A Blog Post With Every HTML Element by Patrick Weaver
I enjoyed this self-documenting journey of exploration.
I enjoyed this self-documenting journey of exploration.
A great introduction to structuring your content well:
Using semantic HTML as building blocks for a website will give you a lovely accessible foundation upon which to add your fancy CSS and whizzy JavaScript.
I remember discussing this with Tantek years ago:
There are a few elements who need to be placed inside of another specific element in order to function properly.
If I recall, he was considering writing “HTML: The Good Parts”.
Anyway, I can relate to what Eric is saying here about web components. My take is that web components give developers a power that previous only browser makers had. That’s very liberating, but it should come with a commensurate weight of responsibility. I fear that we will see this power wielded without sufficient responsibility.
Receive one email a day for 30 days, each featuring at least one HTML element.
Right up my alley!
Matt wrote recently about how different writers keep notes:
I’m also reminded of how writers I love and respect maintain their own reservoirs of knowledge, complete with migratory paths down from the mountains.
I have a section of my site called “notes” but the truth is that every single thing I post on here—whether it’s a link, a blog post, or anything else—is really a “note to self.”
When it comes to retrieving information from this online memex of mine, I use tags. I’ve got search forms on my site, but usually I’ll go to the address bar in my browser instead and think “now, what would past me have tagged that with…” as I type adactio.com/tags/... (or, if I want to be more specific, adactio.com/links/tags/... or adactio.com/journal/tags/...).
It’s very satisfying to use my website as a back-up brain like this. I can get stuff out of my head and squirreled away, but still have it available for quick recall when I want it. It’s especially satisfying when I’m talking to someone else and something they say reminds me of something relevant, and I can go “Oh, let me send you this link…” as I retrieve the tagged item in question.
But I don’t think about other people when I’m adding something to my website. My audience is myself.
I know there’s lots of advice out there about considering your audience when you write, but when it comes to my personal site, I’d find that crippling. It would be one more admonishment from the inner critic whispering “no one’s interested in that”, “you have nothing new to add to this topic”, and “you’re not quailified to write about this.” If I’m writing for myself, then it’s easier to have fewer inhibitions. By treating everything as a scrappy note-to-self, I can avoid agonising about quality control …although I still spend far too long trying to come up with titles for posts.
I’ve noticed—and other bloggers have corroborated this—there’s no correlation whatsover between the amount of time you put into something and how much it’s going to resonate with people. You might spend days putting together a thoroughly-researched article only to have it met with tumbleweeds when you finally publish it. Or you might bash something out late at night after a few beers only to find it on the front page of various aggregators the next morning.
If someone else gets some value from a quick blog post that I dash off here, that’s always a pleasant surprise. It’s a bonus. But it’s not my reason for writing. My website is primarily a tool and a library for myself. It just happens to also be public.
I’m pretty sure that nobody but me uses the tags I add to my links and blog posts, and that’s fine with me. It’s very much a folksonomy.
Likewise, there’s a feature I added to my blog posts recently that is probably only of interest to me. Under each blog post, there’s a heading saying “Previously on this day” followed by links to any blog posts published on the same date in previous years. I find it absolutely fascinating to spelunk down those hyperlink potholes, but I’m sure for anyone else it’s about as interesting as a slideshow of holiday photos.
Matt took this further by adding an “on this day” URL to his site. What a great idea! I’ve now done the same here:
That URL is almost certainly only of interest to me. And that’s fine.
Back at the start of the (first) lockdown, I wrote about using my website as an outlet:
While you’re stuck inside, your website is not just a place you can go to, it’s a place you can control, a place you can maintain, a place you can tidy up, a place you can expand. Most of all, it’s a place you can lose yourself in, even if it’s just for a little while.
Last week was eventful and stressful. For everyone. I found myself once again taking refuge in my website, tinkering with its inner workings in the way that someone else would potter about in their shed or take to their garage to strip down the engine of some automotive device.
Colly drew my attention to Bookshop.org, newly launched in the UK. It’s an umbrella website for independent bookshops to sell through. It’s also got an affiliate scheme, much like Amazon. I set up a Bookshop page for myself.
I’ve been tracking the books I’m reading for the past three years here on my own website. I set about reproducing that list on Bookshop.
It was exactly the kind of not-exactly-mindless but definitely-not-challenging task that was perfect for the state of my brain last week. Search for a book; find the ISBN number; paste that number into a form. It’s the kind of task that a real programmer would immediately set about automating but one that I embraced as a kind of menial task to keep me occupied.
I wasn’t able to get a one-to-one match between the list on my site and my reading list on Bookshop. Some titles aren’t available in the online catalogue. For example, the book I’m reading right now—A Paradise Built in Hell by Rebecca Solnit—is nowhere to be found, which seems like an odd omission.
But most of the books I’ve read are there on Bookshop.org, complete with pretty book covers. Then I decided to reverse the process of my menial task. I took all of the ISBN numbers from Bookshop and add them as machine tags to my reading notes here on my own website. Book cover images on Bookshop have predictable URLs that use the ISBN number (well, technically the EAN number, or ISBN-13, but let’s not go down a 927 rabbit hole here). So now I’m using that metadata to pull in images from Bookshop.org to illustrate my reading notes here on adactio.com.
I’m linking to the corresponding book on Bookshop.org using this URL structure:
https://uk.bookshop.org/a/{{ affiliate code }}/{{ ISBN number }}
I realised that I could also link to the corresponding entry on Open Library using this URL structure:
https://openlibrary.org/isbn/{{ ISBN number }}
Here, for example, is my note for The Raven Tower by Ann Leckie. That entry has a tag:
book:ean=9780356506999
With that information I can illustrate my note with this image:
https://images-eu.bookshop.org/product-images/images/9780356506999.jpg
I’m linking off to this URL on Bookshop.org:
https://uk.bookshop.org/a/980/9780356506999
And this URL on Open Library:
https://openlibrary.org/isbn/9780356506999
The end result is that my reading list now has more links and pretty pictures.
Oh, I also set up a couple of shorter lists on Bookshop.org:
The books listed in those are drawn from my end of the year round-ups when I try to pick one favourite non-fiction book and one favourite work of fiction (almost always speculative fiction). The books in those two lists are the ones that get two hearty thumbs up from me. If you click through to buy one of them, the price might not be as cheap as on Amazon, but you’ll be supporting an independent bookshop.
I think this is quite beautiful—no need to view source; the style sheet is already in the document.
This is a handy tool if you’re messing around with Twitter cards and other metacrap.
Test your knowledge of the original version of HTML—how many elements can you name?
What you see really is what you get. I like this style!
I’ll be in my bunk.
For once, Betteridge’s law of headlines is refuted.
This is a fascinating insight into the heady days of 2005 when Yahoo was the cool company snapping up all the best products like Flickr, Upcoming, and Del.icio.us. It all goes downhill from there.
There’s no mention of the surprising coda.
This presentation on web standards was delivered at the State Of The Browser conference in London in September 2018.
Web standards don’t exist.
At least, they don’t physically exist. They are intangible.
They’re in good company.
Feelings are intangible, but real. Hope. Despair.
Ideas are intangible: liberty, justice, socialism, capitalism.
The economy. Currency. All intangible. I’m sure we’ve all had those “college thoughts”:
Money isn’t real, man! They’re just bits of metal and pieces of paper ! Wake up, sheeple!
Nations are intangible. Geographically, France is a tangible, physical place. But France, the Republic, is an idea. Geographically, North America is a real, tangible, physical land mass. But ideas like “Canada” and “The United States” only exist in our minds.
Faith—the feeling—is intangible.
God—the idea—is intangible.
Art—the concept—is intangible.
A piece of art is an insantiation of the intangible concept of what art is.
Incidentally, I quite like Brian Eno’s working definition of what art is. Art is anything we don’t have to do. We don’t have to make paintings, or sculptures, or films, or music. We have to clothe ourselves for practical reasons, but we don’t have to make clothes beautiful. We have to prepare food to eat it, but don’t have to make it a joyous event.
By this definition, sports are also art. We don’t have to play football. Sports are also intangible.
A game of football is an instantiation of the intangible idea of what football is.
Football, chess, rugby, quiditch and rollerball are equally (in)tangible. But football, chess and rugby have more consensus.
(Christianity, Islam, Judaism, and The Force are equally intangible, but Christianity, Islam, and Judaism have a bit more consensus than The Force).
HTML is intangible.

A web page is an instantiation of the intangible idea of what HTML is.
But we can document our shared consensus.
A rule book for football is like a web standard specification. A documentation of consensus.
By the way, economics, religions, sports and laws are all examples of intangibles that can’t be proven, because they all rely on their own internal logic—there is no outside data that can prove football or Hinduism or capitalism to be “true”. That’s very different to ideas like gravity, evolution, relativity, or germ theory—they are all intangible but provable. They are discovered, rather than created. They are part of objective reality.
Consensus reality is the collection of intangibles that we collectively agree to be true: economy, religion, law, web standards.
We treat consensus reality much the same as we treat objective reality: in our minds, football, capitalism, and Christianity are just as real as buildings, trees, and stars.
Sometimes consensus reality and objective reality get into fights.
Some people have tried to make a consensus reality around the accuracy of astrology or the efficacy of homeopathy, or ideas like the Earth being flat, 9-11 being an inside job, the moon landings being faked, the holocaust never having happened, or vaccines causing autism. These people are unfazed by objective reality, which disproves each one of these ideas.
For a long time, the consensus reality was that the sun revolved around the Earth. Copernicus and Galileo demonstrated that the objective reality was that the Earth (and all the other planets in our solar system) revolve around the sun. After the dust settled on that particular punch-up, we switched up our consensus reality. We changed the story.

That’s another way of thinking about consensus reality: our currencies, our religions, our sports and our laws are stories that we collectively choose to believe.
Web standards are a collection of intangibles that we collectively agree to be true. They’re our stories. They’re our collective consensus reality. They are what web browsers agree to implement, and what we agree to use.
The web is agreement.

For human beings to collaborate together, they need a shared purpose. They must have a shared consensus reality—a shared story.
Once a group of people share a purpose, they can work together to establish principles.
Design principles are points of agreement. There are design principles underlying every human endeavour. Sometimes they are tacit. Sometimes they are written down.
Patterns emerge from principles.

Here’s an example of a human endeavour: the creation of a nation state, like the United States of America.
HTML elements, CSS features, and JavaScript APIs are all patterns (that we agree upon). Those patterns are informed by design principles.

I’ve been collecting design principles of varying quality at principles.adactio.com.
Here’s one of the design principles behind HTML5. It’s my personal favourite—the priority of constituencies:
In case of conflict, consider users over authors over implementors over specifiers over theoretical purity.
“In case of conflict”—that’s exactly what a good design principle does! It establishes the boundaries of agreement. If you disagree with the design principles of a project, there probably isn’t much point contributing to that project.
Also, it’s reversible. You could imagine a different project that favoured theoretical purity above all else. In fact, that’s pretty much what XHTML 2 was all about.
XHTML 1 was simply HTML reformulated with the syntax of XML: lowercase tags, lowercase attributes, always quoting attribute values.
Remember HTML doesn’t care whether tags and attributes are uppercase or lowercase, or whether you put quotes around your attribute values. You can even leave out some closing tags.
So XHTML 1 was actually kind of a nice bit of agreement: professional web developers agreed on using lowercase tags and attributes, and we agreed to quote our attributes. Browsers didn’t care one way or the other.
But XHTML 2 was going to take the error-handling model of XML and apply it to HTML. This is the error handling model of XML: if the parser encounters a single error, don’t render the document.
Of course nobody agreed to this. Browsers didn’t agree to implement XHTML 2. Developers didn’t agree to use it. It ceased to exist.
It turns out that creating a format is relatively straightforward. But how do you turn something into a standard? The really hard part is getting agreement.
Sturgeon’s Law states:
90% of everything is crap.
Coincidentally, 90% is also the percentage of the world’s crap that gets transported by ocean. Your clothes, your food, your furniture, your electronics …chances are that at some point they were transported within an intermodal container.
These shipping containers are probably the most visible—and certainly one of the most important—standards in the physical world. Before the use of intermodal containers, loading and unloading cargo from ships was a long, laborious, and dangerous task.
Along came Malcom McLean who realised that the whole process could be made an order of magnitude more efficient if the cargo were stored in containers that could be moved from ship to truck to train.
But he wasn’t the only one. The movement towards containerisation was already happening independently around the world. But everyone was using different sized containers with different kinds of fittings. If this continued, the result would be a tower of Babel instead of smoothly running global logistics.
Malcolm McLean and his engineer Keith Tantlinger designed two crate sizes—20ft and 40ft—that would work for ships, trucks, and trains. Their design also incorporated an ingenious twistlock mechanism to secure containers together. But the extra step that would ensure that their design would win out was this: Tantlinger convinced McLean to give up the patent rights.
This wasn’t done out of any hippy-dippy ideology. These were hard-nosed businessmen. But they understood that a rising tide raises all boats, and they wanted all boats to be carrying the same kind of containers.
Without the threat of a patent lurking beneath the surface, ready to torpedo the potential benefits, the intermodal container went on to change the world economy. (The world economy is very large and intangible.)
The World Wide Web also ended up changing the world economy, and much more besides. And like the intermodal container, the World Wide Web is patent-free.

Again, this was a pragmatic choice to help foster adoption. When Tim Berners-Lee and his colleague Robert Cailleau were trying to get people to use their World Wide Web project they faced some stiff competition. Lots of people were already using Gopher. Anyone remember Gopher?
The seemingly unstoppable growth of the Gopher protocol was somewhat hobbled in the early ’90s when the University of Minnesota announced that it was going to start charging fees for using it. This was a cautionary lesson for Berners-Lee and Cailleau. They wanted to make sure that CERN didn’t make the same mistake.
On April 30th, 1993, the code for the World Wide Project was made freely available.
This is for everyone.

If you’re trying to get people to adopt a standard or use a new hypertext system, the biggest obstacle you’re going to face is inertia. As the brilliant computer scientist Grace Hopper used to say:
The most dangerous phrase in the English language is “We’ve always done it this way.”

Rear Admiral Grace Hopper waged war on business as usual. She was well aware how abritrary business as usual is. Business as usual is simply the current state of our consensus reality. She said:
Humans are allergic to change.
I try to fight that.
That’s why I have a clock on my wall that runs counter‐clockwise.
Our clocks are a perfect example of a ubiquitous but arbitrary convention. Why should clocks run clockwise rather than counter-clockwise?
One neat explanation is that clocks are mimicing the movement of a shadow across the face of a sundial …in the Northern hemisphere. Had clocks been invented in the Southern hemisphere, they would indeed run counter-clockwise.

But on the clock face itself, why do we carve up time into 24 hours? Why are there 60 minutes in an hour? Why are there are 60 seconds in a minute?

It probably all goes back to Babylonian accountants. Early cuneiform tablets show that they used a sexagecimal system for counting—that’s because 60 is the lowest number that can be divided evenly by 6, 5, 4, 3, 2, and 1.
But we don’t count in base 60; we count in base 10. That in itself is arbitrary—we just happen to have a total of ten digits on our hands.
So if the sexagesimal system of telling time is an accident of accounting, and base ten is more widespread, why don’t we switch to a decimal timekeeping system?
It has been tried. The French revolution introduced not just a new decimal calendar—much neater than our base 12 calendar—but also decimal time. Each day had ten hours. Each hour had 100 minutes. Each minute had 100 seconds. So much better!

It didn’t take. Humans are allergic to change. Sexagesimal time may be arbitrary and messy but …we’ve always done it this way.
Incidentally, this is also why I’m not holding my breath in anticipation of the USA ever switching to the metric system.
Instead of trying to completely change people’s behaviour, you’re likely to have more success by incrementally and subtly altering what people are used to.
That was certainly the case with the World Wide Web.
The Hypertext Transfer Protocol sits on top of the existing TCP/IP stack.
The key building block of the web is the URL. But instead of creating an entirely new addressing scheme, the web uses the existing Domain Name System.

Then there’s the lingua franca of the World Wide Web. These elements probably look familiar to you:
<body> <title> <p> <h1> <h2> <h3> <ol> <ul> <li> <dl> <dt> <dd>
You recognise this language, right? That’s right—it’s SGML. Standard Generalised Markup Language.
Specifically, it’s CERN SGML—a flavour of SGML that was already popular at CERN when Tim Berners-Lee was working on the World Wide Project. He used this vocabulary as the basis for the HyperText Markup Language.
Because this vocabulary was already familiar to people at CERN, convincing them to use HTML wasn’t too much of a hard sell. They could take an existing SGML document, change the file extension to .htm and it would work in one of those new fangled web browsers.

In fact, HTML worked better than expected. The initial idea was that HTML pages would be little more than indices that pointed to other files containing the real meat and potatoes of content—spreadsheets, word processing documents, whatever. But to everyone’s surprise, people started writing and publishing content in HTML.
Was HTML the best format? Far from it. But it was just good enough and easy enough to get the job done.
It has since changed, but that change has happened according to another design principle:
Evolution, not revolution
From its humble beginnings with the handful of elements borrowed from CERN SGML, HTML has grown to encompass an additional 100 elements over its lifespan. And yet, it’s still technically the same format!
This is a classic example of the paradox called the Ship Of Theseus, also known as Trigger’s Broom.
You can take an HTML document written over two decades ago, and open it in a browser today.
Even more astonishing, you can take an HTML document written today and open it in a browser from two decades ago. That’s because the error-handling model of HTML has always been to simply ignore any tags it doesn’t recognise and render the content inside them.
That pattern of behaviour is a direct result of the design principle:
Degrade Gracefully
…document conformance requirements should be designed so that Web content can degrade gracefully in older or less capable user agents, even when making use of new elements, attributes, APIs and content models.
Here’s a picture from 2006.

That’s me in the cowboy hat—the picture was taken in Austin, Texas. This is an impromptu gathering of people involved in the microformats community.
Microformats, like any other standards, are sets of agreements. In this case, they’re agreements on which class values to use to mark up some of the missing elements from HTML—people, places, and events. That’s pretty much it.
And yes, they do have design principles—some very good ones—but that’s not why I’m showing this picture.
Some of the people in this picture—Tantek Çelik, Ryan King, and Chris Messina—were involved in the creation of BarCamp, a series of grassroots geek gatherings.
BarCamps sound like they shouldn’t work, but they do. The schedule for the event is arrived at collectively at the beginning of the gathering. It’s kind of amazing how the agreement emerges—rough consensus and running events.
In the run-up to a BarCamp in 2007, Chris Messina posted this message to the fledgeling social networking site, twitter.com:
how do you feel about using # (pound) for groups. As in #barcamp [msg]?
This was when tagging was all the rage. We were all about folksonomies back then. Chris proposed that we would call this a “hashtag”.
I wasn’t a fan:
Thinking that hashtags disrupt the reading flow of natural language. Sorry @factoryjoe
But it didn’t matter what I thought. People agreed to this convention, and after a while Twitter began turning the hashtagged words into links.
In doing so, they were following another HTML design principle:
Pave the cowpaths
It sounds like advice for agrarian architects, but its meaning is clarified:
When a practice is already widespread among authors, consider adopting it rather than forbidding it or inventing something new.
Twitter had previously paved a cowpath when people started prefacing usernames with the @ symbol. That convention didn’t come from Twitter, but they didn’t try to stop it. They rolled with it, and turned any username prefaced with an @ symbol into a link.

The @ symbol made sense because people were used to using it from email. The choice to use that symbol in email addresses was made by Ray Tomlinson. He needed a symbol to separate the person and the domain, looked down at his keyboard, saw the @ symbol, and thought “that’ll do.”
Perhaps Chris followed a similar process when he proposed the symbol for the hashtag.
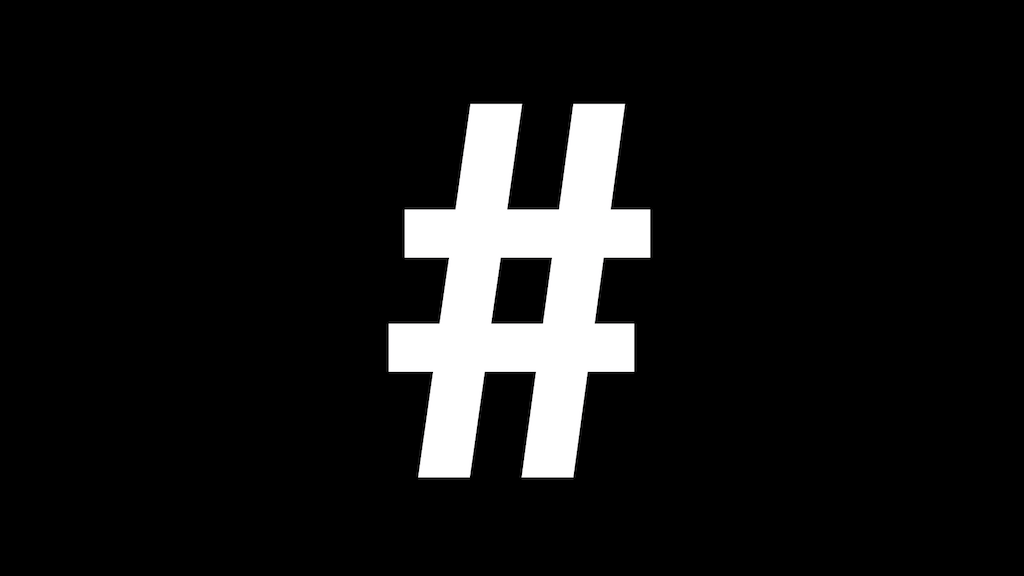
It could have just as easily been called a “number tag” or “octothorpe tag” or “pound tag”.
This symbol started life as a shortcut for “pound”, or more specifically “libra pondo”, meaning a pound in weight. Libra pondo was abbreviated to lb when written. That got turned into a ligature ℔ when written hastily. That shape was the common ancestor of two symbols we use today: £ and #.
The eight-pointed symbol was (perhaps jokingly) renamed the octothorpe in the 1960s when it was added to telephone keypads. It’s still there on the digital keypad of your mobile phone. If you were to ask someone born in this millenium what that key is called, they would probably tell you it’s the hashtag key. And if they’re learning to read sheet music, I’ve heard tell that they refer to the sharp notes as hashtag notes.
If this upsets you, you might be the kind of person who rages at the word “literally” being used to mean “figuratively” or supermarkets with aisles for “10 items or less” instead of “10 items or fewer”.
Tough luck. The English language is agreement. That’s why English dictionaries exist not to dictate usage of the language, but to document usage.
It’s much the same with web standards bodies. They don’t carve the standards into tablets of stone and then come down the mountain to distribute them amongst the browsers. No, it’s what the browsers implement that gets carved in stone. That’s why it’s so important that browsers are in agreement. In the bad old days of the browser wars of the late 90s, we saw what happened when browsers implemented their own proprietary features.
Standards require interoperability.
Interoperability requires agreement.

So what we can learn from the history of standardisation?
Well, there are some direct lessons from the HTML design principles.
Consider users over authors…
Listen, I want developer convenience as much as the next developer. But never at the expense of user needs.
I’ve often said that if I have the choice between making something my problem, and making it the user’s problem, I’ll make it my problem every time. That’s the job.
I worry that these days developer convenience is sometimes prized more highly than user needs. I think we could all use a priority of constituencies on every project we work on, and I would hope that we would prioritise users over authors.
Web content can degrade gracefully in older or less capable user agents…
I know that I go on about progressive enhancement a lot. Sometimes I make it sound like a silver bullet. Well, it kinda is.
I mean, you can’t just buy a bullet made of silver—you have to make it yourself. If you’re not used to crafting bullets from silver, it will take some getting used to.
Again, if developer convenience is your priority, silver bullets are hard to justify. But if you’re prioritising users over authors, progressive enhancement is the logical methodology to use.
It’s a testament to the power and flexibility of the web that we don’t have to build with progressive enhancement. We don’t have to build with a separation of concerns like structure, presentation, and behaviour.
We don’t have to use what the browser gives us: buttons, dropdowns, hyperlinks. If we want to, we can make these things from scratch using JavaScript, divs and ARIA attributes.
But why do that? Is it because those native buttons and dropdowns might be inconsistent from browser to browser.
Consistency is not the purpose of the world wide web.
Universality is the key principle underlying the web.
Our patterns should reflect the intent of the medium.
Use what the browser gives you—build on top of those agreements. Because that’s the bigger lesson to be learned from the history of web standards, clocks, containers, and hashtags.

Our world is made up of incremental improvements to what has come before. And that’s how we will push forward to a better tomorrow: By building on top of what we already have instead of trying to create something entirely from scratch. And by working together to get agreement instead of going it alone.
The future can be a frightening prospect, and I often get people asking me for advice on how they should prepare for the web’s future. Usually they’re thinking about which programming language or framework or library they should be investing their time in. But these specific patterns matter much less than the broader principles of working together, collaborating and coming to agreement. It’s kind of insulting that we refer to these as “soft skills”—they couldn’t be more important.
Working on the web, it’s easy to get downhearted by the seemingly ephemeral nature of what we build. None of it is “real”; none of it is tangible. And yet, looking at the history of civilisation, it’s the intangibles that survive: ideas, philosophies, culture and concepts.
The future can be frightening because it is intangible and unknown. But like all the intangible pieces of our consensus reality, the future is something we construct …through agreement.
Now let’s agree to go forward together to build the future web!
A little while back, I switched from using Chrome as my day-to-day browser to using Firefox. I could feel myself getting a bit too comfortable with one particular browser, and that’s not good. I reckon it’s good to shake things up a little every now and then. Besides, there really isn’t that much difference once you’ve transferred over bookmarks and cookies.
Unfortunately I’m being bitten by this little bug in Firefox. It causes some of my bookmarklets to fail on certain sites with strict Content Security Policies (and CSPs shouldn’t affect bookmarklets). I might have to switch back to Chrome because of this.
I use bookmarklets throughout the day. There’s the Huffduffer bookmarklet, of course, for whenever I come across a podcast episode or other piece of audio that I want to listen to later. But there’s also my own home-rolled bookmarklet for posting links to my site. It doesn’t do anything clever—it grabs the title and URL of the currently open page and pre-populates a form in a new window, leaving me to add a short description and some tags.
If you’re reading this, then you’re familiar with the “journal” section of adactio.com, but the “links” section is where I post the most. Here, for example, are all the links I posted yesterday. It varies from day to day, but there’s generally a handful.
Should you wish to keep track of everything I’m linking to, there’s a twitterbot you can follow called @adactioLinks. It uses a simple IFTTT recipe to poll my RSS feed of links and send out a tweet whenever there’s a new entry.
Or you can drink straight from the source and subscribe to the RSS feed itself, if you’re still rocking it old-school. But if RSS is your bag, then you might appreciate a way to filter those links…
All my links are tagged. Heavily. This is because all my links are “notes to future self”, and all my future self has to do is ask “what would past me have tagged that link with?” when I’m trying to find something I previously linked to. I end up using my site’s URLs as an interface:
At the front-end gatherings at Clearleft, I usually wrap up with a quick tour of whatever I’ve added that week to:
Well, each one of those tags also has a corresponding RSS feed:
adactio.com/links/tags/serviceworkers/rssadactio.com/links/tags/sci-fi/rssadactio.com/links/tags/frontend/rss…and so on.
That means you can subscribe to just the links tagged with something you’re interested in. Here’s the full list of tags if you’re interested in seeing the inside of my head.
This also works for my journal entries. If you’re only interested in my blog posts about frontend development, you might want to subscribe to:
Here are all the tags from my journal.
You can even mix them up. For everything I’ve tagged with “typography”—whether it’s links, journal entries, or articles—the URL is:
The corresponding RSS feed is:
You get the idea. Basically, if something on my site is a list of items, chances are there’s a corresponding RSS feeds. Sometimes there might even be a JSON feed. Hack some URLs to see.
Meanwhile, I’ll be linking, linking, linking…
A fascinating look at an attempt to redefine the taxonomy of online porn.
Porn is part of the ecosystem that tells us what sex and sexuality are. Porn terms are, to use Foucault’s language, part of a network of technologies creating truths about our sexuality.
Reminds of the heady days of 2005, when it was all about tagging and folksonomies.
The project, at its most ambitious, seeks to create a new feedback loop of porn watched and made, unmoored from the vagaries of old, bad, lazy categories.
A nice bit of markup archeology, tracing the early development of HTML from its unspecced roots to the first drafts.
I recognise some of the extinct elements from the line-mode browser hack days at CERN e.g. HP1, HP2, ISINDEX, etc.
It turns out my Boolean URL tag hacking in Huffduffer is answering a real need: Will Myddelton had already put the same functionality together using Yahoo Pipes.
We were having a discussion in the Clearleft office recently about that perennially-tricky navigation pivot: tags. Specifically, we were discussing how to represent the interface for combinatorial tags i.e. displaying results of items that have been tagged with tag A and tag B.
I realised that this was functionality that I wasn’t even offering on Huffduffer, so I set to work on implementing it. I decided to dodge the interface question completely by only offering this functionality through the browser address bar. As a fairly niche, power-user feature, I’m not sure it warrants valuable interface real estate—though I may revisit that challenge later.
I can’t use the + symbol as a tag separator because Huffduffer allows spaces in tags (and spaces are converted to pluses in URLs), so I’ve settled on commas instead.
For example, there are plenty of items tagged with “music” (/tags/music) and plenty of items tagged with “science” (/tags/science) but there’s only a handful of items tagged with both “music” and “science” (/tags/music,science).
This being Huffduffer, where just about every page has corresponding JSON, RSS and Atom representations, you can also subscribe to the podcast of everything tagged with both “music” and “science” (/tags/music,science/rss).
There’s an OR operator as well; the vertical pipe symbol. You can view the 60 items tagged with “html5”, the 14 items tagged with “css3”, or the 66 items tagged with either “html5” or “css3” (/tags/html5|css3).
Wait a minute …66 items? But 60 plus 14 equals 74, not 66!
The discrepancy can be explained by the 8 items tagged with both “css3” and “html5” (/tags/html5,css3).
The AND and OR operators can be combined, so you can find items tagged with either “science” or “religion” that are also tagged with “politics” (/tags/science|religion,politics).
While it’s fun to do this in the browser’s address bar, I think the real power is in the way that the corresponding podcast allows you to subscribe to precisely-tailored content. Find just the right combination of tags, click on the RSS link, and you’re basically telling iTunes to automatically download audio whenever there’s something new that matches criteria like:
/tags/science+fiction|fantasy|horror,romance),/tags/google,apple|microsoft|yahoo).I’m sure there are plenty of intriguing combinations out there. Now I can use Huffduffer’s URLs to go spelunking for audio gems at the most promising intersections of tags.
Slides from a presentation on machine tags by Aaron Straup Cope. I highly recommend downloading the PDF for the bounty of links listed under "Reading List."
I’ve already described how machine tags on Huffduffer trigger a number of third-party API calls. Tagging something with music:artist=..., book:author=..., film:title=... or any number of similar machine tags will fire off calls to places like Amazon, The New York Times, or Last.fm.
For a while now, I’ve wanted to include Flickr in that list of third-party services but I couldn’t think of an easy way of associating audio files with photos. Then I realised that a mechanism already exists, and it’s another machine tag. Anything on Flickr that’s been tagged with lastfm:event=... will probably be a picture of a musical artist.
So if anything is tagged on Huffduffer with music:artist=..., all I need to do is fire off a call to Last.fm to get a list of that artist’s events using the method artist.getEvents. Once I have the event IDs I can search Flickr for photos that have been machine tagged with those IDs.
There’s just one problem. Last.fm’s API only returns future events for an artist. There’s no method for past events.
Undeterred, I found a RESTful interface that provides the past events of an artist on Last.fm. The format returned isn’t JSON or XML. It’s HTML. It turns out that past events are freely available in the profile for any artist on Last.fm with the identifier last.fm/music/{artist}/+events/{year}. Here, for example, are Salter Cane gigs in 2009: last.fm/music/Salter+Cane/+events/2009.
If only those events were structured in hCalendar! As it is, I have to run through all the links in the document to find the hrefs beginning with the string http://www.last.fm/event/ and then extract the event ID that immediately follows that string.
Once I’ve extracted the event IDs for an artist, I can fire off a search on Flickr using the flickr.photos.search method with a machine_tags parameter (as well as passing the artist name in the text parameter just to be sure).
Here’s an example result in the sidebar on Huffduffer: huffduffer.com/tags/music:artist=Bat+for+Lashes
It’s messy but it works. I guess that’s the dictionary definition of a hack.
{kind=link}