CN103034963A - Service selection system and selection method based on correlation - Google Patents
Service selection system and selection method based on correlation Download PDFInfo
- Publication number
- CN103034963A CN103034963A CN2012104945580A CN201210494558A CN103034963A CN 103034963 A CN103034963 A CN 103034963A CN 2012104945580 A CN2012104945580 A CN 2012104945580A CN 201210494558 A CN201210494558 A CN 201210494558A CN 103034963 A CN103034963 A CN 103034963A
- Authority
- CN
- China
- Prior art keywords
- service
- module
- selection
- evaluation
- user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Landscapes
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
本发明涉及一种基于相关性的服务选择系统,包括发布模块、检索模块、评价模块、数据库模块以及选择模块,所述服务信息利用UDDI进行注册发布。数据库根据评价模块提供的评价数据对原子服务资源进行排序,选择模块优先选择评价高的原子服务资源向用户展示。本发明同时涉及该选择系统的选择方法。本发明改变了传统的服务选择模式,突破现有技术在寻找相似邻居用户时可信性不高的局限,通过综合服务之间的相关性考虑服务的选择过程,避免了可能发生的联合欺骗情况,可使选择的结果更为精确;支持开放网络环境的动态特性,适应开放网络环境的需求;有效地提高服务选择的效率,也可以避免服务提供商所提供数据不可信情况的发生。
The invention relates to a correlation-based service selection system, which includes a release module, a search module, an evaluation module, a database module and a selection module, and the service information is registered and published by using UDDI. The database sorts the atomic service resources according to the evaluation data provided by the evaluation module, and the selection module preferentially selects the atomic service resources with high evaluation to display to the user. The invention also relates to the selection method of the selection system. The present invention changes the traditional service selection mode, breaks through the limitation of the existing technology that the credibility is not high when looking for similar neighbor users, considers the service selection process through the correlation between comprehensive services, and avoids possible joint fraud , can make the selection result more accurate; support the dynamic characteristics of the open network environment, adapt to the needs of the open network environment; effectively improve the efficiency of service selection, and can also avoid the occurrence of untrustworthy data provided by service providers.
Description
技术领域technical field
本发明涉及一种服务类产品的查询系统,具体的,在一个开放、异构的复杂网络环境下,构建可信用户联盟并根据服务间的相关性进行服务选择的系统,同时本发明公开了该系统的选择方法。The present invention relates to a query system for service products, specifically, in an open, heterogeneous and complex network environment, a system for building trusted user alliances and selecting services according to the correlation between services. At the same time, the present invention discloses The system selection method.
背景技术Background technique
开放的网络化应用和“软件作为服务”的理念必将导致基于Internet环境下软件系统的主要形态、运行方式、生产方式和使用方式发生巨大的变化。网络上分布着大量的功能相同、非功能特性各异的服务,当用户请求服务时往往没有单一的服务可以直接满足用户的需求,这时就需要选出一些原子服务进行聚合。服务的聚合过程可以用原子服务来表示,每一个原子服务只是一个虚拟的服务模块,它体现的是服务逻辑上的关系,在聚合过程中将被现实的具体原子服务所替换。服务的选择过程依赖于聚合历史,目前已有的相关选择方案大多数都是将服务的选择过程独立于聚合过程的,忽略了服务间的相关性。总之,已有的研究或者缺乏理论深度,或者未给出切合实际的模型或算法,因而都不大适用于大规模的开放网络环境。Open network applications and the concept of "software as a service" will inevitably lead to tremendous changes in the main form, operation mode, production mode and use mode of software systems based on the Internet environment. There are a large number of services with the same function and different non-functional characteristics distributed on the network. When users request services, there is often no single service that can directly meet the needs of users. At this time, some atomic services need to be selected for aggregation. The aggregation process of services can be represented by atomic services. Each atomic service is just a virtual service module, which embodies the logical relationship of services, and will be replaced by actual specific atomic services during the aggregation process. The service selection process depends on the aggregation history. Most existing correlation selection schemes separate the service selection process from the aggregation process, ignoring the correlation between services. In short, the existing research either lacks theoretical depth, or does not give a practical model or algorithm, so it is not suitable for large-scale open network environment.
发明内容Contents of the invention
发明目的:本发明的目的是提供一种在开放、异构网络环境下提供高效率、精确有效可靠的服务选择的系统,同时本发明公开了该系统的选择方法。Purpose of the invention: The purpose of the invention is to provide a system for providing high-efficiency, accurate, effective and reliable service selection in an open and heterogeneous network environment, and the invention discloses a selection method of the system at the same time.
技术方案:本发明通过如下技术方案加以实现:一种基于相关性的服务选择系统,包括发布模块、检索模块、评价模块、数据库模块以及选择模块,检索模块提供检索端口供用户访问,数据库中包含所有相关的原子服务资源及对这些原子服务资源的评价数据,评价模块提供评价机制以便用户对已接受或已使用的服务进行评价,评价数据送入数据库进行保存,选择模块根据用户检索的关键字提供与之相近的服务资源供用户参考,发布模块提供接口供服务提供商发布服务信息,当信息接受完毕,发布模块将服务信息存储在数据库中。Technical solution: the present invention is realized through the following technical solutions: a service selection system based on correlation, including a publishing module, a retrieval module, an evaluation module, a database module and a selection module, the retrieval module provides a retrieval port for users to access, and the database contains All relevant atomic service resources and the evaluation data of these atomic service resources, the evaluation module provides an evaluation mechanism for users to evaluate the services they have accepted or used, and the evaluation data is sent to the database for storage, and the selection module is based on the keywords retrieved by users Provide similar service resources for users' reference. The publishing module provides an interface for service providers to publish service information. When the information is received, the publishing module stores the service information in the database.
所述服务信息利用UDDI进行注册发布。The service information uses UDDI to register and release.
数据库根据评价模块提供的评价数据对原子服务资源进行排序,选择模块优先选择评价高的原子服务资源向用户展示。The database sorts the atomic service resources according to the evaluation data provided by the evaluation module, and the selection module preferentially selects the atomic service resources with high evaluation to display to the user.
一种选择系统的选择方法,包括如下步骤:A selection method for a selection system, comprising the steps of:
1)用户通过检索模块提供的检索端口向选择系统提交欲查询的关键字;1) The user submits the keywords to be queried to the selection system through the search port provided by the search module;
2)关键字送入数据库中,从数据库中选出匹配的服务资源数据;2) The keyword is sent to the database, and the matching service resource data is selected from the database;
3)根据关键字,选择模块挑选与关键字最接近的服务资源;3) According to the keyword, the selection module selects the service resource closest to the keyword;
4)检索模块将匹配的资源通过检索模块反馈给用户。4) The retrieval module feeds back the matched resources to the user through the retrieval module.
还包括评价步骤,用户接受服务后,可通过评价模块撰写对该服务的评价信息,所述评价机制为打分制与撰写评论结合制。It also includes an evaluation step. After the user accepts the service, the user can write evaluation information for the service through the evaluation module. The evaluation mechanism is a combination system of scoring and writing reviews.
数据库返回的资源及选择模块推荐的服务资源中还包括其他用户对该资源的评价。The resources returned by the database and the service resources recommended by the selection module also include other users' comments on the resources.
有益效果:本发明与现有技术相比,改变了传统的服务选择模式,突破现有技术在寻找相似邻居用户时可信性不高的局限,通过综合服务之间的相关性考虑服务的选择过程,避免了可能发生的联合欺骗情况,可使选择的结果更为精确;支持开放网络环境的动态特性保证支持网络的动态特性,适应开放网络环境的需求;有效地提高服务选择的效率,也可以避免服务提供商所提供数据不可信情况的发生;方案具有更强的适用性。Beneficial effects: Compared with the prior art, the present invention changes the traditional service selection mode, breaks through the limitation of the prior art that the credibility is not high when looking for similar neighbor users, and considers the service selection through the correlation between comprehensive services The process avoids possible joint deception and makes the selection result more accurate; supports the dynamic characteristics of the open network environment to ensure the support of the dynamic characteristics of the network and adapts to the needs of the open network environment; effectively improves the efficiency of service selection, and also It can avoid the occurrence of untrustworthy data provided by the service provider; the scheme has stronger applicability.
附图说明Description of drawings
图1是本发明服务选择系统的结构图。Fig. 1 is a structural diagram of the service selection system of the present invention.
图2是本发明可信联盟构建的框架结构图。Fig. 2 is a frame structure diagram of the trusted alliance construction of the present invention.
图3是本发明服务间相关性示意图。Fig. 3 is a schematic diagram of inter-service correlation in the present invention.
图4是本发明常用服务集提取示意图。Fig. 4 is a schematic diagram of extracting common service sets in the present invention.
具体实施方式Detailed ways
下面结合说明书附图对本发明进行进一步详述:Below in conjunction with accompanying drawing, the present invention is further described in detail:
本发明涉及一种基于相关性的服务选择系统,图1给出了服务选择系统的结构图,包括发布模块、检索模块、评价模块、数据库模块以及选择模块,其中发布模块是服务提供商通过服务描述语言,描述所提供服务的功能以及接口信息,并将服务用UDDI(Universal Description Di scovery and Integration)向服务注册中心进行注册发布;检索模块是服务使用者在服务注册中心检索发现自己所需要的服务并获取相应服务的描述文件;评价模块是服务使用者对以往使用过提供商的服务质量进行评价,并将评价信息存储到数据库模块中,综合这两个模块对形成一个可信的服务使用者联盟进行保护;选择模块是服务使用者根据其其他用户的服务交互历史,在提取出常用服务集的前提下,选出最能与其需求相匹配的原子服务,对参考服务间存在的相关性进行服务选择进行保护,图中虚线框内所示的为独立与传统服务选择方案的系统部分。The present invention relates to a service selection system based on correlation. Fig. 1 provides a structural diagram of the service selection system, including a publishing module, a retrieval module, an evaluation module, a database module and a selection module, wherein the publishing module is a service provider through a service Describe the language, describe the function and interface information of the provided service, and use UDDI (Universal Description Discovery and Integration) to register and publish the service to the service registration center; the retrieval module is what the service user searches and finds in the service registration center. service and obtain the description file of the corresponding service; the evaluation module is for service users to evaluate the service quality of previously used providers, and store the evaluation information in the database module, and combine these two modules to form a credible service use The selection module is based on the service interaction history of other users, and on the premise of extracting the common service set, the service user selects the atomic service that best matches its needs, and the correlation between the reference services Carry out service selection for protection, and the dotted box in the figure shows the system part of the independent and traditional service selection scheme.
传统的服务选择方法是服务使用者与服务提供商之间一种简单的请求响应过程,这两者间的绑定往往是基于服务质量QOS的,然而随着资源池中服务数量的日益增多,基于QOS对服务进行查找和选择难以保证服务提供商所提供数据的真实性,同时服务使用者的QOS反馈数据的可信性也无法得到保障,因此传统的方法在服务选择的精确性方面存在不足。The traditional service selection method is a simple request-response process between the service user and the service provider. The binding between the two is often based on the quality of service (QOS). However, with the increasing number of services in the resource pool, Searching and selecting services based on QOS is difficult to guarantee the authenticity of the data provided by the service provider, and the credibility of the QOS feedback data of service users cannot be guaranteed, so the traditional method is insufficient in the accuracy of service selection .
而根据所提出的服务选择系统中的评价模块及数据库模块中的信息,我们可以突破传统的方法,以服务使用者为中心,通过为目标服务使用者找出具有相同服务使用经历的其他用户,根据他们之间的信任关系为目标服务使用者构建一个可信的用户联盟,通过联盟中其他用户的服务使用历史来为目标服务使用者进行服务推荐,从而完成后续的服务选择过程,从一种联盟角度考虑服务选择,既可以确保服务使用者信息的可信性,也可以避免服务提供商声称数据的不可性情况,下面给出建立可信联盟过程中基本的定义及方法:According to the information in the evaluation module and database module in the proposed service selection system, we can break through the traditional method, center on the service user, and find other users with the same service experience for the target service user. Build a credible user alliance for the target service users according to the trust relationship between them, and make service recommendations for the target service users through the service usage history of other users in the alliance, so as to complete the subsequent service selection process, from a Considering service selection from the perspective of the alliance can not only ensure the credibility of service user information, but also avoid the situation where the service provider claims that the data is unreliable. The basic definitions and methods in the process of establishing a trusted alliance are given below:
1)可信联盟(Trus tworthy Community)在服务选择系统中形成的既能保证用户在服务使用行为方面的相似程度,也能确保其行为可信性的用户集合,即可信联盟中的用户是可信的相似邻居用户。1) Trustworthy Community (Trustworthy Community) is a set of users formed in the service selection system that can not only ensure the similarity of users in terms of service usage behavior, but also ensure the credibility of their behavior, that is, the users in the trusted community are Trusted similar neighbor users.
2)服务的属性特征(Service Characteristics)服务的属性特征是体现服务自身特征的一系列属性,可以用来个性化服务,也可以反应用户对其的满意程度,包括服务的信誉度以及使用频率。服务的信誉度(reputat ion)是指收集到的使用过该服务的用户对其的满意程度,而使用频率(frequency)是指过去的一个时间窗口内用户使用该服务的次数。2) Service Characteristics Service characteristics are a series of attributes that reflect the characteristics of the service itself, which can be used to personalize the service, and can also reflect the user's satisfaction with it, including the reputation of the service and the frequency of use. Service reputation (reputation) refers to the satisfaction degree of users who have used the service collected, and frequency of use (frequency) refers to the number of times users use the service in a past time window.
3)推荐行为的信任(Trust Of Recommendation)在服务选择系统中,推荐行为的信任是指以用户为核心,被推荐者对推荐者推荐行为的诚实性、可靠性以及有效性的一种主观判定行为。3) Trust of Recommendation (Trust Of Recommendation) In the service selection system, trust of recommendation refers to a subjective judgment of the recommender on the honesty, reliability and effectiveness of the recommender's recommendation, with the user at the core. Behavior.
4)推荐行为的直接信任(Direct Trust Of Recommendat ion)推荐用户与目标用户两者间通过直接信息交互获得的一种信任关系,即彼此对互相推荐项目的认可程度。4) Direct trust of recommendation behavior (Direct Trust Of Recommendation) is a trust relationship obtained through direct information interaction between the recommended user and the target user, that is, the degree of mutual recognition of each other's recommended items.
5)推荐行为的间接信任(Indi rect Trust Of Recommendat ion)是指目标用户的信任群体对推荐用户信誉度的传递,即通过对推荐行为的直接信任关系的传递而得到的间接信任认可关系。5) Indirect Trust Of Recommendation (Indirect Trust Of Recommendation) refers to the transmission of the credibility of the recommended user by the trust group of the target user, that is, the indirect trust and recognition relationship obtained through the transmission of the direct trust relationship of the recommendation behavior.
6)推荐行为的信任度(Trust Degree Of Recommendation)推荐行为的信任度是存在于被推荐者和推荐者之间的一种点对点的信任关系的度量,由推荐行为的直接信任度和推荐行为的间接信任度两部分构成。6) Trust Degree of Recommended Behavior (Trust Degree Of Recommendation) Trust Degree of Recommended Behavior is a measure of a point-to-point trust relationship between the recommender and the recommender. The indirect trust degree consists of two parts.
图2给出了一个构建可信联盟的框架结构图,这个框架结构图主要由三个部分组成:首先是加入对服务属性特征的考虑,对传统算法中用户间相似度的计算公式进行改进,其次引入用户间的信任关系,通过计算用户信任度来考虑其信息的真实可信度,最后综合相似度及信任度二者进行用户分配,确定目标用户的相似邻居用户,构建可信联盟。Figure 2 shows a frame structure diagram for building a trusted alliance. This frame structure diagram is mainly composed of three parts: first, the consideration of service attribute characteristics is added, and the calculation formula of the similarity between users in the traditional algorithm is improved. Secondly, the trust relationship between users is introduced, and the real credibility of the information is considered by calculating the user's trust degree. Finally, the user is assigned based on the combination of similarity and trust, and the similar neighbor users of the target user are determined to build a trusted alliance.
通常一个服务推荐系统是由M个服务请求者{U1,U2,…Um}以及N个候选服务{S1,S2,…Sn}组成,通过服务请求者的用户日志可以提取出其服务评价信息,即服务请求者与各个服务之间的关系可以用一个M×N的矩阵来表示,其中第i行s列的元素Ri,s表示的是服务请求者i对服务s某项QoS属性值(例如响应时间、成功率等)的评价值,通常评分越高代表用户对此服务的质量越满意,若用户i从没有调用过服务s,那么Ri,s则为0。用户i和j共同评分过的服务集合为si,j,用户i与j的相似度Sim(i,j)可按公式1进行计算:Usually a service recommendation system is composed of M service requesters {U 1 , U 2 ,…U m } and N candidate services {S 1 ,S 2 ,…S n }, and the user logs of service requesters can extract The service evaluation information, that is, the relationship between the service requester and each service can be expressed by an M×N matrix, where the element R i,s in the i-th row and s column represents the service requester i’s relationship with the service s The evaluation value of a certain QoS attribute value (such as response time, success rate, etc.), usually the higher the score, the more satisfied the user is with the quality of the service. If the user i has never called the service s, then R i,s is 0 . The set of services rated by users i and j together is s i, j , and the similarity Sim(i, j) between users i and j can be calculated according to formula 1:
其中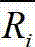
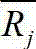
接下来考虑用户行为的可信性:一种有效获取推荐行为的直接信任度的渠道是通过用户间信息交互后彼此互相评价对方的信誉来建立的。使用Beta信任模型来计算两个用户之间推荐行为的直接信任度RDT(i,j)。若用户j和i都与服务s交互过,Ri,s表示用户i对服务s的评分,Rj,s表示用户j对服务s的评分,将j作为i一个单独的邻居对i进行推荐,并将j对服务的评分值与i对服务的真实评分值相比较,若它们之间的误差绝对值小于某一固定值ε,则认为j对i的推荐是正确的,反之则认为推荐是错误的。在两者共同评分过的服务集合si,j中,用户j为用户i正确推荐的总次数记为pi,j,错误推荐的总次数记为ni,j。Beta概率密度函数适用于描述包含二进制事件的后验概率,这里x事件指的是用户j为i做出正确的服务推荐,计算推荐行为的直接信任度的公式如下所示:Next, consider the credibility of user behavior: a channel to effectively obtain direct trust in recommended behavior is established by evaluating each other's reputation after information interaction between users. The Beta trust model is used to calculate the direct trust degree RDT(i,j) between two users in the recommended behavior. If both users j and i have interacted with service s, R i,s represents the rating of user i on service s, R j,s represents the rating of user j on service s, and j is recommended as a single neighbor of i , and compare the rating value of j pair of services with the real rating value of i pair of services, if the absolute value of the error between them is less than a certain fixed value ε, it is considered that j’s recommendation for i is correct, otherwise, the recommendation it is wrong. In the service set si ,j that both have scored together, the total number of correct recommendations for user i by user j is recorded as pi,j, and the total number of incorrect recommendations is recorded as ni,j. The Beta probability density function is suitable for describing binary events The posterior probability of , where the x event refers to the user j making a correct service recommendation for i, the formula for calculating the direct trust degree of the recommended behavior is as follows:
其中Γ为gamma函数,0<<x<<1。Where Γ is the gamma function, 0<<x<<1.
计算推荐行为的间接信任时,设集合D为目标用户i的信任用户群,由集合D内的信任用户对推荐用户j进行信任评估,并结合各自的信任权重作为评估依据。RIDT(i,j)表示用户i对j的推荐行为的间接信任度,计算公式如下所示:When calculating the indirect trust of the recommended behavior, set D as the trusted user group of the target user i, and the trusted users in the set D evaluate the trust of the recommended user j, and combine their respective trust weights as the evaluation basis. RIDT(i,j) represents the indirect trust degree of user i to j's recommendation behavior, and the calculation formula is as follows:
式中,wi为目标用户信任集合D内的用户Di向i推荐用户j的信任权重,其值为两个用户推荐行为的直接信任度,由公式2计算所得。RDT(j,Mi)为用户Di与用户j之间的直接信任度。In the formula, w i is the trust weight of user D i in the target user trust set D recommending user j to i, and its value is the direct trust degree of the two user recommendation behaviors, which is calculated by
得到推荐行为的直接信任和间接信任度之后,用户推荐行为的信任度可由公式4计算得出:After obtaining the direct trust and indirect trust degree of the recommended behavior, the trust degree of the user's recommended behavior can be calculated by formula 4:
RT(i,j)=αRDT(i,j)+βRIDT(i,j) (4)RT(i,j)=αRDT(i,j)+βRIDT(i,j) (4)
式中,RDT(i,j)表示推荐行为的直接信任度,RIDT(i,j)表示推荐行为的间接信任度,α、β分别表示其权重,取值范围为[0,1],且α+β=1。显然,RT(i,j)值越大,说明用户j对目标用户i的推荐越值得信赖。In the formula, RDT(i,j) represents the direct trust degree of the recommended behavior, RIDT(i,j) represents the indirect trust degree of the recommended behavior, α and β represent their weights respectively, and the value range is [0,1], and α+β=1. Obviously, the larger the value of RT(i, j), the more trustworthy the user j's recommendation to the target user i is.
综合目标用户与候选邻居的相似度及信任度时,综合权重计算公式如下:When synthesizing the similarity and trust between the target user and the candidate neighbors, the formula for calculating the comprehensive weight is as follows:
进行用户分配时,由于实际的网络环境中用户比较多,之间的联系也相对较紧密,我们采取传统的top-k方法,根据综合权重值选取前k个用户形成可信联盟。When performing user allocation, since there are many users in the actual network environment and the connections between them are relatively close, we adopt the traditional top-k method and select the top k users according to the comprehensive weight value to form a trusted alliance.
在可信联盟形成的基础上,分析服务使用者之间关系的工作已经结束,系统中选择模块的工作即是参考可信联盟中用户的服务交互历史,包括各个服务的发现、选择及聚合过程,分析考虑不同服务之间所存在的相关性,根据这种潜在的相关性为服务使用者提供最能满足其需求的候选服务,最终完成服务选择的过程,这是本专利需要保护技术的另一个方面。下面给出根据服务间潜在相关性进行服务选择时的基本定义及方法:On the basis of the formation of the trusted alliance, the work of analyzing the relationship between service users has been completed. The work of the selection module in the system is to refer to the service interaction history of users in the trusted alliance, including the discovery, selection and aggregation process of each service , analyze and consider the correlation between different services, provide service users with candidate services that best meet their needs according to this potential correlation, and finally complete the service selection process, which is another aspect of the technology that needs to be protected in this patent one aspect. The basic definitions and methods for service selection based on the potential correlation between services are given below:
1)常用服务集sc sc表示的是在一定时间段内,根据可信联盟中所有用户的服务聚合历史,选出的用户最常用来进行服务聚合的子服务集合,将其表示为sc={sc1,sc2,...scm},其中每个服务相比其他服务都能更好的满足用户的需求。1) The commonly used service set s c s c represents the sub-service set that is most commonly used for service aggregation by selected users according to the service aggregation history of all users in the trusted alliance within a certain period of time, which is denoted as s c ={s c1 ,s c2 ,...s cm }, where each service can better meet the user's needs than the other services.
2)候选服务集c用户进行服务选择时,服务资源池中满足用户需求的候选服务集,表示为c={c1,c2,...cm}。2) Candidate service set c When the user selects a service, the candidate service set in the service resource pool that meets the user's needs is expressed as c={c 1 ,c 2 ,...c m }.
3)服务间相关性R在服务发现、聚合及选择过程中,服务之间具有的某种特定的联系或模式,包括候选服务集与常用服务集中服务以及与整个资源池中的服务之间相互关联程度的大小,R的值越大说明候选服务集中的此服务越能接近用户的需求。3) Inter-service correlation R In the process of service discovery, aggregation, and selection, there is a specific connection or pattern between services, including the interaction between candidate service sets and commonly used services, and services in the entire resource pool. The size of the degree of association, the larger the value of R, the closer the service in the candidate service set is to the user's needs.
4)联盟原则(Association Rules)是数据挖掘领域最重要的一种技术,通常是用来发现大范围数据库中实体之间的联系。用公式可以表示为A→B,其中
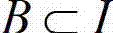
图3给出了服务间存在相关性的示意图,可信联盟中有两个服务使用者U1和U2,他们对某一服务请求S的原子服务聚合过程都一样,但当他们对S2和S5进行具体子服务映射时,用户U1选择的是子服务S21和S51,而用户U2选择的是子服务S22和S52,正因为U1和U2同属于一个用户联盟,他们在服务使用方面的相似程度是很高的,因此可以认为子服务S21,S51,S22,S52之间具有某种特定的联系或模式,也即是潜在的服务间的相关性,参考这种相关性,可以为目标服务使用者实现服务选择。Figure 3 shows a schematic diagram of the correlation between services. There are two service users U 1 and U 2 in the trusted alliance. They have the same atomic service aggregation process for a service request S, but when they request S 2 When mapping specific sub-services with S5 , user U 1 chooses sub-services S 21 and S 51 , while user U 2 chooses sub-services S 22 and S 52 , because U 1 and U 2 belong to the same user Alliance, they have a high degree of similarity in service use, so it can be considered that there is a certain connection or pattern among the sub-services S 21 , S 51 , S 22 , and S 52 , that is, a potential inter-service Dependencies, with reference to which, service selection can be achieved for target service consumers.
图4给出了动态、异构网络环境下,通过综合可信联盟中用户的服务聚合历史,分析整个服务发现、选择及聚合过程,从而提取出常用服务集的示意图,具体方法表述如下:Figure 4 shows a schematic diagram of extracting commonly used service sets by analyzing the entire process of service discovery, selection, and aggregation by synthesizing the service aggregation history of users in trusted alliances in a dynamic and heterogeneous network environment. The specific methods are expressed as follows:
将用户-服务调用率作为形成sc的参考因子。当可信联盟中某一用户k选择服务j时,我们记录下本次调用,服务j被调用的总次数记为number(sj,uk),一段时间后我们按公式6计算出服务的调用率,将其记为freq(sj,uk),然后对可信联盟中用户-服务调用率进行排序,选出数值最高的m个子服务作为常用服务集中的元素。The user-service call rate is used as a reference factor to form sc . When a user k in the trusted alliance chooses service j, we record this call, and the total number of times service j is called is recorded as number(s j , u k ). After a period of time, we calculate the service value according to formula 6 Call rate, which is recorded as freq(s j ,u k ), and then sort the user-service call rates in the trusted alliance, and select the m sub-services with the highest value as the elements of the common service set.
c中某一服务ci与sc之间的相关性可以通过评估两者间存在的联盟原则来进行计算。存在的联盟原则越多,ci与sc的相关性则越强;另外我们将ci与资源池中的所有服务集合的相关性也作为另外一个重要的参考因素,ci与s间存在的联盟原则越多,ci与sc的相关性则越弱。本文用R1和R2分别来表示这两种相关性,将服务间相关性定义为R=R1*R2,联系资源池中所有服务的聚合历史计算出候选服务集c中每一个服务与常用服务集sc中服务的support和confidence值。排除不满足门限confidence(sc→c)>δ,sup port(sc→c)>γ的候选服务,其中δ和γ的值根据具体的模型和环境而改变。在所有满足门限值的候选服务中根据公式7计算出ci与sc中服务的相关性R1 The correlation between a certain service ci and s c in c can be calculated by evaluating the alliance principle existing between them. The more alliance principles exist, the stronger the correlation between c i and s c is; in addition, we also take the correlation between c i and all service sets in the resource pool as another important reference factor, there is a relationship between c i and s The more coalition principles there are, the weaker the correlation between ci and s c will be. In this paper, R 1 and R 2 are used to represent these two kinds of correlations respectively, and the correlation between services is defined as R=R 1 *R 2 , and the aggregation history of all services in the resource pool is used to calculate each service in the candidate service set c The support and confidence values of the services in the common service set s c . Exclude candidate services that do not meet the threshold confidence(s c →c)>δ, support port(s c →c)>γ, where the values of δ and γ vary according to specific models and environments. In all candidate services that meet the threshold value, calculate the correlation R 1 between ci and the service in s c according to formula 7
再根据公式8计算ci与所有服务的相关性R2,其中t是服务资源池中存在的所有联盟原则AR的个数,num(ci,AR)表示的是包含ci参与的联盟原则AR的个数。Then calculate the correlation R 2 between ci and all services according to formula 8, where t is the number of all alliance principles AR existing in the service resource pool, and num( ci ,AR) represents the alliance principles including ci participating The number of ARs.
接着计算服务间的相关性R,返回值最高的候选服务,用户选择其作为最优服务。Then calculate the correlation R between services, return the candidate service with the highest value, and the user selects it as the optimal service.
至此便成功地使用联盟原则在候选服务集c中选出了最能满足用户需求的服务。So far, the coalition principle has been successfully used to select the service that best meets the user's needs from the candidate service set c.
我们在可信联盟构建的基础上,实现了通过分析服务间的潜在相关性来为目标服务使用者选择服务的过程。同时对于选取出的原子服务,在服务选择系统中的UDDI注册中心中更新其发布信息,当其他服务使用者请求服务时,可以减少选择过程的时间开销。Based on the construction of trusted alliance, we realize the process of selecting services for target service users by analyzing the potential correlation between services. At the same time, for the selected atomic service, update its release information in the UDDI registration center in the service selection system. When other service users request services, the time cost of the selection process can be reduced.
为了说明本发明所述的基于相关性的服务选择方案,我们给出了一个具体的例子——用户向网络请求去南京游玩的最佳旅游服务来详细阐述该方法。In order to illustrate the correlation-based service selection scheme of the present invention, we give a specific example—the user requests the best travel service for visiting Nanjing from the network to illustrate the method in detail.
第一步,旅游相关的服务提供商通过可信第三方,在网络上发布关于南京旅游的原子服务资源,例如:旅游景点、旅游路线、出行方式、住宿服务、餐饮服务、金融服务及保险服务等,这些服务资源形成整个服务资源池。In the first step, tourism-related service providers publish atomic service resources about Nanjing tourism on the Internet through a trusted third party, such as: tourist attractions, travel routes, travel methods, accommodation services, catering services, financial services and insurance services etc. These service resources form the entire service resource pool.
第二步,用户向服务访问平台提出南京旅游服务资源请求,查找满足条件需求的候选服务。查找的内容包括服务的种类(本案例中可以分类为:商务、高等、中等、普通)、服务的安全性(如:出行方式安全性、餐饮安全等级等)、可靠性(如:旅行社的信誉、交通工具的准点率等)以及价格(普通价格及优惠价格等),经过一些条件约束对服务进行初步筛选,形成可供用户进行选择的候选服务资源池。In the second step, the user submits a request for Nanjing tourism service resources to the service access platform, and searches for candidate services that meet the requirements. The search content includes the type of service (in this case, it can be classified as: business, high-level, medium, ordinary), service safety (such as: travel mode safety, catering safety level, etc.), reliability (such as: travel agency reputation , transportation punctuality rate, etc.) and price (normal price and preferential price, etc.), after some conditional constraints, the service is initially screened to form a candidate service resource pool for users to choose from.
第三步,用户根据以往的旅游经历,寻找出一部分与自己偏好相同或相似的其他用户,例如在旅行社、景点,交通方式及住宿等方面的选择都与自己相同的那一群用户,他们即是目标用户在旅游行为方面的相似邻居用户,同时若此类用户曾向目标用户进行过直接或间接的旅游推荐,再考虑他们之间存在的信任关系,结合之前分析所得出的相似关系,确定既与用户在旅游行为方面相似又可被其信任的用户群体,定为用户的可信联盟。In the third step, the user finds some other users who have the same or similar preferences as their own based on their past travel experience, for example, the group of users who have the same choices as themselves in terms of travel agencies, scenic spots, transportation methods, and accommodation. The target user’s similar neighbor users in terms of travel behavior, and if such users have made direct or indirect travel recommendations to the target user, then consider the trust relationship between them, combined with the similarity relationship obtained from the previous analysis, determine that both The user group that is similar to the user in terms of travel behavior and can be trusted by the user is defined as the user's trusted alliance.
第四步,若可信联盟中的用户曾到南京旅游过,他们对南京的各个旅游景点、各条旅游路线、各种出行方式、各家住宿及餐饮等都有过使用经验,并且他们对这些服务的质量和可靠性也有较为全面的评价,根据他们的反馈,我们提取出联盟中多数用户最为满意的一些服务,形成关于旅游行程的常用服务集,作为目标用户在进行旅游服务选取时考虑服务相关性的一个参考群。The fourth step, if the users in the trusted alliance have traveled to Nanjing, they have experience in various tourist attractions, various tourist routes, various travel modes, various accommodation and catering in Nanjing, and they are familiar with Nanjing. The quality and reliability of these services have also been comprehensively evaluated. Based on their feedback, we have extracted some services that most users in the alliance are most satisfied with, and formed a set of commonly used services for travel itineraries, which will be considered by target users when selecting travel services. A reference group for service dependencies.
第五步,在上一步得到常用服务集的基础上,我们将候选服务资源池中的服务与常用服务集中的服务进行关联参照,结合曾到南京游玩过用户的所有旅游信息,寻找这些服务之间存在的某些固定的联系,如两个服务集中的服务是否都曾共同被某一些用户同时在一次旅途中调用过之类,利用联盟原则找到这些服务间联系及模式,也即是服务间存在的相关性,类似可以找出候选服务集与整个服务资源池中服务间的相关性。The fifth step, on the basis of the commonly used service set obtained in the previous step, we associate and refer to the services in the candidate service resource pool and the services in the commonly used service set, and combine all the travel information of users who have visited Nanjing to find out which services are the best. There are some fixed connections between them, such as whether the services in the two service collections have been called by some users during a trip at the same time, and the alliance principle is used to find the connections and patterns between these services, that is, between services Existing correlation is similar to finding out the correlation between the candidate service set and the services in the entire service resource pool.
第六步,通过分析并计算服务间的相关性,最终可以选出最能满足目标用户需求的那一组候选服务,用户参照这一组服务进行南京旅游计划,其请求得以解决。用户的服务选择结果也更新为其他用户可以参考借鉴的信息,为今后到南京旅游的用户更快捷、更优质的进行各类服务选择提供了可靠性保障,也提高了整个网络中旅游服务的选择效率。In the sixth step, by analyzing and calculating the correlation between services, a group of candidate services that can best meet the needs of target users can be finally selected, and users can refer to this group of services to plan Nanjing travel, and their requests can be resolved. The user's service selection results are also updated with information that other users can refer to, which provides a reliable guarantee for users who travel to Nanjing in the future to choose various services more quickly and with better quality, and also improves the selection of travel services in the entire network efficiency.
Claims (6)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201210494558.0A CN103034963B (en) | 2012-11-28 | 2012-11-28 | A kind of service selection system and system of selection based on correlation |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201210494558.0A CN103034963B (en) | 2012-11-28 | 2012-11-28 | A kind of service selection system and system of selection based on correlation |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN103034963A true CN103034963A (en) | 2013-04-10 |
| CN103034963B CN103034963B (en) | 2017-10-27 |
Family
ID=48021832
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201210494558.0A Expired - Fee Related CN103034963B (en) | 2012-11-28 | 2012-11-28 | A kind of service selection system and system of selection based on correlation |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN103034963B (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103412918A (en) * | 2013-08-08 | 2013-11-27 | 南京邮电大学 | Quality of service (QoS) and reputation based method for evaluating service trust levels |
| CN104111959A (en) * | 2013-04-22 | 2014-10-22 | 浙江大学 | Social network based service recommending method |
| CN105225175A (en) * | 2015-10-21 | 2016-01-06 | 刘锐光 | C2C, B2C, B2B social platform internet traveling method and system |
| CN105303497A (en) * | 2015-12-01 | 2016-02-03 | 浪潮电子信息产业股份有限公司 | Cloud Computing-based Nurse Query System and Its Application Method |
| CN106209978A (en) * | 2016-06-22 | 2016-12-07 | 安徽大学 | Alliance relation service combination selection system and method |
| CN106961356A (en) * | 2017-04-26 | 2017-07-18 | 中国人民解放军信息工程大学 | Web service choosing method and its device based on dynamic QoS and subjective and objective weight |
| CN108629345A (en) * | 2017-03-17 | 2018-10-09 | 北京京东尚科信息技术有限公司 | Dimensional images feature matching method and device |
| CN110196796A (en) * | 2019-05-15 | 2019-09-03 | 无线生活(杭州)信息科技有限公司 | The effect evaluation method and device of proposed algorithm |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004288118A (en) * | 2003-03-25 | 2004-10-14 | Hewlett Packard Co <Hp> | Method of managing service registration data |
| CN1679037A (en) * | 2002-08-28 | 2005-10-05 | 国际商业机器公司 | Network system, provider, management site, requestor, and program |
| CN101895547A (en) * | 2010-07-16 | 2010-11-24 | 浙江大学 | A recommendation system and method based on uncertain service |
| CN101909055A (en) * | 2010-07-19 | 2010-12-08 | 东南大学 | A QoS-Based Multithreaded Web Service Negotiation Method |
| CN102523247A (en) * | 2011-11-24 | 2012-06-27 | 合肥工业大学 | Cloud service recommendation method and device based on multi-attribute matching |
-
2012
- 2012-11-28 CN CN201210494558.0A patent/CN103034963B/en not_active Expired - Fee Related
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1679037A (en) * | 2002-08-28 | 2005-10-05 | 国际商业机器公司 | Network system, provider, management site, requestor, and program |
| JP2004288118A (en) * | 2003-03-25 | 2004-10-14 | Hewlett Packard Co <Hp> | Method of managing service registration data |
| CN101895547A (en) * | 2010-07-16 | 2010-11-24 | 浙江大学 | A recommendation system and method based on uncertain service |
| CN101909055A (en) * | 2010-07-19 | 2010-12-08 | 东南大学 | A QoS-Based Multithreaded Web Service Negotiation Method |
| CN102523247A (en) * | 2011-11-24 | 2012-06-27 | 合肥工业大学 | Cloud service recommendation method and device based on multi-attribute matching |
Non-Patent Citations (1)
| Title |
|---|
| 朱锐等: "基于偏好推荐的可信服务选择", 《软件学报》 * |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104111959B (en) * | 2013-04-22 | 2017-06-20 | 浙江大学 | Service recommendation method based on social networks |
| CN104111959A (en) * | 2013-04-22 | 2014-10-22 | 浙江大学 | Social network based service recommending method |
| CN103412918A (en) * | 2013-08-08 | 2013-11-27 | 南京邮电大学 | Quality of service (QoS) and reputation based method for evaluating service trust levels |
| CN103412918B (en) * | 2013-08-08 | 2016-07-06 | 南京邮电大学 | A kind of service trust degree appraisal procedure based on service quality and reputation |
| CN105225175A (en) * | 2015-10-21 | 2016-01-06 | 刘锐光 | C2C, B2C, B2B social platform internet traveling method and system |
| CN105303497A (en) * | 2015-12-01 | 2016-02-03 | 浪潮电子信息产业股份有限公司 | Cloud Computing-based Nurse Query System and Its Application Method |
| CN106209978A (en) * | 2016-06-22 | 2016-12-07 | 安徽大学 | Alliance relation service combination selection system and method |
| CN106209978B (en) * | 2016-06-22 | 2019-04-09 | 安徽大学 | Alliance relation service combination selection system and method |
| CN108629345A (en) * | 2017-03-17 | 2018-10-09 | 北京京东尚科信息技术有限公司 | Dimensional images feature matching method and device |
| US11210555B2 (en) | 2017-03-17 | 2021-12-28 | Beijing Jingdong Shangke Information Technology Co., Ltd. | High-dimensional image feature matching method and device |
| CN106961356A (en) * | 2017-04-26 | 2017-07-18 | 中国人民解放军信息工程大学 | Web service choosing method and its device based on dynamic QoS and subjective and objective weight |
| CN106961356B (en) * | 2017-04-26 | 2020-01-10 | 中国人民解放军信息工程大学 | Web service selection method and device based on dynamic QoS and subjective and objective weight |
| CN110196796A (en) * | 2019-05-15 | 2019-09-03 | 无线生活(杭州)信息科技有限公司 | The effect evaluation method and device of proposed algorithm |
| CN110196796B (en) * | 2019-05-15 | 2023-04-28 | 无线生活(杭州)信息科技有限公司 | Effect evaluation method and device for recommendation algorithm |
Also Published As
| Publication number | Publication date |
|---|---|
| CN103034963B (en) | 2017-10-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN103034963B (en) | A kind of service selection system and system of selection based on correlation | |
| Yang et al. | Friend or frenemy? Predicting signed ties in social networks | |
| US11070643B2 (en) | Discovering signature of electronic social networks | |
| CN109408734B (en) | A collaborative filtering recommendation method integrating information entropy similarity and dynamic trust | |
| US8615514B1 (en) | Evaluating website properties by partitioning user feedback | |
| CN102609533B (en) | Kernel method-based collaborative filtering recommendation system and method | |
| EP1653380A1 (en) | Web page ranking with hierarchical considerations | |
| US20120239488A1 (en) | Taxonomy based targeted search advertising | |
| US9400844B2 (en) | System for finding website invitation cueing keywords and for attribute-based generation of invitation-cueing instructions | |
| US20080140641A1 (en) | Knowledge and interests based search term ranking for search results validation | |
| CN1996316A (en) | Search engine searching method based on web page correlation | |
| US11789946B2 (en) | Answer facts from structured content | |
| US20110184815A1 (en) | System and method for sharing profits with one or more content providers | |
| KR20090000814A (en) | Ad list generation method and system | |
| CN103246677A (en) | Search method and search system on basis of social intercourse | |
| Liu | Towards context-aware social recommendation via trust networks | |
| Wu | Geographical knowledge diffusion and spatial diversity citation rank | |
| KR20130033693A (en) | Method, apparatus and computer readable recording medium for search with exetension data-set of concept keywords | |
| Li et al. | From reputation perspective: a hybrid matrix factorization for qos prediction in location‐aware mobile service recommendation system | |
| Saleem et al. | Personalized decision-strategy based web service selection using a learning-to-rank algorithm | |
| Zhuang et al. | User spread influence measurement in microblog | |
| Margaris et al. | Improving collaborative filtering’s rating prediction accuracy by introducing the experiencing period criterion | |
| CN103020083A (en) | Automatic mining method of requirement identification template, requirement identification method and corresponding device | |
| Cacheda et al. | Click through rate prediction for local search results | |
| TW201234204A (en) | Opportunity identification for search engine optimization |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20171027 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |