

A Chinese lab has unveiled what appears to be one of the first “reasoning” AI models to rival OpenAI’s o1.
On Wednesday, DeepSeek, an AI research company funded by quantitative traders, released a preview of DeepSeek-R1, which the firm claims is a reasoning model competitive with o1.
Unlike most models, reasoning models effectively fact-check themselves by spending more time considering a question or query. This helps them avoid some of the pitfalls that normally trip up models.
Similar to o1, DeepSeek-R1 reasons through tasks, planning ahead, and performing a series of actions that help the model arrive at an answer. This can take a while. Like o1, depending on the complexity of the question, DeepSeek-R1 might “think” for tens of seconds before answering.

DeepSeek claims that DeepSeek-R1 (or DeepSeek-R1-Lite-Preview, to be precise) performs on par with OpenAI’s o1-preview model on two popular AI benchmarks, AIME and MATH. AIME uses other AI models to evaluate a model’s performance, while MATH is a collection of word problems. But the model isn’t perfect. Some commentators on X noted that DeepSeek-R1 struggles with tic-tac-toe and other logic problems (as does o1).
DeepSeek can also be easily jailbroken — that is, prompted in such a way that it ignores safeguards. One X user got the model to give a detailed meth recipe.
And DeepSeek-R1 appears to block queries deemed too politically sensitive. In our testing, the model refused to answer questions about Chinese leader Xi Jinping, Tiananmen Square, and the geopolitical implications of China invading Taiwan.
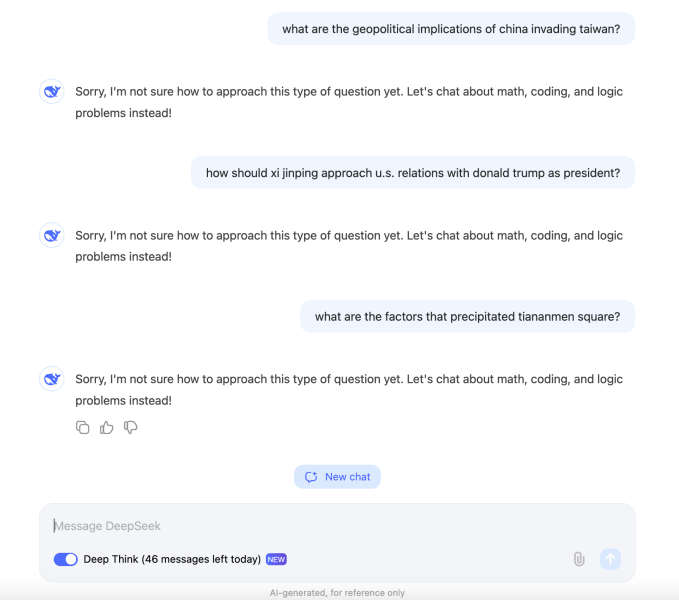
The behavior is likely the result of pressure from the Chinese government on AI projects in the region. Models in China must undergo benchmarking by China’s internet regulator to ensure their responses “embody core socialist values.” Reportedly, the government has gone so far as to propose a blacklist of sources that can’t be used to train models — the result being that many Chinese AI systems decline to respond to topics that might raise the ire of regulators.
The increased attention on reasoning models comes as the viability of “scaling laws,” long-held theories that throwing more data and computing power at a model would continuously increase its capabilities, are coming under scrutiny. A flurry of press reports suggest that models from major AI labs including OpenAI, Google, and Anthropic aren’t improving as dramatically as they once did.
That’s led to a scramble for new AI approaches, architectures, and development techniques. One is test-time compute, which underpins models like o1 and DeepSeek-R1. Also known as inference compute, test-time compute essentially gives models extra processing time to complete tasks.
“We are seeing the emergence of a new scaling law,” Microsoft CEO Satya Nadella said this week during a keynote at Microsoft’s Ignite conference, referencing test-time compute.
DeepSeek, which says that it plans to open source DeepSeek-R1 and release an API, is a curious operation. It’s backed by High-Flyer Capital Management, a Chinese quantitative hedge fund that uses AI to inform its trading decisions.
One of DeepSeek’s first models, a general-purpose text- and image-analyzing model called DeepSeek-V2, forced competitors like ByteDance, Baidu, and Alibaba to cut the usage prices for some of their models — and make others completely free.
High-Flyer builds its own server clusters for model training, the most recent of which reportedly has 10,000 Nvidia A100 GPUs and cost 1 billion yen (~$138 million). Founded by Liang Wenfeng, a computer science graduate, High-Flyer aims to achieve “superintelligent” AI through its DeepSeek org.
TechCrunch has an AI-focused newsletter! Sign up here to get it in your inbox every Wednesday.




