ENH: Add Floyd's algorithm for RandomState.choice, see #2764 #6801
Conversation
Implement Floyd's algorithm for random sampling without replacement. Reference: Bentley, J. Floyd, B., Programming Pearls: A Sample Of Brilliance. Communications of the ACM, Vol.11, No.9, 1987. The crux is the implementation of the hash set. After some benchmarks I settled on the same basic design as used by "khash", see github.com/attractivechaos/klib/blob/master/khash.h This means: * Open-addressing scheme, with quadratic probing. * The size of the underlying array is a power of 2. * The maximum load factor is chosen to be 0.77. Other implementation details: * Negative values are used as flags for empty slots. * A simple randomizing hash function is used to handle the insertion of consecutive integers.
numpy/random/mtrand/mtrand.pyx
Outdated
There was a problem hiding this comment.
You need some non-trivial comments here :-)
|
My biggest concern about this is how the ad hoc set implementation might restrict the range of supported values. Ideal would be if we can support any One way to move the limit up to Any reason we can't just use khash itself btw? It's not a ton of code, but still open-coding a hash set implementation isn't terribly hygenic -- it's easy to get subtle details wrong, end up with a dozen subtly different implementations in different parts of the code, etc. |
|
It's true, some comments here and there wouldn't hurt! But I wasn't really sure about the appropriate amount and style here. To be clear, conceptually my set implementation is almost exactly the same as khash. But without the need for type generality, removing, resizing, and rehashing, it can be implemented in only a few lines of code. I'm positive we can have a bug-free "ad hoc" implementation. The only thing I'm not completely sure about is my choice of hash function. The But just using khash itself is also an option.. Because it's so macro-heavy I d 8000 on't think it can be used directly from Cython, but with a separate *.c file it's not too bad. (I threw together something that seems to work.) IMO it's overkill for only this use case, but if there are other places in Numpy where a hash set/map is useful then maybe it's worthwhile?
I made a deliberate choice to only support up to LONG_MAX, to have a consistent return dtype and to keep the code as simple as possible. I modeled this behavior after |
Benchmarks indicate that a load factor of 0.77 is really on the edge of exhibiting quadratic complexity for the algo as a whole, without a hash function. So for robustness it may be desirable to either reduce the load factor or indeed use a hash function.
|
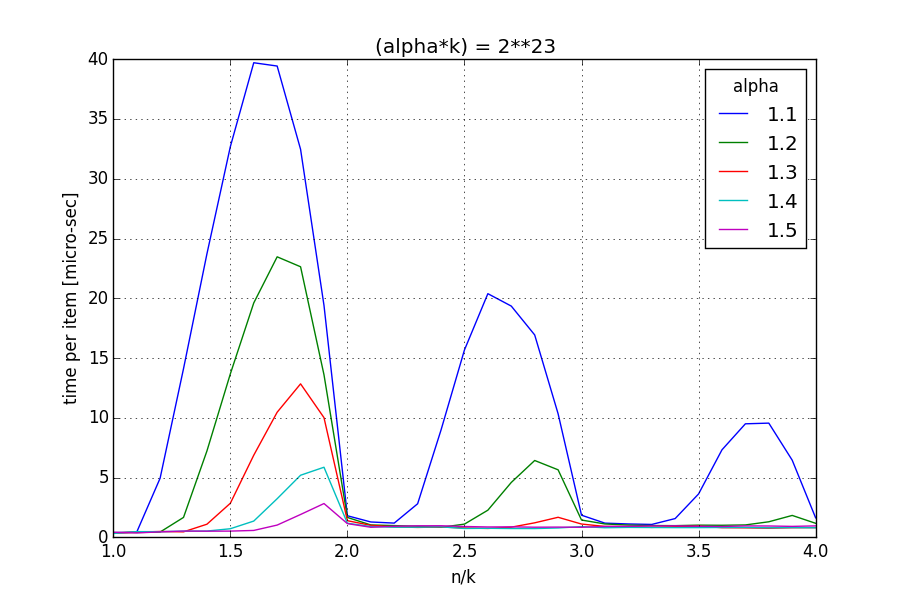
I added some comments to the code and removed the unconventional hash function. Without the hash function, the overall complexity could degrade to O(k2) depending on the choice for maximum load factor (1 / α). For a particular worst-case scenario that I tested against, the currently hard-coded load factor of 1 / 1.3 seems to be acceptable, at least for This leaves the concerns about limited range and ad-hoc implementation intact though, but I don't have any new thoughts about those... |
|
Closing and opening for testing. |
|
I stopped working on this a while ago, closing for the sake of cleanup. |
|
Thanks for attending to that. |
Implement Floyd's algorithm for random sampling without replacement.
This change allows for a faster
np.random.choicewithout replacement or weights, see issue #2764. It requires versioning logic to keep the reproducibility of seeded results, see e.g. discussion in issue #5299 and PR #5911. But I figured it would be best to keep the discussions separate and worry about merging later.. Any comment is appreciated.Reference:
Bentley, J. Floyd, B., Programming Pearls: A Sample Of Brilliance.
Communications of the ACM, Vol.11, No.9, 1987.