CN109949257B - Region-of-interest compressed sensing image reconstruction method based on deep learning - Google Patents
Region-of-interest compressed sensing image reconstruction method based on deep learning Download PDFInfo
- Publication number
- CN109949257B CN109949257B CN201910166307.1A CN201910166307A CN109949257B CN 109949257 B CN109949257 B CN 109949257B CN 201910166307 A CN201910166307 A CN 201910166307A CN 109949257 B CN109949257 B CN 109949257B
- Authority
- CN
- China
- Prior art keywords
- image
- region
- interest
- layer
- convolution
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 68
- 238000013135 deep learning Methods 0.000 title claims abstract description 14
- 208000037170 Delayed Emergence from Anesthesia Diseases 0.000 claims description 34
- 238000000605 extraction Methods 0.000 claims description 26
- 238000011084 recovery Methods 0.000 claims description 22
- 230000006870 function Effects 0.000 claims description 13
- 238000011176 pooling Methods 0.000 claims description 11
- 238000004422 calculation algorithm Methods 0.000 claims description 8
- 230000004913 activation Effects 0.000 claims description 7
- 230000008447 perception Effects 0.000 claims description 4
- 238000012360 testing method Methods 0.000 description 34
- 238000004088 simulation Methods 0.000 description 22
- 238000010586 diagram Methods 0.000 description 16
- 238000005516 engineering process Methods 0.000 description 4
- 238000005070 sampling Methods 0.000 description 4
- 238000005457 optimization Methods 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 238000007635 classification algorithm Methods 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 238000012549 training Methods 0.000 description 2
- 239000002699 waste material Substances 0.000 description 2
- RTAQQCXQSZGOHL-UHFFFAOYSA-N Titanium Chemical compound [Ti] RTAQQCXQSZGOHL-UHFFFAOYSA-N 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 210000003746 feather Anatomy 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
Images


Landscapes
- Image Analysis (AREA)
Abstract
本发明公开了一种基于深度学习的感兴趣区域压缩感知图像重构方法,克服了现有压缩感知图像重构方法在有限的观测资源下对图像中感兴趣区域重构质量低的问题,实现的步骤为:(1)构建感兴趣区域感知重构网络;(2)训练感兴趣区域感知重构网络;(3)对待重构的自然图像进行预处理;(4)获取第一次观测信息;(5)获得初恢复图像;(6)获取感兴趣区域图像;(7)获取第二次观测信息;(8)重构感知恢复图像。本发明利用两次观测的方法,为感兴趣区域分配更多的观测资源,重构的图像中感兴趣区域纹理细节清晰。

The invention discloses a compressive sensing image reconstruction method for a region of interest based on deep learning, which overcomes the problem of low reconstruction quality of the ROI in the image under the limited observation resources of the existing compressive sensing image reconstruction method, and realizes The steps are: (1) construct the ROI-aware reconstruction network; (2) train the ROI-aware reconstruction network; (3) preprocess the natural image to be reconstructed; (4) obtain the first observation information (5) obtain the initial restoration image; (6) obtain the region of interest image; (7) obtain the second observation information; (8) reconstruct the perceptual restoration image. The invention uses the method of two observations to allocate more observation resources to the region of interest, and the texture details of the region of interest in the reconstructed image are clear.
Description
技术领域technical field
本发明属于图像处理技术领域,更进一步涉及图像重构技术领域中的一种基于深度学习的感兴趣区域压缩感知图像重构方法。本发明可以用于在自然图像重构时,在等效观测率下,获得感兴趣区域更高质量的图像。The invention belongs to the technical field of image processing, and further relates to a deep learning-based compressed sensing image reconstruction method for a region of interest in the technical field of image reconstruction. The present invention can be used to obtain a higher quality image of the region of interest under the equivalent observation rate during natural image reconstruction.
背景技术Background technique
信息技术的飞速发展使得人们对信息的需求量剧增。压缩感知理论为信号采集技术带来了革命性的突破,它表明一定条件下能以远低于奈奎斯特频率对信号进行采样,通过数值最优化问题高概率重构出原始信号,从而节省大量资源。相比于传统的优化求解方法,基于深度学习的压缩感知图像重构方法,由于其参数是线下训练的所以有很高的重建速度,可以实现对图像实时重构。现有的这些基于深度学习的压缩感知方法都是对整个场景进行统一的观测,也就是平均分配观测资源,但是更进一步地,人眼感知图像时会将更多的注意力放在感兴趣的区域,比如一幅图像中的物体,显著性标志等区域,医学影像中病理区域,无人机拍摄到的地面上车辆等等。这些区域的信息在成像后的处理过程中也表现出更重要的作用。The rapid development of information technology has made people's demand for information soar. Compressed sensing theory has brought a revolutionary breakthrough to signal acquisition technology. It shows that under certain conditions, the signal can be sampled at a frequency much lower than the Nyquist frequency, and the original signal can be reconstructed with high probability through numerical optimization problems, thereby saving energy. Lots of resources. Compared with the traditional optimization solution method, the compressed sensing image reconstruction method based on deep learning has a high reconstruction speed because its parameters are trained offline, and can realize real-time reconstruction of images. The existing compressed sensing methods based on deep learning are to observe the entire scene uniformly, that is, to evenly distribute observation resources, but further, the human eye will pay more attention to the interested Areas, such as objects in an image, saliency signs and other areas, pathological areas in medical images, vehicles on the ground captured by drones, etc. Information from these regions also appears to play a more important role in post-imaging processing.
Chakraborty等人在其发表的论文“Region of interest aware compressivesensing of Themis images and its reconstruction quality”(Proceedings of theIEEE Aerospace Conference,2018,pp.1-11)中提出了一种基于块的感兴趣区域压缩感知方法。该方法首先将图像分成块,然后根据传统的分类方法找到感兴趣的图像块,其中感兴趣区域为具有特定地貌特征的区域,设计的观测矩阵在与感兴趣区域对应的位置包含更大的采样数量,最后通过解忧化方法对观测值进行重构。该方法存在的不足之处有二点,其一,该方法中重构过程是由传统迭代算法完成,使得时间复杂度很高,影响算法的速度;其二,该方法中感兴趣区域的提取用传统分类算法,提取结果不够准确。In their paper "Region of interest aware compressivesensing of Themis images and its reconstruction quality" (Proceedings of the IEEE Aerospace Conference, 2018, pp.1-11), Chakraborty et al. proposed a block-based region of interest compressive sensing method. The method first divides the image into blocks, and then finds the image blocks of interest according to traditional classification methods, where the region of interest is an area with specific geomorphological features, and the designed observation matrix contains larger samples at the positions corresponding to the region of interest Quantity, and finally reconstruct the observations through the worry-free method. There are two shortcomings in this method. First, the reconstruction process in this method is completed by the traditional iterative algorithm, which makes the time complexity very high and affects the speed of the algorithm. Second, the extraction of the region of interest in this method With traditional classification algorithms, the extraction results are not accurate enough.
西安电子科技大学在其申请的专利文献“基于测量域分块显著性检测的压缩感知图像重构方法”(专利申请号:201510226877.7,申请公开号:CN 105678699 A)中公开了一种基于测量域分块显著性检测的压缩感知图像重构方法。该方法对图像进行两次观测,首先将原图划分成大小相同互不重叠的子块,进行第一次观测,然后通过传统变换算法对子块测量值进行变换,将子块划归为显著块或非显著块。对显著块和非显著块分别通过不同采样率,进行二次观测,最后通过传统优化方法进行重构。该方法在固定的观测资源下,结合两次的观测资源进行重构会提高观测资源的利用率,但是,该方法仍然存在的不足之处有二点,其一,由于只利用了第二次的观测信息对图像,进行重构,而未用到第一次的观测信息,造成资源浪费;其二,该方法只能处理灰度图像,无法对彩色图像进行压缩感知。Xi'an University of Electronic Science and Technology in its patent document "Compressed Sensing Image Reconstruction Method Based on Block Saliency Detection in Measurement Domain" (Patent Application No.: 201510226877.7, Application Publication No.: CN 105678699 A) discloses a method based on measurement domain A compressed sensing image reconstruction method for block saliency detection. This method observes the image twice. First, the original image is divided into sub-blocks of the same size and non-overlapping, and the first observation is performed. Then, the measured values of the sub-blocks are transformed by the traditional transformation algorithm, and the sub-blocks are classified as significant. block or non-significant block. The salient blocks and non-salient blocks are respectively observed at different sampling rates, and finally reconstructed by traditional optimization methods. Under the fixed observation resources, this method will improve the utilization rate of observation resources by combining the two observation resources for reconstruction. However, this method still has two shortcomings. First, because only the second time is used The first observation information is used to reconstruct the image, and the first observation information is not used, resulting in a waste of resources; secondly, this method can only process grayscale images, and cannot perform compressed sensing on color images.
发明内容SUMMARY OF THE INVENTION
本发明的目的在于针对上述现有技术存在的不足,提出一种基于深度学习的感兴趣区域压缩感知图像重构方法。本发明能在有限的观测资源下,使得图像中感兴趣区域的重构质量更好,同时具有很高的重建速度。The purpose of the present invention is to propose a compressive sensing image reconstruction method for a region of interest based on deep learning in view of the above-mentioned shortcomings of the prior art. The invention can make the reconstruction quality of the region of interest in the image better under the limited observation resources, and has a high reconstruction speed at the same time.
本发明的思路是,在初次观测恢复得到的初恢复图像上提取出感兴趣区域获取感兴趣区域图像,再对该图像进行第二次观测,组合两次观测信息进行重构,通过两次观测的方法,为感兴趣区域分配更多的观测资源,以重构出感兴趣区域更高质量的感知恢复图像。The idea of the present invention is to extract the region of interest from the initial restored image obtained by the initial observation and recovery to obtain the image of the region of interest, and then observe the image for a second time, combine the two observation information to reconstruct, and obtain the image through the two observations. The method allocates more observation resources to the region of interest to reconstruct a higher-quality perceptually restored image of the region of interest.
本发明的实现的具体步骤如下:The concrete steps of the realization of the present invention are as follows:
(1)构建感兴趣区域感知重构网络:(1) Build a region-of-interest-aware reconstruction network:
(1a)搭建感兴趣区域感知重构网络中的提取感兴趣区域子网络,该子网络包括一个八层的初次统一观测恢复模块和一个六层的显著性目标区域提取模块;(1a) Build a region-of-interest extraction sub-network in the region-of-interest-aware reconstruction network, which includes an eight-layer initial unified observation recovery module and a six-layer saliency target region extraction module;
所述初次统一观测恢复模块的结构依次为:第一卷积层→反卷积层→第二卷积层→第一残差块→第二残差块→第三残差块→第三卷积层→第四卷积层;The structure of the initial unified observation recovery module is in sequence: first convolutional layer→deconvolutional layer→second convolutional layer→first residual block→second residual block→third residual block→third volume Product layer → fourth convolution layer;
设置初次统一观测恢复模块的各层参数;Set the parameters of each layer of the initial unified observation and recovery module;
所述显著性目标区域提取模块的结构为:五个卷积层与一个池化层依次相连,池化层分别与第一、二、三、四层卷积层连接,第五卷积层分别与第一、二、三、四层卷积层连接,第四卷积层分别与第一、二层卷积层连接,第三卷积层分别与第一、二层卷积层连接,每个卷积层和池化层均连接一个softmax激活层共组成六个分类器;The structure of the saliency target region extraction module is as follows: five convolutional layers are connected to a pooling layer in turn, the pooling layers are respectively connected to the first, second, third and fourth convolutional layers, and the fifth convolutional layer is respectively It is connected with the first, second, third and fourth convolutional layers, the fourth convolutional layer is connected with the first and second convolutional layers respectively, and the third convolutional layer is connected with the first and second convolutional layers respectively. Each convolutional layer and pooling layer are connected to a softmax activation layer to form a total of six classifiers;
设置显著性目标区域提取模块的各层参数;Set the parameters of each layer of the saliency target region extraction module;
(1b)构建感兴趣区域感知重构网络中的感兴趣区域增强压缩感知子网络:(1b) Construct a region-of-interest enhanced compressed sensing sub-network in the region-of-interest-aware reconstruction network:
所述感兴趣区域增强压缩感知子网络的结构依次为:第一卷积层→反卷积层→第二卷积层→第一残差块→第二残差块→第三残差块→第四残差块→第五残差块→第六残差块→第七残差块→第三卷积层→第四卷积层,其中第一卷积层与初次统一观测恢复模块的第一层卷积层均与反卷积层相连;The structure of the enhanced compressed sensing sub-network for the region of interest is in the following order: the first convolutional layer→the deconvolutional layer→the second convolutional layer→the first residual block→the second residual block→the third residual block→ The fourth residual block→the fifth residual block→the sixth residual block→the seventh residual block→the third convolutional layer→the fourth convolutional layer, where the first convolutional layer is the same as the first convolutional layer of the initial unified observation recovery module. One convolutional layer is connected to the deconvolutional layer;
设置感兴趣区域增强压缩感知子网络的各层参数;Set the parameters of each layer of the region of interest enhanced compressed sensing sub-network;
(2)训练感兴趣区域感知重构网络:(2) Train the ROI-aware reconstruction network:
(2a)将3000张自然图像分别输入到感兴趣区域感知重构网络中,经过初次统一观测恢复模块输出每张图像对应的初恢复图像;经过显著性目标区域提取模块输出每张初恢复图像对应的感兴趣区域图像;经过感兴趣区域增强压缩感知子网络输出每张感兴趣区域图像对应的感知恢复图像;(2a) Input 3000 natural images into the region-of-interest perception reconstruction network, and output the corresponding initial restoration image of each image through the initial unified observation restoration module; output the corresponding initial restoration image of each image through the saliency target region extraction module The image of the region of interest; through the enhanced compressed sensing sub-network of the region of interest, the perceptual restoration image corresponding to each image of the region of interest is output;
(2b)利用均方误差函数,计算每张输入图像与对其应的初恢复图像的损失值;(2b) Using the mean square error function, calculate the loss value of each input image and its corresponding initial restored image;
(2c)利用交叉熵函数,计算感兴趣区域图像与该图像对应的显著区域标签图像的损失值;(2c) Using the cross entropy function, calculate the loss value of the region of interest image and the salient region label image corresponding to the image;
(2d)利用均方误差函数,计算输入的每张图像与对应的感知恢复图像的损失值;(2d) Using the mean square error function, calculate the loss value of each input image and the corresponding perceptually restored image;
(2e)计算总损失值,采用随机梯度下降算法,最小化总损失值,得到训练好的感兴趣区域感知重构网络;(2e) Calculate the total loss value, use the stochastic gradient descent algorithm to minimize the total loss value, and obtain a trained ROI-aware reconstruction network;
(3)对待重构的自然图像进行预处理:(3) Preprocess the natural image to be reconstructed:
将待重构的自然图像的大小裁剪成256×256个像素;Crop the size of the natural image to be reconstructed to 256×256 pixels;
(4)获取第一次观测信息:(4) Obtain the first observation information:
将预处理后的图像输入到初次统一观测恢复模块,通过该模块中第一层卷积层进行第一次观测,获取第一次观测信息;Input the preprocessed image to the initial unified observation recovery module, and conduct the first observation through the first convolution layer in the module to obtain the first observation information;
(5)获得初恢复图像:(5) Obtain the initial restored image:
将第一次观测信息输入到初次统一观测恢复模块的剩余结构中进行重构,输出初恢复图像;Input the first observation information into the remaining structure of the initial unified observation recovery module for reconstruction, and output the initial recovery image;
(6)获取感兴趣区域图像:(6) Obtain an image of the region of interest:
将初恢复图像输入到显著性目标区域提取模块,输出感兴趣区域图像;Input the initial restored image to the saliency target region extraction module, and output the region of interest image;
(7)获取第二次观测信息:(7) Obtain the second observation information:
将感兴趣区域图像输入到感兴趣区域增强压缩感知子网络,经过第一层卷积层的卷积操作,获取第二次观测信息;Input the region of interest image into the region of interest enhanced compressed sensing sub-network, and obtain the second observation information through the convolution operation of the first convolution layer;
(8)重构感知恢复图像:(8) Reconstruct the perceptually restored image:
将第一次观测信息和第二次观测信息通过concat操作进行组合,将组合后的观测信息输入到感兴趣区域增强压缩感知子网络的剩余结构中进行重构,获得感知恢复图像。The first observation information and the second observation information are combined through the concat operation, and the combined observation information is input into the remaining structure of the region of interest enhanced compressed sensing sub-network for reconstruction to obtain a perceptually restored image.
与现有技术相比,本发明具有以下优点:Compared with the prior art, the present invention has the following advantages:
第一,本发明通过搭建感兴趣区域增强压缩感知子网络对图像进行重构,克服了现有技术中由传统迭代算法完成重构过程使得时间复杂度很高,影响算法的速度的问题,使得本发明具有很高的重建速度并能达到实时的效果。First, the present invention reconstructs the image by constructing a region of interest enhanced compressed sensing sub-network, which overcomes the problems in the prior art that the reconstruction process is completed by the traditional iterative algorithm, resulting in high time complexity and affecting the speed of the algorithm, so that the The invention has high reconstruction speed and can achieve real-time effect.
第二,本发明通过搭建显著性目标区域提取模块提取图像中的感兴趣区域,克服了现有技术中用传统分类算法提取感兴趣区域,提取结果不够准确的问题,使得本发明能准确的提取到感兴趣区域。Second, the present invention extracts the region of interest in the image by building a salient target region extraction module, which overcomes the problem that the traditional classification algorithm is used to extract the region of interest and the extraction result is not accurate enough in the prior art, so that the present invention can accurately extract the region of interest. to the area of interest.
第三,本发明将第一次观测信息和第二次观测信息进行组合重构出感知恢复图像,克服了现有技术中只利用了第二次的观测信息对图像进行重构而造成资源浪费的问题,使得本发明即使是对图像用较低的观测率进行观测,也能重构出感兴趣区域的质量较好的感知恢复图像。Third, the present invention combines the first observation information and the second observation information to reconstruct a perceptually restored image, which overcomes the waste of resources caused by only using the second observation information to reconstruct the image in the prior art Therefore, the present invention can reconstruct a perceptually restored image with better quality of the region of interest even if the image is observed with a lower observation rate.
附图说明Description of drawings
图1为本发明的流程图;Fig. 1 is the flow chart of the present invention;
图2为用本发明在不同观测率下的仿真结果图。Fig. 2 is a simulation result diagram of the present invention under different observation rates.
具体实施方式Detailed ways
下面结合附图对本发明做进一步描述。The present invention will be further described below with reference to the accompanying drawings.
参照图1,对本发明的具体实施步骤做进一步描述。1, the specific implementation steps of the present invention will be further described.
步骤1,构建感兴趣区域感知重构网络。Step 1. Build a region-of-interest aware reconstruction network.
搭建感兴趣区域感知重构网络中的提取感兴趣区域子网络,该子网络包括一个八层的初次统一观测恢复模块和一个六层的显著性目标区域提取模块。A sub-network for extracting region of interest in the region-of-interest-aware reconstruction network is built. The sub-network includes an eight-layer initial unified observation recovery module and a six-layer saliency target region extraction module.
所述初次统一观测恢复模块的结构依次为:第一卷积层→反卷积层→第二卷积层→第一残差块→第二残差块→第三残差块→第三卷积层→第四卷积层。The structure of the initial unified observation recovery module is in sequence: first convolutional layer→deconvolutional layer→second convolutional layer→first residual block→second residual block→third residual block→third volume Convolutional layer → Fourth convolutional layer.
设置初次统一观测恢复模块的各层参数。Set the parameters of each layer of the initial unified observation recovery module.
所述的初次统一观测恢复模块的各层参数如下:The parameters of each layer of the initial unified observation and recovery module are as follows:
第一卷积层的卷积核大小为32×32,卷积核数量为41,步长为32。The kernel size of the first convolutional layer is 32×32, the number of kernels is 41, and the stride is 32.
反卷积层的反卷积核大小为32×32,卷积核数量为1,步长为32。The deconvolution kernel size of the deconvolution layer is 32 × 32, the number of convolution kernels is 1, and the stride is 32.
第二卷积层的卷积核大小为9×9,卷积核数量为64,步长为1。The kernel size of the second convolutional layer is 9×9, the number of kernels is 64, and the stride is 1.
第一、二、三残差块中卷积核大小为3×3,卷积核数量为64,步长为1。The size of the convolution kernels in the first, second, and third residual blocks is 3×3, the number of convolution kernels is 64, and the stride is 1.
第三卷积层的卷积核大小为3×3,卷积核数量为64,步长为1。The kernel size of the third convolutional layer is 3×3, the number of kernels is 64, and the stride is 1.
第四卷积层的卷积核大小为9×9,卷积核数量为1,步长为1。The kernel size of the fourth convolutional layer is 9×9, the number of kernels is 1, and the stride is 1.
所述显著性目标区域提取模块的结构为:五个卷积层与一个池化层依次相连,池化层分别与第一、二、三、四层卷积层连接,第五卷积层分别与第一、二、三、四层卷积层连接,第四卷积层分别与第一、二层卷积层连接,第三卷积层分别与第一、二层卷积层连接,每个卷积层和池化层均连接一个softmax激活层共组成六个分类器。The structure of the saliency target region extraction module is as follows: five convolutional layers are connected to a pooling layer in turn, the pooling layers are respectively connected to the first, second, third and fourth convolutional layers, and the fifth convolutional layer is respectively It is connected with the first, second, third and fourth convolutional layers, the fourth convolutional layer is connected with the first and second convolutional layers respectively, and the third convolutional layer is connected with the first and second convolutional layers respectively. Each convolutional layer and pooling layer are connected to a softmax activation layer to form a total of six classifiers.
设置显著性目标区域提取模块的各层参数。Set the parameters of each layer of the saliency target region extraction module.
所述的显著性目标区域提取模块的各层参数如下:The parameters of each layer of the saliency target region extraction module are as follows:
第一、二层卷积层的卷积核大小为3×3,卷积核数量为128,步长为1。The convolution kernel size of the first and second convolutional layers is 3×3, the number of convolution kernels is 128, and the stride is 1.
第三、四层卷积层的卷积核大小为5×5,卷积核数量为256,步长为2。The convolution kernel size of the third and fourth convolutional layers is 5×5, the number of convolution kernels is 256, and the stride is 2.
第五卷积层的卷积核大小为5×5,卷积核数量为512,步长为2。The convolution kernel size of the fifth convolutional layer is 5×5, the number of convolution kernels is 512, and the stride is 2.
池化层的卷积核大小为7×7,卷积核数量为512,步长为2。The convolution kernel size of the pooling layer is 7×7, the number of convolution kernels is 512, and the stride is 2.
构建感兴趣区域感知重构网络中的感兴趣区域增强压缩感知子网络。A region-of-interest enhanced compressed sensing sub-network is constructed in the region-of-interest-aware reconstruction network.
所述感兴趣区域增强压缩感知子网络的结构依次为:第一卷积层→反卷积层→第二卷积层→第一残差块→第二残差块→第三残差块→第四残差块→第五残差块→第六残差块→第七残差块→第三卷积层→第四卷积层,其中第一卷积层与初次统一观测恢复模块的第一层卷积层均与反卷积层相连。The structure of the enhanced compressed sensing sub-network for the region of interest is in the following order: the first convolutional layer→the deconvolutional layer→the second convolutional layer→the first residual block→the second residual block→the third residual block→ The fourth residual block→the fifth residual block→the sixth residual block→the seventh residual block→the third convolutional layer→the fourth convolutional layer, where the first convolutional layer is the same as the first convolutional layer of the initial unified observation recovery module. A convolutional layer is connected to a deconvolutional layer.
设置感兴趣区域增强压缩感知子网络的各层参数。Set the parameters of each layer of the region of interest enhanced compressed sensing sub-network.
所述的感兴趣区域增强压缩感知子网络的各层参数如下:The parameters of each layer of the enhanced compressed sensing sub-network for the region of interest are as follows:
第一卷积层的卷积核大小为32×32,卷积核数量为215,步长为32。The kernel size of the first convolutional layer is 32×32, the number of kernels is 215, and the stride is 32.
反卷积层的反卷积核大小为32×32,卷积核数量为1,步长为32。The deconvolution kernel size of the deconvolution layer is 32 × 32, the number of convolution kernels is 1, and the stride is 32.
第二卷积层的卷积核大小为9×9,卷积核数量为64,步长为1。The kernel size of the second convolutional layer is 9×9, the number of kernels is 64, and the stride is 1.
第一、二、三、四、五、六、七残差块中卷积核大小为3×3,卷积核数量为64,步长为1。The size of the convolution kernels in the first, second, third, fourth, fifth, sixth, and seventh residual blocks is 3×3, the number of convolution kernels is 64, and the stride is 1.
第三卷积层的卷积核大小为3×3,卷积核数量为64,步长为1。The kernel size of the third convolutional layer is 3×3, the number of kernels is 64, and the stride is 1.
第四卷积层的卷积核大小为9×9,卷积核数量为1,步长为1。The kernel size of the fourth convolutional layer is 9×9, the number of kernels is 1, and the stride is 1.
步骤2,训练感兴趣区域感知重构网络。Step 2, train the ROI-aware reconstruction network.
将3000张自然图像分别输入到感兴趣区域感知重构网络中,经过初次统一观测恢复模块输出每张图像对应的初恢复图像;经过显著性目标区域提取模块输出每张初恢复图像对应的感兴趣区域图像;经过感兴趣区域增强压缩感知子网络输出每张感兴趣区域图像对应的感知恢复图像。The 3000 natural images are respectively input into the region of interest perception reconstruction network, and the initial restoration image corresponding to each image is output through the initial unified observation and restoration module; the interest corresponding to each initial restoration image is output through the saliency target region extraction module. Region image; the perceptual restoration image corresponding to each region of interest image is output through the region-of-interest enhanced compressed sensing sub-network.
本发明的实施例下载了包含5000张自然图像,及其对应的5000张显著区域标签图像的MSRA-B公开数据集,从其随机分出3000张自然图像及其对应的显著区域标签图像做训练集,其余图像做测试集。The embodiment of the present invention downloads the MSRA-B public data set containing 5,000 natural images and their corresponding 5,000 salient region label images, and randomly selects 3,000 natural images and their corresponding salient region label images for training. set, and the rest of the images are used as the test set.
利用均方误差函数,计算每张输入图像与对其应的初恢复图像的损失值。Using the mean square error function, the loss value of each input image and its corresponding initial restored image is calculated.
所述的均方误差函数如下:The mean squared error function described is as follows:

其中,Li表示第i张输入图像与对其应的初恢复图像的损失值或者对其应的感知恢复图像的损失值,c、w、h分别表示第i张输入图像的通道数、宽、高,n表示第i张输入图像的像素总数,j表示第i张输入图像中像素的序号,j的取值为[1,65536],∑表示求和操作,||·||2表示二范数操作,

利用交叉熵函数,计算感兴趣区域图像与该图像对应的显著区域标签图像的损失值。Using the cross-entropy function, the loss value of the region of interest image and the corresponding salient region label image of the image is calculated.
本发明的实施例中显著区域标签图像来自MSRA-B公开数据集,是与输入的自然图像对应的显著区域标签图像。In the embodiment of the present invention, the salient region label images are from the MSRA-B public data set, and are salient region label images corresponding to the input natural images.
所述的交叉熵函数如下:The cross-entropy function described is as follows:

其中,
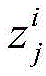



利用均方误差函数,计算输入的每张图像与对应的感知恢复图像的损失值。Using the mean squared error function, the loss value of each input image and the corresponding perceptually restored image is calculated.
计算总损失值,采用随机梯度下降算法,最小化总损失值,得到训练好的感兴趣区域感知重构网络。Calculate the total loss value, use the stochastic gradient descent algorithm to minimize the total loss value, and obtain the trained ROI-aware reconstruction network.
所述的总损失值由下式计算得到:Said total loss value is calculated by the following formula:

其中,li表示第i张输入图像对其应的总损失值,

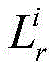


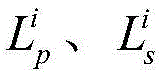
步骤3,对待重构的自然图像进行预处理。Step 3: Preprocess the natural image to be reconstructed.
将待重构的自然图像的大小裁剪成256×256个像素。Crop the size of the natural image to be reconstructed to 256×256 pixels.
步骤4,获取第一次观测信息。Step 4, obtain the first observation information.
将预处理后的图像输入到初次统一观测恢复模块,通过该模块中第一层卷积层进行第一次观测,获取第一次观测信息。The preprocessed image is input to the initial unified observation recovery module, and the first observation is performed through the first convolutional layer in this module to obtain the first observation information.
步骤5,获得初恢复图像。Step 5, obtain an initial restored image.
将第一次观测信息输入到初次统一观测恢复模块的剩余结构中进行重构,输出初恢复图像。Input the first observation information into the remaining structure of the initial unified observation restoration module for reconstruction, and output the initial restoration image.
步骤6,获取感兴趣区域图像。Step 6, acquiring an image of the region of interest.
将初恢复图像输入到显著性目标区域提取模块,输出感兴趣区域图像。Input the initial restoration image to the saliency target region extraction module, and output the region of interest image.
步骤7,获取第二次观测信息。Step 7: Obtain the second observation information.
将感兴趣区域图像输入到感兴趣区域增强压缩感知子网络,经过第一层卷积层的卷积操作,获取第二次观测信息。The region of interest image is input into the region of interest enhanced compressed sensing sub-network, and the second observation information is obtained through the convolution operation of the first convolution layer.
步骤8,重构感知恢复图像。Step 8, reconstruct the perceptually restored image.
将第一次观测信息和第二次观测信息通过concat操作进行组合,将组合后的观测信息输入到感兴趣区域增强压缩感知子网络的剩余结构中进行重构,获得感知恢复图像。The first observation information and the second observation information are combined through the concat operation, and the combined observation information is input into the remaining structure of the region of interest enhanced compressed sensing sub-network for reconstruction to obtain a perceptually restored image.
本发明的效果可以通过以下仿真进一步说明。The effect of the present invention can be further explained by the following simulation.
1、仿真实验条件:1. Simulation experimental conditions:
本发明的仿真实验使用的硬件环境是主频3.4GHz的NVIDIA TITAN XP GPUs、内存128GB的硬件环境,软件环境是pytorch、pycharm2017。The hardware environment used in the simulation experiment of the present invention is the hardware environment of NVIDIA TITAN XP GPUs with a main frequency of 3.4GHz and a memory of 128GB, and the software environment is pytorch and pycharm2017.
2、仿真内容:2. Simulation content:
本发明的仿真实验是下载MSRA-B公开数据集,取其中6张作为测试图像,采用本发明方法和现有技术图像重构方法(基于深度学习的压缩感知图像重构方法)在8%、11%、15%的观测率下,分别对测试图像进行的重构。The simulation experiment of the present invention is to download the MSRA-B public data set, take 6 of them as test images, and adopt the method of the present invention and the prior art image reconstruction method (compressed sensing image reconstruction method based on deep learning) at 8%, 11% and 15% of the observation rate, respectively, the reconstruction of the test image.
3、仿真结果分析:3. Analysis of simulation results:
图2(a)是在观测率为8%时采用本发明方法和现有技术的仿真图。其中,图2(a1)是6张测试图像中的第一张图像,图2(a2)是对第一张测试图中感兴趣区域的局部放大图,图2(a3)是采用本发明方法的对第一张测试图仿真后得到的重构图中感兴趣区域的局部放大图,图2(a4)是采用现有技术的方法的第一张测试图仿真后得到的重构图中感兴趣区域的局部放大图。Figure 2(a) is a simulation diagram of using the method of the present invention and the prior art when the observation rate is 8%. Among them, Fig. 2(a1) is the first image in the 6 test images, Fig. 2(a2) is a partial enlarged view of the region of interest in the first test image, Fig. 2(a3) is the method of the present invention A partial enlarged view of the region of interest in the reconstruction diagram obtained after the simulation of the first test diagram, Fig. 2(a4) is the reconstruction diagram obtained after the simulation of the first test diagram by the method of the prior art. A zoomed-in view of the region of interest.
图2(a5)是6张测试图像中的第二张图像,图2(a6)是对第二张测试图中感兴趣区域的局部放大图,图2(a7)是采用本发明方法的对第一张测试图仿真后得到的重构图中感兴趣区域的局部放大图,图2(a8)是采用现有技术的方法的第一张测试图仿真后得到的重构图中感兴趣区域的局部放大图。Fig. 2(a5) is the second image in the 6 test images, Fig. 2(a6) is a partial enlarged view of the region of interest in the second test image, Fig. 2(a7) is the test image using the method of the present invention A partial enlarged view of the region of interest in the reconstruction map obtained after the simulation of the first test map, Fig. 2(a8) is the region of interest in the reconstruction map obtained after the simulation of the first test map using the prior art method A partial enlarged view of .
由图2(a4)、图2(a8)可以看出,在8%的观测率下使用现有技术仿真后的图像中感兴趣区域是模糊的,图2(a4)中的字母纹理不清楚,图2(a8)中小鸟的羽毛纹理细节也不清晰,可见由图2(a3)、图2(a7)可以看出采用本发明方法重构出的图像中感兴趣区域更接近测试图,本发明在采样率为8%下重构出结果图中的感兴趣区域的图像质量比现有方法好。It can be seen from Figure 2(a4) and Figure 2(a8) that the region of interest in the image simulated by the prior art at an observation rate of 8% is blurred, and the letter texture in Figure 2(a4) is unclear , the details of the feather texture of the bird in Figure 2 (a8) are not clear, it can be seen from Figure 2 (a3), Figure 2 (a7) that the region of interest in the image reconstructed by the method of the present invention is closer to the test image, When the sampling rate is 8%, the image quality of the region of interest reconstructed in the result map of the present invention is better than that of the existing method.
图2(b)是在观测率为11%时采用本发明方法和现有技术的仿真图。其中,图2(b1)是6张测试图像中的第三张图像,图2(b2)是对第三张测试图中感兴趣区域的局部放大图,图2(b3)是采用本发明方法的对第三张测试图仿真后得到的重构图中感兴趣区域的局部放大图,图2(b4)是采用现有技术的方法的第三张测试图仿真后得到的重构图中感兴趣区域的局部放大图。Figure 2(b) is a simulation diagram of using the method of the present invention and the prior art when the observation rate is 11%. Among them, Fig. 2(b1) is the third image in the 6 test images, Fig. 2(b2) is a partial enlarged view of the region of interest in the third test image, Fig. 2(b3) is the method of the present invention Figure 2(b4) is a partial enlarged view of the region of interest in the reconstruction diagram obtained after the simulation of the third test diagram, and Fig. 2(b4) is the reconstruction diagram obtained after the simulation of the third test diagram by the method of the prior art. A zoomed-in view of the region of interest.
图2(b5)是6张测试图像中的第四张图像,图2(b6)是对第四张测试图中感兴趣区域的局部放大图,图2(b7)是采用本发明方法的对第四张测试图仿真后得到的重构图中感兴趣区域的局部放大图,图2(b8)是采用现有技术的方法的第四张测试图仿真后得到的重构图中感兴趣区域的局部放大图。Fig. 2(b5) is the fourth image in the 6 test images, Fig. 2(b6) is a partial enlarged view of the region of interest in the fourth test image, Fig. 2(b7) is the test image using the method of the present invention A partial enlarged view of the region of interest in the reconstruction map obtained after the simulation of the fourth test map, Fig. 2(b8) is the region of interest in the reconstruction map obtained after the simulation of the fourth test map using the method of the prior art A partial enlarged view of .
由图2(b4)、图2(b8)可以看出,在11%的观测率下使用现有技术仿真后的图像中感兴趣区域是模糊的,图2(b4)中的瓶子上的图案和文字纹理不清楚,图2(b8)中花瓣上的水滴也不清晰,可见由图2(b3)、图2(b7)可以看出采用本发明方法重构出的图像中感兴趣区域更接近测试图,本发明在采样率为11%下重构出结果图中的感兴趣区域的图像质量比现有方法好。It can be seen from Figure 2(b4) and Figure 2(b8) that the area of interest in the image simulated by the prior art is blurred at an observation rate of 11%, and the pattern on the bottle in Figure 2(b4) And the text texture is not clear, and the water droplets on the petals in Figure 2 (b8) are not clear, it can be seen from Figure 2 (b3) and Figure 2 (b7) that the region of interest in the image reconstructed by the method of the present invention is more clear. Approaching the test map, the image quality of the region of interest reconstructed in the result map by the present invention is better than that of the existing method when the sampling rate is 11%.
图2(c)是在观测率为15%时采用本发明方法和现有技术的仿真图。其中,图2(c1)是6张测试图像中的第五张图像,图2(c2)是对第五张测试图中感兴趣区域的局部放大图,图2(c3)是采用本发明方法的对第五张测试图仿真后得到的重构图中感兴趣区域的局部放大图,图2(c4)是采用现有技术的方法的第五张测试图仿真后得到的重构图中感兴趣区域的局部放大图。Figure 2(c) is a simulation diagram of using the method of the present invention and the prior art when the observation rate is 15%. Among them, Fig. 2(c1) is the fifth image in the 6 test images, Fig. 2(c2) is a partial enlarged view of the region of interest in the fifth test image, Fig. 2(c3) is the method of the present invention The partial enlarged view of the region of interest in the reconstruction diagram obtained after the simulation of the fifth test diagram, Fig. 2 (c4) is the reconstruction diagram obtained after the simulation of the fifth test diagram by the method of the prior art. A zoomed-in view of the region of interest.
图2(c5)是6张测试图像中的第六张图像,图2(c6)是对第六张测试图中感兴趣区域的局部放大图,图2(c7)是采用本发明方法的对第六张测试图仿真后得到的重构图中感兴趣区域的局部放大图,图2(c8)是采用现有技术的方法的第六张测试图仿真后得到的重构图中感兴趣区域的局部放大图。Fig. 2(c5) is the sixth image in the 6 test images, Fig. 2(c6) is a partial enlarged view of the region of interest in the sixth test image, Fig. 2(c7) is the test image using the method of the present invention A partial enlarged view of the region of interest in the reconstruction map obtained after the sixth test map is simulated, and Figure 2(c8) is the region of interest in the reconstruction map obtained after the sixth test map simulation using the prior art method A partial magnified view of .
由图2(c4)、图2(c8)可以看出,在15%的观测率下使用现有技术仿真后的图像中感兴趣区域是模糊的,图2(c4)中的标志牌上的文字纹理不清楚,图2(c8)中花朵中的花蕊细节也不清晰,可见由图2(c3)、图2(c7)可以看出采用本发明方法重构出的图像中感兴趣区域更接近测试图,本发明在采样率为15%下重构出结果图中的感兴趣区域的图像质量比现有方法好。It can be seen from Figure 2(c4) and Figure 2(c8) that the region of interest in the image simulated by the prior art under the observation rate of 15% is blurred. The texture of the text is not clear, and the details of the stamens in the flower in Figure 2 (c8) are not clear. It can be seen from Figure 2 (c3) and Figure 2 (c7) that the region of interest in the image reconstructed by the method of the present invention is more clear. Approaching the test map, the image quality of the region of interest reconstructed in the result map by the present invention is better than that of the existing method when the sampling rate is 15%.
为了更好的比较本发明方法和现有技术的重构图像中感兴趣区域的恢复质量,计算不同方法仿真结果图中感兴趣区域局部放大图像的峰值信噪比(PSNR),最终数据如下表所示。In order to better compare the restoration quality of the region of interest in the reconstructed image between the method of the present invention and the prior art, the peak signal-to-noise ratio (PSNR) of the locally enlarged image of the region of interest in the simulation results of different methods is calculated, and the final data is as follows shown.
从上表中可以看出,本发明的方法得到的结果图中感兴趣区域局部放大图像的峰值信噪比PSNR都要高于现有技术得到的PSNR,即与现有的重构方法相比,本发明提高了图像中感兴趣区域的重构质量。It can be seen from the above table that the peak signal-to-noise ratio (PSNR) of the locally enlarged image of the region of interest in the result obtained by the method of the present invention is higher than the PSNR obtained by the prior art, that is, compared with the existing reconstruction method , the present invention improves the reconstruction quality of the region of interest in the image.
Claims (7)
















Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910166307.1A CN109949257B (en) | 2019-03-06 | 2019-03-06 | Region-of-interest compressed sensing image reconstruction method based on deep learning |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910166307.1A CN109949257B (en) | 2019-03-06 | 2019-03-06 | Region-of-interest compressed sensing image reconstruction method based on deep learning |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109949257A CN109949257A (en) | 2019-06-28 |
| CN109949257B true CN109949257B (en) | 2021-09-10 |
Family
ID=67008943
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910166307.1A Active CN109949257B (en) | 2019-03-06 | 2019-03-06 | Region-of-interest compressed sensing image reconstruction method based on deep learning |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109949257B (en) |
Families Citing this family (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10678244B2 (en) | 2017-03-23 | 2020-06-09 | Tesla, Inc. | Data synthesis for autonomous control systems |
| US10671349B2 (en) | 2017-07-24 | 2020-06-02 | Tesla, Inc. | Accelerated mathematical engine |
| US11409692B2 (en) | 2017-07-24 | 2022-08-09 | Tesla, Inc. | Vector computational unit |
| US11893393B2 (en) | 2017-07-24 | 2024-02-06 | Tesla, Inc. | Computational array microprocessor system with hardware arbiter managing memory requests |
| US11157441B2 (en) | 2017-07-24 | 2021-10-26 | Tesla, Inc. | Computational array microprocessor system using non-consecutive data formatting |
| US12307350B2 (en) | 2018-01-04 | 2025-05-20 | Tesla, Inc. | Systems and methods for hardware-based pooling |
| US11561791B2 (en) | 2018-02-01 | 2023-01-24 | Tesla, Inc. | Vector computational unit receiving data elements in parallel from a last row of a computational array |
| US11215999B2 (en) | 2018-06-20 | 2022-01-04 | Tesla, Inc. | Data pipeline and deep learning system for autonomous driving |
| US11361457B2 (en) | 2018-07-20 | 2022-06-14 | Tesla, Inc. | Annotation cross-labeling for autonomous control systems |
| US11636333B2 (en) | 2018-07-26 | 2023-04-25 | Tesla, Inc. | Optimizing neural network structures for embedded systems |
| US11562231B2 (en) | 2018-09-03 | 2023-01-24 | Tesla, Inc. | Neural networks for embedded devices |
| CA3115784A1 (en) | 2018-10-11 | 2020-04-16 | Matthew John COOPER | Systems and methods for training machine models with augmented data |
| US11196678B2 (en) | 2018-10-25 | 2021-12-07 | Tesla, Inc. | QOS manager for system on a chip communications |
| US11816585B2 (en) | 2018-12-03 | 2023-11-14 | Tesla, Inc. | Machine learning models operating at different frequencies for autonomous vehicles |
| US11537811B2 (en) | 2018-12-04 | 2022-12-27 | Tesla, Inc. | Enhanced object detection for autonomous vehicles based on field view |
| US11610117B2 (en) | 2018-12-27 | 2023-03-21 | Tesla, Inc. | System and method for adapting a neural network model on a hardware platform |
| US11150664B2 (en) | 2019-02-01 | 2021-10-19 | Tesla, Inc. | Predicting three-dimensional features for autonomous driving |
| US10997461B2 (en) | 2019-02-01 | 2021-05-04 | Tesla, Inc. | Generating ground truth for machine learning from time series elements |
| US11567514B2 (en) | 2019-02-11 | 2023-01-31 | Tesla, Inc. | Autonomous and user controlled vehicle summon to a target |
| US10956755B2 (en) | 2019-02-19 | 2021-03-23 | Tesla, Inc. | Estimating object properties using visual image data |
| CN111428751B (en) * | 2020-02-24 | 2022-12-23 | 清华大学 | Object detection method based on compressed sensing and convolutional network |
| US12462575B2 (en) | 2021-08-19 | 2025-11-04 | Tesla, Inc. | Vision-based machine learning model for autonomous driving with adjustable virtual camera |
| EP4388510A1 (en) | 2021-08-19 | 2024-06-26 | Tesla, Inc. | Vision-based system training with simulated content |
| CN114723836B (en) * | 2022-04-06 | 2024-12-17 | 西安电子科技大学 | Region of interest compression method based on multilayer super prior network |
| CN115311174B (en) * | 2022-10-10 | 2023-03-24 | 深圳大学 | Training method and device for image recovery network and computer readable storage medium |
| CN117412051A (en) * | 2023-09-28 | 2024-01-16 | 国网福建省电力有限公司电力科学研究院 | Data compression method based on deep learning image coding technology |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104103052A (en) * | 2013-04-11 | 2014-10-15 | 北京大学 | Sparse representation-based image super-resolution reconstruction method |
| CN104280705A (en) * | 2014-09-30 | 2015-01-14 | 深圳先进技术研究院 | Magnetic resonance image reconstruction method and device based on compressed sensing |
| US9275294B2 (en) * | 2011-11-03 | 2016-03-01 | Siemens Aktiengesellschaft | Compressed sensing using regional sparsity |
| CN105741252A (en) * | 2015-11-17 | 2016-07-06 | 西安电子科技大学 | Sparse representation and dictionary learning-based video image layered reconstruction method |
| CN108510464A (en) * | 2018-01-30 | 2018-09-07 | 西安电子科技大学 | Compressed sensing network and full figure reconstructing method based on piecemeal observation |
-
2019
- 2019-03-06 CN CN201910166307.1A patent/CN109949257B/en active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9275294B2 (en) * | 2011-11-03 | 2016-03-01 | Siemens Aktiengesellschaft | Compressed sensing using regional sparsity |
| CN104103052A (en) * | 2013-04-11 | 2014-10-15 | 北京大学 | Sparse representation-based image super-resolution reconstruction method |
| CN104280705A (en) * | 2014-09-30 | 2015-01-14 | 深圳先进技术研究院 | Magnetic resonance image reconstruction method and device based on compressed sensing |
| CN105741252A (en) * | 2015-11-17 | 2016-07-06 | 西安电子科技大学 | Sparse representation and dictionary learning-based video image layered reconstruction method |
| CN108510464A (en) * | 2018-01-30 | 2018-09-07 | 西安电子科技大学 | Compressed sensing network and full figure reconstructing method based on piecemeal observation |
Also Published As
| Publication number | Publication date |
|---|---|
| CN109949257A (en) | 2019-06-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109949257B (en) | Region-of-interest compressed sensing image reconstruction method based on deep learning | |
| CN113362223B (en) | Image Super-Resolution Reconstruction Method Based on Attention Mechanism and Two-Channel Network | |
| CN107977969B (en) | Endoscope fluorescence image segmentation method, device and storage medium | |
| CN102243711B (en) | Neighbor embedding-based image super-resolution reconstruction method | |
| CN108647775B (en) | Super-resolution image reconstruction method based on full convolution neural network single image | |
| CN112017192A (en) | Glandular cell image segmentation method and system based on improved U-Net network | |
| CN110852225A (en) | Mangrove extraction method and system from remote sensing images based on deep convolutional neural network | |
| CN113450288A (en) | Single image rain removing method and system based on deep convolutional neural network and storage medium | |
| CN108596833A (en) | Super-resolution image reconstruction method, device, equipment and readable storage medium storing program for executing | |
| CN109858450B (en) | Ten-meter-level spatial resolution remote sensing image town extraction method and system | |
| CN111178121A (en) | Pest image localization and recognition method based on spatial feature and depth feature enhancement technology | |
| CN110288597A (en) | Attention mechanism-based video saliency detection method for wireless capsule endoscopy | |
| CN111666813B (en) | Subcutaneous sweat gland extraction method of three-dimensional convolutional neural network based on non-local information | |
| CN115953303B (en) | Multi-scale image compressed sensing reconstruction method and system combining channel attention | |
| CN103353938A (en) | Cell membrane segmentation method based on hierarchy-level characteristic | |
| CN117474764B (en) | A high-resolution reconstruction method for remote sensing images under complex degradation models | |
| CN115511722A (en) | Remote sensing image denoising method based on depth feature fusion network and joint loss function | |
| CN111080531A (en) | A method, system and device for super-resolution reconstruction of underwater fish images | |
| CN103984963A (en) | Method for classifying high-resolution remote sensing image scenes | |
| CN116703812A (en) | A photovoltaic module crack detection method and system based on deep learning | |
| CN115375983A (en) | Multi-feature fusion target detection method and system based on Pairwise classifier | |
| CN113034390B (en) | Image restoration method and system based on wavelet prior attention | |
| CN118196116A (en) | MRI image segmentation method based on deep learning | |
| CN112070689A (en) | Data enhancement method based on depth image | |
| CN107358625B (en) | SAR image change detection method based on SPP Net and region of interest detection |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |