CN109117440B - Method, system and computer-readable storage medium for acquiring metadata information - Google Patents
Method, system and computer-readable storage medium for acquiring metadata information Download PDFInfo
- Publication number
- CN109117440B CN109117440B CN201710485959.2A CN201710485959A CN109117440B CN 109117440 B CN109117440 B CN 109117440B CN 201710485959 A CN201710485959 A CN 201710485959A CN 109117440 B CN109117440 B CN 109117440B
- Authority
- CN
- China
- Prior art keywords
- data
- matching
- column
- character
- stored
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images









Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
技术领域technical field
本发明涉及大数据领域,尤其涉及一种元数据信息获取方法、系统和计算机可读存储介质。The present invention relates to the field of big data, and in particular, to a method, system and computer-readable storage medium for obtaining metadata information.
背景技术Background technique
在大数据场景中,越来越多的数据被共享,而不是传统的企业内部的数据仓库。针对企业内部数据仓库可以严格定义元数据信息,而在大数据场景中,越来越多的数据来自外部,大家共享的数据开放在平台中。这些数据在结构上、定义上都缺乏统一的描述和标准。In big data scenarios, more and more data is being shared instead of traditional data warehouses within enterprises. Metadata information can be strictly defined for the internal data warehouse of the enterprise, but in the big data scenario, more and more data comes from the outside, and the data shared by everyone is open on the platform. These data lack unified description and standard in structure and definition.
大数据平台场景中的数据的数据格式、数据结构和数据位置有以下几个特点,数据格式:数据以文件格式存放,以某种基础格式,比如每行表示一行数据,字段之间用某用间隔符隔开;数据结构:类型多样,包括结构化、非结构化、半结构化等多种格式;数据位置:大量数据存在于大量异构、不同系统中,甚至不同地域;大量数据整合操作:主要是跨域数据的整合,数据互操作多。然而,目前还没有一种方法可以自动识别数据的元数据。The data format, data structure and data location of the data in the big data platform scenario have the following characteristics. Data format: The data is stored in a file format, in a certain basic format, such as each row represents a row of data, and a certain function is used between fields. Separated by spacers; data structure: various types, including structured, unstructured, semi-structured and other formats; data location: a large amount of data exists in a large number of heterogeneous, different systems, and even different regions; a large number of data integration operations : It is mainly the integration of cross-domain data, and there are many data interoperability. However, there is currently no way to automatically identify the metadata of the data.
发明内容SUMMARY OF THE INVENTION
为解决上述技术问题,本发明实施例提供一种元数据信息获取方法、系统和计算机可读存储介质,可以在识别数据的过程中,自动获取如数据字段类型、度量、数据关系等信息,节省了时间,提高了效率。In order to solve the above technical problems, the embodiments of the present invention provide a metadata information acquisition method, system, and computer-readable storage medium, which can automatically acquire information such as data field types, metrics, data relationships, etc. time and efficiency.
本发明的技术方案是这样实现的:The technical scheme of the present invention is realized as follows:
本发明实施例提供一种元数据信息获取方法,所述方法包括:An embodiment of the present invention provides a method for obtaining metadata information, and the method includes:
根据获取的数据源生成待识别数据,所述待识别数据包括:多个行数据和多个列数据;Generate the data to be identified according to the acquired data source, the data to be identified includes: a plurality of row data and a plurality of column data;
根据预存储的规则对所述待识别数据进行扫描匹配,获得所述数据源的元数据信息,所述元数据信息包括至少一种以下信息:数据结构信息、数据度量信息和数据关系信息。The data to be identified is scanned and matched according to pre-stored rules to obtain metadata information of the data source, where the metadata information includes at least one of the following information: data structure information, data metric information and data relationship information.
进一步地,所述预存储的规则中包括:多个匹配规则;所述方法还包括:Further, the pre-stored rules include: multiple matching rules; the method further includes:
在根据预存储的规则对所述待识别数据进行扫描匹配时,在匹配规则日志中记录匹配日志,所述匹配日志包括:所述多个匹配规则中每一个匹配规则的匹配次数、所述多个匹配规则中每一个匹配规则的匹配成功率;When scanning and matching the data to be identified according to the pre-stored rules, a matching log is recorded in the matching rule log, where the matching log includes: the number of matches of each matching rule in the multiple matching rules, the multiple matching rules The matching success rate of each matching rule in the matching rules;
根据所述匹配日志对所述多个匹配规则的匹配先后顺序进行优化。The matching sequence of the multiple matching rules is optimized according to the matching log.
进一步地,第一行为所述待识别数据中的任意一行数据,对所述待识别数据的第一行进行解析,获得所述数据源的数据结构信息,包括:Further, the first row is any row of data in the data to be identified, and the first row of the data to be identified is parsed to obtain the data structure information of the data source, including:
从所述待识别数据中第一行第一列开始,依次将所述待识别数据中第一行的每一列的字符与知识库中预存储的匹配规则进行扫描匹配,根据匹配结果获得所述待识别数据的数据结构信息,所述待识别数据的数据结构信息包括:所述待识别数据每一列的字段类型。Starting from the first row and the first column in the data to be identified, scan and match the characters in each column of the first row in the data to be identified with the matching rules pre-stored in the knowledge base, and obtain the The data structure information of the data to be identified, the data structure information of the data to be identified includes: the field type of each column of the data to be identified.
进一步地,将所述待识别数据中第一行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得所述待识别数据第一列的字段类型,包括:Further, scanning and matching the characters in the first row and the first column of the data to be identified with the matching rules pre-stored in the knowledge base to obtain the field type of the first column of the data to be identified, including:
将第一字符与知识库中预存储的第一匹配规则进行扫描匹配,所述第一字符为所述待识别数据中第一行第一列的第一个字符;Scanning and matching the first character with the first matching rule pre-stored in the knowledge base, where the first character is the first character in the first row and first column in the data to be identified;
当所述第一字符与所述第一匹配规则中第一预存字符相同时,确定所述待识别数据的第一列的分类为第一分类,根据所述第一行第一列的全部字符的数值范围确定所述第一列的字段类型,所述第一分类包括:数字分类或时间戳分类;When the first character is the same as the first pre-stored character in the first matching rule, it is determined that the classification of the first column of the data to be recognized is the first classification, according to all the characters in the first row and the first column The numerical range of the first column determines the field type of the first column, and the first classification includes: digital classification or timestamp classification;
当所述第一字符与所述第一匹配规则中第一预存字符不同时,将所述第一字符与知识库中预存储的第二匹配规则进行扫描匹配;When the first character is different from the first pre-stored character in the first matching rule, scan and match the first character with the second matching rule pre-stored in the knowledge base;
当所述第一字符与所述第二匹配规则中第二预存字符相同时,确定所述待识别数据的第一列的分类为第二分类,根据所述第一行第一列的全部字符的格式和字符长度确定所述第一列的字段类型,所述第二分类包括:字符分类或者日期分类;When the first character is the same as the second pre-stored character in the second matching rule, it is determined that the classification of the first column of the data to be recognized is the second classification, according to all the characters in the first row and the first column The format and character length of the first column determine the field type of the first column, and the second classification includes: character classification or date classification;
当所述第一字符与所述第二匹配规则中第二预存字符不同时,将所述第一字符与知识库中预存储的第三匹配规则进行扫描匹配;When the first character is different from the second pre-stored character in the second matching rule, scan and match the first character with the third matching rule pre-stored in the knowledge base;
当所述第一字符与所述第三符匹配规则中第三预存字符相同时,确定所述待识别数据的第一列的分类为复杂分类,根据所述第一行第一列的全部字符中的符号和字符组合形式确定所述第一列的字段类型。When the first character is the same as the third pre-stored character in the third character matching rule, it is determined that the classification of the first column of the data to be recognized is a complex classification, according to all the characters in the first row and the first column The combination of symbols and characters in determines the field type of the first column.
进一步地,在将所述待识别数据中第一行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得所述待识别数据第一列的字段类型之后,还包括:Further, after scanning and matching the characters in the first row and the first column of the data to be identified with the matching rules pre-stored in the knowledge base to obtain the field type of the first column of the data to be identified, the method further includes:
若所述待识别数据中第二行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得的第一列的字段类型与所述待识别数据中第一行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得的第一列的字段类型不同,且匹配顺序在后的第一列的字段类型包括的范围大于匹配顺序在前的第一列的字段类型包括的范围时,将匹配顺序在前的第一列的字段类型修改为匹配顺序在后的第一列的字段类型,其中,所述待识别数据中第二行包括:与所述待识别数据中第一行不同的行数据。If the characters in the second row and the first column in the data to be recognized are scanned and matched with the matching rules pre-stored in the knowledge base, the field type in the first column obtained by scanning and matching is the same as the characters in the first row and the first column in the data to be recognized. It is different from the field type of the first column obtained by scanning and matching the pre-stored matching rules in the knowledge base, and the field type of the first column after the matching order includes a larger range than the field type of the first column before the matching order. When the range of the first column in the matching order is changed to the field type in the first column in the matching order, the second row in the data to be identified includes: the same as the data in the data to be identified The first row of different rows of data.
进一步地,根据预存储的规则对所述待识别数据进行扫描匹配,获得所述数据源的数据度量信息和数据关系信息,包括:Further, scan and match the to-be-identified data according to pre-stored rules to obtain data measurement information and data relationship information of the data source, including:
根据预存储的规则对所述待识别数据进行全表扫描匹配,获得所述数据源的数据度量信息,根据预存储的规则确定所述待识别数据中每两列的相关性,确定所述数据源的数据关系信息。Perform full table scan matching on the data to be identified according to pre-stored rules to obtain data measurement information of the data source, determine the correlation of every two columns in the data to be identified according to the pre-stored rules, and determine the data Data relationship information for the source.
进一步地,所述方法还包括:Further, the method also includes:
若根据预存储的规则对所述待识别数据进行扫描匹配不能确定所述数据源的元数据信息,提供类型建议,以使得通过人工判断所述数据源的元数据信息,并根据人工判断的结果完善所述预存储的规则。If the metadata information of the data source cannot be determined by scanning and matching the data to be identified according to the pre-stored rules, a type suggestion is provided, so that the metadata information of the data source can be manually judged, and the result of the manual judgment can be determined according to the metadata information of the data source. Refine the pre-stored rules.
进一步地,在所述获得所述数据源的元数据信息之后,所述方法还包括:Further, after obtaining the metadata information of the data source, the method further includes:
对所述元数据信息进行存储,以使得根据所述元数据信息进行对外服务。The metadata information is stored, so that external services are performed according to the metadata information.
本发明实施例还提供一种元数据信息获取系统,所述系统包括:收发器、处理器和存储器,其中,An embodiment of the present invention further provides a system for obtaining metadata information, the system includes: a transceiver, a processor, and a memory, wherein,
所述收发器,用于获取数据源;the transceiver, for obtaining a data source;
所述处理器,用于根据获取的数据源生成待识别数据,所述待识别数据包括:多个行数据和多个列数据;还用于根据预存储的规则对所述待识别数据进行扫描匹配,获得所述数据源的元数据信息,所述元数据信息包括至少一种以下信息:数据结构信息、数据度量信息和数据关系信息;The processor is configured to generate data to be identified according to the acquired data source, the data to be identified includes: a plurality of row data and a plurality of column data; and is further configured to scan the to-be-identified data according to pre-stored rules matching, to obtain metadata information of the data source, where the metadata information includes at least one of the following information: data structure information, data metric information, and data relationship information;
所述存储器,用于预存储对所述待识别数据进行扫描匹配的规则。The memory is used for pre-storing the rules for scanning and matching the data to be identified.
进一步地,所述预存储的规则中包括:多个匹配规则;Further, the pre-stored rules include: multiple matching rules;
所述存储器,还用于在根据预存储的规则对所述待识别数据进行扫描匹配时,在匹配规则日志中记录匹配日志,所述匹配日志包括:所述多个匹配规则中每一个匹配规则的匹配次数、所述多个匹配规则中每一个匹配规则的匹配成功率;The memory is further configured to record a matching log in a matching rule log when scanning and matching the data to be identified according to a pre-stored rule, where the matching log includes: each matching rule in the multiple matching rules The number of matches, the matching success rate of each matching rule in the multiple matching rules;
所述处理器,还用于根据所述匹配日志对所述多个匹配规则的匹配先后顺序进行优化。The processor is further configured to optimize the matching sequence of the multiple matching rules according to the matching log.
进一步地,第一行为所述待识别数据中的任意一行数据,所述处理器,具体用于从所述待识别数据中第一行第一列开始,依次将所述待识别数据中第一行的每一列的字符与知识库中预存储的匹配规则进行扫描匹配,根据匹配结果获得所述待识别数据的数据结构信息,所述待识别数据的数据结构信息包括:所述待识别数据每一列的字段类型。Further, the first row is any row of data in the data to be identified, and the processor is specifically configured to start from the first row and first column of the data to be identified, and sequentially The characters in each column of the row are scanned and matched with the matching rules pre-stored in the knowledge base, and the data structure information of the data to be identified is obtained according to the matching result, and the data structure information of the data to be identified includes: The field type of a column.
进一步地,所述处理器,具体用于:Further, the processor is specifically used for:
将第一字符与知识库中预存储的第一匹配规则进行扫描匹配,所述第一字符为所述待识别数据中第一行第一列的第一个字符;Scanning and matching the first character with the first matching rule pre-stored in the knowledge base, where the first character is the first character in the first row and first column in the data to be identified;
当所述第一字符与所述第一匹配规则中第一预存字符相同时,确定所述待识别数据的第一列的分类为第一分类,根据所述第一行第一列的全部字符的数值范围确定所述第一列的字段类型,所述第一分类包括:数字分类或时间戳分类;When the first character is the same as the first pre-stored character in the first matching rule, it is determined that the classification of the first column of the data to be recognized is the first classification, according to all the characters in the first row and the first column The numerical range of the first column determines the field type of the first column, and the first classification includes: digital classification or timestamp classification;
当所述第一字符与所述第一匹配规则中第一预存字符不同时,将所述第一字符与知识库中预存储的第二匹配规则进行扫描匹配;When the first character is different from the first pre-stored character in the first matching rule, scan and match the first character with the second matching rule pre-stored in the knowledge base;
当所述第一字符与所述第二匹配规则中第二预存字符相同时,确定所述待识别数据的第一列的分类为第二分类,根据所述第一行第一列的全部字符的格式和字符长度确定所述第一列的字段类型,所述第二分类包括:字符分类或者日期分类;When the first character is the same as the second pre-stored character in the second matching rule, it is determined that the classification of the first column of the data to be recognized is the second classification, according to all the characters in the first row and the first column The format and character length of the first column determine the field type of the first column, and the second classification includes: character classification or date classification;
当所述第一字符与所述第二匹配规则中第二预存字符不同时,将所述第一字符与知识库中预存储的第三匹配规则进行扫描匹配;When the first character is different from the second pre-stored character in the second matching rule, scan and match the first character with the third matching rule pre-stored in the knowledge base;
当所述第一字符与所述第三符匹配规则中第三预存字符相同时,确定所述待识别数据的第一列的分类为复杂分类,根据所述第一行第一列的全部字符中的符号和字符组合形式确定所述第一列的字段类型。When the first character is the same as the third pre-stored character in the third character matching rule, it is determined that the classification of the first column of the data to be recognized is a complex classification, according to all the characters in the first row and the first column The combination of symbols and characters in determines the field type of the first column.
进一步地,所述处理器,还用于若所述待识别数据中第二行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得的第一列的字段类型与所述待识别数据中第一行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得第一列的字段类型不同,且匹配顺序在后的第一列的字段类型包括的范围大于匹配顺序在前的第一列的字段类型包括的范围时,将匹配顺序在前的第一列的字段类型修改为匹配顺序在后的第一列的字段类型,其中,所述待识别数据中第二行包括:与所述待识别数据中第一行不同的行数据。Further, the processor is further configured to match the field type of the first column obtained by scanning and matching the characters in the second row and the first column of the data to be identified with the matching rules pre-stored in the knowledge base and the to-be-identified data. The characters in the first row and the first column of the identification data are scanned and matched with the matching rules pre-stored in the knowledge base to obtain a field type that is different in the first column, and the field type of the first column after the matching order includes a larger range than the matching order. When the field type of the previous first column includes the range, modify the field type of the first column in the matching order to the field type of the first column in the matching order. The row includes: row data different from the first row in the data to be identified.
进一步地,所述处理器,具体用于根据预存储的规则对所述待识别数据进行全表扫描匹配,获得所述数据源的数据度量信息,还用于根据预存储的规则确定所述待识别数据中每两列的相关性,确定所述数据源的数据关系信息。Further, the processor is specifically configured to perform full table scan matching on the data to be identified according to pre-stored rules, obtain data measurement information of the data source, and be further configured to determine the to-be-identified data according to the pre-stored rules. Identify the correlation of every two columns in the data, and determine the data relationship information of the data source.
进一步地,所述处理器,还用于若根据预存储的规则对所述待识别数据进行扫描匹配不能确定所述数据源的元数据信息,提供类型建议,以使得通过人工判断所述数据源的元数据信息,并根据人工判断的结果完善所述预存储的规则。Further, the processor is also configured to provide a type suggestion if the metadata information of the data source cannot be determined by scanning and matching the data to be identified according to the pre-stored rules, so that the data source can be manually judged. metadata information, and improve the pre-stored rules according to the results of human judgment.
进一步地,所述存储器,用于对所述元数据信息进行存储,以使得根据所述元数据信息进行对外服务。Further, the memory is configured to store the metadata information, so that external services are performed according to the metadata information.
本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,该计算机程序被处理器执行时实现上述的元数据信息获取方法。An embodiment of the present invention further provides a computer-readable storage medium, where a computer program is stored in the computer-readable storage medium, and when the computer program is executed by a processor, the foregoing method for obtaining metadata information is implemented.
本发明实施例还提供了一种元数据信息获取系统,所述系统包括处理器和存储器;其中,An embodiment of the present invention further provides a system for obtaining metadata information, the system includes a processor and a memory; wherein,
所述存储器,用于存储能够在所述处理器上运行的计算机程序;the memory for storing a computer program executable on the processor;
所述处理器,用于运行所述计算机程序时执行上述元数据信息获取方法的步骤。The processor is configured to execute the steps of the above method for acquiring metadata information when running the computer program.
本发明实施例提供的元数据信息获取方法、系统和计算机可读存储介质,可以针对大数据特点,面对来自不同系统,未知结构的数据源,通过预存储的规则扫描匹配获取如数据字段类型、度量、数据关系等信息,节省了时间,提高了效率。The method, system, and computer-readable storage medium for obtaining metadata information provided by the embodiments of the present invention can, in view of the characteristics of big data, face data sources from different systems and unknown structures, and scan and match pre-stored rules to obtain, for example, data field types. , metrics, data relationships and other information, saving time and improving efficiency.
附图说明Description of drawings
图1为本发明实施例提供的元数据信息获取方法流程示意图;1 is a schematic flowchart of a method for obtaining metadata information according to an embodiment of the present invention;
图2为本发明实施例提供的元数据信息获取系统设置位置示意图;FIG. 2 is a schematic diagram of a setting position of a system for obtaining metadata information provided by an embodiment of the present invention;
图3为本发明实施例提供的元数据信息获取包括的识别类型示例图;3 is an example diagram of identification types included in metadata information acquisition provided by an embodiment of the present invention;
图4为本发明实施例提供的待识别数据解析匹配示例图;FIG. 4 is an example diagram of parsing and matching of to-be-identified data provided by an embodiment of the present invention;
图5为本发明实施例提供的字段解析流程示例图;FIG. 5 is an example diagram of a field parsing process provided by an embodiment of the present invention;
图6为本发明实施例提供的字符匹配示例图一;FIG. 6 is an example diagram 1 of character matching provided by an embodiment of the present invention;
图7为本发明实施例提供的字符匹配示例图二;FIG. 7 is an example FIG. 2 of character matching provided by an embodiment of the present invention;
图8为本发明实施例提供的字符匹配示例图三;FIG. 8 is an example FIG. 3 of character matching provided by an embodiment of the present invention;
图9为本发明实施例提供的元数据信息获取系统结构示意图。FIG. 9 is a schematic structural diagram of a system for obtaining metadata information provided by an embodiment of the present invention.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention.
本发明实施例提供一种元数据信息获取方法,如图1所示,该方法可以包括:An embodiment of the present invention provides a method for obtaining metadata information. As shown in FIG. 1 , the method may include:
步骤101、根据获取的数据源生成待识别数据。Step 101: Generate data to be identified according to the acquired data source.
其中,所述待识别数据包括:多个行数据和多个列数据。Wherein, the data to be identified includes: a plurality of row data and a plurality of column data.
本发明实施例提供的元数据信息获取方法的执行主体可以为元数据信息获取系统,该元数据信息获取系统可以设置在如图2所示的数据采集模块,即可以在数据采集和装载过程中,实现元数据信息的获取,这样,不用增加新的数据处理步骤,可以部署在数据采集过程中,从而节省了时间,提高了效率。The execution body of the method for acquiring metadata information provided by the embodiment of the present invention may be a system for acquiring metadata information, and the system for acquiring metadata information may be set in the data acquisition module as shown in FIG. 2 , that is, in the process of data acquisition and loading. , to achieve the acquisition of metadata information, so that it can be deployed in the data collection process without adding new data processing steps, thereby saving time and improving efficiency.
本发明实施例提供的方法可以在采集数据的过程中获取数据源的元数据信息,这里,获取的数据源可以是外部数据源,也可以是内部数据源,内部数据源是指已经读取到元数据采集系统中的数据,外部数据源是指未读取到元数据采集系统中的数据,对于外部数据源在进行元数据信息获取时需要先将该数据源读取到元数据信息获取系统中。该元数据信息获取方法可以的应用于非数据库中的数据源的元数据信息的获取。The method provided by this embodiment of the present invention can acquire metadata information of a data source in the process of collecting data. Here, the acquired data source may be an external data source or an internal data source, and the internal data source refers to the data that has been read. For the data in the metadata collection system, the external data source refers to the data that has not been read into the metadata collection system. For the external data source, when obtaining metadata information, the data source needs to be read into the metadata information acquisition system first. middle. The metadata information acquisition method can be applied to the acquisition of metadata information of a data source other than a database.
这里,获取的数据源可以是来自不同系统,未知结构的数据源。元数据信息获取系统在读取数据源的过程中,将该读取的数据源转化为以行和列数据排列的待识别数据,也可以理解为,该待识别数据以表格的形式存在,该表格由多个行和多个列组成,即该待识别数据包括多个行数据和多个列数据。Here, the acquired data source can be a data source with unknown structure from different systems. In the process of reading the data source, the metadata information acquisition system converts the read data source into data to be identified arranged in row and column data. It can also be understood that the data to be identified exists in the form of a table. The table consists of multiple rows and multiple columns, that is, the data to be identified includes multiple row data and multiple column data.
步骤102、根据预存储的规则对所述待识别数据进行扫描匹配,获得所述数据源的元数据信息。Step 102: Scan and match the to-be-identified data according to a pre-stored rule to obtain metadata information of the data source.
其中,元数据信息包括至少一种以下信息:数据结构信息、数据度量信息和数据关系信息。The metadata information includes at least one of the following information: data structure information, data measurement information, and data relationship information.
这里,元数据信息(Metadata)是描述其它数据的数据(data about other data),或者说是用于提供某种资源的有关信息的结构数据(structured data)。元数据是描述信息资源或数据等对象的数据,其使用目的在于:识别资源;评价资源;追踪资源在使用过程中的变化;实现简单高效地管理大量网络化数据;实现信息资源的有效发现、查找、一体化组织和对使用资源的有效管理。元数据是信息共享和交换的基础和前提,记录了所有的数据的结构、大小、什么时间创建、什么时间消亡、被那些人使用、数据表之间的关系、数据流转关系等等。元数据主要包括数据结构、数据流、数据度量、数据模型、数据访问日志、数据业务描述等,其中,数据结构用于描述数据基本信息。Here, the metadata information (Metadata) is data describing other data (data about other data), or structured data (structured data) for providing information about a certain resource. Metadata is data that describes objects such as information resources or data, and its purpose is to: identify resources; evaluate resources; track changes in resources during use; achieve simple and efficient management of large amounts of networked data; Find, integrate and organize and efficiently manage usage resources. Metadata is the basis and premise of information sharing and exchange. It records the structure and size of all data, when it was created, when it died, when it was used by those people, the relationship between data tables, the relationship between data flow, and so on. Metadata mainly includes data structure, data flow, data measurement, data model, data access log, data service description, etc., among which, the data structure is used to describe the basic information of the data.
基于元数据不同的应用可以将元数据分成:数据结构、数据流、数据部署、质量度量、度量逻辑关系、ETL(Extract-Transform-Load)过程、数据集快照、星型模式元数据、报表语义层、数据访问日志、质量稽核日志、数据装载日志等。其中,数据结构,指数据集的名称、关系、字段、约束等;数据部署,指数据集的物理位置;数据流,指数据集之间的流程依赖关系(非参照依赖),包括数据集到另一个数据集的规则;质量度量,指数据集上可以计算的度量;度量逻辑关系,指数据集度量之间的逻辑运算关系;ETL过程,指过程运行的顺序,并行、串行,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程;数据集快照,指一个时间点上,数据在所有数据集上的分布情况;星型模式元数据,指事实表、维度、属性、层次等;报表语义层:指报表指标的规则、过滤条件物理名称和业务名称的对应;数据访问日志,指哪些数据何时被何人访问;质量稽核日志,即何时、何度量被稽核,其结果;数据装载日志,即哪些数据何时被何人装载。Based on different applications of metadata, metadata can be divided into: data structure, data flow, data deployment, quality measurement, measurement logical relationship, ETL (Extract-Transform-Load) process, data set snapshot, star schema metadata, report semantics Layers, data access logs, quality audit logs, data loading logs, etc. Among them, data structure refers to the name, relationship, field, constraint, etc. of the dataset; data deployment refers to the physical location of the dataset; data flow refers to the process dependency (non-reference dependency) between datasets, including the dataset to Rules for another dataset; quality metrics, which refer to computable metrics on datasets; metric logic relationships, which refer to the logical operation relationships between dataset metrics; ETL processes, which refer to the order in which the processes run, parallel and serial, used to Describe the process of extracting, transforming, and loading data from the source to the destination; data set snapshots refer to the distribution of data in all data sets at a point in time; star schema elements Data refers to fact tables, dimensions, attributes, levels, etc.; report semantic layer: refers to the rules of report indicators, the correspondence between physical names of filter conditions and business names; data access log refers to which data is accessed by whom and when; quality audit log, That is, when and what metrics are audited, and the results; data loading logs, that is, which data is loaded by whom and when.
具体的,元数据信息获取系统可以通过全表扫描法和/或部分扫描法获取未知数据源的元数据信息,包括数据字段名称、数据类型、归属用户、创建时间、修改时间、表关系、约束、质量度量。Specifically, the metadata information acquisition system can acquire metadata information of unknown data sources through a full table scan method and/or a partial scan method, including data field names, data types, attributable users, creation time, modification time, table relationships, constraints , quality measurement.
其中,全表扫描法扫描待识别数据中的全部数据,该方法可以获取更多的元数据信息,如数值类型的数据度量,包括数据最大最小值,均值,方差等。部分扫描法只需要判断待识别数据中前top行(例如500行)即可得到结果,例如对待识别数据的前500行进行类型的判断,但是无法得到数据度量。Among them, the full table scan method scans all the data in the data to be identified, and this method can obtain more metadata information, such as numerical data metrics, including data maximum and minimum values, mean, variance, etc. The partial scanning method only needs to judge the top row (for example, 500 rows) of the data to be identified to obtain the result. For example, the type of the first 500 rows of the data to be identified is judged, but the data measurement cannot be obtained.
示例性的,如图3所示,元数据信息获取系统对大数据的元数据信息获取主要可以包括:数据字段识别,即识别数据字段类型;数据度量识别,即识别数据各种度量,如均值、最大最小值等,针对数值型字段;数据关系识别,即识别数据表之间的关联关系,其中,表关系包括:一对一、一对多、多对多;关联字段建议,即在引入新数据源的时候,给出该表与其他表可能关联的字段建议;数据约束识别,即实现对数据约束的识别,识别的约束包括:非空、唯一约束unique、主键约束、外键约束、校验约束等;知识库,即存储了在数据关系识别、字段识别、关联字段建议等所需要的规则及知识。Exemplarily, as shown in Figure 3, the metadata information acquisition system for big data may mainly include: data field identification, that is, identifying data field types; data metric identification, that is, identifying various data metrics, such as mean value. , maximum and minimum values, etc., for numerical fields; data relationship identification, that is, to identify the relationship between data tables, among which table relationships include: one-to-one, one-to-many, many-to-many; When a new data source is used, it will give suggestions on the fields that may be associated with the table and other tables; data constraint identification, that is, to realize the identification of data constraints, the identified constraints include: non-null, unique constraint unique, primary key constraint, foreign key constraint, Verification constraints, etc.; knowledge base, which stores the rules and knowledge required for data relationship identification, field identification, and associated field suggestions.
一种可能的实现方式中,对所述待识别数据的第一行进行解析,获得所述数据源的数据结构信息,包括:In a possible implementation manner, the first line of the data to be identified is parsed to obtain the data structure information of the data source, including:
从所述待识别数据中第一行第一列开始,依次将所述待识别数据中第一行的每一列的字符与知识库中预存储的匹配规则进行扫描匹配,根据匹配结果获得所述待识别数据的数据结构信息,所述待识别数据的数据结构信息包括:所述待识别数据每一列的字段类型。Starting from the first row and the first column in the data to be identified, scan and match the characters in each column of the first row in the data to be identified with the matching rules pre-stored in the knowledge base, and obtain the The data structure information of the data to be identified, the data structure information of the data to be identified includes: the field type of each column of the data to be identified.
一种可能的实现方式中,将所述待识别数据中第一行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得所述待识别数据第一列的字段类型,包括:In a possible implementation manner, the characters in the first row and first column of the data to be identified are scanned and matched with matching rules pre-stored in the knowledge base to obtain the field type of the first column of the data to be identified, including:
将第一字符与知识库中预存储的第一匹配规则进行扫描匹配,所述第一字符为所述待识别数据中第一行第一列的第一个字符;Scanning and matching the first character with the first matching rule pre-stored in the knowledge base, where the first character is the first character in the first row and first column in the data to be identified;
当所述第一字符与所述第一匹配规则中第一预存字符相同时,确定所述待识别数据的第一列的分类为第一分类,根据所述第一行第一列的全部字符的数值范围确定所述第一列的字段类型,所述第一分类包括:数字分类或时间戳分类;When the first character is the same as the first pre-stored character in the first matching rule, it is determined that the classification of the first column of the data to be recognized is the first classification, according to all the characters in the first row and the first column The numerical range of the first column determines the field type of the first column, and the first classification includes: digital classification or timestamp classification;
当所述第一字符与所述第一匹配规则中第一预存字符不同时,将所述第一字符与知识库中预存储的第二匹配规则进行扫描匹配;When the first character is different from the first pre-stored character in the first matching rule, scan and match the first character with the second matching rule pre-stored in the knowledge base;
当所述第一字符与所述第二匹配规则中第二预存字符相同时,确定所述待识别数据的第一列的分类为第二分类,根据所述第一行第一列的全部字符的格式和字符长度确定所述第一列的字段类型,所述第二分类包括:字符分类或者日期分类;When the first character is the same as the second pre-stored character in the second matching rule, it is determined that the classification of the first column of the data to be recognized is the second classification, according to all the characters in the first row and the first column The format and character length of the first column determine the field type of the first column, and the second classification includes: character classification or date classification;
当所述第一字符与所述第二匹配规则中第二预存字符不同时,将所述第一字符与知识库中预存储的第三匹配规则进行扫描匹配;When the first character is different from the second pre-stored character in the second matching rule, scan and match the first character with the third matching rule pre-stored in the knowledge base;
当所述第一字符与所述第三符匹配规则中第三预存字符相同时,确定所述待识别数据的第一列的分类为复杂分类,根据所述第一行第一列的全部字符中的符号和字符组合形式确定所述第一列的字段类型。When the first character is the same as the third pre-stored character in the third character matching rule, it is determined that the classification of the first column of the data to be recognized is a complex classification, according to all the characters in the first row and the first column The combination of symbols and characters in determines the field type of the first column.
具体的,数据字段可以自动识别数字的类型,即字段类型的识别可以首先针对每个数字进行解析,其次通过一个暂存计算空间来记录该列所有字符类型,具体流程如图4所示。其中,字符类型暂存1,字符类型暂存2,字符类型暂存n分别包括数组。Specifically, the data field can automatically identify the type of the number, that is, the identification of the field type can first analyze each number, and then record all the character types of the column through a temporary storage calculation space. The specific process is shown in Figure 4. Among them, the character type temporary storage 1, the character type temporary storage 2, and the character type temporary storage n respectively include arrays.
由于数字类型之间是有规则的,例如,10行中,9行都是int,但一行是Float,则应该整个列判断为Float型;所以数字类型覆盖关系如下:Since there are rules between numeric types, for example, in 10 rows, 9 rows are int, but one row is Float, then the entire column should be judged as Float type; so the coverage relationship of numeric types is as follows:
TINYINT---SMALLINT---INT-----BIGINT-----FLOAT-----DOUBLE------DEICIMALTINYINT---SMALLINT---INT-----BIGINT-----FLOAT-----DOUBLE------DEICIMAL
其中,时间戳类型为固定位数,例如,11位或者13位,如果某个整型INT型所有列该字段均为固定位数,可考虑为其他类型:字符需要记录长度,长度固定为CHAR,不固定位String和VARCHAR,例如表1中所示的类型。只要出现不同位数,则可记录为String和VARCHAR,不超过65534则为VARCHAR。其中,对于特殊类型可以直接匹配得到结果。Among them, the timestamp type is a fixed number of digits, for example, 11 digits or 13 digits. If all columns of an integer type INT type have fixed digits, they can be considered as other types: characters require record length, and the length is fixed to CHAR , non-fixed-bit String and VARCHAR, such as the types shown in Table 1. As long as there are different digits, it can be recorded as String and VARCHAR, and it is VARCHAR if it does not exceed 65534. Among them, for special types, the result can be directly matched.
表1Table 1
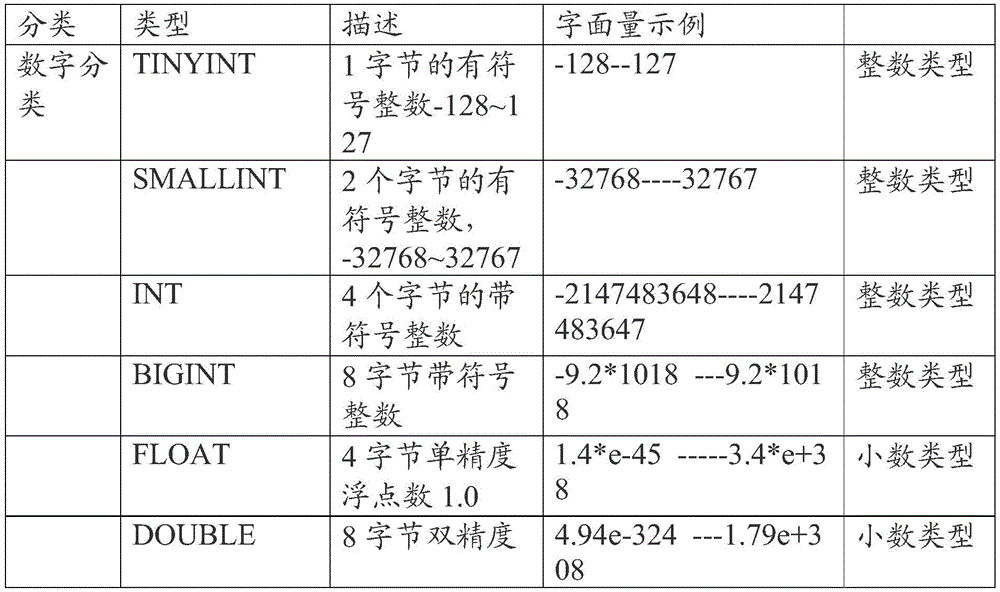
具体的,在字符匹配的过程中都可以用覆盖关系进行判断,即每行识别后刷新字段类型暂存。其中,覆盖关系为,一旦出现更晚判断的类型,则以后判断的规则类型为准。例如,某个字段,早先判断均为smallint型,一旦出现int则整个字段记录为int型。Specifically, in the process of character matching, the coverage relationship can be used for judgment, that is, the temporary storage of field types is refreshed after each line is recognized. Wherein, the coverage relationship is that, once a later-judged type appears, the rule type to be judged later shall prevail. For example, a certain field was previously judged to be of smallint type, and once int appears, the entire field is recorded as int type.
示例性的,以tinyint,smallint,int,bigint为例,这四个类型的判断是有先后顺序的,一个字段一旦出现过BIGINT型一次之后,整个字段都需定义为BIGINT,同样的一旦出现double类型后,整个字段不可回退至int等类型。Exemplarily, taking tinyint, smallint, int, and bigint as examples, the judgments of these four types are in order. Once a field appears BIGINT once, the entire field needs to be defined as BIGINT. Similarly, once double appears After the type, the entire field cannot fall back to types such as int.
示例性的,以如何具体某个字段的识别方式进行说明。首先区分字段的分类,通过第一个字符可以识别时间类型、数字类型、复杂类型等,匹配流程如图5所示,取待识别数据中任意一行任意一列的字段中的第一个字符,判断该第一个字符是否是负号或数字,当该第一个字符是负号-或数字时,该任意一行任意一列的字段为数字类型或时间戳类型,当该第一个字符不是负号-或数字时,判断该第一个字符是否是双引号“或单引号‘,若是,则确定该任意一行任意一列的字段为字符类型或日期类型,若不是,判断该第一个字符是否是括号(,若是,则确定该任意一行任意一列的字段为复杂类型,若不是,则归为其它,通过人工进行判断。Exemplarily, how to identify a specific field is described. First distinguish the classification of the fields. The first character can identify the time type, number type, complex type, etc. The matching process is shown in Figure 5. Take the first character in the field of any row and any column in the data to be identified, and judge Whether the first character is a negative sign or a number, when the first character is a negative sign - or a number, the field of any row or column is a numeric type or a timestamp type, when the first character is not a negative sign - or numbers, determine whether the first character is a double quotation mark "or single quotation mark', if so, determine whether the field of any row or column is a character type or a date type, if not, determine whether the first character is a Brackets (, if it is, it is determined that the field of any row and any column is a complex type, if not, it is classified as other, and judged manually.
示例性的,数字/时间戳类型匹配流程,如图6所示,判断当前匹配的字符是否有小数点,如果有小数点,进一步通过该字符属于的取值范围判断该字符是Float型还是Double,如果没有小数点,再通过该字符属于的取值范围判断该字符是TINYINT还是SMALLINT、INT或BIGINT中的一种,如果都不是,则归为其它,通过人工进行判断。Exemplarily, the number/timestamp type matching process, as shown in Figure 6, judges whether the currently matched character has a decimal point, and if there is a decimal point, further judges whether the character is a Float type or a Double according to the value range to which the character belongs. If there is no decimal point, then judge whether the character is TINYINT or one of SMALLINT, INT or BIGINT according to the value range that the character belongs to.
示例性的,字符类型/日期类型匹配流程,如图7所示,判断当前匹配的字符是否符合日期的格式YYYY-MM-DD,若果符合日期,确定该字符类型为日期,如果不符合日期,获取该字符的长度,通过该字符的长度确定该字符的类型。Exemplarily, the character type/date type matching process, as shown in Figure 7, determines whether the currently matched character conforms to the date format YYYY-MM-DD, and if it conforms to the date, determine that the character type is a date, and if it does not conform to the date , get the length of the character, and determine the type of the character by the length of the character.
示例性的,复杂类型匹配流程:如图8所示,判断当前匹配的字符逗号间隔是否都是同类型,如果是,则确定该字符为ARRAY型,如果不是,判断当前匹配的字符逗号间隔是否是ABAB型,如果是,则确定该字符为MAP型,如果不是,判断当前匹配的字符是否是各种不同类型,如果是,则确定该字符为UNION型,如果不是,判断当前匹配的字符是否为多括号()嵌套,如果是,则确定该字符为STRUCT型,如果不是,则归为其它,通过人工进行判断。Exemplary, complex type matching process: As shown in Figure 8, it is judged whether the currently matched characters and commas are of the same type. If so, it is determined that the character is of type ARRAY. If not, it is judged whether the currently matched characters are separated by commas. It is ABAB type. If it is, it is determined that the character is of MAP type. If it is not, it is determined whether the current matching character is of various types. If it is, it is determined that the character is of UNION type. If not, it is determined whether the current matching character is not. It is nested with multiple brackets (), if it is, it is determined that the character is of STRUCT type, if not, it is classified as other, and it is judged manually.
可选地,在将所述待识别数据中第一行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得所述待识别数据第一列的字段类型之后,还包括:Optionally, after scanning and matching the characters in the first row and the first column of the data to be identified with the matching rules pre-stored in the knowledge base to obtain the field type of the first column of the data to be identified, the method further includes:
若所述待识别数据中第二行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得的第一列的字段类型与所述待识别数据中第一行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得第一列的字段类型不同,且匹配顺序在后的第一列的字段类型包括的范围大于匹配顺序在前的第一列的字段类型包括的范围时,将匹配顺序在前的第一列的字段类型修改为匹配顺序在后的第一列的字段类型,其中,所述待识别数据中第二行包括:与所述待识别数据中第一行不同的行数据。If the characters in the second row and the first column in the data to be recognized are scanned and matched with the matching rules pre-stored in the knowledge base, the field type in the first column obtained by scanning and matching is the same as the characters in the first row and the first column in the data to be recognized. It is different from the pre-stored matching rules in the knowledge base to scan and match to obtain the field type of the first column, and the field type of the first column after the matching order includes a larger range than the field type of the first column before the matching order. In the range, modify the field type of the first column in the matching order to the field type of the first column in the matching order, wherein the second row in the data to be identified includes: A row of different row data.
具体的,由于待识别数据的每一列的数据类型是相同的,所以对每列第一行数据进行判断后,后续行的值对之前的判断进行修正。例如,某个字段,早先判断均为smallint型,一旦出现int则整个字段记录为int型。Specifically, since the data types of each column of the data to be identified are the same, after the data of the first row of each column is judged, the values of the subsequent rows are used to correct the previous judgment. For example, a certain field was previously judged to be of smallint type, and once int appears, the entire field is recorded as int type.
一种可能的实现方式中,根据预存储的规则对所述待识别数据进行扫描匹配,获得所述数据源的数据度量信息和数据关系信息,可以包括:根据预存储的规则对所述待识别数据进行全表扫描匹配,获得所述数据源的数据度量信息,根据预存储的规则确定所述待识别数据中每两列的相关性,确定所述数据源的数据关系信息。In a possible implementation manner, scanning and matching the data to be identified according to pre-stored rules to obtain data measurement information and data relationship information of the data source may include: The data is scanned and matched in a full table to obtain the data metric information of the data source, and the correlation of every two columns in the to-be-identified data is determined according to the pre-stored rule, and the data relationship information of the data source is determined.
具体的,对于数据度量信息,可以选择全表扫描的方式获取数据度量信息,该数据度量信息可以包括某个字段的最大最小值、均值、方差、求和等等。具体可以通过图2中的元数据获取进行实现。Specifically, for the data measurement information, a full table scan can be selected to obtain the data measurement information, and the data measurement information may include the maximum and minimum values, mean, variance, summation, and the like of a certain field. Specifically, it can be implemented through the metadata acquisition in FIG. 2 .
具体的,元数据信息获取系统可以根据预存储的规则自动识别非常相似的两列数据,表明这两列是可以进行关联扩容价值的。其中,预存储的规则中识别数据相关性的规则可以为皮尔逊相关系数法(Pearson Correlation Coefficient)、文本相似度算法,还可以为其它计算相关性的规则,本发明实施例对此不做限定。Specifically, the metadata information acquisition system can automatically identify two columns of data that are very similar according to pre-stored rules, indicating that the two columns can be correlated and expand the value. The rules for identifying data correlation in the pre-stored rules may be a Pearson Correlation Coefficient method, a text similarity algorithm, or other rules for calculating correlations, which are not limited in this embodiment of the present invention .
示例性的,对于数字可以采用皮尔逊相关系数法,皮尔逊相关系数可以衡量两列数据的相关性。Exemplarily, the Pearson correlation coefficient method can be used for numbers, and the Pearson correlation coefficient can measure the correlation of two columns of data.
皮尔逊相关系数的计算公式为: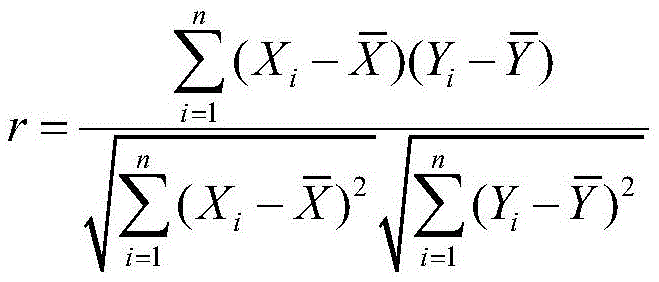
皮尔逊相关的简单分类包括:极强相关、强相关、中等程度相关、弱相关、极弱相关或无相关。当r在0.8-1.0之间时为极强相关,当r在0.6-0.8之间时为强相关,当r在0.4-0.6之间时为中等程度相关,当r在0.2-0.4之间时为弱相关,当r在0.0-0.2之间时为极弱相关或无相关。Simple classifications of Pearson correlation include: very strong correlation, strong correlation, moderate correlation, weak correlation, very weak correlation, or no correlation. Very strong correlation when r is between 0.8-1.0, strong correlation when r is between 0.6-0.8, moderate correlation when r is between 0.4-0.6, and moderate correlation when r is between 0.2-0.4 It is a weak correlation, and when r is between 0.0 and 0.2, it is a very weak correlation or no correlation.
对于极强相关的列,可以作为关联列推荐,即关联字段建议,说明这是两列非常相似的数据,可进行关联。For highly correlated columns, they can be recommended as associated columns, that is, associated field recommendations, indicating that these are two columns of very similar data that can be associated.
示例性的,对于字符类型的数据,可以使用文本相似度算法,进而可以通过向量的计算来获得两列的关系。简单描述如下:Exemplarily, for character type data, a text similarity algorithm can be used, and then the relationship between two columns can be obtained through vector calculation. A brief description is as follows:
第一步,统计列A和列B所有出现的词及词频,生成向量;The first step is to count all the words and word frequencies in column A and column B to generate a vector;
第二步,计算列A和列B的余弦距离,这个值越接近1,表明两列越相似;The second step is to calculate the cosine distance between column A and column B. The closer the value is to 1, the more similar the two columns are;
例如,列A:浙江,上海,浙江,山东,江苏For example, column A: Zhejiang, Shanghai, Zhejiang, Shandong, Jiangsu
列B:北京,上海,浙江,浙江,山东Column B: Beijing, Shanghai, Zhejiang, Zhejiang, Shandong
生成向量为:A={浙江2,上海1,山东1,江苏1,北京,0}The generated vector is: A={Zhejiang 2, Shanghai 1, Shandong 1, Jiangsu 1, Beijing, 0}
B={浙江2,上海1,山东1,江苏0,北京1}B={Zhejiang 2, Shanghai 1, Shandong 1, Jiangsu 0, Beijing 1}
计算{2,1,1,1,0}和{2,1,1,0,1}之间的余弦相似度,可以获得这两列的相似度。Calculate the cosine similarity between {2, 1, 1, 1, 0} and {2, 1, 1, 0, 1} to get the similarity of these two columns.
进一步地,上述元数据信息获取方法还可以包括:若根据预存储的规则对所述待识别数据进行扫描匹配不能确定所述数据源的元数据信息,提供类型建议,以使得通过人工判断所述数据源的元数据信息,并根据人工判断的结果完善预存储的规则。Further, the above-mentioned method for obtaining metadata information may further include: if the metadata information of the data source cannot be determined by scanning and matching the data to be identified according to pre-stored rules, providing a type suggestion, so that the manual judgment of the metadata information of the data source, and improve the pre-stored rules according to the results of human judgment.
具体的,元数据信息获取系统可以针对不同数据源情况根据预存储的规则给出元数据信息,但是,如果依据预存储的规则不能确认结果的情况,可以给出可能类型建议,由人工进行审核确认,待人工审核确认后,可以自动学习完善及优化规则知识库。Specifically, the metadata information acquisition system can provide metadata information according to pre-stored rules for different data sources. However, if the result cannot be confirmed according to the pre-stored rules, it can provide possible types of suggestions, which can be reviewed manually. Confirmation, after manual review and confirmation, can automatically learn to improve and optimize the rule knowledge base.
示例性的,对于无法匹配得到的类型,如图5、6、8所示,所有匹配到其它类型的数据类型,则由人工进行判断,待人工判断后,累计可作为规则完善的输入,由元数据信息获取系统完善规则知识库。Exemplarily, for the types that cannot be matched, as shown in Figures 5, 6, and 8, all data types that match other types are judged manually. After manual judgment, the accumulation can be used as the input for perfect rules. The metadata information acquisition system improves the rule knowledge base.
进一步地,所述预存储的规则中包括:多个匹配规则;上述元数据信息获取方法还包括:在根据预存储的规则对所述待识别数据进行扫描匹配时,在匹配规则日志中记录匹配日志,所述匹配日志包括:所述多个匹配规则中每一个匹配规则的匹配次数、所述多个匹配规则中每一个匹配规则的匹配成功率;根据所述匹配日志对所述多个匹配规则的匹配先后顺序进行优化。Further, the pre-stored rules include: a plurality of matching rules; the above-mentioned metadata information acquisition method further includes: when scanning and matching the data to be identified according to the pre-stored rules, recording the matching in a matching rule log log, the matching log includes: the matching times of each matching rule in the multiple matching rules, the matching success rate of each matching rule in the multiple matching rules; The matching order of the rules is optimized.
具体的,在自动匹配数据类型过程中,匹配规则的先后顺序是可以持续优化的,这与具体数据情况有关,可以在匹配规则日志中记录匹配日志,根据匹配次数及成功率情况,对规则匹配的先后顺序进行优化。Specifically, in the process of automatically matching data types, the sequence of matching rules can be continuously optimized, which is related to the specific data situation. The matching log can be recorded in the matching rule log, and the rules can be matched according to the number of matches and the success rate. order of optimization.
示例性的,如图5所示,匹配规则是:步骤1、先匹配是否数字/时间戳;步骤2、再匹配是否字符类型/日期类型;步骤3、最后匹配复杂类型。在针对某列进行预测过程中,如果前面数据均为字符类型时,则可以跳过对步骤1是否是负号-或数字这个匹配过程,直接进入步骤2的匹配过程,即步骤1、步骤2、步骤3匹配的先后顺序不限于图5所示,可以根据实际匹配过程中的情况进行选择,可以是跳过步骤1直接进入步骤2,也可以是跳过步骤1和步骤2直接进入步骤3。Exemplarily, as shown in FIG. 5 , the matching rules are: Step 1, firstly match whether the number/time stamp; Step 2, then match whether the character type/date type; Step 3, finally match the complex type. In the process of predicting a certain column, if the previous data are all character types, you can skip the matching process of whether step 1 is a negative sign - or a number, and directly enter the matching process of step 2, that is, step 1, step 2 , The sequence of matching in step 3 is not limited to that shown in Figure 5, it can be selected according to the actual matching process, it can be skip step 1 and go directly to step 2, or skip step 1 and step 2 and go directly to step 3 .
同样的进入某个具体匹配流程后,如图6、7、8所示,也可以进一步优化匹配规则的先后。如图8所示,以复杂类型匹配流程为例,如果前面数据判断为MAP后则可以跳过第一步ARRAY判断的环节,从而,可以进行匹配先后性能的优化。Similarly, after entering a specific matching process, as shown in Figures 6, 7, and 8, the sequence of matching rules can also be further optimized. As shown in FIG. 8 , taking the complex type matching process as an example, if the previous data is judged to be MAP, the first step of ARRAY judgment can be skipped, so that the matching sequence performance can be optimized.
进一步地,在所述获得所述数据源的元数据信息之后,上述元数据信息获取方法还包括:对所述元数据信息进行存储,以使得根据所述元数据信息进行对外服务。Further, after the metadata information of the data source is obtained, the method for obtaining the metadata information further includes: storing the metadata information, so that external services are performed according to the metadata information.
具体的,在通过上述方法获取未知数据源的元数据信息后,可以对该元数据信息进行存储,以便对外提供服务,即后续在业务使用时,可以对元数据进行查询和使用。其中,存储格式可采用结构化信息也可采用文件等多种方式,本发明实施例对此不做限定。Specifically, after obtaining the metadata information of the unknown data source through the above method, the metadata information can be stored to provide external services, that is, the metadata can be queried and used in subsequent business use. The storage format may be structured information or a file or other manners, which are not limited in this embodiment of the present invention.
本发明实施例提供的元数据获取方法,是针对大数据数据源众多,数据结构不一问题,给出一种在数据装载过程中,自动获取元数据的方法;可以根据抽样及全部扫描两种方式,获取元数据,及更多元数据信息,如约束、质量度量等;辅助人工判断及规则匹配日志分析,可以实现知识库的完善和性能的优化。The metadata acquisition method provided by the embodiment of the present invention is aimed at the problem of numerous big data data sources and different data structures, and provides a method for automatically acquiring metadata during the data loading process; it can be based on sampling and full scanning. way, obtain metadata, and more metadata information, such as constraints, quality metrics, etc.; assisting manual judgment and rule matching log analysis, can achieve the improvement of the knowledge base and the optimization of performance.
本发明实施例提供的元数据获取方法,可以对未知数据通过数据扫描的方式,自动给出元数据信息,尤其是数据类型,形成元数据,并进行自动学习和优化。现有技术中主要针对传统数据库一些数据操作或者根据定义来抽取元数据,没有涉及根据数据情况自动获取元数据领域,而在混杂的大数据场景中,如何对海量未知数据的识别是本发明实施例提供的元数据信息获取方法解决的问题。The metadata acquisition method provided by the embodiment of the present invention can automatically provide metadata information, especially the data type, for unknown data through data scanning, form metadata, and perform automatic learning and optimization. The prior art mainly focuses on some data operations in traditional databases or extracts metadata according to definitions, and does not involve the field of automatically obtaining metadata according to data conditions. In a mixed big data scenario, how to identify massive unknown data is the implementation of the present invention. The problem solved by the metadata information acquisition method provided by the example.
本发明实施例提供一种元数据信息获取系统90,如图9所示,所述系统包括:处理器901、存储器902、收发器903,其中,An embodiment of the present invention provides a system 90 for obtaining metadata information. As shown in FIG. 9 , the system includes: a processor 901, a memory 902, and a
所述收发器903,用于获取数据源;The
所述处理器901,用于根据获取的数据源生成待识别数据,所述待识别数据包括:多个行数据和多个列数据;还用于根据预存储的规则对所述待识别数据进行扫描匹配,获得所述数据源的元数据信息,所述元数据信息包括至少一种以下信息:数据结构信息、数据度量信息和数据关系信息;The processor 901 is configured to generate data to be identified according to the acquired data source, and the data to be identified includes: multiple row data and multiple column data; and is further configured to perform a process on the to-be-identified data according to pre-stored rules. Scanning and matching to obtain metadata information of the data source, where the metadata information includes at least one of the following information: data structure information, data metric information, and data relationship information;
所述存储器902,用于预存储对所述待识别数据进行扫描匹配的规则。The memory 902 is configured to pre-store the rules for scanning and matching the data to be identified.
进一步地,所述预存储的规则中包括:多个匹配规则;Further, the pre-stored rules include: multiple matching rules;
所述存储器902,还用于在根据预存储的规则对所述待识别数据进行扫描匹配时,在匹配规则日志中记录匹配日志,所述匹配日志包括:所述多个匹配规则中每一个匹配规则的匹配次数、所述多个匹配规则中每一个匹配规则的匹配成功率;The memory 902 is further configured to record a matching log in a matching rule log when scanning and matching the data to be identified according to a pre-stored rule, where the matching log includes: each matching of the multiple matching rules The number of matching rules, and the matching success rate of each matching rule in the multiple matching rules;
所述处理器901,还用于根据所述匹配日志对所述多个匹配规则的匹配先后顺序进行优化。The processor 901 is further configured to optimize the matching sequence of the multiple matching rules according to the matching log.
进一步地,第一行为所述待识别数据中的任意一行数据,所述处理器901,具体用于从所述待识别数据中第一行第一列开始,依次将所述待识别数据中第一行的每一列的字符与知识库中预存储的匹配规则进行扫描匹配,根据匹配结果获得所述待识别数据的数据结构信息,所述待识别数据的数据结构信息包括:所述待识别数据每一列的字段类型。Further, the first row is any row of data in the data to be identified, and the processor 901 is specifically configured to start from the first row and first column of the data to be identified, and sequentially convert the first row of the data to be identified. The characters in each column of a row are scanned and matched with the matching rules pre-stored in the knowledge base, and the data structure information of the data to be recognized is obtained according to the matching result. The data structure information of the data to be recognized includes: the data to be recognized Field type for each column.
进一步地,所述处理器901,具体用于:Further, the processor 901 is specifically used for:
将第一字符与知识库中预存储的第一匹配规则进行扫描匹配,所述第一字符为所述待识别数据中第一行第一列的第一个字符;Scanning and matching the first character with the first matching rule pre-stored in the knowledge base, where the first character is the first character in the first row and first column in the data to be identified;
当所述第一字符与所述第一匹配规则中第一预存字符相同时,确定所述待识别数据的第一列的分类为第一分类,根据所述第一行第一列的全部字符的数值范围确定所述第一列的字段类型,所述第一分类包括:数字分类或时间戳分类;When the first character is the same as the first pre-stored character in the first matching rule, it is determined that the classification of the first column of the data to be recognized is the first classification, according to all the characters in the first row and the first column The numerical range of the first column determines the field type of the first column, and the first classification includes: digital classification or timestamp classification;
当所述第一字符与所述第一匹配规则中第一预存字符不同时,将所述第一字符与知识库中预存储的第二匹配规则进行扫描匹配;When the first character is different from the first pre-stored character in the first matching rule, scan and match the first character with the second matching rule pre-stored in the knowledge base;
当所述第一字符与所述第二匹配规则中第二预存字符相同时,确定所述待识别数据的第一列的分类为第二分类,根据所述第一行第一列的全部字符的格式和字符长度确定所述第一列的字段类型,所述第二分类包括:字符分类或者日期分类;When the first character is the same as the second pre-stored character in the second matching rule, it is determined that the classification of the first column of the data to be recognized is the second classification, according to all the characters in the first row and the first column The format and character length of the first column determine the field type of the first column, and the second classification includes: character classification or date classification;
当所述第一字符与所述第二匹配规则中第二预存字符不同时,将所述第一字符与知识库中预存储的第三匹配规则进行扫描匹配;When the first character is different from the second pre-stored character in the second matching rule, scan and match the first character with the third matching rule pre-stored in the knowledge base;
当所述第一字符与所述第三符匹配规则中第三预存字符相同时,确定所述待识别数据的第一列的分类为复杂分类,根据所述第一行第一列的全部字符中的符号和字符组合形式确定所述第一列的字段类型。When the first character is the same as the third pre-stored character in the third character matching rule, it is determined that the classification of the first column of the data to be recognized is a complex classification, according to all the characters in the first row and the first column The combination of symbols and characters in determines the field type of the first column.
进一步地,所述处理器901,还用于若所述待识别数据中第二行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得的第一列的字段类型与所述待识别数据中第一行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得第一列的字段类型不同,且匹配顺序在后的第一列的字段类型包括的范围大于匹配顺序在前的第一列的字段类型包括的范围时,将匹配顺序在前的第一列的字段类型修改为匹配顺序在后的第一列的字段类型,其中,所述待识别数据中第二行包括:与所述待识别数据中第一行不同的行数据。Further, the processor 901 is further configured to scan and match the characters in the second row and the first column of the to-be-recognized data with the matching rules pre-stored in the knowledge base to obtain the field type of the first column and the The characters in the first row and the first column of the data to be identified are scanned and matched with the matching rules pre-stored in the knowledge base to obtain a different field type in the first column, and the field type in the first column after the matching sequence includes a range greater than the matching range. When the field type of the first column in the previous order includes the range, the field type of the first column in the matching order is modified to the field type of the first column in the matching order. The two rows include: row data different from the first row in the data to be identified.
进一步地,所述处理器901,具体用于根据预存储的规则对所述待识别数据进行全表扫描匹配,获得所述数据源的数据度量信息,还用于根据预存储的规则确定所述待识别数据中每两列的相关性,确定所述数据源的数据关系信息。Further, the processor 901 is specifically configured to perform full table scan matching on the data to be identified according to pre-stored rules, obtain data measurement information of the data source, and be further configured to determine the data according to the pre-stored rules. For the correlation of every two columns in the data to be identified, the data relationship information of the data source is determined.
进一步地,所述处理器901,还用于若根据预存储的规则对所述待识别数据进行扫描匹配不能确定所述数据源的元数据信息,提供类型建议,以使得通过人工判断所述数据源的元数据信息,并根据人工判断的结果完善所述预存储的规则。Further, the processor 901 is further configured to provide type suggestions if the metadata information of the data source cannot be determined by scanning and matching the data to be identified according to pre-stored rules, so that the data can be judged manually. Source metadata information, and improve the pre-stored rules according to the results of human judgment.
进一步地,所述存储器902,用于对所述元数据信息进行存储,收发器903,用于输出存储器902存储的元数据信息,以使得根据收发器903输出的所述元数据信息进行对外服务。Further, the memory 902 is used to store the metadata information, and the
具体的,本发明实施例提供的元数据信息获取系统的理解可以参考上述元数据信息获取方法实施例的说明,本发明实施例在此不再赘述。Specifically, for an understanding of the metadata information obtaining system provided by the embodiment of the present invention, reference may be made to the description of the above-mentioned embodiment of the method for obtaining metadata information, which is not repeated in this embodiment of the present invention.
本发明实施例提供的元数据信息获取系统,可以针对大数据特点,面对来自不同系统,未知结构的数据源,可以在待识别数据的过程中,自动获取如数据字段类型、度量、数据关系等信息,节省了时间,提高了效率。The metadata information acquisition system provided by the embodiment of the present invention can, according to the characteristics of big data, face data sources from different systems and unknown structures, and can automatically acquire data fields such as data field types, metrics, and data relationships in the process of data to be identified. Save time and improve efficiency.
在示例性实施例中,本发明实施例还提供了一种计算机可读存储介质,例如包括计算机程序的存储器902,上述计算机程序可由元数据信息获取系统90中的处理器901执行,以完成前述方法所述步骤。计算机可读存储介质可以是FRAM、ROM、PROM、EPROM、EEPROM、Flash Memory、磁表面存储器、光盘、或CD-ROM等存储器;也可以是包括上述存储器之一或任意组合的各种设备,如移动电话、计算机、平板设备、个人数字助理等。In an exemplary embodiment, an embodiment of the present invention further provides a computer-readable storage medium, such as a memory 902 including a computer program, and the computer program can be executed by the processor 901 in the metadata information acquisition system 90 to complete the foregoing the steps of the method. The computer-readable storage medium can be memory such as FRAM, ROM, PROM, EPROM, EEPROM, Flash Memory, magnetic surface memory, optical disk, or CD-ROM; it can also be various devices including one or any combination of the above-mentioned memories, such as Mobile phones, computers, tablet devices, personal digital assistants, etc.
一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器运行时,执行:A computer-readable storage medium, storing a computer program in the computer-readable storage medium, and when the computer program is run by a processor, executes:
根据获取的数据源生成待识别数据,所述待识别数据包括:多个行数据和多个列数据;Generate the data to be identified according to the acquired data source, the data to be identified includes: a plurality of row data and a plurality of column data;
根据预存储的规则对所述待识别数据进行扫描匹配,获得所述数据源的元数据信息,所述元数据信息包括至少一种以下信息:数据结构信息、数据度量信息和数据关系信息。The data to be identified is scanned and matched according to pre-stored rules to obtain metadata information of the data source, where the metadata information includes at least one of the following information: data structure information, data metric information and data relationship information.
所述预存储的规则中包括:多个匹配规则;所述计算机程序被处理器运行时,还执行:在根据预存储的规则对所述待识别数据进行扫描匹配时,在匹配规则日志中记录匹配日志,所述匹配日志包括:所述多个匹配规则中每一个匹配规则的匹配次数、所述多个匹配规则中每一个匹配规则的匹配成功率;The pre-stored rules include: a plurality of matching rules; when the computer program is run by the processor, it also executes: when the data to be identified is scanned and matched according to the pre-stored rules, record in the matching rule log. a matching log, the matching log includes: the number of matches of each of the multiple matching rules, and the matching success rate of each of the multiple matching rules;
根据所述匹配日志对所述多个匹配规则的匹配先后顺序进行优化。The matching sequence of the multiple matching rules is optimized according to the matching log.
第一行为所述待识别数据中的任意一行数据,所述计算机程序被处理器运行时,还执行:The first row is any row of data in the data to be identified. When the computer program is run by the processor, it also executes:
从所述待识别数据中第一行第一列开始,依次将所述待识别数据中第一行的每一列的字符与知识库中预存储的匹配规则进行扫描匹配,根据匹配结果获得所述待识别数据的数据结构信息,所述待识别数据的数据结构信息包括:所述待识别数据每一列的字段类型。Starting from the first row and the first column in the data to be identified, scan and match the characters in each column of the first row in the data to be identified with the matching rules pre-stored in the knowledge base, and obtain the The data structure information of the data to be identified, the data structure information of the data to be identified includes: the field type of each column of the data to be identified.
所述计算机程序被处理器运行时,还执行:将第一字符与知识库中预存储的第一匹配规则进行扫描匹配,所述第一字符为所述待识别数据中第一行第一列的第一个字符;When the computer program is run by the processor, it also executes: scanning and matching the first character with the first matching rule pre-stored in the knowledge base, where the first character is the first row and the first column in the data to be identified the first character of ;
当所述第一字符与所述第一匹配规则中第一预存字符相同时,确定所述待识别数据的第一列的分类为第一分类,根据所述第一行第一列的全部字符的数值范围确定所述第一列的字段类型,所述第一分类包括:数字分类或时间戳分类;When the first character is the same as the first pre-stored character in the first matching rule, it is determined that the classification of the first column of the data to be recognized is the first classification, according to all the characters in the first row and the first column The numerical range of the first column determines the field type of the first column, and the first classification includes: digital classification or timestamp classification;
当所述第一字符与所述第一匹配规则中第一预存字符不同时,将所述第一字符与知识库中预存储的第二匹配规则进行扫描匹配;When the first character is different from the first pre-stored character in the first matching rule, scan and match the first character with the second matching rule pre-stored in the knowledge base;
当所述第一字符与所述第二匹配规则中第二预存字符相同时,确定所述待识别数据的第一列的分类为第二分类,根据所述第一行第一列的全部字符的格式和字符长度确定所述第一列的字段类型,所述第二分类包括:字符分类或者日期分类;When the first character is the same as the second pre-stored character in the second matching rule, it is determined that the classification of the first column of the data to be recognized is the second classification, according to all the characters in the first row and the first column The format and character length of the first column determine the field type of the first column, and the second classification includes: character classification or date classification;
当所述第一字符与所述第二匹配规则中第二预存字符不同时,将所述第一字符与知识库中预存储的第三匹配规则进行扫描匹配;When the first character is different from the second pre-stored character in the second matching rule, scan and match the first character with the third matching rule pre-stored in the knowledge base;
当所述第一字符与所述第三符匹配规则中第三预存字符相同时,确定所述待识别数据的第一列的分类为复杂分类,根据所述第一行第一列的全部字符中的符号和字符组合形式确定所述第一列的字段类型。When the first character is the same as the third pre-stored character in the third character matching rule, it is determined that the classification of the first column of the data to be recognized is a complex classification, according to all the characters in the first row and the first column The combination of symbols and characters in determines the field type of the first column.
所述计算机程序被处理器运行时,还执行:若所述待识别数据中第二行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得的第一列的字段类型与所述待识别数据中第一行第一列的字符与知识库中预存储的匹配规则进行扫描匹配获得的第一列的字段类型不同,且匹配顺序在后的第一列的字段类型包括的范围大于匹配顺序在前的第一列的字段类型包括的范围时,将匹配顺序在前的第一列的字段类型修改为匹配顺序在后的第一列的字段类型,其中,所述待识别数据中第二行包括:与所述待识别数据中第一行不同的行数据。When the computer program is run by the processor, it also executes: if the character in the second row and the first column in the data to be recognized is scanned and matched with the matching rules pre-stored in the knowledge base, the field type of the first column obtained by scanning and matching is the same as the selected character. The characters in the first row and the first column of the data to be identified are different from the field type of the first column obtained by scanning and matching the pre-stored matching rules in the knowledge base, and the field type of the first column after the matching order includes the range. When it is greater than the range included in the field type of the first column in the matching order, modify the field type of the first column in the matching order to the field type of the first column in the matching order, wherein the data to be identified The second row in the above includes: row data different from the first row in the to-be-identified data.
所述计算机程序被处理器运行时,还执行:根据预存储的规则对所述待识别数据进行扫描匹配,获得所述数据源的数据度量信息和数据关系信息,包括:When the computer program is run by the processor, it also executes: scanning and matching the data to be identified according to pre-stored rules to obtain data measurement information and data relationship information of the data source, including:
根据预存储的规则对所述待识别数据进行全表扫描匹配,获得所述数据源的数据度量信息,根据预存储的规则确定所述待识别数据中每两列的相关性,确定所述数据源的数据关系信息。Perform full table scan matching on the data to be identified according to pre-stored rules to obtain data measurement information of the data source, determine the correlation of every two columns in the data to be identified according to the pre-stored rules, and determine the data Data relationship information for the source.
所述计算机程序被处理器运行时,还执行:若根据预存储的规则对所述待识别数据进行扫描匹配不能确定所述数据源的元数据信息,提供类型建议,以使得通过人工判断所述数据源的元数据信息,并根据人工判断的结果完善所述预存储的规则。When the computer program is run by the processor, it also executes: if the metadata information of the data source cannot be determined by scanning and matching the to-be-identified data according to the pre-stored rules, provide a type suggestion so as to make the manual judgment of the data source. metadata information of the data source, and improve the pre-stored rules according to the results of manual judgment.
所述计算机程序被处理器运行时,还执行:对所述元数据信息进行存储,以使得根据所述元数据信息进行对外服务。When the computer program is run by the processor, it further executes: storing the metadata information, so that external services are performed according to the metadata information.
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。As will be appreciated by one skilled in the art, embodiments of the present invention may be provided as a method, system, or computer program product. Accordingly, the invention may take the form of a hardware embodiment, a software embodiment, or an embodiment combining software and hardware aspects. Furthermore, the present invention may take the form of a computer program product embodied on one or more computer-usable storage media having computer-usable program code embodied therein, including but not limited to disk storage, optical storage, and the like.
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。The present invention is described with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the invention. It will be understood that each process and/or block in the flowchart illustrations and/or block diagrams, and combinations of processes and/or blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to the processor of a general purpose computer, special purpose computer, embedded processor or other programmable data processing device to produce a machine such that the instructions executed by the processor of the computer or other programmable data processing device produce Means for implementing the functions specified in a flow or flow of a flowchart and/or a block or blocks of a block diagram.
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。These computer program instructions may also be stored in a computer-readable memory capable of directing a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory result in an article of manufacture comprising instruction means, the instructions The apparatus implements the functions specified in the flow or flow of the flowcharts and/or the block or blocks of the block diagrams.
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。These computer program instructions can also be loaded on a computer or other programmable data processing device to cause a series of operational steps to be performed on the computer or other programmable device to produce a computer-implemented process such that The instructions provide steps for implementing the functions specified in the flow or blocks of the flowcharts and/or the block or blocks of the block diagrams.
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。The above descriptions are only preferred embodiments of the present invention, and are not intended to limit the protection scope of the present invention.
Claims (16)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710485959.2A CN109117440B (en) | 2017-06-23 | 2017-06-23 | Method, system and computer-readable storage medium for acquiring metadata information |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710485959.2A CN109117440B (en) | 2017-06-23 | 2017-06-23 | Method, system and computer-readable storage medium for acquiring metadata information |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109117440A CN109117440A (en) | 2019-01-01 |
| CN109117440B true CN109117440B (en) | 2021-06-22 |
Family
ID=64733254
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201710485959.2A Active CN109117440B (en) | 2017-06-23 | 2017-06-23 | Method, system and computer-readable storage medium for acquiring metadata information |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109117440B (en) |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110188073A (en) * | 2019-04-19 | 2019-08-30 | 平安科技(深圳)有限公司 | Method, device, storage medium and computer equipment for live body detection log parsing |
| CN110287219B (en) * | 2019-06-28 | 2020-04-07 | 北京九章云极科技有限公司 | Data processing method and system |
| CN112307275A (en) * | 2019-07-30 | 2021-02-02 | 北京国电智深控制技术有限公司 | Information processing method and device and computer storage medium |
| CN113761297B (en) * | 2020-11-10 | 2024-06-18 | 北京沃东天骏信息技术有限公司 | Method and device for determining field relevance in database table |
| CN112434071B (en) * | 2020-12-15 | 2021-07-20 | 北京三维天地科技股份有限公司 | Metadata blood relationship and influence analysis platform based on data map |
| CN112685313B (en) * | 2021-01-04 | 2024-06-04 | 广州品唯软件有限公司 | Mock data updating method, device and computer equipment |
| CN113095624A (en) * | 2021-03-17 | 2021-07-09 | 中国民用航空总局第二研究所 | Method and system for classifying unsafe events of civil aviation airport |
| CN114706979A (en) * | 2022-03-18 | 2022-07-05 | 医惠科技有限公司 | Metadata matching method and system applied to different business systems |
| CN115017256A (en) * | 2022-04-19 | 2022-09-06 | 国网智能电网研究院有限公司 | Power data processing method and device, electronic equipment and storage medium |
| CN114564472B (en) * | 2022-04-26 | 2022-07-05 | 安徽博微广成信息科技有限公司 | Metadata expansion method, storage medium and electronic device |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103902544A (en) * | 2012-12-25 | 2014-07-02 | 中国移动通信集团公司 | Data processing method and system |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8364651B2 (en) * | 2009-08-28 | 2013-01-29 | Optuminsight, Inc. | Apparatus, system, and method for identifying redundancy and consolidation opportunities in databases and application systems |
| CN105653531B (en) * | 2014-11-12 | 2020-02-07 | 中兴通讯股份有限公司 | Data extraction method and device |
| CN104850590A (en) * | 2015-04-24 | 2015-08-19 | 百度在线网络技术(北京)有限公司 | Method and device for generating metadata of structured data |
| CN105095436B (en) * | 2015-07-23 | 2018-07-17 | 苏州国云数据科技有限公司 | Data source data method for automatic modeling |
-
2017
- 2017-06-23 CN CN201710485959.2A patent/CN109117440B/en active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103902544A (en) * | 2012-12-25 | 2014-07-02 | 中国移动通信集团公司 | Data processing method and system |
Also Published As
| Publication number | Publication date |
|---|---|
| CN109117440A (en) | 2019-01-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109117440B (en) | Method, system and computer-readable storage medium for acquiring metadata information | |
| US11281626B2 (en) | Systems and methods for management of data platforms | |
| CN106452450B (en) | Method and system for data compression | |
| US10198460B2 (en) | Systems and methods for management of data platforms | |
| US20210019318A1 (en) | Materialized views for database query optimization | |
| CN103177068B (en) | According to the system and method for existence compatible rule merging source record | |
| US9098566B2 (en) | Method and system for presenting RDF data as a set of relational views | |
| EP3654202A1 (en) | Low-latency predictive database analysis | |
| US20080208855A1 (en) | Method for mapping a data source to a data target | |
| US20120072464A1 (en) | Systems and methods for master data management using record and field based rules | |
| Santos et al. | Big data: concepts, warehousing, and analytics | |
| Chen et al. | Accurate summary-based cardinality estimation through the lens of cardinality estimation graphs | |
| CN112434024B (en) | Data dictionary generation method, device, equipment and medium for relational database | |
| CN103154996A (en) | Providing information management | |
| US20080114801A1 (en) | Statistics based database population | |
| US12111805B2 (en) | Automatic data store architecture detection | |
| Goyal et al. | Cross platform (RDBMS to NoSQL) database validation tool using bloom filter | |
| CN106815268A (en) | The structuring processing method and system of magnanimity destructuring e-file | |
| CN102169491B (en) | Dynamic detection method for multi-data concentrated and repeated records | |
| JP2004030221A (en) | Automatic change table detection method | |
| US10489419B1 (en) | Data modeling translation system | |
| US20180357278A1 (en) | Processing aggregate queries in a graph database | |
| CN116260866A (en) | Government information pushing method and device based on machine learning and computer equipment | |
| Priya et al. | Entity resolution for high velocity streams using semantic measures | |
| CN104809143A (en) | Method and device for implanting table information into information base |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information |
Address after: 100032 Beijing Finance Street, No. 29, Xicheng District Applicant after: CHINA MOBILE COMMUNICATIONS GROUP Co.,Ltd. Address before: 100032 Beijing Finance Street, No. 29, Xicheng District Applicant before: China Mobile Communications Corp. |
|
| CB02 | Change of applicant information | ||
| TA01 | Transfer of patent application right |
Effective date of registration: 20200407 Address after: Room 1006, building 16, yard 16, Yingcai North Third Street, future science city, Changping District, Beijing 100032 Applicant after: China Mobile Information Technology Co.,Ltd. Applicant after: CHINA MOBILE COMMUNICATIONS GROUP Co.,Ltd. Address before: 100032 Beijing Finance Street, No. 29, Xicheng District Applicant before: CHINA MOBILE COMMUNICATIONS GROUP Co.,Ltd. |
|
| TA01 | Transfer of patent application right | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |