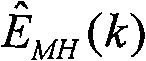Summary of the invention
In order to overcome deficiency of the prior art, the object of the present invention is to provide a kind of efficient configurable frequency domain parameter stereo and multichannel decoding method and system, provide consistent encoding and decoding framework to make too complicated problems of encoding and decoding structure to solve owing to resampling in time domain.
A further object of the present invention is to provide a kind of efficient configurable frequency domain parameter stereo and multichannel decoding method and system, be characterized in to control flexibly according to coding bit rate for the low frequency bandwidth that adopts precision encoding, such as when available coding bit rate is higher, can enlarge the scope of low frequency, otherwise then reduce the scope of low frequency.The consistance that keeps the codec framework simultaneously.
The 3rd purpose of the present invention is to provide a kind of efficient configurable frequency domain parameter stereo and multichannel decoding method and system, be characterized in that HFS carries out gain control and carries out in frequency domain, so improved frequency resolution, the quality of HFS be improved.
The 4th purpose of the present invention is to provide a kind of efficient configurable frequency domain parameter stereo and multichannel decoding method and system, be characterized in according to signal characteristic, the temporal resolution of signal and frequency resolution are simultaneously adjustable, thereby take the signal processing method of suitable current demand signal, make signal quality obtain enhancing.
For finishing the foregoing invention purpose, the invention provides the stereo and multi-channel encoder method of a kind of efficient configurable frequency domain parameter, this method may further comprise the steps:
1) left and right sound track signals is converted to and differ from sound channel signal;
2) will encode with the monophonic audio scrambler with sound channel signal;
3) will carry out forecast analysis with the difference sound channel signal, obtain and differ from the residual signals and the forecast analysis filter coefficient of sound channel; This step can be omitted in some specific embodiment, should look this step this moment and be equivalent to straight-throughly, sets forth for ease of unified, still claims to be output as and to differ under the pass-through state residual signals of sound channel;
4) with difference sound channel residual signals being estimated according to signal type with the sound channel residual signals, the poor sound channel residual signals that obtains estimating, the time quantum that signal is estimated is determined according to signal type, adopts long frame when steady-state signal, and the subframe that then will long frame when transient signal be divided into a plurality of weak points is carried out;
5), and extract radio-frequency component respectively and differ from sound channel residual signals low-frequency component respectively to the poor sound channel residual signals estimated, original poor sound channel residual signals with original carry out time-frequency conversion with the sound channel residual signals; The length of this time-frequency conversion also can change according to signal type;
6) low-frequency component in the original poor sound channel residual signals is carried out quantization encoding;
7) the poor sound channel residual error radio-frequency component of utilize estimating, original poor sound channel residual error radio-frequency component and original carry out gain control with sound channel residual error radio-frequency component are obtained gain coefficient and are quantized; This gain coefficient can for the gain coefficient of difference sound channel form, also can be the gain coefficient of other sound channel forms;
8) data after will encoding and side information carry out multiplexingly, obtain the stereo bit stream of frequency domain parameter.
For finishing the foregoing invention purpose, the present invention also provides a kind of efficient configurable frequency domain parameter stereo and multi-channel decoding method, and this method may further comprise the steps:
1) obtain decoded and sound channel to decoding with the sound channel coded message;
2) the stereo bit stream of frequency domain parameter is carried out demultiplexing, all side informations that obtain difference sound channel residual error low frequency coded data, gain coefficient coded data, signal estimator coefficient and decode used;
3) decoded and sound channel are carried out predictive filtering, obtain residual signals with sound channel; Corresponding to the forecast analysis step of coding side, this step can be omitted in certain embodiments, should look this step this moment and be equivalent to straight-throughly, sets forth for ease of unified, still claims to be output as under the pass-through state residual signals with sound channel;
4) utilize and the residual signals of sound channel and signal estimation weights that demultiplexing obtains are estimated the poor sound channel residual signals that obtains estimating;
5) the poor sound channel residual signals of estimating is carried out the poor sound channel residual error spectral coefficient that time-frequency conversion obtains estimating, and extract radio-frequency component;
6) obtain and sound channel residual error spectral coefficient carrying out time-frequency conversion, and extract low-frequency component and radio-frequency component with the sound channel residual signals with the sound channel residual signals;
7) the poor sound channel residual error radio-frequency component that utilizes decoded gain coefficient, estimation with and the radio-frequency component of sound channel residual error carry out gain control, obtain the frequency domain residual error signal radio-frequency component that needs.According to the difference of coding side gain coefficient expression-form, this frequency domain residual error signal radio-frequency component can for the difference sound channel the frequency-domain residual radio-frequency component, also can be the frequency-domain residual radio-frequency component of other sound channel forms;
8) difference sound channel residual error low frequency coded data is carried out the low-frequency component that the re-quantization decoding obtains difference sound channel residual error, and be transformed into the low-frequency component with the frequency domain residual error signal of the corresponding sound channel form of previous step;
Conversion when 9) radio-frequency component of the low-frequency component of frequency domain residual error signal and frequency domain residual error signal being combined laggard line frequency obtains the time domain residual signals;
10) the time domain residual signals is carried out synthetic filtering and obtain the time domain composite signal; Corresponding to the forecast analysis step of coding side, this step can be omitted in certain embodiments, should look this step this moment and be equivalent to straight-throughly, sets forth for ease of unified, still claims to be output as under the pass-through state time domain composite signal;
11) form module by left and right acoustic channels at last the time domain composite signal is transformed into required left and right sound track signals.
For finishing the foregoing invention purpose, the invention provides the stereo and multi-channel encoder system of following efficient configurable frequency domain parameter.
Stereo and the multi-channel encoder system of efficient configurable frequency domain parameter of the present invention, comprise and differ from sound channel forming module, forecast analysis module, audio coder module, signal estimation module, first, second and the 3rd time-frequency conversion module, signal type analysis module, first, second and the 3rd high frequency extraction module, low frequency extraction module, quantization encoding module, gain control module, gain quantization module and the first and second code stream multiplex modules, it is characterized in that:
Described and poor sound channel forms module, be used for will input the left and right sound channels conversion of signals become and, the difference sound channel signal, output to the forecast analysis module;
Described forecast analysis module is used for and will carries out the residual signals that predictive filtering obtained and differed from sound channel with the output signal of difference sound channel formation module; Described linear prediction analysis module also produces the spectral line frequency vector quantization index, and outputs to the second code stream multiplex module as side information; This module can be omitted in some specific embodiment, should look this module this moment and be equivalent to straight-throughly, sets forth for ease of unified, still claims to be output as and to differ under the pass-through state residual signals of sound channel;
Described audio coder module, will encode with sound channel signal forms and the sound channel encoding code stream outputs to the first code stream multiplex module; The present invention is not limited to a certain special audio scrambler, and it can be any in the existing audio coder, as mp3, AAC, AMR-WB+, WMA, EAAC+ etc.;
The described first code stream multiplex module, will with the multiplexing audio coding bit stream that becomes of sound channel encoding code stream;
Described signal type analysis module, be used for the poor sound channel residual signals of input is carried out type analysis, determine that this frame signal type is to become type or gradual type soon, the signal type information one tunnel that obtains outputs to signal estimation module, one the tunnel outputs to first, second and the 3rd time-frequency conversion module, and another road outputs to the second code stream multiplex module;
Described signal estimation module, with the removing to estimate the poor sound channel residual signals that the poor sound channel residual signals imported obtains estimating and output to the second time-frequency conversion module with the sound channel residual signals of input, and the vector quantization index of generation signal estimation weights outputs to the second code stream multiplex module as side information according to signal type; The time quantum that signal is estimated is determined according to signal type, adopts long frame when steady-state signal, and the subframe that then will long frame when transient signal be divided into a plurality of weak points is carried out;
The described first time-frequency conversion module, using long frame or carry out time-frequency conversion than short subframe with the sound channel residual signals of signal estimation module being exported according to the signal type information of input obtains frequency-region signal;
The described second time-frequency conversion module is used long frame or carries out time-frequency conversion than the subframe of weak point the poor sound channel residual signals of the estimation of signal estimation module output according to the signal type information of input to obtain frequency-region signal;
Described the 3rd time-frequency conversion module is used long frame or carries out time-frequency conversion than the subframe of weak point the poor sound channel residual signals of signal estimation module output according to the signal type information of input to obtain frequency-region signal;
The described first high frequency extraction module extracts the radio-frequency component of this frequency-region signal from the frequency-region signal of first time-frequency conversion module output;
The described second high frequency extraction module extracts the radio-frequency component of this frequency-region signal from the frequency-region signal of second time-frequency conversion module output;
Described the 3rd high frequency extraction module extracts the radio-frequency component of this frequency-region signal from the frequency-region signal of the 3rd time-frequency conversion module output;
Described low frequency extraction module, from the poor sound channel residual error frequency-region signal of the 3rd time-frequency conversion module output, extract the low-frequency component of this frequency-region signal, the division that this low frequency extracts bandwidth allows dynamically to adjust according to contractive condition under same encoding and decoding framework, carries out seamless switching;
Described quantization encoding module, the low-frequency component that the low frequency extraction module is exported carries out quantization encoding, and exports to the second code stream multiplex module;
Described gain control module is carried out gain control according to the radio-frequency component of first, second, third high frequency extraction module output and is obtained gain coefficient, and outputs to the gain quantization module; This gain coefficient can for the gain coefficient of difference sound channel, also can be converted to the gain coefficient of other sound channel forms;
Described gain quantization module is carried out the gain coefficient of importing quantization encoding and quantization encoding information is outputed to the second code stream multiplex module;
The described second code stream multiplex module, the side information of the signal type information of the quantization encoding information of quantization encoding module and gain quantization module output, the output of signal type analysis module and forecast analysis module and signal estimation module output is carried out multiplexing, form the stereo bit stream of frequency domain parameter.
For finishing the foregoing invention purpose, the present invention also provides the following stereo and multi-channel decoding system of efficient configurable frequency domain parameter.
Stereo and the multi-channel decoding system of efficient configurable frequency domain parameter of the present invention, comprise the first and second code stream demultiplexing module, audio decoder module, predictive filtering module, signal estimation module, the first and second time-frequency conversion modules, low frequency extraction module, the first and second high frequency extraction modules, gain re-quantization decoder module, gain control module, low frequency re-quantization decoder module, low high frequency composite module, frequency-time domain transformation module, predict that comprehensive module, left and right acoustic channels form module, is characterized in that:
The described first code stream demultiplexing module is carried out demultiplexing to the audio coding bit stream of importing, and outputs to audio decoder;
Described audio decoder produces decoded and sound channel signal, outputs to the predictive filtering module;
The described second code stream demultiplexing module, the stereo bit stream of frequency domain parameter is carried out demultiplexing, the spectral line frequency vector quantization index that produces outputs to predictive filtering module and the comprehensive module of prediction, the signal that produces estimates that the vector quantization index of weights outputs to signal estimation module, the signal type information that produces outputs to the first and second time-frequency conversion modules, signal estimation module and frequency-time domain transformation module, the gain coefficient of the quantization encoding that produces outputs to gain re-quantization decoder module, and the frequency domain low-frequency component behind the quantization encoding of generation outputs to low frequency re-quantization decoder module;
Described predictive filtering module, carrying out filtering with sound channel signal and obtain and the sound channel residual signals audio decoder output; This module can not realize in some specific embodiment, should look this module this moment and be equivalent to straight-throughly, sets forth for ease of unified, still claims to be output as under the pass-through state and the sound channel residual signals;
Described signal estimation module, utilization estimates that as the signal of side information the vector quantization index of weights constitutes signal estimator, and predictive filtering module output estimated the poor sound channel residual signals that obtains estimating to output to the second time-frequency conversion module with the sound channel residual signals according to signal type; Another road and sound channel residual signals output to the first time-frequency conversion module;
The described first time-frequency conversion module to the carrying out time-frequency conversion with the sound channel residual signals and obtain and sound channel residual error frequency-region signal of input, and outputs to the first high frequency extraction module and low frequency extraction module according to signal type information;
The described second time-frequency conversion module is carried out the poor sound channel residual error frequency-region signal that time-frequency conversion obtains estimating according to signal type information to the poor sound channel residual signals of estimation of input, and is outputed to the second high frequency extraction module;
Described low frequency extraction module, the low-frequency component of extraction and sound channel residual error frequency-region signal, and output to low high frequency composite module;
The described first high frequency extraction module, the radio-frequency component of extraction and sound channel residual error frequency-region signal, and output to gain control module;
The described second high frequency extraction module extracts the radio-frequency component of the poor sound channel residual error frequency-region signal of estimating, and outputs to gain control module;
Described low frequency re-quantization decoder module carries out the re-quantization decoding to the poor sound channel residual error frequency domain low-frequency component behind the quantization encoding of input, obtains difference sound channel residual error frequency domain low-frequency component, and outputs to low high frequency composite module;
Described gain re-quantization decoder module, the gain coefficient of the quantization encoding of utilization input obtains the gain coefficient behind the re-quantization and outputs to gain control module;
Described gain control module, the gain coefficient that utilizes re-quantization carries out frequency domain residual error signal radio-frequency component after gain control obtains gain control to the poor sound channel residual error frequency domain radio-frequency component estimated and sound channel residual error frequency domain radio-frequency component, and outputs to and hang down the high frequency composite module.According to the difference of coding side gain coefficient expression-form, this frequency domain residual error signal radio-frequency component can for the difference sound channel the frequency-domain residual radio-frequency component, also can be the frequency-domain residual radio-frequency component of other sound channel forms;
Described low high frequency composite module is combined into complete frequency domain residual error signal with the poor sound channel residual error frequency domain low-frequency component of input and the frequency domain residual error signal radio-frequency component of sound channel residual error frequency domain low-frequency component and gain control module output, outputs to the frequency-time domain transformation module.Accordingly, this frequency domain residual error signal can for the difference sound channel frequency domain residual error signal, also can be the frequency domain residual error signal of other sound channel forms;
Described frequency-time domain transformation module is carried out frequency-time domain transformation with the frequency domain residual error signal of low high frequency composite module output, obtains the time domain residual signals, outputs to the comprehensive module of prediction;
The comprehensive module of described prediction is utilized the spectral line frequency vector quantization index formation composite filter of input and the time domain residual signals of importing is carried out synthetic filtering to obtain the time domain composite signal, outputs to left and right acoustic channels and forms module; This module can not realize in some specific embodiment, should look this module this moment and be equivalent to straight-throughly, sets forth for ease of unified, still claims to be output as under the pass-through state time domain composite signal;
Described left and right acoustic channels forms module, corresponding to coding side form module with the difference sound channel, time domain composite signal that will the comprehensive module output of prediction forms the time-domain signal of left and right acoustic channels through conversion.
The present invention has the beneficial effect that significantly is better than prior art.Carry out signal Processing with prior art in time domain and compare, signal Processing of the present invention is to carry out at frequency domain.At first, provide consistent encoding and decoding framework to make too complicated problems of encoding and decoding structure to solve owing to resampling in time domain; Secondly, can control flexibly according to coding bit rate for the low frequency bandwidth that adopts precision encoding,, can enlarge the scope of low frequency such as when available coding bit rate is higher, otherwise then reduce the scope of low frequency, keep the consistance of codec framework simultaneously; Once more, the gain control of HFS is to carry out in frequency domain, so improved frequency resolution, the quality of HFS is improved; At last, allow simultaneously time domain resolution and frequency domain resolution to be adjusted, take the signal processing mode of the most suitable current demand signal characteristic, improved signal compression efficiency according to characteristics of signals.
Embodiment
Describe the specific embodiment of the present invention in detail below in conjunction with Figure of description.
Fig. 1 is the theory diagram of coded system of the present invention, and Fig. 2 is the theory diagram of decode system of the present invention.The module that wherein dots can be equivalent to straight-through module in some specific embodiment, i.e. the input of this module directly outputs in the next module as output signal.
Fig. 1 is according to the stereo and multi-channel encoder system principle diagram of efficient configurable frequency domain parameter of the present invention, as shown in Figure 1, coded system of the present invention comprises and differs from sound channel and forms module 200, forecast analysis module 201, audio coder module 203, signal estimation module 204, first, the second and the 3rd time-frequency conversion module 205,206,207, signal type analysis module 208, first, the second and the 3rd high frequency extraction module 213,209,210, low frequency extraction module 211, quantization encoding module 212, gain control module 215, the gain quantization module 216 and the first and second code stream multiplex modules 214,217.Wherein and the difference sound channel form module 200, be used for will input the left and right sound channels conversion of signals become and, the difference sound channel signal, output to the forecast analysis module.Forecast analysis module 201 will be carried out the residual signals that predictive filtering obtained and differed from sound channel with the output signal of difference sound channel formation module.The linear prediction analysis module also produces the spectral line frequency vector quantization index, and outputs to the second code stream multiplex module as side information.This module can be omitted in some specific embodiment, should look this module this moment and be equivalent to straight-throughly, sets forth for ease of unified, still claims to be output as and to differ under the pass-through state residual signals of sound channel.Audio coder module 203, will encode with sound channel signal forms and the sound channel encoding code stream outputs to the first code stream multiplex module.The present invention is not limited to a certain special audio scrambler, and it can be any in the existing audio coder, as mp3, AAC, AMR-WB+, WMA, EAAC+ etc.The first code stream multiplex module 214, will with the multiplexing audio coding bit stream that becomes of sound channel encoding code stream.Signal type analysis module 208, be used for the poor sound channel residual signals of input is carried out type analysis, determine that this frame signal type is to become type or gradual type soon, the signal type information one tunnel that obtains outputs to signal estimation module, one the tunnel outputs to first, second and the 3rd time-frequency conversion module, and another road outputs to the second code stream multiplex module.Signal estimation module 204, with the removing to estimate the poor sound channel residual signals that the poor sound channel residual signals imported obtains estimating and output to the second time-frequency conversion module with the sound channel residual signals of input, and the vector quantization index of generation signal estimation weights outputs to the second code stream multiplex module as side information according to signal type.The time quantum that signal is estimated is determined according to signal type, adopts long frame when steady-state signal, and the subframe that then will long frame when transient signal be divided into a plurality of weak points is carried out.The first time-frequency conversion module 205, using long frame or carry out time-frequency conversion than short subframe with the sound channel residual signals of signal estimation module being exported according to the signal type information of input obtains frequency-region signal.The second time-frequency conversion module 206 is used long frame or carries out time-frequency conversion than the subframe of weak point the poor sound channel residual signals of the estimation of signal estimation module output according to the signal type information of input to obtain frequency-region signal.The 3rd time-frequency conversion module 207 is used long frame or carries out time-frequency conversion than the subframe of weak point the poor sound channel residual signals of signal estimation module output according to the signal type information of input to obtain frequency-region signal.The first high frequency extraction module 213 extracts the radio-frequency component of this frequency-region signal from the frequency-region signal of first time-frequency conversion module output.The second high frequency extraction module 209 extracts the radio-frequency component of this frequency-region signal from the frequency-region signal of second time-frequency conversion module output.The 3rd high frequency extraction module 210 extracts the radio-frequency component of this frequency-region signal from the frequency-region signal of the 3rd time-frequency conversion module output.Low frequency extraction module 211, from the poor sound channel residual error frequency-region signal of the 3rd time-frequency conversion module output, extract the low-frequency component of this frequency-region signal, the division that this low frequency extracts bandwidth allows dynamically to adjust according to contractive condition under same encoding and decoding framework, carries out seamless switching.Quantization encoding module 212, the low-frequency component that the low frequency extraction module is exported carries out quantization encoding, and exports to the second code stream multiplex module.Gain control module 215, carry out gain control according to the radio-frequency component of first, second, third high frequency extraction module output and obtain gain coefficient, and output to the gain quantization module, this gain coefficient can for the gain coefficient of difference sound channel, also can be converted to the gain coefficient of other sound channel forms.Gain quantization module 216 is carried out the gain coefficient of importing quantization encoding and quantization encoding information is outputed to the second code stream multiplex module.The second code stream multiplex module 217, the side information of the signal type information of the quantization encoding information of quantization encoding module and gain quantization module output, the output of signal type analysis module and forecast analysis module and signal estimation module output is carried out multiplexing, form the stereo bit stream of frequency domain parameter.
Fig. 2 is according to the stereo and multi-channel decoding system principle diagram of efficient configurable frequency domain parameter of the present invention.As shown in Figure 2, decode system of the present invention comprises: the first and second code stream demultiplexing module 301,300, audio decoder module 302, predictive filtering module 303, signal estimation module 304, the first and second time-frequency conversion modules 307,306, low frequency extraction module 305, the first and second high frequency extraction modules 309,308, gain re-quantization decoder module 311, gain control module 310, low frequency re-quantization decoder module 312, low high frequency composite module 313, frequency-time domain transformation module 314, the comprehensive module 315 of prediction, left and right acoustic channels form module 316.The first code stream demultiplexing module 301 is carried out demultiplexing to the audio coding bit stream of importing, and outputs to audio decoder.Audio decoder 302 produces decoded and sound channel signal, outputs to the predictive filtering module.The second code stream demultiplexing module 300, the stereo bit stream of frequency domain parameter is carried out demultiplexing, the spectral line frequency vector quantization index that produces outputs to predictive filtering module and the comprehensive module of prediction, the signal that produces estimates that the vector quantization index of weights outputs to signal estimation module, the signal type information that produces outputs to the first and second time-frequency conversion modules, signal estimation module and frequency-time domain transformation module, the gain coefficient of the quantization encoding that produces outputs to gain re-quantization decoder module, and the frequency domain low-frequency component behind the quantization encoding of generation outputs to low frequency re-quantization decoder module.Predictive filtering module 303, carrying out filtering with sound channel signal and obtain and the sound channel residual signals audio decoder output; This module can not realize in some specific embodiment, should look this module this moment and be equivalent to straight-throughly, sets forth for ease of unified, still claims to be output as under the pass-through state and the sound channel residual signals.Signal estimation module 304, utilization estimates that as the signal of side information the vector quantization index of weights constitutes signal estimator, and predictive filtering module output estimated the poor sound channel residual signals that obtains estimating to output to the second time-frequency conversion module with the sound channel residual signals according to signal type; Another road and sound channel residual signals output to the first time-frequency conversion module.The first time-frequency conversion module 307 to the carrying out time-frequency conversion with the sound channel residual signals and obtain and sound channel residual error frequency-region signal of input, and outputs to the first high frequency extraction module and low frequency extraction module according to signal type information.The second time-frequency conversion module 306 is carried out the poor sound channel residual error frequency-region signal that time-frequency conversion obtains estimating according to signal type information to the poor sound channel residual signals of estimation of input, and is outputed to the second high frequency extraction module.Low frequency extraction module 305, the low-frequency component of extraction and sound channel residual error frequency-region signal, and output to low high frequency composite module.The first high frequency extraction module 309, the radio-frequency component of extraction and sound channel residual error frequency-region signal, and output to gain control module.The second high frequency extraction module 308 extracts the radio-frequency component of the poor sound channel residual error frequency-region signal of estimating, and outputs to gain control module.Low frequency re-quantization decoder module 312 carries out the re-quantization decoding to the poor sound channel residual error frequency domain low-frequency component behind the quantization encoding of input, obtains difference sound channel residual error frequency domain low-frequency component, and outputs to low high frequency composite module.Gain re-quantization decoder module 311, the gain coefficient of the quantization encoding of utilization input obtains the gain coefficient behind the re-quantization and outputs to gain control module.Gain control module 310, the gain coefficient that utilizes re-quantization carries out frequency domain residual error signal radio-frequency component after gain control obtains gain control to the poor sound channel residual error frequency domain radio-frequency component estimated and sound channel residual error frequency domain radio-frequency component, and outputs to and hang down the high frequency composite module.According to the difference of coding side gain coefficient expression-form, this frequency domain residual error signal radio-frequency component can for the difference sound channel the frequency-domain residual radio-frequency component, also can be the frequency-domain residual radio-frequency component of other sound channel forms.Low high frequency composite module 313 is combined into complete frequency domain residual error signal with the poor sound channel residual error frequency domain low-frequency component of input and the frequency domain residual error signal radio-frequency component of sound channel residual error frequency domain low-frequency component and gain control module output, outputs to the frequency-time domain transformation module.Accordingly, this frequency domain residual error signal can for the difference sound channel frequency domain residual error signal, also can be the frequency domain residual error signal of other sound channel forms.Frequency-time domain transformation module 314 is carried out frequency-time domain transformation with the frequency domain residual error signal of low high frequency composite module output, obtains the time domain residual signals, outputs to the comprehensive module of prediction.Predict comprehensive module 315, utilize the spectral line frequency vector quantization index formation composite filter of input and the time domain residual signals of importing is carried out synthetic filtering to obtain the time domain composite signal, output to left and right acoustic channels and form module; This module can not realize in some specific embodiment, should look this module this moment and be equivalent to straight-throughly, sets forth for ease of unified, still claims to be output as under the pass-through state time domain composite signal.Left and right acoustic channels forms module 316, corresponding to coding side form module with the difference sound channel, time domain composite signal that will the comprehensive module output of prediction forms the time-domain signal of left and right acoustic channels through conversion.
Fig. 3 is the coded system block diagram of the first embodiment of the present invention.This coded system is to realize in the residual error territory, therefore need forecast analysis module 201, and the forecast analysis module is again by forming with sound channel forecast analysis module 2012, R channel predictive filtering module 2011 and a subtracter 2013.Simultaneously gain control module 215 is made up of gain controller 2150, two totalizers 2151 and 2153, two subtracters 2152 and 2154 again.Therefore the coded system of first embodiment of the invention comprises and differ from sound channel and forms module 200, harmony road linearity forecast analysis module 2012, R channel linear prediction filtration module 2011, audio coder module 203, signal estimation module 204, signal type analysis module 208, signal estimation module 204,205,206, high frequency extraction module 209,210,213, difference sound channel low frequency extraction module 211, quantization encoding module 212, gain control module 215, gain quantization module 216, code stream multiplex module 217,214.
Form module 200 with the difference sound channel, with the left channel signals x of input
L(n) and right-channel signals x
R(n) convert to and sound channel signal x
M(n), its conversion formula as the formula (1).
x
M(n)=0.5·(x
L(n)+x
R(n)) (1)
The linear forecast analysis module 2012 in harmony road, will with the difference sound channel form module 200 outputs carry out forecast analysis with sound channel signal and filtering obtains and sound channel residual signals e
M(n), this module can effectively be eliminated particularly voice signal redundance in time of sound signal, thereby has improved code efficiency.
R channel linear prediction filtration module 2011 will utilize the wave filter by constituting with the sound channel predictive coefficient of module 2012 outputs to carry out filtering with the right-channel signals that the difference sound channel forms module 200 outputs and obtain the R channel residual signals.And, will deduct the R channel residual signals with the sound channel residual signals and obtain difference sound channel residual signals e by subtracter 2013
S(n).
Audio coder module 203 is to signal x
M(n) encode, form specific encoding code stream.The present invention is not limited to a certain special audio scrambler, and it can be any in the existing audio coder, as mp3, AAC, AMR-WB+, WMA, EAAC+ etc.
Signal type analysis module 208 is to signal e
S(n) carry out the signal type analysis, determine that this frame signal type is tempolabile signal or fast changed signal.If be the fast type signal that becomes, in order to control pre-echo (pre-echo), it is that unit carries out signal estimation and time-frequency conversion that signal estimation module and time-frequency conversion module all adopt subframe; Otherwise in order to improve coding gain, it is that unit carries out signal estimation and time-frequency conversion that signal estimation module and time-frequency conversion module all adopt a frame.The result one tunnel of signal type analysis outputs in time-frequency conversion module 207,206 and 205 time-frequency conversion is controlled, and one the tunnel outputs to signal estimation module 204 controls, and another road outputs in the code stream multiplex module 217.
Signal estimation module 204 is used signal e
M(n) remove estimated signal e according to signal type
S(n) obtain the poor sound channel residual signals estimated
Signal estimates at several different methods, as least-squares estimation, and Wei Na estimation and Kalman's estimation etc.The time quantum that signal is estimated is determined according to signal type, when steady-state signal, adopt long frame, the subframe that then will long frame when transient signal be divided into a plurality of weak points is carried out, and can take only signal estimated length at the current demand signal type like this, improves compression efficiency.
Time-frequency conversion module 205 is with signal e
M(n) transform to frequency domain (when adopting conversion) or subband domain (when adopting bank of filters) according to signal type, obtain difference sound channel residual error frequency domain or subband domain signal E
M(k).Conversion has several different methods such as discrete Fourier transform (DFT) (DFT), discrete cosine transform (DCT), revises discrete cosine transform (MDCT), wavelet transformation etc.The length of signal transformation is determined according to signal type, adopts long frame when steady-state signal, and the subframe that then will long frame when transient signal be divided into a plurality of weak points is carried out, and helps improving signal compression efficiency like this.
Similarly, time-
frequency conversion module 206 is with signal
Transform to frequency domain and obtain signal
Similarly, time-frequency conversion module 207 is with signal e
S(n) transform to frequency domain and obtain signal E
S(k).
High
frequency extraction module 209 is from the frequency-region signal of the poor sound channel residual error of the estimation of time-
frequency conversion module 206 output
In extract radio-frequency component
High frequency extraction module 210 is from the frequency-region signal E of the poor sound channel residual error of time-frequency conversion module 207 output
S(k) extract radio-frequency component E in
SH(k).
High frequency extraction module 213, from time-frequency conversion module 205 output with the frequency-region signal E sound channel residual error
M(k) extract radio-frequency component E
MH(k).
Difference sound channel low frequency extraction module 211 is from the frequency-region signal E of the poor sound channel residual error of time-frequency conversion module 207 outputs
S(k) extract low-frequency component in.
Quantization encoding module 212, with 211 outputs of difference sound channel low frequency extraction module low-frequency component carry out quantization encoding.Quantization encoding can add the scheme of entropy coding for scalar quantization, also can be the vector quantization scheme.In Low Bit-rate Coding, vector quantization is a rational selection scheme.
Gain control module 215 is according to the E of input
LH(k) to estimating
In
gain controller 2150, carry out gain control, obtain gain coefficient g
LE according to input
RH(k) to estimating
In
gain controller 2150, carry out gain control, obtain gain coefficient g
RThe g that obtains
L, g
ROutput in the gain quantization module 216.E wherein
LH(k) be to utilize
totalizer 2153 with E
SH(k) and E
MH(k) obtain E after the addition
RH(k) be to utilize
subtracter 2154 with E
SH(k) and E
MH(k) obtain after subtracting each other.
Be to utilize
totalizer 2151 to incite somebody to action
And E
MH(k) obtain after the addition,
Be to utilize
subtracter 2152 to incite somebody to action
And E
MH(k) obtain after subtracting each other.
Gain quantization module 216 is with the g of input
L, g
RCarry out quantization encoding and quantization encoding information is outputed in the code stream multiplex module 217.
Code stream multiplex module 217 receives the coded data of above-mentioned module output and side information and carries out multiplexingly, forms the stereo bit stream of frequency domain parameter.
Code stream multiplex module 214 is with the encoding code stream formation audio coding bit stream of audio coder module 203 outputs.
Fig. 5 is a linear prediction analysis module diagram of the present invention.With reference to figure 5, linear
prediction analysis module 201 is made of linear
prediction analysis device 501, converter 502,
vector quantizer 503,
inverse converter 504 and linear prediction filter 505.At first by the signal x of 501 pairs of inputs of linear prediction analysis device
M(n) carry out linear prediction analysis, obtain predictive coefficient A
M(z), then by converter 502 with A
M(z) convert line spectral frequencies LSF to, again the LSF parameter is sent into the index that carries out vector quantization in the
vector quantizer 503 and obtain vector quantization, the line spectral frequencies after obtaining quantizing according to the index of vector quantization
With what obtain
Process
inverse converter 504 is obtained the predictive coefficient after the quantification
And with the predictive coefficient formation linear prediction filter after quantizing, at last to signal x
M(n) carry out filtering with this linear prediction filter, obtain signal e
M(n).Wherein the index of the vector quantization of line spectral frequencies outputs in the code
stream multiplex module 217 as side information.
Fig. 6 is a coding side signal estimation module pie graph of the present invention, and with reference to figure 6, signal estimation module 204 is by estimating that analyzer 601, vector quantizer 602 and signal estimator 603 constitute.Estimation analyzer 601 is used signal e with certain criterion (such as the square error minimum criteria)
M(n) remove estimated signal e
S(n), obtain one group of weight w that satisfies condition
i, i=0 wherein ..., M and M 〉=0, M is for estimating the exponent number of analyzer.This group weight w that obtains
iBe input in the vector quantizer 602 index that weights is carried out vector quantization and obtain vector quantization, the weights after obtaining quantizing according to the index of vector quantization also are input in the signal estimator 603 signal e
M(n) being input to signal estimator 603 obtains
The signal that wherein obtains estimates that the weighted vector quantization index also outputs in the code stream multiplex module 217 as side information.
The dimension that Fig. 7 adopts for signal estimator among Fig. 6 603 is received the estimator synoptic diagram.With reference to figure 7, according to the signal e of input
M(n) and its 1 to M rank postpone, wherein M receives the exponent number of estimator for dimension, removes estimated signal e
S(n).
Estimate among Fig. 6 that analyzer 601 is used for determining weights { w
k, k=0 ..., M}, these weights make the estimated error mean squares value minimum of signal estimator 603.Optimum weights can be obtained by the wiener-Hopf equation (2) of separating the M order estimator,
(2)
Wherein
R
MM(k-i)=E[e
M(n-i)·e
M(n-k)]
(3)
r
MS(-i)=E[e
M(n-i)·e
S(n)]
(4)
Signal estimator shown in Figure 7 is to signal e
S(n) estimate the poor sound channel residual signals that obtains estimating
As the formula (5).
Fig. 8 is that time-frequency conversion window of the present invention switches synoptic diagram.With reference to figure 8, at first choose the time-domain signal x (n) of M+N sample from the reference position of present frame, wherein M is a current frame data length, and N is the overlapping length of next frame, and the length of M and N is determined by the signal type of present frame.When signal type was tempolabile signal, M and N selected long exponent number to improve coding gain, adopt M=1024 in the present embodiment, N=128; When signal type was fast changed signal, M and N selected short exponent number with the control pre-echo, adopt M=256 in the present embodiment, N=32.Again the time-domain signal of M+N sample is carried out the windowing operation, obtain the signal x after the windowing
w(n)=w (n) x (n).Wherein w (n) is a window function, can use any window function that satisfies the complete reconstruction condition of signal in realization, for example can adopt Cosine Window:
Wherein N0 is the overlapping length of present frame, is determined by the signal type of previous frame.Then the signal after the process windowing is carried out the DFT conversion, thereby obtains M+N frequency coefficient,
k∈[0,M+N-1]
By said method to e
S(n),
And e
M(n) carry out time-frequency conversion respectively and obtain E
S(k),
And E
M(k).The transform method of these time-frequency conversions, window function and exponent number all are consistent.
Figure 12 is the coding method process flow diagram of first embodiment of the invention, hereinafter will coding method is described in detail to frequency domain parameter stereophonic encoder of the present invention with reference to Figure 12.
At first, in step 101, use the method for formula (1) that left and right sound track signals is converted to and sound channel signal.
In step 102, will encode with sound channel signal.The present invention is not limited to a certain special audio coding method, and it can be any in the existing audio coding method, as mp3, AAC, AMR-WB+, WMA, EAAC+ etc.
Secondly,, will carry out linear prediction filtering respectively, obtain residual signals with sound channel with sound channel signal in step 103.In this step, a frame N is ordered with sound channel signal x
M(n) carry out the linear prediction analysis processing of p rank and comprise following steps:
I) calculate present frame time-domain signal x
M(n) coefficient of autocorrelation,
II) utilize the Levinson-Durbin algorithm to obtain predictive coefficient a
k, k ∈ [0, p], and constitute linear prediction filter by predictive coefficient
III) pass through two polynomial expressions
Rooting is with a
kConvert line spectrum pair LSP to
k, and by line spectrum pair LSP
kObtain line spectral frequencies LSF
k IV) line spectral frequencies is carried out vector quantization, the line spectral frequencies after obtaining quantizing
And be converted to line spectrum pair after the quantification
The vector quantization index of line spectral frequencies outputs in the code stream multiplex module as side information, is used for generating composite filter in decoder end.
V) by the line spectrum pair after quantizing
By calculating f
1(z) and f
2(z) obtain filter coefficient after the quantification
And after constitute quantizing and vocal tract filter
VI) with x
M(n) by the wave filter after quantizing calculate after the prediction with the sound channel residual signals
VII) with right-channel signals x
R(n) also by after quantizing and vocal tract filter
R channel residual signals after obtaining predicting
VIII) obtain difference sound channel residual signals e with deducting the R channel residual signals with the sound channel residual signals
S(n)=e
M(n)-e
R(n)
In
step 104, use and sound channel residual signals e
M(n) to difference sound channel residual error sound channel signal e
S(n) estimate the poor sound channel residual signals that obtains estimating
If this frame signal is the fast type signal that becomes, signal estimation module will be grown the subframe that frame signal is divided into a plurality of weak points, then each subframe be carried out signal and estimate; If this frame signal is gradual type signal, signal estimation module is then carried out signal to long frame signal and is estimated.Utilize and the sound channel residual signals carries out estimation approach to difference sound channel residual signals and has multiplely, as least-squares estimation, Wei Na estimates and Kalman's estimation etc.The present invention estimates as a preferred embodiment with Wei Na.
In
step 105, the poor sound channel residual signals to estimating respectively
Original poor sound channel residual signals e
S(n) and original and sound channel residual signals e
M(n) carry out time-frequency conversion, and extract radio-frequency component and difference sound channel low-frequency component respectively.The method of time-frequency conversion has multiple, as discrete Fourier transform (DFT) (DFT), discrete cosine transform (DCT), correction discrete cosine transform (MDCT), wavelet transformation etc.The present invention with discrete Fourier transform (DFT) (DFT) as a preferred embodiment.Wherein the frequency partition of low high frequency allows to determine dynamically to adjust according to the size of coding bit rate, the complexity of current demand signal near the frequency (such as 1kHz) one, for example when coding bit rate is higher, can suitably increase low frequency coding frequency band, otherwise then suitably dwindle.The exponent number of time-frequency conversion is determined according to signal type, if current demand signal is the fast type signal that becomes, then adopts the time-frequency conversion of shorter exponent number; If current demand signal is gradual type signal, then adopt the time-frequency conversion of longer exponent number.
In step 106, the low-frequency component in the original poor sound channel residual signals is carried out quantization encoding.Encoding scheme can add the scheme of entropy coding for scalar quantization, also can be the vector quantization scheme.In Low Bit-rate Coding, vector quantization is a rational selection scheme.The result of quantization encoding outputs in the code stream multiplex module.
In
step 107, utilization is estimated
And E
MH(k) obtain estimation
With
As shown in Equation (6); Utilize original E
MH(k) and E
SH(k) obtain original E
LH(k) and E
RH(k), as shown in Equation (7).
In
step 108, utilize original E
LH(k) and E
RH(k) to estimating
With
Carry out gain control, obtain the gain coefficient g of left and right acoustic channels residual error
LAnd g
RAnd quantize.It can be that unit carries out with critical bandwidth (critical bandwidth) that the left and right acoustic channels residual signals of estimating is carried out gain control, only need the subband in the left and right acoustic channels residual error radio-frequency component of estimating is carried out gain control, like this, the left and right sides residual error channel gain g of each subband b
L[b] and g
R[b] by formula (8) and (9) calculates:
Wherein * is representing complex conjugate, k
bInitial spectral line for critical subband b.
Certainly gain control can be that unit carries out with the scale factor band (scalefactor band) that MPEG was adopted also; For simply, the spectral line number that each subband is comprised is all identical.
The gain coefficient of the left and right residual error sound channel that will calculate then quantizes, and quantification can adopt scalar quantization also can adopt vector quantization, at last quantitative information is outputed in the code stream multiplex module.
In step 109, carry out data behind the coding and side information multiplexing, obtain the stereo bit stream of frequency domain parameter.
Fig. 4 is the decode system block diagram of first embodiment of the invention.This decode system is corresponding with Fig. 3 coded system, therefore also realizes in the residual error territory, need linear prediction filtration module 303, and gain control module 310 is made up of gain controller 3100, totalizer 3101 and subtracter 3102; Low high frequency composite module 313 is made up of totalizer 3130 and subtracter 3131; Frequency-time domain transformation 314 is made up of L channel frequency-time domain transformation 3140 and R channel frequency-time domain transformation 3141; The comprehensive module 315 of linear prediction is made up of comprehensive module 3150 of L channel linear prediction and the comprehensive module 3151 of R channel linear prediction.Therefore the decode system of first embodiment of the invention comprises code stream demultiplexing module 300,301, audio decoder 302, linear prediction filtration module 303, signal estimation module 304, time-frequency conversion module 306,307, high frequency extraction module 308,309, gain re-quantization decoder module 311, gain control module 310, difference sound channel low frequency re-quantization decoder module 312, low frequency extraction module 305, low high frequency composite module 313, frequency-time domain transformation module 314, the comprehensive module 315 of linear prediction.
Code stream demultiplexing module 300 is carried out demultiplexing to the stereo bit stream of frequency domain parameter, obtains respective coding data and side information and correspondence and outputs in each module, so that corresponding data and decoded information to be provided.The side information that wherein outputs to linear prediction filtration module 303 is a harmony road line spectral frequencies vector quantization index; What output to signal estimation module 304 is vector quantization index and the signal type parameter that signal is estimated weights; What output to the comprehensive module 315 of linear prediction is harmony road line spectral frequencies vector quantization index; Output to time- frequency conversion module 306 and 307 and frequency-time domain transformation module 314 be the signal type parameter; What output to gain re-quantization decoder module 311 is gain coefficient behind the quantization encoding; What output to poor sound channel low frequency re-quantization decoder module 312 is the low-frequency data of the poor sound channel residual signals behind the quantization encoding.
Code stream demultiplexing module 301 is carried out demultiplexing and the bit stream of demultiplexing is input in the audio decoder module 302 the audio coding bit stream of input.
Audio decoder 302, utilize the bit stream decoding of input to go out and sound channel signal, this audio decoder is corresponding with the audio coder in the coded system, can be any in the existing audio decoder, as mp3, AAC, AMR-WB+, WMA, EAAC+ etc., obtain decoded and sound channel signal and output in the linear prediction filtration module 303.
Linear
prediction filtration module 303, the harmony road line spectral frequencies that utilizes demultiplexing is to decoded and sound channel signal
Carry out filtering, obtain and the sound channel residual signals
Signal estimation module 304 is right
Estimate to obtain
This 304 module is corresponding with the
signal estimation module 204 of coding side shown in Figure 6, and to adopt dimension shown in Figure 7 to receive estimator as a preferred embodiment.
Time-
frequency conversion module 306, the same with the time-
frequency conversion module 206 of coding side, with signal
Conversion obtains
Time-
frequency conversion module 307, the same with the time-
frequency conversion module 205 of coding side, with signal
Conversion obtains
High
frequency extraction module 309 and high
frequency extraction module 308 extract respectively
With
Radio-frequency component
With
And be input in the
gain control module 310.
Gain re-quantization decoder module 311 is inverse process of coding side gain quantization module 216.Can obtain the left and right residual error channel gain coefficient of one group of de-quantization by this module, and output in the gain control module 310.
Gain control module 310 is made up of
gain controller 3100,
totalizer 3101 and subtracter 3102.Totalizer 3101 will be imported
With
Obtain the L channel residual error radio-frequency component estimated after the
addition
Subtracter 3102 will be imported
With
Obtain the R channel residual error radio-frequency component estimated after subtracting each
other
Gain controller 3100 is right according to the left and right sides residual error channel gain coefficient of input
With
Carry out gain control and obtain the radio-frequency component of left and right sides residual error sound channel
With
And output in the low high frequency
composite module 313.
Difference sound channel low frequency
re-quantization decoder module 312 is inverse process of coding side quantization encoding module 212.Can obtain difference sound channel residual error low-frequency component by this module
And output in the low high frequency
composite module 313.
Low
frequency extraction module 305 extracts
In low frequency
And output in the low high frequency
composite module 313.
Low high frequency
composite module 313 is made up of
totalizer 3130 and subtracter 3131.At
first totalizer 3130 will be imported
With
Obtain L channel residual error low-frequency component after the
addition
Subtracter 3131 will be imported then
With
Obtain R channel residual error low-frequency component after subtracting each other
At last will
With the input
Be combined into L channel residual error full range band spectrum coefficient
Will
With the input
Be combined into R channel residual error full range band spectrum coefficient
And will
With
Output in the frequency-time
domain transformation module 314.
Frequency-time domain transformation module 314 is made up of L channel frequency-time domain transformation module 3140 and R channel frequency-time domain transformation module 3141, is the inverse process of coding side time-frequency conversion module.The frequency coefficient of 3140 pairs of L channel residual errors of module carries out frequency-time domain transformation and obtains the L channel residual signals; The frequency coefficient of 3141 pairs of R channel residual errors of module carries out frequency-time domain transformation and obtains the R channel residual signals.
The comprehensive module 315 of linear prediction is made up of comprehensive module 3150 of L channel linear prediction and the comprehensive module 3151 of R channel linear prediction.Module 3150 and 3151 utilizes spectral line frequency vector quantization index that obtain from side information and sound channel to constitute the prediction synthesizer, with the left and right acoustic channels residual signals by after obtain left and right sound track signals.
Fig. 9 is the pie graph of the linear
prediction filtration module 303 in the decode system shown in Figure 4.With reference to figure 9, linear
prediction filtration module 303 constitutes by separating
vector quantizer 1001,
inverse converter 1002 and linear prediction filter 1003.Separate harmony road line spectral frequencies vector quantization index that
vector quantizer 1001 utilizes input and obtain the line spectral frequencies that quantizes with sound channel by searching code table
Process inverse converter 1002 is obtained the predictive coefficient after the quantification
Linear prediction filter 1003 utilizes
It is right to constitute wave filter
Carry out filtering, obtain
Figure 10 is the pie graph of
signal estimation module 304 in the decode system shown in Figure 4.With reference to Figure 10, signal
estimation module 304 is by separating
vector quantizer 1101 and
signal estimator 1102 constitutes.Separating
vector quantizer 1101 utilizes the signal of importing as side information to estimate that the weighted vector quantization index is by searching the weights after code table obtains quantizing
Weights after
signal estimator 1102 usefulness quantize
Obtain signal estimator, right with this signal estimator
Estimate and to obtain
Figure 11 is the pie graph of the
comprehensive module 3150 of L channel linear prediction of decode system shown in Figure 4.With reference to Figure 11, the
comprehensive module 3150 of L channel linear prediction constitutes by separating
vector quantizer 1201,
inverse converter 1202 and linear prediction compositor 1203.Separate harmony road line spectral frequencies vector quantization index that
vector quantizer 1201 utilizes input and obtain the line spectral frequencies that quantizes with sound channel by searching code table
Obtain
Process
inverse converter 1202 is obtained the predictive coefficient after the quantification
Linear prediction compositor 1203 utilizes
Constitute compositor.Right at last
Synthesize and obtain
Equally, utilize the same compositor right
Synthesize and obtain
Figure 13 is the coding/decoding method process flow diagram of first embodiment of the invention, hereinafter will be described in detail the frequency domain parameter stereophonic encoder coding/decoding method of first embodiment of the invention with reference to Figure 13.
At first, in step 201, obtain decoded and sound channel to decoding with sound channel.The method of decoding is corresponding with coding side.
In step 202, the stereo bit stream of frequency domain parameter is carried out demultiplexing, all side informations that obtain difference sound channel residual error low frequency coded data, gain coefficient coded data and decode used.
Secondly,, decoded and sound channel are carried out linear prediction filtering, obtain residual signals with sound channel in step 203.Described linear prediction filtering comprises following steps:
I) from code stream, read the vector quantization index of harmony road line spectral frequencies, utilize the vector quantization index by searching the line spectral frequencies after corresponding code book obtains quantizing, and be converted to line spectrum pair;
II) pass through to calculate f by the line spectrum pair after quantizing
1(z) and f
2(z) obtain predictive coefficient after the quantification
And the linear prediction filter after the formation quantification
Wherein, p is a prediction order, and identical with coding side;
III) decoded and sound channel is obtained residual signals with sound channel by linear prediction filter:
In
step 204, to estimating the poor sound channel residual signals that obtains estimating with the residual signals of sound channel.To estimating corresponding with coding side with the residual signals of sound channel.At first, read output signal is estimated the weighted vector quantization index from code stream, utilizes the vector quantization index by searching the weights after corresponding code book obtains quantizing
Wherein M is the exponent number of estimator, and is identical with coding side, secondly, constitutes signal estimator with the weights after quantizing, and will pass through this estimator, the poor sound channel residual signals that obtains estimating with the residual signals of sound channel:
In
step 205, the poor sound channel residual signals of estimating is carried out the poor sound channel residual error line spectral frequencies that time-frequency conversion obtains estimating, and extract radio-frequency component.The time-frequency conversion of time-frequency conversion and coding side is consistent, if also the poor sound channel residual signals of estimating is carried out the DFT conversion of M+N rank, then can obtain M+N frequency domain line spectral frequencies
K ∈ [0, M+N-1].With estimated difference sound channel frequency domain line spectral frequencies
Extract radio-frequency component
In
step 206, obtain and sound channel residual error line spectral frequencies carrying out time-frequency conversion, and extract low-frequency component and radio-frequency component with the sound channel residual signals.The time-frequency conversion of time-frequency conversion and coding side is consistent, if also to carrying out the DFT conversion of M+N rank with the sound channel residual signals, then can obtain M+N frequency domain line spectral frequencies
K ∈ [0, M+N-1].With harmony road line spectral frequencies
Extract low-frequency component
And radio-frequency component
In
step 207, utilize the poor sound channel residual error radio-frequency component of the estimation that proposes and the left and right sides residual error sound channel radio-frequency component of estimating with the radio-frequency component formation of sound channel residual error.The left and right sides residual error sound channel radio-frequency component of estimating
With
Utilize formula (10) to try to achieve.
In
step 208, utilize decoded left and right sides residual error channel gain coefficient that the left and right sides residual error sound channel radio-frequency component of estimating is carried out gain control, obtain the radio-frequency component of left and right acoustic channels residual error, and form difference sound channel residual error radio-frequency component.Gain control and coding side correspondence.If gain control is that unit carries out with critical bandwidth (critical bandwidth) also, then the radio-frequency component of left and right sides residual error sound channel
With
By formula (11) calculate:
Wherein k belongs to all spectral lines among the critical subband b,
With
Be the left and right acoustic channels gain coefficient behind the de-quantization of subband b,
With
Be the left and right sides residual error sound channel radio-frequency component of estimating.
In
step 209, difference sound channel residual error low frequency coded data is carried out the low-frequency component that the re-quantization decoding obtains difference sound channel residual error.It is corresponding with coding side of the present invention that difference sound channel residual error low frequency coded data is carried out the re-quantization decoding, obtains difference sound channel residual error low-frequency component
Obtain by step 1406 with sound channel residual error low-frequency component
Utilize formula (12) can calculate left and right acoustic channels residual error low-frequency component
With
In
step 210, the low-frequency component and the radio-frequency component of left and right acoustic channels residual error combined to carry out frequency-time domain transformation mapping corresponding with the time-frequency conversion of coding side.Can adopt contrary discrete Fourier transform (DFT) (IDFT), inverse discrete cosine transform (IDCT), contrary discrete cosine transform (IMDCT), the inverse wavelet transform etc. revised.Respectively left and right acoustic channels residual error frequency domain line spectral frequencies is carried out obtaining the left and right acoustic channels residual signals after the frequency-time domain transformation mapping
With
In step 211, the left and right acoustic channels residual signals is carried out synthetic filtering obtain decoded left and right sound track signals.
To the L channel residual signals
Carry out synthetic filtering and comprise following steps:
At first, from code stream, read the vector quantization index of harmony road line spectral frequencies, utilize the vector quantization index by searching the line spectral frequencies after corresponding code book obtains quantizing, and be converted to line spectrum pair;
Secondly, pass through to calculate f by the line spectrum pair after quantizing
1(z) and f
2(z) obtain predictive coefficient after the quantification
And the linear prediction synthesis filter after the formation quantification
Wherein, p is prediction order, and is identical with coding side;
At last, with the L channel residual signals
Obtain decoded left channel signals by linear prediction synthesis filter:
Equally with the R channel residual signals
Obtain decoded right-channel signals by linear prediction synthesis filter:
Figure 14 is the coded system block diagram of second embodiment of the invention.With reference to Figure 14, the difference of this coded system and coded system shown in Figure 3 is that the realization of forecast analysis module 201 is different, and other module is identical.So only introduce the implementation method of forecast analysis module 201, and the module identical with Fig. 3 repeats no more herein.
The linear forecast analysis module 2012 in harmony road, will with the difference sound channel form module 200 outputs carry out forecast analysis with sound channel signal and filtering obtains and sound channel residual signals e
M(n), this module can effectively be eliminated particularly voice signal redundance in time of sound signal, thereby has improved code efficiency.Specific implementation as shown in Figure 5, the front chatted and, repeat no more herein.Utilize the described method of Fig. 5 to signal x
M(n) carry out filtering, obtain signal e
M(n).Wherein the index of the vector quantization of harmony road line spectral frequencies outputs in the code stream multiplex module 217 as side information.
Difference sound channel linear prediction analysis module 2010 will be carried out forecast analysis with the poor sound channel signal of difference sound channel formation module 200 outputs and filtering obtains difference sound channel residual signals e
S(n), and no longer be as the embodiment 1, the linear analysis filtration module of shared and sound channel.Specific implementation as shown in Figure 5, the front chatted and, repeat no more herein.Utilize the described method of Fig. 5 to signal x
S(n) carry out filtering, obtain signal e
S(n).The index of the vector quantization of wherein poor sound channel line spectral frequencies outputs in the code stream multiplex module 217 as side information.
The function and the principle of work of corresponding each module are identical with corresponding module among Fig. 3 first embodiment in the second embodiment of the invention coded system, repeat no more herein.
The concrete steps of the coding method that the second embodiment of the invention coded system is adopted are as follows:
Step 1, left and right sound track signals converted to and differ from sound channel signal;
Step 2, will encode with sound channel signal;
Step 3, will with the difference sound channel signal carry out linear prediction filtering respectively, obtain and differ from the residual signals of sound channel;
Step 4, with and the sound channel residual signals according to signal type difference sound channel residual error sound channel signal is estimated the poor sound channel residual signals that obtains estimating;
Step 5, respectively to the poor sound channel residual signals estimated, original poor sound channel residual signals with original carry out time-frequency conversion with the sound channel residual signals, and extract radio-frequency component respectively and differ from the sound channel low-frequency component;
Step 6, the low frequency composition in the original poor sound channel residual signals is carried out quantization encoding;
Step 7, the poor sound channel residual error high frequency composition of utilize estimating and original and sound channel residual error high frequency composition are obtained the high frequency composition of the left and right acoustic channels residual error of estimation; Utilize original and difference sound channel residual error high frequency composition to obtain the high frequency composition of original left and right acoustic channels residual error.
Step 8, utilize original left and right acoustic channels residual error high frequency composition that the left and right acoustic channels residual error high frequency composition of estimating is carried out gain control, obtain the gain coefficient of left and right acoustic channels residual error and quantize.
Step 9, the data after will encoding and side information carry out multiplexing, obtain the stereo bit stream of frequency domain parameter.
The particular content of each corresponding steps is identical with the corresponding step of the first embodiment coded system coding method shown in Figure 3 in this second embodiment coded system institute employing method, repeats no more herein.
Figure 15 is the block diagram of the decode system of second embodiment of the invention.With reference to Figure 15, the difference of this decode system and the first embodiment decode system shown in Figure 4 is that low high frequency composite module 313, frequency-time domain transformation module 314, the comprehensive module 315 of linear prediction and left and right acoustic channels form module 316.Other modules and Fig. 4 are identical.So following the module that introduction is different with Fig. 4, and identical module repeats no more herein.
The radio-frequency component of the left and right sides residual error sound channel of low high frequency
composite module 313 receiving
gain control modules 310 outputs
With
And the low-frequency component of the poor sound channel residual error of difference sound channel low frequency
re-quantization decoder module 312
outputs
Module 313 is made up of subtracter 3130.Subtracter 3130 will
With
Subtract each other and divided by the radio-frequency components that obtain difference sound channel residual error after 2
Combine the full range band spectrum coefficient that obtains difference sound channel residual error
And output in the frequency-time
domain transformation module 314.
Frequency-time
domain transformation module 314 is inverse process of coding side time-frequency conversion module.Frequency coefficient with difference sound channel residual error
Obtain the residual signals of difference sound channel by frequency-time domain transformation
And output in the
comprehensive module 315 of linear prediction.Concrete transform method front chatted and, repeat no more herein.
The
comprehensive module 315 of linear prediction constitutes the prediction synthesizer from the spectral line frequency vector quantization index of the poor sound channel that side information obtains, and will differ from the sound channel residual signals
By after obtain the difference sound channel signal
And output in the left and right acoustic channels formation module 316.Specific implementation method front chatted and, repeat no more herein.
Left and right acoustic channels forms the decoded and sound channel signal that
module 316 receives
audio decoder 302 outputs
With 315 outputs of the comprehensive module of
linear prediction
Module 316 is passed through will
With
Addition obtains decoded left channel signals
Subtract each other and obtain decoded right-channel signals
The function of each module of correspondence in the second embodiment of the invention decode system and principle of work are identical with corresponding module among Fig. 4 first embodiment, repeat no more herein.
The coding/decoding method step that the second embodiment of the invention decode system is adopted is as follows:
Step 1, obtain decoded and sound channel to decoding with sound channel;
Step 2, the stereo bit stream of frequency domain parameter is carried out demultiplexing, all side informations that obtain difference sound channel residual error low frequency coded data, gain coefficient coded data and decode used;
Step 3, decoded and sound channel are carried out linear prediction filtering, obtain residual signals with sound channel;
Step 4, to estimating the poor sound channel residual signals that obtains estimating with the residual signals of sound channel;
Step 5, the poor sound channel residual signals of estimating is carried out the poor sound channel residual error spectral coefficient that time-frequency conversion obtains estimating, and extract the high frequency composition;
Step 6, obtain and sound channel residual error spectral coefficient, and extract the high frequency composition carrying out time-frequency conversion with the sound channel residual signals;
The poor sound channel residual error high frequency composition of step 7, the estimation that utilize to propose with and the high frequency composition of sound channel residual error form the left and right sides residual error sound channel high frequency composition of estimation;
Step 8, utilize decoded left and right sides residual error channel gain coefficient that the left and right sides residual error sound channel high frequency composition of estimating is carried out gain control, obtain the high frequency composition of left and right acoustic channels residual error, and form difference sound channel residual error high frequency composition;
Step 9, difference sound channel residual error low frequency coded data is carried out the low frequency composition that the re-quantization decoding obtains difference sound channel residual error;
Conversion when the high frequency composition of step 10, the low frequency composition that will differ from the sound channel residual error and difference sound channel residual error is combined laggard line frequency obtains difference sound channel residual signals;
Step 11, difference sound channel residual signals is carried out synthetic filtering obtain decoded poor sound channel signal;
Step 12, convert decoded and poor sound channel signal to decoded left and right sound track signals.
The particular content of each corresponding steps is identical with the corresponding step of the first embodiment decode system coding/decoding method shown in Figure 4 in this second embodiment institute employing method, repeats no more herein.
Figure 16 is the coded system block diagram of third embodiment of the invention.With reference to Figure 16, the difference of this coded system and the second embodiment coded system shown in Figure 14 is that signal estimation module 204 is made up of signal estimator 2041 and the comprehensive module 2042 of linear prediction.Another difference be input to time-frequency conversion module 206 be and sound channel signal x
M(n) rather than and sound channel residual signals e
M(n).
The realization of signal estimator 2041 is identical with the realization of signal estimation module 204 in the second embodiment coded system.
The poor sound channel residual signals of the estimation of the
comprehensive module 2042 received signal estimators of
linear prediction 2041 outputs
With the poor sound channel predictive coefficient after the quantification that differs from 2011 outputs of sound channel linear prediction analysis module.The
comprehensive module 2042 of linear prediction at first utilizes the poor sound channel predictive coefficient after the quantification of importing to constitute difference sound channel composite filter; The poor sound channel residual signals that to estimate then
Input wherein obtains the poor sound channel signal estimated
At last will
Output in the time-
frequency conversion module 206.
After adding module 2042, after this extraction of time-frequency conversion, low-and high-frequency and gain control are all carried out in original signal domain.
The function of each module of correspondence in the third embodiment of the invention coded system and principle of work are identical with corresponding module among Fig. 3 first embodiment, repeat no more herein.
The concrete steps of the coding method that the third embodiment of the invention coded system is adopted are as follows:
Step 1, left and right sound track signals converted to and differ from sound channel signal;
Step 2, will encode with sound channel signal;
Step 3, will with the difference sound channel signal carry out linear prediction filtering respectively, obtain and differ from the residual signals of sound channel;
Step 4, with and the sound channel residual signals according to signal type difference sound channel residual error sound channel signal is estimated the poor sound channel residual signals that obtains estimating;
Step 5, the poor sound channel residual signals of estimating is synthesized the poor sound channel signal that obtains estimating;
Step 6, respectively to the poor sound channel signal estimated, original poor sound channel signal with original carry out time-frequency conversion with sound channel signal, and extract radio-frequency component respectively and differ from the sound channel low-frequency component;
Step 7, the low frequency composition in the original poor sound channel signal is carried out quantization encoding;
Step 8, the poor sound channel high frequency composition of utilize estimating and original and sound channel high frequency composition are obtained the high frequency composition of the left and right acoustic channels of estimation; Utilize original and difference sound channel high frequency composition to obtain the high frequency composition of original left and right acoustic channels.
Step 9, utilize original left and right acoustic channels high frequency composition that the left and right acoustic channels high frequency composition of estimating is carried out gain control, obtain the gain coefficient of left and right acoustic channels and quantize.
Step 10, the data after will encoding and side information carry out multiplexing, obtain the stereo bit stream of frequency domain parameter.
The particular content of each corresponding steps is identical with the corresponding step of coded system coding method shown in Fig. 3 first embodiment in this 3rd embodiment coded system institute employing method, repeats no more herein.
Figure 17 is the decode system block diagram of third embodiment of the invention.With reference to Figure 17, the difference of this decode system and the second embodiment decode system shown in Figure 15 is to remove the
comprehensive module 315 of linear prediction between frequency-time
domain transformation module 314 and the left and right acoustic
channels formation module 316; And signal
estimation module 304 is made up of
signal estimator 3041 and the
comprehensive module 3042 of linear prediction.Another difference is that what to be input to time-
frequency conversion module 307 is decoded and sound channel signal
Rather than and sound channel residual signals
The realization of signal estimator 3041 is identical with the realization of signal estimation module 304 in the second embodiment decode system.
The poor sound channel residual signals of the estimation of the
comprehensive module 3042 received signal estimators of
linear prediction 3041 outputs
Side information with 300 outputs of code stream demultiplexing module.The
comprehensive module 3042 of linear prediction at first utilizes the side information of input to constitute difference sound channel composite filter; The poor sound channel residual signals that to estimate then
Input wherein obtains the poor sound channel signal estimated
At last will
Output in the time-
frequency conversion module 306.
The function and the principle of work of corresponding each module are identical with corresponding module among Fig. 4 first embodiment in the third embodiment of the invention decode system, repeat no more herein.
The coding/decoding method step that the third embodiment of the invention decode system is adopted is as follows:
Step 1, obtain decoded and sound channel to decoding with sound channel;
Step 2, the stereo bit stream of frequency domain parameter is carried out demultiplexing, all side informations that obtain difference sound channel low frequency coded data, gain coefficient coded data and decode used;
Step 3, decoded and sound channel are carried out linear prediction filtering, obtain residual signals with sound channel;
Step 4, to estimating the poor sound channel residual signals that obtains estimating with the residual signals of sound channel;
Step 5, the poor sound channel residual signals of estimating is carried out the poor sound channel signal that synthetic filtering obtains estimating;
Step 6, the poor sound channel signal of estimating is carried out the poor vocal tract spectrum coefficient that time-frequency conversion obtains estimating, and extract the high frequency composition;
Step 7, obtain and the sound channel spectral coefficient, and extract the high frequency composition carrying out time-frequency conversion with sound channel signal;
The poor sound channel high frequency composition of step 8, the estimation that utilize to propose with and the high frequency composition of sound channel form the left and right acoustic channels high frequency composition of estimation;
Step 9, utilize decoded left and right acoustic channels gain coefficient that the left and right acoustic channels high frequency composition of estimating is carried out gain control, obtain the high frequency composition of left and right acoustic channels, and form difference sound channel high frequency composition;
Step 10, difference sound channel low frequency coded data is carried out the low frequency composition that the re-quantization decoding obtains the difference sound channel;
Conversion when the high frequency composition of step 11, the low frequency composition that will differ from sound channel and difference sound channel is combined laggard line frequency obtains decoded poor sound channel signal;
Step 12, convert decoded and poor sound channel signal to decoded left and right sound track signals.
The particular content of each corresponding steps is identical with the corresponding step of the first embodiment decode system coding/decoding method shown in Figure 4 in this 3rd embodiment decode system institute employing method, repeats no more herein.
Figure 18 is the coded system block diagram of fourth embodiment of the invention.With reference to Figure 18, the difference of this coded system and the 3rd embodiment coded system shown in Figure 14 is that 215 of gain control module carry out gain control to difference sound channel residual signals, therefore the time-frequency conversion module only needs 206 and 207 two to get final product, thereby greatly reduces the complexity of coding.The implementation of gain control module 215 is identical with gain control module 2150 among first embodiment, repeats no more herein.
The function of each module of correspondence in the fourth embodiment of the invention coded system and principle of work are identical with corresponding module among Fig. 3 first embodiment, repeat no more herein.
The concrete steps of the coding method that the fourth embodiment of the invention coded system is adopted are as follows:
Step 1, left and right sound track signals converted to and differ from sound channel signal;
Step 2, will encode with sound channel signal;
Step 3, will with the difference sound channel signal carry out linear prediction filtering respectively, obtain and differ from the residual signals of sound channel;
Step 4, with and the sound channel residual signals according to signal type difference sound channel residual error sound channel signal is estimated the poor sound channel residual signals that obtains estimating;
Step 5, respectively the poor sound channel residual signals of estimating, original poor sound channel residual signals are carried out time-frequency conversion, and extract radio-frequency component respectively and differ from the sound channel low-frequency component;
Step 6, the low frequency composition in the original poor sound channel residual signals is carried out quantization encoding;
Step 7, the poor sound channel residual error high frequency composition of utilize estimating and original poor sound channel residual error high frequency composition carry out gain control, obtain the gain coefficient of poor sound channel residual error and quantize.
Step 8, the data after will encoding and side information carry out multiplexing, obtain the stereo bit stream of frequency domain parameter.
The particular content of each corresponding steps is identical with the corresponding step of the first embodiment coded system coding method shown in Figure 3 in this 4th embodiment coded system institute employing method, repeats no more herein.
Figure 19 is the decode system block diagram of fourth embodiment of the invention.With reference to Figure 19, the difference of this decode system and the 3rd embodiment decode system shown in Figure 15 is that 310 of gain control module carry out gain control to difference sound channel residual error, therefore the time-frequency conversion module only needs 306 1 to get final product, thereby greatly reduces complexity of decoding.The implementation of gain control module 310 is identical with the gain control module 3100 of decoding end among first embodiment, repeats no more herein.
The function of each module of correspondence of fourth embodiment of the invention decode system and principle of work are identical with corresponding module among Fig. 4 first embodiment, repeat no more herein.
The concrete steps of the coding/decoding method that the fourth embodiment of the invention decode system is adopted are as follows:
Step 1, obtain decoded and sound channel to decoding with sound channel;
Step 2, the stereo bit stream of frequency domain parameter is carried out demultiplexing, all side informations that obtain difference sound channel residual error low frequency coded data, gain coefficient coded data and decode used;
Step 3, decoded and sound channel are carried out linear prediction filtering, obtain residual signals with sound channel;
Step 4, to estimating the poor sound channel residual signals that obtains estimating with the residual signals of sound channel;
Step 5, the poor sound channel residual signals of estimating is carried out the poor sound channel residual error spectral coefficient that time-frequency conversion obtains estimating, and extract the high frequency composition;
Step 6, utilize decoded poor sound channel residual error gain coefficient that the high frequency composition of the poor sound channel residual error estimated is carried out gain control, obtain differing from the high frequency composition of sound channel residual error;
Step 7, difference sound channel residual error low frequency coded data is carried out the low frequency composition that the re-quantization decoding obtains difference sound channel residual error;
Conversion when the high frequency composition of step 8, the low frequency composition that will differ from the sound channel residual error and difference sound channel residual error is combined laggard line frequency obtains difference sound channel residual signals;
Step 9, difference sound channel residual signals is carried out synthetic filtering obtain decoded poor sound channel signal;
Step 10, convert decoded and poor sound channel signal to decoded left and right sound track signals.
The particular content of each corresponding steps is identical with the corresponding step of the first embodiment decode system coding/decoding method shown in Figure 4 in this 4th embodiment decode system institute employing method, repeats no more herein.
Those skilled in the art should be noted that only also unrestricted the present invention in order to explanation the present invention of above embodiment; Therefore, although this instructions has been described in detail the present invention with reference to each above-mentioned embodiment,, those of ordinary skill in the art should be appreciated that the present invention can have various changes and variation.Within the spirit and principles in the present invention all, any modification of being done, be equal to replacement, improvement etc., all should be included within the claim scope of the present invention.