CN108257613B - Method and device for correcting pitch deviation of audio content - Google Patents
Method and device for correcting pitch deviation of audio content Download PDFInfo
- Publication number
- CN108257613B CN108257613B CN201711268972.9A CN201711268972A CN108257613B CN 108257613 B CN108257613 B CN 108257613B CN 201711268972 A CN201711268972 A CN 201711268972A CN 108257613 B CN108257613 B CN 108257613B
- Authority
- CN
- China
- Prior art keywords
- pitch
- sound
- frequency sequence
- fundamental frequency
- sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 58
- 230000033764 rhythmic process Effects 0.000 claims abstract description 29
- 238000012545 processing Methods 0.000 claims abstract description 9
- 238000009499 grossing Methods 0.000 claims description 23
- 238000012952 Resampling Methods 0.000 claims description 15
- 238000012216 screening Methods 0.000 claims description 15
- 238000004364 calculation method Methods 0.000 claims description 14
- 238000012937 correction Methods 0.000 claims description 12
- 238000012986 modification Methods 0.000 claims description 6
- 230000004048 modification Effects 0.000 claims description 6
- 238000005070 sampling Methods 0.000 claims description 6
- 238000012163 sequencing technique Methods 0.000 claims description 3
- 230000017105 transposition Effects 0.000 claims 1
- 239000011295 pitch Substances 0.000 description 238
- 238000010586 diagram Methods 0.000 description 10
- 238000003672 processing method Methods 0.000 description 5
- 230000008859 change Effects 0.000 description 4
- 230000001755 vocal effect Effects 0.000 description 4
- 210000001015 abdomen Anatomy 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 238000004891 communication Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000010276 construction Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000012886 linear function Methods 0.000 description 1
- 210000001260 vocal cord Anatomy 0.000 description 1
Images
















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/90—Pitch determination of speech signals
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Electrophonic Musical Instruments (AREA)
Abstract
The application discloses a method and a device for correcting pitch deviation of audio content. The method comprises the following steps: collecting singing voice of a user when singing a song; carrying out audio processing on the singing voice to obtain a voice base frequency sequence of the user; adjusting the rhythm of the human voice base frequency sequence to be consistent with the standard rhythm of the song to obtain a human voice base frequency sequence with standard rhythm; comparing each standard pitch of the song with the human voice fundamental frequency sequence, and determining the pitch difference of each time point in the human voice fundamental frequency sequence; taking the pitch difference corresponding to the pitch to be corrected in the human voice fundamental frequency sequence as an input parameter to obtain a standard pitch human voice fundamental frequency sequence with accurate pitch; and correcting formants of the human voice fundamental frequency sequence with the standard pitch to obtain a corrected human voice fundamental frequency sequence. The method achieves the purpose of correcting the pitch deviation of the audio content, and further solves the technical problems that the singing result is out of tune due to the fact that a user cannot sing the correct pitch of each tone accurately.
Description
Technical Field
The application relates to the technical field of sound processing, in particular to a method and a device for correcting pitch deviation of audio content.
Background
With the improvement of living standard of people, the pursuit of people for cultural entertainment life is also improved, and the music function has become a necessary application in terminals such as computers or mobile phones and the like due to the high-speed development of communication and information technology. More and more music products with the KTV function appear in the terminal of a user, the accompaniment is played according to the music selected by the user and the caption is displayed along with the music accompaniment, and the user prompts the singing time of the corresponding lyric according to the font color prompt or other marks on the displayed caption until the whole song is finished; so that the user can get a similar singing experience as in KTV in any scene.
However, not every user can sing exactly the correct pitch of every tone, resulting in singing flaws such as off-pitch running in the singing result. Although the related art can prompt the user of the correct singing pitch and the singing pitch of the user, the pitch deviation of the corresponding audio content cannot be corrected according to the singing result of the user.
Disclosure of Invention
The present application mainly aims to provide a method and an apparatus for correcting pitch deviation of audio content, so as to solve the problems existing in the prior art.
In order to achieve the above object, according to one aspect of the present application, there is provided a method of correcting a pitch offset of audio contents, comprising:
collecting singing voice of a user when singing a song;
adjusting the rhythm of the singing voice to be consistent with the standard rhythm of the song to obtain a voice base frequency sequence with standard rhythm
Comparing each standard pitch of the song with the human voice fundamental frequency sequence, and determining the pitch difference of each time point in the human voice fundamental frequency sequence;
taking the pitch difference corresponding to the pitch to be corrected in the human voice fundamental frequency sequence as an input parameter, and completing pitch-shifting calculation of the pitch to be corrected through resampling and a PSOLA algorithm in sequence to obtain a standard pitch human voice fundamental frequency sequence with accurate pitch;
and correcting formants of the human voice fundamental frequency sequence with the standard pitch to obtain a corrected human voice fundamental frequency sequence.
Further, the method of correcting pitch offset of audio contents as described above,
after determining the pitch difference of each time point in the human voice fundamental frequency sequence, the method further comprises the following steps: and screening all pitch differences in the human voice fundamental frequency sequence to determine the pitch to be corrected.
Further, the method of correcting pitch offset of audio contents as described above,
screening all pitch differences in the human voice fundamental frequency sequence to determine a pitch to be corrected, wherein the screening comprises the following steps:
screening all the pitch differences to be corrected, wherein the pitch differences to be corrected are the pitch differences in a set pitch difference interval;
and determining the pitch to be corrected in the human voice base frequency sequence according to the pitch difference to be corrected.
Further, as in the foregoing method for correcting pitch deviation of audio content, the performing formant correction on the human voice fundamental frequency sequence with the standard pitch to obtain a corrected human voice fundamental frequency sequence specifically includes:
taking each pitch difference as a pitch variation coefficient of a formant at a corresponding moment in the standard pitch human voice fundamental frequency sequence; by passing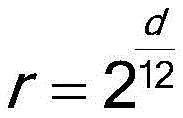 Determining the pitch variation coefficient, wherein d is the pitch difference;
Determining the pitch variation coefficient, wherein d is the pitch difference;
and carrying out reverse formant offset on each formant in the human voice fundamental frequency sequence with the standard pitch according to the corresponding pitch variation coefficient to obtain the corrected human voice fundamental frequency sequence.
Further, as the method for correcting pitch offset of audio content, the audio processing the sound information to obtain the human voice fundamental frequency sequence of the user includes:
obtaining the voice fundamental frequency of each voice in the singing voice according to the voice information;
and sequencing the sound fundamental frequency according to a time sequence to obtain a human sound fundamental frequency sequence of the user.
Further, as in the method for correcting pitch deviation of audio content, the pitch difference corresponding to the pitch to be corrected in the human voice fundamental frequency sequence is used as an input parameter, and the pitch to be corrected is subjected to pitch change calculation sequentially through resampling and a PSOLA algorithm; the method comprises the following steps:
determining the times s by which the pitch to be corrected needs to be increased according to the pitch difference,
resampling the singing voice audio with the rhythm standard according to 1/s times of the sampling rate when the singing voice of the user is collected, and obtaining the resampled audio;
and stretching the resampled audio to s times through a PSOLA algorithm.
In order to achieve the above object, according to another aspect of the present application, there is provided an apparatus for correcting a pitch offset of audio contents.
An apparatus for correcting pitch offset of audio content according to the present application comprises:
the song sound acquisition unit is used for acquiring the song sound when the user sings the song;
a voice base frequency sequence obtaining unit for adjusting the rhythm of the singing voice to be consistent with the standard rhythm of the song to obtain a voice base frequency sequence with standard rhythm
The pitch difference determining unit is used for comparing the human voice base frequency sequence with the standard pitch of the song and determining the pitch difference of each time point in the human voice base frequency sequence;
the pitch variation unit is used for taking the pitch difference corresponding to the pitch to be corrected as an input parameter, and completing pitch variation calculation of the pitch to be corrected through resampling and a PSOLA algorithm in sequence; obtaining a standard pitch human voice fundamental frequency sequence with accurate pitch;
and the formant correction unit is used for correcting formants of the human voice fundamental frequency sequence with the accurate pitch standard to obtain a final human voice fundamental frequency sequence.
Further, the apparatus for correcting pitch offset of audio content as described above further includes:
a pitch to be corrected determining unit, configured to screen all pitch differences in the human voice fundamental frequency sequence, and determine a pitch to be corrected;
further, the apparatus for correcting pitch offset of audio contents as described above,
the pitch determining unit to be corrected includes:
the pitch difference determining module is used for screening all pitch differences to be corrected, wherein the pitch differences to be corrected are the pitch differences in a set pitch difference interval;
and the pitch to be corrected determining module is used for determining the pitch to be corrected in the human voice base frequency sequence according to the pitch difference to be corrected.
Further, the apparatus for correcting pitch offset of audio content as described above, the formant correction unit includes:
the pitch variation coefficient calculation module is used for taking each pitch difference as the pitch variation coefficient of the formant of the corresponding moment in the standard pitch vocal fundamental frequency sequence; by passing Determining the pitch variation coefficient, wherein d is the pitch difference;
Determining the pitch variation coefficient, wherein d is the pitch difference;
and the formant shifting module is used for carrying out reverse formant shifting on each formant in the standard pitch human voice base frequency sequence according to the corresponding pitch variation coefficient to obtain the corrected human voice base frequency sequence.
In the embodiment of the application, the method for correcting the pitch deviation of the audio content is adopted, and the singing voice of a user is collected when the user sings a song; carrying out audio processing on the singing voice to obtain a voice base frequency sequence of the user; adjusting the rhythm of the human voice base frequency sequence to be consistent with the standard rhythm of the song to obtain a human voice base frequency sequence with standard rhythm; comparing each standard pitch of the song with the human voice fundamental frequency sequence, and determining the pitch difference of each time point in the human voice fundamental frequency sequence; taking the pitch difference corresponding to the pitch to be corrected in the human voice fundamental frequency sequence as an input parameter, and completing pitch-shifting calculation of the pitch to be corrected through resampling and a PSOLA algorithm in sequence to obtain a standard pitch human voice fundamental frequency sequence with accurate pitch; and correcting formants of the human voice fundamental frequency sequence with the standard pitch to obtain a corrected human voice fundamental frequency sequence. The method achieves the purpose of correcting the pitch deviation of the audio content, further solves the technical problem that singing flaws such as off-pitch and off-pitch occur in the singing result due to the fact that a user cannot accurately sing the correct pitch of each tone, and meanwhile can guarantee the tone color to be normal through formant correction.
Drawings
The accompanying drawings, which are incorporated in and constitute a part of this application, serve to provide a further understanding of the application and to enable other features, objects, and advantages of the application to be more apparent. The drawings and their description illustrate the embodiments of the invention and do not limit it. In the drawings:
FIG. 1 is a flow diagram of a method of correcting pitch offset of audio content according to one embodiment of the present application;
FIG. 2 is a flow diagram of a method of correcting pitch offset of audio content according to yet another embodiment of the present application;
FIG. 3 is a flowchart of a method according to an embodiment of step S2 in the embodiment of FIG. 2;
FIG. 4 is a flowchart of a method according to an embodiment of step S3 in the embodiment of FIG. 2;
FIG. 5 is a flowchart of a method according to an embodiment of step S4 in the embodiment of FIG. 2;
FIG. 6 is a flowchart of a method according to an embodiment of step S6 in the embodiment of FIG. 2;
FIG. 7 is a flow chart of yet another method of correcting pitch offset of audio content according to an embodiment of the present application;
FIG. 8 is a flowchart of a method according to an embodiment of step S9 in the embodiment of FIG. 8;
FIG. 9 is a flowchart illustrating a method according to an embodiment of the present invention further included after step S7 in the embodiment of FIG. 2;
FIG. 10 is a block diagram of an apparatus for correcting pitch offset in audio content according to an embodiment of the present application;
fig. 11 is a block diagram of a human voice fundamental frequency sequence obtaining unit according to the embodiment shown in fig. 10;
fig. 12 is a block diagram of a singing tone information determination unit according to the embodiment shown in fig. 10;
fig. 13 is a block diagram of a singing tone pitch determination unit according to the embodiment shown in fig. 10;
fig. 14 is a block diagram of a pitch difference sequence obtaining unit according to the embodiment shown in fig. 10;
fig. 15 is a structural diagram of an apparatus for correcting pitch offset of audio contents according to still another embodiment of the present application;
FIG. 16 is a block diagram of a pitch determining unit to be modified according to the embodiment shown in FIG. 13; and
fig. 17 is a block diagram of a formant correction unit according to the embodiment shown in fig. 10.
Detailed Description
In order to make the technical solutions better understood by those skilled in the art, the technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the drawings in the embodiments of the present application, and it is obvious that the described embodiments are only partial embodiments of the present application, but not all embodiments. All other embodiments, which can be derived by a person skilled in the art from the embodiments given herein without making any creative effort, shall fall within the protection scope of the present application.
It should be noted that the terms "first," "second," and the like in the description and claims of this application and in the drawings described above are used for distinguishing between similar elements and not necessarily for describing a particular sequential or chronological order. It should be understood that the data so used may be interchanged under appropriate circumstances such that embodiments of the application described herein may be used. Furthermore, the terms "comprises," "comprising," and "having," and any variations thereof, are intended to cover a non-exclusive inclusion, such that a process, method, system, article, or apparatus that comprises a list of steps or elements is not necessarily limited to those steps or elements expressly listed, but may include other steps or elements not expressly listed or inherent to such process, method, article, or apparatus.
In this application, the terms "upper", "lower", "left", "right", "front", "rear", "top", "bottom", "inner", "outer", "middle", "vertical", "horizontal", "lateral", "longitudinal", and the like indicate orientations or positional relationships based on the orientations or positional relationships shown in the drawings. These terms are used primarily to better describe the invention and its embodiments, and are not intended to limit the indicated devices, elements or components to a particular orientation or to be constructed and operated in a particular orientation.
Moreover, some of the above terms may be used to indicate other meanings besides the orientation or positional relationship, for example, the term "on" may also be used to indicate some kind of attachment or connection relationship in some cases. The specific meaning of these terms in the present invention can be understood by those of ordinary skill in the art as appropriate.
Furthermore, the terms "mounted," "disposed," "provided," "connected," and "sleeved" are to be construed broadly. For example, it may be a fixed connection, a removable connection, or a unitary construction; can be a mechanical connection, or an electrical connection; may be directly connected, or indirectly connected through intervening media, or may be in internal communication between two devices, elements or components. The specific meaning of the above terms in the present invention can be understood according to specific situations by those skilled in the art.
It should be noted that the embodiments and features of the embodiments in the present application may be combined with each other without conflict. The present application will be described in detail below with reference to the embodiments with reference to the attached drawings.
As shown in FIG. 1, the present invention further provides a method for correcting pitch offset of audio contents, the method comprising the steps of
As shown in fig. 2, the present invention further provides a method of correcting a pitch offset of audio contents, the method including steps S1 to S7 as follows:
in order to achieve the above object, according to one aspect of the present application, there is provided a method of correcting a pitch offset of audio contents, comprising:
s1, collecting singing voice of a user when singing a song;
s2, adjusting the rhythm of the singing voice to be consistent with the standard rhythm of the song to obtain a voice base frequency sequence with standard rhythm;
s3, determining a fundamental frequency sequence, starting time and ending time of each singing voice in the human voice fundamental frequency sequence according to the human voice fundamental frequency sequence;
s4, determining the pitch of a user of each singing sound according to the starting time and the ending time of each singing sound and the fundamental frequency sequence of each singing sound;
s5, determining the pitch difference between the user pitch and the standard pitch at each same time point according to the user pitch of each singing tone and the pitch template corresponding to the song;
s6, obtaining a pitch difference sequence according to the pitch difference between the user pitch and the standard pitch at the same time point; the pitch template contains the standard pitch, start time and end time of each note in the song that the user sings.
And S7, using the pitch difference corresponding to the pitch to be corrected in the human voice base frequency sequence as an input parameter, sequentially performing resampling and PSOLA algorithm, and generally, except for meticulously changing the pitch through the resampling and PSOLA algorithm, performing: and (4) time domain pitch modification (speed change after resampling), frequency domain interpolation, and pitch modification calculation of the pitch to be modified based on sine model pitch modification are completed, so that a standard pitch human voice fundamental frequency sequence with accurate pitch is obtained.
According to an embodiment of the present invention, there is provided a specific processing method of the step S2, as shown in fig. 3, the method includes:
s21, obtaining the sound fundamental frequency of each sound in the singing voice according to the sound information;
and S22, sequencing the voice fundamental frequency according to a time sequence to obtain a voice fundamental frequency sequence of the user.
According to an embodiment of the present invention, there is provided a specific processing method in step S3, for determining a fundamental frequency value of each singing tone in the human voice fundamental frequency sequence according to the human voice fundamental frequency sequence, as shown in fig. 4, the method includes:
s31, sampling and calculating the voice base frequency sequence at fixed time intervals; specifically, the fundamental frequency value of singing voice is calculated for the singing voice frequency of the user at fixed time intervals (usually 10-100 ms);
and S32, obtaining a plurality of fundamental frequency values of each singing voice.
According to an embodiment of the present invention, there is provided a specific processing method of the step S4, as shown in fig. 5, the method includes:
s41, dividing the head, the belly and the tail of each singing voice in the fundamental frequency characteristics; specifically, the vocal rule of vocal cords in human singing is that the fundamental frequency converges to a target pitch in a short time (usually 1-30 ms) before a tone, which is called a head of sound; the middle longer time is stable at a fixed fundamental frequency, called antinode; the end deviates from the target pitch by a short time (typically 0-20 ms), called the tail. In the patent, the fixed duration of the sound head is 30ms, and the duration of the sound tail is 20 ms. If the duration of the whole sound is less than 70ms, the duration of the sound head and the sound tail is reduced proportionally, namely the sound head is 30 × t/70, and the sound tail is 20 × t/70. The remaining part is the antinode.
S42, determining a fundamental frequency sequence of the vocal abdomen of each singing voice;
s43, calculating the average number x of fundamental frequency values in the antinodes of each singing sound;
s44, passing through And obtaining the user pitch y of each singing voice.
And obtaining the user pitch y of each singing voice.
According to an embodiment of the present invention, there is provided a specific processing method of the step S5, as shown in fig. 6, the method includes:
s61, determining the standard pitch of each standard tone at the corresponding time in the pitch template according to the starting time and the ending time of each singing tone;
s62, calculating the pitch difference between the user pitch and the standard pitch at each time point.
According to an embodiment of the present invention, there is provided a method between the steps S6 and S7 further including steps S8 and S9, as shown in fig. 7, the method including:
s8, smoothing the pitch difference sequence to obtain a smooth pitch difference sequence;
s9, screening all pitch differences in the human voice fundamental frequency sequence, and determining a pitch to be corrected; preferably, only the sounds in the human voice fundamental frequency sequence with the pitch difference within the (-7,7) interval are corrected.
According to an embodiment of the present invention, there is provided a specific processing method of the step S7, including:
and smoothing the adjacent sound tail and sound head in the sound-height difference sequence, and converting the step sound-height difference sequence into a continuous smooth sound-height difference sequence.
The smoothing processing of the sound tail and the sound head adjacent to each other in the pitch difference sequence specifically includes:
replacing the pitch difference sequence value of the head and tail parts of two adjacent tones by the following function to obtain a smooth pitch difference sequence for smoothing:
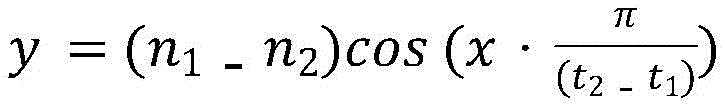
wherein n is1Is the pitch of the tail, n2Is the pitch of the sound head, t1Start time of tail, t, for the first tone2The end time of the sound head for the second sound is.
In particular, since there is only one pitch value for each tone, the pitch of the notes in the pitch template is also discrete step data. Therefore, the obtained pitch difference sequence is also a discontinuous step data value, and the pitch difference sequence of the head and the tail of the sound is smoothed, so that discontinuous step data can be changed into continuous data. The smoothing process may adopt a smoothing algorithm such as gaussian smoothing, sigmoid, sin or linear function in addition to the above method to achieve the purpose of connecting adjacent tones.
According to an embodiment of the present invention, there is provided a specific implementation method of the step S8, as shown in fig. 8, the method includes:
s91, screening all pitch differences in the human voice fundamental frequency sequence to determine a pitch to be corrected;
s92, screening all pitch differences to be corrected, wherein the pitch differences to be corrected are the pitch differences in a set pitch difference interval;
and S93, determining the pitch to be corrected in the human voice base frequency sequence according to the pitch difference to be corrected.
According to the embodiment of the present invention, after the step S6 of obtaining the human voice fundamental frequency sequence with the standard pitch with accurate pitch is provided, the method includes:
and S10, correcting formants of the human voice fundamental frequency sequence with the standard pitch to obtain a corrected human voice fundamental frequency sequence.
According to an embodiment of the present invention, there is provided a specific implementation method of the step S10, as shown in fig. 9, the method includes: the method specifically comprises the following steps:
s101, taking each pitch difference as the standard pitch voice fundamental frequency sequenceThe pitch variation coefficient of the formant at the middle corresponding moment; by passing Determining the pitch variation coefficient, wherein d is the pitch difference;
Determining the pitch variation coefficient, wherein d is the pitch difference;
and S102, carrying out reverse formant offset on each formant in the standard pitch human voice fundamental frequency sequence according to the corresponding tone variation coefficient to obtain the corrected human voice fundamental frequency sequence.
The audio information of normal tone can be obtained by performing formant correction to eliminate the influence of tone change after tone change.
In some embodiments, the pitch difference corresponding to the pitch to be modified in the human voice fundamental frequency sequence is used as an input parameter, and the pitch to be modified is subjected to pitch-shifting calculation sequentially through resampling and a PSOLA algorithm; the method comprises the following steps:
determining the times s by which the pitch to be corrected needs to be increased according to the pitch difference,
resampling the singing voice audio with the rhythm standard according to 1/s times of the sampling rate when the singing voice of the user is collected, and obtaining the resampled audio;
and stretching the resampled audio to s times through a PSOLA algorithm. This gives a sound with a duration of s times higher pitch.
From the above description, it can be seen that the present invention achieves the following technical effects:
it should be noted that the steps illustrated in the flowcharts of the figures may be performed in a computer system such as a set of computer-executable instructions and that, although a logical order is illustrated in the flowcharts, in some cases, the steps illustrated or described may be performed in an order different than presented herein.
According to an embodiment of the present invention, there is also provided an apparatus for implementing the above method of correcting a pitch offset of audio content, as shown in fig. 10, the apparatus including:
a singing voice acquisition unit 1 for acquiring the singing voice of a user when singing a song;
a voice base frequency sequence obtaining unit 2, configured to adjust the rhythm of the singing voice to be consistent with the standard rhythm of the song, so as to obtain a voice base frequency sequence with standard rhythm
A singing voice information determining unit 3, configured to determine a fundamental frequency value, a start time, and an end time of each singing voice according to the vocal fundamental frequency sequence;
a singing tone pitch determining unit 4, configured to determine a user pitch of each singing tone according to the start time and the end time of each singing tone and the fundamental frequency sequence;
the pitch difference determining unit 5 is configured to compare the human voice fundamental frequency sequence with a standard pitch of the song, and determine a pitch difference at each time point in the human voice fundamental frequency sequence;
a pitch difference sequence obtaining unit 6, configured to determine, according to the user pitch of each singing tone and the pitch template corresponding to the song, a pitch difference between the user pitch and a standard pitch at each same time point, and obtain a pitch difference sequence; the pitch template comprises standard pitch, starting time and ending time of each note in a song sung by the user;
and the pitch-shifting unit 7 is used for taking the pitch difference corresponding to the pitch to be corrected in the human voice fundamental frequency sequence as an input parameter, sequentially performing resampling and PSOLA algorithm, completing pitch-shifting calculation of the pitch to be corrected, and obtaining the standard pitch human voice fundamental frequency sequence with accurate pitch.
According to the embodiment of the present invention, as shown in fig. 11, the human voice fundamental frequency sequence obtaining unit 2 includes:
a sound fundamental frequency obtaining module 21, configured to obtain a sound fundamental frequency of each sound in the singing voice according to the sound information;
and a voice base frequency sequence obtaining module 22, configured to sort the voice base frequencies according to a time sequence to obtain a voice base frequency sequence of the user.
According to the embodiment of the present invention, as shown in fig. 12, the singing voice information determining unit 3 includes:
a singing tone fundamental frequency value sampling module 31, configured to perform sampling calculation on the voice fundamental frequency sequence every other fixed time;
a singing tone fundamental frequency value determining module 32, configured to obtain multiple fundamental frequency values of each singing tone.
According to the embodiment of the present invention, as shown in FIG. 13, the singing tone pitch determining unit 4 includes
A singing voice dividing module 41, configured to divide a head, an abdomen, and a tail of each singing voice in the fundamental frequency characteristic;
an antinode determining module 42, configured to determine a fundamental frequency sequence of an antinode of each singing voice;
a fundamental frequency average calculating module 43, configured to calculate an average x of fundamental frequency values in an antinode of each singing voice;
user pitch calculation module 44 for pass-through And obtaining the user pitch y of each singing voice.
And obtaining the user pitch y of each singing voice.
According to the embodiment of the present invention, as shown in fig. 14, the sequence of pitch differences obtaining unit 6 includes:
a corresponding module 61, configured to determine a standard pitch of each standard tone at a corresponding time in the pitch template according to the start time and the end time of each singing tone;
a pitch difference sequence obtaining module 62 for calculating the pitch difference between the user pitch and the standard pitch at each time point.
According to the embodiment of the present invention, there is provided an apparatus further including a smoothing module 8 and a pitch determination unit 9 to be corrected, as shown in fig. 15:
a smoothing module 8, configured to smooth the pitch difference sequence to obtain a smoothed pitch difference sequence;
and the pitch to be corrected determining unit 9 is configured to screen all pitch differences in the human voice fundamental frequency sequence, and determine a pitch to be corrected.
According to an embodiment of the present invention, the smoothing module 8 is specifically configured to:
and smoothing the adjacent sound tail and sound head in the sound-height difference sequence, and converting the step sound-height difference sequence into a continuous smooth sound-height difference sequence.
The smoothing processing of the sound tail and the sound head adjacent to each other in the pitch difference sequence specifically includes:
replacing the pitch difference sequence value of the head and tail parts of two adjacent tones by the following function to obtain a smooth pitch difference sequence for smoothing:

wherein n is1Is the pitch of the tail, n2Is the pitch of the sound head, t1Start time of tail, t, for the first tone2The end time of the sound head for the second sound is.
According to an embodiment of the invention, the pitch to be modified determining unit 9:
the pitch correction device is used for screening all pitch differences in the human voice base frequency sequence and determining pitches to be corrected;
as shown in fig. 16, the pitch determination unit 9 to be modified includes:
a pitch difference to be corrected determining module 91, configured to screen out all the pitch differences to be corrected, where the pitch difference to be corrected is a pitch difference in a set pitch difference interval;
and a pitch to be corrected determining module 92, configured to determine a pitch to be corrected in the human voice fundamental frequency sequence according to the pitch difference to be corrected.
According to the embodiment of the invention, the device further comprises a formant correction unit 10:
and the pitch correction module is used for correcting the formants of the human voice base frequency sequence with the standard pitch to obtain a corrected human voice base frequency sequence.
According to an embodiment of the present invention, as shown in fig. 17, the formant correction unit 10 specifically includes:
a pitch-changing coefficient calculating module 101, configured to use each pitch difference as a pitch-changing coefficient of a formant at a corresponding time in the human voice fundamental frequency sequence with standard pitch(ii) a By passing Determining the pitch variation coefficient, wherein d is the pitch difference; for example, when the pitch difference is 7, the pitch coefficient is 1.5; the shift of the resonance peak was 1/1.5, i.e., 0.67.
Determining the pitch variation coefficient, wherein d is the pitch difference; for example, when the pitch difference is 7, the pitch coefficient is 1.5; the shift of the resonance peak was 1/1.5, i.e., 0.67.
And the formant shifting module 102 is configured to perform reverse formant shifting on each formant in the standard pitch human voice fundamental frequency sequence according to the corresponding pitch variation coefficient to obtain the corrected human voice fundamental frequency sequence.
It will be apparent to those skilled in the art that the modules or steps of the present invention described above may be implemented by a general purpose computing device, they may be centralized on a single computing device or distributed across a network of multiple computing devices, and they may alternatively be implemented by program code executable by a computing device, such that they may be stored in a storage device and executed by a computing device, or fabricated separately as individual integrated circuit modules, or fabricated as a single integrated circuit module from multiple modules or steps. Thus, the present invention is not limited to any specific combination of hardware and software.
The above description is only a preferred embodiment of the present application and is not intended to limit the present application, and various modifications and changes may be made by those skilled in the art. Any modification, equivalent replacement, improvement and the like made within the spirit and principle of the present application shall be included in the protection scope of the present application.
Claims (8)
1. A method of correcting pitch offset in audio content, comprising:
collecting singing voice of a user when singing a song;
adjusting the rhythm of the singing voice to be consistent with the standard rhythm of the song to obtain a voice base frequency sequence with standard rhythm; comparing each standard pitch of the song with a user pitch corresponding to the human voice fundamental frequency sequence, and determining the pitch difference of each time point in the human voice fundamental frequency sequence; the pitch of the userBy an average x based on the fundamental frequency values in the antinodes of each singing tone; passing through type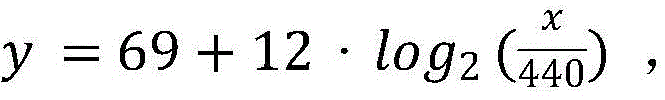 Obtaining the user pitch y of each singing sound;
Obtaining the user pitch y of each singing sound;
smoothing the adjacent sound tail and sound head in the sound height difference sequence, and converting the step sound height difference sequence into a continuous smooth sound height difference sequence; the smoothing processing of the sound tail and the sound head adjacent to each other in the pitch difference sequence specifically includes: replacing the pitch difference sequence value of the head and tail parts of two adjacent tones by the following function to obtain a smooth pitch difference sequence for smoothing: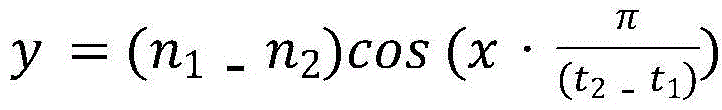 wherein n1 is the pitch of the tail, n2 is the pitch of the head, t1 is the start time of the tail of the first sound, and t2 is the end time of the head of the second sound;
wherein n1 is the pitch of the tail, n2 is the pitch of the head, t1 is the start time of the tail of the first sound, and t2 is the end time of the head of the second sound;
taking the pitch difference corresponding to the pitch to be corrected in the human voice fundamental frequency sequence after smoothing as an input parameter, and completing pitch-shifting calculation of the pitch to be corrected through resampling and a PSOLA algorithm to obtain a standard pitch human voice fundamental frequency sequence with accurate pitch;
correcting formants of the human voice base frequency sequence with the standard pitch based on the pitch difference to obtain a corrected human voice base frequency sequence;
correcting formants for the human voice fundamental frequency sequence with the standard pitch to obtain a corrected human voice fundamental frequency sequence, which specifically comprises:
taking the pitch difference corresponding to the pitch to be corrected in each smoothed human voice fundamental frequency sequence as a pitch variation coefficient of a formant at the corresponding moment in the standard pitch human voice fundamental frequency sequence; by passing Determining the pitch variation coefficient, wherein d is the pitch difference;
Determining the pitch variation coefficient, wherein d is the pitch difference;
and carrying out reverse formant offset on each formant in the human voice fundamental frequency sequence with the standard pitch according to the transposition coefficient to obtain the corrected human voice fundamental frequency sequence.
2. A method of correcting a pitch-offset of audio content according to claim 1,
after determining the pitch difference of each time point in the human voice fundamental frequency sequence, the method further comprises the following steps: and screening all pitch differences in the human voice fundamental frequency sequence to determine the pitch to be corrected.
3. A method of correcting a pitch-offset of audio content according to claim 2,
screening all pitch differences in the human voice fundamental frequency sequence to determine a pitch to be corrected, wherein the screening comprises the following steps:
screening all the pitch differences to be corrected, wherein the pitch differences to be corrected are the pitch differences in a set pitch difference interval;
and determining the pitch to be corrected in the human voice base frequency sequence according to the pitch difference to be corrected.
4. The method of modifying pitch offset in audio content according to claim 1, wherein said adjusting the rhythm of the singing voice to be consistent with the standard rhythm of the song, resulting in a rhythm-standard human voice fundamental frequency sequence, comprises:
obtaining the sound fundamental frequency of each voice in the singing voice according to the singing voice;
and sequencing the sound fundamental frequency according to a time sequence to obtain a human sound fundamental frequency sequence of the user.
5. The method according to claim 1, wherein the pitch difference corresponding to the pitch to be modified in the fundamental frequency sequence of human voice is used as an input parameter, and the pitch modification calculation for the pitch to be modified is completed sequentially through resampling and PSOLA algorithm; the method comprises the following steps:
determining the times s by which the pitch to be corrected needs to be increased according to the pitch difference,
resampling the singing voice audio with the rhythm standard according to 1/s times of the sampling rate when the singing voice of the user is collected, and obtaining the resampled audio;
and stretching the resampled audio to s times through a PSOLA algorithm.
6. An apparatus for correcting pitch offset in audio content, comprising:
the song sound acquisition unit is used for acquiring the song sound when the user sings the song;
a voice base frequency sequence obtaining unit, configured to adjust the rhythm of the singing voice to be consistent with the standard rhythm of the song, so as to obtain a voice base frequency sequence with standard rhythm;
the pitch difference determining unit is used for comparing the user pitch corresponding to the human voice base frequency sequence with the standard pitch of the song and determining the pitch difference of each time point in the human voice base frequency sequence; the user pitch passes through an average number x based on fundamental frequency values in the antinodes of each singing tone; passing through type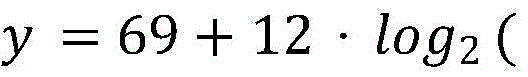
 Obtaining the user pitch y of each singing sound;
Obtaining the user pitch y of each singing sound;
smoothing the adjacent sound tail and sound head in the sound height difference sequence, and converting the step sound height difference sequence into a continuous smooth sound height difference sequence; the smoothing processing of the sound tail and the sound head adjacent to each other in the pitch difference sequence specifically includes: replacing the pitch difference sequence value of the head and tail parts of two adjacent tones by the following function to obtain a smooth pitch difference sequence for smoothing: where n1 is the pitch of the tail, n2 is the pitch of the head, t1 is the start time of the tail of the first sound, t2The end time of the sound head of the second sound;
where n1 is the pitch of the tail, n2 is the pitch of the head, t1 is the start time of the tail of the first sound, t2The end time of the sound head of the second sound;
the pitch-changing unit is used for taking the pitch difference corresponding to the smoothed pitch to be corrected as an input parameter, and completing pitch-changing calculation of the pitch to be corrected through resampling and a PSOLA algorithm in sequence; obtaining a standard pitch human voice fundamental frequency sequence with accurate pitch;
the formant correction unit is used for correcting formants of the human voice fundamental frequency sequence with the accurate standard pitch based on the pitch difference to obtain a final human voice fundamental frequency sequence;
smoothing the adjacent sound tail and sound head in the sound-height difference sequence, and converting the step sound-height difference sequence into a continuous smooth sound-height difference sequence; the smoothing processing of the sound tail and the sound head adjacent to each other in the pitch difference sequence specifically includes: replacing the pitch difference sequence value of the head and tail parts of two adjacent tones by the following function to obtain a smooth pitch difference sequence for smoothing: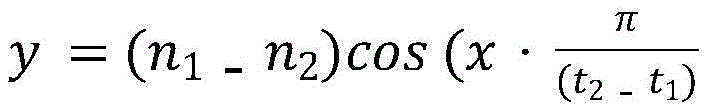
 wherein n1 is the pitch of the tail, n2 is the pitch of the head, t1 is the start time of the tail of the first sound, and t2 is the end time of the head of the second sound;
wherein n1 is the pitch of the tail, n2 is the pitch of the head, t1 is the start time of the tail of the first sound, and t2 is the end time of the head of the second sound;
the formant correction unit includes:
a pitch variation coefficient calculation module, configured to use the pitch difference corresponding to the pitch to be corrected in each smoothed human voice fundamental frequency sequence as the pitch variation coefficient of the formant at the corresponding time in the standard pitch human voice fundamental frequency sequence; by passing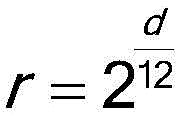 Determining the pitch variation coefficient, wherein d is the pitch difference;
Determining the pitch variation coefficient, wherein d is the pitch difference;
and the formant shifting module is used for carrying out reverse formant shifting on each formant in the standard pitch human voice base frequency sequence according to the corresponding pitch variation coefficient to obtain the corrected human voice base frequency sequence.
7. An apparatus for modifying a pitch bias of audio content according to claim 6, further comprising:
and the pitch to be corrected determining unit is used for screening all pitch differences in the human voice base frequency sequence and determining the pitch to be corrected.
8. An apparatus for correcting pitch offset in audio content according to claim 7,
the pitch determining unit to be corrected includes:
the pitch difference determining module is used for screening all pitch differences to be corrected, wherein the pitch differences to be corrected are the pitch differences in a set pitch difference interval;
and the pitch to be corrected determining module is used for determining the pitch to be corrected in the human voice base frequency sequence according to the pitch difference to be corrected.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201711268972.9A CN108257613B (en) | 2017-12-05 | 2017-12-05 | Method and device for correcting pitch deviation of audio content |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201711268972.9A CN108257613B (en) | 2017-12-05 | 2017-12-05 | Method and device for correcting pitch deviation of audio content |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108257613A CN108257613A (en) | 2018-07-06 |
| CN108257613B true CN108257613B (en) | 2021-12-10 |
Family
ID=62722360
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201711268972.9A Active CN108257613B (en) | 2017-12-05 | 2017-12-05 | Method and device for correcting pitch deviation of audio content |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108257613B (en) |
Families Citing this family (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110675886B (en) * | 2019-10-09 | 2023-09-15 | 腾讯科技(深圳)有限公司 | Audio signal processing method, device, electronic equipment and storage medium |
| CN111063372B (en) * | 2019-12-30 | 2023-01-10 | 广州酷狗计算机科技有限公司 | Method, device and equipment for determining pitch characteristics and storage medium |
| CN111583894B (en) * | 2020-04-29 | 2023-08-29 | 长沙市回音科技有限公司 | Method, device, terminal equipment and computer storage medium for correcting tone color in real time |
| US20230186782A1 (en) * | 2020-06-05 | 2023-06-15 | Sony Group Corporation | Electronic device, method and computer program |
| CN111785238B (en) * | 2020-06-24 | 2024-02-27 | 腾讯音乐娱乐科技(深圳)有限公司 | Audio calibration method, device and storage medium |
| CN111968623B (en) * | 2020-08-19 | 2023-11-28 | 腾讯音乐娱乐科技(深圳)有限公司 | Gas port position detection method and related equipment |
| CN112216259B (en) * | 2020-11-17 | 2024-03-08 | 北京达佳互联信息技术有限公司 | Vocal accompaniment alignment method and device |
| CN112365868B (en) * | 2020-11-17 | 2024-05-28 | 北京达佳互联信息技术有限公司 | Sound processing method, device, electronic equipment and storage medium |
| CN112420062B (en) * | 2020-11-18 | 2024-07-19 | 腾讯音乐娱乐科技(深圳)有限公司 | Audio signal processing method and equipment |
| CN112820255A (en) * | 2020-12-30 | 2021-05-18 | 北京达佳互联信息技术有限公司 | Audio processing method and device |
| CN113192477A (en) * | 2021-04-28 | 2021-07-30 | 北京达佳互联信息技术有限公司 | Audio processing method and device |
| CN113178183B (en) * | 2021-04-30 | 2024-05-14 | 杭州网易云音乐科技有限公司 | Sound effect processing method, device, storage medium and computing equipment |
| CN115331682B (en) * | 2021-05-11 | 2024-07-02 | 北京奇音妙想科技有限公司 | Method and device for correcting pitch of audio |
| CN113257211B (en) * | 2021-05-13 | 2024-05-24 | 杭州网易云音乐科技有限公司 | Audio adjusting method, medium, device and computing equipment |
| CN113066462B (en) * | 2021-06-02 | 2022-05-06 | 北京达佳互联信息技术有限公司 | Sound modification method, device, equipment and storage medium |
| CN115101080B (en) * | 2022-06-20 | 2025-08-19 | 腾讯音乐娱乐科技(深圳)有限公司 | Method for repairing sound, computer equipment and computer readable storage medium |
| CN116320854A (en) * | 2023-02-28 | 2023-06-23 | 北京允芯微电子有限公司 | Pitch adjustment method, device and microphone device |
| CN119028323B (en) * | 2024-10-28 | 2025-03-14 | 上海任意门科技有限公司 | Audio repair method and device and electronic equipment |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1162167A (en) * | 1996-01-18 | 1997-10-15 | 雅马哈株式会社 | Formant conversion device for correcting singing sound for imitating standard sound |
| CN106057208A (en) * | 2016-06-14 | 2016-10-26 | 科大讯飞股份有限公司 | Audio correction method and device |
| CN106157976A (en) * | 2015-04-10 | 2016-11-23 | 科大讯飞股份有限公司 | A kind of singing evaluating method and system |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4067762B2 (en) * | 2000-12-28 | 2008-03-26 | ヤマハ株式会社 | Singing synthesis device |
| JP3732793B2 (en) * | 2001-03-26 | 2006-01-11 | 株式会社東芝 | Speech synthesis method, speech synthesis apparatus, and recording medium |
| TWI394142B (en) * | 2009-08-25 | 2013-04-21 | Inst Information Industry | System, method, and apparatus for singing voice synthesis |
| JP6290858B2 (en) * | 2012-03-29 | 2018-03-07 | スミュール, インク.Smule, Inc. | Computer processing method, apparatus, and computer program product for automatically converting input audio encoding of speech into output rhythmically harmonizing with target song |
| CN107103915A (en) * | 2016-02-18 | 2017-08-29 | 广州酷狗计算机科技有限公司 | A kind of audio data processing method and device |
-
2017
- 2017-12-05 CN CN201711268972.9A patent/CN108257613B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1162167A (en) * | 1996-01-18 | 1997-10-15 | 雅马哈株式会社 | Formant conversion device for correcting singing sound for imitating standard sound |
| CN106157976A (en) * | 2015-04-10 | 2016-11-23 | 科大讯飞股份有限公司 | A kind of singing evaluating method and system |
| CN106057208A (en) * | 2016-06-14 | 2016-10-26 | 科大讯飞股份有限公司 | Audio correction method and device |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108257613A (en) | 2018-07-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108257613B (en) | Method and device for correcting pitch deviation of audio content | |
| CN108206026B (en) | Method and device for determining pitch deviation of audio content | |
| CN104347080B (en) | The medium of speech analysis method and device, phoneme synthesizing method and device and storaged voice analysis program | |
| KR102038171B1 (en) | Automatic conversion of speech into song, rap or other audible expression having target meter or rhythm | |
| US8907195B1 (en) | Method and apparatus for musical training | |
| CN103187046B (en) | Display control unit and method | |
| CN109952609B (en) | sound synthesis method | |
| JP2008516289A (en) | Method and apparatus for extracting a melody that is the basis of an audio signal | |
| CN108766452B (en) | Sound repairing method and device | |
| CN111583894A (en) | Method, device, terminal equipment and computer storage medium for correcting tone in real time | |
| CN108231048B (en) | Method and device for correcting audio rhythm | |
| CN112669811B (en) | Song processing method and device, electronic equipment and readable storage medium | |
| JP6565528B2 (en) | Automatic arrangement device and program | |
| CN108492807B (en) | Method and device for displaying sound modification state | |
| CN115331682B (en) | Method and device for correcting pitch of audio | |
| JP5125958B2 (en) | Range identification system, program | |
| JP2008516288A (en) | Extraction of melody that is the basis of audio signal | |
| JP4170279B2 (en) | Lyric display method and apparatus | |
| US10410616B2 (en) | Chord judging apparatus and chord judging method | |
| CN110853457A (en) | Interactive music teaching guidance method | |
| US20210366455A1 (en) | Sound signal synthesis method, generative model training method, sound signal synthesis system, and recording medium | |
| CN108281130B (en) | Audio correction method and device | |
| CN112164387B (en) | Audio synthesis method, device, electronic device and computer-readable storage medium | |
| CN110111813B (en) | Rhythm detection method and device | |
| CN112530448A (en) | Data processing method and device for harmony generation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |