CN108259567B - A Discovery Method of Large Data Center Business Subsystem Based on Server Application Logic - Google Patents
A Discovery Method of Large Data Center Business Subsystem Based on Server Application Logic Download PDFInfo
- Publication number
- CN108259567B CN108259567B CN201711403565.4A CN201711403565A CN108259567B CN 108259567 B CN108259567 B CN 108259567B CN 201711403565 A CN201711403565 A CN 201711403565A CN 108259567 B CN108259567 B CN 108259567B
- Authority
- CN
- China
- Prior art keywords
- server
- data
- service system
- client
- edge
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 23
- 238000010586 diagram Methods 0.000 claims abstract description 11
- 101100257062 Leishmania major IPCS gene Proteins 0.000 claims description 3
- 238000013507 mapping Methods 0.000 claims description 3
- 230000001186 cumulative effect Effects 0.000 claims description 2
- 238000012544 monitoring process Methods 0.000 claims description 2
- 230000004931 aggregating effect Effects 0.000 claims 3
- 230000035515 penetration Effects 0.000 claims 1
- 238000012423 maintenance Methods 0.000 abstract description 19
- 239000000463 material Substances 0.000 abstract description 5
- 230000007547 defect Effects 0.000 abstract description 3
- 239000000284 extract Substances 0.000 description 3
- 238000004220 aggregation Methods 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
Images

Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/104—Peer-to-peer [P2P] networks
- H04L67/1061—Peer-to-peer [P2P] networks using node-based peer discovery mechanisms
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/104—Peer-to-peer [P2P] networks
- H04L67/1059—Inter-group management mechanisms, e.g. splitting, merging or interconnection of groups
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/14—Session management
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/50—Network services
- H04L67/51—Discovery or management thereof, e.g. service location protocol [SLP] or web services
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L69/00—Network arrangements, protocols or services independent of the application payload and not provided for in the other groups of this subclass
- H04L69/16—Implementation or adaptation of Internet protocol [IP], of transmission control protocol [TCP] or of user datagram protocol [UDP]
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Computer Security & Cryptography (AREA)
- Computer And Data Communications (AREA)
Abstract
本发明涉及服务器运维管理技术领域,尤其涉及一种基于服务器应用逻辑的大型数据中心业务子系统发现方法。所述方法通过构建数据中心系统架构图,有效克服了传统运维方法的缺陷,无须耗费大量人力物力财力去采集、统计数据;无须运维人员对数据中心的应用的系统架构有充分的经验知识;能自动构建基于应用的业务逻辑网络,有效辅助运维人员掌握数据中心的服务器架构及使用情况。
The invention relates to the technical field of server operation and maintenance management, in particular to a large-scale data center business subsystem discovery method based on server application logic. The method effectively overcomes the defects of the traditional operation and maintenance method by constructing the system architecture diagram of the data center, and does not need to spend a lot of manpower, material and financial resources to collect and count data; it does not require the operation and maintenance personnel to have sufficient experience and knowledge of the application system architecture of the data center. ; Can automatically build an application-based business logic network, effectively assisting the operation and maintenance personnel to master the server architecture and usage of the data center.
Description
技术领域technical field
本发明涉及服务器运维管理技术领域,尤其涉及一种基于服务器应用逻辑的大型数据中心业务子系统发现方法。The invention relates to the technical field of server operation and maintenance management, in particular to a large-scale data center business subsystem discovery method based on server application logic.
背景技术Background technique
近年来,大型数据中心的服务器数量的快速增长给其运维管理部门带来了巨大压力。运维管理人员越来越难以掌握数据中心内部的服务器的实际使用情况,及各项业务应用涉及的服务器和服务器之间的应用逻辑关系等情况。In recent years, the rapid increase in the number of servers in large data centers has brought enormous pressure to their operation and maintenance departments. It is increasingly difficult for operation and maintenance managers to grasp the actual usage of servers in the data center, as well as the application logic relationships between servers involved in various business applications.
目前,面对运行着复杂业务系统的数据中心,传统的运维方案是单纯依靠人工统计与一些初级运维工具,将数据中心的服务器使用情况存入CMDB(ConfigurationManagement Database,配置管理数据库)进行登记和统计,然后基于统计结果,人工绘制服务器的业务应用逻辑网络。这样的方式存在很多缺陷。一方面,数据中心在实际运行的过程中,业务系统架构变化快,业务系统复杂度高,CMDB中的服务器使用情况记录往往不完整或已经过时,导致运维人员很难准确把握系统的真实架构,人工统计也需要各部门协调,耗费大量人力和物力;另一方面,基于人工统计数据,依靠运维人员个人经验绘制出的服务器业务应用逻辑网络不具有可继承性,一旦发生人员调动,新的人员由于对业务系统不够了解,缺乏经验知识很难更新业务应用逻辑网络。At present, in the face of data centers running complex business systems, the traditional operation and maintenance solution is to simply rely on manual statistics and some primary operation and maintenance tools to store the server usage of the data center in the CMDB (Configuration Management Database) for registration. and statistics, and then based on the statistical results, manually draw the server's business application logic network. There are many flaws in this approach. On the one hand, during the actual operation of the data center, the business system architecture changes rapidly, the business system is highly complex, and the server usage records in the CMDB are often incomplete or outdated, making it difficult for operation and maintenance personnel to accurately grasp the real architecture of the system , manual statistics also require coordination of various departments, which consumes a lot of manpower and material resources; on the other hand, based on manual statistics, the server business application logic network drawn by the personal experience of operation and maintenance personnel is not inheritable. Once personnel are transferred, new Due to the lack of understanding of the business system and the lack of experience and knowledge, it is difficult for the personnel to update the business application logic network.
发明内容SUMMARY OF THE INVENTION
针对上述现有技术存在的不足,本发明提供了一种基于服务器应用逻辑的大型数据中心业务子系统发现方法,以实现对大型数据中心服务器进行有效的运维管理。Aiming at the shortcomings of the above-mentioned prior art, the present invention provides a large-scale data center service subsystem discovery method based on server application logic, so as to realize effective operation and maintenance management of large-scale data center servers.
本发明提供了如下方案,一种基于服务器应用逻辑的大型数据中心业务子系统发现方法,该方法包括一下步骤:The present invention provides the following solution, a method for discovering a large-scale data center business subsystem based on server application logic, the method comprising the following steps:
S1从大型数据中心服务器的原始日志数据中解析聚合出服务器数据、TCP连接数据以及引入外部CMDB业务系统信息数据,具体包括一下步骤:S1 parses and aggregates server data, TCP connection data, and introduces external CMDB business system information data from the original log data of large-scale data center servers, which includes the following steps:
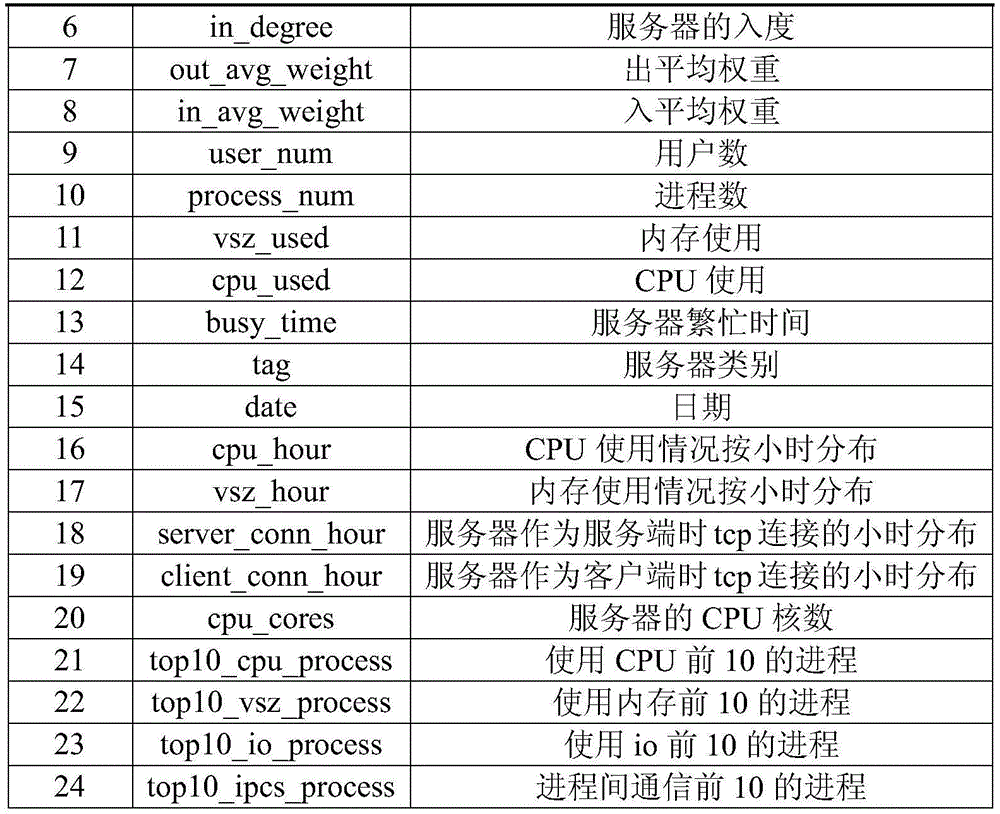
S1.1将一定时间段内的大型数据中心服务器的原始日志数据进行解析聚合,从原始日志数据中提取出服务器数据,该服务器数据中至少包括服务器名称、服务器的IP列表、出度和入度、平均权重、用户数、进程数、内存和CPU使用情况、每小时的连接分布、服务器的分类以及一系列CPU、VSZ、I/O、IPCS的top10进程信息等;S1.1 Analyze and aggregate the raw log data of large data center servers within a certain period of time, and extract server data from the raw log data, which at least includes server name, server IP list, out-degree and in-degree , average weight, number of users, number of processes, memory and CPU usage, connection distribution per hour, server classification, and a series of top10 process information for CPU, VSZ, I/O, IPCS, etc.;
S1.2从原始日志数据中提取出TCP连接数据,该TCP连接数据至少包含了TCP连接两端的服务器名、连接的类别、连接的权重、连接的小时分布、发送以及接收队列等信息;S1.2 extracts the TCP connection data from the original log data. The TCP connection data contains at least the server names at both ends of the TCP connection, the type of the connection, the weight of the connection, the hourly distribution of the connection, the sending and receiving queues and other information;
S1.3从CMDB获取业务系统信息数据,该业务系统信息数据至少包含了业务系统名、业务系统与服务器的映射关系、业务系统负责人等信息;S1.3 Obtain business system information data from the CMDB, which at least includes the business system name, the mapping relationship between the business system and the server, and the person in charge of the business system;
S2基于S1提取出的数据聚合出业务系统的数据信息和业务系统之间的关联关系数据信息;S2 aggregates the data information of the business system and the relationship data information between the business systems based on the data extracted by S1;
其中,业务系统的数据信息具体包括:业务系统名、业务系统负责人、业务系统包含的服务器数量、连接数Sedge_sum、外部连接数Soutside_edge、内部连接数Sinside_edge、出度Sout_degree和入度Sin_degree、平均连接数Savg_edge、平均权重Savg_weight等信息;The data information of the business system specifically includes: the business system name, the person in charge of the business system, the number of servers included in the business system, the number of connections S edge_sum , the number of external connections S outside_edge , the number of internal connections S inside_edge , the out degree S out_degree and the in degree S in_degree , average number of connections S avg_edge , average weight S avg_weight and other information;
连接数Sedge_sum等于外部连接数Soutside_edge与内部连接数Sinside_edge之和,公式如下:The number of connections S edge_sum is equal to the sum of the number of external connections S outside_edge and the number of internal connections S inside_edge , the formula is as follows:
Sedge_sum=Soutside_edge+Sinside_edge S edge_sum =S outside_edge +S inside_edge
外部连接数Soutside_edge表示TCP连接的一端服务器在业务系统内部,另一端服务器不属于该业务系统;内部连接数Sinside_edge表示TCP连接的两端服务器都在业务系统内部;The number of external connections S outside_edge indicates that the server at one end of the TCP connection is inside the business system, and the server at the other end does not belong to the business system; the number of internal connections S inside_edge indicates that the servers at both ends of the TCP connection are inside the business system;
出度Sout_degree表示被该业务系统访问过的其他业务系统的数量;Sin_degree表示访问过该业务系统的其他业务系统的数量;Out degree S out_degree represents the number of other business systems accessed by the business system; S in_degree represents the number of other business systems that have accessed the business system;
平均连接数Savg_edge表示业务系统内部连接数Sinside_edge和业务系统内部存在连接的服务器数量的一个比值;平均权重Savg_weight表示业务系统内部连接权重之和的平均值,公式如下:The average number of connections S avg_edge represents the ratio of the number of internal connections S inside_edge of the business system to the number of servers connected within the business system; the average weight S avg_weight represents the average value of the sum of the weights of the internal connections of the business system, the formula is as follows:
Savg_weight=Sum(W in_degree)/Sinside_edge S avg_weight =Sum(W in_degree )/S inside_edge
其中,业务系统之间的关联关系数据信息包括:关联服务端业务系统、关联客户端业务系统、关联权重Sweight等信息;Wherein, the association relationship data information between business systems includes: associated server business system, associated client business system, associated weight S weight and other information;
业务系统间关联权重Sweight等于位于两个业务系统之间的TCP连接权重累加之和;The association weight S weight between the business systems is equal to the cumulative sum of the TCP connection weights between the two business systems;
S3基于S1和S2数据信息对业务系统内部服务器进行层次划分;S3 divides the internal servers of the business system into layers based on S1 and S2 data information;
S3.1找出业务系统内部的边界服务器bordervm,边界服务器bordervm定义为与公网IP有过连接的或和外部非监控业务系统有过连接的非数据库类型的服务器;将边界服务器bordervm的层次Level标记为0;S3.1 Find out the border server border vm inside the business system, the border server border vm is defined as a non-database type server that has been connected to the public network IP or has been connected to an external non-monitoring business system; the border server border vm The level of Level is marked as 0;
S3.2从0层边界服务器为起点,根据服务器的TCP连接数据,在业务系统内尚未划分层次的服务器中找出被0层边界服务器访问过的服务器作为0层边界服务器的下一层,层次Level标记为1,其中,若服务器不再访问其他服务器而只作为服务端给其他服务器提供服务的,称为根服务器rootvm,根服务器rootvm的Level标记为-1;S3.2 Starting from the
S3.3再以标记为Level+1的服务器为起点重复S3.2,直至业务系统内所有服务器都完成层次划分;S3.3 repeats S3.2 with the server marked as Level+1 as the starting point, until all servers in the business system have completed the level division;
S4基于S3业务系统内部层次划分结果,再根据S1提取出的TCP连接数据对每层服务器进行分组;通过计算每层服务器中任意两个服务器之间的相似度是否达到阈值,达到则可划分到同一组,否则不同组;S4 is based on the internal hierarchical division result of the S3 business system, and then groups each layer of servers according to the TCP connection data extracted by S1; by calculating whether the similarity between any two servers in each layer of servers reaches the threshold, it can be divided into The same group, otherwise different groups;
两个服务器vm1和vm2之间的相似度similarityvm1&vm2定义为客户端雅克比系数clientcoef加上服务端雅克比系数servercoef之和,公式如下:The similarity vm1& vm2 between the two servers vm1 and vm2 is defined as the sum of the client Jacobian coefficient client coef plus the server Jacobian coefficient server coef , the formula is as follows:
similarityvm1&vm2=clientcoef+servercoef similarity vm1&vm2 =client coef +server coef
客户端雅克比系数clientcoef等于服务器vm1作为客户端访问过的服务器集合servervm1与服务器vm2作为客户端访问过的服务器集合servervm2的交集与servervm1和servervm2并集的比,公式如下:The client Jacobian coefficient client coef is equal to the ratio of the intersection of the server set server vm1 accessed by server vm1 as a client and the server set server vm2 accessed by server vm2 as a client to the union set of server vm1 and server vm2 . The formula is as follows:
clientcoef=(servervm1∩servervm2)/(servervm1∪servervm2)client coef =(server vm1 ∩server vm2 )/(server vm1 ∪server vm2 )
服务端雅克比系数servercoef等于服务器vm1作为服务端服务过的服务器集合clientvm1与服务器vm2作为服务端服务过的服务器集合clientvm2的交集与clientvm1和clientvm2并集的比,公式如下:The server Jacobian coefficient server coef is equal to the ratio of the intersection of the server set client vm1 served by server vm1 as the server and the server set client vm2 served by server vm2 as the server to the union of client vm1 and client vm2 . The formula is as follows:
servercoef=(clientvm1∩clientvm2)/(clientvm1∪clientvm2)server coef =(client vm1 ∩client vm2 )/(client vm1 ∪client vm2 )
S5基于S3和S4的分组发现的业务子系统结果建立分组的数据信息以及分组的关联关系数据信息;S5 establishes grouped data information and grouped association relationship data information based on the business subsystem results of the grouping discovery of S3 and S4;
S6基于S5建立的分组关联关系构建出数据中心业务系统架构图。S6 constructs a data center business system architecture diagram based on the grouping association relationship established by S5.
本发明具有以下技术效果:本发明提出的基于服务器应用逻辑的大型数据中心业务子系统发现方法,通过构建数据中心系统架构图,有效克服了传统运维方法的缺陷,无须耗费大量人力物力财力去采集、统计数据;无须运维人员对数据中心的应用的系统架构有充分的经验知识;能自动构建基于应用的业务逻辑网络,有效辅助运维人员掌握数据中心的服务器架构及使用情况。The present invention has the following technical effects: the method for discovering large-scale data center business subsystems based on server application logic proposed by the present invention effectively overcomes the defects of traditional operation and maintenance methods by constructing a data center system architecture diagram, and does not need to spend a lot of manpower, material resources and financial resources. Collect and count data; it is not necessary for the operation and maintenance personnel to have sufficient experience and knowledge of the application system architecture of the data center; it can automatically build an application-based business logic network, effectively assisting the operation and maintenance personnel to master the server architecture and usage of the data center.
附图说明Description of drawings
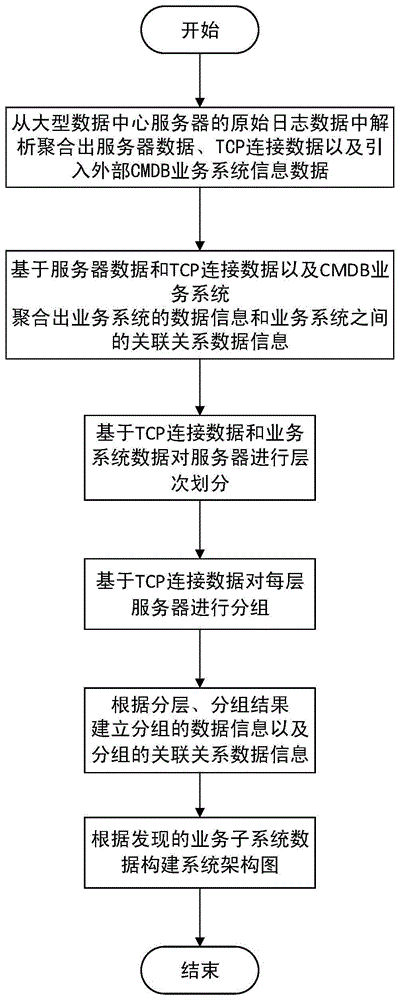
图1为本发明提出的基于服务器应用逻辑的大型数据中心业务子系统发现方法构建业务系统架构图的流程图;Fig. 1 is a flow chart of constructing a business system architecture diagram based on a large-scale data center business subsystem discovery method based on server application logic proposed by the present invention;
图2为本发明最终得到的基于服务器应用逻辑的大型数据中心业务子系统发现方法构建业务系统架构图。FIG. 2 is an architecture diagram of a business system constructed by a method for discovering business subsystems of large data centers based on server application logic finally obtained by the present invention.
具体实施方式Detailed ways
本发明实施例提出的一种基于服务器应用逻辑的大型数据中心业务子系统发现方法,来构建业务系统架构图的处理流程包括以下几个步骤:A method for discovering a large-scale data center business subsystem based on server application logic proposed by an embodiment of the present invention, the processing flow for constructing a business system architecture diagram includes the following steps:
S1从大型数据中心服务器的原始日志数据中解析聚合出服务器数据、TCP连接数据以及引入外部CMDB业务系统信息数据,包括:S1 parses and aggregates server data, TCP connection data and external CMDB business system information data from the original log data of large data center servers, including:
S1.1解析聚合一定时间段的大型数据中心服务器的原始日志数据,上述时间段以天为单位,在实际应用中时间段也可以选择多天数据进行融合,提取出的服务器数据中包括服务器名称、服务器的IP列表、出度和入度、平均权重、用户数、进程数、内存和CPU使用情况、每小时的连接分布、服务器的分类以及一系列CPU、VSZ、I/O、IPCS的top10进程信息等。S1.1 Parse and aggregate the raw log data of large-scale data center servers for a certain period of time. The above period of time is in days. In practical applications, multiple days of data can also be selected for fusion. The extracted server data includes the server name. , IP list of servers, out-degree and in-degree, average weight, number of users, number of processes, memory and CPU usage, connection distribution per hour, classification of servers and a series of top10 for CPU, VSZ, I/O, IPCS process information, etc.
提取出的服务器数据包括如下的表1所示的字段:The extracted server data includes the fields shown in Table 1 below:
表1Table 1

S1.2从原始日志数据中解析聚合提取出TCP连接数据包含了TCP连接两端的服务器名、连接的类别、连接的权重、连接的小时分布、发送以及接收队列等信息。S1.2 parses and aggregates the original log data and extracts the TCP connection data, including the server names at both ends of the TCP connection, the type of the connection, the weight of the connection, the hourly distribution of the connection, and the sending and receiving queues.
提取出的TCP连接数据包括如下的表2所示的字段:The extracted TCP connection data includes the fields shown in Table 2 below:
表2Table 2
S1.3从CMDB获取业务系统信息数据,该业务系统信息数据至少包含了业务系统名、业务系统与服务器的映射关系、业务系统负责人等信息。S1.3 Obtain business system information data from the CMDB, where the business system information data at least includes the business system name, the mapping relationship between the business system and the server, and the person in charge of the business system.
外部引入的CMDB业务系统信息数据包括如下的表3所示的字段:The externally introduced CMDB business system information data includes the fields shown in Table 3 below:
表3table 3


S2基于S1提取出的数据聚合出业务系统的数据信息和业务系统之间的关联关系数据信息。S2 aggregates the data information of the business system and the relational relationship data information between the business systems based on the data extracted by S1.
其中,业务系统的数据信息具体包括:业务系统名、业务系统负责人、业务系统包含的服务器数量、连接数、外部连接数、内部连接数、出度和入度、平均连接数、平均权重等信息。Among them, the data information of the business system specifically includes: the name of the business system, the person in charge of the business system, the number of servers included in the business system, the number of connections, the number of external connections, the number of internal connections, out-degree and in-degree, average number of connections, average weight, etc. information.
聚合后的业务系统的数据信息包括如下的表4所示的字段:The data information of the aggregated business system includes the fields shown in Table 4 below:
表4Table 4
其中,业务系统之间的关联关系数据信息包括:关联服务端业务系统、关联客户端业务系统、关联权重等信息。Wherein, the data information of the association relationship between the business systems includes information such as the association server business system, the association client business system, and the association weight.
聚合后的业务系统之间的关联关系数据信息包括如下的表5所示的字段:The association relationship data information between the aggregated business systems includes the fields shown in Table 5 below:
表5table 5
S3基于S1和S2数据信息对业务系统内部服务器进行的层次划分。S3 is the hierarchical division of the internal server of the business system based on the data information of S1 and S2.
S4基于S3业务系统内部层次划分结果,再根据S1提取出的TCP连接数据对每层服务器进行分组。S4 is based on the internal layer division result of the S3 service system, and then groups each layer of servers according to the TCP connection data extracted by S1.
S5基于S3和S4的分层、分组发现的业务子系统结果建立分组的数据信息以及分组的关联关系数据信息。S5 establishes the data information of the group and the data information of the association relationship of the group based on the layering of S3 and S4 and the service subsystem result of group discovery.
分组的数据信息和分组的关联关系数据信息包含如下表6、表7所示的字段:The data information of the group and the data information of the association relationship of the group include the fields shown in Table 6 and Table 7 below:
表6Table 6
表7Table 7
S6基于S5建立的分组关联关系构建出数据中心业务系统架构图,如图2所示。S6 builds a data center business system architecture diagram based on the grouping association relationship established by S5, as shown in Figure 2.
综上所述,本发明实施例提出的基于服务器应用逻辑的大型数据中心业务子系统发现方法,来构建业务系统架构图,有效克服了传统运维方法的缺陷,无须耗费大量人力物力财力去采集、统计数据;无须运维人员对数据中心的应用的系统架构有充分的经验知识;能自动构建基于应用的业务逻辑网络,有效辅助运维人员掌握数据中心的业务系统架构及使用情况。To sum up, the method for discovering large-scale data center business subsystems based on server application logic proposed in the embodiments of the present invention is used to construct a business system architecture diagram, which effectively overcomes the defects of traditional operation and maintenance methods, and does not need to spend a lot of manpower, material resources and financial resources to collect , statistical data; it is not necessary for the operation and maintenance personnel to have sufficient experience and knowledge of the application system architecture of the data center; it can automatically build an application-based business logic network, effectively assisting the operation and maintenance personnel to master the business system architecture and usage of the data center.
本发明构建的业务系统架构图可以真实反映业务应用系统在服务器上的部署情况,辅助运维人员管理。且该发明的输入仅需要数据中心的服务器日志快照数据,基于解释聚合后的服务器日志快照数据,本发明能够自动发现业务系统架构图,不仅结果准确,而且无须过多人操作,节省了大量人力、物力开支。The business system architecture diagram constructed by the present invention can truly reflect the deployment situation of the business application system on the server and assist the management of operation and maintenance personnel. And the input of the invention only needs the snapshot data of the server log of the data center. Based on the snapshot data of the server log after interpretation and aggregation, the invention can automatically discover the business system architecture diagram, not only the result is accurate, but also there is no need for many people to operate, saving a lot of manpower , material expenses.
Claims (1)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201711403565.4A CN108259567B (en) | 2017-12-22 | 2017-12-22 | A Discovery Method of Large Data Center Business Subsystem Based on Server Application Logic |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201711403565.4A CN108259567B (en) | 2017-12-22 | 2017-12-22 | A Discovery Method of Large Data Center Business Subsystem Based on Server Application Logic |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108259567A CN108259567A (en) | 2018-07-06 |
| CN108259567B true CN108259567B (en) | 2020-09-29 |
Family
ID=62723892
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201711403565.4A Active CN108259567B (en) | 2017-12-22 | 2017-12-22 | A Discovery Method of Large Data Center Business Subsystem Based on Server Application Logic |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108259567B (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110287987B (en) * | 2019-05-16 | 2021-06-25 | 北京交通大学 | A Discovery Method for Hierarchical Organization Structure of Business System with Hierarchical Network Structure |
| CN110572291A (en) * | 2019-09-16 | 2019-12-13 | 南京南瑞信息通信科技有限公司 | System and method for realizing architecture automatic identification function for distributed system |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104217030A (en) * | 2014-09-28 | 2014-12-17 | 北京奇虎科技有限公司 | Method and device for classifying users according to search log data of server |
| CN106209446A (en) * | 2016-07-06 | 2016-12-07 | 北京交通大学 | The construction method of the service application logic network of data center server |
| CN106909478A (en) * | 2015-12-22 | 2017-06-30 | 曹圣航 | A kind of intelligent maintenance system taking based on WMI technologies Yu Decision Tree Algorithm |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7953736B2 (en) * | 2007-01-04 | 2011-05-31 | Intersect Ptp, Inc. | Relevancy rating of tags |
| KR20150079422A (en) * | 2013-12-30 | 2015-07-08 | 주식회사 아이디어웨어 | An appratus for grouping servers, a method for grouping servers and a recording medium |
-
2017
- 2017-12-22 CN CN201711403565.4A patent/CN108259567B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104217030A (en) * | 2014-09-28 | 2014-12-17 | 北京奇虎科技有限公司 | Method and device for classifying users according to search log data of server |
| CN106909478A (en) * | 2015-12-22 | 2017-06-30 | 曹圣航 | A kind of intelligent maintenance system taking based on WMI technologies Yu Decision Tree Algorithm |
| CN106209446A (en) * | 2016-07-06 | 2016-12-07 | 北京交通大学 | The construction method of the service application logic network of data center server |
Non-Patent Citations (1)
| Title |
|---|
| 一种基于层次约简的多层网络社区发现算法;陈立虎,林友芳,武志昊,景丽萍;《1计算机与现代化》;20170630;全文 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108259567A (en) | 2018-07-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109033471B (en) | A kind of information asset identification method and device | |
| CN104317789B (en) | The method for building passenger social network | |
| CN111488261A (en) | User behavior analysis system, method, storage medium and computing device | |
| CN110287987B (en) | A Discovery Method for Hierarchical Organization Structure of Business System with Hierarchical Network Structure | |
| CN107545038B (en) | A text classification method and device | |
| CN104965784B (en) | Automatic test approach and device | |
| CN104462318A (en) | Identity recognition method and device of identical names in multiple networks | |
| CN105471670B (en) | Traffic data classification method and device | |
| CN108259567B (en) | A Discovery Method of Large Data Center Business Subsystem Based on Server Application Logic | |
| CN112785156A (en) | Industrial leader identification method based on clustering and comprehensive evaluation | |
| CN107360271B (en) | Method, system and equipment for acquiring network equipment information and automatically segmenting IP address | |
| CN109271869A (en) | Face characteristic value extracting method, device, computer equipment and storage medium | |
| CN112231203A (en) | Data warehouse test analysis method based on blood relationship | |
| CN113919736A (en) | A kind of blockchain mutual evaluation salary management method, system and storage device | |
| CN107908640A (en) | A kind of Business Entity relation Intelligent exploration engine implementing method | |
| CN104376116A (en) | Search method and device for figure information | |
| CN105634850B (en) | Service flow modeling method and device for PTN network | |
| CN106209446B (en) | The construction method of the service application logical network of data center server | |
| CN107391912A (en) | Hospital clinical operation data selection method based on big and small flow classification applied in cloud data center system | |
| CN110569128A (en) | A method and system for scheduling fog computing resources | |
| CN117672478A (en) | A medical assistance review method and system | |
| CN110209713A (en) | Abnormal grid structure recognition methods and device | |
| CN116303645A (en) | Method, device, equipment and storage medium for quickly locating interpersonal relationship paths | |
| CN111221906B (en) | A plant seed management system and method based on alliance block chain | |
| CN115048431A (en) | Clustering-based business process resource organization mining method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| EE01 | Entry into force of recordation of patent licensing contract | ||
| EE01 | Entry into force of recordation of patent licensing contract |
Application publication date: 20180706 Assignee: Beijing Xinxi Technology Co.,Ltd. Assignor: Beijing Jiaotong University Contract record no.: X2021990000696 Denomination of invention: Discovery method of large data center business subsystem based on server application logic Granted publication date: 20200929 License type: Common License Record date: 20211118 Application publication date: 20180706 Assignee: Beijing youtianxia Technology Co.,Ltd. Assignor: Beijing Jiaotong University Contract record no.: X2021990000697 Denomination of invention: Discovery method of large data center business subsystem based on server application logic Granted publication date: 20200929 License type: Common License Record date: 20211118 |