Scaling One Million Checkboxes to 650,000,000 checks
On June 26th 2024 I launched a website called One Million Checkboxes (OMCB). It had one million global checkboxes on it - checking a box checked it for everyone on the site, immediately.
The site, 30 minutes after launch
I built the site in 2 days. I thought I’d get a few hundred users, max. That is not what happened.
Instead, within hours of launching, tens of thousands of users checked millions of boxes. They piled in from Hacker News, /r/InternetIsBeautiful, Mastodon and Twitter. A few days later OMCB appeared in the Washington Post and the New York Times.
Here’s what activity looked like on the first day (I launched at 11:30 AM EST).
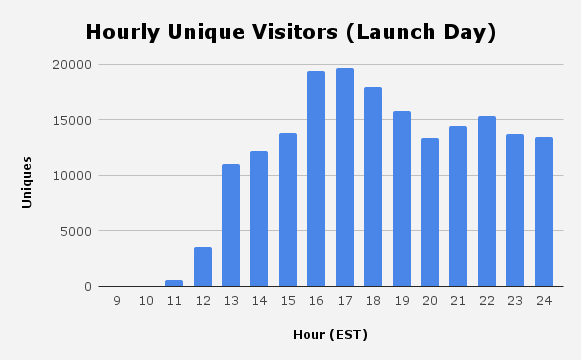
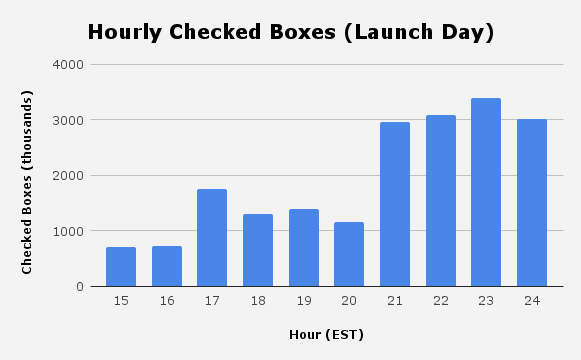
I don't have logs for checked boxes from the first few hours because I originally only kept the latest 1 million logs for a given day(!)
I wasn’t prepared for this level of activity. The site crashed a lot. But by day 2 I started to stabilize things and people checked over 50 million boxes. We passed 650 million before I sunset the site 2 weeks later.
Let’s talk about how I kept the site (mostly) online!
The original architecture
Here’s the gist of the original architecture:
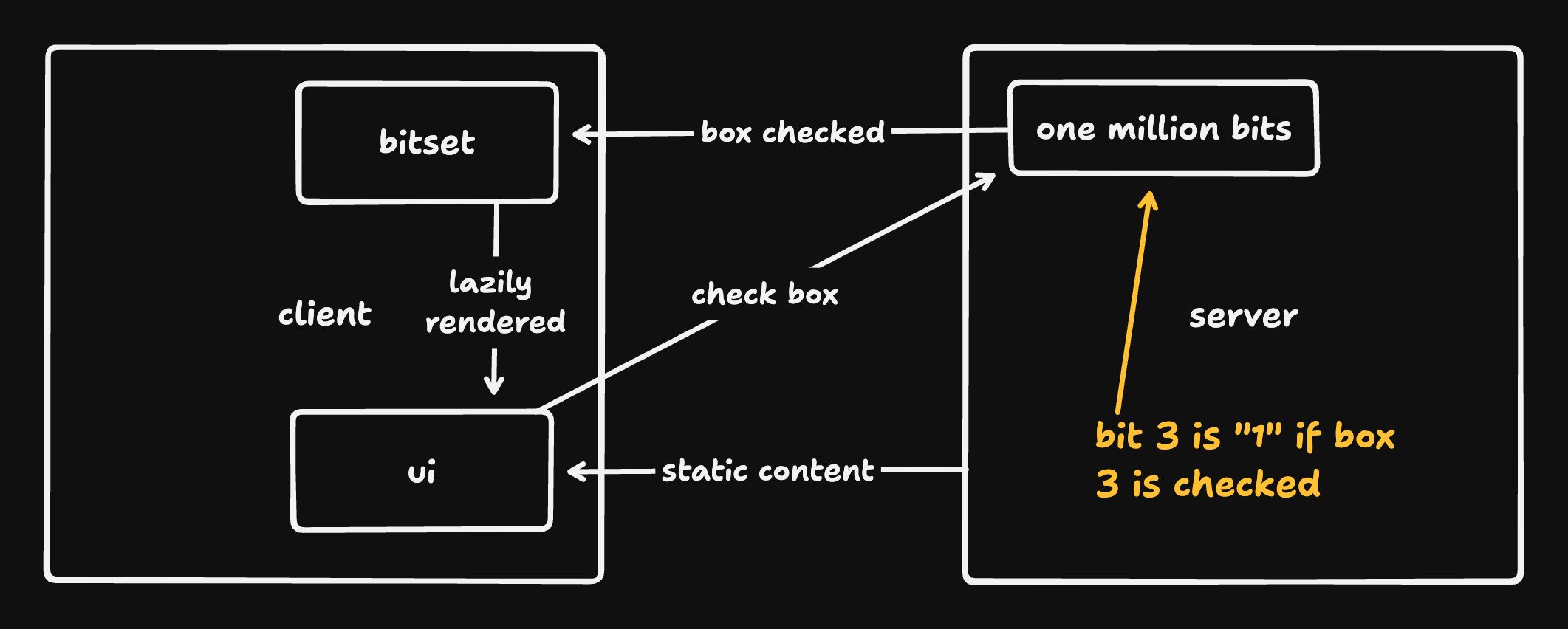
Our checkbox state is just one million bits (125KB). A bit is “1” if the corresponding checkbox is checked and “0” otherwise.
Clients store the bits in a bitset (an array of bytes that makes it easy to store, access, and flip raw bits) and reference that bitset when rendering checkboxes. Clients tell the server when they check a box; the server flips the relevant bit and broadcasts that fact to all connected clients.
To avoid throwing a million elements into the DOM, clients only render the checkboxes in view (plus a small buffer) using react-window.
I could have done this with a single process,I wanted an architecture that I could scale (and an excuse to use Redis for the first time in years). So the actual server setup looked like this:
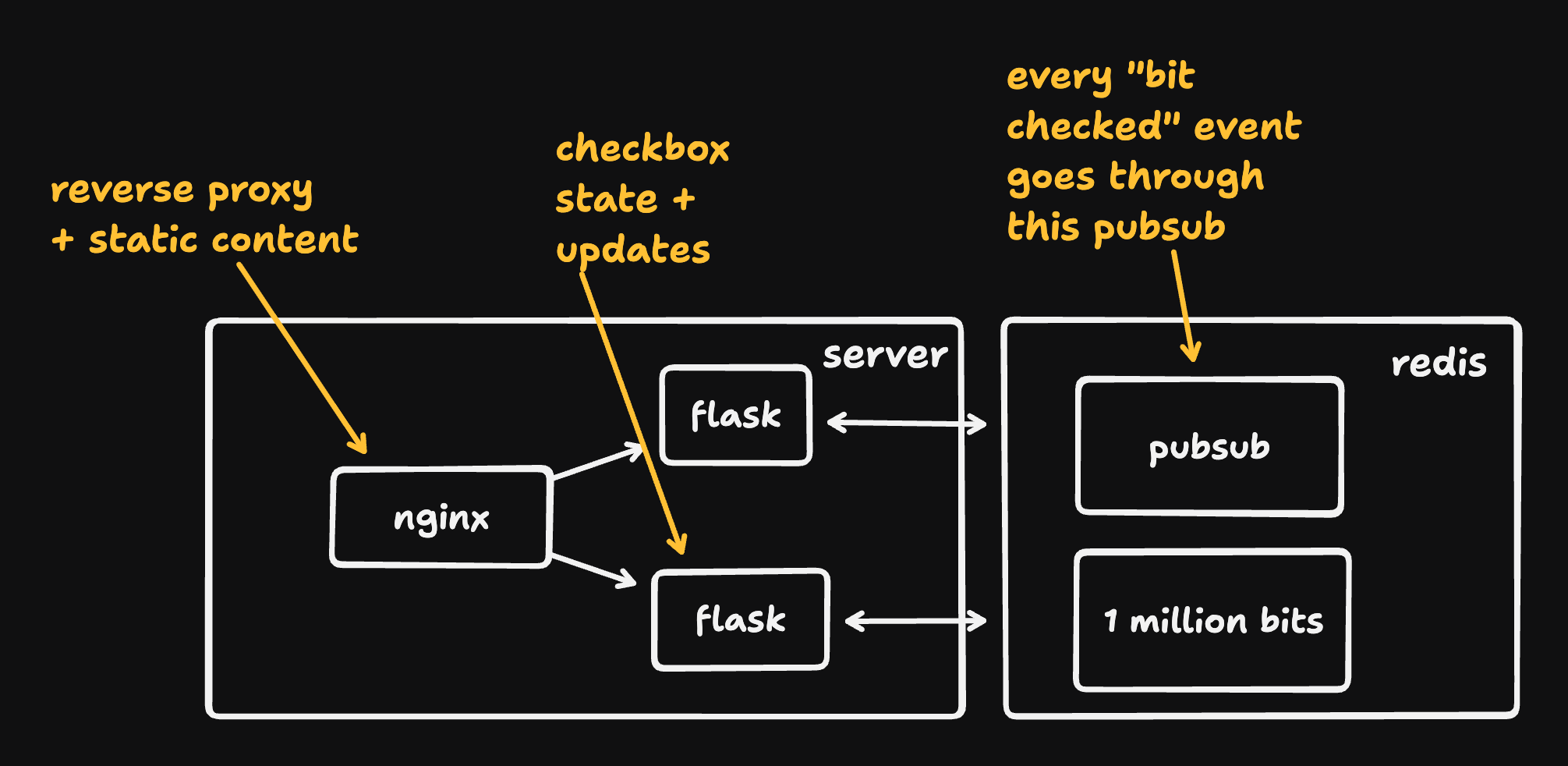
Clients hit nginx for static content, and then make a GET for the bitset state and a websocket connection (for updates); nginx (acting as a reverse proxy) forwards those requests to one of two Flask servers (run via gunicorn).
State is stored in Redis, which has good primitives for flipping individual bits. Clients tell Flask when they check a box; Flask updates the bits in Redis and writes an event to a pubsub (message queue). Both Flask servers read from that pubsub and notify connected clients when checkboxes are checked/unchecked.
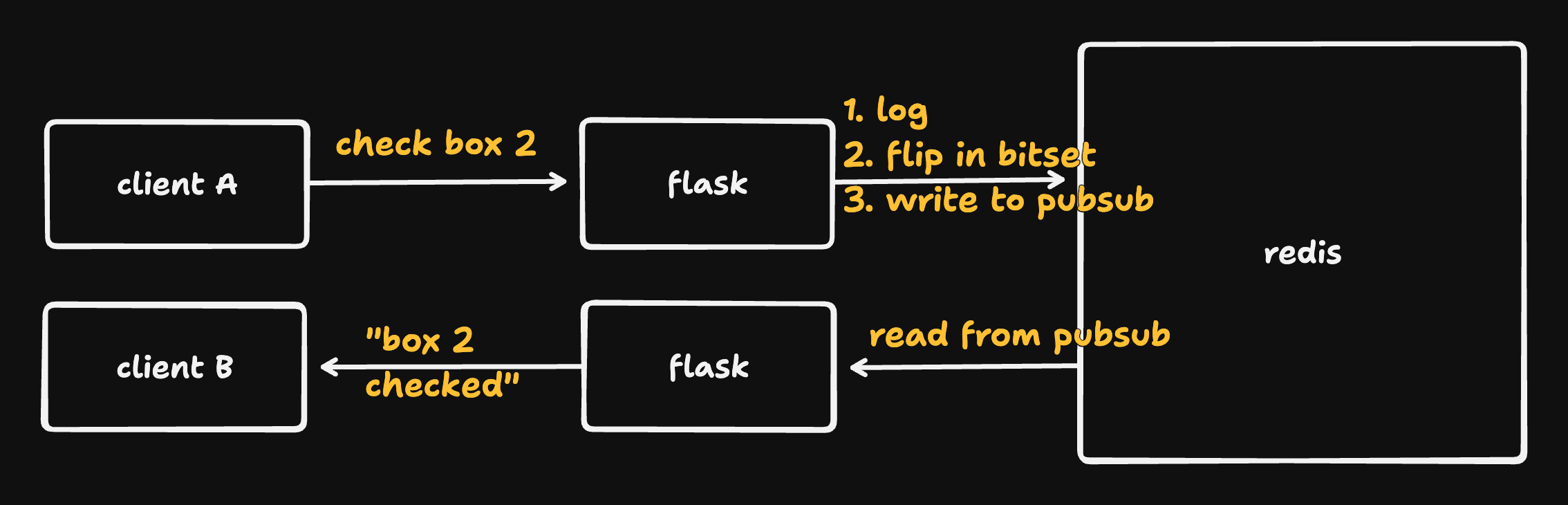
We need the pubsub because we've got two Flask instances; a Flask instance can't just broadcast "box 2 was checked" to its own clients.
Finally, the Flask servers do simple rate-limiting (on requests per session and new sessions per IP1 - foolishly stored in Redis!) and regularly send full state snapshots to connected clients (in case a client missed an update because, say, the tab was backgrounded).
Here's an (abbreviated) implementation of the Flask side.
# This is long, so I've skipped Redis initialization,
# my rate limiting and logging implementation, etc.
# You can run lua inside Redis. The lua runs atomically.
# It's pretty sweet.
set_bit_script = """
local key = KEYS[1]
local index = tonumber(ARGV[1])
local value = tonumber(ARGV[2])
local current = redis.call('getbit', key, index)
local diff = value - current
redis.call('setbit', key, index, value)
redis.call('incrby', 'count', diff)
return diff"""
set_bit_sha = redis_client.script_load(set_bit_script)
def get_bit(index):
return bool(redis_client.getbit('bitset', index))
def set_bit(index, value):
diff = redis_client.evalsha(set_bit_sha, 1, 'bitset', index, int(value))
return diff != 0
def get_full_state():
raw_data = redis_client.get("bitset")
return base64.b64encode(raw_data).decode('utf-8')
def get_count():
return int(redis_client.get('count') or 0)
def publish_toggle_to_redis(index, new_value):
redis_client.publish('bit_toggle_channel', json.dumps({'index': index, 'value': new_value}))
def state_snapshot():
full_state = get_full_state()
count = get_count()
return {'full_state': full_state, 'count': count}
@app.route('/api/initial-state')
def get_initial_state():
return jsonify(state_snapshot())
def emit_full_state():
socketio.emit('full_state', state_snapshot())
@socketio.on('toggle_bit')
def handle_toggle(data):
if not allow_toggle(request.sid):
print(f"Rate limiting toggle request for {request.sid}")
return False
# There's a race here. It bit me pretty early on; I fixed it by
# moving this logic into the lua script.
count = get_count()
if count >= 1_000_000:
print("DISABLED TOGGLE EXCEEDED MAX")
return False
index = data['index']
current_value = get_bit(index)
new_value = not current_value
print(f"Setting bit {index} to {new_value} from {current_value}")
set_bit(index, new_value)
forwarded_for = request.headers.get('X-Forwarded-For') or "UNKNOWN_IP"
# This only keeps the most recent 1 million logs for the day
log_checkbox_toggle(forwarded_for, index, new_value)
publish_toggle_to_redis(index, new_value)
def emit_state_updates():
scheduler.add_job(emit_full_state, 'interval', seconds=30)
scheduler.start()
emit_state_updates()
def handle_redis_messages():
message_count = 0
while True:
message = pubsub.get_message(timeout=0.01)
if message is None:
break
if message['type'] == 'message':
try:
data = json.loads(message['data'])
socketio.emit('bit_toggled', data)
message_count += 1
except json.JSONDecodeError:
print(f"Failed to decode message: {message['data']}")
if message_count >= 100:
break
if message_count > 0:
print(f"Processed {message_count} messages")
def setup_redis_listener():
scheduler.add_job(handle_redis_messages, 'interval', seconds=0.1)
setup_redis_listener()
This code isn’t great! It’s not even async. I haven’t shipped production Python in like 8 years! But I was fine with that. I didn’t think the project would be popular. This was good enough.
I changed a lot of OMCB but the basic architecture - nginx reverse proxy, API workers, Redis for state and message queues - remained.
Principles for scaling
Before I talk about what changed, let’s look at the principles I had in mind while scaling.
Bound my costs
I needed to be able to math out an upper bound on my costs. I aimed to let things break when they broke my expectations instead of going serverless and scaling into bankruptcy.
Embrace the short-term
I assumed the site’s popularity was fleeting. I took on technical debt and aimed for ok solutions that I could hack out in hours over great solutions that would take me days or weeks.
Use simple, self-hosted tech
I’m used to running my own servers. I like to log into boxes and run commands. I tried to only add dependencies that I could run and debug on my own.
Have fun
I optimized for fun, not money. Scaling the site my way was fun. So was saying no to advertisers.
Keep it global
The magic of the site was jumping anywhere and seeing immediate changes. So I didn’t want to scale by, for example, sending clients a view of only the checkboxes they were looking at2.
Day 1: the pop
Within 30 minutes of launch, activity looked like this:
That's a lot of checks
The site was still up, but I knew it wouldn’t tolerate the load for much longer.
The most obvious improvement was more servers. Fortunately this was easy - nginx could easily reverse-proxy to Flask instances on another VM, and my state was already in Redis. I started spinning up more boxes.

I spun up the second server around 12:30 PM. Load immediately hit 100%
I originally assumed another server or two would be sufficient. Instead traffic grew as I scaled. I hit #1 on Hacker News; activity on my tweet skyrocketed. I looked for bigger optimizations.
My Flask servers were struggling. Redis was running out of connections (did you notice I wasn’t using a connection pool?). My best idea was to batch updates - I hacked something in that looked like this:
Batching logic
def handle_Redis_messages():
message_count = 0
updates = []
while True:
message = pubsub.get_message(timeout=0.01)
if message is None:
# No more messages available
break
if message['type'] == 'message':
try:
data = json.loads(message['data'])
updates.append(data)
message_count += 1
except json.JSONDecodeError:
print(f"Failed to decode message: {message['data']}")
if message_count >= 100:
break
if message_count > 0:
socketio.emit('batched_bit_toggles', updates)
print(f"Processed {message_count} messages")I didn’t bother with backwards compatibility. I figured folks were used to the site breaking and would just refresh.
I also added a connection pool. This definitely did not play nicely with gunicorn and Flask3, but it did seem to reduce the number of connections to Redis4.
I also beefed up my Redis box - easy to do since I was using Digital Ocean’s managed Redis - from a tiny (1 shared CPU; 2 GB RAM) instance to a box with 4 dedicated CPUs and 32 GB of RAM (I did this after Redis mysteriously went down). The resizing took about 30 minutes; the server came back up.
And then things got trickier.
It was not a good night to have plans
At around 4:30 PM I accepted it: I had plans. I had spent June at a camp at ITP - a school at NYU5. And the night of the 26th was our final show. I had signed up to display a face-controlled Pacman game and invited some friends - I had to go!
I brought an iPad and put OMCB on it. I spun up servers while my friend Uri and my girlfriend Emma kindly stepped in to explain what I was doing to strangers when they came by my booth.
I had no automation for spinning up servers (oops) so my naming conventions evolved as I worked.
My servers. I ended up with 8 worker VMs
I got home from the show around midnight. I was tired. But there was still more work to do, like:
- Reducing the number of Flask processes on each box (I originally had more workers than the number of cores on a box; this didn’t work well)
- Increasing the batch size of my updates - I found that doubling the batch size substantially reduced load. I tried doubling it again. This appeared to help even more. I don’t know how to pick a principled number here.
Bandwidth
I pushed the updates. I was feeling good! And then I got a text from my friend Greg Technology.
gulp
I realized I hadn’t thought hard enough about bandwidth. Digital Ocean’s bandwidth pricing is pretty sane ($0.01/GB after a pretty generous per-server compounding free allowance). I had a TB of free bandwidth from past work and (pre-launch) didn’t think OMCB would make a dent.
I did back of the envelope math. I send state snapshots (1 million bits; 1 Mbit) every 30 seconds. With 1,000 clients that’s already 2GB a minute! Or 120GB an hour. And we’re probably gonna have more clients than that. And we haven’t even started to think about updates.
It was 2 AM. I was very tired. I did some bad math - maybe I confused GB/hour with GB/minute? - and freaked out. I thought I was already on the hook for thousands of dollars!
So I did a couple of things:
- Frantically texted Greg, who helped me realize that my math was way off.
- Ran
ip -s link show dev eth0on my nginx box to see how many bytes I had sent, confirming that my math was way off6. - Started thinking about how to reduce bandwidth - and how to cap my costs.
I immediately reduced the frequency of my state snapshots, and then (with some help from Greg) pared down the size of the incremental updates I sent to clients.
// Original batch implementation
// (I just took the individual updates I was sending to clients and put them in a list)
[{ "index": 123, "value": true }, { "index": 124, "value": false }, {"index": 125, "value": true}]
// Final implementation - array of true values, array of false values
[[123, 125], [124]]
I moved from stuffing a bunch of dicts into a list to sending two arrays of indices with true and false implied. This was five times shorter than my original implementation!
And then I used linux’s tc utility to slam a hard cap on the amount of data I could send per second. tc is famously hard to use7, so I wrote my configuration script with Claude’s help.
the tc script
INTERFACE=eth0
LIMIT=250mbit
tc qdisc del dev $INTERFACE root
tc qdisc add dev $INTERFACE root handle 1: htb default 10
tc class add dev $INTERFACE parent 1: classid 1:1 htb rate $LIMIT
tc class add dev $INTERFACE parent 1:1 classid 1:10 htb rate $LIMIT
tc filter add dev $INTERFACE protocol ip parent 1:0 prio 1 u32 match ip dst 0.0.0.0/0 flowid 1:10This just limits traffic flowing over eth0 (my public interface) to 250Mbit a second. That’s a lot of bandwidth - ~2GB/min, or just under 3 TB a day. But it let me reason about my costs, and at $0.01/GB I knew I wouldn’t go bankrupt overnight.
At around 3:30 AM I got in bed.
My server was pegged at my 250 Mb/s limit for much of the night. I originally thought I was lucky to add limits when I did; I now realize someone probably saw my tweet about reducing bandwidth and tried to give me a huge bill.
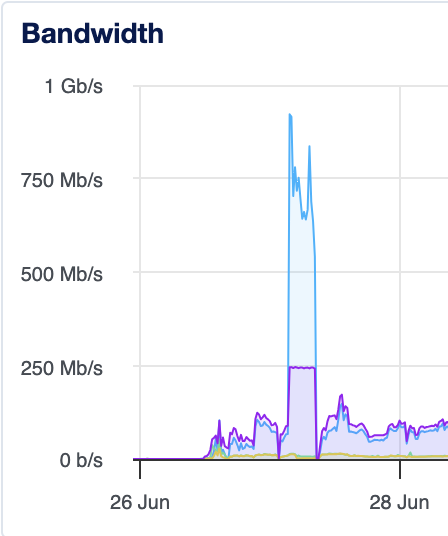
Blue is traffic from my workers to nginx, purple is nginx out to the world. The timing is suspicious
Day 2: it’s still growing
I woke up a few hours later. The site was down. I hadn’t been validating input properly.
The site didn’t prevent folks from checking boxes above 1 million. Someone had checked boxes in the hundred million range! This let them push the count of checked boxes to 1 million, tricking the site into thinking things were over8.
Redis had also added millions of 0s (between bit one million and bit one hundred million), which 100x’d the data I was sending to clients.
This was embarrassing - I’m new to building for the web but like…I know you should validate your inputs! But it was a quick fix. I stopped nginx, copied the first million bits of my old bitset to a new truncated bitset (I wanted to keep the old one for debugging), taught my code to reference the new bitset, and added proper validation.
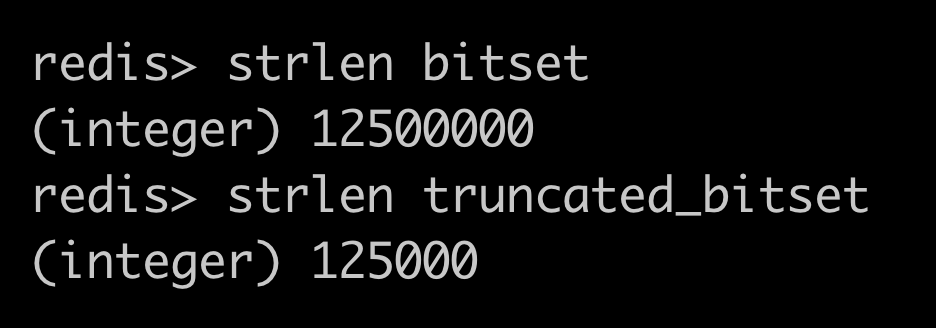
much better
Not too bad! I brought the site back up.
Adding a replica and portscanning my VPC
The site was slow. The number of checked boxes per hour quickly exceeded the day 1 peak.
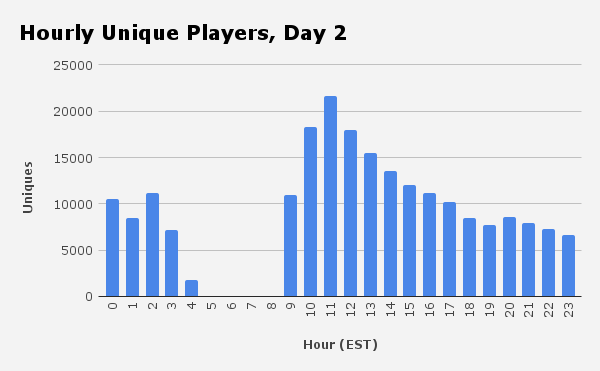
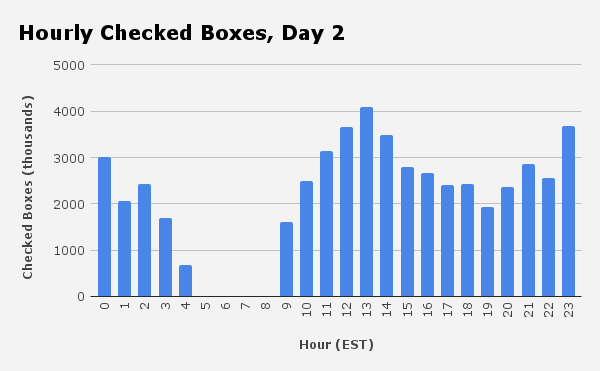
The biggest problem was the initial page load. This made sense - we had to hit Redis, which was under a lot of load (and we were making too many connections to it due to bugs in my connection pooling).
I was tired and didn’t feel equipped to debug my connection pool issues. So I embraced the short term and spun up a Redis replica to take load off the primary and spread my connections out.
But there was a problem - after spinning up the replica, I couldn’t find its private IP!
I got my Redis instance's private IP by prepending "private-" to its DNS entry
To connect to my primary, I used a DNS record - there were records for its public and private IPs. Digital Ocean told me to prepend replica- to those records to get my replica IP. This worked for the public one, but didn’t exist for the private DNS record! And I really wanted the private IP.
I thought sending traffic to a public IP would risk traversing the public internet, which would mean being billed for way more bandwidth9.
Since I couldn’t figure out how to find the replica’s private IP in an official way (I’m sure you can! Tell me how!), I took a different approach and starting making connections to private IPs close to the IPs of my Redis primary and my other servers. This worked on the third or fourth try.
Then I hardcoded that IP as my replica IP!
Stabilizing
My Flask processes kept crashing, requiring me to babysit the site. The crashes seemed to be from running out of Redis connections. I’m wincing as I type this now, but I still didn’t want to debug what was going on there - it was late and the problem was fuzzy.
So I wrote a script that looked at the number of running Flask processes and bounced my systemd unit if too many were down10.
My bash restart script
#!/bin/bash
# We have 4 running processes. This script only restarts them if fewer than 3 are running;
# I figured this might help us reach a stable equilibirum.
# jitter
x=$((RANDOM % 300))
echo "sleeping for $x"
sleep "$x"
count_running_servers() {
ps aux | grep gunicorn | grep -oP 'bind \K0\.0\.0\.0:\d+' | sort | uniq | wc -l
}
running_servers=$(count_running_servers)
if [ $running_servers -lt 3 ]; then
echo "Less than 3 servers running. Restarting all servers..."
sudo systemctl stop one-million-checkboxes.service
sleep 10
sudo systemctl start one-million-checkboxes.service
echo "Servers restarted."
else
echo "At least 3 servers are running. No action needed."
fiI threw that into the crontab on my boxes and updated my nginx config to briefly take servers out of rotation if they were down (I should have done this sooner!). This appeared to work pretty well. The site stabilized.
Stale updates
At around 12:30 AM I posted some stats on Twitter and got ready to go to bed. And then a user reported an issue:

ahhhhhhhhhhhh
I had written a classic bug.
To keep client checkbox state synchronized, I did two things:
- Sent clients incremental updates when checkboxes were checked or unchecked
- Sent clients occasional full-state snapshots in case they missed an update
These updates didn’t have timestamps. A client could receive a new full-state snapshot and then apply an old incremental update - resulting in them having a totally wrong view of the world until the next full-state snapshot11.
I was embarrassed by this - I’ve written a whole lot of state machine code and know better. It was almost 1 AM and I had barely slept the night before; it was a struggle to write code that I (ironically) thought I could write in my sleep. But I:
- Timestamped each full state snapshot
- Timestamped each update written to my Redis pubsub
- Added the max timestamp of each incremental update in the batches I sent to clients
- Taught clients to drop update batches if their timestamp was behind the timestamp of the last full-state snapshot
This isn’t perfect (clients can apply a batch of mostly-stale updates as long as one update is new) but it’s substantially better.

me to claude, 1 AM
I ran my changes by Claude before shipping to prod. Claude’s suggestions weren’t actually super helpful, but talking through why they were wrong gave me more confidence.
Rewrite in go
I woke up the next morning and the site was still up! Hackily restarting your servers is great. This was great timing - the site was attracting more mainstream media attention (I woke up to an email from the Washington Post).
I moved my attention from keeping the site up to thinking about how to wind it down. I was still confident folks wouldn’t be interested in the site forever, and I wanted to provide a real ending before everyone moved on12.
I came up with a plan - I’d make checked boxes freeze if they weren’t unchecked quickly. I wasn’t sure that my current setup could handle this - it might result in a spike of activity plus I’d be asking my servers to do more work.
So (after taking a break for a day) I got brunch with my friend Eliot - a super talented performance engineer - and asked if he was down to give me a hand. He was, and from around 2 PM to 2 AM on Sunday we discussed implementations of my sunsetting plan and then rewrote the whole backend in go!
The go rewrite was straightforward; we ported without many changes. Lots of our sticking points were things like “finding a go socketio library that supports the latest version of the protocol.”
The speedup was staggering.
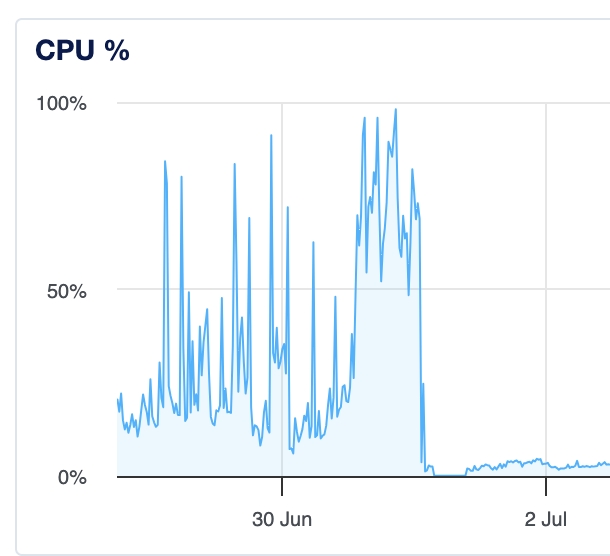
CPU usage on a worker VM
Things were actually so much faster that we ended up needing to add better rate-limiting; originally we scaled too well and bots on the site were able to push absurd amounts of traffic through the site.
The site was DDOS’d on Sunday night, but addressing this was pretty simple - I just threw the site behind CloudFlare and updated my nginx configs a bit.
Sunsetting the site
The site was rock-solid after the go rewrite. I spent the next week doing interviews, enjoying the attention, and trying to relax.
And then I got to work on sunsetting. Checked boxes would freeze if they weren’t unchecked quickly, which would eventually leave the site totally frozen. The architecture here ended up being pretty simple - mostly some more state in Redis:

god i love making diagrams in tldraw
I added a hashtable that tracked the last time that a box was checked (this would be too much state to pass to clients, but was fine to keep in Redis), along with a “time to freeze” value. When trying to uncheck a box, we’d first check whether now - last_checked > time_to_freeze - if it is, we don’t uncheck the box and instead update frozen_bitset to note that the relevant checkbox is now frozen.
I distributed frozen_bitset state to clients the same way that I distributed which boxes were checked, and taught clients to disable a checkbox if it was in the frozen bitset. And I added a job to periodically search for bits that should be frozen (but weren’t yet because nobody had tried to uncheck them) and freeze those.
Redis made it soooo easy to avoid race conditions with this implementation - I put all the relevant logic into a Lua script, meaning that it all ran atomically! Redis is great.
my lua script
local bitset_key = KEYS[1]
local count_key = KEYS[2]
local frozen_bitset_key = KEYS[3]
local frozen_count_key = KEYS[4]
local freeze_time_key = KEYS[5]
local index = tonumber(ARGV[1])
local max_count = tonumber(ARGV[2])
local UNCHECKED_SENTINEL = 0
local redis_time = redis.call('TIME')
local current_time = tonumber(redis_time[1]) * 1000 + math.floor(tonumber(redis_time[2]) / 1000)
local freeze_time = tonumber(redis.call('get', freeze_time_key) or "0")
local current_count = tonumber(redis.call('get', count_key) or "0")
local current_bit = redis.call('getbit', bitset_key, index)
local frozen_bit = redis.call('getbit', frozen_bitset_key, index)
if frozen_bit == 1 then
-- Return current bit value, 0 for no change, and 0 to indicate not newly frozen
return {current_bit, 0, 0}
end
if current_count >= max_count then
return {current_bit, 0, 0}
end
local new_bit = 1 - current_bit
local diff = new_bit - current_bit
-- If we're unchecking (new_bit == 0), check the freeze_time
if new_bit == 0 then
local last_checked = tonumber(redis.call('hget', 'last_checked', index) or UNCHECKED_SENTINEL)
if last_checked ~= UNCHECKED_SENTINEL and current_time - last_checked >= freeze_time then
-- Box is frozen, update frozen bitset and count
redis.call('setbit', frozen_bitset_key, index, 1)
redis.call('incr', frozen_count_key)
-- Return 1 (checked), 0 for no change, and 1 to indicate newly frozen
return {1, 0, 1}
else
redis.call('hset', 'last_checked', index, UNCHECKED_SENTINEL)
end
else
-- We're checking the box, update last_checked time
redis.call('hset', 'last_checked', index, current_time)
end
redis.call('setbit', bitset_key, index, new_bit)
local new_count = current_count + diff
redis.call('set', count_key, new_count)
-- new bit value, the change (-1, 0, or 1), and 0 to indicate not newly frozen
return {new_bit, diff, 0} I rolled the sunsetting changes 2 weeks and 1 day after I launched OMCB. Box 491915 was checked at 4:35 PM Eastern on July 11th, closing out the site.
So what’d I learn?
Well, a lot. This was the second time that I’d put a server with a ‘real’ backend on the public internet, and the last one barely counted. Learning in a high-intensity but low-stakes environment is great13.
Building the site in two days with little regard for scale was a good choice. It’s so hard to know what will do well on the internet - nobody I explained the site to seemed that excited about it - and I doubt I would have launched at all if I spent weeks thinking about scale. Having a bunch of eyes on the site energized me to keep it up and helped me focus on what mattered.
I’m happy with the tech that I used. Redis and nginx are incredible. Running things myself made debugging and fixing things so much easier (it was a little painful to not have full control of my Redis instance). The site cost me something like $850 to run - donations came pretty close to that, so I’m not in the hole for too much.
In the future I might spend some time trying to decode the pricing pages for convex or durable objects. But I’m proud of scaling it on my own terms, and I think it’s worth noting that things worked out ok.
This also validated my belief that people are hungry for constrained anonymous interactions with strangers. I love building sites like this (and I was gonna build more regardless!) but I’m more confident than ever that it’s a good idea.
Wrapping up
This was an absolute blast.
I’ve got one more story to tell about the site. It’s about teens doing cool things. This blog is too long to tell it right now, so stay tuned (I’ll update my newsletter, twitter, and various other platforms) when it’s live.
And in the meantime - build more stupid websites! The internet can still be fun :)
-
I was aiming to strike a balance between “letting someone trivially spam the whole site” and “letting a bunch of students behind the same IP play at all” - which is why I did this instead of just limiting per IP. I later gave up on this approach, although if I had more time I would have tried to keep it in. ↩
-
With sufficient time I could have potentially implemented something that only sent clients “relevant” data but updated its notion of “relevant” fast enough to keep the magic - but per “embrace the short-term” I didn’t think I could deliver a good enough experience there fast enough. ↩
-
This is almost certainly a bad interaction between running a pre-fork web server, Python threading, and the background jobs for pushing out state snapshots and updates that I was running. I can imagine lots of problems here! I never got to the bottom of the issue (I just switched to golang instead :)) but if it’s obvious to you I’d love to hear about it! ↩
-
I also ripped out my rate-limiting around session creation. It was stored in Redis, I was exhausting my Redis connections, and clients weren’t opening lots of sessions - just sending lots of data for a single session. This was definitely risky! But I think it was worth it in the short term. A few nights in and a little delirious, I described this poorly on Hacker News. My bad explanation was kinda funny. ↩
-
This blog is too long for me to talk about ITP camp at length but - it’s really fun! ITP specializes in just the type of weird tech-art bullshit that I love. I met a ton of cool people there and had a blast. Consider checking it out :) ↩
-
One nice thing about using a single nginx reverse proxy is that it was really easy to reason about how much bandwidth I was using! It could basically only come from one nic. ↩
-
I happen to be familiar with
tcfrom a job I had a decade ago! So I still had the muscle memory for inspecting qdiscs. But there was no way I could have written a valid filter without help. ↩ -
The UI was also meant to freeze, but only if the count of checked boxes was exactly 1 million. Because of a race condition the count was above 1 million so it didn’t freeze. I think this was pretty lucky; interest might have died off if the UI froze. ↩
-
This would be particularly annoying because public traffic would no longer be egressing from a single instance! Also I’m not sure this would be a problem; maybe DO would be smart about routing or smart enough not to bill me. But I didn’t want to find out. ↩
-
I was running several Flask processes via one systemd unit and I think systemd wouldn’t bring the process back up unless they all crashed? I’m not sure. ↩
-
I suspect adding a replica aggravated this problem because my servers were doing a better job of sending out updates. ↩
-
I actually missed pretty hard here, and I think the experience would have been better if I shipped the changes sooner. ↩
-
My favorite example of this - during the rewrite, Eliot and I mistakenly thought we had dropped the prod database. We panicked - we’ve been engineers for a while! dropping prod is bad! But then I realized that I could just…tweet out “hey, sorry, I dropped the database. You’re gonna have to recheck the boxes” and it’d be fine? That’s kinda funny? This was freeing. ↩
get new posts via twitter, substack, rss, or a billion other platforms
or subscribe to my newsletter right from this page!