CN102208023B - Method for recognizing and designing video captions based on edge information and distribution entropy - Google Patents
Method for recognizing and designing video captions based on edge information and distribution entropy Download PDFInfo
- Publication number
- CN102208023B CN102208023B CN 201110024330 CN201110024330A CN102208023B CN 102208023 B CN102208023 B CN 102208023B CN 201110024330 CN201110024330 CN 201110024330 CN 201110024330 A CN201110024330 A CN 201110024330A CN 102208023 B CN102208023 B CN 102208023B
- Authority
- CN
- China
- Prior art keywords
- subtitle
- area
- edge
- pixels
- row
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images



Landscapes
- Character Input (AREA)
- Image Analysis (AREA)
Abstract
本发明公开了一种基于边缘信息和分布熵的视频字幕识别方法。它使用角点加强的边缘检测方法得到图像边缘信息,然后连接边缘点并收集连通域,使用分割算法对连通域进行适当分割,再使用精化操作得到它们的准确位置,使用拖尾过滤器和联合熵过滤器过滤掉非文本区域,剩下的就是文本区域。对于检测出的文本域,统一成黑底白字后,使用局部阀值二值化、基于禁止扩展点约束的边缘噪声点扩展移除操作及基于环绕边缘点计数的噪声移除操作,得到二值图送入OCR软件中进行识别。该方法能克服一般方法对语言、字幕排列方式、背景复杂度等较敏感的缺点,通过引入分割算法和联合熵过滤器,能得到很好的检测效果,改进传统的二值化方法极大的提高了识别准确率。

The invention discloses a video subtitle recognition method based on edge information and distribution entropy. It uses the edge detection method of corner point enhancement to get the edge information of the image, then connects the edge points and collects the connected domain, uses the segmentation algorithm to properly segment the connected domain, and then uses the refinement operation to get their accurate position, uses the trailing filter and The joint entropy filter filters out non-text regions, leaving only text regions. For the detected text domain, after unifying into black and white characters, use local threshold binarization, edge noise point expansion removal operation based on forbidden extension point constraint, and noise removal operation based on surrounding edge point counting to obtain binary value The image is sent to the OCR software for identification. This method can overcome the shortcomings of general methods that are sensitive to language, subtitle arrangement, and background complexity. By introducing segmentation algorithms and joint entropy filters, good detection results can be obtained, and the traditional binarization method is greatly improved. Improved recognition accuracy.
Description
技术领域 technical field
本发明涉及一种基于边缘信息和分布熵的视频字幕识别方法,该方法用于实现在视频中检测并提取字幕用于OCR识别,属于计算机图像处理领域。 The invention relates to a video subtitle recognition method based on edge information and distribution entropy. The method is used to detect and extract subtitles in a video for OCR recognition, and belongs to the field of computer image processing.
背景技术 Background technique
随着多媒体和电子工业的发展,越来越多的视频信息被生产出来。如何有效的组织和检索它们就成为一个难题。很多视频资料如电视新闻、体育比赛、电影、综艺节目等都有后期制作中加入的字幕信息,这些字幕信息与视频内容密切相关。如能有效的识别这些字幕,则能利用它们对视频资料进行组织和检索,具有很强的实用价值。 With the development of multimedia and electronic industries, more and more video information is produced. How to effectively organize and retrieve them becomes a difficult problem. Many video materials, such as TV news, sports games, movies, variety shows, etc., have subtitle information added in post-production, and these subtitle information is closely related to video content. If these subtitles can be effectively identified, they can be used to organize and retrieve video materials, which has strong practical value.
视频字幕识别分为四步:字幕检测、字幕定位、字幕提取和OCR识别。字幕检测用于确定字幕区域;字幕定位用于定位每一行字幕的精确位置;字幕提取用于将字幕区域二值化,只保留笔划像素;最后一步一般交由商用OCR软件实现。字幕检测可以分为四种方法:基于边的方法、基于连通域的方法、基于颜色聚类的方法和基于纹理的方法。基于边的方法使用边过滤器来检测文本边,然后用形态学操作来合并它们。第八届文档分析与识别会议(In Proceedings of 8rd International Conference on Document Analysis and Recognition (ICDAR),2005,610-614)公布的方法使用边缘检测方法得到四个边缘映射图,然后使用K-MEANS算法检测候选文本区域,最后使用启发式规则和投影分析来确定和精化文本区域。如果没有复杂的背景,基于边的方法的效果会很好,但是当背景包含很多边信息时,它们的效果就不太好。基于纹理的方法使用Gabor过滤器、小波变换、快速傅里叶变换等提取纹理特征,然后用神经网络、SVM分类器等机器学习的方法检测字幕区域。IEEE通信技术2008年会议论文集中(In Proceeding of IEEE International Conference on Communication Technology(ICCT),2008,722-725) 公布的一种方法使用HARR小波变换通过将4小块小波系数合并成一大块来定位大字体文本中,然后使用形态学膨胀操作和神经网格来增强效果。基于连通域的方法将一帧分割成多个小连通域,然后将它们合并到较大的连通域中用来定位字幕。ACM 多媒体技术2007年会议论文集中(In Proceedings of the ACM International Multimedia Conference and Exhibition 2007(MM),847-850)公布的一种方法使用基于信用的颜色的聚类去掉噪声,他们根据各颜色面板的文本对比度差异来适应性的选择相对最好的颜色面板执行二值化操作。基于颜色聚类的方法假设视频帧中的文本颜色都是统一的,然而这一假设在大多数情况下是不成立的,因此其应用的局限性较大。由于利用一种特征进行字幕检测其效果不理想,因此很多方法联合使用以上多种特征。对于字幕定位,一般使用灰度投影的方法。字幕提取方法可以分为基于颜色的方法和基于笔划的方法。很多基于颜色的方法使用Otsu方法对灰度图进行二值化,但当字幕和背景的灰度级非常相近时,该方法不能很好的分辨出它们,从而不能很好的去噪。《电气和电子工程师协会视频技术电路与系统学报》2005年第15期(IEEE Transactions on Circuits and Systems for Video Technology 2005,15(2):243-255)和《电气和电子工程师协会图像处理学报》2009年第18期(IEEE Transactions on Image Processing 2009,18(2):401-411)中公布的一种方法使用有更好的分辨力的局部适应性阀值,结合dam点标记和向内填充,使得大部分噪声点能去被移除。 Video subtitle recognition is divided into four steps: subtitle detection, subtitle positioning, subtitle extraction and OCR recognition. Subtitle detection is used to determine the subtitle area; subtitle positioning is used to locate the precise position of each line of subtitles; subtitle extraction is used to binarize the subtitle area, and only stroke pixels are reserved; the last step is generally implemented by commercial OCR software. Subtitle detection can be divided into four methods: edge-based methods, connected domain-based methods, color clustering-based methods, and texture-based methods. Edge-based methods use edge filters to detect text edges and then use morphological operations to merge them. The method published in the 8th Conference on Document Analysis and Recognition (In Proceedings of 8 rd International Conference on Document Analysis and Recognition (ICDAR), 2005, 610-614) uses the edge detection method to obtain four edge maps, and then uses K-MEANS Algorithms detect candidate text regions, and finally use heuristic rules and projection analysis to identify and refine text regions. Edge-based methods work well if there is no complex background, but they do not work well when the background contains a lot of side information. Texture-based methods use Gabor filters, wavelet transforms, fast Fourier transforms, etc. to extract texture features, and then use machine learning methods such as neural networks and SVM classifiers to detect subtitle regions. A method published in Proceeding of IEEE International Conference on Communication Technology (ICCT), 2008, 722-725) uses HARR wavelet transform to locate by combining 4 small blocks of wavelet coefficients into a large block. large font text, and then use morphological dilation operations and neural meshes to enhance the effect. Connected domain-based methods segment a frame into multiple small connected domains, and then merge them into a larger connected domain for subtitle localization. A method published in Proceedings of the ACM International Multimedia Conference and Exhibition 2007 (MM), 847-850 uses credit-based clustering of colors to remove noise. Text contrast differences are adaptively selected relative to the best color panel to perform binarization. The method based on color clustering assumes that the text color in the video frame is uniform, but this assumption is not true in most cases, so its application is limited. Since the effect of subtitle detection using one feature is not ideal, many methods use the above features in combination. For subtitle positioning, the method of grayscale projection is generally used. Subtitle extraction methods can be divided into color-based methods and stroke-based methods. Many color-based methods use the Otsu method to binarize the grayscale image, but when the grayscale levels of the subtitle and the background are very similar, this method cannot distinguish them well, so it cannot denoise well. "IEEE Transactions on Circuits and Systems for Video Technology 2005, 15 (2): 243-255" 2005 No. 15 and "IEEE Transactions on Circuits and Systems for Video Technology" A method published in Issue 18 of 2009 (IEEE Transactions on Image Processing 2009, 18(2):401-411) uses a local adaptive threshold with better resolution, combined with dam point marking and inward padding , so that most of the noise points can be removed.
上面这些字幕检测方法均对视频字幕检测工作作出了一些有益的尝试,但这些方法对字幕与背景的分辨效果不是很好,仅采用这些方法检测一些语言、字体及文字对齐方式多变的视频进行处理效果不佳。另外已存的字幕提取方法虽然能去掉大部分噪音,但由于OCR软件对噪声点非常敏感,导致复杂背景下文本识别的效果不佳。 The above subtitle detection methods have made some useful attempts to detect video subtitles, but these methods are not very effective in distinguishing between subtitles and backgrounds. Only these methods are used to detect some videos with changing languages, fonts and text alignments. Handling is poor. In addition, although the existing subtitle extraction methods can remove most of the noise, because OCR software is very sensitive to noise points, the effect of text recognition in complex backgrounds is not good.
发明内容 Contents of the invention
本发明的目的是克服现有技术的不足,提供一种基于边缘信息和分布熵的视频字幕识别方法。 The purpose of the present invention is to overcome the deficiencies of the prior art and provide a video subtitle recognition method based on edge information and distribution entropy.
基于边缘信息和分布熵的视频字幕识别方法的步骤如下: The steps of the video subtitle recognition method based on edge information and distribution entropy are as follows:
1)检测当前帧与前一已处理帧的差别,若差别大,则进行以下字幕识别操作,否则继续取下一帧进行判断; 1) Detect the difference between the current frame and the previous processed frame, if the difference is large, perform the following subtitle recognition operation, otherwise continue to take the next frame for judgment;
2)字幕识别首先进行字幕检测,在字幕检测中使用边缘检测、边缘点连接、连通域收集及分割方法、连通域精化及拖尾过滤方法得到候选文本域及其位置,再用联合熵过滤器移除非文本域,只留下字幕区域; 2) Subtitle recognition First, perform subtitle detection. In subtitle detection, use edge detection, edge point connection, connected domain collection and segmentation methods, connected domain refinement and trailing filtering methods to obtain candidate text domains and their positions, and then use joint entropy filtering The filter removes the non-text field, leaving only the subtitle area;
3)对字幕区域进行重复性检测,若该区域未重复,则将其颜色极统一为黑底白字,然后进行字幕抽取,否则处理下一字幕区域; 3) Check the repeatability of the subtitle area. If the area is not repeated, the color is very uniform as black and white characters, and then the subtitle is extracted, otherwise the next subtitle area is processed;
4)在字幕抽取中对颜色极统一后的字幕区域进行二值化,去除噪声点后送OCR软件识别。 4) In the subtitle extraction, binarize the subtitle area after the color is extremely uniform, remove the noise point and send it to the OCR software for recognition.
所述的检测当前帧与前一已处理帧的差别,若差别大,则进行以下字幕识别操作,否则继续取下一帧进行判断步骤为:设本帧为Ii,其边缘二值图为Ei,其前一已处理帧即前面第5帧为Ii-5,其边缘二值图为Ei-5,令Di,i-5=Ei⊕Ei-5,令上一次检测出的字幕区域为Areai-5,j,又上一次各字幕区域边缘二值图累加和的最小值为pMES,则当前帧中字幕区域累加差值计算如下: The difference between the described detection current frame and the previous processed frame, if the difference is large, then carry out the following subtitle recognition operation, otherwise continue to take the next frame and proceed to the judgment step as follows: set this frame as I i , and its edge binary image is E i , its previous processed frame is I i-5 , its edge binary image is E i-5 , let D i,i-5 =E i ⊕E i-5 , let last time The detected subtitle area is Area i-5,j , and the last time the minimum value of the cumulative sum of the edge binary images of each subtitle area is pMES , then the cumulative difference of the subtitle area in the current frame is calculated as follows:

若cFD小于或等于pMES×0.5,则不需要对本帧进行字幕识别操作,继续取后面第5帧进行判断,否则就需要对本帧进行字幕识别操作,为了进一步防止漏掉字幕,另设一计数值ck,每次cFD小于或等于pMES×0.5时ck值加1,反之则ck重置为0,若ck等于5,则无论前面判断如何,都需要对本帧进行字幕识别操作,同时ck重赋值0。 If cFD is less than or equal to pMES × 0.5, then there is no need to perform subtitle recognition operation on this frame, and continue to take the fifth frame to judge, otherwise, it is necessary to perform subtitle recognition operation on this frame. In order to further prevent missing subtitles, another count value is set ck, every time cFD is less than or equal to pMES × 0.5, the value of ck is increased by 1, otherwise, ck is reset to 0, if ck is equal to 5, no matter what the previous judgment is, the subtitle recognition operation of this frame is required, and ck is reassigned to 0 .
所述的字幕识别首先进行字幕检测,在字幕检测中使用边缘检测、边缘点连接、连通域收集及分割方法、连通域精化及拖尾过滤方法得到候选文本域及其位置,再用联合熵过滤器移除非文本域,只留下字幕区域步骤为: Described subtitle recognition first carries out subtitle detection, uses edge detection, edge point connection, connected domain collection and segmentation method, connected domain refinement and trailing filter method to obtain candidate text domain and its position in subtitle detection, then uses joint entropy The filter removes non-text fields, leaving only subtitles. The steps are:
(1)边缘检测方法 (1) Edge detection method
给定图像I,采用Sobel算子检测边缘,Sobel算子由水平SH、垂直SV、对角线SLD、逆对角线SRD 四个方向上的梯度模板组成,边缘场由下式计算: Given an image I, the Sobel operator is used to detect edges. The Sobel operator is composed of gradient templates in four directions: horizontal S H , vertical S V , diagonal S LD , and anti-diagonal S RD . The edge field is given by the following formula calculate:

其中
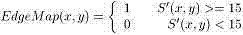
(2)边缘点连接方法 (2) Edge point connection method
对于边缘映射图EdgeMap,若同行两个边缘点的距离小于某一阀值T d ,则将EdgeMap中这两个像素之间的像素值都置为1,也即填充这两个边缘点间的像素,T d 由下式确定: For the edge map EdgeMap , if the distance between two edge points in the same row is less than a certain threshold T d , set the pixel values between these two pixels in the EdgeMap to 1, that is, fill the space between the two edge points pixel, T d is determined by:
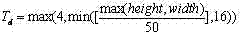
其中height和width分别为图像I的高和宽; Wherein height and width are the height and width of image I respectively;
(3)连通域收集及分割方法 (3) Connected domain collection and segmentation method
对上步得到的EdgeMap进行连通域收集,去掉那些高或宽小于整幅图像高或宽的1%的连通域,同时去掉那些最小包围矩形小于整幅图像面积0.2%的连通域,再使用如下步骤对每个连通域C进行区域分割: Collect the connected domains of the EdgeMap obtained in the previous step, remove those connected domains whose height or width is less than 1% of the entire image height or width, and remove those connected domains whose smallest enclosing rectangle is less than 0.2% of the entire image area, and then use the following The step is to segment each connected domain C:
a) 对于C中的每一行i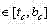
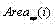
b) 对于C中的每一列j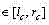
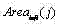
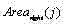
c) 令
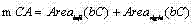
其中t c ,b c l c 和 r c 分别是区域C的上界行号、下界行号、左界列号和右界列号; Among them, t c , b c l c and r c are the upper boundary row number, lower boundary row number, left boundary column number and right boundary column number of area C respectively;
为了防止过分割,只有当连通区域C同时满足以下两个条件时才进行分割: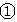

(4)连通域精化及拖尾过滤方法 (4) Connected domain refinement and trailing filtering method
在进行区域精化前,先去掉那些高大于宽的2倍的连通域,这样可能会误删那些竖排的字幕,为了处理竖排字幕,只须将图像旋转90度,其它操作一模一样; Before performing area refinement, first remove those connected domains whose height is greater than twice the width, which may accidentally delete those vertical subtitles. In order to process vertical subtitles, you only need to rotate the image by 90 degrees, and the other operations are exactly the same;
对上步得到的每个连通区域C,对其位置进行进一步精化的步骤如下: For each connected region C obtained in the previous step, the steps to further refine its position are as follows:
输入:边缘映射图edgeMap,连通域C的初始上下边界位置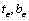
输出:精化后的上下界位置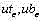
d) 对于连通域C的任意行
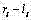
e) 对于连通域C的任意行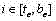

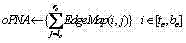
f) 取cSA中的最大值存在中,并将其序号存在pSRN中; f) Take the maximum value in cSA to exist , and store its serial number in pSRN ;
取中的最大值存在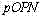
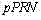
g) 对于在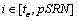
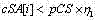
![]()
![]()
对于在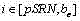

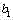
对于在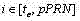
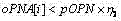
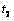
对于在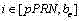
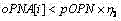
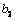
h) 令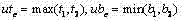
其中
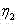
使用如下拖尾过滤方法去掉一些非字幕连通域: Use the following trailing filtering method to remove some non-subtitle connected domains:
i) 在上面步骤g) 完成后,继续在oPNA中向上和下扫描,直到当前行处的值小于
j) 用下式计算尾巴的长: j) Calculate the length of the tail using the following formula:
tl 1 =t 2 -t tail , tl 2 =b tail -b 2 , tl=max (tl 1 , tl 2 ) tl 1 = t 2 - t tail , tl 2 = b tail - b 2 , tl =max ( tl 1 , tl 2 )
k) 用下式进行过滤,若deleteFlag(C)为1,说明此连通域不是字幕区域,应该删除; k) Use the following formula to filter, if deleteFlag(C) is 1, it means that this connected domain is not a subtitle area and should be deleted;
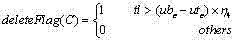
其中ubc和utc分别表示连通域C精化后的上下界位置,而 和 通常取值为0.2和0.3; where ub c and ut c denote the refined upper and lower bounds of connected domain C respectively, and and usually take values of 0.2 and 0.3;
(5)联合熵过滤器 (5) Joint entropy filter
使用联合前景像素分布熵和边缘像素分布熵的联合熵过滤器进行过滤,只留下字幕区域; Use the joint entropy filter of the joint foreground pixel distribution entropy and edge pixel distribution entropy to filter, leaving only the subtitle area;
对于前景像素分布熵,是对某一连通域C的最小包围矩形Rect [tc,bc,lc,rc],其中tc,bc分别是上下界,lc,rc分别是左右界,使用Otsu阀值将其二值化,然后将其分成2行×4列=8部分,使用下式计算分布熵: For the foreground pixel distribution entropy, it is the smallest enclosing rectangle Rect [t c , b c , l c , r c ] for a connected domain C, where t c , b c are the upper and lower bounds respectively, and l c , r c are respectively For the left and right boundaries, use the Otsu threshold to binarize it, then divide it into 2 rows × 4 columns = 8 parts, and use the following formula to calculate the distribution entropy:
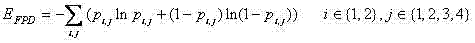
其中pi,j表示第i行第j列那部分非0像素的比率; Among them, p i,j represents the ratio of non-zero pixels in the i-th row and j-th column;
对于边缘像素分布熵,是将连通域C的最小包围矩形Rect [tc,bc,lc,rc]内的Sobel边缘二值图分成2行×4列=8部分,使用下式计算分布熵: For the edge pixel distribution entropy, the Sobel edge binary image in the smallest enclosing rectangle Rect [t c , b c , l c , r c ] of the connected domain C is divided into 2 rows × 4 columns = 8 parts, and calculated using the following formula Distribution entropy:

其中e ij 表示第i行第j列那部分边缘像素数目,而 e r 是8部分边缘像素数目总和, Where e ij represents the number of edge pixels in row i, column j, and e r is the sum of the number of edge pixels in 8 parts,
对于任一精化后的连通域C,若其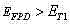

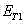
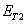
对于某些既有横排又有竖排字幕的图像,在原图和旋转90度所得的图像中进行字幕检测,再将两者检测结果进行合并,消除重复。 For some images with both horizontal and vertical subtitles, subtitle detection is performed in the original image and the image obtained by rotating 90 degrees, and then the detection results of the two are combined to eliminate duplication.
所述的对字幕区域进行重复性检测,若该区域未重复,则将其颜色极统一为黑底白字,然后进行字幕抽取,否则处理下一字幕区域步骤为: Described repeatability detection is carried out to subtitle area, if this area does not repeat, then its color is extremely unified as black and white characters, then carry out subtitle extraction, otherwise process next subtitle area step as:
(6)重复性检测 (6) Repeatability detection
采用结合位置和灰度颜色直方图的方法对检测出的字幕区域进行消重,步骤如下: Use the method of combining position and grayscale color histogram to deduplicate the detected subtitle area, the steps are as follows:
l) 提取并存储前一已处理帧所有字幕区域位置Recti[ti,bi,li,ri]及灰度直方图GHi{gi,0,gi,1,…gi,255},其中
m)计算它们的位置相似度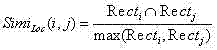
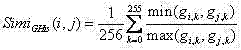
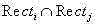


(7)颜色极统一 (7) Extremely uniform color
将字幕区域灰度图统一成黑底白字,采取以下步骤: To unify the grayscale image of the subtitle area into black and white characters, take the following steps:
n) 首先将灰度化后的字幕区域用Otsu方法二值化,然后分别使用3×3的掩模
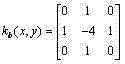
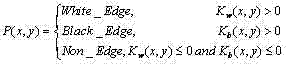
令Nw和Nb分别表示白色边缘像素个数和黑色边缘像素个数,定义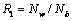
o) 对上步8式得到的边缘映射图P,将边缘像素按列投影,设边缘映射图在列上分解成{x0,x1,…,xn},其中xi为边缘图在列上投影为0的某一连续区间的中点,依次建立矩形Recti[1,height,xi,xi+1],在该矩形范围内的边缘映射图P中从四边向内扫描,将遇到的第一个边缘像素点删除,重新统计白色边缘像素个数和黑色边缘像素个数,分别设为和
p) 定义
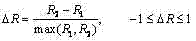
用如下方法判断字幕区域的颜色极: Use the following method to judge the color pole of the subtitle area:
(a) 若,则为白字; (a) if , it is white;
(b) 若
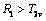
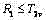
(c) 若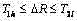
(d) 若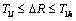
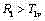

(e) 若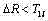
其中
q) 判断出字幕颜色极后,若为黑字,则将该字幕区域灰度图反色,否则不作操作。 q) After judging that the color of the subtitle is extremely high, if it is black, then invert the grayscale image of the subtitle area, otherwise no operation is performed.
所述的在字幕抽取中对颜色极统一后的字幕区域进行二值化,去除噪声点后送OCR软件识别步骤为: In the subtitle extraction, the subtitle area after the extremely unified color is binarized, and the OCR software recognition steps are sent after removing the noise points as follows:
r) 将灰度化的字幕区域的高规整化为24,然后分别向上下扩展4个像素,从而扩展后高度为32,设为EI; r) Normalize the height of the grayscaled subtitle area to 24, and then expand 4 pixels up and down respectively, so that the height after expansion is 32, which is set as EI;
s) 将结果二值图B每个像素初始化为1,然后对EI进行步进式水平局部阀值二值化,在一个16×32的局部窗口中用Otsu方法进行二值化,每次水平步进8个像素,同样的方法对EI进行步进式垂直局部阀值二值化,在一个image_width×8的局部窗口中用Otsu方法进行二值化,每次垂直步进4个像素,在每个子窗口中,EI中灰度值低于局部阀值的,B中相应的像素值设为0; t) 将B中与扩展区域值为1的像素相连的像素置0,为了防止将笔划像素也置为0,定义dam points: s) Initialize each pixel of the resulting binary image B to 1, and then perform step-by-step horizontal local threshold binarization on the EI, and use the Otsu method to binarize in a 16×32 local window, each level Step by 8 pixels, the same method is used to perform step-by-step vertical local threshold binarization on EI, and use the Otsu method to binarize in a local window of image_width×8, each vertical step by 4 pixels, in In each sub-window, if the gray value in EI is lower than the local threshold, the corresponding pixel value in B is set to 0; Pixels are also set to 0, defining dam points:

其中H_len(x,y)表示像素(x,y)所在的最长水平连续1序列的长度,而V_len(x,y) 表示像素(x,y)所在的最长垂直连续1序列的长度,对于dam points点,是无法扩展为背景像素的; Where H_len(x,y) represents the length of the longest horizontally continuous 1 sequence where the pixel (x,y) is located, and V_len(x,y) represents the length of the longest vertically continuous 1 sequence where the pixel (x,y) is located, For dam points, it cannot be expanded into background pixels;
u) 使用Sobel算子得到EI的边缘信息,对B中的每一个值为1的连通域,统计落在其中或环绕它的边缘像素点的个数epn,若epn<tepn,则将该连通域的所有像素置为0,从而将该连通域去掉,tepn用下式确定: u) Use the Sobel operator to get the edge information of EI. For each connected domain with a value of 1 in B, count the number epn of the edge pixels falling in it or surrounding it. If epn<tepn , the connected domain Set all the pixels in the domain to 0, so as to remove the connected domain, tepn is determined by the following formula:
tepn=max(cheight,cwidth) tepn =max( cheight,cwidth )
其中cheight和cwidth分别为该连通域的高和宽。 Among them, cheight and cwidth are the height and width of the connected domain, respectively.
v) 将二值图B送入OCR软件进行识别。 v) Send binary image B to OCR software for recognition.
本发明与现有技术相比具有的有益效果: The present invention has the beneficial effect compared with prior art:
1)本发明中的字幕检测算法能克服常用检测算法对语言、字幕对齐方式和背景复杂性敏感的缺点,通过加强字幕特有的角点信息并使用区域分割算法,同时结合联合熵过滤器,能得到对语言、字幕对齐方式和背景复杂性的变化鲁棒性较好的检测结果; 1) The subtitle detection algorithm in the present invention can overcome the shortcomings of common detection algorithms that are sensitive to language, subtitle alignment and background complexity. Obtain detection results that are robust to changes in language, subtitle alignment, and background complexity;
2)本发明中的字幕提取算法能在一般的提取算法的基础上进一步去掉噪声像素,使后续的OCR识别精度有了一定的提高; 2) The subtitle extraction algorithm in the present invention can further remove noise pixels on the basis of general extraction algorithms, so that the subsequent OCR recognition accuracy has been improved to a certain extent;
3)本发明能在一定程度上解决视频帧中重复字幕过多的问题,同时又能防止某些字幕被漏检,在连续的视频帧序列上取得了较好的效果。 3) The present invention can solve the problem of too many repeated subtitles in video frames to a certain extent, and at the same time prevent some subtitles from being missed, and achieve better results in continuous video frame sequences.
附图说明 Description of drawings
图1是视频字幕识别框架图; Fig. 1 is a frame diagram of video subtitle recognition;
图2是视频字幕检测框架图; Fig. 2 is a frame diagram of video subtitle detection;
图3是对某一帧图像进行视频字幕检测的流程实例图; Fig. 3 is the flowchart example figure that a certain frame image is carried out video subtitle detection;
图4是对某一字幕区域进行视频字幕抽取的实例图; Fig. 4 is the example figure that a certain subtitle area is carried out video subtitle extraction;
具体实施方式 Detailed ways
为了更好的理解本发明的技术方案,以下结合附图1和附图2对本发明作进一步的描述。附图1描述了本发明视频字幕识别方法的框架图,附图2描述了本发明中视频字幕检测方法的框架图。
In order to better understand the technical solution of the present invention, the present invention will be further described below in conjunction with accompanying
基于边缘信息和分布熵的视频字幕识别方法的步骤如下: The steps of the video subtitle recognition method based on edge information and distribution entropy are as follows:
1)检测当前帧与前一已处理帧的差别,若差别大,则进行以下字幕识别操作,否则继续取下一帧进行判断; 1) Detect the difference between the current frame and the previous processed frame, if the difference is large, perform the following subtitle recognition operation, otherwise continue to take the next frame for judgment;
2)字幕识别首先进行字幕检测,在字幕检测中使用边缘检测、边缘点连接、连通域收集及分割方法、连通域精化及拖尾过滤方法得到候选文本域及其位置,再用联合熵过滤器移除非文本域,只留下字幕区域; 2) Subtitle recognition First, perform subtitle detection. In subtitle detection, use edge detection, edge point connection, connected domain collection and segmentation methods, connected domain refinement and trailing filtering methods to obtain candidate text domains and their positions, and then use joint entropy filtering The filter removes the non-text field, leaving only the subtitle area;
3)对字幕区域进行重复性检测,若该区域未重复,则将其颜色极统一为黑底白字,然后进行字幕抽取,否则处理下一字幕区域; 3) Check the repeatability of the subtitle area. If the area is not repeated, the color is very uniform as black and white characters, and then the subtitle is extracted, otherwise the next subtitle area is processed;
4)在字幕抽取中对颜色极统一后的字幕区域进行二值化,去除噪声点后送OCR软件识别。 4) In the subtitle extraction, binarize the subtitle area after the color is extremely uniform, remove the noise point and send it to the OCR software for recognition.
所述的检测当前帧与前一已处理帧的差别,若差别大,则进行以下字幕识别操作,否则继续取下一帧进行判断步骤为:设本帧为Ii,其边缘二值图为Ei,其前一已处理帧即前面第5帧为Ii-5,其边缘二值图为Ei-5,令Di,i-5=Ei⊕Ei-5,令上一次检测出的字幕区域为Areai-5,j,又上一次各字幕区域边缘二值图累加和的最小值为pMES,则当前帧中字幕区域累加差值计算如下: The difference between the described detection current frame and the previous processed frame, if the difference is large, then carry out the following subtitle recognition operation, otherwise continue to take the next frame and proceed to the judgment step as follows: set this frame as I i , and its edge binary image is E i , its previous processed frame is I i-5 , its edge binary image is E i-5 , let D i,i-5 =E i ⊕E i-5 , let last time The detected subtitle area is Area i-5,j , and the last time the minimum value of the cumulative sum of the edge binary images of each subtitle area is pMES , then the cumulative difference of the subtitle area in the current frame is calculated as follows:

若cFD小于或等于pMES×0.5,则不需要对本帧进行字幕识别操作,继续取后面第5帧进行判断,否则就需要对本帧进行字幕识别操作,为了进一步防止漏掉字幕,另设一计数值ck,每次cFD小于或等于pMES×0.5时ck值加1,反之则ck重置为0,若ck等于5,则无论前面判断如何,都需要对本帧进行字幕识别操作,同时ck重赋值0。 If cFD is less than or equal to pMES × 0.5, then there is no need to perform subtitle recognition operation on this frame, and continue to take the fifth frame to judge, otherwise, it is necessary to perform subtitle recognition operation on this frame. In order to further prevent missing subtitles, another count value is set ck, every time cFD is less than or equal to pMES × 0.5, the value of ck is increased by 1, otherwise, ck is reset to 0, if ck is equal to 5, no matter what the previous judgment is, the subtitle recognition operation of this frame is required, and ck is reassigned to 0 .
所述的字幕识别首先进行字幕检测,在字幕检测中使用边缘检测、边缘点连接、连通域收集及分割方法、连通域精化及拖尾过滤方法得到候选文本域及其位置,再用联合熵过滤器移除非文本域,只留下字幕区域步骤为: Described subtitle recognition first carries out subtitle detection, uses edge detection, edge point connection, connected domain collection and segmentation method, connected domain refinement and trailing filter method to obtain candidate text domain and its position in subtitle detection, then uses joint entropy The filter removes non-text fields, leaving only subtitles. The steps are:
(1)边缘检测方法 (1) Edge detection method
给定图像I,采用Sobel算子检测边缘,Sobel算子由水平SH、垂直SV、对角线SLD、逆对角线SRD 四个方向上的梯度模板组成,边缘场由下式计算: Given an image I, the Sobel operator is used to detect edges. The Sobel operator is composed of gradient templates in four directions: horizontal S H , vertical S V , diagonal S LD , and anti-diagonal S RD . The edge field is given by the following formula calculate:
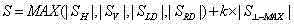
其中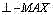

(2)边缘点连接方法 (2) Edge point connection method
对于边缘映射图EdgeMap,若同行两个边缘点的距离小于某一阀值T d ,则将EdgeMap中这两个像素之间的像素值都置为1,也即填充这两个边缘点间的像素,T d 由下式确定: For the edge map EdgeMap , if the distance between two edge points in the same row is less than a certain threshold T d , set the pixel values between these two pixels in the EdgeMap to 1, that is, fill the space between the two edge points pixel, T d is determined by:
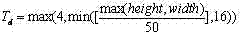
其中height和width分别为图像I的高和宽; Wherein height and width are the height and width of image I respectively;
(3)连通域收集及分割方法 (3) Connected domain collection and segmentation method
对上步得到的EdgeMap进行连通域收集,去掉那些高或宽小于整幅图像高或宽的1%的连通域,同时去掉那些最小包围矩形小于整幅图像面积0.2%的连通域,再使用如下步骤对每个连通域C进行区域分割: Collect the connected domains of the EdgeMap obtained in the previous step, remove those connected domains whose height or width is less than 1% of the entire image height or width, and remove those connected domains whose smallest enclosing rectangle is less than 0.2% of the entire image area, and then use the following The step is to segment each connected domain C:
a) 对于C中的每一行i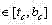
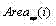
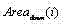
b) 对于C中的每一列j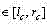
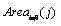

c) 令
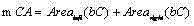
其中t c ,b c l c 和 r c 分别是区域C的上界行号、下界行号、左界列号和右界列号; Among them, t c , b c l c and r c are the upper boundary row number, lower boundary row number, left boundary column number and right boundary column number of area C respectively;
为了防止过分割,只有当连通区域C同时满足以下两个条件时才进行分割:

(4)连通域精化及拖尾过滤方法 (4) Connected domain refinement and trailing filtering method
在进行区域精化前,先去掉那些高大于宽的2倍的连通域,这样可能会误删那些竖排的字幕,为了处理竖排字幕,只须将图像旋转90度,其它操作一模一样; Before performing area refinement, first remove those connected domains whose height is greater than twice the width, which may accidentally delete those vertical subtitles. In order to process vertical subtitles, you only need to rotate the image by 90 degrees, and the other operations are exactly the same;
对上步得到的每个连通区域C,对其位置进行进一步精化的步骤如下: For each connected region C obtained in the previous step, the steps to further refine its position are as follows:
输入:边缘映射图edgeMap,连通域C的初始上下边界位置 Input: edge map edgeMap , the initial upper and lower boundary positions of the connected domain C
输出:精化后的上下界位置 Output: refined upper and lower bound positions
d) 对于连通域C的任意行,计算其在edgeMap中的左右非0像素跨距
e) 对于连通域C的任意行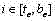
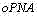
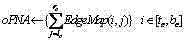
f) 取cSA中的最大值存在中,并将其序号存在pSRN中; f) Take the maximum value in cSA to exist , and store its serial number in pSRN ;
取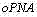


g) 对于在范围内的所有行,取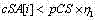
![]()
![]()
对于在
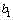
对于在
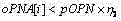
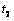
对于在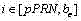

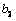
h) 令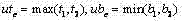
其中 和 
使用如下拖尾过滤方法去掉一些非字幕连通域: Use the following trailing filtering method to remove some non-subtitle connected domains:
i) 在上面步骤g) 完成后,继续在oPNA中向上和下扫描,直到当前行处的值小于,假设得到的行号分别为t tail 和 b tail ; i) After the above step g) is completed, continue to scan up and down in oPNA until the value at the current row is less than , assuming that the obtained line numbers are t tail and b tail respectively;
j) 用下式计算尾巴的长: j) Calculate the length of the tail using the following formula:
tl 1 =t 2 -t tail , tl 2 =b tail -b 2 , tl=max (tl 1 , tl 2 ) tl 1 = t 2 - t tail , tl 2 = b tail - b 2 , tl =max ( tl 1 , tl 2 )
k) 用下式进行过滤,若deleteFlag(C)为1,说明此连通域不是字幕区域,应该删除; k) Use the following formula to filter, if deleteFlag(C) is 1, it means that this connected domain is not a subtitle area and should be deleted;
5 5
其中ubc和utc分别表示连通域C精化后的上下界位置,而

(5)联合熵过滤器 (5) Joint entropy filter
使用联合前景像素分布熵和边缘像素分布熵的联合熵过滤器进行过滤,只留下字幕区域; Use the joint entropy filter of the joint foreground pixel distribution entropy and edge pixel distribution entropy to filter, leaving only the subtitle area;
对于前景像素分布熵,是对某一连通域C的最小包围矩形Rect [tc,bc,lc,rc],其中tc,bc分别是上下界,lc,rc分别是左右界,使用Otsu阀值将其二值化,然后将其分成2行×4列=8部分,使用下式计算分布熵: For the foreground pixel distribution entropy, it is the smallest enclosing rectangle Rect [t c , b c , l c , r c ] for a connected domain C, where t c , b c are the upper and lower bounds respectively, and l c , r c are respectively For the left and right boundaries, use the Otsu threshold to binarize it, then divide it into 2 rows × 4 columns = 8 parts, and use the following formula to calculate the distribution entropy:

其中pi,j表示第i行第j列那部分非0像素的比率; Among them, p i,j represents the ratio of non-zero pixels in the i-th row and j-th column;
对于边缘像素分布熵,是将连通域C的最小包围矩形Rect [tc,bc,lc,rc]内的Sobel边缘二值图分成2行×4列=8部分,使用下式计算分布熵: For the edge pixel distribution entropy, the Sobel edge binary image in the smallest enclosing rectangle Rect [t c , b c , l c , r c ] of the connected domain C is divided into 2 rows × 4 columns = 8 parts, and calculated using the following formula Distribution entropy:

其中e ij 表示第i行第j列那部分边缘像素数目,而 e r 是8部分边缘像素数目总和, Where e ij represents the number of edge pixels in row i, column j, and e r is the sum of the number of edge pixels in 8 parts,
对于任一精化后的连通域C,若其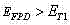
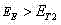


对于某些既有横排又有竖排字幕的图像,在原图和旋转90度所得的图像中进行字幕检测,再将两者检测结果进行合并,消除重复。 For some images with both horizontal and vertical subtitles, subtitle detection is performed in the original image and the image obtained by rotating 90 degrees, and then the detection results of the two are combined to eliminate duplication.
所述的对字幕区域进行重复性检测,若该区域未重复,则将其颜色极统一为黑底白字,然后进行字幕抽取,否则处理下一字幕区域步骤为: Described repeatability detection is carried out to subtitle area, if this area does not repeat, then its color is extremely unified as black and white characters, then carry out subtitle extraction, otherwise process next subtitle area step as:
(6)重复性检测 (6) Repeatability detection
采用结合位置和灰度颜色直方图的方法对检测出的字幕区域进行消重,步骤如下: Use the method of combining position and grayscale color histogram to deduplicate the detected subtitle area, the steps are as follows:
l) 提取并存储前一已处理帧所有字幕区域位置Recti[ti,bi,li,ri]及灰度直方图GHi{gi,0,gi,1,…gi,255},其中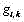
m)计算它们的位置相似度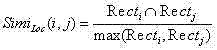



(7)颜色极统一 (7) Extremely uniform color
将字幕区域灰度图统一成黑底白字,采取以下步骤: To unify the grayscale image of the subtitle area into black and white characters, take the following steps:
n) 首先将灰度化后的字幕区域用Otsu方法二值化,然后分别使用3×3的掩模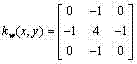
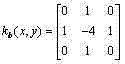
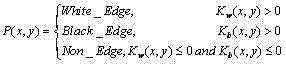
令Nw和Nb分别表示白色边缘像素个数和黑色边缘像素个数,定义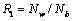
o) 对上步8式得到的边缘映射图P,将边缘像素按列投影,设边缘映射图在列上分解成{x0,x1,…,xn},其中xi为边缘图在列上投影为0的某一连续区间的中点,依次建立矩形Recti[1,height,xi,xi+1],在该矩形范围内的边缘映射图P中从四边向内扫描,将遇到的第一个边缘像素点删除,重新统计白色边缘像素个数和黑色边缘像素个数,分别设为

p) 定义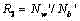

用如下方法判断字幕区域的颜色极: Use the following method to judge the color pole of the subtitle area:
(a) 若
(d) 若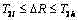
(e) 若
(d) 若
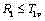
(f) 若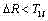
其中
q) 判断出字幕颜色极后,若为黑字,则将该字幕区域灰度图反色,否则不作操作。 q) After judging that the color of the subtitle is extremely high, if it is black, then invert the grayscale image of the subtitle area, otherwise no operation is performed.
所述的在字幕抽取中对颜色极统一后的字幕区域进行二值化,去除噪声点后送OCR软件识别步骤为: In the subtitle extraction, the subtitle area after the extremely unified color is binarized, and the OCR software recognition steps are sent after removing the noise points as follows:
r) 将灰度化的字幕区域的高规整化为24,然后分别向上下扩展4个像素,从而扩展后高度为32,设为EI; r) Normalize the height of the grayscaled subtitle area to 24, and then expand 4 pixels up and down respectively, so that the height after expansion is 32, which is set as EI;
s) 将结果二值图B每个像素初始化为1,然后对EI进行步进式水平局部阀值二值化,在一个16×32的局部窗口中用Otsu方法进行二值化,每次水平步进8个像素,同样的方法对EI进行步进式垂直局部阀值二值化,在一个image_width×8的局部窗口中用Otsu方法进行二值化,每次垂直步进4个像素,在每个子窗口中,EI中灰度值低于局部阀值的,B中相应的像素值设为0; t) 将B中与扩展区域值为1的像素相连的像素置0,为了防止将笔划像素也置为0,定义dam points: s) Initialize each pixel of the resulting binary image B to 1, and then perform step-by-step horizontal local threshold binarization on the EI, and use the Otsu method to binarize in a 16×32 local window, each level Step by 8 pixels, the same method is used to perform step-by-step vertical local threshold binarization on EI, and use the Otsu method to binarize in a local window of image_width×8, each vertical step by 4 pixels, in In each sub-window, if the gray value in EI is lower than the local threshold, the corresponding pixel value in B is set to 0; Pixels are also set to 0, defining dam points:

其中H_len(x,y)表示像素(x,y)所在的最长水平连续1序列的长度,而V_len(x,y) 表示像素(x,y)所在的最长垂直连续1序列的长度,对于dam points点,是无法扩展为背景像素的; Where H_len(x,y) represents the length of the longest horizontally continuous 1 sequence where the pixel (x,y) is located, and V_len(x,y) represents the length of the longest vertically continuous 1 sequence where the pixel (x,y) is located, For dam points, it cannot be expanded into background pixels;
u) 使用Sobel算子得到EI的边缘信息,对B中的每一个值为1的连通域,统计落在其中或环绕它的边缘像素点的个数epn,若epn<tepn,则将该连通域的所有像素置为0,从而将该连通域去掉,tepn用下式确定: u) Use the Sobel operator to get the edge information of EI. For each connected domain with a value of 1 in B, count the number epn of the edge pixels falling in it or surrounding it. If epn<tepn , the connected domain Set all the pixels in the domain to 0, so as to remove the connected domain, tepn is determined by the following formula:
tepn=max(cheight,cwidth) tepn =max( cheight,cwidth )
其中cheight和cwidth分别为该连通域的高和宽。 Among them, cheight and cwidth are the height and width of the connected domain, respectively.
v) 将二值图B送入OCR软件进行识别。 v) Send binary image B to OCR software for recognition.
实施例 Example
如图3、4所示,对于视频中的某一幅帧图像,给出了对包含在其中的字幕的识别流程实例。下面结合本发明的方法详细说明该实例实施的具体步骤,如下: As shown in Figures 3 and 4, for a certain frame image in the video, an example of the process of identifying the subtitles contained in it is given. Below in conjunction with the method of the present invention describe in detail the concrete steps that this example implements, as follows:
对于某一帧图像,如附图3(a)所示,采用权利要求3中的(1)边缘检测方法得出其角点加强的边缘映射图,结果如附图3(b)所示; For a certain frame of image, as shown in Figure 3(a), use the edge detection method (1) in claim 3 to obtain an edge map with enhanced corner points, and the result is shown in Figure 3(b);
(1) 以上步得到的边缘映射图为输入,采用权利要求3中的(2)边缘点连接方法连接边缘点,结果如附图3(c)所示; (1) The edge map obtained in the above step is used as input, and the edge points are connected by (2) edge point connection method in claim 3, and the result is shown in Figure 3 (c);
(2) 以边缘点连接后的映射图为输入,采用权利要求3中的(3)连通域收集及分割算法得到较大的连通域,结果如附图3(d)所示; (2) Taking the map of the connected edge points as input, adopt (3) connected domain collection and segmentation algorithm in claim 3 to obtain a larger connected domain, and the result is shown in Figure 3(d);
(3) 对上步得到的连通域,使用权利要求3中的(4)连通域精化及拖尾过滤方法得到更准确的区域位置大小并进行初步过滤,结果如附图3(e)所示; (3) For the connected domain obtained in the previous step, use the (4) connected domain refinement and tailing filtering method in claim 3 to obtain a more accurate area position size and perform preliminary filtering. The result is shown in Figure 3 (e) Show;
(4) 对过滤后剩下的连通域,使用权利要求3中的(5)联合熵过滤器去掉非字幕区域,最后检测结果如附图3(f)所示; (4) For the remaining connected domains after filtering, use the (5) joint entropy filter in claim 3 to remove the non-subtitle area, and the final detection result is shown in Figure 3 (f);
(5) 对于上步检测出的某一特定字幕区域,如附图4(a)所示,先使用权利要求4中的(6)重复性检测判断其是否与之前已检测区域重复,如不重复,则使用权利要求4中的(7)颜色极统一方法将该区域统一成黑底白字; (5) For a specific subtitle area detected in the previous step, as shown in Figure 4(a), first use the (6) repeatability detection in claim 4 to determine whether it is repeated with the previously detected area, if not Repeatedly, use the (7) color pole unification method in claim 4 to unify the area into white characters on a black background;
(6) 对统一颜色极后的字幕区域,使用权利要求5中的二值化和去噪算法,得到较好的二值图,结果如附图4(b)所示;
(6) For the subtitle area behind the uniform color, use the binarization and denoising algorithm in
(7) 使用商业OCR软件对二值图进行识别,结果如附图4(c)所示。 (7) Use commercial OCR software to identify the binary image, and the result is shown in Figure 4 (c).
从附图中可以看出,本方法能较好的检测视频图像帧中的字幕区域,并将之二值化,二值化后的结果能达到较好的识别精度。 It can be seen from the accompanying drawings that this method can better detect the subtitle area in the video image frame and binarize it, and the binarized result can achieve better recognition accuracy.
Claims (4)



Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 201110024330 CN102208023B (en) | 2011-01-23 | 2011-01-23 | Method for recognizing and designing video captions based on edge information and distribution entropy |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 201110024330 CN102208023B (en) | 2011-01-23 | 2011-01-23 | Method for recognizing and designing video captions based on edge information and distribution entropy |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN102208023A CN102208023A (en) | 2011-10-05 |
| CN102208023B true CN102208023B (en) | 2013-05-08 |
Family
ID=44696845
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN 201110024330 Expired - Fee Related CN102208023B (en) | 2011-01-23 | 2011-01-23 | Method for recognizing and designing video captions based on edge information and distribution entropy |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN102208023B (en) |
Families Citing this family (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102780856B (en) * | 2012-04-12 | 2013-11-27 | 天脉聚源(北京)传媒科技有限公司 | Method for annotating subtitles in news video |
| CN103377379A (en) * | 2012-04-27 | 2013-10-30 | 佳能株式会社 | Text detection device and method and text information extraction system and method |
| CN103136523B (en) * | 2012-11-29 | 2016-06-29 | 浙江大学 | Any direction text line detection method in a kind of natural image |
| US9177383B2 (en) * | 2013-08-29 | 2015-11-03 | Analog Devices Global | Facial detection |
| WO2018023538A1 (en) * | 2016-08-04 | 2018-02-08 | 黄新勇 | Method and system for extracting television broadcast subtitle |
| CN106355172A (en) * | 2016-08-11 | 2017-01-25 | 无锡天脉聚源传媒科技有限公司 | Character recognition method and device |
| CN107590447B (en) * | 2017-08-29 | 2021-01-08 | 北京奇艺世纪科技有限公司 | Method and device for recognizing word title |
| CN108982106B (en) * | 2018-07-26 | 2020-09-22 | 安徽大学 | An efficient method for rapid detection of dynamic mutations in complex systems |
| CN109284751A (en) * | 2018-10-31 | 2019-01-29 | 河南科技大学 | A non-text filtering method based on spectral analysis and SVM for text localization |
| CN111754414B (en) * | 2019-03-29 | 2023-10-27 | 北京搜狗科技发展有限公司 | Image processing method and device for image processing |
| CN110197177B (en) * | 2019-04-22 | 2024-03-19 | 平安科技(深圳)有限公司 | Method, device, computer equipment and storage medium for extracting video captions |
| CN111064990B (en) * | 2019-11-22 | 2021-12-14 | 华中师范大学 | Video processing method, apparatus and electronic device |
| CN113496223B (en) * | 2020-03-19 | 2024-10-18 | 顺丰科技有限公司 | Method and device for establishing text region detection model |
| CN111783771B (en) * | 2020-06-12 | 2024-03-19 | 北京达佳互联信息技术有限公司 | Text detection method, text detection device, electronic equipment and storage medium |
| CN111860521B (en) * | 2020-07-21 | 2022-04-22 | 西安交通大学 | Method for segmenting distorted code-spraying characters layer by layer |
| CN111967526B (en) * | 2020-08-20 | 2023-09-22 | 东北大学秦皇岛分校 | Remote sensing image change detection method and system based on edge mapping and deep learning |
| CN111741236B (en) * | 2020-08-24 | 2021-01-01 | 浙江大学 | Method and device for localized natural image caption generation based on consensus graph representation reasoning |
| CN112925905B (en) * | 2021-01-28 | 2024-02-27 | 北京达佳互联信息技术有限公司 | Method, device, electronic equipment and storage medium for extracting video subtitles |
| CN113485432A (en) * | 2021-07-26 | 2021-10-08 | 西安热工研究院有限公司 | Photovoltaic power station electroluminescence intelligent diagnosis system and method based on unmanned aerial vehicle |
| CN114140798B (en) * | 2021-12-03 | 2024-09-27 | 北京奇艺世纪科技有限公司 | Text region segmentation method and device, electronic equipment and storage medium |
| CN114140729B (en) * | 2021-12-03 | 2025-08-01 | 北京奇艺世纪科技有限公司 | Text region position identification method and device, electronic equipment and storage medium |
| CN116453030B (en) * | 2023-04-07 | 2024-07-05 | 郑州大学 | Building material recycling method based on computer vision |
| CN119763090B (en) * | 2024-12-11 | 2025-09-26 | 浙江大学 | Movie subtitle extraction method and device under background complex change scene based on OCR and color preprocessing |
| CN119692074A (en) * | 2025-02-25 | 2025-03-25 | 泉州市馨帮护卫生用品有限公司 | A numerical control teaching system based on operation behavior analysis |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1835462A1 (en) * | 2004-12-02 | 2007-09-19 | National Institute of Advanced Industrial Science and Technology | Tracing device, and tracing method |
| CN101122952A (en) * | 2007-09-21 | 2008-02-13 | 北京大学 | A method of image text detection |
| CN101833664A (en) * | 2010-04-21 | 2010-09-15 | 中国科学院自动化研究所 | Video image text detection method based on sparse representation |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100836197B1 (en) * | 2006-12-14 | 2008-06-09 | 삼성전자주식회사 | Video caption detection device and method |
-
2011
- 2011-01-23 CN CN 201110024330 patent/CN102208023B/en not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1835462A1 (en) * | 2004-12-02 | 2007-09-19 | National Institute of Advanced Industrial Science and Technology | Tracing device, and tracing method |
| CN101122952A (en) * | 2007-09-21 | 2008-02-13 | 北京大学 | A method of image text detection |
| CN101833664A (en) * | 2010-04-21 | 2010-09-15 | 中国科学院自动化研究所 | Video image text detection method based on sparse representation |
Non-Patent Citations (12)
| Title |
|---|
| A comprehensive method for multilingual video text detection, localization, and extraction;Michael R.Lyu等;《IEEE Transactions on Circuits and Systems for Video Technology 2005》;20050228;第15卷(第2期);243-255 * |
| A New Approach for Overlay Text Detection and Extraction from Complex Video Scene;Wonjun Kim等;《IEEE Transactions on Image Processing 2009》;20090228;第18卷(第2期);401-411 * |
| A robust statistic method for classifying color polarity of video text;J. Song等;《Acoust, Speech, and Signal Processing, 2003. Proceedings.(ICASSP ’03). 2003 IEEE International Conference on》;20030410;第3卷;581-584 * |
| J. Song等.A robust statistic method for classifying color polarity of video text.《Acoust, Speech, and Signal Processing, 2003. Proceedings.(ICASSP ’03). 2003 IEEE International Conference on》.2003,第3卷581–584. |
| Michael R.Lyu等.A comprehensive method for multilingual video text detection, localization, and extraction.《IEEE Transactions on Circuits and Systems for Video Technology 2005》.2005,第15卷(第2期),243-255. |
| Wonjun Kim等.A New Approach for Overlay Text Detection and Extraction from Complex Video Scene.《IEEE Transactions on Image Processing 2009》.2009,第18卷(第2期),401-411. |
| 基于多帧图像的视频文字跟踪和分割算法;密聪杰等;《计算机研究与发展》;20060930;第43卷(第9期);1523-1529 * |
| 基于时空域信息的视频字幕提取算法研究;沈淑娟;《中国优秀硕士学位论文全文数据库》;20040611;45-47 * |
| 密聪杰等.基于多帧图像的视频文字跟踪和分割算法.《计算机研究与发展》.2006,第43卷(第9期),1523-1529. |
| 沈淑娟.基于时空域信息的视频字幕提取算法研究.《中国优秀硕士学位论文全文数据库》.2004,45-47. |
| 视频中的文本提取及其应用;陆兵;《中国优秀硕士学位论文全文数据库》;20071012;7-62 * |
| 陆兵.视频中的文本提取及其应用.《中国优秀硕士学位论文全文数据库》.2007,7-62. |
Also Published As
| Publication number | Publication date |
|---|---|
| CN102208023A (en) | 2011-10-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN102208023B (en) | Method for recognizing and designing video captions based on edge information and distribution entropy | |
| CN111814722B (en) | A form recognition method, device, electronic device and storage medium in an image | |
| CN103136523B (en) | Any direction text line detection method in a kind of natural image | |
| CN102177520B (en) | Segmenting printed media pages into articles | |
| CN101251892B (en) | A character segmentation method and device | |
| CN101453575B (en) | A method for extracting video subtitle information | |
| US6731788B1 (en) | Symbol Classification with shape features applied to neural network | |
| CN105205488B (en) | Word area detection method based on Harris angle points and stroke width | |
| CN104966051B (en) | A kind of Layout Recognition method of file and picture | |
| CN101719142B (en) | Method for detecting picture characters by sparse representation based on classifying dictionary | |
| CN108171104A (en) | A kind of character detecting method and device | |
| CN101515325A (en) | Character extracting method in digital video based on character segmentation and color cluster | |
| CN103295009B (en) | Based on the license plate character recognition method of Stroke decomposition | |
| CN101122952A (en) | A method of image text detection | |
| CN101122953A (en) | A method for image text segmentation | |
| CN103488986B (en) | Self-adaptation character cutting and extracting method | |
| CN101266654A (en) | Image text localization method and device based on connected components and support vector machines | |
| CN107045634A (en) | A kind of text positioning method based on maximum stable extremal region and stroke width | |
| CN107085726A (en) | Single character location method in oracle bone rubbings based on multi-method denoising and connected region analysis | |
| CN110516673A (en) | Character detection method of Yi ancient books based on connected components and regression character segmentation | |
| Kumar et al. | NESP: Nonlinear enhancement and selection of plane for optimal segmentation and recognition of scene word images | |
| CN107506777A (en) | A real-time multi-license plate recognition method and device based on wavelet variation and support vector machine | |
| CN106446920A (en) | Stroke width transformation method based on gradient amplitude constraint | |
| Anthimopoulos et al. | Multiresolution text detection in video frames | |
| CN111583156B (en) | Document image shading removing method and system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C17 | Cessation of patent right | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20130508 Termination date: 20140123 |