we generate captions to the images which are given by user(user input) using prompt engineering and Generative AI
We use Zero-shot prompting technique in developing the prompt to generate image captions
Vision models can look at pictures and then tell you what's in them using words. These are called vision-to-text models. They bring together the power of understanding images and language. Using fancy neural networks, these models can look at pictures and describe them in a way that makes sense. They're like a bridge between what you see and what you can read.
This is super useful for things like making captions for images, helping people who can't see well understand what's in a picture, and organizing information. As these models get even smarter, they're going to make computers even better at understanding and talking about what they "see" in pictures. It's like teaching computers to understand and describe the visual world around us. Based on which model we are using like OPENAI,GEMINI(sub models),Anthropic we use respective API KEY and also we use endpoint if necessary
Based on which model we are using like OPENAI,GEMINI(sub models),Anthropic we use respective API KEY and also we use endpoint if necessary
➡️Generative model (predefined function) may play a key role in the whole process of development.
Evidence suggests Gemini represents the state-of-the-art in foundation models:
It achieves record-breaking results on over 56 benchmarks spanning text, code, math, visual, and audio understanding. This includes benchmarks like MMLU, GSM8K, MATH, Big-Bench Hard, HumanEval, Natural2Code, DROP, and WMT23.
➡️Notably, Gemini Ultra is the first to achieve human-expert performance on MMLU across 57 subjects with scores above 90%.
➡️On conceptual reasoning benchmarks like BIG-Bench, Gemini outperforms expert humans in areas like math, physics, and CS.
➡️Specialized versions create state-of-the-art applications like the code generator AlphaCode 2 which solves programming problems better than 85% of human coders in competitions.
➡️Qualitative examples show Gemini can manipulate complex math symbols, correct errors in derivations, generate relevant UIs based on conversational context, and more.
Google does not disclose details of Gemini architecture. But some multi-modal architectures shared by research community give us some intuitions on how it might work.
The CLIP architecture, introduced in 2021, uses contrastive learning between images with textual representations, with some distance function like cosine similarity to align the embedding spaces.

➡️Flamingo uses a vision encoder pre-trained using CLIP and a Chinchilla pre-trained language model to represent the text. It introduces some special components — the Perceiver Resampler and a special Gated cross-attention — to combine those interleaved multi-modal representations, and is trained to predict next tokens. Flamingo can perform visual question answering or conversations around that content.
 The above diagram represents that examples of visual dialogue from Flamingo paper
The above diagram represents that examples of visual dialogue from Flamingo paper
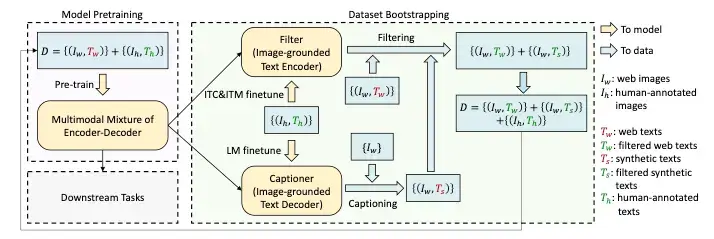
____________________Image from the original BLIP paper.
Since current models require massive amounts of data, it isn't easy to get high-quality data due to high annotation costs. CapFilt is a new method to improve the quality of the text corpus. It introduces two modules both of which are initialized from the same pre-trained objective and fine-tuned individually on the COCO dataset:
It is used to generate captions given the web images. It is an image-grounded text decoder and is fine-tuned with the LM objective to decode texts from given images.
It is used to remove noisy image-text pairs. The filter is an image-grounded text encoder and is finetuned with the ITC and ITM objectives to learn whether a text matches an image. The image captioner generates synthetic captions for the web images and the filter removes noisy texts from both the original web texts and the synthetic texts. A key thing to notice is that the human-labeled captions remain as they are (not filtered) and are assumed to be the ground truth. These filtered image-text pairs along with the human-labeled captions form the new dataset which is then used to pre-train a new model. Image Captioning using PyTorch and Transformers in Python.
The Generative Image-to-text Transformer (GIT) is another model designed to unify vision-language tasks such as image/video captioning and question answering. It was proposed by a team of researchers at Microsoft. The GIT model is unique in its simplicity, consisting of just one image encoder and one text decoder under a single language modeling task.
The GIT model was trained on a massive dataset of 0.8 billion image-text pairs. This large-scale pre-training data and the model size significantly boost the model's performance. The GIT model has achieved impressive performance on numerous challenging benchmarks, even surpassing human performance on the TextCaps benchmark.
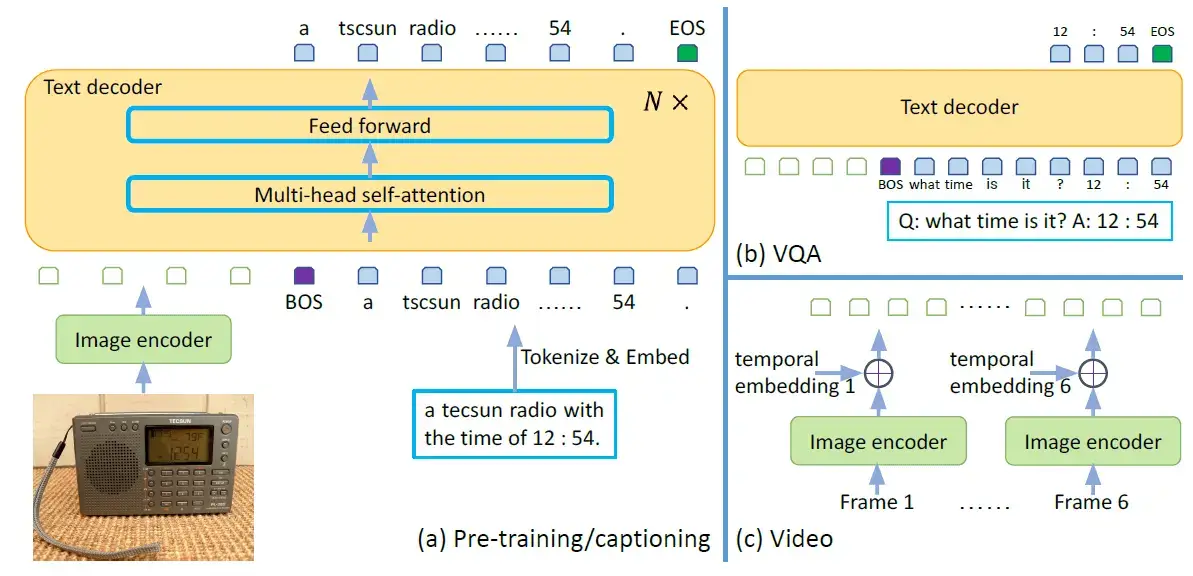
Image from the original GIT paper
The GIT model consists of an image encoder and a text decoder.
It is initialized as a contrastive pre-trained model, which takes a raw image as input and outputs a compact 2D feature map. This feature map is then flattened into a list of features, which are projected into a certain dimension (D) and fed into the text decoder.
It is a randomly initialized transformer module tasked with predicting the text description. It consists of multiple transformer blocks, each of which is composed of a self-attention layer and a feed-forward layer. The text is tokenized and embedded into D dimensions, followed by the addition of positional encoding and a layer normalization layer. The image features are concatenated with the text embeddings as input to the transformer module. The text begins with a [BOS] token and is decoded in an auto-regressive way until the [EOS] token or the maximum steps are reached. The entire model is trained using a language modeling task, where the goal is to predict the next word in a sentence given the previous words.
An important thing to note is that the attention mask is applied such that the text token only depends on the preceding tokens and all image tokens, and image tokens can attend to each other. This is different from a unidirectional attention mask, where not every image token can rely on all other image tokens.
The above figure also illustrates how the GIT model can be used for VQA from videos as well. To do this, we can first pass the different frames of the video through the image encoder to get the different frame embeddings. Then, we can add the temporal embeddings to the frame embeddings to avoid loss of temporal information and pass the final result to the text decoder.
➡️BLIP-2 also uses pre-trained image and LLM encoders, connected by a Q-Former component. The model is trained for multiple tasks: matching images and text representations with both constrastive learning (like CLIP) and with binary classification task. It is also trained on images caption generation.
The illustration for this paper will be as 
Each of the below models represents a unique approach to integrating and aligning text and image data, showcasing the diverse methodologies within the field of VLMs. The choice of architecture and fusion strategy depends largely on the specific application and the nature of the tasks the model is designed to perform.
Architecture: Uses a transformer for text and a ResNet (or a Vision Transformer) for images. Fusion Strategy: Late fusion, with a focus on learning a joint embedding space. Alignment Method: Trained using contrastive learning, where image-text pairs are aligned in a shared embedding space.
Architecture: Based on the GPT-3 architecture, adapted to handle both text and image tokens. Fusion Strategy: Early to intermediate fusion, where text and image features are processed in an intertwined manner. Alignment Method: Uses an autoregressive model that understands text and image features in a sequential manner.
Architecture: A BERT-like model that processes both visual and textual information. Fusion Strategy: Intermediate fusion with cross-modal attention mechanisms. Alignment Method: Aligns text and image features using attention within a transformer framework.
Architecture:
Specifically designed for vision-and-language tasks, uses separate encoders for language and vision, followed by a cross-modality encoder. Fusion Strategy:
Intermediate fusion with a dedicated cross-modal encoder. Alignment Method:
Employs cross-modal attention between language and vision encoders.
Input Modalities:
VLMs: Handle both visual (images) and textual (language) inputs. LLMs: Primarily focused on processing and generating textual content.
Task Versatility:
VLMs: Capable of tasks that require understanding and correlating information from both visual and textual data, like image captioning, visual storytelling, etc. LLMs: Specialize in tasks that involve only text, such as language translation, text generation, question answering purely based on text, etc. Complexity in Integration: VLMs involve a more complex architecture due to the need to integrate and correlate information from two different modalities (visual and textual), whereas LLMs deal with a single modality.
Use Cases:
VLMs are particularly useful in scenarios where both visual and textual understanding is crucial, such as in social media analysis, where both image and text content are prevalent. LLMs are more focused on applications like text summarization, chatbots, and content creation where the primary medium is text. In summary, while both VLMs and LLMs are advanced AI models leveraging deep learning, VLMs stand out for their ability to understand and synthesize information from both visual and textual data, offering a broader range of applications that require multimodal understanding. Connecting Vision and Language Via VLMs Vision-Language Models (VLMs) are designed to understand and generate content that combines both visual and textual data. To effectively integrate these two distinct modalities—vision and language—VLMs use specialized mechanisms, such as adapters and linear layers. This section details popular building blocks that various VLMs utilize to link visual and language input. Let’s delve into how these components work in the context of VLMs. Adapters/MLPs/Fully Connected Layers in VLMs
Vision-Language Models (VLMs) integrate both visual (image) and textual (language) information processing. They are designed to understand and generate content that involves both images and text, enabling them to perform tasks like image captioning, visual question answering, and text-to-image generation. This primer offers an overview of their architecture and how they differ from Large Language Models (LLMs).
Adapters are small neural network modules inserted into pre-existing models. In the context of VLMs, they facilitate the integration of visual and textual data by transforming the representations from one modality to be compatible with the other.
Functioning:
Adapters typically consist of a few fully connected layers (put simply, a Multi-Layer Perceptron). They take the output from one type of encoder (say, a vision encoder) and transform it into a format that is suitable for processing by another type of encoder or decoder (like a language model).
Role of Linear Layers:
Linear layers, or fully connected layers, are a fundamental component in neural networks. In VLMs, they are crucial for processing the output of vision encoders.
Processing Vision Encoder Output:
After an image is processed through a vision encoder (like a CNN or a transformer-based vision model), the resulting feature representation needs to be adapted to be useful for language tasks. Linear layers can transform these vision features into a format that is compatible with the text modality.
Combining Modalities:
In a VLM, after processing through adapters and linear layers, the transformed visual data can be combined with textual data. This combination typically occurs before or within the language model, allowing the VLM to generate responses or analyses that incorporate both visual and textual understanding.
End-to-End Training:
In some advanced VLMs, the entire model, including vision encoders, linear layers, and language models, can be trained end-to-end. This approach allows the model to better learn how to integrate and interpret both visual and textual information.
Flexibility:
Adapters offer flexibility in model training. They allow for fine-tuning a pre-trained model on a specific task without the need to retrain the entire model. This is particularly useful in VLMs where training from scratch is often computationally expensive.
In summary, adapters and linear layers in VLMs serve as critical components for bridging the gap between visual and textual modalities, enabling these models to perform tasks that require an understanding of both images and text.