CN102075766B - Video coding and decoding methods and devices, and video coding and decoding system - Google Patents
Video coding and decoding methods and devices, and video coding and decoding system Download PDFInfo
- Publication number
- CN102075766B CN102075766B CN 200910221967 CN200910221967A CN102075766B CN 102075766 B CN102075766 B CN 102075766B CN 200910221967 CN200910221967 CN 200910221967 CN 200910221967 A CN200910221967 A CN 200910221967A CN 102075766 B CN102075766 B CN 102075766B
- Authority
- CN
- China
- Prior art keywords
- image
- transform domain
- code stream
- data
- transform
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images











Landscapes
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
本发明实施例涉及一种视频编码、解码方法、装置及视频编解码系统,方法包括:获取视频图像数据的原始序列;对原始序列中具有第一尺寸的第一图像进行预测、变换、量化、编码得到第一图像的码流;根据第一图像的预测模式,对原始序列中具有第二尺寸的第二图像进行预测、变换、量化,获得第二图像的变换域数据;若第二尺寸与所述第一尺寸不相同,以第一图像的变换域数据为参考对第二图像的变换域数据在变换域上进行预测,对预测后的第二图像的变换域层间预测数据进行编码,获取第二图像的码流。本发明实施例提供的视频编码、解码方法、装置及视频编解码系统由于不需要对原始序列中的第一图像在变换域上再次进行反变换,因此降低了编码的复杂度。
Embodiments of the present invention relate to a video encoding and decoding method, device, and video encoding and decoding system. The method includes: acquiring an original sequence of video image data; performing prediction, transformation, quantization, and Encoding to obtain the code stream of the first image; according to the prediction mode of the first image, predict, transform, and quantize the second image with the second size in the original sequence to obtain the transform domain data of the second image; if the second size is the same as The first sizes are different, predicting the transform domain data of the second image in the transform domain with reference to the transform domain data of the first image, and encoding the predicted transform domain inter-layer prediction data of the second image, Get the code stream of the second image. The video encoding, decoding method, device and video encoding and decoding system provided by the embodiments of the present invention do not need to inversely transform the first image in the original sequence again in the transform domain, thus reducing the complexity of encoding.
Description
技术领域 technical field
本发明实施例涉及通信技术领域,尤其是一种视频编码、解码方法、装置及视频编解码系统。Embodiments of the present invention relate to the field of communication technologies, in particular, a video encoding and decoding method, device, and video encoding and decoding system.
背景技术 Background technique
随着互联网技术的飞速发展,视频在互联网上的应用越来越广泛。为了能够较好地适应不同客户端的需求,联合视频组(Joint Video Team,简称:JVT)将可伸缩性视频编码(Scalable Video Coding,简称:SVC)纳入到了较为先进的视频编码标准H.264/高级视频编码(Advanced Video Coding,简称:AVC)的扩展中。With the rapid development of Internet technology, the application of video on the Internet is becoming more and more extensive. In order to better adapt to the needs of different clients, the Joint Video Team (JVT for short) incorporates Scalable Video Coding (SVC for short) into the relatively advanced video coding standard H.264/ Advanced Video Coding (Advanced Video Coding, referred to as: AVC) extension.
SVC码流重写是一种将SVC码流转换为AVC码流的技术,现有技术存在三种SVC可伸缩性的码流重写技术,即:本地播放的可伸缩性码流重写、单播的可伸缩性码流重写、广播/组播的可伸缩性码流重写,由于分级B帧已经很好的解决了时间分辨率的可伸缩性,因此码流重写技术不需要考虑时间的可伸缩性;由于JVT已经较好地解决了质量的可伸缩性并能够在实际中应用,因此码流重写技术也不需要考虑质量的可伸缩性。SVC code stream rewriting is a technology that converts SVC code streams into AVC code streams. There are three SVC scalable code stream rewriting technologies in the prior art, namely: scalable code stream rewriting for local playback, Scalable code stream rewriting for unicast and scalable code stream rewriting for broadcast/multicast. Since the hierarchical B frame has already solved the scalability of time resolution, the code stream rewriting technology does not need Consider the scalability of time; since JVT has already solved the scalability of quality and can be applied in practice, the code stream rewriting technology does not need to consider the scalability of quality.
现有技术已经将基于质量可伸缩的码流重写列为SVC标准的一部分,质量可伸缩的码流重写技术通过对编码进行改动,在变换域进行层间预测;基于空间可伸缩的编码、码流重写、解码的过程中需要在像素域进行层间预测,若需要产生空间可伸缩的码流,则需要在像素域进行层间预测,因此在码流重写、解码过程中需要对熵解码后的变换数据进行逆变换,逆变换之后在像素域重建参考值,然后重建图像;或者在重建参考值之后再重新预测、变换、量化和编码,得到新的码流。The existing technology has listed quality-scalable code stream rewriting as a part of the SVC standard. The quality-scalable code stream rewriting technology performs inter-layer prediction in the transform domain by changing the code; , In the process of code stream rewriting and decoding, it is necessary to perform inter-layer prediction in the pixel domain. If it is necessary to generate a spatially scalable code stream, it is necessary to perform inter-layer prediction in the pixel domain. Therefore, in the process of code stream rewriting and decoding, it is necessary to Perform inverse transformation on the transformed data after entropy decoding, reconstruct the reference value in the pixel domain after inverse transformation, and then reconstruct the image; or re-predict, transform, quantize and encode after reconstructing the reference value to obtain a new code stream.
发明人在实施本发明的过程中发现,由于在码流重写及解码的过程中需要对解码后的变换数据进行逆变换,因此增加了码流重写及解码的复杂度。In the process of implementing the present invention, the inventor found that in the process of code stream rewriting and decoding, the decoded transformed data needs to be inversely transformed, thus increasing the complexity of code stream rewriting and decoding.
发明内容 Contents of the invention
本发明实施例的目的在于提供一种视频编码、解码方法、装置及视频编解码系统,通过对视频图像数据的原始序列在变换域进行编码或者解码处理,降低码流重写及解码实现的复杂度。The purpose of the embodiments of the present invention is to provide a video encoding and decoding method, device and video encoding and decoding system, by encoding or decoding the original sequence of video image data in the transform domain, reducing the complexity of code stream rewriting and decoding Spend.
本发明实施例提供一种视频编码方法,包括:An embodiment of the present invention provides a video coding method, including:
获取视频图像数据的原始序列;Obtain a raw sequence of video image data;
对所述原始序列中具有第一尺寸的第一图像进行预测、变换、量化、编码得到所述第一图像的码流;Predicting, transforming, quantizing, and encoding a first image with a first size in the original sequence to obtain a code stream of the first image;
根据所述第一图像的预测模式,对原始序列中具有第二尺寸的第二图像进行预测、变换、量化,获得所述第二图像的变换域数据;Predict, transform, and quantize a second image with a second size in the original sequence according to the prediction mode of the first image, to obtain transform domain data of the second image;
若所述第二尺寸与所述第一尺寸不相同,以所述第一图像的变换域数据为参考对所述第二图像的变换域数据在变换域上进行预测,对预测后的所述第二图像的变换域层间预测数据进行编码,获取所述第二图像的码流;其中,所述第一图像的码流和所述第二图像的码流形成空间可伸缩码流。If the second size is different from the first size, predict the transform domain data of the second image in the transform domain with reference to the transform domain data of the first image, and predict the predicted The transform domain inter-layer prediction data of the second image is encoded to obtain a code stream of the second image; wherein, the code stream of the first image and the code stream of the second image form a spatially scalable code stream.
本发明实施例还提供一种视频码流重写方法,包括:The embodiment of the present invention also provides a video code stream rewriting method, including:
获取通过变换域层间预测编码得到的空间可伸缩码流;Obtaining a spatially scalable code stream obtained through transform domain inter-layer predictive coding;
在对所述空间可伸缩码流进行重写过程中,若所述空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据,对所述第二图像的第二编码纹理的变换域数据进行码流重写。In the process of rewriting the spatially scalable code stream, if the second size of the second image in the spatially scalable code stream is different from the first size of the first image, then in the transform domain with the Using the transform domain data corresponding to the first coded texture of the first image as a reference, reconstructing the transform domain data of the second coded texture of the second image, and encoding the transform domain data of the second coded texture of the second image stream rewriting.
本发明实施例还提供一种视频解码方法,包括:The embodiment of the present invention also provides a video decoding method, including:
获取通过变换域层间预测编码得到的空间可伸缩码流;Obtaining a spatially scalable code stream obtained through transform domain inter-layer predictive coding;
对所述空间可伸缩码流进行解码过程中,若所述空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据;In the process of decoding the spatially scalable code stream, if the second size of the second image in the spatially scalable code stream is different from the first size of the first image, then in the transform domain, the The transform domain data corresponding to the first coded texture of an image is used as a reference, and the transform domain data of the second coded texture of the second image is reconstructed;
对第二编码纹理的变换域数据进行逆变换,获得的第二编码纹理,利用第二编码纹理重建第二图像。Inverse transform is performed on the transformation domain data of the second coded texture to obtain the second coded texture, and the second image is reconstructed by using the second coded texture.
本发明实施例还提供一种视频编码装置,包括:The embodiment of the present invention also provides a video encoding device, including:
获取模块,用于获取视频图像数据的原始序列;Obtaining module, for obtaining the original sequence of video image data;
第一编码模块,用于对所述原始序列中具有第一尺寸的第一图像进行预测、变换、量化、编码得到所述第一图像的码流;A first encoding module, configured to predict, transform, quantize, and encode a first image with a first size in the original sequence to obtain a code stream of the first image;
第一处理模块,用于根据所述第一图像的预测模式,对原始序列中具有第二尺寸的第二图像进行预测、变换、量化,获得所述第二图像的变换域数据;A first processing module, configured to predict, transform, and quantize a second image with a second size in the original sequence according to the prediction mode of the first image, and obtain transform domain data of the second image;
第二编码模块,用于若所述第二尺寸与所述第一尺寸不相同,以所述第一图像的变换域数据为参考对所述第二图像的变换域数据在变换域上进行预测,对预测后的所述第二图像的变换域层间预测数据进行编码,获取所述第二图像的码流;其中,所述第一图像的码流和所述第二图像的码流形成空间可伸缩码流。A second encoding module, configured to predict the transform domain data of the second image in the transform domain with reference to the transform domain data of the first image if the second size is different from the first size , encoding the predicted transform domain inter-layer prediction data of the second image to obtain the code stream of the second image; wherein, the code stream of the first image and the code stream of the second image form Spatial scalable code stream.
本发明实施例还提供一种视频码流重写装置,包括:The embodiment of the present invention also provides a video code stream rewriting device, including:
获取模块,用于获取通过变换域层间预测编码得到的空间可伸缩码流;An acquisition module, configured to acquire a spatially scalable code stream obtained through transform domain inter-layer predictive coding;
码流重写模块,用于在对所述空间可伸缩码流进行重写过程中,若所述空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据,对所述第二图像的第二编码纹理的变换域数据进行码流重写。A code stream rewriting module, configured to rewrite the spatially scalable code stream, if the second image in the spatially scalable code stream has a second size different from the first size of the first image are the same, then in the transform domain, the transform domain data corresponding to the first coded texture of the first image is used as a reference to reconstruct the transform domain data of the second coded texture of the second image, and the second coded texture of the second image is reconstructed. The transform domain data of the encoded texture is codestream rewritten.
本发明实施例还提供一种视频解码装置,包括:The embodiment of the present invention also provides a video decoding device, including:
获取模块,用于获取通过变换域层间预测编码得到的空间可伸缩码流;An acquisition module, configured to acquire a spatially scalable code stream obtained through transform domain inter-layer predictive coding;
第一重建模块,用于获取通过变换域层间预测编码得到的空间可伸缩码流;A first reconstruction module, configured to obtain a spatially scalable code stream obtained through transform domain inter-layer predictive coding;
第二重建模块,用于对所述空间可伸缩码流进行解码过程中,若所述空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据;The second reconstruction module is configured to decode the spatially scalable code stream, if the second size of the second image in the spatially scalable code stream is different from the first size of the first image, then In the transform domain, using the transform domain data corresponding to the first coded texture of the first image as a reference, reconstructing the transform domain data of the second coded texture of the second image;
第三重建模块,用于对第二编码纹理的变换域数据进行逆变换,获得的第二编码纹理,利用第二编码纹理重建第二图像。The third reconstruction module is configured to perform inverse transformation on the transformation domain data of the second coded texture, obtain the second coded texture, and use the second coded texture to reconstruct the second image.
本发明实施例还提供一种视频编解码系统,包括:视频编码装置、至少一视频解码装置、至少一码流重写装置,An embodiment of the present invention also provides a video encoding and decoding system, including: a video encoding device, at least one video decoding device, at least one code stream rewriting device,
所述视频编码装置,用于获取视频图像数据的原始序列;对所述原始序列中具有第一尺寸的第一图像进行预测、变换、量化、编码得到所述第一图像的码流;根据所述第一图像的预测模式,对原始序列中具有第二尺寸的第二图像进行预测、变换、量化,获得所述第二图像的变换域数据;若所述第二尺寸与所述第一尺寸不相同,以所述第一图像的变换域数据为参考对所述第二图像的变换域数据在变换域上进行预测,对预测后的所述第二图像的变换域层间预测数据进行编码,获取所述第二图像的码流;其中,所述第一图像的码流和所述第二图像的码流形成空间可伸缩码流;The video encoding device is configured to obtain an original sequence of video image data; perform prediction, transformation, quantization, and encoding on a first image with a first size in the original sequence to obtain a code stream of the first image; according to the The prediction mode of the first image, predict, transform, and quantize the second image with the second size in the original sequence, and obtain the transform domain data of the second image; if the second size is the same as the first size Not the same, the transform domain data of the second image is predicted in the transform domain with reference to the transform domain data of the first image, and the predicted transform domain inter-layer prediction data of the second image is encoded , acquiring the code stream of the second image; wherein, the code stream of the first image and the code stream of the second image form a spatially scalable code stream;
所述码流重写装置,用于获取通过变换域层间预测编码得到的空间可伸缩码流;在对所述空间可伸缩码流进行重写过程中,若所述空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据,对所述第二图像的第二编码纹理的变换域数据进行码流重写;The code stream rewriting device is used to obtain a spatially scalable code stream obtained through transform domain inter-layer predictive coding; during the process of rewriting the spatially scalable code stream, if the spatially scalable code stream is If the second size of the second image is different from the first size of the first image, then in the transform domain, the transform domain data corresponding to the first coded texture of the first image is used as a reference to reconstruct the second image Transform domain data of the second coded texture, rewriting the code stream of the transform domain data of the second coded texture of the second image;
所述视频解码装置,用于获取通过变换域层间预测编码得到的空间可伸缩码流;对所述空间可伸缩码流进行解码过程中,若所述空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据;对第二编码纹理的变换域数据进行逆变换,获得的第二编码纹理,利用第二编码纹理重建第二图像。The video decoding device is configured to obtain a spatially scalable code stream obtained through transform domain inter-layer predictive coding; during the process of decoding the spatially scalable code stream, if the second image in the spatially scalable code stream If the second size is not the same as the first size of the first image, the second encoded texture of the second image is reconstructed in the transform domain using the transform domain data corresponding to the first encoded texture of the first image as a reference The transform domain data of the second coded texture is inversely transformed to obtain the second coded texture, and the second coded texture is used to reconstruct the second image.
本发明实施例提供的视频编码、解码方法、装置及视频编解码系统,通过对原始序列中具有第二尺寸的第二图像在变换域上以第一图像的变换域数据为参考对第二图像在变换域上进行预测,对预测后的第二图像的数据进行编码,获取第二图像的码流,由于不需要对原始序列中的第一图像在变换域上再次进行反变换处理,因此降低了编码及解码的复杂度。In the video encoding, decoding method, device and video encoding and decoding system provided by the embodiments of the present invention, the second image with the second size in the original sequence is compared in the transform domain with the transform domain data of the first image as a reference. Prediction is performed on the transform domain, and the predicted data of the second image is encoded to obtain the code stream of the second image. Since the first image in the original sequence does not need to be inversely transformed in the transform domain again, it reduces complexity of encoding and decoding.
附图说明 Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the technical solutions in the embodiments of the present invention or the prior art, the following will briefly introduce the drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only These are some embodiments of the present invention. For those skilled in the art, other drawings can also be obtained according to these drawings without any creative effort.
图1为本发明视频编码方法一个实施例的流程示意图;FIG. 1 is a schematic flowchart of an embodiment of a video encoding method of the present invention;
图2为图1所示实施例的视频编码的一个示意图;FIG. 2 is a schematic diagram of video encoding in the embodiment shown in FIG. 1;
图3为图1所示实施例的视频编码的又一个示意图;FIG. 3 is another schematic diagram of video encoding in the embodiment shown in FIG. 1;
图4为本发明视频码流重写方法一个实施例的流程示意图;FIG. 4 is a schematic flow diagram of an embodiment of a method for rewriting a video code stream according to the present invention;
图5为图4所示实施例中码流重写的一个示意图;Fig. 5 is a schematic diagram of code stream rewriting in the embodiment shown in Fig. 4;
图6为图4所示实施例中码流重写的又一个示意图;FIG. 6 is another schematic diagram of code stream rewriting in the embodiment shown in FIG. 4;
图7为本发明视频解码方法一个实施例的流程示意图;FIG. 7 is a schematic flowchart of an embodiment of a video decoding method of the present invention;
图8为图7所示实施例中视频解码的一个示意图;Fig. 8 is a schematic diagram of video decoding in the embodiment shown in Fig. 7;
图9为图7所示实施例中视频解码的又一个示意图;FIG. 9 is another schematic diagram of video decoding in the embodiment shown in FIG. 7;
图10为本发明视频编码装置一个实施例的结构示意图;FIG. 10 is a schematic structural diagram of an embodiment of a video encoding device according to the present invention;
图11为本发明视频码流重写装置一个实施例的结构示意图;FIG. 11 is a schematic structural diagram of an embodiment of a video code stream rewriting device of the present invention;
图12为本发明视频解码装置一个实施例的结构示意图;FIG. 12 is a schematic structural diagram of an embodiment of a video decoding device according to the present invention;
图13为本发明视频编解码系统一个实施例的结构示意图;FIG. 13 is a schematic structural diagram of an embodiment of the video encoding and decoding system of the present invention;
图14为本发明实施例所适用的码流重写系统的结构示意图。FIG. 14 is a schematic structural diagram of a code stream rewriting system applicable to an embodiment of the present invention.
具体实施方式 Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
为了更容易理解本发明实施例,本发明实施例采用如下基本符号进行说明:设fl,n i为第l层,第n帧(也可以是第n个场或者第n个图像),第i个编码块的原始像素值(l、n、i均为正整数);

为了更好地理解本发明实施例的技术方案,对多层码流编码的层间预测技术进行详细说明。在对l层进行层间预测时,需要对参考层l-1层进行完全解码重建,以获取参考层l-1层更多的编码信息,考虑到解码重建的复杂度等因素,将参考层l-1层完全解码重建并非是层间预测最好的方式,因此需要在层间预测和时间预测之间进行选择,例如:运动缓慢并且细节丰富的序列在时间上的相关性会更强,则此时采用时间预测的方式较为简单。多层码流编码的层间预测模式有三种:层间运动预测、层间残差预测、层间帧内预测;其中,在层间运动预测方式中,当参考层l-1对应编码块为层间编码(inter-coded)时,增强层l的编码块也采用层间编码(inter-coded),在此情况下,增强层l的分块信息以及参考帧和运动向量等信息都从低层l-1对应位置的编码块继承;在层间残差预测方式中,所有的层间编码块都可以采用层间残差预测的方式,假设参考层l-1层的残差为当前编码块为fl,n i,在前一帧(或者某一个参考帧)中通过运动搜索的编码块为
此外,由于本发明实施例以预测模式为帧内预测或者帧间预测为例进行说明的,因此需要涉及到第一图像的码流和第二图像的码流,为描述简便,第一图像的码流称为l-1层码流,第二图像的码流称为l层码流;若第二图像具有的第二尺寸与第一图像具有的第一尺寸不相同,也即,l-1层码流和l层码流的分辨率(大小尺寸)不相同,则l层码流的编码模式和l-1层码流在空间上对应位置的编码块的编码模式相同,例如:当l层码流为通用中间格式(Common Intermediate Format,简称:CIF)尺寸,并且l-1层码流为四分之一通用中间格式(Quarter Common Intermediate Format,简称:QCIF)尺寸时,一个l-1层编码块对应四个l层编码块,则该四个l层编码块的编码模式均由同一个l-1层编码块的编码模式确定。In addition, since the embodiment of the present invention is described by taking the prediction mode as an example of intra prediction or inter prediction, it needs to involve the code stream of the first image and the code stream of the second image. For the sake of simplicity of description, the code stream of the first image The code stream is called the l-1 layer code stream, and the code stream of the second image is called the l-layer code stream; if the second size of the second image is different from the first size of the first image, that is, l- If the resolutions (sizes) of the 1-layer code stream and the l-layer code stream are different, then the coding mode of the l-layer code stream is the same as the coding mode of the coding block at the corresponding position in the space of the l-1 layer code stream, for example: when When the l-layer code stream is the Common Intermediate Format (CIF for short) size, and the l-1 layer code stream is a quarter of the Common Intermediate Format (Quarter Common Intermediate Format, QCIF for short) size, an l- A coding block of layer 1 corresponds to four coding blocks of layer l, and the coding modes of the four coding blocks of layer l are all determined by the coding mode of the same coding block of layer l-1.
图1为本发明视频编码方法一个实施例的流程示意图,图2为图1所示实施例的视频编码的一个示意图,图3为图1所示实施例的视频编码的又一个示意图;如图1所示,本发明实施例包括如下步骤:Fig. 1 is a schematic flow chart of an embodiment of the video coding method of the present invention, Fig. 2 is a schematic diagram of the video coding of the embodiment shown in Fig. 1, and Fig. 3 is another schematic diagram of the video coding of the embodiment shown in Fig. 1; 1, the embodiment of the present invention comprises the following steps:
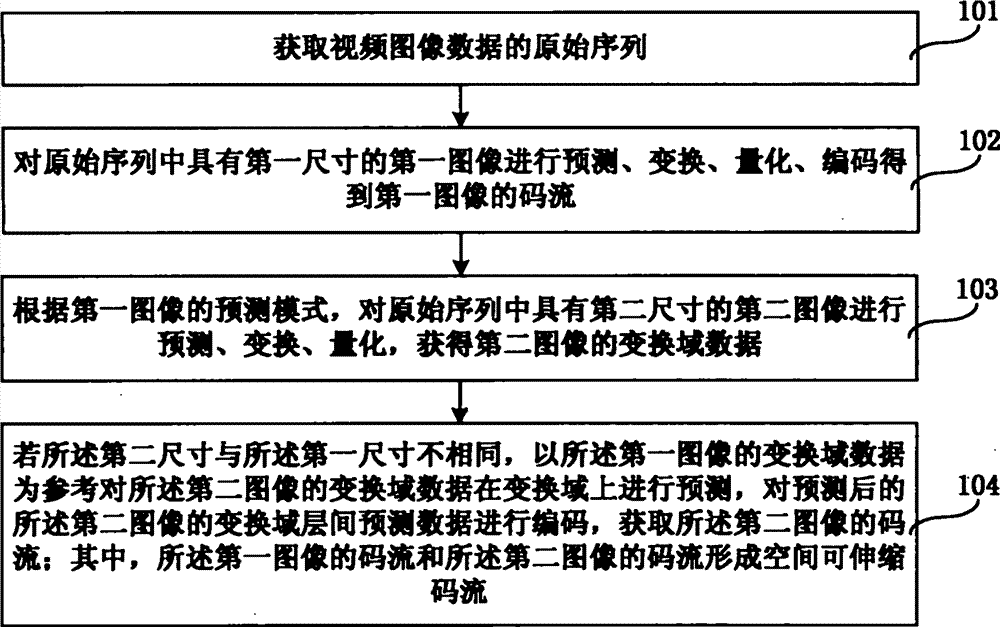
步骤101、获取视频图像数据的原始序列;
步骤102、对原始序列中具有第一尺寸的第一图像进行预测、变换、量化、编码得到第一图像的码流;
步骤103、根据第一图像的预测模式,对原始序列中具有第二尺寸的第二图像进行预测、变换、量化,获得第二图像的变换域数据;
步骤104、若所述第二尺寸与所述第一尺寸不相同,以所述第一图像的变换域数据为参考对所述第二图像的变换域数据在变换域上进行预测,对预测后的所述第二图像的变换域层间预测数据进行编码,获取所述第二图像的码流;其中,所述第一图像的码流和所述第二图像的码流形成空间可伸缩码流。Step 104: If the second size is different from the first size, predict the transform domain data of the second image in the transform domain with reference to the transform domain data of the first image, and predict Encoding the transform domain inter-layer prediction data of the second image to obtain the code stream of the second image; wherein, the code stream of the first image and the code stream of the second image form a spatially scalable code flow.
本发明实施例中的从空间可伸缩码流可以解码得到尺寸大小不同的多个图像,且编码获得该码流的过程中尺寸较大的图像以尺寸较小的图像作为参考进行编码。Multiple images of different sizes can be decoded from the spatially scalable code stream in the embodiment of the present invention, and a larger-sized image is encoded with a smaller-sized image as a reference during encoding to obtain the code stream.
本发明实施例提供的视频编码方法,以第一图像的变换域数据为参考对第二图像在变换域上进行预测,对预测后的第二图像的数据进行编码,获取第二图像的码流,由于不需要对原始序列中的第一图像在变换域上再次进行反变换处理,因此降低了编码的复杂度。The video encoding method provided by the embodiment of the present invention uses the transform domain data of the first image as a reference to predict the second image in the transform domain, encodes the predicted data of the second image, and obtains the code stream of the second image , since the first image in the original sequence does not need to be inversely transformed in the transform domain again, thus reducing the complexity of coding.
进一步地,在上述步骤101中,视频图像数据的原始序列可以是从媒体数据采集设备或者本地存储的视频图像数据中或者通过设备地址接收到,原始序列中的第一图像和第二图像可以分别获得,第一图像也可以通过第二图像的后处理获得,比如通过第二图像下采样或者缩放获得;只要是视频图像数据即可,视频图像数据的来源并不构成对本发明实施例的限制。Further, in the
进一步地,在上述步骤102中,为了与已有的编码标准进行兼容,对原始序列中具有第一尺寸的第一图像的编码块进行单层编码的编码方法可以采用现有的单层编码技术,例如:AVC编码技术;现有的单层编码技术并不能构成对本发明实施例的限制,凡是能够采用单层编码并且满足客户端需求的对图像的原始序列数据进行编码的实现方式均视为本发明实施例所述的能够形成第一图像的码流的方法;本实施例为描述方便,将第一图像的码流称为l-1层码流,将下述的基于l-1层码流编码形成的第二图像的码流称为l层码流,显而易见地,也可以将l层码流作为第一图像的码流,将l+1层码流作为第二图像的码流,因此本发明实施例中第一图像的码流与第二图像的码流仅为相对的概念描述;此外,本发明实施例所称的第一图像是指能够作为原始序列中与第一图像的尺寸不相同的图像的参考图像,因此第一图像并不仅限于分辨率固定的图像。Further, in the
进一步地,结合图2进行示例性说明,若第一图像的预测模式为帧内预测模式,则上述步骤103具体可以为:Further, with reference to FIG. 2 for exemplary illustration, if the prediction mode of the first image is an intra-frame prediction mode, the
获取第一图像的第一编码纹理,对第一编码纹理进行上采样,对上采样后的数据进行变换量化,获得第一编码纹理的变换域数据;例如:若获取到的l-1层(第一图像)的第一编码纹理为


获得第二图像的第二编码纹理,对所述第二编码纹理进行变换量化,获得第二编码纹理的变换域数据;例如:若获取的第二图像的第二编码纹理(或者第二残差)为

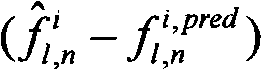

以第一编码纹理的变换域数据为参考对所述第二编码纹理的变换域数据进行层间预测,得到第一变换域层间预测数据,对所述第一变换域层间预测数据进行熵编码,形成第二图像的码流,例如:以第一编码纹理的变换域数据
可替换地,结合图3进行示例性说明,若第一图像的预测模式为帧间预测模式,则在上述步骤103中,获取l-1层(第一图像)的第一编码纹理为








进一步地,上述步骤103中根据第一图像的预测模式还可以有如下两种处理方式:Further, in the
其一,第一图像的预测模式为帧内预测模式的处理方式:First, the prediction mode of the first image is the processing method of the intra prediction mode:
获取第一图像的第三编码纹理,对第三编码纹理进行变换量化,对变换后的数据进行上采样,获得第三编码纹理的变换域数据;例如:若获取到的l-1层(第一图像)的第三编码纹理为

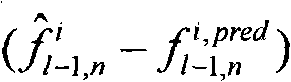



获得第二图像的第四编码纹理,对所述第四编码纹理进行变换量化,获得第四编码纹理的变换域数据;例如:若获取的第二图像的第四编码纹理(或者第二残差)为



以第三编码纹理的变换域数据为参考对所述第四编码纹理的变换域数据进行层间预测,得到第二变换域层间预测数据,对第二变换域层间预测数据进行熵编码,形成第二图像的码流,例如:以第三编码纹理的变换域数据

其二,第一图像的预测模式为帧间预测模式的处理方式:Second, the prediction mode of the first image is the processing method of the inter-frame prediction mode:
获取l-1层(第一图像)的第三编码纹理为




获得第二图像的第四编码纹理对第四编码纹理




进一步地,若所述原始序列中具有至少三种尺寸的图像,则以所述第一图像作为参考,或者将所述第二图像作为参考且将所述第二图像作为第一图像,将所述至少三种尺寸的图像中的剩余图像中的一个作为第二图像,执行若所述原始序列中第二图像具有的第二尺寸与所述第一尺寸不相同,则以所述第一图像为参考对所述第二图像在变换域上进行预测编码,对预测编码后的所述第二图像的数据进行编码,获取所述第二图像的码流。Further, if there are images of at least three sizes in the original sequence, the first image is used as a reference, or the second image is used as a reference and the second image is used as a first image, and the One of the remaining images of the at least three sizes of images is used as a second image, and if the second size of the second image in the original sequence is different from the first size, the first image is used as the second image. In order to refer to the predictive encoding of the second image in the transform domain, encode the data of the second image after predictive encoding, and obtain the code stream of the second image.
在上述图1~图3所示实施例的基础上,还可以包括:发送用于标记所述空间可伸缩码流为变换域层间预测的标识信息,使得接收设备根据所述标识信息对所述编码后形成的空间可伸缩码流在变换域进行重建处理;On the basis of the above-mentioned embodiments shown in Figures 1 to 3, it may further include: sending identification information for marking the spatially scalable code stream as transform-domain inter-layer prediction, so that the receiving device performs The spatially scalable code stream formed after the above coding is reconstructed in the transform domain;
其中,接收设备可以为网络中的能够将多层码流进行重写的网络节点,也可以为对多层码流能够进行解码的多层码流解码器,但上述两种设备并不构成对本发明实施例的限制,只要能够将接收到的多层码流进行重写或者解码的设备均为本发明实施例所述的接收设备。Among them, the receiving device can be a network node capable of rewriting multi-layer code streams in the network, or a multi-layer code stream decoder capable of decoding multi-layer code streams, but the above two devices do not constitute Restricted by the embodiment of the invention, as long as the device capable of rewriting or decoding the received multi-layer code stream is the receiving device described in the embodiment of the invention.
或者,该用于标记多层码流为变换域层间预测的标识信息也可以添加在多层码流中,使得接收设备根据标识信息对编码后形成的多层码流进行变换域重建处理。Alternatively, the identification information for marking the multi-layer code stream as transform-domain inter-layer prediction may also be added to the multi-layer code stream, so that the receiving device performs transform domain reconstruction processing on the encoded multi-layer code stream according to the identification information.
通过在该标记信息中标记该多层码流为变换域层间预测的标识信息,具体地,该标识信息具体可以标记该多层码流具有空间层码流重写功能,或者标记该多层码流在多个空间层编码中采用的是基于变换域的层间预测编码;通过将该标记信息传输到解码设备或者网络节点中,或者以适用默认的方式传输到解码设备或者网络节点中,使得解码设备或者网络节点通过该标记信息获知该多层码流是具有空间层码流重写功能,或者在多个空间层编码中采用了变换域的层间预测编码。若以传输的方式将该标记信息发送到解码设备或者网络节点,则可以将该标记信息通过码流携带,也可以通过相关协议(例如:会话描述协议(Session Description Protocol,简称:SDP))或者消息报文(例如:实时传送控制协议(Real-time Transport Control Protocol,简称:RTCP)报文)或者数据包的方式传输给网络节点或解码设备。By marking the multi-layer code stream as the identification information of transform domain inter-layer prediction in the marking information, specifically, the identification information can mark that the multi-layer code stream has the function of rewriting the spatial layer code stream, or mark the multi-layer code stream The code stream adopts the inter-layer predictive coding based on the transform domain in the encoding of multiple spatial layers; by transmitting the tag information to the decoding device or network node, or transmitting it to the decoding device or network node in a default way, Through the flag information, the decoding device or the network node knows that the multi-layer code stream has the function of rewriting the code stream of the spatial layer, or adopts the inter-layer predictive coding of the transform domain in the coding of multiple spatial layers. If the tag information is sent to the decoding device or network node in the form of transmission, the tag information can be carried through the code stream, or through related protocols (for example: Session Description Protocol (Session Description Protocol, referred to as: SDP)) or The message message (for example: Real-time Transport Control Protocol (Real-time Transport Control Protocol, RTCP for short) message) or data packet is transmitted to the network node or decoding device.
图4为本发明视频码流重写方法一个实施例的流程示意图,图5为图4所示实施例中码流重写的一个示意图,图6为图4所示实施例中码流重写的又一个示意图;如图4所示,本发明实施例包括如下步骤:Fig. 4 is a schematic flow chart of an embodiment of the video code stream rewriting method of the present invention, Fig. 5 is a schematic diagram of the code stream rewriting in the embodiment shown in Fig. 4, and Fig. 6 is a code stream rewriting in the embodiment shown in Fig. 4 Another schematic diagram; as shown in Figure 4, the embodiment of the present invention includes the following steps:
步骤401、获取通过变换域层间预测编码得到的空间可伸缩码流;
步骤402、在对空间可伸缩码流进行重写过程中,若空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据,对第二图像的第二编码纹理的变换域数据进行码流重写。Step 402: In the process of rewriting the spatially scalable code stream, if the second size of the second image in the spatially scalable code stream is different from the first size of the first image, then in the transform domain with the first The transform domain data corresponding to the first coded texture of the image is used as a reference, the transform domain data of the second coded texture of the second image is reconstructed, and the code stream is rewritten for the transform domain data of the second coded texture of the second image.
本发明实施例提供的视频码流重写方法,通过在变换域以第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据,对第二图像的第二编码纹理的变换域数据进行码流重写,由于在重写第二图像的码流时不需要对图像在变换域上再次进行反变换处理,因此降低了码流重写的复杂度。In the video code stream rewriting method provided by the embodiment of the present invention, the transform domain data corresponding to the first coded texture of the first image is reconstructed in the transform domain by using the transform domain data corresponding to the first coded texture of the first image as a reference, The code stream rewriting is performed on the transform domain data of the second coded texture of the second image. Since the code stream of the second image does not need to be inversely transformed in the transform domain again when rewriting the code stream of the second image, the code stream rewriting is reduced. Write complexity.
进一步地,结合图5所示,在上述图4所示实施例的基础上,在步骤402具体可以包括:Further, in conjunction with what is shown in FIG. 5 , on the basis of the above-mentioned embodiment shown in FIG. 4 , step 402 may specifically include:
对所述空间可伸缩码流中具有第一尺寸的第一图像的码流进行熵解码获取第一变换系数,对所述第一变换系数进行上采样后,在变换域进行缩放处理,得到所述第一图像的第一编码纹理的变换域数据;performing entropy decoding on the code stream of the first image with the first size in the spatially scalable code stream to obtain first transform coefficients, performing upsampling on the first transform coefficients, and performing scaling processing in the transform domain to obtain the transform domain data of the first coded texture of the first image;
对所述空间可伸缩码流中具有第二尺寸的第二图像的码流进行熵解码获取第三变换域层间预测数据;performing entropy decoding on a code stream of a second image having a second size in the spatially scalable code stream to obtain third transform domain inter-layer prediction data;
根据第一编码纹理的变换域数据和所述第三变换域层间预测数据重建所述第二图像的第二编码纹理的变换域数据;reconstructing the transform domain data of the second coded texture of the second image from the transform domain data of the first coded texture and the third transform domain inter-layer prediction data;
对所述空间可伸缩码流中的预测模式和所述第二编码纹理的变换域数据进行熵编码得到重写后码流。Entropy coding is performed on the prediction mode in the spatially scalable code stream and the transform domain data of the second coded texture to obtain a rewritten code stream.
进一步地,结合图6所示,在上述图4所示实施例的基础上,步骤402具体可以包括:Further, in combination with what is shown in FIG. 6 , on the basis of the above embodiment shown in FIG. 4 , step 402 may specifically include:
对所述空间可伸缩码流中具有第一尺寸的第一图像的码流进行熵解码获取第一变换数据,对所述第一变换数据进行逆变换,对逆变换后的数据进行上采样和变换量化,得到所述第一图像的第一编码纹理的变换域数据;performing entropy decoding on the code stream of the first image with a first size in the spatially scalable code stream to obtain first transformed data, performing inverse transformation on the first transformed data, and performing upsampling and summing on the inversely transformed data Transform and quantize to obtain transform domain data of the first coded texture of the first image;
对所述空间可伸缩码流中具有第二尺寸的第二图像的码流进行熵解码获取第二变换域层间预测数据;performing entropy decoding on a code stream of a second image having a second size in the spatially scalable code stream to obtain second transform domain inter-layer prediction data;
根据第一编码纹理的变换域数据和所述第二图像的第二变换域层间预测数据重建所述第二图像的第二编码纹理的变换域数据;reconstructing the transform domain data of the second coded texture of the second image from the transform domain data of the first coded texture and the second transform domain inter-layer prediction data of the second image;
对所述第二编码纹理的变换域数据和所述空间可伸缩码流的预测模式进行熵编码得到重写后码流。Entropy coding is performed on the transform domain data of the second coded texture and the prediction mode of the spatially scalable code stream to obtain a rewritten code stream.
进一步地,在上述图4~图6所示实施例中,重写后码流为单层码流或者通过变换域层间预测编码得到的空间可伸缩码流。Further, in the above-mentioned embodiments shown in FIGS. 4 to 6 , the code stream after rewriting is a single-layer code stream or a spatially scalable code stream obtained through transform-domain inter-layer predictive coding.
图7为本发明视频解码方法一个实施例的流程示意图,图8为图7所示实施例中视频解码的一个示意图,图9为图7所示实施例中视频解码的又一个示意图;如图7所示,本发明实施例包括如下步骤:Fig. 7 is a schematic flowchart of an embodiment of the video decoding method of the present invention, Fig. 8 is a schematic diagram of video decoding in the embodiment shown in Fig. 7, and Fig. 9 is another schematic diagram of video decoding in the embodiment shown in Fig. 7; 7, the embodiment of the present invention includes the following steps:
步骤701、获取通过变换域层间预测编码得到的空间可伸缩码流;
步骤702、在对空间可伸缩码流进行解码过程中,若空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以第一图像的第一编码纹理对应的变换域数据为参考,重建第二图像的第二编码纹理的变换域数据;Step 702: In the process of decoding the spatially scalable code stream, if the second size of the second image in the spatially scalable code stream is different from the first size of the first image, then in the transform domain, the first image The transform domain data corresponding to the first coded texture is used as a reference, and the transform domain data of the second coded texture of the second image is reconstructed;
步骤703、对第二编码纹理的变换域数据进行逆变换,获得的第二编码纹理,利用第二编码纹理重建第二图像。Step 703: Perform inverse transformation on the transform domain data of the second coded texture to obtain the second coded texture, and use the second coded texture to reconstruct a second image.
本发明实施例提供的视频解码方法,通过在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建第二图像的第二编码纹理的变换域数据,降低了解码的复杂度。The video decoding method provided by the embodiment of the present invention reconstructs the transform domain data of the second coded texture of the second image by using the transform domain data corresponding to the first coded texture of the first image as a reference in the transform domain, reducing the decoding cost. of complexity.
进一步地,结合图8进行说明,在上述图7所示实施例中,上述步骤702可以包括:Further, it will be described in conjunction with FIG. 8 , in the above embodiment shown in FIG. 7 , the
对空间可伸缩码流中具有第一尺寸的第一图像的码流进行熵解码获取第一变换系数,对所述第一变换系数进行上采样后,在变换域进行缩放处理,得到所述第一图像的第一编码纹理的变换域数据;performing entropy decoding on the code stream of the first image with the first size in the spatially scalable code stream to obtain a first transform coefficient, performing upsampling on the first transform coefficient, and performing scaling processing in the transform domain to obtain the first transform coefficient transform domain data of a first coded texture of an image;
对空间可伸缩码流中具有第二尺寸的第二图像的码流进行熵解码获取第二变换域层间预测数据;performing entropy decoding on a code stream of a second image having a second size in the spatially scalable code stream to obtain second transform domain inter-layer prediction data;
根据第一编码纹理的变换域数据和所述第二变换域层间预测数据重建所述第二图像的第二编码纹理的变换域数据。The transform domain data of the second coded texture of the second image is reconstructed from the transform domain data of the first coded texture and the second transform domain inter-layer prediction data.
上述过程中,由于直接在变换域上以第一图像的第一编码纹理对应的变换域数据为参考,重建第二图像的第二编码纹理的变换域数据,因此降低了解码的复杂度。In the above process, since the transform domain data corresponding to the first coded texture of the first image is directly used as a reference in the transform domain to reconstruct the transform domain data of the second coded texture of the second image, the complexity of decoding is reduced.
进一步地,结合图9进行说明,在上述图7所示实施例中,上述步骤702还可以包括:Further, it will be described with reference to FIG. 9 , in the above embodiment shown in FIG. 7 , the
对所述空间可伸缩码流中具有第一尺寸的第一图像的码流进行熵解码获取第一变换系数,对所述第一变换系数进行逆变换,对逆变换后的数据进行上采样和变换,得到所述第一图像的第一编码纹理的变换域数据;performing entropy decoding on the code stream of the first image with a first size in the spatially scalable code stream to obtain a first transformation coefficient, performing inverse transformation on the first transformation coefficient, and performing upsampling and summing on the inversely transformed data transforming to obtain transform domain data of the first coded texture of the first image;
对所述空间可伸缩码流中具有第二尺寸的第二图像的码流进行熵解码获取第三变换域层间预测数据;performing entropy decoding on a code stream of a second image having a second size in the spatially scalable code stream to obtain third transform domain inter-layer prediction data;
根据第一编码纹理的变换域数据和所述第二图像的第三变换域层间预测数据重建所述第二图像的第二编码纹理的变换域数据。The transform domain data of the second coded texture of the second image is reconstructed from the transform domain data of the first coded texture and the third transform domain inter-layer prediction data of the second image.
进一步地,在上述图7~9所示实施例的基础上,还可以包括:Further, on the basis of the above-mentioned embodiments shown in Figures 7-9, it may also include:
根据所述接收到的用于标记所述具有空间可伸缩的码流为变换域层间预测的标识信息,在变换域重建第二图像的第二编码纹理的变换域数据;Reconstructing the transform domain data of the second coded texture of the second image in the transform domain according to the received identification information for marking the code stream with spatial scalability as transform domain inter-layer prediction;
通过将标记信息传输到解码设备中,或者以适用默认的方式传输到解码设备或者网络节点中,使得解码设备通过该标记信息获知该多层码流是具有空间层码流重写功能,或者在多个空间层编码中采用了变换域的层间预测编码;若以传输的方式将该标记信息发送到解码设备或者网络节点,则可以将该标记信息可以在码流中携带,也可以通过相关协议(例如:SDP)或者消息报文(例如:RTCP报文)或者数据包的方式传输给网络节点或解码设备。By transmitting the marking information to the decoding device, or transmitting it to the decoding device or the network node in an applicable default manner, the decoding device can know that the multi-layer code stream has the function of rewriting the spatial layer code stream through the marking information, or in the Inter-layer predictive coding in the transform domain is used in the coding of multiple spatial layers; if the tag information is sent to the decoding device or network node in the form of transmission, the tag information can be carried in the code stream, or through the relevant The protocol (for example: SDP) or message message (for example: RTCP message) or data packet is transmitted to the network node or decoding device.
图10为本发明视频编码装置一个实施例的结构示意图,本发明实施例可以实现上述图1所示方法实施例的流程,如图10所示,本发明实施例包括:获取模块11、第一编码模块12、第二编码模块13、第一处理模块14;FIG. 10 is a schematic structural diagram of an embodiment of a video encoding device of the present invention. The embodiment of the present invention can realize the flow of the method embodiment shown in FIG. 1 above. As shown in FIG. 10, the embodiment of the present invention includes: an acquisition module 11, Encoding module 12, second encoding module 13, first processing module 14;
其中,获取模块11获取视频图像数据的原始序列;第一编码模块12对所述原始序列中具有第一尺寸的第一图像进行预测、变换、量化、编码得到所述第一图像的码流;第一处理模块14根据所述第一图像的预测模式,对原始序列中具有第二尺寸的第二图像进行预测、变换、量化,获得所述第二图像的变换域数据;若所述原始序列中的第二图像具有的第二尺寸与所述第一尺寸不相同,第二编码模块13以所述第一图像的变换域数据为参考对所述第二图像在变换域上进行预测,对预测后的所述第二图像的变换域层间预测数据进行编码,获取所述第二图像的码流;其中,所述第一图像的码流和所述第二图像的码流形成空间可伸缩码流。Wherein, the acquisition module 11 acquires the original sequence of video image data; the first encoding module 12 predicts, transforms, quantizes, and encodes the first image with the first size in the original sequence to obtain the code stream of the first image; The first processing module 14 predicts, transforms, and quantizes the second image with the second size in the original sequence according to the prediction mode of the first image, and obtains the transform domain data of the second image; if the original sequence The second image in the second image has a second size that is different from the first size, and the second encoding module 13 uses the transform domain data of the first image as a reference to predict the second image in the transform domain. Encoding the predicted transform domain inter-layer prediction data of the second image to obtain the code stream of the second image; wherein, the space formed by the code stream of the first image and the code stream of the second image can be Scalable code stream.
本发明实施例提供的视频编码装置,第二编码模块13以第一图像的变换域数据为参考对第二图像在变换域上进行预测,对预测后的第二图像的数据进行编码,获取第二图像的码流,由于不需要对原始序列中的第一图像在变换域上再次进行反变换处理,因此降低了编码的复杂度。In the video encoding device provided by the embodiment of the present invention, the second encoding module 13 uses the transform domain data of the first image as a reference to predict the second image in the transform domain, encode the predicted data of the second image, and obtain the second image For the code stream of two images, since the first image in the original sequence does not need to be inversely transformed in the transform domain again, the complexity of encoding is reduced.
进一步地,在上述图10所示实施例的基础上,第二编码模块还可以包括:第一处理单元、第二处理单元、第一编码单元;第一处理单元获取所述第一图像的第一编码纹理,对所述第一编码纹理进行上采样,对上采样后的数据进行变换量化,获得所述第一编码纹理的变换域数据;第二处理单元获得第二图像的第二编码纹理,对所述第二编码纹理进行变换量化,获得所述第二编码纹理的变换域数据;第一编码单元以所述第一编码纹理的变换域数据为参考对所述第二编码纹理的变换域数据进行层间预测,得到第一变换域层间预测数据,对所述第一变换域层间预测数据进行熵编码,形成第二图像的码流。Further, on the basis of the above-mentioned embodiment shown in FIG. 10 , the second encoding module may further include: a first processing unit, a second processing unit, and a first encoding unit; the first processing unit acquires the first image of the first image. A coded texture, upsampling the first coded texture, transforming and quantizing the upsampled data to obtain transform domain data of the first coded texture; the second processing unit obtains the second coded texture of the second image , transform and quantize the second coded texture to obtain the transform domain data of the second coded texture; the first coding unit transforms the second coded texture with the transform domain data of the first coded texture as a reference Inter-layer prediction is performed on the domain data to obtain first transform-domain inter-layer prediction data, and entropy coding is performed on the first transform-domain inter-layer prediction data to form a code stream of the second image.
进一步地,在上述图10所示实施例的基础上,第二编码模块还可以包括:第三处理单元、第四处理单元、第二编码单元;其中,第三处理单元获取所述第一图像的第三编码纹理,对所述第三编码纹理进行变换量化,对变换后的数据进行上采样,获得所述第三编码纹理的变换域数据;第四处理单元获得所述第二图像的第四编码纹理,对所述第四编码纹理进行变换量化,获得第二图像的第四编码纹理的变换域数据;第二编码单元以所述第三编码纹理的变换域数据为参考对所述第四编码纹理的变换域数据进行层间预测,得到第二变换域层间预测数据,对所述第二变换域层间预测数据进行熵编码,形成第二图像的码流。Further, on the basis of the above-mentioned embodiment shown in FIG. 10 , the second encoding module may further include: a third processing unit, a fourth processing unit, and a second encoding unit; wherein, the third processing unit acquires the first image the third coded texture, transform and quantize the third coded texture, and upsample the transformed data to obtain the transform domain data of the third coded texture; the fourth processing unit obtains the second image of the second image Four coded textures, performing transformation and quantization on the fourth coded texture to obtain transform domain data of the fourth coded texture of the second image; the second encoding unit uses the transform domain data of the third coded texture as a reference to the fourth coded texture. Perform inter-layer prediction on the transformation domain data of the four-coded texture to obtain second transformation domain inter-layer prediction data, and perform entropy coding on the second transformation domain inter-layer prediction data to form a code stream of the second image.
进一步地,在上述图10所示实施例的基础上,还包括:发送模块,用于发送用于标记所述空间可伸缩码流为变换域层间预测的标识信息,使得接收设备根据所述标识信息对所述编码后形成的空间可伸缩码流在变换域进行解码处理或者转码处理或者码流重写处理。Further, on the basis of the above-mentioned embodiment shown in FIG. 10 , it further includes: a sending module, configured to send identification information for marking the spatially scalable code stream as transform-domain inter-layer prediction, so that the receiving device according to the The identification information performs decoding processing, transcoding processing, or code stream rewriting processing on the spatially scalable code stream formed after the encoding in the transform domain.
图11为本发明视频码流重写装置一个实施例的结构示意图,本发明实施例可以实现上述图4所示方法实施例的流程,如图11所示,本发明实施例包括:获取模块111、码流重写模块112;FIG. 11 is a schematic structural diagram of an embodiment of the video code stream rewriting device of the present invention. The embodiment of the present invention can realize the flow of the method embodiment shown in FIG. 4 above. As shown in FIG. 11 , the embodiment of the present invention includes: an
其中,获取模块111获取通过变换域层间预测编码得到的空间可伸缩码流;码流重写模块112在对所述空间可伸缩码流进行重写过程中,若所述空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据,对所述第二图像的第二编码纹理的变换域数据进行码流重写。Wherein, the
本发明实施例提供的视频码流重写装置,码流重写模块112通过在变换域以第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据,对第二图像的第二编码纹理的变换域数据进行码流重写,由于不需要对原始序列中的图像在变换域上再次进行反变换处理,因此降低了码流重写的复杂度。In the video code stream rewriting device provided by the embodiment of the present invention, the code
进一步地,在上述图11所示实施例的基础上,码流重写模块还可以包括:第一处理单元、第二处理单元、第一重建单元、第一熵编码单元;其中,第一处理单元,用于对所述空间可伸缩码流中具有第一尺寸的第一图像的码流进行熵解码获取第一变换数据,对所述第一变换数据进行逆变换,对逆变换后的数据进行上采样和变换,得到所述第一图像的第一编码纹理的变换域数据;第二处理单元,用于对所述空间可伸缩码流中具有第二尺寸的第二图像的码流进行熵解码获取第二变换域层间预测数据;第一重建单元,用于根据第一编码纹理的变换域数据和所述第二图像的第二变换域层间预测数据重建所述第二图像的第二编码纹理的变换域数据;第一熵编码单元,用于对所述第二编码纹理的变换域数据和所述空间可伸缩码流的预测模式进行熵编码得到重写后码流。Further, on the basis of the above-mentioned embodiment shown in FIG. 11 , the code stream rewriting module may further include: a first processing unit, a second processing unit, a first reconstruction unit, and a first entropy encoding unit; wherein, the first processing A unit, configured to perform entropy decoding on a code stream of a first image having a first size in the spatially scalable code stream to obtain first transformed data, perform inverse transformation on the first transformed data, and perform inverse transformation on the inversely transformed data performing upsampling and transforming to obtain transform domain data of the first coded texture of the first image; a second processing unit configured to process a code stream of a second image having a second size in the spatially scalable code stream Entropy decoding to obtain second transform-domain inter-layer prediction data; a first reconstruction unit configured to reconstruct the second image according to the transform-domain data of the first coded texture and the second transform-domain inter-layer prediction data of the second image Transform domain data of the second coded texture; a first entropy coding unit configured to perform entropy coding on the transform domain data of the second coded texture and the prediction mode of the spatially scalable code stream to obtain a rewritten code stream.
进一步地,在上述图11所示实施例的基础上,码流重写模块还可以包括:第三处理单元、第四处理单元、第二重建单元、第二熵编码单元;其中,第二处理单元,用于对所述空间可伸缩码流中具有第一尺寸的第一图像的码流进行熵解码获取第一变换系数,对所述第一变换系数进行上采样后,在变换域进行缩放处理,得到所述第一图像的第一编码纹理的变换域数据;第四处理单元,用于对所述空间可伸缩码流中具有第二尺寸的第二图像的码流进行熵解码获取第三变换域层间预测数据;第二重建单元,用于根据第一编码纹理的变换域数据和所述第三变换域层间预测数据重建所述第二图像的第二编码纹理的变换域数据;第二熵编码单元,用于对所述空间可伸缩码流中的预测模式和所述第二编码纹理的变换域数据进行熵编码得到重写后码流。Further, on the basis of the above-mentioned embodiment shown in FIG. 11 , the code stream rewriting module may further include: a third processing unit, a fourth processing unit, a second reconstruction unit, and a second entropy encoding unit; wherein, the second processing A unit, configured to perform entropy decoding on a code stream of a first image having a first size in the spatially scalable code stream to obtain a first transform coefficient, perform upsampling on the first transform coefficient, and perform scaling in a transform domain processing to obtain the transform domain data of the first coded texture of the first image; a fourth processing unit, configured to perform entropy decoding on the code stream of the second image having a second size in the spatially scalable code stream to obtain the first Three transform-domain inter-layer prediction data; a second reconstruction unit configured to reconstruct the transform-domain data of the second coded texture of the second image according to the transform-domain data of the first coded texture and the third transform-domain inter-layer prediction data ; A second entropy coding unit, configured to perform entropy coding on the prediction mode in the spatially scalable code stream and the transform domain data of the second coded texture to obtain a rewritten code stream.
图12为本发明视频解码装置一个实施例的结构示意图,本发明实施例可以实现上述图7所示方法实施例的流程,如图12所示,本发明实施例包括:获取模块121、第一重建模块122、第二重建模块123;第三重建模块124。FIG. 12 is a schematic structural diagram of an embodiment of a video decoding device of the present invention. The embodiment of the present invention can realize the flow of the method embodiment shown in FIG. 7 above. As shown in FIG.
其中,获取模块121获取通过变换域层间预测编码得到的空间可伸缩码流;第一重建模块122获取通过变换域层间预测编码得到的空间可伸缩码;第二重建模块123对所述空间可伸缩码流进行解码过程中,若所述空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据;第三重建模块124对第二编码纹理的变换域数据进行逆变换,获得的第二编码纹理,利用第二编码纹理重建第二图像。Among them, the obtaining module 121 obtains the spatially scalable code stream obtained through transform-domain inter-layer predictive coding; the
本发明实施例提供的视频解码装置,第一重建模块122通过在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据,由于不需要对原始序列中的第一图像在变换域上再次进行反变换处理,因此降低了解码的复杂度。In the video decoding device provided by the embodiment of the present invention, the
进一步地,在上述图12所示实施例的基础上,第一重建模块还可以包括:第一处理单元、第一解码单元、第一重建单元;其中,第一处理单元,用于对所述空间可伸缩码流中具有第一尺寸的第一图像的码流进行熵解码获取第一变换系数,对所述第一变换系数进行上采样后,在变换域进行缩放处理,得到所述第一图像的第一编码纹理的变换域数据;第一解码单元,用于对所述空间可伸缩码流中具有第二尺寸的第二图像的码流进行熵解码获取第二变换域层间预测数据;第一重建单元,用于根据第一编码纹理的变换域数据和所述第二变换域层间预测数据重建所述第二图像的第二编码纹理的变换域数据。Further, on the basis of the above-mentioned embodiment shown in FIG. 12 , the first reconstruction module may further include: a first processing unit, a first decoding unit, and a first reconstruction unit; wherein, the first processing unit is used to process the performing entropy decoding on the code stream of the first image with the first size in the spatially scalable code stream to obtain first transform coefficients, performing upsampling on the first transform coefficients, and performing scaling processing in the transform domain to obtain the first Transform domain data of the first coded texture of the image; a first decoding unit configured to perform entropy decoding on a code stream of a second image having a second size in the spatially scalable code stream to obtain second transform domain inter-layer prediction data a first reconstruction unit, configured to reconstruct the transform domain data of the second coded texture of the second image according to the transform domain data of the first coded texture and the second transform domain inter-layer prediction data.
进一步地,在上述图12所示实施例的基础上,第一重建模块还可以包括:第二处理单元、第二解码单元、第二重建单元;其中,第二处理单元,用于对所述空间可伸缩码流中具有第一尺寸的第一图像的码流进行熵解码获取第一变换系数,对所述第一变换系数进行逆变换,对逆变换后的数据进行上采样和变换,得到所述第一图像的第一编码纹理的变换域数据;第二解码单元,用于对所述空间可伸缩码流中具有第二尺寸的第二图像的码流进行熵解码获取第三变换域层间预测数据;第二重建单元,用于根据第一编码纹理的变换域数据和所述第二图像的第三变换域层间预测数据重建所述第二图像的第二编码纹理的变换域数据。Further, on the basis of the above-mentioned embodiment shown in FIG. 12 , the first reconstruction module may further include: a second processing unit, a second decoding unit, and a second reconstruction unit; wherein, the second processing unit is used to process the performing entropy decoding on the code stream of the first image with the first size in the spatially scalable code stream to obtain a first transformation coefficient, performing inverse transformation on the first transformation coefficient, and performing upsampling and transformation on the inversely transformed data to obtain Transform domain data of the first coded texture of the first image; a second decoding unit configured to perform entropy decoding on a code stream of a second image having a second size in the spatially scalable code stream to obtain a third transform domain inter-layer prediction data; a second reconstruction unit for reconstructing the transform domain of the second coded texture of the second image based on the transform domain data of the first coded texture and the third transform-domain inter-layer prediction data of the second image data.
图13为本发明视频编解码系统一个实施例的结构示意图,如图13所示,本发明实施例包括:视频编码装置131、码流重写装置132、视频解码装置133;FIG. 13 is a schematic structural diagram of an embodiment of the video encoding and decoding system of the present invention. As shown in FIG. 13 , the embodiment of the present invention includes: a
其中,视频编码装置131获取视频图像数据的原始序列;对所述原始序列中具有第一尺寸的第一图像进行预测、变换、量化、编码得到所述第一图像的码流;根据所述第一图像的预测模式,对原始序列中具有第二尺寸的第二图像进行预测、变换、量化,获得所述第二图像的变换域数据;若所述第二尺寸与所述第一尺寸不相同,以所述第一图像的变换域数据为参考对所述第二图像的变换域数据在变换域上进行预测,对预测后的所述第二图像的变换域层间预测数据进行编码,获取所述第二图像的码流;其中,所述第一图像的码流和所述第二图像的码流形成空间可伸缩码流;Wherein, the
码流重写装置132获取通过变换域层间预测编码得到的空间可伸缩码流;在对所述空间可伸缩码流进行重写过程中,若所述空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据,对所述第二图像的第二编码纹理的变换域数据进行码流重写;The code
视频解码装置133获取通过变换域层间预测编码得到的空间可伸缩码流;对所述空间可伸缩码流进行解码过程中,若所述空间可伸缩码流中的第二图像具有的第二尺寸与第一图像的第一尺寸不相同,则在变换域以所述第一图像的第一编码纹理对应的变换域数据为参考,重建所述第二图像的第二编码纹理的变换域数据;对第二编码纹理的变换域数据进行逆变换,获得的第二编码纹理,利用第二编码纹理重建第二图像。The video decoding device 133 obtains a spatially scalable code stream obtained through transform-domain inter-layer predictive coding; during the process of decoding the spatially scalable code stream, if the second image in the spatially scalable code stream has a second If the size is different from the first size of the first image, then in the transform domain, the transform domain data corresponding to the first coded texture of the first image is used as a reference to reconstruct the transform domain data of the second coded texture of the second image ; Perform inverse transformation on the transform domain data of the second coded texture to obtain the second coded texture, and use the second coded texture to reconstruct the second image.
本发明实施例提供的视频编解码系统,通过对原始序列中具有第二尺寸的第二图像在变换域上根据第一图像的预测模式并以第一图像的变换域数据为参考对第二图像在变换域上进行预测,对编码预测后的第二图像的数据进行编码,获取第二图像的码流,由于不需要对原始序列中的第一图像在变换域上再次进行反变换处理,因此降低了编码和解码的复杂度。The video encoding and decoding system provided by the embodiment of the present invention performs the second image on the transform domain according to the prediction mode of the first image and takes the transform domain data of the first image as a reference for the second image with the second size in the original sequence. Perform prediction on the transform domain, encode the data of the second image after encoding and prediction, and obtain the code stream of the second image. Since the first image in the original sequence does not need to be inversely transformed in the transform domain again, so Reduced encoding and decoding complexity.
图14为本发明实施例所适用的码流重写系统的结构示意图,如图14所示,本发明实施例包括:编码器141、网络节点142、解码器143;其中,视编码器141具体可以为图10所示实施例的视频编码装置;网络节点142具体可以为图11所示实施例的视频码流重写装置;解码器143具体可以为图12所示实施例的视频解码装置。Fig. 14 is a schematic structural diagram of a code stream rewriting system applicable to the embodiment of the present invention. As shown in Fig. 14, the embodiment of the present invention includes: an encoder 141, a network node 142, and a decoder 143; wherein, depending on the specificity of the encoder 141 It may be the video encoding device in the embodiment shown in FIG. 10; the network node 142 may be specifically the video code stream rewriting device in the embodiment shown in FIG. 11; the decoder 143 may be specifically the video decoding device in the embodiment shown in FIG. 12.
其中,编码器141获取到视频图像数据的原始序列进行编码处理后形成多层码流,多层码流在网络传输过程中存在至少如下三种情况:一、多层码流直接传输到能够对多层码流进行解码的解码器143,二、多层码流传输至能够对多层码流进行重写和转码的网络节点142,网络节点142将多层码流进行重写或者转码成单层码流后,将单层码流传输至解码器143,解码器143对接收到的单层码流进行解码处理,将多层码流继续传输至后续的网络节点,待后续的网络节点进行码流重写直至输入单层码流;三、多层码流经过网络节点142后,形成码流层数小于输入至网络节点142的多层码流的层数的多层码流后,再传输至后续的网路节点,使得后续的网络节点再对多层码流进行重写或者转码,根据终端设备的需求重写或者转换成单层码流或者多层码流。Wherein, the encoder 141 obtains the original sequence of the video image data and performs encoding processing to form a multi-layer code stream. There are at least the following three situations in the network transmission process of the multi-layer code stream: 1. The multi-layer code stream is directly transmitted to the Decoder 143 for decoding the multi-layer code stream, 2. The multi-layer code stream is transmitted to the network node 142 capable of rewriting and transcoding the multi-layer code stream, and the network node 142 rewrites or transcodes the multi-layer code stream After forming a single-layer code stream, the single-layer code stream is transmitted to the decoder 143, and the decoder 143 decodes the received single-layer code stream, and continues to transmit the multi-layer code stream to subsequent network nodes, and waits for subsequent network The node rewrites the code stream until a single-layer code stream is input; 3. After the multi-layer code stream passes through the network node 142, a multi-layer code stream with a number of code stream layers smaller than the layer number of the multi-layer code stream input to the network node 142 is formed , and then transmitted to the subsequent network nodes, so that the subsequent network nodes rewrite or transcode the multi-layer code stream, and rewrite or convert it into a single-layer code stream or multi-layer code stream according to the needs of the terminal equipment.
本发明实施例所适用的码流重写系统中,通过对原始序列中具有第二尺寸的第二图像在变换域上以第一图像的变换域数据为参考对第二图像在变换域上进行预测,对编码预测后的第二图像的数据进行编码,获取第二图像的码流,由于不需要对原始序列中的第一图像在变换域上再次进行反变换处理,因此降低了编码和解码的复杂度。In the code stream rewriting system to which the embodiment of the present invention is applicable, the second image with the second size in the original sequence is performed on the transform domain by using the transform domain data of the first image as a reference to the second image in the transform domain. Prediction: encode the data of the second image after encoding and prediction, and obtain the code stream of the second image. Since the first image in the original sequence does not need to be inversely transformed in the transform domain again, the encoding and decoding are reduced. of complexity.
本发明实施例与现有技术中的不可重写码流的SVC编码的峰值信噪比(Peak Signal-to-Noise Ratio,简称:PSNR)如表1所示,本发明实施例与现有技术中的PSNR如表2所示,可重写的编码方案和同播编码相比较的结果如表3所示,将四层SVC码流重写成一层AVC码流与直接编码一层AVC码流的对比结果如表4所示,其中,deltaQP表示本发明实施例与SVC的量化参数(Quantization Parameter,简称:QP)相差为2、3、6时的结果比较。The peak signal-to-noise ratio (Peak Signal-to-Noise Ratio, referred to as: PSNR) of the SVC encoding of the non-rewritable code stream in the embodiment of the present invention and the prior art is shown in Table 1. The embodiment of the present invention and the prior art The PSNR in Table 2 is shown in Table 2. The rewritable coding scheme and the comparison results of simulcast coding are shown in Table 3. Rewriting the four-layer SVC code stream into one layer of AVC code stream and directly encoding one layer of AVC code stream The comparison results are shown in Table 4, wherein deltaQP represents the comparison of results when the difference between the quantization parameter (Quantization Parameter, QP) of the embodiment of the present invention and SVC is 2, 3, or 6.
表1本发明实施例与SVC的PSNR增益比较The PSNR gain comparison of the embodiment of the present invention and SVC of table 1
表2本发明实施例与同播码流的PSNR增益比较Table 2 Comparison of the embodiment of the present invention and the PSNR gain of the simulcast code stream
表3可重写的编码方案和同播编码相比较Table 3 Comparison of rewritable coding schemes and simulcast coding
表4本发明实施例码流码流重写后和单独编码一层AVC码流相比较Table 4 The code stream of the embodiment of the present invention is compared with the code stream of a single layer of AVC code stream after the code stream is rewritten
上述本发明实施例提供的可实现对多层码流进行码流重写的技术方案,可以综合实现多层质量的码流和多层空间码流的码流重写,本发明实施例生成的多层码流与采用现有技术生成的多层码流的编码性能相比率失真(RateDistortion,简称:RD)性能相同;并且,本发明实施例提供的技术方案中的码流中从作为基本层码流的第一图像(或者低层码流)开始到任意数目的作为增强层码流的第二图像可以在接收端在接收到该多层码流后方便快速地重写成新的多层码流或者单层码流;重写后的单层或者多层码流的解码和重写前的多层码流的解码结果相同。The above-mentioned technical solution provided by the embodiments of the present invention that can realize the code stream rewriting of the multi-layer code stream can comprehensively realize the code stream rewriting of the multi-layer quality code stream and the multi-layer space code stream. The code stream generated by the embodiment of the present invention The rate distortion (RateDistortion, referred to as: RD) performance of the multi-layer code stream is the same as that of the multi-layer code stream generated by the prior art; From the first image (or low-layer code stream) of the code stream to any number of second images as the enhancement layer code stream, the receiving end can conveniently and quickly rewrite the new multi-layer code stream after receiving the multi-layer code stream Or a single-layer code stream; the decoding result of the single-layer or multi-layer code stream after rewriting is the same as the decoding result of the multi-layer code stream before rewriting.
上述本发明实施例中的DCT变换也可以为实现离散变换域变换的其它变换,例如:小波变换,本发明实施例仅以DCT变换进行说明并不构成对本发明实施例中变换域处理的限制,凡是能够通过其它变换域方式实现的处理均为本发明实施例所述的技术方案。The DCT transform in the above-mentioned embodiments of the present invention may also be other transforms that implement discrete transform domain transforms, such as wavelet transforms. The embodiments of the present invention are only described with DCT transforms and do not constitute restrictions on the transform domain processing in the embodiments of the present invention. Any processing that can be realized through other transform domain methods is the technical solution described in the embodiments of the present invention.
本领域普通技术人员可以理解:实现上述实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。Those of ordinary skill in the art can understand that all or part of the steps for realizing the above-mentioned embodiments can be completed by hardware related to program instructions, and the aforementioned program can be stored in a computer-readable storage medium. When the program is executed, the execution includes The steps of the above-mentioned method embodiments; and the aforementioned storage medium includes: ROM, RAM, magnetic disk or optical disk and other various media that can store program codes.
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。Finally, it should be noted that: the above embodiments are only used to illustrate the technical solutions of the present invention, rather than to limit them; although the present invention has been described in detail with reference to the foregoing embodiments, those of ordinary skill in the art should understand that: it can still be Modifications are made to the technical solutions described in the foregoing embodiments, or equivalent replacements are made to some of the technical features; and these modifications or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions of the various embodiments of the present invention.
Claims (17)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 200910221967 CN102075766B (en) | 2009-11-23 | 2009-11-23 | Video coding and decoding methods and devices, and video coding and decoding system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 200910221967 CN102075766B (en) | 2009-11-23 | 2009-11-23 | Video coding and decoding methods and devices, and video coding and decoding system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN102075766A CN102075766A (en) | 2011-05-25 |
| CN102075766B true CN102075766B (en) | 2013-01-09 |
Family
ID=44034087
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN 200910221967 Active CN102075766B (en) | 2009-11-23 | 2009-11-23 | Video coding and decoding methods and devices, and video coding and decoding system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN102075766B (en) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102547282B (en) * | 2011-12-29 | 2013-04-03 | 中国科学技术大学 | Extensible video coding error hiding method, decoder and system |
| EP2830312A4 (en) * | 2012-03-20 | 2015-12-02 | Samsung Electronics Co Ltd | METHOD AND APPARATUS FOR SCREENABLE VIDEO CODING BASED ON ARBORESCENT STRUCTURE CODING UNIT, AND METHOD AND DEVICE FOR DECODING SCREENABLE VIDEO BASED ON ARBORESCENT STRUCTURE CODING UNIT |
| CN104604228B (en) * | 2012-09-09 | 2018-06-29 | Lg 电子株式会社 | Image decoding method and device using same |
| EP2941873A1 (en) * | 2013-01-07 | 2015-11-11 | VID SCALE, Inc. | Motion information signaling for scalable video coding |
| CN105379273B (en) * | 2013-07-14 | 2019-03-15 | 夏普株式会社 | Method and apparatus for decoding video from a bitstream |
| KR102299573B1 (en) * | 2014-10-22 | 2021-09-07 | 삼성전자주식회사 | Application processor for performing real time in-loop filtering, method thereof, and system including the same |
| WO2025255715A1 (en) * | 2024-06-11 | 2025-12-18 | Oppo广东移动通信有限公司 | Image decoding method and apparatus, image encoding method and apparatus, medium, and code stream |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1992903A (en) * | 2005-12-27 | 2007-07-04 | 中国科学院计算技术研究所 | Method for converting compressed domain video transcoding coefficient from MPEG-2 to H.264 |
| CN101193289A (en) * | 2006-11-22 | 2008-06-04 | 中兴通讯股份有限公司 | A real time conversion method from MPEG-4 transmission code stream to Internet stream media alliance stream |
| WO2008084424A1 (en) * | 2007-01-08 | 2008-07-17 | Nokia Corporation | System and method for providing and using predetermined signaling of interoperability points for transcoded media streams |
-
2009
- 2009-11-23 CN CN 200910221967 patent/CN102075766B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1992903A (en) * | 2005-12-27 | 2007-07-04 | 中国科学院计算技术研究所 | Method for converting compressed domain video transcoding coefficient from MPEG-2 to H.264 |
| CN101193289A (en) * | 2006-11-22 | 2008-06-04 | 中兴通讯股份有限公司 | A real time conversion method from MPEG-4 transmission code stream to Internet stream media alliance stream |
| WO2008084424A1 (en) * | 2007-01-08 | 2008-07-17 | Nokia Corporation | System and method for providing and using predetermined signaling of interoperability points for transcoded media streams |
Non-Patent Citations (4)
| Title |
|---|
| BO HU ET AL.Reducing Spatial Resolution H.264/AVC Transcoding.《ADVANCES IN MULITMEDIA INFORMATION PROCESSING - PCM 2005 LECTURE NOTES IN COMPUTER SCIENCE》.2005,第3768卷 |
| BO HU ET AL.Reducing Spatial Resolution H.264/AVC Transcoding.《ADVANCES IN MULITMEDIA INFORMATION PROCESSING- PCM 2005 LECTURE NOTES IN COMPUTER SCIENCE》.2005,第3768卷 * |
| Segall A,Jie Zhao.Bit stream rewriting for SVC-to-AVC conversion.《Image Processing,2008.ICIP.15th IEEE International Conference》.2008,第2778页左栏第4段-右栏第2段、附图3. * |
| SegallA Jie Zhao.Bit stream rewriting for SVC-to-AVC conversion.《Image Processing |
Also Published As
| Publication number | Publication date |
|---|---|
| CN102075766A (en) | 2011-05-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1303817C (en) | System and method for encoding and decoding residual signal for fine granular scalable video | |
| JP6416992B2 (en) | Method and arrangement for transcoding video bitstreams | |
| CN101336549B (en) | Scalable video coding method and apparatus based on multiple layers | |
| TWI357766B (en) | Variable length coding table selection based on vi | |
| JP5795416B2 (en) | A scalable video coding technique for scalable bit depth | |
| CN102075766B (en) | Video coding and decoding methods and devices, and video coding and decoding system | |
| CN1939066B (en) | Method and apparatus for complexity scalable video decoder | |
| CN101584217B (en) | Method and device of extended inter-layer coding for spatial scability | |
| CN1893666B (en) | Video encoding and decoding methods and apparatuses | |
| CN102740078B (en) | Adaptive spatial scalable coding based on HEVC (high efficiency video coding) standard | |
| JP4920110B2 (en) | Improved image quality | |
| CN101112103B (en) | Method for efficiently predicting multi-layer based video frame, and video encoding method and apparatus using the same | |
| CN114467304A (en) | Temporal signaling for video coding techniques | |
| US20060104354A1 (en) | Multi-layered intra-prediction method and video coding method and apparatus using the same | |
| CN102273080A (en) | Switching between DCT coefficient coding modes | |
| CN101204094A (en) | Method for scalable encoding and decoding of video signals | |
| CN100352283C (en) | Method for transcoding a fine granular scalable encoded video | |
| CN101467461A (en) | Multilayer-based video encoding method and apparatus thereof | |
| JP4880222B2 (en) | System and method for partial multiple description channel coding without video drift using forward error correction code | |
| WO2008145039A1 (en) | Methods, systems and devices for generating upsample filter and downsample filter and for performing encoding | |
| CN101288308A (en) | Intra-frame base layer prediction method satisfying single-loop decoding conditions and video coding method and device using the prediction method | |
| CN101888553B (en) | Method and apparatus for scalable video coding | |
| US20120002726A1 (en) | Method and apparatus for scalable video coding | |
| Chai et al. | JPEG2000 image compression: an overview | |
| Naman et al. | JPEG2000-based scalable interactive video (JSIV) |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant |