CN108805036B - Unsupervised video semantic extraction method - Google Patents
Unsupervised video semantic extraction method Download PDFInfo
- Publication number
- CN108805036B CN108805036B CN201810496579.3A CN201810496579A CN108805036B CN 108805036 B CN108805036 B CN 108805036B CN 201810496579 A CN201810496579 A CN 201810496579A CN 108805036 B CN108805036 B CN 108805036B
- Authority
- CN
- China
- Prior art keywords
- video
- neural network
- semantic
- feature
- convolutional neural
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
- G06V20/41—Higher-level, semantic clustering, classification or understanding of video scenes, e.g. detection, labelling or Markovian modelling of sport events or news items
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Image Analysis (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description
技术领域technical field
本发明涉及人工智能和模式识别技术领域,特别是涉及一种基于深度学习模型的非监督视频语义提取方法。The invention relates to the technical fields of artificial intelligence and pattern recognition, in particular to a method for extracting semantics from unsupervised video based on a deep learning model.
背景技术Background technique
“语义”这一概念起源于19世纪末,是虚拟数据所对应的现实世界中的事物所代表的含义的表现,以及这些含义之间的关系,是虚拟数据在某个领域上的解释和逻辑表示。而且“视频语义”是针对人类思维而言的,当我们想用计算机来理解视频之中的“语义”时,计算机只能够识别诸如颜色、形状等底层特征。因此,我们需要采用一些方法将这些底层的特征联系起来,形成一些更高层的含义,从而将视频中所要展示的信息更好的表达出来。The concept of "semantics" originated at the end of the 19th century. It is the expression of the meanings represented by things in the real world corresponding to virtual data, and the relationship between these meanings. It is the interpretation and logical representation of virtual data in a certain field. . Moreover, "video semantics" is aimed at human thinking. When we want to use computers to understand the "semantics" in videos, computers can only recognize low-level features such as color and shape. Therefore, we need to use some methods to connect these low-level features to form some higher-level meanings, so as to better express the information to be displayed in the video.
视频数据通常是非结构化的,因此对视频的语义提取,需要从多方面进行考虑。从内容上,需要考虑视频含有的空间和时间属性。从语义上,需要考虑视频信息包括的图像特征、字幕文本特征、语音特征和视频描述信息文本特征等。视频在物理结构上分成了四个结构层次:帧、镜头、场景和视频。视频帧的内容记录了视频中对象的特征,如色彩、纹路和形态等;镜头是由若干连续帧组成的,其内容记录了连续帧中对象的运动特征,表现了对象的时间特性。在现实中,镜头是生成视频的基本单位,即是摄像机一次拍摄所得到的最小单位;场景由一系列语义内容相关并且时间上连续的镜头组成,其内容记录了较为复杂的语义信息。若干个场景组成一个视频文件,其内容记录了整个视频的语义信息。Video data is usually unstructured, so the semantic extraction of video needs to be considered from many aspects. In terms of content, it is necessary to consider the spatial and temporal attributes contained in the video. Semantically, it is necessary to consider image features, subtitle text features, voice features, and video description text features included in video information. Video is divided into four structural levels in physical structure: frame, shot, scene and video. The content of the video frame records the characteristics of the object in the video, such as color, texture and shape, etc.; the shot is composed of several consecutive frames, and its content records the motion characteristics of the object in the continuous frames, showing the temporal characteristics of the object. In reality, a shot is the basic unit of video generation, that is, the smallest unit obtained by a camera shooting once; a scene is composed of a series of shots with related semantic content and continuous time, and its content records relatively complex semantic information. Several scenes form a video file, and its content records the semantic information of the entire video.
(1)基于关键帧的视频语义提取,通常的关键帧语义提取技术流程为:对视频的帧截图;对帧截图进行关键帧识别,对取得的关键帧进行语义分析;将视频中包含的语音数据通过语音识别转换成文本;对语音文本进行语义识别;将上述关键帧语义和语音语义结合在一起,就得到了这个视频的语义;也就是将视频的图像特征和声音mfcc特征转换为语义特征,然后结合字幕的识别,通过Neuro-Linguistic Programming处理字幕得到词向量和文档相似度。这个方法的优势在于对视频上的文字内容较多的视频有较好的提取效果,比如一些教育类的视频。劣势就是对其他类型的文字较少的视频,因为其关键帧中的字幕信息较少,很难从中获得有用的文本信息。(1) Video semantic extraction based on key frames, the usual technical process of key frame semantic extraction is: screenshot of video frames; key frame recognition of frame screenshots, semantic analysis of the obtained key frames; voice contained in the video The data is converted into text through speech recognition; the speech text is semantically recognized; the above key frame semantics and speech semantics are combined to obtain the semantics of the video; that is, the image features and sound mfcc features of the video are converted into semantic features , and then combined with the identification of subtitles, the subtitles are processed through Neuro-Linguistic Programming to obtain word vectors and document similarity. The advantage of this method is that it has a better extraction effect on videos with more text content on the video, such as some educational videos. The disadvantage is that for other types of videos with less text, because the subtitle information in the key frame is less, it is difficult to obtain useful text information from it.
(2)基于视频文本信息关键词提取,这种方法是对纯文本的提取,且此方法对词本身的重要程度、词所在的位置要求比较高,前面的词比后面的词重要,词频,词的整体出现顺序,也需要综合起来。也就是说标题的内容需要非常切合视频语义,否则这种方法的准确率会非常低。这种方法的优势是计算复杂度较低,业内有成熟的文本处理算法,并且各种算法开源包都很方便。劣势:有一些网络用语其表达的意思与字面意思相差很大,对视频语义的提取会产生极大的干扰。(2) Keyword extraction based on video text information, this method is the extraction of plain text, and this method has relatively high requirements for the importance of the word itself and the position of the word, the former word is more important than the latter word, word frequency, The overall order of appearance of words also needs to be integrated. That is to say, the content of the title needs to be very consistent with the semantics of the video, otherwise the accuracy of this method will be very low. The advantage of this method is that the calculation complexity is low, there are mature text processing algorithms in the industry, and various open source packages of algorithms are very convenient. Disadvantages: There are some Internet terms whose meaning is quite different from the literal meaning, which will greatly interfere with the extraction of video semantics.
对于体育视频的语义分析,目前的方法很少考虑对无标签数据的语义提取,因此当测试数据不属于训练数据种类之一时会发生领域漂移问题,从而影响视频语义提取准确度。For the semantic analysis of sports videos, the current methods rarely consider the semantic extraction of unlabeled data, so when the test data does not belong to one of the training data types, domain drift will occur, which will affect the accuracy of video semantic extraction.
发明内容Contents of the invention
本发明的目的在于克服现有的技术不足,提供一种使用三维卷积神经网络模型和循环自编码器相结合的视频语义提取的方法,能够解决非监督的视频语义分析与提取问题,提高视频语义提取准确度。The purpose of the present invention is to overcome the existing technical deficiencies, and provide a method for video semantic extraction using a combination of a three-dimensional convolutional neural network model and a cyclic autoencoder, which can solve the problem of unsupervised video semantic analysis and extraction, and improve video quality. Semantic extraction accuracy.
具体的,一种非监督视频语义提取方法,其特征在于,包括以下步骤:Specifically, a method for unsupervised video semantic extraction, is characterized in that, comprises the following steps:
S1:构建三维卷积神经网络模型,使用视频数据库中带标签的UCF-101视频集训练三维卷积神经网络模型;S1: Construct a three-dimensional convolutional neural network model, and use the labeled UCF-101 video set in the video database to train the three-dimensional convolutional neural network model;
S2:使用滑动窗口将视频数据库中不带标签视频数据处理成符合三维卷积神经网络输入的数据;S2: Use the sliding window to process the unlabeled video data in the video database into data that conforms to the input of the 3D convolutional neural network;
S3:使用S2步骤生成数据作为三维卷积神经网络模型的输入数据,取三维卷积神经网络模型全连接层的输出数据作为视频段的语义特征;S3: Use the data generated in step S2 as the input data of the three-dimensional convolutional neural network model, and take the output data of the fully connected layer of the three-dimensional convolutional neural network model as the semantic feature of the video segment;
S4:使用S3步骤生成的视频段语义特征序列作为视频语义自编码器的输入,通过自编码器整合得到视频整体语义特征。S4: Use the video segment semantic feature sequence generated in step S3 as the input of the video semantic autoencoder, and obtain the overall semantic feature of the video through the integration of the autoencoder.
优选地,步骤S1包括下列子步骤:Preferably, step S1 includes the following sub-steps:
S11:构建包含五层卷积层、池化层,两层全连接层和一层SOFTMAX层的三维卷积神经网络模型;S11: Construct a three-dimensional convolutional neural network model including five convolutional layers, pooling layers, two fully connected layers and one SOFTMAX layer;
S12:在使用视频数据库中带标签的UCF-101视频集训练三维卷积神经网络之前,需要对视频数据集视频预处理:将UCF-101视频集中的原始视频需要按照一定的FPS转化为视频帧图片集,对图片进行大小调整、噪声过滤的图像预处理,将图片转化为112*112的统一规格;S12: Before using the labeled UCF-101 video set in the video database to train the 3D convolutional neural network, the video data set video preprocessing is required: the original video in the UCF-101 video set needs to be converted into a video frame according to a certain FPS Image collection, image preprocessing of image size adjustment and noise filtering, converting the image into a unified specification of 112*112;
S13:经过预处理的UCF-101视频集训练视频对应数据形式为(Xn,Ln):n为训练视频个数,其中Xn=[xn(1),xn(2),xn(3),...,xn(m)]是视频Xn经过预处理后的视频图片集合,m为视频转化为图片帧的个数,本方法使用ffmpeg将视频按照每秒20帧转化为图片序列,Ln为视频Xn对应标签类型;S13: The data format corresponding to the preprocessed UCF-101 video set training video is (X n , L n ): n is the number of training videos, where X n =[x n(1) ,x n(2) ,x n(3) ,...,x n(m) ] is the preprocessed video picture collection of video X n , m is the number of video frames converted into pictures, this method uses ffmpeg to convert the video at 20 frames per second Converted to a picture sequence, L n is the label type corresponding to the video X n ;
S14:基于三维卷积神经网络模型和学习算法,使用经过预处理的UCF-101视频数据集,训练一个具有高识别率的视频种类识别模型。S14: Based on the three-dimensional convolutional neural network model and learning algorithm, use the preprocessed UCF-101 video dataset to train a video category recognition model with a high recognition rate.
优选地,步骤S2包括下列子步骤:Preferably, step S2 includes the following sub-steps:
S21:将测试数据中视频帧图片数量m不满足m=kw的视频帧图片集进行补充处理,其中,k为任意整数,w为滑动窗口的大小,将视频最后一帧的图片进行复制操作直到满足m为w的倍数;S21: Supplementary processing is performed on the video frame picture set whose number m of video frame pictures in the test data does not satisfy m=kw, wherein k is any integer, w is the size of the sliding window, and the picture of the last frame of the video is copied until Satisfied that m is a multiple of w;
S22:使用滑动窗口对视频帧序列进行滑动读取帧图片,滑动步长为滑动窗口的一半,每滑动一次,获取的帧图片为三维卷积神经网络的一次输入;取滑动窗口大小w=16,因此测试数据形式经过处理变为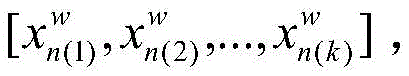
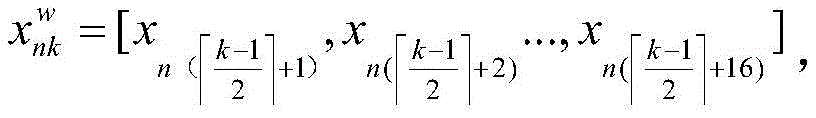
优选地,步骤S3包括下列子步骤:Preferably, step S3 includes the following sub-steps:
S31:使用S1中使用UCF-101视频集训练得到的三维卷积神经网络模型识别S2中处理后的测试视频数据
S32:将三维卷积神经网络的全连接层的输出固定为子动作种类个数;S32: fixing the output of the fully connected layer of the three-dimensional convolutional neural network as the number of sub-action types;
S33:三维卷积神经网络输入为S22中定义的
S34:测试视频数据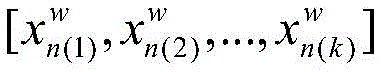
优选地,步骤S4包括下列子步骤:Preferably, step S4 includes the following sub-steps:
S41:使用S3中三维卷积神经网络模型对测试视频数据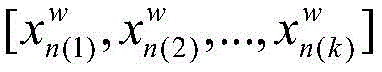
S42:循环自编码器将输入特征序列[F1,F2,F3,...,Fk]转化为特征对序列[[F1,F2],[F2,F3],[F3,F4],...,[Fk-1,Fk]],采取贪心算法思想,其过程为依次选取特征对序列中的每一对特征将其整合为一个父特征,表示为:F1,2=f(W(1)[F1,F2]+b(1)),其中W(1)代表n*n的矩阵参数,b(1)是一个偏置项,W(1)与b(1)是通过学习特征序列对得到的;F1,2的重构过程为:[F1',F2']=W(2)F1,2+b(2)其中W(2)代表n*n的矩阵参数,b(2)是不同于b(1)的偏置项,同样W(2)与b(2)是通过学习重构误差得到;自编码器的重构误差为:

S43:重复S42的自编码过程,直到特征序列中特征向量个数为1;S43: Repeat the self-encoding process of S42 until the number of feature vectors in the feature sequence is 1;
S44:循环自编码器输出最终的特征向量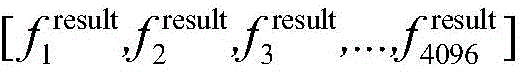
本发明的有益效果在于:The beneficial effects of the present invention are:
本发明通过结合三维卷积神经网络和循环自动编码器的方案,解决了非监督的视频语义分析与提取问题,提高了视频语义提取准确度。The invention solves the problem of unsupervised video semantic analysis and extraction by combining the scheme of the three-dimensional convolutional neural network and the cyclic automatic encoder, and improves the accuracy of video semantic extraction.
附图说明Description of drawings
图1是本发明提出的一种非监督视频语义提取方法的流程图。Fig. 1 is a flow chart of a method for extracting semantic meaning from unsupervised video proposed by the present invention.
图2是本发明构建的三维卷积神经网络模型的结构图。Fig. 2 is a structural diagram of a three-dimensional convolutional neural network model constructed by the present invention.
图3是本发明方法中训练三维卷积神经网络模型的流程示意图。Fig. 3 is a schematic flow chart of training a three-dimensional convolutional neural network model in the method of the present invention.
图4是本发明方法中提取视频语义特征的流程示意图。Fig. 4 is a schematic flow chart of extracting video semantic features in the method of the present invention.
图5是本发明基于三维卷积神经网络与循环自编码器模型的架构图。Fig. 5 is an architecture diagram of the present invention based on a three-dimensional convolutional neural network and a cyclic autoencoder model.
具体实施方式Detailed ways
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图说明本发明的具体实施方式。In order to have a clearer understanding of the technical features, purposes and effects of the present invention, the specific implementation manners of the present invention will now be described with reference to the accompanying drawings.
本发明提出的一种非监督视频语义提取方法实施例流程图如图1所示,包括以下步骤:A flow chart of an embodiment of an unsupervised video semantic extraction method proposed by the present invention is shown in Figure 1, comprising the following steps:
S1:构建三维卷积神经网络模型,使用视频数据库中带标签的UCF-101视频集训练三维卷积神经网络模型;S1: Construct a three-dimensional convolutional neural network model, and use the labeled UCF-101 video set in the video database to train the three-dimensional convolutional neural network model;
S2:使用滑动窗口将视频数据库中不带标签视频数据处理成符合三维卷积神经网络输入的数据;S2: Use the sliding window to process the unlabeled video data in the video database into data that conforms to the input of the 3D convolutional neural network;
S3:使用S2步骤生成数据作为三维卷积神经网络模型的输入数据,取三维卷积神经网络模型全连接层的输出数据作为视频段的语义特征;S3: Use the data generated in step S2 as the input data of the three-dimensional convolutional neural network model, and take the output data of the fully connected layer of the three-dimensional convolutional neural network model as the semantic feature of the video segment;
S4:使用S3步骤生成的视频段语义特征序列作为视频语义自编码器的输入,通过自编码器整合得到视频整体语义特征。S4: Use the video segment semantic feature sequence generated in step S3 as the input of the video semantic autoencoder, and obtain the overall semantic feature of the video through the integration of the autoencoder.
作为一种优选实施例,步骤S1包括下列子步骤:As a preferred embodiment, step S1 includes the following sub-steps:
S11:构建包含五层卷积层、池化层,两层全连接层和一层SOFTMAX层的三维卷积神经网络模型,所构建的三维卷积神经网络模型结构如图2所示;S11: Construct a three-dimensional convolutional neural network model including five convolutional layers, a pooling layer, two fully connected layers and one layer of SOFTMAX. The structure of the constructed three-dimensional convolutional neural network model is shown in Figure 2;
S12:在使用视频数据库中带标签的UCF-101视频集训练三维卷积神经网络之前,需要对视频数据集视频预处理:将UCF-101视频集中的原始视频需要按照一定的FPS转化为视频帧图片集,对图片进行大小调整、噪声过滤的图像预处理,将图片转化为112*112的统一规格;对图像进行预处理,是由于受到各种条件的限制和随机干扰,这些图片集往往不能直接使用,因而需要在图像处理的早期阶段对它们进行大小调整、噪声过滤等图像预处理;S12: Before using the labeled UCF-101 video set in the video database to train the 3D convolutional neural network, the video data set video preprocessing is required: the original video in the UCF-101 video set needs to be converted into a video frame according to a certain FPS Image collection, image preprocessing of image size adjustment and noise filtering, converting the image into a unified specification of 112*112; image preprocessing is due to various conditions and random interference, these image collections often cannot are used directly, thus requiring image preprocessing such as resizing, noise filtering, etc., to be performed on them at an early stage of image processing;
S13:经过预处理的UCF-101视频集训练视频对应数据形式为(Xn,Ln):n为训练视频个数,其中Xn=[xn(1),xn(2),xn(3),...,xn(m)]是视频Xn经过预处理后的视频图片集合,m为视频转化为图片帧的个数,本方法使用ffmpeg将视频按照每秒20帧转化为图片序列,Ln为视频Xn对应标签类型;S13: The data format corresponding to the preprocessed UCF-101 video set training video is (X n , L n ): n is the number of training videos, where X n =[x n(1) ,x n(2) ,x n(3) ,...,x n(m) ] is the preprocessed video picture collection of video X n , m is the number of video frames converted into pictures, this method uses ffmpeg to convert the video at 20 frames per second Converted to a picture sequence, L n is the label type corresponding to the video X n ;
S14:基于三维卷积神经网络模型和学习算法,使用经过预处理的UCF-101视频数据集,训练一个具有高识别率的视频种类识别模型。S14: Based on the three-dimensional convolutional neural network model and learning algorithm, use the preprocessed UCF-101 video dataset to train a video category recognition model with a high recognition rate.
其中,训练三维卷积神经网络模型的流程示意如图3所示。随机初始化三维卷积神经网络参数,并将UCF-101视频数据集进行数据预处理后使用BP算法训练模型,得到最优的视频动作种类识别模型。Among them, the flow chart of training the three-dimensional convolutional neural network model is shown in Fig. 3 . The parameters of the three-dimensional convolutional neural network are randomly initialized, and the UCF-101 video dataset is preprocessed, and then the BP algorithm is used to train the model to obtain the optimal video action category recognition model.
作为一种优选实施例,步骤S2包括下列子步骤:As a preferred embodiment, step S2 includes the following sub-steps:
S21:将测试数据中视频帧图片数量m不满足m=kw的视频帧图片集进行补充处理,其中,k为任意整数,w为滑动窗口的大小,将视频最后一帧的图片进行复制操作直到满足m为w的倍数;S21: Supplementary processing is performed on the video frame picture set whose number m of video frame pictures in the test data does not satisfy m=kw, wherein k is any integer, w is the size of the sliding window, and the picture of the last frame of the video is copied until Satisfied that m is a multiple of w;
S22:使用滑动窗口对视频帧序列进行滑动读取帧图片,滑动步长为滑动窗口的一半,每滑动一次,获取的帧图片为三维卷积神经网络的一次输入;取滑动窗口大小w=16,因此测试数据形式经过处理变为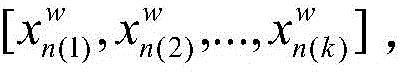

作为一种优选实施例,步骤S3包括下列子步骤:As a preferred embodiment, step S3 includes the following sub-steps:
S31:使用S1中使用UCF-101视频集训练得到的三维卷积神经网络模型识别S2中处理后的测试视频数据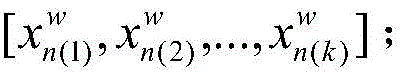
S32:将三维卷积神经网络的全连接层的输出固定为子动作种类个数;S32: fixing the output of the fully connected layer of the three-dimensional convolutional neural network as the number of sub-action types;
S33:三维卷积神经网络输入为S22中定义的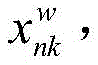
S34:测试视频数据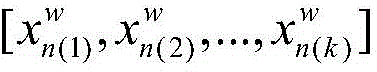
作为一种优选实施例,步骤S4包括下列子步骤:As a preferred embodiment, step S4 includes the following sub-steps:
S41:使用S3中三维卷积神经网络模型对测试视频数据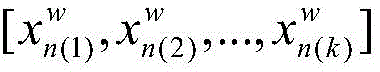
S42:循环自编码器将输入特征序列[F1,F2,F3,...,Fk]转化为特征对序列[[F1,F2],[F2,F3],[F3,F4],...,[Fk-1,Fk]],采取贪心算法思想,其过程为依次选取特征对序列中的每一对特征将其整合为一个父特征,表示为:F1,2=f(W(1)[F1,F2]+b(1)),其中W(1)代表n*n的矩阵参数,b(1)是一个偏置项,W(1)与b(1)是通过学习特征序列对得到的;F1,2的重构过程为:[F1',F2']=W(2)F1,2+b(2)其中W(2)代表n*n的矩阵参数,b(2)是不同于b(1)的偏置项,同样W(2)与b(2)是通过学习重构误差得到;自编码器的重构误差为: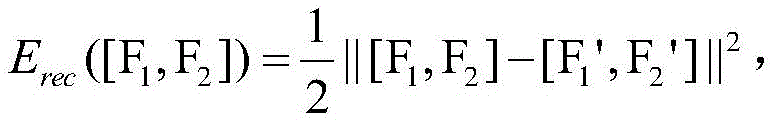
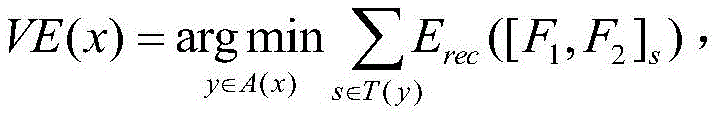
S43:重复S42的自编码过程,直到特征序列中特征向量个数为1;S43: Repeat the self-encoding process of S42 until the number of feature vectors in the feature sequence is 1;
S44:循环自编码器输出最终的特征向量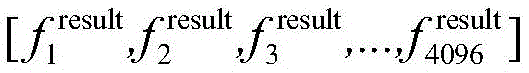
图4是本发明实施例方法中提取视频语义特征的流程示意图,视频数据集通过数据预处理,再经过滑动窗口处理数据,使用训练好的三维卷积神经网络提取特征得到特征序列,最后通过循环自编码器整合特征序列得到语义特征。Fig. 4 is a schematic flow diagram of extracting video semantic features in the method of the embodiment of the present invention. The video data set is preprocessed through data, and then processed through a sliding window, and the trained three-dimensional convolutional neural network is used to extract features to obtain a feature sequence, and finally through a loop The autoencoder integrates feature sequences to obtain semantic features.
图5是本发明实施例基于三维卷积神经网络与循环自编码器模型的架构图,可见,视频经处理得到视频帧序列,处理后的视频帧序列通过三维卷积神经网络提取帧特征,形成视频帧特征序列,再转换为编码特征序列经过循环自编码器得到视频语义特征。Fig. 5 is an architecture diagram based on a three-dimensional convolutional neural network and a cyclic autoencoder model according to an embodiment of the present invention. It can be seen that the video is processed to obtain a video frame sequence, and the processed video frame sequence extracts frame features through a three-dimensional convolutional neural network to form The video frame feature sequence is converted into a coded feature sequence to obtain video semantic features through a loop self-encoder.
本发明实施例通过结合三维卷积神经网络和循环自动编码器的方案,解决了非监督的视频语义分析与提取问题,提高了视频语义提取准确度。The embodiment of the present invention solves the problem of unsupervised video semantic analysis and extraction by combining a three-dimensional convolutional neural network and a cyclic autoencoder, and improves the accuracy of video semantic extraction.
需要说明的是,对于前述的各个方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本申请并不受所描述的动作顺序的限制,因为依据本申请,某一些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和单元并不一定是本申请所必须的。It should be noted that, for the sake of simple description, all the aforementioned method embodiments are expressed as a series of action combinations, but those skilled in the art should know that the present application is not limited by the described action sequence. Because according to the application, certain steps may be performed in other order or simultaneously. Secondly, those skilled in the art should also know that the embodiments described in the specification belong to preferred embodiments, and the actions and units involved are not necessarily required by this application.
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详细描述的部分,可以参见其他实施例的相关描述。In the foregoing embodiments, the descriptions of each embodiment have their own emphases, and for parts not described in detail in a certain embodiment, reference may be made to relevant descriptions of other embodiments.
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、ROM、RAM等。Those of ordinary skill in the art can understand that all or part of the processes in the methods of the above embodiments can be implemented through computer programs to instruct related hardware, and the programs can be stored in computer-readable storage media. During execution, it may include the processes of the embodiments of the above-mentioned methods. Wherein, the storage medium may be a magnetic disk, an optical disk, a ROM, a RAM or the like.
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。The above disclosures are only preferred embodiments of the present invention, and certainly cannot limit the scope of rights of the present invention. Therefore, equivalent changes made according to the claims of the present invention still fall within the scope of the present invention.
Claims (2)



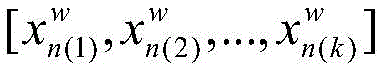
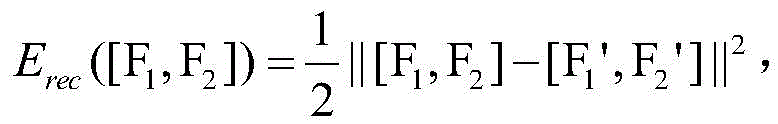
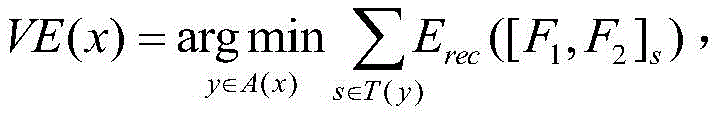
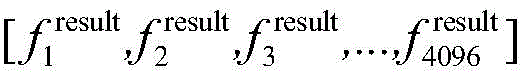
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810496579.3A CN108805036B (en) | 2018-05-22 | 2018-05-22 | Unsupervised video semantic extraction method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810496579.3A CN108805036B (en) | 2018-05-22 | 2018-05-22 | Unsupervised video semantic extraction method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108805036A CN108805036A (en) | 2018-11-13 |
| CN108805036B true CN108805036B (en) | 2022-11-22 |
Family
ID=64091470
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810496579.3A Expired - Fee Related CN108805036B (en) | 2018-05-22 | 2018-05-22 | Unsupervised video semantic extraction method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108805036B (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109948721B (en) * | 2019-03-27 | 2021-07-09 | 北京邮电大学 | A video scene classification method based on video description |
| CN110363090B (en) * | 2019-06-14 | 2024-09-10 | 平安科技(深圳)有限公司 | Intelligent heart disease detection method, device and computer readable storage medium |
| CN110674348B (en) * | 2019-09-27 | 2023-02-03 | 北京字节跳动网络技术有限公司 | Video classification method and device and electronic equipment |
| CN111079532B (en) * | 2019-11-13 | 2021-07-13 | 杭州电子科技大学 | A video content description method based on text autoencoder |
| CN112004113A (en) * | 2020-07-27 | 2020-11-27 | 北京大米科技有限公司 | Teaching interaction method, device, server and storage medium |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103729459A (en) * | 2014-01-10 | 2014-04-16 | 北京邮电大学 | Method for establishing sentiment classification model |
| CN104809474A (en) * | 2015-05-06 | 2015-07-29 | 西安电子科技大学 | Large data set reduction method based on self-adaptation grouping multilayer network |
| CN104866900A (en) * | 2015-01-29 | 2015-08-26 | 北京工业大学 | Deconvolution neural network training method |
| CN105701480A (en) * | 2016-02-26 | 2016-06-22 | 江苏科海智能系统有限公司 | Video semantic analysis method |
| CN107038221A (en) * | 2017-03-22 | 2017-08-11 | 杭州电子科技大学 | A kind of video content description method guided based on semantic information |
| CN107239801A (en) * | 2017-06-28 | 2017-10-10 | 安徽大学 | Video attribute represents that learning method and video text describe automatic generation method |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8180633B2 (en) * | 2007-03-08 | 2012-05-15 | Nec Laboratories America, Inc. | Fast semantic extraction using a neural network architecture |
| US20110301447A1 (en) * | 2010-06-07 | 2011-12-08 | Sti Medical Systems, Llc | Versatile video interpretation, visualization, and management system |
| US10192117B2 (en) * | 2015-06-25 | 2019-01-29 | Kodak Alaris Inc. | Graph-based framework for video object segmentation and extraction in feature space |
| US9818032B2 (en) * | 2015-10-28 | 2017-11-14 | Intel Corporation | Automatic video summarization |
| WO2017210690A1 (en) * | 2016-06-03 | 2017-12-07 | Lu Le | Spatial aggregation of holistically-nested convolutional neural networks for automated organ localization and segmentation in 3d medical scans |
| US9946933B2 (en) * | 2016-08-18 | 2018-04-17 | Xerox Corporation | System and method for video classification using a hybrid unsupervised and supervised multi-layer architecture |
| CN109964224A (en) * | 2016-09-22 | 2019-07-02 | 恩芙润斯公司 | Systems, methods, and computer-readable media for semantic information visualization and temporal signal inference indicating significant associations between life science entities |
| WO2018081751A1 (en) * | 2016-10-28 | 2018-05-03 | Vilynx, Inc. | Video tagging system and method |
| CN106709481A (en) * | 2017-03-03 | 2017-05-24 | 深圳市唯特视科技有限公司 | Indoor scene understanding method based on 2D-3D semantic data set |
| CN107274402A (en) * | 2017-06-27 | 2017-10-20 | 北京深睿博联科技有限责任公司 | A kind of Lung neoplasm automatic testing method and system based on chest CT image |
| CN107888843A (en) * | 2017-10-13 | 2018-04-06 | 深圳市迅雷网络技术有限公司 | Sound mixing method, device, storage medium and the terminal device of user's original content |
-
2018
- 2018-05-22 CN CN201810496579.3A patent/CN108805036B/en not_active Expired - Fee Related
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103729459A (en) * | 2014-01-10 | 2014-04-16 | 北京邮电大学 | Method for establishing sentiment classification model |
| CN104866900A (en) * | 2015-01-29 | 2015-08-26 | 北京工业大学 | Deconvolution neural network training method |
| CN104809474A (en) * | 2015-05-06 | 2015-07-29 | 西安电子科技大学 | Large data set reduction method based on self-adaptation grouping multilayer network |
| CN105701480A (en) * | 2016-02-26 | 2016-06-22 | 江苏科海智能系统有限公司 | Video semantic analysis method |
| CN107038221A (en) * | 2017-03-22 | 2017-08-11 | 杭州电子科技大学 | A kind of video content description method guided based on semantic information |
| CN107239801A (en) * | 2017-06-28 | 2017-10-10 | 安徽大学 | Video attribute represents that learning method and video text describe automatic generation method |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108805036A (en) | 2018-11-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108805036B (en) | Unsupervised video semantic extraction method | |
| Patrick et al. | Multi-modal self-supervision from generalized data transformations | |
| CN101299241B (en) | Multimodal Video Semantic Concept Detection Method Based on Tensor Representation | |
| CN111565318A (en) | Video compression method based on sparse samples | |
| CN117376502B (en) | Video production system based on AI technology | |
| CN108921032B (en) | Novel video semantic extraction method based on deep learning model | |
| Zhang et al. | Pan: Persistent appearance network with an efficient motion cue for fast action recognition | |
| CN111488489A (en) | Video file classification method, device, medium and electronic equipment | |
| CN109948721B (en) | A video scene classification method based on video description | |
| CN112614212A (en) | Method and system for realizing video-audio driving human face animation by combining tone and word characteristics | |
| CN111680190B (en) | A Video Thumbnail Recommendation Method Fused with Visual Semantic Information | |
| Zhao et al. | Videowhisper: Toward discriminative unsupervised video feature learning with attention-based recurrent neural networks | |
| CN118503774A (en) | Mongolian multi-mode emotion analysis method based on pre-training model and transducer | |
| CN119299802A (en) | Video automatic generation system based on Internet | |
| Mahum et al. | A generic framework for generation of summarized video clips using transfer learning (SumVClip) | |
| CN114610893A (en) | Script-to-storyboard sequence automatic generation method and system based on deep learning | |
| CN115909408B (en) | Pedestrian re-recognition method and device based on Transformer network | |
| CN118714337B (en) | Video intelligent compression method based on image analysis | |
| Battocchio et al. | Advance fake video detection via vision transformers | |
| Parmar et al. | MAC-REALM: a video content feature extraction and modelling framework | |
| CN112131429A (en) | Video classification method and system based on depth prediction coding network | |
| CN118965260A (en) | A multimodal sentiment analysis method and system based on hybrid mechanism | |
| CN115379242B (en) | A trilinear coding system and video-language representation learning method | |
| CN114565865B (en) | A Text-to-Image Method Based on Category-aware Consistency | |
| Torabi et al. | Action classification and highlighting in videos |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20221122 |