Summary of the invention
In view of this, the invention provides a kind of intra-frame prediction mode prediction method, can improve and predict the outcome and the actual identical probability of predictive mode that adopts, thereby reduced the expense of coded frame inner estimation mode, improved compression efficiency of intra-frame coding.
For achieving the above object, the present invention adopts following technical scheme:
A kind of intra-frame prediction mode prediction method comprises:
A, according to the adjacent encoding block of present encoding piece, the neighborhood prediction module of present encoding piece and the reference pixel of described neighborhood prediction module are set; Wherein, the top left corner pixel position of present encoding piece is made as coordinate (0,0), the X axis of horizontal direction is right for just, and the Y-axis of vertical direction is downward for just,
If the present encoding piece is image top first row, will be positioned at (1,0), (2,0), (1,1), (2,1), (1,2), (2,2), (1,3), (2,3) 8 pixels are as the neighborhood prediction module of present encoding piece, to be positioned at (3,0), (3,1), (3,2), 4 of (3,3) pixels are as described reference pixel;
If the present encoding piece is positioned at image rightmost and non-image top first row, will be positioned at (2 ,-2), (1,-2), (0 ,-2), (1 ,-2), (2,-2), (3 ,-2), (2 ,-1), (1,-1), (0 ,-1), (1 ,-1), (2,-1), (3 ,-1), (1,0), (2,0), (1,1), (2,1), (1,2), (2,2), (1,3), (2,3) 20 pixels will be positioned at (3 ,-3) as the neighborhood prediction module of present encoding piece, (2,-3), (1 ,-3), (0 ,-3), (1,-3), (2 ,-3), (3 ,-3), (3,-2), (3 ,-1), (3,0), (3,1), (3,2), 13 pixels of (3,3) are as described reference pixel;
If the present encoding piece is positioned at image Far Left and non-image top first row, will be positioned at (0 ,-2), (1 ,-2), (2,-2), (3 ,-2), (4 ,-2), (5 ,-2), (0,-1), (1 ,-1), (2 ,-1), (3 ,-1), (4,-1), 12 pixels of (5 ,-1) are as the neighborhood prediction module of present encoding piece, will be positioned at (0 ,-3), (1,-3), (2 ,-3), (3 ,-3), (4 ,-3), (5,-3), 8 pixels of (6 ,-3), (7 ,-3) are as described reference pixel;
If the present encoding piece is not positioned at first row of image, or rightmost, or Far Left, and be not first encoding block of image, then will be positioned at (2 ,-2), (1,-2), (0 ,-2), (1 ,-2), (2 ,-2), (3,-2), (4 ,-2), (5 ,-2), (2 ,-1), (1,-1), (0 ,-1), (1 ,-1), (2,-1), (3 ,-1), (4 ,-1), (5,-1), (1,0), (2,0), (1,1), (2,1), (1,2), (2,2), (1,3), 24 pixels of (2,3) are as the neighborhood prediction module of present encoding piece, to be positioned at (3 ,-3), (2 ,-3), (1,-3), (0 ,-3), (1 ,-3), (2,-3), (3 ,-3), (4 ,-3), (5,-3), (6 ,-3), (7 ,-3), (3,-2), (3 ,-1), (3,0), (3,1), (3,2), 17 pixels of (3,3) are as described reference pixel;
B, according to the position of described present encoding piece in image, determine H.264/AVC in the video compression standard for available predictive mode in the directional prediction modes 0~8 in the defined 9 kinds of frames of 4 * 4 luminance block, and travel through all available predictive modes, under every kind of predictive mode i, utilize the reference pixel of neighborhood prediction module, calculate the predicted value of pixel in the described neighborhood prediction module, and according to the calculated with actual values cost function of pixel in described predicted value and the described neighborhood prediction module:
With the predictive mode of the cost function value correspondence of minimum as predicting the outcome; Wherein, i is the numbering of predictive mode, predMode (i) (x, y) be the predicted value of pixel in the described neighborhood prediction module under the predictive mode i, x and y are the coordinate of neighborhood prediction module, (x y) is the actual value of pixel in the described neighborhood prediction module to templatePixel, and templateSize is the sum of all pixels in the actual down neighborhood prediction module that adopts of predictive mode i.
Preferably, be positioned at non-first present encoding piece of image first row, available predictive mode is a predictive mode 1,2 and 8;
Be positioned at the present encoding piece of image rightmost and non-first row, available predictive mode is a predictive mode 0,2,3 and 7;
Other present encoding pieces except that being positioned at image first row, image rightmost and first encoding block of image, available predictive mode is all 9 kinds of intra prediction modes.
As seen from the above technical solution, among the present invention,, the neighborhood prediction module of present encoding piece and the reference pixel of described neighborhood prediction module are set according to the adjacent encoding block of present encoding piece; Then, all available predictions patterns of traversal present encoding piece, utilize the neighborhood prediction module of present encoding piece, according to every kind of available predictions pattern reference pixel is predicted, and compare according to predicted value that obtains and reference pixel actual value, determine predictive mode, with its predictive mode as the present encoding piece to the consensus forecast best results of all reference pixels.As seen, not only utilize the encoding block of the left side and top, but utilize the related adjacent encoded pixels of various available predictions patterns, thereby guarantee to travel through various available predictive modes, and according to predicting the outcome to pixel in the neighborhood prediction module under the various available predictions patterns, select the predictive mode of a kind of predictive mode of consensus forecast best results as the present encoding piece, thereby improved the forecasting accuracy of predictive mode, and then reduced the expense of coded frame inner estimation mode, improved compression efficiency of intra-frame coding.
Embodiment
For making purpose of the present invention, technological means and advantage clearer, the present invention is described in further details below in conjunction with accompanying drawing.
Basic thought of the present invention is: various available predictive modes are traveled through, utilize various predictive modes that encoded pixels is predicted, according to predicting the outcome and the matching degree of encoded pixels, select a kind of predictive mode of prediction effect the best as the present encoding piece.
As previously mentioned, in the prior art, determine the predictive mode of present encoding piece according to the predictive mode of the adjacent encoding block in the left side of present encoding piece with the top, and in maximum two kinds of predictive modes that two adjacent encoding blocks adopt, select a kind of, as predicting the outcome of present encoding piece.
Because the pixel interdependence of adjacent encoder piece is bigger, thus among the present invention equally according to the predictive mode of the prediction present encoding piece of adjacent encoding block.Being unlike the prior art can travel through all available predictive modes among the present invention, selects the predictive mode as the present encoding piece of prediction effect the best.
Particularly, the intra-frame prediction mode prediction method flow process comprises among the present invention: the determining of neighborhood prediction module and reference pixel, utilize reference pixel according to various available predictive modes the pixel in the neighborhood prediction module to be predicted successively, select a kind of predictive mode of prediction effect the best as the present encoding piece.
Below specific implementation of the present invention is described in further details.Intra-frame prediction mode prediction method among the present invention is the flow process that other encoding blocks except that first encoding block of present frame are predicted, Fig. 1 is the flow chart of prediction mode among the present invention, and as shown in Figure 1, this method comprises:
Step 101 according to the adjacent encoding block of present encoding piece, is provided with the neighborhood prediction module of present encoding piece and the reference pixel of this neighborhood prediction module.
In this step, neighborhood prediction module and reference pixel are to be made of the pixel in the adjacent encoding block of present encoding piece.Wherein, reference pixel is to be used for encoded pixels that the pixel of neighborhood prediction module is predicted.
Specifically, determine that the mode of neighborhood prediction module and reference pixel is according to the position of present encoding piece:
The top left corner pixel position of supposing the present encoding piece is made as coordinate (0,0), and the X axis of horizontal direction is right for just, and the Y-axis of vertical direction is downward for just;
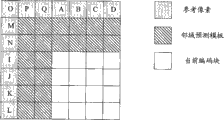
1) when the present encoding piece was in image top first row, only adjacent left side adjacent block had been encoded and can be used as reference, then will be positioned at (1,0), (2,0), (1,1), (2,1), (1,2), (2,2), (1,3), 8 pixels of (2,3) are as the neighborhood prediction module of present encoding piece, will be positioned at (3,0), (3,1), 4 pixels of (3,2), (3,3) are as described reference pixel; Concrete position relation is shown in Fig. 2 a, and the field prediction module is made of 8 adjacent pixels of the present encoding piece left side, and pixel I-L is as the reference pixel;
2) be in the image rightmost when current block, promptly during last row of image the right, the only adjacent left side and directly over adjacent block encoded and can be used as reference, then will be positioned at (2,-2), (1 ,-2), (0 ,-2), (1 ,-2), (2,-2), (3 ,-2), (2 ,-1), (1,-1), (0 ,-1), (1 ,-1), (2,-1), (3 ,-1), (1,0), (2,0), (1,1), (2,1), (1,2), (2,2), (1,3), (2,3) 20 pixels will be positioned at (3 ,-3) as the neighborhood prediction module of present encoding piece, (2,-3), (1 ,-3), (0 ,-3), (1,-3), (2 ,-3), (3 ,-3), (3,-2), (3 ,-1), (3,0), (3,1), (3,2), 13 pixels of (3,3) are as the reference pixel; Concrete position relation is shown in Fig. 2 b, and the field prediction module is the L type zone that 20 pixels constitute, and A-D, I-Q are as the reference pixel;
3) be in the image Far Left when current block, promptly during first row of the image left side, only adjacent directly over adjacent block encoded and can be used as reference, or directly over adjacent block and upper right side adjacent block can be used as reference simultaneously, then will be positioned at (0 ,-2), (1,-2), (2 ,-2), (3 ,-2), (4,-2), (5 ,-2), (0 ,-1), (1,-1), (2 ,-1), (3 ,-1), (4,-1), 12 pixels of (5 ,-1) will be positioned at (0 as the neighborhood prediction module of present encoding piece,-3), (1,-3), (2 ,-3), (3 ,-3), (4,-3), (5,-3), (6 ,-3), 8 pixels of (7 ,-3) are as the reference pixel; Concrete position relation is shown in Fig. 2 c, and the neighborhood prediction module is 12 adjacent with the upper right side directly over current coding macro block pixels, and A-H is as the reference pixel; Particularly, when the present encoding piece is positioned at this image Far Left, according to different predictive modes, may be only with directly over adjacent block as a reference, at this moment, the field prediction module of practical application adjacent 8 pixels directly over being, A-D is as corresponding reference pixel; Perhaps, also may with directly over adjacent block and upper right side adjacent block simultaneously as a reference, at this moment, the field prediction module of practical application be directly over the template that constitutes of adjacent 12 pixels with the upper right side, A-H is as reference pixel accordingly;
4) when current block is in other position in the image, the left side, directly over and top-right adjacent block all can be used as reference, then will be positioned at (2 ,-2), (1,-2), (0 ,-2), (1 ,-2), (2 ,-2), (3,-2), (4 ,-2), (5 ,-2), (2 ,-1), (1,-1), (0 ,-1), (1 ,-1), (2,-1), (3 ,-1), (4 ,-1), (5,-1), (1,0), (2,0), (1,1), (2,1), (1,2), (2,2), (1,3), 24 pixels of (2,3) are as the neighborhood prediction module of present encoding piece, to be positioned at (3 ,-3), (2 ,-3), (1,-3), (0 ,-3), (1 ,-3), (2,-3), (3 ,-3), (4 ,-3), (5,-3), (6 ,-3), (7 ,-3), (3,-2), (3 ,-1), (3,0), (3,1), (3,2), 17 pixels of (3,3) are as the reference pixel; Concrete position relation is shown in Fig. 2 d, and the field prediction module is the L type zone that 24 pixels constitute, and A-Q is as the reference pixel; Similar with the previous case, according to different predictive modes, actual neighborhood prediction module that adopts and reference pixel be difference to some extent, can carry out the actual neighborhood prediction module and the selection of reference pixel according to existing various predictive modes.
On the position of above-mentioned 4 kinds of present encoding pieces, be provided with in the process of neighborhood prediction module and reference pixel, why carry out the setting of aforesaid way, consider under the different predictive modes on the one hand, the actual neighborhood prediction module that adopts can be not identical, thereby can embody the performance difference of different predictive modes, avoid utilizing too much encoded pixels to predict on the other hand as far as possible, to reduce implementation complexity.
Step 102 is determined available predictive mode according to the position of present encoding piece in image.
As previously mentioned, intra prediction mode has 9 kinds, but for some locational encoding block, not all 9 kinds of predictive modes are all available, for disabled predictive mode, with regard to not needing it traveled through.This step is promptly determined available predictive mode according to the position of present encoding piece in image.
Particularly, for above-mentioned steps 101 1) encoding block of described position, available predictive mode is 1,2 and 8; For above-mentioned steps 101 2) encoding block of described position, available predictive mode is 2,3 and 7; For the encoding block of all the other positions, available predictive mode is all 9 kinds of predictive modes.
Step 103 travels through all available predictive modes, under every kind of predictive mode, utilizes the reference pixel of the neighborhood prediction module of present encoding piece, calculates the predicted value of pixel in the neighborhood prediction module.
In this step, travel through all available predictive modes, under every kind of predictive mode, utilize the reference pixel of the neighborhood prediction module of present encoding piece, calculate the predicted value of pixel in the neighborhood prediction module.Wherein, under different predictive modes, need in neighborhood prediction module pixel, select the pixel of the actual employing of current predictive mode, specifically under every kind of predictive mode, select the mode of pixel identical in the account form of predicted value and the neighborhood prediction module with existing mode.
Particularly, in this step, if neighborhood prediction module top left corner pixel position is (0,0), pred4x4L[x, y] under different predictive modes, the pixel in the neighborhood prediction module is predicted resulting predicted value, p[x, y] be reference pixel value, wherein x, the neighborhood prediction module regulation that the value of y is used according to the present encoding piece is promptly come according to the Coordinate Conversion in the step 101.
1) predictive mode 0:
Pred4x4L[x, y]=p[x ,-1], x wherein, the neighborhood prediction module regulation that the value of y is used according to the present encoding piece is promptly come according to the Coordinate Conversion in the step 101.
2) predictive mode 1:
Pred4x4L[x, y]=p[-1, y], x wherein, the neighborhood prediction module regulation that the value of y is used according to the present encoding piece is promptly come according to the Coordinate Conversion in the step 101.
3) predictive mode 2:
If a) p[x ,-1], x=0..3 and p[-1, y], y=0..3 is available, then:
pred4x4L[x,y]=(p[0,-1]+p[1,-1]+p[2,-1]+p[3,-1]+
p[-1,0]+p[-1,1]+p[-1,2]+p[-1,3]+4)>>3
X wherein, y=0..3.
B) if p[x ,-1], the unavailable p[-1 of x=0..3, y], y=0..3 can use, then:
pred4x4L[x,y]=(p[-1,0]+p[-1,1]+p[-1,2]+p[-1,3]+2)>>2
X wherein, y=0..3.
C) if p[x ,-1], x=0..3 can use p[-1, y], y=0..3 is unavailable, then:
pred4x4L[x,y]=(p[0,-1]+p[1,-1]+p[2,-1]+p[3,-1]+2)>>2
X wherein, y=0..3.
D) for other situation,
Pred4x4L[x, y]=(1<<(BitDepthY-1)) be the number of bits of expression brightness, as
Wherein BitDepthY is the number of bits of expression brightness, when representing as 8 bits, pred4x4L[x, y]=8, x wherein, the neighborhood prediction module regulation that the value of y is used according to the present encoding piece is promptly come according to the Coordinate Conversion in the step 101.
4) predictive mode 3:
pred4x4L[x,y]=(p[x+y,-1]+2*p[x+y+1,-1]+
P[x+y+2 ,-1]+2)>>2, x wherein, the neighborhood prediction module regulation that the value of y is used according to the present encoding piece is promptly come according to the Coordinate Conversion in the step 101.
5) predictive mode 4:
If a) x>y,
pred4x4L[x,y]=(p[x-y-2,-1]+2*p[x-y-1,-1]+
p[x-y,-1]+2)>>2,
B) if x<y,
pred4x4L[x,y]=(p[-1,y-x-2]+2*p[-1,y-x-1]+
p[-1,y-x]+2)>>2
C) if x=y,
pred4x4L[x,y]=(p[0,-1]+2*p[-1,-1]+p[-1,0]+2)>>2
X wherein, the neighborhood prediction module regulation that the value of y is used according to the present encoding piece is promptly come according to the Coordinate Conversion in the step 101.
6) predictive mode 5:
Make zVR=2*x-y
If a) zVR=0,2,4,6,8,10,12,14,
pred4x4L[x,y]=(p[x-(y>>1)-1,-1]+p[x-(y>>1),-1]+1)>>1
B) if zVR=1,3,5,7,9,11,13,
pred4x4L[x,y]=(p[x-(y>>1)-2,-1]+2*p[x-(y>>1)-1,-1]+
p[x-(y>>1),-1]+2)>>2
C) if zVR=-1
pred4x4L[x,y]=(p[-1,0]+2*p[-1,-1]+p[0,-1]+2)>>2
D) if zVR=-2,
pred4x4L[x,y]=(p[-1,1]+2*p[-1,0]+p[-1,-1]+2)>>2
E) if zVR=-3,
pred4x4L[x,y]=(p[-1,2]+2*p[-1,1]+p[0,0]+2)>>2
F) if zVR=-4 ,-5,
pred4x4L[x,y]=(p[-1,y-1]+2*p[-1,y-2]+p[-1,y-3]+2)>>2
X wherein, the neighborhood prediction module regulation that the value of y is used according to the present encoding piece is promptly come according to the Coordinate Conversion in the step 101.
7) predictive mode 6:
Make zVR=2*y-x
If a) zVR=0,2,4,6,8,10,
pred4x4L[x,y]=(p[-1,y-(x>>1)-1]+p[-1,y-(x>>1)]+1)>>1
B) if zVR=1,3,5,7,9,
pred4x4L[x,y]=(p[-1,y-(x>>1)-2]+
2*p[-1,y-(x>>1)-1]+p[-1,y-(x>>1)]+2)>>2
C) if zVR=-1,
pred4x4L[x,y]=(p[-1,0]+2*p[-1,-1]+p[0,-1]+2)>>2
D) if zVR=-2,
pred4x4L[x,y]=(p[1,-1]+2*p[0,-1]+p[-1,-1]+2)>>2
C) if zVR=-3,
pred4x4L[x,y]=(p[2,-1]+2*p[1,-1]+p[0,-1]+2)>>2
D) if zVR=-4,
pred4x4L[x,y]=(p[3,-1]+2*p[2,-1]+p[1,-1]+2)>>2
E) if zVR=-5,
pred4x4L[x,y]=(p[4,-1]+2*p[3,-1]+p[2,-1]+2)>>2
F) if zVR=-6 ,-7,
pred4x4L[x,y]=(p[x-1,-1]+2*p[x-2,-1]+p[x-3,-1]+2)>>2
X wherein, the neighborhood prediction module regulation that the value of y is used according to the present encoding piece is promptly come according to the Coordinate Conversion in the step 101.
8) predictive mode 7:
A) as y=0,2,4,
pred4x4L[x,y]=(p[x+(y>>1),-1]+p[x+(y>>1)+1,-1]+1)>>1
B) as y=1,3,5,
pred4x4L[x,y]=(p[x+(y>>1),-1]+2*p[x+(y>>1)+1,-1]+
p[x+(y>>1)+2,-1]+2)>>2
X wherein, the prediction module regulation (with reference to top step 2 and Fig. 2) that the value of y is used according to current block.
9) predictive mode 8:
Make zVR=x+2*y
If a) zVR=0,2,4,6,8,
pred4x4L[x,y]=(p[-1,y+(x>>1)]+p[-1,y+(x>>1)+1]+1)>>1
B) if zVR=1,3,5,7,
pred4x4L[x,y]=(p[-1,y+(x>>1)]+2*p[-1,y+(x>>1)+1]+
p[-1,y+(x>>1)+2]+2)>>2
C) if zVR=9,
pred4x4L[x,y]=(p[-1,4]+3*p[-1,5]+2)>>2
C) if zVR>9,
pred4x4L[x,y]=p[-1,5]
X wherein, the neighborhood prediction module regulation that the value of y is used according to the present encoding piece is promptly come according to the Coordinate Conversion in the step 101.
So far, under every kind of predictive mode, the predictor calculation of pixel finishes in the actual neighborhood prediction module that adopts.
Step 104 according to the predicted value and the actual value of pixel in the neighborhood prediction module, is selected the predictive mode of the predictive mode of prediction effect the best as the present encoding piece.
Prediction effect to pixel in the neighborhood prediction module characterizes by cost function, and specifically this cost function is:
Wherein, i is the numbering of predictive mode, x and y are the coordinate of pixel in the neighborhood prediction module, predMode (i) (x, y) predicted value of pixel, i.e. pred4x4L[x in the abovementioned steps 103 in the neighborhood prediction module under the predictive mode i, y], (x y) is the actual value of pixel in the described neighborhood prediction module to templatePixel, and templateSize is the sum of pixel in the actual down neighborhood prediction module that adopts of predictive mode i.
In available predictive mode, make that the pattern of cost function minimum is predicted value and actual value immediate predictive mode on statistical significance, the predictive mode of consensus forecast effect optimum just, with the most possible predictive mode of this predictive mode as the present encoding piece, be mostProbMode=arg min{Distortion (i) }, mostProbMode is most possible predictive mode, just according to predicting the outcome that mode of the present invention is determined.
So far, the Forecasting Methodology flow process among the present invention finishes.Next, can be according to predicting the outcome, predictive mode to the actual employing of present encoding piece is encoded, the specific coding mode is identical with existing mode, promptly when predicting that the most possible predictive mode that obtains is identical with the actual predictive mode that adopts, utilize this predictive mode of 1 bit transfer, otherwise, the predictive mode of the actual employing of 4 bit transfer utilized.
Predict the most possible prediction mode that obtains by the way, owing to utilized the adjacent encoding block of a plurality of directions of present encoding piece, and all available coding modes have been traveled through, thereby select the predictive mode of the predictive mode of prediction effect optimum, therefore make its probability identical that predict the outcome increase greatly with the predictive mode of the actual employing of present encoding piece as the present encoding piece.Thereby further reduced the coding expense of predictive mode, improved compression efficiency of intra-frame coding.
For further specifying the advantage of the present invention with respect to prior art, on the JM software platform to utilizing the present invention to predict and carry out Methods for Coding according to predicting the outcome and carried out emulation, and with H.264/AVC under same experimental conditions, carried out the contrast experiment.In simulation process, to set full sequence and adopt 4x4 intraframe predictive coding pattern, simulation result is shown in table 1-table 4.The inventive method improves a lot on code check is saved as can be seen.
Table 1 code efficiency compares, image size CIF (352 * 288)
| ?Foreman |
Frame per second |
The coding frame number |
ΔPSNR(dB) |
Δ code check (%) |
| QP=28 |
30 |
100 |
-0.032 |
-1.91 |
| QP=32 |
30 |
100 |
-0.068 |
-4.58 |
| QP=36 |
30 |
100 |
-0.118 |
-8.79 |
| QP=40 |
30 |
100 |
-0.219 |
-12.62 |
Table 2 code efficiency compares, image size CIF (352 * 288)
| Mother?and daughter |
Frame per second |
The coding frame number |
ΔPSNR(dB) |
Δ code check (%) |
| QP=28 |
30 |
100 |
-0.030 |
-0.21 |
| QP=32 |
30 |
100 |
-0.054 |
-1.32 |
| QP=36 |
30 |
100 |
-0.043 |
-2.82 |
| QP=40 |
30 |
100 |
-0.117 |
-5.57 |
Table 3 code efficiency compares, image size CIF (352 * 288)
| Akiyo |
Frame per second |
The coding frame number |
ΔPSNR(dB) |
Δ code check (%) |
| QP=28 |
30 |
100 |
-0.077 |
+1.46 |
| QP=32 |
30 |
100 |
-0.049 |
+0.12 |
| QP=36 |
30 |
100 |
-0.179 |
-1.58 |
| QP=40 |
30 |
100 |
+0.020 |
-3.98 |
Table 4 code efficiency compares, image size 4CIF (704 * 576)
| Ice |
Frame per second |
The coding frame number |
ΔPSNR(dB) |
Δ code check (%) |
| QP=28 |
30 |
100 |
-0.109 |
-0.99 |
| QP=32 |
30 |
100 |
-0.030 |
-3.18 |
| QP=36 |
30 |
100 |
-0.146 |
-2.82 |
| QP=40 |
30 |
100 |
-0.064 |
-4.13 |
Fig. 3 is under the foreman cycle tests, adopts the performance schematic diagram relatively of the accuracy of the most possible predictive mode that calculates in the accuracy of the most possible predictive mode that the inventive method calculates and the coding standard H.264/AVC.As shown in Figure 3, under two kinds of typical QP values, with respect to coding standard H.264/AVC, prediction mode accuracy of the present invention is significantly improved.
Fig. 4 is under the foreman cycle tests, encode again after adopting method of the present invention to predict with coding standard H.264/AVC in the performance schematic diagram relatively of coded prediction pattern.As seen from Figure 4, utilize method of the present invention, under identical code check, make whole coding efficiency be significantly improved.
Being preferred embodiment of the present invention only below, is not to be used to limit protection scope of the present invention.Within the spirit and principles in the present invention all, any modification of being done, be equal to replacement, improvement etc., all should be included within protection scope of the present invention.