CN101001485A - Finite sound source multi-channel sound field system and sound field analogy method - Google Patents
Finite sound source multi-channel sound field system and sound field analogy method Download PDFInfo
- Publication number
- CN101001485A CN101001485A CN 200610113968 CN200610113968A CN101001485A CN 101001485 A CN101001485 A CN 101001485A CN 200610113968 CN200610113968 CN 200610113968 CN 200610113968 A CN200610113968 A CN 200610113968A CN 101001485 A CN101001485 A CN 101001485A
- Authority
- CN
- China
- Prior art keywords
- audio
- data
- sound
- channel
- acquisition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034 method Methods 0.000 title claims abstract description 36
- 230000005236 sound signal Effects 0.000 claims abstract description 33
- 238000012545 processing Methods 0.000 claims abstract description 24
- 238000006243 chemical reaction Methods 0.000 claims abstract description 12
- 238000004806 packaging method and process Methods 0.000 claims abstract 2
- 238000012544 monitoring process Methods 0.000 claims description 15
- 238000004891 communication Methods 0.000 claims description 14
- 239000002245 particle Substances 0.000 claims description 7
- 238000000605 extraction Methods 0.000 claims description 4
- 238000004088 simulation Methods 0.000 abstract description 14
- 238000000926 separation method Methods 0.000 abstract description 9
- 230000003321 amplification Effects 0.000 abstract 1
- 238000003199 nucleic acid amplification method Methods 0.000 abstract 1
- 238000005516 engineering process Methods 0.000 description 16
- 238000010586 diagram Methods 0.000 description 11
- 238000011160 research Methods 0.000 description 8
- 230000005540 biological transmission Effects 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 238000007906 compression Methods 0.000 description 3
- 230000006835 compression Effects 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 241001024304 Mino Species 0.000 description 2
- 238000003491 array Methods 0.000 description 2
- 238000012937 correction Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 239000000203 mixture Substances 0.000 description 2
- 238000007619 statistical method Methods 0.000 description 2
- 238000012706 support-vector machine Methods 0.000 description 2
- 229920001342 Bakelite® Polymers 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 238000013528 artificial neural network Methods 0.000 description 1
- 239000004637 bakelite Substances 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- ZYXYTGQFPZEUFX-UHFFFAOYSA-N benzpyrimoxan Chemical compound O1C(OCCC1)C=1C(=NC=NC=1)OCC1=CC=C(C=C1)C(F)(F)F ZYXYTGQFPZEUFX-UHFFFAOYSA-N 0.000 description 1
- 235000009508 confectionery Nutrition 0.000 description 1
- 210000000883 ear external Anatomy 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 238000001308 synthesis method Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 210000003454 tympanic membrane Anatomy 0.000 description 1
Images





Landscapes
- Stereophonic System (AREA)
Abstract
一种有限声源多通道声场系统及声场模拟方法,包括:麦克风阵列,用于录制M路音频信息及探测声场特性;音频采集子系统,用于各路音频信息的模数转换、音频数据打包及通道号、时间戳;服务器,对各麦克风的音频数据处理,完成音源的分离与处理,并将数据压缩保存;根据M路音源数据及重建声场的特性,混合音源数据并转换为N路扬声器的输出数据和控制信号;音频还音子系统,将不同音源的音频数据组成多通道模拟信号,并控制各路扬声器音频的同步;扬声器阵列用于播放N路音频信号。本发明可以实现音源分离、采集,M与N动态加权匹配,全方位精确再现原声场,减少声场相位失真的影响,避免各音源之间在处理、放大和播出的交调干扰与其它失真。
A limited sound source multi-channel sound field system and sound field simulation method, comprising: a microphone array for recording M channels of audio information and detecting sound field characteristics; an audio collection subsystem for analog-to-digital conversion of each channel of audio information and packaging of audio data And the channel number, time stamp; the server processes the audio data of each microphone, completes the separation and processing of the sound source, and compresses and saves the data; according to the M-channel audio source data and the characteristics of the reconstructed sound field, mixes the audio source data and converts them into N-channel speakers output data and control signals; the audio reproduction subsystem, which composes audio data from different sources into multi-channel analog signals, and controls the audio synchronization of each speaker; the speaker array is used to play N audio signals. The invention can realize the separation and collection of sound sources, the dynamic weighted matching of M and N, the all-round accurate reproduction of the original sound field, the reduction of the influence of the phase distortion of the sound field, and the avoidance of intermodulation interference and other distortions in the processing, amplification and broadcasting of various sound sources.
Description
技术领域technical field
本发明涉及音频采集、还原技术,具体地说,是涉及一种有限声源多通道声场系统。The invention relates to audio collection and restoration technology, in particular to a limited sound source multi-channel sound field system.
背景技术Background technique
音乐是人类文明史的一个重要组成部分。自录音技术发明以来,人们就一直试图想将其美妙的旋律如实地记载下来。声重放技术经历了从单声道到双声道、五声道以及更多声道的发展历程,始终追求的一个目标是更逼真的再现原来的声场或空间感。与双声道立体声相比,尽管多声道系统已经使人们获得了美妙非凡的听音享受,但实际上这样的系统并不能对音源做到无失真的还原,存在着声场相位失真、声源交调干扰、动态范围压缩等问题,在向更先进的多通道声场系统的发展上遇到了前所未有的技术复杂度和理论的挑战。胶木唱片、磁带自不必说,即便是采用数字技术录制的双声道立体声音源,在当今较为流行的5.1/6.1声道还音系统上播放,也不能真实再现三维的空间感。此外,传统的音箱都是有一定的辐射轴向角度的,因此在双声道立体声系统中较明显的存在着“皇帝位”,此位置在两音箱连线的中垂线上,当向左或向右偏离此轴线时,声像就会明显的发生比例偏移,不论是家用的音响系统还是专业的影院还音系统,都普遍存在音源的方向失真问题。在多声道的环绕声系统中,受到各个音箱的限制,最佳听音区变为更窄的一个点,即由各音箱环绕包围起来的区域的中点。只要离开这个点,听音者就会被某只音箱的声场所“吞噬”,产生严重的声场比例失调。Music is an important part of the history of human civilization. Since the invention of recording technology, people have been trying to record its beautiful melody faithfully. Acoustic reproduction technology has experienced the development from monophonic to dual-channel, five-channel and more channels. One of the goals that has always been pursued is to reproduce the original sound field or sense of space more realistically. Compared with two-channel stereo, although the multi-channel system has enabled people to obtain wonderful and extraordinary listening enjoyment, in fact, such a system cannot restore the sound source without distortion, and there are sound field phase distortion and sound source distortion. Issues such as intermodulation interference and dynamic range compression have encountered unprecedented technical complexity and theoretical challenges in the development of more advanced multi-channel sound field systems. Needless to say Bakelite records and tapes, even if the two-channel stereo sound source recorded by digital technology is played on the more popular 5.1/6.1-channel sound reproduction system today, it cannot truly reproduce the three-dimensional sense of space. In addition, traditional speakers all have a certain radiation axial angle, so there is a more obvious "emperor position" in the two-channel stereo system. This position is on the vertical line connecting the two speakers. Or when it deviates from this axis to the right, the sound image will obviously shift in proportion. Whether it is a home audio system or a professional theater sound reproduction system, there is a common problem of distortion of the direction of the sound source. In a multi-channel surround sound system, limited by each speaker, the sweet spot becomes a narrower point, that is, the midpoint of the area surrounded by each speaker. As long as you leave this point, the listener will be "swallowed" by the sound field of a certain speaker, resulting in a serious imbalance in the sound field.
目前立体声录制和回放格式正在被环绕声音格式所取代。许多艺术和技术应用中开发出了各种环绕声技术,通过适当的录制和回放方式为听觉提供空间感。在这方面的研究中,主要有两类方法,一类是感知模拟,一类是声场模拟。Current stereo recording and playback formats are being replaced by surround sound formats. Various surround sound technologies have been developed in many artistic and technical applications to provide a sense of space to the ear through appropriate recording and playback methods. In this research, there are mainly two types of methods, one is perceptual simulation, and the other is sound field simulation.
感知模拟方法:Perceptual simulation method:
双耳声技术属于感知模拟方法,这类技术认为仅仅在听者耳鼓重现声音压力就可以有效重现听觉的空间感,这是基于大家熟知的且被验证的事实----双耳以及头部和胸部能够分辩声源位置的方向和距离。串话消除技术也属于双耳声技术,可以消除左扬声器与听者右耳之间的串话。录音和立体声的传统技术是基于对感知现象的观察和一些经验,生成了人工合成的指导性原则。目前,常见的多声道还音系统都是利用基于感知模拟的技术进行设计的。目前人们所使用的各种声场技术规范非常多,最常见环绕声格式有Dolby(杜比)、DTS(Digital Theatre System,数字化影院系统)、SACD(SuperAudio CD,超级音频光盘系统)和DVD Audio(DVD音频)。其中,SACD与DVD Audio都是高解析度的唱片格式,电影并不使用这两种格式,电影的环绕格式主要采用DTS ES 6.1与Dolby Digital EX 6.1。Binaural sound technology belongs to the perceptual simulation method. This type of technology believes that only by reproducing the sound pressure on the listener's eardrums can effectively reproduce the sense of auditory space. This is based on the well-known and verified facts - binaural and The head and chest can distinguish the direction and distance of the location of the sound source. Crosstalk cancellation technology is also binaural technology, which can eliminate crosstalk between the left speaker and the listener's right ear. The traditional techniques of sound recording and stereophony are based on observations of perceptual phenomena and some experience, generating guiding principles for artificial synthesis. At present, common multi-channel sound reproduction systems are designed using techniques based on perceptual simulation. At present, there are many technical specifications for various sound fields used by people. The most common surround sound formats are Dolby (Dolby), DTS (Digital Theater System, digital theater system), SACD (SuperAudio CD, Super Audio CD System) and DVD Audio ( DVD-Audio). Among them, SACD and DVD Audio are both high-resolution record formats. Movies do not use these two formats. The surround formats of movies mainly use DTS ES 6.1 and Dolby Digital EX 6.1.
声场模拟方法:Sound field simulation method:
基于声场模拟的系统则很少见,因为技术上和物理上的概念非常复杂并且需要深厚声学和信号处理基础背景。Berkhout于1988和1997年分别提出波场综合(Wave Field Synthesis,WFS)技术和波场分析(Wave Field Analysis,WFA)理论。Berkhout和J.Meyer围绕这一理论展开了麦克风阵进行声场的分析和声场记录的研究,Paul D.Henderson和X.Shen则对使用扬声器阵列进行声场还原进行了研究。Systems based on sound field simulations are rare because the technical and physical concepts are complex and require a deep background in acoustics and signal processing. Berkhout proposed Wave Field Synthesis (WFS) technology and Wave Field Analysis (WFA) theory in 1988 and 1997 respectively. Berkhout and J. Meyer carried out research on sound field analysis and sound field recording by microphone arrays around this theory, and Paul D. Henderson and X. Shen conducted research on sound field restoration using speaker arrays.
声场模拟的基本假设是:在重现空间中用具有空间分布的声音压力重现声场,使一个完整的听觉系统(外耳)受到自然的刺激,这个刺激是虚拟的刺激,正是所要重现的。显然这一任务在物理上更自然,但单靠理论或直觉的空间声音感知方法难以实现。波场合成(Wave Field Synthesis,WFS)和全息声(holophonic)是两种声场模拟方法,它们都是用一个扬声器环绕的区域来重现声场。Ambisonic也是一种声场模拟方法,声场可以在Ambisonic环绕扬声器阵列的中心得到部分重现。在重现的声源周围生成方向图,也是一种声场模拟技术。The basic assumption of sound field simulation is: to reproduce the sound field with spatially distributed sound pressure in the reproduction space, so that a complete auditory system (outer ear) is naturally stimulated. This stimulus is a virtual stimulus, which is exactly what is to be reproduced. . Obviously, this task is more natural in physics, but it is difficult to achieve it only by theoretical or intuitive spatial sound perception methods. Wave Field Synthesis (WFS) and holophonic (holophonic) are two sound field simulation methods, they both use an area surrounded by speakers to reproduce the sound field. Ambisonic is also a sound field simulation method in which the sound field can be partially reproduced at the center of the ambisonic surround speaker array. Generating a pattern around the reproduced sound source is also a sound field simulation technique.
以上的研究,都是基于惠更斯原理(Huygens’Principle)对声场进行分解和综合。这样的声场重建系统理论上需要无限多个二次声源,在实际中无法实现,需要进行大量的简化与近似,同时容易产生音源信息失真、声场相位失真、声源交调干扰、动态范围压缩等问题。The above studies are based on the Huygens'Principle to decompose and synthesize the sound field. Such a sound field reconstruction system theoretically needs an infinite number of secondary sound sources, which cannot be realized in practice, and requires a lot of simplification and approximation. At the same time, it is easy to cause sound source information distortion, sound field phase distortion, sound source intermodulation interference, and dynamic range compression. And other issues.
还音系统要真实的再现原声场,录音技术的研究是一个关键问题。如何将各种发声方式不同、声音响度不同的乐器组成的交响乐团演奏的音乐和谐、平衡、清晰、准确的收录下来,是录音成败的关键。现代录音技术往往采用高保真的拾音话筒,采取多话筒、多声轨的录音方式,最大限度接近真实的采集声音,然后经过重新混音,平衡各音轨的音量,使各种乐器以一种和谐精准的状态展现出来。无失真声源提取是音源分离的问题,其目的是将目标音源与其它干扰音源以及噪声信号分开。统计学方法,如神经网络、隐马尔科夫模型(Hidden Markov Model,HMM)、支持向量机(Support VectorMachines,SVM)是目前音源分离领域普遍使用的方法。但是,目前统计学方法在音源分离的应用研究中,存在着需要假设噪声信号为高斯白噪声的限制。所以现有的音源分离研究只能看成是一种信号增强的研究,而当信号噪声为其它音源(如乐器)的干扰时,现有的解决方法就因系统的非高斯性而失去应用价值。In order for the sound reproduction system to truly reproduce the original sound field, the research on recording technology is a key issue. How to record the music played by a symphony orchestra composed of instruments with different sounding methods and loudness in a harmonious, balanced, clear and accurate way is the key to the success of the recording. Modern recording technology often uses high-fidelity pickup microphones, adopts multi-microphone and multi-track recording methods, which is as close as possible to the real collected sound, and then remixes to balance the volume of each track, so that various instruments can be heard in one voice. A state of harmony and precision is displayed. Distortion-free sound source extraction is the problem of sound source separation, the purpose of which is to separate the target sound source from other interfering sound sources and noise signals. Statistical methods, such as neural networks, Hidden Markov Model (HMM), and Support Vector Machines (SVM), are currently commonly used methods in the field of sound source separation. However, the current statistical method in the application research of sound source separation has the limitation of assuming that the noise signal is Gaussian white noise. Therefore, the existing research on sound source separation can only be regarded as a kind of signal enhancement research, and when the signal noise is the interference of other sound sources (such as musical instruments), the existing solutions lose their application value due to the non-Gaussian nature of the system .
发明内容Contents of the invention
本发明所要解决的技术问题是提供一种有限声源多通道声场系统及声场模拟方法,来实现无失真的音源分离、采集,及全方位精确再现原声场。The technical problem to be solved by the present invention is to provide a limited sound source multi-channel sound field system and a sound field simulation method to realize undistorted sound source separation and collection, and to accurately reproduce the original sound field in all directions.
为解决上述技术问题,本发明提供了一种有限声源多通道声场系统,包括:具有多个麦克风的麦克风阵列、具有多个扬声器的扬声器阵列,还包括:音频采集子系统、服务器、音频还音子系统,其中,In order to solve the above technical problems, the present invention provides a limited sound source multi-channel sound field system, including: a microphone array with multiple microphones, a speaker array with multiple speakers, and also includes: an audio collection subsystem, a server, an audio sound subsystem, where,
麦克风阵列用于录制M路音频信息及探测声场特性;The microphone array is used to record M-channel audio information and detect sound field characteristics;
音频采集子系统,用于将从麦克风阵列采集的各路音频信号进行模数转换,并将转换后的音频数据标记采集通道号及时间戳,打包并发送;The audio collection subsystem is used to perform analog-to-digital conversion on each audio signal collected from the microphone array, and mark the converted audio data with the collection channel number and time stamp, package and send it;
服务器,在声场采集过程中,用于接收并解析音频采集子系统发送的音频数据包,将从各麦克风阵列采集的音频数据转化为不同的单一音源数据,并将转化后的单一音源数据转化压缩成音频文件格式,并保存;在声场还音过程中,用于读取已保存的音频文件,根据M路音源数据及重建声场的特性,混合音源数据并通过智能匹配转换为N路扬声器的输出数据和控制信号,发送至音频还音子系统;The server is used to receive and analyze the audio data packets sent by the audio acquisition subsystem during the sound field acquisition process, convert the audio data collected from each microphone array into different single sound source data, and convert and compress the converted single sound source data In the sound field restoration process, it is used to read the saved audio file, according to the characteristics of the M-channel sound source data and the reconstructed sound field, the audio source data is mixed and converted into N-channel speaker output through intelligent matching Data and control signals are sent to the audio reproduction subsystem;
音频还音子系统,用于根据从服务器接收到的控制信号来同步从服务器接收到的各扬声器的输出数据,并还原成多通道模拟音频信号,发送至扬声器阵列播放;The audio reproduction subsystem is used to synchronize the output data of each speaker received from the server according to the control signal received from the server, and restore it into a multi-channel analog audio signal, and send it to the speaker array for playback;
扬声器阵列,用于播放N路音频信号及重建声场。The speaker array is used to play N channels of audio signals and reconstruct the sound field.
在一较佳实施例中,所述音频采集子系统进一步包括:多个音频采集子板和一个音频采集母板;每个音频采集子板包括1个或多个音频采集通道、一模数转换器组及一逻辑处理装置;音频采集母板包括:采集子板数据接口及服务器通讯接口;其中,每个音频采集子板通过音频采集通道从麦克风阵列采集音频信号,并将音频采集通道采集到的音频信号发送至模数转换器组,模数转换器组将音频信息转化音频数据并发送至逻辑处理装置,将模数转换器组中每个模数转换器输出的音频数据标记上通道号及时间戳,并发送至音频采集母板中的采集子板数据接口,再通过音频采集母板中的服务器通讯接口将音频数据发送至服务器。In a preferred embodiment, the audio collection subsystem further includes: a plurality of audio collection sub-boards and an audio collection motherboard; each audio collection sub-board includes 1 or more audio collection channels, an analog-to-digital conversion device group and a logic processing device; the audio acquisition motherboard includes: an acquisition sub-board data interface and a server communication interface; wherein, each audio acquisition sub-board collects audio signals from the microphone array through an audio acquisition channel, and collects the audio acquisition channel to The audio signal of the analog-to-digital converter is sent to the analog-to-digital converter group, and the analog-to-digital converter group converts the audio information into audio data and sends it to the logic processing device, and marks the audio data output by each analog-to-digital converter in the analog-to-digital converter group with the channel number and time stamp, and send it to the data interface of the acquisition sub-board in the audio acquisition motherboard, and then send the audio data to the server through the server communication interface in the audio acquisition motherboard.
在一较佳实施例中,所述音频采集母板进一步包括:采集子板控制接口;服务器通过音频采集母板中的采集子板控制接口向音频采集子板发送控制命令,并从所述采集子板控制接口获取音频采集子板反馈的状态信息。In a preferred embodiment, the audio collection motherboard further includes: a collection sub-board control interface; the server sends a control command to the audio collection sub-board through the collection sub-board control interface in the audio collection The sub-board control interface obtains the status information fed back by the audio collection sub-board.
在一较佳实施例中,所述服务器进一步包括:监听采集模块,用于监听是否有音频数据到达服务器,当监听到有音频数据到达后进行采集;音频数据处理模块,包括粒子滤波器和均衡器,用于将采集的音频数据转化为不同的单一音源数据;存储模块,用于将转化后的单一音源数据转化压缩成音频文件格式,加入文件描述信息并保存;播放控制模块,用于读取已保存的音频文件,根据M路音源数据及重建声场的特性,混合音源数据并通过智能匹配转换为N路扬声器的输出数据和控制信号,发送至音频还音子系统。In a preferred embodiment, the server further includes: a monitoring collection module, which is used to monitor whether audio data arrives at the server, and collects after listening to the arrival of audio data; an audio data processing module, including a particle filter and an equalizer The device is used to convert the collected audio data into different single audio source data; the storage module is used to convert and compress the converted single audio source data into an audio file format, add file description information and save it; the playback control module is used to read Take the saved audio files, mix the audio source data according to the characteristics of the M-channel sound source data and the reconstructed sound field, and convert them into the output data and control signals of the N-channel speakers through intelligent matching, and send them to the audio reproduction subsystem.
在一较佳实施例中,所述音频还音子系统进一步包括:多个音频还音子板和一个音频还音母板;每个音频还音子板包括1个或多个音频还音通道、一数模转换器组及一逻辑处理装置;音频还音母板包括:还音子板控制接口、还音子板数据接口及服务器通讯接口;其中,音频还音母板通过服务器通讯接口接收来自服务器的各扬声器的输出数据和控制信号,并通过还音子板数据接口将各扬声器的输出数据发送至音频还音子板,同时通过还音子板控制接口将控制信号发送至音频还音子板;音频还音子板中的逻辑处理装置根据从音频还音母板收到的控制信号来同步从音频还音母板收到的各扬声器的输出数据,并发送至数模转换器组转换为多通道模拟音频信号,通过音频还音通道发送至扬声器阵列播放。In a preferred embodiment, the audio sound reproduction subsystem further includes: a plurality of audio sound reproduction sub-boards and an audio sound reproduction motherboard; each audio sound reproduction sub-board includes one or more audio sound reproduction channels , a digital-to-analog converter group and a logic processing device; the audio reproduction motherboard includes: a sound reproduction sub-board control interface, a sound reproduction sub-board data interface and a server communication interface; wherein, the audio reproduction motherboard receives through the server communication interface Output data and control signals from each speaker of the server, and send the output data of each speaker to the audio reproduction sub-board through the data interface of the sound reproduction sub-board, and at the same time send the control signal to the audio reproduction sub-board through the control interface of the sound reproduction sub-board Daughter board; the logic processing device in the audio reproduction daughter board synchronizes the output data of each speaker received from the audio reproduction motherboard according to the control signal received from the audio reproduction motherboard, and sends it to the digital-to-analog converter group It is converted into a multi-channel analog audio signal and sent to the speaker array for playback through the audio reproduction channel.
在一较佳实施例中,所述播放控制模块进一步包括扬声器音量控制子模块,用于对扬声器阵列进行音量控制。In a preferred embodiment, the playback control module further includes a speaker volume control sub-module for controlling the volume of the speaker array.
在一较佳实施例中,所述扬声器音量控制子模块,进一步包括对扬声器阵列进行单扬声器音量控制的单扬声器音量控制单元、对分组扬声器音量控制的分组扬声器音量控制单元或对全部扬声器音量控制的全部扬声器音量控制单元。In a preferred embodiment, the speaker volume control sub-module further includes a single speaker volume control unit for controlling the volume of a single speaker for the speaker array, a group speaker volume control unit for controlling the volume of group speakers, or a volume control unit for all speakers All speaker volume control units.
在一较佳实施例中,所述播放控制模块,进一步包括扬声器阵列网络监控子模块,用于对扬声器阵列进行网络监控。In a preferred embodiment, the playback control module further includes a loudspeaker array network monitoring sub-module for network monitoring of the loudspeaker array.
为了解决上述技术问题,本发明还提供一种有限声源多通道声场模拟方法,包括以下步骤:In order to solve the above-mentioned technical problems, the present invention also provides a limited sound source multi-channel sound field simulation method, comprising the following steps:
(a)由音频采集子系统将麦克风阵列采集的M路音频信号进行模数转换,并将转换后的音频数据标记采集通道号及时间戳,打包并发送;(a) The M-channel audio signals collected by the microphone array are subjected to analog-to-digital conversion by the audio collection subsystem, and the converted audio data is marked with a collection channel number and a time stamp, packed and sent;
(b)由一服务器接收并解析音频采集子系统发送的音频数据包,将麦克风阵列采集的音频数据转化为不同的单一音源数据,并将转化后的单一音源数据转化压缩成音频文件格式并保存;(b) A server receives and analyzes the audio data packets sent by the audio collection subsystem, converts the audio data collected by the microphone array into different single sound source data, converts and compresses the converted single sound source data into an audio file format and saves it ;
(c)在声场还音过程中,所述服务器读取已保存的音频文件,根据M路音源数据及重建声场的特性,混合音源数据并通过自适应匹配转换为N路扬声器的输出数据和控制信号,发送至音频还音子系统;(c) During the sound field reproduction process, the server reads the saved audio file, mixes the sound source data and converts the audio source data into the output data and control of the N-way speakers through adaptive matching according to the M-way sound source data and the characteristics of the reconstructed sound field The signal is sent to the audio reproduction subsystem;
(d)所述音频还音子系统根据从服务器接收到的控制信号来同步从服务器接收到的各扬声器的输出数据,并还原成N路多通道模拟音频信号,发送至扬声器阵列播放。(d) The audio reproduction subsystem synchronizes the output data of each speaker received from the server according to the control signal received from the server, and restores it into N-channel multi-channel analog audio signals, and sends them to the speaker array for playback.
在一较佳实施例中,所述步骤(b)将采集的音频数据转化为不同的单一音源数据时,采用粒子滤波器将噪声和干扰从该路音频通道中分离开,即把其它音源信号看作是一种非高斯的噪声干扰,将无失真的音源提取问题转换成一种波形跟踪问题。In a preferred embodiment, when the audio data collected in the step (b) is converted into different single sound source data, a particle filter is used to separate noise and interference from the audio channel, that is, other sound source signals As a non-Gaussian noise interference, the problem of undistorted sound source extraction is transformed into a waveform tracking problem.
本发明还提供了一种音频数据包结构,用于在音频采集过程中标识音频数据属性信息,包括:用于表示音频数据属性的包头部分和用于表示音频数据的包数据部分,其中,包头部分包括包起始标识位、通道标识位、时间戳位;包数据部分包括音频数据位。还可进一步包括校验位。The present invention also provides an audio data packet structure, which is used to identify audio data attribute information during the audio collection process, including: a packet header part used to represent audio data attributes and a packet data part used to represent audio data, wherein the packet header Part includes packet start identification bit, channel identification bit, time stamp bit; packet data part includes audio data bit. A check digit may further be included.
由上可知,本发明所述的系统,通过服务器中的音频处理模块将所采集的各音频数据转化为多个单一音源的音频数据,实现了无失真的音源分离、采集,避免了单个声源的失真,减少了声场相位失真的影响,彻底避免了声源之间的交调干扰;通过服务器中的播放控制模块将所述分离出的M路单一音源的音频数据根据重建声场的特性,转换成N路扬声器输出的数据,并提供必要的控制信号,从而全方位精确再现了原声场。通过音频还音子系统和扬声器阵列技术,避免了最佳听音区窄仄的现象。本发明通过采用所述具有通道号和时间戳标识的音频数据包结构,在音频采集时清楚的记载音频数据所来自的通道号及采集的时间,为全方位精确还音提供了空间和时间上的重要依据。As can be seen from the above, the system of the present invention converts the collected audio data into audio data of multiple single sound sources through the audio processing module in the server, thereby realizing the separation and collection of sound sources without distortion, and avoiding the single sound source The distortion of the sound field reduces the influence of the phase distortion of the sound field, and completely avoids the intermodulation interference between the sound sources; the audio data of the separated M-channel single sound source is converted according to the characteristics of the reconstructed sound field through the playback control module in the server The data outputted by N-channel speakers is converted into and the necessary control signals are provided, thereby accurately reproducing the original sound field in all directions. Through the audio frequency reproduction subsystem and the speaker array technology, the narrow phenomenon of the best listening area is avoided. The present invention clearly records the channel number from which the audio data comes from and the time of collection by adopting the audio data packet structure with the channel number and time stamp identification during audio collection, and provides space and time for all-round and accurate sound reproduction. important basis.
本发明所要解决的技术问题、技术方案要点及有益效果,将结合实施例,参照附图作进一步说明。The technical problems to be solved by the present invention, the key points of the technical solutions and the beneficial effects will be further described in conjunction with the embodiments and with reference to the accompanying drawings.
附图说明Description of drawings
图1为本发明实施例所述系统的结构示意图;Fig. 1 is a schematic structural diagram of the system described in the embodiment of the present invention;
图2为图1音频采集子系统中音频采集子板的结构示意图;Fig. 2 is the structural representation of the audio frequency acquisition sub-board in the audio frequency acquisition subsystem of Fig. 1;
图3为图1音频采集子系统中音频采集母板的结构示意图;Fig. 3 is the structural representation of the audio frequency acquisition motherboard in the audio frequency acquisition subsystem of Fig. 1;
图4为音频采集子板处理后音频数据包结构示意图;Fig. 4 is the schematic diagram of the structure of the audio data packet after processing by the audio acquisition sub-board;
图5为带有校验码的音频数据包结构示意图;Fig. 5 is a schematic diagram of the structure of an audio data packet with a check code;
图6为图1中服务器音频数据监听、音频数据处理及存储的流程图;Fig. 6 is the flowchart of server audio data monitoring, audio data processing and storage in Fig. 1;
图7为图1服务器中的音频数据处理模块的结构示意图;Fig. 7 is a schematic structural diagram of the audio data processing module in the server of Fig. 1;
图8为图1服务器中的MINO智能匹配模块的结构示意图;Fig. 8 is a schematic structural diagram of the MINO intelligent matching module in the server of Fig. 1;
图9为图1音频还音子系统中音频还音子板的结构示意图;Fig. 9 is a structural schematic diagram of the audio sound reproduction sub-board in the audio sound reproduction subsystem of Fig. 1;
图10为图1音频还音子系统中音频还音母板的结构示意图;FIG. 10 is a schematic structural diagram of the audio reproduction motherboard in the audio reproduction subsystem of FIG. 1;
图11为图1服务器中的播放控制模块结构示意图。FIG. 11 is a schematic structural diagram of the playback control module in the server in FIG. 1 .
具体实施方式Detailed ways
参照图1,本发明实施例所述系统的结构示意图。Referring to FIG. 1 , it is a schematic structural diagram of the system described in the embodiment of the present invention.
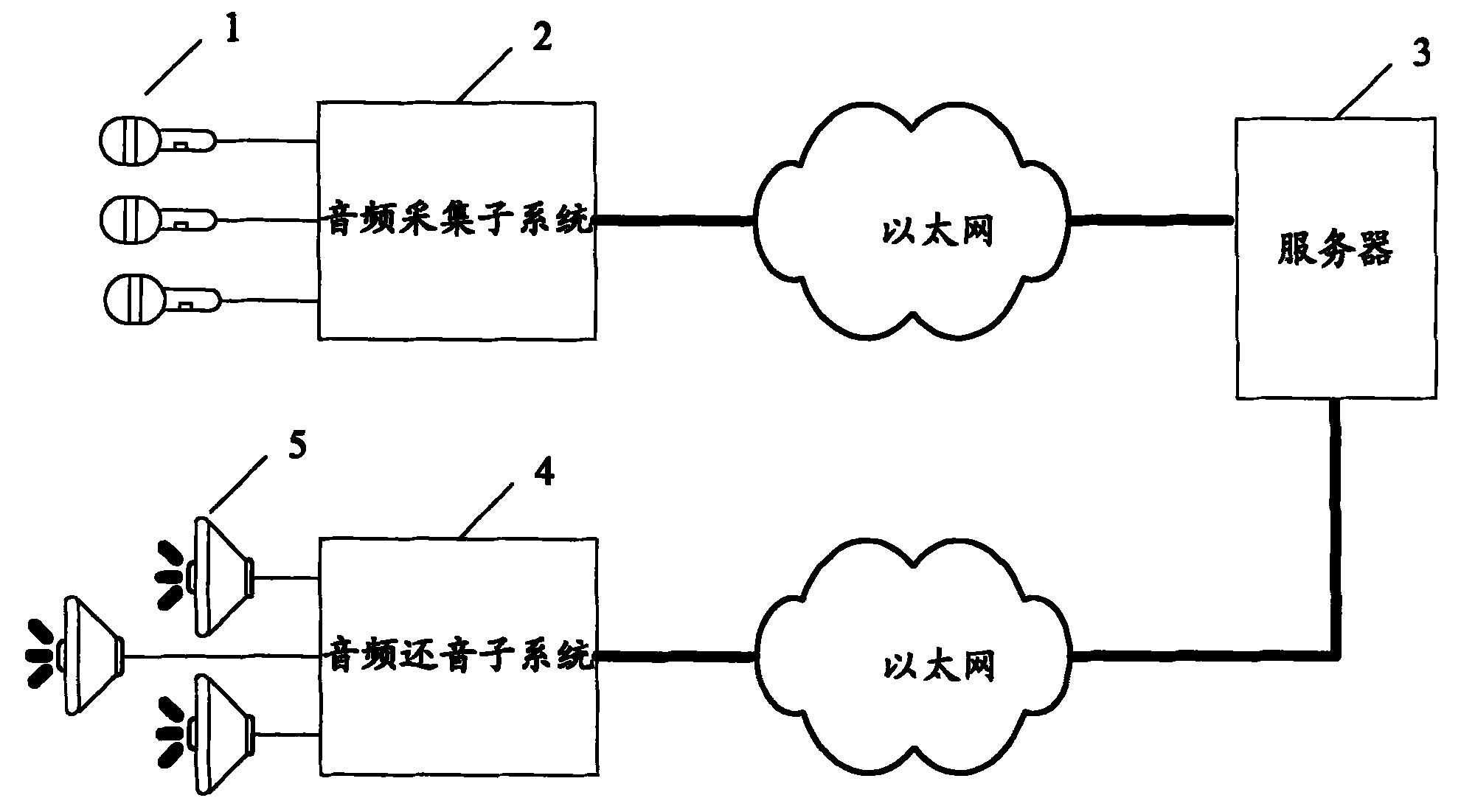
本发明实施例所述系统,包括:具有多个麦克风的麦克风阵列1、具有多个扬声器的扬声器阵列5,还包括:音频采集子系统2、服务器3、音频还音子系统4。The system described in the embodiment of the present invention includes: a
其中,in,
音频采集子系统2,用于将从麦克风阵列采集的各路音频信号进行模数转换,并将转换后的音频数据标记采集通道号及时间戳,打包并发送;The
服务器3,在声场采集过程中,用于接收并解析音频采集子系统发送的音频数据包,将从各麦克风阵列采集的音频数据转化为不同的单一音源数据,并将转化后的单一音源数据转化压缩成音频文件格式,并加入文件描述信息,包括曲名,录音时间,作者,演奏者,场地,麦克风定位信息等保存;在声场还音过程中,用于读取已保存的音频文件,根据M路音源数据及重建声场的特性(包括扬声器的数目,摆放的位置,放映的场合等),混合音源数据并通过智能匹配转换为N路扬声器的输出数据和控制信号,发送至音频还音子系统。
音频还音子系统4,用于根据从服务器接收到的控制信号,包括NM影射矩阵,扬声器最佳结构等信息,来同步从服务器接收到的各扬声器的输出数据,并还原成多通道模拟音频信号,发送至扬声器阵列播放。The
通过音频采集子系统,可将多个音频通道采集来的数据(如256个通道)通过数据接口传输到以太网,再通过以太网传送到服务器。由服务器根据不同的声场处理算法对各麦克风的音频数据进行处理,包括改进型滤波器和均衡器处理,最终把各麦克风采集的音频数据转化为不同的单一音源的音频数据,将这些数据转换成可以播放的音频文件格式,并保存到本地SCSI(SmallComputer System Interface,小型计算机系统接口)硬盘或其它存储媒体中。远程客户端可以通过ISCSI(Internet Small Computer System Interface,互联网小型计算机系统接口)协议访问播放SCSI盘中的音频文件或其它通讯协议访问相应存储媒体,并通过音频还音子系统逼真地再现原声场。Through the audio collection subsystem, the data collected by multiple audio channels (such as 256 channels) can be transmitted to the Ethernet through the data interface, and then transmitted to the server through the Ethernet. The server processes the audio data of each microphone according to different sound field processing algorithms, including improved filter and equalizer processing, and finally converts the audio data collected by each microphone into audio data of different single sound sources, and converts these data into The audio file format can be played, and saved to the local SCSI (SmallComputer System Interface, small computer system interface) hard disk or other storage media. The remote client can access and play the audio files in the SCSI disk through the ISCSI (Internet Small Computer System Interface, Internet Small Computer System Interface) protocol or access the corresponding storage media through other communication protocols, and reproduce the original sound field realistically through the audio reproduction subsystem.
在音频的采集、传输和存储过程中,为了避免单个声源的失真,减少声场相位失真的影响,彻底避免声源之间的交调干扰,本方案采用改进型的粒子滤波器将噪声和干扰从该路音频通道中分离开。即把其它音源信号看作是一种非高斯的噪声干扰,将无失真的音源提取问题转换成一种波形跟踪问题,从而提出了一种全新的基于粒子滤波器的音源分离方法。本方案拾音范围同时包括录音室和为现场录音,如大型交响乐音乐会、体育比赛和晚会录音等。In the process of audio collection, transmission and storage, in order to avoid the distortion of a single sound source, reduce the influence of the phase distortion of the sound field, and completely avoid the intermodulation interference between sound sources, this program adopts an improved particle filter to combine noise and interference Detach from this audio channel. That is, other sound source signals are regarded as a non-Gaussian noise interference, and the problem of undistorted sound source extraction is transformed into a waveform tracking problem, thus a new method of sound source separation based on particle filters is proposed. The sound pickup range of this program includes both recording studios and on-site recordings, such as large-scale symphony concerts, sports competitions and party recordings.
通过把主要的有限声源分离,使其它声场的分析与表示更为简单可行。通过有限声源还原技术与惠更斯原理构建一个M输入与N输出的多解声场系统,得到一个比单一声场综合方法更优越,更灵活,适用于多种实际环境的还音系统。利用本方案的音频还音子系统和扬声器阵列技术,可以较好的解决目前存在的最佳听音区窄仄的问题,可应用于各大剧院、音乐厅、体育场、广场的录音广播系统中,并且可以获得比现在的多声道还音系统更逼真的还音感受。By separating the main finite sound sources, the analysis and representation of other sound fields are made simpler and feasible. A multi-solution sound field system with M input and N output is constructed by means of finite sound source restoration technology and Huygens' principle, and a sound reproduction system that is superior and more flexible than a single sound field synthesis method and suitable for various actual environments is obtained. The audio reproduction subsystem and speaker array technology of this solution can better solve the existing problem of the narrow best listening area, and can be applied to the recording and broadcasting systems of major theaters, concert halls, stadiums, and squares , and can obtain a more realistic sound reproduction experience than the current multi-channel sound reproduction system.
本发明实施例所述的音频采集子系统包括多个音频采集子板和一个音频采集母板。其中,每个音频采集子板包括1个或多个音频采集通道、一模数转换器组及一现场可编程门阵列FPGA(或其它逻辑处理装置);音频采集母板包括:采集子板控制接口(包括串型接口,并行接口)、采集子板数据接口(包括高速串行接口,并行接口)及服务器通讯接口(如,有线以太网接口,无线超宽带接口,无线IP接口等)(如图3所示)。The audio collection subsystem described in the embodiment of the present invention includes a plurality of audio collection sub-boards and an audio collection motherboard. Wherein, each audio collection sub-board includes one or more audio collection channels, an analog-to-digital converter group, and a field programmable gate array FPGA (or other logic processing device); the audio collection motherboard includes: collection sub-board control Interface (including serial interface, parallel interface), data acquisition interface of sub-board (including high-speed serial interface, parallel interface) and server communication interface (such as wired Ethernet interface, wireless ultra-wideband interface, wireless IP interface, etc.) (such as Figure 3).
参照图2,为本发明实施例所述音频采集子系统中音频采集子板的结构示意图,每个音频采集子板通过音频采集通道(CH0-CH7)从麦克风阵列采集音频信号,并将音频采集通道采集到的音频信号发送至模数转换器组(图中示出了4个模数转换器A/D组,每个A/D组负责两个音频采集通道所采集音频信号的模数转换),模数转换器组将音频信息转化音频数据并发送至现场可编程门阵列,现场可编程门阵列将模数转换器组中每个模数转换器输出的音频数据标记上通道号及时间戳,并发送至音频采集母板中的采集子板数据接口,再通过音频采集母板中的服务器通讯接口将音频数据发送至服务器。Referring to Fig. 2, it is a schematic structural diagram of the audio collection sub-board in the audio collection subsystem according to the embodiment of the present invention, each audio collection sub-board collects audio signals from the microphone array through audio collection channels (CH0-CH7), and collects audio signals The audio signal collected by the channel is sent to the analog-to-digital converter group (4 analog-to-digital converter A/D groups are shown in the figure, and each A/D group is responsible for the analog-to-digital conversion of the audio signals collected by two audio collection channels ), the analog-to-digital converter group converts the audio information into audio data and sends it to the field programmable gate array, and the field programmable gate array marks the channel number and time on the audio data output by each analog-to-digital converter in the analog-to-digital converter group stamp, and send it to the data interface of the acquisition sub-board in the audio acquisition motherboard, and then send the audio data to the server through the server communication interface in the audio acquisition motherboard.
这里,音频采集子系统采用模块化设计,即音频采集子板(如图2所示)和音频采集母板(如图3所示)的模式,每个音频采集子板作为一个采集终端,一般可以采集8个音频采集通道(音频采集通道超过8个时,可以采用扩展的方式)的数据,这些数据通过FPGA打上时间戳和通道号,然后再将这些数据传递给母板,母板再通过以太网接口或其它通道由服务器读取,保存到SCSI硬盘或其它存储介质中。服务器3通过音频采集母板中的采集子板控制接口向音频采集子板发送控制命令,并从所述采集子板控制接口获取音频采集子板反馈的状态信息。Here, the audio collection subsystem adopts a modular design, that is, the mode of an audio collection sub-board (as shown in Figure 2) and an audio collection motherboard (as shown in Figure 3), and each audio collection sub-board is used as a collection terminal. It can collect the data of 8 audio acquisition channels (when there are more than 8 audio acquisition channels, it can be extended). The Ethernet interface or other channels are read by the server and saved to the SCSI hard disk or other storage media. The
在图2中,A/D组的作用是把多通道音频模拟信号转换为数字音频数据。用户可以选择性的采样某个或某几个通道的音频数据。每个通道的数据中必须含有通道号参数,由于单板最多支持256通道,所以用一个字节长度的整数作为通道号参数即可,即通道编号从0到255号,0x00~0xff超过256通道时,由服务器记录文件区分。另外,每个通道采集到的数据都必须打上时间戳,以保证采集数据的正确先后顺序,也方便按时间选择性播放。为了保证还音系统中数据的正确性与可靠性,还可以对音频数据进行纠错编码。In Figure 2, the role of the A/D group is to convert multi-channel audio analog signals into digital audio data. Users can selectively sample audio data of one or several channels. The data of each channel must contain the channel number parameter. Since the single board supports up to 256 channels, an integer of one byte length can be used as the channel number parameter, that is, the channel number is from 0 to 255, and 0x00~0xff exceeds 256 channels. , it is distinguished by the server record file. In addition, the data collected by each channel must be time-stamped to ensure the correct order of the collected data and to facilitate selective playback by time. In order to ensure the correctness and reliability of the data in the sound reproduction system, error correction coding can also be performed on the audio data.
如图4所示,为音频采集子板处理后音频数据包结构示意图。经过现场可编程门阵列FPGA将模数转换后的音频数据打上通道号和时间戳后,音频数据包由包头和包数据两部分组成。每个数据包长度为固定的128字节,即总长1024位,数据包的结构如图4所示。在网络传输中,音频数据包还会被以UDP(User Datagram Protocol,用户数据报协议)或者TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/互联网络协议)的形式封装为IP包。在128字节的音频数据包中,包头6个字节,其中包起始标识位1个字节,通道标识位1个字节,时间戳位4个字节,音频数据位122个字节。As shown in FIG. 4 , it is a schematic diagram of the structure of the audio data packet processed by the audio acquisition sub-board. After the field programmable gate array FPGA stamps the channel number and time stamp on the audio data after the analog-to-digital conversion, the audio data packet consists of two parts, the packet header and the packet data. The length of each data packet is fixed at 128 bytes, that is, the total length is 1024 bits. The structure of the data packet is shown in FIG. 4 . In network transmission, audio data packets will also be encapsulated into IP packets in the form of UDP (User Datagram Protocol) or TCP/IP (Transmission Control Protocol/Internet Protocol, Transmission Control Protocol/Internet Protocol). In the 128-byte audio data packet, there are 6 bytes in the header, including 1 byte for the packet start identification bit, 1 byte for the channel identification bit, 4 bytes for the timestamp bit, and 122 bytes for the audio data bit .
其中,in,
包起始标识位采用1字节:The packet start identification bit adopts 1 byte:
包头的第一个字节(0x77)即包起始标识用于同步,以表征一个数据包的开始。The first byte (0x77) of the packet header, the packet start identifier, is used for synchronization to represent the beginning of a data packet.
通道标识位采用1字节:The channel identification bit adopts 1 byte:
每个通道的数据中必须含有通道号参数,由于最多支持256通道,所以用一个字节长度的整数作为通道号参数即可,即通道编号从0到255号,0x0~0xff解码器检测到包头之后的一个字节,即可知道接收到的音频信号是256路音频信号中的哪一路。The data of each channel must contain a channel number parameter. Since a maximum of 256 channels are supported, an integer of one byte length can be used as the channel number parameter, that is, the channel number is from 0 to 255, and the decoder detects the packet header from 0x0 to 0xff. In the next byte, it is possible to know which of the 256 audio signals the received audio signal is.
时间戳位采用4字节:The timestamp bits take 4 bytes:
每个通道采集到的数据都必须打上时间戳,以保证采集数据的正确先后顺序,也方便按时间选择性播放。这里的时间戳是相对时间戳,即定义了各路音频信号的从属关系。选择每组音频信号的第一路为音频主路,其它几路音频信号则定为从属音频。在主路音频的各个单元上打上时间戳,而依照与主路音频的单元在同一时间上的表现,在从属音频相对应的单元上打上相同的时间戳,从属音频各单元上的时间戳是相对于主路音频单元的时间戳而言的。The data collected by each channel must be time-stamped to ensure the correct order of the collected data and to facilitate selective playback by time. The time stamp here is a relative time stamp, which defines the affiliation relationship of each audio signal. Select the first channel of each group of audio signals as the main audio channel, and the other channels of audio signals as slave audio. Put a time stamp on each unit of the master audio, and according to the performance of the unit of the master audio at the same time, put the same time stamp on the unit corresponding to the slave audio, and the time stamp on each unit of the slave audio is Relative to the timestamp of the main audio unit.
为了保证音频还音子系统中数据的正确性与可靠行,还可以对音频信号进行前向纠错。我们的方案中采用T=8、截短的RS(Reed-Solomon,里德-所罗门)编码,并将16个校验字节加到每一个数据包上,此时音频数据位只有106个字节。RS误码保护包的帧结构如图5所示。In order to ensure the correctness and reliability of the data in the audio frequency reproduction subsystem, forward error correction can also be performed on the audio signal. In our scheme, T=8, truncated RS (Reed-Solomon, Reed-Solomon) encoding is adopted, and 16 check bytes are added to each data packet. At this time, the audio data bits only have 106 words Festival. The frame structure of the RS error protection packet is shown in FIG. 5 .
RS编码也同样作用于数据包的同步字节。此处截短的RS(144,128)码的实现方法是在RS(255,239)编码器的输入端输入信息字节之前,添加111个字节,并设置为全0。编码后,再将这些零字节丢弃。同理,音频还音子系统在RS(255,239)解码器的输入端输入信息字节之前,添加111个字节,并设置为全0。解码后,再将这些零字节丢弃。RS encoding is also applied to the synchronization byte of the data packet. Here, the truncated RS (144, 128) code is realized by adding 111 bytes and setting them as all 0s before inputting the information bytes at the input end of the RS (255, 239) encoder. After encoding, these zero bytes are then discarded. Similarly, the audio playback subsystem adds 111 bytes before inputting information bytes at the input terminal of the RS (255, 239) decoder, and sets them as all 0s. After decoding, these zero bytes are then discarded.
本发明实施例所述的服务器,包括:监听采集模块、音频数据处理模块、存储模块和播放控制模块。The server described in the embodiment of the present invention includes: a listening and collecting module, an audio data processing module, a storage module and a playback control module.
监听采集模块,用于监听是否有音频数据到达服务器,当监听到有音频数据到达后进行采集;The monitoring acquisition module is used to monitor whether audio data arrives at the server, and collects when the audio data arrives;
音频数据处理模块,用于将采集的音频数据转化为不同的单一音源数据;这里,音频处理器采用粒子滤波器和均衡器,如图7所示,最终把各麦克风采集的音频信号转化为不同的单一音源信号。每一个音频处理器采用模块插件的设计,这样可以根据需要添加和删除不同的音频处理器,而不影响整个系统,同时也能随着研究的深入不断设计更好的音频处理器。The audio data processing module is used to convert the collected audio data into different single sound source data; here, the audio processor adopts a particle filter and an equalizer, as shown in Figure 7, and finally converts the audio signals collected by each microphone into different single source signal. Each audio processor adopts a modular plug-in design, so that different audio processors can be added and deleted as needed without affecting the entire system. At the same time, better audio processors can be continuously designed with the deepening of research.
存储模块,用于将转化后的单一音源数据有损或无损转化压缩成音频文件格式,加入相关文件信息,包括标示区分大于256声道系统并保存;The storage module is used for lossy or lossless conversion and compression of the converted single audio source data into an audio file format, adding relevant file information, including marking and distinguishing systems greater than 256 channels, and saving them;
播放控制模块,用于读取已保存的音频文件,根据M路音源数据及重建声场的特性,混合音源数据并通过智能匹配转换为N路扬声器的输出数据和控制信号,发送至音频还音子系统。如图8所示,在本实施例中播放控制模块采用智能转换模块来实现MINO的匹配,在转换过程中可进行M与N动态加权匹配。The playback control module is used to read the saved audio files, mix the audio source data and convert them into output data and control signals of N-channel speakers through intelligent matching according to the M-channel audio source data and the characteristics of the reconstructed sound field, and send them to the audio-returning sub system. As shown in FIG. 8 , in this embodiment, the playback control module adopts the intelligent conversion module to realize MINO matching, and M and N dynamic weighted matching can be performed during the conversion process.
在服务器的前端,各麦克风采集到的音频信号通过服务器上以太网口(通讯接口)输入服务器。因此,服务器通过监听采集模块建立端口监听,如图6所示。当有数据到达任何一个以太网口时,以TCP/IP协议读取数据包,并根据数据包包头的声道标识确定此音频流数据包的声道属性,然后把不同声道的音频流数据分别存入不同的硬盘文件中。远程客户端可以通过ISCSI协议访问播放SCSI盘上的这些音频文件或其它传输协议访问相应的存储介质。At the front end of the server, the audio signals collected by each microphone are input to the server through the Ethernet port (communication interface) on the server. Therefore, the server establishes port monitoring through the monitoring collection module, as shown in FIG. 6 . When data arrives at any Ethernet port, read the data packet with the TCP/IP protocol, and determine the channel attribute of the audio stream data packet according to the channel identification of the data packet header, and then transfer the audio stream data of different channels Store them in different hard disk files. The remote client can access and play these audio files on the SCSI disk through the ISCSI protocol or access the corresponding storage medium through other transmission protocols.
在还音过程中,服务器通过播放控制模块读取已保存的音频文件,根据M路音源数据及重建声场的特性,混合音源数据并通过智能匹配转换为N路扬声器的输出数据和控制信号,发送至音频还音子系统。During the sound reproduction process, the server reads the saved audio files through the playback control module, mixes the sound source data according to the characteristics of the M-channel sound source data and the reconstructed sound field, and converts the audio source data into output data and control signals of the N-channel speakers through intelligent matching, and sends the to the audio reproduction subsystem.
本发明实施例所述的音频还音子系统,包括:多个音频还音子板和一个音频还音母板。The audio sound reproduction subsystem described in the embodiment of the present invention includes: a plurality of audio sound reproduction sub-boards and an audio sound reproduction motherboard.
其中,每个音频还音子板包括1个或多个音频还音通道、一数模转换器组及一现场可编程门阵列。Wherein, each audio sound reproduction sub-board includes one or more audio sound reproduction channels, a digital-to-analog converter group and a field programmable gate array.
音频还音母板包括:还音子板控制接口、还音子板数据接口及服务器通讯接口,如图9所示。The audio reproduction motherboard includes: a sound reproduction sub-board control interface, a sound reproduction sub-board data interface and a server communication interface, as shown in FIG. 9 .
音频还音母板通过服务器通讯接口接收来自服务器的各扬声器的输出数据和控制信号,并通过还音子板数据接口将各扬声器的输出数据发送至音频还音子板,同时通过还音子板控制接口将控制信号发送至音频还音子板,如图10所示;请同时参照图9,音频还音子板中的现场可编程门阵列根据从音频还音母板收到的控制信号来同步从音频还音母板收到的各扬声器的输出数据,并发送至数模转换器D/A组(图9中示出了4个双路数模转换器D/A)转换为多通道模拟音频信号,通过音频还音通道(CH0-CHN,音频还音通道一般不超过8个)发送至扬声器阵列播放。The audio reproduction motherboard receives the output data and control signals from the speakers of the server through the server communication interface, and sends the output data of each speaker to the audio reproduction daughter board through the data interface of the reproduction sub-board, and at the same time passes the The control interface sends the control signal to the audio reproduction sub-board, as shown in Figure 10; please refer to Figure 9 at the same time, the field programmable gate array in the audio reproduction sub-board Synchronize the output data of each speaker received from the audio reproduction motherboard, and send to the digital-to-analog converter D/A group (4 dual-channel digital-to-analog converter D/A are shown in Figure 9) to convert into multi-channel The analog audio signal is sent to the speaker array for playback through audio reproduction channels (CH0-CHN, generally no more than 8 audio reproduction channels).
如图11所示,服务器中的播放控制模块中还可以增加扬声器音量控制子模块来对扬声器阵列进行音量控制,比如,增加单扬声器音量控制单元、分组扬声器音量控制单元及全部扬声器音量控制单元,来分别对扬声器阵列进行单扬声器音量控制、分组扬声器音量控制或全部扬声器音量控制。同时,由于服务器和各扬声器采用网络的方式连接,还可以增加扬声器阵列网络监控子模块,使得服务器端能够对每个扬声器的连接状态进行监控,以便及时发现连接不正常的扬声器。这里,对于扬声器音量控制子模块及扬声器阵列网络监控子模块可以采用现有的成熟技术实现,如音频功率放大器里,采用的数字或模拟的音量控制,就是对扬声器进行音量控制的,可以是对单、分组及全部扬声器进行音量控制。As shown in Figure 11, a speaker volume control submodule can also be added to the playback control module in the server to control the volume of the speaker array, such as adding a single speaker volume control unit, a group speaker volume control unit and all speaker volume control units, to perform individual speaker volume control, group speaker volume control, or all speaker volume control for the speaker array individually. At the same time, since the server and each loudspeaker are connected through a network, a loudspeaker array network monitoring sub-module can also be added, so that the server can monitor the connection status of each loudspeaker, so as to find abnormally connected loudspeakers in time. Here, the loudspeaker volume control submodule and the loudspeaker array network monitoring submodule can be implemented using existing mature technologies, such as in the audio power amplifier, the digital or analog volume control used is to control the volume of the loudspeaker, which can be Volume control for single, group and all speakers.
对扬声器的监控,包括扬声器输入电压测量,扬声器声场输出测量,测量结果通过监控网络,送到服务器端,以保证工作正常。在远程播放时,可以选择不对扬声器检测。The monitoring of the loudspeaker includes the measurement of the input voltage of the loudspeaker and the measurement of the output of the sound field of the loudspeaker. The measurement results are sent to the server through the monitoring network to ensure normal operation. When playing remotely, you can choose not to detect the speaker.
本发明所述的一种有限声源多通道声场系统及音频数据包结构,并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明之领域,对于熟悉本领域的人员而言可容易地实现另外的优点和进行修改,因此在不背离权利要求及等同范围所限定的一般概念的精神和范围的情况下,本发明并不限于特定的细节、代表性的设备和这里示出与描述的图示示例。A limited sound source multi-channel sound field system and audio data packet structure described in the present invention are not limited to the use listed in the description and the implementation, and it can be applied to various fields suitable for the present invention. Additional advantages and modifications will readily occur to those skilled in the art, so the invention is not to be limited to the specific details, representative examples, and the like without departing from the spirit and scope of the general concept defined by the claims and equivalents thereof. equipment and illustrated examples shown and described herein.
Claims (12)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 200610113968 CN101001485A (en) | 2006-10-23 | 2006-10-23 | Finite sound source multi-channel sound field system and sound field analogy method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 200610113968 CN101001485A (en) | 2006-10-23 | 2006-10-23 | Finite sound source multi-channel sound field system and sound field analogy method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN101001485A true CN101001485A (en) | 2007-07-18 |
Family
ID=38693249
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN 200610113968 Pending CN101001485A (en) | 2006-10-23 | 2006-10-23 | Finite sound source multi-channel sound field system and sound field analogy method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN101001485A (en) |
Cited By (34)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102231868A (en) * | 2011-05-18 | 2011-11-02 | 上海大学 | High-order-recording-way-based three-dimensional (3D) sound reproducing system |
| CN102694584A (en) * | 2011-03-21 | 2012-09-26 | 冯汉英 | System for audio transmission via wireless network |
| CN103379424A (en) * | 2012-04-24 | 2013-10-30 | 华为技术有限公司 | Sound mixing method and multi-point control server |
| CN103621101A (en) * | 2011-07-01 | 2014-03-05 | 杜比实验室特许公司 | Synchronization and switchover methods and systems for an adaptive audio system |
| CN103702275A (en) * | 2014-01-06 | 2014-04-02 | 黄文忠 | Sound image repositioning technology |
| CN104125534A (en) * | 2013-07-18 | 2014-10-29 | 中国传媒大学 | Synchronous multi-channel audio recording and playing method and system |
| CN104168534A (en) * | 2014-09-01 | 2014-11-26 | 北京塞宾科技有限公司 | Holographic audio device and control method |
| CN104217750A (en) * | 2014-09-01 | 2014-12-17 | 北京塞宾科技有限公司 | A holographic audio record and playback method |
| CN105263093A (en) * | 2015-10-12 | 2016-01-20 | 深圳东方酷音信息技术有限公司 | Omnibearing audio acquisition apparatus, omnibearing audio editing apparatus, and omnibearing audio acquisition and editing system |
| CN105323702A (en) * | 2014-07-09 | 2016-02-10 | 九次元科技有限公司 | Sound mixing method and system |
| CN105897998A (en) * | 2015-12-30 | 2016-08-24 | 乐视致新电子科技(天津)有限公司 | Smart phone recording method and system |
| CN105959841A (en) * | 2016-04-28 | 2016-09-21 | 乐视控股(北京)有限公司 | Mobile terminal audio playing method, device and headset |
| US9510098B2 (en) | 2014-08-20 | 2016-11-29 | National Tsing Hua University | Method for recording and reconstructing three-dimensional sound field |
| CN106664480A (en) * | 2014-04-07 | 2017-05-10 | 哈曼贝克自动系统股份有限公司 | Sound wave field generation |
| CN107195308A (en) * | 2017-04-14 | 2017-09-22 | 苏州科达科技股份有限公司 | Sound mixing method, the apparatus and system of audio/video conference system |
| CN107506409A (en) * | 2017-08-09 | 2017-12-22 | 浪潮金融信息技术有限公司 | A kind of processing method of Multi-audio-frequency data |
| CN108447116A (en) * | 2018-02-13 | 2018-08-24 | 中国传媒大学 | The method for reconstructing three-dimensional scene and device of view-based access control model SLAM |
| CN108769874A (en) * | 2018-06-13 | 2018-11-06 | 广州国音科技有限公司 | A kind of method and apparatus of real-time separating audio |
| CN108848392A (en) * | 2018-07-18 | 2018-11-20 | 广州市兰德电子技术有限公司 | Audio, video data acquires in real time and transmission method |
| US10165387B2 (en) | 2011-07-01 | 2018-12-25 | Dolby Laboratories Licensing Corporation | System and method for adaptive audio signal generation, coding and rendering |
| CN110730398A (en) * | 2019-10-16 | 2020-01-24 | 同响科技股份有限公司 | Distributed Wireless Microphone Array Audio Radio Synchronization Method |
| CN111145773A (en) * | 2019-12-31 | 2020-05-12 | 苏州思必驰信息科技有限公司 | Sound field restoration method and device |
| CN112218115A (en) * | 2020-09-25 | 2021-01-12 | 深圳市捷视飞通科技股份有限公司 | Control method and device for streaming media audio and video synchronization and computer equipment |
| CN112218016A (en) * | 2019-07-09 | 2021-01-12 | 海信视像科技股份有限公司 | Display device |
| CN112216310A (en) * | 2019-07-09 | 2021-01-12 | 海信视像科技股份有限公司 | Audio processing method and device and multi-channel system |
| CN112435682A (en) * | 2020-11-10 | 2021-03-02 | 广州小鹏汽车科技有限公司 | Vehicle noise reduction system, method and device, vehicle and storage medium |
| CN113068056A (en) * | 2021-03-18 | 2021-07-02 | 广州虎牙科技有限公司 | Audio playing method and device, electronic equipment and computer readable storage medium |
| CN113075614A (en) * | 2021-03-17 | 2021-07-06 | 武汉创现科技有限公司 | Sound source direction-finding device for cruise device, cruise device and intelligent garbage can |
| CN113077827A (en) * | 2020-01-03 | 2021-07-06 | 北京地平线机器人技术研发有限公司 | Audio signal acquisition apparatus and audio signal acquisition method |
| CN114217996A (en) * | 2021-12-27 | 2022-03-22 | 北京百度网讯科技有限公司 | Mixing method and apparatus |
| CN114666721A (en) * | 2022-05-05 | 2022-06-24 | 深圳市丰禾原电子科技有限公司 | Wifi sound box with terminal tracking mode and control method thereof |
| CN116193192A (en) * | 2023-03-01 | 2023-05-30 | 海宁奕斯伟集成电路设计有限公司 | Audio output method, device, electronic device and storage medium |
| CN116600230A (en) * | 2023-04-06 | 2023-08-15 | 北京奥特维科技有限公司 | A method and device for simulating ambient sound in a specific scene |
| CN118250601A (en) * | 2024-05-24 | 2024-06-25 | 深圳市维尔晶科技有限公司 | Multi-sound intelligent management control system |
-
2006
- 2006-10-23 CN CN 200610113968 patent/CN101001485A/en active Pending
Cited By (50)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102694584A (en) * | 2011-03-21 | 2012-09-26 | 冯汉英 | System for audio transmission via wireless network |
| CN102231868A (en) * | 2011-05-18 | 2011-11-02 | 上海大学 | High-order-recording-way-based three-dimensional (3D) sound reproducing system |
| TWI651005B (en) * | 2011-07-01 | 2019-02-11 | 杜比實驗室特許公司 | System and method for generating, decoding and presenting adaptive audio signals |
| CN103621101A (en) * | 2011-07-01 | 2014-03-05 | 杜比实验室特许公司 | Synchronization and switchover methods and systems for an adaptive audio system |
| US10165387B2 (en) | 2011-07-01 | 2018-12-25 | Dolby Laboratories Licensing Corporation | System and method for adaptive audio signal generation, coding and rendering |
| US10477339B2 (en) | 2011-07-01 | 2019-11-12 | Dolby Laboratories Licensing Corporation | System and method for adaptive audio signal generation, coding and rendering |
| US10904692B2 (en) | 2011-07-01 | 2021-01-26 | Dolby Laboratories Licensing Corporation | System and method for adaptive audio signal generation, coding and rendering |
| US11412342B2 (en) | 2011-07-01 | 2022-08-09 | Dolby Laboratories Licensing Corporation | System and method for adaptive audio signal generation, coding and rendering |
| US11962997B2 (en) | 2011-07-01 | 2024-04-16 | Dolby Laboratories Licensing Corporation | System and method for adaptive audio signal generation, coding and rendering |
| US12335718B2 (en) | 2011-07-01 | 2025-06-17 | Dolby Laboratories Licensing Corporation | System and method for adaptive audio signal generation, coding and rendering |
| US10327092B2 (en) | 2011-07-01 | 2019-06-18 | Dolby Laboratories Licensing Corporation | System and method for adaptive audio signal generation, coding and rendering |
| CN103379424B (en) * | 2012-04-24 | 2016-08-10 | 华为技术有限公司 | A kind of sound mixing method and multipoint control server |
| CN103379424A (en) * | 2012-04-24 | 2013-10-30 | 华为技术有限公司 | Sound mixing method and multi-point control server |
| CN104125534A (en) * | 2013-07-18 | 2014-10-29 | 中国传媒大学 | Synchronous multi-channel audio recording and playing method and system |
| CN103702275A (en) * | 2014-01-06 | 2014-04-02 | 黄文忠 | Sound image repositioning technology |
| CN106664480A (en) * | 2014-04-07 | 2017-05-10 | 哈曼贝克自动系统股份有限公司 | Sound wave field generation |
| CN106664480B (en) * | 2014-04-07 | 2021-06-15 | 哈曼贝克自动系统股份有限公司 | System and method for acoustic wave field generation |
| CN105323702A (en) * | 2014-07-09 | 2016-02-10 | 九次元科技有限公司 | Sound mixing method and system |
| US9510098B2 (en) | 2014-08-20 | 2016-11-29 | National Tsing Hua University | Method for recording and reconstructing three-dimensional sound field |
| CN104217750A (en) * | 2014-09-01 | 2014-12-17 | 北京塞宾科技有限公司 | A holographic audio record and playback method |
| CN104168534A (en) * | 2014-09-01 | 2014-11-26 | 北京塞宾科技有限公司 | Holographic audio device and control method |
| CN105263093A (en) * | 2015-10-12 | 2016-01-20 | 深圳东方酷音信息技术有限公司 | Omnibearing audio acquisition apparatus, omnibearing audio editing apparatus, and omnibearing audio acquisition and editing system |
| CN105263093B (en) * | 2015-10-12 | 2018-06-26 | 深圳东方酷音信息技术有限公司 | A kind of comprehensive voice collection device, editing device and system |
| CN105897998A (en) * | 2015-12-30 | 2016-08-24 | 乐视致新电子科技(天津)有限公司 | Smart phone recording method and system |
| CN105959841A (en) * | 2016-04-28 | 2016-09-21 | 乐视控股(北京)有限公司 | Mobile terminal audio playing method, device and headset |
| CN107195308A (en) * | 2017-04-14 | 2017-09-22 | 苏州科达科技股份有限公司 | Sound mixing method, the apparatus and system of audio/video conference system |
| CN107506409A (en) * | 2017-08-09 | 2017-12-22 | 浪潮金融信息技术有限公司 | A kind of processing method of Multi-audio-frequency data |
| CN108447116A (en) * | 2018-02-13 | 2018-08-24 | 中国传媒大学 | The method for reconstructing three-dimensional scene and device of view-based access control model SLAM |
| CN108769874A (en) * | 2018-06-13 | 2018-11-06 | 广州国音科技有限公司 | A kind of method and apparatus of real-time separating audio |
| CN108848392A (en) * | 2018-07-18 | 2018-11-20 | 广州市兰德电子技术有限公司 | Audio, video data acquires in real time and transmission method |
| CN112216310B (en) * | 2019-07-09 | 2021-10-26 | 海信视像科技股份有限公司 | Audio processing method and device and multi-channel system |
| CN112218016A (en) * | 2019-07-09 | 2021-01-12 | 海信视像科技股份有限公司 | Display device |
| CN112216310A (en) * | 2019-07-09 | 2021-01-12 | 海信视像科技股份有限公司 | Audio processing method and device and multi-channel system |
| CN110730398A (en) * | 2019-10-16 | 2020-01-24 | 同响科技股份有限公司 | Distributed Wireless Microphone Array Audio Radio Synchronization Method |
| CN111145773A (en) * | 2019-12-31 | 2020-05-12 | 苏州思必驰信息科技有限公司 | Sound field restoration method and device |
| CN113077827A (en) * | 2020-01-03 | 2021-07-06 | 北京地平线机器人技术研发有限公司 | Audio signal acquisition apparatus and audio signal acquisition method |
| CN112218115A (en) * | 2020-09-25 | 2021-01-12 | 深圳市捷视飞通科技股份有限公司 | Control method and device for streaming media audio and video synchronization and computer equipment |
| CN112435682A (en) * | 2020-11-10 | 2021-03-02 | 广州小鹏汽车科技有限公司 | Vehicle noise reduction system, method and device, vehicle and storage medium |
| CN112435682B (en) * | 2020-11-10 | 2024-04-16 | 广州小鹏汽车科技有限公司 | Vehicle noise reduction system, method and device, vehicle and storage medium |
| CN113075614A (en) * | 2021-03-17 | 2021-07-06 | 武汉创现科技有限公司 | Sound source direction-finding device for cruise device, cruise device and intelligent garbage can |
| CN113068056A (en) * | 2021-03-18 | 2021-07-02 | 广州虎牙科技有限公司 | Audio playing method and device, electronic equipment and computer readable storage medium |
| CN113068056B (en) * | 2021-03-18 | 2023-08-22 | 广州虎牙科技有限公司 | Audio playing method, device, electronic equipment and computer readable storage medium |
| CN114217996B (en) * | 2021-12-27 | 2025-06-13 | 北京百度网讯科技有限公司 | Mixing method and device |
| CN114217996A (en) * | 2021-12-27 | 2022-03-22 | 北京百度网讯科技有限公司 | Mixing method and apparatus |
| CN114666721A (en) * | 2022-05-05 | 2022-06-24 | 深圳市丰禾原电子科技有限公司 | Wifi sound box with terminal tracking mode and control method thereof |
| CN114666721B (en) * | 2022-05-05 | 2024-02-06 | 深圳市丰禾原电子科技有限公司 | Wifi sound box with terminal tracking mode and control method thereof |
| CN116193192A (en) * | 2023-03-01 | 2023-05-30 | 海宁奕斯伟集成电路设计有限公司 | Audio output method, device, electronic device and storage medium |
| CN116600230A (en) * | 2023-04-06 | 2023-08-15 | 北京奥特维科技有限公司 | A method and device for simulating ambient sound in a specific scene |
| CN118250601B (en) * | 2024-05-24 | 2025-01-14 | 深圳市维尔晶科技有限公司 | A multi-speaker intelligent management and control system |
| CN118250601A (en) * | 2024-05-24 | 2024-06-25 | 深圳市维尔晶科技有限公司 | Multi-sound intelligent management control system |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101001485A (en) | Finite sound source multi-channel sound field system and sound field analogy method | |
| US10674262B2 (en) | Merging audio signals with spatial metadata | |
| CN107533843B (en) | System and method for capturing, encoding, distributing and decoding immersive audio | |
| JP5956994B2 (en) | Spatial audio encoding and playback of diffuse sound | |
| US9055382B2 (en) | Calibration of headphones to improve accuracy of recorded audio content | |
| US7930048B2 (en) | Apparatus and method for controlling a wave field synthesis renderer means with audio objects | |
| CN102326417B (en) | Method and apparatus for three-dimensional acoustic field encoding and optimal reconstruction | |
| CN105323702B (en) | Audio mixing method and system | |
| CN106535059B (en) | Rebuild stereosonic method and speaker and position information processing method and sound pick-up | |
| JP5611970B2 (en) | Converter and method for converting audio signals | |
| JP2001503942A (en) | Multi-channel audio emphasis system for use in recording and playback and method of providing the same | |
| JP2010538572A (en) | Audio signal decoding method and apparatus | |
| CN108616800A (en) | Playing method and device, storage medium, the electronic device of audio | |
| US9756437B2 (en) | System and method for transmitting environmental acoustical information in digital audio signals | |
| JP2005157278A (en) | Apparatus, method, and program for creating all-around acoustic field | |
| CN103636237B (en) | Method of processing audio signals for improved restoration | |
| CN203206451U (en) | Three-dimensional (3D) audio processing system | |
| CN102752691A (en) | Audio processing technology, 3D (three dimensional) virtual sound and applications of 3D virtual sound | |
| CN110782865B (en) | Three-dimensional sound creation interactive system | |
| US20080013430A1 (en) | Method of Recording, Reproducing and Handling Audio Data in a Data Recording Medium | |
| Li et al. | How Audio is Getting its Groove Back: Deep learning is delivering the century-old promise of truly realistic sound reproduction | |
| Kunchur | 3D imaging in two-channel stereo sound: Portrayal of elevation | |
| CN119943094B (en) | Audio code stream quality analysis and evaluation method based on cyanine color sound Audio Vivid | |
| CN117061984A (en) | Method and system for testing multi-channel audio content | |
| CN100508057C (en) | An audio playback device and audio playback method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C02 | Deemed withdrawal of patent application after publication (patent law 2001) | ||
| WD01 | Invention patent application deemed withdrawn after publication |
Open date: 20070718 |