
Enhancing Air Traffic Control Communication Systems with Integrated Automatic Speech Recognition: Models, Applications and Performance Evaluation


<p>Roles of ASR in the ATC procedure.</p> "> Figure 2
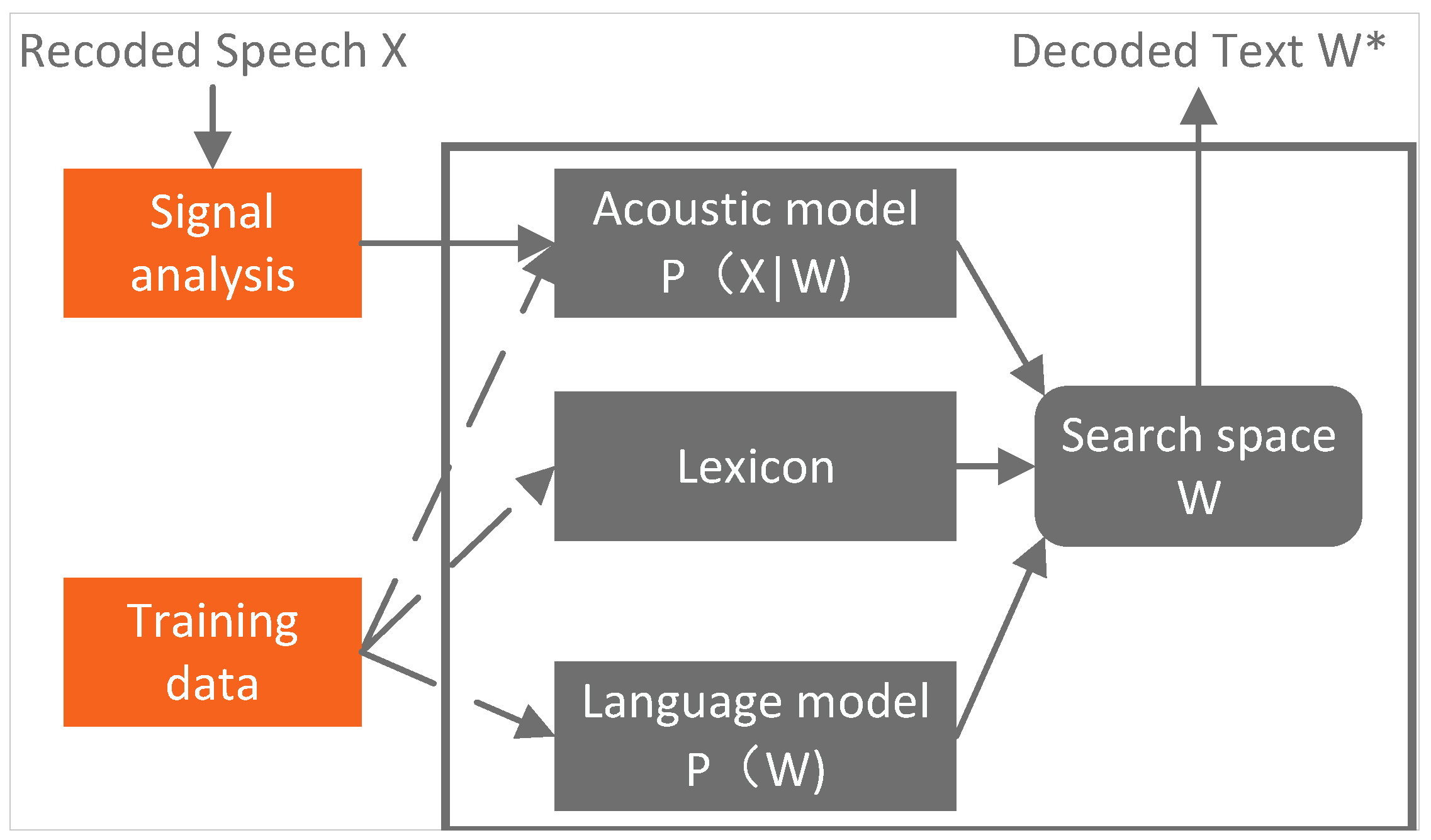
<p>Structure of the statistical model.</p> "> Figure 3
<p>The architecture of connectionist temporal classification.</p> "> Figure 4
<p>Acoustic model in the cascade model and E2E model.</p> "> Figure 5
<p>The improved E2E model.</p> "> Figure 6
<p>Procedure for the cascade model.</p> "> Figure 7
<p>Context information and domain knowledge used in ASR.</p> "> Figure 8
<p>Elements of an ATC instruction.</p> "> Figure 9
<p>The autonomous training process for ATCos.</p> "> Figure 10
<p>Evaluation framework of ASR systems in the ATC domain.</p> ">
Abstract
:1. Introduction
- Specialized vocabulary: Numerous rules and measures to regulate the pronunciation of homophone words have been issued by the International Civil Aviation Organization (ICAO) to eliminate the misunderstanding of ATC speech [6], which makes ATC speech significantly different from daily speech. Developing ASR systems that accurately transcribe these domain-specific terms is a substantial challenge.
- Domain specificity: ATC communication involves industry-specific terminology and communication standards that may be absent or limited in ASR model training data. ASR systems typically require domain-specific data and terminology to achieve a high accuracy. The lack of these domain-specific elements can lead to decreased model performance. ATC speech data cannot be added to the general corpus to avoid interfering with training and affecting the use of the general corpus in other fields.
- Accents and variability: Pilots and ATCos come from diverse linguistic backgrounds and may speak with different accents or dialects. ASR systems must account for this variability to ensure accurate recognition, adding complexity to the training and adaptation processes.
- Unstable speech rate: The pace of communication within the ATC environment is characterized by its inherent variability and unpredictability. This variability arises due to the dynamic nature of aviation operations, where ATCos and pilots must adapt their speaking rates to rapidly changing circumstances. It can fluctuate significantly in response to various factors, such as emergencies, traffic density, radio congestion, language and accent differences and experience.
- Noise and interference: ATC communication often occurs in high-noise environments, including aircraft engine noise, radio communications and other sources of interference. These noise and interference factors can adversely affect ASR performance, necessitating specific handling and adaptation.
- The fundamental models and techniques employed in ASR research within the ATC domain are introduced, including traditional statistical models, DNN-based acoustic and language models and the E2E model.
- A comprehensive analysis is offered from various perspectives, including ATC corpora, models, evaluation measures and applications.
- Recognizing the significance of evaluation measures, we have established a comprehensive evaluation framework. This framework enables a thorough assessment of the developed ASR system, facilitating the identification of shortcomings and the implementation of practical improvements.
- A clear outline of the challenges is provided, along with strategies to enhance the effectiveness of ASR in the ATC domain.
2. Key Models and Technologies for Automatic Speech Recognition
2.1. Statistical Model
2.1.1. Acoustic Model
2.1.2. Language Model
2.1.3. Lexicon
2.1.4. Decoder
2.2. End-to-End Model
3. Application
3.1. Overview
3.2. ATC Corpora
3.3. Models and Their Extensions
3.3.1. Feature Extraction
3.3.2. Acoustic Model
3.3.3. Language Model
3.3.4. Decoder
3.3.5. Training Algorithm
3.4. Evaluation Measures
3.5. Application Scenarios
4. Evaluation Framework and Measurement for ASR Systems in the ATC Domain
4.1. Test Corpus for Evaluation
4.2. Evaluation Framework
5. Discussion
5.1. Challenges of ASR in the ATC Domain
- Safety stands as a paramount criterion in ATC operations. Despite achieving an impressive ASR recognition accuracy of approximately 96%, there remains a residual error rate of around 4%. In real ATC scenarios, such error rates can foster distrust in ASR among ATCos. On the one hand, they must contend with correcting recognition errors, and on the other hand, they also need to verify accurate recognition. This not only fails to reduce ATCos’ workload but also adds to their burdens.
- One of the purposes of implementing ASR is to reduce the workload of ATCos, particularly when integrated with ATC automation systems. However, recognition errors can result in either missed alarms or false alarms. Missed alarms pose safety hazards to aircraft operations, while false alarms place an additional burden on ATCos.
- In real ATC scenarios, not all sentences spoken by ATCos adhere to standardized protocols. This is particularly evident during emergencies, where ASR systems may struggle to recognize and interpret ATCo communications accurately.
- The quality of the ATC corpus significantly affects ASR performance, making it challenging to collect sufficient training samples to develop a capable ASR system. Annotating the training samples for ASR in the ATC domain requires significant expertise and knowledge of ATC principles. Such expertise may only be readily available to some staff, and specialized training may be necessary to ensure competence in this area.
- Generalization is significant to ASR research in the ATC domain. It is essential to recognize that the vocabularies used in different control centers or locations may exhibit unique and distinct characteristics. Consequently, enhancing the generalization capabilities of ASR systems across diverse control centers or areas becomes a crucial technique for broadening the applicability of ASR technology.
- The use of ASR will have an impact on existing ATC operations. The ASR system needs to consider effective interaction with ATCos during design, including voice command confirmation, error correction and system feedback, in order to improve user experience and operational efficiency. Therefore, the introduction of ASR systems may require adjustments and redesign of existing operational processes to adapt to the use of speech recognition technology. ATCos needs to receive training and an adaptation period on new technologies to proficiently use the ASR system and understand its limitations and correct usage methods.
5.2. Approaches to Improve ASR Performance
- To ensure consistency between label text and recognition text, and to accurately represent the intent of ATCos in the recognized text, it is essential to establish design specifications for data annotation and transcription. This standardization plays a crucial role in minimizing recognition errors attributable to non-technical factors. For example, should “Air China 4137” be labeled as “CCA 4137” or “AIR CHINA FOUR ONE THREE SEVEN”.
- Training samples should be thoughtfully chosen to reasonably cover various ATC scenarios, focusing on different control phases, control areas, speech rates, and noise levels. An ASR system trained using a corpus with well-balanced coverage and standardized annotation can significantly enhance its recognition performance in real-world ATC scenarios.
- To tackle the challenge of limited generalization, it is crucial to establish an information database that encompasses control units, airline information, waypoints from various control areas, and route names. During the ASR process, the recognized text can be cross-referenced with the information stored in the database. This approach enhances the generalization capabilities of ASR systems, allowing systems trained for one control area to be effectively utilized in other regions as well.
- Choosing appropriate metrics and developing an evaluation framework aligned with specific application requirements is a crucial step. This process aids in pinpointing shortcomings in ASR performance and facilitates necessary adjustments and improvements. For example, although the lower the WER or SER, the better, considering the limitations of current technological means, they should be set at an achievable and reasonable level. The remaining measures should be selected and set according to actual application requirements.
- In specific ATC speech scenarios, the content can become ambiguous and challenging to recognize accurately without proper context. Integrating contextual information, including system-level integration with surveillance systems and ATC automation systems, as well as ASR-level integration with pre-speech data, can enhance the semantic understanding and intention recognition of ATC speech.
- Implementing a graded alarm mechanism is crucial for minimizing false alarms and missed alarms. In actual ATC scenarios, using different levels of alarms for different types and degrees of risks can enable ATCos to effectively allocate attention and resources, thereby reducing security risks and preventing additional workloads.
- Although not used in the ATC domain, audiovisual speech recognition (AVSR) has shown potential. Currently, ATCos operate in a video surveillance environment, so a combination of audio and video can be used to improve recognition accuracy. In noisy and multiplayer environments, visual signals, such as lip-reading signals, can provide additional sources of information and enhance speech recognition capabilities. When using AVSR in the ATC domain, attention should be paid to issues such as data security and privacy, system complexity and increased costs, real-time performance, and audio–video synchronization [92,93,94].
- With the development of big data, artificial intelligence, E2E and other advanced technologies, ASR technology is evolving and improving. It is imperative to stay current with these advancements and incorporate advanced ASR technology into the ATC domain to enhance overall performance.
- Expanding the functions related to human factors is crucial for improving ASR performance. By analyzing the speech characteristics of ATCos, ASR systems can detect fatigue, stress and emotions, issue timely warnings and help manage work tasks. Conducting ASR trials and training with ATCos provides feedback for improvement and enhances adaptability. This approach not only boosts ASR performance but also ensures better integration into real-world ATC environments.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ABSR | Assistant-based speech recognition |
| AED | Attention-based encoder–decoder |
| AM | Acoustic model |
| AMAN | Arrival manager |
| AP | Average pooling |
| ASR | Automatic speech recognition |
| ATC | Air traffic control |
| ATCos | Air traffic controllers |
| BERT | Bidirectional encoder representations from transformers |
| CER | Character error rate |
| CMVN | Cepstral mean and variance normalization |
| CNNs | Convolutional neural networks |
| CmdER | Command error rate |
| ConER | Concept error rate |
| CSA | Callsign accuracy |
| CTC | Connectionist temporal classification |
| DNN | Deep neural networks |
| E2E | End-to-end |
| FAA | Federal Aviation Administration |
| FBank | Filter bank |
| FC | Fully connected |
| GMM | Gaussian mixture model |
| HMM | Hidden Markov model |
| ICAO | International Civil Aviation Organization |
| LF-MMI | Lattice-free maximum mutual information |
| LM | Language model |
| LSTM | Long short-term memory |
| MCNN | Multiscale CNN |
| MFCC | Mel frequency cepstrum coefficient |
| MTPM | Machine translation PM |
| PLM | Phoneme-based LM |
| PM | Pronunciation model |
| PPR | Parallel phone recognition |
| RIA | Repetition intention accuracy |
| RNNs | Recurrent neural networks |
| RNN-T | Recurrent neural network transducer |
| RTF | Real-time factor |
| SER | Sentence error rate |
| STFT | Short-time Fourier transform |
| TDNN | Time delay neural network |
| VHF | Very high frequency |
| WER | Word error rate |
| WFST | Weighted finite-state transducer |
| WLM | Word-based language model |
References
- Federal Aviation Administration. FAA Aerospace Forecast: Fiscal Years 2020–2040; U.S. Department of Transportation: Washington, DC, USA, 2020.
- Davis, K.; Biddulph, R.; Balashek, S. Automatic recognition of spoken digits. J. Acoust. Soc. Am. 1952, 24, 637–642. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Li, J. Recent advances in end-to-end automatic speech recognition. APSIPA Trans. Signal Inf. Process. 2022, 11, 1–64. [Google Scholar] [CrossRef]
- Xiong, W.; Droppo, J.; Huang, X.; Seide, F.; Seltzer, M.; Stolcke, A.; Dong, Y.; Zweig, G. Toward human parity in conversational speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2410–2423. [Google Scholar] [CrossRef]
- International Civil Aviation Organization. Manual on the Implementation of ICAO Language Proficiency Requirements; International Civil Aviation Organization: Montreal, QC, Canada, 2010. [Google Scholar]
- Nguyen, V.; Holone, H. Possibilities, challenges and the state of the art of automatic speech recognition in air traffic control. Int. J. Comput. Inf. Eng. 2015, 9, 1933–1942. [Google Scholar]
- Rataj, J.; Helmke, K.; Ohneiser, O. AcListant with continuous learning: Speech recognition in air traffic control. In Proceedings of the 6th ENRI International Workshop on ATM/CNS, Tokyo, Japan, 29–31 October 2019; pp. 93–112. [Google Scholar]
- Helmke, H.; Motlicek, P.; Klakow, D.; Kern, C.; Hlousek, P. Cost reductions enabled by machine learning in ATM How can automatic speech recognition enrich human operators’ performance? In Proceedings of the 13th USA/Europe Air Traffic Management Research and Development Seminar, Vienna, Austria, 17–21 June 2019. [Google Scholar]
- Lin, Y. Spoken instruction understanding in air traffic control: Challenge, technique, and application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Gales, M.; Steve, Y. The application of hidden Markov models in speech recognition. Found. Trends Signal Process. 2008, 1, 195–304. [Google Scholar] [CrossRef]
- Sainath, T.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, QLD, Australia, 19–24 April 2019; pp. 4580–4584. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Rabiner, L. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Cho, K.; Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Hofbaue, K.; Petrik, S.; Hering, H. The ATCOSIM corpus of non-prompted clean air traffic control speech. In Proceedings of the 6th Edition of the Language Resources and Evaluation Conference, Marrakech, Morocco, 26 May–1 June 2008; pp. 2147–2152. [Google Scholar]
- De Cordoba, R.; Ferreiros, J.; San-Segundo, R.; Macias-Guarasa, J.; Montero, J.; Fernández, F.; D’Haro, F.; Pardo, J. Air traffic control speech recognition system cross-task and speaker adaptation. IEEE Aerosp. Electron. Syst. Mag. 2006, 21, 12–17. [Google Scholar] [CrossRef]
- Fernández, F.; Ferreiros, J.; Pardo, J.; Gonzalez, G. Human spontaneity and linguistic coverage two related factors relevant to the performance of automatic understanding of ATC speech. IEEE Aerosp. Electron. Syst. Mag. 2006, 21, 1–9. [Google Scholar]
- Pardo, J.; Ferreiros, J.; Fernández, F.; Sama, V.; Gonzalez, G. Automatic understanding of ATC speech: Study of prospectives and field experiments for several controller positions. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 2700–2730. [Google Scholar] [CrossRef]
- Cordero, J.; Dorado, M.; de Pablo, J. Automated speech recognition in ATC environment. In Proceedings of the 2nd International Conference on Application and Theory of Automation in Command and Control Systems, Toulouse, France, 29–31 May 2012; pp. 1–8. [Google Scholar]
- Cordero, J.; Rodríguez, N.; de Pablo, J.; Dorado, M. Automated speech recognition in controller communications applied to workload measurement. In Proceedings of the 3rd SESAR Innovation Days, Stockholm, Sweden, 26–28 December 2013; pp. 1–8. [Google Scholar]
- Helmke, H.; Ehr, H.; Kleinert, M.; Faubel, F.; Klakow, D. Increased acceptance of controller assistance by automatic speech recognition. In Proceedings of the 10th USA/Europe Air Traffic Management Research and Development Seminar, Chicago, IL, USA, 10–13 June 2013; pp. 1–8. [Google Scholar]
- Ohneiser, O.; Helmke, H.; Ehr, H.; Gürlük, H.; Klakow, D. Air traffic controller support by speech recognition. In Proceedings of the 15th International Conference on Applied Human Factors and Ergonomics, Kraków, Poland, 19–23 July 2014; pp. 1–12. [Google Scholar]
- Schmidt, A.; Oualil, Y.; Ohneiser, O.; Kleinert, M.; Klakow, D. Context-based recognition network adaptation for improving on-line ASR in air traffic control. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop, South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 13–18. [Google Scholar]
- Oualil, Y.; Schulder, M.; Helmke, H.; Schmidt, A.; Klakow, D. Real-time integration of dynamic context information for improving automatic speech recognition. In Proceedings of the 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 1–5. [Google Scholar]
- Helmke, H.; Rataj, J.; Mühlhausen, T.; Ohneiser, O.; Ehr, H.; Kleinert, M.; Oualil, Y.; Schulder, M. Assistant-based speech recognition for ATM applications. In Proceedings of the 11th USA/Europe Air Traffic Management Research and Development Seminar, Lisbon, Portugal, 23–26 June 2015; pp. 1–10. [Google Scholar]
- Helmke, H.; Ohneiser, O.; Mühlhausen, T.; Wies, M. Reducing controller workload with automatic speech recognition. In Proceedings of the 35th Digital Avionics Systems Conference, Sacramento, CA, USA, 25–29 September 2016; pp. 1–10. [Google Scholar]
- Helmke, H.; Ohneiser, O.; Buxbaum, J.; Kern, C. Increasing atm efficiency with assistant based speech recognition. In Proceedings of the 12th USA/Europe Air Traffic Management Research and Development Seminar, Seattle, WA, USA, 27–30 June 2017; pp. 1–10. [Google Scholar]
- Johnson, D.; Nenovz, V.; Espinoza, G. Automatic speech semantic recognition and verification in Air Traffic Control. In Proceedings of the 32nd IEEE/AIAA Digital Avionics Systems Conference, East Syracuse, NY, USA, 5–10 October 2013; pp. 5B51–5B54. [Google Scholar]
- Nguyen, V.; Holone, H. N-best list re-ranking using semantic relatedness and syntactic score: An approach for improving speech recognition accuracy in air traffic control. In Proceedings of the 16th International Conference on Control, Automation and Systems, Gyeongju, Republic of Korea, 16–19 October 2016; pp. 1315–1319. [Google Scholar]
- Lu, H.; Cheng, V.; Ballinger, D.; Fong, A.; Nguyen, J.; Jones, S.; Cowart, S. A speech-enabled simulation interface agent for airspace system assessments. In Proceedings of the 2015 AIAA Modeling and Simulation Technologies Conference, Kissimmee, FL, USA, 5–9 January 2015; pp. 1–10. [Google Scholar]
- Delpech, E.; Laignelet, M.; Pimm, C.; Raynal, C.; Trzos, M.; Arnold, A.; Pronto, D. A real-life, french-accented corpus of air traffic control communications. In Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, Japan, 7–12 May 2018; pp. 1–5. [Google Scholar]
- Pellegrini, T.; Farinas, J.; Delpech, E.; Lancelot, F. The Airbus air traffic control speech recognition 2018 challenge: Towards ATC automatic transcription and call sign detection. arXiv 2018, arXiv:1810.12614. [Google Scholar]
- Gupta, V.; Rebout, L.; Boulianne, G.; Ménard, P.; Alam, J. CRIM’s speech transcription and call sign detection system for the ATC airbus challenge task. In Proceedings of the 20th Annual Conference of the International Speech Communication Association INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 3018–3022. [Google Scholar]
- Guimin, J.; Cheng, F.; Jinfeng, Y.; Dan, L. Intelligent checking model of Chinese radiotelephony read-backs in civil aviation air traffic control. Chin. J. Aeronaut. 2018, 31, 2280–2289. [Google Scholar]
- Liu, Y.; Guo, X.; Zhang, H.; Yang, J. An acoustic model of civil aviation’s radiotelephony communication. In Proceedings of the 8th International Conference on Computing and Pattern Recognition, Beijing, China, 23–25 October 2019; pp. 315–319. [Google Scholar]
- Oualil, Y.; Klakow, D.; Szaszák, G.; Srinivasamurthy, A.; Helmke, H.; Motlicek, P. A context-aware speech recognition and understanding system for air traffic control domain. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop, Okinawa, Japan, 16–20 December 2017; pp. 404–408. [Google Scholar]
- Kleinert, M.; Helmke, H.; Siol, G.; Ehr, H.; Srinivasamurthy, A. Machine learning of controller command prediction models from recorded radar data and controller speech utterances. In Proceedings of the 7th SESAR Innovation Days, Belgrade, Serbia, 28–30 November 2017; pp. 404–408. [Google Scholar]
- Srinivasamurthy, A.; Motlicek, P.; Himawan, I.; Szaszák, G.; Oualil, Y.; Helmke, H. Semi-supervised learning with semantic knowledge extraction for improved speech recognition in air traffic control. In Proceedings of the 18th Annual Conference of the International Speech Communication Association INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 2406–2410. [Google Scholar]
- Kleinert, M.; Helmke, H.; Siol, G.; Ehr, H.; Cerna, A.; Kern, C.; Klakow, D.; Motlicek, P.; Oualil, Y.; Singh, M. Semi-supervised adaptation of assistant based speech recognition models for different approach areas. In Proceedings of the 37th IEEE/AIAA Digital Avionics Systems Conference, London, UK, 23–27 September 2018; pp. 1–10. [Google Scholar]
- Kleinert, M.; Helmke, H.; Ehr, H.; Kern, C.; Siol, G. Building blocks of assistant based speech recognition for air traffic management applications. In Proceedings of the 8th SESAR Innovation Days, Salzburg, Austria, 3–7 December 2018; pp. 1–8. [Google Scholar]
- Srinivasamurthy, A.; Motlicek, P.; Singh, M.; Oualil, Y.; Helmke, H. Iterative learning of speech recognition models for air traffic control. In Proceedings of the 19th Annual Conference of the International Speech Communication Association INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 3519–3523. [Google Scholar]
- Helmke, H.; Slotty, M.; Poiger, M.; Herrer, D.; Perez, M. Ontology for transcription of ATC speech commands of SESAR 2020 solution PJ. 16-04. In Proceedings of the 37th IEEE/AIAA Digital Avionics Systems Conference, London, UK, 23–27 September 2018; pp. 1–10. [Google Scholar]
- Kleinert, M.; Helmke, H.; Moos, S.; Hlousek, P.; Windisch, C.; Ohneiser, O.; Ehr, H.; Labreuil, A. Reducing controller workload by automatic speech recognition assisted radar label maintenance. In Proceedings of the 9th SESAR Innovation Days, Athens, Greece, 2–6 December 2019; pp. 1–8. [Google Scholar]
- Helmke, H.; Kleinert, M.; Ohneiser, O.; Ehr, H.; Shetty, S. Machine learning of air traffic controller command extraction models for speech recognition applications. In Proceedings of the 38th IEEE/AIAA Digital Avionics Systems Conference, San Diego, CA, USA, 8–12 September 2019; pp. 1–9. [Google Scholar]
- Hou, N.; Tian, X.; Chng, E.; Ma, B.; Li, H. Improving air traffic control speech intelligibility by reducing speaking rate effectively. In Proceedings of the 2017 International Conference on Asian Language Processing, Shanghai, China, 15–17 November 2019; pp. 197–200. [Google Scholar]
- Subramanian, S.; Kostiuk, P.; Katz, G. Custom IBM Watson speech-to-text model for anomaly detection using ATC-pilot voice communication. In Proceedings of the 2018 Aviation Technology, Integration, and Operations Conference, Atlanta, GA, USA, 25–29 June 2018; pp. 1–14. [Google Scholar]
- Šmídl, L.; Švec, J.; Pražák, A.; Trmal, J. Semi-supervised training of DNN-based acoustic model for ATC speech recognition. In Proceedings of the 2018 Speech and Computer: 20th International Conference, Leipzig, Germany, 18–22 September 2018; pp. 646–655. [Google Scholar]
- Šmídl, L.; Švec, J.; Tihelka, D.; Matoušek, J.; Romportl, J.; Ircing, P. Air traffic control communication (ATCC) speech corpora and their use for ASR and TTS development. Lang. Resour. Eval. 2019, 53, 449–464. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, Q.; Sun, X.; Liu, S.; Lu, J. Improved CTC-attention based end-to-end speech recognition on air traffic control. In Proceedings of the 9th International Conference on Intelligent Science and Big Data Engineering, Nanjing, China, 17–20 October 2019; pp. 187–196. [Google Scholar]
- Lin, Y.; Tan, X.; Yang, B.; Yang, K.; Zhang, J.; Yu, J. Real-time controlling dynamics sensing in air traffic system. Sensors 2019, 19, 679. [Google Scholar] [CrossRef]
- Fan, P.; Hua, X.; Lin, Y.; Yang, B.; Zhang, J. Speech recognition for air traffic control via feature learning and end-to-end training. IEICE Trans. Inf. Syst. 2023, 106, 538–544. [Google Scholar] [CrossRef]
- Lin, Y.; Deng, L.; Chen, Z.; Wu, X.; Zhang, J.; Yang, B. A real-time ATC safety monitoring framework using a deep learning approach. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4572–4581. [Google Scholar] [CrossRef]
- Yang, B.; Tan, X.; Chen, Z.; Wang, B.; Lin, Y. ATCSpeech: A multilingual pilot-controller speech corpus from real air traffic control environment. In Proceedings of the 21st Annual Conference of the International Speech Communication Association INTERSPEECH, Shanghai, China, 25–29 October 2020; pp. 399–403. [Google Scholar]
- Lin, Y.; Guo, D.; Zhang, J.; Chen, Z.; Yang, B. A unified framework for multilingual speech recognition in air traffic control systems. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3608–3620. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Li, Q.; Yang, B.; Yan, Z.; Tan, H.; Chen, Z. Improving speech recognition models with small samples for air traffic control systems. Neurocomputing 2021, 445, 287–297. [Google Scholar] [CrossRef]
- Lin, Y.; Yang, B.; Li, L.; Guo, D.; Zhang, J.; Chen, H.; Zhang, Y. ATCSpeechNet: A multilingual end-to-end speech recognition framework for air traffic control systems. Appl. Soft Comput. 2021, 112, 107847. [Google Scholar] [CrossRef]
- Lin, Y.; Wu, Y.; Guo, D.; Zhang, P.; Yin, C.; Yang, B.; Zhang, J. A deep learning framework of autonomous pilot agent for air traffic controller training. IEEE Trans. Hum. Mach. Syst. 2021, 51, 442–450. [Google Scholar] [CrossRef]
- Guo, D.; Zhang, Z.; Fan, P.; Zhang, J.; Yang, B. A context-aware language model to improve the speech recognition in air traffic control. Aerospace 2021, 8, 348. [Google Scholar] [CrossRef]
- Lin, Y.; Yang, B.; Guo, D.; Fan, P. Towards multilingual end-to-end speech recognition for air traffic control. IET Intell. Transp. Sys. 2021, 15, 1203–1214. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, P.; Guo, D.; Zhou, Y.; Wu, Y.; Yang, B.; Lin, Y. Automatic repetition instruction generation for air traffic control training using multi-task learning with an improved copy network. Knowl.-Based Sys. 2022, 241, 108232. [Google Scholar] [CrossRef]
- Badrinath, S.; Balakrishnan, H. Automatic speech recognition for air traffic control communications. Transport. Res. Rec. 2022, 2676, 798–810. [Google Scholar] [CrossRef]
- Juan, Z.; Motlicek, P.; Zhan, Q.; Braun, R.; Veselý, K. Automatic speech recognition benchmark for air-traffic communications. In Proceedings of the 21st Annual Conference of the International Speech Communication Association INTERSPEECH, Shanghai, China, 25–29 October 2020; pp. 2297–2301. [Google Scholar]
- Juan, Z.; Veselý, K.; Blatt, A.; Motlicek, P.; Klakow, D.; Tart, A.; Szöke, I.; Prasad, A.; Sarfjoo, S.; Kolcárek, P.; et al. Automatic call sign detection: Matching air surveillance data with air traffic spoken communications. Proceedings 2020, 59, 14. [Google Scholar] [CrossRef]
- Ohneiser, O.; Sarfjoo, S.; Helmke, H.; Shetty, S.; Motlicek, P.; Kleinert, M.; Ehr, H.; Murauskas, S. Robust command recognition for lithuanian air traffic control tower utterances. In Proceedings of the 22st Annual Conference of the International Speech Communication Association INTERSPEECH, Brno, Czech Republic, 30 August–3 September 2021; pp. 1–5. [Google Scholar]
- Ohneiser, O.; Helmke, H.; Shetty, S.; Kleinert, M.; Ehr, H.; Murauskas, S.; Pagirys, T. Prediction and extraction of tower controller commands for speech recognition applications. J. Air Transp. Manag. 2020, 95, 102089. [Google Scholar] [CrossRef]
- Kleinert, M.; Helmke, H.; Shetty, S.; Ohneiser, O.; Ehr, H.; Prasad, A.; Motlicek, P.; Harfmann, J. Automated interpretation of air traffic control communication: The journey from spoken words to a deeper understanding of the meaning. In Proceedings of the 40th IEEE/AIAA Digital Avionics Systems Conference, San Antonio, TX, USA, 3–7 October 2021; pp. 1–9. [Google Scholar]
- Helmke, H.; Kleinert, M.; Shetty, S.; Arilíusson, H.; Simiganoschi, T.; Prasad, A.; Motlicek, P.; Veselý, K.; Ondřej, K.; Smrz, P.; et al. Readback error detection by automatic speech recognition to increase ATM safety. In Proceedings of the 14th USA/Europe Air Traffic Management Research and Development Seminar, Virtual Event, 20–23 September 2021; pp. 1–10. [Google Scholar]
- Prasad, A.; Juan, Z.; Motlicek, P.; Ohneiser, O.; Helmke, H.; Sarfjoo, S.; Nigmatulina, I. Grammar based identification of speaker role for improving atco and pilot asr. arXiv 2021, arXiv:2108.12175. [Google Scholar]
- Nigmatulina, I.; Braun, R.; Juan, Z.; Motlicek, P. Improving callsign recognition with air-surveillance data in air-traffic communication. arXiv 2021, arXiv:2108.12156. [Google Scholar]
- Kocour, M.; Veselý, K.; Blatt, A.; Juan, Z.; Szöke, I.; Cernocký, J.; Klakow, D.; Motlicek, P. Boosting of contextual information in ASR for air-traffic call-sign recognition. In Proceedings of the 22st Annual Conference of the International Speech Communication Association INTERSPEECH, Brno, Czech Republic, 30 August–3 September 2021; pp. 3301–3305. [Google Scholar]
- Juan, Z.; Nigmatulina, I.; Prasad, A.; Motlicek, P.; Veselý, K.; Kocour, M.; Szöke, I. Contextual semi-supervised learning: An approach to leverage air-surveillance and untranscribed ATC data in ASR systems. arXiv 2021, arXiv:2104.03643. [Google Scholar]
- Kocour, M.; Veselý, K.; Szöke, I.; Kesiraju, S.; Juan, Z.; Blatt, A.; Prasad, A.; Nigmatulina, I.; Motlícek, P.; Klakow, D.; et al. Automatic processing pipeline for collecting and annotating air-traffic voice communication data. Eng Proc. 2021, 13, 8. [Google Scholar]
- Juan, Z.; Sarfjoo, S.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Ohneiser, O.; Helmke, H. BERTraffic: A robust BERT-based approach for speaker change detection and role identification of air-traffic communications. arXiv 2021, arXiv:2110.05781. [Google Scholar]
- Blatt, A.; Kocour, K.; Veselý, K.; Szöke, I.; Klakow, D. Call-sign recognition and understanding for noisy air-traffic transcripts using surveillance information. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 7–13 May 2022; pp. 8357–8361. [Google Scholar]
- Juan, Z.; Prasad, A.; Nigmatulina, I.; Sarfjoo, S.; Motlicek, P.; Kleinert, M.; Helmke, H.; Ohneiser, O.; Zhan, Q. How does pre-trained Wav2Vec 2.0 perform on domain-shifted ASR? An extensive benchmark on air traffic control communications. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop, Doha, Qatar, 9–12 January 2022; pp. 205–212. [Google Scholar]
- Nigmatulina, I.; Juan, Z.; Prasad, A.; Sarfjoo, S.; Motlicek, P. A two-step approach to leverage contextual data: Speech recognition in air-traffic communications. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 7–13 May 2022; pp. 6282–6286. [Google Scholar]
- Juan, Z.; Sarfjoo, S.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Ondrej, K.; Ohneiser, O.; Helmke, H. Bertraffic: BERT-based joint speaker role and speaker change detection for air traffic control communications. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop, Doha, Qatar, 9–12 January 2022; pp. 633–640. [Google Scholar]
- Juan, Z.; Veselý, K.; Szöke, I.; Motlicek, P.; Kocour, M.; Rigault, M.; Choukri, K.; Prasad, A.; Sarfjoo, S.; Nigmatulina, I.; et al. ATCO2 corpus: A large-scale dataset for research on automatic speech recognition and natural language understanding of air traffic control communications. arXiv 2022, arXiv:2211.04054. [Google Scholar]
- Godfrey, J. Air Traffic Control Complete LDC94S14A; Linguistic Data Consortium: Philadelphia, PA, USA, 1994; Available online: http://catalog.ldc.upenn.edu/LDC94S14A (accessed on 1 May 2024).
- Grieco, J.; Benarousse, L.; Geoffrois, E.; Series, R.; Steeneken, H.; Stumpf, H.; Swail, C.; Thiel, D. N4 NATO Native and Non-Native Speech LDC2006S13; Linguistic Data Consortium: Philadelphia, PA, USA, 2006; Available online: https://catalog.ldc.upenn.edu/LDC2006S13 (accessed on 1 May 2024).
- Segura, J.; Ehrette, T.; Potamianos, A.; Maragos, P. The HIWIRE Database, a Noisy and Non-Native English Speech Corpus for Cockpit Communication. EU-IST HIWIRE Project. 2007. Available online: http://www.hiwire.org (accessed on 1 May 2024).
- LiveATC.net. Available online: https://www.liveatc.net/ (accessed on 1 May 2024).
- Mohan, B. Speech recognition using MFCC and DTW. In Proceedings of the 2014 International Conference on Advances in Electrical Engineering, Vellore, India, 9–11 January 2014; pp. 1–4. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the 16th Annual Conference of the International Speech Communication Association INTERSPPECH, Dresden, Germany, 6–10 September 2015; pp. 3214–3218. [Google Scholar]
- Povey, D.; Cheng, G.; Wang, Y.; Li, K.; Xu, H. Semi-orthogonal low-rank matrix factorization for deep neural networks. In Proceedings of the 19th Annual Conference of the International Speech Communication Association INTERSPPECH, Hyderabad, India, 2–6 September 2018; pp. 3743–3747. [Google Scholar]
- Mohri, M.; Pereira, F.; Riley, M. Weighted finite-state transducers in speech recognition. Comput. Speech Lang. 2022, 16, 69–88. [Google Scholar] [CrossRef]
- Povey, D.; Peddinti, V.; Galvez, D.; Ghahremani, P.; Khudanpur, S. Purely sequence-trained neural networks for asr based on lattice-free mmi. In Proceedings of the 17th Annual Conference of the International Speech Communication Association INTERSPPECH, San Francisco, CA, USA, 8–12 September 2016; pp. 2751–2755. [Google Scholar]
- Lin, Y.; Ruan, M.; Cai, K.; Li, D.; Zeng, Z.; Li, F.; Yang, B. Identifying and managing risks of AI-driven operations: A case study of automatic speech recognition for improving air traffic safety. Chin. J. Aeronaut. 2023, 36, 366–386. [Google Scholar] [CrossRef]
- Ryumin, D.; Ivanko, D.; Ryumina, E.V. Audio-Visual Speech and Gesture Recognition by Sensors of Mobile Devices. Sensors 2023, 23, 2284. [Google Scholar] [CrossRef]
- Ryumin, D.; Axyonov, A.; Ryumina, E.; Ivanko, D.; Kashevnik, A.; Karpov, A. Audio–visual speech recognition based on regulated transformer and spatio–temporal fusion strategy for driver assistive systems. Expert Syst. Appl. 2024, 252, 124159. [Google Scholar] [CrossRef]
- Miao, Z.; Liu, H.; Yang, B. Part-Based Lipreading for Audio-Visual Speech Recognition. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics, Toronto, ON, Canada, 11–14 October 2020; pp. 2722–2726. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Papers | Technique Details | Research Groups or Projects |
|---|---|---|
| [18] | Construction of the ATCOSIM corpus | Eurocontrol |
| [19] | HMM and cross-task adaptation | Polytechnic University of Madrid |
| [20] | Construction of a Spanish and an English corpora separately | Polytechnic University of Madrid |
| [21] | HMM and PPRLM, construction of corpora for tower control | Polytechnic University of Madrid |
| [22,23] | Human interface, callsign recognition, reduction of ATCos’s workload | CRIDA |
| [24] | Combination of AMAN and ASR | AcListant |
| [25] | Construction and annotation of corpora | AcListant |
| [26] | Construction of a simulated corpus with German and Czech accents | AcListant |
| [27] | ABSR, improvement of the corpus to distinguish between male and female | AcListant |
| [28,29,30] | Demonstration of reducing the workload of ATCos | AcListant |
| [31] | Instruction error correction for ATCos | FAA |
| [32] | Semantic understanding to reduce WER | Østfold University College |
| [33] | Proposal of the pseudo-pilot concept | Optimal Synthesis |
| [34] | Publication of the AIRBUS-ATC corpus | AirBus |
| [35] | A challenge competition | AirBus |
| [36] | Proposal of an advanced ASR architecture for ATC | AirBus |
| [37] | Repetition detection matching | Civil Aviation University of China |
| [38] | DNN-HMM | Civil Aviation University of China |
| [39] | Construction of the MALORCA corpus | MALORCA |
| [40] | Proposal of the command prediction model | MALORCA |
| [41] | Semi-supervised training to expand unlabeled data | MALORCA |
| [42] | The generalization of ASR | MALORCA |
| [43] | Use of domain knowledge | MALORCA |
| [44] | Use of iterative methods to utilize unannotated data | MALORCA |
| [45] | Proposal of an ontology for data transcription | CWP HMI |
| [46] | Use of a commercial framework for easy implementation | CWP HMI |
| [47] | Proposal of the command extraction model | CWP HMI |
| [48] | Proposal of a method to reduce speech rate | Nanyang Technological University |
| [49] | Combination with commercial software | Robust Analytics |
| [50,51] | Proposal of a comprehensive method for constructing a corpus | University of West Bohemia |
| [52] | Use of an end-to-end ASR model | NUAA |
| [53] | Use of a cascading model to solve the multilingual problem | Sichuan University |
| [54] | Proposal of a method for feature extraction | Sichuan University |
| [55] | Use of one model to recognize both Chinese and English languages | Sichuan University |
| [56] | Construction of the ATCSpeech corpus | Sichuan University |
| [57] | Optimization of the language model | Sichuan University |
| [58] | Use of unsupervised pretraining and transfer learning | Sichuan University |
| [59] | Combination of self supervision, unsupervised learning and supervised learning | Sichuan University |
| [60] | Proposal of a comprehensive system | Sichuan University |
| [61] | Proposal of a language model containing callsigns | Sichuan University |
| [62] | Use of a residual network | Sichuan University |
| [63] | Proposal of a method for multitasking learning | Sichuan University |
| [64] | Use of multiple corpora | MIT |
| [65] | Use of a hybrid model and LF-MMI | ATCO2, HAAWAII |
| [66] | Callsign recognition | ATCO2 |
| [67] | Tower command recognition | HAAWAII |
| [68] | Remote tower | HAAWAII |
| [69] | Added a pilot role in the speech | HAAWAII |
| [70] | Evaluation indicators with repetition recognition | HAAWAII |
| [71] | Multi-task AM | HAAWAII |
| [72] | Decoder | ATCO2, HAAWAII |
| [73] | Use of semi-supervised learning | ATCO2, HAAWAII |
| [74] | Data annotation | ATCO2 |
| [75] | Proposal of a comprehensive model with contextual information | ATCO2 |
| [76] | Data augmentation and BERT | ATCO2 |
| [77] | Callsign recognition with contextual information | ATCO2 |
| [78] | Discussion of the amount of data required for ASR in ATC | ATCO2, HAAWAII |
| [79] | Proposal of a hybrid model combining CNN, TDNN and LM | ATCO2, HAAWAII |
| [80] | Data augmentation and BERT | ATCO2, HAAWAII |
| [81] | Construction of the ATCO2 corpus | ATCO2, HAAWAII |
| Corpora | Language and Accent | Real/Simulated | ATC Phase | Data Size | Used in Papers |
|---|---|---|---|---|---|
| LDC94S14A | US, English | Real | Tower, approach | 72.5 h | [64,65,66,78,80] |
| N4 NATO | Canadian, German, Dutch and British-accented English | Simulated | Military | 9.5 h | [66,73] |
| HIWIRE | French, Greek, Italian and Spanish-accented English | Simulated | Military | 28.3 h | [65,66,73] |
| Madrid airport | Spanish, English | Real | Ground, tower | 11.8 h | [19,20,21] |
| Madrid ACC | Spanish, English | Real | Approach, en-route | 100 h | [22,23] |
| ATCOSIM | German, Swiss, and French accented English | Simulated | En-route | 10.7 h | [18,33,50,64,65,66,73,78] |
| AcListant | German and Czech-accented English | Simulated | Approach | 8 h | [24,25,26,27,28,29,30] |
| DataComm | US, English | Simulated | Tower, approach, en-route | 144 × 50 min | [31] |
| ATCSC | English | Simulated | Clearance | 4800 utterances | [32] |
| AIRBUS-ATC | French-accented English | Real | Tower, Approach, ATIS | 59 h | [34,35,36,64,65,66,74,77] |
| MALORCA | German and Czech-accented English | Simulated | Approach | 10.9 h | [39,40,41,42,43,44,46,47,65,66,72,74,76,77,79] |
| UWB-ATCC | Czech-accented English | Real | Tower, approach, en-route | 179 h | [50,51,64,65,66,78] |
| SOL-Twr | Lithuanian-accented English | Real | Tower | 1993 utterances | [67] |
| SOL-Cnt | German-accented English | Real | Approach | 800 utterances | [76,80] |
| HAAWAII | Icelandic and British-accented English | Real | Tower, approach, en-route | 34 h | [69,70,76,78,79,80] |
| ATCO2 | English | Real | Ground, tower, approach, en-route | 4+5281 h | [71,75,76,78,80,81] |
| ATCSpeech | Mandarin Chinese, English | Real | Ground, tower, approach, en-route | 58 h | [53,54,55,56,57,58,59,60,61,62,63] |
| LiveATC | Real | Ground, tower, approach, en-route | [50,71,72,74,75,77,78,79,80] |
| Papers | Feature Extraction | Acoustic Model | Language Model | Decoder |
|---|---|---|---|---|
| [19] | CMVN | HMM | \ | \ |
| [20,21] | CMVN | HMM | Stochastic bigram LM | \ |
| [22,23] | \ | HMM | Grammar LM | \ |
| [24] | \ | GMM-HMM | \ | WFST |
| [25] | \ | GMM-HMM | Grammar LM | WFST |
| [26] | \ | GMM-HMM | Grammar LM | Context-dependent WFST |
| [27] | \ | GMM-HMM | N-gram LM | WLD |
| [32] | \ | Generic AM | N-gram LM | N-best |
| [33] | Non-specific | Generic AM | Not given | Non-specific |
| [34] | Non-specific | TDNN | 4-gram LM | \ |
| [35] | Multiple | Multiple | Multiple | Multiple |
| [36] | MFCC | BiLSTM | RNN LM | N-best |
| [38] | MFCC+CMVN | CDNN-HMM | Non-specific | \ |
| [39] | \ | DNN-HMM | 3-gram LM, | Context-aware rescoring N-best |
| [40,42,44] | \ | DNN-HMM | N-gram LM | \ |
| [41] | \ | DNN-HMM | 3-gram LM | \ |
| [43] | \ | DNN-HMM | 3-gram LM | Domain knowledge-based N-best |
| [47] | \ | DNN-HMM | N-gram LM | Command extractor |
| [48] | STRAIGHT | \ | \ | \ |
| [50] | \ | DNN-HMM | 3-gram LM, oracle | \ |
| [51] | \ | DNN-HMM | N-gram LM | \ |
| [52] | \ | E2E model (CNN+BiLSTM+CTC) | LSTM LM | CTC-decoder |
| [53] | MFCC | Cascade model (CNN+BiLSTM+CTC) | PLM+WLM, PM | CTC-decoder |
| [54] | CNN | E2E model (CNN+BiLSTM) | \ | CTC-decoder |
| [55] | \ | Hybrid model (CNN+BiLSTM) | RNN LM | CTC-decoder |
| [56] | \ | DNN+CTC | N-gram LM | CTC-decoder |
| [57] | MFCC | Cascade model (MCNN/AP+BLSTM+CTC) | RNN LM(PLM+WLM), MTPM | Generic decoder |
| [58,59,60] | MFCC | E2E model (MCNN/AP+BLSTM+CTC) | \ | CTC-decoder |
| [61] | \ | E2E model (CNN+RNN) | Context-aware LM | Context-aware decoder |
| [62] | HFE | E2E model (CNN+RNN) | \ | CTC-decoder |
| [64] | MFCC | RNN+CTC | N-gram | Generic decoder |
| [65] | \ | TDNNF | SRI trained N-gram | \ |
| [66] | \ | TDNN | N-gram | WFST |
| [67] | \ | CNN+TDNNF and DNN-HMM | N-gram | \ |
| [70,71] | \ | CNN+TDNNF | 3-gram | \ |
| [72] | MFCC | CNN+TDNNF | 3-gram | \ |
| [73] | MFCC | CNN+TDNNF | 3-gram | WFST |
| [74] | MFCC | CNN+TDNNF | Context-aware 3-gram | WFST |
| [75] | MFCC+CMN | CNN+TDNNF | 3-gram | WFST |
| [78] | \ | E2E model | \ | \ |
| [79] | MFCC | CNN+TDNNF | 4-gram | Context-aware WFST |
| [80,81] | MFCC | CNN+TDNNF | 3-gram | WFST |
| Measure Classification | Evaluation Measure | Used in Papers |
|---|---|---|
| General ASR measure | Word/character accuracy/error rate | [19,20,21,24,25,26,27,29,32,35,36,38,39,41,42,43,44,51,52,53,54,55,56,57,58,61,62,63,64,65,66,67,71,72,73,74,75,77,78,79] |
| Sentence accuracy/error rate | [20,21,24,52] | |
| F1 score | [35,36,53,55,63,66,75,76] | |
| Real-time factor | [26,38,39,53] | |
| ATC key information measure | Concept error rate | [24,26,27,39,41,42,43,64] |
| Command error rate | [25,26,27,29,39,44,46,67] | |
| Callsign accuracy | [61,63,67,70,72,73,74,75,79] | |
| Application measure | Repetition intent accuracy | [55,63] |
| Acceptable detection rate | [22,23,31] | |
| Workload measurements | [29,30] |
| Application | Used in Papers |
|---|---|
| ATC automation system integration | [24,25,26,27,28,29,30,39,40,41,42,43,44] |
| Measurement and reduction of workload for ATCos | [22,23,29,30,46] |
| Callsign detection | [22,23,35,36,61,66,72,73,74,75,77] |
| Read-back checking | [37,55,63,70] |
| Pseudo-pilot | [33,51,60,63] |
| Speaker role identification | [71,75,76,80] |
| Command prediction | [42,43,44,68] |
| Classification | Items | Proportion |
|---|---|---|
| Control phase | Ground | 8% |
| Tower | 30% | |
| Approach | 30% | |
| Area | 30% | |
| Emergency | 2% | |
| Noise | Clean | 20% |
| Low noise | 50% | |
| High noise | 30% | |
| Speech rate | Slow | 20% |
| Normal | 40% | |
| Fast | 40% | |
| Control area | Northeast China | 13% |
| North China | 13% | |
| Northwest China | 13% | |
| East China | 13% | |
| Southwest China | 13% | |
| Central and South China | 13% | |
| Xinjiang, China | 13% | |
| Chinese-accent English | 9% | |
| Gender | Male | 70% |
| Female | 30% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Jiang, P.; Wang, Z.; Han, B.; Liang, H.; Ai, Y.; Pan, W. Enhancing Air Traffic Control Communication Systems with Integrated Automatic Speech Recognition: Models, Applications and Performance Evaluation. Sensors 2024, 24, 4715. https://doi.org/10.3390/s24144715
Wang Z, Jiang P, Wang Z, Han B, Liang H, Ai Y, Pan W. Enhancing Air Traffic Control Communication Systems with Integrated Automatic Speech Recognition: Models, Applications and Performance Evaluation. Sensors. 2024; 24(14):4715. https://doi.org/10.3390/s24144715
Chicago/Turabian StyleWang, Zhuang, Peiyuan Jiang, Zixuan Wang, Boyuan Han, Haijun Liang, Yi Ai, and Weijun Pan. 2024. "Enhancing Air Traffic Control Communication Systems with Integrated Automatic Speech Recognition: Models, Applications and Performance Evaluation" Sensors 24, no. 14: 4715. https://doi.org/10.3390/s24144715
APA StyleWang, Z., Jiang, P., Wang, Z., Han, B., Liang, H., Ai, Y., & Pan, W. (2024). Enhancing Air Traffic Control Communication Systems with Integrated Automatic Speech Recognition: Models, Applications and Performance Evaluation. Sensors, 24(14), 4715. https://doi.org/10.3390/s24144715