点在哪里,哪个购物中心在这个地区最受欢迎,以及哪些用户经常访问这家餐厅等。With the rapid growth of mobile positioning devices and the widespread use of high-speed wireless networks, location-based services (LBS), including location-based social networking, location-based advertising, and location-based information sharing, are widely used. The track is composed of a series of location information represented by <longitude, latitude, timestamp> triples, which contain information such as the user's moving destination, moving path, and moving mode. The service backend can provide users with accurate and useful point-of-interest recommendation services by collecting large-scale historical trajectory data of different mobile users, processing and mining, for example, where are the top 10 points of interest in a city, and which shopping The center is most popular in this area, and which users frequently visit this restaurant, etc.
然而,敏感轨迹数据的暴露可能造成隐私信息的泄露。具体地,表示为二维坐标的位置信息通常与语义含义相关联,例如酒吧、商场或医院等。例如,如果攻击者推断用户和医院相关联,则可以知晓用户的健康状态。因此,保护隐私的轨迹挖掘是一个具有挑战性的问题。但是,通过研究隐私保护制约机理表明,数据挖掘与隐私保护存在利益的矛盾,对数据进行隐私保护处理,势必降低数据挖掘效果。因此,如何权衡两者利益,在保护隐私信息的同时,尽可能提高数据挖掘的效果是进一步亟待解决的问题。However, the exposure of sensitive trajectory data may lead to the leakage of private information. Specifically, location information represented as two-dimensional coordinates is usually associated with semantic meaning, such as bars, shopping malls, or hospitals, etc. For example, if an attacker infers that the user is associated with a hospital, the user's health status can be known. Therefore, privacy-preserving trajectory mining is a challenging problem. However, the research on the restriction mechanism of privacy protection shows that there is a conflict of interests between data mining and privacy protection, and the privacy protection processing of data will inevitably reduce the effect of data mining. Therefore, how to balance the interests of the two, while protecting private information, and improving the effect of data mining as much as possible is a further problem to be solved urgently.
发明内容SUMMARY OF THE INVENTION
本发明的目的在于提供一种兴趣点挖掘方法及系统,以解决现有技术中导致的上述多项缺陷或缺陷之一。The purpose of the present invention is to provide a method and system for mining points of interest, so as to solve the above-mentioned defects or one of the defects caused in the prior art.
为达到上述目的,本发明是采用下述技术方案实现的:To achieve the above object, the present invention adopts the following technical solutions to realize:
第一方面,本发明提供了一种兴趣点挖掘方法,方法包括如下步骤:In a first aspect, the present invention provides a method for mining points of interest, the method comprising the following steps:
步骤1:根据用户轨迹数据集,构建聚类兴趣点数据集,根据聚类兴趣点数据集,构建用户-位置二分图,将用户-位置二分图转换为关联矩阵;Step 1: construct a clustered interest point dataset according to the user trajectory dataset, construct a user-location bipartite graph according to the clustered interest point dataset, and convert the user-location bipartite graph into an association matrix;
步骤2:在关联矩阵中的每一项添加服从拉普拉斯分布的噪声
步骤3:根据关联矩阵和HITS算法,获取未加噪声的用户推荐列表和位置推荐列表;根据扰动关联矩阵和HITS算法,获取加入噪声的用户推荐列表和位置推荐列表;Step 3: According to the correlation matrix and the HITS algorithm, obtain the user recommendation list and location recommendation list without noise; according to the disturbance correlation matrix and the HITS algorithm, obtain the user recommendation list and location recommendation list with noise added;
步骤4:根据未加噪声的用户推荐列表和位置推荐列表、加入噪声的用户推荐列表和位置推荐列表,计算匹配度;若匹配度满足设定的匹配度阈值,转入步骤5;若匹配度不满足设定的匹配度阈值,则转入步骤2,通过调整全局敏感度Δf和隐私预算ε,重新设置噪声
步骤5:将匹配度满足匹配度阈值的加入噪声的用户推荐列表和位置推荐列表保存至数据库供查询用户查询。Step 5: Save the noise-added user recommendation list and the location recommendation list whose matching degree satisfies the matching degree threshold to the database for query by the query user.
进一步的,方法还包括采集包含用户位置信息和与所述位置信息对应的时刻信息的轨迹数据,构建用户原始轨迹数据集。Further, the method further includes collecting trajectory data including user location information and time information corresponding to the location information, and constructing a user original trajectory data set.
进一步的,计算匹配度MR(A)的方法包括:Further, the method for calculating the matching degree MR(A) includes:

其中,ori(A)表示未加噪声的用户推荐列表和位置推荐列表,noi(A)表示加入噪声的用户推荐列表和位置推荐列表,A表示用户-位置二分图中的用户组和位置组取并集。Among them, ori(A) represents the user recommendation list and location recommendation list without noise, noi(A) represents the user recommendation list and location recommendation list with noise added, and A represents the user group and location group in the user-location bipartite graph. union.
构建聚类兴趣点数据集的方法包括如下步骤:The method of constructing a clustered interest point dataset includes the following steps:
根据用户原始轨迹数据集,构建兴趣点数据集;所述兴趣点数据集中的数据包括用户信息、用户的位置信息和与所述位置信息对应的时刻信息;constructing a point of interest dataset according to the user's original trajectory dataset; the data in the point of interest dataset includes user information, user's location information, and time information corresponding to the location information;
采用DBSCAN聚类算法对兴趣点数据集进行聚类分析形成多个聚簇,每个聚簇用该聚簇的中心点的位置信息表示,并用中心点的Id作为该聚簇的唯一标识,并且统计各用户访问该聚簇的频率,构建聚类兴趣点数据集。The DBSCAN clustering algorithm is used to perform cluster analysis on the data set of interest points to form multiple clusters, each cluster is represented by the position information of the center point of the cluster, and the ID of the center point is used as the unique identifier of the cluster, and The frequency of each user accessing the cluster is counted, and a clustered interest point dataset is constructed.
所述用户-位置二分图的数据结构ULBG=(U,L,E),其中U={ui|1≤i≤m}表示用户节点组,L={lj|1≤j≤n}表示位置节点组,E={(ui,lj,wij)|1≤i≤m,1≤j≤n}表示边的访问集;其中,ui表示用户i的Id,lj表示兴趣点j的Id,wij表示用户i访问兴趣点j的频率。The data structure of the user-location bipartite graph ULBG=(U, L, E), where U={u i |1≤i≤m} represents the user node group, and L={l j |1≤j≤n} represents the location node group, E={(u i , l j , w ij )|1≤i≤m, 1≤j≤n} represents the access set of the edge; wherein, ui represents the Id of user i, and l j represents The Id of point of interest j, w ij represents the frequency of user i visiting point of interest j.
关联矩阵包含|U|行、|L|列,关联矩阵中的元素为用户i访问兴趣点j的频率wij。The correlation matrix includes |U| rows and |L| columns, and the elements in the correlation matrix are the frequency w ij of the user i visiting the interest point j.
另一方面,本发明提供了一种兴趣点挖掘系统,系统包括:In another aspect, the present invention provides a system for mining points of interest, the system comprising:
第一获取模块:用于根据用户轨迹数据集,构建聚类兴趣点数据集,根据聚类兴趣点数据集,构建用户-位置二分图,将用户-位置二分图转换为关联矩阵;The first acquisition module is used to construct a clustered interest point data set according to the user trajectory data set, construct a user-location bipartite graph according to the clustered interest point data set, and convert the user-location bipartite graph into an association matrix;
第二获取模块:用于在关联矩阵中的每一项添加服从拉普拉斯分布的噪声
第三获取模块:用于根据关联矩阵和HITS算法,获取未加噪声的用户推荐列表和位置推荐列表;根据扰动关联矩阵和HITS算法,获取加入噪声的用户推荐列表和位置推荐列表;The third obtaining module: used to obtain the user recommendation list and location recommendation list without noise according to the correlation matrix and the HITS algorithm; according to the disturbance correlation matrix and the HITS algorithm, obtain the user recommendation list and location recommendation list with noise added;
数据处理模块:用于根据未加噪声的用户推荐列表和位置推荐列表、加入噪声的用户推荐列表和位置推荐列表,计算匹配度;若匹配度满足设定的匹配度阈值,转入存储模块处理;若匹配度不满足设定的匹配度阈值,则转入第二获取模块处理,通过调整全局敏感度Δf和隐私预算ε,重新设置噪声
存储模块:用于将满足匹配度的加入噪声的用户推荐列表和位置推荐列表保存至数据库供查询用户查询。Storage module: used to save the noise-added user recommendation list and location recommendation list satisfying the matching degree to the database for query by the query user.
进一步的,系统还包括用于采集包含用户位置信息和与所述位置对应的时刻信息的轨迹数据,构建用户原始轨迹数据集的构建模块。Further, the system further includes a building module for collecting trajectory data including user location information and time information corresponding to the location, and constructing a user's original trajectory data set.
第一获取模块还包括用于构建聚类兴趣点数据集的第一构建模块,所述构建模块包括:The first acquisition module also includes a first building module for constructing a clustered interest point dataset, and the building module includes:
第二构建模块:用于根据用户原始轨迹数据集,构建兴趣点数据集;所述兴趣点数据集中的数据包括用户信息、用户的位置信息和与所述位置信息对应的时刻信息;The second building module: for constructing a point of interest data set according to the user's original trajectory data set; the data in the point of interest data set includes user information, user location information and time information corresponding to the location information;
第三构建模块:用于采用DBSCAN聚类算法对兴趣点数据集进行聚类分析形成多个聚簇,每个聚簇用该聚簇的中心点的位置信息表示,并用中心点的Id作为该聚簇的唯一标识,并且统计各用户访问该聚簇的频率,构建聚类兴趣点数据集。The third building module is used to perform cluster analysis on the data set of interest points using the DBSCAN clustering algorithm to form multiple clusters, each cluster is represented by the position information of the center point of the cluster, and the Id of the center point is used as the The unique identification of the cluster, and the frequency of each user accessing the cluster is counted to construct a clustered interest point dataset.
本发明提供的一种兴趣点挖掘方法及系统,将用户原始轨迹数据集转换为用户-位置二分图,然后转化为对应的关联矩阵,并加入拉普拉斯噪声以获取扰动关联矩阵,根据扰动关联矩阵,使用HITS算法生成安全性和可用性满足要求的用户推荐列表和位置推荐列表供查询用户查询。The invention provides a method and system for mining interest points, which converts the user's original trajectory data set into a user-position bipartite graph, and then converts it into a corresponding correlation matrix, and adds Laplace noise to obtain a perturbation correlation matrix. Relevance matrix, using the HITS algorithm to generate user recommendation lists and location recommendation lists that meet the security and usability requirements for query users to query.
附图说明Description of drawings
图1是根据本发明实施例提供的一种轨迹数据迁移图;Fig. 1 is a kind of trajectory data migration diagram provided according to the embodiment of the present invention;
图2是根据本发明实施例提供的一种兴趣点挖掘方法流程图;2 is a flowchart of a method for mining points of interest provided according to an embodiment of the present invention;
图3是根据本发明实施例提供的一种用户-位置二分图的结构图;3 is a structural diagram of a user-location bipartite graph provided according to an embodiment of the present invention;
图4是根据本发明实施例提供的一种兴趣点挖掘的服务构架图。FIG. 4 is a service architecture diagram of a point of interest mining provided according to an embodiment of the present invention.
具体实施方式Detailed ways
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。The present invention will be further described below in conjunction with the accompanying drawings. The following examples are only used to illustrate the technical solutions of the present invention more clearly, and cannot be used to limit the protection scope of the present invention.
本实施例提供一种兴趣点挖掘方法,参照图1和图2,方法包括如下步骤:This embodiment provides a method for mining points of interest. Referring to FIG. 1 and FIG. 2 , the method includes the following steps:
步骤1:数据采集:Step 1: Data Acquisition:
采集用户轨迹数据,构建用户原始轨迹数据集,原始数据集包含多个用户的轨迹数据;每个用户的轨迹数据由多个<经度,纬度,时间戳>三元组构成,表示用户的位置信息和与所述位置信息对应的时刻信息;用户轨迹数据是由GPS设备离散捕获。Collect user trajectory data and construct the user's original trajectory data set. The original data set contains the trajectory data of multiple users; each user's trajectory data is composed of multiple <longitude, latitude, timestamp> triples, representing the user's location information and the time information corresponding to the location information; the user trajectory data is discretely captured by the GPS device.
步骤2:构建用户-位置二分图,将用户-位置二分图转换为关联矩阵:Step 2: Build a user-location bipartite graph and convert the user-location bipartite graph into an association matrix:
步骤21:构建兴趣点数据集Step 21: Build the POI Dataset
根据步骤1中构建的用户原始轨迹数据集,构建兴趣点数据集;应当清楚的是,不是捕捉到的用户的所有位置点都是兴趣点,兴趣点表示在一个距离阈值Dt内停留的时间大于等于时间阈值Tt的空间区域;而用户原始轨迹数据集中有的位置点只是用户经过时被捕捉到的,不属于兴趣点,因此需要对用户原始轨迹数据集中的轨迹数据进行筛选,选取兴趣点,兴趣点的选取方法包括:当第k个轨迹数据{(xk,yk,tk)|a≤k≤b}满足According to the user's original trajectory data set constructed in step 1, a data set of interest points is constructed; it should be clear that not all the captured position points of the user are points of interest, and the points of interest represent the time spent within a distance threshold D t Spatial area greater than or equal to the time threshold T t ; and some position points in the user's original trajectory data set are only captured when the user passes by, and do not belong to points of interest. Therefore, it is necessary to filter the trajectory data in the user's original trajectory data set to select interest The method for selecting interest points includes: when the kth trajectory data {(x k , y k , t k )|a≤k≤b} satisfies


tb-ta≥Tt (3)t b -t a ≥T t (3)
时,称第k个轨迹数据(xk,yk,tk)为兴趣点数据,其中,xk表示用户在时刻tk时所处位置k的经度坐标,yk表示用户在时刻tk时所处位置的纬度坐标;xa表示用户在时刻ta时所处位置的经度坐标,ya表示用户在时刻ta时所处位置的纬度坐标;xb+1表示用户在时刻tb+1时所处位置的经度坐标,yb+1表示用户在时刻tb+1时所处位置的纬度坐标,ta表示采集用户原始轨迹数据的起点位置a对应的时刻,tb表示采集用户原始轨迹数据的终点位置b对应的时刻;, the k-th trajectory data (x k , y k , t k ) is called point of interest data, where x k represents the longitude coordinates of the user’s position k at time t k , and y k represents the user’s position k at time t k latitude coordinates of the user's location at time t a; x a represents the longitude coordinates of the user's location at time t a , y a represents the latitude coordinates of the user's location at time t a ; x b+1 represents the user's location at time t b The longitude coordinates of the location at +1 , y b+1 represents the latitude coordinates of the user's location at time t b+1 , t a represents the time corresponding to the starting point a of the user's original trajectory data, and t b represents the collection The time corresponding to the end position b of the user's original trajectory data;
步骤22:构建聚类兴趣点数据集Step 22: Build a clustered interest point dataset
采用DBSCAN算法对根据步骤21获取的兴趣点集进行聚类分析,形成的每个聚簇用该聚簇的中心点的位置信息表示,并用中心点的Id作为该聚簇的唯一标识,每个聚簇中心点的位置关联一个对应的地理标签,包括旅游景点、购物中心;统计各用户访问该聚簇的频率,用户访问该聚簇的频率表示用户访问与所述聚簇对应的兴趣点的频率,用于构建聚类兴趣点数据集,聚类兴趣点包含用户Id、兴趣点Id以及用户访问兴趣点的频率信息;The DBSCAN algorithm is used to perform cluster analysis on the set of interest points obtained according to step 21, each formed cluster is represented by the location information of the center point of the cluster, and the Id of the center point is used as the unique identifier of the cluster. The location of the cluster center point is associated with a corresponding geographic tag, including tourist attractions and shopping centers; the frequency of each user's visit to the cluster is counted, and the frequency of the user's visit to the cluster indicates the user's access to the point of interest corresponding to the cluster. Frequency, used to construct a clustered POI dataset, where the clustered POI includes user ID, POI ID, and frequency information of users visiting POI;
步骤21和步骤22是对数据预清洗过程,以获取待处理数据集。Steps 21 and 22 are the data pre-cleaning process to obtain the data set to be processed.
步骤23:构建用户-位置二分图;Step 23: Build a user-location bipartite graph;
根据用户和位置之间的访问关系,生成用户-位置二分图,用户-位置二分图的结构参照图3,由用户指向位置的箭头表示用户访问该位置,箭头上的权值表示该用户多次访问该位置,访问的频率越高表示用户对该位置的推荐越高;According to the access relationship between the user and the location, a user-location bipartite graph is generated. Refer to Figure 3 for the structure of the user-location bipartite graph. The arrow pointing to the location by the user indicates that the user visits the location, and the weight on the arrow indicates that the user has multiple times. Visit the location, the higher the frequency of visits, the higher the user's recommendation for the location;
用户-位置二分图的数据结构ULBG=(U,L,E),其中U={ui|1≤i≤m}表示用户节点组,L={lj|1≤j≤n}表示位置节点组,E={(ui,lj,wij)|1≤i≤m,1≤j≤n}表示边的访问集,ui表示用户i的Id,lj表示兴趣点j的Id,wij表示用户i访问兴趣点j的频率。The data structure of the user-location bipartite graph ULBG=(U, L, E), where U={u i |1≤i≤m} represents the user node group, and L={l j |1≤j≤n} represents the location Node group, E={(u i , l j , w ij )|1≤i≤m, 1≤j≤n} represents the access set of the edge, ui represents the Id of user i, and l j represents the point of interest j Id, w ij represents the frequency of user i visiting point of interest j.
步骤24:获取关联矩阵Step 24: Get the Correlation Matrix
将用户-位置二分图转换为关联矩阵M[i][j];所述关联矩阵包含|U|行、|L|列,矩阵中每一项为用户i和兴趣点j之间的边权重,所述边权重等于用户i访问兴趣点j的频率wij,如果用户ui从未访问位置lj,将wij设置为0。Convert the user-location bipartite graph into an association matrix M[i][j]; the association matrix includes |U| rows and |L| columns, and each item in the matrix is the edge weight between user i and interest point j , the edge weight is equal to the frequency w ij of user i visiting point of interest j, if user ui has never visited location l j , set w ij to 0.
步骤3:获取扰动关联矩阵Step 3: Obtain the perturbation correlation matrix
应当清楚的是,差分隐私技术能确保公布的统计数据不依赖于数据中某个记录的存在与否,从而达到保护隐私的效果。本方案中需要保护的是用户-位置二分图,根据步骤23构建的用户-位置二分图数据结构,图中的一条边(ui,lj,1)相当于是一条记录,用户-位置二分图中共包含
本实施例通过拉普拉斯机制来保证差分隐私,实现方法是向根据步骤24获取的关联矩阵中的每一项添加服从拉普拉斯分布的噪声


其中Δf为全局敏感度,用于衡量聚类兴趣点数据集中单个记录变化可能导致的最大影响,全局敏感度Δf满足设定的全局敏感度阈值;ε为隐私预算,隐私预算ε用于衡量对用户隐私保护的安全性,隐私预算ε满足隐私阈值要求;Among them, Δf is the global sensitivity, which is used to measure the maximum impact of a single record change in the clustered interest point dataset. The global sensitivity Δf satisfies the set global sensitivity threshold; ε is the privacy budget, and the privacy budget ε is used to measure the The security of user privacy protection, the privacy budget ε meets the privacy threshold requirements;
步骤4:获取加入噪声的用户推荐列表和位置推荐列表Step 4: Obtain the user recommendation list and location recommendation list with added noise
一个良好的Hub页面会指向许多优秀的Authority页面,许多优秀的Hub页面会指向一个良好的Authority页面,通过类比,将根据步骤23构建的用户-位置二分图的用户视为Hub页面,将位置视为Authority页面,使用HITS算法对每个用户和位置进行评分,得分较高的用户表示更有经验、对兴趣点推荐比较可靠的用户,得分较高的位置表示更值得访问的兴趣点;A good Hub page will point to many good Authority pages, and many good Hub pages will point to a good Authority page. By analogy, the user of the user-location bipartite graph constructed according to step 23 is regarded as the Hub page, and the position is regarded as the Hub page. For the Authority page, use the HITS algorithm to score each user and location. Users with higher scores indicate more experienced users who are more reliable in recommending points of interest, and locations with higher scores indicate more worth visiting points of interest;
本实施例提供的方案,将根据步骤24获取的经用户-位置二分图转换得到的关联矩阵作为输入,使用HITS算法,得到未加噪声的用户推荐列表和位置推荐列表;将根据步骤3获取的扰动关联矩阵作为输入,使用HITS算法,获取加入噪声的用户推荐列表和位置推荐列表;用户推荐列表包括对用户按对应评分的升序排列,位置推荐列表包括对位置按对应位置评分的升序排列。In the solution provided in this embodiment, the user-location bipartite graph conversion obtained according to step 24 is used as input, and the HITS algorithm is used to obtain the user recommendation list and location recommendation list without noise; The perturbation correlation matrix is used as the input, and the HITS algorithm is used to obtain the user recommendation list and location recommendation list with added noise; the user recommendation list includes users in ascending order of their corresponding ratings, and the location recommendation list includes locations.
步骤5:可用性评估Step 5: Usability Assessment
为保证用户的隐私保护和兴趣点推荐结果准确性,对生产的推荐列表进行可用性评估:In order to ensure the privacy protection of users and the accuracy of point of interest recommendation results, the usability evaluation of the produced recommendation list is carried out:
根据上述步骤,通过在关联矩阵中加入噪声获取扰动关联矩阵,根据扰动关联矩阵获取的加入噪声的用户推荐列表和位置推荐列表,达到对采集原始轨迹数据的用户隐私保护的目的,但应当清楚的是,加入噪声越高,推荐结果的准确性越低,兴趣点挖掘的可用性越低,为了权衡安全性和准确性,需要计算推荐的用户列表、位置列表的匹配度,计算匹配度MR(A)的方法包括:According to the above steps, the disturbance correlation matrix is obtained by adding noise to the correlation matrix, and the noise-added user recommendation list and location recommendation list are obtained according to the perturbation correlation matrix, so as to achieve the purpose of protecting the privacy of users who collect the original trajectory data, but it should be clear Yes, the higher the added noise, the lower the accuracy of the recommendation results and the lower the usability of point-of-interest mining. In order to balance security and accuracy, it is necessary to calculate the matching degree of the recommended user list and location list, and calculate the matching degree MR(A ) methods include:

其中,ori(A)表示未加噪声的用户推荐列表和位置推荐列表,noi(A)表示加入噪声的用户推荐列表和位置推荐列表,A=Urec∪Lrec,表示用户-位置二分图的用户组和位置组取并集,其中Urec表示用户组,Lrec表示位置组:Among them, ori(A) represents the user recommendation list and location recommendation list without noise, noi(A) represents the user recommendation list and location recommendation list with noise added, A=U rec ∪L rec , representing the user-location bipartite graph User group and location group take the union, where U rec represents the user group and L rec represents the location group:
Urec={u,score(u)|score(ui)≥score(uj),1≤i<j≤|U|} (6)U rec ={u, score(u)|score(u i )≥score(u j ), 1≤i<j≤|U|} (6)
Lrec={l,score(l)|score(li)≥score(lj),1≤i<j≤|L|} (7)L rec ={l, score(l)|score(l i )≥score(l j ), 1≤i<j≤|L|} (7)
若匹配度MR(A)满足设定的匹配度阈值,转入步骤6;If the matching degree MR(A) satisfies the set matching degree threshold, go to step 6;
若匹配度不满足设定的匹配度阈值,则转入步骤3,通过调整全局敏感度Δf和隐私预算ε,重新设置噪声
隐私预算ε用于控制算法在邻近数据集上获得相同输出的概率比值,反映隐私保护水平,隐私预算ε越小,隐私保护水平越高,需要添加的噪声越高,从而导致匹配度MR越低。Δf表示数据集中的单个记录的变化引起的统计查询结果之间的差异,Δf越小,需要添加的噪声越低,从而导致匹配度MR越高。The privacy budget ε is used to control the probability ratio of the algorithm to obtain the same output on adjacent data sets, reflecting the privacy protection level. The smaller the privacy budget ε, the higher the privacy protection level, and the higher the noise that needs to be added, resulting in a lower matching degree MR. . Δf represents the difference between statistical query results caused by changes in a single record in the dataset. The smaller Δf, the lower the noise that needs to be added, resulting in a higher matching degree MR.
步骤6:将满足匹配度的加入噪声的用户推荐列表和位置列表保存至数据库供查询用户查询,根据查询用户的查询信息,向查询用户推荐和查询信息匹配的用户推荐列表和位置推荐列表。Step 6: Save the noise-added user recommendation list and location list satisfying the matching degree to the database for query by the query user, and recommend the user recommendation list and location recommendation list matching the query information to the query user according to the query information of the query user.
本发明实施例还提供了一种兴趣点挖掘系统,用于实现上述兴趣点挖掘方法,系统包括:The embodiment of the present invention also provides a system for mining points of interest, which is used to implement the above method for mining points of interest. The system includes:
用于根据用户原始轨迹数据集,构建用户-位置二分图,将用户-位置二分图转换为关联矩阵的第一获取模块;A first acquisition module for constructing a user-location bipartite graph according to the user's original trajectory data set, and converting the user-location bipartite graph into an association matrix;
用于在关联矩阵中的每一项添加服从拉普拉斯分布的噪声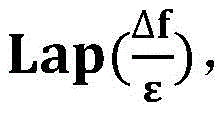
用于根据关联矩阵和HITS算法,获取未加噪声的用户推荐列表和位置推荐列表;根据扰动关联矩阵和HITS算法,获取加入噪声的用户推荐列表和位置推荐列表的第三获取模块;The third acquisition module is used to obtain the user recommendation list and location recommendation list without noise according to the correlation matrix and the HITS algorithm; according to the disturbance correlation matrix and the HITS algorithm, obtain the user recommendation list and the location recommendation list with noise added; the third acquisition module;
用于根据未加噪声的用户推荐列表和位置推荐列表、加入噪声的用户推荐列表和位置推荐列表,计算匹配度;若匹配度满足设定的匹配度阈值,转入存储模块处理;若匹配度不满足设定的匹配度阈值,则转入第二获取模块处理,通过调整全局敏感度Δf和隐私预算ε,重新设置噪声的数据处理模块;It is used to calculate the matching degree according to the user recommendation list and location recommendation list without noise, and the user recommendation list and location recommendation list with noise added; if the matching degree satisfies the set matching degree threshold, it is transferred to the storage module for processing; If the set matching degree threshold is not met, it will be transferred to the second acquisition module for processing, and the noise data processing module will be reset by adjusting the global sensitivity Δf and the privacy budget ε;
用于将满足匹配度的加入噪声的用户推荐列表和位置列表保存至数据库供查询用户查询的存储模块。A storage module for storing the noise-added user recommendation list and location list satisfying the matching degree to the database for query by the querying user.
进一步的,系统还包括用于采集包含用户位置信息和与所述位置对应的时刻信息的轨迹数据,构建用户原始轨迹数据集的构建模块。Further, the system further includes a building module for collecting trajectory data including user location information and time information corresponding to the location, and constructing a user's original trajectory data set.
第一获取模块还包括用于构建用户-位置二分图的第一构建模块,所述构建模块包括:The first acquisition module also includes a first building module for constructing a user-location bipartite graph, the building module includes:
第二构建模块:用于根据用户原始轨迹数据集,构建兴趣点数据集;所述兴趣点数据集包括用户信息、位置信息和时刻信息;The second building module: for constructing a point of interest dataset according to the user's original trajectory dataset; the point of interest dataset includes user information, location information and time information;
第三构建模块:用于采用DBSCAN聚类算法对兴趣点数据集进行聚类分析形成多个聚簇,并且统计各用户访问该聚簇的频率,构建聚类兴趣点数据集;The third building module: used to perform cluster analysis on the data set of interest points using the DBSCAN clustering algorithm to form multiple clusters, and count the frequency of each user accessing the cluster to construct a clustered interest point data set;
第四构建模块:用于根据聚类兴趣点数据集,构建用户位置二分图。The fourth building module is used to construct a user location bipartite graph according to the clustered interest point dataset.
本发明实施例提供的一种兴趣点挖掘方法及系统,将用户原始轨迹数据集转换为用户-位置二分图,然后转化为对应的关联矩阵,并加入噪声
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。The above are only the preferred embodiments of the present invention. It should be pointed out that for those skilled in the art, without departing from the technical principle of the present invention, several improvements and modifications can also be made. These improvements and modifications It should also be regarded as the protection scope of the present invention.
Claims (9)





Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910241403.8A CN109977324B (en) | 2019-03-28 | 2019-03-28 | A method and system for mining points of interest |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910241403.8A CN109977324B (en) | 2019-03-28 | 2019-03-28 | A method and system for mining points of interest |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109977324A CN109977324A (en) | 2019-07-05 |
| CN109977324B true CN109977324B (en) | 2022-09-16 |
Family
ID=67080990
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910241403.8A Active CN109977324B (en) | 2019-03-28 | 2019-03-28 | A method and system for mining points of interest |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109977324B (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2019407410B2 (en) * | 2018-12-20 | 2022-09-01 | Ntt, Inc. | Analysis query response system, analysis query execution apparatus, analysis query verification apparatus, analysis query response method, and program |
| CN110300029B (en) * | 2019-07-06 | 2021-11-30 | 桂林电子科技大学 | Position privacy protection method for preventing edge-weight attack and position semantic attack |
| CN113438603B (en) * | 2021-03-31 | 2024-01-23 | 南京邮电大学 | A trajectory data publishing method and system based on differential privacy protection |
| CN116680484B (en) * | 2023-06-05 | 2026-01-30 | 中国工商银行股份有限公司 | User information inquiry protection methods, devices, equipment, media and program products |
| CN116992488B (en) * | 2023-09-26 | 2024-01-05 | 济南三泽信息安全测评有限公司 | Differential privacy protection method and system |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140025538A1 (en) * | 2012-07-19 | 2014-01-23 | Avinash Kalgi | Dual Encoding of Machine Readable Code for Automatic Scan-Initiated Purchase or Uniform Resource Locator Checkout |
| CN106960044A (en) * | 2017-03-30 | 2017-07-18 | 浙江鸿程计算机系统有限公司 | A kind of Time Perception personalization POI based on tensor resolution and Weighted H ITS recommends method |
| CN107491557A (en) * | 2017-09-06 | 2017-12-19 | 徐州医科大学 | A kind of TopN collaborative filtering recommending methods based on difference privacy |
-
2019
- 2019-03-28 CN CN201910241403.8A patent/CN109977324B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140025538A1 (en) * | 2012-07-19 | 2014-01-23 | Avinash Kalgi | Dual Encoding of Machine Readable Code for Automatic Scan-Initiated Purchase or Uniform Resource Locator Checkout |
| CN106960044A (en) * | 2017-03-30 | 2017-07-18 | 浙江鸿程计算机系统有限公司 | A kind of Time Perception personalization POI based on tensor resolution and Weighted H ITS recommends method |
| CN107491557A (en) * | 2017-09-06 | 2017-12-19 | 徐州医科大学 | A kind of TopN collaborative filtering recommending methods based on difference privacy |
Non-Patent Citations (1)
| Title |
|---|
| 位置大数据服务中基于差分隐私的数据发布技术;张琳等;《通信学报》;20160930;全文 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN109977324A (en) | 2019-07-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109977324B (en) | A method and system for mining points of interest | |
| Sun et al. | Identifying the city center using human travel flows generated from location-based social networking data | |
| Hang et al. | Exploring student check-in behavior for improved point-of-interest prediction | |
| Gambs et al. | De-anonymization attack on geolocated data | |
| Zheng et al. | Detecting collective anomalies from multiple spatio-temporal datasets across different domains | |
| Xiao et al. | Inferring social ties between users with human location history | |
| Yuan et al. | Measuring similarity of mobile phone user trajectories–a Spatio-temporal Edit Distance method | |
| CN103493044B (en) | Augmentation of place ranking using 3d model activity in an area | |
| Comito et al. | Mining human mobility patterns from social geo-tagged data | |
| CN112199609B (en) | POI recommendation system and method for sensing space-time semantic interval under self-attention | |
| CN110334293B (en) | Position social network-oriented position recommendation method with time perception based on fuzzy clustering | |
| US20060058958A1 (en) | Proximity search methods using tiles to represent geographical zones | |
| CN108256914B (en) | A Prediction Method of Interest Point Types Based on Tensor Decomposition Model | |
| Yoo et al. | Quality of hybrid location data drawn from GPS‐enabled mobile phones: Does it matter? | |
| CN108804551A (en) | It is a kind of to take into account diversity and personalized space point of interest recommendation method | |
| Li et al. | Region sampling and estimation of geosocial data with dynamic range calibration | |
| Zhang et al. | Detecting colocation flow patterns in the geographical interaction data | |
| TW200928795A (en) | Data classification system and method for building classification tree thereof | |
| Abdelhaq et al. | Efficient online extraction of keywords for localized events in twitter | |
| Huang et al. | Unsupervised interesting places discovery in location-based social sensing | |
| Li et al. | Differentially private trajectory analysis for points-of-interest recommendation | |
| CN103279560A (en) | Continuous keyword query method based on security region | |
| US20180270620A1 (en) | Collaborative geo-positioning of electronic devices | |
| Shen et al. | Novel model for predicting individuals’ movements in dynamic regions of interest | |
| Liao et al. | Fusing geographic information into latent factor model for pick-up region recommendation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |