CN101751309B - An Optimized Replica Distribution Method in Data Grid - Google Patents
An Optimized Replica Distribution Method in Data Grid Download PDFInfo
- Publication number
- CN101751309B CN101751309B CN2009102654216A CN200910265421A CN101751309B CN 101751309 B CN101751309 B CN 101751309B CN 2009102654216 A CN2009102654216 A CN 2009102654216A CN 200910265421 A CN200910265421 A CN 200910265421A CN 101751309 B CN101751309 B CN 101751309B
- Authority
- CN
- China
- Prior art keywords
- resource
- domain
- node
- nodes
- access
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images




Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明主要设计数据网格中一种优化的副本分布方法,属于网格计算(Grid)领域,具体涉及网格系统,尤其是数据网格系统中副本的分布问题。本发明给出了数据网络中一种分布式动态自适应的副本分布方法,以降低资源请求方的访问代价为主要目的,通过资源的响应时间计算副本数量;综合考虑节点的负载率、节点性能,以及实时带宽等因素确定合适的副本放置地点,使副本分布能够动态地适应访问请求的变化和网络通讯状况。与现有单纯追求副本数量来提高数据访问性能的方法相比,本发明从系统全局角度评估副本数量和最佳的副本放置地点,能够有效平衡副本数量和副本维护开销之间的关系。该方法不仅适用于只读资源的数据网格系统,尤其适用于拥有可读写数据资源的数据网格系统。

The present invention mainly designs an optimized copy distribution method in a data grid, belongs to the grid computing (Grid) field, and specifically relates to a grid system, especially the distribution of copies in a data grid system. The invention provides a distributed dynamic self-adaptive copy distribution method in the data network, with the main purpose of reducing the access cost of the resource requester, calculating the number of copies through the response time of the resource; comprehensively considering the load rate of the node and the performance of the node , and factors such as real-time bandwidth to determine the appropriate place to place the replica, so that the replica distribution can dynamically adapt to changes in access requests and network communication conditions. Compared with the existing method of simply pursuing the number of copies to improve data access performance, the present invention evaluates the number of copies and the best place to place copies from the perspective of the overall system, and can effectively balance the relationship between the number of copies and the cost of copy maintenance. This method is not only suitable for data grid systems with read-only resources, but especially suitable for data grid systems with readable and writable data resources.
Description
技术领域technical field
本发明主要设计数据网格中一种优化的副本分布方法,属于网格计算(Grid)领域,具体涉及网格系统,尤其是数据网格系统中副本的分布问题。The present invention mainly designs an optimized copy distribution method in a data grid, belongs to the grid computing (Grid) field, and specifically relates to a grid system, especially the distribution of copies in a data grid system.
背景技术Background technique
作为一种新型网络计算平台,网格的目的是为了在分布、异构、自治的网络资源环境上构造动态的虚拟组织,并在其内部实现跨自治域的资源共享与资源协作。数据网格是网格技术在数据管理方面的应用和实现,面向广域网异构环境,通过集成网络上分布的多种数据资源,屏蔽底层物理资源的异构性,为上层应用提供通用和可靠的数据服务,实现分布、异构、海量数据的一体化访问、存储与服务架构。As a new type of network computing platform, the purpose of the grid is to construct a dynamic virtual organization on a distributed, heterogeneous, and autonomous network resource environment, and to realize resource sharing and resource collaboration across autonomous domains within it. Data grid is the application and realization of grid technology in data management. Facing the heterogeneous environment of wide area network, it integrates various data resources distributed on the network, shields the heterogeneity of underlying physical resources, and provides general and reliable data for upper-layer applications. Data service, realizing the integrated access, storage and service architecture of distributed, heterogeneous and massive data.
副本技术是提高数据网格系统的数据可用性、数据访问性能和容错能力的重要技术。一方面,数据网格系统中的节点具有高度动态性,随时加入和离开系统,副本技术能够提高数据的可获取性和系统容错性;另一方面,通过对数据网格中被频繁访问的数据资源进行复制、提供多个数据副本,可以减少访问延迟、消除热点瓶颈和实现负载均衡,有效改善网格系统性能。Replica technology is an important technology to improve data availability, data access performance and fault tolerance of data grid system. On the one hand, the nodes in the data grid system are highly dynamic and can join and leave the system at any time. The replica technology can improve the availability of data and the fault tolerance of the system; Resources are replicated and multiple copies of data are provided, which can reduce access delays, eliminate hotspot bottlenecks and achieve load balancing, effectively improving grid system performance.
数据网格中的副本创建策略可分为动态副本创建策略和静态副本创建策略,静态副本创建策略不考虑实际应用情况,预先在指定的多个节点上创建副本,一般较少使用。动态副本创建策略能够更好地满足数据网格系统动态性以及大规模的要求。The replica creation strategy in the data grid can be divided into dynamic replica creation strategy and static replica creation strategy. The static replica creation strategy does not consider the actual application situation, and creates replicas on multiple specified nodes in advance, which is generally seldom used. The dynamic replica creation strategy can better meet the dynamic and large-scale requirements of the data grid system.
动态副本创建又可分为集中式副本创建和分布式副本创建两种不同的策略。Napster和Gnutella是采用集中式副本管理方法的典型系统,由于单点失效和扩展性不好很难应用到大规模分布式系统中。比较成熟的分布式副本创建策略是由Ranganathan和Foster以欧洲数据网格为基础提出的六种动态复制策略:无副本策略、最佳客户复制策略、瀑布复制策略、简单的缓存策略、缓存加瀑布策略、快速扩散策略。这些策略主要针对欧洲数据网格的系统特征,运用层次化的复制过程对副本进行创建,没有考虑源数据分布、网络通信能力、节点存储能力以及副本更新的代价。另一种动态副本创建策略是基于经济模型的副本创建策略,主要解决的问题是利用一些经济模型判断数据副本的创建是否能给本地系统带来“利润”,并以此决定是否在本地创建副本。Dynamic replica creation can be divided into two different strategies: centralized replica creation and distributed replica creation. Napster and Gnutella are typical systems that adopt centralized copy management methods, but it is difficult to apply them to large-scale distributed systems due to single point of failure and poor scalability. The more mature distributed replica creation strategy is six dynamic replication strategies proposed by Ranganathan and Foster based on the European data grid: no replica strategy, optimal customer replication strategy, waterfall replication strategy, simple caching strategy, caching plus waterfall Strategies, Rapid Diffusion Strategies. These strategies are mainly aimed at the system characteristics of the European data grid, using a hierarchical replication process to create replicas, without considering the distribution of source data, network communication capabilities, node storage capabilities, and the cost of replica updates. Another dynamic replica creation strategy is the replica creation strategy based on economic models. The main problem is to use some economic models to judge whether the creation of data replicas can bring "profit" to the local system, and to decide whether to create replicas locally. .
此外,现有数据网格系统中,通常假定共享的数据资源是静态的和只读的,如果有数据资源的更新,则作为新的只读资源出现,因此副本技术大多在查询资源的路径中的每个节点上创建副本,或者在路径的两端创建副本,只考虑副本数量上的差异,并不考虑存放位置的差异。In addition, in the existing data grid system, it is usually assumed that shared data resources are static and read-only. If there is an update of the data resource, it will appear as a new read-only resource, so the copy technology is mostly in the path of querying resources Create copies on each node of the path, or create copies at both ends of the path, only considering the difference in the number of copies, not the difference in storage location.
对于只读数据资源来讲,副本数量越多就越能获得好的性能。但是,在拥有可写数据资源的数据网格系统中应用这些方法将会带来不必要的资源复制和高额的副本一致性维护开销。例如对于一个以多媒体音像共享和制作为主要应用的数据网格系统,所有节点在网格系统服务支持下形成了一个大容量的虚拟媒体存储系统,每个节点既为其它节点提供存储服务,也可以下载多媒体文件、参与多媒体文件的制作更新,处于不同地理位置的人们可以共同协作完成多媒体制作任务。在这样的数据网格系统中,由于需要维护副本的数据一致性,单纯追求副本数量会极大增加副本一致性维护的代价。For read-only data resources, the greater the number of replicas, the better the performance. However, applying these methods in a data grid system with writable data resources will bring unnecessary resource duplication and high cost of replica consistency maintenance. For example, for a data grid system whose main application is multimedia audio-visual sharing and production, all nodes form a large-capacity virtual media storage system with the support of grid system services. Each node not only provides storage services for other nodes, but also It can download multimedia files, participate in the production update of multimedia files, and people in different geographic locations can work together to complete multimedia production tasks. In such a data grid system, due to the need to maintain the data consistency of the replicas, simply pursuing the number of replicas will greatly increase the cost of replica consistency maintenance.
因此,对于拥有可读写数据资源的数据网格系统,副本的位置和数量会直接影响到资源的访问性能。需要从系统全局角度对数据副本进行优化分布,确定适当的副本数量和分布位置,平衡副本维护的开销和多副本带来的访问性能提升之间的关系,提高整体数据访问性能。Therefore, for a data grid system with readable and writable data resources, the location and number of replicas will directly affect the resource access performance. It is necessary to optimize the distribution of data copies from the perspective of the overall system, determine the appropriate number of copies and distribution locations, balance the relationship between the cost of copy maintenance and the access performance improvement brought by multiple copies, and improve the overall data access performance.
为更好地说明本发明内容,下面对所针对的数据网格系统的网络结构做如下说明:In order to better illustrate the content of the present invention, the network structure of the targeted data grid system is described as follows:
(1)网络中所有节点之间以全分布方式连接,根据节点的网络带宽和处理能力的差异性,可分为超级节点和普通节点。超级节点由性能好、带宽高、在线时间长的节点承担,除了共享自身资源、访问系统中其他资源外,还要承担维护系统正常运行的管理功能。在超级节点的管理下,网络结构呈现出层次式的树状结构,树结构中的叶节点是普通节点,树结构中的其他节点是超级节点。特别地,树状结构中树内所有节点形成了域,树的根节点称为域超级节点。(1) All nodes in the network are connected in a fully distributed manner. According to the differences in network bandwidth and processing capabilities of nodes, they can be divided into super nodes and ordinary nodes. Super nodes are undertaken by nodes with good performance, high bandwidth, and long online time. In addition to sharing their own resources and accessing other resources in the system, they also undertake the management function of maintaining the normal operation of the system. Under the management of super nodes, the network structure presents a hierarchical tree structure. The leaf nodes in the tree structure are ordinary nodes, and other nodes in the tree structure are super nodes. In particular, all nodes in the tree form a domain in the tree structure, and the root node of the tree is called a domain super node.
图1显示了一个超级节点的网络结构示例。为了便于表现,附图1只简化体现了超级节点和普通节点之间的管理关系,而忽略了节点之间的全分布连接。图1中虚线所示的节点集合即为域。Figure 1 shows an example of the network structure of a super node. For ease of presentation, Figure 1 only simplifies the management relationship between super nodes and ordinary nodes, while ignoring the fully distributed connections between nodes. The set of nodes shown by the dotted line in Figure 1 is the domain.
(2)每个超级节点对本地共享资源和它所管理的普通节点的共享资源承担副本管理的职责,负责制定优化的副本分布策略。超级节点P管理的所有数据资源集合记做LR,其中LR={LR0,LR1,...,LRn},n是超级节点P负责管理的数据资源的个数。(2) Each super node undertakes the copy management responsibility for the local shared resources and the shared resources of the ordinary nodes it manages, and is responsible for formulating an optimized copy distribution strategy. The set of all data resources managed by supernode P is recorded as LR, where LR={LR 0 , LR 1 , ..., LR n }, n is the number of data resources managed by supernode P.
(3)网络中的每个节点都维护一个本地副本目录,保存自身共享资源的副本信息。超级节点的本地副本目录中,除了本地共享资源的副本信息之外,还包含由它管理的所有节点的副本目录信息。副本管理服务部署在超级节点上,提供副本管理服务,记录副本访问的所有信息,包括哪个节点发起的请求、访问了哪个副本、资源响应时间,以及节点的实时网络带宽等信息。这些数据将为副本的优化分布提供充足的依据。(3) Each node in the network maintains a local replica directory to save the replica information of its own shared resources. In addition to the copy information of the local shared resource, the local copy directory of the super node also contains the copy directory information of all nodes managed by it. The copy management service is deployed on the supernode, provides copy management service, and records all information about copy access, including which node initiates the request, which copy is accessed, resource response time, and real-time network bandwidth of the node. These data will provide sufficient basis for the optimal distribution of replicas.
发明内容Contents of the invention
本发明的目的是为解决现有副本技术应用在数据网格中、当共享资源为可读写资源时,副本一致性维护代价大、访问性能差的问题,而提供一种优化的副本分布方法,根据节点对数据资源的访问情况计算副本的数量和位置,动态适应数据访问请求的变化和网络通讯状况。该方法能够有效平衡副本数量和副本维护开销之间的关系,不仅适用于只读资源的数据网格系统,尤其适用于拥有可读写数据资源的数据网格系统。The purpose of the present invention is to provide an optimized replica distribution method to solve the problems of high cost of replica consistency maintenance and poor access performance when the shared resources are read-write resources when the existing replica technology is applied in the data grid , calculate the number and location of replicas according to the node's access to data resources, and dynamically adapt to changes in data access requests and network communication conditions. This method can effectively balance the relationship between the number of replicas and the cost of replica maintenance. It is not only suitable for data grid systems with read-only resources, but especially suitable for data grid systems with readable and writable data resources.
本发明的数据网格中一种优化的副本分布方法,如图2所示,具体步骤如下:An optimized copy distribution method in the data grid of the present invention, as shown in Figure 2, the specific steps are as follows:
步骤一.在整个网格系统范围内确定需要放置副本的所有域Step 1. Identify all domains in the entire grid system where replicas need to be placed
确定原则为:如果某个域内的节点访问超级节点P所管理的数据资源LRj(0≤j<n)的时间超过整个系统内资源LRj的平均响应时间,则需要在该域内创建副本。The determination principle is: if the time for a node in a certain domain to access the data resource LR j (0≤j<n) managed by the supernode P exceeds the average response time of the resource LR j in the entire system, a copy needs to be created in the domain.
(1)超级节点P计算整个系统内数据资源LRj的平均响应时间。资源LRj的平均响应时间(Average Response Time,ART)定义为单位时间间隔内,访问资源LRj的所有副本的响应时间之和与访问次数之比。计算公式如下:(1) The super node P calculates the average response time of the data resource LR j in the whole system. The average response time (Average Response Time, ART) of the resource LR j is defined as the ratio of the sum of the response times of all copies of the access resource LR j to the number of visits within a unit time interval. Calculated as follows:
其中,Timej表示单位时间间隔内资源LRj所有副本被访问的次数,RTk表示单位时间间隔内第k次访问资源LRj副本的响应时间。Among them, Time j represents the number of times all copies of resource LR j are accessed within a unit time interval, and RT k represents the response time of the kth access to a copy of resource LR j within a unit time interval.
(2)超级节点P根据本地副本目录中记录的数据资源LRj的所有副本的访问情况,统计不同域(记做Dk,k=0,1,...,m,m是系统内域的个数)内的节点访问资源LRj的域平均响应时间。计算方法如下:(2) According to the access situation of all copies of the data resource LR j recorded in the local copy directory, the super node P counts different domains (denoted as D k , k=0, 1, ..., m, m is the domain in the system The domain average response time of nodes accessing resources LR j in the number of ). The calculation method is as follows:
其中,RTj,i是域Dk内节点Pi访问资源LRj的响应时间,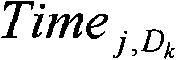
(3)如果
步骤二.在每一个需要放置副本的域内确定需要创建的副本数量Step 2. Determine the number of replicas to be created in each domain where replicas need to be placed
根据域Dk内所有请求资源LRj的实际响应时间计算创建副本的数目。Calculate the number of created replicas according to the actual response time of all request resources LR j in the domain D k .
引入记号:单位时间间隔内,域Dk中的节点访问资源LRj的副本数目记做count,需要新增副本的数量记做Δcount,Tavg表示域内节点对资源LRj的平均访问时间,Tlow表示域内节点对资源LRj的最小访问时间。Introduce notation: within a unit time interval, the number of copies of resources LR j accessed by nodes in domain D k is recorded as count, the number of new copies that need to be added is recorded as Δcount, T avg represents the average access time of nodes in the domain to resource LR j , T low indicates the minimum access time of nodes in the domain to resource LR j .
考虑到增加副本数量的目的是降低域Dk内对资源LRj的平均访问时间Tavg,使Tavg能够尽量接近域Dk内对资源LRj的最小访问时间Tlow。如果最小访问时间Tlow与平均访问时间Tavg相差比较大,则需要创建多的副本数量。因此,新增副本的数量应该满足下式:Considering that the purpose of increasing the number of replicas is to reduce the average access time T avg to resource LR j in domain D k , so that T avg can be as close as possible to the minimum access time T low to resource LR j in domain D k . If the difference between the minimum access time T low and the average access time T avg is relatively large, it is necessary to create a large number of copies. Therefore, the number of new replicas should satisfy the following formula:
根据公式3可以推导出需要创建的副本数量Δcount的计算公式如下:According to Formula 3, the calculation formula for the number of replicas Δcount that needs to be created can be deduced as follows:

步骤三.在每一个需要放置副本的域内确定适合放置副本的地点Step 3. Determine a suitable place to place a replica in each domain that needs to place a replica
在广域网范围内,由于网络带宽有限、节点的动态性等特点使网络传输延迟成为影响数据访问性能的最重要的指标,相比之下节点本身的CPU和I/O的处理时间是可以忽略不计的。定义复制因子(RF),用来衡量节点适合放置资源LRj的副本的程度。节点Pi的复制因子的计算公式如下:In the wide area network, due to the characteristics of limited network bandwidth and node dynamics, network transmission delay becomes the most important indicator affecting data access performance. Compared with the CPU and I/O processing time of the node itself, it is negligible of. Define the replication factor (RF), which is used to measure the degree to which a node is suitable for placing a replica of resource LR j . The calculation formula of the replication factor of node P i is as follows:
其中,Memoryi是节点Pi的可用内存,filesize是资源LRj所占空间的大小,AvgBWi是节点Pi的平均可用带宽。Among them, Memory i is the available memory of node P i , filesize is the space occupied by resource LR j , and AvgBW i is the average available bandwidth of node P i .
因为超级节点P并不拥有域Dk内所有节点的信息,所以域Dk内副本位置的确定工作交由域Dk的域超级节点完成。节点P发送请求消息,通知域Dk的域超级节点确定放置副本的地点。Because the super node P does not possess the information of all the nodes in the domain D k , the determination of the location of the replica in the domain D k is done by the domain super node of the domain D k . Node P sends a request message to notify the domain super node of domain D k to determine the place to place the copy.
域Dk的域超级节点接到请求消息后,完成下面的工作:域Dk内没有资源LRj副本的节点属于待选地点,域超级节点计算每个待选节点的复制因子,节点的复制因子值越大,说明该节点越适合放置该副本。选择Δcount个具有最大复制因子的节点作为副本创建的地点。根据复制因子的定义,可知在这些节点上放置副本,可以有效降低资源的访问时间。域Dk的域超级节点将Δcount个适合放置副本的节点地址返回给超级节点P。After the domain super node of domain D k receives the request message, it completes the following work: the nodes in domain D k that do not have a copy of resource LR j belong to the candidate site, the domain super node calculates the replication factor of each candidate node, and the replication of the node The larger the factor value, the more suitable the node is to place the copy. Select Δcount nodes with the largest replication factor as the locations for replica creation. According to the definition of replication factor, it can be seen that placing replicas on these nodes can effectively reduce the access time of resources. The domain supernode of domain D k returns Δcount node addresses suitable for placing replicas to supernode P.
步骤四.在指定的副本放置地点创建副本Step 4. Create a copy at the specified copy placement location
由超级节点P负责在Δcount个适合放置副本的地点上创建副本,完成优化的副本分布。The super node P is responsible for creating replicas on Δcount locations suitable for placing replicas, and completes the optimized replica distribution.
有益效果Beneficial effect
本发明给出的动态自适应的副本分布方法,通过资源的平均响应时间计算新增副本的数目,根据访问请求的变化和网络通讯状况计算副本放置地点,能够在减少资源响应时间和降低副本一致性维护开销之间获得有效平衡。其合理性、优点和积极效果如下:The dynamic self-adaptive replica distribution method provided by the present invention calculates the number of newly added replicas through the average response time of resources, and calculates the location of replicas according to changes in access requests and network communication conditions, which can reduce resource response time and reduce replica consistency. Effective balance between maintenance costs. Its rationality, advantages and positive effects are as follows:
(1)统计单位时间内的资源访问情况,对每个域计算域内节点访问该资源的平均响应时间。域内平均响应时间能够综合反映该域内节点对数据资源的缺乏程度和访问热度。在平均响应时间大的域内分布副本会极大地改善或减少数据访问的代价。(1) Statistics resource access situation per unit time, and calculate the average response time of nodes in the domain to access the resource for each domain. The average response time in the domain can comprehensively reflect the lack of data resources and access popularity of nodes in the domain. Distributing replicas in a domain with a large average response time can greatly improve or reduce the cost of data access.
(2)根据域内节点访问资源的平均响应时间计算新建副本的数量,能够有效控制副本的数量,减少副本一致性维护的代价。(2) Calculate the number of new replicas based on the average response time of nodes in the domain to access resources, which can effectively control the number of replicas and reduce the cost of replica consistency maintenance.
(3)提出复制因子的概念,根据用户访问特征和节点实时带宽数据等计算适合放置副本的最佳地点,实现副本的优化分布。(3) The concept of replication factor is proposed, and the optimal location for placing replicas is calculated according to user access characteristics and real-time bandwidth data of nodes, so as to realize the optimal distribution of replicas.
(4)适用与任何具有超级节点的数据网格系统,不仅适用拥有只读数据资源的系统,尤其适合拥有可读写数据资源的系统,应用领域广,解决了现有网格副本技术不适用于拥有可读写数据资源的缺陷。(4) It is suitable for any data grid system with super nodes, not only for systems with read-only data resources, but especially for systems with readable and writable data resources. It has a wide range of applications and solves the problem that the existing grid copy technology is not applicable Deficiencies in owning readable and writable data resources.
(5)操作简单,不依赖中心控制节点,仅通过超级节点之间简单协作即可完成。(5) The operation is simple, does not rely on the central control node, and can be completed only through simple cooperation between super nodes.
(6)方法运行代价小,多数操作在超级节点本地完成,很少占用广域网带宽。(6) The operation cost of the method is low, and most operations are completed locally on the super node, which rarely occupies the bandwidth of the wide area network.
附图说明Description of drawings
图1为具有超级节点的数据网格系统的网络结构示意图;Fig. 1 is a schematic diagram of the network structure of a data grid system with super nodes;
图2为副本分布方法的操作流程图;Fig. 2 is the operation flowchart of replica distribution method;
图3为资源LRj的副本分布情况示意图;Fig. 3 is a schematic diagram of the replica distribution of resource LR j ;
图4为单位时间内网格系统中的节点对资源LRj的访问情况示例。Fig. 4 is an example of access to resource LR j by nodes in the grid system per unit time.
具体实施方式Detailed ways
下面结合附图和具体实施方式对本发明作进一步说明。The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
每个超级节点对自身的共享资源和自己管理的普通节点的共享资源承担副本管理的职责,负责制定优化的副本分布策略。超级节点周期性的记录自己管理的数据资源下所有副本的访问情况,包括何时、从哪个域内的哪个节点发出过请求,访问了哪个副本,资源的响应时间等。这些副本访问信息记录在超级节点的本地副本目录中。Each super node undertakes the responsibility of copy management for its own shared resources and the shared resources of ordinary nodes it manages, and is responsible for formulating an optimized copy distribution strategy. The super node periodically records the access status of all copies under the data resources it manages, including when and from which node in which domain the request was sent, which copy was accessed, the response time of the resource, etc. These replica access information are recorded in the super node's local replica directory.
例如,资源LRj的副本分布情况如附图3所示,图中显示了两个域,域超级节点分别是节点A和节点B。资源LRj拥有4个副本,分别放置在节点A1、节点A12、节点A2和节点B11上。资源LRj是节点A12的共享资源,因为节点A12是普通节点,所以节点A12的父节点P负责资源LRj的副本管理,节点P的本地副本目录中记录资源LRj的所有副本信息,如附图3中虚线所示。For example, the replica distribution of resource LR j is shown in Figure 3, which shows two domains, and the domain super nodes are node A and node B respectively. Resource LR j has 4 copies, which are respectively placed on node A1, node A12, node A2 and node B11. Resource LR j is a shared resource of node A12, because node A12 is a common node, so node A12's parent node P is responsible for the copy management of resource LR j , and all copy information of resource LR j is recorded in the local copy directory of node P, as shown in the attached Shown in dotted line in Figure 3.
图4显示了单位时间内网格系统中的节点对资源LRj的访问情况,图4中用带箭头的线段表示所有对资源LRj的访问请求,线段起始端表示资源发起点所在域,键头所指表示访问的具体副本。线段旁边的数字表示资源的响应时间。Figure 4 shows the access situation of the nodes in the grid system to resource LR j in unit time. In Figure 4, the lines with arrows represent all the access requests to resource LR j . The specific copy that the header points to indicates the access. The numbers next to the lines indicate the resource's response time.
假设超级节点P负责管理的数据资源LRj需要创建副本,则超级节点P执行以下操作:Assuming that the data resource LR j managed by the super node P needs to create a copy, the super node P performs the following operations:
1.在整个网格系统范围内确定需要放置副本的所有域1. Determine all domains that need to place replicas within the entire grid system
节点P根据单位时间内资源LRj的响应时间,依据公式1计算资源LRj的平均响应时间是118,即According to the response time of resource LR j in unit time, node P calculates the average response time of resource LR j according to formula 1 to be 118, namely
依据公式2计算域A内节点访问资源LRj的平均响应时间为60,即According to formula 2, the average response time of nodes accessing resource LR j in domain A is calculated as 60, namely
域B内节点访问资源LRj的平均访问代价为140,即The average access cost for nodes in domain B to access resource LR j is 140, namely
域C内节点访问资源LRj的平均访问代价为200,即The average access cost for nodes in domain C to access resource LR j is 200, namely
因为ARTj,A<ARTj,ARTj,B>ARTj,ARTj,C>ARTj,所以需要在域C和域B内创建资源LRj的副本。Since ART j, A < ART j , ART j, B > ART j , ART j, C > ART j , a copy of resource LR j needs to be created in domain C and domain B.
2.在每一个需要放置副本的域内确定创建副本的数量2. Determine the number of replicas to be created in each domain where replicas need to be placed
依据公式4计算附图4实例中需要创建的副本数量。域B内访问过的副本数目为2,则需要在域B内创建的副本数目为:Calculate the number of replicas that need to be created in the example shown in Figure 4 according to Formula 4. If the number of replicas visited in domain B is 2, the number of replicas to be created in domain B is:
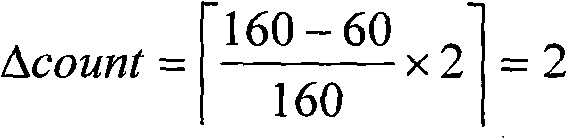
域C内访问过的副本数目为1,需要在域C创建的副本数目为:The number of replicas visited in domain C is 1, and the number of replicas to be created in domain C is:
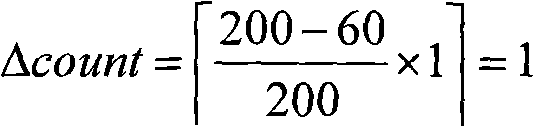
3.在每一个需要放置副本的域内确定适合放置副本的地点3. Determine a suitable place to place a copy in each domain where a copy needs to be placed
节点P发送请求消息,通知域B的域超级节点B和域C的域超级节点C确定放置副本的地点。因为节点B和节点C拥有域内所有节点的信息,可以分别计算资源LRj放置在每个待选节点上的复制因子(RF)。节点B选择域内2个具有最大复制因子的节点作为副本创建地点;节点C选择域内1个具有最大复制因子的节点作为副本创建地点。最后,节点B和节点C将适合放置副本的节点地址返回给超级节点P。Node P sends a request message to notify domain super node B of domain B and domain super node C of domain C to determine the place to place the replica. Because node B and node C have the information of all nodes in the domain, the replication factor (RF) of resource LRj placed on each candidate node can be calculated respectively. Node B selects two nodes with the largest replication factor in the domain as the replica creation location; node C selects a node with the largest replication factor in the domain as the replica creation location. Finally, node B and node C return the address of the node suitable for placing the replica to super node P.
4.节点P依据域超级节点B和域超级节点C返回的节点信息,分别在域B指定的节点上分别创建两个新副本,在域C指定节点上创建一个新副本。4. According to the node information returned by domain super node B and domain super node C, node P creates two new replicas on the node specified by domain B and creates a new replica on the node specified by domain C respectively.
Claims (1)





Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2009102654216A CN101751309B (en) | 2009-12-28 | 2009-12-28 | An Optimized Replica Distribution Method in Data Grid |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2009102654216A CN101751309B (en) | 2009-12-28 | 2009-12-28 | An Optimized Replica Distribution Method in Data Grid |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN101751309A CN101751309A (en) | 2010-06-23 |
| CN101751309B true CN101751309B (en) | 2011-06-29 |
Family
ID=42478319
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2009102654216A Expired - Fee Related CN101751309B (en) | 2009-12-28 | 2009-12-28 | An Optimized Replica Distribution Method in Data Grid |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN101751309B (en) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102137141B (en) * | 2010-10-11 | 2014-01-01 | 华为技术有限公司 | Data storage control method and data storage control device |
| CN102156730B (en) * | 2011-04-07 | 2013-03-20 | 江苏省电力公司 | Optimization Method Based on File Storage Dynamic Aggregation |
| CN102375893A (en) * | 2011-11-17 | 2012-03-14 | 浪潮(北京)电子信息产业有限公司 | Distributed file system and method for establishing duplicate copy |
| CN102497394B (en) * | 2011-11-28 | 2014-01-15 | 中国科学院研究生院 | An Optimization Model-Based Method for Duplicate File Placement in Content Distribution Network |
| CN102801772B (en) * | 2012-03-07 | 2015-05-27 | 武汉理工大学 | DCell network-oriented energy-saving copy placement method for cloud computing environment |
| CN102984280B (en) * | 2012-12-18 | 2015-05-20 | 北京工业大学 | Data backup system and method for social cloud storage network application |
| CN103095812B (en) * | 2012-12-29 | 2016-04-13 | 华中科技大学 | A kind of copy creating method based on user's request response time |
| CN103491128B (en) * | 2013-06-13 | 2016-08-10 | 中国科学院大学 | An Optimal Placement Method for Popular Resource Replicas in Peer-to-Peer Networks |
| CN107465706B (en) * | 2016-06-06 | 2021-06-18 | 中国船舶工业系统工程研究院 | Distributed data object storage device based on wireless communication network |
| CN108319618B (en) * | 2017-01-17 | 2022-05-06 | 阿里巴巴集团控股有限公司 | Data distribution control method, system and device of distributed storage system |
| CN106911777A (en) * | 2017-02-24 | 2017-06-30 | 郑州云海信息技术有限公司 | A kind of data processing method and server |
| CN108924203B (en) * | 2018-06-25 | 2021-07-27 | 深圳市金蝶天燕云计算股份有限公司 | Data copy self-adaptive distribution method, distributed computing system and related equipment |
| CN114095573B (en) * | 2021-10-19 | 2023-11-28 | 陕西悟空云信息技术有限公司 | Content copy placement method of CDN-P2P network based on edge cache |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101022396A (en) * | 2007-03-15 | 2007-08-22 | 上海交通大学 | Grid data duplicate management system |
| CN101187931A (en) * | 2007-12-12 | 2008-05-28 | 浙江大学 | Management Method of Multiple File Copy in Distributed File System |
| CN101340458A (en) * | 2008-07-09 | 2009-01-07 | 南京邮电大学 | A Method of Grid Data Replica Generation Based on Time-Spatial Locality |
-
2009
- 2009-12-28 CN CN2009102654216A patent/CN101751309B/en not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101022396A (en) * | 2007-03-15 | 2007-08-22 | 上海交通大学 | Grid data duplicate management system |
| CN101187931A (en) * | 2007-12-12 | 2008-05-28 | 浙江大学 | Management Method of Multiple File Copy in Distributed File System |
| CN101340458A (en) * | 2008-07-09 | 2009-01-07 | 南京邮电大学 | A Method of Grid Data Replica Generation Based on Time-Spatial Locality |
Also Published As
| Publication number | Publication date |
|---|---|
| CN101751309A (en) | 2010-06-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101751309B (en) | An Optimized Replica Distribution Method in Data Grid | |
| CN101753625B (en) | Method for deploying copy service and creating copy in peer-to-peer network environment | |
| CN101370030B (en) | Resource load stabilization method based on contents duplication | |
| CN110213352B (en) | Namespace unified decentralized autonomous storage resource aggregation method | |
| CN101493826B (en) | Database system based on WEB application and data management method thereof | |
| CN104462432B (en) | Adaptive distributed computing method | |
| CN103607424B (en) | Server connection method and server system | |
| CN102143215A (en) | Network-based PB level cloud storage system and processing method thereof | |
| CN102244685A (en) | Distributed type dynamic cache expanding method and system supporting load balancing | |
| CN101187931A (en) | Management Method of Multiple File Copy in Distributed File System | |
| CN110119405A (en) | Distributed parallel database method for managing resource | |
| CN118509339B (en) | Platform operation and maintenance cluster central control management system | |
| CN101800768B (en) | Gridding data transcription generation method based on storage alliance subset partition | |
| WO2024221633A1 (en) | Micro-service application data sharing method, apparatus and device | |
| US20010027467A1 (en) | Massively distributed database system and associated method | |
| CN100583802C (en) | Replica selection method based on global minimum access cost | |
| Liao et al. | A QoS-aware dynamic data replica deletion strategy for distributed storage systems under cloud computing environments | |
| Zhang et al. | Data replication placement strategy based on bidding mode for cloud storage cluster | |
| Yadgar et al. | Cooperative caching with return on investment | |
| Gorbenko et al. | Analysis of trade-offs in fault-tolerant distributed computing and replicated databases | |
| CN106790705A (en) | A kind of Distributed Application local cache realizes system and implementation method | |
| CN103095812A (en) | Copy establishing method based on user request response time | |
| CN105282203B (en) | A kind of method for building up and equipment of catalogue centralized P2P network | |
| CN109067898A (en) | A method of being distributed by file hash, which reduces content distributing network fringe node, returns source rate | |
| CN117076391B (en) | A water conservancy metadata management system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C17 | Cessation of patent right | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20110629 Termination date: 20121228 |