Distributing Global State to Serve over 1 Billion Daily Requests
Jake Malachowski
May 23, 2024
Jake Malachowski
With over a million active services hosted across five regions, the Render platform is a globe-spanning exercise in state distribution. At all times, our networking layer needs to know exactly how to route incoming requests for each of those services, and it needs to route them fast.
24 hours of recent HTTP traffic to a single Render K8s cluster, in 2-minute intervals
Naturally, we didn't start at this scale—Render initially operated out of a single region with a single Kubernetes cluster, serving a small (but mighty) user base. This allowed us to simplify some architectural assumptions and iterate rapidly during those all-important early days.As customers continued to join the platform and our service count grew, the foundations of our networking layer started to creak under the load. Over time, we revisited one early assumption after another, steadily evolving our architecture to support scaling to our current size and beyond.In this post, we'll take a look at where Render started with its networking layer, where we are now, and the challenges we faced along that road. But first, a little context to set the stage:
What makes routing hard
Render's networking layer is responsible for routing each incoming request to its destination service. To achieve this, we run a fleet of request routers. When a request comes in, a router instance looks up which service should handle it and forwards it accordingly:
Basic routing in a Render K8s cluster
Every router instance needs to maintain an up-to-date association between each service's public URL and its internal routing. This mapping might appear straightforward, but a surprising amount of context goes into determining the correct route for a given request. Here are just a few examples:
Render web services and static sites each have a unique onrender.com subdomain, and users can also add custom domains.
A router must therefore know all of a service's domains to correctly match all incoming requests for that service.
Requests to free web services need to pass through a dedicated networking stack that supports scale-to-zero behavior.
A router must therefore be able to determine whether a given web service uses the free instance type.
Requests to a static site are not forwarded to a backend service—instead, the router fetches the site's static content from object storage.
To support this, a router must be able to determine a static site's current active build, which is used in the storage path for the site's content.
Additionally, a static site might have custom headers or redirect/rewrite rules to apply.
To complicate matters, any of this context might change at any time. A user might add a new custom domain, upgrade from a free instance to paid, or add new headers to their static site. In all of these cases, we need to reflect those changes in our routing as quickly as possible.
What we need to optimize for
With every change to our networking layer, we take great care to optimize for two key metrics:
Low latency. Our users trust us to run their critical, performance-sensitive apps. To support them, we must minimize any latency we introduce in the request path.
High update frequency. Our users continually deploy updates to their services that must be reflected across the networking layer. To orchestrate such a large-scale, dynamic system, we can't rely on off-the-shelf tooling that assumes a comparatively static configuration.
Gen 1: Basic in-memory caching
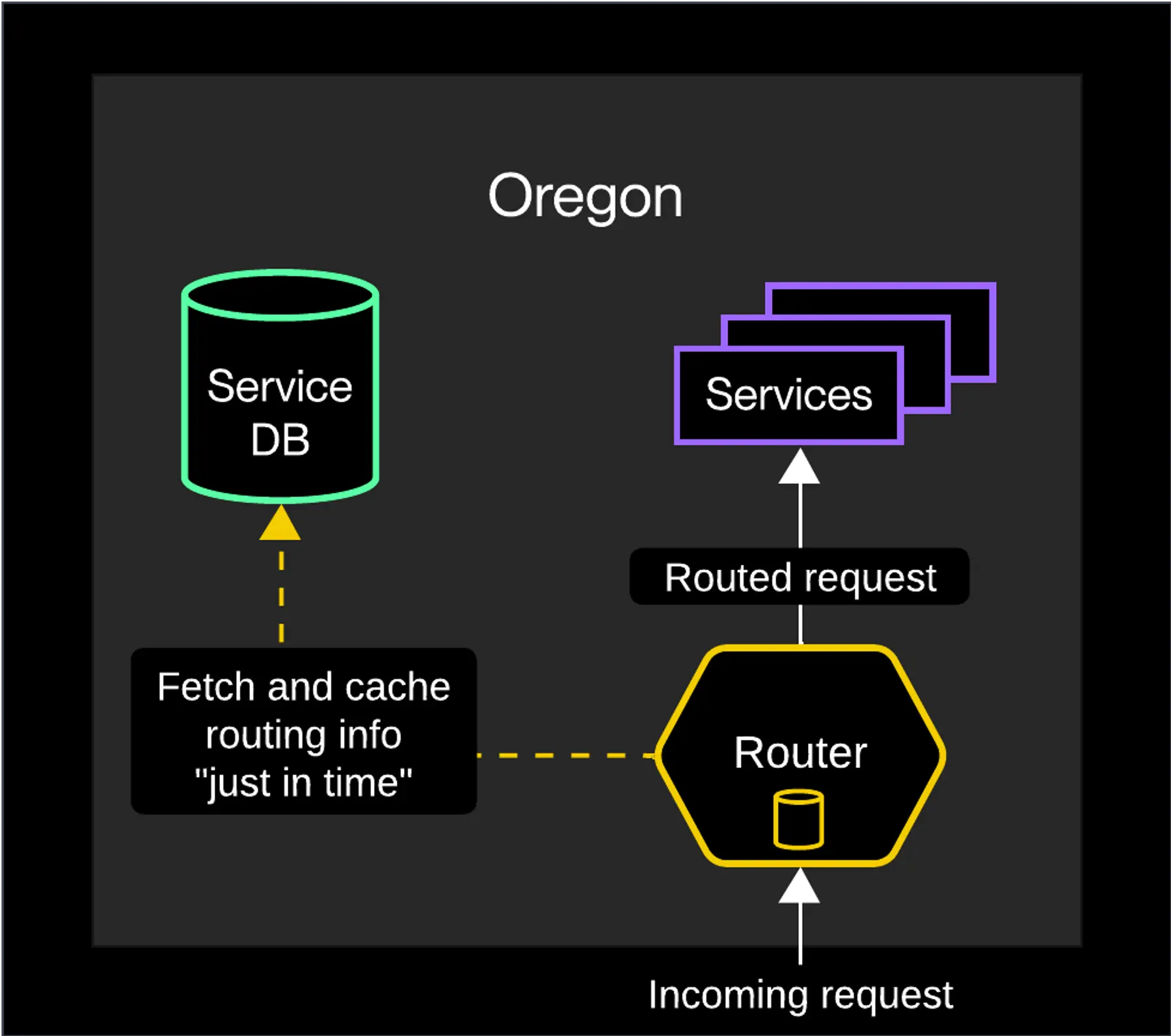
In Render's earliest days (pre-2020), we operated exclusively in the Oregon region. Conveniently, all user services ran in close proximity to Render's PostgreSQL database that maintains all service information (the service database). We nevertheless wanted to avoid the cost of a database lookup whenever possible, so each router instance maintained an in-memory cache:
The first iteration of router in-memory caching
When a router instance received an incoming request, it first checked its cache for the destination service's routing info. If unsuccessful, it fetched (and cached) the info from the service database. This enabled the cache to handle future requests to the same service, minimizing latency. To ensure that any routing changes to a service were reflected promptly, cache entries had a short TTL (5 minutes).This architecture worked well enough for a single region and a small user base, but it didn't take long for critical limitations to show:
Limitation 1: Global cache wipes
Redeploying our routing layer cleared all router caches. Following a redeploy, virtually every incoming request triggered a database lookup. Plus, some of these lookups were redundant—the router occasionally received multiple requests to the same service before the first lookup returned.Once Render had reached sufficient scale, the service database became overwhelmed every time we redeployed our routing layer.
Limitation 2: Tightly coupled data and control planes
Downtime for the service database meant downtime for routers. If the service database became unavailable, the networking layer degraded rapidly as cache entries expired and replacement lookups failed. And the service database received maintenance updates a few times a year, each causing up to ten minutes of service interruption.
Rethinking the foundation
The limitations above were preventing our initial architecture from maintaining an acceptable level of availability. We began designing the next iteration of our networking layer, listing out our hard requirements:
The service database must not experience usage spikes with each redeployment of our routing layer.
Total router load on the service database must scale sub-linearly with the total number of active services.
The networking layer must remain available during service database downtime.
Propagation of service updates across the networking layer must remain as fast as possible.
We were unlikely to achieve all four of these with incremental tweaks, so we opted for a more fundamental design change.
Gen 2: Push-based caching
Our original architecture struggled in large part because it required frequent requests to the service database. Whenever routing info was available in the cache, routing was fast—plus, it worked even if the database was unavailable.We were caught in the classic tension between caching more aggressively and propagating updates more quickly. But what if we could have the best of both worlds?We realized that we didn't need to wait for an incoming request to update a router's cache. Instead of querying the service database just in time, we could proactively push updates to our routers with every relevant database change.Now whenever a router instance starts, it immediately connects to the service database and subscribes to all updates that it cares about. These subscriptions use PostgreSQL's built-in LISTEN and NOTIFY features under the hood.Whenever a router receives notification of an update, it adds the ID of the updated record to an internal queue. An asynchronous process handles pulling items from the queue, fetching the updated records from the database, and updating the router's cache with the new data:
Push-based router caching
A router instance begins serving traffic only after it both initializes its internal state and catches up on updates. This means that a router never queries the database in the hot path of serving a request—lookups are performed exclusively on the in-memory cache.With this change, the p99 time to route a request dropped to under 4ms, which dramatically improved our worst-case response latency.
A favorable comparison
Let's revisit the primary items we wanted to improve over our initial architecture and see how Gen 2 stacks up:
1. The service database must not experience usage spikes with each redeployment of our routing layer.
Now when a new router instance starts, it executes a few queries to bulk-fetch its initial state. This does involve substantial data throughput, but the queries are simple and well indexed, so the database can serve them efficiently. ✅
2. Total router load on the service database must scale sub-linearly with the total number of active services.
With the push-based architecture, routers subscribe to updates from the service database and then run queries to fetch updated records. This means that database usage scales with the number of updates—not the number of services. This reduced query volume by multiple orders of magnitude, because a very small percentage of services are being updated at any given time. ✅
3. The networking layer must remain available during service database downtime.
When the service database becomes unavailable, our networking layer does still stop receiving updates. However, router caches no longer expire their records, so we can continue serving requests for existing services indefinitely.Whenever a router instance reconnects to the service database, it refreshes its state to reflect any updates that occurred while disconnected. ✅
4. Propagation of service updates across the networking layer must remain as fast as possible.
With a push-based architecture, we don't need to wait for cache entries to expire before obtaining updated data. Now, the expected latency for update propagation consists of:
How long it takes the database to notify a router instance of a changed record
How long the notification waits in the router instance's internal queue before being processed
How long it takes the router to fetch the record from the database and update its cache
In most cases, all of these take less than one second combined. ✅
From local to global
If we stopped here, you'd have a solid understanding of how an individual router instance operates in Render's networking layer today. This architecture has served us well for years now, and we believe it will continue to for many more.Next, let's look at the work we've done adapting this architecture to scale beyond our initial single-region setup.
Gen 3: The move to multi-region
In 2020, we added support for our second region: Frankfurt. To achieve this, we replicated our networking layer in the new region with its own set of router instances. The routers in each region cached routing information only for the services hosted in that region.
Routing in the Frankfurt region
Because database fetches were no longer in the request hot path, we were able to provide the same low-latency routing for Frankfurt-hosted services, despite the physical distance from the Oregon-hosted service database.A couple years later, we added two more regions (Ohio and Singapore), with each following the same pattern as Frankfurt. On top of that, we were also spinning up additional Kubernetes clusters within existing regions. Each cluster has its own completely separate networking layer, including its own set of routers.It was at this point that we started running up against a couple of bottlenecks:
Bottleneck 1: Service database connection limit
Each router instance in each cluster maintained multiple direct connections to the service database, and we now had hundreds of routers. During major traffic spikes, we would sometimes hit the database's connection limit, preventing us from spinning up as many routers as we needed.Our stopgap solution here was to throw money at the problem, periodically upgrading our PostgreSQL instance to support additional connections. We knew this wasn't a viable long-term solution, especially given our plans to continue expanding to more regions (such as Virginia).
Bottleneck 2: Router startup time
Active router instances in Frankfurt and Singapore were just as performant as those in Oregon, but they took significantly longer to start up. This was because each new instance needed to fetch the latest state from the service database, and the round trip was (understandably) much slower. In the worst case, a new router instance took over a minute to become ready.To compensate, we were over-provisioning our router count in non-Oregon regions to handle any sudden traffic spikes. Most of the time, we were using just a fraction of our provisioned capacity, costing us much more to run than a "right-sized" capacity would.
Solution: Fully decoupling routers from the service database
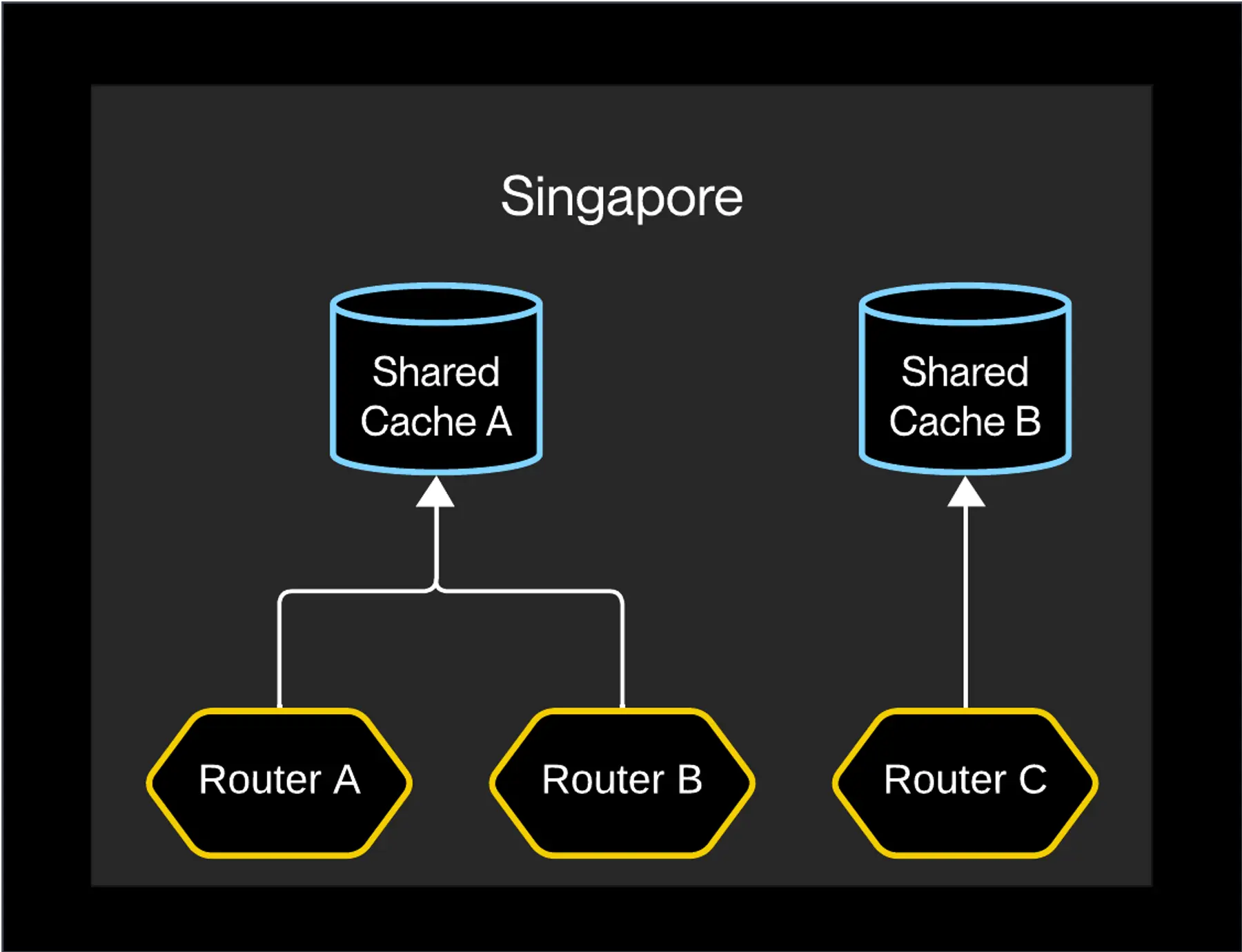
Nothing about our architecture required that each router instance get its state directly from the service database—this pattern was a design remnant from our single-region past. Could we offload the majority of that request volume to an intermediate datastore? Absolutely.Each router's cache contained all the information needed to route requests. We replicated that datastore as a set of highly available shared cache instances running in each cluster:
Routing with shared cache instances
These cache instances stay up to date using the same logic that individual router instances used previously: on startup, they fetch the latest state from the database and subscribe to notifications for any updates. When a cache's internal state is fully initialized, it's ready to serve requests to keep router instances up to date.Each shared cache instance provides:
An endpoint for fetching a complete snapshot of current networking state
Endpoints for fetching individual records by ID
A WebSocket endpoint for subscribing to notifications for any updated records
Router instances now interact with this in-cluster cache instead of with the service database, making lookups much faster. In Frankfurt and Singapore, the average time for a router to come online dropped from over a minute to less than twenty seconds.
Single-cache affinity
Shared cache instances are rarely in perfect sync with each other, because each maintains its own connection to the service database. This means that a router might enter an undefined state if it receives a notification from one cache and pulls the corresponding record from another.To avoid this, each router instance randomly selects a single shared cache instance to connect to exclusively:
Single-cache affinity for each router instance
If this single instance becomes unavailable for any reason, the router randomly selects a new cache, resubscribes, and initializes its state from scratch. When this occurs, the router's state is slightly stale for only about fifteen seconds.
Building to the next billion
It's been a couple of years now since our multi-region changes, and our networking layer has held strong amidst continued growth. Now with well over one billion requests hitting Render every day, we're proud of what we've built and how we've adapted to support that immense scale. If you're interested in helping us reach the next billion, we're hiring!
Render takes your infrastructure problems away and gives you a battle-tested, powerful, and cost-effective cloud with an outstanding developer experience.
Focus on building your apps, shipping fast, and delighting your customers, and leave your cloud infrastructure to us.