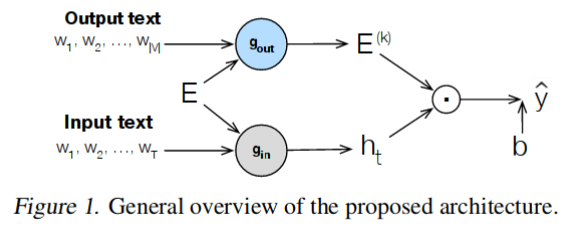
drill — a Pytorch implementation of DRILL which allows to build deep residual output layers for neural language generation, to be presented at ICML 2019 [1]. Our deep output mapping explicitly captures the similarity structure of the output space while it avoids overfitting with two different dropout strategies between layers, and preserves useful information with residual connections to the word embeddings and, optionally, to the outputs of previous layers. Evaluations on three language generation tasks show that our output label mapping can match or improve state-of-the-art recurrent and self-attention architectures.
@inproceedings{Pappas_ICML_2019,
author = {Nikolaos Pappas, James Henderson},
title = {Deep Residual Output Layers for Neural Language Generation},
booktitle = {Proceedings of the 36th International Conference on Machine Learning},
address = {Long Beach, California},
year = {2019}
}
The code for DRILL requires Python 3.5 programming language and pip package manager to run.
For detailed instructions on how to install them please refer to the corresponding links. Next, you should be able to install the required libraries as follows using the provided list of dependencies:
pip install -r dependencies.txt
To avoid creating library conflicts in your existing pip environment, it may be more convenient to use a folder-specific pip environment with pipenv instead. Our experiments were run on NVIDIA GTX 1080 Ti GPUs with CUDA 8.0 and cuDNN 5110.
To obtain our pretrained models from Google Drive directly from command line you can download the following script:
wget https://raw.githubusercontent.com/circulosmeos/gdown.pl/master/gdown.pl; chmod +x gdown.pl;
To obtain the corresponding datasets for language modeling and machine translation please follow the instructions from [2] and [3] respectively, e.g. the former can be easily obtained by running this script.
Under the main folder (./) you can find the code related to the neural language modeling experiments on PennTreebank and Wikitext-2 datasets from [2]. Note that a large portion of this repository is borrowed from awd-lstm. Below you can find the commands for training our model on the two examined datasets.
The commands for our main results in Table 1 and 4 are the following:
python main.py --data data/penn --dropouti 0.4 --dropouth 0.25 --seed 28 --batch_size 20 --epoch 1000 \
--save exp/pen-drill-4l --joint_emb 400 --joint_emb_depth 4 --joint_dropout 0.6 --joint_locked_dropout \
--joint_emb_activation Sigmoidpython finetune.py --data data/penn --dropouti 0.4 --dropouth 0.25 --seed 28 --batch_size 20 --epoch \
1000 --save exp/pen-drill-4l --joint_emb 400 --joint_emb_depth 4 --joint_dropout 0.6 --joint_locked_\
dropout --joint_emb_activation SigmoidOur pretrained version of the above model can be obtained as follows:
./gdown.pl https://drive.google.com/open?id=1H6xELj0gaqhiAZJUzPuKJmMqws3WWbLx penn.zip
The commands for our main results in Table 2 are the following:
python main.py --data data/wiki2 --dropouth 0.2 --seed 1882 --epoch 2000 --save exp/wiki2-drill --joint\
_emb 400 --joint_emb_depth 4 --joint_dropout 0.6 --joint_emb_activation ReLUpython finetune.py --data data/wiki2 --dropouth 0.2 --seed 1882 --epoch 2000 --save exp/wiki2-drill \
--joint_emb 400 --joint_emb_depth 4 --joint_dropout 0.6 --joint_emb_activation ReLUOur pretrained version of the above model can be obtained as follows:
./gdown.pl https://drive.google.com/open?id=1Mf1GXAGsCgjWNaj2JEGgEe0KsU45K_jo wiki2.zip
Under the onmt/ folder you can find the code related to the neural machine translation experiments on the WMT 2014 English to German dataset as in [3]. Due to its large scope, we haven't included the whole OpenNMT-py framework but one can directly copy our files to the original onmt/ directory. Below you can find the command for training our model.
The command for our main results in Table 5 is the following:
python train.py -data data/en-de_32k -save_model drill -layers 6 -rnn_size 512 -word_vec_size 512 -transformer_ff 2048 -heads 8 -encoder_type transformer -decoder_type transformer -position_encoding -train_steps 350000 -max_generator_batches 2 -dropout 0.1 -batch_size 4096 -batch_type tokens -normalization tokens -accum_count 2 -optim adam -adam_beta2 0.998
-decay_method noam -warmup_steps 8000 -learning_rate 2 -max_grad_norm 0 -param_init 0 -param_init_glorot -label_smoothing 0.1 -valid_steps 10000 -save_checkpoint_steps 10000 -world_size 1 -gpu_ranks 0 -share_decoder_embeddings --joint_emb 512 --joint_emb_depth 2 --joint_dropout 0.0 --joint_locked_dropout --joint_emb_activation Sigmoid Our pretrained version of the above model can be obtained as follows:
./gdown.pl https://drive.google.com/open?id=1xZyZ8P97roMuhRSrxn6HTURgTEs2r9FM en-de_32k.zip
- [1] Nikolaos Pappas, James Henderson, Deep Residual Output Layers for Neural Language Generation, Thirty-sixth International Conference on Machine Learning, Long Beach, California, 2019
- [2] Stephen Merity, Nitish Shirish Keskar, Richard Socher, Regularizing and Optimizing LSTM Language Models, Sixth International Conference on Learning Representations, Vancouver, Canada, 2018
- [3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin Attention is All You Need, Advances in Neural Information Processing Systems, Montreal, Canada, 2018
This work was supported by the European Union through SUMMA project (n. 688139) and the Swiss National Science Foundation within INTERPID project (FNS-30106).