CN108833928B - Traffic monitoring video coding method - Google Patents
Traffic monitoring video coding method Download PDFInfo
- Publication number
- CN108833928B CN108833928B CN201810720989.1A CN201810720989A CN108833928B CN 108833928 B CN108833928 B CN 108833928B CN 201810720989 A CN201810720989 A CN 201810720989A CN 108833928 B CN108833928 B CN 108833928B
- Authority
- CN
- China
- Prior art keywords
- vehicle
- coded
- background
- current
- block
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/85—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using pre-processing or post-processing specially adapted for video compression
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/26—Segmentation of patterns in the image field; Cutting or merging of image elements to establish the pattern region, e.g. clustering-based techniques; Detection of occlusion
- G06V10/267—Segmentation of patterns in the image field; Cutting or merging of image elements to establish the pattern region, e.g. clustering-based techniques; Detection of occlusion by performing operations on regions, e.g. growing, shrinking or watersheds
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/50—Context or environment of the image
- G06V20/52—Surveillance or monitoring of activities, e.g. for recognising suspicious objects
- G06V20/54—Surveillance or monitoring of activities, e.g. for recognising suspicious objects of traffic, e.g. cars on the road, trains or boats
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/172—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a picture, frame or field
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/08—Detecting or categorising vehicles
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Signal Processing (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Computation (AREA)
- Evolutionary Biology (AREA)
- General Engineering & Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Traffic Control Systems (AREA)
Abstract
Description
技术领域technical field
本发明涉及视频编码技术领域,尤其涉及一种交通监控视频编码方法。The invention relates to the technical field of video coding, in particular to a video coding method for traffic monitoring.
背景技术Background technique
近年来,随着智慧交通的迅速发展,监控视频的数据量出现出了爆炸性的增长。为了有效的存储与传输监控视频数据,首先要解决的问题就是监控视频的编码问题。In recent years, with the rapid development of smart transportation, the amount of surveillance video data has exploded. In order to effectively store and transmit surveillance video data, the first problem to be solved is the encoding of surveillance video.
当前,监控视频的压缩通常采用通用视频编码标准H.264/AVC或者H.265/HEVC。然而,考虑到监控视频具有的一些特性,如监控摄像头静止等,直接将通用视频编码技术用在监控视频的编码上,不能充分利用监控视频自有的特性。为了进一步提高监控视频编码的性能,许多研究者发明了一系列针对监控视频的编码技术。Currently, the compression of surveillance video usually adopts the general video coding standard H.264/AVC or H.265/HEVC. However, considering some characteristics of surveillance video, such as the stillness of surveillance cameras, etc., the general video coding technology is directly used in the coding of surveillance video, which cannot make full use of the inherent characteristics of surveillance video. In order to further improve the performance of surveillance video coding, many researchers have invented a series of coding techniques for surveillance video.
一般来讲,监控视频中的内容可以大致分为背景内容和前景内容。相应的,针对监控视频的编码可以分别从优化背景编码和优化前景编码两个方面来设计。考虑到监控摄像头静止这个特点,优化背景编码通常先生成一个高质量背景帧,然后依靠质量传递来提高整体监控视频的编码效率。优化前景编码方面,研究者先后提出了一些基于模型和物体分割的前景编码技术。Generally speaking, the content in the surveillance video can be roughly divided into background content and foreground content. Correspondingly, the coding for surveillance video can be designed from two aspects: optimizing background coding and optimizing foreground coding. Considering the static characteristics of surveillance cameras, optimized background encoding usually generates a high-quality background frame first, and then relies on quality transfer to improve the encoding efficiency of the overall surveillance video. In terms of optimizing foreground encoding, researchers have successively proposed some foreground encoding techniques based on models and object segmentation.
有一些工作还提出了其他的监控视频编码技术,例如:Some works also propose other surveillance video coding techniques, such as:
基于背景建模的自适应预测技术(Xianguo Zhang,Tiejun Huang,YonghongTian,andWenGao,“Background-modeling-based adaptive predictionfor surveillancevideo coding,”IEEE Transactions on ImageProcessing,vol.23,no.2,pp.769–784,2014.)Adaptive prediction techniques based on background modeling (Xianguo Zhang, Tiejun Huang, YonghongTian, and WenGao, “Background-modeling-based adaptive prediction for surveillance video coding,” IEEE Transactions on ImageProcessing, vol.23, no.2, pp.769–784 , 2014.)
基于车辆3D模型数据库的全局车辆编码技术(Jing Xiao,Ruimin Hu,LiangLiao,Yu Chen,ZhongyuanWang,and ZixiangXiong,“Knowledge-based coding ofobjectsfor multisource surveillance video data,”IEEETransactions on Multimedia,vol.18,no.9,pp.1691–1706,2016.)Global Vehicle Coding Technology Based on Vehicle 3D Model Database (Jing Xiao, Ruimin Hu, LiangLiao, Yu Chen, Zhongyuan Wang, and ZixiangXiong, "Knowledge-based coding of objects for multisource surveillance video data," IEEE Transactions on Multimedia, vol.18, no.9 , pp.1691–1706, 2016.)
以上方法的缺点:Disadvantages of the above method:
1、基于高质量背景帧的背景编码技术在生成高质量背景帧时会引起码流的激增,对网络传输造成不良影响,且编码性能也有待提高。1. The background encoding technology based on high-quality background frames will cause a surge of code streams when generating high-quality background frames, which will cause adverse effects on network transmission, and the encoding performance also needs to be improved.
2、基于模型和物体分割的前景编码技术在对前景进行像素级别的精细分割方面本身存在困难,而且由于分割出的前景可能形状不规则,用于表示它的码率是十分巨大的。2. The foreground coding technology based on model and object segmentation is difficult to perform fine pixel-level segmentation of the foreground, and since the segmented foreground may be irregular in shape, the code rate used to represent it is very huge.
3、基于背景建模的自适应预测技术在当前帧与参考帧上同时减去重建的背景帧,然后编码前景时直接以得到的当前帧前景像素在参考帧前景像素上做帧间预测。当前景像素的分割效果不佳时,对前景编码效率的提升容易造成不良影响。3. The adaptive prediction technology based on background modeling subtracts the reconstructed background frame from the current frame and the reference frame at the same time, and then directly uses the obtained foreground pixels of the current frame to perform inter-frame prediction on the foreground pixels of the reference frame when encoding the foreground. When the segmentation effect of foreground pixels is not good, it is easy to cause adverse effects on the improvement of foreground coding efficiency.
4、基于车辆3D模型数据库的全局车辆编码技术由于未存储车辆的纹理信息,导致车辆的重建质量无法提高。除此之外,该技术所需的车辆3D模型、监控摄像头的内部参数与外部参数、道路上车辆的位置和姿态信息难以获得或估计,从而为该技术的实用化带来困难。4. The global vehicle coding technology based on the vehicle 3D model database does not store the texture information of the vehicle, so the reconstruction quality of the vehicle cannot be improved. In addition, the 3D model of the vehicle, the internal and external parameters of the surveillance camera, and the position and attitude information of the vehicle on the road required by the technology are difficult to obtain or estimate, which brings difficulties to the practical application of the technology.
发明内容SUMMARY OF THE INVENTION
本发明的目的是提供一种交通监控视频编码方法,可以提高交通监控视频的编码性能。The purpose of the present invention is to provide a traffic monitoring video coding method, which can improve the coding performance of the traffic monitoring video.
本发明的目的是通过以下技术方案实现的:The purpose of this invention is to realize through the following technical solutions:
一种交通监控视频编码方法,其主要包括如下步骤:A traffic monitoring video coding method, which mainly comprises the following steps:
步骤1、采用前背景分割方法对原始交通监控视频序列进行处理,分离出车辆与背景,并分别去除分离出的车辆与背景之间存在的冗余后放入数据库。
步骤2、对于待编码的交通监控视频同样采用前背景分割方法,分离出待编码车辆与待编码背景;对于待编码车辆采用特征匹配与快速运动估计的方式从数据库中选出匹配车辆;对于待编码背景基于绝对差和从数据库中选出匹配背景。Step 2: For the traffic monitoring video to be encoded, the foreground and background segmentation method is also used to separate the vehicle to be encoded and the background to be encoded; for the vehicle to be encoded, the matching vehicle is selected from the database by means of feature matching and rapid motion estimation; Encoded backgrounds are based on absolute differences and matching backgrounds are selected from the database.
步骤3、当采用帧间预测模式或者帧内预测模式时,使用预定方式判断待编码车辆或待编码背景是否需要在匹配车辆或匹配背景上进行率失真优化处理;根据判断结果进行相应处理,并使用相应的预测模式进行编码。
由上述本发明提供的技术方案可以看出,基于车辆和背景数据库实现交通监控视频编码,在付出一定存储空间的代价后,可以有效去除交通监控视频在时间维度上存在的全局冗余,最终,总体的效果是在未明显增加编、解码端复杂度的情况下,有效的提升了交通监控视频的整体编码性能。It can be seen from the above technical solution provided by the present invention that the traffic monitoring video coding based on the vehicle and the background database can effectively remove the global redundancy existing in the time dimension of the traffic monitoring video after paying a certain storage space cost. Finally, The overall effect is to effectively improve the overall encoding performance of traffic surveillance video without significantly increasing the complexity of encoding and decoding.
附图说明Description of drawings
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。In order to illustrate the technical solutions of the embodiments of the present invention more clearly, the following briefly introduces the accompanying drawings used in the description of the embodiments. Obviously, the drawings in the following description are only some embodiments of the present invention. For those of ordinary skill in the art, other drawings can also be obtained from these drawings without any creative effort.
图1为本发明实施例提供的一种交通监控视频编码方法的流程图;1 is a flowchart of a traffic monitoring video encoding method provided by an embodiment of the present invention;
图2为本发明实施例提供的一种交通监控视频编码框架的原理图;2 is a schematic diagram of a traffic monitoring video coding framework provided by an embodiment of the present invention;
图3为本发明实施例提供的车辆区域背景SIFT特征去除流程图;FIG. 3 is a flowchart of removing SIFT features of vehicle area background provided by an embodiment of the present invention;
图4为本发明实施例提供的车辆和背景相似度分析流程图;FIG. 4 is a flow chart of vehicle and background similarity analysis provided by an embodiment of the present invention;
图5为本发明实施例提供的参考索引比特变化信息示意图;5 is a schematic diagram of reference index bit change information provided by an embodiment of the present invention;
图6为本发明实施例提供的测试序列截图。FIG. 6 is a screenshot of a test sequence provided by an embodiment of the present invention.
具体实施方式Detailed ways
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, rather than all the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative work fall within the protection scope of the present invention.
本发明实施例提供一种交通监控视频编码方法,如图1所示,其主要包括如下步骤:An embodiment of the present invention provides a traffic monitoring video encoding method, as shown in FIG. 1 , which mainly includes the following steps:
步骤1、采用前背景分割方法对原始交通监控视频序列进行处理,分离出车辆与背景,并分别去除分离出的车辆与背景之间存在的冗余后放入数据库。
步骤2、对于待编码的交通监控视频同样采用前背景分割方法,分离出待编码车辆与待编码背景;对于待编码车辆采用特征匹配与快速运动估计的方式从数据库中选出匹配车辆;对于待编码背景基于绝对差和从数据库中选出匹配背景。Step 2: For the traffic monitoring video to be encoded, the foreground and background segmentation method is also used to separate the vehicle to be encoded and the background to be encoded; for the vehicle to be encoded, the matching vehicle is selected from the database by means of feature matching and rapid motion estimation; Encoded backgrounds are based on absolute differences and matching backgrounds are selected from the database.
步骤3、当采用帧间预测模式或者帧内预测模式时,使用预定方式判断待编码车辆或待编码背景是否需要在匹配车辆或匹配背景上进行率失真优化处理;根据判断结果进行相应处理,并使用相应的预测模式进行编码。
整个编码框架的原理图如图2所示,其中线下部分也即上述的步骤1,线上部分也即上述步骤2~步骤3。The schematic diagram of the entire coding framework is shown in Figure 2, wherein the offline part is the above-mentioned
为了便于理解,下面针对上述三个步骤做详细的介绍。For ease of understanding, the above three steps are described in detail below.
一、车辆和背景数据库建立。1. Establishment of vehicle and background database.
本发明实施例中,对于原始交通监控视频序列,采用前背景分割方法(例如,SuBSENSE方法)分离出其中的车辆,背景从前景分离时产生的背景模型处提取,将属于视频序列前段的车辆和背景用于构建数据库。主要实现过程可以参照下述方式:In the embodiment of the present invention, for the original traffic monitoring video sequence, a foreground and background segmentation method (for example, the SuBSENSE method) is used to separate the vehicles, the background is extracted from the background model generated when the foreground is separated, and the vehicles and The background is used to build the database. The main implementation process can refer to the following methods:
1、车辆数据库建立。1. Establish vehicle database.
车辆数据库建立的较佳实施方式如下:The preferred embodiment of vehicle database establishment is as follows:
从原始交通监控视频序列前段分离出车辆并去除冗余后,将车辆从1到N进行编号;N为分离出的车辆数目。After the vehicles are separated from the front part of the original traffic monitoring video sequence and the redundancy is removed, the vehicles are numbered from 1 to N; N is the number of separated vehicles.
初始时,数据库中车辆为空;对于某个去除冗余的车辆vi,采用基于倒排表的方法从除车辆vi外所有其余车辆中检索出相似的车辆{vi1,vi2,...,vim},其中m为相似车辆的数目。Initially, the vehicle in the database is empty; for a certain vehicle v i with redundancy removed, the method based on the inverted table is used to retrieve similar vehicles {v i1 , v i2 , . .., v im }, where m is the number of similar vehicles.
为了确定m的大小,考虑车辆vi和vj匹配的SIFT特征数目,确定两个SIFT特征是否匹配的方式可以采用常规技术,也可以采用后文介绍车辆匹配时所提到的方式来实现。In order to determine the size of m, considering the number of SIFT features matched by vehicles v i and v j , the way to determine whether the two SIFT features match can be implemented by conventional techniques or by the methods mentioned in the introduction of vehicle matching later.
检索相似车辆时,比较车辆vi和其余车辆中任一车辆vj匹配的SIFT特征数目,当车辆vi和车辆vj匹配的SIFT特征数目满足下式时,将车辆vj放入{vi1,vi2,...,vim}中:When retrieving similar vehicles, compare the number of SIFT features matched by vehicle v i and any vehicle v j among the other vehicles. When the number of SIFT features matched by vehicle v i and vehicle v j satisfies the following formula, put vehicle v j into {v i1 , v i2 , ..., v im } in:
Nij≥β×Ni;N ij ≥β×N i ;
Nij≥min(N0,Ni);N ij ≥ min(N 0 , N i );
上式中,Nij为车辆vi和车辆vj匹配的SIFT特征数目,Ni为车辆vi中的SIFT特征数目,β和N0为常数;示例性的,β和N0可以分别设置为0.1和4。通过上述方式处理后,可以得到车辆vi对应的相似的车辆{vi1,vi2,...,vim}。In the above formula, N ij is the number of SIFT features matched by vehicle v i and vehicle v j , N i is the number of SIFT features in vehicle v i , β and N 0 are constants; exemplarily, β and N 0 can be set respectively are 0.1 and 4. After processing in the above manner, similar vehicles {v i1 , v i2 , . . . , v im } corresponding to the vehicle v i can be obtained.
之后,对车辆进行像素级别相似度的比较:对于车辆vi,如果数据库中的车辆为空,则将车辆vi放入数据库;否则,将车辆vi与{vi1,vi2,...,vim}中已经放入数据库的车辆进行像素级别相似度的比较,相似度比较时使用快速运动估计方式,损失函数使用绝对差和(Sum of Absolute Difference,SAD)。After that, the pixel-level similarity is compared for the vehicles: for the vehicle v i , if the vehicle in the database is empty, put the vehicle v i into the database; otherwise, put the vehicle v i with {v i1 , v i2 , .. ., v im } The vehicles that have been put into the database are compared for pixel-level similarity, and the fast motion estimation method is used when the similarity is compared, and the sum of absolute difference (SAD) is used as the loss function.
此处提到的快速运动估计方式可以通过常规技术实现,也可以采用后文介绍车辆匹配时所采用的特定的快速运动估计方式。The fast motion estimation method mentioned here can be implemented by conventional techniques, or a specific fast motion estimation method used in vehicle matching described later.
如果计算得到的绝对差和平均值小于设定值(例如5),则判定判断两辆车在像素级别是相似的。本领域技术人员可以理解,在进行相似度计算时,每一次的计算对象是车辆vi与{vi1,vi2,...,vim}中已经放入数据库的某一车辆,当进行绝对差和计算时,将车辆vi划分成一定尺寸的块,车辆vi上的某一个块在放入数据库中某一车辆的整个图像上做快速运动估计;如后文提到的16x16的块,对于每一个16x16的块都会得到一个SAD值;此处考虑的绝对差和平均值也即vi中所有16x16的块的绝对差和的平均值。If the calculated absolute difference and average value are less than a set value (eg, 5), it is determined that the two vehicles are similar at the pixel level. Those skilled in the art can understand that when the similarity is calculated, the object of each calculation is a vehicle v i and {v i1 , v i2 , . . . , vim } that has been put into the database. When calculating the absolute difference sum, the vehicle vi is divided into blocks of a certain size, and a certain block on the vehicle vi is used for fast motion estimation on the entire image of a vehicle in the database; For each 16x16 block, an SAD value is obtained; the absolute difference and average value considered here are also the average of the absolute difference sums of all 16x16 blocks in vi.
如果{vi1,vi2,...,vim}中已经放入数据库的车辆连续多辆(例如,10辆)没有与车辆vi在像素级别相似,将车辆vi放入数据库,反之,车辆vi不放入数据库。If the vehicles in {v i1 , v i2 , . , the vehicle vi is not put into the database.
如果将最终决定车辆vi放入数据库中,则将{vi1,vi2,...,vim}中已经放入数据库的车辆与车辆vi进行像素级别相似度的比较,如果存在与车辆vi在像素级别相似的车辆,则将已放入数据库中的相似的车辆剔除出数据库;如果累计超过多辆车辆与车辆vi在像素级别不相似,上述检查过程停止。If the final decision vehicle v i is put into the database, compare the pixel-level similarity between the vehicles already put into the database in {v i1 , v i2 , ..., vim } and the vehicle v i , if there is a If the vehicle v i is similar to the vehicle at the pixel level, the similar vehicles that have been put into the database will be removed from the database; if the cumulative number of vehicles is not similar to the vehicle v i at the pixel level, the above checking process will stop.
采用上述方式处理每一车辆,确定最终放入数据库中的车辆并进行编码后放入数据库。Each vehicle is processed in the above-mentioned manner, and the final vehicle to be put into the database is determined, encoded and put into the database.
2、背景数据库建立2. Background database establishment
对于去除冗余的背景,每隔一段时间(例如,20s)取一帧背景并进行编码后放入数据库。For the redundant background, take a frame of background every time period (for example, 20s) and put it into the database after encoding.
在实际应用中,监控摄像头安装完成后,编码器首先进行车辆和背景数据库的建立工作。对于车辆,编码器依据前述车辆数据库的建立步骤,将准备放入数据库中的车辆进行高质量编码,并将编码后的车辆放入数据库。同时用于标识这些车辆的信息也被编入码流,解码端解出重建图像后,依据解出的车辆标识信息进行相同的车辆数据库建立过程;对于背景,编码器依据前述背景数据库的建立步骤,每隔一段时间对生成的背景帧进行高质量编码,并将编码后的背景放入数据库。同时高质量编码的背景以及用于标识这些背景的信息也被编入码流,解码器按照上述信息解出高质量的背景帧后,将其放入数据库中。这样,在编解码端可以建立相同的车辆和背景数据库。In practical applications, after the installation of the surveillance camera is completed, the encoder first performs the establishment of the vehicle and background database. For the vehicle, the encoder performs high-quality encoding on the vehicle to be put into the database according to the aforementioned steps of establishing the vehicle database, and puts the encoded vehicle into the database. At the same time, the information used to identify these vehicles is also encoded into the code stream. After the decoding end decodes the reconstructed image, the same vehicle database establishment process is performed according to the decoded vehicle identification information; for the background, the encoder follows the previous steps of establishing the background database. , perform high-quality encoding on the generated background frames at regular intervals, and put the encoded background into the database. At the same time, the high-quality encoded backgrounds and the information used to identify these backgrounds are also encoded into the code stream. After the decoder decodes the high-quality background frames according to the above information, it puts them into the database. In this way, the same vehicle and background database can be established on the codec side.
本发明实施例中,可以将原始交通监控视频序列进行划分,前一部分数据用来建立车辆和背景数据库;后一部分作为待编码的交通监控视频。当然,也可以将第一天的交通监控视频来建立车辆和背景数据库,从第二天开始的数据作为待编码的交通监控视频。编解码器按照本发明所述的方法进行交通监控视频的编解码工作。一般的交通监控视频通常要保存几个月的期限,当将保存的数据清空后,重复上述的工作。In the embodiment of the present invention, the original traffic monitoring video sequence can be divided, the former part of the data is used to establish a vehicle and background database; the latter part is used as the traffic monitoring video to be encoded. Of course, the traffic surveillance video of the first day can also be used to establish a vehicle and background database, and the data from the second day can be used as the traffic surveillance video to be encoded. The codec performs the codec work of the traffic monitoring video according to the method of the present invention. The general traffic surveillance video is usually saved for a period of several months, and the above-mentioned work is repeated after the saved data is emptied.
二、车辆和背景检索2. Vehicle and Background Search
1、车辆检索。1. Vehicle search.
1)车辆与背景的分离及去冗余操作。1) Vehicle and background separation and de-redundancy operations.
本发明实施例中,对于待编码的交通监控视频同样需要进行车辆与背景的分离,以及去冗余操作;这部分操作过程与车辆和背景数据库建立时的操作类似。这一操作过程较佳实施方式如下:In the embodiment of the present invention, the separation of the vehicle and the background and the redundancy removal operation are also required for the traffic surveillance video to be encoded; this part of the operation process is similar to the operation when the vehicle and background database is established. The preferred implementation of this operation process is as follows:
采用SuBSENSE方法分离出监控视频序列(原始交通监控视频序列或者待编码的交通监控视频)中的车辆后,由于车辆的形状可能不规则,将分离出的车辆的左上角至右下角的方形区域中的像素作为车辆,剩余部分作为背景。提取车辆的SIFT特征,将其中的背景SIFT特征去除,背景SIFT特征去除的流程见图3。After the vehicle in the surveillance video sequence (original traffic surveillance video sequence or traffic surveillance video to be encoded) is separated by the SuBSENSE method, since the shape of the vehicle may be irregular, the separated vehicle is separated from the upper left corner to the lower right corner of the square area. The pixels of the vehicle are used as the vehicle, and the remaining part is used as the background. The SIFT features of the vehicle are extracted, and the background SIFT features are removed. The process of removing the background SIFT features is shown in Figure 3.
采用SuBSENSE方法分离车辆的同时,会逐步生成比较干净的背景帧。从监控视频序列上提取车辆的同时,将背景帧上对应位置的背景提取出来。While using the SuBSENSE method to separate vehicles, it will gradually generate relatively clean background frames. While extracting the vehicle from the surveillance video sequence, the background of the corresponding position on the background frame is extracted.
以待编码的交通监控视频为例,对于分离出的当前待编码车辆与对应的背景,分别提取二者的SIFT特征,对于从当前待编码车辆上提取的每一SIFT特征,采用下式在对应背景上一定的位置邻域范围内进行检索:Taking the traffic surveillance video to be encoded as an example, for the separated current vehicle to be encoded and the corresponding background, the SIFT features of the two are extracted respectively. For each SIFT feature extracted from the current vehicle to be encoded, the following formula is used in the corresponding Search within a certain location neighborhood range on the background:
(xsc-xsb)2+(ysc-ysb)2≤d2;(xs c -xs b ) 2 +(ys c -ys b ) 2 ≤d 2 ;
其中,xsc和ysc表示从当前待编码车辆上提取的SIFT特征的坐标,xsb和ysb表示从对应背景上提取的SIFT特征的坐标;d为位置邻域的界定范围;示例性的,可以设置d=5。Wherein, xs c and ys c represent the coordinates of the SIFT features extracted from the current vehicle to be encoded, xs b and ys b represent the coordinates of the SIFT features extracted from the corresponding background; d is the bounded range of the location neighborhood; an exemplary , you can set d=5.
如果检索到的归一化后欧氏距离最小的SIFT特征与当前待编码车辆的某一SIFT特征的距离小于一定的阈值:Dmin≤D1;其中,Dmin为归一化后欧氏距离最小的SIFT特征与当前待编码车辆的某一SIFT特征之间的归一化后的欧氏距离,D1为阈值,示例性的可以设置D1=1.1;则说明背景区域中存在与当前待编码车辆的SIFT特征相像的SIFT特征,当前待编码车辆的相应SIFT特征为背景SIFT特征,将其从车辆SIFT中去除。If the distance between the retrieved SIFT feature with the smallest Euclidean distance after normalization and a certain SIFT feature of the current vehicle to be encoded is less than a certain threshold: D min ≤ D 1 ; where D min is the normalized Euclidean distance The normalized Euclidean distance between the smallest SIFT feature and a certain SIFT feature of the currently to-be-coded vehicle, D 1 is the threshold, and D 1 =1.1 can be set exemplarily; The SIFT feature of the encoded vehicle is similar to the SIFT feature of the vehicle, and the corresponding SIFT feature of the current vehicle to be encoded is the background SIFT feature, which is removed from the vehicle SIFT.
2)采用特征匹配进行粗检索。2) Use feature matching for rough retrieval.
本发明实施例中,提取车辆(包含数据库中车辆及待编码车辆)的SIFT特征,数据库中的车辆基于SIFT特征建立倒排表索引,对于待编码车辆,基于SIFT特征匹配从数据库中粗略的检索出若干候选车辆。这一过程较佳实施方式如下:In the embodiment of the present invention, the SIFT features of the vehicles (including the vehicles in the database and the vehicles to be encoded) are extracted, the vehicles in the database establish an inverted table index based on the SIFT features, and for the vehicles to be encoded, a rough search is performed from the database based on the SIFT feature matching Select several candidate vehicles. The preferred implementation of this process is as follows:
采用特征匹配的方式从数据库中粗略的选出若干候选车辆:将数据库中每一车辆的SIFT特征采用k-means算法量化成视觉文字,对于每一视觉文字,计算对应的映射均值向量;再将数据库中每一车辆的每一SIFT特征映射到最近邻的视觉文字,比较映射的SIFT特征向量与最近邻视觉文字对应的映射均值向量,得到每一SIFT特征向量的二值化表征;同时,将数据库中的每一车辆用其SIFT特征对应的视觉文字的频率直方图表示,采用倒排表的方式组织数据库中每一车辆的频率直方图。Use feature matching to roughly select several candidate vehicles from the database: quantify the SIFT features of each vehicle in the database into visual text using the k-means algorithm, and calculate the corresponding mapping mean vector for each visual text; Each SIFT feature of each vehicle in the database is mapped to the nearest neighbor visual text, and the mapped SIFT feature vector is compared with the mapped mean vector corresponding to the nearest neighbor visual text, and the binary representation of each SIFT feature vector is obtained. Each vehicle in the database is represented by the frequency histogram of the visual text corresponding to its SIFT feature, and the frequency histogram of each vehicle in the database is organized by means of an inverted table.
对于当前待编码车辆,同样按照上述处理数据库中车辆的方法,将其每一SIFT特征分配到最近邻的视觉文字,得到当前待编码车辆的频率直方图,同时计算每一SIFT特征的二值化表征。For the current vehicle to be coded, according to the above method of processing vehicles in the database, each SIFT feature is assigned to the nearest visual text to obtain the frequency histogram of the current vehicle to be coded, and the binarization of each SIFT feature is calculated at the same time. characterization.
在比较当前待编码车辆与数据库中某个车辆的相似度时,在映射到同一视觉文字的SIFT特征的二值化表征的汉明距离小于一定阈值的条件下,以tf-idf(term frequency-inverse document frequency,项频率-反文档频率)项加权的频率直方图的距离作为相似度的评价指标,得到当前待编码车辆与数据库中每一车辆的相似度的比较结果;依照计算的相似度的比较结果进行排序,选出相似度排名靠前的若干车辆作为候选车辆。When comparing the similarity between the current vehicle to be encoded and a vehicle in the database, under the condition that the Hamming distance of the binarized representation of the SIFT feature mapped to the same visual text is less than a certain threshold, tf-idf (term frequency- Inverse document frequency, item frequency - inverse document frequency) item weighted frequency histogram distance is used as the evaluation index of similarity, and the comparison result of the similarity between the current vehicle to be encoded and each vehicle in the database is obtained; according to the calculated similarity The comparison results are sorted, and several vehicles with the highest similarity ranking are selected as candidate vehicles.
示例性的,在具体的实现中,可以检索出10个候选车辆。Exemplarily, in a specific implementation, 10 candidate vehicles may be retrieved.
3)使用快速运动估计的方式进行车辆精选。3) Vehicle selection using fast motion estimation.
本发明实施例中,使用快速运动估计的方式从若干候选车辆中精选出一个匹配车辆;这一过程较佳实施方式如下:In the embodiment of the present invention, a matching vehicle is selected from several candidate vehicles by means of fast motion estimation; the preferred implementation of this process is as follows:
a、将当前待编码车辆与每一候选车辆进行对齐。a. Align the current vehicle to be encoded with each candidate vehicle.
对齐的较佳实施方式如下:The preferred implementation of alignment is as follows:
对于当前待编码车辆的某个SIFT特征,计算其与每一候选车辆的所有SIFT特征的距离,将计算得到的距离按从小到大的方式排序后,如果满足下式,则判定当前待编码车辆的相应SIFT特征在相应候选车辆中找到了匹配SIFT特征:For a certain SIFT feature of the current vehicle to be encoded, calculate the distance between it and all SIFT features of each candidate vehicle, sort the calculated distances in ascending order, and determine the current vehicle to be encoded if the following formula is satisfied The corresponding SIFT features of are found matching SIFT features in the corresponding candidate vehicles:
d1≤D2;d 1 ≤ D 2 ;
d1/d2≤α;d 1 /d 2 ≤α;
其中,d1和d2分别为最小和第二小距离,D2和α为常数;Among them, d 1 and d 2 are the smallest and second smallest distances, respectively, and D 2 and α are constants;
按照上述方式计算当前待编码车辆的每一SIFT特征,得到当前待编码车辆与每一候选车辆的SIFT匹配对;依照得到的SIFT特征匹配对的结果,计算当前待编码车辆与每一候选车辆的位置偏移,如下式所示:Calculate each SIFT feature of the current vehicle to be encoded according to the above method, and obtain the SIFT matching pair of the current vehicle to be encoded and each candidate vehicle; position offset, as follows:


其中,MVx和MVy为偏移的水平分量和竖直分量,n为匹配的SIFT特征对的数目,xci和yci为当前待编码车辆的SIFT特征的坐标,xvi和yvi为候选车辆的SIFT特征的坐标;i为SIFT特征匹配对的序号;Among them, MV x and MV y are the horizontal and vertical components of the offset, n is the number of matched SIFT feature pairs, xci and yci are the coordinates of the SIFT feature of the current vehicle to be encoded , and xvi and yvi are The coordinates of the SIFT feature of the candidate vehicle; i is the sequence number of the SIFT feature matching pair;
再采用迭代的方式去除异常点,得到最终的位置偏移结果;依照计算得到的位置偏移结果,将当前待编码车辆与相应候选车辆进行对齐。Then an iterative method is used to remove abnormal points to obtain the final position offset result; according to the calculated position offset result, the current vehicle to be encoded is aligned with the corresponding candidate vehicle.
异常点可以通过如下方式来确定:如果由某对SIFT匹配对计算得到的运动向量偏离均值运动向量较远(即超过设定值),则该SIFT特征匹配对为异常点。The abnormal point can be determined by the following way: if the motion vector calculated by a certain pair of SIFT matching pairs deviates far from the mean motion vector (ie, exceeds the set value), the SIFT feature matching pair is an abnormal point.
b、再将当前待编码车辆划分成固定大小为16x16的块,每一16x16的块在某一候选车辆中搜索损失函数最小的块,其中损失函数由绝对差和及运动矢量的编码码率组成;搜索的方式为以当前16x16的块的位置为起始点,在该起始点周围上下左右64像素范围内进行八点钻石型搜索,将所有16x16的块的损失函数累加作为整个当前待编码车辆在某一候选车辆上的整体损失函数;最终保留整体损失函数最小的候选车辆作为匹配车辆。b. Divide the current vehicle to be encoded into blocks with a fixed size of 16x16, each 16x16 block searches for the block with the smallest loss function in a candidate vehicle, where the loss function is composed of the absolute difference sum and the encoding code rate of the motion vector ; The search method is to take the position of the current 16x16 block as the starting point, perform an eight-point diamond search within 64 pixels around the starting point, and accumulate the loss functions of all 16x16 blocks as the entire current vehicle to be encoded. The overall loss function on a candidate vehicle; the candidate vehicle with the smallest overall loss function is finally reserved as the matching vehicle.
2、背景检索。2. Background search.
本发明实施例中,对于待编码背景基于绝对差和从数据库中选出匹配背景,这一过程较佳实施方式如下:In the embodiment of the present invention, for the background to be encoded, the matching background is selected from the database based on the absolute difference and the preferred implementation of this process is as follows:
以当前待编码背景与数据库中背景对应位置像素的绝对差和作为相似度评价准则,计算当前待编码背景与数据库中每个背景的绝对差和,如下式所示:Taking the absolute difference sum of the current background to be encoded and the pixels corresponding to the background in the database as the similarity evaluation criterion, calculate the absolute difference sum of the current background to be encoded and each background in the database, as shown in the following formula:
SAD=∑k∈B|pck-plk|;SAD = ∑ k∈B |pc k -pl k |;
其中,pck与plk分别为当前待编码背景与数据库中背景第k个像素的值,B为当前待编码背景像素的集合;Wherein, pc k and pl k are the current background to be encoded and the value of the kth pixel of the background in the database, respectively, and B is the set of current background pixels to be encoded;
将计算结果从小到大排序,以绝对差和最小的背景作为当前待编码背景的匹配背景。Sort the calculation results from small to large, and use the background with the absolute difference and the smallest as the matching background of the current background to be encoded.
三、编码。3. Coding.
1、相似度分析。1. Similarity analysis.
本发明实施例中,确定当前待编码车辆和背景的匹配车辆和背景后,确定当前车辆和背景是否在匹配车辆和背景上做率失真优化(RDO)。当前车辆和背景采取帧间预测方式时,将匹配车辆和背景与当前车辆和背景的已有参考帧信息作RDO比较;当前车辆和背景采取帧内预测方式时,将候选车辆和背景与当前车辆和背景粗略的帧内预测方式作RDO比较。车辆和背景相似度分析的具体流程见图4。下面将分别详细介绍帧间、帧内预测方式下RDO的比较。In the embodiment of the present invention, after determining the matching vehicle and background of the current vehicle to be encoded and the background, it is determined whether rate-distortion optimization (RDO) is performed on the matching vehicle and background for the current vehicle and background. When the current vehicle and background are in the inter-frame prediction mode, the matching vehicle and background are compared with the existing reference frame information of the current vehicle and the background for RDO; when the current vehicle and the background are in the intra-frame prediction mode, the candidate vehicle and background are compared with the current vehicle. Compare with RDO with rough background intra-frame prediction. The specific process of vehicle and background similarity analysis is shown in Figure 4. The comparison of RDO in the inter-frame and intra-frame prediction modes will be described in detail below.
1)帧间预测模式下RDO的比较。1) Comparison of RDO in inter prediction mode.
帧间预测模式下率失真优化的比较准则为:The comparison criteria for rate-distortion optimization in inter prediction mode are:

其中,I为拉格朗日损失函数,D为预测块与匹配块的绝对差和,R为用于表示模式信息的比特数,λ为拉格朗日乘子;Among them, I is the Lagrangian loss function, D is the absolute difference sum of the prediction block and the matching block, R is the number of bits used to represent the pattern information, and λ is the Lagrangian multiplier;
为了将匹配车辆与背景和现有的参考帧作比较,先计算得到当前待编码车辆和背景与现有参考帧的拉格朗日损失函数,再计算考虑检索得到的匹配车辆和背景后,得到更新的拉格朗日损失函数,比较更新前后的拉格朗日损失函数,确定是否在匹配的车辆和背景上做RDO。这一过程较佳实施方式如下:In order to compare the matching vehicle with the background and the existing reference frame, first calculate the Lagrangian loss function of the current vehicle to be encoded and the background and the existing reference frame, and then calculate the matching vehicle and background obtained by considering the retrieval. The updated Lagrangian loss function, compare the Lagrangian loss function before and after the update, and determine whether to do RDO on the matching vehicle and background. The preferred implementation of this process is as follows:
a、计算当前待编码车辆和当前待编码背景与现有参考帧的拉格朗日损失函数:a. Calculate the Lagrangian loss function of the current vehicle to be encoded, the current background to be encoded and the existing reference frame:
对于当前待编码车辆的每一个现有参考帧,首先估计出当前车辆在现有参考帧上的位移,然后得到当前车辆在现有参考帧上的最优RDO结果,最后将其与当前车辆在候选匹配车辆上的最优RDO结果作比较,确定是否要在候选匹配车辆上做RDO,相关过程如下:For each existing reference frame of the current vehicle to be encoded, first estimate the displacement of the current vehicle on the existing reference frame, then obtain the optimal RDO result of the current vehicle on the existing reference frame, and finally compare it with the current vehicle on the existing reference frame. Compare the optimal RDO results on the candidate matching vehicle to determine whether to do RDO on the candidate matching vehicle. The relevant process is as follows:
以4×4的块为单位,得到当前待编码车辆对应位置上采用帧间预测4×4的块的运动矢量(Motion Vector,MV)和及其参考帧的图像编号(POC)信息,以此为基础,估计当前待编码车辆上对应4×4的块的运动矢量信息,估计的公式如下:Taking a 4×4 block as a unit, obtain the motion vector (Motion Vector, MV) of the 4×4 block using inter-frame prediction and the picture number (POC) information of its reference frame at the corresponding position of the current vehicle to be encoded. Based on this, the motion vector information of the corresponding 4×4 block on the current vehicle to be encoded is estimated. The estimated formula is as follows:


其中,MVXref和MVYref分别为现有参考帧上帧间预测4×4的块运动矢量的水平分量和竖直分量;POCcur、POCref和POCcolref分别为当前待编码车辆所在的帧的POC、现有参考帧的POC和现有参考帧上帧间预测4×4的块参考帧的POC;MVXcur和MVYcur分别为估计得到的当前待编码车辆对应4×4的块运动矢量的水平分量和竖直分量;遍历当前待编码车辆中的每一个4x4小的块,记录帧间预测4×4的块的数目及其对应的当前待编码车辆4×4的块的运动矢量,最终估计的当前待编码车辆运动矢量的水平分量与竖直分量为所有帧间预测4x4小的块运动矢量的平均值;Among them, MVX ref and MVY ref are the horizontal component and vertical component of the 4×4 block motion vector of the inter-frame prediction on the existing reference frame, respectively; POC cur , POC ref and POC colref are respectively the frame of the current to-be-encoded vehicle. POC, the POC of the existing reference frame, and the POC of the 4×4 block reference frame for inter-frame prediction on the existing reference frame; MVX cur and MVY cur are the estimated values of the 4×4 block motion vector corresponding to the current vehicle to be encoded, respectively. Horizontal component and vertical component; traverse each 4×4 small block in the current vehicle to be encoded, record the number of
从而得到当前待编码车辆在每个现有参考帧上的位移,之后,将当前待编码车辆划分成固定大小为16x16的块,每一16x16的块在所有现有参考帧中依次搜索损失函数最小的块,其中损失函数由绝对差和及运动矢量的编码码率组成;搜索的方式为以当前16x16的块按估计得到的位移平移后的位置为起始点,在该起始点周围上下左右64像素范围内进行八点钻石型搜索;以16x16的块为单位,记录当前待编码车辆中所有块与所有现有参考帧中匹配块的最小损失函数;依次遍历当前待编码车辆中每个16x16的块,累加其记录得最小损失函数和,得到当前待编码车辆相对于现有参考帧的拉格朗日损失函数
对于当前待编码背景,将其划分成16x16的块;对于当前16x16的块,从所有现有参考帧中搜索最小损失函数对应的匹配块;搜索的方式为比较所有参考帧对应位置的16x16的块与当前待编码背景内当前16x16的块的绝对差和,选出最小的绝对差和作为当前待编码背景内当前16x16的块的损失函数;遍历当前待编码背景中所有16x16的块,累加所有16x16的块的损失函数,作为当前待编码背景的拉格朗日损失函数
b、将匹配车辆和背景考虑进来,计算更新后的拉格朗日损失函数:b. Taking into account the matching vehicle and background, calculate the updated Lagrangian loss function:
对于当前待编码车辆内的每个16x16的块,在拉格朗日损失函数




对于当前待编码背景内的每个16x16的块,在拉格朗日损失函数

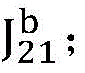


以参考索引比特变化信息的比特数计算方式为例进行介绍:Take the calculation method of the number of bits of the reference index bit change information as an example to introduce:
如图5所示,对于当前待编码车辆和背景中的每个16x16的块,在计算其与现有的参考帧和匹配车辆与背景的最小损失函数时,如果其最小损失函数对应的匹配块索引是n-1,则比特数加1,其中,n为现有的参考帧数目;否则,如果其最小损失函数对应的匹配块在匹配的车辆或背景上,则比特数增加n-1-idx,其中,idx为在不考虑匹配的车辆和背景时,该16x16的块最小损失函数对应的匹配块索引。除此之外,比特数不变。遍历当前待编码车辆和背景内的每个16x16的块,最终的参考索引比特变化信息的比特数位每个16x16的块变化比特数的求和。将比特数变化和前面计算得到的拉格朗日损失函数组合起来,得到更新后的对应于当前待编码车辆和背景的拉格朗日损失函数。As shown in Figure 5, for each 16x16 block in the current vehicle to be encoded and the background, when calculating its minimum loss function with the existing reference frame and matching vehicle and background, if the matching block corresponding to its minimum loss function If the index is n-1, the number of bits is increased by 1, where n is the number of existing reference frames; otherwise, if the matching block corresponding to its minimum loss function is on the matched vehicle or background, the number of bits is increased by n-1- idx, where idx is the matching block index corresponding to the 16x16 block minimum loss function when the matched vehicle and background are not considered. Other than that, the number of bits remains the same. Traverse the current vehicle to be encoded and each 16x16 block in the background, and the final reference index bit change information is the sum of the bit number of each 16x16 block change. Combining the change in the number of bits with the Lagrangian loss function calculated earlier, the updated Lagrangian loss function corresponding to the current vehicle to be encoded and the background is obtained.
最后,比较拉格朗日损失函数




2、帧内预测模式下RDO的比较。2. Comparison of RDO in intra prediction mode.
帧内预测模式下率失真优化的比较准则与帧间预测模式类似,也表示为:The comparison criterion for rate-distortion optimization in intra prediction mode is similar to that in inter prediction mode, which is also expressed as:

其中,J为拉格朗日损失函数,D为预测块与匹配块的绝对差和,R为用于表示模式信息的比特数,λ为拉格朗日乘子。Among them, J is the Lagrangian loss function, D is the absolute difference sum of the prediction block and the matching block, R is the number of bits used to represent the pattern information, and λ is the Lagrangian multiplier.
a、对于当前待编码背景,在帧内预测模式下,始终在匹配背景上进行率失真优化处理。a. For the current background to be encoded, in the intra-frame prediction mode, rate-distortion optimization is always performed on the matching background.
b、对于当前待编码车辆,首先,粗略估计出当前待编码车辆采用帧内预测时的损失函数:将当前待编码车辆划分成固定大小为16x16的块,对于每个16x16的块,依次进行均值模式(DC)、平滑模式(planar)、水平和垂直帧内预测模式的估计,得到每个16x16的块对应于每种模式的绝对差和;帧内预测模式估计时,当前16x16的块的参考像素值由邻近16x16的块的原始值推出;对于每个16x16的块,将其在所有模式下估计得到的绝对差和按照从小到大的顺序排序,以绝对差和最小的结果作为当前16x16的块的最优匹配结果;遍历当前待编码车辆中所有16x16的块,累加每个16x16的块的最优匹配结果,得到当前待编码车辆的拉格朗日损失函数
将匹配车辆考虑进来,计算更新后的拉格朗日损失函数:对于当前待编码车辆内的每个16x16的块,在拉格朗日损失函数


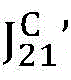

比较拉格朗日损失函数


2、车辆与背景的编码。2. Coding of vehicles and backgrounds.
1)当采用帧间预测模式时,如果判定需要在匹配车辆或匹配背景上进行率失真优化处理,则新申请一个参考帧的空间,将匹配车辆或匹配背景贴于新申请的参考帧上与现有的参考帧一起供当前待编码车辆或待编码背景做帧间预测;帧间预测结束后,遍历当前待编码车辆或当前待编码背景覆盖的每个4x4的块,如果某个4x4的块参考了当前待编码车辆或当前待编码背景的信息,则将相应的语法元素编入码流;1) When the inter-frame prediction mode is adopted, if it is determined that rate-distortion optimization processing is required on the matching vehicle or the matching background, a space for a new reference frame is newly applied, and the matching vehicle or matching background is pasted on the newly applied reference frame. The existing reference frames are used for inter-frame prediction of the current vehicle to be encoded or the background to be encoded; after the inter-frame prediction is over, traverse each 4x4 block covered by the current vehicle to be encoded or the current background to be encoded, if a certain 4x4 block With reference to the information of the current vehicle to be encoded or the current background to be encoded, the corresponding syntax element is encoded into the code stream;
2)当采用帧内预测模式时,如果判定需要在匹配车辆或匹配背景上进行率失真优化处理,则新申请一个参考帧的空间,将匹配车辆或匹配背景贴于新申请的参考帧上供当前待编码车辆或待编码背景做帧内预测。2) When the intra-frame prediction mode is adopted, if it is determined that rate-distortion optimization processing is required on the matching vehicle or the matching background, a space for a new reference frame is newly applied, and the matching vehicle or matching background is pasted on the newly applied reference frame for reference. Intra-frame prediction is performed on the current vehicle to be encoded or the background to be encoded.
上述两部分中,将匹配车辆贴于新申请的参考帧的位置由下式确定:In the above two parts, the position where the matching vehicle is attached to the reference frame of the new application is determined by the following formula:
x0=xc+MVx;x 0 =x c +MV x ;
y0=yc+MVy;y 0 =y c +MV y ;
其中,x0和y0表示匹配车辆贴到新申请的参考帧上的位置,xc和yc表示当前待编码车辆在当前帧的位置,MVx和MVy为当前待编码车辆相对于匹配车辆偏移的水平分量和竖直分量(通过前述快速运动估计获得);Among them, x 0 and y 0 represent the position where the matching vehicle is attached to the reference frame of the new application, x c and y c represent the position of the current vehicle to be encoded in the current frame, MV x and MV y are the relative position of the current vehicle to be encoded relative to the matching vehicle the horizontal and vertical components of the vehicle offset (obtained by the aforementioned fast motion estimation);
将匹配背景贴在参考帧上时,与参考帧位置对齐即可。When the matching background is pasted on the reference frame, it can be aligned with the reference frame position.
3、编码码流结构3. Encoding code stream structure
本发明实施例中,编码码流的结构分为片(slice)和树形编码单元(CTU)两层;其中:In the embodiment of the present invention, the structure of the encoded code stream is divided into two layers: slice and tree coding unit (CTU); wherein:
slice层:对于当前待编码车辆,slice层包含一个表示当前slice层中是否有匹配车辆被参考的标记(flag);遍历当前slice层中所有车辆覆盖的4x4的块,判断其是否参考了匹配车辆,如果存在某个4x4的块参考了匹配车辆,则标记为真,否则标记为假;如果标记为真,则slice层还要包含表示当前slice层中被参考匹配车辆数目的语法元素;对于每个匹配车辆,其在数据库中的位置索引、其贴在新申请的参考帧上的位置一并编入码流,被参考的匹配车辆数目、每个匹配车辆的索引、以及每个匹配车辆贴在新申请的参考帧上的位置采用定长编码方式进行编码;Slice layer: For the current vehicle to be encoded, the slice layer contains a flag that indicates whether there is a matching vehicle in the current slice layer; traverse the 4x4 blocks covered by all vehicles in the current slice layer to determine whether it refers to a matching vehicle. , if there is a 4x4 block that references a matching vehicle, it is marked as true, otherwise it is marked as false; if it is marked as true, the slice layer also contains a syntax element indicating the number of referenced matching vehicles in the current slice layer; for each matching vehicles, their position index in the database, their position on the reference frame of the new application are encoded into the code stream together, the number of referenced matching vehicles, the index of each matching vehicle, and the labeling of each matching vehicle The position on the reference frame of the new application is coded using fixed-length coding;
对于当前待编码背景,slice层包含一个表示当前slice层中是否有匹配背景被参考的标记;遍历当前slice层中所有背景覆盖的4x4的块,判断其是否参考了匹配背景,如果存在某个4x4的块参考了匹配背景,则标记为真,否则标记为假;如果标记为真,则slice层还要包含被参考的匹配背景在数据库中的位置索引语法元素,该语法元素采用定长编码方式进行编码;For the current background to be coded, the slice layer contains a flag indicating whether there is a matching background in the current slice layer to be referenced; traverse all the 4x4 blocks covered by the background in the current slice layer to determine whether it refers to the matching background, if there is a certain 4x4 If the block refers to the matching background, it is marked as true, otherwise it is marked as false; if it is marked as true, the slice layer also contains the position index syntax element of the referenced matching background in the database, and the syntax element adopts the fixed-length encoding method. to encode;
CTU层:对于当前待编码车辆,CTU层包含一个表示当前CTU层是否参考了匹配车辆像素的标记;遍历当前CTU层中每个4x4的块,如果存在某个4x4的块参考了匹配车辆像素,则标记为真,否则标记为假;当标记为真时,CTU层还要包含一个表示匹配车辆索引(index)的语法元素;CTU layer: For the current vehicle to be encoded, the CTU layer contains a flag indicating whether the current CTU layer refers to the matching vehicle pixel; traverse each 4x4 block in the current CTU layer, if there is a 4x4 block that refers to the matching vehicle pixel, If it is marked as true, otherwise it is marked as false; when it is marked as true, the CTU layer also contains a syntax element indicating the matching vehicle index (index);
对于当前待编码背景,CTU层包含一个表示当前CTU层是否参考了匹配背景像素的标记。For the current background to be encoded, the CTU layer contains a flag indicating whether the current CTU layer refers to matching background pixels.
另一方面,为了说明本发明上述方案的编码性能还进行了相关测试。On the other hand, in order to illustrate the coding performance of the above scheme of the present invention, relevant tests are also carried out.
测试条件包括:1)帧间配置:随机接入即Random Access,RA;低延时B即Low-delayB,LDB;低延时P即Low-delay P,LDP。2)基本量化步长(QP)设置为{27,32,37,42},基于的软件是HM16.7,测试序列为自己拍摄的14段测试序列,截图如图6所示。实验结果见表1与表2。The test conditions include: 1) Inter-frame configuration: random access is Random Access, RA; low-delay B is Low-delayB, LDB; low-delay P is Low-delay P, LDP. 2) The basic quantization step size (QP) is set to {27, 32, 37, 42}, the software based on it is HM16.7, and the test sequence is a 14-segment test sequence taken by myself, as shown in Figure 6. The experimental results are shown in Table 1 and Table 2.
其中表1为RA、LDB、LDP设置下的性能对比结果,表2为RA、LDB、LDP设置下的编解码端复杂度对比结果。Among them, Table 1 shows the performance comparison results under the RA, LDB, and LDP settings, and Table 2 shows the codec side complexity comparison results under the RA, LDB, and LDP settings.

表1RA、LDB、LDP设置下的性能对比结果Table 1. Performance comparison results under RA, LDB, and LDP settings

表2RA、LDB、LDP设置下的编解码端复杂度对比结果Table 2 Comparison results of codec complexity under RA, LDB and LDP settings
从表1~表2中可以看出,本发明实施例上述方案相对于HM16.7在RA、LDB和LDP模式下可分别获得35.1%、31.3%和28.8.0%的码率节省,并且编解码端的复杂度的增加在合理范围内。It can be seen from Table 1 to Table 2 that, compared with HM16.7, the above scheme in the embodiment of the present invention can obtain 35.1%, 31.3% and 28.8.0% of the code rate saving in RA, LDB and LDP modes respectively, and the coding The increase in complexity at the decoding end is within a reasonable range.
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。From the description of the above embodiments, those skilled in the art can clearly understand that the above embodiments can be implemented by software or by means of software plus a necessary general hardware platform. Based on this understanding, the technical solutions of the above embodiments may be embodied in the form of software products, and the software products may be stored in a non-volatile storage medium (which may be CD-ROM, U disk, mobile hard disk, etc.), including Several instructions are used to cause a computer device (which may be a personal computer, a server, or a network device, etc.) to execute the methods described in various embodiments of the present invention.
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。The above description is only a preferred embodiment of the present invention, but the protection scope of the present invention is not limited to this. Substitutions should be covered within the protection scope of the present invention. Therefore, the protection scope of the present invention should be based on the protection scope of the claims.
Claims (9)


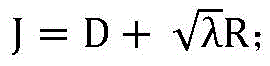

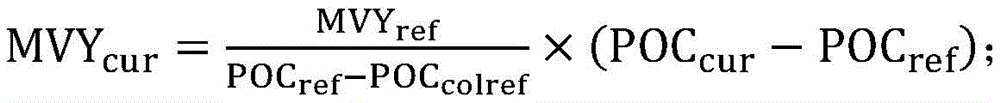















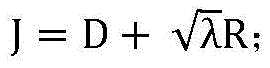






Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810720989.1A CN108833928B (en) | 2018-07-03 | 2018-07-03 | Traffic monitoring video coding method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810720989.1A CN108833928B (en) | 2018-07-03 | 2018-07-03 | Traffic monitoring video coding method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108833928A CN108833928A (en) | 2018-11-16 |
| CN108833928B true CN108833928B (en) | 2020-06-26 |
Family
ID=64135268
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810720989.1A Active CN108833928B (en) | 2018-07-03 | 2018-07-03 | Traffic monitoring video coding method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108833928B (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109871024A (en) * | 2019-01-04 | 2019-06-11 | 中国计量大学 | A UAV Pose Estimation Method Based on Lightweight Visual Odometry |
| CN111582251B (en) * | 2020-06-15 | 2021-04-02 | 江苏航天大为科技股份有限公司 | Method for detecting passenger crowding degree of urban rail transit based on convolutional neural network |
| CN112714322B (en) * | 2020-12-28 | 2023-08-01 | 福州大学 | An optimization method of inter-frame reference for game video |
| CN113891090B (en) * | 2021-10-27 | 2025-08-19 | 北京达佳互联信息技术有限公司 | Video encoding method, video encoding device, storage medium and electronic equipment |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009111498A3 (en) * | 2008-03-03 | 2009-12-03 | Videoiq, Inc. | Object matching for tracking, indexing, and search |
| CN104301735A (en) * | 2014-10-31 | 2015-01-21 | 武汉大学 | Global encoding method and system for urban traffic surveillance video |
| CN104539962A (en) * | 2015-01-20 | 2015-04-22 | 北京工业大学 | Layered video coding method fused with visual perception features |
| CN105849771A (en) * | 2013-12-19 | 2016-08-10 | Metaio有限公司 | Simultaneous positioning and mapping on mobile devices |
-
2018
- 2018-07-03 CN CN201810720989.1A patent/CN108833928B/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009111498A3 (en) * | 2008-03-03 | 2009-12-03 | Videoiq, Inc. | Object matching for tracking, indexing, and search |
| CN105849771A (en) * | 2013-12-19 | 2016-08-10 | Metaio有限公司 | Simultaneous positioning and mapping on mobile devices |
| CN104301735A (en) * | 2014-10-31 | 2015-01-21 | 武汉大学 | Global encoding method and system for urban traffic surveillance video |
| CN104539962A (en) * | 2015-01-20 | 2015-04-22 | 北京工业大学 | Layered video coding method fused with visual perception features |
Non-Patent Citations (4)
| Title |
|---|
| Background-modeling-based adaptive prediction for surveillance video coding;Xianguo Zhang;《IEEE Transactions on Image Processing》;20141231;全文 * |
| Global coding of multi-source surveillance video data;Jing Xiao;《Data Compression Conference (DCC)》;20151231;全文 * |
| Knowledge-based coding of objects for multisource surveillance video data;Jing Xiao;《IEEE Transactions on Multimedia》;20161231;全文 * |
| Surveillance video coding with vehicle library;Changyue Ma;《2017 IEEE International Conference on Image Processing (ICIP)》;20170920;第1-4节 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108833928A (en) | 2018-11-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110087087B (en) | VVC inter-frame coding unit prediction mode early decision and block division early termination method | |
| CN108833928B (en) | Traffic monitoring video coding method | |
| CN110809161B (en) | Method and device for constructing motion information candidate list | |
| US6618507B1 (en) | Methods of feature extraction of video sequences | |
| CN112437310B (en) | VVC intra-frame coding rapid CU partition decision method based on random forest | |
| CN101873500B (en) | Interframe prediction encoding method, interframe prediction decoding method and equipment | |
| US11070803B2 (en) | Method and apparatus for determining coding cost of coding unit and computer-readable storage medium | |
| CN107657228B (en) | Video scene similarity analysis method and system, video encoding and decoding method and system | |
| CN104754357B (en) | Intraframe coding optimization method and device based on convolutional neural networks | |
| CN109104609B (en) | A Shot Boundary Detection Method Fusing HEVC Compression Domain and Pixel Domain | |
| EP3405904B1 (en) | Method for processing keypoint trajectories in video | |
| WO2018192235A1 (en) | Coding unit depth determination method and device | |
| CN105430391B (en) | The intraframe coding unit fast selecting method of logic-based recurrence classifier | |
| CN107371022B (en) | Inter-frame coding unit rapid dividing method applied to HEVC medical image lossless coding | |
| Chen et al. | A novel fast intra mode decision for versatile video coding | |
| CN111479110B (en) | Fast Affine Motion Estimation Method for H.266/VVC | |
| CN103327327B (en) | For the inter prediction encoding unit selection method of high-performance video coding HEVC | |
| Song et al. | An efficient low-complexity block partition scheme for VVC intra coding | |
| CN108712647A (en) | A kind of CU division methods for HEVC | |
| CN102917225A (en) | Method for quickly selecting HEVC (high-efficiency video coding) inframe coding units | |
| CN106507106A (en) | Video Inter-frame Predictive Coding Method Based on Reference Slices | |
| CN116962708B (en) | Intelligent service cloud terminal data optimization transmission method and system | |
| CN103020138A (en) | Method and device for video retrieval | |
| CN106791828A (en) | High performance video code-transferring method and its transcoder based on machine learning | |
| CN110519597B (en) | HEVC-based encoding method and device, computing equipment and medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |