CN108764527B - Screening method for soil organic carbon library time-space dynamic prediction optimal environment variables - Google Patents
Screening method for soil organic carbon library time-space dynamic prediction optimal environment variables Download PDFInfo
- Publication number
- CN108764527B CN108764527B CN201810365926.9A CN201810365926A CN108764527B CN 108764527 B CN108764527 B CN 108764527B CN 201810365926 A CN201810365926 A CN 201810365926A CN 108764527 B CN108764527 B CN 108764527B
- Authority
- CN
- China
- Prior art keywords
- soil
- indicator
- environmental variable
- variable
- relative
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images













Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/04—Forecasting or optimisation specially adapted for administrative or management purposes, e.g. linear programming or "cutting stock problem"
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/18—Complex mathematical operations for evaluating statistical data, e.g. average values, frequency distributions, probability functions, regression analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/10—Services
- G06Q50/26—Government or public services
Landscapes
- Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Strategic Management (AREA)
- Human Resources & Organizations (AREA)
- Economics (AREA)
- Tourism & Hospitality (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- General Business, Economics & Management (AREA)
- Pure & Applied Mathematics (AREA)
- Marketing (AREA)
- Mathematical Physics (AREA)
- Computational Mathematics (AREA)
- Operations Research (AREA)
- Development Economics (AREA)
- Software Systems (AREA)
- Algebra (AREA)
- General Engineering & Computer Science (AREA)
- Educational Administration (AREA)
- Databases & Information Systems (AREA)
- Health & Medical Sciences (AREA)
- Bioinformatics & Computational Biology (AREA)
- General Health & Medical Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Primary Health Care (AREA)
- Life Sciences & Earth Sciences (AREA)
- Probability & Statistics with Applications (AREA)
- Game Theory and Decision Science (AREA)
- Entrepreneurship & Innovation (AREA)
- Quality & Reliability (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
本发明涉及一种土壤有机碳库时空动态预测最优环境变量筛选方法,收集整理不同时期的土壤数据库、动态与静态的环境变量集合,根据土壤数据的时效性,规定土壤碳库模拟有效的时间段——“时间片”。依据不同景观区域内部的土壤有机碳密度信息,分析各种动态、静态环境变量的各种属性信息,进而使用层次分析法与专家知识构建特定时间片内有效的最优环境变量集合。

The invention relates to a method for screening optimal environmental variables for the temporal and spatial dynamic prediction of soil organic carbon pools, which collects and sorts soil databases and sets of dynamic and static environmental variables in different periods, and specifies the effective time for soil carbon pool simulation according to the timeliness of soil data. Segments - "time slices". According to the soil organic carbon density information in different landscape areas, the attribute information of various dynamic and static environmental variables is analyzed, and then the analytic hierarchy process and expert knowledge are used to construct an effective optimal set of environmental variables in a specific time slice.
Description
技术领域technical field
本发明涉及一种土壤有机碳库时空动态预测最优环境变量筛选方法,属于计量土壤学技术领域。The invention relates to a method for screening optimal environmental variables for temporal and spatial dynamic prediction of soil organic carbon pools, and belongs to the technical field of quantitative soil science.
背景技术Background technique
土壤有机碳是动植物残体、微生物体、土壤微生物作用生成的腐殖质的合称。与土壤无机碳库相比,土壤有机碳含量对于土壤耕作、土地利用变化响应较为敏感。自工业革命以来的全球气候变暖问题迫使各国政府日益高度重视温室气体的减排。据相关数据统计,一米土体内部的有机碳储量是土壤碳库的最主要组成部分。作为全球陆地生态系统最大的碳库,土壤碳库的储量约是大气碳库储量与陆地生态圈碳库储量的总和(1200-2500Pg)。因此,土壤碳库的微小变动对于整个陆地生态系统的碳库将产生巨大影响。鉴于土壤有机碳含量也是土壤肥力评价的最重要指标之一,土壤有机碳含量/储量的空间分析技术已受到农业、环境、工业等诸多部门的广泛关注。Soil organic carbon is a collective term for the humus produced by the action of animal and plant residues, microorganisms and soil microorganisms. Compared with soil inorganic carbon pools, soil organic carbon content is more sensitive to soil cultivation and land use changes. Global warming since the Industrial Revolution has forced governments around the world to pay increasing attention to reducing greenhouse gas emissions. According to relevant statistics, the organic carbon storage within one meter of soil is the most important component of soil carbon pool. As the largest carbon pool in the global terrestrial ecosystem, the storage of soil carbon pool is about the sum of atmospheric carbon pool and terrestrial ecosystem carbon pool (1200-2500Pg). Therefore, small changes in soil carbon stock will have a huge impact on the carbon stock of the entire terrestrial ecosystem. Considering that soil organic carbon content is also one of the most important indicators for soil fertility evaluation, spatial analysis techniques for soil organic carbon content/storage have received extensive attention in many sectors such as agriculture, environment, and industry.
土壤碳库估算技术的相关研究包括固碳潜力、储量分布、影响因素与不确定性评估等方面。按照研究区域大小,土壤有机碳空间分布图的尺度可以分为全球尺度、国家尺度、省级尺度、流域尺度等。不同尺度的土壤图制作对于土壤样点、土壤图的精度具有不同的要求。目前,我国省域尺度上的土壤有机碳储量估算工作较多关注于中比例尺(1:20万),大比例尺(≥1:5万)的工作鲜有报道。在土壤有机碳储量估算方法上面,国内外相关学者将其分为两大类:图斑法与模型法。图斑法是将土壤剖面的土壤属性(容重、砾石含量、有机碳含量)相应地赋值给一个面状的地理信息图层(如土壤类型图、土地利用类型图、植被类型图),然后将单个图斑的面积与单个或多个土体的有机碳密度相乘,最终得到该区域的土壤有机碳储量。图斑法简单、高效,是相关行业领域使用最普遍的方法之一。土壤类型、面积等基础数据源主要来源于第二次全国土壤普查。图斑法假设图斑类型内部的土壤是均质的,这与现实世界中土壤的高度空间异质性是相矛盾的。随着地理信息系统与计算机科学技术的发展,土壤学家正逐渐倾向于采用模型法进行土壤有机碳储量估算。模型法是使用数据驱动或过程驱动的预测模型,构建土壤有机碳等其他土壤属性受成土因素(气候、植被、地形、母质)或土壤有机质分解速率的各种相关因素影响的预测模型,典型的碳循环模型如Century模型和DeNitrification-DeComposition模型,典型的数据驱动的模型如随机森林、人工神经网络、地理加权回归等方法。Related research on soil carbon pool estimation technology includes carbon sequestration potential, storage distribution, influencing factors and uncertainty assessment. According to the size of the study area, the scale of the spatial distribution map of soil organic carbon can be divided into global scale, national scale, provincial scale, and watershed scale. The production of soil maps at different scales has different requirements for the accuracy of soil samples and soil maps. At present, the estimation of soil organic carbon storage at the provincial scale in my country focuses more on the medium scale (1:200,000), and the work on the large scale (≥1:50,000) is rarely reported. In terms of soil organic carbon storage estimation methods, domestic and foreign scholars have divided them into two categories: map method and model method. The map spot method is to assign the soil properties (bulk density, gravel content, organic carbon content) of the soil profile to a planar geographic information layer (such as soil type map, land use type map, vegetation type map), and then assign the The area of a single plot is multiplied by the organic carbon density of a single or multiple soils, and finally the soil organic carbon storage in this area is obtained. The graph spot method is simple and efficient, and is one of the most commonly used methods in related industries. The basic data sources such as soil type and area mainly come from the second national soil census. The patch method assumes that the soil within the patch type is homogeneous, which contradicts the high spatial heterogeneity of soils in the real world. With the development of geographic information system and computer science technology, soil scientists are gradually tending to use the model method to estimate soil organic carbon storage. The model method is to use a data-driven or process-driven prediction model to construct a prediction model in which other soil properties such as soil organic carbon are affected by soil-forming factors (climate, vegetation, topography, parent material) or various factors related to the decomposition rate of soil organic matter, typically Carbon cycle models such as Century model and DeNitrification-DeComposition model, typical data-driven models such as random forest, artificial neural network, geographically weighted regression and other methods.
土壤理化属性的空间变异性指的是其在不同的时间与空间条件下处于永恒的变化过程中。这种时空变异性与土壤演变过程中涉及到的人为、自然因素密切相关。相关研究学者已证明土壤有机碳与土壤物理性质(土壤质地、容重)与化学性质(氮储量、无机碳、重金属含量)密切相关,这种关系也反映在水文学中的PTF函数的广泛应用等方面。另外,鉴于土壤有机碳储量的地带性分布特征,土壤有机碳储量的分布与经度与纬度等位置信息也具有较高的相关性。部分学者已证明土壤有机碳的矿化速率与植被恢复、气候变化、保护性耕作等因素也具有一定的定量耦合关系。基于不同时期的遥感影像与GIS分析对各景观类型的地表覆盖进行绘制,能够对比分析土壤有机碳储量受动态土地利用变化的影响。基于此,Century模型对土壤有机碳储量进行模拟的过程中,需要在相关模块中集成土地利用的动态模拟机制。有鉴于此,多尺度土壤有机碳储量的时空动态估算技术迫切需要定量化土壤有机碳空间分布规律与各环境要素的关系。The spatial variability of soil physical and chemical properties means that it is in an eternal process of change under different time and space conditions. This temporal and spatial variability is closely related to the man-made and natural factors involved in soil evolution. Relevant researchers have proved that soil organic carbon is closely related to soil physical properties (soil texture, bulk density) and chemical properties (nitrogen storage, inorganic carbon, heavy metal content), and this relationship is also reflected in the extensive application of the PTF function in hydrology, etc. aspect. In addition, in view of the zonal distribution characteristics of soil organic carbon storage, the distribution of soil organic carbon storage also has a high correlation with location information such as longitude and latitude. Some scholars have proved that the mineralization rate of soil organic carbon also has a certain quantitative coupling relationship with factors such as vegetation restoration, climate change, and conservation tillage. Based on remote sensing images in different periods and GIS analysis, the surface cover of each landscape type can be drawn, which can compare and analyze the impact of soil organic carbon storage on dynamic land use changes. Based on this, in the process of simulating soil organic carbon storage by the Century model, it is necessary to integrate the dynamic simulation mechanism of land use in related modules. In view of this, the spatiotemporal dynamic estimation technology of multi-scale soil organic carbon storage urgently needs to quantify the relationship between the spatial distribution of soil organic carbon and various environmental factors.
然而,土壤有机碳储量的时空动态估算技术在不同景观区域的实施过程中,仍面临一系列技术问题:However, the spatiotemporal dynamic estimation technology of soil organic carbon storage still faces a series of technical problems in the implementation process of different landscape areas:
(1)数字土壤制图与地理信息系统技术虽已较为成熟,但主要关注流域、县级尺度的研究区域,这些区域的土壤-景观关系空间异质性较低,往往具有明显的梯度序列或地貌特征,土壤有机碳含量等属性与环境变量一般具有较高的相关性,导致构建的预测模型移植性、稳健性非常低,很难在相邻或相似的区域直接实施。这种模型的低移植性问题也间接造成了不同区域土壤碳库估算工作中存在着严重的区域性不确定性问题,世界土壤信息参比中心(荷兰,ISRIC)、悉尼大学与中国科学院南京土壤研究所等国际一流的土壤研究机构均证实,构建国家、全球尺度的预测模型已是当代土壤地理学的最重要工作之一。(1) Although digital soil mapping and geographic information system technologies are relatively mature, they mainly focus on research areas at the river basin and county level. The spatial heterogeneity of soil-landscape relationships in these areas is low, and there are often obvious gradient sequences or landforms. Characteristics, soil organic carbon content and other attributes generally have a high correlation with environmental variables, resulting in very low portability and robustness of the constructed prediction model, and it is difficult to directly implement it in adjacent or similar areas. The low portability of this model also indirectly causes serious regional uncertainties in the estimation of soil carbon stocks in different regions. International first-class soil research institutions such as the Institute have confirmed that the construction of national and global scale prediction models is one of the most important tasks in contemporary soil geography.
(2)现有空间预测技术较多关注模型的构建及其不确定性评估,相对忽视了模型输入参数的遴选问题。部分数字土壤制图工作仅根据专家知识或数据的可获取性选择模型的输入数据,未能综合考虑土壤的空间变化特征与环境变量的空间耦合关系。如果使用特定的变量筛选机制选择最优环境变量,在基于不同假设的预测模型中可能无法最大程度上挖掘所有环境变量涵盖的土壤景观信息。如果仅使用基于功能论的精度评价机制对环境变量集合进行评价,又会降低构建预测模型与衍生分析结果的稳定性,进而无法明确地指示环境变量对于土壤有机碳含量的空间表征关系。(2) Existing spatial prediction technologies pay more attention to the construction of models and their uncertainty assessment, while relatively ignoring the selection of model input parameters. Some digital soil mapping work only selects the input data of the model based on expert knowledge or data availability, and fails to comprehensively consider the spatial coupling relationship between the spatial variation characteristics of soil and environmental variables. If a specific variable screening mechanism is used to select the optimal environmental variables, the soil landscape information covered by all environmental variables may not be mined to the greatest extent in the prediction models based on different assumptions. If only using the functional theory-based precision evaluation mechanism to evaluate the set of environmental variables, it will reduce the stability of the construction of the prediction model and the derived analysis results, and thus cannot clearly indicate the spatial representation relationship between environmental variables and soil organic carbon content.
(3)数字土壤制图的关键环节是选择合适的数据源和环境变量。影响土壤空间变异的环境变量非常多,例如,常用的地形因子不少于五十种、常用的气候变量不少于二十种、常用的遥感变量不少于三十种。同时,相同变量的不同提取算法的研究成果也不断呈现。这些环境变量之间具有一定的不确定性,且相互之间相互影响,用传统的变量筛选机制很难精确的界定。(3) The key link of digital soil mapping is to select appropriate data sources and environmental variables. There are many environmental variables that affect soil spatial variability. For example, there are no less than 50 commonly used topographic factors, no less than 20 commonly used climate variables, and no less than 30 commonly used remote sensing variables. At the same time, the research results of different extraction algorithms for the same variable are also continuously presented. These environmental variables have certain uncertainties and influence each other, so it is difficult to accurately define them with the traditional variable screening mechanism.
综上所述的技术缺陷已严重影响了不同行业部门的土壤碳库时空动态估算工作,不仅降低了应用部门在生产加工土壤信息产品的效率与精度,同时也给国家经济规划与调控带来了潜在的损失。To sum up, the technical deficiencies mentioned above have seriously affected the spatiotemporal dynamic estimation of soil carbon pools in different industries, which not only reduces the efficiency and accuracy of the application departments in the production and processing of soil information products, but also brings great challenges to national economic planning and regulation. potential losses.
发明内容SUMMARY OF THE INVENTION
本发明所要解决的技术问题是提供一种土壤有机碳库时空动态预测最优环境变量筛选方法,不仅能够给出详细的最优环境变量选择方法,同时也能定量化表达土壤属性与环境变量的空间耦合关系,基于不同时间点的环境变量集合,能够有效筛选获得环境变量在不同时期内对于区域土壤碳库变化的影响。The technical problem to be solved by the present invention is to provide an optimal environmental variable screening method for the spatiotemporal dynamic prediction of soil organic carbon pool, which can not only provide a detailed optimal environmental variable selection method, but also quantitatively express the relationship between soil attributes and environmental variables. The spatial coupling relationship, based on the set of environmental variables at different time points, can effectively screen and obtain the impact of environmental variables on the changes of regional soil carbon pools in different periods.
本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种土壤有机碳库时空动态预测最优环境变量筛选方法,获得用于目标土壤区域土壤有机碳密度预测所对应的最优环境变量集合,包括如下步骤:In order to solve the above-mentioned technical problems, the present invention adopts the following technical solutions: The present invention designs a method for screening the optimal environmental variables for the temporal and spatial dynamic prediction of soil organic carbon pools, and obtains the optimal environmental variables corresponding to the prediction of soil organic carbon density in the target soil area. Collection, including the following steps:
步骤A.收集目标土壤区域中、对应预设总时间跨度的各个土壤样点,并基于预设子时间段,获得不同时期下的各土壤样点,且预设子时间段内各土壤样点的投影坐标互不相同,然后进入步骤B;其中,总时间段由相等时间间隔的子时间段构成,子时间段小于总时间跨度,以及基于土壤样点所对应的子时间段,总时间跨度下子时间段的个数不少于3个;Step A. Collect each soil sample point in the target soil area corresponding to the preset total time span, and based on the preset sub-time period, obtain each soil sample point in different periods, and each soil sample point within the preset sub-time period The projection coordinates of , are different from each other, and then proceed to step B; wherein, the total time period is composed of sub-time periods with equal time intervals, and the sub-time period is smaller than the total time span, and based on the sub-time period corresponding to the soil sample point, the total time span The number of next time periods is not less than 3;
步骤B.获得不同时期下、各土壤样点在预设深度下分别所对应各指定土壤属性数据,以及相应各指定种类环境变量数据,然后进入步骤C;Step B. Obtain the respective designated soil attribute data corresponding to each soil sample point at a preset depth in different periods, and the corresponding environmental variable data of each designated type, and then enter step C;
步骤C.根据不同时期下、各土壤样点在预设深度下分别所对应各指定土壤属性数据,获得不同时期下、各土壤样点位置对应预设深度的土壤有机碳密度,然后进入步骤D;Step C. According to the respective designated soil attribute data corresponding to each soil sample point at a preset depth in different periods, obtain the soil organic carbon density of each soil sample point corresponding to the preset depth in different periods, and then proceed to step D ;
步骤D.预设定义层次分析法中、不同遴选指标属性之间的相对重要性,然后进入步骤E;Step D. Preset the relative importance of different selection index attributes in the AHP, and then enter Step E;
步骤E.根据不同时期下、各土壤样点位置对应预设深度的土壤有机碳密度,以及相应各指定种类环境变量数据,获得层次分析法中、各指定种类环境变量的遴选指标属性数据,然后进入步骤F;Step E. According to the soil organic carbon density of each soil sample point corresponding to the preset depth in different periods, and the corresponding environmental variable data of each designated type, obtain the selection index attribute data of each designated type of environmental variable in the AHP, and then Go to step F;
步骤F.根据层次分析法中、各指定种类环境变量分别相对目标土壤区域的各遴选指标属性数据,以及预设不同遴选指标属性之间的相对重要性,计算获得层次分析法中、不同指定种类环境变量之间相对各遴选指标属性的重要性,然后进入步骤G;Step F. According to the attribute data of each selection index relative to the target soil area for each designated type of environmental variables in the AHP, and the relative importance between the preset attributes of different selection indicators, calculate and obtain the different designated types in the AHP. The relative importance of each selection index attribute among environmental variables, and then enter step G;
步骤G.根据层次分析法中、不同指定种类环境变量之间相对各遴选指标属性的重要性,以及不同时期下、各土壤样点分别所对应各指定种类环境变量数据,构建目标土壤区域所对应土壤有机碳密度的层次分析树,获得用于目标土壤区域土壤有机碳密度预测所对应的最优环境变量集合。Step G. According to the analytic hierarchy process, the relative importance of each selected index attribute among different designated types of environmental variables, and the data of each designated type of environmental variables corresponding to each soil sample point in different periods, construct the corresponding soil area corresponding to the target soil. The analytic hierarchy process tree of soil organic carbon density is used to obtain the optimal set of environmental variables corresponding to the prediction of soil organic carbon density in the target soil area.
本发明所述一种土壤有机碳库时空动态预测最优环境变量筛选方法采用以上技术方案与现有技术相比,具有以下技术效果:。Compared with the prior art, the method for screening the optimal environmental variables for the spatio-temporal dynamic prediction of soil organic carbon pool according to the present invention has the following technical effects:
(1)本发明设计的土壤有机碳库时空动态预测最优环境变量筛选方法,将土壤碳库估算问题中涉及到的成百上千的环境变量选择作为一个系统问题,根据其隐含的信息量将众多变量分解为若干层次,在保留各变量对计算结果影响的同时,又非常明确、清晰地量化了各环境变量对土壤碳库时空变异的影响程度,实现了“多时期、多目标、多准则、高效益”的通用土壤碳库估算技术,对于无明显结构特征的土壤碳库估算工作具有重要的实践意义,在全球变化、耕地和湿地保护、政府决策、农业区划制定、农业生产与可持续发展、生态环境保护等相关部门具有十分重要的现实意义与应用价值;(1) The optimal environmental variable screening method for temporal-spatial dynamic prediction of soil organic carbon pools designed by the present invention selects hundreds or thousands of environmental variables involved in the soil carbon pool estimation problem as a systematic problem, and according to its implicit information It decomposes many variables into several levels. While retaining the influence of each variable on the calculation results, it also clearly and clearly quantifies the degree of influence of each environmental variable on the spatial and temporal variation of soil carbon pool. The multi-criteria, high-efficiency general soil carbon pool estimation technology has important practical significance for soil carbon pool estimation without obvious structural characteristics. Sustainable development, ecological environment protection and other related departments have very important practical significance and application value;
(2)本发明所设计土壤有机碳库时空动态预测最优环境变量筛选方法,简洁实用,不仅融合了土壤地理学等学科的专家知识,也系统地将复杂的信息筛选问题转化为容易实施的推理问题;所使用的两两比较方法,能够确定同一类型的环境变量相对于其他类型的环境变量的重要性,相对于机器学习与人工智能等领域中的复杂数学方法,本发明更易于推广;(2) The optimal environmental variable screening method for temporal-spatial dynamic prediction of soil organic carbon pools designed by the present invention is simple and practical, not only integrates the expert knowledge of soil geography and other disciplines, but also systematically transforms complex information screening problems into easy-to-implement Reasoning problem; the pairwise comparison method used can determine the importance of the same type of environmental variables relative to other types of environmental variables, and the present invention is easier to generalize than complex mathematical methods in the fields of machine learning and artificial intelligence;
(3)本发明所设计土壤有机碳库时空动态预测最优环境变量筛选方法,能够无缝衔接多种空间预测技术,最大程度上保证了环境变量的信息量与预测技术的模型假设“高内聚、低耦合”。静态、动态变量的分类机制在有效保证历史土壤数据与基础环境信息高效利用的同时,也降低了一般时空预测模型割裂不同时期土壤数据与动态环境变量耦合关系的缺陷。(3) The optimal environmental variable screening method for temporal-spatial dynamic prediction of soil organic carbon pools designed in the present invention can seamlessly connect a variety of spatial prediction techniques, and to the greatest extent guarantees the information content of environmental variables and the model assumptions of the prediction techniques "high internal" Poly, low coupling". The classification mechanism of static and dynamic variables not only effectively ensures the efficient use of historical soil data and basic environmental information, but also reduces the defect that the general spatiotemporal prediction model splits the coupling relationship between soil data and dynamic environmental variables in different periods.
附图说明Description of drawings
图1是本发明所设计土壤有机碳库时空动态预测最优环境变量筛选方法的流程示意图;Fig. 1 is a schematic flow chart of the optimal environmental variable screening method for the spatiotemporal dynamic prediction of soil organic carbon pools designed by the present invention;
图2是层次分析法涉及到的环境变量属性与主要环境变量;Figure 2 is the environmental variable attributes and main environmental variables involved in the AHP;
图3是对环境变量与土壤有机碳密度的皮尔逊相关系数进行比较的步骤流程图;Figure 3 is a flow chart of the steps for comparing the Pearson correlation coefficient of environmental variables with soil organic carbon density;
图4是对环境变量与土壤有机碳密度的差异性显著程度进行比较的步骤流程图;Figure 4 is a flow chart of the steps for comparing the significant degree of difference between environmental variables and soil organic carbon density;
图5是对环境变量的数值类型进行比较的步骤流程图;Fig. 5 is the flow chart of the steps that the numerical value type of environment variable is compared;
图6是对环境变量是否为动态环境变量进行比较的步骤流程图;Fig. 6 is a flow chart of the steps of comparing whether the environment variable is a dynamic environment variable;
图7是对环境变量对土壤有机碳密度的土壤发生学意义进行比较的步骤流程图;Figure 7 is a flow chart of steps for comparing the pedogenetic significance of environmental variables to soil organic carbon density;
图8是对环境变量的共线性比重进行比较的步骤流程图;Fig. 8 is a flow chart of the steps of comparing the collinear proportions of environmental variables;
图9是对环境变量的线性回归系数的绝对值进行比较的步骤流程图;Fig. 9 is a flow chart of the steps of comparing the absolute values of the linear regression coefficients of environmental variables;
图10是对环境变量的平均精度下降值进行比较的步骤流程图;Figure 10 is a flow chart of the steps for comparing the mean precision drop values of environmental variables;
图11是对研究区预测的2010年0-20cm深度土壤有机碳密度空间分布图;Fig. 11 is the spatial distribution map of soil organic carbon density at 0-20cm depth predicted for the study area in 2010;
图12是对研究区预测的2020年0-20cm深度土壤有机碳密度空间分布图;Figure 12 is the spatial distribution map of soil organic carbon density at 0-20cm depth predicted for the study area in 2020;
图13是对研究区预测的2030年0-20cm深度土壤有机碳密度空间分布图。Figure 13 is the spatial distribution map of soil organic carbon density at 0-20 cm depth predicted for the study area in 2030.
具体实施方式Detailed ways
下面结合说明书附图对本发明的具体实施方式作进一步详细的说明。The specific embodiments of the present invention will be described in further detail below with reference to the accompanying drawings.
本发明所设计土壤有机碳库时空动态预测最优环境变量筛选方法的基本思想是,收集整理不同时期的土壤数据库、动态与静态的环境变量集合,根据土壤数据的时效性,规定土壤碳库模拟有效的时间段——“时间片”。依据不同景观区域内部的土壤有机碳密度信息,分析各种动态、静态环境变量的各种属性信息,进而使用层次分析法与专家知识构建特定时间片内有效的最优环境变量集合。The basic idea of the optimal environmental variable screening method for temporal and spatial dynamic prediction of soil organic carbon pools designed in the present invention is to collect and sort out soil databases and dynamic and static environmental variable sets in different periods, and to specify the simulation of soil carbon pools according to the timeliness of soil data. Valid time period - "time slice". According to the soil organic carbon density information in different landscape areas, the attribute information of various dynamic and static environmental variables is analyzed, and then the analytic hierarchy process and expert knowledge are used to construct an effective optimal set of environmental variables in a specific time slice.
如图1所示,本发明设计了一种土壤有机碳库时空动态预测最优环境变量筛选方法,获得用于目标土壤区域土壤有机碳密度预测所对应的最优环境变量集合,实际应用过程当中,具体包括如下步骤:As shown in Figure 1, the present invention designs a method for selecting optimal environmental variables for the spatiotemporal dynamic prediction of soil organic carbon pools, and obtains the optimal environmental variable set corresponding to the prediction of soil organic carbon density in the target soil area. , including the following steps:
步骤A.收集目标土壤区域中、对应预设总时间跨度的各个土壤样点,并基于预设子时间段,获得不同时期下的各土壤样点,且预设子时间段内各土壤样点的投影坐标互不相同,然后进入步骤B;其中,总时间段由相等时间间隔的子时间段构成,子时间段小于总时间跨度,以及基于土壤样点所对应的子时间段,总时间跨度下子时间段的个数不少于3个。Step A. Collect each soil sample point in the target soil area corresponding to the preset total time span, and based on the preset sub-time period, obtain each soil sample point in different periods, and each soil sample point within the preset sub-time period The projection coordinates of , are different from each other, and then proceed to step B; wherein, the total time period is composed of sub-time periods with equal time intervals, and the sub-time period is smaller than the total time span, and based on the sub-time period corresponding to the soil sample point, the total time span The number of the next time period shall not be less than 3.
上述步骤A,实际应用中,具体包括如下步骤:The above-mentioned step A, in practical application, specifically includes the following steps:
步骤A1.收集目标土壤区域中、对应预设总时间跨度的各个土壤样点,并将所有土壤样点的位置信息进行标准化,生成具有地理坐标的经纬度位置信息与投影坐标的经纬度位置信息。其中,地理坐标统一转换为GCS_WGS_1984,投影坐标统一转换为WGS_1984_Albers;标准化后的投影坐标记为(LongX,LatiY),基于标准化的坐标位置,使得预设子时间段内各土壤样点的投影坐标互不相同,然后进入步骤A2;其中,子时间段小于总时间跨度。Step A1. Collect each soil sample point in the target soil area corresponding to the preset total time span, and standardize the location information of all soil sample points to generate latitude and longitude location information with geographic coordinates and projected coordinates. Among them, the geographic coordinates are uniformly converted to GCS_WGS_1984, and the projected coordinates are uniformly converted to WGS_1984_Albers; the standardized projected coordinates are marked as (LongX, LatiY), based on the standardized coordinate positions, so that the projected coordinates of each soil sample point in the preset sub-time period are mutually If not, then go to step A2; wherein, the sub time period is less than the total time span.
步骤A2.以子时间段t,按如下公式:Step A2. Take the sub-time period t, according to the following formula:
T=int(Year/t)*tT=int(Year/t)*t
针对各个土壤样点分别设定时间片标签,即获得不同时期下的各土壤样点,然后进入步骤A3;其中,T表示土壤样点所设定的时间片标签,Year表示土壤样点的采集时间,int()表示向下取整函数。Set time slice labels for each soil sample point, that is, to obtain each soil sample point in different periods, and then enter step A3; where T represents the time slice label set for the soil sample point, and Year represents the collection of soil sample points time, int() represents the round down function.
注:如果某一个时间段的土壤数据非常少,可以从最近几年的土壤图中提取一些样点,具体数字可参考前后时间间隔内的土壤样点数量,相差数量不超过50%。Note: If there is very little soil data in a certain time period, some sample points can be extracted from the soil map in recent years. The specific number can refer to the number of soil sample points in the time interval before and after, and the difference does not exceed 50%.
步骤A3.判断各个土壤样点所对应不同时间片标签的个数是否小于3,是则进入步骤A4,否则进入步骤B。Step A3. Determine whether the number of different time slice labels corresponding to each soil sample point is less than 3, if yes, go to Step A4, otherwise go to Step B.
步骤A4.按预设增量,扩大总时间跨度,实现总时间跨度的更新,然后返回步骤A1。Step A4. Expand the total time span according to the preset increment to realize the update of the total time span, and then return to step A1.
步骤B.获得不同时期下、各土壤样点在预设深度下分别所对应各指定土壤属性数据,以及相应各指定种类环境变量数据,然后进入步骤C。Step B. Obtain each designated soil attribute data corresponding to each soil sample point at a preset depth in different periods and corresponding environmental variable data of each designated type, and then proceed to step C.
实际应用中,上述步骤B中,具体执行如下步骤B1至步骤B4,即获得不同时期下、各土壤样点在预设深度下分别所对应各指定土壤属性数据,以及相应各指定种类环境变量数据。In practical applications, in the above step B, the following steps B1 to B4 are specifically executed, that is, the specified soil attribute data corresponding to each soil sample point at the preset depth in different periods and the corresponding environmental variable data of each specified type are obtained. .
步骤B1.获得各时间片标签下、各土壤样点分别所对应各指定土壤属性数据,如下表1所示,然后进入步骤B2。Step B1. Obtain each designated soil attribute data corresponding to each soil sample point under each time slice label, as shown in Table 1 below, and then proceed to Step B2.
表1Table 1
步骤B2.针对各时间片标签下、各土壤样点分别所对应各指定土壤属性数据,执行标准化操作进行更新,然后进入步骤B3。Step B2. For each designated soil attribute data corresponding to each soil sample point under each time slice label, perform a standardization operation to update, and then proceed to step B3.
其中,具体执行步骤B2,针对各时间片标签下、各土壤样点分别所对应各指定土壤属性数据,执行如下步骤B2-1至步骤B2-2,实现标准化操作进行更新。Wherein, step B2 is specifically performed, and the following steps B2-1 to B2-2 are performed for each designated soil attribute data corresponding to each soil sample point under each time slice label to realize a standardized operation for updating.
步骤B2-1.针对各指定土壤属性数据的单位进行标准化,即针对土壤属性数据的单位进行转换统一。Step B2-1. Standardize the units of each designated soil attribute data, that is, transform and unify the units of the soil attribute data.
步骤B2-2.针对各指定土壤属性数据进行异常值处理,其中,根据指定土壤属性数据与其所对应平均值的偏差、是否超过其所对应标准差两倍的判断,分别按如下执行不同操作;Step B2-2. Perform outlier processing for each designated soil attribute data, wherein, according to the judgment of whether the deviation of the designated soil attribute data and its corresponding average value exceeds twice its corresponding standard deviation, different operations are performed as follows;
如果s_i≥s_mean-2×s_std且s_i≤s_mean+2×s_std,则s_i不是异常值;If s_i≥s_mean-2×s_std and s_i≤s_mean+2×s_std, then s_i is not an outlier;
如果s_i<s_mean-2×s_std,则s_i是异常值,定义s_i的值为s_mean-2×s_std;If s_i<s_mean-2×s_std, then s_i is an outlier, and the value of s_i is defined as s_mean-2×s_std;
如果s_i>s_mean+2×s_std,则s_i是异常值,定义s_i的值为s_mean+2×s_std;If s_i>s_mean+2×s_std, then s_i is an outlier, and the value of s_i is defined as s_mean+2×s_std;
其中,s_i、s_mean、s_std分别是土壤属性s中的第i个值、平均值与标准差。Among them, s_i, s_mean, and s_std are the ith value, mean and standard deviation of soil attribute s, respectively.
注:上述步骤中所设计的土壤属性数据异常值检测方法,也可采用概率统计法、PCA法、孤立森林法等方法。Note: The method for detecting outliers in soil attribute data designed in the above steps can also adopt methods such as probability and statistics method, PCA method, and isolated forest method.
步骤B3.收集覆盖目标土壤区域的各指定种类环境变量图层,然后进入步骤B4。Step B3. Collect each designated type of environmental variable layer covering the target soil area, and then proceed to Step B4.
覆盖目标土壤区域的各指定种类环境变量图层,包含栅格与矢量等格式,常见的环境变量包括五大成土因素:时间、地形、生物、母质与气候。地形变量可以由数字高程模型衍生,包括坡度、坡向、曲率、地形湿度指数等变量;气候变量包括不同时期的降雨、气温、风速、日照时间等变量;生物变量包括不同时期的地表植被类型、土地利用及由不同时期遥感影像提取的各种变量;母质变量包括水文地质图、风化层类型等变量。部分数据可由相关数据平台申请,例如国家基础地理信息中心、国家测绘地理信息局、国家地球系统科学数据共享平台等。Layers of specified types of environmental variables covering the target soil area, including raster and vector formats. Common environmental variables include five soil-forming factors: time, terrain, organisms, parent material and climate. Terrain variables can be derived from digital elevation models, including slope, aspect, curvature, terrain humidity index and other variables; climatic variables include rainfall, temperature, wind speed, sunshine time and other variables in different periods; biological variables include surface vegetation types in different periods, Land use and various variables extracted from remote sensing images in different periods; parent material variables include variables such as hydrogeological maps, regolith types, etc. Some data can be applied for by relevant data platforms, such as the National Basic Geographic Information Center, the National Bureau of Surveying and Mapping Geographic Information, and the National Earth System Science Data Sharing Platform.
步骤B4.针对各指定种类环境变量图层中的环境变量数据,执行标准化操作进行更新。Step B4. Perform a normalization operation to update the environmental variable data in each designated type of environmental variable layer.
其中,具体执行步骤B4,针对各指定种类环境变量图层中的环境变量数据,执行如下步骤B4-1至步骤B4-5,实现标准化操作进行更新。Wherein, step B4 is specifically executed, and the following steps B4-1 to B4-5 are executed for the environmental variable data in each designated type of environmental variable layer to realize the standardization operation for updating.
步骤B4-1.采用预设重采样方法,将各指定种类环境变量图层转换为指定分辨率的各指定种类环境变量栅格图层,然后进入步骤B4-2。Step B4-1. Using the preset resampling method, convert each specified type of environment variable layer into each specified type of environmental variable raster layer with a specified resolution, and then go to step B4-2.
上述栅格数据重采样方法为:双线性内插法。指定分辨率可以设定为50m、100m、250m、1000m与2000m。The above grid data resampling method is: bilinear interpolation method. The specified resolution can be set to 50m, 100m, 250m, 1000m and 2000m.
注:栅格数据重采样方法也可以采用最邻近法、三次卷积插值法、众数法等方法。Note: The raster data resampling method can also use the nearest neighbor method, cubic convolution interpolation method, mode method and other methods.
步骤B4-2.将各指定种类环境变量栅格图层的坐标统一转换为预设标准的投影坐标,然后进入步骤B4-3。Step B4-2. Uniformly transform the coordinates of each specified type of environment variable raster layer into the pre-set standard projection coordinates, and then proceed to step B4-3.
步骤B4-3.针对各指定种类环境变量图层中的环境变量数据进行归一化,以消除不同环境变量量纲的差异对因变量的影响,归一化方法可以选择z-score标准化、Min-max标准化等方法,然后进入步骤B4-4。Step B4-3. Normalize the environmental variable data in each specified type of environmental variable layer to eliminate the influence of the difference of different environmental variable dimensions on the dependent variable. The normalization method can choose z-score standardization, Min -max normalization and other methods, then go to step B4-4.
步骤B4-4.判断各指定种类环境变量图层中是否存在缺失数据,是则选择重采样进行补充或删除该指定种类环境变量,否则进入步骤B4-5。Step B4-4. Determine whether there is missing data in each designated type of environment variable layer, if yes, select resampling to supplement or delete the designated type of environment variable, otherwise go to step B4-5.
步骤B4-5.将各土壤样点叠加至面状的各指定种类环境变量栅格图层上,获得各土壤样点分别所对应的各指定种类环境变量数据。Step B4-5. Superimpose each soil sample point on the surface-shaped environmental variable raster layer of each designated type, and obtain the environmental variable data of each designated type corresponding to each soil sample point.
步骤C.根据不同时期下、各土壤样点在预设深度下分别所对应各指定土壤属性数据,按如下公式:Step C. According to the specified soil attribute data corresponding to each soil sample point at a preset depth in different periods, according to the following formula:

获得不同时期下、各土壤样点位置对应预设深度的土壤有机碳密度,然后进入步骤D。其中,n∈{1、…、N},N表示土壤样点的个数,SOCSn表示第n个土壤样点位置的土壤有机碳密度(kg/m2),I表示土壤样点位置土壤层次的数目,SOC_in表示第n个土壤样点位置第i层所对应土壤属性数据中的土壤有机碳含量,BD_in表示第n个土壤样点位置第i层所对应土壤属性数据中的土壤容重,Gr_in表示第n个土壤样点位置第i层所对应土壤属性数据中、大于2mm的砾石含量体积百分比,T_in表示第n个土壤样点位置第i层所对应土壤属性数据中的土壤厚度。Obtain the soil organic carbon density corresponding to the preset depth of each soil sample point in different periods, and then proceed to step D. Among them, n∈{1,...,N}, N represents the number of soil sample points, SOCS n represents the soil organic carbon density (kg/m 2 ) at the nth soil sample point location, I represents the soil sample location of the soil sample point The number of layers, SOC_in represents the soil organic carbon content in the soil attribute data corresponding to the i-th layer of the n -th soil sample point, BD_in represents the soil in the soil attribute data corresponding to the i-th layer of the n-th soil sample point Bulk density, Gr_in represents the volume percentage of the gravel content greater than 2 mm in the soil attribute data corresponding to the i-th layer of the n -th soil sample point, T_in represents the soil attribute data of the i-th layer corresponding to the n-th soil sample point soil thickness.
注:如果部分土壤样点位置的采样深度小于预设深度,则可以采用样条函数、加权函数,拟合获得土壤样点位置对应对预设深度的土壤有机碳密度。Note: If the sampling depth of some soil sample points is less than the preset depth, the spline function and weighting function can be used to obtain the soil organic carbon density corresponding to the preset depth at the soil sample position.
注:预设深度指的是土壤地表以下的固定深度值。Note: Preset depth refers to a fixed depth value below the soil surface.
步骤D.预设定义层次分析法中、不同遴选指标属性之间的相对重要性,然后进入步骤E。Step D. Preset to define the relative importance of different selection index attributes in the AHP, and then proceed to Step E.
对环境变量的属性信息进行分类,作为层次分析模型中的计算信息。共考虑六种层次分析法的遴选指标:皮尔逊相关系数、差异性显著程度、环境变量数值类型、是否为动态环境变量、共线性比重与变量的重要性。定义如下变量来表达环境变量的属性类型,如下表2所示。The attribute information of environmental variables is classified as the calculation information in the AHP model. A total of six selection indicators of AHP are considered: Pearson correlation coefficient, significant degree of difference, numerical type of environmental variables, whether it is a dynamic environmental variable, the proportion of collinearity and the importance of variables. Define the following variables to express the property types of environment variables, as shown in Table 2 below.
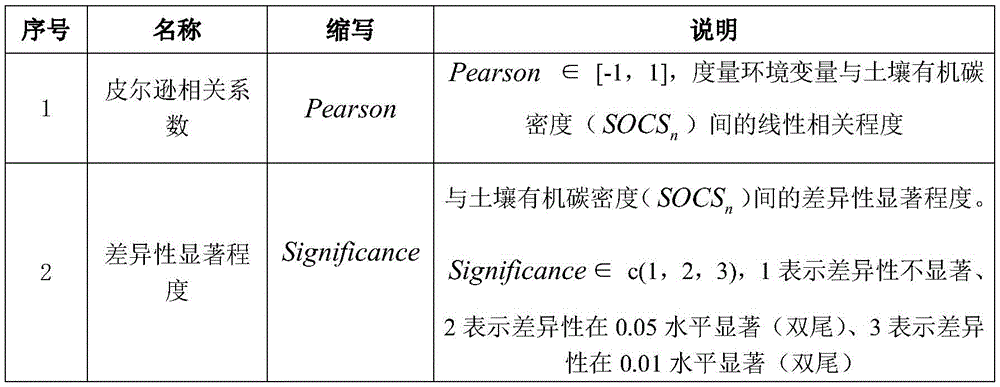
表2Table 2
上述变量的关系如图2所示。The relationship of the above variables is shown in Figure 2.
实际应用中,上述步骤D,具体执行如下步骤D1至步骤D3,预设定义层次分析法中、不同遴选指标属性之间的相对重要性。In practical applications, in the above step D, the following steps D1 to D3 are specifically performed, and the relative importance of different selection index attributes in the AHP is preset and defined.
步骤D1.定义形式化表达式[a,b,va]或[a,b,1/va],表示遴选指标属性a与遴选指标属性b之间的相对重要程度,其中,va是范围为1~9的整数取值,[a,b,va]表示遴选指标属性a相对遴选指标属性b更加重要的程度,[a,b,1/va]表示遴选指标属性b相对遴选指标属性a更加重要的程度,va的值越大,重要程度越大。Step D1. Define a formal expression [a, b, va] or [a, b, 1/va], indicating the relative importance between the selection index attribute a and the selection index attribute b, where va is a range of 1 The integer value of ~9, [a, b, va] indicates that the selection index attribute a is more important than the selection index attribute b, [a, b, 1/va] indicates that the selection index attribute b is more important than the selection index attribute a The greater the value of va, the greater the importance.
步骤D2.基于形式化表达式,定义第一大类遴选指标属性之间的相对重要性如下:Step D2. Based on the formal expression, define the relative importance of the first category of selection index attributes as follows:
[Pearson,Significance,3][Pearson, Significance, 3]
[Pearson,VariableType,9][Pearson, VariableType, 9]
[Pearson,Soilforming,3][Pearson, Soilforming, 3]
[Pearson,ConMulticoll,3][Pearson, ConMulticoll, 3]
[Pearson,Importance,1/3][Pearson, Importance, 1/3]
[Significance,VariableType,9][Significance, VariableType, 9]
[Significance,Soilforming,1][Significance, Soilforming, 1]
[Significance,ConMulticoll,1][Significance, ConMulticoll, 1]
[Significance,Importance,1/9][Significance, Importance, 1/9]
[VariableType,Soilforming,1/7][VariableType, Soilforming, 1/7]
[VariableType,ConMulticoll,1/7][VariableType, ConMulticoll, 1/7]
[VariableType,Importance,1/9][VariableType, Importance, 1/9]
[Soilforming,ConMulticoll,1/7][Soilforming, ConMulticoll, 1/7]
[Soilforming,Importance,1/7][Soilforming, Importance, 1/7]
[ConMulticoll,Importance,1/5][ConMulticoll, Importance, 1/5]
其中,Pearson表示皮尔逊相关系数,Significance表示差异性显著程度,VariableType表示变量类型,Soilforming表示土壤发生学意义,ConMulticoll表示共线性比重,Importance表示变量重要性。Among them, Pearson represents the Pearson correlation coefficient, Significance represents the significant degree of difference, VariableType represents the variable type, Soilforming represents the significance of soil genetics, ConMulticoll represents the proportion of collinearity, and Importance represents the variable importance.
由于环境变量类型涉及两类属性:数值类型与是否为动态环境变量,变量的重要性也包含两类属性:线性回归系数与平均精度下降,因此执行如下步骤D3。Since the type of environment variable involves two types of attributes: numerical type and whether it is a dynamic environment variable, the importance of the variable also includes two types of attributes: linear regression coefficient and average precision reduction, so the following step D3 is performed.
步骤D3.基于形式化表达式,定义第二大类遴选指标属性之间的相对重要性如下:Step D3. Based on the formal expression, define the relative importance of the second largest category of selection index attributes as follows:
[Scenario,Numeric,3][Scenario, Numeric, 3]
[Regression,MDA,1][Regression, MDA, 1]
其中,Scenario和Numeric均属于变量类型VariableType,Scenario表示是否为动态环境变量,Numeric表示数值类型,Regression和MDA均属于变量重要性Importance,Regression表示线性回归系数的绝对值,MDA表示平均精度下降。Among them, Scenario and Numeric belong to the variable type VariableType, Scenario indicates whether it is a dynamic environment variable, Numeric indicates the numerical type, Regression and MDA belong to the variable importance Importance, Regression indicates the absolute value of the linear regression coefficient, and MDA indicates the average precision drop.
步骤E.根据不同时期下、各土壤样点位置对应预设深度的土壤有机碳密度,以及相应各指定种类环境变量数据,执行如下步骤E1至步骤E8,获得层次分析法中、各指定种类环境变量的遴选指标属性数据,然后进入步骤F。Step E. According to the soil organic carbon density corresponding to the preset depth of each soil sample point in different periods, and the corresponding environmental variable data of each designated type, perform the following steps E1 to E8 to obtain the environment of each designated type in the analytic hierarchy process. Variable selection index attribute data, and then enter step F.
步骤E1.获得各指定种类环境变量分别相对土壤有机碳密度的皮尔逊相关系数(Pearson),具体计算方法如下:Step E1. Obtain the Pearson correlation coefficient (Pearson) of each designated type of environmental variable relative to the soil organic carbon density, and the specific calculation method is as follows:

式中:ai是第i个环境变量。In the formula: ai is the ith environment variable.
步骤E2.获得各指定种类环境变量分别相对土壤有机碳密度的差异性显著程度。Step E2. Obtain the significant degree of difference of each designated type of environmental variables relative to soil organic carbon density respectively.
步骤E3.确认各指定种类环境变量分别相对土壤有机碳密度的类型为分类变量或连续型变量。Step E3. Confirm that the type of each designated type of environmental variable relative to soil organic carbon density is a categorical variable or a continuous variable.
步骤E4.确认各指定种类环境变量分别相对土壤有机碳密度的类型为静态环境变量或动态环境变量。Step E4. Confirm that the type of each designated type of environmental variable relative to the soil organic carbon density is a static environmental variable or a dynamic environmental variable.
步骤E5.确认各指定种类环境变量分别相对土壤有机碳密度是否与土壤有机碳含量具有土壤发生学意义。Step E5. Confirm whether the relative soil organic carbon density and soil organic carbon content have pedogenetic significance for each specified type of environmental variable.
步骤E6.获得各指定种类环境变量分别相对土壤有机碳密度的共线性比重(ConMulticoll)。其中,环境变量ai的方差膨胀因子计算方法如下:Step E6. Obtain the collinear proportion (ConMulticoll) of each designated type of environmental variable relative to soil organic carbon density. Among them, the calculation method of the variance inflation factor of the environmental variable ai is as follows:

其中,R2表示ai对常数项与其他环境变量回归后的确定系数。Among them, R 2 represents the coefficient of determination of ai after the regression of the constant term and other environmental variables.
步骤E7.获得各指定种类环境变量分别相对土壤有机碳密度的线性回归系数的绝对值(Regression)。Step E7. Obtain the absolute value (Regression) of the linear regression coefficient of each designated type of environmental variable relative to the soil organic carbon density.
步骤E8.获得各指定种类环境变量分别相对土壤有机碳密度的平均精度下降(MDA)。具体计算方法如下。Step E8. Obtain the average precision drop (MDA) of each designated type of environmental variable relative to soil organic carbon density. The specific calculation method is as follows.
步骤E8-1.使用随机森林模型,构建环境变量与土壤有机碳密度(SOCS)的预测模型。Step E8-1. Using a random forest model, build a prediction model for environmental variables and soil organic carbon density (SOCS).
步骤E8-2.随机修改ai的值,记录预测模型的误差。Step E8-2. Randomly modify the value of ai and record the error of the prediction model.
步骤E8-3.根据每一个环境变量对应的误差,设定其平均精度下降。MDA值越大,说明对应的环境变量对于预测模型越重要。Step E8-3. According to the error corresponding to each environmental variable, set the average precision drop. The larger the MDA value, the more important the corresponding environmental variable is to the prediction model.
步骤F.根据层次分析法中、各指定种类环境变量分别相对目标土壤区域的各遴选指标属性数据,以及预设不同遴选指标属性之间的相对重要性,依次执行如下步骤F1至步骤F8,计算获得层次分析法中、不同指定种类环境变量之间相对各遴选指标属性的重要性,然后进入步骤G。Step F. According to the analytic hierarchy process, the relative importance of each selection index attribute of each designated type of environmental variable relative to the target soil area, and the relative importance between the preset different selection index attributes, execute the following steps F1 to F8 in sequence, calculate Obtain the relative importance of each selection index attribute between different specified types of environmental variables in the AHP, and then enter step G.
步骤F1.基于第k个指定种类环境变量相对目标土壤区域的皮尔逊相关系数Pearson_ak,与第j个指定种类环境变量相对目标土壤区域的皮尔逊相关系数Pearson_aj之间的比较,若Pearson_ak≥Pearson_aj,则进入步骤F1-1;否则进入步骤F1-2;其中,k∈{1,2,…,K},j∈{1,2,…,K},K表示指定种类环境变量的数量,ak表示第k个指定种类环境变量,aj表示第j个指定种类环境变量。Step F1. Based on the comparison between the Pearson correlation coefficient Pearson_ak of the kth specified type environmental variable relative to the target soil area, and the Pearson correlation coefficient Pearson_aj of the jth specified type environmental variable relative to the target soil area, if Pearson_ak≥Pearson_aj, Then go to step F1-1; otherwise go to step F1-2; where k∈{1, 2,...,K}, j∈{1, 2,...,K}, K represents the number of environment variables of the specified type, ak Represents the k-th specified type of environment variable, and aj represents the j-th specified type of environment variable.
步骤F1-1.如图3所示,基于皮尔逊相关系数(Pearson),第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va计算如下:Step F1-1. As shown in Figure 3, based on the Pearson correlation coefficient (Pearson), the importance of the kth specified type environmental variable ak relative to the jth specified type environmental variable aj is calculated in va [ak, aj, va] as follows:
若Indicator1>10,且Pearson_ak>0.2,则va=4;If Indicator 1 >10, and Pearson_ak>0.2, then va=4;
若Indicator1>5,且Pearson_ak>0.1,则va=2;If Indicator 1 >5, and Pearson_ak>0.1, then va=2;
否则,va=1;otherwise, va = 1;
其中,Indicator1=Pearson_ak/Pearson_aj。Wherein, Indicator 1 =Pearson_ak/Pearson_aj.
步骤F1-2.基于皮尔逊相关系数,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va计算如下:Step F1-2. Based on the Pearson correlation coefficient, the degree of importance [ak, aj, va] of the environmental variable ak of the kth designated type relative to the environmental variable aj of the jth designated type [ak, aj, va] is calculated as follows:
若Indicator2>10,且Pearson_aj>0.2,则va=1/4;If Indicator 2 >10, and Pearson_aj>0.2, then va=1/4;
若Indicator2>5,且Pearson_aj>0.1,则va=1/2;If Indicator 2 >5, and Pearson_aj>0.1, then va=1/2;
否则,va=1;otherwise, va = 1;
式中:Indicator2=Pearson_aj/Pearson_ak。In the formula: Indicator 2 =Pearson_aj/Pearson_ak.
步骤F2.如图4所示,基于第k个指定种类环境变量相对目标土壤区域的差异性显著程度Significance_ak,与第j个指定种类环境变量相对目标土壤区域的差异性显著程度Significance_aj之间的比较,按如下,实现基于差异性显著程度,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va获得;Step F2. As shown in Figure 4, based on the comparison between the significance level Significance_ak of the environmental variable of the kth specified type relative to the target soil area, and the significance level Significance_aj of the environmental variable of the jth specified type relative to the target soil area , as follows, to achieve the importance of the kth specified type of environment variable ak relative to the jth of the jth of the specified type of environmental variable aj based on the degree of significance of the difference [ak, aj, va] obtained in va;
若Indicator3=2,则va=9;If Indicator 3 =2, then va=9;
若Indicator3=1,则va=6;If Indicator 3 =1, then va=6;
若Indicator3=0,则va=1;If Indicator 3 =0, then va=1;
若Indicator3=-1,则va=1/6;If Indicator 3 = -1, then va = 1/6;
若Indicator3=-2,则va=1/9;If Indicator 3 =-2, then va=1/9;
其中,Indicator3=Significance_ak-Significance_aj。Wherein, Indicator 3 =Significance_ak-Significance_aj.
步骤F3.如图5所示,基于第k个指定种类环境变量相对目标土壤区域的数值类型Numeric_ak,与第j个指定种类环境变量相对目标土壤区域的数值类型Numeric_aj之间的比较,按如下,实现基于数值类型,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va获得;Step F3. As shown in FIG. 5, based on the comparison between the numerical type Numeric_ak of the kth specified type environmental variable relative to the target soil area, and the jth specified type environmental variable relative to the numerical type Numeric_aj of the target soil area, as follows, Based on the numerical type, the importance of the kth specified type environment variable ak relative to the jth specified type environment variable aj is obtained from va in [ak, aj, va];
若Indicator4=1,则va=3;If Indicator 4 =1, then va=3;
若Indicator4=0,则va=1;If Indicator 4 =0, then va=1;
否则,va=1/3;otherwise, va = 1/3;
其中,Indicator4=Numeric_ak-Numeric_aj。Wherein, Indicator 4 =Numeric_ak-Numeric_aj.
步骤F4.如图6所示,基于第k个指定种类环境变量相对目标土壤区域是否为动态环境变量Scenario_ak,与第j个指定种类环境变量相对目标土壤区域是否为动态环境变量Scenario_aj之间的比较,按如下,实现基于是否为动态环境变量,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va获得;Step F4. As shown in Figure 6, based on whether the kth specified type environmental variable relative to the target soil area is a dynamic environmental variable Scenario_ak, and the jth specified type environmental variable relative to whether the target soil area is a dynamic environmental variable Scenario_aj comparison between , as follows, the realization is based on whether it is a dynamic environment variable, the importance of the kth specified type environment variable ak relative to the jth specified type environment variable aj is obtained in va [ak, aj, va];
若Indicator5=1,则va=6;If Indicator 5 =1, then va=6;
若Indicator5=0,则va=1;If Indicator 5 = 0, then va = 1;
否则,va=1/6。Otherwise, va=1/6.
其中,Indicator5=Scenario_ak-Scenario_aj。Wherein, Indicator 5 =Scenario_ak-Scenario_aj.
步骤F5.如图7所示,基于第k个指定种类环境变量相对目标土壤区域的土壤发生学意义Soilforming_ak,与第j个指定种类环境变量相对目标土壤区域的土壤发生学意义Soilforming_aj之间的比较,按如下,实现基于土壤发生学意义,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va获得;Step F5. As shown in Figure 7, based on the comparison between the soil genetic significance Soilforming_ak of the kth designated type environmental variable relative to the target soil area, and the soil genetic significance Soilforming_aj of the jth designated type environmental variable relative to the target soil area , as follows, to achieve the importance of the environmental variable ak of the kth specified species relative to the environmental variable aj of the jth specified species based on the significance of soil genetics [ak, aj, va] obtained in va;
若Indicator6=1,则va=6;If Indicator 6 =1, then va=6;
若Indicator6=2,则va=9;If Indicator 6 =2, then va=9;
若Indicator6=1,则va=6;If Indicator 6 =1, then va=6;
若Indicator6=0,则va=1;If Indicator 6 =0, then va=1;
若Indicator6=-1,则va=1/6;If Indicator 6 = -1, then va = 1/6;
若Indicator6=-2,则va=1/9;If Indicator 6 = -2, then va = 1/9;
其中,Indicator6=Soilforming_ak-Soilforming_aj。Wherein, Indicator 6 =Soilforming_ak-Soilforming_aj.
步骤F6.如图8所示,基于第k个指定种类环境变量相对目标土壤区域的共线性比重ConMulticoll_ak,与第j个指定种类环境变量相对目标土壤区域的共线性比重ConMulticoll_aj之间的比较,若ConMulticoll_ak≥ConMulticoll_aj,则进入步骤F6-1;否则进入步骤F6-2。Step F6. As shown in Figure 8, based on the comparison between the collinear proportion ConMulticoll_ak of the kth specified type environmental variable relative to the target soil area, and the collinear proportion ConMulticoll_aj of the jth specified type environmental variable relative to the target soil area, if ConMulticoll_ak≥ConMulticoll_aj, go to step F6-1; otherwise go to step F6-2.
步骤F6-1.基于共线性比重,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va计算如下:Step F6-1. Based on the proportion of collinearity, the importance of the kth specified type environmental variable ak relative to the jth specified type environmental variable aj [ak, aj, va] in va is calculated as follows:
若Indicator7>10,且ConMulticoll_ak>10,则va=1/4;If Indicator 7 >10, and ConMulticoll_ak>10, then va=1/4;
若Indicator7>5,则va=1/3;If Indicator 7 > 5, then va=1/3;
否则,va=1;otherwise, va = 1;
其中,Indicator7=ConMulticoll_ak-ConMulticoll_aj。Wherein, Indicator 7 =ConMulticoll_ak-ConMulticoll_aj.
步骤F6-2.基于共线性比重,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va计算如下:Step F6-2. Based on the proportion of collinearity, the importance of the kth specified type environmental variable ak relative to the jth specified type environmental variable aj [ak, aj, va] in va is calculated as follows:
若Indicator8>10,且ConMulticoll_aj>10,则va=4;If Indicator 8 >10, and ConMulticoll_aj>10, then va=4;
若Indicator8>5,则va=3;If Indicator 8 > 5, then va=3;
否则,va=1;otherwise, va = 1;
其中,Indicator8=ConMulticoll_aj-ConMulticoll_ak。Wherein, Indicator 8 =ConMulticoll_aj-ConMulticoll_ak.
F7.如图9所示,基于第k个指定种类环境变量相对目标土壤区域的线性回归系数的绝对值Regression_ak,与第j个指定种类环境变量相对目标土壤区域的线性回归系数的绝对值Regression_aj之间的比较,若Regression_ak≥Regression_aj,则进入步骤F7-1;否则进入步骤F7-2。F7. As shown in Figure 9, based on the absolute value Regression_ak of the linear regression coefficient of the kth specified type of environmental variable relative to the target soil area, and the absolute value of the linear regression coefficient of the jth specified type of environmental variable relative to the target soil area Regression_aj If Regression_ak≥Regression_aj, go to step F7-1; otherwise, go to step F7-2.
步骤F7-1.基于线性回归系数的绝对值,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va计算如下:Step F7-1. Based on the absolute value of the linear regression coefficient, the degree of importance [ak, aj, va] of the kth specified type environmental variable ak relative to the jth specified type environmental variable aj [ak, aj, va] is calculated as follows:
若Indicator9>10,则va=9;If Indicator 9 > 10, then va=9;
若Indicator9>5,则va=6;If Indicator 9 > 5, then va=6;
否则,va=3。Otherwise, va=3.
其中,Indicator9=Regression_ak/Regression_aj。Wherein, Indicator 9 =Regression_ak/Regression_aj.
步骤F7-2.基于线性回归系数的绝对值,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va计算如下:Step F7-2. Based on the absolute value of the linear regression coefficient, the degree of importance [ak, aj, va] of the kth specified type environmental variable ak relative to the jth specified type environmental variable aj [ak, aj, va] is calculated as follows:
若Indicator10>10,则va=1/9;If Indicator 10 > 10, then va=1/9;
若Indicator10>5,则va=1/6;If Indicator 10 >5, then va=1/6;
否则,va=1/3。Otherwise, va=1/3.
其中,Indicator10=Regression_aj/Regression_ak。Wherein, Indicator 10 =Regression_aj/Regression_ak.
步骤F8.如图10所示,基于第k个指定种类环境变量相对目标土壤区域的平均精度下降值MDA_ak,与第j个指定种类环境变量相对目标土壤区域的平均精度下降值MDA_aj之间的比较,若MDA_ak≥MDA_aj,则进入步骤F8-1;否则进入步骤F8-2。Step F8. As shown in Figure 10, based on the comparison between the average precision drop value MDA_ak of the kth specified type environmental variable relative to the target soil area, and the jth specified type environmental variable relative to the target soil area The comparison between the average precision drop value MDA_aj , if MDA_ak≥MDA_aj, go to step F8-1; otherwise, go to step F8-2.
步骤F8-1.基于平均精度下降值,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va计算如下:Step F8-1. Based on the average precision drop value, the degree of importance [ak, aj, va] of the kth specified type environment variable ak relative to the jth specified type environment variable aj [ak, aj, va] is calculated as follows:
若Indicator11>15,则va=9;If Indicator 11 >15, then va=9;
若Indicator11>10,则va=7;If Indicator 11 >10, then va=7;
若Indicator11>5,则va=5;If Indicator 11 >5, then va=5;
若Indicator11>2,则va=3;If Indicator 11 >2, then va=3;
否则,va=1。Otherwise, va=1.
其中,Indicator11=MDA_ak/MDA_aj。Wherein, Indicator 11 =MDA_ak/MDA_aj.
步骤F8-2.基于平均精度下降值,第k个指定种类环境变量ak相对第j个指定种类环境变量aj的重要程度[ak,aj,va]中va计算如下:Step F8-2. Based on the average precision drop value, the degree of importance [ak, aj, va] of the kth specified type environment variable ak relative to the jth specified type environment variable aj [ak, aj, va] is calculated as follows:
若Indicator12>15,则va=1/9;If Indicator 12 >15, then va=1/9;
若Indicator12>10,则va=1/7;If Indicator 12 >10, then va=1/7;
若Indicator12>5,则va=1/5;If Indicator 12 >5, then va=1/5;
若Indicator12>2,则va=1/3;If Indicator 12 > 2, then va=1/3;
否则,va=1。Otherwise, va=1.
式中:Indicator12=MDA_aj/MDA_ak。In the formula: Indicator 12 =MDA_aj/MDA_ak.
步骤G.根据层次分析法中、不同指定种类环境变量之间相对各遴选指标属性的重要性,以及不同时期下、各土壤样点分别所对应各指定种类环境变量数据,构建目标土壤区域所对应土壤有机碳密度的层次分析树,获得用于目标土壤区域土壤有机碳密度预测所对应的最优环境变量集合。Step G. According to the analytic hierarchy process, the relative importance of each selected index attribute among different designated types of environmental variables, and the data of each designated type of environmental variables corresponding to each soil sample point in different periods, construct the corresponding soil area corresponding to the target soil. The analytic hierarchy process tree of soil organic carbon density is used to obtain the optimal set of environmental variables corresponding to the prediction of soil organic carbon density in the target soil area.
实际应用当中,上述步骤G执行,具体包括如下步骤:In practical applications, the above-mentioned step G is performed, and specifically includes the following steps:
步骤G1.根据层次分析法中、不同指定种类环境变量之间相对各遴选指标属性的重要性,以及不同时期下、各土壤样点分别所对应各指定种类环境变量数据,构建目标土壤区域所对应土壤有机碳密度的层次分析树。Step G1. According to the analytic hierarchy process, the relative importance of each selection index attribute among different designated types of environmental variables, and the data of each designated type of environmental variables corresponding to each soil sample point in different periods, construct the corresponding soil area corresponding to the target soil. Analytic Hierarchy Tree for Soil Organic Carbon Density.
步骤G2.根据环境变量的总体贡献率进行排序,选择前预设百分比,诸如80%的环境变量,用于目标土壤区域土壤有机碳密度预测所对应的最优环境变量集合。Step G2. Sort according to the overall contribution rate of the environmental variables, and select a pre-set percentage, such as 80% of the environmental variables, for the optimal set of environmental variables corresponding to the prediction of soil organic carbon density in the target soil area.
步骤G3.根据目标土壤区域土壤有机碳密度预测所对应的最优环境变量集合,采用预设指定预测模型,预测获得不同时间片标签下、历史土壤有机碳密度空间分布图与未来土壤有机碳密度空间分布图。Step G3. According to the optimal set of environmental variables corresponding to the prediction of soil organic carbon density in the target soil area, a preset specified prediction model is used to predict and obtain the spatial distribution map of historical soil organic carbon density and future soil organic carbon density under different time slice labels Spatial distribution map.
下面以丹阳市有机碳库时空动态估算的最优环境变量筛选为例The following is an example of the optimal environmental variable screening for the spatiotemporal dynamic estimation of organic carbon pools in Danyang City
丹阳市江苏省镇江市辖县级市,综合经济实力居江苏省十强县(市)第7位,地势西北高、东南低,有低山丘陵和平原,以平原为主。丹阳位于中纬度北亚热带,属海洋性气候。由于较快的经济发展节奏,导致了工业、农业土地利用变化迅速。不同土地利用条件又导致了土壤有机碳库的快速变化。以1980年以来不同部门采集的1200个土壤样点与环境变量为输入数据,土壤采样深度为0-20cm,选择有机碳库时空动态估算的最优环境变量集合。Danyang City is a county-level city under the jurisdiction of Zhenjiang City, Jiangsu Province. Its comprehensive economic strength ranks seventh among the top ten counties (cities) in Jiangsu Province. The terrain is high in the northwest and low in the southeast, with low mountains and plains, mainly plains. Danyang is located in the mid-latitude north subtropical zone and has an oceanic climate. Due to the fast pace of economic development, industrial and agricultural land use has changed rapidly. Different land use conditions led to rapid changes in soil organic carbon pools. Taking 1200 soil sample points and environmental variables collected by different departments since 1980 as input data, the soil sampling depth is 0-20cm, and the optimal set of environmental variables for the spatiotemporal dynamic estimation of organic carbon pools is selected.
收集1980年-2015年,共1200个土壤样点,按以10年为时间间隔,设定各土壤样点数据的时间片标签。共四个时间片标签,分别为1980、1999、2000、2010。A total of 1200 soil sample points were collected from 1980 to 2015, and the time slice label of each soil sample point data was set at a time interval of 10 years. A total of four time slice labels are 1980, 1999, 2000, and 2010.
基于所获土壤样点,执行上述本发明所设计土壤有机碳库时空动态预测最优环境变量筛选方法,其中,步骤G中的步骤G1,构建目标土壤区域所对应土壤有机碳密度的层次分析树,具体结果见如下表3。Based on the obtained soil sample points, the above-mentioned optimal environmental variable screening method for the spatiotemporal dynamic prediction of soil organic carbon pools designed by the present invention is performed, wherein, step G1 in step G is to construct a hierarchical analysis tree of soil organic carbon density corresponding to the target soil area , and the specific results are shown in Table 3 below.
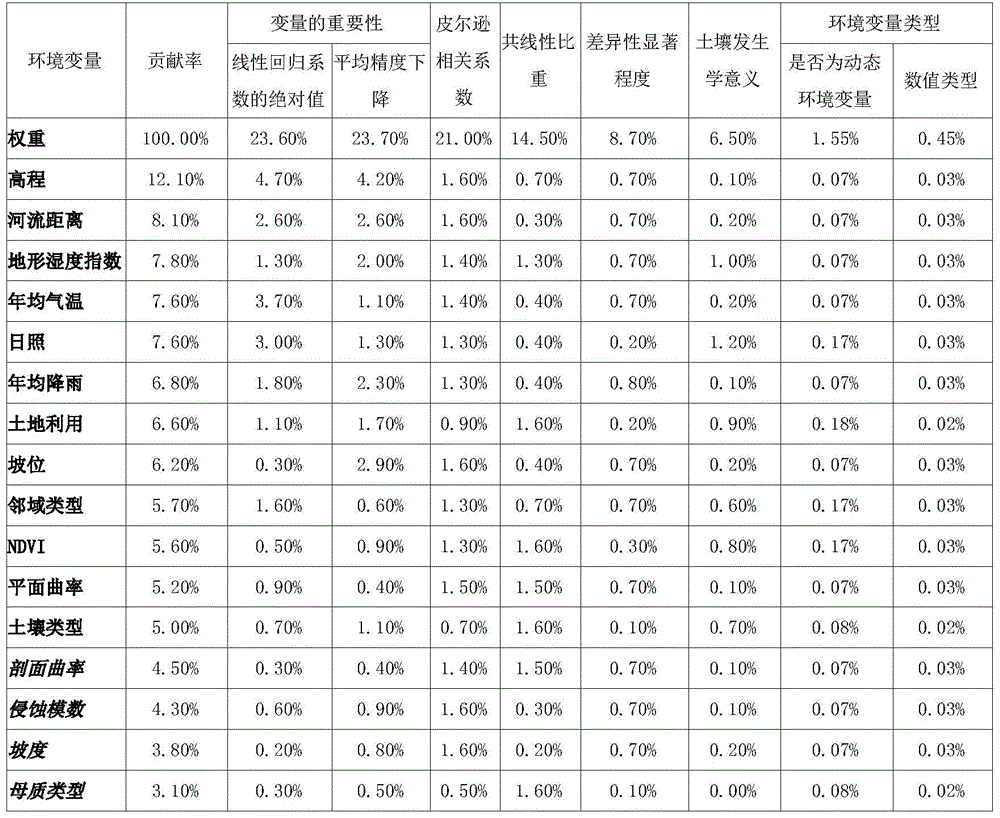
表3table 3
步骤G2.根据变量的总体贡献率进行排序,选择前80%作为预测土壤有机碳密度的环境变量集合,具体选择的环境变量为:高程、河流距离、地形湿度指数、年均气温、日照、年均降雨、土地利用、坡位、邻域类型、NDVI、平面曲率、土壤类型。Step G2. Sort according to the overall contribution rate of the variables, and select the top 80% as the set of environmental variables for predicting soil organic carbon density. The specific environmental variables selected are: elevation, river distance, terrain humidity index, annual average temperature, sunshine, annual Average rainfall, land use, slope position, neighborhood type, NDVI, plane curvature, soil type.
步骤G3.根据目标土壤区域土壤有机碳密度预测所对应的最优环境变量集合,基于随机森林的元胞自动机模型。预测2010年、2020年、2030年土壤有机碳密度空间分布图,分别如图11、图12、图13所示。Step G3. According to the optimal set of environmental variables corresponding to the prediction of soil organic carbon density in the target soil region, a cellular automata model based on random forest is used. The spatial distribution map of soil organic carbon density is predicted in 2010, 2020 and 2030, as shown in Figure 11, Figure 12, and Figure 13, respectively.
面向土壤碳库的时空动态估算,环境变量的筛选对预测精度具有十分重要的意义。与常规的基于数据的环境变量筛选技术不同,本发明充分考虑了环境变量的属性对预测模型的综合影响,例如环境变量数值类型、是否为动态环境变量、共线性比重与变量的重要性等。这些信息的综合考虑为研究区土壤碳库的准确工程度量提供了最优环境变量集合,有效地客服了动态环境变量与土壤有机碳密度多时期影响的不确定性。该技术对于科学制定合理的工程方案、实现多尺度的土壤调查及生态系统服务规划具有十分重要的指导意义。For the spatiotemporal dynamic estimation of soil carbon pool, the screening of environmental variables is of great significance to the prediction accuracy. Different from the conventional data-based environmental variable screening technology, the present invention fully considers the comprehensive influence of environmental variable attributes on the prediction model, such as the environmental variable numerical type, whether it is a dynamic environmental variable, collinearity proportion and variable importance. The comprehensive consideration of these information provides an optimal set of environmental variables for accurate engineering measurement of soil carbon pools in the study area, effectively overcoming the uncertainty of the multi-period effects of dynamic environmental variables and soil organic carbon density. This technology has very important guiding significance for scientifically formulating reasonable engineering plans, realizing multi-scale soil survey and ecosystem service planning.
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。The embodiments of the present invention have been described in detail above in conjunction with the accompanying drawings, but the present invention is not limited to the above-mentioned embodiments, and can also be made within the scope of knowledge possessed by those of ordinary skill in the art without departing from the purpose of the present invention. Various changes.
Claims (10)

Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810365926.9A CN108764527B (en) | 2018-04-23 | 2018-04-23 | Screening method for soil organic carbon library time-space dynamic prediction optimal environment variables |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810365926.9A CN108764527B (en) | 2018-04-23 | 2018-04-23 | Screening method for soil organic carbon library time-space dynamic prediction optimal environment variables |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108764527A CN108764527A (en) | 2018-11-06 |
| CN108764527B true CN108764527B (en) | 2020-06-09 |
Family
ID=64011540
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810365926.9A Active CN108764527B (en) | 2018-04-23 | 2018-04-23 | Screening method for soil organic carbon library time-space dynamic prediction optimal environment variables |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108764527B (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111508569B (en) | 2020-03-19 | 2023-05-09 | 中国科学院南京土壤研究所 | A Prediction Method of Target Soil Properties and Content Based on Soil Transfer Function |
| CN112116070B (en) * | 2020-09-07 | 2024-04-05 | 北方工业大学 | Subway station environment parameter monitoring method and device |
| CN112198299B (en) * | 2020-09-29 | 2023-07-04 | 南京林业大学 | Method for measuring mineralization capacity of organic carbon in soil based on Bayes theory |
| CN112990330B (en) * | 2021-03-26 | 2022-09-20 | 国网河北省电力有限公司营销服务中心 | User energy abnormal data detection method and device |
| CN114970934B (en) * | 2022-02-28 | 2025-05-13 | 四川省烟草公司凉山州公司 | A soil thickness type prediction method based on feature ensemble learning |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104408258A (en) * | 2014-12-01 | 2015-03-11 | 四川农业大学 | Large-scale soil organic carbon spatial distribution simulation method involving environmental factors |
| WO2017053273A1 (en) * | 2014-09-12 | 2017-03-30 | The Climate Corporation | Estimating intra-field properties within a field using hyperspectral remote sensing |
| CN106934491A (en) * | 2017-02-23 | 2017-07-07 | 北京农业信息技术研究中心 | A kind of soil restoring technology screening technique and device |
| CN106980750A (en) * | 2017-02-23 | 2017-07-25 | 中国科学院南京土壤研究所 | A kind of Soil Nitrogen estimation method of reserve based on typical correspondence analysis |
-
2018
- 2018-04-23 CN CN201810365926.9A patent/CN108764527B/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017053273A1 (en) * | 2014-09-12 | 2017-03-30 | The Climate Corporation | Estimating intra-field properties within a field using hyperspectral remote sensing |
| CN104408258A (en) * | 2014-12-01 | 2015-03-11 | 四川农业大学 | Large-scale soil organic carbon spatial distribution simulation method involving environmental factors |
| CN106934491A (en) * | 2017-02-23 | 2017-07-07 | 北京农业信息技术研究中心 | A kind of soil restoring technology screening technique and device |
| CN106980750A (en) * | 2017-02-23 | 2017-07-25 | 中国科学院南京土壤研究所 | A kind of Soil Nitrogen estimation method of reserve based on typical correspondence analysis |
Non-Patent Citations (1)
| Title |
|---|
| 复杂地区土壤调查样点可达性研究—以我国西北黑河流域为例;邱霞霞等;《土壤》;20151015;第47卷(第5期);第984-988页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108764527A (en) | 2018-11-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Liu et al. | Spatio-temporal prediction and factor identification of urban air quality using support vector machine | |
| CN108764527B (en) | Screening method for soil organic carbon library time-space dynamic prediction optimal environment variables | |
| WO2024152865A1 (en) | Meteorological-station-based ecosystem carbon-water flux calculation method and system | |
| Yin et al. | Ecosystem services assessment and sensitivity analysis based on ANN model and spatial data: A case study in Miaodao Archipelago | |
| CN113902580A (en) | A Reconstruction Method of Historical Farmland Distribution Based on Random Forest Model | |
| CN111667183A (en) | Method and system for monitoring cultivated land quality | |
| Yu et al. | Deep learning-based downscaling of tropospheric nitrogen dioxide using ground-level and satellite observations | |
| CN118916658A (en) | Method and system for identifying ecological restoration area | |
| CN108536908A (en) | Method based on the assessment of non-point source nitrogen and phosphorus loss risk watershed water environment safety | |
| CN106980750B (en) | A kind of Soil Nitrogen estimation method of reserve based on typical correspondence analysis | |
| Xiang et al. | Mapping potential wetlands by a new framework method using random forest algorithm and big Earth data: A case study in China's Yangtze River Basin | |
| CN119538710A (en) | Pollution research and water quality prediction method based on river segment water environmental capacity analysis | |
| CN118607923B (en) | A digital twin scenario-based system for water and salt dynamics in irrigation areas | |
| CN115905902A (en) | A Method for Dividing Rural Landscape Ecologically Sensitive Areas Based on K-MEANS Clustering Algorithm | |
| CN115481366A (en) | A Calculation Method of Cultivated Land Resource Production Potential Based on Spatial Downscaling Regression Model | |
| Deng | Modeling the dynamics and consequences of land system change | |
| Cao et al. | Soil organic carbon sequestration potential, storage, and influencing mechanisms in China | |
| Zhan et al. | Factors and mechanism driving the land-use conversion in Jiangxi Province | |
| Mansor et al. | Optimization of land use suitability for agriculture using integrated geospatial model and genetic algorithms | |
| CN120509784A (en) | Highway network ecological system evaluation method and system | |
| CN120147468A (en) | A soil organic matter prediction and mapping method, device, equipment and medium based on deep learning | |
| CN118228029A (en) | An integrated management method and system for multidimensional data | |
| CN120011953B (en) | Ozone concentration estimation method, medium and equipment based on regional and factor heterogeneity | |
| CN120727143B (en) | Prediction method for anabasine pesticide pollution of surface water body in river basin based on sub-river basin and machine learning model | |
| CN119577050B (en) | Grass Germplasm Resources Geographic Information Management System |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |