CN108923952B - 基于服务监控指标的故障诊断方法、设备及存储介质 - Google Patents
基于服务监控指标的故障诊断方法、设备及存储介质 Download PDFInfo
- Publication number
- CN108923952B CN108923952B CN201810556786.3A CN201810556786A CN108923952B CN 108923952 B CN108923952 B CN 108923952B CN 201810556786 A CN201810556786 A CN 201810556786A CN 108923952 B CN108923952 B CN 108923952B
- Authority
- CN
- China
- Prior art keywords
- service monitoring
- service
- degree
- fluctuation
- abnormal fluctuation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/14—Network analysis or design
- H04L41/142—Network analysis or design using statistical or mathematical methods
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/06—Management of faults, events, alarms or notifications
- H04L41/0631—Management of faults, events, alarms or notifications using root cause analysis; using analysis of correlation between notifications, alarms or events based on decision criteria, e.g. hierarchy, tree or time analysis
- H04L41/064—Management of faults, events, alarms or notifications using root cause analysis; using analysis of correlation between notifications, alarms or events based on decision criteria, e.g. hierarchy, tree or time analysis involving time analysis
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/06—Management of faults, events, alarms or notifications
- H04L41/0677—Localisation of faults
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/06—Management of faults, events, alarms or notifications
- H04L41/0695—Management of faults, events, alarms or notifications the faulty arrangement being the maintenance, administration or management system
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/0803—Configuration setting
- H04L41/0813—Configuration setting characterised by the conditions triggering a change of settings
- H04L41/0816—Configuration setting characterised by the conditions triggering a change of settings the condition being an adaptation, e.g. in response to network events
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/085—Retrieval of network configuration; Tracking network configuration history
- H04L41/0853—Retrieval of network configuration; Tracking network configuration history by actively collecting configuration information or by backing up configuration information
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/085—Retrieval of network configuration; Tracking network configuration history
- H04L41/0859—Retrieval of network configuration; Tracking network configuration history by keeping history of different configuration generations or by rolling back to previous configuration versions
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L43/00—Arrangements for monitoring or testing data switching networks
- H04L43/08—Monitoring or testing based on specific metrics, e.g. QoS, energy consumption or environmental parameters
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Physics & Mathematics (AREA)
- Algebra (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Mathematical Physics (AREA)
- Probability & Statistics with Applications (AREA)
- Pure & Applied Mathematics (AREA)
- Environmental & Geological Engineering (AREA)
- Debugging And Monitoring (AREA)
Abstract
本发明实施例提供一种基于服务监控指标的故障诊断方法、设备及存储介质。该基于服务监控指标的故障诊断方法包括:通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度;根据所述服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,聚类后的结果包括所述服务器和所述服务监控指标;根据所述聚类后的结果确定所述服务发生故障的位置。本发明实施例可以及时、有效地进行故障诊断并止损,提升服务的稳定性。
Description
技术领域
本发明实施例涉及互联网技术,尤其涉及一种基于服务监控指标的故障诊断方法、设备及存储介质。
背景技术
近年来,随着互联网技术的迅猛发展,网络服务系统的规模和内部模块间的复杂度不断增加,由此导致对于服务故障的诊断难度也在不断增加。
现有的故障诊断主要依靠人工分析排查,耗费较多的人力成本和时间成本,并且部分故障诊断过程耗时过长,很难及时、有效的进行故障诊断并止损。
因此,亟需一种及时、有效地进行故障诊断并止损的故障诊断方案。
发明内容
本发明实施例提供一种基于服务监控指标的故障诊断方法、设备及存储介质,以及时、有效地进行故障诊断并止损,提升服务的稳定性。
第一方面,本发明实施例提供一种基于服务监控指标的故障诊断方法,包括:
通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度;
根据所述服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,聚类后的结果包括所述服务器和所述服务监控指标;
根据所述聚类后的结果确定所述服务发生故障的位置。
在一种可能的设计中,所述通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度,包括:
采用核密度估计KDE计算所述服务监控指标的第一波动程度及第二波动程度,其中,所述第一波动程度为故障发生当天所述服务监控指标的波动程度,所述第二波动程度为故障发生之前预设时间段内所述服务监控指标的波动程度;
通过极值理论对比所述第一波动程度和所述第二波动程度,判断所述第一波动程度是异常波动的概率,得到所述服务监控指标的异常波动程度。
在一种可能的设计中,所述根据所述服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,包括:
根据所述服务监控指标的异常波动程度,采用预设聚类算法对异常波动程度类似的服务器进行聚类,所述预设聚类算法为层次聚类算法或DBSCAN 算法。
在一种可能的设计中,所述采用预设聚类算法对异常波动程度类似的服务器进行聚类之前,还包括:
对于每一所述服务器,将各服务器分别对应的所述服务监控指标的异常波动程度进行排序处理,得到每一所述服务器对应的排序结果;
计算每两个所述服务器对应的排序结果之间的相关系数;
相应地,所述采用预设聚类算法对异常波动程度类似的服务器进行聚类,包括:基于所述相关系数,采用预设聚类算法对异常波动程度类似的服务器进行聚类。
在一种可能的设计中,每个机房包括多个所述服务器,所述服务包括至少一个模块;采用预设聚类算法对异常波动程度类似的服务器进行聚类,包括:
按照所述服务包括的所述模块对每个机房所包括的所述服务器进行聚类。
在一种可能的设计中,所述根据所述聚类后的结果确定所述服务发生故障的位置,包括:
根据预设排序策略,对所述聚类后的结果进行排序;
根据排序后的结果确定所述服务发生故障的位置。
在一种可能的设计中,所述通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度之前,所述方法还包括:
获取所述服务所在服务器的所述服务监控指标的历史数据;
相应地,所述通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度,包括:通过所述异常波动检测算法分析所述历史数据,得到所述服务监控指标的异常波动程度。
第二方面,本发明实施例提供一种基于服务监控指标的故障诊断装置,包括:
分析模块,用于通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度;
聚类模块,用于根据所述服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,聚类后的结果包括所述服务器和所述服务监控指标;
确定模块,用于根据所述聚类后的结果确定所述服务发生故障的位置。
在一种可能的设计中,所述分析模块具体用于:
采用核密度估计KDE计算所述服务监控指标的第一波动程度及第二波动程度,其中,所述第一波动程度为故障发生当天所述服务监控指标的波动程度,所述第二波动程度为故障发生之前预设时间段内所述服务监控指标的波动程度;
通过极值理论对比所述第一波动程度和所述第二波动程度,判断所述第一波动程度是异常波动的概率,得到所述服务监控指标的异常波动程度。
在一种可能的设计中,所述聚类模块具体用于:
根据所述服务监控指标的异常波动程度,采用预设聚类算法对异常波动程度类似的服务器进行聚类,所述预设聚类算法为层次聚类算法或DBSCAN 算法。
在一种可能的设计中,所述聚类模块还用于:
在所述采用预设聚类算法对异常波动程度类似的服务器进行聚类之前,
对于每一所述服务器,将各服务器分别对应的所述服务监控指标的异常波动程度进行排序处理,得到每一所述服务器对应的排序结果;
计算每两个所述服务器对应的排序结果之间的相关系数;
相应地,所述聚类模块在采用预设聚类算法对异常波动程度类似的服务器进行聚类时,具体为:基于所述相关系数,采用预设聚类算法对异常波动程度类似的服务器进行聚类。
在一种可能的设计中,每个机房包括多个所述服务器,所述服务包括至少一个模块;
所述聚类模块在采用预设聚类算法对异常波动程度类似的服务器进行聚类时,具体为:
按照所述服务包括的所述模块对每个机房所包括的所述服务器进行聚类。
在一种可能的设计中,所述确定模块具体用于:
根据预设排序策略,对所述聚类后的结果进行排序;
根据排序后的结果确定所述服务发生故障的位置。
在一种可能的设计中,所述装置还包括:
获取模块,用于在所述分析模块通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度之前,获取所述服务所在服务器的所述服务监控指标的历史数据;
相应地,所述分析模块具体用于:通过所述异常波动检测算法分析所述历史数据,得到所述服务监控指标的异常波动程度。
第三方面,本发明实施例提供一种基于服务监控指标的故障诊断装置,包括:处理器和存储器;
所述存储器存储计算机执行指令;
所述处理器执行所述存储器存储的计算机执行指令,使得所述处理器执行如第一方面任一项所述的基于服务监控指标的故障诊断方法。
第四方面,本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如第一方面任一项所述的基于服务监控指标的故障诊断方法。
本发明实施例提供的基于服务监控指标的故障诊断方法、设备及存储介质,通过异常波动检测算法分析服务所在服务器的服务监控指标,得到服务监控指标的异常波动程度,之后根据服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,进而根据聚类后的结果确定服务发生故障的位置。由于本发明实施例自动扫描所有服务器的所有服务监控指标,最终将可能引发故障的服务器和服务监控指标推荐出来,可以极大的压缩了故障诊断空间,从而可以帮助运维人员及时、有效地进行故障诊断并止损,提升服务的稳定性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一模块调用关系图;
图2为本发明一实施例提供的基于服务监控指标的故障诊断方法的流程图;
图3为本发明一实施例提供的服务监控指标的趋势示例图;
图4为本发明另一实施例提供的基于服务监控指标的故障诊断方法的流程图;
图5为本发明一实施例提供的基于服务监控指标的故障诊断装置的结构示意图;
图6为本发明另一实施例提供的基于服务监控指标的故障诊断装置的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
目前,现有技术主要通过人工诊断故障。具体地,运维人员根据模块调用关系图来排查网络服务系统,其中,模块调用关系图例如图1所示。大多数情况下,故障都是由于在最上游的前端模块(图1所示的模块A) 上出现了很多失败的请求发现的。这时,运维人员就会沿着模块A往下查。由于模块A调用了模块B,所以需要查看模块B的指标,如果模块B的指标异常,则怀疑是模块B导致故障。然后,再检查模块B的直接下游模块C,以此类推。在这个过程中,怀疑通过模块的调用关系不断往下传递,直到传不下去为止。在图1所示的例子中,怀疑最后就停在了模块G。当然,真实的场景要更加复杂一些,并不是只要下游模块有异常就可以,还需要考察异常的程度,这里仅为示例说明,以便于理解。比如,如果模块 G的异常程度比模块E的异常程度小很多,故障产生的根因就更有可能在模块E。
确定故障根因模块之后,再分析故障根因,所以寻找故障根因模块是故障诊断中很重要的步骤。
由于大型的服务部署在成千上万个服务器上,每个服务器上又有几十个到上百个服务监控指标,通过人工分析排查来诊断故障会耗费大量的时间和人力,很难及时、有效的进行故障诊断并止损。
基于上述问题,本发明实施例提供一种基于服务监控指标的故障诊断方法、设备及存储介质,及时、有效地进行故障诊断并止损,提升服务的稳定性。
下面采用详细的实施例,来说明本发明实施例如何基于服务监控指标实现故障诊断。
图2为本发明一实施例提供的基于服务监控指标的故障诊断方法的流程图。本发明实施例提供一种基于服务监控指标的故障诊断方法,该基于服务监控指标的故障诊断方法的执行主体可以为基于服务监控指标的故障诊断装置,该基于服务监控指标的故障诊断装置可以通过软件和/或硬件的方式实现。具体地,该基于服务监控指标的故障诊断装置可以为一个独立的设备,例如计算机等终端,或者,该基于服务监控指标的故障诊断装置也可以集成于例如计算机等终端中。以下以终端为执行主体进行说明。
如图2所示,该基于服务监控指标的故障诊断方法包括:
S201、通过异常波动检测算法分析服务所在服务器的服务监控指标,得到服务监控指标的异常波动程度。
该步骤中,异常波动检测算法是指可以检测出服务监控指标的波动是否异常的任意算法。其中,服务监控指标的波动具体为该服务监控指标的值随时间变化的趋势。
具体地,服务可以部署在成千上万的服务器上,每个服务器上有几十个甚至上百个服务监控指标。该步骤中,终端分析服务涉及的所有服务器的所有服务监控指标,确定哪些服务监控指标出现异常。
对于异常波动,可以理解:当波动程度(即波动的概率)小于某一数值,例如0.01,就认为是异常波动。服务监控指标的异常波动程度越大,由于该服务监控指标诊断的故障原因可靠性越高。
通过该步骤,可以将服务涉及的所有服务监控指标的异常进行量化,得到异常波动程度,通过该异常波动程度可以比较不同服务监控指标的异常程度大小。
S202、根据服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类。
其中,聚类后的结果包括服务器和服务监控指标。
为了便于阅读,需要把异常波动程度类似的服务器聚在一起。因此,该步骤的目的是:根据服务监控指标的异常波动程度,将服务器进行聚类,得到不同的簇。
聚类是无监督学习(Unsupervised Learning)的典型方法之一。聚类以相似性为基础,在一个簇中的模式之间比不在同一簇中的模式之间具有更多的相似性。其中,进行聚类的算法可以包括划分法(Partitioning Methods)、层次法(Hierarchical Methods)、基于密度的方法(density-based methods)、基于网格的方法(grid-based methods)、基于模型的方法(Model-Based Methods),等等。
S203、根据聚类后的结果确定服务发生故障的位置。
由于S202已经把异常波动程度相似的服务器聚到了一起,聚类后的结果包括服务器和服务监控指标,因此,根据该聚类后的结果即可确定服务发生故障的位置,例如是哪一服务器的哪一服务监控指标。
之后,运维人员可以根据该步骤得到的结果进一步进行故障定位。
上述步骤自动扫描所有服务器的所有服务监控指标,最终将可能引发故障的服务器和服务监控指标推荐出来,可以极大的压缩了故障诊断空间,从之前的“几千台服务器×上百个服务监控指标”,压缩到只关注聚类后的前几条结果。
本发明实施例中,通过异常波动检测算法分析服务所在服务器的服务监控指标,得到服务监控指标的异常波动程度,之后根据服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,进而根据聚类后的结果确定服务发生故障的位置。由于本发明实施例自动扫描所有服务器的所有服务监控指标,最终将可能引发故障的服务器和服务监控指标推荐出来,可以极大的压缩了故障诊断空间,从而可以帮助运维人员及时、有效地进行故障诊断并止损,提升服务的稳定性。
在上述实施例的基础上,以下对异常波动检测算法和聚类进行说明。
一、异常波动检测算法
考虑到异常波动检测算法需要解决跨服务器跨服务监控指标的异常波动程度比较问题,发明人引入指标值的观测概率,通过指标值的观测概率衡量服务监控指标的异常波动程度。明显地,指标值的观测概率是可以比较的,而且可以跨服务器、跨服务监控指标地比较。
指标值的观测概率可以从多个不同的角度来建模计算,本发明实施例主要关注指标值突增突降的情况。一方面,指标值的突增突降是很容易被理解的,比如,运维人员很容易就同意图3中的服务监控指标有异常。如图3所示,横轴表示时间,纵轴表示服务监控指标的指标值,其中,在时间段 00:00:00~12:00:00,CPU_WAIT_IO这一服务监控指标的指标值突增,而CPU_WAIT_IO的指标值突增说明出现了磁盘竞争。另一方面,许多故障都会体现在某些指标值的突增突降上。又一方面,计算指标值的突增突降对应的观测概率是比较容易的,适合需要扫描大量服务监控指标的场景。
计算指标值的观测概率需要先收集一些数据。假设故障从t时刻开始发生,则收集服务监控指标在区间[t-w1,t]内的数据{xi},和区间[t,t+w2]内的数据{yj}。显然{xi}是故障发生前的数据,如果w2小于故障持续时间,{yj}就是故障发生中的数据。一般来说,可以让w1取值大些,提高观测概率的准确度。但是w2须尽量短,这样才能尽快的生成故障诊断结果。
有了{xi}和{yj},就可以比较两组数据,生成观测概率,用数学的语言说就是要计算P({yj}|{xi}),也就是在t时刻之前观测到{xi}的前提下,在t时刻之后观测到{yj}的概率。
首先,计算单点概率P(yj|{xi})。假设{xi}是由某一个随机变量X产生的样本,可以通过{xi}来估算X的分布,然后根据X的分布计算yj的观测概率。因为大多数服务监控指标的指标值都是连续的,所以X也应该是连续型随机变量,相应的概率就变成
上溢概率:P(X≥yj|{xi})
下溢概率:P(X≤yj|{xi})
当X比yj大的概率很小时,说明yj太大了,对应的是突增;当X比yj小的概率很小时,说明yj太小了,对应的是突降。假设{yj}是由与相互之间独立且与X同分布的随机变量产生的样本,则集合概率如下:
上溢概率:Po({yj}|{xi})=∏jP(X≥yj|{xi})
下溢概率:Pu({yj}|{xi})=∏jP(X≤yj|{xi})
为了方便计算和查看,通常会计算概率的对数。但由于概率的对数都是负数,所以将概率的对数的负数作为异常分数,即异常波动程度。因此:
上溢分数:o=-logPo({yj}|{xi})=-∑jlogP(X≥yj|{xi})
下溢分数:u=-logPu({yj}|{xi})=-∑jlogP(X≤yj|{xi})
接下来说明如何确定X的分布。常用的办法是假设X服从正态分布,并利用{xi}估计正态分布的两个参数:


最后,基于yj计算z检验的统计量:
其中,zj服从以0为均值,以1为标准差的正态分布 可以通过正态分布来计算单点的上溢概率和下溢概率:
可以通过正态分布来计算单点的上溢概率和下溢概率:
单点的上溢概率:
单点的下溢概率:
示例性地,zj大于3或者小于-3的概率大约是0.13%,已经很小了,所以异常波动检测时,以3作为统计量zj的阈值,即常用的3σ方法。
考虑到多数服务监控指标的指标值并不服从正态分布。比如,CPU_IDLE 这一服务监控指标的指标值是在0到1之间取值。按照上面所述的方法计算时, 通常会小于0,而
通常会小于0,而 通常会大于1,这样就无法正确反应服务监控指标的异常波动程度。因此,本发明实施例采用核密度估计(Kernel Density Estimation,简称:KDE)计算服务监控指标的第一波动程度及第二波动程度。其中,第一波动程度为故障发生当天服务监控指标的波动程度,第二波动程度为故障发生之前预设时间段内服务监控指标的波动程度。
通常会大于1,这样就无法正确反应服务监控指标的异常波动程度。因此,本发明实施例采用核密度估计(Kernel Density Estimation,简称:KDE)计算服务监控指标的第一波动程度及第二波动程度。其中,第一波动程度为故障发生当天服务监控指标的波动程度,第二波动程度为故障发生之前预设时间段内服务监控指标的波动程度。
核密度估计是一个估计概率密度函数的非参数(non-parametric)方法,适用于随机变量服从的分布类型未知的情况。基于{xi},X的概率密度函数可以估计为:
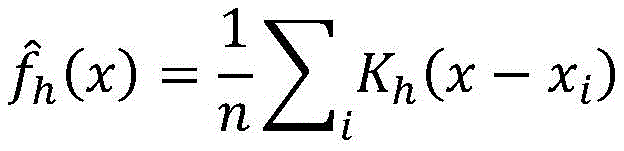
其中,Kh是核函数。如果核函数是正态分布,那么参数h大约就接近于{xi} 的标准差 于是概率密度函数就变成了:
于是概率密度函数就变成了:

对于类似CPU_IDLE的服务监控指标,可以用Beta分布作为核函数,这时,X的概率密度函数估计为:

这里k是一个正数,用来控制Beta分布的形状。k越大,Beta分布越尖; k越小,Beta分布越平坦。
有了X的概率密度函数,单点的概率(包括上溢概率和下溢概率)就可以利用积分计算了,具体如下:
单点的上溢概率:
单点的下溢概率:
其中,单点的概率即表示单点的异常波动程度。
综上,S201、通过异常波动检测算法分析服务所在服务器的服务监控指标,得到服务监控指标的异常波动程度,可以包括:采用核密度估计计算服务监控指标的第一波动程度及第二波动程度;通过极值理论对比第一波动程度和第二波动程度,判断第一波动程度是异常波动的概率,得到该服务监控指标的异常波动程度。其中,第一波动程度为故障发生当天服务监控指标的波动程度,第二波动程度为故障发生之前预设时间段内服务监控指标的波动程度。
二、聚类
可选地,S202、根据服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,可以包括:根据服务监控指标的异常波动程度,采用预设聚类算法对异常波动程度类似的服务器进行聚类。其中,预设聚类算法可以为层次聚类算法或DBSCAN算法。
对于预设聚类算法,由于事先无法获取异常波动的种类,因此,层次聚类算法和DBSCAN算法可以更好地适应各种需求。
进一步地,上述采用预设聚类算法对异常波动程度类似的服务器进行聚类之前,还可以包括:对于每一服务器,将各服务器分别对应的服务监控指标的异常波动程度进行排序处理,得到每一服务器对应的排序结果;计算每两个服务器对应的排序结果之间的相关系数。
具体地,在为每个服务监控指标计算异常波动程度之后,将属于同一个服务器的服务监控指标的异常波动程度合起来,形成一个异常波动程度的向量<o1,o2,…,u1,u2,…>,这里的每一个下标对应一个服务监控指标。
为了便于阅读,需要把异常波动程度类似的向量通过聚类的方法聚在一起。聚类是无监督学习(Unsupervised Learning)的典型方法之一。与监督式学习(SupervisedLearning)不同,聚类不能通过样本的标记(Label)来控制输出的结果,所以控制聚类方向的核心就落在了距离函数和聚类算法上。
距离函数的选择很多。通常的有欧氏距离、或者更加一般的Lp距离、计算向量之间夹角大小的余弦(cosine)距离、甚至可以使用相关系数来度量两个向量之间的距离。当属于同一个模块的不同服务器之间负载几乎完全相同时,欧式距离就应该能给出不错的结果。但是,实际中服务器之间的负载总是会有差别,这就使得同样的异常波动在不同的服务器上表现出不同的异常波动程度,欧式距离就会影响聚类的效果。而相关系数可以计算两个服务器对应异常波动程度的相关性,同时能够忽略数值的绝对水位。首先将一个服务器的服务监控指标按照异常波动程度排序,然后计算两个服务器对应的异常程度排序之间的相关系数。
相应地,所述采用预设聚类算法对异常波动程度类似的服务器进行聚类,可以包括:基于所述相关系数,采用预设聚类算法对异常波动程度类似的服务器进行聚类。
另外,聚类时,理论上可以把所有模块的所有服务器放在一起聚类。但在实验中,发明人发现把所有模块的所有服务器放在一起聚类的聚类结果,虽然可以发现跨模块的问题,比如由于网络故障导致多个模块之间通信受到影响最终产生整个网络服务系统的故障,但是,部分情况下的对故障的诊断效果较差。因此,本发明实施例将聚类局限在属于同一个模块或同一个机房中,以更好地进行故障诊断。其中,每个机房包括多个服务器,服务包括至少一个模块。
大型的网络服务系统为了保证性能和可用性,通常会在多个机房中部署镜像系统。由于大多数的故障只发生在一个机房的系统中,因此,运维人员不但需要知道导致故障的根因模块,还需要模块所在的机房。
基于上述,所述采用预设聚类算法对异常波动程度类似的服务器进行聚类,可以包括:按照服务包括的模块对每个机房所包括的服务器进行聚类。
在上述实施例中,一种具体实现方式中,S203、根据聚类后的结果确定服务发生故障的位置,可以包括:根据预设排序策略,对聚类后的结果进行排序;根据排序后的结果确定服务发生故障的位置。
其中,预设排序策略是通过使用已标注的数据训练得到的排序策略。已标注的数据是指历史故障(或在先故障)发生时的数据。
上述实施例通过聚类将异常波动模式类似的服务器聚到了一起,形成摘要。每个摘要已经具备一定的可读性,这里只需要把属于根因模块的摘要排在前面推荐给运维人员。
预设排序策略的设置需考虑的因素包括:
1、摘要中服务器的个数,服务器越多说明影响越大,就越有可能是导致故障的根因模块。
2、摘要中异常波动程度特别高的服务监控指标的个数,服务监控指标越多越可能是导致故障的根因模块。
3、摘要中各服务器的服务监控指标的平均异常波动程度,平均异常波动程度越高越可能是导致故障的根因模块。
将以上三个因素的值计算出来,就形成了三个特征值,之后,根据该三个特征值得到排序后的结果。
示例性地,表1是图1所示的故障案例的自动分析结果。表1中第一列是摘要所属的模块与机房,第二列是摘要中服务器在同模块同机房的服务器中所占的比例,第三列是摘要中的服务器列表,第四列是异常波动程度特别高的服务监控指标以及各自对应的异常波动程度。
本发明实施例将模块G中的一个摘要作为第一个结果推荐出来。通过第四列的内容,可以看出机房DC1中的模块G因为某种原因超载了。模块G 超载后,模块G对上游模块的响应变慢,从而使得同机房中的模块E维护更多的RPC连接,所以,同机房的模块E被排在了第二位,而且与网络连接数相关的服务监控指标也出现了异常。
表1

图4为本发明另一实施例提供的基于服务监控指标的故障诊断方法的流程图。参考图4,在图1所示流程的基础上,该基于服务监控指标的故障诊断方法可以包括:
S401、获取服务所在服务器的服务监控指标的历史数据。
例如,上述服务监控指标在区间[t-w1,t]内的数据{xi},和区间[t,t+w2] 内的数据{yj}等。
S402、通过异常波动检测算法分析所述历史数据,得到服务监控指标的异常波动程度。
S403、根据服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类。
S404、根据聚类后的结果确定服务发生故障的位置。
其中,S402-S404与图2所示实施例中S201至S203类似,具体实现方案参考如图2所示实施例,此处不再赘述。
下述为本发明装置实施例,可以用于执行本发明上述方法实施例,其实现原理和技术效果类似。
图5为本发明一实施例提供的基于服务监控指标的故障诊断装置的结构示意图。本发明实施例提供一种基于服务监控指标的故障诊断装置,该基于服务监控指标的故障诊断装置可以通过软件和/或硬件的方式实现。如图5所示,基于服务监控指标的故障诊断装置50包括:分析模块51、聚类模块52 和确定模块53。其中,
分析模块51,用于通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度;
聚类模块52,用于根据所述服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,聚类后的结果包括所述服务器和所述服务监控指标;
确定模块53,用于根据所述聚类后的结果确定所述服务发生故障的位置。
本实施例提供的基于服务监控指标的故障诊断装置,可用于执行上述的方法实施例,其实现方式和技术效果类似,本实施例此处不再赘述。
可选地,分析模块51可具体用于:采用核密度估计计算所述服务监控指标的第一波动程度及第二波动程度;通过极值理论对比所述第一波动程度和所述第二波动程度,判断所述第一波动程度是异常波动的概率,得到所述服务监控指标的异常波动程度。其中,所述第一波动程度为故障发生当天所述服务监控指标的波动程度,所述第二波动程度为故障发生之前预设时间段内所述服务监控指标的波动程度。
一些实施例中,聚类模块52可具体用于:根据所述服务监控指标的异常波动程度,采用预设聚类算法对异常波动程度类似的服务器进行聚类。其中,所述预设聚类算法可以为层次聚类算法或DBSCAN算法。
进一步地,聚类模块52还可以用于:在所述采用预设聚类算法对异常波动程度类似的服务器进行聚类之前,对于每一所述服务器,将各服务器分别对应的所述服务监控指标的异常波动程度进行排序处理,得到每一所述服务器对应的排序结果;计算每两个所述服务器对应的排序结果之间的相关系数。
相应地,聚类模块52在采用预设聚类算法对异常波动程度类似的服务器进行聚类时,具体为:基于所述相关系数,采用预设聚类算法对异常波动程度类似的服务器进行聚类。
一些实施例中,每个机房包括多个所述服务器,所述服务包括至少一个模块。因此,可选地,聚类模块52在采用预设聚类算法对异常波动程度类似的服务器进行聚类时,具体为:按照所述服务包括的所述模块对每个机房所包括的所述服务器进行聚类。
可选地,确定模块53可具体用于:根据预设排序策略,对所述聚类后的结果进行排序;根据排序后的结果确定所述服务发生故障的位置。
更进一步地,基于服务监控指标的故障诊断装置50还可以包括:获取模块(未示出)。其中,该获取模块,用于在分析模块51通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度之前,获取所述服务所在服务器的所述服务监控指标的历史数据。此时,分析模块51可具体用于:通过所述异常波动检测算法分析所述历史数据,得到所述服务监控指标的异常波动程度。
图6为本发明另一实施例提供的基于服务监控指标的故障诊断装置的结构示意图。如图6所示,该基于服务监控指标的故障诊断装置60包括:处理器61和存储器62。其中,
存储器62存储计算机执行指令。
处理器61执行存储器62存储的计算机执行指令,使得处理器61执行如上所述的基于服务监控指标的故障诊断方法。
处理器61的具体实现过程可参见上述方法实施例,其实现原理和技术效果类似,本实施例此处不再赘述。
可选地,该基于服务监控指标的故障诊断装置60还包括通信部件63。其中,处理器61、存储器62以及通信部件63可以通过总线64连接。
本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如上所述的基于服务监控指标的故障诊断方法。
在上述的实施例中,应该理解到,所揭露的设备和方法,可以通过其它的方式实现。例如,以上所描述的设备实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个模块可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或模块的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的模块可以是或者也可以不是物理上分开的,作为模块显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能模块可以集成在一个处理单元中,也可以是各个模块单独物理存在,也可以两个或两个以上模块集成在一个单元中。上述模块成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
上述以软件功能模块的形式实现的集成的模块,可以存储在一个计算机可读取存储介质中。上述软件功能模块存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等) 或处理器(英文:processor)执行本申请各个实施例所述方法的部分步骤。
应理解,上述处理器可以是中央处理单元(英文:Central Processing Unit,简称:CPU),还可以是其他通用处理器、数字信号处理器(英文:Digital Signal Processor,简称:DSP)、专用集成电路(英文:Application Specific Integrated Circuit,简称:ASIC)等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合发明所公开的方法的步骤可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。
存储器可能包含高速RAM存储器,也可能还包括非易失性存储NVM,例如至少一个磁盘存储器,还可以为U盘、移动硬盘、只读存储器、磁盘或光盘等。
总线可以是工业标准体系结构(Industry Standard Architecture,ISA)总线、外部设备互连(Peripheral Component,PCI)总线或扩展工业标准体系结构(ExtendedIndustry Standard Architecture,EISA)总线等。总线可以分为地址总线、数据总线、控制总线等。为便于表示,本申请附图中的总线并不限定仅有一根总线或一种类型的总线。
上述存储介质可以是由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(SRAM),电可擦除可编程只读存储器(EEPROM),可擦除可编程只读存储器(EPROM),可编程只读存储器 (PROM),只读存储器(ROM),磁存储器,快闪存储器,磁盘或光盘。存储介质可以是通用或专用计算机能够存取的任何可用介质。
一种示例性的存储介质耦合至处理器,从而使处理器能够从该存储介质读取信息,且可向该存储介质写入信息。当然,存储介质也可以是处理器的组成部分。处理器和存储介质可以位于专用集成电路(Application Specific Integrated Circuits,简称:ASIC)中。当然,处理器和存储介质也可以作为分立组件存在于终端或服务器中。
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成。前述的程序可以存储于一计算机可读取存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
Claims (10)
1.一种基于服务监控指标的故障诊断方法,其特征在于,包括:
通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度;
根据所述服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,聚类后的结果包括所述服务器和所述服务监控指标;
根据所述聚类后的结果确定所述服务发生故障的位置;
所述根据所述服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,包括:
根据所述服务监控指标的异常波动程度,采用预设聚类算法对异常波动程度类似的服务器进行聚类,所述预设聚类算法为层次聚类算法或DBSCAN算法;
所述采用预设聚类算法对异常波动程度类似的服务器进行聚类之前,还包括:
对于每一所述服务器,将各服务器分别对应的所述服务监控指标的异常波动程度进行排序处理,得到每一所述服务器对应的排序结果;
计算每两个所述服务器对应的排序结果之间的相关系数;
相应地,所述采用预设聚类算法对异常波动程度类似的服务器进行聚类,包括:基于所述相关系数,采用预设聚类算法对异常波动程度类似的服务器进行聚类;
每个机房包括多个所述服务器,所述服务包括至少一个模块;采用预设聚类算法对异常波动程度类似的服务器进行聚类,包括:
按照所述服务包括的所述模块对每个机房所包括的所述服务器进行聚类。
2.根据权利要求1所述的方法,其特征在于,所述通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度,包括:
采用核密度估计KDE计算所述服务监控指标的第一波动程度及第二波动程度,其中,所述第一波动程度为故障发生当天所述服务监控指标的波动程度,所述第二波动程度为故障发生之前预设时间段内所述服务监控指标的波动程度;
通过极值理论对比所述第一波动程度和所述第二波动程度,判断所述第一波动程度是异常波动的概率,得到所述服务监控指标的异常波动程度。
3.根据权利要求1所述的方法,其特征在于,所述根据所述聚类后的结果确定所述服务发生故障的位置,包括:
根据预设排序策略,对所述聚类后的结果进行排序;
根据排序后的结果确定所述服务发生故障的位置。
4.根据权利要求1所述的方法,其特征在于,所述通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度之前,所述方法还包括:
获取所述服务所在服务器的所述服务监控指标的历史数据;
相应地,所述通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度,包括:通过所述异常波动检测算法分析所述历史数据,得到所述服务监控指标的异常波动程度。
5.一种基于服务监控指标的故障诊断装置,其特征在于,包括:
分析模块,用于通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度;
聚类模块,用于根据所述服务监控指标的异常波动程度,对异常波动程度类似的服务器进行聚类,聚类后的结果包括所述服务器和所述服务监控指标;
确定模块,用于根据所述聚类后的结果确定所述服务发生故障的位置;
所述聚类模块具体用于:
根据所述服务监控指标的异常波动程度,采用预设聚类算法对异常波动程度类似的服务器进行聚类,所述预设聚类算法为层次聚类算法或DBSCAN算法;
所述聚类模块还用于:
在所述采用预设聚类算法对异常波动程度类似的服务器进行聚类之前,
对于每一所述服务器,将各服务器分别对应的所述服务监控指标的异常波动程度进行排序处理,得到每一所述服务器对应的排序结果;
计算每两个所述服务器对应的排序结果之间的相关系数;
相应地,所述聚类模块在采用预设聚类算法对异常波动程度类似的服务器进行聚类时,具体为:基于所述相关系数,采用预设聚类算法对异常波动程度类似的服务器进行聚类;
每个机房包括多个所述服务器,所述服务包括至少一个模块;
所述聚类模块在采用预设聚类算法对异常波动程度类似的服务器进行聚类时,具体为:
按照所述服务包括的所述模块对每个机房所包括的所述服务器进行聚类。
6.根据权利要求5所述的装置,其特征在于,所述分析模块具体用于:
采用核密度估计KDE计算所述服务监控指标的第一波动程度及第二波动程度,其中,所述第一波动程度为故障发生当天所述服务监控指标的波动程度,所述第二波动程度为故障发生之前预设时间段内所述服务监控指标的波动程度;
通过极值理论对比所述第一波动程度和所述第二波动程度,判断所述第一波动程度是异常波动的概率,得到所述服务监控指标的异常波动程度。
7.根据权利要求5所述的装置,其特征在于,所述确定模块具体用于:
根据预设排序策略,对所述聚类后的结果进行排序;
根据排序后的结果确定所述服务发生故障的位置。
8.根据权利要求5所述的装置,其特征在于,所述装置还包括:
获取模块,用于在所述分析模块通过异常波动检测算法分析服务所在服务器的服务监控指标,得到所述服务监控指标的异常波动程度之前,获取所述服务所在服务器的所述服务监控指标的历史数据;
相应地,所述分析模块具体用于:通过所述异常波动检测算法分析所述历史数据,得到所述服务监控指标的异常波动程度。
9.一种基于服务监控指标的故障诊断装置,其特征在于,包括:处理器和存储器;
所述存储器存储计算机执行指令;
所述处理器执行所述存储器存储的计算机执行指令,使得所述处理器执行如权利要求1至4任一项所述的基于服务监控指标的故障诊断方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如权利要求1至4任一项所述的基于服务监控指标的故障诊断方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810556786.3A CN108923952B (zh) | 2018-05-31 | 2018-05-31 | 基于服务监控指标的故障诊断方法、设备及存储介质 |
| US16/354,074 US10805151B2 (en) | 2018-05-31 | 2019-03-14 | Method, apparatus, and storage medium for diagnosing failure based on a service monitoring indicator of a server by clustering servers with similar degrees of abnormal fluctuation |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810556786.3A CN108923952B (zh) | 2018-05-31 | 2018-05-31 | 基于服务监控指标的故障诊断方法、设备及存储介质 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108923952A CN108923952A (zh) | 2018-11-30 |
| CN108923952B true CN108923952B (zh) | 2021-11-30 |
Family
ID=64418875
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810556786.3A Active CN108923952B (zh) | 2018-05-31 | 2018-05-31 | 基于服务监控指标的故障诊断方法、设备及存储介质 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10805151B2 (zh) |
| CN (1) | CN108923952B (zh) |
Families Citing this family (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11126465B2 (en) * | 2017-03-23 | 2021-09-21 | Microsoft Technology Licensing, Llc | Anticipatory collection of metrics and logs |
| CN110086655B (zh) * | 2019-04-02 | 2022-03-08 | 武汉烽火技术服务有限公司 | 基于网络震荡强度的通信网告警数据分析方法及系统 |
| CN110413703B (zh) * | 2019-06-21 | 2023-07-25 | 平安科技(深圳)有限公司 | 基于人工智能的监控指标数据的分类方法及相关设备 |
| CN112153685B (zh) * | 2019-06-26 | 2022-02-25 | 大唐移动通信设备有限公司 | Rrc故障检测方法和装置 |
| CN110837953A (zh) * | 2019-10-24 | 2020-02-25 | 北京必示科技有限公司 | 一种自动化异常实体定位分析方法 |
| CN111160329B (zh) * | 2019-12-27 | 2025-03-18 | 深圳前海微众银行股份有限公司 | 一种根因分析的方法及装置 |
| CN111104260B (zh) * | 2019-12-30 | 2023-04-14 | 北京三快在线科技有限公司 | 服务升级的监测方法、装置、服务器及存储介质 |
| CN110826648B (zh) * | 2020-01-09 | 2020-04-21 | 浙江鹏信信息科技股份有限公司 | 一种利用时序聚类算法实现故障检测的方法 |
| CN112217691A (zh) * | 2020-02-19 | 2021-01-12 | 杜义平 | 基于云平台的网络诊断处理方法及装置 |
| CN111459746B (zh) * | 2020-02-27 | 2023-06-27 | 北京三快在线科技有限公司 | 告警生成方法、装置、电子设备及可读存储介质 |
| CN111474442B (zh) * | 2020-03-30 | 2022-05-24 | 国网山东省电力公司德州供电公司 | 一种配电网单相接地故障定位方法及系统 |
| CN111447329A (zh) * | 2020-03-31 | 2020-07-24 | 携程旅游信息技术(上海)有限公司 | 呼叫中心中状态服务器的监控方法、系统、设备及介质 |
| CN111488289B (zh) * | 2020-04-26 | 2024-01-23 | 支付宝实验室(新加坡)有限公司 | 一种故障定位方法、装置和设备 |
| CN113722403B (zh) * | 2020-05-25 | 2024-10-15 | 中国石油化工股份有限公司 | 异常运行数据的聚类方法、装置、存储介质及处理器 |
| CN114528175B (zh) * | 2020-10-30 | 2024-12-03 | 亚信科技(中国)有限公司 | 一种微服务应用系统根因定位方法、装置、介质及设备 |
| CN112506763A (zh) * | 2020-11-30 | 2021-03-16 | 清华大学 | 数据库系统故障根因自动定位方法和装置 |
| CN114610560B (zh) * | 2020-12-07 | 2024-04-02 | 腾讯科技(深圳)有限公司 | 系统异常监控方法、装置和存储介质 |
| CN112764957B (zh) * | 2021-01-15 | 2025-02-18 | 中国工商银行股份有限公司 | 应用故障定界方法及装置 |
| CN113688008B (zh) * | 2021-08-18 | 2022-11-25 | 南方电网数字电网研究院有限公司 | 基于聚类算法技术的电网监控系统前置服务故障处理方法 |
| CN113900845A (zh) * | 2021-09-28 | 2022-01-07 | 大唐互联科技(武汉)有限公司 | 一种基于神经网络的微服务故障诊断的方法和存储介质 |
| CN114760190B (zh) * | 2022-04-11 | 2023-06-20 | 北京邮电大学 | 一种面向服务的融合网络性能异常检测方法 |
| CN115001997B (zh) * | 2022-04-11 | 2024-02-09 | 北京邮电大学 | 基于极值理论的智慧城市网络设备性能异常阈值评估方法 |
| CN115269319B (zh) * | 2022-07-21 | 2023-09-01 | 河南职业技术学院 | 一种ceph分布式计算机故障诊断方法 |
| US12050506B2 (en) | 2022-10-12 | 2024-07-30 | International Business Machines Corporation | Generating incident explanations using spatio-temporal log clustering |
| CN118395311A (zh) * | 2024-07-01 | 2024-07-26 | 惠州盛世达科技有限公司 | 一种电子元器件生产数据智能分析方法及系统 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102664961A (zh) * | 2012-05-04 | 2012-09-12 | 北京邮电大学 | MapReduce环境下的异常检测方法 |
| CN105320585A (zh) * | 2014-07-08 | 2016-02-10 | 北京启明星辰信息安全技术有限公司 | 一种实现应用故障诊断的方法及装置 |
| CN107426019A (zh) * | 2017-07-06 | 2017-12-01 | 国家电网公司 | 网络故障确定方法、计算机设备及计算机可读存储介质 |
Family Cites Families (58)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6282175B1 (en) * | 1998-04-23 | 2001-08-28 | Hewlett-Packard Company | Method for tracking configuration changes in networks of computer systems through historical monitoring of configuration status of devices on the network. |
| US6363420B1 (en) * | 1998-06-04 | 2002-03-26 | Mortel Networks Limited | Method and system for heuristically designing and managing a network |
| US6678250B1 (en) * | 1999-02-19 | 2004-01-13 | 3Com Corporation | Method and system for monitoring and management of the performance of real-time networks |
| EP1305909A2 (en) * | 2000-03-20 | 2003-05-02 | Pingtel Corporation | Method and system for combining configuration parameters for an entity profile |
| CA2413285A1 (en) * | 2000-06-21 | 2001-12-27 | Will C. Lauer | Liveexception system |
| US7363656B2 (en) * | 2002-11-04 | 2008-04-22 | Mazu Networks, Inc. | Event detection/anomaly correlation heuristics |
| JP3922375B2 (ja) * | 2004-01-30 | 2007-05-30 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 異常検出システム及びその方法 |
| US7590669B2 (en) * | 2004-04-06 | 2009-09-15 | Microsoft Corporation | Managing client configuration data |
| US7574490B2 (en) * | 2004-11-20 | 2009-08-11 | Microsoft Corporation | Strategies for configuring a server-based information-transmission infrastructure |
| WO2006063118A2 (en) * | 2004-12-07 | 2006-06-15 | Pure Networks, Inc. | Network management |
| US7953703B2 (en) * | 2005-02-17 | 2011-05-31 | International Business Machines Corporation | Creation of highly available pseudo-clone standby servers for rapid failover provisioning |
| US9137251B2 (en) * | 2005-03-16 | 2015-09-15 | Fortinet, Inc. | Inheritance based network management |
| US20080140817A1 (en) * | 2006-12-06 | 2008-06-12 | Agarwal Manoj K | System and method for performance problem localization |
| US8700953B2 (en) * | 2008-09-18 | 2014-04-15 | Nec Corporation | Operation management device, operation management method, and operation management program |
| CN102713861B (zh) * | 2010-01-08 | 2015-09-23 | 日本电气株式会社 | 操作管理装置、操作管理方法以及程序存储介质 |
| US8892960B2 (en) * | 2011-01-19 | 2014-11-18 | Oracle International Corporation | System and method for determining causes of performance problems within middleware systems |
| EP2679044B1 (en) * | 2011-02-21 | 2016-04-20 | Telefonaktiebolaget LM Ericsson (publ) | Service problem diagnosis for mobile wireless networks |
| US9195563B2 (en) * | 2011-03-30 | 2015-11-24 | Bmc Software, Inc. | Use of metrics selected based on lag correlation to provide leading indicators of service performance degradation |
| US20140058705A1 (en) * | 2011-04-27 | 2014-02-27 | Decision Makers Ltd. | System and Method for Detecting Abnormal Occurrences |
| US8700875B1 (en) * | 2011-09-20 | 2014-04-15 | Netapp, Inc. | Cluster view for storage devices |
| US9019121B1 (en) * | 2011-12-22 | 2015-04-28 | Landis+Gyr Technologies, Llc | Configuration over power distribution lines |
| CN102590683B (zh) * | 2012-02-27 | 2015-02-18 | 浙江大学 | 一种电力设备载流故障在线诊断预警方法 |
| US9094309B2 (en) * | 2012-03-13 | 2015-07-28 | International Business Machines Corporation | Detecting transparent network communication interception appliances |
| US9417892B2 (en) * | 2012-09-28 | 2016-08-16 | International Business Machines Corporation | Configuration command template creation assistant using cross-model analysis to identify common syntax and semantics |
| US9071535B2 (en) * | 2013-01-03 | 2015-06-30 | Microsoft Technology Licensing, Llc | Comparing node states to detect anomalies |
| JP5888561B2 (ja) * | 2013-01-21 | 2016-03-22 | アラクサラネットワークス株式会社 | 管理装置、及び管理方法 |
| US20140317255A1 (en) * | 2013-04-17 | 2014-10-23 | Avaya Inc. | System and method for fast network discovery updating and synchronization using dynamic hashes and hash function values aggregated at multiple levels |
| US9355007B1 (en) * | 2013-07-15 | 2016-05-31 | Amazon Technologies, Inc. | Identifying abnormal hosts using cluster processing |
| US9558056B2 (en) * | 2013-07-28 | 2017-01-31 | OpsClarity Inc. | Organizing network performance metrics into historical anomaly dependency data |
| US20150081880A1 (en) * | 2013-09-17 | 2015-03-19 | Stackdriver, Inc. | System and method of monitoring and measuring performance relative to expected performance characteristics for applications and software architecture hosted by an iaas provider |
| JP6152770B2 (ja) * | 2013-10-07 | 2017-06-28 | 富士通株式会社 | 管理プログラム、管理方法、および情報処理装置 |
| WO2015095974A1 (en) * | 2013-12-27 | 2015-07-02 | Metafor Software Inc. | System and method for anomaly detection in information technology operations |
| US9904584B2 (en) * | 2014-11-26 | 2018-02-27 | Microsoft Technology Licensing, Llc | Performance anomaly diagnosis |
| US9424121B2 (en) * | 2014-12-08 | 2016-08-23 | Alcatel Lucent | Root cause analysis for service degradation in computer networks |
| US9544812B2 (en) * | 2015-01-30 | 2017-01-10 | Alcatel Lucent | System and method for mitigating network congestion using fast congestion detection in a wireless radio access network (RAN) |
| US10042697B2 (en) * | 2015-05-28 | 2018-08-07 | Oracle International Corporation | Automatic anomaly detection and resolution system |
| CN105071983B (zh) * | 2015-07-16 | 2017-02-01 | 清华大学 | 一种面向云计算在线业务的异常负载检测方法 |
| CN106452934B (zh) * | 2015-08-10 | 2020-02-11 | 中国移动通信集团公司 | 一种网络性能指标变化趋势的分析方法和装置 |
| US10082787B2 (en) * | 2015-08-28 | 2018-09-25 | International Business Machines Corporation | Estimation of abnormal sensors |
| US10616040B2 (en) * | 2015-11-10 | 2020-04-07 | Telefonaktiebolaget Lm Ericsson (Publ) | Managing network alarms |
| JP2017118355A (ja) * | 2015-12-24 | 2017-06-29 | 富士通株式会社 | 影響範囲特定プログラム及び影響範囲特定装置 |
| US10546241B2 (en) * | 2016-01-08 | 2020-01-28 | Futurewei Technologies, Inc. | System and method for analyzing a root cause of anomalous behavior using hypothesis testing |
| CN105764066B (zh) * | 2016-01-29 | 2018-10-16 | 江苏省电力公司南京供电公司 | 一种面向配网信息感知的协作覆盖方法 |
| CN105891629B (zh) * | 2016-03-31 | 2017-12-29 | 广西电网有限责任公司电力科学研究院 | 一种变压器设备故障的辨识方法 |
| CN107846295B (zh) * | 2016-09-19 | 2020-06-26 | 华为技术有限公司 | 微服务配置装置及方法 |
| CN106502907B (zh) * | 2016-10-28 | 2018-11-30 | 中国科学院软件研究所 | 一种基于执行轨迹追踪的分布式软件异常诊断方法 |
| US10756950B2 (en) * | 2017-01-05 | 2020-08-25 | Hewlett Packard Enterprise Development Lp | Identifying a potentially erroneous device in an internet of things (IoT) network |
| US11277420B2 (en) * | 2017-02-24 | 2022-03-15 | Ciena Corporation | Systems and methods to detect abnormal behavior in networks |
| US10122872B1 (en) * | 2017-05-31 | 2018-11-06 | Xerox Corporation | Automatic configuration of network devices in remote managed print service applications utilizing groups of historical device data |
| US10708139B2 (en) * | 2017-08-01 | 2020-07-07 | Servicenow, Inc. | Automatic grouping of similar applications and devices on a network map |
| KR101910926B1 (ko) * | 2017-09-13 | 2018-10-23 | 주식회사 티맥스 소프트 | It 시스템의 장애 이벤트를 처리하기 위한 기법 |
| US10394631B2 (en) * | 2017-09-18 | 2019-08-27 | Callidus Software, Inc. | Anomaly detection and automated analysis using weighted directed graphs |
| CN107943668B (zh) * | 2017-12-15 | 2019-02-26 | 江苏神威云数据科技有限公司 | 计算机服务器集群日志监控方法及监控平台 |
| KR20190096706A (ko) * | 2018-02-09 | 2019-08-20 | 주식회사 케이티 | 서비스 연관성 추적을 통한 시스템 이상 징후 모니터링 방법 및 시스템 |
| US10536344B2 (en) * | 2018-06-04 | 2020-01-14 | Cisco Technology, Inc. | Privacy-aware model generation for hybrid machine learning systems |
| CN110032480B (zh) * | 2019-01-17 | 2024-02-06 | 创新先进技术有限公司 | 一种服务器异常检测方法、装置及设备 |
| US11095540B2 (en) * | 2019-01-23 | 2021-08-17 | Servicenow, Inc. | Hybrid anomaly detection for response-time-based events in a managed network |
| CN110287081A (zh) * | 2019-06-21 | 2019-09-27 | 腾讯科技(成都)有限公司 | 一种服务监控系统和方法 |
-
2018
- 2018-05-31 CN CN201810556786.3A patent/CN108923952B/zh active Active
-
2019
- 2019-03-14 US US16/354,074 patent/US10805151B2/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102664961A (zh) * | 2012-05-04 | 2012-09-12 | 北京邮电大学 | MapReduce环境下的异常检测方法 |
| CN105320585A (zh) * | 2014-07-08 | 2016-02-10 | 北京启明星辰信息安全技术有限公司 | 一种实现应用故障诊断的方法及装置 |
| CN107426019A (zh) * | 2017-07-06 | 2017-12-01 | 国家电网公司 | 网络故障确定方法、计算机设备及计算机可读存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20190372832A1 (en) | 2019-12-05 |
| CN108923952A (zh) | 2018-11-30 |
| US10805151B2 (en) | 2020-10-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108923952B (zh) | 基于服务监控指标的故障诊断方法、设备及存储介质 | |
| Bodik et al. | Fingerprinting the datacenter: automated classification of performance crises | |
| CN107729210B (zh) | 分布式服务集群的异常诊断方法和装置 | |
| WO2022001125A1 (zh) | 一种存储系统的存储故障预测方法、系统及装置 | |
| WO2022166481A1 (zh) | 一种针对硬盘的故障预测方法、装置及设备 | |
| Lim et al. | Identifying recurrent and unknown performance issues | |
| WO2017020614A1 (zh) | 一种检测磁盘的方法及装置 | |
| CN106383760A (zh) | 一种计算机故障管理方法及装置 | |
| US9489379B1 (en) | Predicting data unavailability and data loss events in large database systems | |
| CN110502395A (zh) | 基于聚类的设备运行状态评估方法、终端设备及存储介质 | |
| CN111949429A (zh) | 基于密度聚类算法的服务器故障监测方法及系统 | |
| WO2022072017A1 (en) | Methods and systems for multi-resource outage detection for a system of networked computing devices and root cause identification | |
| CN111400122A (zh) | 一种硬盘健康度评估方法及装置 | |
| CN113359665B (zh) | 一种基于加权关键主元的工业过程故障检测方法及系统 | |
| CN115705274A (zh) | 硬盘故障预测方法、装置、计算机可读介质及电子设备 | |
| CN117811903A (zh) | 一种sas链路故障诊断方法、装置、设备及存储介质 | |
| CN116057902B (zh) | 服务的健康指数 | |
| CN115729907A (zh) | 为数据库实例的监控指标分类的方法和装置、为数据库实例分类的方法和装置 | |
| CN111966515A (zh) | 业务异常数据处理方法、装置、计算机设备和存储介质 | |
| CN113591813B (zh) | 基于关联规则算法的异常研判方法、模型构建方法及装置 | |
| CN117407207B (zh) | 一种内存故障处理方法、装置、电子设备及存储介质 | |
| CN109474445B (zh) | 一种分布式系统根源故障定位方法及装置 | |
| US20250036971A1 (en) | Managing data processing system failures using hidden knowledge from predictive models | |
| CN108957296B (zh) | 一种基于纠缠关系判别的电路健康检测方法 | |
| CN116595452A (zh) | 服务器故障预测方法、装置、计算机设备及存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |