CN102035884B - Cloud storage system and data deployment method thereof - Google Patents
Cloud storage system and data deployment method thereof Download PDFInfo
- Publication number
- CN102035884B CN102035884B CN 201010572302 CN201010572302A CN102035884B CN 102035884 B CN102035884 B CN 102035884B CN 201010572302 CN201010572302 CN 201010572302 CN 201010572302 A CN201010572302 A CN 201010572302A CN 102035884 B CN102035884 B CN 102035884B
- Authority
- CN
- China
- Prior art keywords
- data
- user
- storage
- node
- cloud
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images











Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明公开了一种云存储系统,用于为用户提供云存储服务,其特征在于,该云存储系统包括:云存储服务提供商(103),一级代理节点(102),二级代理节点和存储云(105),用户发出服务请求,所述一级代理节点根据该请求选择出最佳的云存储服务提供商配置所提供的服务方案,所述二级代理点选择数据存储云中的存储中心,实现云存储服务。本发明还提供了一种云存储系统的数据部署方法,应用在删除、修改或增加用户数据。本发明能够支持多种云存储服务提供商所提供的服务,加快用户使用服务的响应速度,并能够根据用户的特点动态配置底层存储架构,以同时具有主从式与对等式存储架构的优点。
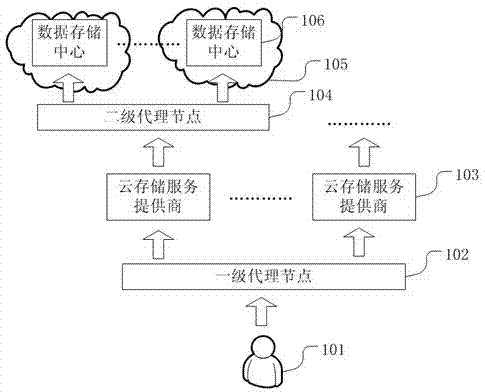
The invention discloses a cloud storage system, which is used to provide cloud storage services for users, and is characterized in that the cloud storage system includes: a cloud storage service provider (103), a first-level agent node (102), and a second-level agent node and storage cloud (105), the user sends a service request, the first-level proxy node selects the best cloud storage service provider configuration service plan according to the request, and the second-level proxy node selects the cloud storage service provider in the data storage cloud The storage center implements cloud storage services. The invention also provides a data deployment method of the cloud storage system, which is applied to delete, modify or add user data. The present invention can support services provided by various cloud storage service providers, speed up the response speed of users using services, and can dynamically configure the underlying storage architecture according to the characteristics of users, so as to have the advantages of master-slave and peer-to-peer storage architectures at the same time .
Description
技术领域 technical field
本发明涉及网络数据存储技术,尤其涉及一种云存储系统及其数据部署方法。The invention relates to network data storage technology, in particular to a cloud storage system and a data deployment method thereof.
背景技术 Background technique
随着云存储技术的日益发展,云存储服务提供商的数量和种类也将不断增多。然而,现有的各云存储系统都是采用一种封闭式的组成结构,只能支持特定的云存储服务提供商所提供的数据存储服务;而且,各种云存储服务提供商之间并不能有效的交换和共享数据资源。这将阻碍云存储服务多样化发展和云存储服务商之间的合作,使得用户局限于某一个云存储服务提供商。With the increasing development of cloud storage technology, the number and types of cloud storage service providers will also continue to increase. However, the existing cloud storage systems all adopt a closed structure, which can only support data storage services provided by specific cloud storage service providers; moreover, various cloud storage service providers cannot Efficient exchange and sharing of data resources. This will hinder the diversified development of cloud storage services and the cooperation between cloud storage service providers, making users limited to a certain cloud storage service provider.
传统的网络存储方式通常是由用户直接与数据存储中心进行通信,这种方法在用户数量较少,数据存储量不大的情况下是可行的。但是在云存储系统中,随着使用云存储服务的用户数量的快速增加,而网络传输速度增长相对缓慢的情况下,如果还采用这种方式将会使得用户请求响应时间过长,影响云存储服务的质量。In the traditional network storage method, users usually communicate directly with the data storage center. This method is feasible when the number of users is small and the amount of data storage is not large. However, in the cloud storage system, with the rapid increase in the number of users using cloud storage services and the relatively slow increase in network transmission speed, if this method is still used, the response time of user requests will be too long, which will affect cloud storage. the quality of the service.
目前典型的云存储的架构有两种,一种是以谷歌为代表的主从式存储架构,这种架构的主要优点是维护方便,容易进行数据同步与更新;另外一种是以亚马逊为代表的对等存储架构,该架构的主要优点是无热点,无单点故障,自我管理性强。但是目前还没有一种云存储系统,能够根据用户的时空行为特征对底层架构按需进行动态配置,以发挥存储架构对于环境的适应性。At present, there are two typical cloud storage architectures. One is the master-slave storage architecture represented by Google. The main advantage of this architecture is that it is easy to maintain and data synchronization and update; the other is represented by Amazon. The peer-to-peer storage architecture, the main advantages of this architecture are no hot spots, no single point of failure, and strong self-management. However, there is currently no cloud storage system that can dynamically configure the underlying architecture on demand according to the user's spatiotemporal behavior characteristics, so as to maximize the adaptability of the storage architecture to the environment.
发明内容 Contents of the invention
本发明所要解决的技术问题是需要提供一种云存储系统及其数据部署方法,使其能够支持多种云存储服务提供商所提供的服务,加快用户使用服务的响应速度,并能够根据用户的时空行为特征动态配置底层存储架构,以同时具有主从式与对等式存储架构的优点。The technical problem to be solved by the present invention is to provide a cloud storage system and its data deployment method, so that it can support services provided by various cloud storage service providers, speed up the response speed of users using services, and can The spatio-temporal behavior characteristics dynamically configure the underlying storage architecture to have the advantages of both master-slave and peer-to-peer storage architectures.
为了解决上述技术问题,本发明提供了一种云存储系统,以使得用户能够高效的从各种云存储服务提供商处获得云存储服务。该云存储系统包括:In order to solve the above technical problems, the present invention provides a cloud storage system, so that users can efficiently obtain cloud storage services from various cloud storage service providers. The cloud storage system includes:
1.云存储服务提供商:其作用是按照用户的请求,向用户提供数据存储服务;1. Cloud storage service provider: its role is to provide users with data storage services according to their requests;
2.一级代理节点:根据用户的选择策略,选择恰当的云存储服务提供商配置方案;2. First-level agent node: select the appropriate cloud storage service provider configuration scheme according to the user's selection strategy;
3.二级代理节点:根据用户的选择策略,选择恰当的数据存储中心配置方案;3. Secondary agent node: select the appropriate data storage center configuration scheme according to the user's selection strategy;
4.存储云:包括数据存储中心和辅助存储节点;4. Storage cloud: including data storage center and auxiliary storage nodes;
5.用户:是指能够连接到互联网的终端,包括普通终端或移动终端,其发出服务请求,使用一级代理节点所选择的最佳所述云存储服务提供商配置所提供的服务方案。5. User: refers to a terminal that can be connected to the Internet, including ordinary terminals or mobile terminals, which sends service requests and uses the best cloud storage service provider configuration selected by the first-level proxy node to provide a service plan.
所述云存储服务提供商把数据存储在多个存储云中,存储云由数据存储中心和辅助存储节点组成。The cloud storage service provider stores data in multiple storage clouds, and the storage cloud is composed of a data storage center and auxiliary storage nodes.
所述数据存储中心包含了多个虚拟节点,数据都存储在虚拟节点中。所述虚拟节点是通过在真实的物理节点上部署虚拟化存储软件后所形成的抽象节点。The data storage center includes multiple virtual nodes, and data is stored in the virtual nodes. The virtual node is an abstract node formed by deploying virtualized storage software on a real physical node.
进一步的,一个真实的物理节点上可以部署一个或多个所述虚拟节点,也可以在多个真实的物理节点上部署一个所述的虚拟节点。Further, one or more virtual nodes may be deployed on a real physical node, or one virtual node may be deployed on multiple real physical nodes.
进一步的,所述虚拟节点通过内部专用网络连接。Further, the virtual nodes are connected through an internal private network.
进一步的,所述虚拟节点间可以完全采用对等式结构,由虚拟对等节点组成,每个所述虚拟对等节点是能够同时存储用户数据信息和相应的元数据信息的虚拟节点。Further, the peer-to-peer structure may be completely adopted among the virtual nodes, which are composed of virtual peer-to-peer nodes, and each of the virtual peer-to-peer nodes is a virtual node capable of simultaneously storing user data information and corresponding metadata information.
进一步的,所述虚拟节点间也可以完全采用主从式结构,由虚拟管理节点和虚拟存储节点组成。所述虚拟管理节点是用来存储和管理元数据信息的虚拟节点,并负责管理虚拟存储节点。所述虚拟存储节点是用于存储用户数据信息的虚拟节点。Further, the virtual nodes may also completely adopt a master-slave structure, consisting of virtual management nodes and virtual storage nodes. The virtual management node is a virtual node for storing and managing metadata information, and is responsible for managing virtual storage nodes. The virtual storage node is a virtual node for storing user data information.
进一步的,所述虚拟节点可以同时采用对等结构和主从式结构,首先配置采用主从式结构的所述虚拟节点,构成一个主从式结构网络;然后配置其它的未采用主从式结构的所述虚拟节点为对等结构,构成一个对等结构网络,之后各个主从式结构网络作为一个整体加入到对等结构网络中。Further, the virtual nodes can adopt a peer-to-peer structure and a master-slave structure at the same time, first configure the virtual nodes adopting the master-slave structure to form a master-slave structure network; then configure other non-master-slave structures The said virtual nodes are in a peer-to-peer structure, forming a peer-to-peer structure network, and then each master-slave structure network is added to the peer-to-peer structure network as a whole.
所述对等结构网络在一个所述数据存储中心中最多可以有一个或者没有。The peer-to-peer structure network may have at most one or none in one data storage center.
所述主从式结构网络在一个所述数据存储中心中可以有多个也可以没有,当没有主从式结构网络或者主从式结构网络中只有一个所述虚拟节点时,所述数据存储中心就是完全采用对等结构;当只有一个所述主从式结构网络而且包括了所述数据存储中心里的所有所述虚拟节点时,所述数据存储中心就是完全采用主从式结构。The master-slave network may have multiple or no master-slave networks in one data storage center. When there is no master-slave network or there is only one virtual node in the master-slave network, the data storage center That is, a peer-to-peer structure is completely adopted; when there is only one master-slave network and includes all the virtual nodes in the data storage center, the data storage center completely adopts a master-slave structure.
进一步的,用户的数据存储在主从式结构中还是存储在对等结构中,或者既存储在主从式结构又存储在对等结构中,这主要是根据用户的时空特征和数据的特点来进行动态配置的。当用户的时空特征或数据的特点改变之后,可以动态的调整存储数据的底层存储结构,也可以把数据迁移到不同的存储架构中。Further, whether the user's data is stored in the master-slave structure or in the peer-to-peer structure, or both in the master-slave structure and in the peer-to-peer structure, mainly depends on the user's spatiotemporal characteristics and data characteristics. for dynamic configuration. When the user's spatiotemporal characteristics or data characteristics change, the underlying storage structure for storing data can be dynamically adjusted, and data can also be migrated to different storage architectures.
所述用户的时空特征主要是指用户在特定的时间段内或者是在特定的地理位置中对数据进行处理的特点。如在节假日对数据的处理次数特别多,而平时则特别少;在地点A对数据的处理次数特别多,而在地点B则特别少。The spatio-temporal characteristics of the user mainly refer to the characteristics of the user processing data within a specific time period or in a specific geographic location. For example, the number of data processing is particularly large during holidays, but less during normal times; the number of data processing at location A is particularly large, while that at location B is particularly small.
所述数据的特点可以包括数据的高可靠性、高可用性、高安全性和高访问速度等。The characteristics of the data may include high data reliability, high availability, high security, and high access speed.
所述辅助存储节点是部署在存储云中的多个不同的区域,一般一个存储云有一个所述数据存储中心,但是有多个所述辅助存储节点。The auxiliary storage nodes are deployed in multiple different areas in the storage cloud. Generally, a storage cloud has one data storage center, but there are multiple auxiliary storage nodes.
进一步的,所述数据存储中心可以和多个所述辅助存储节点连接;一个辅助存储节点只可以和一个所述数据存储中心连接。Further, the data storage center can be connected to multiple auxiliary storage nodes; one auxiliary storage node can only be connected to one data storage center.
进一步的,所述辅助存储节点用于存储使用频率超过预先设定的阈值的用户数据。所述使用频率指数据在一个特定的时间段内被访问的次数。Further, the auxiliary storage node is used for storing user data whose usage frequency exceeds a preset threshold. The frequency of use refers to the number of times data is accessed within a specific time period.
进一步的,存储在所述辅助存储节点的数据在辅助存储节点中无其它备份,其备份是放置到所连接的所述数据存储中心中。Further, the data stored in the auxiliary storage node has no other backup in the auxiliary storage node, and its backup is placed in the connected data storage center.
进一步的,为了简化其结构,所述辅助存储节点采用传统的存储架构(如SAN,NAS等),但并不限定采用何种典型的云存储架构。Further, in order to simplify its structure, the auxiliary storage node adopts a traditional storage architecture (such as SAN, NAS, etc.), but does not limit which typical cloud storage architecture is used.
进一步的,所述辅助存储节点可以由多个所述虚拟节点组成,也可以由物理节点组成,内部采用专用网络连接。Further, the auxiliary storage node may be composed of a plurality of virtual nodes, or may be composed of physical nodes, which are internally connected by a dedicated network.
所述一级代理节点由一级决策层和一级调度层组成。The first-level proxy node is composed of a first-level decision-making layer and a first-level scheduling layer.
所述一级决策层是根据用户的请求信息和所述云存储服务提供商的信息,并按照特定的选择策略,帮助用户选择最合适的所述云存储服务提供商配置。The first-level decision-making layer is based on the user's request information and the information of the cloud storage service provider, and according to a specific selection strategy, to help the user choose the most suitable configuration of the cloud storage service provider.
所述选择策略主要是从存储花费、地理位置、访问速度和安全级别四个方面考虑的。The selection strategy is mainly considered from four aspects: storage cost, geographical location, access speed and security level.
所述一级调度层负责用户和所述一级决策层所选择的所述云存储服务提供商之间的通信,并与其它的所述一级代理节点之间同步和共享云存储服务提供商的信息;当该一级代理节点的负载超过预设的阈值时,转移用户到其它的所述一级代理节点。The first-level scheduling layer is responsible for the communication between the user and the cloud storage service provider selected by the first-level decision-making layer, and synchronizes and shares the cloud storage service provider with other first-level agent nodes information; when the load of the first-level proxy node exceeds a preset threshold, the user is transferred to other said first-level proxy nodes.
进一步的,所述用户在获得了最合适的所述云存储服务提供商之后,通过二级代理节点获得该所述云存储服务提供商的一个最合适的所述数据存储中心。然后用户再与该数据存储中心通信。Further, after obtaining the most suitable cloud storage service provider, the user obtains the most suitable data storage center of the cloud storage service provider through a secondary proxy node. The user then communicates with the data storage center.
所述二级代理节点由二级决策层和二级调度层组成。The second-level proxy node is composed of a second-level decision-making layer and a second-level scheduling layer.
所述二级决策层是根据用户的请求信息和所述数据存储中心的信息,并按照特定的选择策略,帮助用户选择最合适的所述数据存储中心。The secondary decision-making layer is based on the user's request information and the information of the data storage center, and according to a specific selection strategy, to help the user choose the most suitable data storage center.
所述二级调度层负责用户和所述二级决策层所选择的所述数据存储中心之间的通信,并与其它的所述二级代理节点之间同步数据存储中心的信息;当该所述二代理节点的负载超过预设的阈值时,转移用户到其它的所述二级代理节点。The second-level scheduling layer is responsible for the communication between the user and the data storage center selected by the second-level decision-making layer, and synchronizes the information of the data storage center with other second-level proxy nodes; When the load of the second proxy node exceeds a preset threshold, the user is transferred to other secondary proxy nodes.
为了解决上述技术问题,本发明还公开了一种用户对数据进行操作之后数据的部署方法,以方便用户快速处理数据,减少用户和所述数据存储中心交互的响应时间。该数据部署方法包括:In order to solve the above technical problem, the present invention also discloses a data deployment method after the user operates the data, so as to facilitate the user to quickly process the data and reduce the response time for the user to interact with the data storage center. The data deployment method includes:
1.增加用户数据之后的数据部署方法;1. Data deployment method after adding user data;
2.修改用户数据之后的数据部署方法;2. Data deployment method after modifying user data;
3.删除用户数据之后的数据部署方法。3. Data deployment method after deleting user data.
进一步的,增加用户数据之后的数据部署方法按以下步骤进行:Further, the data deployment method after adding user data is performed in the following steps:
1.用户建立与所述数据存储中心的连接,并发送增加请求;1. The user establishes a connection with the data storage center and sends an increase request;
2.所述数据存储中心通过预先设定的策略找到最适合用户进行增加数据的所述辅助存储节点;2. The data storage center finds the auxiliary storage node that is most suitable for the user to add data through a preset strategy;
3.用户与该所述辅助节点建立通信连接,并增加数据到该所述辅助存储节点;该所述辅助存储节点同时建立该用户数据的一个临时副本;3. The user establishes a communication connection with the auxiliary node, and adds data to the auxiliary storage node; the auxiliary storage node simultaneously creates a temporary copy of the user data;
4.当该所述辅助存储节点接收完用户数据时,发送一个增加数据完成的消息给所述数据存储中心,所述数据存储中心初始化该数据的所述使用频率和所述辅助存储节点位置信息,并发送增加完成的信息给用户;4. When the auxiliary storage node has finished receiving user data, send a message of completion of adding data to the data storage center, and the data storage center initializes the usage frequency of the data and the location information of the auxiliary storage node , and send the message that the addition is completed to the user;
5.所述辅助存储节点与所述数据存储中心按照预先设定的策略定期同步更新数据,以确保所述数据存储中心中有用户新增加的数据;5. The auxiliary storage node and the data storage center regularly update data synchronously according to a preset strategy, so as to ensure that there is new data added by the user in the data storage center;
6.同步更新之后,删除所述辅助存储节点中新增数据的临时副本,以腾出更多空间存放其它数据;6. After the synchronous update, delete the temporary copy of the newly added data in the auxiliary storage node to free up more space for storing other data;
7.当新增加的数据在一段预先设定的时间之后,所述使用频率没有达到预先设定的阈值,那么将会在所述辅助存储节点中删除该数据,并修改该数据元数据中所述辅助存储节点位置信息。7. When the usage frequency of the newly added data does not reach the preset threshold after a preset period of time, the data will be deleted in the auxiliary storage node, and the metadata of the data will be modified. The location information of the auxiliary storage node described above.
进一步的,用户建立与所述数据存储中心的连接的方法可以为以下任一种:Further, the method for the user to establish a connection with the data storage center may be any of the following:
1、用户通过所述一级代理节点选择最合适的所述云存储服务提供商;然后在所选择的云存储服务提供商相关联的数据存储中心范围内,由所述二级代理节点选择最合适的所述数据存储中心以建立连接。1. The user selects the most suitable cloud storage service provider through the first-level proxy node; then, within the scope of the data storage center associated with the selected cloud storage service provider, the second-level proxy node selects the most suitable cloud storage service provider. Appropriate said data storage center to establish a connection.
2、用户通过所述一级代理节点选择最合适的所述云存储服务提供商;然后在所选择的云存储服务提供商相关联的数据存储中心范围内,直接与特定的所述数据存储中心以建立连接。2. The user selects the most suitable cloud storage service provider through the first-level proxy node; and then directly communicates with the specific data storage center within the scope of the data storage center associated with the selected cloud storage service provider to establish a connection.
3、用户直接指定特定的所述云存储服务提供商;然后在所选择的云存储服务提供商相关联的数据存储中心范围内,由所述二级代理节点选择最合适的所述数据存储中心以建立连接。3. The user directly specifies the specific cloud storage service provider; then within the scope of the data storage center associated with the selected cloud storage service provider, the secondary proxy node selects the most suitable data storage center to establish a connection.
4、用户直接指定特定的所述云存储服务提供商和所述数据存储中心以建立连接。4. The user directly specifies the specific cloud storage service provider and the data storage center to establish a connection.
进一步的,修改用户数据之后的数据部署方法按以下步骤进行:Further, the data deployment method after modifying user data is performed in the following steps:
1.用户建立与所述数据存储中心的连接,并发送修改请求;1. The user establishes a connection with the data storage center and sends a modification request;
2.所述数据存储中心通过查找过程找到所需要的数据;2. The data storage center finds the required data through a search process;
3.如果有一份用户所请求的数据存储在所述辅助存储节点,则用户修改所述辅助存储节点中的该数据。所述辅助存储节点接收了用户的修改数据之后,发送修改完成的信息给所述数据存储中心,所述数据存储中心更新数据的所述使用频率信息,并发送修改完成的信息给用户,之后数据存储中心按照预先设定的策略与辅助存储节点中用户所修改数据进行同步更新;3. If a piece of data requested by the user is stored in the auxiliary storage node, the user modifies the data in the auxiliary storage node. After the auxiliary storage node receives the modified data from the user, it sends the modification completion information to the data storage center, and the data storage center updates the data usage frequency information, and sends the modification completion information to the user, and then the data The storage center performs synchronous updates with the data modified by the user in the auxiliary storage node according to the preset strategy;
4.如果用户数据只存储在所述数据存储中心中,则用户直接修改所述数据存储中心中的数据,所述数据存储中心接受用户的修改数据之后,更新该数据的所述使用频率,并发送修改完成的信息给用户;4. If the user data is only stored in the data storage center, the user directly modifies the data in the data storage center, and the data storage center updates the frequency of use of the data after accepting the modified data from the user, and Send the modified information to the user;
5.如果用户对数据只进行浏览查看,而并不进行修改时,分为两种情况进行处理:一种是数据存储在辅助存储节点中,用户在辅助存储节点中查看完该数据后,则发送相关的信息给数据存储中心,数据存储中心更新该数据的使用频率;另一种情况是数据存储在数据存储中心中,则用户在数据存储中心查看完该数据之后,直接更新该数据的使用频率即可。5. If the user only browses and views the data without modifying it, it is divided into two cases for processing: one is that the data is stored in the auxiliary storage node, and after the user views the data in the auxiliary storage node, then Send relevant information to the data storage center, and the data storage center updates the usage frequency of the data; in another case, if the data is stored in the data storage center, the user directly updates the usage frequency of the data after viewing the data in the data storage center frequency.
6.所述数据存储中心按照预先设定的策略检查用户数据的所述使用频率,当用户数据的所述使用频率高于设定的阈值且该用户数据没有存储在任何所述辅助存储节点中时,发送该用户数据到所述辅助存储节点中,并修改该数据的元数据中的所述辅助存储节点位置信息,当用户数据的所述使用频率低于设定的阈值且该用户数据存储在所述辅助存储节点中时,删除存储在所述辅助存储节点中的该数据,并修改该数据的元数据中的所述辅助存储节点位置信息。6. The data storage center checks the frequency of use of user data according to a preset policy, when the frequency of use of user data is higher than a set threshold and the user data is not stored in any of the auxiliary storage nodes , send the user data to the auxiliary storage node, and modify the location information of the auxiliary storage node in the metadata of the data, when the usage frequency of the user data is lower than the set threshold and the user data is stored When in the auxiliary storage node, delete the data stored in the auxiliary storage node, and modify the location information of the auxiliary storage node in the metadata of the data.
进一步的,删除用户数据之后的数据部署方法按以下步骤进行:Further, the data deployment method after deleting user data is performed in the following steps:
1.用户建立与所述数据存储中心的连接,并发送删除请求;1. The user establishes a connection with the data storage center and sends a deletion request;
2.所述数据存储中心通过查找过程找到所需要的数据;2. The data storage center finds the required data through a search process;
3.如果有一份用户所请求的数据存储在所述辅助存储节点,则删除所述辅助存储节点中的该数据;删除完成之后,所述辅助存储节点发送删除完成的信息给所述数据存储中心,所述数据存储中心删除该数据的所有备份,但保留一份该用户数据,并设定一个剩余期限时间,以防止由于用户不当操作造成使用频率较高的数据丢失,方便用户恢复数据。当剩余期限时间为零时,再把该份用户数据删除;3. If there is a copy of the data requested by the user stored in the auxiliary storage node, delete the data in the auxiliary storage node; after the deletion is completed, the auxiliary storage node sends the deletion completion information to the data storage center , the data storage center deletes all backups of the data, but retains a copy of the user data, and sets a remaining period of time to prevent the loss of frequently used data due to improper operations by the user, and to facilitate data recovery by the user. When the remaining period is zero, delete the user data;
4.如果用户数据仅存储在所述数据存储中心中,则直接删除该用户数据及其备份数据。4. If the user data is only stored in the data storage center, directly delete the user data and its backup data.
进一步的,用户建立与所述数据存储中心的连接的方法可以为以下任一种:Further, the method for the user to establish a connection with the data storage center may be any of the following:
1、用户通过所述一级代理节点选择最合适的所述云存储服务提供商;然后在所选择的云存储服务提供商相关联的数据存储中心范围内,由所述二级代理节点选择最合适的所述数据存储中心以建立连接。1. The user selects the most suitable cloud storage service provider through the first-level proxy node; then, within the scope of the data storage center associated with the selected cloud storage service provider, the second-level proxy node selects the most suitable cloud storage service provider. Appropriate said data storage center to establish a connection.
2、用户通过所述一级代理节点选择最合适的所述云存储服务提供商;然后在所选择的云存储服务提供商相关联的数据存储中心范围内,直接与特定的所述数据存储中心以建立连接。2. The user selects the most suitable cloud storage service provider through the first-level proxy node; and then directly communicates with the specific data storage center within the scope of the data storage center associated with the selected cloud storage service provider to establish a connection.
3、用户直接指定特定的所述云存储服务提供商;然后在所选择的云存储服务提供商相关联的数据存储中心范围内,由所述二级代理节点选择最合适的所述数据存储中心以建立连接。3. The user directly specifies the specific cloud storage service provider; then within the scope of the data storage center associated with the selected cloud storage service provider, the secondary proxy node selects the most suitable data storage center to establish a connection.
4、用户直接指定特定的所述云存储服务提供商和所述数据存储中心以建立连接。4. The user directly specifies the specific cloud storage service provider and the data storage center to establish a connection.
用户对数据进行修改和删除之前,首先得通过查找过程找到所需要的数据,所述数据存储中心通过查找过程找到所需数据的步骤包括:Before the user modifies and deletes the data, he must first find the required data through the search process. The steps for the data storage center to find the required data through the search process include:
1.用户发送查找请求给所述数据存储中心;1. The user sends a search request to the data storage center;
2.所述数据存储中心查找用户所请求的数据;2. The data storage center searches for the data requested by the user;
3.如果用户所请求的数据存储在所述数据存储中心中,通过该数据的元数据中的所述辅助存储节点位置信息可以确认该数据是否还存储在所述辅助存储节点中;3. If the data requested by the user is stored in the data storage center, it can be confirmed whether the data is still stored in the auxiliary storage node through the location information of the auxiliary storage node in the metadata of the data;
4.如果用户所请求的数据不存在,则返回数据不存在的信息给用户。4. If the data requested by the user does not exist, return the information that the data does not exist to the user.
与现有云存储系统相比,本发明至少具有以下优点:Compared with the existing cloud storage system, the present invention has at least the following advantages:
(1)本发明引入两级代理模式,帮助用户智能选择最合适的云存储服务提供商和最合适的数据存储中心。支持多种云存储服务提供商和多个数据存储中心,有利于提供多样化的云存储服务,拓宽用户的选择范围。(1) The present invention introduces a two-level agency model to help users intelligently select the most suitable cloud storage service provider and the most suitable data storage center. It supports multiple cloud storage service providers and multiple data storage centers, which is conducive to providing diversified cloud storage services and broadening the range of choices for users.
(2)本发明可以动态的配置数据存储中心的底层云存储架构,能够在不中断服务的前提下,可以灵活的调整底层的存储架构,底层架构可以完全是主从式结构或对等结构,也可以是两种结构的综合形式。这样,既可以有对等结构的无热点、无单点故障、自我管理性强的优点;又有主从式结构维护方便、容易进行数据同步及更新的优点。(2) The present invention can dynamically configure the underlying cloud storage architecture of the data storage center, and can flexibly adjust the underlying storage architecture without interrupting the service. The underlying architecture can be completely a master-slave structure or a peer-to-peer structure. It can also be a combination of the two structures. In this way, it can not only have the advantages of no hot spot, no single point of failure, and strong self-management of the peer-to-peer structure; it also has the advantages of easy maintenance of the master-slave structure, and easy data synchronization and update.
(3)本发明通过在数据存储中心的周围设置辅助存储节点,用于保存用户使用频率最高的(系统可配置)数据资源,这样不但缩短了用户与所需数据资源之间的距离,缩短了云存储系统对用户请求的响应时间;而且有效缓解数据存储中心的访问压力。(3) The present invention sets auxiliary storage nodes around the data storage center to save the most frequently used (system configurable) data resources by users, which not only shortens the distance between the user and the required data resources, but also shortens the The response time of the cloud storage system to user requests; and effectively alleviate the access pressure of the data storage center.
附图说明 Description of drawings
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成本发明的限制。在附图中:The accompanying drawings are used to provide a further understanding of the present invention, and constitute a part of the description, together with the embodiments of the present invention, are used to explain the present invention, and do not constitute a limitation of the present invention. In the attached picture:
图1为本发明实施例的云存储系统组成结构示意图。FIG. 1 is a schematic diagram of the composition and structure of a cloud storage system according to an embodiment of the present invention.
图2为本发明实施例的一级代理节点结构示意图。FIG. 2 is a schematic structural diagram of a first-level proxy node according to an embodiment of the present invention.
图3为本发明实施例的云存储服务提供商结构示意图。Fig. 3 is a schematic structural diagram of a cloud storage service provider according to an embodiment of the present invention.
图4为本发明实施例的二级代理节点结构示意图。FIG. 4 is a schematic diagram of the structure of a secondary proxy node according to an embodiment of the present invention.
图5为本发明实施例的存储云结构示意图。FIG. 5 is a schematic diagram of a storage cloud structure according to an embodiment of the present invention.
图6为本发明实施例的数据存储中心结构示意图。FIG. 6 is a schematic structural diagram of a data storage center according to an embodiment of the present invention.
图7为本发明实施例的元数据信息结构示意图。Fig. 7 is a schematic diagram of metadata information structure according to an embodiment of the present invention.
图8为本发明实施例中用户选择云存储系统的流程示意图。Fig. 8 is a schematic flow diagram of a user selecting a cloud storage system in an embodiment of the present invention.
图9为本发明实施例中用户增加数据到云存储系统中的流程示意图。FIG. 9 is a schematic flow diagram of a user adding data to a cloud storage system in an embodiment of the present invention.
图10为本发明实施例中用户查找云存储系统中数据的流程示意图。FIG. 10 is a schematic flow diagram of a user searching for data in a cloud storage system in an embodiment of the present invention.
图11为本发明实施例中用户修改云存储系统中数据的流程示意图。FIG. 11 is a schematic flow diagram of a user modifying data in a cloud storage system in an embodiment of the present invention.
图12为本发明实施例中用户删除云存储系统中数据的流程示意图。FIG. 12 is a schematic flow diagram of a user deleting data in a cloud storage system in an embodiment of the present invention.
具体实施方式 Detailed ways
以下将结合附图及实施例来详细说明本发明的实施方式,借此对本发明如何应用技术手段来解决技术问题,并达成技术效果的实现过程能充分理解并据以实施。The implementation of the present invention will be described in detail below in conjunction with the accompanying drawings and examples, so as to fully understand and implement the process of how to apply technical means to solve technical problems and achieve technical effects in the present invention.
需要说明的是,如果不冲突,本发明的实施例以及实施例中的各个特征可以相互结合,均在本发明的保护范围之内。另外,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。It should be noted that, if there is no conflict, the embodiments of the present invention and various features in the embodiments can be combined with each other, and all are within the protection scope of the present invention. In addition, although a logical order is shown in the flowcharts, in some cases the steps shown or described may be performed in an order different from that shown or described herein.
图1是云存储系统的组成结构示意图,该系统实施例主要包括用户101、一级代理节点102、云存储服务提供商103、二级代理节点104和存储云105。其中:FIG. 1 is a schematic diagram of the composition and structure of a cloud storage system. The system embodiment mainly includes a
用户101通过一级代理节点102选择最合适的云存储服务提供商103,然后再通过二级代理节点104选择存储云105。The
用户101可以是普通的终端用户,也可以是移动的终端用户,只需要能够连接到互联网的就可以。The
图2是一级代理节点102的组成结构示意图,该系统实施例主要包括一级决策层201和一级调度层202。其中:FIG. 2 is a schematic diagram of the composition and structure of a first-
一级决策层201根据用户所提供的信息选择最合适的云存储服务提供商103给用户,用户提供的信息可能包括优先选择存储价格最低的云存储服务提供商,也可能是优先选择距离最近的云存储服务提供商,但并不局限于此。The first-level decision-
一级调度层202的功能主要有三个方面:其一是确保用户与所选择的云存储服务提供商103之间的正常通信;其二是与其它的一级代理节点102之间同步云存储服务提供商103的信息;其三,当该代理节点的负载超过预设的值时,转移用户到其它的一级代理节点102。The functions of the first-
图3是云存储服务提供商103的组成结构示意图,该系统实施例主要包括众多的存储云105,各个存储云105可以通过内部的专用网络或光纤通信网络进行通信。不同云存储服务提供商之间的存储云通过外部网络进行通信,外部网络可以是普通的百兆以太网或千兆以太网。连接不同的云存储服务提供商主要是为了更好的交换或共享各自所拥有的数据。FIG. 3 is a schematic diagram of the composition and structure of a cloud
图4是二级代理节点104的组成结构示意图,该系统实施例主要包括二级决策层401和二级调度层402,其中:FIG. 4 is a schematic diagram of the composition structure of the
二级决策层401主要是根据用户所提供的信息选择最合适的数据存储中心106提供给用户,用户提供的选择信息可能包括优先选择访问速度最快的数据存储中心,也可能是优先选择安全级别最高的数据存储中心,但并不局限于此。The secondary decision-
二级调度层402的功能主要有三个方面:其一是确保用户与所选择的数据存储中心106之间的正常通信;其二是与其它的二级代理节点104之间同步数据存储中心106的信息;其三,当该代理节点的负载超过预设的值时,转移用户到其它的二级代理节点104。The function of the
本发明的核心思想之一是采用两级代理,用户通过使用一级代理节点来选择最合适的云存储服务提供商,通过使用二级代理来选择最合适的数据存储中心;用户可以不使用一级代理,直接指定特定的云存储服务提供商,也可以不使用二级代理,直接指定所选择的云存储服务提供商中的特定数据存储中心。One of the core ideas of the present invention is to use a two-level agent, the user selects the most suitable cloud storage service provider by using the first-level agent node, and selects the most suitable data storage center by using the second-level agent; the user does not need to use a The first-level agent can directly designate a specific cloud storage service provider, or directly designate a specific data storage center in the selected cloud storage service provider without using a second-level agent.
图7是数据的元数据的组成结构示意图,元数据信息包括了数据副本信息、路由信息等基本的信息,本发明在元数据中增加了该数据的使用频率702和辅助存储节点的位置信息703,其中:Fig. 7 is a schematic diagram of the composition and structure of the metadata of the data. The metadata information includes basic information such as data copy information and routing information. The present invention adds the
使用频率702记录了该数据的使用频率,使用频率的计算方式为某一时间段内对某一数据的访问次数。The frequency of
辅助存储节点的位置信息703为记录该数据存储在哪个辅助存储节点中,如果使用频率没有达到预先设定的阈值,那么数据将不会存储在辅助存储节点中,辅助存储节点的位置信息将会为空。The
图5是存储云105的组成结构示意图,该系统实施例主要包括辅助存储节点501和数据存储中心106,辅助存储节点501用于存放用户使用频率超过系统预先设定的阈值的数据资源,该辅助存储节点501中各个数据资源都只存储一份,所述数据存储中心106用于存储原始数据和备份数据。当有用户对存放在辅助存储节点501中的数据资源进行操作时,更新相应数据资源的使用频率702,辅助存储节点501定期扫描各个数据资源的使用频率702,当有数据资源的使用频率702低于系统设定的阈值时,删除该数据资源,以腾出更多的存储空间给其它的使用频率更高的数据资源。该阈值可以根据需要人为配置。Fig. 5 is a schematic diagram of the composition and structure of the
辅助存储节点501可以是由虚拟节点503或真实的物理节点502,还可以由虚拟节点503和真实的物理节点502组成。其中,虚拟节点503是通过在真实的物理节点502上部署虚拟化软件而构建的;一台物理节点502可以运行多个虚拟节点503,一个虚拟节点503也可以运行在多个物理节点502中。通过使用虚拟化节点,可以更好提高资源的利用率和负载均衡,并且安全性也更高。The
数据存储中心106定期检查各个数据的使用,对于使用频率超过了预先设定的阈值的并且没有在任何辅助存储节点501中存放的数据资源,数据存储中心106将会发送一份数据到辅助存储节点501中。并更新该数据的辅助存储节点信息703,记录辅助存储节点的位置。The
其中,使用频率702记录了该数据的使用频率,使用频率的计算方式为某一时间段内对某一数据的访问次数。辅助存储节点的位置信息703为记录该数据在存储在哪个辅助存储节点中,如果使用频率没有达到预先设定的阈值,那么数据将不会存储在辅助存储节点中,辅助存储节点的位置信息将会为空。Wherein, the frequency of
使用频率702和辅助存储节点的位置信息703存放于元数据信息中。图7为数据的元数据的组成结构示意图。The
本发明的核心思想之二是采用辅助存储节点,当用户对数据存储中心的某一特定数据资源的使用频率超过一个预先设定的阈值时,将该数据资源复制一份存储到辅助存储节点。该辅助节点是通过预先设定的策略来选择的,该策略可以是短距离优先、高访问速度优先等,但并不局限于这两个。借此提高对用户请求的响应速度,缓解数据存储中心的请求压力。The second core idea of the present invention is to use an auxiliary storage node. When the user's usage frequency of a specific data resource in the data storage center exceeds a preset threshold, the data resource is copied and stored in the auxiliary storage node. The auxiliary node is selected through a preset strategy, and the strategy may be short distance priority, high access speed priority, etc., but not limited to these two. In this way, the response speed to user requests is improved, and the request pressure of the data storage center is relieved.
图6是数据存储中心106的组成结构示意图,该系统实施例可以是主从式存储网络603也可以是对等存储网络605。其中:FIG. 6 is a schematic diagram of the composition and structure of the
主从式存储网络603主要包括虚拟管理节点601和虚拟存储节点602。The master-slave storage network 603 mainly includes a
对等式存储网络605为DHT分布式网络,可以完全由虚拟对等节点604构成,也可以由多个虚拟对等节点604和多个主从式存储网络共同构成。The peer-to-
虚拟管理节点601一方面作为主从式存储网络603的管理节点,一方面作为对等存储网络605的虚拟对等节点604。The
虚拟对等节点604和虚拟管理节点601记录了每一个数据项的使用频率702和该数据项是否存储在辅助存储节点501中,如果存储在辅助存储节点501中,记录该辅助存储节点501的位置。The
当需要把底层架构设置为主从式时,只需要把主从式网络603中的虚拟存储节点602进行迁移,把需要迁移的虚拟存储节点602从主从式存储网络603中退出,然后作为一个新增的虚拟对等节点604加入到对等存储网络605中。该虚拟存储节点602中的存放的原用户数据并不需要做任何的修改,加入到对等存储网络后仍然可以使用。When it is necessary to set the underlying architecture as master-slave, it is only necessary to migrate the
本发明的核心思想之三是采用了可动态调整的底层存储架构。云存储服务提供商可以根据自身的需求,把数据存储中心106的底层存储架构调整为主从式结构或是对等结构的,以便能够充分利用主从式结构维护方便和容易进行数据的同步与更新等优点,又可以有效的利用对等结构无热点、无单点故障、自我管理性强的优点。The third core idea of the present invention is to adopt a dynamically adjustable underlying storage architecture. Cloud storage service providers can adjust the underlying storage architecture of the
图8是用户选择数据存储中心的方法实施例的流程示意图。图8所示的方法始于步骤S801。Fig. 8 is a schematic flowchart of an embodiment of a method for a user to select a data storage center. The method shown in FIG. 8 begins with step S801.
步骤S802,判断用户是否使用一级代理选择云存储服务提供商,若选择,则跳转到步骤S803;反之,则跳转到步骤S811。In step S802, it is judged whether the user selects a cloud storage service provider through a first-level proxy, and if yes, then jumps to step S803; otherwise, jumps to step S811.
步骤S803,如果用户选择使用一级代理,则发送相关的请求到一级代理服务节点。Step S803, if the user chooses to use a first-level proxy, send a related request to the first-level proxy service node.
步骤S804,一级代理节点收到了用户发来的请求时,通过一级决策层,选择最合适的云存储服务提供商。Step S804, when the first-level proxy node receives the request from the user, it selects the most suitable cloud storage service provider through the first-level decision-making layer.
步骤S805,之后,一级代理节点通过一级调度层负责云存储服务商与用户的通信,并返回云存储服务提供商的信息给用户。Step S805, after that, the first-level proxy node is responsible for the communication between the cloud storage service provider and the user through the first-level scheduling layer, and returns the information of the cloud storage service provider to the user.
步骤S806,用户接受到了一级代理节点所选择的最合适的云存储服务提供商的信息之后,连接到该云存储服务提供商处。Step S806, after receiving the information of the most suitable cloud storage service provider selected by the first-level proxy node, the user connects to the cloud storage service provider.
步骤S811,如果用户没有使用一级代理选择云存储服务提供商,则用户直接连接到指定的云存储服务提供商处。In step S811, if the user does not select a cloud storage service provider through a primary agent, the user directly connects to the designated cloud storage service provider.
步骤S812,之后再判断用户是否使用二级代理选择数据存储中心,若选择,则跳转到步骤S813;反之,则跳转到步骤S821。Step S812, and then judge whether the user selects a data storage center by using a second-level proxy, and if so, go to step S813; otherwise, go to step S821.
步骤S821,若用户不使用二级代理节点,则直接建立用户与用户指定的数据存储中心的连接。至此,建立了与某一云存储服务提供商中的指定数据存储中心的连接。Step S821, if the user does not use a secondary proxy node, directly establish a connection between the user and the data storage center designated by the user. So far, the connection with the designated data storage center in a certain cloud storage service provider has been established.
步骤S813,若用户选择使用二级代理选择数据存储中心,则发送相关的请求信息到二级代理服务节点。Step S813, if the user chooses to use the second-level agent to select the data storage center, send related request information to the second-level agent service node.
步骤S814,二级代理通过二级决策层选择最合适的数据存储中心。Step S814, the secondary agent selects the most suitable data storage center through the secondary decision-making layer.
步骤S815,二级代理通过二级调度层负责用户与所选的数据存储中心的通信,并返回数据存储中心的信息给用户。Step S815, the second-level agent is responsible for the communication between the user and the selected data storage center through the second-level scheduling layer, and returns the information of the data storage center to the user.
步骤S816,用户接收二级代理发送的所选择最合适数据存储中心的信息,并连接到该数据存储中心中。Step S816, the user receives the information of the selected most suitable data storage center sent by the secondary agent, and connects to the data storage center.
步骤S830,至此,用户既可以直接指定特定的云存储服务提供商,也可以通过一级代理节点选择了最合适的云存储服务提供商,既可以直接指定特定的数据存储中心,也可以通过二级代理选择了最合适的数据存储中心之,方便用户建立与云存储服务提供商的数据存储中心之间的连接。Step S830, so far, the user can either directly designate a specific cloud storage service provider, or select the most suitable cloud storage service provider through a first-level proxy node, and either directly designate a specific data storage center, or pass two The level agent selects the most suitable data storage center, which is convenient for users to establish a connection with the data storage center of the cloud storage service provider.
图9是用户增加数据到云存储系统中的方法实施例的流程示意图。图9所示的方法始于步骤S901。Fig. 9 is a schematic flowchart of an embodiment of a method for a user to add data to a cloud storage system. The method shown in FIG. 9 begins with step S901.
步骤S902,当用户发送增加数据请求的时,数据存储中心根据预先制定的策略选择最合适的辅助存储节点。Step S902, when the user sends a request for adding data, the data storage center selects the most suitable auxiliary storage node according to a pre-established strategy.
步骤S903,用户直接把数据增加到所选择的辅助存储节点中,并对该数据做一个临时备份。In step S903, the user directly adds data to the selected auxiliary storage node, and makes a temporary backup of the data.
步骤S904,当用户数据增加完成时,辅助存储节点向数据存储中心发送一个增加完成的消息,数据存储节点建立该数据的元数据信息,初始化该数据的使用频率和辅助存储节点的位置信息。Step S904, when the addition of user data is completed, the auxiliary storage node sends an addition completion message to the data storage center, and the data storage node creates metadata information of the data, and initializes the use frequency of the data and the location information of the auxiliary storage node.
步骤S905,当负载低于某一阈值时,辅助存储节点中的所有数据的临时副本都更新到数据存储中心中,数据存储中心增加该数据的备份信息,并修改相关的元数据信息。Step S905, when the load is lower than a certain threshold, the temporary copies of all data in the auxiliary storage node are updated to the data storage center, and the data storage center adds backup information of the data and modifies related metadata information.
步骤S906,辅助存储节点删除所有数据的临时副本,以腾出更多的空间存储新的数据。In step S906, the auxiliary storage node deletes all temporary copies of data, so as to free up more space for storing new data.
最后,增加步骤结束于步骤S907。Finally, the adding step ends in step S907.
图10是用户查找云存储系统中数据的方法实施例的流程示意图。图10所示的方法始于步骤S1001。Fig. 10 is a schematic flowchart of an embodiment of a method for a user to search for data in a cloud storage system. The method shown in FIG. 10 starts with step S1001.
步骤S1002,用户首先发送查找数据请求到数据存储中心中。In step S1002, the user first sends a data search request to the data storage center.
步骤S1003,数据是否存储在数据存储中心中,如果是存储在数据中心中,转到步骤S094;反之,则转到步骤S1007。Step S1003, whether the data is stored in the data storage center, if it is stored in the data center, go to step S094; otherwise, go to step S1007.
步骤S1007,如果数据不存储在数据存储中心中,则返回该数据不存在的信息给用户。Step S1007, if the data is not stored in the data storage center, return the information that the data does not exist to the user.
步骤S1004,如果数据存储在数据存储中心中,则再检查该数据的辅助节点位置信息,如果该数据还存储在辅助存储节点中,则转到步骤S1005;否则转到步骤S1006。Step S1004, if the data is stored in the data storage center, then check the auxiliary node location information of the data, if the data is still stored in the auxiliary storage node, then go to step S1005; otherwise, go to step S1006.
步骤S1006,如果数据不存储在辅助存储节点中,则返回数据存储中心中该数据的信息给用户。Step S1006, if the data is not stored in the auxiliary storage node, return the information of the data in the data storage center to the user.
步骤S1005,如果数据存储在辅助存储节点中,则返回辅助存储节点中该数据的信息给用户。Step S1005, if the data is stored in the auxiliary storage node, return the information of the data in the auxiliary storage node to the user.
最后,查找步骤结束于S1008。Finally, the searching step ends at S1008.
图11是用户修改云存储系统中数据的方法实施例的流程示意图。图11所示的方法开始于步骤S1101。Fig. 11 is a schematic flowchart of an embodiment of a method for a user to modify data in a cloud storage system. The method shown in FIG. 11 starts at step S1101.
步骤S1102,用户通过查找过程找到所需要的数据。Step S1102, the user finds the required data through the search process.
步骤S1103,判断该数据是否存储在辅助存储节点中,如果是,则转步骤S1109;反之,则转到S1104。Step S1103, judge whether the data is stored in the auxiliary storage node, if yes, go to step S1109; otherwise, go to S1104.
步骤S1104,如果数据不存储在辅助存储节点中,则用户与数据存储中心直接建立连接,修改数据。Step S1104, if the data is not stored in the auxiliary storage node, the user directly establishes a connection with the data storage center to modify the data.
步骤S1105,更新该数据的使用频率。Step S1105, updating the usage frequency of the data.
步骤S1106,判断该数据的使用频率是否达到设定的阈值,如果达到,则转到步骤S1107;反之,转到步骤S1112。Step S1106, judging whether the usage frequency of the data reaches the set threshold, if so, go to step S1107; otherwise, go to step S1112.
步骤S1107,当该数据的使用频率达到设定的阈值时,根据设定的算法,选择合适的辅助存储节点;然后更新该数据的元数据信息中辅助存储节点的信息。Step S1107, when the usage frequency of the data reaches the set threshold, select an appropriate auxiliary storage node according to the set algorithm; and then update the information of the auxiliary storage node in the metadata information of the data.
步骤S1108,发送该数据到辅助存储节点。Step S1108, sending the data to the auxiliary storage node.
步骤S1109,如果需要查找的数据在辅助存储节点中,则与辅助存储节点建立连接,在辅助存储节点中修改该数据。Step S1109, if the data to be searched is in the auxiliary storage node, establish a connection with the auxiliary storage node, and modify the data in the auxiliary storage node.
步骤S1110,数据修改完成时,辅助存储节点发送修改完成的信息给数据存储中心,数据存储中心更新数据的使用频率。Step S1110, when the data modification is completed, the auxiliary storage node sends the modification completion information to the data storage center, and the data storage center updates the usage frequency of the data.
步骤S1111,数据存储中心定期与辅助存储节点之间进行数据更新。In step S1111, the data storage center periodically updates data with the auxiliary storage nodes.
最后,修改步骤结束于S1112。Finally, the modifying step ends at S1112.
图12是用户修改云存储系统中数据的方法实施例的流程示意图。图12所示的方法开始于步骤S1201。Fig. 12 is a schematic flowchart of an embodiment of a method for a user to modify data in a cloud storage system. The method shown in FIG. 12 starts at step S1201.
步骤S1202,用户通过查找过程找到所需要的数据。Step S1202, the user finds the required data through the search process.
步骤S1203,判断该数据是否存储在辅助存储节点中,如果是,则跳转到S1204;反之,则跳转到S1206。Step S1203, judging whether the data is stored in the auxiliary storage node, if yes, jump to S1204; otherwise, jump to S1206.
步骤S1204,如果待删除的数据存储在辅助存储节点中,则在数据存储中心中删除该数据的副本,但保留一份原始数据,因为一般能够存储在辅助存储节点的数据块的使用频率都较高,误删的可能性比较大,方便用户快速恢复;当保留的用户数据超过了设定的时间值时,再将其删除。Step S1204, if the data to be deleted is stored in the auxiliary storage node, delete the copy of the data in the data storage center, but keep a copy of the original data, because generally the data blocks that can be stored in the auxiliary storage node are less frequently used. High, the possibility of accidental deletion is relatively high, which is convenient for users to quickly restore; when the retained user data exceeds the set time value, it will be deleted.
步骤S1205,在删除了数据存储中心的相关数据之后,再删除辅助存储节点中存储的该数据。Step S1205, after deleting the relevant data in the data storage center, delete the data stored in the auxiliary storage node.
步骤S1206,如果用户所查找的数据不在辅助存储节点中,则直接在数据存储中心中删除该数据的原始数据和所有备份数据。Step S1206, if the data the user is looking for is not in the auxiliary storage node, directly delete the original data and all backup data of the data in the data storage center.
最后,删除步骤结束于S1207。Finally, the deletion step ends at S1207.
至此,用户可以通过两级代理选择云存储系统,并且可以通过利用辅助存储节点对数据进行增加、查找、修改和查找的操作。So far, users can select cloud storage systems through two-level agents, and can add, search, modify and search operations on data by using auxiliary storage nodes.
以上所述仅是本发明的具体实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干的改进和润饰,这些改进和润饰也应视为本发明的保护范围。The above are only specific embodiments of the present invention, and it should be pointed out that for those of ordinary skill in the art, without departing from the principle of the present invention, some improvements and modifications can also be made. These improvements and modifications It should also be regarded as the protection scope of the present invention.
Claims (14)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 201010572302 CN102035884B (en) | 2010-12-03 | 2010-12-03 | Cloud storage system and data deployment method thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 201010572302 CN102035884B (en) | 2010-12-03 | 2010-12-03 | Cloud storage system and data deployment method thereof |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN102035884A CN102035884A (en) | 2011-04-27 |
| CN102035884B true CN102035884B (en) | 2013-01-23 |
Family
ID=43888201
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN 201010572302 Expired - Fee Related CN102035884B (en) | 2010-12-03 | 2010-12-03 | Cloud storage system and data deployment method thereof |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN102035884B (en) |
Families Citing this family (35)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102457571B (en) * | 2011-09-15 | 2014-11-05 | 中标软件有限公司 | Method for uniformly distributing data in cloud storage |
| CN102523267A (en) * | 2011-12-08 | 2012-06-27 | 华中科技大学 | Cloud backup system and method |
| CN102377827A (en) * | 2011-12-13 | 2012-03-14 | 方正国际软件有限公司 | Multilevel cloud storage system and storage method thereof |
| US8434080B2 (en) * | 2011-12-22 | 2013-04-30 | Software Ag Usa, Inc. | Distributed cloud application deployment systems and/or associated methods |
| CN102684903B (en) * | 2011-12-23 | 2015-09-16 | 中兴通讯股份有限公司 | A kind of management platform, system and method realizing the access of cloud storage multiple resource node |
| CN103186536A (en) * | 2011-12-27 | 2013-07-03 | 中兴通讯股份有限公司 | Method and system for scheduling data shearing devices |
| KR101765996B1 (en) * | 2012-02-16 | 2017-08-07 | 엠파이어 테크놀로지 디벨롭먼트 엘엘씨 | Local access to cloud-based storage |
| CN102624732A (en) * | 2012-03-13 | 2012-08-01 | 上海华御信息技术有限公司 | Network storage system based on cloud computing |
| US8949179B2 (en) | 2012-04-23 | 2015-02-03 | Google, Inc. | Sharing and synchronizing electronically stored files |
| CN108804213B (en) * | 2012-04-23 | 2022-04-19 | 谷歌有限责任公司 | Sharing and synchronizing electronically stored files |
| CN102882928A (en) * | 2012-08-31 | 2013-01-16 | 浪潮电子信息产业股份有限公司 | Hierarchical storage management method of cloud storing system |
| CN103685340B (en) * | 2012-08-31 | 2016-12-21 | 百度在线网络技术(北京)有限公司 | Notification Method, system and cloud server that data change is applied in cloud storage |
| CN103778025A (en) * | 2012-10-22 | 2014-05-07 | 深圳市腾讯计算机系统有限公司 | Storage method and storage device |
| CN103841168B (en) * | 2012-11-27 | 2017-09-29 | 中国电信股份有限公司 | Data trnascription update method and meta data server |
| CN103036994B (en) * | 2012-12-18 | 2015-08-19 | 曙光信息产业(北京)有限公司 | Realize the cloud storage system of load balancing |
| CN103973731B (en) * | 2013-01-29 | 2017-12-29 | 中兴通讯股份有限公司 | The recycle bin management method and device of a kind of cloud storage |
| US10073626B2 (en) * | 2013-03-15 | 2018-09-11 | Virident Systems, Llc | Managing the write performance of an asymmetric memory system |
| CN103235905A (en) * | 2013-04-27 | 2013-08-07 | 成都菲普迪斯科技有限公司 | DUDP real-time data protection method |
| CN103281374B (en) * | 2013-05-30 | 2015-12-09 | 成都信息工程学院 | A kind of method of data fast dispatch during cloud stores |
| CN104283912A (en) * | 2013-07-04 | 2015-01-14 | 北京中科同向信息技术有限公司 | Cloud backup dynamic balance technology |
| CN104571935A (en) * | 2013-10-18 | 2015-04-29 | 宇宙互联有限公司 | Global scheduling system and method |
| CN104639590B (en) * | 2013-11-13 | 2017-11-07 | 同济大学 | A kind of method that terminal obtains cloud service |
| CN104796270B (en) * | 2014-01-16 | 2018-03-27 | 国际商业机器公司 | Recommend the method and device of suspect assembly in being diagnosed in the problem of cloud application |
| CN103944988A (en) * | 2014-04-22 | 2014-07-23 | 南京邮电大学 | Repeating data deleting system and method applicable to cloud storage |
| CN105320461B (en) * | 2014-07-01 | 2018-04-03 | 先智云端数据股份有限公司 | Adaptive fast response control system for software defined storage systems |
| CN104112049B (en) * | 2014-07-18 | 2015-11-11 | 西安交通大学 | Based on the MapReduce task of P2P framework across data center scheduling system and method |
| CN106161516A (en) * | 2015-03-31 | 2016-11-23 | 西门子公司 | For storing the method for data, device and system |
| CN105245375B (en) * | 2015-10-14 | 2018-07-10 | 成都携恩科技有限公司 | A kind of network-based high-efficiency storage method |
| CN105827744A (en) * | 2016-06-08 | 2016-08-03 | 四川新环佳科技发展有限公司 | Data processing method of cloud storage platform |
| CN106302656A (en) * | 2016-08-01 | 2017-01-04 | 成都鼎智汇科技有限公司 | The Medical Data processing method of cloud storage platform |
| CN107979630B (en) | 2016-10-25 | 2020-04-03 | 新华三技术有限公司 | A kind of information acquisition method and device |
| CN107172222A (en) * | 2017-07-27 | 2017-09-15 | 郑州云海信息技术有限公司 | A kind of date storage method and device based on distributed memory system |
| CN112069259B (en) * | 2020-09-09 | 2023-08-18 | 天津大学 | A blockchain-based multi-cloud environment data storage system and method |
| CN115714817B (en) * | 2022-11-03 | 2025-08-29 | 天翼视联科技有限公司 | A dynamic feedback weighted cloud storage resource scheduling method, device and equipment |
| CN118409714B (en) * | 2024-07-01 | 2024-11-01 | 杭州海康威视系统技术有限公司 | Data storage method, device, equipment and storage medium |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101072163A (en) * | 2007-03-31 | 2007-11-14 | 腾讯科技(深圳)有限公司 | Network file automatic dump method and system |
| WO2009031976A1 (en) * | 2007-09-05 | 2009-03-12 | Creative Technology Ltd. | Method of enabling access to data protected by firewall |
| CN101873348A (en) * | 2010-06-09 | 2010-10-27 | 清华大学 | Cloud storage system based on network egress device and network access method thereof |
-
2010
- 2010-12-03 CN CN 201010572302 patent/CN102035884B/en not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101072163A (en) * | 2007-03-31 | 2007-11-14 | 腾讯科技(深圳)有限公司 | Network file automatic dump method and system |
| WO2009031976A1 (en) * | 2007-09-05 | 2009-03-12 | Creative Technology Ltd. | Method of enabling access to data protected by firewall |
| CN101873348A (en) * | 2010-06-09 | 2010-10-27 | 清华大学 | Cloud storage system based on network egress device and network access method thereof |
Non-Patent Citations (2)
| Title |
|---|
| Jincai Chen等.The Business Model of Cloud Storage.《CLOUD COMPUTING 2010, The First International Conference on Cloud Computing, GRIDs, and Virtualization》.2010, |
| The Business Model of Cloud Storage;Jincai Chen等;《CLOUD COMPUTING 2010, The First International Conference on Cloud Computing, GRIDs, and Virtualization》;20101121;74-79 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN102035884A (en) | 2011-04-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN102035884B (en) | Cloud storage system and data deployment method thereof | |
| CN105284094B (en) | A network function virtualization network system, data processing method and device | |
| CN108400945B (en) | Arranging management system and network slice processing method | |
| CN105934919B (en) | Network service capability automatic adjustment method and system | |
| CN101980192B (en) | Object-based cluster file system management method and cluster file system | |
| CN108632063B (en) | Method, device and system for managing network slice instances | |
| CN103237046A (en) | Distributed file system supporting mixed cloud storage application and realization method thereof | |
| CN105068758B (en) | Towards the Distributed File System Data I/O optimization methods of parallel data acquisition | |
| US8819137B2 (en) | System and method for sharing mobile internet service | |
| CN106899503B (en) | A routing selection method and network manager for a data center network | |
| CN106357432A (en) | Hybrid virtual host management platform based on web servers | |
| JP7678892B2 (en) | Geographically Distributed Hybrid Cloud Clusters | |
| CN110196843A (en) | A kind of document distribution method and container cluster based on container cluster | |
| JP6221717B2 (en) | Storage device, storage system, and data management program | |
| CN105245307A (en) | Method and device for determining a communication path in a communication network | |
| CN102917287A (en) | Intelligent optical network exchange device and edge cashing method facing content center | |
| CN103795606A (en) | Service transfer control method based on sdn in optical network | |
| CN102739703A (en) | Method and system for data migration in peer-to-peer network | |
| US11757716B2 (en) | Network management apparatus, method, and program | |
| CN116582902A (en) | Network slice management method, device and storage medium based on satellite-ground integration | |
| CN109542482A (en) | A kind of piece of storage service upgrade method, device, equipment and readable storage medium storing program for executing | |
| JPWO2022251324A5 (en) | ||
| CN101369915B (en) | P2P operating network resource management system | |
| WO2016177135A1 (en) | Resource management method, device, and control terminal | |
| CN114338714B (en) | Block synchronization method and device, electronic equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20130123 Termination date: 20181203 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |