Bug Description
I was decoding some UUEncoded data when I encountered a 'Trailing Garbage' error from the binascii.a2b_uu function. After digging into Linux's uu decode implementation(L248) and other resources (linked below) I'm decently certain the python implementation is bugged.
The following is what I tried:
from binascii import a2b_uu
s = '%-@ !'
decoded = a2b_uu(s)
The expected output is:
print(decoded) # b'6\x00\x00\x00\x00'
The actual output is:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
binascii.Error: Trailing garbage
Notice there are 5 bytes in the expected output (b'6\x00\x00\x00\x00') because the % (first byte of input string, s) means 5 bytes of data follow (ascii code 37 - 32 = 5). UUEncoding requires output be divisible by 3 bytes so an extra padding character is added. In this case it's an !.
The python implementation assumes the padding is always whitespace. Different uuencoders will use different characters for padding though. I've seen three so far: , `, and !.
The following several lines of code are the issue
Proposed fix
Simply remove the following lines (279 - 296). Or if we really want the verification of padding we can include the '!' in the condition of valid padding chars. (The linked linux implementation does not verify padding, however.) And based on my research, there isn't a well defined padding character so we will be jumping to the same potentially false conclusion that we have here: believing we've accounted for all the padding characters that exist in the wild.
/*
** Finally, check that if there's anything left on the line
** that it's whitespace only.
*/
while( ascii_len-- > 0 ) {
this_ch = *ascii_data++;
/* Extra '`' may be written as padding in some cases */
if ( this_ch != ' ' && this_ch != ' '+64 &&
this_ch != '\n' && this_ch != '\r' ) {
state = get_binascii_state(module);
if (state == NULL) {
return NULL;
}
PyErr_SetString(state->Error, "Trailing garbage");
Py_DECREF(rv);
return NULL;
}
}Problematically, this bug propagated up to the uu_codec decode implementation as well. See the following code
A comment indicates the caught exception and "workaround" are due to broken uuencoders. According to what I've read, it's the broken python binascii.a2b_uu that incorrectly assumes any padding bytes are or `.
Here are the sources for my understanding of uu encoding:
Examples of non whitespace padding
Wikipedia uuencoding
Busybox uudecode implementation
Following is an illustration that helped me find a sense of understanding:
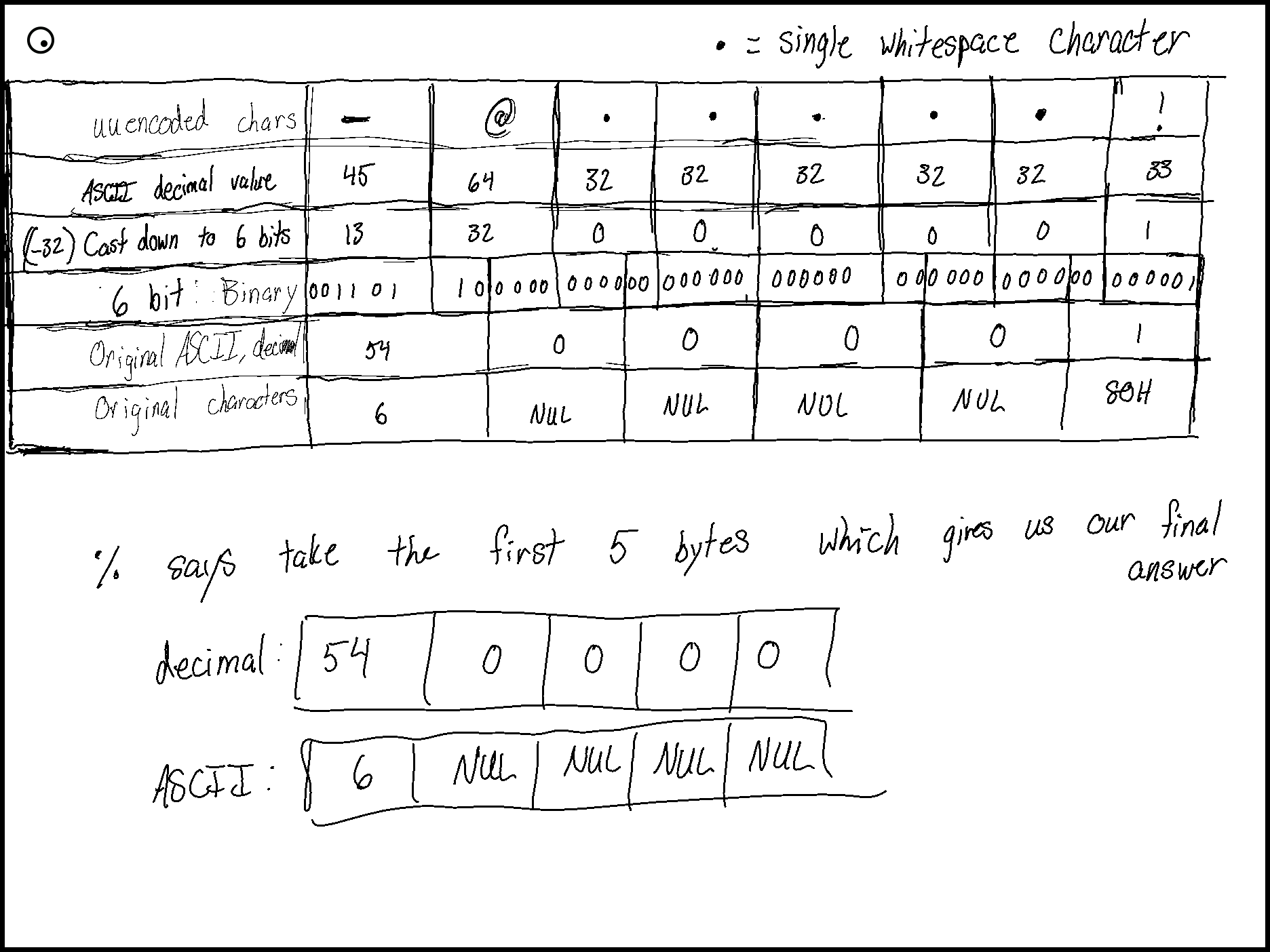
[1] I couldn't find an RFC or other standards document so I looked for the earliest implementation I could find (1983 Linux implementation) along with the wikipedia entry.
In the meantime
If others encounter this issue I'm using the following workaround:
import binascii
from binascii import a2b_uu
from io import BytesIO
my_bytes = BytesIO()
line_bytes = b'%-@ !'
line = line_bytes.decode(encoding='ascii')
try:
my_bytes.write(a2b_uu(line))
except binascii.Error as err:
if 'trailing garbage' in str(err).lower():
n_bytes = line_bytes[0] - 32
assert n_bytes <= 45 and n_bytes <= len(line[1:])
workaround_line = f'M{line[1:]}' # replace first byte of UUEncoded line with max length specifier (M)
data = a2b_uu(workaround_line)[:n_bytes]
my_bytes.write(data)
else:
raise err
Bug Description
I was decoding some UUEncoded data when I encountered a 'Trailing Garbage' error from the
binascii.a2b_uufunction. After digging into Linux's uu decode implementation(L248) and other resources (linked below) I'm decently certain the python implementation is bugged.The following is what I tried:
The expected output is:
The actual output is:
Notice there are 5 bytes in the expected output (b'6\x00\x00\x00\x00') because the
%(first byte of input string,s) means 5 bytes of data follow (ascii code 37 - 32 = 5). UUEncoding requires output be divisible by 3 bytes so an extra padding character is added. In this case it's an!.The python implementation assumes the padding is always whitespace. Different uuencoders will use different characters for padding though. I've seen three so far:
`, and!.The following several lines of code are the issue
Proposed fix
Simply remove the following lines (279 - 296). Or if we really want the verification of padding we can include the '!' in the condition of valid padding chars. (The linked linux implementation does not verify padding, however.) And based on my research, there isn't a well defined padding character so we will be jumping to the same potentially false conclusion that we have here: believing we've accounted for all the padding characters that exist in the wild.
Problematically, this bug propagated up to the uu_codec decode implementation as well. See the following code
A comment indicates the caught exception and "workaround" are due to broken uuencoders. According to what I've read, it's the broken python binascii.a2b_uu that incorrectly assumes any padding bytes are
`.Here are the sources for my understanding of uu encoding:
Examples of non whitespace padding
Wikipedia uuencoding
Busybox uudecode implementation
Following is an illustration that helped me find a sense of understanding:

[1] I couldn't find an RFC or other standards document so I looked for the earliest implementation I could find (1983 Linux implementation) along with the wikipedia entry.
In the meantime
If others encounter this issue I'm using the following workaround: