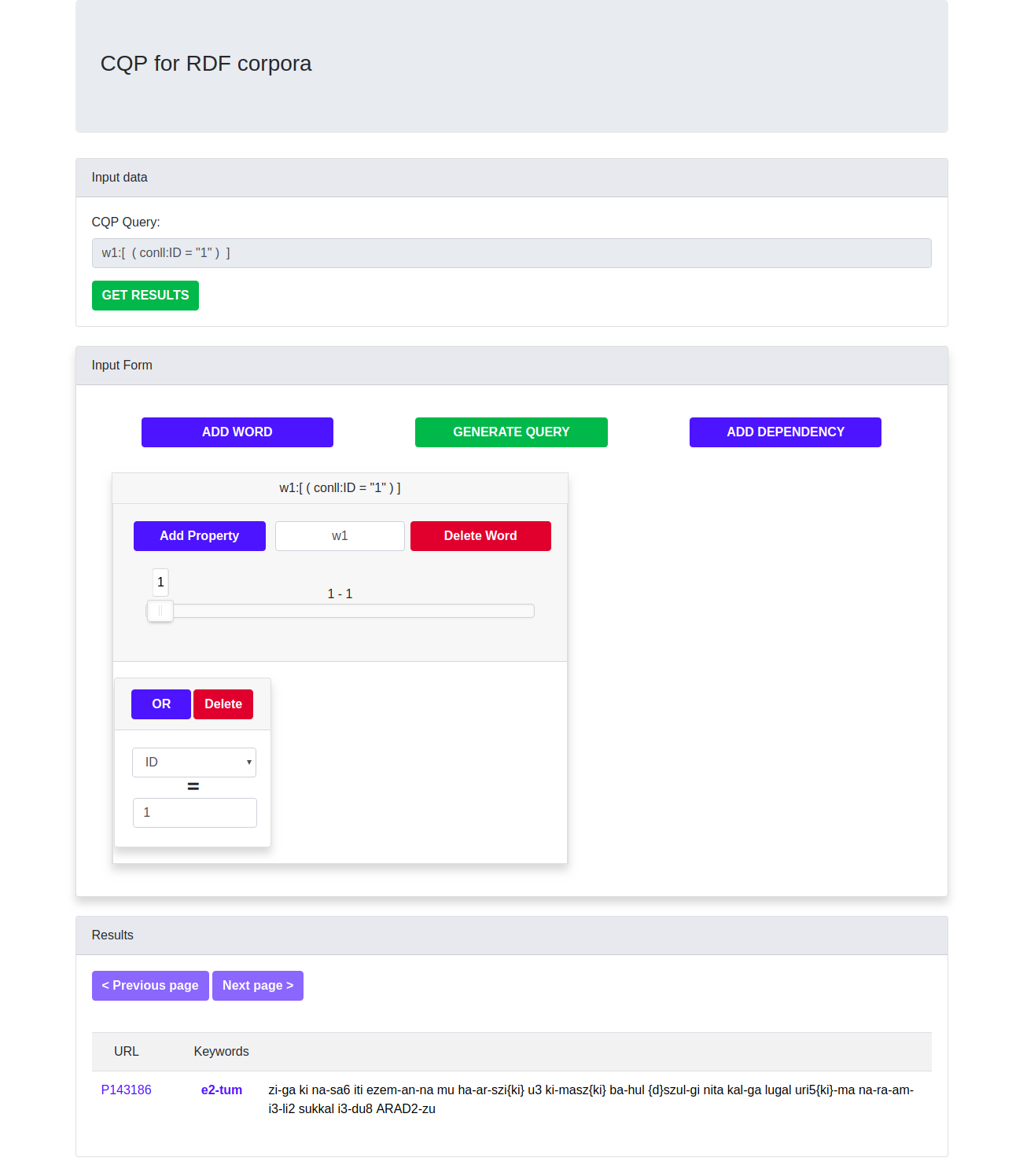
CQP4RDF is a tool which can be used to easily query from a corpus which has multiple layers of annotations. For querying either the query can be written directly in form of CQP or the query can be generated from the Query Generator GUI which we have developed and is capable to generate complex CQP queries.
In our experiments with SPARQL for corpora querying, we stumbled upon a problem: writing complex SPARQL queries is hard. Especially for people without enough expertise in the field. To make the process easier, it makes sense to use a widely-known corpus query language, use it and then translate queries to SPARQL queries which are then run against our data.
A good candidate for the query language is CQP — a language developed for the IMS Corpus Workbench. It is used in corpus management systems like SketchEngine, NoSketchEngine, Corpus Tool and others. Many linguists have experience with it, and even for those who have never worked with it, it is relatively easy to get started.
Here is an example, a query that looks for sentences that contain exactly two verbs: one with a lemma է (to be), and another one which is either a perfective converb or an imperfective converb:
( v1:[conll:LEM='է' and rdfs:type='olia:Verb']
v2:[a='eanc:ImperfectiveConverb' or rdfs:type='eanc:PerfectiveConverb'])
within
(<powla:sentence/> !containing v3:[rdfs:type='olia:Verb'])
) & v1.ID != v3.ID and v2.ID != v3.ID
Although it is a bit complicated, it is easier to write and to understand than its SPARQL counterpart with all the UNIONs and FILTERs.
Further, we have also have built a query builder, which is capable of generating complex CQP format queries.
CQP grammar is parsed by the Lark Python module which parses context-free grammars in eBNF notation into its abstract syntax tree. AST is then been transformed into SPARQL.
The details of the CQP dialect can be found in the corresponding document.
Currently, there is a simple web interface for searching with CQP in EANC (or any other POWLA-annotated corpus) written in Python. Its description can be found in the corresponding document.
Built with
This project is the first of its kind, which is using SPARQL to query over the multiple layers of corpus annotations. We use the format of the CQP language, which is much easier as compared to SPARQL. The CQP query is then converted to SPARQL query which is then queried over the RDF endpoint, which then retrieves the results.
To expand the power of the tool, we had to leave one of the constraints of CQP. We have left the constraint that the words in the CQP query will be always continuous. The words are not always next to each other. For making the words to be continuous, a separate nextWord dependency has to be added. Leaving this constraint helps to add a lot of power to the tool.
For CDLI version, the docker version of config file has been made the default config.yaml file.
- Create a virtualenv in python
virtualenv cqp4rdf_env --python=python3
- Shift to that enviornment
source cqp4rdf_env/bin/activate
- Install
dockeranddocker-compose. - Clone the repository
git clone https://github.com/cdli-gh/cqp4rdf
- Shift to the CQP4RDF repository
cd cqp4rdf
- Make the
config.yamlfile
cp cqp4rdf/config.docker.yaml cqp4rdf/config.yaml
-
Edit the
config.yamlas per your requirements and needs. -
Edit the
docker-composefile as per your needs. If the ports specified in the docker-compose file are not available, i.e. 8088 and 3030, then the mapping can be updated as per the need. After update, the docker-compose file will have to build again. -
Build the
docker-composeimage
docker-compose build
- Run the docker-compose containers
docker-compose up
This will start the 2 docker containers i.e. the CQP4RDF
You will need a triple store with a SPARQL endpoint to use cqp4rdf. It was tested with Apache Jena Fuseki and Blazegraph.
Apart from that, you need to create a config file config.yaml in the installation directory (you can make a copy of config.example.yaml and modify it). The URL for the SPARQL endpoint is configured there.
Triples should be stored in a named graph that is also specified in config.
- Create a virtualenv in python
virtualenv cqp4rdf_env --python=python3
- Shift to that enviornment
source cqp4rdf_env/bin/activate
- Clone the repository
git clone https://github.com/cdli-gh/cqp4rdf
- Shift to the CQP4RDF repository
cd cqp4rdf
- Make the
config.yamlfile
cp cqp4rdf/config.example.yaml cqp4rdf/config.yaml
- Install the dependencies in the virtual enviornment
pip install -r requirements.txt
-
Edit the
config.yamlas per your requirements and needs. -
Run cqp4rdf
python cqp4rdf/main.py
- Shift to the repository, where you have installed your SPARQL endpoint and run the SPARQL endpoint. You can also change the port on which you are running your fuseki endpoint, but same has to update in the
config.yaml
./fuseki-server
All the fields in the config.yaml files have already been commented.
Here we would be explainign the most important thing in setting the config.yaml, i.e. the fields that we are specifying in the corpus.
For eg:-
FEATS:
name: FEATS
query: conll:FEATS
disabled: false
type: list
multivalued: true
separator: "|"
values:
- "Case"
- "Animacy"
This is one of the field, which has various options:-
- name:- This specifies the name of the field.
- query:- When being added in the query, this field would be represented like "conll:FEATS".
- disabled:- This option refers to the whether the field has to disabled or enabled.
disabled=True:- it means that the field is disabled and would be ignored.disabled=False:- it means that the field is not disabled and would not be ignored.
- type:- This option refers to the type of field.
type = list:- would be showing the values in the dropdowntype = suggest:- would be suggesting the valuestype = integer:- would be having an input box with only integers allowed
- multivalued:- This option refers whether that field has mutiple values or not. WOuld be used when showing the info for the word.
multivalued = true:- would be referring that the field can have multiple values.multivalued = false:- would be referring that the field does not have multiple values.
- separator:- The value of the separator would be used to separate the values for a field, if the field has multiple values. Used when showing the word info for the retrieved sentences. It option is only required when
mulivalued=true - values:- This option is only required when the
type=listor thetype=suggest. This option is a list, which would would be containing the value to be suggetsed or in the dropdown.- if
type=list, then these values would be shown in the dropdown. - if
type=suggest, then these values would be suggested in the text box.
- if
Since we have the docker containers, the app can be directly deployed. All the instructions are same as that of running the docker container. Just a few more additions:-
- Just for security purposes, after the data has been uploaded on the fuseki server, it would be better to comment out the ports section for the fuseki server, so that it is not publically accessible.
- Also, since you would be leaving the terminal, it would be nice to run the
docker-composein daemon mode, so that yu can exit the container easily. It can be done in the following way ( use -d for the same):-
docker-compose up -d
Also the RDF data files in form of .ttl files have been added in the /data folder.
Once the fuseki server is up, all these files can be uploaded to the database with configurations as in config.yaml file.
We also have a separate docker file hosted on docker hub so that everything can be deployed easily.
- once done with your update in the config file and the docker-compose file, build the docker file and push the docker file to your docker hub. Unfortunately, we can't push docker-compose on docker hub.
- instead, the docker-compose is written in comments so that it can be made on the go
- while making a docker-compose to be public on the docker hub, update the cp4rdf section from being built to the image
- now login to your server, where you want to host it
- now install docker and docker-compose on the server
- once installed, now make a docker-compose file
- in the docker-compose file, update the d
- Install the docker and docker-compose
- Pull the docker image
- Make a docker-compose file as on the docker hub page
- run the docker-compose file
- The fuseki-server would be a port number 3030 and the CQP4RDF would be at the server 8088, by default. this could be updated as per the need.
- The data can be uploaded on the SARQL endpoint, port number as specified by
and your website is up
Some of the possible future improvements:-
- An
ADMINportal, which can be used to configure and would be saved as config file. - The portal which can be used to upload the data directly without uploading from the SPRQL endpoint
- Improving the API, so that they can return multiple types of value
- Max Ionov
- Florian Stein
- Ilya Khait
- Sagar
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.