CN1054695C - 计算机汉字八四码输入法及键盘 - Google Patents
计算机汉字八四码输入法及键盘 Download PDFInfo
- Publication number
- CN1054695C CN1054695C CN96114178A CN96114178A CN1054695C CN 1054695 C CN1054695 C CN 1054695C CN 96114178 A CN96114178 A CN 96114178A CN 96114178 A CN96114178 A CN 96114178A CN 1054695 C CN1054695 C CN 1054695C
- Authority
- CN
- China
- Prior art keywords
- code
- chinese
- characters
- syllable
- chinese character
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 title claims abstract description 203
- 239000000203 mixture Substances 0.000 claims abstract description 6
- 150000001875 compounds Chemical class 0.000 claims description 192
- 230000008859 change Effects 0.000 claims description 26
- 239000002023 wood Substances 0.000 claims description 11
- 235000017166 Bambusa arundinacea Nutrition 0.000 claims description 10
- 235000017491 Bambusa tulda Nutrition 0.000 claims description 10
- 241001330002 Bambuseae Species 0.000 claims description 10
- 235000015334 Phyllostachys viridis Nutrition 0.000 claims description 10
- 239000011425 bamboo Substances 0.000 claims description 10
- 230000008676 import Effects 0.000 claims description 8
- 244000025254 Cannabis sativa Species 0.000 claims description 6
- 239000004575 stone Substances 0.000 claims description 5
- PCTMTFRHKVHKIS-BMFZQQSSSA-N (1s,3r,4e,6e,8e,10e,12e,14e,16e,18s,19r,20r,21s,25r,27r,30r,31r,33s,35r,37s,38r)-3-[(2r,3s,4s,5s,6r)-4-amino-3,5-dihydroxy-6-methyloxan-2-yl]oxy-19,25,27,30,31,33,35,37-octahydroxy-18,20,21-trimethyl-23-oxo-22,39-dioxabicyclo[33.3.1]nonatriaconta-4,6,8,10 Chemical compound C1C=C2C[C@@H](OS(O)(=O)=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2.O[C@H]1[C@@H](N)[C@H](O)[C@@H](C)O[C@H]1O[C@H]1/C=C/C=C/C=C/C=C/C=C/C=C/C=C/[C@H](C)[C@@H](O)[C@@H](C)[C@H](C)OC(=O)C[C@H](O)C[C@H](O)CC[C@@H](O)[C@H](O)C[C@H](O)C[C@](O)(C[C@H](O)[C@H]2C(O)=O)O[C@H]2C1 PCTMTFRHKVHKIS-BMFZQQSSSA-N 0.000 claims description 4
- 244000241257 Cucumis melo Species 0.000 claims description 4
- 235000015510 Cucumis melo subsp melo Nutrition 0.000 claims description 4
- 240000007594 Oryza sativa Species 0.000 claims description 4
- 235000007164 Oryza sativa Nutrition 0.000 claims description 4
- 244000046052 Phaseolus vulgaris Species 0.000 claims description 4
- 235000010627 Phaseolus vulgaris Nutrition 0.000 claims description 4
- 241000209140 Triticum Species 0.000 claims description 4
- 235000021307 Triticum Nutrition 0.000 claims description 4
- 229910052770 Uranium Inorganic materials 0.000 claims description 4
- FJJCIZWZNKZHII-UHFFFAOYSA-N [4,6-bis(cyanoamino)-1,3,5-triazin-2-yl]cyanamide Chemical compound N#CNC1=NC(NC#N)=NC(NC#N)=N1 FJJCIZWZNKZHII-UHFFFAOYSA-N 0.000 claims description 4
- 239000008280 blood Substances 0.000 claims description 4
- 210000004369 blood Anatomy 0.000 claims description 4
- 210000000988 bone and bone Anatomy 0.000 claims description 4
- 235000013339 cereals Nutrition 0.000 claims description 4
- 239000000835 fiber Substances 0.000 claims description 4
- 235000013305 food Nutrition 0.000 claims description 4
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 claims description 4
- 229910052737 gold Inorganic materials 0.000 claims description 4
- 239000010931 gold Substances 0.000 claims description 4
- 235000013372 meat Nutrition 0.000 claims description 4
- 239000004570 mortar (masonry) Substances 0.000 claims description 4
- 235000009566 rice Nutrition 0.000 claims description 4
- 238000005096 rolling process Methods 0.000 claims description 4
- 241000238631 Hexapoda Species 0.000 claims description 3
- 241001494479 Pecora Species 0.000 claims description 3
- 229910052736 halogen Inorganic materials 0.000 claims description 3
- 150000002367 halogens Chemical class 0.000 claims description 3
- 238000012163 sequencing technique Methods 0.000 claims description 3
- 239000002689 soil Substances 0.000 claims description 3
- 241000251468 Actinopterygii Species 0.000 claims description 2
- 241000282994 Cervidae Species 0.000 claims description 2
- 241000196324 Embryophyta Species 0.000 claims description 2
- 241001465754 Metazoa Species 0.000 claims description 2
- 230000015572 biosynthetic process Effects 0.000 claims description 2
- 238000005194 fractionation Methods 0.000 claims description 2
- 230000014759 maintenance of location Effects 0.000 claims description 2
- 210000000056 organ Anatomy 0.000 claims description 2
- 238000003825 pressing Methods 0.000 claims description 2
- 230000000630 rising effect Effects 0.000 claims description 2
- 235000015170 shellfish Nutrition 0.000 claims description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims 4
- 230000001037 epileptic effect Effects 0.000 claims 2
- 239000010985 leather Substances 0.000 claims 2
- 230000001360 synchronised effect Effects 0.000 abstract 1
- 230000008901 benefit Effects 0.000 description 5
- 241000040710 Chela Species 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 239000011435 rock Substances 0.000 description 3
- 230000006870 function Effects 0.000 description 2
- 241000272814 Anser sp. Species 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- DNYWZCXLKNTFFI-UHFFFAOYSA-N uranium Chemical compound [U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U] DNYWZCXLKNTFFI-UHFFFAOYSA-N 0.000 description 1
Images


Landscapes
- Document Processing Apparatus (AREA)
Abstract
本发明为一种计算机汉字八四码输入法及键盘,属于计算机数据输入方法和数据输入装置领域。八四码由八位码和四位码组成,八位码也称八四形声码,按汉字书写顺序对汉字拆字编码,编码方法简单易学、重码少;四位码也称八四同步码,按汉字的拼音规则对汉字编码,操作者易于掌握,可实现并行输入,输入速度快。两套编码可单独或混合使用,在专用键盘上输入时速度更快。八四码可输入简体字、繁体字和异体字,也可作为准拼音文字使用。
Description
本发明涉及一种计算机汉字八四码输入法及键盘,属于计算机数据输入方法和计算机数据输入装置领域。
目前,计算机汉字输入中使用的汉字编码主要有形码、音码和音形码三类,这三种类型的编码各有优点和不足,如形码的优点是输入速度快,重码少,但形码的编码规则复杂,不易掌握;音码的优点是易学易记,但音码的重码多,输入速度慢,现在有的双拼音码引入了声调符或义符,利用声调或字形特点的帮助,减少重码数量,这些声调符或义符编码规则复杂,虽可减少一些重码数量,但输入速度仍比较慢;音形码由表示字音和字形的两部分编码组成,可以综合形码和音码的优点,现有的音形码在解决重码的规则上复杂,使用不方便。
本发明的目的是发明一种符合人们记忆、书写汉字的习惯,编码规则简单易记,重码少,输入速度快的计算机汉字输入法及键盘。本发明的编码属于音码和音形码范围。
一种计算机汉字八四码输入法,八四码由等长八位码或等长四位码两种码组成,等长八位码由八位代码构成,其左起第1位代码是区别码,第2-5位代码是形码,第6-8位代码是声码;等长四位码由四位代码构成,其左起第1位代码是义码,第2-4位代码是声码,等长四位码中的代码不重复;
一、按下述方法确定主部首及主部首代码:
参考《新华字典》中的部首,将现有简体字所用的部首分类归为171个主部首,其中一些主部首带有附属部首,将171个主部首及其附属部首分配到标准计算机键盘的26个字母键上,作为主部首及其附属部首的输入代码,具体分配如下,括号中的是与主部首相关的附属部首,有读音的主部首及其附属部首的读音用汉语拼音标注,
yī
代码A表示简体字主部首一(
),
shù jué
代码B表示简体字主部首丨(亅、
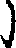 ),
),
piě
代码C表示简体字主部首丿,
diǎn nà
代码D表示简体字主部首丶 (),
yī tóu fāng
代码E表示简体字主部首乙(
、乛、

 等一画笔划),亠,匚,jiōng chuáng yǐn kǎn zhǐ hū jié jì冂(
等一画笔划),亠,匚,jiōng chuáng yǐn kǎn zhǐ hū jié jì冂(
 ),疒, 廴,凵, ,,卩(
),疒, 廴,凵, ,,卩(
 ),
),
 (彐、、彑),gǒng bīng bāo mì廾, 冫, 勹, 冖
(彐、、彑),gǒng bīng bāo mì廾, 冫, 勹, 冖
shuǐ yǔ qì
代码F表示简体字主部首水(氵,水,
 ),雨(
),雨(
 ),气,
),气,
jīn rì yuē
代码G表示简体字主部首金(钅),日(曰),
tǔ Fēng chén xué shí
代码H表示简体字主部首土,风, 辰, 穴,石,
fù shān tián yóu chuān
代码I表示简体字主部首阜(阝左),山, 田, (由),川,chuān huǒ(巛,ㄍ),火(灬),
hé mài gǔ mǐ dòu zhú
代码J表示简体字主部首禾,麦,谷,米,豆,竹(),
cǎo shí má
代码K表示简体字主部首草(艹),食(饣),麻,
mù guā
代码L表示简体字主部首木(木),瓜,
rén rù zǐ shì jǐ sì yǐ ér
代码M表示简体字主部首人 (入,亻),子(孑),士,己(巳,已),儿,zì fù nǚ自,父,女,
niǎo wūc chóng zhuīyáng
代码N表示简体字主部首鸟( 乌,
 ),虫, 隹, 羊(
),虫, 隹, 羊(

 ),shǐ zhì lù miǎn豕(
),shǐ zhì lù miǎn豕(
 ),豸,鹿,黾,
),豸,鹿,黾,
quǎn shǔ mǎ yú niú
代码O表示简体字主部首犬(犭),鼠,马,鱼,牛(
 ),
),
ròu yuè mù bí yǔ jiǎo
代码P表示简体字主部首肉(月,
 ),目,鼻,羽,角,
),目,鼻,羽,角,
xīn biāo ěr gǔ zhuǎ
代码Q表示简体字主部首心(忄,),髟, 耳,骨,爪(爫),
kǒu zú shēn
代码R表示简体字主部首口, 足(),身,
shǒu shī máo xuè pí chǐ
代码S表示简体字主部首手(扌,),尸,毛,血,皮,齿,shé yá舌,牙,
gē gōng mì bǐ jīn jiù
代码T表示简体字主部首戈,弓,糸(糹,纟),匕,巾,臼(
 ),hù mǐn dǒu lǐ户,皿,斗,里(
),hù mǐn dǒu lǐ户,皿,斗,里(
 ),
),
wǎng shū yù wáng shǐ shí
代码U表示简体字主部首网(
 ),殳,玉(王,
),矢,十,bā chǎng wéi mián lǔ八(丷),厂, 韦, 宀, 卤,
),殳,玉(王,
),矢,十,bā chǎng wéi mián lǔ八(丷),厂, 韦, 宀, 卤,
dāo jīn chē wǎ fǒu yì
代码V表示简体字主部首刀(刂,ク),斤, 车,瓦,缶,邑(阝右),gèn zhōu lěi máo艮(
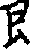 ),舟,耒,矛,
),舟,耒,矛,
bèi cùn piàn mén dòu fāng
代码W表示简体字主部首贝, 寸, 片, 门 (鬥),方,qiáng yǒu yī爿(丬,
),酉,衣(衤),
chuò chì yòng guǎng
代码X表示简体字主部首辵(辶),赤,用(
 ),广,zōu gōng jǐ lǎo shān dà wú mǔ guàn lì qiàn走,工, 几(
),广,zōu gōng jǐ lǎo shān dà wú mǔ guàn lì qiàn走,工, 几(
 ),老(
),老(
 ),彡,大,毋(母,
),彡,大,毋(母,
 ),力,欠,bǔ yè(), 业,
),力,欠,bǔ yè(), 业,
chì shū biàn gé wéi
代码Y表示简体字主部首彳,疋(
 ),采,革,口(O),xīn zhǐ dǎi bǐ xī sī wāng shì qīng yè yāo yì lóng辛,止,歹,比,夕,厶,尢,示(礻),青,页,幺,弋,龙,
),采,革,口(O),xīn zhǐ dǎi bǐ xī sī wāng shì qīng yè yāo yì lóng辛,止,歹,比,夕,厶,尢,示(礻),青,页,幺,弋,龙,
yán yīn pū guǐ xiǎo
代码Z表示简体字主部首言(讠),音,攴(攵),鬼,小(),yù yòu jiàn xī bái hēi wén lì聿(肀,

 ),又,见,西(
),又,见,西(
 ),白,黑(
),文,立,
),白,黑(
),文,立,
在每个键上的部首又排列成四层,从上到下依次为1、2、3、4层,部分键上有的部首层次空缺,下面用表1将主部首及其附属部首与主部首代码的对应关系表示出来:表1续表1
二、按下述方法确定汉语拼音的代码:
将汉语拼音的字母、声母、韵母分配到标准计算机键盘的26个字母键上,作为汉语拼音的字母、声母、韵母的输入代码,汉语拼音的声母、韵母分配原则如下:
(1)单字母声母用声母本身字母作代码,
(2)双字母声母ch、sh、zh分别用字母O、U、V作代码,
(3)将字母Y、W看作特殊声母,并用其本身字母作代码,
(4)韵母的代码键不能设置在能与其相拼的声母代码键上,
(5)将34个韵母分为上层韵母11个和下层韵母23个,
(6)将字母组合ng看作特殊韵母,用代码G表示,
(7)音节shu中的韵母u用代码v表示,
汉语拼音的字母、声母、韵母的具体分配如下,其中汉语拼音的字母的代码与26个字母键相对应;
代码A表示下层韵母a,
代码B表示声母b,
代码C表示声母c,
代码D表示声母d,
代码E表示下层韵母e,
代码F表示声母f、下层韵母ao,
代码G表示声母g、上层韵母ng、下层韵母in,
代码H表示声母h、下层韵母iao,
代码I表示下层韵母i,
代码J表示声母j、上层韵母ang、下层韵母ei,
代码K表示声母k、下层韵母ing,
代码L表示声母l、上层韵母en、下层韵母uei,
代码M表示声母m、上层韵母iang、下层韵母uo,
代码N表示声母n、下层韵母üan,
代码O表示声母ch、下层韵母o,
代码P表示声母p、上层韵母iong、下层韵母ong,
代码Q表示声母q、上层韵母ua、下层韵母an,
代码R表示声母r、上层韵母uai、下层韵母ai,
代码S表示声母s、上层韵母ün、下层韵母ie,
代码T表示声母t、上层韵母iou、下层韵母üe,
代码U表示声母sh、下层韵母u,
代码V表示声母zh、下层韵母ü,
代码W表示声母w、上层韵母uan、下层韵母ou,
代码X表示声母x、上层韵母uang、下层韵母eng,
代码Y表示声母y、上层韵母uen、下层韵母ia,
代码Z表示声母z、下层韵母ian;
下面用表2将汉语拼音的字母、声母及韵母与汉语拼音代码的对应关系表示出来:
表2
| 代码 | 声母 | 上层韵母下层韵母 | 代码 | 声母 | 上层韵母下层韵母 | 代码 | 声母 | 上层韵母下层韵母 |
| A | a | J | j | angei | S | s | ünie | |
| B | b | K | k | ing | T | t | iouüe | |
| C | c | L | l | enuei | U | sh | u | |
| D | d | M | m | iang | V | zh | ü | |
| E | e | N | n | üan | W | w | uanou | |
| F | f | ao | O | ch | o | X | x | uangeng |
| G | g | ngin | P | p | iongong | Y | y | uenia |
| H | h | iao | Q | q | uaan | Z | z | ian |
| I | i | R | r | uaiai |
三、按下述方法确定汉语拼音声调的代码:
将汉语拼音的四声声调分配到标准计算机键盘的字母键上,作为声调的输入代码,在标准计算机键盘上分配出六组声调代码,其中的一组为上层声调级,另外五组为下层声调级,具体分配如下:
下层第一声调级的声调代码为




下层第二声调级的声调代码为



下层第三声调级的声调代码为



下层第四声调级的声调代码为


下层第五声调级只有一个声调代码为

上层第一声调级的声调代码为


四、按下述方法对汉字进行编码:
<1>等长八位码的编码方法:
等长八位码由区别码、形码和声码三部分组成,这三部分的编码方法分述如下:
(1)区别码的编码方法:
区别码的代码与等长八位码的左起第二位代码相同,取等长八位码的左起第2位代码作为区别码的代码,
(2)形码的编码方法:
形码的编码原则如下:
1).按汉字的书写顺序拆分汉字中的部首,拆分出的部首应与171个主部首中的主部首或附属部首基本一致,既笔划种类一致,笔画数一致,笔划书写顺序一致,允许拆分的部首的笔划有延长或整个部首变形,但不能引起字义的改变,
2).汉字拆分时,若有多种拆分方法,取拆分部首少的拆分方法,
3).汉字拆分成部首后,按这些部首的书写顺序,取与这些部首对应的主部首代码或附属部首的代码组成形码,形码构成等长八位码中的第2-5位的代码;
形码的具体编码方法如下:
1).汉字由一个部首形成,这个部首与171个主部首中主部首或附属部首相同,其编码方法如下:
①取与该汉字的部首对应的主部首代码或附属部首代码作为形码左起第1位代码,
②取与该汉字的拼音的声母对应的声母代码或与其韵母对应的韵母代码作为形码左起第2位代码,
③将该汉字按书写顺序拆分为部首,取与其第一个部首对应的主部首代码或附属部首代码,作为形码的左起第3位代码,
④将该汉字按上述③中的方法拆分后,取与其最后一个部首对应的主部首代码或附属部首代码,作为形码的左起第4位代码;
2).汉字由二个部首形成的字的编码方法:
按二个部首的书写顺序,按下述步骤编码:
①取与该汉字的第一个部首对应的主部首代码或附属部首代码,作为形码左起第1位代码,
②取与该汉字的第二个部首对应的主部首代码或附属部首代码,作为形码左起第2位代码,
③取与该汉字的第一个部首拼音的声母对应的声母代码或与其韵母对应的韵母代码,作为形码的左起第3位代码,
④取与该汉字的第二个部首拼音的声母对应的声母代码或与其韵母对应的韵母代码,作为形码的左起第4位代码,
3).汉字由三个部首形成的字的编码方法:
按三个部首的书写顺序,按下述步骤编码:
①取与该汉字的第一个部首对应的主部首代码或附属部首代码,作为形码左起第1位代码,
②取与该汉字的第二个部首对应的主部首代码或附属部首代码,作为形码左起第2位代码,
③取与该汉字的第三个部首对应的主部首代码或附属部首代码,作为形码左起第3位代码,
④取与该汉字的第一个部首拼音的声母对应的声母代码或与其韵母对应的韵母代码,作为形码的左起第4位代码,
4).汉字由四个部首形成的字的编码方法:
按四个部首的书写顺序,按下述步骤编码:
①取与该汉字的第一个部首对应的主部首代码或附属部首代码,作为形码左起第1位代码,
②取与该汉字的第二个部首对应的主部首代码或附属部首代码,作为形码左起第2位代码,
③取与该汉字的第三个部首对应的主部首代码或附属部首代码,作为形码左起第3位代码,
④取与该汉字的第四个部首对应的主部首代码或附属部首代码,作为形码左起第4位代码,
5).汉字由五个或五个以上部首形成的字的编码方法:
按五个或五个以上部首的书写顺序,按下述步骤编码:
①取与该汉字的第一个部首对应的主部首代码或附属部首代码,作为形码左起第1位代码,
②取与该汉字的第二个部首对应的主部首代码或附属部首代码,作为形码左起第2位代码,
③取与该汉字的第三个部首对应的主部首代码或附属部首代码,作为形码左起第3位代码,
④取与该汉字的最后一个部首对应的主部首代码或附属部首代码,作为形码左起第4位代码,
(3)声码的编码方法:
声码由表示声母、韵母和声调的三个代码组成,按照汉字的拼音的声母、韵母和声调,选取相应的声母代码、韵母代码和声调代码组成声码,声码构成等长八位码的第6~8位代码;
对有不同音节的汉字的声码编码方法分述如下:
1).声韵音节的汉字的声码编码方法:
①取与该汉字的拼音的声母对应的声母代码,作为声码的左起第1位代码,
②取与该汉字的拼音的韵母对应的韵母代码,作为声码的左起第2位代码,
③取与该汉字的拼音的声调对应的声调代码,作为声码的左起第3位代码,
选取声调代码时,若汉字的拼音的韵母为下层韵母,声调代码在下层声调级中选取,选取的顺序为第一声调级,第二声调级,第三声调级,第四声调级;
若汉字的拼音的韵母为上层韵母,声调级在上层声调级中选取;
2).单字母韵母音节的汉字声码编码方法:
①取与该汉字的拼音的韵母对应的韵母代码,作为声码的左起第1位代码,
②取字母D的代码,作为声码的左起第2位代码,
③取与该汉字的拼音的声调对应的声调代码,作为声码的左起第3位代码,声调代码在下层声调级中选取;
3).双字母韵母音节的汉字声码编码方法:
①取与该汉字的拼音的韵母中的第一个字母对应的汉语拼音字母代码,作为声码的左起第1位代码,
②取与该汉字的拼音的韵母中的第二个字母对应的汉语拼音字母代码,作为声码的左起第2位代码,
③取与该汉字的拼音的声调对应的声调代码,作为声码的左起第3位代码,声调代码在上层声调级中选取;
4).三字母韵母音节的汉字声码编码方法:(ang,eng)
①取与该汉字的拼音的韵母中的第一个字母对应的汉语拼音字母代码,作为声码的左起第1位代码,
②取字母组合ng的代码,作为声码的左起第2位代码,
③取与该汉字的拼音的声调对应的声调代码,作为声码的左起第3位代码,声调代码在上层声调级中选取;
5).以i、u开头的韵母音节的汉字的声码编码方法:
用特殊声母y、w替换i、u,将以i、u开头的原韵母看作是特殊声母y、w与原韵母中去掉i、u后剩余部分相拼或与不去掉i的原韵母相拼,按汉语拼音规则决定是否去掉i、u,按声韵音节的汉字的编码方法给有这种音节的汉字编码;
6).声母组合音节的汉字的声码编码方法:(m,n,ng,hm,hng)
①单字母的声母音节的汉字的编码方法,按单字母韵母音节的汉字的编码方法编码,
②双字母声母音节的汉字的编码方法,按双字母韵母音节的汉字的编码方法编码,
③三字母声母音节的汉字的编码方法,按三字母韵母音节的汉字的编码方法编码,
在进行声码编码时,用下述声调级错位规则对声码编码进行调整:
①下层第一声调级的代码ABCD中,如有某个声调代码被声母代码或韵母代码占用,则该声调代码后错1位,其后的声调代码依次后错,如声调代码B被声母代码B占用,则错位后的声调级代码为ACDE;最多允许同时错位两个声调代码;
②下层第二声调级代码EFGH也允许错位,错位方法同①中的方法,但下层第二声调级代码仅允许错1位,如果错2位时,该音节的这个声调级取消;
③下层第三、四声调级代码不允许错位;
④上层声调级代码允许错1位或2位代码,错位方法同①中的方法;
<2>等长四位码的编码方法:
等长四位码由义码和声码两部分构成,这两部分的编码方法分述如下:
(1)义码的编码方法:
1).选取该字的偏旁部首,在171个主部首中找到与之对应的主部首代码或附属部首代码,作为该字的义码的代码,
2).当确定的义码的代码与该字的拼音的声母代码相同时,则改用代码C代表义码,
3).当确定的义码的代码与该字的拼音的韵母代码相同时,则改用代码B代表义码,
4).如该字属于使用上层韵母的字,当确定的义码与其声调代码相同时,则改用代码A代表义码,
5).如果该字本身的声母代码、韵母代码为A、B,当发生3)、4)的情况时,用代码C代替A或代码C代替B,用代码C作为义码代码,
6).171个主部首及其附属部首分配到标准计算机键盘上的26个字母键上,其中ABCD键上的部首为笔划类部首,E键上的部首为罕用字部首,FGHI键上的部首为自然类部首,JKL键上的部首为植物类部首,M键上的部首为人类部首,NO键上的部首为动物类部首,PQRS键上的部首为器官类部首,TUVW键上的部首为物品量度类部首,XYZ键上的部首为事物类部首,
当不能用1)到5)的方法确定义码时,可根据上述171个主部首及其附属部首分为七大类部首的规则,在与该字的偏旁部首同一类的主部首代码中选用其他代码作为该字的义码代码,一般优先选取靠近键盘中心的代码,
7).当上述方法均不能确定该字的义码代码时,在171个主部首及其附属部首中可以任选一个代码作为该字的义码代码;
(2)声码的编码方法:
声码的编码方法与等长八位码中的声码的编码方法相同,
(3)等长四位码的具体编码方法如下:
1).声韵音节的汉字的编码方法如下:
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的声韵音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
2).单字母韵母音节的汉字的编码方法:
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的单字母韵母音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
3).双字母韵母音节的汉字的编码方法:
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的双字母韵母音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
4).三字母韵母音节的汉字的编码方法:(ang,eng)
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的三字母韵母音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
5).以i、u开头的韵母音节的汉字的编码方法:
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的以i、u开头的韵母音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
6).以声母组合音节的汉字的编码方法:(m,n,ng,hm,hng)
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的以声母组合音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
在等长四位码的声码编码时,也采用等长八位码中的声调级错位规则对声码编码进行调整。
五、八四码的输入方法:
按上述等长八位码或等长四位码的编码方法将汉字编成对应的等长八位码或等长四位码,按下述方法在标准计算机键盘上输入汉字:
<1>等长八位码的输入方法:
1).输入等长八位码的左起第1位代码,
2).输入等长八位码的左起第2-5位代码,
3).输入等长八位码的左起第6-8位代码,
<2>等长四位码的输入方法之一:
1).输入等长四位码的左起第1位代码,
2).输入等长四位码的左起第2-4位代码,
<3>等长四位码的输入方法之二:
1).输入等长四位码的左起第2-4位代码,
2).输入等长四位码的左起第1位代码,
<4>等长四位码的输入方法之三:
将等长四位码的四个代码同时输入或将四位代码按任意先后顺序输入,即并行输入;
使用八四码在计算机上输入汉字时,可以单独使用等长八位码输入汉字,也可以单独使用等长四位码输入汉字,还可以交替使用等长八位码和等长四位码输入汉字。
繁体汉字的八四码输入方法是参考《新华字典》中的部首,将繁体字所用的部首分类归为171个主部首,其中一些主部首带有附属部首,将171个主部首及其附属部首分配到标准计算机键盘的26个字母键上,作为主部首及其附属部首的输入代码,具体分配如下,括号中的是与主部首相关的附属部首,
yī
代码A表示繁体字主部首一(
 ),
),
shùjué
代码B表示繁体字主部首丨(亅、
 ),
),
piě
代码C表示繁体字主部首丿,
diǎn nà
代码D表示繁体字主部首丶 (),
yǐ tóu fāng
代码E表示繁体字主部首乙(
 、乛、
、乛、

 等一画笔划),亠,匚,jiōng chuángyǐn kǎn zhǐ hū jié jì冂(
等一画笔划),亠,匚,jiōng chuángyǐn kǎn zhǐ hū jié jì冂(
 ),疒,廴,凵,
,,卩(
),疒,廴,凵,
,,卩(
 ),
),
 (彐、、彑),gǒng bīng bāo mì廾, 冫, 勹,冖,
(彐、、彑),gǒng bīng bāo mì廾, 冫, 勹,冖,
shuǐ yǔ qì
代码F表示繁体字主部首水(氵,水,
 ),雨(
),雨(
 ),气,
),气,
jīn rì yuē
代码G表示繁体字主部首金(钅),日(曰),
tǔ Fēng chén xué shí
代码H表示繁体字主部首土,風, 辰, 穴, 石,
fù shān tián yóu chuān
代码I表示繁体字主部首阜(阝左),山,田, (由),川,chuān huǒ(巛,ㄍ),火(灬),
hé mài gǔ mǐ dòu zhú
代码J表示繁体字主部首禾,麥,谷,米,豆,竹(),
cǎo shí má
代码K表示繁体字主部首草(艹),食(饣),麻,
mù guā
代码L表示繁体字主部首木(木),瓜,
rén rù zǐ shì jǐ sì yǐ ér
代码M表示繁体字主部首人 (入,亻),子(孑),士,己(巳,已),儿,zì fù nǚ自,父,女,
niǎowū chóng zhuīyáng
代码N表示繁体字主部首鳥(烏,
 ),虫,隹,羊(
),虫,隹,羊(

 ),shǐ zhìlù miǎn豕(
),shǐ zhìlù miǎn豕(
 ),豸,鹿,黽,
),豸,鹿,黽,
quǎn shǔ mǎ yú niú
代码O表示繁体字主部首犬(犭),鼠,馬,,魚,牛(
 ),
),
ròuyuè mù bí yǔ jiǎo
代码P表示繁体字主部首肉(月,
 ),目,鼻,羽,角,
),目,鼻,羽,角,
xīn biāo ěr gǔ zhuǎ
代码Q表示繁体字主部首心(忄,),髟, 耳,骨,爪(爫),
kǒu zú shēn
代码R表示繁体字主部首口,足(),身,
shǒu shī máo xuè pí chǐ
代码S表示繁体字主部首手(扌,),尸,毛, 血,皮,齒,shé yá舌,牙,
gē gōng mì bǐ jīn jiù
代码T表示繁体字主部首戈,弓,糸(糹,纟),匕,巾,臼(
 ),hù mǐn dǒu lǐ户,皿,斗,里(
),
),hù mǐn dǒu lǐ户,皿,斗,里(
),
wǎng shū yù wáng shǐshí
代码U表示繁体字主部首网(
),殳,玉(王,
 ),矢,十,bā chǎng wéi mián lǔ八(丷),厂, 韋, 宀, 鹵,
),矢,十,bā chǎng wéi mián lǔ八(丷),厂, 韋, 宀, 鹵,
dāo jīn chē wǎ fǒu yì代码V表示繁体字主部首刀(刂,ク),斤,車,瓦,缶,邑(阝右),gèn zhōu lěi máo艮(
),舟,耒,矛,
bèi cùn piàn mén dòu fāng
代码W表示繁体字主部首貝, 寸, 片, 門 (鬥),方,qiáng yǒu yī爿(
 ,丬),酉,衣(衤),
,丬),酉,衣(衤),
chuò chì yòng guǎng
代码X表示繁体字主部首辵(辶),赤,用(

 ),广,zǒu gōngjǐ lǎo shān dà wú mǔ guàn lìqiàn走,工,几(
),广,zǒu gōngjǐ lǎo shān dà wú mǔ guàn lìqiàn走,工,几(
 ),老(
),老(
 ),彡,大,毋(母,
),力,欠,bǔ yè卜(),业,
),彡,大,毋(母,
),力,欠,bǔ yè卜(),业,
chì shū biàn gé wéi
代码Y表示繁体字主部首彳,疋(

 ),采,革,口(O),xīn zhǐ dǎi bǐ xī sī wāng shì qīng yè yāo yì lóng辛,止,歹,比,夕,厶,尢,示(礻),青,頁,幺,弋,龍,
),采,革,口(O),xīn zhǐ dǎi bǐ xī sī wāng shì qīng yè yāo yì lóng辛,止,歹,比,夕,厶,尢,示(礻),青,頁,幺,弋,龍,
yán yīn pū guǐ xiǎo
代码Z表示繁体字主部首言(讠),音,攴(攵),鬼,小(),yù yòujiàn xī bái hēi wén lì聿(肀,

 ),又,見,西(
),又,見,西(
 ),白,黑(
),文,立,
),白,黑(
),文,立,
在每个键上的部首又排列成四层,从上到下依次为1、2、3、4层,部分键上有的部首层次空缺。
下面用表3将繁体字主部首及其附属部首与主部首代码的对应关系表示出来:
表3
续表3
在用等长八位码对汉字进行编码时,用下述方法对重码字的编码进行调整:
(1)当重码字是用下层声调级表示声调时,用下述方法调整重码字的编码:
①比较两个重码字的第一、二、三、末四个部首中不同部首的拼音的声母,声母的代码排序在前的字,采用下层第一声调级作该字的声调代码,声母的代码排序在后的字,采用下层第二声调级作该字的声调代码;
当重码字是3个或4个时,应按字母先后排序依次确定该字声调级代码为第一、二、三、四级声调代码;
例如,坷、砢两字的编码同为HHARBKEA,这两个字中的不同部首为土和石,其部首的拼音的声母代码分别为T和U,声母代码U的排序在后,因此对砢字的编码的声调码进行调整,采用下层第二声调级的声调代码,则砢字的编码改为HHARBKEF,
②当不能用上述方法①区别重码字时,可比较两个重码字的笔画数,笔画数少的字采用下层第一声调级作该字的声调代码,笔画数多的字采用下层第二声调级作该字的声调代码;
当重码字是3个或4个时,应按笔画数的少、多排序,依次确定该字声调级代码为第一、二、三、四级声调代码;例如,盤、縏两字的编码同为VVUTVPQB,这两个字的笔画数不同,縏字的笔画数多于盤字的笔画数,因此对縏字的编码的声调码进行调整,采用下层第二声调级的声调代码,则縏字的编码改为VVUTVPQF,
(2)当重码字是用上层声调级表示声调时,用下述方法调整重码字的编码:
①比较两个重码字的第一、二、三、末四个部首中不同部首的拼音的声母,声母的代码排序在后的字先改,将该字编码的第五位形码代码改为其部首拼音的声母代码;
例如,嶅、熬两字的编码同为AAHCIAOP,这两个字中的不同部首为山和
 其部首的拼音的声母代码分别为U和H,声母代码U的排序在后,因此对嶅字的编码的左起第五位的形码进行调整,采用其声母代码U代替原形码I,嶅字的编码改为AAHCUAOP,
其部首的拼音的声母代码分别为U和H,声母代码U的排序在后,因此对嶅字的编码的左起第五位的形码进行调整,采用其声母代码U代替原形码I,嶅字的编码改为AAHCUAOP,
②当不能用上述方法①区别重码字时,可比较两个重码字的笔画数,笔画数多的字先改,改变方法同上述方法①中的方法;
③当用上述方法①或②改变一个先改的重码字的编码后,该字的改变后的编码的形码部分又与其它字的的编码中的形码部分构成重码时,则原来应先改的重码字不改编码,而对另外一个重码字改变编码,改变方法同上述方法①中的方法;
例如,螯、鼇两字的编码同为AAHCNAOP,这两个字中的不同部首为虫和黾,若按两不同部首的声母代码确定修改顺序,则螯应改为AAHCOAOP,但这个编码与獒字的编码相同,故不改螯字的编码,而改鼇字的编码为AAHCMAOP,
④如按上述方法③改变完第二个重码字的编码后,该字的编码中的形码部分仍与其它字的编码中的形码部分构成重码时,则依照上述方法①、②、③确定两个重码字的改动顺序,使用上述方法①中的改变编码的方法,对确定应改的重码字编码进行改变,使改变的字的八位编码不与其它字的八位编码构成重码;
(3)当不能采用上述方法(1)或(2)区别重码时,采用下述方法调整重码字:
①利用《汉字频度表》确定两个重码字的频度,频度高的字用下层第一声调级作该字的声调代码,频度低的字用下层第二声调级作该字的声调代码;
例如,岂、屺两字的编码同为IIMUJQIC,这两个字的部首和笔画都相同,因此根据《汉字频度表》确定这两个字的频度,屺的频度低,因此将屺的编码改为IIMUJQIG,
②用任意一个字母(一般应按字母顺序取)改变频度低的字的编码的第五位,使之编码不与其它字重码。
利用繁体字主部首代码对繁体字编码时,当遇到有几个繁体字、异体字简化为一个简体字的情况时,仅允许有一个繁体字编码与简体字编码相同,其余繁体字、异体字需另行编码。
计算机汉字八四码输入法所用的键盘保留标准键盘上的ESC键,F1-F12功能键和小键盘的键,其排列方式不变,对标准键盘主键盘区的键和其排列方式进行改变,具体方法如下,主键盘区分为四排,第一排为15个键,从左到右依次为:! @ # $ % ^& * ( ) — + |1, 2, 3, 4, 5, 6, 7, 8, 9,0, -,=,\,第二排为14个键,从左到右依次为:Caps Lock,N,O,P,Q,R,S,T,U,V,W,X,Y,Z字母代码键,第三排为15个键,从左到右依次为:
Shift,A,B,C,D,E,F,G,H,I,J,K,L,M字母代码键,Shift,第四排为15个键,从左到右依次为:Ctrl,Alt,空格 [ ]{ }< >
* ( )《 》, . 连音符,升调,降调,#升半音,b降半音,o全音符,d=分音符,‘ " / ~ ’; : ? 。 !
连音符,升调,降调,#升半音,b降半音,o全音符,d=分音符,‘ " / ~ ’; : ? 。 !
 四分音符,
四分音符,
 八分音符,
八分音符,
 十六分音符,
十六分音符,
 三十二分音符,休止,。
三十二分音符,休止,。
另外一种八四码输入法所用的键盘是在标准的计算机键盘的空格键下面增加二排共26个键,其中第一排为13个字母代码键,第二排为13个字母代码键,第一排的13个字母代码键上的字母从左到右依次为N,O,P,Q,R,S,T,U,V,W,X,Y,Z,第二排的13个字母代码键上的字母从左到右依次为A,B,C,D,E,F,G,H,I,J,K,L,M。
当采用等长四位码输入方法之二时,等长四位码的声调代码都可以先选取下层第一声调级代码,由屏幕显示所有下层四个声调级的汉字及其义码,再选取所需输入的汉字的义码代码输入。
八四码输入法中带有带声调的全拼音输入法,其编码规则为:
(1)汉字的拼音声母、韵母全部由字母代码逐个表示,按拼音规则顺序输入,
(2)拼音的声调代码由
 表示,按汉字的声调选取声调代码,在输入汉字的拼音的声母、韵母的字母代码后输入声调代码;
表示,按汉字的声调选取声调代码,在输入汉字的拼音的声母、韵母的字母代码后输入声调代码;
带声调的全拼音输入法可与八四码交替使用,也可单独使用。
为便于清楚地理解本发明的内容,对本发明中用到的一些概念作如下解释:
1.部首:本发明中所说的部首,不仅包括一般汉字概念中所述的偏旁部首,还包括了汉字的基本笔划,因此部首的含义相当于字根的含义。
2.主部首:主部首主要是从《新华字典》中的偏旁部首中分类选出171个有代表性的偏旁部首,作为本发明中汉字编码的基本字形部首,称为主部首。
3.附属部首:主要是将《新华字典》中未归为主部首的偏旁部首和汉字的基本笔划,根据它们的笔划特点,分类归到某个主部首中,作为这个主部首的附属部首。
4.等长八位码:等长八位码是八四码中一种汉字编码,由八位代码构成,每个汉字的对应编码都是八位代码,代码长度相符,故称等长八位码。
5.等长四位码:等长四位码是八四码中的另一种汉字编码,由四位代码构成,每个汉字的对应编码都是四位代码,代码长度相等,并且四位代码中没有重复的代码,即没有两个代码相同,故称等长四位码。
6.区别码:区别码是等长八位码中的左起第1位代码,它的代码与等长八位码的左起第二位代码相同,其作用是在计算机键盘上输入等长八位码时,使计算机能够识别所输入的汉字编码是等长八位码,而不是等长四位码。
7.形码:形码是等长八位码中的左起第2-5位代码,它是根据汉字的字形编码,将汉字按其书写顺序拆分,拆分出的汉字部首要与主部首或附属部首相一致,然后按这些部首的书写顺序编出汉字的形码。
为满足等长八位码的等长要求,形码必须是四位代码组成。当拆分汉字所得部首不足四位时,将拆分出的部首拼音的声母代码、韵母代码、将汉字的部首再细拆分为基本笔划,用与这些基本笔划对应的主部首代码或附属部首代码补足形码中的不足部分。当拆分汉字所得部首超出四位时,取汉字拆分后的第一、二、三、未位四个主部首代码或附属部首代码编码。
8.声码:声码是等长八位码中的左起第6-8位代码,也是等长四位码中的左起第2-4位代码,它是根据汉字的拼音编码,汉字的拼音一般由声母、韵母和声调组成,因此声码一般由声母代码、韵母代码和声调代码组成。
为满足等长八位码或等长四位码的等长要求,声码必须是三位代码组成。当汉字的拼音不是由声母、韵母组成的声韵音节时,而是单字母韵母音节、双字母韵母音节、三字母韵母音节、以i、u开头的韵母音节、声母组合音节时,声码代码将出现码位不足3位码的现象,这时需用其它拼音字母代码补足声码代码的码位数,具体方法见声码的编码方法。
9.义码:义码(也可看作是部首码)是等长四位码中的左起第一位代码,它主要是根据汉字的偏旁部首编码,其作用是减少等长四位码的重码。
10.等长八位码与等长四位码的交替使用是指在利用八四码对汉字编码后,在计算机键盘上输入八四码时,除了可以单独使用等长八位码对汉字编码输入,或单独使用等长四位码对汉字编码输入外,还可以同时使用等长八位码和等长四位码对汉字编码输入,即对一个汉字用等长八位码或等长四位码编码输入后,对下一个汉字可以用等长四位码或等长八位码编码输入,也就是说等长八位码和等长四位码可以交替使用,而不影响输入效果,因为计算机可以根据输入的代码中有无区别码而识别出输入的编码是等长八位码还是等长四位码。
使用本发明所设计的计算机汉字八四码输入法及键盘,进行汉字编码和计算机汉字输入,有如下优点:
1.八位码的排列方式为区别码+形码+声码,符合人们记忆汉字先形后声的习惯,便于记忆,容易直接写出编码,亦可作为准拼音文字使用。
2.八位码中的形码编码规则主要是以汉字书写中部首出现的先后顺序为准,部首的选择参考现有《新华字典》中的部首,人们对汉字部首熟悉,书写顺序习惯,因而形码规则易学易记,使用方便。
3.调整八位码重码的规则简单。
4.八位码输入时最少为4键,最多为8键,平均为4-5键,重码少,输入速度快。
5.四位码的排列方式为义码+声码,符合人们记忆汉字先形后声的习惯,便于记忆。
6.义码按汉字部首特点取码,减少了重码数量。
7.声码由声母代码+韵母代码+声调代码组成,符合汉语拼音使用规则,容易记忆,使用方便,减少重码数量。
8.韵母分为上层韵母和下层韵母,一个键位可表示两个韵母,使键盘布局合理,便于使用。
9.声调代码有5组完整声调级代码,分为上下层声调级,上层声调级有一组完整声调级,下层声调级有四组完整声调级,下层声调级另有一组不完整声调级,这些声调级分组合理,便于记忆使用,利用这些声调级,可表示汉字声调,区分韵母所在层,区分字义、减少重码。
10.调整四位码重码的方法简单。
11.利用四位码编码规则对汉字编码,可使每个汉字的编码中无相同代码,因此,输入四位码时既可按顺序输入,也可按任意顺序输入或同时输入,即并行输入,提高了输入速度。四位码亦可作为准拼音文字使用。
12.本输入方法中带有带声调全拼输入方法,规则简单易学,重码少。带声调的全拼输入法可与八四码混合使用。
13.专用键盘中各代码键排列合理,功能多,便于使用,提高输入速度。
一般使用者只要熟悉汉字部首或汉语拼音,就可学会八四码编码方法,并可很快学会输入操作。
图1是一种键盘的排列结构示意图。
图2是另一种键盘排列结构示意图。
实施例1
八位码编码实施例如下:
(1)单字为一个部首的成字:
一:AAYAAYIA,勹:EEBCEBFA,龙:YYLYDLPB
(2)单字为二个部首的字:
计:ZZUYUJID,划:TTVGDHQR,七:AAEYYQIA,兀:AAMYEWUA
(3)单字为三个部首的字:
花:KKMTCHQN,浪:FFDVULJQ,努:MMZXNNUC
(4)单字为四个部首的字:
副:AARIVFUD,陈:IIAEZOLP,洞:FFEARDPE
(5)单字为五个或五个以上部首的字:
霞:FFEAZXYB,缝:TTEAXFXB,输:VVMAVUVA
实施例2
四位码编码实施例如下:
(1)声韵音节的字
给:TGJH,个:MGED,跟:RGLN
(2)韵母为一个字母的字
俄:MEDB,鹅:NEDB,啊:RADJ
(3)韵母为二个字母的字
爱:ZAIQ,安:UANO,恩:QENO
(4)韵母为三个字母的字
肮:VAGN,昂:CAGO,鞥:YEGN
(5)以i、u开头韵母去掉i、u,改为y、w开头的字
弯:TWQA,湾:FWQA,玩:UWQB,
油:FYWB,铀:GYWB,有:PYWC
(6)以i开头的韵母,不去掉i,前面加y的字:
音:ZYGA,英:BYKA
(7)声母组合音节的字
噷:RHMQ,哼:SHGQ,呣:TMDE,嗯:RNDH,嗯:RNGP
实施例3
一种键盘排列结构示意图如图1所示,这种键盘称为中式键盘。
该键盘的ESC键,F1-F12功能键和小键盘的键与标准键排列方式相同,主键盘区的键的排列方式与标准键盘不同,具体排列方法见图1所示。键上的部首是简体字主部首。
实施例4
另一种键盘排列结构如图2所示,这种键盘称为标准及速录组合式键盘。
在标准键盘上的空格键下方增加两排共26个键,其中第一排为13个字母代码键,字母代码键上的字母从左到右依次为N,O,P,Q,R,S,T,U,V,W,X,Y,Z,第二排为另外13个字母代码键,字母代码键上的字母从左到右依次为A,B,C,D,E,F,G,H,I,J,K,L,M。键上的部首是简体字主部首。
Claims (6)
1.一种计算机汉字八四码输入法,其特征是:八四码由等长八位码或等长四位码两种码组成,等长八位码由八位代码构成,其左起第1位代码是区别码,第2-5位代码是形码,第6-8位代码是声码;等长四位码由四位代码构成,其左起第1位代码是义码,第2-4位代码是声码,等长四位码中的代码不重复;
一、按下述方法确定主部首及主部首代码:
参考《新华字典》中的部首,将现有简体字所用的部首分类归为171个主部首,其中一些主部首带有附属部首,将171个主部首及其附属部首分配到标准计算机键盘的26个字母键上,作为主部首及其附属部首的输入代码,具体分配如下:
yī
代码A表示简体字主部首一(
),
shùjué
代码B表示简体字主部首丨(亅、
 ),
),
piě
代码C表示简体字主部首丿,
diǎn nà
代码D表示简体字主部首丶 (),
yǐ tóu fāng
代码E表示简体字主部首乙(
 、乛、
、乛、

 等一画笔划),亠,匚jiōng chuáng yǐn kǒn zhǐ hū jié jì冂(
),疒, 廴,凵,
,,卩(
等一画笔划),亠,匚jiōng chuáng yǐn kǒn zhǐ hū jié jì冂(
),疒, 廴,凵,
,,卩(
 ),
),
 (彐、、彑),gǒng bīng bāo mì廾, 冫,勹,冖,
(彐、、彑),gǒng bīng bāo mì廾, 冫,勹,冖,
shuǐ yǔ qì
代码F表示简体字主部首水(氵,水,
 ),雨(
),气,
),雨(
),气,
jīn rìyuē
代码G表示简体字主部首金(钅),日(曰),
tǔ Fēng chén xuéshí
代码H表示简体字主部首 土,风,辰,穴,石,
fù shān tián yóu chuān
代码I表示简体字主部首阜(阝左),山,田,(由),川,chuān huǒ(巛,ㄍ),火(灬),
hé mài gǔ mǐ dòu zhú
代码J表示简体字主部首禾,麦,谷,米,豆,竹(),
cǎo shí má
代码K表示简体字主部首草(艹),食(饣),麻,
mù guā
代码L表示简体字主部首木(木),瓜,
rénrù zǐ shì jǐ sì yǐ ér
代码M表示简体字主部首人 (入,亻),子(孑),士,己(巳,已),儿,zì fù nǚ自,父,女,
niǎo wū chóng zhuīyáng
代码N表示简体字主部首鸟(乌,
 ),虫,隹,羊(
),虫,隹,羊(
 ),shǐ zhìlùmiǎn豕(
),shǐ zhìlùmiǎn豕(
 ),豸,鹿,黾,
),豸,鹿,黾,
quǎn shǔ mǎ yú niú
代码O表示简体字主部首犬(犭),鼠,马,鱼,牛(
 ),
),
ròu yuè mù bí yǔ jiǎo
代码P表示简体字主部首肉(月,
 ),目,鼻,羽,角,
),目,鼻,羽,角,
xīn biāo ěr gǔ zhuǎ
代码Q表示简体字主部首心(忄,),髟,耳,骨,爪(爫),
kǒu zú shēn
代码R表示简体字主部首口, 足(),身,
shǒu shī máo xuè pí chǐ
代码S表示简体字主部首手(扌,),尸,毛, 血,皮,齿,shé yá舌,牙,
gē gōng mì bǐ jīn jiù
代码T表示简体字主部首戈,弓,糸(糹,纟),匕,巾,臼(
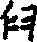 ),hù mǐn dǒu lǐ户,皿,斗,里(
),
),hù mǐn dǒu lǐ户,皿,斗,里(
),
wǎng shū yù wáng shǐshí
代码U表示简体字主部首网(
),殳,玉(王,
 ),矢,十,bā chǎng wéi mián lǔ八(丷),厂, 韦, 宀, 卤,
),矢,十,bā chǎng wéi mián lǔ八(丷),厂, 韦, 宀, 卤,
dāo jīn chē wǎ fǒu yì
代码V表示简体字主部首刀(刂,ク),斤,车,瓦,缶,邑(阝右),gèn zhōu lěi máo艮(
 ),舟,耒,矛,
),舟,耒,矛,
bèi cùn piàn mén dòu fāng
代码W表示简体字主部首贝, 寸,片, 门 (鬥),方,qiáng yǒu yī爿(丬,
),酉,衣(衤),
chuò chìyòng guǎng
代码X表示简体字主部首辵(辶),赤,用(

 ),广,zǒu gōngjǐ lǎo shān dà wú mǔ guàn lì qiàn走,工,几(
),广,zǒu gōngjǐ lǎo shān dà wú mǔ guàn lì qiàn走,工,几(
 ),老(
),老(
 ),彡,大,毋(母,
),力,欠,hǔ yè卜(),业,
),彡,大,毋(母,
),力,欠,hǔ yè卜(),业,
chì shū biàn gé wéi
代码Y表示简体字主部首彳,疋(
),采,革,口(O),xīn zhǐdǎi bǐ xī sī wāng shì qīng yè yāo yì lóng辛,止,歹,比,夕,厶,尢,示(礻),青,页,幺,弋,龙,
yán yīn pū guǐ xiǎo
代码Z表示简体字主部首言(讠),音,攴(攵),鬼,小(),yù yòu jiànxī bái hēi wén lì聿(肀,
 ),又,见,西(
),又,见,西(
 ),白,黑(
),白,黑(
 ),文,立,
),文,立,
二、按下述方法确定汉语拼音的代码:
将汉语拼音的字母、声母、韵母分配到标准计算机键盘的26个字母键上,作为汉语拼音的字母、声母、韵母的输入代码,汉语拼音的声母、韵母分配原则如下:
(1)单字母声母用声母本身字母作代码,
(2)双字母声母ch、sh、zh分别用字母O、U、V作代码,
(3)将字母Y、W看作特殊声母,并用其本身字母作代码,
(4)韵母的代码键不能设置在能与其相拼的声母代码键上,
(5)将34个韵母分为上层韵母11个和下层韵母23个,
(6)将字母组合ng看作特殊韵母,用代码G表示,
(7)音节shu中的韵母u用代码v表示,
汉语拼音的字母、声母、韵母的具体分配如下,其中汉语拼音的字母的代码与26个字母键相对应:
代码A表示下层韵母a,
代码B表示声母b,
代码C表示声母c,
代码D表示声母d,
代码E表示下层韵母e,
代码F表示声母f、下层韵母ao,
代码G表示声母g、上层韵母ng、下层韵母in,
代码H表示声母h、下层韵母iao,
代码I表示下层韵母i,
代码J表示声母j、上层韵母ang、下层韵母ei,
代码K表示声母k、下层韵母ing,
代码L表示声母l、上层韵母en、下层韵母uei,
代码M表示声母m、上层韵母iang、下层韵母uo,
代码N表示声母n、下层韵母üan,
代码O表示声母ch、下层韵母o,
代码P表示声母p、上层韵母iong、下层韵母ong,
代码Q表示声母q、上层韵母ua、下层韵母an,
代码R表示声母r、上层韵母uai、下层韵母ai,
代码S表示声母s、上层韵母ün、下层韵母ie,
代码T表示声母t、上层韵母iou、下层韵母üe,
代码U表示声母sh、下层韵母u,
代码V表示声母zh、下层韵母ü,
代码W表示声母w、上层韵母uan、下层韵母ou,
代码X表示声母x、上层韵母uang、下层韵母eng,
代码Y表示声母y、上层韵母uen、下层韵母ia,
代码Z表示声母z、下层韵母ian;
三、按下述方法确定汉语拼音声调的代码:
将汉语拼音的四声声调分配到标准计算机键盘的字母键上,作为声调的输入代码,在标准计算机键盘上分配出六组声调代码,其中的一组为上层声调级,另外五组为下层声调级,具体分配如下:
下层第一声调级的声调代码为



下层第二声调级的声调代码为


下层第三声调级的声调代码为



下层第四声调级的声调代码为



下层第五声调级只有一个声调代码为

上层第一声调级的声调代码为




四、按下述方法对汉字进行编码:
<1>等长八位码的编码方法:
等长八位码由区别码、形码和声码三部分组成,这三部分的编码方法分述如下:
(1)区别码的编码方法:
区别码的代码与等长八位码的左起第二位代码相同,取等长八位码的左起第2位代码作为区别码的代码,
(2)形码的编码方法:
形码的编码原则如下:
1).按汉字的书写顺序拆分汉字中的部首,拆分出的部首应与171个主部首中的主部首或附属部首基本一致,既笔划种类一致,笔画数一致,笔划书写顺序一致,允许拆分的部首的笔划有延长或整个部首变形,但不能引起字义的改变,
2).汉字拆分时,若有多种拆分方法,取拆分部首少的拆分方法,
3).汉字拆分成部首后,按这些部首的书写顺序,取与这些部首对应的主部首代码或附属部首的代码组成形码,形码构成等长八位码中的第2-5位的代码;
形码的具体编码方法如下:
1).汉字由一个部首形成,这个部首与171个主部首中主部首或附属部首相同,其编码方法如下:
①取与该汉字的部首对应的主部首代码或附属部首代码作为形码左起第1位代码,
②取与该汉字的拼音的声母对应的声母代码或与其韵母对应的韵母代码作为形码左起第2位代码,
③将该汉字按书写顺序拆分为部首,取与其第一个部首对应的主部首代码或附属部首代码,作为形码的左起第3位代码,
④将该汉字按上述③中的方法拆分后,取与其最后一个部首对应的主部首代码或附属部首代码,作为形码的左起第4位代码;
2).汉字由二个部首形成的字的编码方法:
按二个部首的书写顺序,按下述步骤编码:
①取与该汉字的第一个部首对应的主部首代码或附属部首代码,作为形码左起第1位代码,
②取与该汉字的第二个部首对应的主部首代码或附属部首代码,作为形码左起第2位代码,
③取与该汉字的第一个部首拼音的声母对应的声母代码或与其韵母对应的韵母代码,作为形码的左起第3位代码,
④取与该汉字的第二个部首拼音的声母对应的声母代码或与其韵母对应的韵母代码,作为形码的左起第4位代码,
3).汉字由三个部首形成的字的编码方法:
按三个部首的书写顺序,按下述步骤编码:
①取与汉汉字的第一个部首对应的主部首代码或附属部首代码,作为形码左起第1位代码,
②取与该汉字的第二个部首对应的主部首代码或附属部首代码,作为形码左起第2位代码,
③取与该汉字的第三个部首对应的主部首代码或附属部首代码,作为形码左起第3位代码,
④取与该汉字的第一个部首拼音的声母对应的声母代码或与其韵母对应的韵母代码,作为形码的左起第4位代码,
4).汉字由四个部首形成的字的编码方法:
按四个部首的书写顺序,按下述步骤编码:
①取与该汉字的第一个部首对应的主部首代码或附属部首代码,作为形码左起第1位代码,
②取与该汉字的第二个部首对应的主部首代码或附属部首代码,作为形码左起第2位代码,
③取与该汉字的第三个部首对应的主部首代码或附属部首代码,作为形码左起第3位代码,
④取与该汉字的第四个部首对应的主部首代码或附属部首代码,作为形码左起第4位代码,
5).汉字由五个或五个以上部首形成的字的编码方法:
按五个或五个以上部首的书写顺序,按下述步骤编码:
①取与该汉字的第一个部首对应的主部首代码或附属部首代码,作为形码左起第1位代码,
②取与该汉字的第二个部首对应的主部首代码或附属部首代码,作为形码左起第2位代码,
③取与该汉字的第三个部首对应的主部首代码或附属部首代码,作为形码左起第3位代码,
④取与该汉字的最后一个部首对应的主部首代码或附属部首代码,作为形码左起第4位代码,
(3)声码的编码方法:
声码由表示声母、韵母和声调的三个代码组成,按照汉字的拼音的声母、韵母和声调,选取相应的声母代码、韵母代码和声调代码组成声码,声码构成等长八位码的第6~8位代码;
对有不同音节的汉字的声码编码方法分述如下:
1).声韵音节的汉字的声码编码方法:
①取与该汉字的拼音的声母对应的声母代码,作为声码的左起第1位代码,
②取与该汉字的拼音的韵母对应的韵母代码,作为声码的左起第2位代码,
③取与该汉字的拼音的声调对应的声调代码,作为声码的左起第3位代码,
选取声调代码时,若汉字的拼音的韵母为下层韵母,声调代码在下层声调级中选取,选取的顺序为第一声调级,第二声调级,第三声调级,第四声调级;
若汉字的拼音的韵母为上层韵母,声调级在上层声调级中选取;
2).单字母韵母音节的汉字声码编码方法:
①取与该汉字的拼音的韵母对应的韵母代码,作为声码的左起第1位代码,
②取字母D的代码,作为声码的左起第2位代码,
③取与该汉字的拼音的声调对应的声调代码,作为声码的左起第3位代码,声调代码在下层声调级中选取;
3).双字母韵母音节的汉字声码编码方法:
①取与该汉字的拼音的韵母中的第一个字母对应的汉语拼音字母代码,作为声码的左起第1位代码,
②取与该汉字的拼音的韵母中的第二个字母对应的汉语拼音字母代码,作为声码的左起第2位代码,
③取与该汉字的拼音的声调对应的声调代码,作为声码的左起第3位代码,声调代码在上层声调级中选取;
4).三字母韵母音节的汉字声码编码方法:
①取与该汉字的拼音的韵母中的第一个字母对应的汉语拼音字母代码,作为声码的左起第1位代码,
②取字母组合ng的代码,作为声码的左起第2位代码,
③取与该汉字的拼音的声调对应的声调代码,作为声码的左起第3位代码,声调代码在上层声调级中选取;
5).以i、u开头的韵母音节的汉字的声码编码方法:
用特殊声母y.w替换i、u,将以i、u开头的原韵母看作是特殊声母y、w与原韵母中去掉i、u后剩余部分相拼或与不去掉i的原韵母相拼,按汉语拼音规则决定是否去掉i、u,按声韵音节的汉字的编码方法给有这种音节的汉字编码;
6).声母组合音节的汉字的声码编码方法:
①单字母的声母音节的汉字的编码方法,按单字母韵母音节的汉字的编码方法编码,
②双字母声母音节的汉字的编码方法,按双字母韵母音节的汉字的编码方法编码,
③三字母声母音节的汉字的编码方法,按三字母韵母音节的汉字的编码方法编码,
在进行声码编码时,用下述声调级错位规则对声码编码进行调整:
①下层第一声调级的代码ABCD中,如有某个声调代码被声母代码或韵母代码占用,则该声调代码后错1位,其后的声调代码依次后错,如声调代码B被声母代码B占用,则错位后的声调级代码为ACDE;最多允许同时错位两个声调代码;
②下层第二声调级代码EFGH也允许错位,错位方法同①中的方法,但下层第二声调级代码仅允许错1位,如果错2位时,该音节的这个声调级取消;
③下层第三、四声调级代码不允许错位;
④上层声调级代码允许错1位或2位代码,错位方法同①中的方法;
<2>等长四位码的编码方法:
等长四位码由义码和声码两部分构成,这两部分的编码方法分述如下:
(1)义码的编码方法:
1).选取该字的偏旁部首,在171个主部首中找到与之对应的主部首代码或附属部首代码,作为该字的义码的代码,
2).当确定的义码的代码与该字的拼音的声母代码相同时,则改用代码C代表义码,
3).当确定的义码的代码与该字的拼音的韵母代码相同时,则改用代码B代表义码,
4).如该字属于使用上层韵母的字,当确定的义码与其声调代码相同时,则改用代码A代表义码,
5).如果该字本身的声母代码、韵母代码为A、B,当发生3)、4)的情况时,用代码C代替A或代码C代替B,用代码C作为义码代码,
6).171个主部首及其附属部首分配到标准计算机键盘上的26个字母键上,其中ABCD键上的部首为笔划类部首,E键上的部首为罕用字部首,FGHI键上的部首为自然类部首,JKL键上的部首为植物类部首,M键上的部首为人类部首,NO键上的部首为动物类部首,PQRS键上的部首为器官类部首,TUVW键上的部首为物品量度类部首,XYZ键上的部首为事物类部首,
当不能用1)到5)的方法确定义码时,可根据上述171个主部首及其附属部首分为七大类部首的规则,在与该字的偏旁部首同一类的主部首代码中选用其他代码作为该字的义码代码,一般优先选取靠近键盘中心的代码,
7).当上述方法均不能确定该字的义码代码时,在171个主部首及其附属部首中可以任选一个代码作为该字的义码代码;
(2)声码的编码方法:
声码的编码方法与等长八位码中的声码的编码方法相同,
(3)等长四位码的具体编码方法如下:
1).声韵音节的汉字的编码方法如下:
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的声韵音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
2).单字母韵母音节的汉字的编码方法:
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的单字母韵母音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
3).双字母韵母音节的汉字的编码方法:
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的双字母韵母音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
4).三字母韵母音节的汉字的编码方法:
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的三字母韵母音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
5).以i、u开头的韵母音节的汉字的编码方法:
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的以i、u开头的韵母音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
6).以声母组合音节的汉字的编码方法:
①按义码的编码方法编出该汉字的义码代码,作为等长四位码的左起第1位代码,
②按等长八位码中的声码编码方法中的以声母组合音节的汉字的编码方法编码,作为等长四位码的左起第2-4位代码,
五、八四码的输入方法:
按上述等长八位码或等长四位码的编码方法将汉字编成对应的等长八位码或等长四位码,按下述方法在标准计算机键盘上输入汉字:
<1>等长八位码的输入方法:
1).输入等长八位码的左起第1位代码,
2).输入等长八位码的左起第2-5位代码,
3).输入等长八位码的左起第6-8位代码,
<2>等长四位码的输入方法之一:
1).输入等长四位码的左起第1位代码,
2).输入等长四位码的左起第2-4位代码,
<3>等长四位码的输入方法之二:
1).输入等长四位码的左起第2-4位代码,
2).输入等长四位码的左起第1位代码,
<4>等长四位码的输入方法之三:
将等长四位码的四个代码同时输入或将四位代码按任意先后顺序输入,即并行输入;
使用八四码在计算机上输入汉字时,可以单独使用等长八位码输入汉字,也可以单独使用等长四位码输入汉字,还可以交替使用等长八位码和等长四位码输入汉字。
2.根据权利要求1所述的计算机汉字八四码输入方法,其特征是:
参考《新华字典》中的部首,将繁体字所用的部首分类归为171个主部首,其中一些主部首带有附属部首,将171个主部首及其附属部首分配到标准计算机键盘的26个字母键上,作为主部首及其附属部首的输入代码,具体分配如下:
yī
代码A表示繁体字主部首一(
 ),
),
shù jué
代码B表示繁体字主部首丨(亅、
 ),
),
piě
代码C表示繁体字主部首丿,
diǎnnà
代码D表示繁体字主部首丶(),
yǐ tóu fāng
代码E表示繁体字主部首乙(
 、乛、
、乛、
 等一画笔划),亠,匚,jiōng chuǎngyǐn kǎn zhǐ hū jié jì冂(
等一画笔划),亠,匚,jiōng chuǎngyǐn kǎn zhǐ hū jié jì冂(

 ),疒,廴,凵,
,,卩(
),
),疒,廴,凵,
,,卩(
),
 (彐、、彑),
(彐、、彑),
gǒng bīng bāo mì廾, 冫,勹, 冖,
shuǐ yǔ qì
代码F表示繁体字主部首水(氵,水,
 ),雨(
),雨(
 ),气,
),气,
jīn rìyuē
代码G表示繁体字主部首金(钅),日(曰),
tǔ Fēng chén xué shí
代码H表示繁体字主部首土,風, 辰, 穴,石,
fù shāntián yóu chuān
代码I表示繁体字主部首阜(阝左),山,田, (由), 川,chuān huǒ(巛,ㄍ),火(灬),
hé mài gǔ mǐ dòu zhú
代码J表示繁体字主部首禾,麥,谷,米,豆,竹(),
cǎo shí má
代码K表示繁体字主部首草(艹),食(饣),麻,
mù guā
代码L表示繁体字主部首木(木),瓜,
rénrù zǐ shì jǐ sì yī ér
代码M表示繁体字主部首人(入,亻),子(孑),士,己(巳,已),儿,zì fù nǚ自,父,女,
niǎo wū chóngzhuīyáng
代码N表示繁体字主部首鳥(烏,
),虫,隹,羊(
 ),shǐ zhì lù miǎn豕(
),豸,鹿,黽,
),shǐ zhì lù miǎn豕(
),豸,鹿,黽,
quǎn shǔ mǎ yú niú
代码O表示繁体字主部首犬(犭),鼠,馬,魚,牛(

 ),
),
ròuyuè mù bí yǔjiǎo
代码P表示繁体字主部首肉(月,
 ),目,鼻,羽,角,
),目,鼻,羽,角,
xīn biāo ěr gǔ zhuǎ
代码Q表示繁体字主部首心(忄,),髟, 耳,骨,爪(爫),
kǒu zú shēn
代码R表示繁体字主部首口, 足(),身,
shǒu shī mǎo xuè pí chǐ
代码S表示繁体字主部首手(扌,),尸,毛, 血,皮,齒,shé yá舌,牙,
gē gōng mì bǐ jīn jiù
代码T表示繁体字主部首戈,弓,糸(糹,纟),匕,巾,臼(
 ),hù mǐn dǒu lǐ户,皿,斗,里(
),
),hù mǐn dǒu lǐ户,皿,斗,里(
),
wǎng shū yùwáng shǐ shí
代码U表示繁体字主部首网(
 ),殳,玉(王,
),殳,玉(王,
 ),矢,十,bā chǎng wéi mián lǔ八(丷),厂,韋,宀, 鹵,
),矢,十,bā chǎng wéi mián lǔ八(丷),厂,韋,宀, 鹵,
dāo jīn chē wǎ fǒu yì
代码V表示繁体字主部首刀(刂,ク),斤,車,瓦,缶,邑(阝右),gèn zhōu lěi máo艮(
 ),舟,耒,矛,
),舟,耒,矛,
bèi cùn piàn mén dòu fāng
代码W表示繁体字主部首貝,寸, 片, 門 (鬥),方,qiáng yǒu yī爿(
 ,丬),酉,衣(衤),
,丬),酉,衣(衤),
chuò chì yòng gu ǎng
代码X表示繁体字主部首辵(辶),赤,用(
),广,zǒu gōng jǐ lǎo shān dà wú mǔ guàn lìqiàn走,工, 几(
 ),老(
),老(
 ),彡, 大,毋(母,
),彡, 大,毋(母,
 ),力,欠,bǔ yè卜(),业,
),力,欠,bǔ yè卜(),业,
chì shū biàngé wéi
代码Y表示繁体字主部首彳,疋(

 ),采,革,口(O),xīn zhǐ dǎi bǐ xī sī wāng shì qīngyè yāo yì lóng辛, 止,歹,比,夕,厶,尢,示(礻),青,頁,幺,弋,龍,
),采,革,口(O),xīn zhǐ dǎi bǐ xī sī wāng shì qīngyè yāo yì lóng辛, 止,歹,比,夕,厶,尢,示(礻),青,頁,幺,弋,龍,
yán yīn pū guǐ xiǎo
代码Z表示繁体字主部首言(讠),音, 攴(攵),鬼,小(),yù yòu jiàn xī bái hēi wén lì聿(肀,

 ),又,見,西(
),白,黑(
),又,見,西(
),白,黑(
 ),文,立。
),文,立。
3.根据权利要求1所述的计算机汉字八四码输入方法,其特征是:在用等长八位码对汉字进行编码时,用下述方法对重码字的编码进行调整:
(1)当重码字是用下层声调级表示声调时,用下述方法调整重码字的编码:
①比较两个重码字的第一、二、三、末四个部首中不同部首的拼音的声母,声母的代码排序在前的字,采用下层第一声调级作该字的声调代码,声母的代码排序在后的字,采用下层第二声调级作该字的声调代码;
当重码字是3个或4个时,应按字母先后排序依次确定该字声调级代码为第一、二、三、四级声调代码;
②当不能用上述方法①区别重码字时,可比较两个重码字的笔画数,笔画数少的字采用下层第一声调级作该字的声调代码,笔画数多的字采用下层第二声调级作该字的声调代码;
当重码字是3个或4个时,应按笔画数的少、多排序,依次确定该字声调级代码为第一、二、三、四级声调代码;
(2)当重码字是用上层声调级表示声调时,用下述方法调整重码字的编码:
①比较两个重码字的第一、二、三、末四个部首中不同部首的拼音的声母,声母的代码排序在后的字先改,将该字编码的左起第五位形码代码改为其部首拼音的声母代码;
②当不能用上述方法①区别重码字时,可比较两个重码字的笔画数,笔画数多的字先改,改变方法同上述方法①中的方法;
③当用上述方法①或②改变一个先改的重码字的编码后,该字的改变后的编码的形码部分又与其它字的的编码中的形码部分构成重码时,则原来应先改的重码字不改编码,而对另外一个重码字改变编码,改变方法同上述方法①中的方法;
(3)当不能采用上述方法(1)或(2)区别重码时,采用下述方法调整重码字:
①利用《汉字频度表》确定两个重码字的频度,频度高的字用下层第一声调级作该字的声调代码,频度低的字用下层第二声调级作该字的声调代码;
②用任意一个字母(一般应按字母顺序取)改变频度低的字的编码的左起第五位,使之编码不与其它字重码。
4.根据权利要求2所述的计算机汉字八四码输入法,其特征是:利用繁体字主部首代码对繁体字编码时,当遇到有几个繁体字、异体字简化为一个简体字的情况时,仅允许有一个繁体字编码与简体字编码相同,其余繁体字、异体字需另行编码。
5.一种实现权利要求1所述的计算机汉字八四码输入法所用的键盘,保留标准键盘上的ESC键,F1-F12功能键和小键盘的键,其排列方式不变,其特征是:对标准键盘主键盘区的键和其排列方式进行改变,具体方法如下,主键盘区分为四排,第一排为15个键,从左到右依次为: ! @ # $ % ^& * ( ) — + |1, 2, 3, 4, 5, 6, 7, 8, 9, 0, -, =, \,第二排为14个键,从左到右依次为:Caps Lock,N,O,P,Q,R,S,T,U,V,W,X,Y,Z字母代码键,第三排为15个键,从左到右依次为:
! @ # $ % ^& * ( ) — + |1, 2, 3, 4, 5, 6, 7, 8, 9, 0, -, =, \,第二排为14个键,从左到右依次为:Caps Lock,N,O,P,Q,R,S,T,U,V,W,X,Y,Z字母代码键,第三排为15个键,从左到右依次为:
Shift,A,B,C,D,E,F,G,H,I,J,K,L,M字母代码键,Shift,第四排为15个键,从左到右依次为:Ctrl,Alt,空格 [ ] { } < >
* ( ) 《 》 , . 连音符,升调,降调,#升半音,b降半音,o全音符,d=分音符,‘ " / ~ ,; : ? 。 !
连音符,升调,降调,#升半音,b降半音,o全音符,d=分音符,‘ " / ~ ,; : ? 。 !

 四分音符,
八分音符,
十六分音符,
四分音符,
八分音符,
十六分音符,
 三十二分音符,休止,。
三十二分音符,休止,。
6.一种实现权利要求1所述的计算机汉字八四码输入法所用的键盘,其特征是:在标准的计算机键盘的空格键下面增加二排共26个键,其中第一排为13个字母代码键,第二排为13个字母代码键,第一排的13个字母代码键上的字母从左到右依次为N,O,P,Q,R,S,T,U,V,W,X,Y,Z,第二排的13个字母代码键上的字母从左到右依次为A,B,C,D,E,F,G,H,I,J,K,L,M。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN96114178A CN1054695C (zh) | 1996-12-30 | 1996-12-30 | 计算机汉字八四码输入法及键盘 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN96114178A CN1054695C (zh) | 1996-12-30 | 1996-12-30 | 计算机汉字八四码输入法及键盘 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1186976A CN1186976A (zh) | 1998-07-08 |
| CN1054695C true CN1054695C (zh) | 2000-07-19 |
Family
ID=5121986
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN96114178A Expired - Fee Related CN1054695C (zh) | 1996-12-30 | 1996-12-30 | 计算机汉字八四码输入法及键盘 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN1054695C (zh) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101581977B (zh) * | 2009-05-08 | 2011-07-06 | 刘金远 | 共用键盘的中文与英文的数码输入法(26音码键元方案) |
| CN101957662B (zh) * | 2010-04-11 | 2015-07-22 | 李春华 | 带有汉字元素的计算机和手机汉字输入键盘及输入方法 |
| CN103760988B (zh) * | 2013-11-18 | 2016-08-31 | 赵树清 | 一种音节汉字输入法 |
-
1996
- 1996-12-30 CN CN96114178A patent/CN1054695C/zh not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| CN1186976A (zh) | 1998-07-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1577229A (zh) | 输入音符串进入计算机及文句生产方法及其计算机与媒体 | |
| CN85101817A (zh) | 安子介式汉字笔形电脑编码法及其键盘 | |
| CN1900886A (zh) | 单击与多键并击混合输入中、英文的方法和键盘 | |
| CN1054695C (zh) | 计算机汉字八四码输入法及键盘 | |
| CN1101139A (zh) | 图符编码计算机输入法 | |
| CN1154502A (zh) | 教育规范五笔字型汉字输入法及其装置 | |
| CN1163815C (zh) | 汉语形声字输入方法 | |
| CN1025896C (zh) | 新概念编码计算机汉字输入键盘 | |
| CN1808355A (zh) | 中文谐音输入法 | |
| CN1124539C (zh) | 计算机汉字输入方法及键盘 | |
| CN1089919C (zh) | 一种叠加式按形归类的文字拆分编码输入方法及键盘 | |
| CN1116634C (zh) | 一种汉字拼音语言文字编码的计算机汉字输入方法 | |
| CN1399185A (zh) | 整体汉字输入法及其键盘 | |
| CN1038366C (zh) | 计算机汉字输入方法 | |
| CN1129836C (zh) | 形意类字母汉字多功能输入法 | |
| CN1908870A (zh) | 单击与多键并击混合输入中英文的方法和键盘 | |
| CN1417674A (zh) | 汉语音节双读方案和汉语键盘及其信息输入处理方法 | |
| CN1140865C (zh) | 超级数字码 | |
| CN1059280C (zh) | 部首编码计算机汉字输入法 | |
| CN1109287C (zh) | 一种中文词组输入法 | |
| CN1276337C (zh) | 计算机汉字编码输入方法 | |
| CN1074842C (zh) | 简明数码汉字输入方法 | |
| CN1068127C (zh) | 文字信息处理方法和装置 | |
| CN1131293A (zh) | 易通快速全息汉字编码及其键盘 | |
| CN1387106A (zh) | 一种汉字拼音语言文字编码方法及其键盘 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C06 | Publication | ||
| PB01 | Publication | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C19 | Lapse of patent right due to non-payment of the annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee |