ASID-Caption: Towards Universal Video MLLMs with Attribute-Structured and Quality-Verified Instructions
Yunheng Li1 · Hengrui Zhang1 · Meng-Hao Guo3 · Wenzhao Gao2 · Shaoyong Jia2 · Shaohui Jiao2 ·Qibin Hou1† · Ming-Ming Cheng1
1VCIP, Nankai University 2 ByteDance Inc. 3 Tsinghua University
†Corresponding author
Existing video instruction datasets often treat each video as a single unstructured caption, which leads to incomplete descriptions and makes it hard to learn controllable, fine-grained understanding. Simply making captions longer can introduce more hallucinations without systematic verification.
Our key idea is to provide attribute-structured supervision and verify each attribute against audiovisual evidence, enabling more reliable fine-grained learning.






First, clone the project and navigate into the directory:
git clone https://github.com/HVision-NKU/ASID-Caption.git
cd ASID-CaptionRequires Python 3.11 (pre-installed).
pip install torch==2.6.0 torchaudio==2.6.0 torchvision==0.21.0 --index-url https://download.pytorch.org/whl/cu124
pip install transformers==4.57.0 qwen-omni-utils accelerate
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu12torch2.6cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
sudo apt update && sudo apt install -y ffmpegSingle Video Inference
python demo_inference.py assets/titanic.mp4Batch Video Inference
python batch_inference.py --video_dir /demo_test --model_path Model/ASID-Captioner-3Bcd ms-swift-3.9.3/
pip install -e .
pip install deepspeed==0.18.3 liger-kernel==0.6.4Stage 1-2
bash train_qwen2.5-omi-stage1-2.shStage 3
bash train_qwen2.5-omi-stage3.sh-
video-SALMONN2-testset:
cd eval_scripts/video-SALMONN2-testset bash eval_video-SALMONN2-test.sh -
UGC-VideoCap:
cd eval_scripts/UGC-VideoCap bash eval_UGC-VideoCap.sh
-
Daily-Omni:
cd eval_scripts/Daily-Omni/ bash Daily-Omni_pipeline.sh -
WorldSense:
cd eval_scripts/WorldSense/ bash WorldSense_pipeline.sh
-
VDC:
cd eval_scripts/VDC/VDC.sh bash VDC.sh -
VidCapBench-AE
cd eval_scripts/VidCapBench-AE/ bash VidCapBench.sh
Charades-STA
cd eval_scripts/Charades/
bash Charades.shpython eval_scripts/Attrbute/evaluation.py --caption_file pred.jsonl --prompt_file eval_scripts/Attrbute/prompts.jsonlWe provide detailed quantitative results on different benchmarks and settings as shown below.
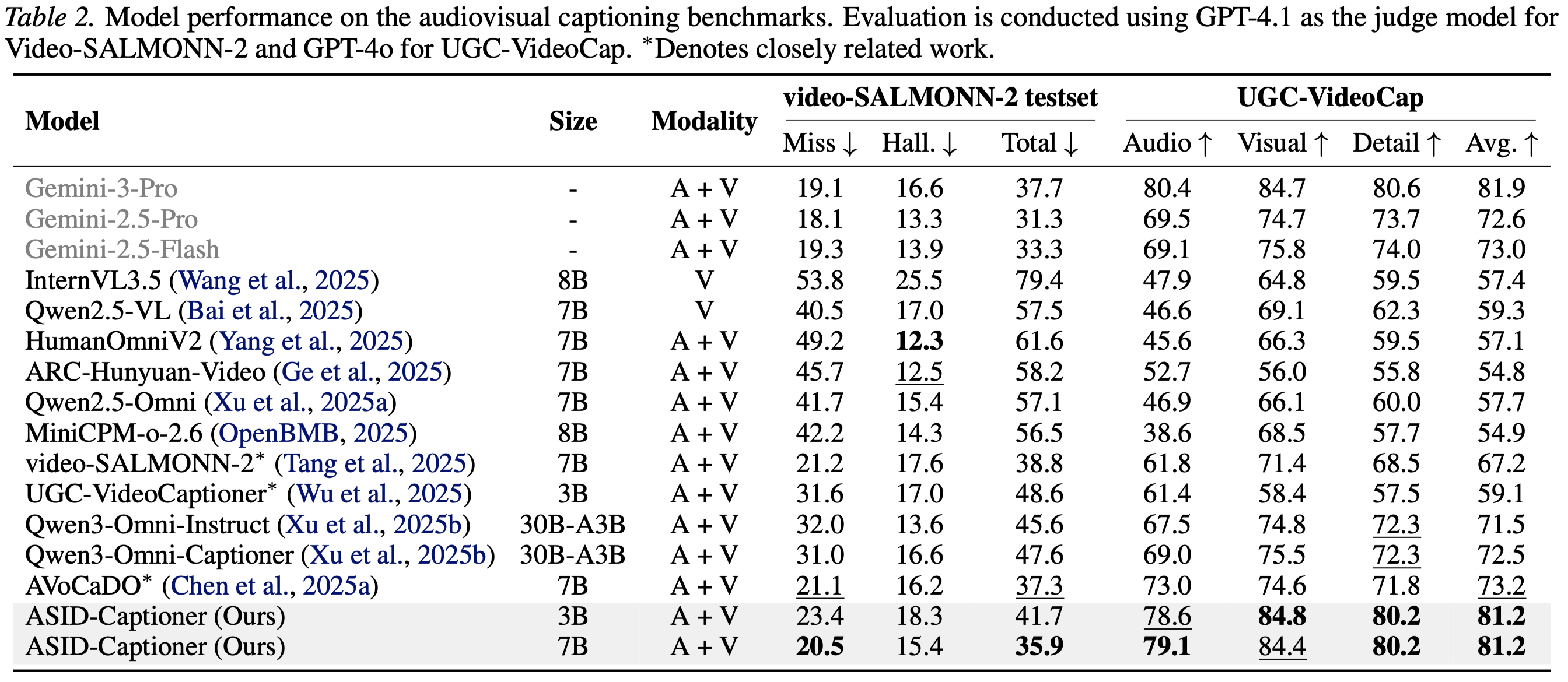
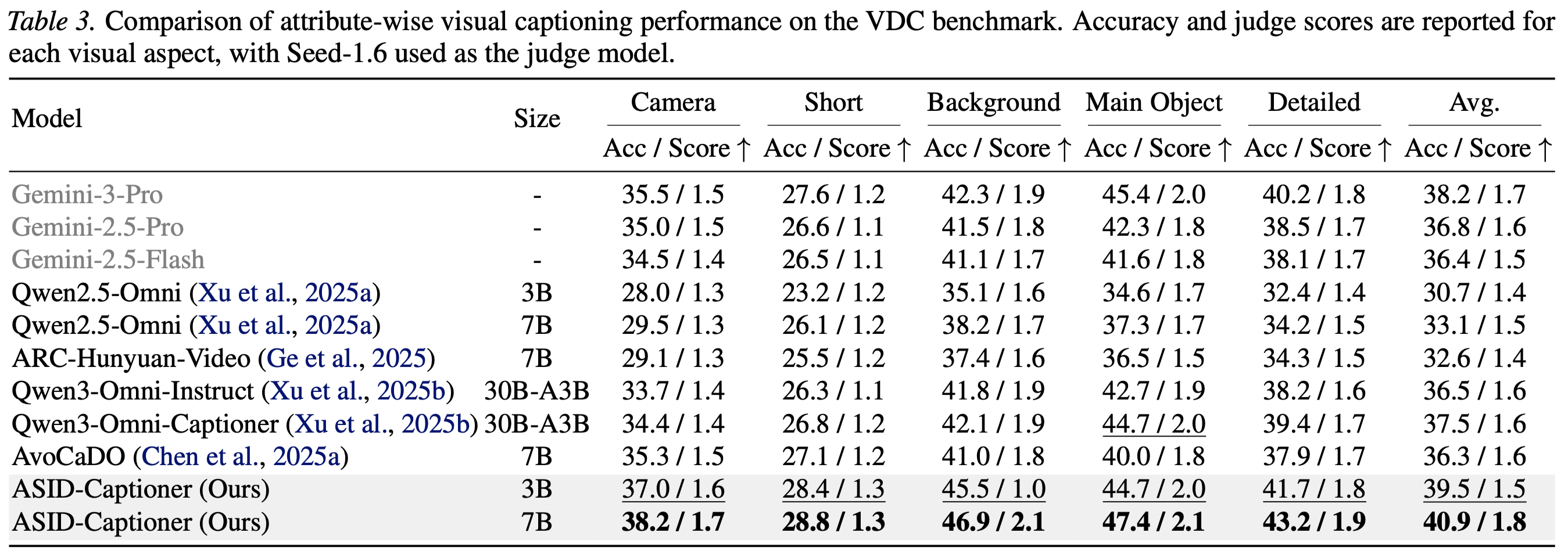
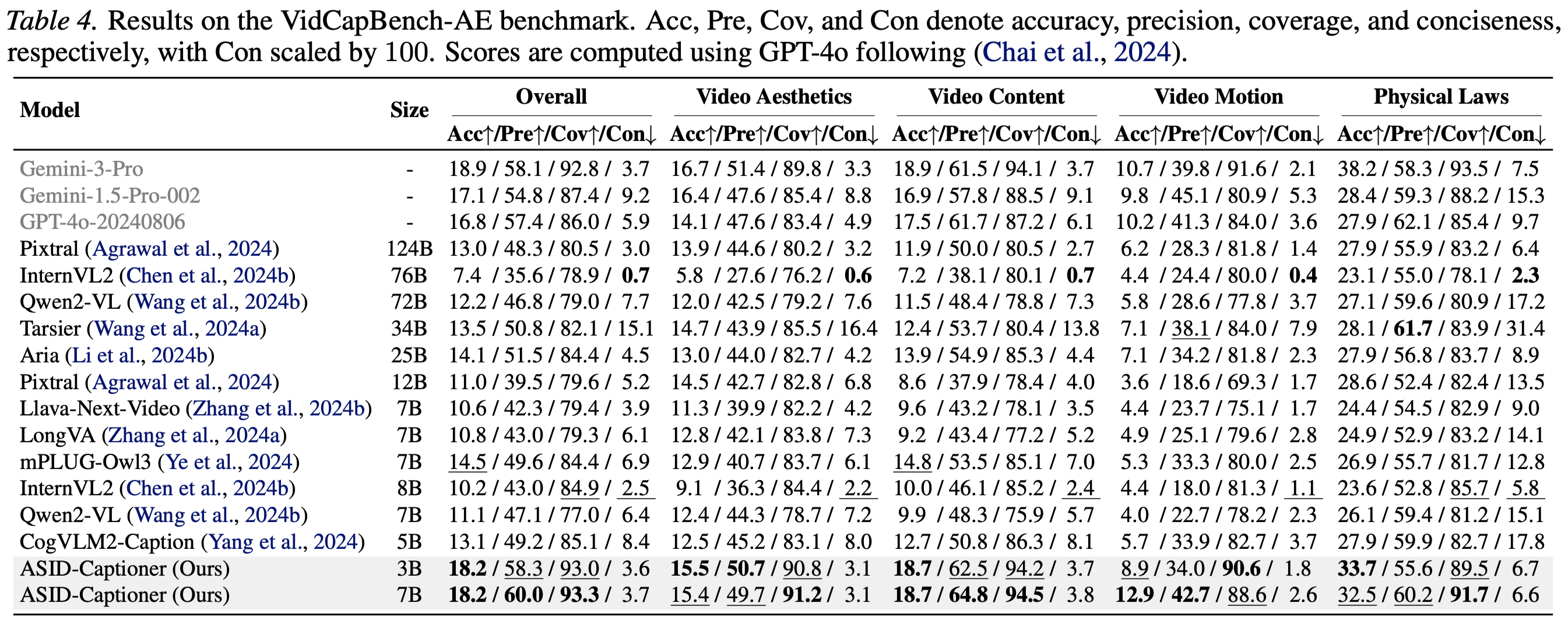
If you find our work helpful for your research, please consider giving a star ⭐ and citing our paper. We appreciate your support!
@article{li2026towards,
title={Towards Universal Video MLLMs with Attribute-Structured and Quality-Verified Instructions},
author={Li, Yunheng and Zhang, Hengrui and Guo, Meng-Hao and Gao, Wenzhao and Jia, Shaoyong and Jiao, Shaohui and Hou, Qibin and Cheng, Ming-Ming},
journal={arXiv preprint arXiv:2602.13013},
year={2026}
}