CN107614762B - 一种由噬菌体表达的单链变异片段抗体库 - Google Patents
一种由噬菌体表达的单链变异片段抗体库 Download PDFInfo
- Publication number
- CN107614762B CN107614762B CN201680009046.7A CN201680009046A CN107614762B CN 107614762 B CN107614762 B CN 107614762B CN 201680009046 A CN201680009046 A CN 201680009046A CN 107614762 B CN107614762 B CN 107614762B
- Authority
- CN
- China
- Prior art keywords
- cdr
- nucleic acid
- antibody
- scfv
- phage
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 239000012634 fragment Substances 0.000 title claims abstract description 51
- 108091007433 antigens Proteins 0.000 claims abstract description 151
- 102000036639 antigens Human genes 0.000 claims abstract description 151
- 239000000427 antigen Substances 0.000 claims abstract description 94
- 238000000034 method Methods 0.000 claims abstract description 67
- 108010047041 Complementarity Determining Regions Proteins 0.000 claims abstract description 37
- 238000009826 distribution Methods 0.000 claims abstract description 22
- 241001515965 unidentified phage Species 0.000 claims abstract description 21
- 125000003118 aryl group Chemical group 0.000 claims abstract description 19
- 150000007523 nucleic acids Chemical group 0.000 claims description 199
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 104
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 claims description 95
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 claims description 87
- 210000004027 cell Anatomy 0.000 claims description 66
- 108020004414 DNA Proteins 0.000 claims description 64
- 108090000623 proteins and genes Proteins 0.000 claims description 59
- 108091026890 Coding region Proteins 0.000 claims description 44
- 102000004169 proteins and genes Human genes 0.000 claims description 43
- 229940027941 immunoglobulin g Drugs 0.000 claims description 41
- 108060003951 Immunoglobulin Proteins 0.000 claims description 38
- 102000018358 immunoglobulin Human genes 0.000 claims description 38
- 239000013598 vector Substances 0.000 claims description 36
- 239000000203 mixture Substances 0.000 claims description 32
- 201000010099 disease Diseases 0.000 claims description 20
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 20
- -1 MBP Proteins 0.000 claims description 13
- 241001524679 Escherichia virus M13 Species 0.000 claims description 12
- 108010026228 mRNA guanylyltransferase Proteins 0.000 claims description 12
- 238000012216 screening Methods 0.000 claims description 12
- 239000013604 expression vector Substances 0.000 claims description 11
- 108010063919 Glucagon Receptors Proteins 0.000 claims description 9
- 102100040890 Glucagon receptor Human genes 0.000 claims description 9
- 108700005091 Immunoglobulin Genes Proteins 0.000 claims description 9
- 206010028980 Neoplasm Diseases 0.000 claims description 9
- 238000002360 preparation method Methods 0.000 claims description 9
- 102000016943 Muramidase Human genes 0.000 claims description 8
- 108010014251 Muramidase Proteins 0.000 claims description 8
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 claims description 8
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 claims description 8
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 claims description 8
- 239000004325 lysozyme Substances 0.000 claims description 8
- 229960000274 lysozyme Drugs 0.000 claims description 8
- 235000010335 lysozyme Nutrition 0.000 claims description 8
- 238000002741 site-directed mutagenesis Methods 0.000 claims description 8
- 229960004641 rituximab Drugs 0.000 claims description 7
- 229940099472 immunoglobulin a Drugs 0.000 claims description 5
- 241000712461 unidentified influenza virus Species 0.000 claims description 5
- 108091003079 Bovine Serum Albumin Proteins 0.000 claims description 4
- 102000001301 EGF receptor Human genes 0.000 claims description 4
- 102000003777 Interleukin-1 beta Human genes 0.000 claims description 4
- 108090000193 Interleukin-1 beta Proteins 0.000 claims description 4
- 150000001413 amino acids Chemical group 0.000 claims description 4
- 230000002194 synthesizing effect Effects 0.000 claims description 4
- 238000011144 upstream manufacturing Methods 0.000 claims description 4
- LOGFVTREOLYCPF-KXNHARMFSA-N (2s,3r)-2-[[(2r)-1-[(2s)-2,6-diaminohexanoyl]pyrrolidine-2-carbonyl]amino]-3-hydroxybutanoic acid Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H]1CCCN1C(=O)[C@@H](N)CCCCN LOGFVTREOLYCPF-KXNHARMFSA-N 0.000 claims description 3
- 108060006698 EGF receptor Proteins 0.000 claims description 3
- 101000851181 Homo sapiens Epidermal growth factor receptor Proteins 0.000 claims description 3
- 108091006905 Human Serum Albumin Proteins 0.000 claims description 3
- 102000008100 Human Serum Albumin Human genes 0.000 claims description 3
- 102000004157 Hydrolases Human genes 0.000 claims description 3
- 108090000604 Hydrolases Proteins 0.000 claims description 3
- 101710175625 Maltose/maltodextrin-binding periplasmic protein Proteins 0.000 claims description 3
- 229940098773 bovine serum albumin Drugs 0.000 claims description 3
- 239000003814 drug Substances 0.000 claims description 3
- 210000004962 mammalian cell Anatomy 0.000 claims description 3
- 101710154606 Hemagglutinin Proteins 0.000 claims description 2
- 102000011931 Nucleoproteins Human genes 0.000 claims description 2
- 108010061100 Nucleoproteins Proteins 0.000 claims description 2
- 101710093908 Outer capsid protein VP4 Proteins 0.000 claims description 2
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 claims description 2
- 101710176177 Protein A56 Proteins 0.000 claims description 2
- 239000000185 hemagglutinin Substances 0.000 claims description 2
- 239000003446 ligand Substances 0.000 claims description 2
- 238000004519 manufacturing process Methods 0.000 claims description 2
- 102000009024 Epidermal Growth Factor Human genes 0.000 claims 1
- 101800003838 Epidermal growth factor Proteins 0.000 claims 1
- 108010009202 Growth Factor Receptors Proteins 0.000 claims 1
- 102000009465 Growth Factor Receptors Human genes 0.000 claims 1
- 102000004856 Lectins Human genes 0.000 claims 1
- 108090001090 Lectins Proteins 0.000 claims 1
- SQVRNKJHWKZAKO-UHFFFAOYSA-N beta-N-Acetyl-D-neuraminic acid Natural products CC(=O)NC1C(O)CC(O)(C(O)=O)OC1C(O)C(O)CO SQVRNKJHWKZAKO-UHFFFAOYSA-N 0.000 claims 1
- 210000003989 endothelium vascular Anatomy 0.000 claims 1
- 229940116977 epidermal growth factor Drugs 0.000 claims 1
- 239000002523 lectin Substances 0.000 claims 1
- SQVRNKJHWKZAKO-OQPLDHBCSA-N sialic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@](O)(C(O)=O)OC1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-OQPLDHBCSA-N 0.000 claims 1
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 claims 1
- 238000011160 research Methods 0.000 abstract description 2
- 102000053602 DNA Human genes 0.000 description 59
- 238000006243 chemical reaction Methods 0.000 description 44
- 235000018102 proteins Nutrition 0.000 description 37
- 238000003752 polymerase chain reaction Methods 0.000 description 36
- 125000003275 alpha amino acid group Chemical group 0.000 description 30
- 241000699670 Mus sp. Species 0.000 description 25
- 101000841411 Homo sapiens Protein ecdysoneless homolog Proteins 0.000 description 23
- 102000047791 human ECD Human genes 0.000 description 23
- 241000699666 Mus <mouse, genus> Species 0.000 description 20
- 239000002773 nucleotide Chemical group 0.000 description 20
- 125000003729 nucleotide group Chemical group 0.000 description 20
- 230000004044 response Effects 0.000 description 20
- 241001465754 Metazoa Species 0.000 description 17
- 230000014509 gene expression Effects 0.000 description 16
- 108090000765 processed proteins & peptides Proteins 0.000 description 16
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 15
- 238000004458 analytical method Methods 0.000 description 15
- 230000000295 complement effect Effects 0.000 description 15
- 102000005962 receptors Human genes 0.000 description 14
- 108020003175 receptors Proteins 0.000 description 14
- 239000000047 product Substances 0.000 description 13
- 239000000872 buffer Substances 0.000 description 12
- 102000004196 processed proteins & peptides Human genes 0.000 description 12
- 241000588724 Escherichia coli Species 0.000 description 11
- 230000028993 immune response Effects 0.000 description 11
- UQLDLKMNUJERMK-UHFFFAOYSA-L di(octadecanoyloxy)lead Chemical compound [Pb+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O UQLDLKMNUJERMK-UHFFFAOYSA-L 0.000 description 10
- 229960000575 trastuzumab Drugs 0.000 description 10
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 9
- 239000006143 cell culture medium Substances 0.000 description 9
- 239000002299 complementary DNA Substances 0.000 description 9
- 102000039446 nucleic acids Human genes 0.000 description 9
- 108020004707 nucleic acids Proteins 0.000 description 9
- 239000002953 phosphate buffered saline Substances 0.000 description 9
- 108020001580 protein domains Proteins 0.000 description 9
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 8
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 8
- 238000010494 dissociation reaction Methods 0.000 description 8
- 230000005593 dissociations Effects 0.000 description 8
- 230000000694 effects Effects 0.000 description 8
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 8
- 229920001184 polypeptide Polymers 0.000 description 8
- 239000000126 substance Substances 0.000 description 8
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 8
- 229920001213 Polysorbate 20 Polymers 0.000 description 7
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 7
- 239000002671 adjuvant Substances 0.000 description 7
- 238000003556 assay Methods 0.000 description 7
- 238000004520 electroporation Methods 0.000 description 7
- 230000006870 function Effects 0.000 description 7
- 230000003053 immunization Effects 0.000 description 7
- 230000035772 mutation Effects 0.000 description 7
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 7
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 7
- 238000003786 synthesis reaction Methods 0.000 description 7
- 108010074708 B7-H1 Antigen Proteins 0.000 description 6
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 6
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 6
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 6
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 6
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 6
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 6
- 108010029180 Sialic Acid Binding Ig-like Lectin 3 Proteins 0.000 description 6
- 125000000539 amino acid group Chemical group 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 230000002401 inhibitory effect Effects 0.000 description 6
- 238000006386 neutralization reaction Methods 0.000 description 6
- 238000007481 next generation sequencing Methods 0.000 description 6
- 108091008146 restriction endonucleases Proteins 0.000 description 6
- 230000002441 reversible effect Effects 0.000 description 6
- 239000000523 sample Substances 0.000 description 6
- 238000012163 sequencing technique Methods 0.000 description 6
- 238000005406 washing Methods 0.000 description 6
- 102100034343 Integrase Human genes 0.000 description 5
- 108010076504 Protein Sorting Signals Proteins 0.000 description 5
- 241001112090 Pseudovirus Species 0.000 description 5
- 238000003776 cleavage reaction Methods 0.000 description 5
- FFYPMLJYZAEMQB-UHFFFAOYSA-N diethyl pyrocarbonate Chemical compound CCOC(=O)OC(=O)OCC FFYPMLJYZAEMQB-UHFFFAOYSA-N 0.000 description 5
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 5
- 238000000605 extraction Methods 0.000 description 5
- 108020001507 fusion proteins Proteins 0.000 description 5
- 102000037865 fusion proteins Human genes 0.000 description 5
- 238000002649 immunization Methods 0.000 description 5
- 230000003472 neutralizing effect Effects 0.000 description 5
- 239000013612 plasmid Substances 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 230000007017 scission Effects 0.000 description 5
- 210000000952 spleen Anatomy 0.000 description 5
- 210000004989 spleen cell Anatomy 0.000 description 5
- 239000006228 supernatant Substances 0.000 description 5
- 238000012360 testing method Methods 0.000 description 5
- 238000001262 western blot Methods 0.000 description 5
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 4
- 241000283707 Capra Species 0.000 description 4
- 238000002965 ELISA Methods 0.000 description 4
- 239000004471 Glycine Substances 0.000 description 4
- 101000863721 Homo sapiens Deoxyribonuclease-1 Proteins 0.000 description 4
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 4
- 108060001084 Luciferase Proteins 0.000 description 4
- 239000005089 Luciferase Substances 0.000 description 4
- TWRXJAOTZQYOKJ-UHFFFAOYSA-L Magnesium chloride Chemical compound [Mg+2].[Cl-].[Cl-] TWRXJAOTZQYOKJ-UHFFFAOYSA-L 0.000 description 4
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 239000013504 Triton X-100 Substances 0.000 description 4
- 229920004890 Triton X-100 Polymers 0.000 description 4
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 4
- 230000003321 amplification Effects 0.000 description 4
- 230000000890 antigenic effect Effects 0.000 description 4
- 108010006025 bovine growth hormone Proteins 0.000 description 4
- 238000010367 cloning Methods 0.000 description 4
- 238000002967 competitive immunoassay Methods 0.000 description 4
- 238000010790 dilution Methods 0.000 description 4
- 239000012895 dilution Substances 0.000 description 4
- 235000019253 formic acid Nutrition 0.000 description 4
- 210000004408 hybridoma Anatomy 0.000 description 4
- 210000000987 immune system Anatomy 0.000 description 4
- 238000000338 in vitro Methods 0.000 description 4
- 239000000463 material Substances 0.000 description 4
- 238000003199 nucleic acid amplification method Methods 0.000 description 4
- 230000002018 overexpression Effects 0.000 description 4
- 102000013415 peroxidase activity proteins Human genes 0.000 description 4
- 108040007629 peroxidase activity proteins Proteins 0.000 description 4
- 230000008488 polyadenylation Effects 0.000 description 4
- 102000040430 polynucleotide Human genes 0.000 description 4
- 108091033319 polynucleotide Proteins 0.000 description 4
- 239000002157 polynucleotide Substances 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 230000000638 stimulation Effects 0.000 description 4
- 239000000758 substrate Substances 0.000 description 4
- 208000024891 symptom Diseases 0.000 description 4
- 238000001890 transfection Methods 0.000 description 4
- UAIUNKRWKOVEES-UHFFFAOYSA-N 3,3',5,5'-tetramethylbenzidine Chemical compound CC1=C(N)C(C)=CC(C=2C=C(C)C(N)=C(C)C=2)=C1 UAIUNKRWKOVEES-UHFFFAOYSA-N 0.000 description 3
- CSCPPACGZOOCGX-UHFFFAOYSA-N Acetone Chemical compound CC(C)=O CSCPPACGZOOCGX-UHFFFAOYSA-N 0.000 description 3
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- 229920000936 Agarose Polymers 0.000 description 3
- 108020004705 Codon Proteins 0.000 description 3
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 3
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 3
- 108010058683 Immobilized Proteins Proteins 0.000 description 3
- 241000124008 Mammalia Species 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 241000283973 Oryctolagus cuniculus Species 0.000 description 3
- 229920002873 Polyethylenimine Polymers 0.000 description 3
- 239000013614 RNA sample Substances 0.000 description 3
- 239000003929 acidic solution Substances 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- 210000003719 b-lymphocyte Anatomy 0.000 description 3
- 230000001580 bacterial effect Effects 0.000 description 3
- 230000008827 biological function Effects 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 239000003795 chemical substances by application Substances 0.000 description 3
- 230000002860 competitive effect Effects 0.000 description 3
- 239000001963 growth medium Substances 0.000 description 3
- 229940127121 immunoconjugate Drugs 0.000 description 3
- 229940072221 immunoglobulins Drugs 0.000 description 3
- 238000001727 in vivo Methods 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- 235000013336 milk Nutrition 0.000 description 3
- 239000008267 milk Substances 0.000 description 3
- 210000004080 milk Anatomy 0.000 description 3
- 229960002087 pertuzumab Drugs 0.000 description 3
- 238000002823 phage display Methods 0.000 description 3
- 229920002401 polyacrylamide Polymers 0.000 description 3
- 239000011347 resin Substances 0.000 description 3
- 229920005989 resin Polymers 0.000 description 3
- 229920002477 rna polymer Polymers 0.000 description 3
- 235000020183 skimmed milk Nutrition 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- 230000003595 spectral effect Effects 0.000 description 3
- 239000012137 tryptone Substances 0.000 description 3
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 2
- XKRFYHLGVUSROY-UHFFFAOYSA-N Argon Chemical compound [Ar] XKRFYHLGVUSROY-UHFFFAOYSA-N 0.000 description 2
- 101001117471 Aspergillus phoenicis Aspergillopepsin-1 Proteins 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 108020004635 Complementary DNA Proteins 0.000 description 2
- 238000007400 DNA extraction Methods 0.000 description 2
- 102100027088 Dual specificity protein phosphatase 5 Human genes 0.000 description 2
- 102100027272 Dual specificity protein phosphatase 8 Human genes 0.000 description 2
- 238000012286 ELISA Assay Methods 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 2
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 description 2
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 2
- 102400000058 Neuregulin-1 Human genes 0.000 description 2
- 108090000556 Neuregulin-1 Proteins 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 108020004682 Single-Stranded DNA Proteins 0.000 description 2
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 2
- 239000012505 Superdex™ Substances 0.000 description 2
- PZBFGYYEXUXCOF-UHFFFAOYSA-N TCEP Chemical compound OC(=O)CCP(CCC(O)=O)CCC(O)=O PZBFGYYEXUXCOF-UHFFFAOYSA-N 0.000 description 2
- 239000007983 Tris buffer Substances 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 238000000246 agarose gel electrophoresis Methods 0.000 description 2
- 235000001014 amino acid Nutrition 0.000 description 2
- 230000009830 antibody antigen interaction Effects 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 239000012472 biological sample Substances 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 239000004202 carbamide Substances 0.000 description 2
- 239000013592 cell lysate Substances 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 239000003599 detergent Substances 0.000 description 2
- 229910052805 deuterium Inorganic materials 0.000 description 2
- 239000012153 distilled water Substances 0.000 description 2
- 239000012149 elution buffer Substances 0.000 description 2
- 229940088598 enzyme Drugs 0.000 description 2
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 2
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 239000012091 fetal bovine serum Substances 0.000 description 2
- 239000007850 fluorescent dye Substances 0.000 description 2
- 238000002523 gelfiltration Methods 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 239000008101 lactose Substances 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 229910001629 magnesium chloride Inorganic materials 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 244000005700 microbiome Species 0.000 description 2
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 235000020030 perry Nutrition 0.000 description 2
- 239000013641 positive control Substances 0.000 description 2
- 239000002244 precipitate Substances 0.000 description 2
- 238000004321 preservation Methods 0.000 description 2
- 238000010791 quenching Methods 0.000 description 2
- 238000010839 reverse transcription Methods 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 238000007790 scraping Methods 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical group CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 230000004614 tumor growth Effects 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- IVLXQGJVBGMLRR-UHFFFAOYSA-N 2-aminoacetic acid;hydron;chloride Chemical compound Cl.NCC(O)=O IVLXQGJVBGMLRR-UHFFFAOYSA-N 0.000 description 1
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- 108010032595 Antibody Binding Sites Proteins 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- 102000012410 DNA Ligases Human genes 0.000 description 1
- 108010061982 DNA Ligases Proteins 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- YZCKVEUIGOORGS-OUBTZVSYSA-N Deuterium Chemical compound [2H] YZCKVEUIGOORGS-OUBTZVSYSA-N 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 241000192016 Finegoldia magna Species 0.000 description 1
- 239000012739 FreeStyle 293 Expression medium Substances 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- 206010069767 H1N1 influenza Diseases 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 101000638154 Homo sapiens Transmembrane protease serine 2 Proteins 0.000 description 1
- 241000701024 Human betaherpesvirus 5 Species 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 101710203526 Integrase Proteins 0.000 description 1
- HRNLUBSXIHFDHP-UHFFFAOYSA-N N-(2-aminophenyl)-4-[[[4-(3-pyridinyl)-2-pyrimidinyl]amino]methyl]benzamide Chemical compound NC1=CC=CC=C1NC(=O)C(C=C1)=CC=C1CNC1=NC=CC(C=2C=NC=CC=2)=N1 HRNLUBSXIHFDHP-UHFFFAOYSA-N 0.000 description 1
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 239000002033 PVDF binder Substances 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 108010021757 Polynucleotide 5'-Hydroxyl-Kinase Proteins 0.000 description 1
- 102000008422 Polynucleotide 5'-hydroxyl-kinase Human genes 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 241000191967 Staphylococcus aureus Species 0.000 description 1
- 239000012163 TRI reagent Substances 0.000 description 1
- RTAQQCXQSZGOHL-UHFFFAOYSA-N Titanium Chemical compound [Ti] RTAQQCXQSZGOHL-UHFFFAOYSA-N 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- 102100031989 Transmembrane protease serine 2 Human genes 0.000 description 1
- 239000008351 acetate buffer Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N adenyl group Chemical group N1=CN=C2N=CNC2=C1N GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 230000001464 adherent effect Effects 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 229910052786 argon Inorganic materials 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 230000008275 binding mechanism Effects 0.000 description 1
- 239000013060 biological fluid Substances 0.000 description 1
- 238000010804 cDNA synthesis Methods 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 229940041514 candida albicans extract Drugs 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 229920006317 cationic polymer Polymers 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 238000011260 co-administration Methods 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000008094 contradictory effect Effects 0.000 description 1
- 239000013068 control sample Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- SUYVUBYJARFZHO-RRKCRQDMSA-N dATP Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 SUYVUBYJARFZHO-RRKCRQDMSA-N 0.000 description 1
- SUYVUBYJARFZHO-UHFFFAOYSA-N dATP Natural products C1=NC=2C(N)=NC=NC=2N1C1CC(O)C(COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 SUYVUBYJARFZHO-UHFFFAOYSA-N 0.000 description 1
- RGWHQCVHVJXOKC-SHYZEUOFSA-J dCTP(4-) Chemical compound O=C1N=C(N)C=CN1[C@@H]1O[C@H](COP([O-])(=O)OP([O-])(=O)OP([O-])([O-])=O)[C@@H](O)C1 RGWHQCVHVJXOKC-SHYZEUOFSA-J 0.000 description 1
- HAAZLUGHYHWQIW-KVQBGUIXSA-N dGTP Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 HAAZLUGHYHWQIW-KVQBGUIXSA-N 0.000 description 1
- NHVNXKFIZYSCEB-XLPZGREQSA-N dTTP Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C1 NHVNXKFIZYSCEB-XLPZGREQSA-N 0.000 description 1
- 238000005034 decoration Methods 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 239000005549 deoxyribonucleoside Substances 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 101150097231 eg gene Proteins 0.000 description 1
- 238000000132 electrospray ionisation Methods 0.000 description 1
- 230000009881 electrostatic interaction Effects 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 238000001125 extrusion Methods 0.000 description 1
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 102000034356 gene-regulatory proteins Human genes 0.000 description 1
- 108091006104 gene-regulatory proteins Proteins 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 150000002333 glycines Chemical class 0.000 description 1
- 230000036433 growing body Effects 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- 230000000423 heterosexual effect Effects 0.000 description 1
- 102000051957 human ERBB2 Human genes 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 230000003100 immobilizing effect Effects 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 238000003125 immunofluorescent labeling Methods 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 238000000530 impalefection Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 239000013067 intermediate product Substances 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 230000000155 isotopic effect Effects 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 239000012139 lysis buffer Substances 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 239000012120 mounting media Substances 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 238000011392 neighbor-joining method Methods 0.000 description 1
- 238000007857 nested PCR Methods 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 125000003835 nucleoside group Chemical group 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 210000004180 plasmocyte Anatomy 0.000 description 1
- 230000004983 pleiotropic effect Effects 0.000 description 1
- 229920001223 polyethylene glycol Polymers 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 1
- 230000001915 proofreading effect Effects 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 230000000171 quenching effect Effects 0.000 description 1
- 239000011535 reaction buffer Substances 0.000 description 1
- 239000011541 reaction mixture Substances 0.000 description 1
- 230000035484 reaction time Effects 0.000 description 1
- 239000002265 redox agent Substances 0.000 description 1
- 239000003161 ribonuclease inhibitor Substances 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- 239000012146 running buffer Substances 0.000 description 1
- 235000004400 serine Nutrition 0.000 description 1
- 150000003355 serines Chemical class 0.000 description 1
- 230000001568 sexual effect Effects 0.000 description 1
- 238000001542 size-exclusion chromatography Methods 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 230000003381 solubilizing effect Effects 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 238000012916 structural analysis Methods 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 201000010740 swine influenza Diseases 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 238000004885 tandem mass spectrometry Methods 0.000 description 1
- 235000008521 threonine Nutrition 0.000 description 1
- 150000003588 threonines Chemical class 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 229910052719 titanium Inorganic materials 0.000 description 1
- 239000010936 titanium Substances 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- YNJBWRMUSHSURL-UHFFFAOYSA-N trichloroacetic acid Chemical compound OC(=O)C(Cl)(Cl)Cl YNJBWRMUSHSURL-UHFFFAOYSA-N 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- UNXRWKVEANCORM-UHFFFAOYSA-N triphosphoric acid Chemical compound OP(O)(=O)OP(O)(=O)OP(O)(O)=O UNXRWKVEANCORM-UHFFFAOYSA-N 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 239000003643 water by type Substances 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 239000012138 yeast extract Substances 0.000 description 1
Images





Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/005—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies constructed by phage libraries
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from RNA viruses
- C07K16/1018—Orthomyxoviridae, e.g. influenza virus
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/22—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against growth factors ; against growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/24—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against cytokines, lymphokines or interferons
- C07K16/244—Interleukins [IL]
- C07K16/245—IL-1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2887—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against CD20
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1037—Screening libraries presented on the surface of microorganisms, e.g. phage display, E. coli display
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/77—Internalization into the cell
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Landscapes
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Medicinal Chemistry (AREA)
- Virology (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Zoology (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Crystallography & Structural Chemistry (AREA)
- Oncology (AREA)
- Communicable Diseases (AREA)
- Pulmonology (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Abstract
本揭示内容是关于一种由噬菌体表达的单链变异片段抗体库,其包含复数个由噬菌体表达的单链变异片段,各单链变异片段的特征在于:(1)具有特定的正则结构组合;(2)各互补性决定区域具有特定分布的芳香族残基;以及(3)各互补性决定区域具有特定序列。本揭示内容的单链变异片段抗体库可用以有效制备能结合至不同抗原的不同抗体。据此,本揭示内容提供了一种方法,可针对不同抗原制备不同抗体,以实时因应实验研究及/或临床应用的需求。
Description
技术领域
本揭示内容是关于包含不同抗体片段的抗体库。更具体来说,本揭示内容是关于一种由噬菌体表达的单链变异片段 (phage-displayed single-chain variablefragment,scFv)抗体库及其用途。
背景技术
抗体亦称为免疫球蛋白,其由免疫系统中负责辨识及中和外来物质(例如细菌及病毒)的浆细胞(plasma cell)所制造的一种大分子量的Y型蛋白。抗体可辨识一般称作抗原的外来标的物中的特定部位。抗体Y型结构的端点分别包含一抗原结合位置(paratope),可专一性地结合至抗原上特定的抗原决定位置(epitope),藉以使抗原与抗体二结构可准确地结合在一起。利用此种结合机制,一抗体可标定一微生物或一受感染的细胞,进而协助免疫系统其他成份进行后续的攻击,或是直接中和该标的物(举例来说,阻断一微生物用以侵入个体或存活的部分)。人体体液免疫系统(humoral immune system) 最主要的功能即是产生抗体。
抗体通常是由基本结构单元所组成;一般来说,抗体具有二条分子量较大的重链及二条分子量较小的轻链。已知有五种重链,分别命名为α(alpha)、δ(delta)、ε(epsilon)、γ(gamma) 及μ(mu)。依据重链种类的不同会产生各种同型抗体 (isotype),分别为免疫球蛋白A(immunoglobulin A,IgA)、免疫球蛋白D(immunoglobulin D,IgD)、免疫球蛋白E(immunoglobulin E,IgE)、免疫球蛋白G(immunoglobulin G, IgG)及免疫球蛋白M(immunoglobulin M,IgM)抗体。各重链具有二个区域:恒定区域(constant region,CH)及变异区域 (variable region,VH)。相同的同型抗体具有相同的恒定区域,而不同的同型抗体则具有不同的恒定区域。由不同B细胞产生的抗体具有不同的重链变异区域;反之,经一特定抗原刺激及活化的单一B细胞或B细胞群,会产生具有相同重链变异区域的抗体。至于轻链,目前已知有二种形式,分别命名为λ(lambda)及κ(kappa)。与重链的结构相似,各轻链皆具有二个区域:恒定区域(constant region,CH)及变异区域 (variable region,VH),相同的同型抗体会具有相同的恒定区域,而变异区域则会随者刺激抗原的不同而不同。
纵使所有的抗体皆具有相似的蛋白结构,位于抗体端点的小区域却完全不同,因此,每一个体体内可同时存在着数以百万的抗体(其端点结构仅具微小差异;即不同的抗原结合位置)。该小区域一般称为高变异区域(hypervariable region)或互补性决定区域(complementarity determining region,CDR)。不同的变异区域可与不同抗原结合,此一抗体多样性可确保免疫系统能辨识相当数量的不同抗原。这些大量且具多样性的抗体是先由一组可用以编码不同抗原结合位置的基因片段 (即变异片段(variable segment)、多样片段(diversity segment) 及连接片段(joining segment))进行随机重组,再于该些基因片段进行随机突变(亦称为体细胞超突变(somatic hypermutation,SHM)所产生,其中随机突变可进一步增加抗体的多样性。
在制备抗体的过程中,通常会将天然或重组蛋白或其片段免疫注射至动物体内,使其产生免疫反应(immunize);产生的抗体可专一性地辨识及结合该蛋白/片段。接着,因应不同需要可使用不同方法自动物体内制备抗体(例如单克隆抗体或多株抗体)。一般来说,本领域技术人员是利用杂交瘤技术 (hybridoma technique)来制备单克隆抗体。该项技术是在使动物产生免疫反应后,由动物体内取出细胞并进行融合,以制备可产生抗体的杂交瘤;接着,再将该杂交瘤建构为用以制备抗体的细胞株,进而纯化及分析所得抗体。虽然该些技术已为制备抗体的惯用技术,但仍有以下缺点:牵涉复杂技术致使制备时间过长、抗原决定位置识别不全及制备成本过高等。此外,并不是每一种蛋白/蛋白片段皆可利用该些技术来制备相对应的抗体,例如低溶解度抗原、低免疫性 (immunogenicity)抗原或具有毒性的抗原。
有鉴于此,相关领域极需一种系统及/或方法,以更具成本效益的方式制备一种对特定抗原具有结合亲和性及专一性的抗体。
发明内容
发明内容旨在提供本揭示内容的简化摘要,以使阅读者对本揭示内容具备基本的理解。此发明内容并非本揭示内容的完整概述,且其用意并非在指出本发明实施例的重要/关键组件或界定本发明的范围。
本揭示内容的第一方面是关于一种由噬菌体表达的单链变异片段(phage-displayed single-chain variable fragment, scFv)抗体库,其包含复数个由噬菌体表达的scFv。在本发明抗体库中,各个由噬菌体表达的scFv皆包含一第一重链互补性决定区域(complementarity determining region,CDR-H1)、一第二重链CDR(CDR-H2)、一第三重链CDR(CDR-H3)、一第一轻链CDR(CDR-L1)、一第二轻链CDR(CDR-L2)及一第三轻链CDR(CDR-L3);其中,
各CDR-H1、CDR-L2及CDR-L3具有第一型的正则结构 (canonical structure,CS),且各CDR-H2及CDR-L1具有第二型的CS;以及
各CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2及 CDR-L3中芳香族残基的分布与一天然抗体的对应CDR-H1、 CDR-H2、CDR-H3、CDR-L1、CDR-L2及CDR-L3中芳香族残基的分布相似。
依据本揭示内容实施方式,CDR-L1是由一包含SEQ ID NO:2-10中任一核酸序列的第一编码序列编码而成,CDR-L2 是由一包含SEQ ID NO:11-14中任一核酸序列的第二编码序列编码而成,CDR-L3是由一包含SEQ ID NO:15-22中任一核酸序列的第三编码序列编码而成,CDR-H1是由一包含 SEQ ID NO:23-26中任一核酸序列的第四编码序列编码而成,CDR-H2是由一包含SEQ ID NO:27-28中任一核酸序列的第五编码序列编码而成,且CDR-H3是由一包含SEQ ID NO:29-106中任一核酸序列的第六编码序列编码而成。
依据本揭示内容一实施方式,该噬菌体是M13噬菌体或 T7噬菌体。较佳的情况是,该噬菌体是M13噬菌体。
在本揭示内容实施方式中,至少一由噬菌体表达的scFv 对蛋白抗原具有专一性,其中该蛋白抗原选自由第二型的人类表皮生长因子受体(human epidermal growthfactor receptor 2,HER2)、麦芽糖结合蛋白质(maltose-binding protein,MBP)、牛血清白蛋白(bovine serum albumin,BSA)、人类血清白蛋白(human serum albumin,HSA)、溶菌酶 (lysozyme)、白介素-1β(interleukin-1 beta,IL-1β)、流感病毒的血球凝集素(hemagglutinin of influenza virus,HA)、流感病毒的核蛋白(nucleoprotein ofinfluenza virus,NP)、血管内皮生长因子(vascular endothelial growth factor,VEGF)、第一型的表皮生长因子受体(epidermal growth factor receptor 1, EGFR1)、第三型表皮生长因子受体(epidermal growth factor receptor 3,EGFR3)、高血糖素受体(glucagon receptor)、人类脱氧核糖核酸水解酶(human DNase I)、第一型的程序性死亡配体(programmed death-ligand 1,PD-L1)、第三型唾液酸结合免疫球蛋白相似凝集素(sialic acid binding Ig-like lectin 3, SIGLEC 3)、免疫球蛋白G(immunoglobulinG,IgG)的结芯片段区域(fragment crystallizable region,Fc region)及利妥昔(rituximab)所组成的群组。
本揭示内容的第二方面是关于一种用以制备本发明由噬菌体表达的scFv抗体库的方法。该方法包含以下步骤:
(1)合成一第一核酸序列,其包含分别用以编码一免疫球白基因的CDR-L1、CDR-L2、CDR-L3、CDR-H1、CDR-H2及 CDR-H3的一第一、一第二、一第三、一第四、一第五及一第六编码序列;
(2)将该第一核酸序列插入一第一噬菌粒(phagemid)载体中;
(3)以定位点突变方法(site-directed mutagenesis)分别修饰该第一、第二及第三编码序列以制备一变异轻链(VL)抗体库,其包含一第一组由噬菌体表达的scFv,其中各scFv分别具有经修饰的CDR-L1、CDR-L2及CDR-L3;以及以定位点突变方法分别修饰该第四、第五及第六编码序列以制备一变异重链(VH)抗体库,其包含一第二组由噬菌体表达的scFv,其中各scFv分别具有经修饰的CDR-H1、CDR-H2及CDR-H3;
(4)利用蛋白L来筛选该VL抗体库,由该VL抗体库挑选一第三组由噬菌体表达的scFv;且利用蛋白A来筛选该VH 抗体库,由该VH抗体库挑选一第四组由噬菌体表达的scFv;
(5)由对应的噬菌体中扩增复数个第二核酸序列,其用以编码经修饰的CDR-L1、CDR-L2及CDR-L3,且由对应的噬菌体中扩增复数个第三核酸序列,其用以编码经修饰的CDR-H1、CDR-H2及CDR-H3;以及
(6)将该些第二及第三核酸序列插入一第二噬菌粒载体以制备本发明的由噬菌体表达的scFv抗体库。
依据本揭示内容实施方式,在步骤(3)中,该第一、第二及第三编码序列是分别以SEQ ID NO:107-115、116-119及 120-127的核酸序列进行修饰,且该第四、第五及第六编码序列是分别以SEQ ID NO:128-131、132-133及134-211的核酸序列进行修饰。
依据本揭示内容某些实施方式,在步骤(3)前更包含一步骤,其是将该免疫球蛋白基因的CDR-H1、CDR-H2、CDR-H3、 CDR-L1、CDR-L2及CDR-L3中芳香族残基的分布及一天然抗体的对应CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2 及CDR-L3中芳香族残基的分布进行比对。
依据本揭示内容某些实施方式,步骤(1)的免疫球蛋白基因源自一哺乳动物;例如小鼠、大鼠、仓鼠、兔、猴、山羊及绵羊。在一实施例中,该免疫球蛋白基因源自小鼠。依据本揭示内容一较佳实施方式,该免疫球蛋白基因可用以编码一对VEGF具有专一性的抗体。
依据本揭示内容实施方式,该第一及第二噬菌粒载体可以是相同或不同的噬菌粒载体。具选择性地,该第一及第二噬菌粒载体皆是源自M13噬菌体。
本揭示内容的第三方面是关于一种利用本发明由噬菌体表达的scFv抗体库来制备一重组抗体的方法,其中该重组抗体对一蛋白抗原具有结合亲和性及专一性。该方法包含以下步骤:
(a)以该蛋白抗原筛选本发明的由噬菌体表达的scFv抗体库;
(b)挑选复数个噬菌体,其中该些噬菌体会分别表达对该蛋白抗原具有结合亲和性及专一性的scFv;
(c)使步骤(b)挑选的该些噬菌体分别表达可溶形式的 scFv;
(d)由步骤(c)的scFv挑选一对该蛋白抗原具有高结合亲和性及专一性的可溶形式scFv;
(e)由会表达步骤(d)的可溶形式scFv的噬菌体中萃取一噬菌粒DNA;
(f)以步骤(e)的噬菌粒DNA作为模版,利用聚合酶连锁反应(polymerase chainreaction,PCR)分别扩增一用以编码 CDR-H1、CDR-H2及CDR-H3的第一核酸序列,及一用以编码CDR-L1、CDR-L2及CDR-L3的第二核酸序列;
(g)将该第一及第二核酸序列插入一表达载体中,其包含一第三及一第四核酸序列,其中该第三核酸序列用以编码一免疫球蛋白的重链恒定区域,且该第四核酸序列用以编码该免疫球蛋白的轻链恒定区域;以及
(h)将步骤(g)的包含该第一、第二、第三及第四核酸序列的表达载体转染至一宿主细胞,以制备该重组抗体。
在本揭示内容实施方式中,该第一核酸序列是位于该第三核酸序列的上游,且该第二核酸序列是位于该第四核酸序列的上游。
依据本揭示内容一实施方式,步骤(g)的免疫球蛋白选自由免疫球蛋白G(immunoglobulin G,IgG)、免疫球蛋白A (immunoglobulin A,IgA)、免疫球蛋白D(immunoglobulin D, IgD)、免疫球蛋白E(immunoglobulin E,IgE)及免疫球蛋白M(immunoglobulin M,IgM)所组成的群组;较佳的情况是,该免疫球蛋白是IgG。
在本揭示内容一实施方式中,步骤(h)的宿主细胞是一哺乳动物细胞。
依据本揭示内容另一实施方式,该蛋白抗原可以是HER2、 MBP、BSA、HSA、溶菌酶、IL-1β、人类DNase I、HA、NP、 VEGF、EGFR1、EGFR3、PD-L1、SIGLEC 3、IgG的Fc区域、高血糖素受体或利妥昔。
本揭示内容的第四方面是关于利用本发明由噬菌体表达的scFv抗体库制备的重组抗体。依据本揭示内容实施方式,该重组抗体包含:(1)一CDR-L1,其具有第二型的CS,且由一包含SEQ ID NO:2-10中任一核酸序列的第一编码序列编码而成;(2)一CDR-L2,其具有第一型的CS,且由一包含SEQ ID NO:11-14中任一核酸序列的第二编码序列编码而成;(3)一CDR-L3,其具有第一型的CS,且由一包含SEQ ID NO:15-22中任一核酸序列的第三编码序列编码而成;(4)一 CDR-H1,其具有第一型的CS,且由一包含SEQ ID NO:23-26 中任一核酸序列的第四编码序列编码而成;(5)一CDR-H2,其具有第二型的CS,且由一包含SEQ ID NO:27或28的第五编码序列编码而成;以及(6)一CDR-H3,其由一包含SEQ ID NO:29-106中任一核酸序列的第六编码序列编码而成。依据本揭示内容某些实施方式,各CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2及CDR-L3中芳香族残基的分布与一天然抗体的对应CDR-H1、CDR-H2、CDR-H3、CDR-L1、 CDR-L2及CDR-L3中芳香族残基的分布相似。
依据本揭示内容某些实施方式,重组抗体的离解常数 (dissociation constant,KD)约为10-7至10-11M。
依据本揭示内容某些实施方式,制备的重组抗体包含一与 SEQ ID NO:241-330中任一序列至少有90%相似度的氨基酸序列。
或者是,本揭示内容亦提供一种由HER2免疫的小鼠制备及纯化的重组抗体。依据一实施方式,该重组抗体包含一与SEQ ID NO:233、237及331-334中任一序列至少有90%相似度的氨基酸序列。此外,由小鼠制备的重组抗体可经人源化(humanized)处理,处理后的抗体包含一与SEQ ID NO:235 至少有90%相似度的氨基酸序列。
依据本揭示内容实施方式,本发明重组抗体(即由噬菌体表达的scFv抗体库制备的重组抗体、由经HER2免疫的小鼠制备的重组抗体及人源化的重组抗体)可具专一性地结合至 HER2的抗原决定位置。依据一实施方式,本发明重组抗体会引发HER2受体被内化(internalization)。依据另一实施方式,本发明重组抗体会抑制HER2受体的功能。
据此,本发明亦提供一种用以治疗一罹患或疑似罹患与 HER2相关的疾病的个体的方法;该方法包含对该个体投予一治疗有效量的本发明重组抗体,以减缓或改善该与HER2相关的疾病的病征。依据本揭示内容一实施方式,该种与HER2 相关的疾病是肿瘤,且投予本发明重组抗体可有效抑制肿瘤生长。较佳的情况是,该个体是人类。
依据本揭示内容较佳的实施方式,该可用以治疗与HER2 相关的疾病的抗体包含一与SEQ ID NO:233、235、237及 241-330中任一序列至少有90%相似度的氨基酸序列。
本揭示内容的另一方面是关于一种用以治疗一与HER2相关的疾病的组合物。依据本揭示内容某些实施方式,该组合物包含一第一重组抗体及一第二重组抗体,其中该第一重组抗体及第二重组抗体皆是由本发明由噬菌体表达的scFv抗体库所制备。较佳的情况是,该第一重组抗体会结合至HER2 的第一抗原决定位置,且该第二重组抗体会结合至HER2的第二抗原决定位置。依据本揭示内容一特定实施方式,该第一重组抗体包含SEQ ID NO:253的氨基酸序列,且该第二重组抗体包含SEQ ID NO:274或301的氨基酸序列。
本揭示内容更提供一种用以治疗一罹患或疑似罹患与 HER2相关的疾病的个体的方法;该方法包含对该个体投予一治疗有效量的本发明组合物,以减缓或改善该与HER2相关的疾病的病征。依据本揭示内容一实施方式,该种与HER2 相关的疾病是肿瘤,且投予本发明组合物可有效抑制肿瘤生长。较佳的情况是,该个体是人类。
依据本揭示内容较佳的实施方式,该第一重组抗体包含 SEQ ID NO:253的氨基酸序列,且该第二重组抗体包含SEQ ID NO:274或301的氨基酸序列。
在参阅下文实施方式后,本发明所属技术领域中具有通常知识者当可轻易了解本发明的基本精神及其他发明目的,以及本发明所采用的技术手段与实施方式。
附图简单说明
为让本发明的上述与其他目的、特征、优点与实施例能更明显易懂,所附图式的说明如下:
图1A是依据本揭示内容实施例3所绘示的SKBR3细胞荧光染色照片,其中该细胞是分别以特定的抗体进行处理;比例尺代表25微米(μm);
图1B是依据本揭示内容实施例3所绘示的SKBR3细胞荧光染色照片,其中该细胞是分别以特定的抗体进行处理;比例尺代表25微米;
图2是依据本揭示内容实施例3所绘示的Western印迹分析结果,其关于SKBR3细胞的蛋白表达量,其中该些细胞是分别以特定抗体进行处理后,分别利用抗-磷酸化HER2(anti-phosphorylated HER2,p-HER2)抗体、抗-HER2抗体、抗磷酸化AKT(anti-phosphorylated AKT,p-AKT)抗体、抗-AKT 抗体、抗-磷酸化ERK(anti-phosphorylatedERK,p-ERK)抗体、抗-ERK抗体及抗-微管蛋白(anti-tubulin)抗体来侦测蛋白的表达;
图3A是依据本揭示内容实施例3所绘示的结果,其关于由噬菌体表达的scFv抗体库制备的重组抗体,其对H1N1 中和能力及天然HA结合亲和性的关联性;以及
图3B是依据本揭示内容实施例3所绘示的结果,其关于由噬菌体表达的scFv抗体库制备的重组抗体,其对天然HA 结合亲和性及对重组HA结合亲和性的关联性。
根据惯常的作业方式,图中各种特征与组件并未依比例绘制,其绘制方式是为了以最佳的方式呈现与本发明相关的具体特征与组件。
具体实施方式
为了使本揭示内容的叙述更加详尽与完备,下文针对了本发明的实施方式与具体实施例提出了说明性的描述;但这并非实施或运用本发明具体实施例的唯一形式。实施方式中涵盖了多个具体实施例的特征以及用以建构与操作这些具体实施例的方法步骤与其顺序。然而,亦可利用其他具体实施例来达成相同或均等的功能与步骤顺序。
为便于读者了解,本说明书收集部分阐述于说明书、实施例及权利要求范围的词汇。除非本说明书另有定义,此处所用的科学与技术词汇的含义与本发明所属技术领域中具有通常知识者所理解与惯用的意义相同。此外,在不和上下文冲突的情形下,本说明书所用的单数名词涵盖该名词的复数型;而所用的复数名词时亦涵盖该名词的单数型。具体来说,除非另有所指,否则在本说明书及权利要求范围中,单数型的“一”包含其复数型。此外,在本说明书及权利要求范围中,“至少一”及“一或多”具有相同意义,且包含一、二、三或更多。
虽然用以界定本发明较广范围的数值范围与参数皆是约略的数值,此处已尽可能精确地呈现具体实施例中的相关数值。然而,任何数值本质上不可避免地含有因个别测试方法所致的标准偏差。在此处,“约”通常指实际数值在一特定数值或范围的正负10%、5%、1%或0.5%之内。或者是,“约”一词代表实际数值落在平均值的可接受标准误差之内,视本发明所属技术领域中具有通常知识者的考虑而定。除了实验例之外,或除非另有明确的说明,当可理解此处所用的所有范围、数量、数值与百分比(例如用以描述材料用量、时间长短、温度、操作条件、数量比例及其他相似者)均经过“约”的修饰。因此,除非另有相反的说明,本说明书与附随申请专利范围所揭示的数值参数皆为约略的数值,且可视需求而更动。至少应将这些数值参数理解为所指出的有效位数与套用一般进位法所得到的数值。在此处,将数值范围表示成由一端点至另一段点或介于二端点之间;除非另有说明,此处所述的数值范围皆包含端点。
在本说明书中,“抗原”(antigen或Ag)一词是指可引发免疫反应的分子。该免疫反应可以是产生抗体、活化特定的免疫胜任细胞,或二者。本领域技术人员当可了解包含几乎所有蛋白及肽等大分子皆可作为抗原。此外,抗原亦可源自重组或基因体DNA。本领域技术人员当可了解可用以编码一“抗原”(antigen或Ag)的DNA包含一用以编码可引发免疫反应的蛋白的核酸序列或部分核酸序列。此外,本所属领域具有通常知识者亦可了解抗原不必然是由基因中单一全长核酸序列编码而成,而是有可能由源自多个基因、经不同重组方式排列的部分核酸序列编码而成,藉以引发特定的免疫反应。此外,本领域技术人员当可了解抗原不必然是由一“基因”(gene)编码而成;日渐增多的数据显示抗原可以为合成或源自生物样本的物质。所述生物样本包含,但不限于,组织样本、肿瘤样本、细胞或生物体液。
在本说明书中,“免疫”(immunization)一词是指所属领域本领域技术人员所熟知、藉由对动物体投予(例如注射、黏膜刺激(mucosal challenge)等)一抗原剂或物质来引发免疫反应产生的过程,其中产生的免疫反应对该抗原剂或物质具有专一性。该抗原剂或物质可以单独投予或与佐剂(adjuvant)共同投予至动物体内。
“抗体”(antibody)一词在本说明书泛指单克隆抗体 (monoclonal antibody;包含全长单克隆抗体)、多株抗体 (polyclonal antibody)、多效抗体(multi-specificantibody;例如双效抗体)及能产生特定生物活性的抗体片段。“抗体片段”(antibodyfragment)一词在本说明书中包含全长抗体的一部分,该部分通常为抗体中与抗原结合的位置或变异区域。例示性的抗体片段包含Fab、Fab′、F(ab′)2、Fv片段、双链抗体(diabody)、线性抗体(linear antibody)、单链抗体分子 (single-chain antibody molecule)及由抗体片段形成的多效抗体。
“抗体库”(antibody library)一词在本说明书是指一群经表达的抗体及/或抗体片段,用以筛选及/或组合成完整抗体。抗体及/或抗体片段可以表达于核糖体(ribosome)、噬菌体或细胞表面(特别是酵母菌细胞表面)。
在本说明书中,“单链变异片段”(single-chain variable fragment或scFv)是指包含一免疫球蛋白的重链变异区域 (variable regions of the heavy chain,VH)及轻链变异区域 (variable regions of the light chain,VL)的融合蛋白,其中该 VH及VL是共价键结以形成一VH::VL异二聚体 (heterodimer)。该VH及VL可直接连结或透过一由肽编码的连接符链接,其中该连接符可连接VH的N端及VL的C端,或是连接VH的C端及VL的N端。连接符通常为包含多个能增加可挠性的甘氨酸(glycine)及多个能增加溶解性的丝氨酸(serine)或苏氨酸(threonine)的片段。即使移除抗体的恒定区域且插入连接符,scFv蛋白仍保有原免疫球蛋白的专一性。可由包含用以编码VH及VL序列的核酸来表达单链Fv多肽抗体。
“互补性决定区域”(complementarity determining region,CDR)在本说明书是指一抗体分子的高变异区域,其可与结合抗原的三维立体表面形成互补表面。由N端到C端,各抗体重链及轻链皆包含三个CDR(CDR 1、CDR 2及CDR3)。因此,一个HLA-DR抗原结合位置共包含6个CDR(3个重链变异区域的CDR及3个轻链变异区域的CDR)。各CDR的氨基酸残基会与结合抗原紧密接触,其中与抗原接触最紧密的位置通常为重链CDR3。
本所属领域具有通常知识者皆知,“正则结构” (canonical structure,CS)一词是指由抗原结合(即CDR)环状区域形成的主链构形(main chain conformation)。比对结构可发现,在6个抗原结合环状区域中,其中5个是选自由有限的既有构形结构所组成的群组。可由多肽骨架的扭转角 (torsion angle)来辨别各正则结构。
在本说明书中,“EC50”一词是指一抗体或其抗原结合区域的浓度,该浓度在活体外或活体试验中可引发一反应,其为最大反应的一半量(即最大反应及基准质的中间量)。
在本说明书中,“结合速率常数”(association rate constant,kon)是指一数值,用以表示抗体与抗体标的抗原间的结合强度,通常是以抗原-抗体的反应动力学来测定该数值。“解离速率常数”(dissociation rate constant,koff)在本说明书是指一数值,用以表示抗体与抗体标的抗原间的解离强度,通常是以抗原-抗体的反应动力学来测定该数值。将“解离速率常数”(dissociation rate constant,koff)除以“结合速率常数”(association rate constant,kon)可得到“离解常数”(dissociation constant,Kd)。该些常数可作为表示抗体对其抗原的亲和力及中和该抗原的活性的指数。
“噬菌粒”(phagemid)一词在本说明书是指一结合细菌噬菌体及质粒特性的载体。细菌噬菌体是指任何一种可感染细菌的病毒。
“核酸序列”(nucleic acid sequence)、“多核苷酸”(polynucleotide)或“核酸”(nucleic acid)在本说明书中可交替使用,可指一双股脱氧核糖核酸(deoxyribonuclicacid, DNA)、一单股DNA或所述DNA的转录产物(例如核糖核酸分子,ribonucleic acid,RNA)。需知本揭示内容无关乎自然界或自然状态下的基因多核苷酸序列。能用以分离或纯化(或部份纯化)本发明的核酸、多核苷酸或核苷酸序列的方法包含,但不限于离子交换色层分析(ion-exchange chromatography)、分子筛选色层分析(molecular size exclusionchromatography) 或是可用于基因工程技术诸如扩增(amplification)、扣除杂交法(subtractive hybridization)、克隆(cloning)、亚克隆 (sub-cloning)、化学合成(chemical synthesis)或其组合等基因工程技术。
本发明亦包含所有简并核苷酸序列(degenerate nucleotide sequence),其用以编码于生物体中具有特定活性或功能的肽/ 多肽/蛋白(例如本发明CDR)。“简并核苷酸序列”(degenerate nucleotide sequence)是指包含一或多个简并密码子(degeneratecodon;与可编码一多肽的参考多核苷酸分子相比)的核苷酸序列。简并密码子可包含不同的核苷酸三联体(triplet),却可编码出相同的氨基酸残基(例如GAU及GAC 三联体皆用以编码天门冬氨酸(aspartic acid,Asp))。
“编码序列”(coding sequence)及“编码区域”(coding region)在本说明书中可交替使用,是包含RNA及DNA的核苷酸序列及及核酸序列,其可用以编码合成RNA、蛋白、部分RNA或部分蛋白时需要的基因信息。“外来核苷酸序列”(foreign nucleotide sequence)、“异源性核苷酸序列”(heterologous nucleotide sequences)或“外源性核苷酸序列”(exogenous nucleotide sequences)是指特定生物体基因组的自然产物以外的核苷酸序列。“异源性蛋白”(Heterologous proteins)是指由外来、异源性或外源性核苷酸编码的蛋白,该些蛋白通常不会表达于细胞中。分离后重新导入相同种类的生物体的核苷酸序列不会被视为特定生物体基因组自然产生的产物,而会视为异性或外源性核苷酸序列。
“相似”(similar或similarity)在本说明书是指不同核酸或氨基酸序列间的关联性,其中该些序列的部分序列相同,或是序列中一或多个区域具有相似性。相似的氨基酸残基可以是不同氨基酸序列间相同的氨基酸残基,或是不同序列间保留性置换的氨基酸取代。
本揭示内容的主旨为提供一种由噬菌体表达的scFv抗体库,其可辨识及结合至不同的抗原蛋白,例如HER2。该抗体库包含复数个由噬菌体表达的scFvs,该些scFv的特征在于: (1)具有特定的CS组合;(2)各CDR具有特定分布的芳香族残基;以及(3)各CDR具有特定的序列。因此,在不需要重复常规步骤(例如使宿主动物免疫及/或制备杂交瘤)的情况下,利用抗原筛选本发明抗体库可简单制备出对特定抗原具有结合亲和性及专一性的抗体,因而能大幅缩减制备抗体所需的时间和劳力。据此,因应各种实验研究及/或临床应用需求,本揭示内容提供了一种用以制备对抗原具有专一性的抗体的方法。
为建立本发明由噬菌体表达的scFv抗体库,先从小鼠的抗体群组(antibodyrepertoire)决定各scFv的CS组合。在本揭示内容一实施方式中,用以建立小鼠抗体群组的方法包含:
(A)利用一蛋白抗原使一宿主动物免疫;
(B)由该免疫的小鼠体中分离脾脏细胞,并萃取脾脏细胞中的信使核糖核酸(messenger ribonucleic acid,mRNA);
(C)由萃取出的mRNA合成互补脱氧核糖核酸 (complementary deoxyribonucleicacid,cDNA);
(D)以步骤(C)合成的cDNA作为模版,利用PCR分别扩增复数个用以编码免疫球蛋白基因的CDR-H1、CDR-H2及 CDR-H3的第一核酸序列,以及复数个用以编码免疫球蛋白基因的CDR-L1、CDR-L2及CDR-L3的第二核酸序列;
(E)分别将该些第一及第二核酸序列插入噬菌粒载体,以制备一噬菌体;以及
(F)对步骤(E)的噬菌体抗体库进行测序分析。
在步骤(A)中,先以适量蛋白抗原(例如一自然蛋白或一合成多肽)使一宿主动物(例如小鼠、大鼠或兔子)免疫,以引发该宿主动物产生对该抗原具有专一性的抗体。依据本揭示内容一实施方式,是对该宿主动物投予一SEQ ID NO:224的融合蛋白,其包含一MBP及一包含HER2的细胞外域 (extracellular domain,ECD)中第203-262氨基酸残基的多肽。一般来说,在使宿主动物免疫时,会将佐剂及抗原混合后一并投予至宿主动物体内。适用于本发明的例示性佐剂包含弗氏完全佐剂(Freund’s complete adjuvant,FCA)、弗氏不完全佐剂(Freund’s incomplete adjuvant,FIA)、TiterMax及氢氧化铝佐剂。依据本揭示内容一实施方式,是将SEQ ID NO:224 的融合蛋白与TiterMax进行混合。免疫主要是将抗原以静脉内注射、淋巴结内注射、皮下注射、腹腔内注射或肌肉内注射方式投予至宿主动物体内,使其产生相关免疫反应。依据本揭示内容另一实施方式,是将包含SEQ ID NO:224的融合蛋白及佐剂TiterMax的混合物投予至小鼠的腹股沟淋巴结 (inguinal lymph node)内。每次投予的间隔时间并无特别限制。间隔时间可以是数天至数周;较佳是投予2次,且投予间隔时间为4周。依据本揭示内容一特定实施例,藉由对宿主动物投予SEQ ID NO:225(包含HER2的ECD;即 HER2/ECD)的多肽来增加宿主动物体内的免疫反应(即再免疫(re-immunization))。
在步骤(B)中,由步骤(A)制备的免疫宿主动物体内分离出脾脏细胞,并由该些脾脏细胞中萃取总mRNA;之后于步骤 (C)中,利用反转录酶(reverse transcriptase)将mRNA反转为 cDNA。在本领域技术人员所熟知的萃取方法中,是先以高腐蚀性的化学溶液(例如酚(phenol)、三氯乙酸(trichloroacetic acid)/丙酮(acetone)及Trizol)来溶解由免疫宿主动物体内萃取的脾脏细胞,再以三氯甲烷(chloroform)进行中和。离心后,利用有机溶液(例如乙醇及异丙醇)来沉淀包含RNA样本的水层。以乙醇洗涤RNA样本以移除残留蛋白后,干燥(例如风干及真空干燥)RNA样本,以得到RNA沉淀物。
在步骤(C)中,将步骤(B)得到的RNA沉淀物溶解于加入二乙基焦碳酸盐(diethylpyrocarbonate,DEPC)的蒸馏水 (DEPC H2O)中,利用反转录法(reversetranscription,RT)将 RNA反转为对应的cDNA。一般来说,是将RNA与引物 Oligo(dT)20、三磷酸脱氧核糖核苷(deoxy-ribonucleoside triphosphate,dNTP;其包含dATP、dGTP、dTTP及dCTP)、反转录酶、反应缓冲液及非必要性地,反转录酶的共因子(例如MgCl2)均匀混合以进行RT。较佳的情况是,反应混合物更包含二硫苏糖醇(dithiothreitol,DTT),其是一种氧化还原剂,可稳定反转录酶;以及RNase抑制剂,藉以抑制RT过程中 RNA的降解。
在步骤(D)中,将步骤(C)反转的cDNA作为模版,以标的特定引物利用PCR反应扩增标的基因。在一实施方式中,标的基因是用以编码一免疫球蛋白基因的CDR-H1、CDR-H2及CDR-H3的第一核酸序列;在另一实施方式中,标的基因是用以编码相同免疫球蛋白基因的CDR-L1、CDR-L2及CDR-L3 的第二核酸序列。依据本揭示内容某些实施方式,该免疫球蛋白是IgG、IgA、IgD、IgE或IgM;较佳的情况是,该免疫球蛋白是IgG。以Barbas等人发表的引物混合物(G.J.Phage Display A Laboratory Manual,Cold Spring Harbor Press, ColdSpring Harbor,New York;2001)分别扩增第一及第二核酸序列。本本领域技术人员在不过度实验的情况下,当可选用适当的引物由一免疫球蛋白中扩增特定的第一及第二核酸序列。
在步骤(E)中,将扩增的第一及第二核酸序列分别插入一噬菌粒载体中,以建立包含复数个可分别表达不同scFv的噬菌体的噬菌体抗体库。依据Barbas等人所发表的方法(G.J. Phage Display A Laboratory Manual,Cold Spring Harbor Press,Cold SpringHarbor,New York;2001),是先将第一及第二核酸序列组合后,再插入该噬菌粒中,其中是利用交迭延伸聚合酶连锁反应(overlap extension polymerase chain reaction,OE-PCR)来组合第一及第二核酸序列;OE-PCR亦称为以交迭延伸聚合酶连锁反应进行迭接反应(splicing by overlap extension PCR)或以突出延伸进行迭接反应(splicing byoverhang extension),上述二者皆简称为SOE-PCR。一般来说,需要4条引物进行OE-PCR,其中第一及第二引物分别为第一核酸序列的正向和反向引物,而第三及第四引物则分别为第二核酸序列的正向和反向引物。相较于其他PCR反应, OE-PCR所使用的引物需经特定设计,其中第二引物包含一3’端突出序列(互补序列1),其与第三引物的5’端突出序列(互补序列2)相互互补。在第一轮PCR反应中,先利用第一及第二引物扩增第一核酸序列,且以第三及第四引物扩增第二核酸序列;因此,互补序列1会插入第一核酸序列的3’端,而互补序列2则会插入第二核酸序列的5’端。在第二轮PCR反应中,混合二条经扩增的核酸序列,再仅以第一及第四引物进行PCR反应。由于互补序列1及互补序列2彼此相互互补,因此第一核酸序列的3’端会与第二核酸序列的5’端交迭,并形成一以第一及第四引物进行的PCR扩增反应的中间产物。基于此概念,在步骤(D)中扩增的第一核酸序列的3’端包含互补序列1(即GGAAGATCTAGAGGAACCACC;SEQ ID NO: 335),而第二核酸序列的5’端则包含互补序列2(即GGTGGTTCCTCTAGATCTTCC;SEQ ID NO:336),其中二互补序列会形成一交迭区域,进而可利用SEQ ID NO:226及 227的引物来组合第一及第二核酸序列。依据本揭示内容某些实施方式,SEQ ID NO:226及227的核酸序列分别包含第一及第二限制酶切点,藉以将组合产物插入噬菌粒载体的多克隆位点(multiple cloning site),以制备一重组噬菌粒。在一实施方式中,第一限制酶切点是SfiI,且第二限制酶切点是NotI。噬菌粒载体可以源自M13噬菌体或T7噬菌体;较佳是,噬菌粒载体是源自M13噬菌体。
之后将重组噬菌粒转入一宿主细胞中。一般来说,可利用转化法(transformation)或电穿孔法(electroporation)将噬菌粒转入宿主细胞;较佳的情况是,利用电穿孔法将噬菌粒转入宿主细胞。宿主细胞一般是一细菌细胞;例如大肠杆菌(Escherichia coli,E.coli)细胞。各转形后的宿主细胞皆包含一重组噬菌粒,并可于培养基上形成一菌落(colony);因此,依据本揭示内容某些实施方式,步骤(E)可获得约109个独立的菌落,将所有的菌落刮下后,冷冻于保存缓冲液中,即为噬菌体抗体库。
在步骤(F)中,以测序试验分析各个由步骤(E)的噬菌体抗体库表达的scFv。首先,利用传统DNA萃取技术由噬菌体抗体库中萃取重组噬菌粒;举例来说,酚/三氯甲烷萃取法及清洁剂(例如十二烷基硫酸钠(sodiumdodecyl sulfate)、吐温-20 (Tween-20)、NP-40及氚核X-100(Triton X-100))/乙酸(acetic acid)萃取法。接者,利用焦磷酸测序法(shotgun sequencing)、单分子实时测序法(single-molecule real-time sequencing)或次世代测序法(next generation sequencing,NGS)来分析重组噬菌粒。依据一较佳实施例,是利用SEQ ID NO:228及229 的引物来分析噬菌体抗体库中的VL序列,且使用SEQ IDNO:230及231的引物来分析噬菌体抗体库中的VH序列。
依据测序结果可发现,CDR-H1及CDR-H2主要的CS形态分别为第一型及第二型,而CDR-L1、CDR-L2及CDR-L3 主要的CS形态则分别为第二型、第一型及第一型;据此,依据该抗体架构(CDR-H1、CDR-H2、CDR-L1、CDR-L2及 CDR-L3的CS组合依序为1-2-2-1-1)来建构本发明由噬菌体表达的scFv抗体库的抗体。因此,本揭示内容的一方式是关于一种用以建立由噬菌体表达的scFv抗体库的方法。该方法包含以下步骤:
(1)合成一第一核酸序列,其包含分别用以编码一免疫球白基因的CDR-L1、CDR-L2、CDR-L3、CDR-H1、CDR-H2及 CDR-H3的一第一、一第二、一第三、一第四、一第五及一第六编码序列;
(2)将该第一核酸序列插入一第一噬菌粒载体中;
(3)以定位点突变方法(site-directed mutagenesis)分别修饰该第一、第二及第三编码序列以制备一变异轻链(VL)抗体库,其包含第一组由噬菌体表达的scFv,其中各scFv分别具有经修饰的CDR-L1、CDR-L2及CDR-L3;以及以定位点突变方法分别修饰该第四、第五及第六编码序列以制备一变异重链(VH)抗体库,其包含第二组由噬菌体表达的scFv,其中各scFv分别具有经修饰的CDR-H1、CDR-H2及CDR-H3;
(4)利用蛋白L来筛选该VL抗体库,由该VL抗体库挑选第三组由噬菌体表达的scFv;且利用蛋白A来筛选该VH抗体库,由该VH抗体库挑选第四组由噬菌体表达的scFv;
(5)由对应的噬菌体中扩增复数个第二核酸序列,其用以编码经修饰的CDR-L1、CDR-L2及CDR-L3,且由对应的噬菌体中扩增复数个第三核酸序列,其用以编码经修饰的CDR-H1、CDR-H2及CDR-H3;以及
(6)将该些第二及第三核酸序列插入第二噬菌粒载体以制备本发明由噬菌体表达的scFv抗体库。
在步骤(1)中,先合成第一核酸序列,其作为本发明scFv 抗体库的scFv的骨架。如本领域技术人员所熟知,合成步骤可于活体外进行,而不需起始的模版DNA样本。依据本揭示内容某些实施方式,第一核酸序列至少90%相似于SEQ ID NO:1的核苷酸序列,其用以编码人类抗-VEGF抗体的 CDR-L1、CDR-L2、CDR-L3、CDR-H1、CDR-H2及CDR-H3。依据本揭示内容其他实施方式,第一核酸序列包含第一及一第二限制酶切点,藉以在步骤(2)中将合成的第一核酸序列插入第一噬菌粒载体中。在一实施方式中,第一限制酶切点是 SfiI,而第二限制酶切点是NotI。
在步骤(2)中,利用第一及第二限制酶切点将合成的第一核酸序列插入第一噬菌粒载体。依据本揭示内容一实施方式,第一噬菌粒载体可以源自M13噬菌体或T7噬菌体;较佳的情况是,第一噬菌粒载体是源自M13噬菌体。
为增加该些由噬菌体表达的scFv的多样性,在步骤(3)中利用定位点突变方法分别修饰该些包含CDR-L1、CDR-L2、 CDR-L3、CDR-H1、CDR-H2及CDR-H3的第一到第六编码序列;本领域技术人员皆知,定位点突变方法是一种常用以特定且刻意改变基因(即DNA及RNA)序列的方法。一般来说,定位点突变方法是利用一包含特定突变及与模版DNA突变位置附近的序列互补(藉此与特定基因杂合)的引物来进行;突变可以是单一碱基改变(即点突变)、多碱基改变、删除或插入。在本揭示内容一实施方式中,分别利用具有SEQ ID NO:107-115、116-119及120-127核苷酸序列的DNA片段来修饰第一到第三编码序列;较佳的情况是,同时修饰第一到第三编码序列。经修饰后的第一编码序列包含SEQ ID NO:2-10 中任一核苷酸序列;经修饰后的第二编码序列包含SEQ ID NO:11-14中任一核苷酸序列,而经修饰后的第三编码序列则包含SEQ ID NO:15-22中任一核苷酸序列。包含经修饰的 CDR-L1、CDR-L2及CDR-L3的利用噬菌体表达的scFv即构成VL(变异轻链)抗体库。
在本揭示内容一实施方式中,分别利用具有SEQ ID NO: 128-131、132-133及134-211核苷酸序列的DNA片段来修饰第四到第六编码序列;较佳的情况是,同时修饰第四到第六编码序列。经修饰后的第四编码序列包含SEQ ID NO:23-26 中任一核苷酸序列;经修饰后的第五编码序列包含SEQ ID NO:27或28的核苷酸序列,而经修饰后的第六编码序列则包含SEQ ID NO:29-106中任一核苷酸序列。包含经修饰的 CDR-L1、CDR-L2及CDR-L3的利用噬菌体表达的scFv即构成VH(变异重链)抗体库。
SEQ ID NO:2-211的核苷酸序列皆是依据本所属领域本领域技术人员熟知的生物化学国际单位(international unit of biochemistry,IUB)编码来表示,其中A代表腺嘌呤(adenine); C代表胞嘧啶(cytosine);G代表鸟嘌呤(guanine);T代表胸嘧啶(thymine);B代表C、G或T中任一核苷酸;D代表A、 T或G中任一核苷酸;H代表A、C或T中任一核苷酸;K代表核苷酸G或T;M代表A或C;N代表A、T、C或G中任一核苷酸;R代表核苷酸A或G;S代表核苷酸G或C;V代表A、C或G中任一核苷酸;W代表核苷酸A或T;而Y则代表核苷酸C或T。
由于序列突变可能影响会scFv的折迭,步骤(4)进一步利用蛋白L及蛋白来分别筛选VL及VH抗体库。如本领域技术人员所熟知,由马格努斯消化链球菌(Peptostreptococcusmagnus)分离的蛋白L对免疫球蛋白的轻链具有结合亲和性;而由金黄色葡萄球菌(Staphylococcus aureus)分离的蛋白A则对免疫球蛋白的重链具有结合亲和性。操作时分别将蛋白L 及蛋白A固定在一基质(例如琼脂糖树脂聚丙烯酰胺)上,再分别与VL及VH抗体库的利用噬菌体表达的scFv进行混合。完整折迭的scFv可结合于固定蛋白上,进而利用冲提缓冲液 (通常是甘氨酸(pH 2.2)等酸性溶液)破坏固定蛋白及由噬菌体表达的scFv间的键结,以收集该些完整折迭的scFv。因此,由VL抗体库中可筛选出第三群的利用噬菌体表达的scFv,其具有完整折迭的轻链且可结合至蛋白L;由VH抗体库中可筛选出第四群的利用噬菌体表达的scFv,其具有完整折迭的重链且可结合至蛋白A。
在步骤(5)中,以SEQ ID NO:212-215的引物利用OE-PCR 来扩增第三及第四群噬菌体的核酸序列。具体来说,先以SEQ ID NO:212-213的引物由相对应的噬菌体扩增复数个用以编码经修饰的CDR-H1、CDR-H2及CDR-H3的第二核酸序列;以SEQ ID NO:214-215的引物由相对应的噬菌体扩增复数个用以编码经修饰的CDR-H1、CDR-H2及CDR-H3的第三核酸序列。须知,SEQ ID NO:213及214的核酸序列分别包含二互补序列(即GGAAGATCTAGAGGAACCACC及 GGTGGTTCCTCTAGATCTTCC;分别为SEQ ID NO:335及 336),会分别插入第二核酸序列的3’端及第三核酸序列的5’端。利用二互补序列间的重迭区域,第二及第三核酸序列会形成一中间模版,之后可以SEQ ID NO:216及217的引物利用PCR反应来组合二核酸序列。
依据本揭示内容一实施方式,SEQ ID NO:216及217的核酸序列分别包含第一及第二限制酶切点(即SfiI及NotI);因此,在步骤(6)中,可利用上述二限制酶切点将组合产物插入第二噬菌粒载体的多克隆位点,藉以制备一重组噬菌粒。第二噬菌粒载体可以源自M13噬菌体或T7噬菌体;较佳的情况是,第二噬菌粒载体是源自M13噬菌体。接着将该重组噬菌粒转入一宿主细胞中。一般来说,可利用转化法或电穿孔法将噬菌粒转入宿主细胞;较佳的情况是,利用电穿孔法将噬菌粒转入宿主细胞。各个转化后的宿主细胞皆包含一重组噬菌粒,并可于培养基上形成一细胞群。依据一实施方式,宿主细胞一般是一细菌细胞;例如大肠杆菌细胞。步骤(6)共可获得约109个独立的细胞群,将所有的细胞群刮下后,冷冻于保存缓冲液中,即为本揭示内容的由噬菌体表达的scFv 抗体库。
须知,第一及第二噬菌粒不必然是相同的噬菌粒。依据本揭示内容一实施方式,第一及第二噬菌粒皆源自M13噬菌体。
因此,本发明制备的由噬菌体表达的scFv抗体库包含复数个由噬菌体表达的scFv,其中各个由噬菌体表达的scFv皆包含一CDR-H1、一CDR-H2、一CDR-H3、一CDR-L1、一CDR-L2及一CDR-L3,其中
各CDR-H1、CDR-L2及CDR-L3皆具有第一型的CS,且各CDR-H2及CDR-L1皆具有第二型的CS;
各CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2及 CDR-L3中芳香族残基的分布与一天然抗体的对应CDR-H1、 CDR-H2、CDR-H3、CDR-L1、CDR-L2及CDR-L3中芳香族残基的分布相似。
依据本揭示内容某些实施方式,CDR-L1是由一包含SEQ ID NO:2-10中任一核酸序列的第一编码序列编码而成, CDR-L2是由一包含SEQ ID NO:11-14中任一核酸序列的第二编码序列编码而成,CDR-L3是由一包含SEQ ID NO: 15-22中任一核酸序列的第三编码序列编码而成,CDR-H1是由一包含SEQ ID NO:23-26中任一核酸序列的第四编码序列编码而成,CDR-H2是由一包含SEQ ID NO:27-28中任一核酸序列的第五编码序列编码而成,且CDR-H3是由一包含SEQ ID NO:29-106中任一核酸序列的第六编码序列编码而成。
依据本揭示内容某些实施方式,本发明由噬菌体表达的 scFv抗体库中每个噬菌体皆带有单一个噬菌粒。
在本揭示内容一实施方式中,至少一由噬菌体表达的scFv 对蛋白抗原具有专一性,其中该蛋白抗原选自由HER2、MBP、 BSA、HSA、溶菌酶、IL-1β、HA、NP、VEGF、EGFR1、EGFR3、高血糖素受体、人类脱氧核糖核酸水解酶、PD-L1、SIGLEC 3、 IgG及利妥昔所组成的群组。依据本揭示内容某些实施方式,蛋白抗原HA是源自H1N1、H3N2或H5N1。依据本揭示内容其他实施方式,蛋白抗原NP是源自H3N2或H1N1。依据本揭示内容一实施例,至少一由噬菌体表达的scFv对HER2具有结合亲和性及专一性;较佳的情况是,该HER2是源自于人类。在本揭示内容某些实施方式中,至少一由噬菌体表达的scFv可结合至HER2、EGFR1、EGFR3、PD-L1、SIGLEC 3 及/或高血糖素受体的ECD。在本揭示内容其他实施方式中,至少一由噬菌体表达的scFv可结合至IgG的Fc区域。
依据一实施方式,由噬菌体表达的scFv抗体库表达的 scFv具有完整折迭的结构;较佳的情况是,该些scFv可表达于噬菌体表面,或是表达为可分泌的可溶形式。
本发明建构的由噬菌体表达的scFv抗体库可有效制备一重组抗体,其对一蛋白抗原具有结合亲和性及专一性。具体来说,利用本发明由噬菌体表达的scFv抗体库来制备重组抗体的方法包含以下步骤:
(a)以该蛋白抗原筛选本发明由噬菌体表达的scFv抗体库;
(b)挑选复数个噬菌体,其中该些噬菌体会分别表达对该蛋白抗原具有结合亲和性及专一性的scFv;
(c)使步骤(b)挑选的该些噬菌体分别表达可溶形式的 scFv;
(d)由步骤(c)的scFv挑选一对该蛋白抗原具有高结合亲和性及专一性的可溶形式scFv;
(e)由会表达步骤(d)的可溶形式scFv的噬菌体中萃取一噬菌粒DNA;
(f)以步骤(e)的噬菌粒DNA作为模版,利用PCR反应分别扩增用以编码CDR-H1、CDR-H2及CDR-H3的第一核酸序列,及用以编码CDR-L1、CDR-L2及CDR-L3的第二核酸序列;
(g)将该第一及第二核酸序列插入表达载体中,其包含第三及第四核酸序列,其中第三核酸序列用以编码免疫球蛋白的重链恒定区域,且第四核酸序列用以编码免疫球蛋白的轻链恒定区域;以及
(h)将步骤(g)的包含该第一、第二、第三及第四核酸序列的表达载体转染至宿主细胞,以制备该重组抗体。
在步骤(a)中,是先利用蛋白抗原来筛选本发明由噬菌体表达的scFv抗体库。与前述方法步骤(4)的筛选方法相似,将蛋白抗原固定于基质(例如琼脂糖树脂聚丙烯酰胺)后,与本发明由噬菌体表达的scFv抗体库进行混合。依据本揭示内容某些实施方式,该蛋白抗原可以是HER2、MBP、BSA、HA、溶菌酶、IL-1β、NA、VEGF、EGFR1、EGFR3、高血糖素受体或利妥昔。在一特定实施方式中,该蛋白抗原是HER2。
在步骤(b)中,以冲提缓冲液(通常是甘氨酸(pH 2.2)等酸性溶液)破坏固定蛋白及由噬菌体表达的scFv间的键结,进而收集该些对蛋白抗原具有结合亲和性及专一性的由噬菌体表达的scFv。
在步骤(c)中,为排除上述键结是透过噬菌体(而非抗体) 与蛋白抗原结合的可能性,进一步使步骤(b)筛选出的由噬菌体表达的scFv表达为可分泌的可溶形式。依据本揭示内容某些实施方式,于前述步骤(6)建构的包含于第二噬菌粒中的第二及第三核酸是由一乳糖操纵组(lactose operon,lac operon) 所趋动;如本所属领域具有通常知识者所熟知,添加异丙基- 硫代β-D-半乳糖苷(isopropyl-thio-β-D-galactoside,IPTG)可引发乳糖操纵组表达,进而趋动下游基因(即第二及第三核酸序列)表达。产生的scFv因此会分泌至培养液的上清液中,本领域技术人员可由此收集该些scFv。
在步骤(d)中,是利用蛋白抗原来筛选步骤(c)所制备的 scFv。与步骤(a)的筛选方法相似,先将蛋白抗原固定于基质 (例如琼脂糖树脂聚丙烯酰胺)后,与scFv进行混合。接着挑选出对该蛋白抗原具有结合亲和性及专一性的scFv。在一特定实施方式中,该蛋白抗原是HER2。
在步骤(e)中,将步骤(d)挑选的会表达可溶形式的scFv的噬菌体溶解后,萃取其噬菌粒DNA。可利用任何本领域技术人员所熟知的DNA萃取技术来溶解及萃取噬菌粒DNA;举例来说,酚/三氯甲烷萃取法及清洁剂(例如十二烷基硫酸钠、吐温-20、NP-40及氚核X-100)/乙酸萃取法。
在步骤(f)中,以步骤(e)萃取的噬菌粒DNA作为模版,利用SEQ ID NO:220及221的引物进行PCR反应来扩增包含 CDR-H1、CDR-H2及CDR-H3的第一核酸序列,并利用SEQ IDNO:218及219的引物进行PCR反应来扩增包含CDR-L1、 CDR-L2及CDR-L3的第二核酸序列。
在步骤(g)中,将扩增的第一及第二核酸序列插入表达载体中,其包含第三及第四核酸序列,其中第三核酸序列用以编码一免疫球蛋白的重链恒定区域,而该第四核酸序列则用以编码该免疫球蛋白的轻链恒定区域。当可想见,该免疫球蛋白可以是IgG、IgA、IgD、IgE及IgM。在本揭示内容一较佳实施方式中,该免疫球蛋白是IgG。具体来说,第一及第二核酸序列是藉由一连接符来相互连接,其中该连接符是以 pIgG载体作为模版,利用SEQ IDNO:222及223的引物进行PCR反应扩增而得。依据本揭示内容某些实施方式,该连接符依序包含以下序列:一轻链的恒定区(CL)、一牛生长激素的多腺苷酸化信号片段(bovinegrowth hormone polyadenylation signal,BGA-polyA signal)、一人类细胞巨大病毒(cytomegalovirus,CMV)启动子及一IgG重链的信号肽 (signal peptide)。利用第二核酸序列的3’端与连接符的5’端的互补序列(即TGCAGCCACCGTACGTTTGATTTCCACCTT及AAGGTGGAAATCAAACGTACGGTGGCTGCA;分别为SEQ ID NO:337及338),以及连接符的3’端与第一核酸序列的5’端的互补序列(即CTGCACTTCAGATGCGACACG及 CGTGTCGCATCTGAAGTGCAG;分别为SEQ ID NO:339及 340),可以SEQ ID NO:218及221的引物进行PCR反应依序组合第二核酸序列、连接符及第一核酸序列,其中SEQ ID NO:218及221的引物分别包含限制酶切点KpnI及NheI。接着利用该些限制酶切点将重组产物插入表达载体pIgG中。结构上,建构后的表达载体依序包含:第一人类CMV启动子、 IgG轻链的信号肽、第二核酸序列、CL、第一BGH-polyA信息片段、第二人类CMV启动子、IgG重链的信号肽、第一核酸序列、CH及第二BGH-polyA信息片段,其中是利用第一人类CMV启动子来趋动第二核酸序列及CL,以表达重组抗体的轻链,且利用第二人类CMV启动子来趋动第一核酸序列及CH,以表达重组抗体的重链。
在步骤(h)中,是将步骤(g)建构的表达载体转染至宿主细胞,以制备本发明重组抗体。常用的宿主细胞为哺乳动物细胞,例如HEK293 Freestyle细胞。可利用本领域技术人员熟知的方法进行转染,包含化学方法(例如磷酸钙、脂质体 (liposome)及阳离子聚合物(cationic polymer))、非化学方法 (例如电穿孔法、细胞挤压法(cell squeezing)、声孔法 (sonoporation)、光转染(optical transfection)、原生质体融合 (protoplastfusion)及流体动力传递(hydrodynamic delivery))、颗粒法(例如基因枪(gene gun)、磁转染(magnetofection)及穿刺转染(impalefection)),以及病毒法(例如腺病毒载体(adenoviral vector)、辛得比斯病毒载体(sindbis viral vector)、及慢病毒载体(lentiviral vector))。制得的重组抗体会分泌到培养液的上清液中,本领域技术人员可利用任何熟知的方法由上清液中纯化重组抗体;举例来说,可利用与蛋白A或蛋白G的结合亲和力来进行纯化。
依据本揭示内容某些实施方式,本发明重组抗体对蛋白抗原具有结合亲和性及专一性,其中该蛋白抗原是选自由 HER2、MBP、BSA、HSA、溶菌酶、IL-1β、HA、NP、VEGF、 EGFR1、EGFR3、高血糖素受体、人类DNase I、PD-L1、SIGLEC 3、IgG/Fc区域及利妥昔所组成的群组。依据本揭示内容某些实施方式,该蛋白抗原HA是源自H1N1、H3N2或H5N1。依据本揭示内容其他实施方式,该蛋白抗原NP是源自H3N2或 H1N1。在本揭示内容某些实施方式中,至少一重组抗体可结合至HER2、EGFR1、EGFR3、PD-L1、SIGLEC 3及/或高血糖素受体的ECD。在本揭示内容其他实施方式中,至少一重组抗体可结合至IgG的Fc区域。
本发明方法可用以制备一重组抗体,其对蛋白抗原具有结合亲和性及专一性。依据本揭示内容某些实施方式,制成的重组抗体包含(1)一CDR-L1,其具有第二型的CS,且由一包含SEQ ID NO:2-10中任一核酸序列的第一编码序列编码而成;(2)一CDR-L2,其具有第一型的CS,且由一包含SEQ ID NO:11-14中任一核酸序列的第二编码序列编码而成;(3)一CDR-L3,其具有第一型的CS,且由一包含SEQ ID NO:15-22 中任一核酸序列的第三编码序列编码而成;(4)一CDR-H1,其具有第一型的CS,且由一包含SEQ ID NO:23-26中任一核酸序列的第四编码序列编码而成;(5)一CDR-H2,其具有第二型的CS,且由一包含SEQ ID NO:27或28的第五编码序列编码而成;以及(6)一CDR-H3,其由一包含SEQ ID NO: 29-106中任一核酸序列的第六编码序列编码而成。依据本揭示内容某些实施方式,各CDR-H1、CDR-H2、CDR-H3、 CDR-L1、CDR-L2及CDR-L3中芳香族残基的分布与天然抗体的对应CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2及 CDR-L3中芳香族残基的分布相似。在某些实施方式中,本发明重组抗体的离解常数约为10-7至10-11M。
依据本揭示内容一实施方式,制备的重组抗体包含一与SEQ ID NO:241-330中任一核酸序列至少有90%相似度的氨基酸序列;意即,重组抗体包含一氨基酸序列,其是90%、 91%、92%、93%、94%、95%、96%、97%、98%、99%或100%相似于SEQ ID NO:241-330中任一氨基酸序列。在一较佳实施方式中,本发明重组抗体包含一与SEQ ID NO:241-330 中任一核酸序列100%相似的氨基酸序列。
或者是,本揭示内容亦提供一种由HER2免疫的小鼠体内制备及纯化的重组抗体。依据一实施方式,本发明重组抗体包含一与SEQ ID NO:233、237及331-334中任一核酸序列至少有90%相似度的氨基酸序列;意即,本发明重组抗体包含一氨基酸序列,其是90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%相似于SEQ ID NO:233、237 及331-334中任一氨基酸序列。在一较佳实施方式中,本发明重组抗体包含一与SEQ ID NO:233、237及331-334中任一核酸序列100%相似的氨基酸序列。
此外,所述源自小鼠的重组抗体亦可经人源化处理,因此包含一与SEQ ID NO:235至少有90%相似度的氨基酸序列;意即,本发明重组抗体包含一氨基酸序列,其是90%、91%、 92%、93%、94%、95%、96%、97%、98%、99%或100%相似于SEQ ID NO:235的氨基酸序列。在一较佳实施方式中,本发明重组抗体包含一与SEQ ID NO:235完全相同的氨基酸序列。
在本揭示内容某些实施方式中,重组抗体可具专一性地结合至HER2的抗原决定位置。依据一实施方式,重组抗体会造成HER2表达量下降及内化,进而抑制与HER2相关的信息传递路径。
基于本发明重组抗体具有抑制HER2表达的功效,本揭示内容亦提供一种用以治疗一罹患或疑似罹患一种与HER2相关的疾病的个体的方法;该方法包含对该个体投予一治疗有效量的本发明重组抗体,以减缓或改善该与HER2相关的疾病的病征。
HER2是人类表皮生长因子受体(human epidermal growth factor receptor,HER,EGFR,ERBB)家族中的一员。已知该致癌基因的扩增或过量表达会导致某些侵犯型肿瘤(例如乳癌的生成及进程)。有鉴于本发明重组抗体可抑制HER2受体的功能,该重组抗体可用以制备一药物,以治疗由HER2过量表达所造成的疾病(例如肿瘤)。依据本揭示内容一实施方式,本发明重组抗体可抑制因HER2过量表达所造成的肿瘤。依据本揭示内容另一实施方式,该个体是一哺乳动物;较佳是一人类。
依据本揭示内容某些实施方式,用以治疗与HER2相关的疾病的重组抗体包含一与SEQ ID NO:233、235、237及 241-334中任一核酸序列至少有90%相似度的氨基酸序列。
本揭示内容的另一方面是关于一种用以抑制HER2表达的组合物。依据本揭示内容一实施方式,该组合物包含第一重组抗体及第二重组抗体,其中该第一及第二重组抗体皆是以本揭示内容的方法制备而得,且该第一及第二重组抗体皆是 IgG抗体。依据本揭示内容另一实施方式,该第一重组抗体会结合至HER2的第一抗原决定位置,且该第二重组抗体会结合至HER2的第二抗原决定位置,其中该第一及第二抗原决定位置是不同的抗原决定位置。
依据本揭示内容一实施方式,该第一重组抗体包含SEQ ID NO:253的氨基酸序列,且该第二重组抗体包含SEQ ID NO:274的氨基酸序列。依据本揭示内容另一实施方式,该第一重组抗体包含SEQ ID NO:253的氨基酸序列,且该第二重组抗体包含SEQ ID NO:301的氨基酸序列。
依据本揭示内容某些实施方式,本发明组合物会造成 HER2受体被内化。依据本揭示内容其他实施方式,本发明组合物会抑制HER2受体的功能。
在本揭示内容某些实施方式中,该第一及第二重组抗体于抑制与HER2相关的信息传递路径时,会产生相加(additive) 的功效;意即,本发明组合物所产生的功效等于个别抗体(即第一抗体及第二抗体)所产生的功效的总合。在本揭示内容其他实施方式中,该第一及第二重组抗体于抑制与HER2相关的信息传递路径时,会产生加乘性(synergistic)功效;意即,本发明组合物所产生的功效大于个别抗体(即第一抗体及第二抗体)所产生的功效的总合。
基于本发明组合物的抑制功效,本揭示内容提供了一种用以治疗一罹患或疑似罹患一种与HER2相关的疾病的个体的方法;该方法包含对该个体投予一治疗有效量的本发明组合物,以减缓或改善该与HER2相关的疾病的病征。在本揭示内容一特定实施方式中,该疾病是肿瘤。依据本揭示内容一实施方式,该个体是一哺乳动物;较佳是一人类。在一较佳实施方式中,本发明组合物包含二个重组抗体,其中一重组抗体包含SEQ ID NO:253的氨基酸序列,而另一重组抗体则包含SEQ ID NO:274或301的氨基酸序列。
下文提出多个实验例来说明本发明的某些方面,以利本发明所属技术领域中具有通常知识者实作本发明,且不应将这些实验例视为对本发明范围的限制。据信本领域技术人员在阅读了此处提出的说明后,可在不需过度解读的情形下,完整利用并实践本发明。此处所引用的所有公开文献,其全文皆视为本说明书的一部分。
实施例
材料及方法
细胞株及试剂
SKBR3细胞是购买自美国菌种保存中心(American Type Culture Collection,ATCC),并培养于包含10%胎牛血清及抗生素/抗真菌剂的RPMI 1640(Gibco)细胞培养液中。调节蛋白 Heregulin(HRG)是购买R&D系统。使用于Western印迹分析的抗-磷酸化ERK抗体、抗-ERK抗体、抗-磷酸化AKT抗体及抗-AKT抗体是购买自Cell Signaling Technology;兔子抗-HER2抗体及抗-微管蛋白抗体则是购买自Sigma。
使小鼠免疫
将8-12周大的雌性BalbC/j小鼠饲育于经认证的SPF环境。依据免疫流程将小鼠分为四组:(1)m0组,为不接受免疫源刺激的小鼠,作为实验对照组;于16周大时犠牲m0组的小鼠,之后收集其脾脏进行后续试验分析;(2)m3组,先对该些小鼠投予SEQ ID NO:224的融合蛋白MBP-3(包含 MBP及源自人类HER2蛋白的第203-262氨基酸残基的多肽),使其产生免疫反应,之后再投予SEQ ID NO:225的多肽 HER2/ECD,以增强小鼠体内的免疫反应;于第二次抗原刺激后5周将小鼠犠牲,之后取出其脾脏进行后续试验分析;(3) m4组,先对该些小鼠投予融合蛋白MBP-3,再以多肽 HER2/ECD增强小鼠体内的免疫反应;于第二次抗原刺激后12周将小鼠犠牲,之后取其脾脏进行后续试验分析;以及(4) m6组,仅对该些小鼠投予多肽HER2/ECD,投予后14周将小鼠犠牲。
建立小鼠抗体群组
将已免疫的小鼠犠牲后,取出其脾脏并与2毫升的TRI 试剂(Invitrogen)均匀混合。紧接着,将样本均质化后置于1.5 毫升的微管中(每管0.5毫升),冷冻于-80℃。利用QIAGEN RNeasy Plus Mini试剂盒萃取解冻后样本的RNA,平均四分之一的脾脏可获得60-80微克的总RNA。依据使用操作手册,以SuperScript III第一股合成系统(SuperScriptIII First-Strand Synthesis System,Invitrogen)将萃取的RNA进行反转录。反应如下:将包含10微克的总RNA、1微升的10 μM引物Oligo(dT)20及1微升的10mM dNTP的混合物加入0.2毫升小管中,以0.1%DEPC水(加入二乙基焦碳酸盐的蒸馏水)将体积调整至10微升。将混合物放置于65℃反应5分钟后,立即放置于冰上降温。每管加入10微升的cDNA合成混合物(2微升的10X RT缓冲液、4微升的20mM MgCl2、 2微升的0.1M二硫苏糖醇、1微升的RNaseOut(每微升40 U)及1微升的SuperScript III RT(每微升200U))。将混合物置于50℃反应50分钟,以合成cDNA的第一股。将混合物置于85℃反应5分钟以中止反应,再将小管维持于4℃。将 1微升的RNase H加入样本中,并置于37℃反应20分钟,以移除残存的RNA。测定OD260的浓度后,将样本存放于 -20℃以供后续PCR反应使用。
以二轮PCR反应建立小鼠抗体群组。在第一轮反应中,依据Barbas等人建立的步骤(G.J.Phage Display A Laboratory Manual,Cold Spring Harbor Press,Cold SpringHarbor,New York;2001),以cDNA作为模版,利用引物混合物分别扩增轻链κ及λ的变异区域(即Vκ及Vλ)及重链的变异区域(即VH) 片段。PCR反应体积为50微升,其中包含MyTaq Hot热起始聚合酶(MyTaq Hot Start polymerase,Bioline)、0.5微克的 cDNA模版及0.3μM的各引物混合物;反应25个循环(95℃: 30秒、65℃:30秒、72℃:1分钟)后,进行10分钟最终合成步骤。利用琼脂糖凝胶电泳(agarose gel electrophoresis)分析并纯化PCR产物。
在第二轮PCR反应中,利用SEQ ID NO:226及227的交迭引物分别将Vκ及Vλ与VH进行组合。简单来说,将100 奈克的由第一轮PCR产物回收的Vκ、Vλ及VH PCR产物加入总体积为50微升的混合液中,该混合液包含MyTaq热起始聚合酶(Bioline)及0.3μM的各引物,反应30个PCR循环 (95℃:30秒、65℃:30秒、72℃:1分30秒)后,进行10 分钟最终合成步骤。以SfiI及NotI(New England BioLabs)切割组合后的Vκ-VH或Vλ-VH片段,再将其克隆至噬菌粒载体 pCANTAB5E中。以电穿孔方法(3,000伏特)将10-5微克的接合产物转化至大肠杆菌ER2738中。得到的小鼠抗体群组包含至少109个scFv。
利用次世代测序分析小鼠抗体群组的CS组合
为分析各scFv表达抗体的VL及VH序列,利用SEQ ID NO:228-231的引物进行PCR反应,以制备次世代测序所需要的DNA样本,其中SEQ ID NO:228及229的引物是分别位置VL序列的两侧,而SEQ ID NO:230及231的引物则是分别位置VH序列的两侧。依据钛测序流程(titanium sequencing protocol),以Roche 454 GS junior sequencer分析纯化后的DNA片段的序列。
由次世代测序分别收集对照组小鼠及免疫小鼠的VH及 VL序列的原始读出数据。以Antibodyomics 1.0软件包处理原始读出数据,藉以过滤序列长度,并转译为各个氨基酸。在分析各抗体序列时,将分析序列与由357个抗体结构建立的重链特定或轻链特定的隐马尔可夫模型(hidden Markov model,HMM)进行比对,藉以辨识各CDR。以MEGA程序及邻接法(neighbor-joining method)建立亲缘演化树来分析VH 及VL序列的亲缘关系。利用abysis网站分析各CDR的CS。以WebLogo及未设定的背景概率与参数建立各CDR的序列标签。
建立本发明由噬菌体表达的scFv抗体库(GH2)
制备模版Av1
先以活体外方式合成用以编码G6抗-VEGF Fab的核酸序列(SEQ ID NO:1),再将其克隆至噬菌粒载体pCANTAB5E,以建立模版Av1。接着,将TAA终止密码子转入各CDR中,以确保唯有携带经修饰的基因的抗体可表达于噬菌体表面。以分别具有SEQ ID NO:107-127的核酸序列的21个DNA片段来修饰模版Av1中CDR-L1、CDR-L2及CDR-L3的核酸序列,以建立VL抗体库;以分别具有SEQ ID NO:128-154的核酸序列的27个DNA片段来修饰模版Av1中CDR-H1、 CDR-H2及CDR-H3的核酸序列,以建立VH2抗体库;以分别具有SEQ ID NO:128-133及155的核酸序列的7个DNA 片段来修饰模版Av1中CDR-H1、CDR-H2及CDR-H3的核酸序列,以建立VH3抗体库;以分别具有SEQ ID NO:128-133 及156-157的核酸序列的8个DNA片段来修饰模版Av1中 CDR-H1、CDR-H2及CDR-H3的核酸序列,以建立VH4抗体库;以分别具有SEQ ID NO:128-133及158-160的核酸序列的9个DNA片段来修饰模版Av1中CDR-H1、CDR-H2及 CDR-H3的核酸序列,以建立VH5抗体库;以分别具有SEQ ID NO:128-133及161-164的核酸序列的10个DNA片段来修饰模版Av1中CDR-H1、CDR-H2及CDR-H3的核酸序列,以建立VH6抗体库;以分别具有SEQ ID NO:128-133及165-169 的核酸序列的11个DNA片段来修饰模版Av1中CDR-H1、CDR-H2及CDR-H3的核酸序列,以建立VH7抗体库;以分别具有SEQ ID NO:128-133及170-175的核酸序列的12个 DNA片段来修饰模版Av1中CDR-H1、CDR-H2及CDR-H3 的核酸序列,以建立VH8抗体库;以分别具有SEQ ID NO: 128-133及176-182的核酸序列的13个DNA片段来修饰模版 Av1中CDR-H1、CDR-H2及CDR-H3的核酸序列,以建立VH9 抗体库;以分别具有SEQ IDNO:128-133及183-192的核酸序列的16个DNA片段来修饰模版Av1中CDR-H1、CDR-H2 及CDR-H3的核酸序列,以建立VH11抗体库;以分别具有 SEQ ID NO:128-133及193-198的核酸序列的12个DNA片段来修饰模版Av1中CDR-H1、CDR-H2及CDR-H3的核酸序列,以建立VH12抗体库;以分别具有SEQ ID NO:128-133 及199-201的核酸序列的9个DNA片段来修饰模版Av1中CDR-H1、CDR-H2及CDR-H3的核酸序列,以建立VH13抗体库;以分别具有SEQ ID NO:128-133及202-204的核酸序列的9个DNA片段来修饰模版Av1中CDR-H1、CDR-H2及 CDR-H3的核酸序列,以建立VH14抗体库;以分别具有SEQ ID NO:128-133及205-207的核酸序列的9个DNA片段来修饰模版Av1中CDR-H1、CDR-H2及CDR-H3的核酸序列,以建立VH15抗体库;以分别具有SEQ ID NO:128-133及 208-209的核酸序列的8个DNA片段来修饰模版Av1中 CDR-H1、CDR-H2及CDR-H3的核酸序列,以建立VH16抗体库;以及以分别具有SEQ ID NO:128-133及210-211的核酸序列的8个DNA片段来修饰模版Av1中CDR-H1、CDR-H2 及CDR-H3的核酸序列,以建立VH17抗体库。为修饰序列,先将与各CDR对应的DNA片段及T4多核苷酸激酶(New EnglandBioLabs)加至包含70mM Tris–HCl(pH 7.6)、10mM MgCl2、1mM ATP及5mM二硫苏糖醇的溶液中,均匀混合后置于37℃反应1小时以使各DNA片段进行磷酸化。将磷酸化的DNA片段与尿嘧啶化(uracilated)的单股DNA模版接合,两者反应摩尔比为3:1(寡核苷酸:ssDNA),将混合物以热循环仪加热至90℃反应2分钟,再以每分钟1℃的速率逐渐降温,直至温度达20℃。接着,将模版-引物接合混合物与0.32mM ATP、0.8mM dNTP、5mM DTT、600单位的T4 DNA接合酶及75单位的T7DNA聚合酶(New England BioLabs)共同反应以于活体外合成DNA。于20℃反应至隔日后,以离心过滤管(centrifugal filter, Ultra 0.5mL 30K device)将dsDNA中的盐类去除且进行浓缩,再以3,000 伏特的电压,以电穿孔法将处理后的dsDNA转染至大肠杆菌 ER2738。一般来说,1微克的dU-ssDNA约会产生107-108重组变异型(variant)(scFv变异型),其中约75–90%的scFv变异型同时包含三个经修饰的CDR。
Ultra 0.5mL 30K device)将dsDNA中的盐类去除且进行浓缩,再以3,000 伏特的电压,以电穿孔法将处理后的dsDNA转染至大肠杆菌 ER2738。一般来说,1微克的dU-ssDNA约会产生107-108重组变异型(variant)(scFv变异型),其中约75–90%的scFv变异型同时包含三个经修饰的CDR。
以蛋白A及蛋白L筛选具有功能的scFv变异型
利用蛋白L筛选VL抗体库(即具有经修饰的CDR-L1、 CDR-L2及CDR-L3的scFv变异型),且以蛋白A筛选VH2-VH9 抗体库及VH11-VH17抗体库(即具有经修饰的CDR-H1、 CDR-H2及CDR-H3的scFv变异型)。在筛选时,先以20% PEG/NaCl沉淀VL、VH2-VH9及VH11-VH17抗体库的各个 scFv变异型后,使各scFv变异型再悬浮于磷酸盐-缓冲生理食盐水(phosphate-buffered saline,PBS)中;同时,将蛋白A 及蛋白L分别涂布于96孔Maxisorb免疫盘上(每孔洞包含100 微升的PBS及1微克的蛋白A或L),置于4℃至隔日;之后与5%的溶于PBS-T(包含0.05%吐温-20的PBS)的脱脂牛奶反应1小时。接着,每孔洞加入100微升的经悬浮的scFv变异型(每毫升1013cfu),温和摇晃1小时。以200微升的PBST 及200微升的PBS分别洗涤12次及2次。每孔洞加入100 微升的0.1M HCl/甘氨酸(pH 2.2),以冲提收集附着的变异型,之后以8微升的2M包含Tris的缓冲液(pH 9.1)中和冲提液。将冲提后的scFv变异型与1毫升的大肠杆菌ER2738 (A600nm=0.6)均匀混合,置于37℃培养15分钟。将大肠杆菌滴定分析(titrate)后,置于50毫升的包含每毫升100微克的氨苄青霉素(ampicillin)的2倍酵母菌萃取物及胰化蛋白培养液(Yeast extract and Tryptone medium,YT medium)中,于 37℃培养至隔日。离心后,重新悬浮细菌沉淀物,再以下述方法萃取其噬菌粒DNA。
将具有功能的scFv变异型组合为GH2抗体库
以萃取自VL抗体库变异型的噬菌粒DNA作为模版,利用具有SEQ ID NO:212的核酸序列的正向引物及具有SEQ ID NO:213的核酸序列的负向引物扩增VL的核酸序列;而以萃取自VH抗体库(即VH2-VH9及VH11-VH17)变异型的噬菌粒DNA作为模版,利用具有SEQ IDNO:214的核酸序列的正向引物及具有SEQ ID NO:215的核酸序列的负向引物扩增VH的核酸序列。PCR反应体积为50微升,其包含KOD 热启动聚合酶(KOD Hot Start polymerase,Novagen)、100奈克的DNA模版及0.3μM的各引物;反应25个循环(95℃: 30秒、65℃:30秒、72℃:1分钟)后,进行10分钟最终合成步骤。以EcoRⅠ切割产物后,利用琼脂糖凝胶电泳进行纯化。
以另一PCR反应来组合VL及VH核酸序列;在该次反应中,二条引物分别具有SEQ IDNO:216及217的核酸序列。在第二轮的PCR反应中,将100毫微克的第一轮PCR反应产物(即经纯化的VL及VH)加至总体积为50微升的混合液中,该混合液包含MyTaq热启动聚合酶及0.3μM的各引物,反应 30个PCR循环(95℃:30秒、65℃:30秒、72℃:1分30 秒)后,进行10分钟最终合成步骤。以SfiI及NotI(New England BioLabs)切割组合后的VL-VH片段,再将其克隆至噬菌粒载体pCANTAB5E。以电脉冲穿孔方法(3,000伏特)将接合产物转形至大肠杆菌ER2738中。
将得到的由噬菌体表达的scFv抗体库分别命名为GH2 (generic human,第2版)-GH9及GH11-GH17,其分别包含可表达特定VL及VH序列的噬菌体(如表1所示)。
表1特定抗体库的CDR序列

由GH2-GH9及GH11-GH17抗体库制备重组抗体
以IgG形式进行表达,以萃取自GH2-GH9及GH11-GH17 抗体库的噬菌粒作为模版,利用PCR反应扩增其中用以编码 VH及VL的核酸序列,并将各序列克隆至哺乳动物表达载体pIgG中。以具有合成校对功能(proof-reading)的DNA聚合酶 (KOD热起始DNA聚合酶,Novagen)及SEQ ID NO:218及 219的引物进行PCR反应扩增VL序列;利用SEQ ID NO: 220及221的引物来扩增VH序列。PCR反应总体积为50微升,其包含100毫微克的DNA模版及1微升的10μM的各引物,反应30个循环(95℃:30秒、56℃:30秒、72℃:30 秒)后,于72℃进行10分钟最终合成步骤。利用一连接符来连接VL及VH序列,其中该连接符是以SEQ ID NO:222及 223的引物进行PCR反应由pIgG载体扩增而得。连接符依序包含以下序列:一轻链的恒定区(CL)、一牛生长激素的多腺苷酸化信息片段(bovine growth hormone polyadenylationsignal,BGA-polyA signal)、一人类CMV启动子及一IgG重链的信号肽。为连接VL序列、连接符及VH序列,利用SEQ ID NO:218及221的引物对进行PCR反应,共30个循环 (95℃:30秒、58℃:30秒、90℃:30秒)。将PCR产物克隆至pIgG载体。简单来说,将2微升(20毫微克)的线性化(linearized,先以KpnI及NheI切割)pIgG载体、2微升(20 毫微克)欲殖入的DNA及4微升的Gibson Assembly Master Mix(New England BioLabs Inc.Ipswich,MA,USA)均匀混合,并置于50℃反应1小时。之后,将一半体积的接合混合物转化至大肠杆菌JM109感受态细胞。以限制酶切割位点及 DNA测序来确认插入质粒中的DNA序列是否正确。得到的构建体同时包含IgG的轻链及重链,其分别以人类CMV启动子来趋动表达。
将上述构建体转染至HEK293 Freestyle(293-F,Life Technologies,USA)细胞,并将其培养于无血清的Freestyle 293表达培养液(Freestyle 293 expression media,Life Technologies)中,温和摇晃(110rpm)并置于37℃的包含7% CO2培养箱(ThermoScientific)中培养。若欲将构建体转染至 500毫升细胞培养液中,先将293-F细胞悬浮于2升 Erlenmeyer三角瓶中,并将细胞密度调整为每毫升1.0x106细胞。将质粒DNA(500微克)溶于25毫升的无血清细胞培养液中,再0.2微米注射式过滤器过滤;之后,将处理后的质粒DNA与25毫升的包含1毫克聚乙烯亚胺(polyethylenimine, PEI,Polysciences)的细胞培养液剧烈混合。放置于室温20分钟后,将混合物加入细胞,并轻微摇晃,接着将细胞置于37℃的环境中培养。转染24小时后,加入最终浓度为0.5%的胰化蛋白N1(Tryptone N1,STBio,Inc)。培养5 天后,以8000xg的转速离心30分钟以收集上清液,再以0.8 微米的膜式过滤器(Pall Corporation,Michigan)过滤。将上清液注入HiTrap蛋白A亲和管柱(HiTrapProtein A affinity column,GE Healthcare,Uppsala,Sweden)中,以0.2N的甘氨酸-HCl(pH 2.5)冲提进入十分之一体积的1M Tris-HCl缓冲液(pH 9.1)。进一步利用Superdex200凝胶过滤管柱(Superdex 200 gel filtration column,10/300GL,GE Healthcare,Uppsala,Sweden)移除高分子量凝集体,以纯化IgG蛋白。
竞争型免疫分析(Competition assay)
将溶于PBS缓冲液(pH7.4)的HER2/ECD肽涂布于NUNC 96孔洞Maxisorb免疫盘上(每孔洞0.2微克),置于4℃至隔日,之后加入5%的溶于PBST的脱脂牛奶,反应1小时。接着,将1-3微克的经纯化的scFv或IgG抗体加至各孔洞,轻微摇晃30分钟,加入50微升的测试噬菌体后,培养1小时。以300微升PBST(包含0.05%(体积/体积)的Tween-20)洗涤各孔洞6次,再加入辣根过氧化物酶(horse-radish peroxidase)/抗-M13抗体共轭物(稀释比例为1:2000)及辣根过氧化物酶/抗-E-标签抗体共轭物(稀释比例为1:3000),反应30分钟。以PBST及PBS缓冲液分别洗涤6次及2次后,加入3,3’,5,5’-四甲基-联苯胺过氧化物酶受质 (3,3’,5,5’-tetramethyl-benzidine peroxidase substrate, Kirkegaard&PerryLaboratories)反应5分钟,以1.0M HCl 停止反应,并读取波长450奈米(nm)时的光谱读值。藉由比对不加入scFv抗体或IgG抗体的各对照组样本来计算竞争型免疫分析值。利用R软件的gplots组件来产生具有竞争结果的树形图结构的热图(将竞争数值标准化为0到100),以分析竞争数值。
BIAcore试验
利用BIAcore T200(GE Healthcare)仪器来检测抗体及抗原HER2/ECD之间的结合亲和性及动力学参数。以胺共轭接合试剂盒(amine coupling kit)将溶于10mM乙酸盐缓冲液(pH 5.0)的HER2/ECD固定在CM5感应芯片上,反应单位(response unit)为1000。在检测IgG及HER2/ECD作用间的结合常数(kon) 及解离常数(koff)时,是利用PBST(包含0.05%的Tween-20) 作为运行缓冲液(running buffer),且将流速设定为每分钟30 微升。在注入新IgG抗体前,先以10mM甘氨酸(pH 1.5)将感应芯片表面再生(regenerate),将得到的讯号值减去参照值 (未以配体(ligand)涂布的孔道)。以Biaevaluation软件(GE Healthcare)的1:1结合模式进行全局比对(global fitting)以决定结合动力学。
定位抗原决定位置(Epitope mapping)
分别制备氘化抗原-抗体复合物、氘化抗原及非氘化抗原,以利用LC-串联质谱测定氢氘交换法(hydrogen-deuterium exchange measured with LC-tandem massspectroscopy, HDX-MS)分析抗原决定位置。在制备氘化抗原-抗体复合物时,将每毫升1.1毫克的HER2/ECD与每毫升6毫克的抗体混合后,置于室温反应1小时,以制备一摩尔比为1:2的抗原-抗体复合物。将样本与2微克的去聚糖酶-PNGase(P0704S, NEB)混合后,置于37℃反应2小时,藉以对蛋白进行去糖化反应,并增加质谱分析的序列覆盖率(sequencecoverage)。将5微升的抗原或抗原-抗体复合物与20微升的氘化缓冲液 (100%D2O,10mMTRIS,140mM NaCl,pH 7.2)混合后,于室温进行10分钟的交换培养,使样本氘化。加入75微升的冰淬熄溶液(包含0.15%甲酸、8M尿素及1M TCEP,pH 2.5) 来淬熄交换反应,再利用离心浓缩机(Vivaspin 500,10kDa, GE Healthcare)于0℃以7,500rpm的转速将样本体积减少至 20微升。加入40微升的预冷酸性溶液(包含0.15%甲酸及100 mM TCEP,pH 2.5)稀释样本以减少尿素浓度,之后再将样本、 3微升的胃蛋白酶(pepsin,每毫升5毫克)及3微升的第XIII 型蛋白酶(protease type XIII,每毫升50毫克)置于冰上反应 30分钟。以液态氮冷冻反应后的样本,再将其冷冻于-80℃。利用与上述相似的步骤(不需进行氘化步骤)来制备非氘化抗原。
为决定肽质量,将10微升的解冻后的样本注入串联式液相层析系统(tandemliquid chromatographic system,Accela pump,Thermo Scientific)及ESI质谱仪(VelosPro LTQ, Thermo Scientific)以进行分离及分析。以C18管柱(XBridge C18,3.5μm,1.0x150mm,Waters)及由10%到60%的溶剂B (溶剂A:水及0.15%甲酸;溶剂B:乙腈及0.1%甲酸)的线性梯度进行分离,流速设定为每分钟50微升,反应时间为30 分钟。将C18管柱、注射器及离心管置于冰上,以减少逆交换(back-exchange)。由配有标准电喷雾离子源(standard electrospray ionization source)的质谱仪以分辨率模式 (resolutionmode,m/z 300–2,000)来收集质谱数据。利用 HX-Express 2检测各肽同位素分布(isotopic envelope)的质心值(centroid value)。以式(1)计算源自抗原的各肽的氘化量:

其中,m(P)、m(N)及m(F)分别为氘化抗原-抗体复合物、非氘化抗原及氘化抗原的质心值。唯有当氘化量改变大于 10%时,方将该位置视为结合位置。
抗体-抗原作用的EC50
将抗体逐量加至固定的HER2/ECD,以ELISA分析抗体的 EC50。简单来说,将溶于PBS缓冲液(pH 7.4)的HER2/ECD 肽涂布于NUNC 96孔洞的Maxisorb免疫盘上(每孔洞0.2微克),置于4℃至隔日;之后,加入5%的溶于PBST的脱脂牛奶,反应1小时。同时,以包含5%牛奶的PBST连续二倍稀释抗体,最终产生11种不同浓度的抗体。之后,取100微升的不同浓度的稀释抗体,将其分别加入孔洞中,轻微摇晃反应1小时。以300微升的PBST洗涤6次后,加入100微升的辣根过氧化物酶/抗-人类IgG抗体共轭物(溶于包含5%牛奶的PBST,稀释比例为1:2000),反应1小时。以PBST及PBS 缓冲液分别洗涤6次及2次后,加入3,3’,5,5’-四甲基-联苯胺过氧化物酶受质(Kirkegaard&Perry Laboratories)反应3 分钟,之后以1.0M HCl停止反应,并读取波长450奈米(nm) 时的光谱读值。依据Stewart及Watson法计算EC50(奈克每毫升)。
免疫荧光染色
将SKBR3细胞种植于Lab-Tek II腔室玻片(Nunc)上,生长至隔夜后,加入抗体置于37℃作用特定时间,再以甲醇进行固定。以TBS-Tx(包含0.1%氚核X-100的TBS)使细胞膜穿孔(permeabilize)后,加入阻断缓冲液(blocking buffer;包含2%BSA的TBS-Tx),于室温作用10分钟。接着,加入溶于阻断缓冲液的一级抗体,于4℃作用至隔日;洗涤后,加入溶于阻断缓冲液的二级抗体(与Alexa-488连接的山羊抗- 兔子抗体,以及与Alexa-647连接的山羊抗-人类抗体, Invitrogen),于室温反应60分钟;洗涤后,以包含DAPI(LifeTechnologies)的封固剂进行封固。以配有40倍及100倍的复消色差物镜(apochromatobjectives)的TCS-SP5-MP-SMD共焦显微镜(Leica)观察玻片。分别以Argon以及NeHe雷射光于 488奈米及647奈米波长激发Alexa荧光团。以LAS AF软件(Leica)分析所得影像。
Western印迹分析
将取自经抗体处理的细胞及对照组细胞的细胞溶解物分别注入SDS-PAGE,之后将其转移至PVDF膜上。加入5%的溶于TBS(包含0.1%Tween-20)的脱脂牛奶反应30分钟后,加入一级抗体,于4℃作用至隔日;之后加入与辣根过氧化物酶键结的二级抗体(AmershamBiosciences,Piscataway)进行反应。利用Pierce ECLWestern印迹受质(Thermo FisherScientific)及ImageQuant LAS-4000(GE Healthcare)来观察蛋白表达。
伪病毒中和试验(Pseudovirus neutralization assay)
将用以编码荧光素酶(luciferase)的慢病毒核质粒 (lentiviral coreplasmid)与用以编码HA、NA及TMPRSS2蛋白(A/California/04/2009)的质粒一起转染至细胞中,以制备H1N1伪病毒。将293T细胞的最终浓度调整为每毫升2×105个细胞。将50微升的293T细胞加至96孔洞盘中。因此,每孔洞包含10,000个细胞。将细胞置于37℃CO2培养箱中18 个小时。藉由通过0.45微米的96孔洞过滤盘(PALL corp.)来制备无菌的scFv。将无菌的scFv连续稀释于包含0.3%BSA 的MEM细胞培养液(Gibco)中。将80微升的伪病毒与80微升的无菌的scFv共同培养于37℃CO2培养箱45分钟,以进行中和反应。测试前先移除培养18小时后的293T细胞的细胞培养液,将混合物加至细胞后,置于37℃CO2培养箱培养 10-12小时。之篒,以包含10%FBS(Gibco)的新鲜DMEM (Gibco)置换伪病毒/scFv混合物。继续将细胞培养48小时。移除细胞培养液以侦测荧光素酶表达。每孔洞加入20微升的 1倍的溶解缓冲液(Promega),并摇晃15分钟均匀混合以溶液细胞。将50微升的荧光素酶试剂(Promega)加至白色96孔洞盘(Griener Bio-one)的各孔洞中。将对应孔洞的细胞溶解物转移至白色96孔洞盘。以Victor3(Perkin Elmer)分析盘中荧光素酶的活性。
实施例1分析小鼠抗体群组
为分析小鼠抗体群组,分别萃取m0、m3、m4及m6组老鼠(如“材料及方法”所述)的mRNA,并将其反转为对应的 cDNA后,以cDNA作为模版来扩增VH及VL序列,其中VH 序列包含VH-DH-JH DNA片段,Vκ序列包含Vκ-JκDNA片段,而Vλ序列则包含Vλ-JλDNA片段。分别将扩增后的VH及 VL序列插入噬菌粒载体pCANTAB5E中,再将该噬菌粒载体转形至大肠杆菌ER2738株以扩增该些会表达scFv的噬菌体。共可得到316个噬菌体,其会分别表达对肽HER2/ECD具有结合亲和性的scFv,将该些噬菌体标记为S316。
利用NGS来分析各CDR的CS类型;分析结果指出,四组小鼠及S316的VH、Vκ及Vλ具有相似的CS类型,其中 CDR-H1及CDR-H2的主要CS类型分别为第一型及第二型, CDR-Lκ1及CDR-Lκ2的主要CS类型分别为第二型及第一型,在CDR-Vλ序列中只能观察到一种CS组合(结果未显示)。该些结果亦暗示,不论是免疫化流程的差异或是抗体筛选的过程,皆不会影响抗体群组的分布。已知小鼠抗体群组中的VL 主要为Vκ,而Vκ的CDR-L3的分布主要集中在9个残基的长度,其中CDR-L3主要为第一型的CS(结果未显示)。因此,所有抗体群组的CS组合主要皆为:第一型的CS的CDR-H1、第二型的CS的CDR-H2、第二型的CS的CDR-L1、第一型的 CS的CDR-L2及第第一型的CS的CDR-L3。至于CDR-H3,虽然未具有特定形式的CS类型,其长度分布主要集中在11 个残基的长度。
该些结果指出,小鼠抗体群组包含至少109scFv,其中 CDR-H1及CDR-H2的主要CS类型分别为第一型及第二型,而CDR-L1、CDR-L2及CDR-L3的主要CS类型则分别为第二型、第一型及第一型。
实施例2建立本发明抗体库GH2-GH9及GH11-GH17
2.1建构及修饰
基于实施例1的分析结果(即小鼠抗体群组的CDR-H1、 CDR-H2、CDR-L1、CDR-L2及CDR-L3分别具有1-2-2-1-1 的CS组合),合成SEQ ID NO:1的核酸序列,其可用以编码G6抗-VEGF的Fab;将合成序列克隆至噬菌体载体 pCANTAB5E中,以制备重组噬菌粒Av1。重组噬菌粒Av1与分别源自四组小鼠(即m0、m3、m4及m6)、S316及发表于蛋白数据库(Protein DataBank)的584个抗体(标记为S584)的抗体群组的CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2及CDR-L3,具有相似的芳香族残基分布(结果未显示)。
由于CDR中,抗体-抗原作用表面的短链亲水性残基会藉由短程静电作用及直接的氢键键结影响抗体对抗原辨识的专一性,因此以具有SEQ ID NO:107-127的核酸序列的21条 DNA片段修饰抗体库重组噬菌粒Av1的CDR-L1、CDR-L2及 CDR-L3的核酸序列,以建立一VL抗体库;且以具有SEQ ID NO:128-211的核酸序列的84条DNA片段修饰抗体库重组噬菌粒Av1的CDR-H1、CDR-H2及CDR-H3的核酸序列,以建立一VH抗体库(即VH2、VH3、VH4、VH5、VH6、VH7、 VH8、VH9、VH11、VH12、VH13、VH14、VH15、VH16或 VH17抗体库)。分别以蛋白L及蛋白A筛选VL及VH抗体库;由对蛋白L及蛋白A具有结合亲和性的scFv变异型萃取噬菌粒DNA,并利用该些噬菌粒DNA作为模版来分别扩增 VL及VH核酸序列。将该些扩增的核酸序列插入噬菌粒载体 pCANTAB5E中,之后将该载体转化至大肠杆菌ER2738株,以扩增该些会表达scFv的噬菌体。将由噬菌体表达得到的的 scFv抗体库分别命名为抗体库GH2、GH3、GH4、GH5、GH6、GH7、GH8、GH9、GH11、GH12、GH13、GH14、GH15、GH16 及GH17。
上述结果显示,本发明抗体库(即GH2、GH3、GH4、GH5、 GH6、GH7、GH8、GH9、GH11、GH12、GH13、GH14、GH15、 GH16及GH17)包含复数个由噬菌体表达的scFv,该些scFv 具有以下特征:(1)特定的CS组合,其中CDR-H1、CDR-L2 及CDR-L3具有第一型的CS,而CDR-H2及CDR-L1则具有第二型的CS;(2)特定的芳香族残基分布,其与一天然抗体的芳香族残基分布相似;以及(3)各CDR中特定的核酸序列,其中CDR-L1由一包含SEQ ID NO:2-10中任一核酸序列的序列编码而成,CDR-L2由一包含SEQ ID NO:11-14中任一核酸序列的序列编码而成,CDR-L3由一包含SEQ ID NO:15-22 中任一核酸序列的序列编码而成,CDR-H1由一包含SEQID NO:23-26中任一核酸序列的序列编码而成,CDR-H2由一包含SEQ ID NO:27-28的序列编码而成,而CDR-H3则由一包含SEQ ID NO:29-106中任一核酸序列的序列编码而成。
2.2确认抗体库GH2-GH9及GH11-GH17
由以下试验分析确认实施例2.1建立的抗体库GH2-GH9 及GH11-GH17:(1)竞争型免疫分析,其用以决定一抗原的抗原决定位置;(2)EC50及BIAcore试验方法,其用以评估抗原-抗体间的结合亲和性;以及(3)定位抗原决定位置,其用以分析抗体辨识的抗原分子的抗原决定位置。
由GH2抗体库随机挑选90个抗-HER2/ECD scFv(标示为 S90抗体),其中三个主要抗原结合位置为:抗原结合位置 M32-M62、抗原结合位置M63-M64及抗原结合位置M41-M61(结果未显示)。以竞争型免疫分析评估抗体S316及6种小鼠抗体(即M32、M41、M61、M62、M63及M64;该些抗体皆是直接由免疫小鼠体内取得,且具有不同的基因片段)对肽 HER2/ECD的结合亲和性;在本实验中,四种已知对HER2 具有专一性的抗体(即A21、Fab37、帕妥珠单抗(pertuzumab) 及曲妥珠单抗(trastuzumab))作为对照组。在结构分析数据中,已知肽HER2/ECD可分为四个蛋白域(domain;即蛋白域I、 II、III及IV),其中能被A21、Fab37、帕妥珠单抗及曲妥珠单抗辨识的抗原决定位置分别位于蛋白域I、III、II及IV;而能被抗原结合位置M32-M62、M63-M64及M41-M61辨识的抗原决定位置则分别位于蛋白域I、III及IV(结果未显示)。至于竞争型免疫分析指出,部分抗原结合位置M32-M62会与 A21的抗原结合位置重迭;抗原结合位置M63-M64会与Fab37 的抗原结合位置重迭;而抗原结合位置M41-M61则不会与任何已知抗体的抗原结合位置重迭(结果未显示)。抗原决定位置定位结果指出,可为抗原结合位置M32-M62辨识的抗原决定位置E1与可为A21辨识的抗原决定位置相邻,但二抗原决定位置并无重迭;而可为抗原结合位置M41-M61辨识的抗原决定位置E3是位于一表面块(surface patch)上,其位于可为曲妥珠单抗辨识的抗原决定位置的远程。
因此,该些结果显示GH2抗体库包含多种可辨识一抗原 (即肽HER2/ECD)的不同抗原决定位置的scFv;且可为GH2 抗体库辨识的抗原决定位置可能不同于该些可为已知抗体辨识的抗原决定位置。
实施例3由抗体库GH2-GH9及GH11-GH17制备重组抗体
3.1由抗体库GH2制备及分析重组抗体
为制备对抗原HER2具有结合亲和性的重组抗体,对抗体库GH2进行2-3轮挑选/扩增步骤,以挑选出可结合至肽 HER2/ECD的scFv变异型。使挑选出的scFv变异型表达为可溶形式的scFv后,以相同肽HER2/ECD进行筛选。为将重组抗体制备为免疫球蛋白形式,依据“材料与方法”的步骤,将与HER2/ECD结合的scFv转换为IgG抗体。利用ELISA 及BIAcore评估重组抗体,以决定重组抗体对肽HER2/ECD 的EC50及抗原结合亲和性。
由实施例2.2的S90抗体随机挑选29个scFv,并将该些 scFv表达为IgG形式(即GH2-3、GH2-7、GH2-8、GH2-13、 GH2-14、GH2-16、GH2-18、GH2-21、GH2-23、GH2-36、GH2-40、GH2-42、GH2-54、GH2-59、GH2-60、GH2-61、GH2-65、GH2-66、 GH2-72、GH2-75、GH2-78、GH2-81、GH2-87、GH2-91、GH2-95、 GH2-96、GH2-98、GH2-102及GH2-104),以下标示为S29 IgG。 6个抗体(即M32、M41、M61、M62、M63及M64)及一商品化抗体-曲妥珠单抗在本实验作为对照组。如表2所示,比对 S29 IgG与亲和力成熟(affinity-matured)的抗体(即M32、 M41、M61、M62、M63、M64及曲妥珠单抗)的EC50下限。值得注意的是,S29 IgG中有12个IgG抗体的EC50低于曲妥珠单抗的EC50。至于结合亲和性,BIAcore测量结果指出, S29 IgG的KD的下限约为10-11M,该数值与亲和力成熟的抗体(即M32、M41、M61、M62、M63、M64及曲妥珠单抗)的 KD下限相似。
表2 分析S29 IgG、6小鼠的亲和力成熟抗体、人源化抗体及商品化抗体


此外,亦分析S29 IgG、6小鼠的亲和力成熟抗体、人源化抗体及商品化抗体的CDR序列,分别将其定为SEQ ID NO: 233、235、237及241-334,其中抗体M32是由SEQ ID NO:232的核酸序列编码而成;抗体M62是由SEQ ID NO:236 的核酸序列编码而成;而人源化抗体H32的CDR序列则是由 SEQ ID NO:234的核酸序列编码而成。
除了肽HER2/ECD,亦利用GH2抗体库制备对其他抗原具有结合亲和性的重组抗体。与实施例3.1第一段相似的操作步骤,利用22种不同的蛋白抗原来筛选GH2抗体库,其中20种蛋白抗原可被GH2制备的抗体辨识(表3)。
表3 GH2抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
整体来看,该结果指出GH2抗体库可用以制备不同的重组抗体,其对不同抗原具有高结合亲和性(约10-7至10-11M),且该些重组抗体具有与亲和力成熟或商品化抗体相似的抗原结合亲和性。
3.2分析由抗体库GH3-GH9及GH11-GH17制备的重组抗体
本实施例将进一步分析检测由抗体库GH3-GH9及 GH11-GH17制备的重组抗体。
表4-17分别阐述由抗体库GH3-GH9及GH11-GH17制备的重组抗体对特定蛋白抗原的结合专一性。
表4 GH3抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表5 GH4抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表6 GH5抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表7 GH6抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表8 GH7抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表9 GH8抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表10 GH9抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表11 GH11抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表12 GH12抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表13 GH13抗体库对特定蛋白抗原的结合专一性


a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表14 GH14抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表15 GH15抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
表16 GH16抗体库对特定蛋白抗原的结合专一性


a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
表17 GH17抗体库对特定蛋白抗原的结合专一性

a比例是指在总分析单一群中,对相对应的抗原具有阳性反应的阳性株。
b比例是指在所有经测序的阳性株中,序列具有独特性的阳性株。
CECD:受体的细胞外域。
该些结果指出,由GH3-GH9及GH11-GH17分别制备的重组抗体对不同的蛋白抗原(包含IL-1β、HA、NP、EGFR1、EGFR 2、EGFR3、人类DNase I、PD-L1及SIGLEC 3)皆具有结合专一性。
3.3分析重组抗体的生物功能
利用功能性试验来评估6种直接取自HER2/ECD免疫小鼠的抗体(即M32、M41、M61、M62、M63及M64)及由GH2 抗体库制备的重组抗体的生物功能。相较于曲妥珠单抗及帕妥珠单抗,抗体M32会结合至HER2/ECD的蛋白域I的新颖抗原决定位置(结果未显示),并造成HER2被内化,进而减少会过量表达HER2的SKBR3细胞表面的受体表达量(图1A及图2)。抗体M62与M32具有相似的抗原决定位置(结果未显示),且与M32具有相似的减少细胞表面HER2表达量的功效 (第图1A及图2)。抗体M63及M41分别会结合至HER2的蛋白域III及蛋白域IV的抗原决定位置,二者皆不会减少HER2 的表达量(结果未显示).
至于重组抗体,虽然重组抗体GH2-42及GH2-75会辨识相似的抗原决定位置且与M32具有相似的结合亲和性(约~ 10-10M,表2),然而重组抗体GH2-42及GH2-75并不像M32会造成HER2的表达量减少(图1B及图2)。合并投予GH2-42 及曲妥珠单抗或GH2-18(一个与曲妥珠单抗具有相似的抗原结合位置的重组抗体),会造成HER2表达量下降。此外,合并投予GH2-75及GH2-18亦会造成HER2被内化(图1B及图 2)。该些结果暗示若抗体同时结合至HER2/ECD的蛋白域I 及IV会造成HER2表达下降,而同时结合至HER2的蛋白域 II及IV则不会产生此功效。
由于HER2参与了不同的信息传递路径,接着分析本发明的不同抗体与HER2结合是否会影响下游基因的表达或活化。如图2的Western印迹分析结果所示,与HER2不同抗原决定位置结合的各种抗体会不同程度地抑制AKT及ERK的活化。
该些结果指出,以本发明GH2抗体库制备的重组抗体具有多样性,可辨识一抗原的不同抗原决定位置,因此,产生不同的生物功能。
3.4分析由GH2-GH9及GH11-GH17抗体库制备的重组抗体的结合及中和特性
依据ELISA试验得到的重组HA结合结果,经源自A/加州/2009 H1N1的HA进行三次筛选,得到125个独特的scFv。利用FACS及H1N1 CA/09假病毒中和试验来分析该些scFv 与天然HA蛋白的结合特性。在本实施例中,是利用F10 scFv (一个已知可强效中和H1N1流感病毒的抗体)作为正对照组; S40作为另一正对照组;而AV1则作为负对照组。
由总数为125个独特的scFv中挑选出14个scFv,相较于 F10 scFv,该些scFv具有更佳的中和能力(约为1500RLU~ 3000RLU;图3A)。进一步分析对天然蛋白的结合能力及中和结果发现,14个scFv中有12个scFv可具高专一性地结合至天然蛋白。推测其他二个scFv有可能是由于分泌至细胞培养液的数量较少,致使结合效果不佳。
分别利用FACS分析及ELISA试验来评估14个scFv对天然HA及合成HA的结合亲和性。如图3B所示,有一半于 ELISA试验中呈阳性反应的scFv无法结合至天然HA蛋白。有趣的是,14个scFv于ELISA及FACS分析结果呈现正相关性。该结果反应出在细胞培养液中不同的scFv含量及亲和性。
综合上述,本揭示内容提供了一种由噬菌体表达的scFv 抗体库(即GH2抗体库)其包含复数个由噬菌体表达的scFv,该些scFv具有特定的CS组合、特定分布于CDR的芳香族残基,以及特定的CDR序列。本揭示内容GH2抗体库可用以有效制备复数个重组抗体,其对特定抗体具有高度结合亲和性。制备出的重组抗体具有多样性的CDR,因此可结合至特定抗原的不同的抗原决定位置,藉以产生不同的生物功效。本揭示内容据此提供一种方法,可因应不同的实验研究及/或临床应用实时制备不同的具有抗原专一性的抗体。
虽然上文实施方式中揭露了本发明的具体实施例,然其并非用以限定本发明,本发明所属技术领域中具有通常知识者,在不悖离本发明的原理与精神的情形下,当可对其进行各种更动与修饰,因此本发明的保护范围当以附随申请专利范围所界定者为准。
序列表
<110>台湾地区“ 中央研究院”


































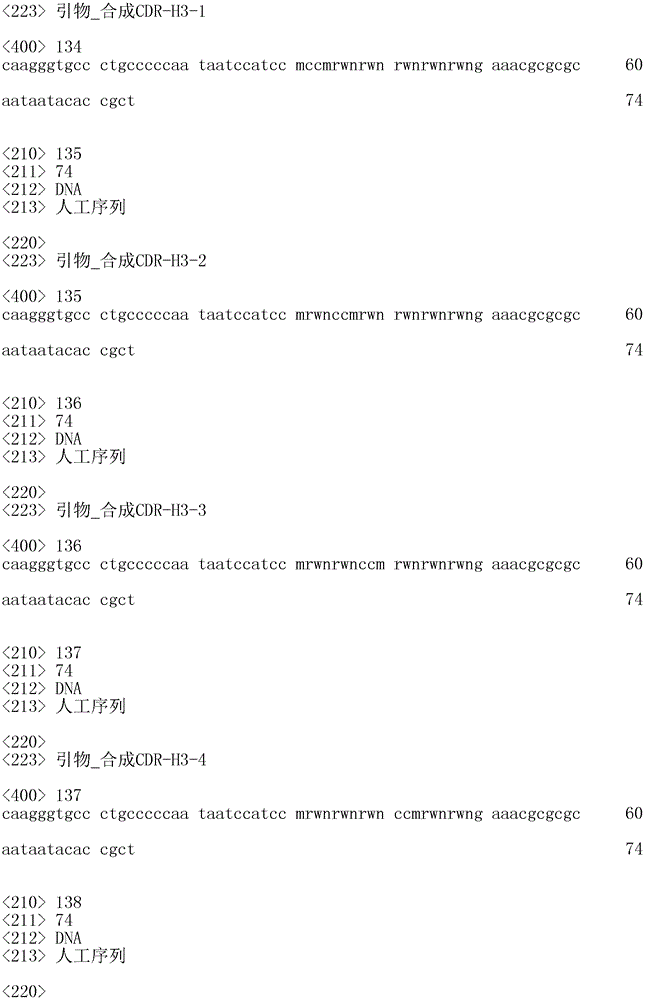








































































































Claims (17)
1.一种由噬菌体表达的单链变异片段抗体库,包含复数个由噬菌体表达的scFv,其中各该些由噬菌体表达的scFv皆包含一第一重链互补性决定区域、一第二重链CDR、一第三重链CDR、一第一轻链CDR、一第二轻链CDR及一第三轻链CDR,
其中,
各该CDR-H1、CDR-L2及CDR-L3具有一第一型的正则结构,且各该CDR-H2及CDR-L1具有一第二型的正则结构;以及
各该CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2及CDR-L3中芳香族残基的分布与一天然抗体的对应CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2及CDR-L3中芳香族残基的分布相似;
其特征在于,
该CDR-L1是由一包含SEQ ID NO:2-10中任一核酸序列的第一编码序列编码而成,
该CDR-L2是由一包含SEQ ID NO:11-14中任一核酸序列的第二编码序列编码而成,
该CDR-L3是由一包含SEQ ID NO:15-22中任一核酸序列的第三编码序列编码而成,
该CDR-H1是由一包含SEQ ID NO:23-26中任一核酸序列的第四编码序列编码而成,
该CDR-H2是由一包含SEQ ID NO:27-28中任一核酸序列的第五编码序列编码而成,
且该CDR-H3是由一包含SEQ ID NO:29-106中任一核酸序列的第六编码序列编码而成。
2.如权利要求1所述的由噬菌体表达的scFv抗体库,其特征在于,该噬菌体是一M13噬菌体或一T7噬菌体。
3.如权利要求1所述的由噬菌体表达的scFv抗体库,其特征在于,在该些由噬菌体表达的scFv中,至少一由噬菌体表达的scFv对一蛋白抗原具有专一性,其中该蛋白抗原选自由第二型的人类表皮生长因子受体、麦芽糖结合蛋白质、牛血清白蛋白、人类血清白蛋白、溶菌酶、白介素-1β、流感病毒的血球凝集素、流感病毒的核蛋白、血管内皮生长因子、第一型的表皮生长因子受体、第三型表皮生长因子受体、高血糖素受体、人类脱氧核糖核酸水解酶、第一型的程序性死亡配体、第三型唾液酸结合免疫球蛋白相似凝集素、免疫球蛋白G的结晶片段区域及利妥昔所组成的群组。
4.一种用以制备权利要求1的由噬菌体表达的scFv抗体库的方法,包含:
(1)合成一第一核酸序列,其包含分别用以编码一免疫球蛋白基因的CDR-L1、CDR-L2、CDR-L3、CDR-H1、CDR-H2及CDR-H3的一第一、一第二、一第三、一第四、一第五及一第六编码序列,且该第一核酸序列为如SEQ ID NO:1所示的核酸序列;
(2)将该第一核酸序列插入一第一噬菌粒载体中;
(3)以定位点突变方法分别以SEQ ID NO:107-115、116-119及120-127的核酸序列修饰该第一、第二及第三编码序列以制备一变异轻链抗体库,其包含一第一组由噬菌体表达的scFv,其中各scFv分别具有经修饰的CDR-L1、CDR-L2及CDR-L3;以及以定位点突变方法分别以SEQ ID NO:128-131、132-133及134-211的核酸序列修饰该第四、第五及第六编码序列以制备一变异重链抗体库,其包含一第二组由噬菌体表达的scFv,其中各scFv分别具有经修饰的CDR-H1、CDR-H2及CDR-H3;
(4)利用一蛋白L来筛选该VL抗体库,由该VL抗体库挑选一第三组由噬菌体表达的scFv;且利用一蛋白A来筛选该VH抗体库,由该VH抗体库挑选一第四组由噬菌体表达的scFv;
(5)由对应的噬菌体中扩增复数个第二核酸序列,其用以编码经修饰的CDR-L1、CDR-L2及CDR-L3,且由对应的噬菌体中扩增复数个第三核酸序列,其用以编码经修饰的CDR-H1、CDR-H2及CDR-H3;以及
(6)将该些第二及第三核酸序列插入一第二噬菌粒载体以制备权利要求1的由噬菌体表达的scFv抗体库。
5.如权利要求4所述的方法,其特征在于,在步骤(3)前更包含一步骤,其是将该免疫球蛋白基因的CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2及CDR-L3中芳香族残基的分布与一天然抗体的对应CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2及CDR-L3中芳香族残基的分布进行比对。
6.如权利要求4所述的方法,其特征在于,该第一及第二噬菌粒载体皆是源自M13噬菌体。
7.一种利用权利要求1的由噬菌体表达的scFv抗体库制备一重组抗体的方法,其中该重组抗体对一蛋白抗原具有结合亲和性及专一性;该方法包含:
(1)以该蛋白抗原筛选权利要求1的由噬菌体表达的scFv抗体库;
(2)挑选复数个噬菌体,其中该些噬菌体会分别表达对该蛋白抗原具有结合亲和性及专一性的scFv;
(3)使步骤(2)挑选的该些噬菌体分别表达可溶形式的scFv;
(4)由步骤(3)的scFv中挑选一对该蛋白抗原具有高结合亲和性及专一性的可溶形式scFv;
(5)由会表达步骤(4)的可溶形式scFv的噬菌体中萃取一噬菌粒DNA;
(6)以步骤(5)的噬菌粒DNA作为模版,利用聚合酶连锁反应分别扩增一用以编码CDR-H1、CDR-H2及CDR-H3的第一核酸序列,及一用以编码CDR-L1、CDR-L2及CDR-L3的第二核酸序列;
(7)将该第一及第二核酸序列插入一表达载体中,其包含一第三及一第四核酸序列,其中该第三核酸序列用以编码一免疫球蛋白的重链恒定区域,且该第四核酸序列用以编码该免疫球蛋白的轻链恒定区域;以及
(8)将步骤(7)的包含该第一、第二、第三及第四核酸序列的表达载体转染至一宿主细胞,以制备该重组抗体。
8.如权利要求7所述的方法,其特征在于,该第一核酸序列是位于该第三核酸序列的上游,且该第二核酸序列是位于该第四核酸序列的上游。
9.如权利要求7所述的方法,其特征在于,该免疫球蛋白选自由免疫球蛋白G、免疫球蛋白A、免疫球蛋白D、免疫球蛋白E及免疫球蛋白M所组成的群组。
10.如权利要求7所述的方法,其特征在于,该宿主细胞是一哺乳动物细胞。
11.如权利要求7所述的方法,其特征在于,该蛋白抗原是HER2、MBP、BSA、HSA、溶菌酶、IL-1β、HA、VEGF、EGFR1、EGFR3、高血糖素受体或利妥昔。
12.一种由权利要求1的由噬菌体表达的scFv抗体库制备的重组抗体,其特征在于,该重组抗体包含SEQ ID NO:253的氨基酸序列。
13.一种如权利要求12所述的重组抗体的用途,其用以制备一药物以治疗一罹患或疑似罹患一种与HER2相关的疾病的个体。
14.如权利要求13所述的用途,其特征在于,该与HER2相关的疾病是一肿瘤。
15.一种用以治疗一与HER2相关的疾病的组合物,包含一第一重组抗体及一第二重组抗体,其分别由权利要求1的由噬菌体表达的scFv抗体库制备而得,其特征在于,该第一重组抗体包含SEQ ID NO:253的氨基酸序列,且该第二重组抗体包含SEQ ID NO:274或301的氨基酸序列。
16.一种如权利要求15所述的组合物的用途,其用以制备一药物以治疗一罹患或疑似罹患一种与HER2相关的疾病的个体。
17.如权利要求16所述的用途,其特征在于,该与HER2相关的疾病是一肿瘤。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562120352P | 2015-02-24 | 2015-02-24 | |
| US62/120,352 | 2015-02-24 | ||
| PCT/US2016/019128 WO2016137992A2 (en) | 2015-02-24 | 2016-02-23 | A phage-displayed single-chain variable fragment library |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN107614762A CN107614762A (zh) | 2018-01-19 |
| CN107614762B true CN107614762B (zh) | 2022-08-05 |
Family
ID=56789830
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201680009046.7A Active CN107614762B (zh) | 2015-02-24 | 2016-02-23 | 一种由噬菌体表达的单链变异片段抗体库 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US10336816B2 (zh) |
| EP (2) | EP3262216A4 (zh) |
| CN (1) | CN107614762B (zh) |
| TW (1) | TWI636060B (zh) |
| WO (1) | WO2016137992A2 (zh) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101865426B1 (ko) * | 2010-06-09 | 2018-07-13 | 다나-파버 캔서 인스티튜트 인크. | Raf와 mek 억제제에 대한 내성을 부여하는 mek1 돌연변이 |
| WO2018046997A2 (en) * | 2016-09-07 | 2018-03-15 | Saksin Lifesciences Pvt Ltd | Synthetic antibodies against vegf and their uses |
| CN111465409A (zh) * | 2017-10-20 | 2020-07-28 | 中央研究院 | 中和性抗体的高通量筛选方法、由该方法制备的中和性抗体,以及其用途 |
| CN110079502B (zh) * | 2018-02-07 | 2020-11-06 | 阿思科力(苏州)生物科技有限公司 | Pd-l1 car-nk细胞及其制备和应用 |
| CN109929835A (zh) * | 2019-03-27 | 2019-06-25 | 中国人民解放军第四军医大学 | 一种鼠单克隆抗体功能轻链可变区基因的扩增方法 |
| US20230168249A1 (en) * | 2020-05-06 | 2023-06-01 | Academia Sinica | Recombinant antibodies, kits comprising the same, and uses thereof |
| TWI867224B (zh) * | 2020-06-08 | 2024-12-21 | 中央研究院 | 重組抗體或片段,以及其用途 |
| WO2022261261A2 (en) * | 2021-06-08 | 2022-12-15 | Academia Sinica | A phage-displayed single-chain variable fragment library for selecting antibody fragments specific to mesothelin |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1345334A (zh) * | 1999-01-29 | 2002-04-17 | 伊姆克罗尼系统公司 | 对kdr特异的抗体及其应用 |
| CN1105728C (zh) * | 1993-09-07 | 2003-04-16 | 史密丝克莱恩比彻姆公司 | 用于治疗il4介导疾病的重组il4抗体 |
| WO2005044853A2 (en) * | 2003-11-01 | 2005-05-19 | Genentech, Inc. | Anti-vegf antibodies |
| CN101854950A (zh) * | 2007-09-11 | 2010-10-06 | 航道生物技术有限责任公司 | 供体特异性抗体文库 |
| WO2011137245A2 (en) * | 2010-04-30 | 2011-11-03 | Esperance Pharmaceuticals, Inc. | Lytic-peptide-her2/neu (human epidermal growth factor receptor 2) ligand conjugates and methods of use |
| WO2012142662A1 (en) * | 2011-04-21 | 2012-10-26 | Garvan Institute Of Medical Research | Modified variable domain molecules and methods for producing and using them b |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7244826B1 (en) * | 1998-04-24 | 2007-07-17 | The Regents Of The University Of California | Internalizing ERB2 antibodies |
| CN1672160B (zh) * | 2002-05-20 | 2010-06-09 | 埃博马可西斯公司 | 基于前导抗体的结构构建抗体文库的方法 |
| WO2011019827A2 (en) * | 2009-08-11 | 2011-02-17 | Academia Sinica | Phage displaying system expressing single chain antibody |
| WO2013166604A1 (en) * | 2012-05-10 | 2013-11-14 | Zymeworks Inc. | Single-arm monovalent antibody constructs and uses thereof |
-
2016
- 2016-02-23 CN CN201680009046.7A patent/CN107614762B/zh active Active
- 2016-02-23 EP EP16756185.1A patent/EP3262216A4/en not_active Withdrawn
- 2016-02-23 US US15/547,523 patent/US10336816B2/en active Active
- 2016-02-23 EP EP19154062.4A patent/EP3514181A1/en not_active Withdrawn
- 2016-02-23 WO PCT/US2016/019128 patent/WO2016137992A2/en active Application Filing
- 2016-02-24 TW TW105105362A patent/TWI636060B/zh active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1105728C (zh) * | 1993-09-07 | 2003-04-16 | 史密丝克莱恩比彻姆公司 | 用于治疗il4介导疾病的重组il4抗体 |
| CN1345334A (zh) * | 1999-01-29 | 2002-04-17 | 伊姆克罗尼系统公司 | 对kdr特异的抗体及其应用 |
| WO2005044853A2 (en) * | 2003-11-01 | 2005-05-19 | Genentech, Inc. | Anti-vegf antibodies |
| CN101854950A (zh) * | 2007-09-11 | 2010-10-06 | 航道生物技术有限责任公司 | 供体特异性抗体文库 |
| WO2011137245A2 (en) * | 2010-04-30 | 2011-11-03 | Esperance Pharmaceuticals, Inc. | Lytic-peptide-her2/neu (human epidermal growth factor receptor 2) ligand conjugates and methods of use |
| WO2012142662A1 (en) * | 2011-04-21 | 2012-10-26 | Garvan Institute Of Medical Research | Modified variable domain molecules and methods for producing and using them b |
Non-Patent Citations (5)
| Title |
|---|
| A compact phage display human scFv library for selection of antibodies to a wide variety of antigens;Potjamas Pansri等;《BMC Biotechnology》;20090129;第9卷(第6期);第1页摘要,第4页,"抗体片段的多样性" * |
| Antibody Variable Domain Interface and Framework Sequence Requirements for Stability and Function by High-Throughput Experiments;Hung-Ju Hsu等;《Structure》;20140107;第22卷(第1期);第25页右栏第2段,第32页左栏最后1段-右栏第1段,补充材料表S5,图S4 * |
| Canonical Structure Repertoire of the Antigen-binding Site of Immunoglobulins Suggests Strong Geometrical Restrictions Associated to the Mechanism of Immune Recognition;EnriqueVargas-Madrazo等;《Journal of molecular biology》;20020525;第254卷(第3期);第497页摘要,第499页表1,第500页右栏第3段,501页右栏第1段 * |
| 人源性抗乳腺癌噬菌体单链抗体库的构建、筛选与初步鉴定;王净;《中国优秀硕士学位论文全文数据库 医药卫生科技辑》;20130215(第2期);E072-789 * |
| 噬菌体抗体库技术的研究进展;黄甦;《噬菌体抗体库技术的研究进展》;20020215;第24卷(第1期);1-4 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3262216A4 (en) | 2018-12-05 |
| US10336816B2 (en) | 2019-07-02 |
| CN107614762A (zh) | 2018-01-19 |
| WO2016137992A2 (en) | 2016-09-01 |
| EP3514181A1 (en) | 2019-07-24 |
| TWI636060B (zh) | 2018-09-21 |
| TW201632547A (zh) | 2016-09-16 |
| US20180009877A1 (en) | 2018-01-11 |
| WO2016137992A3 (en) | 2016-10-27 |
| EP3262216A2 (en) | 2018-01-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107614762B (zh) | 一种由噬菌体表达的单链变异片段抗体库 | |
| US10472411B2 (en) | Recombinant antibody and uses thereof | |
| JP6392923B2 (ja) | Muc1*抗体 | |
| ES2408582T3 (es) | Biblioteca de Fab para la preparación de una mezcla de anticuerpos | |
| US7718174B2 (en) | Anti-HGF/SF humanized antibody | |
| EP3037525A1 (en) | Method for producing antigen-binding molecule using modified helper phage | |
| JP2009526857A (ja) | 機能性抗体 | |
| CN111148759B (zh) | 结合至纤维连接蛋白b结构域的蛋白 | |
| CN111333723B (zh) | 针对狂犬病病毒g蛋白的单克隆抗体及其用途 | |
| WO2023273595A1 (zh) | 一种结合trop2的抗体及靶向trop2和cd3的双特异性抗体及其制备方法与应用 | |
| CN112961250A (zh) | 抗体融合蛋白及其应用 | |
| US11365247B2 (en) | IL-5 antibody, antigen binding fragment thereof, and medical application therefor | |
| CN101531718B (zh) | 抗VEGFR-2抗体嵌合Fab抗体片段及其制备方法、应用 | |
| US12258394B2 (en) | IL-5 antibody, antigen binding fragment thereof, and medical application therefor | |
| CN114426580B (zh) | 抗csf-1r抗体及其产品、方法和用途 | |
| CN116265487B (zh) | 抗ang2-vegf双特异性抗体及其用途 | |
| RU2772716C2 (ru) | Антитело против il-5, его антигенсвязывающий фрагмент и его медицинское применение | |
| EP4482860A1 (en) | Human-like target-binding proteins | |
| CN115975020A (zh) | 靶向sars-cov-2s蛋白的抗原结合蛋白及其应用 | |
| CN115073596A (zh) | 一种人源化Claudin 18.2抗体及其应用 | |
| CN116178540A (zh) | 抗ang2抗体及其用途 | |
| Kusada et al. | Production of a human antibody fragment against the insulin-like growth factor I receptor as a fusion protein. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |