diff --git a/.gitattributes b/.gitattributes
index 05d15409683..2f2cad2e13a 100644
--- a/.gitattributes
+++ b/.gitattributes
@@ -1,4 +1,3 @@
-# Auto detect text files and perform LF normalization
* text=auto
*.js linguist-language=java
*.css linguist-language=java
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 00000000000..2dc9c784aa8
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,4 @@
+/node_modules
+/package-lock.json
+/dist
+.DS_Store
diff --git a/.nojekyll b/.nojekyll
new file mode 100755
index 00000000000..e69de29bb2d
diff --git "a/Java\347\233\270\345\205\263/ArrayList-Grow.md" "b/Java\347\233\270\345\205\263/ArrayList-Grow.md"
deleted file mode 100644
index 79837e34553..00000000000
--- "a/Java\347\233\270\345\205\263/ArrayList-Grow.md"
+++ /dev/null
@@ -1,347 +0,0 @@
-
-## 一 先从 ArrayList 的构造函数说起
-
-**ArrayList有三种方式来初始化,构造方法源码如下:**
-
-```java
- /**
- * 默认初始容量大小
- */
- private static final int DEFAULT_CAPACITY = 10;
-
-
- private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
-
- /**
- *默认构造函数,使用初始容量10构造一个空列表(无参数构造)
- */
- public ArrayList() {
- this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
- }
-
- /**
- * 带初始容量参数的构造函数。(用户自己指定容量)
- */
- public ArrayList(int initialCapacity) {
- if (initialCapacity > 0) {//初始容量大于0
- //创建initialCapacity大小的数组
- this.elementData = new Object[initialCapacity];
- } else if (initialCapacity == 0) {//初始容量等于0
- //创建空数组
- this.elementData = EMPTY_ELEMENTDATA;
- } else {//初始容量小于0,抛出异常
- throw new IllegalArgumentException("Illegal Capacity: "+
- initialCapacity);
- }
- }
-
-
- /**
- *构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回
- *如果指定的集合为null,throws NullPointerException。
- */
- public ArrayList(Collection<? extends E> c) {
- elementData = c.toArray();
- if ((size = elementData.length) != 0) {
- // c.toArray might (incorrectly) not return Object[] (see 6260652)
- if (elementData.getClass() != Object[].class)
- elementData = Arrays.copyOf(elementData, size, Object[].class);
- } else {
- // replace with empty array.
- this.elementData = EMPTY_ELEMENTDATA;
- }
- }
-
-```
-
-细心的同学一定会发现 :**以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为10。** 下面在我们分析 ArrayList 扩容时会降到这一点内容!
-
-## 二 一步一步分析 ArrayList 扩容机制
-
-这里以无参构造函数创建的 ArrayList 为例分析
-
-### 1. 先来看 `add` 方法
-
-```java
- /**
- * 将指定的元素追加到此列表的末尾。
- */
- public boolean add(E e) {
- //添加元素之前,先调用ensureCapacityInternal方法
- ensureCapacityInternal(size + 1); // Increments modCount!!
- //这里看到ArrayList添加元素的实质就相当于为数组赋值
- elementData[size++] = e;
- return true;
- }
-```
-### 2. 再来看看 `ensureCapacityInternal()` 方法
-
-可以看到 `add` 方法 首先调用了`ensureCapacityInternal(size + 1)`
-
-```java
- //得到最小扩容量
- private void ensureCapacityInternal(int minCapacity) {
- if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
- // 获取默认的容量和传入参数的较大值
- minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
- }
-
- ensureExplicitCapacity(minCapacity);
- }
-```
-**当 要 add 进第1个元素时,minCapacity为1,在Math.max()方法比较后,minCapacity 为10。**
-
-### 3. `ensureExplicitCapacity()` 方法
-
-如果调用 `ensureCapacityInternal()` 方法就一定会进过(执行)这个方法,下面我们来研究一下这个方法的源码!
-
-```java
- //判断是否需要扩容
- private void ensureExplicitCapacity(int minCapacity) {
- modCount++;
-
- // overflow-conscious code
- if (minCapacity - elementData.length > 0)
- //调用grow方法进行扩容,调用此方法代表已经开始扩容了
- grow(minCapacity);
- }
-
-```
-
-我们来仔细分析一下:
-
-- 当我们要 add 进第1个元素到 ArrayList 时,elementData.length 为0 (因为还是一个空的 list),因为执行了 `ensureCapacityInternal()` 方法 ,所以 minCapacity 此时为10。此时,`minCapacity - elementData.length > 0 `成立,所以会进入 `grow(minCapacity)` 方法。
-- 当add第2个元素时,minCapacity 为2,此时e lementData.length(容量)在添加第一个元素后扩容成 10 了。此时,`minCapacity - elementData.length > 0 ` 不成立,所以不会进入 (执行)`grow(minCapacity)` 方法。
-- 添加第3、4···到第10个元素时,依然不会执行grow方法,数组容量都为10。
-
-直到添加第11个元素,minCapacity(为11)比elementData.length(为10)要大。进入grow方法进行扩容。
-
-### 4. `grow()` 方法
-
-```java
- /**
- * 要分配的最大数组大小
- */
- private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
-
- /**
- * ArrayList扩容的核心方法。
- */
- private void grow(int minCapacity) {
- // oldCapacity为旧容量,newCapacity为新容量
- int oldCapacity = elementData.length;
- //将oldCapacity 右移一位,其效果相当于oldCapacity /2,
- //我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
- int newCapacity = oldCapacity + (oldCapacity >> 1);
- //然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
- if (newCapacity - minCapacity < 0)
- newCapacity = minCapacity;
- // 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,
- //如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
- if (newCapacity - MAX_ARRAY_SIZE > 0)
- newCapacity = hugeCapacity(minCapacity);
- // minCapacity is usually close to size, so this is a win:
- elementData = Arrays.copyOf(elementData, newCapacity);
- }
-```
-
-**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍!** 记清楚了!不是网上很多人说的 1.5 倍+1!
-
-> ">>"(移位运算符):>>1 右移一位相当于除2,右移n位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了1位所以相当于oldCapacity /2。对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
-
-**我们再来通过例子探究一下`grow()` 方法 :**
-
-- 当add第1个元素时,oldCapacity 为0,经比较后第一个if判断成立,newCapacity = minCapacity(为10)。但是第二个if判断不会成立,即newCapacity 不比 MAX_ARRAY_SIZE大,则不会进入 `hugeCapacity` 方法。数组容量为10,add方法中 return true,size增为1。
-- 当add第11个元素进入grow方法时,newCapacity为15,比minCapacity(为11)大,第一个if判断不成立。新容量没有大于数组最大size,不会进入hugeCapacity方法。数组容量扩为15,add方法中return true,size增为11。
-- 以此类推······
-
-**这里补充一点比较重要,但是容易被忽视掉的知识点:**
-
-- java 中的 `length `属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
-- java 中的 `length()` 方法是针对字符串说的,如果想看这个字符串的长度则用到 `length()` 这个方法.
-- java 中的 `size()` 方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
-
-### 5. `hugeCapacity()` 方法。
-
-从上面 `grow()` 方法源码我们知道: 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
-
-
-```java
- private static int hugeCapacity(int minCapacity) {
- if (minCapacity < 0) // overflow
- throw new OutOfMemoryError();
- //对minCapacity和MAX_ARRAY_SIZE进行比较
- //若minCapacity大,将Integer.MAX_VALUE作为新数组的大小
- //若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小
- //MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
- return (minCapacity > MAX_ARRAY_SIZE) ?
- Integer.MAX_VALUE :
- MAX_ARRAY_SIZE;
- }
-```
-
-
-
-## 三 `System.arraycopy()` 和 `Arrays.copyOf()`方法
-
-
-阅读源码的话,我们就会发现 ArrayList 中大量调用了这两个方法。比如:我们上面讲的扩容操作以及`add(int index, E element)`、`toArray()` 等方法中都用到了该方法!
-
-
-### 3.1 `System.arraycopy()` 方法
-
-```java
- /**
- * 在此列表中的指定位置插入指定的元素。
- *先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
- *再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
- */
- public void add(int index, E element) {
- rangeCheckForAdd(index);
-
- ensureCapacityInternal(size + 1); // Increments modCount!!
- //arraycopy()方法实现数组自己复制自己
- //elementData:源数组;index:源数组中的起始位置;elementData:目标数组;index + 1:目标数组中的起始位置; size - index:要复制的数组元素的数量;
- System.arraycopy(elementData, index, elementData, index + 1, size - index);
- elementData[index] = element;
- size++;
- }
-```
-
-我们写一个简单的方法测试以下:
-
-```java
-public class ArraycopyTest {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- int[] a = new int[10];
- a[0] = 0;
- a[1] = 1;
- a[2] = 2;
- a[3] = 3;
- System.arraycopy(a, 2, a, 3, 3);
- a[2]=99;
- for (int i = 0; i < a.length; i++) {
- System.out.println(a[i]);
- }
- }
-
-}
-```
-
-结果:
-
-```
-0 1 99 2 3 0 0 0 0 0
-```
-
-### 3.2 `Arrays.copyOf()`方法
-
-```java
- /**
- 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。
- */
- public Object[] toArray() {
- //elementData:要复制的数组;size:要复制的长度
- return Arrays.copyOf(elementData, size);
- }
-```
-
-个人觉得使用 `Arrays.copyOf()`方法主要是为了给原有数组扩容,测试代码如下:
-
-```java
-public class ArrayscopyOfTest {
-
- public static void main(String[] args) {
- int[] a = new int[3];
- a[0] = 0;
- a[1] = 1;
- a[2] = 2;
- int[] b = Arrays.copyOf(a, 10);
- System.out.println("b.length"+b.length);
- }
-}
-```
-
-结果:
-
-```
-10
-```
-
-
-### 3.3 两者联系和区别
-
-**联系:**
-
-看两者源代码可以发现 copyOf() 内部实际调用了 `System.arraycopy()` 方法
-
-**区别:**
-
-`arraycopy()` 需要目标数组,将原数组拷贝到你自己定义的数组里或者原数组,而且可以选择拷贝的起点和长度以及放入新数组中的位置 `copyOf()` 是系统自动在内部新建一个数组,并返回该数组。
-
-
-
-## 四 `ensureCapacity`方法
-
-ArrayList 源码中有一个 `ensureCapacity` 方法不知道大家注意到没有,这个方法 ArrayList 内部没有被调用过,所以很显然是提供给用户调用的,那么这个方法有什么作用呢?
-
-```java
- /**
- 如有必要,增加此 ArrayList 实例的容量,以确保它至少可以容纳由minimum capacity参数指定的元素数。
- *
- * @param minCapacity 所需的最小容量
- */
- public void ensureCapacity(int minCapacity) {
- int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
- // any size if not default element table
- ? 0
- // larger than default for default empty table. It's already
- // supposed to be at default size.
- : DEFAULT_CAPACITY;
-
- if (minCapacity > minExpand) {
- ensureExplicitCapacity(minCapacity);
- }
- }
-
-```
-
-**最好在 add 大量元素之前用 `ensureCapacity` 方法,以减少增量从新分配的次数**
-
-我们通过下面的代码实际测试以下这个方法的效果:
-
-```java
-public class EnsureCapacityTest {
- public static void main(String[] args) {
- ArrayList<Object> list = new ArrayList<Object>();
- final int N = 10000000;
- long startTime = System.currentTimeMillis();
- for (int i = 0; i < N; i++) {
- list.add(i);
- }
- long endTime = System.currentTimeMillis();
- System.out.println("使用ensureCapacity方法前:"+(endTime - startTime));
-
- list = new ArrayList<Object>();
- long startTime1 = System.currentTimeMillis();
- list.ensureCapacity(N);
- for (int i = 0; i < N; i++) {
- list.add(i);
- }
- long endTime1 = System.currentTimeMillis();
- System.out.println("使用ensureCapacity方法后:"+(endTime1 - startTime1));
- }
-}
-```
-
-运行结果:
-
-```
-使用ensureCapacity方法前:4637
-使用ensureCapacity方法后:241
-
-```
-
-通过运行结果,我们可以很明显的看出向 ArrayList 添加大量元素之前最好先使用`ensureCapacity` 方法,以减少增量从新分配的次数
diff --git "a/Java\347\233\270\345\205\263/Java IO\344\270\216NIO.md" "b/Java\347\233\270\345\205\263/Java IO\344\270\216NIO.md"
deleted file mode 100644
index 905df527c40..00000000000
--- "a/Java\347\233\270\345\205\263/Java IO\344\270\216NIO.md"
+++ /dev/null
@@ -1,200 +0,0 @@
-<!-- MarkdownTOC -->
-
-- [IO流学习总结](#io流学习总结)
- - [一 Java IO,硬骨头也能变软](#一-java-io,硬骨头也能变软)
- - [二 java IO体系的学习总结](#二-java-io体系的学习总结)
- - [三 Java IO面试题](#三-java-io面试题)
-- [NIO与AIO学习总结](#nio与aio学习总结)
- - [一 Java NIO 概览](#一-java-nio-概览)
- - [二 Java NIO 之 Buffer\(缓冲区\)](#二-java-nio-之-buffer缓冲区)
- - [三 Java NIO 之 Channel(通道)](#三-java-nio-之-channel(通道))
- - [四 Java NIO之Selector(选择器)](#四-java-nio之selector(选择器))
- - [五 Java NIO之拥抱Path和Files](#五-java-nio之拥抱path和files)
- - [六 NIO学习总结以及NIO新特性介绍](#六-nio学习总结以及nio新特性介绍)
- - [七 Java NIO AsynchronousFileChannel异步文件通](#七-java-nio-asynchronousfilechannel异步文件通)
- - [八 高并发Java(8):NIO和AIO](#八-高并发java(8):nio和aio)
-- [推荐阅读](#推荐阅读)
- - [在 Java 7 中体会 NIO.2 异步执行的快乐](#在-java-7-中体会-nio2-异步执行的快乐)
- - [Java AIO总结与示例](#java-aio总结与示例)
-
-<!-- /MarkdownTOC -->
-
-
-
-## IO流学习总结
-
-### [一 Java IO,硬骨头也能变软](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483981&idx=1&sn=6e5c682d76972c8d2cf271a85dcf09e2&chksm=fd98542ccaefdd3a70428e9549bc33e8165836855edaa748928d16c1ebde9648579d3acaac10#rd)
-
-**(1) 按操作方式分类结构图:**
-
-
-
-
-**(2)按操作对象分类结构图**
-
-
-
-### [二 java IO体系的学习总结](https://blog.csdn.net/nightcurtis/article/details/51324105)
-1. **IO流的分类:**
- - 按照流的流向分,可以分为输入流和输出流;
- - 按照操作单元划分,可以划分为字节流和字符流;
- - 按照流的角色划分为节点流和处理流。
-2. **流的原理浅析:**
-
- java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java Io流的40多个类都是从如下4个抽象类基类中派生出来的。
-
- - **InputStream/Reader**: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- - **OutputStream/Writer**: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
-3. **常用的io流的用法**
-
-### [三 Java IO面试题](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483985&idx=1&sn=38531c2cee7b87f125df7aef41637014&chksm=fd985430caefdd26b0506aa84fc26251877eccba24fac73169a4d6bd1eb5e3fbdf3c3b940261#rd)
-
-## NIO与AIO学习总结
-
-
-### [一 Java NIO 概览](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483956&idx=1&sn=57692bc5b7c2c6dfb812489baadc29c9&chksm=fd985455caefdd4331d828d8e89b22f19b304aa87d6da73c5d8c66fcef16e4c0b448b1a6f791#rd)
-
-1. **NIO简介**:
-
- Java NIO 是 java 1.4, 之后新出的一套IO接口NIO中的N可以理解为Non-blocking,不单纯是New。
-
-2. **NIO的特性/NIO与IO区别:**
- - 1)IO是面向流的,NIO是面向缓冲区的;
- - 2)IO流是阻塞的,NIO流是不阻塞的;
- - 3)NIO有选择器,而IO没有。
-3. **读数据和写数据方式:**
- - 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
-
- - 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
-
-4. **NIO核心组件简单介绍**
- - **Channels**
- - **Buffers**
- - **Selectors**
-
-
-### [二 Java NIO 之 Buffer(缓冲区)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483961&idx=1&sn=f67bef4c279e78043ff649b6b03fdcbc&chksm=fd985458caefdd4e3317ccbdb2d0a5a70a5024d3255eebf38183919ed9c25ade536017c0a6ba#rd)
-
-1. **Buffer(缓冲区)介绍:**
- - Java NIO Buffers用于和NIO Channel交互。 我们从Channel中读取数据到buffers里,从Buffer把数据写入到Channels;
- - Buffer本质上就是一块内存区;
- - 一个Buffer有三个属性是必须掌握的,分别是:capacity容量、position位置、limit限制。
-2. **Buffer的常见方法**
- - Buffer clear()
- - Buffer flip()
- - Buffer rewind()
- - Buffer position(int newPosition)
-3. **Buffer的使用方式/方法介绍:**
- - 分配缓冲区(Allocating a Buffer):
- ```java
- ByteBuffer buf = ByteBuffer.allocate(28);//以ByteBuffer为例子
- ```
- - 写入数据到缓冲区(Writing Data to a Buffer)
-
- **写数据到Buffer有两种方法:**
-
- 1.从Channel中写数据到Buffer
- ```java
- int bytesRead = inChannel.read(buf); //read into buffer.
- ```
- 2.通过put写数据:
- ```java
- buf.put(127);
- ```
-
-4. **Buffer常用方法测试**
-
- 说实话,NIO编程真的难,通过后面这个测试例子,你可能才能勉强理解前面说的Buffer方法的作用。
-
-
-### [三 Java NIO 之 Channel(通道)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483966&idx=1&sn=d5cf18c69f5f9ec2aff149270422731f&chksm=fd98545fcaefdd49296e2c78000ce5da277435b90ba3c03b92b7cf54c6ccc71d61d13efbce63#rd)
-
-
-1. **Channel(通道)介绍**
- - 通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
- - NIO Channel通道和流的区别:
-2. **FileChannel的使用**
-3. **SocketChannel和ServerSocketChannel的使用**
-4. **️DatagramChannel的使用**
-5. **Scatter / Gather**
- - Scatter: 从一个Channel读取的信息分散到N个缓冲区中(Buufer).
- - Gather: 将N个Buffer里面内容按照顺序发送到一个Channel.
-6. **通道之间的数据传输**
- - 在Java NIO中如果一个channel是FileChannel类型的,那么他可以直接把数据传输到另一个channel。
- - transferFrom() :transferFrom方法把数据从通道源传输到FileChannel
- - transferTo() :transferTo方法把FileChannel数据传输到另一个channel
-
-
-### [四 Java NIO之Selector(选择器)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483970&idx=1&sn=d5e2b133313b1d0f32872d54fbdf0aa7&chksm=fd985423caefdd354b587e57ce6cf5f5a7bec48b9ab7554f39a8d13af47660cae793956e0f46#rd)
-
-
-1. **Selector(选择器)介绍**
- - Selector 一般称 为选择器 ,当然你也可以翻译为 多路复用器 。它是Java NIO核心组件中的一个,用于检查一个或多个NIO Channel(通道)的状态是否处于可读、可写。如此可以实现单线程管理多个channels,也就是可以管理多个网络链接。
- - 使用Selector的好处在于: 使用更少的线程来就可以来处理通道了, 相比使用多个线程,避免了线程上下文切换带来的开销。
-2. **Selector(选择器)的使用方法介绍**
- - Selector的创建
- ```java
- Selector selector = Selector.open();
- ```
- - 注册Channel到Selector(Channel必须是非阻塞的)
- ```java
- channel.configureBlocking(false);
- SelectionKey key = channel.register(selector, Selectionkey.OP_READ);
- ```
- - SelectionKey介绍
-
- 一个SelectionKey键表示了一个特定的通道对象和一个特定的选择器对象之间的注册关系。
- - 从Selector中选择channel(Selecting Channels via a Selector)
-
- 选择器维护注册过的通道的集合,并且这种注册关系都被封装在SelectionKey当中.
- - 停止选择的方法
-
- wakeup()方法 和close()方法。
-3. **模板代码**
-
- 有了模板代码我们在编写程序时,大多数时间都是在模板代码中添加相应的业务代码。
-4. **客户端与服务端简单交互实例**
-
-
-
-### [五 Java NIO之拥抱Path和Files](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483976&idx=1&sn=2296c05fc1b840a64679e2ad7794c96d&chksm=fd985429caefdd3f48e2ee6fdd7b0f6fc419df90b3de46832b484d6d1ca4e74e7837689c8146&token=537240785&lang=zh_CN#rd)
-
-**一 文件I/O基石:Path:**
-- 创建一个Path
-- File和Path之间的转换,File和URI之间的转换
-- 获取Path的相关信息
-- 移除Path中的冗余项
-
-**二 拥抱Files类:**
-- Files.exists() 检测文件路径是否存在
-- Files.createFile() 创建文件
-- Files.createDirectories()和Files.createDirectory()创建文件夹
-- Files.delete()方法 可以删除一个文件或目录
-- Files.copy()方法可以吧一个文件从一个地址复制到另一个位置
-- 获取文件属性
-- 遍历一个文件夹
-- Files.walkFileTree()遍历整个目录
-
-### [六 NIO学习总结以及NIO新特性介绍](https://blog.csdn.net/a953713428/article/details/64907250)
-
-- **内存映射:**
-
-这个功能主要是为了提高大文件的读写速度而设计的。内存映射文件(memory-mappedfile)能让你创建和修改那些大到无法读入内存的文件。有了内存映射文件,你就可以认为文件已经全部读进了内存,然后把它当成一个非常大的数组来访问了。将文件的一段区域映射到内存中,比传统的文件处理速度要快很多。内存映射文件它虽然最终也是要从磁盘读取数据,但是它并不需要将数据读取到OS内核缓冲区,而是直接将进程的用户私有地址空间中的一部分区域与文件对象建立起映射关系,就好像直接从内存中读、写文件一样,速度当然快了。
-
-### [七 Java NIO AsynchronousFileChannel异步文件通](http://wiki.jikexueyuan.com/project/java-nio-zh/java-nio-asynchronousfilechannel.html)
-
-Java7中新增了AsynchronousFileChannel作为nio的一部分。AsynchronousFileChannel使得数据可以进行异步读写。
-
-### [八 高并发Java(8):NIO和AIO](http://www.importnew.com/21341.html)
-
-
-
-## 推荐阅读
-
-### [在 Java 7 中体会 NIO.2 异步执行的快乐](https://www.ibm.com/developerworks/cn/java/j-lo-nio2/index.html)
-
-### [Java AIO总结与示例](https://blog.csdn.net/x_i_y_u_e/article/details/52223406)
-AIO是异步IO的缩写,虽然NIO在网络操作中,提供了非阻塞的方法,但是NIO的IO行为还是同步的。对于NIO来说,我们的业务线程是在IO操作准备好时,得到通知,接着就由这个线程自行进行IO操作,IO操作本身是同步的。
-
-
-**欢迎关注我的微信公众号:"Java面试通关手册"(一个有温度的微信公众号,期待与你共同进步~~~坚持原创,分享美文,分享各种Java学习资源):**
diff --git "a/Java\347\233\270\345\205\263/Java\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/Java\347\233\270\345\205\263/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
deleted file mode 100644
index f198aa09d0a..00000000000
--- "a/Java\347\233\270\345\205\263/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ /dev/null
@@ -1,458 +0,0 @@
-<!-- MarkdownTOC -->
-
-- [1. 面向对象和面向过程的区别](#1-面向对象和面向过程的区别)
- - [面向过程](#面向过程)
- - [面向对象](#面向对象)
-- [2. Java 语言有哪些特点](#2-java-语言有哪些特点)
-- [3. 什么是 JDK 什么是 JRE 什么是 JVM 三者之间的联系与区别](#3-什么是-jdk-什么是-jre-什么是-jvm-三者之间的联系与区别)
-- [4. 什么是字节码 采用字节码的最大好处是什么](#4-什么是字节码-采用字节码的最大好处是什么)
- - [先看下 java 中的编译器和解释器:](#先看下-java-中的编译器和解释器)
- - [采用字节码的好处:](#采用字节码的好处)
-- [5. Java和C++的区别](#5-java和c的区别)
-- [6. 什么是 Java 程序的主类 应用程序和小程序的主类有何不同](#6-什么是-java-程序的主类-应用程序和小程序的主类有何不同)
-- [7. Java 应用程序与小程序之间有那些差别](#7-java-应用程序与小程序之间有那些差别)
-- [8. 字符型常量和字符串常量的区别](#8-字符型常量和字符串常量的区别)
-- [9. 构造器 Constructor 是否可被 override](#9-构造器-constructor-是否可被-override)
-- [10. 重载和重写的区别](#10-重载和重写的区别)
-- [11. Java 面向对象编程三大特性:封装、继承、多态](#11-java-面向对象编程三大特性封装继承多态)
- - [封装](#封装)
- - [继承](#继承)
- - [多态](#多态)
-- [12. String 和 StringBuffer、StringBuilder 的区别是什么 String 为什么是不可变的](#12-string-和-stringbuffer、stringbuilder-的区别是什么-string-为什么是不可变的)
-- [13. 自动装箱与拆箱](#13-自动装箱与拆箱)
-- [14. 在一个静态方法内调用一个非静态成员为什么是非法的](#14-在一个静态方法内调用一个非静态成员为什么是非法的)
-- [15. 在 Java 中定义一个不做事且没有参数的构造方法的作用](#15-在-java-中定义一个不做事且没有参数的构造方法的作用)
-- [16. import java和javax有什么区别](#16-import-java和javax有什么区别)
-- [17. 接口和抽象类的区别是什么](#17-接口和抽象类的区别是什么)
-- [18. 成员变量与局部变量的区别有那些](#18-成员变量与局部变量的区别有那些)
-- [19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?](#19-创建一个对象用什么运算符对象实体与对象引用有何不同)
-- [20. 什么是方法的返回值?返回值在类的方法里的作用是什么?](#20-什么是方法的返回值返回值在类的方法里的作用是什么)
-- [21. 一个类的构造方法的作用是什么 若一个类没有声明构造方法,该程序能正确执行吗 为什么](#21-一个类的构造方法的作用是什么-若一个类没有声明构造方法,该程序能正确执行吗-为什么)
-- [22. 构造方法有哪些特性](#22-构造方法有哪些特性)
-- [23. 静态方法和实例方法有何不同](#23-静态方法和实例方法有何不同)
-- [24. 对象的相等与指向他们的引用相等,两者有什么不同?](#24-对象的相等与指向他们的引用相等,两者有什么不同)
-- [25. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?](#25-在调用子类构造方法之前会先调用父类没有参数的构造方法其目的是)
-- [26. == 与 equals\(重要\)](#26--与-equals重要)
-- [27. hashCode 与 equals(重要)](#27-hashcode-与-equals(重要))
- - [hashCode()介绍](#hashcode()介绍)
- - [为什么要有 hashCode](#为什么要有-hashcode)
- - [hashCode()与equals()的相关规定](#hashcode()与equals()的相关规定)
-- [28. 为什么Java中只有值传递](#28-为什么java中只有值传递)
-- [29. 简述线程,程序、进程的基本概念。以及他们之间关系是什么](#29-简述线程,程序、进程的基本概念。以及他们之间关系是什么)
-- [30. 线程有哪些基本状态?这些状态是如何定义的?](#30-线程有哪些基本状态?这些状态是如何定义的)
-- [31 关于 final 关键字的一些总结](#31-关于-final-关键字的一些总结)
-- [32 Java 中的异常处理](#32-java-中的异常处理)
- - [Java异常类层次结构图](#java异常类层次结构图)
- - [Trowable类常用方法](#trowable类常用方法)
- - [异常处理总结](#异常处理总结)
-- [33 Java序列话中如果有些字段不想进行序列化 怎么办](#33-java序列话中如果有些字段不想进行序列化-怎么办)
-- [Java基础学习书籍推荐](#java基础学习书籍推荐)
-
-<!-- /MarkdownTOC -->
-
-## 1. 面向对象和面向过程的区别
-
-### 面向过程
-
-**优点:** 性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
-
-**缺点:** 没有面向对象易维护、易复用、易扩展
-
-### 面向对象
-
-**优点:** 易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
-
-**缺点:** 性能比面向过程低
-
-## 2. Java 语言有哪些特点
-
-1. 简单易学;
-2. 面向对象(封装,继承,多态);
-3. 平台无关性( Java 虚拟机实现平台无关性);
-4. 可靠性;
-5. 安全性;
-6. 支持多线程( C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持);
-7. 支持网络编程并且很方便( Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便);
-8. 编译与解释并存;
-
-## 3. 什么是 JDK 什么是 JRE 什么是 JVM 三者之间的联系与区别
-
-这几个是Java中很基本很基本的东西,但是我相信一定还有很多人搞不清楚!为什么呢?因为我们大多数时候在使用现成的编译工具以及环境的时候,并没有去考虑这些东西。
-
-**JDK:** 顾名思义它是给开发者提供的开发工具箱,是给程序开发者用的。它除了包括完整的JRE(Java Runtime Environment),Java运行环境,还包含了其他供开发者使用的工具包。
-
-**JRE:** 普通用户而只需要安装 JRE(Java Runtime Environment)来运行 Java 程序。而程序开发者必须安装JDK来编译、调试程序。
-
-**JVM:** 当我们运行一个程序时,JVM 负责将字节码转换为特定机器代码,JVM 提供了内存管理/垃圾回收和安全机制等。这种独立于硬件和操作系统,正是 java 程序可以一次编写多处执行的原因。
-
-**区别与联系:**
-
- 1. JDK 用于开发,JRE 用于运行java程序 ;
- 2. JDK 和 JRE 中都包含 JVM ;
- 3. JVM 是 java 编程语言的核心并且具有平台独立性。
-
-## 4. 什么是字节码 采用字节码的最大好处是什么
-
-### 先看下 java 中的编译器和解释器:
-
-Java 中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。
-
-编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在 Java 中,这种供虚拟机理解的代码叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。
-
-每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java 源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行。这也就是解释了 Java 的编译与解释并存的特点。
-
- Java 源代码---->编译器---->jvm 可执行的 Java 字节码(即虚拟指令)---->jvm---->jvm 中解释器----->机器可执行的二进制机器码---->程序运行。
-
-### 采用字节码的好处:
-
-**Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。**
-
-> 解释性语言:解释型语言,是在运行的时候将程序翻译成机器语言。解释型语言的程序不需要在运行前编译,在运行程序的时候才翻译,专门的解释器负责在每个语句执行的时候解释程序代码。这样解释型语言每执行一次就要翻译一次,效率比较低。——百度百科
-
-## 5. Java和C++的区别
-
-我知道很多人没学过 C++,但是面试官就是没事喜欢拿咱们 Java 和 C++ 比呀!没办法!!!就算没学过C++,也要记下来!
-
-- 都是面向对象的语言,都支持封装、继承和多态
-- Java 不提供指针来直接访问内存,程序内存更加安全
-- Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
-- Java 有自动内存管理机制,不需要程序员手动释放无用内存
-
-
-## 6. 什么是 Java 程序的主类 应用程序和小程序的主类有何不同
-
-一个程序中可以有多个类,但只能有一个类是主类。在 Java 应用程序中,这个主类是指包含 main()方法的类。而在 Java 小程序中,这个主类是一个继承自系统类 JApplet 或 Applet 的子类。应用程序的主类不一定要求是 public 类,但小程序的主类要求必须是 public 类。主类是 Java 程序执行的入口点。
-
-## 7. Java 应用程序与小程序之间有那些差别
-
-简单说应用程序是从主线程启动(也就是 main() 方法)。applet 小程序没有main方法,主要是嵌在浏览器页面上运行(调用init()线程或者run()来启动),嵌入浏览器这点跟 flash 的小游戏类似。
-
-## 8. 字符型常量和字符串常量的区别
-
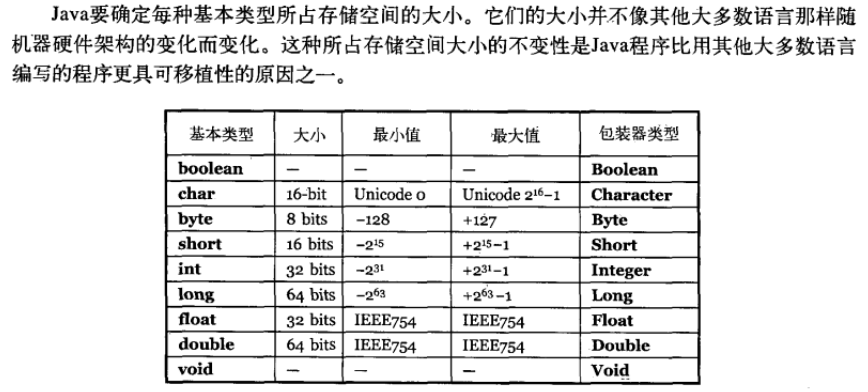
-1. 形式上: 字符常量是单引号引起的一个字符 字符串常量是双引号引起的若干个字符
-2. 含义上: 字符常量相当于一个整形值( ASCII 值),可以参加表达式运算 字符串常量代表一个地址值(该字符串在内存中存放位置)
-3. 占内存大小 字符常量只占2个字节 字符串常量占若干个字节(至少一个字符结束标志) (**注意: char在Java中占两个字节**)
-
-> java编程思想第四版:2.2.2节
-
-
-## 9. 构造器 Constructor 是否可被 override
-
-在讲继承的时候我们就知道父类的私有属性和构造方法并不能被继承,所以 Constructor 也就不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况。
-
-## 10. 重载和重写的区别
-
-**重载:** 发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
-
-**重写:** 发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为 private 则子类就不能重写该方法。
-
-## 11. Java 面向对象编程三大特性:封装、继承、多态
-
-### 封装
-
-封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。
-
-
-### 继承
-继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码。
-
-**关于继承如下 3 点请记住:**
-
-1. 子类拥有父类非 private 的属性和方法。
-2. 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
-3. 子类可以用自己的方式实现父类的方法。(以后介绍)。
-
-### 多态
-
-所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
-
-在Java中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。
-
-## 12. String 和 StringBuffer、StringBuilder 的区别是什么 String 为什么是不可变的
-
-**可变性**
-
-
-简单的来说:String 类中使用 final 关键字字符数组保存字符串,`private final char value[]`,所以 String 对象是不可变的。而StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串`char[]value` 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
-
-StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。
-
-AbstractStringBuilder.java
-
-```java
-abstract class AbstractStringBuilder implements Appendable, CharSequence {
- char[] value;
- int count;
- AbstractStringBuilder() {
- }
- AbstractStringBuilder(int capacity) {
- value = new char[capacity];
- }
-```
-
-
-**线程安全性**
-
-String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
-
-
-**性能**
-
-每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StirngBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
-
-**对于三者使用的总结:**
-1. 操作少量的数据 = String
-2. 单线程操作字符串缓冲区下操作大量数据 = StringBuilder
-3. 多线程操作字符串缓冲区下操作大量数据 = StringBuffer
-
-## 13. 自动装箱与拆箱
-**装箱**:将基本类型用它们对应的引用类型包装起来;
-
-**拆箱**:将包装类型转换为基本数据类型;
-
-## 14. 在一个静态方法内调用一个非静态成员为什么是非法的
-
-由于静态方法可以不通过对象进行调用,因此在静态方法里,不能调用其他非静态变量,也不可以访问非静态变量成员。
-
-## 15. 在 Java 中定义一个不做事且没有参数的构造方法的作用
- Java 程序在执行子类的构造方法之前,如果没有用 super() 来调用父类特定的构造方法,则会调用父类中“没有参数的构造方法”。因此,如果父类中只定义了有参数的构造方法,而在子类的构造方法中又没有用 super() 来调用父类中特定的构造方法,则编译时将发生错误,因为 Java 程序在父类中找不到没有参数的构造方法可供执行。解决办法是在父类里加上一个不做事且没有参数的构造方法。
-
-## 16. import java和javax有什么区别
-
-刚开始的时候 JavaAPI 所必需的包是 java 开头的包,javax 当时只是扩展 API 包来说使用。然而随着时间的推移,javax 逐渐的扩展成为 Java API 的组成部分。但是,将扩展从 javax 包移动到 java 包将是太麻烦了,最终会破坏一堆现有的代码。因此,最终决定 javax 包将成为标准API的一部分。
-
-所以,实际上java和javax没有区别。这都是一个名字。
-
-## 17. 接口和抽象类的区别是什么
-
-1. 接口的方法默认是 public,所有方法在接口中不能有实现(Java 8 开始接口方法可以有默认实现),抽象类可以有非抽象的方法
-2. 接口中的实例变量默认是 final 类型的,而抽象类中则不一定
-3. 一个类可以实现多个接口,但最多只能实现一个抽象类
-4. 一个类实现接口的话要实现接口的所有方法,而抽象类不一定
-5. 接口不能用 new 实例化,但可以声明,但是必须引用一个实现该接口的对象 从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
-
-## 18. 成员变量与局部变量的区别有那些
-
-1. 从语法形式上,看成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰;
-2. 从变量在内存中的存储方式来看,成员变量是对象的一部分,而对象存在于堆内存,局部变量存在于栈内存
-3. 从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
-4. 成员变量如果没有被赋初值,则会自动以类型的默认值而赋值(一种情况例外被 final 修饰但没有被 static 修饰的成员变量必须显示地赋值);而局部变量则不会自动赋值。
-
-## 19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?
-
-new运算符,new创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向0个或1个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有n个引用指向它(可以用n条绳子系住一个气球)。
-
-## 20. 什么是方法的返回值?返回值在类的方法里的作用是什么?
-
-方法的返回值是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用:接收出结果,使得它可以用于其他的操作!
-
-## 21. 一个类的构造方法的作用是什么 若一个类没有声明构造方法,该程序能正确执行吗 为什么
-
-主要作用是完成对类对象的初始化工作。可以执行。因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。
-
-## 22. 构造方法有哪些特性
-
-1. 名字与类名相同;
-2. 没有返回值,但不能用void声明构造函数;
-3. 生成类的对象时自动执行,无需调用。
-
-## 23. 静态方法和实例方法有何不同
-
-1. 在外部调用静态方法时,可以使用"类名.方法名"的方式,也可以使用"对象名.方法名"的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
-
-2. 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制.
-
-## 24. 对象的相等与指向他们的引用相等,两者有什么不同?
-
-对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
-
-## 25. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?
-
-帮助子类做初始化工作。
-
-## 26. == 与 equals(重要)
-
-**==** : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
-
-**equals()** : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
-- 情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
-- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来两个对象的内容相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
-
-
-**举个例子:**
-
-```java
-public class test1 {
- public static void main(String[] args) {
- String a = new String("ab"); // a 为一个引用
- String b = new String("ab"); // b为另一个引用,对象的内容一样
- String aa = "ab"; // 放在常量池中
- String bb = "ab"; // 从常量池中查找
- if (aa == bb) // true
- System.out.println("aa==bb");
- if (a == b) // false,非同一对象
- System.out.println("a==b");
- if (a.equals(b)) // true
- System.out.println("aEQb");
- if (42 == 42.0) { // true
- System.out.println("true");
- }
- }
-}
-```
-
-**说明:**
-- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
-- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
-
-
-
-## 27. hashCode 与 equals(重要)
-
-面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写equals时必须重写hashCode方法?”
-
-### hashCode()介绍
-hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。
-
-散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
-
-### 为什么要有 hashCode
-
-
-**我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:**
-
-当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
-
-
-
-### hashCode()与equals()的相关规定
-
-1. 如果两个对象相等,则hashcode一定也是相同的
-2. 两个对象相等,对两个对象分别调用equals方法都返回true
-3. 两个对象有相同的hashcode值,它们也不一定是相等的
-4. **因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖**
-5. hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
-
-
-## 28. 为什么Java中只有值传递
-
- [为什么Java中只有值传递?](https://github.com/Snailclimb/Java-Guide/blob/master/%E9%9D%A2%E8%AF%95%E5%BF%85%E5%A4%87/%E6%9C%80%E6%9C%80%E6%9C%80%E5%B8%B8%E8%A7%81%E7%9A%84Java%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93/%E7%AC%AC%E4%B8%80%E5%91%A8%EF%BC%882018-8-7%EF%BC%89.md)
-
-
-## 29. 简述线程,程序、进程的基本概念。以及他们之间关系是什么
-
-**线程**与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
-
-**程序**是含有指令和数据的文件,被存储在磁盘或其他的数据存储设备中,也就是说程序是静态的代码。
-
-**进程**是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。简单来说,一个进程就是一个执行中的程序,它在计算机中一个指令接着一个指令地执行着,同时,每个进程还占有某些系统资源如CPU时间,内存空间,文件,文件,输入输出设备的使用权等等。换句话说,当程序在执行时,将会被操作系统载入内存中。
-线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。从另一角度来说,进程属于操作系统的范畴,主要是同一段时间内,可以同时执行一个以上的程序,而线程则是在同一程序内几乎同时执行一个以上的程序段。
-
-## 30. 线程有哪些基本状态?这些状态是如何定义的?
-
-1. **新建(new)**:新创建了一个线程对象。
-2. **可运行(runnable)**:线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获 取cpu的使用权。
-3. **运行(running)**:可运行状态(runnable)的线程获得了cpu时间片(timeslice),执行程序代码。
-4. **阻塞(block)**:阻塞状态是指线程因为某种原因放弃了cpu使用权,也即让出了cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有 机会再次获得cpu timeslice转到运行(running)状态。阻塞的情况分三种:
-(一). 等待阻塞:运行(running)的线程执行o.wait()方法,JVM会把该线程放 入等待队列(waitting queue)中。
-(二). 同步阻塞:运行(running)的线程在获取对象的同步锁时,若该同步锁 被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
-(三). 其他阻塞: 运行(running)的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
-5. **死亡(dead)**:线程run()、main()方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
-
-
-
-备注: 可以用早起坐地铁来比喻这个过程:
-
-还没起床:sleeping
-
-起床收拾好了,随时可以坐地铁出发:Runnable
-
-等地铁来:Waiting
-
-地铁来了,但要排队上地铁:I/O阻塞
-
-上了地铁,发现暂时没座位:synchronized阻塞
-
-地铁上找到座位:Running
-
-到达目的地:Dead
-
-## 31 关于 final 关键字的一些总结
-
-final关键字主要用在三个地方:变量、方法、类。
-
-1. 对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
-2. 当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。
-3. 使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为fianl。
-
-## 32 Java 中的异常处理
-
-### Java异常类层次结构图
-
-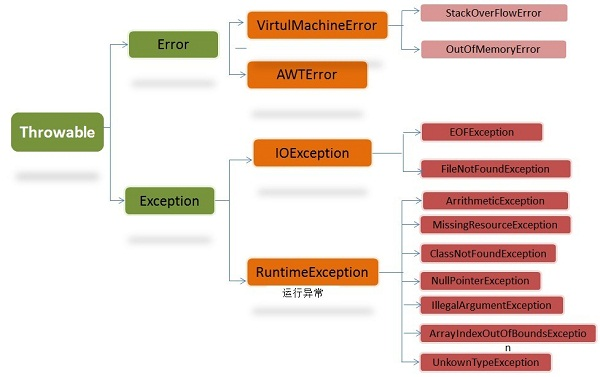
- 在 Java 中,所有的异常都有一个共同的祖先java.lang包中的 **Throwable类**。Throwable: 有两个重要的子类:**Exception(异常)** 和 **Error(错误)** ,二者都是 Java 异常处理的重要子类,各自都包含大量子类。
-
-**Error(错误):是程序无法处理的错误**,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
-
-这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java中,错误通过Error的子类描述。
-
-**Exception(异常):是程序本身可以处理的异常**。</font>Exception 类有一个重要的子类 **RuntimeException**。RuntimeException 异常由Java虚拟机抛出。**NullPointerException**(要访问的变量没有引用任何对象时,抛出该异常)、**ArithmeticException**(算术运算异常,一个整数除以0时,抛出该异常)和 **ArrayIndexOutOfBoundsException** (下标越界异常)。
-
-**注意:异常和错误的区别:异常能被程序本身可以处理,错误是无法处理。**
-
-### Throwable类常用方法
-
-- **public string getMessage()**:返回异常发生时的详细信息
-- **public string toString()**:返回异常发生时的简要描述
-- **public string getLocalizedMessage()**:返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以声称本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同
-- **public void printStackTrace()**:在控制台上打印Throwable对象封装的异常信息
-
-### 异常处理总结
-
-- try 块:用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。
-- catch 块:用于处理try捕获到的异常。
-- finally 块:无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return语句时,finally语句块将在方法返回之前被执行。
-
-**在以下4种特殊情况下,finally块不会被执行:**
-
-1. 在finally语句块中发生了异常。
-2. 在前面的代码中用了System.exit()退出程序。
-3. 程序所在的线程死亡。
-4. 关闭CPU。
-
-## 33 Java序列话中如果有些字段不想进行序列化 怎么办
-
-对于不想进行序列化的变量,使用transient关键字修饰。
-
-transient关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被transient修饰的变量值不会被持久化和恢复。transient只能修饰变量,不能修饰类和方法。
-
-## 34 获取用键盘输入常用的的两种方法
-
-方法1:通过 Scanner
-
-```java
-Scanner input = new Scanner(System.in);
-String s = input.nextLine();
-input.close();
-```
-
-方法2:通过 BufferedReader
-
-```java
-BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
-String s = input.readLine();
-```
-
-
-# Java基础学习书籍推荐
-
-**《Head First Java.第二版》:**
-可以说是我的 Java 启蒙书籍了,特别适合新手读当然也适合我们用来温故Java知识点。
-
-**《Java核心技术卷1+卷2》:**
-很棒的两本书,建议有点 Java 基础之后再读,介绍的还是比较深入的,非常推荐。
-
-**《Java编程思想(第4版)》:**
-这本书要常读,初学者可以快速概览,中等程序员可以深入看看 Java,老鸟还可以用之回顾 Java 的体系。这本书之所以厉害,因为它在无形中整合了设计模式,这本书之所以难读,也恰恰在于他对设计模式的整合是无形的。
-
-
diff --git "a/Java\347\233\270\345\205\263/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md" "b/Java\347\233\270\345\205\263/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md"
deleted file mode 100644
index 238e7c8b5df..00000000000
--- "a/Java\347\233\270\345\205\263/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md"
+++ /dev/null
@@ -1,67 +0,0 @@
-Java面试通关手册(Java学习指南)github地址(欢迎star和pull):[https://github.com/Snailclimb/Java_Guide](https://github.com/Snailclimb/Java_Guide)
-
-
-
-下面是按jvm虚拟机知识点分章节总结的一些jvm学习与面试相关的一些东西。一般作为Java程序员在面试的时候一般会问的大多就是**Java内存区域、虚拟机垃圾算法、虚拟垃圾收集器、JVM内存管理**这些问题了。这些内容参考周的《深入理解Java虚拟机》中第二章和第三章就足够了对应下面的[深入理解虚拟机之Java内存区域:](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzU4NDQ4MzU5OA%3D%3D%26mid%3D2247483910%26idx%3D1%26sn%3D246f39051a85fc312577499691fba89f%26chksm%3Dfd985467caefdd71f9a7c275952be34484b14f9e092723c19bd4ef557c324169ed084f868bdb%23rd)和[深入理解虚拟机之垃圾回收](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzU4NDQ4MzU5OA%3D%3D%26mid%3D2247483914%26idx%3D1%26sn%3D9aa157d4a1570962c39783cdeec7e539%26chksm%3Dfd98546bcaefdd7d9f61cd356e5584e56b64e234c3a403ed93cb6d4dde07a505e3000fd0c427%23rd)这两篇文章。
-
-
-> ### 常见面试题
-
-[深入理解虚拟机之Java内存区域:](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzU4NDQ4MzU5OA%3D%3D%26mid%3D2247483910%26idx%3D1%26sn%3D246f39051a85fc312577499691fba89f%26chksm%3Dfd985467caefdd71f9a7c275952be34484b14f9e092723c19bd4ef557c324169ed084f868bdb%23rd)
-
-1. 介绍下Java内存区域(运行时数据区)。
-
-2. 对象的访问定位的两种方式。
-
-
-[深入理解虚拟机之垃圾回收](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzU4NDQ4MzU5OA%3D%3D%26mid%3D2247483914%26idx%3D1%26sn%3D9aa157d4a1570962c39783cdeec7e539%26chksm%3Dfd98546bcaefdd7d9f61cd356e5584e56b64e234c3a403ed93cb6d4dde07a505e3000fd0c427%23rd)
-
-1. 如何判断对象是否死亡(两种方法)。
-
-2. 简单的介绍一下强引用、软引用、弱引用、虚引用(虚引用与软引用和弱引用的区别、使用软引用能带来的好处)。
-
-3. 垃圾收集有哪些算法,各自的特点?
-
-4. HotSpot为什么要分为新生代和老年代?
-
-5. 常见的垃圾回收器有那些?
-
-6. 介绍一下CMS,G1收集器。
-
-7. Minor Gc和Full GC 有什么不同呢?
-
-
-
-[虚拟机性能监控和故障处理工具](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzU4NDQ4MzU5OA%3D%3D%26mid%3D2247483922%26idx%3D1%26sn%3D0695ff4c2700ccebb8fbc39011866bd8%26chksm%3Dfd985473caefdd6583eb42dbbc7f01918dc6827c808292bb74a5b6333e3d526c097c9351e694%23rd)
-
-1. JVM调优的常见命令行工具有哪些?
-
-[深入理解虚拟机之类文件结构](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzU4NDQ4MzU5OA%3D%3D%26mid%3D2247483926%26idx%3D1%26sn%3D224413da998f7e024f7b8d87397934d9%26chksm%3Dfd985477caefdd61a2fe1a3f0be29e057082252e579332f5b6d9072a150b838cefe2c47b6e5a%23rd)
-
-1. 简单介绍一下Class类文件结构(常量池主要存放的是那两大常量?Class文件的继承关系是如何确定的?字段表、方法表、属性表主要包含那些信息?)
-
-[深入理解虚拟机之虚拟机类加载机制](http://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483934&idx=1&sn=f247f9bee4e240f5e7fac25659da3bff&chksm=fd98547fcaefdd6996e1a7046e03f29df9308bdf82ceeffd111112766ffd3187892700f64b40#rd)
-
-1. 简单说说类加载过程,里面执行了哪些操作?
-
-2. 对类加载器有了解吗?
-
-3. 什么是双亲委派模型?
-
-4. 双亲委派模型的工作过程以及使用它的好处。
-
-
-
-
-
-> ### 推荐阅读
-
-[深入理解虚拟机之虚拟机字节码执行引擎](https://juejin.im/post/5aebcb076fb9a07a9a10b5f3)
-
-[《深入理解 Java 内存模型》读书笔记](http://www.54tianzhisheng.cn/2018/02/28/Java-Memory-Model/) (非常不错的文章)
-
-[全面理解Java内存模型(JMM)及volatile关键字 ](https://blog.csdn.net/javazejian/article/details/72772461)
-
-**欢迎关注我的微信公众号:"Java面试通关手册"(一个有温度的微信公众号,期待与你共同进步~~~坚持原创,分享美文,分享各种Java学习资源):**
-
-
diff --git "a/Java\347\233\270\345\205\263/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/Java\347\233\270\345\205\263/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
deleted file mode 100644
index d18c68e0020..00000000000
--- "a/Java\347\233\270\345\205\263/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
+++ /dev/null
@@ -1,352 +0,0 @@
-<!-- MarkdownTOC -->
-
-1. [List,Set,Map三者的区别及总结](#list,setmap三者的区别及总结)
-1. [Arraylist 与 LinkedList 区别](#arraylist-与-linkedlist-区别)
-1. [ArrayList 与 Vector 区别(为什么要用Arraylist取代Vector呢?)](#arraylist-与-vector-区别)
-1. [HashMap 和 Hashtable 的区别](#hashmap-和-hashtable-的区别)
-1. [HashSet 和 HashMap 区别](#hashset-和-hashmap-区别)
-1. [HashMap 和 ConcurrentHashMap 的区别](#hashmap-和-concurrenthashmap-的区别)
-1. [HashSet如何检查重复](#hashset如何检查重复)
-1. [comparable 和 comparator的区别](#comparable-和-comparator的区别)
- 1. [Comparator定制排序](#comparator定制排序)
- 1. [重写compareTo方法实现按年龄来排序](#重写compareto方法实现按年龄来排序)
-1. [如何对Object的list排序?](#如何对object的list排序)
-1. [如何实现数组与List的相互转换?](#如何实现数组与list的相互转换)
-1. [如何求ArrayList集合的交集 并集 差集 去重复并集](#如何求arraylist集合的交集-并集-差集-去重复并集)
-1. [HashMap 的工作原理及代码实现](#hashmap-的工作原理及代码实现)
-1. [ConcurrentHashMap 的工作原理及代码实现](#concurrenthashmap-的工作原理及代码实现)
-1. [集合框架底层数据结构总结](#集合框架底层数据结构总结)
- 1. [- Collection](#--collection)
- 1. [1. List](#1-list)
- 1. [2. Set](#2-set)
- 1. [- Map](#--map)
-1. [集合的选用](#集合的选用)
-1. [集合的常用方法](#集合的常用方法)
-
-<!-- /MarkdownTOC -->
-
-
-## <font face="楷体">List,Set,Map三者的区别及总结</font>
-- **List:对付顺序的好帮手**
-
- List接口存储一组不唯一(可以有多个元素引用相同的对象),有序的对象
-- **Set:注重独一无二的性质**
-
- 不允许重复的集合。不会有多个元素引用相同的对象。
-
-- **Map:用Key来搜索的专家**
-
- 使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
-
-
-## <font face="楷体">Arraylist 与 LinkedList 区别</font>
-Arraylist底层使用的是数组(存读数据效率高,插入删除特定位置效率低),LinkedList底层使用的是双向循环链表数据结构(插入,删除效率特别高)。学过数据结构这门课后我们就知道采用链表存储,插入,删除元素时间复杂度不受元素位置的影响,都是近似O(1)而数组为近似O(n),因此当数据特别多,而且经常需要插入删除元素时建议选用LinkedList.一般程序只用Arraylist就够用了,因为一般数据量都不会蛮大,Arraylist是使用最多的集合类。
-
-## <font face="楷体">ArrayList 与 Vector 区别</font>
-Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector
-,代码要在同步操作上耗费大量的时间。Arraylist不是同步的,所以在不需要同步时建议使用Arraylist。
-
-## <font face="楷体">HashMap 和 Hashtable 的区别</font>
-1. HashMap是非线程安全的,HashTable是线程安全的;HashTable内部的方法基本都经过synchronized修饰。
-
-2. 因为线程安全的问题,HashMap要比HashTable效率高一点,HashTable基本被淘汰。
-3. HashMap允许有null值的存在,而在HashTable中put进的键值只要有一个null,直接抛出NullPointerException。
-
-Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java5或以上的话,请使用ConcurrentHashMap吧
-
-## <font face="楷体">HashSet 和 HashMap 区别</font>
-
-
-## <font face="楷体">HashMap 和 ConcurrentHashMap 的区别</font>
-[HashMap与ConcurrentHashMap的区别](https://blog.csdn.net/xuefeng0707/article/details/40834595)
-
-1. ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的synchronized锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。(JDK1.8之后ConcurrentHashMap启用了一种全新的方式实现,利用CAS算法。)
-2. HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
-
-## <font face="楷体">HashSet如何检查重复</font>
-当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。(摘自我的Java启蒙书《Head fist java》第二版)
-
-**hashCode()与equals()的相关规定:**
-1. 如果两个对象相等,则hashcode一定也是相同的
-2. 两个对象相等,对两个equals方法返回true
-3. 两个对象有相同的hashcode值,它们也不一定是相等的
-4. 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
-5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
-
-**==与equals的区别**
-
-1. ==是判断两个变量或实例是不是指向同一个内存空间 equals是判断两个变量或实例所指向的内存空间的值是不是相同
-2. ==是指对内存地址进行比较 equals()是对字符串的内容进行比较3.==指引用是否相同 equals()指的是值是否相同
-
-## <font face="楷体">comparable 和 comparator的区别</font>
-- comparable接口实际上是出自java.lang包 它有一个 compareTo(Object obj)方法用来排序
-- comparator接口实际上是出自 java.util 包它有一个compare(Object obj1, Object obj2)方法用来排序
-
-一般我们需要对一个集合使用自定义排序时,我们就要重写compareTo方法或compare方法,当我们需要对某一个集合实现两种排序方式,比如一个song对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo方法和使用自制的Comparator方法或者以两个Comparator来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的Collections.sort().
-
-### <font face="楷体">Comparator定制排序<font face="楷体">
-```java
-import java.util.ArrayList;
-import java.util.Collections;
-import java.util.Comparator;
-
-/**
- * TODO Collections类方法测试之排序
- * @author 寇爽
- * @date 2017年11月20日
- * @version 1.8
- */
-public class CollectionsSort {
-
- public static void main(String[] args) {
-
- ArrayList<Integer> arrayList = new ArrayList<Integer>();
- arrayList.add(-1);
- arrayList.add(3);
- arrayList.add(3);
- arrayList.add(-5);
- arrayList.add(7);
- arrayList.add(4);
- arrayList.add(-9);
- arrayList.add(-7);
- System.out.println("原始数组:");
- System.out.println(arrayList);
- // void reverse(List list):反转
- Collections.reverse(arrayList);
- System.out.println("Collections.reverse(arrayList):");
- System.out.println(arrayList);
-/*
- * void rotate(List list, int distance),旋转。
- * 当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将
- * list的前distance个元素整体移到后面。
-
- Collections.rotate(arrayList, 4);
- System.out.println("Collections.rotate(arrayList, 4):");
- System.out.println(arrayList);*/
-
- // void sort(List list),按自然排序的升序排序
- Collections.sort(arrayList);
- System.out.println("Collections.sort(arrayList):");
- System.out.println(arrayList);
-
- // void shuffle(List list),随机排序
- Collections.shuffle(arrayList);
- System.out.println("Collections.shuffle(arrayList):");
- System.out.println(arrayList);
-
- // 定制排序的用法
- Collections.sort(arrayList, new Comparator<Integer>() {
-
- @Override
- public int compare(Integer o1, Integer o2) {
- return o2.compareTo(o1);
- }
- });
- System.out.println("定制排序后:");
- System.out.println(arrayList);
- }
-
-}
-
-```
-### <font face="楷体">重写compareTo方法实现按年龄来排序</font>
-```java
-package map;
-
-import java.util.Set;
-import java.util.TreeMap;
-
-public class TreeMap2 {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- TreeMap<Person, String> pdata = new TreeMap<Person, String>();
- pdata.put(new Person("张三", 30), "zhangsan");
- pdata.put(new Person("李四", 20), "lisi");
- pdata.put(new Person("王五", 10), "wangwu");
- pdata.put(new Person("小红", 5), "xiaohong");
- // 得到key的值的同时得到key所对应的值
- Set<Person> keys = pdata.keySet();
- for (Person key : keys) {
- System.out.println(key.getAge() + "-" + key.getName());
-
- }
- }
-}
-
-// person对象没有实现Comparable接口,所以必须实现,这样才不会出错,才可以使treemap中的数据按顺序排列
-// 前面一个例子的String类已经默认实现了Comparable接口,详细可以查看String类的API文档,另外其他
-// 像Integer类等都已经实现了Comparable接口,所以不需要另外实现了
-
-class Person implements Comparable<Person> {
- private String name;
- private int age;
-
- public Person(String name, int age) {
- super();
- this.name = name;
- this.age = age;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- /**
- * TODO重写compareTo方法实现按年龄来排序
- */
- @Override
- public int compareTo(Person o) {
- // TODO Auto-generated method stub
- if (this.age > o.getAge()) {
- return 1;
- } else if (this.age < o.getAge()) {
- return -1;
- }
- return age;
- }
-}
-```
-
-## <font face="楷体">如何对Object的list排序</font>
-- 对objects数组进行排序,我们可以用Arrays.sort()方法
-- 对objects的集合进行排序,需要使用Collections.sort()方法
-
-
-## <font face="楷体">如何实现数组与List的相互转换</font>
-List转数组:toArray(arraylist.size()方法;数组转List:Arrays的asList(a)方法
-```java
-List<String> arrayList = new ArrayList<String>();
- arrayList.add("s");
- arrayList.add("e");
- arrayList.add("n");
- /**
- * ArrayList转数组
- */
- int size=arrayList.size();
- String[] a = arrayList.toArray(new String[size]);
- //输出第二个元素
- System.out.println(a[1]);//结果:e
- //输出整个数组
- System.out.println(Arrays.toString(a));//结果:[s, e, n]
- /**
- * 数组转list
- */
- List<String> list=Arrays.asList(a);
- /**
- * list转Arraylist
- */
- List<String> arrayList2 = new ArrayList<String>();
- arrayList2.addAll(list);
- System.out.println(list);
-```
-## <font face="楷体">如何求ArrayList集合的交集 并集 差集 去重复并集</font>
-需要用到List接口中定义的几个方法:
-
-- addAll(Collection<? extends E> c) :按指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾
-实例代码:
-- retainAll(Collection<?> c): 仅保留此列表中包含在指定集合中的元素。
-- removeAll(Collection<?> c) :从此列表中删除指定集合中包含的所有元素。
-```java
-package list;
-
-import java.util.ArrayList;
-import java.util.List;
-
-/**
- *TODO 两个集合之间求交集 并集 差集 去重复并集
- * @author 寇爽
- * @date 2017年11月21日
- * @version 1.8
- */
-public class MethodDemo {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- List<Integer> list1 = new ArrayList<Integer>();
- list1.add(1);
- list1.add(2);
- list1.add(3);
- list1.add(4);
-
- List<Integer> list2 = new ArrayList<Integer>();
- list2.add(2);
- list2.add(3);
- list2.add(4);
- list2.add(5);
- // 并集
- // list1.addAll(list2);
- // 交集
- //list1.retainAll(list2);
- // 差集
- // list1.removeAll(list2);
- // 无重复并集
- list2.removeAll(list1);
- list1.addAll(list2);
- for (Integer i : list1) {
- System.out.println(i);
- }
- }
-
-}
-
-```
-
-## <font face="楷体">HashMap 的工作原理及代码实现</font>
-
-[集合框架源码学习之HashMap(JDK1.8)](https://juejin.im/post/5ab0568b5188255580020e56)
-
-## <font face="楷体">ConcurrentHashMap 的工作原理及代码实现</font>
-
-[ConcurrentHashMap实现原理及源码分析](http://www.cnblogs.com/chengxiao/p/6842045.html)
-
-
-## <font face="楷体">集合框架底层数据结构总结</font>
-### - Collection
-
-#### 1. List
- - Arraylist:数组(查询快,增删慢 线程不安全,效率高 )
- - Vector:数组(查询快,增删慢 线程安全,效率低 )
- - LinkedList:链表(查询慢,增删快 线程不安全,效率高 )
-
-#### 2. Set
- - HashSet(无序,唯一):哈希表或者叫散列集(hash table)
- - LinkedHashSet:链表和哈希表组成 。 由链表保证元素的排序 , 由哈希表证元素的唯一性
- - TreeSet(有序,唯一):红黑树(自平衡的排序二叉树。)
-
-### - Map
- - HashMap:基于哈希表的Map接口实现(哈希表对键进行散列,Map结构即映射表存放键值对)
- - LinkedHashMap:HashMap 的基础上加上了链表数据结构
- - HashTable:哈希表
- - TreeMap:红黑树(自平衡的排序二叉树)
-
-
-## <font face="楷体">集合的选用</font>
-主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用Map接口下的集合,需要排序时选择TreeMap,不需要排序时就选择HashMap,需要保证线程安全就选用ConcurrentHashMap.当我们只需要存放元素值时,就选择实现Collection接口的集合,需要保证元素唯一时选择实现Set接口的集合比如TreeSet或HashSet,不需要就选择实现List接口的比如ArrayList或LinkedList,然后再根据实现这些接口的集合的特点来选用。
-
-2018/3/11更新
-## <font face="楷体">集合的常用方法</font>
-今天下午无意看见一道某大厂的面试题,面试题的内容就是问你某一个集合常见的方法有哪些。虽然平时也经常见到这些集合,但是猛一下让我想某一个集合的常用的方法难免会有遗漏或者与其他集合搞混,所以建议大家还是照着API文档把常见的那几个集合的常用方法看一看。
-
-会持续更新。。。
-
-**参考书籍:**
-
-《Head first java 》第二版 推荐阅读真心不错 (适合基础较差的)
-
- 《Java核心技术卷1》推荐阅读真心不错 (适合基础较好的)
-
- 《算法》第四版 (适合想对数据结构的Java实现感兴趣的)
-
diff --git "a/Java\347\233\270\345\205\263/LinkedList.md" "b/Java\347\233\270\345\205\263/LinkedList.md"
deleted file mode 100644
index 15f67f88a00..00000000000
--- "a/Java\347\233\270\345\205\263/LinkedList.md"
+++ /dev/null
@@ -1,515 +0,0 @@
-
-<!-- MarkdownTOC -->
-
-- [简介](#简介)
-- [内部结构分析](#内部结构分析)
-- [LinkedList源码分析](#linkedlist源码分析)
- - [构造方法](#构造方法)
- - [添加(add)方法](#add方法)
- - [根据位置取数据的方法](#根据位置取数据的方法)
- - [根据对象得到索引的方法](#根据对象得到索引的方法)
- - [检查链表是否包含某对象的方法:](#检查链表是否包含某对象的方法:)
- - [删除(remove/pop)方法](#删除方法)
-- [LinkedList类常用方法测试:](#linkedlist类常用方法测试)
-
-<!-- /MarkdownTOC -->
-
-## <font face="楷体" id="1">简介</font>
-<font color="red">LinkedList</font>是一个实现了<font color="red">List接口</font>和<font color="red">Deque接口</font>的<font color="red">双端链表</font>。
-LinkedList底层的链表结构使它<font color="red">支持高效的插入和删除操作</font>,另外它实现了Deque接口,使得LinkedList类也具有队列的特性;
-LinkedList<font color="red">不是线程安全的</font>,如果想使LinkedList变成线程安全的,可以调用静态类<font color="red">Collections类</font>中的<font color="red">synchronizedList</font>方法:
-```java
-List list=Collections.synchronizedList(new LinkedList(...));
-```
-## <font face="楷体" id="2">内部结构分析</font>
-**如下图所示:**
-
-看完了图之后,我们再看LinkedList类中的一个<font color="red">**内部私有类Node**</font>就很好理解了:
-```java
-private static class Node<E> {
- E item;//节点值
- Node<E> next;//后继节点
- Node<E> prev;//前驱节点
-
- Node(Node<E> prev, E element, Node<E> next) {
- this.item = element;
- this.next = next;
- this.prev = prev;
- }
- }
-```
-这个类就代表双端链表的节点Node。这个类有三个属性,分别是前驱节点,本节点的值,后继结点。
-
-## <font face="楷体" id="3">LinkedList源码分析</font>
-### <font face="楷体" id="3.1">构造方法</font>
-**空构造方法:**
-```java
- public LinkedList() {
- }
-```
-**用已有的集合创建链表的构造方法:**
-```java
- public LinkedList(Collection<? extends E> c) {
- this();
- addAll(c);
- }
-```
-### <font face="楷体" id="3.2">add方法</font>
-**add(E e)** 方法:将元素添加到链表尾部
-```java
-public boolean add(E e) {
- linkLast(e);//这里就只调用了这一个方法
- return true;
- }
-```
-
-```java
- /**
- * 链接使e作为最后一个元素。
- */
- void linkLast(E e) {
- final Node<E> l = last;
- final Node<E> newNode = new Node<>(l, e, null);
- last = newNode;//新建节点
- if (l == null)
- first = newNode;
- else
- l.next = newNode;//指向后继元素也就是指向下一个元素
- size++;
- modCount++;
- }
-```
-**add(int index,E e)**:在指定位置添加元素
-```java
-public void add(int index, E element) {
- checkPositionIndex(index); //检查索引是否处于[0-size]之间
-
- if (index == size)//添加在链表尾部
- linkLast(element);
- else//添加在链表中间
- linkBefore(element, node(index));
- }
-```
-<font color="red">linkBefore方法</font>需要给定两个参数,一个<font color="red">插入节点的值</font>,一个<font color="red">指定的node</font>,所以我们又调用了<font color="red">Node(index)去找到index对应的node</font>
-
-**addAll(Collection c ):将集合插入到链表尾部**
-
-```java
-public boolean addAll(Collection<? extends E> c) {
- return addAll(size, c);
- }
-```
-**addAll(int index, Collection c):** 将集合从指定位置开始插入
-```java
-public boolean addAll(int index, Collection<? extends E> c) {
- //1:检查index范围是否在size之内
- checkPositionIndex(index);
-
- //2:toArray()方法把集合的数据存到对象数组中
- Object[] a = c.toArray();
- int numNew = a.length;
- if (numNew == 0)
- return false;
-
- //3:得到插入位置的前驱节点和后继节点
- Node<E> pred, succ;
- //如果插入位置为尾部,前驱节点为last,后继节点为null
- if (index == size) {
- succ = null;
- pred = last;
- }
- //否则,调用node()方法得到后继节点,再得到前驱节点
- else {
- succ = node(index);
- pred = succ.prev;
- }
-
- // 4:遍历数据将数据插入
- for (Object o : a) {
- @SuppressWarnings("unchecked") E e = (E) o;
- //创建新节点
- Node<E> newNode = new Node<>(pred, e, null);
- //如果插入位置在链表头部
- if (pred == null)
- first = newNode;
- else
- pred.next = newNode;
- pred = newNode;
- }
-
- //如果插入位置在尾部,重置last节点
- if (succ == null) {
- last = pred;
- }
- //否则,将插入的链表与先前链表连接起来
- else {
- pred.next = succ;
- succ.prev = pred;
- }
-
- size += numNew;
- modCount++;
- return true;
- }
-```
-上面可以看出addAll方法通常包括下面四个步骤:
-1. 检查index范围是否在size之内
-2. toArray()方法把集合的数据存到对象数组中
-3. 得到插入位置的前驱和后继节点
-4. 遍历数据,将数据插入到指定位置
-
-**addFirst(E e):** 将元素添加到链表头部
-```java
- public void addFirst(E e) {
- linkFirst(e);
- }
-```
-```java
-private void linkFirst(E e) {
- final Node<E> f = first;
- final Node<E> newNode = new Node<>(null, e, f);//新建节点,以头节点为后继节点
- first = newNode;
- //如果链表为空,last节点也指向该节点
- if (f == null)
- last = newNode;
- //否则,将头节点的前驱指针指向新节点,也就是指向前一个元素
- else
- f.prev = newNode;
- size++;
- modCount++;
- }
-```
-**addLast(E e):** 将元素添加到链表尾部,与 **add(E e)** 方法一样
-```java
-public void addLast(E e) {
- linkLast(e);
- }
-```
-### <font face="楷体" id="3.3">根据位置取数据的方法</font>
-**get(int index):**:根据指定索引返回数据
-```java
-public E get(int index) {
- //检查index范围是否在size之内
- checkElementIndex(index);
- //调用Node(index)去找到index对应的node然后返回它的值
- return node(index).item;
- }
-```
-**获取头节点(index=0)数据方法:**
-```java
-public E getFirst() {
- final Node<E> f = first;
- if (f == null)
- throw new NoSuchElementException();
- return f.item;
- }
-public E element() {
- return getFirst();
- }
-public E peek() {
- final Node<E> f = first;
- return (f == null) ? null : f.item;
- }
-
-public E peekFirst() {
- final Node<E> f = first;
- return (f == null) ? null : f.item;
- }
-```
-**区别:**
-getFirst(),element(),peek(),peekFirst()
-这四个获取头结点方法的区别在于对链表为空时的处理,是抛出异常还是返回null,其中**getFirst()** 和**element()** 方法将会在链表为空时,抛出异常
-
-element()方法的内部就是使用getFirst()实现的。它们会在链表为空时,抛出NoSuchElementException
-**获取尾节点(index=-1)数据方法:**
-```java
- public E getLast() {
- final Node<E> l = last;
- if (l == null)
- throw new NoSuchElementException();
- return l.item;
- }
- public E peekLast() {
- final Node<E> l = last;
- return (l == null) ? null : l.item;
- }
-```
-**两者区别:**
-**getLast()** 方法在链表为空时,会抛出**NoSuchElementException**,而**peekLast()** 则不会,只是会返回 **null**。
-### <font face="楷体" id="3.4">根据对象得到索引的方法</font>
-**int indexOf(Object o):** 从头遍历找
-```java
-public int indexOf(Object o) {
- int index = 0;
- if (o == null) {
- //从头遍历
- for (Node<E> x = first; x != null; x = x.next) {
- if (x.item == null)
- return index;
- index++;
- }
- } else {
- //从头遍历
- for (Node<E> x = first; x != null; x = x.next) {
- if (o.equals(x.item))
- return index;
- index++;
- }
- }
- return -1;
- }
-```
-**int lastIndexOf(Object o):** 从尾遍历找
-```java
-public int lastIndexOf(Object o) {
- int index = size;
- if (o == null) {
- //从尾遍历
- for (Node<E> x = last; x != null; x = x.prev) {
- index--;
- if (x.item == null)
- return index;
- }
- } else {
- //从尾遍历
- for (Node<E> x = last; x != null; x = x.prev) {
- index--;
- if (o.equals(x.item))
- return index;
- }
- }
- return -1;
- }
-```
-### <font face="楷体" id="3.5">检查链表是否包含某对象的方法:</font>
-**contains(Object o):** 检查对象o是否存在于链表中
-```java
- public boolean contains(Object o) {
- return indexOf(o) != -1;
- }
-```
-###<font face="楷体" id="3.6">删除方法</font>
-**remove()** ,**removeFirst(),pop():** 删除头节点
-```
-public E pop() {
- return removeFirst();
- }
-public E remove() {
- return removeFirst();
- }
-public E removeFirst() {
- final Node<E> f = first;
- if (f == null)
- throw new NoSuchElementException();
- return unlinkFirst(f);
- }
-```
-**removeLast(),pollLast():** 删除尾节点
-```java
-public E removeLast() {
- final Node<E> l = last;
- if (l == null)
- throw new NoSuchElementException();
- return unlinkLast(l);
- }
-public E pollLast() {
- final Node<E> l = last;
- return (l == null) ? null : unlinkLast(l);
- }
-```
-**区别:** removeLast()在链表为空时将抛出NoSuchElementException,而pollLast()方法返回null。
-
-**remove(Object o):** 删除指定元素
-```java
-public boolean remove(Object o) {
- //如果删除对象为null
- if (o == null) {
- //从头开始遍历
- for (Node<E> x = first; x != null; x = x.next) {
- //找到元素
- if (x.item == null) {
- //从链表中移除找到的元素
- unlink(x);
- return true;
- }
- }
- } else {
- //从头开始遍历
- for (Node<E> x = first; x != null; x = x.next) {
- //找到元素
- if (o.equals(x.item)) {
- //从链表中移除找到的元素
- unlink(x);
- return true;
- }
- }
- }
- return false;
- }
-```
-当删除指定对象时,只需调用remove(Object o)即可,不过该方法一次只会删除一个匹配的对象,如果删除了匹配对象,返回true,否则false。
-
-unlink(Node<E> x) 方法:
-```java
-E unlink(Node<E> x) {
- // assert x != null;
- final E element = x.item;
- final Node<E> next = x.next;//得到后继节点
- final Node<E> prev = x.prev;//得到前驱节点
-
- //删除前驱指针
- if (prev == null) {
- first = next;如果删除的节点是头节点,令头节点指向该节点的后继节点
- } else {
- prev.next = next;//将前驱节点的后继节点指向后继节点
- x.prev = null;
- }
-
- //删除后继指针
- if (next == null) {
- last = prev;//如果删除的节点是尾节点,令尾节点指向该节点的前驱节点
- } else {
- next.prev = prev;
- x.next = null;
- }
-
- x.item = null;
- size--;
- modCount++;
- return element;
- }
-```
-**remove(int index)**:删除指定位置的元素
-```java
-public E remove(int index) {
- //检查index范围
- checkElementIndex(index);
- //将节点删除
- return unlink(node(index));
- }
-```
-## <font face="楷体" id="4">LinkedList类常用方法测试</font>
-
-```java
-package list;
-
-import java.util.Iterator;
-import java.util.LinkedList;
-
-public class LinkedListDemo {
- public static void main(String[] srgs) {
- //创建存放int类型的linkedList
- LinkedList<Integer> linkedList = new LinkedList<>();
- /************************** linkedList的基本操作 ************************/
- linkedList.addFirst(0); // 添加元素到列表开头
- linkedList.add(1); // 在列表结尾添加元素
- linkedList.add(2, 2); // 在指定位置添加元素
- linkedList.addLast(3); // 添加元素到列表结尾
-
- System.out.println("LinkedList(直接输出的): " + linkedList);
-
- System.out.println("getFirst()获得第一个元素: " + linkedList.getFirst()); // 返回此列表的第一个元素
- System.out.println("getLast()获得第最后一个元素: " + linkedList.getLast()); // 返回此列表的最后一个元素
- System.out.println("removeFirst()删除第一个元素并返回: " + linkedList.removeFirst()); // 移除并返回此列表的第一个元素
- System.out.println("removeLast()删除最后一个元素并返回: " + linkedList.removeLast()); // 移除并返回此列表的最后一个元素
- System.out.println("After remove:" + linkedList);
- System.out.println("contains()方法判断列表是否包含1这个元素:" + linkedList.contains(1)); // 判断此列表包含指定元素,如果是,则返回true
- System.out.println("该linkedList的大小 : " + linkedList.size()); // 返回此列表的元素个数
-
- /************************** 位置访问操作 ************************/
- System.out.println("-----------------------------------------");
- linkedList.set(1, 3); // 将此列表中指定位置的元素替换为指定的元素
- System.out.println("After set(1, 3):" + linkedList);
- System.out.println("get(1)获得指定位置(这里为1)的元素: " + linkedList.get(1)); // 返回此列表中指定位置处的元素
-
- /************************** Search操作 ************************/
- System.out.println("-----------------------------------------");
- linkedList.add(3);
- System.out.println("indexOf(3): " + linkedList.indexOf(3)); // 返回此列表中首次出现的指定元素的索引
- System.out.println("lastIndexOf(3): " + linkedList.lastIndexOf(3));// 返回此列表中最后出现的指定元素的索引
-
- /************************** Queue操作 ************************/
- System.out.println("-----------------------------------------");
- System.out.println("peek(): " + linkedList.peek()); // 获取但不移除此列表的头
- System.out.println("element(): " + linkedList.element()); // 获取但不移除此列表的头
- linkedList.poll(); // 获取并移除此列表的头
- System.out.println("After poll():" + linkedList);
- linkedList.remove();
- System.out.println("After remove():" + linkedList); // 获取并移除此列表的头
- linkedList.offer(4);
- System.out.println("After offer(4):" + linkedList); // 将指定元素添加到此列表的末尾
-
- /************************** Deque操作 ************************/
- System.out.println("-----------------------------------------");
- linkedList.offerFirst(2); // 在此列表的开头插入指定的元素
- System.out.println("After offerFirst(2):" + linkedList);
- linkedList.offerLast(5); // 在此列表末尾插入指定的元素
- System.out.println("After offerLast(5):" + linkedList);
- System.out.println("peekFirst(): " + linkedList.peekFirst()); // 获取但不移除此列表的第一个元素
- System.out.println("peekLast(): " + linkedList.peekLast()); // 获取但不移除此列表的第一个元素
- linkedList.pollFirst(); // 获取并移除此列表的第一个元素
- System.out.println("After pollFirst():" + linkedList);
- linkedList.pollLast(); // 获取并移除此列表的最后一个元素
- System.out.println("After pollLast():" + linkedList);
- linkedList.push(2); // 将元素推入此列表所表示的堆栈(插入到列表的头)
- System.out.println("After push(2):" + linkedList);
- linkedList.pop(); // 从此列表所表示的堆栈处弹出一个元素(获取并移除列表第一个元素)
- System.out.println("After pop():" + linkedList);
- linkedList.add(3);
- linkedList.removeFirstOccurrence(3); // 从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表)
- System.out.println("After removeFirstOccurrence(3):" + linkedList);
- linkedList.removeLastOccurrence(3); // 从此列表中移除最后一次出现的指定元素(从头部到尾部遍历列表)
- System.out.println("After removeFirstOccurrence(3):" + linkedList);
-
- /************************** 遍历操作 ************************/
- System.out.println("-----------------------------------------");
- linkedList.clear();
- for (int i = 0; i < 100000; i++) {
- linkedList.add(i);
- }
- // 迭代器遍历
- long start = System.currentTimeMillis();
- Iterator<Integer> iterator = linkedList.iterator();
- while (iterator.hasNext()) {
- iterator.next();
- }
- long end = System.currentTimeMillis();
- System.out.println("Iterator:" + (end - start) + " ms");
-
- // 顺序遍历(随机遍历)
- start = System.currentTimeMillis();
- for (int i = 0; i < linkedList.size(); i++) {
- linkedList.get(i);
- }
- end = System.currentTimeMillis();
- System.out.println("for:" + (end - start) + " ms");
-
- // 另一种for循环遍历
- start = System.currentTimeMillis();
- for (Integer i : linkedList)
- ;
- end = System.currentTimeMillis();
- System.out.println("for2:" + (end - start) + " ms");
-
- // 通过pollFirst()或pollLast()来遍历LinkedList
- LinkedList<Integer> temp1 = new LinkedList<>();
- temp1.addAll(linkedList);
- start = System.currentTimeMillis();
- while (temp1.size() != 0) {
- temp1.pollFirst();
- }
- end = System.currentTimeMillis();
- System.out.println("pollFirst()或pollLast():" + (end - start) + " ms");
-
- // 通过removeFirst()或removeLast()来遍历LinkedList
- LinkedList<Integer> temp2 = new LinkedList<>();
- temp2.addAll(linkedList);
- start = System.currentTimeMillis();
- while (temp2.size() != 0) {
- temp2.removeFirst();
- }
- end = System.currentTimeMillis();
- System.out.println("removeFirst()或removeLast():" + (end - start) + " ms");
- }
-}
-```
diff --git "a/Java\347\233\270\345\205\263/Multithread/AQS.md" "b/Java\347\233\270\345\205\263/Multithread/AQS.md"
deleted file mode 100644
index dcd9b4a3a1b..00000000000
--- "a/Java\347\233\270\345\205\263/Multithread/AQS.md"
+++ /dev/null
@@ -1,436 +0,0 @@
-
-> 常见问题:AQS 原理?;CountDownLatch和CyclicBarrier了解吗,两者的区别是什么?用过Semaphore吗?
-
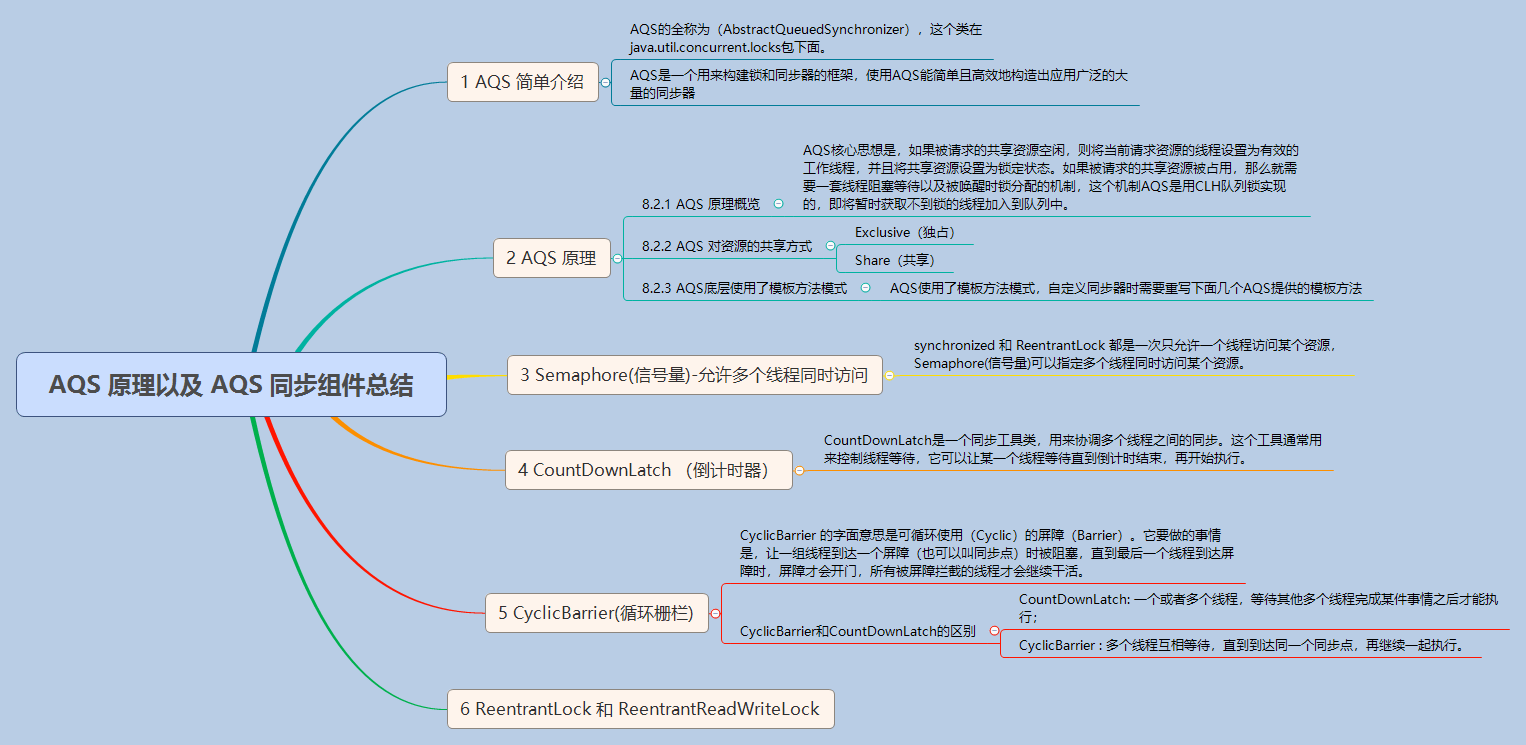
-**本节思维导图:**
-
-
-
-### 1 AQS 简单介绍
-AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包下面。
-
-
-
-AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Semaphore,其他的诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。当然,我们自己也能利用AQS非常轻松容易地构造出符合我们自己需求的同步器。
-
-### 2 AQS 原理
-
-> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于AQS原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要假如自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
-
-下面大部分内容其实在AQS类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
-
-#### 2.1 AQS 原理概览
-
-**AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。**
-
-> CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。
-
-看个AQS(AbstractQueuedSynchronizer)原理图:
-
-
-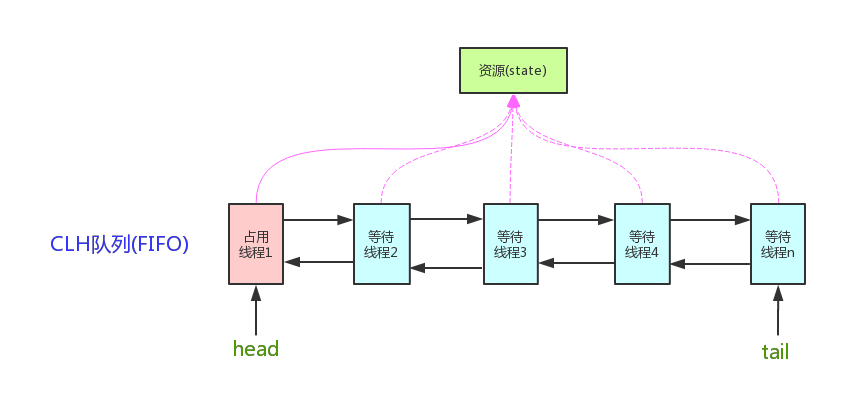
-
-AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。AQS使用CAS对该同步状态进行原子操作实现对其值的修改。
-
-```java
-private volatile int state;//共享变量,使用volatile修饰保证线程可见性
-```
-
-状态信息通过procted类型的getState,setState,compareAndSetState进行操作
-
-```java
-
-//返回同步状态的当前值
-protected final int getState() {
- return state;
-}
- // 设置同步状态的值
-protected final void setState(int newState) {
- state = newState;
-}
-//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
-protected final boolean compareAndSetState(int expect, int update) {
- return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
-}
-```
-
-#### 2.2 AQS 对资源的共享方式
-
-**AQS定义两种资源共享方式**
-
-- **Exclusive**(独占):只有一个线程能执行,如ReentrantLock。又可分为公平锁和非公平锁:
- - 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
- - 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
-- **Share**(共享):多个线程可同时执行,如Semaphore/CountDownLatch。Semaphore、CountDownLatCh、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
-
-ReentrantReadWriteLock 可以看成是组合式,因为ReentrantReadWriteLock也就是读写锁允许多个线程同时对某一资源进行读。
-
-不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在上层已经帮我们实现好了。
-
-#### 2.3 AQS底层使用了模板方法模式
-
-同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
-
-1. 使用者继承AbstractQueuedSynchronizer并重写指定的方法。(这些重写方法很简单,无非是对于共享资源state的获取和释放)
-2. 将AQS组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
-
-这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用,下面简单的给大家介绍一下模板方法模式,模板方法模式是一个很容易理解的设计模式之一。
-
-> 模板方法模式是基于”继承“的,主要是为了在不改变模板结构的前提下在子类中重新定义模板中的内容以实现复用代码。举个很简单的例子假如我们要去一个地方的步骤是:购票`buyTicket()`->安检`securityCheck()`->乘坐某某工具回家`ride()`->到达目的地`arrive()`。我们可能乘坐不同的交通工具回家比如飞机或者火车,所以除了`ride()`方法,其他方法的实现几乎相同。我们可以定义一个包含了这些方法的抽象类,然后用户根据自己的需要继承该抽象类然后修改 `ride()`方法。
-
-**AQS使用了模板方法模式,自定义同步器时需要重写下面几个AQS提供的模板方法:**
-
-```java
-isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
-tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
-tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
-tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
-tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
-
-```
-
-默认情况下,每个方法都抛出 `UnsupportedOperationException`。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS类中的其他方法都是final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
-
-以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
-
-再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS(Compare and Swap)减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
-
-一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
-
-推荐两篇 AQS 原理和相关源码分析的文章:
-
-- http://www.cnblogs.com/waterystone/p/4920797.html
-- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
-
-
-
-### 3 Semaphore(信号量)-允许多个线程同时访问
-
-**synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。**示例代码如下:
-
-```java
-/**
- *
- * @author Snailclimb
- * @date 2018年9月30日
- * @Description: 需要一次性拿一个许可的情况
- */
-public class SemaphoreExample1 {
- // 请求的数量
- private static final int threadCount = 550;
-
- public static void main(String[] args) throws InterruptedException {
- // 创建一个具有固定线程数量的线程池对象(如果这里线程池的线程数量给太少的话你会发现执行的很慢)
- ExecutorService threadPool = Executors.newFixedThreadPool(300);
- // 一次只能允许执行的线程数量。
- final Semaphore semaphore = new Semaphore(20);
-
- for (int i = 0; i < threadCount; i++) {
- final int threadnum = i;
- threadPool.execute(() -> {// Lambda 表达式的运用
- try {
- semaphore.acquire();// 获取一个许可,所以可运行线程数量为20/1=20
- test(threadnum);
- semaphore.release();// 释放一个许可
- } catch (InterruptedException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
-
- });
- }
- threadPool.shutdown();
- System.out.println("finish");
- }
-
- public static void test(int threadnum) throws InterruptedException {
- Thread.sleep(1000);// 模拟请求的耗时操作
- System.out.println("threadnum:" + threadnum);
- Thread.sleep(1000);// 模拟请求的耗时操作
- }
-}
-```
-
-执行 `acquire` 方法阻塞,直到有一个许可证可以获得然后拿走一个许可证;每个 `release` 方法增加一个许可证,这可能会释放一个阻塞的acquire方法。然而,其实并没有实际的许可证这个对象,Semaphore只是维持了一个可获得许可证的数量。 Semaphore经常用于限制获取某种资源的线程数量。
-
-当然一次也可以一次拿取和释放多个许可,不过一般没有必要这样做:
-
-```java
- semaphore.acquire(5);// 获取5个许可,所以可运行线程数量为20/5=4
- test(threadnum);
- semaphore.release(5);// 获取5个许可,所以可运行线程数量为20/5=4
-```
-
-除了 `acquire`方法之外,另一个比较常用的与之对应的方法是`tryAcquire`方法,该方法如果获取不到许可就立即返回false。
-
-
-Semaphore 有两种模式,公平模式和非公平模式。
-
-- **公平模式:** 调用acquire的顺序就是获取许可证的顺序,遵循FIFO;
-- **非公平模式:** 抢占式的。
-
-**Semaphore 对应的两个构造方法如下:**
-
-```java
- public Semaphore(int permits) {
- sync = new NonfairSync(permits);
- }
-
- public Semaphore(int permits, boolean fair) {
- sync = fair ? new FairSync(permits) : new NonfairSync(permits);
- }
-```
-**这两个构造方法,都必须提供许可的数量,第二个构造方法可以指定是公平模式还是非公平模式,默认非公平模式。**
-
-由于篇幅问题,如果对 Semaphore 源码感兴趣的朋友可以看下面这篇文章:
-
-- https://blog.csdn.net/qq_19431333/article/details/70212663
-
-### 4 CountDownLatch (倒计时器)
-
-CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
-
-#### 4.1 CountDownLatch 的两种典型用法
-
-①某一线程在开始运行前等待n个线程执行完毕。将 CountDownLatch 的计数器初始化为n :`new CountDownLatch(n) `,每当一个任务线程执行完毕,就将计数器减1 `countdownlatch.countDown()`,当计数器的值变为0时,在`CountDownLatch上 await()` 的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。
-
-②实现多个线程开始执行任务的最大并行性。注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的 `CountDownLatch` 对象,将其计数器初始化为 1 :`new CountDownLatch(1) `,多个线程在开始执行任务前首先 `coundownlatch.await()`,当主线程调用 countDown() 时,计数器变为0,多个线程同时被唤醒。
-
-#### 4.2 CountDownLatch 的使用示例
-
-```java
-/**
- *
- * @author SnailClimb
- * @date 2018年10月1日
- * @Description: CountDownLatch 使用方法示例
- */
-public class CountDownLatchExample1 {
- // 请求的数量
- private static final int threadCount = 550;
-
- public static void main(String[] args) throws InterruptedException {
- // 创建一个具有固定线程数量的线程池对象(如果这里线程池的线程数量给太少的话你会发现执行的很慢)
- ExecutorService threadPool = Executors.newFixedThreadPool(300);
- final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
- for (int i = 0; i < threadCount; i++) {
- final int threadnum = i;
- threadPool.execute(() -> {// Lambda 表达式的运用
- try {
- test(threadnum);
- } catch (InterruptedException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- } finally {
- countDownLatch.countDown();// 表示一个请求已经被完成
- }
-
- });
- }
- countDownLatch.await();
- threadPool.shutdown();
- System.out.println("finish");
- }
-
- public static void test(int threadnum) throws InterruptedException {
- Thread.sleep(1000);// 模拟请求的耗时操作
- System.out.println("threadnum:" + threadnum);
- Thread.sleep(1000);// 模拟请求的耗时操作
- }
-}
-
-```
-上面的代码中,我们定义了请求的数量为550,当这550个请求被处理完成之后,才会执行`System.out.println("finish");`。
-
-#### 4.3 CountDownLatch 的不足
-
-CountDownLatch是一次性的,计数器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当CountDownLatch使用完毕后,它不能再次被使用。
-
-### 5 CyclicBarrier(循环栅栏)
-
-CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。
-
-CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier默认的构造方法是 `CyclicBarrier(int parties)`,其参数表示屏障拦截的线程数量,每个线程调用`await`方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
-
-#### 5.1 CyclicBarrier 的应用场景
-
-CyclicBarrier 可以用于多线程计算数据,最后合并计算结果的应用场景。比如我们用一个Excel保存了用户所有银行流水,每个Sheet保存一个帐户近一年的每笔银行流水,现在需要统计用户的日均银行流水,先用多线程处理每个sheet里的银行流水,都执行完之后,得到每个sheet的日均银行流水,最后,再用barrierAction用这些线程的计算结果,计算出整个Excel的日均银行流水。
-
-#### 5.2 CyclicBarrier 的使用示例
-
-示例1:
-
-```java
-/**
- *
- * @author Snailclimb
- * @date 2018年10月1日
- * @Description: 测试 CyclicBarrier 类中带参数的 await() 方法
- */
-public class CyclicBarrierExample2 {
- // 请求的数量
- private static final int threadCount = 550;
- // 需要同步的线程数量
- private static final CyclicBarrier cyclicBarrier = new CyclicBarrier(5);
-
- public static void main(String[] args) throws InterruptedException {
- // 创建线程池
- ExecutorService threadPool = Executors.newFixedThreadPool(10);
-
- for (int i = 0; i < threadCount; i++) {
- final int threadNum = i;
- Thread.sleep(1000);
- threadPool.execute(() -> {
- try {
- test(threadNum);
- } catch (InterruptedException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- } catch (BrokenBarrierException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- });
- }
- threadPool.shutdown();
- }
-
- public static void test(int threadnum) throws InterruptedException, BrokenBarrierException {
- System.out.println("threadnum:" + threadnum + "is ready");
- try {
- cyclicBarrier.await(2000, TimeUnit.MILLISECONDS);
- } catch (Exception e) {
- System.out.println("-----CyclicBarrierException------");
- }
- System.out.println("threadnum:" + threadnum + "is finish");
- }
-
-}
-```
-
-运行结果,如下:
-
-```
-threadnum:0is ready
-threadnum:1is ready
-threadnum:2is ready
-threadnum:3is ready
-threadnum:4is ready
-threadnum:4is finish
-threadnum:0is finish
-threadnum:1is finish
-threadnum:2is finish
-threadnum:3is finish
-threadnum:5is ready
-threadnum:6is ready
-threadnum:7is ready
-threadnum:8is ready
-threadnum:9is ready
-threadnum:9is finish
-threadnum:5is finish
-threadnum:8is finish
-threadnum:7is finish
-threadnum:6is finish
-......
-```
-可以看到当线程数量也就是请求数量达到我们定义的 5 个的时候, `await`方法之后的方法才被执行。
-
-另外,CyclicBarrier还提供一个更高级的构造函数`CyclicBarrier(int parties, Runnable barrierAction)`,用于在线程到达屏障时,优先执行`barrierAction`,方便处理更复杂的业务场景。示例代码如下:
-
-```java
-/**
- *
- * @author SnailClimb
- * @date 2018年10月1日
- * @Description: 新建 CyclicBarrier 的时候指定一个 Runnable
- */
-public class CyclicBarrierExample3 {
- // 请求的数量
- private static final int threadCount = 550;
- // 需要同步的线程数量
- private static final CyclicBarrier cyclicBarrier = new CyclicBarrier(5, () -> {
- System.out.println("------当线程数达到之后,优先执行------");
- });
-
- public static void main(String[] args) throws InterruptedException {
- // 创建线程池
- ExecutorService threadPool = Executors.newFixedThreadPool(10);
-
- for (int i = 0; i < threadCount; i++) {
- final int threadNum = i;
- Thread.sleep(1000);
- threadPool.execute(() -> {
- try {
- test(threadNum);
- } catch (InterruptedException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- } catch (BrokenBarrierException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- });
- }
- threadPool.shutdown();
- }
-
- public static void test(int threadnum) throws InterruptedException, BrokenBarrierException {
- System.out.println("threadnum:" + threadnum + "is ready");
- cyclicBarrier.await();
- System.out.println("threadnum:" + threadnum + "is finish");
- }
-
-}
-```
-
-运行结果,如下:
-
-```
-threadnum:0is ready
-threadnum:1is ready
-threadnum:2is ready
-threadnum:3is ready
-threadnum:4is ready
-------当线程数达到之后,优先执行------
-threadnum:4is finish
-threadnum:0is finish
-threadnum:2is finish
-threadnum:1is finish
-threadnum:3is finish
-threadnum:5is ready
-threadnum:6is ready
-threadnum:7is ready
-threadnum:8is ready
-threadnum:9is ready
-------当线程数达到之后,优先执行------
-threadnum:9is finish
-threadnum:5is finish
-threadnum:6is finish
-threadnum:8is finish
-threadnum:7is finish
-......
-```
-#### 5.3 CyclicBarrier和CountDownLatch的区别
-
-CountDownLatch是计数器,只能使用一次,而CyclicBarrier的计数器提供reset功能,可以多次使用。但是我不那么认为它们之间的区别仅仅就是这么简单的一点。我们来从jdk作者设计的目的来看,javadoc是这么描述它们的:
-
-> CountDownLatch: A synchronization aid that allows one or more threads to wait until a set of operations being performed in other threads completes.(CountDownLatch: 一个或者多个线程,等待其他多个线程完成某件事情之后才能执行;)
-> CyclicBarrier : A synchronization aid that allows a set of threads to all wait for each other to reach a common barrier point.(CyclicBarrier : 多个线程互相等待,直到到达同一个同步点,再继续一起执行。)
-
-对于CountDownLatch来说,重点是“一个线程(多个线程)等待”,而其他的N个线程在完成“某件事情”之后,可以终止,也可以等待。而对于CyclicBarrier,重点是多个线程,在任意一个线程没有完成,所有的线程都必须等待。
-
-CountDownLatch是计数器,线程完成一个记录一个,只不过计数不是递增而是递减,而CyclicBarrier更像是一个阀门,需要所有线程都到达,阀门才能打开,然后继续执行。
-
-
-
-CyclicBarrier和CountDownLatch的区别这部分内容参考了如下两篇文章:
-
-- https://blog.csdn.net/u010185262/article/details/54692886
-- https://blog.csdn.net/tolcf/article/details/50925145?utm_source=blogxgwz0
-
-### 6 ReentrantLock 和 ReentrantReadWriteLock
-
-ReentrantLock 和 synchronized 的区别在上面已经讲过了这里就不多做讲解。另外,需要注意的是:读写锁 ReentrantReadWriteLock 可以保证多个线程可以同时读,所以在读操作远大于写操作的时候,读写锁就非常有用了。
-
-由于篇幅问题,关于 ReentrantLock 和 ReentrantReadWriteLock 详细内容可以查看我的这篇原创文章。
-
-- [ReentrantLock 和 ReentrantReadWriteLock](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483745&idx=2&sn=6778ee954a19816310df54ef9a3c2f8a&chksm=fd985700caefde16b9970f5e093b0c140d3121fb3a8458b11871e5e9723c5fd1b5a961fd2228&token=1829606453&lang=zh_CN#rd)
\ No newline at end of file
diff --git "a/Java\347\233\270\345\205\263/Multithread/Atomic.md" "b/Java\347\233\270\345\205\263/Multithread/Atomic.md"
deleted file mode 100644
index 5c794055b0c..00000000000
--- "a/Java\347\233\270\345\205\263/Multithread/Atomic.md"
+++ /dev/null
@@ -1,337 +0,0 @@
-> 个人觉得这一节掌握基本的使用即可!
-
-**本节思维导图:**
-
-
-
-### 1 Atomic 原子类介绍
-
-Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的。在我们这里 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
-
-所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
-
-并发包 `java.util.concurrent` 的原子类都存放在`java.util.concurrent.atomic`下,如下图所示。
-
-
-
-根据操作的数据类型,可以将JUC包中的原子类分为4类
-
-**基本类型**
-
-使用原子的方式更新基本类型
-
-- AtomicInteger:整形原子类
-- AtomicLong:长整型原子类
-- AtomicBoolean :布尔型原子类
-
-**数组类型**
-
-使用原子的方式更新数组里的某个元素
-
-
-- AtomicIntegerArray:整形数组原子类
-- AtomicLongArray:长整形数组原子类
-- AtomicReferenceArray :引用类型数组原子类
-
-**引用类型**
-
-- AtomicReference:引用类型原子类
-- AtomicStampedRerence:原子更新引用类型里的字段原子类
-- AtomicMarkableReference :原子更新带有标记位的引用类型
-
-**对象的属性修改类型**
-
-- AtomicIntegerFieldUpdater:原子更新整形字段的更新器
-- AtomicLongFieldUpdater:原子更新长整形字段的更新器
-- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
-
-下面我们来详细介绍一下这些原子类。
-
-### 2 基本类型原子类
-
-#### 2.1 基本类型原子类介绍
-
-使用原子的方式更新基本类型
-
-- AtomicInteger:整形原子类
-- AtomicLong:长整型原子类
-- AtomicBoolean :布尔型原子类
-
-上面三个类提供的方法几乎相同,所以我们这里以 AtomicInteger 为例子来介绍。
-
- **AtomicInteger 类常用方法**
-
-```java
-public final int get() //获取当前的值
-public final int getAndSet(int newValue)//获取当前的值,并设置新的值
-public final int getAndIncrement()//获取当前的值,并自增
-public final int getAndDecrement() //获取当前的值,并自减
-public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
-boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
-public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
-```
-
-#### 2.2 AtomicInteger 常见方法使用
-
-```java
-import java.util.concurrent.atomic.AtomicInteger;
-
-public class AtomicIntegerTest {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- int temvalue = 0;
- AtomicInteger i = new AtomicInteger(0);
- temvalue = i.getAndSet(3);
- System.out.println("temvalue:" + temvalue + "; i:" + i);//temvalue:0; i:3
- temvalue = i.getAndIncrement();
- System.out.println("temvalue:" + temvalue + "; i:" + i);//temvalue:3; i:4
- temvalue = i.getAndAdd(5);
- System.out.println("temvalue:" + temvalue + "; i:" + i);//temvalue:4; i:9
- }
-
-}
-```
-
-#### 2.3 基本数据类型原子类的优势
-
-通过一个简单例子带大家看一下基本数据类型原子类的优势
-
-**①多线程环境不使用原子类保证线程安全(基本数据类型)**
-
-```java
-class Test {
- private volatile int count = 0;
- //若要线程安全执行执行count++,需要加锁
- public synchronized void increment() {
- count++;
- }
-
- public int getCount() {
- return count;
- }
-}
-```
-**②多线程环境使用原子类保证线程安全(基本数据类型)**
-
-```java
-class Test2 {
- private AtomicInteger count = new AtomicInteger();
-
- public void increment() {
- count.incrementAndGet();
- }
- //使用AtomicInteger之后,不需要加锁,也可以实现线程安全。
- public int getCount() {
- return count.get();
- }
-}
-
-```
-#### 2.4 AtomicInteger 线程安全原理简单分析
-
-AtomicInteger 类的部分源码:
-
-```java
- // setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
- private static final Unsafe unsafe = Unsafe.getUnsafe();
- private static final long valueOffset;
-
- static {
- try {
- valueOffset = unsafe.objectFieldOffset
- (AtomicInteger.class.getDeclaredField("value"));
- } catch (Exception ex) { throw new Error(ex); }
- }
-
- private volatile int value;
-```
-
-AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
-
-CAS的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个volatile变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
-
-
-### 3 数组类型原子类
-
-#### 3.1 数组类型原子类介绍
-
-使用原子的方式更新数组里的某个元素
-
-
-- AtomicIntegerArray:整形数组原子类
-- AtomicLongArray:长整形数组原子类
-- AtomicReferenceArray :引用类型数组原子类
-
-上面三个类提供的方法几乎相同,所以我们这里以 AtomicIntegerArray 为例子来介绍。
-
-**AtomicIntegerArray 类常用方法**
-
-```java
-public final int get(int i) //获取 index=i 位置元素的值
-public final int getAndSet(int i, int newValue)//返回 index=i 位置的当前的值,并将其设置为新值:newValue
-public final int getAndIncrement(int i)//获取 index=i 位置元素的值,并让该位置的元素自增
-public final int getAndDecrement(int i) //获取 index=i 位置元素的值,并让该位置的元素自减
-public final int getAndAdd(int delta) //获取 index=i 位置元素的值,并加上预期的值
-boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将 index=i 位置的元素值设置为输入值(update)
-public final void lazySet(int i, int newValue)//最终 将index=i 位置的元素设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
-```
-#### 3.2 AtomicIntegerArray 常见方法使用
-
-```java
-
-import java.util.concurrent.atomic.AtomicIntegerArray;
-
-public class AtomicIntegerArrayTest {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- int temvalue = 0;
- int[] nums = { 1, 2, 3, 4, 5, 6 };
- AtomicIntegerArray i = new AtomicIntegerArray(nums);
- for (int j = 0; j < nums.length; j++) {
- System.out.println(i.get(j));
- }
- temvalue = i.getAndSet(0, 2);
- System.out.println("temvalue:" + temvalue + "; i:" + i);
- temvalue = i.getAndIncrement(0);
- System.out.println("temvalue:" + temvalue + "; i:" + i);
- temvalue = i.getAndAdd(0, 5);
- System.out.println("temvalue:" + temvalue + "; i:" + i);
- }
-
-}
-```
-
-### 4 引用类型原子类
-
-#### 4.1 引用类型原子类介绍
-
-基本类型原子类只能更新一个变量,如果需要原子更新多个变量,需要使用 引用类型原子类。
-
-- AtomicReference:引用类型原子类
-- AtomicStampedRerence:原子更新引用类型里的字段原子类
-- AtomicMarkableReference :原子更新带有标记位的引用类型
-
-上面三个类提供的方法几乎相同,所以我们这里以 AtomicReference 为例子来介绍。
-
-#### 4.2 AtomicReference 类使用示例
-
-```java
-import java.util.concurrent.atomic.AtomicReference;
-
-public class AtomicReferenceTest {
-
- public static void main(String[] args) {
- AtomicReference<Person> ar = new AtomicReference<Person>();
- Person person = new Person("SnailClimb", 22);
- ar.set(person);
- Person updatePerson = new Person("Daisy", 20);
- ar.compareAndSet(person, updatePerson);
-
- System.out.println(ar.get().getName());
- System.out.println(ar.get().getAge());
- }
-}
-
-class Person {
- private String name;
- private int age;
-
- public Person(String name, int age) {
- super();
- this.name = name;
- this.age = age;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
-}
-```
-上述代码首先创建了一个 Person 对象,然后把 Person 对象设置进 AtomicReference 对象中,然后调用 compareAndSet 方法,该方法就是通过通过 CAS 操作设置 ar。如果 ar 的值为 person 的话,则将其设置为 updatePerson。实现原理与 AtomicInteger 类中的 compareAndSet 方法相同。运行上面的代码后的输出结果如下:
-
-```
-Daisy
-20
-```
-
-
-### 5 对象的属性修改类型原子类
-
-#### 5.1 对象的属性修改类型原子类介绍
-
-如果需要原子更新某个类里的某个字段时,需要用到对象的属性修改类型原子类。
-
-- AtomicIntegerFieldUpdater:原子更新整形字段的更新器
-- AtomicLongFieldUpdater:原子更新长整形字段的更新器
-- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
-
-要想原子地更新对象的属性需要两步。第一步,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新的对象属性必须使用 public volatile 修饰符。
-
-上面三个类提供的方法几乎相同,所以我们这里以 `AtomicIntegerFieldUpdater`为例子来介绍。
-
-#### 5.2 AtomicIntegerFieldUpdater 类使用示例
-
-```java
-import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;
-
-public class AtomicIntegerFieldUpdaterTest {
- public static void main(String[] args) {
- AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
-
- User user = new User("Java", 22);
- System.out.println(a.getAndIncrement(user));// 22
- System.out.println(a.get(user));// 23
- }
-}
-
-class User {
- private String name;
- public volatile int age;
-
- public User(String name, int age) {
- super();
- this.name = name;
- this.age = age;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
-}
-```
-
-输出结果:
-
-```
-22
-23
-```
-
diff --git "a/Java\347\233\270\345\205\263/Multithread/BATJ\351\203\275\347\210\261\351\227\256\347\232\204\345\244\232\347\272\277\347\250\213\351\235\242\350\257\225\351\242\230.md" "b/Java\347\233\270\345\205\263/Multithread/BATJ\351\203\275\347\210\261\351\227\256\347\232\204\345\244\232\347\272\277\347\250\213\351\235\242\350\257\225\351\242\230.md"
deleted file mode 100644
index 00526cf4705..00000000000
--- "a/Java\347\233\270\345\205\263/Multithread/BATJ\351\203\275\347\210\261\351\227\256\347\232\204\345\244\232\347\272\277\347\250\213\351\235\242\350\257\225\351\242\230.md"
+++ /dev/null
@@ -1,429 +0,0 @@
-
-
-
-# 一 面试中关于 synchronized 关键字的 5 连击
-
-### 1.1 说一说自己对于 synchronized 关键字的了解
-
-synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。
-
-另外,在 Java 早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的 synchronized 效率低的原因。庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
-
-
-### 1.2 说说自己是怎么使用 synchronized 关键字,在项目中用到了吗
-
-**synchronized关键字最主要的三种使用方式:**
-
-- **修饰实例方法,作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁**
-- **修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁** 。也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份,所以对该类的所有对象都加了锁)。所以如果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,**因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁**。
-- **修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。** 和 synchronized 方法一样,synchronized(this)代码块也是锁定当前对象的。synchronized 关键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上锁。这里再提一下:synchronized关键字加到非 static 静态方法上是给对象实例上锁。另外需要注意的是:尽量不要使用 synchronized(String a) 因为JVM中,字符串常量池具有缓冲功能!
-
-下面我已一个常见的面试题为例讲解一下 synchronized 关键字的具体使用。
-
-面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单利模式的原理呗!”
-
-
-
-**双重校验锁实现对象单例(线程安全)**
-
-```java
-public class Singleton {
-
- private volatile static Singleton uniqueInstance;
-
- private Singleton() {
- }
-
- public static Singleton getUniqueInstance() {
- //先判断对象是否已经实例过,没有实例化过才进入加锁代码
- if (uniqueInstance == null) {
- //类对象加锁
- synchronized (Singleton.class) {
- if (uniqueInstance == null) {
- uniqueInstance = new Singleton();
- }
- }
- }
- return uniqueInstance;
- }
-}
-```
-另外,需要注意 uniqueInstance 采用 volatile 关键字修饰也是很有必要。
-
-uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
-
-1. 为 uniqueInstance 分配内存空间
-2. 初始化 uniqueInstance
-3. 将 uniqueInstance 指向分配的内存地址
-
-但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出先问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
-
-使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
-
-### 1.3 讲一下 synchronized 关键字的底层原理
-
-**synchronized 关键字底层原理属于 JVM 层面。**
-
-**① synchronized 同步语句块的情况**
-
-```java
-public class SynchronizedDemo {
- public void method() {
- synchronized (this) {
- System.out.println("synchronized 代码块");
- }
- }
-}
-
-```
-
-通过 JDK 自带的 javap 命令查看 SynchronizedDemo 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
-
-
-
-从上面我们可以看出:
-
-**synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。** 当执行 monitorenter 指令时,线程试图获取锁也就是获取 monitor(monitor对象存在于每个Java对象的对象头中,synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因) 的持有权.当计数器为0则可以成功获取,获取后将锁计数器设为1也就是加1。相应的在执行 monitorexit 指令后,将锁计数器设为0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
-
-**② synchronized 修饰方法的的情况**
-
-```java
-public class SynchronizedDemo2 {
- public synchronized void method() {
- System.out.println("synchronized 方法");
- }
-}
-
-```
-
-
-
-synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
-
-
-### 1.4 说说 JDK1.6 之后的synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗
-
-JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
-
-锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-
-关于这几种优化的详细信息可以查看:[synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484539&idx=1&sn=3500cdcd5188bdc253fb19a1bfa805e6&chksm=fd98521acaefdb0c5167247a1fa903a1a53bb4e050b558da574f894f9feda5378ec9d0fa1ac7&token=1604028915&lang=zh_CN#rd)
-
-### 1.5 谈谈 synchronized和ReenTrantLock 的区别
-
-
-**① 两者都是可重入锁**
-
-两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
-
-**② synchronized 依赖于 JVM 而 ReenTrantLock 依赖于 API**
-
-synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReenTrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
-
-**③ ReenTrantLock 比 synchronized 增加了一些高级功能**
-
-相比synchronized,ReenTrantLock增加了一些高级功能。主要来说主要有三点:**①等待可中断;②可实现公平锁;③可实现选择性通知(锁可以绑定多个条件)**
-
-- **ReenTrantLock提供了一种能够中断等待锁的线程的机制**,通过lock.lockInterruptibly()来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
-- **ReenTrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。** ReenTrantLock默认情况是非公平的,可以通过 ReenTrantLock类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
-- synchronized关键字与wait()和notify/notifyAll()方法相结合可以实现等待/通知机制,ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition() 方法。Condition是JDK1.5之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个Lock对象中可以创建多个Condition实例(即对象监视器),**线程对象可以注册在指定的Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用notify/notifyAll()方法进行通知时,被通知的线程是由 JVM 选择的,用ReentrantLock类结合Condition实例可以实现“选择性通知”** ,这个功能非常重要,而且是Condition接口默认提供的。而synchronized关键字就相当于整个Lock对象中只有一个Condition实例,所有的线程都注册在它一个身上。如果执行notifyAll()方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而Condition实例的signalAll()方法 只会唤醒注册在该Condition实例中的所有等待线程。
-
-如果你想使用上述功能,那么选择ReenTrantLock是一个不错的选择。
-
-**④ 性能已不是选择标准**
-
-# 二 面试中关于线程池的 4 连击
-
-### 2.1 讲一下Java内存模型
-
-
-在 JDK1.2 之前,Java的内存模型实现总是从<font color="red">**主存**(即共享内存)读取变量</font>,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存<font color="red">**本地内存**</font>(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成<font color="red">**数据的不一致**</font>。
-
-
-
-要解决这个问题,就需要把变量声明为<font color="red"> **volatile**</font>,这就指示 JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。
-
-说白了,<font color="red"> **volatile**</font> 关键字的主要作用就是保证变量的可见性然后还有一个作用是防止指令重排序。
-
-
-
-
-### 2.2 说说 synchronized 关键字和 volatile 关键字的区别
-
- synchronized关键字和volatile关键字比较
-
-- **volatile关键字**是线程同步的**轻量级实现**,所以**volatile性能肯定比synchronized关键字要好**。但是**volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块**。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,**实际开发中使用 synchronized 关键字的场景还是更多一些**。
-- **多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞**
-- **volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。**
-- **volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性。**
-
-
-# 三 面试中关于 线程池的 2 连击
-
-
-### 3.1 为什么要用线程池?
-
-线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
-
-这里借用《Java并发编程的艺术》提到的来说一下使用线程池的好处:
-
-- **降低资源消耗。** 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
-- **提高响应速度。** 当任务到达时,任务可以不需要的等到线程创建就能立即执行。
-- **提高线程的可管理性。** 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
-
-
-### 3.2 实现Runnable接口和Callable接口的区别
-
-如果想让线程池执行任务的话需要实现的Runnable接口或Callable接口。 Runnable接口或Callable接口实现类都可以被ThreadPoolExecutor或ScheduledThreadPoolExecutor执行。两者的区别在于 Runnable 接口不会返回结果但是 Callable 接口可以返回结果。
-
- **备注:** 工具类`Executors`可以实现`Runnable`对象和`Callable`对象之间的相互转换。(`Executors.callable(Runnable task)`或`Executors.callable(Runnable task,Object resule)`)。
-
-### 3.3 执行execute()方法和submit()方法的区别是什么呢?
-
- 1)**`execute()` 方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;**
-
- 2)**submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功**,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
-
-
-### 3.4 如何创建线程池
-
-《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险**
-
-> Executors 返回线程池对象的弊端如下:
->
-> - **FixedThreadPool 和 SingleThreadExecutor** : 允许请求的队列长度为 Integer.MAX_VALUE,可能堆积大量的请求,从而导致OOM。
-> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致OOM。
-
-**方式一:通过构造方法实现**
-
-**方式二:通过Executor 框架的工具类Executors来实现**
-我们可以创建三种类型的ThreadPoolExecutor:
-
-- **FixedThreadPool** : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
-- **SingleThreadExecutor:** 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
-- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
-
-对应Executors工具类中的方法如图所示:
-
-
-
-# 四 面试中关于 Atomic 原子类的 4 连击
-
-### 4.1 介绍一下Atomic 原子类
-
-Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的。在我们这里 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
-
-所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
-
-
-并发包 `java.util.concurrent` 的原子类都存放在`java.util.concurrent.atomic`下,如下图所示。
-
-
-
-### 4.2 JUC 包中的原子类是哪4类?
-
-**基本类型**
-
-使用原子的方式更新基本类型
-
-- AtomicInteger:整形原子类
-- AtomicLong:长整型原子类
-- AtomicBoolean :布尔型原子类
-
-**数组类型**
-
-使用原子的方式更新数组里的某个元素
-
-
-- AtomicIntegerArray:整形数组原子类
-- AtomicLongArray:长整形数组原子类
-- AtomicReferenceArray :引用类型数组原子类
-
-**引用类型**
-
-- AtomicReference:引用类型原子类
-- AtomicStampedRerence:原子更新引用类型里的字段原子类
-- AtomicMarkableReference :原子更新带有标记位的引用类型
-
-**对象的属性修改类型**
-
-- AtomicIntegerFieldUpdater:原子更新整形字段的更新器
-- AtomicLongFieldUpdater:原子更新长整形字段的更新器
-- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
-
-
-### 4.3 讲讲 AtomicInteger 的使用
-
- **AtomicInteger 类常用方法**
-
-```java
-public final int get() //获取当前的值
-public final int getAndSet(int newValue)//获取当前的值,并设置新的值
-public final int getAndIncrement()//获取当前的值,并自增
-public final int getAndDecrement() //获取当前的值,并自减
-public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
-boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
-public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
-```
-
- **AtomicInteger 类的使用示例**
-
-使用 AtomicInteger 之后,不用对 increment() 方法加锁也可以保证线程安全。
-```java
-class AtomicIntegerTest {
- private AtomicInteger count = new AtomicInteger();
- //使用AtomicInteger之后,不需要对该方法加锁,也可以实现线程安全。
- public void increment() {
- count.incrementAndGet();
- }
-
- public int getCount() {
- return count.get();
- }
-}
-
-```
-
-### 4.4 能不能给我简单介绍一下 AtomicInteger 类的原理
-
-AtomicInteger 线程安全原理简单分析
-
-AtomicInteger 类的部分源码:
-
-```java
- // setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
- private static final Unsafe unsafe = Unsafe.getUnsafe();
- private static final long valueOffset;
-
- static {
- try {
- valueOffset = unsafe.objectFieldOffset
- (AtomicInteger.class.getDeclaredField("value"));
- } catch (Exception ex) { throw new Error(ex); }
- }
-
- private volatile int value;
-```
-
-AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
-
-CAS的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个volatile变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
-
-关于 Atomic 原子类这部分更多内容可以查看我的这篇文章:并发编程面试必备:[JUC 中的 Atomic 原子类总结](https://mp.weixin.qq.com/s/joa-yOiTrYF67bElj8xqvg)
-
-# 五 AQS
-
-### 5.1 AQS 介绍
-
-AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包下面。
-
-
-
-AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Semaphore,其他的诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。当然,我们自己也能利用AQS非常轻松容易地构造出符合我们自己需求的同步器。
-
-### 5.2 AQS 原理分析
-
-AQS 原理这部分参考了部分博客,在5.2节末尾放了链接。
-
-> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于AQS原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要假如自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
-
-下面大部分内容其实在AQS类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
-
-#### 5.2.1 AQS 原理概览
-
-
-
-**AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。**
-
-> CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。
-
-看个AQS(AbstractQueuedSynchronizer)原理图:
-
-
-
-
-AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。AQS使用CAS对该同步状态进行原子操作实现对其值的修改。
-
-```java
-private volatile int state;//共享变量,使用volatile修饰保证线程可见性
-```
-
-状态信息通过procted类型的getState,setState,compareAndSetState进行操作
-
-```java
-
-//返回同步状态的当前值
-protected final int getState() {
- return state;
-}
- // 设置同步状态的值
-protected final void setState(int newState) {
- state = newState;
-}
-//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
-protected final boolean compareAndSetState(int expect, int update) {
- return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
-}
-```
-
-#### 5.2.2 AQS 对资源的共享方式
-
-**AQS定义两种资源共享方式**
-
-- **Exclusive**(独占):只有一个线程能执行,如ReentrantLock。又可分为公平锁和非公平锁:
- - 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
- - 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
-- **Share**(共享):多个线程可同时执行,如Semaphore/CountDownLatch。Semaphore、CountDownLatCh、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
-
-ReentrantReadWriteLock 可以看成是组合式,因为ReentrantReadWriteLock也就是读写锁允许多个线程同时对某一资源进行读。
-
-不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。
-
-#### 5.2.3 AQS底层使用了模板方法模式
-
-同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
-
-1. 使用者继承AbstractQueuedSynchronizer并重写指定的方法。(这些重写方法很简单,无非是对于共享资源state的获取和释放)
-2. 将AQS组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
-
-这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
-
-**AQS使用了模板方法模式,自定义同步器时需要重写下面几个AQS提供的模板方法:**
-
-```java
-isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
-tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
-tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
-tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
-tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
-
-```
-
-默认情况下,每个方法都抛出 `UnsupportedOperationException`。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS类中的其他方法都是final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
-
-以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
-
-再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS(Compare and Swap)减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
-
-一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
-
-推荐两篇 AQS 原理和相关源码分析的文章:
-
-- http://www.cnblogs.com/waterystone/p/4920797.html
-- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
-
-### 5.3 AQS 组件总结
-
-- **Semaphore(信号量)-允许多个线程同时访问:** synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。
-- **CountDownLatch (倒计时器):** CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
-- **CyclicBarrier(循环栅栏):** CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
-
-关于AQS这部分的更多内容可以查看我的这篇文章:[并发编程面试必备:AQS 原理以及 AQS 同步组件总结](https://mp.weixin.qq.com/s/joa-yOiTrYF67bElj8xqvg)
-
-# Reference
-
-- 《深入理解 Java 虚拟机》
-- 《实战 Java 高并发程序设计》
-- 《Java并发编程的艺术》
-- http://www.cnblogs.com/waterystone/p/4920797.html
-- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
\ No newline at end of file
diff --git "a/Java\347\233\270\345\205\263/final\343\200\201static\343\200\201this\343\200\201super.md" "b/Java\347\233\270\345\205\263/final\343\200\201static\343\200\201this\343\200\201super.md"
deleted file mode 100644
index b6b47bfb770..00000000000
--- "a/Java\347\233\270\345\205\263/final\343\200\201static\343\200\201this\343\200\201super.md"
+++ /dev/null
@@ -1,84 +0,0 @@
-## final 关键字
-
-**final关键字主要用在三个地方:变量、方法、类。**
-
-1. **对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。**
-
-2. **当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。**
-
-3. 使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为final。
-
-## static 关键字
-
-**static 关键字主要有以下四种使用场景:**
-
-1. **修饰成员变量和成员方法:** 被 static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享,可以并且建议通过类名调用。被static 声明的成员变量属于静态成员变量,静态变量 存放在 Java 内存区域的方法区。调用格式:`类名.静态变量名` `类名.静态方法名()`
-2. **静态代码块:** 静态代码块定义在类中方法外, 静态代码块在非静态代码块之前执行(静态代码块—>非静态代码块—>构造方法)。 该类不管创建多少对象,静态代码块只执行一次.
-3. **静态内部类(static修饰类的话只能修饰内部类):** 静态内部类与非静态内部类之间存在一个最大的区别: 非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围类,但是静态内部类却没有。没有这个引用就意味着:1. 它的创建是不需要依赖外围类的创建。2. 它不能使用任何外围类的非static成员变量和方法。
-4. **静态导包(用来导入类中的静态资源,1.5之后的新特性):** 格式为:`import static` 这两个关键字连用可以指定导入某个类中的指定静态资源,并且不需要使用类名调用类中静态成员,可以直接使用类中静态成员变量和成员方法。
-
-## this 关键字
-
-this关键字用于引用类的当前实例。 例如:
-
-```java
-class Manager {
- Employees[] employees;
-
- void manageEmployees() {
- int totalEmp = this.employees.length;
- System.out.println("Total employees: " + totalEmp);
- this.report();
- }
-
- void report() { }
-}
-```
-
-在上面的示例中,this关键字用于两个地方:
-
-- this.employees.length:访问类Manager的当前实例的变量。
-- this.report():调用类Manager的当前实例的方法。
-
-此关键字是可选的,这意味着如果上面的示例在不使用此关键字的情况下表现相同。 但是,使用此关键字可能会使代码更易读或易懂。
-
-
-
-## super 关键字
-
-super关键字用于从子类访问父类的变量和方法。 例如:
-
-```java
-public class Super {
- protected int number;
-
- protected showNumber() {
- System.out.println("number = " + number);
- }
-}
-
-public class Sub extends Super {
- void bar() {
- super.number = 10;
- super.showNumber();
- }
-}
-```
-
-在上面的例子中,Sub 类访问父类成员变量 number 并调用其其父类 Super 的 `showNumber()` 方法。
-
-**使用 this 和 super 要注意的问题:**
-
-- super 调用父类中的其他构造方法时,调用时要放在构造方法的首行!this 调用本类中的其他构造方法时,也要放在首行。
-- this、super不能用在static方法中。
-
-**简单解释一下:**
-
-被 static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享。而 this 代表对本类对象的引用,指向本类对象;而 super 代表对父类对象的引用,指向父类对象;所以, **this和super是属于对象范畴的东西,而静态方法是属于类范畴的东西**。
-
-
-
-## 参考
-
-- https://www.codejava.net/java-core/the-java-language/java-keywords
-- https://blog.csdn.net/u013393958/article/details/79881037
diff --git "a/Java\347\233\270\345\205\263/static.md" "b/Java\347\233\270\345\205\263/static.md"
deleted file mode 100644
index 8d37affa446..00000000000
--- "a/Java\347\233\270\345\205\263/static.md"
+++ /dev/null
@@ -1,241 +0,0 @@
-
-# static 关键字
-
-## static 关键字主要有以下四种使用场景
-
-1. 修饰成员变量和成员方法
-2. 静态代码块
-3. 修饰类(只能修饰内部类)
-4. 静态导包(用来导入类中的静态资源,1.5之后的新特性)
-
-### 修饰成员变量和成员方法(常用)
-
-被 static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享,可以并且建议通过类名调用。被static 声明的成员变量属于静态成员变量,静态变量 存放在 Java 内存区域的方法区。
-
-方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
-
- HotSpot 虚拟机中方法区也常被称为 “永久代”,本质上两者并不等价。仅仅是因为 HotSpot 虚拟机设计团队用永久代来实现方法区而已,这样 HotSpot 虚拟机的垃圾收集器就可以像管理 Java 堆一样管理这部分内存了。但是这并不是一个好主意,因为这样更容易遇到内存溢出问题。
-
-
-
-调用格式:
-
-- 类名.静态变量名
-- 类名.静态方法名()
-
-如果变量或者方法被 private 则代表该属性或者该方法只能在类的内部被访问而不能在类的外部被方法。
-
-测试方法:
-
-```java
-public class StaticBean {
-
- String name;
- 静态变量
- static int age;
-
- public StaticBean(String name) {
- this.name = name;
- }
- 静态方法
- static void SayHello() {
- System.out.println(Hello i am java);
- }
- @Override
- public String toString() {
- return StaticBean{ +
- name=' + name + ''' + age + age +
- '}';
- }
-}
-```
-
-```java
-public class StaticDemo {
-
- public static void main(String[] args) {
- StaticBean staticBean = new StaticBean(1);
- StaticBean staticBean2 = new StaticBean(2);
- StaticBean staticBean3 = new StaticBean(3);
- StaticBean staticBean4 = new StaticBean(4);
- StaticBean.age = 33;
- StaticBean{name='1'age33} StaticBean{name='2'age33} StaticBean{name='3'age33} StaticBean{name='4'age33}
- System.out.println(staticBean+ +staticBean2+ +staticBean3+ +staticBean4);
- StaticBean.SayHello();Hello i am java
- }
-
-}
-```
-
-
-### 静态代码块
-
-静态代码块定义在类中方法外, 静态代码块在非静态代码块之前执行(静态代码块—非静态代码块—构造方法)。 该类不管创建多少对象,静态代码块只执行一次.
-
-静态代码块的格式是
-
-```
-static {
-语句体;
-}
-```
-
-
-一个类中的静态代码块可以有多个,位置可以随便放,它不在任何的方法体内,JVM加载类时会执行这些静态的代码块,如果静态代码块有多个,JVM将按照它们在类中出现的先后顺序依次执行它们,每个代码块只会被执行一次。
-
-
-
-静态代码块对于定义在它之后的静态变量,可以赋值,但是不能访问.
-
-
-### 静态内部类
-
-静态内部类与非静态内部类之间存在一个最大的区别,我们知道非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围类,但是静态内部类却没有。没有这个引用就意味着:
-
-1. 它的创建是不需要依赖外围类的创建。
-2. 它不能使用任何外围类的非static成员变量和方法。
-
-
-Example(静态内部类实现单例模式)
-
-```java
-public class Singleton {
-
- 声明为 private 避免调用默认构造方法创建对象
- private Singleton() {
- }
-
- 声明为 private 表明静态内部该类只能在该 Singleton 类中被访问
- private static class SingletonHolder {
- private static final Singleton INSTANCE = new Singleton();
- }
-
- public static Singleton getUniqueInstance() {
- return SingletonHolder.INSTANCE;
- }
-}
-```
-
-当 Singleton 类加载时,静态内部类 SingletonHolder 没有被加载进内存。只有当调用 `getUniqueInstance() `方法从而触发 `SingletonHolder.INSTANCE` 时 SingletonHolder 才会被加载,此时初始化 INSTANCE 实例,并且 JVM 能确保 INSTANCE 只被实例化一次。
-
-这种方式不仅具有延迟初始化的好处,而且由 JVM 提供了对线程安全的支持。
-
-### 静态导包
-
-格式为:import static
-
-这两个关键字连用可以指定导入某个类中的指定静态资源,并且不需要使用类名调用类中静态成员,可以直接使用类中静态成员变量和成员方法
-
-```java
-
-
- Math. --- 将Math中的所有静态资源导入,这时候可以直接使用里面的静态方法,而不用通过类名进行调用
- 如果只想导入单一某个静态方法,只需要将换成对应的方法名即可
-
-import static java.lang.Math.;
-
- 换成import static java.lang.Math.max;具有一样的效果
-
-public class Demo {
- public static void main(String[] args) {
-
- int max = max(1,2);
- System.out.println(max);
- }
-}
-
-```
-
-
-## 补充内容
-
-### 静态方法与非静态方法
-
-静态方法属于类本身,非静态方法属于从该类生成的每个对象。 如果您的方法执行的操作不依赖于其类的各个变量和方法,请将其设置为静态(这将使程序的占用空间更小)。 否则,它应该是非静态的。
-
-Example
-
-```java
-class Foo {
- int i;
- public Foo(int i) {
- this.i = i;
- }
-
- public static String method1() {
- return An example string that doesn't depend on i (an instance variable);
-
- }
-
- public int method2() {
- return this.i + 1; Depends on i
- }
-
-}
-```
-你可以像这样调用静态方法:`Foo.method1()`。 如果您尝试使用这种方法调用 method2 将失败。 但这样可行:`Foo bar = new Foo(1);bar.method2();`
-
-总结:
-
-- 在外部调用静态方法时,可以使用”类名.方法名”的方式,也可以使用”对象名.方法名”的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
-- 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制
-
-### static{}静态代码块与{}非静态代码块(构造代码块)
-
-相同点: 都是在JVM加载类时且在构造方法执行之前执行,在类中都可以定义多个,定义多个时按定义的顺序执行,一般在代码块中对一些static变量进行赋值。
-
-不同点: 静态代码块在非静态代码块之前执行(静态代码块—非静态代码块—构造方法)。静态代码块只在第一次new执行一次,之后不再执行,而非静态代码块在每new一次就执行一次。 非静态代码块可在普通方法中定义(不过作用不大);而静态代码块不行。
-
-一般情况下,如果有些代码比如一些项目最常用的变量或对象必须在项目启动的时候就执行的时候,需要使用静态代码块,这种代码是主动执行的。如果我们想要设计不需要创建对象就可以调用类中的方法,例如:Arrays类,Character类,String类等,就需要使用静态方法, 两者的区别是 静态代码块是自动执行的而静态方法是被调用的时候才执行的.
-
-Example
-
-```java
-public class Test {
- public Test() {
- System.out.print(默认构造方法!--);
- }
-
- 非静态代码块
- {
- System.out.print(非静态代码块!--);
- }
- 静态代码块
- static {
- System.out.print(静态代码块!--);
- }
-
- public static void test() {
- System.out.print(静态方法中的内容! --);
- {
- System.out.print(静态方法中的代码块!--);
- }
-
- }
- public static void main(String[] args) {
-
- Test test = new Test();
- Test.test();静态代码块!--静态方法中的内容! --静态方法中的代码块!--
- }
-```
-
-当执行 `Test.test();` 时输出:
-
-```
-静态代码块!--静态方法中的内容! --静态方法中的代码块!--
-```
-
-当执行 `Test test = new Test();` 时输出:
-
-```
-静态代码块!--非静态代码块!--默认构造方法!--
-```
-
-
-非静态代码块与构造函数的区别是: 非静态代码块是给所有对象进行统一初始化,而构造函数是给对应的对象初始化,因为构造函数是可以多个的,运行哪个构造函数就会建立什么样的对象,但无论建立哪个对象,都会先执行相同的构造代码块。也就是说,构造代码块中定义的是不同对象共性的初始化内容。
-
-### 参考
-
-- httpsblog.csdn.netchen13579867831articledetails78995480
-- httpwww.cnblogs.comchenssyp3388487.html
-- httpwww.cnblogs.comQian123p5713440.html
diff --git "a/Java\347\233\270\345\205\263/synchronized.md" "b/Java\347\233\270\345\205\263/synchronized.md"
deleted file mode 100644
index dfca675f14a..00000000000
--- "a/Java\347\233\270\345\205\263/synchronized.md"
+++ /dev/null
@@ -1,171 +0,0 @@
-以下内容摘自我的 Gitchat :[Java 程序员必备:并发知识系统总结](https://gitbook.cn/gitchat/activity/5bc2b6af56f0425673d299bb),欢迎订阅!
-
-Github 地址:[https://github.com/Snailclimb/JavaGuide/edit/master/Java相关/synchronized.md](https://github.com/Snailclimb/JavaGuide/edit/master/Java相关/synchronized.md)
-
-
-
-### synchronized关键字最主要的三种使用方式的总结
-
-- **修饰实例方法,作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁**
-- **修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁** 。也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份,所以对该类的所有对象都加了锁)。所以如果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,**因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁**。
-- **修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。** 和 synchronized 方法一样,synchronized(this)代码块也是锁定当前对象的。synchronized 关键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上锁。这里再提一下:synchronized关键字加到非 static 静态方法上是给对象实例上锁。另外需要注意的是:尽量不要使用 synchronized(String a) 因为JVM中,字符串常量池具有缓冲功能!
-
-下面我已一个常见的面试题为例讲解一下 synchronized 关键字的具体使用。
-
-面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单利模式的原理呗!”
-
-
-
-**双重校验锁实现对象单例(线程安全)**
-
-```java
-public class Singleton {
-
- private volatile static Singleton uniqueInstance;
-
- private Singleton() {
- }
-
- public static Singleton getUniqueInstance() {
- //先判断对象是否已经实例过,没有实例化过才进入加锁代码
- if (uniqueInstance == null) {
- //类对象加锁
- synchronized (Singleton.class) {
- if (uniqueInstance == null) {
- uniqueInstance = new Singleton();
- }
- }
- }
- return uniqueInstance;
- }
-}
-```
-另外,需要注意 uniqueInstance 采用 volatile 关键字修饰也是很有必要。
-
-uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
-
-1. 为 uniqueInstance 分配内存空间
-2. 初始化 uniqueInstance
-3. 将 uniqueInstance 指向分配的内存地址
-
-但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出先问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
-
-使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
-
-
-###synchronized 关键字底层原理总结
-
-
-
-**synchronized 关键字底层原理属于 JVM 层面。**
-
-**① synchronized 同步语句块的情况**
-
-```java
-public class SynchronizedDemo {
- public void method() {
- synchronized (this) {
- System.out.println("synchronized 代码块");
- }
- }
-}
-
-```
-
-通过 JDK 自带的 javap 命令查看 SynchronizedDemo 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
-
-
-
-从上面我们可以看出:
-
-**synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。** 当执行 monitorenter 指令时,线程试图获取锁也就是获取 monitor(monitor对象存在于每个Java对象的对象头中,synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因) 的持有权.当计数器为0则可以成功获取,获取后将锁计数器设为1也就是加1。相应的在执行 monitorexit 指令后,将锁计数器设为0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
-
-**② synchronized 修饰方法的的情况**
-
-```java
-public class SynchronizedDemo2 {
- public synchronized void method() {
- System.out.println("synchronized 方法");
- }
-}
-
-```
-
-
-
-synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
-
-
-在 Java 早期版本中,synchronized 属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的 synchronized 效率低的原因。庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
-
-
-### JDK1.6 之后的底层优化
-
-JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
-
-锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-
-**①偏向锁**
-
-**引入偏向锁的目的和引入轻量级锁的目的很像,他们都是为了没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。但是不同是:轻量级锁在无竞争的情况下使用 CAS 操作去代替使用互斥量。而偏向锁在无竞争的情况下会把整个同步都消除掉**。
-
-偏向锁的“偏”就是偏心的偏,它的意思是会偏向于第一个获得它的线程,如果在接下来的执行中,该锁没有被其他线程获取,那么持有偏向锁的线程就不需要进行同步!关于偏向锁的原理可以查看《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版的13章第三节锁优化。
-
-但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。
-
-**② 轻量级锁**
-
-倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(1.6之后加入的)。**轻量级锁不是为了代替重量级锁,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗,因为使用轻量级锁时,不需要申请互斥量。另外,轻量级锁的加锁和解锁都用到了CAS操作。** 关于轻量级锁的加锁和解锁的原理可以查看《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版的13章第三节锁优化。
-
-**轻量级锁能够提升程序同步性能的依据是“对于绝大部分锁,在整个同步周期内都是不存在竞争的”,这是一个经验数据。如果没有竞争,轻量级锁使用 CAS 操作避免了使用互斥操作的开销。但如果存在锁竞争,除了互斥量开销外,还会额外发生CAS操作,因此在有锁竞争的情况下,轻量级锁比传统的重量级锁更慢!如果锁竞争激烈,那么轻量级将很快膨胀为重量级锁!**
-
-**③ 自旋锁和自适应自旋**
-
-轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。
-
-互斥同步对性能最大的影响就是阻塞的实现,因为挂起线程/恢复线程的操作都需要转入内核态中完成(用户态转换到内核态会耗费时间)。
-
-**一般线程持有锁的时间都不是太长,所以仅仅为了这一点时间去挂起线程/恢复线程是得不偿失的。** 所以,虚拟机的开发团队就这样去考虑:“我们能不能让后面来的请求获取锁的线程等待一会而不被挂起呢?看看持有锁的线程是否很快就会释放锁”。**为了让一个线程等待,我们只需要让线程执行一个忙循环(自旋),这项技术就叫做自旋**。
-
-百度百科对自旋锁的解释:
-
-> 何谓自旋锁?它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,"自旋"一词就是因此而得名。
-
-自旋锁在 JDK1.6 之前其实就已经引入了,不过是默认关闭的,需要通过`--XX:+UseSpinning`参数来开启。JDK1.6及1.6之后,就改为默认开启的了。需要注意的是:自旋等待不能完全替代阻塞,因为它还是要占用处理器时间。如果锁被占用的时间短,那么效果当然就很好了!反之,相反!自旋等待的时间必须要有限度。如果自旋超过了限定次数任然没有获得锁,就应该挂起线程。**自旋次数的默认值是10次,用户可以修改`--XX:PreBlockSpin`来更改**。
-
-另外,**在 JDK1.6 中引入了自适应的自旋锁。自适应的自旋锁带来的改进就是:自旋的时间不在固定了,而是和前一次同一个锁上的自旋时间以及锁的拥有者的状态来决定,虚拟机变得越来越“聪明”了**。
-
-**④ 锁消除**
-
-锁消除理解起来很简单,它指的就是虚拟机即使编译器在运行时,如果检测到那些共享数据不可能存在竞争,那么就执行锁消除。锁消除可以节省毫无意义的请求锁的时间。
-
-**⑤ 锁粗化**
-
-原则上,我们再编写代码的时候,总是推荐将同步快的作用范围限制得尽量小——只在共享数据的实际作用域才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待线程也能尽快拿到锁。
-
-大部分情况下,上面的原则都是没有问题的,但是如果一系列的连续操作都对同一个对象反复加锁和解锁,那么会带来很多不必要的性能消耗。
-
-### Synchronized 和 ReenTrantLock 的对比
-
-
-**① 两者都是可重入锁**
-
-两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
-
-**② synchronized 依赖于 JVM 而 ReenTrantLock 依赖于 API**
-
-synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReenTrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
-
-**③ ReenTrantLock 比 synchronized 增加了一些高级功能**
-
-相比synchronized,ReenTrantLock增加了一些高级功能。主要来说主要有三点:**①等待可中断;②可实现公平锁;③可实现选择性通知(锁可以绑定多个条件)**
-
-- **ReenTrantLock提供了一种能够中断等待锁的线程的机制**,通过lock.lockInterruptibly()来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
-- **ReenTrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。** ReenTrantLock默认情况是非公平的,可以通过 ReenTrantLock类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
-- synchronized关键字与wait()和notify/notifyAll()方法相结合可以实现等待/通知机制,ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition() 方法。Condition是JDK1.5之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个Lock对象中可以创建多个Condition实例(即对象监视器),**线程对象可以注册在指定的Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用notify/notifyAll()方法进行通知时,被通知的线程是由 JVM 选择的,用ReentrantLock类结合Condition实例可以实现“选择性通知”** ,这个功能非常重要,而且是Condition接口默认提供的。而synchronized关键字就相当于整个Lock对象中只有一个Condition实例,所有的线程都注册在它一个身上。如果执行notifyAll()方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而Condition实例的signalAll()方法 只会唤醒注册在该Condition实例中的所有等待线程。
-
-如果你想使用上述功能,那么选择ReenTrantLock是一个不错的选择。
-
-**④ 性能已不是选择标准**
-
-在JDK1.6之前,synchronized 的性能是比 ReenTrantLock 差很多。具体表示为:synchronized 关键字吞吐量岁线程数的增加,下降得非常严重。而ReenTrantLock 基本保持一个比较稳定的水平。我觉得这也侧面反映了, synchronized 关键字还有非常大的优化余地。后续的技术发展也证明了这一点,我们上面也讲了在 JDK1.6 之后 JVM 团队对 synchronized 关键字做了很多优化。**JDK1.6 之后,synchronized 和 ReenTrantLock 的性能基本是持平了。所以网上那些说因为性能才选择 ReenTrantLock 的文章都是错的!JDK1.6之后,性能已经不是选择synchronized和ReenTrantLock的影响因素了!而且虚拟机在未来的性能改进中会更偏向于原生的synchronized,所以还是提倡在synchronized能满足你的需求的情况下,优先考虑使用synchronized关键字来进行同步!优化后的synchronized和ReenTrantLock一样,在很多地方都是用到了CAS操作**。
diff --git "a/Java\347\233\270\345\205\263/\345\217\257\350\203\275\346\230\257\346\212\212Java\345\206\205\345\255\230\345\214\272\345\237\237\350\256\262\347\232\204\346\234\200\346\270\205\346\245\232\347\232\204\344\270\200\347\257\207\346\226\207\347\253\240.md" "b/Java\347\233\270\345\205\263/\345\217\257\350\203\275\346\230\257\346\212\212Java\345\206\205\345\255\230\345\214\272\345\237\237\350\256\262\347\232\204\346\234\200\346\270\205\346\245\232\347\232\204\344\270\200\347\257\207\346\226\207\347\253\240.md"
deleted file mode 100644
index 4f38f3a1261..00000000000
--- "a/Java\347\233\270\345\205\263/\345\217\257\350\203\275\346\230\257\346\212\212Java\345\206\205\345\255\230\345\214\272\345\237\237\350\256\262\347\232\204\346\234\200\346\270\205\346\245\232\347\232\204\344\270\200\347\257\207\346\226\207\347\253\240.md"
+++ /dev/null
@@ -1,341 +0,0 @@
-
-
-## 写在前面(常见面试题)
-
-### 基本问题:
-
-- **介绍下 Java 内存区域(运行时数据区)**
-- **Java 对象的创建过程(五步,建议能默写出来并且要知道每一步虚拟机做了什么)**
-- **对象的访问定位的两种方式(句柄和直接指针两种方式)**
-
-### 拓展问题:
-
-- **String类和常量池**
-- **8种基本类型的包装类和常量池**
-
-
-## 1 概述
-
-对于 Java 程序员来说,在虚拟机自动内存管理机制下,不再需要像C/C++程序开发程序员这样为内一个 new 操作去写对应的 delete/free 操作,不容易出现内存泄漏和内存溢出问题。正是因为 Java 程序员把内存控制权利交给 Java 虚拟机,一旦出现内存泄漏和溢出方面的问题,如果不了解虚拟机是怎样使用内存的,那么排查错误将会是一个非常艰巨的任务。
-
-
-## 2 运行时数据区域
-Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域。
-
-这些组成部分一些是线程私有的,其他的则是线程共享的。
-
-**线程私有的:**
-
-- 程序计数器
-- 虚拟机栈
-- 本地方法栈
-
-**线程共享的:**
-
-- 堆
-- 方法区
-- 直接内存
-
-
-### 2.1 程序计数器
-程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。**字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完。**
-
-另外,**为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。**
-
-**从上面的介绍中我们知道程序计数器主要有两个作用:**
-
-1. 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
-2. 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
-
-**注意:程序计数器是唯一一个不会出现OutOfMemoryError的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡。**
-
-### 2.2 Java 虚拟机栈
-
-**与程序计数器一样,Java虚拟机栈也是线程私有的,它的生命周期和线程相同,描述的是 Java 方法执行的内存模型。**
-
-**Java 内存可以粗糙的区分为堆内存(Heap)和栈内存(Stack),其中栈就是现在说的虚拟机栈,或者说是虚拟机栈中局部变量表部分。** (实际上,Java虚拟机栈是由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法出口信息。)
-
-**局部变量表主要存放了编译器可知的各种数据类型**(boolean、byte、char、short、int、float、long、double)、**对象引用**(reference类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
-
-**Java 虚拟机栈会出现两种异常:StackOverFlowError 和 OutOfMemoryError。**
-
-- **StackOverFlowError:** 若Java虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前Java虚拟机栈的最大深度的时候,就抛出StackOverFlowError异常。
-- **OutOfMemoryError:** 若 Java 虚拟机栈的内存大小允许动态扩展,且当线程请求栈时内存用完了,无法再动态扩展了,此时抛出OutOfMemoryError异常。
-
-Java 虚拟机栈也是线程私有的,每个线程都有各自的Java虚拟机栈,而且随着线程的创建而创建,随着线程的死亡而死亡。
-
-### 2.3 本地方法栈
-
-和虚拟机栈所发挥的作用非常相似,区别是: **虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。** 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
-
-本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。
-
-方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 StackOverFlowError 和 OutOfMemoryError 两种异常。
-
-### 2.4 堆
-Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。**此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。**
-
-Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC堆(Garbage Collected Heap)**.从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以Java堆还可以细分为:新生代和老年代:再细致一点有:Eden空间、From Survivor、To Survivor空间等。**进一步划分的目的是更好地回收内存,或者更快地分配内存。**
-
-
-
-**在 JDK 1.8中移除整个永久代,取而代之的是一个叫元空间(Metaspace)的区域(永久代使用的是JVM的堆内存空间,而元空间使用的是物理内存,直接受到本机的物理内存限制)。**
-
-推荐阅读:
-
-- 《Java8内存模型—永久代(PermGen)和元空间(Metaspace)》:[http://www.cnblogs.com/paddix/p/5309550.html](http://www.cnblogs.com/paddix/p/5309550.html)
-
-### 2.5 方法区
-
-**方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。**
-
-HotSpot 虚拟机中方法区也常被称为 **“永久代”**,本质上两者并不等价。仅仅是因为 HotSpot 虚拟机设计团队用永久代来实现方法区而已,这样 HotSpot 虚拟机的垃圾收集器就可以像管理 Java 堆一样管理这部分内存了。但是这并不是一个好主意,因为这样更容易遇到内存溢出问题。
-
-
-
-**相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。**
-
-### 2.6 运行时常量池
-
-运行时常量池是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池信息(用于存放编译期生成的各种字面量和符号引用)
-
-既然运行时常量池时方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 异常。
-
-**JDK1.7及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。**
-
-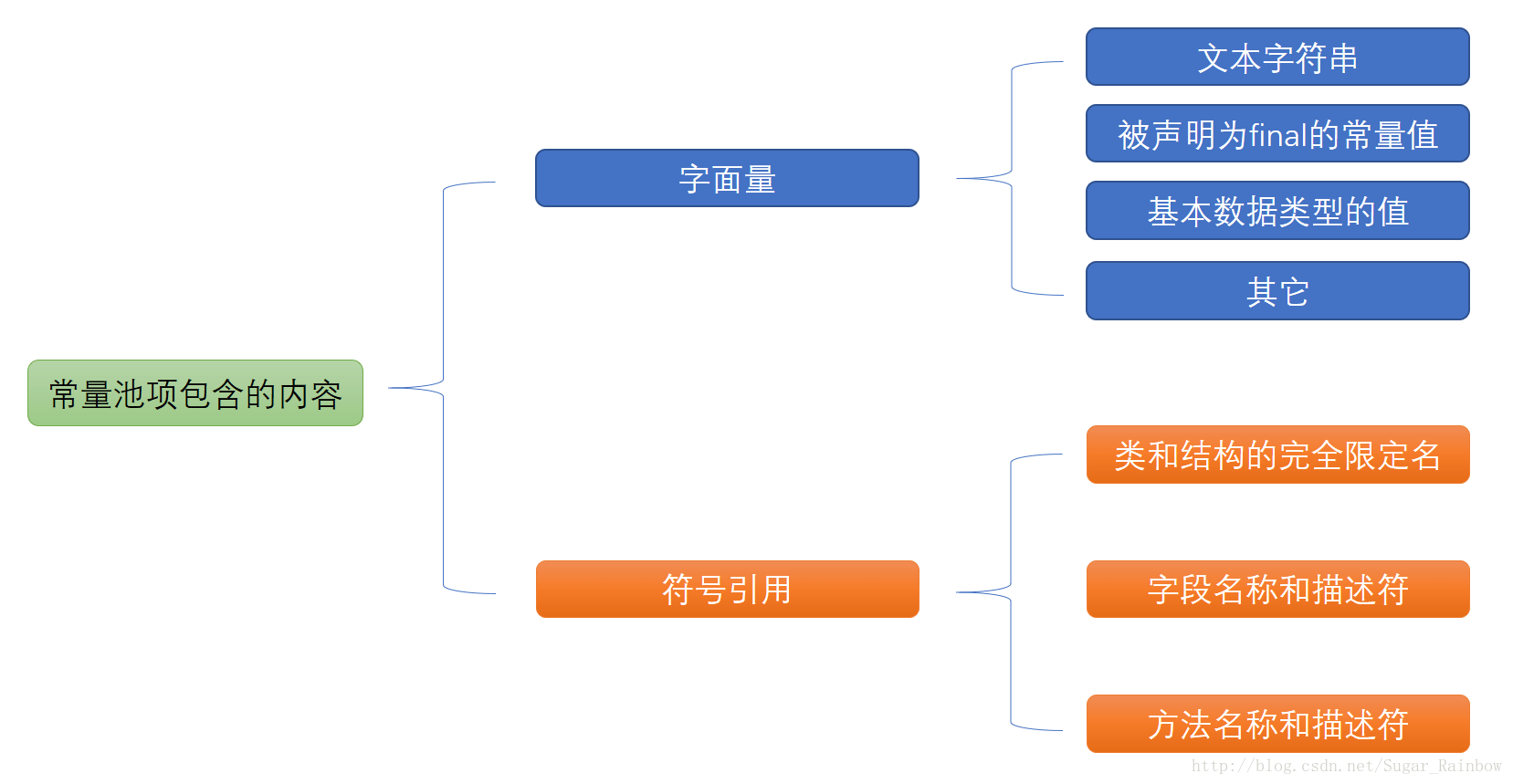
-——图片来源:https://blog.csdn.net/wangbiao007/article/details/78545189
-
-
-
-推荐阅读:
-
-- 《Java 中几种常量池的区分》: [https://blog.csdn.net/qq_26222859/article/details/73135660](https://blog.csdn.net/qq_26222859/article/details/73135660)
-
-
-### 2.7 直接内存
-
-直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致OutOfMemoryError异常出现。
-
-JDK1.4中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**通道(Channel)** 与**缓存区(Buffer)** 的 I/O 方式,它可以直接使用Native函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为**避免了在 Java 堆和 Native 堆之间来回复制数据**。
-
-本机直接内存的分配不会收到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
-
-
-## 3 HotSpot 虚拟机对象探秘
-通过上面的介绍我们大概知道了虚拟机的内存情况,下面我们来详细的了解一下 HotSpot 虚拟机在 Java 堆中对象分配、布局和访问的全过程。
-
-### 3.1 对象的创建
-下图便是 Java 对象的创建过程,我建议最好是能默写出来,并且要掌握每一步在做什么。
-
-
-**①类加载检查:** 虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
-
-**②分配内存:** 在**类加载检查**通过后,接下来虚拟机将为新生对象**分配内存**。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。**分配方式**有 **“指针碰撞”** 和 **“空闲列表”** 两种,**选择那种分配方式由 Java 堆是否规整决定,而Java堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定**。
-
-
-**内存分配的两种方式:(补充内容,需要掌握)**
-
-选择以上两种方式中的哪一种,取决于 Java 堆内存是否规整。而 Java 堆内存是否规整,取决于 GC 收集器的算法是"标记-清除",还是"标记-整理"(也称作"标记-压缩"),值得注意的是,复制算法内存也是规整的
-
-
-
-**内存分配并发问题(补充内容,需要掌握)**
-
-在创建对象的时候有一个很重要的问题,就是线程安全,因为在实际开发过程中,创建对象是很频繁的事情,作为虚拟机来说,必须要保证线程是安全的,通常来讲,虚拟机采用两种方式来保证线程安全:
-
-- **CAS+失败重试:** CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。**虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。**
-- **TLAB:** 为每一个线程预先在Eden区分配一块儿内存,JVM在给线程中的对象分配内存时,首先在TLAB分配,当对象大于TLAB中的剩余内存或TLAB的内存已用尽时,再采用上述的CAS进行内存分配
-
-
-
-**③初始化零值:** 内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
-
-**④设置对象头:** 初始化零值完成之后,**虚拟机要对对象进行必要的设置**,例如这个对象是那个类的实例、如何才能找到类的元数据信息、对象的哈希吗、对象的 GC 分代年龄等信息。 **这些信息存放在对象头中。** 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
-
-
-**⑤执行 init 方法:** 在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,`<init>` 方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行 `<init>` 方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
-
-
-### 3.2 对象的内存布局
-
-在 Hotspot 虚拟机中,对象在内存中的布局可以分为3块区域:**对象头**、**实例数据**和**对齐填充**。
-
-**Hotspot虚拟机的对象头包括两部分信息**,**第一部分用于存储对象自身的自身运行时数据**(哈希码、GC分代年龄、锁状态标志等等),**另一部分是类型指针**,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是那个类的实例。
-
-**实例数据部分是对象真正存储的有效信息**,也是在程序中所定义的各种类型的字段内容。
-
-**对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。** 因为Hotspot虚拟机的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是对象的大小必须是8字节的整数倍。而对象头部分正好是8字节的倍数(1倍或2倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
-
-### 3.3 对象的访问定位
-建立对象就是为了使用对象,我们的Java程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式有虚拟机实现而定,目前主流的访问方式有**①使用句柄**和**②直接指针**两种:
-
-1. **句柄:** 如果使用句柄的话,那么Java堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
-
-
-2. **直接指针:** 如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而reference 中存储的直接就是对象的地址。
-
-
-
-**这两种对象访问方式各有优势。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。**
-
-
-
-
-## 四 重点补充内容
-
-### String 类和常量池
-
-**1 String 对象的两种创建方式:**
-
-```java
- String str1 = "abcd";
- String str2 = new String("abcd");
- System.out.println(str1==str2);//false
-```
-
-这两种不同的创建方法是有差别的,第一种方式是在常量池中拿对象,第二种方式是直接在堆内存空间创建一个新的对象。
-
-记住:只要使用new方法,便需要创建新的对象。
-
-
-
-**2 String 类型的常量池比较特殊。它的主要使用方法有两种:**
-
-- 直接使用双引号声明出来的 String 对象会直接存储在常量池中。
-- 如果不是用双引号声明的 String 对象,可以使用 String 提供的 intern 方法。String.intern() 是一个 Native 方法,它的作用是:如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用。
-
-```java
- String s1 = new String("计算机");
- String s2 = s1.intern();
- String s3 = "计算机";
- System.out.println(s2);//计算机
- System.out.println(s1 == s2);//false,因为一个是堆内存中的String对象一个是常量池中的String对象,
- System.out.println(s3 == s2);//true,因为两个都是常量池中的String对象
-```
-**3 String 字符串拼接**
-```java
- String str1 = "str";
- String str2 = "ing";
-
- String str3 = "str" + "ing";//常量池中的对象
- String str4 = str1 + str2; //在堆上创建的新的对象
- String str5 = "string";//常量池中的对象
- System.out.println(str3 == str4);//false
- System.out.println(str3 == str5);//true
- System.out.println(str4 == str5);//false
-```
-
-
-尽量避免多个字符串拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用 StringBuilder 或者 StringBuffer。
-### String s1 = new String("abc");这句话创建了几个对象?
-
-**创建了两个对象。**
-
-**验证:**
-
-```java
- String s1 = new String("abc");// 堆内存的地值值
- String s2 = "abc";
- System.out.println(s1 == s2);// 输出false,因为一个是堆内存,一个是常量池的内存,故两者是不同的。
- System.out.println(s1.equals(s2));// 输出true
-```
-
-**结果:**
-
-```
-false
-true
-```
-
-**解释:**
-
-先有字符串"abc"放入常量池,然后 new 了一份字符串"abc"放入Java堆(字符串常量"abc"在编译期就已经确定放入常量池,而 Java 堆上的"abc"是在运行期初始化阶段才确定),然后 Java 栈的 str1 指向Java堆上的"abc"。
-
-### 8种基本类型的包装类和常量池
-
-- **Java 基本类型的包装类的大部分都实现了常量池技术,即Byte,Short,Integer,Long,Character,Boolean;这5种包装类默认创建了数值[-128,127]的相应类型的缓存数据,但是超出此范围仍然会去创建新的对象。**
-- **两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。**
-
-```java
- Integer i1 = 33;
- Integer i2 = 33;
- System.out.println(i1 == i2);// 输出true
- Integer i11 = 333;
- Integer i22 = 333;
- System.out.println(i11 == i22);// 输出false
- Double i3 = 1.2;
- Double i4 = 1.2;
- System.out.println(i3 == i4);// 输出false
-```
-
-**Integer 缓存源代码:**
-
-```java
-/**
-*此方法将始终缓存-128到127(包括端点)范围内的值,并可以缓存此范围之外的其他值。
-*/
- public static Integer valueOf(int i) {
- if (i >= IntegerCache.low && i <= IntegerCache.high)
- return IntegerCache.cache[i + (-IntegerCache.low)];
- return new Integer(i);
- }
-
-```
-
-**应用场景:**
-1. Integer i1=40;Java 在编译的时候会直接将代码封装成Integer i1=Integer.valueOf(40);,从而使用常量池中的对象。
-2. Integer i1 = new Integer(40);这种情况下会创建新的对象。
-
-```java
- Integer i1 = 40;
- Integer i2 = new Integer(40);
- System.out.println(i1==i2);//输出false
-```
-**Integer比较更丰富的一个例子:**
-
-```java
- Integer i1 = 40;
- Integer i2 = 40;
- Integer i3 = 0;
- Integer i4 = new Integer(40);
- Integer i5 = new Integer(40);
- Integer i6 = new Integer(0);
-
- System.out.println("i1=i2 " + (i1 == i2));
- System.out.println("i1=i2+i3 " + (i1 == i2 + i3));
- System.out.println("i1=i4 " + (i1 == i4));
- System.out.println("i4=i5 " + (i4 == i5));
- System.out.println("i4=i5+i6 " + (i4 == i5 + i6));
- System.out.println("40=i5+i6 " + (40 == i5 + i6));
-```
-
-结果:
-
-```
-i1=i2 true
-i1=i2+i3 true
-i1=i4 false
-i4=i5 false
-i4=i5+i6 true
-40=i5+i6 true
-```
-
-解释:
-
-语句i4 == i5 + i6,因为+这个操作符不适用于Integer对象,首先i5和i6进行自动拆箱操作,进行数值相加,即i4 == 40。然后Integer对象无法与数值进行直接比较,所以i4自动拆箱转为int值40,最终这条语句转为40 == 40进行数值比较。
-
-
-**参考:**
-
-- 《深入理解Java虚拟机:JVM高级特性与最佳实践(第二版》
-- 《实战java虚拟机》
-- https://www.cnblogs.com/CZDblog/p/5589379.html
-- https://www.cnblogs.com/java-zhao/p/5180492.html
-- https://blog.csdn.net/qq_26222859/article/details/73135660
-- https://blog.csdn.net/cugwuhan2014/article/details/78038254
-
-
-
-
-
diff --git "a/Java\347\233\270\345\205\263/\345\244\232\347\272\277\347\250\213\347\263\273\345\210\227.md" "b/Java\347\233\270\345\205\263/\345\244\232\347\272\277\347\250\213\347\263\273\345\210\227.md"
deleted file mode 100644
index 649d44e1f4f..00000000000
--- "a/Java\347\233\270\345\205\263/\345\244\232\347\272\277\347\250\213\347\263\273\345\210\227.md"
+++ /dev/null
@@ -1,69 +0,0 @@
-> ## 多线程系列文章
-下列文章,我都更新在了我的博客专栏:[Java并发编程指南](https://blog.csdn.net/column/details/20860.html)。
-
-1. [Java多线程学习(一)Java多线程入门](http://blog.csdn.net/qq_34337272/article/details/79640870)
-2. [Java多线程学习(二)synchronized关键字(1)](http://blog.csdn.net/qq_34337272/article/details/79655194)
-3. [Java多线程学习(二)synchronized关键字(2)](http://blog.csdn.net/qq_34337272/article/details/79670775)
-4. [Java多线程学习(三)volatile关键字](http://blog.csdn.net/qq_34337272/article/details/79680771)
-5. [Java多线程学习(四)等待/通知(wait/notify)机制](http://blog.csdn.net/qq_34337272/article/details/79690279)
-
-6. [Java多线程学习(五)线程间通信知识点补充](http://blog.csdn.net/qq_34337272/article/details/79694226)
-7. [Java多线程学习(六)Lock锁的使用](http://blog.csdn.net/qq_34337272/article/details/79714196)
-8. [Java多线程学习(七)并发编程中一些问题](https://blog.csdn.net/qq_34337272/article/details/79844051)
-9. [Java多线程学习(八)线程池与Executor 框架](https://blog.csdn.net/qq_34337272/article/details/79959271)
-
-
-> ## 多线程系列文章重要知识点与思维导图
-
-### Java多线程学习(一)Java多线程入门
-
-
-
-### Java多线程学习(二)synchronized关键字(1)
-
-
-注意:**可重入锁的概念**。
-
- 另外要注意:**synchronized取得的锁都是对象锁,而不是把一段代码或方法当做锁。** 如果多个线程访问的是同一个对象,哪个线程先执行带synchronized关键字的方法,则哪个线程就持有该方法,那么其他线程只能呈等待状态。如果多个线程访问的是多个对象则不一定,因为多个对象会产生多个锁。
-
-### Java多线程学习(二)synchronized关键字(2)
-
-
-
- **注意:**
-
- - 其他线程执行对象中**synchronized同步方法**(上一节我们介绍过,需要回顾的可以看上一节的文章)和**synchronized(this)代码块**时呈现同步效果;
- - **如果两个线程使用了同一个“对象监视器”(synchronized(object)),运行结果同步,否则不同步**.
-
- **synchronized关键字加到static静态方法**和**synchronized(class)代码块**上都是是给**Class类**上锁,而**synchronized关键字加到非static静态方法**上是给**对象**上锁。
-
- 数据类型String的常量池属性:**在Jvm中具有String常量池缓存的功能**
-
-### Java多线程学习(三)volatile关键字
-
-
- **注意:**
-
- **synchronized关键字**和**volatile关键字**比较
-
-### Java多线程学习(四)等待/通知(wait/notify)机制
-
-
-
-### Java多线程学习(五)线程间通信知识点补充
-
-
- **注意:** ThreadLocal类主要解决的就是让每个线程绑定自己的值,可以将ThreadLocal类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。
-
-### Java多线程学习(六)Lock锁的使用
-
- 
-
-### Java多线程学习(七)并发编程中一些问题
-
-
-
-### Java多线程学习(八)线程池与Executor 框架
-
-
-
diff --git "a/Java\347\233\270\345\205\263/\346\220\236\345\256\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\260\261\346\230\257\350\277\231\344\271\210\347\256\200\345\215\225.md" "b/Java\347\233\270\345\205\263/\346\220\236\345\256\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\260\261\346\230\257\350\277\231\344\271\210\347\256\200\345\215\225.md"
deleted file mode 100644
index ff2e871ff50..00000000000
--- "a/Java\347\233\270\345\205\263/\346\220\236\345\256\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\260\261\346\230\257\350\277\231\344\271\210\347\256\200\345\215\225.md"
+++ /dev/null
@@ -1,374 +0,0 @@
-
-上文回顾:[《可能是把Java内存区域讲的最清楚的一篇文章》](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484303&idx=1&sn=af0fd436cef755463f59ee4dd0720cbd&chksm=fd9855eecaefdcf8d94ac581cfda4e16c8a730bda60c3b50bc55c124b92f23b6217f7f8e58d5&token=506869459&lang=zh_CN#rd)
-## 写在前面
-
-### 本节常见面试题:
-
-问题答案在文中都有提到
-
-- 如何判断对象是否死亡(两种方法)。
-- 简单的介绍一下强引用、软引用、弱引用、虚引用(虚引用与软引用和弱引用的区别、使用软引用能带来的好处)。
-- 如何判断一个常量是废弃常量
-- 如何判断一个类是无用的类
-- 垃圾收集有哪些算法,各自的特点?
-- HotSpot为什么要分为新生代和老年代?
-- 常见的垃圾回收器有那些?
-- 介绍一下CMS,G1收集器。
-- Minor Gc和Full GC 有什么不同呢?
-
-### 本文导火索
-
-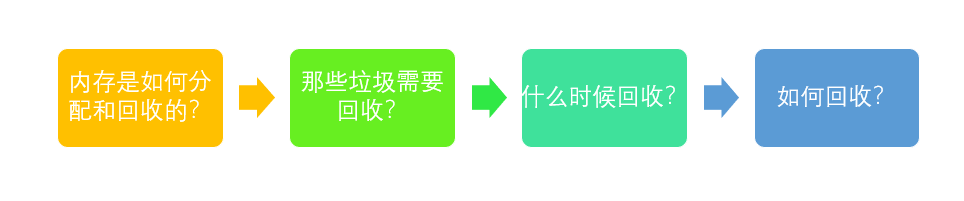
-
-当需要排查各种 内存溢出问题、当垃圾收集成为系统达到更高并发的瓶颈时,我们就需要对这些“自动化”的技术实施必要的监控和调节。
-
-
-
-## 1 揭开JVM内存分配与回收的神秘面纱
-
-Java 的自动内存管理主要是针对对象内存的回收和对象内存的分配。同时,Java 自动内存管理最核心的功能是 **堆** 内存中对象的分配与回收。
-
-**JDK1.8之前的堆内存示意图:**
-
-
-
-从上图可以看出堆内存分为新生代、老年代和永久代。新生代又被进一步分为:Eden 区+Survivor1 区+Survivor2 区。值得注意的是,在 JDK 1.8中移除整个永久代,取而代之的是一个叫元空间(Metaspace)的区域(永久代使用的是JVM的堆内存空间,而元空间使用的是物理内存,直接受到本机的物理内存限制)。
-
-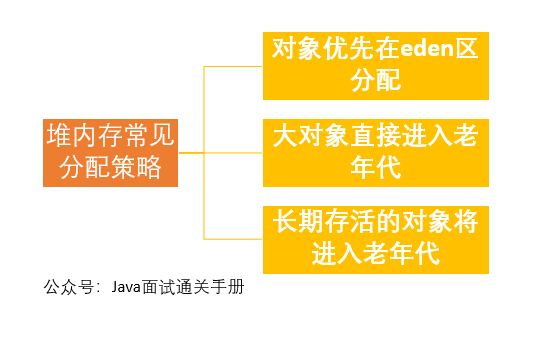
-
-### 1.1 对象优先在eden区分配
-
-目前主流的垃圾收集器都会采用分代回收算法,因此需要将堆内存分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
-
-大多数情况下,对象在新生代中 eden 区分配。当 eden 区没有足够空间进行分配时,虚拟机将发起一次Minor GC.下面我们来进行实际测试以下。
-
-在测试之前我们先来看看 **Minor GC和Full GC 有什么不同呢?**
-
-- **新生代GC(Minor GC)**:指发生新生代的的垃圾收集动作,Minor GC非常频繁,回收速度一般也比较快。
-- **老年代GC(Major GC/Full GC)**:指发生在老年代的GC,出现了Major GC经常会伴随至少一次的Minor GC(并非绝对),Major GC的速度一般会比Minor GC的慢10倍以上。
-
-**测试:**
-
-```java
-public class GCTest {
-
- public static void main(String[] args) {
- byte[] allocation1, allocation2;
- allocation1 = new byte[30900*1024];
- //allocation2 = new byte[900*1024];
- }
-}
-```
-通过以下方式运行:
-
-
-添加的参数:`-XX:+PrintGCDetails`
-
-
-运行结果:
-
-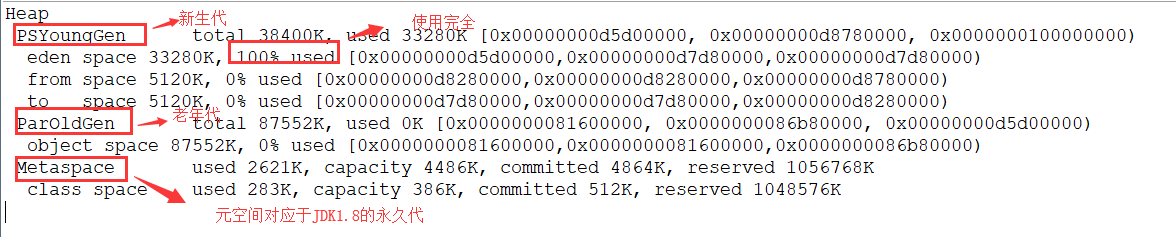
-
-从上图我们可以看出eden区内存几乎已经被分配完全(即使程序什么也不做,新生代也会使用2000多k内存)。假如我们再为allocation2分配内存会出现什么情况呢?
-
-```java
-allocation2 = new byte[900*1024];
-```
-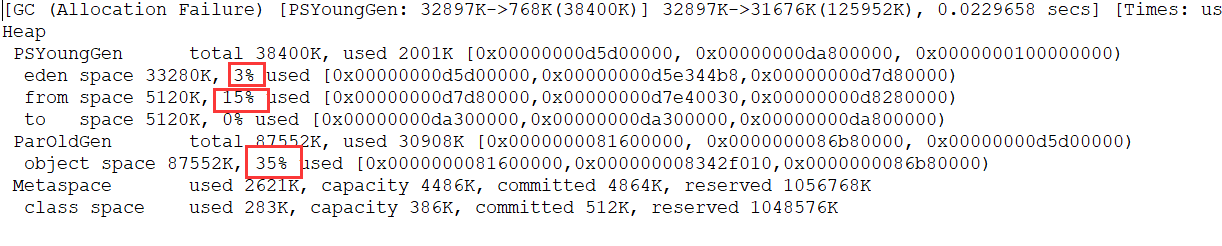
-
-**简单解释一下为什么会出现这种情况:** 因为给allocation2分配内存的时候eden区内存几乎已经被分配完了,我们刚刚讲了当Eden区没有足够空间进行分配时,虚拟机将发起一次Minor GC.GC期间虚拟机又发现allocation1无法存入Survivor空间,所以只好通过 **分配担保机制** 把新生代的对象提前转移到老年代中去,老年代上的空间足够存放allocation1,所以不会出现Full GC。执行Minor GC后,后面分配的对象如果能够存在eden区的话,还是会在eden区分配内存。可以执行如下代码验证:
-
-```java
-public class GCTest {
-
- public static void main(String[] args) {
- byte[] allocation1, allocation2,allocation3,allocation4,allocation5;
- allocation1 = new byte[32000*1024];
- allocation2 = new byte[1000*1024];
- allocation3 = new byte[1000*1024];
- allocation4 = new byte[1000*1024];
- allocation5 = new byte[1000*1024];
- }
-}
-
-```
-
-
-### 1.2 大对象直接进入老年代
-大对象就是需要大量连续内存空间的对象(比如:字符串、数组)。
-
-**为什么要这样呢?**
-
-为了避免为大对象分配内存时由于分配担保机制带来的复制而降低效率。
-
-### 1.3 长期存活的对象将进入老年代
-既然虚拟机采用了分代收集的思想来管理内存,那么内存回收时就必须能识别哪些对象应放在新生代,哪些对象应放在老年代中。为了做到这一点,虚拟机给每个对象一个对象年龄(Age)计数器。
-
-如果对象在 Eden 出生并经过第一次 Minor GC 后仍然能够存活,并且能被 Survivor 容纳的话,将被移动到 Survivor 空间中,并将对象年龄设为1.对象在 Survivor 中每熬过一次 MinorGC,年龄就增加1岁,当它的年龄增加到一定程度(默认为15岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
-
-### 1.4 动态对象年龄判定
-
-为了更好的适应不同程序的内存情况,虚拟机不是永远要求对象年龄必须达到了某个值才能进入老年代,如果 Survivor 空间中相同年龄所有对象大小的总和大于 Survivor 空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无需达到要求的年龄。
-
-
-## 2 对象已经死亡?
-
-堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断那些对象已经死亡(即不能再被任何途径使用的对象)。
-
-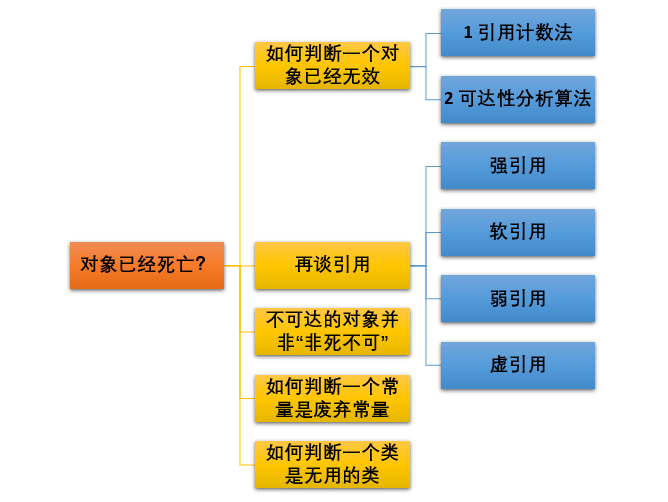
-
-### 2.1 引用计数法
-
-给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加1;当引用失效,计数器就减1;任何时候计数器为0的对象就是不可能再被使用的。
-
-**这个方法实现简单,效率高,但是目前主流的虚拟机中并没有选择这个算法来管理内存,其最主要的原因是它很难解决对象之间相互循环引用的问题。** 所谓对象之间的相互引用问题,如下面代码所示:除了对象objA 和 objB 相互引用着对方之外,这两个对象之间再无任何引用。但是他们因为互相引用对方,导致它们的引用计数器都不为0,于是引用计数算法无法通知 GC 回收器回收他们。
-
-```java
-public class ReferenceCountingGc {
- Object instance = null;
- public static void main(String[] args) {
- ReferenceCountingGc objA = new ReferenceCountingGc();
- ReferenceCountingGc objB = new ReferenceCountingGc();
- objA.instance = objB;
- objB.instance = objA;
- objA = null;
- objB = null;
-
- }
-}
-```
-
-
-
-### 2.2 可达性分析算法
-
-这个算法的基本思想就是通过一系列的称为 **“GC Roots”** 的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的。
-
-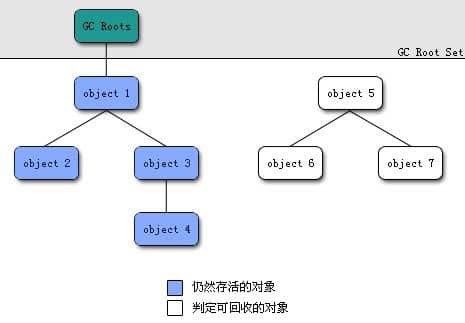
-
-
-### 2.3 再谈引用
-
-无论是通过引用计数法判断对象引用数量,还是通过可达性分析法判断对象的引用链是否可达,判定对象的存活都与“引用”有关。
-
-JDK1.2之前,Java中引用的定义很传统:如果reference类型的数据存储的数值代表的是另一块内存的起始地址,就称这块内存代表一个引用。
-
-JDK1.2以后,Java对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱)
-
-
-
-**1.强引用**
-
-以前我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于**必不可少的生活用品**,垃圾回收器绝不会回收它。当内存空 间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
-
-**2.软引用(SoftReference)**
-
-如果一个对象只具有软引用,那就类似于**可有可无的生活用品**。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
-
-软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,JAVA虚拟机就会把这个软引用加入到与之关联的引用队列中。
-
-**3.弱引用(WeakReference)**
-
-如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
-
-弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
-
-**4.虚引用(PhantomReference)**
-
-"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
-
-**虚引用主要用来跟踪对象被垃圾回收的活动**。
-
-**虚引用与软引用和弱引用的一个区别在于:** 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃 圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是 否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
-
-特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为**软引用可以加速JVM对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生**。
-
-### 2.4 不可达的对象并非“非死不可”
-
-即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或 finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。
-
-被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。
-
-### 2.5 如何判断一个常量是废弃常量
-
-运行时常量池主要回收的是废弃的常量。那么,我们如何判断一个常量是废弃常量呢?
-
-假如在常量池中存在字符串 "abc",如果当前没有任何String对象引用该字符串常量的话,就说明常量 "abc" 就是废弃常量,如果这时发生内存回收的话而且有必要的话,"abc" 就会被系统清理出常量池。
-
-注意:我们在 [可能是把Java内存区域讲的最清楚的一篇文章](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484303&idx=1&sn=af0fd436cef755463f59ee4dd0720cbd&chksm=fd9855eecaefdcf8d94ac581cfda4e16c8a730bda60c3b50bc55c124b92f23b6217f7f8e58d5&token=506869459&lang=zh_CN#rd) 也讲了JDK1.7及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。
-
-### 2.6 如何判断一个类是无用的类
-
-方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
-
-判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面3个条件才能算是 **“无用的类”** :
-
-- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
-- 加载该类的 ClassLoader 已经被回收。
-- 该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
-
-虚拟机可以对满足上述3个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
-
-
-## 3 垃圾收集算法
-
-
-
-### 3.1 标记-清除算法
-
-算法分为“标记”和“清除”阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。它是最基础的收集算法,效率也很高,但是会带来两个明显的问题:
-
-1. **效率问题**
-2. **空间问题(标记清除后会产生大量不连续的碎片)**
-
-
-
-### 3.2 复制算法
-
-为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
-
-
-
-### 3.3 标记-整理算法
-根据老年代的特点特出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
-
-
-
-### 3.4 分代收集算法
-
-当前虚拟机的垃圾手机都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将java堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
-
-**比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。**
-
-**延伸面试问题:** HotSpot为什么要分为新生代和老年代?
-
-根据上面的对分代收集算法的介绍回答。
-
-## 4 垃圾收集器
-
-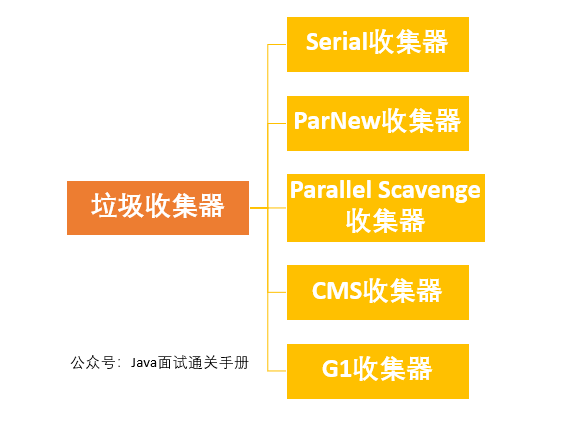
-
-**如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。**
-
-虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为知道现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的HotSpot虚拟机就不会实现那么多不同的垃圾收集器了。
-
-
-### 4.1 Serial收集器
-Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
-
- **新生代采用复制算法,老年代采用标记-整理算法。**
-
-
-虚拟机的设计者们当然知道Stop The World带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
-
-但是Serial收集器有没有优于其他垃圾收集器的地方呢?当然有,它**简单而高效(与其他收集器的单线程相比)**。Serial收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial收集器对于运行在Client模式下的虚拟机来说是个不错的选择。
-
-
-
-### 4.2 ParNew收集器
-**ParNew收集器其实就是Serial收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和Serial收集器完全一样。**
-
- **新生代采用复制算法,老年代采用标记-整理算法。**
-
-
-它是许多运行在Server模式下的虚拟机的首要选择,除了Serial收集器外,只有它能与CMS收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
-
-**并行和并发概念补充:**
-
-- **并行(Parallel)** :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
-
-- **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个CPU上。
-
-
-### 4.3 Parallel Scavenge收集器
-
-Parallel Scavenge 收集器类似于ParNew 收集器。 **那么它有什么特别之处呢?**
-
-```
--XX:+UseParallelGC
-
- 使用Parallel收集器+ 老年代串行
-
--XX:+UseParallelOldGC
-
- 使用Parallel收集器+ 老年代并行
-
-```
-
-**Parallel Scavenge收集器关注点是吞吐量(高效率的利用CPU)。CMS等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是CPU中用于运行用户代码的时间与CPU总消耗时间的比值。** Parallel Scavenge收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
-
- **新生代采用复制算法,老年代采用标记-整理算法。**
-
-
-
-### 4.4.Serial Old收集器
-**Serial收集器的老年代版本**,它同样是一个单线程收集器。它主要有两大用途:一种用途是在JDK1.5以及以前的版本中与Parallel Scavenge收集器搭配使用,另一种用途是作为CMS收集器的后备方案。
-
-### 4.5 Parallel Old收集器
- **Parallel Scavenge收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及CPU资源的场合,都可以优先考虑 Parallel Scavenge收集器和Parallel Old收集器。
-
-### 4.6 CMS收集器
-
-**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它而非常符合在注重用户体验的应用上使用。**
-
-**CMS(Concurrent Mark Sweep)收集器是HotSpot虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。**
-
-从名字中的**Mark Sweep**这两个词可以看出,CMS收集器是一种 **“标记-清除”算法**实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
-
-- **初始标记:** 暂停所有的其他线程,并记录下直接与root相连的对象,速度很快 ;
-- **并发标记:** 同时开启GC和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以GC线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
-- **重新标记:** 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
-- **并发清除:** 开启用户线程,同时GC线程开始对为标记的区域做清扫。
-
-
-
-从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:**并发收集、低停顿**。但是它有下面三个明显的缺点:
-
-- **对CPU资源敏感;**
-- **无法处理浮动垃圾;**
-- **它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。**
-
-### 4.7 G1收集器
-
-
-**G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征.**
-
-被视为JDK1.7中HotSpot虚拟机的一个重要进化特征。它具备一下特点:
-
-- **并行与并发**:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短Stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
-- **分代收集**:虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但是还是保留了分代的概念。
-- **空间整合**:与CMS的“标记--清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
-- **可预测的停顿**:这是G1相对于CMS的另一个大优势,降低停顿时间是G1 和 CMS 共同的关注点,但G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内。
-
-
-G1收集器的运作大致分为以下几个步骤:
-
-- **初始标记**
-- **并发标记**
-- **最终标记**
-- **筛选回收**
-
-
-**G1收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的Region(这也就是它的名字Garbage-First的由来)**。这种使用Region划分内存空间以及有优先级的区域回收方式,保证了GF收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
-
-
-
-
-
-参考:
-
-- 《深入理解Java虚拟机:JVM高级特性与最佳实践(第二版》
-- https://my.oschina.net/hosee/blog/644618
-
-
-
-
-
-
-
-
-
-
-
-
-
diff --git "a/Java\347\233\270\345\205\263/\350\256\276\350\256\241\346\250\241\345\274\217.md" "b/Java\347\233\270\345\205\263/\350\256\276\350\256\241\346\250\241\345\274\217.md"
deleted file mode 100644
index 32a78ea6780..00000000000
--- "a/Java\347\233\270\345\205\263/\350\256\276\350\256\241\346\250\241\345\274\217.md"
+++ /dev/null
@@ -1,116 +0,0 @@
-下面是自己学习设计模式的时候做的总结,有些是自己的原创文章,有些是网上写的比较好的文章,保存下来细细消化吧!
-
-## 创建型模式:
-
-> ### 创建型模式概述:
-
-- 创建型模式(Creational Pattern)对类的实例化过程进行了抽象,能够将软件模块中对象的创建和对象的使用分离。为了使软件的结构更加清晰,外界对于这些对象只需要知道它们共同的接口,而不清楚其具体的实现细节,使整个系统的设计更加符合单一职责原则。
-- 创建型模式在创建什么(What),由谁创建(Who),何时创建(When)等方面都为软件设计者提供了尽可能大的灵活性。创建型模式隐藏了类的实例的创建细节,通过隐藏对象如何被创建和组合在一起达到使整个系统独立的目的。
-
-
-
-> ### 创建型模式系列文章推荐:
-
-- **单例模式:**
-
-[深入理解单例模式——只有一个实例](https://blog.csdn.net/qq_34337272/article/details/80455972)
-
-- **工厂模式:**
-
-[深入理解工厂模式——由对象工厂生成对象](https://blog.csdn.net/qq_34337272/article/details/80472071)
-
-- **建造者模式:**
-
-[深入理解建造者模式 ——组装复杂的实例](http://blog.csdn.net/qq_34337272/article/details/80540059)
-
-- **原型模式:**
-
-[深入理解原型模式 ——通过复制生成实例](https://blog.csdn.net/qq_34337272/article/details/80706444)
-
-
-## 结构型模式:
-
-> ### 结构型模式概述:
-
-- **结构型模式(Structural Pattern):** 描述如何将类或者对象结合在一起形成更大的结构,就像搭积木,可以通过简单积木的组合形成复杂的、功能更为强大的结构
-
-- **结构型模式可以分为类结构型模式和对象结构型模式:**
- - 类结构型模式关心类的组合,由多个类可以组合成一个更大的系统,在类结构型模式中一般只存在继承关系和实现关系。
- - 对象结构型模式关心类与对象的组合,通过关联关系使得在一个类中定义另一个类的实例对象,然后通过该对象调用其方法。根据“合成复用原则”,在系统中尽量使用关联关系来替代继承关系,因此大部分结构型模式都是对象结构型模式。
-
-
-
-> ### 结构型模式系列文章推荐:
-
-- **适配器模式:**
-
-[深入理解适配器模式——加个“适配器”以便于复用](https://segmentfault.com/a/1190000011856448)
-
-[适配器模式原理及实例介绍-IBM](https://www.ibm.com/developerworks/cn/java/j-lo-adapter-pattern/index.html)
-
-- **桥接模式:**
-
-[设计模式笔记16:桥接模式(Bridge Pattern)](https://blog.csdn.net/yangzl2008/article/details/7670996)
-
-- **组合模式:**
-
-[大话设计模式—组合模式](https://blog.csdn.net/lmb55/article/details/51039781)
-
-- **装饰模式:**
-
-[java模式—装饰者模式](https://www.cnblogs.com/chenxing818/p/4705919.html)
-
-[Java设计模式-装饰者模式](https://blog.csdn.net/cauchyweierstrass/article/details/48240147)
-
-- **外观模式:**
-
-[java设计模式之外观模式(门面模式)](https://www.cnblogs.com/lthIU/p/5860607.html)
-
-- **享元模式:**
-
-[享元模式](http://www.jasongj.com/design_pattern/flyweight/)
-
-- **代理模式:**
-
-[代理模式原理及实例讲解 (IBM出品,很不错)](https://www.ibm.com/developerworks/cn/java/j-lo-proxy-pattern/index.html)
-
-[轻松学,Java 中的代理模式及动态代理](https://blog.csdn.net/briblue/article/details/73928350)
-
-[Java代理模式及其应用](https://blog.csdn.net/justloveyou_/article/details/74203025)
-
-
-## 行为型模式
-
-> ### 行为型模式概述:
-
-- 行为型模式(Behavioral Pattern)是对在不同的对象之间划分责任和算法的抽象化。
-- 行为型模式不仅仅关注类和对象的结构,而且重点关注它们之间的相互作用。
-- 通过行为型模式,可以更加清晰地划分类与对象的职责,并研究系统在运行时实例对象之间的交互。在系统运行时,对象并不是孤立的,它们可以通过相互通信与协作完成某些复杂功能,一个对象在运行时也将影响到其他对象的运行。
-
-**行为型模式分为类行为型模式和对象行为型模式两种:**
-
-- **类行为型模式:** 类的行为型模式使用继承关系在几个类之间分配行为,类行为型模式主要通过多态等方式来分配父类与子类的职责。
-- **对象行为型模式:** 对象的行为型模式则使用对象的聚合关联关系来分配行为,对象行为型模式主要是通过对象关联等方式来分配两个或多个类的职责。根据“合成复用原则”,系统中要尽量使用关联关系来取代继承关系,因此大部分行为型设计模式都属于对象行为型设计模式。
-
-
-
-- **职责链模式:**
-
-[Java设计模式之责任链模式、职责链模式](https://blog.csdn.net/jason0539/article/details/45091639)
-
-[责任链模式实现的三种方式](https://www.cnblogs.com/lizo/p/7503862.html)
-
-- **命令模式:**
-
-
-
-- **解释器模式:**
-- **迭代器模式:**
-- **中介者模式:**
-- **备忘录模式:**
-- **观察者模式:**
-- **状态模式:**
-- **策略模式:**
-- **模板方法模式:**
-- **访问者模式:**
-
diff --git "a/Java\347\233\270\345\205\263/\350\277\231\345\207\240\351\201\223Java\351\233\206\345\220\210\346\241\206\346\236\266\351\235\242\350\257\225\351\242\230\345\207\240\344\271\216\345\277\205\351\227\256.md" "b/Java\347\233\270\345\205\263/\350\277\231\345\207\240\351\201\223Java\351\233\206\345\220\210\346\241\206\346\236\266\351\235\242\350\257\225\351\242\230\345\207\240\344\271\216\345\277\205\351\227\256.md"
deleted file mode 100644
index ec9e0b3dcfb..00000000000
--- "a/Java\347\233\270\345\205\263/\350\277\231\345\207\240\351\201\223Java\351\233\206\345\220\210\346\241\206\346\236\266\351\235\242\350\257\225\351\242\230\345\207\240\344\271\216\345\277\205\351\227\256.md"
+++ /dev/null
@@ -1,276 +0,0 @@
-> 本文是“最最最常见Java面试题总结”系列第三周的文章。
-> 主要内容:
-> 1. Arraylist 与 LinkedList 异同
-> 2. ArrayList 与 Vector 区别
-> 3. HashMap的底层实现
-> 4. HashMap 和 Hashtable 的区别
-> 5. HashMap 的长度为什么是2的幂次方
-> 6. HashMap 多线程操作导致死循环问题
-> 7. HashSet 和 HashMap 区别
-> 8. ConcurrentHashMap 和 Hashtable 的区别
-> 9. ConcurrentHashMap线程安全的具体实现方式/底层具体实现
-> 10. 集合框架底层数据结构总结
-
-
-
-## Arraylist 与 LinkedList 异同
-
-- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-- **2. 底层数据结构:** Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别:);
-- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。**
-- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
-- **5. 内存空间占用:** ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
-
-**补充内容:RandomAccess接口**
-
-```java
-public interface RandomAccess {
-}
-```
-
-查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
-
-在binarySearch()方法中,它要判断传入的list 是否RamdomAccess的实例,如果是,调用indexedBinarySearch()方法,如果不是,那么调用iteratorBinarySearch()方法
-
-```java
- public static <T>
- int binarySearch(List<? extends Comparable<? super T>> list, T key) {
- if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
- return Collections.indexedBinarySearch(list, key);
- else
- return Collections.iteratorBinarySearch(list, key);
- }
-
-```
-ArraysList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArraysList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,ArraysList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArraysList 实现 RandomAccess 接口才具有快速随机访问功能的!
-
-
-**下面再总结一下 list 的遍历方式选择:**
-
-- 实现了RadmoAcces接口的list,优先选择普通for循环 ,其次foreach,
-- 未实现RadmoAcces接口的ist, 优先选择iterator遍历(foreach遍历底层也是通过iterator实现的),大size的数据,千万不要使用普通for循环
-
-
-### 补充:数据结构基础之双向链表
-
-双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表,如下图所示,同时下图也是LinkedList 底层使用的是双向循环链表数据结构。
-
-
-
-
-## ArrayList 与 Vector 区别
-
- Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
-
-Arraylist不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。
-
-
-## HashMap的底层实现
-
-### JDK1.8之前
-
-JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
-
-**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
-
-**JDK 1.8 HashMap 的 hash 方法源码:**
-
-JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
-
- ```java
- static final int hash(Object key) {
- int h;
- // key.hashCode():返回散列值也就是hashcode
- // ^ :按位异或
- // >>>:无符号右移,忽略符号位,空位都以0补齐
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- }
- ```
-对比一下 JDK1.7的 HashMap 的 hash 方法源码.
-
-```java
-static int hash(int h) {
- // This function ensures that hashCodes that differ only by
- // constant multiples at each bit position have a bounded
- // number of collisions (approximately 8 at default load factor).
-
- h ^= (h >>> 20) ^ (h >>> 12);
- return h ^ (h >>> 7) ^ (h >>> 4);
-}
-```
-
-相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
-
-所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
-
-
-
-
-
-
-### JDK1.8之后
-相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
-
-
-
->TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
-
-**推荐阅读:**
-
-- 《Java 8系列之重新认识HashMap》 :[https://zhuanlan.zhihu.com/p/21673805](https://zhuanlan.zhihu.com/p/21673805)
-
-## HashMap 和 Hashtable 的区别
-
-1. **线程是否安全:** HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过 `synchronized` 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
-2. **效率:** 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
-3. **对Null key 和Null value的支持:** HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
-4. **初始容量大小和每次扩充容量大小的不同 :** ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
-5. **底层数据结构:** JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
-
-**HasMap 中带有初始容量的构造函数:**
-
-```java
- public HashMap(int initialCapacity, float loadFactor) {
- if (initialCapacity < 0)
- throw new IllegalArgumentException("Illegal initial capacity: " +
- initialCapacity);
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- if (loadFactor <= 0 || Float.isNaN(loadFactor))
- throw new IllegalArgumentException("Illegal load factor: " +
- loadFactor);
- this.loadFactor = loadFactor;
- this.threshold = tableSizeFor(initialCapacity);
- }
- public HashMap(int initialCapacity) {
- this(initialCapacity, DEFAULT_LOAD_FACTOR);
- }
-```
-
-下面这个方法保证了 HashMap 总是使用2的幂作为哈希表的大小。
-
-```java
- /**
- * Returns a power of two size for the given target capacity.
- */
- static final int tableSizeFor(int cap) {
- int n = cap - 1;
- n |= n >>> 1;
- n |= n >>> 2;
- n |= n >>> 4;
- n |= n >>> 8;
- n |= n >>> 16;
- return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
- }
-```
-
-## HashMap 的长度为什么是2的幂次方
-
-为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483648,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash` ”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
-
-**这个算法应该如何设计呢?**
-
-我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。**
-
-## HashMap 多线程操作导致死循环问题
-
-在多线程下,进行 put 操作会导致 HashMap 死循环,原因在于 HashMap 的扩容 resize()方法。由于扩容是新建一个数组,复制原数据到数组。由于数组下标挂有链表,所以需要复制链表,但是多线程操作有可能导致环形链表。复制链表过程如下:
-以下模拟2个线程同时扩容。假设,当前 HashMap 的空间为2(临界值为1),hashcode 分别为 0 和 1,在散列地址 0 处有元素 A 和 B,这时候要添加元素 C,C 经过 hash 运算,得到散列地址为 1,这时候由于超过了临界值,空间不够,需要调用 resize 方法进行扩容,那么在多线程条件下,会出现条件竞争,模拟过程如下:
-
- 线程一:读取到当前的 HashMap 情况,在准备扩容时,线程二介入
-
-
-
-线程二:读取 HashMap,进行扩容
-
-
-
-线程一:继续执行
-
-
-
-这个过程为,先将 A 复制到新的 hash 表中,然后接着复制 B 到链头(A 的前边:B.next=A),本来 B.next=null,到此也就结束了(跟线程二一样的过程),但是,由于线程二扩容的原因,将 B.next=A,所以,这里继续复制A,让 A.next=B,由此,环形链表出现:B.next=A; A.next=B
-
-**注意:jdk1.8已经解决了死循环的问题。**
-
-
-## HashSet 和 HashMap 区别
-
-如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone() 方法、writeObject()方法、readObject()方法是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。)
-
-
-
-## ConcurrentHashMap 和 Hashtable 的区别
-
-ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
-
-- **底层数据结构:** JDK1.7的 ConcurrentHashMap 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
-- **实现线程安全的方式(重要):** ① **在JDK1.7的时候,ConcurrentHashMap(分段锁)** 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。) **到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化)** 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **Hashtable(同一把锁)** :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
-
-**两者的对比图:**
-
-图片来源:http://www.cnblogs.com/chengxiao/p/6842045.html
-
-HashTable:
-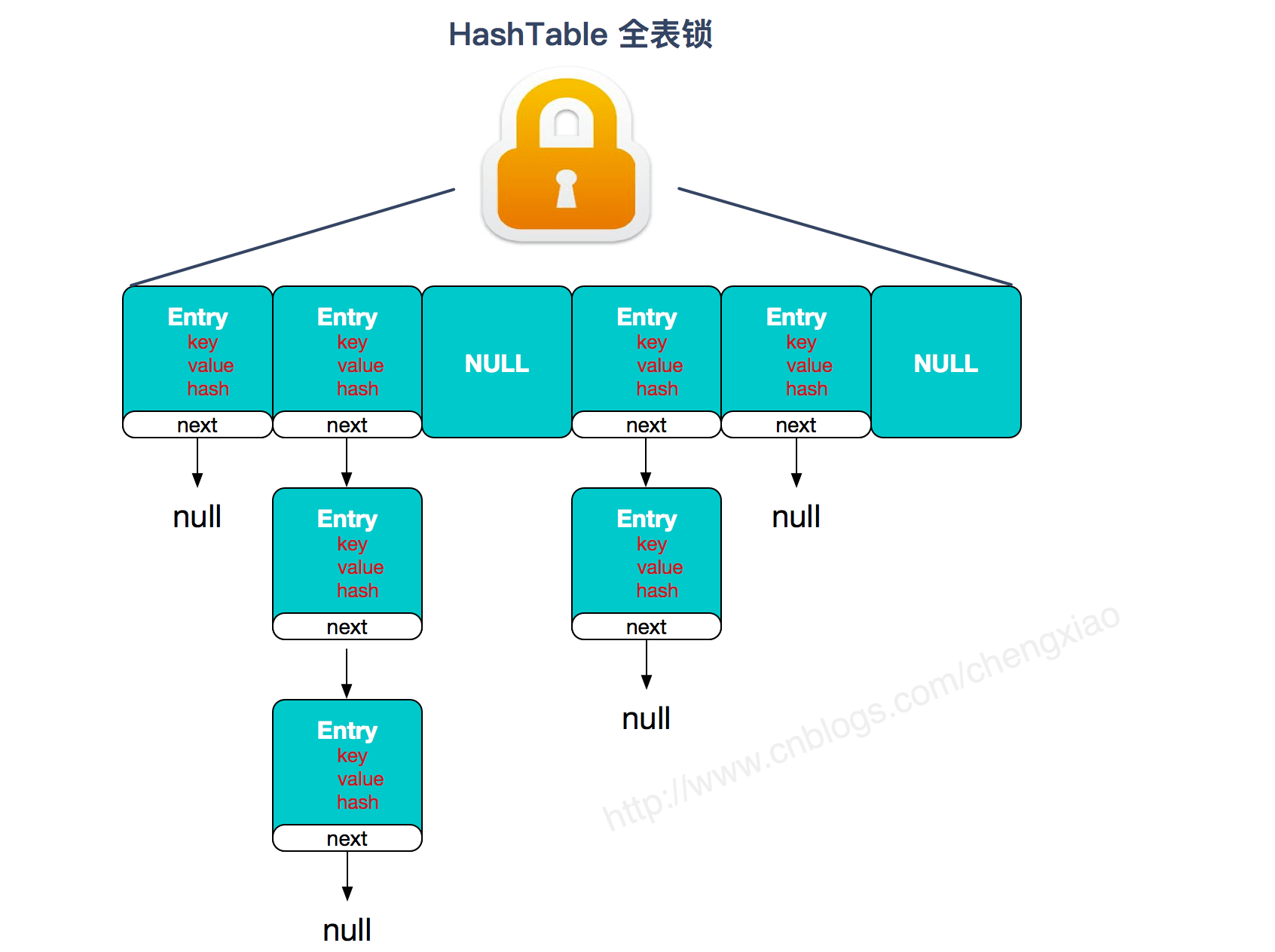
-
-JDK1.7的ConcurrentHashMap:
-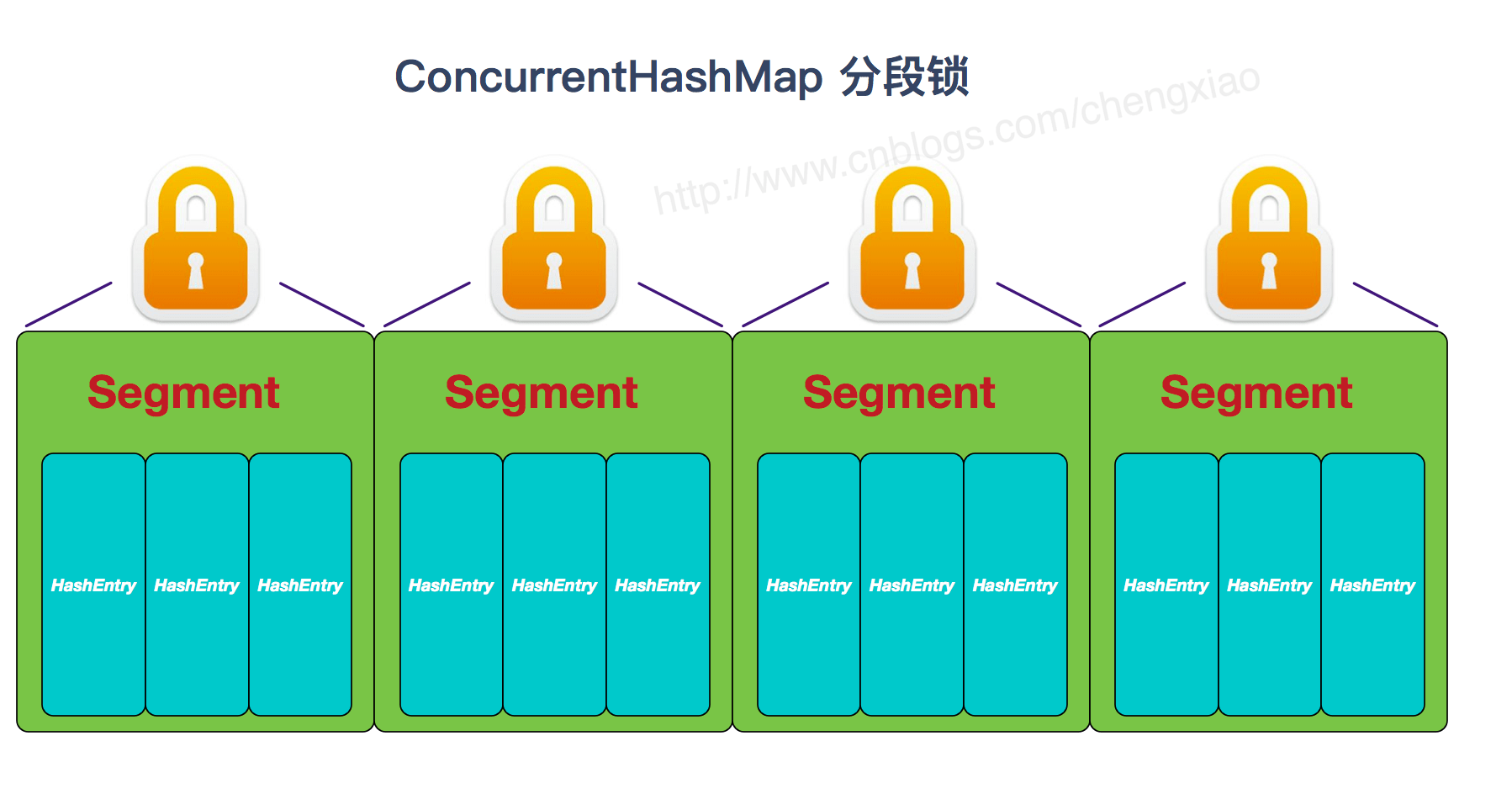
-JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点
-Node: 链表节点):
-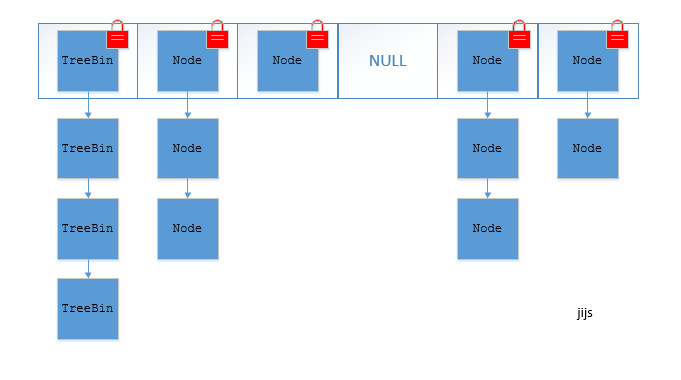
-
-## ConcurrentHashMap线程安全的具体实现方式/底层具体实现
-
-### JDK1.7(上面有示意图)
-
-首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
-
-**ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成**。
-
-Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
-
-```java
-static class Segment<K,V> extends ReentrantLock implements Serializable {
-}
-```
-
-一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
-
-### JDK1.8 (上面有示意图)
-
-ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构类似,数组+链表/红黑二叉树。
-
-synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
-
-
-
-## 集合框架底层数据结构总结
-### Collection
-
-#### 1. List
- - **Arraylist:** Object数组
- - **Vector:** Object数组
- - **LinkedList:** 双向循环链表
-
-#### 2. Set
- - **HashSet(无序,唯一):** 基于 HashMap 实现的,底层采用 HashMap 来保存元素
- - **LinkedHashSet:** LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 Hashmap 实现一样,不过还是有一点点区别的。
- - **TreeSet(有序,唯一):** 红黑树(自平衡的排序二叉树。)
-
-### Map
- - **HashMap:** JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间
- - **LinkedHashMap:** LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:[《LinkedHashMap 源码详细分析(JDK1.8)》](https://www.imooc.com/article/22931)
- - **HashTable:** 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
- - **TreeMap:** 红黑树(自平衡的排序二叉树)
-
-
-
-
-### 推荐阅读:
-
-- [jdk1.8中ConcurrentHashMap的实现原理](https://blog.csdn.net/fjse51/article/details/55260493)
-- [HashMap? ConcurrentHashMap? 相信看完这篇没人能难住你!](https://crossoverjie.top/2018/07/23/java-senior/ConcurrentHashMap/)
-- [HASHMAP、HASHTABLE、CONCURRENTHASHMAP的原理与区别](http://www.yuanrengu.com/index.php/2017-01-17.html)
-- [ConcurrentHashMap实现原理及源码分析](https://www.cnblogs.com/chengxiao/p/6842045.html)
-- [java-并发-ConcurrentHashMap高并发机制-jdk1.8](https://blog.csdn.net/jianghuxiaojin/article/details/52006118#commentBox)
diff --git a/README.md b/README.md
old mode 100644
new mode 100755
index 52f269b66a0..f8e670983e3
--- a/README.md
+++ b/README.md
@@ -1,230 +1,367 @@
-为了增加大家的阅读体验,我重新进行了排版,并且增加了较为详细的目录供大家参考!如果有老哥对操作系统比较重要的知识总结过的话,欢迎找我哦!
-
-<div align="center">
-
-<img src="http://my-blog-to-use.oss-cn-beijing.aliyuncs.com/18-11-16/49833984.jpg" width=""/>
-</br>
-
-[](//shang.qq.com/wpa/qunwpa?idkey=f128b25264f43170c2721e0789b24b180fc482113b6f256928b6198ae07fe5d4)
-
-</div>
-
-仓库新增了【备战春招/秋招系列】,希望可以为马上面临春招或者以后需要面试的小老哥助力!目前更新了美团常见面试题以及一些面试必备内容。下面是腾讯云双11做的活动,最后几天了哦,秒杀的服务器很便宜哦!
-> 腾讯云热门云产品1折起,送13000元续费/升级大礼包:https://cloud.tencent.com/redirect.php?redirect=1034&cps_key=2b96dd3b35e69197e2f3dfb779a6139b&from=console
->
-> 腾讯云新用户大额代金券:https://cloud.tencent.com/redirect.php?redirect=1025&cps_key=2b96dd3b35e69197e2f3dfb779a6139b&from=console
-
-
-## 目录
-
-- [:coffee: Java](#coffee-java)
- - [Java/J2EE 基础](#javaj2ee-基础)
- - [Java 集合框架](#java-集合框架)
- - [Java 多线程](#java-多线程)
- - [Java IO 与 NIO](#java-io-与-nio)
- - [Java 虚拟机 jvm](#java-虚拟机-jvm)
-- [:open_file_folder: 数据结构与算法](#open_file_folder-数据结构与算法)
- - [数据结构](#数据结构)
- - [算法](#算法)
-- [:computer: 计算机网络与数据通信](#computer-计算机网络与数据通信)
- - [网络相关](#网络相关)
- - [数据通信\(RESTful、RPC、消息队列\)](#数据通信restfulrpc消息队列)
-- [:iphone: 操作系统](#iphone-操作系统)
- - [Linux相关](#linux相关)
-- [:pencil2: 主流框架/软件](#pencil2-主流框架软件)
- - [Spring](#spring)
- - [ZooKeeper](#zookeeper)
-- [:floppy_disk: 数据存储](#floppy_disk-数据存储)
- - [MySQL](#mysql)
- - [Redis](#redis)
-- [:punch: 架构](#punch-架构)
- - [分布式相关](#分布式相关)
-- [:musical_note: 面试必备](#musical_note-面试必备)
- - [备战春招/秋招系列](#备战春招秋招系列)
- - [最最最常见的Java面试题总结](#最最最常见的java面试题总结)
-- [:art: 闲谈](#art-闲谈)
-- [:envelope: 说明](#envelope-说明)
- - [项目介绍](#项目介绍)
- - [关于转载](#关于转载)
- - [如何对该开源文档进行贡献](#如何对该开源文档进行贡献)
- - [为什么要做这个开源文档?](#为什么要做这个开源文档)
- - [最后](#最后)
- - [福利](#福利)
- - [公众号](#公众号)
-
-## :coffee: Java
-
-### Java/J2EE 基础
-
-* [Java 基础知识回顾](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/Java基础知识.md)
-* [J2EE 基础知识回顾](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/J2EE基础知识.md)
-* [static、final、this、super关键字总结](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/final、static、this、super.md)
-* [static 关键字详解](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/static.md)
-
-### Java 集合框架
-
-* [这几道Java集合框架面试题几乎必问](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/这几道Java集合框架面试题几乎必问.md)
-* [Java 集合框架常见面试题总结](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/Java集合框架常见面试题总结.md)
-* [ArrayList 源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/ArrayList.md)
-* [【面试必备】透过源码角度一步一步带你分析 ArrayList 扩容机制](https://github.com/Snailclimb/JavaGuide/blob/master/Java相关/ArrayList-Grow.md)
-* [LinkedList 源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/LinkedList.md)
-* [HashMap(JDK1.8)源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/HashMap.md)
-
-### Java 多线程
-* [多线程系列文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/多线程系列.md)
-* [并发编程面试必备:synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/synchronized.md)
-* [并发编程面试必备:乐观锁与悲观锁](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/面试必备之乐观锁与悲观锁.md)
-* [并发编程面试必备:JUC 中的 Atomic 原子类总结](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Multithread/Atomic.md)
-* [并发编程面试必备:AQS 原理以及 AQS 同步组件总结](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Multithread/AQS.md)
-* [BATJ都爱问的多线程面试题](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Multithread/BATJ都爱问的多线程面试题.md)
-
-### Java IO 与 NIO
-
-* [Java IO 与 NIO系列文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Java%20IO与NIO.md)
-
-### Java 虚拟机 jvm
-
-* [可能是把Java内存区域讲的最清楚的一篇文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/可能是把Java内存区域讲的最清楚的一篇文章.md)
-* [搞定JVM垃圾回收就是这么简单](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/搞定JVM垃圾回收就是这么简单.md)
-* [Java虚拟机(jvm)学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Java虚拟机(jvm).md)
-
-### 设计模式
-
-* [设计模式系列文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/设计模式.md)
-
-## :open_file_folder: 数据结构与算法
-
-### 数据结构
-
-* [数据结构知识学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/数据结构.md)
-
-### 算法
-
-* [算法学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/算法.md)
-* [常见安全算法(MD5、SHA1、Base64等等)总结](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/常见安全算法(MD5、SHA1、Base64等等)总结.md)
-* [算法总结——几道常见的子符串算法题 ](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/搞定BAT面试——几道常见的子符串算法题.md)
-* [算法总结——几道常见的链表算法题 ](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/Leetcode-LinkList1.md)
-
-## :computer: 计算机网络与数据通信
-
-### 网络相关
-
-* [计算机网络常见面试题](https://github.com/Snailclimb/Java_Guide/blob/master/计算机网络与数据通信/计算机网络.md)
-* [计算机网络基础知识总结](https://github.com/Snailclimb/Java_Guide/blob/master/计算机网络与数据通信/干货:计算机网络知识总结.md)
-
-### 数据通信(RESTful、RPC、消息队列)
-
-* [数据通信(RESTful、RPC、消息队列)相关知识点总结](https://github.com/Snailclimb/Java-Guide/blob/master/计算机网络与数据通信/数据通信(RESTful、RPC、消息队列).md)
-
-
-## :iphone: 操作系统
-
-### Linux相关
-
-* [后端程序员必备的 Linux 基础知识](https://github.com/Snailclimb/Java-Guide/blob/master/操作系统/后端程序员必备的Linux基础知识.md)
-* [Shell 编程入门](https://github.com/Snailclimb/Java-Guide/blob/master/操作系统/Shell.md)
-## :pencil2: 主流框架/软件
-
-### Spring
-
-* [Spring 学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/主流框架/Spring学习与面试.md)
-* [Spring中bean的作用域与生命周期](https://github.com/Snailclimb/Java_Guide/blob/master/主流框架/SpringBean.md)
-* [SpringMVC 工作原理详解](https://github.com/Snailclimb/JavaGuide/blob/master/主流框架/SpringMVC%20%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3.md)
-
-### ZooKeeper
-
-* [可能是把 ZooKeeper 概念讲的最清楚的一篇文章](https://github.com/Snailclimb/Java_Guide/blob/master/主流框架/ZooKeeper.md)
-
-## :floppy_disk: 数据存储
-
-### MySQL
-
-* [MySQL 学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/MySQL.md)
-* [【思维导图-索引篇】搞定数据库索引就是这么简单](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/MySQL%20Index.md)
-
-### Redis
-
-* [Redis 总结](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/Redis/Redis.md)
-* [Redlock分布式锁](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/Redis/Redlock分布式锁.md)
-* [如何做可靠的分布式锁,Redlock真的可行么](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
-
-## :punch: 架构
-
-### 分布式相关
-
-* [一文读懂分布式应该学什么](https://github.com/Snailclimb/Java_Guide/blob/master/架构/分布式.md)
-
-## :musical_note: 面试必备
-
-### 备战春招/秋招系列
-
-* [【备战春招/秋招系列1】程序员的简历就该这样写](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/程序员的简历之道.md)
-* [手把手教你用Markdown写一份高质量的简历](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/手把手教你用Markdown写一份高质量的简历.md)
-* [【备战春招/秋招系列2】初出茅庐的程序员该如何准备面试?](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/interviewPrepare.md)
-* [【备战春招/秋招系列3】Java程序员必备书单](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/books.md)
-* [ 【备战春招/秋招系列4】美团面经总结基础篇 (附详解答案)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/美团-基础篇.md)
-* [ 【备战春招/秋招系列5】美团面经总结进阶篇 (附详解答案)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/美团-进阶篇.md)
-* [ 【备战春招/秋招系列5】美团面经总结终结篇篇 (附详解答案)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/美团-终结篇.md)
-
-### 最最最常见的Java面试题总结
-
-这里会分享一些出现频率极其极其高的面试题,初定周更一篇,什么时候更完什么时候停止。
-
-* [第一周(2018-8-7)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/最最最常见的Java面试题总结/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
-* [第二周(2018-8-13)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/最最最常见的Java面试题总结/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
-* [第三周(2018-08-22)](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/这几道Java集合框架面试题几乎必问.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
-* [第四周(2018-8-30).md](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/最最最常见的Java面试题总结/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
-
-
-## :art: 闲谈
-
-* [选择技术方向都要考虑哪些因素](https://github.com/Snailclimb/Java-Guide/blob/master/其他/选择技术方向都要考虑哪些因素.md)
-* [结束了我短暂的秋招,说点自己的感受](https://github.com/Snailclimb/JavaGuide/blob/master/%E5%85%B6%E4%BB%96/2018%20%E7%A7%8B%E6%8B%9B.md)
-
-
-***
-
-## :envelope: 说明
-
-### 项目介绍
-
-该文档主要是笔主在学习 Java 的过程中的一些学习笔记,但是为了能够涉及到大部分后端学习所需的技术知识点我也会偶尔引用一些别人的优秀文章的链接。文档大部分内容都是笔者参考书籍以及自己的原创。少部分面试题回答参考了其他人已有答案,上面都已注明。
-
-该文档涉及的主要内容包括: Java、 数据结构与算法、计算机网络与数据通信、 操作系统、主流框架、数据存储、架构、面试必备知识点等等。相信不论你是前端还是后端都能在这份文档中收获到东西。
-
-### 关于转载
-
-**如果需要引用到本仓库的一些东西,必须注明转载地址!!!毕竟大多都是手敲的,或者引用的是我的原创文章,希望大家尊重一下作者的劳动**:smiley::smiley::smiley:!
-
-### 如何对该开源文档进行贡献
-
-1. 笔记内容大多是手敲,所以难免会有笔误,你可以帮我找错别字。
-2. 很多知识点我可能没有涉及到,所以你可以对其他知识点进行补充。
-3. 现有的知识点难免存在不完善或者错误,所以你可以对已有知识点的修改/补充。
-
-### 为什么要做这个开源文档?
-
-在我们学习Java的时候,很多人会面临我不知道继续学什么或者面试会问什么的尴尬情况(我本人之前就很迷茫:smile:)。所以,我决定通过这个开源平台来帮助一些有需要的人,通过下面的内容,你会掌握系统的Java学习以及面试的相关知识。本来是想通过Gitbook的形式来制作的,后来想了想觉得可能有点大题小做 :grin: 。另外,我自己一个人的力量毕竟有限,希望各位有想法的朋友可以提issue。开源的最大目的是,让更多人参与进来,这样文档的正确性才能得以保障!
-
-### 最后
-
-本人会利用业余时间一直更新下去,目前还有很多地方不完善,一些知识点我会原创总结,还有一些知识点如果说网上有比较好的文章了,我会把这些文章加入进去。您也可以关注我的微信公众号:“Java面试通关手册”,我会在这里分享一些自己的原创文章。 另外该文档格式参考:[Github Markdown格式](https://guides.github.com/features/mastering-markdown/),表情素材来自:[EMOJI CHEAT SHEET](https://www.webpagefx.com/tools/emoji-cheat-sheet/)。如果大家需要与我交流,可以扫描下方二维码添加我的微信:
-
-
-
-### 福利
-
-> 阿里云技术有保障,在云服务技术上远远领先于国内其他云服务提供商。大家或者公司如果需要用到云服务器的话,推荐阿里云服务器,下面是阿里云目前正在做的一些活动,错过这波,后续可能多花很多钱:
-
-1. [全民云计算:ECS云服务器2折起,1核1G仅需293元/年](https://promotion.aliyun.com/ntms/act/qwbk.html?userCode=hf47liqn)
-2. [高性能企业级性能云服务器限时2折起,2核4G仅需720元/年](https://promotion.aliyun.com/ntms/act/enterprise-discount.html?userCode=hf47liqn)
-3. [拉1人拼团,立享云服务器¥234/年](https://promotion.aliyun.com/ntms/act/vmpt/aliyun-group/home.html?spm=5176.8849694.home.4.27a24b70kENhtV&userCode=hf47liqn)
-4. [最高¥1888云产品通用代金券](https://promotion.aliyun.com/ntms/yunparter/invite.html?userCode=hf47liqn)
-5. [阿里云建站服务](https://promotion.aliyun.com/ntms/act/jianzhanquan.html?userCode=hf47liqn)(企业官网、电商网站,多种可供选择模板,代金券免费领取)
-
-### 公众号
-
-**你若盛开,清风自来。 欢迎关注我的微信公众号:“Java面试通关手册”,一个有温度的微信公众号。公众号多篇优质文章被各大社区转载,公众号后台回复关键字“1”你可能看到想要的东西哦!:**
-
-
-
+👏 重大更新!!!重磅!
+
+- JavaGuide 在线阅读版(新版,推荐👍):https://javaguide.cn/
+- JavaGuide 在线阅读版(老版):https://snailclimb.gitee.io/javaguide/#/
+
+👉 [朋友开源的面试八股文系列](https://github.com/csguide-dabai/interview-guide)。
+
+> 1. **介绍**:关于 JavaGuide 的相关介绍请看:[关于 JavaGuide 的一些说明](https://www.yuque.com/snailclimb/dr6cvl/mr44yt) 。
+> 2. **贡献指南** :欢迎参与 [JavaGuide的维护工作](https://github.com/Snailclimb/JavaGuide/issues/1235),这是一件非常有意义的事情。
+> 3. **PDF版本** : [《JavaGuide 面试突击版》PDF 版本](#公众号) 。
+> 4. **图解计算机基础** :[图解计算机基础 PDF 下载](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=100021725&idx=1&sn=2db9664ca25363139a81691043e9fd8f&chksm=4ea19a1679d61300d8990f7e43bfc7f476577a81b712cf0f9c6f6552a8b219bc081efddb5c54#rd) 。
+> 5. **知识星球** : 简历指导/Java学习/面试指导/面试小册。欢迎加入[我的知识星球](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=100015911&idx=1&sn=2e8a0f5acb749ecbcbb417aa8a4e18cc&chksm=4ea1b0ec79d639fae37df1b86f196e8ce397accfd1dd2004bcadb66b4df5f582d90ae0d62448#rd) 。
+> 6. **面试专版** :准备面试的小伙伴可以考虑面试专版:[《Java面试进阶指北 》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7) (质量很高,专为面试打造,星球用户免费)
+> 7. **转载须知** :以下所有文章如非文首说明皆为我(Guide哥)的原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!⛽️
+
+<p align="center">
+<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
+ <img src="https://img-blog.csdnimg.cn/img_convert/1c00413c65d1995993bf2b0daf7b4f03.png#pic_center" width=""/>
+</a>
+</p>
+<p align="center">
+ <a href="https://snailclimb.gitee.io/javaguide"><img src="https://img.shields.io/badge/阅读-read-brightgreen.svg" alt="阅读"></a>
+ <img src="https://img.shields.io/github/stars/Snailclimb/JavaGuide" alt="stars">
+</p>
+
+
+<h3 align="center">Sponsor</h3>
+
+<table>
+ <tbody>
+ <tr>
+ <td align="center" valign="middle">
+ <a href="https://t.1yb.co/iskv">
+ <img src="./media/sponsor/知识星球.png" style="margin: 0 auto;width:850px" /></a>
+ </td>
+ </tr>
+ </tbody>
+</table>
+
+## Java
+
+### 基础
+
+**知识点/面试题** : (必看:+1: ):[Java 基础知识点/面试题总结](docs/java/basis/java基础知识总结.md)
+
+**重要知识点详解:**
+
+- [什么是反射机制?反射机制的应用场景有哪些?](docs/java/basis/反射机制详解.md)
+- [代理模式详解:静态代理+JDK/CGLIB 动态代理实战](docs/java/basis/代理模式详解.md)
+- [常见的 IO 模型有哪些?Java 中的 BIO、NIO、AIO 有啥区别?](docs/java/basis/java基础知识总结)
+
+### 集合
+
+1. **[Java 集合常见问题总结](docs/java/collection/java集合框架基础知识&面试题总结.md)** (必看 :+1:)
+2. [Java 容器使用注意事项总结](docs/java/collection/java集合使用注意事项总结.md)
+3. **源码分析** :[ArrayList 源码+扩容机制分析](docs/java/collection/arraylist-source-code.md) 、[HashMap(JDK1.8)源码+底层数据结构分析](docs/java/collection/hashmap-source-code.md) 、[ConcurrentHashMap 源码+底层数据结构分析](docs/java/collection/concurrent-hash-map-source-code.md)
+
+### 并发
+
+**知识点/面试题:** (必看 :+1:)
+
+1. **[Java 并发基础常见面试题总结](docs/java/concurrent/java并发基础常见面试题总结.md)**
+2. **[Java 并发进阶常见面试题总结](docs/java/concurrent/java并发进阶常见面试题总结.md)**
+
+**重要知识点详解:**
+
+1. **线程池**:[Java 线程池学习总结](./docs/java/concurrent/java线程池学习总结.md)、[拿来即用的 Java 线程池最佳实践](./docs/java/concurrent/拿来即用的java线程池最佳实践.md)
+2. [ThreadLocal 关键字解析](docs/java/concurrent/threadlocal.md)
+3. [Java 并发容器总结](docs/java/concurrent/并发容器总结.md)
+4. [Atomic 原子类总结](docs/java/concurrent/atomic原子类总结.md)
+5. [AQS 原理以及 AQS 同步组件总结](docs/java/concurrent/aqs原理以及aqs同步组件总结.md)
+6. [CompletableFuture入门](docs/java/concurrent/completablefuture-intro.md)
+
+### JVM (必看 :+1:)
+
+JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) 和周志明老师的[《深入理解Java虚拟机(第3版)》](https://book.douban.com/subject/34907497/) (强烈建议阅读多遍!)。
+
+1. **[Java 内存区域](docs/java/jvm/内存区域.md)**
+2. **[JVM 垃圾回收](docs/java/jvm/jvm垃圾回收.md)**
+3. [JDK 监控和故障处理工具](docs/java/jvm/jdk监控和故障处理工具总结.md)
+4. [类文件结构](docs/java/jvm/类文件结构.md)
+5. **[类加载过程](docs/java/jvm/类加载过程.md)**
+6. [类加载器](docs/java/jvm/类加载器.md)
+7. **[【待完成】最重要的 JVM 参数总结(翻译完善了一半)](docs/java/jvm/jvm参数指南.md)**
+9. **[【加餐】大白话带你认识 JVM](docs/java/jvm/[加餐]大白话带你认识jvm.md)**
+
+### 新特性
+
+1. **Java 8** :[Java 8 新特性总结](docs/java/new-features/Java8新特性总结.md)、[Java8常用新特性总结](docs/java/new-features/java8-common-new-features.md)
+2. **Java9~Java15** : [一文带你看遍 JDK9~15 的重要新特性!](./docs/java/new-features/java新特性总结.md)
+
+### 小技巧
+
+1. [JAD 反编译](docs/java/tips/JAD反编译tricks.md)
+2. [手把手教你定位常见 Java 性能问题](./docs/java/tips/locate-performance-problems/手把手教你定位常见Java性能问题.md)
+
+## 计算机基础
+
+👉 **[图解计算机基础 PDF 下载](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=100021725&idx=1&sn=2db9664ca25363139a81691043e9fd8f&chksm=4ea19a1679d61300d8990f7e43bfc7f476577a81b712cf0f9c6f6552a8b219bc081efddb5c54#rd)** 。
+
+### 操作系统
+
+1. [操作系统常见问题总结!](docs/cs-basics/operating-system/basis.md)
+2. [后端程序员必备的 Linux 基础知识总结](docs/cs-basics/operating-system/linux.md)
+3. [Shell 编程入门](docs/cs-basics/operating-system/Shell.md)
+
+### 网络
+
+1. [计算机网络常见面试题](docs/cs-basics/network/计算机网络.md)
+2. [计算机网络基础知识总结](docs/cs-basics/network/计算机网络知识总结.md)
+
+### 数据结构
+
+**图解数据结构:**
+
+1. [线性数据结构 :数组、链表、栈、队列](docs/cs-basics/data-structure/线性数据结构.md)
+2. [图](docs/cs-basics/data-structure/图.md)
+3. [堆](docs/cs-basics/data-structure/堆.md)
+4. [树](docs/cs-basics/data-structure/树.md) :重点关注[红黑树](docs/cs-basics/data-structure/红黑树.md)、B-,B+,B*树、LSM树
+
+其他常用数据结构 :
+
+1. [布隆过滤器](docs/cs-basics/data-structure/bloom-filter.md)
+
+### 算法
+
+算法这部分内容非常重要,如果你不知道如何学习算法的话,可以看下我写的:
+
+- [算法学习书籍+资源推荐](https://www.zhihu.com/question/323359308/answer/1545320858) 。
+- [如何刷Leetcode?](https://www.zhihu.com/question/31092580/answer/1534887374)
+
+**常见算法问题总结** :
+
+- [几道常见的字符串算法题总结 ](docs/cs-basics/algorithms/几道常见的字符串算法题.md)
+- [几道常见的链表算法题总结 ](docs/cs-basics/algorithms/几道常见的链表算法题.md)
+- [剑指 offer 部分编程题](docs/cs-basics/algorithms/剑指offer部分编程题.md)
+
+另外,[GeeksforGeeks]( https://www.geeksforgeeks.org/fundamentals-of-algorithms/) 这个网站总结了常见的算法 ,比较全面系统。
+
+## 数据库
+
+### MySQL
+
+**总结:**
+
+1. [数据库基础知识总结](docs/database/数据库基础知识.md)
+2. **[MySQL知识点总结](docs/database/mysql/mysql知识点&面试题总结.md)** (必看 :+1:)
+4. [一千行 MySQL 学习笔记](docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md)
+5. [MySQL 高性能优化规范建议](docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md)
+
+**重要知识点:**
+
+1. [MySQL数据库索引总结](docs/database/mysql/mysql-index.md)
+2. [事务隔离级别(图文详解)](docs/database/mysql/transaction-isolation-level.md)
+3. [MySQL三大日志(binlog、redo log和undo log)详解](docs/database/mysql/mysql-logs.md)
+4. [InnoDB存储引擎对MVCC的实现](docs/database/mysql/innodb-implementation-of-mvcc.md)
+5. [一条 SQL 语句在 MySQL 中如何被执行的?](docs/database/mysql/how-sql-executed-in-mysql.md)
+6. [字符集详解:为什么不建议在MySQL中使用 utf8 ?](docs/database/字符集.md)
+7. [关于数据库中如何存储时间的一点思考](docs/database/mysql/some-thoughts-on-database-storage-time.md)
+
+### Redis
+
+1. [Redis 常见问题总结](docs/database/redis/redis-all.md)
+2. [3种常用的缓存读写策略](docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md)
+
+## 搜索引擎
+
+用于提高搜索效率,功能和浏览器搜索引擎类似。比较常见的搜索引擎是 Elasticsearch(推荐) 和 Solr。
+
+## 系统设计
+
+### 系统设计必备基础
+
+#### RESTful API
+
+我们在进行后端开发的时候,主要的工作就是为前端或者其他后端服务提供 API 比如查询用户数据的 API 。RESTful API 是一种基于 REST 构建的 API,它是一种被设计的更好使用的 API。
+
+相关阅读:[RestFul API 简明教程](docs/system-design/basis/RESTfulAPI.md)
+
+#### 命名
+
+编程过程中,一定要重视命名。因为好的命名即是注释,别人一看到你的命名就知道你的变量、方法或者类是做什么的!
+
+相关阅读: [Java 命名之道](docs/system-design/naming.md) 。
+
+### 常用框架
+
+如果你没有接触过 Java Web 开发的话,可以先看一下我总结的 [《J2EE 基础知识》](docs/system-design/J2EE基础知识.md) 。虽然,这篇文章中的很多内容已经淘汰,但是可以让你对 Java 后台技术发展有更深的认识。
+
+#### Spring/SpringBoot (必看 :+1:)
+
+**知识点/面试题:**
+
+1. **[Spring 常见问题总结](docs/system-design/framework/spring/Spring常见问题总结.md)**
+2. **[SpringBoot 入门指南](https://github.com/Snailclimb/springboot-guide)**
+
+**重要知识点详解:**
+
+1. **[Spring/Spring Boot 常用注解总结!安排!](./docs/system-design/framework/spring/Spring&SpringBoot常用注解总结.md)**
+2. **[Spring 事务总结](docs/system-design/framework/spring/Spring事务总结.md)**
+3. [Spring 中都用到了那些设计模式?](docs/system-design/framework/spring/Spring设计模式总结.md)
+4. **[SpringBoot 自动装配原理?”](docs/system-design/framework/spring/SpringBoot自动装配原理.md)**
+
+#### MyBatis
+
+[MyBatis 常见面试题总结](docs/system-design/framework/mybatis/mybatis-interview.md)
+
+#### Spring Cloud
+
+[ 大白话入门 Spring Cloud](docs/system-design/framework/springcloud/springcloud-intro.md)
+
+### 安全
+
+#### 认证授权
+
+**[《认证授权基础》](docs/system-design/security/basis-of-authority-certification.md)** 这篇文章中我会介绍认证授权常见概念: **Authentication**,**Authorization** 以及 **Cookie**、**Session**、Token、**OAuth 2**、**SSO** 。如果你不清楚这些概念的话,建议好好阅读一下这篇文章。
+
+- **JWT** :JWT(JSON Web Token)是一种身份认证的方式,JWT 本质上就一段签名的 JSON 格式的数据。由于它是带有签名的,因此接收者便可以验证它的真实性。相关阅读:
+ - [JWT 优缺点分析以及常见问题解决方案](docs/system-design/security/jwt优缺点分析以及常见问题解决方案.md)
+ - [适合初学者入门 Spring Security With JWT 的 Demo](https://github.com/Snailclimb/spring-security-jwt-guide)
+
+- **SSO(单点登录)** :**SSO(Single Sign On)** 即单点登录说的是用户登陆多个子系统的其中一个就有权访问与其相关的其他系统。举个例子我们在登陆了京东金融之后,我们同时也成功登陆京东的京东超市、京东家电等子系统。相关阅读:[**SSO 单点登录看这篇就够了!**](docs/system-design/security/sso-intro.md)
+
+#### 数据脱敏
+
+数据脱敏说的就是我们根据特定的规则对敏感信息数据进行变形,比如我们把手机号、身份证号某些位数使用 * 来代替。
+
+### 定时任务
+
+最近有朋友问到定时任务相关的问题。于是,我简单写了一篇文章总结一下定时任务的一些概念以及一些常见的定时任务技术选型:[《Java定时任务大揭秘》](./docs/system-design/定时任务.md)
+
+## 分布式
+
+### CAP 理论和 BASE 理论
+
+CAP 也就是 Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性) 这三个单词首字母组合。
+
+**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
+
+相关阅读:[CAP 理论和 BASE 理论解读](docs/distributed-system/理论&算法/cap&base理论.md)
+
+### Paxos 算法和 Raft 算法
+
+**Paxos 算法**诞生于 1990 年,这是一种解决分布式系统一致性的经典算法 。但是,由于 Paxos 算法非常难以理解和实现,不断有人尝试简化这一算法。到了2013 年才诞生了一个比 Paxos 算法更易理解和实现的分布式一致性算法—**Raft 算法**。
+
+### RPC
+
+RPC 让调用远程服务调用像调用本地方法那样简单。
+
+Dubbo 是一款国产的 RPC 框架,由阿里开源。相关阅读:
+
+- [Dubbo 常见问题总结](docs/distributed-system/rpc/dubbo.md)
+- [服务之间的调用为啥不直接用 HTTP 而用 RPC?](docs/distributed-system/rpc/why-use-rpc.md)
+
+### API 网关
+
+网关主要用于请求转发、安全认证、协议转换、容灾。
+
+相关阅读:
+
+- [为什么要网关?你知道有哪些常见的网关系统?](docs/distributed-system/api-gateway.md)
+- [百亿规模API网关服务Shepherd的设计与实现](https://tech.meituan.com/2021/05/20/shepherd-api-gateway.html)
+
+### 分布式 id
+
+在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。比如数据量太大之后,往往需要对数据进行分库分表,分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求。相关阅读:[为什么要分布式 id ?分布式 id 生成方案有哪些?](docs/distributed-system/distributed-id.md)
+
+### 分布式事务
+
+**分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。**
+
+简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
+
+### 分布式协调
+
+**ZooKeeper** :
+
+> 前两篇文章可能有内容重合部分,推荐都看一遍。
+
+1. [【入门】ZooKeeper 相关概念总结](docs/distributed-system/分布式协调/zookeeper/zookeeper-intro.md)
+2. [【进阶】ZooKeeper 相关概念总结](docs/distributed-system/分布式协调/zookeeper/zookeeper-plus.md)
+3. [【实战】ZooKeeper 实战](docs/distributed-system/分布式协调/zookeeper/zookeeper-in-action.md)
+
+## 高性能
+
+### 消息队列
+
+消息队列在分布式系统中主要是为了解耦和削峰。相关阅读: [消息队列常见问题总结](docs/high-performance/message-queue/message-queue.md)。
+
+1. **RabbitMQ** : [RabbitMQ 入门](docs/high-performance/message-queue/rabbitmq-intro.md)
+2. **RocketMQ** : [RocketMQ 入门](docs/high-performance/message-queue/rocketmq-intro)、[RocketMQ 的几个简单问题与答案](docs/high-performance/message-queue/rocketmq-questions.md)
+3. **Kafka** :[Kafka 常见问题总结](docs/high-performance/message-queue/kafka知识点&面试题总结.md)
+
+### 读写分离&分库分表
+
+读写分离主要是为了将数据库的读和写操作分不到不同的数据库节点上。主服务器负责写,从服务器负责读。另外,一主一从或者一主多从都可以。
+
+读写分离可以大幅提高读性能,小幅提高写的性能。因此,读写分离更适合单机并发读请求比较多的场景。
+
+分库分表是为了解决由于库、表数据量过大,而导致数据库性能持续下降的问题。
+
+常见的分库分表工具有:`sharding-jdbc`(当当)、`TSharding`(蘑菇街)、`MyCAT`(基于 Cobar)、`Cobar`(阿里巴巴)...。 推荐使用 `sharding-jdbc`。 因为,`sharding-jdbc` 是一款轻量级 `Java` 框架,以 `jar` 包形式提供服务,不要我们做额外的运维工作,并且兼容性也很好。
+
+相关阅读: [读写分离&分库分表常见问题总结](docs/high-performance/读写分离&分库分表.md)
+
+### 负载均衡
+
+负载均衡系统通常用于将任务比如用户请求处理分配到多个服务器处理以提高网站、应用或者数据库的性能和可靠性。
+
+常见的负载均衡系统包括 3 种:
+
+1. **DNS 负载均衡** :一般用来实现地理级别的均衡。
+2. **硬件负载均衡** : 通过单独的硬件设备比如 F5 来实现负载均衡功能(硬件的价格一般很贵)。
+3. **软件负载均衡** :通过负载均衡软件比如 Nginx 来实现负载均衡功能。
+
+## 高可用
+
+高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的 。
+
+相关阅读: **《[如何设计一个高可用系统?要考虑哪些地方?](docs/high-availability/高可用系统设计.md)》** 。
+
+### 限流
+
+限流是从用户访问压力的角度来考虑如何应对系统故障。
+
+限流为了对服务端的接口接受请求的频率进行限制,防止服务挂掉。比如某一接口的请求限制为 100 个每秒, 对超过限制的请求放弃处理或者放到队列中等待处理。限流可以有效应对突发请求过多。相关阅读:[何为限流?限流算法有哪些?](docs/high-availability/limit-request.md)
+
+### 降级
+
+降级是从系统功能优先级的角度考虑如何应对系统故障。
+
+服务降级指的是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
+
+### 熔断
+
+熔断和降级是两个比较容易混淆的概念,两者的含义并不相同。
+
+降级的目的在于应对系统自身的故障,而熔断的目的在于应对当前系统依赖的外部系统或者第三方系统的故障。
+
+### 排队
+
+另类的一种限流,类比于现实世界的排队。玩过英雄联盟的小伙伴应该有体会,每次一有活动,就要经历一波排队才能进入游戏。
+
+### 集群
+
+相同的服务部署多份,避免单点故障。
+
+### 超时和重试机制
+
+**一旦用户的请求超过某个时间得不到响应就结束此次请求并抛出异常。** 如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法在处理请求。
+
+另外,重试的次数一般设为 3 次,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。
+
+### 灾备设计和异地多活
+
+**灾备** = 容灾+备份。
+
+- **备份** : 将系统所产生的的所有重要数据多备份几份。
+- **容灾** : 在异地建立两个完全相同的系统。当某个地方的系统突然挂掉,整个应用系统可以切换到另一个,这样系统就可以正常提供服务了。
+
+**异地多活** 描述的是将服务部署在异地并且服务同时对外提供服务。和传统的灾备设计的最主要区别在于“多活”,即所有站点都是同时在对外提供服务的。异地多活是为了应对突发状况比如火灾、地震等自然或者认为灾害。
+
+相关阅读:
+
+- [搞懂异地多活,看这篇就够了](https://mp.weixin.qq.com/s/T6mMDdtTfBuIiEowCpqu6Q)
+- [四步构建异地多活](https://mp.weixin.qq.com/s/hMD-IS__4JE5_nQhYPYSTg)
+- [《从零开始学架构》— 28 | 业务高可用的保障:异地多活架构](http://gk.link/a/10pKZ)
diff --git a/docs/.vuepress/config.js b/docs/.vuepress/config.js
new file mode 100644
index 00000000000..b9ce3f6d372
--- /dev/null
+++ b/docs/.vuepress/config.js
@@ -0,0 +1,383 @@
+const { config } = require("vuepress-theme-hope");
+
+module.exports = config({
+ title: "JavaGuide",
+ description: "Java学习&&面试指南",
+ dest: "./dist",
+ head: [
+ [
+ "script",
+ { src: "https://cdn.jsdelivr.net/npm/react/umd/react.production.min.js" },
+ ],
+ [
+ "script",
+ {
+ src: "https://cdn.jsdelivr.net/npm/react-dom/umd/react-dom.production.min.js",
+ },
+ ],
+ ["script", { src: "https://cdn.jsdelivr.net/npm/vue/dist/vue.min.js" }],
+ [
+ "script",
+ { src: "https://cdn.jsdelivr.net/npm/@babel/standalone/babel.min.js" },
+ ],
+ // 添加百度统计
+ [
+ "script",{},
+ `var _hmt = _hmt || [];
+ (function() {
+ var hm = document.createElement("script");
+ hm.src = "https://hm.baidu.com/hm.js?5dd2e8c97962d57b7b8fea1737c01743";
+ var s = document.getElementsByTagName("script")[0];
+ s.parentNode.insertBefore(hm, s);
+ })();`
+ ]
+ ],
+
+ themeConfig: {
+ logo: "/logo.png",
+ hostname: "https://javaguide.cn/",
+ author: "Guide哥",
+ repo: "https://github.com/Snailclimb/JavaGuide",
+ nav: [
+ { text: "Java面试指南", icon: "java", link: "/", },
+ { text: "Java面试指北", icon: "java", link: "https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7?#%20%E3%80%8A%E3%80%8AJava%E9%9D%A2%E8%AF%95%E8%BF%9B%E9%98%B6%E6%8C%87%E5%8C%97%20%20%E6%89%93%E9%80%A0%E4%B8%AA%E4%BA%BA%E7%9A%84%E6%8A%80%E6%9C%AF%E7%AB%9E%E4%BA%89%E5%8A%9B%E3%80%8B%E3%80%8B", },
+ {
+ text: "Java精选", icon: "file", icon: "java",
+ items: [
+ { text: "Java书单精选", icon: "book", link: "https://gitee.com/SnailClimb/awesome-cs" },
+ { text: "Java学习路线", icon: "luxianchaxun", link: "https://zhuanlan.zhihu.com/p/379041500" },
+ { text: "Java开源项目精选", icon: "git", link: "https://gitee.com/SnailClimb/awesome-java" }
+ ],
+ },
+ { text: "IDEA指南", icon: "intellijidea", link: "/idea-tutorial/", },
+ { text: "开发工具", icon: "Tools", link: "/tools/", },
+ {
+ text: "PDF资源", icon: "pdf",
+ items: [
+ { text: "JavaGuide面试突击版", link: "https://t.1yb.co/Fy1e", },
+ { text: "消息队列常见知识点&面试题总结", link: "https://t.1yb.co/Fy0u", },
+ { text: "图解计算机基础!", link: "https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=100021725&idx=1&sn=2db9664ca25363139a81691043e9fd8f&chksm=4ea19a1679d61300d8990f7e43bfc7f476577a81b712cf0f9c6f6552a8b219bc081efddb5c54#rd" }
+ ],
+ },
+ {
+ text: "关于作者", icon: "zuozhe", link: "/about-the-author/"
+ },
+ ],
+ sidebar: {
+ "/about-the-author/": [
+ "internet-addiction-teenager", "feelings-after-one-month-of-induction-training"
+ ],
+ // 应该把更精确的路径放置在前边
+ '/tools/': [
+ {
+ title: "数据库",
+ icon: "database",
+ prefix: "database/",
+ collapsable: false,
+ children: ["CHINER", "DBeaver", "screw"]
+ },
+ {
+ title: "Git",
+ icon: "git",
+ prefix: "git/",
+ collapsable: false,
+ children: ["git-intro", "github技巧"]
+ },
+ {
+ title: "Docker",
+ icon: "docker1",
+ prefix: "docker/",
+ collapsable: false,
+ children: ["docker", "docker从入门到实战"]
+ },
+ ],
+ '/idea-tutorial/':
+ [
+ {
+ title: "IDEA小技巧",
+ icon: "creative",
+ prefix: "idea-tips/",
+ collapsable: false,
+ children: [
+ "idea-refractor-intro",
+ "idea-plug-in-development-intro",
+ "idea-source-code-reading-skills",
+ ]
+ },
+ {
+ title: "IDEA插件推荐",
+ icon: "plugin",
+ collapsable: false,
+ prefix: "idea-plugins/",
+ children: [
+ "shortcut-key", "idea-themes", "improve-code", "interface-beautification",
+ "camel-case", "code-glance", "code-statistic",
+ "git-commit-template", "gson-format", "idea-features-trainer", "jclasslib",
+ "maven-helper", "rest-devlop", "save-actions", "sequence-diagram", "translation",
+ "others"
+ ]
+ },
+ ],
+ // 必须放在最后面
+ '/': [{
+ title: "Java", icon: "java", prefix: "java/",
+ children: [
+ {
+ title: "基础", prefix: "basis/",
+ children: [
+ "java基础知识总结",
+ {
+ title: "重要知识点",
+ children: ["反射机制详解", "代理模式详解", "io模型详解"],
+ },],
+ },
+ {
+ title: "容器", prefix: "collection/",
+ children: [
+ "java集合框架基础知识&面试题总结", "java集合使用注意事项",
+ {
+ title: "源码分析",
+ children: ["arraylist-source-code", "hashmap-source-code", "concurrent-hash-map-source-code"],
+ },],
+ },
+ {
+ title: "并发编程", prefix: "concurrent/",
+ children: [
+ "java并发基础常见面试题总结", "java并发进阶常见面试题总结",
+ {
+ title: "重要知识点",
+ children: ["java线程池学习总结", "并发容器总结", "拿来即用的java线程池最佳实践", "aqs原理以及aqs同步组件总结", "reentrantlock",
+ "atomic原子类总结", "threadlocal", "completablefuture-intro"],
+ },
+ ],
+ },
+ {
+ title: "JVM", prefix: "jvm/",
+ children: ["memory-area", "jvm-garbage-collection", "class-file-structure", "class-loading-process", "classloader", "jvm-parameters-intro", "jvm-intro", "jdk-monitoring-and-troubleshooting-tools"],
+ },
+ {
+ title: "新特性", prefix: "new-features/",
+ children: ["java8-common-new-features", "java8-tutorial-translate", "java新特性总结"],
+ },
+ {
+ title: "小技巧", prefix: "tips/",
+ children: ["locate-performance-problems/手把手教你定位常见Java性能问题", "jad"],
+ },
+ ],
+ },
+ {
+ title: "计算机基础", icon: "computer", prefix: "cs-basics/",
+ children: [
+ {
+ title: "计算机网络", prefix: "network/", icon: "network",
+ children: [
+ "计算机网络常见面试题", "谢希仁老师的《计算机网络》内容总结", "HTTPS中的TLS"
+ ],
+ },
+ {
+ title: "操作系统", prefix: "operating-system/", icon: "caozuoxitong",
+ children: [
+ "操作系统常见面试题&知识点总结", "linux-intro", "shell-intro"
+ ],
+ },
+ {
+ title: "数据结构", prefix: "data-structure/", icon: "people-network-full",
+ children: [
+ "线性数据结构", "图", "堆", "树", "红黑树", "bloom-filter"
+ ],
+ },
+ {
+ title: "算法", prefix: "algorithms/", icon: "suanfaku",
+ children: [
+ "几道常见的字符串算法题", "几道常见的链表算法题", "剑指offer部分编程题"
+ ],
+ },
+ ],
+
+ },
+ {
+ title: "数据库", icon: "database", prefix: "database/",
+ children: [
+ "数据库基础知识",
+ "字符集",
+ {
+ title: "MySQL", prefix: "mysql/",
+ children: [
+ "mysql知识点&面试题总结",
+ "a-thousand-lines-of-mysql-study-notes",
+ "mysql-high-performance-optimization-specification-recommendations",
+ "mysql-index", "mysql-logs", "transaction-isolation-level",
+ "innodb-implementation-of-mvcc", "how-sql-executed-in-mysql",
+ "some-thoughts-on-database-storage-time"
+ ],
+ },
+ {
+ title: "Redis", prefix: "redis/",
+ children: ["redis知识点&面试题总结", "3-commonly-used-cache-read-and-write-strategies"],
+ },
+ ],
+ },
+ {
+ title: "系统设计", icon: "xitongsheji", prefix: "system-design/",
+ children: [
+ {
+ title: "基础", prefix: "basis/", icon: "jibendebasic",
+ children: [
+ "RESTfulAPI",
+ "naming",
+ ],
+ },
+ {
+ title: "常用框架", prefix: "framework/", icon: "framework",
+ children: [{
+ title: "Spring", prefix: "spring/",
+ children: ["Spring常见问题总结", "Spring&SpringBoot常用注解总结", "Spring事务总结", "Spring设计模式总结", "SpringBoot自动装配原理"]
+ },
+ "mybatis/mybatis-interview", "netty",
+ {
+ title: "SpringCloud", prefix: "springcloud/",
+ children: ["springcloud-intro"]
+ },
+ ],
+ },
+ {
+ title: "安全", prefix: "security/", icon: "security-fill",
+ children: ["basis-of-authority-certification", "jwt优缺点分析以及常见问题解决方案", "sso-intro", "数据脱敏"]
+ },
+ "定时任务"
+ ],
+ },
+ {
+ title: "分布式", icon: "distributed-network", prefix: "distributed-system/",
+ children: [
+ {
+ title: "理论&算法", prefix: "理论&算法/",
+ children: ["cap&base理论", "paxos&raft算法"],
+ },
+ "api-gateway", "distributed-id",
+ {
+ title: "rpc", prefix: "rpc/",
+ children: ["dubbo", "why-use-rpc"]
+ },
+ "distributed-transaction",
+ {
+ title: "分布式协调", prefix: "分布式协调/",
+ children: ["zookeeper/zookeeper-intro", "zookeeper/zookeeper-plus", "zookeeper/zookeeper-in-action"]
+ },
+ ],
+ }, {
+ title: "高性能", icon: "gaojixiaozuzhibeifen", prefix: "high-performance/",
+ children: [
+ "读写分离&分库分表", "负载均衡",
+ {
+ title: "消息队列", prefix: "message-queue/",
+ children: ["message-queue", "kafka知识点&面试题总结", "rocketmq-intro", "rocketmq-questions", "rabbitmq-intro"],
+ },
+ ],
+ }, {
+ title: "高可用", icon: "CalendarAvailability-1", prefix: "high-availability/",
+ children: [
+ "高可用系统设计", "limit-request", "降级&熔断", "超时和重试机制", "集群", "灾备设计和异地多活", "性能测试"
+ ],
+ }],
+ },
+ blog: {
+ intro: "/intro/",
+ sidebarDisplay: "mobile",
+ links: {
+ Zhihu: "https://www.zhihu.com/people/javaguide",
+ Github: "https://github.com/Snailclimb",
+ Gitee: "https://gitee.com/SnailClimb",
+ },
+ },
+
+ footer: {
+ display: true,
+ content: '<a href="https://beian.miit.gov.cn/" target="_blank">鄂ICP备2020015769号-1</a>',
+ },
+
+ copyright: {
+ status: "global",
+ },
+
+ git: {
+ timezone: "Asia/Shanghai",
+ },
+
+ mdEnhance: {
+ enableAll: true,
+ presentation: {
+ plugins: [
+ "highlight",
+ "math",
+ "search",
+ "notes",
+ "zoom",
+ "anything",
+ "audio",
+ "chalkboard",
+ ],
+ },
+ },
+
+ pwa: {
+ favicon: "/favicon.ico",
+ cachePic: true,
+ apple: {
+ icon: "/assets/icon/apple-icon-152.png",
+ statusBarColor: "black",
+ },
+ msTile: {
+ image: "/assets/icon/ms-icon-144.png",
+ color: "#ffffff",
+ },
+ manifest: {
+ icons: [
+ {
+ src: "/assets/icon/chrome-mask-512.png",
+ sizes: "512x512",
+ purpose: "maskable",
+ type: "image/png",
+ },
+ {
+ src: "/assets/icon/chrome-mask-192.png",
+ sizes: "192x192",
+ purpose: "maskable",
+ type: "image/png",
+ },
+ {
+ src: "/assets/icon/chrome-512.png",
+ sizes: "512x512",
+ type: "image/png",
+ },
+ {
+ src: "/assets/icon/chrome-192.png",
+ sizes: "192x192",
+ type: "image/png",
+ },
+ ],
+ shortcuts: [
+ {
+ name: "Guide",
+ short_name: "Guide",
+ url: "/guide/",
+ icons: [
+ {
+ src: "/assets/icon/guide-maskable.png",
+ sizes: "192x192",
+ purpose: "maskable",
+ type: "image/png",
+ },
+ {
+ src: "/assets/icon/guide-monochrome.png",
+ sizes: "192x192",
+ purpose: "monochrome",
+ type: "image/png",
+ },
+ ],
+ },
+ ],
+ },
+ },
+ },
+});
diff --git a/docs/.vuepress/public/assets/icon/apple-icon-152.png b/docs/.vuepress/public/assets/icon/apple-icon-152.png
new file mode 100644
index 00000000000..3eabbeb1dc3
Binary files /dev/null and b/docs/.vuepress/public/assets/icon/apple-icon-152.png differ
diff --git a/docs/.vuepress/public/assets/icon/chrome-192.png b/docs/.vuepress/public/assets/icon/chrome-192.png
new file mode 100644
index 00000000000..851ad3a224d
Binary files /dev/null and b/docs/.vuepress/public/assets/icon/chrome-192.png differ
diff --git a/docs/.vuepress/public/assets/icon/chrome-512.png b/docs/.vuepress/public/assets/icon/chrome-512.png
new file mode 100644
index 00000000000..2fb9f40be37
Binary files /dev/null and b/docs/.vuepress/public/assets/icon/chrome-512.png differ
diff --git a/docs/.vuepress/public/assets/icon/chrome-mask-192.png b/docs/.vuepress/public/assets/icon/chrome-mask-192.png
new file mode 100644
index 00000000000..530977a9e69
Binary files /dev/null and b/docs/.vuepress/public/assets/icon/chrome-mask-192.png differ
diff --git a/docs/.vuepress/public/assets/icon/chrome-mask-512.png b/docs/.vuepress/public/assets/icon/chrome-mask-512.png
new file mode 100644
index 00000000000..a4f90ae484b
Binary files /dev/null and b/docs/.vuepress/public/assets/icon/chrome-mask-512.png differ
diff --git a/docs/.vuepress/public/assets/icon/guide-maskable.png b/docs/.vuepress/public/assets/icon/guide-maskable.png
new file mode 100644
index 00000000000..75449b6098b
Binary files /dev/null and b/docs/.vuepress/public/assets/icon/guide-maskable.png differ
diff --git a/docs/.vuepress/public/assets/icon/guide-monochrome.png b/docs/.vuepress/public/assets/icon/guide-monochrome.png
new file mode 100644
index 00000000000..5b1dc406d6a
Binary files /dev/null and b/docs/.vuepress/public/assets/icon/guide-monochrome.png differ
diff --git a/docs/.vuepress/public/assets/icon/ms-icon-144.png b/docs/.vuepress/public/assets/icon/ms-icon-144.png
new file mode 100644
index 00000000000..24641244228
Binary files /dev/null and b/docs/.vuepress/public/assets/icon/ms-icon-144.png differ
diff --git a/docs/.vuepress/public/favicon.ico b/docs/.vuepress/public/favicon.ico
new file mode 100644
index 00000000000..3a14635ac46
Binary files /dev/null and b/docs/.vuepress/public/favicon.ico differ
diff --git a/docs/.vuepress/public/logo.png b/docs/.vuepress/public/logo.png
new file mode 100644
index 00000000000..7675a8b5aa3
Binary files /dev/null and b/docs/.vuepress/public/logo.png differ
diff --git a/docs/.vuepress/public/logo.svg b/docs/.vuepress/public/logo.svg
new file mode 100644
index 00000000000..fdfe9e6c1ce
--- /dev/null
+++ b/docs/.vuepress/public/logo.svg
@@ -0,0 +1,317 @@
+<?xml version="1.0" encoding="UTF-8" standalone="no"?>
+<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd">
+<svg version="1.1" id="Layer_1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" x="0px" y="0px" width="404px" height="314px" viewBox="0 0 404 314" enable-background="new 0 0 404 314" xml:space="preserve"> <image id="image0" width="404" height="314" x="0" y="0"
+ href="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAZQAAAE6CAYAAAAx06Q+AAAABGdBTUEAALGPC/xhBQAAACBjSFJN
+AAB6JgAAgIQAAPoAAACA6AAAdTAAAOpgAAA6mAAAF3CculE8AAAABmJLR0QA/wD/AP+gvaeTAAAA
+CXBIWXMAAA7EAAAOxAGVKw4bAABEiklEQVR42u3dd3xTVf8H8O/NapLudFK6oEAZZcgWVLbsocgQ
+UBQUBwrifn6PIj7uBxSExy2oCAgoylCWTJlljwKlUOjeI22z1/39kQTSNGmTrtumn/frlVebm3Pv
+Pecmud/cc88gAgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
+AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
+AAAAAIAGxHCdAYCm5vj6794j83fDRER8ImIHzHz6LVfW3ZueOv5EbtbQS8WFPQO8vIqDxZKiUIl3
+nrdQVE5Ehme79VrBdfkAGoqA6wwANDXntm54S69R33kuFEuIiBwGFJZlmdeP7v/hr4zUx/REvBeO
+7Xe4TZ1eT/eHhP9FRCu4Lh9AQ0FAAbDjLQvOkOdkRts8z3OUbtXFU+/03LT6baXJxCeGcXq5rzcY
+KLe4iAol3jKuywbQkBBQAOx4BwZlVwoogUGVAgrLsrxBv/9ctOrKhcCatmUwGim3uJC0eh2llcvj
+uC4bQEPicZ0BgKbGOzCowO55kfV/lmV5k3f+lpyn1dQYTIyWYKLR6YiIKK2sNJTrsgE0JAQUADve
+suAcu+f51v/fO3Xku6Sy0vY1bcNoMlFucRGptdo7y4LEUm1N6wE0ZwgoAHZEUh+53fNSIqLLRfk9
+1924Oqum9U0sS7nFhaTSaiotby8LusJ12QAaEgIKgB2Jr1+x3fN8IqIliUc+IB6vorp1WWsw0Wiq
+vNYuIOgy12UDaEi4KQ8thkmvF+lu3OhjyM1pyxhNAl5QUI4wMvI6LzAwlycS3amO8vLxK7Vdz8vH
+r+hyUX7Cw3u2jmIYhgQGA/lotNS2QkmtFAoq4/HpQqtQUkgllFtcREq12uH+u4aEneP6GAA0JAQU
+8GiKPbvnav85PIO9fatn2fQpUiISkk2HXg2R1mQ0mQofnsRScHCJsHefrSUmNomIlEQkJSKVmMc3
+HVy+bM2vGdmm8AoFT8CyxBfwK+/ofBIZGR4pfXzobFAg+7G/hDklrvT10oxs034318cDoCGhpzx4
+JMWff87X/P7bO/wyeUht1tcRkdLbm7yVKhIRW6s83GjViv4vOoz2sXqSiSUZJQvfiuH6uAA0JAQU
+8CjGiorAkpcXXRCUFEXXfWu1V5xXQGqFkhiRiG73633u12H3p6x9aMajXB8fgIaEKi/wGLrU1HtK
+np67X6DX1dhHpCFZgwkREavTUeyR4z3/rTPo1hQXhwmCgvLruHmAJgutvMAjqP45PEX5+isnmlIw
+saVLPNU/7cUXd2vT0ztwmT+AhoQqL2j29MXFERVPz7nJMIyEy3w4Cya2vHv1OhL77bdDeQKBgcu8
+AjQEft03AcCt+bdupgmI/LjMgyvBhIhIn5sbQwaDcNnu3ftd2CxAs4IqL2jWCt5+a6cXa+J0FF9X
+g4lV4Zo1i8oPHx7PZZ4BGgICCjRb2oyMTqazZ0ZzmQd3g4mFuOCbb1yasAugOUFAgWZLue7n970k
+Ys72X8tgQkRE6itXelUcOTKWs8wDNAAEFGi2jEmXh3C177oEEwt+2d69U7jKP0BDQECBZkmTdHmw
+wIU5SRpCPQQTIiIq+/vvidrs7FguygDQEBBQoFlS7907j4v91lcwISIyqdUB6itX+nJRDoCGgIAC
+zZLpVmrPxt5nfQYTK31OTmxjlwOgoSCgQLPEFhdHNOb+GiKYEBHp8/I4HXMMoD4hoECzxGg1Xo21
+r4YKJkRE+txcBBTwGAgo0Cw11phBDRlMiIhMOp2okYoC0OAQUKBZMrFkauh9NHQwISLi+/iUN3Q5
+ABoLAgo0SyyPadCA0hjBhIiI5+NT1uA7AWgkCCjQLJn4fGNDbbuxggkREd/Xt7TuWwFoGhBQoFli
+AmR5DbHdxgwmRMQKZLLCxtoZQENDQIFmSdC+/Zn63mYjBxMiIpO4ffukxtwhQENCQIFmyatLl4P1
+uT0OggkRkV7cvv3Fxt4pQENBQIFmyXvM2O8MJpO6PrbFUTAhUVRUhjA0NKfRdwzQQBBQoNliW7W+
+XtdtcBVMiIh8+vY9wMmOARoIAgo0W5Jx47+uy/pcBhMi0gROnvw9VzsHaAgIKNBs+Y4Z841OIq1V
+KymOgwnJJk/+Qdqly1nOMgDQABBQoFkTDRrys7vrcB1MyHx1sprLDAA0BAQUaNYCn376Fb3IK9/V
+9E0gmFDIE098iqsT8EQIKNDs+cx75lWWZWtM1xSCiU+/fnvDFy16i9NMADQQBBRo9qRDhq7jD3/w
+y+rSNIVgQkQVEYsXP8N1JgAaCgIKeAT/5+fPN3Xs/Lej15pIMNG3Xrz4Ja/IyDSuMwLQUBBQwGME
+ffDhg8yDo1YS0Z36ryYSTNStFy9+XjZ58hquMwLQkBprniKARlOx7uf/GP7Y8lZxXgHDdTARtmqV
+H/nee4/69OlTr0PFADRFCCjgkRS/bn4jb8vvz6mvXYvhKg9+Q4dujXjzzReFYWFZXB8PgMaAgAIe
+y6TTiYs3bHijeMOGhfr8/MDG2q9XXFxG8OzZ78omTkQVF7QoCCjg8XR5eTHFGza8Urxhw5OsXi+k
+u/cOWSLiWx61YTtrJMPz8tIEz579efDs2R/zMRMjtEAIKNBiqK5e7a84dmyy8vTpYYrExHvqY5uM
+l5fWd+DA49IePY769O37p6RTp1NclxOAKwgo4PFYlrVekVg/74yxvDxYceLEXMXJky9obtwIN8rl
+ZJTLyahQON0O39+f+AEBJAgMJGmPHmm+Awa8J+3RYzMjElmH0be2LmMZhqm5pyWAh0FAgXp3PVfd
+Y/HOglVXi0zdtCxfoiWe0JsxKKpZhXFhOWPzlyFztZXt33r7LLMmlohlyRwfGCKGIYZX718V6w5M
+Nv9bH7ZpnB0X2+Nxh4IVioiIonmKzCBGbT9NMsvnkSHET5Qb5i/KDvMXZYcFeOXEBItT+8T5n6jv
+AkLLg4AC9WrBrzkbt6ay07jOR0umLywgQ7l7t3D8pQLt+J4h6x7sHrRjdI/gbVyXAZonBBSoNz+f
+LH7h34c0q7jOR0tWm2BiT+rF1z3cJ/TnF0dFfdI2THqD6zJB84GAAvUm4cOb5eU8iS/X+Wip6iOY
+2GEn9Ar57f1p7Ra1CvTK5rp80PRh6BWoFyqt0bucESOYcKQBggkREbP9bOGUvv9OvPnFnoxXuS4j
+NH0IKFAvSlSGEGJwwcuFBgomd2j0JvGS324tfeKrpD+UGoMP1+WFpgsBBepFZKBXGmMycp2NFqeh
+g4mtv84VTRr18flTWcWaaK7LDU0TAgrUm74hpn+4zkNL0pjBxCo5W9lp2Ptnz1/NUnTjuvzQ9KCO
+AuqNSmv07v5pRoGWJ5JynRdPx0UwsdVa5pV54O3e98h8hMVcHwtoOnCFAvVG6sVXHp3fun0YT1XE
+dV48GdfBhIgou0Qb9eRXV/7k+lhA04IrFGgQyTnK7ifTNcMUOjaQzD9ceETEYxiGZVnW/nNnfc46
+WFYT1slz1sHrDnuXu7hdhpz3XHdUFnfL4WzftuVgicjUI4x/jIiMdLeXvcvHimWJKarQhRQr9EE5
+pbqYracLZmcWa0JrkUciIpo7pPXXH89o/1xt1wfPgoAC0MKdvVXed8OxvKfW/pPzdG3W//G5Lo+M
+7RmyhetyAPcQUACAiIiySzSRy3dm/PunwznPurNeZJA47/zH/VtxnX/gHu6hAAAREbWWibOWzerw
+3HfzOk11Z72sYk34139nvsx1/oF7uEIBgCqOX5cPmb7y0gG1zuRSepmPsOjsR/3a+IgFCpdWAI+E
+KxQAqGJAfMDBL+d0etTV9CUKffCagzkLuM43cAsBBQAcGtcrZOMr42K+dDX95pP5c7jOM3ALVV7Q
+6HQ6nYSIAujuXO7WiaZsH46a7do+iCp/fk1EZKC7zWmNlgdDd+eNt52Uy/Y5OdiXo/+tqmuq7Oz/
+6v462qajfdpvu7r1naV3tA6PiAQ2D8ZyDPUmlgTDPziffz1XLSYXnHy/b3xcmDTFlbTgeQRcZwBa
+FqPRKMjMzFxORH2JyNpHhaW7AcA2KJio8gyNtkHA9sESkY6IVESkJiItEeUR0TXLbhOIKISIfIhI
+SObPvcjyP98me9bgYT9lsD1n/URMDv6anLxmf4J3FIisaY12DwPdDZrOtmmySWugysfW9vhay8u3
+HBeJ5ThpiOg6EWUtGhG049m1WVNceX//PFc4hYg+qPMHBZolBBRobH5E9AARdWroHf35559seno6
+M3/+fK7L3BTZBipr50gRVQ6iZURU2itKYOzd1pfO3KqocaOHr5aOIgSUFgv3UKCxSYmoUfospKen
+M0uXLuW6vE0VQ+YflF5EJLb8tb8i8yeiWCKKG9fN1+DKRk+llg/kumDAHQQUaGzWqpUGN3/+fEpL
+S+O6vB7h/jihwJXpbrR6E5NeqG7DdX6BG6jygsYmIXNdvlNCoZDrPLZYer3e4XI/MUMdWknpeo6q
+xm2k5qs6EtFtrssCjQ8BBRoVj8eTxMTEZJG5lRc0I7EhFS4FlKwSbSzXeQVuoMoLGpuIzPdRoJmJ
+CnKp5TDll+miuM4rcAMBBRqbgMzNdaGZ8Ze6VqGhUBv8uM4rcAMBBRqbgPC5a5by5FqX0km9+BjP
+q4XCPRRobHqDweDKRFXQxBSU6VxK5ycVlHCdV+AGAgo0KpPJpM/Ozg7iOh/gvmvZSpfSxQSLb3Kd
+V+AGqh6gsekIY8g1OzcLDZRV4lqVV1yYNJnr/AI3EFCgsanIHFSgGTmS6tpbJhHxKD7C+yrX+QVu
+IKBAYysndHprLkxERDoDS7+eLnVphT5x/ke4zjRwB/dQoLGVE9EeMgcVfzKPI2UdNv3OKL98Pp/I
+PEyLyJLG15Lek6vLTGQeKVlLRHq6OypwdcPQOxvS3rbhg+2IzfYPMhqN1tdNRKQkokIiyieiYiIK
+33ZZ062wXB/pSgEe6BSwZwvXRxE448lfTmiiWJbl0d1h5G3nKLGd58Q6pLoXEcmIKIrMw9B3svwf
+SUThZB5qvbkpJ6ICMp+084goh4jSiSjN8ighc1CxBhQix/OlsDU8tx7L6gKK7RQABjIPW68mc0Aj
+pdbYuvf/Jd4qrnA8JIu9Mx/2i4sJkdzi+gADN3CFAo2OYRjbX+I1Ylk2i4iSieg4EQVZHhFE1I6I
+oskcYGIsfwOo6f1Q0hFRps0ji+4GkQwiKiXzvSWN5ZgYGIZplKbVLMveOVb2+zSZWP6cr6/udDWY
+DIwPOI5g0rIhoECTZwlAGsuj2HISFJK5OkxC5iuYGCJqT+Yrl9aWv5FEFErmqxi++3uukyIyB400
+IkololtEdJPMVX3FlrLoyBw8TLXcR30cW6eB66Ott78+eKWko6vbempI65VbuSoINAlN7ZccQK3Y
+BBkhmavJ/Ml8FRNFRMGW5z5kHkdMRHdnbBRZlntZnkss6WVkrgayVj9Zq4wENutZf5CpyRxAsogo
+m8yBJN/yN4XM1VpqhmFc+6nPMYPRJFjy263vv9mXNdvVddqGSnJOvNc3ksdrnCsraJpwhQIewfJL
+W2d5KMkcCG5bAo31foH9vPKM3f+2fx1NNWxdbp0qV2LZpprMVx1Kqnzl0exOrrml2uiHPr3458kb
+ZV3dWe/fD7V5DcEEEFDAo1lO6tapbpvFFQIXdAaT8Ku/M9+89+1T7yi1RreqBwd1Djw0oXfoBq7L
+ANxDlRdAC6XSGqXHU+QPHE2Wj9hxrnBGRpEm3N1t+EkEFUfe7d05IlCcxXV5gHsIKNAgvjhU+O6h
+VPVYrZEkZNMcmL3b18S2esSVqhKmmudMNcucYZ38rSkPfCISBHpRWUKg6ZzNcmvTW5PdX2fLnPUp
+cZQf+z4lrrLfnklnMHndzFN1vJajTLiVr67zvCU/Pd9l8ph7Qn6v63bAMyCgQL1af7r0ubf+Lv/S
+yPPc2lR9YQEZysu4zgbnXhgZteydR+Je4zof0HQgoEC9uZip6jthXUkiy3juxwrBxGzGwPC1nz/R
+0eVWYNAyNHbbfPBglyLn3Cg3CT12NkYEE7Mp/cM2/G9Op8e4zgc0PRgcEupNllYk4ToPDQXBxOyJ
+QRHffDm300yu8wFNEwIK1IubBdrOxPPMjxOCCVGon6h03QsJE5bO6vAs13mBpstz75xCo4oLEV0j
+1kTEeFZQQTAhen5E5PLXJsQu9hELMFc8VAsBBepNrFhHaVox19moNy09mAzqHHjo/WntXugY4X3l
+Xa4zA82C5zbHgUZ3LUc1cNSPxUdZD6j6asnBZFiCbP+cIRErHuwW/CfXeYHmBQEF6gXLsnwiYn4/
+L//3KzuKlpi8pFxnqdZaUjDxlwqoR6zv6R4xvid7tfE9MrBj4B4/iaCc63xB84SAAm4zFhZG6TIz
+uhpzczsYCwraG4uL25pKSuLIoJcQUZDGyEguqn1UxSTWGhm+hMwzLjYLhV4BpPDx5zob9cU6htmd
+nvoCIm2IlEmO7dlxW6cecdtjQsQpRMQ2x4EsoelBQIEa6QsKoio2bFhsuHBunKC8LIRhGI/sv1Sc
+V0BqhZLrbDQOhqHQp5/+OvT5559HMIH6goACDpkMBkHZF6u+0ieemshXKWU8Ps8jg4hViwomNlq/
+++4LskmTvuA6H+AZEFCgirIf1nyo2b5tvojH+HGdl8bQUoMJERHPy0sTv2dPtCAwsJDrvEDz1/yb
+40C9UR8/9nD+jOkFpj+3/wvBpGUwabVixYkTo7jOB3gG9EMBMikU/iWL396tXvbf/iIPHtjRXksP
+Jlb6wkK350EBcAQBpYVTnz8/vPDxWVtEDPkRgkmLJAgJyeE6D+AZUOXVgsnX/vSB+r0lu0UMtYjq
+LSsEk7t4Xl4Kn/7993KdD/AMHt1yBxxjTSbeixr1YebEsVkM42GDb9UAwaQSU6s333zRp3fvI1xn
+BDwDqrxaGJZlmeLZs3L4SmUY13lpbAgmd/EkkuKQuXP/GzR16ndc5wU8R8upNAciIip6+aXT/PS0
+3vWwKb3RZDKwfIGBpJJS8g8sZMRilV0a27neq5sDvrr54t3laI52E+vtXWwKC08hIoNdGmfq87vB
+1vC8Nuu5O+f8nTLzAwIKAx966Ae+WKypxzIC4AqlJZGvWrmaPXSg1sFEr9MZKDgkR3hPz93ekx5a
+LoqOTua6TADQdOAKpYVQHTv6sObTpb8xjPtNuQxGo5669dgT8OKC54UhIZlclwUAmiYElBbAqFT6
+Fc2akSXiMb5urxsTezrw7XfG8wMD87kuBwA0bQgoLUDBa68cEd5Kvc+ddUwsaxQ//cwC79FjvuQ6
+/wDQPLSoJqMtkSYlpQ9zPdmtYGLk8dR+K1beg2ACAO5APxQP93x52XEvoyHA1fQGoag06Of1YYKg
+oGyu8w4AzQtaeXkw1cULw5RvvxVDQtfeZhMxJtmPa6N5Xl5q2+Usy1qb/Tq7orVv3upKVWpNaZha
+rMfU8L+zZsqOmuC6u6y6NFWOUW3nILG8FzUeC4ZhTLXZPkBd4B6KB8uf91SKqLiovStpWYYh1cJF
+TxuiopOIyJ+IwogokoiiiciPzLMuehERn8/n68n82RFYHjzLg3HyILvXeXZ/7dNW9z9Vsx/GJi88
+F/dj32fF9v8q/VlsHka7/60Pg+Vh+79tegMR6W3S2O+LyHE/FesyhogERqPRj4hEZK5lsJbDmgcF
+Ed2WyWSr/fz80LQbGg2uUDyUoawsuPSxGe1IKHQpvX7GrKWGqOgsIupERPFE9AAR9SAiiX1ao9HI
+dfGgZnlEdJiIEFCg0SCgeKiy775dLhAKXboC1beKUKh79tpPRO2JaCARDSeiYK7LAHUSTuarTIBG
+g4DioXSJJyeJXUyrf3jyR0TUgYhGEdFQMldvQfMn4joD0LKg2bAH0uXmthWbjFJX0urbxin0beOy
+iGgwIZg0FQYi0hCRiogqiEhOREVElE/mqqw8IiogomLLa0oi0tHd+ywGIrppSQPQaHCF4oGUG39Z
+TC7+WJAMGrxZFhmpIqKOhGDChXwyn/zTiSibzMFCTuZgYr157+hGvrWxgZDMVyISIpJa/uqJKINl
+2USuCwctCwKKBzKeOzvelQ5GRmIoYOy494hoMZnvn0DjyiOiY0R0ioiuE1EGma9EFGS+4rC2ImPt
+/reybdnGJ3Nw4VvSqBmG0XFdQGhZEFA8kVrtUnUXRUYSEd1HRMPIfDKCxqMjootEdNLyuEXmKiyd
+G31UrOmMZL4qwXD0wCkEFA/EGA084tVc4yXqf+8tInqUzH1NoHEVkfkKpZDM1VtE5u8jy7Lsnf4p
+7naAZFmWV5v1AOoDAoqH0ZeUhCuenuNSWq/uPf4iorFc57mF4hNRIJk7jxqIKIKI1GS+crF2UDSx
+LGvtDGnbWdK2I6WJzNVetlVeepZlixiGUXBdSGhZEFA8jKmgIIZcHKOtNCDgBuXnS1xJC/UujMzB
+vC+ZW3JZb7qzdg/beyf2vfVt76lYRy5gyFz1dbu0tPS7wMDAU1wXFFoOBBQPYywubk0uBBQjw5BG
+p0OrLm7xydwBMbwBtl3q5eV1msw3/AEaBfqheBhTaYlLJydWJCIi0pL5lzF4nkAiCuA6E9CyIKB4
+GEYiLXcpncFIZL4ZrHYlPTQ7BjL/YABoNKjy8jC8sLB0utvxzXk6o4HIXHdfRObBIBua3rK/CjIH
+MWtLJiLXhpd3dA/B/v6BgMwjIls7+Amo8ojIDFV/XOz7fRjJ3Au9jKqODkx26QwO0lj3x7fkwdoJ
+UWTJp5flf4EljaM8OhoBmaXKN+hZy7oiyz6MRJRGRDmN8L4C3IGA4mH4ISEZLMsaGYap9r1liCiU
+qIIJC/uZzAGlIQaDLCSifUR0hsw9wYuIqJzudtpzFlDss1rdEPPWNNbOfQK6e9K2Hcbe+lovIgqi
+ylfnBiLKIqJrZA581n4dOstDT3eDDVHVoebtb5Rb82QbUGzzJqa70wFYg4BtQOHZbIN1sB9rMLHm
+lSzrWwMVkTkIXm6A9xTAKQQUDyMKC0svnDjOKBAIanxv2WvXhktiYr4goplEdH89Z0VNRFuI6Hsi
+utyEem3vIqo8URXXfTZYlrUGE2fzthA5vkoz2uadZVkhmYMTQ0QahmEwzwA0KtxD8UCsQGhwJZ3m
+5IkJZB4/agsRldRzNorJ3HGvuAkFkzsYhmGtjyaQFyPDMHqGYbQMw2gYhlEzDKNiGEZp81BZlmsY
+htExDGOwzzvDMNbe8ggmwAkEFA/EBgS4FBxMN2+0JnOVzi9EdK6esyEkolgi6sqybATLshhKncxX
+RizL8liW5bMsK7B5CG0eIpuHl83/Qst6jJNtC8lyb8byP0CjQpWXB+K373CSTidG1ZROoFGLjXm5
+nfjhrVKI6Dci6klEsnrKhh+ZRzAeRkShRJTOsmwJmVuW2d9nsK3Gsd5otp02l6XKnfvs7ysQUY1T
+6Nrur6aJx6qbJ97+uaNpiW3v29g+7Ku0nOXR9q9tNdedm/+WHvS2x1FAd+/LMESkYFk2tylcgUHL
+gYDigSQD79usO504xZW0JTt2vKN6cOS3ZO63UEJ2AUUkqvWFhYSI+hNRV7o7HLuazCdEospzvdvf
+H7Cdr92+VZezud7t/7cfmZeo+pZejoKHfaMBcrCu/Tz2fKocTBzdG3EUsJyd+G3LZaC7jQSMRMTq
+dLoQujvsivXBElGuTCZ7n4gO1PYNBHCXS1PEQvPCGo384smTtHw+v8Ye8waGR8plnz1A5gEip5N5
+1kb80Gj+CmUy2Qt+fn6buc4ItBy4h+KBGD7fyAaHZLmSVsCaSLp392tkbs57hMzzckDzJ6W7TYoB
+GgUCiocSjxv/ucuJd+4cz+fxCsk8J8c2MgcV1L03b4VkrmoEaDSo8vJQrMnE5D38UJmYz/i6kt4Q
+3kqufO2NiWQe/6ktEd1DRJ3J3AnQl8yd5ogc39twNBquoxvZzm6q23bYs99mdfdE7Pts8Jw8HPXt
+qOk+iqN7MtXly1n5HN20t71/VFM+7Rss2A5fb7KsZ9uZk0/m0QiuymSyZX5+fim1/hABuAkBxYOV
+fv3V5/T3ngWupjfFxBZ4f/hxezKfqMR0d57yYCLyIfPnxXZ+c2sQMNo8tw8wttgaHs5uvFf318rR
+idt2uaO0zji7ae5q3qrLl30enQU7R8PPOApe9q3KGMv7USEWi+UE0IgQUDwYazTy8x95uNiLx/i7
+uo6pU5ersvfeT3DU3JRlWQbNUAHAGdxD8WAMn2+UTJu+jGVdjwG8a1c6ly55J9FR5zkEEwCoDq5Q
+WoDc2Y+liRUVMe6sY2wdeVu27LPOPJFIw3X+AaB5wBVKCyB7971xOp3e5M46/OysNkXTpyorNm18
+j+v8A0DzgIDSAnjFxiYJh4/4wd31hAzxDJs3vpX/5Owc7bWrA7kuBwA0bajyakFyHn/stkRZEVub
+dVmWJaOffzG/e4+dvo/OeEcYHn6b6/IAQNOCgNKCGCoqAgufnJ0sZk2hddyUXseSmieT5Qti21zk
+x8RcZMLCbzKBgQXUfDtENpV8u/OdrKlJtKMysTyxWCXu2PEcTyjUc11Y8CwIKC2MQS4PKZ7zxDUR
+Q0H1tc2y4lKqKJVzXTRwgyA4uCjy/fdn+N57799c5wU8BwJKC2SQy0MKn557WWwyhtV1W/KiYlLI
+y7kuEtQCIxSWt/3xx2HShIQzXOcFPAMCSgtlVKl8855+KkmqUUXXdhulBUWkLK/guihQB8KwsPQO
+27d35InFaB4OdYZWXi0UXyqtaLXmh3hdbNsTtVm/JL8QwcQD6PPzYxSnTg3nOh/gGRBQWjCel5cm
+7NPPBjATJn2k1eld/oVanFdAqgoF19mHeqJNS+vAdR7AMyCgAAXMfuL/gn76ua0uPOKS0Vj9FBpF
+OfmkVii5zjLUI763Ny41oV4goAAREQllstywL77sLln48iytxDuLNZmqNDktzM4ljUrFdVahfpmk
+vXod5joT4BlwUx4cUp8/P7z8++8+4WVldhEI+F6F2bmkVeO+raeRPfLIl63ffns+1/kAz4CAAtUy
+aTTS8g3r36xIudFVkZg42FBSEsB1nqBesD733rs3ZuXKCTyRSMd1ZsAzIKCAWzQ3b3ZVJyf31Kam
+JmhSUzubFIqa5lphXVzWkFg3X6spf+5+b1g3n7uKcWF5lYm7+IGBhUGPPrrK+557DjN8vluDhgIA
+AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANAnoKQ8ATdLupMxRo1bu3FVl+YIxD45KiMLUxU0Q
+RhsGgKaK7+Zy4BgCCgA0Va6MVQZNiIDrDHiyz/dffmXhpuPLbJcF+4hp36Kx9/SICr7Adf6gdgrK
+1SGHUnIG/X0ta9SJ1IJBBRXqVgUVam/r61KRgCIDvdN7RYecHNkl8q9BHVodipb5ZPF5vMYeFLNO
+9lzJHD1v3T9/ZJUqvQZ3iDj2zaz7n2gX6n+T63xR4w8uCi5CQGlYjn5JGQlfiGanRKkJXJd4Y9bK
+A0mvh766NrK6tCqdgVLyy2JS8stifjl9cxoRUUSAtHzJjjOfvTy822d+ElGTnyHxRGr+wNGrdu6U
+q8wj2+9Pzh444/sDWwsr1INDfCVFHGcP358mClVeDcvRB59P+EI0G+Vqne8bWxKXRr6xvmTBxuMr
+bxaUR9ZmOzlyld+SHWeXRL25vvzbf649zXW5arL1Qtqj1mBidTajsMvFrOJujZgNZ98TVHk1UQgo
+DcvZ8cUXookzmkzMlnO3Jnd4e1PJJ3suvKrSGeplu2VqHc1b98+3s384+FOZWivmupzVcPYZxTkD
+nMKHo2EhcDRDpUptwNy1h3+a+u2+3/LKVbWtFmapmivR02mFI1Q6gx/XZXVmUo/YDQFSUaVl3SOD
+rnduFXiF67xB04WA0rBwfJuZHLkyYuKXe3b/eDzlMaOpTjWTtjMlVjG2a/SmVv7eBVyX15l748KO
+bXp6+JiYIB85n8fQsI6tT2yeN3xCRIB3Ltd5g6YLN+UBLDJLFFFjVu06eCGzOK6mtDFBPsVPDoj/
+akL3mN9jZL7pgVKvUh6PYYmIFBq9d36FKuzIjbwHNp+5NePva1kj9Ma7M+0GSEXGqb3bblzKdYFr
+MLJL1C4iCiQi2k9E7V5u9CzgXmMzg4DCDVSFNTFlaq3vrNUHv6spmAzq0OrIZ1PuffmeqOCzPB7D
+LnGQxkcsVBLRLcvjxxKlJvD7o8lPfbDz/Mdlah1vaHzrnQkRsgtcl7kZQ6BpohBQAIho8fYzH+24
+lD7S2evhflLFFzMGPjG5Z9stvV51b9syb3EpES3NLlVueOW3E8uHd2q9VyISaLkuM0B9Q0BpWGj2
+2AxsvXD74enf7Z/v7PUH2rc6sm7ukJnRMt/MuuyndaB3NhFN3ch1gQEaCAIKNxBQmogcuTJi3P92
+f6jRGx2+PqpL1J6fnhw8M8xPWsx1XlsgfE+aGbRCalio623ifj17a8a5jKJ4R6/1iAq6/N1jD8xF
+MOEMAkozgyuUZqKgXB2692rWqDXHk+dezyvrki1XBhER8XkMRQZ6Zw1qH7F/cs82WwbHtzroL/FS
+WNdzNJ5Yx/CArEOvjO8T7i/Nsy77/dztaVO+/XujbVNZPo+hX54a9sjU3nFb3MmrycQyb/yeuGLp
+3osLbJd3CPPP/vulsQNignwzqls/o6QiauuFtIkbT6fOvFlQ3qWgQu1LRCTk8yguxC9lSHzEvim9
+2v42IC7smFgouNOd+9l1R77/+p+rc223NSYh+s/N84ZP9BELTfb7KShXh45audNhr3WpSEArpg54
+MUrmk90Ib28Vn++//PLCTcc/tSvL35vnDX/IctO/VhQavffUb/f9uTMpY3Cl/U0b8PrCYV3vNDz7
+fP/lNxduOv6RbZqO4QF5h14Z3yPcX5rvzj5LlJrAnZczx246kzrtXEZR72y5Mtz6WusA79ye0cFn
+RnWJ2j2xR8y2yMBKx7vefpAVlKtD9l7NGmXJQ99suTKE6M73J7db66Bz03rHbRzTNWqHzFtcVl/7
+bWkQUJq463ny+Ne3JC5v9frPox31izCaWEovVkSuLU6ZvfZkymwhn0czV+9ft2Rc7/+0D/O/QY6H
++tbZL7ivXfjh7pFBt85lFLW13fbX/1x9tkyt3eov8XJcJ+RAZqkiZtvFtGn2yyd2j/21umByPDXv
+3td+S1we/eaGfo5e1xtNlJwn75CcJ+/w1eGrz0tFAnr1txPLXh3RfZnlJOfoiptxFEyIiI7ezBty
+Mau4g6PX5g7suGpwfMThOrx1deWoLCa3t+KYo/fS/mrA0clcRW5cNVzPk8f/39ZTn4S9+vNE22bT
+trLlylbZcuX4HZfSxy/YdOyLQcu2H/7oob7/HhAXfsydfVWXh9e3JH7a6vWfx1bz/WmVXqwYu+NS
++ljL92fjknG932kf5p9ST8e7xUCVV8Oq9S8stc4gXrz99AcJ7/6avO1i2mhXO9npjSZan3hzVucl
+m1Pe2JL4X4VW7+sgmdA+b6F+krznB3f+3D7h8dT84WfTiwa6k/etF9KmpuSXhdkuiwiQyucMjP/a
+UfpSpTbwiR8Prr1/6fbjx1Lz+rm2F/MgjMv2Xno1fvGm7FUHkhbpjEaJg2QOP+MavYH3y+mbsxwd
+14gAqfz5wZ2/cKfMDcDRybQhv6+ufMCErmxIqdVL39iSuDTh3V+Tt5y77TSY2DOaWDqckjvo/qXb
+D89cvX9jXrnK2bhpNQYaSx4+sXx/xrr5/Zneecnm6//dc+ENtc4gcmlFICJcoXCl2k93frkq7KGv
+9v6y+0rmkNruQG800Sd7LrzmZF88cvClHNEpcnuHMP83U/LLWlmXafRGWp94cw4R/ePKfgvK1SGj
+Vu6ca798dJfovzq1CrxuvzwlXx5//9Ltu5NySmJrW9YytY7/4sZjnzl52eFkTHll6piz6UX3Onpt
+dJfoLY7y2gQwVD/VQIwLyxztp8bIkCNXRoxeueu3f27k3ltTWmeMJpa/PvHmtPWJN6fWZv0cubLV
+6JW7ttQlD3qjiV7fkvjxkRt5Q/LLVbPD/Nyr5mupcIXSxGSWKKLH/2/PwboEEzuOTh58R8tjgnzT
+JnaP/c1++Zbzt6afTivo48rOjt7MG2xfjSQW8mlmv3Y/2qe9kFnUa/jyv47VJZi4QqHRVylreklF
+m5wy832oSgeGx9Ajvdr82pD5qYP6uqfgSlWS2/vKLFFEj1m163BdTuS1yKd9HqLqMw87LqWPnP3D
+oV/yy1Xhdd+a58MVSsNy6wtRptb6z1p9cPWptIJOjl4P95OWvzGq+38m9Yj9PVrmk87n8UwavcHr
+UlZJ9zXHrs9bezJlhkpnkLiwK6c/JKb2brvuu6PX5slVOi/rMrlK57X5zK3pRHS6uo2qdQbhzNUH
+nrSvXhgQF3aiV0zwCdtlmSWKmPFf7N6YUaIIcrStjuEBqW+O6vHBqC5RO0N9JQU8HsMqNHrvU2kF
+fb84dOXF7RfTx+mNJleqYBhLeSvdN7iSU9rNUVPhGJlvQafwwKvuvG8NxNlVRGO1fHIUUJzuu0yt
+9Zu1+uD3FzKL2zl6PSbIJ+elYV0/ndg99o/IQO8skYCv1xmMwqxSZeS2i2kTV+y/vCi9WBFdlwxb
+vj/fXcgsbu/o9SBvsfK5QZ1XzBkYv9qaB43e4HWzoLz9/w5eeWntyZTZKp2hyjlx95XMIfN+PrJW
+odFP9BEL1Y10/JslBJQm5IdjKc/uuJQ+3H65kM+jDyb1+deLQxI+k4gEukU2r4mFAi0RnSKiU9ml
+ynde+e3Eyo2nUx+uYVdOTwwJEbJzQ+NbH/j9/O3Rtsu3XUx7OL24YkVMkPPOfSdu5Q/emZQx2n75
+jL7tfvaXeN1pmaQzGJmXNh9f4ujk4y8R6b+ccd+T0/vEbbCf4dDSuukgER28niePn/PT4bXHUvP6
+ulDWKgGlWKkJcZS4Xajf5SAfryY7aGM9cfT+szU8d7YemUws8+9tpxbvuJQ+wv41qUig+nBS37ef
+eaDTlxKRQGP72RUJ+Hoiuk1EK9Q6w1ffHb027+1tZ94tU+sCa5F/+nj3hbecjXYwq1/7jaumD3w+
+0Nur9H2b5ZbvTxIRPZVdqnzn2fVHvttxKb3KZ/jPy+kj1hxPfoGImvoQbJxCQGkikvNKOz+4Yuf/
+2S/3l4h0a58cMmNij9gtr9ewjdaB3tk6g3F6+1D//3y46/ybtRktVyISGH4/d3utfUOAlPyy2K0X
+0iYT0QpH6+mNRubZdUfn2P/q7x4ZlDqqS9RW22XHU/OH/Xg85Qn7bUTLfEq2PDtiVJ/Y0NMza8hn
+fHjA9TK1dsSCjce//OlESk3Jq8gudXzDN9xPmu8rFtVpWJTdSZnDR63c+bc763w+bcCihcO62h5b
+V+5z1EZdtuFw3cTbBfd+dfjqIvvlEQHS/F+eGjZ9UIeIQy/VsGHLUDSrTt0uSJz01Z4/cuSqCHcy
+diI1/97Rq3ZWGRSHz2OM/zf6nk/eHttziSWAOdU60DtbrTM89PqWxM9WHUx63vY1o4mlZXsvLU7O
+K/2rY9O4gm2ScA+liVh99Pr8jBJFpfkxxEI+/fTk4BkTe8S63A9EJODr3x7bc/ELQ7pU10qp2kgz
+OL7V7vvahSfaL//pRMqcgnJ1qKN1bhaUd951JWOc/fJH+8b9HBnoc2fIc7XOIFp5IKnKhFXBPmLD
+H889+GCf2NBqq9Vs+Uu8yldOH/Dc+G4xu2pI6vJJVCoSqFxNW43atAyybzzQ2J1iXdlflSo3vdHI
+//5o8jNyla7SuUQqEui/mfnAvEEdIg65k4m+bUJPfTPzgeekIoHe1XX0RiPv+6PJz9rPMElE9MKQ
+Ll+/Pbbn2zUFEyuJSKB9f1Lvf43vFvOX/WsZJQqf1Uevv1CXg+zpEFCagPTiithtF9Om2y+fMzB+
+zaQebdzqVEhkDiqvjOj234QIWXpt8iPzFssf69/+J/vlF7OKux69mfeAo3XWnkx5Okeu8rFdFhEg
+Vdrf5E/KKbnnwPXsofbrvzWm52u9YkLOuptXf4lXxZLxvRYH+4jdvapg3Fzujtp8r1xZpzF7jjtr
+HVjJzYLyDruuZEyyX75wWMKK8d1jttdmx+O7x2xfOCzh02qSVDoOV3JKu267mDbLPlFChOzWKyO6
+LRMJ+G7137H8UHkxLsSv0P61jadTH0/Jl8e7s72WBAGlCTiVVjAgJb9MZrss2EdM8+7v9L/abjNa
+5pvx0vCE/9Z2/RGdInd2CPPPs11mNLG0LvFGlS9uenFF7JZztx+1Xz66S/S2TnYz/O2+kjlBrtJV
+upnePTLo+iO92tR6zMReMSFnnhwQ79axEvJ5OkfLs+XK1kqtnu/OthxwuROoDfsTeH11YnRlX66q
+cr7YezVrVI5cVenKOiJAWvF4/w4/1iWDj/fvsDYiQOrsarFS/ndfyRxVpNBUydtLwxM+jZb5ptVm
+/22C/W4vGJpQ5X5JZqnC+3hq/v11KZsnQ0BpAvZezRprv2xMQvSGHlHB5+uy3eEdI3e1DfYrdfBS
+jSeUmCDf9IndY6s0n92ZlDHxQHL2INtlf1/LGp2SX1apKsxRU+EKjc7nyI28Ks2hH+nVZkNkoE8e
+1cHknm02+zrpEe9Iu1A/h72g88pVrTV6o7QueSGi6qpXTC4ud6uVVSOptH+N3iA6ejNvsH2i4R0j
+/2oX6pdclx11ahV4bXjHyG01pdPoDYKz6UW97Zd3CPPPGtEpslZXSFaTesRu6hDmn2O//EByzsja
+bK8lQEDhxp2TRYVG55NerIi1TzC0Y4RbN3UdCfeXZPSKCT5S2/Wn9m67LkAqqnRytHR0fNL6vESp
+Cfj55I3Z9us6aipcodH7pRVXVOmj8kD7VofqWtb2of43OoYHuDzfeVyIn8OOixkliva5ZaqouuRl
+VELUPvr2GcbRY/eCMWOdrNaY90xcaeXlSKXzhVJr8E0rroi1TzS0Y8Q+Id+9aiZH+rcNTXTy0p28
+ylW6wMvZJVUCSv82YSciAqR1+pESESDN6d8mbL/98nMZRQOd3Uts6dDKixt3vhBKrcE3o0RR6SRr
+HfCxrjsRCwXGN7Yk3qzt+gkRsrND41vvs29CvOtKxuRruaWfdGoVeO3Q9dzhR29WHi6Fz2PohcEJ
+K2wHqSQiKqhQh5UotZX6nfhLRKYgb3FRXcvq7SUojw3yvXU6rbCr3UsO+27EBvneCvOTaPLL1WLb
+5fnlavGZ9MJ+RNRQLXkMriS6WVDe5OvptQajV5laJ7NfHu4nrZcBNdsG+zn77N75/uSVq8KLFJoq
+PwDWnkyZsvZkyhSa902t9y987nuHy8vUuiC5WisjIk9vXu42XKFwjyG7Fj6BUi822EdcL0OmRwTU
+/sstEQmMLwzpslwsrHxLIUeu8vn9/O1pSq1evC7xxhz75sndI4Ou3dcu/KCTslYSKPXKDfYR1/mL
+KRYKjEHe4hJX00cGemfGhwU4DBrbL6Y/rHbQwa2eOKu2qvRd1BtNXi5sq7FVyntBhTq0RKl19Eu9
+sa+2nF1xWR/1Sq03iFQ6Q12rRT0SAkrT1JA3ZIncqIvvFRN8YkBc2Cn75T+dSJm7Mylj8oHrle+n
+EBFN7d32l1A/SaFreyAiDuaNCZB6ye9tG3bc0WsHrmePTMop6dnIWar0njhpNMD1PZSm0pTZfnl1
+owpwfcxaFASUBnQtV55Qm/VKVVp+kUITXB95yJGrWjtY7PKXzF/ipZjRt916++Up+WWRj605+L1c
+pav0Sy0iQKpxNB5YNWUNL1Jo6lwfrdEbBMVKTZA76zzSq836AKmoSossuUon/OLQlYbqb+CsBVml
+98TJTe36ODnW5Vd7pfXC/aR5jq4u88odfubcdquoPM7FpNVdodS23JgcrxYQUBpIhUYnvFVU3sZ+
+uUQo0Np2nvP2ElREy3zSbNMYTSxdySntUtc8aPQGnhtfSqdGdIrc0SHMv8qJQ6M3iu2XWUbqveZo
+O6G+knyZt1elqrwihYafWaqIqWselVqDX1pxRVt31kmIkF0YGt96n6PXNp5Onbn1wu0Jdc2XAy4F
+hYgAaZUhbvLKVREqncG7LjtX6QzeeeWqMAcvuT1gpJDP0/uKhXL7RAeSc0a4sK0anbxV4GyAxzt5
+DfeT5gf7iHOdpGGqeV4Tp2ll3l7yUF9JnW74eyrclG8gyXnyHqfSCqrM7dEm2DfF9sPoKxZVPL/h
+SPLeq3SPbbrDKblDyMkwJ67KK1NHuzuXiSMxQb63X/vt5K9L916cX126AKnI9NR9Hb9a7eR1P7Go
+pF2I/9WU/LI77fiNJpYOJOeMIqLddcnjjYKy+OQ8eWd31pGIBJoDydmf7kzKGGk/ZIxGb+Q9v+Ho
+2nMZhYN7RodcqOsxtOHsRFXpZN0uxP9mkLeYipWaO8uu5pa2T8op6UpE+6mWjt7Mu/9iVrFbx8lZ
+Hv0kwpJO4YFXT6cVVroS35ecNeFabmnnTq1qP0TJtdzSTsOW/zm2pnS+YmFF+1D/y8l58la2yx/v
+32HH6tkPTBbyXesh744UIop4r7636hlwheLArqSM8WVqbZ1uuv1w/Poz9h34iIgSWgeeDZB6Vdgu
+GxIfUeVkeuB69oTTaQW96pKHfclZI28VlddL1dnU3m3XBkirH+NqaHzrXT2igs44e91HLFTfGxd6
+zH75totpj6QXV9Spqe6Wc7enVWj0bn+e72sXvm96n7hNjl7Lkav85/x0eG1miaKVu9uthku/ktsE
++6Z2iQisdCw1eiMt23vpTYVGX6sfgmVqrd+3R64952SMN1eqeCpVGwn5fHZox4i9Do6bdO3JqmO1
+uWPtyZTZ9h0mHfH2EqoGtgur0jR+X3LWsJsF5e1qWh/qFwKKnROp+fc/+v3+7W9tPfO5Wmeo1fHZ
+cTF9oqPBD8VCPj3Ss22VHuF9Y0MPdwjzr9R0Vq7S0ReHriysbTkySipiVuxL+peTl92ui+8TG3pq
+8j1tf3f2Op/H0Kx+7X+yDPLn1KguUdvs71uk5Je1Xpd44wmqpbPphX1+OH79mWqSOD1ZigR89uXh
+3T6OCJA66gBKFzKLu45euetASr68zlWHRpOJScopcXZfrVIeA6ReZWO6Ru2wT7TnaubwNceTn6da
++OlEyhN/X8saVtdy2BoQF3YkKtBHbr/88/1Jr+64mF6rKsMdF9PHf74/6eVqklT6/A7r2HpvgLTy
+8GmWoPZUfZYVaoaAYqNEqQl684/EL+UqHa06mPTUwk3HVyu1ereab+69mvngkz8d+kGlM1S5+Tog
+Lux8r5jgKp21LL3SN9sv//nkjcdWHri8wN1y6AxG/qd/X3o9KaekzvcmbM3s1+5H+ybEVt0jg1Kc
+NBWuJCFCdn5ofOsqnTY/2Hn+Pzsupo+raX17ZWqtz5IdZ98rUmjE1SSr9td3t8igCyumDniRz3Mc
+Z5NySjr2+fCP5PWJNx6lWsouVUY8/sPBn9/4PfEjV9eZ2D32t4gAaaX5N4wmlt78/dTnv5y6OcOd
+/X9/9NrcN38/9VltRqCuToewgJTpfeLW2i9X6QzMM+v/WXc4JWewO9s7dbug7zPr/1mt0hlcmm6Y
+yPyZGtk5qkqv+s/3J72842L6xHotMFQLAcXGV4evvnQ4JffOL8hvj1x74sEVOw9fz6t5MDilVi/9
+ZPeFN8au2r2rSKGpMp+DWMinl4d3e89f4iV3tP7c++JXRct8Kl2lWE8eWy/cdvlLoTMYhe/9de79
+/x28UqtfsdXpFRN8bEBc2AlHr03t3XZdqJ+kxg6KEpFAu2BowqdSUeVaG5XOQM+s/2ftqdsFLs8p
+X6bW+i3YePxrZ3NgWLjUumdq77j1Lwzp4rQXXJlaJ5i5+sCGgZ9sO3bkRu79RpPJpau8EqUmcPH2
+0+90XrL52vrEmzONJtblQSnbhfpdm3xP2yot7FQ6A81ac2D9K7+eWFau1vlQNcrVOt9Xfj3x6TPr
+jnzv6EeOmxwex7n3xX8TLfOp0gcoR67yHb1y18EV+y4vrGludrXOIF554PKLI1b8dShHrgqh6lU6
+VhKRQP/SsK5L7a9SLJ+pHw+n5AwiaBQIKBZn0wt7Lt93+S375cdS8/olvPtr8jPr/vn21O2CvgqN
+/k4rG4VG730tt7TTv/5I/Cj6zQ2Fb/ye+LHeaHJ4TOcMjF8zrlvMH8723zE8MPnVB7t9bP8rWaUz
+0JRv9m39754Lr6lr+NWWXaqMfPyHg7+899e5Ws2FUhN/iZdyRt92VX6NRst8Kia5McT+4PiIfU/f
+3/Fb++U5clXgiBV/HV7vYABKe9fz5PFjVu7+28W5UFzq17N0cv/5C4clfF1dmmOpeQPuX7r9n7b/
+/iV7yY4zS47dzBtQrNAEmCyBwmgy8bJLlRGbz6ROmfDF7q1hr/5c9J8/zy0pU+tqvB9gT8jnsy+P
+6PphXIhflZO10cTSp39feqXD25tyl++7tPBWYXmMzmAUEpl/VNwqLG+zfN+lRR3e3pTz6d+XXnbh
+81DrD0zH8MCrrz7Y7SNHV3gqnYFe2nx8Rcd3Nt1evu/Si7cKy6Ps8hm7fN+lhR3f2XR7wcbjK8vU
+OldmHK3i3riwY3MGdKzy3uXIVQETvthzaOWByy+odYbqrmLpfEZR9/i3N12ned+wjh6vbzm5ytUf
+Ei0VDo7FuYzCHuP+tzsxR66qzVwW1eoRFXR7x/xRg6JkPpnVpStTa31mrT64dceldIf13OF+0rI3
+RnVfMqlH7K/RMp9cmymA71lz7PpTzqYwtdcxPKDo0Cvju4X7S3NrSmsvvbgiZsSKvxJT8svuND19
+7cHuK5c+0t+t+z2ZJYqo8V/sPuBsytiO4QFpb47q8Z9RXaJ2hPpKim2mAO7/xaEr87dfTJ+kN9b8
+5R6TEL1v87zhI31cHDhSrTMI/2/rqeUrDyTNb4ig7Mzn0wa8tnBY12WOXttxMX3StO/2/WE/h0w9
+7//VhcO63hky/vP9l19euOl4pSHkO4YH5Bx6ZXyvcP+qY2QpNHrJzNUHtm27mFYvTYars3vBmLGj
+EqJ22i+3TEP8x45L6UMdrRcT5FP00rCu70/sHrstMtA722YK4HarDia9sObY9Tl6o8nh9398t5gT
+6+YOGesv8XJ4rw3M0GzYomd0yIUdF9Mfnfbdvi31+cVNiJBlbJ43fExNwYTI3Ikws0QxJ79cvetU
+WkGVpp155Sr/RZtPLF+0+cRyIiKa9w2J56+uabP1KibIN/21307+Zm1CHCAVsVN7t13n7ryoUTKf
+zAuZRdMmfLFnZ0aJokq/iOQ8eewTPx5ac2fBvG/IZ8Eat/Zh4VZUkJgndnrhm3+uXl20+cQKd+ry
+G8r47jFbVx64/PKizSfq/R5INdz6sekjFqrzy1WPaw3GjbuvZHJSxeQv8SrPLFE8mVmqOHIhs7jK
+/PTpxYrgRZtPrFi0+cQKInL5+9MjKij1yxn3zUIwqRmqvGyM7x7z+8rpA56VigT18q3tGxt6eccL
+I4d0CAtweSjvKJlPxo4XRg4b1SXqENfHw5k5A+O/ts5VMTS+9Y6ECNm52mynR1TwuX2Lxg5KiJCl
+cl0me8880PnLY69P7Ne1tazWg2vWpwVDuy7/Ztb9z0hFgtrMtXKHr1hokHl71WkbzoT5SfN+enLw
+tPHdYvbWdVv+EpFy7sCObk8uFyXzydg+f+QDD7RvdcbddR3pGxt66Y/nHhwZJfO51RDHzNMgoNh5
+6r5O3+xZOGZItMyn1oMzCvk8emNkj6UHXxnXv02wn9sfxDA/ad4fzz04evG4nh84mwjKxTx888Gk
+Pp87eLlOY4W1C/W7MrpL9DZLU+H1kjqc5DqEBVw/8tqEPk8M6LCBz2NqFcj9JSJaNX3g23MGxjub
+/6JWVbv3RAefP/WvhxLWzx36WLiftKI227AnFvJr9X4SET11X6dvd744ekS0rGozXVcM6tAq8chr
+Ewb2bxN21IXkjo5Zje9zmJ80f/O84eP/O7nfv4X82p1eekYHXzz+xsQBU3q1/clJkmo/J9Ey3/Rd
+C0bf/8bIHp/VNg9CPs/4+sjuy/YtGntfm2C/JveDp6lCQHHg/vatDie9MyV22SP9Xw/yFtvPGud0
+FFMhn8dO7tnm96R3pnT4ZHK/1729hLWen1wiEmj+M6HPW0nvTOk6sXvsX3we41IQEPJ5NLNfuw1X
+l0xt/8nkfs/6eAlzHCSr0y9UIZ/PzuzXbnWf2JDc+9qFH67r8Q709ir98YkhM4+8NuGBgXHhLk8D
+LBUJ2Fcf7Lb8+n+mhb44NOF9EZ9f5iAZS3W4VygRCbQz+7Vfd/vDR0O3zx85YVCHVv84a15MTk50
+UpHA+OSA+LWn/vVQ39+fffAhd9a1Nzg+4mDSO1OiFo/r+YG/xLXbfTFBPkVbnh0x9fCrE/q3C/G/
+SC4Ooe+AwZV8SkQC3esje3x48/3pMU8M6PCzqyf1mCCfvPVzhz5+7PWJvbtEyC4RkdqlFR3w9hJq
+Ppnc75Wkd6Z0mNyzzTZX88DnMTSxe+yOpHemdPnv5P6v+UlE9fJDoqXAPRQn/CQiBREt1RmMK46l
+5g3cdiF9wsHrOUNuFJR1V+kMd84orQO8C3tGBydO6x23aUzXqL9k3uLSLc/WXz7iwwNSiGhcQbk6
+eO/VrDFrjifPvZ5X1ilbrgwhujN3Su6g9hEHJ/ds8+vg+FYH/CVe5TZtTR2dPMRUx8HvesUEH//X
+qHueD/WT5NdXWQfEhR8lot4ZJRXRWy+kTd54OvXRmwXl8QUVaj8ic7CMC/G7NSQ+4sCUXm03DogL
+OyoWCrQ2d7IdnYB4RCSi2p9Eicgc4IloBxHtKFNr/U6kFty7+0rm6MMpuYOy5cqYggp1IFkCV6iv
+pKRdqN+10QlRu8Z3i9nRuVXgVZGAb/iBiHYnOb2/4PJVo+Wz+ZZSq/9w37XsEVvO3X7k8I2coVml
+ygijiSU+j6E2wb5pIzpF7pnau+3mgXHhR0SCO0OQsESkdWE3jqKm2IX17ogJ8s0gosdLlJoFOy9n
+jtt0JnXauYyivtlyZajN+3ljSHzEgam9226y5NP2fXI2bIrLxyo+POAGEU0qUWoCLXl49FxGUZ9s
+uTKY6M73J69b66AL03rH/fJg58hdoX6Swm3zXd0DAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
+AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
+AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
+AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
+AAAAAAAAAABAc/T/4CDJFaJwvz0AAAAldEVYdGRhdGU6Y3JlYXRlADIwMjEtMTEtMDVUMTU6MTA6
+MDcrMDM6MDBF1Hj/AAAAJXRFWHRkYXRlOm1vZGlmeQAyMDIxLTExLTA1VDE1OjEwOjA3KzAzOjAw
+NInAQwAAAABJRU5ErkJggg==" />
+</svg>
diff --git a/docs/.vuepress/public/me.png b/docs/.vuepress/public/me.png
new file mode 100644
index 00000000000..cfa3a6ea375
Binary files /dev/null and b/docs/.vuepress/public/me.png differ
diff --git a/docs/.vuepress/styles/index.styl b/docs/.vuepress/styles/index.styl
new file mode 100644
index 00000000000..e67a4cf0381
--- /dev/null
+++ b/docs/.vuepress/styles/index.styl
@@ -0,0 +1,2 @@
+// import icon
+@import '//at.alicdn.com/t/font_2922463_74fu8o5xg3.css'
\ No newline at end of file
diff --git a/docs/about-the-author/feelings-after-one-month-of-induction-training.md b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
new file mode 100644
index 00000000000..9f81220150f
--- /dev/null
+++ b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
@@ -0,0 +1,19 @@
+# 入职培训一个月后的感受
+
+不知不觉已经入职一个多月了,在入职之前我没有在某个公司实习过或者工作过,所以很多东西刚入职工作的我来说还是比较新颖的。学校到职场的转变,带来了角色的转变,其中的差别因人而异。对我而言,在学校的时候课堂上老师课堂上教的东西,自己会根据自己的兴趣选择性接受,甚至很多课程你不想去上的话,还可以逃掉。到了公司就不一样了,公司要求你会的技能你不得不学,除非你不想干了。在学校的时候大部分人编程的目的都是为了通过考试或者找到一份好工作,真正靠自己兴趣支撑起来的很少,到了工作岗位之后我们编程更多的是因为工作的要求,相比于学校的来说会一般会更有挑战而且压力更大。在学校的时候,我们最重要的就是对自己负责,我们不断学习知识去武装自己,但是到了公司之后我们不光要对自己负责,更要对公司负责,毕竟公司出钱请你过来,不是让你一直 on beach 的。
+
+刚来公司的时候,因为公司要求,我换上了 Mac 电脑。由于之前一直用的是 Windows 系统,所以非常不习惯。刚开始用 Mac 系统的时候笨手笨脚,自己会很明显的感觉自己的编程效率降低了至少 3 成。当时内心还是挺不爽的,心里也总是抱怨为什么不直接用 Windows 系统或者 Linux 系统。不过也挺奇怪,大概一个星期之后,自己就开始慢慢适应使用 Mac 进行编程,甚至非常喜欢。我这里不想对比 Mac 和 Windows 编程体验哪一个更好,我觉得还是因人而异,相同价位的 Mac 的配置相比于 Windows确实要被甩几条街。不过 Mac 的编程和使用体验确实不错,当然你也可以选择使用 Linux 进行日常开发,相信一定很不错。 另外,Mac 不能玩一些主流网络游戏,对于一些克制不住自己想玩游戏的朋友是一个不错的选择。
+
+不得不说 ThoughtWorks 的培训机制还是很不错的。应届生入职之后一般都会安排培训,与往年不同的是,今年的培训多了中国本地班(TWU-C)。作为本地班的第一期学员,说句心里话还是很不错。8周的培训,除了工作需要用到的基本技术比如ES6、SpringBoot等等之外,还会增加一些新员工基本技能的培训比如如何高效开会、如何给别人正确的提 Feedback、如何对代码进行重构、如何进行 TDD 等等。培训期间不定期的有活动,比如Weekend Trip、 City Tour、Cake time等等。最后三周还会有一个实际的模拟项目,这个项目基本和我们正式工作的实际项目差不多,我个人感觉很不错。目前这个项目已经正式完成了一个迭代,我觉得在做项目的过程中,收获最大的不是项目中使用的技术,而是如何进行团队合作、如何正确使用 Git 团队协同开发、一个完成的迭代是什么样子的、做项目的过程中可能遇到那些问题、一个项目运作的完整流程等等。
+
+ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司的这段时间深有感触。培训期间,我们每个人会有一个 Trainer 负责,Trainer 就是日常带我们上课和做项目的同事,一个 Trainer 大概会负责5-6个人。Trainer不定期都会给我们最近表现的 Feedback( 反馈) ,我个人觉得这个并不是这是走走形式,Trainer 们都很负责,很多时候都是在下班之后找我们聊天。同事们也都很热心,如果你遇到问题,向别人询问,其他人如果知道的话一般都会毫无保留的告诉你,如果遇到大部分都不懂的问题,甚至会组织一次技术 Session 分享。上周五我在我们小组内进行了一次关于 Feign 远程调用的技术分享,因为 team 里面大家对这部分知识都不太熟悉,但是后面的项目进展大概率会用到这部分知识。我刚好研究了这部分内容,所以就分享给了组内的其他同事,以便于项目更好的进行。
+
+ 另外,ThoughtWorks 也是一家非常提倡 Feedback( 反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
+
+
+
+工作之后,平时更新公众号、专栏还有维护 Github 的时间变少了。实际上,很多时候下班回来后,都有自己的时间来干自己的事情,但是自己也总是找工作太累或者时间比较零散的接口来推掉了。到了今天,翻看 Github 突然发现 14 天前别人在 Github 上给我提的 pr 我还没有处理。这一点确实是自己没有做好的地方,没有合理安排好自己的时间。实际上自己有很多想写的东西,后面会慢慢将他们提上日程。工作之后,更加发现下班后的几个小时如何度过确实很重要 ,如果你觉得自己没有完成好自己白天该做的工作的话,下班后你可以继续忙白天没有忙完的工作,如果白天的工作对于你游刃有余的话,下班回来之后,你大可去干自己感兴趣的事情,学习自己感兴趣的技术。做任何事情都要基于自身的基础,切不可好高骛远。
+
+工作之后身边也会有很多厉害的人,多从他人身上学习我觉得是每个职场人都应该做的。这一届和我们一起培训的同事中,有一些技术很厉害的,也有一些技术虽然不是那么厉害,但是组织能力以及团队协作能力特别厉害的。有一个特别厉害的同事,在我们还在学 SpringBoot 各种语法的时候,他自己利用业余时间写了一个简化版的 SpringBoot ,涵盖了 Spring 的一些常用注解比如 `@RestController`、`@Autowried`、`@Pathvairable`、`@RestquestParam`等等(已经联系这位同事,想让他开源一下,后面会第一时间同步到公众号,期待一下吧!)。我觉得这位同事对于编程是真的有兴趣,他好像从初中就开始接触编程了,对于各种底层知识也非常感兴趣,自己写过实现过很多比较底层的东西。他的梦想是在 Github 上造一个 20k Star 以上的轮子。我相信以这位同事的能力一定会达成目标的,在这里祝福这位同事,希望他可以尽快实现这个目标。
+
+这是我入职一个多月之后的个人感受,很多地方都是一带而过,后面我会抽时间分享自己在公司或者业余学到的比较有用的知识给各位,希望看过的人都能有所收获。
\ No newline at end of file
diff --git a/docs/about-the-author/internet-addiction-teenager.md b/docs/about-the-author/internet-addiction-teenager.md
new file mode 100644
index 00000000000..52458b4a0c0
--- /dev/null
+++ b/docs/about-the-author/internet-addiction-teenager.md
@@ -0,0 +1,104 @@
+# 我曾经也是网瘾少年
+
+聊到高考,无数人都似乎有很多话说。今天就假借高考的名义,**简单**来聊聊我的求学经历吧!因为我自己的求学经历真的还不算平淡,甚至有点魔幻,所以还是有很多话想要说的。这篇文章大概会从我的初中一直介绍到大学,每一部分我都不会花太多篇幅。实际上,每一段经历我都可以增加很多“有趣”的经历,考虑到篇幅问题,以后有机会再慢慢说吧!
+
+整个初中我都属于有点网瘾少年的状态,不过初三的时候稍微克制一些。到了高二下学期的时候,自己才对游戏没有真的没有那么沉迷了。
+
+另外,关于大学的详细经历我已经在写了。想要知道我是如何从一个普通的不能再普通的少年慢慢成长起来的朋友不要错过~
+
+
+
+**以下所有内容皆是事实,没有任何夸大的地方,稍微有一点点魔幻。**
+
+## 01 刚开始接触电脑
+
+最开始接触电脑是在我五年级的时候,那时候家里没电脑,都是在黑网吧玩的。我现在已经记不清当时是被哥哥还是姐姐带进网吧的了。
+
+起初的时候,自己就是玩玩流行蝴蝶剑、单机摩托之类的单机游戏。但是,也没有到沉迷的地步,只是觉得这东西确实挺好玩的。
+
+
+
+开始有网瘾是在小学毕业的时候,在我玩了一款叫做 **QQ 飞车**的游戏之后(好像是六年级就开始玩了)。我艹,当时真的被这游戏吸引了。**每天上课都幻想自己坐在车里面飘逸,没错,当时就觉得秋名山车神就是我啦!**
+
+我记得,那时候上网还不要身份证,10 元办一张网卡就行了,网费也是一元一小时。但凡,我口袋里有余钱,我都会和我的小伙伴奔跑到网吧一起玩 QQ 飞车。Guide 的青回啊!说到这,我情不自禁地打开自己的 Windows 电脑,下载了 Wegame ,然后下载了 QQ 飞车。
+
+到了初二的时候,就没玩 QQ 飞车了。我的等级也永久定格在了 **120** 级,这个等级在当时那个升级难的一匹的年代,算的上非常高的等级了。
+
+
+
+## 02 初二网瘾爆发
+
+网瘾爆发是在上了初中之后。初二的时候,最为猖狂,自己当时真的是太痴迷 **穿越火线** 了,每天上课都在想像自己拿起枪横扫地方阵营的场景。除了周末在网吧度过之外,我经常每天早上还会起早去玩别人包夜留下的机子,毕竟那时候上学也没什么钱嘛!
+
+
+
+那时候成绩挺差的。这样说吧!我当时在很普通的一个县级市的高中,全年级有 500 来人,我基本都是在 280 名左右。
+
+而且,整个初二我都没有学物理。因为开学不久的一次物理课,物理老师误会我在上课吃东西还狡辩,闪了我一巴掌。从此,我上物理课就睡觉,平常的物理考试就交白卷。那时候心里一直记仇,想着以后自己长大了把这个物理暴打他一顿。
+
+初中时候的觉悟是在初三上学期的时候,当时就突然意识到自己马上就要升高中了。为了让自己能在家附近上学,因为当时我家就在我们当地的二中附近(_附近网吧多是主要原因,哈哈_)。年级前 80 的话基本才有可能考得上二中。**经过努力,初三上学期的第一次月考我直接从 280 多名进不到了年级 50 多名。当时,还因为进步太大,被当做进步之星在讲台上给整个年级做演讲。**那也是我第一次在这么多人面前讲话,挺紧张的,但是挺爽的。
+
+**其实在初三的时候,我的网瘾还是很大。不过,我去玩游戏的前提都是自己把所有任务做完,并且上课听讲也很认真。** 我参加高中提前考试前的一个晚上,我半夜12点乘着妈妈睡着,跑去了网吧玩CF到凌晨 3点多回来。那一次我被抓了现行,到家之后发现妈妈就坐在客厅等我,训斥一顿后,我就保证以后不再晚上偷偷跑出去了(*其实整个初二我通宵了无数次,每个周五晚上都回去通宵*)。
+
+_这里要说明一点:我的智商我自己有自知之明的,属于比较普通的水平吧! 前进很大的主要原因是自己基础还行,特别是英语和物理。英语是因为自己喜欢,加上小学就学了很多初中的英语课程。 物理的话就很奇怪,虽然初二也不怎么听物理课,也不会物理,但是到了初三之后自己就突然开窍了。真的!我现在都感觉很奇怪。然后,到了高中之后,我的英语和物理依然是我最好的两门课。大学的兼职,我出去做家教都是教的高中物理。_
+
+后面,自己阴差阳错参加我们那个县级市的提前招生考试,然后就到了我们当地的二中,也没有参加中考。
+
+## 03 高中生活
+
+上了高中的之后,我上课就偷偷看小说,神印王座、斗罗大陆很多小说都是当时看的。中午和晚上回家之后,就在家里玩几把 DNF,当时家里也买了电脑。没记错的话,到我卸载 DNF 的时候已经练了 4 个满级的号。大量时间投入在游戏和小说上,我成功把自己从学校最好的小班玩到奥赛班,然后再到平行班。有点魔幻吧!
+
+高中觉悟是在高二下学期的时候,当时是真的觉悟了,就突然觉得游戏不香了,觉得 DNF 也不好玩了。我妈妈当时还很诧异,还奇怪地问我:“怎么不玩游戏了?”(*我妈属于不怎么管我玩游戏的,她觉得这东西还是要靠自觉*)。
+
+*当时,自己就感觉这游戏没啥意思了。内心的真实写照是:“我练了再多的满级的DNF账号有啥用啊?以后有钱了,直接氪金不久能很牛逼嘛!” 就突然觉悟了!*
+
+然后,我就开始牟足劲学习。当时,理科平行班大概有 7 个,每次考试都是平行班之间会单独拍一个名次。 后面的话,自己基本每次都能在平行班得第一,并且很多时候都是领先第二名个 30 来分。因为成绩还算亮眼,高三上学期快结束的时候,我就向年级主任申请去了奥赛班。
+
+## 04 高考前的失眠
+
+> **失败之后,不要抱怨外界因素,自始至终实际都是自己的问题,自己不够强大!** 然后,高考前的失眠也是我自己问题,要怪只能怪自己,别的没有任何接口。
+
+我的高考经历其实还蛮坎坷的,毫不夸张的说,高考那今天可能是我到现在为止,经历的最难熬的时候,特别是在晚上。
+
+我在高考那几天晚上都经历了失眠,想睡都睡不着那种痛苦想必很多人或许都体验过。
+
+其实我在之前是从来没有过失眠的经历的。高考前夕,因为害怕自己睡不着,所以,我提前让妈妈去买了几瓶老师推荐的安神补脑液。我到现在还记得这个安神补脑液是敖东牌的。
+
+高考那几天的失眠,我觉得可能和我喝了老师推荐的安神补脑液有关系,又或者是我自己太过于紧张了。因为那几天睡觉总会感觉有很多蚂蚁在身上爬一样,然后还起了一些小痘痘。
+
+然后,这里要格外说明一点,避免引起误导: **睡不着本身就是自身的问题,上述言论并没有责怪这个补脑液的意思。** 另外, 这款安神补脑液我去各个平台都查了一下,发现大家对他的评价都挺好,和我们老师当时推荐的理由差不多。如果大家需要改善睡眠的话,可以咨询相关医生之后尝试一下。
+
+## 05 还算充实的大学生活
+
+高考成绩出来之后,比一本线高了 20 多分。自己挺不满意的,因为比平时考差了太多。加上自己泪点很低,就哭了一上午之后。后面,自我安慰说以后到了大学好好努力也是一样的。然后,我的第一志愿学校就报了长江大学,第一志愿专业就报了计算机专业。
+
+后面,就开始了自己还算充实的大学生活。
+
+大一的时候,满腔热血,对于高考结果的不满意,化作了我每天早起的动力。雷打不动,每天早上 6点左右就出去背英语单词。这也奠定了我后面的四六级都是一次过,并且六级的成绩还算不错。大一那年的暑假,我还去了孝感当了主管,几乎从无到有办了 5 个家教点。不过,其中两个家教点的话,是去年都已经办过的,没有其他几个那么费心。
+
+
+
+大二的时候,加了学校一个偏技术方向的传媒组织(做网站、APP 之类的工作),后面成功当了副站长。在大二的时候,我才开始因为组织需要而接触 Java,不过当时主要学的是安卓开发。
+
+
+
+大三的时候,正式确定自己要用 Java 语言找工作,并且要走 Java 后台(当时感觉安卓后台在求职时长太不吃香了)。我每天都在寝室学习 Java 后台开发,自己看视频,看书,做项目。我的开源项目 JavaGuide 和公众号都是这一年创建的。这一年,我大部分时间都是在寝室学习。带上耳机之后,即使室友在玩游戏或者追剧,都不会对我有什么影响。
+
+我记得当时自己独立做项目的时候,遇到了很多问题。**就很多时候,你看书很容易就明白的东西,等到你实践的时候,总是会遇到一些小问题。我一般都是通过 Google 搜索解决的,用好搜索引擎真的能解决自己 99% 的问题。**
+
+
+
+大四的时候,开始找工作。我是参加的秋招,开始的较晚,基本很多公司都没有 HC 了。这点需要 diss 一下学校了,你其他地方都很好,但是,大四的时候就不要再上课点名了吧!然后,**希望国内的学校尽量能多给学生点机会吧!很多人连春招和秋招都不清楚,毕业了连实习都没实习过。**
+
+## 06 一些心里话
+
+关于大学要努力学习专业知识、多去读书馆这类的鸡汤,Guide 就不多说了。就谈几条自己写这篇文章的时候,想到了一些心理话吧!
+
+1. **不要抱怨学校** :高考之后,不论你是 985、211 还是普通一本,再或者是 二本、三本,都不重要了,好好享受高考之后的生活。如果你觉得自己考的不满意的话,就去复读,没必要天天抱怨,复读的一年在你的人生长河里根本算不了什么的!
+2. **克制** :大学的时候,克制住自己,诱惑太多了。你不去上课,在寝室睡到中午,都没人管你。你的努力不要只是感动自己!追求形式的努力不过是你打得幌子而已。到了社会之后,这个说法依然适用! 说一个真实的发生在我身边的事情吧!高中的时候有一个特别特别特别努力的同班同学,家里的条件也很差,大学之前没有接触过手机和游戏。后来到了大学之后,因为接触了手机还有手机游戏,每天沉迷,不去上课。最后,直接就导致大学没读完就离开了。我听完我的好朋友给我说了之后,非常非常非常诧异!真的太可惜了!
+3. **不要总抱怨自己迷茫,多和优秀的学长学姐沟通交流。**
+4. **不知道做什么的时候,就把手头的事情做好比如你的专业课学习。**
+
+*不论以前的自己是什么样,自己未来变成什么样自己是可以决定的,未来的路也终究还是要自己走。大环境下,大部分人都挺难的,当 996 成为了常态,Life Balance 是不可能的了。我们只能试着寻求一种平衡,试着去热爱自己现在所做的事情。*
+
+**往后余生,爱家人,亦爱自己;好好生活,不忧不恼。**
diff --git a/docs/about-the-author/readme.md b/docs/about-the-author/readme.md
new file mode 100644
index 00000000000..cdf185586d7
--- /dev/null
+++ b/docs/about-the-author/readme.md
@@ -0,0 +1,52 @@
+# 个人介绍 Q&A
+
+大家好,我是 Gudie哥!这篇文章我会通过 Q&A 的形式简单介绍一下我自己。
+
+## 我是什么时候毕业的?
+
+很多老读者应该比较清楚,我是 19 年本科毕业的,刚毕业就去了某家外企“养老”。
+
+我的学校背景是比较差的,高考失利,勉强过了一本线 20 来分,去了荆州的一所很普通的双非一本。不过,还好我没有因为学校而放弃自己,反倒是比身边的同学都要更努力,整个大学还算过的比较充实。
+
+下面这张是当时拍的毕业照:
+
+
+
+## 为什么要做 JavaGuide 这个项目?
+
+我从大二坚持写作,坚持分享让我收获了 30w+ 的读者以及一笔不错的副业收入。
+
+2018 年,我还在读大三的时候,JavaGuide 开源项目&公众号诞生了。很难想到,日后,他们会陪伴我度过这么长的时间。
+
+开源 JavaGuide 初始想法源于自己的个人那一段比较迷茫的学习经历。主要目的是为了通过这个开源平台来帮助一些在学习 Java 以及面试过程中遇到问题的小伙伴。
+
+- **对于 Java 初学者来说:** 本文档倾向于给你提供一个比较详细的学习路径,让你对于 Java 整体的知识体系有一个初步认识。另外,本文的一些文章也是你学习和复习 Java 知识不错的实践;
+- **对于非 Java 初学者来说:** 本文档更适合回顾知识,准备面试,搞清面试应该把重心放在那些问题上。要搞清楚这个道理:提前知道那些面试常见,不是为了背下来应付面试,而是为了让你可以更有针对的学习重点。
+
+## 如何看待 JavaGuide 的 star 数量很多?
+
+[JavaGuide](https://github.com/Snailclimb) 目前已经是 Java 领域 star 数量最多的几个项目之一,登顶过很多次 Github Trending。
+
+不过,这个真心没啥好嘚瑟的。因为,教程类的含金量其实是比较低的,Star 数量比较多主要也是因为受众面比较广,大家觉得不错,点个 star 就相当于收藏了。很多特别优秀的框架,star 数量可能只有几 K。所以,单纯看 star 数量没啥意思,就当看个笑话吧!
+
+维护这个项目的过程中,也被某些人 diss 过:“md 项目,没啥含金量,给国人丢脸!”。
+
+对于说这类话的人,我觉得对我没啥影响,就持续完善,把 JavaGuide 做的更好吧!其实,国外的很多项目也是纯 MD 啊!就比如外国的朋友发起的 awesome 系列、求职面试系列。无需多说,行动自证!凎!
+
+开源非常重要的一点就是协作。如果你开源了一个项目之后,就不再维护,别人给你提交 issue/pr,你都不处理,那开源也没啥意义了!
+
+## 我在大学期间赚了多少钱?
+
+在校期间,我还通过接私活、技术培训、编程竞赛等方式变现 20w+,成功实现“经济独立”。我用自己赚的钱去了重庆、三亚、恩施、青岛等地旅游,还给家里补贴了很多,减轻的父母的负担。
+
+如果你也想通过接私活变现的话,可以在我的公众号后台回复“**接私活**”来了解详细情况。
+
+
+
+## 为什么自称 Guide哥?
+
+可能是因为我的项目名字叫做 JavaGudie ,所以导致有很多人称呼我为 **Guide哥**。
+
+后面,为了读者更方便称呼,我就将自己的笔名改成了 **Guide哥**。
+
+我早期写文章用的笔名是 SnailClimb 。很多人不知道这个名字是啥意思,给大家拆解一下就清楚了。SnailClimb=Snail(蜗牛)+Climb(攀登)。我从小就非常喜欢听周杰伦的歌曲,特别是他的《蜗牛》🐌 这首歌曲,另外,当年我高考发挥的算是比较失常,上了大学之后还算是比较“奋青”,所以,我就给自己起的笔名叫做 SnailClimb ,寓意自己要不断向上攀登,哈哈
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\346\220\236\345\256\232BAT\351\235\242\350\257\225\342\200\224\342\200\224\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md" "b/docs/cs-basics/algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\227\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
similarity index 83%
rename from "\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\346\220\236\345\256\232BAT\351\235\242\350\257\225\342\200\224\342\200\224\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
rename to "docs/cs-basics/algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\227\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
index b7b1c3145c8..37176650df7 100644
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\346\220\236\345\256\232BAT\351\235\242\350\257\225\342\200\224\342\200\224\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
+++ "b/docs/cs-basics/algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\227\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
@@ -1,27 +1,10 @@
-<!-- MarkdownTOC -->
+# 几道常见的字符串算法题
-- [说明](#说明)
-- [1. KMP 算法](#1-kmp-算法)
-- [2. 替换空格](#2-替换空格)
-- [3. 最长公共前缀](#3-最长公共前缀)
-- [4. 回文串](#4-回文串)
- - [4.1. 最长回文串](#41-最长回文串)
- - [4.2. 验证回文串](#42-验证回文串)
- - [4.3. 最长回文子串](#43-最长回文子串)
- - [4.4. 最长回文子序列](#44-最长回文子序列)
-- [5. 括号匹配深度](#5-括号匹配深度)
-- [6. 把字符串转换成整数](#6-把字符串转换成整数)
+> 授权转载!
+>
+> - 本文作者:wwwxmu
+> - 原文地址:https://www.weiweiblog.cn/13string/
-<!-- /MarkdownTOC -->
-
-
-## 说明
-
-- 本文作者:wwwxmu
-- 原文地址:https://www.weiweiblog.cn/13string/
-- 作者的博客站点:https://www.weiweiblog.cn/ (推荐哦!)
-
-考虑到篇幅问题,我会分两次更新这个内容。本篇文章只是原文的一部分,我在原文的基础上增加了部分内容以及修改了部分代码和注释。另外,我增加了爱奇艺 2018 秋招 Java:`求给定合法括号序列的深度` 这道题。所有代码均编译成功,并带有注释,欢迎各位享用!
## 1. KMP 算法
@@ -108,38 +91,57 @@ public class Solution {
思路很简单!先利用Arrays.sort(strs)为数组排序,再将数组第一个元素和最后一个元素的字符从前往后对比即可!
```java
-//https://leetcode-cn.com/problems/longest-common-prefix/description/
public class Main {
- public static String replaceSpace(String[] strs) {
-
- // 数组长度
- int len = strs.length;
- // 用于保存结果
- StringBuffer res = new StringBuffer();
- // 注意:=是赋值,==是判断
- if (strs == null || strs.length == 0) {
- return "";
- }
- // 给字符串数组的元素按照升序排序(包含数字的话,数字会排在前面)
- Arrays.sort(strs);
- int m = strs[0].length();
- int n = strs[len - 1].length();
- int num = Math.min(m, n);
- for (int i = 0; i < num; i++) {
- if (strs[0].charAt(i) == strs[len - 1].charAt(i)) {
- res.append(strs[0].charAt(i));
- } else
- break;
-
- }
- return res.toString();
-
- }
- //测试
- public static void main(String[] args) {
- String[] strs = { "customer", "car", "cat" };
- System.out.println(Main.replaceSpace(strs));//c
- }
+ public static String replaceSpace(String[] strs) {
+
+ // 如果检查值不合法及就返回空串
+ if (!checkStrs(strs)) {
+ return "";
+ }
+ // 数组长度
+ int len = strs.length;
+ // 用于保存结果
+ StringBuilder res = new StringBuilder();
+ // 给字符串数组的元素按照升序排序(包含数字的话,数字会排在前面)
+ Arrays.sort(strs);
+ int m = strs[0].length();
+ int n = strs[len - 1].length();
+ int num = Math.min(m, n);
+ for (int i = 0; i < num; i++) {
+ if (strs[0].charAt(i) == strs[len - 1].charAt(i)) {
+ res.append(strs[0].charAt(i));
+ } else
+ break;
+
+ }
+ return res.toString();
+
+ }
+
+ private static boolean chechStrs(String[] strs) {
+ boolean flag = false;
+ if (strs != null) {
+ // 遍历strs检查元素值
+ for (int i = 0; i < strs.length; i++) {
+ if (strs[i] != null && strs[i].length() != 0) {
+ flag = true;
+ } else {
+ flag = false;
+ break;
+ }
+ }
+ }
+ return flag;
+ }
+
+ // 测试
+ public static void main(String[] args) {
+ String[] strs = { "customer", "car", "cat" };
+ // String[] strs = { "customer", "car", null };//空串
+ // String[] strs = {};//空串
+ // String[] strs = null;//空串
+ System.out.println(Main.replaceSpace(strs));// c
+ }
}
```
@@ -171,7 +173,7 @@ public class Main {
我们上面已经知道了什么是回文串?现在我们考虑一下可以构成回文串的两种情况:
- 字符出现次数为双数的组合
-- 字符出现次数为双数的组合+一个只出现一次的字符
+- **字符出现次数为偶数的组合+单个字符中出现次数最多且为奇数次的字符** (参见 **[issue665](https://github.com/Snailclimb/JavaGuide/issues/665)** )
统计字符出现的次数即可,双数才能构成回文。因为允许中间一个数单独出现,比如“abcba”,所以如果最后有字母落单,总长度可以加 1。首先将字符串转变为字符数组。然后遍历该数组,判断对应字符是否在hashset中,如果不在就加进去,如果在就让count++,然后移除该字符!这样就能找到出现次数为双数的字符个数。
@@ -263,10 +265,7 @@ class Solution {
输出: "bb"
```
-以某个元素为中心,分别计算偶数长度的回文最大长度和奇数长度的回文最大长度。给大家大致花了个草图,不要嫌弃!
-
-
-
+以某个元素为中心,分别计算偶数长度的回文最大长度和奇数长度的回文最大长度。
```java
//https://leetcode-cn.com/problems/longest-palindromic-substring/description/
@@ -380,11 +379,6 @@ class Solution {
2
```
-思路草图:
-
-
-
-
代码如下:
```java
@@ -444,7 +438,7 @@ public class Main {
return 0;
}
}
- return flag == 1 ? res : -res;
+ return flag != 2 ? res : -res;
}
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/Leetcode-LinkList1.md" "b/docs/cs-basics/algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\351\223\276\350\241\250\347\256\227\346\263\225\351\242\230.md"
similarity index 88%
rename from "\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/Leetcode-LinkList1.md"
rename to "docs/cs-basics/algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\351\223\276\350\241\250\347\256\227\346\263\225\351\242\230.md"
index 79b74441deb..1b64653cd9f 100644
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/Leetcode-LinkList1.md"
+++ "b/docs/cs-basics/algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\351\223\276\350\241\250\347\256\227\346\263\225\351\242\230.md"
@@ -1,29 +1,6 @@
-<!-- MarkdownTOC -->
-
-- [1. 两数相加](#1-两数相加)
- - [题目描述](#题目描述)
- - [问题分析](#问题分析)
- - [Solution](#solution)
-- [2. 翻转链表](#2-翻转链表)
- - [题目描述](#题目描述-1)
- - [问题分析](#问题分析-1)
- - [Solution](#solution-1)
-- [3. 链表中倒数第k个节点](#3-链表中倒数第k个节点)
- - [题目描述](#题目描述-2)
- - [问题分析](#问题分析-2)
- - [Solution](#solution-2)
-- [4. 删除链表的倒数第N个节点](#4-删除链表的倒数第n个节点)
- - [问题分析](#问题分析-3)
- - [Solution](#solution-3)
-- [5. 合并两个排序的链表](#5-合并两个排序的链表)
- - [题目描述](#题目描述-3)
- - [问题分析](#问题分析-4)
- - [Solution](#solution-4)
-
-<!-- /MarkdownTOC -->
-
-
-# 1. 两数相加
+# 几道常见的链表算法题
+
+## 1. 两数相加
### 题目描述
@@ -50,7 +27,7 @@ Leetcode官方详细解答地址:
我们使用变量来跟踪进位,并从包含最低有效位的表头开始模拟逐
位相加的过程。
-
+
### Solution
@@ -92,13 +69,13 @@ public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
}
```
-# 2. 翻转链表
+## 2. 翻转链表
### 题目描述
> 剑指 offer:输入一个链表,反转链表后,输出链表的所有元素。
-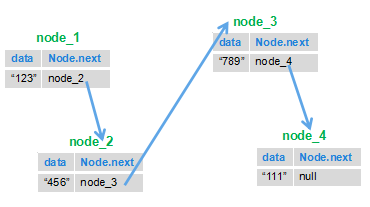
+
### 问题分析
@@ -180,7 +157,7 @@ public class Solution {
1
```
-# 3. 链表中倒数第k个节点
+## 3. 链表中倒数第k个节点
### 题目描述
@@ -225,7 +202,7 @@ public class Solution {
while (node1 != null) {
node1 = node1.next;
count++;
- if (k < 1 && node1 != null) {
+ if (k < 1) {
node2 = node2.next;
}
k--;
@@ -240,7 +217,7 @@ public class Solution {
```
-# 4. 删除链表的倒数第N个节点
+## 4. 删除链表的倒数第N个节点
> Leetcode:给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
@@ -269,7 +246,7 @@ public class Solution {
我们注意到这个问题可以容易地简化成另一个问题:删除从列表开头数起的第 (L - n + 1)个结点,其中 L是列表的长度。只要我们找到列表的长度 L,这个问题就很容易解决。
-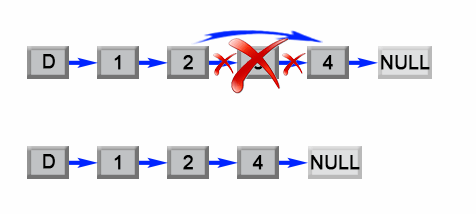
+
### Solution
@@ -324,7 +301,7 @@ public class Solution {
**进阶——一次遍历法:**
-> **链表中倒数第N个节点也就是正数第(L-N+1)个节点。
+> 链表中倒数第N个节点也就是正数第(L-N+1)个节点。
其实这种方法就和我们上面第四题找“链表中倒数第k个节点”所用的思想是一样的。**基本思路就是:** 定义两个节点 node1、node2;node1 节点先跑,node1节点 跑到第 n+1 个节点的时候,node2 节点开始跑.当node1 节点跑到最后一个节点时,node2 节点所在的位置就是第 (L-n ) 个节点(L代表总链表长度,也就是倒数第 n+1 个节点)
@@ -367,7 +344,7 @@ public class Solution {
-# 5. 合并两个排序的链表
+## 5. 合并两个排序的链表
### 题目描述
diff --git "a/docs/cs-basics/algorithms/\345\211\221\346\214\207offer\351\203\250\345\210\206\347\274\226\347\250\213\351\242\230.md" "b/docs/cs-basics/algorithms/\345\211\221\346\214\207offer\351\203\250\345\210\206\347\274\226\347\250\213\351\242\230.md"
new file mode 100644
index 00000000000..790422342fc
--- /dev/null
+++ "b/docs/cs-basics/algorithms/\345\211\221\346\214\207offer\351\203\250\345\210\206\347\274\226\347\250\213\351\242\230.md"
@@ -0,0 +1,681 @@
+# 剑指offer部分编程题
+
+## 斐波那契数列
+
+**题目描述:**
+
+大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项。
+n<=39
+
+**问题分析:**
+
+可以肯定的是这一题通过递归的方式是肯定能做出来,但是这样会有一个很大的问题,那就是递归大量的重复计算会导致内存溢出。另外可以使用迭代法,用fn1和fn2保存计算过程中的结果,并复用起来。下面我会把两个方法示例代码都给出来并给出两个方法的运行时间对比。
+
+**示例代码:**
+
+采用迭代法:
+
+```java
+int Fibonacci(int number) {
+ if (number <= 0) {
+ return 0;
+ }
+ if (number == 1 || number == 2) {
+ return 1;
+ }
+ int first = 1, second = 1, third = 0;
+ for (int i = 3; i <= number; i++) {
+ third = first + second;
+ first = second;
+ second = third;
+ }
+ return third;
+}
+```
+
+采用递归:
+
+```java
+public int Fibonacci(int n) {
+ if (n <= 0) {
+ return 0;
+ }
+ if (n == 1||n==2) {
+ return 1;
+ }
+
+ return Fibonacci(n - 2) + Fibonacci(n - 1);
+}
+```
+
+## 跳台阶问题
+
+**题目描述:**
+
+一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
+
+**问题分析:**
+
+正常分析法:
+
+> a.如果两种跳法,1阶或者2阶,那么假定第一次跳的是一阶,那么剩下的是n-1个台阶,跳法是f(n-1);
+> b.假定第一次跳的是2阶,那么剩下的是n-2个台阶,跳法是f(n-2)
+> c.由a,b假设可以得出总跳法为: f(n) = f(n-1) + f(n-2)
+> d.然后通过实际的情况可以得出:只有一阶的时候 f(1) = 1 ,只有两阶的时候可以有 f(2) = 2
+
+找规律分析法:
+
+> f(1) = 1, f(2) = 2, f(3) = 3, f(4) = 5, 可以总结出f(n) = f(n-1) + f(n-2)的规律。但是为什么会出现这样的规律呢?假设现在6个台阶,我们可以从第5跳一步到6,这样的话有多少种方案跳到5就有多少种方案跳到6,另外我们也可以从4跳两步跳到6,跳到4有多少种方案的话,就有多少种方案跳到6,其他的不能从3跳到6什么的啦,所以最后就是f(6) = f(5) + f(4);这样子也很好理解变态跳台阶的问题了。
+
+**所以这道题其实就是斐波那契数列的问题。**
+
+代码只需要在上一题的代码稍做修改即可。和上一题唯一不同的就是这一题的初始元素变为 1 2 3 5 8.....而上一题为1 1 2 3 5 .......。另外这一题也可以用递归做,但是递归效率太低,所以我这里只给出了迭代方式的代码。
+
+**示例代码:**
+
+```java
+int jumpFloor(int number) {
+ if (number <= 0) {
+ return 0;
+ }
+ if (number == 1) {
+ return 1;
+ }
+ if (number == 2) {
+ return 2;
+ }
+ int first = 1, second = 2, third = 0;
+ for (int i = 3; i <= number; i++) {
+ third = first + second;
+ first = second;
+ second = third;
+ }
+ return third;
+}
+```
+
+## 变态跳台阶问题
+
+**题目描述:**
+
+一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
+
+**问题分析:**
+
+假设n>=2,第一步有n种跳法:跳1级、跳2级、到跳n级
+跳1级,剩下n-1级,则剩下跳法是f(n-1)
+跳2级,剩下n-2级,则剩下跳法是f(n-2)
+......
+跳n-1级,剩下1级,则剩下跳法是f(1)
+跳n级,剩下0级,则剩下跳法是f(0)
+所以在n>=2的情况下:
+f(n)=f(n-1)+f(n-2)+...+f(1)
+因为f(n-1)=f(n-2)+f(n-3)+...+f(1)
+所以f(n)=2*f(n-1) 又f(1)=1,所以可得**f(n)=2^(number-1)**
+
+**示例代码:**
+
+```java
+int JumpFloorII(int number) {
+ return 1 << --number;//2^(number-1)用位移操作进行,更快
+}
+```
+
+**补充:**
+
+java中有三种移位运算符:
+
+1. “<<” : **左移运算符**,等同于乘2的n次方
+2. “>>”: **右移运算符**,等同于除2的n次方
+3. “>>>” : **无符号右移运算符**,不管移动前最高位是0还是1,右移后左侧产生的空位部分都以0来填充。与>>类似。
+
+```java
+int a = 16;
+int b = a << 2;//左移2,等同于16 * 2的2次方,也就是16 * 4
+int c = a >> 2;//右移2,等同于16 / 2的2次方,也就是16 / 4
+```
+
+
+## 二维数组查找
+
+**题目描述:**
+
+在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
+
+**问题解析:**
+
+这一道题还是比较简单的,我们需要考虑的是如何做,效率最快。这里有一种很好理解的思路:
+
+> 矩阵是有序的,从左下角来看,向上数字递减,向右数字递增,
+> 因此从左下角开始查找,当要查找数字比左下角数字大时。右移
+> 要查找数字比左下角数字小时,上移。这样找的速度最快。
+
+**示例代码:**
+
+```java
+public boolean Find(int target, int [][] array) {
+ //基本思路从左下角开始找,这样速度最快
+ int row = array.length-1;//行
+ int column = 0;//列
+ //当行数大于0,当前列数小于总列数时循环条件成立
+ while((row >= 0)&& (column< array[0].length)){
+ if(array[row][column] > target){
+ row--;
+ }else if(array[row][column] < target){
+ column++;
+ }else{
+ return true;
+ }
+ }
+ return false;
+}
+```
+
+## 替换空格
+
+**题目描述:**
+
+请实现一个函数,将一个字符串中的空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
+
+**问题分析:**
+
+这道题不难,我们可以通过循环判断字符串的字符是否为空格,是的话就利用append()方法添加追加“%20”,否则还是追加原字符。
+
+或者最简单的方法就是利用:replaceAll(String regex,String replacement)方法了,一行代码就可以解决。
+
+**示例代码:**
+
+常规做法:
+
+```java
+public String replaceSpace(StringBuffer str) {
+ StringBuffer out = new StringBuffer();
+ for (int i = 0; i < str.toString().length(); i++) {
+ char b = str.charAt(i);
+ if(String.valueOf(b).equals(" ")){
+ out.append("%20");
+ }else{
+ out.append(b);
+ }
+ }
+ return out.toString();
+}
+```
+
+一行代码解决:
+
+```java
+public String replaceSpace(StringBuffer str) {
+ //return str.toString().replaceAll(" ", "%20");
+ //public String replaceAll(String regex,String replacement)
+ //用给定的替换替换与给定的regular expression匹配的此字符串的每个子字符串。
+ //\ 转义字符. 如果你要使用 "\" 本身, 则应该使用 "\\". String类型中的空格用“\s”表示,所以我这里猜测"\\s"就是代表空格的意思
+ return str.toString().replaceAll("\\s", "%20");
+}
+```
+
+## 数值的整数次方
+
+**题目描述:**
+
+给定一个double类型的浮点数base和int类型的整数exponent。求base的exponent次方。
+
+**问题解析:**
+
+这道题算是比较麻烦和难一点的一个了。我这里采用的是**二分幂**思想,当然也可以采用**快速幂**。
+更具剑指offer书中细节,该题的解题思路如下:
+1.当底数为0且指数<0时,会出现对0求倒数的情况,需进行错误处理,设置一个全局变量;
+2.判断底数是否等于0,由于base为double型,所以不能直接用==判断
+3.优化求幂函数(二分幂)。
+当n为偶数,a^n =(a^n/2)*(a^n/2);
+当n为奇数,a^n = a^[(n-1)/2] * a^[(n-1)/2] * a。时间复杂度O(logn)
+
+**时间复杂度**:O(logn)
+
+**示例代码:**
+
+```java
+public class Solution {
+ boolean invalidInput=false;
+ public double Power(double base, int exponent) {
+ //如果底数等于0并且指数小于0
+ //由于base为double型,不能直接用==判断
+ if(equal(base,0.0)&&exponent<0){
+ invalidInput=true;
+ return 0.0;
+ }
+ int absexponent=exponent;
+ //如果指数小于0,将指数转正
+ if(exponent<0)
+ absexponent=-exponent;
+ //getPower方法求出base的exponent次方。
+ double res=getPower(base,absexponent);
+ //如果指数小于0,所得结果为上面求的结果的倒数
+ if(exponent<0)
+ res=1.0/res;
+ return res;
+ }
+ //比较两个double型变量是否相等的方法
+ boolean equal(double num1,double num2){
+ if(num1-num2>-0.000001&&num1-num2<0.000001)
+ return true;
+ else
+ return false;
+ }
+ //求出b的e次方的方法
+ double getPower(double b,int e){
+ //如果指数为0,返回1
+ if(e==0)
+ return 1.0;
+ //如果指数为1,返回b
+ if(e==1)
+ return b;
+ //e>>1相等于e/2,这里就是求a^n =(a^n/2)*(a^n/2)
+ double result=getPower(b,e>>1);
+ result*=result;
+ //如果指数n为奇数,则要再乘一次底数base
+ if((e&1)==1)
+ result*=b;
+ return result;
+ }
+}
+```
+
+当然这一题也可以采用笨方法:累乘。不过这种方法的时间复杂度为O(n),这样没有前一种方法效率高。
+
+```java
+// 使用累乘
+public double powerAnother(double base, int exponent) {
+ double result = 1.0;
+ for (int i = 0; i < Math.abs(exponent); i++) {
+ result *= base;
+ }
+ if (exponent >= 0)
+ return result;
+ else
+ return 1 / result;
+}
+```
+
+## 调整数组顺序使奇数位于偶数前面
+
+**题目描述:**
+
+输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
+
+**问题解析:**
+
+这道题有挺多种解法的,给大家介绍一种我觉得挺好理解的方法:
+我们首先统计奇数的个数假设为n,然后新建一个等长数组,然后通过循环判断原数组中的元素为偶数还是奇数。如果是则从数组下标0的元素开始,把该奇数添加到新数组;如果是偶数则从数组下标为n的元素开始把该偶数添加到新数组中。
+
+**示例代码:**
+
+时间复杂度为O(n),空间复杂度为O(n)的算法
+
+```java
+public class Solution {
+ public void reOrderArray(int [] array) {
+ //如果数组长度等于0或者等于1,什么都不做直接返回
+ if(array.length==0||array.length==1)
+ return;
+ //oddCount:保存奇数个数
+ //oddBegin:奇数从数组头部开始添加
+ int oddCount=0,oddBegin=0;
+ //新建一个数组
+ int[] newArray=new int[array.length];
+ //计算出(数组中的奇数个数)开始添加元素
+ for(int i=0;i<array.length;i++){
+ if((array[i]&1)==1) oddCount++;
+ }
+ for(int i=0;i<array.length;i++){
+ //如果数为基数新数组从头开始添加元素
+ //如果为偶数就从oddCount(数组中的奇数个数)开始添加元素
+ if((array[i]&1)==1)
+ newArray[oddBegin++]=array[i];
+ else newArray[oddCount++]=array[i];
+ }
+ for(int i=0;i<array.length;i++){
+ array[i]=newArray[i];
+ }
+ }
+}
+```
+
+## 链表中倒数第k个节点
+
+**题目描述:**
+
+输入一个链表,输出该链表中倒数第k个结点
+
+**问题分析:**
+
+**一句话概括:**
+两个指针一个指针p1先开始跑,指针p1跑到k-1个节点后,另一个节点p2开始跑,当p1跑到最后时,p2所指的指针就是倒数第k个节点。
+
+**思想的简单理解:**
+前提假设:链表的结点个数(长度)为n。
+规律一:要找到倒数第k个结点,需要向前走多少步呢?比如倒数第一个结点,需要走n步,那倒数第二个结点呢?很明显是向前走了n-1步,所以可以找到规律是找到倒数第k个结点,需要向前走n-k+1步。
+
+**算法开始:**
+
+1. 设两个都指向head的指针p1和p2,当p1走了k-1步的时候,停下来。p2之前一直不动。
+2. p1的下一步是走第k步,这个时候,p2开始一起动了。至于为什么p2这个时候动呢?看下面的分析。
+3. 当p1走到链表的尾部时,即p1走了n步。由于我们知道p2是在p1走了k-1步才开始动的,也就是说p1和p2永远差k-1步。所以当p1走了n步时,p2走的应该是在n-(k-1)步。即p2走了n-k+1步,此时巧妙的是p2正好指向的是规律一的倒数第k个结点处。
+ 这样是不是很好理解了呢?
+
+**考察内容:**
+
+链表+代码的鲁棒性
+
+**示例代码:**
+
+```java
+/*
+//链表类
+public class ListNode {
+ int val;
+ ListNode next = null;
+
+ ListNode(int val) {
+ this.val = val;
+ }
+}*/
+
+//时间复杂度O(n),一次遍历即可
+public class Solution {
+ public ListNode FindKthToTail(ListNode head,int k) {
+ ListNode pre=null,p=null;
+ //两个指针都指向头结点
+ p=head;
+ pre=head;
+ //记录k值
+ int a=k;
+ //记录节点的个数
+ int count=0;
+ //p指针先跑,并且记录节点数,当p指针跑了k-1个节点后,pre指针开始跑,
+ //当p指针跑到最后时,pre所指指针就是倒数第k个节点
+ while(p!=null){
+ p=p.next;
+ count++;
+ if(k<1){
+ pre=pre.next;
+ }
+ k--;
+ }
+ //如果节点个数小于所求的倒数第k个节点,则返回空
+ if(count<a) return null;
+ return pre;
+
+ }
+}
+```
+
+## 反转链表
+
+**题目描述:**
+
+输入一个链表,反转链表后,输出链表的所有元素。
+
+**问题分析:**
+
+链表的很常规的一道题,这一道题思路不算难,但自己实现起来真的可能会感觉无从下手,我是参考了别人的代码。
+思路就是我们根据链表的特点,前一个节点指向下一个节点的特点,把后面的节点移到前面来。
+就比如下图:我们把1节点和2节点互换位置,然后再将3节点指向2节点,4节点指向3节点,这样以来下面的链表就被反转了。
+
+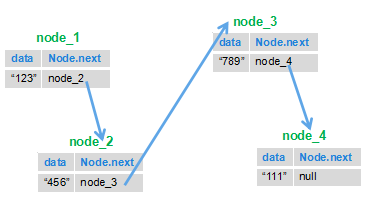
+
+**考察内容:**
+
+链表+代码的鲁棒性
+
+**示例代码:**
+
+```java
+/*
+public class ListNode {
+ int val;
+ ListNode next = null;
+
+ ListNode(int val) {
+ this.val = val;
+ }
+}*/
+public class Solution {
+ public ListNode ReverseList(ListNode head) {
+ ListNode next = null;
+ ListNode pre = null;
+ while (head != null) {
+ //保存要反转到头来的那个节点
+ next = head.next;
+ //要反转的那个节点指向已经反转的上一个节点
+ head.next = pre;
+ //上一个已经反转到头部的节点
+ pre = head;
+ //一直向链表尾走
+ head = next;
+ }
+ return pre;
+ }
+}
+```
+
+## 合并两个排序的链表
+
+**题目描述:**
+
+输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
+
+**问题分析:**
+
+我们可以这样分析:
+
+1. 假设我们有两个链表 A,B;
+2. A的头节点A1的值与B的头结点B1的值比较,假设A1小,则A1为头节点;
+3. A2再和B1比较,假设B1小,则,A1指向B1;
+4. A2再和B2比较。。。。。。。
+ 就这样循环往复就行了,应该还算好理解。
+
+**考察内容:**
+
+链表+代码的鲁棒性
+
+**示例代码:**
+
+非递归版本:
+
+```java
+/*
+public class ListNode {
+ int val;
+ ListNode next = null;
+
+ ListNode(int val) {
+ this.val = val;
+ }
+}*/
+public class Solution {
+ public ListNode Merge(ListNode list1,ListNode list2) {
+ //list1为空,直接返回list2
+ if(list1 == null){
+ return list2;
+ }
+ //list2为空,直接返回list1
+ if(list2 == null){
+ return list1;
+ }
+ ListNode mergeHead = null;
+ ListNode current = null;
+ //当list1和list2不为空时
+ while(list1!=null && list2!=null){
+ //取较小值作头结点
+ if(list1.val <= list2.val){
+ if(mergeHead == null){
+ mergeHead = current = list1;
+ }else{
+ current.next = list1;
+ //current节点保存list1节点的值因为下一次还要用
+ current = list1;
+ }
+ //list1指向下一个节点
+ list1 = list1.next;
+ }else{
+ if(mergeHead == null){
+ mergeHead = current = list2;
+ }else{
+ current.next = list2;
+ //current节点保存list2节点的值因为下一次还要用
+ current = list2;
+ }
+ //list2指向下一个节点
+ list2 = list2.next;
+ }
+ }
+ if(list1 == null){
+ current.next = list2;
+ }else{
+ current.next = list1;
+ }
+ return mergeHead;
+ }
+}
+```
+
+递归版本:
+
+```java
+public ListNode Merge(ListNode list1,ListNode list2) {
+ if(list1 == null){
+ return list2;
+ }
+ if(list2 == null){
+ return list1;
+ }
+ if(list1.val <= list2.val){
+ list1.next = Merge(list1.next, list2);
+ return list1;
+ }else{
+ list2.next = Merge(list1, list2.next);
+ return list2;
+ }
+}
+```
+
+## 用两个栈实现队列
+
+**题目描述:**
+
+用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
+
+**问题分析:**
+
+先来回顾一下栈和队列的基本特点:
+**栈:**后进先出(LIFO)
+**队列:** 先进先出
+很明显我们需要根据JDK给我们提供的栈的一些基本方法来实现。先来看一下Stack类的一些基本方法:
+
+
+既然题目给了我们两个栈,我们可以这样考虑当push的时候将元素push进stack1,pop的时候我们先把stack1的元素pop到stack2,然后再对stack2执行pop操作,这样就可以保证是先进先出的。(负[pop]负[pop]得正[先进先出])
+
+**考察内容:**
+
+队列+栈
+
+示例代码:
+
+```java
+//左程云的《程序员代码面试指南》的答案
+import java.util.Stack;
+
+public class Solution {
+ Stack<Integer> stack1 = new Stack<Integer>();
+ Stack<Integer> stack2 = new Stack<Integer>();
+
+ //当执行push操作时,将元素添加到stack1
+ public void push(int node) {
+ stack1.push(node);
+ }
+
+ public int pop() {
+ //如果两个队列都为空则抛出异常,说明用户没有push进任何元素
+ if(stack1.empty()&&stack2.empty()){
+ throw new RuntimeException("Queue is empty!");
+ }
+ //如果stack2不为空直接对stack2执行pop操作,
+ if(stack2.empty()){
+ while(!stack1.empty()){
+ //将stack1的元素按后进先出push进stack2里面
+ stack2.push(stack1.pop());
+ }
+ }
+ return stack2.pop();
+ }
+}
+```
+
+## 栈的压入,弹出序列
+
+**题目描述:**
+
+输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
+
+**题目分析:**
+
+这道题想了半天没有思路,参考了Alias的答案,他的思路写的也很详细应该很容易看懂。
+作者:Alias
+https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106
+来源:牛客网
+
+【思路】借用一个辅助的栈,遍历压栈顺序,先讲第一个放入栈中,这里是1,然后判断栈顶元素是不是出栈顺序的第一个元素,这里是4,很显然1≠4,所以我们继续压栈,直到相等以后开始出栈,出栈一个元素,则将出栈顺序向后移动一位,直到不相等,这样循环等压栈顺序遍历完成,如果辅助栈还不为空,说明弹出序列不是该栈的弹出顺序。
+
+举例:
+
+入栈1,2,3,4,5
+
+出栈4,5,3,2,1
+
+首先1入辅助栈,此时栈顶1≠4,继续入栈2
+
+此时栈顶2≠4,继续入栈3
+
+此时栈顶3≠4,继续入栈4
+
+此时栈顶4=4,出栈4,弹出序列向后一位,此时为5,,辅助栈里面是1,2,3
+
+此时栈顶3≠5,继续入栈5
+
+此时栈顶5=5,出栈5,弹出序列向后一位,此时为3,,辅助栈里面是1,2,3
+
+….
+依次执行,最后辅助栈为空。如果不为空说明弹出序列不是该栈的弹出顺序。
+
+**考察内容:**
+
+栈
+
+**示例代码:**
+
+```java
+import java.util.ArrayList;
+import java.util.Stack;
+//这道题没想出来,参考了Alias同学的答案:https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106
+public class Solution {
+ public boolean IsPopOrder(int [] pushA,int [] popA) {
+ if(pushA.length == 0 || popA.length == 0)
+ return false;
+ Stack<Integer> s = new Stack<Integer>();
+ //用于标识弹出序列的位置
+ int popIndex = 0;
+ for(int i = 0; i< pushA.length;i++){
+ s.push(pushA[i]);
+ //如果栈不为空,且栈顶元素等于弹出序列
+ while(!s.empty() &&s.peek() == popA[popIndex]){
+ //出栈
+ s.pop();
+ //弹出序列向后一位
+ popIndex++;
+ }
+ }
+ return s.empty();
+ }
+}
+```
\ No newline at end of file
diff --git a/docs/cs-basics/data-structure/bloom-filter.md b/docs/cs-basics/data-structure/bloom-filter.md
new file mode 100644
index 00000000000..d013be7471f
--- /dev/null
+++ b/docs/cs-basics/data-structure/bloom-filter.md
@@ -0,0 +1,306 @@
+---
+category: 计算机基础
+tag:
+ - 数据结构
+---
+
+# 布隆过滤器
+
+海量数据处理以及缓存穿透这两个场景让我认识了 布隆过滤器 ,我查阅了一些资料来了解它,但是很多现成资料并不满足我的需求,所以就决定自己总结一篇关于布隆过滤器的文章。希望通过这篇文章让更多人了解布隆过滤器,并且会实际去使用它!
+
+下面我们将分为几个方面来介绍布隆过滤器:
+
+1. 什么是布隆过滤器?
+2. 布隆过滤器的原理介绍。
+3. 布隆过滤器使用场景。
+4. 通过 Java 编程手动实现布隆过滤器。
+5. 利用 Google 开源的 Guava 中自带的布隆过滤器。
+6. Redis 中的布隆过滤器。
+
+## 什么是布隆过滤器?
+
+首先,我们需要了解布隆过滤器的概念。
+
+布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于 1970 年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
+
+
+
+位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。
+
+总结:**一个名叫 Bloom 的人提出了一种来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。**
+
+## 布隆过滤器的原理介绍
+
+**当一个元素加入布隆过滤器中的时候,会进行如下操作:**
+
+1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
+2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
+
+**当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:**
+
+1. 对给定元素再次进行相同的哈希计算;
+2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+
+举个简单的例子:
+
+
+
+如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1(当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
+
+如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+
+**不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。**
+
+综上,我们可以得出:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
+
+## 布隆过滤器使用场景
+
+1. 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5 亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
+2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
+
+
+## 编码实战
+
+### 通过 Java 编程手动实现布隆过滤器
+
+我们上面已经说了布隆过滤器的原理,知道了布隆过滤器的原理之后就可以自己手动实现一个了。
+
+如果你想要手动实现一个的话,你需要:
+
+1. 一个合适大小的位数组保存数据
+2. 几个不同的哈希函数
+3. 添加元素到位数组(布隆过滤器)的方法实现
+4. 判断给定元素是否存在于位数组(布隆过滤器)的方法实现。
+
+下面给出一个我觉得写的还算不错的代码(参考网上已有代码改进得到,对于所有类型对象皆适用):
+
+```java
+import java.util.BitSet;
+
+public class MyBloomFilter {
+
+ /**
+ * 位数组的大小
+ */
+ private static final int DEFAULT_SIZE = 2 << 24;
+ /**
+ * 通过这个数组可以创建 6 个不同的哈希函数
+ */
+ private static final int[] SEEDS = new int[]{3, 13, 46, 71, 91, 134};
+
+ /**
+ * 位数组。数组中的元素只能是 0 或者 1
+ */
+ private BitSet bits = new BitSet(DEFAULT_SIZE);
+
+ /**
+ * 存放包含 hash 函数的类的数组
+ */
+ private SimpleHash[] func = new SimpleHash[SEEDS.length];
+
+ /**
+ * 初始化多个包含 hash 函数的类的数组,每个类中的 hash 函数都不一样
+ */
+ public MyBloomFilter() {
+ // 初始化多个不同的 Hash 函数
+ for (int i = 0; i < SEEDS.length; i++) {
+ func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);
+ }
+ }
+
+ /**
+ * 添加元素到位数组
+ */
+ public void add(Object value) {
+ for (SimpleHash f : func) {
+ bits.set(f.hash(value), true);
+ }
+ }
+
+ /**
+ * 判断指定元素是否存在于位数组
+ */
+ public boolean contains(Object value) {
+ boolean ret = true;
+ for (SimpleHash f : func) {
+ ret = ret && bits.get(f.hash(value));
+ }
+ return ret;
+ }
+
+ /**
+ * 静态内部类。用于 hash 操作!
+ */
+ public static class SimpleHash {
+
+ private int cap;
+ private int seed;
+
+ public SimpleHash(int cap, int seed) {
+ this.cap = cap;
+ this.seed = seed;
+ }
+
+ /**
+ * 计算 hash 值
+ */
+ public int hash(Object value) {
+ int h;
+ return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h = value.hashCode()) ^ (h >>> 16)));
+ }
+
+ }
+}
+```
+
+测试:
+
+```java
+String value1 = "https://javaguide.cn/";
+String value2 = "https://github.com/Snailclimb";
+MyBloomFilter filter = new MyBloomFilter();
+System.out.println(filter.contains(value1));
+System.out.println(filter.contains(value2));
+filter.add(value1);
+filter.add(value2);
+System.out.println(filter.contains(value1));
+System.out.println(filter.contains(value2));
+```
+
+Output:
+
+```
+false
+false
+true
+true
+```
+
+测试:
+
+```java
+Integer value1 = 13423;
+Integer value2 = 22131;
+MyBloomFilter filter = new MyBloomFilter();
+System.out.println(filter.contains(value1));
+System.out.println(filter.contains(value2));
+filter.add(value1);
+filter.add(value2);
+System.out.println(filter.contains(value1));
+System.out.println(filter.contains(value2));
+```
+
+Output:
+
+```java
+false
+false
+true
+true
+```
+
+### 利用 Google 开源的 Guava 中自带的布隆过滤器
+
+自己实现的目的主要是为了让自己搞懂布隆过滤器的原理,Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要手动实现一个布隆过滤器。
+
+首先我们需要在项目中引入 Guava 的依赖:
+
+```java
+<dependency>
+ <groupId>com.google.guava</groupId>
+ <artifactId>guava</artifactId>
+ <version>28.0-jre</version>
+</dependency>
+```
+
+实际使用如下:
+
+我们创建了一个最多存放 最多 1500 个整数的布隆过滤器,并且我们可以容忍误判的概率为百分之(0.01)
+
+```java
+// 创建布隆过滤器对象
+BloomFilter<Integer> filter = BloomFilter.create(
+ Funnels.integerFunnel(),
+ 1500,
+ 0.01);
+// 判断指定元素是否存在
+System.out.println(filter.mightContain(1));
+System.out.println(filter.mightContain(2));
+// 将元素添加进布隆过滤器
+filter.put(1);
+filter.put(2);
+System.out.println(filter.mightContain(1));
+System.out.println(filter.mightContain(2));
+```
+
+在我们的示例中,当 `mightContain()` 方法返回 _true_ 时,我们可以 99%确定该元素在过滤器中,当过滤器返回 _false_ 时,我们可以 100%确定该元素不存在于过滤器中。
+
+**Guava 提供的布隆过滤器的实现还是很不错的(想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了。**
+
+## Redis 中的布隆过滤器
+
+### 介绍
+
+Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍 :https://redis.io/modules
+
+另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom
+其他还有:
+
+* redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
+* pyreBloom(Python 中的快速 Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
+* ......
+
+RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
+
+### 使用 Docker 安装
+
+如果我们需要体验 Redis 中的布隆过滤器非常简单,通过 Docker 就可以了!我们直接在 Google 搜索 **docker redis bloomfilter** 然后在排除广告的第一条搜素结果就找到了我们想要的答案(这是我平常解决问题的一种方式,分享一下),具体地址:https://hub.docker.com/r/redislabs/rebloom/ (介绍的很详细 )。
+
+**具体操作如下:**
+
+```
+➜ ~ docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
+➜ ~ docker exec -it redis-redisbloom bash
+root@21396d02c252:/data# redis-cli
+127.0.0.1:6379>
+```
+
+### 常用命令一览
+
+> 注意: key : 布隆过滤器的名称,item : 添加的元素。
+
+1. **`BF.ADD`**:将元素添加到布隆过滤器中,如果该过滤器尚不存在,则创建该过滤器。格式:`BF.ADD {key} {item}`。
+2. **`BF.MADD`** : 将一个或多个元素添加到“布隆过滤器”中,并创建一个尚不存在的过滤器。该命令的操作方式`BF.ADD`与之相同,只不过它允许多个输入并返回多个值。格式:`BF.MADD {key} {item} [item ...]` 。
+3. **`BF.EXISTS`** : 确定元素是否在布隆过滤器中存在。格式:`BF.EXISTS {key} {item}`。
+4. **`BF.MEXISTS`** : 确定一个或者多个元素是否在布隆过滤器中存在格式:`BF.MEXISTS {key} {item} [item ...]`。
+
+另外, `BF. RESERVE` 命令需要单独介绍一下:
+
+这个命令的格式如下:
+
+`BF. RESERVE {key} {error_rate} {capacity} [EXPANSION expansion]` 。
+
+下面简单介绍一下每个参数的具体含义:
+
+1. key:布隆过滤器的名称
+2. error_rate : 期望的误报率。该值必须介于 0 到 1 之间。例如,对于期望的误报率 0.1%(1000 中为 1),error_rate 应该设置为 0.001。该数字越接近零,则每个项目的内存消耗越大,并且每个操作的 CPU 使用率越高。
+3. capacity: 过滤器的容量。当实际存储的元素个数超过这个值之后,性能将开始下降。实际的降级将取决于超出限制的程度。随着过滤器元素数量呈指数增长,性能将线性下降。
+
+可选参数:
+
+* expansion:如果创建了一个新的子过滤器,则其大小将是当前过滤器的大小乘以`expansion`。默认扩展值为 2。这意味着每个后续子过滤器将是前一个子过滤器的两倍。
+
+### 实际使用
+
+```shell
+127.0.0.1:6379> BF.ADD myFilter java
+(integer) 1
+127.0.0.1:6379> BF.ADD myFilter javaguide
+(integer) 1
+127.0.0.1:6379> BF.EXISTS myFilter java
+(integer) 1
+127.0.0.1:6379> BF.EXISTS myFilter javaguide
+(integer) 1
+127.0.0.1:6379> BF.EXISTS myFilter github
+(integer) 0
+```
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\233\276.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\233\276.png"
new file mode 100644
index 00000000000..10547ded08d
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\233\276.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.drawio"
new file mode 100644
index 00000000000..72381b7ae28
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:11:57.013Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="B6MeSWDkbwDCadNkhl8o" version="13.4.5" type="device"><diagram id="eB035yKR6LJ1ptgLsSbM" name="Page-1">7V1dj6M2G/01XHbE98dlksm0qtqqerdqdy+Z4CS0TEgJmUn661+bmCTGJpCJjb3I0mgXGzDgcx4ffHgghjN7O/xYxNv1r3kCMsM2k4PhPBu2bVmmD/9DNcdTTWSap4pVkSZ4o0vFl/Q/gCvrzfZpAnbEhmWeZ2W6JSsX+WYDFiVRFxdF/kFutswz8qjbeAWoii+LOKNr/0qTcn2qDe3gUv8TSFfr+siWH53WvMX1xvhKdus4yT+uqpy54cyKPC9PS2+HGchQ59X9ctrvpWXt+cQKsCn77LD/cvC9dPaz98+f//322x/r2fTr7gfcynuc7fEFG7afwfamr+iUyyPuB//fPTrP6TLflD/sKpQmcAPb2x4uK+HSCv1v1m3Ak3mtK3EnnFu04dlBEGFh+rFOS/BlGy/Qmg/II1i3Lt8yWLLgYrzbnpBdpgeQoJNIs2yWZ3lRNeQsl8BfLGD9rizyf8DVmiSIXiHf6oO/g6IEh9bus86gQDaD/A2UxRFugnewfYwjJnLg4vLHFS1w1fqKEXVdjIm4Ord8wQouYLjugM5mQNfs4k0yQTEAS5t8A8huhdddHL/CglkXvl0Xng9E6ViXDmn5tW4BLlf7PHm4dNkJFep9TucFEirSGn0Pzz3fFwtw46LxaFLGxQqUN7Zz2FheYeUxsKrrCpDFZfpOni4LQHyE3/MUXsiZKp4TPUWRF9hh4MFCaJHEsc0n03TtwLLdwPWtiGz+1AW4xetwbh7E8p88n2rmzE7nyXWoU6gPcuo/6iAVD8/d9XlqOiJGFXuMo4rnkaNKaEkeVVwR0DljhM61GtBFkqHzREDnjhG6ppZLh84XAZ01RuiaUSf9Nix48DaM481RPT/qujnyZd4cuWH4ZIfn+xbbchoC2Fj9ybuj0HoKrPP9T0DeHYUuc+1Ad0ehOozxejKmJSaHYYzTuEcKokYs9yWFa3c0JBj46EHg67lXPcHqM/c6z/LOU76rvW7M8ziSzO1JMk8qyRq6cvap7iVZs6HQGZZk9eEfZ9mZWd+u1nSw7IpYfdwEjizr6wy4UsWvMQJF7mdZ5nU0JJplLOPw0bGsJ8fkjWTOd8Gx5uSmOQD1lku/Y0gUzTFbFY6pN4pJ1crxMIxhVM4jIwqN6MWYe0YIFwJj/mJMZ0Y0ocgHZ7ElyThy6osZeT1PxlVxlq42sLiABAGwformxOkiziZ4xVuaJFnbpLzI95sETcEr9iEvAD83s3n5IyGJi2UG9Cy7ftB1TTDbbOfSQ7Nsq92XTNL3i7lxqtpt400v38Rk+SZX1stND+xcdzocVU2cmJLU4UAV32mEsEczxWUMReKY0m6DimdKi9GtmcJiiimbKe2uq3im2JopN5hCPjENpY8pLJN3KKa02PiaKSymSB9TWObuUExpybvRTGEwJZA+pvRwg3freIsWy/g1a8xtWZ22g9OleiqAum0BWRSnG9T71T6LPMvi7S6tGjttsU6z5Jf4mO/L+jB1iZpXVGV8bpZBPf5LYhAumY///EUIXpd8YAzdBow9H/817TF+WVg97NYaRniZZRpn/wOLMt6s+iBKI5YU+faP2h1AFVs0OQbF/B324K6eEtLhWOZbvDIDy3rf17ws8zdcKHBvnRutusqbwj94jTNktHnwamawbF3K8A9tXpSzfAORj9MKRxDvyg+w66ZRH0bcCJ+bDsiwPKANUZcrEar01vhChBz22jKrnK81HEnBhgfugsC6yndtA4s19ooDi+Usvmi4OuA6kLBIQ4+VXqiVs0M5A9dTTDlZlp5WTuHKaXfnRg/LA9qws7gS4bseirsfJQ479rI8M43VTaxUkc0emYpaNpuoWWZzxtkzV1gcjj3yB7VuCgjvQDHdpA0kPeMkg0Qd3XRYNpGecXbBpYh0OrS5o6WzUzoj1ZTTYdk+WjmFK6fT/frAsDygDSRHD8VEkCiknIJtojFipYpsslKxtGze+4hTumwK9ny0bN4KH4VkkzaQ9FBMBolCsinYJRojVqrIps4M4vF8U7ZsuizLR8umeNlULDPIpc0jUw/FRJCoI5uuYItojFgpIpuuTgviMNsMZacFuTotSIpsuoqlBbm0eaRNWjJIFJJNlkWkH292waWKcurMIA4TTvnKqROD5CinYolBLu0f6YRaMkjUUU5PsEs0RqwUkU1PZwVxyArq++1dcTAKtny0bN4KH3Vk06P9I51PSwaJQrLJcon0hLMLLlWUUycG8bBqpSunTgySo5yKJQZ5OjGoK0gUUk6dGHQ3VqrIpk4M4uHTypZNX7Dlo2XzVvioI5s+7R9pn5YMEnVk0xfsEo0RK0Vk09eJQRx82kj2401fJwZJkU1fscQgXycGdQWJQrKpE4M+A5cqyqkTgzj4tPKVUycGyVFOxRKDfNo/0hNOMkjUUc5AsEs0RqwUkc1AJwZx8Gmly2Yg2PLRsnkrfNSRzYD2j/QLnGSQKCSb+nNBd2OlimwqnxUkQxb9gJxNsr7bzvqtT4E46bSf27r4QIR+7ndd6zd/+EN9hwGk7Gj6ABzduTvDwqGNnKEj70hCKg35O1J/xhiI3ebMoHCEgs0ZHYhtgRj5cgMxvMPbGWEght1pOcPCoT0aSYFo1R9qkQb9HWk9Y4zEbuNlWDh0eo6sSIxsyZF4h3EzxkjszrkZFg6f6n3y55QhSdf5Kt/E2S951Ueo6/8GZXnEVlm8L3MSmKYjCXukOH7F7VWFb6gAQwEXnw/XK5+PRC+DZAVa+xhXlXVst11m2+foCpDFZfpOHoDVyXjX31GIX/ltUeMtO6vho+3yfbEAeK8LVFRDQfN1vWZDpyukGqowP1/PAzQI1KUBw9Dmwom2L/s+yInQ4sUJr/EuSvPnxUVzIhwZJ7hDHTWhNqMn73NgU1+6oJsSDXek4b4Nt2Xyw5v6qcDhAY/oB9PKAM5xmG/7pU3O0h/4nKSfakg0Dei0PmVoIEr62360nLP0f54TDekPgoE5Qc/JlOEERxq0fTOM96yA19BANSSaBvS7MsrQQNTQ0Pb5Vd6zAl5DQzj00EB/50oZTnCkQdtrqpyHhoiXYUA1JJoGnro0EDU0tH3xg/PQ8HlONIaGaGDDIFLYS1RjBtk0DCJ+hgGjKdFwK+wZcoz6tkRY3krA6yaRakg0DcZmE/a5OxAzcaCUgNdNYjT0TaL2Eu9VAo+fEtBNCYbbMhkpbvPQmM4NOIWce0YYGNOJMX8xpjMjmlDcKMGhJMEms+TxM1rGY9s4S1cbWFwA9DgfVqBnsukiziZ4xVuaJNWDY9bTYpKTTYLhS3okH//87lH99N1y6IT8+k1bIiFfVD6+ZTJy0hBULwikeWBMQiOcaqiQ2S8dKpsBFQym0Iie0cIkqKCC/06MqW/MfQNeQ2hh8MIZ2mYKa3wE8MSvVvlGZBrRDO01dY2JjRYgzKGLVsEYhWvnkTGxqgZhy7Yxjaq9XBTN6OjwuB7aBup+9FKfD30rOFqiOPWXFW8RxWG+ZSOOKd/3V6tEgOLToAz6gppl8v0g/Hef0iboPUXMfZoZ8oCnM9z0K8CNsBgCLlgs8ry8vtWFPbj+NU8A2uL/</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.png"
new file mode 100644
index 00000000000..46b67b62e85
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.drawio"
new file mode 100644
index 00000000000..f4ad6803c4f
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:17:01.344Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="_-veHJdt8GyZRG2S5hoi" version="13.4.5" type="device"><diagram id="0kJCOVOw4mzpPHpbBMS6" name="Page-1">7V1dj6u2Fv01PHbElw08JmmmVdUjVT2VbvtUMYEk3MuElJCZpL/+mg8TwCaQxMY+Oa6OOmDAgNfae9vLG0ezFu+nn1J/v/2SBGGsmXpw0qwfNdM0DB2iP3nJuSzxdL0s2KRRUJ10Kfga/RtWhfi0YxSEh9aJWZLEWbRvF66S3S5cZa0yP02Tz/Zp6yRu33Xvb0Ki4OvKj8nS/0RBti1LXdO5lP8cRpstvrMBvfLIu49Prt7ksPWD5LNRZC01a5EmSVZuvZ8WYZw3Hm6X8rrXnqP1g6XhLhtzATj/8vHl01wdX0+f7t+zv/eGt/2hquXDj4/VC2smjFF987f8kbNz1Q7wn2P+nPN1sst+OBQozdAJJtifLgfR1ib/q+M60MO84cKqEeoaTfR0CES0M//cRln4de+v8iOfiEeobJu9x2jPQJv+YV8iu45OYZA/RBTHiyRO0qIia70O4WqFyg9ZmvwvbBwJHO8N8Q3f/CNMs/DU23xGDQpic5i8h1l6RqfgC6wKx4rIAFT7nw1aVEXbBiNwmV8RcVPXfMEKbVRw3QCdSYGu28S7YJbbANrbJbuw3azovdPzn2hHxzt/NXd+PLX2znjvFGV/4hrQdnHNC6j2LhflO/ia8rnCgLC0TtujZ0+O6Sq88tKVN8n8dBNmV86z6Fg2sAIUrHBZGsZ+Fn20H5cGYHWH35IIvUhNFVv3XjwPOKbrABNYru60mWPpL7pum45h2o4NDa9df9kGVZVNe+7cxXLhC4BENTU9rRfbujxD5yXKBiRuUhCxbq/7uWnxcCvmM7oV22y7FWgKdis2D+isZ4SuxqCCztEFQwd4QGc/I3TdYC4cOsgDOuMZoetanfB+mPNgP4xh7wgPkIZ6R1Bk78gC7ovp1v0WZIudANg5fF/vyAbGi2PU/R/HbffBYOdwpw/GuXvkykMZMJIyPUY5DWXMbidJ7xjzWFaY3kBFnIH3HgQej77wEGvM6Kse59WDvsZVV0Z6DElmjyQZEEkyo9udM+4kWbciaE9LMvzcj7OsZtZfjSMDLGsQa4yewJBlY7UBW6gr63ggB9zrysyBinizjCYdPurLRnJMnCezvgWOWdaAAxotMXWHSV2XyJtjpiwck8+LCY2Vz8MwilK59DTP1bxXbQk0F2042vJVmy80b0aQDw1jszbj2mPfipHNgXJV5MfRZod2V4ggISqf54PiaOXHs+rAexQEcd+oPE2OuyAfgxfsy8WAaubMZCWQgDYuLu7TNPiFZ7qa/DL1fio9NMo2+nXJIPq4iBtl0WHv70bpJjpNN2lIL1c1sLqsvB1R3HowKZnDgClA71gwJJliUzwRP6b0y6D8mdIjdCum0JhiiGZKv+rKnymmYsoVphjt7oVwn0ITeadiSo+Mr5hCY4pwn0LTdqdiSk/ijWIKhSlAtE9xIdHY7ZdO0mybbJKdH/+aJPuq9f8bZtm56uz7xyxpY9MdCfTk+DBUTIaVEJ0Oy4MjUAA7ht/FaewIFBoDFfGeC3LkpUFRT/VcBkNOWD0TkA9yArqsOGGCdkXWxJxwn4wTzKF2ulAb3gu4D2y36wDIqnjD7Sm4r8PtsoPbEw43ngGSEW6GTt7smQNhHPiBwyjwExXxpoEhLw14BX6TT2ewG/jv50Qn8INu1hhvTpjycoIhDWx3EtcAWbkGoiLeNLDkpQEv12DzCRfEmICVa4BTuwZbXk4wpAGcRi5wWMkFREW8aQDkpQEv1wCmkQvu50THNTgTywWexEqiHOPHrlzgsJMLKFXxhltixZCh1TvmNJGAVSeRqIg3DZ5NJBzTO+AzcCAiAatOojN1J1EpibdGAsguEpBVcc/0p6T6L11tvtTQEDJPX3S0+UylL5qeTU72Tpu+iGefu0i95hgtHW3mau5cIWW6lO/fJ0bKpCCFTOlVQ/3si03VScKeNoPFIYTgTHPNHE30/7lXoekuSJPUG8eANtc1F4170XUIedfOizxUtMxL5nNt5hQ3MbQ5JOp2tSW6+UKbzfKbzJY5ofJHc/LtJr+qmsurvOIqO3+o/ImANgOUrGf2HIzDdSYdAxHn2gzECaTND4odg6Rgd5THjoIGOUOUh0ocPS9BfHkpna+O6UfRTgbRandEfeIb7tdXC/13Qxefeejufvntenf20ixjoCLun06RwYBE/DsxN1poBgbF3Ph5/BFf5R62/j7fzPy3oukaqNBa8YAYhBsub7cVakc/2uXxt7hmlcSxvz9ERWXlGdsoDn71z8kxw7fBewQK7Z40sQ5D4IfumroOA1y54duaDY5Od/p05DoM3S+F2K2HNeKzVwwjes0s8uPfw1Xm7zZjECURC9Jk/wcesOYF+9xfhOnyA7XgARsQaZ1Z4YHzg6V9FptvSZYl79VOWrVWXWnRVGCO/qF3XORDLYDeZoH2jcs++pefnmaLZIeQ96MCx9A/ZJ/hYZhGYxhxxXxIngjjAelcyamTR4hQLDToX4iQoFZbx8UXiFvkWsMdC9w5gdU3AT+QBMsPLEpnG1Wo4LoO16kNizD0aOu8qcg5EDmh0UkyER45ad9WqsjJPXKaw6tUTssD8stJMkftu3XFw0s6TOt7aR8vKqyuYiVL2ByxZJwKm13UiMTtkWs28oNxxDJuKmxysG5HsrBJ6kdqwNk2EnnCpkVTidSAcwguSSKnRZlFVZFzKHISX7iJjpwWTfVRkZN75LR6eCKMB6R+RH758L264tJIJIqcnFWiZ8RKlrBJWxJLhc0bZzjFh03Oko8Km9fMR6KwSepHyhUPrS0izPdyVomeEStZwqZKDGIwvSk8bNo0yUeFTf5hU7LEIHtM1uX36or7lmkT5XttzhLRM2IlSdi0VVYQi9Gm6KwgW2UFCQmbtmRZQTYpHimRdmjVGmG+lyYRqenNIbhkiZwqMYjFgFN45FSJQWIip2SJQTapH6l82qE1AEX5XsBZJXpGrCQJm0BlBTHIChr7G+j8YOQs+aiwec185AmbgNSPVD5t20gkCps0lUgNOIfgkiVyqsQgBlKt+MipEoPERE7JEoOASgwaMhKJIqdKDLoZK1nCpkoMYqDTCg+bkLPko8LmNfORJ2xCUj9SOu3QDzI0fS+YEizOKtEzYnVq49SAzpoUOpUYxEKnFT29CVVikJCwCSVLDIIqMWjISK6ChT8vmAYslRh0D1ynNlTNTg9liVp+6KnEIBY6rfDIqRKDxEROyRKDIKkfqQHn0G/8iIqcDmeV6BmxkiRsOqSwo8LmYNgkdFrRYdPhLPmosHnNfOQJmw6pH6kPOId+LlHUHJmjlgu6GStJpjcd6bOCRIRFYLdHk7Rl2wEFJo44qbSf63HxAQsdzuyhYY2//GEP9Q0CkLTe9AE4hnN3poVDCTlTW965Dakw5G9I/XlGQxwWZyaFw+UszihD7DNED4o1RPcGbecJDdEdTsuZFg6l0QgyRAMv1CIM+hvSep7REoeFl2nhUOk5oizRMwVb4g3CzTNa4nDOzaRwGPq3nfD4uGZm4t/Gwb+07QiWNg2d7afE37wz5PWjwPpwsuLEwNN8I4xxG6Ajq1o3hv8ckzJSWOt18bP3jSK4yf/q+GL0NOX1Zfm352+5MUCypdEM/Qa5/Cm9sYWnS69440kndA2ds6yt3PNVW5Bnat/QaYr6/e7ZUO55iAHDOZETu2easn4/A2zFgDsZwD0LAe2mSQ5Wfewn1KDbL0kQ5mf8Hw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.png"
new file mode 100644
index 00000000000..758f84e4a10
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.drawio"
new file mode 100644
index 00000000000..bbe5df10382
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:16:36.629Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="nIl0iNm7MDMt_npkXUNt" version="13.4.5" type="device"><diagram id="3SB0d3gYCvH_tWMfFJ3L" name="Page-1">7V1ts6I4Gv01fJxbvL98VFtnpna6qmt6a7f7I1dQ2eWKg3ivzq/fBBIlJAhqArluprrmmiABcs6TQ04eULNmb8df83C3+ZpFcaqZenTUrC+aaRqG7oI/sOZU1QS6XlWs8yRCX7pUfE/+jlEl/tohieI98cUiy9Ii2ZGVy2y7jZcFURfmefZBfm2VpeRRd+E6piq+L8OUrv13EhWbqtY3vUv9b3Gy3uAjG25QbXkL8ZfRlew3YZR91KqsuWbN8iwrqk9vx1mcws7D/VLtt2jZej6xPN4WfXawv36L8t+m/8rNX6PdP34/7X/+vvoFtfIepgd0wZrppqC96Ss85eKE+sH96wDPc7rKtsUv+xKlCfiC6eyOl43g0xr+1XEb4GRecSXqhHOLJjg7ACIoTD82SRF/34VLuOUD8AjUbYq3FJQM8DHc7ypkV8kxjuBJJGk6y9IsLxuyVqvYXS5B/b7Is//GtS2RF7wCvuGDv8d5ER9bu884gwLYHGdvcZGfwFfQDqaDcEREdgNU/qjRAlVtaozAdSEi4vrc8gUr8AHBdQN0JgO6ZhdvowmMAVDaZtuY7FZw3fnpByjouPCzXvhyJEonXDomxQ/cAvhc7vPioNJlJ1jA+1TnFUdUpDX6Hpx7dsiX8ZWLRqNJEebruLjyPYuNZQ0rh4EVrsvjNCySd/J0WQCiI3zLEnAhZ6o4ZvASBI5n+p5jOpZvkMTx9Bddt03PMG3Pdo2AbL7qAtRiPZybB9HdF8elmjmz03qxLeoU8EGq/qMOUvLw3F33U9MSMaqYzziqODY5qnjuyKOKLQI66xmhs3USOt8eGTpHBHT2M0LX1PLRoXNFQGc8I3TNqBv9Nsx78DaM480Rnh913Ry5Y94c2Z7/AgIO37eYhtUQwMbmO++OPOPFM873Px55d+QFzK0D3R358jDG6cmYlpgchjFW8x7JbsRyX1LYRkdDgoEPHgQez73wBKvP3Os8yztP+Wp7XZnncSSZ3ZNkzqgka97NOXeSrNmQ11QewSTDHH+cZWdm/axt6WBZjVh93ASOLOvrDNijil9jBPKDe1lmdzQkmmUs4/DRsawnx8YbyaxPwTGnYwDqLZfNWVJzSBTNMVMWjsk3io2qlc/DMIZROQ+0wNeChTZ3NB988LT5QpvOtGBCkQ/MYguSceTUFzGyPk9GVWGarLeguAQEiUH9FM6Jk2WYTtCGtySK0rZJeZ4dthGcgpfsg14AWjczefkjHomLoeNFrBrB8EJXnWCm3s6lh2bZRrsvGSXvF3Ojqtrvwm0v30Rn+SY16+WqB3auqw5HVRMnJiV1OFDFNUmqnNd3a0yxGUOROKa026DimdJidCumMJhyHuxHY0q76yqeKaZiyhWmkCum/uhjCsvkHYopLTa+YgqDKd7oYwrL3B2KKS15N4opLKaMPqb0cIP3m3AHPxbha9qY27I6bQ+mS3gqALttCVgUJlvY++U+yyxNw90+KRurvrFJ0uiP8JQdCnwYXKLmFWUZnRtNBM203KUfv640amEwCmN/teQDo281kml6Lv81nX5+WVg97FYMI7jMIgnTP+NlEW7XfRClEYvybPdP7A7Aih2cHMf5/B304B5PCelwLLId2pjGK7zva1YU2Rsq5Ki3zo2WXeVMwT9wjTNotDngamagbFzK4B/8el7Msi1gRJiUOMbhvviI99006sOIK+Fz1QEZlge0IWpzJUKZ3hpeiJCBXlulpfO1ASNpvOWBuyCwavmubWCxxl5xYLGcxYWCqwOuIwnLaOix0guVcnYop2c5kikny9JTyilcOc3u3OhheUAbdgZXInzqobh7KXHYsZflmSmsrmIli2z2yFRUstlEzdAbM06vZ66wOBx75A8q3RQQ3p5kukkbSGrGSQaJPLppsWwiNePsgksS6bRoc0dJZ6d0BrIpp8WyfZRyCldOq/vxgWF5QBtIlhqKiSCRSDkF20TPiJUssslKxVKyeeMS5/iyKdjzUbJ5LXwkkk3aQFJDMRkkEsmmYJfoGbGSRTZVZhCH9c3RZdNmWT5KNsXLpmSZQTZtHulqKCaCRB7ZtAVbRM+IlSSyaau0IB6zzbHTgmyVFjSKbNqSpQXZtHmkTFoySCSSTZZFpJY3u+CSRTk/e2ZQmz62KyoH5aQmnKMrp0oMGkc5JUsMsmn/SCXUkkEij3I6gl2iZ8RKEtl0VFYQh6ygvu/eFQejYMtHyea18JFHNh3aP1L5tGSQSCSbLJdITTi74JJFOVViEAerdnzlVIlB4yinZIlBjkoM6goSiZRTJQbdjJUssqkSgzj4tKPLpivY8lGyeS185JFNl/aPlE9LBok8sukKdomeEStJZNNViUE8fNqxlzddlRg0imy6kiUGuSoxqCtIJJJNlRh0D1yyKOdnTwySw6cdXTlVYtA4yilZYpBL+0dqwkkGiTzK6Ql2iZ4RK0lk01OJQTx82rFl0xNs+SjZvBY+8simR/tH6gFOMkgkkk31uqCbsZJFNmXPChpFFl2XnE2y3tvO+q1PgTiptJ/ruvhAhN73u674yR/+UN9gAEk7mj4AR3fuzrBwKCNn6Mg7kZCOhvwNqT/PGIjd5sygcPiCzRkViG2BGLjjBqJ/g7fzhIHod6flDAuH8mhGCkQDv6hlNOhvSOt5xkjsNl6GhUOl54wViYE5ciTeYNw8YyR259wMC4dL9T75c8qApJtsnW3D9I+s7CPY9f+Ji+KErLLwUGQkME1HEvRIfvqB2isLP2EBhAIqfjnWN345Eb0cR+u4tY9RVYFju+0y215Hl8dpWCTv5AFYnYx2/QZDvOa3+aTf5rkNH22fHfJljPa6QEU15DXfrNZsqLpCqqES8/P1PEADT14aMAxtLpxoe7Pvg5zwdV6csBvvDPIG5oT/ZJzgDnXQhNoJXpz7wKZ+/4ZuSjTcgYL7OtyGzg9v+qcCBwc8oBempQGc4zDf9kubvKXf4CX9zYZE04BO65OGBqKkv+1Hy3lL/92caEq/OTAn6DmZNJzgSIO2d4ZxHhp8XkMD1ZBoGtDPykhDA1FDQ9vrVzkPDfdzojE0+EMPDfR7rqThBEcatD2mynto4GUYUA2JpoEjLw1EDQ1tb/zgPTTwMgz8gQ2DQGIvUY4ZZNMw8PkZBoymRMMtsWfIMerbEmE5K0HA6yaRakg0DZ7NJuxzdyBm4tBUgvs50VCCYOibROUl3qgEgc5NCRhNCYbb0BkpbnNfm841MIWcO5rvadOJNl9o05kWTChuFPGxIMEms+fRGi1j2TZMk/UWFJcxXM4HFXBNNlmG6QRteEuiqFw4Zq0Wk5xsEgxd0iP5+Ca+A8Or7zpOBqyt9+InbYmEfFH5+AbmXROqBQRp7mkTX/OnCiozcEdHymQgBWJpoYEb7UtQBRpQ4GABP0zcchNAcKL5JkQT/H8aIDT9GR2TRm2bo011zXcNuB9A3rdhVQCq5rBmOtUmXnkQQ5u6VNu+NgcHn2mTCTzIZA4JBU/Ng5/r/EItV3sF5V42PCl4Ro42cWoX5MBmGXeZj3OwyvGQjIEW/i2OKwx08F3jQBRkPc2IGUOvGzwtMH73KO4YwyJzQwadhI+N848WIGwjPwJu6IJT2z59VqOgR1VRMNBUGY8JrKce3RT3AdiyPD8A6v51yKqUT2u1ssB/9Sp3Df8aeGdwNtX+VT1Xdn3mh5VR6F1lwKCPJxs6/TCk+oGQTrgkebgcCPz/ubrafnPiylBXwxwWFMGPNSp5vRoNVwfXgalg0H6TGl0bgSKRGBoMz+mB2yFT3Q7dyQBZ9NVgWFsPEMJShHiMEAw/Y2BC0JlmcFEGX/pluWh+qZ0uD/l76fsYlAt0x/oS9cKexaJkW//FZO6LRLbdvAuz7lwQtKmFiGZLdy8RgWKewXC8fB2EzOZrFsXwG/8D</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.png"
new file mode 100644
index 00000000000..4b254eb8077
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.drawio"
new file mode 100644
index 00000000000..620445a7606
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:25:55.080Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="8WiHXBkHtgRdnOqTx93g" version="13.4.5" type="device"><diagram id="4oGk1i_xgKgO_iptbDTg" name="Page-1">7V1dk6o2GP41XHaHhO9Lte7pxelM29OZ9lx1WEGlZcUi7rr99U34EkgU1ITkcNI505UAAfM870ceXqJmLF5Pn1J/v/05CcJYg3pw0owfNQgB0G30B7d8FC2erhcNmzQKyoPODV+i/8KysTrsGAXhoXVgliRxFu3bjatktwtXWavNT9PkvX3YOonbV937m5Bo+LLyY7L1jyjItkWrC51z+09htNlWVwa2V+x59auDy29y2PpB8t5oMpaasUiTJCs+vZ4WYYwHrxqX4rznC3vrG0vDXTbkhN3Xf2I9PX41Pv26/LyAf/0U/538UPby5sfH8gtr0I5Rf/MXfMvZRzkO9r9HfJ/zdbLLfjjkKM3QAdDan8470acN/qtXfaCbeakay0Goe4To7hCIaGP+vo2y8MveX+E974hHqG2bvcZoC6CP/mFfILuOTmGAbyKK40USJ2nekbFeh/ZqhdoPWZr8Ezb2BI73gvhWXfwtTLPwdHH4QA0KYnOYvIZZ+oEOqU4wSxxLIgOn3H5v0KJs2jYYUbX5JRE3dc9nrNCHEq4boIMU6LpDvAtm2AbQ1i7Zhe1hRd87/fgTbejVxtfmxo+n1tZHtXWKsj+rHtDn/Jwnq9w6n4Q3qnOK+woDwtI6Y4/uPTmmq/DKly69SeanmzC7cpxBx7KBlUXBqmpLw9jPorf27dIALK/wSxKhL1JTxQTek+dZDnQdC1qGqztt5lj6k66b0AHQdEwbeEb7AsUglH02DbpzGcOznyy70U+Hn8aTaZxvAnSuUgwhcZWcivWI3c9Og4djgVN0LKbRdizQFOxYTB7QGVOEDmUzLegMKBg6iwd05hSh64Zz4dDZPKADU4Sua3XCMzHnwUyMYX5UTZH68iNbZH5k2O4TdOvEBVapSR0A6btvzY9QSvTkgDoDctx2Gob6p+4eKUFy5SGNNZA0F8xyHNLAbpoEO+Y8OG3WezriDLz3IPDVDKyaZg2ZgdVzvXri1zjrymyPIcnMgSSzRJIMdBM6406SdTuC9rgkq+Szx1lWM+trY08PyxrEGqIpMGTZUH3AFBr/Oh7IcO5kWdcnEh3xZhlNPnzUlw3kmDhPZnwTHDN7HNDgcNmdKHVdIm+OQVk4Jp8XExorp8Mwila59DTP1bxnbWlpLvrgaMtnbb7QvBlBPjSRzdqMa89+S0Y2p8plkx9Hmx3aXCGChKh9jqfF0cqPZ+WO1ygI4kvz8jQ57gI8C8/Zh+WA8ukZZCWR2G1crCpsNfhVPe1q8qubTzObZ4PLymQQvZ3ljaLpsPd3g5QTnaacNMSXqypY3VZcjmhu3ZiUzGHAFAt0LNglmWJSPBE/plwWQvkz5YLUrZhCY4ohmimXdVf+TIGKKVeYAtrphXCfQpN5x2LKBSFfMYXGFOE+habtjsWUC8U3iikUpgDRPsW1icFuf+kkzbbJJtn58eck2Zej/3eYZR9lsu8fs6SNTXcmcKHOh6Fi0q+E6HRYHpyBWk7H8M07Z6A27OmI97MgR14a5P2U9wUYcsK48AjyQU7YHitOGFa7I2tkTrgT4wRzqJ0u1Ib3ZN0Httt1AGRXvOH2FNzX4XbZwe0Jh7t6PCgj3AydPLzwDIRx4K+ftj4a+ImOeNMAyEsDXoEf8kkGu4H/fk50A78+MiegvJxgSAPTHcU1QFaugeiINw0MeWnAyzWYfMIFMSdg5RqMsV2DKS8nGNLAHkcuMFjJBURHvGlgyUsDXq7BGkcuuJ8TXdcwslzgSawkyjF/7MoFBju5gNIVb7glVgwZWr0Dx4kErJJEoiPeNJiaSDgkO+AzcSAiAask0Rw7SVRK4q2RwGUXCciuuFf6U0r9l642X2poConLFx1tPlPli9CyyYe945Yv6pRyeYzUM8Zo6WgzV3PnCiloUt6AHxkpSEEKmdKzhvLss03VRcKeNrPzXQjBmeZCjCb6/9wr0XQXpEmajX2WNtc11zbxeQh518RNKAC5S9wyn2szJ78I0OY20berLdHFF9pshi8yW2JC4Vtz8Ocmv8qei7O8/CwT3xS+I0ubWZSqZ/YcjMN1Jh0DUbTvZ6AFRqUgWZWu14wB9SdSEZosRG6vO6/re0aCiFaP3kEDpzdVxnNOvJbn1vnqmL7lAweIYbwjUyPevH9+NtB/N0zLmKdbdTV4hRy4M7M2YU9HvFOtAa/uHrb+Hn/M/Jcc3QY0NLM5oFuuLAUjvkKG40c7HKTzc1ZJHPv7Q5R3VhyxjeLgs/+RHLPqMtUWYXbtdJtYriHwQ3dNXa7BXrnhy5qN4TrdZ6wDl2voKnHsFs4a8G5sBSP6mlnkx7+Fq8zfbYYgSiIWpMn+92pWixv2mKBhunxDI3ioPCbpjrPc5PHOwiHnH1+SLEtey420HK2603yorDn6h77jAs/HLPRtFmgbnLfRP3x4mi2SHULej3IcQ/+QvYeHfhoNYcQV8yF5IowHZDpORtNHiJCvSOifiZCgUVvH+WuKWxRLwx0L3DmBdekpfU+lLD+wKBk56lDBdR2uUxsWYejRloNTkbMnctqwrSSKj5wDEl4VOTlYd/9yluPygHy9kixk+25dcf+6D+P6Xtobjgqrq1jJEjYHrCynwmYXNaK6e+DSjvxgHLDWmwqbHKzbkSxskvqRmnC2jUSesGnQVCI14eyDS5LIaVAetarI2Rc5idfgREdOg6b6qMjJPXIaF3gijAekfkS+HvG9uuLCSCSKnJxVoiliJUvYpK2bpcLmjU84xYdNzpKPCpvXzEeisEnqR8oV9y1AIsz3claJpoiVLGFTFQYxeLwpPGyaNMlHhU3+YVOywiCTFI/I5Vq+V1d8aS03Ub7X5CwRTRErScKmqaqCWMw2RVcFmaoqSEjYNCWrCjJJ8UiJtH1L2wjzvTSJSD3e7INLlsipCoNYTDiFR05VGCQmckpWGGSS+pGqp+1bKFCU77U4q0RTxEqSsGmRwo4Km71hk1jjRLROa3GWfFTYvGY+8oRNi9SPVD1t20gkCps0lUhNOPvgkiVyqsIgBlKt+MipCoPERE7JCoMsVRjUZyQSRU5VGHQzVrKETVUYxECnFR42bc6Sjwqb18xHnrBpk/qR0mn7frVBlO+1OatEU8RKkrBpq8IgFjqt6MebtioMEhI2bckKg2xVGNRnJBKFTVUYdA9cskROVRjEQqcVHjlVYZCYyClZYZBN6kdqwtn3Q0CifK/DWSWaIlaShE2HFHZU2OwNm4ROKzpsOpwlHxU2r5mPPGHTof12inLF139TUZjvVcsF3YyVLGFT+qogEWHRstqzSdqy7RYFJo44qbKf63HxAQvtr+yhYV29+cMe6hsEIGm96QNw9NfujAuHEnLGtryPNqTCkL+h9GeKhtgvzowKh8tZnFGGeMkQPVusIbo3aDsTNES3vyxnXDiURiPIEEG1UIsw6G8o65miJfYLL+PCocpzRFmiBwVb4g3CzRQtsb/mZlQ4gC69kPawvnldMyN+gN0jNTMAx9Q2ga5EMzE/E6z3S2pjU4EmqtlxNQhoz6qWku1/j0kRPIz1Ov/p9UaTvcF/zepkdDfF+UX7t+eCuVFAslfwgE7qeN9gxBwbLkkeUwGd1OImV4D8SD7UB6ArGkBwg3o3yfzIHJAfjVpiAQBnWU2lR1dtQZ5iGwBIRU/Fxo6dSJTKAPVbanfAxT2VQZtpgqcJ9b5PaEC3PydBiI/4Hw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.png"
new file mode 100644
index 00000000000..072bda258e0
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.drawio"
new file mode 100644
index 00000000000..8dc681fa499
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:27:27.506Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="wdYw9fv3CkE8DWJwPg9r" version="13.4.5" type="device"><diagram id="mifzlOfuH5t4TGWJTCWP" name="Page-1">7V1fs6q2Hv00PHYPfwM8qlvPfWhnOj1t7zl9Ywsqt2yxiHtrP/1NEJCQIKgJyXHSOdNtggTIWr+sZPEDNWv2fvySBbvNL2kYJZqph0fNetVM0zB0AP+gmtO5xtf1c8U6i8PyS5eKr/G/UVlZfe0Qh9Ee+2Kepkke7/DKZbrdRsscqwuyLP3Ev7ZKE/you2AdERVfl0FC1v43DvPNudYz3Uv9f6J4vamObAD/vOU9qL5cXsl+E4TpZ6PKmmvWLEvT/Pzp/TiLEtR5Vb+c91t0bK1PLIu2+ZAd/v37y5+rP798OtHy1fvDBpn9x18/la18BMmhvGDNBAlsb/qGTjk/lf0A/jmg85yu0m3+075AaQK/YDq742Uj/LRGf/WqDXgyb1Vl2Ql1iyY8OwgiLEw/N3Eefd0FS7TlE/II1m3y9wSWDPgx2O/OyK7iYxSik4iTZJYmaVY0ZK1WEVguYf0+z9K/o8aW0PXfIN+qg39EWR4dO7vPqEGBbI7S9yjPTvAr5Q62VeJYEhn4ZfmzQYuyatNgRFUXlERc1y1fsIIfSrhugM6kQNfu4m04QTEAS9t0G+HdCq87O32DBb0qfG8WXo9Y6VSVjnH+rWoBfi72eXHK0mUnVKj2OZ9XFBKR1up7eO7pIVtGVy66HE3yIFtH+ZXvWXQsG1g5FKyquixKgjz+wE+XBmB5hF/TGF5ITRVX919833FNz3VMx/IMnDiu/qLrtukapu3awPDx5s9dULbYDOfWQYAHXhxANFOz03qxLeIUqoOc+484SMHDurvup6bFY1Qxn3FUcU18VHGB4FHF5gGd9YzQOR4OnWcLhs7hAZ39jNC1tVw4dIAHdMYzQteOOuHTMPfBaRjDyVG1PuqbHAGRkyPgeC8w4Kp5i4lPjlxA3Xrr5Mh1jBfXqKc/Lj45cn3q1pEmR548hHEGEqYjJMchjNOeItmtUB5KCsfvaYgz8P6DwFdLr2p9NWTpVS/y6hVfY68ryzyGJLMHkswRSTK7PZlz7iRZuyG3LTycSVb5Zo+zrGbW98aWHpY1iDXETGDIsqHGgC10KGuNQJ5/71Bm9jTEm2U03/DRsWwgx8SNZNaPwDFg9QxAgw2m9iKpPSTy5pgpC8fkG8WEauXzMIziU859zfc0f6HNHc2DH1xtvtCmM82fEOSDi9gcZxy+8i0Z2Vwml1VBEq+3sLiEBIlg/RQtieNlkEzKDe9xGCZda/IsPWxDtAIv2IesgPK2mcnKHnFwXAy9kpsGwar7XE2CmXo3lx5aZBvdtmQYf1y8jXPVfhdsB9kmOs02aTgvVy2wuu58OKIaOzEpqcOAKp6OU6W+vdtgik0ZivgxpdsF5c+UDp9bMYXClHqwF8aUbtOVP1NMxZQrTME9QU/4mELzeMdiSoeLr5hCYYorfEyhmbtjMaUj7UYxhcYU4WPKADd4vwl26GMevCWttS2t0/ZwuVQtBVC3LSGLgniLer/YZ5kmSbDbx0Vj529s4iT8OTilh7w6TFUi1hVFuTw3QyPu/oVB5K2od//A0oveVmxgNHQDx3Ho7b+21c8uC2uA31rhCK8zj4Pkt2iZB9v1EEhJyMIs3f1e2QOoYodWx1E2/4BduK/WhGQ85umu3JhEq2rftzTP0/eykJW9VTdadJUzhf/gNc6Q0+bAq5nBsnEpw3/o61k+S7cQ+iAugIyCff4Z7ft5NIQSV+LnqgUyLg9IR9RmSoQivTW4ECGFvbZKCutrA4fSaMsCd05gNfJdu8CiDb78wKJZiwsFVw9cRxwWYejR0guVdPZIp185I9IoJ83TU8rJXTnN/tzocXlAOnYGUyL80ENx/73EccdemmmmsLqKlSyyOSBTUckmseI0WytOd2CuMD8cByQQKt3kEN6uZLpJOkhqxYkHiTy6adFsIrXi7INLEum0BqS7KekkpNOQTTotmu+jpJO7dFr9DxCMywPSQbLUWIwFiUTSydknekasZNFNWjKW0s1bb3KK103Oro/SzWvxI5FukhaSGovxIJFINzn7RM+IlSy6qZKDGNzhFC6bNs30UbLJXzYlyw2ySftIV0MxFiTyyKbN2SN6RqwkkU1bJQYxWW6KzgyyVWaQEN20JcsMskn7SNm0eJBIpJs0j0jd4eyDSxbpVMlBLFacwpVT5QaJUU7JcoNs0kBSObV4kMijnA5nm+gZsZJENh2VGMQiMWjo+3f54cjZ9FG6eS1+5NFNh3SQVE4tHiQS6SbNJlIrzj64ZJFOlRvEwqwVL50qN0iMdEqWG+So3KC+IJFIOlVu0M1YyaKbKjeIgVMrXDYBZ9NHyea18JFHNgHpICmnFg8SeWQTcLaJnhErSWQTqNwgJk6t6DucQOUGCdFNIFluEFC5QX1BIpFuqtyge+CSRTpVbhATp1a4dKrkIDHSKVlyECAdJLXkxINEHul0VXLQzVhJopuuSg5i4dSKlk2Xs+mjZPNa+Mgjmy7pIKmnOPEgkUg21UuDbsZKFtmUPjFIhCx6Nr6apL2+nfabnxxxUok/13XxgQi97/ddq6d/2EN9gwMk7Wj6ABz92TvjwqGMnLEj74RDKgz5G5J/njEQ+82ZUeHwOJszKhC7AtEHYgPRu8HbecJA9PoTc8aFQ3k0ggLRqF7WIgz6GxJ7njES+42XceFQ+TmiItE3BUfiDcbNM0Zif9LNuHAAovfxn1WGJN2k63QbJD+nRR+hrv9flOen0ioLDnmKA9N2JGGPZKdvZXtF4TsqwFAoi6/H5sbXE9bLUbiOOvu4rMqr2O66zK530mVREuTxB34AWieXu/6KQrzhtwHcb3NBy0fbp4dsGZV7XaAiGvLbb1drN3S+QqKhAvP6eh6ggSsvDSiGNhNOdL3e90FO+B4rTpit9wa5I3PCezJOMIfa0NtYO/6Lcx/a5O/gkG3xBtxXgPcAbjAEnPjNwNEB98lb09IAznCg7/rJTdbib7AS/3ZDvGlAJvZJQwNe4t/16+Wsxf9uTrTF3xyZE+SqTBpOMKRB15vDGA8NHquhgWiINw3Ix2WkoQGvoaHrJayMh4b7OdEaGryxhwbyZVfScIIhDboeVWU9NLCyDIiGeNPAkZcGvIaGrrd+sB4aWFkG3siWgS+xmyjJCrJtGXgMLQNKW7wBl9g3ZBj3XcmwjLXAZzVNJBriTYNnswqHzA/4LB3aWnA/J1pa4I89TVRu4q1a4OvstIDSFmfADZ2S6Db3tOlcg8vIuaN5rjadaPOFNp1p/oRgRx4dcxxuPFe+vFNLuXkbJPF6C4vLCN3UhxXozmy8DJJJueE9DsPi9jHtnjHOyjbFykt6JCvfru7onmrcybT86nlbLC2fV1a+oVMy0xBUCwTS3NUmnuZNFVSmD4QjZVKQgrG00OBk+xJUvgY12F+gDxNQbIIITjTPRGjC/0/9Ek1vRsak2djmaFNd80CxH0Tes1GVD6vmqGY61SZucRBDmwKibU+bw4PPtMkEHWQyR4RCp+aiz01+lS2f9/KLvWx0UuiMHG3iNC7IQc1S5pmPc/Cc6SEZAx3T72dg9YsCI1GQ9kxjxRij/lTjOSO946cFy+sf2R1jXLQG5NahyU41/7lMw+aX2unykH0UPWcQ/XjHvI146G2xsOB/NyzSmE++gNkWZfPuyRcA/W1xn3xJ/0Dkw8+p3jZwwjmO4HcCGLp6+FHISwHKYCCpIo4JtGcjQVL1AdyyrAdH8M8hPecAW6tVMUw2qsAa/a13hmdz3v9cz5RdP/LT62XoXWXAqM+rw5kBwQD1KsJeuCR524Ch/9jvU39cXYHbnuJQ1HVcTAyK3aTUdQx17X87+shMIN0sNba24mQMuGAxS9FE5bKygT24+SUNI/SN/wM=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.png"
new file mode 100644
index 00000000000..37255d9bae6
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.drawio"
new file mode 100644
index 00000000000..d1072768e67
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:28:55.104Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="QBg4q7WOk0wTtNt3vV2g" version="13.4.5" type="device"><diagram id="PY_AcYCt6KOp1RRPQ6IG" name="Page-1">7V1bk6O4Gf01PE4XN3F5tD12UpXdqs1MqjLzSBtss6GNF+NuO78+EhYYIWFwWwIN0dbUNggQoHM+HenwgTVr8Xb+WxYcdr+nYZRoph6eNeurZpqGoTvwDyq5XEt8Xb8WbLM4xDvdCr7H/41wYbnbKQ6jI7FjnqZJHh/IwnW630frnCgLsiz9IHfbpAl51kOwjaiC7+sgoUv/HYf57lrqme6t/O9RvN2VZzYc/7rlLSh3xndy3AVh+lErspaatcjSNL8uvZ0XUYIar2yX63Grlq3VhWXRPu9zgH6ax8Fb+u1yOv4z3oI//5F++/IF1/IeJCd8w5rpJLC++Su65PyC28H564Suc75J9/mXY4HSDO5ggsP5thEubdFfvawDXsxrWYgboarRhFcHQYQr849dnEffD8EabfmAPIJlu/wtgWsGXAyOhyuym/gchegi4iRZpEmaFRVZm03krNew/Jhn6X+i2pbQ9V8h38qTv0dZHp1bm8+oQIFsjtK3KM8ucBd8gOVgHDGRXRuvf9RogYt2NUaUZQEm4raq+YYVXMBwPQCdyYCu2cT7cIZiAK7t031ENiu87+zyA67o5crP+srXM7F2KdfOcf6jrAEuF8e8ALx2OwitlMdcrysKqUhrtD289vSUraM7N417kzzItlF+Zz+LjWUNK8DAqizLoiTI43fyclkA4jP8kcbwRiqqOJb/4vvANT0XmMDyDJI4pv6i67bpGqbt2o7hk9VfmwDXWA/n5kkM5wU4VDUVO60X26IuoTzJtf2okxQ8rJrr89S0RPQq5hR7FQeQvYpnjNyr2CKgs6YIHTAa0PkjQwdEQGdPEbqmlo8OnSMCOmOK0DWjbvRhmPvkMIzj4KicH3UNjpwxB0fA815Mrxq3mOTgyDOYWx8eHHnGi2tUwx+XHBx5NnPrQIMjTx7CgJ6EaQnJYQhjN4ZIrt8I5b6kAGZHRYKB958Evpx6lfOrPlOvapJXzfhqR92Z5nEkmd2TZGBUkjVkpbKpHiVZsyLPGpZk5emfZ1nFrJ+1LR0sqxGrj5nAkWV9jQF7VO1r9EC+/VmWgY6KRLOM5Rs+25f15Nh4PZn1S3CsObdpdkC95dLp6BJFc8yUhWPy9WKjauV0GMbwKZe+5nuav9KWQPPggqstV9p8ofkzinxwEpuTjCNnvpiR9WkyLgqSeLuHq2tIkAiWz9GUOF4HyQxveIvDMGmbk2fpaR+iGXjBPmQF4MdmJi97xCNxMXSXnmSXz7nqBDP1di49Nck22m3JMH6/eRvXouMh2PeyTXSWbVJzXu5aYFXZ9XRUMXFhUlKHA1VcqxHCgGaKzeiKxDGl3QUVz5QWn1sxhcUUfWymtJuu4pliKqbcYUrDExy9T2F5vEMxpcXFV0xhMWX0PoVl7g7FlJa0G8UUBlPc0fuUHm7wcRcc0GIevCaNuS2r0Y5wulROBVCzrSGLgniPWr84Zp0mSXA4xkVl1z12cRL+FlzSU16eplyj5hXFOr42Q6Oe/oVB5G2YT/+ctRe9bvjA6NsNGHs+/WvaY/ySsHrYrSWM8DbzOEi+Res82G/7IEojFmbp4V+lO4AKDmhyHGXLd9iCx3JKSIdjnh7wxiTalMe+pnmevuGVDLdWVWnRVGAO/8F7XCCjDcC7WcB147YO/6Hds3yR7iHyQVzgGAXH/CM6dtOoDyPuhM9dB2RYHtCGqM2VCEV2a3AjQgpbbZMUztcO9qTRngfugsCqpbu2gcXqe8WBxXIWVwquDrjOJCyjocfKLlTK2aGcng0kU06WpaeUU7hymt2p0cPygDbsDK5E+KW74u5HicP2vSzPTGF1FytZZLNHoqKSzSZqhtGccfZMFRaHY4/8QaWbAsLblUw3aQNJzTjJIJFHNy2WTaRmnF1wSSKdFm3uKOnslk5dNum0WL6Pkk7h0ml1vz8wLA9oB8lSfTERJBJJp2CfaIpYyaKbrFwspZuPPuMcXTYFmz5KNu+Fj0SySTtIqismg0Qi2RRsE00RK1lkU6UG8XjAObZs2izPR8mmeNmULDXIpt0jXXXFRJDII5u2YItoilhJIpu2ygviMNv0xs4LslVe0CiyaUuWF2TT5pEyackgkUg2WRaRer7ZBZcsyqlSgzhMOMdXTpUZNI5ySpYZZNP+kcqoJYNEHuUEgl2iKWIliWwClRbEIy2o78d3xeEo2PNRunkvfuTRTUAbSCqjlgwSiXSTZROpGWcXXLJIp8oM4uHVjq6cKjNoHOWULDMIqMygriCRSDlVZtDDWMkimyoziIdRO7ZsOoI9HyWb98JHHtl0aANJGbVkkMgjm45gl2iKWEkim47KDOJh1PpjP+B0VGrQKLrpSJYa5KjUoK4gkUg3VWrQZ+CSRTpVahAHo3Z85VSpQeMop2SpQQ5tIKkZJxkk8iinK9gmmiJWksimq1KDOBi1o8umK9jzUbJ5L3zkkU2XNpDUK5xkkEgkm+qDQQ9jJYtsSp8WNIYsui45m2R9up31c58CcVJ5P/d18YkI/dxPu5bv/vCH+gEDSNre9Ak4upN3hoVDGTlDR96FhHQ05B/I/ZliIHabM4PC4Qk2Z1QgtgWi74wbiN4D3s4EA9HrzssZFg7l0YwUiEb5qZbRoH8gr2eKkdhtvAwLh0rPGSsSfXPkSHzAuJliJHbn3AwLh0O1PvmLypCku3Sb7oPkt7RoI9T0f0Z5fsFWWXDKUxKYpiMJWyS7/MD1FSs/0QoMBbz69Vzf+PVCtHIUbqPWNsZFeRnbbbfZ9kG6LEqCPH4nT8BqZHzoHyjEa36b33jNzmj4aMf0lK0jfNQNKqoir/m+XrOi6x1SFRWYV/fzBA1ceWnAMLS5cKLt275PcsI3eHECNF5Gaf7CuGhOeBPjBHeoDb2Jte6/gM+hTX/sgq5LNOC+ArwDcIMj4M3fCxwecJ9+NC0N4Bw7+raf2+Qs/q7DSfypikTTgE7sk4YGosS/7ZfLOYv/5znREH/XHZgT9KxMGk5wpEHbd8N4zwt4dQ1URaJpQL8tIw0NRHUNbZ9g5T0v4NU1eEN3DfSnrqThBEcatL2pyrlr8HlZBlRFomkA5KWBqK6h7aMfnLuGz3Oi0TX4A1sGvsRuoiQzyKZl4HO0DBh1iQZcYt+QY9y3JcPy1gJew0SqItE0mJpV2Gd8IGbqQGkBr2GiP/QwUbmJD2sB4KgFdF2CATd0RqLb0tPmSw1OI5dA81xtPtOWK22+0PwZxY48Ouck3GSuPH5Sy3h4GyTxdg9X1xF6qA8L0JPZeB0kM7zhLQ7D4vEx65kxycomxfAtPZOVb5UZgOUzeMOi0/LL922JtHxRWfmQeWyoVgikpavNPM2bK6hQiI4OlcmACgbTSoOj7VtU+RoUYX+FFmZOsQlCONM8E8EJ/z/3MZzegg5Kq7YNaHNd8xwLHQeh92xU5MOiJSqZz7WZW5zE0OYOVbenLeHJF9pshk4yWyJGoUtz0XKdYLjm61F+cZSNLgpdEdBmoHZDAFULa7hdIr0JHusVzQBP5N96GbRzcc3oXuEpvqKj+JP5mjIiGZXt8hOQ96jsWsagXGa9HVlCZVRLFTEWZrVEG5GTxc3rVgtgDItbj3w9NIAqx1S3od3yVjpfn7L3ouUMqh0/MRakXqRbrSz43wMTP+4DOmA01cP99IAOgO66hA/opH/J8ul3Xx/tQx06Fgd97xVeQX9M/i9TZwW9D42DgabKeExgvW/pJGUbwC3rqnN0/jql17xia7MpuslakbNFf63yYHg11+Ov5VzZ9Su/EY9DTyYGPPCK5yT7Z+A0RXL8/lnwy5eqf74bDBJFp8Gww1RfSoTJEGjB1SxFSncbGsMW3P2ehhHa438=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.png"
new file mode 100644
index 00000000000..8b0b528bde5
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.drawio"
new file mode 100644
index 00000000000..4e40d1522e7
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:06:03.875Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="J37IoMD33P3y1AJRJJDg" version="13.4.5" type="device"><diagram id="48qJXlv0dCf99pJ8nCJ8" name="Page-1">3Vrfc9o4EP5r/FiP9dPyI1C4PrQznWbuLu2bwAp4zljUVgL0rz8JS8YWJqEJhDQ8gLRarWR9n1baNQEaLTd/lXy1+CJTkQcwSjcB+hhACEBE9Y+RbGtJEkW1YF5mqVXaC26yX8IKndp9loqqo6ikzFW26gpnsijETHVkvCzluqt2J/PuqCs+FweCmxnPD6X/Zqla1FIG4738k8jmCzcyoEndsuRO2T5JteCpXLdEaBygUSmlqkvLzUjkZvHcutT9Jkdam4mVolCndPjnVrHB3+vP6MvP9bf1YvTrB5p8sFYeeH5vHziANNf2hlMzZbW160B/3pt5Du9koT5UO5QGWgGS1WbfqEtz8xs5G3oyUye0i9BYhHp2GkRdGa4XmRI3Kz4zLWvNIy1bqGWua0AXebWqkb3LNiI1k8jyfCRzWe4Mobs7QWczLa9UKf8TrZY0Tqaab27wB1EqsTm6fKABRbNZyKVQ5Var2A6QkLqLJTLBFtd1ixZWtGgxwsm4JeK8sbzHShcsXL8BHeyBzl/iIh2YPaBrhSxEd1n1c5fbW12JXOV7u/Jx06ltXW2TqVtnQZd3fUJia/tOpuL61PMS6cFO89Zez13elzPxyENbb6J4ORfqET3Uj2ULK9KDlZOVIucqe+hOtw9AO8JXmekHaahCEA6ThMSQxURXGOgSB0ZhFGEYA4hjTEHSNV8vgbXY3s7+IACEhLbMII+eKMToYA5ulHoBD0bZEbFZr+dzE13CrcD36FYI7roVCq7sVvAloEPvETocedAlV4aOXAI6/B6h8w/zq0NHLwEdeI/Q+bvu6vew+IX3sDPejlyA9NTtiF7zdoQZCiFrLi4QdC8uFLBu8zOvRzENY9Dcf+KkOwgGfa2vdDtib4cx5ETGHNmTr8MY5N2RSOLt5VNJgcEThi4MfPJC4F3w5SKsU4KvJsxrYr5Wr0cCvTOSDJ9IMnJVknnnShw9k2S+IYpel2QugHg5yxpmfW+1PMGyFrFOSSeckWWnpgbwVQ8/zwPF+Lksw08YOsIyDTvfttRWRqF6ZMJ+fEo7WUZdqC2el8J9acmXOsoTCXw9N4n+CAL7kZPv3U4+i8kT/vbSbhK+FY69PRd51YP4/TCsLwvqMcyEwtmM55/5VORfZZWpTBa6aSqVkkuNvlMY5NncNCjpReXVgq+MseVmbt7AhVNeZbOQl3Ugzks1KOa70aIQxCyOccIQ00FXjA0CQ0PxRsE4u5RXCxPd74x7Eb4gAO/ieJN+6ET+5tNE/u5FGezLBUwmSH/OkwsAiIaMdUDGFDSiFl8RoCEkh5yFaC8/e2YA9OVSr0kACDBkKGKQERjrb+oTAMcoYSABNGY00lxBfxghnKuwZEDsMDdESA8N0MWyQ+B4UrZa8SI4JbkX9SX3gjENdPiajIJxHAxxMIDBOAkGIBgOgjEx32wSjCfBcBQkg8iW2Ag0JdyUYFNq5+nr6R1JGmqIlEfDDq72uGzTxYq45fFMQyrKHoIvszTNj6UjS3lfpDs2Rj41z0AfSLsnBut5GdObXIS/Tx9d3b/7r4+c/T8o0Ph/</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.png"
new file mode 100644
index 00000000000..784add44411
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\345\271\277\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.drawio"
new file mode 100644
index 00000000000..055cf29683b
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-19T10:20:44.307Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="ESmHvqxonDcUpBYq1nN6" version="13.4.5" type="device"><diagram id="hxIiUUJUZaj2I0l0lVWC" name="Page-1">7V1bj5s4FP41fmwE5mYeQyYzu9qtVLUr9fJGwElQScgSMpP0169tMAHsTGgmXHZkdaRi4+v5vnN8fIxngDHbHJ9Sf7f+mIQ4BlALj8B4ABDqumaT/2jOKc9xNS3PWKVRWBQ6Z3yJfuEikxc7RCHe1wpmSRJn0a6eGSTbLQ6yWp6fpslLvdgyieu97vwVFjK+BH4s5n6Nwmyd5yLonPP/wNFqzXvWbTd/s/F54WIm+7UfJi+VLGMOjFmaJFn+tDnOcEyFx+WS13u88LYcWIq3WZsKn/+co3D/6S8UfPR/Tb8+hU/LHx+sYh7PfnwoZgzmFvDmYDoHcxN4j2Cqg7kNXA24MzCHALEHaMekU2+ZkL6p8OMkZbXtfw90Ph6AxnLpuoZRzbJX9P+nKFsfFrRNNAcuAnMXIAe4pBdEO6XdWQAh4ELeC5lT3lHeAB/FA3+/SKl4s1OBGe+Q1vmwZ4yakgK6uTuKo6GduR5w5/RhagL0cJdJfnp4vDp6Ml8iAc9h830Erl2MhQifisIBU6MiE4c+uA7DYga8KSv8yB4cWgBxmpVygBk+0h7X2SYmGTp53Gdp8hPPiplsky2m84viuJHlx9FqS5IB4RYm+d4zTrOIaMW0eLGJwpB2472sowx/2fkB7fOF2ACSlyaHbYgp7TSSiv0Fjj0/+Lli+c3OiWgKrdfNIj0rJW147B+TIqMpGQY+XlQAvVQrYo9wssFZeiJFigqmU1QpTJHNRfZyVuxSW9cVpeZ5fmFLVmXTZ3UjD4XG/Yb26ToU1Y+Tug2noSXjtFah3qLkXZMdZHzEiF7CsEIaf7/LLesyOlJUa4RhOoDtIBDYRd6EjrvQtPugB22thp6jieghCXioO/AMCXhNIW/DKV2FzoSvCJbMPD19K9SEJb5XEw/HWurEU8co+8ZbIM+szsQqUudKNMHr5OPCobDWNaRPxp4c0gC/Ou1iycj8dIWzV0uackQriFkSxHheimM/i57rQ5bBWPTwKYmYoS4IYxnuxHUtByLHIgkkKP9E00zo6MQumLbu1pvPxVC0WF1Um53o9sSyhWZKjhoT0xCGwDvJJSh0wthYiustBDW7sC7wPVoXy2pYF2dw62J1AZ7xHsEz9Tp4yBocPLsL8Mz3CF5zXR8BeJI90dvB098jeE3NG4FTht7olN3VVYKtXSVnSFfJRGgCUenFQO7Zloth4/WNvhLSJ45eekNO3VdCmvRtb76SOybe2K15A4fkjdH0mqyGXrelhgmvNNQ1/Lz/2/dyxa6Mb73a7MrK/V+5GazUemUHeFeqWa2pZg9KtaaPZ99ItWZDjts31fR7Ua2k1/fKmytUq7CrTbDhrlRrHziwBl0NG8aoPLL4bapZVxrqnGqwA6vWkmhD2jTzf0K0ZkizaYpaL5/NPVTTOHZNNOtypCmMns+7nTxrv/O3rTZSmvTE5rwXezXcXebl3QnZtYE1lGIcJyfg7Rs0G8EaM2xX3KCZvR55WJfjWt1T5cImXFGFWh84OqpcjqJ1TxWoqHKZKvboqHI5Ztc9VS4E1RVVqCuijY4qsghhX1S5EMJXVKFUMUdHFVlQUFFleKrYDaqgwanCd1xqARo7VSTniz1TRRYAVG7tCKmiD04VWQBPbZbHRxXZ90I9U0X2NaIKwY2QKsbgVJFFaxvi7+dYAIzy9GnQg873cyhgSyK99PaCA6Yau72gsVsf5Z0HB7hTgEx2IQQCzyuuiEwt9uoRTF36ykXAs9hljQd2e8SihadopPajcr0B3uubK9uu4epKlh5o9GpQYIsv4fdrf0cfM38RN8yJTIx7wk4uOSq4gAjSj7YUD1YnSOLY3+0j1lheYh3F4d/+KTlkvBueEmBg6WJsOhA+ngt9jJbSj+fsAOHF8k4LQ+NsxoESIDUpkN0h2WJp4EiSmWaRH3/GQeZvV21AFUEL02T3D7fINGNHzRFO589EiHuuRKKOZsmueBnjJa+7SLIs2RSJtJBX2SiTleWRHyK9GT2RtshsZiStn9PkhxZPs1myJeD7EYMS+/vsBe+vM6kNKV5ToVcXHSkXzO6oIJpv8YrZW7jALmz6Zy4kRHDLmLkca2Jh8fYe0HeG1/W7LTKnrkO4xMMyXcF1Da5jHZbh0BPPr5SytUVPco+zZ/TEIyWFXlv0dInb0zN84jGPMp2t4bOHho/vdZTPOhKf9XRxUe3ZhTXEkxal2A29GZELa4inHWoZvQrXWFxYQwwCKWVri97gLqwhBn4Uem3RG96FNcRgjYKvNXzDu7CyL52VCzu4Cyv7DVE9u7AqMHRVb8bkwoqRIGWHr8I1GhdWDAQpZWuL3uAuLG9Z6d4N6A3vwppisEYpX2v4Bndh+VduyoUdlwsrU+yefVhTjAwpzW4ozoh8WFOFgm6Aayw+rKkiQbejN7wPKwaClKlsi94IfFgxWqOUrzV8w/uwLX55pPJhB/BhJczo24dV3whdVZwR+bD8Mo6C63fgGosPa6lQ0O3oDe7DWmIkSOleW/SG92EtFa15A3zd+bAkef5jYfklzfOfXDPm/wE=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.png"
new file mode 100644
index 00000000000..5d2a50290da
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.drawio"
new file mode 100644
index 00000000000..053d6656491
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T02:16:10.479Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="k1GW4w4a8eAJ490EksK_" version="13.4.5" type="device"><diagram id="iLyd2CJtKd0pi580Kj23" name="Page-1">7V1tj5u4Gv01/thReIePeWF6d7UrVbcrtd1vBJyEWyakhMwk99evzVswhkBmbPBGVisNNmDA5zw++PBAgLZ8OX9OvMPuzziAEVBnwRloK6CqijIz0R9cc8lrnNksr9gmYVBsdK34Gv4fFpXlZqcwgEdiwzSOozQ8kJV+vN9DPyXqvCSJ38jNNnFEHvXgbSFV8dX3Irr2Wxiku7zWVq1r/X9guN2VR1ZMJ1/z4pUbF1dy3HlB/Far0lygLZM4TvOll/MSRrjzyn7J93vuWFudWAL36ZAdYPIr+hb//VP77fTr+/lb8OX31flT0cqrF52KCwaqGaH2Fmt8yuml6Afz1wmf52IT79NPxwylOdpANQ7n60q0tMV/Z2Ub6GTWZWXRCVWLKjo7BCIqLN52YQq/Hjwfr3lDPEJ1u/QlQiUFLXrHQ47sJjzDAJ9EGEXLOIqTrCFts4Gm76P6Y5rEP2FtTWA5a8S38uCvMEnhubP7lAoUxGYYv8A0uaBNih10vcCxILJpFeW3Gi2Kql2NEWWdVxBxW7V8xQotFHDdAZ3aAl2zi/fBHMcAKu3jPSS7FV13cvmOCrOy8KNeWJ2J0qUsncP0e9kCWs72eTKK0nUnXCj3yc8LBlSkNfoenXt8Snx446KL0ST1ki1Mb2yntWNZw8powaqsS2DkpeErebptABZH+BKH6EIqqliK8+Q4hqXalqEamq2QxDFmT7OZjrZSdUs3FYdsPu+CosV6ODcOYjrmk2FSzVTs1J50jTqF8iB5/1EHyXhYddf7qanxGFXURxxVLI0cVSx94lFF5wGd9ojQGQ4Jna1ODJ3BAzr9EaFravnk0Jk8oFMeEbpm1E1+G2Z98DaM4c1ROT/quzkyp7w5Mk37SbWr+xaVvDmy9Na1994cWabyZCnV7Y9F3hxZVuvakW6ObHEIYwwkTEdIjkMYo3mLpDZCefAd86ynIc7AOx8Evpx6lfOrIVOvapJXzfhqe92Y5jEkmT6QZMaUJNObN3PaO0nWbMgyxyVZ6Zt9nGUVs37U1vSwrEasIWYCQ5YNNQb0SbWvMQLZ1jtZ1hwTqYZ4s6zNN/zoWDaQY9ONZNq/gmN6zwA0WC6bk6TmkMibY6ooHBNvFJtUKx+HYS0+pWsCxwLzGXANgKTcUbKFBVi4wLWAMwe2DlwH2CpYLPDGtgvmBnBtMFfA3MYbz1fAyRbQNnOboiya+qYkT8n5csHj+uS6qPKicLtHRR/RCqL6BZ5Ih74XzYsVL2EQRF0z+SQ+7QM8b884iw2E4mGbymhmbjZmWU5JtxorVa2Fls3bcGZTc6XbzAzC16sjklcdD95+kNkyazNban7NTeOsqssPR1UTJyYkdRhQxVYagW/TVNFHZUq3d8qfKR3uuGRKG1O0qZnSbdXyZ4oqmXKDKQ0ncfIxpc0ZHospHd6/ZEobUyYfU9os4bGY0pGsI5nSwhRz8jFlgId83HkHvJh666gxI27rtCOaZJVTAdxtPmKRF+5x72f7+HEUeYdjmDWWb7ELo+AP7xKf0vIwZYmaV2Tl4twUQD0zDDxob1qfGZq+DdcbNjAqs8ZTpqEPDXVeOJYEGYIjus409KL/Qj/19tshkNKQBUl8+Ks0FXDFAc+pYeK+oi48lnNCOh7T+FCsjOCm3Hcdp2n8UhSSoreqRrOuMhboP7rGJfbnDHQ1S1RWrmX0H2+epMt4j6D3wgxI6B3TN3js59EQStyIn5vGybg8oH1UnSkRsqRY70qEGPXaJsoMsx0aSuGeBe6cwKplyXaB1Tb48gOrzZB8lnD1wHUmYZkMvbakRCmdPdLpqIZgytnm6Unl5K6can9G9bg8oB07hSkR/tVDcf8TyHHH3jbTTGJ1EytRZHNAfqOUTWrGqTZmnFWu2WTj5YC0Q6mbHMLbEkw3aQdJzjjJIBFHN7U2m0jOOPvgEkQ6tQFJclI6KelURJNOrc33kdLJXTq1/tcOxuUB7SBpciwmgkQg6eTsEz0iVqLoZlsyltTNex9yTq+bnF0fqZu34kcg3aQtJDkWk0EikG5y9okeEStRdFMmBzF4wjm5bOptpo+UTf6yKVhukE7bRzM5FBNBIo5s6pw9okfEShDZ1GViEJPp5tSZQbrMDJpEN3XBMoN02j6SNi0ZJALpZptHJJ9w9sElinTK5CAWM87JlVPmBk2jnILlBum0gSRzaskgEUc5Dc420SNiJYhsGjIxiEVi0NCv9vLDkbPpI3XzVvyIo5sG7SDJnFoySATSzTabSM44++ASRTplbhALs3Z66ZS5QdNIp2C5QYbMDeoLEoGkU+YG3Y2VKLopc4MYOLWTy6bJ2fSRsnkrfMSRTZN2kKRTSwaJOLJpcraJHhErQWTTlLlBTJzaqZ9wmjI3aBLdNAXLDTJlblBfkAikmzI36D1wiSKdMjeIiVM7uXTK5KBppFOw5CBTJgf1BYk40mlx9okeEStBdNOSyUEsnNqpZdPibPpI2bwVPuLIpkU7SPItTjJIBJJN+dGgu7ESRTaFTwyaQhZtg5xNtn2+ve2XQjniJBN/buviByL0fb8KW779wx7qOxwgYUfTD8DRn70zLhzSyBk78i4kpJMhf0fyzyMGYr85MyocNmdzRgZiVyA65rSBaN/h7TxgINr9iTnjwiE9mokCUSk/1jIZ9Hck9jxiJPYbL+PCIfNzpopER504Eu8wbh4xEvuTbsaFw6R6n/xZZUTSXbyN9170R5z1Ee76/8E0vRRWmXdKYxKYpiOJeiS5fC/aywo/cAGFQlFcnesrVxeil2GwhZ19XFSlZWx3XWbXN+kSGHlp+EoeoK2Ti12/4BCv+W0W6bdZTR/tGJ8SHxZ7XaGiGnKaX1drNpRfIdVQhnl1PR+ggSUuDVoMbSac6Pq87wc54TisOKE1vhtkjMwJ+8E4wRxqZdbEWnOejPehTf8ODt0Wb8AdCXgP4ApDwKnfDBwdcId+NC0M4AwH+q6f3GQs/qbDSPyphnjTgE7sE4YGvMRf5XND2BT/93OiKf6zkTlBz8qE4QRDGnR9OYz1vIDV0EA1xJsG9OsywtCA19DQ9RFW1vMCVkODPfbQQH/sShhOMKRB16uqjIcGm5VlQDXEmwaGuDTgNTR0ffWD8dDwfk40h4aRLQNHYDdRkBlk0zKwGVoGLW3xBlxg35Bh3Hclw7LWAla3iVRDvGnwaFbhkPsDPlMHSgtY3SY6Y98mSjfxbi2wGWoB3RZnwJWSYPVHu64BFi6Yu8DVweIZzBXgmgBR2lkCVwV2tqCaUfmGENrbr1LjzV+nOH8Yrm02joN/j/taZW7x389hujutcZu2C9Ao5DrAtgDqVtfGB8WHM4BtA2xn5EdBl5YfKG+gPItVuX6dEJwtD4j3+XTMqDdHGyj64UyfDT6YswCOixfmOrBXTC7yy+q59+zR9aIeWFjZ9T4DdCOWnwvqfNwVFphrtT6x8ALSbozFEizm2cbP2YKFN7BpYziF55QMRvJNhuI5esujdS8Kt3tU9CFOuUAV+Ll56HvRvFjxEgZB9nC/7Yk+OWZE3hpGC8//uc3qmwe/Dg+KXpRrb1ossn+AyZsWpjYjwq0q1x7kV69+Ea9a3P+mBSomMWbENVpR3+z+jAOIt/gH</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.png"
new file mode 100644
index 00000000000..2a669ee2066
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\227\240\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.drawio"
new file mode 100644
index 00000000000..d090804e912
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T02:03:26.196Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="d1dYeaT7O6CDyL8oXn3e" version="13.4.5" type="device"><diagram id="FzY8Ofb7lh1C4Hv9kcNF" name="Page-1">7V1dj5s4FP01fuwqfMNjkiHdSl2palfa9tFJnIQtg7PEmUn2169tTPgwJEwaYjJrdaTBFxuMz7n24eLbAdb0+fAxhdvNH3iJYmCOlgdgPQHTNIyRS38xyzGzBKNRZlin0VJUKgzfon+RMObV9tES7SoVCcYxibZV4wInCVqQig2mKX6tVlvhuHrXLVwjyfBtAWPZ+le0JJvM6pteYf8dRetNfmfDDbIzzzCvLJ5kt4FL/FoyWSGwpinGJDt6PkxRzAYvH5es3azl7KljKUpIlwbHWeiv/dDdup+i/WQWf4g/ff0grrIjx/yB0ZI+vyjilGzwGicwDgvrJMX7ZInYVUe0VNT5jPGWGg1q/BsRchRgwj3B1LQhz7E4iw4R+V46/sEu9ZsjSk8HcWVeOOaFhKTH7+VCqRUrFs14KW+3wgkRHTF5OYrjKY5xyp/WWq2Qu1hQ+46k+CcqnTHG7B89k40QG5bWgc9HEe/TBToz2pYgMEzXiJxDxTzxgzoWws+IPhJtmKIYkuil2hEoGL4+1StIQA8ED97ACVMlJwoe/CidaebEQ2Lrq4RWdPIFxntxJ2C6Me3uZF5B3P1nz6YlPsIfdnyIx7SC6WwPxUl6tGa/R/k1aJfmuVHmUBzTOZtx5XUTEfRtC/lwvtJlo8oEuNtmE/kqOjBGdYd16QXz0eh08xeUEnQ4D6wMhGhgOWLaFuuWny9Ir6VVQJg2pQUgt90cOvusVyY4ua0bXjM1Gw88NTsd3ddV6b5OH+5rvkf3de2a+/qK3dftAzrrPULnjKrQBa5i6Ly7zrz/O1HsP8LM6/fhvvZ7dN+6cFLuvoE0or2opPOvKi0a6ZH81DAf4Q0nl+n30smP+rraGU2l065xPj6lcu2to3n1WvwQLHB+kQWi6Rcc0S4WUi9wq2uFU1sEsn6JVjUunbrxC/Qy+1jWjfe4rNdVufJ4iNEey1pGL8WwZ6bdFiadEB01IVoixdmQ18mW3U4yVzpW4wOFhlSBr+Ip5roy+MIE42id0OKCQomofcKAjhYwHosTz9FyGbcxrTp53oApXs2p/ZHMFLuBKWZvTLEVMqVlMtBMYcywhsaU9gBb/0xpicNppjBmeENjSns8r3+mtIT9NFOYhDSGxhRPIVNaIkyaKfxlY2hMaQ8yaqYoVbQ1phgj5VQJ9PLzEFRpin7flSn5hbWkHTpTTNVMMRQyRb8md2dK016G+zKlPWyqQ2+DYoqtmikNQdrQBcEU+AEIHRCMQGDwgwmYhCD0QDAGvg3CAPgmmExYZT8EY4efmoFxwE4FPpg4rNX4iR3TA1p57A8U1/qHohvg7EiCtGFKMK27In1+f+Igd5IX3+au+Ri/2KcvvO8GUPwVr+vexZt8xBunKTyWKmzZx7ld6cq1b3xebSdernNmHev71vn6rn+2Pj3IenzTD4dmU6C4Rv/dBm7ZIYFzTvYSbZsmjR2FL+cXpxelG4wSNvvwNgscx3C7i/jFshqbKF5+hke8J/lt8pK814CVRd8a+LqEyF818tVd+Gi+utHyVP8yZDXMWqPGWau3aaspjtsCJH1QEsH4K1oQmKy7YCpjtkzx9s/cT5mBuw9KwxfEvEjeEiAWJMInRHYyRqu87RwTgp9FIRXDdbooHypnQn/o4E3ZZOfQp5nSslGU6Q+rnpIpTij2MOJIIrgjr2h3mUhdOHHGgWSmXGKC3RsR5DCtvJPoV5jA09NgwQRMh20V84SwDRUTKLkF8H2h1bIJ6IKs7A8sOVIqbxTSYDVOwh1fCfrDTg5dakfriF3HF//esMvXa43d27EzOsb3+gNPju/pSbMreB3D+P2B1xRy0zpVmU49ti6m95Wtlhxg0zNy1WmGI1steSOiBusSWAORrZYc8dGrZ0fslMtWOcijseuInXrZKgdmNHhdwVMuW5u2tGnZqlq2Nn0tvK9s1UGgS04zHNmaX1iD9QawBiJbbR30uRo71bLVlmM+GruO2CmXrbYOzFwPnmrZajdljGrZqlq2Njn1fXWrLUeBtFdXvWZAulUO+2iwLoE1FN2qt+NcjZ1y3SoHfTR2HbFTr1t1ZOZ68FTr1vy/T9K6dVi6tYEX99WtjhwG0l5d9Zrh6FZHjvtosC6BNRDd6uiwz9XYqdatjhz10fHWjtgp162OjsxcD55y3dqQhRU6LCN4HILQBpMZGBs8cXjEcodDE/j8QKR3s1EC7E9A5VlrRRK5tVoFAdskWc8r/xiRzX4u8otZEnEAfI8nI/vspmOelez7IDBLSeTZjUQWuejF0ylDPa2QrSXL3bAbs9yzFOgg5FnNNvCfbvKQX55mF3tPn5eOwMTjzzsDgVtKx6ZD4YGxVRoTjx0Enkjinox55Rk/8FgFX3a6YWRhx3CO4glc/Fxze/3mhd8ZtiiXkiAn/B+4Te62W02C9IKGlwOzwfuuSN2mxeLvi2W5r8VfabPC/wA=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.png"
new file mode 100644
index 00000000000..4ea176bdc27
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250\347\232\204\345\211\257\346\234\254.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250\347\232\204\345\211\257\346\234\254.drawio"
new file mode 100644
index 00000000000..f4a1af66763
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\347\237\251\351\230\265\345\255\230\345\202\250\347\232\204\345\211\257\346\234\254.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T02:02:47.191Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="9FneORdGZP89w_YEhYEE" version="13.4.5" type="device"><diagram id="5t9a7hb9L9JXNoTOYt3Y" name="Page-1">3VlJl9soEP41HDNP+3KUbLnnvUnykvRhOrlhCUtKY+HGqC3n1wcksBbHiqfHjpfng6migKKWrwABc7KsHihcZR9IgjAwtKQC5hQYhq5rDv8TnG3D8TWtYaQ0T6RQy3jMfyDJVGJlnqB1T5ARglm+6jNjUhQoZj0epJRs+mILgvurrmCK9hiPMcT73H/zhGUN1zPclv83ytNMraw7ftOzhEpY7mSdwYRsOiwzAuaEEsKa1rKaICyMp+zSjJsd6N0pRlHBjhngf3yqXrzvwQspzRhZ0xn7uHgnZ1mzrdowSvj+JUkoy0hKCoijlhtSUhYJErNqnGpl3hOy4kydM78jxrbSmbBkhLMytsSyF1U5e+q0v4qp/rIlNa3kzDWxVUTB6PapS3RGCbIdVlNq3IIUTCpi1HSO8YRgQuvdmosFcuKY89eMkmfU6dED8eM9+3ZWRiMljdGIcU0Zr5CmiI05wWgEhek7K0g3PiCyRHxLXIAiDFn+2g9NKCM83cm1QcAbMg7+Q0wYl4yJNg6+dnp+HRO34FvvqlwrtX6FuJQrAcPBXP9w3vO481IKWKot/G5dmzjgAoa9qtpO3krFv6bm4CrNFXM/hjDmmC1iZZPlDD2uYG3fDS8b/UiA61UD5Iu8EhF1vFsT159r2phbXxFlqBp1hOw1HAnbsm5ZnqQ3nSogWVmnACjeyV1njWZlQYrTpuFboFm/HWi2j0xf56rS1z5H+hr3mL623U/fHX2p9HXO4TrzHl1n6X3XOeaFXef+UeS990Oxd5PI650jfa17TN/hweni6evvWfQsp6Txq8qBM9IV56m6lN7YDUcVjz91Tr6R6+rR3rwu2NXH36cuWXuH3nxzLb7GKLBPHQVy6CeSc53bU7p6HVa1whgUgUZROWoQSzs1/kd4Geco6/o9lvXhqfzi7yHG+IPIVT5dt2Dwluofl/S11l2/0seS86BGQCncdgRWAg3Wh0HFGV79/cF3kd/Ja+Pyar4D8rzRaPxWpNp+e/+cfaY/4uD5kfzzZZHPlrH6TtMFqsgGYQSCCEQWCGcg0EHkAK6bPwGRAby6IYFIRBIQ38hUVLSQxSPH901zH8UecpaVczGnFwHfA5EPPBf4fBVPLCqWs4HnAb/7ftQsJBFPajHdQSo9BlN161eYKhbzQ+BHohFYwJueZJOfprPfas/3yy0QuvV+Z8B3pC7c+MIULgjMjk1c0fDd2hcTEAa18KxuuELA2z+fcgRmfZTpJ7E85XQzXrIgztOCkzFPacT5ocDzPIY4kB3LPEnwoRrTB0MM5wiHMH5Oa/5w8RaLdEvSHZAJ69+JLpDeoNJY+5Vm91G1W2qGh4cjSg0n2w+wTa62n7HN6Cc=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.drawio"
new file mode 100644
index 00000000000..a2ee5e47f22
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:05:17.571Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="lASJpg5Gj8Rj6XXFs8kq" version="13.4.5" type="device"><diagram id="Os7iT1nvRo9H4LHwW2Lk" name="Page-1">7V1tk6o2FP41zLQf2pH35COu2s70dXo709tPHVRUWhSLuKv99c0JCRAC6rog2b3M7NxLDiEkeZ5zTnISiWY+bU/fJf5+81O8DCLNGC1PmjnRDEPXRw75DyTnTIJHo0ywTsIly1QIPoX/BUzIsx3DZXAQMqZxHKXhXhQu4t0uWKSCzE+S+EXMtooj8a17fx1Igk8LP5Klf4TLdJNJkeEW8u+DcL3hb9YdnN3Z+jwza8lh4y/jl5LInGrmUxLHaXa1PT0FEXQe75fsuVnD3bxiSbBLb3ngrz9++Pyz8f3frn2I/w3RNP70y/obVsohPfMGB0vSfpaMk3QTr+OdH00L6TiJj7tlAKWOSKrI82Mc74lQJ8K/gzQ9MzD9YxoT0SbdRuxucArTz6XrP6Gob22WmpxYyTRx5oldmpw/lxOlpyBZPEZT/LlVvEtZRQxIZ+2FRjZ2I++T+Jgsggt9ZzI6+sk6SC/1sZGjTdQkiLcBqSB5MAkiPw2fxYr4jK/rPF8BKblgqL4CYaNPhAtU/yzdqUdYAaRQn0CxSj770ZG9STOciFR3PBfwc/49gsmg/fXNgXaYRzIY9v5U3CRXa/h/xMsgVZpzocyIKCL2FJB/2YRp8Gnv0+58ISZdxNU/7DMjuwpPwI/xKoyipziKE1qQuVoFzmJB5Ic0if8JSneWLp6PClifgyQNTpeBlYFgD5iYmVTmU1zuLF5KFpqJNiXjzGWtQ2dd1LFdvGtXqe4xm7oyZtO+URmdPpXR7kIZjY+ojA6qKCPqWRmdLqAzPyJ0tiVCh5yeoXMfakff+fATvQc7irpQRusjKmN1UNO7MmKpRzsZwVyeFDSMX/rTOt14D3MJPiB+1IhUjWnezdj0ahL1yzGXPr1cFZt7vV4fmNpvxJQ9+msckioWo1vTEa2yXTG3Wb3YUxVm5NV4A1mMLhyo/hEdaHU023tUQG+O6CzD56LbM9Fh7+9uQnRUh2iJFBfHSLkse50kFipW4QOBJhWBF/FklqsMPhP5UbjekeSCQBkQ+RiADhd+5LEb23C5jJqYJprCFpjiVoZa2JCZYtUwxeiMKVaPTGmY2g5MqWEKcvtmSnNgqnumNMSvBqZQpugiU3q3Kc1xsO6Z0jDAGJhSwxS3d5vi9siUhgWqgSl1TOndpjSH8xppsci6GCiRrOf+V6Ru5I+8f1R79bXGogIjyqeVvw2jc/b4Nt7FB9rlQpaCcg2Ms6vbU2zSZJDSvRd5ineBTTuBSCZwDRWzoZk26blrefU8L0f5rmKMopisp/M75J8pGQHYY3jeg3+mFiShTA/ePiVW34ZBi42fIAlPoDxJsSKFUV2l5Wfo8PKzvoMMkCLzNoxNU74BHQvX34Xp5jjnb0VQHYwgiSHpQpLWCfHKZlWEBiCQYaNcJ9o3vGL8FWIbJuX884S2IGOc3IKCGyTl0ay6BQRpag2vGoYrPOVJDzoYTTrvzF8nszt6g/Yt7fmxm/ctFIQdoT2UMBkQkM8za3BxeRK7OZOgoWMvL2qWJ13+GCqYXcEiM8RQb2qKQazTZNkcg5RaX9qTuUkWxJlZBhEzzCAUTTPcZMYZbpbMM9yhBhrk3ESDcEQlkT8PorG/+GdN79VVigfFaAOsXPYkoE3mUWM6l2LYMfXNzP8tBiK/lduGwiHY4BLynI5Z6vJzgzxzEYVJKRkg7iuKm6V7xGfk8nWpAlXTRZO5/SoLRavK8knmt97BE9IRyiGsEboRK0bMB1yMNUJfwjjsacjSiHVBhjammQnzPVsjRCZU9BBk9iYaphckj4cUHRvUx8DftgxvYDGmgeWxgmE+dLAgLyApv7ewiGzfs8y0OCbPtO56julDd8y0EgL3ksQ/lzLsIbR9KJVciZC7lf0ffOI7uzG/a17Jb1zMTy6yGrcadufvFAa6FTIfNv4eLlN/TqlbImGdBTgQ+DhbKFkIefxwB6aEPkMGD5G/P4S0sCzHJoyWP/rn+Jjy1/BUNcK+9AO0qo2wOwsUzFft2BhkVuYjNRF2u87EWF3ZGN6GW3Ai7UxDP/otWKT+bn0LZDIkyyTe/87VEARUO4Jk+hyAkjCzIDuPlFovuBkFK/7sPE7TeMsSCeuuvFDaVfaY/MHUCCyTPYE5kg3BFZ4mf5A9IYORHYHeDymQgX9IX4JDeivqF1RA5sIVrC3UFdRGt1DTnw/4BdQx6bRVRDfsb4hnD3ZtIPsGOBpUszc46ha3Bs3rUvPOIqS9IV+3WPUFKaKpmCLWrQgNivgARcROz4pYt8LzBSliw3SnNzjqllEGRXyAIuqW1bMmNq+LZCHc+5fLZqVQWVZWw6rXR9Z0VzFNx4Om96Tp2OhX081XBIY+oiZitTTRfEX8p584XSVETNOsbrrWUxxPH42uB/Lqtsp2FsczOw7uvHuLeplHd+uzeT2q9FgeyFEl+bfVytvXrsAyroJVtxuoO7DqAkGzAa4rcJ1EWHpD7xVxo8F1ctTwyFbMc3YcBBo85yX1UchzytEn+XeGX6wpbvjBZ2+2ty5eNGB1EStV3OYrYj+D28xnnHp1xnnj1w06w9HqOJAz+M1L+qOO37TkCNIw4xSVRB2/adWFiYYZ5zW4FHGd1iu2DA2uszlY27vr7HgD0OA6L+mPQq5TjiCZgy0WlEQh1/kRNgs9GCtV/OYrNhYNfrMxUtu72+w46DO4zUvqo5DblCNIgykWlUQdt2l3HCb6iFgp4jbtYW9QG9NN1PcKp10X9Bn8Zud+01Zsb5Ath4+G6aaoJAr5zWFv0D1wqeI6h71BLcw4+/ecw96gfjynYnuDbDmANMxiRCVRyHMOe4NejZUqbnPYG9SC28R9u02n45jP4DYvqY86btORA0jDhFNUEnXcplMXJRomnNfgUsRzOrJivflLgI8/zObqB/qa9ja/8ZAaZIshW/6JvLyI7AuD0iE1UkG4utWoWlDHp9048tZLZWhQo4jtcKIhFPRGTmC3LU7olXX0qhHomhO2upxokQZNi2ltm4bqaUd3m4ZqQV3TwFGXBl2ZhqZ9SW2bhrs5UTUN+MGckM+Lfd+caB1qfVTF2sXf2vehLf+GRy6ra8DlD3orA3iLet8U5mrZF6C2holSQV3TQP6yuDI06MoXNK0YtuwL7udExRegBw8T+SFKKnKiRRo0zeNbNg24LdMgFdQ1DWo2fU1tOD/Cm2pTSxvP4KgIOGZiBCdNTA0N0Qvxa32LPNJdfJAvP8Cl+o0+dgpOdhoFnD2BNeTSoysQvNSjZ1ggpMGny+o/5cdqMckPx0oEIjd8MTA7zUb6YmB2YAae0sMwLA1NWmkkPZ3mSu1Je0kPjF3a3pmGndLhHaQrXM0zS33iwgV22ZEfY49mntELFzIgWaHVOLyj9sSY4uWFzdAtli4tnLBTYto58kMXdc1BchQvP97jjUd+aOxcl5KyFie6mNP/AQ==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.png"
new file mode 100644
index 00000000000..6fd51040397
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\234\211\345\220\221\345\233\276\347\232\204\351\202\273\346\216\245\350\241\250\345\255\230\345\202\250.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.drawio"
new file mode 100644
index 00000000000..bceea69589d
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:46:44.567Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="WI8UacRvKQP8SDKfnp3P" version="13.4.5" type="device"><diagram id="30Cgl7Zjz6abKrNjlxG3" name="Page-1">7V1dk5s2FP01PGYHJPH1aHuddDLtTKdpp80ja7BNyxoHs7ve/voKDNhIwmBbQqpXmUwCAgToHN2je3WRDTh73n/Jgu36lzSMEgOY4d6AjwYAlmU6+L+i5P1Q4pvmoWCVxWF10rHgW/xvVBXWp73EYbRrnZinaZLH23bhIt1sokXeKguyLH1rn7ZMk/Zdt8Eqogq+LYKELv0zDvP1odQD7rH8pyheres7W45/OPIc1CdXb7JbB2H6dlIE5wacZWmaH7ae97MoKRqvbpfDdZ87jjYPlkWbfMgFf3zavoXL39Cj4z99/eP15cfy649PVS2vQfJSvbABnATXN30qHjl/r9rB+fFSPOd0mW7yT7sSpQk+Adjb/fEg3loV/5t1HfhhnurCqhGaGgF+Ogwi3pm+reM8+rYNFsWRN8wjXLbOnxO8Z+HNYLc9ILuM91FYPEScJLM0SbOyIrhcRs5igct3eZb+E50cCV3/CfOtvvlrlOXRvrP5rAYUzOYofY7y7B2fUl9gVzhWRG5wfTuhRVW0PmFEXRZURFw1NR+xwhsVXBdABxjQkU28CSdFH8B7m3QTtZsVv3f2/hfeMeud76c7j/vW3nu9t4/zv+oa8HZ5zYNd7R0vKnbqaw7PFYVUTyPaHj97+pItojMvXVmTPMhWUX7mPMjG8gQrm4FVXZZFSZDHr+3HZQFY3eHXNMYv0lAFAf/B920XeK4NbOiZbps5pvlgmgi4FkAuciwftm9waISqztMOTd7GdB5s56Qegp/wAcHjQ1jEXQ5NSN2lpGLTYtezE4owLECwYek2IF0mh4NhQYgwLL5kw4JEQAfvETpotqGDrmTobBHQoXuEjpRz6dA5IqCz7hE6stdJH4m5N47EOI6Pahepb3zkyBwfQdd7AF4zcAH10KQRQPbhi8dHrvXgWs0IyPXawzAI2IdHGiB56pDGHkiajm45DmkAOUxyie48lBbQ6qlIMPD+jcDXHljtZg3xwBpfr3H8Tq464+1xJBkaSDJbKsnIAR2pGUNJRlVkjUuy+na3s6xh1veTIz0sOyHWkJgCR5YNjQ8gqfpHWCAErmUZ6qlINMtY4cNbbdlAjsmzZPB/wTHSvyEN0GC5JCsiTaJojgFVOKaeFZOqlffDMEascu4YE9PwPGP+2ZjODH9CcQ77r3mbaG1nuCLiqR9cFQVJvNrg3QXmRYTLp4U3HC+CZFIdeI7DMOlyx7P0ZRMWzndJuiIKUE2aAV4THW4bDruG54RW9STXKa1I7eHmXlvdAckwfj1GNQ5Fu22wGRQwMVkBk5OYy9ngV1N2uB1V3HowJZnDgSk2IIYfkGYKYhggcUzpjn+KZ0pHhFszhcGUxsRLY0p3uFU8U4BmyhmmWG2mSLcprOjuWEzpiN9rpjCYAqTbFFZIdyymdOTcaKawmCLbpngO1djtl06zfJ2u0k2Q/Jym26r1/47y/L0a7AcvedrGhvQEOtJ7OAZK+gMgJhuWGx1P2yPg9K90PB3YU5HoKSBXXRqU9VTPZXHkBOyYebyRE67JixPIbo8/zJE54d0ZJ7hD7ZFQe/6DfR3YHmkA6KpEw+1ruM/D7fOD25cOd22VVISbo5EHHVMfvIUf8RJ+siLRNLDUpYEo4QdiBoOU8F/NCUL4m2mSsTgB1OUERxogbxTTAHmZBqoi0TSA6tJAlGlAYuSCNA3Xc4L0CcY2DUhdTnCkgTNOuADyChdQFYmmga0uDUSZBnuccMH1nCBMAxo5XOArHElUw38kwwWQX7iAUZVouBWOGHLs9S4YRQkQr0EiVZFoGtxbkHDI6ECM40AqwfWcIJVg7EGijiReqAQIclMCRlXCE/wZGf5zz5jODexCzm3Dc43pRKcvAseiJ3vHTV+saUci9bnAaO4aE8/wphopgBgfvo+MFGAgZRdpwP5jsTFxS6TwvxNj6hRJwp5p4EHFATtvVpwzxSVOge/EKQ85Bn4tf1ZcNUXGBBQbGGUPFYdwD8VH574xscoKcc3AmPrlVajoy8Xd8X3tk4RkXI4rf/w4PMHE6OUJZCW6CyQKa3kLAo+zHyVQH06b5Z/mSL3W0CVfetINONaXmW187Ot1FTq9VQnXVVa2uYa2qtblBy1dlXBoWenhHxZa4qubG6Clqhq/1w74qHq3DrbFZh48JQSuLFnb4UeulaxAeIGFLYg3hT6W1yzSJAm2u7is7HDGOk7Cn4P39CWvb1PvUbLY9oio5TLCIPKWzCXNnIUXPS35CKtLToMPXEiDdJH5LWk24KvlGkb8mnkcJL9FizzYrIYgSiMWZun29zrwUBRsC4JG2fwVt+CuHtHQA6a89J+Lg0m0rK99SvM8fa52sqq1mkrLprKn+C9+x1nhMtv4bWZ43zru47/F6Vk+SzcY+SAucYyCXf4W7fppNIQRZ7rPWUs0Lg9oj4meAruFCOVakcGRCClutWVSWv01HutGGx64CwKrK5GiJ5lZHFgMpwlXqOE6D9e+DYs09AZ4Mlo5SdQcSCQLSVfOAV6LVk4Bvbt/odFxeUC7OHSu4Yc1xf0rcoxre1kfoWqszmKlimwOWPNPyyaJGpWAP3DRTXEwDliFT8umgN7tKiabdPxIO5ztTqKObEJWlEg7nH1wKaKckI7taOXsVU7qS0XZyglZUR+tnMKVE/ZPGo3LAzp+RH/B8lFN8aGTKKScgqNE94iVKrI5YO5ay2bvDKd02RQc8tGyea77KCSbdPxIm+K+NWKk2V7BUaJ7xEoV2dSJQTymN2XLJmKFfLRsipdNxRKDEB08olfU+aimuGu5PVm2FwkOEd0jVorIJtJZQRy8TSg7KwjprCApsokUywpCdPBIB2n7Vh+SZntZISI9vdkHlyrKqRODODic8pVTJwbJUU7FEoMQHT/S+bR9aznKsr224CjRPWKliGzaOiuIQ1bQ0B+xFwej4JCPls1z3Ucd2bTp+JHOp213EoVkkxUl0g5nH1yqKKdODOIRqpWunDoxSI5yKpYYZOvEoL5OopBy6sSgi7FSRTZ1YhCPOK1s2XR0YpAc2VQsMcih40c6Ttv3wxqybK8jOEp0j1gpIpuOTgziEKdFsqc3HZ0YJEU2HcUSgxydGNTXSRSSTZ0YdA1cqiinTgziEKeVr5w6MUiOciqWGOTQ8SPtcPb9VpMs2+sKjhLdI1aKyKarE4M4xGmly6YrOOSjZfNc91FHNl06fqQ/4Oz72UtptlcvF3QxVqrIpvJZQTJk0Xba3iRr2XbmD4mJw0mn/ZzXxRt6aH9mDwvr+ssf/lBfEABS1preAEd/7s64cOhAztg9770NqTTkL0j9uceO2B+cGRUOT3BwRnfEro7oO3I7ondBbOcOO6LXn5YzLhw6RiOpI1r1Qi3SoL8grecee2J/4GVcOHR6jqye6APJPfGCwM099sT+nJtR4bDMCwI0Cs4/3R4zO/PjzrKCm5bpanM4xs8Cm4p9b2WZdNBGTx8R3WIMuPBulqb5ybEvuAXXv6RhVJzxHw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.png"
new file mode 100644
index 00000000000..ef97be64bb5
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2421.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.drawio"
new file mode 100644
index 00000000000..a25027440d0
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:48:28.432Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="CvE3ne5Dy7j87GUfEagG" version="13.4.5" type="device"><diagram id="MGIOEjQTzljkyi59MuMZ" name="Page-1">7V1bk6q4Gv01PO4u7oRHtXXOw0zV1OypM3s/0hKVObQ4SHfr/PoTLlEgQVATkrazq6u2BAiQtb6sZPEZNWv2evglDXab35IQxpqphwfNetZM0zB0F/2XlxzLEl/Xy4J1GoXVQeeC79G/sCrEh71FIdw3DsySJM6iXbNwmWy3cJk1yoI0TT6ah62SuHnVXbCGRMH3ZRCTpX9FYbYpS4Hpncv/A6P1Bl/ZcP1yz2uAD66eZL8JwuSjVmTNNWuWJklWfno9zGCcNx5ul/K8Rcfe042lcJsNOWGdfvzy34/vURD8cBffnM36j+jwrarlPYjfqgfWTDdG9U1f8lvOjlU7uP+85fc5XSXb7Nu+QGmCDjCd3eG8E31a5//ruA50My+4sGqEU40mujsEItqYfmyiDH7fBct8zwfiESrbZK8x2jLQx2C/K5FdRQcY5jcRxfEsiZO0qMharaC7XKLyfZYm/4O1PaHnvyC+4Yu/wzSDh87mM06gIDbD5BVm6REdUp1geRWOFZE9zNCPGi2qok2NEbgsqIi4PtV8xgp9qOC6AjqTAl27ibfhJI8BtLVNtrDZrOi50+MPtKHjjZ/1jedDY+uItw5R9gPXgD4X5zw51db5pHwDn1PeFwyJSGu1Pbr35C1dwgsPXfUmWZCuYXbhOIuOZQ0rh4IVLkthHGTRe/N2aQBWV/g9idCDnKji2v6T7zueCTzHdCxgNIjj+vqTrtuIQKbt2a7hN6svm6CqsR7O7YuY7pPjEtWc2Gk92RZxC/giZfsRFyl4eGqu26lp8ehVzEfsVVy31asAwb2KzQM66xGhc8wmdMAVDJ3DAzr7EaFra7lw6Fwe0BmPCF076oQPw7w7h2EMB0d4ftQ3OHJFDo4cHzyZ4DRuMZuDIw9Q9149OPKNJ884DX+85uAIGNS9Iw2OgDyEcQYSpiMkxyGM3R4iua1QHkoKx+qpiDPw/p3A46kXnl8NmXqdJnmnGV/trAvTPIYksweSzBFKsvZgzruRZERF+rgkw3J4P8tOzPpZ29PDshqxhpgJDFk21BiwhWpfqwfyjVtZ5vZUxJtlNN/w3r5sIMfE9WTWp+BYe27T7oAGy2W7onaXyJtjpiwck68XE6qVj8Mwik85d7WJrgGgzRfadKb5E4JzaO6aNYnWnPBWRKzPjquiII7WW7S5RLyAqHyaz4SjZRBPqh2vURjGXVPxNHnbhvnEuyBd7gBUb8tMVq6I34TD0G1ybo1fb9V5ZerdFLprbm10u5Fh9H62NMqi/S7YDnJLdJpbUjNcLjpfp7LyckRx48akpA4Dqnh2a/xhkkyxKT0QP6Z0m5/8mdJhbyumUJhy6uOFMaXba+XPFFMx5QJTmlYgEN6n0KzdsZjSYd4rplCY4gnvU2ie7lhM6ci2UUyhMUV4nzLABN5vgl3+MQte4taUltZoezRLwlOBvNmWiEVBtM1bvzhnmcRxsNtHRWXlEZsoDn8Njslbhi+Dt4h5RbFd3ZuhES/9wgCCFfWln7sE8GXFBkbfacE48KWfzQtGzI8hMKLHzKIg/gMus2C7HoIoiViYJrs/sSmQF+zyOTFM5++oBfd4SkiGY5bsqp0xXOFzX5IsS16rjbRqrVOlRVM5U/SHnnGW+2sOepoZ2jbO2+gvPzzNZskWIR9EBY4w2GcfcN9PoyGMuBA+F42PcXlA+qA2UyIUSa3BmQgJarVVXBheG9STwi0L3DmBVcty7QKL1vfyA4tmKC4UXD1wHZqwCEOPllSolLNHOYHjSKacNEtPKSd35TT7M6LH5QFp2BlMifCpu+L+N4jj9r00z0xhdRErWWRzQH6iks02aobRnnEOzBDmh+OAtEGlmxzC25NMN0kDSc04m0Eij27idC8147wKLkmk0xqQ5Kakk5BOXTbptGi+j5JO7tJp9X9tYFwekA6SpfriRpBIJJ2cfaJHxEoW3aTlYindvPYdp3DZ5Gz6KNm8FD4SySbpIKmuuBkkEskmZ5voEbGSRTZVahCLF5yiZRNXrGRzZNmULDXIJt0jXXXFjSCRRzZtzhbRI2IliWzaKi+IwWwTiM4LslVekBDZtCXLC7JJ80iZtM0gkUg2aRaRer/ZB5csyqlSgxhMOMUrp8oMEqOckmUG2aR/pDJqm0Eij3LipVjUhHM4VpLIpkMaO0o2e2WTSAsauuYuPxw5ez5KNy/Fjzy66ZAGksqobQaJRLpJs4nUjLMPLlmkU2UGsfBqhSunygwSo5ySZQY5KjOoL0gkUk6VGXQ1VrLIpsoMYmHUipZNfH0lmyPLpmSZQS5pICmjthkk8simy9klekSsJJFNV2UGsTBqfdEvOF2VGiREN13JUoNclRrUFyQS6aZKDboFLlmkU6UGMTBqxSunSg0So5ySpQa5pIGkZpzNIJFHOfFi9mrGORwrSWTTU6lBDIxa4bLpcfZ8lGxeCh95ZNMjDSRddcWNIJFINtWCQVdjJYtsSp8WJEIWPdBaEIgii7Rf+eSIk8r7uayLd0Tobb/oir/7wx7qKwwgaXvTO+DoT94ZFw5l5IwdeccmpMKQvyL35xEDsd+cGRUOPP9QgTh2IPqu2EAEV3g7DxiIoD8vZ1w4lEcjKBANvFSLMOivyOt5xEjsN17GhUOl54iKRN8UHIlXGDePGIn9OTfjwuESrd/8RWVE0k2yTrZB/GtStFHe9H/DLDtWVlnwliVNYNqOJGqR9Pijqq/Y+JlvoFCoNp8P9Z3Px0Yrw3ANO9u4KspwbHc9ZteCdCmMgyx6b16A1sjVqb/nIX7224De8tvwWB9XsU/e0iWszjpDRVbUXsm7XVH5hERFBean57mDBp68NKAY2kw40bW2752c8E1WnHBby9T6I3MCPBgnmENt6G2sPf/JuQ1t8jdwyLp4A+4rwHsANxgCTvxe4OiA4w5FRsAZdvRdP7fJWvwtVuLfrog3DcjEPmlowEv8u365nLX438yJtvi339Dy5gQ5K5OGEwxp0LVuGOOuAbDqGoiKeNOA/LaMNDTg1TV0LcHKuGu4nROtrgGM3TWQS11JwwmGNOj6pirrroGVZUBUxJsGjrw04NU1dC36wbprYGUZgJEtA19iN1GSGWTbMgAMLQNKXbwBl9g3ZBj3XcmwjLXAZzVMJCriTYNHswqHjA/4TB3aWnA7J1pa4I89TFRu4rVa4JvstIBSF2fADZ2S6DYH2nSuoWnk3NGAp00n2nyhTWeaPyHYkcFD1oS7mStfvamlvLwN4mi9RZtLmL/URwX5m9loGcSTasdrFIbF62PaO+MmK9sUqx7pnqx8C4/C8Dv4U0vV3vri79s20vJ5ZeUbWHjaUC1ykOaeNgEamCqoTB8IR8qkIIViaaGhwfY5qFxtomsAaHNfmxjatNyF/qwczamd7y3RBDMyJuv7HG2KKkKTX3QeQh7YeRFqFTAvappqE692EU8Dpjb18fkgvxF/pk0m+UUm85xQ6GA0SkSf6/yqai7P8ouz7PymyrueOLUHQuWoqmcOHCwzPSRjoI3pdYmBeDm4kSg4IHkObsNJmhZpNlUrdwKjmZZe/Dvt+at6NOOKUTvZgD0pNLjsTtFu44MC9GbRdkB/XdxFe0Aq3hcG12UILlkXd3AHJNt9HXA9nRm4ZF0CIveKr1ZKuHIEA6m8AIKo7yUbOumIfelMZk5fT6/Yf7EvGRl42vct3Ri3AdqzPHWj7j9vSZnmba1WFvpXL3LX+f86PhndTXl+Wc6UXZ95gYIq0mRiwIDvXX4ZtXUB0TmDW9UW6P118VZbvJKCApcKrssQXLIu7uAO+KImM3Dz/q925GJRCMBnAN1gBjpZl4CIpjhrn2j83Eeku4bWl/ARtbSWYbBduvnBh9Z38uNSzFzsgUbmBGlfkdnMn3yIzAfJ/pXaxx09G6RX9XC/qTkqkpKs1GYYA3yq2uBqGQf7fbSkja/qoyhixPV5xlFGe8DrtNp+8CiKMMDaNXEfQ5FrfpHfKfoib+ror/UZvapDm2mSG0Rn+NBjbn5LQpgf8X8=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.png"
new file mode 100644
index 00000000000..a7074d37b28
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2422.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.drawio"
new file mode 100644
index 00000000000..0c727214ab0
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:49:29.286Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="RE2yXWkCA_Scx2RjOj4p" version="13.4.5" type="device"><diagram id="y_rejXg0V4Tvyw0t4x3a" name="Page-1">7V3bcqO4Fv0aHieFuPNoO86Zh56qqe5TNd1PpwgQmxli3Jgk9nz9ERdhQOJiW0KKW12paiNAgNbaWtJiW1b01evxP6m33/6RBGGsaGpwVPRHRdMAUC34X15yKktcVS0LNmkUVAedC75F/4ZVITrsLQrCQ+vALEniLNq3C/1ktwv9rFXmpWny0T7sJYnbV917mxAr+OZ7MV76VxRk27LU0exz+e9htNmiKwPLLfe8eujg6kkOWy9IPhpF+lrRV2mSZOWn1+MqjPPGQ+1SnvfUs7e+sTTcZVNO+Af8/P37++vXr//798tz8v3gffwd/VbV8u7Fb9UDK5oVw/qWz/ktZ6eqHayfb/l9Ll+SXfbboUBpAQ/QzP3xvBN+2uT/q6gOeDPPqLBqhLpGDd4dBBFuLD+2URZ+23t+vucD8giWbbPXGG4B+NE77EtkX6JjGOQ3EcXxKomTtKhIf3kJLd+H5YcsTf4JG3sC232GfEMXfw/TLDz2Nh+oQYFsDpPXMEtP8JDqBB0RtyKyjbY/GrSoirYNRqAyryLipq75jBX8UMF1AXQaAbpuE++CRR4DcGuX7MJ2s8LnTk/f4YaKNn40Nx6Pra0T2jpG2XdUA/xcnPNgVlvnk/INdE55X2GARVqn7eG9J2+pHw48dNWbZF66CbOB43Qylg2sTAJWqCwNYy+L3tu3SwKwusKfSQQfpKaKabsPrmvammObmqk7oEUcy1EfVNXQbKAZtmEBt1192QRVjc1w7l7EtB5MC6umZqf+YOjYLaCLlO2HXaTgYd1c11NTZ9GraPfYq5hup1exOfcqBgvo9HuEzjDb0DkmZ+hMFtAZ9whdV8u5Q2exgA7cI3TdqOM+DLNvHIZRHByh+dHY4MjiOjjSnAfNqcctWntwZNvEvZcOjuCJDzaohz92e3DkqMS9Mw2OHHEIY04kTE9IzkMYvTtEMjuhPJUUhjVSEWPg3RuBR1MvNL+aMvWqJ3n1jK9x1sA0jyLJjIkkM7mSrDuYs64kWbci252XZMg3u51lNbN+NPaMsKxBrClmAkWWTTUGDJ4s6/ZAtRl6McvckYpYs4zkG97al03kGL+eTP8MHDO7PmW3A5psMHUnSd0ukTXHNFE4Jl4vxlUr74dhBJ9ybSkLVXEcZf2kLFeKu8A4B+euWZto7QlvRcTm7Lgq8uJos4ObPuRFCMuX+Uw48r14Ue14jYIg7puKp8nbLsgn3gXpcgegelum0XJFtDYcQNXxuTV6vdXklab2U+imuTXodyOD6P1saZRFh723m+SWqCS3pGG4DDpfdVl5Oay4dWNCUocCVSy7M/4AOFMMQg/Ejin95id7pvTY25IpBKbUfTw3pvR7reyZokmmDDClbQU63PsUkrU7F1N6zHvJFAJTbO59CsnTnYspPdk2kikkpnDvUyaYwIett88/Zt5z3JnSkhrtAGdJaCqQN5sPWeRFu7z1i3P8JI69/SEqKiuP2EZx8MU7JW8ZugzawuYVxXZ1b0DBXvoFXui8EF/6Wb4TPr/QgdHppNBMfelnsIIR8WMKjPAxs8iLv4Z+5u02UxDFEQvSZP9fZArkBft8Thym63fYggc0JcTDMUv21c44fEHnPidZlrxWG2nVWnWlRVOZS/gHn3GV+2smfJoV3AbnbfiXH55mq2QHkfeiAsfQO2Qf4WGcRlMYMRA+g8bHvDzAfVCDKhGKpFbvTIQEttpLXBheW9iThjsauDMCq5Hl2gcWqe9lBxbJUHyScI3AdWzDwg09UlKhVM4R5bQdUzDlJFl6UjmZK6c2nhE9Lw9www5QJcKn7orH3yDO2/eSPDOJ1SBWosjmhPxEKZtd1IDanXFOzBBmh+OEtEGpmwzC2xZMN3EDSc4420Eijm7qJJtIzjjH4BJEOvUJSW5SOruouaIpp06yfaRyMldOffxbA/PyADeQdNkVt4JEIOVkbBPdI1aiyCYpFUvK5qWvOLnLJmPPR8rmUPgIJJu4gSS74naQCCSbjF2ie8RKFNmUmUE03m/ylk2DZPlI2WQvm4JlBhm4eaTKrrgVJOLIpsHYIrpHrASRTUOmBVGYbTq804IMmRbERTYNwdKCDNw8kiZtO0gEkk2SRSRfb47BJYpyyswgChNO/sopE4P4KKdgiUEG7h/JhNp2kIijnCZjl+gesRJENk2ZFUQhK2jqirvsYGRs+UjZHAofcWTTxP0jmU/bDhKBZJPkEskJ5xhcoiinTAyiYdVyV06ZGMRHOQVLDDJlYtBYkAiknDIx6GKsRJFNmRhEw6flLZsWY8tHyuZQ+IgjmxbuH0mfth0k4simxdglukesBJFNSyYGUfBpXd6vNy2ZGMRFNi3BEoMsmRg0FiQCyaZMDLoGLlGUUyYGUfBp+SunTAzio5yCJQZZuH8kJ5ztIBFHOW3GLtE9YiWIbNq4sSNlc1Q2uz4td9m0GVs+UjaHwkcc2bRx/0h+gbMdJALJplwu6GKsRJFN4bOCuMgiaM8mSeu2k37ikyFOMu1nWBdviNDrfs4VffOHPtQXGEDC9qY3wDGeuzMvHNLImTvyTm1IuSF/QerPPQbiuDkzKxwOY3NGBmJfILoW30B0LvB27jAQnfG0nHnhkB4Np0AEaKEWbtBfkNZzj5E4brzMC4dMz+EVia7GORIvMG7uMRLHc27mhcPCWr/9c8qQpNtkk+y8+EtStFHe9H+HWXaqrDLvLUvawHQdSdgi6el7VV+x8SPfgKFQbT4emzsfT61WDoNN2NvGVVGGYrvvMfuWo0vD2Mui9/YFSI1cnfpnHuINv03v+G12x0c7JG+pH1ZnnaHCK+qu492tqHxCrKIC8/p5bqCBLS4NCIY2FU70rex7IycckxYn3M4itc7MnHDujBPUoXa7UFvug3kd2Njv3+BVsYbblXAPww1UenjjPxU4O+Au/mJaGMApdvN9v7RJW/o1WtLfrYg1DfC0PmFowEr6+360nLb0X82JrvTrM3MCn5MJwwmKNOhbM4xy1+DQ6hqwiljTAP+ujDA0YNU19C2/SrlruJ4Tna7BmbtrwNe5EoYTFGnQ9zVV2l0DLcMAq4g1DUxxacCqa+hb8YN210DLMHBmNgxcgb1EMWaQXcPAoWcYEKpiDbfAniHFqO9LhKWsBC6tQSJWEWsa3JtNOGV0wGbi0FWC6znRUQJ37kGi9BIvVAIXUFMCQlWM4QYozbz5UnftKMu1AqeQa1NxbGW5UNZPynKluAuMG1l4zNpgt7Pkq3e0hNe2XhxtdnDTD/PX+bAgfycb+V68qHa8RkFQvDgmvS1uc7JLsOqRbsnH11EAo7fvKjJdG+970TdtWwn5rPLxgUrIScuhespBWtvKwlGcpYRKc23uSGkEpGAsPSlwoH0OKktZqIrjKGtXWQBlWe6Cf3qO5tLI95ZoOis8Jo3GPlNZwoosIz8PIu8YeRHkq7MualoqC7txEVtxNGXpovOd/EbclbJY5BdZrHNCwYPhGBF+bvKrqrk8yy3OMvKbKu96YTYeCJbDqh4ZcLDM8RCNgUg1hxiI1oGbiYIT0ubCXbBI0yLBpmrlXmAUTVeLf/Wev6pHAxeM2fEGHEmeQWU3SrYFup05cK7V7NrQH6iLuWhPSML7hcE1KYKL18Uc3AlpdtTAzTvDxpFPTzr89ylAB9RAx+viENEXfNlSzLUkBol0k7oO4cNrsQCg4hbaL532zJQfQzEz2APNzAnS9zatGDUP3OPXLWD9fEvKdHHUPTeKrE3+P0Anw7spzy/LqRJPgIUO2JBjfFGuWVc9ACr+1c67W89yViQFWc4CAIKDNjBe82PvcIh80pCtOTDDBnGfZmhmGt0xdLftJw/M1LGaWA/LAG65nT0ZPJ3iF7E3yF7ovP4GIFhsv+wUGAfo+ncSJhivi3nYSfNqCFyTIrh4XczBndO8+qz+hoFJ3/Wg43VxiGjhF/3i528M4cNtLgvwjDDpb8w78QGC/f4fAKRlwqS/wYccgv3eIAC4+XV3v6s8K5LM/Q24mSZ5RJ6VHrb19o8kCPMj/g8=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.png"
new file mode 100644
index 00000000000..063d9ca8a6c
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2423.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.drawio"
new file mode 100644
index 00000000000..b115c61ee2d
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:50:48.777Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="gXIhcKcSGzLmD1JHt_Ix" version="13.4.5" type="device"><diagram id="_B_lt8A41LRaqq57eL1I" name="Page-1">7V1dj6M4Fv01PE4J82HgMUmnZqTtkVbbq92epxGVkIQZKqQJqUrtr18TMAHbCSSxsYt2q6QOBgzhnHvP9fXFMezZ6/HXLNxtfk+XUWJY5vJo2F8MywLAhOi/ouWjbAlMs2xYZ/GyOujc8C3+X1Q14sMO8TLatw7M0zTJ4127cZFut9Eib7WFWZa+tw9bpUn7qrtwHVEN3xZhQrf+N17mm7LVt7xz+29RvN7gKwMYlHteQ3xw9U32m3CZvjea7Llhz7I0zctPr8dZlBQPDz+X8rznC3vrG8uibd7nBOswh3/H+ezH13/kf/7H2y7A4vsvVS9vYXKovrBhwQT1N30pbjn/qJ4D/HEo7nO6Srf5L/sTShN0gOXujued6NO6+N/EfaCbecGN1UOoe7TQ3SEQ0cb0fRPn0bdduCj2vCMeobZN/pqgLYA+hvtdiewqPkbL4ibiJJmlSZqdOrJXqwguFqh9n2fp31Fjz9ILXhDf8MXfoiyPjhcfH6hBQWyO0tcozz7QIfgEWOFYEdnB2+8NWlRNmwYjcFtYEXFd93zGCn2o4LoBOosBHfmIt8tJYQNoa5tuo/ZjRd87+/iONky88Udz48uxtfWBt45x/h33gD6fznlyq63zScUGPqe8r2hJWRrx7NG9p4dsEV350pU3ycNsHeVXjrPZWDawchlY4bYsSsI8fmvfLgvA6gr/TGP0RWqqOHbwFASuZ/mea7m2b3pt5jjmk2k6lgcsx3MgCOz2BcqHUPXZNGjyMgA+ubDRD8FP+8mxzzdBfIvyCVIXOTGxfmD3k9MW4VesMfoVx237FdeW7FccEdDZY4TOBm3oIJAMnSsCOmeM0JFqLh06KAI6MEboSKuTHoh5DwZiHMMjPELqCo+gzPDI9v0ny6/jFgvYhAASu++Mjnzw5IE6/vH8dhDmwvbuYNDwyFeHMm5PylwwymEoY5FBEiCMuS8rbKujI8HABw8Cj4dfeIzVZ/hVD/TqUV/jrCtDPY4kc3qSzJVKMjKcs+4kGdmR6w5LMnz5x1lWM+uPxp4OljWI1SehwJFlfZMDjlT1IzwQhPeyzO3oSDTLWLnDR31ZT47J82T2p+AY7HBAveWSHCaRLlE0xyxVOKaeF5OqleNhGCNTOYfGxDR835g/G9OZEUwozqHRa94mWnvIWxGxOT6umsIkXm/R5gLxIkLt02IsHC/CZFLteI2Xy+TSYDxLD9tlMfQ+ka7IAVQzZhavvIjfhsML6ME1nuFq0opEjdvgGlxORy7jt3NOo2za78Jtr3SJyUqXNDIuV1NfdVt5Oaq5dWNKMocDU+o8NTZcj2aKw3BA4phyOfspnikX8tuaKSymWLKZcjnZKp4plmbKFaaAdlQh3aewcrtDMeVC9l4zhcUU6T6FldIdiikXCm40UxhMcWT7FB9SD7v9pdMs36TrdBsmX9N0Vz39v6I8/6iC/fCQp21syJHAhdoejomS7gSIyYblwYGnGxCGb9858IROR0eip4A8dWlw6qe6L8CRE/aFeccHOeEBXpxw3XZHzsCc8EfGCe5Q+yTUVvDk3ge2TzoAuivRcAca7utwB/zgDqTDjVNpKsLN0clbF6Y+OAu/Q9bz3Cv8VEeiaQDUpYEo4bfEBIOk8N/PCUL4nWBgTljqcoIjDRx/ENfg8nINVEeiaWCrSwNRrsERIxfUmICXa3CHdg2OupzgSAM4TLoA8koXUB2JpoGrLg1EuQZ3mHTB/ZwgXAMcOF0QKJxJVGP8SKYLIL90AaMr0XArnDHkaPWeNYwS8AoSqY5E02BsScI+0YGYgQOlBLyCRDh0kKgzibcqgcdPCeiuhBf4Myr8574xnRtoCDl3Dd8zphNdvmj5Lj3ZO2z5osmoki+Qei4wmnvGxDf8qUbK8hivvQ+MlMVACpnSs4Hi7LNN1bXBgTEBxrTchf7sAs2pU+wt0fRntEnajX2uMUUdwdN5CHnfKZqQbvjzU09TY+I1LuIZvmVMA3y+X9xIMDMmk+Iik3lBKHQwChHR5ya/qp7Ls4LTWU5xU+VdT9zGF0LtqKsvAjiYRKtcOQaiiLCbgRAMSkHWshkEGldfd6BevDZP/+o9eAmjW94hpR/gQKuoeISH8Px7FbvO2V3uSrhis+rYNbQ4OOMGLaMr4dCyCs9FQVs4wsaRz882+vcpIAe8ICe7kmDNN75hu0jC/T5esFBvYkvx4POgaxJWaN45kHZgR0fCkaXj9XNAVwdSM3qi7ieJkpgjqmGjpIdfCh2TlFJR7P15jXoRlMtdCbc+HQBfMT3ADVpGV8KhHTIA/qxRkkXK3/2Qk11JsOYei93sN+Gu+JiHLwmBN0vu9uiWscIVyC8QzmG8LfJbp3MWaZKEu3186qw8YhMny6/hR3rI8WXwFiWX7Uw1tbzZMoz8FXN5M7jwo5cVH8H1yPLEnsubkXPP/NaZ7RHrYhjR18zjMPlXtMjD7boPojRiyyzd/RtPCBUNu4KgUTZ/Q09wjyMdOozKT/Maxc4ykDp9fEnzPH2tNrLqadWdnh6VO0V/6DvOiqkMF32bGdoG5230VxyeIYeyRciH8QnHKNzn79G+m0Z9GHHFfK56omF5QEfGdGnSI0Q4LeAdnomQoqe2Sk5qsEExcLTlgbsgsC4VuHa8ZCYOLFaM/Kzh6oDr2IZFGno9wmCtnCRq0CGKuKUrZ4+QVyunAOvuXv19WB7QCWL6HZCf1hV3r5Q2rO9lLQ6isbqKlSqy2WMlZi2bJGrUi5E9l0IXB2OP1ZG1bAqwbk8x2aTzR3rA2TYSdWTTZmWJ9ICzCy5FlNOmcztaOTuVk1pBQrZy2qysj1ZO4cppd08aDcsDOn9EFyz8rK64NBKFlFNwlmiMWKkimz0q/7Rsds1wypdNwSkfLZvXzEch2aTzR9oVd63dJ833Cs4SjRErVWRTFwZxmN6ULpsOK+WjZVO8bCpWGOTQySN6pcOf1RVfWgZZlu91BKeIxoiVIrLp6KogHqNN2VVBjq4KkiKbjmJVQQ6dPNJJ2q5VIaX5XlaKSE9vdsGlinLqwiAeA07pyqkLg+Qop2KFQQ6dP9L1tF1rbMvyva7gLNEYsVJENl1dFcShKgjKztO6glM+WjavmY86sunS+SNdT9s2EoVkk5Ul0gPOLrhUUU5dGMQhVStfOXVhkBzlVKwwyNWFQV1GopBy6sKgm7FSRTZ1YRCHPK102YSCUz5aNq+ZjzqyCen8kc7Tdv3gmSzfCwVnicaIlSKyCXVhEI88rezpTagLg6TIJlSsMAjqwqAuI1FINnVh0D1wqaKcujCIR55WunLqwiA5yqlYYRCk80d6wNn1G5qyfK8nOEs0RqwUkU2PTuxo2eyUTSpPK1s2PcEpHy2b18xHHdn06PyRfoGz6+fIpflevVzQzVipIpvKVwXJkEWX+Dk/1rLtrJ/cEYiTLvu5rosPWGh3ZQ8La/zmD3+ob0gAKetNH4Cju3ZnWDh0Imdoy/toQyoN+RtKf8ZoiN3JmUHh8AUnZ7QhXjLEAMo1RP+G3M4IDdHvLssZFg6do5FkiAAv1CIN+hvKesZoid2Jl2Hh0OU5siwxsCRb4g2JmzFaYnfNzaBwAPOGBI2a80/ptd+nfiid5hDpNM/z8e8+y5pfAKanPWX/eaUH6XHNZNSZcwImK9UDE/x40J5F/QTgj0NaKgz+0fdGE1wX/wN8Mrqb8vyy/fP5aRnk6K7jGXSiBJh0NugTKq5CSCoyAwaA8lNg8pTbwhNftXIH0pUbQK3ckpUbKPYyPACsOTOt3HLIodjL9wDQYd3oXl4ZFEnhyo02s7SwyHrfr+hZb35Pl1FxxP8B</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.png"
new file mode 100644
index 00000000000..72456379dc5
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2424.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.drawio"
new file mode 100644
index 00000000000..a5a6d89bd82
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:51:41.770Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="-MVK6w1W0YCMoigiOuOH" version="13.4.5" type="device"><diagram id="u5kIgGnqsk5s8JGxCxMm" name="Page-1">7V3dkqq4Gn0aLqeLvwS4VLc9czEzNTV7V83MJS2onEOLg9htn6c/QQhCEg0qIWk7u7pqS4CArJVvJSsf0XBmr4ef83C7/i2L4tSwzehgON8M27YsE6L/ypKPqiQwzapglSdRfdCp4Hvyv7guxIftkyjedQ4ssiwtkm23cJFtNvGi6JSFeZ69dw9bZmn3qttwFVMF3xdhSpf+lUTFuir1be9U/kucrNb4yhYMqj2vIT64/ia7dRhl760iZ244szzLiurT62EWp+XDw8+lOu/5zN7mxvJ4U/Q54S+4ef2x/yUL1r9PneUP+OePbfpTXctbmO7rL2zYMEX1TV/KWy4+6ucA/92X9zldZpvip90RpQk6wAbbw2kn+rQq/zdxHehmXnBh/RCaGm10dwhEtDF9XydF/H0bLso974hHqGxdvKZoy0Ifw922QnaZHOKovIkkTWdZmuXHipzlMoaLBSrfFXn237i1J/KCF8Q3fPG3OC/iw9nHZzWgIDbH2Wtc5B/okPoEr4ax5rGLefzeYkVdtG4RApeFNQ9XTcUnqNCHGq0rkLMZyJFPeBNNyiaAtjbZJu4+VfS184+/0YaJN/5pb3w7dLY+8NYhKf7GNaDPx3OeQL11OqncwOdU9xVHVEMjHj2692yfL+ILX7oOJkWYr+LiwnEOG8oWVoCBFS7L4zQskrfu7bIArK/wR5agL9IwxXGDpyAAnu17wAaOb3WI4/jmk2m6tmfZrudCK3C69VfPoK6y3ZzJq9jwCUC6noafzpPrUDeBr1I9QeoqRyY2D+x2cjoiwor9iGHFgURc8STHFVcEdM4jQtcoew0dAJKhAyKgcx8ROk8x5KAI5KxHRI5sdNL7Yd6d/bABe0d4fMTrHUGZvSM78J9sv+m32BbRb/HYu6/uHgXWk2c1/R/P97ot3mTvHql/5KtDGtCTNGea5TikscheEiCac19a2A6nIsHAB3cCj8dfeJDVZ/zVjPSaYV/rrAtjvQFJ5vYkGZBKMrI/B28kGVmRG4xLMuyd3c+yhln/tPZwWNYiVh9HYUCW9XUHXKn6R0QgaN7KMsipSDTLWN7hvbGsJ8fkRTLnU3CMNCvJANRbLsmBEhkSRXPMVoVj6kUxqVr5OAxjWJVzaExMw/eN+bMxnRnBhOIcGr8WXaJ1B701Edsj5LooTJPVBm0uEC9iVD4tR8PJIkwn9Y7XJIrSc8PxPNtvonLwfSRd6QLUM2b2QMProIuGh8WqxSo8wdVmlW2eJ9Bdo2vrvB0ZJW8nU6Mq2m3DTS+/xGT5JS3L5aL11ZRVl6OKOzemJHEGIIrrEr0Pi2aKy4g/4phy3v0Uz5Qz/rZmCoMpTYSXxpTzbqt4ptiaKReY0p0qBdJjCsvcHYspZ+x7zRQGU1zpMYXl6I7FlDP5NpopLKbIjik+pB5290tnebHOVtkmTH/Nsm399P8TF8VH3dcP90XWxYYcCJzJ7RnQJ+H7HyYbljvHncAk4PRuHHcCwKlI9AyQpy4NjvXU92UNyAnnzMTjnZyA9lCcgKBbETlpLJoT/oNxYnCoPRJqGDyB28D2yABAVyUa7kDDfRlufzi4felwY2tNRbgHDPL2mZmPoYWf7KDdLPxkRaJpYKlLA1HCb4vpDFLCfzMnSOF3RuaErS4nBqSB648SGsBQoYGqSDQNHHVpICo0uGLkggwNt3OCCA1g7NDgqsuJAWkAx7ELwFB2AVWRaBoAdWkgKjSAceyC2zlBhoaR7YJAYSdRjfEjaReA4ewCRlWi4VbYMRyw1Xv2KEoAh+okUhWJpsGjmYR9egdiBg6kEtzOCUIJ4NidRO0kXqkE0BpMCRhVCc/vZyT4z31jOjfQEHIODN8zphOdvegF9FzvuNmLWHRIoJ5LiOaeMfENf6qBgoyX3kcGymYAhRrSs4F62acW1SQGB8bEMqbVLvTnlGBO3XJvBaY/oxuk3doHjCmqCNrleQh43y2L0FPx58eapsbEa13EM3zbmAb4fL+8kWBmTCblRSbzkk/oYNRBRJ/b9Kprrs4Kjme55U1Vdz0BrS+EylFV3wRQMI2XhXIEbJbpucRAaI1KQdaiGQQaF991oN67No//mj14/aJrXiClH+BIa6j4RCi3/Fv1GpjcqoTrNSuLXUOL+1PDQUtXJRxaVtq5KGjLQNg68vnZQf8+BeTWUJBTVUlozde9xL1Iw90uWbBQb2NL8eDzoGsRrdC9cRjteJyKhL/RSo+rTh26piM1c5pPNPBfpL/EHFqN21+6+/3jRxJVCp/b/Q3b51YlvB0yRmMa2kY8h4OWrko4tGOOcj5rf8kihfB2yKmqxm/NPbpLu3W4LT8W4UtK4M2Sux26ZaxwJfILhHOYbEqj63jOIkvTcLtLjpVVR6yTNPo1/Mj2Bb4M3qLksutYU+ucRWHsL5nrnMGFH78shxFcSKYp9lznjOwyDbfebI9FZTCM6GsWSZj+GS+KcLPqgyiNWJRn2x94Yqgs2JYEjfP5G3qCO9zTobtRxXF+o9xZdaSOH1+yoshe6428flpNpcdHBaboD33HWTmlAdC3maFt67SN/srDcxRQNgj5MDniGIe74j3e8WnUhxEXms/FSDQuD+huF52idA8Rjut4hyciZOipLdOjGqxRHzjeDIG7ILDOJbpyXjYTBxarI/Ws4eLAdejCIg29Hn0lrZwkagAQydzSlbOH+6uVU0Dr5q8CPy4PaKuYfhfky4Zi/oJp48Ze1iIhGquLWKkimz2WZNaySaJGvSDZc010cTD2WCRZy6aA1u0pJpu0f6QHnN1Goo5sOiyXSA84eXApopxOjyk1rZwkatRKErKV02G5Plo5hSunw580GpcHtH9Ev2H8VUNx1UgUUk7BLtEjYqWKbPbIAdSyyZ3hlC6bgi0fLZuXmo9Cskn7RzoU89bwkxZ7BbtEj4iVKrKpE4OGmN6ULZsuy/LRsileNhVLDHJp84he8fCrhuJzyyHLir2uYIvoEbFSRDZdnRU0wGgTyM4KcnVWkBTZdBXLCnJp80ibtLzVIaXFXpZFpKc3eXCpopw6MWiAAad85dSJQXKUU7HEIJf2j3Q+LW+tbVmxFwh2iR4RK0VkE9DGjpZNrmxSC8bK9mmBYMtHy+al5qOObALaP9L5tN1GopBsslwiPeDkwaWKcurEoCGsWunKqROD5CinYolBQCcG8RqJQsqpE4OuxkoV2dSJQUP4tLJlEwq2fLRsXmo+6sgmpP0j7dPyfvhMVuyFgl2iR8RKEdmEOjFoAJ8Wyp7ehDoxSIpsQsUSg6BODOI1EoVkUycG3QKXKsqpE4MG8GnlK6dODJKjnIolBkHaP9IDTt5vacqKvZ5gl+gRsVJENj2dGDSATytdNj3Blo+WzUvNRx3Z9Gj/SL/AyftZcmmxVy8XdDVWqsim8llBMmTRJX7Yj7VsO+sndwTipNN+LuviHS2Un9nDwhq/+TM81FcYQMpG0zvg4OfujAuHNnLGbnkfXUilIX9F6s8jNkS+OTMqHL5gc0Y3xHMNMYByG6J/hbfzgA3R56fljAuH9mgkNUQLL9QiDfor0noesSXyjZdx4dDpObJaYmBLbolXGDeP2BL5OTejwmGZVxg0as4/ZZd+n/ouO80h7DTP8vHvPsvyPS3T05Gy/7zSnfS41GTUmcawTJbVA1P8eNCeRfME4L/7rFIY/KPvrSK4Kv+38Mnobqrzq/LPF6dlkIOfxzMuOawr+lpfLcBbOHGmCfABI8CPOoFsWUAHeMkB3uJ30kbmBKuTpgO8HHLwp91GDvBf4I36UZEUnuKANvOsbJHNvp/Rs17/lkVxecT/AQ==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.png"
new file mode 100644
index 00000000000..0a9d4084789
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2425.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.drawio"
new file mode 100644
index 00000000000..dcf6c68ef18
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:53:46.145Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="4-NnNN85JfE_xheUeO5_" version="13.4.5" type="device"><diagram id="pNHz1chyNOht0hOROlCL" name="Page-1">7V1dc6M4Fv01PE4K8c2j7Tg7VdtTM7W9W929bwQUmxlivJgk9vz6FV82QsJgW0JqR12paiRAgM6590pHF6yZi9f9P7Jgu/4tjWCiGXq018xHzTAA0B30X1FzqGp8Xa8qVlkc1QedKr7Gf8O6sjnsLY7gDjswT9Mkj7d4ZZhuNjDMsbogy9IP/LCXNMGvug1WkKj4GgYJWfstjvJ1VesZ7qn+Vxiv1s2VgeNXe16D5uD6SXbrIEo/WlXmUjMXWZrm1dbrfgGTovOafqnOe+rZe7yxDG7yMSf4f3/7Ev7+6/yff/7+n+XajNz4v3/9UrfyHiRv9QNrhpOg9ubPxS3nh7ofnP+9Ffc5f0k3+S+7EqUZOsCwt/vTTrS1Kv7XmzbQzTw3lXUnHFs00N0hEFFh/rGOc/h1G4TFng/EI1S3zl8TVAJoM9htK2Rf4j2MipuIk2SRJmlWNmS+vEAnDFH9Ls/Sv2BrT+T6z4hvzcXfYZbDfW/3gSMoiM0wfYV5dkCH1Cc0MNY8Nu26/NFiRV21bhGiqQtqHq6ODZ+gQhs1WhcgZ1CQ6/bwJpoVJoBKm3QD8V5Fj50dvqOC3hR+tAuPe6x0aEr7OP/etIC2y3Me7Lp0OqkoNOdU9wUjwtA6XY/uPX3LQnjmoWtnkgfZCuZnjjPpULawsilYNXUZTII8fsdvlwZgfYU/0hg9yIkpvv/g+7ZreK5t2KYHcOKY+oOuW4YLDMu1HOCbePtVH9RNts25exXXebAdsp0jP80HyyRuorlK1YPEVUomHjvsenKaPNyKcY9uxQS4X7EMwX7F4gGdeY/QAReHztYFQ2fzgM66R+gMyZBzeCAH7hG5rtEJH4e5N47DGI6OmvnR0OjIETo6srwHwzuOWwyAj1ssg7770uGRaYEHFxzHP67n4pex6bsnGh958pDGHkmaHrOchjSgO0rSO+Y8lhbAG2iIM/D+jcA3869mkjVm/nWc6R2nfa2zzsz1GJLMGkkyWyTJusM5cCXHOu1Y1rQUa277do4defWjtWeAYy1ajdETGHJsrDZgCXVkHf9j29c6MjDQEG+W0ZTDWz3ZSI6J82Pmz8Cx7uyGcECjJabuNKnrEXlzzJCFY/J5MaGR8n4YRhEql4420zXP05ZP2nyh+TOCc2j2muNEw6e8NRHb8+O6Kkji1QYVQ8QLiOrnxVw4DoNkVu94jaMo6ZuMZ+nbJiqm3iXpCg2gXi8zGE2uLRwNpwlWLVY1y1ttVhl6P4FumluDfjEyit9PkkZVtdsGm1FqiU5TS1qCy1nh61hXXY6oxm5MSuIwIIrpd+zWIZliUfwPP6b0a5/8mdKjbium0JgCRDOlX2vlzxRDMeUMU/CFUku4T6FJu1MxpUe8V0yhMUW4T6HpuVMxpSfbRjGFwhRTuE8ZIQDv1sG22MyD56QzoaV12g7NkZqJQNFtIWJREG+K3i/PCdMkCba7uGysOmIdJ9GX4JC+5c1lmhIxqyjL9b0BjVj0iwLovVAX/ZzQg88vbGB09A6MIxf9utNSdslXIzTWBkb0mHkcJP+CYR5sVmMQJRGLsnT770YSKCq2xYwYZst31IO7ZkJImmOebuudCXxpzn1O8zx9rQtZ3VvHRsuusufoDz3jolDXbPQ0C1QGpzL6Kw7P8kW6QcgHcYkjDHb5B9wN02gMI86Yz1nZY1oekCqoxZQIZVJrcCJCinrtJSnlrjXypHDDAndOYLWyXPvAovlefmDR5MQnBdcAXB1tSBh6tJxCFTkHIqet25JFTpqkpyIn98hpDKdET8sDUrADTInwU7vi4fXDaX0vTTNTWJ3FSpawOSI/UYXNLmpeZ8JpjUwQ5gfjiIxBFTY5WLcrWdgk9SM14cSNRJ6wadJUIjXhHIJLkshpjshwU5Gzi5orW+Q0aaqPipzcI6c5/MLAtDwg9SNTuWLMSCSKnJxVonvESpawScvEUmHzwhVO8WGTs+SjwuY585EobJL6kXLFuJFIFDY5q0T3iJUsYVMlBjFY3hQeNi2a5KPCJv+wKVlikEWKR7pyxZiRyBM2Lc4S0T1iJUnYtFRWEIvZpuisIEtlBQkJm5ZkWUEWKR4pkRY3EonCJk0iUsubQ3DJEjlVYhCLCafwyKkSg8RETskSgyxSP1L5tLiRyBM5bc4q0T1iJUnYtFVWEIOsoLEf3OUHI2fJR4XNc+YjT9i0Sf1I5dPiRiJR2KSpRGrCOQSXLJFTJQYxkGrFR06VGCQmckqWGGSrxKAhI5EocqrEoIuxkiVsqsQgBjqt8LDpcJZ8VNg8Zz7yhE2H1I+UTosbiTxh0+GsEt0jVpKETUclBrHQaUUvbzoqMUhI2HQkSwxyVGLQkJFIFDZVYtA1cMkSOVViEAudVnjkVIlBYiKnZIlBDqkfqQknbiTyRE6Xs0p0j1hJEjZdlRjEQqcVHTZdzpKPCpvnzEeesOmS+pF6gRM3EonCpvpc0MVYyRI2pc8KEhEWLROfTdI+2077fU+OOKm0n/Nx8QYLve63XJs3f9hDfYEAJK03vQGO4dydaeFQQs7UlnfAIRWG/AWpP/doiMPizKRweJzFGWWIfYboO2IN0btA27lDQ/SG03KmhUNpNIIMETQfahEG/QVpPfdoicPCy7RwqPQcUZboG4It8QLh5h4tcTjnZlo4HKL38V9TRiRdp6t0EyRf0rKPiq7/E+b5oZbKgrc8xYHpKpKoR7LD97q9svCjKCBTqIuP+/bOxwPWyzBawd4+rqvyxrb7HrPvc3QZTII8fscvQOvk+tQ/ChNv6W02rrdZ3R+A3qVvWQjrs05QEQ3Z3S+rdRuqnpBoqMT8+Dw30MCVlwYUQZsJJ/q+7HsjJ2yXFSdA55tB5sSc8O6ME8yhdrpQA//Bvg5s4vdvyKZ4w+0ruM/D7bKDm/ihwMnh9sllaWngZujk+35mk3HgN11GgZ9oiDcNyKQ+aWjAK/D3/WI548B/PSc6gd/0JuYEOSOThhMMadD3xTDWcwJWroFoiDcNyDdlpKEBL9fQ9/FV1nMCVq7Bmto1kF+5koYTDGnQ95IqY9dgs5ILiIZ408CWlwa8XEPf9z4Yu4brOdFxDfbEcoEvsZIox/yxKxfY7OQCSlO84ZZYMWRo9X1psKwjAatBItEQbxrcm0g4ZnTAZ+JARAJWg0R76kGiUhIvjQQOu0hANsUZbtB8I6u9pLv0tPlSQ1PIpa15rjafacsnbb7Q/BnBjRzucxxsPEe+XqGlLNoGSbzaoGIIi8V8VFGsyMZhkMzqHa9xFJXLxrS1YpyTXYLVj3RTNr6OIeNS3plo3rLFkvF55eKDhipdoJ4KiJauNvM0b66AcgzhQBkUoJAhPWlolH2yKEeb6ZrnaUtfmwFtXu1Cf2YB5twq9lZgegvSIEFrn63NUUMOKM5DwHtWUeWjqmXZ0lybua2LuJpnaHO/Od8rbsRfaLNZcZHZsuATOhgNENF2m151y9VZfnmWVdxUddczu/VAqB419di6RXxX8fSoff/kWIpjylstHhG1/Kj55KdDbmdwlR0iGX8B8AcJ7DbNTsTgEQl3cBPNsqxMzal7uRcYzTD18t9xz7f60cAF432yAwfSbpq6G8O9aXYcjONdG+6PPxzU3xT3cD8iee/TQuvqzKClNMUd2hHJecygLRxh68inJxP9+ykgB6wg7zYlwppHvKDZgjxMgt0uDmmot7ElePDToGs4HQfrXzkLN42BhrgjS76PeRoPHsdhC/O4ZRy3yKSATzJyos7RnGlHTiPe2/w04ZUY2V4vlBjmYFPcLXLEi5mfFlpXZwYtpSne0IIRL3l++pETMLoj3Ksh7zYlwJrBBW93yvnlrrM0ui2u9sMj6osxAPTD8ynfMeNKj3Mmc9b9TMwJUqYix77Sv44mAkljKiRRMUvTvO28Ueeuf0sjWBzxfw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.png"
new file mode 100644
index 00000000000..5393b0c06fe
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\2426.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.drawio" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.drawio"
new file mode 100644
index 00000000000..ae770165460
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-20T05:41:52.303Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="LCfAV2g3_ip9GB3J-c8-" version="13.4.5" type="device"><diagram id="zlsS6F1qTQtopJuG0L2e" name="Page-1">3VpLk6M2EP41HMclifcRv5JDtmoqU6nNHhkjYzYYsUKewfn1kYzEy2Dj8TOew1hqdUsgfV833aDpk3X+G/XT1TcS4FhDIMg1faohBCGw+I+QbAuJC0AhCGkUSKVK8Bb9i6VQqW2iAGcNRUZIzKK0KVyQJMEL1pD5lJLPptqSxM1VUz/Ee4K3hR/vS79HAVsVUgfZlfx3HIUrtTK03GJk7StleSfZyg/IZ02kzzR9QglhRWudT3AsNk/tS2E37xktL4zihA0xCN0cvE1oDl+nKZn+lX3/Mwxf5CwZ26obxgG/f9kllK1ISBI/nlXS8WJDP7CYFPIOJZsk2PUA71UGfxCSSpWfmLGtPFl/wwgXrdg6lqM4j9jf0ly0f4j2yJS9aV4bmm5VJ2F0K4xewAhAJSgsLegoQWW86zWsXzGN1phhKoUZo+QfPCExobt90Odznf/xkWKHxLb0brzaRbKhC3xgt5EEsE9DzA7ouSU8OK8w4ddJt9yO4thn0UfzOnwJ8LDUk6Yepf62ppCSKGFZbeZXIeAKiqu2BKpkKnRaeDqir+tuXZ83iitQvdqtVKIdRk/Aq9zBDz/eyG3QkBXzvRy/N2Bs/doIXo2XJGEv2Q57HldAZppXg7wVil+g5uCX9K6E+8SIY+50BAE+VxHDb6m/O+tP7veaiPaztPBEyygXzBgvoziuIWu5xNZi0YW5wHbfASgX/8CU4fww6vZRIg1Kv6OO05D9z5obk6JVzYMpWReuamd7+tHpHUfX3uIk8ITP5r2EJLjlKBTpQYPwx8gu3Qs8wb1ckPEqjB2lvNl9mLXDMjsOS8lO8wx7VDZcd+S6po0c20Sm7gC7CR3E3SwwkA2RYRsWdPXmAsUuyDkPeAzDtkamVZunBVB9ZOjVRcDWKsUW7q1yKc9iPE4kLOH5o47Ow5FQGg2lxU3CnTkQ+xB0g38wqs/yS+Y1Qgp6xpBiwmZIKR/S7xVSrIfhbD28wC8xFj4CY+3zotVtCGtfg7D6MxJWbz2i8+z7voR1HoawzSD7P6asO5Cy9pmU/VJOiawmAA1wOKc04EH96+SU7jX8ifGM/qSdU97dnyi4XPbs4DOeXTsW3L0eAGHH2Z1SELigEx1amOvLVG6UphvOCDll/oxUhlw+jncPn5qmmwYc2bBMxO1mmo5ao47dXOXKaTrsqgDeCTVDQy+6J2j0VkiFbovQQ2GhO0cmuvbJn11APOdNQ+stQ/kc2PPod0GUDc3Jel4a3AZlqP0yAHwRZe2J+Ey3RZlxKZRdIME4VsW7IMoGF6p78ogbObOWD9KNrzozeGSiHpidmgC1ExqVEF01oYFdJc1zPeVABN/PTw6tNt8VwEY7g2q7t8HvUtARh3ttP2k9CsYe0EfeNRQ/D8T6C71Z6ieD8nvQld9rM1sbe5qHZGM812aO5kHNc4TEM4RwZmn8Aded7HSMnbKjjfkoVza18UxzyhLPO61m3rdyxcxiQlP8d7j5XBtPNNcDsuVMjLKlly1UturliOLGeyoSDOesSbJmRUGSsF5+kCI/jsKEdxecE+KTmLEoNUQLP/bkwDoKgriv1tEsygZ+tirrtdr5hYsSv6omqPo1OnVWLhDop05P5YJ3qw+yChxXn7Xps/8A</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.png" "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.png"
new file mode 100644
index 00000000000..95655ea4138
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\233\276/\346\267\261\345\272\246\344\274\230\345\205\210\346\220\234\347\264\242\345\233\276\347\244\272.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2401.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2401.png"
new file mode 100644
index 00000000000..63381b522c1
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2401.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2402.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2402.png"
new file mode 100644
index 00000000000..c23bbfa8cda
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2402.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2403.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2403.png"
new file mode 100644
index 00000000000..46fdb57bd9c
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2403.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2404.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2404.png"
new file mode 100644
index 00000000000..a2e3a937acf
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2404.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2405.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2405.png"
new file mode 100644
index 00000000000..1129eeac765
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2405.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2406.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2406.png"
new file mode 100644
index 00000000000..d18889c3e55
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\210\240\351\231\244\345\240\206\351\241\266\345\205\203\347\264\2406.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206-\346\217\222\345\205\245\345\205\203\347\264\2401.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206-\346\217\222\345\205\245\345\205\203\347\264\2401.png"
new file mode 100644
index 00000000000..424fe3d91c0
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206-\346\217\222\345\205\245\345\205\203\347\264\2401.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206-\346\217\222\345\205\245\345\205\203\347\264\2402.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206-\346\217\222\345\205\245\345\205\203\347\264\2402.png"
new file mode 100644
index 00000000000..f58aa672c3a
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206-\346\217\222\345\205\245\345\205\203\347\264\2402.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206-\346\217\222\345\205\245\345\205\203\347\264\2403.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206-\346\217\222\345\205\245\345\205\203\347\264\2403.png"
new file mode 100644
index 00000000000..24977de86a4
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206-\346\217\222\345\205\245\345\205\203\347\264\2403.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\2061.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\2061.png"
new file mode 100644
index 00000000000..fa08e776ec0
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\2061.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\2062.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\2062.png"
new file mode 100644
index 00000000000..ec8a89d0943
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\2062.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2171.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2171.png"
new file mode 100644
index 00000000000..655aa65a38c
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2171.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2172.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2172.png"
new file mode 100644
index 00000000000..fe60da909c5
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2172.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2173.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2173.png"
new file mode 100644
index 00000000000..61633b1d3d9
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2173.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2174.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2174.png"
new file mode 100644
index 00000000000..e502b808f20
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2174.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2175.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2175.png"
new file mode 100644
index 00000000000..9d287858305
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2175.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2176.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2176.png"
new file mode 100644
index 00000000000..85bf1308cfb
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\346\216\222\345\272\2176.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\347\232\204\345\255\230\345\202\250.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\347\232\204\345\255\230\345\202\250.png"
new file mode 100644
index 00000000000..de77a9af2ab
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\240\206\347\232\204\345\255\230\345\202\250.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2061.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2061.png"
new file mode 100644
index 00000000000..f69153d0c06
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2061.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2062.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2062.png"
new file mode 100644
index 00000000000..fcbf71ca5a9
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2062.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2063.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2063.png"
new file mode 100644
index 00000000000..c4f890b18f8
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2063.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2064.png" "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2064.png"
new file mode 100644
index 00000000000..6d6c57fdc0c
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\345\240\206/\345\273\272\345\240\2064.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\206.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\206.drawio"
new file mode 100644
index 00000000000..f8fe81d2c06
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\206.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-05-29T04:49:35.956Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="C0yATZcJo9RVnSwHs8Dx" version="13.4.5" type="device"><diagram id="EVHAlbz1pNCSG6H1n3D9" name="Page-1">7Vtbk6I4FP41eZwukgBJHr1g727tVk1VV+30PNKSVmbQuIit7q/fBAISBLVbFHfa8sHkJORyzpcv5xwR4MFs8xj7i+lfIuARQFawAXgIEILQcuWXkmwzCWMkE0ziMNCddoKn8F+uhZaWrsKAL42OiRBREi5M4VjM53ycGDI/jsXa7PYqInPWhT/he4KnsR/tS7+FQTLNpBSRnfw3Hk6m+czQZVnLzM87650sp34g1iUR9gAexEIkWWm2GfBIKS/XS/bcqKG1WFjM58kpD6yenT8ev/39O3VCf/C2ZpuF7X/Ro7z50UpvGCA3kuP1X9SSk63Wg/vPSq2z/yrmyZdlaqWe7ICcxWbXKEsT9d3Lx5CLecmFWgnFiEiuThpRVvrraZjwp4U/Vi1riSMpmyazSNagLPrLRWbZ13DDA7WIMIoGIhJxOhB+feXueCzlyyQWP3mpJSDsxbKKyd94nPBNo/pgYRSJZi5mPIm3sot+gGBtRw1kzHR9XYKFFk1LiMhlvgbipBh5ZytZ0OZ6h+lQjemqKp4HPXUGZG0u5txUq9x3vH0uV76XK0O1b6uobXUtm4MHe6emoke5DrGKx/zABrA+zn484ckxjO7bpaR3p0bvuSzmkZ+Eb+Zy64yhZ/gqQrmRndktYpidWBV7ZtvUT5WPX3Ug5jwgaiMCkU1sN1+JHtYm1GzF5iyZkvZmSYFT6OTjWMKNNLBc+POPM0GJTDLBoJ4aClk23a/BGJSajGF3zRj2tazc/0RWdq0bs7JzLSsPP5GVHWRa2SEdW9m9lpUfP5GVmXtjVibn+nibMHkulb/nPp0s7xw8Vcn9u8IrLCpX9grt/4NX6FaAQuAHvUKKqIk4hq7q+NFzAVYbRFhH4JLD0irBEh6EZQcAc7oEGKneN+yjYYdDD4UdrNOwg52JvhZR4Z6ICtwlKiiCDy7GDrapdEgQNI3pUPjAIGO27AZtNw9c301J2D2AGIdada1XAkxOs5d3e7xP5Pa49MbcHliXljzX7zl8wdT7Pccusi78HqvelldyfMw8FWQmcCB8INAhiBIHOZhWhj/5zrJqh8nvLFq7hGsxEGpkIEU0LTKQfYSBsukaGEiSQWIeCZNB9JEp040W+VE4mcvqWCKYS3lfUUs49qOebpiFQRA1cVssVvNAMdmwLW5ilfSKtc9Ndg3e0cW4qTlX2jIA0B0AilOcyuXUOQCa06gtA8C9AyD1R28NAM0Z1pYBAO8ASC/8CgBo1wBw971R6QI+6arWoqkHESdTMRFzP/pTiIU2yA+eJFv9zoO/SkRDbsV6cDpKxuVvXHwwGXeys3meOeqypBcJCkefKCik1q0Fha3lKt+V2n5/Cr3N80dOPICdpqWgZQZsxIwKXYjrWt8bFbKDmUwJzy7zUnWZzIu4BM7dJZAthNyYS5APfHkAkDsAFBlUg4LOAdD8JmXLAMB3AKhLxb41ADQnBs/zQod9rzcalF/DOOhm/jIWJpXf2N3OLYz3/c1LhH35j+NZ1HdtlzPH8VGXM+vYVdCHarJwngP6Huh5wLOBjNV6EHguYBZgA+AhQNOCycnjInbanToZXzGG8f5BfAyT6epFjUk9wCjwGKAEMDkLVZOq6RxAKWCoiY31KoYFp8en0AK0a+8FORnrA+apQs8GdNjKJr8OR0dXL/crNSA9EbXfEWCuXotUvlIFAT1c0glRBUZSWwxAv5d2HqUFojrkx/rmOCzyX3jU98c/J6m8OrlUjT7D0Nb1UijeTz8theLQZEIb7zNhQXtnUqGs7v6SkoVHuz/2YO8/</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\206.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\206.png"
new file mode 100644
index 00000000000..3ad5782c8bd
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\206.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\2062.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\2062.drawio"
new file mode 100644
index 00000000000..31e3097a914
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\2062.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-05-29T05:07:59.001Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="kfCcmOqPzhMfcE_oloNB" version="13.4.5" type="device"><diagram id="I4wgBHwh16mVk95mslPn" name="Page-1">5ZhNc5swEIZ/jY/uYLDBHGPsuIdmpmMfmhxlkEGtYKkQBvLrK1niq46bJm0Zpj6hfSWtpH12NSMmlheXW4bS6AECTCemEZQTaz0xzdnMsMVHKpVSXNdRQshIoAe1wp48Yy0aWs1JgLPeQA5AOUn7og9Jgn3e0xBjUPSHHYH2V01RiC+EvY/opfqFBDxS6tJ0Wv0jJmFUrzyzXdUTo3qwPkkWoQCKjmRtJpbHALhqxaWHqQxeHRc17/5Kb7MxhhP+OxN22UPg7CLH2z06MV1Pt0bxPNVeTojm+sAT06bC3+ogt8wrHQf7ey73uTpCwqfZmdKdGGAu0rLtFK1Qfu9qH2Izh1rUQWg8mmJ3AqIwVkVEON6nyJc9hcgjoUU8psKaiSbKUkX2SEocyE0QSj2gwM6OrOMR274v9Iwz+IY7PYHjHgyjWfyEGcfl1fDNGigimzHEmLNKDNET7DojdSLPa7vopIWWok5G1BrSiRg2nltWoqFxvQGdeRVdlqLk/fQ6CaAE72WcjaaW+z8oO+7IKFtDUV7dEOW5NTLK86Eor2+IsjUfGeXFUJS3N0R56bjjomwPRXlzQ5QX5shq2bmMaCAeDtpMIJGhZZAngQzaWoYBGI8ghATRTwCpDu9XzHmlnz0o59APvogOqx7l/A+L2nzq9q1L7VxZlbbey0ie4deExJEhZz5+/U3BEQsxf23cJXGGKeLk1N/HX+e3HKpK72+oSh1jZFXqDlOlJeGdIhXWU12Vot2WqDT+fYX+QUXpqZ+BCI/ty/enu7e5i2sX6kbQs7p/IN7qSF0ZF47O6JvzvJQNwmx/pKjh7e8oa/MD</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\2062.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\2062.png"
new file mode 100644
index 00000000000..fe6956b9d09
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\344\270\255\345\272\217\351\201\215\345\216\2062.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\345\205\210\345\272\217\351\201\215\345\216\206.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\205\210\345\272\217\351\201\215\345\216\206.drawio"
new file mode 100644
index 00000000000..b92e5c29cc9
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\205\210\345\272\217\351\201\215\345\216\206.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-05-29T04:48:12.234Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="hkPLy-zMIJkJ0CVjwNx3" version="13.4.5" type="device"><diagram id="2ziagjPv7Po7rTjOazMm" name="Page-1">7Vtbk6I4FP41eZwuIDfyKIq9D7tVU9u1tTOPKGllGo2L2Or8+k0kIEFQ2xvOtOWDyUnI5ZwvJ985IoDdyeo5CWbjv0TIY+BY4QrAHnAc27aI/FKSdSZhjGaCURKFutNW8BL95FpoaekiCvnc6JgKEafRzBQOxXTKh6khC5JELM1uryI2Z50FI74jeBkG8a703yhMx5nUdehW/gePRuN8ZpuwrGUS5J31TubjIBTLkgj6AHYTIdKsNFl1eayUl+sle67f0FosLOHT9JgHEuvvH2+rZPbTI6O56/T+WTrPX/Qo70G80BsGDonleN5ALTldaz2Q/xZqnd6rmKZf5hsrdWQHB89W20ZZGqnvTj6GXMwgF2olFCM6cnXSiLLiLcdRyl9mwVC1LCWOpGycTmJZs2UxmM8yy75GKx6qRURx3BWxSDYDwddXToZDKZ+niXjjpZaQsoFlFZO/8yTlq0b12YVRJJq5mPA0Wcsu+gGCtB01kCHW9WUJFlo0LiEilwUaiKNi5K2tZEGb6wOmc2pMV1XxNOyoMyBrUzHlplrlvpP1t3Lle7nSU/u2itpa17I5eLhzaip6lOsQi2TI92wA6uMcJCOeHsLorl1Kesc1es9lCY+DNHo3l1tnDD3DVxHJjWzNblPD7IRU7JltUz9VPn6VgaiFnxwXOdR2EEUkX4keFkHXbIXmLJmSdmbZAKfQyelYgo1uYD4Lpqd7gpIzyQTdetdQyLLpfg+PQZnpMVDbHgPdysreJ7Iytu/MyvhWVu59IisjaFoZw5atTG5l5edPZGWX3pmV6bkcbxWl30rl7zmnk+UtwVOVnN8VrLCo3JgVol+BFeIKUAg9lRVC10Qcdm5K/NxzAVYbRFgH4JLD0irB0t4LyxYAhtsEGKneN/hEgBHi7gs7cKthBzsTfRdEBTkSFbBNVFBoPxEIMUQulhe4bRoTI/uJ2YwhV7YgYtETXRIiexCDkVXXeiPA5Fz7+rTH/0S0B7M7oz12XVryXN6z/4Kp5z2HLrI2eI9Vb8sbER/XuDBsZl4n1H6iNqaSSGOJIrcy/NF3ll07TD4Jql3CrTyQ0+iBlKO5oAeyD3igbLoGDySdQWoeCdOD6CNTdjdaFMTRaCqrQ4lgLuWeci3RMIg7umEShWHc5NsSsZiGypP1LpV2typpd7Lrm1AN3p2r+abmXOmFAeA8AKCMS0wAoNYB0JxGvTAA8AMAGz56bwBozrBeGADwAQDl8qv0FLUNALLLRiUFfNFVrUVTDyJJx2IkpkH8pxAzbZAfPE3X+p2HYJGKhtyK9YRbSsblb1ycmIw7mmyeZ466LOlVgsL+JwoKqX1vQeHFcpUfSm1/PIV+yfNHjzyAraalmBmvUTMoxBTWtX40KHT3JjIlOttMS9UlMq/CCMiDEcgW4t4ZI8gHvj4A6AMAyhmgewNA84uUFwYAegAAlH4PuxsANOcFzyOhHa/nd/vltzD2sszfxsKk+hN76xaGu3TzGlFf/tt4FvTdmnHmOD7IOLOObcV8Tk0SzsfA80HHBz4CMlTr2MAngFmAdYHvAHdTMH3ysAidtqdOhleMQbh7EJ+jdLwYqDFdHzAX+Ay4FDA5i6smVdNh4LqAOU3eWK+iV/j05Bi3YKPae0FOxjzAfFXoIOD2LrLJr73+wdXL/UoNSCai9tsHjOi1SOUrVVDQgSWdUFVgdGOLLvA6m879TYGqDjmVuzsfFgcDHnvB8G20kVcnl6rRZ9hGul6KxL3N50KReOVdkCIfVvKEhds70xXK6vYfKVl4tP1fD/T/Bw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\345\205\210\345\272\217\351\201\215\345\216\206.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\205\210\345\272\217\351\201\215\345\216\206.png"
new file mode 100644
index 00000000000..5c80cedf7d6
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\205\210\345\272\217\351\201\215\345\216\206.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\345\220\216\345\272\217\351\201\215\345\216\206.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\220\216\345\272\217\351\201\215\345\216\206.drawio"
new file mode 100644
index 00000000000..c324e801447
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\220\216\345\272\217\351\201\215\345\216\206.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-05-29T05:13:41.075Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="yfEGH1DOOH5Vsjp4lb7P" version="13.4.5" type="device"><diagram id="FIgDf6u-rJ36MxwX6W4d" name="Page-1">7VvLluI2EP0aLacPlqzXEoPpLJKcySHJPHZurAZnDCLGdEN/fSQsGwtsoHmZTHNYIJVkPaqurqoKA1BnvHhMgunoNxmKGMBWuACoCyB0nBZRX1qyzCSc00wwTKLQdFoL+tGbMMKWkc6jUMysjqmUcRpNbeFATiZikFqyIEnkq93tWcb2rNNgKLYE/UEQb0u/RGE6yqQM0rX8FxENR/nMDuFZyzjIO5udzEZBKF9LIuQD1EmkTLPSeNERsVZerpfsuV5Na7GwREzSQx6I2vhvtYG/fv/jz7cvuP+9P38bfTKjvATx3GwYQBKr8bwnveR0afRA/p3rdXrPcpJ+mq2s1FYdIJ4u1o2qNNTf7XwMtZinXGiUUIwI1eqUEVXFex1FqehPg4FueVU4UrJROo5VzVHFYDbNLPscLUSoFxHFcUfGMlkNhJ6fBRkMlHyWJvKHKLWElD+1WsXkLyJJxaJWfU5hFIVmIcciTZaqi3mA5HY0QIbU1F9LsDCiUQkRuSwwQBwWI69tpQrGXO8wHaww3aaKJ2FbnwFVm8iJsNWq9p0sv5Yr38qVrt53q6gtTS2bQ4Rbp2ZDj2odcp4MxI4NIHOcg2Qo0n0Y3bZLSe+4Qu+5LBFxkEYv9nKrjGFm+CwjtZHC7DjnK2N2vGnPbJvmqfLx2xiIMPwAmQupA13qknwlZliEmd2K7FkyJW3NsgJOoZPjsYRqaWA2DSbHM0GJTDJBp5oaClk23c/BGJTajIGaZgz3Wlb2PpCVXX5jVsbXsnL3I1nZsa3s4oatTK5l5ccPZGWGb8zK9FQfbxGlX0vlb7lPp8prB09Xcv+u8AqLypW9Qvd/4RVuAAXzI71C6jAbcRRe1fFjpwKsMoho7YFLDstWCZbOTlg2ADDcJMDI5n1Djw07XLYr7KCNhh38RPSdERXkQFSgJlFBHeeBIISRy7C6wB3bmC5xHrjDuctUi0ta9EhKgmQHYtS4TSImPxaX93v8D+T3YHpjfo9TlZc81fHZfcNUOz77brImHJ9WtS2v5PkQ68ZwuH2fcOeBOphCRjHEiG0MfygF4eph8kmql3AtBoK1DKSJ5owMRPcwUDZdDQMpMkjtI2EziDkyZboxoiCOhhNVHSgECyX3NLVEgyBum4ZxFIZxHbclcj4JNZN1z8VNzOamgnRKeHcr8A4vxk31ydIzAwDdAaCN69oAQI0DoD6PemYAkDsAVg7prQGgPsV6ZgA4dwCAUkp9HYM0DACy7Y0qF7BvqkaLth5kko7kUE6C+Fcpp8Yg/4g0XZqXHoJ5KmuSK60H3FA2Ln/l4shs3MHO5mnmqEqTXiQo7H2goJDwWwsKz5asfFdu+/059HOeP3rgAWw0L8XseI3aQaHLkdXKjkxMsZ2pTAXPRhNTVbnMi/gE7t0n0OxEbswnyAe+PADwHQCaDeCtAaD+XcozAwDeAaDvLnRrAKjPDJ7mhnZ9r/fYKb9Vu9PP/GksTDZ/ZW/cwmjb4bxE3Jf/PJ6Ffdf2OXMc7/U5s45NRX2wIg3nY+D5oO0D3wUqWGs7wCdAxTG8A3wI2Kpgc/KgCJ7Wp04FWJwjtH0QH6N0NH/SYzIfcAZ8DpQzy9UsTE+qp8OAMcBhHRubVXQLTk8OoQXHrbwX1GTcA9zXhbYLWPcsm/zc7e1dvdqv0oBHV/vtAU7MWpTytSooaKOSTqgucLqyRQd47VXn3qpAdYc8Yrw5DouDJxF7weDHcCXfnFypxpxhxzX1UizurT6XicUR3GbCgvZOpEJVXf8pJQuP1n/tQf5/</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\345\220\216\345\272\217\351\201\215\345\216\206.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\220\216\345\272\217\351\201\215\345\216\206.png"
new file mode 100644
index 00000000000..87bf512ec50
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\220\216\345\272\217\351\201\215\345\216\206.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\345\256\214\345\205\250\344\272\214\345\217\211\346\240\221.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\256\214\345\205\250\344\272\214\345\217\211\346\240\221.drawio"
new file mode 100644
index 00000000000..107a75dd043
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\256\214\345\205\250\344\272\214\345\217\211\346\240\221.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-09-13T02:02:53.966Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="dKxw4KtKSwJUg7jbYpyW" version="13.4.5" type="device"><diagram id="uNQEILGOwt5n9zeOTizL" name="Page-1">5VpLc+I4EP41OoaynpaOPJzsZatSNYedOW0ZWwHvGMwYM8D8+m3bsrGMCQwhhAyVQ9QtoUf3p+5PDYgOZ5un1F9M/05CHSPihBtER4gQjB0B/3LNttRIRUrFJI1CM2in+BL90kbpGO0qCvXSGpglSZxFC1sZJPO5DjJL56dpsraHvSSxverCn+g9xZfAj/e1/0RhNjWnIO5O/5eOJtNqZSxU2TPzq8HmJMupHybrhop6iA7TJMnK1mwz1HFuvMou5eceD/TWG0v1PDvlA5GOgn9/JWv68PTfdumwH6Px8sHM8tOPV+bAiIgY5huMoTHJG/Dfny2gMR8vF6VcDHhJYF04VrY1thI/VknV8bAsPNmHAYQvNrvOalanmgY2XM5Ur1apGzsg1kIEDgb+B2GwnkaZ/rLwg7xnDRAE3TSbxSBhaPrLRQmKl2ijw3xvURwPkzhJi4noy4sWQQD6ZZYm33WjJ3TV2HHqxZtmrmym00xvGipj9iedzHSWbmGI6aXCQMDcAVLJ6waijGraAFOl8w2GJ/XMOzdDw3j6N7xOOrzeNvE87OfXB6R5Mte2WcEU6fZrU/jWFEb5uZ1a2hrpgrZfJqs00K+ckJpQ4acTnR3Hvw6tKLDvyYaneIenKl2qYz+Lftqxo8t9ZoXnJCouUQUUZgOF8xYCynObTzXvensi1ZrIaU1UGmZvogJN9bHPBxg9KaxcIIyQOwojTArLqZR/cBhhB728XPjz8526hxXc7c5aVy73Z3iZUOe2vMyvdZfpHd1lzG0vM/rBXhbX8jK/Iy8zzG7Ly+5bid8myr422t8qogftHevLhYr01VSxFm6NKrI/gyqKM6kid6SNUUauShXlWyHZ+RZxjgCsArLTADJ+Fci3CEl+W5Bs57SzXy9S9ohkxMWEuUwQTFuMqLv7SoBVlwLszUZEcSL86E3Bj1PVE5RyyiQH8oGxDUasegorxST0MOG450GTMfsNxtl1H9ZVWfT931zsjt5cFN8YG8ddddm3ErXX81t3WDqWR28xK1bOvJG4RB0rXWFlJzMX91zMXSJdDiFMtqY/OWXSzmmqRVjnFq4Vs8jBmHXht6W4o7clF7cWs7qKvm9n8pcnRjX372GXNx+yPaeWD8RIEJ51GoHBdGp058ez6l58Mp7FlOwpIYjCDgOqJbkNQ+H0uMvyb0g5kVxwcV5A49QmWuzaROtwcfvCQcu9o6DV/lrqo2vb+HBx+8J0Wt4Rna5/8tCuTX2Ym7uq2+e92Xv805SZjhNl1plYTkhd/CMTEJbwlFc113WlXWTnGBK50ygPnZmBsBA9Lg5WoTilPUZ3u7gyp36PSv7VkLkHuONQ5Z8BmZRdBZntcsVe7f+dwSc6wOdxNPBQ30MeQ4NH1MfIEwjSvRoijyBZNGy6FNSI2SVPQJVSlO7n06com67G+ZzSQ0oiTyHpIgWryHzRfDmOpESKHGJTZhejOjOnp2R3zDqzOyymBkh5eaPPkBxd5JDPo8eju4fzggWANObnfURKmL2A8XNTuKhPGzZx84ZyC18M0aBfDH4sGm4+oMq4jagBOT6zQ4V9wU0oaUYDo/LjaDIHMYDrnj+PBjljiAI/7puOWRSG8SEWkyareZhzliLYxP5YxwM/+D4p9O3FwTTmp6KQw0q5EYAGxd+FSoPuccpa851mSCG/T2ZA3P0ctLysux/VUu9/</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\345\256\214\345\205\250\344\272\214\345\217\211\346\240\221.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\256\214\345\205\250\344\272\214\345\217\211\346\240\221.png"
new file mode 100644
index 00000000000..bc0fe0dce14
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\256\214\345\205\250\344\272\214\345\217\211\346\240\221.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\345\271\263\350\241\241\344\272\214\345\217\211\346\240\221.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\271\263\350\241\241\344\272\214\345\217\211\346\240\221.drawio"
new file mode 100644
index 00000000000..11133b532ad
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\271\263\350\241\241\344\272\214\345\217\211\346\240\221.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-05-29T04:12:43.504Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="csU4omjrt7oruFe75GcO" version="13.4.5" type="device"><diagram id="1XXsLY0auXVlGK_2y-eQ" name="Page-1">7VnJdpswFP0aL+OjiWmZOEm7SIdzsmjSHQbZcAqIynKM+/UVRmIysR2SYKfuCr0r8TTcq6eHGOFJnH3ibhp8YT6NRgj42QhfjxCCEJjykSPrAnEcqwDmPPRVowq4D/9QBQKFLkOfLhoNBWORCNMm6LEkoZ5oYC7nbNVsNmNRs9fUndMt4N5zo230R+iLoEBtZFX4ZxrOA90zNJ2iJnZ1YzWTReD6bFWD8M0ITzhjoijF2YRG+eLpdSneu32mthwYp4k45IU7eumBOPrJb52v09m3AKzusgvl5cmNlmrCI2RG0t/VVBbmeUE+3TiVhWS6SAt702DGZL9yWmKt1sr8vWS64mKxYfJSNkBGmlWV2ivQbuSAC09lbxqujQA1OkJyYpJ/aVytglDQ+9T18pqVlKDEAhFH0oKy6C7SQhSzMKN+PrYwiiYsYnzjCM9m1PQ8iS8EZ79orca3nCkAZedPlAuaPbvysORTbgTKYir4WjZRL2BTSUDtAaTtVU1RCgpqYtKYqzQ8Lz1XNMuCYvoFrKMO1ttLnPiX+faRVsIS2lxWOW++fqgbj3XjOp83KK21svquPfW3tmhr5eXI2ZJ7dMeUsYodLp9TsW9DbDNZY8roYEpjnEauCJ+aw+2iT/XwnYWbTaSFQppCMYyWAoppqrfqe73tyGk5Ai1HxTpsOdqoqZx2f4Hhg8LKG4QRdEZhhLTUUarlWGGEPMvyInWT/qRuaQV201liRXf/BsslXafCsjHUXsZntJcRaLJM0JFZNodi2Tgjlg10Yixbr038slA81MqPOtGT5Srryw2d9JWpYmmcfKpIPmSqaPZMFQ1gNzVK0KCpov1aSXZ+i4A9AtNCBjUhw51C/hCSNI4pSdI+00hPSRJsj5FNkAURsYiJIG5lRN3VAwnWeRfBnnRENA+UHz6q/Bw8NjE2pDzkuYvKm0etRuCMHeg4xEYQEhNYPbXZErmBh/2y1vei7//RRc7oo6t9Q3f0RA12Xcy+NlPbfcB1Z2r7DtIPcSxC0M3+QKma0TivoNM8zUw4tqBhIdsyZDSxW+4PvvGzO93oTnDnEIaKWWiomGWeUcxqXxSVd7xHi1ldt77/Y1b3ddr+mIVON2YRuDOcvE3MImRnYOwds6RZ/XQtmle/rvHNXw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\345\271\263\350\241\241\344\272\214\345\217\211\346\240\221.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\271\263\350\241\241\344\272\214\345\217\211\346\240\221.png"
new file mode 100644
index 00000000000..673f3e32beb
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\345\271\263\350\241\241\344\272\214\345\217\211\346\240\221.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\346\226\234\346\240\221.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\346\226\234\346\240\221.drawio"
new file mode 100644
index 00000000000..6eeaa610144
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\346\226\234\346\240\221.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-05-29T04:15:40.180Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="tAGOABOmbL2WRh0a8tL1" version="13.4.5" type="device"><diagram id="vMa7lu0pAO2kmhAGVbwg" name="Page-1">5VhNc9owEP01HMnY+rCtY0LSdibNTKc5NOnN2AJ7KixXiGD667vGsi0bSGlKcTI5sfskrbT73grBCE8WxUcV5smdjLkYIScuRvh6hJDrOh58lMimQhjzK2Cu0thMaoH79Bc3oGPQVRrzZWeillLoNO+CkcwyHukOFiol191pMym6u+bhnO8A91EodtFvaayTCg2Q3+KfeDpP6p1dj1Uji7CebDJZJmEs1xaEb0Z4oqTUlbUoJlyUxavrUq37cGC0OZjimT5mwfT2s7i+U1/V7ePDOLv8TokYj02Up1CsTMIj5AmIdzUFY14a8BkucjCy6TKv/O2EmYR9IS29MbXyfq5kPTBebpm8hAmI5kU7WEd16jBw4CpSs1sNWydAnY0QJAb8g3O1TlLN7/MwKkfWIEHAEr0Q4Llghsu8EsUsLXhcni0VYiKFVNtAeDbjXhQBvtRK/uDWSOyzqeM0mz9xpXlxsPJuwyc0ApcLrtUGppgFxDcSMD2AqPHXlqIMlFhiqrHQaHjeRG5pBsMw/Resoz2s90ucxZdl+4CXyYx3ywp5q82D7TzaznWZt9N4G+O9tPY83mnRXuXh5HKlIv5MytjcHaGac/2nhthl0mKK7mGqxhQXoU6fusfdR5/Z4YtMt01UC4V2hUJxTwFVmmaV3eu9QNTpBiJ9KVV12Am0VVOT9ssFho+6Vk5wjbjv6BqhPXVgPPA1Qg6y/G+k7mgF7afzAPNvm2UP91rXHZhleq5exu+ol323xzIbmGXvXCyT98Qy632f+wOz7A/y8ONFqh8s+9Gy2yWl8yqeiuTIpyJ+VU9FcqqnIjvvUzE4lSQdW5LOkZJ0LUm6b1+SdEhJUoYvPIwpJgGF2991u69Vn10wlzESwAjxHP+FciXBBQoIfIHCz2riod4mqDeKz6plNsj1OqgyvbegTM95VpnBaZRJn1Um/k/KBLf9D7Ga3v4Ti29+Aw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\346\226\234\346\240\221.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\346\226\234\346\240\221.png"
new file mode 100644
index 00000000000..af12915808e
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\346\226\234\346\240\221.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\346\273\241\344\272\214\345\217\211\346\240\221.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\346\273\241\344\272\214\345\217\211\346\240\221.drawio"
new file mode 100644
index 00000000000..8379028d2a9
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\346\273\241\344\272\214\345\217\211\346\240\221.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-05-29T04:39:49.228Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="muDFVz9R5z3fWmbL7Wg8" version="13.4.5" type="device"><diagram id="9pQr6OEqs1j3d8CnLuWx" name="Page-1">5VnLcpswFP0aL+PRG1gmTpq2M5nJTBZNuiNGNkwxogLHOF9fYSSMME5c2/WjXqF7JK4e5+jqCnp4MCnupZ+GDyLgcQ+BoOjh2x5CEAKmHiUyrxDPcypgLKNAN1oCT9E71yDQ6DQKeGY1zIWI8yi1waFIEj7MLcyXUszsZiMR272m/pivAE9DP15Ff0RBHlaoi5wl/pVH49D0DJlX1Ux801jPJAv9QMwaEL7r4YEUIq9Kk2LA43LxzLpU731ZU1sPTPIk3+SFZ4cW19/kzzALJmPy8P39HlxdaS9vfjzVE+4hFit/N6+qMC4L6ulPUlVIXrO0shcNRkL1q6aVz/Vasd9TYSqusgWT16oBommxrDRegXGjBlx5qnszcGMEyOoIqYkp/pVxMwujnD+l/rCsmSkJKizMJ7GyoCr6WVqJYhQVPCjHFsXxQMRCLhzh0Yiz4VDhWS7FL96oCRzvFYC68zcuc16sXXlY86k2AhcTnsu5aqJfwExLQO8BZOxZQ1EaChtiMpivNTyuPS9pVgXN9F+wjjpYby9xElyX20dZiUi4vaxq3nL+3DRemsZtOW9QW3Ntbbv2PFjZoq2VVyMXUznkH0wZ69jhyzHPP9sQq0w2mKIdTBlM8tjPozd7uF306R4eRbTYREYoxBYKpS0FVNPUbzX3etuR13IEWo6qdVhxtFBTPe3tBYY3Cit7CCPogsIIcZlFKqZHDiNkLctZ6ifbk7qiFdhNZ41V3f0fLCMMTotleqi9jC9oL0Nqs0zwkVlmh2KZXhDLBJLTYtnZNfErovy5UX4xiZ4qL7O+0jBJX50q1sbJp4rkLFNFtmWqSIFra5Sgg6aK7q6S7LyLgE8EZoQMGkKGHwr5LCRJjyrJ9pm29e3FdfvIJciBiDiEIYhbGVF39YEE6+1LsOcTEdmG8sPHlB/FXp9hTDFxqUo+ILTFCL2+Bz2PuKqGMOBsJ01C7DsYJYe9WJvPov/+zkUu6M6F4Yll47Dru+yuidrH51t3WPrsHD2LUxGCbvYPdCwC67iCnn2YObDvQOog16EqhLkt9xsfmbjTjemEdA7hUDFr/XeiPd8t2QXdLSk7tZjV9Qlh90x+/4lRnfv3oUObF9k+qO01MVIZj1xGasG41Nge4xncNKAdNc8intv3GEMeBESlWi61ZchAnzqk/ENKkUsZZdsFNIrtRIvsLdFS5vKna9V8+esa3/0B</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\346\273\241\344\272\214\345\217\211\346\240\221.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\346\273\241\344\272\214\345\217\211\346\240\221.png"
new file mode 100644
index 00000000000..c0f30c04c56
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\346\273\241\344\272\214\345\217\211\346\240\221.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\351\223\276\345\274\217\345\255\230\345\202\250\344\272\214\345\217\211\346\240\221.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\223\276\345\274\217\345\255\230\345\202\250\344\272\214\345\217\211\346\240\221.drawio"
new file mode 100644
index 00000000000..37585459182
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\223\276\345\274\217\345\255\230\345\202\250\344\272\214\345\217\211\346\240\221.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-05-29T04:06:33.188Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="t34LwBo12ySwl6wqXax5" version="13.4.5" type="device"><diagram id="ox7Zji1cJtBwcgYqQnlA" name="Page-1">7Zxbb9owFMc/DY+bcg95LPQyaUya2kntHl1iiFcTZ8bc+ul3HBxIloXCgMQPFkjEx5fE/h38z3EMPXc4Wz9wlCXfWIxpz7Hidc+97TmObVsBfEjLZmuJonBrmHISq0J7wxN5x8poKeuCxHheKSgYo4JkVeOYpSkei4oNcc5W1WITRqtnzdAU1wxPY0Tr1mcSi2Rr7Tvh3v4Fk2lSnNkOom3ODBWFVU/mCYrZqmRy73rukDMmtkez9RBTOXjFuGzr3Tfk7i6M41QcU2HgfX9xfi98h44e3r/es+dF9PbJUdcmNkWHcQz9V8mUpfAx4GyRxlg2Y0GKcZGwKUsRHTGWgdEG4y8sxEbRQwvBwJSIGVW5cIV88yLrf/aL5E/VXJ64XVdSG5WaC87e8JBRxvOLcy0rCPw+5ExYKkp2fyhfYN92R/ahcZSUac4WfIwPDU1fuRviUywOFfR2NOFrgNkMQx+gIscUCbKsXglS/jjdldsjgwNF7QSCriF4NkE76JKgZwge/modQbDfJUDfADwboOt0STAwBA/PjcdMop0SDA3BswmWbks7IKjEeonoQp3pFglUwwq30Zk8FOhVmsp0VgkR+ClD+WisIB7JRx5xoXh6EgUECgKRFHNVacwoRdmc5K3lsMYJofEIbdhCFOcpUjmuwqlkbUTJNIXjMVCRTQ6WmAsC4cONypiROM6vc0IoLYF27KF145/hGvJEeH3YOeooVQWvCK9UVOb1VXq1j3HsInBJSvFNaF2JftQIGnolCKKPEN2hdHoM8zrSmLPsR+H+0pAxIoHdLWHA5spWJqQmDJHPCzKT4klR95UJwWYqwdXY7BrNB8YfwBuGaijnCR96M4S0vU/DWxbnwDcFBwB/lG1gNBcrPBfX84pT7p0K1zjSM9xreUbhqqWJYSRhXNJf8rUDtPeXs12BAYgJzcP9BGYAnLbMNPo30xLEoFWGdo3hY35aA/F0iOsqwM6YOkawWxPsMNRNsO36wpNR7JYmhqZQSxvJ9oxknw7V1UyzfaPZl6Ooi2gHRrRbE+3+X6Ltel7Xol1fJjOi3dbM0PCQSRvRri/AGdH+EGqomWhHRrQvR1ET0XbqK2BGtK8l2pF2kfbuQY8R7dZFu+mRmC6i7dQX4Yxofwi1YQbobH53jWhfjqIuol1fAzOifS3R9m3dIm2nvinMiHZbM0PDhlxtRLu+CGdE+0OovmaiHRrRvhxFXUTbbEJrT7SDqCrau1/KdCfaZhdad6Kt+Ta0omEj2qdA1Wwfmmv2oV2Qoiai7dbXwIxoX020tds57pqNaJ2JdtOvtrQRbbMR7T+garYRzTUb0S5I8eqiDcn9nxrkeaW/hnDv/gA=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\351\223\276\345\274\217\345\255\230\345\202\250\344\272\214\345\217\211\346\240\221.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\223\276\345\274\217\345\255\230\345\202\250\344\272\214\345\217\211\346\240\221.png"
new file mode 100644
index 00000000000..c0ce15b72e4
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\223\276\345\274\217\345\255\230\345\202\250\344\272\214\345\217\211\346\240\221.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\250.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\250.drawio"
new file mode 100644
index 00000000000..1ddbb02dc6e
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\250.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-05-29T04:45:41.829Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="iKUbU63_jbqeO2KKhoI_" version="13.4.5" type="device"><diagram id="781hTf24KyYCwh97XMbf" name="Page-1">7V1dc5s4FP01PDYDSAh49FfSh3amu+nMto8yyDYtRi6WE3t//UogMGCwiSHgjZlkJuiCJXHP0dXVMSgKmKz3TyHerL5Sl/iKrrp7BUwVXdc0FfE/wnKILbZtxoZl6LnyoqPh2fuXSKMqrTvPJdvchYxSn3mbvNGhQUAclrPhMKSv+csW1M+3usFLcmJ4drB/av3Hc9kqtlq6ebR/Jt5ylbSsITs+s8bJxfJOtivs0teMCcwUMAkpZfHRej8hvnBe4pf4c48VZ9OOhSRgdT7w9OMPePm6oQxPv88OwRr9+uvwSY9recH+Tt6woiOf1zeeiy6zg/QD+rMT/RwvaMA+bSOURvwC3djsjyf50VL8HSV18M7ME6N0QlqjznvHQeSF8evKY+R5gx1x5pXziNtWbO3zksYP8XYTI7vw9sQVnfB8f0J9GkYVgcWCIMfh9i0L6W+SOeOa9lxV08ZfSMjIvtJ9WgoKZzOha8LCA79EfsBMcJREBglDXzO0kKZVhhGJDUsiLtOaj1jxAwnXG6ADJdAVXRy4IzEGeCmgAcm7ld93ePiRLfzMFqbivtW0dJCluA3inoyagh95P+gudMiZG4ByOONwSdgljp7ikvG7UeL3xBYSHzPvJd/dMjBkC9+ox28khR0l8UrCjvQCnvFtyk9lh1+hItMyHnQL6qamQxOipCcJm2wrfxbkW4mddNJKRJzUJ9dzCVaGge0GB9dHgkwwiQ2T8tCQ2uLmPkbEsMx8xIB9RwyjK5THd4SyYd8YyqgrlKf3hLJWQNnuGWWzK5Sf7ghl27gxlK2mOd7eYz8yxz+TnI4fHxM8UUjyuzQrTAsdZ4XG/yIrLBAFgSuzQkuzchUZmt5p4mc3JVjpIkK9QJeElmqGltpZWvZAMNQnwczCfJPOP29edkDrzLIDar0uO5Kbupp+LdLCrEkL2CctLE17QAAYAFoGn8G1PJqGqj3Ymm1Di5+BSDWvjEk6OkMZQ1V7pYzWVeIzu6PEBxWXqn0nPsk02Grmc36KKc98Lk1lPUxMWgWWHaU+KDdlaHaeOEB7MDXD1C3T0A1gFaqvG4KQXVpN0oha2oWuIlCZ8PouEejzHUUgCAoJj9l3BCrTRK+JQPWT3OuS6RYjEKobgcANRyDrbHBoJwIZ2tkw994RqFrIFYGmxQikXYhAcXMVEYgHA5YfEvkIIodMNtxIE/a9ZcCLDmcw4faxCC2eg/2RPLH2XNevim0h3QWuiGTTtrIjKx+bgH4am2AJ34tfFbUXm6o13pYJoA8EEMMdFtLj3glQLf+2TAAwEEBkGfqtEaBMGX4XAsCBAALcwgLZUPsmQJly+y4EMAYCKBmF/1YIkFT8/gSwBgIop98AGyUSWbcEKFNCC97frvBGHDI89wvL0zKnbfnChclnMIXbHI4s9gLh/egzDvV9vNl6UWXxFSvPd7/gA92xpJmkVNQRXEysRamOgByLzBdtBWqUgwkh4wQmpHYpJCSw1MGJ3yfzsP83cRgOlnUgO4XEDenme7KCF4aNWIeScPbCXbiVtpLxxuhGnvTJIvnsnDJG17IQSm+llUauMsb8lztvoj4YisHvZsLL2rHMf8XlIZvQgEOPvQhIgrfslWxZXdTPDIGzOkQp1vDdsK7WBmsHZbVWUPZ4dNs3CcxNKBc9ao2PlGvMJsrRX/iRkLbiUZ0EzWih16BFl6yofryyZVaoAyPexIh9ng29EaQFQa8eQRoJevdLEK1kvd8tQ1pQ/OoxpJHid8cMsfpmSAuSYD2GNJIE75chKfS9MaQFzbAeQxpphvfLEFCiKXXLkBZExXoMaSQq3jFD+s5UQQuqYz2GoIEh1zCk7JupbhlS/YBmywwxB4ZcxZC+M1VQJoi+C0MafXNxvwwx+s5UQY132wfJvFXJ/JCHtDcFHXSmlcYtDAGiegDejoIOygTSAY4bka9BZ+Jkxc4yw3g9T5De5WvQmTg5HhhyFUN6XxR0Jk5e2oJmYMhtytegM3FyOjDkGob0Ll/DzsTJS+8GDwy5TfkadiZOPg4MuYYhvcvXsDNx8tLGSgNDblO+htXPeJ7A2IwynyvZUGN71ftlSO/yNYQnaIjXs59lUXow/4YCDdmKLmmA/S80cq1A5xdh7CCfx8c7RvPYHTeseDCUfjbrksHy2s26ar8I3gyOzva9vDTpf6QNG8zivpd9bxkDy1TIoo9r7WWmvmU0vX2LvRbHH6y7Z0yvu1bZ+b0UzPyGDQYAZWffumGDfX6jM7vXXatgZ+9rN3ps5sO8rGeifHDq/W1N2Nn72o2eivkwBLD1GyOAUaJNzQxlPFNGM2UGFZ47jDRlhhQ+jdoTZaYrVnSQJ4mTzuVHHvD53rZFSlykxpPHVru5qNOaKbalzGzFMhWbt2KJRkVzhmJZiq1X0UP2ItVD52EdomqwlKi8MXus2DNxMIKKNW3lJr9NHy/2nt8v9wAfGeJ+HxUbyb5w5wtXmMoIZHxiigPbjLCYKONRdPFjdGCKC5IE5uaGjY/nxB9j5/cyshcb566RSwkNynImNRxHP+0MPlTYLgWVDL50pDUcfbx4/Bcq8XR9/Ec0YPYf</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\250.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\250.png"
new file mode 100644
index 00000000000..33f3c6e3ff3
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\250.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\2502.drawio" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\2502.drawio"
new file mode 100644
index 00000000000..8048a1a724c
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\2502.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-05-29T04:44:09.293Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="qoIVzM2KSH4_Q9T_5mZ7" version="13.4.5" type="device"><diagram id="KL8qVs7MDRylIb7IQKVJ" name="Page-1">7V1dc5s4FP01PDaDAPHxaDtOOp12p7PZ2W32ZUc2ss2WWC6WE3t//UogMGBhE4OBFqaZKbrCCO45ulwdybKiT172jwHarL4QF/uKprp7Rb9XNA0A1WT/ccshsjiOFRmWgeeKk46GJ+8/LIyqsO48F28zJ1JCfOptssY5Wa/xnGZsKAjIW/a0BfGzrW7QEp8YnubIP7X+5bl0FVltzTraP2JvuYpbBqYT1byg+GTxJNsVcslbyqRPFX0SEEKjo5f9BPvcebFfos89FNQmNxbgNS3zgd/G33/s9s92oH3Bn/w9/DH+MvsgrvKK/J14YEUzfXa98YzfMj0IP5g/dvw+xwuyph+2IUojdoIGN/tjJTta8v9H8TXYzcxio3BCckWN3R0DkRXGbyuP4qcNmvOaN8YjZlvRF5+VADtE202E7MLbY5ffhOf7E+KTILyQvlhgcz5n9i0NyHecqnEtZ6aqSeNpX8UPjgOK9ymT8N0jJi+YBgd2iqi1ocBREFmPcX1L0UKYVilGxDYkiLhMrnzEih0IuN4BnSaBLu/itTvifYCV1mSNs25lrggO39KF53Thnj+3mpQOolToyS3ZBXN85n510XtRsMT0MiWxm+mYp7ik/A4lfo9tAfYR9V6z3VkGhmjhK/HYkx1hj3u6gN3Uc3hGzy0+le5+uQs5AN5ptqFZQDMsw4zvRFzWUO1srZ5tJfLaSSshcRKfXM8lvTAMbDdofX0kSAWTyDCRh4bEFjX3a0QMoKrZkGG0HTKMpmAe9whmS+sYyrAplO97hLJpZFGGassom02h/NAjlIFqdwxmq2qWt/fot9Txc5zVseNjiscLcYaX5IVJ4bZ5ofFT5oVWjihJfHh3XmjYWcbFCDeU+tlVCSYdRqgX6BLTUk3REpyl5e0JBjtFMDv/wtGuJJht2ecGHlqrAw+nIvuuZ4VZkhV6p1jhGODO1HWoGzYjhAayYEIA7hzgsJDCagxTta4MSdA8wxgI1DYZEwuDt098HnuU+OQHMdBuOe8BMmWyauJz/g0jT3wuvcmuj0CwbOKjdioEWU7mjQGc7PuEBSgLQIu9dqAGdTt3+dIvLU16mbgRIL2FpiKQ1lQE+tijCHSilrUfgmSq6K8VguKofzkGaT9TDJLX1huDoLy2qRhULOXyUFNjDAIXYlDUXEEMYn2fZvtENoaIPpMOOMKEfG+5ZsU54zRm9jGPJN4c+SNR8eK5rl8U3QKyW7s8lp3vH++Y/QPZ4KTrp8HJkPA9P2irLzgVq7w1E0AbCMBqTCun8rdOgGIBuGYC6AMBFD4o7hoBZNLwTQhgDATgESCfn4K2CSCTbm9CAGcgACdAXvKXzA01SwDnxNk8P38SReHFrB9IQFdkSdbI/0zIRgDyL6b0INbeoR0lilzhV++g0siUULzQr64podKjjWoLshpTJqc90gWcvDLZ9oysVlmZvGqC9f0Tudf3v9KyQLcmRwDIjsmtrCwADV1W+15ZAKhnJ9QYP9ucHonJePukwBySAh5mnI5lhVrxWs6aCWANBAjDAewaA5rTBgdpIExRzI4NDDSZOJjz/naFNvyQopmfS1BkTtuy9xYVQwTutjlDFnlr7v3wM3Pi+2iz9cKLRWesPN/9jA5kR+Nm4lI+k3QRthfSTNKc23i2qAemRLERMFmSjuqojaaSMg2vACf26NRD/u8sJUfrZRnITiFxA7L5I87puGHD0xAcTF+ZV7fCJulvNBwp8kofL+LPzgil5EUUAuGt5KKhq+CY/THnTfjIEbKnmbAyOJbZHz89oBOyZtAjL8QWoy19w1sqRf083y9z4RLW+WV89WFdg1ynlorKHotu+yqBuQrlwm/hoSPlKrOJMFAXfjiUWrGojtfvoIV5DS3MRllRg4ZXjhXqwIh3MWKfZUNrBJGtkLwJQSpN9PaXIEDydZ9GGRJnNbdniDYw5CqGSBYyNcuQ4m9518yQSuPB/jIkgb41htSgGpZjSKW55P4yRJdICs0ypAZZsRxD4MCQqxjSdqaq1yA7lmNIpZmH/jJE9sX0ZhlSw5rFcgypNDXRY4a0nqnWsKixHEPsgSHXMAS2nqkWy6iz6+lRsMBtgD2/9rE12It10gqwgwJRdMA9xr31pLJY/qyCe4HWOeCe/zpwW7gbxaJmFdwLFMwB9/yuJq3hXnVDSjnuBbrkgHt+s5HWcJcJkDXCM6yEOIH+kIW0tYURRmPKYtTCMO479rbuLowwZGriAEdHViUYjSl5BXtJD/2146sSjMaUvPHAkKsY0nqq39iCyEubTg8M6eaqBKOxxZH3A0OuYUjrqxKMEvtH9hiettNEWKzilf5GdLkOXOkb0f1lSOtLAmCx3lczQyptY95jhrSdJsIbK4M/Nzytz8fDGn46plwHrrQdb38Z0vrUPTQGNLozoQ7hgEZ3prmhOaDRnclnWKxI1fwuq7Sxc38Z0uQ0NWtt/s/u9dMfSH3Wta+Pf/+528h+LnMKFTb6HE2VqaGwQcYIKFNTcVTFmShTTbHDg6xoNU+2NzjyRF8sHId/xyJPnUePrnYzfk17qji2MnUU21Ic1orNG+XNQcW2FUdTCuQqcReJxDULyhAZGFIis8acseJM+cHIUOz7Wh7y6/3Dxbtnz8s8MLbC531QHFPcC3M+d4WljPSUTyx+4FghFhNlPApPfggPLH5CHGo6tx2Jj2bYH6P592VozzfOXCM24QCGKKd2yxiH/5IeeNKxJBtoXI7G8aYmkswl2cGk4q4mrHj8HdxoJ6zjrwnr0/8B</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\2502.png" "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\2502.png"
new file mode 100644
index 00000000000..70c6da26d22
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\346\240\221/\351\241\272\345\272\217\345\255\230\345\202\2502.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\215\225\351\223\276\350\241\2502.png" "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\215\225\351\223\276\350\241\2502.png"
new file mode 100644
index 00000000000..9fe82753c80
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\215\225\351\223\276\350\241\2502.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\217\214\345\220\221\345\276\252\347\216\257\351\223\276\350\241\250.png" "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\217\214\345\220\221\345\276\252\347\216\257\351\223\276\350\241\250.png"
new file mode 100644
index 00000000000..9d134bcbea0
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\217\214\345\220\221\345\276\252\347\216\257\351\223\276\350\241\250.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\217\214\345\220\221\351\223\276\350\241\250.png" "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\217\214\345\220\221\351\223\276\350\241\250.png"
new file mode 100644
index 00000000000..ffb3b3efa0e
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\217\214\345\220\221\351\223\276\350\241\250.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\276\252\347\216\257\351\230\237\345\210\227-\345\240\206\346\273\241.png" "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\276\252\347\216\257\351\230\237\345\210\227-\345\240\206\346\273\241.png"
new file mode 100644
index 00000000000..225c46d7797
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\345\276\252\347\216\257\351\230\237\345\210\227-\345\240\206\346\273\241.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\225\260\347\273\204.png" "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\225\260\347\273\204.png"
new file mode 100644
index 00000000000..923e8c042d8
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\225\260\347\273\204.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\240\210.png" "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\240\210.png"
new file mode 100644
index 00000000000..2d704d564c6
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\240\210.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\240\210\345\256\236\347\216\260\346\265\217\350\247\210\345\231\250\345\200\222\351\200\200\345\222\214\345\211\215\350\277\233.drawio" "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\240\210\345\256\236\347\216\260\346\265\217\350\247\210\345\231\250\345\200\222\351\200\200\345\222\214\345\211\215\350\277\233.drawio"
new file mode 100644
index 00000000000..25a0512ed99
--- /dev/null
+++ "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\240\210\345\256\236\347\216\260\346\265\217\350\247\210\345\231\250\345\200\222\351\200\200\345\222\214\345\211\215\350\277\233.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-11-09T06:56:47.201Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="psfGgMNo4nzL4IA4JRTh" version="13.4.5" type="device"><diagram id="syluBulH61jp7zpPZQu4" name="Page-1">7Vpbc6M2FP41PCbDHfNobCedTne60+xMm77JIGN1BaJCvu2vrwTiToLt4Mt0sw8bdJCOpO87+o4koxizaP9MQbL+QgKIFV0N9ooxV3Rd01Sb/xGWQ25xVTU3hBQFslJleEE/oDQW1TYogGmjIiMEM5Q0jT6JY+izhg1QSnbNaiuCm70mIIQdw4sPcNf6JwrYOrdOdKey/wJRuC561mw3fxOBorKcSboGAdnVTMZCMWaUEJY/RfsZxAK8Ape83dMbb8uBURizYxq8vk42//y9/DZPbY8eovTLD8d6kF62AG/khOVg2aFAYLdGDL4kwBflHWdZMbw1izAvafwRpEmO+wrtIe/KWyGMZwQTmjU3VquV7vvcnjJKvsPam8Be2pbN38gxQMrg/s3JaSVkPNYgiSCjB15FNtAdibIMM82W5V1FWhlT6xphpRHIQAlL3xWW/EHCeQK0+jC0MA6mIkZ5KSYxbAJ7Lo4w6ET0IIo1lKwekAobhRgwtG267wNO9vCVIN7xMEmFi5RsqA9lq3ooDzhyW34YoCFkHT8ZjeWsz2fW+GS2RYjpuI/WONyak5tya94tt3wMGYRDan6rGDBai1JXR1rdHUdvhAAnBRxq1RJRIX0naCf9/VQRlXscNb6su42vm2lHmwZzrLhpO7pU3JhXiBv7M24GaDCMkeKm4+hCcVP0c9G4cT7jZmj5tncYZ+vNkVuVD+uNe4W4mQzHDSWbOBBHvrnKaR84Jt7kVGg2gStwHDoTtvPGaEdC9/8AqqU1UXVvjWrR2ZEa52OQpshvItlBTM3+8TdCyF6kI0LZmoQkBnhRWT1/Q7cZY8IRB5Ee/hL0PRpuUX7l5Qf1UXWswjLfS4bz0qFe+gop4shAKo3HCqqu5oLzHlTmLZW39FOcEc89IRhtRxfK2O0BW+rAsPR3ql9Gp7XuDV6ySdedBcDXO3sv5GXmryuKNAGMwlisGx5tIiY9oR7IB3gqX0QoCLKF0KdWTT1bkZjJO17dGunmz25lx64cOT0h3Y6Y8dRI7xJCkp+HD1Mz7ouP027rTswObQDPzhb1VKE+DuWJEVOCe8uMYKoDQn70raHVv9UbeyuunpQQ2lulqySEI24w73+T2fmpoEdGrrzL7Lm5W9jKVFUmE2XhKlNN8Wyx4M4QewGe4y5zRWnDDe0M7juXffuNhVzjSzOvqvs9N2YVX5biTRWXU6ouCWMk+qSsuva6HWWnXVZ9MFUfm0Nvdlpq5RrDNIvf2D58w2m2HF34RzXtiNukn5dYrc3GubR2HF2a1r77LBsL3QzQtkGv/e9GfOfiCVl9kLo45TUwXLHqLX8K5d/MS5qAuNeNoPwhzTgXXjQr2fd4WZiKN1fcmbKYKHxDOLGUxZPizRR3+hIDhGcYRUteGURCbuNlmtS65oDkvTdHxM3Z1JpWMZwPjPMCmBUIWGLW01kGBZ+4k1k4CE457/z/Z8TWm2WJz69gC57Fl1dnwcGtOSKFeTC3jpkpy++shONQSIl89kkkRCXf1NY0QzQi3CNiYh25oojBEmIP+N/DzHf7UM4b9wlR3orQANKeFk8gQlj08AwoiEgcFMOQwKiS6t/LoThqzqeP4vAb31Yac6My/CaioGHx8p1Mw/aHVC9jpLvf1l3LBXflvFh9G5crVvWFobH4Dw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\240\210\345\256\236\347\216\260\346\265\217\350\247\210\345\231\250\345\200\222\351\200\200\345\222\214\345\211\215\350\277\233.png" "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\240\210\345\256\236\347\216\260\346\265\217\350\247\210\345\231\250\345\200\222\351\200\200\345\222\214\345\211\215\350\277\233.png"
new file mode 100644
index 00000000000..07bdb36a2c6
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\346\240\210\345\256\236\347\216\260\346\265\217\350\247\210\345\231\250\345\200\222\351\200\200\345\222\214\345\211\215\350\277\233.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\351\230\237\345\210\227.png" "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\351\230\237\345\210\227.png"
new file mode 100644
index 00000000000..2fa16dcdb3a
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\351\230\237\345\210\227.png" differ
diff --git "a/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\351\241\272\345\272\217\351\230\237\345\210\227\345\201\207\346\272\242\345\207\272.png" "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\351\241\272\345\272\217\351\230\237\345\210\227\345\201\207\346\272\242\345\207\272.png"
new file mode 100644
index 00000000000..f3b01def266
Binary files /dev/null and "b/docs/cs-basics/data-structure/pictures/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204/\351\241\272\345\272\217\351\230\237\345\210\227\345\201\207\346\272\242\345\207\272.png" differ
diff --git "a/docs/cs-basics/data-structure/\345\233\276.md" "b/docs/cs-basics/data-structure/\345\233\276.md"
new file mode 100644
index 00000000000..cb9f55c1f88
--- /dev/null
+++ "b/docs/cs-basics/data-structure/\345\233\276.md"
@@ -0,0 +1,159 @@
+---
+category: 计算机基础
+tag:
+ - 数据结构
+---
+
+# 图
+
+> 开头还是求点赞,求转发!原创优质公众号,希望大家能让更多人看到我们的文章。
+>
+> 图片都是我们手绘的,可以说非常用心了!
+
+图是一种较为复杂的非线性结构。 **为啥说其较为复杂呢?**
+
+根据前面的内容,我们知道:
+
+- 线性数据结构的元素满足唯一的线性关系,每个元素(除第一个和最后一个外)只有一个直接前趋和一个直接后继。
+- 树形数据结构的元素之间有着明显的层次关系。
+
+但是,图形结构的元素之间的关系是任意的。
+
+**何为图呢?** 简单来说,图就是由顶点的有穷非空集合和顶点之间的边组成的集合。通常表示为:**G(V,E)**,其中,G表示一个图,V表示顶点的集合,E表示边的集合。
+
+下图所展示的就是图这种数据结构,并且还是一张有向图。
+
+
+
+图在我们日常生活中的例子很多!比如我们在社交软件上好友关系就可以用图来表示。
+
+## 图的基本概念
+
+### 顶点
+图中的数据元素,我们称之为顶点,图至少有一个顶点(非空有穷集合)
+
+对应到好友关系图,每一个用户就代表一个顶点。
+
+### 边
+顶点之间的关系用边表示。
+
+对应到好友关系图,两个用户是好友的话,那两者之间就存在一条边。
+
+### 度
+度表示一个顶点包含多少条边,在有向图中,还分为出度和入度,出度表示从该顶点出去的边的条数,入度表示进入该顶点的边的条数。
+
+对应到好友关系图,度就代表了某个人的好友数量。
+
+### 无向图和有向图
+边表示的是顶点之间的关系,有的关系是双向的,比如同学关系,A是B的同学,那么B也肯定是A的同学,那么在表示A和B的关系时,就不用关注方向,用不带箭头的边表示,这样的图就是无向图。
+
+有的关系是有方向的,比如父子关系,师生关系,微博的关注关系,A是B的爸爸,但B肯定不是A的爸爸,A关注B,B不一定关注A。在这种情况下,我们就用带箭头的边表示二者的关系,这样的图就是有向图。
+
+### 无权图和带权图
+
+对于一个关系,如果我们只关心关系的有无,而不关心关系有多强,那么就可以用无权图表示二者的关系。
+
+对于一个关系,如果我们既关心关系的有无,也关心关系的强度,比如描述地图上两个城市的关系,需要用到距离,那么就用带权图来表示,带权图中的每一条边一个数值表示权值,代表关系的强度。
+
+
+
+## 图的存储
+### 邻接矩阵存储
+邻接矩阵将图用二维矩阵存储,是一种较为直观的表示方式。
+
+如果第i个顶点和第j个顶点之间有关系,且关系权值为n,则 `A[i][j]=n` 。
+
+在无向图中,我们只关心关系的有无,所以当顶点i和顶点j有关系时,`A[i][j]`=1,当顶点i和顶点j没有关系时,`A[i][j]`=0。如下图所示:
+
+
+
+值得注意的是:**无向图的邻接矩阵是一个对称矩阵,因为在无向图中,顶点i和顶点j有关系,则顶点j和顶点i必有关系。**
+
+
+
+邻接矩阵存储的方式优点是简单直接(直接使用一个二维数组即可),并且,在获取两个定点之间的关系的时候也非常高效(直接获取指定位置的数组元素的值即可)。但是,这种存储方式的缺点也比较明显,那就是比较浪费空间,
+
+### 邻接表存储
+
+针对上面邻接矩阵比较浪费内存空间的问题,诞生了图的另外一种存储方法—**邻接表** 。
+
+邻接链表使用一个链表来存储某个顶点的所有后继相邻顶点。对于图中每个顶点Vi,把所有邻接于Vi的顶点Vj链成一个单链表,这个单链表称为顶点Vi的 **邻接表**。如下图所示:
+
+
+
+
+
+
+
+
+
+大家可以数一数邻接表中所存储的元素的个数以及图中边的条数,你会发现:
+
+- 在无向图中,邻接表元素个数等于边的条数的两倍,如左图所示的无向图中,边的条数为7,邻接表存储的元素个数为14。
+- 在有向图中,邻接表元素个数等于边的条数,如右图所示的有向图中,边的条数为8,邻接表存储的元素个数为8。
+
+## 图的搜索
+### 广度优先搜索
+广度优先搜索就像水面上的波纹一样一层一层向外扩展,如下图所示:
+
+
+
+**广度优先搜索的具体实现方式用到了之前所学过的线性数据结构——队列** 。具体过程如下图所示:
+
+**第1步:**
+
+
+
+**第2步:**
+
+
+
+**第3步:**
+
+
+
+**第4步:**
+
+
+
+**第5步:**
+
+
+
+**第6步:**
+
+
+
+### 深度优先搜索
+
+深度优先搜索就是“一条路走到黑”,从源顶点开始,一直走到没有后继节点,才回溯到上一顶点,然后继续“一条路走到黑”,如下图所示:
+
+
+
+
+**和广度优先搜索类似,深度优先搜索的具体实现用到了另一种线性数据结构——栈** 。具体过程如下图所示:
+
+**第1步:**
+
+
+
+**第2步:**
+
+
+
+**第3步:**
+
+
+
+**第4步:**
+
+
+
+**第5步:**
+
+
+
+**第6步:**
+
+
+
diff --git "a/docs/cs-basics/data-structure/\345\240\206.md" "b/docs/cs-basics/data-structure/\345\240\206.md"
new file mode 100644
index 00000000000..f86308fafe4
--- /dev/null
+++ "b/docs/cs-basics/data-structure/\345\240\206.md"
@@ -0,0 +1,198 @@
+---
+category: 计算机基础
+tag:
+ - 数据结构
+---
+
+# 堆
+
+## 什么是堆
+
+堆是一种满足以下条件的树:
+
+堆中的每一个节点值都大于等于(或小于等于)子树中所有节点的值。或者说,任意一个节点的值都大于等于(或小于等于)所有子节点的值。
+
+> 大家可以把堆(最大堆)理解为一个公司,这个公司很公平,谁能力强谁就当老大,不存在弱的人当老大,老大手底下的人一定不会比他强。这样有助于理解后续堆的操作。
+
+**!!!特别提示:**
+
+- 很多博客说堆是完全二叉树,其实并非如此,**堆不一定是完全二叉树**,只是为了方便存储和索引,我们通常用完全二叉树的形式来表示堆,事实上,广为人知的斐波那契堆和二项堆就不是完全二叉树,它们甚至都不是二叉树。
+- (**二叉**)堆是一个数组,它可以被看成是一个 **近似的完全二叉树**。——《算法导论》第三版
+
+大家可以尝试判断下面给出的图是否是堆?
+
+
+
+第1个和第2个是堆。第1个是最大堆,每个节点都比子树中所有节点大。第2个是最小堆,每个节点都比子树中所有节点小。
+
+第3个不是,第三个中,根结点1比2和15小,而15却比3大,19比5大,不满足堆的性质。
+
+## 堆的用途
+当我们只关心所有数据中的最大值或者最小值,存在多次获取最大值或者最小值,多次插入或删除数据时,就可以使用堆。
+
+有小伙伴可能会想到用有序数组,初始化一个有序数组时间复杂度是 `O(nlog(n))`,查找最大值或者最小值时间复杂度都是 `O(1)`,但是,涉及到更新(插入或删除)数据时,时间复杂度为 `O(n)`,即使是使用复杂度为 `O(log(n))` 的二分法找到要插入或者删除的数据,在移动数据时也需要 `O(n)` 的时间复杂度。
+
+**相对于有序数组而言,堆的主要优势在于更新数据效率较高。** 堆的初始化时间复杂度为 `O(nlog(n))`,堆可以做到`O(1)`时间复杂度取出最大值或者最小值,`O(log(n))`时间复杂度插入或者删除数据,具体操作在后续章节详细介绍。
+
+## 堆的分类
+
+堆分为 **最大堆** 和 **最小堆**。二者的区别在于节点的排序方式。
+- **最大堆** :堆中的每一个节点的值都大于等于子树中所有节点的值
+- **最小堆** :堆中的每一个节点的值都小于等于子树中所有节点的值
+
+如下图所示,图1是最大堆,图2是最小堆
+
+
+
+
+## 堆的存储
+之前介绍树的时候说过,由于完全二叉树的优秀性质,利用数组存储二叉树即节省空间,又方便索引(若根结点的序号为1,那么对于树中任意节点i,其左子节点序号为 `2*i`,右子节点序号为 `2*i+1`)。
+
+为了方便存储和索引,(二叉)堆可以用完全二叉树的形式进行存储。存储的方式如下图所示:
+
+
+
+## 堆的操作
+堆的更新操作主要包括两种 : **插入元素** 和 **删除堆顶元素**。操作过程需要着重掌握和理解。
+> 在进入正题之前,再重申一遍,堆是一个公平的公司,有能力的人自然会走到与他能力所匹配的位置
+### 插入元素
+> 插入元素,作为一个新入职的员工,初来乍到,这个员工需要从基层做起
+
+**1.将要插入的元素放到最后**
+
+
+
+> 有能力的人会逐渐升职加薪,是金子总会发光的!!!
+
+**2.从底向上,如果父结点比该元素大,则该节点和父结点交换,直到无法交换**
+
+
+
+
+
+### 删除堆顶元素
+
+根据堆的性质可知,最大堆的堆顶元素为所有元素中最大的,最小堆的堆顶元素是所有元素中最小的。当我们需要多次查找最大元素或者最小元素的时候,可以利用堆来实现。
+
+删除堆顶元素后,为了保持堆的性质,需要对堆的结构进行调整,我们将这个过程称之为"**堆化**",堆化的方法分为两种:
+
+- 一种是自底向上的堆化,上述的插入元素所使用的就是自底向上的堆化,元素从最底部向上移动。
+- 另一种是自顶向下堆化,元素由最顶部向下移动。在讲解删除堆顶元素的方法时,我将阐述这两种操作的过程,大家可以体会一下二者的不同。
+
+#### 自底向上堆化
+
+> 在堆这个公司中,会出现老大离职的现象,老大离职之后,他的位置就空出来了
+
+首先删除堆顶元素,使得数组中下标为1的位置空出。
+
+
+
+
+
+
+> 那么他的位置由谁来接替呢,当然是他的直接下属了,谁能力强就让谁上呗
+
+比较根结点的左子节点和右子节点,也就是下标为2,3的数组元素,将较大的元素填充到根结点(下标为1)的位置。
+
+
+
+
+> 这个时候又空出一个位置了,老规矩,谁有能力谁上
+
+一直循环比较空出位置的左右子节点,并将较大者移至空位,直到堆的最底部
+
+
+
+这个时候已经完成了自底向上的堆化,没有元素可以填补空缺了,但是,我们可以看到数组中出现了“气泡”,这会导致存储空间的浪费。接下来我们试试自顶向下堆化。
+
+#### 自顶向下堆化
+自顶向下的堆化用一个词形容就是“石沉大海”,那么第一件事情,就是把石头抬起来,从海面扔下去。这个石头就是堆的最后一个元素,我们将最后一个元素移动到堆顶。
+
+
+
+然后开始将这个石头沉入海底,不停与左右子节点的值进行比较,和较大的子节点交换位置,直到无法交换位置。
+
+
+
+
+
+
+
+### 堆的操作总结
+
+- **插入元素** :先将元素放至数组末尾,再自底向上堆化,将末尾元素上浮
+- **删除堆顶元素** :删除堆顶元素,将末尾元素放至堆顶,再自顶向下堆化,将堆顶元素下沉。也可以自底向上堆化,只是会产生“气泡”,浪费存储空间。最好采用自顶向下堆化的方式。
+
+
+## 堆排序
+
+堆排序的过程分为两步:
+
+- 第一步是建堆,将一个无序的数组建立为一个堆
+- 第二步是排序,将堆顶元素取出,然后对剩下的元素进行堆化,反复迭代,直到所有元素被取出为止。
+
+### 建堆
+
+如果你已经足够了解堆化的过程,那么建堆的过程掌握起来就比较容易了。建堆的过程就是一个对所有非叶节点的自顶向下堆化过程。
+
+首先要了解哪些是非叶节点,最后一个节点的父结点及它之前的元素,都是非叶节点。也就是说,如果节点个数为n,那么我们需要对n/2到1的节点进行自顶向下(沉底)堆化。
+
+具体过程如下图:
+
+
+
+将初始的无序数组抽象为一棵树,图中的节点个数为6,所以4,5,6节点为叶节点,1,2,3节点为非叶节点,所以要对1-3号节点进行自顶向下(沉底)堆化,注意,顺序是从后往前堆化,从3号节点开始,一直到1号节点。
+3号节点堆化结果:
+
+
+
+2号节点堆化结果:
+
+
+
+1号节点堆化结果:
+
+
+
+至此,数组所对应的树已经成为了一个最大堆,建堆完成!
+
+### 排序
+
+由于堆顶元素是所有元素中最大的,所以我们重复取出堆顶元素,将这个最大的堆顶元素放至数组末尾,并对剩下的元素进行堆化即可。
+
+现在思考两个问题:
+
+- 删除堆顶元素后需要执行自顶向下(沉底)堆化还是自底向上(上浮)堆化?
+- 取出的堆顶元素存在哪,新建一个数组存?
+
+先回答第一个问题,我们需要执行自顶向下(沉底)堆化,这个堆化一开始要将末尾元素移动至堆顶,这个时候末尾的位置就空出来了,由于堆中元素已经减小,这个位置不会再被使用,所以我们可以将取出的元素放在末尾。
+
+机智的小伙伴已经发现了,这其实是做了一次交换操作,将堆顶和末尾元素调换位置,从而将取出堆顶元素和堆化的第一步(将末尾元素放至根结点位置)进行合并。
+
+详细过程如下图所示:
+
+取出第一个元素并堆化:
+
+
+
+取出第二个元素并堆化:
+
+
+
+取出第三个元素并堆化:
+
+
+
+取出第四个元素并堆化:
+
+
+
+取出第五个元素并堆化:
+
+
+
+取出第六个元素并堆化:
+
+
+
+堆排序完成!
diff --git "a/docs/cs-basics/data-structure/\346\240\221.md" "b/docs/cs-basics/data-structure/\346\240\221.md"
new file mode 100644
index 00000000000..34f7d49dba9
--- /dev/null
+++ "b/docs/cs-basics/data-structure/\346\240\221.md"
@@ -0,0 +1,180 @@
+---
+category: 计算机基础
+tag:
+ - 数据结构
+---
+
+# 树
+
+树就是一种类似现实生活中的树的数据结构(倒置的树)。任何一颗非空树只有一个根节点。
+
+一棵树具有以下特点:
+
+1. 一棵树中的任意两个结点有且仅有唯一的一条路径连通。
+2. 一棵树如果有 n 个结点,那么它一定恰好有 n-1 条边。
+3. 一棵树不包含回路。
+
+下图就是一颗树,并且是一颗二叉树。
+
+
+
+如上图所示,通过上面这张图说明一下树中的常用概念:
+
+- **节点** :树中的每个元素都可以统称为节点。
+- **根节点** :顶层节点或者说没有父节点的节点。上图中 A 节点就是根节点。
+- **父节点** :若一个节点含有子节点,则这个节点称为其子节点的父节点。上图中的 B 节点是 D 节点、E 节点的父节点。
+- **子节点** :一个节点含有的子树的根节点称为该节点的子节点。上图中 D 节点、E 节点是 B 节点的子节点。
+- **兄弟节点** :具有相同父节点的节点互称为兄弟节点。上图中 D 节点、E 节点的共同父节点是 B 节点,故 D 和 E 为兄弟节点。
+- **叶子节点** :没有子节点的节点。上图中的 D、F、H、I 都是叶子节点。
+- **节点的高度** :该节点到叶子节点的最长路径所包含的边数。
+- **节点的深度** :根节点到该节点的路径所包含的边数
+- **节点的层数** :节点的深度+1。
+- **树的高度** :根节点的高度。
+
+## 二叉树的分类
+
+**二叉树**(Binary tree)是每个节点最多只有两个分支(即不存在分支度大于 2 的节点)的树结构。
+
+**二叉树** 的分支通常被称作“**左子树**”或“**右子树**”。并且,**二叉树** 的分支具有左右次序,不能随意颠倒。
+
+**二叉树** 的第 i 层至多拥有 `2^(i-1)` 个节点,深度为 k 的二叉树至多总共有 `2^k-1` 个节点
+
+### 满二叉树
+
+一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是 **满二叉树**。也就是说,如果一个二叉树的层数为 K,且结点总数是(2^k) -1 ,则它就是 **满二叉树**。如下图所示:
+
+
+
+### 完全二叉树
+
+除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 **完全二叉树** 。
+
+大家可以想象为一棵树从根结点开始扩展,扩展完左子节点才能开始扩展右子节点,每扩展完一层,才能继续扩展下一层。如下图所示:
+
+
+
+完全二叉树有一个很好的性质:**父结点和子节点的序号有着对应关系。**
+
+细心的小伙伴可能发现了,当根节点的值为 1 的情况下,若父结点的序号是 i,那么左子节点的序号就是 2i,右子节点的序号是 2i+1。这个性质使得完全二叉树利用数组存储时可以极大地节省空间,以及利用序号找到某个节点的父结点和子节点,后续二叉树的存储会详细介绍。
+
+### 平衡二叉树
+
+**平衡二叉树** 是一棵二叉排序树,且具有以下性质:
+
+1. 可以是一棵空树
+2. 如果不是空树,它的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
+
+平衡二叉树的常用实现方法有 **红黑树**、**AVL 树**、**替罪羊树**、**加权平衡树**、**伸展树** 等。
+
+在给大家展示平衡二叉树之前,先给大家看一棵树:
+
+
+
+**你管这玩意儿叫树???**
+
+没错,这玩意儿还真叫树,只不过这棵树已经退化为一个链表了,我们管它叫 **斜树**。
+
+**如果这样,那我为啥不直接用链表呢?**
+
+谁说不是呢?
+
+二叉树相比于链表,由于父子节点以及兄弟节点之间往往具有某种特殊的关系,这种关系使得我们在树中对数据进行**搜索**和**修改**时,相对于链表更加快捷便利。
+
+但是,如果二叉树退化为一个链表了,那么那么树所具有的优秀性质就难以表现出来,效率也会大打折,为了避免这样的情况,我们希望每个做 “家长”(父结点) 的,都 **一碗水端平**,分给左儿子和分给右儿子的尽可能一样多,相差最多不超过一层,如下图所示:
+
+
+
+## 二叉树的存储
+
+二叉树的存储主要分为 **链式存储** 和 **顺序存储** 两种:
+
+### 链式存储
+
+和链表类似,二叉树的链式存储依靠指针将各个节点串联起来,不需要连续的存储空间。
+
+每个节点包括三个属性:
+
+- 数据 data。data 不一定是单一的数据,根据不同情况,可以是多个具有不同类型的数据。
+- 左节点指针 left
+- 右节点指针 right。
+
+可是 JAVA 没有指针啊!
+
+那就直接引用对象呗(别问我对象哪里找)
+
+
+
+### 顺序存储
+
+顺序存储就是利用数组进行存储,数组中的每一个位置仅存储节点的 data,不存储左右子节点的指针,子节点的索引通过数组下标完成。根结点的序号为 1,对于每个节点 Node,假设它存储在数组中下标为 i 的位置,那么它的左子节点就存储在 2 _ i 的位置,它的右子节点存储在下标为 2 _ i+1 的位置。
+
+一棵完全二叉树的数组顺序存储如下图所示:
+
+
+
+大家可以试着填写一下存储如下二叉树的数组,比较一下和完全二叉树的顺序存储有何区别:
+
+
+
+可以看到,如果我们要存储的二叉树不是完全二叉树,在数组中就会出现空隙,导致内存利用率降低
+
+## 二叉树的遍历
+
+### 先序遍历
+
+
+
+二叉树的先序遍历,就是先输出根结点,再遍历左子树,最后遍历右子树,遍历左子树和右子树的时候,同样遵循先序遍历的规则,也就是说,我们可以递归实现先序遍历。
+
+代码如下:
+
+```java
+public void preOrder(TreeNode root){
+ if(root == null){
+ return;
+ }
+ system.out.println(root.data);
+ preOrder(root.left);
+ preOrder(root.right);
+}
+```
+
+### 中序遍历
+
+
+
+二叉树的中序遍历,就是先递归中序遍历左子树,再输出根结点的值,再递归中序遍历右子树,大家可以想象成一巴掌把树压扁,父结点被拍到了左子节点和右子节点的中间,如下图所示:
+
+
+
+代码如下:
+
+```java
+public void inOrder(TreeNode root){
+ if(root == null){
+ return;
+ }
+ inOrder(root.left);
+ system.out.println(root.data);
+ inOrder(root.right);
+}
+```
+
+### 后序遍历
+
+
+
+二叉树的后序遍历,就是先递归后序遍历左子树,再递归后序遍历右子树,最后输出根结点的值
+
+代码如下:
+
+```java
+public void postOrder(TreeNode root){
+ if(root == null){
+ return;
+ }
+ postOrder(root.left);
+ postOrder(root.right);
+ system.out.println(root.data);
+}
+```
\ No newline at end of file
diff --git "a/docs/cs-basics/data-structure/\347\272\242\351\273\221\346\240\221.md" "b/docs/cs-basics/data-structure/\347\272\242\351\273\221\346\240\221.md"
new file mode 100644
index 00000000000..ce18d6e0138
--- /dev/null
+++ "b/docs/cs-basics/data-structure/\347\272\242\351\273\221\346\240\221.md"
@@ -0,0 +1,22 @@
+---
+category: 计算机基础
+tag:
+ - 数据结构
+---
+
+# 红黑树
+
+**红黑树特点** :
+
+1. 每个节点非红即黑;
+2. 根节点总是黑色的;
+3. 每个叶子节点都是黑色的空节点(NIL节点);
+4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
+5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
+
+**红黑树的应用** :TreeMap、TreeSet以及JDK1.8的HashMap底层都用到了红黑树。
+
+**为什么要用红黑树?** 简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
+
+**相关阅读** :[《红黑树深入剖析及Java实现》](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
+
diff --git "a/docs/cs-basics/data-structure/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204.md" "b/docs/cs-basics/data-structure/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204.md"
new file mode 100644
index 00000000000..5a55d496696
--- /dev/null
+++ "b/docs/cs-basics/data-structure/\347\272\277\346\200\247\346\225\260\346\215\256\347\273\223\346\236\204.md"
@@ -0,0 +1,316 @@
+---
+category: 计算机基础
+tag:
+ - 数据结构
+---
+
+# 线性数据结构 :数组、链表、栈、队列
+
+> 开头还是求点赞,求转发!原创优质公众号,希望大家能让更多人看到我们的文章。
+>
+> 图片都是我们手绘的,可以说非常用心了!
+
+## 1. 数组
+
+**数组(Array)** 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。
+
+我们直接可以利用元素的索引(index)可以计算出该元素对应的存储地址。
+
+数组的特点是:**提供随机访问** 并且容量有限。
+
+```java
+假如数组的长度为 n。
+访问:O(1)//访问特定位置的元素
+插入:O(n )//最坏的情况发生在插入发生在数组的首部并需要移动所有元素时
+删除:O(n)//最坏的情况发生在删除数组的开头发生并需要移动第一元素后面所有的元素时
+```
+
+
+
+## 2. 链表
+
+### 2.1. 链表简介
+
+**链表(LinkedList)** 虽然是一种线性表,但是并不会按线性的顺序存储数据,使用的不是连续的内存空间来存储数据。
+
+链表的插入和删除操作的复杂度为 O(1) ,只需要知道目标位置元素的上一个元素即可。但是,在查找一个节点或者访问特定位置的节点的时候复杂度为 O(n) 。
+
+使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但链表不会节省空间,相比于数组会占用更多的空间,因为链表中每个节点存放的还有指向其他节点的指针。除此之外,链表不具有数组随机读取的优点。
+
+### 2.2. 链表分类
+
+**常见链表分类:**
+
+1. 单链表
+2. 双向链表
+3. 循环链表
+4. 双向循环链表
+
+```java
+假如链表中有n个元素。
+访问:O(n)//访问特定位置的元素
+插入删除:O(1)//必须要要知道插入元素的位置
+```
+
+#### 2.2.1. 单链表
+
+**单链表** 单向链表只有一个方向,结点只有一个后继指针 next 指向后面的节点。因此,链表这种数据结构通常在物理内存上是不连续的。我们习惯性地把第一个结点叫作头结点,链表通常有一个不保存任何值的 head 节点(头结点),通过头结点我们可以遍历整个链表。尾结点通常指向 null。
+
+
+
+#### 2.2.2. 循环链表
+
+**循环链表** 其实是一种特殊的单链表,和单链表不同的是循环链表的尾结点不是指向 null,而是指向链表的头结点。
+
+
+
+#### 2.2.3. 双向链表
+
+**双向链表** 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
+
+
+
+#### 2.2.4. 双向循环链表
+
+**双向循环链表** 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
+
+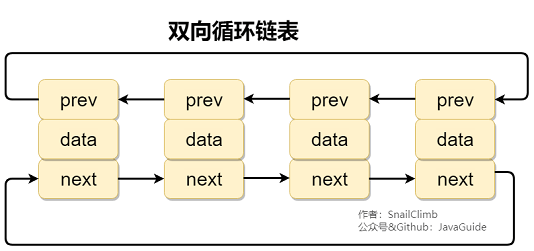
+
+### 2.3. 应用场景
+
+- 如果需要支持随机访问的话,链表没办法做到。
+- 如果需要存储的数据元素的个数不确定,并且需要经常添加和删除数据的话,使用链表比较合适。
+- 如果需要存储的数据元素的个数确定,并且不需要经常添加和删除数据的话,使用数组比较合适。
+
+### 2.4. 数组 vs 链表
+
+- 数组支持随机访问,而链表不支持。
+- 数组使用的是连续内存空间对 CPU 的缓存机制友好,链表则相反。
+- 数组的大小固定,而链表则天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间存放数组元素,然后将原数组拷贝进去,这个操作是比较耗时的!
+
+## 3. 栈
+
+### 3.1. 栈简介
+
+**栈** (stack)只允许在有序的线性数据集合的一端(称为栈顶 top)进行加入数据(push)和移除数据(pop)。因而按照 **后进先出(LIFO, Last In First Out)** 的原理运作。**在栈中,push 和 pop 的操作都发生在栈顶。**
+
+栈常用一维数组或链表来实现,用数组实现的栈叫作 **顺序栈** ,用链表实现的栈叫作 **链式栈** 。
+
+```java
+假设堆栈中有n个元素。
+访问:O(n)//最坏情况
+插入删除:O(1)//顶端插入和删除元素
+```
+
+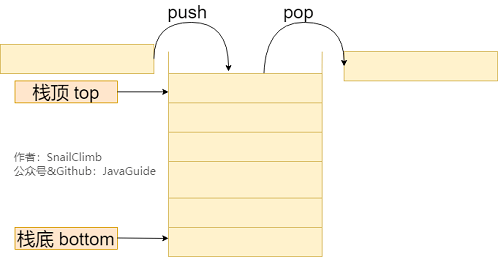
+
+### 3.2. 栈的常见应用常见应用场景
+
+当我们我们要处理的数据只涉及在一端插入和删除数据,并且满足 **后进先出(LIFO, Last In First Out)** 的特性时,我们就可以使用栈这个数据结构。
+
+#### 3.2.1. 实现浏览器的回退和前进功能
+
+我们只需要使用两个栈(Stack1 和 Stack2)和就能实现这个功能。比如你按顺序查看了 1,2,3,4 这四个页面,我们依次把 1,2,3,4 这四个页面压入 Stack1 中。当你想回头看 2 这个页面的时候,你点击回退按钮,我们依次把 4,3 这两个页面从 Stack1 弹出,然后压入 Stack2 中。假如你又想回到页面 3,你点击前进按钮,我们将 3 页面从 Stack2 弹出,然后压入到 Stack1 中。示例图如下:
+
+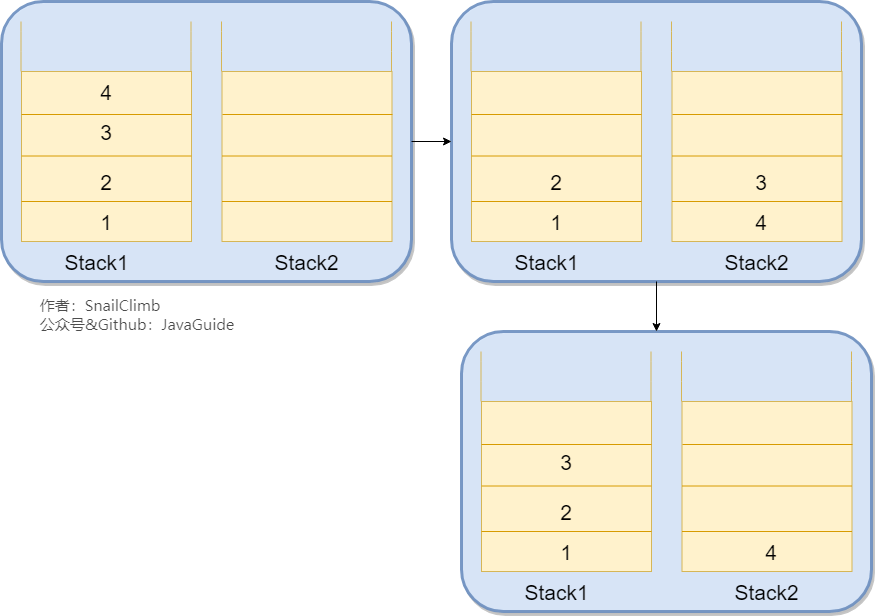
+
+#### 3.2.2. 检查符号是否成对出现
+
+> 给定一个只包括 `'('`,`')'`,`'{'`,`'}'`,`'['`,`']'` 的字符串,判断该字符串是否有效。
+>
+> 有效字符串需满足:
+>
+> 1. 左括号必须用相同类型的右括号闭合。
+> 2. 左括号必须以正确的顺序闭合。
+>
+> 比如 "()"、"()[]{}"、"{[]}" 都是有效字符串,而 "(]" 、"([)]" 则不是。
+
+这个问题实际是 Leetcode 的一道题目,我们可以利用栈 `Stack` 来解决这个问题。
+
+1. 首先我们将括号间的对应规则存放在 `Map` 中,这一点应该毋容置疑;
+2. 创建一个栈。遍历字符串,如果字符是左括号就直接加入`stack`中,否则将`stack` 的栈顶元素与这个括号做比较,如果不相等就直接返回 false。遍历结束,如果`stack`为空,返回 `true`。
+
+```java
+public boolean isValid(String s){
+ // 括号之间的对应规则
+ HashMap<Character, Character> mappings = new HashMap<Character, Character>();
+ mappings.put(')', '(');
+ mappings.put('}', '{');
+ mappings.put(']', '[');
+ Stack<Character> stack = new Stack<Character>();
+ char[] chars = s.toCharArray();
+ for (int i = 0; i < chars.length; i++) {
+ if (mappings.containsKey(chars[i])) {
+ char topElement = stack.empty() ? '#' : stack.pop();
+ if (topElement != mappings.get(chars[i])) {
+ return false;
+ }
+ } else {
+ stack.push(chars[i]);
+ }
+ }
+ return stack.isEmpty();
+}
+```
+
+#### 3.2.3. 反转字符串
+
+将字符串中的每个字符先入栈再出栈就可以了。
+
+#### 3.2.4. 维护函数调用
+
+最后一个被调用的函数必须先完成执行,符合栈的 **后进先出(LIFO, Last In First Out)** 特性。
+
+### 3.3. 栈的实现
+
+栈既可以通过数组实现,也可以通过链表来实现。不管基于数组还是链表,入栈、出栈的时间复杂度都为 O(1)。
+
+下面我们使用数组来实现一个栈,并且这个栈具有`push()`、`pop()`(返回栈顶元素并出栈)、`peek()` (返回栈顶元素不出栈)、`isEmpty()`、`size()`这些基本的方法。
+
+> 提示:每次入栈之前先判断栈的容量是否够用,如果不够用就用`Arrays.copyOf()`进行扩容;
+
+```java
+public class MyStack {
+ private int[] storage;//存放栈中元素的数组
+ private int capacity;//栈的容量
+ private int count;//栈中元素数量
+ private static final int GROW_FACTOR = 2;
+
+ //不带初始容量的构造方法。默认容量为8
+ public MyStack() {
+ this.capacity = 8;
+ this.storage=new int[8];
+ this.count = 0;
+ }
+
+ //带初始容量的构造方法
+ public MyStack(int initialCapacity) {
+ if (initialCapacity < 1)
+ throw new IllegalArgumentException("Capacity too small.");
+
+ this.capacity = initialCapacity;
+ this.storage = new int[initialCapacity];
+ this.count = 0;
+ }
+
+ //入栈
+ public void push(int value) {
+ if (count == capacity) {
+ ensureCapacity();
+ }
+ storage[count++] = value;
+ }
+
+ //确保容量大小
+ private void ensureCapacity() {
+ int newCapacity = capacity * GROW_FACTOR;
+ storage = Arrays.copyOf(storage, newCapacity);
+ capacity = newCapacity;
+ }
+
+ //返回栈顶元素并出栈
+ private int pop() {
+ if (count == 0)
+ throw new IllegalArgumentException("Stack is empty.");
+ count--;
+ return storage[count];
+ }
+
+ //返回栈顶元素不出栈
+ private int peek() {
+ if (count == 0){
+ throw new IllegalArgumentException("Stack is empty.");
+ }else {
+ return storage[count-1];
+ }
+ }
+
+ //判断栈是否为空
+ private boolean isEmpty() {
+ return count == 0;
+ }
+
+ //返回栈中元素的个数
+ private int size() {
+ return count;
+ }
+
+}
+```
+
+验证
+
+```java
+MyStack myStack = new MyStack(3);
+myStack.push(1);
+myStack.push(2);
+myStack.push(3);
+myStack.push(4);
+myStack.push(5);
+myStack.push(6);
+myStack.push(7);
+myStack.push(8);
+System.out.println(myStack.peek());//8
+System.out.println(myStack.size());//8
+for (int i = 0; i < 8; i++) {
+ System.out.println(myStack.pop());
+}
+System.out.println(myStack.isEmpty());//true
+myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
+```
+
+## 4. 队列
+
+### 4.1. 队列简介
+
+**队列** 是 **先进先出( FIFO,First In, First Out)** 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 **顺序队列** ,用链表实现的队列叫作 **链式队列** 。**队列只允许在后端(rear)进行插入操作也就是 入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue**
+
+队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加。
+
+```java
+假设队列中有n个元素。
+访问:O(n)//最坏情况
+插入删除:O(1)//后端插入前端删除元素
+```
+
+
+
+### 4.2. 队列分类
+
+#### 4.2.1. 单队列
+
+单队列就是常见的队列, 每次添加元素时,都是添加到队尾。单队列又分为 **顺序队列(数组实现)** 和 **链式队列(链表实现)**。
+
+**顺序队列存在“假溢出”的问题也就是明明有位置却不能添加的情况。**
+
+假设下图是一个顺序队列,我们将前两个元素 1,2 出队,并入队两个元素 7,8。当进行入队、出队操作的时候,front 和 rear 都会持续往后移动,当 rear 移动到最后的时候,我们无法再往队列中添加数据,即使数组中还有空余空间,这种现象就是 **”假溢出“** 。除了假溢出问题之外,如下图所示,当添加元素 8 的时候,rear 指针移动到数组之外(越界)。
+
+> 为了避免当只有一个元素的时候,队头和队尾重合使处理变得麻烦,所以引入两个指针,front 指针指向对头元素,rear 指针指向队列最后一个元素的下一个位置,这样当 front 等于 rear 时,此队列不是还剩一个元素,而是空队列。——From 《大话数据结构》
+
+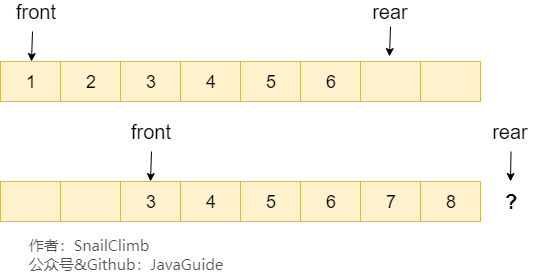
+
+#### 4.2.2. 循环队列
+
+循环队列可以解决顺序队列的假溢出和越界问题。解决办法就是:从头开始,这样也就会形成头尾相接的循环,这也就是循环队列名字的由来。
+
+还是用上面的图,我们将 rear 指针指向数组下标为 0 的位置就不会有越界问题了。当我们再向队列中添加元素的时候, rear 向后移动。
+
+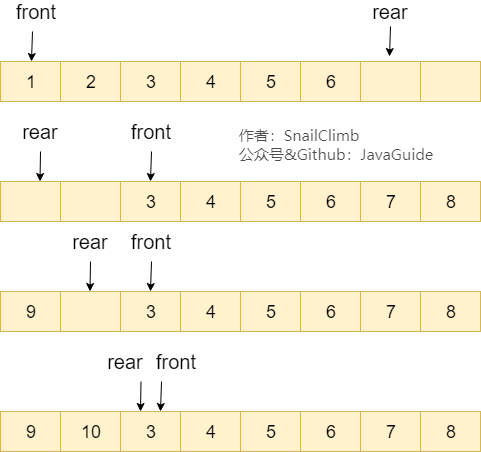
+
+顺序队列中,我们说 `front==rear` 的时候队列为空,循环队列中则不一样,也可能为满,如上图所示。解决办法有两种:
+
+1. 可以设置一个标志变量 `flag`,当 `front==rear` 并且 `flag=0` 的时候队列为空,当`front==rear` 并且 `flag=1` 的时候队列为满。
+2. 队列为空的时候就是 `front==rear` ,队列满的时候,我们保证数组还有一个空闲的位置,rear 就指向这个空闲位置,如下图所示,那么现在判断队列是否为满的条件就是: `(rear+1) % QueueSize= front` 。
+
+
+
+### 4.3. 常见应用场景
+
+当我们需要按照一定顺序来处理数据的时候可以考虑使用队列这个数据结构。
+
+- **阻塞队列:** 阻塞队列可以看成在队列基础上加了阻塞操作的队列。当队列为空的时候,出队操作阻塞,当队列满的时候,入队操作阻塞。使用阻塞队列我们可以很容易实现“生产者 - 消费者“模型。
+- **线程池中的请求/任务队列:** 线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如 :`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出`java.util.concurrent.RejectedExecutionException` 异常。
+- Linux 内核进程队列(按优先级排队)
+- 现实生活中的排队,播放器上的播放列表;
+- 消息队列
+- 等等......
diff --git "a/docs/cs-basics/network/HTTPS\344\270\255\347\232\204TLS.md" "b/docs/cs-basics/network/HTTPS\344\270\255\347\232\204TLS.md"
new file mode 100644
index 00000000000..f665eb22da4
--- /dev/null
+++ "b/docs/cs-basics/network/HTTPS\344\270\255\347\232\204TLS.md"
@@ -0,0 +1,124 @@
+---
+title: HTTPS中的TLS
+category: 计算机基础
+tag:
+ - 计算机网络
+---
+
+# 1. SSL 与 TLS
+
+SSL:(Secure Socket Layer) 安全套接层,于 1994 年由网景公司设计,并于 1995 年发布了 3.0 版本
+TLS:(Transport Layer Security)传输层安全性协议,是 IETF 在 SSL3.0 的基础上设计的协议
+以下全部使用 TLS 来表示
+
+# 2. 从网络协议的角度理解 HTTPS
+
+![此图并不准确][1]
+HTTP:HyperText Transfer Protocol 超文本传输协议
+HTTPS:Hypertext Transfer Protocol Secure 超文本传输安全协议
+TLS:位于 HTTP 和 TCP 之间的协议,其内部有 TLS握手协议、TLS记录协议
+HTTPS 经由 HTTP 进行通信,但利用 TLS 来保证安全,即 HTTPS = HTTP + TLS
+
+# 3. 从密码学的角度理解 HTTPS
+
+HTTPS 使用 TLS 保证安全,这里的“安全”分两部分,一是传输内容加密、二是服务端的身份认证
+
+## 3.1. TLS 工作流程
+
+![此图并不准确][2]
+此为服务端单向认证,还有客户端/服务端双向认证,流程类似,只不过客户端也有自己的证书,并发送给服务器进行验证
+
+## 3.2. 密码基础
+
+### 3.2.1. 伪随机数生成器
+
+为什么叫伪随机数,因为没有真正意义上的随机数,具体可以参考 Random/TheadLocalRandom
+它的主要作用在于生成对称密码的秘钥、用于公钥密码生成秘钥对
+
+### 3.2.2. 消息认证码
+
+消息认证码主要用于验证消息的完整性与消息的认证,其中消息的认证指“消息来自正确的发送者”
+
+>消息认证码用于验证和认证,而不是加密
+
+![消息认证码过程][3]
+
+1. 发送者与接收者事先共享秘钥
+2. 发送者根据发送消息计算 MAC 值
+3. 发送者发送消息和 MAC 值
+4. 接收者根据接收到的消息计算 MAC 值
+5. 接收者根据自己计算的 MAC 值与收到的 MAC 对比
+6. 如果对比成功,说明消息完整,并来自于正确的发送者
+
+### 3.2.3. 数字签名
+
+消息认证码的缺点在于**无法防止否认**,因为共享秘钥被 client、server 两端拥有,server 可以伪造 client 发送给自己的消息(自己给自己发送消息),为了解决这个问题,我们需要它们有各自的秘钥不被第二个知晓(这样也解决了共享秘钥的配送问题)
+
+![数字签名过程][4]
+
+>数字签名和消息认证码都**不是为了加密**
+>可以将单向散列函数获取散列值的过程理解为使用 md5 摘要算法获取摘要的过程
+
+使用自己的私钥对自己所认可的消息生成一个该消息专属的签名,这就是数字签名,表明我承认该消息来自自己
+注意:**私钥用于加签,公钥用于解签,每个人都可以解签,查看消息的归属人**
+
+### 3.2.4. 公钥密码
+
+公钥密码也叫非对称密码,由公钥和私钥组成,它最开始是为了解决秘钥的配送传输安全问题,即,我们不配送私钥,只配送公钥,私钥由本人保管
+它与数字签名相反,公钥密码的私钥用于解密、公钥用于加密,每个人都可以用别人的公钥加密,但只有对应的私钥才能解开密文
+client:明文 + 公钥 = 密文
+server:密文 + 私钥 = 明文
+注意:**公钥用于加密,私钥用于解密,只有私钥的归属者,才能查看消息的真正内容**
+
+### 3.2.5. 证书
+
+证书:全称公钥证书(Public-Key Certificate, PKC),里面保存着归属者的基本信息,以及证书过期时间、归属者的公钥,并由认证机构(Certification Authority, **CA**)施加数字签名,表明,某个认证机构认定该公钥的确属于此人
+
+>想象这个场景:你想在支付宝页面交易,你需要支付宝的公钥进行加密通信,于是你从百度上搜索关键字“支付宝公钥”,你获得了支什宝的公钥,这个时候,支什宝通过中间人攻击,让你访问到了他们支什宝的页面,最后你在这个支什宝页面完美的使用了支什宝的公钥完成了与支什宝的交易
+>![证书过程][5]
+
+在上面的场景中,你可以理解支付宝证书就是由支付宝的公钥、和给支付宝颁发证书的企业的数字签名组成
+任何人都可以给自己或别人的公钥添加自己的数字签名,表明:我拿我的尊严担保,我的公钥/别人的公钥是真的,至于信不信那是另一回事了
+
+### 3.2.6. 密码小结
+
+| 密码 | 作用 | 组成 |
+| :-- | :-- | :-- |
+| 消息认证码 | 确认消息的完整、并对消息的来源认证 | 共享秘钥+消息的散列值 |
+| 数字签名 | 对消息的散列值签名 | 公钥+私钥+消息的散列值 |
+| 公钥密码 | 解决秘钥的配送问题 | 公钥+私钥+消息 |
+| 证书 | 解决公钥的归属问题 | 公钥密码中的公钥+数字签名 |
+
+## 3.3. TLS 使用的密码技术
+
+1. 伪随机数生成器:秘钥生成随机性,更难被猜测
+2. 对称密码:对称密码使用的秘钥就是由伪随机数生成,相较于非对称密码,效率更高
+3. 消息认证码:保证消息信息的完整性、以及验证消息信息的来源
+4. 公钥密码:证书技术使用的就是公钥密码
+5. 数字签名:验证证书的签名,确定由真实的某个 CA 颁发
+6. 证书:解决公钥的真实归属问题,降低中间人攻击概率
+
+## 3.4. TLS 总结
+
+TLS 是一系列密码工具的框架,作为框架,它也是非常的灵活,体现在每个工具套件它都可以替换,即:客户端与服务端之间协商密码套件,从而更难的被攻破,例如使用不同方式的对称密码,或者公钥密码、数字签名生成方式、单向散列函数技术的替换等
+
+# 4. RSA 简单示例
+
+RSA 是一种公钥密码算法,我们简单的走一遍它的加密解密过程
+加密算法:密文 = (明文^E) mod N,其中公钥为{E,N},即”求明文的E次方的对 N 的余数“
+解密算法:明文 = (密文^D) mod N,其中秘钥为{D,N},即”求密文的D次方的对 N 的余数“
+例:我们已知公钥为{5,323},私钥为{29,323},明文为300,请写出加密和解密的过程:
+>加密:密文 = 123 ^ 5 mod 323 = 225
+>解密:明文 = 225 ^ 29 mod 323 = [[(225 ^ 5) mod 323] * [(225 ^ 5) mod 323] * [(225 ^ 5) mod 323] * [(225 ^ 5) mod 323] * [(225 ^ 5) mod 323] * [(225 ^ 4) mod 323]] mod 323 = (4 * 4 * 4 * 4 * 4 * 290) mod 323 = 123
+
+# 5. 参考
+
+1. SSL加密发生在哪里:<https://security.stackexchange.com/questions/19681/where-does-ssl-encryption-take-place>
+2. TLS工作流程:<https://blog.csdn.net/ustccw/article/details/76691248>
+3. 《图解密码技术》:<https://book.douban.com/subject/26822106/> 豆瓣评分 9.5
+
+[1]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/%E4%B8%83%E5%B1%82.png
+[2]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/tls%E6%B5%81%E7%A8%8B.png
+[3]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/%E6%B6%88%E6%81%AF%E8%AE%A4%E8%AF%81%E7%A0%81%E8%BF%87%E7%A8%8B.png
+[4]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/%E6%95%B0%E5%AD%97%E7%AD%BE%E5%90%8D%E8%BF%87%E7%A8%8B.png
+[5]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/dns%E4%B8%AD%E9%97%B4%E4%BA%BA%E6%94%BB%E5%87%BB.png
\ No newline at end of file
diff --git a/docs/cs-basics/network/images/Cut-Trough-Switching_0.gif b/docs/cs-basics/network/images/Cut-Trough-Switching_0.gif
new file mode 100644
index 00000000000..170dc3bbb19
Binary files /dev/null and b/docs/cs-basics/network/images/Cut-Trough-Switching_0.gif differ
diff --git a/docs/cs-basics/network/images/isp.png b/docs/cs-basics/network/images/isp.png
new file mode 100644
index 00000000000..fe5c0e96adb
Binary files /dev/null and b/docs/cs-basics/network/images/isp.png differ
diff --git "a/docs/cs-basics/network/images/\344\270\203\345\261\202\344\275\223\347\263\273\347\273\223\346\236\204\345\233\276.png" "b/docs/cs-basics/network/images/\344\270\203\345\261\202\344\275\223\347\263\273\347\273\223\346\236\204\345\233\276.png"
new file mode 100644
index 00000000000..a2d24300fcb
Binary files /dev/null and "b/docs/cs-basics/network/images/\344\270\203\345\261\202\344\275\223\347\263\273\347\273\223\346\236\204\345\233\276.png" differ
diff --git "a/docs/cs-basics/network/images/\344\274\240\350\276\223\345\261\202.png" "b/docs/cs-basics/network/images/\344\274\240\350\276\223\345\261\202.png"
new file mode 100644
index 00000000000..192af24536b
Binary files /dev/null and "b/docs/cs-basics/network/images/\344\274\240\350\276\223\345\261\202.png" differ
diff --git "a/docs/cs-basics/network/images/\345\272\224\347\224\250\345\261\202.png" "b/docs/cs-basics/network/images/\345\272\224\347\224\250\345\261\202.png"
new file mode 100644
index 00000000000..31e1e447b73
Binary files /dev/null and "b/docs/cs-basics/network/images/\345\272\224\347\224\250\345\261\202.png" differ
diff --git "a/docs/cs-basics/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png" "b/docs/cs-basics/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png"
new file mode 100644
index 00000000000..c2b51a7c589
Binary files /dev/null and "b/docs/cs-basics/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png" differ
diff --git "a/docs/cs-basics/network/images/\347\211\251\347\220\206\345\261\202.png" "b/docs/cs-basics/network/images/\347\211\251\347\220\206\345\261\202.png"
new file mode 100644
index 00000000000..abb979261c1
Binary files /dev/null and "b/docs/cs-basics/network/images/\347\211\251\347\220\206\345\261\202.png" differ
diff --git "a/docs/cs-basics/network/images/\347\275\221\347\273\234\345\261\202.png" "b/docs/cs-basics/network/images/\347\275\221\347\273\234\345\261\202.png"
new file mode 100644
index 00000000000..376479d7989
Binary files /dev/null and "b/docs/cs-basics/network/images/\347\275\221\347\273\234\345\261\202.png" differ
diff --git "a/docs/cs-basics/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png" "b/docs/cs-basics/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png"
new file mode 100644
index 00000000000..6af03daa96a
Binary files /dev/null and "b/docs/cs-basics/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png" differ
diff --git "a/docs/cs-basics/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230.md" "b/docs/cs-basics/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230.md"
new file mode 100644
index 00000000000..ef63192cb18
--- /dev/null
+++ "b/docs/cs-basics/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230.md"
@@ -0,0 +1,309 @@
+---
+title: 计算机网络常见面试题
+category: 计算机基础
+tag:
+ - 计算机网络
+---
+
+## 一 OSI 与 TCP/IP 各层的结构与功能, 都有哪些协议?
+
+学习计算机网络时我们一般采用折中的办法,也就是中和 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚。
+
+
+
+结合互联网的情况,自上而下地,非常简要的介绍一下各层的作用。
+
+### 1.1 应用层
+
+**应用层(application-layer)的任务是通过应用进程间的交互来完成特定网络应用。**应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和交互的规则。对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如**域名系统 DNS**,支持万维网应用的 **HTTP 协议**,支持电子邮件的 **SMTP 协议**等等。我们把应用层交互的数据单元称为报文。
+
+**域名系统**
+
+> 域名系统(Domain Name System 缩写 DNS,Domain Name 被译为域名)是因特网的一项核心服务,它作为可以将域名和 IP 地址相互映射的一个分布式数据库,能够使人更方便的访问互联网,而不用去记住能够被机器直接读取的 IP 数串。(百度百科)例如:一个公司的 Web 网站可看作是它在网上的门户,而域名就相当于其门牌地址,通常域名都使用该公司的名称或简称。例如上面提到的微软公司的域名,类似的还有:IBM 公司的域名是 www.ibm.com、Oracle 公司的域名是 www.oracle.com、Cisco 公司的域名是 www.cisco.com 等。
+
+**HTTP 协议**
+
+> 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW(万维网) 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。(百度百科)
+
+### 1.2 运输层
+
+**运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务**。应用进程利用该服务传送应用层报文。“通用的”是指并不针对某一个特定的网络应用,而是多种应用可以使用同一个运输层服务。由于一台主机可同时运行多个线程,因此运输层有复用和分用的功能。所谓复用就是指多个应用层进程可同时使用下面运输层的服务,分用和复用相反,是运输层把收到的信息分别交付上面应用层中的相应进程。
+
+**运输层主要使用以下两种协议:**
+
+1. **传输控制协议 TCP**(Transmission Control Protocol)--提供**面向连接**的,**可靠的**数据传输服务。
+2. **用户数据协议 UDP**(User Datagram Protocol)--提供**无连接**的,尽最大努力的数据传输服务(**不保证数据传输的可靠性**)。
+
+**TCP 与 UDP 的对比见问题三。**
+
+### 1.3 网络层
+
+**在计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。** 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 **IP 协议**,因此分组也叫 **IP 数据报** ,简称 **数据报**。
+
+这里要注意:**不要把运输层的“用户数据报 UDP ”和网络层的“ IP 数据报”弄混**。另外,无论是哪一层的数据单元,都可笼统地用“分组”来表示。
+
+这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称.
+
+互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Internet Protocol)和许多路由选择协议,因此互联网的网络层也叫做**网际层**或**IP 层**。
+
+### 1.4 数据链路层
+
+**数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。** 在两个相邻节点之间传送数据时,**数据链路层将网络层交下来的 IP 数据报组装成帧**,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
+
+在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结束。这样,数据链路层在收到一个帧后,就可从中提出数据部分,上交给网络层。
+控制信息还使接收端能够检测到所收到的帧中有无差错。如果发现差错,数据链路层就简单地丢弃这个出了差错的帧,以避免继续在网络中传送下去白白浪费网络资源。如果需要改正数据在链路层传输时出现差错(这就是说,数据链路层不仅要检错,而且还要纠错),那么就要采用可靠性传输协议来纠正出现的差错。这种方法会使链路层的协议复杂些。
+
+### 1.5 物理层
+
+在物理层上所传送的数据单位是比特。
+
+**物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异,** 使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
+
+在互联网使用的各种协议中最重要和最著名的就是 TCP/IP 两个协议。现在人们经常提到的 TCP/IP 并不一定单指 TCP 和 IP 这两个具体的协议,而往往表示互联网所使用的整个 TCP/IP 协议族。
+
+### 1.6 总结一下
+
+上面我们对计算机网络的五层体系结构有了初步的了解,下面附送一张七层体系结构图总结一下(图片来源于网络)。
+
+
+
+## 二 TCP 三次握手和四次挥手(面试常客)
+
+为了准确无误地把数据送达目标处,TCP 协议采用了三次握手策略。
+
+### 2.1 TCP 三次握手漫画图解
+
+如下图所示,下面的两个机器人通过 3 次握手确定了对方能正确接收和发送消息(图片来源:《图解 HTTP》)。
+
+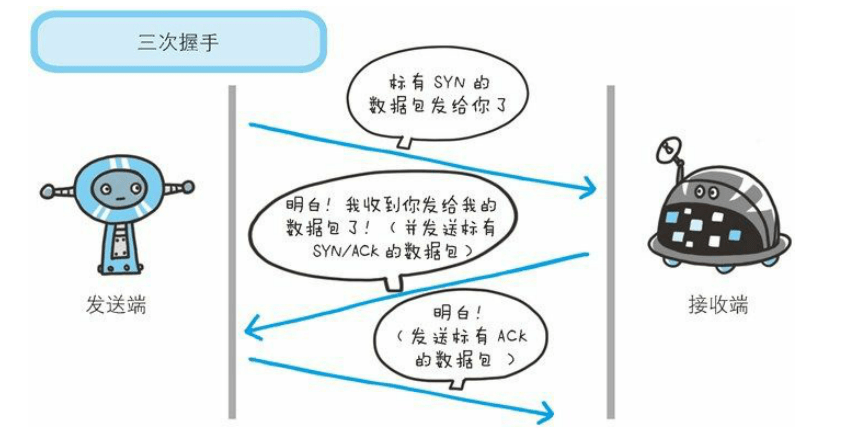
+
+**简单示意图:**
+
+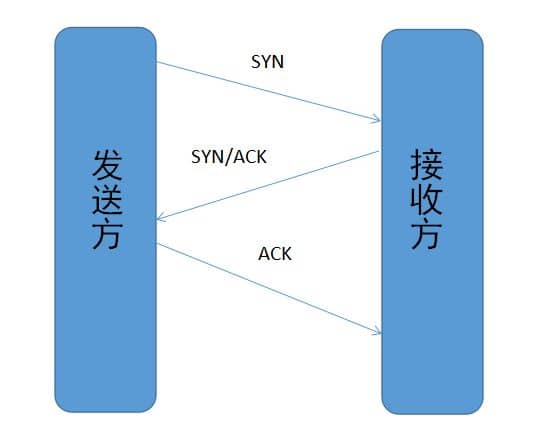
+
+* 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
+* 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
+* 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
+
+**详细示意图(图片来源不详)**
+
+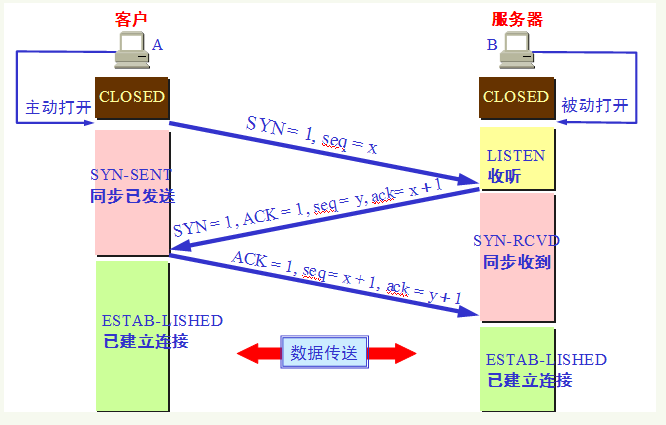
+
+### 2.2 为什么要三次握手
+
+**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
+
+第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
+
+第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
+
+第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
+
+所以三次握手就能确认双发收发功能都正常,缺一不可。
+
+### 2.3 第 2 次握手传回了 ACK,为什么还要传回 SYN?
+
+接收端传回发送端所发送的 ACK 是为了告诉客户端,我接收到的信息确实就是你所发送的信号了,这表明从客户端到服务端的通信是正常的。而回传 SYN 则是为了建立并确认从服务端到客户端的通信。”
+
+> SYN 同步序列编号(Synchronize Sequence Numbers) 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement)消息响应。这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
+
+### 2.5 为什么要四次挥手
+
+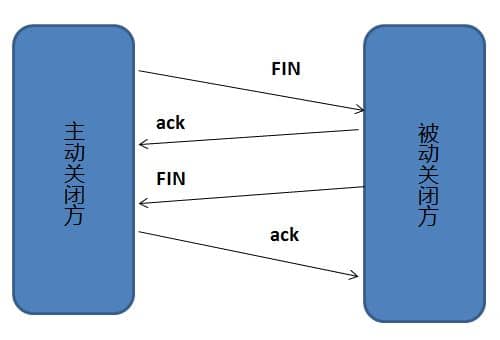
+
+断开一个 TCP 连接则需要“四次挥手”:
+
+* 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
+* 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加 1 。和 SYN 一样,一个 FIN 将占用一个序号
+* 服务器-关闭与客户端的连接,发送一个 FIN 给客户端
+* 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加 1
+
+任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
+
+举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
+
+上面讲的比较概括,推荐一篇讲的比较细致的文章:[https://blog.csdn.net/qzcsu/article/details/72861891](https://blog.csdn.net/qzcsu/article/details/72861891)
+
+## 三 TCP, UDP 协议的区别
+
+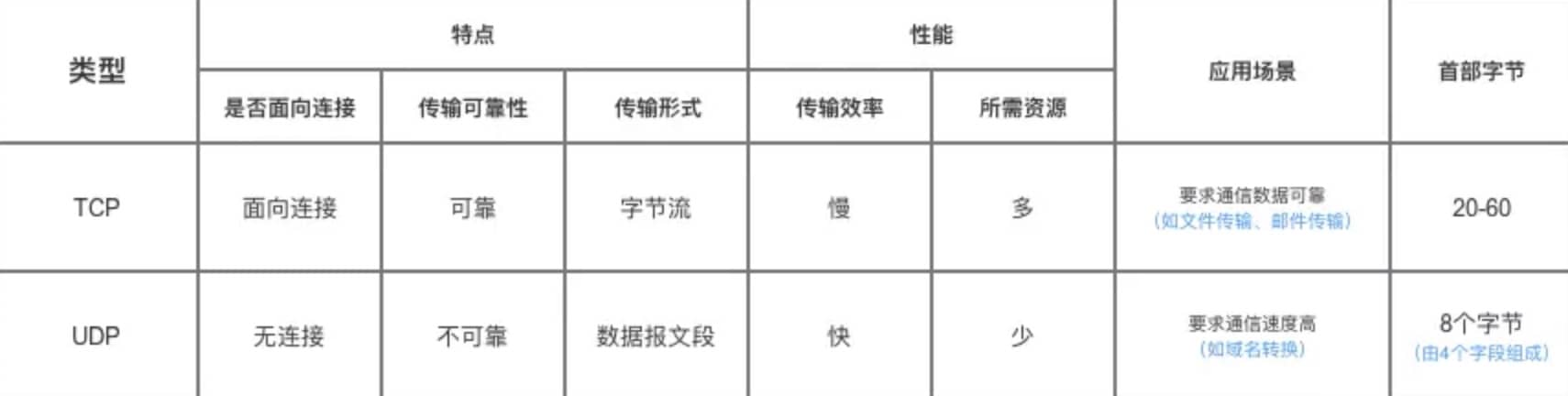
+
+UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 却是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
+
+TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务(TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
+
+## 四 TCP 协议如何保证可靠传输
+
+1. 应用数据被分割成 TCP 认为最适合发送的数据块。
+2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
+3. **校验和:** TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
+4. TCP 的接收端会丢弃重复的数据。
+5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
+6. **拥塞控制:** 当网络拥塞时,减少数据的发送。
+7. **ARQ 协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
+8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
+
+### 4.1 ARQ 协议
+
+**自动重传请求**(Automatic Repeat-reQuest,ARQ)是 OSI 模型中数据链路层和传输层的错误纠正协议之一。它通过使用确认和超时这两个机制,在不可靠服务的基础上实现可靠的信息传输。如果发送方在发送后一段时间之内没有收到确认帧,它通常会重新发送。ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
+
+#### 停止等待 ARQ 协议
+
+停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认(回复 ACK)。如果过了一段时间(超时时间后),还是没有收到 ACK 确认,说明没有发送成功,需要重新发送,直到收到确认后再发下一个分组。
+
+在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认。
+
+**优缺点:**
+
+* **优点:** 简单
+* **缺点:** 信道利用率低,等待时间长
+
+**1) 无差错情况:**
+
+发送方发送分组, 接收方在规定时间内收到, 并且回复确认. 发送方再次发送。
+
+**2) 出现差错情况(超时重传):**
+
+停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为 **自动重传请求 ARQ** 。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。**连续 ARQ 协议** 可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
+
+**3) 确认丢失和确认迟到**
+
+* **确认丢失** :确认消息在传输过程丢失。当 A 发送 M1 消息,B 收到后,B 向 A 发送了一个 M1 确认消息,但却在传输过程中丢失。而 A 并不知道,在超时计时过后,A 重传 M1 消息,B 再次收到该消息后采取以下两点措施:1. 丢弃这个重复的 M1 消息,不向上层交付。 2. 向 A 发送确认消息。(不会认为已经发送过了,就不再发送。A 能重传,就证明 B 的确认消息丢失)。
+* **确认迟到** :确认消息在传输过程中迟到。A 发送 M1 消息,B 收到并发送确认。在超时时间内没有收到确认消息,A 重传 M1 消息,B 仍然收到并继续发送确认消息(B 收到了 2 份 M1)。此时 A 收到了 B 第二次发送的确认消息。接着发送其他数据。过了一会,A 收到了 B 第一次发送的对 M1 的确认消息(A 也收到了 2 份确认消息)。处理如下:1. A 收到重复的确认后,直接丢弃。2. B 收到重复的 M1 后,也直接丢弃重复的 M1。
+
+#### 连续 ARQ 协议
+
+连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
+
+**优缺点:**
+
+* **优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
+* **缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5 条 消息,中间第三条丢失(3 号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
+
+### 4.2 滑动窗口和流量控制
+
+**TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。** 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
+
+### 4.3 拥塞控制
+
+在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
+
+为了进行拥塞控制,TCP 发送方要维持一个 **拥塞窗口(cwnd)** 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
+
+TCP 的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免** 、**快重传** 和 **快恢复**。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
+
+* **慢开始:** 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd 初始值为 1,每经过一个传播轮次,cwnd 加倍。
+* **拥塞避免:** 拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢增大,即每经过一个往返时间 RTT 就把发送放的 cwnd 加 1.
+* **快重传与快恢复:**
+ 在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。 当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
+
+## 五 在浏览器中输入 url 地址 ->> 显示主页的过程(面试常客)
+
+百度好像最喜欢问这个问题。
+
+> 打开一个网页,整个过程会使用哪些协议?
+
+图解(图片来源:《图解 HTTP》):
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/url输入到展示出来的过程.jpg" style="zoom:50%; " />
+
+> 上图有一个错误,请注意,是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
+
+总体来说分为以下几个过程:
+
+1. DNS 解析
+2. TCP 连接
+3. 发送 HTTP 请求
+4. 服务器处理请求并返回 HTTP 报文
+5. 浏览器解析渲染页面
+6. 连接结束
+
+具体可以参考下面这篇文章:
+
+* [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700)
+
+## 六 状态码
+
+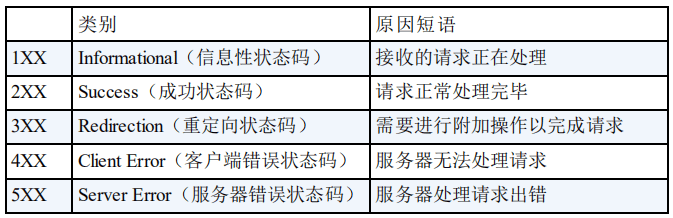
+
+## 七 各种协议与 HTTP 协议之间的关系
+
+一般面试官会通过这样的问题来考察你对计算机网络知识体系的理解。
+
+图片来源:《图解 HTTP》
+
+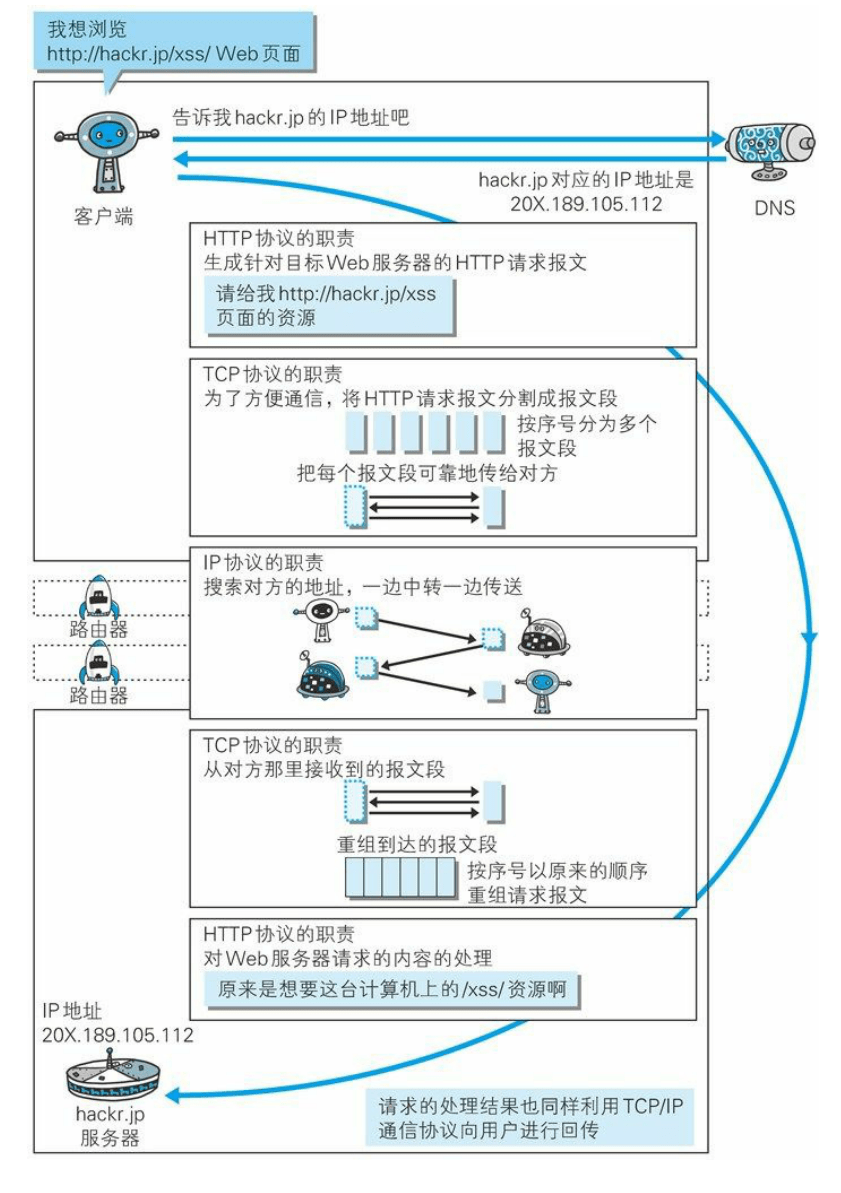
+
+## 八 HTTP 长连接, 短连接
+
+在 HTTP/1.0 中默认使用短连接。也就是说,客户端和服务器每进行一次 HTTP 操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如 JavaScript 文件、图像文件、CSS 文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个 HTTP 会话。
+
+而从 HTTP/1.1 起,默认使用长连接,用以保持连接特性。使用长连接的 HTTP 协议,会在响应头加入这行代码:
+
+```
+Connection:keep-alive
+```
+
+在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive 不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如 Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
+
+**HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。**
+
+—— [《HTTP 长连接、短连接究竟是什么?》](https://www.cnblogs.com/gotodsp/p/6366163.html)
+
+## 九 HTTP 是不保存状态的协议, 如何保存用户状态?
+
+HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个 Session)。
+
+在服务端保存 Session 的方法很多,最常用的就是内存和数据库(比如是使用内存数据库 redis 保存)。既然 Session 存放在服务器端,那么我们如何实现 Session 跟踪呢?大部分情况下,我们都是通过在 Cookie 中附加一个 Session ID 来方式来跟踪。
+
+**Cookie 被禁用怎么办?**
+
+最常用的就是利用 URL 重写把 Session ID 直接附加在 URL 路径的后面。
+
+
+
+## 十 Cookie 的作用是什么? 和 Session 有什么区别?
+
+Cookie 和 Session 都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
+
+**Cookie 一般用来保存用户信息** 比如 ① 我们在 Cookie 中保存已经登录过得用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了;② 一般的网站都会有保持登录也就是说下次你再访问网站的时候就不需要重新登录了,这是因为用户登录的时候我们可以存放了一个 Token 在 Cookie 中,下次登录的时候只需要根据 Token 值来查找用户即可(为了安全考虑,重新登录一般要将 Token 重写);③ 登录一次网站后访问网站其他页面不需要重新登录。**Session 的主要作用就是通过服务端记录用户的状态。** 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
+
+Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。
+
+Cookie 存储在客户端中,而 Session 存储在服务器上,相对来说 Session 安全性更高。如果要在 Cookie 中存储一些敏感信息,不要直接写入 Cookie 中,最好能将 Cookie 信息加密然后使用到的时候再去服务器端解密。
+
+## 十一 HTTP 1.0 和 HTTP 1.1 的主要区别是什么?
+
+> 这部分回答引用这篇文章 <https://mp.weixin.qq.com/s/GICbiyJpINrHZ41u_4zT-A?> 的一些内容。
+
+HTTP1.0 最早在网页中使用是在 1996 年,那个时候只是使用一些较为简单的网页上和网络请求上,而 HTTP1.1 则在 1999 年才开始广泛应用于现在的各大浏览器网络请求中,同时 HTTP1.1 也是当前使用最为广泛的 HTTP 协议。 主要区别主要体现在:
+
+1. **长连接** : **在 HTTP/1.0 中,默认使用的是短连接**,也就是说每次请求都要重新建立一次连接。HTTP 是基于 TCP/IP 协议的,每一次建立或者断开连接都需要三次握手四次挥手的开销,如果每次请求都要这样的话,开销会比较大。因此最好能维持一个长连接,可以用个长连接来发多个请求。**HTTP 1.1 起,默认使用长连接** ,默认开启 Connection: keep-alive。 **HTTP/1.1 的持续连接有非流水线方式和流水线方式** 。流水线方式是客户在收到 HTTP 的响应报文之前就能接着发送新的请求报文。与之相对应的非流水线方式是客户在收到前一个响应后才能发送下一个请求。
+1. **错误状态响应码** :在 HTTP1.1 中新增了 24 个错误状态响应码,如 409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
+1. **缓存处理** :在 HTTP1.0 中主要使用 header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
+1. **带宽优化及网络连接的使用** :HTTP1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
+
+## 十二 URI 和 URL 的区别是什么?
+
+* URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
+* URL(Uniform Resource Locator) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
+
+URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL 是一种具体的 URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
+
+## 十三 HTTP 和 HTTPS 的区别?
+
+1. **端口** :HTTP 的 URL 由“http://”起始且默认使用端口80,而HTTPS的URL由“https://”起始且默认使用端口443。
+2. **安全性和资源消耗:** HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
+ - 对称加密:密钥只有一个,加密解密为同一个密码,且加解密速度快,典型的对称加密算法有 DES、AES 等;
+ - 非对称加密:密钥成对出现(且根据公钥无法推知私钥,根据私钥也无法推知公钥),加密解密使用不同密钥(公钥加密需要私钥解密,私钥加密需要公钥解密),相对对称加密速度较慢,典型的非对称加密算法有 RSA、DSA 等。
+
+## 建议
+
+非常推荐大家看一下 《图解 HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
+
+## 参考
+
+* [https://blog.csdn.net/qq_16209077/article/details/52718250](https://blog.csdn.net/qq_16209077/article/details/52718250)
+* [https://blog.csdn.net/zixiaomuwu/article/details/60965466](https://blog.csdn.net/zixiaomuwu/article/details/60965466)
+* [https://blog.csdn.net/turn\_\_back/article/details/73743641](https://blog.csdn.net/turn__back/article/details/73743641)
+* <https://mp.weixin.qq.com/s/GICbiyJpINrHZ41u_4zT-A?>
diff --git "a/docs/cs-basics/network/\350\260\242\345\270\214\344\273\201\350\200\201\345\270\210\347\232\204\343\200\212\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\343\200\213\345\206\205\345\256\271\346\200\273\347\273\223.md" "b/docs/cs-basics/network/\350\260\242\345\270\214\344\273\201\350\200\201\345\270\210\347\232\204\343\200\212\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\343\200\213\345\206\205\345\256\271\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..df0b07537fd
--- /dev/null
+++ "b/docs/cs-basics/network/\350\260\242\345\270\214\344\273\201\350\200\201\345\270\210\347\232\204\343\200\212\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\343\200\213\345\206\205\345\256\271\346\200\273\347\273\223.md"
@@ -0,0 +1,355 @@
+---
+title: 谢希仁老师的《计算机网络》内容总结
+category: 计算机基础
+tag:
+ - 计算机网络
+---
+
+
+本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的《计算机网络》这本书。
+
+为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
+
+
+
+<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
+
+<!-- code_chunk_output -->
+
+- [1. 计算机网络概述](#1-计算机网络概述)
+ - [1.1. 基本术语](#11-基本术语)
+ - [1.2. 重要知识点总结](#12-重要知识点总结)
+- [2. 物理层(Physical Layer)](#2-物理层physical-layer)
+ - [2.1. 基本术语](#21-基本术语)
+ - [2.2. 重要知识点总结](#22-重要知识点总结)
+ - [2.3. 补充](#23-补充)
+ - [2.3.1. 物理层主要做啥?](#231-物理层主要做啥)
+ - [2.3.2. 几种常用的信道复用技术](#232-几种常用的信道复用技术)
+ - [2.3.3. 几种常用的宽带接入技术,主要是 ADSL 和 FTTx](#233-几种常用的宽带接入技术主要是-adsl-和-fttx)
+- [3. 数据链路层(Data Link Layer)](#3-数据链路层data-link-layer)
+ - [3.1. 基本术语](#31-基本术语)
+ - [3.2. 重要知识点总结](#32-重要知识点总结)
+ - [3.3. 补充](#33-补充)
+- [4. 网络层(Network Layer)](#4-网络层network-layer)
+ - [4.1. 基本术语](#41-基本术语)
+ - [4.2. 重要知识点总结](#42-重要知识点总结)
+- [5. 传输层(Transport Layer)](#5-传输层transport-layer)
+ - [5.1. 基本术语](#51-基本术语)
+ - [5.2. 重要知识点总结](#52-重要知识点总结)
+ - [5.3. 补充(重要)](#53-补充重要)
+- [6. 应用层(Application Layer)](#6-应用层application-layer)
+ - [6.1. 基本术语](#61-基本术语)
+ - [6.2. 重要知识点总结](#62-重要知识点总结)
+ - [6.3. 补充(重要)](#63-补充重要)
+
+<!-- /code_chunk_output -->
+
+
+## 1. 计算机网络概述
+
+### 1.1. 基本术语
+
+1. **结点 (node)** :网络中的结点可以是计算机,集线器,交换机或路由器等。
+2. **链路(link )** : 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
+3. **主机(host)** :连接在因特网上的计算机。
+4. **ISP(Internet Service Provider)** :因特网服务提供者(提供商)。
+
+
+
+5. **IXP(Internet eXchange Point)** : 互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
+
+
+
+<p style="text-align:center;font-size:13px;color:gray">https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive</p>
+
+6. **RFC(Request For Comments)** :意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
+7. **广域网 WAN(Wide Area Network)** :任务是通过长距离运送主机发送的数据。
+8. **城域网 MAN(Metropolitan Area Network)**:用来将多个局域网进行互连。
+9. **局域网 LAN(Local Area Network)** : 学校或企业大多拥有多个互连的局域网。
+
+
+
+<p style="text-align:center;font-size:13px;color:gray">http://conexionesmanwman.blogspot.com/</p>
+
+10. **个人区域网 PAN(Personal Area Network)** :在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
+
+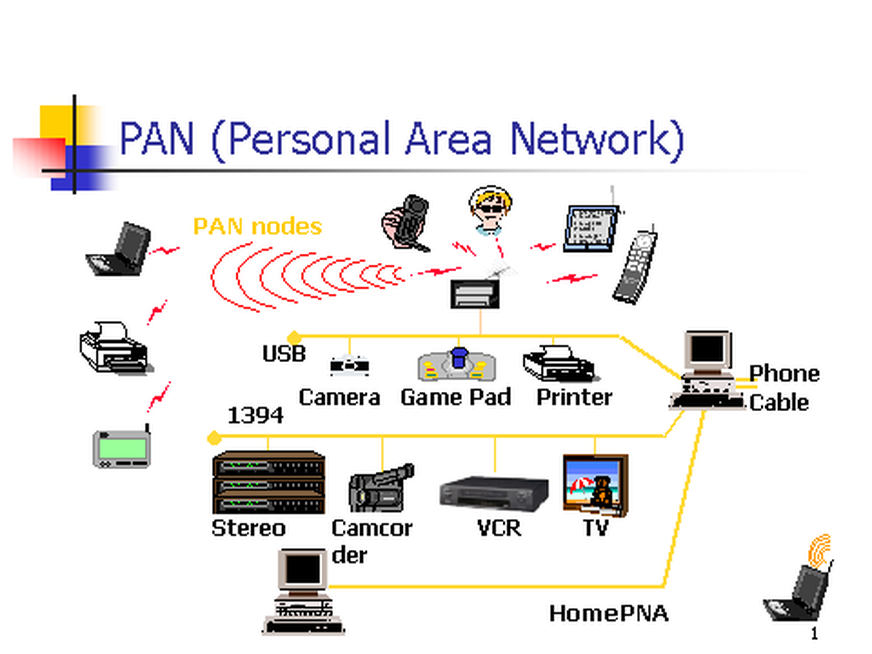
+
+<p style="text-align:center;font-size:13px;color:gray">https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/</p>
+
+12. **分组(packet )** :因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
+13. **存储转发(store and forward )** :路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
+
+
+
+14. **带宽(bandwidth)** :在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
+15. **吞吐量(throughput )** :表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
+
+### 1.2. 重要知识点总结
+
+1. **计算机网络(简称网络)把许多计算机连接在一起,而互联网把许多网络连接在一起,是网络的网络。**
+2. 小写字母 i 开头的 internet(互联网)是通用名词,它泛指由多个计算机网络相互连接而成的网络。在这些网络之间的通信协议(即通信规则)可以是任意的。大写字母 I 开头的 Internet(互联网)是专用名词,它指全球最大的,开放的,由众多网络相互连接而成的特定的互联网,并采用 TCP/IP 协议作为通信规则,其前身为 ARPANET。Internet 的推荐译名为因特网,现在一般流行称为互联网。
+3. 路由器是实现分组交换的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后再进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据端的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组又称为包。分组是在互联网中传送的数据单元,正是由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
+4. 互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由器组成核心部分,其作用是提供连通性和交换。
+5. 计算机通信是计算机中进程(即运行着的程序)之间的通信。计算机网络采用的通信方式是客户-服务器方式(C/S 方式)和对等连接方式(P2P 方式)。
+6. 客户和服务器都是指通信中所涉及的应用进程。客户是服务请求方,服务器是服务提供方。
+7. 按照作用范围的不同,计算机网络分为广域网 WAN,城域网 MAN,局域网 LAN,个人区域网 PAN。
+8. **计算机网络最常用的性能指标是:速率,带宽,吞吐量,时延(发送时延,处理时延,排队时延),时延带宽积,往返时间和信道利用率。**
+9. 网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
+10. **五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是 TCP 和 UDP 协议,网络层最重要的协议是 IP 协议。**
+
+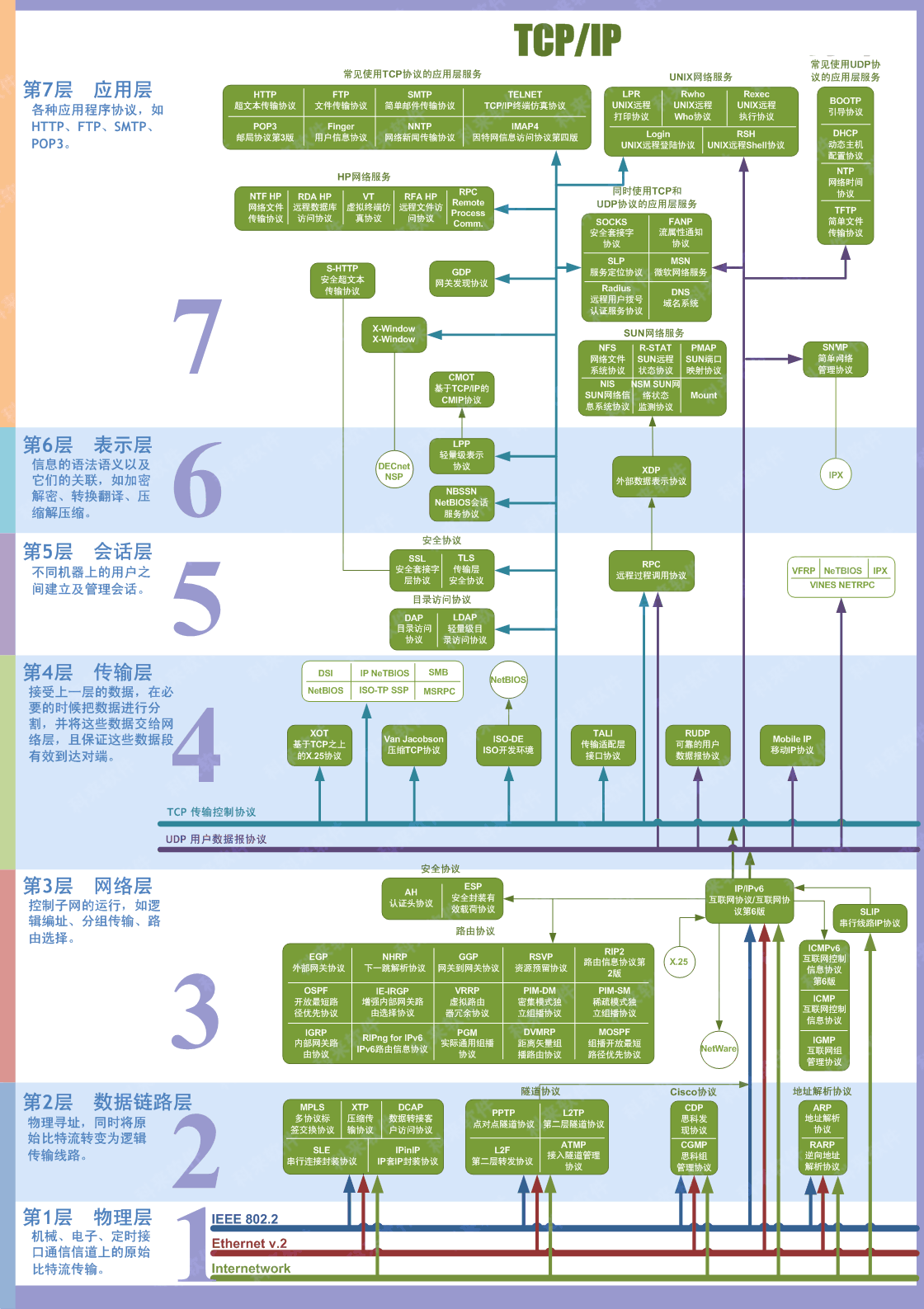
+
+下面的内容会介绍计算机网络的五层体系结构:**物理层+数据链路层+网络层(网际层)+运输层+应用层**。
+
+## 2. 物理层(Physical Layer)
+
+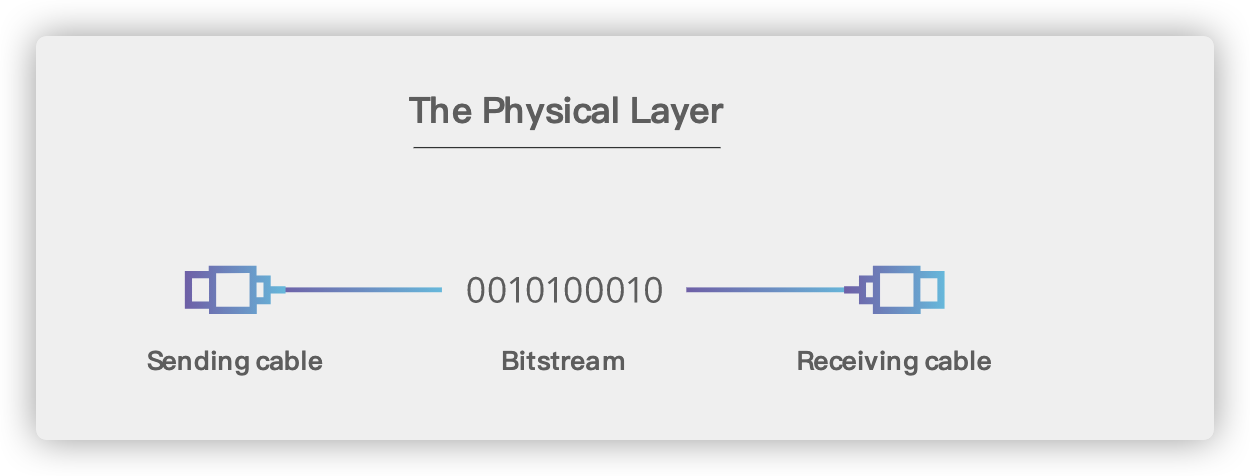
+
+### 2.1. 基本术语
+
+1. **数据(data)** :运送消息的实体。
+2. **信号(signal)** :数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
+3. **码元( code)** :在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
+4. **单工(simplex )** : 只能有一个方向的通信而没有反方向的交互。
+5. **半双工(half duplex )** :通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
+6. **全双工(full duplex)** : 通信的双方可以同时发送和接收信息。
+
+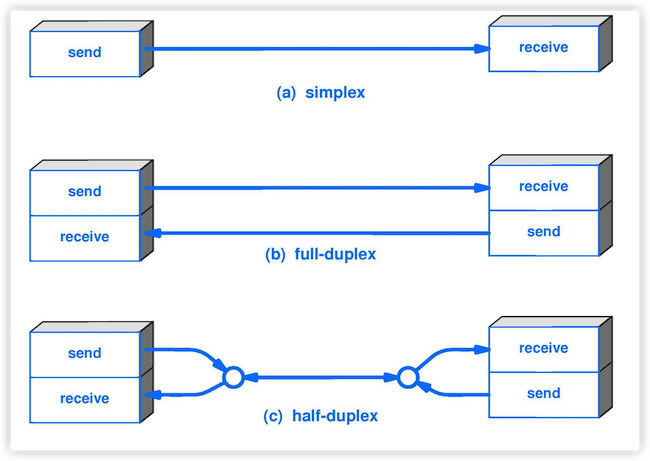
+
+7. **失真**:失去真实性,主要是指接受到的信号和发送的信号不同,有磨损和衰减。影响失真程度的因素:1.码元传输速率 2.信号传输距离 3.噪声干扰 4.传输媒体质量
+
+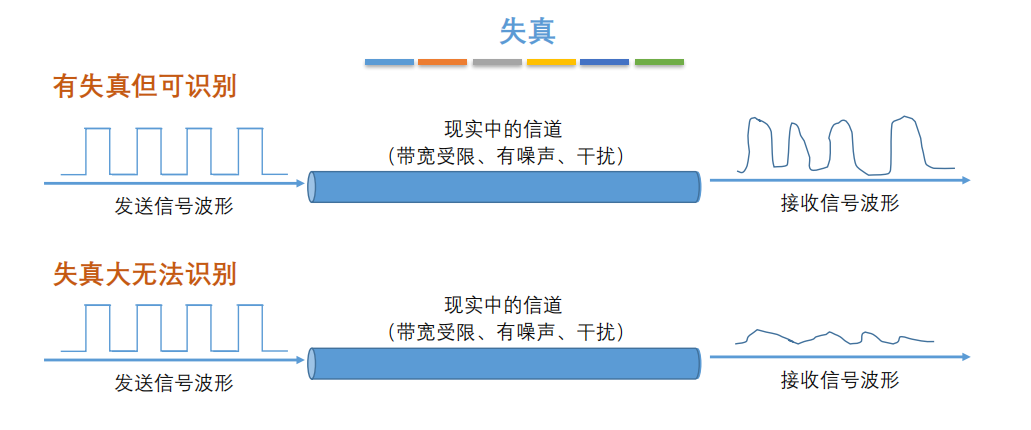
+
+8. **奈氏准则** : 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
+9. **香农定理** :在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
+10. **基带信号(baseband signal)** : 来自信源的信号。指没有经过调制的数字信号或模拟信号。
+11. **带通(频带)信号(bandpass signal)** :把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
+12. **调制(modulation )** : 对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
+13. **信噪比(signal-to-noise ratio )** : 指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
+14. **信道复用(channel multiplexing )** :指多个用户共享同一个信道。(并不一定是同时)。
+
+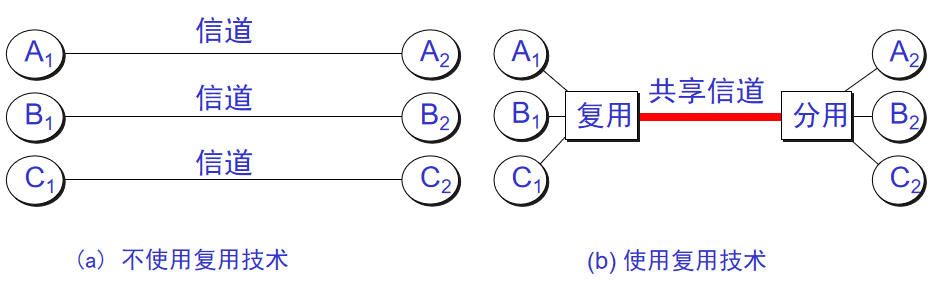
+
+15. **比特率(bit rate )** :单位时间(每秒)内传送的比特数。
+16. **波特率(baud rate)** :单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
+17. **复用(multiplexing)** :共享信道的方法。
+18. **ADSL(Asymmetric Digital Subscriber Line )** :非对称数字用户线。
+19. **光纤同轴混合网(HFC 网)** :在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
+
+### 2.2. 重要知识点总结
+
+1. **物理层的主要任务就是确定与传输媒体接口有关的一些特性,如机械特性,电气特性,功能特性,过程特性。**
+2. 一个数据通信系统可划分为三大部分,即源系统,传输系统,目的系统。源系统包括源点(或源站,信源)和发送器,目的系统包括接收器和终点。
+3. **通信的目的是传送消息。如话音,文字,图像等都是消息,数据是运送消息的实体。信号则是数据的电气或电磁的表现。**
+4. 根据信号中代表消息的参数的取值方式不同,信号可分为模拟信号(或连续信号)和数字信号(或离散信号)。在使用时间域(简称时域)的波形表示数字信号时,代表不同离散数值的基本波形称为码元。
+5. 根据双方信息交互的方式,通信可划分为单向通信(或单工通信),双向交替通信(或半双工通信),双向同时通信(全双工通信)。
+6. 来自信源的信号称为基带信号。信号要在信道上传输就要经过调制。调制有基带调制和带通调制之分。最基本的带通调制方法有调幅,调频和调相。还有更复杂的调制方法,如正交振幅调制。
+7. 要提高数据在信道上的传递速率,可以使用更好的传输媒体,或使用先进的调制技术。但数据传输速率不可能任意被提高。
+8. 传输媒体可分为两大类,即导引型传输媒体(双绞线,同轴电缆,光纤)和非导引型传输媒体(无线,红外,大气激光)。
+9. 为了有效利用光纤资源,在光纤干线和用户之间广泛使用无源光网络 PON。无源光网络无需配备电源,其长期运营成本和管理成本都很低。最流行的无源光网络是以太网无源光网络 EPON 和吉比特无源光网络 GPON。
+
+### 2.3. 补充
+
+#### 2.3.1. 物理层主要做啥?
+
+物理层主要做的事情就是 **透明地传送比特流**。也可以将物理层的主要任务描述为确定与传输媒体的接口的一些特性,即:机械特性(接口所用接线器的一些物理属性如形状和尺寸),电气特性(接口电缆的各条线上出现的电压的范围),功能特性(某条线上出现的某一电平的电压的意义),过程特性(对于不同功能的各种可能事件的出现顺序)。
+
+**物理层考虑的是怎样才能在连接各种计算机的传输媒体上传输数据比特流,而不是指具体的传输媒体。** 现有的计算机网络中的硬件设备和传输媒体的种类非常繁多,而且通信手段也有许多不同的方式。物理层的作用正是尽可能地屏蔽掉这些传输媒体和通信手段的差异,使物理层上面的数据链路层感觉不到这些差异,这样就可以使数据链路层只考虑完成本层的协议和服务,而不必考虑网络的具体传输媒体和通信手段是什么。
+
+#### 2.3.2. 几种常用的信道复用技术
+
+1. **频分复用(FDM)** :所有用户在同样的时间占用不同的带宽资源。
+2. **时分复用(TDM)** :所有用户在不同的时间占用同样的频带宽度(分时不分频)。
+3. **统计时分复用 (Statistic TDM)** :改进的时分复用,能够明显提高信道的利用率。
+4. **码分复用(CDM)** : 用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
+5. **波分复用( WDM)** :波分复用就是光的频分复用。
+
+#### 2.3.3. 几种常用的宽带接入技术,主要是 ADSL 和 FTTx
+
+用户到互联网的宽带接入方法有非对称数字用户线 ADSL(用数字技术对现有的模拟电话线进行改造,而不需要重新布线。ADSL 的快速版本是甚高速数字用户线 VDSL。),光纤同轴混合网 HFC(是在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网)和 FTTx(即光纤到······)。
+
+## 3. 数据链路层(Data Link Layer)
+
+
+
+### 3.1. 基本术语
+
+1. **链路(link)** :一个结点到相邻结点的一段物理链路。
+2. **数据链路(data link)** :把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路。
+3. **循环冗余检验 CRC(Cyclic Redundancy Check)** :为了保证数据传输的可靠性,CRC 是数据链路层广泛使用的一种检错技术。
+4. **帧(frame)** :一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
+5. **MTU(Maximum Transfer Uint )** :最大传送单元。帧的数据部分的的长度上限。
+6. **误码率 BER(Bit Error Rate )** :在一段时间内,传输错误的比特占所传输比特总数的比率。
+7. **PPP(Point-to-Point Protocol )** :点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
+ 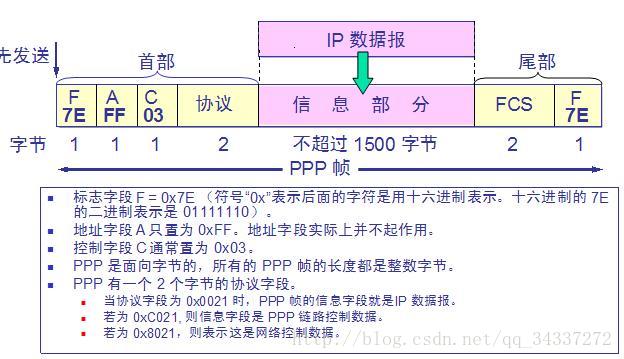
+8. **MAC 地址(Media Access Control 或者 Medium Access Control)** :意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
+
+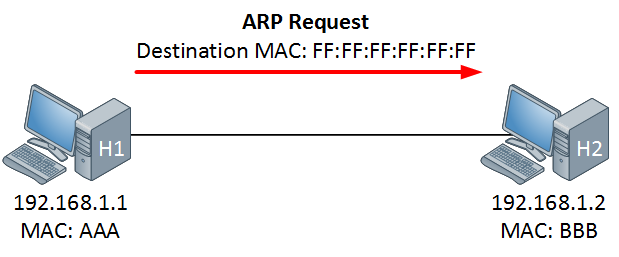
+
+9. **网桥(bridge)** :一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
+10. **交换机(switch )** :广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
+
+### 3.2. 重要知识点总结
+
+1. 链路是从一个结点到相邻结点的一段物理链路,数据链路则在链路的基础上增加了一些必要的硬件(如网络适配器)和软件(如协议的实现)
+2. 数据链路层使用的主要是**点对点信道**和**广播信道**两种。
+3. 数据链路层传输的协议数据单元是帧。数据链路层的三个基本问题是:**封装成帧**,**透明传输**和**差错检测**
+4. **循环冗余检验 CRC** 是一种检错方法,而帧检验序列 FCS 是添加在数据后面的冗余码
+5. **点对点协议 PPP** 是数据链路层使用最多的一种协议,它的特点是:简单,只检测差错而不去纠正差错,不使用序号,也不进行流量控制,可同时支持多种网络层协议
+6. PPPoE 是为宽带上网的主机使用的链路层协议
+7. **局域网的优点是:具有广播功能,从一个站点可方便地访问全网;便于系统的扩展和逐渐演变;提高了系统的可靠性,可用性和生存性。**
+8. 计算机与外接局域网通信需要通过通信适配器(或网络适配器),它又称为网络接口卡或网卡。**计算器的硬件地址就在适配器的 ROM 中**。
+9. 以太网采用的无连接的工作方式,对发送的数据帧不进行编号,也不要求对方发回确认。目的站收到有差错帧就把它丢掉,其他什么也不做
+10. 以太网采用的协议是具有冲突检测的**载波监听多点接入 CSMA/CD**。协议的特点是:**发送前先监听,边发送边监听,一旦发现总线上出现了碰撞,就立即停止发送。然后按照退避算法等待一段随机时间后再次发送。** 因此,每一个站点在自己发送数据之后的一小段时间内,存在着遭遇碰撞的可能性。以太网上的各站点平等地争用以太网信道
+11. 以太网的适配器具有过滤功能,它只接收单播帧,广播帧和多播帧。
+12. 使用集线器可以在物理层扩展以太网(扩展后的以太网仍然是一个网络)
+
+### 3.3. 补充
+
+1. 数据链路层的点对点信道和广播信道的特点,以及这两种信道所使用的协议(PPP 协议以及 CSMA/CD 协议)的特点
+2. 数据链路层的三个基本问题:**封装成帧**,**透明传输**,**差错检测**
+3. 以太网的 MAC 层硬件地址
+4. 适配器,转发器,集线器,网桥,以太网交换机的作用以及适用场合
+
+## 4. 网络层(Network Layer)
+
+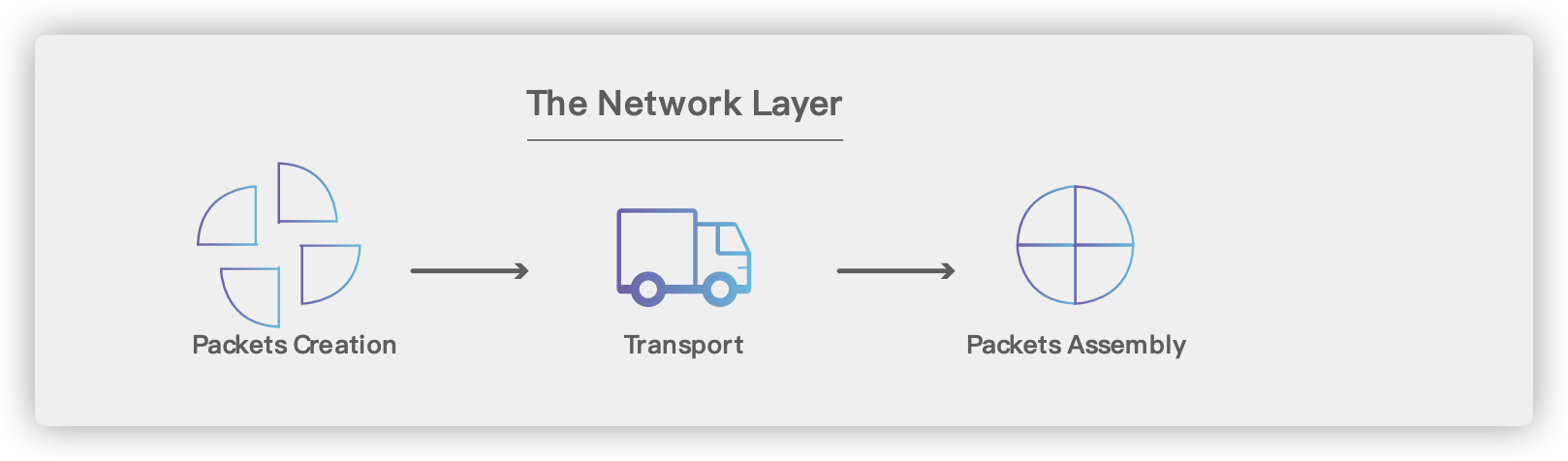
+
+### 4.1. 基本术语
+
+1. **虚电路(Virtual Circuit)** : 在两个终端设备的逻辑或物理端口之间,通过建立的双向的透明传输通道。虚电路表示这只是一条逻辑上的连接,分组都沿着这条逻辑连接按照存储转发方式传送,而并不是真正建立了一条物理连接。
+2. **IP(Internet Protocol )** : 网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一,是 TCP/IP 体系结构网际层的核心。配套的有 ARP,RARP,ICMP,IGMP。
+3. **ARP(Address Resolution Protocol)** : 地址解析协议。地址解析协议 ARP 把 IP 地址解析为硬件地址。
+4. **ICMP(Internet Control Message Protocol )** :网际控制报文协议 (ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告)。
+5. **子网掩码(subnet mask )** :它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
+6. **CIDR( Classless Inter-Domain Routing )**:无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
+7. **默认路由(default route)** :当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
+8. **路由选择算法(Virtual Circuit)** :路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
+
+### 4.2. 重要知识点总结
+
+1. **TCP/IP 协议中的网络层向上只提供简单灵活的,无连接的,尽最大努力交付的数据报服务。网络层不提供服务质量的承诺,不保证分组交付的时限所传送的分组可能出错,丢失,重复和失序。进程之间通信的可靠性由运输层负责**
+2. 在互联网的交付有两种,一是在本网络直接交付不用经过路由器,另一种是和其他网络的间接交付,至少经过一个路由器,但最后一次一定是直接交付
+3. 分类的 IP 地址由网络号字段(指明网络)和主机号字段(指明主机)组成。网络号字段最前面的类别指明 IP 地址的类别。IP 地址是一种分等级的地址结构。IP 地址管理机构分配 IP 地址时只分配网络号,主机号由得到该网络号的单位自行分配。路由器根据目的主机所连接的网络号来转发分组。一个路由器至少连接到两个网络,所以一个路由器至少应当有两个不同的 IP 地址
+4. IP 数据报分为首部和数据两部分。首部的前一部分是固定长度,共 20 字节,是所有 IP 数据包必须具有的(源地址,目的地址,总长度等重要地段都固定在首部)。一些长度可变的可选字段固定在首部的后面。IP 首部中的生存时间给出了 IP 数据报在互联网中所能经过的最大路由器数。可防止 IP 数据报在互联网中无限制的兜圈子。
+5. **地址解析协议 ARP 把 IP 地址解析为硬件地址。ARP 的高速缓存可以大大减少网络上的通信量。因为这样可以使主机下次再与同样地址的主机通信时,可以直接从高速缓存中找到所需要的硬件地址而不需要再去以广播方式发送 ARP 请求分组**
+6. 无分类域间路由选择 CIDR 是解决目前 IP 地址紧缺的一个好办法。CIDR 记法在 IP 地址后面加上斜线“/”,然后写上前缀所占的位数。前缀(或网络前缀)用来指明网络,前缀后面的部分是后缀,用来指明主机。CIDR 把前缀都相同的连续的 IP 地址组成一个“CIDR 地址块”,IP 地址分配都以 CIDR 地址块为单位。
+7. 网际控制报文协议是 IP 层的协议。ICMP 报文作为 IP 数据报的数据,加上首部后组成 IP 数据报发送出去。使用 ICMP 数据报并不是为了实现可靠传输。ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告。ICMP 报文的种类有两种,即 ICMP 差错报告报文和 ICMP 询问报文。
+8. **要解决 IP 地址耗尽的问题,最根本的办法是采用具有更大地址空间的新版本 IP 协议-IPv6。** IPv6 所带来的变化有 ① 更大的地址空间(采用 128 位地址)② 灵活的首部格式 ③ 改进的选项 ④ 支持即插即用 ⑤ 支持资源的预分配 ⑥IPv6 的首部改为 8 字节对齐。
+9. **虚拟专用网络 VPN 利用公用的互联网作为本机构专用网之间的通信载体。VPN 内使用互联网的专用地址。一个 VPN 至少要有一个路由器具有合法的全球 IP 地址,这样才能和本系统的另一个 VPN 通过互联网进行通信。所有通过互联网传送的数据都需要加密。**
+10. MPLS 的特点是:① 支持面向连接的服务质量 ② 支持流量工程,平衡网络负载 ③ 有效的支持虚拟专用网 VPN。MPLS 在入口节点给每一个 IP 数据报打上固定长度的“标记”,然后根据标记在第二层(链路层)用硬件进行转发(在标记交换路由器中进行标记交换),因而转发速率大大加快。
+
+## 5. 传输层(Transport Layer)
+
+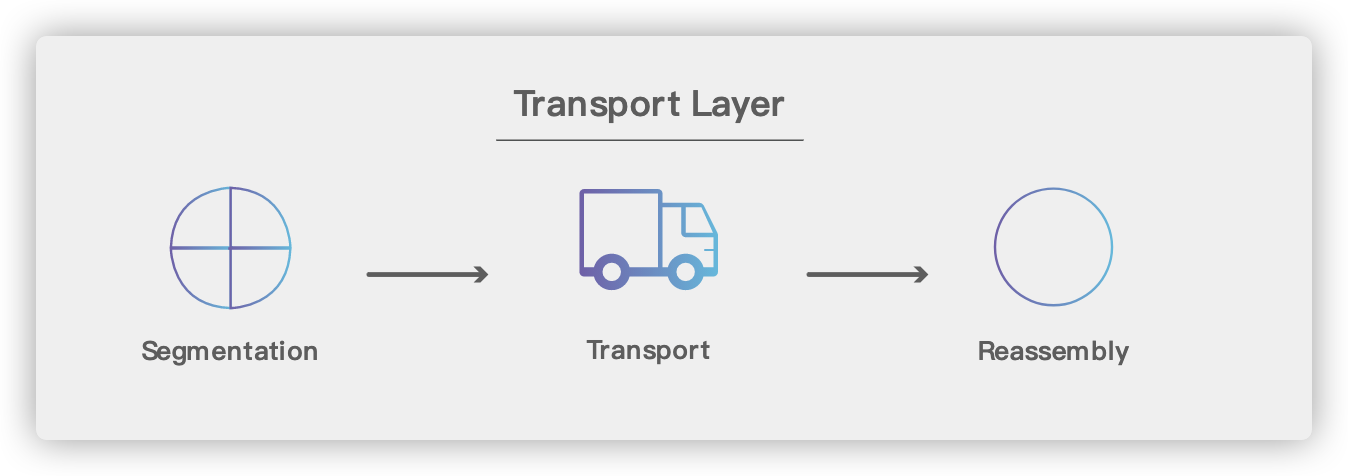
+
+### 5.1. 基本术语
+
+1. **进程(process)** :指计算机中正在运行的程序实体。
+2. **应用进程互相通信** :一台主机的进程和另一台主机中的一个进程交换数据的过程(另外注意通信真正的端点不是主机而是主机中的进程,也就是说端到端的通信是应用进程之间的通信)。
+3. **传输层的复用与分用** :复用指发送方不同的进程都可以通过同一个运输层协议传送数据。分用指接收方的运输层在剥去报文的首部后能把这些数据正确的交付到目的应用进程。
+4. **TCP(Transmission Control Protocol)** :传输控制协议。
+5. **UDP(User Datagram Protocol)** :用户数据报协议。
+
+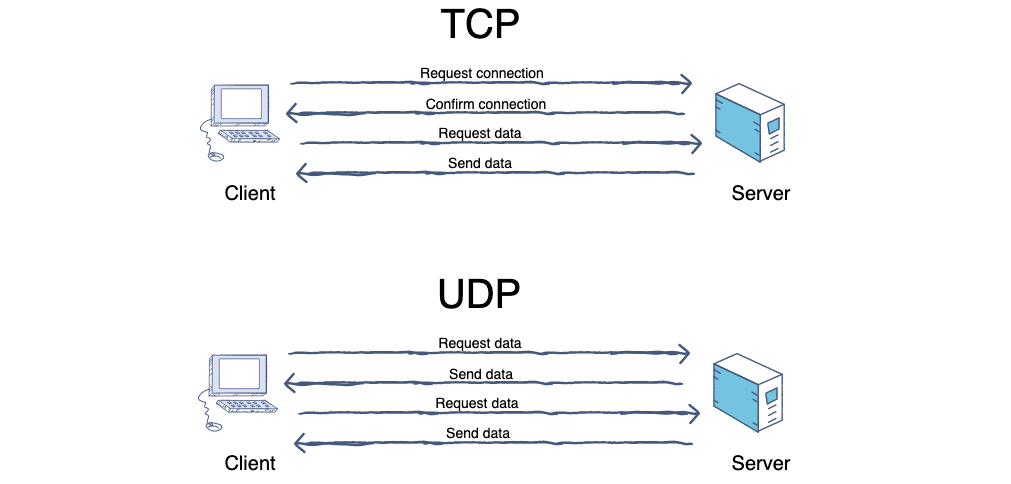
+
+6. **端口(port)** :端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
+7. **停止等待协议(stop-and-wait)** :指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
+8. **流量控制** : 就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。
+9. **拥塞控制** :防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
+
+### 5.2. 重要知识点总结
+
+1. **运输层提供应用进程之间的逻辑通信,也就是说,运输层之间的通信并不是真正在两个运输层之间直接传输数据。运输层向应用层屏蔽了下面网络的细节(如网络拓补,所采用的路由选择协议等),它使应用进程之间看起来好像两个运输层实体之间有一条端到端的逻辑通信信道。**
+2. **网络层为主机提供逻辑通信,而运输层为应用进程之间提供端到端的逻辑通信。**
+3. 运输层的两个重要协议是用户数据报协议 UDP 和传输控制协议 TCP。按照 OSI 的术语,两个对等运输实体在通信时传送的数据单位叫做运输协议数据单元 TPDU(Transport Protocol Data Unit)。但在 TCP/IP 体系中,则根据所使用的协议是 TCP 或 UDP,分别称之为 TCP 报文段或 UDP 用户数据报。
+4. **UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式。 TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务,难以避免地增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。**
+5. 硬件端口是不同硬件设备进行交互的接口,而软件端口是应用层各种协议进程与运输实体进行层间交互的一种地址。UDP 和 TCP 的首部格式中都有源端口和目的端口这两个重要字段。当运输层收到 IP 层交上来的运输层报文时,就能够根据其首部中的目的端口号把数据交付应用层的目的应用层。(两个进程之间进行通信不光要知道对方 IP 地址而且要知道对方的端口号(为了找到对方计算机中的应用进程))
+6. 运输层用一个 16 位端口号标志一个端口。端口号只有本地意义,它只是为了标志计算机应用层中的各个进程在和运输层交互时的层间接口。在互联网的不同计算机中,相同的端口号是没有关联的。协议端口号简称端口。虽然通信的终点是应用进程,但只要把所发送的报文交到目的主机的某个合适端口,剩下的工作(最后交付目的进程)就由 TCP 和 UDP 来完成。
+7. 运输层的端口号分为服务器端使用的端口号(0˜1023 指派给熟知端口,1024˜49151 是登记端口号)和客户端暂时使用的端口号(49152˜65535)
+8. **UDP 的主要特点是 ① 无连接 ② 尽最大努力交付 ③ 面向报文 ④ 无拥塞控制 ⑤ 支持一对一,一对多,多对一和多对多的交互通信 ⑥ 首部开销小(只有四个字段:源端口,目的端口,长度和检验和)**
+9. **TCP 的主要特点是 ① 面向连接 ② 每一条 TCP 连接只能是一对一的 ③ 提供可靠交付 ④ 提供全双工通信 ⑤ 面向字节流**
+10. **TCP 用主机的 IP 地址加上主机上的端口号作为 TCP 连接的端点。这样的端点就叫做套接字(socket)或插口。套接字用(IP 地址:端口号)来表示。每一条 TCP 连接唯一地被通信两端的两个端点所确定。**
+11. 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
+12. 为了提高传输效率,发送方可以不使用低效率的停止等待协议,而是采用流水线传输。流水线传输就是发送方可连续发送多个分组,不必每发完一个分组就停下来等待对方确认。这样可使信道上一直有数据不间断的在传送。这种传输方式可以明显提高信道利用率。
+13. 停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求 ARQ。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。连续 ARQ 协议可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
+14. TCP 报文段的前 20 个字节是固定的,后面有 4n 字节是根据需要增加的选项。因此,TCP 首部的最小长度是 20 字节。
+15. **TCP 使用滑动窗口机制。发送窗口里面的序号表示允许发送的序号。发送窗口后沿的后面部分表示已发送且已收到确认,而发送窗口前沿的前面部分表示不允许发送。发送窗口后沿的变化情况有两种可能,即不动(没有收到新的确认)和前移(收到了新的确认)。发送窗口的前沿通常是不断向前移动的。一般来说,我们总是希望数据传输更快一些。但如果发送方把数据发送的过快,接收方就可能来不及接收,这就会造成数据的丢失。所谓流量控制就是让发送方的发送速率不要太快,要让接收方来得及接收。**
+16. 在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
+17. **为了进行拥塞控制,TCP 发送方要维持一个拥塞窗口 cwnd 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。**
+18. **TCP 的拥塞控制采用了四种算法,即慢开始,拥塞避免,快重传和快恢复。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。**
+19. 运输连接的三个阶段,即:连接建立,数据传送和连接释放。
+20. **主动发起 TCP 连接建立的应用进程叫做客户,而被动等待连接建立的应用进程叫做服务器。TCP 连接采用三报文握手机制。服务器要确认用户的连接请求,然后客户要对服务器的确认进行确认。**
+21. TCP 的连接释放采用四报文握手机制。任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送时,则发送连接释放通知,对方确认后就完全关闭了 TCP 连接
+
+### 5.3. 补充(重要)
+
+以下知识点需要重点关注:
+
+1. 端口和套接字的意义
+2. UDP 和 TCP 的区别以及两者的应用场景
+3. 在不可靠的网络上实现可靠传输的工作原理,停止等待协议和 ARQ 协议
+4. TCP 的滑动窗口,流量控制,拥塞控制和连接管理
+5. TCP 的三次握手,四次挥手机制
+
+## 6. 应用层(Application Layer)
+
+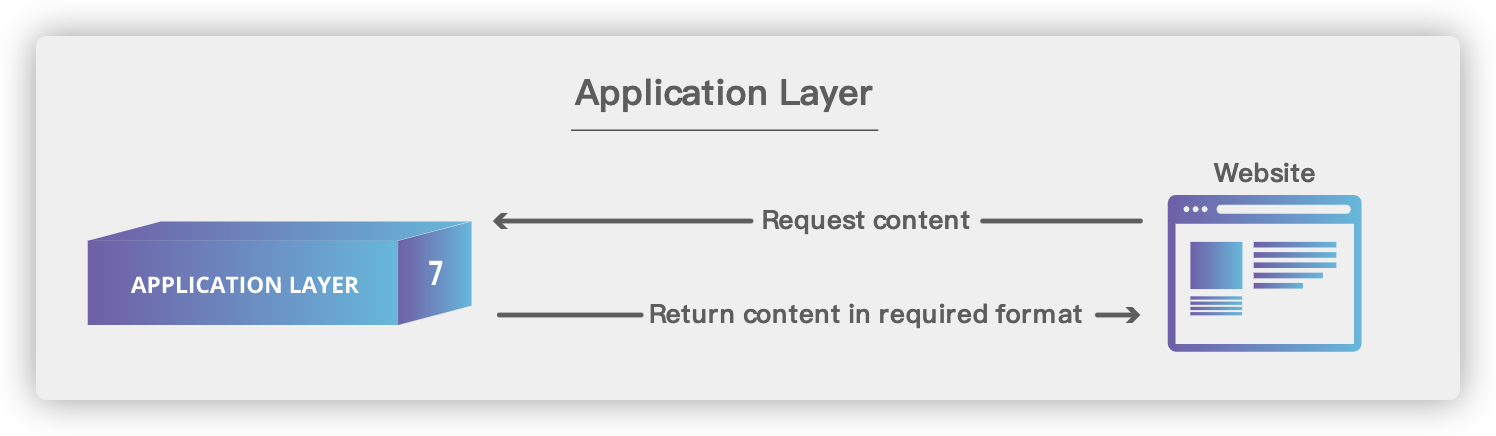
+
+### 6.1. 基本术语
+
+1. **域名系统(DNS)** :域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
+
+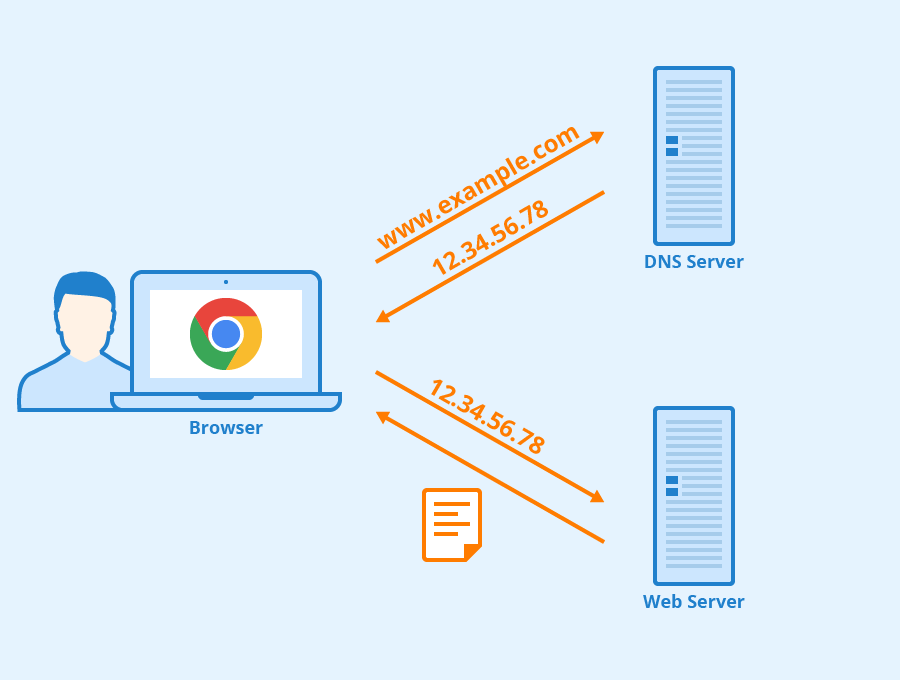
+
+<p style="text-align:right;font-size:12px">https://www.seobility.net/en/wiki/HTTP_headers</p>
+
+2. **文件传输协议(FTP)** :FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
+
+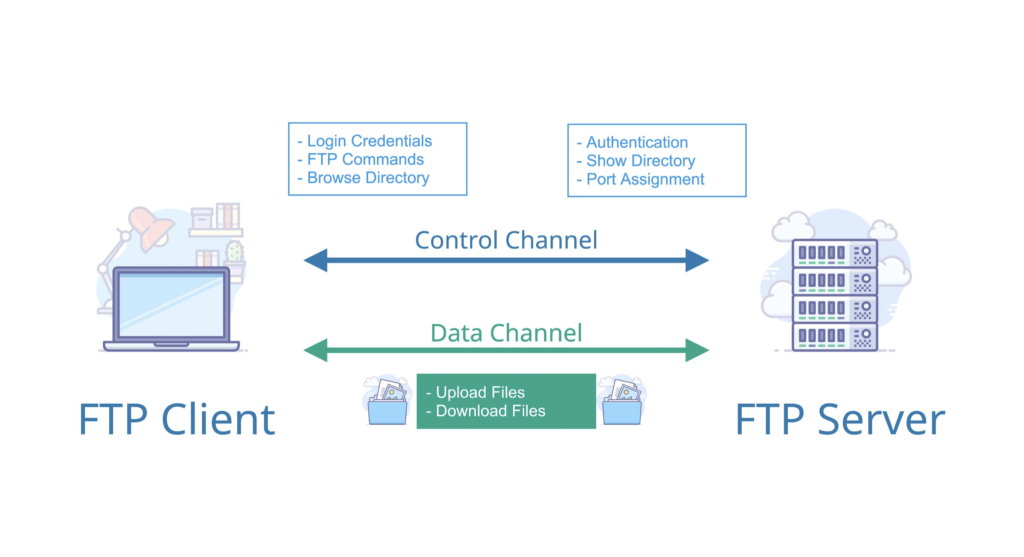
+
+3. **简单文件传输协议(TFTP)** :TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
+4. **远程终端协议(TELNET)** :Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
+5. **万维网(WWW)** :WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
+6. **万维网的大致工作工程:**
+
+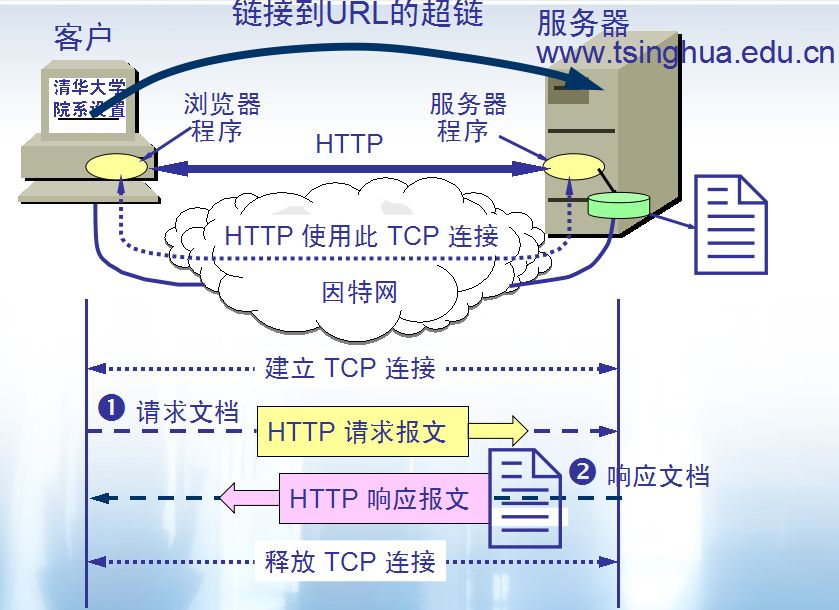
+
+7. **统一资源定位符(URL)** :统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
+8. **超文本传输协议(HTTP)** :超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
+
+HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
+
+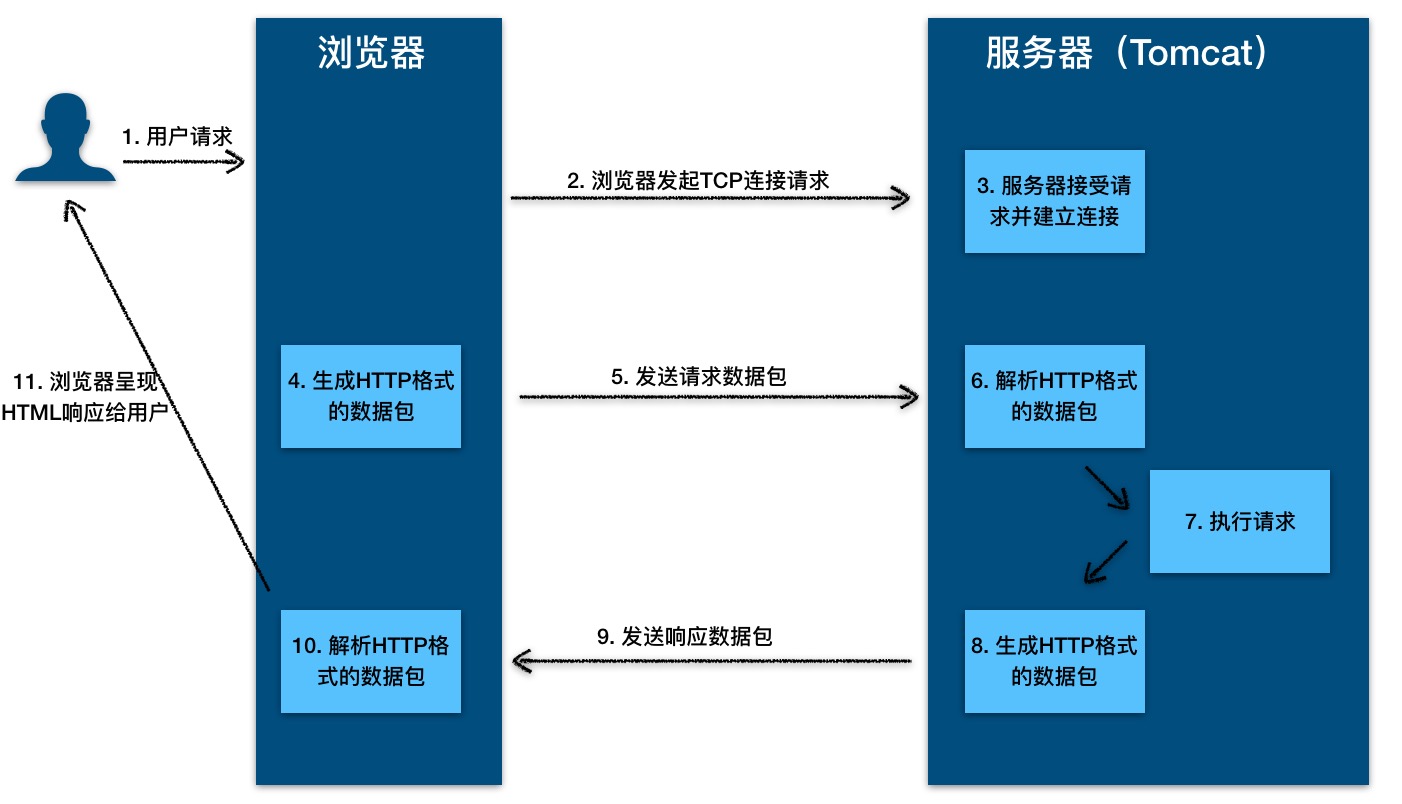
+
+10. **代理服务器(Proxy Server)** : 代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
+11. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
+
+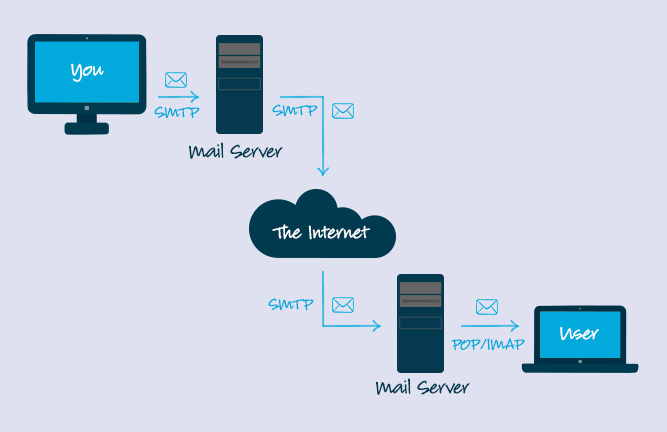
+
+<p style="text-align:right;font-size:12px">https://www.campaignmonitor.com/resources/knowledge-base/what-is-the-code-that-makes-bcc-or-cc-operate-in-an-email/<p>
+
+11. **搜索引擎** :搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
+
+
+
+12. **垂直搜索引擎** :垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
+13. **全文索引** :全文索引技术是目前搜索引擎的关键技术。试想在 1M 大小的文件中搜索一个词,可能需要几秒,在 100M 的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
+14. **目录索引** :目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
+
+### 6.2. 重要知识点总结
+
+1. 文件传输协议(FTP)使用 TCP 可靠的运输服务。FTP 使用客户服务器方式。一个 FTP 服务器进程可以同时为多个用户提供服务。在进行文件传输时,FTP 的客户和服务器之间要先建立两个并行的 TCP 连接:控制连接和数据连接。实际用于传输文件的是数据连接。
+2. 万维网客户程序与服务器之间进行交互使用的协议是超文本传输协议 HTTP。HTTP 使用 TCP 连接进行可靠传输。但 HTTP 本身是无连接、无状态的。HTTP/1.1 协议使用了持续连接(分为非流水线方式和流水线方式)
+3. 电子邮件把邮件发送到收件人使用的邮件服务器,并放在其中的收件人邮箱中,收件人可随时上网到自己使用的邮件服务器读取,相当于电子邮箱。
+4. 一个电子邮件系统有三个重要组成构件:用户代理、邮件服务器、邮件协议(包括邮件发送协议,如 SMTP,和邮件读取协议,如 POP3 和 IMAP)。用户代理和邮件服务器都要运行这些协议。
+
+### 6.3. 补充(重要)
+
+以下知识点需要重点关注:
+
+1. 应用层的常见协议(重点关注 HTTP 协议)
+2. 域名系统-从域名解析出 IP 地址
+3. 访问一个网站大致的过程
+4. 系统调用和应用编程接口概念
diff --git a/docs/cs-basics/operating-system/images/Linux-Logo.png b/docs/cs-basics/operating-system/images/Linux-Logo.png
new file mode 100644
index 00000000000..40e75aaac8a
Binary files /dev/null and b/docs/cs-basics/operating-system/images/Linux-Logo.png differ
diff --git "a/docs/cs-basics/operating-system/images/Linux\344\271\213\347\210\266.png" "b/docs/cs-basics/operating-system/images/Linux\344\271\213\347\210\266.png"
new file mode 100644
index 00000000000..33145373b68
Binary files /dev/null and "b/docs/cs-basics/operating-system/images/Linux\344\271\213\347\210\266.png" differ
diff --git "a/docs/cs-basics/operating-system/images/Linux\346\235\203\351\231\220\345\221\275\344\273\244.png" "b/docs/cs-basics/operating-system/images/Linux\346\235\203\351\231\220\345\221\275\344\273\244.png"
new file mode 100644
index 00000000000..f59b2e638c6
Binary files /dev/null and "b/docs/cs-basics/operating-system/images/Linux\346\235\203\351\231\220\345\221\275\344\273\244.png" differ
diff --git "a/docs/cs-basics/operating-system/images/Linux\346\235\203\351\231\220\350\247\243\350\257\273.png" "b/docs/cs-basics/operating-system/images/Linux\346\235\203\351\231\220\350\247\243\350\257\273.png"
new file mode 100644
index 00000000000..1292c125aca
Binary files /dev/null and "b/docs/cs-basics/operating-system/images/Linux\346\235\203\351\231\220\350\247\243\350\257\273.png" differ
diff --git "a/docs/cs-basics/operating-system/images/Linux\347\233\256\345\275\225\346\240\221.png" "b/docs/cs-basics/operating-system/images/Linux\347\233\256\345\275\225\346\240\221.png"
new file mode 100644
index 00000000000..beef42034bf
Binary files /dev/null and "b/docs/cs-basics/operating-system/images/Linux\347\233\256\345\275\225\346\240\221.png" differ
diff --git a/docs/cs-basics/operating-system/images/linux.png b/docs/cs-basics/operating-system/images/linux.png
new file mode 100644
index 00000000000..20ead246915
Binary files /dev/null and b/docs/cs-basics/operating-system/images/linux.png differ
diff --git a/docs/cs-basics/operating-system/images/macos.png b/docs/cs-basics/operating-system/images/macos.png
new file mode 100644
index 00000000000..332945774ee
Binary files /dev/null and b/docs/cs-basics/operating-system/images/macos.png differ
diff --git a/docs/cs-basics/operating-system/images/unix.png b/docs/cs-basics/operating-system/images/unix.png
new file mode 100644
index 00000000000..0afabcd8621
Binary files /dev/null and b/docs/cs-basics/operating-system/images/unix.png differ
diff --git a/docs/cs-basics/operating-system/images/windows.png b/docs/cs-basics/operating-system/images/windows.png
new file mode 100644
index 00000000000..c2687dc72f7
Binary files /dev/null and b/docs/cs-basics/operating-system/images/windows.png differ
diff --git "a/docs/cs-basics/operating-system/images/\344\277\256\346\224\271\346\226\207\344\273\266\346\235\203\351\231\220.png" "b/docs/cs-basics/operating-system/images/\344\277\256\346\224\271\346\226\207\344\273\266\346\235\203\351\231\220.png"
new file mode 100644
index 00000000000..de9409410c8
Binary files /dev/null and "b/docs/cs-basics/operating-system/images/\344\277\256\346\224\271\346\226\207\344\273\266\346\235\203\351\231\220.png" differ
diff --git "a/docs/cs-basics/operating-system/images/\346\226\207\344\273\266inode\344\277\241\346\201\257.png" "b/docs/cs-basics/operating-system/images/\346\226\207\344\273\266inode\344\277\241\346\201\257.png"
new file mode 100644
index 00000000000..b47551e8314
Binary files /dev/null and "b/docs/cs-basics/operating-system/images/\346\226\207\344\273\266inode\344\277\241\346\201\257.png" differ
diff --git "a/docs/cs-basics/operating-system/images/\347\224\250\346\210\267\346\200\201\344\270\216\345\206\205\346\240\270\346\200\201.png" "b/docs/cs-basics/operating-system/images/\347\224\250\346\210\267\346\200\201\344\270\216\345\206\205\346\240\270\346\200\201.png"
new file mode 100644
index 00000000000..aa0dafc2f02
Binary files /dev/null and "b/docs/cs-basics/operating-system/images/\347\224\250\346\210\267\346\200\201\344\270\216\345\206\205\346\240\270\346\200\201.png" differ
diff --git a/docs/cs-basics/operating-system/linux-intro.md b/docs/cs-basics/operating-system/linux-intro.md
new file mode 100644
index 00000000000..723cd9b7e88
--- /dev/null
+++ b/docs/cs-basics/operating-system/linux-intro.md
@@ -0,0 +1,412 @@
+---
+title: 后端程序员必备的 Linux 基础知识总结
+category: 计算机基础
+tag:
+ - 操作系统
+ - Linux
+---
+
+简单介绍一下 Java 程序员必知的 Linux 的一些概念以及常见命令。
+
+_如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!笔芯!_
+
+## 1. 从认识操作系统开始
+
+
+
+正式开始 Linux 之前,简单花一点点篇幅科普一下操作系统相关的内容。
+
+### 1.1. 操作系统简介
+
+我通过以下四点介绍什么是操作系统:
+
+1. **操作系统(Operating System,简称 OS)是管理计算机硬件与软件资源的程序,是计算机的基石。**
+2. **操作系统本质上是一个运行在计算机上的软件程序 ,用于管理计算机硬件和软件资源。** 举例:运行在你电脑上的所有应用程序都通过操作系统来调用系统内存以及磁盘等等硬件。
+3. **操作系统存在屏蔽了硬件层的复杂性。** 操作系统就像是硬件使用的负责人,统筹着各种相关事项。
+4. **操作系统的内核(Kernel)是操作系统的核心部分,它负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理**。
+
+> 内核(Kernel)在后文中会提到。
+
+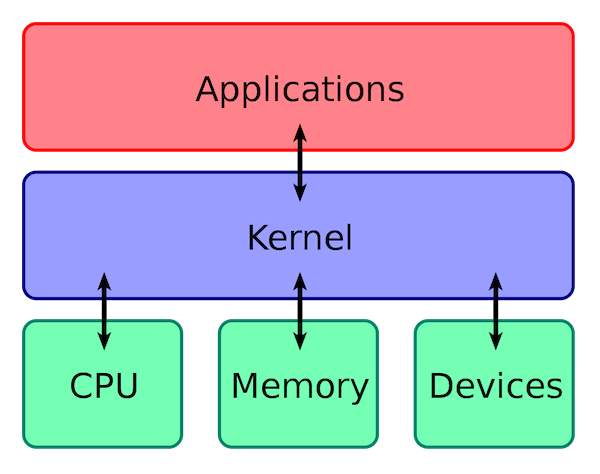
+
+### 1.2. 操作系统简单分类
+
+#### 1.2.1. Windows
+
+目前最流行的个人桌面操作系统 ,不做多的介绍,大家都清楚。界面简单易操作,软件生态非常好。
+
+_玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Windows 用于玩游戏,一台 Mac 用于平时日常开发和学习使用。_
+
+
+
+#### 1.2.2. Unix
+
+最早的多用户、多任务操作系统 。后面崛起的 Linux 在很多方面都参考了 Unix。
+
+目前这款操作系统已经逐渐逐渐退出操作系统的舞台。
+
+
+
+#### 1.2.3. Linux
+
+**Linux 是一套免费使用、开源的类 Unix 操作系统。** Linux 存在着许多不同的发行版本,但它们都使用了 **Linux 内核** 。
+
+> 严格来讲,Linux 这个词本身只表示 Linux 内核,在 GNU/Linux 系统中,Linux 实际就是 Linux 内核,而该系统的其余部分主要是由 GNU 工程编写和提供的程序组成。单独的 Linux 内核并不能成为一个可以正常工作的操作系统。
+>
+> **很多人更倾向使用 “GNU/Linux” 一词来表达人们通常所说的 “Linux”。**
+
+
+
+#### 1.2.4. Mac OS
+
+苹果自家的操作系统,编程体验和 Linux 相当,但是界面、软件生态以及用户体验各方面都要比 Linux 操作系统更好。
+
+
+
+### 1.3. 操作系统的内核(Kernel)
+
+我们先来看看维基百科对于内核的解释,我觉得总结的非常好!
+
+> **内核**(英语:Kernel,又称核心)在计算机科学中是一个用来管理软件发出的数据 I/O(输入与输出)要求的电脑程序,将这些要求转译为数据处理的指令并交由中央处理器(CPU)及电脑中其他电子组件进行处理,是现代操作系统中最基本的部分。它是为众多应用程序提供对计算机硬件的安全访问的一部分软件,这种访问是有限的,并由内核决定一个程序在什么时候对某部分硬件操作多长时间。 **直接对硬件操作是非常复杂的。所以内核通常提供一种硬件抽象的方法,来完成这些操作。有了这个,通过进程间通信机制及系统调用,应用进程可间接控制所需的硬件资源(特别是处理器及 IO 设备)。**
+>
+> 早期计算机系统的设计中,还没有操作系统的内核这个概念。随着计算机系统的发展,操作系统内核的概念才渐渐明晰起来了!
+
+简单概括两点:
+
+1. **操作系统的内核(Kernel)是操作系统的核心部分,它负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理。**
+2. **操作系统的内核是连接应用程序和硬件的桥梁,决定着操作系统的性能和稳定性。**
+
+### 1.4. 中央处理器(CPU,Central Processing Unit)
+
+关于 CPU 简单概括三点:
+
+1. **CPU 是一台计算机的运算核心(Core)+控制核心( Control Unit),可以称得上是计算机的大脑。**
+2. **CPU 主要包括两个部分:控制器+运算器。**
+3. **CPU 的根本任务就是执行指令,对计算机来说最终都是一串由“0”和“1”组成的序列。**
+
+### 1.5. CPU vs Kernel(内核)
+
+很多人容易无法区分操作系统的内核(Kernel)和中央处理器(CPU),你可以简单从下面两点来区别:
+
+1. 操作系统的内核(Kernel)属于操作系统层面,而 CPU 属于硬件。
+2. CPU 主要提供运算,处理各种指令的能力。内核(Kernel)主要负责系统管理比如内存管理,它屏蔽了对硬件的操作。
+
+下图清晰说明了应用程序、内核、CPU 这三者的关系。
+
+
+
+### 1.6. 系统调用
+
+介绍系统调用之前,我们先来了解一下用户态和系统态。
+
+根据进程访问资源的特点,我们可以把进程在系统上的运行分为两个级别:
+
+1. **用户态(user mode)** : 用户态运行的进程或可以直接读取用户程序的数据。
+2. **系统态(kernel mode)**: 可以简单的理解系统态运行的进程或程序几乎可以访问计算机的任何资源,不受限制。
+
+**说了用户态和系统态之后,那么什么是系统调用呢?**
+
+我们运行的程序基本都是运行在用户态,如果我们调用操作系统提供的系统态级别的子功能咋办呢?那就需要系统调用了!
+
+也就是说在我们运行的用户程序中,凡是与系统态级别的资源有关的操作(如文件管理、进程控制、内存管理等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
+
+这些系统调用按功能大致可分为如下几类:
+
+- **设备管理** :完成设备的请求或释放,以及设备启动等功能。
+- **文件管理** :完成文件的读、写、创建及删除等功能。
+- **进程控制** :完成进程的创建、撤销、阻塞及唤醒等功能。
+- **进程通信** :完成进程之间的消息传递或信号传递等功能。
+- **内存管理** :完成内存的分配、回收以及获取作业占用内存区大小及地址等功能。
+
+我在网上找了一个图,通过这个图可以很清晰的说明用户程序、系统调用、内核和硬件之间的关系。(_太难了~木有自己画_)
+
+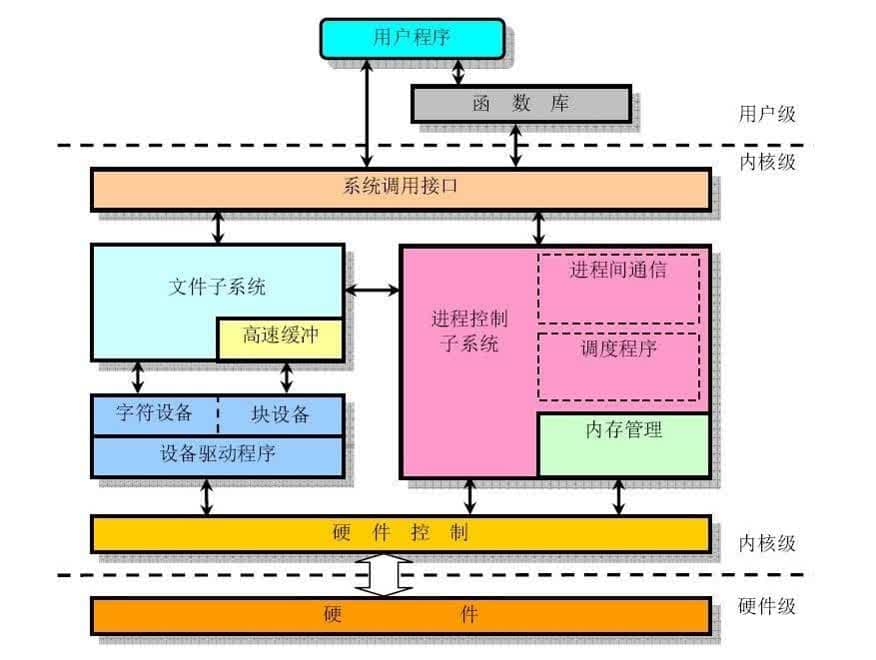
+
+## 2. 初探 Linux
+
+### 2.1. Linux 简介
+
+我们上面已经简单了 Linux,这里只强调三点。
+
+- **类 Unix 系统** : Linux 是一种自由、开放源码的类似 Unix 的操作系统
+- **Linux 本质是指 Linux 内核** : 严格来讲,Linux 这个词本身只表示 Linux 内核,单独的 Linux 内核并不能成为一个可以正常工作的操作系统。所以,就有了各种 Linux 发行版。
+- **Linux 之父(林纳斯·本纳第克特·托瓦兹 Linus Benedict Torvalds)** : 一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 **Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
+
+
+
+### 2.2. Linux 诞生
+
+1989 年,Linus Torvalds 进入芬兰陆军新地区旅,服 11 个月的国家义务兵役,军衔为少尉,主要服务于计算机部门,任务是弹道计算。服役期间,购买了安德鲁·斯图尔特·塔能鲍姆所著的教科书及 minix 源代码,开始研究操作系统。1990 年,他退伍后回到大学,开始接触 Unix。
+
+> **Minix** 是一个迷你版本的类 Unix 操作系统,由塔能鲍姆教授为了教学之用而创作,采用微核心设计。它启发了 Linux 内核的创作。
+
+1991 年,Linus Torvalds 开源了 Linux 内核。Linux 以一只可爱的企鹅作为标志,象征着敢作敢为、热爱生活。
+
+
+
+### 2.3. 常见 Linux 发行版本有哪些?
+
+Linus Torvalds 开源的只是 Linux 内核,我们上面也提到了操作系统内核的作用。一些组织或厂商将 Linux 内核与各种软件和文档包装起来,并提供系统安装界面和系统配置、设定与管理工具,就构成了 Linux 的发行版本。
+
+> 内核主要负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理。
+
+Linux 的发行版本可以大体分为两类:
+
+- 商业公司维护的发行版本,以著名的 Red Hat 为代表,比较典型的有 CentOS 。
+- 社区组织维护的发行版本,以 Debian 为代表,比较典型的有 Ubuntu、Debian。
+
+对于初学者学习 Linux ,推荐选择 CentOS 。
+
+## 3. Linux 文件系统概览
+
+### 3.1. Linux 文件系统简介
+
+**在 Linux 操作系统中,所有被操作系统管理的资源,例如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或是目录都被看作是一个文件。** 也就是说在 Linux 系统中有一个重要的概念:**一切都是文件**。
+
+其实这是 UNIX 哲学的一个体现,在 UNIX 系统中,把一切资源都看作是文件,Linux 的文件系统也是借鉴 UNIX 文件系统而来。
+
+### 3.2. inode 介绍
+
+**inode 是 linux/unix 文件系统的基础。那么,inode 是什么?有什么作用呢?**
+
+硬盘的最小存储单位是扇区(Sector),块(block)由多个扇区组成。文件数据存储在块中。块的最常见的大小是 4kb,约为 8 个连续的扇区组成(每个扇区存储 512 字节)。一个文件可能会占用多个 block,但是一个块只能存放一个文件。
+
+虽然,我们将文件存储在了块(block)中,但是我们还需要一个空间来存储文件的 **元信息 metadata** :如某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等。这种 **存储文件元信息的区域就叫 inode**,译为索引节点:**i(index)+node**。 每个文件都有一个 inode,存储文件的元信息。
+
+可以使用 `stat` 命令可以查看文件的 inode 信息。每个 inode 都有一个号码,Linux/Unix 操作系统不使用文件名来区分文件,而是使用 inode 号码区分不同的文件。
+
+简单来说:inode 就是用来维护某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等信息。
+
+简单总结一下:
+
+- **inode** :记录文件的属性信息,可以使用 stat 命令查看 inode 信息。
+- **block** :实际文件的内容,如果一个文件大于一个块时候,那么将占用多个 block,但是一个块只能存放一个文件。(因为数据是由 inode 指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)
+
+
+
+### 3.3. Linux 文件类型
+
+Linux 支持很多文件类型,其中非常重要的文件类型有: **普通文件**,**目录文件**,**链接文件**,**设备文件**,**管道文件**,**Socket 套接字文件**等。
+
+- **普通文件(-)** : 用于存储信息和数据, Linux 用户可以根据访问权限对普通文件进行查看、更改和删除。比如:图片、声音、PDF、text、视频、源代码等等。
+- **目录文件(d,directory file)** :目录也是文件的一种,用于表示和管理系统中的文件,目录文件中包含一些文件名和子目录名。打开目录事实上就是打开目录文件。
+- **符号链接文件(l,symbolic link)** :保留了指向文件的地址而不是文件本身。
+- **字符设备(c,char)** :用来访问字符设备比如键盘。
+- **设备文件(b,block)** : 用来访问块设备比如硬盘、软盘。
+- **管道文件(p,pipe)** : 一种特殊类型的文件,用于进程之间的通信。
+- **套接字(s,socket)** :用于进程间的网络通信,也可以用于本机之间的非网络通信。
+
+### 3.4. Linux 目录树
+
+所有可操作的计算机资源都存在于目录树这个结构中,对计算资源的访问,可以看做是对这棵目录树的访问。
+
+**Linux 的目录结构如下:**
+
+Linux 文件系统的结构层次鲜明,就像一棵倒立的树,最顶层是其根目录:
+
+
+**常见目录说明:**
+
+- **/bin:** 存放二进制可执行文件(ls、cat、mkdir 等),常用命令一般都在这里;
+- **/etc:** 存放系统管理和配置文件;
+- **/home:** 存放所有用户文件的根目录,是用户主目录的基点,比如用户 user 的主目录就是/home/user,可以用~user 表示;
+- **/usr :** 用于存放系统应用程序;
+- **/opt:** 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把 tomcat 等都安装到这里;
+- **/proc:** 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
+- **/root:** 超级用户(系统管理员)的主目录(特权阶级^o^);
+- **/sbin:** 存放二进制可执行文件,只有 root 才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如 ifconfig 等;
+- **/dev:** 用于存放设备文件;
+- **/mnt:** 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
+- **/boot:** 存放用于系统引导时使用的各种文件;
+- **/lib :** 存放着和系统运行相关的库文件 ;
+- **/tmp:** 用于存放各种临时文件,是公用的临时文件存储点;
+- **/var:** 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
+- **/lost+found:** 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows 下叫什么.chk)就在这里。
+
+## 4. Linux 基本命令
+
+下面只是给出了一些比较常用的命令。推荐一个 Linux 命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。
+
+Linux 命令大全:[http://man.linuxde.net/](http://man.linuxde.net/)
+
+### 4.1. 目录切换命令
+
+- **`cd usr`:** 切换到该目录下 usr 目录
+- **`cd ..(或cd../)`:** 切换到上一层目录
+- **`cd /`:** 切换到系统根目录
+- **`cd ~`:** 切换到用户主目录
+- **`cd -`:** 切换到上一个操作所在目录
+
+### 4.2. 目录的操作命令(增删改查)
+
+- **`mkdir 目录名称`:** 增加目录。
+- **`ls/ll`**(ll 是 ls -l 的别名,ll 命令可以看到该目录下的所有目录和文件的详细信息):查看目录信息。
+- **`find 目录 参数`:** 寻找目录(查)。示例:① 列出当前目录及子目录下所有文件和文件夹: `find .`;② 在`/home`目录下查找以.txt 结尾的文件名:`find /home -name "*.txt"` ,忽略大小写: `find /home -iname "*.txt"` ;③ 当前目录及子目录下查找所有以.txt 和.pdf 结尾的文件:`find . \( -name "*.txt" -o -name "*.pdf" \)`或`find . -name "*.txt" -o -name "*.pdf"`。
+- **`mv 目录名称 新目录名称`:** 修改目录的名称(改)。注意:mv 的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩包等进行 重命名的操作。mv 命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。后面会介绍到 mv 命令的另一个用法。
+- **`mv 目录名称 目录的新位置`:** 移动目录的位置---剪切(改)。注意:mv 语法不仅可以对目录进行剪切操作,对文件和压缩包等都可执行剪切操作。另外 mv 与 cp 的结果不同,mv 好像文件“搬家”,文件个数并未增加。而 cp 对文件进行复制,文件个数增加了。
+- **`cp -r 目录名称 目录拷贝的目标位置`:** 拷贝目录(改),-r 代表递归拷贝 。注意:cp 命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r 递归。
+- **`rm [-rf] 目录` :** 删除目录(删)。注意:rm 不仅可以删除目录,也可以删除其他文件或压缩包,为了增强大家的记忆, 无论删除任何目录或文件,都直接使用`rm -rf` 目录/文件/压缩包。
+
+### 4.3. 文件的操作命令(增删改查)
+
+- **`touch 文件名称`:** 文件的创建(增)。
+- **`cat/more/less/tail 文件名称`** :文件的查看(查) 。命令 `tail -f 文件` 可以对某个文件进行动态监控,例如 tomcat 的日志文件, 会随着程序的运行,日志会变化,可以使用 `tail -f catalina-2016-11-11.log` 监控 文 件的变化 。
+- **`vim 文件`:** 修改文件的内容(改)。vim 编辑器是 Linux 中的强大组件,是 vi 编辑器的加强版,vim 编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用 vim 编辑修改文件的方式基本会使用就可以了。在实际开发中,使用 vim 编辑器主要作用就是修改配置文件,下面是一般步骤: `vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q!` (输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存)。
+- **`rm -rf 文件`:** 删除文件(删)。
+
+### 4.4. 压缩文件的操作命令
+
+**1)打包并压缩文件:**
+
+Linux 中的打包文件一般是以.tar 结尾的,压缩的命令一般是以.gz 结尾的。而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般.tar.gz。
+命令:`tar -zcvf 打包压缩后的文件名 要打包压缩的文件` ,其中:
+
+- z:调用 gzip 压缩命令进行压缩
+- c:打包文件
+- v:显示运行过程
+- f:指定文件名
+
+比如:假如 test 目录下有三个文件分别是:aaa.txt bbb.txt ccc.txt,如果我们要打包 test 目录并指定压缩后的压缩包名称为 test.tar.gz 可以使用命令:**`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt` 或 `tar -zcvf test.tar.gz /test/`**
+
+**2)解压压缩包:**
+
+命令:`tar [-xvf] 压缩文件`
+
+其中:x:代表解压
+
+示例:
+
+- 将 /test 下的 test.tar.gz 解压到当前目录下可以使用命令:**`tar -xvf test.tar.gz`**
+- 将 /test 下的 test.tar.gz 解压到根目录/usr 下:**`tar -xvf test.tar.gz -C /usr`**(- C 代表指定解压的位置)
+
+### 4.5. Linux 的权限命令
+
+操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(excutable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
+
+通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
+
+示例:在随意某个目录下`ls -l`
+
+
+
+第一列的内容的信息解释如下:
+
+
+
+> 下面将详细讲解文件的类型、Linux 中权限以及文件有所有者、所在组、其它组具体是什么?
+
+**文件的类型:**
+
+- d: 代表目录
+- -: 代表文件
+- l: 代表软链接(可以认为是 window 中的快捷方式)
+
+**Linux 中权限分为以下几种:**
+
+- r:代表权限是可读,r 也可以用数字 4 表示
+- w:代表权限是可写,w 也可以用数字 2 表示
+- x:代表权限是可执行,x 也可以用数字 1 表示
+
+**文件和目录权限的区别:**
+
+对文件和目录而言,读写执行表示不同的意义。
+
+对于文件:
+
+| 权限名称 | 可执行操作 |
+| :------- | --------------------------: |
+| r | 可以使用 cat 查看文件的内容 |
+| w | 可以修改文件的内容 |
+| x | 可以将其运行为二进制文件 |
+
+对于目录:
+
+| 权限名称 | 可执行操作 |
+| :------- | -----------------------: |
+| r | 可以查看目录下列表 |
+| w | 可以创建和删除目录下文件 |
+| x | 可以使用 cd 进入目录 |
+
+需要注意的是: **超级用户可以无视普通用户的权限,即使文件目录权限是 000,依旧可以访问。**
+
+**在 linux 中的每个用户必须属于一个组,不能独立于组外。在 linux 中每个文件有所有者、所在组、其它组的概念。**
+
+- **所有者(u)** :一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用 `ls ‐ahl` 命令可以看到文件的所有者 也可以使用 chown 用户名 文件名来修改文件的所有者 。
+- **文件所在组(g)** :当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组用 `ls ‐ahl`命令可以看到文件的所有组也可以使用 chgrp 组名 文件名来修改文件所在的组。
+- **其它组(o)** :除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组。
+
+> 我们再来看看如何修改文件/目录的权限。
+
+**修改文件/目录的权限的命令:`chmod`**
+
+示例:修改/test 下的 aaa.txt 的权限为文件所有者有全部权限,文件所有者所在的组有读写权限,其他用户只有读的权限。
+
+**`chmod u=rwx,g=rw,o=r aaa.txt`** 或者 **`chmod 764 aaa.txt`**
+
+
+
+**补充一个比较常用的东西:**
+
+假如我们装了一个 zookeeper,我们每次开机到要求其自动启动该怎么办?
+
+1. 新建一个脚本 zookeeper
+2. 为新建的脚本 zookeeper 添加可执行权限,命令是:`chmod +x zookeeper`
+3. 把 zookeeper 这个脚本添加到开机启动项里面,命令是:`chkconfig --add zookeeper`
+4. 如果想看看是否添加成功,命令是:`chkconfig --list`
+
+### 4.6. Linux 用户管理
+
+Linux 系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
+
+用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
+
+**Linux 用户管理相关命令:**
+
+- `useradd 选项 用户名`:添加用户账号
+- `userdel 选项 用户名`:删除用户帐号
+- `usermod 选项 用户名`:修改帐号
+- `passwd 用户名`:更改或创建用户的密码
+- `passwd -S 用户名` :显示用户账号密码信息
+- `passwd -d 用户名`: 清除用户密码
+
+`useradd` 命令用于 Linux 中创建的新的系统用户。`useradd`可用来建立用户帐号。帐号建好之后,再用`passwd`设定帐号的密码.而可用`userdel`删除帐号。使用`useradd`指令所建立的帐号,实际上是保存在 `/etc/passwd`文本文件中。
+
+`passwd`命令用于设置用户的认证信息,包括用户密码、密码过期时间等。系统管理者则能用它管理系统用户的密码。只有管理者可以指定用户名称,一般用户只能变更自己的密码。
+
+### 4.7. Linux 系统用户组的管理
+
+每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同 Linux 系统对用户组的规定有所不同,如 Linux 下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
+
+用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对`/etc/group`文件的更新。
+
+**Linux 系统用户组的管理相关命令:**
+
+- `groupadd 选项 用户组` :增加一个新的用户组
+- `groupdel 用户组`:要删除一个已有的用户组
+- `groupmod 选项 用户组` : 修改用户组的属性
+
+### 4.8. 其他常用命令
+
+- **`pwd`:** 显示当前所在位置
+
+- `sudo + 其他命令`:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行。
+
+- **`grep 要搜索的字符串 要搜索的文件 --color`:** 搜索命令,--color 代表高亮显示
+
+- **`ps -ef`/`ps -aux`:** 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:**`ps aux|grep redis`** (查看包括 redis 字符串的进程),也可使用 `pgrep redis -a`。
+
+ 注意:如果直接用 ps((Process Status))命令,会显示所有进程的状态,通常结合 grep 命令查看某进程的状态。
+
+- **`kill -9 进程的pid`:** 杀死进程(-9 表示强制终止。)
+
+ 先用 ps 查找进程,然后用 kill 杀掉
+
+- **网络通信命令:**
+ - 查看当前系统的网卡信息:ifconfig
+ - 查看与某台机器的连接情况:ping
+ - 查看当前系统的端口使用:netstat -an
+- **net-tools 和 iproute2 :**
+ `net-tools`起源于 BSD 的 TCP/IP 工具箱,后来成为老版本 LinuxLinux 中配置网络功能的工具。但自 2001 年起,Linux 社区已经对其停止维护。同时,一些 Linux 发行版比如 Arch Linux 和 CentOS/RHEL 7 则已经完全抛弃了 net-tools,只支持`iproute2`。linux ip 命令类似于 ifconfig,但功能更强大,旨在替代它。更多详情请阅读[如何在 Linux 中使用 IP 命令和示例](https://linoxide.com/linux-command/use-ip-command-linux)
+- **`shutdown`:** `shutdown -h now`: 指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定 5 分钟后关机,同时送出警告信息给登入用户。
+
+- **`reboot`:** **`reboot`:** 重开机。**`reboot -w`:** 做个重开机的模拟(只有纪录并不会真的重开机)。
diff --git "a/\346\223\215\344\275\234\347\263\273\347\273\237/Shell.md" b/docs/cs-basics/operating-system/shell-intro.md
similarity index 73%
rename from "\346\223\215\344\275\234\347\263\273\347\273\237/Shell.md"
rename to docs/cs-basics/operating-system/shell-intro.md
index fb1a7411d5c..074f7bfbe55 100644
--- "a/\346\223\215\344\275\234\347\263\273\347\273\237/Shell.md"
+++ b/docs/cs-basics/operating-system/shell-intro.md
@@ -1,33 +1,10 @@
-
-<!-- MarkdownTOC -->
-
-- [Shell 编程入门](#shell-编程入门)
- - [走进 Shell 编程的大门](#走进-shell-编程的大门)
- - [为什么要学Shell?](#为什么要学shell)
- - [什么是 Shell?](#什么是-shell)
- - [Shell 编程的 Hello World](#shell-编程的-hello-world)
- - [Shell 变量](#shell-变量)
- - [Shell 编程中的变量介绍](#shell-编程中的变量介绍)
- - [Shell 字符串入门](#shell-字符串入门)
- - [Shell 字符串常见操作](#shell-字符串常见操作)
- - [Shell 数组](#shell-数组)
- - [Shell 基本运算符](#shell-基本运算符)
- - [算数运算符](#算数运算符)
- - [关系运算符](#关系运算符)
- - [逻辑运算符](#逻辑运算符)
- - [布尔运算符](#布尔运算符)
- - [字符串运算符](#字符串运算符)
- - [文件相关运算符](#文件相关运算符)
- - [shell流程控制](#shell流程控制)
- - [if 条件语句](#if-条件语句)
- - [for 循环语句](#for-循环语句)
- - [while 语句](#while-语句)
- - [shell 函数](#shell-函数)
- - [不带参数没有返回值的函数](#不带参数没有返回值的函数)
- - [有返回值的函数](#有返回值的函数)
- - [带参数的函数](#带参数的函数)
-
-<!-- /MarkdownTOC -->
+---
+title: Shell 编程入门
+category: 计算机基础
+tag:
+ - 操作系统
+ - Linux
+---
# Shell 编程入门
@@ -41,24 +18,23 @@
目前Linux系统下最流行的运维自动化语言就是Shell和Python了。
-两者之间,Shell几乎是IT企业必须使用的运维自动化编程语言,特别是在运维工作中的服务监控、业务快速部署、服务启动停止、数据备份及处理、日制分析等环节里,shell是不可缺的。Python 更适合处理复杂的业务逻辑,以及开发复杂的运维软件工具,实现通过web访问等。Shell是一个命令解释器,解释执行用户所输入的命令和程序。一输入命令,就立即回应的交互的对话方式。
+两者之间,Shell几乎是IT企业必须使用的运维自动化编程语言,特别是在运维工作中的服务监控、业务快速部署、服务启动停止、数据备份及处理、日志分析等环节里,shell是不可缺的。Python 更适合处理复杂的业务逻辑,以及开发复杂的运维软件工具,实现通过web访问等。Shell是一个命令解释器,解释执行用户所输入的命令和程序。一输入命令,就立即回应的交互的对话方式。
另外,了解 shell 编程也是大部分互联网公司招聘后端开发人员的要求。下图是我截取的一些知名互联网公司对于 Shell 编程的要求。
-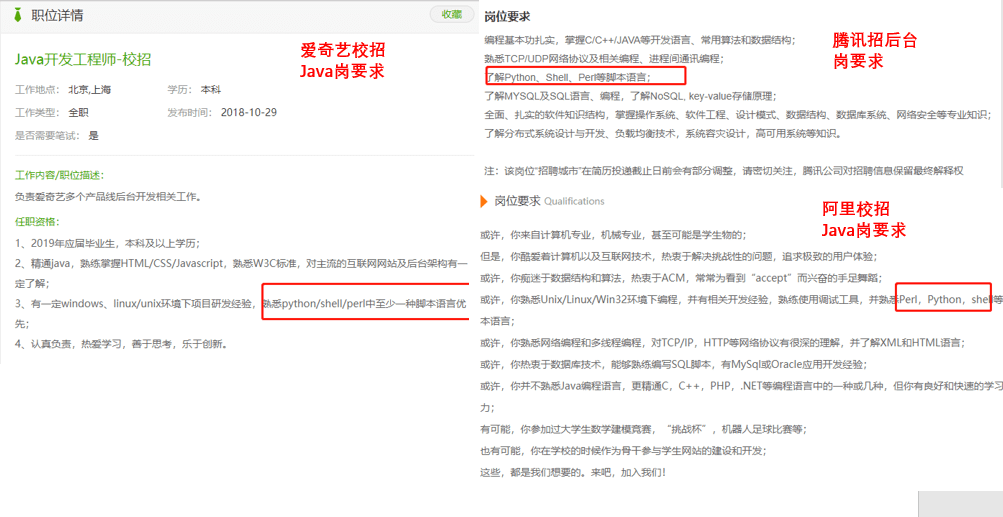
+
### 什么是 Shell?
简单来说“Shell编程就是对一堆Linux命令的逻辑化处理”。
-
W3Cschool 上的一篇文章是这样介绍 Shell的,如下图所示。
-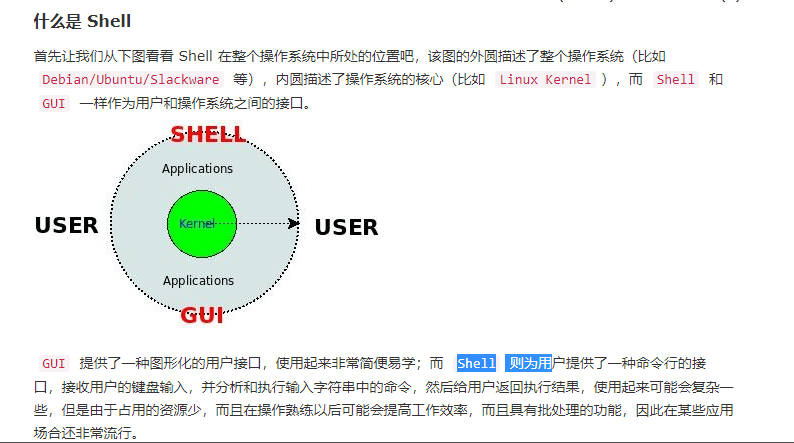
+
### Shell 编程的 Hello World
-学习任何一门编程语言第一件事就是输出HelloWord了!下面我会从新建文件到shell代码编写来说下Shell 编程如何输出Hello World。
+学习任何一门编程语言第一件事就是输出HelloWorld了!下面我会从新建文件到shell代码编写来说下Shell 编程如何输出Hello World。
(1)新建一个文件 helloworld.sh :`touch helloworld.sh`,扩展名为 sh(sh代表Shell)(扩展名并不影响脚本执行,见名知意就好,如果你用 php 写 shell 脚本,扩展名就用 php 好了)
@@ -78,9 +54,9 @@ echo "helloworld!"
shell中 # 符号表示注释。**shell 的第一行比较特殊,一般都会以#!开始来指定使用的 shell 类型。在linux中,除了bash shell以外,还有很多版本的shell, 例如zsh、dash等等...不过bash shell还是我们使用最多的。**
-(4) 运行脚本:`./helloworld.sh` 。(注意,一定要写成 `./helloworld.sh` ,而不是 `helloworld.sh` ,运行其它二进制的程序也一样,直接写 `helloworld.sh` ,linux 系统会去 PATH 里寻找有没有叫 test.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 `helloworld.sh` 是会找不到命令的,要用`./helloworld.sh` 告诉系统说,就在当前目录找。)
+(4) 运行脚本:`./helloworld.sh` 。(注意,一定要写成 `./helloworld.sh` ,而不是 `helloworld.sh` ,运行其它二进制的程序也一样,直接写 `helloworld.sh` ,linux 系统会去 PATH 里寻找有没有叫 helloworld.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 `helloworld.sh` 是会找不到命令的,要用`./helloworld.sh` 告诉系统说,就在当前目录找。)
-
+
## Shell 变量
@@ -91,18 +67,18 @@ shell中 # 符号表示注释。**shell 的第一行比较特殊,一般都会
**Shell编程中一般分为三种变量:**
1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
-2. **Linux已定义的环境变量**(环境变量, 例如:$PATH, $HOME 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而set命令既可以查看环境变量也可以查看自定义变量。
+2. **Linux已定义的环境变量**(环境变量, 例如:`PATH`, `HOME` 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而set命令既可以查看环境变量也可以查看自定义变量。
3. **Shell变量** :Shell变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
**常用的环境变量:**
-> PATH 决定了shell将到哪些目录中寻找命令或程序
-HOME 当前用户主目录
-HISTSIZE 历史记录数
-LOGNAME 当前用户的登录名
-HOSTNAME 指主机的名称
-SHELL 当前用户Shell类型
-LANGUGE 语言相关的环境变量,多语言可以修改此环境变量
-MAIL 当前用户的邮件存放目录
+> PATH 决定了shell将到哪些目录中寻找命令或程序
+HOME 当前用户主目录
+HISTSIZE 历史记录数
+LOGNAME 当前用户的登录名
+HOSTNAME 指主机的名称
+SHELL 当前用户Shell类型
+LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
+MAIL 当前用户的邮件存放目录
PS1 基本提示符,对于root用户是#,对于普通用户是$
**使用 Linux 已定义的环境变量:**
@@ -118,7 +94,7 @@ hello="hello world"
echo $hello
echo "helloworld!"
```
-
+
**Shell 编程中的变量名的命名的注意事项:**
@@ -183,7 +159,7 @@ echo $greeting_2 $greeting_3
输出结果:
-
+
**获取字符串长度:**
@@ -210,7 +186,7 @@ expr length "$name";
expr 5+6 // 直接输出 5+6
expr 5 + 6 // 输出 11
```
-对于某些运算符,还需要我们使用符号"\"进行转义,否则就会提示语法错误。
+对于某些运算符,还需要我们使用符号`\`进行转义,否则就会提示语法错误。
```shell
expr 5 * 6 // 输出错误
@@ -234,13 +210,17 @@ echo ${str:0:10} #输出:SnailClimb
#!bin/bash
#author:amau
-var="http://www.runoob.com/linux/linux-shell-variable.html"
-
-s1=${var%%t*}#h
-s2=${var%t*}#http://www.runoob.com/linux/linux-shell-variable.h
-s3=${var%%.*}#http://www
-s4=${var#*/}#/www.runoob.com/linux/linux-shell-variable.html
-s5=${var##*/}#linux-shell-variable.html
+var="https://www.runoob.com/linux/linux-shell-variable.html"
+# %表示删除从后匹配, 最短结果
+# %%表示删除从后匹配, 最长匹配结果
+# #表示删除从头匹配, 最短结果
+# ##表示删除从头匹配, 最长匹配结果
+# 注: *为通配符, 意为匹配任意数量的任意字符
+s1=${var%%t*} #h
+s2=${var%t*} #https://www.runoob.com/linux/linux-shell-variable.h
+s3=${var%%.*} #http://www
+s4=${var#*/} #/www.runoob.com/linux/linux-shell-variable.html
+s5=${var##*/} #linux-shell-variable.html
```
### Shell 数组
@@ -260,9 +240,9 @@ echo $length #输出:5
echo $length2 #输出:5
# 输出数组第三个元素
echo ${array[2]} #输出:3
-unset array[1]# 删除下表为1的元素也就是删除第二个元素
+unset array[1]# 删除下标为1的元素也就是删除第二个元素
for i in ${array[@]};do echo $i ;done # 遍历数组,输出: 1 3 4 5
-unset arr_number; # 删除数组中的所有元素
+unset array; # 删除数组中的所有元素
for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没有任何输出内容
```
@@ -272,7 +252,7 @@ for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没
> 说明:图片来自《菜鸟教程》
Shell 编程支持下面几种运算符
-
+
- 算数运算符
- 关系运算符
- 布尔运算符
@@ -281,16 +261,16 @@ for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没
### 算数运算符
-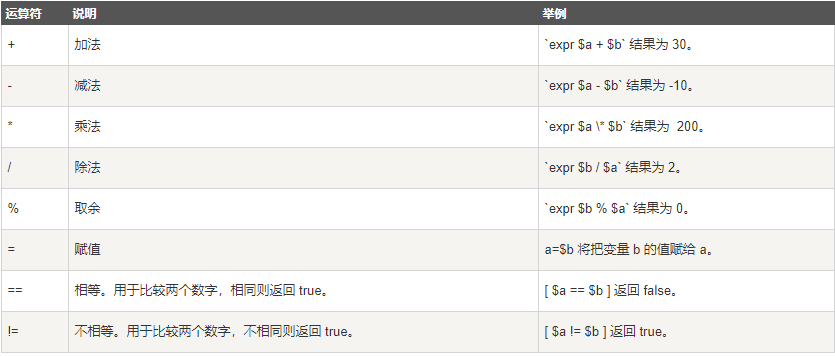
+
-我以加法运算符做一个简单的示例:
+我以加法运算符做一个简单的示例(注意:不是单引号,是反引号):
```shell
#!/bin/bash
a=3;b=3;
val=`expr $a + $b`
#输出:Total value : 6
-echo "Total value : $val
+echo "Total value : $val"
```
@@ -298,7 +278,7 @@ echo "Total value : $val
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
-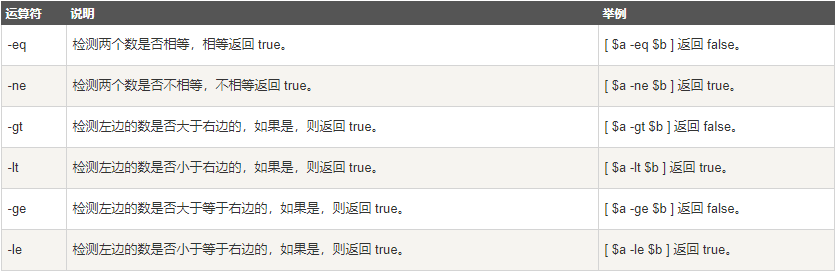
+
通过一个简单的示例演示关系运算符的使用,下面shell程序的作用是当score=100的时候输出A否则输出B。
@@ -322,7 +302,7 @@ B
### 逻辑运算符
-
+
示例:
@@ -336,18 +316,17 @@ echo $a;
### 布尔运算符
-
+
这里就不做演示了,应该挺简单的。
### 字符串运算符
-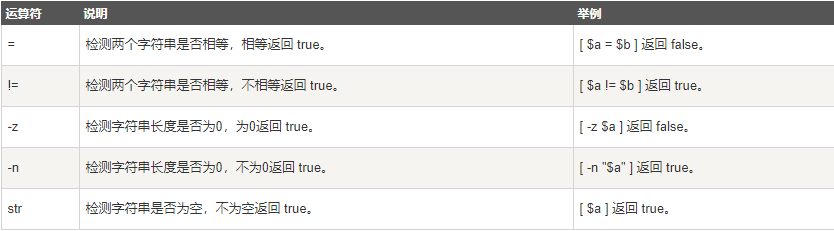
+
简单示例:
```shell
-
#!/bin/bash
a="abc";
b="efg";
@@ -366,7 +345,7 @@ a 不等于 b
### 文件相关运算符
-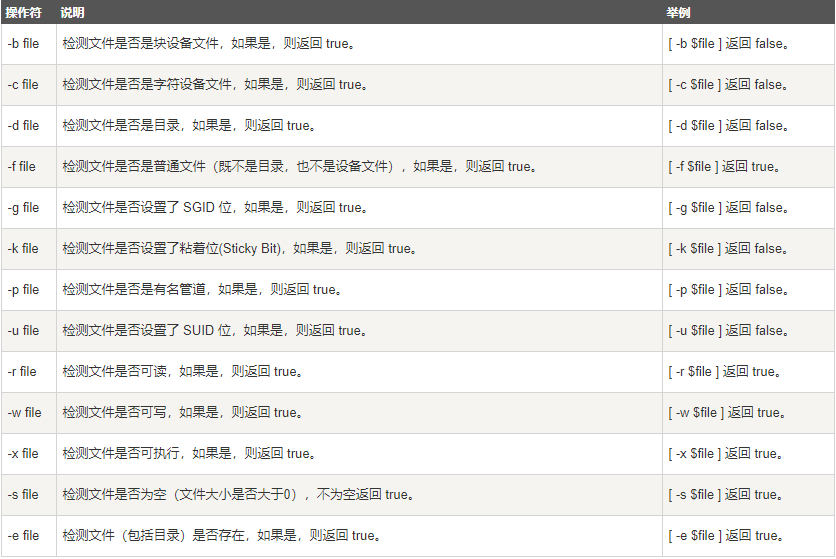
+
使用方式很简单,比如我们定义好了一个文件路径`file="/usr/learnshell/test.sh"` 如果我们想判断这个文件是否可读,可以这样`if [ -r $file ]` 如果想判断这个文件是否可写,可以这样`-w $file`,是不是很简单。
@@ -380,10 +359,10 @@ a 不等于 b
#!/bin/bash
a=3;
b=9;
-if [ $a = $b ]
+if [ $a -eq $b ]
then
echo "a 等于 b"
-elif [ $a > $b ]
+elif [ $a -gt $b ]
then
echo "a 大于 b"
else
@@ -394,7 +373,7 @@ fi
输出结果:
```
-a 大于 b
+a 小于 b
```
相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。不过,还要提到的一点是,不同于我们常见的 Java 以及 PHP 中的 if 条件语句,shell if 条件语句中不能包含空语句也就是什么都不做的语句。
@@ -467,7 +446,7 @@ done
是的!变形金刚 是一个好电影
```
-**无线循环:**
+**无限循环:**
```shell
while true
@@ -482,16 +461,20 @@ done
```shell
#!/bin/bash
-function(){
+hello(){
echo "这是我的第一个 shell 函数!"
}
-function
+echo "-----函数开始执行-----"
+hello
+echo "-----函数执行完毕-----"
```
输出结果:
```
+-----函数开始执行-----
这是我的第一个 shell 函数!
+-----函数执行完毕-----
```
@@ -526,8 +509,6 @@ echo "输入的两个数字之和为 $?"
### 带参数的函数
-
-
```shell
#!/bin/bash
funWithParam(){
@@ -540,7 +521,6 @@ funWithParam(){
echo "作为一个字符串输出所有参数 $* !"
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73
-
```
输出结果:
@@ -553,5 +533,4 @@ funWithParam 1 2 3 4 5 6 7 8 9 34 73
第十一个参数为 73 !
参数总数有 11 个!
作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !
-
-```
\ No newline at end of file
+```
diff --git "a/docs/cs-basics/operating-system/\346\223\215\344\275\234\347\263\273\347\273\237\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230&\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223.md" "b/docs/cs-basics/operating-system/\346\223\215\344\275\234\347\263\273\347\273\237\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230&\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..db158c68faf
--- /dev/null
+++ "b/docs/cs-basics/operating-system/\346\223\215\344\275\234\347\263\273\347\273\237\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230&\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223.md"
@@ -0,0 +1,373 @@
+---
+title: 操作系统常见面试题总结
+category: 计算机基础
+tag:
+ - 操作系统
+---
+
+大家好,我是 Guide 哥!
+
+很多读者抱怨计算操作系统的知识点比较繁杂,自己也没有多少耐心去看,但是面试的时候又经常会遇到。所以,我带着我整理好的操作系统的常见问题来啦!这篇文章总结了一些我觉得比较重要的操作系统相关的问题比如**进程管理**、**内存管理**、**虚拟内存**等等。
+
+文章形式通过大部分比较喜欢的面试官和求职者之间的对话形式展开。另外,Guide哥 也只是在大学的时候学习过操作系统,不过基本都忘了,为了写这篇文章这段时间看了很多相关的书籍和博客。如果文中有任何需要补充和完善的地方,你都可以在 issue 中指出!
+
+这篇文章只是对一些操作系统比较重要概念的一个概览,深入学习的话,建议大家还是老老实实地去看书。另外, 这篇文章的很多内容参考了《现代操作系统》第三版这本书,非常感谢。
+
+开始本文的内容之前,我们先聊聊为什么要学习操作系统。
+
+- **从对个人能力方面提升来说** :操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存看作外存的高速缓存,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
+- **从面试角度来说** :尤其是校招,对于操作系统方面知识的考察是非常非常多的。
+
+**简单来说,学习操作系统能够提高自己思考的深度以及对技术的理解力,并且,操作系统方面的知识也是面试必备。**
+
+关于如何学习操作系统,可以看这篇回答:[https://www.zhihu.com/question/270998611/answer/1640198217](https://www.zhihu.com/question/270998611/answer/1640198217)。
+
+## 一 操作系统基础
+
+面试官顶着蓬松的假发向我走来,只见他一手拿着厚重的 Thinkpad ,一手提着他那淡黄的长裙。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/ceeb653ely1gd8wj5evc4j20i00n0dh0.jpg" height="300"></img>
+
+### 1.1 什么是操作系统?
+
+👨💻**面试官** : 先来个简单问题吧!**什么是操作系统?**
+
+🙋 **我** :我通过以下四点向您介绍一下什么是操作系统吧!
+
+1. **操作系统(Operating System,简称 OS)是管理计算机硬件与软件资源的程序,是计算机的基石。**
+2. **操作系统本质上是一个运行在计算机上的软件程序 ,用于管理计算机硬件和软件资源。** 举例:运行在你电脑上的所有应用程序都通过操作系统来调用系统内存以及磁盘等等硬件。
+3. **操作系统存在屏蔽了硬件层的复杂性。** 操作系统就像是硬件使用的负责人,统筹着各种相关事项。
+4. **操作系统的内核(Kernel)是操作系统的核心部分,它负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理**。 内核是连接应用程序和硬件的桥梁,决定着系统的性能和稳定性。
+
+
+
+### 1.2 系统调用
+
+👨💻**面试官** :**什么是系统调用呢?** 能不能详细介绍一下。
+
+🙋 **我** :介绍系统调用之前,我们先来了解一下用户态和系统态。
+
+根据进程访问资源的特点,我们可以把进程在系统上的运行分为两个级别:
+
+1. 用户态(user mode) : 用户态运行的进程可以直接读取用户程序的数据。
+2. 系统态(kernel mode):可以简单的理解系统态运行的进程或程序几乎可以访问计算机的任何资源,不受限制。
+
+说了用户态和系统态之后,那么什么是系统调用呢?
+
+我们运行的程序基本都是运行在用户态,如果我们调用操作系统提供的系统态级别的子功能咋办呢?那就需要系统调用了!
+
+也就是说在我们运行的用户程序中,凡是与系统态级别的资源有关的操作(如文件管理、进程控制、内存管理等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
+
+这些系统调用按功能大致可分为如下几类:
+
+- 设备管理。完成设备的请求或释放,以及设备启动等功能。
+- 文件管理。完成文件的读、写、创建及删除等功能。
+- 进程控制。完成进程的创建、撤销、阻塞及唤醒等功能。
+- 进程通信。完成进程之间的消息传递或信号传递等功能。
+- 内存管理。完成内存的分配、回收以及获取作业占用内存区大小及地址等功能。
+
+## 二 进程和线程
+
+### 2.1 进程和线程的区别
+
+👨💻**面试官**: 好的!我明白了!那你再说一下: **进程和线程的区别**。
+
+🙋 **我:** 好的! 下图是 Java 内存区域,我们从 JVM 的角度来说一下线程和进程之间的关系吧!
+
+> 如果你对 Java 内存区域 (运行时数据区) 这部分知识不太了解的话可以阅读一下这篇文章:[《可能是把 Java 内存区域讲的最清楚的一篇文章》](https://snailclimb.gitee.io/javaguide/#/docs/java/jvm/Java内存区域)
+
+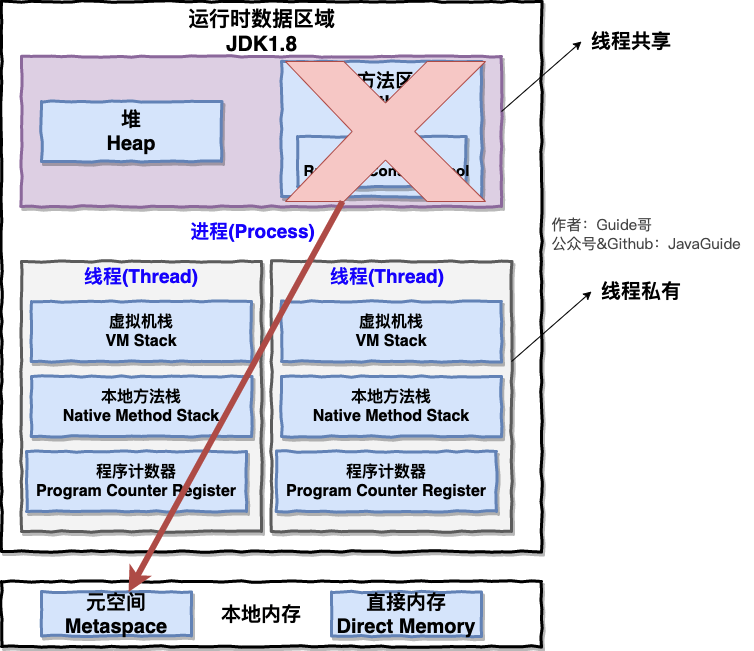
+
+从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
+
+**总结:** 线程是进程划分成的更小的运行单位,一个进程在其执行的过程中可以产生多个线程。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。
+
+### 2.2 进程有哪几种状态?
+
+👨💻**面试官** : 那你再说说**进程有哪几种状态?**
+
+🙋 **我** :我们一般把进程大致分为 5 种状态,这一点和[线程](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md#6-%E8%AF%B4%E8%AF%B4%E7%BA%BF%E7%A8%8B%E7%9A%84%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E5%92%8C%E7%8A%B6%E6%80%81)很像!
+
+- **创建状态(new)** :进程正在被创建,尚未到就绪状态。
+- **就绪状态(ready)** :进程已处于准备运行状态,即进程获得了除了处理器之外的一切所需资源,一旦得到处理器资源(处理器分配的时间片)即可运行。
+- **运行状态(running)** :进程正在处理器上上运行(单核 CPU 下任意时刻只有一个进程处于运行状态)。
+- **阻塞状态(waiting)** :又称为等待状态,进程正在等待某一事件而暂停运行如等待某资源为可用或等待 IO 操作完成。即使处理器空闲,该进程也不能运行。
+- **结束状态(terminated)** :进程正在从系统中消失。可能是进程正常结束或其他原因中断退出运行。
+
+> 订正:下图中 running 状态被 interrupt 向 ready 状态转换的箭头方向反了。
+
+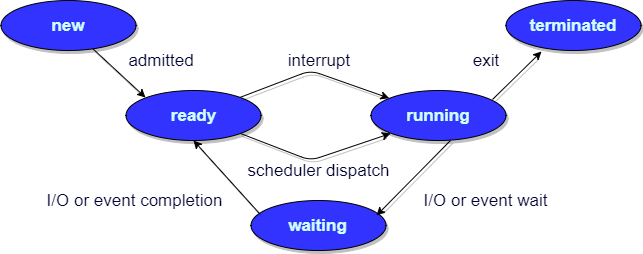
+
+### 2.3 进程间的通信方式
+
+👨💻**面试官** :**进程间的通信常见的的有哪几种方式呢?**
+
+🙋 **我** :大概有 7 种常见的进程间的通信方式。
+
+> 下面这部分总结参考了:[《进程间通信 IPC (InterProcess Communication)》](https://www.jianshu.com/p/c1015f5ffa74) 这篇文章,推荐阅读,总结的非常不错。
+
+1. **管道/匿名管道(Pipes)** :用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
+1. **有名管道(Names Pipes)** : 匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循**先进先出(first in first out)**。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
+1. **信号(Signal)** :信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
+1. **消息队列(Message Queuing)** :消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。**消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。**
+1. **信号量(Semaphores)** :信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
+1. **共享内存(Shared memory)** :使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
+1. **套接字(Sockets)** : 此方法主要用于在客户端和服务器之间通过网络进行通信。套接字是支持 TCP/IP 的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
+
+### 2.4 线程间的同步的方式
+
+👨💻**面试官** :**那线程间的同步的方式有哪些呢?**
+
+🙋 **我** :线程同步是两个或多个共享关键资源的线程的并发执行。应该同步线程以避免关键的资源使用冲突。操作系统一般有下面三种线程同步的方式:
+
+1. **互斥量(Mutex)** :采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 synchronized 关键词和各种 Lock 都是这种机制。
+1. **信号量(Semphares)** :它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
+1. **事件(Event)** :Wait/Notify:通过通知操作的方式来保持多线程同步,还可以方便地实现多线程优先级的比较操作。
+
+### 2.5 进程的调度算法
+
+👨💻**面试官** :**你知道操作系统中进程的调度算法有哪些吗?**
+
+🙋 **我** :嗯嗯!这个我们大学的时候学过,是一个很重要的知识点!
+
+为了确定首先执行哪个进程以及最后执行哪个进程以实现最大 CPU 利用率,计算机科学家已经定义了一些算法,它们是:
+
+- **先到先服务(FCFS)调度算法** : 从就绪队列中选择一个最先进入该队列的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
+- **短作业优先(SJF)的调度算法** : 从就绪队列中选出一个估计运行时间最短的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
+- **时间片轮转调度算法** : 时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法,又称 RR(Round robin)调度。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。
+- **多级反馈队列调度算法** :前面介绍的几种进程调度的算法都有一定的局限性。如**短进程优先的调度算法,仅照顾了短进程而忽略了长进程** 。多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。,因而它是目前**被公认的一种较好的进程调度算法**,UNIX 操作系统采取的便是这种调度算法。
+- **优先级调度** : 为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推。具有相同优先级的进程以 FCFS 方式执行。可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
+
+### 2.6 什么是死锁
+
+👨💻**面试官** :**你知道什么是死锁吗?**
+
+🙋 **我** :多个进程可以竞争有限数量的资源。当一个进程申请资源时,如果这时没有可用资源,那么这个进程进入等待状态。有时,如果所申请的资源被其他等待进程占有,那么该等待进程有可能再也无法改变状态。这种情况称为**死锁**。
+
+### 2.7 死锁的四个条件
+
+👨💻**面试官** :**产生死锁的四个必要条件是什么?**
+
+🙋 **我** :如果系统中以下四个条件同时成立,那么就能引起死锁:
+
+- **互斥**:资源必须处于非共享模式,即一次只有一个进程可以使用。如果另一进程申请该资源,那么必须等待直到该资源被释放为止。
+- **占有并等待**:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
+- **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
+- **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,......,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
+
+注意,只有四个条件同时成立时,死锁才会出现。
+
+## 三 操作系统内存管理基础
+
+### 3.1 内存管理介绍
+
+👨💻 **面试官**: **操作系统的内存管理主要是做什么?**
+
+🙋 **我:** 操作系统的内存管理主要负责内存的分配与回收(malloc 函数:申请内存,free 函数:释放内存),另外地址转换也就是将逻辑地址转换成相应的物理地址等功能也是操作系统内存管理做的事情。
+
+### 3.2 常见的几种内存管理机制
+
+👨💻 **面试官**: **操作系统的内存管理机制了解吗?内存管理有哪几种方式?**
+
+🙋 **我:** 这个在学习操作系统的时候有了解过。
+
+简单分为**连续分配管理方式**和**非连续分配管理方式**这两种。连续分配管理方式是指为一个用户程序分配一个连续的内存空间,常见的如 **块式管理** 。同样地,非连续分配管理方式允许一个程序使用的内存分布在离散或者说不相邻的内存中,常见的如**页式管理** 和 **段式管理**。
+
+1. **块式管理** : 远古时代的计算机操系统的内存管理方式。将内存分为几个固定大小的块,每个块中只包含一个进程。如果程序运行需要内存的话,操作系统就分配给它一块,如果程序运行只需要很小的空间的话,分配的这块内存很大一部分几乎被浪费了。这些在每个块中未被利用的空间,我们称之为碎片。
+2. **页式管理** :把主存分为大小相等且固定的一页一页的形式,页较小,相对相比于块式管理的划分力度更大,提高了内存利用率,减少了碎片。页式管理通过页表对应逻辑地址和物理地址。
+3. **段式管理** : 页式管理虽然提高了内存利用率,但是页式管理其中的页实际并无任何实际意义。 段式管理把主存分为一段段的,每一段的空间又要比一页的空间小很多 。但是,最重要的是段是有实际意义的,每个段定义了一组逻辑信息,例如,有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。 段式管理通过段表对应逻辑地址和物理地址。
+
+👨💻**面试官** : 回答的还不错!不过漏掉了一个很重要的 **段页式管理机制** 。段页式管理机制结合了段式管理和页式管理的优点。简单来说段页式管理机制就是把主存先分成若干段,每个段又分成若干页,也就是说 **段页式管理机制** 中段与段之间以及段的内部的都是离散的。
+
+🙋 **我** :谢谢面试官!刚刚把这个给忘记了~
+
+### 3.3 快表和多级页表
+
+👨💻**面试官** : 页表管理机制中有两个很重要的概念:快表和多级页表,这两个东西分别解决了页表管理中很重要的两个问题。你给我简单介绍一下吧!
+
+🙋 **我** :在分页内存管理中,很重要的两点是:
+
+1. 虚拟地址到物理地址的转换要快。
+2. 解决虚拟地址空间大,页表也会很大的问题。
+
+#### 快表
+
+为了解决虚拟地址到物理地址的转换速度,操作系统在 **页表方案** 基础之上引入了 **快表** 来加速虚拟地址到物理地址的转换。我们可以把快表理解为一种特殊的高速缓冲存储器(Cache),其中的内容是页表的一部分或者全部内容。作为页表的 Cache,它的作用与页表相似,但是提高了访问速率。由于采用页表做地址转换,读写内存数据时 CPU 要访问两次主存。有了快表,有时只要访问一次高速缓冲存储器,一次主存,这样可加速查找并提高指令执行速度。
+
+使用快表之后的地址转换流程是这样的:
+
+1. 根据虚拟地址中的页号查快表;
+2. 如果该页在快表中,直接从快表中读取相应的物理地址;
+3. 如果该页不在快表中,就访问内存中的页表,再从页表中得到物理地址,同时将页表中的该映射表项添加到快表中;
+4. 当快表填满后,又要登记新页时,就按照一定的淘汰策略淘汰掉快表中的一个页。
+
+看完了之后你会发现快表和我们平时经常在我们开发的系统使用的缓存(比如 Redis)很像,的确是这样的,操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。
+
+#### 多级页表
+
+引入多级页表的主要目的是为了避免把全部页表一直放在内存中占用过多空间,特别是那些根本就不需要的页表就不需要保留在内存中。多级页表属于时间换空间的典型场景,具体可以查看下面这篇文章
+
+- 多级页表如何节约内存:[https://www.polarxiong.com/archives/多级页表如何节约内存.html](https://www.polarxiong.com/archives/多级页表如何节约内存.html)
+
+#### 总结
+
+为了提高内存的空间性能,提出了多级页表的概念;但是提到空间性能是以浪费时间性能为基础的,因此为了补充损失的时间性能,提出了快表(即 TLB)的概念。 不论是快表还是多级页表实际上都利用到了程序的局部性原理,局部性原理在后面的虚拟内存这部分会介绍到。
+
+### 3.4 分页机制和分段机制的共同点和区别
+
+👨💻**面试官** : **分页机制和分段机制有哪些共同点和区别呢?**
+
+🙋 **我** :
+
+1. **共同点** :
+ - 分页机制和分段机制都是为了提高内存利用率,减少内存碎片。
+ - 页和段都是离散存储的,所以两者都是离散分配内存的方式。但是,每个页和段中的内存是连续的。
+2. **区别** :
+ - 页的大小是固定的,由操作系统决定;而段的大小不固定,取决于我们当前运行的程序。
+ - 分页仅仅是为了满足操作系统内存管理的需求,而段是逻辑信息的单位,在程序中可以体现为代码段,数据段,能够更好满足用户的需要。
+
+### 3.5 逻辑(虚拟)地址和物理地址
+
+👨💻**面试官** :你刚刚还提到了**逻辑地址和物理地址**这两个概念,我不太清楚,你能为我解释一下不?
+
+🙋 **我:** em...好的嘛!我们编程一般只有可能和逻辑地址打交道,比如在 C 语言中,指针里面存储的数值就可以理解成为内存里的一个地址,这个地址也就是我们说的逻辑地址,逻辑地址由操作系统决定。物理地址指的是真实物理内存中地址,更具体一点来说就是内存地址寄存器中的地址。物理地址是内存单元真正的地址。
+
+### 3.6 CPU 寻址了解吗?为什么需要虚拟地址空间?
+
+👨💻**面试官** :**CPU 寻址了解吗?为什么需要虚拟地址空间?**
+
+🙋 **我** :这部分我真不清楚!
+
+于是面试完之后我默默去查阅了相关文档!留下了没有技术的泪水。。。
+
+> 这部分内容参考了 Microsoft 官网的介绍,地址:<https://docs.microsoft.com/zh-cn/windows-hardware/drivers/gettingstarted/virtual-address-spaces?redirectedfrom=MSDN>
+
+现代处理器使用的是一种称为 **虚拟寻址(Virtual Addressing)** 的寻址方式。**使用虚拟寻址,CPU 需要将虚拟地址翻译成物理地址,这样才能访问到真实的物理内存。** 实际上完成虚拟地址转换为物理地址转换的硬件是 CPU 中含有一个被称为 **内存管理单元(Memory Management Unit, MMU)** 的硬件。如下图所示:
+
+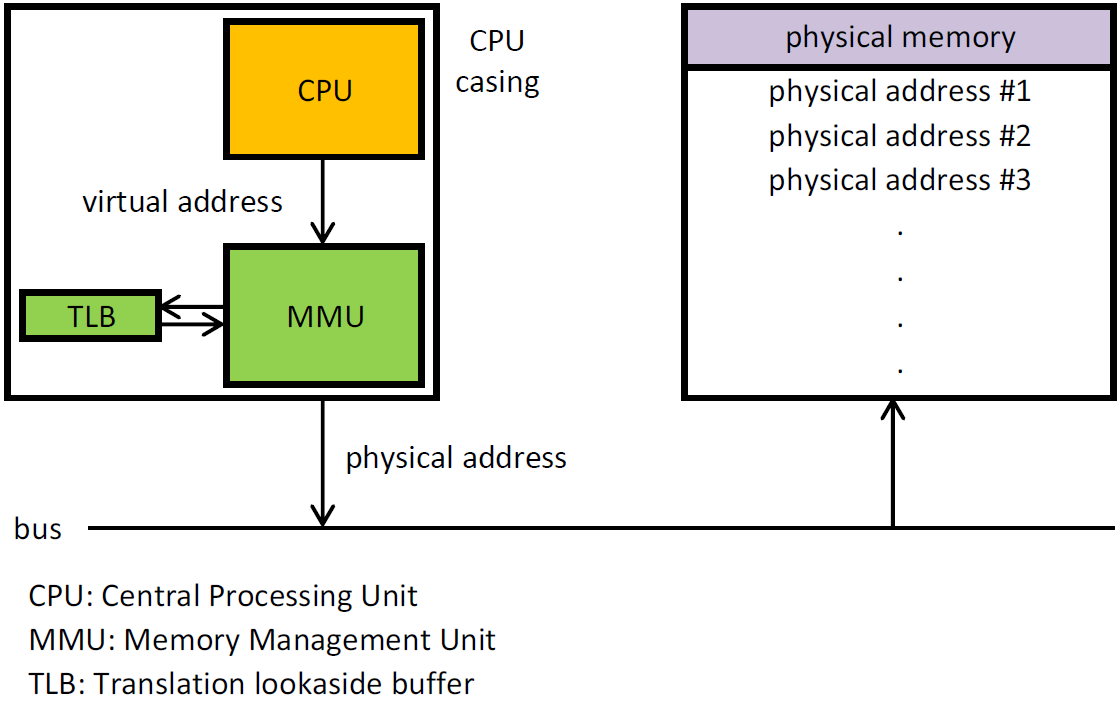
+
+**为什么要有虚拟地址空间呢?**
+
+先从没有虚拟地址空间的时候说起吧!没有虚拟地址空间的时候,**程序都是直接访问和操作的都是物理内存** 。但是这样有什么问题呢?
+
+1. 用户程序可以访问任意内存,寻址内存的每个字节,这样就很容易(有意或者无意)破坏操作系统,造成操作系统崩溃。
+2. 想要同时运行多个程序特别困难,比如你想同时运行一个微信和一个 QQ 音乐都不行。为什么呢?举个简单的例子:微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就造成了微信这个程序就会崩溃。
+
+**总结来说:如果直接把物理地址暴露出来的话会带来严重问题,比如可能对操作系统造成伤害以及给同时运行多个程序造成困难。**
+
+通过虚拟地址访问内存有以下优势:
+
+- 程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区。
+- 程序可以使用一系列虚拟地址来访问大于可用物理内存的内存缓冲区。当物理内存的供应量变小时,内存管理器会将物理内存页(通常大小为 4 KB)保存到磁盘文件。数据或代码页会根据需要在物理内存与磁盘之间移动。
+- 不同进程使用的虚拟地址彼此隔离。一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
+
+## 四 虚拟内存
+
+### 4.1 什么是虚拟内存(Virtual Memory)?
+
+👨💻**面试官** :再问你一个常识性的问题!**什么是虚拟内存(Virtual Memory)?**
+
+🙋 **我** :这个在我们平时使用电脑特别是 Windows 系统的时候太常见了。很多时候我们使用点开了很多占内存的软件,这些软件占用的内存可能已经远远超出了我们电脑本身具有的物理内存。**为什么可以这样呢?** 正是因为 **虚拟内存** 的存在,通过 **虚拟内存** 可以让程序可以拥有超过系统物理内存大小的可用内存空间。另外,**虚拟内存为每个进程提供了一个一致的、私有的地址空间,它让每个进程产生了一种自己在独享主存的错觉(每个进程拥有一片连续完整的内存空间)**。这样会更加有效地管理内存并减少出错。
+
+**虚拟内存**是计算机系统内存管理的一种技术,我们可以手动设置自己电脑的虚拟内存。不要单纯认为虚拟内存只是“使用硬盘空间来扩展内存“的技术。**虚拟内存的重要意义是它定义了一个连续的虚拟地址空间**,并且 **把内存扩展到硬盘空间**。推荐阅读:[《虚拟内存的那点事儿》](https://juejin.im/post/59f8691b51882534af254317)
+
+维基百科中有几句话是这样介绍虚拟内存的。
+
+> **虚拟内存** 使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如 RAM)的使用也更有效率。目前,大多数操作系统都使用了虚拟内存,如 Windows 家族的“虚拟内存”;Linux 的“交换空间”等。From:<https://zh.wikipedia.org/wiki/虚拟内存>
+
+### 4.2 局部性原理
+
+👨💻**面试官** :要想更好地理解虚拟内存技术,必须要知道计算机中著名的**局部性原理**。另外,局部性原理既适用于程序结构,也适用于数据结构,是非常重要的一个概念。
+
+🙋 **我** :局部性原理是虚拟内存技术的基础,正是因为程序运行具有局部性原理,才可以只装入部分程序到内存就开始运行。
+
+> 以下内容摘自《计算机操作系统教程》 第 4 章存储器管理。
+
+早在 1968 年的时候,就有人指出我们的程序在执行的时候往往呈现局部性规律,也就是说在某个较短的时间段内,程序执行局限于某一小部分,程序访问的存储空间也局限于某个区域。
+
+局部性原理表现在以下两个方面:
+
+1. **时间局部性** :如果程序中的某条指令一旦执行,不久以后该指令可能再次执行;如果某数据被访问过,不久以后该数据可能再次被访问。产生时间局部性的典型原因,是由于在程序中存在着大量的循环操作。
+2. **空间局部性** :一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址,可能集中在一定的范围之内,这是因为指令通常是顺序存放、顺序执行的,数据也一般是以向量、数组、表等形式簇聚存储的。
+
+时间局部性是通过将近来使用的指令和数据保存到高速缓存存储器中,并使用高速缓存的层次结构实现。空间局部性通常是使用较大的高速缓存,并将预取机制集成到高速缓存控制逻辑中实现。虚拟内存技术实际上就是建立了 “内存一外存”的两级存储器的结构,利用局部性原理实现髙速缓存。
+
+### 4.3 虚拟存储器
+
+> **勘误:虚拟存储器又叫做虚拟内存,都是 Virtual Memory 的翻译,属于同一个概念。**
+
+👨💻**面试官** :~~都说了虚拟内存了。你再讲讲**虚拟存储器**把!~~
+
+🙋 **我** :
+
+> 这部分内容来自:[王道考研操作系统知识点整理](https://wizardforcel.gitbooks.io/wangdaokaoyan-os/content/13.html)。
+
+基于局部性原理,在程序装入时,可以将程序的一部分装入内存,而将其他部分留在外存,就可以启动程序执行。由于外存往往比内存大很多,所以我们运行的软件的内存大小实际上是可以比计算机系统实际的内存大小大的。在程序执行过程中,当所访问的信息不在内存时,由操作系统将所需要的部分调入内存,然后继续执行程序。另一方面,操作系统将内存中暂时不使用的内容换到外存上,从而腾出空间存放将要调入内存的信息。这样,计算机好像为用户提供了一个比实际内存大的多的存储器——**虚拟存储器**。
+
+实际上,我觉得虚拟内存同样是一种时间换空间的策略,你用 CPU 的计算时间,页的调入调出花费的时间,换来了一个虚拟的更大的空间来支持程序的运行。不得不感叹,程序世界几乎不是时间换空间就是空间换时间。
+
+### 4.4 虚拟内存的技术实现
+
+👨💻**面试官** :**虚拟内存技术的实现呢?**
+
+🙋 **我** :**虚拟内存的实现需要建立在离散分配的内存管理方式的基础上。** 虚拟内存的实现有以下三种方式:
+
+1. **请求分页存储管理** :建立在分页管理之上,为了支持虚拟存储器功能而增加了请求调页功能和页面置换功能。请求分页是目前最常用的一种实现虚拟存储器的方法。请求分页存储管理系统中,在作业开始运行之前,仅装入当前要执行的部分段即可运行。假如在作业运行的过程中发现要访问的页面不在内存,则由处理器通知操作系统按照对应的页面置换算法将相应的页面调入到主存,同时操作系统也可以将暂时不用的页面置换到外存中。
+2. **请求分段存储管理** :建立在分段存储管理之上,增加了请求调段功能、分段置换功能。请求分段储存管理方式就如同请求分页储存管理方式一样,在作业开始运行之前,仅装入当前要执行的部分段即可运行;在执行过程中,可使用请求调入中断动态装入要访问但又不在内存的程序段;当内存空间已满,而又需要装入新的段时,根据置换功能适当调出某个段,以便腾出空间而装入新的段。
+3. **请求段页式存储管理**
+
+**这里多说一下?很多人容易搞混请求分页与分页存储管理,两者有何不同呢?**
+
+请求分页存储管理建立在分页管理之上。他们的根本区别是是否将程序全部所需的全部地址空间都装入主存,这也是请求分页存储管理可以提供虚拟内存的原因,我们在上面已经分析过了。
+
+它们之间的根本区别在于是否将一作业的全部地址空间同时装入主存。请求分页存储管理不要求将作业全部地址空间同时装入主存。基于这一点,请求分页存储管理可以提供虚存,而分页存储管理却不能提供虚存。
+
+不管是上面那种实现方式,我们一般都需要:
+
+1. 一定容量的内存和外存:在载入程序的时候,只需要将程序的一部分装入内存,而将其他部分留在外存,然后程序就可以执行了;
+2. **缺页中断**:如果**需执行的指令或访问的数据尚未在内存**(称为缺页或缺段),则由处理器通知操作系统将相应的页面或段**调入到内存**,然后继续执行程序;
+3. **虚拟地址空间** :逻辑地址到物理地址的变换。
+
+### 4.5 页面置换算法
+
+👨💻**面试官** :虚拟内存管理很重要的一个概念就是页面置换算法。那你说一下 **页面置换算法的作用?常见的页面置换算法有哪些?**
+
+🙋 **我** :
+
+> 这个题目经常作为笔试题出现,网上已经给出了很不错的回答,我这里只是总结整理了一下。
+
+地址映射过程中,若在页面中发现所要访问的页面不在内存中,则发生缺页中断 。
+
+> **缺页中断** 就是要访问的**页**不在主存,需要操作系统将其调入主存后再进行访问。 在这个时候,被内存映射的文件实际上成了一个分页交换文件。
+
+当发生缺页中断时,如果当前内存中并没有空闲的页面,操作系统就必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。用来选择淘汰哪一页的规则叫做页面置换算法,我们可以把页面置换算法看成是淘汰页面的规则。
+
+- **OPT 页面置换算法(最佳页面置换算法)** :最佳(Optimal, OPT)置换算法所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若千页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现。一般作为衡量其他置换算法的方法。
+- **FIFO(First In First Out) 页面置换算法(先进先出页面置换算法)** : 总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。
+- **LRU (Least Recently Used)页面置换算法(最近最久未使用页面置换算法)** :LRU算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。
+- **LFU (Least Frequently Used)页面置换算法(最少使用页面置换算法)** : 该置换算法选择在之前时期使用最少的页面作为淘汰页。
+
+## Reference
+
+- 《计算机操作系统—汤小丹》第四版
+- [《深入理解计算机系统》](https://book.douban.com/subject/1230413/)
+- [https://zh.wikipedia.org/wiki/输入输出内存管理单元](https://zh.wikipedia.org/wiki/输入输出内存管理单元)
+- [https://baike.baidu.com/item/快表/19781679](https://baike.baidu.com/item/快表/19781679)
+- https://www.jianshu.com/p/1d47ed0b46d5
+- <https://www.studytonight.com/operating-system>
+- <https://www.geeksforgeeks.org/interprocess-communication-methods/>
+- <https://juejin.im/post/59f8691b51882534af254317>
+- 王道考研操作系统知识点整理: https://wizardforcel.gitbooks.io/wangdaokaoyan-os/content/13.html
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/database/Redis/images/redis-all/redis-list.drawio b/docs/database/Redis/images/redis-all/redis-list.drawio
new file mode 100644
index 00000000000..afa767154b7
--- /dev/null
+++ b/docs/database/Redis/images/redis-all/redis-list.drawio
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-07-27T06:27:52.340Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="dsqbsLB26jrO3YkREjOb" version="13.4.5" type="device"><diagram id="tTBfL0GptSJyUtbD2ZoE" name="Page-1">7VlNc5swFPw1PiaDENjmmNjpx6Gdjt1J2lNHAzKoEYgRcmzn11cYyRgJT1w3DnScU3grIaHd5b2HM4CTdP2Rozz5wiJMB64TrQdwOnBdEEAo/5TIpkICx6mAmJNITaqBOXnGCtTTliTCRWOiYIwKkjfBkGUZDkUDQ5yzVXPagtHmrjmKsQXMQ0Rt9IFEIqnQsTuq8U+YxIneGQyDaiRFerI6SZGgiK32IHg3gBPOmKiu0vUE05I8zUt134cDo7sH4zgTx9wwu/+V/H4g/myezsD35/vZ56/ulVrlCdGlOrB6WLHRDHC2zCJcLgIG8HaVEIHnOQrL0ZXUXGKJSKkaLh6xCBMVLFgmlKJgJGO1F+YCrw8eAuyokZ7CLMWCb+QUdcOVp9hUdnKhile1OL62WLInzEhhSPkh3i1dUyYvFGt/waBrMbi9BD3lUfPm2bwFLbT556INttPWc/sB035d0+i10wj7TaM77hmNw5fTIM6im7KeyCikqChI2ORMHp1vfsjA0cHPMrh2fR1P1/uj042KjiAbR1aRMqiWVRHxGIuXUr0tSSNxHqacY4oEeWo+RpsOaodvjMgHrPM2gKbk4+YaBVvyEKvb9suYuZLpHdcwRUWEtdDWF7tzn26V0f9ula4s4A0N4cbOtX+aB3zfWupNPaCb01cxAXjPF0cofGq68AJjIT8wXXdusxzRY/fbLJ0VDbPbOj1j2PXnrVOG/Z3A82WRWFaQXZUwujHB2SOeMMq4RDKW4VJLQqkBIUrirHSQVA9L/Lbs0Yj8lL1RAymJonKb1vavbhCP9M0/dYA+OFDF95zltTjLLPav1gECu5PmOcvf5aloD7qWx7fkoRf8+siiYggEuhbI/oSil/v+2Pp0/gLZ3y18u20/BTqDJp5O8VoSp2tJxvYrgxcXpIjV351PERnWv7RXPV39/wp49wc=</diagram></mxfile>
\ No newline at end of file
diff --git a/docs/database/Redis/images/redis-all/redis-list.png b/docs/database/Redis/images/redis-all/redis-list.png
new file mode 100644
index 00000000000..4fb4e36cb49
Binary files /dev/null and b/docs/database/Redis/images/redis-all/redis-list.png differ
diff --git a/docs/database/Redis/images/redis-all/redis-rollBack.png b/docs/database/Redis/images/redis-all/redis-rollBack.png
new file mode 100644
index 00000000000..91f7f46d66d
Binary files /dev/null and b/docs/database/Redis/images/redis-all/redis-rollBack.png differ
diff --git a/docs/database/Redis/images/redis-all/redis-vs-memcached.png b/docs/database/Redis/images/redis-all/redis-vs-memcached.png
new file mode 100644
index 00000000000..23844d67e6f
Binary files /dev/null and b/docs/database/Redis/images/redis-all/redis-vs-memcached.png differ
diff --git a/docs/database/Redis/images/redis-all/redis4.0-more-thread.png b/docs/database/Redis/images/redis-all/redis4.0-more-thread.png
new file mode 100644
index 00000000000..e7e19e52e17
Binary files /dev/null and b/docs/database/Redis/images/redis-all/redis4.0-more-thread.png differ
diff --git "a/docs/database/Redis/images/redis-all/redis\344\272\213\344\273\266\345\244\204\347\220\206\345\231\250.png" "b/docs/database/Redis/images/redis-all/redis\344\272\213\344\273\266\345\244\204\347\220\206\345\231\250.png"
new file mode 100644
index 00000000000..fc280fffaba
Binary files /dev/null and "b/docs/database/Redis/images/redis-all/redis\344\272\213\344\273\266\345\244\204\347\220\206\345\231\250.png" differ
diff --git "a/docs/database/Redis/images/redis-all/redis\344\272\213\345\212\241.png" "b/docs/database/Redis/images/redis-all/redis\344\272\213\345\212\241.png"
new file mode 100644
index 00000000000..eb0c404cafd
Binary files /dev/null and "b/docs/database/Redis/images/redis-all/redis\344\272\213\345\212\241.png" differ
diff --git "a/docs/database/Redis/images/redis-all/redis\350\277\207\346\234\237\346\227\266\351\227\264.png" "b/docs/database/Redis/images/redis-all/redis\350\277\207\346\234\237\346\227\266\351\227\264.png"
new file mode 100644
index 00000000000..27df6ead8e4
Binary files /dev/null and "b/docs/database/Redis/images/redis-all/redis\350\277\207\346\234\237\346\227\266\351\227\264.png" differ
diff --git a/docs/database/Redis/images/redis-all/try-redis.png b/docs/database/Redis/images/redis-all/try-redis.png
new file mode 100644
index 00000000000..cd21a6518e4
Binary files /dev/null and b/docs/database/Redis/images/redis-all/try-redis.png differ
diff --git a/docs/database/Redis/images/redis-all/what-is-redis.png b/docs/database/Redis/images/redis-all/what-is-redis.png
new file mode 100644
index 00000000000..913881ac6cf
Binary files /dev/null and b/docs/database/Redis/images/redis-all/what-is-redis.png differ
diff --git "a/docs/database/Redis/images/redis-all/\344\275\277\347\224\250\347\274\223\345\255\230\344\271\213\345\220\216.png" "b/docs/database/Redis/images/redis-all/\344\275\277\347\224\250\347\274\223\345\255\230\344\271\213\345\220\216.png"
new file mode 100644
index 00000000000..2c73bd90276
Binary files /dev/null and "b/docs/database/Redis/images/redis-all/\344\275\277\347\224\250\347\274\223\345\255\230\344\271\213\345\220\216.png" differ
diff --git "a/docs/database/Redis/images/redis-all/\345\212\240\345\205\245\345\270\203\351\232\206\350\277\207\346\273\244\345\231\250\345\220\216\347\232\204\347\274\223\345\255\230\345\244\204\347\220\206\346\265\201\347\250\213.png" "b/docs/database/Redis/images/redis-all/\345\212\240\345\205\245\345\270\203\351\232\206\350\277\207\346\273\244\345\231\250\345\220\216\347\232\204\347\274\223\345\255\230\345\244\204\347\220\206\346\265\201\347\250\213.png"
new file mode 100644
index 00000000000..a2c2ed6906f
Binary files /dev/null and "b/docs/database/Redis/images/redis-all/\345\212\240\345\205\245\345\270\203\351\232\206\350\277\207\346\273\244\345\231\250\345\220\216\347\232\204\347\274\223\345\255\230\345\244\204\347\220\206\346\265\201\347\250\213.png" differ
diff --git "a/docs/database/Redis/images/redis-all/\345\215\225\344\275\223\346\236\266\346\236\204.png" "b/docs/database/Redis/images/redis-all/\345\215\225\344\275\223\346\236\266\346\236\204.png"
new file mode 100644
index 00000000000..648a404af8c
Binary files /dev/null and "b/docs/database/Redis/images/redis-all/\345\215\225\344\275\223\346\236\266\346\236\204.png" differ
diff --git "a/docs/database/Redis/images/redis-all/\347\274\223\345\255\230\347\232\204\345\244\204\347\220\206\346\265\201\347\250\213.png" "b/docs/database/Redis/images/redis-all/\347\274\223\345\255\230\347\232\204\345\244\204\347\220\206\346\265\201\347\250\213.png"
new file mode 100644
index 00000000000..11860ae1f02
Binary files /dev/null and "b/docs/database/Redis/images/redis-all/\347\274\223\345\255\230\347\232\204\345\244\204\347\220\206\346\265\201\347\250\213.png" differ
diff --git "a/docs/database/Redis/images/redis-all/\347\274\223\345\255\230\347\251\277\351\200\217\346\203\205\345\206\265.png" "b/docs/database/Redis/images/redis-all/\347\274\223\345\255\230\347\251\277\351\200\217\346\203\205\345\206\265.png"
new file mode 100644
index 00000000000..e7298c15ed6
Binary files /dev/null and "b/docs/database/Redis/images/redis-all/\347\274\223\345\255\230\347\251\277\351\200\217\346\203\205\345\206\265.png" differ
diff --git "a/docs/database/Redis/images/redis-all/\351\233\206\344\270\255\345\274\217\347\274\223\345\255\230\346\236\266\346\236\204.png" "b/docs/database/Redis/images/redis-all/\351\233\206\344\270\255\345\274\217\347\274\223\345\255\230\346\236\266\346\236\204.png"
new file mode 100644
index 00000000000..5aff414baa4
Binary files /dev/null and "b/docs/database/Redis/images/redis-all/\351\233\206\344\270\255\345\274\217\347\274\223\345\255\230\346\236\266\346\236\204.png" differ
diff --git "a/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio" "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio"
new file mode 100644
index 00000000000..bc4c6d0cca7
--- /dev/null
+++ "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-19T10:09:54.115Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="ouO_wanaVWn605JgN_9b" version="13.4.5" type="device"><diagram id="3s-LqK6m4lkifnhmqHE2" name="Page-1">7Vpbc+o2EP41ekzHl/j2iAmk02nmdA6dpn3qCFsYTWSLY0Qg/fWVbMnYluE4B4jTQh4Se6WVVt+32pU2BvY43T3mcLV8ojEiwDLiHbAfgGWZluPzP0LyVkoCwygFSY5j2WkvmOF/kBSqbhsco3WjI6OUMLxqCiOaZShiDRnMc7ptdltQ0px1BROkCWYRJLr0GcdsWUp9y9vLf0Y4WaqZTTcoW1KoOsuVrJcwptuayJ4Ae5xTysqndDdGRICncCn1pgdaK8NylLE+Ck/Pf/xthHPraf7NePliLeLZ1+c7OcorJBu5YGkse1MI5HSTxUgMYgI73C4xQ7MVjETrlnPOZUuWEtm8wISMKaF5oWsvFgsrirh8zXL6gmotsTt3HVe0KFiEekRTzLs/GPw5IXC9ls/SSpQztDu4fLMClXsjoili+RvvIhVs5VHSEX3fKd+3e1pNxdWyRqkrZVB6UlINvQebP0i834G9db3YW0Njb2vYx5BBDX++ZNYEuQlmRjN0BHlIcJJxWcRxQrwxFChiHlxGsiHFcSzm6qR2T75RTaxiUME3zZgMmFbQIq1O5jkIvG8RqN5rBLod/NmX4u9e4y8TVN3468dflYWH4s+5mtjnGJ8t77jXi/3gece75Z13EWi3845OYFfcUjyfnT//lndO4W/wvBNcTexzg8+Wd9Ql4BrBHzzxmPpN/5Z5jjDoWZ/sxmPq5YJb6nkHgYOnHlOvOfxfw5/vf7rcoxcMrgb84XOPftu/5Z4jDAbtcunguUcvGdxyzzsIHD736HUHjTyUxSPxDzNBgIBGANKIeC38mgjbXIJ2mP0pe4vnvwSiPzny7WEnAS5e3hpoo1j7L1wLa24q3eQROrbIbk5qmDsdmCtZjghk+LVpRhcRcobfKOYGHiw1BSrjqCFK86XWns4eA7VqGQzmCWLaQIVfVMs+wVX0Esd/zFWGcgG/vevbzPV1gXYG/3AX6FElublAF3Nu+9Lxo1GgXUDQBrqwC6h1NFzAJUV2t/bK7reN+HwhBJN7EPrAD8DEAf4U+GPxwNcQmGASgMAG4QRMfDAywcivqdVdSgmF59ytC9cZ8Q62vdrVNdyknJDP8wACp3N4UnadClNlfymM8esJk8pB5vnpY3DrCluU9PSTlBSd9RBVv7IcOi/Vdrptn+f8ZPt+w/s9Vz8/OeZHHqAsvXz2PZcSFN5JNoQ/ELRgh/1hvYJZH68yne7twPcf3w5jsQt49uD37ckUhGMQjGYZxGRMcDrnnWEqSM7m61XTFcvZj3toKRXmnGDnBTCrBQQHjMYFFHzhngxFoVetu/z9iNlyM6/w+QW+wkfxkdkPwcGlJSK99/HF92e9vNDOxEKJ8hExEzsrEK8EzhEJYfSSFGO3AwxXrl3VjOKn0qJ5jPIOjSlMMREzPMIcpjSLlRkSGENS/aUyxTNKPiOcJb/TlTwiSMGvwgsakpAyRtOm7KsMA2eKQZ6qWakM7OhlFKsrBt1fLAbpFeDbsazXscw0vnep6nsuMw1v2LO5pVeRs41Q+9jAM2R1RefgcuUV/rr/QrfkcP+dsz35Fw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.png" "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.png"
new file mode 100644
index 00000000000..f8b9589d6d7
Binary files /dev/null and "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.png" differ
diff --git "a/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.drawio" "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.drawio"
new file mode 100644
index 00000000000..6fddf10f064
--- /dev/null
+++ "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-11-22T06:15:41.782Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="xEbpVhUlxZyJQJUx4ASQ" version="13.4.5" type="device"><diagram id="3s-LqK6m4lkifnhmqHE2" name="Page-1">7LzXsuTYkSX6NWl254FtAAIqHqG11ngZgwporfH1A5zMLFaRySZ5L7unZ26fqjwHsYGt3Zcv9+2Iby+qPbgpGgqlT7PmGwSkx7cX/Q2CwPfrdf95Ss7vJW8A+F6QT2X646E/F1jllf0o/PnYWqbZ/IcHl75vlnL4Y2HSd12WLH8oi6ap3//42Kdv/tjrEOXZXxVYSdT8dalXpkvxvRSHsD+X81mZFz97BtH39ztt9PPhHzOZiyjt998VvZhvL2rq++X7VXtQWfMs3s91+V6P/Rt3fxvYlHXLP1LhaIIYQnDfkqb05QKximXAn34u8xY1648Zf4PQ5m6QjO+L/Ln4WTAPUffMYzl/LA46rs/gyaRv+unbi7hvTnn8/yD30O5mqfv3Hy7/x3P9NHfvQrf86RO1ZXN+r3a3FbXD183XC77/ttk0lXt2r2E2/dXN39r8qzvD8gwwm8rPP1Epz/opL6N/osZStrdMQkCX7c+c+/ZZmH+49rzMfZf/7Qo/xv/7tZq/9OJZKRD7N2Q4/uLu9x15bnf91EbNb7ebbFmy6U/3ziXl3eWvHlmyY/lT1JR59/12k32WP94su/RLxJ67wO/6/rq5TFE3f+4mfzbeZb89sPdT+se+f189jpI6n/q1S//0FwIEIchvi/EX1//jj72nWdJP0VL23S+6T8t5aKIfElZ2Tfm7e5+mj5bf1/kpyz+FHvq3bwz+jWC/keQ3BvmGs9/e6DcG/kbi33D6qwT/RgLfGOzbm/iGwz8eftM/leXWw+/68t869F9dh/7fCuJfisxvo+ni+fugqC9B+ZKVR3TIbzhDfxcn4hsBPDJD0s//txTdIkSiz603cD/19Qz67f3+0QCBJFFSZD8EkPh7UnYX/w69oT8IHPQozl2+F+WSWbdyPsX7bbzvsmJpm/sTeF8+S/bDGv9Yp7+0Nj8M0JZNd4u/K/phfbisb7NlOu9Hftx9IT+MzQ8q8EJ/fN7/bFihn/Sg+J1RhX+URT9sef5b0382d/fFD4v3z1g/8G9av/9W1P96ivp/sLH7D7ZWf8XZwH/7DXHuSt/B427tN/z4hW274Qb5MmnoY+GIG4PuB6hvOPWrh39v/8hvJPxVi7lx6gvU7mfgLywjv72Z38Y2/fsw9TcQ7V+CXk0UZw35G85T33X4bu/Ffv38awAO/wt8Q/4a30D0F/iG/wvwTaedpuK5M2cg0KMIasRg+k+/gLcf9oT6EgXq2xv7sakk9mO/34QYbRH3uF2/2LmnFv3t/SUT97Dvpn7W+l7j2fTXIwZ/Y99+t0fzMvV19nMrvuT63riyaf6i6Ie60sm9MTc+vshnQ8rbQyN+3GjLNH26+aVQfO139izSvyMHPzv/C6l5Pv9OVMiv//5FtvD1+jfkD9ICY/+gNYT+BdKSMkbzbv5nOG1tTP/PbKnwvPqVtPzlLj7LNvyNuf7mg0fxz8eBv7FSf3NZoNffpwgg9ItFAf/jOMLfX5Xbsx+ey7L9Cib8JqDyI216P5ffIZ+O+2Xp238Xjj5fP78Q8qV/pDmah+9Bjk95PEJNfnVJ/CwFfpbc12m0RLfJ+P4RYofHCFOlS2rmDkhc3hP3j2o5BePk95Xy/KIFigjuv9TiSWh2XzgL0DCGa8L+CqXUx/oGkRBo8xtmWrAxyqgaWkBkUmbSg4Nxhm2JSs7KcgUjOJyvxapZyJbVWbkyOC93D2vQqM+UBGpgegVFHd3zAfXtjfkLht1NP/sEsdn3PzN+X5Dvq9s0PPy6SYKvzb//YBt+/w6R93tbP8g248j17mgxtCyKMijt4GCTk+znej1YIV/ttDbKhOiZ2lLhrHQIS9TuBkhToTiDRshYLpoRYAxLEBRlYRCbnCnLJOJ4aUaGsO5iVUkJzC5qwjqEMF6KnsktWxBILd0x46sYDqOFrJmcsmXB1JI9NvLa8M6vYoYpKZqWTc3ZY6KuDQ7CwqggmPoutnlDA+CQYGaL87AgIgWmPinC7hINEJ7ijPMmIyQFoj5Pxu4UDhBEhp3Xp9gkhTzfT8BuFG4XRYZcVsjrDVK8i4EDoBeNM0iZKZoV4nKLFJU8Z5BbkqinmH8mzRkWISpzwSAXuVCU+ffXggNu00zmkRWX/oAP0jpr+sU43VZvxkfDMORzvrebXbIRvFkuic7YO7WsVMjaiapY7VZBclo/p/02Pi3uLFJ8SyVrtW2pPPMqY7iRrWq8ao3j6gq+77kbqMU+PqGRZ/l3n2AoZ0BUfe56JN5SpnAd9j5gDfG07JTHrfCsfP+r73+mXA9wi8bOsR+Lbx0yo2+ZL9e4XOocmFau691PIaOQzNO4heeujLYgx+Inpu7qJFChNrtdyHhDADkfdFMh02vTBa0+6UsciJdD4zlqbZ2abS264IvJN4V6hGBc51ao9kznokISv4fmld79gMFbyprq5XZhHpDiM8DTxMOT58FP+lnHfroGH3CYdvMQ360CUM3XnesEDffPPcaT2AbGE3sjSXeGWvyOy7MahPwA8GCCxo+UtaiELPqItTiWiQM+vj0y+ERy3pz4fGWuKl4i+xocKn0fWJU5dUWZFdoIIsGsn3LBGcj6tPrdpfJon3RP2X8LEqnEVQDcosPDevXAiJB1V8bdV9NqIOLFGPVI+bzh4/oEUX5Df0iLfAMTatb1xh2QLQoFIDvNxusgp3Ex/iwEIuDDaM5mmwoiPpfus2VNVe4FxWUE/o6DCoXgC4OfLVYaP7fjktzILvPk5UL8yK/orknvNhL1OzCc44gEL7NJaBmPcE+VFu4oOerqP035yMMDLtdWnuZ7Qg3MwsViniJ8Cnf2RnXIvF4jj9T5ym65C7r2p2as7qnSg0SHFewirONan6A9EpiD4x7cUu4H7T3TyZcjBhplvDpzCYodfERuZEX1bTetAxZbGFjBIzp9XHSdpViIElnR7PILFXOAv8pbMqUn+uFuikx6Xt2HZ2vel6YgF+jrimEX3lSMUB5JcdDdH1f0Vr8bYjt/OacAyBD9BCX53rQipC0KZItozrqW1/xNw5YqI/TbEZVXtr18+5blx/pR6Svq49Ii/RowOEZGq4LcdsPlJWntyG1OWBRD3wPFUVMdlJS4nF1JmkkTiVd/6zOo651lmGkxN9P5lqdPykrZ4V436wwS/Bl7sPGQ0SBjGtQpYgMezHA6YFv2Ho8oKLsSYRZR4nOq8wiY8RYuoTCWntIskcdXNJk9jtFtuU7yk75Bo7mtTG0Er0oVQFAcIdm4J6FH1TUh+m3vWYpM/agPb3BjzhdvYeKjz3VnXpaZwqzvP4+3SZNEVc9GwipgNAg13PLAE2MXKhk2uWAWUPSiPlQ1VpGpHI4dfzdAfD3nAhry92UTmBunIxF5trw9EHyTKxf2NX5vEauN6dHoGU0dKDaJlErdpa8QUmRF8yzqI0i1jphMJTe8X9pDWsAsH2eqx03vJTKn9Dq4BrrbFanex6vJ/dhc6oCZoal6A1jzgXjp2uWYOUpyjqi0mBSdpQ+kZZlvfM9FXigxjbPJNDCT/cBI66NmfO69lwq42QVhhmfDzOG4Nb1xi8LHOA55qjVHFnnm/JQdL6g3hjlzgsW383wbCDj1p6KomAZIRMDHGSoAcnsH4NezlLjxOuPFjSiDsCGOJCpodDEDLjCSRPu3g57X3sKr20p8c2hz7Nz2X6AP9uXITUFbtkZVJzbfDSWwNvePYuZ6hU8vvheeDw/mHtdtxE6U7aX9MTSkkqMCKAfGrels/2AyKpWVfvOpGeJeVMNFr+YzghN6c9H1RpOjwRU7x8/OdegixMPMq7yNlovPVtZ2mpFgUFgFba+BjjbWO4RFPDoZToUWOYjE4zDzduIN2VcG0X8r5LsBaj3dzG1aW92UmOMydfqeT3OQWRYHLWLKlS4h+rhq1lthxlAIuzHxOnfsqxGC2nQCzIHx1rEDCd2ZLRvFzcI+iktgfb0pzshhnGALDxNsmzdjGEYtiLQLRnyJDQWSQMF4Sx9Z+n5hU6alN1YmkRSrQu5WuWbmgYlO6u3M5KN0gYqetGGes44OI01lQDYD+/y7HloT4FJpW1kBmoDZNsnE6FAsFgaMMDafwhHyHlILn55KzkjLj5IxY0XshUKukXKJqFEsC50INFVu3xtcX0tx3WMoldcaSm3cB58Hg6Vb84jR5ltYs8oXDu8SB8s3X/gUQBOQWxmuJEhrcxomhtoftTRmEXpt8vuRKWupvvCNy4uNFBoJLztsrRXv6oj9oYPzcssSMEjItCC2pYgys4b3Ijcqo0bp633AIP/24fFpazp1P3XmkEiHZK5EqCCuvezCYQ+1qB04eTuQ1QopL9thi8mJs00KTDr5Ngtkq6lHfAkMGmjghx3yxWkMcgcW08zK0ELpcnPjgeLf/jBE2qlkizoYYgGc3B8fPGlwaq3i9eE3YtjRC6mb9Q0R7Oq4VIElGkWXb3WYnPzUmmbz8DPhhKqpceNWm+nsm7bzjTBjNflFjWADNnX8uk1IXEqYjzbGEKNWFkECUa1kYS2jxcz9SXP9o0MFZ+hTZxGMrrrJPkMEOpqy9lB10SpwDAqwiNT49llKTATrxx7WsqwO0oUgWaOuU3mmsJyPTJt70oOpEB55gfF2z+Nth5rPSyWpZkU7broUpe3L0oBHKq230KUGPE73NRc3ibS+DaOQc2q7yWZx9u9+w1wJ2w3EOETwJbQs5J+PK4bMTJIZNCyuwFSaI6yq0amGz6iOKAVLQsDeIhIAvgbWRZi8W5I20DeDG6cPJrPhxgyGkOIDF8pi5cfSFZHxho5tuRxhb1ck4tPjszSo9jCN4NkP+GCPvTQCWMP3oIkFtkk4aOCH3ni0AXw1qMmh9XRj8yv2zHi8zRhLCuJs4A3JQ443NbDpww8ZJdkJ7ffaqo0DydCzZvRX5/Xqx9DePUmw5WclIFPh/REOnRNiPCuk+8cwSLS1E3nnFxOkq2QQQHGKarZtg3r9ncCMN9PoVIQBv6hAwDm14ZNWyVSv6+TOoxgBwL02t6pPg7ZK8MU+2GgWInYzR95ue8dICqCUF77Q6ON86xVDOWKycHO99g4GfwRfmfohyU2sEgumdoyPRAgPXbGlNXK0nk31Zx8hWyCzDxcesnDpwv0MfptRJzVUhtGM2QpMNetdErfMSBhl9WH5m/OuW6NGeArapZthVY8Tl5Q29KhFeTteRsEba3dDAwcrN6O9aenju2lRIdeZYpWdZW4eKChXCH1qFHsxq3k9HoGQMBnJwOFCN6ctYEX3yK+wv3qTsZbGfp4j6wL2FUnAJqVoXraeiEo5AJaSy0pv4ilqfRb48mIbvJ21Nuseycs+myuUHMmiq/CM+3E9bvAh72XVSvl1viex2PDbSN3THUnjWMCCFCWCf7Yegu7dfFtM6Ipo0NUjXb08xqMBpmyaDL/dUOgxbP4UITnT2mHnWIiMTdBSnDSM8AstqK3zDoc8CLVXOVSos3ehCsKvJOyCuiRATHxDj+u7bmt3K4xpmC+nWhVfLQRqIU/pIquMMZ1NToBRy4NmkV9jP2TY4N2+XOBfc3Go11A2w6i7sXXbUzKFtqnLrIHGrG4sl1S3qlkpbAB4/Gk2wdr3R/HeHiWQGGZZdmbsrXRl5k4oILkwn6cJ70E7pqnFfRm1clKy25fSei11YQzFXQsQnOWB/+t1xFAh4m8r84r6E72YydLM4O32Mp6fFtWjB5UZvETrRt+svhgWF9aULUi54kO2DvliM6axG3F2K+g6nNGgr+069DBxrllU7rUdlylHSo+dpMxOEaNmIHNpLcfLm0MFuvbKqg4JquPZgS8/0IkWhBkNb+6iN0/F1an1JtzQ+yN8fXOzC0MM2dvzCIrOufQ1zCxBjcIpzbQZEztN9exDfxQzebkBJTz+pJ6nuNty1yFFgwu01JtOLp5ajGOVLXpRlWPvvXygYMw7+f6zW7Wmjd+fq68byr3b5b1lmHwVIcWIqeENb+/GVtHl9BVMxXwzEOVguxjMXFNvxdMTCkpzMd365O5HCWwTQ7B8tQWCyd2GJmeDEjn7oiATaO5WqUguLHJLsrCaQikLP5LwfpzWgFRbHXBFP+ER7qES1HQJ8O15UUyoRLdz6BpADaUxziS+8x7b220lVaVkX01qQ1FXY8IN3nPZXWSaN81NmUxhupTqE8/1WINhkb3ISd9FthfhaN2PWVXQMbLQB3WNutR96MssaygyP6MBIK+wCCfbkloAUAp6RlQPPvTGxJhfdHMFmS+/q2MvW2YMhICsqdK6+rbqSCHL9IL1pF4D1uddFk9siEkiMixgwMunQwJyIDXXoH0ZWIYSFjJR1imCU/MJJcEd9vkZI4P7TXT3Brx0q4gUG9Fu79IreRvTJw7sBWO5bXB0znWese5q3S5Sc4ZZx9ge7L5U7DAHfH5kh1/sykK8VRy0TkTw3DyI/DGdV4zpVJrwBXNA1nGDiMhOn0IONsvz+fNNmWRVkkRRiDpbHInrBW6DOUbBygqN+ToedAHMm69lZx7AKeQJnNEa/PLETQplvmRCmSf7VjZaLCOdfiEk3VKEjDg2xtMpKhOykKk17lIMAYuadQGWECfQQjxaZnTlZHmU+N3izDG9e3l1O41yXajo21XalqbjzqQyaXnYuHjVK3yRr34yQqyZKC2I/IeuXarMTwWUCtpeXEyXiyq4TJNWNRZ9U5fyrXByqXEIWGF6t80mgNLPLh88H+un7njX3cbnPW0n4Eb4HvZuyjkNxTCTTji40sqj86FPXrYstzD1gtVFIXKyl4l2KphsqSPAkbg3N64Ypzs3sF/0rKt5lLd0ynsJ/RTt4LYzN+iNLLeRgLah24vm1MLbUNwuSJO2h8AbQOpIuoIPWN9jWjfPt8Pv0fnZWNdwSMjwmAVIDW3nGeu1ls1DT5UHCVEYHGMnE8tsCTlgKx+bhCq6rDPGcbNJhC4OSqvYlD4C2j09dPK2hRB3sbW6KvULOMn9Mx/69kZkyg+QGdH9DjeJ3g6ZFpuYcHcSN0pEE6UAkscoUZAzyKqFAb5lMFzOVx3HCNKSdp8S2areXOkJnAAcHpdZnASHRXaT0773Ky4HRk/PqidvfjW+hlhnLISVrFGjq9P1GCBDyhJT+S5/eTlBrahfbVffUzoX5kg1sn4v5uf5FXdwCQK63VmtZrhWJEatVvJ+mZbytNOrGtcbG/NNySPsEj0B6DF1u5xcoXXpdMxVuqUXx1SjE5SY2+lLcmwhLynbuZfSTZX7N6HZwCtQlU/ARCNKUCT7Kr7LZ7A9yKFWpV9J2LyYj/1nGWZNumRQqK4VyE47gEJDqlhVOJEgWITXDqSwJmmYQURleOMAp01dYLP5RFeC5tw7XMamzoiFpWaRC5pMXYqlay6/V/LXKQ9twMOv2rFuWHASk4JvduJ/NIgQ4hlCbnaZz+hjE9cuhljCLPlzlDwlx5lBVPc+GtvlbmnOMcbr/WI7MvUKLPIiVlglrMt/C9tNnOJEV9ZnJvVGf5J6c8TuFTMcrj6GSeHSIKpBrODbfUDNjDZvhuOG5PnU2A6jPmVftu9xNHymtC+etq66zhpOJl1GOEiRbvdrjf2Na4wl7w4WCt6w1DBp+NJ7WFI7bfNVo7+NPd5alubYYmLNL7CyPkAwTIxjYPwqiKqkmPNyiSL/eSMvs2zUj7IbQpIQZB25xqAeJrOlfKsa9W1DuE4IMhUskifuQtu4Ze3UftsxB+RgXmK5JyibvTgZLZ4999MHWIYGeIL4c3XPjL2or+AqMVp8j1T8+7YnkgMlPdFl7pshO2hAUnID48wczY4enKhQmACstUclzx60kunZkmq0QjFzpvbj0viHsIVQHwm4n5FNj15PLMdy3kk6NjiKjIZJzHDhZPG5jNTFr4zi2UR8QlWk98Peh/GB6WN15TOwCWborl7BMDCqfhAEkBgxzORzLnb/MbrO6ntQ1Dq0thswAKtr52DPaNBrtlzSG9RauR2KwaQ4lS6TWYoZoSZwhq/FjBMT/aTQVBpA2zwi71BrKbw9Dv1tJMnSOUAm2ROqP/v+IkdbAWDeT+SrNJl8wKZQ9itlvKbAqcEuXYGstki2jUQK3C8bG4UPPRrCh9vcYDVDoj5TdDiNVTMMWr+ZEN7e+09ynDGlyKoaCqChI7eLV3JwLCczgEHWskouyH5Zk87BISE1PU30puGI3rx+TIIhwjfttHrtmE5Q9+UsAEQUOTAKFkxW8kK4kbXZM70LAkyVnYC425p0PTodK71fv2GBKGj/duNXNk/Vcuc+fIhbN0ln82EgIEol1fzZ4NsDju7HRGZpRHovdrt2Gal2sxWhMsoQiVBO89PxkSm0aTOneAcdhCKwJbPmXQ1goMeIGiq5OUUiNppm7cwoFopMpNs4jfZyOxDEcR2iXVFGGEaKFad2KpBcZxaUH9EcC2L+46yogrhgpJEgliJ1aNKNRIrOcvABuk0CBFIGLgvAli0C3V6cj25l5UiEqfmI8WSBgIOEzQ/XI317jLVFROdHeG+moYTpLHWn/UTVfCDyNd8FXQKmlGbTqGSeUjiDH5VpxxwXBSEhg+tNtTfn+LRGb3MNn8ubHNl5bBoxln/FT9AxRWqlPVnGyTxH8fzy9NnYus3noyH3I3CMZK4lj+OSODzSPaQWvEGWjD/3Ly3++C9UCASQqRkt2Y7DDg3LEkSHtDd/MktCnFcMecIK8yQgxE2uj/3WqBdx+1Fp8v54DR7mNz8MA9J+Nq83LUGaH48G+6rUCyLDjARyjSAMEreLlOLIx3OBIKdcIYRZ66mU3z1qa7Z9VVFyUayVnhge0ACfPr3PBx/uSoxTUi4RwGCEx89J3Lom2xQ9VQxSqpWZGj7Lc07Ge7r/vis4z1mbSzgYiD79xfL6qO82Saf2VSGRho+6373xvu6Dw4cLmNriPMJ5mAD69Dbx20Ng7yrPKZmUawm6ZOqu4zQYZPS7dL878mzynKoSluNqpoRQgSA8p7q/Shj4dw/g/34WwfnHVIC/ezr+r8gZ+OXpOPqLDBPsKyHk9eSCEPS3N/5fNBfkV9ke1o9B/iK5/v/jjv1McIB/pn38bs8w8D8xywP635/lgUD/QKIU/Cs5Rv+j5PgfWJX/a7M8bKD+c5ZHiu6QaXYsDZY76dqM31DHew9GMt+gqWKs9WShWXEk47Eae3mMWNCvZaCavaWdbwKVqC1QS8oYPIfl54f/tYr87MmWYl9BqbB5ha/P7ccfEIaB9nX7idcQdte65+3B7MSyMAGRVsFuKbscmArD4qlZkrJJ7IZ/IBzB2IeaEUxS0DutCnwLr8tNSmyRYjV1oi9GJ0ilo6/I8e7pi3NB8hlSIJSY51lcIiAjGArDeHCb68qOk8xp6CqSRhQhtCcjJJjHt4JHUYjGt06+kDthhqWkvC96v/sg8Bd7jIJRBgKxHIuQhQVMiHWfxdYJMISp1kKAQYqu3H3wZ8JrQ2GReV5eDGAiLZ8LN/VCVnlyjKfjwq6iHT/onbDFHYeeuBRBxYJhvtYge/p4JpeaFEOTJLuKPX0pOmEqNX1lvpfn1D05itfAAinZPF/tAmkE2UhuOxmUlZ78nNwJudDQWdEyNNfD04UnJI1/cYYCmN7yc9K91gqWHr6evD5PyFB8bxOkP5t39JRY55Ff8a8n6G8vTCq6IHJ1oD3iINuSkkjePgIYAE8glVMxbubq05g+0HtFjdgC+2YPnTYb2uR1j/V9OukT0GhgKzmipXKElqI7UnOi+p4qageFEVIIhOG0E8M1aq3WVsYD+VI+qfoVKQyBXEUkIIQTxzpJpoNWOkS6imjq/CJay15BO+EQpKkDg+LJl+UvMlRvVpN9WoCZqiCMkYDKUmdsU2QcUqJmIQq1CE6yryeSmbGR7/c2zPT8PvE6cH6Fxdt3Zy2kXFxCIqf7xuaRfC8XA/O220YeZL/mCwbyJIzzTG4zu4sgJa9wUaQbP5Q0ydUfd0H2lcIinog/a8G4Qrz1cVp3l7NeJSfCqLmguYVMqEGLKrgCDRrEz3hCK4VnNAJtPhMdyhdl67sn9SziQDyj2z/Tmwfyufn44AgjcGRYcIF6LcmzOp1N3vfTbEQGEMRnuFOehUGEgZRUNQDBdx5XRIHpa4wZmMwq6hy9nZHPyvYQsYfvr61qhNdHFUgiN66vtshIE3I5JSpbTAlXDBnhgYI6k5EiuB9Ab44LypYRPpXXseYKzLjYQMLF6phospnKWGQgHq5ERTgERqn38S2rLLXT03NgZqoiwevo8aKomjrcWUSzUbm5mT+kdiaqzVAThlHAAvlugeTD8spsV9UVp6UzLX4E0rcgRJZsDtp14p/M+NiI7mk1B9vvt8Nj+IBGmqUXkoB/5lZ3o815Hfe+3N1lDfoOe9TEXziOtS+RktQWU1Xf3xHifGY4oPFxEUSo3xLpnIyycSHmoGvMPH5abGFDJTDXEh5jOcpNHClDJN4AkhTUs/s9S1BMcdyGIovk5Jr4KVEPipMEZ3K1ftwjVb0sY2FW41V3wYIRdNbq99pjFuChH8rRprIubkmwOCtuRhhf3tI6jfXr8FYVW1Ewr06xbvWTxNTVmK3E6IdXA+12k4JqLmNkJBgsO0mtxm+Pj9p+BqtPnPotk3y7DozG0VJov0vIqgYagBwZXMNxYTyCFSv9CW32HpE1LEy7Z79ux+iVjDC7Bs7sO6jXQiqttW2cy/lgxM5gBVXyfAnzkMRcpqqp+sQfbCDs48vwjSQ/Z+V1aBTdtyBOkvDH6CXuBmNbfUg2MQcfi6i5oJnq5px8n+zkPUjuMXh0LuIZZeUNV02+uvBAkZ4UkvTgLpJ6cWVf5kYpwK7i7Jr1vbCi5AM2eHqQTuOdecrbT3UDIuyisbjt3UlKm+lEJwjr/GIYnHRkqJFU7zFTkwUP5jV2zdcpwKc9CZ164vexk3/OtG5nYTJVcmfxY1hXl9PVRzcWm0J8Sb9CMhnDT9+Wm2f0BIgpBylXnsPrtQFRUmJs6nTPWa3u5ypY2SoLF8yaVegEpQgWfyM2w30lLpF4xSizd1YAZLyBpvT9VvKdj5WCiqRx+EVpFBafH6h4MiPeCwDMznlh9/wQW6UJzF5zJ+FHCOg66BDID19NpHBw70/nUIS0xvRKLPL7yfowjO5dBlOq1oxNlGqKflohDCGcJvyDv1hIai1iiAQXgxhoSettbid1yw3yJT0OpHXwqlAOdS55JbsJ1t6/xLLd4ecYQDhAUWrafDSeWx9xbY/Wc9NYVoTt9gyDS4pVhjnzSA+sPX5OP42jB2vHZjSi4qHnoHf1IgqhBP8s+LIqNPyJlS2EQMy+fHdsIalSE5ImpFYKJfZkGCPhRYSU17mYPhlJJ1+a0L4bAyySAWnNohAMPksGjBpxo1PO0gpAkUDUGipubvSWMaFx2ucUqQZRKxQMigBBynY7NwAtx5llH1fdUHf5Luesjyq6K9qXuBcV7O26Dy1rN30hMkMIgizN3otlA6eh6rhyzlAst4FrMOkJcvZAnlltCJLjnTUwMz3+0dMJekTvOcTKN5RTHvznSboBAE5rFAdfJsUMWD7SnyM4Gyk/iHBctC5wUrlFpkYJFEXOT/hUgoHVloTXiG3Jk0+6TGoPGGZfnFz/2ui3wMHwYaTTbqDvLBOywa8I9/IsSlQI0eOU9wyd2yPsGyQJVzy/nBcKXxgrouBmDM8pwITYkKTuaaDrYAyI8JOQC34FbAVMf1B8fgIbmrRPmIF8UN56/PmPP5YDs71iNBY7qfSHZ7JnhsCt+X4SCp2HH1oFSSQPpTk9UH/xgrDnD0FB9w+7BZ9XrHzCo/bzOBQzuW8WbNpbPWH81bBEO6b0g9VopiuoGUdRwbC0OrCdC+TS981JSJ3imdKACkeoyqyL1QqmMB2EQ6acNpslme2wy5I6LBPLBbCJPk6h5lxqeX4j7lHIYu9LO2qntQQxtg6lVucnkAmTFFu5F2SvpT6jQYUr3iOg5g18w/uNMJBx64BNfaR3r0cpoDzZBa5t5FZ9VIVz3gjcNZuyO5hms1VLJBuiB55rHBNy/1reJDMTpQQuFx8ugdg+Z+7xrbwehppq0QDNu2vEvjcRplO80mblS8VSYxF1uezamw/lQ1S7QFdqQC7mp8mMvoR7QS2FN6FodmXwREDUnCmQTuctxEx5E0ZzVlWq4JqByBaZnOT90YV7NWOevA5J+SS12VjBob3eCVOVvsoh4Br5mRyz1lNbkcXr9dqeeHBU4glww1cimOKhN2unch0490kdB/2u40LJwF0jIU8KDQ11/dWZ2NDkrYGGoFJ7afIuCdUMpoHTmM845E7FDN3+MYWYnv0Lqs3goYRBgdzsmMyDj1HItfxEtbK9cQbUP610YAHAp+du/nwY3xbay7R0Dc84YyQr6uq96sW9MMbCN8sAB+i6XjevmfV9Dsk32emqAuRrMjIJu48SbOGx95hOuQE8gpHIjo3zVHWYh+ZkXlUP8AWT7t578LwVQ7YDmqIdKbXnxkDe+JFwGxmLEkoCPimXJyr11REzXScHJUW5wk2RcjdIfQELVW1yH4dpvPY4dxYwFMigaOjIFmmr5OMxP05TEmnOzWHyJGlwtkhRtlUyKjnMafG67Fys2LknhNrC9TFRT2RscCDjMxUutfs8Hgnk1aMFS+N9U6k4egoZ7VKJX8HixpOpqLZ5u1uY7S78Vx5RzYEtu8gfc8V0SIE+/iFdpNZ4N2c/k/7GX5FJZ7XH6ZI1nkij4Vr+6XaTfrwftNAZ6RJn23c5UqvxaNUBDhWYvKOTaIy27lKL3UyNyVrpVqNUBjXS9IUFRumEfCRCTZbUCPXiUg2Gxdq12FvqXjqlR098N5yTE7rtLdOTk2fnK93r8A3qniWRT1ZxtC6fMcqe1UyVUilYpTYpnLjMualheWaw0VlWwSjiiQYGnTFaVfNm4dQJrlA8W2ZffeBXWdVXxUkIxz0TujYHMbFwBCH8BgZDlnHZQlP28gpqnxBpihFuR/ZTrEzGADrHDAMEKrmcRNNNJ9j28+I6mWRq4lMWZNDctl0YUI9NxUh9h+ep7k6dANWQhCMUUSJHZt/xCImEpKfFDLIB4t3xAUYg18bAlM8s885YCYWqDIfasZIJ3lC8LKqwcSzidxaCayEucRPtaKTNN5OUbufOCsn10Zx4rCUPlHFHTGjPbIwZr1cJrkg0FIg2H0yJGbfMOHhwnTbuiFXcyJUknl3wksBBWNPH3+sZBC98OlnXTNoaMnFTSfzYGv/REaMlqkAIpawDi9Z7d2FDxIVGyuTtZuyQDncjYOdiszSPK/oqfdgldj8bxgt8WMhOuU884yY84bbUIpbB0nHwUWXeSEG8SDRCOHYWD0uAvKUA6o+1VR1ye+IrI7IV/lYlNbELps4iEb7pX/DhV3H8uMR2FRk86zBbMLawkqZOIeCEGwlNtfSFkL1VObZIeket4/uTu82qMruOnDp4fiLsBMBEzUhCDvqCJTVaZ2mHxb4iNFslmoPuowAcJuQDtMqutRQV7iynrNRRZuD4Kl+eMAPwPJVzeYCVVyYhaN5OPuNjj3MxEw1vTUNk6GgUCArxIE057Y028vdi3jhcnohWkQ/L3Ag4KAVBVG5TWRaKcUA75XlXJbzIXGCyhzK5t04+WSskojq1KbOn5bAGg06la7cXWTDKkOyMFLj1gKCvggAaIk09fudKBiEoaHpTznmjjktWjYlL0/H5+DF3U53s7Z8097JGKngOBuj0cS5TT9tXwXltx0yI8iwuBVg+1DW8yPx1RWjzARh7oN9e/tLPoV9CMiXE3iafl3pqRpKMiofdeJyK7dlw9R5mllXw1MFgTsMxSyN5TMhPJJ7lxGYvvMv/Sk3aecrmOajCYpLraqGUcXi+PbuyFFMDkVvwBbdKi3JORcoMG9jG0uaTnRe2+zY0XOpHQroQlglUPKkIUjlJwrZWsI9ktxfrUvaXhutwbK4FX1XijUri9xqTx7y8d7dq9fRT2kxhThMKxqniMFan3mZOPT5uY3grPMqOVa02IpeZ1xNCghOOS2nL53N8WJdVQrnM8xaOK2kqMsUCGCR1jIL0FPs6SBpv3qSTgE/CGmSxsgu1ZjUittuaB4hYKsFswJwh5V39cUfmvaCUpV69lNM07GZ/bLicV8GYGTsb1aoiV7tZzG0xLIQODh6iEnKP13cVGTCllg08olGhgTdHvTtWRaeYpX7iFP8VH/UnvyFPnVQ/aynikaqyYWs1r3nMKD13eFsMRISgGGZOc5gUwT2JHnKsFLdHH0ENZUoxUj2hJpPhswJ6MbHuGMHNkVJZ0jCqGwJYeE5NJMEz4iE1lP4mhbdLrOAzZSBRjTw5yBOffI416G7WRYg5hqjAC7bxkARu//ITGmQIxZbnejrnQfo9lPIj1EgO3oick+lmIW6pJeTlnzp4cuVikiNUKgaIfORgtWTO2jvOKKjCrapURhODwifBF1AzT62YZ4ag4pUExMfcqrKPo9gh6Q9nYTWirGmolVtHCtsVtYlp/ritq3CcTHKAEgHsva6zCVy1W90GPgZMKzobDQVS1aSA4uLg4vESRRawS01XcAOJhyvqk/j03xylrXrfsabz4Rz6Y2zuVWpgMDBecPtnh8YYn9u+f0VliIpq77kxuXV7OjldZdYW7yb7eFAfUBMmyuqulCx498nPIz3N+EpmOcfaN+cOl02CUTx9tX1tVjMOxoEpMk0Zqx+NnkqeTNgvrpN3t+G0mx0VJmYyNVO7XjOYoEeGP2Qd+1x4dey7hDihUFwvnen0cbE2f/EgQ6Rii5PVTEJCjYL9NZ4aK6/4OYsfn1Ge0pc83Z5OQdFvfMcZiC0ynduESXv5gQjH+cvqJgBS1LGwSDpEOKGH/eqYoNLKu+elDHvuh2HfsY6q3Tyn6OrQddkxBDK6/Q6zvqBBovB7/256wNT8TgZr8eVQ+We5J+4+ie+P7zACVnH4maJd9AXD0MIE1hNHYCVls12p7f3qHNnQuXLt9WQqtD6b8eDbKA0zd98oAV6KeGRRsRpVrnU/cldADEQHt29uDbFM2qpunTOP5xj2lagnIk9CzzNZAo3A9IzQMmAjCuu8PUnxjU65dSkFHeWzVxVrcsvKFYoVlVtFhTaTWU/q8jriMhCP5Mg043xPFU2EH2VWwOgE9V5lYAK13oLAObK5+3Td8dQ1FJk3jqBuu7fYoCIPCx8rnHXDuxLx8TfjW+9oCHPIV/YQ6BVeo5BhRAotR6Oz/AlfZcKNfHC4NYZ4r33Ob59KyIu1F6WBsUxq7pL8bAtZsT95e9UgniJEJWmd+rh8pV1+9MRAhKLeUOBN8nl141jhAYMCjKHG3FTySpYVny1hVlBW4BlcotazEtOmHbXV5LZrHV+RBEYcs23c8lgzLy2SUxVSon9ioKdoaixyX7ALMt6TecKQIkEFkwXUEyN4ndJYZJIUmhQ4FiGNvpGHJMvbUmk5uDIzXiL7T4aRDg4hUUvY5VFJVjoiXt/879G2V0Tybbng80zYrGGCLSMHQD4CWOq8ZVXMALfqjm52Gvw5rS6tQdMpxuQQM50sKpbHlDJxRp5bwaL5C5j3UOCDE9Y3VihMHFMXYuHw4FpF5PCFvNyHed+iuTjNd9iWgrExGE9aGi1cBjFmEnRMjE48rxmFGDkKRNOih8bimAY5kL07TGeJzJNdZXKy0wgcRYkC7SrnurUUI01IiOR45J3HUUHr1K00cDmJhvOWCF7YB23dbGU4FprAAYMbuGn3e+nc0NeK5DljQTJVrkZBIm6fhXWbBGV3U6nlBgZWrX/OW5zc9dyr95+zh9WvLBgtqZz47zb+VhtPtEcR8YNgU3ocvtIHCFI0HYSZajHP868Egn8ihwD6G+e2/1QOwS/PXv/D3rCHf5FD8NdfRnJ/JJ6sgv97kwn+8a37mUzw/qute/9nfmHELzbuPzuV4E9/+Z1Sv0olAH8pzsh/kDi//n+cSmBSv/vCiAzeP67p8xfSLXFZth+AcBx/z8VR6L0X9rryd8K9GcGxzfEj0eftXFDllgsRaal9SUb5wlNuDgSmNXnkSZilwr96wL8pCX7h58y4tT4RAADorUpYmNrcZvt121AIyl5Zlh7IS38IWb1BE4Ic2LV9Ehv6tOkLvnbY0FmBoKzzboAIJEPgGtYgcogEDZggJIIkZ/rMCUMm+J55slhJn2DOKIk3eizveQ+WpJphBbME83wRwSujXcZwCItJosqWL8kgCXytuQmGe4IhUKAtndbBSUIUdfVVgE8SJTCR3BMy3949XPWj2oWQlxz4m2Xe9P540OVsvpw3syLF88ViZNWjzwsT7TAGWeRWoz8GtEFOBrhq+nMCiYTVhaGo1ikfuje3hCgH+1mnqAGloLb8MIQUpR52gRCldA/jCswmyM5LAq6CXHlePGMF5qMWwtI7pMK1u0ftwvN+I+uLoUkItDMzPqWwZ7XEqFEy8BK9mrYbzrQLgYTuE70pHDsJcsISPMxgJiQmFE55TgN4IL498pu4PcwfS+u3bgOXpoFr4XgEaRnx2jRE1gViWR2DMnq0cPSMaS5ySy3xkRE9AccjbgQFcHEXzX0FJUFPr+L8pAKe2DkdbYr4KfVIitKgsmQ0ymHhw9OaObfe94xYXXUVGw5Zgsi5xDqV7AVm40oLNMlXsgO9Cz9qn/XFxfnDHWXUDeNzAONlHDq5sJSLtrNt/IEnKmcC9y8t3EKnKfzARO4ltR4WzYByL2NsoRGNSppS5mLORSusvLs8+gLdTil4/HNMESis944QTk7CibLrtJeG6D4wUui593NVFgl1aYt+7LTAQrOEU2rHlAdvzRV60PBpsvebQyNCtWiRPmOssrkqj9VG/8IDlYJ7aSYOToqvYwN8h2QKsIUXFWBu0gfkO1m3EZjgKLXFC4HqUM4ITxAxeGLp5NpzQ6w9ybRnoM1gppK+elopTxtUzdvx4lWGe92YbfYAURBltGr5BCFSy7eT0w5VXVovUITk8+swhw5yPb9Qv8WVVq30zyjaZ7rQgeWQOK/bYcxFvjrBGlfNrEUk3MeCw1nolldEHQxMKjZzzp3Yhu1nbWLzvm9HMRR5qgqrHLazIvkCW2LCIiRACIxx3OieDOAuhKIVEytLC2+bKLnn3CcAqOAFP8epe6QKp1JxWLo951OofrTxgMK4q2TFdCCx7a1vJX5b6JoDYfZimD2iNtpdnhd8j/MJWAUI8Fnk3vC06R5yPr3AXFZOGA10zs0lyniCztju5kzDPN/8oE2um3O0gRx4QJ3D+JKogw3IHNCSN0fMcqyc+S1uBEXx3lDj/SFRW4IcBna3d+RiSXYgybBnvtho82DyTLHW2+jlkHxaV4g9IvSEOguDguhjDgjgeVXg1aGoo004+3guGEOPiJ+Hr6EHlYmzbY/ucyMYzvA6uXK+kafmR/B4MhQWZ6VaN1q8Lm6aEwl5PwsT6SQLTkSb5QMrjP0Kw5ATsAig6D0kcSkmA5rcXY9dciIv5NZvLXB3i6lKHYecPi5qiez7dHzmx33+vg84hVilrkCF/pGygAc2LogjAiMJCtIhKOT4eVcYuVBmXPI5eHxw+kYkxDJo6QEK27ilSxH5hAUnkIanEGuUikBrbbKpqFbPmjfuCJaE9vNOMcQsySyZB8fFI1tND/45kq3BYzmwDR4uJDnBLmq02aJck5AnuGSdG33+at/f81wahAGCmiJD04KlAKsWxCqc1iOsJxOANYC701MdjtuOsPmIawJWaedrptvCoiz6/Xkc061Rh0xlO9jY2Zi8BQw8XTHo0MLJCpuyyNsAJSbgJnJoDJ0kkiphA5C6xUz/pCgz0z4a571Hwbsb88txJCkiwG4sUXXBxl2uW8AEsok9YQNglXLd1R6r0EvFLl/rSZIoDj5ssSIVWRkxBGmmLv5AWMb5XFn/emGwZUiWg9QNWhzh92eEhFLx9AEzKUg+T1oB4hKeIA9C/ZFYws6fcBI/f47zJaNYp9AC4zv5Q5jsx37aGW7g4+ISBmmNj9IEm1ZLhEi16V4hrKsRrZ2yjm9pDSs3JWESSZ9zzSvoE/HzHH6v+22pkGYaHNKi16gor/TrnXQD7Ib0RsX2QMGL3+nS77IZ4A221btSEiZPRoSO4BoUR6iPsz9NJSlJksgztDidoeeQwWYOGyYOqcMpFXFuhG5AtaPhD5WFpnDj4GsRdPHsZyILG9g3U0ZtFoYsJddQuEexiOHDJuEF5gFDDDr4NndflnRyGVKLfc58+d2+WocoCcQUVFk7LFjeSwrfI3q3cHkgFoLqcx6EgrFX5al6wnhuTcKE5LBMwZW32chmb/JHBlyhWG1sp+6JgTIKJgozMrno/sKTZ2u4zQJgOheNWVJEd8QJ2ltn+ezGCLakgUDI57UFuHOtxn5eDaBLbQOLclNcijBpnijV57jeGJIxtNCgyh8TP75w4CvgdyvNyJCN3EgUAW4T9uBlgxU4Zjba7Aw9y4jONNNbmZWlJjzfKeN/Oml9wl41ObfHIDuUt67yvVehwZgIto6XvyZEUVWsVKvsQRVpHt12V813jnhwx3tNdUww935H70ADLcJ77O7oyiNemuJnDc/OOI/bWnKzR492/xAV5aPzfVmi1wJYqyXQNXuee9QopA0j2rVgSACnz/kn4oYLZQU5Z9S9ybTCLkUS8KrgU/HpOqCVCxOQDSUsUsWCi88+N9+VUOX52qnboi6GYLCTcSPY826CvHlZB1miqCzSTZoWqQhjBwGfM6IRxMx37OYGEbkdDQ3xGrvTRDut1araTezgu4MVA3spwSC+vZmiE3sIOeWpxAQUsAms+nSAF8LWz4wHCfCreAGILNcGTpwWE/k3Au3y/nmJh0YHHzoKcOaWskyNtdXpUK+rkfeEwgwvwbJBnhL62nrfuWHFvHj3tSQSQR+r3GjWA3bPqanAL2b0AjvT90ENnQiFqom5CMRwrInkQDw8l50izzWjqKxS9WqCkRYPNt3ZrUQkurV2EnvJkI4aXwghZ3PwtmnBmVkFY1BHVPbEHMqicSpEsLgOwQlNDaccofyv9q5r2XHciH6N30kx6pE5iaSYwxtzELNIieTXG9Cd8e56Z+yt8tqucrnqvuAKJVINoPscnEbDmWeLB3glurcWp/i+zjaqr8v1yAra1gNEsfTuG2EaNnAtr/r/s37yrARhCTkXcs32HZc7vJm9VUI1DRe5qAOlO++EFOKvTzouAjiuyBLnXFg5QKfaBR9G3/Oc+qvIHssNlipwsjCDyLuhA8bwRikLIUybmuHahI7isjCbddp3h1XGgVup7Vv8czxniK8ID2KKJApheWxTyB78S9XUpWksDbvg3ONVjlHuOsGDBn5dDR8p6h629MC+NsrLRXXJLBYFPF+NTyxaFz5UDJgjO+/Rs7i9t6+eX38Qw8VykYGYpCmB90lP9fSmGHo7NmWqfPv0651O13B0LZt9KrPWQr/v5H1IJ3Yuq0X4Xu60d3B4XBfqEmwrT0SG2JTlDRNjxnXbtk7CF0YNULjSiQ2+qAn9kX43Cc+2r2pYMOhNOhS8jt13s7dxV/q8DXOZ2DvBKZWFP9S+bGn7nqJVi10BLimlLD2oiD1mkWUmIu2Eqxk0TnYvbwgnCNJVAZjJhUdcWRTdNgBHerwVG5+ZlMIOiJ5oi+ARHiH0NfWbNYcv84lYfPG70xz8pEkxQDXehZ2L1zhznrLKQcDk66d+EjWLF+xDzHkfkDqBuK51y++PXC7Rd7HakRdE974cDk2B4T7oICYV9qbMyZdtAj9dJ34t5q1hBJauvKH2KgaX7mBgEZigSmlDlofhsZvDRMJMoVBMn4ElnIf3mE49TepF0EhxzldYaQvu0M9dx/d5MfZtuF5enbycGd9ktxYSkDTiK0fUnm2AsCpz8uLRdLf+1j/xyS8F/pV685QTlgE4zQ5Cp87Ma7icRLNHo49eJKWXMGplJEtnzjAhMaPPVPaSLLdYxgxsQak71r5eJRR6VMIMp1BeK/3spCitfeCxuQM7qWWPH29BhaWHOFpUzmGTZg+gj1NgnHQ8ajgHa7PfK7apwRvShuU9OjgReaz0By4VUkepvOf8eT6Z2+rS2g1Rb743GWKJ22P/IfOM2t2Cx0KEjXLYux5imBslqzFuR8Qqs09zrZkiZIcuD7sl2tXRJWJfs7jJ7KfaCB1Syif9NGTbs0x4ot9f48mp10B7TtDOBUBC5hJqjwCnmqA62s1c5AyK6JHRSkyrhTnMJAuDHfDCSHykNsIZYWhslWBb894RFe0grmQa8hJVvHDoC5SJPvWaIRfCOGRf1FqCRlJCxuca0YwuEX80fbCQAHmGEaMogWV9CvU4wUcT8cx4+c7Xr+eavY8JSd5czOILMdAb81yBG4WCsDFX6aOXTFPyNyLbvLAx25VvguvdClv1TYUH65B5xEXkeiszGs2H/QjmQL232lOwmXYXguhy7ha+qyLNucbd7iTk4ss0Jokpl9XZWqJfPwbMro6RxdJ8+bNH+5CjhM+7PmA2vt7JkwnuYDpdXOR6d3UEfUbak+1tHeF1HSXL84FyiUZxytDhTJZf993GSb2Vj6IRqVUZMhcBYNM8n5Rpv036PF9H5yct/loA1Dktc9BHQ/AVSYjKh7jAVUWEJsXPHw5pmwswjUDqt+qdHO8IesRwUGLPfRDqvC0PoWTEjmNyWm4Dj/3ifSH5ORwwHQRDymPcLXp42a4IsZuoG44aOrsdUligR3LDzb56cs8mMYI1oPL+JLAR+FHMdlMHAiyKYLFrG11M10MNKB3LCVbftROr9PdEgnnytCowy6e7AJa/XJDbDqh+s6aR5PF9lWpm71whJDb8DokJSFaLjFXvF/QqRE0xL76y9obUluOBUnCXtSZzhna8G+nRvVLpqpRI+OY0q1S33et+Z8bGo5dOiNXPCVT91uFbSl/pCJbqGm4BTdSp+pbimaIMQN1TGEvQHZZc9bCjhokwLcy7RMTkQgHorDd5KVmFccC4edryoXUF5qd5hzA50zTj+6SuRn5aGxsBf96HeiqQQ9YidgnMfznTMSDJgijx3CZYUZQWfpSFWrmhBYXA3TfkfGEaMW0lkV/SYp7cpOdsdQpLhMh61GVp5jk6iWvTyFnlAncXpxismlNB9ts14kkbvQ7hmxUqNo67DM1zdmRYkXupQXw6pmvXGINnQbWQ1cbotvO2IlParrupv/Z4ZYdLjnenxSp2FYiClFqJGQ343uWXC79hCfeazYpRlYIDfQFbvKpwiWqrzFubBognnH2sed2ogXkwmsY1XSlH5FdagBxhBQ/PAoDuRam9mWneYHuo2nhrn8l23kbtOhWMqHrvEO69pnaFJDP6UjjlPI9PNsiLceJgRQAmbUYeNWTenpe06I2DysmZfaSIDkJisaY5Vz1zk3/Nt5V1gJWDcxtZiX/VKqyOoQmGAJZiwNtg3qXq1ESWwdwEa0Zod//0a7W0Tq6Eg6auvh60VZhUY1aKQ2XdCXh4dTDKHfoywcayYEnQrdx3Ntl2BizfV9hOMI9xpMxHNhkA+6yA3e+nb5l0sGeM0hjOSKzImO8S0pqOIBJ4DaJ2tb5oRIvlo+/SujJhuItkWCWkwn2GY0zWwiCWaJFL2vZs3FJts+gv4TmtrqE+OpSIaOU1wB1a9brR5qwwFfdQcFTqy4fHcDyRK0Zo7xajsOhk6Is+vRnmT96VnkRppHeaqzirvC3sfOiQgLN59bazw4ZVUMr0/a+KlPhPFKGfipTY7w/N/ljVQf9dIiX1A5HyS5LEP5cg4H9h/pcPOv/xEfuuTaI/OOhMUv9BdfL3dxAUeVV8/+HjstZjNQ5JJ/zy378z3C99biNU0z4j2BbrenwzZ7Kt42/H9+uZ8EG/ETp/cFfAc9yWrPgHM+77bXfJUhXrP9Mbfz8OS9Ela/P67Xv86UYm/xtGBqZcjvDXjQh+GZhw35r8/u3Lv1rHt9afODiXPzg4P1kk/+rgwHD8t4sDP5/96vpFTPgr</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.png" "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.png"
new file mode 100644
index 00000000000..c976cc99b91
Binary files /dev/null and "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.png" differ
diff --git "a/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.drawio" "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.drawio"
new file mode 100644
index 00000000000..7f7bfd71641
--- /dev/null
+++ "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-11-22T06:23:24.055Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="b5Y-KPRFUqSfQH-Vqe1B" version="13.4.5" type="device"><diagram id="3s-LqK6m4lkifnhmqHE2" name="Page-1">7LzXsuvIkiX4NWk281Bt0AAfobXWeGmDIrTW+PoG9sm8om7eriqbqp6xnj6CBAMI6R7Ll3s4+RtMdyc/x2OpDlne/gYB2fkbzPwGQeAHhp+3t+T6VfIBgF8FxVxlvz/01wK7uvPfC/94bKuyfPm7B9dhaNdq/PvCdOj7PF3/riye5+H4+8e+Q/v3vY5xkf9DgZ3G7T+W+lW2lr9KCQj/a7mQV0X5R88g9vl1p4v/ePj3mSxlnA3H3xTB7G8wPQ/D+uuqO+m8fRfvj3X5VY/7J3f/MrA579d/T4WzDRMIJQJbnjPYAxINz4F/AX9vZo/b7fcZ/wZh7dMgtYxx/w57vX5fC2za3rFS6dAO828w+dyci+T/Qp8mnp7p5/XvLv/v9xqmfha9X//lG3dVe/2q9rQVd+PPTRhGnvcun+fqyJ8ly+d/uPmXNv/hzri+A8zn6vsfqFTkw1xU8X+gxlp1jwpCQJ8f75yH7l2Yf3ftZV2GvvjnFX4f/9+u1fKzDd6VAvH/ho7nv7r7SyLv7X6Yu7j9y+02X9d8/pdHcmn1dPlnj6z5uf5L3FZF/+t2m3/Xv79Z9dmPRr13gb/p++fmOsf98n2a/KPxPv/LA8cwZ3/f9z9Uz/J0mOO1Gvo/qZ9Vy9jGv6tI1bfV39z7tkO8/m2dP5TxuSp+f//R2uSPAvC//caivxHPP+I3Fvvtw/1Goi9OxGmZ/8Zyv1H0bwT969PTCYv8RhG/kczvFwTzVn4+foj34kP/Rj4X+G8f6jcKeZsj2Le5t90/Sj7YbxTA/HUc878e2bMzkz8p+7XN/iiG/m7HQe+iPeVHWa25/azsW3w8QPuUlWvXPp/A5/LVit+R82e92jjJWypOm2Ietj6jf+3Xpz2Y+/nzl57+Fjz+AIJ8fjr9m6LfwYTPhy5f5+t55C/Y/juw/Y7sGPr75+OvOPmXZ8q/wUji97L4d2gu/tL0X9HrufgdwP4czAzGbWuBvwoWAn2apCccYf7lT7DslwqQ9I9c6d8++E/JI338dx34kFK8x/xrZf5EdG8t5hU/++gE8Db1R61fNV7dgH8U688F9zdCWtZ5aPI/ZPGjxI/kqrb9V0W/700mfSTzgCFMvRKpHoNE/n6jq7Ls7eZPteJH4Pm7SP8TRfij83+lNu/nv9EV6ufvf46uwDD839C/0xYE/0dtgYA/0RboP0FbMtZsP+1/j+a9S5j/nq81UdR/pi3/Worvso3/ZK5/oRxx8sfjwD9ZqX+6LBD891sIxv5kC0F/sigg8p+wKn9OCP7tVXmIzPheVt0Pd/qLgiqvthnDUv3CdyYZ1nXo/qd49P358ydKvg6vNsfL+IvTfavzVWrqp0vyj1Lgj5LnOovX+LEPvz5C3PhaXLryKN06AJkvBvL5o9luybrFc6W+L4xIk+HzTq++jOXPhbsCLWt6FhJsUEZ/7d8gCgIdYcctGzEnBdMiG4gt2koHcDSvqKsw2d04vmRFlw/0RLNKxbZ7u1BHF/aOqAHN5soooAFmOCyb+JkPaOwfPFjxhz2+2P/8y3+9LcRzQX3ufteJ6OcmBcJ78LzhO/G8Rujns29fdF8I9P70jBTZNk2btH7yiMXLznu9nZxYbE7WmFVKDmxja0heuaQt6U8DlKXSvMmgVKKU7QSwpi2KqrqyqEMttG2RSbK2E0vaT7GmZiTulA1pn2KUrOXAFrYjipSeHbj5U4xE8Uo1bEE7imjp6ZGYRWP6108xy1Y0wyiW7h4J2TQmD+FRXJJs8xQ7gqkDSESyi837eBhTIttcNOn0qQ6Ib3HO+7MZUSLZXBfr9CoPiBLLLdtbbFFiURwX4LQqf0gSS60b5A8mJT3FwAkwq86blMKW7QbxhU1JalGw6KNJ9FssvJPmTZuU1KVk0Ztaadr6t9eCBx7bTBWxnVTBSIzytujGzbr93uzmV8dx9Ht99odKcjGy2x6FLfgns+1MzLuZrjn92YLUvH0v52N+O8Jd5eTRSs7uukp951UlSKvY9XQ3Os83NfLc83ZQTwJixmLfDp4+wUjJgbj+PvUooqMt8T6dY8Rb8m3Zrc5nw3PK8795/ltKMyIdlrjnca6BfSqsseeB0hBKZfBgVnue/zyFTmK6zNMeXYc6OaKSSN+EfqpTQI053H6j0wMB1HIybY3O8G6IenMxtzSSsMsQBWbvvZbvHbYSqyW0pXZGYNIUdqQNbO9hYpp8xhbOnn7A8CPnbQ17fVSElPQO8LKI6BIE8Jt9t2mY7zEAXLbbfTTw6hDUiu3ge1EngutIiDRxgOnCP2jaX5GefJLqqkexOAEinKHpK+cdJqOrMeEdgefSSEwfnwq/sVK0F7HcuadJt8TBo0tnnxOvc7epaavGWlEi2e1brQQL2d/OeLpU390nP1MOPqJMqUkdAo/qCIhRvzAi5v2d88/VvJmodLNmM9GBYAaEMUN00DJfyqY+wIxZTbPzJ+RIYgkobrsLBsjrfEK8C4GKxDhZi9VlokQslfeKrK2ro6T5nCQ+SVhjEHLjyCtitQ0KJ6monepzX1lvNIiDmunb7Gkj1X4BwzVNaAhbbcooREz4mrzyZ8XT9/Btq1cfXnC59+qyPjNm4jYhlcscE3N0cA+qQ9YNTwLaFBu3Fx7oOd+Gtfu3ygCSPV5yq7hNW3OBzkTiLkH4SEd7X2zwLbdYzwRo1enurTUsD/BVuYmTtI/Tdi5Y7lFoh6/qDEnZ97Zqo2psx4snrHTCA8Gm7OmcXdiXZ5+HfL8ZoquznktLVEoMvhPEQ3YNJ9VXU1zsCKYNe7bfA7F9sF5zCOSocYGy8gitjBibBrkyXvK+E/Rg1/G1zknj8TqVjevuwHl0+bV+dAbHQ1LZVNAAJs8qWF1S+2F6gixvPbUvKYfh2GekeXpuwoqW1quvKCttY+kenv0MGkZvm1ZWLu18fZT5m3Fyfnr3wzrDlHjHHu4CZLbolIVNhjqAj7C8ATi2cyQTBiqeTFplnAa85r4KZn7EWyzNdaB1WxKIDUsXn2cNR2nS4mIe0GgfK9OYIVxrIghKE6SYzySMuL5n1HjsPUdTWRAP0QNu7AULNi69+7nprdu2MoQLgvfxLm3TuB64WNxEnAGhll9feGKdUqOithCtEoph+kvXUx1b6uk6yS8DJDRLIWKR8Fy2obXzBhpTVyc4Iym0hXrjP+P3V6ne2QGL39E0oepQaKU2fQZHkKqoum/TX1FuDNRia6UVgsoZsxLhhCTXfH7+rLE1Z/fJt9DTrkQPAVHP3tfhMxfMTV0zWsBeTtTPtr7ArUlWClRjpLTsbWOkbNv6EEchCWKF67xDZaGVHidO2V8tFwr/s9bAwy5IK7padommvR3MRxW+5nkqc6O7iiSw17fqBVF7MMxdUjx5POXHQCBZMJdlzbZAKgEBwdIhUDgHgMDvUhImfCWrF9Mm6UA8RdbQ5OEmUuIUhQ0fF7vuo0M2r5OF9tSXxH3sv8icHOwqbcnYjk7XF748DaWIvgzvxiyMmphhYRDfDy/mnvdjxC6MG+TjNTSUWmAiqITms9O54cVkTK5q4+FTC8TDdMvHcPudwBl7uOj2oMnZEqpTEFfvuUwZEVHu1/7OKOV3rxonyykwLO2ScbbQwFr7EyESEV8sr0GrEsbSeVpFNwumEqijFHxU6tMCjZHt1j5vnWHJ7HlbBvPMpz2pPE/CDrWU2pBRY9p0+6OyUyRG/ZT6vTcN9QRBXTYD1sj629SDpOEutoMRVumc5S1ygdGWV+yybrhHpwV27Yc1TbMRJcYDY6HCxxJNoXB6tI+qgqB0aMs2WjuXKZrTIG+vPSv3wdSgjG5hi0m+QdVIu6goONdA0LY2IYdFAuHTjJ0F8Jm8b5wIzcDiWFRq9hieiCNOmntAEyj1DKlDLl+jFrQTJtlc8DLxI7HQKaVCtThRxF4C2rpwHgE391rezxgqFd4iuUuG8PtisPzsPHJyhA7R7QomkEPmEeXhC98SaENqr6KNAhl9yaLU1Iazkac8xu5d+bw6Za/1D77xRblTYisTVY9vjerfPXm8dHBZH10CRhmdV9SxVUlht+hZ5FZjtTiDPycCCp8Amd625ssIMneJyGxMl1qCSvI+qj4aj0iPu5FX9hPd7Ij28wOx2YK8urTE5Uvo8lCx22Yi1tBkgBZ52aFQXuao9GA5L5wCrbShtA8eqMHjD0OUk8mOZIARHiLp8/HFk5agtzrZXn4jRT2zUobVPBDBba5Hl3iq00z10cbZLS69bXefuFJerNuGMJ9tM19D2/WBGeWcrsD0BLZg2yTwY0KSSsYDrDXHBLPzGBLJeqNKe51sdhkuhh/ePVTypjH3NskampceC0Rik6XoL1WX7JLAoRCPKV3o3qXEJbB57WGjKNoo3yiat9o2V1eGKMXEdoUvv5gKEbEfmh/vOj9OpAeCXFFaXnbTbshx1sG2DrxaaX/EPjORaX6u+aRN5e1jmqVS0PtDNstr+Aw77sn4YaLmKYGw2HFQcL2uGLqwaW4yiLQBc2VNiKbFlxa9ozrjDKxIEf9IaAgEOtiUUfrpKMbEPixhXgGYLqaXsDhKSS9cqKtdnGtfxuYHOvf1dsWj29BYyM7v2mL6yzTCVx7IyZ1HZYaIThxhm4hcm/LQKIyD+e4GEG4xi8ea+cFmOPGtZHrMGEeJ0mISLSVArj+3iBUgLxmluBkbjsZuzBPNsathDbj3B+1r6p+BIrnqu5GQpQrBhETuBbG+HTHDaxhkxj7Iog/KGTI0KgyhJMN0x3FAo/lFYKaHafQayoI/VCDk3cYMKLtia/i++OssJwDw7t2rm8tk7AqEuRcbrVLCH+YoON3gmmkJVMoqlDpzXh+jZmlXSld+abbBxZGvGKjzMKaFhddSyTau+ZVJ8aUrjrzFrj5wmfHKEXJEKv/y0amItyE+zxCPGXUzU2NZ3Vzs0NLywaMI24rFSdFelr+7n6YzG1SgoUN+GFb9OnFp5UDvtqgex8ssBXPrH2jgEfVhtA8tfX03PS6VJlftqret3QdF9Y6gb4PhMLtZ9+sRiCmbUywSrUx7OSJe9q/+igc8WKy9ts77HNWUSKDKIj6rZQs7Riqp1QjYaqGog0VkmP1dkdtPHPBx1rq8fzUv/+6eWPEUh23iO+7X9XjAh3qWVa8U+PrMUrkTj5F6pjtR5rmCJSXJpPCKHoIeaX5sNvIkLOybialhn/UZgK3aNiceNxR6DVswx2jBdk7Uuzaq4DO0lheDoMLKiFrnfqKxCCMdrsYac48+0kAETqM+bCoSxKUP9Lq+2771z4axTAt2600NtFKkV+qSb6rOWcvdlRSY9CJsVwWehjHHR//x5cLgXspTu8eqHSfDS+zHnlIZtM99bo8MbvdTtWaGXS9q6QDA609zKd59vqr/8WmRwnHbdnLz6OQ7tw5SBamV/b5N+C/asW0jHeukV7OaP76UPuiZh+AY4dmA6K4v/N/wmUClRHzs3C+bbwyzs61b4ccbFKK4bHrATjo3BZkxzKHdAikqb7ytOpD2pJdsncrN5WzrtNLi1dB9upPJ3Pt9GlHq3oukPms7rXOBVj43y7mToWbDQtba2a5ftKcG9N2d1z0a1ucrgR8/0I1XlJ1Mf+njj0An9aUPFtIyx6t8Q/uwC1OKuMfzCMvevY0tym1Ri6M5y/UFl3pd853TeDdmCnshLb7+pFFkhNfx9ynHowd09IdJb4FezXNTbGbV1PMY/GKkEdy/hOF72I2uT7+ea+4Hyv3H5X10mILLiGalzPTHj/9gq+TxxgZmUrGbqHpyfQLmnmV00uWLJa17uGF/C++rho6Fo3ixOSLJFl7LUItJS7xz05AFtE+rdKyUNrWneVTPkZxHX1n8vE5rSGmdAXhSkAoo/1IJer5F5PG8aDZS48c59EyggbKEYNPA/Uzd47ZSmlpxcJs5UNw3uPiA91L1N5UVbftQJkucb7X+JkszNWBU5jA1G4fEDRISb8e5aCo2xTb2oq7ZVEYA/ZhlHUOXdzQA5Jc26eZ72ogARkPviJoxgD64lAirYW0g++N39dztKKyJkpA913rfPFYdLRWFWfGBMhrA/n6q8o0NsWlMRSUC+MV8ykABZNYWdrCJ5xhpozNtXxI4t99IFr3xWN4xskTQxk9vAGzYZaw6qP54l34lOLgx8+Agmutjg+NraYqc8zb7cZHaK8p71vERD9bw0xqJ5dUdYXVqG/U3adR7CSUK6ySL13TeCW7QWSqU7AnZ5wMiEjd/SyXcbT8Qrg9tUXVFkWUpGVx5pp4fei3umiWnqAweGETYh4hgwevBvoBTKjO4YA3444lbNMb+6IS6zM6z2Ripig0GRimmo0kFdR1cYDJMIRUx1xrCo1kSkXT7BmwxSaGVfHeZ2Vez7dPSL4uzJMzhF/XjNCpNqWEfT+06hkl6i87l9WXj0t1syE3Bw2xGeDvTehgHL127NUWYSygT9aO82b6QNHCdZ71ubeahLtVH5ZVK51Gwxo1+XywAY14pn4KQGJfh+vfTxvcz7xfgxcQRDV7Guy3NsrNBuoTaKZP7ZS5BsW2vtIySMyQxdnPYwnoNTPfMFZFYOtoHV8zLW1okKAfO033aX3v1s0ZBhvVI11s79EHXx0hA+9gfZXvp0WMoHhekzbpTFEwgc2VDJUZ8GHC9X5bH4feZ4mrtezxldHzNAqRFjvuO9d6q9qWn6ouEGAJOiZtLVb5GPLBXr03CVEMxWPN82CTKlCet11zGnCHjXT42+/tKSofU2X2dBSWSFsFVjEP3IDIdhOiCGkFPWOTgRGyHz2x0uKkXp5KF0QAl4LQkKjlkN+KIPDoYrRfcJAmKdpQzZGS+aQ9XegMnAE8kVZ6k4WlT/ex2n+NOqpE1sqseqIdfTfCYGKyNcrI96Ux9eT4L5GhV4ZrQF7BfkPSGBfV+DwNt8FGB1hMXDFJxXT9xB48koced1RuW7yRy0hu1GNZ5rS4nu+tpe7Cx2NUixm/JF4EB1/bbLVTGkC/X2uRHewlcM3tRTfiDuWXXEYuKdtxnKb1MfV5J3QHgUFO/IRtPGElTHFz+0s9wf5FDq6uglvFltV77z7HslvbpqNJ9J1K9fgKljtaJpvISSXKooJ9oac/yuICoxgrmCc67tiJW+43vFCv4T7RObZOTK0cvEh+2ubaWa9/ewaAW8KWMXSggcOPaDyy4qUUjDzsJvjpEiskCoQ+7LBbstYlbn0AcaVXCNcm+WhDsKGnHEE/d+rS0FDjrD0G5n7l2hzZ1kxuikfYdfMT9IU5JaqjbO5NmZ75ps7tSDycsT2ivYVL5LIwbEC+F7hgxK2esh+F4EXW9NfbTbC4lUJxnHK2Qqx0sMPbdNHnLK5THiiclMd1xb0mw8625Fv3JQeEHkVs2i2BjQGSt1/dAM4fH2BOdbeuuI6X2AoO1/QXCcWZdExc2UdJk1VrWW5KE7weFrarVvuphimlKUk3smaN2WuyeCZ1mNo8N4XsxzDWwTN+4C+MQtn3Qx2PHXJBHBJnj36BsDvMKVr4yD7IXWMYWeIP4S/3MjLvpn+AqOdnCgNbC57EnsgulA9nn3oelemhEM2oHk9yarJ4Z3bhU2RBs9HdLXgNop/MrknqyIyl35+7rMcSXdMTImEhkWNDdiOE3lmO7nzSbWgJDJ9MiF6R08+RaJ/oWNlb1HTK5oDo2hvEYouTEjam+iwXYRSvyNr9kWQTTvigKyKwU5cq1lEfwGl13C3wo7lxGP0wEQLStd/F3NNi92B7lj1qjPg7FaNG8xlTpIies2JAEKzRSzkupcdFYJo+gY52xf2qNHD0eh/Ex03TtXSCXnRkzXrnD1OSoACIEqXJXFluM+BwpQa1O9xy6DdhnG5A3NsV1sUSDx+3gk/hlJlP88rsXblZENleGjZe56abJGA8TIrpH/hTPm3OGbpqpAjo28Yd0pyfP8QoLmFSjaNSKHrc9GzwSkXI7MORgma7kL9vXIlky+jBuZzSu5YbNUC0iQMaxi2BgyeaVIEY71VgDO3ggwNb5BUiHo8v3u6cTdQiaDyKSJRM8bvzGFZlWHfxXiAj7IelcMY4kRGuUVrwCfjzg+HlMYtdWYo7ycBqPlRsv31A6p02JjJSsuNwAnSOHsQpacLFRLENHthrB0wEWeo2oqVG7W6ZSq+v2wU5SqSpktk/z5KyPA0Ge9yk5NW1GUazaSeZkIsX3VkkHMcNzIB68zoomSitOmSlqq3KPpf1EZtiihF+g32VApBTgtgF83WPQG6Tl7DdOiSWEXs6ESFcIOCnE+vIDOnTn1NhkfH3Fz26ZapQtcn85b1QtAOJADzzQIxFabXedTpc5Q3Lk3TLdVBCSKKZUeH/o7uEc384cHL4VCmVXYqdILDPBi5/4CTZlaKN2F8e6ue+qflBdAZfYj/l8d8jzCJKguWcr07SmroD2L6kFH5Clku/zoiffAMbEUATZhtXT/TydyLRtUXIpZw9mqyKlZcPRN6ywzCJKPuT6PJ4dBZOPH5Wln6/fElHx8MMopJxXeINli/LyejT4T6VBlFh2ItF7AhGQfFykjEC/vgeEBe2JEcLZb6Xi6VHf8v2nilpIUqMO5PiCBvj26X+/xPhUYt2K9sgQAWMieU/iti3d5/itYlJyoy70+F3fczLBN4LPU8F9z9o80sVB7O0vUbZ3++6zfOk/FVJ5/GrH05sQGAE4fvmQbWzeJ92XCWBvb7OwvwT2qfKeksmFnmJrrh0GwYBhznwq75cjz6XvqSppu55uySgdiuJ7qvtnCQP/0wP4fzuL4Pr7VIB/83T8PyNn4E9Px7E/yTDBfxJC4L8mDP1/Mxfkz7I97N8H+Se5hP8PJfZHggPyR9rH38gMB/8XZnlA/+9neaDQv8ry+LNEKeTP9Bj7r9Ljf8eq/G+b5eEAzV+zPDLsgCyr5xiwOijPYYOWPj9HOFHFDs01a28XBy2qK5uv1Tiqc8LDYatCzRps/fqQmEzvoVbR5ui7nLC8/K9TlVcme4b/BKWiFo7g7+PHnxCOg879+In3GPX3dhTdyR7kurIhmdXhYauHEloqyxGZVVGKRR5mcKI8yTqnlpNsWjIHo4lCh2zrQ0ocieZ0bWZu1iAptWfu2PWf6UtLSQk5WqK0VBR5UqEgK5oqy/pIVxjqQVDsZRoamsU0KXYXK6a4L3SiT9OoLnRusVIHaUWVrH5u5nj6IAmYOyfRrEKRXM9VzKMSIaVmyBP7AljS0hoxxCHVUJ8+hCsV9LG0qaKobhaw0E4oxId6oZsyu+bbcenU8UGczEE60kFAb1yKpBPRtOAtzN8+3sllFs0yFMVt0sDcqkFaasPceeAXBf1MjhZ0sEQrrig2p0RbUTHTx06GVW2kf0zugjxo7O14Hdv75eniG5ImfjhDCcwf5T3p3hoVz87ASOHvGzKUPvsMGa/wzoGWmiIOagF+g/7OymaSB6J3DzoTAXIdJUvU4yOAIfAGUnkN5xe+ucz5C302zExscGiPyO3ysUvhZ6yfy83egEaL2OkZr7UrdjTTU7obN89UMScszYhGIZxg3ARpMHuz9yoZKVj9ZtpPpDACCg2VgQhJXfui2B7amAjta7JtipvsbGcDnZRH0bYJTVqgYDtYFajZ7Tb/dgA712GUoCGdZ+7UZeg0ZmTDQTRmk7zs3G8kM+fiIBgchB2EYxYM4PoJi3ef3l4ppbzFVMmOnSti5VkuFhEcr4t9yIGXGwGKNEqKXOlyp48htagJSWLaIJJ12TNed0EJ1NIm34g/ZyOESn6Mad4Oj7fhipcQzFqxwkZnzGQkDdyAFguTdzyRnSELFoOOkEsuHUiK/cuTehdxJN/RHd/5IwDF0n4DcEJQJDZtpMT8jhI4g8ln/9dpNqoAKBqw/KUs4ighQEZpOoASh0CoksgODc6ObG6XTYE9zsh34waIPKLPj6haEf5qIkUW5v3TFhXrYqFkZO1IGelJESu+UNDkClqGzwPYw3FBxTajt/I2NXyJmzcXyoRUnzNDtXOVSCwkILWkiqfIqs0xfRSNow9mfg/MLE0iBQM7YZpu6NNbJCyf1IebBWPm5JLWjg1pmiUiUp8OSL+coC5OXd9JVrnzGsQg8yhCbCvWqN8X8c3Nr4Mavt7wiPP5uAJOjFis20Ypi8R36Qwv3l34fOTydJe32CcaMIuACQLvYImWtQ7XtCA4UPJ6ZzhiyXmTZGQ8GulerLrzEe5iW8K+flpi42MtsvcanVM1KW0Sq2MsPQCSlvQr/YEjabY8H0ORx0p6z8KcaifNy6I7e/owHbGm3ba5spsJN3244iSTd8az9rgN+NiXdvW5aspHE2zeTtoJIdaPvM1TA5/+puEbBhb1JTWdcVG4tpmLnZrDCLfQ4bQZqBUKTsWiyXGz3OnC/vqo3Xe0h9RtPgoldNvI6jwjR86ngux6ZADIVcAtmlbWJzmpNt7Q5uCTecshjHcN235OfsWKi2cS7HGARiNm8tY45rVeL0YcLF7SlSBUiADJ7G1pumbMwsmF4jHBZmCmxbWo8KnTzNCBBEUhX3OQ+QeMHe0l2eQSfm2y4cN2btprDgKqV44wfcbgM4VE5LRdtHw9B9oqAGV20Wg6gIdEGeWd/5gbtQT7mncaLvCjmlZOxBSYUb7MT+6rnyAzTIh0ytbm908vq11ukL0obgvMsgTlKlAra/5rpmYbGa176tufU4Bvd5EG/cbvE7f4XlnTLeJsadTBEee4bR5vaO/eWB0aDWTjjqh0ir5DV+2+OZAgrp6UUvuuYDQmRMupuWvzM2etfp6rEXWvbUK0Gk5lUowmOeKDOiz/k7hEETWrLv5VA5D5AdoqCDo5cL92BqqyzhM3rdN4cn2h8s2M+KwAsLjXjT/zQx2NIXFnK9xUmCCg76FTpL5CPVPiyX++vUuT8pYwG7kqnzfrwzT7TxXOmdawDllpGfbtxCiCCIYMTuHmILmzyTEWPRxioTVr9qWbtb0wKVh+HUj7FDSxGptC9ituF+1jgKWqO5D3GEA8QUluu2Iy31tfaevOzveyRFHF/fEMw1tONJa9itgI7SN5Tz/NcwAb12F1shag96B382MapcXgKoWqLnXijZWtpEgugfJ0bKOZ2pCyLmZ2BqXObJoT6cekXDSFlL0ZSZdQWdBxmCMiUSFlL5IYjgFHhawW85NbLfIGQLFINjom7V78UXCxdbv3FKkBMTsSTZoEQdrxei8EbdddlIDQvMjwhL7g7a8meRs2VIQfl9zjuo8d57RDKbFjBIIcwz2L5QCXqRmEei1QonShZ7LZBfLOSF15Y4qy618NsLAD8TWyGXpV7z3EKnaMV1/8FyimBQBeb1WXWGfVCjkhNt4jOAetvqh43owh8nK1x5ZOizRNLW/4VEaAzZFFeML39M0nXWdtAExrKC9+gHfmI/IIcprZfJjYJ8/FfAxq0rt9m5ZUUvJ59bNA1/4q+w7J4p0ssAtjyI1zEgbu5vieAsyoA8nakYWGASaAhLwJueBPwFbEjRfFlzewocvHjJvoFxPs15//BlM1sjucYInUy1UwvpO9chTprM+bUOi+/NAuKTJ9Kc3lgwYsiOJRvAQFO77cHn7hRP1GZxMUSSTlytCu+Hx0RsoGm2lLTkIbJ6czbF/SC4FhomnrTei4N8hnn4eTUAYtsJUJla5YV3mfaDVC4waIRGw17w5HsfvpVBV92hZeiGAbf91SK/jM9oNWOuKIwz+3fjZuZ4tSYp9qoy1vIBOhaK72bsjZKmPBwppQ/VdBrQf4xs8HZSHz2QMO/ZU/gxFngPpmF3iOWdjNWZfu9SBw3+7q4eK6w9Udme6oEfqeec7o87J+KHYhKxlcbyFaQ6l7z9yTZ/P6OGZpZQu0n76VhsFC2V71K4dTbg3PzFUylKrvHj5UjHHjAX2lA4VUXBY7BTLhh40cPYSiPdTRlwBJd+dQvtyPmLDVQxitRdPokm9HMl8ValaOdy88q5kI1H3K6jdtrNYOTx3+pGxdBRqPglsc5ErC2W9tVZFuGN7feHBcESnwwFcqWtJptFuv8T24DGmThMNhEGLFIn0ro28KDQP1w91b+NgWnYlFoNr4WfqpSM0K55HX2e80Fm7Njv3xtcSEWYIbaqzwpYRhiT7smCrCr1kqjfJGtfKjdUcsuOxs5AAgYJZ++X7ZwBG727INnch5c6Jq+h78GuZhnLWJ3TbBEbpv+OE1i3EsEfWhekNTgWJLJzbljklGbCLxX9OptIBPsjLVc0mRaS770pzcr5sRuRHKOwYfWfZyzA9AV/Uzo4/CHKkHP1J+pxJJxiggoJTqwuShPhO275WwomlPfChS4YVZIOKRps/e6zBN95EU7gpGIhWWLRM7EmNXQjIV52XJEsN7BUJdFAMuNiUpjkbFFY+7HdFUvYeXB/+GUDukOWf6jYyNLmR+59Kjj0AgYpG6B6zkGGJoa43ALjFnPDoNakTaBSqTtK7oDht3vFX4ySNqeLDjVuVrbbgBqdA3OOWb0lv/4exXOjz4K7HZog0EU3HmG2k0PTu4vH42zs+LFgYr39LiBB5P6Q0RbwbAYyJb9EwaT/He31p5WJk52xvT6bTGYmaWwXhoVm4kxBLU5mmD0jCf6QgiNZ7NPVoHG7QRv/HdaEkv6LG37EDNvlNszGAgD6j7tky9WcXxtn6nOH9XM1MrteTUxqIJ8raWtkGUhcUnd91Es0xmBhgN1uw03V/EyyD5UvUdhYOHMKjzeqjLixTPZyZMY41SahMoSgYtAkYc63Glrh7VHTYBKTE0Kz6O7Lfc2JwFDJ4dRwhUCyWN54dOcN0X5nuFYhvyW5VU2D62XRwxn8ukWPtE16UdbpMC9ZhGExTTEk/lv/AIjcV0YKQccgDy0wshTqL3ziJ0wK7LwdopjWksjzmJmov+WMI2XToEHgsHByGNmFSEhfUM2hW7RcmPc2dH1PbunGRqZB9UCFdKGd9qzYVoNhmpKSwSya4YLZmd9tw8BXCbd/5MNMIs1DRZPPCWwVHcstffG1iUKAMm3bZc3lsq9TJZ+jq68DVQsyPrUIzkvAfLzv/0UUsmpU4p1ONmHJCB9BPgFFK7tq8rClcB4pFHkI/TDb4s5KC9N57xEJ5oXxsJzxH5PIW4th6kIGEKi1GeW6TTFiF/LYHma+91jz6e+MZKXE18NFlLnZJt8lhCHvoXfoVNmr4eud9ljiwGwpWsI26UZdAoOBNmytAdc6PUYNeuI1H+2RjE8eZuc5rCbROvjX6QigcJsHE7UZCLwYisxdsiH4g01KTuaGR7MkMcguOMfoFOPfSOpqOD49WNPqscnOAK9sUFQJa5WqoTrP0qjUDrcfLZAH+di4VsBXseY9PA4lBUyRdpqvlo9Ul4FvPB4epC9Zp6WeZOImElipL6mMqqVM0TOmjfv2sRpgqRzV/K5D178s1aoVDNbSyFu2yXM1lsrjynu6mSVcf0YOXQa0YUg0sSaMks84WDr1iUpKH5Q7vXgzoeVbcWIc/n9xsk/EN18k9wMTxsT3T4Hgww2etcZr5+bKIL7+dCSsoirSVYvdQ1uqkCvmOs/QKsMzIfv4CNaxzWiMpIaXCo90s9DSvLZi0gXjLN5f4KXHuGmec1MvcIWDBIwjFokZDKG4nneKk9Sv8OflKTDoF2BB6q8YTi+0asFAJZHs+uqqTMRJUOhJFO7TDerSmF5ULHXLtidorS8T6mTsjDRMo3yrGhRqQ1SakXRTr2Bg6x4g1SUynB2vI9gS+NGGhqstNp8tkS6lzWz+HVnZF9K4ctrXnGwCRTXdbutcfMaefXa01/QybFtevNQZUq9wdSTAnS9Wh9/X7PL+dxaqRURdEhSS3PZa7aAItmrllSvurcJ8UQ7YdyU/BNWINsTvGgzqon1PE66wRRWyPZHVhytHqqv+7IcpS0ujabn/G6jj/sj4vW6y5ZK+cWs9409O52m30sho0y4SlAdEodyfapYxOhtapFJiwudfDhqE/HmuSWizzMvBrAydl8iwfytFkL8o4mX62qWq7RikbAzcr3xo/NQmQESlHutqdFk/yb6KEkavl49DHU0pacoPUbarJYIS8hmE0M1wwfjpQpso7T/Rgi4ntqIou+mYyZqQ4PKXxcYpVYaBONG/TNQZ6F9HtuYf+wLlIqcFQDYMQhIgp4/MtvZFIRlNi+5xu8DxnPUKqv2KAF+CByQWW7jXqVnlJ3cBngxVerRU1QpZog+lXCzVZ4++h5s6RLr64zBUtNmpjFQMSsIrMTgR3DWlBTkJgKu86/rupEVDBepd1Kiq5jdmGfGeLU9C5lxeu2buJ5sekJyiRwDIbBpUjd7U0XBjgwb9hitjRI17MKSqtLSCcsSRzgVLqhEiaajHc8pMkVfHha34yh5yz3y7vM19y9u9LBcGT98PHPTp01v499/4nKkDXdPXNjC/vxdAqmzu09OSzu9aC+oC7OtN3fGVUK3pufR/m6+ZPMck1NYC09oVgkq/rG5gT6ouU8QgBzbFkK3rw7eq4EKuV+uE7RP4bTaQ9MnNnZ0i39hhcwxc6ceMk6/r2J+jwOGXUjsbxhg+2NabX3YPUhU6ITm1e0XEYjnUaCLZlbu6iFJU9en1GZM1iZH0+npJkPcRAsxJW5we/irMNBKCFJAdv9DECqNpU2xUQoLw5IUJ8zVNlF/34pw1mGcTwOvKcbryhopj4NQ3FNkYofv8NqbmiUaeKR30MP2EY4qHArfxyq4KqO1Dtm6fMNXFbEa564MqyPf2AYWtnQfuMInKzujid3Q1BfExe5d6HDb6ZCF3C5AH7MyrQK74OR4K1KZx6Xm1kXev977gqIg9joDe2zQ2yLsetnz1nnewwLp9qFKrM4CGyeQhMwvyO0TcSMo6boLkr6YHNh32rJxMXi1+WWPrpyR1JNF3ZZY+1sNbO2wmdShdKZnrluXp+5Zsjoqy4qGF+gMWgsQmL2RxR5V7GOgGl6gb7HMvenCTQc71EbTBIQ8WtHi2H6dyq9/mby7DsGwl0Kzl8CvSFbHLGsRGPVZPZ2MBObQnpxAI7PjiE/21AI+7cWi3IbJHlkbYte+rS4ulJRnW/R3Q1IZChZy3qvvS5f5VRfIzVRsWx2DPhQQlE/OFb6wKgCU6SzD5W803UjFltcVIwTBZaQ6e2qpaztJn2z+P3eJjiWwZhn951fX2vmZ2V6aWJGDm8M9JIsnUOfC25Fp2cybxhSIulwtoFmZkW/V1ubStNSl0PXJuUpMIuI4gRHrmyXUBfWT5XgzTAywDEiGxm/fTrNK1cimof/vbsNjimhq1ZiWUiHMy2wY5UQKCYAz9yPokk54NX92S9uS7yn1ZU96gbNWjxqZbNNJ8qU0RbBKksn2oxwA8sRiUJ4IcbOiaVF4NpKrjwR3puEnoFYVMe4HHu8lJf1ibpKNHcWFyhbZ8TbJKdchs6ZNcj3a0YRTk0i2XbYqXMErkMu5Bwu29sS+2ZXWbzitiJP05LIeOq17R3NyjMaoQUR+9d51tA29xsD3G6qE4ItgTf+xTov31ieg2ZwxJEWabvjWTovCvQyfc9Y0FxT6kmUycdn4bw2xbjDUhulRYBNH97zFrfwfO8egvfsYQtqG8EquiD/Txv/rI032qNKxElyGTONP+kDJCVZLsrOjVQUxU8CwX8ghwD6J+e2/6Ecgj89e/0v+4Y98ic5BNhvH/Q3Cvj5ZRHmN5J9kwko8s0q+N83meDfL7o/kgk+/yC6P/t5kf+yVII/Edz/6lSCf0H/HakE4J+qM/pfpM7w/49TCSz6b34wIkeOr2cFwo32a1JV3RcgXTc4CmkSBx/G4bv4pPyHFV3Hmr4ycz3OBV3thRhTtjZUVFysAu0VQGjZs09dpFWpAjwAwUNJiJu4FtZrjJkEAMDoNNLGtfYx2/BjQyEoh/M8O1HYeAlZs0Mzip74vX9TB/p2GYzcB2IanEjS9vU0QIayKfItZ5IFRIEmQpIySVELcxWkqZDCwL5ZrFRAslecJjszVc+8R1vWrKhGOJJ9f4gAzhmPNV3SZtO4dpRbNimS2Bp+RpCBZEkM6Cq3cwmKlCRDg0vwTaIEZop/Q+b7Z0DqYdL6CPLTk/hw7Ic5Xg+6WizY/bAbWr6/IkbVA/Z+YaIbpzCPvXoKppAxqdkEN914TyDRqL5xDNN79csM1p6S1ei86xS3oBw2dhBFkKo24yGSkpwdUVKD+Qw5RUUidVio7xfPOJH9aqW4Di6l8t3h04f4fr+RC6TIIkXGXdiAVrmrXhPMrFhkjeG268cr6yMgZYbUaEvXScOCtEUfN9kZTUiVV9/TAAFIHo/8IW4v88ez5mM4wK3r4Fa6PknZZrK1LZn3oVTV56hOPiOeA2tZq9LRa3Lm5EAiyUSYYQnc/M3wP0FJ0DfqpLjoUCAP3sDaMnlLfYqmdaiqWJ12OeT09XYp7M8zI87QPNVBIo4kCz61LzWHwXzaGJGhhFpxoU8ZxN27voS0fPmzivtxeg9g/JzHZg+RC8lx9104iVTjLeB50aM9ctsyCC30WVL7ZdEsqAwKzpU62WqUJece7t6MyimHJ2Aw6PVqKRDfc45BcXskQroFhaTqYTB+FmHHyMqR7z3P1XksNpUjBYnbASvDkW6ln3MRfnRPHEAzYKghaE+djLSyQ4ectav2rn1On4KbCDUaGeSFPHk5uc8dCFyKLcEOWTWAfUgfUBxU08VgSmD0nqwkZkAFK75BxPCNpVPbwI+J/ibTXqG+gLlGBdplZwJj0o3gJKtfm979YLY1AGRJVvGmFzOEyp3QzW431k1lw6AEKdfPYQ4TFkZxY0FHqJ1WG99Jcq5sZULbpQjBcKKEjwNtRnS+XjibTPmvjUSL2K9wTJ8sQqkOey291EXdd2sT67nvxAkU+5qGaDx+cBIFgx054zEaoiTOul78TAbwVlLVy5lT5FVwLIw6Cv4bAnQII+9x6hFr4qXWPJ7t7/kUZpxdMmII4al5OZ9o4vjbR00+NrYVQJTDLHvE9M546/sF3/N6A1YhCnxXZTB9fX6GXMwwWCjqhWChwXuFTJtv0Bk/vIJt2feXH/TZ8wqeMdGTCOlrnGCZPrmQKgA9/fDkoiTqVTzqRtK04I8NMZwyvafoaeJPe2chVVQPUix3FauDtS8mLzRnf8xBiai3dZU8YtJI6as0aYg5l5AE3q8KwD2GufpMcK/ngrPMhAZFBI8DqM684/jMUJjheEX3xVfLgzyNMIHnm6GwuhvdefHq90nbXmgkBHmUyhdV8hLWrl9EZR04iiJexGOAZo6IIuSEChnq8HxuLciiVLqgs8HDK+c6c11q/nqYLXGfyw3Y3+8Lz33ALaU680Q6Cs6MA3yw9UACFVlZVNEexSA3KPrSLMQq59PvKRCjO7QSKVVhx4xQ1CUdU0noNyp5kTJ9ldziTAI6e1csVbMHznpwR7RlbFgOmiUXWeGoIjxvAd0bZgyuiepMAS+AffQJMS1IbtXi3ZGUhoJ80aOawhwKuPv8ynNpURYIG5qKLBuRQ7xeUbt0O5+030wAzgSeTi9tPB87whUToYt4rV/wwnSlTdvM5/s6pnurjbnG9Yh5cAn1KBh4eVLYY6Wblw5tU48BSi3AS5XIHHtZojTSASBtT9jhTVFm52Myr0dG4aefitt1ZTkmwX6qMG3Fp0NpOsAC8pm7EBPg1Go7tAGvsVvD70AfKIosTyHq8DKTOAU1RXmhb+FEOdb93vkAwzhim7Ltok2LlWf06xkxpTUie8FMDtPvm1aAeqQvKqPYfGWOdIo3nCQs3/OCFQzvVUZkA7d4CZPz2k8nJ0xiWj3SpOzp3TThrjcyKdFddtQo5+lk52ScG9h6yyltRVpkOhR8C4dDKn3fw+/teCwV2s6jS9nMFpfVnf18J90E+zF7ULE7MfAWDqYK+nwBBJPrjL6SxdlXULEn+RYjUPrrHm9TaUZRFPoOLckW6D1kcNjTQchT7glaQ90HoVtQ6xnkS+eRJT44CK+iIV3DQuZRiwRWxmrtylKV7Jkq/24scvxyaXSDRciSowF+rCNQZINax8zm3jNf4XDuziUrErVETdFPG1GOiiaOmDlsQhnJlaSHQgChcBo0Za7fMJ7XUAgpuxxb8tVjNvLFn4OJBTco0VrHbQZypM2SjaOcSm9muIn0FQ2/2wDCFJK5yKrkTQTJ+NuiXP0UI7Y8kij1fm0B6T27dd6vBjCVvoNltaseTVqMQFbae1xvjukU2VhYF6+Jn2AC+An4PZtmYqlWaWWaBPcZf/GyxUsCt1p9cceBYyV3Xpi9yqtKF9/flAm+vby9Ya+GWrpzVFza3zblkVVkshaKb9MdbClZ1jUnNxp30mVWxI/d1YqDJ1/c8eG5SUj2kXf8CXXQJv3X7k6eMhGVJX236OrN63ysJb/4zOQML1FRv4YwVBV2r4C92SLTcNd1xK1KOQiq3yuOhkj2nn+iXrTSdljwZjNYbCceciwDcI1casA0IaPeuIjuGGlTGh7eQv59+K6Mqe/PTj0WdTVFk5vNB8He7yYou5/3kC1J6io/pGmVyyhxUfA9I5pA3PokXmGSsdcz0JhsiTfPjNvZnaY/xA55OthwcJBTHBK6hym6iY9Sc5HJbEgDu8hpbwdEKe7DwvqQiMAlDKCK0pgEedlsHDwIdCjHF5ZOnQm/TBwS7KNluZbom9tjft+gnxlDWEFGFJO6ZAzeh8B9YMW6BQ9eU5lkzk1pdfsFu/fUVBRWK4bB3goCUMdmUqUbcilDKZoaMj1RnygUtywK3Sxru9L8hmTl1Ucsb/FqCY2fXTtLg2zKZ0OspFhwBfjYtPDK7ZI16TOuBnKJFMm8VDJcPZfkxbZBMp5U7WkymYevhEZt0qLnqVQleapQDhQrb93DKObOOQCyonzHdIv/09c/6SsGKFTI2Ey2PNuhL3eilIItxh4S8tIX2/t/tHdlTW4iSfjXzOsGiPuR+xIgQJxv3Ie4BRLw65dSt8dju2fXEePdCe86ol9oJQJlVX2ZWV9W5gUTffTxSseFjhhXYLB9zMz08E7VE9r1ruPY5VuRPYbtTIVnJX48LO8CdwjN6bnE+yBtagRrEwDFaaIXc7cuNiP3HTsTy7v9sx27CymIO2yKKPB+vi2Dz2zcQ1GVqapMFTmh7O2R90F6tb0beeC64t9i+LpZ4g152yjPJ+WKJ6HAo+msv2zRPHG+rIMc2XEN7tn5ubxJvv0BHy6UsuSwSarsOa/0VEersq61QkMi8qdLPp7xQPn91bSYuzyqNcB9O219MrJSScn853QhnY1FwzJTJm+ZOSzQhSrPz4gQ0tdrXZeR/0CIDhBXGraAFzUAHmkXA3Msi1L8jIbP4iajZXh9VmsdNrnLWSCXiblgrFyY6E1p85q0LjFc1Ah1+CW5mMQbETDbKDD0gMUNTxleZSeX/AyxPC9S8uEzXcERVwaGl+VwR1q0FiqXHuTM8rAWqzPv5m8+wJryyRjdm/oEJDy5zW50blTFyBFqPDMrFagwse+SwgKHydV2bcdKBs2Ym5By7hHU8Rg1lzW33lIph5/ZbAWOF1zavNtUGZh7rwE+Kb9WeYo/LOPA6TJySyGtdd0zNfkJuFfBOzUbDYrAeEVM6pLUdbfV6AYcZAr5Qnz3TH7fnNuwa3FUTryKC2M6g0pbYId+bBquTbO+rf359GikaU+4KjnXIACJA66wBfVeexCj0DsnbFVzbs/tHR3cnOcesTMOKWbqR0yzHqZTo8fZn3asWoPehU+i3IoIMdOiqdG7H+GI3iYKc4qmcyghOjLBxAWpH48cED0KZviDL82FtjdiEJfugdjshuzEtIa3J6+A0kMsKch7t4ijc3gfO0/bcb+VYA6WRrsWTFUeb0jqpnNrwETkkNzt2JiPbblw7uPr+XhqKVNtVVi5uM6gCzlq9e0rmKeV5uzdJsyv5M1aNR9BrkE06/2yBYw8uiRbGzGEN/B0s2qsnm1NxNY5CavEuisV30C5tJN3XbIc0wAn+t05HOxy9tT7APScHZ6QMfnqzUOJyiu2ejEmKQEkeqDXIl2rfgoyyXxvPeLCQLjFFsTqvq8vBW+Z49pgBWlDV9HQpSkoOH7TJkATvQo2g1gIYaF1UkoRKEn2aZetBCM4BdxWtd6EH56nH9Cy7Jnmq1CP7b04EccIp0/xOrXPyXMboOjJhgw6YR250Pf5gFFACOtjEd9a0TBEd8GSxfEro565yqMupl8rT8LfGBtPAzbA53OekHDarZs3esqlVu+8Rdcr7wWnfTXRVRFI9qpfrEaETq5EIqIQs0mZzDn89mOO2dXQkpAbD3d0SBfEKP79onWIhc4XfKe9yzGdTleIulw1CL4H6p1pLQ3iNA3G8/0Gs5FKsHLXoHSSUutqobhWS1tWCcQsd8kVOpxNY78ThvU0yH1/bI0b1ehjOlyd3TQ6rdd5Vxb5IL8JE1hVmG8Q3PiKIS1jOlTD49q5eEbbMwCI6Hdy6FxvmDIu043PaaFh6ZSUas9h3uI+H38dDhg2jMalPmwmzT8tFIStBnz1exUerw2UmYdEdEaNtriz9yrSvdkj0nbHkP7AUcS6xjZwsAiMQag6OBlXB9YBdSxFSHlRd6TQngN+zJO7WRyzfLjwx/KXMnxZj1C/muNAdLi2iFWjtSngEutuA4UYCFazhFEuJ5jigyobJ1eeW12s836DCbDLWuIpTdrOGXfIVi40RYxEdLGrWSzr5nG50H3lkFPDh8rrBKp2btAlJikyAKW6urNHYmWsPMVwJAj9CN1jYEvgFZRcdZCtBIkwNci7hIToRByus1aluWhm+gbs5m5Jm9pkiBunDUSndFX1z52g9HQ3FyY48Lz1tZjHu6SGrPxQ/2mPew/HMyxHUwtjBEGcuF7iS/kMZwQEdt+g/YGo2LDkWHqKs3G4Ri1rKYOfQ1jSwleGpO+9HV0tEtqLlGcvwhAeq2aXofVMBRxuwVTnPxm+YMKwSeA0ZXqaEdiH4oW7bVytEqHRxCsmvFhozbKfZmCIC7Ua2mMNZ6Y7pWizm4xsFZ7Ai7EZGUGHrk16OnELErGP0ShoRc7YQ/aIFikFLFF1ljhzUY/AE8w+xqAWoqNvtKqyVZNLAf6WFiAFSMaBswCHeJarT3oYF3DdFXW41Pdo2c+9Sg0ZLSjO0wd7r7FVQNEIP2RW3vftlQ3yoO3Qm6HDJ616DtYlzhqnOGv1jUjxkbnFkHaYxGyOU7a4pwb3GM8zYx9a9valZ0TuUSqgOobK6/yxFD3OOuZdrAxVYOr0mTdHiLyuL7lajcuIwmw4vmrzRpqZQVRGIdtE0uxHHF5stHwBWMZbSOJNEbzk68pEy0ofy/fh1wPIY+wJ45YM+uH7zEd0v+6uaZDemtBypds9NkN9uopQbdi8gKHlYbWL+UFCaihtbROXhQHMXSCBKiEF6tIsbTAmAnyJGjrFdcuENVFXk/bg78N81ZVbA2MBKT86sEOrUAtpjDJdsDcZhcU2vzk0y2GprPvWatIyAw+6NmnDk6Z/8K70IIg9uZJswZr5eWLGTQMBOJMWTyvZLFAFJY+ff5WkRP+EEfpTkhL59tDsx6wO/J8iKYkPSMo3ShJ99UFAQUOE/11u8vtH7BM3CX9w0Bkn/ovsJPHNcGRpkX364f00l33Rd1HDf/7vV4r7LHPuAZv2GsE6m+ftXZ3RMvdfju/bM8GDviA6P+gVcO+XKcn+PY84R1ORzf9C7k/GYcqaaK4eX77HD1fyt3P+51Iy/J1KPv2dSqb+DiUfqpw2H9x/LOT3y+CPn3Hr+5e/XW3vV3/DCvirg/N+66WvuvkPVQq+SCwgvsapt7d6v+fzANPTFG1/EBuAwP17n4J/3bLqa+mvW8x8KQ82qV/P/zzXftfHX+gL8lFxhF8tsX61xPrpW2Kd/vHbpwZYX7S8+rDTFf0biYK2R7TwG8X93jDry55aP3Pvqw/ys74/Dwv/jjQs/AOH/Ue0vvoYtD5Kw/oFWr9A66cHLeQfL7A6MOeVG/sN7Byf/j8hD/I19HzUMuwHQQ/YBfu9Pembe/W5ySvC/xM=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.png" "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.png"
new file mode 100644
index 00000000000..f8f457c7490
Binary files /dev/null and "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.png" differ
diff --git "a/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.drawio" "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.drawio"
new file mode 100644
index 00000000000..7626c8d1f50
--- /dev/null
+++ "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-02-01T02:02:31.185Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="9PudAcx6My1N9F9azB1q" version="13.4.5" type="device"><diagram id="3s-LqK6m4lkifnhmqHE2" name="Page-1">7LzXsuvIkiX4NWk281Bl0AAfobXWeGmDIrTW+PoG9sm8om6WsqnqGevpI0gwgNDuy5d7OPkbTHcnP8djqQ5Z3v4GAdn5G8z8BkHgB4aft7fk+r0EAH4vKeYq+73srwV2ded/PPh76VZl+fJ3D67D0K7V+PeF6dD3ebr+XVk8z8Px9499h/bvex3jIv+HAjuN238s9atsLX+VEhD+13Ihr4ryj55B7PPrThf/8fDvM1nKOBuOvymC2d9geh6G9ddVd9J5+67eH+vyqx73r9z9y8DmvF//IxXONkwglAhsec5gD0g0PAf+Cfy9mT1ut99n/BuEtU+D1DLG/Tvs9fp9LbBpe8dKpUM7zL/B5HNzLpL/C32aeHqmn9e/u/y/32uY+ln0fv2nb9xV7fWr2tNW3I0/N2EYed67fJ6rI3+WLJ//4eZf2vyHO+P6DjCfq+9/olKRD3NRxf+JGmvVPSIIAX1+vHMeundh/sO1l3UZ+uJfr/D7+P92rZYfNXhXCsT/GR3Pf3H31468t/th7uL2L7fbfF3z+Z+enUurp8s/e2TNz/Wf4rYq+l+32/y7/v3Nqs9+JOq9C/xN3z831znul+/T5B+N9/lfHjiGOfv7vv+hepanwxyv1dD/Sf2sWsY2/l1Eqr6t/ubetx3i9W/r/CGMz1Xx+/uP1CZ/FID//BuL/kY8/4jfWOy3D/cbib44Eadl/hvL/UbRvxH0r09PJyzyG0X8RjK/XxDMW/n5+CHeiw/9G/lc4L99qN8o5G2OYN/m3nb/KPlgv1EA89dxzP9yZI9mJn9S9kvN/iiG/k7joHfRnvKjrNbcflb2LT4epH3KyrVrn0/gc/lKxe/I+bNebZzkLRWnTTEPW5/Rv/T1aQ/mfv78pae/BY8/gCCfn07/puh3MOHzocvX+Xoe+Qu4/w5sv0M7hv7++fgrTv7lmfJvMJL4vSz+HZqLvzT9V/R6Ln4HsD8HM4Nx21rgr4KFQJ8m6QlHmH/6Eyz7JQIk/bOv9G8f/Kfk2X38dxn4kFK8x/xrZf5k695azLv97CMTwNvUH7V+1XhlA/4RrD/fuL/ZpGWdhyb/Yy9+hPjZuapt/0XR77rJpM/OPGAIU++OVI9BIn+/0VVZ9nbzp1Lxs+H5u0j/hiD80fm/EJv389/ICvXz979GVmAY/mf076QFwf9RWh7A+Edpgf4LpCVjzfbT/o9o3ruE+R/5WhNF/WfS8i938V228T8+/b+wkDj5owXg31wWCP57FYKxP1Eh6E8WBUT+C1blzwnBv78qD5EZ38uq++FOfxFQ5ZU2Y1iqX/jOJMO6Dt2/iUffnz9/IuTr8EpzvIy/ON23Ol+hpn66JP8oBf4oea6zeI0f+/DrI8SNr8WlK4/SrQOQ+WIgnz+a7ZasWzxX6vvCiDQZPu/06stY/ly4K9CypmchwQZl9Nf+DaIg0BF23LIRc1IwLbKB2KKtdABH84q6CpPdjeNLVnT5QE80q1Rsu7cLdXRh74ga0GyujAIaYIbDsomf+YDG/sGDFX/Y44v9z7/819tCPBfU5+53nYh+blIgvAfPG74Tz2uEfj779kX3hUDvT89IkW3TtEnrJ49YvOy819vJicXmZI1ZpeTANraG5JVL2pL+NEBZKs2bDEolStlOAGvaoqiqK4s61ELbFpkkazuxpP0Ua2pG4k7ZkPYpRslaDmxhO6JI6dmBmz/FSBSvVMMWtKOIlp4eiVk0pn/9FLNsRTOMYunukZBNY/IQHsUlyTZPsSOYOoBEJLvYvI+HMSWyzUWTTp/qgPgW57w/mxElks11sU6v8oAosdyyvcUWJRbFcQFOq/KHJLHUukH+YFLSUwycALPqvEkpbNluEF/YlKQWBYs+kkS/xcI7ad60SUldSha9qZWmrX9/LXjgsc1UEdtJFYzEKG+Lbtys2+/Nbn51HEe/12d/qCQXI7vtUdiCfzLbzsS8m+ma0x8VpObtezkf89sR7ionj1RydtdV6juvKkFaxa6nu9F5vqmR5563g3oSEDMW+3bw9AlGSg7E9fepRxEdbYn36Rwj3pJvy251PgrPKc//5vlvKc2IdFjinse5BvapsMaeB0pDKJXBg1ntef7zFDqJ6TJPe3Qd6uSISiJ9E/qpTgE15nD7jU4PBFDLybQ1OsO7IerNxdzSSMIuQxSYvfdavnfYSqyW0JbaGYFJU9iRNrC9h4lp8hlbOHv6AcOPnLc17PVREVLSO8DLIqJLEMBv9t2mYb7HAHDZbvfRwKtDUCu2g+9FnQiuIyHSxAGmC/+gaX9FevJJqqsexeIEiHCGpq+cd5iMrsaEdwSeSyMxfXwq/MZK0V7EcueeJt0SB48unX1OvM7dpqatGmtFiWS3b7USLGR/O+PpUn21T36mHHxEmVKTOgQe0REQo35hRMz7O+efq3kzUelmzWaiA8EMCGOG6KBlvpRNfYAZs5pm50/IkcQSUNx2FwyQ1/mEeBcCFYlxshary0SJWCrv3bK2ro6S5nOS+CRhjUHIjSPvFqttUDhJRe1Un/vKeqNBHNRM32ZPG6n2CxiuaUJD2GpTRiFiwtfklT8rnr6Hb1u98vCCy71Xl/WZMRO3Calc5piYo4N7UB2ybngS0KbYuL3wQM/5Nqzdv1UGkOzxklvFbdqaC3QmEncJwkc62vtig2+5xXomQKtOd2+tYXmAr8hNnKR9nLZzwXKPQjt8RWdIyr63VRtVYztePGGlEx4INmVP5+zCvjz7POT7zRBdnfVcWqJSYvCdIB6yazipvpLiYkcwbdijfg/E9sF6zSGQo8YFysqzaWXE2DTIlfGS952gB7uOr3VOGo/XqWxcdwfOI8uv9aMzOB6SyqaCBjB5VsHqktoP0xNkeeupfUk5DMc+I83TcxNWtLRefUVZaRtL9/DoM2gYvW1aWbm08/VR5m/Gyfnp3Q/rDFPiHXu4C5DZolMWNhnqAD7C8gbg2M6RTBioeDJplXEa8Jr7Cpj5EW+xNNeB1m1JIDYsXXyeNRylSYuLeUCjfaxMY4ZwrYkgKE2QYj6TMOL6nlHjsfccTWVBPEQPuLEXLNi49Opz01u3bWUIFwTv413apnE9cLG4iTgDQi2/vvDEOqVGRW0hWiUUw/SXrqc6ttTTdZJfBkholkLEIuG5bENr5w00pq5OcEZSaAv1xn/G769SvbMDFr+jaULVodBKbfoMjiBVUXXfpr+i3BioxdZKKwSVM2YlwglJrvn8/Flja87uk2+hp12JHgKinr2vw2cumJu6ZrSAvZyon219gVuTrBSoxkhp2dvGSNm29SGOQhLECtd5h8pCKz1OnLK/Wi4U/metgYddkFZ0tewSTXs7mI8ofM3zVOZGdxVJYK9v1Qui9mCYu6R48njKj4FAsmAuy5ptgVQCAoKlQ6BwDgCB36UkTPhKVi+mTdKBeIqsocnDTaTEKQobPi523UeHbF4nC+2pL4n72H+ROTnYVdqSsR2dri98eRpKEX0ZXsUsjJqYYWEQ3w8v5p73Y8QujBvk4zU0lFpgIqiE5qPp3PBiMiZXtfHwqQXiYbrlY7j9TuCMPcRze9DkbAnVKYir91ymjIgo92t/Z5Tyu1eNk+UUGJZ2yThbaGCt/YkQiYgvltegVQlj6TytopsFUwnUUQo+KvVpgcbIdmuft86wZPa8LYN55tOeVJ4nYYdaSm3IqDFtuv1R2SkSo35K/d6bhnqCoC6bAWtk/W3qQdJwF9vBCKt0zvIWucBoyyt2WTfco9MCu/bDmqbZiBLjgbFQ4WOJplA4PdJHVUFQOrRlG62dyxTNaZC3156V+2BqUEa3sMUk36BqpF1UFJxrIGhbm5DDIoHwacbOAvhM3jdOhGZgcSwqNXsMT8QRJ809oAmUeobUIZevUQvaCZNsLniZ+JFY6JRSoVqcKGIvAW1dOM8GN/da3s8YKhXeIrlLhvD7YrD8aB45OUKH6HYFE8gh84jy8IVvCbQhtVfRRoGMvmRRamrD2chTHmP3rnxembLX+gff+KLcKbGViarHt0b17548Xjq4rI8sAaOMzivq2KqksFv0LHKrsVqcwZ8TAYVPgExvW/NlBJm7RGQ2pkstQSV5H1UfjUekx93IK/uJbnZE+/mB2GxBXl1a4vIldHmo2G0zEWtoMkCLvOxQKC9zVHqwnBdOgVbaUNoHD9Tg8YchyslkRzLACA+R9Pn44klL0FudbC+/kaKeWSnDah6I4DbXo0s81Wmm+mjj7BaX3ra7T1wpL9ZtQ5iP2szX0HZ9YEY5pyswPYEt2DYJ/JiQpJLxAGvNMcHsPIZEst6o0l4nm12Gi+GHV4dK3jTm3iZZQ/PSY4FIbLIU/aXqkl0SOBTiMaUL3buUuAQ2rz1sFEUb5RtF81bb5urKEKWY2K7w5RdTISL2Q/PjXefHifRAkCtKy8tu2g05zjrY1oFXKu2P2GcmMs3PNZ+0qbx9TLNUCnp/yGZ5DZ9hxz0ZP0zUPCUQFjsOCq7XFUMXNs1NBpE2YK6sCdG0+NKid1RnnIEVKeIfCQ2BQAebMko/HcWY2IclzCsA08X0EhZHKemFC3W1i3Pty9j8QOe+3q54dBsaC9n5XVtMf5lG+O4HcnLnUZkhohNH2CYi16Y8NArjYL7aAMItZvFYMz/YDCe+lUyPGeMoUVpMoqUEyPXnFrEC5CWjFDdjw9HYjXmiOXY1rAH3/qB9Tf0zUCRXfTcSslQhmJDIvSDWtyNmeA2DzNgHWfRBOUOGRoUhlGSY7jgOaDS/CMz0MI1eQ1nwhwqEvNuYAWVXbA3fF3+d5QQA3r17dXOZjF2BMPdio1VK+MMcBacbXDMtgUpZhVJnzutj1CztSunKL802uDjyFQN1Hsa0sPBaKtnGNb8yKb50xZG32NUHLjPefYQckcq/fHQq4m2IzzPEY0bdzNRYVjcXO7S0fPAowrZicVK0l+Xv7qfpzAYVaOiQH4ZVv05cWjnQqxbV43iZpWBu/QMNPKI+jPahpa/vpsel0uSqXfW2tfugqN4R9G0wHGY36349AjFlc4pFopVpL0fEy/6VX/GAB4u119Z5n6OaEglUWcRntWxhx0gltRoBWy0UdbCIDLO/K3L7iQM+zlqX96/k5d/dEyue4rBNfMf9uh4P+FDPsuqVAl+fWSp34jFSz3QnyjxXsKQkmRTerYegZzc/Nht5Ehb2zcTUsM/6DMBWbZsTjxsKvYYtmGO0YDsn6l0bVfAZWsuLQVBhZUStcz/RWISRDldjjblHH2kgAqdRHzYVCeLSB3pd323f+kdhLNOC3XpTA60U6ZW65Juqc9ZydyUFJr0I21WBp2HM8dF/fLkwuJfy1O6xasfJ8BL7sadUBu1zn9sjg9v9VK2ZYdeLWjoA8PrTXIp3n6/qf3xapHDctp3cPDr5zq2DVEFqZb9vE/6LdmzbSMc66dWs5o8vpQ965iE4Rng2ILrrC/83fCZQKREfO/fL5hvD7GzrVvjxBoUoLpsesJPOTUFmDHNot0CKyhtvqw6kPeklW6dycznbOq20eDV0n+5kMvd+n0aUuvciqc/aTutcoJXPzXLuZKjZsJC1drbrF+2pAX1353WPhvX57sCPH+jGK8pOpr/08Uegk/rSBwtpmeMVvqF92IUpRdzjeYRl797GFuW2qMXRnOX6gku9rvnOabyKmcJeSIuvP2kUGeF1/H3K8egBHf1h0lugV/PcFJtZNfU8Br8YaQT3L2H4Hnaj69Ov55r7gXL/cXkfGabgMqJZKTP98eM/2Cp5vLGBmVTsJqqeXJ+AuWcZnXT5YknrHm7Y38L7qqFj4ShebI5IsoXXMtRi0hLv3DRkAe3TKh0rpU3taR7VcyTn0VcWP6/TGlJaZwCeFKQCyr9Ugp5vEXk8L5qN1PhxDj0TaKAsIdg0cD9T97itlKZWHNxmDhT3DS4+4L1U/U1lRds+lMkS51utv8nSTA0YlTlMzcYhcYOExNtxLpqKTbGNvahrNpURQD9mWcfQ5R0NAPmlTbr5njYigNHQO6JmDKAPLiXCalgbyP74XT13OwproiRkz7XeN49VR0tFYVZ8oIwGsL+fqnxjQ2waU1GJAH4xnzJQAJm1hR1s4jlG2uhM25cEzu03kkVvPJZ3jCwRtPHTGwAbdhmrDqo/3qVfCQ5uzDw4iOb62OD4Wpoi57zNflyk9orynnV8xIM1/LRGYnllR1id2kb9TRr1XkKJwjrJ4jWdd4IbdJYKJXtC9vmAiMTN31IJd9sPhOtDW1RdUWRZSgZXnqnnh16Lu2bJKSqDBwYR9iEiWPB6sC/glMoMLlgD/njiFo2xPzKhLrPzKBsjVbHBwCjFdDSpoK6DC0yGKaQi5lpDeDRLIpJu34AtJim0kq+WmX012z4t/bI4S8IcflE/TqPSlBr28dSuY5ikt+hcXl82Lt3NhtwUPMxmhLczrYdx8NK1W1OEuYQyUT/Km+0LSQPXedbr1mYe6lJ9VF6pdB4Fa9zo98UCMObd5VMQEuMyXP9+2vh+5v0CvJg4osHLeLelWXY2SJdQO2Vyv8wlKLbtlZZRcoYkxm4OW1ivgemeuSISS0f74Ip5eUuLBOXAebpP+2uvftYoyLAe6Xprhz7o+hgJaB/7o2wvPXoMxeOCtFl3ioIJZK5sqMSIDwOu98vyOPw+U1ytfY+njI6vWYC0yHHfsd5b1b70VH2REEPAKXFzqcrXiAf26rVJmGooBmueD5tEmfKk9ZrLmDNkvMvHZn9fSemQOruvs6BE0iK4inHoHkSmgxBdUCPoCYscnIjt8JmNDjf14lSyMBqgBJyWRCWH7EYckUcGo/WCmyRB0Y5yhozMN+3hSm/gBOCJpMqTNDxtqp/d7nPcSTWyRnbVA/XwqwkeE4O1UU62J52pL89ngRytKlwT+gL2C5LesKDe72GgDT4q0HrigkEqrusn7uCRJPS4s3rD8p1ETnqjFsM6r9XlZHc9bQ82FrtaxPgt+SIw4Np+u4XKGPLlWpv8SC+Ba2Yvqgl/MLfsOmJR0Y77LKWXqc8rqTsAHGrqN2TjCSNpioPLX/IZ7i9yaHUV1DK+rNZr/zmW3dI+HVW670Sq10+g1NE60VReIkkOFfQTLe1ZHhcQ1VjBPMF511bEar/xnWIF/4nWqW1ycuXoReLDNtfWcu3bOxjUAr6UsQsFBG5c+4EFN7Vo5GEnwVeHSDFZIPRhl8WCvTZx6xOII61KuCbZVwuCHSXtGOKpW5+WlgJn/SEo9zPX7tCmbnJDNNK+g4+4P8QpSQ11e2fS7Mw3bXZX6uGE5QntNUwqn4VxA+Kl0B0jZuWM9TAcL6Kut8Z+ms2lBIrzjKMVcrWDBca+myZveYXyWPGkJKY77i0Jdr4116I/OSj8IHLLZhFsDIis9foeaObwGHuis23ddaTUXmCwtr9AOM6sa+LCJkqarFrLekuS8P2gsFW12lc9TDFNSaqJPXPUTovdM6HTzOaxIXwvhrkGlukbd2EcwrYP+njsmAvyiCBz/BuUzWFewcp3z4PsBZaxBd4g/lI/M+Nu+ie4Sk62MKC18HnsiexC6UD2ufdhqR4a0YzawSS3JqtnRjcuVTYEG/1VyWsA7XR+t6Se7EjK3bn7egzxJR0xMiYSGRZ0N2L4jeXY7ifNppbA0Mm0yAUp3Ty51om+hY1VfYdMLqiOjWE8hig5cWOq72IBdtGKvM0vWRbBtC+KAjIrRblyLeURvEbX3QIfijuX0Q8TARBt6138HQ12L7ZH+aPWqI9DMVo0rzFVusgJKzYkwQqNlPNSalw0lskj6Fhn7J9aI0ePx2F8zDRdexfIZWfGjHffYWpyVAARglS5K4stRnyOlKBWp3sO3Qbssw3IG5viuliiweN28En8MpMpfvndCzcrIpsrw8bL3HTTZIyHCRHds/8Uz5tzhm6aqQI6NvGHdKcnz/EKC5hUo2jUih63PRs8EpFyOzDkYJmu5C/b1yJZMvowbmc0ruWGzVAtIkDGsYtgYMnmlSBGO9VYAzt4IMDW+QVIh6PL96vTiToEzQcRyZIJHjd+44pMqw7+K0SE/ZB0rhhHEqI1SiveDX484Ph5TGLXVmKO8nAaj5UbL99QOqdNiYyUrLjcAJ0jh7EKWnCxUSxDR7YawdMBFnqNqKlRu1umUqvr9sFOUqkqZLZP8+SsjwNBnvcpOTVtRlGs2knmZCLF91ZJBzHDcyAevM6KJkorTpkpaqtyj6X9RGbYooRfoN9lQKQU4LYBfN1j0Buk5ew3ToklhF7OhEhXCDgpxPryAzp059TYZHx9xc9umWqULXJ/OW9ULQDiQA880CMRWm13nU6XOUNy5FWZbioISRRTKrw/dPdwjm9nDg7fCoWyK7FTJJaZ4MVP/ASbMrRRu4tj3dx3VT+oroBL7Md8vhryPIIkaO7ZyjStqSug/UtqwQdkqeT7vOjJN4AxMRRBtmH1dD9PJzJtW5RcytmD2apIadlw9A0rLLOIkg+5Po9Ho2Dy8aOy9PP1WyIqHn4YhZTzbt5g2aK8vB4N/lNpECWWnUj0nkAEJB8XKSPQr+8BYUF7YoRw9lupeHrUt3z/qaIWktSoAzm+oAG+ffrfLzE+lVi3oj0yRMCYSN6TuG1L9zl+q5iU3KgLPX7X95xM8I3g81Rw37M2j3RxEHv7S5TtVd99li/9p0Iqj1/teHoTAiMAxy8fso3N+6T7MgHs7W0W9pfAPlXeUzK50FNszbXDIBgwzJlP5f1y5Ln0PVUlbdfTLRmlQ1F8T3X/LGHg3zyA//ezCK6/TwX4d0/H/ytyBv70dBz7kwwT/CchBP5rwtD/N3NB/izbw/59kH+SS/j/cMf+SHBA/kj7+Js9w8H/hVke0P/7WR4o9C+yPP4sUQr5MznG/rvk+D+wKv/bZnk4QPPXLI8MOyDL6jkGrA7Kc9igpc/PEU5UsUNzzdrbxUGL6srmazWO6pzwcNiqULMGW78+JCbTe6hVtDn6LicsL//rVOXdkz3Df4JSUQtH8Pfx408Ix0HnfvzEe4z6ezuK7mQPcl3ZkMzq8LDVQwktleWIzKooxSIPMzhRnmSdU8tJNi2Zg9FEoUO29SEljkRzujYzN2uQlNozd+z6z/SlpaSEHC1RWiqKPKlQkBVNlWV9pCsM9SAo9jINDc1imhS7ixVT3Bc60adpVBc6t1ipg7SiSlY/N3M8fZAEzJ2TaFahSK7nKuZRiZBSM+SJfQEsaWmNGOKQaqhPH8KVCvpY2lRRVDcLWGgnFOJDvdBNmV3z7bh06vggTuYgHekgoDcuRdKJaFrwFuZvH+/kMotmGYriNmlgbtUgLbVh7jzwi4J+JkcLOliiFVcUm1OiraiY6WMnw6o20j8md0EeNPZ2vI7t/fJ08Q1JEz+coQTmj/KedG+NimdnYKTw9w0ZSp99hox3886BlpoiDmoBfoP+zspmkgeidw86EwFyHSVL1OMjgCHwBlJ5DecXvrnM+Qt9NsxMbHBoj8jt8rFL4Wesn8vN3oBGi9jpGa+1K3Y001O6GzfPVDEnLM2IRiGcYNwEaTB7s/cqGSlY/WbaT6QwAgoNlYEISV37otge2pgI7WuybYqb7GxnA52UR9G2CU1aoGA7WBWo2e02/3YAO9dhlKAhnWfu1GXoNGZkw0E0ZpO87NxvJDPn4iAYHIQdhGMWDOD6CYt3n95eKaW8xVTJjp0rYuVZLhYRHK+LfciBlxsBijRKilzpcqePIbWoCUli2iCSddkzXndBCdTSJt+IP2cjhEp+jGneDo+34YqXEMxascJGZ8xkJA3cgBYLk3c8kZ0hCxaDjpBLLh1Iiv3Lk3oXcSTf0R3f+SMAxdJ+A3BCUCQ2baTE/I4SOIPJZ//XaTaqACgasPylLOIoIUBGaTqAEodAqJLIDg3Ojmxul02BPc7Id+MGiDyiz89WtSL81USKLMz7py0q1sVCycjakTLSkyJWfKGgyRW0DJ8HsIfjgoptRm/lbWr4EjdvLpQJqT5nhmrnKpFYSEBqSRVPkVWbY/ooGkcfzPwemFmaRAoGdsI03dCnt0hYPqkPNwvGzMklrR0b0jRLRKQ+HZB+OUFdnLq+k6xy5zWIQeYRhNhWrFG/L+Kbm18HNXy94RHn83EFnBixWLeNUhaJ79IZXry78Pnsy9Nd3mKfaMAsAiYIvIMlWtY6XNOC4EDJ653hiCXnTZKR8Uike7Hqzke4i20J+/ppiY2Ptcjea3RO1aS0SayOsfQASFrS7+4PHEmz5fkYijxW0nsW5lQ7aV4W3dnTh+mINe22zZXdTLjpwxUnmbwznrXHbcDHvrSrz1VTPpJg83bSTgixfuRtnhr49DcN3zCwqC+p6YyLwrXNXOzUHEa4hQ6nzUCtUHAqFk2Om+VOF/bXR+2+oz2kbvNRKKHbRlbnGTlyPhVk1yMDQK4CbtG0sj7JSbXxhjYHn8xbDmG8a9j2c/IrVlw8k2CPAzQaMZO3xjGv9Xox4mDxkq4EoUIESGZvS9M1YxZOLhSPCTYDMy2uRYVPnWaGDiQoCvmag8w/YOxoL8kml/Brkw0ftnPTXnMQUL1yhOkzBp8pJCKn7aLl6znQVgEos4tG0wE8JMoo7/zH3Kgl2Ne803CBH9W0ciKmwIzyZX5yX/0EmWFCpFO2Nr9/elntcoPsRXFbYJYlKFeBWlnzXzM128ho3VPf/pwCfLuLNOg3fp+4xffKmm4RZ0ujDo44x23zeEN7dWN1aDSQjTui0in6Dl21++ZAgrh6Ukrtu4LRmBAtp+auzc+ctfp5rkbUvbYJ0Wo4lUkxmuSID+qw/E/iEkXUrLr4Vw1A5gdoqyDo5MD92hmoyjpP3LRO48n1hco3M+KzAsDiXjf+zA91NIbEna1wU2GCgL6HTpH6CvVMiSf/+fYuTcpbwmzkqnzerA/T7D9VOGdawzpkpWXYtxOjCCIYMjiFm4PkzibHWPRwiIXWrNmXbtb2wqRg+XUg7VPQxGpsCtmvuF20jwGWqu5A3mMA8QQlue2KyXxvfaWtOzvfyxJFFffHMwxvOdFY9ipiI7SP5D39NM8BbFyH1clagN6D3s2PaZQWg6sUqrrUiTdWtpIiuQTK07GNZmpDyrqY2RmUOrNpTqQfk3LRFFL2ZiRdQmVBx2GOiESFlL1IYjgGHBWyWsxPbrXIGwDFItnomLR78UfBxdbt3lOkBsTsSDRpEgRpx+u9ELRdd1ECQvMiwxP6gre/muRt2FARflxyj+s+dpzTDqXEjhEIcgz3LJYDXKZmEOq1QInShZ7JZhfIOyN15Y0pyq5/NcDCDsTXyGboFb33EKvYMV598V+gmBYAeL1VXWKdVSvkhNh4j+ActPqi4nkzhsjL1R5bOi3SNLW84VMZATZHFuEJ39M3n3SdtQEwraG8+AHemY/II8hpZvNhYp88F/MxqEnv9m1aUknJ59XPAl37K+w7JIt3ssAujCE3zkkYuJvjewowow4ka0cWGgaYABLyJuSCPwFbETdeFF/ewIYuHzNuol9MsF9//htM1cjucIIlUi9XwfhO9spRpLM+b0Kh+/JDu6TI9KU0lw8asCCKR/ESFOz4cnv4hRP1G51NUCSRlCtDu+Lz0RkpG2ymLTkJbZyczrB9SS8EhommrTeh494gn30eTkIZtMBWJlS6Yl3lfaLVCI0bIBKx1bw7HMXup1NV9GlbeCGCbfx1S63gM9sPWumIIw7/3PrZuJ0tSol9qo22vIFMhKK52rshZ6uMBQtrQvVfAbUe4Bs/H5SFzEcHHPorfwYjzgD1zS7wHLOwm7Mu3etB4L7d1cPFdYerOzLdUSP0PfOc0edl/VDsQlYyuN5CtIZS9565J4/y+jhmaWULtJ++lYbBQtle9SuHU24Nz8xVMpSq7x4+VIxx4wF9pQOFVFwWOwUy4YeNHD2Eoj3U0ZcASXfnUL7cj5iw1UMYrUXT6JJvRzJfFWpWjlcXntVMBOo+ZfWbNlZrh6cOf1K2rgKNR8EtDnIl4ey3tqpINwzvbzw4rogUeOArFS3pNNqt1/geXIa0ScLhMAixYpG+ldE3hYaB+uHuLXxsi87EIlBt/Cz9VKRmhfPI6+x3Ggu3Zsf++FpiwizBDTVW+FLCsEQfdkwV4dcslUZ5o1r50bojFlx2NnIAEDBLv3y/bOCI3W3Zhk7kvDlRNX0Pfg3zMM7axG6b4AjdN/zwmsU4loj6UL2hqUCxpRObcsckIzaR+K/pVFrAJ1mZ6rmkyDSXfWlO7tfNiNwI5R2Djyx7OeYHoKv6mdFHYY7Ugx8pv1OJJGMUEFBKdWHyUJ8J2/dKWNG0Jz4UqfDCLBDxSNNn73WYpvtICncFI5EKy5aJHYmxKyGZivOyZInhvQKhLooBF5uSFEej4orH3Y5oqt7Dy4N/Q6gd0pwz/UbGRhcyv3Pp0UcgELFI3QNWcgwxtLVGYJeYMx6dBjUi7QKVSVpXdIeNO94q/OQRNTzYcavytTbcgFToG5zyTemt/3D2Kx0e/JXYbNEGgqk48400mp4dXF4/G+fnRQuDlW9pcQKPp/SGiDcD4DGRLXomjad472+tPKzMnO2N6XRaYzEzy2A8NCs3EmIJavO0QWmYz3QEkRrP5h6pgw3aiN/4brSkF/TYW3agZt8pNmYwkAfUfVum3qzieFu/U5y/q5mplVpyamPRBHlbS9sgysLik7tuolkmMwOMBmt2mu4v4mWQfKn6jsLBQxjUeT3U5UWK5zMTprFGKbUJFCWDFgEjjvW4UleP6g6bgJQYmhUfR/ZbbmzOAgbPjiMEqoWSxvNDJ7juC/O9QrEN+a1KKmwf2y6OmM9lUqx9ouvSDrdJgXpMowmKaYmn8l94hMZiOjBSDjkA+emFECfRe2cROmDX5WDtlMY0lsecRM1Ffyxhmy4dAo+Fg4OQRkwqwsJ6Bu2K3aLkx7mzI2p7NSeZGtkHFcKVUsa3WnMhmk1GagqLRLIrRktmpz03TwHc5p0/E40wCzVNFg+8ZXAUt+z19wYWJcqASbctl/eWSr1Mlr6OLnwN1OzIOhQjOe/BsvM/fdSSSalTCvW4GQdkIP0EOIXUru3risJVgHjkEeTjdIMvCzlo741nPIQn2tdGwnNEPk8hrq0HKUiYwmKU5xbptEXIX0ug+dp73aOPJ76xElcTH03WUqdkmzyWkIf+hV9hk6avR+53mSOLgXAl64gbZRk0Cs6EmTJ0x9woNdi160iUfzYGcby525ymcNvEa6MfpOJBAmzcThTkYjAia/G2yAciDTWpOxrZnswQh+A4o1+gUw+9o+no4Hh1o88qBye4gn1xAZBlrpbqBGu/SiPQepx8NsBf52IhW8Gex9g0sDgUVfJFmmo+Wn0SnsV8cLi6UL2mXpa5k0hYiaKkPqayKlXzhA7a9+9ahKlCZPOXMnmPTr5ZKxSquY2lcJftciaLzZXndDdVsuqYHqwces2IYnBJAi2ZZb5w8BWLkjQ0f2j3elDHo+rWIuT5/H6DhH+oTv4JLoaH7YkO34MBJnudy8zXj0104f1cSElZpLUEq5e6RjdVwHeMtV+AdUbm4xewcY3DGlEZKQ0O9X6pp2Fl2awFxEumudzfDdeeYeZ5jcw9AhYMknAMWiSk8kbiOV5qj9K/g5/UpEOgHYGHajyh+L4RK4VAlsezqyopM1GlA2GkUzuMd2tKYbnQMdeumJ2idLyPqRPyMJHyjXJsqBFpTVLqRZGOvYFDrHiD1FRKsLZ8T+BLIwaamux0mny2hDqX9XN4dWdk38phS2ueMTDJVJe1e+0xc9r59VrT35BJce16c1Clyv2BFFOCdD1aX7/f88t5nBopVVF0SFLLc5mrNsCimWuWlK8690kxRPuh3BR8E9Ygm1M8qLPqCXW8zjpB1NZIdgeWHK2e6q87shwlra7N5me8ruMP++Oi9bpL1sq5xaw3Db273WYfi2GjTHgKEJ1SR7J96thEaK1qkQmLSx18OOrTsSa55SIPM68GcHI23+KBPG3WgryjyVeqqpZrtKIRcLPyvfFjsxAZgVKUu+1p0ST/JnooiVo+Hn0MtbQlJ2j9hposVshLCGYTwzXDhyNliqzjdD+GiPiemsiibyZjZqrDQwofl1glFtpE4wZ9c5BnIf2eW9g/rIuUChzVABhxiIgCHv/yG5lUBCW27/kG70PGM5TqKzZoAT6IXFDZbqNepafUHVwGePHValETVKkmiH6VcLMV3j563izp0qvrTMFSkyZmMRAxq8jsRGDHsBbUFCSmwq7zr6s6ERWMV2m3kqLrmF3YZ4Y4Nb1LWfG6rZt4Xmx6gjIJHINhcClSd3vThQEOzBu2mC0N0vWsgtLqEtIJSxIHOJVuqISJJuMdD2lyBR+e1jdj6DnL/fIu8zV37650MBxZP3z8s1Nnze9j33+iMmRNd8/c2MJ+PJ2CqXN7Tw6Lez2oL6iLM233d0aVgvfm51G+bv4ks1xTE1hLTygWyaq+sTmBvmg5jxDAHFuWgjevRs+VQKXcD9cp+sdwOu2BiTM7W7ql3/ACptiZEy9Zx783UZ/HIaNuJJY3bLC9Ma32Hqw+ZEp0YvOKlstopNNIsCVzaxe1sOTJ6zMqcwYr8+PplDTzIQ6ChbgyN/hdnHU4CCUkKWC7nwFI1abSppgI5cUBCepzhiq76N8vZTjLMI7Hgfd04xUFzdSnYSiuKVLx43dYzQ2NMk08+/fQA7YRDircyh+HKriqI/WOWfp8A5cV8Zonrgzr4x8YhlY2tN84Aieru+PJ3RDU18RF7l3o8Jup0AVcLoAfszKtwvtgJHir0pnH5WbWhd7/nrsC4iA2ekP7aIhtMXb96Jx1vsewcKpdqDKLg8DmKTQB8ztC20TMOGqK7qKkDzYX9q2WTFwsfl1u6SMrdyTVdGGXNdbOVjNrK3wmVSid6Znr5vWZa4aMvuqigvEFGoPGIiRmf0SRdxXrCJimF+h7LHN/mkDD8R6xwSQBEb92tBimf6fS628mj94xEO5ScP4S6A3Z4ohlJRqrJrO3g5nYFNKLA3B8NIb8bEMh7N9aLMptkOSRtS166dPi6kpFdb5FdzcgkaFkLeu99rp8lVN9jdRExbLZMeBDCUX94FjpA6MKTJHOPlTyTteNWGxxUTFOFFhCprerlrK2m/TN4vd7m+BYBmOe3Xd+fa2Zn5XppYkZObwx0EuydA59LrgVnZ7JvGFIiaTD2QaamRX9Xm1tKk1LXQ5dm5SnwCwiihMcubJdQl1YP1WCN8PIAMeIbGT89uk0r1yJaB7+92obHFNCV63EspAOZ1pgxyohUEwAnrkfRZNywKv7s1/clnhPqyt71A2atXjUymabTpQpoy2CVZZOtBnhBpYjEoXwQoydE0uLwLWVXHkivDcJPQOxqI5xOfZ4KS/rE3WVaO4sLlC2zoi3SU65DJ0za5Dv14winJpEsu2wU+cIXIdcyDlctrcl9s2usnjFbUWepiWR8dRr2zualWc0Qgsi9q/zrKFt7jcGuN1UJwRbAm/8i3VevrE8B83giCMt0nbHs3ReFOhl+p6xoLmm1JMok4/PwnltinGHpTZKiwCbPrznLW7h+d49BO/ZwxbUNoJVdEH+nzb+tTbeaI8qESfJZcw0/qQPkJRkuSg7N1JRFD8JBP+JHALoXzmk/U/lEPzp2et/2zfskT/JIcB++6C/UcDPL4swv5Hsm0xAkW9Wwf++yQT/8a37I5ng8w9b92c/L/LflkrwJxv3vzqV4J/Q/0AqAfin4oz+N4kz/P/jVAKL/psfjMiR4+tZgXCj/ZpUVfcFSNcNjkKaxMGHcfguPin/YUXXsaavzFyPc0FXeyHGlK0NFRUXq0B7BRBa9uxTF2lVqgAPQPBQEuImroX1GmMmAQAwOo20ca19zDb82FAIyuE8z04UNl5C1uzQjKInfu/f1IG+XQYj94GYBieStH09DZChbIp8y5lkAVGgiZCkTFLUwlwFaSqkMLBvFisVkOwVp8nOTNUz79GWNSuqEY5k3x8igHPGY02XtNk0rh3llk2KJLaGnxFkIFkSA7rK7VyCIiXJ0OASfJMogZni35D5/hmQepi0PoL89CQ+HPthjteDrhYLdj/shpbvr4hR9YC9X5joxinMY6+egilkTGo2wU033hNINKpvHMP0Xv0yg7WnZDU67zrFLSiHjR1EEaSqzXiIpCRnR5TUYD5DTlGRSB0W6vvFM05kv1oproNLqXx3+PQhvt9v5AIpskiRcRc2oFXuqtcEMysWWWO47frxyvoISJkhNdrSddKwIG3Rx012RhNS5dX3NEAAkscjf4jby/zxrPkYDnDrOriVrk9StplsbUvmfShV9Tmqk8+I58Ba1qp09JqcOTmQSDIRZlgCN38z/E9QEvSNOikuOhTIgzewtkzeUp+iaR2qKlanXQ45fb1dCvvzzIgzNE91kIgjyYJP7UvNYTCfNkZkKKFWXOhTBnH3ri8hLV/+rOJ+nN4DGD/nsdlD5EJy3H0XTiLVeAt4XvRoj9y2DEILfZbUflk0CyqDgnOlTrYaZcm5h7s3o3LK4QkYDHq9WgrE95xjUNyeHSHdgkJS9TAYP4uwY2TlyPee5+o8FpvKkYLE7YCV4Ui30s+5CD+6Jw6gGTDUELSnTkZa2aFDztpVe9c+p0/BTYQajQzyQp68nNznDgQuxZZgh6wawD6kDygOquliMCUwek9WEjOgghXfIGL4xtKpbeDHRH+Taa9QX8BcowLtsjOBMelGcJLVr03vfgDaGgCyJKt404sZQuVO6Ga3G+umsmFQgpTr5zCHCQujuLGgI9ROq43vJDlXtjKh7VKEYDhRwseBNiM6Xy+cTab810aiRexXOKZPFqFUh72WXuqi7ru1ifXcd+IEin1NQzQePziJgsGOnPEYDVESZ10vfiYDeCup6uXMKfIqOBZGHQX/DQE6hJH3OPWINfFSax7P9vd8CjPOLhkxhPDUvJxPNHH87aMmHxvbCiDKYZY9YnpnvPX9gu95vQGrEAW+qzKYvj4/Qy5mGCwU9UKw0OC9QqbNN+iMH17Btuz7yw/67HkFz5joSYT0NU6wTJ9cSBWAnn54clES9SoecSNpWvDHhhhOmd5T9DTxp72zkCqqBymWu4rVwdoXkxeasz/moETU27pKHjFppPRVmjTEnEtIAu9XBeAew1x9JrjXc8FZZkKDIoLHAVRn3nF8ZijMcLyi++Kr5UGeRpjA881QWN2N7rx49fukbS80EoI8SuWLKnkJa9cvorIOHEURL+IxQDNHRBFyQoUMdXg+txZkUSpd0Nng4ZVznbkuNX89zJa4z+UG7O/3hec+4JZSnXkiHQVnxgE+2HoggYqsLKpoj2KQGxR9aRZilfPp9xSI0R1aiZSqsGNGKOqSjqkk9BuVvEiZvkpucSYBnb0rlqrZA2c9uCPaMjYsB82Si6xwVBGet4DuDTMG10R1poAXwD76hJgWJLdq8e5ISkNBvuhRTWEOBdx9fuW5tCgLhA1NRZaNyCFer6hdup1P2m8mAGcCT6eXNp6PHeGKidBFvNYveGG60qZt5vN9HdO91cZc43rEPLiEegQMvDwp7LHSzUuHtqnHAKUW4KVKZI69LFEa6QCQtifs8KYos/MxmdezR+Gnn4rbdWU5JsF+qjBtxadDaTrAAvKZuxAT4NRqO7QBr7Fbw+9AHyiKLE8h6vAykzgFNUV5oW/hRDnW/d75AMM4Ypuy7aJNi5Vn9OsZMaU1InvBTA7T75tWgHqkLyqj2HxljnSKN5wkLN/zghUM71VGZAO3eAmT89pPJydMYlo90qTs6VWacNcbmZToLjtqlPN0snMyzg1sveWUtiItMh0KvoXDIZW+7+H3djyWCm3n0aVsZovL6s5+vpNugv2YPajYnRh4CwdTBX2+AILJdUZfyeLsK6jYk3yLESj9dY+3qTSjKAp9h5ZkC/QeMjjs6SDkKfcEraHug9AtqPUM8qXzyBIfHIRX0ZCuYSHzqEUCK2O1dmWpSvZMlX8Vixy/XBrdYBGy5GiAH+sIFNmg1jGzuffMVzicu3PJikQtUVP000aUo6KJI2YOm1BGciXpoRBAKJwGTZnrN4znNRRCyi7Hlnz1mI188edgYsENSrTWcZuBHGmzZOMop9KbGW4ifbeG320AYQrJXGRV8iaCZPxtUa5+ihFbHkmUer+2gPSe3TrvVwOYSt/BstpVjyYtRiAr7T2uN8d0imwsrIvXxE8wAfwE/B6lmViqVVqZJsF9xl+8bPGSwK1WX9xx4FjJnRdmr/Kq0sX3N2WCby9vb9iroZbuHBWX9rdNefYqMlkLxbfpDraULOuakxuNO+kyK+LH7mrFwZMv7vjw3CQk++x3/Al10Cb91+5OnjIRlSV9t+jqzet8rCW/+MzkDC9RUb+GMFQVdq+Avdki03DXdcStSjkIqt8rjoZI9p5/ol600nZY8GYzWGwnHnIsA3CNXGrANCGj3riI7hhpUxoe3kL+ffiujKnvz049FnU1RZObzQfB3u8mKLuf95AtSeoqP6RplcsocVHwPSOaQNz6JF5hkrHXM9CYbIk3z4zb2Z2mP8QOeTrYcHCQUxwSuocpuomPUnORyWxIA7vIaW8HRCnuw8L6kIjAJQygitKYBHnZbBw8CHQoxxeWTp0Jv0wcEuwjZbmW6JvbY37foJ8ZQ1hBRhSTumQM3ofAfWDFugUPXlOZZM5NaXX7Bbv31FQUViuGwd4KAlDHZlKlG3IpQymaGjI9UZ8oFLcsCt0sa7vS/IZk5dVHLG/xagmNH62dpUE25bMhVlIsuAJ8bFp45XbJmvQZVwO5RIpkXioZrp5L8mLbIBlPqvY0mczDV0KjNmnR81SqkjxVKAeKlbfuYRRz5xwAWVG+Y7rF/+nrX+krBihUyNhMtjzboS93opSCLcYeEvLSF9vbQPn/2d6VNTlqJOFf41cHiPuR+xIgQJxv3Ie4BRLw65dS93g8M23vRHi8a+86ol9oJSBlVX2ZWZmVn48+XuW40BHjCgy2j5mZHt6pekK73nUcu3xrssewnanwrMSPh+Vd4A6hOT2XeB+UTY1gbQKgOE30Yu7WxWbkvmNnYnm3f7ZjdyEFcYdNEQXez7dl8JmNeyiqMlWVqSInlL098j5Ir7Z3Iw9cV/xbDF83S7whbxvl+aRc8SQUeDSd9ZctmifOl3VQIzuuwT07P5c3ybc/4MOFUpYcNkmVPedVnupoVda1VmhIRP50ycczHii/v5oWc5dHtQa4b6etT0ZWKimZ/5wupLOxaFhmyuQtM4cFulDl+RkRQvp6resy8h8I0YHElYYt4IsaAI+0i4E5lkUpfkbDZ3GT0TK8Pqu1Dpvc5SxQy8RcMFYuTPSmtHlNWpcYLmqEOvySXEzijQiYbRQYesDihqcMr7KTS36GWJ4XKfnwma7giCsDw8tyuCMtWguVSw9yZnlYi9WZd/M3H2BN+WSM7k19AhKe3GY3OjeqYuQINZ6ZlQpUmNh3SWGBw+Rqu7ZjJYNmzE1IOfcI6niMmsuaW2+plMPPbLYCxwsubd5tqgzMvdcAn5RfqzzFH5Zx4HQZuaWQ1rrumZr8BLlXwTs1Gw2awHhFTOqS1HW31egGHFQK+UJ890x+35zbsGtxVE68igtjOoNOW2CHfmwark2zvq39+fRopGlPuCo51yAAiQOusAX1XnsQo9A7J2xVc27P7R0d3JznHrEzDilm6kdMsx6mU6PH2Z92rFqD3oVPotyKCDHToqnRux/hiN4mCnOKpnMoIToywcQFqR+PHCR6FMzwB1+aC21vxCAu3QOx2Q3ZiWkNb09eAa2HWFKQ924RR+fwPnaetuN+K8EcLI12LZiqPL4hqZvOrQETkUNyt2NjPrblwrmPr/fjqaVMtVVh5eI6gy7kqNW3r2CeVpqzd5swv5I3a9V8BLkG0az3yxYw8uiSbG3EEN7A082qsXq2NRFb5ySsEuuuVHwD5dJO3nXJckwDnOh353Cwy9lT7wPQc3Z4QsbkqzcPJSqv2OrFmKQEJNEDvRbpWvVTUEnme+sRFwbCLbYgVvd9fSl4yxzXBitIG7qKhi5NQcHxmzaBNNGrYTOIhRAWWielFIGSZJ922UowglPAbVXrTfjhefoBLcueab4a9djeKyfiGOH0KV6n9jl5bgMUPdmQQSesIxf6Ph8wChLC+ljEt1Y0DNFdsGRx/MqoZ67yqIvp18qT8DfGxtOADfD5nCcknHbr5o2ecqnVO2/R9cp7wWlfTXRVBJK96herEaGTK5GIKMRsUiZzDr/9mGN2NbQk5MbDHR3SBTGKf79oHWKh8wXfae9yTKfTFaIuVw2C74F6Z1pLgzhNg/F8v8FspBKs3DUonaTUuloortXSllUCMctdcoUOZ9PY74RhPQ1y3x9b40Y1+pgOV2c3jU7rdd6VRT7Ib8IEVhXmGwQ3vmJIy5gO1fC4di6e0fYMACL6nRw61xumjMt043NaaFg6JaXac5i3uM/HX4cDhg2jcakPm0nzTwsFYasBX/1ehcdrA2XmIRGdUaMt7uy9inRv9oi03TGkP3AUsa6xDRwsAmMQqg5OxtWBdZA6liKkvKg7UmjPAT/myd0sjlk+XPhj+UsZvqxHqF/NcSA6XFvEqtHaFHCJdbeBQgwEq1nCKJcTTPFBlY2TK8+tLtZ5v8EE2GUt8ZQmbeeMO2QrF5oiRiK62NUslnXzuFzovnLIqeFD5XUCVTs36BKTFBmAVl3d2SOxMlaeYjgShH6E7jGwJfAKWq46yFaCQpga1F1CQnQiDtdZq9JcNDN9A3Zzt6RNbTLEjdMGolO6qvrnTlB6upsLExx43vpazONdUkNWfqj/tMe9h+MZlqOphTGCIE5cL/GlfIYzAgK7b9D+QFRsWHIsPcXZOFyjlrWUwc8hLGnhK0PS996OrhYJ7UXKsxdhCI9Vs8vQeqYCDrdgqvOfDF8wYdgkcJoyPc0I7EPxwt02rlaJ0GjiFRNeLLRm2U8zMMSFWg3tsYYz051StNlNRrYKT+DF2IyMoEPXJj2duAWJ2MdoFLQiZ+whe0SLlAKWqDpLnLmoR+AJZh9jUAvR0TdaVdmqyaUAfysLkAIk48BZgEM8y9UnPYwLuO6KOlzqe7Ts516lhowWFOfpg73X2CqgaIQfMivv+/aqBnnQdujN0OGTVj0H6xJnjVOctfpGpPjI3GJIO0xiNscpW9xTg3uM55mxDy17+9IzIvcoFdAdQ+V1/liKHmcd8y5WhiowdfrMmyNEXteXXK3GZURhNhxftXkjzcwgKqOQbSJp9iMOLzZavgAs4y0k8aYIXvJ1ZaJlpY/l+/DrAdQx9oRxSwb98H3mI7pfd9c0SG9NaLnS7R6boT5dRag2bF7A0PKw2sX8ICE1lLa2icvCAOYukECXkAJ1aZY2GBMBvkQNneK6ZcKaqKtJe/D3Yb7qyq2BsYCUHx3YoVWohTRGmS7Ym4zCYpvfHJrlsFTWfWs1aZmBB12btOFJ0z94V3oQxJ5cSbZgzfw8MeOmgQCcSYunlWwW6IKSx88/mqREfyP985tJSuTbQ7MfZ3XgPytJSXyQpHxLSaIvHgQUECL87+Ymv3/EPuUm4Q8OOuPEfzA7SXwzHFlaZJ9+eD/NZV/0XdTwn//7leI+y5x7kE17jWCdzfP2rs5omfsvx/c3U533fpmS7N+nDedoKrL5d+Tenwd+y++Ow5Q10Vw9vmTt+eFK/nbO/6WVDH+nkk9/KSVT/w0lH7qdNh/cfyzk98vg159x6/vD366296s/fwX88MF5v/XSV938qy4FXxQWEF/j1NvXfL/n8wDT0xRtvxIbgMD9e9+Cf01Z9bX01xQzX8qDTerX+z/PtV/08Qd4QT5qjvAPJdY/lFh/e0qs088/fSLA+oLy6kOmK/onEgW0R7TwE8X9Qpj1JafWF9xX7w/+f6G/wr+jEgv/wGf/EexXH+PWR5VY/+DWP7j1t8ct5OcXXh2w8yqP/QZ5jk//n4j3kK+h5yPWsB8EPWAj7BeG0jcP6zPRK8L/Cw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.png" "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.png"
new file mode 100644
index 00000000000..ecdbd6d2c2e
Binary files /dev/null and "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.png" differ
diff --git a/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md b/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
new file mode 100644
index 00000000000..53350ec5ae7
--- /dev/null
+++ b/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
@@ -0,0 +1,953 @@
+---
+title: 一千行 MySQL 学习笔记
+category: 数据库
+tag:
+ - MySQL
+---
+
+> 原文地址:https://shockerli.net/post/1000-line-mysql-note/ ,JavaGuide 对本文进行了简答排版,新增了目录。
+> 作者:格物
+
+非常不错的总结,强烈建议保存下来,需要的时候看一看。
+
+### 基本操作
+
+```mysql
+/* Windows服务 */
+-- 启动MySQL
+ net start mysql
+-- 创建Windows服务
+ sc create mysql binPath= mysqld_bin_path(注意:等号与值之间有空格)
+/* 连接与断开服务器 */
+mysql -h 地址 -P 端口 -u 用户名 -p 密码
+SHOW PROCESSLIST -- 显示哪些线程正在运行
+SHOW VARIABLES -- 显示系统变量信息
+```
+
+### 数据库操作
+
+```mysql
+/* 数据库操作 */ ------------------
+-- 查看当前数据库
+ SELECT DATABASE();
+-- 显示当前时间、用户名、数据库版本
+ SELECT now(), user(), version();
+-- 创建库
+ CREATE DATABASE[ IF NOT EXISTS] 数据库名 数据库选项
+ 数据库选项:
+ CHARACTER SET charset_name
+ COLLATE collation_name
+-- 查看已有库
+ SHOW DATABASES[ LIKE 'PATTERN']
+-- 查看当前库信息
+ SHOW CREATE DATABASE 数据库名
+-- 修改库的选项信息
+ ALTER DATABASE 库名 选项信息
+-- 删除库
+ DROP DATABASE[ IF EXISTS] 数据库名
+ 同时删除该数据库相关的目录及其目录内容
+```
+
+### 表的操作
+
+```mysql
+-- 创建表
+ CREATE [TEMPORARY] TABLE[ IF NOT EXISTS] [库名.]表名 ( 表的结构定义 )[ 表选项]
+ 每个字段必须有数据类型
+ 最后一个字段后不能有逗号
+ TEMPORARY 临时表,会话结束时表自动消失
+ 对于字段的定义:
+ 字段名 数据类型 [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string']
+-- 表选项
+ -- 字符集
+ CHARSET = charset_name
+ 如果表没有设定,则使用数据库字符集
+ -- 存储引擎
+ ENGINE = engine_name
+ 表在管理数据时采用的不同的数据结构,结构不同会导致处理方式、提供的特性操作等不同
+ 常见的引擎:InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive
+ 不同的引擎在保存表的结构和数据时采用不同的方式
+ MyISAM表文件含义:.frm表定义,.MYD表数据,.MYI表索引
+ InnoDB表文件含义:.frm表定义,表空间数据和日志文件
+ SHOW ENGINES -- 显示存储引擎的状态信息
+ SHOW ENGINE 引擎名 {LOGS|STATUS} -- 显示存储引擎的日志或状态信息
+ -- 自增起始数
+ AUTO_INCREMENT = 行数
+ -- 数据文件目录
+ DATA DIRECTORY = '目录'
+ -- 索引文件目录
+ INDEX DIRECTORY = '目录'
+ -- 表注释
+ COMMENT = 'string'
+ -- 分区选项
+ PARTITION BY ... (详细见手册)
+-- 查看所有表
+ SHOW TABLES[ LIKE 'pattern']
+ SHOW TABLES FROM 库名
+-- 查看表结构
+ SHOW CREATE TABLE 表名 (信息更详细)
+ DESC 表名 / DESCRIBE 表名 / EXPLAIN 表名 / SHOW COLUMNS FROM 表名 [LIKE 'PATTERN']
+ SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern']
+-- 修改表
+ -- 修改表本身的选项
+ ALTER TABLE 表名 表的选项
+ eg: ALTER TABLE 表名 ENGINE=MYISAM;
+ -- 对表进行重命名
+ RENAME TABLE 原表名 TO 新表名
+ RENAME TABLE 原表名 TO 库名.表名 (可将表移动到另一个数据库)
+ -- RENAME可以交换两个表名
+ -- 修改表的字段机构(13.1.2. ALTER TABLE语法)
+ ALTER TABLE 表名 操作名
+ -- 操作名
+ ADD[ COLUMN] 字段定义 -- 增加字段
+ AFTER 字段名 -- 表示增加在该字段名后面
+ FIRST -- 表示增加在第一个
+ ADD PRIMARY KEY(字段名) -- 创建主键
+ ADD UNIQUE [索引名] (字段名)-- 创建唯一索引
+ ADD INDEX [索引名] (字段名) -- 创建普通索引
+ DROP[ COLUMN] 字段名 -- 删除字段
+ MODIFY[ COLUMN] 字段名 字段属性 -- 支持对字段属性进行修改,不能修改字段名(所有原有属性也需写上)
+ CHANGE[ COLUMN] 原字段名 新字段名 字段属性 -- 支持对字段名修改
+ DROP PRIMARY KEY -- 删除主键(删除主键前需删除其AUTO_INCREMENT属性)
+ DROP INDEX 索引名 -- 删除索引
+ DROP FOREIGN KEY 外键 -- 删除外键
+-- 删除表
+ DROP TABLE[ IF EXISTS] 表名 ...
+-- 清空表数据
+ TRUNCATE [TABLE] 表名
+-- 复制表结构
+ CREATE TABLE 表名 LIKE 要复制的表名
+-- 复制表结构和数据
+ CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名
+-- 检查表是否有错误
+ CHECK TABLE tbl_name [, tbl_name] ... [option] ...
+-- 优化表
+ OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
+-- 修复表
+ REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
+-- 分析表
+ ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
+```
+
+### 数据操作
+
+```mysql
+/* 数据操作 */ ------------------
+-- 增
+ INSERT [INTO] 表名 [(字段列表)] VALUES (值列表)[, (值列表), ...]
+ -- 如果要插入的值列表包含所有字段并且顺序一致,则可以省略字段列表。
+ -- 可同时插入多条数据记录!
+ REPLACE 与 INSERT 完全一样,可互换。
+ INSERT [INTO] 表名 SET 字段名=值[, 字段名=值, ...]
+-- 查
+ SELECT 字段列表 FROM 表名[ 其他子句]
+ -- 可来自多个表的多个字段
+ -- 其他子句可以不使用
+ -- 字段列表可以用*代替,表示所有字段
+-- 删
+ DELETE FROM 表名[ 删除条件子句]
+ 没有条件子句,则会删除全部
+-- 改
+ UPDATE 表名 SET 字段名=新值[, 字段名=新值] [更新条件]
+```
+
+### 字符集编码
+
+```mysql
+/* 字符集编码 */ ------------------
+-- MySQL、数据库、表、字段均可设置编码
+-- 数据编码与客户端编码不需一致
+SHOW VARIABLES LIKE 'character_set_%' -- 查看所有字符集编码项
+ character_set_client 客户端向服务器发送数据时使用的编码
+ character_set_results 服务器端将结果返回给客户端所使用的编码
+ character_set_connection 连接层编码
+SET 变量名 = 变量值
+ SET character_set_client = gbk;
+ SET character_set_results = gbk;
+ SET character_set_connection = gbk;
+SET NAMES GBK; -- 相当于完成以上三个设置
+-- 校对集
+ 校对集用以排序
+ SHOW CHARACTER SET [LIKE 'pattern']/SHOW CHARSET [LIKE 'pattern'] 查看所有字符集
+ SHOW COLLATION [LIKE 'pattern'] 查看所有校对集
+ CHARSET 字符集编码 设置字符集编码
+ COLLATE 校对集编码 设置校对集编码
+```
+
+### 数据类型(列类型)
+
+```mysql
+/* 数据类型(列类型) */ ------------------
+1. 数值类型
+-- a. 整型 ----------
+ 类型 字节 范围(有符号位)
+ tinyint 1字节 -128 ~ 127 无符号位:0 ~ 255
+ smallint 2字节 -32768 ~ 32767
+ mediumint 3字节 -8388608 ~ 8388607
+ int 4字节
+ bigint 8字节
+ int(M) M表示总位数
+ - 默认存在符号位,unsigned 属性修改
+ - 显示宽度,如果某个数不够定义字段时设置的位数,则前面以0补填,zerofill 属性修改
+ 例:int(5) 插入一个数'123',补填后为'00123'
+ - 在满足要求的情况下,越小越好。
+ - 1表示bool值真,0表示bool值假。MySQL没有布尔类型,通过整型0和1表示。常用tinyint(1)表示布尔型。
+-- b. 浮点型 ----------
+ 类型 字节 范围
+ float(单精度) 4字节
+ double(双精度) 8字节
+ 浮点型既支持符号位 unsigned 属性,也支持显示宽度 zerofill 属性。
+ 不同于整型,前后均会补填0.
+ 定义浮点型时,需指定总位数和小数位数。
+ float(M, D) double(M, D)
+ M表示总位数,D表示小数位数。
+ M和D的大小会决定浮点数的范围。不同于整型的固定范围。
+ M既表示总位数(不包括小数点和正负号),也表示显示宽度(所有显示符号均包括)。
+ 支持科学计数法表示。
+ 浮点数表示近似值。
+-- c. 定点数 ----------
+ decimal -- 可变长度
+ decimal(M, D) M也表示总位数,D表示小数位数。
+ 保存一个精确的数值,不会发生数据的改变,不同于浮点数的四舍五入。
+ 将浮点数转换为字符串来保存,每9位数字保存为4个字节。
+2. 字符串类型
+-- a. char, varchar ----------
+ char 定长字符串,速度快,但浪费空间
+ varchar 变长字符串,速度慢,但节省空间
+ M表示能存储的最大长度,此长度是字符数,非字节数。
+ 不同的编码,所占用的空间不同。
+ char,最多255个字符,与编码无关。
+ varchar,最多65535字符,与编码有关。
+ 一条有效记录最大不能超过65535个字节。
+ utf8 最大为21844个字符,gbk 最大为32766个字符,latin1 最大为65532个字符
+ varchar 是变长的,需要利用存储空间保存 varchar 的长度,如果数据小于255个字节,则采用一个字节来保存长度,反之需要两个字节来保存。
+ varchar 的最大有效长度由最大行大小和使用的字符集确定。
+ 最大有效长度是65532字节,因为在varchar存字符串时,第一个字节是空的,不存在任何数据,然后还需两个字节来存放字符串的长度,所以有效长度是65535-1-2=65532字节。
+ 例:若一个表定义为 CREATE TABLE tb(c1 int, c2 char(30), c3 varchar(N)) charset=utf8; 问N的最大值是多少? 答:(65535-1-2-4-30*3)/3
+-- b. blob, text ----------
+ blob 二进制字符串(字节字符串)
+ tinyblob, blob, mediumblob, longblob
+ text 非二进制字符串(字符字符串)
+ tinytext, text, mediumtext, longtext
+ text 在定义时,不需要定义长度,也不会计算总长度。
+ text 类型在定义时,不可给default值
+-- c. binary, varbinary ----------
+ 类似于char和varchar,用于保存二进制字符串,也就是保存字节字符串而非字符字符串。
+ char, varchar, text 对应 binary, varbinary, blob.
+3. 日期时间类型
+ 一般用整型保存时间戳,因为PHP可以很方便的将时间戳进行格式化。
+ datetime 8字节 日期及时间 1000-01-01 00:00:00 到 9999-12-31 23:59:59
+ date 3字节 日期 1000-01-01 到 9999-12-31
+ timestamp 4字节 时间戳 19700101000000 到 2038-01-19 03:14:07
+ time 3字节 时间 -838:59:59 到 838:59:59
+ year 1字节 年份 1901 - 2155
+datetime YYYY-MM-DD hh:mm:ss
+timestamp YY-MM-DD hh:mm:ss
+ YYYYMMDDhhmmss
+ YYMMDDhhmmss
+ YYYYMMDDhhmmss
+ YYMMDDhhmmss
+date YYYY-MM-DD
+ YY-MM-DD
+ YYYYMMDD
+ YYMMDD
+ YYYYMMDD
+ YYMMDD
+time hh:mm:ss
+ hhmmss
+ hhmmss
+year YYYY
+ YY
+ YYYY
+ YY
+4. 枚举和集合
+-- 枚举(enum) ----------
+enum(val1, val2, val3...)
+ 在已知的值中进行单选。最大数量为65535.
+ 枚举值在保存时,以2个字节的整型(smallint)保存。每个枚举值,按保存的位置顺序,从1开始逐一递增。
+ 表现为字符串类型,存储却是整型。
+ NULL值的索引是NULL。
+ 空字符串错误值的索引值是0。
+-- 集合(set) ----------
+set(val1, val2, val3...)
+ create table tab ( gender set('男', '女', '无') );
+ insert into tab values ('男, 女');
+ 最多可以有64个不同的成员。以bigint存储,共8个字节。采取位运算的形式。
+ 当创建表时,SET成员值的尾部空格将自动被删除。
+```
+
+### 列属性(列约束)
+
+```mysql
+/* 列属性(列约束) */ ------------------
+1. PRIMARY 主键
+ - 能唯一标识记录的字段,可以作为主键。
+ - 一个表只能有一个主键。
+ - 主键具有唯一性。
+ - 声明字段时,用 primary key 标识。
+ 也可以在字段列表之后声明
+ 例:create table tab ( id int, stu varchar(10), primary key (id));
+ - 主键字段的值不能为null。
+ - 主键可以由多个字段共同组成。此时需要在字段列表后声明的方法。
+ 例:create table tab ( id int, stu varchar(10), age int, primary key (stu, age));
+2. UNIQUE 唯一索引(唯一约束)
+ 使得某字段的值也不能重复。
+3. NULL 约束
+ null不是数据类型,是列的一个属性。
+ 表示当前列是否可以为null,表示什么都没有。
+ null, 允许为空。默认。
+ not null, 不允许为空。
+ insert into tab values (null, 'val');
+ -- 此时表示将第一个字段的值设为null, 取决于该字段是否允许为null
+4. DEFAULT 默认值属性
+ 当前字段的默认值。
+ insert into tab values (default, 'val'); -- 此时表示强制使用默认值。
+ create table tab ( add_time timestamp default current_timestamp );
+ -- 表示将当前时间的时间戳设为默认值。
+ current_date, current_time
+5. AUTO_INCREMENT 自动增长约束
+ 自动增长必须为索引(主键或unique)
+ 只能存在一个字段为自动增长。
+ 默认为1开始自动增长。可以通过表属性 auto_increment = x进行设置,或 alter table tbl auto_increment = x;
+6. COMMENT 注释
+ 例:create table tab ( id int ) comment '注释内容';
+7. FOREIGN KEY 外键约束
+ 用于限制主表与从表数据完整性。
+ alter table t1 add constraint `t1_t2_fk` foreign key (t1_id) references t2(id);
+ -- 将表t1的t1_id外键关联到表t2的id字段。
+ -- 每个外键都有一个名字,可以通过 constraint 指定
+ 存在外键的表,称之为从表(子表),外键指向的表,称之为主表(父表)。
+ 作用:保持数据一致性,完整性,主要目的是控制存储在外键表(从表)中的数据。
+ MySQL中,可以对InnoDB引擎使用外键约束:
+ 语法:
+ foreign key (外键字段) references 主表名 (关联字段) [主表记录删除时的动作] [主表记录更新时的动作]
+ 此时需要检测一个从表的外键需要约束为主表的已存在的值。外键在没有关联的情况下,可以设置为null.前提是该外键列,没有not null。
+ 可以不指定主表记录更改或更新时的动作,那么此时主表的操作被拒绝。
+ 如果指定了 on update 或 on delete:在删除或更新时,有如下几个操作可以选择:
+ 1. cascade,级联操作。主表数据被更新(主键值更新),从表也被更新(外键值更新)。主表记录被删除,从表相关记录也被删除。
+ 2. set null,设置为null。主表数据被更新(主键值更新),从表的外键被设置为null。主表记录被删除,从表相关记录外键被设置成null。但注意,要求该外键列,没有not null属性约束。
+ 3. restrict,拒绝父表删除和更新。
+ 注意,外键只被InnoDB存储引擎所支持。其他引擎是不支持的。
+
+```
+
+### 建表规范
+
+```mysql
+/* 建表规范 */ ------------------
+ -- Normal Format, NF
+ - 每个表保存一个实体信息
+ - 每个具有一个ID字段作为主键
+ - ID主键 + 原子表
+ -- 1NF, 第一范式
+ 字段不能再分,就满足第一范式。
+ -- 2NF, 第二范式
+ 满足第一范式的前提下,不能出现部分依赖。
+ 消除复合主键就可以避免部分依赖。增加单列关键字。
+ -- 3NF, 第三范式
+ 满足第二范式的前提下,不能出现传递依赖。
+ 某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。
+ 将一个实体信息的数据放在一个表内实现。
+```
+
+### SELECT
+
+```mysql
+/* SELECT */ ------------------
+SELECT [ALL|DISTINCT] select_expr FROM -> WHERE -> GROUP BY [合计函数] -> HAVING -> ORDER BY -> LIMIT
+a. select_expr
+ -- 可以用 * 表示所有字段。
+ select * from tb;
+ -- 可以使用表达式(计算公式、函数调用、字段也是个表达式)
+ select stu, 29+25, now() from tb;
+ -- 可以为每个列使用别名。适用于简化列标识,避免多个列标识符重复。
+ - 使用 as 关键字,也可省略 as.
+ select stu+10 as add10 from tb;
+b. FROM 子句
+ 用于标识查询来源。
+ -- 可以为表起别名。使用as关键字。
+ SELECT * FROM tb1 AS tt, tb2 AS bb;
+ -- from子句后,可以同时出现多个表。
+ -- 多个表会横向叠加到一起,而数据会形成一个笛卡尔积。
+ SELECT * FROM tb1, tb2;
+ -- 向优化符提示如何选择索引
+ USE INDEX、IGNORE INDEX、FORCE INDEX
+ SELECT * FROM table1 USE INDEX (key1,key2) WHERE key1=1 AND key2=2 AND key3=3;
+ SELECT * FROM table1 IGNORE INDEX (key3) WHERE key1=1 AND key2=2 AND key3=3;
+c. WHERE 子句
+ -- 从from获得的数据源中进行筛选。
+ -- 整型1表示真,0表示假。
+ -- 表达式由运算符和运算数组成。
+ -- 运算数:变量(字段)、值、函数返回值
+ -- 运算符:
+ =, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
+ in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
+ is/is not 加上ture/false/unknown,检验某个值的真假
+ <=>与<>功能相同,<=>可用于null比较
+d. GROUP BY 子句, 分组子句
+ GROUP BY 字段/别名 [排序方式]
+ 分组后会进行排序。升序:ASC,降序:DESC
+ 以下[合计函数]需配合 GROUP BY 使用:
+ count 返回不同的非NULL值数目 count(*)、count(字段)
+ sum 求和
+ max 求最大值
+ min 求最小值
+ avg 求平均值
+ group_concat 返回带有来自一个组的连接的非NULL值的字符串结果。组内字符串连接。
+e. HAVING 子句,条件子句
+ 与 where 功能、用法相同,执行时机不同。
+ where 在开始时执行检测数据,对原数据进行过滤。
+ having 对筛选出的结果再次进行过滤。
+ having 字段必须是查询出来的,where 字段必须是数据表存在的。
+ where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值。
+ where 不可以使用合计函数。一般需用合计函数才会用 having
+ SQL标准要求HAVING必须引用GROUP BY子句中的列或用于合计函数中的列。
+f. ORDER BY 子句,排序子句
+ order by 排序字段/别名 排序方式 [,排序字段/别名 排序方式]...
+ 升序:ASC,降序:DESC
+ 支持多个字段的排序。
+g. LIMIT 子句,限制结果数量子句
+ 仅对处理好的结果进行数量限制。将处理好的结果的看作是一个集合,按照记录出现的顺序,索引从0开始。
+ limit 起始位置, 获取条数
+ 省略第一个参数,表示从索引0开始。limit 获取条数
+h. DISTINCT, ALL 选项
+ distinct 去除重复记录
+ 默认为 all, 全部记录
+```
+
+### UNION
+
+```mysql
+/* UNION */ ------------------
+ 将多个select查询的结果组合成一个结果集合。
+ SELECT ... UNION [ALL|DISTINCT] SELECT ...
+ 默认 DISTINCT 方式,即所有返回的行都是唯一的
+ 建议,对每个SELECT查询加上小括号包裹。
+ ORDER BY 排序时,需加上 LIMIT 进行结合。
+ 需要各select查询的字段数量一样。
+ 每个select查询的字段列表(数量、类型)应一致,因为结果中的字段名以第一条select语句为准。
+```
+
+### 子查询
+
+```mysql
+/* 子查询 */ ------------------
+ - 子查询需用括号包裹。
+-- from型
+ from后要求是一个表,必须给子查询结果取个别名。
+ - 简化每个查询内的条件。
+ - from型需将结果生成一个临时表格,可用以原表的锁定的释放。
+ - 子查询返回一个表,表型子查询。
+ select * from (select * from tb where id>0) as subfrom where id>1;
+-- where型
+ - 子查询返回一个值,标量子查询。
+ - 不需要给子查询取别名。
+ - where子查询内的表,不能直接用以更新。
+ select * from tb where money = (select max(money) from tb);
+ -- 列子查询
+ 如果子查询结果返回的是一列。
+ 使用 in 或 not in 完成查询
+ exists 和 not exists 条件
+ 如果子查询返回数据,则返回1或0。常用于判断条件。
+ select column1 from t1 where exists (select * from t2);
+ -- 行子查询
+ 查询条件是一个行。
+ select * from t1 where (id, gender) in (select id, gender from t2);
+ 行构造符:(col1, col2, ...) 或 ROW(col1, col2, ...)
+ 行构造符通常用于与对能返回两个或两个以上列的子查询进行比较。
+ -- 特殊运算符
+ != all() 相当于 not in
+ = some() 相当于 in。any 是 some 的别名
+ != some() 不等同于 not in,不等于其中某一个。
+ all, some 可以配合其他运算符一起使用。
+```
+
+### 连接查询(join)
+
+```mysql
+/* 连接查询(join) */ ------------------
+ 将多个表的字段进行连接,可以指定连接条件。
+-- 内连接(inner join)
+ - 默认就是内连接,可省略inner。
+ - 只有数据存在时才能发送连接。即连接结果不能出现空行。
+ on 表示连接条件。其条件表达式与where类似。也可以省略条件(表示条件永远为真)
+ 也可用where表示连接条件。
+ 还有 using, 但需字段名相同。 using(字段名)
+ -- 交叉连接 cross join
+ 即,没有条件的内连接。
+ select * from tb1 cross join tb2;
+-- 外连接(outer join)
+ - 如果数据不存在,也会出现在连接结果中。
+ -- 左外连接 left join
+ 如果数据不存在,左表记录会出现,而右表为null填充
+ -- 右外连接 right join
+ 如果数据不存在,右表记录会出现,而左表为null填充
+-- 自然连接(natural join)
+ 自动判断连接条件完成连接。
+ 相当于省略了using,会自动查找相同字段名。
+ natural join
+ natural left join
+ natural right join
+select info.id, info.name, info.stu_num, extra_info.hobby, extra_info.sex from info, extra_info where info.stu_num = extra_info.stu_id;
+```
+
+### TRUNCATE
+
+```mysql
+/* TRUNCATE */ ------------------
+TRUNCATE [TABLE] tbl_name
+清空数据
+删除重建表
+区别:
+1,truncate 是删除表再创建,delete 是逐条删除
+2,truncate 重置auto_increment的值。而delete不会
+3,truncate 不知道删除了几条,而delete知道。
+4,当被用于带分区的表时,truncate 会保留分区
+```
+
+### 备份与还原
+
+```mysql
+/* 备份与还原 */ ------------------
+备份,将数据的结构与表内数据保存起来。
+利用 mysqldump 指令完成。
+-- 导出
+mysqldump [options] db_name [tables]
+mysqldump [options] ---database DB1 [DB2 DB3...]
+mysqldump [options] --all--database
+1. 导出一张表
+ mysqldump -u用户名 -p密码 库名 表名 > 文件名(D:/a.sql)
+2. 导出多张表
+ mysqldump -u用户名 -p密码 库名 表1 表2 表3 > 文件名(D:/a.sql)
+3. 导出所有表
+ mysqldump -u用户名 -p密码 库名 > 文件名(D:/a.sql)
+4. 导出一个库
+ mysqldump -u用户名 -p密码 --lock-all-tables --database 库名 > 文件名(D:/a.sql)
+可以-w携带WHERE条件
+-- 导入
+1. 在登录mysql的情况下:
+ source 备份文件
+2. 在不登录的情况下
+ mysql -u用户名 -p密码 库名 < 备份文件
+```
+
+### 视图
+
+```mysql
+什么是视图:
+ 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
+ 视图具有表结构文件,但不存在数据文件。
+ 对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。
+ 视图是存储在数据库中的查询的sql语句,它主要出于两种原因:安全原因,视图可以隐藏一些数据,如:社会保险基金表,可以用视图只显示姓名,地址,而不显示社会保险号和工资数等,另一原因是可使复杂的查询易于理解和使用。
+-- 创建视图
+CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement
+ - 视图名必须唯一,同时不能与表重名。
+ - 视图可以使用select语句查询到的列名,也可以自己指定相应的列名。
+ - 可以指定视图执行的算法,通过ALGORITHM指定。
+ - column_list如果存在,则数目必须等于SELECT语句检索的列数
+-- 查看结构
+ SHOW CREATE VIEW view_name
+-- 删除视图
+ - 删除视图后,数据依然存在。
+ - 可同时删除多个视图。
+ DROP VIEW [IF EXISTS] view_name ...
+-- 修改视图结构
+ - 一般不修改视图,因为不是所有的更新视图都会映射到表上。
+ ALTER VIEW view_name [(column_list)] AS select_statement
+-- 视图作用
+ 1. 简化业务逻辑
+ 2. 对客户端隐藏真实的表结构
+-- 视图算法(ALGORITHM)
+ MERGE 合并
+ 将视图的查询语句,与外部查询需要先合并再执行!
+ TEMPTABLE 临时表
+ 将视图执行完毕后,形成临时表,再做外层查询!
+ UNDEFINED 未定义(默认),指的是MySQL自主去选择相应的算法。
+```
+
+### 事务(transaction)
+
+```mysql
+事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。
+ - 支持连续SQL的集体成功或集体撤销。
+ - 事务是数据库在数据完整性方面的一个功能。
+ - 需要利用 InnoDB 或 BDB 存储引擎,对自动提交的特性支持完成。
+ - InnoDB被称为事务安全型引擎。
+-- 事务开启
+ START TRANSACTION; 或者 BEGIN;
+ 开启事务后,所有被执行的SQL语句均被认作当前事务内的SQL语句。
+-- 事务提交
+ COMMIT;
+-- 事务回滚
+ ROLLBACK;
+ 如果部分操作发生问题,映射到事务开启前。
+-- 事务的特性
+ 1. 原子性(Atomicity)
+ 事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
+ 2. 一致性(Consistency)
+ 事务前后数据的完整性必须保持一致。
+ - 事务开始和结束时,外部数据一致
+ - 在整个事务过程中,操作是连续的
+ 3. 隔离性(Isolation)
+ 多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间的数据要相互隔离。
+ 4. 持久性(Durability)
+ 一个事务一旦被提交,它对数据库中的数据改变就是永久性的。
+-- 事务的实现
+ 1. 要求是事务支持的表类型
+ 2. 执行一组相关的操作前开启事务
+ 3. 整组操作完成后,都成功,则提交;如果存在失败,选择回滚,则会回到事务开始的备份点。
+-- 事务的原理
+ 利用InnoDB的自动提交(autocommit)特性完成。
+ 普通的MySQL执行语句后,当前的数据提交操作均可被其他客户端可见。
+ 而事务是暂时关闭“自动提交”机制,需要commit提交持久化数据操作。
+-- 注意
+ 1. 数据定义语言(DDL)语句不能被回滚,比如创建或取消数据库的语句,和创建、取消或更改表或存储的子程序的语句。
+ 2. 事务不能被嵌套
+-- 保存点
+ SAVEPOINT 保存点名称 -- 设置一个事务保存点
+ ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点
+ RELEASE SAVEPOINT 保存点名称 -- 删除保存点
+-- InnoDB自动提交特性设置
+ SET autocommit = 0|1; 0表示关闭自动提交,1表示开启自动提交。
+ - 如果关闭了,那普通操作的结果对其他客户端也不可见,需要commit提交后才能持久化数据操作。
+ - 也可以关闭自动提交来开启事务。但与START TRANSACTION不同的是,
+ SET autocommit是永久改变服务器的设置,直到下次再次修改该设置。(针对当前连接)
+ 而START TRANSACTION记录开启前的状态,而一旦事务提交或回滚后就需要再次开启事务。(针对当前事务)
+
+```
+
+### 锁表
+
+```mysql
+/* 锁表 */
+表锁定只用于防止其它客户端进行不正当地读取和写入
+MyISAM 支持表锁,InnoDB 支持行锁
+-- 锁定
+ LOCK TABLES tbl_name [AS alias]
+-- 解锁
+ UNLOCK TABLES
+```
+
+### 触发器
+
+```mysql
+/* 触发器 */ ------------------
+ 触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
+ 监听:记录的增加、修改、删除。
+-- 创建触发器
+CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt
+ 参数:
+ trigger_time是触发程序的动作时间。它可以是 before 或 after,以指明触发程序是在激活它的语句之前或之后触发。
+ trigger_event指明了激活触发程序的语句的类型
+ INSERT:将新行插入表时激活触发程序
+ UPDATE:更改某一行时激活触发程序
+ DELETE:从表中删除某一行时激活触发程序
+ tbl_name:监听的表,必须是永久性的表,不能将触发程序与TEMPORARY表或视图关联起来。
+ trigger_stmt:当触发程序激活时执行的语句。执行多个语句,可使用BEGIN...END复合语句结构
+-- 删除
+DROP TRIGGER [schema_name.]trigger_name
+可以使用old和new代替旧的和新的数据
+ 更新操作,更新前是old,更新后是new.
+ 删除操作,只有old.
+ 增加操作,只有new.
+-- 注意
+ 1. 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发程序。
+-- 字符连接函数
+concat(str1,str2,...])
+concat_ws(separator,str1,str2,...)
+-- 分支语句
+if 条件 then
+ 执行语句
+elseif 条件 then
+ 执行语句
+else
+ 执行语句
+end if;
+-- 修改最外层语句结束符
+delimiter 自定义结束符号
+ SQL语句
+自定义结束符号
+delimiter ; -- 修改回原来的分号
+-- 语句块包裹
+begin
+ 语句块
+end
+-- 特殊的执行
+1. 只要添加记录,就会触发程序。
+2. Insert into on duplicate key update 语法会触发:
+ 如果没有重复记录,会触发 before insert, after insert;
+ 如果有重复记录并更新,会触发 before insert, before update, after update;
+ 如果有重复记录但是没有发生更新,则触发 before insert, before update
+3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert
+```
+
+### SQL编程
+
+```mysql
+/* SQL编程 */ ------------------
+--// 局部变量 ----------
+-- 变量声明
+ declare var_name[,...] type [default value]
+ 这个语句被用来声明局部变量。要给变量提供一个默认值,请包含一个default子句。值可以被指定为一个表达式,不需要为一个常数。如果没有default子句,初始值为null。
+-- 赋值
+ 使用 set 和 select into 语句为变量赋值。
+ - 注意:在函数内是可以使用全局变量(用户自定义的变量)
+--// 全局变量 ----------
+-- 定义、赋值
+set 语句可以定义并为变量赋值。
+set @var = value;
+也可以使用select into语句为变量初始化并赋值。这样要求select语句只能返回一行,但是可以是多个字段,就意味着同时为多个变量进行赋值,变量的数量需要与查询的列数一致。
+还可以把赋值语句看作一个表达式,通过select执行完成。此时为了避免=被当作关系运算符看待,使用:=代替。(set语句可以使用= 和 :=)。
+select @var:=20;
+select @v1:=id, @v2=name from t1 limit 1;
+select * from tbl_name where @var:=30;
+select into 可以将表中查询获得的数据赋给变量。
+ -| select max(height) into @max_height from tb;
+-- 自定义变量名
+为了避免select语句中,用户自定义的变量与系统标识符(通常是字段名)冲突,用户自定义变量在变量名前使用@作为开始符号。
+@var=10;
+ - 变量被定义后,在整个会话周期都有效(登录到退出)
+--// 控制结构 ----------
+-- if语句
+if search_condition then
+ statement_list
+[elseif search_condition then
+ statement_list]
+...
+[else
+ statement_list]
+end if;
+-- case语句
+CASE value WHEN [compare-value] THEN result
+[WHEN [compare-value] THEN result ...]
+[ELSE result]
+END
+-- while循环
+[begin_label:] while search_condition do
+ statement_list
+end while [end_label];
+- 如果需要在循环内提前终止 while循环,则需要使用标签;标签需要成对出现。
+ -- 退出循环
+ 退出整个循环 leave
+ 退出当前循环 iterate
+ 通过退出的标签决定退出哪个循环
+--// 内置函数 ----------
+-- 数值函数
+abs(x) -- 绝对值 abs(-10.9) = 10
+format(x, d) -- 格式化千分位数值 format(1234567.456, 2) = 1,234,567.46
+ceil(x) -- 向上取整 ceil(10.1) = 11
+floor(x) -- 向下取整 floor (10.1) = 10
+round(x) -- 四舍五入去整
+mod(m, n) -- m%n m mod n 求余 10%3=1
+pi() -- 获得圆周率
+pow(m, n) -- m^n
+sqrt(x) -- 算术平方根
+rand() -- 随机数
+truncate(x, d) -- 截取d位小数
+-- 时间日期函数
+now(), current_timestamp(); -- 当前日期时间
+current_date(); -- 当前日期
+current_time(); -- 当前时间
+date('yyyy-mm-dd hh:ii:ss'); -- 获取日期部分
+time('yyyy-mm-dd hh:ii:ss'); -- 获取时间部分
+date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- 格式化时间
+unix_timestamp(); -- 获得unix时间戳
+from_unixtime(); -- 从时间戳获得时间
+-- 字符串函数
+length(string) -- string长度,字节
+char_length(string) -- string的字符个数
+substring(str, position [,length]) -- 从str的position开始,取length个字符
+replace(str ,search_str ,replace_str) -- 在str中用replace_str替换search_str
+instr(string ,substring) -- 返回substring首次在string中出现的位置
+concat(string [,...]) -- 连接字串
+charset(str) -- 返回字串字符集
+lcase(string) -- 转换成小写
+left(string, length) -- 从string2中的左边起取length个字符
+load_file(file_name) -- 从文件读取内容
+locate(substring, string [,start_position]) -- 同instr,但可指定开始位置
+lpad(string, length, pad) -- 重复用pad加在string开头,直到字串长度为length
+ltrim(string) -- 去除前端空格
+repeat(string, count) -- 重复count次
+rpad(string, length, pad) --在str后用pad补充,直到长度为length
+rtrim(string) -- 去除后端空格
+strcmp(string1 ,string2) -- 逐字符比较两字串大小
+-- 流程函数
+case when [condition] then result [when [condition] then result ...] [else result] end 多分支
+if(expr1,expr2,expr3) 双分支。
+-- 聚合函数
+count()
+sum();
+max();
+min();
+avg();
+group_concat()
+-- 其他常用函数
+md5();
+default();
+--// 存储函数,自定义函数 ----------
+-- 新建
+ CREATE FUNCTION function_name (参数列表) RETURNS 返回值类型
+ 函数体
+ - 函数名,应该合法的标识符,并且不应该与已有的关键字冲突。
+ - 一个函数应该属于某个数据库,可以使用db_name.funciton_name的形式执行当前函数所属数据库,否则为当前数据库。
+ - 参数部分,由"参数名"和"参数类型"组成。多个参数用逗号隔开。
+ - 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。
+ - 多条语句应该使用 begin...end 语句块包含。
+ - 一定要有 return 返回值语句。
+-- 删除
+ DROP FUNCTION [IF EXISTS] function_name;
+-- 查看
+ SHOW FUNCTION STATUS LIKE 'partten'
+ SHOW CREATE FUNCTION function_name;
+-- 修改
+ ALTER FUNCTION function_name 函数选项
+--// 存储过程,自定义功能 ----------
+-- 定义
+存储存储过程 是一段代码(过程),存储在数据库中的sql组成。
+一个存储过程通常用于完成一段业务逻辑,例如报名,交班费,订单入库等。
+而一个函数通常专注与某个功能,视为其他程序服务的,需要在其他语句中调用函数才可以,而存储过程不能被其他调用,是自己执行 通过call执行。
+-- 创建
+CREATE PROCEDURE sp_name (参数列表)
+ 过程体
+参数列表:不同于函数的参数列表,需要指明参数类型
+IN,表示输入型
+OUT,表示输出型
+INOUT,表示混合型
+注意,没有返回值。
+```
+
+### 存储过程
+
+```mysql
+/* 存储过程 */ ------------------
+存储过程是一段可执行性代码的集合。相比函数,更偏向于业务逻辑。
+调用:CALL 过程名
+-- 注意
+- 没有返回值。
+- 只能单独调用,不可夹杂在其他语句中
+-- 参数
+IN|OUT|INOUT 参数名 数据类型
+IN 输入:在调用过程中,将数据输入到过程体内部的参数
+OUT 输出:在调用过程中,将过程体处理完的结果返回到客户端
+INOUT 输入输出:既可输入,也可输出
+-- 语法
+CREATE PROCEDURE 过程名 (参数列表)
+BEGIN
+ 过程体
+END
+```
+
+### 用户和权限管理
+
+```mysql
+/* 用户和权限管理 */ ------------------
+-- root密码重置
+1. 停止MySQL服务
+2. [Linux] /usr/local/mysql/bin/safe_mysqld --skip-grant-tables &
+ [Windows] mysqld --skip-grant-tables
+3. use mysql;
+4. UPDATE `user` SET PASSWORD=PASSWORD("密码") WHERE `user` = "root";
+5. FLUSH PRIVILEGES;
+用户信息表:mysql.user
+-- 刷新权限
+FLUSH PRIVILEGES;
+-- 增加用户
+CREATE USER 用户名 IDENTIFIED BY [PASSWORD] 密码(字符串)
+ - 必须拥有mysql数据库的全局CREATE USER权限,或拥有INSERT权限。
+ - 只能创建用户,不能赋予权限。
+ - 用户名,注意引号:如 'user_name'@'192.168.1.1'
+ - 密码也需引号,纯数字密码也要加引号
+ - 要在纯文本中指定密码,需忽略PASSWORD关键词。要把密码指定为由PASSWORD()函数返回的混编值,需包含关键字PASSWORD
+-- 重命名用户
+RENAME USER old_user TO new_user
+-- 设置密码
+SET PASSWORD = PASSWORD('密码') -- 为当前用户设置密码
+SET PASSWORD FOR 用户名 = PASSWORD('密码') -- 为指定用户设置密码
+-- 删除用户
+DROP USER 用户名
+-- 分配权限/添加用户
+GRANT 权限列表 ON 表名 TO 用户名 [IDENTIFIED BY [PASSWORD] 'password']
+ - all privileges 表示所有权限
+ - *.* 表示所有库的所有表
+ - 库名.表名 表示某库下面的某表
+ GRANT ALL PRIVILEGES ON `pms`.* TO 'pms'@'%' IDENTIFIED BY 'pms0817';
+-- 查看权限
+SHOW GRANTS FOR 用户名
+ -- 查看当前用户权限
+ SHOW GRANTS; 或 SHOW GRANTS FOR CURRENT_USER; 或 SHOW GRANTS FOR CURRENT_USER();
+-- 撤消权限
+REVOKE 权限列表 ON 表名 FROM 用户名
+REVOKE ALL PRIVILEGES, GRANT OPTION FROM 用户名 -- 撤销所有权限
+-- 权限层级
+-- 要使用GRANT或REVOKE,您必须拥有GRANT OPTION权限,并且您必须用于您正在授予或撤销的权限。
+全局层级:全局权限适用于一个给定服务器中的所有数据库,mysql.user
+ GRANT ALL ON *.*和 REVOKE ALL ON *.*只授予和撤销全局权限。
+数据库层级:数据库权限适用于一个给定数据库中的所有目标,mysql.db, mysql.host
+ GRANT ALL ON db_name.*和REVOKE ALL ON db_name.*只授予和撤销数据库权限。
+表层级:表权限适用于一个给定表中的所有列,mysql.talbes_priv
+ GRANT ALL ON db_name.tbl_name和REVOKE ALL ON db_name.tbl_name只授予和撤销表权限。
+列层级:列权限适用于一个给定表中的单一列,mysql.columns_priv
+ 当使用REVOKE时,您必须指定与被授权列相同的列。
+-- 权限列表
+ALL [PRIVILEGES] -- 设置除GRANT OPTION之外的所有简单权限
+ALTER -- 允许使用ALTER TABLE
+ALTER ROUTINE -- 更改或取消已存储的子程序
+CREATE -- 允许使用CREATE TABLE
+CREATE ROUTINE -- 创建已存储的子程序
+CREATE TEMPORARY TABLES -- 允许使用CREATE TEMPORARY TABLE
+CREATE USER -- 允许使用CREATE USER, DROP USER, RENAME USER和REVOKE ALL PRIVILEGES。
+CREATE VIEW -- 允许使用CREATE VIEW
+DELETE -- 允许使用DELETE
+DROP -- 允许使用DROP TABLE
+EXECUTE -- 允许用户运行已存储的子程序
+FILE -- 允许使用SELECT...INTO OUTFILE和LOAD DATA INFILE
+INDEX -- 允许使用CREATE INDEX和DROP INDEX
+INSERT -- 允许使用INSERT
+LOCK TABLES -- 允许对您拥有SELECT权限的表使用LOCK TABLES
+PROCESS -- 允许使用SHOW FULL PROCESSLIST
+REFERENCES -- 未被实施
+RELOAD -- 允许使用FLUSH
+REPLICATION CLIENT -- 允许用户询问从属服务器或主服务器的地址
+REPLICATION SLAVE -- 用于复制型从属服务器(从主服务器中读取二进制日志事件)
+SELECT -- 允许使用SELECT
+SHOW DATABASES -- 显示所有数据库
+SHOW VIEW -- 允许使用SHOW CREATE VIEW
+SHUTDOWN -- 允许使用mysqladmin shutdown
+SUPER -- 允许使用CHANGE MASTER, KILL, PURGE MASTER LOGS和SET GLOBAL语句,mysqladmin debug命令;允许您连接(一次),即使已达到max_connections。
+UPDATE -- 允许使用UPDATE
+USAGE -- “无权限”的同义词
+GRANT OPTION -- 允许授予权限
+```
+
+### 表维护
+
+```mysql
+/* 表维护 */
+-- 分析和存储表的关键字分布
+ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE 表名 ...
+-- 检查一个或多个表是否有错误
+CHECK TABLE tbl_name [, tbl_name] ... [option] ...
+option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
+-- 整理数据文件的碎片
+OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
+```
+
+### 杂项
+
+```mysql
+/* 杂项 */ ------------------
+1. 可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符!
+2. 每个库目录存在一个保存当前数据库的选项文件db.opt。
+3. 注释:
+ 单行注释 # 注释内容
+ 多行注释 /* 注释内容 */
+ 单行注释 -- 注释内容 (标准SQL注释风格,要求双破折号后加一空格符(空格、TAB、换行等))
+4. 模式通配符:
+ _ 任意单个字符
+ % 任意多个字符,甚至包括零字符
+ 单引号需要进行转义 \'
+5. CMD命令行内的语句结束符可以为 ";", "\G", "\g",仅影响显示结果。其他地方还是用分号结束。delimiter 可修改当前对话的语句结束符。
+6. SQL对大小写不敏感
+7. 清除已有语句:\c
+```
+
diff --git a/docs/database/mysql/how-sql-executed-in-mysql.md b/docs/database/mysql/how-sql-executed-in-mysql.md
new file mode 100644
index 00000000000..07404d0e930
--- /dev/null
+++ b/docs/database/mysql/how-sql-executed-in-mysql.md
@@ -0,0 +1,138 @@
+---
+title: 一条 SQL 语句在 MySQL 中如何被执行的?
+category: 数据库
+tag:
+ - MySQL
+---
+
+本文来自[木木匠](https://github.com/kinglaw1204)投稿。
+
+本篇文章会分析下一个 sql 语句在 MySQL 中的执行流程,包括 sql 的查询在 MySQL 内部会怎么流转,sql 语句的更新是怎么完成的。
+
+在分析之前我会先带着你看看 MySQL 的基础架构,知道了 MySQL 由那些组件组成以及这些组件的作用是什么,可以帮助我们理解和解决这些问题。
+
+## 一 MySQL 基础架构分析
+
+### 1.1 MySQL 基本架构概览
+
+下图是 MySQL 的一个简要架构图,从下图你可以很清晰的看到用户的 SQL 语句在 MySQL 内部是如何执行的。
+
+先简单介绍一下下图涉及的一些组件的基本作用帮助大家理解这幅图,在 1.2 节中会详细介绍到这些组件的作用。
+
+- **连接器:** 身份认证和权限相关(登录 MySQL 的时候)。
+- **查询缓存:** 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
+- **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
+- **优化器:** 按照 MySQL 认为最优的方案去执行。
+<!-- - **执行器:** 执行语句,然后从存储引擎返回数据。 -->
+
+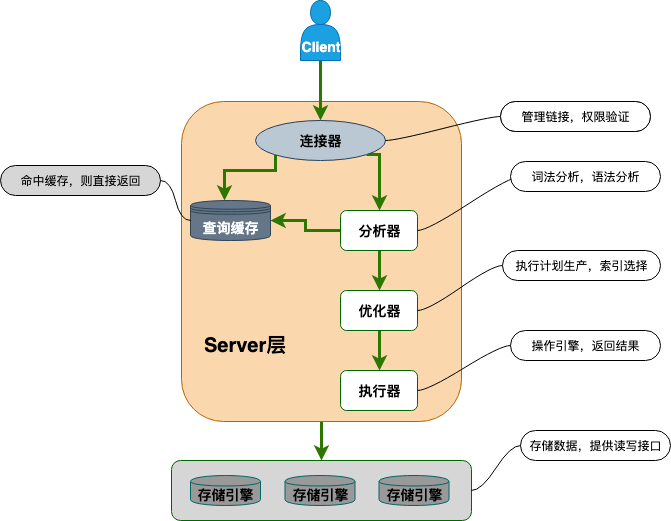
+
+简单来说 MySQL 主要分为 Server 层和存储引擎层:
+
+- **Server 层**:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binglog 日志模块。
+- **存储引擎**: 主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。**现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始就被当做默认存储引擎了。**
+
+### 1.2 Server 层基本组件介绍
+
+#### 1) 连接器
+
+连接器主要和身份认证和权限相关的功能相关,就好比一个级别很高的门卫一样。
+
+主要负责用户登录数据库,进行用户的身份认证,包括校验账户密码,权限等操作,如果用户账户密码已通过,连接器会到权限表中查询该用户的所有权限,之后在这个连接里的权限逻辑判断都是会依赖此时读取到的权限数据,也就是说,后续只要这个连接不断开,即时管理员修改了该用户的权限,该用户也是不受影响的。
+
+#### 2) 查询缓存(MySQL 8.0 版本后移除)
+
+查询缓存主要用来缓存我们所执行的 SELECT 语句以及该语句的结果集。
+
+连接建立后,执行查询语句的时候,会先查询缓存,MySQL 会先校验这个 sql 是否执行过,以 Key-Value 的形式缓存在内存中,Key 是查询预计,Value 是结果集。如果缓存 key 被命中,就会直接返回给客户端,如果没有命中,就会执行后续的操作,完成后也会把结果缓存起来,方便下一次调用。当然在真正执行缓存查询的时候还是会校验用户的权限,是否有该表的查询条件。
+
+MySQL 查询不建议使用缓存,因为查询缓存失效在实际业务场景中可能会非常频繁,假如你对一个表更新的话,这个表上的所有的查询缓存都会被清空。对于不经常更新的数据来说,使用缓存还是可以的。
+
+所以,一般在大多数情况下我们都是不推荐去使用查询缓存的。
+
+MySQL 8.0 版本后删除了缓存的功能,官方也是认为该功能在实际的应用场景比较少,所以干脆直接删掉了。
+
+#### 3) 分析器
+
+MySQL 没有命中缓存,那么就会进入分析器,分析器主要是用来分析 SQL 语句是来干嘛的,分析器也会分为几步:
+
+**第一步,词法分析**,一条 SQL 语句有多个字符串组成,首先要提取关键字,比如 select,提出查询的表,提出字段名,提出查询条件等等。做完这些操作后,就会进入第二步。
+
+**第二步,语法分析**,主要就是判断你输入的 sql 是否正确,是否符合 MySQL 的语法。
+
+完成这 2 步之后,MySQL 就准备开始执行了,但是如何执行,怎么执行是最好的结果呢?这个时候就需要优化器上场了。
+
+#### 4) 优化器
+
+优化器的作用就是它认为的最优的执行方案去执行(有时候可能也不是最优,这篇文章涉及对这部分知识的深入讲解),比如多个索引的时候该如何选择索引,多表查询的时候如何选择关联顺序等。
+
+可以说,经过了优化器之后可以说这个语句具体该如何执行就已经定下来。
+
+#### 5) 执行器
+
+当选择了执行方案后,MySQL 就准备开始执行了,首先执行前会校验该用户有没有权限,如果没有权限,就会返回错误信息,如果有权限,就会去调用引擎的接口,返回接口执行的结果。
+
+## 二 语句分析
+
+### 2.1 查询语句
+
+说了以上这么多,那么究竟一条 sql 语句是如何执行的呢?其实我们的 sql 可以分为两种,一种是查询,一种是更新(增加,更新,删除)。我们先分析下查询语句,语句如下:
+
+```sql
+select * from tb_student A where A.age='18' and A.name=' 张三 ';
+```
+
+结合上面的说明,我们分析下这个语句的执行流程:
+
+* 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 sql 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
+* 通过分析器进行词法分析,提取 sql 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 sql 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
+* 接下来就是优化器进行确定执行方案,上面的 sql 语句,可以有两种执行方案:
+
+ a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。
+ b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。
+ 那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
+
+* 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
+
+### 2.2 更新语句
+
+以上就是一条查询 sql 的执行流程,那么接下来我们看看一条更新语句如何执行的呢?sql 语句如下:
+
+```
+update tb_student A set A.age='19' where A.name=' 张三 ';
+```
+我们来给张三修改下年龄,在实际数据库肯定不会设置年龄这个字段的,不然要被技术负责人打的。其实这条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块是 **binlog(归档日志)** ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 **redo log(重做日志)**,我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
+
+* 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
+* 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
+* 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
+* 更新完成。
+
+**这里肯定有同学会问,为什么要用两个日志模块,用一个日志模块不行吗?**
+
+这是因为最开始 MySQL 并没有 InnoDB 引擎(InnoDB 引擎是其他公司以插件形式插入 MySQL 的),MySQL 自带的引擎是 MyISAM,但是我们知道 redo log 是 InnoDB 引擎特有的,其他存储引擎都没有,这就导致会没有 crash-safe 的能力(crash-safe 的能力即使数据库发生异常重启,之前提交的记录都不会丢失),binlog 日志只能用来归档。
+
+并不是说只用一个日志模块不可以,只是 InnoDB 引擎就是通过 redo log 来支持事务的。那么,又会有同学问,我用两个日志模块,但是不要这么复杂行不行,为什么 redo log 要引入 prepare 预提交状态?这里我们用反证法来说明下为什么要这么做?
+
+* **先写 redo log 直接提交,然后写 binlog**,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 bingog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
+* **先写 binlog,然后写 redo log**,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
+
+如果采用 redo log 两阶段提交的方式就不一样了,写完 binglog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binglog 也已经写完了,这个时候发生了异常重启会怎么样呢?
+这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
+
+* 判断 redo log 是否完整,如果判断是完整的,就立即提交。
+* 如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
+
+这样就解决了数据一致性的问题。
+
+## 三 总结
+
+* MySQL 主要分为 Server 层和引擎层,Server 层主要包括连接器、查询缓存、分析器、优化器、执行器,同时还有一个日志模块(binlog),这个日志模块所有执行引擎都可以共用,redolog 只有 InnoDB 有。
+* 引擎层是插件式的,目前主要包括,MyISAM,InnoDB,Memory 等。
+* 查询语句的执行流程如下:权限校验(如果命中缓存)--->查询缓存--->分析器--->优化器--->权限校验--->执行器--->引擎
+* 更新语句执行流程如下:分析器---->权限校验---->执行器--->引擎---redo log(prepare 状态)--->binlog--->redo log(commit状态)
+
+## 四 参考
+
+* 《MySQL 实战45讲》
+* MySQL 5.6参考手册:<https://dev.MySQL.com/doc/refman/5.6/en/>
diff --git a/docs/database/mysql/innodb-implementation-of-mvcc.md b/docs/database/mysql/innodb-implementation-of-mvcc.md
new file mode 100644
index 00000000000..96fa1f7982b
--- /dev/null
+++ b/docs/database/mysql/innodb-implementation-of-mvcc.md
@@ -0,0 +1,226 @@
+---
+title: InnoDB存储引擎对MVCC的实现
+category: 数据库
+tag:
+ - MySQL
+---
+
+## 一致性非锁定读和锁定读
+
+### 一致性非锁定读
+
+对于 [**一致性非锁定读(Consistent Nonlocking Reads)** ](https://dev.mysql.com/doc/refman/5.7/en/innodb-consistent-read.html)的实现,通常做法是加一个版本号或者时间戳字段,在更新数据的同时版本号 + 1 或者更新时间戳。查询时,将当前可见的版本号与对应记录的版本号进行比对,如果记录的版本小于可见版本,则表示该记录可见
+
+在 `InnoDB` 存储引擎中,[多版本控制 (multi versioning)](https://dev.mysql.com/doc/refman/5.7/en/innodb-multi-versioning.html) 就是对非锁定读的实现。如果读取的行正在执行 `DELETE` 或 `UPDATE` 操作,这时读取操作不会去等待行上锁的释放。相反地,`InnoDB` 存储引擎会去读取行的一个快照数据,对于这种读取历史数据的方式,我们叫它快照读 (snapshot read)
+
+在 `Repeatable Read` 和 `Read Committed` 两个隔离级别下,如果是执行普通的 `select` 语句(不包括 `select ... lock in share mode` ,`select ... for update`)则会使用 `一致性非锁定读(MVCC)`。并且在 `Repeatable Read` 下 `MVCC` 实现了可重复读和防止部分幻读
+
+### 锁定读
+
+如果执行的是下列语句,就是 [**锁定读(Locking Reads)**](https://dev.mysql.com/doc/refman/5.7/en/innodb-locking-reads.html)
+
+- `select ... lock in share mode`
+- `select ... for update`
+- `insert`、`update`、`delete` 操作
+
+在锁定读下,读取的是数据的最新版本,这种读也被称为 `当前读(current read)`。锁定读会对读取到的记录加锁:
+
+- `select ... lock in share mode`:对记录加 `S` 锁,其它事务也可以加`S`锁,如果加 `x` 锁则会被阻塞
+
+- `select ... for update`、`insert`、`update`、`delete`:对记录加 `X` 锁,且其它事务不能加任何锁
+
+在一致性非锁定读下,即使读取的记录已被其它事务加上 `X` 锁,这时记录也是可以被读取的,即读取的快照数据。上面说了,在 `Repeatable Read` 下 `MVCC` 防止了部分幻读,这边的 “部分” 是指在 `一致性非锁定读` 情况下,只能读取到第一次查询之前所插入的数据(根据 Read View 判断数据可见性,Read View 在第一次查询时生成)。但是!如果是 `当前读` ,每次读取的都是最新数据,这时如果两次查询中间有其它事务插入数据,就会产生幻读。所以, **`InnoDB` 在实现`Repeatable Read` 时,如果执行的是当前读,则会对读取的记录使用 `Next-key Lock` ,来防止其它事务在间隙间插入数据**
+
+## InnoDB 对 MVCC 的实现
+
+`MVCC` 的实现依赖于:**隐藏字段、Read View、undo log**。在内部实现中,`InnoDB` 通过数据行的 `DB_TRX_ID` 和 `Read View` 来判断数据的可见性,如不可见,则通过数据行的 `DB_ROLL_PTR` 找到 `undo log` 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 `Read View` 之前已经提交的修改和该事务本身做的修改
+
+### 隐藏字段
+
+在内部,`InnoDB` 存储引擎为每行数据添加了三个 [隐藏字段](https://dev.mysql.com/doc/refman/5.7/en/innodb-multi-versioning.html):
+
+- `DB_TRX_ID(6字节)`:表示最后一次插入或更新该行的事务 id。此外,`delete` 操作在内部被视为更新,只不过会在记录头 `Record header` 中的 `deleted_flag` 字段将其标记为已删除
+- `DB_ROLL_PTR(7字节)` 回滚指针,指向该行的 `undo log` 。如果该行未被更新,则为空
+- `DB_ROW_ID(6字节)`:如果没有设置主键且该表没有唯一非空索引时,`InnoDB` 会使用该 id 来生成聚簇索引
+
+### ReadView
+
+```c
+class ReadView {
+ /* ... */
+private:
+ trx_id_t m_low_limit_id; /* 大于等于这个 ID 的事务均不可见 */
+
+ trx_id_t m_up_limit_id; /* 小于这个 ID 的事务均可见 */
+
+ trx_id_t m_creator_trx_id; /* 创建该 Read View 的事务ID */
+
+ trx_id_t m_low_limit_no; /* 事务 Number, 小于该 Number 的 Undo Logs 均可以被 Purge */
+
+ ids_t m_ids; /* 创建 Read View 时的活跃事务列表 */
+
+ m_closed; /* 标记 Read View 是否 close */
+}
+```
+
+[`Read View`](https://github.com/facebook/mysql-8.0/blob/8.0/storage/innobase/include/read0types.h#L298) 主要是用来做可见性判断,里面保存了 “当前对本事务不可见的其他活跃事务”
+
+主要有以下字段:
+
+- `m_low_limit_id`:目前出现过的最大的事务 ID+1,即下一个将被分配的事务 ID。大于等于这个 ID 的数据版本均不可见
+- `m_up_limit_id`:活跃事务列表 `m_ids` 中最小的事务 ID,如果 `m_ids` 为空,则 `m_up_limit_id` 为 `m_low_limit_id`。小于这个 ID 的数据版本均可见
+- `m_ids`:`Read View` 创建时其他未提交的活跃事务 ID 列表。创建 `Read View`时,将当前未提交事务 ID 记录下来,后续即使它们修改了记录行的值,对于当前事务也是不可见的。`m_ids` 不包括当前事务自己和已提交的事务(正在内存中)
+- `m_creator_trx_id`:创建该 `Read View` 的事务 ID
+
+**事务可见性示意图**([图源](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/#MVCC-1)):
+
+
+
+### undo-log
+
+`undo log` 主要有两个作用:
+
+- 当事务回滚时用于将数据恢复到修改前的样子
+- 另一个作用是 `MVCC` ,当读取记录时,若该记录被其他事务占用或当前版本对该事务不可见,则可以通过 `undo log` 读取之前的版本数据,以此实现非锁定读
+
+**在 `InnoDB` 存储引擎中 `undo log` 分为两种: `insert undo log` 和 `update undo log`:**
+
+1. **`insert undo log`** :指在 `insert` 操作中产生的 `undo log`。因为 `insert` 操作的记录只对事务本身可见,对其他事务不可见,故该 `undo log` 可以在事务提交后直接删除。不需要进行 `purge` 操作
+
+**`insert` 时的数据初始状态:**
+
+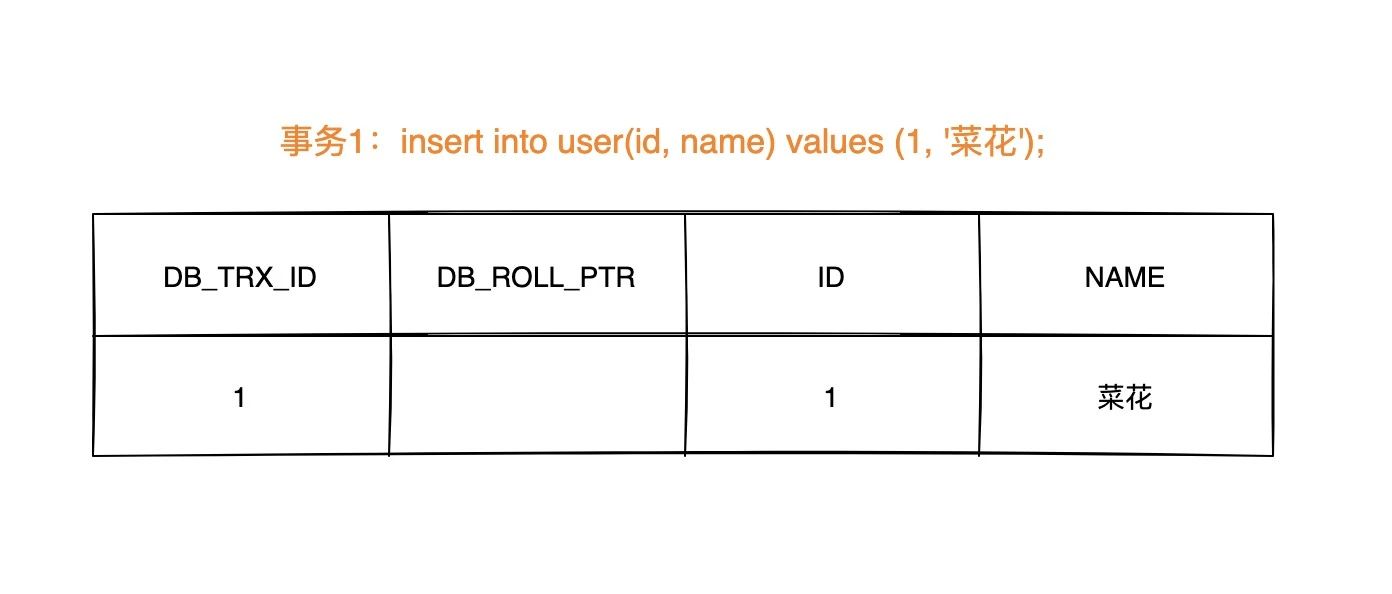
+
+2. **`update undo log`** :`update` 或 `delete` 操作中产生的 `undo log`。该 `undo log`可能需要提供 `MVCC` 机制,因此不能在事务提交时就进行删除。提交时放入 `undo log` 链表,等待 `purge线程` 进行最后的删除
+
+**数据第一次被修改时:**
+
+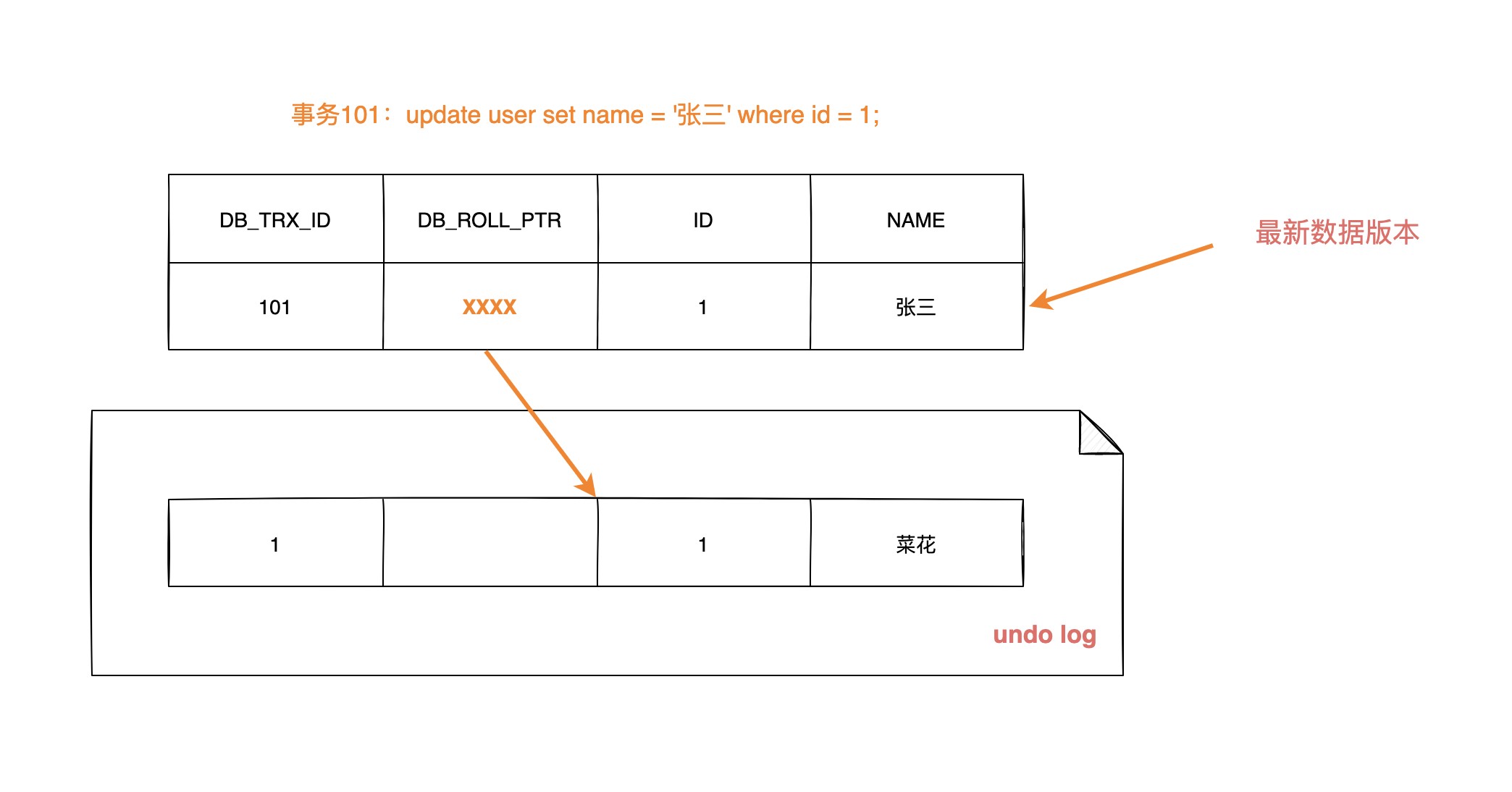
+
+**数据第二次被修改时:**
+
+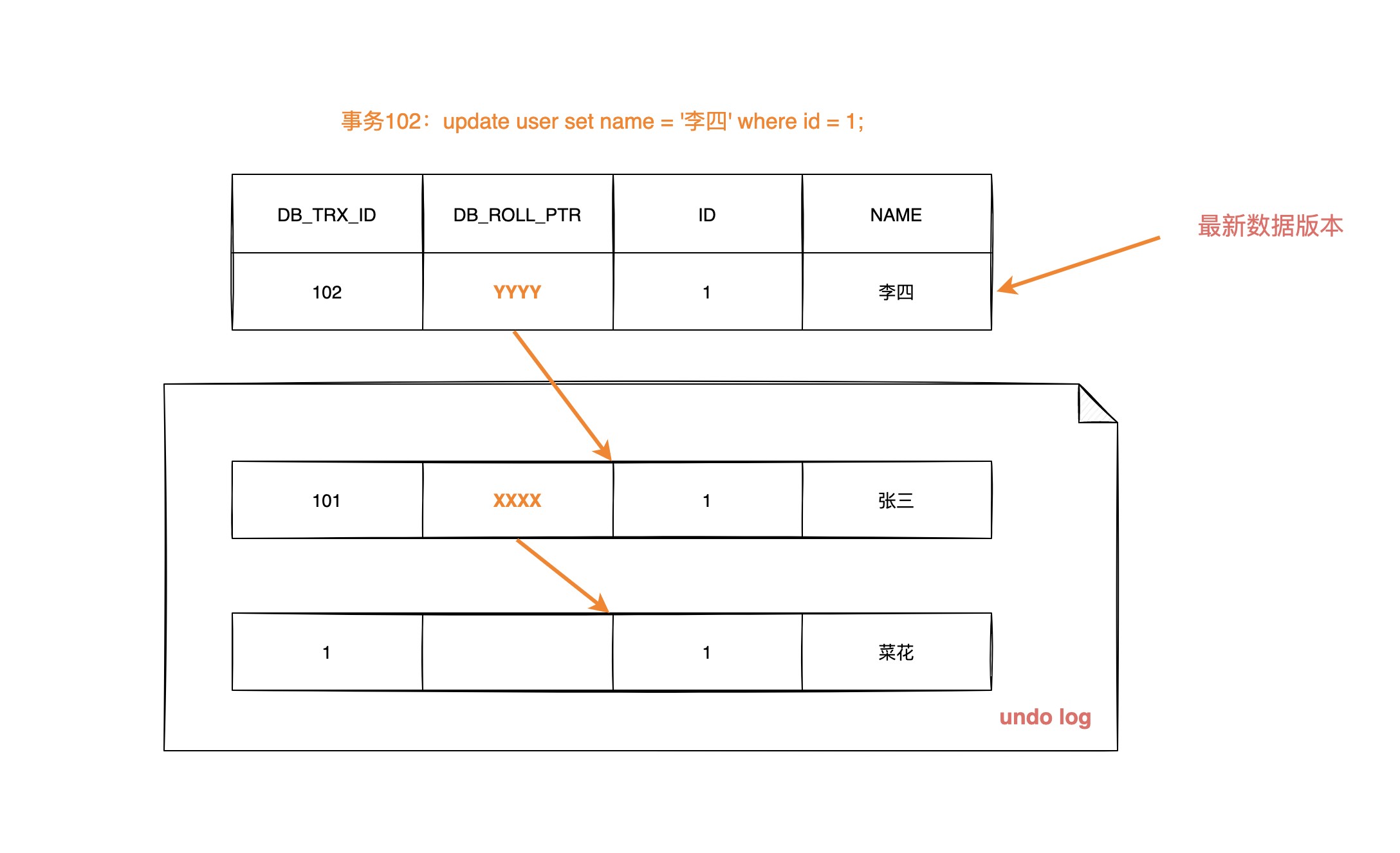
+
+不同事务或者相同事务的对同一记录行的修改,会使该记录行的 `undo log` 成为一条链表,链首就是最新的记录,链尾就是最早的旧记录。
+
+### 数据可见性算法
+
+在 `InnoDB` 存储引擎中,创建一个新事务后,执行每个 `select` 语句前,都会创建一个快照(Read View),**快照中保存了当前数据库系统中正处于活跃(没有 commit)的事务的 ID 号**。其实简单的说保存的是系统中当前不应该被本事务看到的其他事务 ID 列表(即 m_ids)。当用户在这个事务中要读取某个记录行的时候,`InnoDB` 会将该记录行的 `DB_TRX_ID` 与 `Read View` 中的一些变量及当前事务 ID 进行比较,判断是否满足可见性条件
+
+[具体的比较算法](https://github.com/facebook/mysql-8.0/blob/8.0/storage/innobase/include/read0types.h#L161)如下:[图源](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/#MVCC-1)
+
+
+
+1. 如果记录 DB_TRX_ID < m_up_limit_id,那么表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照之前就提交了,所以该记录行的值对当前事务是可见的
+
+2. 如果 DB_TRX_ID >= m_low_limit_id,那么表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照之后才修改该行,所以该记录行的值对当前事务不可见。跳到步骤 5
+
+3. m_ids 为空,则表明在当前事务创建快照之前,修改该行的事务就已经提交了,所以该记录行的值对当前事务是可见的
+
+4. 如果 m_up_limit_id <= DB_TRX_ID < m_low_limit_id,表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照的时候可能处于“活动状态”或者“已提交状态”;所以就要对活跃事务列表 m_ids 进行查找(源码中是用的二分查找,因为是有序的)
+
+ - 如果在活跃事务列表 m_ids 中能找到 DB_TRX_ID,表明:① 在当前事务创建快照前,该记录行的值被事务 ID 为 DB_TRX_ID 的事务修改了,但没有提交;或者 ② 在当前事务创建快照后,该记录行的值被事务 ID 为 DB_TRX_ID 的事务修改了。这些情况下,这个记录行的值对当前事务都是不可见的。跳到步骤 5
+
+ - 在活跃事务列表中找不到,则表明“id 为 trx_id 的事务”在修改“该记录行的值”后,在“当前事务”创建快照前就已经提交了,所以记录行对当前事务可见
+
+5. 在该记录行的 DB_ROLL_PTR 指针所指向的 `undo log` 取出快照记录,用快照记录的 DB_TRX_ID 跳到步骤 1 重新开始判断,直到找到满足的快照版本或返回空
+
+## RC 和 RR 隔离级别下 MVCC 的差异
+
+在事务隔离级别 `RC` 和 `RR` (InnoDB 存储引擎的默认事务隔离级别)下,`InnoDB` 存储引擎使用 `MVCC`(非锁定一致性读),但它们生成 `Read View` 的时机却不同
+
+- 在 RC 隔离级别下的 **`每次select`** 查询前都生成一个`Read View` (m_ids 列表)
+- 在 RR 隔离级别下只在事务开始后 **`第一次select`** 数据前生成一个`Read View`(m_ids 列表)
+
+## MVCC 解决不可重复读问题
+
+虽然 RC 和 RR 都通过 `MVCC` 来读取快照数据,但由于 **生成 Read View 时机不同**,从而在 RR 级别下实现可重复读
+
+举个例子:
+
+
+
+### 在 RC 下 ReadView 生成情况
+
+1. **`假设时间线来到 T4 ,那么此时数据行 id = 1 的版本链为`:**
+
+ 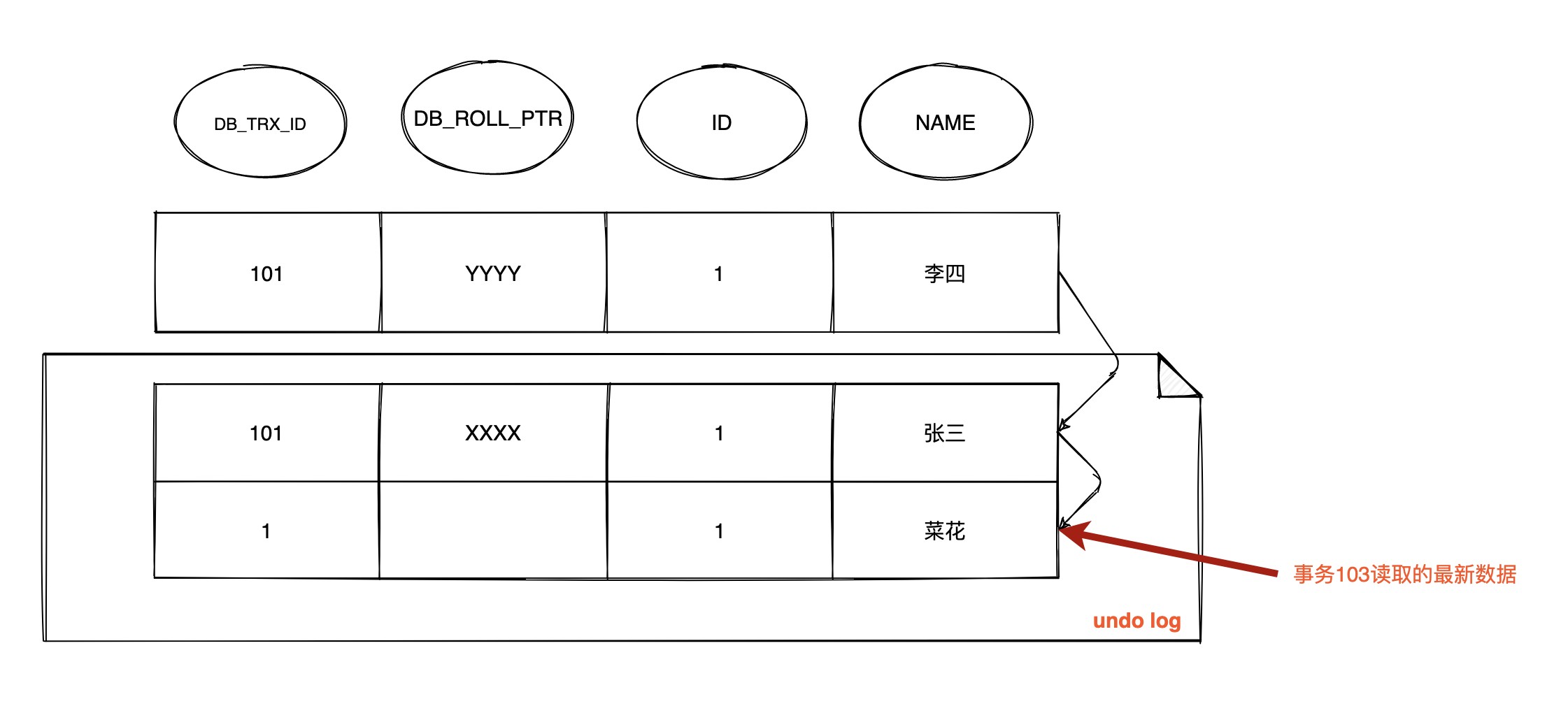
+
+由于 RC 级别下每次查询都会生成`Read View` ,并且事务 101、102 并未提交,此时 `103` 事务生成的 `Read View` 中活跃的事务 **`m_ids` 为:[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103
+
+- 此时最新记录的 `DB_TRX_ID` 为 101,m_up_limit_id <= 101 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见
+- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 还是 101,不可见
+- 继续找上一条 `DB_TRX_ID`为 1,满足 1 < m_up_limit_id,可见,所以事务 103 查询到数据为 `name = 菜花`
+
+2. **`时间线来到 T6 ,数据的版本链为`:**
+
+ 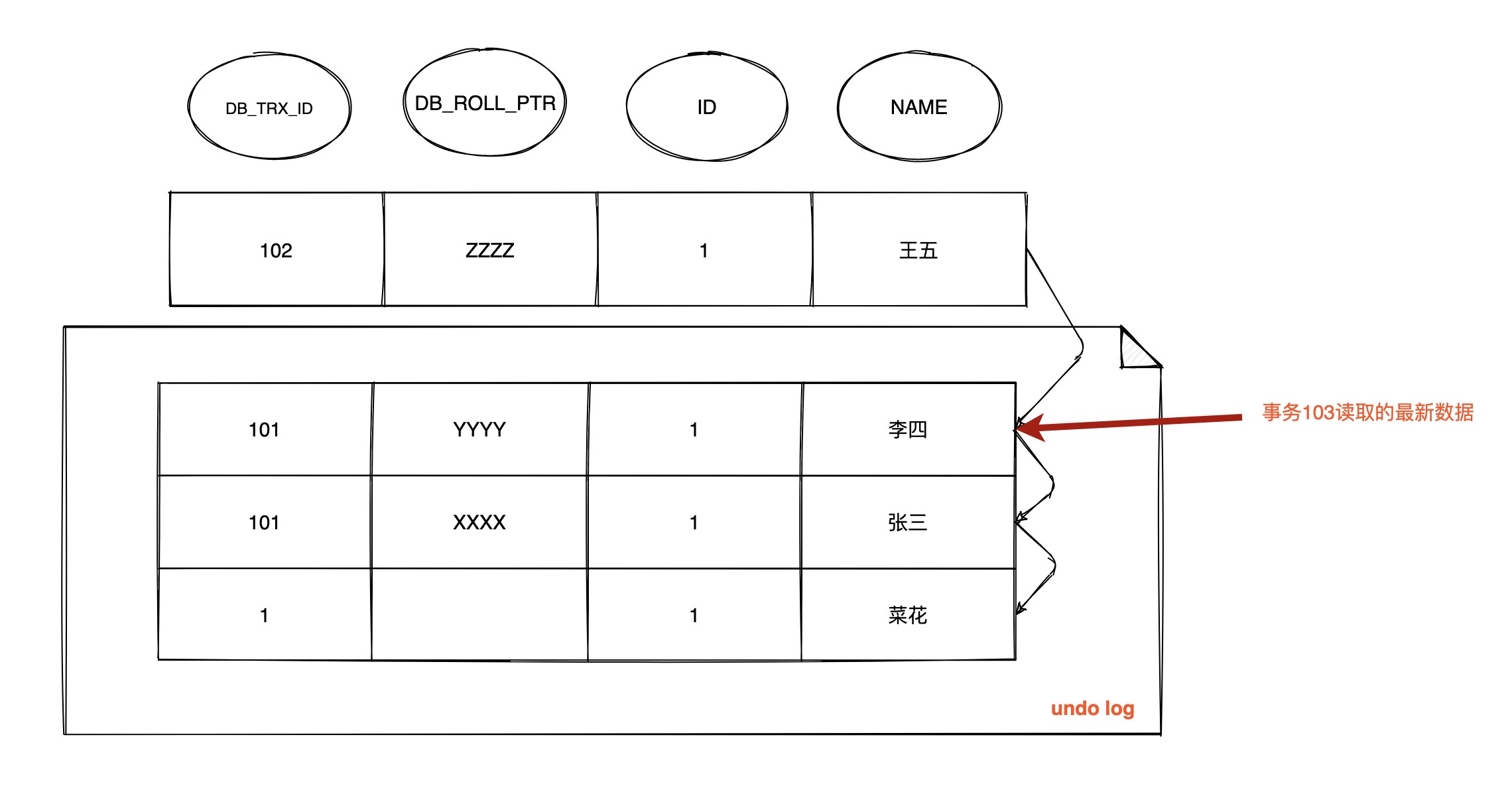
+
+因为在 RC 级别下,重新生成 `Read View`,这时事务 101 已经提交,102 并未提交,所以此时 `Read View` 中活跃的事务 **`m_ids`:[102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:102,`m_creator_trx_id`为:103
+
+- 此时最新记录的 `DB_TRX_ID` 为 102,m_up_limit_id <= 102 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见
+
+- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 为 101,满足 101 < m_up_limit_id,记录可见,所以在 `T6` 时间点查询到数据为 `name = 李四`,与时间 T4 查询到的结果不一致,不可重复读!
+
+3. **`时间线来到 T9 ,数据的版本链为`:**
+
+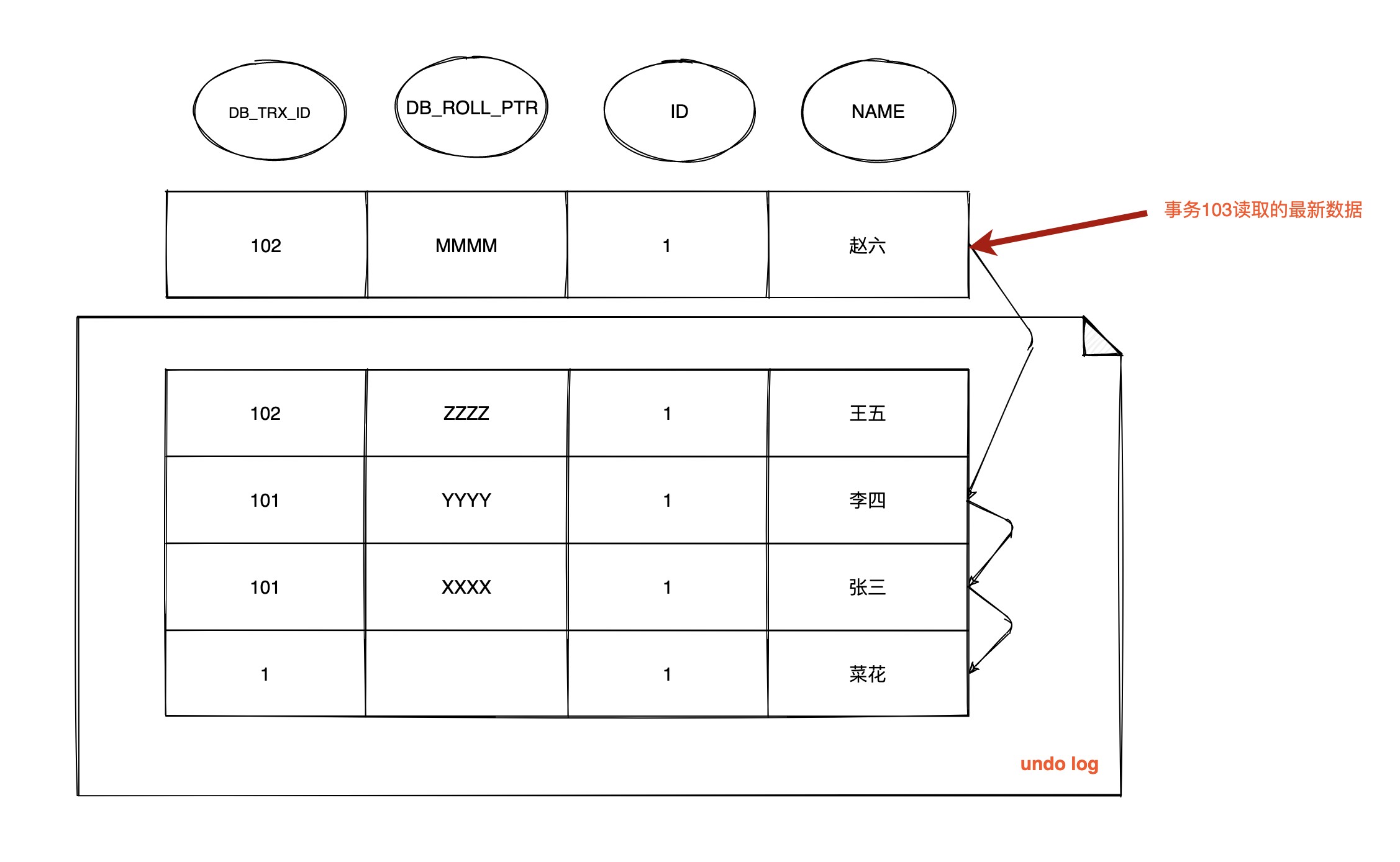
+
+重新生成 `Read View`, 这时事务 101 和 102 都已经提交,所以 **m_ids** 为空,则 m_up_limit_id = m_low_limit_id = 104,最新版本事务 ID 为 102,满足 102 < m_low_limit_id,可见,查询结果为 `name = 赵六`
+
+> **总结:** **在 RC 隔离级别下,事务在每次查询开始时都会生成并设置新的 Read View,所以导致不可重复读**
+
+### 在 RR 下 ReadView 生成情况
+
+**在可重复读级别下,只会在事务开始后第一次读取数据时生成一个 Read View(m_ids 列表)**
+
+1. **`在 T4 情况下的版本链为`:**
+
+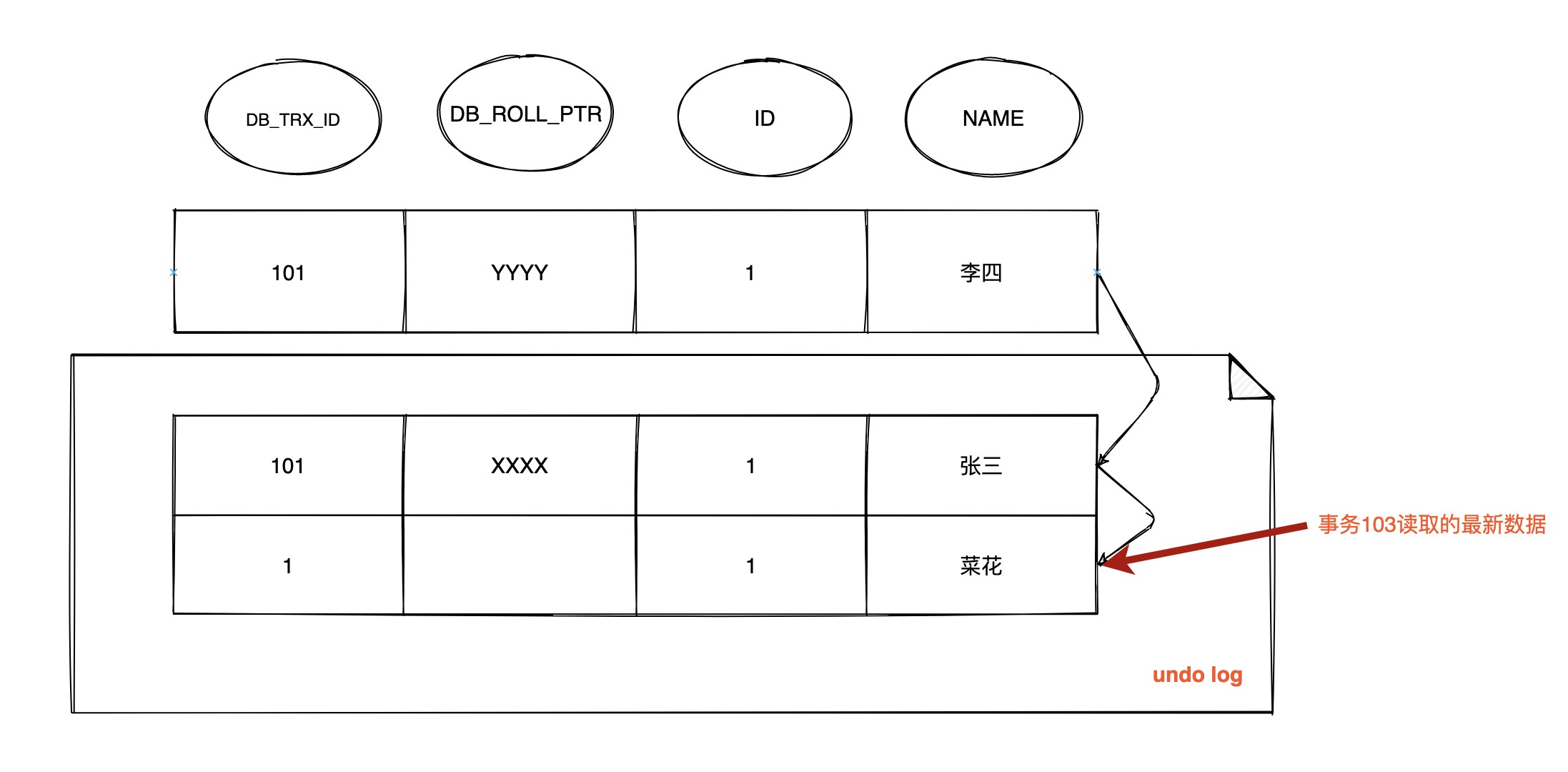
+
+在当前执行 `select` 语句时生成一个 `Read View`,此时 **`m_ids`:[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103
+
+此时和 RC 级别下一样:
+
+- 最新记录的 `DB_TRX_ID` 为 101,m_up_limit_id <= 101 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见
+- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 还是 101,不可见
+- 继续找上一条 `DB_TRX_ID`为 1,满足 1 < m_up_limit_id,可见,所以事务 103 查询到数据为 `name = 菜花`
+
+2. **`时间点 T6 情况下`:**
+
+ 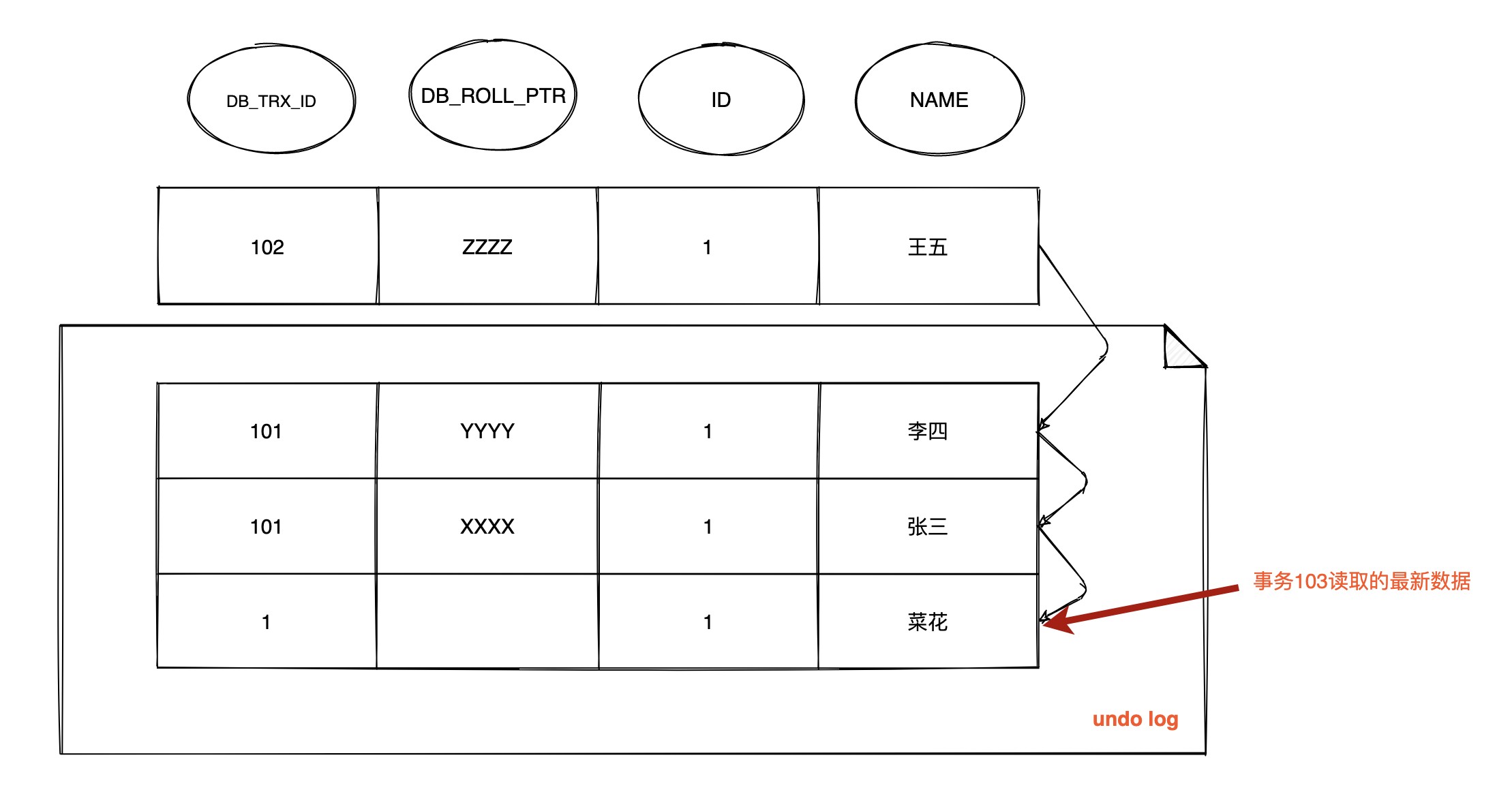
+
+ 在 RR 级别下只会生成一次`Read View`,所以此时依然沿用 **`m_ids` :[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103
+
+- 最新记录的 `DB_TRX_ID` 为 102,m_up_limit_id <= 102 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见
+
+- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 为 101,不可见
+
+- 继续根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 还是 101,不可见
+
+- 继续找上一条 `DB_TRX_ID`为 1,满足 1 < m_up_limit_id,可见,所以事务 103 查询到数据为 `name = 菜花`
+
+3. **时间点 T9 情况下:**
+
+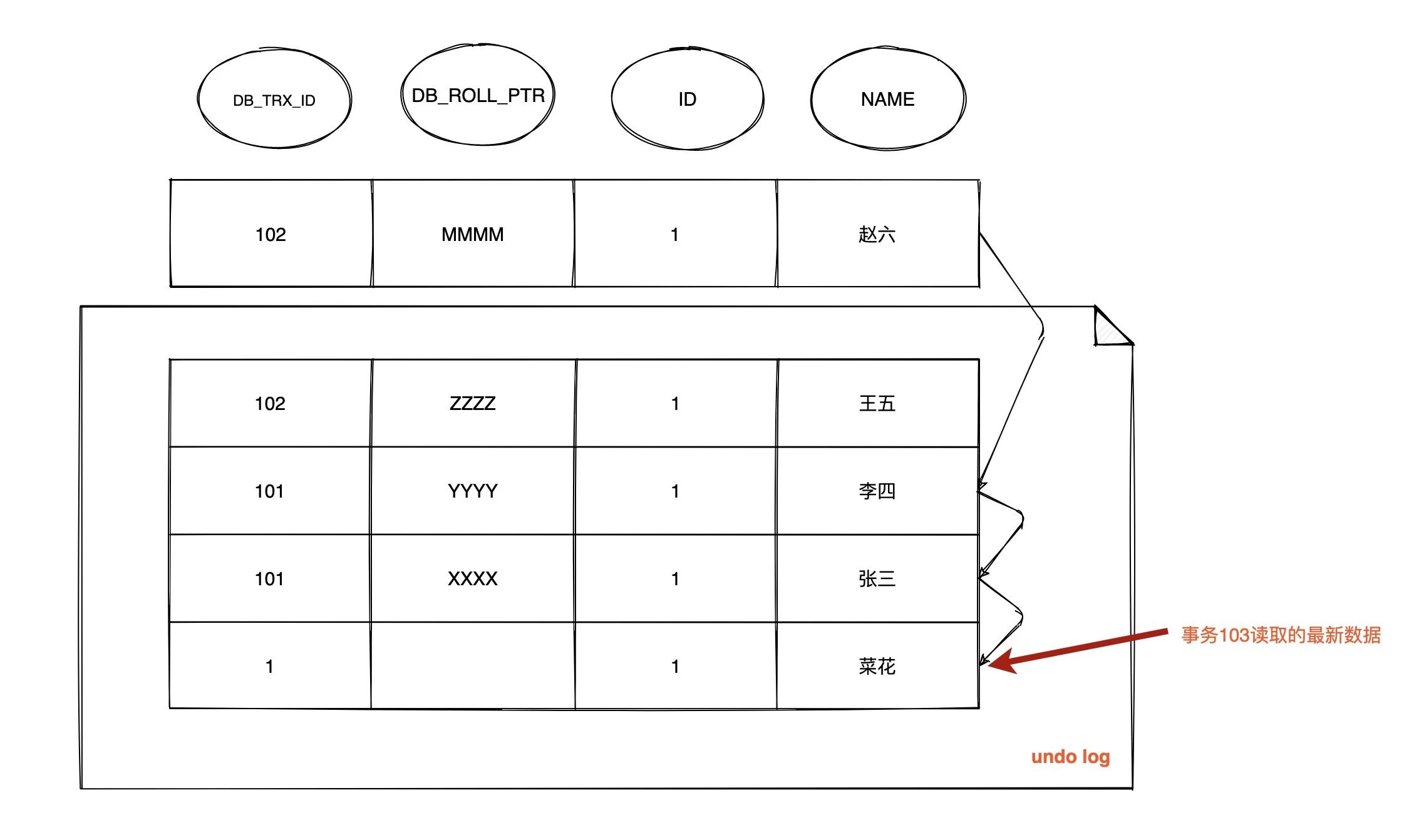
+
+此时情况跟 T6 完全一样,由于已经生成了 `Read View`,此时依然沿用 **`m_ids` :[101,102]** ,所以查询结果依然是 `name = 菜花`
+
+## MVCC➕Next-key-Lock 防止幻读
+
+`InnoDB`存储引擎在 RR 级别下通过 `MVCC`和 `Next-key Lock` 来解决幻读问题:
+
+**1、执行普通 `select`,此时会以 `MVCC` 快照读的方式读取数据**
+
+在快照读的情况下,RR 隔离级别只会在事务开启后的第一次查询生成 `Read View` ,并使用至事务提交。所以在生成 `Read View` 之后其它事务所做的更新、插入记录版本对当前事务并不可见,实现了可重复读和防止快照读下的 “幻读”
+
+**2、执行 select...for update/lock in share mode、insert、update、delete 等当前读**
+
+在当前读下,读取的都是最新的数据,如果其它事务有插入新的记录,并且刚好在当前事务查询范围内,就会产生幻读!`InnoDB` 使用 [Next-key Lock](https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-next-key-locks) 来防止这种情况。当执行当前读时,会锁定读取到的记录的同时,锁定它们的间隙,防止其它事务在查询范围内插入数据。只要我不让你插入,就不会发生幻读
+
+## 参考
+
+- **《MySQL 技术内幕 InnoDB 存储引擎第 2 版》**
+- [Innodb 中的事务隔离级别和锁的关系](https://tech.meituan.com/2014/08/20/innodb-lock.html)
+- [MySQL 事务与 MVCC 如何实现的隔离级别](https://blog.csdn.net/qq_35190492/article/details/109044141)
+- [InnoDB 事务分析-MVCC](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/)
diff --git a/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md b/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
new file mode 100644
index 00000000000..7c2b7def8ad
--- /dev/null
+++ b/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
@@ -0,0 +1,396 @@
+---
+title: MySQL 高性能优化规范建议
+category: 数据库
+tag:
+ - MySQL
+---
+
+> 作者: 听风,原文地址: <https://www.cnblogs.com/huchong/p/10219318.html>。JavaGuide 已获得作者授权。
+
+## 数据库命令规范
+
+- 所有数据库对象名称必须使用小写字母并用下划线分割
+- 所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)
+- 数据库对象的命名要能做到见名识意,并且最后不要超过 32 个字符
+- 临时库表必须以 tmp_为前缀并以日期为后缀,备份表必须以 bak_为前缀并以日期 (时间戳) 为后缀
+- 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)
+
+------
+
+## 数据库基本设计规范
+
+### 1. 所有表必须使用 Innodb 存储引擎
+
+没有特殊要求(即 Innodb 无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用 Innodb 存储引擎(MySQL5.5 之前默认使用 Myisam,5.6 以后默认的为 Innodb)。
+
+Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
+
+### 2. 数据库和表的字符集统一使用 UTF8
+
+兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
+
+参考文章:[MySQL 字符集不一致导致索引失效的一个真实案例](https://blog.csdn.net/horses/article/details/107243447)
+
+### 3. 所有表和字段都需要添加注释
+
+使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护
+
+### 4. 尽量控制单表数据量的大小,建议控制在 500 万以内。
+
+500 万并不是 MySQL 数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题。
+
+可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小
+
+### 5. 谨慎使用 MySQL 分区表
+
+分区表在物理上表现为多个文件,在逻辑上表现为一个表;
+
+谨慎选择分区键,跨分区查询效率可能更低;
+
+建议采用物理分表的方式管理大数据。
+
+### 6.尽量做到冷热数据分离,减小表的宽度
+
+> MySQL 限制每个表最多存储 4096 列,并且每一行数据的大小不能超过 65535 字节。
+
+减少磁盘 IO,保证热数据的内存缓存命中率(表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的 IO);
+
+更有效的利用缓存,避免读入无用的冷数据;
+
+经常一起使用的列放到一个表中(避免更多的关联操作)。
+
+### 7. 禁止在表中建立预留字段
+
+预留字段的命名很难做到见名识义。
+
+预留字段无法确认存储的数据类型,所以无法选择合适的类型。
+
+对预留字段类型的修改,会对表进行锁定。
+
+### 8. 禁止在数据库中存储图片,文件等大的二进制数据
+
+通常文件很大,会短时间内造成数据量快速增长,数据库进行数据库读取时,通常会进行大量的随机 IO 操作,文件很大时,IO 操作很耗时。
+
+通常存储于文件服务器,数据库只存储文件地址信息
+
+### 9. 禁止在线上做数据库压力测试
+
+### 10. 禁止从开发环境,测试环境直接连接生产环境数据库
+
+------
+
+## 数据库字段设计规范
+
+### 1. 优先选择符合存储需要的最小的数据类型
+
+**原因:**
+
+列的字段越大,建立索引时所需要的空间也就越大,这样一页中所能存储的索引节点的数量也就越少也越少,在遍历时所需要的 IO 次数也就越多,索引的性能也就越差。
+
+**方法:**
+
+**a.将字符串转换成数字类型存储,如:将 IP 地址转换成整形数据**
+
+MySQL 提供了两个方法来处理 ip 地址
+
+- inet_aton 把 ip 转为无符号整型 (4-8 位)
+- inet_ntoa 把整型的 ip 转为地址
+
+插入数据前,先用 inet_aton 把 ip 地址转为整型,可以节省空间,显示数据时,使用 inet_ntoa 把整型的 ip 地址转为地址显示即可。
+
+**b.对于非负型的数据 (如自增 ID,整型 IP) 来说,要优先使用无符号整型来存储**
+
+**原因:**
+
+无符号相对于有符号可以多出一倍的存储空间
+
+```
+SIGNED INT -2147483648~2147483647
+UNSIGNED INT 0~4294967295
+```
+
+VARCHAR(N) 中的 N 代表的是字符数,而不是字节数,使用 UTF8 存储 255 个汉字 Varchar(255)=765 个字节。**过大的长度会消耗更多的内存。**
+
+### 2. 避免使用 TEXT,BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
+
+**a. 建议把 BLOB 或是 TEXT 列分离到单独的扩展表中**
+
+MySQL 内存临时表不支持 TEXT、BLOB 这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。而且对于这种数据,MySQL 还是要进行二次查询,会使 sql 性能变得很差,但是不是说一定不能使用这样的数据类型。
+
+如果一定要使用,建议把 BLOB 或是 TEXT 列分离到单独的扩展表中,查询时一定不要使用 select * 而只需要取出必要的列,不需要 TEXT 列的数据时不要对该列进行查询。
+
+**2、TEXT 或 BLOB 类型只能使用前缀索引**
+
+因为[MySQL](https://mp.weixin.qq.com/s?__biz=MzI4Njc5NjM1NQ==&mid=2247487885&idx=1&sn=65b1bf5f7d4505502620179669a9c2df&chksm=ebd62ea1dca1a7b7bf884bcd9d538d78ba064ee03c09436ca8e57873b1d98a55afd6d7884cfc&scene=21#wechat_redirect) 对索引字段长度是有限制的,所以 TEXT 类型只能使用前缀索引,并且 TEXT 列上是不能有默认值的
+
+### 3. 避免使用 ENUM 类型
+
+修改 ENUM 值需要使用 ALTER 语句
+
+ENUM 类型的 ORDER BY 操作效率低,需要额外操作
+
+禁止使用数值作为 ENUM 的枚举值
+
+### 4. 尽可能把所有列定义为 NOT NULL
+
+**原因:**
+
+索引 NULL 列需要额外的空间来保存,所以要占用更多的空间
+
+进行比较和计算时要对 NULL 值做特别的处理
+
+### 5. 使用 TIMESTAMP(4 个字节) 或 DATETIME 类型 (8 个字节) 存储时间
+
+TIMESTAMP 存储的时间范围 1970-01-01 00:00:01 ~ 2038-01-19-03:14:07
+
+TIMESTAMP 占用 4 字节和 INT 相同,但比 INT 可读性高
+
+超出 TIMESTAMP 取值范围的使用 DATETIME 类型存储
+
+**经常会有人用字符串存储日期型的数据(不正确的做法)**
+
+- 缺点 1:无法用日期函数进行计算和比较
+- 缺点 2:用字符串存储日期要占用更多的空间
+
+### 6. 同财务相关的金额类数据必须使用 decimal 类型
+
+- 非精准浮点:float,double
+- 精准浮点:decimal
+
+Decimal 类型为精准浮点数,在计算时不会丢失精度
+
+占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节
+
+可用于存储比 bigint 更大的整型数据
+
+------
+
+## 索引设计规范
+
+### 1. 限制每张表上的索引数量,建议单张表索引不超过 5 个
+
+索引并不是越多越好!索引可以提高效率同样可以降低效率。
+
+索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
+
+因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+
+### 2. 禁止给表中的每一列都建立单独的索引
+
+5.6 版本之前,一个 sql 只能使用到一个表中的一个索引,5.6 以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好。
+
+### 3. 每个 Innodb 表必须有个主键
+
+Innodb 是一种索引组织表:数据的存储的逻辑顺序和索引的顺序是相同的。每个表都可以有多个索引,但是表的存储顺序只能有一种。
+
+Innodb 是按照主键索引的顺序来组织表的
+
+- 不要使用更新频繁的列作为主键,不适用多列主键(相当于联合索引)
+- 不要使用 UUID,MD5,HASH,字符串列作为主键(无法保证数据的顺序增长)
+- 主键建议使用自增 ID 值
+
+------
+
+### 4. 常见索引列建议
+
+- 出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列
+- 包含在 ORDER BY、GROUP BY、DISTINCT 中的字段
+- 并不要将符合 1 和 2 中的字段的列都建立一个索引, 通常将 1、2 中的字段建立联合索引效果更好
+- 多表 join 的关联列
+
+------
+
+### 5.如何选择索引列的顺序
+
+建立索引的目的是:希望通过索引进行数据查找,减少随机 IO,增加查询性能 ,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
+
+- 区分度最高的放在联合索引的最左侧(区分度=列中不同值的数量/列的总行数)
+- 尽量把字段长度小的列放在联合索引的最左侧(因为字段长度越小,一页能存储的数据量越大,IO 性能也就越好)
+- 使用最频繁的列放到联合索引的左侧(这样可以比较少的建立一些索引)
+
+------
+
+### 6. 避免建立冗余索引和重复索引(增加了查询优化器生成执行计划的时间)
+
+- 重复索引示例:primary key(id)、index(id)、unique index(id)
+- 冗余索引示例:index(a,b,c)、index(a,b)、index(a)
+
+------
+
+### 7. 对于频繁的查询优先考虑使用覆盖索引
+
+> 覆盖索引:就是包含了所有查询字段 (where,select,order by,group by 包含的字段) 的索引
+
+**覆盖索引的好处:**
+
+- **避免 Innodb 表进行索引的二次查询:** Innodb 是以聚集索引的顺序来存储的,对于 Innodb 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询 ,减少了 IO 操作,提升了查询效率。
+- **可以把随机 IO 变成顺序 IO 加快查询效率:** 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
+
+------
+
+### 8.索引 SET 规范
+
+**尽量避免使用外键约束**
+
+- 不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引
+- 外键可用于保证数据的参照完整性,但建议在业务端实现
+- 外键会影响父表和子表的写操作从而降低性能
+
+------
+
+## 数据库 SQL 开发规范
+
+### 1. 建议使用预编译语句进行数据库操作
+
+预编译语句可以重复使用这些计划,减少 SQL 编译所需要的时间,还可以解决动态 SQL 所带来的 SQL 注入的问题。
+
+只传参数,比传递 SQL 语句更高效。
+
+相同语句可以一次解析,多次使用,提高处理效率。
+
+### 2. 避免数据类型的隐式转换
+
+隐式转换会导致索引失效如:
+
+```
+select name,phone from customer where id = '111';
+```
+
+### 3. 充分利用表上已经存在的索引
+
+避免使用双%号的查询条件。如:`a like '%123%'`,(如果无前置%,只有后置%,是可以用到列上的索引的)
+
+一个 SQL 只能利用到复合索引中的一列进行范围查询。如:有 a,b,c 列的联合索引,在查询条件中有 a 列的范围查询,则在 b,c 列上的索引将不会被用到。
+
+在定义联合索引时,如果 a 列要用到范围查找的话,就要把 a 列放到联合索引的右侧,使用 left join 或 not exists 来优化 not in 操作,因为 not in 也通常会使用索引失效。
+
+### 4. 数据库设计时,应该要对以后扩展进行考虑
+
+### 5. 程序连接不同的数据库使用不同的账号,禁止跨库查询
+
+- 为数据库迁移和分库分表留出余地
+- 降低业务耦合度
+- 避免权限过大而产生的安全风险
+
+### 6. 禁止使用 SELECT * 必须使用 SELECT <字段列表> 查询
+
+**原因:**
+
+- 消耗更多的 CPU 和 IO 以网络带宽资源
+- 无法使用覆盖索引
+- 可减少表结构变更带来的影响
+
+### 7. 禁止使用不含字段列表的 INSERT 语句
+
+如:
+
+```
+insert into values ('a','b','c');
+```
+
+应使用:
+
+```
+insert into t(c1,c2,c3) values ('a','b','c');
+```
+
+### 8. 避免使用子查询,可以把子查询优化为 join 操作
+
+通常子查询在 in 子句中,且子查询中为简单 SQL(不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
+
+**子查询性能差的原因:**
+
+子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
+
+由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
+
+### 9. 避免使用 JOIN 关联太多的表
+
+对于 MySQL 来说,是存在关联缓存的,缓存的大小可以由 join_buffer_size 参数进行设置。
+
+在 MySQL 中,对于同一个 SQL 多关联(join)一个表,就会多分配一个关联缓存,如果在一个 SQL 中关联的表越多,所占用的内存也就越大。
+
+如果程序中大量的使用了多表关联的操作,同时 join_buffer_size 设置的也不合理的情况下,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
+
+同时对于关联操作来说,会产生临时表操作,影响查询效率,MySQL 最多允许关联 61 个表,建议不超过 5 个。
+
+### 10. 减少同数据库的交互次数
+
+数据库更适合处理批量操作,合并多个相同的操作到一起,可以提高处理效率。
+
+### 11. 对应同一列进行 or 判断时,使用 in 代替 or
+
+in 的值不要超过 500 个,in 操作可以更有效的利用索引,or 大多数情况下很少能利用到索引。
+
+### 12. 禁止使用 order by rand() 进行随机排序
+
+order by rand() 会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值,如果满足条件的数据集非常大,就会消耗大量的 CPU 和 IO 及内存资源。
+
+推荐在程序中获取一个随机值,然后从数据库中获取数据的方式。
+
+### 13. WHERE 从句中禁止对列进行函数转换和计算
+
+对列进行函数转换或计算时会导致无法使用索引
+
+**不推荐:**
+
+```
+where date(create_time)='20190101'
+```
+
+**推荐:**
+
+```
+where create_time >= '20190101' and create_time < '20190102'
+```
+
+### 14. 在明显不会有重复值时使用 UNION ALL 而不是 UNION
+
+- UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作
+- UNION ALL 不会再对结果集进行去重操作
+
+### 15. 拆分复杂的大 SQL 为多个小 SQL
+
+- 大 SQL 逻辑上比较复杂,需要占用大量 CPU 进行计算的 SQL
+- MySQL 中,一个 SQL 只能使用一个 CPU 进行计算
+- SQL 拆分后可以通过并行执行来提高处理效率
+
+------
+
+## 数据库操作行为规范
+
+### 1. 超 100 万行的批量写 (UPDATE,DELETE,INSERT) 操作,要分批多次进行操作
+
+**大批量操作可能会造成严重的主从延迟**
+
+主从环境中,大批量操作可能会造成严重的主从延迟,大批量的写操作一般都需要执行一定长的时间,
+而只有当主库上执行完成后,才会在其他从库上执行,所以会造成主库与从库长时间的延迟情况
+
+**binlog 日志为 row 格式时会产生大量的日志**
+
+大批量写操作会产生大量日志,特别是对于 row 格式二进制数据而言,由于在 row 格式中会记录每一行数据的修改,我们一次修改的数据越多,产生的日志量也就会越多,日志的传输和恢复所需要的时间也就越长,这也是造成主从延迟的一个原因
+
+**避免产生大事务操作**
+
+大批量修改数据,一定是在一个事务中进行的,这就会造成表中大批量数据进行锁定,从而导致大量的阻塞,阻塞会对 MySQL 的性能产生非常大的影响。
+
+特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批
+
+### 2. 对于大表使用 pt-online-schema-change 修改表结构
+
+- 避免大表修改产生的主从延迟
+- 避免在对表字段进行修改时进行锁表
+
+对大表数据结构的修改一定要谨慎,会造成严重的锁表操作,尤其是生产环境,是不能容忍的。
+
+pt-online-schema-change 它会首先建立一个与原表结构相同的新表,并且在新表上进行表结构的修改,然后再把原表中的数据复制到新表中,并在原表中增加一些触发器。把原表中新增的数据也复制到新表中,在行所有数据复制完成之后,把新表命名成原表,并把原来的表删除掉。把原来一个 DDL 操作,分解成多个小的批次进行。
+
+### 3. 禁止为程序使用的账号赋予 super 权限
+
+- 当达到最大连接数限制时,还运行 1 个有 super 权限的用户连接
+- super 权限只能留给 DBA 处理问题的账号使用
+
+### 4. 对于程序连接数据库账号,遵循权限最小原则
+
+- 程序使用数据库账号只能在一个 DB 下使用,不准跨库
+- 程序使用的账号原则上不准有 drop 权限
diff --git a/docs/database/mysql/mysql-index.md b/docs/database/mysql/mysql-index.md
new file mode 100644
index 00000000000..5dd4e526492
--- /dev/null
+++ b/docs/database/mysql/mysql-index.md
@@ -0,0 +1,266 @@
+---
+title: MySQL 索引详解
+category: 数据库
+tag:
+ - MySQL
+---
+
+
+
+## 何为索引?有什么作用?
+
+**索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B 树, B+树和 Hash。**
+
+索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+
+## 索引的优缺点
+
+**优点** :
+
+- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
+- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+
+**缺点** :
+
+- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
+- 索引需要使用物理文件存储,也会耗费一定空间。
+
+但是,**使用索引一定能提高查询性能吗?**
+
+大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
+
+## 索引的底层数据结构
+
+### Hash表 & B+树
+
+哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
+
+**为何能够通过 key 快速取出 value呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 value 对应的 index,找到了 index 也就找到了对应的 value。
+
+```java
+hash = hashfunc(key)
+index = hash % array_size
+```
+
+
+
+
+
+但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了减少链表过长的时候搜索时间过长引入了红黑树。
+
+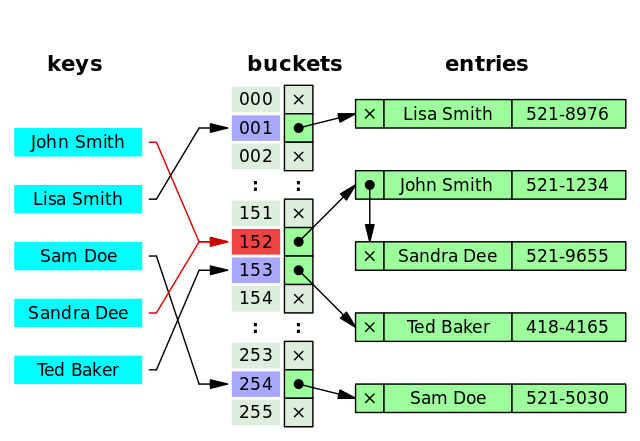
+
+为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
+
+既然哈希表这么快,**为什么MySQL 没有使用其作为索引的数据结构呢?**
+
+**1.Hash 冲突问题** :我们上面也提到过Hash 冲突了,不过对于数据库来说这还不算最大的缺点。
+
+**2.Hash 索引不支持顺序和范围查询(Hash 索引不支持顺序和范围查询是它最大的缺点:** 假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。
+
+试想一种情况:
+
+```java
+SELECT * FROM tb1 WHERE id < 500;Copy to clipboardErrorCopied
+```
+
+在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
+
+### B 树& B+树
+
+B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一种变体。B 树和 B+树中的 B 是 `Balanced` (平衡)的意思。
+
+目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
+
+**B 树& B+树两者有何异同呢?**
+
+- B 树的所有节点既存放键(key) 也存放 数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key。
+- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
+- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
+
+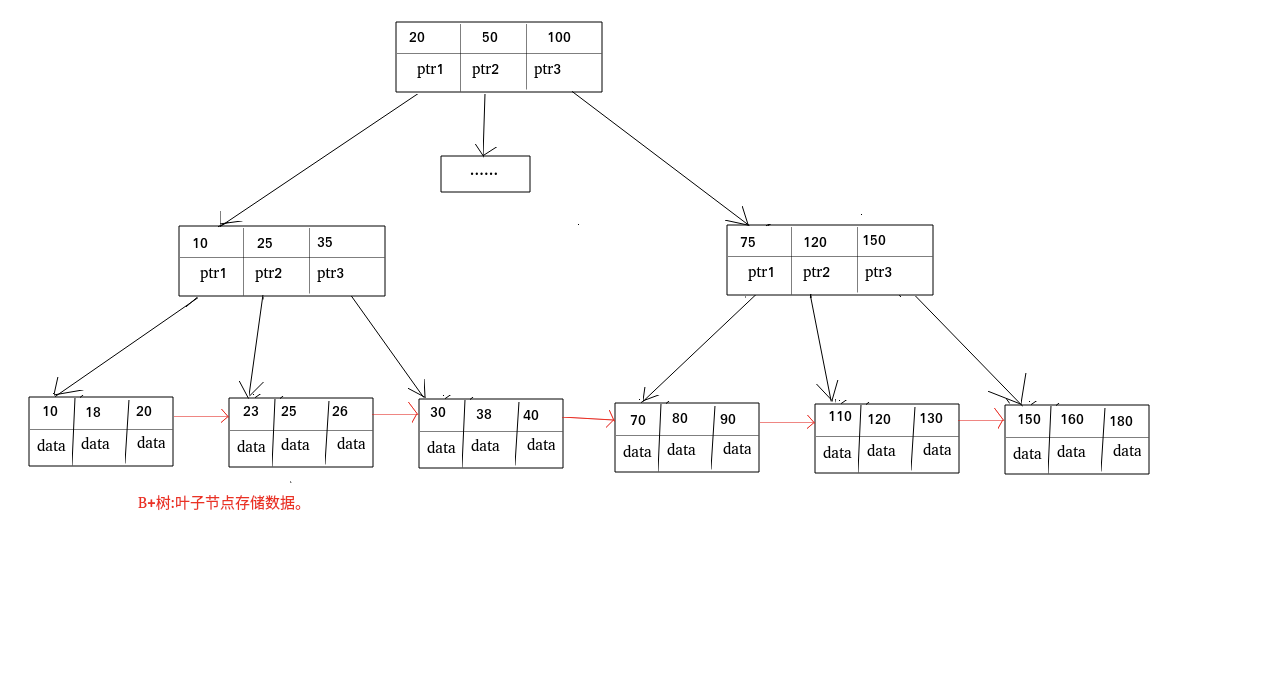
+
+在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
+
+MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
+
+InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
+
+## 索引类型
+
+### 主键索引(Primary Key)
+
+数据表的主键列使用的就是主键索引。
+
+一张数据表有只能有一个主键,并且主键不能为 null,不能重复。
+
+在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
+
+### 二级索引(辅助索引)
+
+**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
+
+唯一索引,普通索引,前缀索引等索引属于二级索引。
+
+**PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。**
+
+1. **唯一索引(Unique Key)** :唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。** 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)** :**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。**
+3. **前缀索引(Prefix)** :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
+ 因为只取前几个字符。
+4. **全文索引(Full Text)** :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
+
+二级索引:
+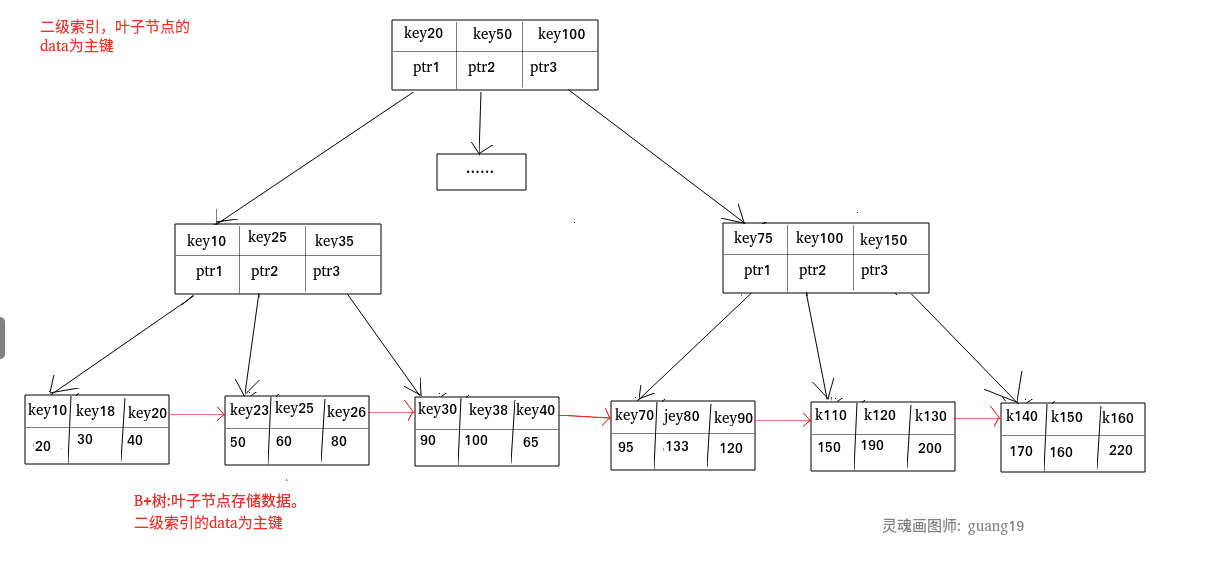
+
+## 聚集索引与非聚集索引
+
+### 聚集索引
+
+**聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。**
+
+在 Mysql 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
+
+#### 聚集索引的优点
+
+聚集索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
+
+#### 聚集索引的缺点
+
+1. **依赖于有序的数据** :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+2. **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,
+ 而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,
+ 所以对于主键索引来说,主键一般都是不可被修改的。
+
+### 非聚集索引
+
+**非聚集索引即索引结构和数据分开存放的索引。**
+
+**二级索引属于非聚集索引。**
+
+> MYISAM 引擎的表的.MYI 文件包含了表的索引,
+> 该表的索引(B+树)的每个叶子非叶子节点存储索引,
+> 叶子节点存储索引和索引对应数据的指针,指向.MYD 文件的数据。
+>
+> **非聚集索引的叶子节点并不一定存放数据的指针,
+> 因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。**
+
+#### 非聚集索引的优点
+
+**更新代价比聚集索引要小** 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
+
+#### 非聚集索引的缺点
+
+1. 跟聚集索引一样,非聚集索引也依赖于有序的数据
+2. **可能会二次查询(回表)** :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+
+这是 MySQL 的表的文件截图:
+
+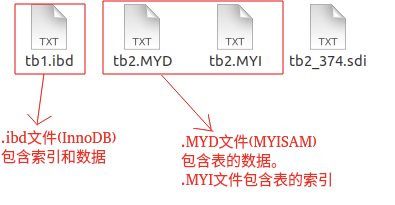
+
+聚集索引和非聚集索引:
+
+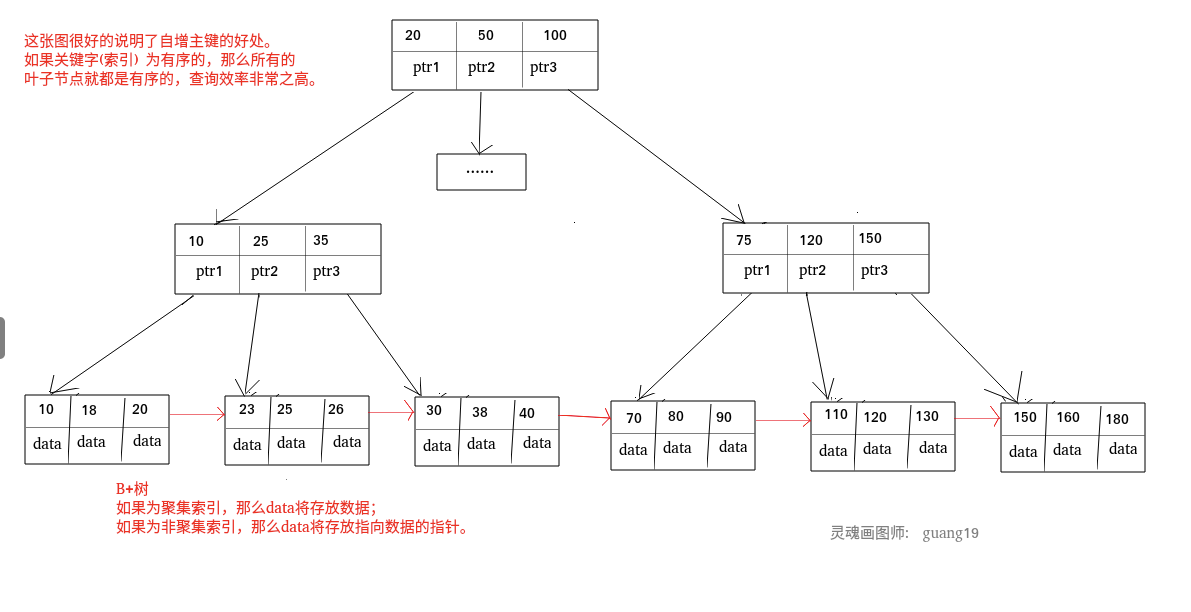
+
+### 非聚集索引一定回表查询吗(覆盖索引)?
+
+**非聚集索引不一定回表查询。**
+
+> 试想一种情况,用户准备使用 SQL 查询用户名,而用户名字段正好建立了索引。
+
+```text
+ SELECT name FROM table WHERE name='guang19';
+```
+
+> 那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。
+
+**即使是 MYISAM 也是这样,虽然 MYISAM 的主键索引确实需要回表,
+因为它的主键索引的叶子节点存放的是指针。但是如果 SQL 查的就是主键呢?**
+
+```text
+SELECT id FROM table WHERE id=1;
+```
+
+主键索引本身的 key 就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
+
+## 覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,
+而无需回表查询。**
+
+> 如主键索引,如果一条 SQL 需要查询主键,那么正好根据主键索引就可以查到主键。
+>
+> 再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引,
+> 那么直接根据这个索引就可以查到数据,也无需回表。
+
+覆盖索引:
+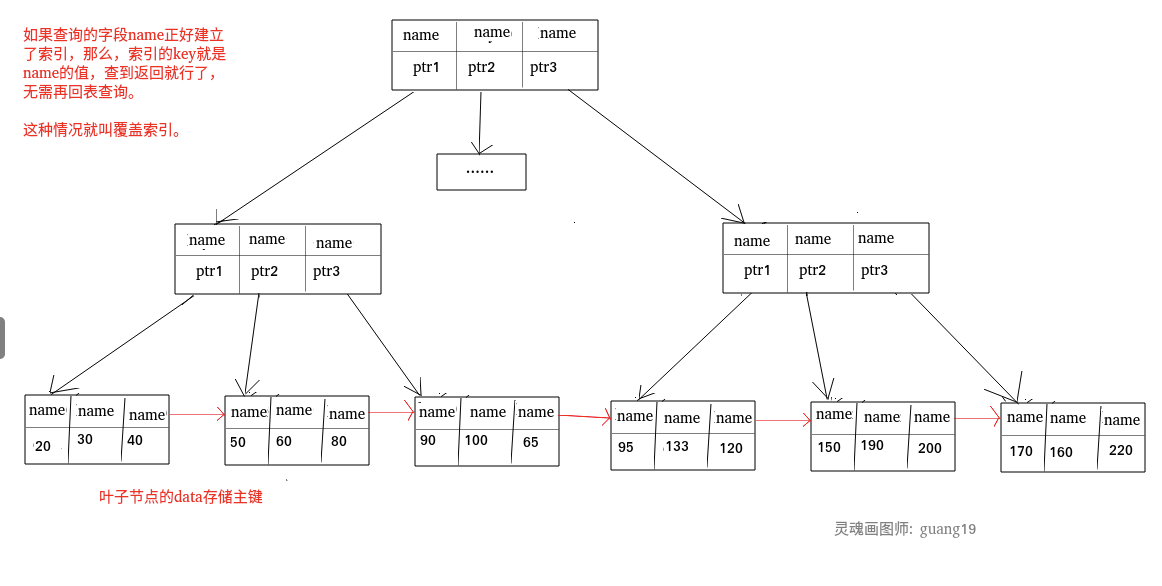
+
+## 创建索引的注意事项
+
+**1.选择合适的字段创建索引:**
+
+- **不为 NULL 的字段** :索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
+- **被频繁查询的字段** :我们创建索引的字段应该是查询操作非常频繁的字段。
+- **被作为条件查询的字段** :被作为 WHERE 条件查询的字段,应该被考虑建立索引。
+- **频繁需要排序的字段** :索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
+- **被经常频繁用于连接的字段** :经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+**2.被频繁更新的字段应该慎重建立索引。**
+
+虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。
+如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
+
+**3.尽可能的考虑建立联合索引而不是单列索引。**
+
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+
+**4.注意避免冗余索引** 。
+
+冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+
+**5.考虑在字符串类型的字段上使用前缀索引代替普通索引。**
+
+前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
+
+## 使用索引的一些建议
+
+- 对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引
+- 避免 where 子句中对字段施加函数,这会造成无法命中索引。
+- 在使用 InnoDB 时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
+- 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
+- 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
+
+## MySQL 如何为表字段添加索引?
+
+1.添加 PRIMARY KEY(主键索引)
+
+```sql
+ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
+```
+
+2.添加 UNIQUE(唯一索引)
+
+```sqlite
+ALTER TABLE `table_name` ADD UNIQUE ( `column` )
+```
+
+3.添加 INDEX(普通索引)
+
+```sql
+ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
+```
+
+4.添加 FULLTEXT(全文索引)
+
+```sql
+ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
+```
+
+5.添加多列索引
+
+```sql
+ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
+```
\ No newline at end of file
diff --git a/docs/database/mysql/mysql-logs.md b/docs/database/mysql/mysql-logs.md
new file mode 100644
index 00000000000..697cf30f6a1
--- /dev/null
+++ b/docs/database/mysql/mysql-logs.md
@@ -0,0 +1,289 @@
+---
+title: MySQL三大日志(binlog、redo log和undo log)详解
+category: 数据库
+tag:
+ - MySQL
+---
+
+
+
+> 本文来自公号程序猿阿星投稿,JavaGuide 对其做了补充完善。
+
+## 前言
+
+`MySQL` 日志 主要包括错误日志、查询日志、慢查询日志、事务日志、二进制日志几大类。其中,比较重要的还要属二进制日志 `binlog`(归档日志)和事务日志 `redo log`(重做日志)和 `undo log`(回滚日志)。
+
+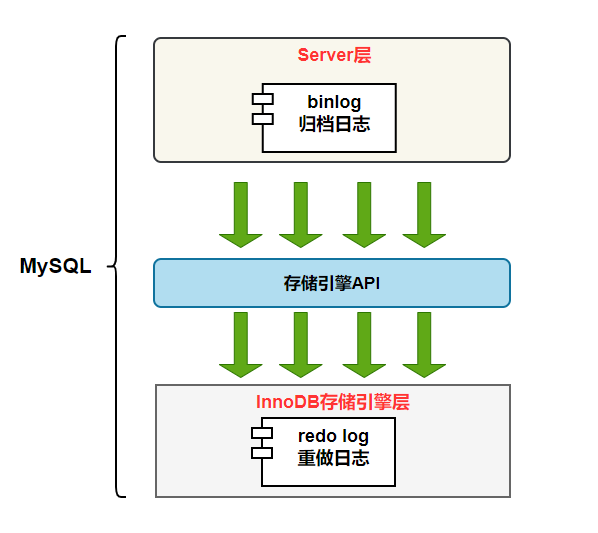
+
+今天就来聊聊 `redo log`(重做日志)、`binlog`(归档日志)、两阶段提交、`undo log` (回滚日志)。
+
+## redo log
+
+`redo log`(重做日志)是`InnoDB`存储引擎独有的,它让`MySQL`拥有了崩溃恢复能力。
+
+比如 `MySQL` 实例挂了或宕机了,重启时,`InnoDB`存储引擎会使用`redo log`恢复数据,保证数据的持久性与完整性。
+
+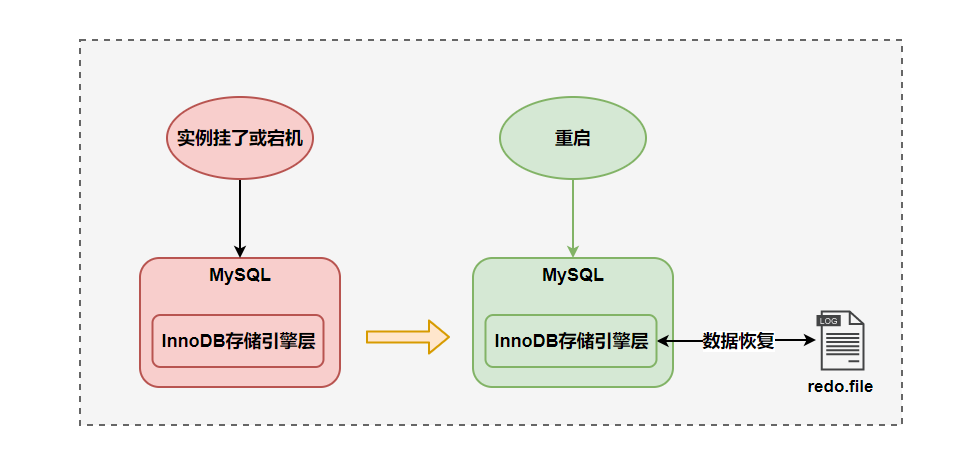
+
+`MySQL` 中数据是以页为单位,你查询一条记录,会从硬盘把一页的数据加载出来,加载出来的数据叫数据页,会放入到 `Buffer Pool` 中。
+
+后续的查询都是先从 `Buffer Pool` 中找,没有命中再去硬盘加载,减少硬盘 `IO` 开销,提升性能。
+
+更新表数据的时候,也是如此,发现 `Buffer Pool` 里存在要更新的数据,就直接在 `Buffer Pool` 里更新。
+
+然后会把“在某个数据页上做了什么修改”记录到重做日志缓存(`redo log buffer`)里,接着刷盘到 `redo log` 文件里。
+
+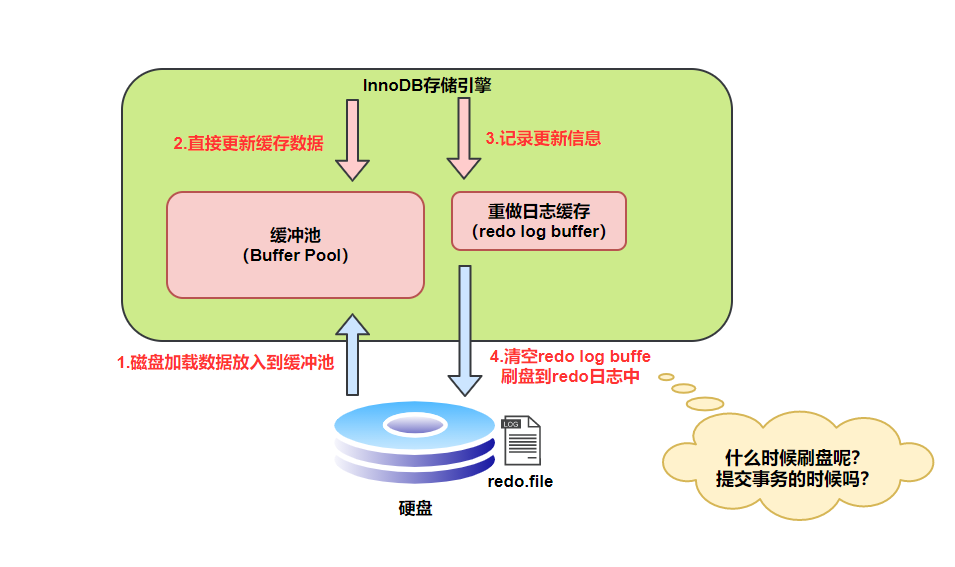
+
+理想情况,事务一提交就会进行刷盘操作,但实际上,刷盘的时机是根据策略来进行的。
+
+> 小贴士:每条 redo 记录由“表空间号+数据页号+偏移量+修改数据长度+具体修改的数据”组成
+
+### 刷盘时机
+
+`InnoDB` 存储引擎为 `redo log` 的刷盘策略提供了 `innodb_flush_log_at_trx_commit` 参数,它支持三种策略:
+
+- **0** :设置为 0 的时候,表示每次事务提交时不进行刷盘操作
+- **1** :设置为 1 的时候,表示每次事务提交时都将进行刷盘操作(默认值)
+- **2** :设置为 2 的时候,表示每次事务提交时都只把 redo log buffer 内容写入 page cache
+
+`innodb_flush_log_at_trx_commit` 参数默认为 1 ,也就是说当事务提交时会调用 `fsync` 对 redo log 进行刷盘
+
+另外,`InnoDB` 存储引擎有一个后台线程,每隔`1` 秒,就会把 `redo log buffer` 中的内容写到文件系统缓存(`page cache`),然后调用 `fsync` 刷盘。
+
+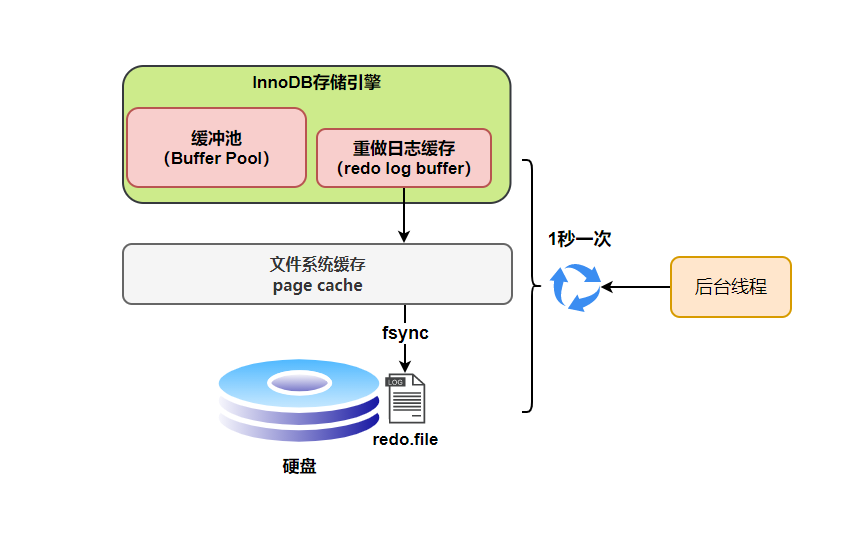
+
+也就是说,一个没有提交事务的 `redo log` 记录,也可能会刷盘。
+
+**为什么呢?**
+
+因为在事务执行过程 `redo log` 记录是会写入`redo log buffer` 中,这些 `redo log` 记录会被后台线程刷盘。
+
+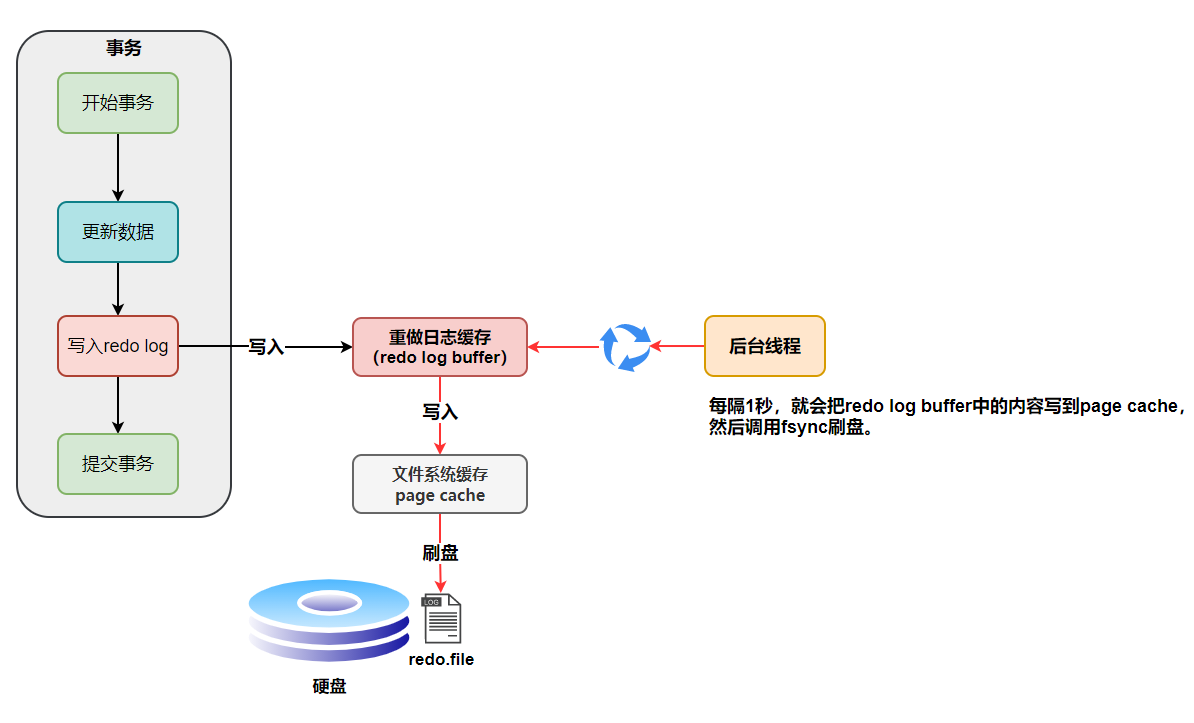
+
+除了后台线程每秒`1`次的轮询操作,还有一种情况,当 `redo log buffer` 占用的空间即将达到 `innodb_log_buffer_size` 一半的时候,后台线程会主动刷盘。
+
+下面是不同刷盘策略的流程图。
+
+#### innodb_flush_log_at_trx_commit=0
+
+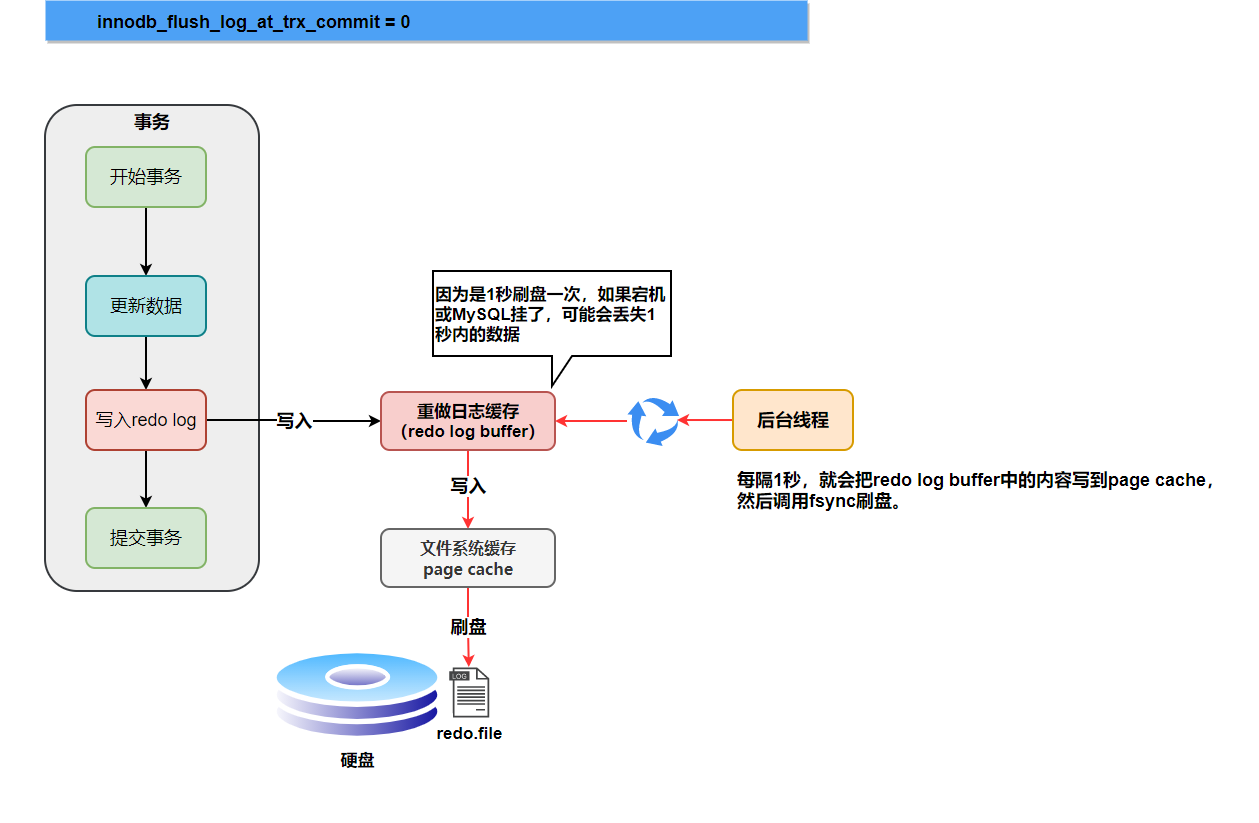
+
+为`0`时,如果`MySQL`挂了或宕机可能会有`1`秒数据的丢失。
+
+#### innodb_flush_log_at_trx_commit=1
+
+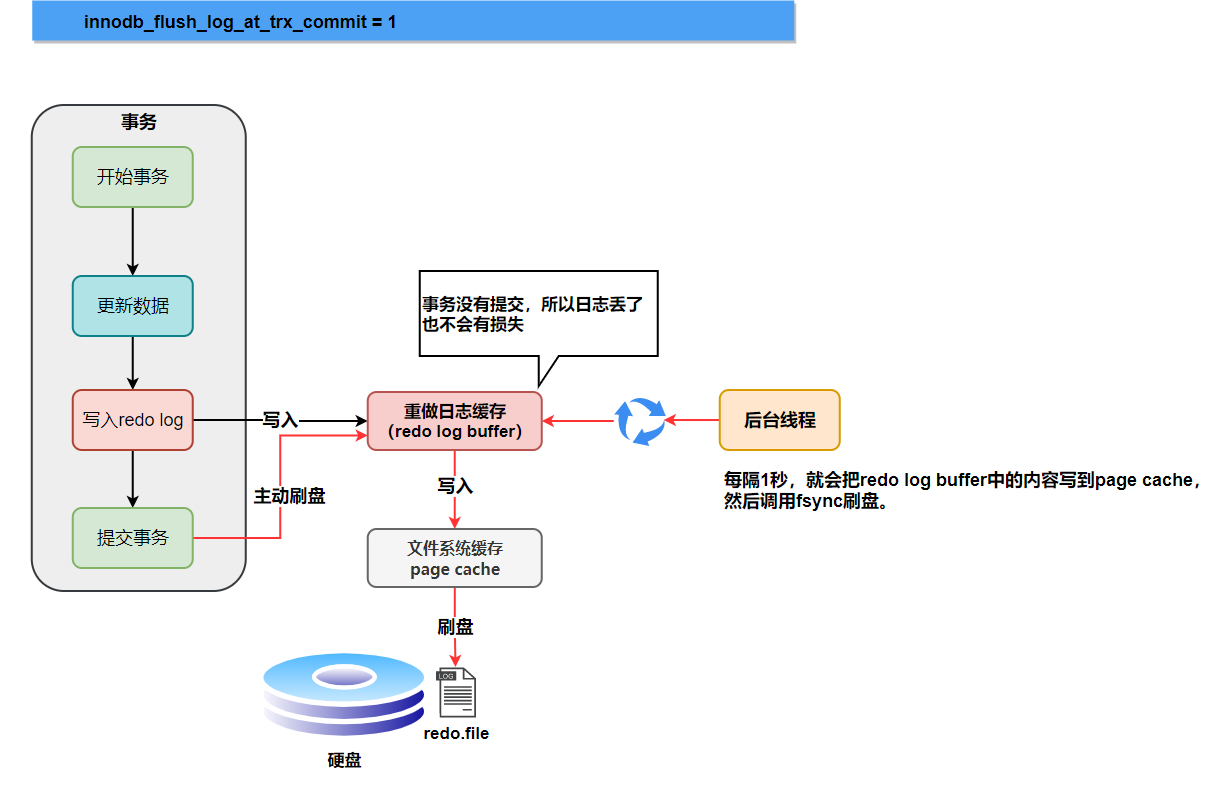
+
+为`1`时, 只要事务提交成功,`redo log`记录就一定在硬盘里,不会有任何数据丢失。
+
+如果事务执行期间`MySQL`挂了或宕机,这部分日志丢了,但是事务并没有提交,所以日志丢了也不会有损失。
+
+#### innodb_flush_log_at_trx_commit=2
+
+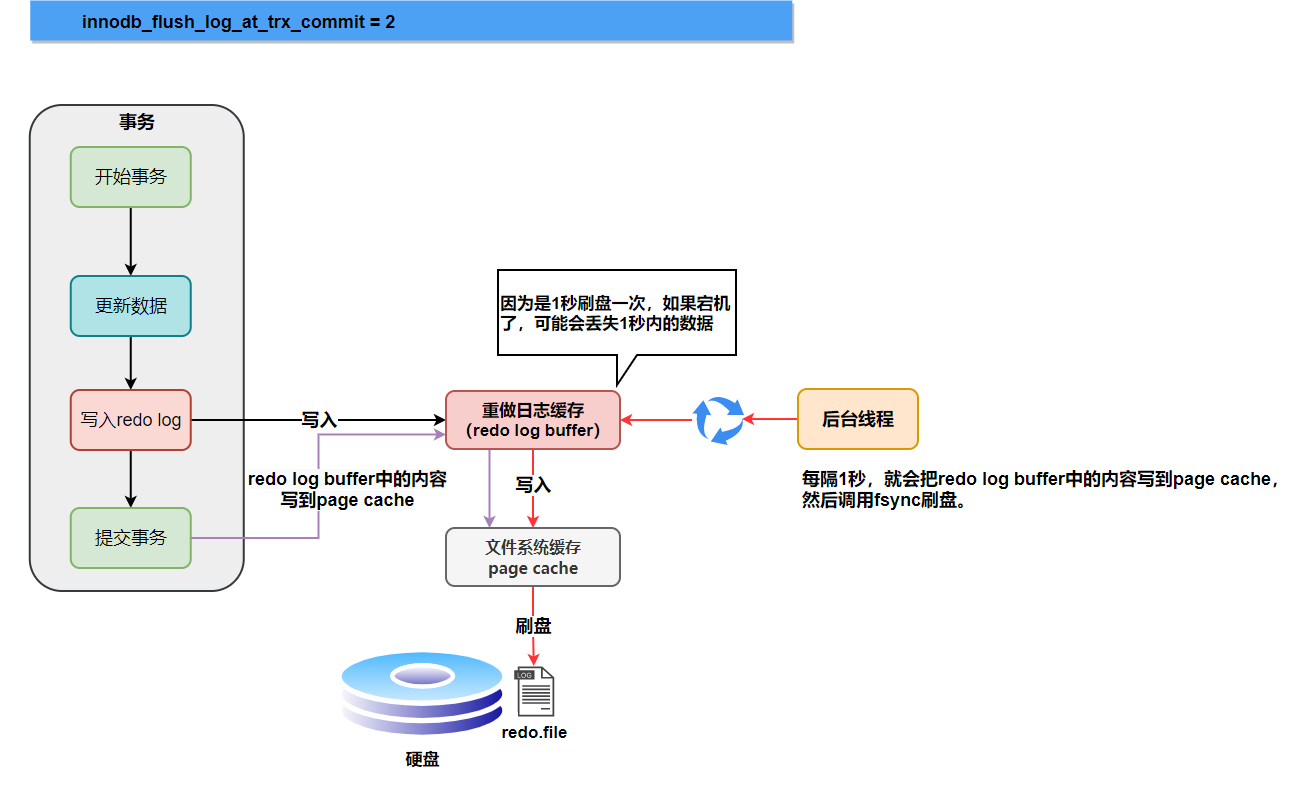
+
+为`2`时, 只要事务提交成功,`redo log buffer`中的内容只写入文件系统缓存(`page cache`)。
+
+如果仅仅只是`MySQL`挂了不会有任何数据丢失,但是宕机可能会有`1`秒数据的丢失。
+
+### 日志文件组
+
+硬盘上存储的 `redo log` 日志文件不只一个,而是以一个**日志文件组**的形式出现的,每个的`redo`日志文件大小都是一样的。
+
+比如可以配置为一组`4`个文件,每个文件的大小是 `1GB`,整个 `redo log` 日志文件组可以记录`4G`的内容。
+
+它采用的是环形数组形式,从头开始写,写到末尾又回到头循环写,如下图所示。
+
+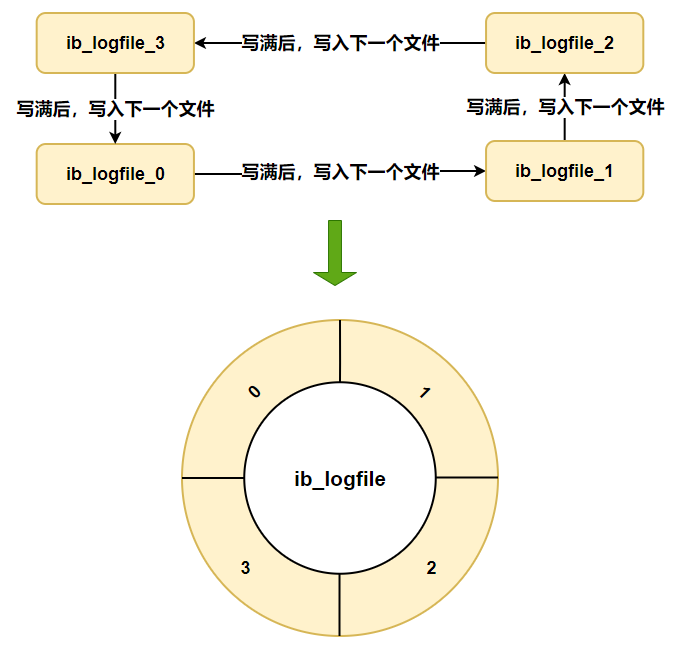
+
+在个**日志文件组**中还有两个重要的属性,分别是 `write pos、checkpoint`
+
+- **write pos** 是当前记录的位置,一边写一边后移
+- **checkpoint** 是当前要擦除的位置,也是往后推移
+
+每次刷盘 `redo log` 记录到**日志文件组**中,`write pos` 位置就会后移更新。
+
+每次 `MySQL` 加载**日志文件组**恢复数据时,会清空加载过的 `redo log` 记录,并把 `checkpoint` 后移更新。
+
+`write pos` 和 `checkpoint` 之间的还空着的部分可以用来写入新的 `redo log` 记录。
+
+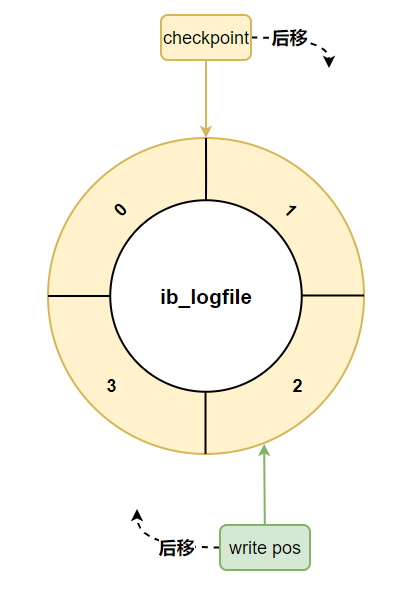
+
+如果 `write pos` 追上 `checkpoint` ,表示**日志文件组**满了,这时候不能再写入新的 `redo log` 记录,`MySQL` 得停下来,清空一些记录,把 `checkpoint` 推进一下。
+
+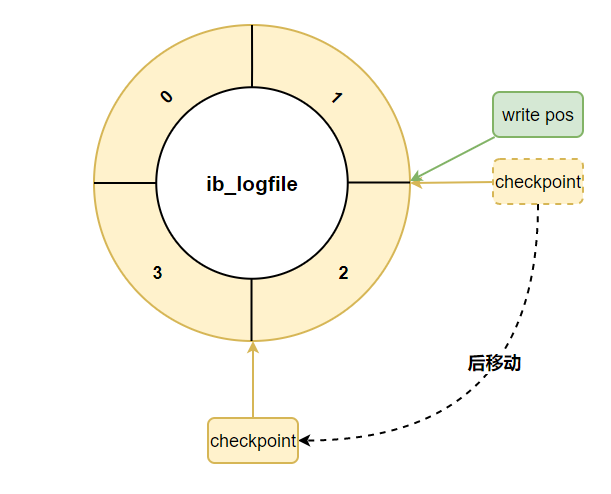
+
+### redo log 小结
+
+相信大家都知道 `redo log` 的作用和它的刷盘时机、存储形式。
+
+现在我们来思考一个问题: **只要每次把修改后的数据页直接刷盘不就好了,还有 `redo log` 什么事?**
+
+它们不都是刷盘么?差别在哪里?
+
+```java
+1 Byte = 8bit
+1 KB = 1024 Byte
+1 MB = 1024 KB
+1 GB = 1024 MB
+1 TB = 1024 GB
+```
+
+实际上,数据页大小是`16KB`,刷盘比较耗时,可能就修改了数据页里的几 `Byte` 数据,有必要把完整的数据页刷盘吗?
+
+而且数据页刷盘是随机写,因为一个数据页对应的位置可能在硬盘文件的随机位置,所以性能是很差。
+
+如果是写 `redo log`,一行记录可能就占几十 `Byte`,只包含表空间号、数据页号、磁盘文件偏移
+量、更新值,再加上是顺序写,所以刷盘速度很快。
+
+所以用 `redo log` 形式记录修改内容,性能会远远超过刷数据页的方式,这也让数据库的并发能力更强。
+
+> 其实内存的数据页在一定时机也会刷盘,我们把这称为页合并,讲 `Buffer Pool`的时候会对这块细说
+
+## binlog
+
+`redo log` 它是物理日志,记录内容是“在某个数据页上做了什么修改”,属于 `InnoDB` 存储引擎。
+
+而 `binlog` 是逻辑日志,记录内容是语句的原始逻辑,类似于“给 ID=2 这一行的 c 字段加 1”,属于`MySQL Server` 层。
+
+不管用什么存储引擎,只要发生了表数据更新,都会产生 `binlog` 日志。
+
+那 `binlog` 到底是用来干嘛的?
+
+可以说`MySQL`数据库的**数据备份、主备、主主、主从**都离不开`binlog`,需要依靠`binlog`来同步数据,保证数据一致性。
+
+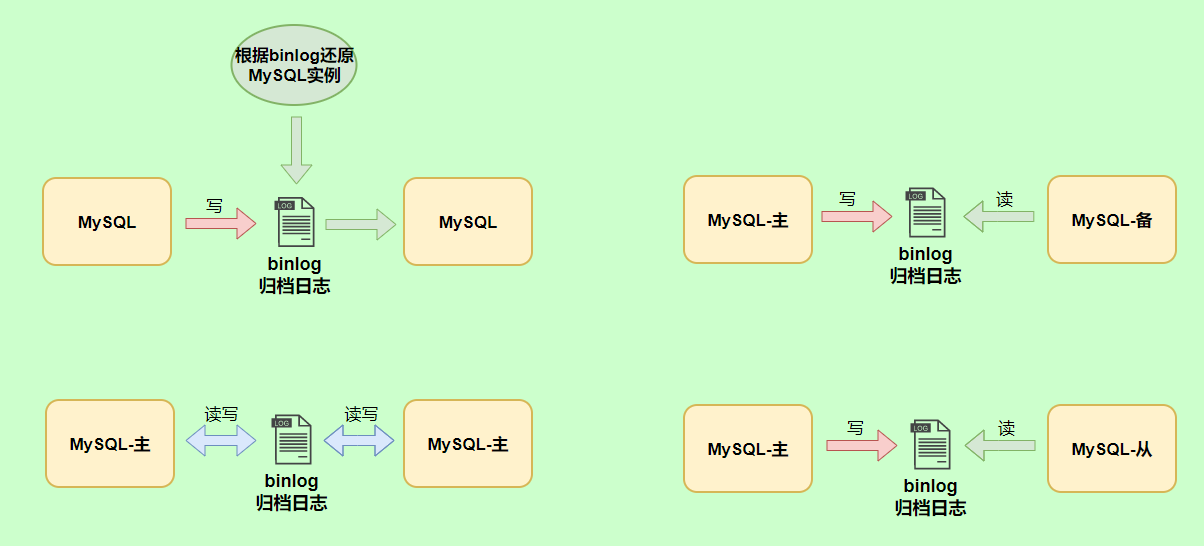
+
+`binlog`会记录所有涉及更新数据的逻辑操作,并且是顺序写。
+
+### 记录格式
+
+`binlog` 日志有三种格式,可以通过`binlog_format`参数指定。
+
+- **statement**
+- **row**
+- **mixed**
+
+指定`statement`,记录的内容是`SQL`语句原文,比如执行一条`update T set update_time=now() where id=1`,记录的内容如下。
+
+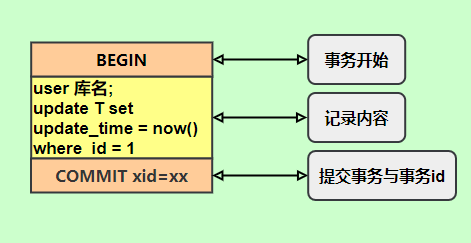
+
+同步数据时,会执行记录的`SQL`语句,但是有个问题,`update_time=now()`这里会获取当前系统时间,直接执行会导致与原库的数据不一致。
+
+为了解决这种问题,我们需要指定为`row`,记录的内容不再是简单的`SQL`语句了,还包含操作的具体数据,记录内容如下。
+
+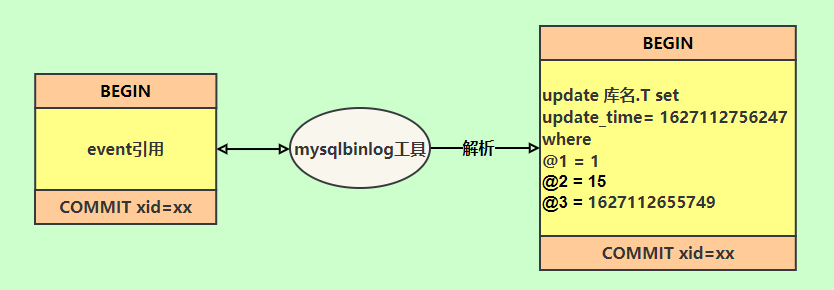
+
+`row`格式记录的内容看不到详细信息,要通过`mysqlbinlog`工具解析出来。
+
+`update_time=now()`变成了具体的时间`update_time=1627112756247`,条件后面的@1、@2、@3 都是该行数据第 1 个~3 个字段的原始值(**假设这张表只有 3 个字段**)。
+
+这样就能保证同步数据的一致性,通常情况下都是指定为`row`,这样可以为数据库的恢复与同步带来更好的可靠性。
+
+但是这种格式,需要更大的容量来记录,比较占用空间,恢复与同步时会更消耗`IO`资源,影响执行速度。
+
+所以就有了一种折中的方案,指定为`mixed`,记录的内容是前两者的混合。
+
+`MySQL`会判断这条`SQL`语句是否可能引起数据不一致,如果是,就用`row`格式,否则就用`statement`格式。
+
+### 写入机制
+
+`binlog`的写入时机也非常简单,事务执行过程中,先把日志写到`binlog cache`,事务提交的时候,再把`binlog cache`写到`binlog`文件中。
+
+因为一个事务的`binlog`不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为`binlog cache`。
+
+我们可以通过`binlog_cache_size`参数控制单个线程 binlog cache 大小,如果存储内容超过了这个参数,就要暂存到磁盘(`Swap`)。
+
+`binlog`日志刷盘流程如下
+
+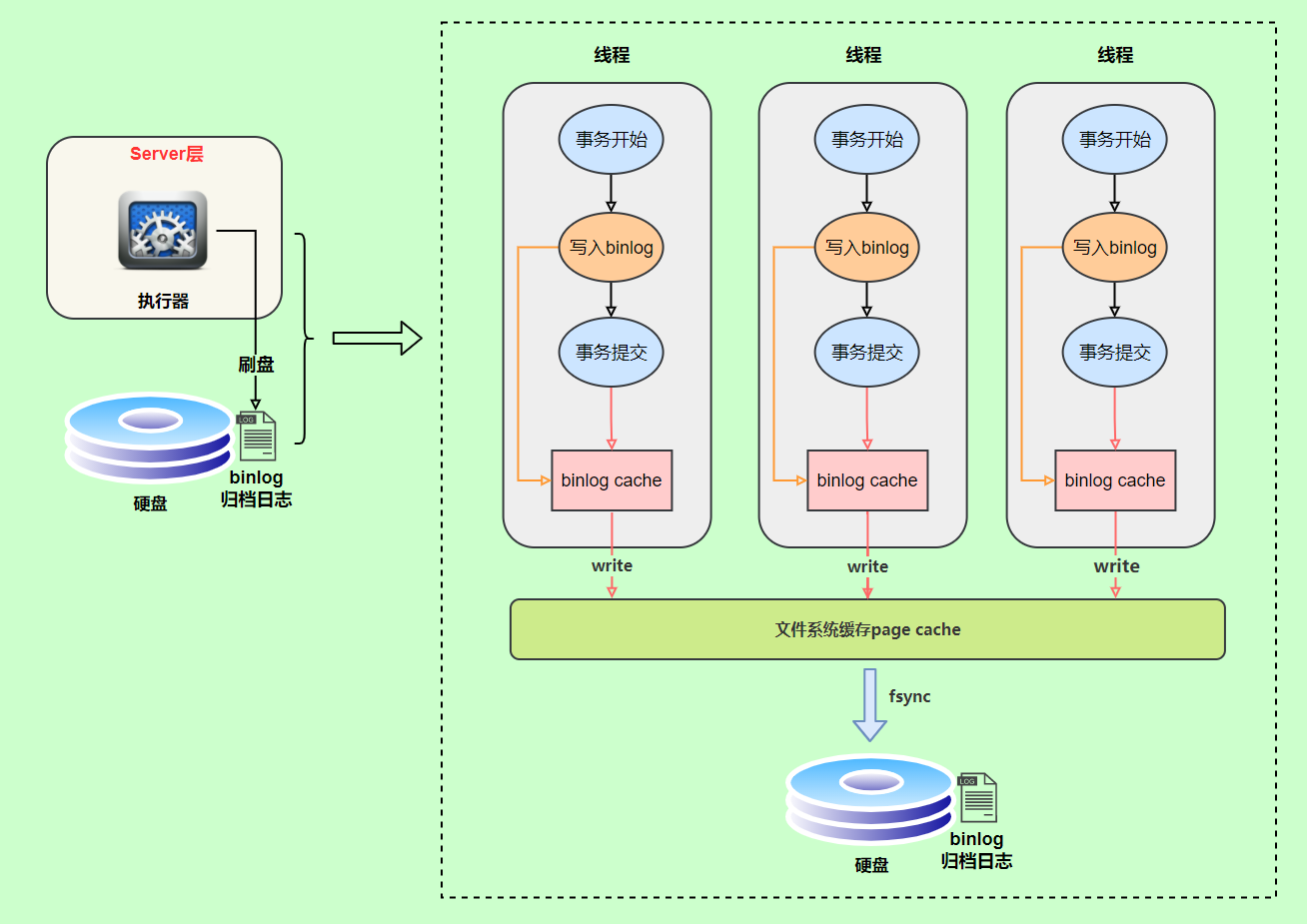
+
+- **上图的 write,是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快**
+- **上图的 fsync,才是将数据持久化到磁盘的操作**
+
+`write`和`fsync`的时机,可以由参数`sync_binlog`控制,默认是`0`。
+
+为`0`的时候,表示每次提交事务都只`write`,由系统自行判断什么时候执行`fsync`。
+
+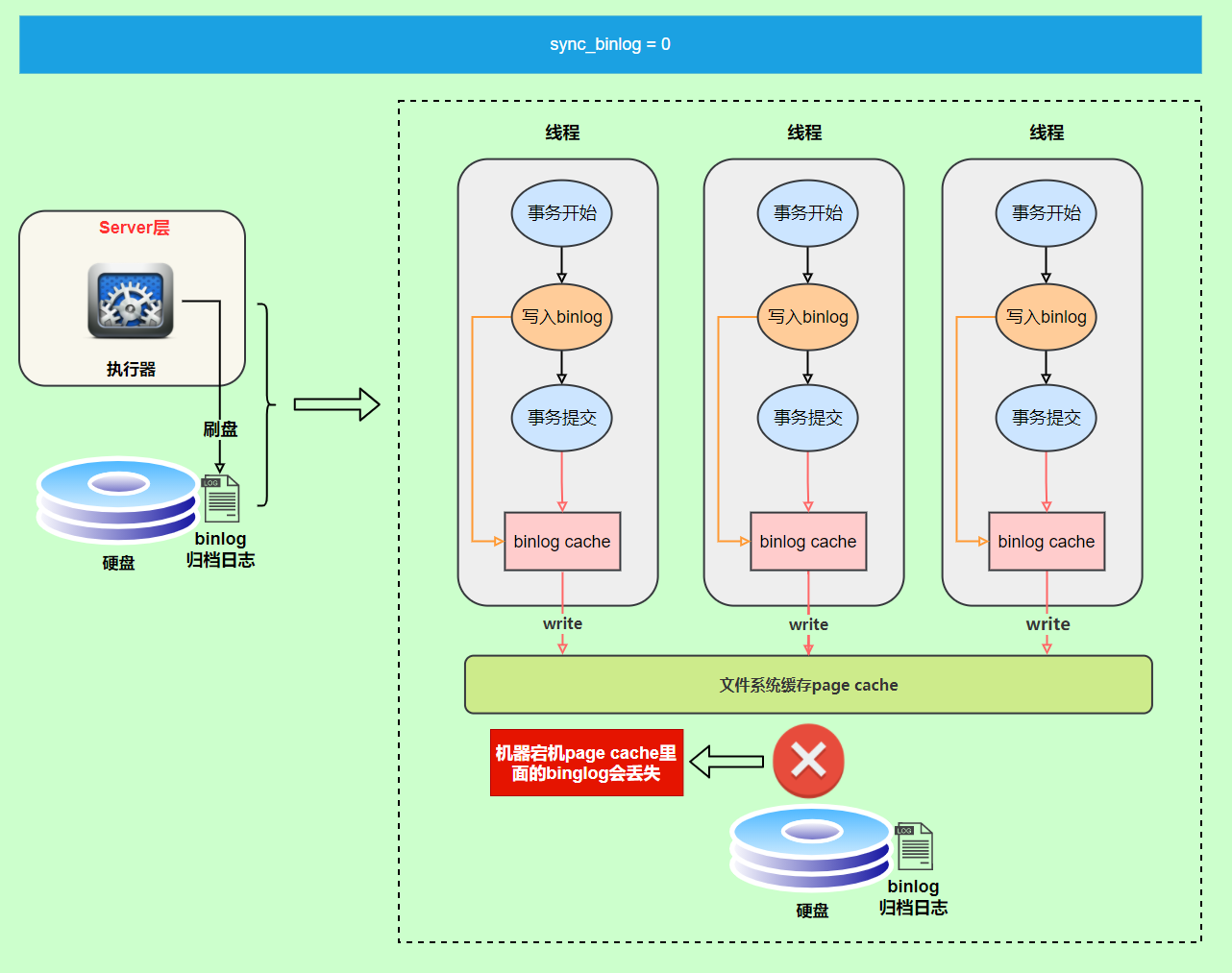
+
+虽然性能得到提升,但是机器宕机,`page cache`里面的 binglog 会丢失。
+
+为了安全起见,可以设置为`1`,表示每次提交事务都会执行`fsync`,就如同**binlog 日志刷盘流程**一样。
+
+最后还有一种折中方式,可以设置为`N(N>1)`,表示每次提交事务都`write`,但累积`N`个事务后才`fsync`。
+
+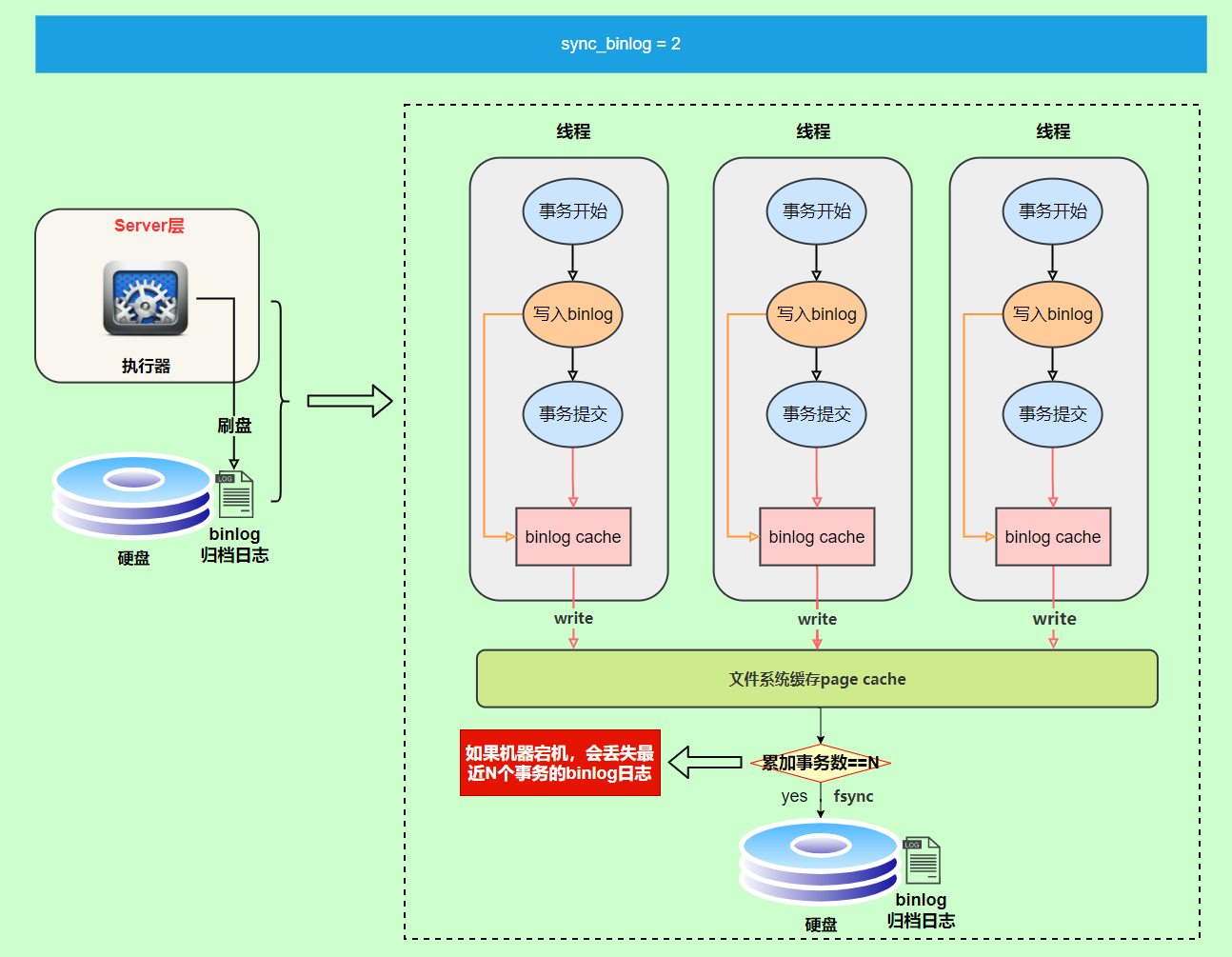
+
+在出现`IO`瓶颈的场景里,将`sync_binlog`设置成一个比较大的值,可以提升性能。
+
+同样的,如果机器宕机,会丢失最近`N`个事务的`binlog`日志。
+
+## 两阶段提交
+
+`redo log`(重做日志)让`InnoDB`存储引擎拥有了崩溃恢复能力。
+
+`binlog`(归档日志)保证了`MySQL`集群架构的数据一致性。
+
+虽然它们都属于持久化的保证,但是侧重点不同。
+
+在执行更新语句过程,会记录`redo log`与`binlog`两块日志,以基本的事务为单位,`redo log`在事务执行过程中可以不断写入,而`binlog`只有在提交事务时才写入,所以`redo log`与`binlog`的写入时机不一样。
+
+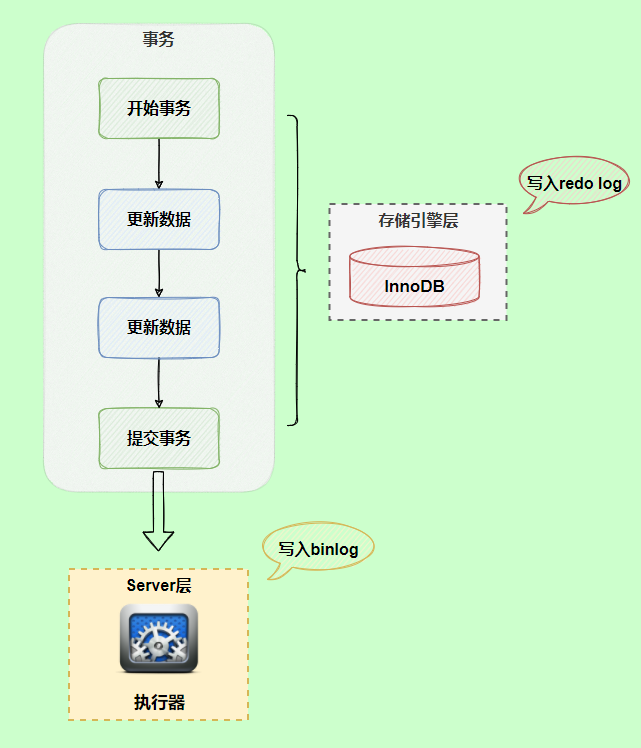
+
+回到正题,`redo log`与`binlog`两份日志之间的逻辑不一致,会出现什么问题?
+
+我们以`update`语句为例,假设`id=2`的记录,字段`c`值是`0`,把字段`c`值更新成`1`,`SQL`语句为`update T set c=1 where id=2`。
+
+假设执行过程中写完`redo log`日志后,`binlog`日志写期间发生了异常,会出现什么情况呢?
+
+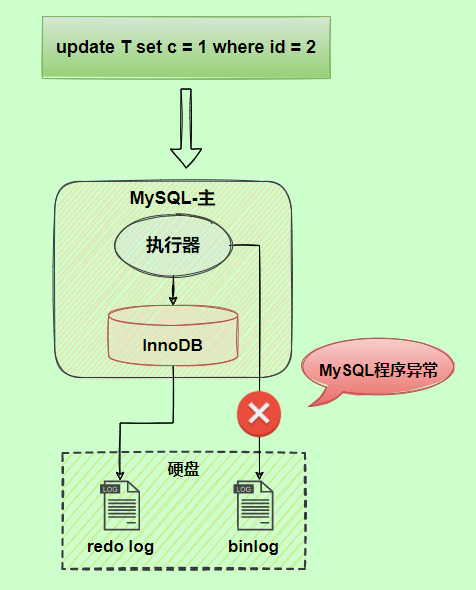
+
+由于`binlog`没写完就异常,这时候`binlog`里面没有对应的修改记录。因此,之后用`binlog`日志恢复数据时,就会少这一次更新,恢复出来的这一行`c`值是`0`,而原库因为`redo log`日志恢复,这一行`c`值是`1`,最终数据不一致。
+
+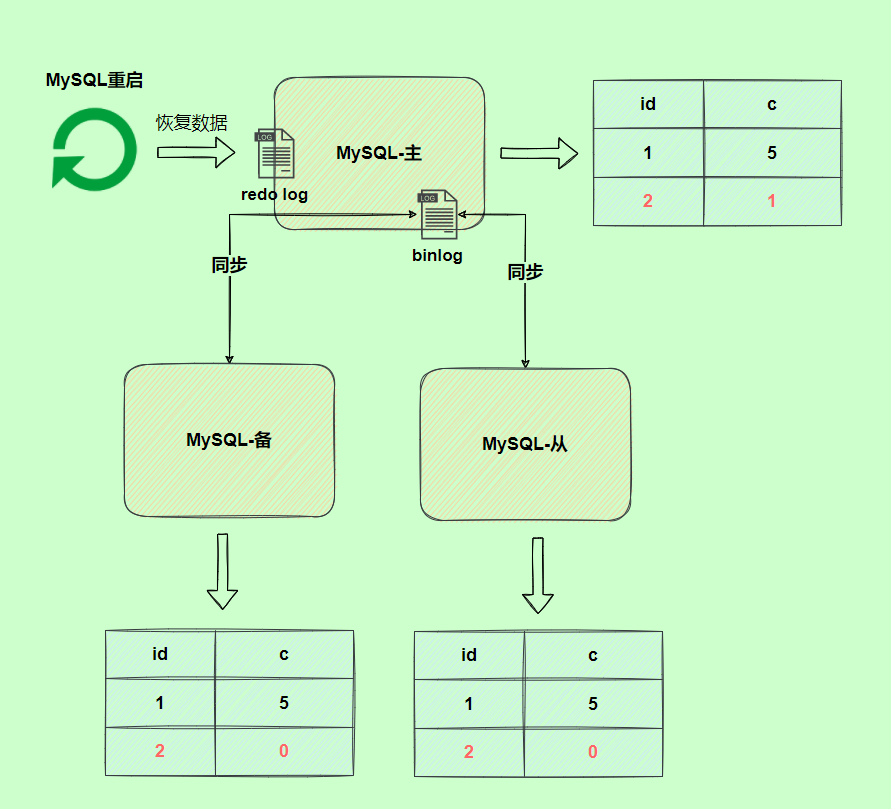
+
+为了解决两份日志之间的逻辑一致问题,`InnoDB`存储引擎使用**两阶段提交**方案。
+
+原理很简单,将`redo log`的写入拆成了两个步骤`prepare`和`commit`,这就是**两阶段提交**。
+
+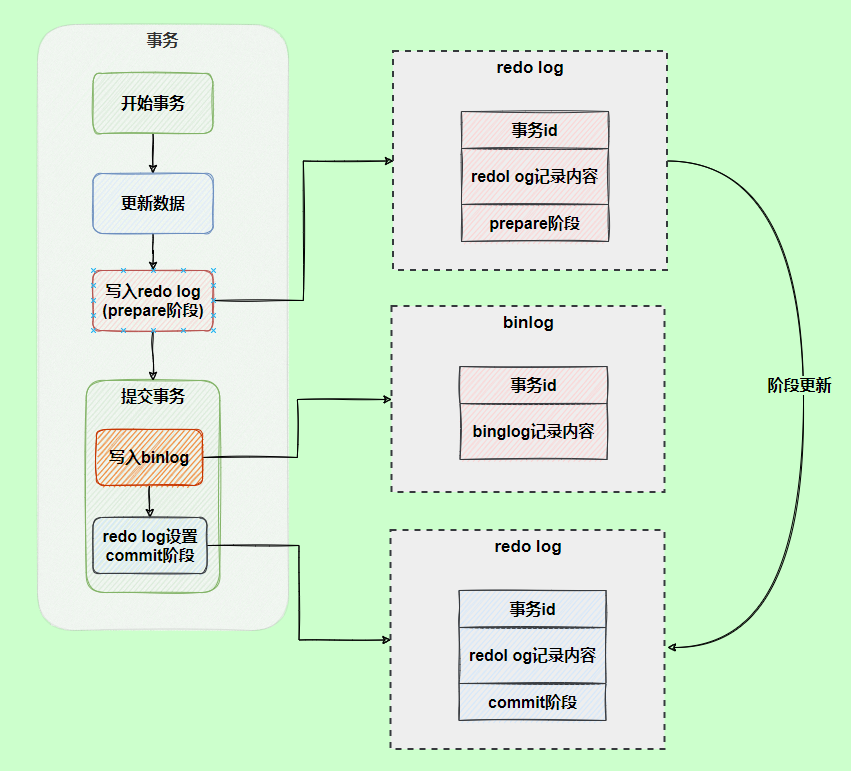
+
+使用**两阶段提交**后,写入`binlog`时发生异常也不会有影响,因为`MySQL`根据`redo log`日志恢复数据时,发现`redo log`还处于`prepare`阶段,并且没有对应`binlog`日志,就会回滚该事务。
+
+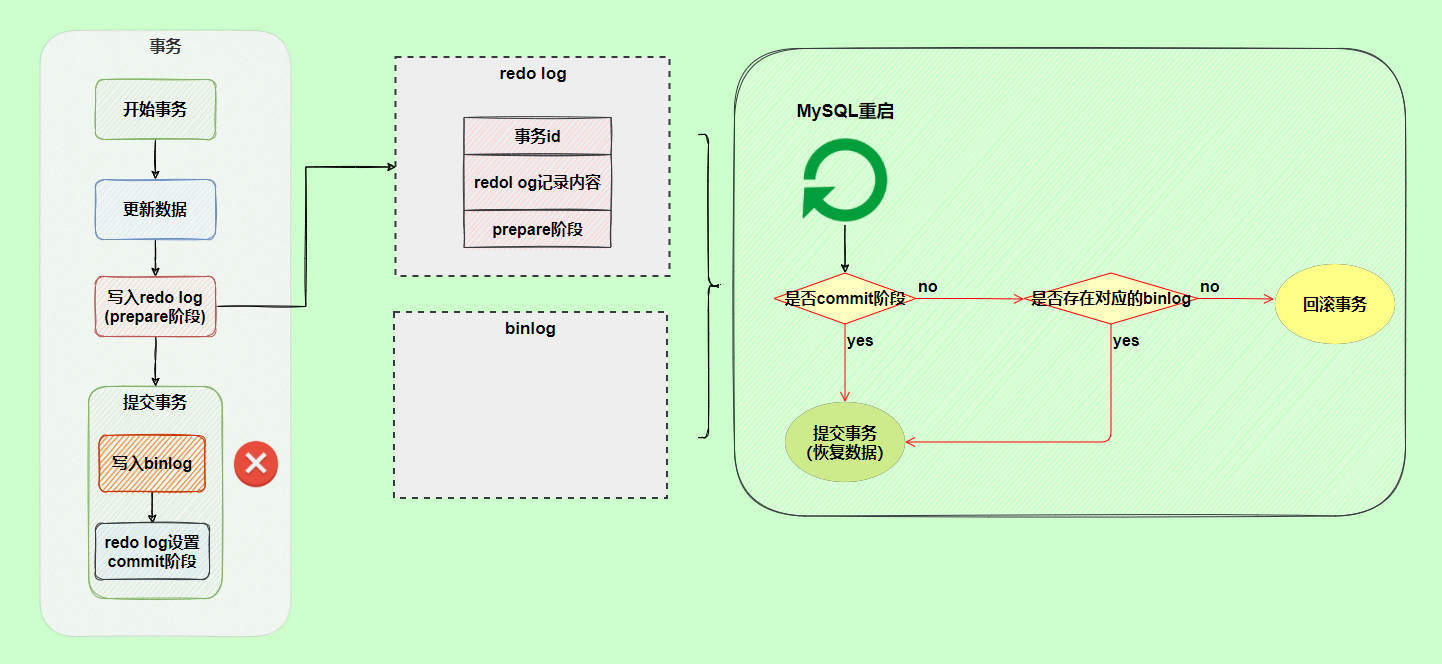
+
+再看一个场景,`redo log`设置`commit`阶段发生异常,那会不会回滚事务呢?
+
+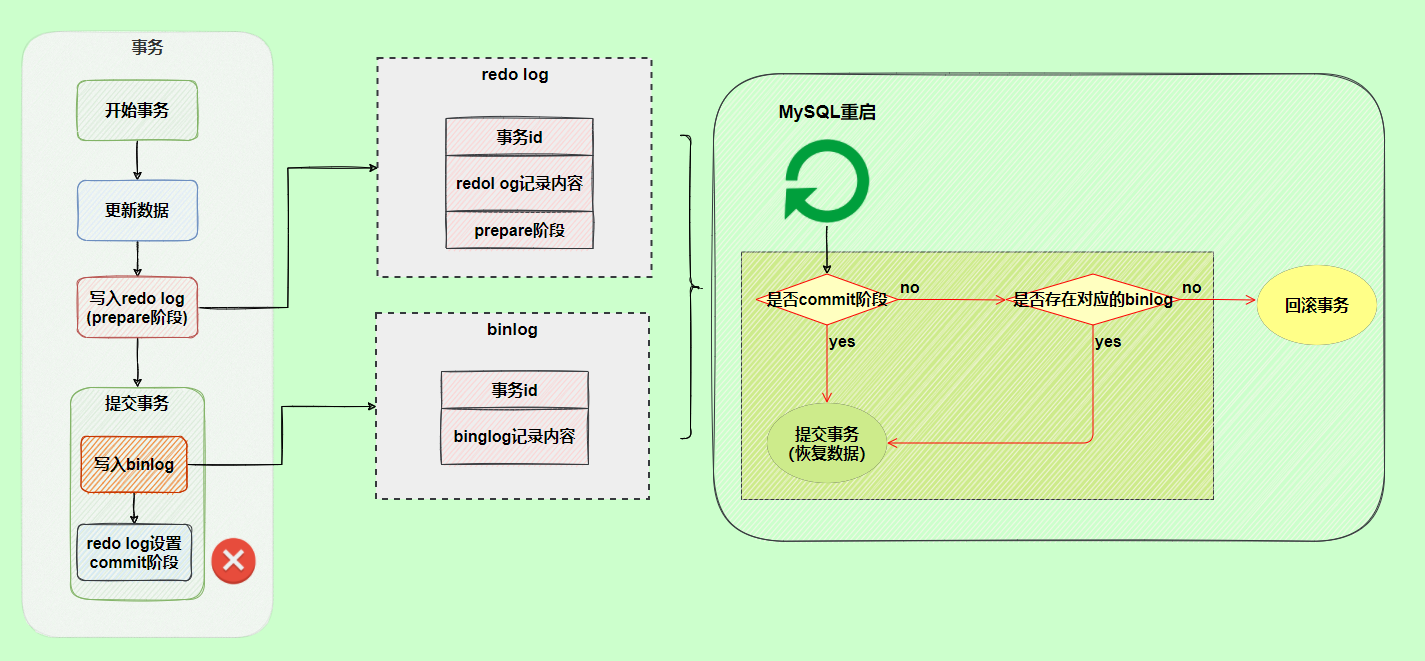
+
+并不会回滚事务,它会执行上图框住的逻辑,虽然`redo log`是处于`prepare`阶段,但是能通过事务`id`找到对应的`binlog`日志,所以`MySQL`认为是完整的,就会提交事务恢复数据。
+
+## undo log
+
+> 这部分内容为 JavaGuide 的补充:
+
+我们知道如果想要保证事务的原子性,就需要在异常发生时,对已经执行的操作进行**回滚**,在 MySQL 中,恢复机制是通过 **回滚日志(undo log)** 实现的,所有事务进行的修改都会先记录到这个回滚日志中,然后再执行相关的操作。如果执行过程中遇到异常的话,我们直接利用 **回滚日志** 中的信息将数据回滚到修改之前的样子即可!并且,回滚日志会先于数据持久化到磁盘上。这样就保证了即使遇到数据库突然宕机等情况,当用户再次启动数据库的时候,数据库还能够通过查询回滚日志来回滚将之前未完成的事务。
+
+另外,`MVCC` 的实现依赖于:**隐藏字段、Read View、undo log**。在内部实现中,`InnoDB` 通过数据行的 `DB_TRX_ID` 和 `Read View` 来判断数据的可见性,如不可见,则通过数据行的 `DB_ROLL_PTR` 找到 `undo log` 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 `Read View` 之前已经提交的修改和该事务本身做的修改
+
+## 总结
+
+> 这部分内容为 JavaGuide 的补充:
+
+MySQL InnoDB 引擎使用 **redo log(重做日志)** 保证事务的**持久性**,使用 **undo log(回滚日志)** 来保证事务的**原子性**。
+
+`MySQL`数据库的**数据备份、主备、主主、主从**都离不开`binlog`,需要依靠`binlog`来同步数据,保证数据一致性。
+
+## 站在巨人的肩膀上
+
+- 《MySQL 实战 45 讲》
+- 《从零开始带你成为 MySQL 实战优化高手》
+- 《MySQL 是怎样运行的:从根儿上理解 MySQL》
+- 《MySQL 技术 Innodb 存储引擎》
+
+## MySQL 好文推荐
+
+- [CURD 这么多年,你有了解过 MySQL 的架构设计吗?](https://mp.weixin.qq.com/s/R-1km7r0z3oWfwYQV8iiqA)
+- [浅谈 MySQL InnoDB 的内存组件](https://mp.weixin.qq.com/s/7Kab4IQsNcU_bZdbv_MuOg)
diff --git "a/docs/database/mysql/mysql\347\237\245\350\257\206\347\202\271&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/database/mysql/mysql\347\237\245\350\257\206\347\202\271&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..b07247b20f5
--- /dev/null
+++ "b/docs/database/mysql/mysql\347\237\245\350\257\206\347\202\271&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -0,0 +1,292 @@
+---
+title: MySQL知识点&面试题总结
+category: 数据库
+tag:
+ - MySQL
+ - 大厂面试
+---
+
+
+## MySQL 基础
+
+### 关系型数据库介绍
+
+顾名思义,关系型数据库就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
+
+关系型数据库中,我们的数据都被存放在了各种表中(比如用户表),表中的每一行就存放着一条数据(比如一个用户的信息)。
+
+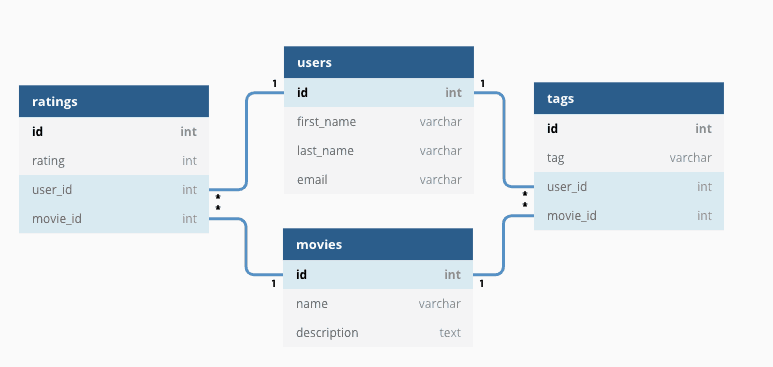
+
+大部分关系型数据库都使用 SQL 来操作数据库中的数据。并且,大部分关系型数据库都支持事务的四大特性(ACID)。
+
+**有哪些常见的关系型数据库呢?**
+
+MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录的存储就是用的 SQLite) ......。
+
+### MySQL 介绍
+
+
+
+**MySQL 是一种关系型数据库,主要用于持久化存储我们的系统中的一些数据比如用户信息。**
+
+由于 MySQL 是开源免费并且比较成熟的数据库,因此,MySQL 被大量使用在各种系统中。任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL 的默认端口号是**3306**。
+
+## 存储引擎
+
+### 存储引擎相关的命令
+
+**查看 MySQL 提供的所有存储引擎**
+
+```sql
+mysql> show engines;
+```
+
+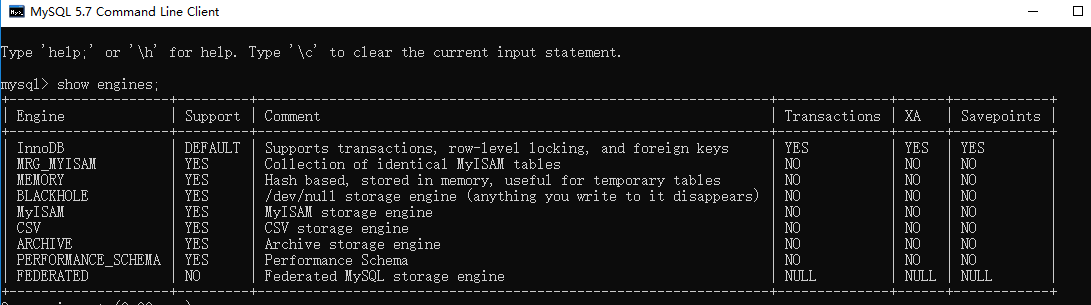
+
+从上图我们可以查看出 MySQL 当前默认的存储引擎是 InnoDB,并且在 5.7 版本所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。
+
+**查看 MySQL 当前默认的存储引擎**
+
+我们也可以通过下面的命令查看默认的存储引擎。
+
+```sql
+mysql> show variables like '%storage_engine%';
+```
+
+**查看表的存储引擎**
+
+```sql
+show table status like "table_name" ;
+```
+
+
+
+### MyISAM 和 InnoDB 的区别
+
+
+
+MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎,可谓是风光一时。
+
+虽然,MyISAM 的性能还行,各种特性也还不错(比如全文索引、压缩、空间函数等)。但是,MyISAM 不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。
+
+5.5 版本之后,MySQL 引入了 InnoDB(事务性数据库引擎),MySQL 5.5 版本后默认的存储引擎为 InnoDB。小伙子,一定要记好这个 InnoDB ,你每次使用 MySQL 数据库都是用的这个存储引擎吧?
+
+言归正传!咱们下面还是来简单对比一下两者:
+
+**1.是否支持行级锁**
+
+MyISAM 只有表级锁(table-level locking),而 InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
+
+也就说,MyISAM 一锁就是锁住了整张表,这在并发写的情况下是多么滴憨憨啊!这也是为什么 InnoDB 在并发写的时候,性能更牛皮了!
+
+**2.是否支持事务**
+
+MyISAM 不提供事务支持。
+
+InnoDB 提供事务支持,具有提交(commit)和回滚(rollback)事务的能力。
+
+**3.是否支持外键**
+
+MyISAM 不支持,而 InnoDB 支持。
+
+🌈 拓展一下:
+
+一般我们也是不建议在数据库层面使用外键的,应用层面可以解决。不过,这样会对数据的一致性造成威胁。具体要不要使用外键还是要根据你的项目来决定。
+
+**4.是否支持数据库异常崩溃后的安全恢复**
+
+MyISAM 不支持,而 InnoDB 支持。
+
+使用 InnoDB 的数据库在异常崩溃后,数据库重新启动的时候会保证数据库恢复到崩溃前的状态。这个恢复的过程依赖于 `redo log` 。
+
+🌈 拓展一下:
+
+- MySQL InnoDB 引擎使用 **redo log(重做日志)** 保证事务的**持久性**,使用 **undo log(回滚日志)** 来保证事务的**原子性**。
+- MySQL InnoDB 引擎通过 **锁机制**、**MVCC** 等手段来保证事务的隔离性( 默认支持的隔离级别是 **`REPEATABLE-READ`** )。
+- 保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。
+
+**5.是否支持 MVCC**
+
+MyISAM 不支持,而 InnoDB 支持。
+
+讲真,这个对比有点废话,毕竟 MyISAM 连行级锁都不支持。
+
+MVCC 可以看作是行级锁的一个升级,可以有效减少加锁操作,提供性能。
+
+### 关于 MyISAM 和 InnoDB 的选择问题
+
+大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊!)。
+
+《MySQL 高性能》上面有一句话这样写到:
+
+> 不要轻易相信“MyISAM 比 InnoDB 快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB 的速度都可以让 MyISAM 望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
+
+一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择 MyISAM 也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
+
+因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由再使用 MyISAM 作为自己的 MySQL 数据库的存储引擎。
+
+## 锁机制与 InnoDB 锁算法
+
+**MyISAM 和 InnoDB 存储引擎使用的锁:**
+
+- MyISAM 采用表级锁(table-level locking)。
+- InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁
+
+**表级锁和行级锁对比:**
+
+- **表级锁:** MySQL 中锁定 **粒度最大** 的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM 和 InnoDB 引擎都支持表级锁。
+- **行级锁:** MySQL 中锁定 **粒度最小** 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
+
+**InnoDB 存储引擎的锁的算法有三种:**
+
+- Record lock:记录锁,单个行记录上的锁
+- Gap lock:间隙锁,锁定一个范围,不包括记录本身
+- Next-key lock:record+gap 临键锁,锁定一个范围,包含记录本身
+
+## 查询缓存
+
+执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
+
+`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
+
+```properties
+query_cache_type=1
+query_cache_size=600000
+```
+
+MySQL 执行以下命令也可以开启查询缓存
+
+```properties
+set global query_cache_type=1;
+set global query_cache_size=600000;
+```
+
+如上,**开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果**。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。(**查询缓存不命中的情况:(1)**)因此任何两个查询在任何字符上的不同都会导致缓存不命中。此外,(**查询缓存不命中的情况:(2)**)如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
+
+(**查询缓存不命中的情况:(3)**)**缓存建立之后**,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
+
+**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十 MB 比较合适。此外,**还可以通过 sql_cache 和 sql_no_cache 来控制某个查询语句是否需要缓存:**
+
+```sql
+select sql_no_cache count(*) from usr;
+```
+
+## 事务
+
+### 何为事务?
+
+一言蔽之,**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
+
+**可以简单举一个例子不?**
+
+事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作就是:
+
+1. 将小明的余额减少 1000 元
+2. 将小红的余额增加 1000 元。
+
+事务会把这两个操作就可以看成逻辑上的一个整体,这个整体包含的操作要么都成功,要么都要失败。
+
+这样就不会出现小明余额减少而小红的余额却并没有增加的情况。
+
+### 何为数据库事务?
+
+数据库事务在我们日常开发中接触的最多了。如果你的项目属于单体架构的话,你接触到的往往就是数据库事务了。
+
+平时,我们在谈论事务的时候,如果没有特指**分布式事务**,往往指的就是**数据库事务**。
+
+**那数据库事务有什么作用呢?**
+
+简单来说:数据库事务可以保证多个对数据库的操作(也就是 SQL 语句)构成一个逻辑上的整体。构成这个逻辑上的整体的这些数据库操作遵循:**要么全部执行成功,要么全部不执行** 。
+
+```sql
+# 开启一个事务
+START TRANSACTION;
+# 多条 SQL 语句
+SQL1,SQL2...
+## 提交事务
+COMMIT;
+```
+
+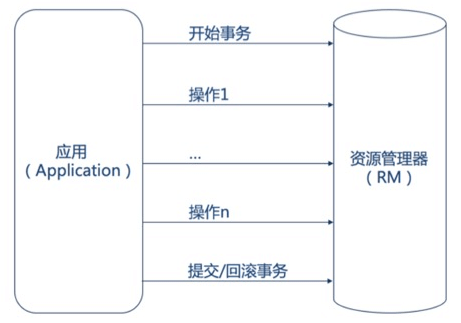
+
+另外,关系型数据库(例如:`MySQL`、`SQL Server`、`Oracle` 等)事务都有 **ACID** 特性:
+
+
+
+### 何为 ACID 特性呢?
+
+1. **原子性**(`Atomicity`) : 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **一致性**(`Consistency`): 执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
+3. **隔离性**(`Isolation`): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+4. **持久性**(`Durability`): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+
+**数据事务的实现原理呢?**
+
+我们这里以 MySQL 的 InnoDB 引擎为例来简单说一下。
+
+MySQL InnoDB 引擎使用 **redo log(重做日志)** 保证事务的**持久性**,使用 **undo log(回滚日志)** 来保证事务的**原子性**。
+
+MySQL InnoDB 引擎通过 **锁机制**、**MVCC** 等手段来保证事务的隔离性( 默认支持的隔离级别是 **`REPEATABLE-READ`** )。
+
+保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。
+
+### 并发事务带来哪些问题?
+
+在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
+
+- **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
+- **丢失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 修改 A=A-1,事务 2 也修改 A=A-1,最终结果 A=19,事务 1 的修改被丢失。
+- **不可重复读(Unrepeatable read):** 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
+- **幻读(Phantom read):** 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
+
+**不可重复读和幻读区别:**
+
+不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次读取一条记录发现记录增多或减少了。
+
+### 事务隔离级别有哪些?
+
+SQL 标准定义了四个隔离级别:
+
+- **READ-UNCOMMITTED(读取未提交):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**。
+- **READ-COMMITTED(读取已提交):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**。
+- **REPEATABLE-READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生**。
+- **SERIALIZABLE(可串行化):** 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。
+
+---
+
+| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
+| :--------------: | :--: | :--------: | :--: |
+| READ-UNCOMMITTED | √ | √ | √ |
+| READ-COMMITTED | × | √ | √ |
+| REPEATABLE-READ | × | × | √ |
+| SERIALIZABLE | × | × | × |
+
+### MySQL 的默认隔离级别是什么?
+
+MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+
+```sql
+mysql> SELECT @@tx_isolation;
++-----------------+
+| @@tx_isolation |
++-----------------+
+| REPEATABLE-READ |
++-----------------+
+```
+
+~~这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)** 事务隔离级别下使用的是 Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说 InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了 SQL 标准的 **SERIALIZABLE(可串行化)** 隔离级别。~~
+
+🐛 问题更正:**MySQL InnoDB 的 REPEATABLE-READ(可重读)并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁度使用到的机制就是 Next-Key Locks。**
+
+因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ(可重读)** 并不会有任何性能损失。
+
+InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALIZABLE(可串行化)** 隔离级别。
+
+🌈 拓展一下(以下内容摘自《MySQL 技术内幕:InnoDB 存储引擎(第 2 版)》7.7 章):
+
+> InnoDB 存储引擎提供了对 XA 事务的支持,并通过 XA 事务来支持分布式事务的实现。分布式事务指的是允许多个独立的事务资源(transactional resources)参与到一个全局的事务中。事务资源通常是关系型数据库系统,但也可以是其他类型的资源。全局事务要求在其中的所有参与的事务要么都提交,要么都回滚,这对于事务原有的 ACID 要求又有了提高。另外,在使用分布式事务时,InnoDB 存储引擎的事务隔离级别必须设置为 SERIALIZABLE。
+
+## 参考
+
+- 《高性能 MySQL》
+- https://www.omnisci.com/technical-glossary/relational-database
diff --git a/docs/database/mysql/some-thoughts-on-database-storage-time.md b/docs/database/mysql/some-thoughts-on-database-storage-time.md
new file mode 100644
index 00000000000..ccad646e5d4
--- /dev/null
+++ b/docs/database/mysql/some-thoughts-on-database-storage-time.md
@@ -0,0 +1,162 @@
+---
+title: 关于数据库中如何存储时间的一点思考
+category: 数据库
+tag:
+ - MySQL
+---
+
+
+
+我们平时开发中不可避免的就是要存储时间,比如我们要记录操作表中这条记录的时间、记录转账的交易时间、记录出发时间等等。你会发现时间这个东西与我们开发的联系还是非常紧密的,用的好与不好会给我们的业务甚至功能带来很大的影响。所以,我们有必要重新出发,好好认识一下这个东西。
+
+这是一篇短小精悍的文章,仔细阅读一定能学到不少东西!
+
+### 1.切记不要用字符串存储日期
+
+我记得我在大学的时候就这样干过,而且现在很多对数据库不太了解的新手也会这样干,可见,这种存储日期的方式的优点还是有的,就是简单直白,容易上手。
+
+但是,这是不正确的做法,主要会有下面两个问题:
+
+1. 字符串占用的空间更大!
+2. 字符串存储的日期效率比较低(逐个字符进行比对),无法用日期相关的 API 进行计算和比较。
+
+### 2.Datetime 和 Timestamp 之间抉择
+
+Datetime 和 Timestamp 是 MySQL 提供的两种比较相似的保存时间的数据类型。他们两者究竟该如何选择呢?
+
+**通常我们都会首选 Timestamp。** 下面说一下为什么这样做!
+
+#### 2.1 DateTime 类型没有时区信息
+
+**DateTime 类型是没有时区信息的(时区无关)** ,DateTime 类型保存的时间都是当前会话所设置的时区对应的时间。这样就会有什么问题呢?当你的时区更换之后,比如你的服务器更换地址或者更换客户端连接时区设置的话,就会导致你从数据库中读出的时间错误。不要小看这个问题,很多系统就是因为这个问题闹出了很多笑话。
+
+**Timestamp 和时区有关**。Timestamp 类型字段的值会随着服务器时区的变化而变化,自动换算成相应的时间,说简单点就是在不同时区,查询到同一个条记录此字段的值会不一样。
+
+下面实际演示一下!
+
+建表 SQL 语句:
+
+```sql
+CREATE TABLE `time_zone_test` (
+ `id` bigint(20) NOT NULL AUTO_INCREMENT,
+ `date_time` datetime DEFAULT NULL,
+ `time_stamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+```
+
+插入数据:
+
+```sql
+INSERT INTO time_zone_test(date_time,time_stamp) VALUES(NOW(),NOW());
+```
+
+查看数据:
+
+```sql
+select date_time,time_stamp from time_zone_test;
+```
+
+结果:
+
+```
++---------------------+---------------------+
+| date_time | time_stamp |
++---------------------+---------------------+
+| 2020-01-11 09:53:32 | 2020-01-11 09:53:32 |
++---------------------+---------------------+
+```
+
+现在我们运行
+
+修改当前会话的时区:
+
+```sql
+set time_zone='+8:00';
+```
+
+再次查看数据:
+
+```
++---------------------+---------------------+
+| date_time | time_stamp |
++---------------------+---------------------+
+| 2020-01-11 09:53:32 | 2020-01-11 17:53:32 |
++---------------------+---------------------+
+```
+
+**扩展:一些关于 MySQL 时区设置的一个常用 sql 命令**
+
+```sql
+# 查看当前会话时区
+SELECT @@session.time_zone;
+# 设置当前会话时区
+SET time_zone = 'Europe/Helsinki';
+SET time_zone = "+00:00";
+# 数据库全局时区设置
+SELECT @@global.time_zone;
+# 设置全局时区
+SET GLOBAL time_zone = '+8:00';
+SET GLOBAL time_zone = 'Europe/Helsinki';
+```
+
+#### 2.2 DateTime 类型耗费空间更大
+
+Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
+
+- DateTime :1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
+- Timestamp: 1970-01-01 00:00:01 ~ 2037-12-31 23:59:59
+
+> Timestamp 在不同版本的 MySQL 中有细微差别。
+
+### 3 再看 MySQL 日期类型存储空间
+
+下图是 MySQL 5.6 版本中日期类型所占的存储空间:
+
+
+
+可以看出 5.6.4 之后的 MySQL 多出了一个需要 0 ~ 3 字节的小数位。DateTime 和 Timestamp 会有几种不同的存储空间占用。
+
+为了方便,本文我们还是默认 Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗费 8 个字节的存储空间。
+
+### 4.数值型时间戳是更好的选择吗?
+
+很多时候,我们也会使用 int 或者 bigint 类型的数值也就是时间戳来表示时间。
+
+这种存储方式的具有 Timestamp 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
+
+时间戳的定义如下:
+
+> 时间戳的定义是从一个基准时间开始算起,这个基准时间是「1970-1-1 00:00:00 +0:00」,从这个时间开始,用整数表示,以秒计时,随着时间的流逝这个时间整数不断增加。这样一来,我只需要一个数值,就可以完美地表示时间了,而且这个数值是一个绝对数值,即无论的身处地球的任何角落,这个表示时间的时间戳,都是一样的,生成的数值都是一样的,并且没有时区的概念,所以在系统的中时间的传输中,都不需要进行额外的转换了,只有在显示给用户的时候,才转换为字符串格式的本地时间。
+
+数据库中实际操作:
+
+```sql
+mysql> select UNIX_TIMESTAMP('2020-01-11 09:53:32');
++---------------------------------------+
+| UNIX_TIMESTAMP('2020-01-11 09:53:32') |
++---------------------------------------+
+| 1578707612 |
++---------------------------------------+
+1 row in set (0.00 sec)
+
+mysql> select FROM_UNIXTIME(1578707612);
++---------------------------+
+| FROM_UNIXTIME(1578707612) |
++---------------------------+
+| 2020-01-11 09:53:32 |
++---------------------------+
+1 row in set (0.01 sec)
+```
+
+### 5.总结
+
+MySQL 中时间到底怎么存储才好?Datetime?Timestamp? 数值保存的时间戳?
+
+好像并没有一个银弹,很多程序员会觉得数值型时间戳是真的好,效率又高还各种兼容,但是很多人又觉得它表现的不够直观。这里插一嘴,《高性能 MySQL 》这本神书的作者就是推荐 Timestamp,原因是数值表示时间不够直观。下面是原文:
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/高性能mysql-不推荐用数值时间戳.jpg" style="zoom:50%;" />
+
+每种方式都有各自的优势,根据实际场景才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/总结-常用日期存储方式.jpg" style="zoom:50%;" />
\ No newline at end of file
diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
new file mode 100644
index 00000000000..4be2f5fde44
--- /dev/null
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -0,0 +1,146 @@
+---
+title: 事务隔离级别(图文详解)
+category: 数据库
+tag:
+ - MySQL
+---
+
+
+> 本文由 [SnailClimb](https://github.com/Snailclimb) 和 [guang19](https://github.com/guang19) 共同完成。
+
+## 事务隔离级别(图文详解)
+
+### 什么是事务?
+
+事务是逻辑上的一组操作,要么都执行,要么都不执行。
+
+事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
+
+### 事务的特性(ACID)
+
+
+
+
+1. **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **一致性:** 执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
+3. **隔离性:** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+4. **持久性:** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+
+### 并发事务带来的问题
+
+在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
+
+- **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
+- **丢失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
+- **不可重复读(Unrepeatableread):** 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
+- **幻读(Phantom read):** 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
+
+**不可重复度和幻读区别:**
+
+不可重复读的重点是修改,幻读的重点在于新增或者删除。
+
+例1(同样的条件, 你读取过的数据, 再次读取出来发现值不一样了 ):事务1中的A先生读取自己的工资为 1000的操作还没完成,事务2中的B先生就修改了A的工资为2000,导 致A再读自己的工资时工资变为 2000;这就是不可重复读。
+
+ 例2(同样的条件, 第1次和第2次读出来的记录数不一样 ):假某工资单表中工资大于3000的有4人,事务1读取了所有工资大于3000的人,共查到4条记录,这时事务2 又插入了一条工资大于3000的记录,事务1再次读取时查到的记录就变为了5条,这样就导致了幻读。
+
+### 事务隔离级别
+
+**SQL 标准定义了四个隔离级别:**
+
+- **READ-UNCOMMITTED(读取未提交):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**。
+- **READ-COMMITTED(读取已提交):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**。
+- **REPEATABLE-READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生**。
+- **SERIALIZABLE(可串行化):** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。
+
+----
+
+| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
+| :---: | :---: | :---:| :---: |
+| READ-UNCOMMITTED | √ | √ | √ |
+| READ-COMMITTED | × | √ | √ |
+| REPEATABLE-READ | × | × | √ |
+| SERIALIZABLE | × | × | × |
+
+MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+
+```sql
+mysql> SELECT @@tx_isolation;
++-----------------+
+| @@tx_isolation |
++-----------------+
+| REPEATABLE-READ |
++-----------------+
+```
+
+~~这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)** 事务隔离级别下使用的是 Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说 InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了 SQL 标准的 **SERIALIZABLE(可串行化)** 隔离级别。~~
+
+🐛 问题更正:**MySQL InnoDB 的 REPEATABLE-READ(可重读)并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁度使用到的机制就是 Next-Key Locks。**
+
+因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ(可重读)** 并不会有任何性能损失。
+
+InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALIZABLE(可串行化)** 隔离级别。
+
+🌈 拓展一下(以下内容摘自《MySQL 技术内幕:InnoDB 存储引擎(第 2 版)》7.7 章):
+
+> InnoDB 存储引擎提供了对 XA 事务的支持,并通过 XA 事务来支持分布式事务的实现。分布式事务指的是允许多个独立的事务资源(transactional resources)参与到一个全局的事务中。事务资源通常是关系型数据库系统,但也可以是其他类型的资源。全局事务要求在其中的所有参与的事务要么都提交,要么都回滚,这对于事务原有的 ACID 要求又有了提高。另外,在使用分布式事务时,InnoDB 存储引擎的事务隔离级别必须设置为 SERIALIZABLE。
+
+### 实际情况演示
+
+在下面我会使用 2 个命令行mysql ,模拟多线程(多事务)对同一份数据的脏读问题。
+
+MySQL 命令行的默认配置中事务都是自动提交的,即执行SQL语句后就会马上执行 COMMIT 操作。如果要显式地开启一个事务需要使用命令:`START TARNSACTION`。
+
+我们可以通过下面的命令来设置隔离级别。
+
+```sql
+SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
+```
+
+我们再来看一下我们在下面实际操作中使用到的一些并发控制语句:
+
+- `START TARNSACTION` |`BEGIN`:显式地开启一个事务。
+- `COMMIT`:提交事务,使得对数据库做的所有修改成为永久性。
+- `ROLLBACK`:回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。
+
+#### 脏读(读未提交)
+
+<div align="center">
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-31-1脏读(读未提交)实例.jpg" width="800px"/>
+</div>
+
+#### 避免脏读(读已提交)
+
+<div align="center">
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-31-2读已提交实例.jpg" width="800px"/>
+</div>
+
+#### 不可重复读
+
+还是刚才上面的读已提交的图,虽然避免了读未提交,但是却出现了,一个事务还没有结束,就发生了 不可重复读问题。
+
+<div align="center">
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-32-1不可重复读实例.jpg"/>
+</div>
+
+#### 可重复读
+
+<div align="center">
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-33-2可重复读.jpg"/>
+</div>
+
+#### 防止幻读(可重复读)
+
+<div align="center">
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-33防止幻读(使用可重复读).jpg"/>
+</div>
+
+一个事务对数据库进行操作,这种操作的范围是数据库的全部行,然后第二个事务也在对这个数据库操作,这种操作可以是插入一行记录或删除一行记录,那么第一个是事务就会觉得自己出现了幻觉,怎么还有没有处理的记录呢? 或者 怎么多处理了一行记录呢?
+
+幻读和不可重复读有些相似之处 ,但是不可重复读的重点是修改,幻读的重点在于新增或者删除。
+
+### 参考
+
+- 《MySQL技术内幕:InnoDB存储引擎》
+- <https://dev.mysql.com/doc/refman/5.7/en/>
+- [Mysql 锁:灵魂七拷问](https://tech.youzan.com/seven-questions-about-the-lock-of-mysql/)
+- [Innodb 中的事务隔离级别和锁的关系](https://tech.meituan.com/2014/08/20/innodb-lock.html)
diff --git a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
new file mode 100644
index 00000000000..841067861f2
--- /dev/null
+++ b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
@@ -0,0 +1,116 @@
+---
+title: 3种常用的缓存读写策略
+category: 数据库
+tag:
+ - Redis
+---
+
+
+看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的3种读写策略**”的时候却一脸懵逼。
+
+在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单了写一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
+
+但是,搞懂3种常见的缓存读写策略对于实际工作中使用缓存以及面试中被问到缓存都是非常有帮助的!
+
+下面我会简单介绍一下自己对于这 3 种缓存读写策略的理解。
+
+另外,**这3 种缓存读写策略各有优劣,不存在最佳,需要我们根据具体的业务场景选择更适合的。**
+
+*个人能力有限。如果文章有任何需要补充/完善/修改的地方,欢迎在评论区指出,共同进步!——爱你们的 Guide 哥*
+
+### Cache Aside Pattern(旁路缓存模式)
+
+**Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。**
+
+Cache Aside Pattern 中服务端需要同时维系 DB 和 cache,并且是以 DB 的结果为准。
+
+下面我们来看一下这个策略模式下的缓存读写步骤。
+
+**写** :
+
+- 先更新 DB
+- 然后直接删除 cache 。
+
+简单画了一张图帮助大家理解写的步骤。
+
+
+
+**读** :
+
+- 从 cache 中读取数据,读取到就直接返回
+- cache中读取不到的话,就从 DB 中读取数据返回
+- 再把数据放到 cache 中。
+
+简单画了一张图帮助大家理解读的步骤。
+
+
+
+
+你仅仅了解了上面这些内容的话是远远不够的,我们还要搞懂其中的原理。
+
+比如说面试官很可能会追问:“**在写数据的过程中,可以先删除 cache ,后更新 DB 么?**”
+
+**答案:** 那肯定是不行的!因为这样可能会造成**数据库(DB)和缓存(Cache)数据不一致**的问题。为什么呢?比如说请求1 先写数据A,请求2随后读数据A的话就很有可能产生数据不一致性的问题。这个过程可以简单描述为:
+
+> 请求1先把cache中的A数据删除 -> 请求2从DB中读取数据->请求1再把DB中的A数据更新。
+
+当你这样回答之后,面试官可能会紧接着就追问:“**在写数据的过程中,先更新DB,后删除cache就没有问题了么?**”
+
+**答案:** 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小,因为缓存的写入速度是比数据库的写入速度快很多!
+
+比如请求1先读数据 A,请求2随后写数据A,并且数据A不在缓存中的话也有可能产生数据不一致性的问题。这个过程可以简单描述为:
+
+> 请求1从DB读数据A->请求2写更新数据 A 到数据库并把删除cache中的A数据->请求1将数据A写入cache。
+
+现在我们再来分析一下 **Cache Aside Pattern 的缺陷**。
+
+**缺陷1:首次请求数据一定不在 cache 的问题**
+
+解决办法:可以将热点数据可以提前放入cache 中。
+
+**缺陷2:写操作比较频繁的话导致cache中的数据会被频繁被删除,这样会影响缓存命中率 。**
+
+解决办法:
+
+- 数据库和缓存数据强一致场景 :更新DB的时候同样更新cache,不过我们需要加一个锁/分布式锁来保证更新cache的时候不存在线程安全问题。
+- 可以短暂地允许数据库和缓存数据不一致的场景 :更新DB的时候同样更新cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
+
+### Read/Write Through Pattern(读写穿透)
+
+Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 DB,从而减轻了应用程序的职责。
+
+这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入DB的功能。
+
+**写(Write Through):**
+
+- 先查 cache,cache 中不存在,直接更新 DB。
+- cache 中存在,则先更新 cache,然后 cache 服务自己更新 DB(**同步更新 cache 和 DB**)。
+
+简单画了一张图帮助大家理解写的步骤。
+
+
+
+**读(Read Through):**
+
+- 从 cache 中读取数据,读取到就直接返回 。
+- 读取不到的话,先从 DB 加载,写入到 cache 后返回响应。
+
+简单画了一张图帮助大家理解读的步骤。
+
+
+
+Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
+
+和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
+
+### Write Behind Pattern(异步缓存写入)
+
+Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 DB 的读写。
+
+但是,两个又有很大的不同:**Read/Write Through 是同步更新 cache 和 DB,而 Write Behind Caching 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。**
+
+很明显,这种方式对数据一致性带来了更大的挑战,比如cache数据可能还没异步更新DB的话,cache服务可能就就挂掉了。
+
+这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 InnoDB Buffer Pool 机制都用到了这种策略。
+
+Write Behind Pattern 下 DB 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
diff --git a/docs/database/redis/images/redis-all/redis-list.drawio b/docs/database/redis/images/redis-all/redis-list.drawio
new file mode 100644
index 00000000000..afa767154b7
--- /dev/null
+++ b/docs/database/redis/images/redis-all/redis-list.drawio
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-07-27T06:27:52.340Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="dsqbsLB26jrO3YkREjOb" version="13.4.5" type="device"><diagram id="tTBfL0GptSJyUtbD2ZoE" name="Page-1">7VlNc5swFPw1PiaDENjmmNjpx6Gdjt1J2lNHAzKoEYgRcmzn11cYyRgJT1w3DnScU3grIaHd5b2HM4CTdP2Rozz5wiJMB64TrQdwOnBdEEAo/5TIpkICx6mAmJNITaqBOXnGCtTTliTCRWOiYIwKkjfBkGUZDkUDQ5yzVXPagtHmrjmKsQXMQ0Rt9IFEIqnQsTuq8U+YxIneGQyDaiRFerI6SZGgiK32IHg3gBPOmKiu0vUE05I8zUt134cDo7sH4zgTx9wwu/+V/H4g/myezsD35/vZ56/ulVrlCdGlOrB6WLHRDHC2zCJcLgIG8HaVEIHnOQrL0ZXUXGKJSKkaLh6xCBMVLFgmlKJgJGO1F+YCrw8eAuyokZ7CLMWCb+QUdcOVp9hUdnKhile1OL62WLInzEhhSPkh3i1dUyYvFGt/waBrMbi9BD3lUfPm2bwFLbT556INttPWc/sB035d0+i10wj7TaM77hmNw5fTIM6im7KeyCikqChI2ORMHp1vfsjA0cHPMrh2fR1P1/uj042KjiAbR1aRMqiWVRHxGIuXUr0tSSNxHqacY4oEeWo+RpsOaodvjMgHrPM2gKbk4+YaBVvyEKvb9suYuZLpHdcwRUWEtdDWF7tzn26V0f9ula4s4A0N4cbOtX+aB3zfWupNPaCb01cxAXjPF0cofGq68AJjIT8wXXdusxzRY/fbLJ0VDbPbOj1j2PXnrVOG/Z3A82WRWFaQXZUwujHB2SOeMMq4RDKW4VJLQqkBIUrirHSQVA9L/Lbs0Yj8lL1RAymJonKb1vavbhCP9M0/dYA+OFDF95zltTjLLPav1gECu5PmOcvf5aloD7qWx7fkoRf8+siiYggEuhbI/oSil/v+2Pp0/gLZ3y18u20/BTqDJp5O8VoSp2tJxvYrgxcXpIjV351PERnWv7RXPV39/wp49wc=</diagram></mxfile>
\ No newline at end of file
diff --git a/docs/database/redis/images/redis-all/redis-list.png b/docs/database/redis/images/redis-all/redis-list.png
new file mode 100644
index 00000000000..4fb4e36cb49
Binary files /dev/null and b/docs/database/redis/images/redis-all/redis-list.png differ
diff --git a/docs/database/redis/images/redis-all/redis-rollBack.png b/docs/database/redis/images/redis-all/redis-rollBack.png
new file mode 100644
index 00000000000..91f7f46d66d
Binary files /dev/null and b/docs/database/redis/images/redis-all/redis-rollBack.png differ
diff --git a/docs/database/redis/images/redis-all/redis-vs-memcached.png b/docs/database/redis/images/redis-all/redis-vs-memcached.png
new file mode 100644
index 00000000000..23844d67e6f
Binary files /dev/null and b/docs/database/redis/images/redis-all/redis-vs-memcached.png differ
diff --git a/docs/database/redis/images/redis-all/redis4.0-more-thread.png b/docs/database/redis/images/redis-all/redis4.0-more-thread.png
new file mode 100644
index 00000000000..e7e19e52e17
Binary files /dev/null and b/docs/database/redis/images/redis-all/redis4.0-more-thread.png differ
diff --git "a/docs/database/redis/images/redis-all/redis\344\272\213\344\273\266\345\244\204\347\220\206\345\231\250.png" "b/docs/database/redis/images/redis-all/redis\344\272\213\344\273\266\345\244\204\347\220\206\345\231\250.png"
new file mode 100644
index 00000000000..fc280fffaba
Binary files /dev/null and "b/docs/database/redis/images/redis-all/redis\344\272\213\344\273\266\345\244\204\347\220\206\345\231\250.png" differ
diff --git "a/docs/database/redis/images/redis-all/redis\344\272\213\345\212\241.png" "b/docs/database/redis/images/redis-all/redis\344\272\213\345\212\241.png"
new file mode 100644
index 00000000000..eb0c404cafd
Binary files /dev/null and "b/docs/database/redis/images/redis-all/redis\344\272\213\345\212\241.png" differ
diff --git "a/docs/database/redis/images/redis-all/redis\350\277\207\346\234\237\346\227\266\351\227\264.png" "b/docs/database/redis/images/redis-all/redis\350\277\207\346\234\237\346\227\266\351\227\264.png"
new file mode 100644
index 00000000000..27df6ead8e4
Binary files /dev/null and "b/docs/database/redis/images/redis-all/redis\350\277\207\346\234\237\346\227\266\351\227\264.png" differ
diff --git a/docs/database/redis/images/redis-all/try-redis.png b/docs/database/redis/images/redis-all/try-redis.png
new file mode 100644
index 00000000000..cd21a6518e4
Binary files /dev/null and b/docs/database/redis/images/redis-all/try-redis.png differ
diff --git a/docs/database/redis/images/redis-all/what-is-redis.png b/docs/database/redis/images/redis-all/what-is-redis.png
new file mode 100644
index 00000000000..913881ac6cf
Binary files /dev/null and b/docs/database/redis/images/redis-all/what-is-redis.png differ
diff --git "a/docs/database/redis/images/redis-all/\344\275\277\347\224\250\347\274\223\345\255\230\344\271\213\345\220\216.png" "b/docs/database/redis/images/redis-all/\344\275\277\347\224\250\347\274\223\345\255\230\344\271\213\345\220\216.png"
new file mode 100644
index 00000000000..2c73bd90276
Binary files /dev/null and "b/docs/database/redis/images/redis-all/\344\275\277\347\224\250\347\274\223\345\255\230\344\271\213\345\220\216.png" differ
diff --git "a/docs/database/redis/images/redis-all/\345\212\240\345\205\245\345\270\203\351\232\206\350\277\207\346\273\244\345\231\250\345\220\216\347\232\204\347\274\223\345\255\230\345\244\204\347\220\206\346\265\201\347\250\213.png" "b/docs/database/redis/images/redis-all/\345\212\240\345\205\245\345\270\203\351\232\206\350\277\207\346\273\244\345\231\250\345\220\216\347\232\204\347\274\223\345\255\230\345\244\204\347\220\206\346\265\201\347\250\213.png"
new file mode 100644
index 00000000000..a2c2ed6906f
Binary files /dev/null and "b/docs/database/redis/images/redis-all/\345\212\240\345\205\245\345\270\203\351\232\206\350\277\207\346\273\244\345\231\250\345\220\216\347\232\204\347\274\223\345\255\230\345\244\204\347\220\206\346\265\201\347\250\213.png" differ
diff --git "a/docs/database/redis/images/redis-all/\345\215\225\344\275\223\346\236\266\346\236\204.png" "b/docs/database/redis/images/redis-all/\345\215\225\344\275\223\346\236\266\346\236\204.png"
new file mode 100644
index 00000000000..648a404af8c
Binary files /dev/null and "b/docs/database/redis/images/redis-all/\345\215\225\344\275\223\346\236\266\346\236\204.png" differ
diff --git "a/docs/database/redis/images/redis-all/\347\274\223\345\255\230\347\232\204\345\244\204\347\220\206\346\265\201\347\250\213.png" "b/docs/database/redis/images/redis-all/\347\274\223\345\255\230\347\232\204\345\244\204\347\220\206\346\265\201\347\250\213.png"
new file mode 100644
index 00000000000..11860ae1f02
Binary files /dev/null and "b/docs/database/redis/images/redis-all/\347\274\223\345\255\230\347\232\204\345\244\204\347\220\206\346\265\201\347\250\213.png" differ
diff --git "a/docs/database/redis/images/redis-all/\347\274\223\345\255\230\347\251\277\351\200\217\346\203\205\345\206\265.png" "b/docs/database/redis/images/redis-all/\347\274\223\345\255\230\347\251\277\351\200\217\346\203\205\345\206\265.png"
new file mode 100644
index 00000000000..e7298c15ed6
Binary files /dev/null and "b/docs/database/redis/images/redis-all/\347\274\223\345\255\230\347\251\277\351\200\217\346\203\205\345\206\265.png" differ
diff --git "a/docs/database/redis/images/redis-all/\351\233\206\344\270\255\345\274\217\347\274\223\345\255\230\346\236\266\346\236\204.png" "b/docs/database/redis/images/redis-all/\351\233\206\344\270\255\345\274\217\347\274\223\345\255\230\346\236\266\346\236\204.png"
new file mode 100644
index 00000000000..5aff414baa4
Binary files /dev/null and "b/docs/database/redis/images/redis-all/\351\233\206\344\270\255\345\274\217\347\274\223\345\255\230\346\236\266\346\236\204.png" differ
diff --git "a/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio" "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio"
new file mode 100644
index 00000000000..bc4c6d0cca7
--- /dev/null
+++ "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-12-19T10:09:54.115Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="ouO_wanaVWn605JgN_9b" version="13.4.5" type="device"><diagram id="3s-LqK6m4lkifnhmqHE2" name="Page-1">7Vpbc+o2EP41ekzHl/j2iAmk02nmdA6dpn3qCFsYTWSLY0Qg/fWVbMnYluE4B4jTQh4Se6WVVt+32pU2BvY43T3mcLV8ojEiwDLiHbAfgGWZluPzP0LyVkoCwygFSY5j2WkvmOF/kBSqbhsco3WjI6OUMLxqCiOaZShiDRnMc7ptdltQ0px1BROkCWYRJLr0GcdsWUp9y9vLf0Y4WaqZTTcoW1KoOsuVrJcwptuayJ4Ae5xTysqndDdGRICncCn1pgdaK8NylLE+Ck/Pf/xthHPraf7NePliLeLZ1+c7OcorJBu5YGkse1MI5HSTxUgMYgI73C4xQ7MVjETrlnPOZUuWEtm8wISMKaF5oWsvFgsrirh8zXL6gmotsTt3HVe0KFiEekRTzLs/GPw5IXC9ls/SSpQztDu4fLMClXsjoili+RvvIhVs5VHSEX3fKd+3e1pNxdWyRqkrZVB6UlINvQebP0i834G9db3YW0Njb2vYx5BBDX++ZNYEuQlmRjN0BHlIcJJxWcRxQrwxFChiHlxGsiHFcSzm6qR2T75RTaxiUME3zZgMmFbQIq1O5jkIvG8RqN5rBLod/NmX4u9e4y8TVN3468dflYWH4s+5mtjnGJ8t77jXi/3gece75Z13EWi3845OYFfcUjyfnT//lndO4W/wvBNcTexzg8+Wd9Ql4BrBHzzxmPpN/5Z5jjDoWZ/sxmPq5YJb6nkHgYOnHlOvOfxfw5/vf7rcoxcMrgb84XOPftu/5Z4jDAbtcunguUcvGdxyzzsIHD736HUHjTyUxSPxDzNBgIBGANKIeC38mgjbXIJ2mP0pe4vnvwSiPzny7WEnAS5e3hpoo1j7L1wLa24q3eQROrbIbk5qmDsdmCtZjghk+LVpRhcRcobfKOYGHiw1BSrjqCFK86XWns4eA7VqGQzmCWLaQIVfVMs+wVX0Esd/zFWGcgG/vevbzPV1gXYG/3AX6FElublAF3Nu+9Lxo1GgXUDQBrqwC6h1NFzAJUV2t/bK7reN+HwhBJN7EPrAD8DEAf4U+GPxwNcQmGASgMAG4QRMfDAywcivqdVdSgmF59ytC9cZ8Q62vdrVNdyknJDP8wACp3N4UnadClNlfymM8esJk8pB5vnpY3DrCluU9PSTlBSd9RBVv7IcOi/Vdrptn+f8ZPt+w/s9Vz8/OeZHHqAsvXz2PZcSFN5JNoQ/ELRgh/1hvYJZH68yne7twPcf3w5jsQt49uD37ckUhGMQjGYZxGRMcDrnnWEqSM7m61XTFcvZj3toKRXmnGDnBTCrBQQHjMYFFHzhngxFoVetu/z9iNlyM6/w+QW+wkfxkdkPwcGlJSK99/HF92e9vNDOxEKJ8hExEzsrEK8EzhEJYfSSFGO3AwxXrl3VjOKn0qJ5jPIOjSlMMREzPMIcpjSLlRkSGENS/aUyxTNKPiOcJb/TlTwiSMGvwgsakpAyRtOm7KsMA2eKQZ6qWakM7OhlFKsrBt1fLAbpFeDbsazXscw0vnep6nsuMw1v2LO5pVeRs41Q+9jAM2R1RefgcuUV/rr/QrfkcP+dsz35Fw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.png" "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.png"
new file mode 100644
index 00000000000..f8b9589d6d7
Binary files /dev/null and "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.png" differ
diff --git "a/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.drawio" "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.drawio"
new file mode 100644
index 00000000000..6fddf10f064
--- /dev/null
+++ "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-11-22T06:15:41.782Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="xEbpVhUlxZyJQJUx4ASQ" version="13.4.5" type="device"><diagram id="3s-LqK6m4lkifnhmqHE2" name="Page-1">7LzXsuTYkSX6NWl254FtAAIqHqG11ngZgwporfH1A5zMLFaRySZ5L7unZ26fqjwHsYGt3Zcv9+2Iby+qPbgpGgqlT7PmGwSkx7cX/Q2CwPfrdf95Ss7vJW8A+F6QT2X646E/F1jllf0o/PnYWqbZ/IcHl75vlnL4Y2HSd12WLH8oi6ap3//42Kdv/tjrEOXZXxVYSdT8dalXpkvxvRSHsD+X81mZFz97BtH39ztt9PPhHzOZiyjt998VvZhvL2rq++X7VXtQWfMs3s91+V6P/Rt3fxvYlHXLP1LhaIIYQnDfkqb05QKximXAn34u8xY1648Zf4PQ5m6QjO+L/Ln4WTAPUffMYzl/LA46rs/gyaRv+unbi7hvTnn8/yD30O5mqfv3Hy7/x3P9NHfvQrf86RO1ZXN+r3a3FbXD183XC77/ttk0lXt2r2E2/dXN39r8qzvD8gwwm8rPP1Epz/opL6N/osZStrdMQkCX7c+c+/ZZmH+49rzMfZf/7Qo/xv/7tZq/9OJZKRD7N2Q4/uLu9x15bnf91EbNb7ebbFmy6U/3ziXl3eWvHlmyY/lT1JR59/12k32WP94su/RLxJ67wO/6/rq5TFE3f+4mfzbeZb89sPdT+se+f189jpI6n/q1S//0FwIEIchvi/EX1//jj72nWdJP0VL23S+6T8t5aKIfElZ2Tfm7e5+mj5bf1/kpyz+FHvq3bwz+jWC/keQ3BvmGs9/e6DcG/kbi33D6qwT/RgLfGOzbm/iGwz8eftM/leXWw+/68t869F9dh/7fCuJfisxvo+ni+fugqC9B+ZKVR3TIbzhDfxcn4hsBPDJD0s//txTdIkSiz603cD/19Qz67f3+0QCBJFFSZD8EkPh7UnYX/w69oT8IHPQozl2+F+WSWbdyPsX7bbzvsmJpm/sTeF8+S/bDGv9Yp7+0Nj8M0JZNd4u/K/phfbisb7NlOu9Hftx9IT+MzQ8q8EJ/fN7/bFihn/Sg+J1RhX+URT9sef5b0382d/fFD4v3z1g/8G9av/9W1P96ivp/sLH7D7ZWf8XZwH/7DXHuSt/B427tN/z4hW274Qb5MmnoY+GIG4PuB6hvOPWrh39v/8hvJPxVi7lx6gvU7mfgLywjv72Z38Y2/fsw9TcQ7V+CXk0UZw35G85T33X4bu/Ffv38awAO/wt8Q/4a30D0F/iG/wvwTaedpuK5M2cg0KMIasRg+k+/gLcf9oT6EgXq2xv7sakk9mO/34QYbRH3uF2/2LmnFv3t/SUT97Dvpn7W+l7j2fTXIwZ/Y99+t0fzMvV19nMrvuT63riyaf6i6Ie60sm9MTc+vshnQ8rbQyN+3GjLNH26+aVQfO139izSvyMHPzv/C6l5Pv9OVMiv//5FtvD1+jfkD9ICY/+gNYT+BdKSMkbzbv5nOG1tTP/PbKnwvPqVtPzlLj7LNvyNuf7mg0fxz8eBv7FSf3NZoNffpwgg9ItFAf/jOMLfX5Xbsx+ey7L9Cib8JqDyI216P5ffIZ+O+2Xp238Xjj5fP78Q8qV/pDmah+9Bjk95PEJNfnVJ/CwFfpbc12m0RLfJ+P4RYofHCFOlS2rmDkhc3hP3j2o5BePk95Xy/KIFigjuv9TiSWh2XzgL0DCGa8L+CqXUx/oGkRBo8xtmWrAxyqgaWkBkUmbSg4Nxhm2JSs7KcgUjOJyvxapZyJbVWbkyOC93D2vQqM+UBGpgegVFHd3zAfXtjfkLht1NP/sEsdn3PzN+X5Dvq9s0PPy6SYKvzb//YBt+/w6R93tbP8g248j17mgxtCyKMijt4GCTk+znej1YIV/ttDbKhOiZ2lLhrHQIS9TuBkhToTiDRshYLpoRYAxLEBRlYRCbnCnLJOJ4aUaGsO5iVUkJzC5qwjqEMF6KnsktWxBILd0x46sYDqOFrJmcsmXB1JI9NvLa8M6vYoYpKZqWTc3ZY6KuDQ7CwqggmPoutnlDA+CQYGaL87AgIgWmPinC7hINEJ7ijPMmIyQFoj5Pxu4UDhBEhp3Xp9gkhTzfT8BuFG4XRYZcVsjrDVK8i4EDoBeNM0iZKZoV4nKLFJU8Z5BbkqinmH8mzRkWISpzwSAXuVCU+ffXggNu00zmkRWX/oAP0jpr+sU43VZvxkfDMORzvrebXbIRvFkuic7YO7WsVMjaiapY7VZBclo/p/02Pi3uLFJ8SyVrtW2pPPMqY7iRrWq8ao3j6gq+77kbqMU+PqGRZ/l3n2AoZ0BUfe56JN5SpnAd9j5gDfG07JTHrfCsfP+r73+mXA9wi8bOsR+Lbx0yo2+ZL9e4XOocmFau691PIaOQzNO4heeujLYgx+Inpu7qJFChNrtdyHhDADkfdFMh02vTBa0+6UsciJdD4zlqbZ2abS264IvJN4V6hGBc51ao9kznokISv4fmld79gMFbyprq5XZhHpDiM8DTxMOT58FP+lnHfroGH3CYdvMQ360CUM3XnesEDffPPcaT2AbGE3sjSXeGWvyOy7MahPwA8GCCxo+UtaiELPqItTiWiQM+vj0y+ERy3pz4fGWuKl4i+xocKn0fWJU5dUWZFdoIIsGsn3LBGcj6tPrdpfJon3RP2X8LEqnEVQDcosPDevXAiJB1V8bdV9NqIOLFGPVI+bzh4/oEUX5Df0iLfAMTatb1xh2QLQoFIDvNxusgp3Ex/iwEIuDDaM5mmwoiPpfus2VNVe4FxWUE/o6DCoXgC4OfLVYaP7fjktzILvPk5UL8yK/orknvNhL1OzCc44gEL7NJaBmPcE+VFu4oOerqP035yMMDLtdWnuZ7Qg3MwsViniJ8Cnf2RnXIvF4jj9T5ym65C7r2p2as7qnSg0SHFewirONan6A9EpiD4x7cUu4H7T3TyZcjBhplvDpzCYodfERuZEX1bTetAxZbGFjBIzp9XHSdpViIElnR7PILFXOAv8pbMqUn+uFuikx6Xt2HZ2vel6YgF+jrimEX3lSMUB5JcdDdH1f0Vr8bYjt/OacAyBD9BCX53rQipC0KZItozrqW1/xNw5YqI/TbEZVXtr18+5blx/pR6Svq49Ii/RowOEZGq4LcdsPlJWntyG1OWBRD3wPFUVMdlJS4nF1JmkkTiVd/6zOo651lmGkxN9P5lqdPykrZ4V436wwS/Bl7sPGQ0SBjGtQpYgMezHA6YFv2Ho8oKLsSYRZR4nOq8wiY8RYuoTCWntIskcdXNJk9jtFtuU7yk75Bo7mtTG0Er0oVQFAcIdm4J6FH1TUh+m3vWYpM/agPb3BjzhdvYeKjz3VnXpaZwqzvP4+3SZNEVc9GwipgNAg13PLAE2MXKhk2uWAWUPSiPlQ1VpGpHI4dfzdAfD3nAhry92UTmBunIxF5trw9EHyTKxf2NX5vEauN6dHoGU0dKDaJlErdpa8QUmRF8yzqI0i1jphMJTe8X9pDWsAsH2eqx03vJTKn9Dq4BrrbFanex6vJ/dhc6oCZoal6A1jzgXjp2uWYOUpyjqi0mBSdpQ+kZZlvfM9FXigxjbPJNDCT/cBI66NmfO69lwq42QVhhmfDzOG4Nb1xi8LHOA55qjVHFnnm/JQdL6g3hjlzgsW383wbCDj1p6KomAZIRMDHGSoAcnsH4NezlLjxOuPFjSiDsCGOJCpodDEDLjCSRPu3g57X3sKr20p8c2hz7Nz2X6AP9uXITUFbtkZVJzbfDSWwNvePYuZ6hU8vvheeDw/mHtdtxE6U7aX9MTSkkqMCKAfGrels/2AyKpWVfvOpGeJeVMNFr+YzghN6c9H1RpOjwRU7x8/OdegixMPMq7yNlovPVtZ2mpFgUFgFba+BjjbWO4RFPDoZToUWOYjE4zDzduIN2VcG0X8r5LsBaj3dzG1aW92UmOMydfqeT3OQWRYHLWLKlS4h+rhq1lthxlAIuzHxOnfsqxGC2nQCzIHx1rEDCd2ZLRvFzcI+iktgfb0pzshhnGALDxNsmzdjGEYtiLQLRnyJDQWSQMF4Sx9Z+n5hU6alN1YmkRSrQu5WuWbmgYlO6u3M5KN0gYqetGGes44OI01lQDYD+/y7HloT4FJpW1kBmoDZNsnE6FAsFgaMMDafwhHyHlILn55KzkjLj5IxY0XshUKukXKJqFEsC50INFVu3xtcX0tx3WMoldcaSm3cB58Hg6Vb84jR5ltYs8oXDu8SB8s3X/gUQBOQWxmuJEhrcxomhtoftTRmEXpt8vuRKWupvvCNy4uNFBoJLztsrRXv6oj9oYPzcssSMEjItCC2pYgys4b3Ijcqo0bp633AIP/24fFpazp1P3XmkEiHZK5EqCCuvezCYQ+1qB04eTuQ1QopL9thi8mJs00KTDr5Ngtkq6lHfAkMGmjghx3yxWkMcgcW08zK0ELpcnPjgeLf/jBE2qlkizoYYgGc3B8fPGlwaq3i9eE3YtjRC6mb9Q0R7Oq4VIElGkWXb3WYnPzUmmbz8DPhhKqpceNWm+nsm7bzjTBjNflFjWADNnX8uk1IXEqYjzbGEKNWFkECUa1kYS2jxcz9SXP9o0MFZ+hTZxGMrrrJPkMEOpqy9lB10SpwDAqwiNT49llKTATrxx7WsqwO0oUgWaOuU3mmsJyPTJt70oOpEB55gfF2z+Nth5rPSyWpZkU7broUpe3L0oBHKq230KUGPE73NRc3ibS+DaOQc2q7yWZx9u9+w1wJ2w3EOETwJbQs5J+PK4bMTJIZNCyuwFSaI6yq0amGz6iOKAVLQsDeIhIAvgbWRZi8W5I20DeDG6cPJrPhxgyGkOIDF8pi5cfSFZHxho5tuRxhb1ck4tPjszSo9jCN4NkP+GCPvTQCWMP3oIkFtkk4aOCH3ni0AXw1qMmh9XRj8yv2zHi8zRhLCuJs4A3JQ443NbDpww8ZJdkJ7ffaqo0DydCzZvRX5/Xqx9DePUmw5WclIFPh/REOnRNiPCuk+8cwSLS1E3nnFxOkq2QQQHGKarZtg3r9ncCMN9PoVIQBv6hAwDm14ZNWyVSv6+TOoxgBwL02t6pPg7ZK8MU+2GgWInYzR95ue8dICqCUF77Q6ON86xVDOWKycHO99g4GfwRfmfohyU2sEgumdoyPRAgPXbGlNXK0nk31Zx8hWyCzDxcesnDpwv0MfptRJzVUhtGM2QpMNetdErfMSBhl9WH5m/OuW6NGeArapZthVY8Tl5Q29KhFeTteRsEba3dDAwcrN6O9aenju2lRIdeZYpWdZW4eKChXCH1qFHsxq3k9HoGQMBnJwOFCN6ctYEX3yK+wv3qTsZbGfp4j6wL2FUnAJqVoXraeiEo5AJaSy0pv4ilqfRb48mIbvJ21Nuseycs+myuUHMmiq/CM+3E9bvAh72XVSvl1viex2PDbSN3THUnjWMCCFCWCf7Yegu7dfFtM6Ipo0NUjXb08xqMBpmyaDL/dUOgxbP4UITnT2mHnWIiMTdBSnDSM8AstqK3zDoc8CLVXOVSos3ehCsKvJOyCuiRATHxDj+u7bmt3K4xpmC+nWhVfLQRqIU/pIquMMZ1NToBRy4NmkV9jP2TY4N2+XOBfc3Go11A2w6i7sXXbUzKFtqnLrIHGrG4sl1S3qlkpbAB4/Gk2wdr3R/HeHiWQGGZZdmbsrXRl5k4oILkwn6cJ70E7pqnFfRm1clKy25fSei11YQzFXQsQnOWB/+t1xFAh4m8r84r6E72YydLM4O32Mp6fFtWjB5UZvETrRt+svhgWF9aULUi54kO2DvliM6axG3F2K+g6nNGgr+069DBxrllU7rUdlylHSo+dpMxOEaNmIHNpLcfLm0MFuvbKqg4JquPZgS8/0IkWhBkNb+6iN0/F1an1JtzQ+yN8fXOzC0MM2dvzCIrOufQ1zCxBjcIpzbQZEztN9exDfxQzebkBJTz+pJ6nuNty1yFFgwu01JtOLp5ajGOVLXpRlWPvvXygYMw7+f6zW7Wmjd+fq68byr3b5b1lmHwVIcWIqeENb+/GVtHl9BVMxXwzEOVguxjMXFNvxdMTCkpzMd365O5HCWwTQ7B8tQWCyd2GJmeDEjn7oiATaO5WqUguLHJLsrCaQikLP5LwfpzWgFRbHXBFP+ER7qES1HQJ8O15UUyoRLdz6BpADaUxziS+8x7b220lVaVkX01qQ1FXY8IN3nPZXWSaN81NmUxhupTqE8/1WINhkb3ISd9FthfhaN2PWVXQMbLQB3WNutR96MssaygyP6MBIK+wCCfbkloAUAp6RlQPPvTGxJhfdHMFmS+/q2MvW2YMhICsqdK6+rbqSCHL9IL1pF4D1uddFk9siEkiMixgwMunQwJyIDXXoH0ZWIYSFjJR1imCU/MJJcEd9vkZI4P7TXT3Brx0q4gUG9Fu79IreRvTJw7sBWO5bXB0znWese5q3S5Sc4ZZx9ge7L5U7DAHfH5kh1/sykK8VRy0TkTw3DyI/DGdV4zpVJrwBXNA1nGDiMhOn0IONsvz+fNNmWRVkkRRiDpbHInrBW6DOUbBygqN+ToedAHMm69lZx7AKeQJnNEa/PLETQplvmRCmSf7VjZaLCOdfiEk3VKEjDg2xtMpKhOykKk17lIMAYuadQGWECfQQjxaZnTlZHmU+N3izDG9e3l1O41yXajo21XalqbjzqQyaXnYuHjVK3yRr34yQqyZKC2I/IeuXarMTwWUCtpeXEyXiyq4TJNWNRZ9U5fyrXByqXEIWGF6t80mgNLPLh88H+un7njX3cbnPW0n4Eb4HvZuyjkNxTCTTji40sqj86FPXrYstzD1gtVFIXKyl4l2KphsqSPAkbg3N64Ypzs3sF/0rKt5lLd0ynsJ/RTt4LYzN+iNLLeRgLah24vm1MLbUNwuSJO2h8AbQOpIuoIPWN9jWjfPt8Pv0fnZWNdwSMjwmAVIDW3nGeu1ls1DT5UHCVEYHGMnE8tsCTlgKx+bhCq6rDPGcbNJhC4OSqvYlD4C2j09dPK2hRB3sbW6KvULOMn9Mx/69kZkyg+QGdH9DjeJ3g6ZFpuYcHcSN0pEE6UAkscoUZAzyKqFAb5lMFzOVx3HCNKSdp8S2areXOkJnAAcHpdZnASHRXaT0773Ky4HRk/PqidvfjW+hlhnLISVrFGjq9P1GCBDyhJT+S5/eTlBrahfbVffUzoX5kg1sn4v5uf5FXdwCQK63VmtZrhWJEatVvJ+mZbytNOrGtcbG/NNySPsEj0B6DF1u5xcoXXpdMxVuqUXx1SjE5SY2+lLcmwhLynbuZfSTZX7N6HZwCtQlU/ARCNKUCT7Kr7LZ7A9yKFWpV9J2LyYj/1nGWZNumRQqK4VyE47gEJDqlhVOJEgWITXDqSwJmmYQURleOMAp01dYLP5RFeC5tw7XMamzoiFpWaRC5pMXYqlay6/V/LXKQ9twMOv2rFuWHASk4JvduJ/NIgQ4hlCbnaZz+hjE9cuhljCLPlzlDwlx5lBVPc+GtvlbmnOMcbr/WI7MvUKLPIiVlglrMt/C9tNnOJEV9ZnJvVGf5J6c8TuFTMcrj6GSeHSIKpBrODbfUDNjDZvhuOG5PnU2A6jPmVftu9xNHymtC+etq66zhpOJl1GOEiRbvdrjf2Na4wl7w4WCt6w1DBp+NJ7WFI7bfNVo7+NPd5alubYYmLNL7CyPkAwTIxjYPwqiKqkmPNyiSL/eSMvs2zUj7IbQpIQZB25xqAeJrOlfKsa9W1DuE4IMhUskifuQtu4Ze3UftsxB+RgXmK5JyibvTgZLZ4999MHWIYGeIL4c3XPjL2or+AqMVp8j1T8+7YnkgMlPdFl7pshO2hAUnID48wczY4enKhQmACstUclzx60kunZkmq0QjFzpvbj0viHsIVQHwm4n5FNj15PLMdy3kk6NjiKjIZJzHDhZPG5jNTFr4zi2UR8QlWk98Peh/GB6WN15TOwCWborl7BMDCqfhAEkBgxzORzLnb/MbrO6ntQ1Dq0thswAKtr52DPaNBrtlzSG9RauR2KwaQ4lS6TWYoZoSZwhq/FjBMT/aTQVBpA2zwi71BrKbw9Dv1tJMnSOUAm2ROqP/v+IkdbAWDeT+SrNJl8wKZQ9itlvKbAqcEuXYGstki2jUQK3C8bG4UPPRrCh9vcYDVDoj5TdDiNVTMMWr+ZEN7e+09ynDGlyKoaCqChI7eLV3JwLCczgEHWskouyH5Zk87BISE1PU30puGI3rx+TIIhwjfttHrtmE5Q9+UsAEQUOTAKFkxW8kK4kbXZM70LAkyVnYC425p0PTodK71fv2GBKGj/duNXNk/Vcuc+fIhbN0ln82EgIEol1fzZ4NsDju7HRGZpRHovdrt2Gal2sxWhMsoQiVBO89PxkSm0aTOneAcdhCKwJbPmXQ1goMeIGiq5OUUiNppm7cwoFopMpNs4jfZyOxDEcR2iXVFGGEaKFad2KpBcZxaUH9EcC2L+46yogrhgpJEgliJ1aNKNRIrOcvABuk0CBFIGLgvAli0C3V6cj25l5UiEqfmI8WSBgIOEzQ/XI317jLVFROdHeG+moYTpLHWn/UTVfCDyNd8FXQKmlGbTqGSeUjiDH5VpxxwXBSEhg+tNtTfn+LRGb3MNn8ubHNl5bBoxln/FT9AxRWqlPVnGyTxH8fzy9NnYus3noyH3I3CMZK4lj+OSODzSPaQWvEGWjD/3Ly3++C9UCASQqRkt2Y7DDg3LEkSHtDd/MktCnFcMecIK8yQgxE2uj/3WqBdx+1Fp8v54DR7mNz8MA9J+Nq83LUGaH48G+6rUCyLDjARyjSAMEreLlOLIx3OBIKdcIYRZ66mU3z1qa7Z9VVFyUayVnhge0ACfPr3PBx/uSoxTUi4RwGCEx89J3Lom2xQ9VQxSqpWZGj7Lc07Ge7r/vis4z1mbSzgYiD79xfL6qO82Saf2VSGRho+6373xvu6Dw4cLmNriPMJ5mAD69Dbx20Ng7yrPKZmUawm6ZOqu4zQYZPS7dL878mzynKoSluNqpoRQgSA8p7q/Shj4dw/g/34WwfnHVIC/ezr+r8gZ+OXpOPqLDBPsKyHk9eSCEPS3N/5fNBfkV9ke1o9B/iK5/v/jjv1McIB/pn38bs8w8D8xywP635/lgUD/QKIU/Cs5Rv+j5PgfWJX/a7M8bKD+c5ZHiu6QaXYsDZY76dqM31DHew9GMt+gqWKs9WShWXEk47Eae3mMWNCvZaCavaWdbwKVqC1QS8oYPIfl54f/tYr87MmWYl9BqbB5ha/P7ccfEIaB9nX7idcQdte65+3B7MSyMAGRVsFuKbscmArD4qlZkrJJ7IZ/IBzB2IeaEUxS0DutCnwLr8tNSmyRYjV1oi9GJ0ilo6/I8e7pi3NB8hlSIJSY51lcIiAjGArDeHCb68qOk8xp6CqSRhQhtCcjJJjHt4JHUYjGt06+kDthhqWkvC96v/sg8Bd7jIJRBgKxHIuQhQVMiHWfxdYJMISp1kKAQYqu3H3wZ8JrQ2GReV5eDGAiLZ8LN/VCVnlyjKfjwq6iHT/onbDFHYeeuBRBxYJhvtYge/p4JpeaFEOTJLuKPX0pOmEqNX1lvpfn1D05itfAAinZPF/tAmkE2UhuOxmUlZ78nNwJudDQWdEyNNfD04UnJI1/cYYCmN7yc9K91gqWHr6evD5PyFB8bxOkP5t39JRY55Ff8a8n6G8vTCq6IHJ1oD3iINuSkkjePgIYAE8glVMxbubq05g+0HtFjdgC+2YPnTYb2uR1j/V9OukT0GhgKzmipXKElqI7UnOi+p4qageFEVIIhOG0E8M1aq3WVsYD+VI+qfoVKQyBXEUkIIQTxzpJpoNWOkS6imjq/CJay15BO+EQpKkDg+LJl+UvMlRvVpN9WoCZqiCMkYDKUmdsU2QcUqJmIQq1CE6yryeSmbGR7/c2zPT8PvE6cH6Fxdt3Zy2kXFxCIqf7xuaRfC8XA/O220YeZL/mCwbyJIzzTG4zu4sgJa9wUaQbP5Q0ydUfd0H2lcIinog/a8G4Qrz1cVp3l7NeJSfCqLmguYVMqEGLKrgCDRrEz3hCK4VnNAJtPhMdyhdl67sn9SziQDyj2z/Tmwfyufn44AgjcGRYcIF6LcmzOp1N3vfTbEQGEMRnuFOehUGEgZRUNQDBdx5XRIHpa4wZmMwq6hy9nZHPyvYQsYfvr61qhNdHFUgiN66vtshIE3I5JSpbTAlXDBnhgYI6k5EiuB9Ab44LypYRPpXXseYKzLjYQMLF6phospnKWGQgHq5ERTgERqn38S2rLLXT03NgZqoiwevo8aKomjrcWUSzUbm5mT+kdiaqzVAThlHAAvlugeTD8spsV9UVp6UzLX4E0rcgRJZsDtp14p/M+NiI7mk1B9vvt8Nj+IBGmqUXkoB/5lZ3o815Hfe+3N1lDfoOe9TEXziOtS+RktQWU1Xf3xHifGY4oPFxEUSo3xLpnIyycSHmoGvMPH5abGFDJTDXEh5jOcpNHClDJN4AkhTUs/s9S1BMcdyGIovk5Jr4KVEPipMEZ3K1ftwjVb0sY2FW41V3wYIRdNbq99pjFuChH8rRprIubkmwOCtuRhhf3tI6jfXr8FYVW1Ewr06xbvWTxNTVmK3E6IdXA+12k4JqLmNkJBgsO0mtxm+Pj9p+BqtPnPotk3y7DozG0VJov0vIqgYagBwZXMNxYTyCFSv9CW32HpE1LEy7Z79ux+iVjDC7Bs7sO6jXQiqttW2cy/lgxM5gBVXyfAnzkMRcpqqp+sQfbCDs48vwjSQ/Z+V1aBTdtyBOkvDH6CXuBmNbfUg2MQcfi6i5oJnq5px8n+zkPUjuMXh0LuIZZeUNV02+uvBAkZ4UkvTgLpJ6cWVf5kYpwK7i7Jr1vbCi5AM2eHqQTuOdecrbT3UDIuyisbjt3UlKm+lEJwjr/GIYnHRkqJFU7zFTkwUP5jV2zdcpwKc9CZ164vexk3/OtG5nYTJVcmfxY1hXl9PVRzcWm0J8Sb9CMhnDT9+Wm2f0BIgpBylXnsPrtQFRUmJs6nTPWa3u5ypY2SoLF8yaVegEpQgWfyM2w30lLpF4xSizd1YAZLyBpvT9VvKdj5WCiqRx+EVpFBafH6h4MiPeCwDMznlh9/wQW6UJzF5zJ+FHCOg66BDID19NpHBw70/nUIS0xvRKLPL7yfowjO5dBlOq1oxNlGqKflohDCGcJvyDv1hIai1iiAQXgxhoSettbid1yw3yJT0OpHXwqlAOdS55JbsJ1t6/xLLd4ecYQDhAUWrafDSeWx9xbY/Wc9NYVoTt9gyDS4pVhjnzSA+sPX5OP42jB2vHZjSi4qHnoHf1IgqhBP8s+LIqNPyJlS2EQMy+fHdsIalSE5ImpFYKJfZkGCPhRYSU17mYPhlJJ1+a0L4bAyySAWnNohAMPksGjBpxo1PO0gpAkUDUGipubvSWMaFx2ucUqQZRKxQMigBBynY7NwAtx5llH1fdUHf5Luesjyq6K9qXuBcV7O26Dy1rN30hMkMIgizN3otlA6eh6rhyzlAst4FrMOkJcvZAnlltCJLjnTUwMz3+0dMJekTvOcTKN5RTHvznSboBAE5rFAdfJsUMWD7SnyM4Gyk/iHBctC5wUrlFpkYJFEXOT/hUgoHVloTXiG3Jk0+6TGoPGGZfnFz/2ui3wMHwYaTTbqDvLBOywa8I9/IsSlQI0eOU9wyd2yPsGyQJVzy/nBcKXxgrouBmDM8pwITYkKTuaaDrYAyI8JOQC34FbAVMf1B8fgIbmrRPmIF8UN56/PmPP5YDs71iNBY7qfSHZ7JnhsCt+X4SCp2HH1oFSSQPpTk9UH/xgrDnD0FB9w+7BZ9XrHzCo/bzOBQzuW8WbNpbPWH81bBEO6b0g9VopiuoGUdRwbC0OrCdC+TS981JSJ3imdKACkeoyqyL1QqmMB2EQ6acNpslme2wy5I6LBPLBbCJPk6h5lxqeX4j7lHIYu9LO2qntQQxtg6lVucnkAmTFFu5F2SvpT6jQYUr3iOg5g18w/uNMJBx64BNfaR3r0cpoDzZBa5t5FZ9VIVz3gjcNZuyO5hms1VLJBuiB55rHBNy/1reJDMTpQQuFx8ugdg+Z+7xrbwehppq0QDNu2vEvjcRplO80mblS8VSYxF1uezamw/lQ1S7QFdqQC7mp8mMvoR7QS2FN6FodmXwREDUnCmQTuctxEx5E0ZzVlWq4JqByBaZnOT90YV7NWOevA5J+SS12VjBob3eCVOVvsoh4Br5mRyz1lNbkcXr9dqeeHBU4glww1cimOKhN2unch0490kdB/2u40LJwF0jIU8KDQ11/dWZ2NDkrYGGoFJ7afIuCdUMpoHTmM845E7FDN3+MYWYnv0Lqs3goYRBgdzsmMyDj1HItfxEtbK9cQbUP610YAHAp+du/nwY3xbay7R0Dc84YyQr6uq96sW9MMbCN8sAB+i6XjevmfV9Dsk32emqAuRrMjIJu48SbOGx95hOuQE8gpHIjo3zVHWYh+ZkXlUP8AWT7t578LwVQ7YDmqIdKbXnxkDe+JFwGxmLEkoCPimXJyr11REzXScHJUW5wk2RcjdIfQELVW1yH4dpvPY4dxYwFMigaOjIFmmr5OMxP05TEmnOzWHyJGlwtkhRtlUyKjnMafG67Fys2LknhNrC9TFRT2RscCDjMxUutfs8Hgnk1aMFS+N9U6k4egoZ7VKJX8HixpOpqLZ5u1uY7S78Vx5RzYEtu8gfc8V0SIE+/iFdpNZ4N2c/k/7GX5FJZ7XH6ZI1nkij4Vr+6XaTfrwftNAZ6RJn23c5UqvxaNUBDhWYvKOTaIy27lKL3UyNyVrpVqNUBjXS9IUFRumEfCRCTZbUCPXiUg2Gxdq12FvqXjqlR098N5yTE7rtLdOTk2fnK93r8A3qniWRT1ZxtC6fMcqe1UyVUilYpTYpnLjMualheWaw0VlWwSjiiQYGnTFaVfNm4dQJrlA8W2ZffeBXWdVXxUkIxz0TujYHMbFwBCH8BgZDlnHZQlP28gpqnxBpihFuR/ZTrEzGADrHDAMEKrmcRNNNJ9j28+I6mWRq4lMWZNDctl0YUI9NxUh9h+ep7k6dANWQhCMUUSJHZt/xCImEpKfFDLIB4t3xAUYg18bAlM8s885YCYWqDIfasZIJ3lC8LKqwcSzidxaCayEucRPtaKTNN5OUbufOCsn10Zx4rCUPlHFHTGjPbIwZr1cJrkg0FIg2H0yJGbfMOHhwnTbuiFXcyJUknl3wksBBWNPH3+sZBC98OlnXTNoaMnFTSfzYGv/REaMlqkAIpawDi9Z7d2FDxIVGyuTtZuyQDncjYOdiszSPK/oqfdgldj8bxgt8WMhOuU884yY84bbUIpbB0nHwUWXeSEG8SDRCOHYWD0uAvKUA6o+1VR1ye+IrI7IV/lYlNbELps4iEb7pX/DhV3H8uMR2FRk86zBbMLawkqZOIeCEGwlNtfSFkL1VObZIeket4/uTu82qMruOnDp4fiLsBMBEzUhCDvqCJTVaZ2mHxb4iNFslmoPuowAcJuQDtMqutRQV7iynrNRRZuD4Kl+eMAPwPJVzeYCVVyYhaN5OPuNjj3MxEw1vTUNk6GgUCArxIE057Y028vdi3jhcnohWkQ/L3Ag4KAVBVG5TWRaKcUA75XlXJbzIXGCyhzK5t04+WSskojq1KbOn5bAGg06la7cXWTDKkOyMFLj1gKCvggAaIk09fudKBiEoaHpTznmjjktWjYlL0/H5+DF3U53s7Z8097JGKngOBuj0cS5TT9tXwXltx0yI8iwuBVg+1DW8yPx1RWjzARh7oN9e/tLPoV9CMiXE3iafl3pqRpKMiofdeJyK7dlw9R5mllXw1MFgTsMxSyN5TMhPJJ7lxGYvvMv/Sk3aecrmOajCYpLraqGUcXi+PbuyFFMDkVvwBbdKi3JORcoMG9jG0uaTnRe2+zY0XOpHQroQlglUPKkIUjlJwrZWsI9ktxfrUvaXhutwbK4FX1XijUri9xqTx7y8d7dq9fRT2kxhThMKxqniMFan3mZOPT5uY3grPMqOVa02IpeZ1xNCghOOS2nL53N8WJdVQrnM8xaOK2kqMsUCGCR1jIL0FPs6SBpv3qSTgE/CGmSxsgu1ZjUittuaB4hYKsFswJwh5V39cUfmvaCUpV69lNM07GZ/bLicV8GYGTsb1aoiV7tZzG0xLIQODh6iEnKP13cVGTCllg08olGhgTdHvTtWRaeYpX7iFP8VH/UnvyFPnVQ/aynikaqyYWs1r3nMKD13eFsMRISgGGZOc5gUwT2JHnKsFLdHH0ENZUoxUj2hJpPhswJ6MbHuGMHNkVJZ0jCqGwJYeE5NJMEz4iE1lP4mhbdLrOAzZSBRjTw5yBOffI416G7WRYg5hqjAC7bxkARu//ITGmQIxZbnejrnQfo9lPIj1EgO3oick+lmIW6pJeTlnzp4cuVikiNUKgaIfORgtWTO2jvOKKjCrapURhODwifBF1AzT62YZ4ag4pUExMfcqrKPo9gh6Q9nYTWirGmolVtHCtsVtYlp/ritq3CcTHKAEgHsva6zCVy1W90GPgZMKzobDQVS1aSA4uLg4vESRRawS01XcAOJhyvqk/j03xylrXrfsabz4Rz6Y2zuVWpgMDBecPtnh8YYn9u+f0VliIpq77kxuXV7OjldZdYW7yb7eFAfUBMmyuqulCx498nPIz3N+EpmOcfaN+cOl02CUTx9tX1tVjMOxoEpMk0Zqx+NnkqeTNgvrpN3t+G0mx0VJmYyNVO7XjOYoEeGP2Qd+1x4dey7hDihUFwvnen0cbE2f/EgQ6Rii5PVTEJCjYL9NZ4aK6/4OYsfn1Ge0pc83Z5OQdFvfMcZiC0ynduESXv5gQjH+cvqJgBS1LGwSDpEOKGH/eqYoNLKu+elDHvuh2HfsY6q3Tyn6OrQddkxBDK6/Q6zvqBBovB7/256wNT8TgZr8eVQ+We5J+4+ie+P7zACVnH4maJd9AXD0MIE1hNHYCVls12p7f3qHNnQuXLt9WQqtD6b8eDbKA0zd98oAV6KeGRRsRpVrnU/cldADEQHt29uDbFM2qpunTOP5xj2lagnIk9CzzNZAo3A9IzQMmAjCuu8PUnxjU65dSkFHeWzVxVrcsvKFYoVlVtFhTaTWU/q8jriMhCP5Mg043xPFU2EH2VWwOgE9V5lYAK13oLAObK5+3Td8dQ1FJk3jqBuu7fYoCIPCx8rnHXDuxLx8TfjW+9oCHPIV/YQ6BVeo5BhRAotR6Oz/AlfZcKNfHC4NYZ4r33Ob59KyIu1F6WBsUxq7pL8bAtZsT95e9UgniJEJWmd+rh8pV1+9MRAhKLeUOBN8nl141jhAYMCjKHG3FTySpYVny1hVlBW4BlcotazEtOmHbXV5LZrHV+RBEYcs23c8lgzLy2SUxVSon9ioKdoaixyX7ALMt6TecKQIkEFkwXUEyN4ndJYZJIUmhQ4FiGNvpGHJMvbUmk5uDIzXiL7T4aRDg4hUUvY5VFJVjoiXt/879G2V0Tybbng80zYrGGCLSMHQD4CWOq8ZVXMALfqjm52Gvw5rS6tQdMpxuQQM50sKpbHlDJxRp5bwaL5C5j3UOCDE9Y3VihMHFMXYuHw4FpF5PCFvNyHed+iuTjNd9iWgrExGE9aGi1cBjFmEnRMjE48rxmFGDkKRNOih8bimAY5kL07TGeJzJNdZXKy0wgcRYkC7SrnurUUI01IiOR45J3HUUHr1K00cDmJhvOWCF7YB23dbGU4FprAAYMbuGn3e+nc0NeK5DljQTJVrkZBIm6fhXWbBGV3U6nlBgZWrX/OW5zc9dyr95+zh9WvLBgtqZz47zb+VhtPtEcR8YNgU3ocvtIHCFI0HYSZajHP868Egn8ihwD6G+e2/1QOwS/PXv/D3rCHf5FD8NdfRnJ/JJ6sgv97kwn+8a37mUzw/qute/9nfmHELzbuPzuV4E9/+Z1Sv0olAH8pzsh/kDi//n+cSmBSv/vCiAzeP67p8xfSLXFZth+AcBx/z8VR6L0X9rryd8K9GcGxzfEj0eftXFDllgsRaal9SUb5wlNuDgSmNXnkSZilwr96wL8pCX7h58y4tT4RAADorUpYmNrcZvt121AIyl5Zlh7IS38IWb1BE4Ic2LV9Ehv6tOkLvnbY0FmBoKzzboAIJEPgGtYgcogEDZggJIIkZ/rMCUMm+J55slhJn2DOKIk3eizveQ+WpJphBbME83wRwSujXcZwCItJosqWL8kgCXytuQmGe4IhUKAtndbBSUIUdfVVgE8SJTCR3BMy3949XPWj2oWQlxz4m2Xe9P540OVsvpw3syLF88ViZNWjzwsT7TAGWeRWoz8GtEFOBrhq+nMCiYTVhaGo1ikfuje3hCgH+1mnqAGloLb8MIQUpR52gRCldA/jCswmyM5LAq6CXHlePGMF5qMWwtI7pMK1u0ftwvN+I+uLoUkItDMzPqWwZ7XEqFEy8BK9mrYbzrQLgYTuE70pHDsJcsISPMxgJiQmFE55TgN4IL498pu4PcwfS+u3bgOXpoFr4XgEaRnx2jRE1gViWR2DMnq0cPSMaS5ySy3xkRE9AccjbgQFcHEXzX0FJUFPr+L8pAKe2DkdbYr4KfVIitKgsmQ0ymHhw9OaObfe94xYXXUVGw5Zgsi5xDqV7AVm40oLNMlXsgO9Cz9qn/XFxfnDHWXUDeNzAONlHDq5sJSLtrNt/IEnKmcC9y8t3EKnKfzARO4ltR4WzYByL2NsoRGNSppS5mLORSusvLs8+gLdTil4/HNMESis944QTk7CibLrtJeG6D4wUui593NVFgl1aYt+7LTAQrOEU2rHlAdvzRV60PBpsvebQyNCtWiRPmOssrkqj9VG/8IDlYJ7aSYOToqvYwN8h2QKsIUXFWBu0gfkO1m3EZjgKLXFC4HqUM4ITxAxeGLp5NpzQ6w9ybRnoM1gppK+elopTxtUzdvx4lWGe92YbfYAURBltGr5BCFSy7eT0w5VXVovUITk8+swhw5yPb9Qv8WVVq30zyjaZ7rQgeWQOK/bYcxFvjrBGlfNrEUk3MeCw1nolldEHQxMKjZzzp3Yhu1nbWLzvm9HMRR5qgqrHLazIvkCW2LCIiRACIxx3OieDOAuhKIVEytLC2+bKLnn3CcAqOAFP8epe6QKp1JxWLo951OofrTxgMK4q2TFdCCx7a1vJX5b6JoDYfZimD2iNtpdnhd8j/MJWAUI8Fnk3vC06R5yPr3AXFZOGA10zs0lyniCztju5kzDPN/8oE2um3O0gRx4QJ3D+JKogw3IHNCSN0fMcqyc+S1uBEXx3lDj/SFRW4IcBna3d+RiSXYgybBnvtho82DyTLHW2+jlkHxaV4g9IvSEOguDguhjDgjgeVXg1aGoo004+3guGEOPiJ+Hr6EHlYmzbY/ucyMYzvA6uXK+kafmR/B4MhQWZ6VaN1q8Lm6aEwl5PwsT6SQLTkSb5QMrjP0Kw5ATsAig6D0kcSkmA5rcXY9dciIv5NZvLXB3i6lKHYecPi5qiez7dHzmx33+vg84hVilrkCF/pGygAc2LogjAiMJCtIhKOT4eVcYuVBmXPI5eHxw+kYkxDJo6QEK27ilSxH5hAUnkIanEGuUikBrbbKpqFbPmjfuCJaE9vNOMcQsySyZB8fFI1tND/45kq3BYzmwDR4uJDnBLmq02aJck5AnuGSdG33+at/f81wahAGCmiJD04KlAKsWxCqc1iOsJxOANYC701MdjtuOsPmIawJWaedrptvCoiz6/Xkc061Rh0xlO9jY2Zi8BQw8XTHo0MLJCpuyyNsAJSbgJnJoDJ0kkiphA5C6xUz/pCgz0z4a571Hwbsb88txJCkiwG4sUXXBxl2uW8AEsok9YQNglXLd1R6r0EvFLl/rSZIoDj5ssSIVWRkxBGmmLv5AWMb5XFn/emGwZUiWg9QNWhzh92eEhFLx9AEzKUg+T1oB4hKeIA9C/ZFYws6fcBI/f47zJaNYp9AC4zv5Q5jsx37aGW7g4+ISBmmNj9IEm1ZLhEi16V4hrKsRrZ2yjm9pDSs3JWESSZ9zzSvoE/HzHH6v+22pkGYaHNKi16gor/TrnXQD7Ib0RsX2QMGL3+nS77IZ4A221btSEiZPRoSO4BoUR6iPsz9NJSlJksgztDidoeeQwWYOGyYOqcMpFXFuhG5AtaPhD5WFpnDj4GsRdPHsZyILG9g3U0ZtFoYsJddQuEexiOHDJuEF5gFDDDr4NndflnRyGVKLfc58+d2+WocoCcQUVFk7LFjeSwrfI3q3cHkgFoLqcx6EgrFX5al6wnhuTcKE5LBMwZW32chmb/JHBlyhWG1sp+6JgTIKJgozMrno/sKTZ2u4zQJgOheNWVJEd8QJ2ltn+ezGCLakgUDI57UFuHOtxn5eDaBLbQOLclNcijBpnijV57jeGJIxtNCgyh8TP75w4CvgdyvNyJCN3EgUAW4T9uBlgxU4Zjba7Aw9y4jONNNbmZWlJjzfKeN/Oml9wl41ObfHIDuUt67yvVehwZgIto6XvyZEUVWsVKvsQRVpHt12V813jnhwx3tNdUww935H70ADLcJ77O7oyiNemuJnDc/OOI/bWnKzR492/xAV5aPzfVmi1wJYqyXQNXuee9QopA0j2rVgSACnz/kn4oYLZQU5Z9S9ybTCLkUS8KrgU/HpOqCVCxOQDSUsUsWCi88+N9+VUOX52qnboi6GYLCTcSPY826CvHlZB1miqCzSTZoWqQhjBwGfM6IRxMx37OYGEbkdDQ3xGrvTRDut1araTezgu4MVA3spwSC+vZmiE3sIOeWpxAQUsAms+nSAF8LWz4wHCfCreAGILNcGTpwWE/k3Au3y/nmJh0YHHzoKcOaWskyNtdXpUK+rkfeEwgwvwbJBnhL62nrfuWHFvHj3tSQSQR+r3GjWA3bPqanAL2b0AjvT90ENnQiFqom5CMRwrInkQDw8l50izzWjqKxS9WqCkRYPNt3ZrUQkurV2EnvJkI4aXwghZ3PwtmnBmVkFY1BHVPbEHMqicSpEsLgOwQlNDaccofyv9q5r2XHciH6N30kx6pE5iaSYwxtzELNIieTXG9Cd8e56Z+yt8tqucrnqvuAKJVINoPscnEbDmWeLB3glurcWp/i+zjaqr8v1yAra1gNEsfTuG2EaNnAtr/r/s37yrARhCTkXcs32HZc7vJm9VUI1DRe5qAOlO++EFOKvTzouAjiuyBLnXFg5QKfaBR9G3/Oc+qvIHssNlipwsjCDyLuhA8bwRikLIUybmuHahI7isjCbddp3h1XGgVup7Vv8czxniK8ID2KKJApheWxTyB78S9XUpWksDbvg3ONVjlHuOsGDBn5dDR8p6h629MC+NsrLRXXJLBYFPF+NTyxaFz5UDJgjO+/Rs7i9t6+eX38Qw8VykYGYpCmB90lP9fSmGHo7NmWqfPv0651O13B0LZt9KrPWQr/v5H1IJ3Yuq0X4Xu60d3B4XBfqEmwrT0SG2JTlDRNjxnXbtk7CF0YNULjSiQ2+qAn9kX43Cc+2r2pYMOhNOhS8jt13s7dxV/q8DXOZ2DvBKZWFP9S+bGn7nqJVi10BLimlLD2oiD1mkWUmIu2Eqxk0TnYvbwgnCNJVAZjJhUdcWRTdNgBHerwVG5+ZlMIOiJ5oi+ARHiH0NfWbNYcv84lYfPG70xz8pEkxQDXehZ2L1zhznrLKQcDk66d+EjWLF+xDzHkfkDqBuK51y++PXC7Rd7HakRdE974cDk2B4T7oICYV9qbMyZdtAj9dJ34t5q1hBJauvKH2KgaX7mBgEZigSmlDlofhsZvDRMJMoVBMn4ElnIf3mE49TepF0EhxzldYaQvu0M9dx/d5MfZtuF5enbycGd9ktxYSkDTiK0fUnm2AsCpz8uLRdLf+1j/xyS8F/pV685QTlgE4zQ5Cp87Ma7icRLNHo49eJKWXMGplJEtnzjAhMaPPVPaSLLdYxgxsQak71r5eJRR6VMIMp1BeK/3spCitfeCxuQM7qWWPH29BhaWHOFpUzmGTZg+gj1NgnHQ8ajgHa7PfK7apwRvShuU9OjgReaz0By4VUkepvOf8eT6Z2+rS2g1Rb743GWKJ22P/IfOM2t2Cx0KEjXLYux5imBslqzFuR8Qqs09zrZkiZIcuD7sl2tXRJWJfs7jJ7KfaCB1Syif9NGTbs0x4ot9f48mp10B7TtDOBUBC5hJqjwCnmqA62s1c5AyK6JHRSkyrhTnMJAuDHfDCSHykNsIZYWhslWBb894RFe0grmQa8hJVvHDoC5SJPvWaIRfCOGRf1FqCRlJCxuca0YwuEX80fbCQAHmGEaMogWV9CvU4wUcT8cx4+c7Xr+eavY8JSd5czOILMdAb81yBG4WCsDFX6aOXTFPyNyLbvLAx25VvguvdClv1TYUH65B5xEXkeiszGs2H/QjmQL232lOwmXYXguhy7ha+qyLNucbd7iTk4ss0Jokpl9XZWqJfPwbMro6RxdJ8+bNH+5CjhM+7PmA2vt7JkwnuYDpdXOR6d3UEfUbak+1tHeF1HSXL84FyiUZxytDhTJZf993GSb2Vj6IRqVUZMhcBYNM8n5Rpv036PF9H5yct/loA1Dktc9BHQ/AVSYjKh7jAVUWEJsXPHw5pmwswjUDqt+qdHO8IesRwUGLPfRDqvC0PoWTEjmNyWm4Dj/3ifSH5ORwwHQRDymPcLXp42a4IsZuoG44aOrsdUligR3LDzb56cs8mMYI1oPL+JLAR+FHMdlMHAiyKYLFrG11M10MNKB3LCVbftROr9PdEgnnytCowy6e7AJa/XJDbDqh+s6aR5PF9lWpm71whJDb8DokJSFaLjFXvF/QqRE0xL76y9obUluOBUnCXtSZzhna8G+nRvVLpqpRI+OY0q1S33et+Z8bGo5dOiNXPCVT91uFbSl/pCJbqGm4BTdSp+pbimaIMQN1TGEvQHZZc9bCjhokwLcy7RMTkQgHorDd5KVmFccC4edryoXUF5qd5hzA50zTj+6SuRn5aGxsBf96HeiqQQ9YidgnMfznTMSDJgijx3CZYUZQWfpSFWrmhBYXA3TfkfGEaMW0lkV/SYp7cpOdsdQpLhMh61GVp5jk6iWvTyFnlAncXpxismlNB9ts14kkbvQ7hmxUqNo67DM1zdmRYkXupQXw6pmvXGINnQbWQ1cbotvO2IlParrupv/Z4ZYdLjnenxSp2FYiClFqJGQ343uWXC79hCfeazYpRlYIDfQFbvKpwiWqrzFubBognnH2sed2ogXkwmsY1XSlH5FdagBxhBQ/PAoDuRam9mWneYHuo2nhrn8l23kbtOhWMqHrvEO69pnaFJDP6UjjlPI9PNsiLceJgRQAmbUYeNWTenpe06I2DysmZfaSIDkJisaY5Vz1zk3/Nt5V1gJWDcxtZiX/VKqyOoQmGAJZiwNtg3qXq1ESWwdwEa0Zod//0a7W0Tq6Eg6auvh60VZhUY1aKQ2XdCXh4dTDKHfoywcayYEnQrdx3Ntl2BizfV9hOMI9xpMxHNhkA+6yA3e+nb5l0sGeM0hjOSKzImO8S0pqOIBJ4DaJ2tb5oRIvlo+/SujJhuItkWCWkwn2GY0zWwiCWaJFL2vZs3FJts+gv4TmtrqE+OpSIaOU1wB1a9brR5qwwFfdQcFTqy4fHcDyRK0Zo7xajsOhk6Is+vRnmT96VnkRppHeaqzirvC3sfOiQgLN59bazw4ZVUMr0/a+KlPhPFKGfipTY7w/N/ljVQf9dIiX1A5HyS5LEP5cg4H9h/pcPOv/xEfuuTaI/OOhMUv9BdfL3dxAUeVV8/+HjstZjNQ5JJ/zy378z3C99biNU0z4j2BbrenwzZ7Kt42/H9+uZ8EG/ETp/cFfAc9yWrPgHM+77bXfJUhXrP9Mbfz8OS9Ela/P67Xv86UYm/xtGBqZcjvDXjQh+GZhw35r8/u3Lv1rHt9afODiXPzg4P1kk/+rgwHD8t4sDP5/96vpFTPgr</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.png" "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.png"
new file mode 100644
index 00000000000..c976cc99b91
Binary files /dev/null and "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-write.png" differ
diff --git "a/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.drawio" "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.drawio"
new file mode 100644
index 00000000000..7f7bfd71641
--- /dev/null
+++ "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2020-11-22T06:23:24.055Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="b5Y-KPRFUqSfQH-Vqe1B" version="13.4.5" type="device"><diagram id="3s-LqK6m4lkifnhmqHE2" name="Page-1">7LzXsuvIkiX4NWk281Bt0AAfobXWeGmDIrTW+PoG9sm8om7eriqbqp6xnj6CBAMI6R7Ll3s4+RtMdyc/x2OpDlne/gYB2fkbzPwGQeAHhp+3t+T6VfIBgF8FxVxlvz/01wK7uvPfC/94bKuyfPm7B9dhaNdq/PvCdOj7PF3/riye5+H4+8e+Q/v3vY5xkf9DgZ3G7T+W+lW2lr9KCQj/a7mQV0X5R88g9vl1p4v/ePj3mSxlnA3H3xTB7G8wPQ/D+uuqO+m8fRfvj3X5VY/7J3f/MrA579d/T4WzDRMIJQJbnjPYAxINz4F/AX9vZo/b7fcZ/wZh7dMgtYxx/w57vX5fC2za3rFS6dAO828w+dyci+T/Qp8mnp7p5/XvLv/v9xqmfha9X//lG3dVe/2q9rQVd+PPTRhGnvcun+fqyJ8ly+d/uPmXNv/hzri+A8zn6vsfqFTkw1xU8X+gxlp1jwpCQJ8f75yH7l2Yf3ftZV2GvvjnFX4f/9+u1fKzDd6VAvH/ho7nv7r7SyLv7X6Yu7j9y+02X9d8/pdHcmn1dPlnj6z5uf5L3FZF/+t2m3/Xv79Z9dmPRr13gb/p++fmOsf98n2a/KPxPv/LA8cwZ3/f9z9Uz/J0mOO1Gvo/qZ9Vy9jGv6tI1bfV39z7tkO8/m2dP5TxuSp+f//R2uSPAvC//caivxHPP+I3Fvvtw/1Goi9OxGmZ/8Zyv1H0bwT969PTCYv8RhG/kczvFwTzVn4+foj34kP/Rj4X+G8f6jcKeZsj2Le5t90/Sj7YbxTA/HUc878e2bMzkz8p+7XN/iiG/m7HQe+iPeVHWa25/azsW3w8QPuUlWvXPp/A5/LVit+R82e92jjJWypOm2Ietj6jf+3Xpz2Y+/nzl57+Fjz+AIJ8fjr9m6LfwYTPhy5f5+t55C/Y/juw/Y7sGPr75+OvOPmXZ8q/wUji97L4d2gu/tL0X9HrufgdwP4czAzGbWuBvwoWAn2apCccYf7lT7DslwqQ9I9c6d8++E/JI338dx34kFK8x/xrZf5EdG8t5hU/++gE8Db1R61fNV7dgH8U688F9zdCWtZ5aPI/ZPGjxI/kqrb9V0W/700mfSTzgCFMvRKpHoNE/n6jq7Ls7eZPteJH4Pm7SP8TRfij83+lNu/nv9EV6ufvf46uwDD839C/0xYE/0dtgYA/0RboP0FbMtZsP+1/j+a9S5j/nq81UdR/pi3/Worvso3/ZK5/oRxx8sfjwD9ZqX+6LBD891sIxv5kC0F/sigg8p+wKn9OCP7tVXmIzPheVt0Pd/qLgiqvthnDUv3CdyYZ1nXo/qd49P358ydKvg6vNsfL+IvTfavzVWrqp0vyj1Lgj5LnOovX+LEPvz5C3PhaXLryKN06AJkvBvL5o9luybrFc6W+L4xIk+HzTq++jOXPhbsCLWt6FhJsUEZ/7d8gCgIdYcctGzEnBdMiG4gt2koHcDSvqKsw2d04vmRFlw/0RLNKxbZ7u1BHF/aOqAHN5soooAFmOCyb+JkPaOwfPFjxhz2+2P/8y3+9LcRzQX3ufteJ6OcmBcJ78LzhO/G8Rujns29fdF8I9P70jBTZNk2btH7yiMXLznu9nZxYbE7WmFVKDmxja0heuaQt6U8DlKXSvMmgVKKU7QSwpi2KqrqyqEMttG2RSbK2E0vaT7GmZiTulA1pn2KUrOXAFrYjipSeHbj5U4xE8Uo1bEE7imjp6ZGYRWP6108xy1Y0wyiW7h4J2TQmD+FRXJJs8xQ7gqkDSESyi837eBhTIttcNOn0qQ6Ib3HO+7MZUSLZXBfr9CoPiBLLLdtbbFFiURwX4LQqf0gSS60b5A8mJT3FwAkwq86blMKW7QbxhU1JalGw6KNJ9FssvJPmTZuU1KVk0Ztaadr6t9eCBx7bTBWxnVTBSIzytujGzbr93uzmV8dx9Ht99odKcjGy2x6FLfgns+1MzLuZrjn92YLUvH0v52N+O8Jd5eTRSs7uukp951UlSKvY9XQ3Os83NfLc83ZQTwJixmLfDp4+wUjJgbj+PvUooqMt8T6dY8Rb8m3Zrc5nw3PK8795/ltKMyIdlrjnca6BfSqsseeB0hBKZfBgVnue/zyFTmK6zNMeXYc6OaKSSN+EfqpTQI053H6j0wMB1HIybY3O8G6IenMxtzSSsMsQBWbvvZbvHbYSqyW0pXZGYNIUdqQNbO9hYpp8xhbOnn7A8CPnbQ17fVSElPQO8LKI6BIE8Jt9t2mY7zEAXLbbfTTw6hDUiu3ge1EngutIiDRxgOnCP2jaX5GefJLqqkexOAEinKHpK+cdJqOrMeEdgefSSEwfnwq/sVK0F7HcuadJt8TBo0tnnxOvc7epaavGWlEi2e1brQQL2d/OeLpU390nP1MOPqJMqUkdAo/qCIhRvzAi5v2d88/VvJmodLNmM9GBYAaEMUN00DJfyqY+wIxZTbPzJ+RIYgkobrsLBsjrfEK8C4GKxDhZi9VlokQslfeKrK2ro6T5nCQ+SVhjEHLjyCtitQ0KJ6monepzX1lvNIiDmunb7Gkj1X4BwzVNaAhbbcooREz4mrzyZ8XT9/Btq1cfXnC59+qyPjNm4jYhlcscE3N0cA+qQ9YNTwLaFBu3Fx7oOd+Gtfu3ygCSPV5yq7hNW3OBzkTiLkH4SEd7X2zwLbdYzwRo1enurTUsD/BVuYmTtI/Tdi5Y7lFoh6/qDEnZ97Zqo2psx4snrHTCA8Gm7OmcXdiXZ5+HfL8ZoquznktLVEoMvhPEQ3YNJ9VXU1zsCKYNe7bfA7F9sF5zCOSocYGy8gitjBibBrkyXvK+E/Rg1/G1zknj8TqVjevuwHl0+bV+dAbHQ1LZVNAAJs8qWF1S+2F6gixvPbUvKYfh2GekeXpuwoqW1quvKCttY+kenv0MGkZvm1ZWLu18fZT5m3Fyfnr3wzrDlHjHHu4CZLbolIVNhjqAj7C8ATi2cyQTBiqeTFplnAa85r4KZn7EWyzNdaB1WxKIDUsXn2cNR2nS4mIe0GgfK9OYIVxrIghKE6SYzySMuL5n1HjsPUdTWRAP0QNu7AULNi69+7nprdu2MoQLgvfxLm3TuB64WNxEnAGhll9feGKdUqOithCtEoph+kvXUx1b6uk6yS8DJDRLIWKR8Fy2obXzBhpTVyc4Iym0hXrjP+P3V6ne2QGL39E0oepQaKU2fQZHkKqoum/TX1FuDNRia6UVgsoZsxLhhCTXfH7+rLE1Z/fJt9DTrkQPAVHP3tfhMxfMTV0zWsBeTtTPtr7ArUlWClRjpLTsbWOkbNv6EEchCWKF67xDZaGVHidO2V8tFwr/s9bAwy5IK7padommvR3MRxW+5nkqc6O7iiSw17fqBVF7MMxdUjx5POXHQCBZMJdlzbZAKgEBwdIhUDgHgMDvUhImfCWrF9Mm6UA8RdbQ5OEmUuIUhQ0fF7vuo0M2r5OF9tSXxH3sv8icHOwqbcnYjk7XF748DaWIvgzvxiyMmphhYRDfDy/mnvdjxC6MG+TjNTSUWmAiqITms9O54cVkTK5q4+FTC8TDdMvHcPudwBl7uOj2oMnZEqpTEFfvuUwZEVHu1/7OKOV3rxonyykwLO2ScbbQwFr7EyESEV8sr0GrEsbSeVpFNwumEqijFHxU6tMCjZHt1j5vnWHJ7HlbBvPMpz2pPE/CDrWU2pBRY9p0+6OyUyRG/ZT6vTcN9QRBXTYD1sj629SDpOEutoMRVumc5S1ygdGWV+yybrhHpwV27Yc1TbMRJcYDY6HCxxJNoXB6tI+qgqB0aMs2WjuXKZrTIG+vPSv3wdSgjG5hi0m+QdVIu6goONdA0LY2IYdFAuHTjJ0F8Jm8b5wIzcDiWFRq9hieiCNOmntAEyj1DKlDLl+jFrQTJtlc8DLxI7HQKaVCtThRxF4C2rpwHgE391rezxgqFd4iuUuG8PtisPzsPHJyhA7R7QomkEPmEeXhC98SaENqr6KNAhl9yaLU1Iazkac8xu5d+bw6Za/1D77xRblTYisTVY9vjerfPXm8dHBZH10CRhmdV9SxVUlht+hZ5FZjtTiDPycCCp8Amd625ssIMneJyGxMl1qCSvI+qj4aj0iPu5FX9hPd7Ij28wOx2YK8urTE5Uvo8lCx22Yi1tBkgBZ52aFQXuao9GA5L5wCrbShtA8eqMHjD0OUk8mOZIARHiLp8/HFk5agtzrZXn4jRT2zUobVPBDBba5Hl3iq00z10cbZLS69bXefuFJerNuGMJ9tM19D2/WBGeWcrsD0BLZg2yTwY0KSSsYDrDXHBLPzGBLJeqNKe51sdhkuhh/ePVTypjH3NskampceC0Rik6XoL1WX7JLAoRCPKV3o3qXEJbB57WGjKNoo3yiat9o2V1eGKMXEdoUvv5gKEbEfmh/vOj9OpAeCXFFaXnbTbshx1sG2DrxaaX/EPjORaX6u+aRN5e1jmqVS0PtDNstr+Aw77sn4YaLmKYGw2HFQcL2uGLqwaW4yiLQBc2VNiKbFlxa9ozrjDKxIEf9IaAgEOtiUUfrpKMbEPixhXgGYLqaXsDhKSS9cqKtdnGtfxuYHOvf1dsWj29BYyM7v2mL6yzTCVx7IyZ1HZYaIThxhm4hcm/LQKIyD+e4GEG4xi8ea+cFmOPGtZHrMGEeJ0mISLSVArj+3iBUgLxmluBkbjsZuzBPNsathDbj3B+1r6p+BIrnqu5GQpQrBhETuBbG+HTHDaxhkxj7Iog/KGTI0KgyhJMN0x3FAo/lFYKaHafQayoI/VCDk3cYMKLtia/i++OssJwDw7t2rm8tk7AqEuRcbrVLCH+YoON3gmmkJVMoqlDpzXh+jZmlXSld+abbBxZGvGKjzMKaFhddSyTau+ZVJ8aUrjrzFrj5wmfHKEXJEKv/y0amItyE+zxCPGXUzU2NZ3Vzs0NLywaMI24rFSdFelr+7n6YzG1SgoUN+GFb9OnFp5UDvtqgex8ssBXPrH2jgEfVhtA8tfX03PS6VJlftqret3QdF9Y6gb4PhMLtZ9+sRiCmbUywSrUx7OSJe9q/+igc8WKy9ts77HNWUSKDKIj6rZQs7Riqp1QjYaqGog0VkmP1dkdtPHPBx1rq8fzUv/+6eWPEUh23iO+7X9XjAh3qWVa8U+PrMUrkTj5F6pjtR5rmCJSXJpPCKHoIeaX5sNvIkLOybialhn/UZgK3aNiceNxR6DVswx2jBdk7Uuzaq4DO0lheDoMLKiFrnfqKxCCMdrsYac48+0kAETqM+bCoSxKUP9Lq+2771z4axTAt2600NtFKkV+qSb6rOWcvdlRSY9CJsVwWehjHHR//x5cLgXspTu8eqHSfDS+zHnlIZtM99bo8MbvdTtWaGXS9q6QDA609zKd59vqr/8WmRwnHbdnLz6OQ7tw5SBamV/b5N+C/asW0jHeukV7OaP76UPuiZh+AY4dmA6K4v/N/wmUClRHzs3C+bbwyzs61b4ccbFKK4bHrATjo3BZkxzKHdAikqb7ytOpD2pJdsncrN5WzrtNLi1dB9upPJ3Pt9GlHq3oukPms7rXOBVj43y7mToWbDQtba2a5ftKcG9N2d1z0a1ucrgR8/0I1XlJ1Mf+njj0An9aUPFtIyx6t8Q/uwC1OKuMfzCMvevY0tym1Ri6M5y/UFl3pd853TeDdmCnshLb7+pFFkhNfx9ynHowd09IdJb4FezXNTbGbV1PMY/GKkEdy/hOF72I2uT7+ea+4Hyv3H5X10mILLiGalzPTHj/9gq+TxxgZmUrGbqHpyfQLmnmV00uWLJa17uGF/C++rho6Fo3ixOSLJFl7LUItJS7xz05AFtE+rdKyUNrWneVTPkZxHX1n8vE5rSGmdAXhSkAoo/1IJer5F5PG8aDZS48c59EyggbKEYNPA/Uzd47ZSmlpxcJs5UNw3uPiA91L1N5UVbftQJkucb7X+JkszNWBU5jA1G4fEDRISb8e5aCo2xTb2oq7ZVEYA/ZhlHUOXdzQA5Jc26eZ72ogARkPviJoxgD64lAirYW0g++N39dztKKyJkpA913rfPFYdLRWFWfGBMhrA/n6q8o0NsWlMRSUC+MV8ykABZNYWdrCJ5xhpozNtXxI4t99IFr3xWN4xskTQxk9vAGzYZaw6qP54l34lOLgx8+Agmutjg+NraYqc8zb7cZHaK8p71vERD9bw0xqJ5dUdYXVqG/U3adR7CSUK6ySL13TeCW7QWSqU7AnZ5wMiEjd/SyXcbT8Qrg9tUXVFkWUpGVx5pp4fei3umiWnqAweGETYh4hgwevBvoBTKjO4YA3444lbNMb+6IS6zM6z2Ripig0GRimmo0kFdR1cYDJMIRUx1xrCo1kSkXT7BmwxSaGVfHeZ2Vez7dPSL4uzJMzhF/XjNCpNqWEfT+06hkl6i87l9WXj0t1syE3Bw2xGeDvTehgHL127NUWYSygT9aO82b6QNHCdZ71ubeahLtVH5ZVK51Gwxo1+XywAY14pn4KQGJfh+vfTxvcz7xfgxcQRDV7Guy3NsrNBuoTaKZP7ZS5BsW2vtIySMyQxdnPYwnoNTPfMFZFYOtoHV8zLW1okKAfO033aX3v1s0ZBhvVI11s79EHXx0hA+9gfZXvp0WMoHhekzbpTFEwgc2VDJUZ8GHC9X5bH4feZ4mrtezxldHzNAqRFjvuO9d6q9qWn6ouEGAJOiZtLVb5GPLBXr03CVEMxWPN82CTKlCet11zGnCHjXT42+/tKSofU2X2dBSWSFsFVjEP3IDIdhOiCGkFPWOTgRGyHz2x0uKkXp5KF0QAl4LQkKjlkN+KIPDoYrRfcJAmKdpQzZGS+aQ9XegMnAE8kVZ6k4WlT/ex2n+NOqpE1sqseqIdfTfCYGKyNcrI96Ux9eT4L5GhV4ZrQF7BfkPSGBfV+DwNt8FGB1hMXDFJxXT9xB48koced1RuW7yRy0hu1GNZ5rS4nu+tpe7Cx2NUixm/JF4EB1/bbLVTGkC/X2uRHewlcM3tRTfiDuWXXEYuKdtxnKb1MfV5J3QHgUFO/IRtPGElTHFz+0s9wf5FDq6uglvFltV77z7HslvbpqNJ9J1K9fgKljtaJpvISSXKooJ9oac/yuICoxgrmCc67tiJW+43vFCv4T7RObZOTK0cvEh+2ubaWa9/ewaAW8KWMXSggcOPaDyy4qUUjDzsJvjpEiskCoQ+7LBbstYlbn0AcaVXCNcm+WhDsKGnHEE/d+rS0FDjrD0G5n7l2hzZ1kxuikfYdfMT9IU5JaqjbO5NmZ75ps7tSDycsT2ivYVL5LIwbEC+F7hgxK2esh+F4EXW9NfbTbC4lUJxnHK2Qqx0sMPbdNHnLK5THiiclMd1xb0mw8625Fv3JQeEHkVs2i2BjQGSt1/dAM4fH2BOdbeuuI6X2AoO1/QXCcWZdExc2UdJk1VrWW5KE7weFrarVvuphimlKUk3smaN2WuyeCZ1mNo8N4XsxzDWwTN+4C+MQtn3Qx2PHXJBHBJnj36BsDvMKVr4yD7IXWMYWeIP4S/3MjLvpn+AqOdnCgNbC57EnsgulA9nn3oelemhEM2oHk9yarJ4Z3bhU2RBs9HdLXgNop/MrknqyIyl35+7rMcSXdMTImEhkWNDdiOE3lmO7nzSbWgJDJ9MiF6R08+RaJ/oWNlb1HTK5oDo2hvEYouTEjam+iwXYRSvyNr9kWQTTvigKyKwU5cq1lEfwGl13C3wo7lxGP0wEQLStd/F3NNi92B7lj1qjPg7FaNG8xlTpIies2JAEKzRSzkupcdFYJo+gY52xf2qNHD0eh/Ex03TtXSCXnRkzXrnD1OSoACIEqXJXFluM+BwpQa1O9xy6DdhnG5A3NsV1sUSDx+3gk/hlJlP88rsXblZENleGjZe56abJGA8TIrpH/hTPm3OGbpqpAjo28Yd0pyfP8QoLmFSjaNSKHrc9GzwSkXI7MORgma7kL9vXIlky+jBuZzSu5YbNUC0iQMaxi2BgyeaVIEY71VgDO3ggwNb5BUiHo8v3u6cTdQiaDyKSJRM8bvzGFZlWHfxXiAj7IelcMY4kRGuUVrwCfjzg+HlMYtdWYo7ycBqPlRsv31A6p02JjJSsuNwAnSOHsQpacLFRLENHthrB0wEWeo2oqVG7W6ZSq+v2wU5SqSpktk/z5KyPA0Ge9yk5NW1GUazaSeZkIsX3VkkHMcNzIB68zoomSitOmSlqq3KPpf1EZtiihF+g32VApBTgtgF83WPQG6Tl7DdOiSWEXs6ESFcIOCnE+vIDOnTn1NhkfH3Fz26ZapQtcn85b1QtAOJADzzQIxFabXedTpc5Q3Lk3TLdVBCSKKZUeH/o7uEc384cHL4VCmVXYqdILDPBi5/4CTZlaKN2F8e6ue+qflBdAZfYj/l8d8jzCJKguWcr07SmroD2L6kFH5Clku/zoiffAMbEUATZhtXT/TydyLRtUXIpZw9mqyKlZcPRN6ywzCJKPuT6PJ4dBZOPH5Wln6/fElHx8MMopJxXeINli/LyejT4T6VBlFh2ItF7AhGQfFykjEC/vgeEBe2JEcLZb6Xi6VHf8v2nilpIUqMO5PiCBvj26X+/xPhUYt2K9sgQAWMieU/iti3d5/itYlJyoy70+F3fczLBN4LPU8F9z9o80sVB7O0vUbZ3++6zfOk/FVJ5/GrH05sQGAE4fvmQbWzeJ92XCWBvb7OwvwT2qfKeksmFnmJrrh0GwYBhznwq75cjz6XvqSppu55uySgdiuJ7qvtnCQP/0wP4fzuL4Pr7VIB/83T8PyNn4E9Px7E/yTDBfxJC4L8mDP1/Mxfkz7I97N8H+Se5hP8PJfZHggPyR9rH38gMB/8XZnlA/+9neaDQv8ry+LNEKeTP9Bj7r9Ljf8eq/G+b5eEAzV+zPDLsgCyr5xiwOijPYYOWPj9HOFHFDs01a28XBy2qK5uv1Tiqc8LDYatCzRps/fqQmEzvoVbR5ui7nLC8/K9TlVcme4b/BKWiFo7g7+PHnxCOg879+In3GPX3dhTdyR7kurIhmdXhYauHEloqyxGZVVGKRR5mcKI8yTqnlpNsWjIHo4lCh2zrQ0ocieZ0bWZu1iAptWfu2PWf6UtLSQk5WqK0VBR5UqEgK5oqy/pIVxjqQVDsZRoamsU0KXYXK6a4L3SiT9OoLnRusVIHaUWVrH5u5nj6IAmYOyfRrEKRXM9VzKMSIaVmyBP7AljS0hoxxCHVUJ8+hCsV9LG0qaKobhaw0E4oxId6oZsyu+bbcenU8UGczEE60kFAb1yKpBPRtOAtzN8+3sllFs0yFMVt0sDcqkFaasPceeAXBf1MjhZ0sEQrrig2p0RbUTHTx06GVW2kf0zugjxo7O14Hdv75eniG5ImfjhDCcwf5T3p3hoVz87ASOHvGzKUPvsMGa/wzoGWmiIOagF+g/7OymaSB6J3DzoTAXIdJUvU4yOAIfAGUnkN5xe+ucz5C302zExscGiPyO3ysUvhZ6yfy83egEaL2OkZr7UrdjTTU7obN89UMScszYhGIZxg3ARpMHuz9yoZKVj9ZtpPpDACCg2VgQhJXfui2B7amAjta7JtipvsbGcDnZRH0bYJTVqgYDtYFajZ7Tb/dgA712GUoCGdZ+7UZeg0ZmTDQTRmk7zs3G8kM+fiIBgchB2EYxYM4PoJi3ef3l4ppbzFVMmOnSti5VkuFhEcr4t9yIGXGwGKNEqKXOlyp48htagJSWLaIJJ12TNed0EJ1NIm34g/ZyOESn6Mad4Oj7fhipcQzFqxwkZnzGQkDdyAFguTdzyRnSELFoOOkEsuHUiK/cuTehdxJN/RHd/5IwDF0n4DcEJQJDZtpMT8jhI4g8ln/9dpNqoAKBqw/KUs4ighQEZpOoASh0CoksgODc6ObG6XTYE9zsh34waIPKLPj6haEf5qIkUW5v3TFhXrYqFkZO1IGelJESu+UNDkClqGzwPYw3FBxTajt/I2NXyJmzcXyoRUnzNDtXOVSCwkILWkiqfIqs0xfRSNow9mfg/MLE0iBQM7YZpu6NNbJCyf1IebBWPm5JLWjg1pmiUiUp8OSL+coC5OXd9JVrnzGsQg8yhCbCvWqN8X8c3Nr4Mavt7wiPP5uAJOjFis20Ypi8R36Qwv3l34fOTydJe32CcaMIuACQLvYImWtQ7XtCA4UPJ6ZzhiyXmTZGQ8GulerLrzEe5iW8K+flpi42MtsvcanVM1KW0Sq2MsPQCSlvQr/YEjabY8H0ORx0p6z8KcaifNy6I7e/owHbGm3ba5spsJN3244iSTd8az9rgN+NiXdvW5aspHE2zeTtoJIdaPvM1TA5/+puEbBhb1JTWdcVG4tpmLnZrDCLfQ4bQZqBUKTsWiyXGz3OnC/vqo3Xe0h9RtPgoldNvI6jwjR86ngux6ZADIVcAtmlbWJzmpNt7Q5uCTecshjHcN235OfsWKi2cS7HGARiNm8tY45rVeL0YcLF7SlSBUiADJ7G1pumbMwsmF4jHBZmCmxbWo8KnTzNCBBEUhX3OQ+QeMHe0l2eQSfm2y4cN2btprDgKqV44wfcbgM4VE5LRdtHw9B9oqAGV20Wg6gIdEGeWd/5gbtQT7mncaLvCjmlZOxBSYUb7MT+6rnyAzTIh0ytbm908vq11ukL0obgvMsgTlKlAra/5rpmYbGa176tufU4Bvd5EG/cbvE7f4XlnTLeJsadTBEee4bR5vaO/eWB0aDWTjjqh0ir5DV+2+OZAgrp6UUvuuYDQmRMupuWvzM2etfp6rEXWvbUK0Gk5lUowmOeKDOiz/k7hEETWrLv5VA5D5AdoqCDo5cL92BqqyzhM3rdN4cn2h8s2M+KwAsLjXjT/zQx2NIXFnK9xUmCCg76FTpL5CPVPiyX++vUuT8pYwG7kqnzfrwzT7TxXOmdawDllpGfbtxCiCCIYMTuHmILmzyTEWPRxioTVr9qWbtb0wKVh+HUj7FDSxGptC9ituF+1jgKWqO5D3GEA8QUluu2Iy31tfaevOzveyRFHF/fEMw1tONJa9itgI7SN5Tz/NcwAb12F1shag96B382MapcXgKoWqLnXijZWtpEgugfJ0bKOZ2pCyLmZ2BqXObJoT6cekXDSFlL0ZSZdQWdBxmCMiUSFlL5IYjgFHhawW85NbLfIGQLFINjom7V78UXCxdbv3FKkBMTsSTZoEQdrxei8EbdddlIDQvMjwhL7g7a8meRs2VIQfl9zjuo8d57RDKbFjBIIcwz2L5QCXqRmEei1QonShZ7LZBfLOSF15Y4qy618NsLAD8TWyGXpV7z3EKnaMV1/8FyimBQBeb1WXWGfVCjkhNt4jOAetvqh43owh8nK1x5ZOizRNLW/4VEaAzZFFeML39M0nXWdtAExrKC9+gHfmI/IIcprZfJjYJ8/FfAxq0rt9m5ZUUvJ59bNA1/4q+w7J4p0ssAtjyI1zEgbu5vieAsyoA8nakYWGASaAhLwJueBPwFbEjRfFlzewocvHjJvoFxPs15//BlM1sjucYInUy1UwvpO9chTprM+bUOi+/NAuKTJ9Kc3lgwYsiOJRvAQFO77cHn7hRP1GZxMUSSTlytCu+Hx0RsoGm2lLTkIbJ6czbF/SC4FhomnrTei4N8hnn4eTUAYtsJUJla5YV3mfaDVC4waIRGw17w5HsfvpVBV92hZeiGAbf91SK/jM9oNWOuKIwz+3fjZuZ4tSYp9qoy1vIBOhaK72bsjZKmPBwppQ/VdBrQf4xs8HZSHz2QMO/ZU/gxFngPpmF3iOWdjNWZfu9SBw3+7q4eK6w9Udme6oEfqeec7o87J+KHYhKxlcbyFaQ6l7z9yTZ/P6OGZpZQu0n76VhsFC2V71K4dTbg3PzFUylKrvHj5UjHHjAX2lA4VUXBY7BTLhh40cPYSiPdTRlwBJd+dQvtyPmLDVQxitRdPokm9HMl8ValaOdy88q5kI1H3K6jdtrNYOTx3+pGxdBRqPglsc5ErC2W9tVZFuGN7feHBcESnwwFcqWtJptFuv8T24DGmThMNhEGLFIn0ro28KDQP1w91b+NgWnYlFoNr4WfqpSM0K55HX2e80Fm7Njv3xtcSEWYIbaqzwpYRhiT7smCrCr1kqjfJGtfKjdUcsuOxs5AAgYJZ++X7ZwBG727INnch5c6Jq+h78GuZhnLWJ3TbBEbpv+OE1i3EsEfWhekNTgWJLJzbljklGbCLxX9OptIBPsjLVc0mRaS770pzcr5sRuRHKOwYfWfZyzA9AV/Uzo4/CHKkHP1J+pxJJxiggoJTqwuShPhO275WwomlPfChS4YVZIOKRps/e6zBN95EU7gpGIhWWLRM7EmNXQjIV52XJEsN7BUJdFAMuNiUpjkbFFY+7HdFUvYeXB/+GUDukOWf6jYyNLmR+59Kjj0AgYpG6B6zkGGJoa43ALjFnPDoNakTaBSqTtK7oDht3vFX4ySNqeLDjVuVrbbgBqdA3OOWb0lv/4exXOjz4K7HZog0EU3HmG2k0PTu4vH42zs+LFgYr39LiBB5P6Q0RbwbAYyJb9EwaT/He31p5WJk52xvT6bTGYmaWwXhoVm4kxBLU5mmD0jCf6QgiNZ7NPVoHG7QRv/HdaEkv6LG37EDNvlNszGAgD6j7tky9WcXxtn6nOH9XM1MrteTUxqIJ8raWtkGUhcUnd91Es0xmBhgN1uw03V/EyyD5UvUdhYOHMKjzeqjLixTPZyZMY41SahMoSgYtAkYc63Glrh7VHTYBKTE0Kz6O7Lfc2JwFDJ4dRwhUCyWN54dOcN0X5nuFYhvyW5VU2D62XRwxn8ukWPtE16UdbpMC9ZhGExTTEk/lv/AIjcV0YKQccgDy0wshTqL3ziJ0wK7LwdopjWksjzmJmov+WMI2XToEHgsHByGNmFSEhfUM2hW7RcmPc2dH1PbunGRqZB9UCFdKGd9qzYVoNhmpKSwSya4YLZmd9tw8BXCbd/5MNMIs1DRZPPCWwVHcstffG1iUKAMm3bZc3lsq9TJZ+jq68DVQsyPrUIzkvAfLzv/0UUsmpU4p1ONmHJCB9BPgFFK7tq8rClcB4pFHkI/TDb4s5KC9N57xEJ5oXxsJzxH5PIW4th6kIGEKi1GeW6TTFiF/LYHma+91jz6e+MZKXE18NFlLnZJt8lhCHvoXfoVNmr4eud9ljiwGwpWsI26UZdAoOBNmytAdc6PUYNeuI1H+2RjE8eZuc5rCbROvjX6QigcJsHE7UZCLwYisxdsiH4g01KTuaGR7MkMcguOMfoFOPfSOpqOD49WNPqscnOAK9sUFQJa5WqoTrP0qjUDrcfLZAH+di4VsBXseY9PA4lBUyRdpqvlo9Ul4FvPB4epC9Zp6WeZOImElipL6mMqqVM0TOmjfv2sRpgqRzV/K5D178s1aoVDNbSyFu2yXM1lsrjynu6mSVcf0YOXQa0YUg0sSaMks84WDr1iUpKH5Q7vXgzoeVbcWIc/n9xsk/EN18k9wMTxsT3T4Hgww2etcZr5+bKIL7+dCSsoirSVYvdQ1uqkCvmOs/QKsMzIfv4CNaxzWiMpIaXCo90s9DSvLZi0gXjLN5f4KXHuGmec1MvcIWDBIwjFokZDKG4nneKk9Sv8OflKTDoF2BB6q8YTi+0asFAJZHs+uqqTMRJUOhJFO7TDerSmF5ULHXLtidorS8T6mTsjDRMo3yrGhRqQ1SakXRTr2Bg6x4g1SUynB2vI9gS+NGGhqstNp8tkS6lzWz+HVnZF9K4ctrXnGwCRTXdbutcfMaefXa01/QybFtevNQZUq9wdSTAnS9Wh9/X7PL+dxaqRURdEhSS3PZa7aAItmrllSvurcJ8UQ7YdyU/BNWINsTvGgzqon1PE66wRRWyPZHVhytHqqv+7IcpS0ujabn/G6jj/sj4vW6y5ZK+cWs9409O52m30sho0y4SlAdEodyfapYxOhtapFJiwudfDhqE/HmuSWizzMvBrAydl8iwfytFkL8o4mX62qWq7RikbAzcr3xo/NQmQESlHutqdFk/yb6KEkavl49DHU0pacoPUbarJYIS8hmE0M1wwfjpQpso7T/Rgi4ntqIou+mYyZqQ4PKXxcYpVYaBONG/TNQZ6F9HtuYf+wLlIqcFQDYMQhIgp4/MtvZFIRlNi+5xu8DxnPUKqv2KAF+CByQWW7jXqVnlJ3cBngxVerRU1QpZog+lXCzVZ4++h5s6RLr64zBUtNmpjFQMSsIrMTgR3DWlBTkJgKu86/rupEVDBepd1Kiq5jdmGfGeLU9C5lxeu2buJ5sekJyiRwDIbBpUjd7U0XBjgwb9hitjRI17MKSqtLSCcsSRzgVLqhEiaajHc8pMkVfHha34yh5yz3y7vM19y9u9LBcGT98PHPTp01v499/4nKkDXdPXNjC/vxdAqmzu09OSzu9aC+oC7OtN3fGVUK3pufR/m6+ZPMck1NYC09oVgkq/rG5gT6ouU8QgBzbFkK3rw7eq4EKuV+uE7RP4bTaQ9MnNnZ0i39hhcwxc6ceMk6/r2J+jwOGXUjsbxhg+2NabX3YPUhU6ITm1e0XEYjnUaCLZlbu6iFJU9en1GZM1iZH0+npJkPcRAsxJW5we/irMNBKCFJAdv9DECqNpU2xUQoLw5IUJ8zVNlF/34pw1mGcTwOvKcbryhopj4NQ3FNkYofv8NqbmiUaeKR30MP2EY4qHArfxyq4KqO1Dtm6fMNXFbEa564MqyPf2AYWtnQfuMInKzujid3Q1BfExe5d6HDb6ZCF3C5AH7MyrQK74OR4K1KZx6Xm1kXev977gqIg9joDe2zQ2yLsetnz1nnewwLp9qFKrM4CGyeQhMwvyO0TcSMo6boLkr6YHNh32rJxMXi1+WWPrpyR1JNF3ZZY+1sNbO2wmdShdKZnrluXp+5Zsjoqy4qGF+gMWgsQmL2RxR5V7GOgGl6gb7HMvenCTQc71EbTBIQ8WtHi2H6dyq9/mby7DsGwl0Kzl8CvSFbHLGsRGPVZPZ2MBObQnpxAI7PjiE/21AI+7cWi3IbJHlkbYte+rS4ulJRnW/R3Q1IZChZy3qvvS5f5VRfIzVRsWx2DPhQQlE/OFb6wKgCU6SzD5W803UjFltcVIwTBZaQ6e2qpaztJn2z+P3eJjiWwZhn951fX2vmZ2V6aWJGDm8M9JIsnUOfC25Fp2cybxhSIulwtoFmZkW/V1ubStNSl0PXJuUpMIuI4gRHrmyXUBfWT5XgzTAywDEiGxm/fTrNK1cimof/vbsNjimhq1ZiWUiHMy2wY5UQKCYAz9yPokk54NX92S9uS7yn1ZU96gbNWjxqZbNNJ8qU0RbBKksn2oxwA8sRiUJ4IcbOiaVF4NpKrjwR3puEnoFYVMe4HHu8lJf1ibpKNHcWFyhbZ8TbJKdchs6ZNcj3a0YRTk0i2XbYqXMErkMu5Bwu29sS+2ZXWbzitiJP05LIeOq17R3NyjMaoQUR+9d51tA29xsD3G6qE4ItgTf+xTov31ieg2ZwxJEWabvjWTovCvQyfc9Y0FxT6kmUycdn4bw2xbjDUhulRYBNH97zFrfwfO8egvfsYQtqG8EquiD/Txv/rI032qNKxElyGTONP+kDJCVZLsrOjVQUxU8CwX8ghwD6J+e2/6Ecgj89e/0v+4Y98ic5BNhvH/Q3Cvj5ZRHmN5J9kwko8s0q+N83meDfL7o/kgk+/yC6P/t5kf+yVII/Edz/6lSCf0H/HakE4J+qM/pfpM7w/49TCSz6b34wIkeOr2cFwo32a1JV3RcgXTc4CmkSBx/G4bv4pPyHFV3Hmr4ycz3OBV3thRhTtjZUVFysAu0VQGjZs09dpFWpAjwAwUNJiJu4FtZrjJkEAMDoNNLGtfYx2/BjQyEoh/M8O1HYeAlZs0Mzip74vX9TB/p2GYzcB2IanEjS9vU0QIayKfItZ5IFRIEmQpIySVELcxWkqZDCwL5ZrFRAslecJjszVc+8R1vWrKhGOJJ9f4gAzhmPNV3SZtO4dpRbNimS2Bp+RpCBZEkM6Cq3cwmKlCRDg0vwTaIEZop/Q+b7Z0DqYdL6CPLTk/hw7Ic5Xg+6WizY/bAbWr6/IkbVA/Z+YaIbpzCPvXoKppAxqdkEN914TyDRqL5xDNN79csM1p6S1ei86xS3oBw2dhBFkKo24yGSkpwdUVKD+Qw5RUUidVio7xfPOJH9aqW4Di6l8t3h04f4fr+RC6TIIkXGXdiAVrmrXhPMrFhkjeG268cr6yMgZYbUaEvXScOCtEUfN9kZTUiVV9/TAAFIHo/8IW4v88ez5mM4wK3r4Fa6PknZZrK1LZn3oVTV56hOPiOeA2tZq9LRa3Lm5EAiyUSYYQnc/M3wP0FJ0DfqpLjoUCAP3sDaMnlLfYqmdaiqWJ12OeT09XYp7M8zI87QPNVBIo4kCz61LzWHwXzaGJGhhFpxoU8ZxN27voS0fPmzivtxeg9g/JzHZg+RC8lx9104iVTjLeB50aM9ctsyCC30WVL7ZdEsqAwKzpU62WqUJece7t6MyimHJ2Aw6PVqKRDfc45BcXskQroFhaTqYTB+FmHHyMqR7z3P1XksNpUjBYnbASvDkW6ln3MRfnRPHEAzYKghaE+djLSyQ4ectav2rn1On4KbCDUaGeSFPHk5uc8dCFyKLcEOWTWAfUgfUBxU08VgSmD0nqwkZkAFK75BxPCNpVPbwI+J/ibTXqG+gLlGBdplZwJj0o3gJKtfm979YLY1AGRJVvGmFzOEyp3QzW431k1lw6AEKdfPYQ4TFkZxY0FHqJ1WG99Jcq5sZULbpQjBcKKEjwNtRnS+XjibTPmvjUSL2K9wTJ8sQqkOey291EXdd2sT67nvxAkU+5qGaDx+cBIFgx054zEaoiTOul78TAbwVlLVy5lT5FVwLIw6Cv4bAnQII+9x6hFr4qXWPJ7t7/kUZpxdMmII4al5OZ9o4vjbR00+NrYVQJTDLHvE9M546/sF3/N6A1YhCnxXZTB9fX6GXMwwWCjqhWChwXuFTJtv0Bk/vIJt2feXH/TZ8wqeMdGTCOlrnGCZPrmQKgA9/fDkoiTqVTzqRtK04I8NMZwyvafoaeJPe2chVVQPUix3FauDtS8mLzRnf8xBiai3dZU8YtJI6as0aYg5l5AE3q8KwD2GufpMcK/ngrPMhAZFBI8DqM684/jMUJjheEX3xVfLgzyNMIHnm6GwuhvdefHq90nbXmgkBHmUyhdV8hLWrl9EZR04iiJexGOAZo6IIuSEChnq8HxuLciiVLqgs8HDK+c6c11q/nqYLXGfyw3Y3+8Lz33ALaU680Q6Cs6MA3yw9UACFVlZVNEexSA3KPrSLMQq59PvKRCjO7QSKVVhx4xQ1CUdU0noNyp5kTJ9ldziTAI6e1csVbMHznpwR7RlbFgOmiUXWeGoIjxvAd0bZgyuiepMAS+AffQJMS1IbtXi3ZGUhoJ80aOawhwKuPv8ynNpURYIG5qKLBuRQ7xeUbt0O5+030wAzgSeTi9tPB87whUToYt4rV/wwnSlTdvM5/s6pnurjbnG9Yh5cAn1KBh4eVLYY6Wblw5tU48BSi3AS5XIHHtZojTSASBtT9jhTVFm52Myr0dG4aefitt1ZTkmwX6qMG3Fp0NpOsAC8pm7EBPg1Go7tAGvsVvD70AfKIosTyHq8DKTOAU1RXmhb+FEOdb93vkAwzhim7Ltok2LlWf06xkxpTUie8FMDtPvm1aAeqQvKqPYfGWOdIo3nCQs3/OCFQzvVUZkA7d4CZPz2k8nJ0xiWj3SpOzp3TThrjcyKdFddtQo5+lk52ScG9h6yyltRVpkOhR8C4dDKn3fw+/teCwV2s6jS9nMFpfVnf18J90E+zF7ULE7MfAWDqYK+nwBBJPrjL6SxdlXULEn+RYjUPrrHm9TaUZRFPoOLckW6D1kcNjTQchT7glaQ90HoVtQ6xnkS+eRJT44CK+iIV3DQuZRiwRWxmrtylKV7Jkq/24scvxyaXSDRciSowF+rCNQZINax8zm3jNf4XDuziUrErVETdFPG1GOiiaOmDlsQhnJlaSHQgChcBo0Za7fMJ7XUAgpuxxb8tVjNvLFn4OJBTco0VrHbQZypM2SjaOcSm9muIn0FQ2/2wDCFJK5yKrkTQTJ+NuiXP0UI7Y8kij1fm0B6T27dd6vBjCVvoNltaseTVqMQFbae1xvjukU2VhYF6+Jn2AC+An4PZtmYqlWaWWaBPcZf/GyxUsCt1p9cceBYyV3Xpi9yqtKF9/flAm+vby9Ya+GWrpzVFza3zblkVVkshaKb9MdbClZ1jUnNxp30mVWxI/d1YqDJ1/c8eG5SUj2kXf8CXXQJv3X7k6eMhGVJX236OrN63ysJb/4zOQML1FRv4YwVBV2r4C92SLTcNd1xK1KOQiq3yuOhkj2nn+iXrTSdljwZjNYbCceciwDcI1casA0IaPeuIjuGGlTGh7eQv59+K6Mqe/PTj0WdTVFk5vNB8He7yYou5/3kC1J6io/pGmVyyhxUfA9I5pA3PokXmGSsdcz0JhsiTfPjNvZnaY/xA55OthwcJBTHBK6hym6iY9Sc5HJbEgDu8hpbwdEKe7DwvqQiMAlDKCK0pgEedlsHDwIdCjHF5ZOnQm/TBwS7KNluZbom9tjft+gnxlDWEFGFJO6ZAzeh8B9YMW6BQ9eU5lkzk1pdfsFu/fUVBRWK4bB3goCUMdmUqUbcilDKZoaMj1RnygUtywK3Sxru9L8hmTl1Ucsb/FqCY2fXTtLg2zKZ0OspFhwBfjYtPDK7ZI16TOuBnKJFMm8VDJcPZfkxbZBMp5U7WkymYevhEZt0qLnqVQleapQDhQrb93DKObOOQCyonzHdIv/09c/6SsGKFTI2Ey2PNuhL3eilIItxh4S8tIX2/t/tHdlTW4iSfjXzOsGiPuR+xIgQJxv3Ie4BRLw65dSt8dju2fXEePdCe86ol9oJQJlVX2ZWV9W5gUTffTxSseFjhhXYLB9zMz08E7VE9r1ruPY5VuRPYbtTIVnJX48LO8CdwjN6bnE+yBtagRrEwDFaaIXc7cuNiP3HTsTy7v9sx27CymIO2yKKPB+vi2Dz2zcQ1GVqapMFTmh7O2R90F6tb0beeC64t9i+LpZ4g152yjPJ+WKJ6HAo+msv2zRPHG+rIMc2XEN7tn5ubxJvv0BHy6UsuSwSarsOa/0VEersq61QkMi8qdLPp7xQPn91bSYuzyqNcB9O219MrJSScn853QhnY1FwzJTJm+ZOSzQhSrPz4gQ0tdrXZeR/0CIDhBXGraAFzUAHmkXA3Msi1L8jIbP4iajZXh9VmsdNrnLWSCXiblgrFyY6E1p85q0LjFc1Ah1+CW5mMQbETDbKDD0gMUNTxleZSeX/AyxPC9S8uEzXcERVwaGl+VwR1q0FiqXHuTM8rAWqzPv5m8+wJryyRjdm/oEJDy5zW50blTFyBFqPDMrFagwse+SwgKHydV2bcdKBs2Ym5By7hHU8Rg1lzW33lIph5/ZbAWOF1zavNtUGZh7rwE+Kb9WeYo/LOPA6TJySyGtdd0zNfkJuFfBOzUbDYrAeEVM6pLUdbfV6AYcZAr5Qnz3TH7fnNuwa3FUTryKC2M6g0pbYId+bBquTbO+rf359GikaU+4KjnXIACJA66wBfVeexCj0DsnbFVzbs/tHR3cnOcesTMOKWbqR0yzHqZTo8fZn3asWoPehU+i3IoIMdOiqdG7H+GI3iYKc4qmcyghOjLBxAWpH48cED0KZviDL82FtjdiEJfugdjshuzEtIa3J6+A0kMsKch7t4ijc3gfO0/bcb+VYA6WRrsWTFUeb0jqpnNrwETkkNzt2JiPbblw7uPr+XhqKVNtVVi5uM6gCzlq9e0rmKeV5uzdJsyv5M1aNR9BrkE06/2yBYw8uiRbGzGEN/B0s2qsnm1NxNY5CavEuisV30C5tJN3XbIc0wAn+t05HOxy9tT7APScHZ6QMfnqzUOJyiu2ejEmKQEkeqDXIl2rfgoyyXxvPeLCQLjFFsTqvq8vBW+Z49pgBWlDV9HQpSkoOH7TJkATvQo2g1gIYaF1UkoRKEn2aZetBCM4BdxWtd6EH56nH9Cy7Jnmq1CP7b04EccIp0/xOrXPyXMboOjJhgw6YR250Pf5gFFACOtjEd9a0TBEd8GSxfEro565yqMupl8rT8LfGBtPAzbA53OekHDarZs3esqlVu+8Rdcr7wWnfTXRVRFI9qpfrEaETq5EIqIQs0mZzDn89mOO2dXQkpAbD3d0SBfEKP79onWIhc4XfKe9yzGdTleIulw1CL4H6p1pLQ3iNA3G8/0Gs5FKsHLXoHSSUutqobhWS1tWCcQsd8kVOpxNY78ThvU0yH1/bI0b1ehjOlyd3TQ6rdd5Vxb5IL8JE1hVmG8Q3PiKIS1jOlTD49q5eEbbMwCI6Hdy6FxvmDIu043PaaFh6ZSUas9h3uI+H38dDhg2jMalPmwmzT8tFIStBnz1exUerw2UmYdEdEaNtriz9yrSvdkj0nbHkP7AUcS6xjZwsAiMQag6OBlXB9YBdSxFSHlRd6TQngN+zJO7WRyzfLjwx/KXMnxZj1C/muNAdLi2iFWjtSngEutuA4UYCFazhFEuJ5jigyobJ1eeW12s836DCbDLWuIpTdrOGXfIVi40RYxEdLGrWSzr5nG50H3lkFPDh8rrBKp2btAlJikyAKW6urNHYmWsPMVwJAj9CN1jYEvgFZRcdZCtBIkwNci7hIToRByus1aluWhm+gbs5m5Jm9pkiBunDUSndFX1z52g9HQ3FyY48Lz1tZjHu6SGrPxQ/2mPew/HMyxHUwtjBEGcuF7iS/kMZwQEdt+g/YGo2LDkWHqKs3G4Ri1rKYOfQ1jSwleGpO+9HV0tEtqLlGcvwhAeq2aXofVMBRxuwVTnPxm+YMKwSeA0ZXqaEdiH4oW7bVytEqHRxCsmvFhozbKfZmCIC7Ua2mMNZ6Y7pWizm4xsFZ7Ai7EZGUGHrk16OnELErGP0ShoRc7YQ/aIFikFLFF1ljhzUY/AE8w+xqAWoqNvtKqyVZNLAf6WFiAFSMaBswCHeJarT3oYF3DdFXW41Pdo2c+9Sg0ZLSjO0wd7r7FVQNEIP2RW3vftlQ3yoO3Qm6HDJ616DtYlzhqnOGv1jUjxkbnFkHaYxGyOU7a4pwb3GM8zYx9a9valZ0TuUSqgOobK6/yxFD3OOuZdrAxVYOr0mTdHiLyuL7lajcuIwmw4vmrzRpqZQVRGIdtE0uxHHF5stHwBWMZbSOJNEbzk68pEy0ofy/fh1wPIY+wJ45YM+uH7zEd0v+6uaZDemtBypds9NkN9uopQbdi8gKHlYbWL+UFCaihtbROXhQHMXSCBKiEF6tIsbTAmAnyJGjrFdcuENVFXk/bg78N81ZVbA2MBKT86sEOrUAtpjDJdsDcZhcU2vzk0y2GprPvWatIyAw+6NmnDk6Z/8K70IIg9uZJswZr5eWLGTQMBOJMWTyvZLFAFJY+ff5WkRP+EEfpTkhL59tDsx6wO/J8iKYkPSMo3ShJ99UFAQUOE/11u8vtH7BM3CX9w0Bkn/ovsJPHNcGRpkX364f00l33Rd1HDf/7vV4r7LHPuAZv2GsE6m+ftXZ3RMvdfju/bM8GDviA6P+gVcO+XKcn+PY84R1ORzf9C7k/GYcqaaK4eX77HD1fyt3P+51Iy/J1KPv2dSqb+DiUfqpw2H9x/LOT3y+CPn3Hr+5e/XW3vV3/DCvirg/N+66WvuvkPVQq+SCwgvsapt7d6v+fzANPTFG1/EBuAwP17n4J/3bLqa+mvW8x8KQ82qV/P/zzXftfHX+gL8lFxhF8tsX61xPrpW2Kd/vHbpwZYX7S8+rDTFf0biYK2R7TwG8X93jDry55aP3Pvqw/ys74/Dwv/jjQs/AOH/Ue0vvoYtD5Kw/oFWr9A66cHLeQfL7A6MOeVG/sN7Byf/j8hD/I19HzUMuwHQQ/YBfu9Pembe/W5ySvC/xM=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.png" "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.png"
new file mode 100644
index 00000000000..f8f457c7490
Binary files /dev/null and "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/read-through.png" differ
diff --git "a/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.drawio" "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.drawio"
new file mode 100644
index 00000000000..7626c8d1f50
--- /dev/null
+++ "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-02-01T02:02:31.185Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="9PudAcx6My1N9F9azB1q" version="13.4.5" type="device"><diagram id="3s-LqK6m4lkifnhmqHE2" name="Page-1">7LzXsuvIkiX4NWk281Bl0AAfobXWeGmDIrTW+PoG9sm8om6WsqnqGevpI0gwgNDuy5d7OPkbTHcnP8djqQ5Z3v4GAdn5G8z8BkHgB4aft7fk+r0EAH4vKeYq+73srwV2ded/PPh76VZl+fJ3D67D0K7V+PeF6dD3ebr+XVk8z8Px9499h/bvex3jIv+HAjuN238s9atsLX+VEhD+13Ihr4ryj55B7PPrThf/8fDvM1nKOBuOvymC2d9geh6G9ddVd9J5+67eH+vyqx73r9z9y8DmvF//IxXONkwglAhsec5gD0g0PAf+Cfy9mT1ut99n/BuEtU+D1DLG/Tvs9fp9LbBpe8dKpUM7zL/B5HNzLpL/C32aeHqmn9e/u/y/32uY+ln0fv2nb9xV7fWr2tNW3I0/N2EYed67fJ6rI3+WLJ//4eZf2vyHO+P6DjCfq+9/olKRD3NRxf+JGmvVPSIIAX1+vHMeundh/sO1l3UZ+uJfr/D7+P92rZYfNXhXCsT/GR3Pf3H31468t/th7uL2L7fbfF3z+Z+enUurp8s/e2TNz/Wf4rYq+l+32/y7/v3Nqs9+JOq9C/xN3z831znul+/T5B+N9/lfHjiGOfv7vv+hepanwxyv1dD/Sf2sWsY2/l1Eqr6t/ubetx3i9W/r/CGMz1Xx+/uP1CZ/FID//BuL/kY8/4jfWOy3D/cbib44Eadl/hvL/UbRvxH0r09PJyzyG0X8RjK/XxDMW/n5+CHeiw/9G/lc4L99qN8o5G2OYN/m3nb/KPlgv1EA89dxzP9yZI9mJn9S9kvN/iiG/k7joHfRnvKjrNbcflb2LT4epH3KyrVrn0/gc/lKxe/I+bNebZzkLRWnTTEPW5/Rv/T1aQ/mfv78pae/BY8/gCCfn07/puh3MOHzocvX+Xoe+Qu4/w5sv0M7hv7++fgrTv7lmfJvMJL4vSz+HZqLvzT9V/R6Ln4HsD8HM4Nx21rgr4KFQJ8m6QlHmH/6Eyz7JQIk/bOv9G8f/Kfk2X38dxn4kFK8x/xrZf5k695azLv97CMTwNvUH7V+1XhlA/4RrD/fuL/ZpGWdhyb/Yy9+hPjZuapt/0XR77rJpM/OPGAIU++OVI9BIn+/0VVZ9nbzp1Lxs+H5u0j/hiD80fm/EJv389/ICvXz979GVmAY/mf076QFwf9RWh7A+Edpgf4LpCVjzfbT/o9o3ruE+R/5WhNF/WfS8i938V228T8+/b+wkDj5owXg31wWCP57FYKxP1Eh6E8WBUT+C1blzwnBv78qD5EZ38uq++FOfxFQ5ZU2Y1iqX/jOJMO6Dt2/iUffnz9/IuTr8EpzvIy/ON23Ol+hpn66JP8oBf4oea6zeI0f+/DrI8SNr8WlK4/SrQOQ+WIgnz+a7ZasWzxX6vvCiDQZPu/06stY/ly4K9CypmchwQZl9Nf+DaIg0BF23LIRc1IwLbKB2KKtdABH84q6CpPdjeNLVnT5QE80q1Rsu7cLdXRh74ga0GyujAIaYIbDsomf+YDG/sGDFX/Y44v9z7/819tCPBfU5+53nYh+blIgvAfPG74Tz2uEfj779kX3hUDvT89IkW3TtEnrJ49YvOy819vJicXmZI1ZpeTANraG5JVL2pL+NEBZKs2bDEolStlOAGvaoqiqK4s61ELbFpkkazuxpP0Ua2pG4k7ZkPYpRslaDmxhO6JI6dmBmz/FSBSvVMMWtKOIlp4eiVk0pn/9FLNsRTOMYunukZBNY/IQHsUlyTZPsSOYOoBEJLvYvI+HMSWyzUWTTp/qgPgW57w/mxElks11sU6v8oAosdyyvcUWJRbFcQFOq/KHJLHUukH+YFLSUwycALPqvEkpbNluEF/YlKQWBYs+kkS/xcI7ad60SUldSha9qZWmrX9/LXjgsc1UEdtJFYzEKG+Lbtys2+/Nbn51HEe/12d/qCQXI7vtUdiCfzLbzsS8m+ma0x8VpObtezkf89sR7ionj1RydtdV6juvKkFaxa6nu9F5vqmR5563g3oSEDMW+3bw9AlGSg7E9fepRxEdbYn36Rwj3pJvy251PgrPKc//5vlvKc2IdFjinse5BvapsMaeB0pDKJXBg1ntef7zFDqJ6TJPe3Qd6uSISiJ9E/qpTgE15nD7jU4PBFDLybQ1OsO7IerNxdzSSMIuQxSYvfdavnfYSqyW0JbaGYFJU9iRNrC9h4lp8hlbOHv6AcOPnLc17PVREVLSO8DLIqJLEMBv9t2mYb7HAHDZbvfRwKtDUCu2g+9FnQiuIyHSxAGmC/+gaX9FevJJqqsexeIEiHCGpq+cd5iMrsaEdwSeSyMxfXwq/MZK0V7EcueeJt0SB48unX1OvM7dpqatGmtFiWS3b7USLGR/O+PpUn21T36mHHxEmVKTOgQe0REQo35hRMz7O+efq3kzUelmzWaiA8EMCGOG6KBlvpRNfYAZs5pm50/IkcQSUNx2FwyQ1/mEeBcCFYlxshary0SJWCrv3bK2ro6S5nOS+CRhjUHIjSPvFqttUDhJRe1Un/vKeqNBHNRM32ZPG6n2CxiuaUJD2GpTRiFiwtfklT8rnr6Hb1u98vCCy71Xl/WZMRO3Calc5piYo4N7UB2ybngS0KbYuL3wQM/5Nqzdv1UGkOzxklvFbdqaC3QmEncJwkc62vtig2+5xXomQKtOd2+tYXmAr8hNnKR9nLZzwXKPQjt8RWdIyr63VRtVYztePGGlEx4INmVP5+zCvjz7POT7zRBdnfVcWqJSYvCdIB6yazipvpLiYkcwbdijfg/E9sF6zSGQo8YFysqzaWXE2DTIlfGS952gB7uOr3VOGo/XqWxcdwfOI8uv9aMzOB6SyqaCBjB5VsHqktoP0xNkeeupfUk5DMc+I83TcxNWtLRefUVZaRtL9/DoM2gYvW1aWbm08/VR5m/Gyfnp3Q/rDFPiHXu4C5DZolMWNhnqAD7C8gbg2M6RTBioeDJplXEa8Jr7Cpj5EW+xNNeB1m1JIDYsXXyeNRylSYuLeUCjfaxMY4ZwrYkgKE2QYj6TMOL6nlHjsfccTWVBPEQPuLEXLNi49Opz01u3bWUIFwTv413apnE9cLG4iTgDQi2/vvDEOqVGRW0hWiUUw/SXrqc6ttTTdZJfBkholkLEIuG5bENr5w00pq5OcEZSaAv1xn/G769SvbMDFr+jaULVodBKbfoMjiBVUXXfpr+i3BioxdZKKwSVM2YlwglJrvn8/Flja87uk2+hp12JHgKinr2vw2cumJu6ZrSAvZyon219gVuTrBSoxkhp2dvGSNm29SGOQhLECtd5h8pCKz1OnLK/Wi4U/metgYddkFZ0tewSTXs7mI8ofM3zVOZGdxVJYK9v1Qui9mCYu6R48njKj4FAsmAuy5ptgVQCAoKlQ6BwDgCB36UkTPhKVi+mTdKBeIqsocnDTaTEKQobPi523UeHbF4nC+2pL4n72H+ROTnYVdqSsR2dri98eRpKEX0ZXsUsjJqYYWEQ3w8v5p73Y8QujBvk4zU0lFpgIqiE5qPp3PBiMiZXtfHwqQXiYbrlY7j9TuCMPcRze9DkbAnVKYir91ymjIgo92t/Z5Tyu1eNk+UUGJZ2yThbaGCt/YkQiYgvltegVQlj6TytopsFUwnUUQo+KvVpgcbIdmuft86wZPa8LYN55tOeVJ4nYYdaSm3IqDFtuv1R2SkSo35K/d6bhnqCoC6bAWtk/W3qQdJwF9vBCKt0zvIWucBoyyt2WTfco9MCu/bDmqbZiBLjgbFQ4WOJplA4PdJHVUFQOrRlG62dyxTNaZC3156V+2BqUEa3sMUk36BqpF1UFJxrIGhbm5DDIoHwacbOAvhM3jdOhGZgcSwqNXsMT8QRJ809oAmUeobUIZevUQvaCZNsLniZ+JFY6JRSoVqcKGIvAW1dOM8GN/da3s8YKhXeIrlLhvD7YrD8aB45OUKH6HYFE8gh84jy8IVvCbQhtVfRRoGMvmRRamrD2chTHmP3rnxembLX+gff+KLcKbGViarHt0b17548Xjq4rI8sAaOMzivq2KqksFv0LHKrsVqcwZ8TAYVPgExvW/NlBJm7RGQ2pkstQSV5H1UfjUekx93IK/uJbnZE+/mB2GxBXl1a4vIldHmo2G0zEWtoMkCLvOxQKC9zVHqwnBdOgVbaUNoHD9Tg8YchyslkRzLACA+R9Pn44klL0FudbC+/kaKeWSnDah6I4DbXo0s81Wmm+mjj7BaX3ra7T1wpL9ZtQ5iP2szX0HZ9YEY5pyswPYEt2DYJ/JiQpJLxAGvNMcHsPIZEst6o0l4nm12Gi+GHV4dK3jTm3iZZQ/PSY4FIbLIU/aXqkl0SOBTiMaUL3buUuAQ2rz1sFEUb5RtF81bb5urKEKWY2K7w5RdTISL2Q/PjXefHifRAkCtKy8tu2g05zjrY1oFXKu2P2GcmMs3PNZ+0qbx9TLNUCnp/yGZ5DZ9hxz0ZP0zUPCUQFjsOCq7XFUMXNs1NBpE2YK6sCdG0+NKid1RnnIEVKeIfCQ2BQAebMko/HcWY2IclzCsA08X0EhZHKemFC3W1i3Pty9j8QOe+3q54dBsaC9n5XVtMf5lG+O4HcnLnUZkhohNH2CYi16Y8NArjYL7aAMItZvFYMz/YDCe+lUyPGeMoUVpMoqUEyPXnFrEC5CWjFDdjw9HYjXmiOXY1rAH3/qB9Tf0zUCRXfTcSslQhmJDIvSDWtyNmeA2DzNgHWfRBOUOGRoUhlGSY7jgOaDS/CMz0MI1eQ1nwhwqEvNuYAWVXbA3fF3+d5QQA3r17dXOZjF2BMPdio1VK+MMcBacbXDMtgUpZhVJnzutj1CztSunKL802uDjyFQN1Hsa0sPBaKtnGNb8yKb50xZG32NUHLjPefYQckcq/fHQq4m2IzzPEY0bdzNRYVjcXO7S0fPAowrZicVK0l+Xv7qfpzAYVaOiQH4ZVv05cWjnQqxbV43iZpWBu/QMNPKI+jPahpa/vpsel0uSqXfW2tfugqN4R9G0wHGY36349AjFlc4pFopVpL0fEy/6VX/GAB4u119Z5n6OaEglUWcRntWxhx0gltRoBWy0UdbCIDLO/K3L7iQM+zlqX96/k5d/dEyue4rBNfMf9uh4P+FDPsuqVAl+fWSp34jFSz3QnyjxXsKQkmRTerYegZzc/Nht5Ehb2zcTUsM/6DMBWbZsTjxsKvYYtmGO0YDsn6l0bVfAZWsuLQVBhZUStcz/RWISRDldjjblHH2kgAqdRHzYVCeLSB3pd323f+kdhLNOC3XpTA60U6ZW65Juqc9ZydyUFJr0I21WBp2HM8dF/fLkwuJfy1O6xasfJ8BL7sadUBu1zn9sjg9v9VK2ZYdeLWjoA8PrTXIp3n6/qf3xapHDctp3cPDr5zq2DVEFqZb9vE/6LdmzbSMc66dWs5o8vpQ965iE4Rng2ILrrC/83fCZQKREfO/fL5hvD7GzrVvjxBoUoLpsesJPOTUFmDHNot0CKyhtvqw6kPeklW6dycznbOq20eDV0n+5kMvd+n0aUuvciqc/aTutcoJXPzXLuZKjZsJC1drbrF+2pAX1353WPhvX57sCPH+jGK8pOpr/08Uegk/rSBwtpmeMVvqF92IUpRdzjeYRl797GFuW2qMXRnOX6gku9rvnOabyKmcJeSIuvP2kUGeF1/H3K8egBHf1h0lugV/PcFJtZNfU8Br8YaQT3L2H4Hnaj69Ov55r7gXL/cXkfGabgMqJZKTP98eM/2Cp5vLGBmVTsJqqeXJ+AuWcZnXT5YknrHm7Y38L7qqFj4ShebI5IsoXXMtRi0hLv3DRkAe3TKh0rpU3taR7VcyTn0VcWP6/TGlJaZwCeFKQCyr9Ugp5vEXk8L5qN1PhxDj0TaKAsIdg0cD9T97itlKZWHNxmDhT3DS4+4L1U/U1lRds+lMkS51utv8nSTA0YlTlMzcYhcYOExNtxLpqKTbGNvahrNpURQD9mWcfQ5R0NAPmlTbr5njYigNHQO6JmDKAPLiXCalgbyP74XT13OwproiRkz7XeN49VR0tFYVZ8oIwGsL+fqnxjQ2waU1GJAH4xnzJQAJm1hR1s4jlG2uhM25cEzu03kkVvPJZ3jCwRtPHTGwAbdhmrDqo/3qVfCQ5uzDw4iOb62OD4Wpoi57zNflyk9orynnV8xIM1/LRGYnllR1id2kb9TRr1XkKJwjrJ4jWdd4IbdJYKJXtC9vmAiMTN31IJd9sPhOtDW1RdUWRZSgZXnqnnh16Lu2bJKSqDBwYR9iEiWPB6sC/glMoMLlgD/njiFo2xPzKhLrPzKBsjVbHBwCjFdDSpoK6DC0yGKaQi5lpDeDRLIpJu34AtJim0kq+WmX012z4t/bI4S8IcflE/TqPSlBr28dSuY5ikt+hcXl82Lt3NhtwUPMxmhLczrYdx8NK1W1OEuYQyUT/Km+0LSQPXedbr1mYe6lJ9VF6pdB4Fa9zo98UCMObd5VMQEuMyXP9+2vh+5v0CvJg4osHLeLelWXY2SJdQO2Vyv8wlKLbtlZZRcoYkxm4OW1ivgemeuSISS0f74Ip5eUuLBOXAebpP+2uvftYoyLAe6Xprhz7o+hgJaB/7o2wvPXoMxeOCtFl3ioIJZK5sqMSIDwOu98vyOPw+U1ytfY+njI6vWYC0yHHfsd5b1b70VH2REEPAKXFzqcrXiAf26rVJmGooBmueD5tEmfKk9ZrLmDNkvMvHZn9fSemQOruvs6BE0iK4inHoHkSmgxBdUCPoCYscnIjt8JmNDjf14lSyMBqgBJyWRCWH7EYckUcGo/WCmyRB0Y5yhozMN+3hSm/gBOCJpMqTNDxtqp/d7nPcSTWyRnbVA/XwqwkeE4O1UU62J52pL89ngRytKlwT+gL2C5LesKDe72GgDT4q0HrigkEqrusn7uCRJPS4s3rD8p1ETnqjFsM6r9XlZHc9bQ82FrtaxPgt+SIw4Np+u4XKGPLlWpv8SC+Ba2Yvqgl/MLfsOmJR0Y77LKWXqc8rqTsAHGrqN2TjCSNpioPLX/IZ7i9yaHUV1DK+rNZr/zmW3dI+HVW670Sq10+g1NE60VReIkkOFfQTLe1ZHhcQ1VjBPMF511bEar/xnWIF/4nWqW1ycuXoReLDNtfWcu3bOxjUAr6UsQsFBG5c+4EFN7Vo5GEnwVeHSDFZIPRhl8WCvTZx6xOII61KuCbZVwuCHSXtGOKpW5+WlgJn/SEo9zPX7tCmbnJDNNK+g4+4P8QpSQ11e2fS7Mw3bXZX6uGE5QntNUwqn4VxA+Kl0B0jZuWM9TAcL6Kut8Z+ms2lBIrzjKMVcrWDBca+myZveYXyWPGkJKY77i0Jdr4116I/OSj8IHLLZhFsDIis9foeaObwGHuis23ddaTUXmCwtr9AOM6sa+LCJkqarFrLekuS8P2gsFW12lc9TDFNSaqJPXPUTovdM6HTzOaxIXwvhrkGlukbd2EcwrYP+njsmAvyiCBz/BuUzWFewcp3z4PsBZaxBd4g/lI/M+Nu+ie4Sk62MKC18HnsiexC6UD2ufdhqR4a0YzawSS3JqtnRjcuVTYEG/1VyWsA7XR+t6Se7EjK3bn7egzxJR0xMiYSGRZ0N2L4jeXY7ifNppbA0Mm0yAUp3Ty51om+hY1VfYdMLqiOjWE8hig5cWOq72IBdtGKvM0vWRbBtC+KAjIrRblyLeURvEbX3QIfijuX0Q8TARBt6138HQ12L7ZH+aPWqI9DMVo0rzFVusgJKzYkwQqNlPNSalw0lskj6Fhn7J9aI0ePx2F8zDRdexfIZWfGjHffYWpyVAARglS5K4stRnyOlKBWp3sO3Qbssw3IG5viuliiweN28En8MpMpfvndCzcrIpsrw8bL3HTTZIyHCRHds/8Uz5tzhm6aqQI6NvGHdKcnz/EKC5hUo2jUih63PRs8EpFyOzDkYJmu5C/b1yJZMvowbmc0ruWGzVAtIkDGsYtgYMnmlSBGO9VYAzt4IMDW+QVIh6PL96vTiToEzQcRyZIJHjd+44pMqw7+K0SE/ZB0rhhHEqI1SiveDX484Ph5TGLXVmKO8nAaj5UbL99QOqdNiYyUrLjcAJ0jh7EKWnCxUSxDR7YawdMBFnqNqKlRu1umUqvr9sFOUqkqZLZP8+SsjwNBnvcpOTVtRlGs2knmZCLF91ZJBzHDcyAevM6KJkorTpkpaqtyj6X9RGbYooRfoN9lQKQU4LYBfN1j0Buk5ew3ToklhF7OhEhXCDgpxPryAzp059TYZHx9xc9umWqULXJ/OW9ULQDiQA880CMRWm13nU6XOUNy5FWZbioISRRTKrw/dPdwjm9nDg7fCoWyK7FTJJaZ4MVP/ASbMrRRu4tj3dx3VT+oroBL7Md8vhryPIIkaO7ZyjStqSug/UtqwQdkqeT7vOjJN4AxMRRBtmH1dD9PJzJtW5RcytmD2apIadlw9A0rLLOIkg+5Po9Ho2Dy8aOy9PP1WyIqHn4YhZTzbt5g2aK8vB4N/lNpECWWnUj0nkAEJB8XKSPQr+8BYUF7YoRw9lupeHrUt3z/qaIWktSoAzm+oAG+ffrfLzE+lVi3oj0yRMCYSN6TuG1L9zl+q5iU3KgLPX7X95xM8I3g81Rw37M2j3RxEHv7S5TtVd99li/9p0Iqj1/teHoTAiMAxy8fso3N+6T7MgHs7W0W9pfAPlXeUzK50FNszbXDIBgwzJlP5f1y5Ln0PVUlbdfTLRmlQ1F8T3X/LGHg3zyA//ezCK6/TwX4d0/H/ytyBv70dBz7kwwT/CchBP5rwtD/N3NB/izbw/59kH+SS/j/cMf+SHBA/kj7+Js9w8H/hVke0P/7WR4o9C+yPP4sUQr5MznG/rvk+D+wKv/bZnk4QPPXLI8MOyDL6jkGrA7Kc9igpc/PEU5UsUNzzdrbxUGL6srmazWO6pzwcNiqULMGW78+JCbTe6hVtDn6LicsL//rVOXdkz3Df4JSUQtH8Pfx408Ix0HnfvzEe4z6ezuK7mQPcl3ZkMzq8LDVQwktleWIzKooxSIPMzhRnmSdU8tJNi2Zg9FEoUO29SEljkRzujYzN2uQlNozd+z6z/SlpaSEHC1RWiqKPKlQkBVNlWV9pCsM9SAo9jINDc1imhS7ixVT3Bc60adpVBc6t1ipg7SiSlY/N3M8fZAEzJ2TaFahSK7nKuZRiZBSM+SJfQEsaWmNGOKQaqhPH8KVCvpY2lRRVDcLWGgnFOJDvdBNmV3z7bh06vggTuYgHekgoDcuRdKJaFrwFuZvH+/kMotmGYriNmlgbtUgLbVh7jzwi4J+JkcLOliiFVcUm1OiraiY6WMnw6o20j8md0EeNPZ2vI7t/fJ08Q1JEz+coQTmj/KedG+NimdnYKTw9w0ZSp99hox3886BlpoiDmoBfoP+zspmkgeidw86EwFyHSVL1OMjgCHwBlJ5DecXvrnM+Qt9NsxMbHBoj8jt8rFL4Wesn8vN3oBGi9jpGa+1K3Y001O6GzfPVDEnLM2IRiGcYNwEaTB7s/cqGSlY/WbaT6QwAgoNlYEISV37otge2pgI7WuybYqb7GxnA52UR9G2CU1aoGA7WBWo2e02/3YAO9dhlKAhnWfu1GXoNGZkw0E0ZpO87NxvJDPn4iAYHIQdhGMWDOD6CYt3n95eKaW8xVTJjp0rYuVZLhYRHK+LfciBlxsBijRKilzpcqePIbWoCUli2iCSddkzXndBCdTSJt+IP2cjhEp+jGneDo+34YqXEMxascJGZ8xkJA3cgBYLk3c8kZ0hCxaDjpBLLh1Iiv3Lk3oXcSTf0R3f+SMAxdJ+A3BCUCQ2baTE/I4SOIPJZ//XaTaqACgasPylLOIoIUBGaTqAEodAqJLIDg3Ojmxul02BPc7Id+MGiDyiz89WtSL81USKLMz7py0q1sVCycjakTLSkyJWfKGgyRW0DJ8HsIfjgoptRm/lbWr4EjdvLpQJqT5nhmrnKpFYSEBqSRVPkVWbY/ooGkcfzPwemFmaRAoGdsI03dCnt0hYPqkPNwvGzMklrR0b0jRLRKQ+HZB+OUFdnLq+k6xy5zWIQeYRhNhWrFG/L+Kbm18HNXy94RHn83EFnBixWLeNUhaJ79IZXry78Pnsy9Nd3mKfaMAsAiYIvIMlWtY6XNOC4EDJ653hiCXnTZKR8Uike7Hqzke4i20J+/ppiY2Ptcjea3RO1aS0SayOsfQASFrS7+4PHEmz5fkYijxW0nsW5lQ7aV4W3dnTh+mINe22zZXdTLjpwxUnmbwznrXHbcDHvrSrz1VTPpJg83bSTgixfuRtnhr49DcN3zCwqC+p6YyLwrXNXOzUHEa4hQ6nzUCtUHAqFk2Om+VOF/bXR+2+oz2kbvNRKKHbRlbnGTlyPhVk1yMDQK4CbtG0sj7JSbXxhjYHn8xbDmG8a9j2c/IrVlw8k2CPAzQaMZO3xjGv9Xox4mDxkq4EoUIESGZvS9M1YxZOLhSPCTYDMy2uRYVPnWaGDiQoCvmag8w/YOxoL8kml/Brkw0ftnPTXnMQUL1yhOkzBp8pJCKn7aLl6znQVgEos4tG0wE8JMoo7/zH3Kgl2Ne803CBH9W0ciKmwIzyZX5yX/0EmWFCpFO2Nr9/elntcoPsRXFbYJYlKFeBWlnzXzM128ho3VPf/pwCfLuLNOg3fp+4xffKmm4RZ0ujDo44x23zeEN7dWN1aDSQjTui0in6Dl21++ZAgrh6Ukrtu4LRmBAtp+auzc+ctfp5rkbUvbYJ0Wo4lUkxmuSID+qw/E/iEkXUrLr4Vw1A5gdoqyDo5MD92hmoyjpP3LRO48n1hco3M+KzAsDiXjf+zA91NIbEna1wU2GCgL6HTpH6CvVMiSf/+fYuTcpbwmzkqnzerA/T7D9VOGdawzpkpWXYtxOjCCIYMjiFm4PkzibHWPRwiIXWrNmXbtb2wqRg+XUg7VPQxGpsCtmvuF20jwGWqu5A3mMA8QQlue2KyXxvfaWtOzvfyxJFFffHMwxvOdFY9ipiI7SP5D39NM8BbFyH1clagN6D3s2PaZQWg6sUqrrUiTdWtpIiuQTK07GNZmpDyrqY2RmUOrNpTqQfk3LRFFL2ZiRdQmVBx2GOiESFlL1IYjgGHBWyWsxPbrXIGwDFItnomLR78UfBxdbt3lOkBsTsSDRpEgRpx+u9ELRdd1ECQvMiwxP6gre/muRt2FARflxyj+s+dpzTDqXEjhEIcgz3LJYDXKZmEOq1QInShZ7JZhfIOyN15Y0pyq5/NcDCDsTXyGboFb33EKvYMV598V+gmBYAeL1VXWKdVSvkhNh4j+ActPqi4nkzhsjL1R5bOi3SNLW84VMZATZHFuEJ39M3n3SdtQEwraG8+AHemY/II8hpZvNhYp88F/MxqEnv9m1aUknJ59XPAl37K+w7JIt3ssAujCE3zkkYuJvjewowow4ka0cWGgaYABLyJuSCPwFbETdeFF/ewIYuHzNuol9MsF9//htM1cjucIIlUi9XwfhO9spRpLM+b0Kh+/JDu6TI9KU0lw8asCCKR/ESFOz4cnv4hRP1G51NUCSRlCtDu+Lz0RkpG2ymLTkJbZyczrB9SS8EhommrTeh494gn30eTkIZtMBWJlS6Yl3lfaLVCI0bIBKx1bw7HMXup1NV9GlbeCGCbfx1S63gM9sPWumIIw7/3PrZuJ0tSol9qo22vIFMhKK52rshZ6uMBQtrQvVfAbUe4Bs/H5SFzEcHHPorfwYjzgD1zS7wHLOwm7Mu3etB4L7d1cPFdYerOzLdUSP0PfOc0edl/VDsQlYyuN5CtIZS9565J4/y+jhmaWULtJ++lYbBQtle9SuHU24Nz8xVMpSq7x4+VIxx4wF9pQOFVFwWOwUy4YeNHD2Eoj3U0ZcASXfnUL7cj5iw1UMYrUXT6JJvRzJfFWpWjlcXntVMBOo+ZfWbNlZrh6cOf1K2rgKNR8EtDnIl4ey3tqpINwzvbzw4rogUeOArFS3pNNqt1/geXIa0ScLhMAixYpG+ldE3hYaB+uHuLXxsi87EIlBt/Cz9VKRmhfPI6+x3Ggu3Zsf++FpiwizBDTVW+FLCsEQfdkwV4dcslUZ5o1r50bojFlx2NnIAEDBLv3y/bOCI3W3Zhk7kvDlRNX0Pfg3zMM7axG6b4AjdN/zwmsU4loj6UL2hqUCxpRObcsckIzaR+K/pVFrAJ1mZ6rmkyDSXfWlO7tfNiNwI5R2Djyx7OeYHoKv6mdFHYY7Ugx8pv1OJJGMUEFBKdWHyUJ8J2/dKWNG0Jz4UqfDCLBDxSNNn73WYpvtICncFI5EKy5aJHYmxKyGZivOyZInhvQKhLooBF5uSFEej4orH3Y5oqt7Dy4N/Q6gd0pwz/UbGRhcyv3Pp0UcgELFI3QNWcgwxtLVGYJeYMx6dBjUi7QKVSVpXdIeNO94q/OQRNTzYcavytTbcgFToG5zyTemt/3D2Kx0e/JXYbNEGgqk48400mp4dXF4/G+fnRQuDlW9pcQKPp/SGiDcD4DGRLXomjad472+tPKzMnO2N6XRaYzEzy2A8NCs3EmIJavO0QWmYz3QEkRrP5h6pgw3aiN/4brSkF/TYW3agZt8pNmYwkAfUfVum3qzieFu/U5y/q5mplVpyamPRBHlbS9sgysLik7tuolkmMwOMBmt2mu4v4mWQfKn6jsLBQxjUeT3U5UWK5zMTprFGKbUJFCWDFgEjjvW4UleP6g6bgJQYmhUfR/ZbbmzOAgbPjiMEqoWSxvNDJ7juC/O9QrEN+a1KKmwf2y6OmM9lUqx9ouvSDrdJgXpMowmKaYmn8l94hMZiOjBSDjkA+emFECfRe2cROmDX5WDtlMY0lsecRM1Ffyxhmy4dAo+Fg4OQRkwqwsJ6Bu2K3aLkx7mzI2p7NSeZGtkHFcKVUsa3WnMhmk1GagqLRLIrRktmpz03TwHc5p0/E40wCzVNFg+8ZXAUt+z19wYWJcqASbctl/eWSr1Mlr6OLnwN1OzIOhQjOe/BsvM/fdSSSalTCvW4GQdkIP0EOIXUru3risJVgHjkEeTjdIMvCzlo741nPIQn2tdGwnNEPk8hrq0HKUiYwmKU5xbptEXIX0ug+dp73aOPJ76xElcTH03WUqdkmzyWkIf+hV9hk6avR+53mSOLgXAl64gbZRk0Cs6EmTJ0x9woNdi160iUfzYGcby525ymcNvEa6MfpOJBAmzcThTkYjAia/G2yAciDTWpOxrZnswQh+A4o1+gUw+9o+no4Hh1o88qBye4gn1xAZBlrpbqBGu/SiPQepx8NsBf52IhW8Gex9g0sDgUVfJFmmo+Wn0SnsV8cLi6UL2mXpa5k0hYiaKkPqayKlXzhA7a9+9ahKlCZPOXMnmPTr5ZKxSquY2lcJftciaLzZXndDdVsuqYHqwces2IYnBJAi2ZZb5w8BWLkjQ0f2j3elDHo+rWIuT5/H6DhH+oTv4JLoaH7YkO34MBJnudy8zXj0104f1cSElZpLUEq5e6RjdVwHeMtV+AdUbm4xewcY3DGlEZKQ0O9X6pp2Fl2awFxEumudzfDdeeYeZ5jcw9AhYMknAMWiSk8kbiOV5qj9K/g5/UpEOgHYGHajyh+L4RK4VAlsezqyopM1GlA2GkUzuMd2tKYbnQMdeumJ2idLyPqRPyMJHyjXJsqBFpTVLqRZGOvYFDrHiD1FRKsLZ8T+BLIwaamux0mny2hDqX9XN4dWdk38phS2ueMTDJVJe1e+0xc9r59VrT35BJce16c1Clyv2BFFOCdD1aX7/f88t5nBopVVF0SFLLc5mrNsCimWuWlK8690kxRPuh3BR8E9Ygm1M8qLPqCXW8zjpB1NZIdgeWHK2e6q87shwlra7N5me8ruMP++Oi9bpL1sq5xaw3Db273WYfi2GjTHgKEJ1SR7J96thEaK1qkQmLSx18OOrTsSa55SIPM68GcHI23+KBPG3WgryjyVeqqpZrtKIRcLPyvfFjsxAZgVKUu+1p0ST/JnooiVo+Hn0MtbQlJ2j9hposVshLCGYTwzXDhyNliqzjdD+GiPiemsiibyZjZqrDQwofl1glFtpE4wZ9c5BnIf2eW9g/rIuUChzVABhxiIgCHv/yG5lUBCW27/kG70PGM5TqKzZoAT6IXFDZbqNepafUHVwGePHValETVKkmiH6VcLMV3j563izp0qvrTMFSkyZmMRAxq8jsRGDHsBbUFCSmwq7zr6s6ERWMV2m3kqLrmF3YZ4Y4Nb1LWfG6rZt4Xmx6gjIJHINhcClSd3vThQEOzBu2mC0N0vWsgtLqEtIJSxIHOJVuqISJJuMdD2lyBR+e1jdj6DnL/fIu8zV37650MBxZP3z8s1Nnze9j33+iMmRNd8/c2MJ+PJ2CqXN7Tw6Lez2oL6iLM233d0aVgvfm51G+bv4ks1xTE1hLTygWyaq+sTmBvmg5jxDAHFuWgjevRs+VQKXcD9cp+sdwOu2BiTM7W7ql3/ACptiZEy9Zx783UZ/HIaNuJJY3bLC9Ma32Hqw+ZEp0YvOKlstopNNIsCVzaxe1sOTJ6zMqcwYr8+PplDTzIQ6ChbgyN/hdnHU4CCUkKWC7nwFI1abSppgI5cUBCepzhiq76N8vZTjLMI7Hgfd04xUFzdSnYSiuKVLx43dYzQ2NMk08+/fQA7YRDircyh+HKriqI/WOWfp8A5cV8Zonrgzr4x8YhlY2tN84Aieru+PJ3RDU18RF7l3o8Jup0AVcLoAfszKtwvtgJHir0pnH5WbWhd7/nrsC4iA2ekP7aIhtMXb96Jx1vsewcKpdqDKLg8DmKTQB8ztC20TMOGqK7qKkDzYX9q2WTFwsfl1u6SMrdyTVdGGXNdbOVjNrK3wmVSid6Znr5vWZa4aMvuqigvEFGoPGIiRmf0SRdxXrCJimF+h7LHN/mkDD8R6xwSQBEb92tBimf6fS628mj94xEO5ScP4S6A3Z4ohlJRqrJrO3g5nYFNKLA3B8NIb8bEMh7N9aLMptkOSRtS166dPi6kpFdb5FdzcgkaFkLeu99rp8lVN9jdRExbLZMeBDCUX94FjpA6MKTJHOPlTyTteNWGxxUTFOFFhCprerlrK2m/TN4vd7m+BYBmOe3Xd+fa2Zn5XppYkZObwx0EuydA59LrgVnZ7JvGFIiaTD2QaamRX9Xm1tKk1LXQ5dm5SnwCwiihMcubJdQl1YP1WCN8PIAMeIbGT89uk0r1yJaB7+92obHFNCV63EspAOZ1pgxyohUEwAnrkfRZNywKv7s1/clnhPqyt71A2atXjUymabTpQpoy2CVZZOtBnhBpYjEoXwQoydE0uLwLWVXHkivDcJPQOxqI5xOfZ4KS/rE3WVaO4sLlC2zoi3SU65DJ0za5Dv14winJpEsu2wU+cIXIdcyDlctrcl9s2usnjFbUWepiWR8dRr2zualWc0Qgsi9q/zrKFt7jcGuN1UJwRbAm/8i3VevrE8B83giCMt0nbHs3ReFOhl+p6xoLmm1JMok4/PwnltinGHpTZKiwCbPrznLW7h+d49BO/ZwxbUNoJVdEH+nzb+tTbeaI8qESfJZcw0/qQPkJRkuSg7N1JRFD8JBP+JHALoXzmk/U/lEPzp2et/2zfskT/JIcB++6C/UcDPL4swv5Hsm0xAkW9Wwf++yQT/8a37I5ng8w9b92c/L/LflkrwJxv3vzqV4J/Q/0AqAfin4oz+N4kz/P/jVAKL/psfjMiR4+tZgXCj/ZpUVfcFSNcNjkKaxMGHcfguPin/YUXXsaavzFyPc0FXeyHGlK0NFRUXq0B7BRBa9uxTF2lVqgAPQPBQEuImroX1GmMmAQAwOo20ca19zDb82FAIyuE8z04UNl5C1uzQjKInfu/f1IG+XQYj94GYBieStH09DZChbIp8y5lkAVGgiZCkTFLUwlwFaSqkMLBvFisVkOwVp8nOTNUz79GWNSuqEY5k3x8igHPGY02XtNk0rh3llk2KJLaGnxFkIFkSA7rK7VyCIiXJ0OASfJMogZni35D5/hmQepi0PoL89CQ+HPthjteDrhYLdj/shpbvr4hR9YC9X5joxinMY6+egilkTGo2wU033hNINKpvHMP0Xv0yg7WnZDU67zrFLSiHjR1EEaSqzXiIpCRnR5TUYD5DTlGRSB0W6vvFM05kv1oproNLqXx3+PQhvt9v5AIpskiRcRc2oFXuqtcEMysWWWO47frxyvoISJkhNdrSddKwIG3Rx012RhNS5dX3NEAAkscjf4jby/zxrPkYDnDrOriVrk9StplsbUvmfShV9Tmqk8+I58Ba1qp09JqcOTmQSDIRZlgCN38z/E9QEvSNOikuOhTIgzewtkzeUp+iaR2qKlanXQ45fb1dCvvzzIgzNE91kIgjyYJP7UvNYTCfNkZkKKFWXOhTBnH3ri8hLV/+rOJ+nN4DGD/nsdlD5EJy3H0XTiLVeAt4XvRoj9y2DEILfZbUflk0CyqDgnOlTrYaZcm5h7s3o3LK4QkYDHq9WgrE95xjUNyeHSHdgkJS9TAYP4uwY2TlyPee5+o8FpvKkYLE7YCV4Ui30s+5CD+6Jw6gGTDUELSnTkZa2aFDztpVe9c+p0/BTYQajQzyQp68nNznDgQuxZZgh6wawD6kDygOquliMCUwek9WEjOgghXfIGL4xtKpbeDHRH+Taa9QX8BcowLtsjOBMelGcJLVr03vfgDaGgCyJKt404sZQuVO6Ga3G+umsmFQgpTr5zCHCQujuLGgI9ROq43vJDlXtjKh7VKEYDhRwseBNiM6Xy+cTab810aiRexXOKZPFqFUh72WXuqi7ru1ifXcd+IEin1NQzQePziJgsGOnPEYDVESZ10vfiYDeCup6uXMKfIqOBZGHQX/DQE6hJH3OPWINfFSax7P9vd8CjPOLhkxhPDUvJxPNHH87aMmHxvbCiDKYZY9YnpnvPX9gu95vQGrEAW+qzKYvj4/Qy5mGCwU9UKw0OC9QqbNN+iMH17Btuz7yw/67HkFz5joSYT0NU6wTJ9cSBWAnn54clES9SoecSNpWvDHhhhOmd5T9DTxp72zkCqqBymWu4rVwdoXkxeasz/moETU27pKHjFppPRVmjTEnEtIAu9XBeAew1x9JrjXc8FZZkKDIoLHAVRn3nF8ZijMcLyi++Kr5UGeRpjA881QWN2N7rx49fukbS80EoI8SuWLKnkJa9cvorIOHEURL+IxQDNHRBFyQoUMdXg+txZkUSpd0Nng4ZVznbkuNX89zJa4z+UG7O/3hec+4JZSnXkiHQVnxgE+2HoggYqsLKpoj2KQGxR9aRZilfPp9xSI0R1aiZSqsGNGKOqSjqkk9BuVvEiZvkpucSYBnb0rlqrZA2c9uCPaMjYsB82Si6xwVBGet4DuDTMG10R1poAXwD76hJgWJLdq8e5ISkNBvuhRTWEOBdx9fuW5tCgLhA1NRZaNyCFer6hdup1P2m8mAGcCT6eXNp6PHeGKidBFvNYveGG60qZt5vN9HdO91cZc43rEPLiEegQMvDwp7LHSzUuHtqnHAKUW4KVKZI69LFEa6QCQtifs8KYos/MxmdezR+Gnn4rbdWU5JsF+qjBtxadDaTrAAvKZuxAT4NRqO7QBr7Fbw+9AHyiKLE8h6vAykzgFNUV5oW/hRDnW/d75AMM4Ypuy7aJNi5Vn9OsZMaU1InvBTA7T75tWgHqkLyqj2HxljnSKN5wkLN/zghUM71VGZAO3eAmT89pPJydMYlo90qTs6VWacNcbmZToLjtqlPN0snMyzg1sveWUtiItMh0KvoXDIZW+7+H3djyWCm3n0aVsZovL6s5+vpNugv2YPajYnRh4CwdTBX2+AILJdUZfyeLsK6jYk3yLESj9dY+3qTSjKAp9h5ZkC/QeMjjs6SDkKfcEraHug9AtqPUM8qXzyBIfHIRX0ZCuYSHzqEUCK2O1dmWpSvZMlX8Vixy/XBrdYBGy5GiAH+sIFNmg1jGzuffMVzicu3PJikQtUVP000aUo6KJI2YOm1BGciXpoRBAKJwGTZnrN4znNRRCyi7Hlnz1mI188edgYsENSrTWcZuBHGmzZOMop9KbGW4ifbeG320AYQrJXGRV8iaCZPxtUa5+ihFbHkmUer+2gPSe3TrvVwOYSt/BstpVjyYtRiAr7T2uN8d0imwsrIvXxE8wAfwE/B6lmViqVVqZJsF9xl+8bPGSwK1WX9xx4FjJnRdmr/Kq0sX3N2WCby9vb9iroZbuHBWX9rdNefYqMlkLxbfpDraULOuakxuNO+kyK+LH7mrFwZMv7vjw3CQk++x3/Al10Cb91+5OnjIRlSV9t+jqzet8rCW/+MzkDC9RUb+GMFQVdq+Avdki03DXdcStSjkIqt8rjoZI9p5/ol600nZY8GYzWGwnHnIsA3CNXGrANCGj3riI7hhpUxoe3kL+ffiujKnvz049FnU1RZObzQfB3u8mKLuf95AtSeoqP6RplcsocVHwPSOaQNz6JF5hkrHXM9CYbIk3z4zb2Z2mP8QOeTrYcHCQUxwSuocpuomPUnORyWxIA7vIaW8HRCnuw8L6kIjAJQygitKYBHnZbBw8CHQoxxeWTp0Jv0wcEuwjZbmW6JvbY37foJ8ZQ1hBRhSTumQM3ofAfWDFugUPXlOZZM5NaXX7Bbv31FQUViuGwd4KAlDHZlKlG3IpQymaGjI9UZ8oFLcsCt0sa7vS/IZk5dVHLG/xagmNH62dpUE25bMhVlIsuAJ8bFp45XbJmvQZVwO5RIpkXioZrp5L8mLbIBlPqvY0mczDV0KjNmnR81SqkjxVKAeKlbfuYRRz5xwAWVG+Y7rF/+nrX+krBihUyNhMtjzboS93opSCLcYeEvLSF9vbQPn/2d6VNTlqJOFf41cHiPuR+xIgQJxv3Ie4BRLw65dS93g8M23vRHi8a+86ol9oJSBlVX2ZWZmVn48+XuW40BHjCgy2j5mZHt6pekK73nUcu3xrssewnanwrMSPh+Vd4A6hOT2XeB+UTY1gbQKgOE30Yu7WxWbkvmNnYnm3f7ZjdyEFcYdNEQXez7dl8JmNeyiqMlWVqSInlL098j5Ir7Z3Iw9cV/xbDF83S7whbxvl+aRc8SQUeDSd9ZctmifOl3VQIzuuwT07P5c3ybc/4MOFUpYcNkmVPedVnupoVda1VmhIRP50ycczHii/v5oWc5dHtQa4b6etT0ZWKimZ/5wupLOxaFhmyuQtM4cFulDl+RkRQvp6resy8h8I0YHElYYt4IsaAI+0i4E5lkUpfkbDZ3GT0TK8Pqu1Dpvc5SxQy8RcMFYuTPSmtHlNWpcYLmqEOvySXEzijQiYbRQYesDihqcMr7KTS36GWJ4XKfnwma7giCsDw8tyuCMtWguVSw9yZnlYi9WZd/M3H2BN+WSM7k19AhKe3GY3OjeqYuQINZ6ZlQpUmNh3SWGBw+Rqu7ZjJYNmzE1IOfcI6niMmsuaW2+plMPPbLYCxwsubd5tqgzMvdcAn5RfqzzFH5Zx4HQZuaWQ1rrumZr8BLlXwTs1Gw2awHhFTOqS1HW31egGHFQK+UJ890x+35zbsGtxVE68igtjOoNOW2CHfmwark2zvq39+fRopGlPuCo51yAAiQOusAX1XnsQo9A7J2xVc27P7R0d3JznHrEzDilm6kdMsx6mU6PH2Z92rFqD3oVPotyKCDHToqnRux/hiN4mCnOKpnMoIToywcQFqR+PHCR6FMzwB1+aC21vxCAu3QOx2Q3ZiWkNb09eAa2HWFKQ924RR+fwPnaetuN+K8EcLI12LZiqPL4hqZvOrQETkUNyt2NjPrblwrmPr/fjqaVMtVVh5eI6gy7kqNW3r2CeVpqzd5swv5I3a9V8BLkG0az3yxYw8uiSbG3EEN7A082qsXq2NRFb5ySsEuuuVHwD5dJO3nXJckwDnOh353Cwy9lT7wPQc3Z4QsbkqzcPJSqv2OrFmKQEJNEDvRbpWvVTUEnme+sRFwbCLbYgVvd9fSl4yxzXBitIG7qKhi5NQcHxmzaBNNGrYTOIhRAWWielFIGSZJ922UowglPAbVXrTfjhefoBLcueab4a9djeKyfiGOH0KV6n9jl5bgMUPdmQQSesIxf6Ph8wChLC+ljEt1Y0DNFdsGRx/MqoZ67yqIvp18qT8DfGxtOADfD5nCcknHbr5o2ecqnVO2/R9cp7wWlfTXRVBJK96herEaGTK5GIKMRsUiZzDr/9mGN2NbQk5MbDHR3SBTGKf79oHWKh8wXfae9yTKfTFaIuVw2C74F6Z1pLgzhNg/F8v8FspBKs3DUonaTUuloortXSllUCMctdcoUOZ9PY74RhPQ1y3x9b40Y1+pgOV2c3jU7rdd6VRT7Ib8IEVhXmGwQ3vmJIy5gO1fC4di6e0fYMACL6nRw61xumjMt043NaaFg6JaXac5i3uM/HX4cDhg2jcakPm0nzTwsFYasBX/1ehcdrA2XmIRGdUaMt7uy9inRv9oi03TGkP3AUsa6xDRwsAmMQqg5OxtWBdZA6liKkvKg7UmjPAT/myd0sjlk+XPhj+UsZvqxHqF/NcSA6XFvEqtHaFHCJdbeBQgwEq1nCKJcTTPFBlY2TK8+tLtZ5v8EE2GUt8ZQmbeeMO2QrF5oiRiK62NUslnXzuFzovnLIqeFD5XUCVTs36BKTFBmAVl3d2SOxMlaeYjgShH6E7jGwJfAKWq46yFaCQpga1F1CQnQiDtdZq9JcNDN9A3Zzt6RNbTLEjdMGolO6qvrnTlB6upsLExx43vpazONdUkNWfqj/tMe9h+MZlqOphTGCIE5cL/GlfIYzAgK7b9D+QFRsWHIsPcXZOFyjlrWUwc8hLGnhK0PS996OrhYJ7UXKsxdhCI9Vs8vQeqYCDrdgqvOfDF8wYdgkcJoyPc0I7EPxwt02rlaJ0GjiFRNeLLRm2U8zMMSFWg3tsYYz051StNlNRrYKT+DF2IyMoEPXJj2duAWJ2MdoFLQiZ+whe0SLlAKWqDpLnLmoR+AJZh9jUAvR0TdaVdmqyaUAfysLkAIk48BZgEM8y9UnPYwLuO6KOlzqe7Ts516lhowWFOfpg73X2CqgaIQfMivv+/aqBnnQdujN0OGTVj0H6xJnjVOctfpGpPjI3GJIO0xiNscpW9xTg3uM55mxDy17+9IzIvcoFdAdQ+V1/liKHmcd8y5WhiowdfrMmyNEXteXXK3GZURhNhxftXkjzcwgKqOQbSJp9iMOLzZavgAs4y0k8aYIXvJ1ZaJlpY/l+/DrAdQx9oRxSwb98H3mI7pfd9c0SG9NaLnS7R6boT5dRag2bF7A0PKw2sX8ICE1lLa2icvCAOYukECXkAJ1aZY2GBMBvkQNneK6ZcKaqKtJe/D3Yb7qyq2BsYCUHx3YoVWohTRGmS7Ym4zCYpvfHJrlsFTWfWs1aZmBB12btOFJ0z94V3oQxJ5cSbZgzfw8MeOmgQCcSYunlWwW6IKSx88/mqREfyP985tJSuTbQ7MfZ3XgPytJSXyQpHxLSaIvHgQUECL87+Ymv3/EPuUm4Q8OOuPEfzA7SXwzHFlaZJ9+eD/NZV/0XdTwn//7leI+y5x7kE17jWCdzfP2rs5omfsvx/c3U533fpmS7N+nDedoKrL5d+Tenwd+y++Ow5Q10Vw9vmTt+eFK/nbO/6WVDH+nkk9/KSVT/w0lH7qdNh/cfyzk98vg159x6/vD366296s/fwX88MF5v/XSV938qy4FXxQWEF/j1NvXfL/n8wDT0xRtvxIbgMD9e9+Cf01Z9bX01xQzX8qDTerX+z/PtV/08Qd4QT5qjvAPJdY/lFh/e0qs088/fSLA+oLy6kOmK/onEgW0R7TwE8X9Qpj1JafWF9xX7w/+f6G/wr+jEgv/wGf/EexXH+PWR5VY/+DWP7j1t8ct5OcXXh2w8yqP/QZ5jk//n4j3kK+h5yPWsB8EPWAj7BeG0jcP6zPRK8L/Cw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.png" "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.png"
new file mode 100644
index 00000000000..ecdbd6d2c2e
Binary files /dev/null and "b/docs/database/redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/write-through.png" differ
diff --git "a/docs/database/redis/redis\347\237\245\350\257\206\347\202\271&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/database/redis/redis\347\237\245\350\257\206\347\202\271&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..f2ef0eb8756
--- /dev/null
+++ "b/docs/database/redis/redis\347\237\245\350\257\206\347\202\271&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -0,0 +1,799 @@
+---
+title: Redis知识点&面试题总结
+category: 数据库
+tag:
+ - Redis
+---
+
+### 简单介绍一下 Redis 呗!
+
+简单来说 **Redis 就是一个使用 C 语言开发的数据库**,不过与传统数据库不同的是 **Redis 的数据是存在内存中的** ,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
+
+另外,**Redis 除了做缓存之外,也经常用来做分布式锁,甚至是消息队列。**
+
+**Redis 提供了多种数据类型来支持不同的业务场景。Redis 还支持事务 、持久化、Lua 脚本、多种集群方案。**
+
+### 分布式缓存常见的技术选型方案有哪些?
+
+分布式缓存的话,使用的比较多的主要是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
+
+Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
+
+分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用信息的问题。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。
+
+### 说一下 Redis 和 Memcached 的区别和共同点
+
+现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!不过,了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
+
+**共同点** :
+
+1. 都是基于内存的数据库,一般都用来当做缓存使用。
+2. 都有过期策略。
+3. 两者的性能都非常高。
+
+**区别** :
+
+1. **Redis 支持更丰富的数据类型(支持更复杂的应用场景)**。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
+2. **Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。**
+3. **Redis 有灾难恢复机制。** 因为可以把缓存中的数据持久化到磁盘上。
+4. **Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。**
+5. **Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的。**
+6. **Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。** (Redis 6.0 引入了多线程 IO )
+7. **Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。**
+8. **Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。**
+
+相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
+
+### 缓存数据的处理流程是怎样的?
+
+作为暖男一号,我给大家画了一个草图。
+
+
+
+简单来说就是:
+
+1. 如果用户请求的数据在缓存中就直接返回。
+2. 缓存中不存在的话就看数据库中是否存在。
+3. 数据库中存在的话就更新缓存中的数据。
+4. 数据库中不存在的话就返回空数据。
+
+### 为什么要用 Redis/为什么要用缓存?
+
+_简单,来说使用缓存主要是为了提升用户体验以及应对更多的用户。_
+
+下面我们主要从“高性能”和“高并发”这两点来看待这个问题。
+
+
+
+**高性能** :
+
+对照上面 👆 我画的图。我们设想这样的场景:
+
+假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。
+
+**这样有什么好处呢?** 那就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
+
+不过,要保持数据库和缓存中的数据的一致性。 如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
+
+**高并发:**
+
+一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 redis 的情况,redis 集群的话会更高)。
+
+> QPS(Query Per Second):服务器每秒可以执行的查询次数;
+
+由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
+
+### Redis 除了做缓存,还能做什么?
+
+- **分布式锁** : 通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。相关阅读:[《分布式锁中的王者方案 - Redisson》](https://mp.weixin.qq.com/s/CbnPRfvq4m1sqo2uKI6qQw)。
+- **限流** :一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:[《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》](https://mp.weixin.qq.com/s/kyFAWH3mVNJvurQDt4vchA)。
+- **消息队列** :Redis 自带的 list 数据结构可以作为一个简单的队列使用。Redis5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
+- **复杂业务场景** :通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
+- ......
+
+### Redis 常见数据结构以及使用场景分析
+
+你可以自己本机安装 redis 或者通过 redis 官网提供的[在线 redis 环境](https://try.redis.io/)。
+
+
+
+#### string
+
+1. **介绍** :string 数据结构是简单的 key-value 类型。虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 **简单动态字符串**(simple dynamic string,**SDS**)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
+2. **常用命令:** `set,get,strlen,exists,decr,incr,setex` 等等。
+3. **应用场景:** 一般常用在需要计数的场景,比如用户的访问次数、热点文章的点赞转发数量等等。
+
+下面我们简单看看它的使用!
+
+**普通字符串的基本操作:**
+
+```bash
+127.0.0.1:6379> set key value #设置 key-value 类型的值
+OK
+127.0.0.1:6379> get key # 根据 key 获得对应的 value
+"value"
+127.0.0.1:6379> exists key # 判断某个 key 是否存在
+(integer) 1
+127.0.0.1:6379> strlen key # 返回 key 所储存的字符串值的长度。
+(integer) 5
+127.0.0.1:6379> del key # 删除某个 key 对应的值
+(integer) 1
+127.0.0.1:6379> get key
+(nil)
+```
+
+**批量设置** :
+
+```bash
+127.0.0.1:6379> mset key1 value1 key2 value2 # 批量设置 key-value 类型的值
+OK
+127.0.0.1:6379> mget key1 key2 # 批量获取多个 key 对应的 value
+1) "value1"
+2) "value2"
+```
+
+**计数器(字符串的内容为整数的时候可以使用):**
+
+```bash
+127.0.0.1:6379> set number 1
+OK
+127.0.0.1:6379> incr number # 将 key 中储存的数字值增一
+(integer) 2
+127.0.0.1:6379> get number
+"2"
+127.0.0.1:6379> decr number # 将 key 中储存的数字值减一
+(integer) 1
+127.0.0.1:6379> get number
+"1"
+```
+
+**过期(默认为永不过期)**:
+
+```bash
+127.0.0.1:6379> expire key 60 # 数据在 60s 后过期
+(integer) 1
+127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
+OK
+127.0.0.1:6379> ttl key # 查看数据还有多久过期
+(integer) 56
+```
+
+#### list
+
+1. **介绍** :**list** 即是 **链表**。链表是一种非常常见的数据结构,特点是易于数据元素的插入和删除并且可以灵活调整链表长度,但是链表的随机访问困难。许多高级编程语言都内置了链表的实现比如 Java 中的 **LinkedList**,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 list 的实现为一个 **双向链表**,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
+2. **常用命令:** `rpush,lpop,lpush,rpop,lrange,llen` 等。
+3. **应用场景:** 发布与订阅或者说消息队列、慢查询。
+
+下面我们简单看看它的使用!
+
+**通过 `rpush/lpop` 实现队列:**
+
+```bash
+127.0.0.1:6379> rpush myList value1 # 向 list 的头部(右边)添加元素
+(integer) 1
+127.0.0.1:6379> rpush myList value2 value3 # 向list的头部(最右边)添加多个元素
+(integer) 3
+127.0.0.1:6379> lpop myList # 将 list的尾部(最左边)元素取出
+"value1"
+127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end
+1) "value2"
+2) "value3"
+127.0.0.1:6379> lrange myList 0 -1 # 查看列表中的所有元素,-1表示倒数第一
+1) "value2"
+2) "value3"
+```
+
+**通过 `rpush/rpop` 实现栈:**
+
+```bash
+127.0.0.1:6379> rpush myList2 value1 value2 value3
+(integer) 3
+127.0.0.1:6379> rpop myList2 # 将 list的头部(最右边)元素取出
+"value3"
+```
+
+我专门画了一个图方便小伙伴们来理解:
+
+
+
+**通过 `lrange` 查看对应下标范围的列表元素:**
+
+```bash
+127.0.0.1:6379> rpush myList value1 value2 value3
+(integer) 3
+127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end
+1) "value1"
+2) "value2"
+127.0.0.1:6379> lrange myList 0 -1 # 查看列表中的所有元素,-1表示倒数第一
+1) "value1"
+2) "value2"
+3) "value3"
+```
+
+通过 `lrange` 命令,你可以基于 list 实现分页查询,性能非常高!
+
+**通过 `llen` 查看链表长度:**
+
+```bash
+127.0.0.1:6379> llen myList
+(integer) 3
+```
+
+#### hash
+
+1. **介绍** :hash 类似于 JDK1.8 前的 HashMap,内部实现也差不多(数组 + 链表)。不过,Redis 的 hash 做了更多优化。另外,hash 是一个 string 类型的 field 和 value 的映射表,**特别适合用于存储对象**,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。
+2. **常用命令:** `hset,hmset,hexists,hget,hgetall,hkeys,hvals` 等。
+3. **应用场景:** 系统中对象数据的存储。
+
+下面我们简单看看它的使用!
+
+```bash
+127.0.0.1:6379> hmset userInfoKey name "guide" description "dev" age "24"
+OK
+127.0.0.1:6379> hexists userInfoKey name # 查看 key 对应的 value中指定的字段是否存在。
+(integer) 1
+127.0.0.1:6379> hget userInfoKey name # 获取存储在哈希表中指定字段的值。
+"guide"
+127.0.0.1:6379> hget userInfoKey age
+"24"
+127.0.0.1:6379> hgetall userInfoKey # 获取在哈希表中指定 key 的所有字段和值
+1) "name"
+2) "guide"
+3) "description"
+4) "dev"
+5) "age"
+6) "24"
+127.0.0.1:6379> hkeys userInfoKey # 获取 key 列表
+1) "name"
+2) "description"
+3) "age"
+127.0.0.1:6379> hvals userInfoKey # 获取 value 列表
+1) "guide"
+2) "dev"
+3) "24"
+127.0.0.1:6379> hset userInfoKey name "GuideGeGe" # 修改某个字段对应的值
+127.0.0.1:6379> hget userInfoKey name
+"GuideGeGe"
+```
+
+#### set
+
+1. **介绍 :** set 类似于 Java 中的 `HashSet` 。Redis 中的 set 类型是一种无序集合,集合中的元素没有先后顺序。当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。比如:你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
+2. **常用命令:** `sadd,spop,smembers,sismember,scard,sinterstore,sunion` 等。
+3. **应用场景:** 需要存放的数据不能重复以及需要获取多个数据源交集和并集等场景
+
+下面我们简单看看它的使用!
+
+```bash
+127.0.0.1:6379> sadd mySet value1 value2 # 添加元素进去
+(integer) 2
+127.0.0.1:6379> sadd mySet value1 # 不允许有重复元素
+(integer) 0
+127.0.0.1:6379> smembers mySet # 查看 set 中所有的元素
+1) "value1"
+2) "value2"
+127.0.0.1:6379> scard mySet # 查看 set 的长度
+(integer) 2
+127.0.0.1:6379> sismember mySet value1 # 检查某个元素是否存在set 中,只能接收单个元素
+(integer) 1
+127.0.0.1:6379> sadd mySet2 value2 value3
+(integer) 2
+127.0.0.1:6379> sinterstore mySet3 mySet mySet2 # 获取 mySet 和 mySet2 的交集并存放在 mySet3 中
+(integer) 1
+127.0.0.1:6379> smembers mySet3
+1) "value2"
+```
+
+#### sorted set
+
+1. **介绍:** 和 set 相比,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。
+2. **常用命令:** `zadd,zcard,zscore,zrange,zrevrange,zrem` 等。
+3. **应用场景:** 需要对数据根据某个权重进行排序的场景。比如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。
+
+```bash
+127.0.0.1:6379> zadd myZset 3.0 value1 # 添加元素到 sorted set 中 3.0 为权重
+(integer) 1
+127.0.0.1:6379> zadd myZset 2.0 value2 1.0 value3 # 一次添加多个元素
+(integer) 2
+127.0.0.1:6379> zcard myZset # 查看 sorted set 中的元素数量
+(integer) 3
+127.0.0.1:6379> zscore myZset value1 # 查看某个 value 的权重
+"3"
+127.0.0.1:6379> zrange myZset 0 -1 # 顺序输出某个范围区间的元素,0 -1 表示输出所有元素
+1) "value3"
+2) "value2"
+3) "value1"
+127.0.0.1:6379> zrange myZset 0 1 # 顺序输出某个范围区间的元素,0 为 start 1 为 stop
+1) "value3"
+2) "value2"
+127.0.0.1:6379> zrevrange myZset 0 1 # 逆序输出某个范围区间的元素,0 为 start 1 为 stop
+1) "value1"
+2) "value2"
+```
+
+#### bitmap
+
+1. **介绍:** bitmap 存储的是连续的二进制数字(0 和 1),通过 bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 bitmap 本身会极大的节省储存空间。
+2. **常用命令:** `setbit` 、`getbit` 、`bitcount`、`bitop`
+3. **应用场景:** 适合需要保存状态信息(比如是否签到、是否登录...)并需要进一步对这些信息进行分析的场景。比如用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
+
+```bash
+# SETBIT 会返回之前位的值(默认是 0)这里会生成 7 个位
+127.0.0.1:6379> setbit mykey 7 1
+(integer) 0
+127.0.0.1:6379> setbit mykey 7 0
+(integer) 1
+127.0.0.1:6379> getbit mykey 7
+(integer) 0
+127.0.0.1:6379> setbit mykey 6 1
+(integer) 0
+127.0.0.1:6379> setbit mykey 8 1
+(integer) 0
+# 通过 bitcount 统计被被设置为 1 的位的数量。
+127.0.0.1:6379> bitcount mykey
+(integer) 2
+```
+
+针对上面提到的一些场景,这里进行进一步说明。
+
+**使用场景一:用户行为分析**
+很多网站为了分析你的喜好,需要研究你点赞过的内容。
+
+```bash
+# 记录你喜欢过 001 号小姐姐
+127.0.0.1:6379> setbit beauty_girl_001 uid 1
+```
+
+**使用场景二:统计活跃用户**
+
+使用时间作为 key,然后用户 ID 为 offset,如果当日活跃过就设置为 1
+
+那么我该如何计算某几天/月/年的活跃用户呢(暂且约定,统计时间内只要有一天在线就称为活跃),有请下一个 redis 的命令
+
+```bash
+# 对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上。
+# BITOP 命令支持 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种参数
+BITOP operation destkey key [key ...]
+```
+
+初始化数据:
+
+```bash
+127.0.0.1:6379> setbit 20210308 1 1
+(integer) 0
+127.0.0.1:6379> setbit 20210308 2 1
+(integer) 0
+127.0.0.1:6379> setbit 20210309 1 1
+(integer) 0
+```
+
+统计 20210308~20210309 总活跃用户数: 1
+
+```bash
+127.0.0.1:6379> bitop and desk1 20210308 20210309
+(integer) 1
+127.0.0.1:6379> bitcount desk1
+(integer) 1
+```
+
+统计 20210308~20210309 在线活跃用户数: 2
+
+```bash
+127.0.0.1:6379> bitop or desk2 20210308 20210309
+(integer) 1
+127.0.0.1:6379> bitcount desk2
+(integer) 2
+```
+
+**使用场景三:用户在线状态**
+
+对于获取或者统计用户在线状态,使用 bitmap 是一个节约空间且效率又高的一种方法。
+
+只需要一个 key,然后用户 ID 为 offset,如果在线就设置为 1,不在线就设置为 0。
+
+### Redis 单线程模型详解
+
+**Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型** (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
+
+**既然是单线程,那怎么监听大量的客户端连接呢?**
+
+Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
+
+这样的好处非常明显: **I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗**(和 NIO 中的 `Selector` 组件很像)。
+
+另外, Redis 服务器是一个事件驱动程序,服务器需要处理两类事件:1. 文件事件; 2. 时间事件。
+
+时间事件不需要多花时间了解,我们接触最多的还是 **文件事件**(客户端进行读取写入等操作,涉及一系列网络通信)。
+
+《Redis 设计与实现》有一段话是如是介绍文件事件的,我觉得写得挺不错。
+
+> Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
+>
+> 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关 闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
+>
+> **虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字**,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
+
+可以看出,文件事件处理器(file event handler)主要是包含 4 个部分:
+
+- 多个 socket(客户端连接)
+- IO 多路复用程序(支持多个客户端连接的关键)
+- 文件事件分派器(将 socket 关联到相应的事件处理器)
+- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
+
+
+
+<p style="text-align:right; font-size:14px; color:gray">《Redis设计与实现:12章》</p>
+
+### Redis 没有使用多线程?为什么不使用多线程?
+
+虽然说 Redis 是单线程模型,但是,实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
+
+
+
+不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主处理之外的其他线程来“异步处理”。
+
+大体上来说,**Redis 6.0 之前主要还是单线程处理。**
+
+**那,Redis6.0 之前 为什么不使用多线程?**
+
+我觉得主要原因有下面 3 个:
+
+1. 单线程编程容易并且更容易维护;
+2. Redis 的性能瓶颈不在 CPU ,主要在内存和网络;
+3. 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
+
+### Redis6.0 之后为何引入了多线程?
+
+**Redis6.0 引入多线程主要是为了提高网络 IO 读写性能**,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
+
+虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了,执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。
+
+Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis 配置文件 `redis.conf` :
+
+```bash
+io-threads-do-reads yes
+```
+
+开启多线程后,还需要设置线程数,否则是不生效的。同样需要修改 redis 配置文件 `redis.conf` :
+
+```bash
+io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
+```
+
+推荐阅读:
+
+1. [Redis 6.0 新特性-多线程连环 13 问!](https://mp.weixin.qq.com/s/FZu3acwK6zrCBZQ_3HoUgw)
+2. [为什么 Redis 选择单线程模型](https://draveness.me/whys-the-design-redis-single-thread/)
+
+### Redis 给缓存数据设置过期时间有啥用?
+
+一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
+
+因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接 Out of memory。
+
+Redis 自带了给缓存数据设置过期时间的功能,比如:
+
+```bash
+127.0.0.1:6379> exp key 60 # 数据在 60s 后过期
+(integer) 1
+127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
+OK
+127.0.0.1:6379> ttl key # 查看数据还有多久过期
+(integer) 56
+```
+
+注意:**Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外, `persist` 命令可以移除一个键的过期时间。 **
+
+**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
+
+很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 token 可能只在 1 天内有效。
+
+如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
+
+### Redis 是如何判断数据是否过期的呢?
+
+Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
+
+
+
+过期字典是存储在 redisDb 这个结构里的:
+
+```c
+typedef struct redisDb {
+ ...
+
+ dict *dict; //数据库键空间,保存着数据库中所有键值对
+ dict *expires // 过期字典,保存着键的过期时间
+ ...
+} redisDb;
+```
+
+### 过期的数据的删除策略了解么?
+
+如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
+
+常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
+
+1. **惰性删除** :只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
+2. **定期删除** : 每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
+
+定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
+
+但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就 Out of memory 了。
+
+怎么解决这个问题呢?答案就是:**Redis 内存淘汰机制。**
+
+### Redis 内存淘汰机制了解么?
+
+> 相关问题:MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
+
+Redis 提供 6 种数据淘汰策略:
+
+1. **volatile-lru(least recently used)**:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
+2. **volatile-ttl**:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
+3. **volatile-random**:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
+4. **allkeys-lru(least recently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)
+5. **allkeys-random**:从数据集(server.db[i].dict)中任意选择数据淘汰
+6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
+
+4.0 版本后增加以下两种:
+
+7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
+8. **allkeys-lfu(least frequently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
+
+### Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)
+
+很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
+
+Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持两种不同的持久化操作。**Redis 的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file, AOF)**。这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
+
+**快照(snapshotting)持久化(RDB)**
+
+Redis 可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis 创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis 主从结构,主要用来提高 Redis 性能),还可以将快照留在原地以便重启服务器的时候使用。
+
+快照持久化是 Redis 默认采用的持久化方式,在 Redis.conf 配置文件中默认有此下配置:
+
+```conf
+save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
+
+save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
+
+save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
+```
+
+**AOF(append-only file)持久化**
+
+与快照持久化相比,AOF 持久化的实时性更好,因此已成为主流的持久化方案。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 appendonly 参数开启:
+
+```conf
+appendonly yes
+```
+
+开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到内存缓存 `server.aof_buf` 中,然后再根据 `appendfsync` 配置来决定何时将其同步到硬盘中的 AOF 文件。
+
+AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 dir 参数设置的,默认的文件名是 `appendonly.aof`。
+
+在 Redis 的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
+
+```conf
+appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
+appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
+appendfsync no #让操作系统决定何时进行同步
+```
+
+为了兼顾数据和写入性能,用户可以考虑 `appendfsync everysec` 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
+
+**相关 issue** :[783:Redis 的 AOF 方式](https://github.com/Snailclimb/JavaGuide/issues/783)
+
+**拓展:Redis 4.0 对于持久化机制的优化**
+
+Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
+
+如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
+
+官方文档地址:https://redis.io/topics/persistence
+
+
+
+**补充内容:AOF 重写**
+
+AOF 重写可以产生一个新的 AOF 文件,这个新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。
+
+AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
+
+在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
+
+### Redis 事务
+
+Redis 可以通过 **`MULTI`,`EXEC`,`DISCARD` 和 `WATCH`** 等命令来实现事务(transaction)功能。
+
+```bash
+> MULTI
+OK
+> SET USER "Guide哥"
+QUEUED
+> GET USER
+QUEUED
+> EXEC
+1) OK
+2) "Guide哥"
+```
+
+使用 [`MULTI`](https://redis.io/commands/multi) 命令后可以输入多个命令。Redis 不会立即执行这些命令,而是将它们放到队列,当调用了 [`EXEC`](https://redis.io/commands/exec) 命令将执行所有命令。
+
+这个过程是这样的:
+
+1. 开始事务(`MULTI`)。
+2. 命令入队(批量操作 Redis 的命令,先进先出(FIFO)的顺序执行)。
+3. 执行事务(`EXEC`)。
+
+你也可以通过 [`DISCARD`](https://redis.io/commands/discard) 命令取消一个事务,它会清空事务队列中保存的所有命令。
+
+```bash
+> MULTI
+OK
+> SET USER "Guide哥"
+QUEUED
+> GET USER
+QUEUED
+> DISCARD
+OK
+```
+
+[`WATCH`](https://redis.io/commands/watch) 命令用于监听指定的键,当调用 `EXEC` 命令执行事务时,如果一个被 `WATCH` 命令监视的键被修改的话,整个事务都不会执行,直接返回失败。
+
+```bash
+> WATCH USER
+OK
+> MULTI
+> SET USER "Guide哥"
+OK
+> GET USER
+Guide哥
+> EXEC
+ERR EXEC without MULTI
+```
+
+Redis 官网相关介绍 [https://redis.io/topics/transactions](https://redis.io/topics/transactions) 如下:
+
+
+
+但是,Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性: **1. 原子性**,**2. 隔离性**,**3. 持久性**,**4. 一致性**。
+
+1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+3. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+4. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+
+**Redis 是不支持 roll back 的,因而不满足原子性的(而且不满足持久性)。**
+
+Redis 官网也解释了自己为啥不支持回滚。简单来说就是 Redis 开发者们觉得没必要支持回滚,这样更简单便捷并且性能更好。Redis 开发者觉得即使命令执行错误也应该在开发过程中就被发现而不是生产过程中。
+
+
+
+你可以将 Redis 中的事务就理解为 :**Redis 事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。**
+
+**相关 issue** :
+
+- [issue452: 关于 Redis 事务不满足原子性的问题](https://github.com/Snailclimb/JavaGuide/issues/452) 。
+- [Issue491:关于 redis 没有事务回滚?](https://github.com/Snailclimb/JavaGuide/issues/491)
+
+### 缓存穿透
+
+#### 什么是缓存穿透?
+
+缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
+
+#### 缓存穿透情况的处理流程是怎样的?
+
+如下图所示,用户的请求最终都要跑到数据库中查询一遍。
+
+
+
+#### 有哪些解决办法?
+
+最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
+
+**1)缓存无效 key**
+
+如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下: `SET key value EX 10086` 。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
+
+另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值` 。
+
+如果用 Java 代码展示的话,差不多是下面这样的:
+
+```java
+public Object getObjectInclNullById(Integer id) {
+ // 从缓存中获取数据
+ Object cacheValue = cache.get(id);
+ // 缓存为空
+ if (cacheValue == null) {
+ // 从数据库中获取
+ Object storageValue = storage.get(key);
+ // 缓存空对象
+ cache.set(key, storageValue);
+ // 如果存储数据为空,需要设置一个过期时间(300秒)
+ if (storageValue == null) {
+ // 必须设置过期时间,否则有被攻击的风险
+ cache.expire(key, 60 * 5);
+ }
+ return storageValue;
+ }
+ return cacheValue;
+}
+```
+
+**2)布隆过滤器**
+
+布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
+
+具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
+
+加入布隆过滤器之后的缓存处理流程图如下。
+
+
+
+但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是: **布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
+
+_为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理来说!_
+
+我们先来看一下,**当一个元素加入布隆过滤器中的时候,会进行哪些操作:**
+
+1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
+2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
+
+我们再来看一下,**当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行哪些操作:**
+
+1. 对给定元素再次进行相同的哈希计算;
+2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+
+然后,一定会出现这样一种情况:**不同的字符串可能哈希出来的位置相同。** (可以适当增加位数组大小或者调整我们的哈希函数来降低概率)
+
+更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/cs-basics/data-structure/bloom-filter.md) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
+
+### 缓存雪崩
+
+#### 什么是缓存雪崩?
+
+我发现缓存雪崩这名字起的有点意思,哈哈。
+
+实际上,缓存雪崩描述的就是这样一个简单的场景:**缓存在同一时间大面积的失效,后面的请求都直接落到了数据库上,造成数据库短时间内承受大量请求。** 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
+
+举个例子:系统的缓存模块出了问题比如宕机导致不可用。造成系统的所有访问,都要走数据库。
+
+还有一种缓存雪崩的场景是:**有一些被大量访问数据(热点缓存)在某一时刻大面积失效,导致对应的请求直接落到了数据库上。** 这样的情况,有下面几种解决办法:
+
+举个例子 :秒杀开始 12 个小时之前,我们统一存放了一批商品到 Redis 中,设置的缓存过期时间也是 12 个小时,那么秒杀开始的时候,这些秒杀的商品的访问直接就失效了。导致的情况就是,相应的请求直接就落到了数据库上,就像雪崩一样可怕。
+
+#### 有哪些解决办法?
+
+**针对 Redis 服务不可用的情况:**
+
+1. 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
+2. 限流,避免同时处理大量的请求。
+
+**针对热点缓存失效的情况:**
+
+1. 设置不同的失效时间比如随机设置缓存的失效时间。
+2. 缓存永不失效。
+
+### 如何保证缓存和数据库数据的一致性?
+
+细说的话可以扯很多,但是我觉得其实没太大必要(小声 BB:很多解决方案我也没太弄明白)。我个人觉得引入缓存之后,如果为了短时间的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
+
+下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。
+
+Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
+
+如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
+
+1. **缓存失效时间变短(不推荐,治标不治本)** :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
+2. **增加 cache 更新重试机制(常用)**: 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将缓存中对应的 key 删除即可。
+
+### 参考
+
+- 《Redis 开发与运维》
+- 《Redis 设计与实现》
+- Redis 命令总结:http://Redisdoc.com/string/set.html
+- 通俗易懂的 Redis 数据结构基础教程:[https://juejin.im/post/5b53ee7e5188251aaa2d2e16](https://juejin.im/post/5b53ee7e5188251aaa2d2e16)
+- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
diff --git "a/docs/database/\345\255\227\347\254\246\351\233\206.md" "b/docs/database/\345\255\227\347\254\246\351\233\206.md"
new file mode 100644
index 00000000000..1cca2575e6e
--- /dev/null
+++ "b/docs/database/\345\255\227\347\254\246\351\233\206.md"
@@ -0,0 +1,160 @@
+---
+title: 字符集
+category: 数据库
+tag:
+ - 数据库基础
+---
+
+
+MySQL 字符编码集中有两套 UTF-8 编码实现:**`utf8`** 和 **`utf8mb4`**。
+
+如果使用 **`utf8`** 的话,存储emoji 符号和一些比较复杂的汉字、繁体字就会出错。
+
+为什么会这样呢?这篇文章可以从源头给你解答。
+
+## 何为字符集?
+
+字符是各种文字和符号的统称,包括各个国家文字、标点符号、表情、数字等等。 **字符集** 就是一系列字符的集合。字符集的种类较多,每个字符集可以表示的字符范围通常不同,就比如说有些字符集是无法表示汉字的。
+
+**计算机只能存储二进制的数据,那英文、汉字、表情等字符应该如何存储呢?**
+
+我们要将这些字符和二级制的数据一一对应起来,比如说字符“a”对应“01100001”,反之,“01100001”对应 “a”。我们将字符对应二进制数据的过程称为"**字符编码**",反之,二进制数据解析成字符的过程称为“**字符解码**”。
+
+## 有哪些常见的字符集?
+
+常见的字符集有 ASCII、GB2312、GBK、UTF-8......。
+
+不同的字符集的主要区别在于:
+
+- 可以表示的字符范围
+- 编码方式
+
+### ASCII
+
+**ASCII** (**A**merican **S**tandard **C**ode for **I**nformation **I**nterchange,美国信息交换标准代码) 是一套主要用于现代美国英语的字符集(这也是 ASCII 字符集的局限性所在)。
+
+**为什么 ASCII 字符集没有考虑到中文等其他字符呢?** 因为计算机是美国人发明的,当时,计算机的发展还处于比较雏形的时代,还未在其他国家大规模使用。因此,美国发布 ASCII 字符集的时候没有考虑兼容其他国家的语言。
+
+ASCII 字符集至今为止共定义了 128 个字符,其中有 33 个控制字符(比如回车、删除)无法显示。
+
+一个 ASCII 码长度是一个字节也就是 8 个 bit,比如“a”对应的 ASCII 码是“01100001”。不过,最高位是 0 仅仅作为校验位,其余 7 位使用 0 和 1 进行组合,所以,ASCII 字符集可以定义 128(2^7)个字符。
+
+由于,ASCII 码可以表示的字符实在是太少了。后来,人们对其进行了扩展得到了 **ASCII 扩展字符集** 。ASCII 扩展字符集使用 8 位(bits)表示一个字符,所以,ASCII 扩展字符集可以定义 256(2^8)个字符。
+
+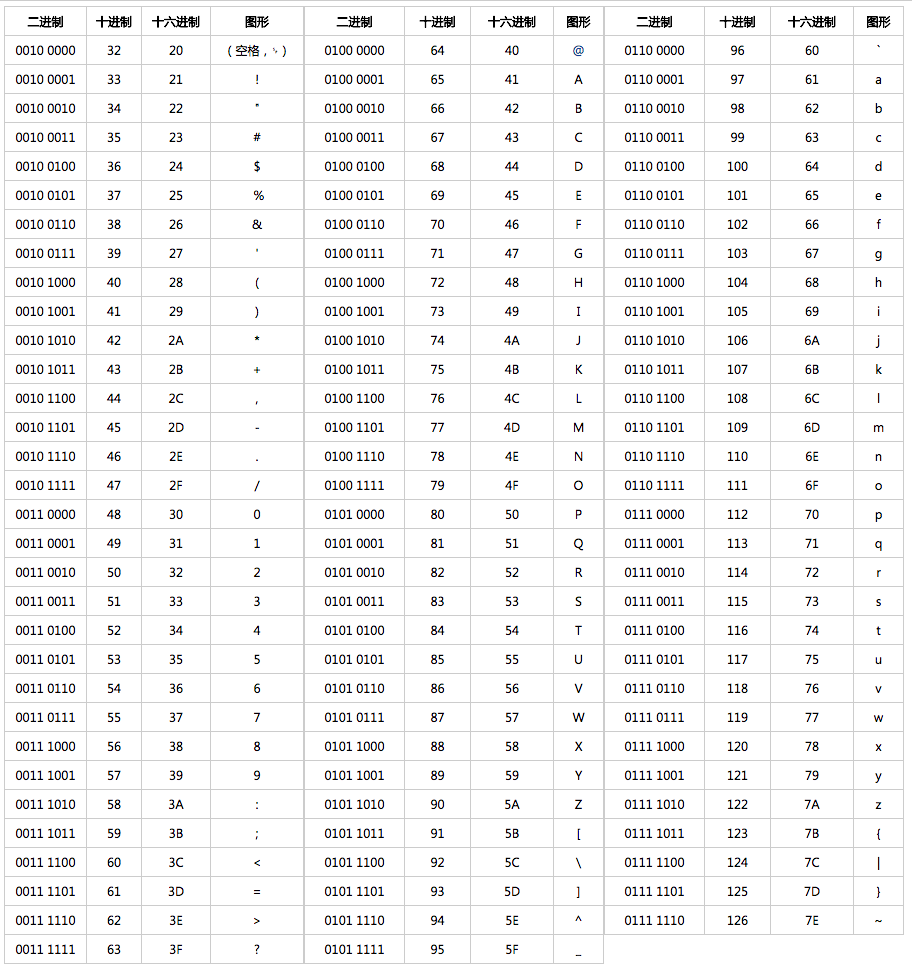
+
+### GB2312
+
+我们上面说了,ASCII 字符集是一种现代美国英语适用的字符集。因此,很多国家都捣鼓了一个适合自己国家语言的字符集。
+
+GB2312 字符集是一种对汉字比较友好的字符集,共收录 6700 多个汉字,基本涵盖了绝大部分常用汉字。不过,GB2312 字符集不支持绝大部分的生僻字和繁体字。
+
+对于英语字符,GB2312 编码和 ASCII 码是相同的,1 字节编码即可。对于非英字符,需要 2 字节编码。
+
+### GBK
+
+GBK 字符集可以看作是 GB2312 字符集的扩展,兼容 GB2312 字符集,共收录了 20000 多个汉字。
+
+GBK 中 K 是汉语拼音 Kuo Zhan(扩展)中的“Kuo”的首字母。
+
+### GB18030
+
+GB18030 完全兼容 GB2312 和 GBK 字符集,纳入中国国内少数民族的文字,且收录了日韩汉字,是目前为止最全面的汉字字符集,共收录汉字 70000 多个。
+
+### BIG5
+
+BIG5 主要针对的是繁体中文,收录了 13000 多个汉字。
+
+### Unicode & UTF-8编码
+
+为了更加适合本国语言,诞生了很多种字符集。
+
+我们上面也说了不同的字符集可以表示的字符范围以及编码规则存在差异。这就导致了一个非常严重的问题:**使用错误的编码方式查看一个包含字符的文件就会产生乱码现象。**
+
+就比如说你使用 UTF-8 编码方式打开 GB2312 编码格式的文件就会出现乱码。示例:“牛”这个汉字 GB2312 编码后的十六进制数值为 “C5A3”,而 “C5A3” 用 UTF-8 解码之后得到的却是 “ţ”。
+
+你可以通过这个网站在线进行编码和解码:https://www.haomeili.net/HanZi/ZiFuBianMaZhuanHuan
+
+
+
+这样我们就搞懂了乱码的本质: **编码和解码时用了不同或者不兼容的字符集** 。
+
+
+
+为了解决这个问题,人们就想:“如果我们能够有一种字符集将世界上所有的字符都纳入其中就好了!”。
+
+然后,**Unicode** 带着这个使命诞生了。
+
+Unicode 字符集中包含了世界上几乎所有已知的字符。不过,Unicode 字符集并没有规定如何存储这些字符(也就是如何使用二进制数据表示这些字符)。
+
+然后,就有了 **UTF-8**(**8**-bit **U**nicode **T**ransformation **F**ormat)。类似的还有 UTF-16、 UTF-32。
+
+UTF-8 使用 1 到 4 个字节为每个字符编码, UTF-16 使用 2 或 4 个字节为每个字符编码,UTF-32 固定位 4 个字节为每个字符编码。
+
+UTF-8 可以根据不同的符号自动选择编码的长短,像英文字符只需要 1 个字节就够了,这一点 ASCII 字符集一样 。因此,对于英语字符,UTF-8 编码和 ASCII 码是相同的。
+
+UTF-32 的规则最简单,不过缺陷也比较明显,对于英文字母这类字符消耗的空间是 UTF-8 的 4 倍之多。
+
+**UTF-8** 是目前使用最广的一种字符编码,。
+
+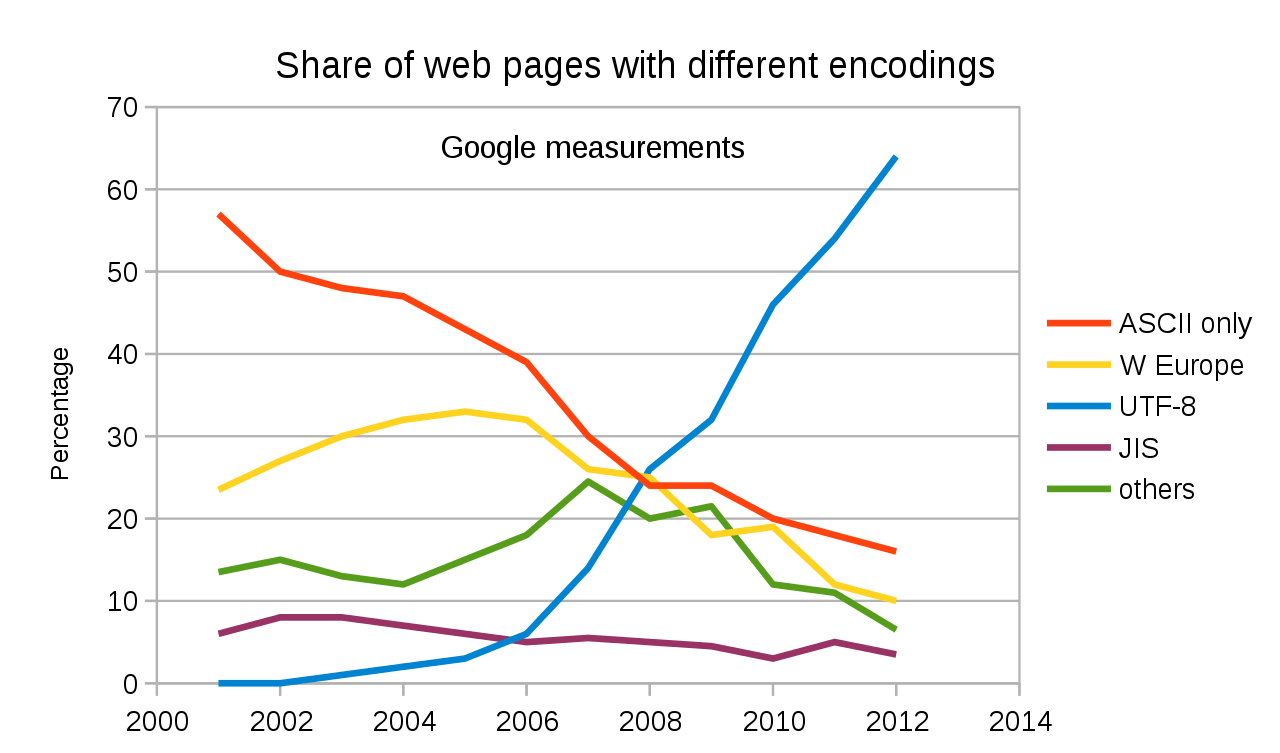
+
+## MySQL 字符集
+
+MySQL 支持很多种字符编码的方式,比如 UTF-8、GB2312、GBK、BIG5。
+
+你可以通过 `SHOW CHARSET` 命令来查看。
+
+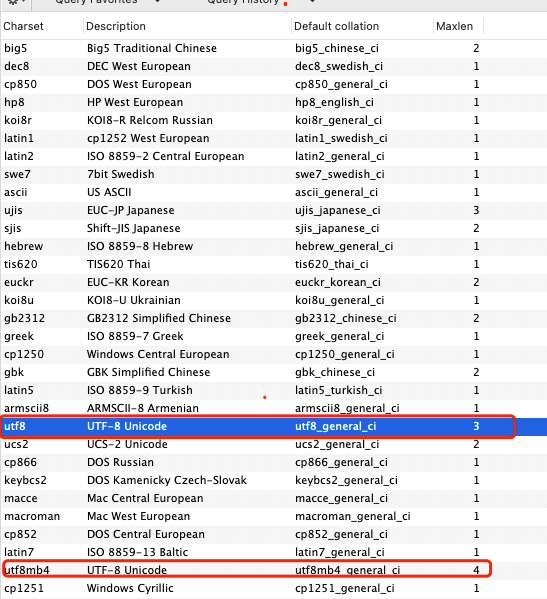
+
+通常情况下,我们建议使用 UTF-8 作为默认的字符编码方式。
+
+不过,这里有一个小坑。
+
+MySQL 字符编码集中有两套 UTF-8 编码实现:
+
+- **`utf8`** : `utf8`编码只支持`1-3`个字节 。 在 `utf8` 编码中,中文是占 3 个字节,其他数字、英文、符号占一个字节。但 emoji 符号占 4 个字节,一些较复杂的文字、繁体字也是 4 个字节。
+- **`utf8mb4`** : UTF-8 的完整实现,正版!最多支持使用 4 个字节表示字符,因此,可以用来存储 emoji 符号。
+
+**为什么有两套 UTF-8 编码实现呢?** 原因如下:
+
+
+
+因此,如果你需要存储`emoji`类型的数据或者一些比较复杂的文字、繁体字到 MySQL 数据库的话,数据库的编码一定要指定为`utf8mb4` 而不是`utf8` ,要不然存储的时候就会报错了。
+
+演示一下吧!(环境:MySQL 5.7+)
+
+建表语句如下,我们指定数据库 CHARSET 为 `utf8` 。
+
+```sql
+CREATE TABLE `user` (
+ `id` varchar(66) CHARACTER SET utf8mb4 NOT NULL,
+ `name` varchar(33) CHARACTER SET utf8mb4 NOT NULL,
+ `phone` varchar(33) CHARACTER SET utf8mb4 DEFAULT NULL,
+ `password` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+```
+
+当我们执行下面的 insert 语句插入数据到数据库时,果然报错!
+
+```sql
+INSERT INTO `user` (`id`, `name`, `phone`, `password`)
+VALUES
+ ('A00003', 'guide哥😘😘😘', '181631312312', '123456');
+
+```
+
+报错信息如下:
+
+```
+Incorrect string value: '\xF0\x9F\x98\x98\xF0\x9F...' for column 'name' at row 1
+```
+
+## 参考
+
+- 字符集和字符编码(Charset & Encoding): https://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html
+- 十分钟搞清字符集和字符编码:http://cenalulu.github.io/linux/character-encoding/
+- Unicode-维基百科:https://zh.wikipedia.org/wiki/Unicode
+- GB2312-维基百科:https://zh.wikipedia.org/wiki/GB_2312
+- UTF-8-维基百科:https://zh.wikipedia.org/wiki/UTF-8
+- GB18030-维基百科: https://zh.wikipedia.org/wiki/GB_18030
\ No newline at end of file
diff --git "a/docs/database/\346\225\260\346\215\256\345\272\223\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/database/\346\225\260\346\215\256\345\272\223\345\237\272\347\241\200\347\237\245\350\257\206.md"
new file mode 100644
index 00000000000..92d30998a71
--- /dev/null
+++ "b/docs/database/\346\225\260\346\215\256\345\272\223\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -0,0 +1,150 @@
+---
+title: 数据库基础知识
+category: 数据库
+tag:
+ - 数据库基础
+---
+
+数据库知识基础,这部分内容一定要理解记忆。虽然这部分内容只是理论知识,但是非常重要,这是后面学习 MySQL 数据库的基础。PS: 这部分内容由于涉及太多概念性内容,所以参考了维基百科和百度百科相应的介绍。
+
+## 什么是数据库, 数据库管理系统, 数据库系统, 数据库管理员?
+
+* **数据库** : 数据库(DataBase 简称 DB)就是信息的集合或者说数据库是由数据库管理系统管理的数据的集合。
+* **数据库管理系统** : 数据库管理系统(Database Management System 简称 DBMS)是一种操纵和管理数据库的大型软件,通常用于建立、使用和维护数据库。
+* **数据库系统** : 数据库系统(Data Base System,简称 DBS)通常由软件、数据库和数据管理员(DBA)组成。
+* **数据库管理员** : 数据库管理员(Database Administrator, 简称 DBA)负责全面管理和控制数据库系统。
+
+数据库系统基本构成如下图所示:
+
+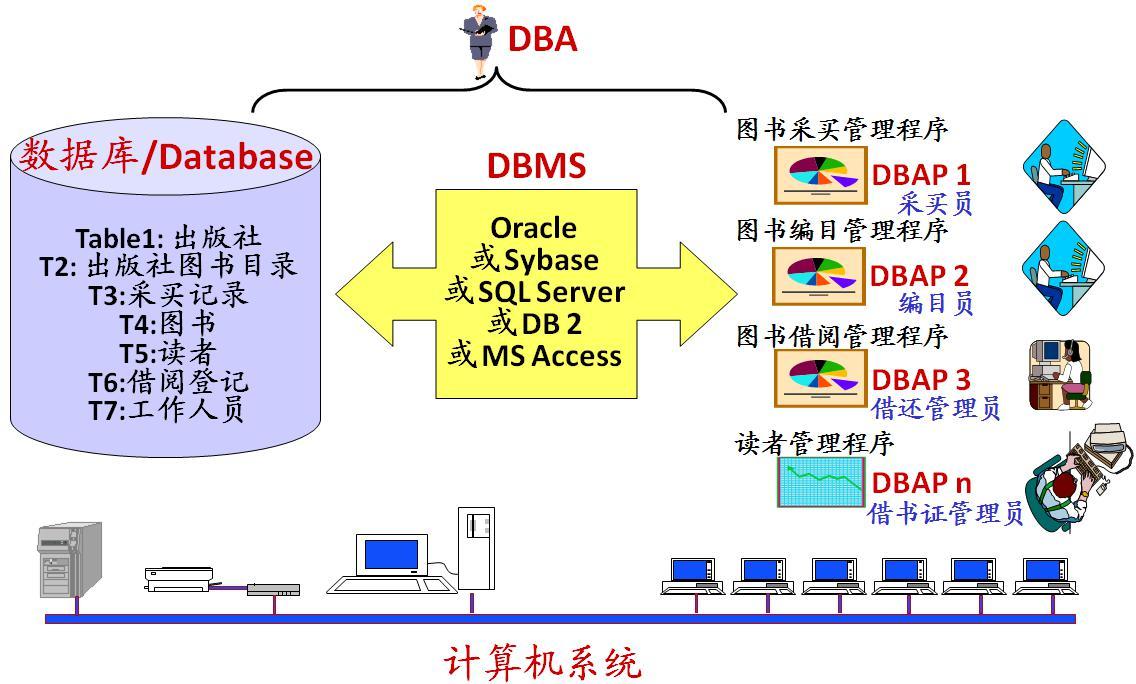
+
+## 什么是元组, 码, 候选码, 主码, 外码, 主属性, 非主属性?
+
+* **元组** : 元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
+* **码** :码就是能唯一标识实体的属性,对应表中的列。
+* **候选码** : 若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
+* **主码** : 主码也叫主键。主码是从候选码中选出来的。 一个实体集中只能有一个主码,但可以有多个候选码。
+* **外码** : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。
+* **主属性** : 候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
+* **非主属性:** 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
+
+## 主键和外键有什么区别?
+
+* **主键(主码)** :主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
+* **外键(外码)** :外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
+
+## 为什么不推荐使用外键与级联?
+
+对于外键和级联,阿里巴巴开发手册这样说到:
+
+> 【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
+>
+> 说明: 以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群; 级联更新是强阻塞,存在数据库更新风暴的风 险; 外键影响数据库的插入速度
+
+为什么不要用外键呢?大部分人可能会这样回答:
+
+> 1. **增加了复杂性:** a. 每次做DELETE 或者UPDATE都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
+> 2. **增加了额外工作**: 数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
+> 3. 外键还会因为需要请求对其他表内部加锁而容易出现死锁情况;
+> 4. **对分库分表不友好** :因为分库分表下外键是无法生效的。
+> 5. ......
+
+我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
+
+1. 保证了数据库数据的一致性和完整性;
+2. 级联操作方便,减轻了程序代码量;
+3. ......
+
+所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分库分表,并发量不是很高的情况还是可以考虑使用外键的。
+
+
+## 什么是 ER 图?
+
+> 我们做一个项目的时候一定要试着画 ER 图来捋清数据库设计,这个也是面试官问你项目的时候经常会被问道的。
+
+**E-R 图** 也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。 它是描述现实世界关系概念模型的有效方法。 是表示概念关系模型的一种方式。
+
+下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种关系是:1 对 1(1:1)、1 对多(1: N)。
+
+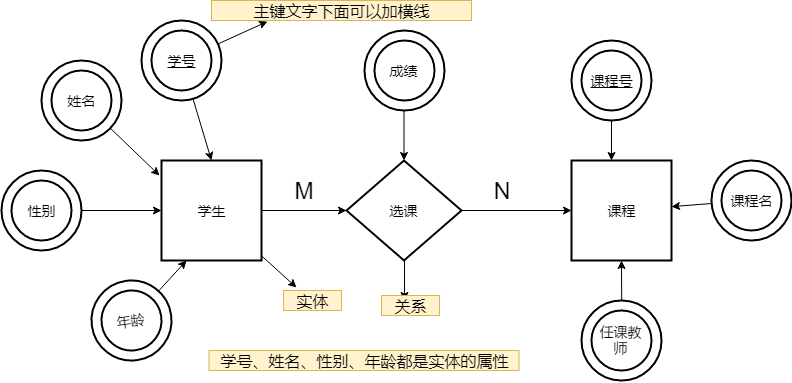
+
+我们试着将上面的 ER 图转换成数据库实际的关系模型(实际设计中,我们通常会将任课教师也作为一个实体来处理):
+
+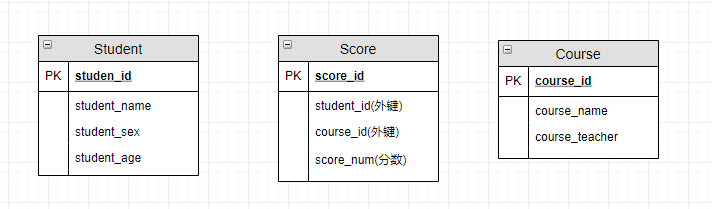
+
+## 数据库范式了解吗?
+
+**1NF(第一范式)**
+
+属性(对应于表中的字段)不能再被分割,也就是这个字段只能是一个值,不能再分为多个其他的字段了。**1NF 是所有关系型数据库的最基本要求** ,也就是说关系型数据库中创建的表一定满足第一范式。
+
+**2NF(第二范式)**
+
+2NF 在 1NF 的基础之上,消除了非主属性对于码的部分函数依赖。如下图所示,展示了第一范式到第二范式的过渡。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。
+
+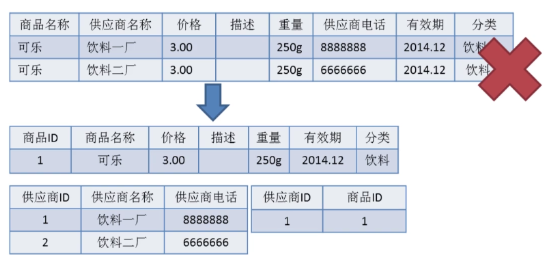
+
+一些重要的概念:
+
+* **函数依赖(functional dependency)** :若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
+* **部分函数依赖(partial functional dependency)** :如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);
+* **完全函数依赖(Full functional dependency)** :在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
+* **传递函数依赖** : 在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。。
+
+**3NF(第三范式)**
+
+3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。符合 3NF 要求的数据库设计,**基本**上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖,所以该表的设计,不符合 3NF 的要求。
+
+**总结**
+
+* 1NF:属性不可再分。
+* 2NF:1NF 的基础之上,消除了非主属性对于码的部分函数依赖。
+* 3NF:3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。
+
+## 什么是存储过程?
+
+我们可以把存储过程看成是一些 SQL 语句的集合,中间加了点逻辑控制语句。存储过程在业务比较复杂的时候是非常实用的,比如很多时候我们完成一个操作可能需要写一大串 SQL 语句,这时候我们就可以写有一个存储过程,这样也方便了我们下一次的调用。存储过程一旦调试完成通过后就能稳定运行,另外,使用存储过程比单纯 SQL 语句执行要快,因为存储过程是预编译过的。
+
+存储过程在互联网公司应用不多,因为存储过程难以调试和扩展,而且没有移植性,还会消耗数据库资源。
+
+阿里巴巴 Java 开发手册里要求禁止使用存储过程。
+
+
+
+## drop、delete 与 truncate 区别?
+
+### 用法不同
+
+* drop(丢弃数据): `drop table 表名` ,直接将表都删除掉,在删除表的时候使用。
+* truncate (清空数据) : `truncate table 表名` ,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。
+* delete(删除数据) : `delete from 表名 where 列名=值`,删除某一列的数据,如果不加 where 子句和`truncate table 表名`作用类似。
+
+truncate 和不带 where 子句的 delete、以及 drop 都会删除表内的数据,但是 **truncate 和 delete 只删除数据不删除表的结构(定义),执行 drop 语句,此表的结构也会删除,也就是执行 drop 之后对应的表不复存在。**
+
+### 属于不同的数据库语言
+
+truncate 和 drop 属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。而 delete 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segement 中,事务提交之后才生效。
+
+**DML 语句和 DDL 语句区别:**
+
+* DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入(insert)、更新(update)、删除(delete)和查询(select),是开发人员日常使用最频繁的操作。
+* DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。
+
+### 执行速度不同
+
+一般来说:drop>truncate>delete(这个我没有设计测试过)。
+
+## 数据库设计通常分为哪几步?
+
+1. **需求分析** : 分析用户的需求,包括数据、功能和性能需求。
+2. **概念结构设计** : 主要采用 E-R 模型进行设计,包括画 E-R 图。
+3. **逻辑结构设计** : 通过将 E-R 图转换成表,实现从 E-R 模型到关系模型的转换。
+4. **物理结构设计** : 主要是为所设计的数据库选择合适的存储结构和存取路径。
+5. **数据库实施** : 包括编程、测试和试运行
+6. **数据库的运行和维护** : 系统的运行与数据库的日常维护。
+
+## 参考
+
+* <https://blog.csdn.net/rl529014/article/details/48391465>
+* <https://www.zhihu.com/question/24696366/answer/29189700>
+* <https://blog.csdn.net/bieleyang/article/details/77149954>
diff --git a/docs/distributed-system/api-gateway.md b/docs/distributed-system/api-gateway.md
new file mode 100644
index 00000000000..11bab874ff1
--- /dev/null
+++ b/docs/distributed-system/api-gateway.md
@@ -0,0 +1,107 @@
+
+# 网关
+
+## 何为网关?为什么要网关?
+
+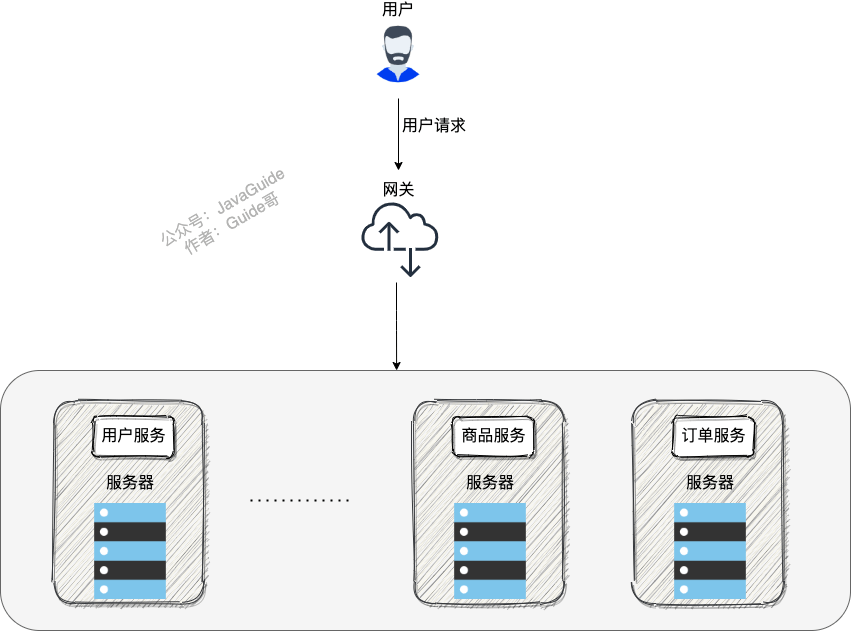
+
+微服务背景下,一个系统被拆分为多个服务,但是像安全认证,流量控制,日志,监控等功能是每个服务都需要的,没有网关的话,我们就需要在每个服务中单独实现,这使得我们做了很多重复的事情并且没有一个全局的视图来统一管理这些功能。
+
+综上:**一般情况下,网关都会提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、容灾、日志、监控这些功能。**
+
+上面介绍了这么多功能,实际上,网关主要做了一件事情:**请求过滤** 。
+
+## 有哪些常见的网关系统?
+
+### Netflix Zuul
+
+Zuul 是 Netflix 开发的一款提供动态路由、监控、弹性、安全的网关服务。
+
+Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网关必备的各种功能。
+
+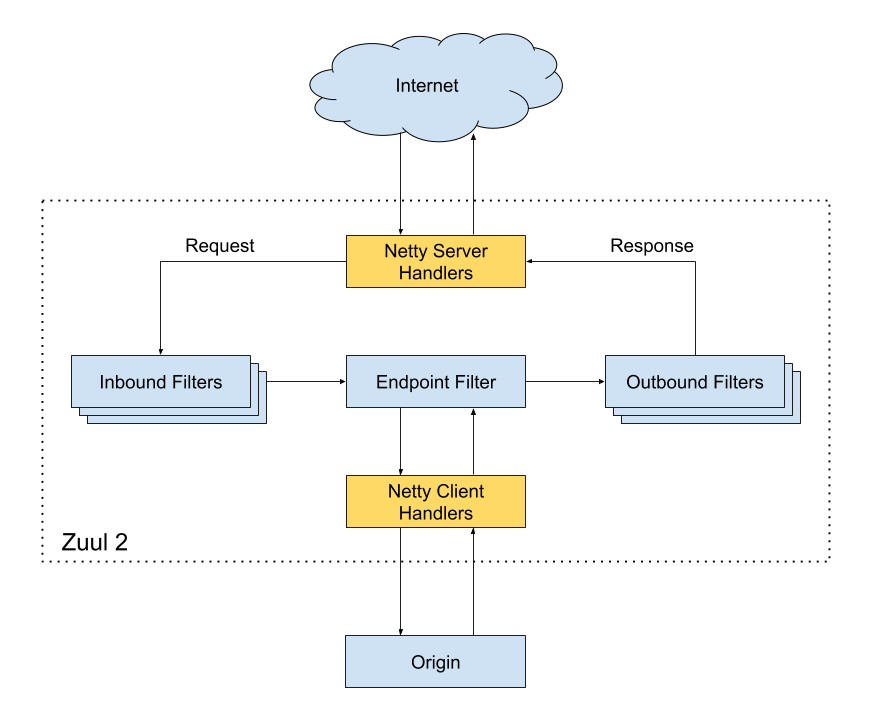
+
+我们可以自定义过滤器来处理请求,并且,Zuul 生态本身就有很多现成的过滤器供我们使用。就比如限流可以直接用国外朋友写的 [spring-cloud-zuul-ratelimit](https://github.com/marcosbarbero/spring-cloud-zuul-ratelimit) (这里只是举例说明,一般是配合 hystrix 来做限流):
+
+```xml
+<dependency>
+ <groupId>org.springframework.cloud</groupId>
+ <artifactId>spring-cloud-starter-netflix-zuul</artifactId>
+</dependency>
+<dependency>
+ <groupId>com.marcosbarbero.cloud</groupId>
+ <artifactId>spring-cloud-zuul-ratelimit</artifactId>
+ <version>2.2.0.RELEASE</version>
+</dependency>
+```
+
+Zuul 1.x 基于同步 IO,性能较差。Zuul 2.x 基于 Netty 实现了异步 IO,性能得到了大幅改进。
+
+- Github 地址 : https://github.com/Netflix/zuul
+- 官方 Wiki : https://github.com/Netflix/zuul/wiki
+
+### Spring Cloud Gateway
+
+SpringCloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标是为了替代老牌网关 **Zuul **。准确点来说,应该是 Zuul 1.x。SpringCloud Gateway 起步要比 Zuul 2.x 更早。
+
+为了提升网关的性能,SpringCloud Gateway 基于 Spring WebFlux 。Spring WebFlux 使用 Reactor 库来实现响应式编程模型,底层基于 Netty 实现异步 IO。
+
+Spring Cloud Gateway 的目标,不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,和限流。
+
+Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
+
+- Github 地址 : https://github.com/spring-cloud/spring-cloud-gateway
+- 官网 : https://spring.io/projects/spring-cloud-gateway
+
+### Kong
+
+Kong 是一款基于 [OpenResty](https://github.com/openresty/) 的高性能、云原生、可扩展的网关系统。
+
+> OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
+
+Kong 提供了插件机制来扩展其功能。比如、在服务上启用 Zipkin 插件
+
+```shell
+$ curl -X POST http://kong:8001/services/{service}/plugins \
+ --data "name=zipkin" \
+ --data "config.http_endpoint=http://your.zipkin.collector:9411/api/v2/spans" \
+ --data "config.sample_ratio=0.001"
+```
+
+- Github 地址: https://github.com/Kong/kong
+- 官网地址 : https://konghq.com/kong
+
+### APISIX
+
+APISIX 是一款基于 Nginx 和 etcd 的高性能、云原生、可扩展的网关系统。
+
+> *etcd*是使用 Go 语言开发的一个开源的、高可用的分布式 key-value 存储系统,使用 Raft 协议做分布式共识。
+
+与传统 API 网关相比,APISIX 具有动态路由和插件热加载,特别适合微服务系统下的 API 管理。并且,APISIX 与 SkyWalking(分布式链路追踪系统)、Zipkin(分布式链路追踪系统)、Prometheus(监控系统) 等 DevOps 生态工具对接都十分方便。
+
+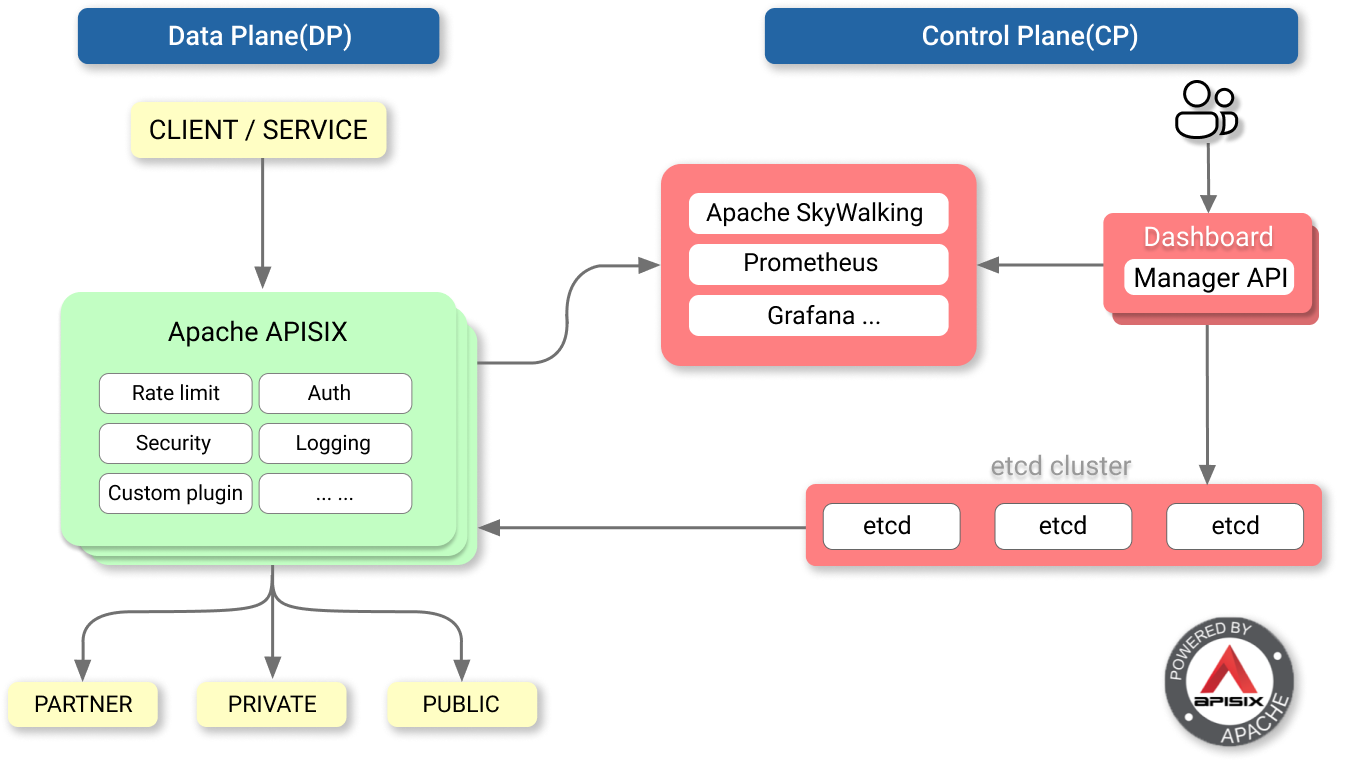
+
+作为 NGINX 和 Kong 的替代项目,APISIX 目前已经是 Apache 顶级开源项目,并且是最快毕业的国产开源项目。国内目前已经有很多知名企业(比如金山、有赞、爱奇艺、腾讯、贝壳)使用 APISIX 处理核心的业务流量。
+
+根据官网介绍:“APISIX 已经生产可用,功能、性能、架构全面优于 Kong”。
+
+- Github 地址 :https://github.com/apache/apisix
+- 官网地址: https://apisix.apache.org/zh/
+
+相关阅读:
+
+- [有了 NGINX 和 Kong,为什么还需要 Apache APISIX](https://www.apiseven.com/zh/blog/why-we-need-Apache-APISIX)
+- [APISIX 技术博客](https://www.apiseven.com/zh/blog)
+- [APISIX 用户案例](https://www.apiseven.com/zh/usercases)
+
+### Shenyu
+
+Shenyu 是一款基于 WebFlux 的可扩展、高性能、响应式网关,Apache 顶级开源项目。
+
+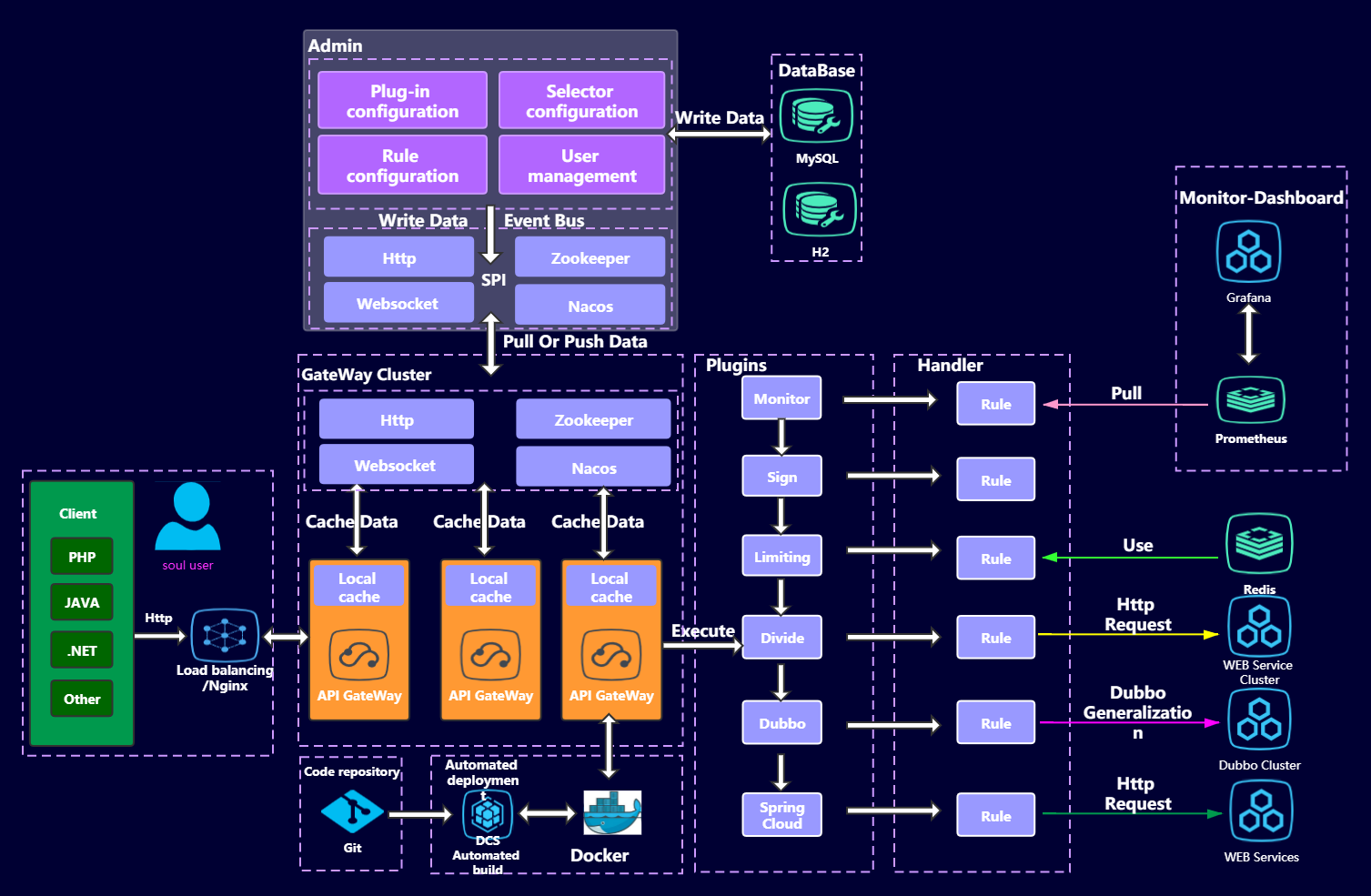
+
+Shenyu 通过插件扩展功能,插件是 ShenYu 的灵魂,并且插件也是可扩展和热插拔的。不同的插件实现不同的功能。Shenyu 自带了诸如限流、熔断、转发 、重写、重定向、和路由监控等插件。
+
+- Github 地址: https://github.com/apache/incubator-shenyu
+- 官网地址 : https://shenyu.apache.org/
+
diff --git a/docs/distributed-system/distributed-id.md b/docs/distributed-system/distributed-id.md
new file mode 100644
index 00000000000..0ec45819e55
--- /dev/null
+++ b/docs/distributed-system/distributed-id.md
@@ -0,0 +1,357 @@
+# 分布式 ID
+
+## 分布式 ID 介绍
+
+### 何为 ID?
+
+日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。
+
+
+
+我们现实生活中也有各种 ID,比如身份证 ID 对应且仅对应一个人、地址 ID 对应且仅对应
+
+简单来说,**ID 就是数据的唯一标识**。
+
+### 何为分布式 ID?
+
+分布式 ID 是分布式系统下的 ID。分布式 ID 不存在与现实生活中,属于计算机系统中的一个概念。
+
+我简单举一个分库分表的例子。
+
+我司的一个项目,使用的是单机 MySQL 。但是,没想到的是,项目上线一个月之后,随着使用人数越来越多,整个系统的数据量将越来越大。
+
+单机 MySQL 已经没办法支撑了,需要进行分库分表(推荐 Sharding-JDBC)。
+
+在分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。**我们如何为不同的数据节点生成全局唯一主键呢?**
+
+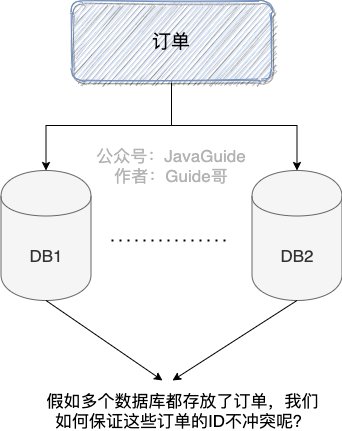
+
+这个时候就需要生成**分布式 ID**了。
+
+### 分布式 ID 需要满足哪些要求?
+
+
+
+分布式 ID 作为分布式系统中必不可少的一环,很多地方都要用到分布式 ID。
+
+一个最基本的分布式 ID 需要满足下面这些要求:
+
+- **全局唯一** :ID 的全局唯一性肯定是首先要满足的!
+- **高性能** : 分布式 ID 的生成速度要快,对本地资源消耗要小。
+- **高可用** :生成分布式 ID 的服务要保证可用性无限接近于 100%。
+- **方便易用** :拿来即用,使用方便,快速接入!
+
+除了这些之外,一个比较好的分布式 ID 还应保证:
+
+- **安全** :ID 中不包含敏感信息。
+- **有序递增** :如果要把 ID 存放在数据库的话,ID 的有序性可以提升数据库写入速度。并且,很多时候 ,我们还很有可能会直接通过 ID 来进行排序。
+- **有具体的业务含义** :生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
+- **独立部署** :也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的。
+
+## 分布式 ID 常见解决方案
+
+### 数据库
+
+#### 数据库主键自增
+
+这种方式就比较简单直白了,就是通过关系型数据库的自增主键产生来唯一的 ID。
+
+
+
+以 MySQL 举例,我们通过下面的方式即可。
+
+**1.创建一个数据库表。**
+
+```sql
+CREATE TABLE `sequence_id` (
+ `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
+ `stub` char(10) NOT NULL DEFAULT '',
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `stub` (`stub`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+`stub` 字段无意义,只是为了占位,便于我们插入或者修改数据。并且,给 `stub` 字段创建了唯一索引,保证其唯一性。
+
+**2.通过 `replace into` 来插入数据。**
+
+```java
+BEGIN;
+REPLACE INTO sequence_id (stub) VALUES ('stub');
+SELECT LAST_INSERT_ID();
+COMMIT;
+```
+
+插入数据这里,我们没有使用 `insert into` 而是使用 `replace into` 来插入数据,具体步骤是这样的:
+
+1)第一步: 尝试把数据插入到表中。
+
+2)第二步: 如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
+
+这种方式的优缺点也比较明显:
+
+- **优点** :实现起来比较简单、ID 有序递增、存储消耗空间小
+- **缺点** : 支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)
+
+#### 数据库号段模式
+
+数据库主键自增这种模式,每次获取 ID 都要访问一次数据库,ID 需求比较大的时候,肯定是不行的。
+
+如果我们可以批量获取,然后存在在内存里面,需要用到的时候,直接从内存里面拿就舒服了!这也就是我们说的 **基于数据库的号段模式来生成分布式 ID。**
+
+数据库的号段模式也是目前比较主流的一种分布式 ID 生成方式。像滴滴开源的[Tinyid](https://github.com/didi/tinyid/wiki/tinyid%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D) 就是基于这种方式来做的。不过,TinyId 使用了双号段缓存、增加多 db 支持等方式来进一步优化。
+
+以 MySQL 举例,我们通过下面的方式即可。
+
+**1.创建一个数据库表。**
+
+```sql
+CREATE TABLE `sequence_id_generator` (
+ `id` int(10) NOT NULL,
+ `current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
+ `step` int(10) NOT NULL COMMENT '号段的长度',
+ `version` int(20) NOT NULL COMMENT '版本号',
+ `biz_type` int(20) NOT NULL COMMENT '业务类型',
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+`current_max_id` 字段和`step`字段主要用于获取批量 ID,获取的批量 id 为: `current_max_id ~ current_max_id+step`。
+
+
+
+`version` 字段主要用于解决并发问题(乐观锁),`biz_type` 主要用于表示业余类型。
+
+**2.先插入一行数据。**
+
+```sql
+INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`)
+VALUES
+ (1, 0, 100, 0, 101);
+```
+
+**3.通过 SELECT 获取指定业务下的批量唯一 ID**
+
+```sql
+SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
+```
+
+结果:
+
+```
+id current_max_id step version biz_type
+1 0 100 1 101
+```
+
+**4.不够用的话,更新之后重新 SELECT 即可。**
+
+```sql
+UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101
+SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
+```
+
+结果:
+
+```
+id current_max_id step version biz_type
+1 100 100 1 101
+```
+
+相比于数据库主键自增的方式,**数据库的号段模式对于数据库的访问次数更少,数据库压力更小。**
+
+另外,为了避免单点问题,你可以从使用主从模式来提高可用性。
+
+**数据库号段模式的优缺点:**
+
+- **优点** :ID 有序递增、存储消耗空间小
+- **缺点** :存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )
+
+#### NoSQL
+
+
+
+一般情况下,NoSQL 方案使用 Redis 多一些。我们通过 Redis 的 `incr` 命令即可实现对 id 原子顺序递增。
+
+```bash
+127.0.0.1:6379> set sequence_id_biz_type 1
+OK
+127.0.0.1:6379> incr sequence_id_biz_type
+(integer) 2
+127.0.0.1:6379> get sequence_id_biz_type
+"2"
+```
+
+为了提高可用性和并发,我们可以使用 Redis Cluser。Redis Cluser 是 Redis 官方提供的 Redis 集群解决方案(3.0+版本)。
+
+除了 Redis Cluser 之外,你也可以使用开源的 Redis 集群方案[Codis](https://github.com/CodisLabs/codis) (大规模集群比如上百个节点的时候比较推荐)。
+
+除了高可用和并发之外,我们知道 Redis 基于内存,我们需要持久化数据,避免重启机器或者机器故障后数据丢失。Redis 支持两种不同的持久化方式:**快照(snapshotting,RDB)**、**只追加文件(append-only file, AOF)**。 并且,Redis 4.0 开始支持 **RDB 和 AOF 的混合持久化**(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
+
+关于 Redis 持久化,我这里就不过多介绍。不了解这部分内容的小伙伴,可以看看 [JavaGuide 对于 Redis 知识点的总结](https://snailclimb.gitee.io/javaguide/#/docs/database/Redis/redis-all)。
+
+**Redis 方案的优缺点:**
+
+- **优点** : 性能不错并且生成的 ID 是有序递增的
+- **缺点** : 和数据库主键自增方案的缺点类似
+
+除了 Redis 之外,MongoDB ObjectId 经常也会被拿来当做分布式 ID 的解决方案。
+
+
+
+MongoDB ObjectId 一共需要 12 个字节存储:
+
+- 0~3:时间戳
+- 3~6: 代表机器 ID
+- 7~8:机器进程 ID
+- 9~11 :自增值
+
+**MongoDB 方案的优缺点:**
+
+- **优点** : 性能不错并且生成的 ID 是有序递增的
+- **缺点** : 需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID) 、有安全性问题(ID 生成有规律性)
+
+### 算法
+
+#### UUID
+
+UUID 是 Universally Unique Identifier(通用唯一标识符) 的缩写。UUID 包含 32 个 16 进制数字(8-4-4-4-12)。
+
+JDK 就提供了现成的生成 UUID 的方法,一行代码就行了。
+
+```java
+//输出示例:cb4a9ede-fa5e-4585-b9bb-d60bce986eaa
+UUID.randomUUID()
+```
+
+[RFC 4122](https://tools.ietf.org/html/rfc4122) 中关于 UUID 的示例是这样的:
+
+
+
+我们这里重点关注一下这个 Version(版本),不同的版本对应的 UUID 的生成规则是不同的。
+
+5 种不同的 Version(版本)值分别对应的含义(参考[维基百科对于 UUID 的介绍](https://zh.wikipedia.org/wiki/%E9%80%9A%E7%94%A8%E5%94%AF%E4%B8%80%E8%AF%86%E5%88%AB%E7%A0%81)):
+
+- **版本 1** : UUID 是根据时间和节点 ID(通常是 MAC 地址)生成;
+- **版本 2** : UUID 是根据标识符(通常是组或用户 ID)、时间和节点 ID 生成;
+- **版本 3、版本 5** : 版本 5 - 确定性 UUID 通过散列(hashing)名字空间(namespace)标识符和名称生成;
+- **版本 4** : UUID 使用[随机性](https://zh.wikipedia.org/wiki/随机性)或[伪随机性](https://zh.wikipedia.org/wiki/伪随机性)生成。
+
+下面是 Version 1 版本下生成的 UUID 的示例:
+
+
+
+JDK 中通过 `UUID` 的 `randomUUID()` 方法生成的 UUID 的版本默认为 4。
+
+```java
+UUID uuid = UUID.randomUUID();
+int version = uuid.version();// 4
+```
+
+另外,Variant(变体)也有 4 种不同的值,这种值分别对应不同的含义。这里就不介绍了,貌似平时也不怎么需要关注。
+
+需要用到的时候,去看看维基百科对于 UUID 的 Variant(变体) 相关的介绍即可。
+
+从上面的介绍中可以看出,UUID 可以保证唯一性,因为其生成规则包括 MAC 地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,计算机基于这些规则生成的 UUID 是肯定不会重复的。
+
+虽然,UUID 可以做到全局唯一性,但是,我们一般很少会使用它。
+
+比如使用 UUID 作为 MySQL 数据库主键的时候就非常不合适:
+
+- 数据库主键要尽量越短越好,而 UUID 的消耗的存储空间比较大(32 个字符串,128 位)。
+- UUID 是无顺序的,InnoDB 引擎下,数据库主键的无序性会严重影响数据库性能。
+
+最后,我们再简单分析一下 **UUID 的优缺点** (面试的时候可能会被问到的哦!) :
+
+- **优点** :生成速度比较快、简单易用
+- **缺点** : 存储消耗空间大(32 个字符串,128 位) 、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)
+
+#### Snowflake(雪花算法)
+
+Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 由 64 bit 的二进制数字组成,这 64bit 的二进制被分成了几部分,每一部分存储的数据都有特定的含义:
+
+- **第 0 位**: 符号位(标识正负),始终为 0,没有用,不用管。
+- **第 1~41 位** :一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
+- **第 42~52 位** :一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
+- **第 53~64 位** :一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
+
+
+
+如果你想要使用 Snowflake 算法的话,一般不需要你自己再造轮子。有很多基于 Snowflake 算法的开源实现比如美团 的 Leaf、百度的 UidGenerator,并且这些开源实现对原有的 Snowflake 算法进行了优化。
+
+另外,在实际项目中,我们一般也会对 Snowflake 算法进行改造,最常见的就是在 Snowflake 算法生成的 ID 中加入业务类型信息。
+
+我们再来看看 Snowflake 算法的优缺点 :
+
+- **优点** :生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)
+- **缺点** : 需要解决重复 ID 问题(依赖时间,当机器时间不对的情况下,可能导致会产生重复 ID)。
+
+### 开源框架
+
+#### UidGenerator(百度)
+
+[UidGenerator](https://github.com/baidu/uid-generator) 是百度开源的一款基于 Snowflake(雪花算法)的唯一 ID 生成器。
+
+不过,UidGenerator 对 Snowflake(雪花算法)进行了改进,生成的唯一 ID 组成如下。
+
+
+
+可以看出,和原始 Snowflake(雪花算法)生成的唯一 ID 的组成不太一样。并且,上面这些参数我们都可以自定义。
+
+UidGenerator 官方文档中的介绍如下:
+
+
+
+自 18 年后,UidGenerator 就基本没有再维护了,我这里也不过多介绍。想要进一步了解的朋友,可以看看 [UidGenerator 的官方介绍](https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md)。
+
+#### Leaf(美团)
+
+**[Leaf](https://github.com/Meituan-Dianping/Leaf)** 是美团开源的一个分布式 ID 解决方案 。这个项目的名字 Leaf(树叶) 起源于德国哲学家、数学家莱布尼茨的一句话: “There are no two identical leaves in the world”(世界上没有两片相同的树叶) 。这名字起得真心挺不错的,有点文艺青年那味了!
+
+
+
+Leaf 提供了 **号段模式** 和 **Snowflake(雪花算法)** 这两种模式来生成分布式 ID。并且,它支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper 。
+
+Leaf 的诞生主要是为了解决美团各个业务线生成分布式 ID 的方法多种多样以及不可靠的问题。
+
+Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是我一个号段还没用完之前,我自己就主动提前去获取下一个号段(图片来自于美团官方文章:[《Leaf——美团点评分布式 ID 生成系统》](https://tech.meituan.com/2017/04/21/mt-leaf.html))。
+
+
+
+根据项目 README 介绍,在 4C8G VM 基础上,通过公司 RPC 方式调用,QPS 压测结果近 5w/s,TP999 1ms。
+
+#### Tinyid(滴滴)
+
+[Tinyid](https://github.com/didi/tinyid) 是滴滴开源的一款基于数据库号段模式的唯一 ID 生成器。
+
+数据库号段模式的原理我们在上面已经介绍过了。**Tinyid 有哪些亮点呢?**
+
+为了搞清楚这个问题,我们先来看看基于数据库号段模式的简单架构方案。(图片来自于 Tinyid 的官方 wiki:[《Tinyid 原理介绍》](https://github.com/didi/tinyid/wiki/tinyid%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D))
+
+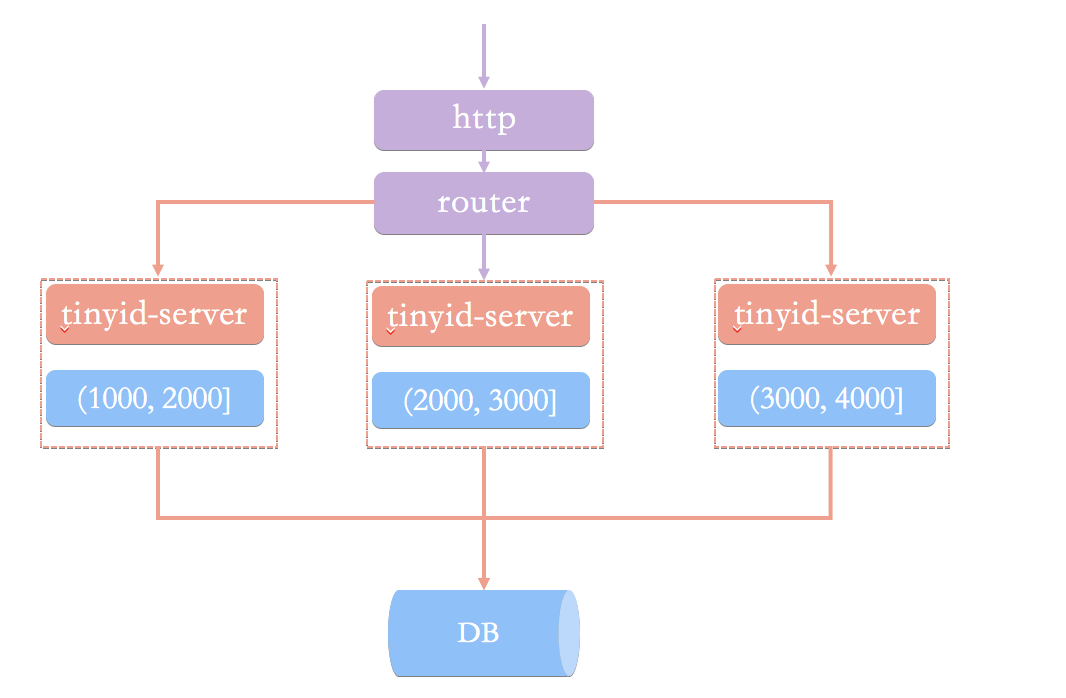
+
+在这种架构模式下,我们通过 HTTP 请求向发号器服务申请唯一 ID。负载均衡 router 会把我们的请求送往其中的一台 tinyid-server。
+
+这种方案有什么问题呢?在我看来(Tinyid 官方 wiki 也有介绍到),主要由下面这 2 个问题:
+
+- 获取新号段的情况下,程序获取唯一 ID 的速度比较慢。
+- 需要保证 DB 高可用,这个是比较麻烦且耗费资源的。
+
+除此之外,HTTP 调用也存在网络开销。
+
+Tinyid 的原理比较简单,其架构如下图所示:
+
+
+
+相比于基于数据库号段模式的简单架构方案,Tinyid 方案主要做了下面这些优化:
+
+- **双号段缓存** :为了避免在获取新号段的情况下,程序获取唯一 ID 的速度比较慢。 Tinyid 中的号段在用到一定程度的时候,就会去异步加载下一个号段,保证内存中始终有可用号段。
+- **增加多 db 支持** :支持多个 DB,并且,每个 DB 都能生成唯一 ID,提高了可用性。
+- **增加 tinyid-client** :纯本地操作,无 HTTP 请求消耗,性能和可用性都有很大提升。
+
+Tinyid 的优缺点这里就不分析了,结合数据库号段模式的优缺点和 Tinyid 的原理就能知道。
+
+## 分布式 ID 生成方案总结
+
+这篇文章中,我基本上已经把最常见的分布式 ID 生成方案都总结了一波。
+
+除了上面介绍的方式之外,像 ZooKeeper 这类中间件也可以帮助我们生成唯一 ID。**没有银弹,一定要结合实际项目来选择最适合自己的方案。**
\ No newline at end of file
diff --git a/docs/distributed-system/distributed-transaction.md b/docs/distributed-system/distributed-transaction.md
new file mode 100644
index 00000000000..985fefbee09
--- /dev/null
+++ b/docs/distributed-system/distributed-transaction.md
@@ -0,0 +1,7 @@
+# 分布式事务
+
+这部分内容为我的星球专属,已经整理到了[《Java面试进阶指北 打造个人的技术竞争力》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7?# )中。
+
+欢迎加入我的星球,[一个纯 Java 面试交流圈子 !Ready!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=100015911&idx=1&sn=2e8a0f5acb749ecbcbb417aa8a4e18cc&chksm=4ea1b0ec79d639fae37df1b86f196e8ce397accfd1dd2004bcadb66b4df5f582d90ae0d62448#rd) (点击链接了解星球详细信息,还有专属优惠款可以领取)。
+
+
diff --git a/docs/distributed-system/rpc/dubbo.md b/docs/distributed-system/rpc/dubbo.md
new file mode 100644
index 00000000000..870cc45dc5f
--- /dev/null
+++ b/docs/distributed-system/rpc/dubbo.md
@@ -0,0 +1,501 @@
+# Dubbo知识点&面试题总结
+
+这篇文章是我根据官方文档以及自己平时的使用情况,对 Dubbo 所做的一个总结。欢迎补充!
+
+## RPC基础
+
+### 何为 RPC?
+
+**RPC(Remote Procedure Call)** 即远程过程调用,通过名字我们就能看出 RPC 关注的是远程调用而非本地调用。
+
+**为什么要 RPC ?** 因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP还是UDP)、序列化方式等等方面。
+
+
+**RPC 能帮助我们做什么呢?** 简单来说,通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。并且!我们不需要了解底层网络编程的具体细节。
+
+
+举个例子:两个不同的服务 A、B 部署在两台不同的机器上,服务 A 如果想要调用服务 B 中的某个方法的话就可以通过 RPC 来做。
+
+一言蔽之:**RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。**
+
+### RPC 的原理是什么?
+
+为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC的 核心功能看作是下面👇 6 个部分实现的:
+
+
+1. **客户端(服务消费端)** :调用远程方法的一端。
+1. **客户端 Stub(桩)** : 这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
+1. **网络传输** : 网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket或者性能以及封装更加优秀的 Netty(推荐)。
+1. **服务端 Stub(桩)** :这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去指定对应的方法然后返回结果给客户端的类。
+1. **服务端(服务提供端)** :提供远程方法的一端。
+
+具体原理图如下,后面我会串起来将整个RPC的过程给大家说一下。
+
+
+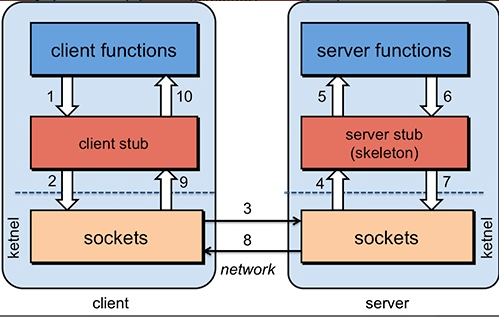
+
+1. 服务消费端(client)以本地调用的方式调用远程服务;
+1. 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):`RpcRequest`;
+1. 客户端 Stub(client stub) 找到远程服务的地址,并将消息发送到服务提供端;
+1. 服务端 Stub(桩)收到消息将消息反序列化为Java对象: `RpcRequest`;
+1. 服务端 Stub(桩)根据`RpcRequest`中的类、方法、方法参数等信息调用本地的方法;
+1. 服务端 Stub(桩)得到方法执行结果并将组装成能够进行网络传输的消息体:`RpcResponse`(序列化)发送至消费方;
+1. 客户端 Stub(client stub)接收到消息并将消息反序列化为Java对象:`RpcResponse` ,这样也就得到了最终结果。over!
+
+相信小伙伴们看完上面的讲解之后,已经了解了 RPC 的原理。
+
+虽然篇幅不多,但是基本把 RPC 框架的核心原理讲清楚了!另外,对于上面的技术细节,我会在后面的章节介绍到。
+
+**最后,对于 RPC 的原理,希望小伙伴不单单要理解,还要能够自己画出来并且能够给别人讲出来。因为,在面试中这个问题在面试官问到 RPC 相关内容的时候基本都会碰到。**
+
+## Dubbo基础
+
+### 什么是 Dubbo?
+
+
+
+[Apache Dubbo](https://github.com/apache/dubbo) |ˈdʌbəʊ| 是一款高性能、轻量级的开源 Java RPC 框架。
+
+根据 [Dubbo 官方文档](https://dubbo.apache.org/zh/)的介绍,Dubbo 提供了六大核心能力
+
+1. 面向接口代理的高性能RPC调用。
+2. 智能容错和负载均衡。
+3. 服务自动注册和发现。
+4. 高度可扩展能力。
+5. 运行期流量调度。
+6. 可视化的服务治理与运维。
+
+
+
+简单来说就是: **Dubbo 不光可以帮助我们调用远程服务,还提供了一些其他开箱即用的功能比如智能负载均衡。**
+
+Dubbo 目前已经有接近 34.4 k 的 Star 。
+
+在 **2020 年度 OSC 中国开源项目** 评选活动中,Dubbo 位列开发框架和基础组件类项目的第7名。想比几年前来说,热度和排名有所下降。
+
+
+
+Dubbo 是由阿里开源,后来加入了 Apache 。正式由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
+
+### 为什么要用 Dubbo?
+
+随着互联网的发展,网站的规模越来越大,用户数量越来越多。单一应用架构 、垂直应用架构无法满足我们的需求,这个时候分布式服务架构就诞生了。
+
+分布式服务架构下,系统被拆分成不同的服务比如短信服务、安全服务,每个服务独立提供系统的某个核心服务。
+
+我们可以使用 Java RMI(Java Remote Method Invocation)、Hessian这种支持远程调用的框架来简单地暴露和引用远程服务。但是!当服务越来越多之后,服务调用关系越来越复杂。当应用访问压力越来越大后,负载均衡以及服务监控的需求也迫在眉睫。我们可以用 F5 这类硬件来做负载均衡,但这样增加了成本,并且存在单点故障的风险。
+
+不过,Dubbo 的出现让上述问题得到了解决。**Dubbo 帮助我们解决了什么问题呢?**
+
+1. **负载均衡** : 同一个服务部署在不同的机器时该调用哪一台机器上的服务。
+2. **服务调用链路生成** : 随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
+3. **服务访问压力以及时长统计、资源调度和治理** :基于访问压力实时管理集群容量,提高集群利用率。
+4. ......
+
+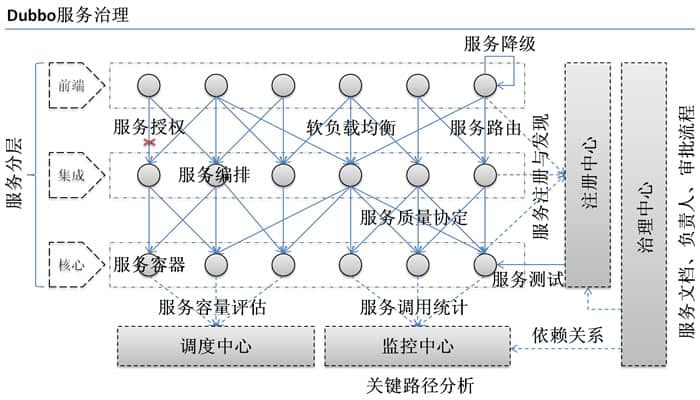
+
+另外,Dubbo 除了能够应用在分布式系统中,也可以应用在现在比较火的微服务系统中。不过,由于 Spring Cloud 在微服务中应用更加广泛,所以,我觉得一般我们提 Dubbo 的话,大部分是分布式系统的情况。
+
+**我们刚刚提到了分布式这个概念,下面再给大家介绍一下什么是分布式?为什么要分布式?**
+
+## 分布式基础
+
+### 什么是分布式?
+
+分布式或者说 SOA 分布式重要的就是面向服务,说简单的分布式就是我们把整个系统拆分成不同的服务然后将这些服务放在不同的服务器上减轻单体服务的压力提高并发量和性能。比如电商系统可以简单地拆分成订单系统、商品系统、登录系统等等,拆分之后的每个服务可以部署在不同的机器上,如果某一个服务的访问量比较大的话也可以将这个服务同时部署在多台机器上。
+
+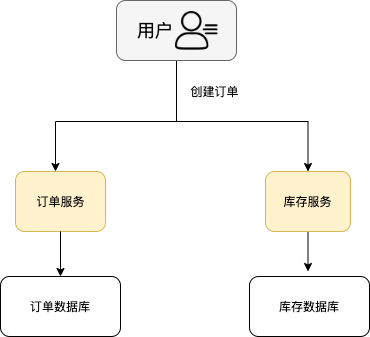
+
+### 为什么要分布式?
+
+从开发角度来讲单体应用的代码都集中在一起,而分布式系统的代码根据业务被拆分。所以,每个团队可以负责一个服务的开发,这样提升了开发效率。另外,代码根据业务拆分之后更加便于维护和扩展。
+
+另外,我觉得将系统拆分成分布式之后不光便于系统扩展和维护,更能提高整个系统的性能。你想一想嘛?把整个系统拆分成不同的服务/系统,然后每个服务/系统 单独部署在一台服务器上,是不是很大程度上提高了系统性能呢?
+
+## Dubbo 架构
+
+### Dubbo 架构中的核心角色有哪些?
+
+[官方文档中的框架设计章节](https://dubbo.apache.org/zh/docs/v2.7/dev/design/) 已经介绍的非常详细了,我这里把一些比较重要的点再提一下。
+
+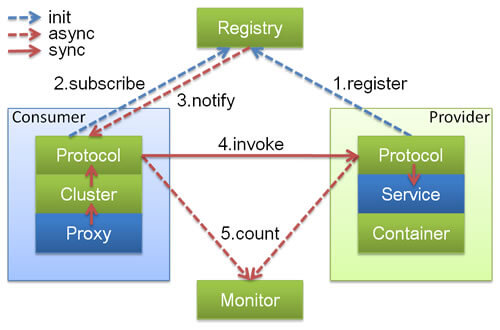
+
+上述节点简单介绍以及他们之间的关系:
+
+- **Container:** 服务运行容器,负责加载、运行服务提供者。必须。
+- **Provider:** 暴露服务的服务提供方,会向注册中心注册自己提供的服务。必须。
+- **Consumer:** 调用远程服务的服务消费方,会向注册中心订阅自己所需的服务。必须。
+- **Registry:** 服务注册与发现的注册中心。注册中心会返回服务提供者地址列表给消费者。非必须。
+- **Monitor:** 统计服务的调用次数和调用时间的监控中心。服务消费者和提供者会定时发送统计数据到监控中心。 非必须。
+
+### Dubbo 中的 Invoker 概念了解么?
+
+`Invoker` 是 Dubbo 领域模型中非常重要的一个概念,你如果阅读过 Dubbo 源码的话,你会无数次看到这玩意。就比如下面我要说的负载均衡这块的源码中就有大量 `Invoker` 的身影。
+
+简单来说,`Invoker` 就是 Dubbo 对远程调用的抽象。
+
+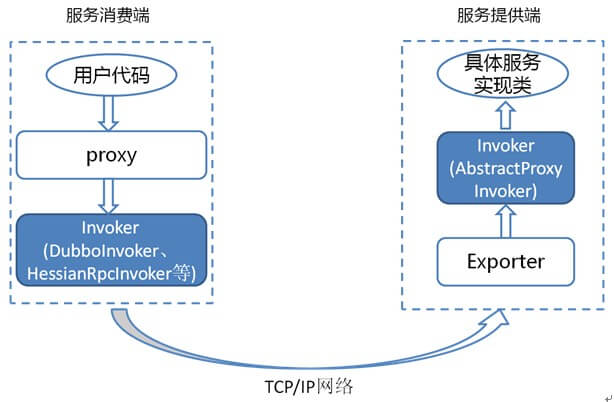
+
+按照 Dubbo 官方的话来说,`Invoker` 分为
+
+- 服务提供 `Invoker`
+- 服务消费 `Invoker`
+
+假如我们需要调用一个远程方法,我们需要动态代理来屏蔽远程调用的细节吧!我们屏蔽掉的这些细节就依赖对应的 `Invoker` 实现, `Invoker` 实现了真正的远程服务调用。
+
+### Dubbo 的工作原理了解么?
+
+下图是 Dubbo 的整体设计,从下至上分为十层,各层均为单向依赖。
+
+> 左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。
+
+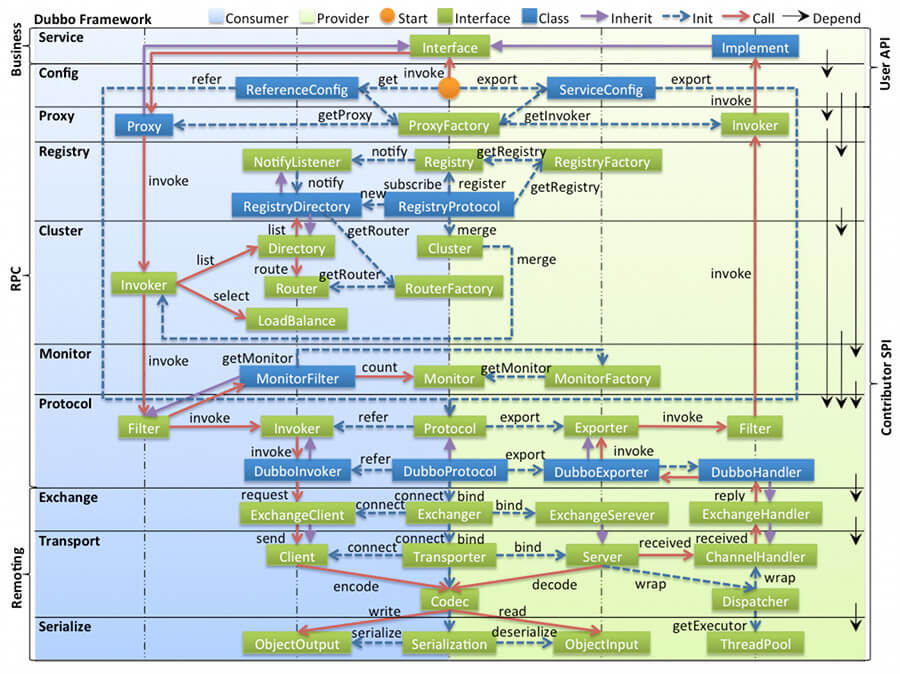
+
+- **config 配置层**:Dubbo相关的配置。支持代码配置,同时也支持基于 Spring 来做配置,以 `ServiceConfig`, `ReferenceConfig` 为中心
+- **proxy 服务代理层**:调用远程方法像调用本地的方法一样简单的一个关键,真实调用过程依赖代理类,以 `ServiceProxy` 为中心。
+- **registry 注册中心层**:封装服务地址的注册与发现。
+- **cluster 路由层**:封装多个提供者的路由及负载均衡,并桥接注册中心,以 `Invoker` 为中心。
+- **monitor 监控层**:RPC 调用次数和调用时间监控,以 `Statistics` 为中心。
+- **protocol 远程调用层**:封装 RPC 调用,以 `Invocation`, `Result` 为中心。
+- **exchange 信息交换层**:封装请求响应模式,同步转异步,以 `Request`, `Response` 为中心。
+- **transport 网络传输层**:抽象 mina 和 netty 为统一接口,以 `Message` 为中心。
+- **serialize 数据序列化层** :对需要在网络传输的数据进行序列化。
+
+### Dubbo 的 SPI 机制了解么? 如何扩展 Dubbo 中的默认实现?
+
+SPI(Service Provider Interface) 机制被大量用在开源项目中,它可以帮助我们动态寻找服务/功能(比如负载均衡策略)的实现。
+
+SPI 的具体原理是这样的:我们将接口的实现类放在配置文件中,我们在程序运行过程中读取配置文件,通过反射加载实现类。这样,我们可以在运行的时候,动态替换接口的实现类。和 IoC 的解耦思想是类似的。
+
+Java 本身就提供了 SPI 机制的实现。不过,Dubbo 没有直接用,而是对 Java原生的 SPI机制进行了增强,以便更好满足自己的需求。
+
+**那我们如何扩展 Dubbo 中的默认实现呢?**
+
+比如说我们想要实现自己的负载均衡策略,我们创建对应的实现类 `XxxLoadBalance` 实现 `LoadBalance` 接口或者 `AbstractLoadBalance` 类。
+
+```java
+package com.xxx;
+
+import org.apache.dubbo.rpc.cluster.LoadBalance;
+import org.apache.dubbo.rpc.Invoker;
+import org.apache.dubbo.rpc.Invocation;
+import org.apache.dubbo.rpc.RpcException;
+
+public class XxxLoadBalance implements LoadBalance {
+ public <T> Invoker<T> select(List<Invoker<T>> invokers, Invocation invocation) throws RpcException {
+ // ...
+ }
+}
+```
+
+我们将这个实现类的路径写入到`resources` 目录下的 `META-INF/dubbo/org.apache.dubbo.rpc.cluster.LoadBalance`文件中即可。
+
+```java
+src
+ |-main
+ |-java
+ |-com
+ |-xxx
+ |-XxxLoadBalance.java (实现LoadBalance接口)
+ |-resources
+ |-META-INF
+ |-dubbo
+ |-org.apache.dubbo.rpc.cluster.LoadBalance (纯文本文件,内容为:xxx=com.xxx.XxxLoadBalance)
+```
+
+`org.apache.dubbo.rpc.cluster.LoadBalance`
+
+```
+xxx=com.xxx.XxxLoadBalance
+```
+
+其他还有很多可供扩展的选择,你可以在[官方文档@SPI扩展实现](https://dubbo.apache.org/zh/docs/v2.7/dev/impls/)这里找到。
+
+
+
+### Dubbo 的微内核架构了解吗?
+
+Dubbo 采用 微内核(Microkernel) + 插件(Plugin) 模式,简单来说就是微内核架构。微内核只负责组装插件。
+
+**何为微内核架构呢?** 《软件架构模式》 这本书是这样介绍的:
+
+> 微内核架构模式(有时被称为插件架构模式)是实现基于产品应用程序的一种自然模式。基于产品的应用程序是已经打包好并且拥有不同版本,可作为第三方插件下载的。然后,很多公司也在开发、发布自己内部商业应用像有版本号、说明及可加载插件式的应用软件(这也是这种模式的特征)。微内核系统可让用户添加额外的应用如插件,到核心应用,继而提供了可扩展性和功能分离的用法。
+
+微内核架构包含两类组件:**核心系统(core system)** 和 **插件模块(plug-in modules)**。
+
+
+
+核心系统提供系统所需核心能力,插件模块可以扩展系统的功能。因此, 基于微内核架构的系统,非常易于扩展功能。
+
+我们常见的一些IDE,都可以看作是基于微内核架构设计的。绝大多数 IDE比如IDEA、VSCode都提供了插件来丰富自己的功能。
+
+正是因为Dubbo基于微内核架构,才使得我们可以随心所欲替换Dubbo的功能点。比如你觉得Dubbo 的序列化模块实现的不满足自己要求,没关系啊!你自己实现一个序列化模块就好了啊!
+
+通常情况下,微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。Dubbo 不想依赖 Spring 等 IoC 容器,也不想自己造一个小的 IoC 容器(过度设计),因此采用了一种最简单的 Factory 方式管理插件 :**JDK 标准的 SPI 扩展机制** (`java.util.ServiceLoader`)。
+
+### 关于Dubbo架构的一些自测小问题
+
+#### 注册中心的作用了解么?
+
+注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互。
+
+#### 服务提供者宕机后,注册中心会做什么?
+
+注册中心会立即推送事件通知消费者。
+
+#### 监控中心的作用呢?
+
+监控中心负责统计各服务调用次数,调用时间等。
+
+#### 注册中心和监控中心都宕机的话,服务都会挂掉吗?
+
+不会。两者都宕机也不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表。注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
+
+
+## Dubbo 的负载均衡策略
+
+### 什么是负载均衡?
+
+先来看一下稍微官方点的解释。下面这段话摘自维基百科对负载均衡的定义:
+
+> 负载均衡改善了跨多个计算资源(例如计算机,计算机集群,网络链接,中央处理单元或磁盘驱动)的工作负载分布。负载平衡旨在优化资源使用,最大化吞吐量,最小化响应时间,并避免任何单个资源的过载。使用具有负载平衡而不是单个组件的多个组件可以通过冗余提高可靠性和可用性。负载平衡通常涉及专用软件或硬件。
+
+**上面讲的大家可能不太好理解,再用通俗的话给大家说一下。**
+
+我们的系统中的某个服务的访问量特别大,我们将这个服务部署在了多台服务器上,当客户端发起请求的时候,多台服务器都可以处理这个请求。那么,如何正确选择处理该请求的服务器就很关键。假如,你就要一台服务器来处理该服务的请求,那该服务部署在多台服务器的意义就不复存在了。负载均衡就是为了避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题,我们从负载均衡的这四个字就能明显感受到它的意义。
+
+### Dubbo 提供的负载均衡策略有哪些?
+
+在集群负载均衡时,Dubbo 提供了多种均衡策略,默认为 `random` 随机调用。我们还可以自行扩展负载均衡策略(参考Dubbo SPI机制)。
+
+在 Dubbo 中,所有负载均衡实现类均继承自 `AbstractLoadBalance`,该类实现了 `LoadBalance` 接口,并封装了一些公共的逻辑。
+
+```java
+public abstract class AbstractLoadBalance implements LoadBalance {
+
+ static int calculateWarmupWeight(int uptime, int warmup, int weight) {
+ }
+
+ @Override
+ public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {
+ }
+
+ protected abstract <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation);
+
+
+ int getWeight(Invoker<?> invoker, Invocation invocation) {
+
+ }
+}
+```
+
+`AbstractLoadBalance` 的实现类有下面这些:
+
+
+
+官方文档对负载均衡这部分的介绍非常详细,推荐小伙伴们看看,地址:[https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#m-zhdocsv27devsourceloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#m-zhdocsv27devsourceloadbalance ) 。
+
+#### RandomLoadBalance
+
+根据权重随机选择(对加权随机算法的实现)。这是Dubbo默认采用的一种负载均衡策略。
+
+` RandomLoadBalance` 具体的实现原理非常简单,假如有两个提供相同服务的服务器 S1,S2,S1的权重为7,S2的权重为3。
+
+我们把这些权重值分布在坐标区间会得到:S1->[0, 7) ,S2->[7, 10)。我们生成[0, 10) 之间的随机数,随机数落到对应的区间,我们就选择对应的服务器来处理请求。
+
+
+
+`RandomLoadBalance` 的源码非常简单,简单花几分钟时间看一下。
+
+> 以下源码来自 Dubbo master 分支上的最新的版本 2.7.9。
+
+```java
+public class RandomLoadBalance extends AbstractLoadBalance {
+
+ public static final String NAME = "random";
+
+ @Override
+ protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
+
+ int length = invokers.size();
+ boolean sameWeight = true;
+ int[] weights = new int[length];
+ int totalWeight = 0;
+ // 下面这个for循环的主要作用就是计算所有该服务的提供者的权重之和 totalWeight(),
+ // 除此之外,还会检测每个服务提供者的权重是否相同
+ for (int i = 0; i < length; i++) {
+ int weight = getWeight(invokers.get(i), invocation);
+ totalWeight += weight;
+ weights[i] = totalWeight;
+ if (sameWeight && totalWeight != weight * (i + 1)) {
+ sameWeight = false;
+ }
+ }
+ if (totalWeight > 0 && !sameWeight) {
+ // 随机生成一个 [0, totalWeight) 区间内的数字
+ int offset = ThreadLocalRandom.current().nextInt(totalWeight);
+ // 判断会落在哪个服务提供者的区间
+ for (int i = 0; i < length; i++) {
+ if (offset < weights[i]) {
+ return invokers.get(i);
+ }
+ }
+
+ return invokers.get(ThreadLocalRandom.current().nextInt(length));
+ }
+
+}
+
+```
+
+#### LeastActiveLoadBalance
+
+`LeastActiveLoadBalance` 直译过来就是**最小活跃数负载均衡**。
+
+这个名字起得有点不直观,不仔细看官方对活跃数的定义,你压根不知道这玩意是干嘛的。
+
+我这么说吧!初始状态下所有服务提供者的活跃数均为 0(每个服务提供者的中特定方法都对应一个活跃数,我在后面的源码中会提到),每收到一个请求后,对应的服务提供者的活跃数 +1,当这个请求处理完之后,活跃数 -1。
+
+因此,**Dubbo 就认为谁的活跃数越少,谁的处理速度就越快,性能也越好,这样的话,我就优先把请求给活跃数少的服务提供者处理。**
+
+**如果有多个服务提供者的活跃数相等怎么办?**
+
+很简单,那就再走一遍 `RandomLoadBalance` 。
+
+```java
+public class LeastActiveLoadBalance extends AbstractLoadBalance {
+
+ public static final String NAME = "leastactive";
+
+ @Override
+ protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
+ int length = invokers.size();
+ int leastActive = -1;
+ int leastCount = 0;
+ int[] leastIndexes = new int[length];
+ int[] weights = new int[length];
+ int totalWeight = 0;
+ int firstWeight = 0;
+ boolean sameWeight = true;
+ // 这个 for 循环的主要作用是遍历 invokers 列表,找出活跃数最小的 Invoker
+ // 如果有多个 Invoker 具有相同的最小活跃数,还会记录下这些 Invoker 在 invokers 集合中的下标,并累加它们的权重,比较它们的权重值是否相等
+ for (int i = 0; i < length; i++) {
+ Invoker<T> invoker = invokers.get(i);
+ // 获取 invoker 对应的活跃(active)数
+ int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
+ int afterWarmup = getWeight(invoker, invocation);
+ weights[i] = afterWarmup;
+ if (leastActive == -1 || active < leastActive) {
+ leastActive = active;
+ leastCount = 1;
+ leastIndexes[0] = i;
+ totalWeight = afterWarmup;
+ firstWeight = afterWarmup;
+ sameWeight = true;
+ } else if (active == leastActive) {
+ leastIndexes[leastCount++] = i;
+ totalWeight += afterWarmup;
+ if (sameWeight && afterWarmup != firstWeight) {
+ sameWeight = false;
+ }
+ }
+ }
+ // 如果只有一个 Invoker 具有最小的活跃数,此时直接返回该 Invoker 即可
+ if (leastCount == 1) {
+ return invokers.get(leastIndexes[0]);
+ }
+ // 如果有多个 Invoker 具有相同的最小活跃数,但它们之间的权重不同
+ // 这里的处理方式就和 RandomLoadBalance 一致了
+ if (!sameWeight && totalWeight > 0) {
+ int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
+ for (int i = 0; i < leastCount; i++) {
+ int leastIndex = leastIndexes[i];
+ offsetWeight -= weights[leastIndex];
+ if (offsetWeight < 0) {
+ return invokers.get(leastIndex);
+ }
+ }
+ }
+ return invokers.get(leastIndexes[ThreadLocalRandom.current().nextInt(leastCount)]);
+ }
+}
+
+```
+
+活跃数是通过 `RpcStatus` 中的一个 `ConcurrentMap` 保存的,根据 URL 以及服务提供者被调用的方法的名称,我们便可以获取到对应的活跃数。也就是说服务提供者中的每一个方法的活跃数都是互相独立的。
+
+```java
+public class RpcStatus {
+
+ private static final ConcurrentMap<String, ConcurrentMap<String, RpcStatus>> METHOD_STATISTICS =
+ new ConcurrentHashMap<String, ConcurrentMap<String, RpcStatus>>();
+
+ public static RpcStatus getStatus(URL url, String methodName) {
+ String uri = url.toIdentityString();
+ ConcurrentMap<String, RpcStatus> map = METHOD_STATISTICS.computeIfAbsent(uri, k -> new ConcurrentHashMap<>());
+ return map.computeIfAbsent(methodName, k -> new RpcStatus());
+ }
+ public int getActive() {
+ return active.get();
+ }
+
+}
+```
+
+#### ConsistentHashLoadBalance
+
+`ConsistentHashLoadBalance` 小伙伴们应该也不会陌生,在分库分表、各种集群中就经常使用这个负载均衡策略。
+
+`ConsistentHashLoadBalance` 即**一致性Hash负载均衡策略**。 `ConsistentHashLoadBalance` 中没有权重的概念,具体是哪个服务提供者处理请求是由你的请求的参数决定的,也就是说相同参数的请求总是发到同一个服务提供者。
+
+
+
+另外,Dubbo 为了避免数据倾斜问题(节点不够分散,大量请求落到同一节点),还引入了虚拟节点的概念。通过虚拟节点可以让节点更加分散,有效均衡各个节点的请求量。
+
+
+
+
+
+官方有详细的源码分析:[https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance) 。这里还有一个相关的 [PR#5440](https://github.com/apache/dubbo/pull/5440) 来修复老版本中 ConsistentHashLoadBalance 存在的一些Bug。感兴趣的小伙伴,可以多花点时间研究一下。我这里不多分析了,这个作业留给你们!
+
+#### RoundRobinLoadBalance
+
+加权轮询负载均衡。
+
+轮询就是把请求依次分配给每个服务提供者。加权轮询就是在轮询的基础上,让更多的请求落到权重更大的服务提供者上。比如假如有两个提供相同服务的服务器 S1,S2,S1的权重为7,S2的权重为3。
+
+如果我们有 10 次请求,那么 7 次会被 S1处理,3次被 S2处理。
+
+但是,如果是 `RandomLoadBalance` 的话,很可能存在10次请求有9次都被 S1 处理的情况(概率性问题)。
+
+Dubbo 中的 `RoundRobinLoadBalance` 的代码实现被修改重建了好几次,Dubbo-2.6.5 版本的 `RoundRobinLoadBalance` 为平滑加权轮询算法。
+
+## Dubbo序列化协议
+
+### Dubbo 支持哪些序列化方式呢?
+
+
+
+Dubbo 支持多种序列化方式:JDK自带的序列化、hessian2、JSON、Kryo、FST、Protostuff,ProtoBuf等等。
+
+Dubbo 默认使用的序列化方式是 hession2。
+
+### 谈谈你对这些序列化协议了解?
+
+一般我们不会直接使用 JDK 自带的序列化方式。主要原因有两个:
+
+1. **不支持跨语言调用** : 如果调用的是其他语言开发的服务的时候就不支持了。
+2. **性能差** :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
+
+JSON 序列化由于性能问题,我们一般也不会考虑使用。
+
+像 Protostuff,ProtoBuf、hessian2这些都是跨语言的序列化方式,如果有跨语言需求的话可以考虑使用。
+
+Kryo和FST这两种序列化方式是 Dubbo 后来才引入的,性能非常好。不过,这两者都是专门针对 Java 语言的。Dubbo 官网的一篇文章中提到说推荐使用 Kryo 作为生产环境的序列化方式。(文章地址:[https://dubbo.apache.org/zh/docs/v2.7/user/references/protocol/rest/](https://dubbo.apache.org/zh/docs/v2.7/user/references/protocol/rest/))
+
+
+
+Dubbo 官方文档中还有一个关于这些[序列化协议的性能对比图](https://dubbo.apache.org/zh/docs/v2.7/user/serialization/#m-zhdocsv27userserialization)可供参考。
+
+
+
diff --git a/docs/distributed-system/rpc/why-use-rpc.md b/docs/distributed-system/rpc/why-use-rpc.md
new file mode 100644
index 00000000000..a2fe5dbefa2
--- /dev/null
+++ b/docs/distributed-system/rpc/why-use-rpc.md
@@ -0,0 +1,75 @@
+# 服务之间的调用为啥不直接用 HTTP 而用 RPC?
+
+## 什么是 RPC?RPC原理是什么?
+
+### **什么是 RPC?**
+
+RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。比如两个不同的服务 A、B 部署在两台不同的机器上,那么服务 A 如果想要调用服务 B 中的某个方法该怎么办呢?使用 HTTP请求 当然可以,但是可能会比较慢而且一些优化做的并不好。 RPC 的出现就是为了解决这个问题。
+
+### **RPC原理是什么?**
+
+
+
+1. 服务消费端(client)以本地调用的方式调用远程服务;
+2. 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):`RpcRequest`;
+3. 客户端 Stub(client stub) 找到远程服务的地址,并将消息发送到服务提供端;
+4. 服务端 Stub(桩)收到消息将消息反序列化为Java对象: `RpcRequest`;
+5. 服务端 Stub(桩)根据`RpcRequest`中的类、方法、方法参数等信息调用本地的方法;
+6. 服务端 Stub(桩)得到方法执行结果并将组装成能够进行网络传输的消息体:`RpcResponse`(序列化)发送至消费方;
+7. 客户端 Stub(client stub)接收到消息并将消息反序列化为Java对象:`RpcResponse` ,这样也就得到了最终结果。
+
+下面再贴一个网上的时序图,辅助理解:
+
+
+
+### RPC 解决了什么问题?
+
+从上面对 RPC 介绍的内容中,概括来讲RPC 主要解决了:**让分布式或者微服务系统中不同服务之间的调用像本地调用一样简单。**
+
+### 常见的 RPC 框架总结?
+
+- **RMI(JDK自带):** JDK自带的RPC,有很多局限性,不推荐使用。
+- **Dubbo:** Dubbo是 阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。目前 Dubbo 已经成为 Spring Cloud Alibaba 中的官方组件。
+- **gRPC** :gRPC是可以在任何环境中运行的现代开源高性能RPC框架。它可以通过可插拔的支持来有效地连接数据中心内和跨数据中心的服务,以实现负载平衡,跟踪,运行状况检查和身份验证。它也适用于分布式计算的最后一英里,以将设备,移动应用程序和浏览器连接到后端服务。
+- **Hessian:** Hessian是一个轻量级的remoting on http工具,使用简单的方法提供了RMI的功能。 相比WebService,Hessian更简单、快捷。采用的是二进制RPC协议,因为采用的是二进制协议,所以它很适合于发送二进制数据。
+- **Thrift:** Apache Thrift是Facebook开源的跨语言的RPC通信框架,目前已经捐献给Apache基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用,有能力的公司甚至会基于thrift研发一套分布式服务框架,增加诸如服务注册、服务发现等功能。
+
+### RPC学习材料
+
+- [跟着 Guide 哥造轮子](https://github.com/Snailclimb/guide-rpc-framework)
+
+## 既有 HTTP ,为啥用 RPC 进行服务调用?
+
+### RPC 只是一种设计而已
+
+RPC 只是一种概念、一种设计,就是为了解决 **不同服务之间的调用问题**, 它一般会包含有 **传输协议** 和 **序列化协议** 这两个。
+
+但是,HTTP 是一种协议,RPC框架可以使用 HTTP协议作为传输协议或者直接使用TCP作为传输协议,使用不同的协议一般也是为了适应不同的场景。
+
+### HTTP 和 TCP
+
+**可能现在很多对计算机网络不太熟悉的朋友已经被搞蒙了,要想真正搞懂,还需要来简单复习一下计算机网络基础知识:**
+
+> 我们通常谈计算机网络的五层协议的体系结构是指:应用层、传输层、网络层、数据链路层、物理层。
+>
+> **应用层(application-layer)的任务是通过应用进程间的交互来完成特定网络应用。** HTTP 属于应用层协议,它会基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。HTTP协议工作于客户端-服务端架构上。浏览器作为HTTP客户端通过 URL 向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。HTTP协议建立在 TCP 协议之上。
+>
+> **传输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务**。TCP是传输层协议,主要解决数据如何在网络中传输。相比于UDP,**TCP** 提供的是**面向连接**的,**可靠的**数据传输服务。
+
+### RPC框架功能更齐全
+
+成熟的 RPC框架还提供好了“服务自动注册与发现”、"智能负载均衡"、“可视化的服务治理和运维”、“运行期流量调度”等等功能,这些也算是选择
+RPC 进行服务注册和发现的一方面原因吧!
+
+**相关阅读:**
+
+- http://www.ruanyifeng.com/blog/2016/08/http.html (HTTP 协议入门- 阮一峰)
+
+### 一个常见的错误观点
+
+很多文章中还会提到说 HTTP 协议相较于自定义 TCP 报文协议,增加的开销在于连接的建立与断开,但是这个观点已经被否认,下面截取自知乎中一个回答,原回答地址:https://www.zhihu.com/question/41609070/answer/191965937 。
+
+>首先要否认一点 HTTP 协议相较于自定义 TCP 报文协议,增加的开销在于连接的建立与断开。HTTP 协议是支持连接池复用的,也就是建立一定数量的连接不断开,并不会频繁的创建和销毁连接。二一要说的是 HTTP 也可以使用 Protobuf 这种二进制编码协议对内容进行编码,因此二者最大的区别还是在传输协议上。
+
+
+
diff --git "a/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/curator.png" "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/curator.png"
new file mode 100644
index 00000000000..28da0247ec3
Binary files /dev/null and "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/curator.png" differ
diff --git "a/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/watche\346\234\272\345\210\266.png" "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/watche\346\234\272\345\210\266.png"
new file mode 100644
index 00000000000..68144db1e54
Binary files /dev/null and "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/watche\346\234\272\345\210\266.png" differ
diff --git "a/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/znode-structure.png" "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/znode-structure.png"
new file mode 100644
index 00000000000..746c3f6e3a4
Binary files /dev/null and "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/znode-structure.png" differ
diff --git "a/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/zookeeper\351\233\206\347\276\244.png" "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/zookeeper\351\233\206\347\276\244.png"
new file mode 100644
index 00000000000..a3067cda18e
Binary files /dev/null and "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/zookeeper\351\233\206\347\276\244.png" differ
diff --git "a/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png" "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png"
new file mode 100644
index 00000000000..6b118fe08e1
Binary files /dev/null and "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png" differ
diff --git "a/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png" "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png"
new file mode 100644
index 00000000000..d391329949d
Binary files /dev/null and "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png" differ
diff --git "a/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/zookeeper-in-action.md" "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/zookeeper-in-action.md"
new file mode 100644
index 00000000000..71dad09a4a2
--- /dev/null
+++ "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/zookeeper-in-action.md"
@@ -0,0 +1,296 @@
+# ZooKeeper 实战
+
+## 1. 前言
+
+这篇文章简单给演示一下 ZooKeeper 常见命令的使用以及 ZooKeeper Java客户端 Curator 的基本使用。介绍到的内容都是最基本的操作,能满足日常工作的基本需要。
+
+如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!
+
+## 2. ZooKeeper 安装和使用
+
+### 2.1. 使用Docker 安装 zookeeper
+
+**a.使用 Docker 下载 ZooKeeper**
+
+```shell
+docker pull zookeeper:3.5.8
+```
+
+**b.运行 ZooKeeper**
+
+```shell
+docker run -d --name zookeeper -p 2181:2181 zookeeper:3.5.8
+```
+
+### 2.2. 连接 ZooKeeper 服务
+
+**a.进入ZooKeeper容器中**
+
+先使用 `docker ps` 查看 ZooKeeper 的 ContainerID,然后使用 `docker exec -it ContainerID /bin/bash` 命令进入容器中。
+
+**b.先进入 bin 目录,然后通过 `./zkCli.sh -server 127.0.0.1:2181`命令连接ZooKeeper 服务**
+
+```bash
+root@eaf70fc620cb:/apache-zookeeper-3.5.8-bin# cd bin
+```
+
+如果你看到控制台成功打印出如下信息的话,说明你已经成功连接 ZooKeeper 服务。
+
+
+
+### 2.3. 常用命令演示
+
+#### 2.3.1. 查看常用命令(help 命令)
+
+通过 `help` 命令查看 ZooKeeper 常用命令
+
+#### 2.3.2. 创建节点(create 命令)
+
+通过 `create` 命令在根目录创建了 node1 节点,与它关联的字符串是"node1"
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 34] create /node1 “node1”
+```
+
+通过 `create` 命令在根目录创建了 node1 节点,与它关联的内容是数字 123
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 1] create /node1/node1.1 123
+Created /node1/node1.1
+```
+
+#### 2.3.3. 更新节点数据内容(set 命令)
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 11] set /node1 "set node1"
+```
+
+#### 2.3.4. 获取节点的数据(get 命令)
+
+`get` 命令可以获取指定节点的数据内容和节点的状态,可以看出我们通过 `set` 命令已经将节点数据内容改为 "set node1"。
+
+```shell
+set node1
+cZxid = 0x47
+ctime = Sun Jan 20 10:22:59 CST 2019
+mZxid = 0x4b
+mtime = Sun Jan 20 10:41:10 CST 2019
+pZxid = 0x4a
+cversion = 1
+dataVersion = 1
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 9
+numChildren = 1
+
+```
+
+#### 2.3.5. 查看某个目录下的子节点(ls 命令)
+
+通过 `ls` 命令查看根目录下的节点
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 37] ls /
+[dubbo, ZooKeeper, node1]
+```
+
+通过 `ls` 命令查看 node1 目录下的节点
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 5] ls /node1
+[node1.1]
+```
+
+ZooKeeper 中的 ls 命令和 linux 命令中的 ls 类似, 这个命令将列出绝对路径 path 下的所有子节点信息(列出 1 级,并不递归)
+
+#### 2.3.6. 查看节点状态(stat 命令)
+
+通过 `stat` 命令查看节点状态
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 10] stat /node1
+cZxid = 0x47
+ctime = Sun Jan 20 10:22:59 CST 2019
+mZxid = 0x47
+mtime = Sun Jan 20 10:22:59 CST 2019
+pZxid = 0x4a
+cversion = 1
+dataVersion = 0
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 11
+numChildren = 1
+```
+
+上面显示的一些信息比如 cversion、aclVersion、numChildren 等等,我在上面 “znode(数据节点)的结构” 这部分已经介绍到。
+
+#### 2.3.7. 查看节点信息和状态(ls2 命令)
+
+`ls2` 命令更像是 `ls` 命令和 `stat` 命令的结合。 `ls2` 命令返回的信息包括 2 部分:
+
+1. 子节点列表
+2. 当前节点的 stat 信息。
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 7] ls2 /node1
+[node1.1]
+cZxid = 0x47
+ctime = Sun Jan 20 10:22:59 CST 2019
+mZxid = 0x47
+mtime = Sun Jan 20 10:22:59 CST 2019
+pZxid = 0x4a
+cversion = 1
+dataVersion = 0
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 11
+numChildren = 1
+
+```
+
+#### 2.3.8. 删除节点(delete 命令)
+
+这个命令很简单,但是需要注意的一点是如果你要删除某一个节点,那么这个节点必须无子节点才行。
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 3] delete /node1/node1.1
+```
+
+在后面我会介绍到 Java 客户端 API 的使用以及开源 ZooKeeper 客户端 ZkClient 和 Curator 的使用。
+
+## 3. ZooKeeper Java客户端 Curator简单使用
+
+Curator 是Netflix公司开源的一套 ZooKeeper Java客户端框架,相比于 Zookeeper 自带的客户端 zookeeper 来说,Curator 的封装更加完善,各种 API 都可以比较方便地使用。
+
+
+
+下面我们就来简单地演示一下 Curator 的使用吧!
+
+Curator4.0+版本对ZooKeeper 3.5.x支持比较好。开始之前,请先将下面的依赖添加进你的项目。
+
+```xml
+<dependency>
+ <groupId>org.apache.curator</groupId>
+ <artifactId>curator-framework</artifactId>
+ <version>4.2.0</version>
+</dependency>
+<dependency>
+ <groupId>org.apache.curator</groupId>
+ <artifactId>curator-recipes</artifactId>
+ <version>4.2.0</version>
+</dependency>
+```
+
+### 3.1. 连接 ZooKeeper 客户端
+
+通过 `CuratorFrameworkFactory` 创建 `CuratorFramework` 对象,然后再调用 `CuratorFramework` 对象的 `start()` 方法即可!
+
+```java
+private static final int BASE_SLEEP_TIME = 1000;
+private static final int MAX_RETRIES = 3;
+
+// Retry strategy. Retry 3 times, and will increase the sleep time between retries.
+RetryPolicy retryPolicy = new ExponentialBackoffRetry(BASE_SLEEP_TIME, MAX_RETRIES);
+CuratorFramework zkClient = CuratorFrameworkFactory.builder()
+ // the server to connect to (can be a server list)
+ .connectString("127.0.0.1:2181")
+ .retryPolicy(retryPolicy)
+ .build();
+zkClient.start();
+```
+
+对于一些基本参数的说明:
+
+- `baseSleepTimeMs`:重试之间等待的初始时间
+- `maxRetries` :最大重试次数
+- `connectString` :要连接的服务器列表
+- `retryPolicy` :重试策略
+
+### 3.2. 数据节点的增删改查
+
+#### 3.2.1. 创建节点
+
+我们在 [ZooKeeper常见概念解读](./zookeeper-intro.md) 中介绍到,我们通常是将 znode 分为 4 大类:
+
+- **持久(PERSISTENT)节点** :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
+- **临时(EPHEMERAL)节点** :临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,临时节点 **只能做叶子节点** ,不能创建子节点。
+- **持久顺序(PERSISTENT_SEQUENTIAL)节点** :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001` 、`/node1/app0000000002` 。
+- **临时顺序(EPHEMERAL_SEQUENTIAL)节点** :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
+
+你在使用的ZooKeeper 的时候,会发现 `CreateMode` 类中实际有 7种 znode 类型 ,但是用的最多的还是上面介绍的 4 种。
+
+**a.创建持久化节点**
+
+你可以通过下面两种方式创建持久化的节点。
+
+```java
+//注意:下面的代码会报错,下文说了具体原因
+zkClient.create().forPath("/node1/00001");
+zkClient.create().withMode(CreateMode.PERSISTENT).forPath("/node1/00002");
+```
+
+但是,你运行上面的代码会报错,这是因为的父节点`node1`还未创建。
+
+你可以先创建父节点 `node1` ,然后再执行上面的代码就不会报错了。
+
+```java
+zkClient.create().forPath("/node1");
+```
+
+更推荐的方式是通过下面这行代码, **`creatingParentsIfNeeded()` 可以保证父节点不存在的时候自动创建父节点,这是非常有用的。**
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath("/node1/00001");
+```
+
+**b.创建临时节点**
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/node1/00001");
+```
+
+**c.创建节点并指定数据内容**
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/node1/00001","java".getBytes());
+zkClient.getData().forPath("/node1/00001");//获取节点的数据内容,获取到的是 byte数组
+```
+
+**d.检测节点是否创建成功**
+
+```java
+zkClient.checkExists().forPath("/node1/00001");//不为null的话,说明节点创建成功
+```
+
+#### 3.2.2. 删除节点
+
+**a.删除一个子节点**
+
+```java
+zkClient.delete().forPath("/node1/00001");
+```
+
+**b.删除一个节点以及其下的所有子节点**
+
+```java
+zkClient.delete().deletingChildrenIfNeeded().forPath("/node1");
+```
+
+#### 3.2.3. 获取/更新节点数据内容
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/node1/00001","java".getBytes());
+zkClient.getData().forPath("/node1/00001");//获取节点的数据内容
+zkClient.setData().forPath("/node1/00001","c++".getBytes());//更新节点数据内容
+```
+
+#### 3.2.4. 获取某个节点的所有子节点路径
+
+```java
+List<String> childrenPaths = zkClient.getChildren().forPath("/node1");
+```
+
+
+
+
+
diff --git "a/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/zookeeper-intro.md" "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/zookeeper-intro.md"
new file mode 100644
index 00000000000..3ead663c4b3
--- /dev/null
+++ "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/zookeeper-intro.md"
@@ -0,0 +1,280 @@
+# ZooKeeper 相关概念总结(入门)
+
+## 1. 前言
+
+相信大家对 ZooKeeper 应该不算陌生。但是你真的了解 ZooKeeper 到底有啥用不?如果别人/面试官让你给他讲讲对于 ZooKeeper 的认识,你能回答到什么地步呢?
+
+拿我自己来说吧!我本人曾经使用 Dubbo 来做分布式项目的时候,使用了 ZooKeeper 作为注册中心。为了保证分布式系统能够同步访问某个资源,我还使用 ZooKeeper 做过分布式锁。另外,我在学习 Kafka 的时候,知道 Kafka 很多功能的实现依赖了 ZooKeeper。
+
+前几天,总结项目经验的时候,我突然问自己 ZooKeeper 到底是个什么东西?想了半天,脑海中只是简单的能浮现出几句话:
+
+1. ZooKeeper 可以被用作注册中心、分布式锁;
+2. ZooKeeper 是 Hadoop 生态系统的一员;
+3. 构建 ZooKeeper 集群的时候,使用的服务器最好是奇数台。
+
+由此可见,我对于 ZooKeeper 的理解仅仅是停留在了表面。
+
+所以,通过本文,希望带大家稍微详细的了解一下 ZooKeeper 。如果没有学过 ZooKeeper ,那么本文将会是你进入 ZooKeeper 大门的垫脚砖。如果你已经接触过 ZooKeeper ,那么本文将带你回顾一下 ZooKeeper 的一些基础概念。
+
+另外,本文不光会涉及到 ZooKeeper 的一些概念,后面的文章会介绍到 ZooKeeper 常见命令的使用以及使用 Apache Curator 作为 ZooKeeper 的客户端。
+
+_如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!_
+
+## 2. ZooKeeper 介绍
+
+### 2.1. ZooKeeper 由来
+
+正式介绍 ZooKeeper 之前,我们先来看看 ZooKeeper 的由来,还挺有意思的。
+
+下面这段内容摘自《从 Paxos 到 ZooKeeper 》第四章第一节,推荐大家阅读一下:
+
+> ZooKeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
+>
+> 关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的 Pig 项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家 RaghuRamakrishnan 开玩笑地说:“在这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧一一一因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而 ZooKeeper 正好要用来进行分布式环境的协调一一于是,ZooKeeper 的名字也就由此诞生了。
+
+### 2.2. ZooKeeper 概览
+
+ZooKeeper 是一个开源的**分布式协调服务**,它的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
+
+> **原语:** 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性·即原语的执行必须是连续的,在执行过程中不允许被中断。
+
+**ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。**
+
+另外,**ZooKeeper 将数据保存在内存中,性能是非常棒的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景)。**
+
+### 2.3. ZooKeeper 特点
+
+- **顺序一致性:** 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
+- **原子性:** 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
+- **单一系统映像 :** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
+- **可靠性:** 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
+
+### 2.4. ZooKeeper 典型应用场景
+
+ZooKeeper 概览中,我们介绍到使用其通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
+
+下面选 3 个典型的应用场景来专门说说:
+
+1. **分布式锁** : 通过创建唯一节点获得分布式锁,当获得锁的一方执行完相关代码或者是挂掉之后就释放锁。
+2. **命名服务** :可以通过 ZooKeeper 的顺序节点生成全局唯一 ID
+3. **数据发布/订阅** :通过 **Watcher 机制** 可以很方便地实现数据发布/订阅。当你将数据发布到 ZooKeeper 被监听的节点上,其他机器可通过监听 ZooKeeper 上节点的变化来实现配置的动态更新。
+
+实际上,这些功能的实现基本都得益于 ZooKeeper 可以保存数据的功能,但是 ZooKeeper 不适合保存大量数据,这一点需要注意。
+
+### 2.5. 有哪些著名的开源项目用到了 ZooKeeper?
+
+1. **Kafka** : ZooKeeper 主要为 Kafka 提供 Broker 和 Topic 的注册以及多个 Partition 的负载均衡等功能。
+2. **Hbase** : ZooKeeper 为 Hbase 提供确保整个集群只有一个 Master 以及保存和提供 regionserver 状态信息(是否在线)等功能。
+3. **Hadoop** : ZooKeeper 为 Namenode 提供高可用支持。
+
+## 3. ZooKeeper 重要概念解读
+
+_破音:拿出小本本,下面的内容非常重要哦!_
+
+### 3.1. Data model(数据模型)
+
+ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二级制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都一个唯一的路径标识。
+
+强调一句:**ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据在 znode 上,ZooKeeper 给出的上限是每个结点的数据大小最大是 1M。**
+
+从下图可以更直观地看出:ZooKeeper 节点路径标识方式和 Unix 文件系统路径非常相似,都是由一系列使用斜杠"/"进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。这些操作我们后面都会介绍到。
+
+
+
+### 3.2. znode(数据节点)
+
+介绍了 ZooKeeper 树形数据模型之后,我们知道每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。你要存放的数据就放在上面,是你使用 ZooKeeper 过程中经常需要接触到的一个概念。
+
+#### 3.2.1. znode 4 种类型
+
+我们通常是将 znode 分为 4 大类:
+
+- **持久(PERSISTENT)节点** :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
+- **临时(EPHEMERAL)节点** :临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
+- **持久顺序(PERSISTENT_SEQUENTIAL)节点** :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001` 、`/node1/app0000000002` 。
+- **临时顺序(EPHEMERAL_SEQUENTIAL)节点** :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
+
+#### 3.2.2. znode 数据结构
+
+每个 znode 由 2 部分组成:
+
+- **stat** :状态信息
+- **data** : 节点存放的数据的具体内容
+
+如下所示,我通过 get 命令来获取 根目录下的 dubbo 节点的内容。(get 命令在下面会介绍到)。
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 6] get /dubbo
+# 该数据节点关联的数据内容为空
+null
+# 下面是该数据节点的一些状态信息,其实就是 Stat 对象的格式化输出
+cZxid = 0x2
+ctime = Tue Nov 27 11:05:34 CST 2018
+mZxid = 0x2
+mtime = Tue Nov 27 11:05:34 CST 2018
+pZxid = 0x3
+cversion = 1
+dataVersion = 0
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 0
+numChildren = 1
+```
+
+Stat 类中包含了一个数据节点的所有状态信息的字段,包括事务 ID-cZxid、节点创建时间-ctime 和子节点个数-numChildren 等等。
+
+下面我们来看一下每个 znode 状态信息究竟代表的是什么吧!(下面的内容来源于《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》,因为 Guide 确实也不是特别清楚,要学会参考资料的嘛! ) :
+
+| znode 状态信息 | 解释 |
+| -------------- | ------------------------------------------------------------ |
+| cZxid | create ZXID,即该数据节点被创建时的事务 id |
+| ctime | create time,即该节点的创建时间 |
+| mZxid | modified ZXID,即该节点最终一次更新时的事务 id |
+| mtime | modified time,即该节点最后一次的更新时间 |
+| pZxid | 该节点的子节点列表最后一次修改时的事务 id,只有子节点列表变更才会更新 pZxid,子节点内容变更不会更新 |
+| cversion | 子节点版本号,当前节点的子节点每次变化时值增加 1 |
+| dataVersion | 数据节点内容版本号,节点创建时为 0,每更新一次节点内容(不管内容有无变化)该版本号的值增加 1 |
+| aclVersion | 节点的 ACL 版本号,表示该节点 ACL 信息变更次数 |
+| ephemeralOwner | 创建该临时节点的会话的 sessionId;如果当前节点为持久节点,则 ephemeralOwner=0 |
+| dataLength | 数据节点内容长度 |
+| numChildren | 当前节点的子节点个数 |
+
+### 3.3. 版本(version)
+
+在前面我们已经提到,对应于每个 znode,ZooKeeper 都会为其维护一个叫作 **Stat** 的数据结构,Stat 中记录了这个 znode 的三个相关的版本:
+
+- **dataVersion** :当前 znode 节点的版本号
+- **cversion** : 当前 znode 子节点的版本
+- **aclVersion** : 当前 znode 的 ACL 的版本。
+
+### 3.4. ACL(权限控制)
+
+ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。
+
+对于 znode 操作的权限,ZooKeeper 提供了以下 5 种:
+
+- **CREATE** : 能创建子节点
+- **READ** :能获取节点数据和列出其子节点
+- **WRITE** : 能设置/更新节点数据
+- **DELETE** : 能删除子节点
+- **ADMIN** : 能设置节点 ACL 的权限
+
+其中尤其需要注意的是,**CREATE** 和 **DELETE** 这两种权限都是针对 **子节点** 的权限控制。
+
+对于身份认证,提供了以下几种方式:
+
+- **world** : 默认方式,所有用户都可无条件访问。
+- **auth** :不使用任何 id,代表任何已认证的用户。
+- **digest** :用户名:密码认证方式: _username:password_ 。
+- **ip** : 对指定 ip 进行限制。
+
+### 3.5. Watcher(事件监听器)
+
+Watcher(事件监听器),是 ZooKeeper 中的一个很重要的特性。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
+
+
+
+_破音:非常有用的一个特性,都能出小本本记好了,后面用到 ZooKeeper 基本离不开 Watcher(事件监听器)机制。_
+
+### 3.6. 会话(Session)
+
+Session 可以看作是 ZooKeeper 服务器与客户端的之间的一个 TCP 长连接,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向 ZooKeeper 服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的 Watcher 事件通知。
+
+Session 有一个属性叫做:`sessionTimeout` ,`sessionTimeout` 代表会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在`sessionTimeout`规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。
+
+另外,在为客户端创建会话之前,服务端首先会为每个客户端都分配一个 `sessionID`。由于 `sessionID`是 ZooKeeper 会话的一个重要标识,许多与会话相关的运行机制都是基于这个 `sessionID` 的,因此,无论是哪台服务器为客户端分配的 `sessionID`,都务必保证全局唯一。
+
+## 4. ZooKeeper 集群
+
+为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。ZooKeeper 官方提供的架构图就是一个 ZooKeeper 集群整体对外提供服务。
+
+
+
+上图中每一个 Server 代表一个安装 ZooKeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)来保持数据的一致性。
+
+**最典型集群模式: Master/Slave 模式(主备模式)**。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
+
+### 4.1. ZooKeeper 集群角色
+
+但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了 Leader、Follower 和 Observer 三种角色。如下图所示
+
+
+
+ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定一台称为 “**Leader**” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,**Follower** 和 **Observer** 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
+
+| 角色 | 说明 |
+| -------- | ------------------------------------------------------------ |
+| Leader | 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态。 |
+| Follower | 为客户端提供读服务,如果是写服务则转发给 Leader。参与选举过程中的投票。 |
+| Observer | 为客户端提供读服务,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
+
+当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,就会进入 Leader 选举过程,这个过程会选举产生新的 Leader 服务器。
+
+这个过程大致是这样的:
+
+1. **Leader election(选举阶段)**:节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
+2. **Discovery(发现阶段)** :在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
+3. **Synchronization(同步阶段)** :同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后
+ 准 leader 才会成为真正的 leader。
+4. **Broadcast(广播阶段)** :到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
+
+### 4.2. ZooKeeper 集群中的服务器状态
+
+- **LOOKING** :寻找 Leader。
+- **LEADING** :Leader 状态,对应的节点为 Leader。
+- **FOLLOWING** :Follower 状态,对应的节点为 Follower。
+- **OBSERVING** :Observer 状态,对应节点为 Observer,该节点不参与 Leader 选举。
+
+### 4.3. ZooKeeper 集群为啥最好奇数台?
+
+ZooKeeper 集群在宕掉几个 ZooKeeper 服务器之后,如果剩下的 ZooKeeper 服务器个数大于宕掉的个数的话整个 ZooKeeper 才依然可用。假如我们的集群中有 n 台 ZooKeeper 服务器,那么也就是剩下的服务数必须大于 n/2。先说一下结论,2n 和 2n-1 的容忍度是一样的,都是 n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
+
+比如假如我们有 3 台,那么最大允许宕掉 1 台 ZooKeeper 服务器,如果我们有 4 台的的时候也同样只允许宕掉 1 台。
+假如我们有 5 台,那么最大允许宕掉 2 台 ZooKeeper 服务器,如果我们有 6 台的的时候也同样只允许宕掉 2 台。
+
+综上,何必增加那一个不必要的 ZooKeeper 呢?
+
+### 4.4. ZooKeeper 选举的过半机制防止脑裂
+
+**何为集群脑裂?**
+
+对于一个集群,通常多台机器会部署在不同机房,来提高这个集群的可用性。保证可用性的同时,会发生一种机房间网络线路故障,导致机房间网络不通,而集群被割裂成几个小集群。这时候子集群各自选主导致“脑裂”的情况。
+
+举例说明:比如现在有一个由 6 台服务器所组成的一个集群,部署在了 2 个机房,每个机房 3 台。正常情况下只有 1 个 leader,但是当两个机房中间网络断开的时候,每个机房的 3 台服务器都会认为另一个机房的 3 台服务器下线,而选出自己的 leader 并对外提供服务。若没有过半机制,当网络恢复的时候会发现有 2 个 leader。仿佛是 1 个大脑(leader)分散成了 2 个大脑,这就发生了脑裂现象。脑裂期间 2 个大脑都可能对外提供了服务,这将会带来数据一致性等问题。
+
+**过半机制是如何防止脑裂现象产生的?**
+
+ZooKeeper 的过半机制导致不可能产生 2 个 leader,因为少于等于一半是不可能产生 leader 的,这就使得不论机房的机器如何分配都不可能发生脑裂。
+
+## 5. ZAB 协议和 Paxos 算法
+
+Paxos 算法应该可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并没有完全采用 Paxos 算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。另外,在 ZooKeeper 的官方文档中也指出,ZAB 协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为 Zookeeper 设计的崩溃可恢复的原子消息广播算法。
+
+### 5.1. ZAB 协议介绍
+
+ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
+
+### 5.2. ZAB 协议两种基本的模式:崩溃恢复和消息广播
+
+ZAB 协议包括两种基本的模式,分别是
+
+- **崩溃恢复** :当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,**所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致**。
+- **消息广播** :**当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。** 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
+
+关于 **ZAB 协议&Paxos 算法** 需要讲和理解的东西太多了,具体可以看下面这两篇文章:
+
+- [图解 Paxos 一致性协议](http://codemacro.com/2014/10/15/explain-poxos/)
+- [Zookeeper ZAB 协议分析](https://dbaplus.cn/news-141-1875-1.html)
+
+## 6. 总结
+
+1. ZooKeeper 本身就是一个分布式程序(只要半数以上节点存活,ZooKeeper 就能正常服务)。
+2. 为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。
+3. ZooKeeper 将数据保存在内存中,这也就保证了 高吞吐量和低延迟(但是内存限制了能够存储的容量不太大,此限制也是保持 znode 中存储的数据量较小的进一步原因)。
+4. ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地明显,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)
+5. ZooKeeper 有临时节点的概念。 当创建临时节点的客户端会话一直保持活动,瞬时节点就一直存在。而当会话终结时,瞬时节点被删除。持久节点是指一旦这个 znode 被创建了,除非主动进行 znode 的移除操作,否则这个 znode 将一直保存在 ZooKeeper 上。
+6. ZooKeeper 底层其实只提供了两个功能:① 管理(存储、读取)用户程序提交的数据;② 为用户程序提供数据节点监听服务。
+
+## 7. 参考
+
+1. 《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》
diff --git "a/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/zookeeper-plus.md" "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/zookeeper-plus.md"
new file mode 100644
index 00000000000..11f2ac5a1a8
--- /dev/null
+++ "b/docs/distributed-system/\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203/zookeeper/zookeeper-plus.md"
@@ -0,0 +1,375 @@
+# ZooKeeper 相关概念总结(进阶)
+
+> [FrancisQ](https://juejin.im/user/5c33853851882525ea106810) 投稿。
+
+## 1. 好久不见
+
+离上一篇文章的发布也快一个月了,想想已经快一个月没写东西了,其中可能有期末考试、课程设计和驾照考试,但这都不是借口!
+
+一到冬天就懒的不行,望广大掘友督促我🙄🙄✍️✍️。
+
+> 文章很长,先赞后看,养成习惯。❤️ 🧡 💛 💚 💙 💜
+
+## 2. 什么是ZooKeeper
+
+`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 `Paxos` 算法的 `ZAB` 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理、分布式事务等。
+
+
+
+简单来说, `ZooKeeper` 是一个 **分布式协调服务框架** 。分布式?协调服务?这啥玩意?🤔🤔
+
+其实解释到分布式这个概念的时候,我发现有些同学并不是能把 **分布式和集群 **这两个概念很好的理解透。前段时间有同学和我探讨起分布式的东西,他说分布式不就是加机器吗?一台机器不够用再加一台抗压呗。当然加机器这种说法也无可厚非,你一个分布式系统必定涉及到多个机器,但是你别忘了,计算机学科中还有一个相似的概念—— `Cluster` ,集群不也是加机器吗?但是 集群 和 分布式 其实就是两个完全不同的概念。
+
+比如,我现在有一个秒杀服务,并发量太大单机系统承受不住,那我加几台服务器也 **一样** 提供秒杀服务,这个时候就是 **`Cluster` 集群** 。
+
+
+
+但是,我现在换一种方式,我将一个秒杀服务 **拆分成多个子服务** ,比如创建订单服务,增加积分服务,扣优惠券服务等等,**然后我将这些子服务都部署在不同的服务器上** ,这个时候就是 **`Distributed` 分布式** 。
+
+
+
+而我为什么反驳同学所说的分布式就是加机器呢?因为我认为加机器更加适用于构建集群,因为它真是只有加机器。而对于分布式来说,你首先需要将业务进行拆分,然后再加机器(不仅仅是加机器那么简单),同时你还要去解决分布式带来的一系列问题。
+
+
+
+比如各个分布式组件如何协调起来,如何减少各个系统之间的耦合度,分布式事务的处理,如何去配置整个分布式系统等等。`ZooKeeper` 主要就是解决这些问题的。
+
+## 3. 一致性问题
+
+设计一个分布式系统必定会遇到一个问题—— **因为分区容忍性(partition tolerance)的存在,就必定要求我们需要在系统可用性(availability)和数据一致性(consistency)中做出权衡** 。这就是著名的 `CAP` 定理。
+
+理解起来其实很简单,比如说把一个班级作为整个系统,而学生是系统中的一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的大嘴巴小花发现了,小花欣喜若狂告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你抓到一个同学问他们的情况,如果回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。
+
+
+
+而上述前者就是 `Eureka` 的处理方式,它保证了AP(可用性),后者就是我们今天所要讲的 `ZooKeeper` 的处理方式,它保证了CP(数据一致性)。
+
+## 4. 一致性协议和算法
+
+而为了解决数据一致性问题,在科学家和程序员的不断探索中,就出现了很多的一致性协议和算法。比如 2PC(两阶段提交),3PC(三阶段提交),Paxos算法等等。
+
+这时候请你思考一个问题,同学之间如果采用传纸条的方式去传播消息,那么就会出现一个问题——我咋知道我的小纸条有没有传到我想要传递的那个人手中呢?万一被哪个小家伙给劫持篡改了呢,对吧?
+
+
+
+这个时候就引申出一个概念—— **拜占庭将军问题** 。它意指 **在不可靠信道上试图通过消息传递的方式达到一致性是不可能的**, 所以所有的一致性算法的 **必要前提** 就是安全可靠的消息通道。
+
+而为什么要去解决数据一致性的问题?你想想,如果一个秒杀系统将服务拆分成了下订单和加积分服务,这两个服务部署在不同的机器上了,万一在消息的传播过程中积分系统宕机了,总不能你这边下了订单却没加积分吧?你总得保证两边的数据需要一致吧?
+
+### 4.1. 2PC(两阶段提交)
+
+两阶段提交是一种保证分布式系统数据一致性的协议,现在很多数据库都是采用的两阶段提交协议来完成 **分布式事务** 的处理。
+
+在介绍2PC之前,我们先来想想分布式事务到底有什么问题呢?
+
+还拿秒杀系统的下订单和加积分两个系统来举例吧(我想你们可能都吐了🤮🤮🤮),我们此时下完订单会发个消息给积分系统告诉它下面该增加积分了。如果我们仅仅是发送一个消息也不收回复,那么我们的订单系统怎么能知道积分系统的收到消息的情况呢?如果我们增加一个收回复的过程,那么当积分系统收到消息后返回给订单系统一个 `Response` ,但在中间出现了网络波动,那个回复消息没有发送成功,订单系统是不是以为积分系统消息接收失败了?它是不是会回滚事务?但此时积分系统是成功收到消息的,它就会去处理消息然后给用户增加积分,这个时候就会出现积分加了但是订单没下成功。
+
+所以我们所需要解决的是在分布式系统中,整个调用链中,我们所有服务的数据处理要么都成功要么都失败,即所有服务的 **原子性问题** 。
+
+在两阶段提交中,主要涉及到两个角色,分别是协调者和参与者。
+
+第一阶段:当要执行一个分布式事务的时候,事务发起者首先向协调者发起事务请求,然后协调者会给所有参与者发送 `prepare` 请求(其中包括事务内容)告诉参与者你们需要执行事务了,如果能执行我发的事务内容那么就先执行但不提交,执行后请给我回复。然后参与者收到 `prepare` 消息后,他们会开始执行事务(但不提交),并将 `Undo` 和 `Redo` 信息记入事务日志中,之后参与者就向协调者反馈是否准备好了。
+
+第二阶段:第二阶段主要是协调者根据参与者反馈的情况来决定接下来是否可以进行事务的提交操作,即提交事务或者回滚事务。
+
+比如这个时候 **所有的参与者** 都返回了准备好了的消息,这个时候就进行事务的提交,协调者此时会给所有的参与者发送 **`Commit` 请求** ,当参与者收到 `Commit` 请求的时候会执行前面执行的事务的 **提交操作** ,提交完毕之后将给协调者发送提交成功的响应。
+
+而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送 **回滚事务的 `rollback` 请求**,参与者收到之后将会 **回滚它在第一阶段所做的事务处理** ,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。
+
+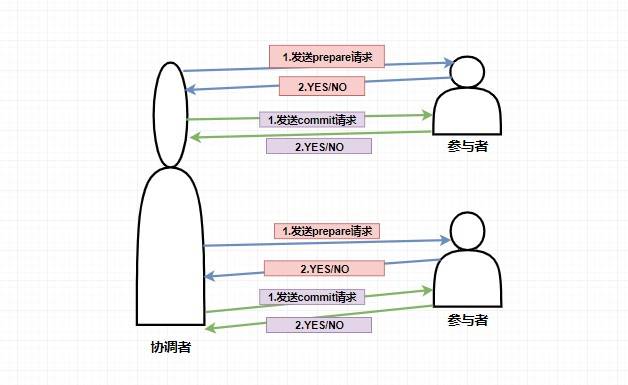
+
+个人觉得 2PC 实现得还是比较鸡肋的,因为事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。
+
+
+
+* **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
+* **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
+* **数据不一致问题**,比如当第二阶段,协调者只发送了一部分的 `commit` 请求就挂了,那么也就意味着,收到消息的参与者会进行事务的提交,而后面没收到的则不会进行事务提交,那么这时候就会产生数据不一致性问题。
+
+### 4.2. 3PC(三阶段提交)
+
+因为2PC存在的一系列问题,比如单点,容错机制缺陷等等,从而产生了 **3PC(三阶段提交)** 。那么这三阶段又分别是什么呢?
+
+> 千万不要吧PC理解成个人电脑了,其实他们是 phase-commit 的缩写,即阶段提交。
+
+1. **CanCommit阶段**:协调者向所有参与者发送 `CanCommit` 请求,参与者收到请求后会根据自身情况查看是否能执行事务,如果可以则返回 YES 响应并进入预备状态,否则返回 NO 。
+2. **PreCommit阶段**:协调者根据参与者返回的响应来决定是否可以进行下面的 `PreCommit` 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 `PreCommit` 预提交请求,**参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中** ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 **任何一个 NO** 的信息,或者 **在一定时间内** 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
+3. **DoCommit阶段**:这个阶段其实和 `2PC` 的第二阶段差不多,如果协调者收到了所有参与者在 `PreCommit` 阶段的 YES 响应,那么协调者将会给所有参与者发送 `DoCommit` 请求,**参与者收到 `DoCommit` 请求后则会进行事务的提交工作**,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 `PreCommit` 阶段 **收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应** ,那么就会进行中断请求的发送,参与者收到中断请求后则会 **通过上面记录的回滚日志** 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
+
+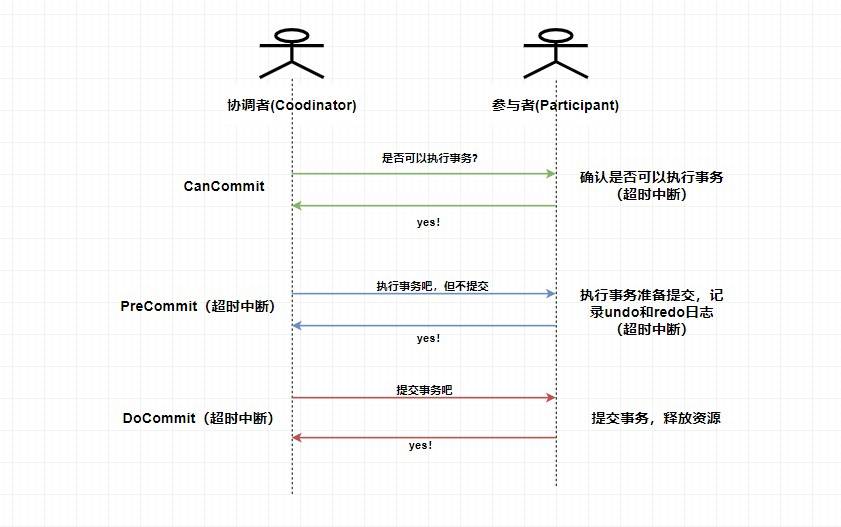
+
+> 这里是 `3PC` 在成功的环境下的流程图,你可以看到 `3PC` 在很多地方进行了超时中断的处理,比如协调者在指定时间内为收到全部的确认消息则进行事务中断的处理,这样能 **减少同步阻塞的时间** 。还有需要注意的是,**`3PC` 在 `DoCommit` 阶段参与者如未收到协调者发送的提交事务的请求,它会在一定时间内进行事务的提交**。为什么这么做呢?是因为这个时候我们肯定**保证了在第一阶段所有的协调者全部返回了可以执行事务的响应**,这个时候我们有理由**相信其他系统都能进行事务的执行和提交**,所以**不管**协调者有没有发消息给参与者,进入第三阶段参与者都会进行事务的提交操作。
+
+总之,`3PC` 通过一系列的超时机制很好的缓解了阻塞问题,但是最重要的一致性并没有得到根本的解决,比如在 `PreCommit` 阶段,当一个参与者收到了请求之后其他参与者和协调者挂了或者出现了网络分区,这个时候收到消息的参与者都会进行事务提交,这就会出现数据不一致性问题。
+
+所以,要解决一致性问题还需要靠 `Paxos` 算法⭐️ ⭐️ ⭐️ 。
+
+### 4.3. `Paxos` 算法
+
+`Paxos` 算法是基于**消息传递且具有高度容错特性的一致性算法**,是目前公认的解决分布式一致性问题最有效的算法之一,**其解决的问题就是在分布式系统中如何就某个值(决议)达成一致** 。
+
+在 `Paxos` 中主要有三个角色,分别为 `Proposer提案者`、`Acceptor表决者`、`Learner学习者`。`Paxos` 算法和 `2PC` 一样,也有两个阶段,分别为 `Prepare` 和 `accept` 阶段。
+
+#### 4.3.1. prepare 阶段
+
+* `Proposer提案者`:负责提出 `proposal`,每个提案者在提出提案时都会首先获取到一个 **具有全局唯一性的、递增的提案编号N**,即在整个集群中是唯一的编号 N,然后将该编号赋予其要提出的提案,在**第一阶段是只将提案编号发送给所有的表决者**。
+* `Acceptor表决者`:每个表决者在 `accept` 某提案后,会将该提案编号N记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个**编号最大的提案**,其编号假设为 `maxN`。每个表决者仅会 `accept` 编号大于自己本地 `maxN` 的提案,在批准提案时表决者会将以前接受过的最大编号的提案作为响应反馈给 `Proposer` 。
+
+> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。
+
+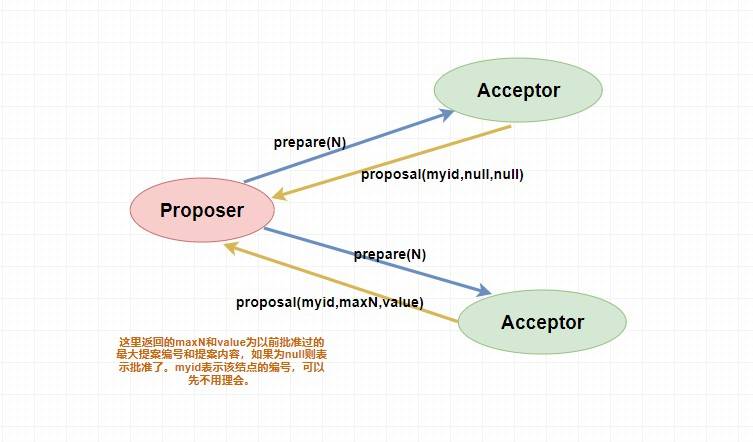
+
+#### 4.3.2. accept 阶段
+
+当一个提案被 `Proposer` 提出后,如果 `Proposer` 收到了超过半数的 `Acceptor` 的批准(`Proposer` 本身同意),那么此时 `Proposer` 会给所有的 `Acceptor` 发送真正的提案(你可以理解为第一阶段为试探),这个时候 `Proposer` 就会发送提案的内容和提案编号。
+
+表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号 **大于等于** 已经批准过的最大提案编号,那么就 `accept` 该提案(此时执行提案内容但不提交),随后将情况返回给 `Proposer` 。如果不满足则不回应或者返回 NO 。
+
+
+
+当 `Proposer` 收到超过半数的 `accept` ,那么它这个时候会向所有的 `acceptor` 发送提案的提交请求。需要注意的是,因为上述仅仅是超过半数的 `acceptor` 批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要**向未批准的 `acceptor` 发送提案内容和提案编号并让它无条件执行和提交**,而对于前面已经批准过该提案的 `acceptor` 来说 **仅仅需要发送该提案的编号** ,让 `acceptor` 执行提交就行了。
+
+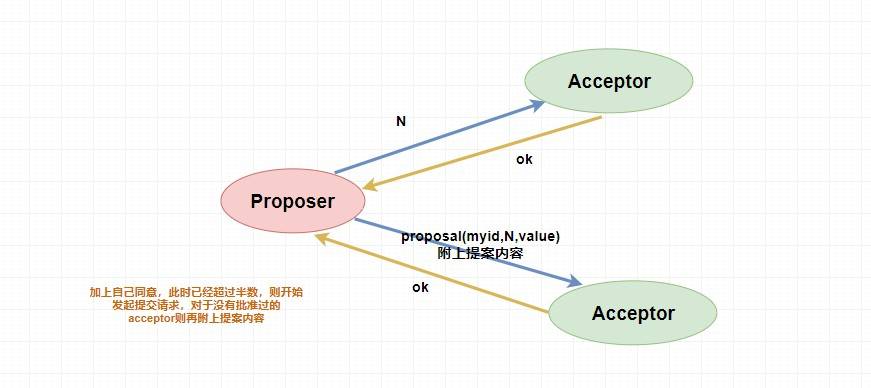
+
+而如果 `Proposer` 如果没有收到超过半数的 `accept` 那么它将会将 **递增** 该 `Proposal` 的编号,然后 **重新进入 `Prepare` 阶段** 。
+
+> 对于 `Learner` 来说如何去学习 `Acceptor` 批准的提案内容,这有很多方式,读者可以自己去了解一下,这里不做过多解释。
+
+#### 4.3.3. `paxos` 算法的死循环问题
+
+其实就有点类似于两个人吵架,小明说我是对的,小红说我才是对的,两个人据理力争的谁也不让谁🤬🤬。
+
+比如说,此时提案者 P1 提出一个方案 M1,完成了 `Prepare` 阶段的工作,这个时候 `acceptor` 则批准了 M1,但是此时提案者 P2 同时也提出了一个方案 M2,它也完成了 `Prepare` 阶段的工作。然后 P1 的方案已经不能在第二阶段被批准了(因为 `acceptor` 已经批准了比 M1 更大的 M2),所以 P1 自增方案变为 M3 重新进入 `Prepare` 阶段,然后 `acceptor` ,又批准了新的 M3 方案,它又不能批准 M2 了,这个时候 M2 又自增进入 `Prepare` 阶段。。。
+
+就这样无休无止的永远提案下去,这就是 `paxos` 算法的死循环问题。
+
+
+
+那么如何解决呢?很简单,人多了容易吵架,我现在 **就允许一个能提案** 就行了。
+
+## 5. 引出 `ZAB`
+
+### 5.1. `Zookeeper` 架构
+
+作为一个优秀高效且可靠的分布式协调框架,`ZooKeeper` 在解决分布式数据一致性问题时并没有直接使用 `Paxos` ,而是专门定制了一致性协议叫做 `ZAB(ZooKeeper Atomic Broadcast)` 原子广播协议,该协议能够很好地支持 **崩溃恢复** 。
+
+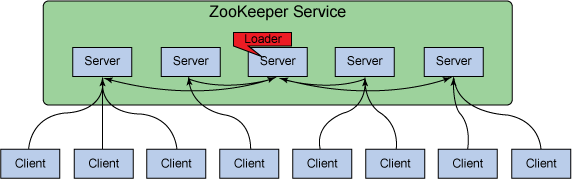
+
+### 5.2. `ZAB` 中的三个角色
+
+和介绍 `Paxos` 一样,在介绍 `ZAB` 协议之前,我们首先来了解一下在 `ZAB` 中三个主要的角色,`Leader 领导者`、`Follower跟随者`、`Observer观察者` 。
+
+* `Leader` :集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
+* `Follower`:能够接收客户端的请求,如果是读请求则可以自己处理,**如果是写请求则要转发给 `Leader`** 。在选举过程中会参与投票,**有选举权和被选举权** 。
+* `Observer` :就是没有选举权和被选举权的 `Follower` 。
+
+在 `ZAB` 协议中对 `zkServer`(即上面我们说的三个角色的总称) 还有两种模式的定义,分别是 **消息广播** 和 **崩溃恢复** 。
+
+### 5.3. 消息广播模式
+
+说白了就是 `ZAB` 协议是如何处理写请求的,上面我们不是说只有 `Leader` 能处理写请求嘛?那么我们的 `Follower` 和 `Observer` 是不是也需要 **同步更新数据** 呢?总不能数据只在 `Leader` 中更新了,其他角色都没有得到更新吧?
+
+不就是 **在整个集群中保持数据的一致性** 嘛?如果是你,你会怎么做呢?
+
+
+
+废话,第一步肯定需要 `Leader` 将写请求 **广播** 出去呀,让 `Leader` 问问 `Followers` 是否同意更新,如果超过半数以上的同意那么就进行 `Follower` 和 `Observer` 的更新(和 `Paxos` 一样)。当然这么说有点虚,画张图理解一下。
+
+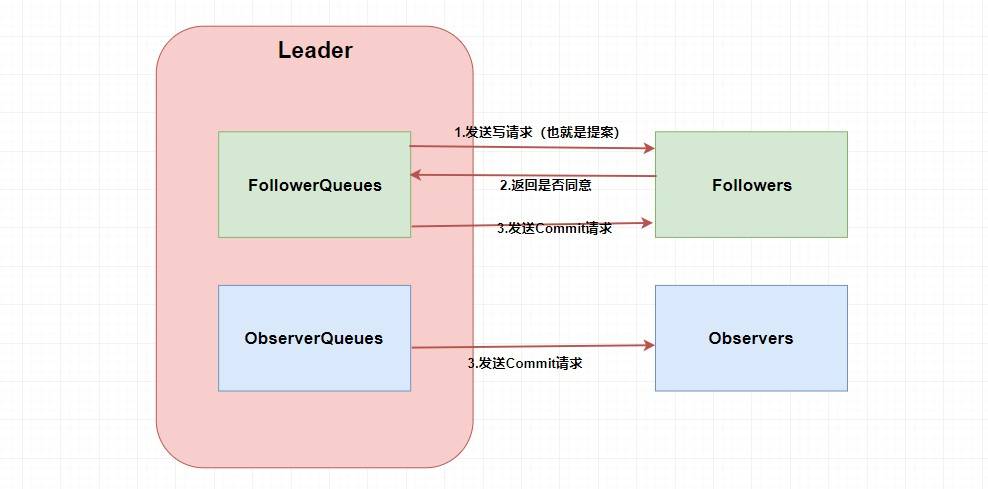
+
+嗯。。。看起来很简单,貌似懂了🤥🤥🤥。这两个 `Queue` 哪冒出来的?答案是 **`ZAB` 需要让 `Follower` 和 `Observer` 保证顺序性** 。何为顺序性,比如我现在有一个写请求A,此时 `Leader` 将请求A广播出去,因为只需要半数同意就行,所以可能这个时候有一个 `Follower` F1因为网络原因没有收到,而 `Leader` 又广播了一个请求B,因为网络原因,F1竟然先收到了请求B然后才收到了请求A,这个时候请求处理的顺序不同就会导致数据的不同,从而 **产生数据不一致问题** 。
+
+所以在 `Leader` 这端,它为每个其他的 `zkServer` 准备了一个 **队列** ,采用先进先出的方式发送消息。由于协议是 **通过 `TCP` **来进行网络通信的,保证了消息的发送顺序性,接受顺序性也得到了保证。
+
+除此之外,在 `ZAB` 中还定义了一个 **全局单调递增的事务ID `ZXID`** ,它是一个64位long型,其中高32位表示 `epoch` 年代,低32位表示事务id。`epoch` 是会根据 `Leader` 的变化而变化的,当一个 `Leader` 挂了,新的 `Leader` 上位的时候,年代(`epoch`)就变了。而低32位可以简单理解为递增的事务id。
+
+定义这个的原因也是为了顺序性,每个 `proposal` 在 `Leader` 中生成后需要 **通过其 `ZXID` 来进行排序** ,才能得到处理。
+
+### 5.4. 崩溃恢复模式
+
+说到崩溃恢复我们首先要提到 `ZAB` 中的 `Leader` 选举算法,当系统出现崩溃影响最大应该是 `Leader` 的崩溃,因为我们只有一个 `Leader` ,所以当 `Leader` 出现问题的时候我们势必需要重新选举 `Leader` 。
+
+`Leader` 选举可以分为两个不同的阶段,第一个是我们提到的 `Leader` 宕机需要重新选举,第二则是当 `Zookeeper` 启动时需要进行系统的 `Leader` 初始化选举。下面我先来介绍一下 `ZAB` 是如何进行初始化选举的。
+
+假设我们集群中有3台机器,那也就意味着我们需要两台以上同意(超过半数)。比如这个时候我们启动了 `server1` ,它会首先 **投票给自己** ,投票内容为服务器的 `myid` 和 `ZXID` ,因为初始化所以 `ZXID` 都为0,此时 `server1` 发出的投票为 (1,0)。但此时 `server1` 的投票仅为1,所以不能作为 `Leader` ,此时还在选举阶段所以整个集群处于 **`Looking` 状态**。
+
+接着 `server2` 启动了,它首先也会将投票选给自己(2,0),并将投票信息广播出去(`server1`也会,只是它那时没有其他的服务器了),`server1` 在收到 `server2` 的投票信息后会将投票信息与自己的作比较。**首先它会比较 `ZXID` ,`ZXID` 大的优先为 `Leader`,如果相同则比较 `myid`,`myid` 大的优先作为 `Leader`**。所以此时`server1` 发现 `server2` 更适合做 `Leader`,它就会将自己的投票信息更改为(2,0)然后再广播出去,之后`server2` 收到之后发现和自己的一样无需做更改,并且自己的 **投票已经超过半数** ,则 **确定 `server2` 为 `Leader`**,`server1` 也会将自己服务器设置为 `Following` 变为 `Follower`。整个服务器就从 `Looking` 变为了正常状态。
+
+当 `server3` 启动发现集群没有处于 `Looking` 状态时,它会直接以 `Follower` 的身份加入集群。
+
+还是前面三个 `server` 的例子,如果在整个集群运行的过程中 `server2` 挂了,那么整个集群会如何重新选举 `Leader` 呢?其实和初始化选举差不多。
+
+首先毫无疑问的是剩下的两个 `Follower` 会将自己的状态 **从 `Following` 变为 `Looking` 状态** ,然后每个 `server` 会向初始化投票一样首先给自己投票(这不过这里的 `zxid` 可能不是0了,这里为了方便随便取个数字)。
+
+假设 `server1` 给自己投票为(1,99),然后广播给其他 `server`,`server3` 首先也会给自己投票(3,95),然后也广播给其他 `server`。`server1` 和 `server3` 此时会收到彼此的投票信息,和一开始选举一样,他们也会比较自己的投票和收到的投票(`zxid` 大的优先,如果相同那么就 `myid` 大的优先)。这个时候 `server1` 收到了 `server3` 的投票发现没自己的合适故不变,`server3` 收到 `server1` 的投票结果后发现比自己的合适于是更改投票为(1,99)然后广播出去,最后 `server1` 收到了发现自己的投票已经超过半数就把自己设为 `Leader`,`server3` 也随之变为 `Follower`。
+
+> 请注意 `ZooKeeper` 为什么要设置奇数个结点?比如这里我们是三个,挂了一个我们还能正常工作,挂了两个我们就不能正常工作了(已经没有超过半数的节点数了,所以无法进行投票等操作了)。而假设我们现在有四个,挂了一个也能工作,**但是挂了两个也不能正常工作了**,这是和三个一样的,而三个比四个还少一个,带来的效益是一样的,所以 `Zookeeper` 推荐奇数个 `server` 。
+
+那么说完了 `ZAB` 中的 `Leader` 选举方式之后我们再来了解一下 **崩溃恢复** 是什么玩意?
+
+其实主要就是 **当集群中有机器挂了,我们整个集群如何保证数据一致性?**
+
+如果只是 `Follower` 挂了,而且挂的没超过半数的时候,因为我们一开始讲了在 `Leader` 中会维护队列,所以不用担心后面的数据没接收到导致数据不一致性。
+
+如果 `Leader` 挂了那就麻烦了,我们肯定需要先暂停服务变为 `Looking` 状态然后进行 `Leader` 的重新选举(上面我讲过了),但这个就要分为两种情况了,分别是 **确保已经被Leader提交的提案最终能够被所有的Follower提交** 和 **跳过那些已经被丢弃的提案** 。
+
+确保已经被Leader提交的提案最终能够被所有的Follower提交是什么意思呢?
+
+假设 `Leader (server2)` 发送 `commit` 请求(忘了请看上面的消息广播模式),他发送给了 `server3`,然后要发给 `server1` 的时候突然挂了。这个时候重新选举的时候我们如果把 `server1` 作为 `Leader` 的话,那么肯定会产生数据不一致性,因为 `server3` 肯定会提交刚刚 `server2` 发送的 `commit` 请求的提案,而 `server1` 根本没收到所以会丢弃。
+
+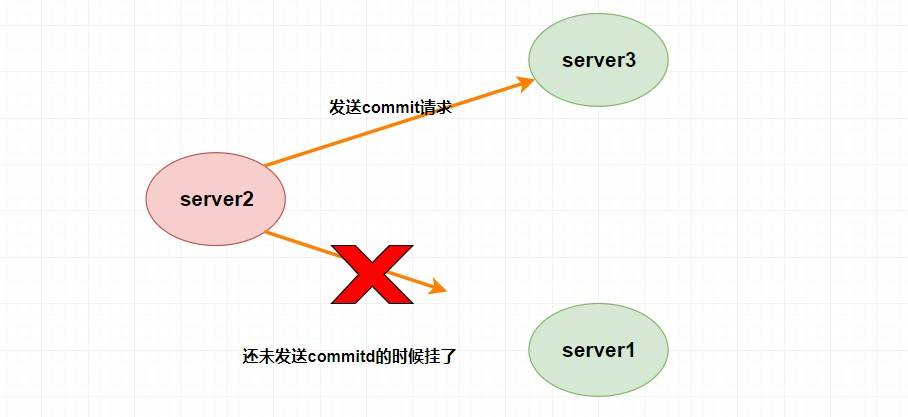
+
+那怎么解决呢?
+
+聪明的同学肯定会质疑,**这个时候 `server1` 已经不可能成为 `Leader` 了,因为 `server1` 和 `server3` 进行投票选举的时候会比较 `ZXID` ,而此时 `server3` 的 `ZXID` 肯定比 `server1` 的大了**。(不理解可以看前面的选举算法)
+
+那么跳过那些已经被丢弃的提案又是什么意思呢?
+
+假设 `Leader (server2)` 此时同意了提案N1,自身提交了这个事务并且要发送给所有 `Follower` 要 `commit` 的请求,却在这个时候挂了,此时肯定要重新进行 `Leader` 的选举,比如说此时选 `server1` 为 `Leader` (这无所谓)。但是过了一会,这个 **挂掉的 `Leader` 又重新恢复了** ,此时它肯定会作为 `Follower` 的身份进入集群中,需要注意的是刚刚 `server2` 已经同意提交了提案N1,但其他 `server` 并没有收到它的 `commit` 信息,所以其他 `server` 不可能再提交这个提案N1了,这样就会出现数据不一致性问题了,所以 **该提案N1最终需要被抛弃掉** 。
+
+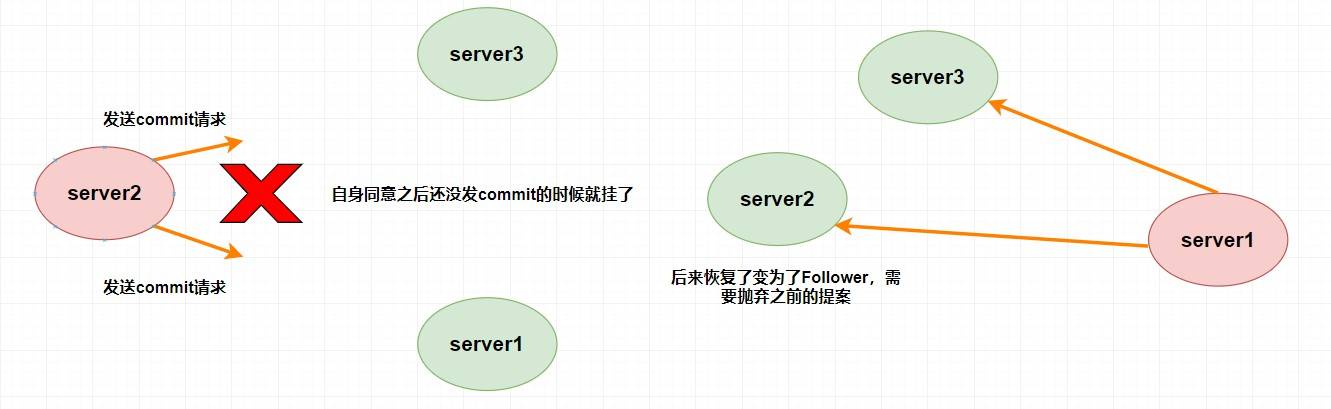
+
+## 6. Zookeeper的几个理论知识
+
+了解了 `ZAB` 协议还不够,它仅仅是 `Zookeeper` 内部实现的一种方式,而我们如何通过 `Zookeeper` 去做一些典型的应用场景呢?比如说集群管理,分布式锁,`Master` 选举等等。
+
+这就涉及到如何使用 `Zookeeper` 了,但在使用之前我们还需要掌握几个概念。比如 `Zookeeper` 的 **数据模型** 、**会话机制**、**ACL**、**Watcher机制** 等等。
+
+### 6.1. 数据模型
+
+`zookeeper` 数据存储结构与标准的 `Unix` 文件系统非常相似,都是在根节点下挂很多子节点(树型)。但是 `zookeeper` 中没有文件系统中目录与文件的概念,而是 **使用了 `znode` 作为数据节点** 。`znode` 是 `zookeeper` 中的最小数据单元,每个 `znode` 上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。
+
+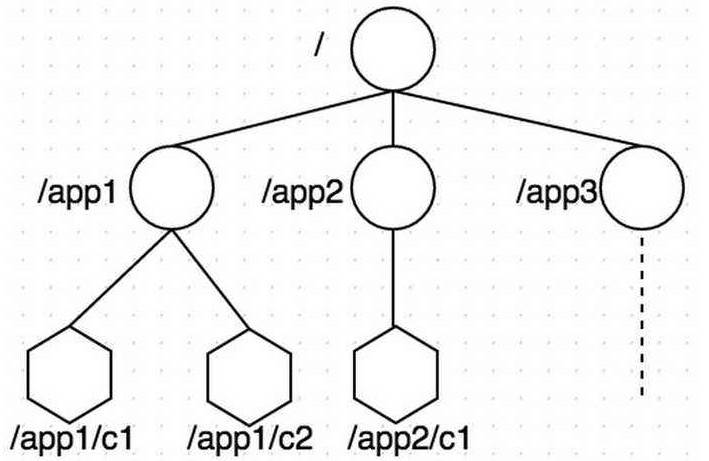
+
+每个 `znode` 都有自己所属的 **节点类型** 和 **节点状态**。
+
+其中节点类型可以分为 **持久节点**、**持久顺序节点**、**临时节点** 和 **临时顺序节点**。
+
+* 持久节点:一旦创建就一直存在,直到将其删除。
+* 持久顺序节点:一个父节点可以为其子节点 **维护一个创建的先后顺序** ,这个顺序体现在 **节点名称** 上,是节点名称后自动添加一个由 10 位数字组成的数字串,从 0 开始计数。
+* 临时节点:临时节点的生命周期是与 **客户端会话** 绑定的,**会话消失则节点消失** 。临时节点 **只能做叶子节点** ,不能创建子节点。
+* 临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
+
+节点状态中包含了很多节点的属性比如 `czxid` 、`mzxid` 等等,在 `zookeeper` 中是使用 `Stat` 这个类来维护的。下面我列举一些属性解释。
+
+* `czxid`:`Created ZXID`,该数据节点被 **创建** 时的事务ID。
+* `mzxid`:`Modified ZXID`,节点 **最后一次被更新时** 的事务ID。
+* `ctime`:`Created Time`,该节点被创建的时间。
+* `mtime`: `Modified Time`,该节点最后一次被修改的时间。
+* `version`:节点的版本号。
+* `cversion`:**子节点** 的版本号。
+* `aversion`:节点的 `ACL` 版本号。
+* `ephemeralOwner`:创建该节点的会话的 `sessionID` ,如果该节点为持久节点,该值为0。
+* `dataLength`:节点数据内容的长度。
+* `numChildre`:该节点的子节点个数,如果为临时节点为0。
+* `pzxid`:该节点子节点列表最后一次被修改时的事务ID,注意是子节点的 **列表** ,不是内容。
+
+### 6.2. 会话
+
+我想这个对于后端开发的朋友肯定不陌生,不就是 `session` 吗?只不过 `zk` 客户端和服务端是通过 **`TCP` 长连接** 维持的会话机制,其实对于会话来说你可以理解为 **保持连接状态** 。
+
+在 `zookeeper` 中,会话还有对应的事件,比如 `CONNECTION_LOSS 连接丢失事件` 、`SESSION_MOVED 会话转移事件` 、`SESSION_EXPIRED 会话超时失效事件` 。
+
+### 6.3. ACL
+
+`ACL` 为 `Access Control Lists` ,它是一种权限控制。在 `zookeeper` 中定义了5种权限,它们分别为:
+
+* `CREATE` :创建子节点的权限。
+* `READ`:获取节点数据和子节点列表的权限。
+* `WRITE`:更新节点数据的权限。
+* `DELETE`:删除子节点的权限。
+* `ADMIN`:设置节点 ACL 的权限。
+
+### 6.4. Watcher机制
+
+`Watcher` 为事件监听器,是 `zk` 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端 **注册** 指定的 `watcher` ,当服务端符合了 `watcher` 的某些事件或要求则会 **向客户端发送事件通知** ,客户端收到通知后找到自己定义的 `Watcher` 然后 **执行相应的回调方法** 。
+
+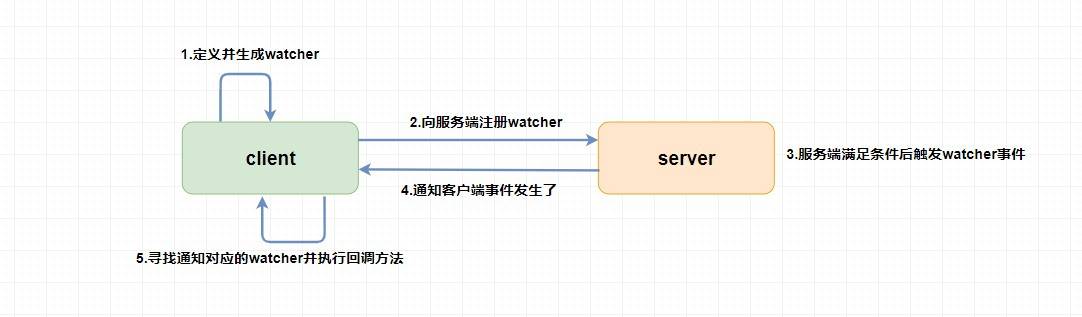
+
+## 7. Zookeeper的几个典型应用场景
+
+前面说了这么多的理论知识,你可能听得一头雾水,这些玩意有啥用?能干啥事?别急,听我慢慢道来。
+
+
+
+### 7.1. 选主
+
+还记得上面我们的所说的临时节点吗?因为 `Zookeeper` 的强一致性,能够很好地在保证 **在高并发的情况下保证节点创建的全局唯一性** (即无法重复创建同样的节点)。
+
+利用这个特性,我们可以 **让多个客户端创建一个指定的节点** ,创建成功的就是 `master`。
+
+但是,如果这个 `master` 挂了怎么办???
+
+你想想为什么我们要创建临时节点?还记得临时节点的生命周期吗?`master` 挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得 `watcher` 吗?我们是不是可以 **让其他不是 `master` 的节点监听节点的状态** ,比如说我们监听这个临时节点的父节点,如果子节点个数变了就代表 `master` 挂了,这个时候我们 **触发回调函数进行重新选举** ,或者我们直接监听节点的状态,我们可以通过节点是否已经失去连接来判断 `master` 是否挂了等等。
+
+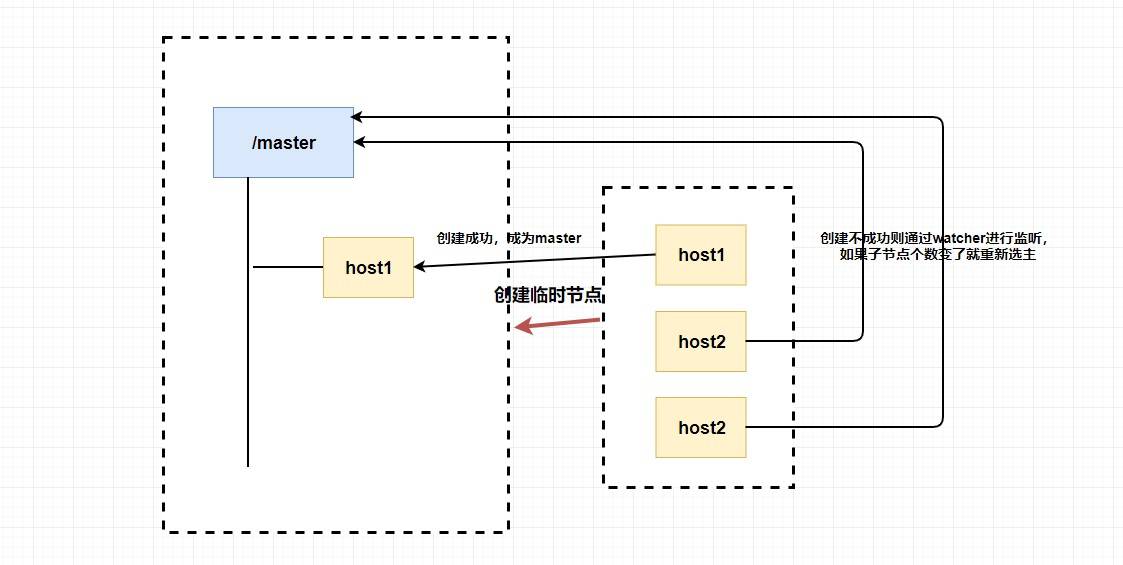
+
+总的来说,我们可以完全 **利用 临时节点、节点状态 和 `watcher` 来实现选主的功能**,临时节点主要用来选举,节点状态和`watcher` 可以用来判断 `master` 的活性和进行重新选举。
+
+### 7.2. 分布式锁
+
+分布式锁的实现方式有很多种,比如 `Redis` 、数据库 、`zookeeper` 等。个人认为 `zookeeper` 在实现分布式锁这方面是非常非常简单的。
+
+上面我们已经提到过了 **zk在高并发的情况下保证节点创建的全局唯一性**,这玩意一看就知道能干啥了。实现互斥锁呗,又因为能在分布式的情况下,所以能实现分布式锁呗。
+
+如何实现呢?这玩意其实跟选主基本一样,我们也可以利用临时节点的创建来实现。
+
+首先肯定是如何获取锁,因为创建节点的唯一性,我们可以让多个客户端同时创建一个临时节点,**创建成功的就说明获取到了锁** 。然后没有获取到锁的客户端也像上面选主的非主节点创建一个 `watcher` 进行节点状态的监听,如果这个互斥锁被释放了(可能获取锁的客户端宕机了,或者那个客户端主动释放了锁)可以调用回调函数重新获得锁。
+
+> `zk` 中不需要向 `redis` 那样考虑锁得不到释放的问题了,因为当客户端挂了,节点也挂了,锁也释放了。是不是很简答?
+
+那能不能使用 `zookeeper` 同时实现 **共享锁和独占锁** 呢?答案是可以的,不过稍微有点复杂而已。
+
+还记得 **有序的节点** 吗?
+
+这个时候我规定所有创建节点必须有序,当你是读请求(要获取共享锁)的话,如果 **没有比自己更小的节点,或比自己小的节点都是读请求** ,则可以获取到读锁,然后就可以开始读了。**若比自己小的节点中有写请求** ,则当前客户端无法获取到读锁,只能等待前面的写请求完成。
+
+如果你是写请求(获取独占锁),若 **没有比自己更小的节点** ,则表示当前客户端可以直接获取到写锁,对数据进行修改。若发现 **有比自己更小的节点,无论是读操作还是写操作,当前客户端都无法获取到写锁** ,等待所有前面的操作完成。
+
+这就很好地同时实现了共享锁和独占锁,当然还有优化的地方,比如当一个锁得到释放它会通知所有等待的客户端从而造成 **羊群效应** 。此时你可以通过让等待的节点只监听他们前面的节点。
+
+具体怎么做呢?其实也很简单,你可以让 **读请求监听比自己小的最后一个写请求节点,写请求只监听比自己小的最后一个节点** ,感兴趣的小伙伴可以自己去研究一下。
+
+### 7.3. 命名服务
+
+如何给一个对象设置ID,大家可能都会想到 `UUID`,但是 `UUID` 最大的问题就在于它太长了。。。(太长不一定是好事,嘿嘿嘿)。那么在条件允许的情况下,我们能不能使用 `zookeeper` 来实现呢?
+
+我们之前提到过 `zookeeper` 是通过 **树形结构** 来存储数据节点的,那也就是说,对于每个节点的 **全路径**,它必定是唯一的,我们可以使用节点的全路径作为命名方式了。而且更重要的是,路径是我们可以自己定义的,这对于我们对有些有语意的对象的ID设置可以更加便于理解。
+
+### 7.4. 集群管理和注册中心
+
+看到这里是不是觉得 `zookeeper` 实在是太强大了,它怎么能这么能干!
+
+别急,它能干的事情还很多呢。可能我们会有这样的需求,我们需要了解整个集群中有多少机器在工作,我们想对集群中的每台机器的运行时状态进行数据采集,对集群中机器进行上下线操作等等。
+
+而 `zookeeper` 天然支持的 `watcher` 和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的 `watcher` 进行状态监控和回调。
+
+
+
+至于注册中心也很简单,我们同样也是让 **服务提供者** 在 `zookeeper` 中创建一个临时节点并且将自己的 `ip、port、调用方式` 写入节点,当 **服务消费者** 需要进行调用的时候会 **通过注册中心找到相应的服务的地址列表(IP端口什么的)** ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
+
+当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,我记得 `Eureka` 会先试错,然后再更新)。
+
+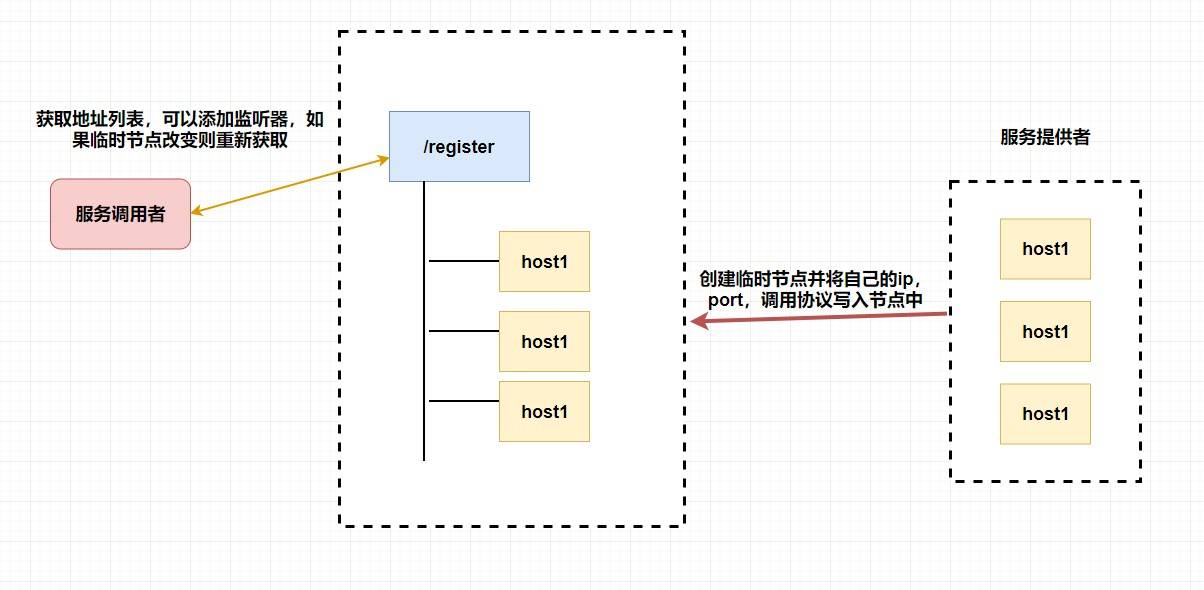
+
+## 8. 总结
+
+看到这里的同学实在是太有耐心了👍👍👍,如果觉得我写得不错的话点个赞哈。
+
+不知道大家是否还记得我讲了什么😒。
+
+
+
+这篇文章中我带大家入门了 `zookeeper` 这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
+
+* 分布式与集群的区别
+
+* `2PC` 、`3PC` 以及 `paxos` 算法这些一致性框架的原理和实现。
+
+* `zookeeper` 专门的一致性算法 `ZAB` 原子广播协议的内容(`Leader` 选举、崩溃恢复、消息广播)。
+
+* `zookeeper` 中的一些基本概念,比如 `ACL`,数据节点,会话,`watcher`机制等等。
+
+* `zookeeper` 的典型应用场景,比如选主,注册中心等等。
+
+ 如果忘了可以回去看看再次理解一下,如果有疑问和建议欢迎提出🤝🤝🤝。
diff --git "a/docs/distributed-system/\347\220\206\350\256\272&\347\256\227\346\263\225/cap&base\347\220\206\350\256\272.md" "b/docs/distributed-system/\347\220\206\350\256\272&\347\256\227\346\263\225/cap&base\347\220\206\350\256\272.md"
new file mode 100644
index 00000000000..3340409a799
--- /dev/null
+++ "b/docs/distributed-system/\347\220\206\350\256\272&\347\256\227\346\263\225/cap&base\347\220\206\350\256\272.md"
@@ -0,0 +1,157 @@
+
+# CAP & BASE理论
+
+经历过技术面试的小伙伴想必对这个两个概念已经再熟悉不过了!
+
+Guide哥当年参加面试的时候,不夸张地说,只要问到分布式相关的内容,面试官几乎是必定会问这两个分布式相关的理论。
+
+并且,这两个理论也可以说是小伙伴们学习分布式相关内容的基础了!
+
+因此,小伙伴们非常非常有必要将这理论搞懂,并且能够用自己的理解给别人讲出来。
+
+这篇文章我会站在自己的角度对这两个概念进行解读!
+
+*个人能力有限。如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!——爱你们的Guide哥*
+
+## CAP理论
+
+[CAP 理论/定理](https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86)起源于 2000年,由加州大学伯克利分校的Eric Brewer教授在分布式计算原理研讨会(PODC)上提出,因此 CAP定理又被称作 **布鲁尔定理(Brewer’s theorem)**
+
+2年后,麻省理工学院的Seth Gilbert和Nancy Lynch 发表了布鲁尔猜想的证明,CAP理论正式成为分布式领域的定理。
+
+### 简介
+
+**CAP** 也就是 **Consistency(一致性)**、**Availability(可用性)**、**Partition Tolerance(分区容错性)** 这三个单词首字母组合。
+
+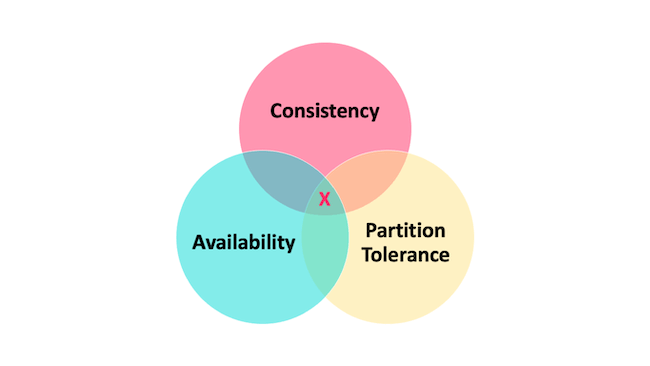
+
+CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细定义 **Consistency**、**Availability**、**Partition Tolerance** 三个单词的明确定义。
+
+因此,对于 CAP 的民间解读有很多,一般比较被大家推荐的是下面 👇 这种版本的解读。
+
+在理论计算机科学中,CAP 定理(CAP theorem)指出对于一个分布式系统来说,当设计读写操作时,只能同时满足以下三点中的两个:
+
+- **一致性(Consistency)** : 所有节点访问同一份最新的数据副本
+- **可用性(Availability)**: 非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应)。
+- **分区容错性(Partition tolerance)** : 分布式系统出现网络分区的时候,仍然能够对外提供服务。
+
+**什么是网络分区?**
+
+> 分布式系统中,多个节点之前的网络本来是连通的,但是因为某些故障(比如部分节点网络出了问题)某些节点之间不连通了,整个网络就分成了几块区域,这就叫网络分区。
+
+
+
+### 不是所谓的“3 选 2”
+
+大部分人解释这一定律时,常常简单的表述为:“一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到”。实际上这是一个非常具有误导性质的说法,而且在 CAP 理论诞生 12 年之后,CAP 之父也在 2012 年重写了之前的论文。
+
+> **当发生网络分区的时候,如果我们要继续服务,那么强一致性和可用性只能 2 选 1。也就是说当网络分区之后 P 是前提,决定了 P 之后才有 C 和 A 的选择。也就是说分区容错性(Partition tolerance)我们是必须要实现的。**
+>
+> 简而言之就是:CAP 理论中分区容错性 P 是一定要满足的,在此基础上,只能满足可用性 A 或者一致性 C。
+
+因此,**分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。** 比如 ZooKeeper、HBase 就是 CP 架构,Cassandra、Eureka 就是 AP 架构,Nacos 不仅支持 CP 架构也支持 AP 架构。
+
+**为啥不可能选择 CA 架构呢?** 举个例子:若系统出现“分区”,系统中的某个节点在进行写操作。为了保证 C, 必须要禁止其他节点的读写操作,这就和 A 发生冲突了。如果为了保证 A,其他节点的读写操作正常的话,那就和 C 发生冲突了。
+
+**选择 CP 还是 AP 的关键在于当前的业务场景,没有定论,比如对于需要确保强一致性的场景如银行一般会选择保证 CP 。**
+
+另外,需要补充说明的一点是: **如果网络分区正常的话(系统在绝大部分时候所处的状态),也就说不需要保证 P 的时候,C 和 A 能够同时保证。**
+
+### CAP 实际应用案例
+
+我这里以注册中心来探讨一下 CAP 的实际应用。考虑到很多小伙伴不知道注册中心是干嘛的,这里简单以 Dubbo 为例说一说。
+
+下图是 Dubbo 的架构图。**注册中心 Registry 在其中扮演了什么角色呢?提供了什么服务呢?**
+
+注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。
+
+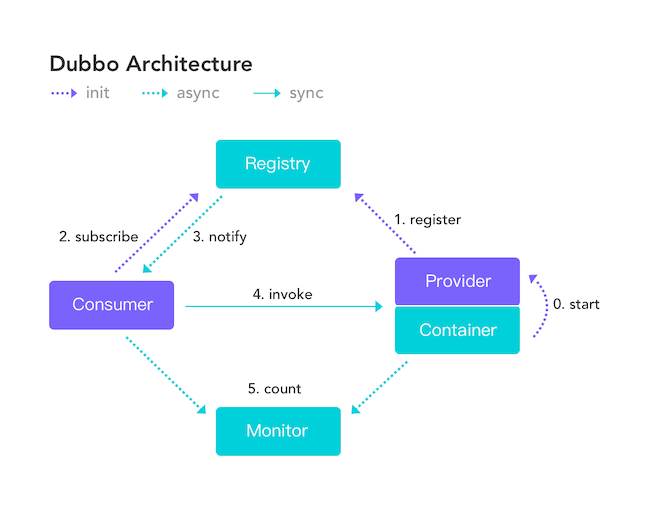
+
+常见的可以作为注册中心的组件有:ZooKeeper、Eureka、Nacos...。
+
+1. **ZooKeeper 保证的是 CP。** 任何时刻对 ZooKeeper 的读请求都能得到一致性的结果,但是, ZooKeeper 不保证每次请求的可用性比如在 Leader 选举过程中或者半数以上的机器不可用的时候服务就是不可用的。
+2. **Eureka 保证的则是 AP。** Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。
+3. **Nacos 不仅支持 CP 也支持 AP。**
+
+### 总结
+
+在进行分布式系统设计和开发时,我们不应该仅仅局限在 CAP 问题上,还要关注系统的扩展性、可用性等等
+
+在系统发生“分区”的情况下,CAP 理论只能满足 CP 或者 AP。要注意的是,这里的前提是系统发生了“分区”
+
+如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。
+
+总结:**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。**
+
+### 推荐阅读
+
+1. [CAP 定理简化](https://medium.com/@ravindraprasad/cap-theorem-simplified-28499a67eab4) (英文,有趣的案例)
+2. [神一样的 CAP 理论被应用在何方](https://juejin.im/post/6844903936718012430) (中文,列举了很多实际的例子)
+3. [请停止呼叫数据库 CP 或 AP ](https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.html) (英文,带给你不一样的思考)
+
+## BASE 理论
+
+[BASE 理论](https://dl.acm.org/doi/10.1145/1394127.1394128)起源于 2008 年, 由eBay的架构师Dan Pritchett在ACM上发表。
+
+### 简介
+
+**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
+
+### BASE 理论的核心思想
+
+即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
+
+> 也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。
+
+**BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。**
+
+**为什么这样说呢?**
+
+CAP 理论这节我们也说过了:
+
+> 如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。因此,**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。**
+
+因此,AP 方案只是在系统发生分区的时候放弃一致性,而不是永远放弃一致性。在分区故障恢复后,系统应该达到最终一致性。这一点其实就是 BASE 理论延伸的地方。
+
+### BASE 理论三要素
+
+
+
+#### 1. 基本可用
+
+基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。
+
+**什么叫允许损失部分可用性呢?**
+
+- **响应时间上的损失**: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。
+- **系统功能上的损失**:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
+
+#### 2. 软状态
+
+软状态指允许系统中的数据存在中间状态(**CAP 理论中的数据不一致**),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
+
+#### 3. 最终一致性
+
+最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
+
+> 分布式一致性的 3 种级别:
+>
+> 1. **强一致性** :系统写入了什么,读出来的就是什么。
+>
+> 2. **弱一致性** :不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
+>
+> 3. **最终一致性** :弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
+>
+> **业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。**
+
+那实现最终一致性的具体方式是什么呢? [《分布式协议与算法实战》](http://gk.link/a/10rZM) 中是这样介绍:
+
+> - **读时修复** : 在读取数据时,检测数据的不一致,进行修复。比如 Cassandra 的 Read Repair 实现,具体来说,在向 Cassandra 系统查询数据的时候,如果检测到不同节点 的副本数据不一致,系统就自动修复数据。
+> - **写时修复** : 在写入数据,检测数据的不一致时,进行修复。比如 Cassandra 的 Hinted Handoff 实现。具体来说,Cassandra 集群的节点之间远程写数据的时候,如果写失败 就将数据缓存下来,然后定时重传,修复数据的不一致性。
+> - **异步修复** : 这个是最常用的方式,通过定时对账检测副本数据的一致性,并修复。
+
+比较推荐 **写时修复**,这种方式对性能消耗比较低。
+
+### 总结
+
+**ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。**
diff --git "a/docs/distributed-system/\347\220\206\350\256\272&\347\256\227\346\263\225/paxos&raft\347\256\227\346\263\225.md" "b/docs/distributed-system/\347\220\206\350\256\272&\347\256\227\346\263\225/paxos&raft\347\256\227\346\263\225.md"
new file mode 100644
index 00000000000..36bd77241dd
--- /dev/null
+++ "b/docs/distributed-system/\347\220\206\350\256\272&\347\256\227\346\263\225/paxos&raft\347\256\227\346\263\225.md"
@@ -0,0 +1,4 @@
+# Paxos 算法和 Raft 算法
+
+Paxos 算法诞生于 1990 年,这是一种解决分布式系统一致性的经典算法 。但是,由于 Paxos 算法非常难以理解和实现,不断有人尝试简化这一算法。到了2013 年才诞生了一个比 Paxos 算法更易理解和实现的分布式一致性算法—Raft 算法。
+
diff --git a/docs/high-availability/limit-request.md b/docs/high-availability/limit-request.md
new file mode 100644
index 00000000000..1c611e55a41
--- /dev/null
+++ b/docs/high-availability/limit-request.md
@@ -0,0 +1,203 @@
+# 限流
+
+## 何为限流?为什么要限流?
+
+针对软件系统来说,限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。毕竟,软件系统的处理能力是有限的。如果说超过了其处理能力的范围,软件系统可能直接就挂掉了。
+
+限流可能会导致用户的请求无法被正确处理,不过,这往往也是权衡了软件系统的稳定性之后得到的最优解。
+
+现实生活中,处处都有限流的实际应用,就比如排队买票是为了避免大量用户涌入购票而导致售票员无法处理。
+
+
+
+## 常见限流算法
+
+简单介绍 4 种非常好理解并且容易实现的限流算法!
+
+> 图片来源于 InfoQ 的一篇文章[《分布式服务限流实战,已经为你排好坑了》](https://www.infoq.cn/article/Qg2tX8fyw5Vt-f3HH673)。
+
+### 固定窗口计数器算法
+
+固定窗口其实就是时间窗口。**固定窗口计数器算法** 规定了我们单位时间处理的请求数量。
+
+假如我们规定系统中某个接口 1 分钟只能访问 33 次的话,使用固定窗口计数器算法的实现思路如下:
+
+- 给定一个变量 `counter` 来记录当前接口处理的请求数量,初始值为 0(代表接口当前 1 分钟内还未处理请求)。
+- 1 分钟之内每处理一个请求之后就将 `counter+1` ,当 `counter=33` 之后(也就是说在这 1 分钟内接口已经被访问 33 次的话),后续的请求就会被全部拒绝。
+- 等到 1 分钟结束后,将 `counter` 重置 0,重新开始计数。
+
+**这种限流算法无法保证限流速率,因而无法保证突然激增的流量。**
+
+就比如说我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为 500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。然后,在当前场景下,这 1000 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
+
+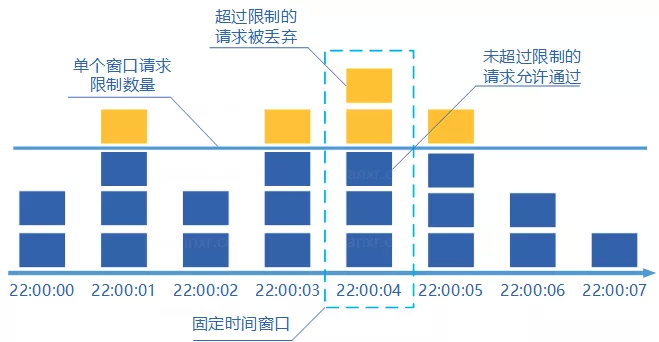
+
+### 滑动窗口计数器算法
+
+**滑动窗口计数器算法** 算的上是固定窗口计数器算法的升级版。
+
+滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:**它把时间以一定比例分片** 。
+
+例如我们的借口限流每分钟处理 60 个请求,我们可以把 1 分钟分为 60 个窗口。每隔 1 秒移动一次,每个窗口一秒只能处理 不大于 `60(请求数)/60(窗口数)` 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
+
+很显然, **当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。**
+
+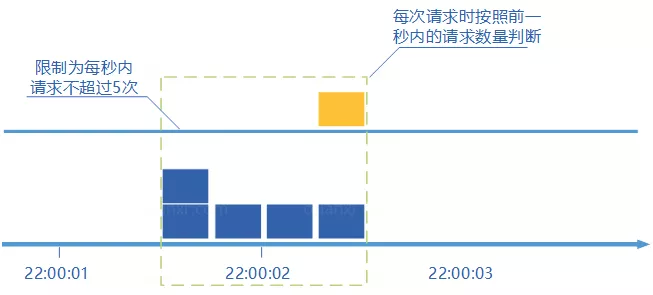
+
+### 漏桶算法
+
+我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
+
+如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了(和消息队列削峰/限流的思想是一样的)。
+
+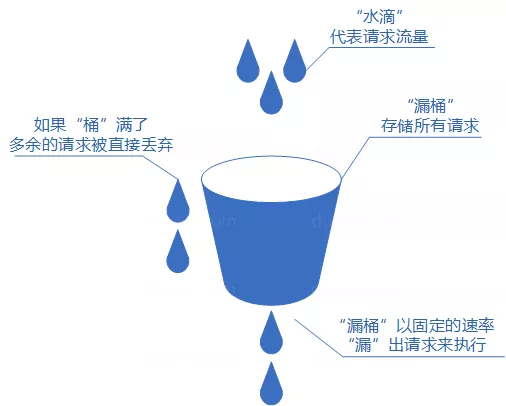
+
+### 令牌桶算法
+
+令牌桶算法也比较简单。和漏桶算法算法一样,我们的主角还是桶(这限流算法和桶过不去啊)。不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。如果桶装满了,就不能继续往里面继续添加令牌了。
+
+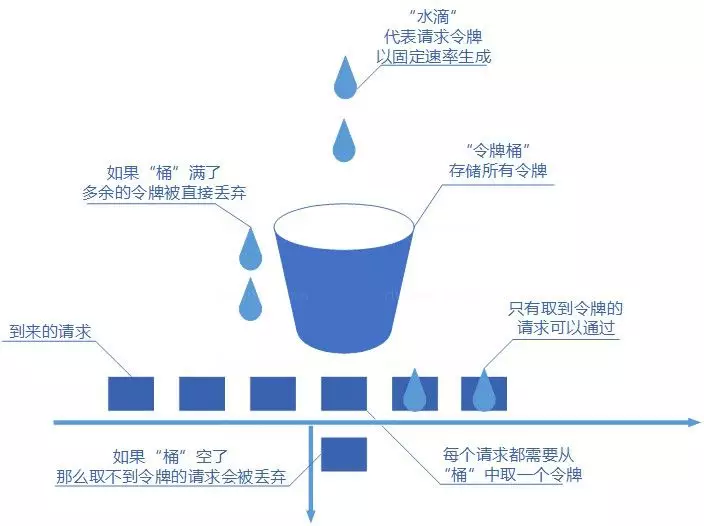
+
+## 单机限流
+
+单机限流可以直接使用 Google Guava 自带的限流工具类 `RateLimiter` 。 `RateLimiter` 基于令牌桶算法,可以应对突发流量。
+
+> Guava 地址:https://github.com/google/guava
+
+除了最基本的令牌桶算法(平滑突发限流)实现之外,Guava 的`RateLimiter`还提供了 **平滑预热限流** 的算法实现。
+
+平滑突发限流就是按照指定的速率放令牌到桶里,而平滑预热限流会有一段预热时间,预热时间之内,速率会逐渐提升到配置的速率。
+
+我们下面通过两个简单的小例子来详细了解吧!
+
+我们直接在项目中引入 Guava 相关的依赖即可使用。
+
+```xml
+<dependency>
+ <groupId>com.google.guava</groupId>
+ <artifactId>guava</artifactId>
+ <version>31.0.1-jre</version>
+</dependency>
+```
+
+下面是一个简单的 Guava 平滑突发限流的 Demo。
+
+```java
+import com.google.common.util.concurrent.RateLimiter;
+
+/**
+ * 微信搜 JavaGuide 回复"面试突击"即可免费领取个人原创的 Java 面试手册
+ *
+ * @author Guide哥
+ * @date 2021/10/08 19:12
+ **/
+public class RateLimiterDemo {
+
+ public static void main(String[] args) {
+ // 1s 放 5 个令牌到桶里也就是 0.2s 放 1个令牌到桶里
+ RateLimiter rateLimiter = RateLimiter.create(5);
+ for (int i = 0; i < 10; i++) {
+ double sleepingTime = rateLimiter.acquire(1);
+ System.out.printf("get 1 tokens: %ss%n", sleepingTime);
+ }
+ }
+}
+
+```
+
+输出:
+
+```bash
+get 1 tokens: 0.0s
+get 1 tokens: 0.188413s
+get 1 tokens: 0.197811s
+get 1 tokens: 0.198316s
+get 1 tokens: 0.19864s
+get 1 tokens: 0.199363s
+get 1 tokens: 0.193997s
+get 1 tokens: 0.199623s
+get 1 tokens: 0.199357s
+get 1 tokens: 0.195676s
+```
+
+下面是一个简单的 Guava 平滑预热限流的 Demo。
+
+```java
+import com.google.common.util.concurrent.RateLimiter;
+import java.util.concurrent.TimeUnit;
+
+/**
+ * 微信搜 JavaGuide 回复"面试突击"即可免费领取个人原创的 Java 面试手册
+ *
+ * @author Guide哥
+ * @date 2021/10/08 19:12
+ **/
+public class RateLimiterDemo {
+
+ public static void main(String[] args) {
+ // 1s 放 5 个令牌到桶里也就是 0.2s 放 1个令牌到桶里
+ // 预热时间为3s,也就说刚开始的 3s 内发牌速率会逐渐提升到 0.2s 放 1 个令牌到桶里
+ RateLimiter rateLimiter = RateLimiter.create(5, 3, TimeUnit.SECONDS);
+ for (int i = 0; i < 20; i++) {
+ double sleepingTime = rateLimiter.acquire(1);
+ System.out.printf("get 1 tokens: %sds%n", sleepingTime);
+ }
+ }
+}
+```
+
+输出:
+
+```bash
+get 1 tokens: 0.0s
+get 1 tokens: 0.561919s
+get 1 tokens: 0.516931s
+get 1 tokens: 0.463798s
+get 1 tokens: 0.41286s
+get 1 tokens: 0.356172s
+get 1 tokens: 0.300489s
+get 1 tokens: 0.252545s
+get 1 tokens: 0.203996s
+get 1 tokens: 0.198359s
+```
+
+另外,**Bucket4j** 是一个非常不错的基于令牌/漏桶算法的限流库。
+
+> Bucket4j 地址:https://github.com/vladimir-bukhtoyarov/bucket4j
+
+相对于,Guava 的限流工具类来说,Bucket4j 提供的限流功能更加全面。不仅支持单机限流和分布式限流,还可以集成监控,搭配 Prometheus 和 Grafana 使用。
+
+不过,毕竟 Guava 也只是一个功能全面的工具类库,其提供的开箱即用的限流功能在很多单机场景下还是比较实用的。
+
+Spring Cloud Gateway 中自带的单机限流的早期版本就是基于 Bucket4j 实现的。后来,替换成了 **Resilience4j**。
+
+Resilience4j 是一个轻量级的容错组件,其灵感来自于 Hystrix。自[Netflix 宣布不再积极开发 Hystrix](https://github.com/Netflix/Hystrix/commit/a7df971cbaddd8c5e976b3cc5f14013fe6ad00e6) 之后,Spring 官方和 Netflix 都更推荐使用 Resilience4j 来做限流熔断。
+
+> Resilience4j 地址: https://github.com/resilience4j/resilience4j
+
+一般情况下,为了保证系统的高可用,项目的限流和熔断都是要一起做的。
+
+Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重试等保障系统高可用开箱即用的功能。并且,Resilience4j 的生态也更好,很多网关都使用 Resilience4j 来做限流熔断的。
+
+因此,在绝大部分场景下 Resilience4j 或许会是更好的选择。如果是一些比较简单的限流场景的话,Guava 或者 Bucket4j 也是不错的选择。
+
+## 分布式限流
+
+分布式限流常见的方案:
+
+- **借助中间件架限流** :可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
+- **网关层限流** :比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现`RedisRateLimiter`就是基于 Redis+Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
+
+如果你要基于 Redis 来手动实现限流逻辑的话,建议配合 Lua 脚本来做。
+
+网上也有很多现成的脚本供你参考,就比如 Apache 网关项目 ShenYu 的 RateLimiter 限流插件就基于 Redis + Lua 实现了令牌桶算法/并发令牌桶算法、漏桶算法、滑动窗口算法。
+
+> ShenYu 地址: https://github.com/apache/incubator-shenyu
+
+
+
+## 相关阅读
+
+- 服务治理之轻量级熔断框架 Resilience4j :https://xie.infoq.cn/article/14786e571c1a4143ad1ef8f19
+- 超详细的 Guava RateLimiter 限流原理解析:https://cloud.tencent.com/developer/article/1408819
+- 实战 Spring Cloud Gateway 之限流篇 👍:https://www.aneasystone.com/archives/2020/08/spring-cloud-gateway-current-limiting.html
diff --git "a/docs/high-availability/\346\200\247\350\203\275\346\265\213\350\257\225.md" "b/docs/high-availability/\346\200\247\350\203\275\346\265\213\350\257\225.md"
new file mode 100644
index 00000000000..dc3ff9ba749
--- /dev/null
+++ "b/docs/high-availability/\346\200\247\350\203\275\346\265\213\350\257\225.md"
@@ -0,0 +1,150 @@
+# 性能测试入门
+
+性能测试一般情况下都是由测试这个职位去做的,那还需要我们开发学这个干嘛呢?了解性能测试的指标、分类以及工具等知识有助于我们更好地去写出性能更好的程序,另外作为开发这个角色,如果你会性能测试的话,相信也会为你的履历加分不少。
+
+这篇文章是我会结合自己的实际经历以及在测试这里取的经所得,除此之外,我还借鉴了一些优秀书籍,希望对你有帮助。
+
+本文思维导图:
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/网站性能测试.png" style="zoom:50%;" />
+
+## 一 不同角色看网站性能
+
+### 1.1 用户
+
+当用户打开一个网站的时候,最关注的是什么?当然是网站响应速度的快慢。比如我们点击了淘宝的主页,淘宝需要多久将首页的内容呈现在我的面前,我点击了提交订单按钮需要多久返回结果等等。
+
+所以,用户在体验我们系统的时候往往根据你的响应速度的快慢来评判你的网站的性能。
+
+### 1.2 开发人员
+
+用户与开发人员都关注速度,这个速度实际上就是我们的系统**处理用户请求的速度**。
+
+开发人员一般情况下很难直观的去评判自己网站的性能,我们往往会根据网站当前的架构以及基础设施情况给一个大概的值,比如:
+
+1. 项目架构是分布式的吗?
+2. 用到了缓存和消息队列没有?
+3. 高并发的业务有没有特殊处理?
+4. 数据库设计是否合理?
+5. 系统用到的算法是否还需要优化?
+6. 系统是否存在内存泄露的问题?
+7. 项目使用的 Redis 缓存多大?服务器性能如何?用的是机械硬盘还是固态硬盘?
+8. ......
+
+### 1.3 测试人员
+
+测试人员一般会根据性能测试工具来测试,然后一般会做出一个表格。这个表格可能会涵盖下面这些重要的内容:
+
+1. 响应时间;
+2. 请求成功率;
+3. 吞吐量;
+4. ......
+
+### 1.4 运维人员
+
+运维人员会倾向于根据基础设施和资源的利用率来判断网站的性能,比如我们的服务器资源使用是否合理、数据库资源是否存在滥用的情况、当然,这是传统的运维人员,现在 Devpos 火起来后,单纯干运维的很少了。我们这里暂且还保留有这个角色。
+
+## 二 性能测试需要注意的点
+
+几乎没有文章在讲性能测试的时候提到这个问题,大家都会讲如何去性能测试,有哪些性能测试指标这些东西。
+
+### 2.1 了解系统的业务场景
+
+**性能测试之前更需要你了解当前的系统的业务场景。** 对系统业务了解的不够深刻,我们很容易犯测试方向偏执的错误,从而导致我们忽略了对系统某些更需要性能测试的地方进行测试。比如我们的系统可以为用户提供发送邮件的功能,用户配置成功邮箱后只需输入相应的邮箱之后就能发送,系统每天大概能处理上万次发邮件的请求。很多人看到这个可能就直接开始使用相关工具测试邮箱发送接口,但是,发送邮件这个场景可能不是当前系统的性能瓶颈,这么多人用我们的系统发邮件, 还可能有很多人一起发邮件,单单这个场景就这么人用,那用户管理可能才是性能瓶颈吧!
+
+### 2.2 历史数据非常有用
+
+当前系统所留下的历史数据非常重要,一般情况下,我们可以通过相应的些历史数据初步判定这个系统哪些接口调用的比较多、哪些 service 承受的压力最大,这样的话,我们就可以针对这些地方进行更细致的性能测试与分析。
+
+另外,这些地方也就像这个系统的一个短板一样,优化好了这些地方会为我们的系统带来质的提升。
+
+### 三 性能测试的指标
+
+### 3.1 响应时间
+
+**响应时间就是用户发出请求到用户收到系统处理结果所需要的时间。** 重要吗?实在太重要!
+
+比较出名的 2-5-8 原则是这样描述的:通常来说,2到5秒,页面体验会比较好,5到8秒还可以接受,8秒以上基本就很难接受了。另外,据统计当网站慢一秒就会流失十分之一的客户。
+
+但是,在某些场景下我们也并不需要太看重 2-5-8 原则 ,比如我觉得系统导出导入大数据量这种就不需要,系统生成系统报告这种也不需要。
+
+### 3.2 并发数
+
+**并发数是系统能同时处理请求的数目即同时提交请求的用户数目。**
+
+不得不说,高并发是现在后端架构中非常非常火热的一个词了,这个与当前的互联网环境以及中国整体的互联网用户量都有很大关系。一般情况下,你的系统并发量越大,说明你的产品做的就越大。但是,并不是每个系统都需要达到像淘宝、12306 这种亿级并发量的。
+
+### 3.3 吞吐量
+
+吞吐量指的是系统单位时间内系统处理的请求数量。衡量吞吐量有几个重要的参数:QPS(TPS)、并发数、响应时间。
+
+1. QPS(Query Per Second):服务器每秒可以执行的查询次数;
+2. TPS(Transaction Per Second):服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
+3. 并发数;系统能同时处理请求的数目即同时提交请求的用户数目。
+4. 响应时间: 一般取多次请求的平均响应时间
+
+理清他们的概念,就很容易搞清楚他们之间的关系了。
+
+- **QPS(TPS)** = 并发数/平均响应时间
+- **并发数** = QPS\平均响应时间
+
+书中是这样描述 QPS 和 TPS 的区别的。
+
+> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器2次,一次访问,产生一个“T”,产生2个“Q”。
+
+### 3.4 性能计数器
+
+**性能计数器是描述服务器或者操作系统的一些数据指标如内存使用、CPU使用、磁盘与网络I/O等情况。**
+
+### 四 几种常见的性能测试
+
+### 性能测试
+
+性能测试方法是通过测试工具模拟用户请求系统,目的主要是为了测试系统的性能是否满足要求。通俗地说,这种方法就是要在特定的运行条件下验证系统的能力状态。
+
+性能测试是你在对系统性能已经有了解的前提之后进行的,并且有明确的性能指标。
+
+### 负载测试
+
+对被测试的系统继续加大请求压力,直到服务器的某个资源已经达到饱和了,比如系统的缓存已经不够用了或者系统的响应时间已经不满足要求了。
+
+负载测试说白点就是测试系统的上线。
+
+### 压力测试
+
+不去管系统资源的使用情况,对系统继续加大请求压力,直到服务器崩溃无法再继续提供服务。
+
+### 稳定性测试
+
+模拟真实场景,给系统一定压力,看看业务是否能稳定运行。
+
+## 五 常用性能测试工具
+
+这里就不多扩展了,有时间的话会单独拎一个熟悉的说一下。
+
+### 5.1 后端常用
+
+没记错的话,除了 LoadRunner 其他几款性能测试工具都是开源免费的。
+
+1. Jmeter :Apache JMeter 是 JAVA 开发的性能测试工具。
+2. LoadRunner:一款商业的性能测试工具。
+3. Galtling :一款基于Scala 开发的高性能服务器性能测试工具。
+4. ab :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
+
+### 5.2 前端常用
+
+1. Fiddler:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是Web 调试的利器。
+2. HttpWatch: 可用于录制HTTP请求信息的工具。
+
+## 六 常见的性能优化策略
+
+性能优化之前我们需要对请求经历的各个环节进行分析,排查出可能出现性能瓶颈的地方,定位问题。
+
+下面是一些性能优化时,我经常拿来自问的一些问题:
+
+1. 系统是否需要缓存?
+2. 系统架构本身是不是就有问题?
+3. 系统是否存在死锁的地方?
+4. 系统是否存在内存泄漏?(Java 的自动回收内存虽然很方便,但是,有时候代码写的不好真的会造成内存泄漏)
+5. 数据库索引使用是否合理?
+6. ......
\ No newline at end of file
diff --git "a/docs/high-availability/\347\201\276\345\244\207\350\256\276\350\256\241\345\222\214\345\274\202\345\234\260\345\244\232\346\264\273.md" "b/docs/high-availability/\347\201\276\345\244\207\350\256\276\350\256\241\345\222\214\345\274\202\345\234\260\345\244\232\346\264\273.md"
new file mode 100644
index 00000000000..18756b69127
--- /dev/null
+++ "b/docs/high-availability/\347\201\276\345\244\207\350\256\276\350\256\241\345\222\214\345\274\202\345\234\260\345\244\232\346\264\273.md"
@@ -0,0 +1,14 @@
+# 灾备设计&异地多活
+
+**灾备** = 容灾+备份。
+
+- **备份** : 将系统所产生的所有重要数据多备份几份。
+- **容灾** : 在异地建立两个完全相同的系统。当某个地方的系统突然挂掉,整个应用系统可以切换到另一个,这样系统就可以正常提供服务了。
+
+**异地多活** 描述的是将服务部署在异地并且服务同时对外提供服务。和传统的灾备设计的最主要区别在于“多活”,即所有站点都是同时在对外提供服务的。异地多活是为了应对突发状况比如火灾、地震等自然或者人为灾害。
+
+相关阅读:
+
+- [搞懂异地多活,看这篇就够了](https://mp.weixin.qq.com/s/T6mMDdtTfBuIiEowCpqu6Q)
+- [四步构建异地多活](https://mp.weixin.qq.com/s/hMD-IS__4JE5_nQhYPYSTg)
+- [《从零开始学架构》— 28 | 业务高可用的保障:异地多活架构](http://gk.link/a/10pKZ)
\ No newline at end of file
diff --git "a/docs/high-availability/\350\266\205\346\227\266\345\222\214\351\207\215\350\257\225\346\234\272\345\210\266.md" "b/docs/high-availability/\350\266\205\346\227\266\345\222\214\351\207\215\350\257\225\346\234\272\345\210\266.md"
new file mode 100644
index 00000000000..ee4f90f2056
--- /dev/null
+++ "b/docs/high-availability/\350\266\205\346\227\266\345\222\214\351\207\215\350\257\225\346\234\272\345\210\266.md"
@@ -0,0 +1,5 @@
+# 超时&重试机制
+
+**一旦用户的请求超过某个时间得不到响应就结束此次请求并抛出异常。** 如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法再处理请求。
+
+另外,重试的次数一般设为 3 次,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。
\ No newline at end of file
diff --git "a/docs/high-availability/\351\231\215\347\272\247&\347\206\224\346\226\255.md" "b/docs/high-availability/\351\231\215\347\272\247&\347\206\224\346\226\255.md"
new file mode 100644
index 00000000000..2ff7b922893
--- /dev/null
+++ "b/docs/high-availability/\351\231\215\347\272\247&\347\206\224\346\226\255.md"
@@ -0,0 +1,9 @@
+# 降级&熔断
+
+降级是从系统功能优先级的角度考虑如何应对系统故障。
+
+服务降级指的是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
+
+熔断和降级是两个比较容易混淆的概念,两者的含义并不相同。
+
+降级的目的在于应对系统自身的故障,而熔断的目的在于应对当前系统依赖的外部系统或者第三方系统的故障。
\ No newline at end of file
diff --git "a/docs/high-availability/\351\233\206\347\276\244.md" "b/docs/high-availability/\351\233\206\347\276\244.md"
new file mode 100644
index 00000000000..5da34020f32
--- /dev/null
+++ "b/docs/high-availability/\351\233\206\347\276\244.md"
@@ -0,0 +1,3 @@
+# 集群
+
+相同的服务部署多份,避免单点故障。
\ No newline at end of file
diff --git "a/docs/high-availability/\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\350\256\276\350\256\241.md" "b/docs/high-availability/\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\350\256\276\350\256\241.md"
new file mode 100644
index 00000000000..e336f676251
--- /dev/null
+++ "b/docs/high-availability/\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\350\256\276\350\256\241.md"
@@ -0,0 +1,70 @@
+# 高可用系统设计
+
+一篇短小的文章,面试经常遇到的这个问题。本文主要包括下面这些内容:
+
+1. 高可用的定义
+2. 哪些情况可能会导致系统不可用?
+3. 有哪些提高系统可用性的方法?只是简单的提一嘴,更具体内容在后续的文章中介绍,就拿限流来说,你需要搞懂:何为限流?如何限流?为什么要限流?如何做呢?说一下原理?。
+
+## 什么是高可用?可用性的判断标准是啥?
+
+**高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。**
+
+**一般情况下,我们使用多少个 9 来评判一个系统的可用性,比如 99.9999% 就是代表该系统在所有的运行时间中只有 0.0001% 的时间是不可用的,这样的系统就是非常非常高可用的了!当然,也会有系统如果可用性不太好的话,可能连 9 都上不了。**
+
+除此之外,系统的可用性还可以用某功能的失败次数与总的请求次数之比来衡量,比如对网站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。
+
+## 哪些情况会导致系统不可用?
+
+1. 黑客攻击;
+2. 硬件故障,比如服务器坏掉。
+3. 并发量/用户请求量激增导致整个服务宕掉或者部分服务不可用。
+4. 代码中的坏味道导致内存泄漏或者其他问题导致程序挂掉。
+5. 网站架构某个重要的角色比如 Nginx 或者数据库突然不可用。
+6. 自然灾害或者人为破坏。
+7. ......
+
+## 有哪些提高系统可用性的方法?
+
+### 1. 注重代码质量,测试严格把关
+
+我觉得这个是最最最重要的,代码质量有问题比如比较常见的内存泄漏、循环依赖都是对系统可用性极大的损害。大家都喜欢谈限流、降级、熔断,但是我觉得从代码质量这个源头把关是首先要做好的一件很重要的事情。如何提高代码质量?比较实际可用的就是 CodeReview,不要在乎每天多花的那 1 个小时左右的时间,作用可大着呢!
+
+另外,安利这个对提高代码质量有实际效果的宝贝:
+
+1. sonarqube :保证你写出更安全更干净的代码!(ps: 目前所在的项目基本都会用到这个插件)。
+2. Alibaba 开源的 Java 诊断工具 Arthas 也是很不错的选择。
+3. IDEA 自带的代码分析等工具进行代码扫描也是非常非常棒的。
+
+### 2.使用集群,减少单点故障
+
+先拿常用的 Redis 举个例子!我们如何保证我们的 Redis 缓存高可用呢?答案就是使用集群,避免单点故障。当我们使用一个 Redis 实例作为缓存的时候,这个 Redis 实例挂了之后,整个缓存服务可能就挂了。使用了集群之后,即使一台 Redis 实例挂了,不到一秒就会有另外一台 Redis 实例顶上。
+
+### 3.限流
+
+流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。——来自 alibaba-[Sentinel](https://github.com/alibaba/Sentinel "Sentinel") 的 wiki。
+
+### 4.超时和重试机制设置
+
+一旦用户请求超过某个时间的得不到响应,就抛出异常。这个是非常重要的,很多线上系统故障都是因为没有进行超时设置或者超时设置的方式不对导致的。我们在读取第三方服务的时候,尤其适合设置超时和重试机制。一般我们使用一些 RPC 框架的时候,这些框架都自带的超时重试的配置。如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法再处理请求。重试的次数一般设为 3 次,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。
+
+### 5.熔断机制
+
+超时和重试机制设置之外,熔断机制也是很重要的。 熔断机制说的是系统自动收集所依赖服务的资源使用情况和性能指标,当所依赖的服务恶化或者调用失败次数达到某个阈值的时候就迅速失败,让当前系统立即切换依赖其他备用服务。 比较常用的流量控制和熔断降级框架是 Netflix 的 Hystrix 和 alibaba 的 Sentinel。
+
+### 6.异步调用
+
+异步调用的话我们不需要关心最后的结果,这样我们就可以用户请求完成之后就立即返回结果,具体处理我们可以后续再做,秒杀场景用这个还是蛮多的。但是,使用异步之后我们可能需要 **适当修改业务流程进行配合**,比如**用户在提交订单之后,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**。除了可以在程序中实现异步之外,我们常常还使用消息队列,消息队列可以通过异步处理提高系统性能(削峰、减少响应所需时间)并且可以降低系统耦合性。
+
+### 7.使用缓存
+
+如果我们的系统属于并发量比较高的话,如果我们单纯使用数据库的话,当大量请求直接落到数据库可能数据库就会直接挂掉。使用缓存缓存热点数据,因为缓存存储在内存中,所以速度相当地快!
+
+### 8.其他
+
+1. **核心应用和服务优先使用更好的硬件**
+2. **监控系统资源使用情况增加报警设置。**
+3. **注意备份,必要时候回滚。**
+4. **灰度发布:** 将服务器集群分成若干部分,每天只发布一部分机器,观察运行稳定没有故障,第二天继续发布一部分机器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可
+5. **定期检查/更换硬件:** 如果不是购买的云服务的话,定期还是需要对硬件进行一波检查的,对于一些需要更换或者升级的硬件,要及时更换或者升级。
+6. .....(想起来再补充!也欢迎各位欢迎补充!)
diff --git "a/docs/high-performance/message-queue/kafka\347\237\245\350\257\206\347\202\271&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/high-performance/message-queue/kafka\347\237\245\350\257\206\347\202\271&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..8cea44f2225
--- /dev/null
+++ "b/docs/high-performance/message-queue/kafka\347\237\245\350\257\206\347\202\271&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -0,0 +1,222 @@
+
+# Kafka知识点&面试题总结
+
+### Kafka 是什么?主要应用场景有哪些?
+
+Kafka 是一个分布式流式处理平台。这到底是什么意思呢?
+
+流平台具有三个关键功能:
+
+1. **消息队列**:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
+2. **容错的持久方式存储记录消息流**: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
+3. **流式处理平台:** 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
+
+Kafka 主要有两大应用场景:
+
+1. **消息队列** :建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
+2. **数据处理:** 构建实时的流数据处理程序来转换或处理数据流。
+
+### 和其他消息队列相比,Kafka的优势在哪里?
+
+我们现在经常提到 Kafka 的时候就已经默认它是一个非常优秀的消息队列了,我们也会经常拿它跟 RocketMQ、RabbitMQ 对比。我觉得 Kafka 相比其他消息队列主要的优势如下:
+
+1. **极致的性能** :基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
+2. **生态系统兼容性无可匹敌** :Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
+
+实际上在早期的时候 Kafka 并不是一个合格的消息队列,早期的 Kafka 在消息队列领域就像是一个衣衫褴褛的孩子一样,功能不完备并且有一些小问题比如丢失消息、不保证消息可靠性等等。当然,这也和 LinkedIn 最早开发 Kafka 用于处理海量的日志有很大关系,哈哈哈,人家本来最开始就不是为了作为消息队列滴,谁知道后面误打误撞在消息队列领域占据了一席之地。
+
+随着后续的发展,这些短板都被 Kafka 逐步修复完善。所以,**Kafka 作为消息队列不可靠这个说法已经过时!**
+
+### 队列模型了解吗?Kafka 的消息模型知道吗?
+
+> 题外话:早期的 JMS 和 AMQP 属于消息服务领域权威组织所做的相关的标准,我在 [JavaGuide](https://github.com/Snailclimb/JavaGuide)的 [《消息队列其实很简单》](https://github.com/Snailclimb/JavaGuide#%E6%95%B0%E6%8D%AE%E9%80%9A%E4%BF%A1%E4%B8%AD%E9%97%B4%E4%BB%B6)这篇文章中介绍过。但是,这些标准的进化跟不上消息队列的演进速度,这些标准实际上已经属于废弃状态。所以,可能存在的情况是:不同的消息队列都有自己的一套消息模型。
+
+#### 队列模型:早期的消息模型
+
+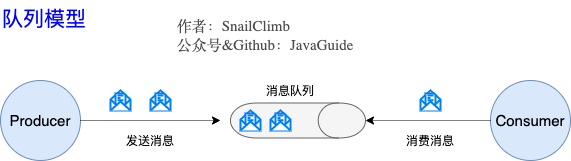
+
+**使用队列(Queue)作为消息通信载体,满足生产者与消费者模式,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。** 比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
+
+**队列模型存在的问题:**
+
+假如我们存在这样一种情况:我们需要将生产者产生的消息分发给多个消费者,并且每个消费者都能接收到完整的消息内容。
+
+这种情况,队列模型就不好解决了。很多比较杠精的人就说:我们可以为每个消费者创建一个单独的队列,让生产者发送多份。这是一种非常愚蠢的做法,浪费资源不说,还违背了使用消息队列的目的。
+
+#### 发布-订阅模型:Kafka 消息模型
+
+发布-订阅模型主要是为了解决队列模型存在的问题。
+
+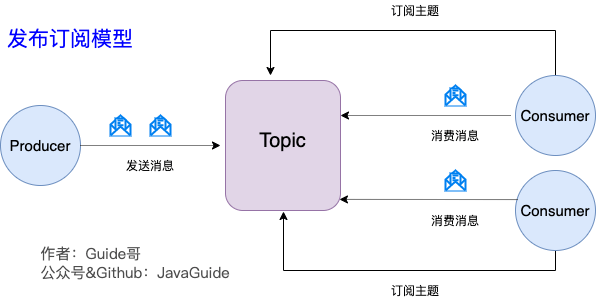
+
+发布订阅模型(Pub-Sub) 使用**主题(Topic)** 作为消息通信载体,类似于**广播模式**;发布者发布一条消息,该消息通过主题传递给所有的订阅者,**在一条消息广播之后才订阅的用户则是收不到该条消息的**。
+
+**在发布 - 订阅模型中,如果只有一个订阅者,那它和队列模型就基本是一样的了。所以说,发布 - 订阅模型在功能层面上是可以兼容队列模型的。**
+
+**Kafka 采用的就是发布 - 订阅模型。**
+
+> **RocketMQ 的消息模型和 Kafka 基本是完全一样的。唯一的区别是 Kafka 中没有队列这个概念,与之对应的是 Partition(分区)。**
+
+### 什么是Producer、Consumer、Broker、Topic、Partition?
+
+Kafka 将生产者发布的消息发送到 **Topic(主题)** 中,需要这些消息的消费者可以订阅这些 **Topic(主题)**,如下图所示:
+
+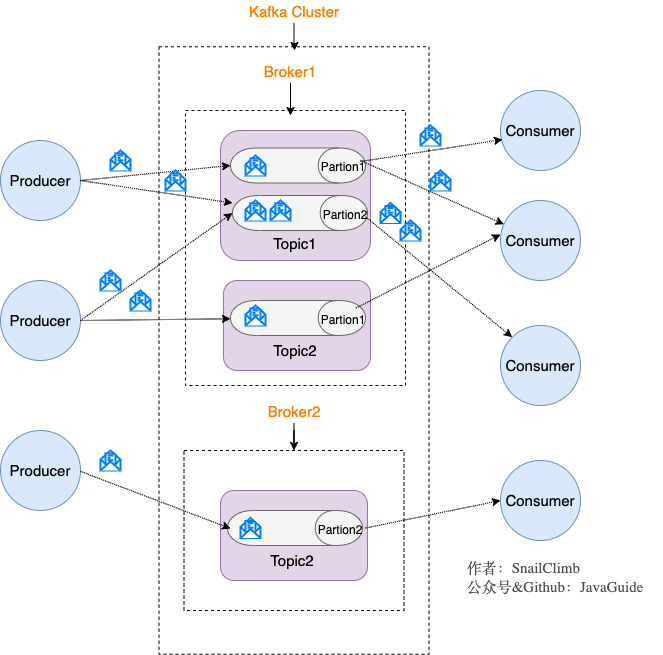
+
+上面这张图也为我们引出了,Kafka 比较重要的几个概念:
+
+1. **Producer(生产者)** : 产生消息的一方。
+2. **Consumer(消费者)** : 消费消息的一方。
+3. **Broker(代理)** : 可以看作是一个独立的 Kafka 实例。多个 Kafka Broker 组成一个 Kafka Cluster。
+
+同时,你一定也注意到每个 Broker 中又包含了 Topic 以及 Partition 这两个重要的概念:
+
+- **Topic(主题)** : Producer 将消息发送到特定的主题,Consumer 通过订阅特定的 Topic(主题) 来消费消息。
+- **Partition(分区)** : Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker 。这正如我上面所画的图一样。
+
+> 划重点:**Kafka 中的 Partition(分区) 实际上可以对应成为消息队列中的队列。这样是不是更好理解一点?**
+
+### Kafka 的多副本机制了解吗?带来了什么好处?
+
+还有一点我觉得比较重要的是 Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。
+
+> 生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。当 leader 副本发生故障时会从 follower 中选举出一个 leader,但是 follower 中如果有和 leader 同步程度达不到要求的参加不了 leader 的竞选。
+
+**Kafka 的多分区(Partition)以及多副本(Replica)机制有什么好处呢?**
+
+1. Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。
+2. Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
+
+### Zookeeper 在 Kafka 中的作用知道吗?
+
+> **要想搞懂 zookeeper 在 Kafka 中的作用 一定要自己搭建一个 Kafka 环境然后自己进 zookeeper 去看一下有哪些文件夹和 Kafka 有关,每个节点又保存了什么信息。** 一定不要光看不实践,这样学来的也终会忘记!这部分内容参考和借鉴了这篇文章:https://www.jianshu.com/p/a036405f989c 。
+
+
+
+下图就是我的本地 Zookeeper ,它成功和我本地的 Kafka 关联上(以下文件夹结构借助 idea 插件 Zookeeper tool 实现)。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/zookeeper-kafka.jpg" style="zoom:50%;" />
+
+ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
+
+从图中我们可以看出,Zookeeper 主要为 Kafka 做了下面这些事情:
+
+1. **Broker 注册** :在 Zookeeper 上会有一个专门**用来进行 Broker 服务器列表记录**的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 `/brokers/ids` 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
+2. **Topic 注册** : 在 Kafka 中,同一个**Topic 的消息会被分成多个分区**并将其分布在多个 Broker 上,**这些分区信息及与 Broker 的对应关系**也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:`/brokers/topics/my-topic/Partitions/0`、`/brokers/topics/my-topic/Partitions/1`
+3. **负载均衡** :上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
+4. ......
+
+### Kafka 如何保证消息的消费顺序?
+
+我们在使用消息队列的过程中经常有业务场景需要严格保证消息的消费顺序,比如我们同时发了 2 个消息,这 2 个消息对应的操作分别对应的数据库操作是:
+
+1. 更改用户会员等级。
+2. 根据会员等级计算订单价格。
+
+假如这两条消息的消费顺序不一样造成的最终结果就会截然不同。
+
+我们知道 Kafka 中 Partition(分区)是真正保存消息的地方,我们发送的消息都被放在了这里。而我们的 Partition(分区) 又存在于 Topic(主题) 这个概念中,并且我们可以给特定 Topic 指定多个 Partition。
+
+
+
+每次添加消息到 Partition(分区) 的时候都会采用尾加法,如上图所示。 **Kafka 只能为我们保证 Partition(分区) 中的消息有序。**
+
+> 消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。Kafka 通过偏移量(offset)来保证消息在分区内的顺序性。
+
+所以,我们就有一种很简单的保证消息消费顺序的方法:**1 个 Topic 只对应一个 Partition**。这样当然可以解决问题,但是破坏了 Kafka 的设计初衷。
+
+Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data(数据) 4 个参数。如果你发送消息的时候指定了 Partition 的话,所有消息都会被发送到指定的 Partition。并且,同一个 key 的消息可以保证只发送到同一个 partition,这个我们可以采用表/对象的 id 来作为 key 。
+
+总结一下,对于如何保证 Kafka 中消息消费的顺序,有了下面两种方法:
+
+1. 1 个 Topic 只对应一个 Partition。
+2. (推荐)发送消息的时候指定 key/Partition。
+
+当然不仅仅只有上面两种方法,上面两种方法是我觉得比较好理解的,
+
+### Kafka 如何保证消息不丢失
+
+#### 生产者丢失消息的情况
+
+生产者(Producer) 调用`send`方法发送消息之后,消息可能因为网络问题并没有发送过去。
+
+所以,我们不能默认在调用`send`方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 `send` 方法发送消息实际上是异步的操作,我们可以通过 `get()`方法获取调用结果,但是这样也让它变为了同步操作,示例代码如下:
+
+> **详细代码见我的这篇文章:[Kafka系列第三篇!10 分钟学会如何在 Spring Boot 程序中使用 Kafka 作为消息队列?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486269&idx=2&sn=ec00417ad641dd8c3d145d74cafa09ce&chksm=cea244f6f9d5cde0c8eb233fcc4cf82e11acd06446719a7af55230649863a3ddd95f78d111de&token=1633957262&lang=zh_CN#rd)**
+
+```java
+SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get();
+if (sendResult.getRecordMetadata() != null) {
+ logger.info("生产者成功发送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendRe
+ sult.getProducerRecord().value().toString());
+}
+```
+
+但是一般不推荐这么做!可以采用为其添加回调函数的形式,示例代码如下:
+
+````java
+ ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);
+ future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),
+ ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
+````
+
+如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
+
+**另外这里推荐为 Producer 的`retries `(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你3次一下子就重试完了**
+
+#### 消费者丢失消息的情况
+
+我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
+
+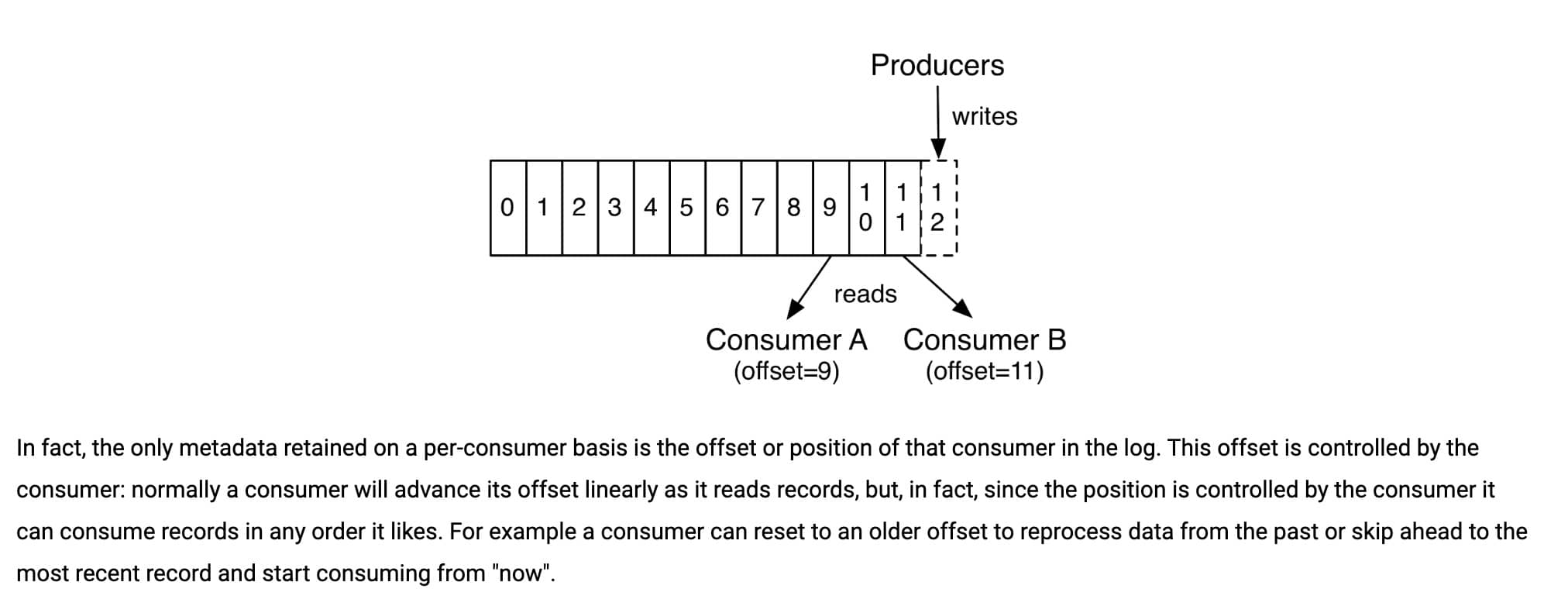
+
+当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
+
+**解决办法也比较粗暴,我们手动关闭自动提交 offset,每次在真正消费完消息之后再自己手动提交 offset 。** 但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
+
+#### Kafka 弄丢了消息
+
+ 我们知道 Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。
+
+**试想一种情况:假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被 follower 副本的同步的话,就会造成消息丢失。**
+
+**设置 acks = all**
+
+解决办法就是我们设置 **acks = all**。acks 是 Kafka 生产者(Producer) 很重要的一个参数。
+
+acks 的默认值即为1,代表我们的消息被leader副本接收之后就算被成功发送。当我们配置 **acks = all** 代表则所有副本都要接收到该消息之后该消息才算真正成功被发送。
+
+**设置 replication.factor >= 3**
+
+为了保证 leader 副本能有 follower 副本能同步消息,我们一般会为 topic 设置 **replication.factor >= 3**。这样就可以保证每个 分区(partition) 至少有 3 个副本。虽然造成了数据冗余,但是带来了数据的安全性。
+
+**设置 min.insync.replicas > 1**
+
+一般情况下我们还需要设置 **min.insync.replicas> 1** ,这样配置代表消息至少要被写入到 2 个副本才算是被成功发送。**min.insync.replicas** 的默认值为 1 ,在实际生产中应尽量避免默认值 1。
+
+但是,为了保证整个 Kafka 服务的高可用性,你需要确保 **replication.factor > min.insync.replicas** 。为什么呢?设想一下假如两者相等的话,只要是有一个副本挂掉,整个分区就无法正常工作了。这明显违反高可用性!一般推荐设置成 **replication.factor = min.insync.replicas + 1**。
+
+**设置 unclean.leader.election.enable = false**
+
+> **Kafka 0.11.0.0版本开始 unclean.leader.election.enable 参数的默认值由原来的true 改为false**
+
+我们最开始也说了我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。多个 follower 副本之间的消息同步情况不一样,当我们配置了 **unclean.leader.election.enable = false** 的话,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
+
+### Kafka 如何保证消息不重复消费
+
+**kafka出现消息重复消费的原因:**
+
+- 服务端侧已经消费的数据没有成功提交 offset(根本原因)。
+- Kafka 侧 由于服务端处理业务时间长或者网络链接等等原因让 Kafka 认为服务假死,触发了分区 rebalance。
+
+**解决方案:**
+
+- 消费消息服务做幂等校验,比如 Redis 的set、MySQL 的主键等天然的幂等功能。这种方法最有效。
+- 将 **`enable.auto.commit`** 参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:**什么时候提交offset合适?**
+ * 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
+ * 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
+
+### Reference
+
+- Kafka 官方文档: https://kafka.apache.org/documentation/
+- 极客时间—《Kafka核心技术与实战》第11节:无消息丢失配置怎么实现?
diff --git a/docs/high-performance/message-queue/message-queue.md b/docs/high-performance/message-queue/message-queue.md
new file mode 100644
index 00000000000..161bd5a021d
--- /dev/null
+++ b/docs/high-performance/message-queue/message-queue.md
@@ -0,0 +1,138 @@
+# 消息队列知识点&面试题总结
+
+“RabbitMQ?”“Kafka?”“RocketMQ?”...在日常学习与开发过程中,我们常常听到消息队列这个关键词。我也在我的多篇文章中提到了这个概念。可能你是熟练使用消息队列的老手,又或者你是不懂消息队列的新手,不论你了不了解消息队列,本文都将带你搞懂消息队列的一些基本理论。如果你是老手,你可能从本文学到你之前不曾注意的一些关于消息队列的重要概念,如果你是新手,相信本文将是你打开消息队列大门的一板砖。
+
+## 一 什么是消息队列
+
+我们可以把消息队列看作是一个存放消息的容器,当我们需要使用消息的时候,直接从容器中取出消息供自己使用即可。
+
+
+
+消息队列是分布式系统中重要的组件之一。使用消息队列主要是为了通过异步处理提高系统性能和削峰、降低系统耦合性。
+
+我们知道队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。
+
+## 二 为什么要用消息队列
+
+通常来说,使用消息队列能为我们的系统带来下面三点好处:
+
+1. **通过异步处理提高系统性能(减少响应所需时间)。**
+2. **削峰/限流**
+3. **降低系统耦合性。**
+
+如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
+
+《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。
+
+### 2.1 通过异步处理提高系统性能(减少响应所需时间)
+
+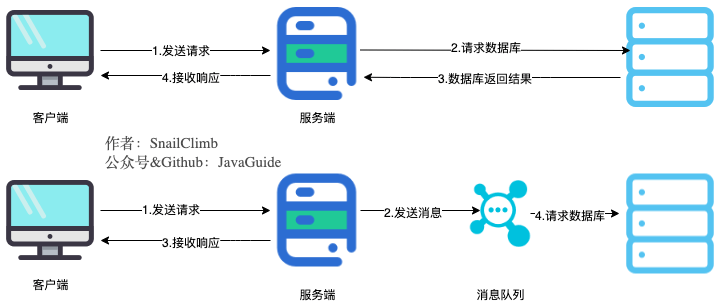
+
+将用户的请求数据存储到消息队列之后就立即返回结果。随后,系统再对消息进行消费。
+
+因为用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败。因此,**使用消息队列进行异步处理之后,需要适当修改业务流程进行配合**,比如用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
+
+### 2.2 削峰/限流
+
+**先将短时间高并发产生的事务消息存储在消息队列中,然后后端服务再慢慢根据自己的能力去消费这些消息,这样就避免直接把后端服务打垮掉。**
+
+举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
+
+
+
+### 2.3 降低系统耦合性
+
+使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
+
+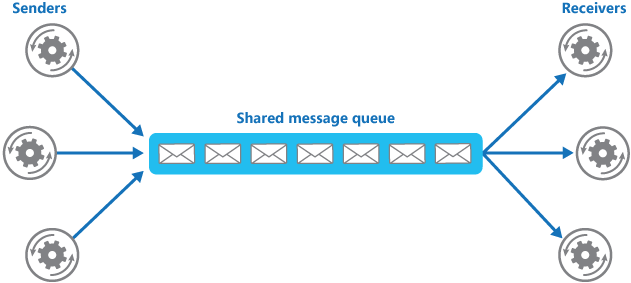
+
+生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
+
+**消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
+
+消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
+
+另外,为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。
+
+**备注:** 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的。除了发布-订阅模式,还有点对点订阅模式(一个消息只有一个消费者),我们比较常用的是发布-订阅模式。另外,这两种消息模型是 JMS 提供的,AMQP 协议还提供了 5 种消息模型。
+
+## 三 使用消息队列带来的一些问题
+
+- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
+- **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
+- **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
+
+## 四 JMS VS AMQP
+
+### 4.1 JMS
+
+#### 4.1.1 JMS 简介
+
+JMS(JAVA Message Service,java 消息服务)是 java 的消息服务,JMS 的客户端之间可以通过 JMS 服务进行异步的消息传输。**JMS(JAVA Message Service,Java 消息服务)API 是一个消息服务的标准或者说是规范**,允许应用程序组件基于 JavaEE 平台创建、发送、接收和读取消息。它使分布式通信耦合度更低,消息服务更加可靠以及异步性。
+
+**ActiveMQ 就是基于 JMS 规范实现的。**
+
+#### 4.1.2 JMS 两种消息模型
+
+**① 点到点(P2P)模型**
+
+
+
+使用**队列(Queue)**作为消息通信载体;满足**生产者与消费者模式**,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
+
+**② 发布/订阅(Pub/Sub)模型**
+
+
+
+发布订阅模型(Pub/Sub) 使用**主题(Topic)**作为消息通信载体,类似于**广播模式**;发布者发布一条消息,该消息通过主题传递给所有的订阅者,**在一条消息广播之后才订阅的用户则是收不到该条消息的**。
+
+#### 4.1.3 JMS 五种不同的消息正文格式
+
+JMS 定义了五种不同的消息正文格式,以及调用的消息类型,允许你发送并接收以一些不同形式的数据,提供现有消息格式的一些级别的兼容性。
+
+- StreamMessage -- Java 原始值的数据流
+- MapMessage--一套名称-值对
+- TextMessage--一个字符串对象
+- ObjectMessage--一个序列化的 Java 对象
+- BytesMessage--一个字节的数据流
+
+### 4.2 AMQP
+
+AMQP,即 Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准 **高级消息队列协议**(二进制应用层协议),是应用层协议的一个开放标准,为面向消息的中间件设计,兼容 JMS。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件同产品,不同的开发语言等条件的限制。
+
+**RabbitMQ 就是基于 AMQP 协议实现的。**
+
+### 4.3 JMS vs AMQP
+
+| 对比方向 | JMS | AMQP |
+| :----------- | :-------------------------------------- | :----------------------------------------------------------- |
+| 定义 | Java API | 协议 |
+| 跨语言 | 否 | 是 |
+| 跨平台 | 否 | 是 |
+| 支持消息类型 | 提供两种消息模型:①Peer-2-Peer;②Pub/sub | 提供了五种消息模型:①direct exchange;②fanout exchange;③topic change;④headers exchange;⑤system exchange。本质来讲,后四种和 JMS 的 pub/sub 模型没有太大差别,仅是在路由机制上做了更详细的划分; |
+| 支持消息类型 | 支持多种消息类型 ,我们在上面提到过 | byte[](二进制) |
+
+**总结:**
+
+- AMQP 为消息定义了线路层(wire-level protocol)的协议,而 JMS 所定义的是 API 规范。在 Java 体系中,多个 client 均可以通过 JMS 进行交互,不需要应用修改代码,但是其对跨平台的支持较差。而 AMQP 天然具有跨平台、跨语言特性。
+- JMS 支持 TextMessage、MapMessage 等复杂的消息类型;而 AMQP 仅支持 byte[] 消息类型(复杂的类型可序列化后发送)。
+- 由于 Exchange 提供的路由算法,AMQP 可以提供多样化的路由方式来传递消息到消息队列,而 JMS 仅支持 队列 和 主题/订阅 方式两种。
+
+## 五 常见的消息队列对比
+
+| 对比方向 | 概要 |
+| -------- | ------------------------------------------------------------ |
+| 吞吐量 | 万级的 ActiveMQ 和 RabbitMQ 的吞吐量(ActiveMQ 的性能最差)要比 十万级甚至是百万级的 RocketMQ 和 Kafka 低一个数量级。 |
+| 可用性 | 都可以实现高可用。ActiveMQ 和 RabbitMQ 都是基于主从架构实现高可用性。RocketMQ 基于分布式架构。 kafka 也是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
+| 时效性 | RabbitMQ 基于 erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。其他三个都是 ms 级。 |
+| 功能支持 | 除了 Kafka,其他三个功能都较为完备。 Kafka 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
+| 消息丢失 | ActiveMQ 和 RabbitMQ 丢失的可能性非常低, RocketMQ 和 Kafka 理论上不会丢失。 |
+
+**总结:**
+
+- ActiveMQ 的社区算是比较成熟,但是较目前来说,ActiveMQ 的性能比较差,而且版本迭代很慢,不推荐使用。
+- RabbitMQ 在吞吐量方面虽然稍逊于 Kafka 和 RocketMQ ,但是由于它基于 erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。但是也因为 RabbitMQ 基于 erlang 开发,所以国内很少有公司有实力做 erlang 源码级别的研究和定制。如果业务场景对并发量要求不是太高(十万级、百万级),那这四种消息队列中,RabbitMQ 一定是你的首选。如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
+- RocketMQ 阿里出品,Java 系开源项目,源代码我们可以直接阅读,然后可以定制自己公司的 MQ,并且 RocketMQ 有阿里巴巴的实际业务场景的实战考验。RocketMQ 社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用 RocketMQ 挺好的
+- Kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。
+
+参考:《Java 工程师面试突击第 1 季-中华石杉老师》
\ No newline at end of file
diff --git a/docs/high-performance/message-queue/rabbitmq-intro.md b/docs/high-performance/message-queue/rabbitmq-intro.md
new file mode 100644
index 00000000000..d676114c8e6
--- /dev/null
+++ b/docs/high-performance/message-queue/rabbitmq-intro.md
@@ -0,0 +1,304 @@
+
+# RabbitMQ 入门总结
+
+## 一 RabbitMQ 介绍
+
+这部分参考了 《RabbitMQ实战指南》这本书的第 1 章和第 2 章。
+
+### 1.1 RabbitMQ 简介
+
+RabbitMQ 是采用 Erlang 语言实现 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)的消息中间件,它最初起源于金融系统,用于在分布式系统中存储转发消息。
+
+RabbitMQ 发展到今天,被越来越多的人认可,这和它在易用性、扩展性、可靠性和高可用性等方面的卓著表现是分不开的。RabbitMQ 的具体特点可以概括为以下几点:
+
+- **可靠性:** RabbitMQ使用一些机制来保证消息的可靠性,如持久化、传输确认及发布确认等。
+- **灵活的路由:** 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能,RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起,也可以通过插件机制来实现自己的交换器。这个后面会在我们讲 RabbitMQ 核心概念的时候详细介绍到。
+- **扩展性:** 多个RabbitMQ节点可以组成一个集群,也可以根据实际业务情况动态地扩展集群中节点。
+- **高可用性:** 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队列仍然可用。
+- **支持多种协议:** RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP、MQTT 等多种消息中间件协议。
+- **多语言客户端:** RabbitMQ几乎支持所有常用语言,比如 Java、Python、Ruby、PHP、C#、JavaScript等。
+- **易用的管理界面:** RabbitMQ提供了一个易用的用户界面,使得用户可以监控和管理消息、集群中的节点等。在安装 RabbitMQ 的时候会介绍到,安装好 RabbitMQ 就自带管理界面。
+- **插件机制:** RabbitMQ 提供了许多插件,以实现从多方面进行扩展,当然也可以编写自己的插件。感觉这个有点类似 Dubbo 的 SPI机制。
+
+### 1.2 RabbitMQ 核心概念
+
+RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。可以把消息传递的过程想象成:当你将一个包裹送到邮局,邮局会暂存并最终将邮件通过邮递员送到收件人的手上,RabbitMQ就好比由邮局、邮箱和邮递员组成的一个系统。从计算机术语层面来说,RabbitMQ 模型更像是一种交换机模型。
+
+下面再来看看图1—— RabbitMQ 的整体模型架构。
+
+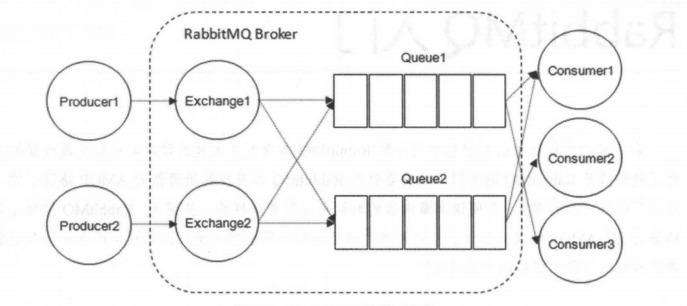
+
+下面我会一一介绍上图中的一些概念。
+
+#### 1.2.1 Producer(生产者) 和 Consumer(消费者)
+
+- **Producer(生产者)** :生产消息的一方(邮件投递者)
+- **Consumer(消费者)** :消费消息的一方(邮件收件人)
+
+消息一般由 2 部分组成:**消息头**(或者说是标签 Label)和 **消息体**。消息体也可以称为 payLoad ,消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括 routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。生产者把消息交由 RabbitMQ 后,RabbitMQ 会根据消息头把消息发送给感兴趣的 Consumer(消费者)。
+
+#### 1.2.2 Exchange(交换器)
+
+在 RabbitMQ 中,消息并不是直接被投递到 **Queue(消息队列)** 中的,中间还必须经过 **Exchange(交换器)** 这一层,**Exchange(交换器)** 会把我们的消息分配到对应的 **Queue(消息队列)** 中。
+
+**Exchange(交换器)** 用来接收生产者发送的消息并将这些消息路由给服务器中的队列中,如果路由不到,或许会返回给 **Producer(生产者)** ,或许会被直接丢弃掉 。这里可以将RabbitMQ中的交换器看作一个简单的实体。
+
+**RabbitMQ 的 Exchange(交换器) 有4种类型,不同的类型对应着不同的路由策略**:**direct(默认)**,**fanout**, **topic**, 和 **headers**,不同类型的Exchange转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。
+
+Exchange(交换器) 示意图如下:
+
+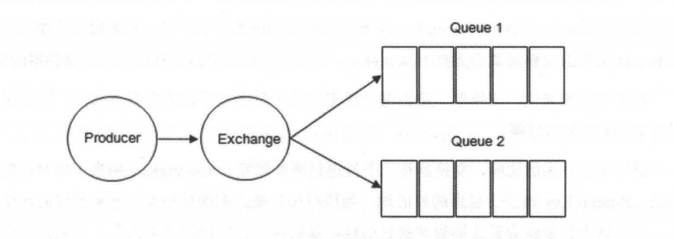
+
+生产者将消息发给交换器的时候,一般会指定一个 **RoutingKey(路由键)**,用来指定这个消息的路由规则,而这个 **RoutingKey 需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效**。
+
+RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(消息队列)** 关联起来,在绑定的时候一般会指定一个 **BindingKey(绑定建)** ,这样 RabbitMQ 就知道如何正确将消息路由到队列了,如下图所示。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和 Queue 的绑定可以是多对多的关系。
+
+Binding(绑定) 示意图:
+
+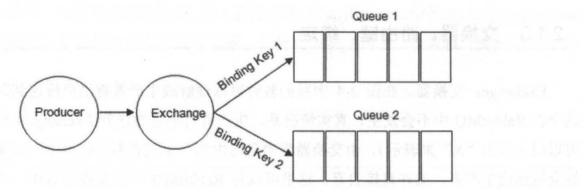
+
+生产者将消息发送给交换器时,需要一个RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如fanout类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。
+
+#### 1.2.3 Queue(消息队列)
+
+**Queue(消息队列)** 用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
+
+**RabbitMQ** 中消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是topic实际存储文件中的位移标识。 RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
+
+**多个消费者可以订阅同一个队列**,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。
+
+**RabbitMQ** 不支持队列层面的广播消费,如果有广播消费的需求,需要在其上进行二次开发,这样会很麻烦,不建议这样做。
+
+#### 1.2.4 Broker(消息中间件的服务节点)
+
+对于 RabbitMQ 来说,一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务节点,或者RabbitMQ服务实例。大多数情况下也可以将一个 RabbitMQ Broker 看作一台 RabbitMQ 服务器。
+
+下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从Broker中消费数据的整个流程。
+
+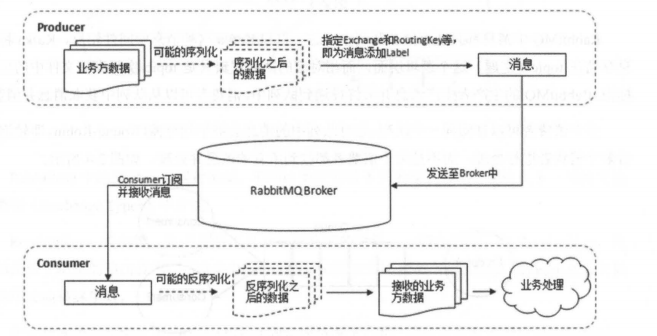
+
+这样图1中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 **Exchange Types(交换器类型)** 。
+
+#### 1.2.5 Exchange Types(交换器类型)
+
+RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP规范里还提到两种 Exchange Type,分别为 system 与 自定义,这里不予以描述)。
+
+##### ① fanout
+
+fanout 类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
+
+##### ② direct
+
+direct 类型的Exchange路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。
+
+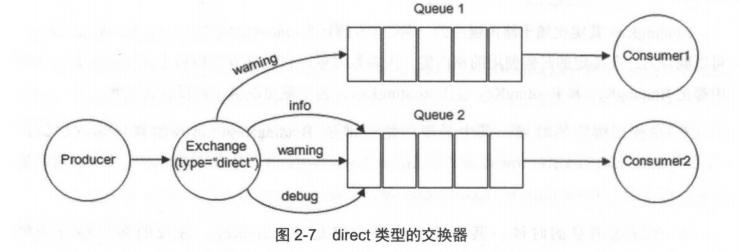
+
+以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为"Info”或者"debug”,消息只会路由到Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。
+
+direct 类型常用在处理有优先级的任务,根据任务的优先级把消息发送到对应的队列,这样可以指派更多的资源去处理高优先级的队列。
+
+##### ③ topic
+
+前面讲到direct类型的交换器路由规则是完全匹配 BindingKey 和 RoutingKey ,但是这种严格的匹配方式在很多情况下不能满足实际业务的需求。topic类型的交换器在匹配规则上进行了扩展,它与 direct 类型的交换器相似,也是将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,但这里的匹配规则有些不同,它约定:
+
+- RoutingKey 为一个点号“.”分隔的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”;
+- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
+- BindingKey 中可以存在两种特殊字符串“\*”和“#”,用于做模糊匹配,其中“\*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
+
+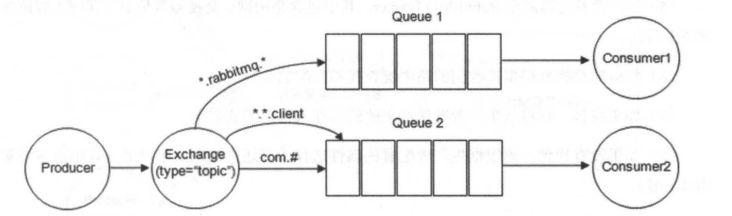
+
+以上图为例:
+
+- 路由键为 “com.rabbitmq.client” 的消息会同时路由到 Queue1 和 Queue2;
+- 路由键为 “com.hidden.client” 的消息只会路由到 Queue2 中;
+- 路由键为 “com.hidden.demo” 的消息只会路由到 Queue2 中;
+- 路由键为 “java.rabbitmq.demo” 的消息只会路由到 Queue1 中;
+- 路由键为 “java.util.concurrent” 的消息将会被丢弃或者返回给生产者(需要设置 mandatory 参数),因为它没有匹配任何路由键。
+
+##### ④ headers(不推荐)
+
+headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。在绑定队列和交换器时指定一组键值对,当发送消息到交换器时,RabbitMQ会获取到该消息的 headers(也是一个键值对的形式),对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列。headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
+
+## 二 安装 RabbitMQ
+
+通过 Docker 安装非常方便,只需要几条命令就好了,我这里是只说一下常规安装方法。
+
+前面提到了 RabbitMQ 是由 Erlang语言编写的,也正因如此,在安装RabbitMQ 之前需要安装 Erlang。
+
+注意:在安装 RabbitMQ 的时候需要注意 RabbitMQ 和 Erlang 的版本关系,如果不注意的话会导致出错,两者对应关系如下:
+
+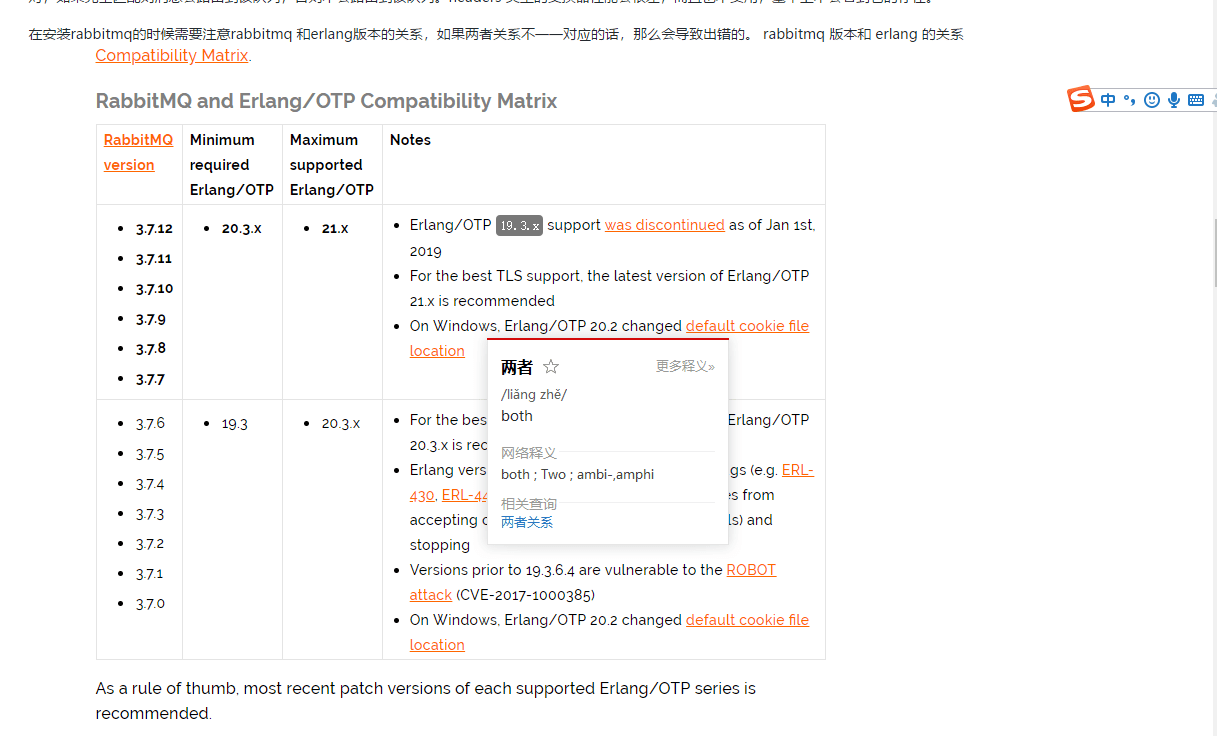
+
+### 2.1 安装 erlang
+
+**1 下载 erlang 安装包**
+
+在官网下载然后上传到 Linux 上或者直接使用下面的命令下载对应的版本。
+
+```shell
+[root@SnailClimb local]#wget https://erlang.org/download/otp_src_19.3.tar.gz
+```
+
+erlang 官网下载:[https://www.erlang.org/downloads](https://www.erlang.org/downloads)
+
+ **2 解压 erlang 安装包**
+
+```shell
+[root@SnailClimb local]#tar -xvzf otp_src_19.3.tar.gz
+```
+
+**3 删除 erlang 安装包**
+
+```shell
+[root@SnailClimb local]#rm -rf otp_src_19.3.tar.gz
+```
+
+**4 安装 erlang 的依赖工具**
+
+```shell
+[root@SnailClimb local]#yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC-devel
+```
+
+**5 进入erlang 安装包解压文件对 erlang 进行安装环境的配置**
+
+新建一个文件夹
+
+```shell
+[root@SnailClimb local]# mkdir erlang
+```
+
+对 erlang 进行安装环境的配置
+
+```shell
+[root@SnailClimb otp_src_19.3]#
+./configure --prefix=/usr/local/erlang --without-javac
+```
+
+**6 编译安装**
+
+```shell
+[root@SnailClimb otp_src_19.3]#
+make && make install
+```
+
+**7 验证一下 erlang 是否安装成功了**
+
+```shell
+[root@SnailClimb otp_src_19.3]# ./bin/erl
+```
+运行下面的语句输出“hello world”
+
+```erlang
+ io:format("hello world~n", []).
+```
+
+
+大功告成,我们的 erlang 已经安装完成。
+
+**8 配置 erlang 环境变量**
+
+```shell
+[root@SnailClimb etc]# vim profile
+```
+
+追加下列环境变量到文件末尾
+
+```shell
+#erlang
+ERL_HOME=/usr/local/erlang
+PATH=$ERL_HOME/bin:$PATH
+export ERL_HOME PATH
+```
+
+运行下列命令使配置文件`profile`生效
+
+```shell
+[root@SnailClimb etc]# source /etc/profile
+```
+
+输入 erl 查看 erlang 环境变量是否配置正确
+
+```shell
+[root@SnailClimb etc]# erl
+```
+
+
+
+### 2.2 安装 RabbitMQ
+
+**1. 下载rpm**
+
+```shell
+wget https://www.rabbitmq.com/releases/rabbitmq-server/v3.6.8/rabbitmq-server-3.6.8-1.el7.noarch.rpm
+```
+或者直接在官网下载
+
+[https://www.rabbitmq.com/install-rpm.html](https://www.rabbitmq.com/install-rpm.html)
+
+**2. 安装rpm**
+
+```shell
+rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
+```
+紧接着执行:
+
+```shell
+yum install rabbitmq-server-3.6.8-1.el7.noarch.rpm
+```
+中途需要你输入"y"才能继续安装。
+
+**3 开启 web 管理插件**
+
+```shell
+rabbitmq-plugins enable rabbitmq_management
+```
+
+**4 设置开机启动**
+
+```shell
+chkconfig rabbitmq-server on
+```
+
+**5. 启动服务**
+
+```shell
+service rabbitmq-server start
+```
+
+**6. 查看服务状态**
+
+```shell
+service rabbitmq-server status
+```
+
+**7. 访问 RabbitMQ 控制台**
+
+浏览器访问:http://你的ip地址:15672/
+
+默认用户名和密码:guest/guest; 但是需要注意的是:guest用户只是被容许从localhost访问。官网文档描述如下:
+
+```shell
+“guest” user can only connect via localhost
+```
+
+**解决远程访问 RabbitMQ 远程访问密码错误**
+
+新建用户并授权
+
+```shell
+[root@SnailClimb rabbitmq]# rabbitmqctl add_user root root
+Creating user "root" ...
+[root@SnailClimb rabbitmq]# rabbitmqctl set_user_tags root administrator
+
+Setting tags for user "root" to [administrator] ...
+[root@SnailClimb rabbitmq]#
+[root@SnailClimb rabbitmq]# rabbitmqctl set_permissions -p / root ".*" ".*" ".*"
+Setting permissions for user "root" in vhost "/" ...
+
+```
+
+再次访问:http://你的ip地址:15672/ ,输入用户名和密码:root root
+
+
+
+
diff --git a/docs/high-performance/message-queue/rocketmq-intro.md b/docs/high-performance/message-queue/rocketmq-intro.md
new file mode 100644
index 00000000000..2fbacfabec4
--- /dev/null
+++ b/docs/high-performance/message-queue/rocketmq-intro.md
@@ -0,0 +1,456 @@
+# RocketMQ入门总结
+
+> 文章很长,点赞再看,养成好习惯😋😋😋
+>
+> [本文由 FrancisQ 老哥投稿!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485969&idx=1&sn=6bd53abde30d42a778d5a35ec104428c&chksm=cea245daf9d5cccce631f93115f0c2c4a7634e55f5bef9009fd03f5a0ffa55b745b5ef4f0530&token=294077121&lang=zh_CN#rd)
+
+## 消息队列扫盲
+
+消息队列顾名思义就是存放消息的队列,队列我就不解释了,别告诉我你连队列都不知道是啥吧?
+
+所以问题并不是消息队列是什么,而是 **消息队列为什么会出现?消息队列能用来干什么?用它来干这些事会带来什么好处?消息队列会带来副作用吗?**
+
+### 消息队列为什么会出现?
+
+消息队列算是作为后端程序员的一个必备技能吧,因为**分布式应用必定涉及到各个系统之间的通信问题**,这个时候消息队列也应运而生了。可以说分布式的产生是消息队列的基础,而分布式怕是一个很古老的概念了吧,所以消息队列也是一个很古老的中间件了。
+
+### 消息队列能用来干什么?
+
+#### 异步
+
+你可能会反驳我,应用之间的通信又不是只能由消息队列解决,好好的通信为什么中间非要插一个消息队列呢?我不能直接进行通信吗?
+
+很好👍,你又提出了一个概念,**同步通信**。就比如现在业界使用比较多的 `Dubbo` 就是一个适用于各个系统之间同步通信的 `RPC` 框架。
+
+我来举个🌰吧,比如我们有一个购票系统,需求是用户在购买完之后能接收到购买完成的短信。
+
+
+
+我们省略中间的网络通信时间消耗,假如购票系统处理需要 150ms ,短信系统处理需要 200ms ,那么整个处理流程的时间消耗就是 150ms + 200ms = 350ms。
+
+当然,乍看没什么问题。可是仔细一想你就感觉有点问题,我用户购票在购票系统的时候其实就已经完成了购买,而我现在通过同步调用非要让整个请求拉长时间,而短信系统这玩意又不是很有必要,它仅仅是一个辅助功能增强用户体验感而已。我现在整个调用流程就有点 **头重脚轻** 的感觉了,购票是一个不太耗时的流程,而我现在因为同步调用,非要等待发送短信这个比较耗时的操作才返回结果。那我如果再加一个发送邮件呢?
+
+
+
+这样整个系统的调用链又变长了,整个时间就变成了550ms。
+
+当我们在学生时代需要在食堂排队的时候,我们和食堂大妈就是一个同步的模型。
+
+我们需要告诉食堂大妈:“姐姐,给我加个鸡腿,再加个酸辣土豆丝,帮我浇点汁上去,多打点饭哦😋😋😋” 咦~~~ 为了多吃点,真恶心。
+
+然后大妈帮我们打饭配菜,我们看着大妈那颤抖的手和掉落的土豆丝不禁咽了咽口水。
+
+最终我们从大妈手中接过饭菜然后去寻找座位了...
+
+回想一下,我们在给大妈发送需要的信息之后我们是 **同步等待大妈给我配好饭菜** 的,上面我们只是加了鸡腿和土豆丝,万一我再加一个番茄牛腩,韭菜鸡蛋,这样是不是大妈打饭配菜的流程就会变长,我们等待的时间也会相应的变长。
+
+
+
+那后来,我们工作赚钱了有钱去饭店吃饭了,我们告诉服务员来一碗牛肉面加个荷包蛋 **(传达一个消息)** ,然后我们就可以在饭桌上安心的玩手机了 **(干自己其他事情)** ,等到我们的牛肉面上了我们就可以吃了。这其中我们也就传达了一个消息,然后我们又转过头干其他事情了。这其中虽然做面的时间没有变短,但是我们只需要传达一个消息就可以干其他事情了,这是一个 **异步** 的概念。
+
+所以,为了解决这一个问题,聪明的程序员在中间也加了个类似于服务员的中间件——消息队列。这个时候我们就可以把模型给改造了。
+
+
+
+这样,我们在将消息存入消息队列之后我们就可以直接返回了(我们告诉服务员我们要吃什么然后玩手机),所以整个耗时只是 150ms + 10ms = 160ms。
+
+> 但是你需要注意的是,整个流程的时长是没变的,就像你仅仅告诉服务员要吃什么是不会影响到做面的速度的。
+
+#### 解耦
+
+回到最初同步调用的过程,我们写个伪代码简单概括一下。
+
+
+
+那么第二步,我们又添加了一个发送邮件,我们就得重新去修改代码,如果我们又加一个需求:用户购买完还需要给他加积分,这个时候我们是不是又得改代码?
+
+
+
+如果你觉得还行,那么我这个时候不要发邮件这个服务了呢,我是不是又得改代码,又得重启应用?
+
+
+
+这样改来改去是不是很麻烦,那么 **此时我们就用一个消息队列在中间进行解耦** 。你需要注意的是,我们后面的发送短信、发送邮件、添加积分等一些操作都依赖于上面的 `result` ,这东西抽象出来就是购票的处理结果呀,比如订单号,用户账号等等,也就是说我们后面的一系列服务都是需要同样的消息来进行处理。既然这样,我们是不是可以通过 **“广播消息”** 来实现。
+
+我上面所讲的“广播”并不是真正的广播,而是接下来的系统作为消费者去 **订阅** 特定的主题。比如我们这里的主题就可以叫做 `订票` ,我们购买系统作为一个生产者去生产这条消息放入消息队列,然后消费者订阅了这个主题,会从消息队列中拉取消息并消费。就比如我们刚刚画的那张图,你会发现,在生产者这边我们只需要关注 **生产消息到指定主题中** ,而 **消费者只需要关注从指定主题中拉取消息** 就行了。
+
+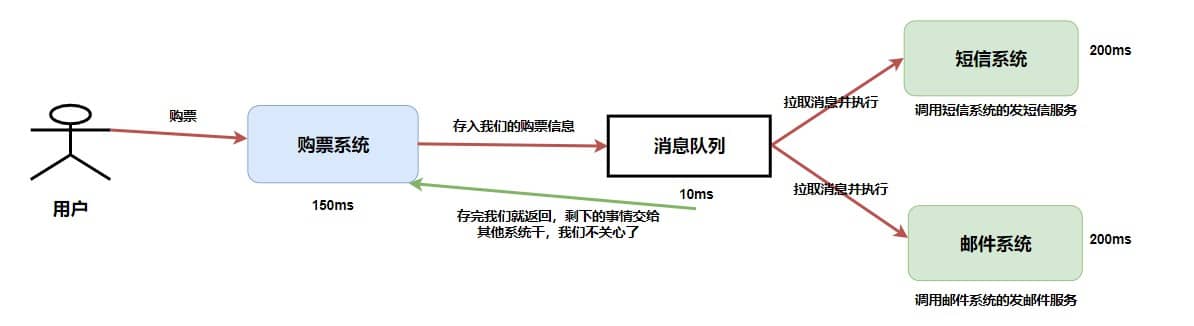
+
+> 如果没有消息队列,每当一个新的业务接入,我们都要在主系统调用新接口、或者当我们取消某些业务,我们也得在主系统删除某些接口调用。有了消息队列,我们只需要关心消息是否送达了队列,至于谁希望订阅,接下来收到消息如何处理,是下游的事情,无疑极大地减少了开发和联调的工作量。
+
+#### 削峰
+
+我们再次回到一开始我们使用同步调用系统的情况,并且思考一下,如果此时有大量用户请求购票整个系统会变成什么样?
+
+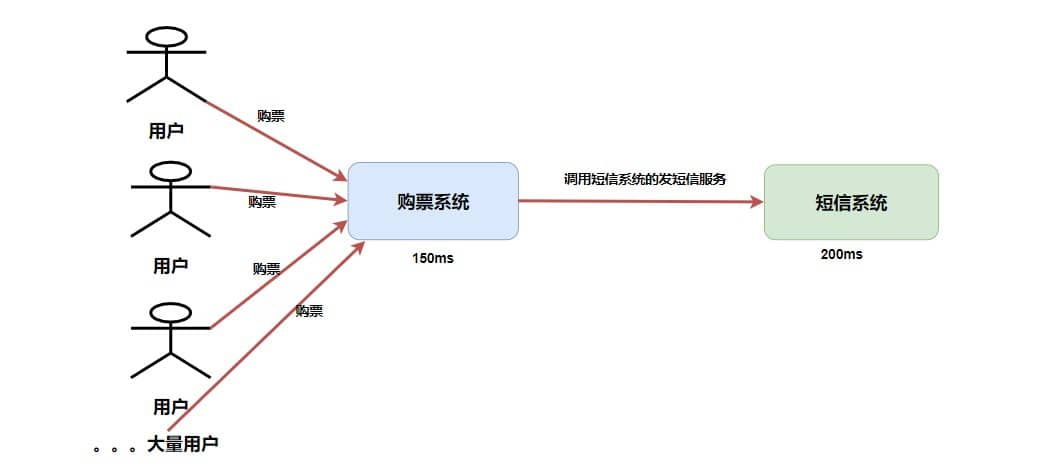
+
+如果,此时有一万的请求进入购票系统,我们知道运行我们主业务的服务器配置一般会比较好,所以这里我们假设购票系统能承受这一万的用户请求,那么也就意味着我们同时也会出现一万调用发短信服务的请求。而对于短信系统来说并不是我们的主要业务,所以我们配备的硬件资源并不会太高,那么你觉得现在这个短信系统能承受这一万的峰值么,且不说能不能承受,系统会不会 **直接崩溃** 了?
+
+短信业务又不是我们的主业务,我们能不能 **折中处理** 呢?如果我们把购买完成的信息发送到消息队列中,而短信系统 **尽自己所能地去消息队列中取消息和消费消息** ,即使处理速度慢一点也无所谓,只要我们的系统没有崩溃就行了。
+
+留得江山在,还怕没柴烧?你敢说每次发送验证码的时候是一发你就收到了的么?
+
+#### 消息队列能带来什么好处?
+
+其实上面我已经说了。**异步、解耦、削峰。** 哪怕你上面的都没看懂也千万要记住这六个字,因为他不仅是消息队列的精华,更是编程和架构的精华。
+
+#### 消息队列会带来副作用吗?
+
+没有哪一门技术是“银弹”,消息队列也有它的副作用。
+
+比如,本来好好的两个系统之间的调用,我中间加了个消息队列,如果消息队列挂了怎么办呢?是不是 **降低了系统的可用性** ?
+
+那这样是不是要保证HA(高可用)?是不是要搞集群?那么我 **整个系统的复杂度是不是上升了** ?
+
+抛开上面的问题不讲,万一我发送方发送失败了,然后执行重试,这样就可能产生重复的消息。
+
+或者我消费端处理失败了,请求重发,这样也会产生重复的消息。
+
+对于一些微服务来说,消费重复消息会带来更大的麻烦,比如增加积分,这个时候我加了多次是不是对其他用户不公平?
+
+那么,又 **如何解决重复消费消息的问题** 呢?
+
+如果我们此时的消息需要保证严格的顺序性怎么办呢?比如生产者生产了一系列的有序消息(对一个id为1的记录进行删除增加修改),但是我们知道在发布订阅模型中,对于主题是无顺序的,那么这个时候就会导致对于消费者消费消息的时候没有按照生产者的发送顺序消费,比如这个时候我们消费的顺序为修改删除增加,如果该记录涉及到金额的话是不是会出大事情?
+
+那么,又 **如何解决消息的顺序消费问题** 呢?
+
+就拿我们上面所讲的分布式系统来说,用户购票完成之后是不是需要增加账户积分?在同一个系统中我们一般会使用事务来进行解决,如果用 `Spring` 的话我们在上面伪代码中加入 `@Transactional` 注解就好了。但是在不同系统中如何保证事务呢?总不能这个系统我扣钱成功了你那积分系统积分没加吧?或者说我这扣钱明明失败了,你那积分系统给我加了积分。
+
+那么,又如何 **解决分布式事务问题** 呢?
+
+我们刚刚说了,消息队列可以进行削峰操作,那如果我的消费者如果消费很慢或者生产者生产消息很快,这样是不是会将消息堆积在消息队列中?
+
+那么,又如何 **解决消息堆积的问题** 呢?
+
+可用性降低,复杂度上升,又带来一系列的重复消费,顺序消费,分布式事务,消息堆积的问题,这消息队列还怎么用啊😵?
+
+
+
+别急,办法总是有的。
+
+## RocketMQ是什么?
+
+
+
+哇,你个混蛋!上面给我抛出那么多问题,你现在又讲 `RocketMQ` ,还让不让人活了?!🤬
+
+别急别急,话说你现在清楚 `MQ` 的构造吗,我还没讲呢,我们先搞明白 `MQ` 的内部构造,再来看看如何解决上面的一系列问题吧,不过你最好带着问题去阅读和了解喔。
+
+`RocketMQ` 是一个 **队列模型** 的消息中间件,具有**高性能、高可靠、高实时、分布式** 的特点。它是一个采用 `Java` 语言开发的分布式的消息系统,由阿里巴巴团队开发,在2016年底贡献给 `Apache`,成为了 `Apache` 的一个顶级项目。 在阿里内部,`RocketMQ` 很好地服务了集团大大小小上千个应用,在每年的双十一当天,更有不可思议的万亿级消息通过 `RocketMQ` 流转。
+
+废话不多说,想要了解 `RocketMQ` 历史的同学可以自己去搜寻资料。听完上面的介绍,你只要知道 `RocketMQ` 很快、很牛、而且经历过双十一的实践就行了!
+
+## 队列模型和主题模型
+
+在谈 `RocketMQ` 的技术架构之前,我们先来了解一下两个名词概念——**队列模型** 和 **主题模型** 。
+
+首先我问一个问题,消息队列为什么要叫消息队列?
+
+你可能觉得很弱智,这玩意不就是存放消息的队列嘛?不叫消息队列叫什么?
+
+的确,早期的消息中间件是通过 **队列** 这一模型来实现的,可能是历史原因,我们都习惯把消息中间件成为消息队列。
+
+但是,如今例如 `RocketMQ` 、`Kafka` 这些优秀的消息中间件不仅仅是通过一个 **队列** 来实现消息存储的。
+
+### 队列模型
+
+就像我们理解队列一样,消息中间件的队列模型就真的只是一个队列。。。我画一张图给大家理解。
+
+
+
+在一开始我跟你提到了一个 **“广播”** 的概念,也就是说如果我们此时我们需要将一个消息发送给多个消费者(比如此时我需要将信息发送给短信系统和邮件系统),这个时候单个队列即不能满足需求了。
+
+当然你可以让 `Producer` 生产消息放入多个队列中,然后每个队列去对应每一个消费者。问题是可以解决,创建多个队列并且复制多份消息是会很影响资源和性能的。而且,这样子就会导致生产者需要知道具体消费者个数然后去复制对应数量的消息队列,这就违背我们消息中间件的 **解耦** 这一原则。
+
+### 主题模型
+
+那么有没有好的方法去解决这一个问题呢?有,那就是 **主题模型** 或者可以称为 **发布订阅模型** 。
+
+> 感兴趣的同学可以去了解一下设计模式里面的观察者模式并且手动实现一下,我相信你会有所收获的。
+
+在主题模型中,消息的生产者称为 **发布者(Publisher)** ,消息的消费者称为 **订阅者(Subscriber)** ,存放消息的容器称为 **主题(Topic)** 。
+
+其中,发布者将消息发送到指定主题中,订阅者需要 **提前订阅主题** 才能接受特定主题的消息。
+
+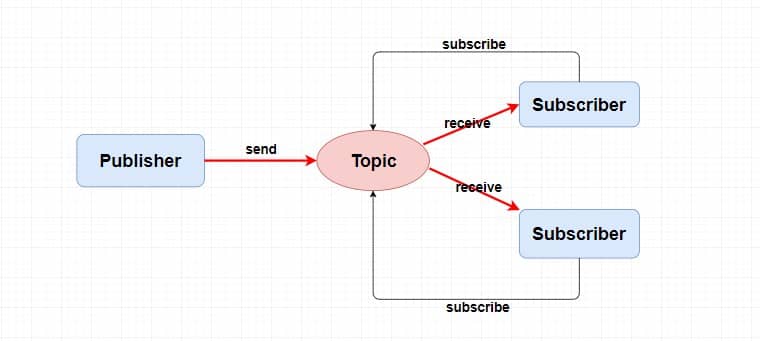
+
+### RocketMQ中的消息模型
+
+`RocketMQ` 中的消息模型就是按照 **主题模型** 所实现的。你可能会好奇这个 **主题** 到底是怎么实现的呢?你上面也没有讲到呀!
+
+其实对于主题模型的实现来说每个消息中间件的底层设计都是不一样的,就比如 `Kafka` 中的 **分区** ,`RocketMQ` 中的 **队列** ,`RabbitMQ` 中的 `Exchange` 。我们可以理解为 **主题模型/发布订阅模型** 就是一个标准,那些中间件只不过照着这个标准去实现而已。
+
+所以,`RocketMQ` 中的 **主题模型** 到底是如何实现的呢?首先我画一张图,大家尝试着去理解一下。
+
+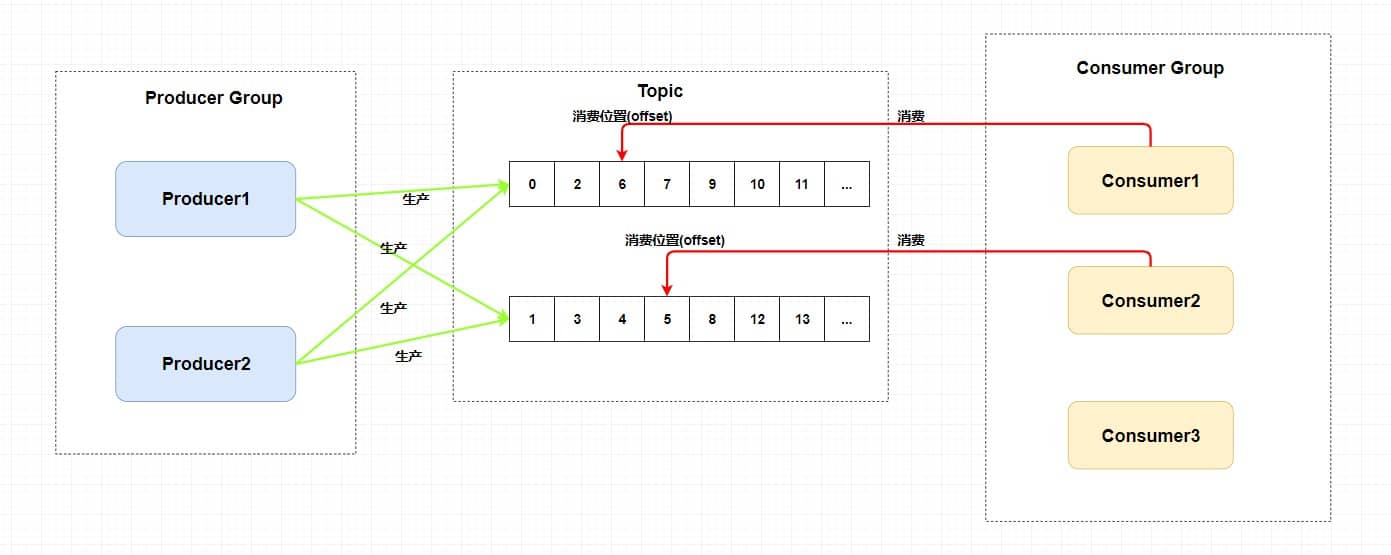
+
+我们可以看到在整个图中有 `Producer Group` 、`Topic` 、`Consumer Group` 三个角色,我来分别介绍一下他们。
+
+- `Producer Group` 生产者组: 代表某一类的生产者,比如我们有多个秒杀系统作为生产者,这多个合在一起就是一个 `Producer Group` 生产者组,它们一般生产相同的消息。
+- `Consumer Group` 消费者组: 代表某一类的消费者,比如我们有多个短信系统作为消费者,这多个合在一起就是一个 `Consumer Group` 消费者组,它们一般消费相同的消息。
+- `Topic` 主题: 代表一类消息,比如订单消息,物流消息等等。
+
+你可以看到图中生产者组中的生产者会向主题发送消息,而 **主题中存在多个队列**,生产者每次生产消息之后是指定主题中的某个队列发送消息的。
+
+每个主题中都有多个队列(分布在不同的 `Broker`中,如果是集群的话,`Broker`又分布在不同的服务器中),集群消费模式下,一个消费者集群多台机器共同消费一个 `topic` 的多个队列,**一个队列只会被一个消费者消费**。如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费。就像上图中 `Consumer1` 和 `Consumer2` 分别对应着两个队列,而 `Consumer3` 是没有队列对应的,所以一般来讲要控制 **消费者组中的消费者个数和主题中队列个数相同** 。
+
+当然也可以消费者个数小于队列个数,只不过不太建议。如下图。
+
+
+
+**每个消费组在每个队列上维护一个消费位置** ,为什么呢?
+
+因为我们刚刚画的仅仅是一个消费者组,我们知道在发布订阅模式中一般会涉及到多个消费者组,而每个消费者组在每个队列中的消费位置都是不同的。如果此时有多个消费者组,那么消息被一个消费者组消费完之后是不会删除的(因为其它消费者组也需要呀),它仅仅是为每个消费者组维护一个 **消费位移(offset)** ,每次消费者组消费完会返回一个成功的响应,然后队列再把维护的消费位移加一,这样就不会出现刚刚消费过的消息再一次被消费了。
+
+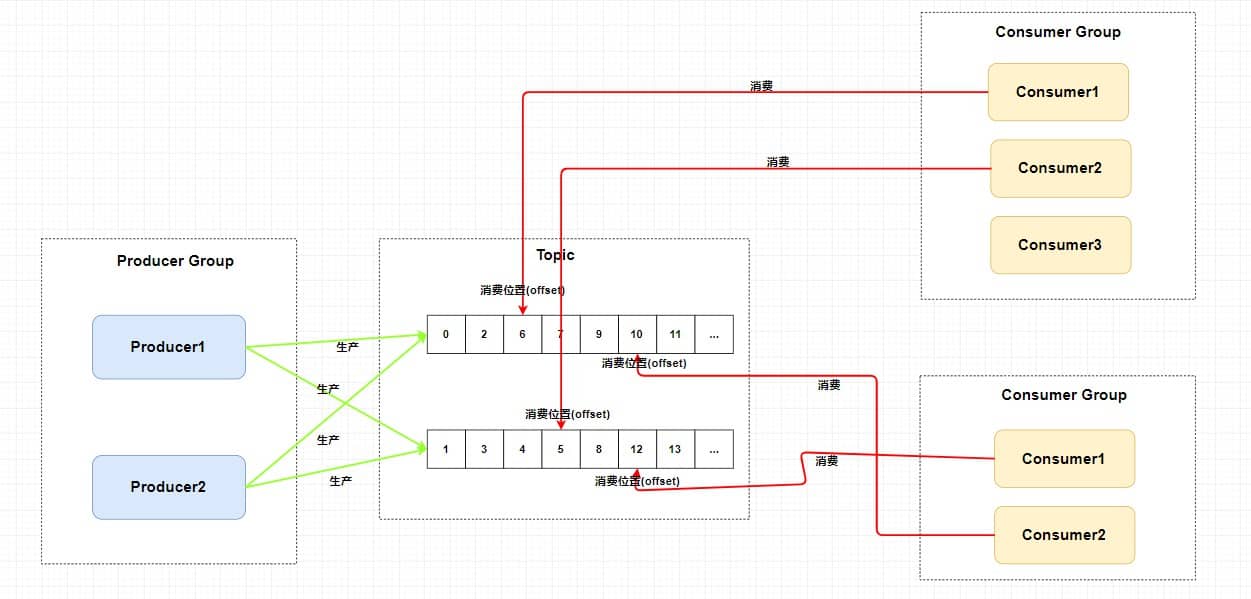
+
+可能你还有一个问题,**为什么一个主题中需要维护多个队列** ?
+
+答案是 **提高并发能力** 。的确,每个主题中只存在一个队列也是可行的。你想一下,如果每个主题中只存在一个队列,这个队列中也维护着每个消费者组的消费位置,这样也可以做到 **发布订阅模式** 。如下图。
+
+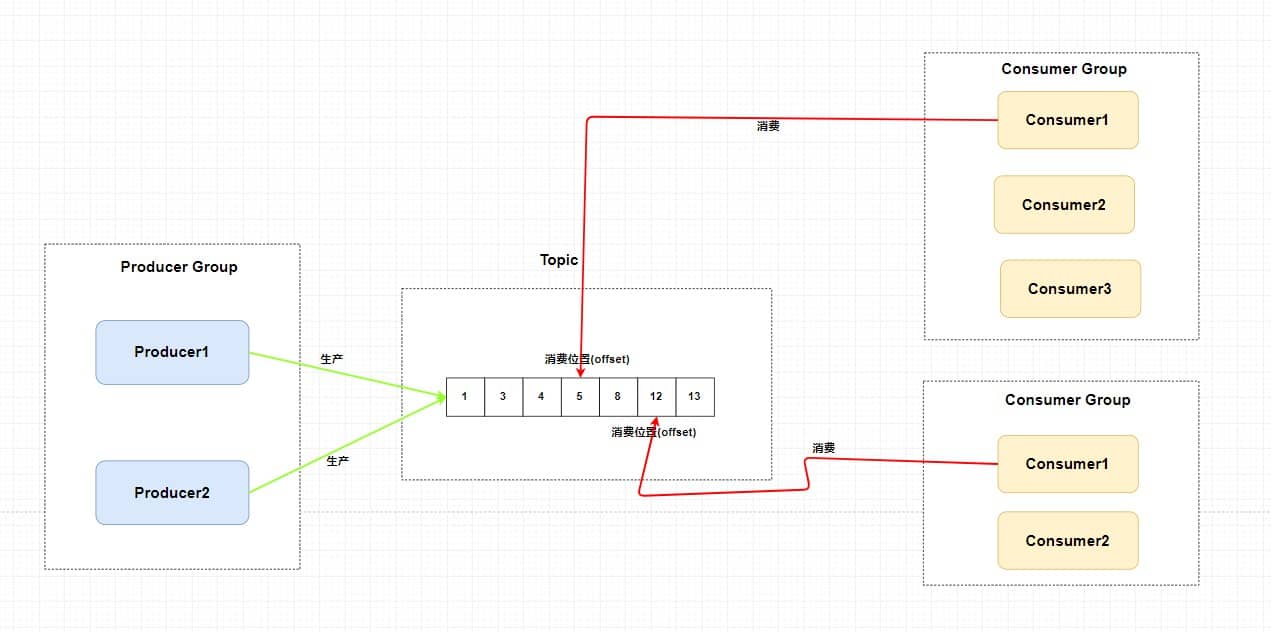
+
+但是,这样我生产者是不是只能向一个队列发送消息?又因为需要维护消费位置所以一个队列只能对应一个消费者组中的消费者,这样是不是其他的 `Consumer` 就没有用武之地了?从这两个角度来讲,并发度一下子就小了很多。
+
+所以总结来说,`RocketMQ` 通过**使用在一个 `Topic` 中配置多个队列并且每个队列维护每个消费者组的消费位置** 实现了 **主题模式/发布订阅模式** 。
+
+## RocketMQ的架构图
+
+讲完了消息模型,我们理解起 `RocketMQ` 的技术架构起来就容易多了。
+
+`RocketMQ` 技术架构中有四大角色 `NameServer` 、`Broker` 、`Producer` 、`Consumer` 。我来向大家分别解释一下这四个角色是干啥的。
+
+- `Broker`: 主要负责消息的存储、投递和查询以及服务高可用保证。说白了就是消息队列服务器嘛,生产者生产消息到 `Broker` ,消费者从 `Broker` 拉取消息并消费。
+
+ 这里,我还得普及一下关于 `Broker` 、`Topic` 和 队列的关系。上面我讲解了 `Topic` 和队列的关系——一个 `Topic` 中存在多个队列,那么这个 `Topic` 和队列存放在哪呢?
+
+ **一个 `Topic` 分布在多个 `Broker`上,一个 `Broker` 可以配置多个 `Topic` ,它们是多对多的关系**。
+
+ 如果某个 `Topic` 消息量很大,应该给它多配置几个队列(上文中提到了提高并发能力),并且 **尽量多分布在不同 `Broker` 上,以减轻某个 `Broker` 的压力** 。
+
+ `Topic` 消息量都比较均匀的情况下,如果某个 `broker` 上的队列越多,则该 `broker` 压力越大。
+
+ 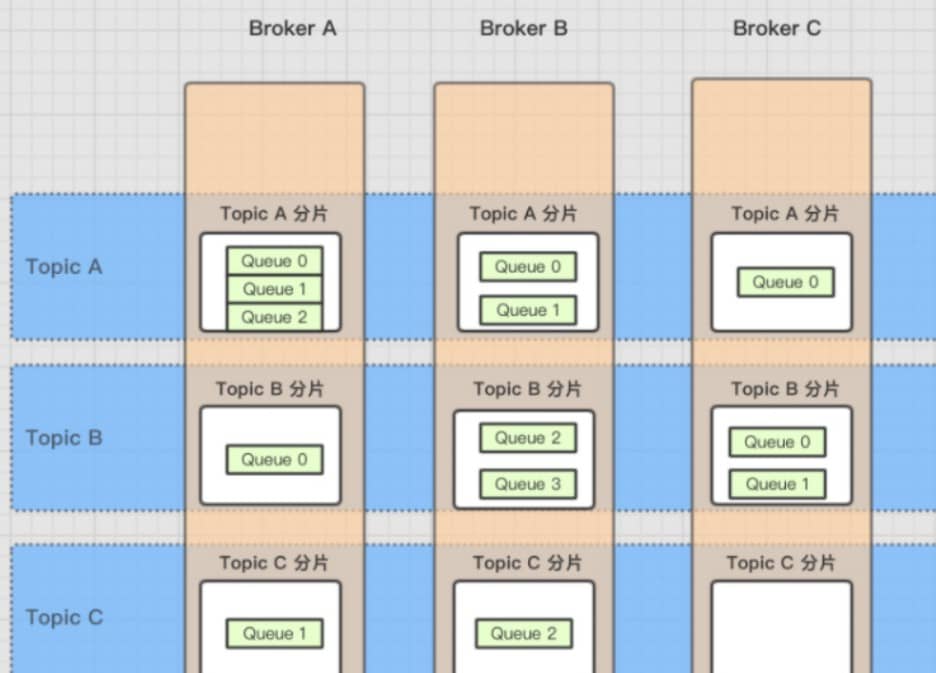
+
+ > 所以说我们需要配置多个Broker。
+
+- `NameServer`: 不知道你们有没有接触过 `ZooKeeper` 和 `Spring Cloud` 中的 `Eureka` ,它其实也是一个 **注册中心** ,主要提供两个功能:**Broker管理** 和 **路由信息管理** 。说白了就是 `Broker` 会将自己的信息注册到 `NameServer` 中,此时 `NameServer` 就存放了很多 `Broker` 的信息(Broker的路由表),消费者和生产者就从 `NameServer` 中获取路由表然后照着路由表的信息和对应的 `Broker` 进行通信(生产者和消费者定期会向 `NameServer` 去查询相关的 `Broker` 的信息)。
+
+- `Producer`: 消息发布的角色,支持分布式集群方式部署。说白了就是生产者。
+
+- `Consumer`: 消息消费的角色,支持分布式集群方式部署。支持以push推,pull拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制。说白了就是消费者。
+
+听完了上面的解释你可能会觉得,这玩意好简单。不就是这样的么?
+
+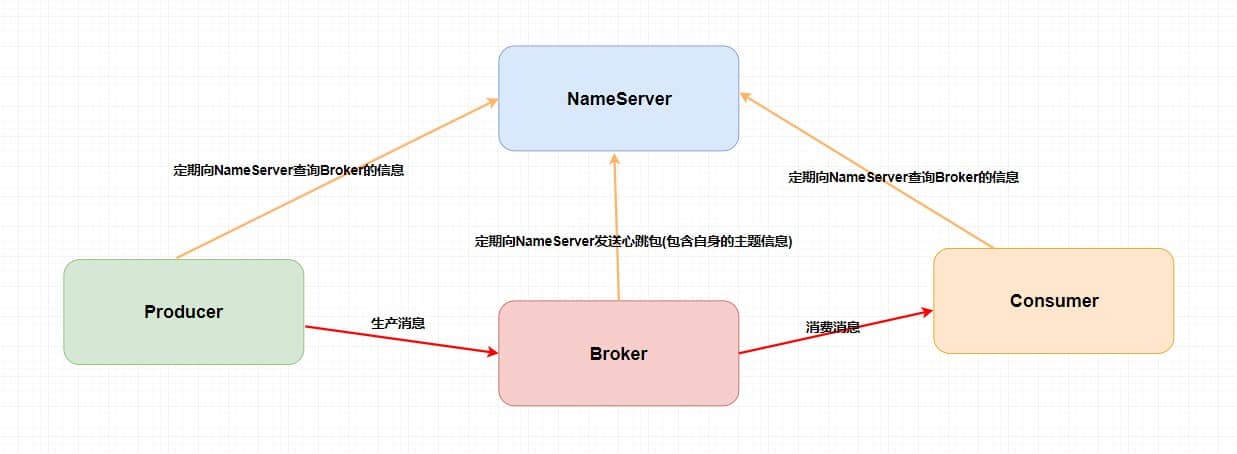
+
+嗯?你可能会发现一个问题,这老家伙 `NameServer` 干啥用的,这不多余吗?直接 `Producer` 、`Consumer` 和 `Broker` 直接进行生产消息,消费消息不就好了么?
+
+但是,我们上文提到过 `Broker` 是需要保证高可用的,如果整个系统仅仅靠着一个 `Broker` 来维持的话,那么这个 `Broker` 的压力会不会很大?所以我们需要使用多个 `Broker` 来保证 **负载均衡** 。
+
+如果说,我们的消费者和生产者直接和多个 `Broker` 相连,那么当 `Broker` 修改的时候必定会牵连着每个生产者和消费者,这样就会产生耦合问题,而 `NameServer` 注册中心就是用来解决这个问题的。
+
+> 如果还不是很理解的话,可以去看我介绍 `Spring Cloud` 的那篇文章,其中介绍了 `Eureka` 注册中心。
+
+当然,`RocketMQ` 中的技术架构肯定不止前面那么简单,因为上面图中的四个角色都是需要做集群的。我给出一张官网的架构图,大家尝试理解一下。
+
+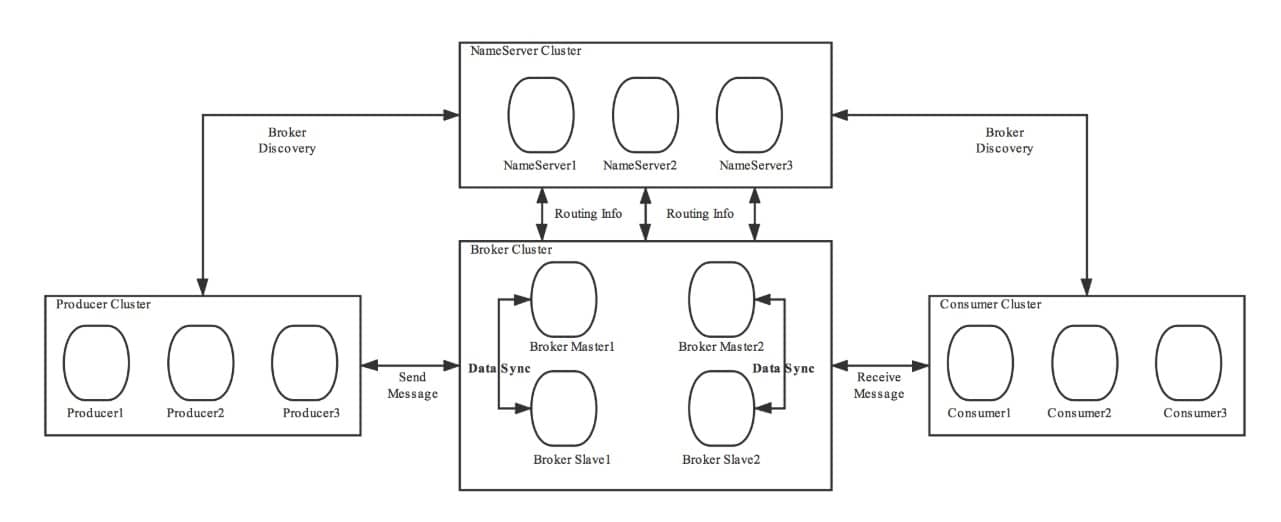
+
+其实和我们最开始画的那张乞丐版的架构图也没什么区别,主要是一些细节上的差别。听我细细道来🤨。
+
+第一、我们的 `Broker` **做了集群并且还进行了主从部署** ,由于消息分布在各个 `Broker` 上,一旦某个 `Broker` 宕机,则该`Broker` 上的消息读写都会受到影响。所以 `Rocketmq` 提供了 `master/slave` 的结构,` salve` 定时从 `master` 同步数据(同步刷盘或者异步刷盘),如果 `master` 宕机,**则 `slave` 提供消费服务,但是不能写入消息** (后面我还会提到哦)。
+
+第二、为了保证 `HA` ,我们的 `NameServer` 也做了集群部署,但是请注意它是 **去中心化** 的。也就意味着它没有主节点,你可以很明显地看出 `NameServer` 的所有节点是没有进行 `Info Replicate` 的,在 `RocketMQ` 中是通过 **单个Broker和所有NameServer保持长连接** ,并且在每隔30秒 `Broker` 会向所有 `Nameserver` 发送心跳,心跳包含了自身的 `Topic` 配置信息,这个步骤就对应这上面的 `Routing Info` 。
+
+第三、在生产者需要向 `Broker` 发送消息的时候,**需要先从 `NameServer` 获取关于 `Broker` 的路由信息**,然后通过 **轮询** 的方法去向每个队列中生产数据以达到 **负载均衡** 的效果。
+
+第四、消费者通过 `NameServer` 获取所有 `Broker` 的路由信息后,向 `Broker` 发送 `Pull` 请求来获取消息数据。`Consumer` 可以以两种模式启动—— **广播(Broadcast)和集群(Cluster)**。广播模式下,一条消息会发送给 **同一个消费组中的所有消费者** ,集群模式下消息只会发送给一个消费者。
+
+## 如何解决 顺序消费、重复消费
+
+其实,这些东西都是我在介绍消息队列带来的一些副作用的时候提到的,也就是说,这些问题不仅仅挂钩于 `RocketMQ` ,而是应该每个消息中间件都需要去解决的。
+
+在上面我介绍 `RocketMQ` 的技术架构的时候我已经向你展示了 **它是如何保证高可用的** ,这里不涉及运维方面的搭建,如果你感兴趣可以自己去官网上照着例子搭建属于你自己的 `RocketMQ` 集群。
+
+> 其实 `Kafka` 的架构基本和 `RocketMQ` 类似,只是它注册中心使用了 `Zookeeper` 、它的 **分区** 就相当于 `RocketMQ` 中的 **队列** 。还有一些小细节不同会在后面提到。
+
+### 顺序消费
+
+在上面的技术架构介绍中,我们已经知道了 **`RocketMQ` 在主题上是无序的、它只有在队列层面才是保证有序** 的。
+
+这又扯到两个概念——**普通顺序** 和 **严格顺序** 。
+
+所谓普通顺序是指 消费者通过 **同一个消费队列收到的消息是有顺序的** ,不同消息队列收到的消息则可能是无顺序的。普通顺序消息在 `Broker` **重启情况下不会保证消息顺序性** (短暂时间) 。
+
+所谓严格顺序是指 消费者收到的 **所有消息** 均是有顺序的。严格顺序消息 **即使在异常情况下也会保证消息的顺序性** 。
+
+但是,严格顺序看起来虽好,实现它可会付出巨大的代价。如果你使用严格顺序模式,`Broker` 集群中只要有一台机器不可用,则整个集群都不可用。你还用啥?现在主要场景也就在 `binlog` 同步。
+
+一般而言,我们的 `MQ` 都是能容忍短暂的乱序,所以推荐使用普通顺序模式。
+
+那么,我们现在使用了 **普通顺序模式** ,我们从上面学习知道了在 `Producer` 生产消息的时候会进行轮询(取决你的负载均衡策略)来向同一主题的不同消息队列发送消息。那么如果此时我有几个消息分别是同一个订单的创建、支付、发货,在轮询的策略下这 **三个消息会被发送到不同队列** ,因为在不同的队列此时就无法使用 `RocketMQ` 带来的队列有序特性来保证消息有序性了。
+
+
+
+那么,怎么解决呢?
+
+其实很简单,我们需要处理的仅仅是将同一语义下的消息放入同一个队列(比如这里是同一个订单),那我们就可以使用 **Hash取模法** 来保证同一个订单在同一个队列中就行了。
+
+### 重复消费
+
+emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。比如说,这个时候我们有一个订单的处理积分的系统,每当来一个消息的时候它就负责为创建这个订单的用户的积分加上相应的数值。可是有一次,消息队列发送给订单系统 FrancisQ 的订单信息,其要求是给 FrancisQ 的积分加上 500。但是积分系统在收到 FrancisQ 的订单信息处理完成之后返回给消息队列处理成功的信息的时候出现了网络波动(当然还有很多种情况,比如Broker意外重启等等),这条回应没有发送成功。
+
+那么,消息队列没收到积分系统的回应会不会尝试重发这个消息?问题就来了,我再发这个消息,万一它又给 FrancisQ 的账户加上 500 积分怎么办呢?
+
+所以我们需要给我们的消费者实现 **幂等** ,也就是对同一个消息的处理结果,执行多少次都不变。
+
+那么如何给业务实现幂等呢?这个还是需要结合具体的业务的。你可以使用 **写入 `Redis`** 来保证,因为 `Redis` 的 `key` 和 `value` 就是天然支持幂等的。当然还有使用 **数据库插入法** ,基于数据库的唯一键来保证重复数据不会被插入多条。
+
+不过最主要的还是需要 **根据特定场景使用特定的解决方案** ,你要知道你的消息消费是否是完全不可重复消费还是可以忍受重复消费的,然后再选择强校验和弱校验的方式。毕竟在 CS 领域还是很少有技术银弹的说法。
+
+而在整个互联网领域,幂等不仅仅适用于消息队列的重复消费问题,这些实现幂等的方法,也同样适用于,**在其他场景中来解决重复请求或者重复调用的问题** 。比如将HTTP服务设计成幂等的,**解决前端或者APP重复提交表单数据的问题** ,也可以将一个微服务设计成幂等的,解决 `RPC` 框架自动重试导致的 **重复调用问题** 。
+
+## 分布式事务
+
+如何解释分布式事务呢?事务大家都知道吧?**要么都执行要么都不执行** 。在同一个系统中我们可以轻松地实现事务,但是在分布式架构中,我们有很多服务是部署在不同系统之间的,而不同服务之间又需要进行调用。比如此时我下订单然后增加积分,如果保证不了分布式事务的话,就会出现A系统下了订单,但是B系统增加积分失败或者A系统没有下订单,B系统却增加了积分。前者对用户不友好,后者对运营商不利,这是我们都不愿意见到的。
+
+那么,如何去解决这个问题呢?
+
+如今比较常见的分布式事务实现有 2PC、TCC 和事务消息(half 半消息机制)。每一种实现都有其特定的使用场景,但是也有各自的问题,**都不是完美的解决方案**。
+
+在 `RocketMQ` 中使用的是 **事务消息加上事务反查机制** 来解决分布式事务问题的。我画了张图,大家可以对照着图进行理解。
+
+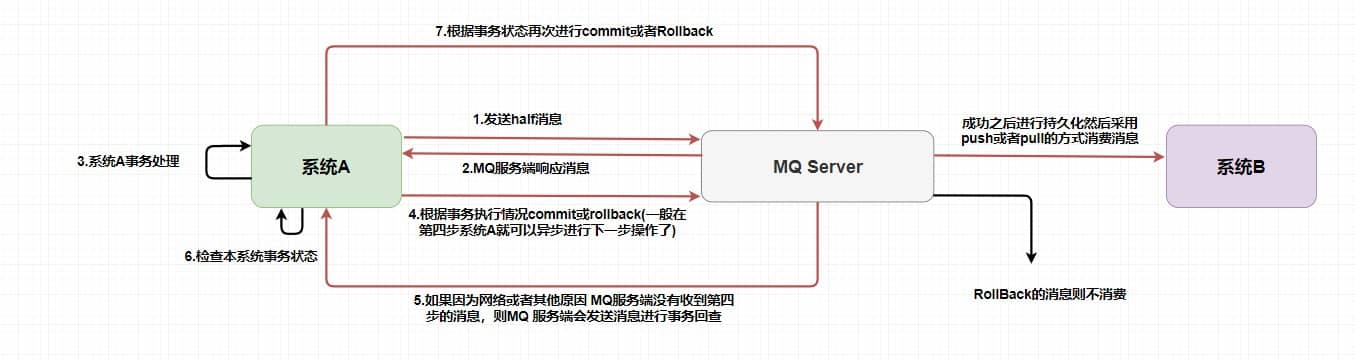
+
+在第一步发送的 half 消息 ,它的意思是 **在事务提交之前,对于消费者来说,这个消息是不可见的** 。
+
+> 那么,如何做到写入消息但是对用户不可见呢?RocketMQ事务消息的做法是:如果消息是half消息,将备份原消息的主题与消息消费队列,然后 **改变主题** 为RMQ_SYS_TRANS_HALF_TOPIC。由于消费组未订阅该主题,故消费端无法消费half类型的消息,**然后RocketMQ会开启一个定时任务,从Topic为RMQ_SYS_TRANS_HALF_TOPIC中拉取消息进行消费**,根据生产者组获取一个服务提供者发送回查事务状态请求,根据事务状态来决定是提交或回滚消息。
+
+你可以试想一下,如果没有从第5步开始的 **事务反查机制** ,如果出现网路波动第4步没有发送成功,这样就会产生 MQ 不知道是不是需要给消费者消费的问题,他就像一个无头苍蝇一样。在 `RocketMQ` 中就是使用的上述的事务反查来解决的,而在 `Kafka` 中通常是直接抛出一个异常让用户来自行解决。
+
+你还需要注意的是,在 `MQ Server` 指向系统B的操作已经和系统A不相关了,也就是说在消息队列中的分布式事务是——**本地事务和存储消息到消息队列才是同一个事务**。这样也就产生了事务的**最终一致性**,因为整个过程是异步的,**每个系统只要保证它自己那一部分的事务就行了**。
+
+## 消息堆积问题
+
+在上面我们提到了消息队列一个很重要的功能——**削峰** 。那么如果这个峰值太大了导致消息堆积在队列中怎么办呢?
+
+其实这个问题可以将它广义化,因为产生消息堆积的根源其实就只有两个——生产者生产太快或者消费者消费太慢。
+
+我们可以从多个角度去思考解决这个问题,当流量到峰值的时候是因为生产者生产太快,我们可以使用一些 **限流降级** 的方法,当然你也可以增加多个消费者实例去水平扩展增加消费能力来匹配生产的激增。如果消费者消费过慢的话,我们可以先检查 **是否是消费者出现了大量的消费错误** ,或者打印一下日志查看是否是哪一个线程卡死,出现了锁资源不释放等等的问题。
+
+> 当然,最快速解决消息堆积问题的方法还是增加消费者实例,不过 **同时你还需要增加每个主题的队列数量** 。
+>
+> 别忘了在 `RocketMQ` 中,**一个队列只会被一个消费者消费** ,如果你仅仅是增加消费者实例就会出现我一开始给你画架构图的那种情况。
+
+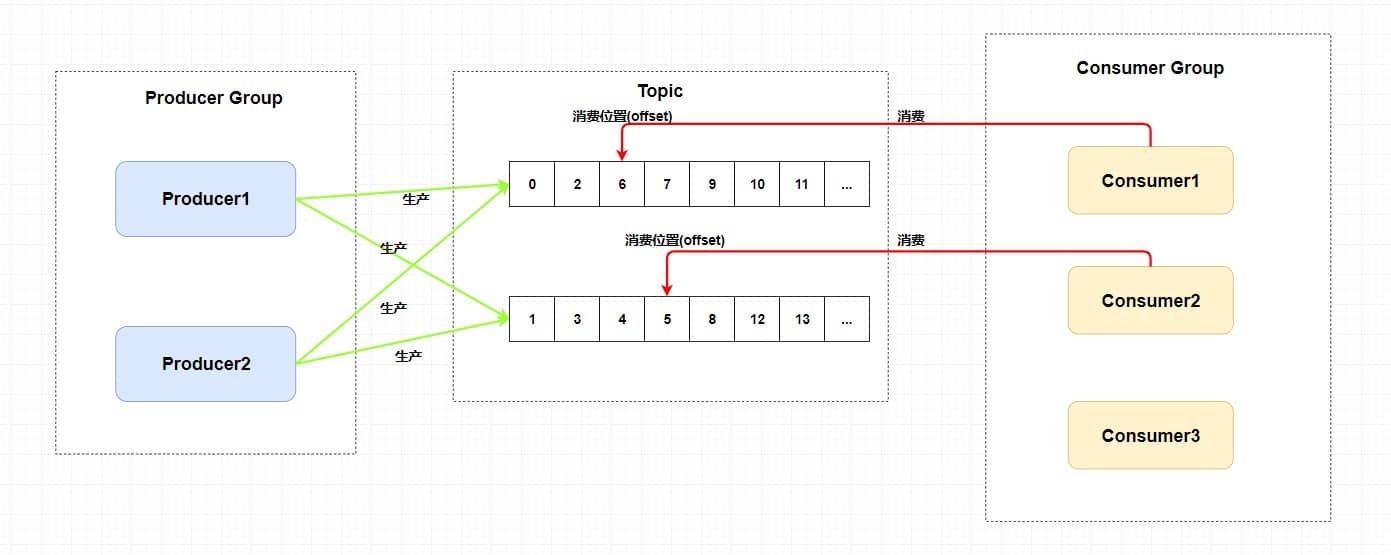
+
+## 回溯消费
+
+回溯消费是指 `Consumer` 已经消费成功的消息,由于业务上需求需要重新消费,在`RocketMQ` 中, `Broker` 在向`Consumer` 投递成功消息后,**消息仍然需要保留** 。并且重新消费一般是按照时间维度,例如由于 `Consumer` 系统故障,恢复后需要重新消费1小时前的数据,那么 `Broker` 要提供一种机制,可以按照时间维度来回退消费进度。`RocketMQ` 支持按照时间回溯消费,时间维度精确到毫秒。
+
+这是官方文档的解释,我直接照搬过来就当科普了😁😁😁。
+
+## RocketMQ 的刷盘机制
+
+上面我讲了那么多的 `RocketMQ` 的架构和设计原理,你有没有好奇
+
+在 `Topic` 中的 **队列是以什么样的形式存在的?**
+
+**队列中的消息又是如何进行存储持久化的呢?**
+
+我在上文中提到的 **同步刷盘** 和 **异步刷盘** 又是什么呢?它们会给持久化带来什么样的影响呢?
+
+下面我将给你们一一解释。
+
+### 同步刷盘和异步刷盘
+
+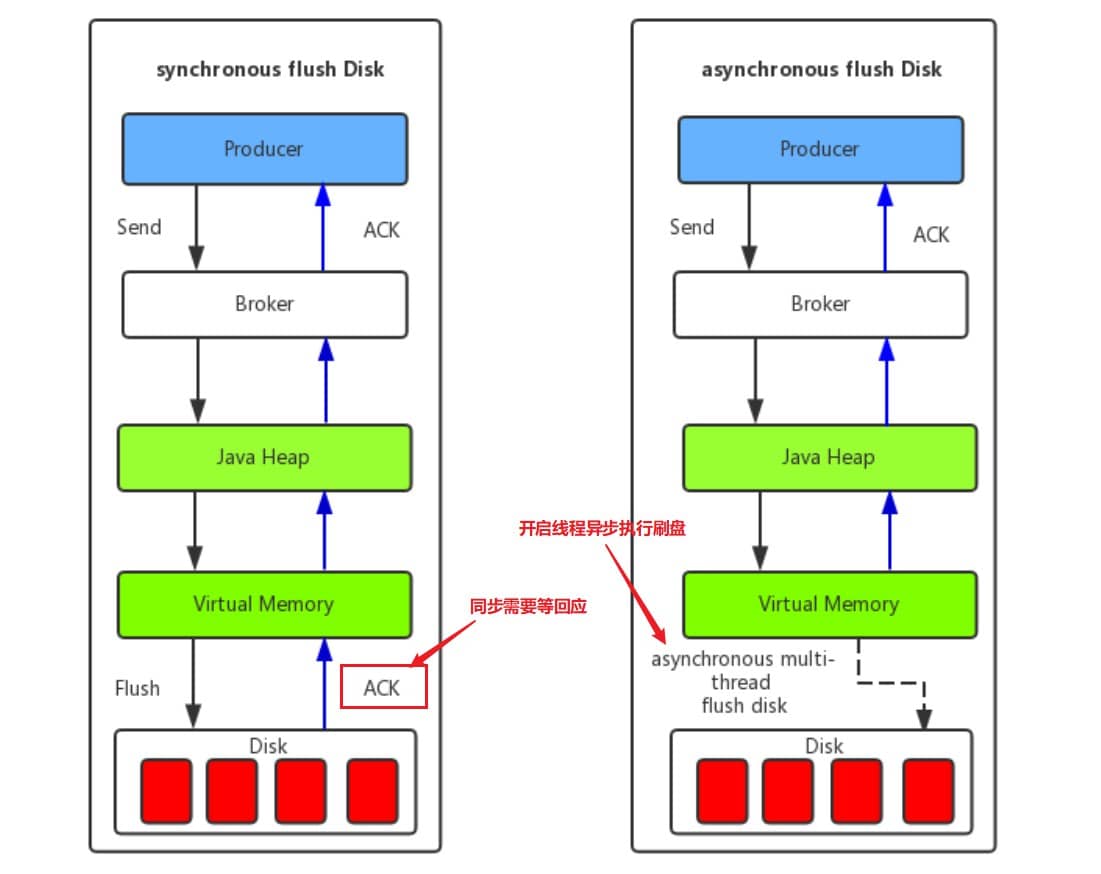
+
+如上图所示,在同步刷盘中需要等待一个刷盘成功的 `ACK` ,同步刷盘对 `MQ` 消息可靠性来说是一种不错的保障,但是 **性能上会有较大影响** ,一般地适用于金融等特定业务场景。
+
+而异步刷盘往往是开启一个线程去异步地执行刷盘操作。消息刷盘采用后台异步线程提交的方式进行, **降低了读写延迟** ,提高了 `MQ` 的性能和吞吐量,一般适用于如发验证码等对于消息保证要求不太高的业务场景。
+
+一般地,**异步刷盘只有在 `Broker` 意外宕机的时候会丢失部分数据**,你可以设置 `Broker` 的参数 `FlushDiskType` 来调整你的刷盘策略(ASYNC_FLUSH 或者 SYNC_FLUSH)。
+
+### 同步复制和异步复制
+
+上面的同步刷盘和异步刷盘是在单个结点层面的,而同步复制和异步复制主要是指的 `Borker` 主从模式下,主节点返回消息给客户端的时候是否需要同步从节点。
+
+- 同步复制: 也叫 “同步双写”,也就是说,**只有消息同步双写到主从结点上时才返回写入成功** 。
+- 异步复制: **消息写入主节点之后就直接返回写入成功** 。
+
+然而,很多事情是没有完美的方案的,就比如我们进行消息写入的节点越多就更能保证消息的可靠性,但是随之的性能也会下降,所以需要程序员根据特定业务场景去选择适应的主从复制方案。
+
+那么,**异步复制会不会也像异步刷盘那样影响消息的可靠性呢?**
+
+答案是不会的,因为两者就是不同的概念,对于消息可靠性是通过不同的刷盘策略保证的,而像异步同步复制策略仅仅是影响到了 **可用性** 。为什么呢?其主要原因**是 `RocketMQ` 是不支持自动主从切换的,当主节点挂掉之后,生产者就不能再给这个主节点生产消息了**。
+
+比如这个时候采用异步复制的方式,在主节点还未发送完需要同步的消息的时候主节点挂掉了,这个时候从节点就少了一部分消息。但是此时生产者无法再给主节点生产消息了,**消费者可以自动切换到从节点进行消费**(仅仅是消费),所以在主节点挂掉的时间只会产生主从结点短暂的消息不一致的情况,降低了可用性,而当主节点重启之后,从节点那部分未来得及复制的消息还会继续复制。
+
+在单主从架构中,如果一个主节点挂掉了,那么也就意味着整个系统不能再生产了。那么这个可用性的问题能否解决呢?**一个主从不行那就多个主从的呗**,别忘了在我们最初的架构图中,每个 `Topic` 是分布在不同 `Broker` 中的。
+
+
+
+但是这种复制方式同样也会带来一个问题,那就是无法保证 **严格顺序** 。在上文中我们提到了如何保证的消息顺序性是通过将一个语义的消息发送在同一个队列中,使用 `Topic` 下的队列来保证顺序性的。如果此时我们主节点A负责的是订单A的一系列语义消息,然后它挂了,这样其他节点是无法代替主节点A的,如果我们任意节点都可以存入任何消息,那就没有顺序性可言了。
+
+而在 `RocketMQ` 中采用了 `Dledger` 解决这个问题。他要求在写入消息的时候,要求**至少消息复制到半数以上的节点之后**,才给客⼾端返回写⼊成功,并且它是⽀持通过选举来动态切换主节点的。这里我就不展开说明了,读者可以自己去了解。
+
+> 也不是说 `Dledger` 是个完美的方案,至少在 `Dledger` 选举过程中是无法提供服务的,而且他必须要使用三个节点或以上,如果多数节点同时挂掉他也是无法保证可用性的,而且要求消息复制半数以上节点的效率和直接异步复制还是有一定的差距的。
+
+### 存储机制
+
+还记得上面我们一开始的三个问题吗?到这里第三个问题已经解决了。
+
+但是,在 `Topic` 中的 **队列是以什么样的形式存在的?队列中的消息又是如何进行存储持久化的呢?** 还未解决,其实这里涉及到了 `RocketMQ` 是如何设计它的存储结构了。我首先想大家介绍 `RocketMQ` 消息存储架构中的三大角色——`CommitLog` 、`ConsumeQueue` 和 `IndexFile` 。
+
+- `CommitLog`: **消息主体以及元数据的存储主体**,存储 `Producer` 端写入的消息主体内容,消息内容不是定长的。单个文件大小默认1G ,文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是**顺序写入日志文件**,当文件满了,写入下一个文件。
+- `ConsumeQueue`: 消息消费队列,**引入的目的主要是提高消息消费的性能**(我们再前面也讲了),由于`RocketMQ` 是基于主题 `Topic` 的订阅模式,消息消费是针对主题进行的,如果要遍历 `commitlog` 文件中根据 `Topic` 检索消息是非常低效的。`Consumer` 即可根据 `ConsumeQueue` 来查找待消费的消息。其中,`ConsumeQueue`(逻辑消费队列)**作为消费消息的索引**,保存了指定 `Topic` 下的队列消息在 `CommitLog` 中的**起始物理偏移量 `offset` **,消息大小 `size` 和消息 `Tag` 的 `HashCode` 值。**`consumequeue` 文件可以看成是基于 `topic` 的 `commitlog` 索引文件**,故 `consumequeue` 文件夹的组织方式如下:topic/queue/file三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样 `consumequeue` 文件采取定长设计,每一个条目共20个字节,分别为8字节的 `commitlog` 物理偏移量、4字节的消息长度、8字节tag `hashcode`,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个 `ConsumeQueue`文件大小约5.72M;
+- `IndexFile`: `IndexFile`(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。这里只做科普不做详细介绍。
+
+总结来说,整个消息存储的结构,最主要的就是 `CommitLoq` 和 `ConsumeQueue` 。而 `ConsumeQueue` 你可以大概理解为 `Topic` 中的队列。
+
+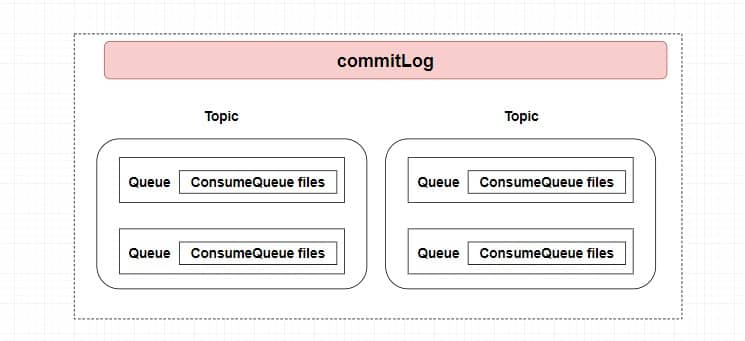
+
+`RocketMQ` 采用的是 **混合型的存储结构** ,即为 `Broker` 单个实例下所有的队列共用一个日志数据文件来存储消息。有意思的是在同样高并发的 `Kafka` 中会为每个 `Topic` 分配一个存储文件。这就有点类似于我们有一大堆书需要装上书架,`RockeMQ` 是不分书的种类直接成批的塞上去的,而 `Kafka` 是将书本放入指定的分类区域的。
+
+而 `RocketMQ` 为什么要这么做呢?原因是 **提高数据的写入效率** ,不分 `Topic` 意味着我们有更大的几率获取 **成批** 的消息进行数据写入,但也会带来一个麻烦就是读取消息的时候需要遍历整个大文件,这是非常耗时的。
+
+所以,在 `RocketMQ` 中又使用了 `ConsumeQueue` 作为每个队列的索引文件来 **提升读取消息的效率**。我们可以直接根据队列的消息序号,计算出索引的全局位置(索引序号*索引固定⻓度20),然后直接读取这条索引,再根据索引中记录的消息的全局位置,找到消息。
+
+讲到这里,你可能对 `RockeMQ` 的存储架构还有些模糊,没事,我们结合着图来理解一下。
+
+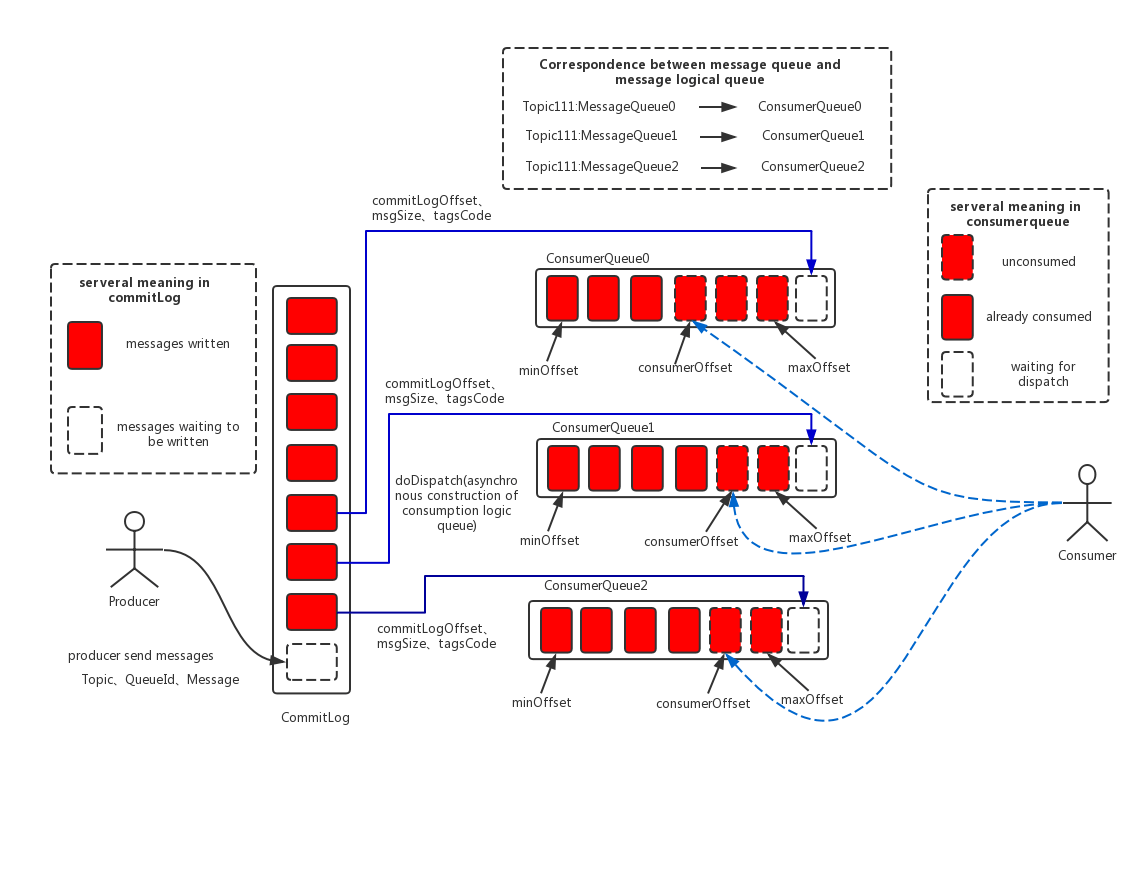
+
+emmm,是不是有一点复杂🤣,看英文图片和英文文档的时候就不要怂,硬着头皮往下看就行。
+
+> 如果上面没看懂的读者一定要认真看下面的流程分析!
+
+首先,在最上面的那一块就是我刚刚讲的你现在可以直接 **把 `ConsumerQueue` 理解为 `Queue`**。
+
+在图中最左边说明了 <font color = red>红色方块 </font> 代表被写入的消息,虚线方块代表等待被写入的。左边的生产者发送消息会指定 `Topic` 、`QueueId` 和具体消息内容,而在 `Broker` 中管你是哪门子消息,他直接 **全部顺序存储到了 CommitLog**。而根据生产者指定的 `Topic` 和 `QueueId` 将这条消息本身在 `CommitLog` 的偏移(offset),消息本身大小,和tag的hash值存入对应的 `ConsumeQueue` 索引文件中。而在每个队列中都保存了 `ConsumeOffset` 即每个消费者组的消费位置(我在架构那里提到了,忘了的同学可以回去看一下),而消费者拉取消息进行消费的时候只需要根据 `ConsumeOffset` 获取下一个未被消费的消息就行了。
+
+上述就是我对于整个消息存储架构的大概理解(这里不涉及到一些细节讨论,比如稀疏索引等等问题),希望对你有帮助。
+
+因为有一个知识点因为写嗨了忘讲了,想想在哪里加也不好,所以我留给大家去思考🤔🤔一下吧。
+
+
+
+为什么 `CommitLog` 文件要设计成固定大小的长度呢?提醒:**内存映射机制**。
+
+## 总结
+
+总算把这篇博客写完了。我讲的你们还记得吗😅?
+
+这篇文章中我主要想大家介绍了
+
+1. 消息队列出现的原因
+2. 消息队列的作用(异步,解耦,削峰)
+3. 消息队列带来的一系列问题(消息堆积、重复消费、顺序消费、分布式事务等等)
+4. 消息队列的两种消息模型——队列和主题模式
+5. 分析了 `RocketMQ` 的技术架构(`NameServer` 、`Broker` 、`Producer` 、`Comsumer`)
+6. 结合 `RocketMQ` 回答了消息队列副作用的解决方案
+7. 介绍了 `RocketMQ` 的存储机制和刷盘策略。
+
+等等。。。
+
+> 如果喜欢可以点赞哟👍👍👍。
diff --git a/docs/high-performance/message-queue/rocketmq-questions.md b/docs/high-performance/message-queue/rocketmq-questions.md
new file mode 100644
index 00000000000..68957689c11
--- /dev/null
+++ b/docs/high-performance/message-queue/rocketmq-questions.md
@@ -0,0 +1,199 @@
+# RocketMQ常见问题
+
+本文来自读者 [PR](https://github.com/Snailclimb/JavaGuide/pull/291)。
+
+## 1 单机版消息中心
+
+一个消息中心,最基本的需要支持多生产者、多消费者,例如下:
+
+```java
+class Scratch {
+
+ public static void main(String[] args) {
+ // 实际中会有 nameserver 服务来找到 broker 具体位置以及 broker 主从信息
+ Broker broker = new Broker();
+ Producer producer1 = new Producer();
+ producer1.connectBroker(broker);
+ Producer producer2 = new Producer();
+ producer2.connectBroker(broker);
+
+ Consumer consumer1 = new Consumer();
+ consumer1.connectBroker(broker);
+ Consumer consumer2 = new Consumer();
+ consumer2.connectBroker(broker);
+
+ for (int i = 0; i < 2; i++) {
+ producer1.asyncSendMsg("producer1 send msg" + i);
+ producer2.asyncSendMsg("producer2 send msg" + i);
+ }
+ System.out.println("broker has msg:" + broker.getAllMagByDisk());
+
+ for (int i = 0; i < 1; i++) {
+ System.out.println("consumer1 consume msg:" + consumer1.syncPullMsg());
+ }
+ for (int i = 0; i < 3; i++) {
+ System.out.println("consumer2 consume msg:" + consumer2.syncPullMsg());
+ }
+ }
+
+}
+
+class Producer {
+
+ private Broker broker;
+
+ public void connectBroker(Broker broker) {
+ this.broker = broker;
+ }
+
+ public void asyncSendMsg(String msg) {
+ if (broker == null) {
+ throw new RuntimeException("please connect broker first");
+ }
+ new Thread(() -> {
+ broker.sendMsg(msg);
+ }).start();
+ }
+}
+
+class Consumer {
+ private Broker broker;
+
+ public void connectBroker(Broker broker) {
+ this.broker = broker;
+ }
+
+ public String syncPullMsg() {
+ return broker.getMsg();
+ }
+
+}
+
+class Broker {
+
+ // 对应 RocketMQ 中 MessageQueue,默认情况下 1 个 Topic 包含 4 个 MessageQueue
+ private LinkedBlockingQueue<String> messageQueue = new LinkedBlockingQueue(Integer.MAX_VALUE);
+
+ // 实际发送消息到 broker 服务器使用 Netty 发送
+ public void sendMsg(String msg) {
+ try {
+ messageQueue.put(msg);
+ // 实际会同步或异步落盘,异步落盘使用的定时任务定时扫描落盘
+ } catch (InterruptedException e) {
+
+ }
+ }
+
+ public String getMsg() {
+ try {
+ return messageQueue.take();
+ } catch (InterruptedException e) {
+
+ }
+ return null;
+ }
+
+ public String getAllMagByDisk() {
+ StringBuilder sb = new StringBuilder("\n");
+ messageQueue.iterator().forEachRemaining((msg) -> {
+ sb.append(msg + "\n");
+ });
+ return sb.toString();
+ }
+}
+```
+
+问题:
+1. 没有实现真正执行消息存储落盘
+2. 没有实现 NameServer 去作为注册中心,定位服务
+3. 使用 LinkedBlockingQueue 作为消息队列,注意,参数是无限大,在真正 RocketMQ 也是如此是无限大,理论上不会出现对进来的数据进行抛弃,但是会有内存泄漏问题(阿里巴巴开发手册也因为这个问题,建议我们使用自制线程池)
+4. 没有使用多个队列(即多个 LinkedBlockingQueue),RocketMQ 的顺序消息是通过生产者和消费者同时使用同一个 MessageQueue 来实现,但是如果我们只有一个 MessageQueue,那我们天然就支持顺序消息
+5. 没有使用 MappedByteBuffer 来实现文件映射从而使消息数据落盘非常的快(实际 RocketMQ 使用的是 FileChannel+DirectBuffer)
+
+## 2 分布式消息中心
+
+### 2.1 问题与解决
+
+#### 2.1.1 消息丢失的问题
+
+1. 当你系统需要保证百分百消息不丢失,你可以使用生产者每发送一个消息,Broker 同步返回一个消息发送成功的反馈消息
+2. 即每发送一个消息,同步落盘后才返回生产者消息发送成功,这样只要生产者得到了消息发送生成的返回,事后除了硬盘损坏,都可以保证不会消息丢失
+3. 但是这同时引入了一个问题,同步落盘怎么才能快?
+
+#### 2.1.2 同步落盘怎么才能快
+
+1. 使用 FileChannel + DirectBuffer 池,使用堆外内存,加快内存拷贝
+2. 使用数据和索引分离,当消息需要写入时,使用 commitlog 文件顺序写,当需要定位某个消息时,查询index 文件来定位,从而减少文件IO随机读写的性能损耗
+
+#### 2.1.3 消息堆积的问题
+
+1. 后台定时任务每隔72小时,删除旧的没有使用过的消息信息
+2. 根据不同的业务实现不同的丢弃任务,具体参考线程池的 AbortPolicy,例如FIFO/LRU等(RocketMQ没有此策略)
+3. 消息定时转移,或者对某些重要的 TAG 型(支付型)消息真正落库
+
+#### 2.1.4 定时消息的实现
+
+1. 实际 RocketMQ 没有实现任意精度的定时消息,它只支持某些特定的时间精度的定时消息
+2. 实现定时消息的原理是:创建特定时间精度的 MessageQueue,例如生产者需要定时1s之后被消费者消费,你只需要将此消息发送到特定的 Topic,例如:MessageQueue-1 表示这个 MessageQueue 里面的消息都会延迟一秒被消费,然后 Broker 会在 1s 后发送到消费者消费此消息,使用 newSingleThreadScheduledExecutor 实现
+
+#### 2.1.5 顺序消息的实现
+
+1. 与定时消息同原理,生产者生产消息时指定特定的 MessageQueue ,消费者消费消息时,消费特定的 MessageQueue,其实单机版的消息中心在一个 MessageQueue 就天然支持了顺序消息
+2. 注意:同一个 MessageQueue 保证里面的消息是顺序消费的前提是:消费者是串行的消费该 MessageQueue,因为就算 MessageQueue 是顺序的,但是当并行消费时,还是会有顺序问题,但是串行消费也同时引入了两个问题:
+>1. 引入锁来实现串行
+>2. 前一个消费阻塞时后面都会被阻塞
+
+#### 2.1.6 分布式消息的实现
+
+1. 需要前置知识:2PC
+2. RocketMQ4.3 起支持,原理为2PC,即两阶段提交,prepared->commit/rollback
+3. 生产者发送事务消息,假设该事务消息 Topic 为 Topic1-Trans,Broker 得到后首先更改该消息的 Topic 为 Topic1-Prepared,该 Topic1-Prepared 对消费者不可见。然后定时回调生产者的本地事务A执行状态,根据本地事务A执行状态,来是否将该消息修改为 Topic1-Commit 或 Topic1-Rollback,消费者就可以正常找到该事务消息或者不执行等
+
+>注意,就算是事务消息最后回滚了也不会物理删除,只会逻辑删除该消息
+
+#### 2.1.7 消息的 push 实现
+
+1. 注意,RocketMQ 已经说了自己会有低延迟问题,其中就包括这个消息的 push 延迟问题
+2. 因为这并不是真正的将消息主动的推送到消费者,而是 Broker 定时任务每5s将消息推送到消费者
+3. pull模式需要我们手动调用consumer拉消息,而push模式则只需要我们提供一个listener即可实现对消息的监听,而实际上,RocketMQ的push模式是基于pull模式实现的,它没有实现真正的push。
+4. push方式里,consumer把轮询过程封装了,并注册MessageListener监听器,取到消息后,唤醒MessageListener的consumeMessage()来消费,对用户而言,感觉消息是被推送过来的。
+
+#### 2.1.8 消息重复发送的避免
+
+1. RocketMQ 会出现消息重复发送的问题,因为在网络延迟的情况下,这种问题不可避免的发生,如果非要实现消息不可重复发送,那基本太难,因为网络环境无法预知,还会使程序复杂度加大,因此默认允许消息重复发送
+2. RocketMQ 让使用者在消费者端去解决该问题,即需要消费者端在消费消息时支持幂等性的去消费消息
+3. 最简单的解决方案是每条消费记录有个消费状态字段,根据这个消费状态字段来判断是否消费或者使用一个集中式的表,来存储所有消息的消费状态,从而避免重复消费
+4. 具体实现可以查询关于消息幂等消费的解决方案
+
+#### 2.1.9 广播消费与集群消费
+
+1. 消息消费区别:广播消费,订阅该 Topic 的消息者们都会消费**每个**消息。集群消费,订阅该 Topic 的消息者们只会有一个去消费**某个**消息
+2. 消息落盘区别:具体表现在消息消费进度的保存上。广播消费,由于每个消费者都独立的去消费每个消息,因此每个消费者各自保存自己的消息消费进度。而集群消费下,订阅了某个 Topic,而旗下又有多个 MessageQueue,每个消费者都可能会去消费不同的 MessageQueue,因此总体的消费进度保存在 Broker 上集中的管理
+
+#### 2.1.10 RocketMQ 不使用 ZooKeeper 作为注册中心的原因,以及自制的 NameServer 优缺点?
+
+1. ZooKeeper 作为支持顺序一致性的中间件,在某些情况下,它为了满足一致性,会丢失一定时间内的可用性,RocketMQ 需要注册中心只是为了发现组件地址,在某些情况下,RocketMQ 的注册中心可以出现数据不一致性,这同时也是 NameServer 的缺点,因为 NameServer 集群间互不通信,它们之间的注册信息可能会不一致
+2. 另外,当有新的服务器加入时,NameServer 并不会立马通知到 Producer,而是由 Producer 定时去请求 NameServer 获取最新的 Broker/Consumer 信息(这种情况是通过 Producer 发送消息时,负载均衡解决)
+
+#### 2.1.11 其它
+
+![][1]
+
+加分项咯
+1. 包括组件通信间使用 Netty 的自定义协议
+2. 消息重试负载均衡策略(具体参考 Dubbo 负载均衡策略)
+3. 消息过滤器(Producer 发送消息到 Broker,Broker 存储消息信息,Consumer 消费时请求 Broker 端从磁盘文件查询消息文件时,在 Broker 端就使用过滤服务器进行过滤)
+4. Broker 同步双写和异步双写中 Master 和 Slave 的交互
+5. Broker 在 4.5.0 版本更新中引入了基于 Raft 协议的多副本选举,之前这是商业版才有的特性 [ISSUE-1046][2]
+
+## 3 参考
+
+1. 《RocketMQ技术内幕》:https://blog.csdn.net/prestigeding/article/details/85233529
+2. 关于 RocketMQ 对 MappedByteBuffer 的一点优化:https://lishoubo.github.io/2017/09/27/MappedByteBuffer%E7%9A%84%E4%B8%80%E7%82%B9%E4%BC%98%E5%8C%96/
+3. 十分钟入门RocketMQ:https://developer.aliyun.com/article/66101
+4. 分布式事务的种类以及 RocketMQ 支持的分布式消息:https://www.infoq.cn/article/2018/08/rocketmq-4.3-release
+5. 滴滴出行基于RocketMQ构建企业级消息队列服务的实践:https://yq.aliyun.com/articles/664608
+6. 基于《RocketMQ技术内幕》源码注释:https://github.com/LiWenGu/awesome-rocketmq
+
+[1]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/RocketMQ%E6%B5%81%E7%A8%8B.png
+[2]: http://rocketmq.apache.org/release_notes/release-notes-4.5.0/
diff --git "a/docs/high-performance/\350\257\273\345\206\231\345\210\206\347\246\273&\345\210\206\345\272\223\345\210\206\350\241\250.md" "b/docs/high-performance/\350\257\273\345\206\231\345\210\206\347\246\273&\345\210\206\345\272\223\345\210\206\350\241\250.md"
new file mode 100644
index 00000000000..4937d9fd7f3
--- /dev/null
+++ "b/docs/high-performance/\350\257\273\345\206\231\345\210\206\347\246\273&\345\210\206\345\272\223\345\210\206\350\241\250.md"
@@ -0,0 +1,190 @@
+# 读写分离&分库分表
+
+大家好呀!今天和小伙伴们聊聊读写分离以及分库分表。
+
+相信很多小伙伴们对于这两个概念已经比较熟悉了,这篇文章全程都是大白话的形式,希望能够给你带来不一样的感受。
+
+如果你之前不太了解这两个概念,那我建议你搞懂之后,可以把自己对于读写分离以及分库分表的理解讲给你的同事/朋友听听。
+
+**原创不易,若有帮助,点赞/分享就是对我最大的鼓励!**
+
+_个人能力有限。如果文章有任何需要补充/完善/修改的地方,欢迎在评论区指出,共同进步!_
+
+## 读写分离
+
+### 何为读写分离?
+
+见名思意,根据读写分离的名字,我们就可以知道:**读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上。** 这样的话,就能够小幅提升写性能,大幅提升读性能。
+
+我简单画了一张图来帮助不太清楚读写分离的小伙伴理解。
+
+
+
+一般情况下,我们都会选择一主多从,也就是一台主数据库负责写,其他的从数据库负责读。主库和从库之间会进行数据同步,以保证从库中数据的准确性。这样的架构实现起来比较简单,并且也符合系统的写少读多的特点。
+
+### 读写分离会带来什么问题?如何解决?
+
+读写分离对于提升数据库的并发非常有效,但是,同时也会引来一个问题:主库和从库的数据存在延迟,比如你写完主库之后,主库的数据同步到从库是需要时间的,这个时间差就导致了主库和从库的数据不一致性问题。这也就是我们经常说的 **主从同步延迟** 。
+
+主从同步延迟问题的解决,没有特别好的一种方案(可能是我太菜了,欢迎评论区补充)。你可以根据自己的业务场景,参考一下下面几种解决办法。
+
+**1.强制将读请求路由到主库处理。**
+
+既然你从库的数据过期了,那我就直接从主库读取嘛!这种方案虽然会增加主库的压力,但是,实现起来比较简单,也是我了解到的使用最多的一种方式。
+
+比如 `Sharding-JDBC` 就是采用的这种方案。通过使用 Sharding-JDBC 的 `HintManager` 分片键值管理器,我们可以强制使用主库。
+
+```java
+HintManager hintManager = HintManager.getInstance();
+hintManager.setMasterRouteOnly();
+// 继续JDBC操作
+```
+
+对于这种方案,你可以将那些必须获取最新数据的读请求都交给主库处理。
+
+**2.延迟读取。**
+
+还有一些朋友肯定会想既然主从同步存在延迟,那我就在延迟之后读取啊,比如主从同步延迟 0.5s,那我就 1s 之后再读取数据。这样多方便啊!方便是方便,但是也很扯淡。
+
+不过,如果你是这样设计业务流程就会好很多:对于一些对数据比较敏感的场景,你可以在完成写请求之后,避免立即进行请求操作。比如你支付成功之后,跳转到一个支付成功的页面,当你点击返回之后才返回自己的账户。
+
+另外,[《MySQL 实战 45 讲》](https://time.geekbang.org/column/intro/100020801?code=ieY8HeRSlDsFbuRtggbBQGxdTh-1jMASqEIeqzHAKrI%3D)这个专栏中的[《读写分离有哪些坑?》](https://time.geekbang.org/column/article/77636)这篇文章还介绍了很多其他比较实际的解决办法,感兴趣的小伙伴可以自行研究一下。
+
+### 如何实现读写分离?
+
+不论是使用哪一种读写分离具体的实现方案,想要实现读写分离一般包含如下几步:
+
+1. 部署多台数据库,选择其中的一台作为主数据库,其他的一台或者多台作为从数据库。
+2. 保证主数据库和从数据库之间的数据是实时同步的,这个过程也就是我们常说的**主从复制**。
+3. 系统将写请求交给主数据库处理,读请求交给从数据库处理。
+
+落实到项目本身的话,常用的方式有两种:
+
+**1.代理方式**
+
+
+
+我们可以在应用和数据中间加了一个代理层。应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。
+
+提供类似功能的中间件有 **MySQL Router**(官方)、**Atlas**(基于 MySQL Proxy)、**Maxscale**、**MyCat**。
+
+**2.组件方式**
+
+在这种方式中,我们可以通过引入第三方组件来帮助我们读写请求。
+
+这也是我比较推荐的一种方式。这种方式目前在各种互联网公司中用的最多的,相关的实际的案例也非常多。如果你要采用这种方式的话,推荐使用 `sharding-jdbc` ,直接引入 jar 包即可使用,非常方便。同时,也节省了很多运维的成本。
+
+你可以在 shardingsphere 官方找到[sharding-jdbc 关于读写分离的操作](https://shardingsphere.apache.org/document/legacy/3.x/document/cn/manual/sharding-jdbc/usage/read-write-splitting/)。
+
+### 主从复制原理了解么?
+
+MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据库中数据的所有变化(数据库执行的所有 DDL 和 DML 语句)。因此,我们根据主库的 MySQL binlog 日志就能够将主库的数据同步到从库中。
+
+更具体和详细的过程是这个样子的(图片来自于:[《MySQL Master-Slave Replication on the Same Machine》](https://www.toptal.com/mysql/mysql-master-slave-replication-tutorial)):
+
+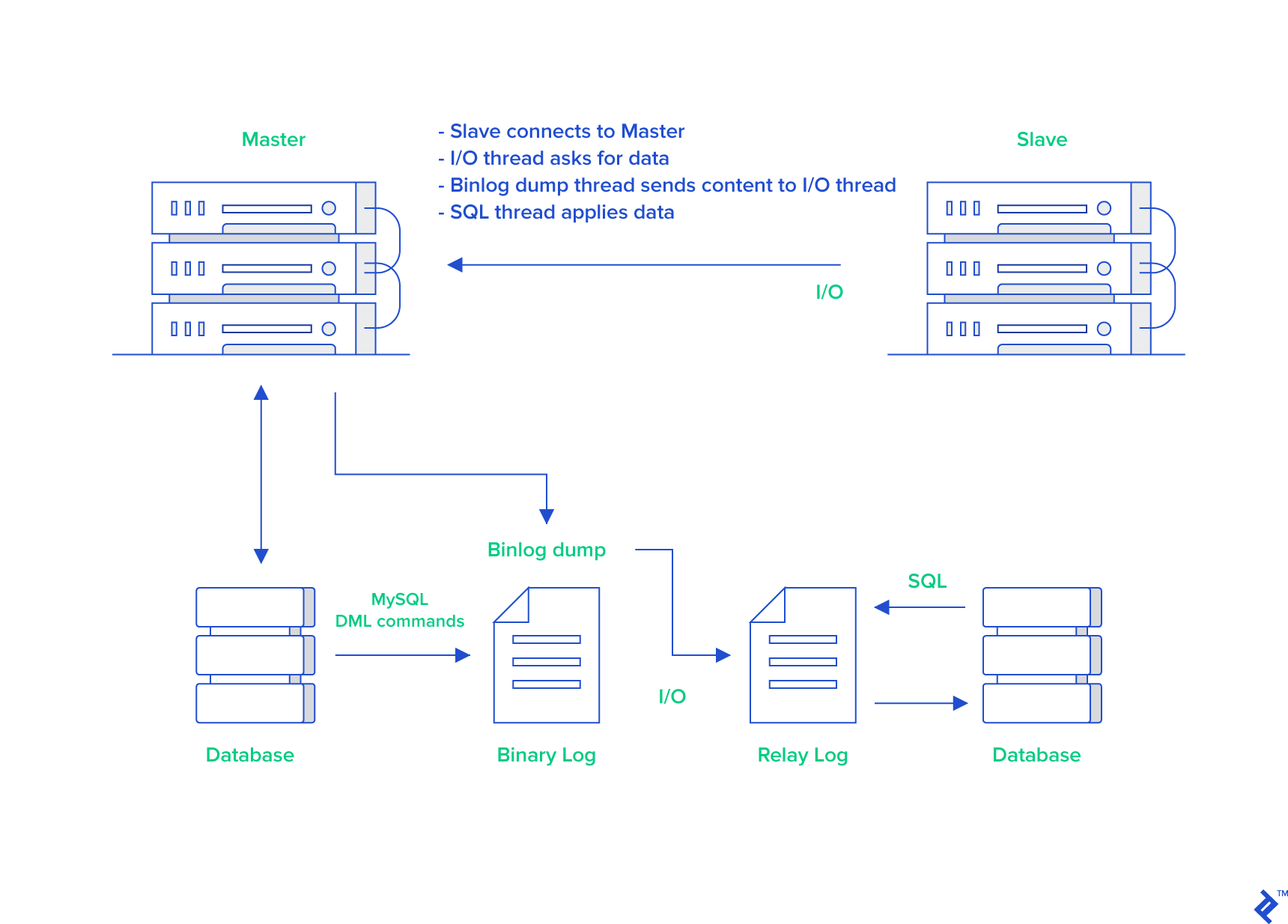
+
+1. 主库将数据库中数据的变化写入到 binlog
+2. 从库连接主库
+3. 从库会创建一个 I/O 线程向主库请求更新的 binlog
+4. 主库会创建一个 binlog dump 线程来发送 binlog ,从库中的 I/O 线程负责接收
+5. 从库的 I/O 线程将接收的 binlog 写入到 relay log 中。
+6. 从库的 SQL 线程读取 relay log 同步数据本地(也就是再执行一遍 SQL )。
+
+怎么样?看了我对主从复制这个过程的讲解,你应该搞明白了吧!
+
+你一般看到 binlog 就要想到主从复制。当然,除了主从复制之外,binlog 还能帮助我们实现数据恢复。
+
+🌈 拓展一下:
+
+不知道大家有没有使用过阿里开源的一个叫做 canal 的工具。这个工具可以帮助我们实现 MySQL 和其他数据源比如 Elasticsearch 或者另外一台 MySQL 数据库之间的数据同步。很显然,这个工具的底层原理肯定也是依赖 binlog。canal 的原理就是模拟 MySQL 主从复制的过程,解析 binlog 将数据同步到其他的数据源。
+
+另外,像咱们常用的分布式缓存组件 Redis 也是通过主从复制实现的读写分离。
+
+🌕 简单总结一下:
+
+**MySQL 主从复制是依赖于 binlog 。另外,常见的一些同步 MySQL 数据到其他数据源的工具(比如 canal)的底层一般也是依赖 binlog 。**
+
+## 分库分表
+
+读写分离主要应对的是数据库读并发,没有解决数据库存储问题。试想一下:**如果 MySQL 一张表的数据量过大怎么办?**
+
+换言之,**我们该如何解决 MySQL 的存储压力呢?**
+
+答案之一就是 **分库分表**。
+
+### 何为分库?
+
+**分库** 就是将数据库中的数据分散到不同的数据库上。
+
+下面这些操作都涉及到了分库:
+
+- 你将数据库中的用户表和用户订单表分别放在两个不同的数据库。
+- 由于用户表数据量太大,你对用户表进行了水平切分,然后将切分后的 2 张用户表分别放在两个不同的数据库。
+
+### 何为分表?
+
+**分表** 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
+
+**何为垂直拆分?**
+
+简单来说,垂直拆分是对数据表列的拆分,把一张列比较多的表拆分为多张表。
+
+举个例子:我们可以将用户信息表中的一些列单独抽出来作为一个表。
+
+**何为水平拆分?**
+
+简单来说,水平拆分是对数据表行的拆分,把一张行比较多的表拆分为多张表。
+
+举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
+
+[《从零开始学架构》](https://time.geekbang.org/column/intro/100006601?code=i00Nq3pHUcUj04ZWy70NCRl%2FD2Lfj8GVzcGzZ3Wf5Ug%3D) 中的有一张图片对于垂直拆分和水平拆分的描述还挺直观的。
+
+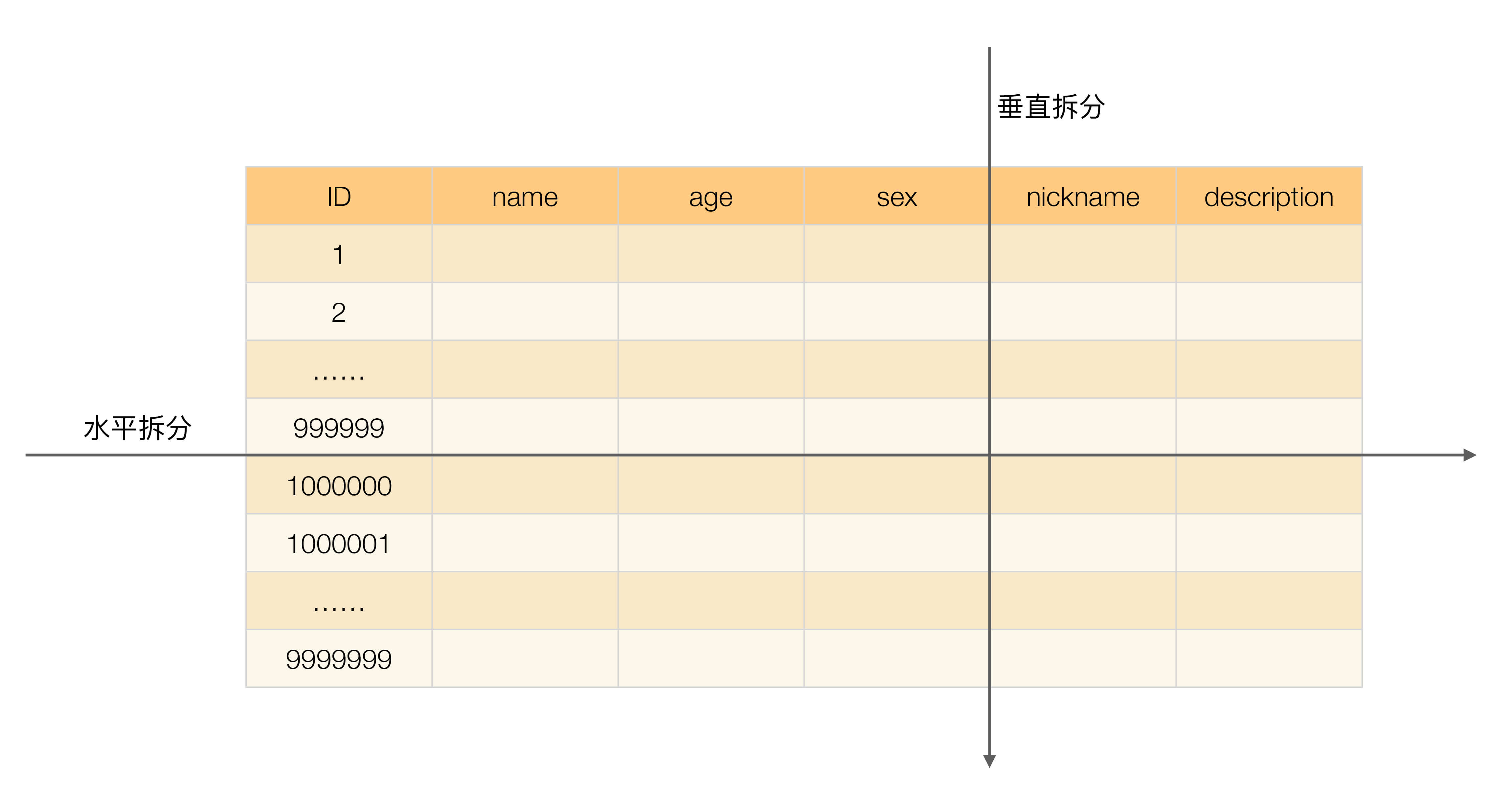
+
+### 什么情况下需要分库分表?
+
+遇到下面几种场景可以考虑分库分表:
+
+- 单表的数据达到千万级别以上,数据库读写速度比较缓慢(分表)。
+- 数据库中的数据占用的空间越来越大,备份时间越来越长(分库)。
+- 应用的并发量太大(分库)。
+
+### 分库分表会带来什么问题呢?
+
+记住,你在公司做的任何技术决策,不光是要考虑这个技术能不能满足我们的要求,是否适合当前业务场景,还要重点考虑其带来的成本。
+
+引入分库分表之后,会给系统带来什么挑战呢?
+
+- **join 操作** : 同一个数据库中的表分布在了不同的数据库中,导致无法使用 join 操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。
+- **事务问题** :同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。
+- **分布式 id** :分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 id 了。
+- ......
+
+另外,引入分库分表之后,一般需要 DBA 的参与,同时还需要更多的数据库服务器,这些都属于成本。
+
+### 分库分表有没有什么比较推荐的方案?
+
+ShardingSphere 项目(包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar)是当当捐入 Apache 的,目前主要由京东数科的一些巨佬维护。
+
+
+
+ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。
+
+另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
+
+艿艿之前写了一篇分库分表的实战文章,各位朋友可以看看:[《芋道 Spring Boot 分库分表入门》](https://mp.weixin.qq.com/s/A2MYOFT7SP-7kGOon8qJaw) 。
+
+### 分库分表后,数据怎么迁移呢?
+
+分库分表之后,我们如何将老库(单库单表)的数据迁移到新库(分库分表后的数据库系统)呢?
+
+比较简单同时也是非常常用的方案就是**停机迁移**,写个脚本老库的数据写到新库中。比如你在凌晨 2 点,系统使用的人数非常少的时候,挂一个公告说系统要维护升级预计 1 小时。然后,你写一个脚本将老库的数据都同步到新库中。
+
+如果你不想停机迁移数据的话,也可以考虑**双写方案**。双写方案是针对那种不能停机迁移的场景,实现起来要稍微麻烦一些。具体原理是这样的:
+
+- 我们对老库的更新操作(增删改),同时也要写入新库(双写)。如果操作的数据不存在于新库的话,需要插入到新库中。 这样就能保证,咱们新库里的数据是最新的。
+- 在迁移过程,双写只会让被更新操作过的老库中的数据同步到新库,我们还需要自己写脚本将老库中的数据和新库的数据做比对。如果新库中没有,那咱们就把数据插入到新库。如果新库有,旧库没有,就把新库对应的数据删除(冗余数据清理)。
+- 重复上一步的操作,直到老库和新库的数据一致为止。
+
+想要在项目中实施双写还是比较麻烦的,很容易会出现问题。我们可以借助上面提到的数据库同步工具 Canal 做增量数据迁移(还是依赖 binlog,开发和维护成本较低)。
diff --git "a/docs/high-performance/\350\264\237\350\275\275\345\235\207\350\241\241.md" "b/docs/high-performance/\350\264\237\350\275\275\345\235\207\350\241\241.md"
new file mode 100644
index 00000000000..a9d98b2cea5
--- /dev/null
+++ "b/docs/high-performance/\350\264\237\350\275\275\345\235\207\350\241\241.md"
@@ -0,0 +1,13 @@
+# 负载均衡
+
+负载均衡系统通常用于将任务比如用户请求处理分配到多个服务器处理以提高网站、应用或者数据库的性能和可靠性。
+
+常见的负载均衡系统包括 3 种:
+
+1. **DNS 负载均衡** :一般用来实现地理级别的均衡。
+2. **硬件负载均衡** : 通过单独的硬件设备比如 F5 来实现负载均衡功能(硬件的价格一般很贵)。
+3. **软件负载均衡** :通过负载均衡软件比如 Nginx 来实现负载均衡功能。
+
+## 推荐阅读
+
+- [《凤凰架构》-负载均衡](http://icyfenix.cn/architect-perspective/general-architecture/diversion-system/load-balancing.html)
diff --git a/docs/idea-tutorial/idea-plugins/camel-case.md b/docs/idea-tutorial/idea-plugins/camel-case.md
new file mode 100644
index 00000000000..5456378f4b2
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/camel-case.md
@@ -0,0 +1,27 @@
+---
+title: Camel Case:命名之间快速切换
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+非常有用!这个插件可以实现包含6种常见命名格式之间的切换。并且,你还可以对转换格式进行相关配置(转换格式),如下图所示:
+
+
+
+有了这个插件之后,你只需要使用快捷键 `shift+option+u(mac)` / `shift+alt+u` 对准你要修改的变量或者方法名字,就能实现在多种格式之间切换了,如下图所示:
+
+
+
+如果你突然忘记快捷键的话,可以直接在IDEA的菜单栏的 Edit 部分找到。
+
+
+
+使用这个插件对开发效率提升高吗?拿我之前项目组的情况举个例子:
+
+我之前有一个项目组的测试名字是驼峰这种形式: `ShouldReturnTicketWhenRobotSaveBagGiven1LockersWith2FreeSpace` 。但是,使用驼峰形式命名测试方法的名字不太明显,一般建议用下划线_的形式: `should_return_ticket_when_robot_save_bag_given_1_lockers_with_2_free_space`
+
+如果我们不用这个插件,而是手动去一个一个改的话,工作量想必会很大,而且正确率也会因为手工的原因降低。
+
+>
diff --git a/docs/idea-tutorial/idea-plugins/code-glance.md b/docs/idea-tutorial/idea-plugins/code-glance.md
new file mode 100644
index 00000000000..9345ab427bb
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/code-glance.md
@@ -0,0 +1,11 @@
+---
+title: CodeGlance:代码微型地图
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+CodeGlance提供一个代码的微型地图,当你的类比较多的时候可以帮忙你快速定位到要去的位置。这个插件在我们日常做普通开发的时候用处不大,不过,在你阅读源码的时候还是很有用的,如下图所示:
+
+
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/code-statistic.md b/docs/idea-tutorial/idea-plugins/code-statistic.md
new file mode 100644
index 00000000000..1d60c81bad6
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/code-statistic.md
@@ -0,0 +1,39 @@
+---
+title: Statistic:项目代码统计
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+编程是一个很奇妙的事情,大部分的我们把大部分时间实际都花在了复制粘贴,而后修改代码上面。
+
+很多时候,我们并不关注代码质量,只要功能能实现,我才不管一个类的代码有多长、一个方法的代码有多长。
+
+因此,我们经常会碰到让自己想要骂街的项目,不过,说真的,你自己写的代码也有极大可能被后者 DISS。
+
+为了快速分析项目情况,判断这个项目是不是一个“垃圾”项目,有一个方法挺简单的。
+
+那就是**对代码的总行数、单个文件的代码行数、注释行数等信息进行统计。**
+
+**怎么统计呢?**
+
+首先想到的是 Excel 。不过,显然太麻烦了。
+
+**有没有专门用于代码统计的工具呢?**
+
+基于Perl语言开发的cloc(count lines of code)或许可以满足你的要求。
+
+**有没有什么更简单的办法呢?**
+
+如果你使用的是 IDEA 进行开发的话,推荐你可以使用一下 **Statistic** 这个插件。
+
+有了这个插件之后你可以非常直观地看到你的项目中所有类型的文件的信息比如数量、大小等等,可以帮助你更好地了解你们的项目。
+
+
+
+你还可以使用它看所有类的总行数、有效代码行数、注释行数、以及有效代码比重等等这些东西。
+
+
+
+如果,你担心插件过多影响IDEA速度的话,可以只在有代码统计需求的时候开启这个插件,其他时间禁用它就完事了!
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/git-commit-template.md b/docs/idea-tutorial/idea-plugins/git-commit-template.md
new file mode 100644
index 00000000000..c75dae11c79
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/git-commit-template.md
@@ -0,0 +1,19 @@
+---
+title: Git Commit Template:提交代码格式规范
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+没有安装这个插件之前,我们使用IDEA提供的Commit功能提交代码是下面这样的:
+
+
+
+使用了这个插件之后是下面这样的,提供了一个commit信息模板的输入框:
+
+
+
+完成之后的效果是这样的:
+
+
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/gson-format.md b/docs/idea-tutorial/idea-plugins/gson-format.md
new file mode 100644
index 00000000000..56750e1cb05
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/gson-format.md
@@ -0,0 +1,32 @@
+---
+title: GsonFormat:JSON转对象
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+GsonFormat 这个插件可以根据Gson库使用的要求,将JSONObject格式的String 解析成实体类。
+
+> 说明:2021.x 版本以上的 IDEA 可以使用:GsonFormatPlus
+
+这个插件使用起来非常简单,我们新建一个类,然后在类中使用快捷键 `option + s`(Mac)或`alt + s` (win)调出操作窗口(**必须在类中使用快捷键才有效**),如下图所示。
+
+
+
+这个插件是一个国人几年前写的,不过已经很久没有更新了,可能会因为IDEA的版本问题有一些小Bug。而且,这个插件无法将JSON转换为Kotlin(这个其实无关痛痒,IDEA自带的就有Java转Kotlin的功能)。
+
+
+
+另外一个与之相似的插件是 **:RoboPOJOGenerator** ,这个插件的更新频率比较快。
+
+`File-> new -> Generate POJO from JSON`
+
+
+
+然后将JSON格式的数据粘贴进去之后,配置相关属性之后选择“*Generate*”
+
+
+
+
+
diff --git a/docs/idea-tutorial/idea-plugins/idea-features-trainer.md b/docs/idea-tutorial/idea-plugins/idea-features-trainer.md
new file mode 100644
index 00000000000..a5cb4960c4d
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/idea-features-trainer.md
@@ -0,0 +1,17 @@
+---
+title: IDE Features Trainer:IDEA 交互式教程
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+**有了这个插件之后,你可以在 IDE 中以交互方式学习IDEA最常用的快捷方式和最基本功能。** 非常非常非常方便!强烈建议大家安装一个,尤其是刚开始使用IDEA的朋友。
+
+当我们安装了这个插件之后,你会发现我们的IDEA 编辑器的右边多了一个“**Learn**”的选项,我们点击这个选项就可以看到如下界面。
+
+
+
+我们选择“Editor Basics”进行,然后就可以看到如下界面,这样你就可以按照指示来练习了!非常不错!
+
+
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/idea-themes.md b/docs/idea-tutorial/idea-plugins/idea-themes.md
new file mode 100644
index 00000000000..ca38f19f51f
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/idea-themes.md
@@ -0,0 +1,99 @@
+---
+title: IDEA主题推荐
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+经常有小伙伴问我:“Guide哥,你的IDEA 主题怎么这么好看,能推荐一下不?”。就实在有点不耐烦了,才索性写了这篇文章。
+
+在这篇文章中,我精选了几个比较是和 Java 编码的 IDEA 主题供小伙伴们选择。另外,我自己用的是 One Dark theme 这款。
+
+**注意:以下主题按照使用人数降序排序。**
+
+## [Material Theme UI](https://plugins.jetbrains.com/plugin/8006-material-theme-ui)
+
+**推荐指数** :⭐⭐⭐⭐
+
+这是 IDEA 中使用人数最多的一款主题。
+
+当你安装完这个插件之后,你会发现这个主题本身又提供了多种相关的主题供你选择。
+
+
+
+ **Material Deep Ocean** 这款的效果图如下。默认的字体是真的小,小伙伴们需要自行调整一下。
+
+
+
+## [One Dark theme](https://plugins.jetbrains.com/plugin/11938-one-dark-theme)
+
+**推荐指数** :⭐⭐⭐⭐⭐
+
+我比较喜欢的一款(*黄色比较多?*)。 没有花里花哨,简单大气,看起来比较舒服。颜色搭配也很棒,适合编码!
+
+这款主题的效果图如下。
+
+
+
+## [Gradianto](https://plugins.jetbrains.com/plugin/12334-gradianto)
+
+**推荐指数** :⭐⭐⭐⭐⭐
+
+Gradianto这个主题的目标是在保持页面色彩比较层次分明的情况下,让我们因为代码而疲惫的双眼更加轻松。
+
+Gradianto附带了自然界的渐变色,看着挺舒服的。另外,这个主题本身也提供了多种相关的主题供你选择。
+
+
+
+**Gradianto Nature Green** 的效果图如下。
+
+
+
+## [Dark Purple Theme](https://plugins.jetbrains.com/plugin/12100-dark-purple-theme)
+
+**推荐指数** :⭐⭐⭐⭐⭐
+
+这是一款紫色色调的深色主题,喜欢紫色的小伙伴不要错过。
+
+这个主题的效果图如下。个人觉得整体颜色搭配的是比较不错的,适合编码!
+
+
+
+## [Hiberbee Theme](https://plugins.jetbrains.com/plugin/12118-hiberbee-theme)
+
+**推荐指数** :⭐⭐⭐⭐⭐
+
+一款受到了 Monokai Pro 和 MacOS Mojave启发的主题,是一款色彩层次分明的深色主题。
+
+这个主题的效果图如下。看着也是非常赞!适合编码!
+
+
+
+上面推荐的都是偏暗色系的主题,这里我再推荐两款浅色系的主题。
+
+## [Gray Theme](https://plugins.jetbrains.com/plugin/12103-gray-theme)
+
+**推荐指数** :⭐⭐⭐
+
+这是一款对比度比较低的一款浅色主题,不太适合代码阅读,毕竟这款主题是专门为在IntelliJ IDE中使用Markdown而设计的。
+
+这个主题的效果图如下。
+
+
+
+## [Roboticket Light Theme](https://plugins.jetbrains.com/plugin/12191-roboticket-light-theme)
+
+**推荐指数** :⭐⭐⭐
+
+这是一款对比度比较低的浅色主题,不太适合代码阅读。
+
+这个主题的效果图如下。
+
+
+
+## 后记
+
+我个人还是比较偏爱深色系的主题。
+
+小伙伴们比较喜欢哪款主题呢?可以在评论区简单聊聊不?如果你还有其他比较喜欢的主题也可以在评论区说出来供大家参考哦!
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/improve-code.md b/docs/idea-tutorial/idea-plugins/improve-code.md
new file mode 100644
index 00000000000..91b31b4e232
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/improve-code.md
@@ -0,0 +1,153 @@
+---
+title: IDEA 代码优化插件推荐
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+ - 代码优化
+---
+
+## Lombok:帮你简化代码
+
+之前没有推荐这个插件的原因是觉得已经是人手必备的了。如果你要使用 Lombok 的话,不光是要安装这个插件,你的项目也要引入相关的依赖。
+
+```xml
+ <dependency>
+ <groupId>org.projectlombok</groupId>
+ <artifactId>lombok</artifactId>
+ <optional>true</optional>
+ </dependency>
+```
+
+使用 Lombok 能够帮助我们少写很多代码比如 Getter/Setter、Constructor等等。
+
+关于Lombok的使用,可以查看这篇文章:[《十分钟搞懂Java效率工具Lombok使用与原理》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485385&idx=2&sn=a7c3fb4485ffd8c019e5541e9b1580cd&chksm=cea24802f9d5c1144eee0da52cfc0cc5e8ee3590990de3bb642df4d4b2a8cd07f12dd54947b9&token=1667678311&lang=zh_CN#rd)。
+
+
+## Codota:代码智能提示
+
+我一直在用的一个插件,可以说非常好用了(*我身边的很多大佬平时写代码也会用这个插件*)。
+
+Codota 这个插件用于智能代码补全,它基于数百万Java程序,能够根据程序上下文提示补全代码。相比于IDEA自带的智能提示来说,Codota 的提示更加全面一些。
+
+如果你觉得 IDEA 插件安装的太多比较卡顿的话,不用担心!Codota 插件还有一个对应的在线网站([https://www.codota.com/code](https://www.codota.com/code)),在这个网站上你可以根据代码关键字搜索相关代码示例,非常不错!
+
+我在工作中经常会用到,说实话确实给我带来了很大便利,比如我们搜索 `Files.readAllLines`相关的代码,搜索出来的结果如下图所示:
+
+
+
+另外,Codota 插件的基础功能都是免费的。你的代码也不会被泄露,这点你不用担心。
+
+简单来看看 Codota 插件的骚操作吧!
+
+### 代码智能补全
+
+我们使用`HttpUrlConnection ` 建立一个网络连接是真的样的:
+
+
+
+我们创建线程池现在变成下面这样:
+
+
+
+上面只是为了演示这个插件的强大,实际上创建线程池不推荐使用这种方式, 推荐使用 `ThreadPoolExecutor` 构造函数创建线程池。我下面要介绍的一个阿里巴巴的插件-**Alibaba Java Code Guidelines** 就检测出来了这个问题,所以,`Executors`下面用波浪线标记了出来。
+
+### 代码智能搜索
+
+除了,在写代码的时候智能提示之外。你还可以直接选中代码然后搜索相关代码示例。
+
+
+
+## Alibaba Java Code Guidelines:阿里巴巴 Java 代码规范
+
+阿里巴巴 Java 代码规范,对应的Github地址为:[https://github.com/alibaba/p3c](https://github.com/alibaba/p3c ) 。非常推荐安装!
+
+安装完成之后建议将与语言替换成中文,提示更加友好一点。
+
+
+
+根据官方描述:
+
+> 目前这个插件实现了开发手册中的的53条规则,大部分基于PMD实现,其中有4条规则基于IDEA实现,并且基于IDEA [Inspection](https://www.jetbrains.com/help/idea/code-inspection.html)实现了实时检测功能。部分规则实现了Quick Fix功能,对于可以提供Quick Fix但没有提供的,我们会尽快实现,也欢迎有兴趣的同学加入进来一起努力。 目前插件检测有两种模式:实时检测、手动触发。
+
+上述提到的开发手册也就是在Java开发领域赫赫有名的《阿里巴巴Java开发手册》。
+
+### 手动配置检测规则
+
+你还可以手动配置相关 inspection规则:
+
+
+
+### 使用效果
+
+这个插件会实时检测出我们的代码不匹配它的规则的地方,并且会给出修改建议。比如我们按照下面的方式去创建线程池的话,这个插件就会帮我们检测出来,如下图所示。
+
+
+
+这个可以对应上 《阿里巴巴Java开发手册》 这本书关于创建线程池的方式说明。
+
+
+
+## CheckStyle: Java代码格式规范
+
+### 为何需要CheckStyle插件?
+
+**CheckStyle 几乎是 Java 项目开发必备的一个插件了,它会帮助我们检查 Java 代码的格式是否有问题比如变量命名格式是否有问题、某一行代码的长度是否过长等等。**
+
+在项目上,**通过项目开发人员自我约束来规范代码格式必然是不靠谱的!** 因此,我们非常需要这样一款工具来帮助我们规范代码格式。
+
+如果你看过我写的轮子的话,可以发现我为每一个项目都集成了 CheckStyle,并且设置了 **Git Commit 钩子**,保证在提交代码之前代码格式没有问题。
+
+> **Guide哥造的轮子**(*代码简洁,结构清晰,欢迎学习,欢迎一起完善*):
+>
+> 1. [guide-rpc-framework](https://github.com/Snailclimb/guide-rpc-framework) :A custom RPC framework implemented by Netty+Kyro+Zookeeper.(一款基于 Netty+Kyro+Zookeeper 实现的自定义 RPC 框架-附详细实现过程和相关教程)
+> 2. [jsoncat](https://github.com/Snailclimb/jsoncat) :仿 Spring Boot 但不同于 Spring Boot 的一个轻量级的 HTTP 框架
+>
+> **Git 钩子**: Git 能在特定的重要动作比如commit、push发生时触发自定义脚本。 钩子都被存储在 Git 目录下的 `hooks` 子目录中。 也即绝大部分项目中的 `.git/hooks` 。
+
+### 如何在Maven/Gradle项目中集成 Checksytle?
+
+一般情况下,我们都是将其集成在项目中,并设置相应的 Git 钩子。网上有相应的介绍文章,这里就不多提了。
+
+如果你觉得网上的文章不直观的话,可以参考我上面提到了两个轮子:
+
+1. [guide-rpc-framework](https://github.com/Snailclimb/guide-rpc-framework) :Maven项目集成 Checksytle。
+2. [jsoncat](https://github.com/Snailclimb/jsoncat) :Gradle项目集成 Checksytle。
+
+如果你在项目中集成了 Checksytle 的话,每次检测会生成一个 HTML格式的文件告诉你哪里的代码格式不对,这样看着非常不直观。通过 Checksytle插件的话可以非常直观的将项目中存在格式问题的地方显示出来。
+
+
+
+如果你只是自己在本地使用,并不想在项目中集成 Checksytle 的话也可以,只需要下载一个 Checksytle插件就足够了。
+
+### 如何安装?
+
+我们直接在 IDEA 的插件市场即可找到这个插件。我这里已经安装好了。
+
+
+
+安装插件之后重启 IDEA,你会发现就可以在底部菜单栏找到 CheckStyle 了。
+
+
+
+### 如何自定义检测规则?
+
+如果你需要自定义代码格式检测规则的话,可以按照如下方式进行配置(你可以导入用于自定义检测规则的`CheckStyle.xml`文件)。
+
+
+
+### 使用效果
+
+配置完成之后,按照如下方式使用这个插件!
+
+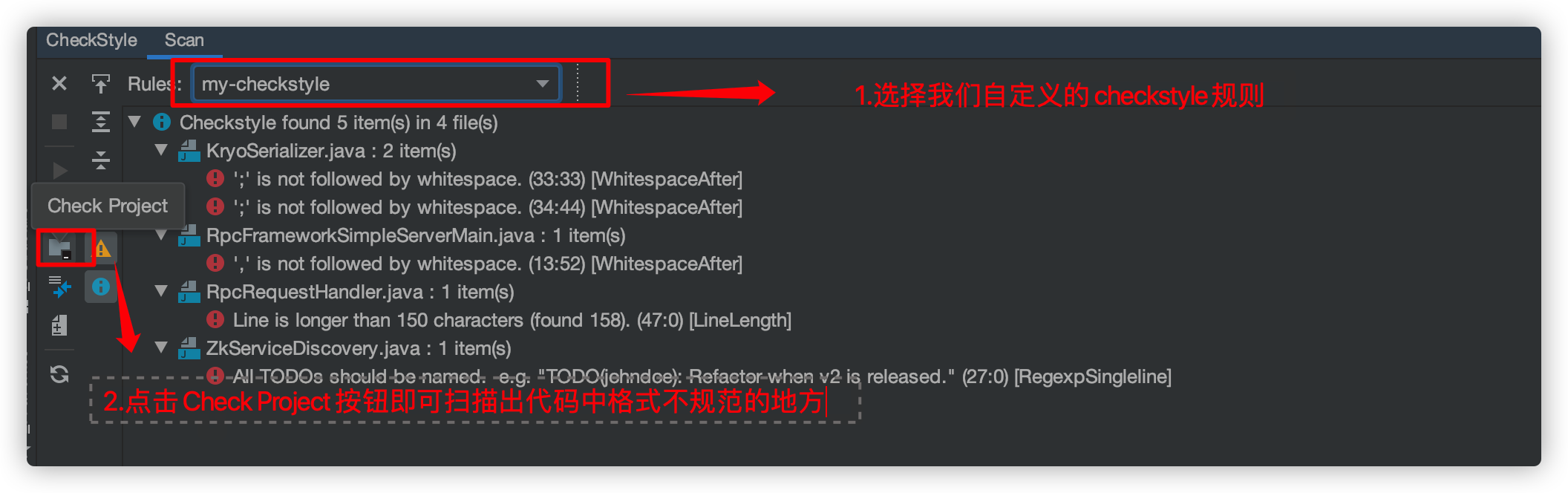
+
+可以非常清晰的看到:CheckStyle 插件已经根据我们自定义的规则将项目中的代码存在格式问题的地方都检测了出来。
+
+## SonarLint:帮你优化代码
+
+SonarLint 帮助你发现代码的错误和漏洞,就像是代码拼写检查器一样,SonarLint 可以实时显示出代码的问题,并提供清晰的修复指导,以便你提交代码之前就可以解决它们。
+
+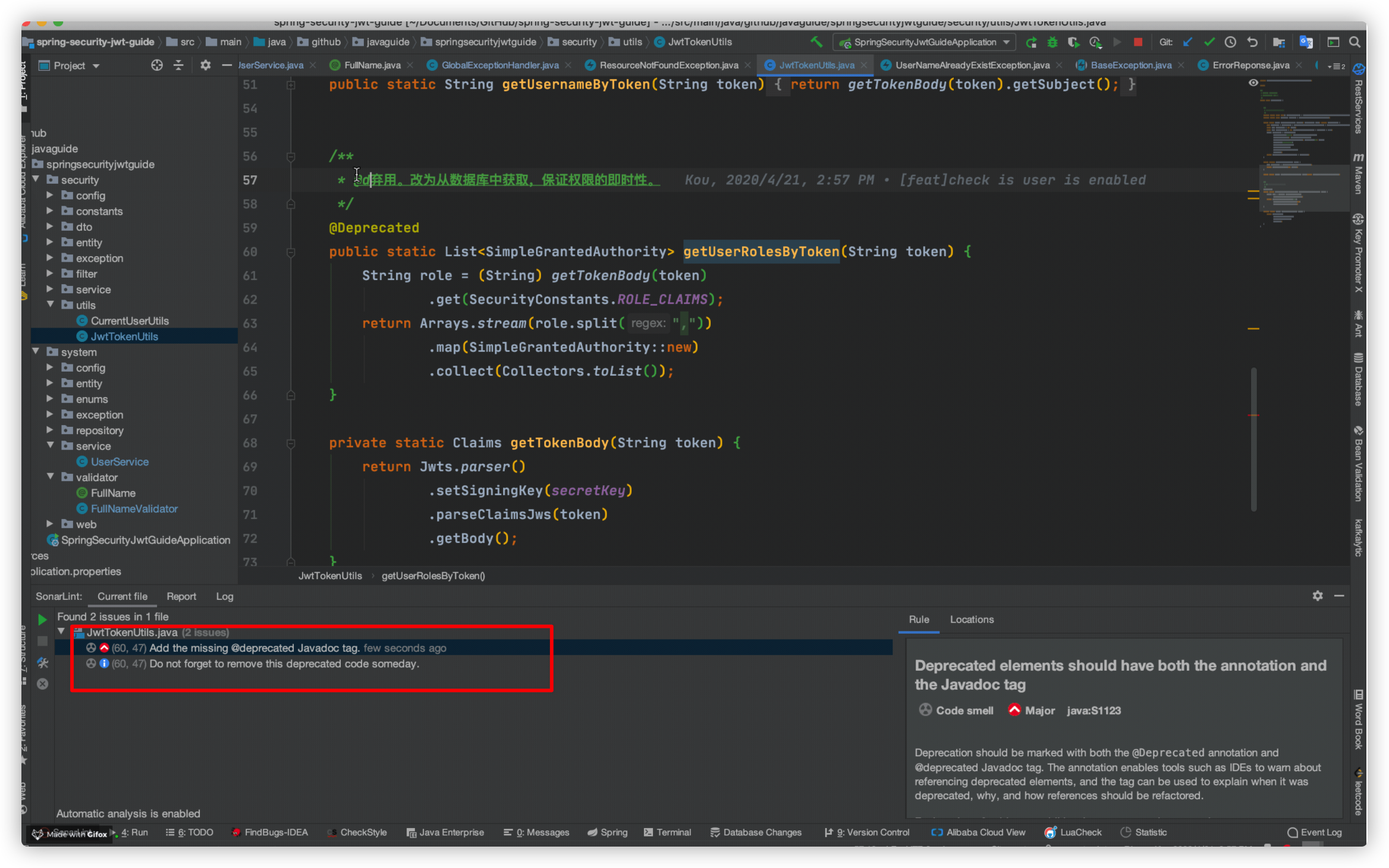
+
+并且,很多项目都集成了 SonarQube,SonarLint 可以很方便地与 SonarQube 集成。
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/interface-beautification.md b/docs/idea-tutorial/idea-plugins/interface-beautification.md
new file mode 100644
index 00000000000..3f3f62fb679
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/interface-beautification.md
@@ -0,0 +1,67 @@
+---
+title: IDEA 界面美化插件推荐
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+ - 代码优化
+---
+
+
+## Background Image Plus:背景图片
+
+我这里推荐使用国人 Jack Chu 基于 Background Image Plus 开发的最新版本,适用于 2021.x 版本的 IDEA。
+
+前面几个下载量比较高的,目前都还未支持 2021.x 版本的 IDEA。
+
+
+
+通过这个插件,你可以将 IDEA 背景设置为指定的图片,支持随机背景。
+
+效果图如下:
+
+
+
+如果你想要设置随机背景的话,可以通过 IDEA 设置页 **Settings** -> **Appearance & Behaviour** -> **Background Image Plus** 自定义设置项,随机显示目录下的图片为背景图。
+
+## Power Mode II : 代码特效
+
+使用了这个插件之后,写代码会自带特效,适用于 2021.x 版本的 IDEA。 2021.x 版本之前,可以使用 **activate-power-mode** 。
+
+
+
+你可以通过 IDEA 设置页 **Settings** -> **Appearance & Behaviour** -> **Power Mode II** 自定义设置项。
+
+
+
+## Nyan Progress Bar : 进度条美化
+
+可以让你拥有更加漂亮的进度条。
+
+
+
+## Grep Console:控制台输出处理
+
+可以说是必备的一个 IDEA 插件,非常实用!
+
+这个插件主要的功能有两个:
+
+**1. 自定义设置控制台输出颜色**
+
+我们可以在设置中进行相关的配置:
+
+
+
+配置完成之后的 log warn 的效果对比图如下:
+
+
+
+**2. 过滤控制台输出**
+
+
+
+## Rainbow Brackets : 彩虹括号
+
+使用各种鲜明的颜色来展示你的括号,效果图如下。可以看出代码层级变得更加清晰了,可以说非常实用友好了!
+
+
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/jclasslib.md b/docs/idea-tutorial/idea-plugins/jclasslib.md
new file mode 100644
index 00000000000..c5f29d2b657
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/jclasslib.md
@@ -0,0 +1,93 @@
+---
+title: jclasslib :一款IDEA字节码查看神器
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+ - 字节码
+---
+
+由于后面要分享的一篇文章中用到了这篇文章要推荐的一个插件,所以这里分享一下。非常实用!你会爱上它的!
+
+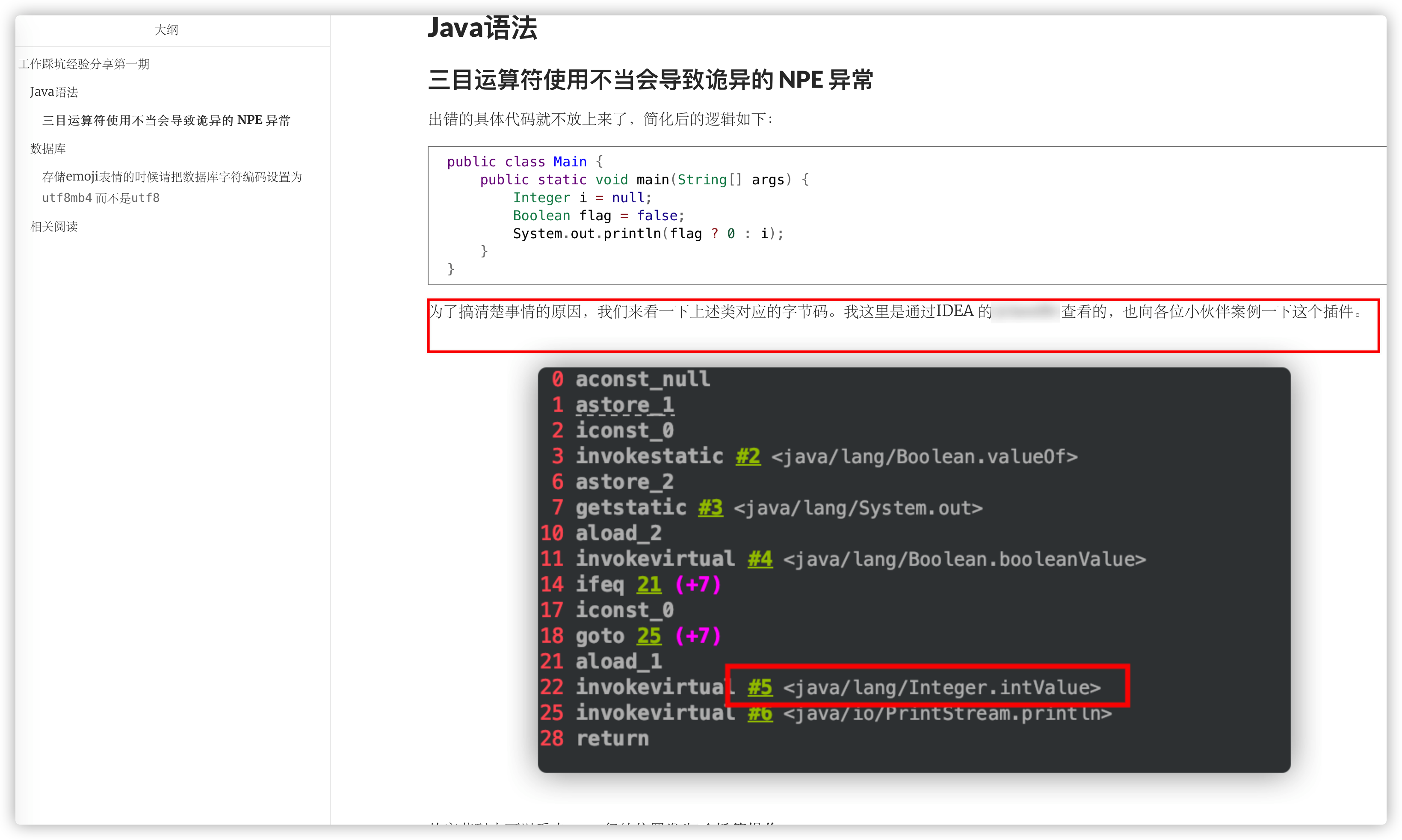
+
+**开始推荐 IDEA 字节码查看神器之前,先来回顾一下 Java 字节码是啥。**
+
+## 何为 Java 字节码?
+
+Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
+
+**什么是字节码?采用字节码的好处是什么?**
+
+> 在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
+
+**Java 程序从源代码到运行一般有下面 3 步:**
+
+
+
+## 为什么要查看 Java 字节码?
+
+我们在平时学习的时候,经常需要查看某个 java 类的字节码文件。查看字节码文件更容易让我们搞懂 java 代码背后的原理比如搞懂 java 中的各种语法糖的本质。
+
+## 如何查看 Java 字节码?
+
+如果我们通过命令行来查看某个 class 的字节码文件的话,可以直接通过 `javap` 命令,不过这种方式太原始了,效率十分低,并且看起来不直观。
+
+下面介绍两种使用 IDEA 查看类对应字节码文件的方式(_`javap`这种方式就不提了_)。
+
+我们以这段代码作为案例:
+
+```java
+public class Main {
+ public static void main(String[] args) {
+ Integer i = null;
+ Boolean flag = false;
+ System.out.println(flag ? 0 : i);
+ }
+}
+```
+
+上面这段代码由于使用三目运算符不当导致诡异了 NPE 异常。为了搞清楚事情的原因,我们来看其对应的字节码。
+
+### 使用 IDEA 自带功能
+
+我们点击 `View -> Show Bytecode` 即可通过 IDEA 查看某个类对应的字节码文件。
+
+> 需要注意的是:**查看某个类对应的字节码文件之前确保它已经被编译过。**
+
+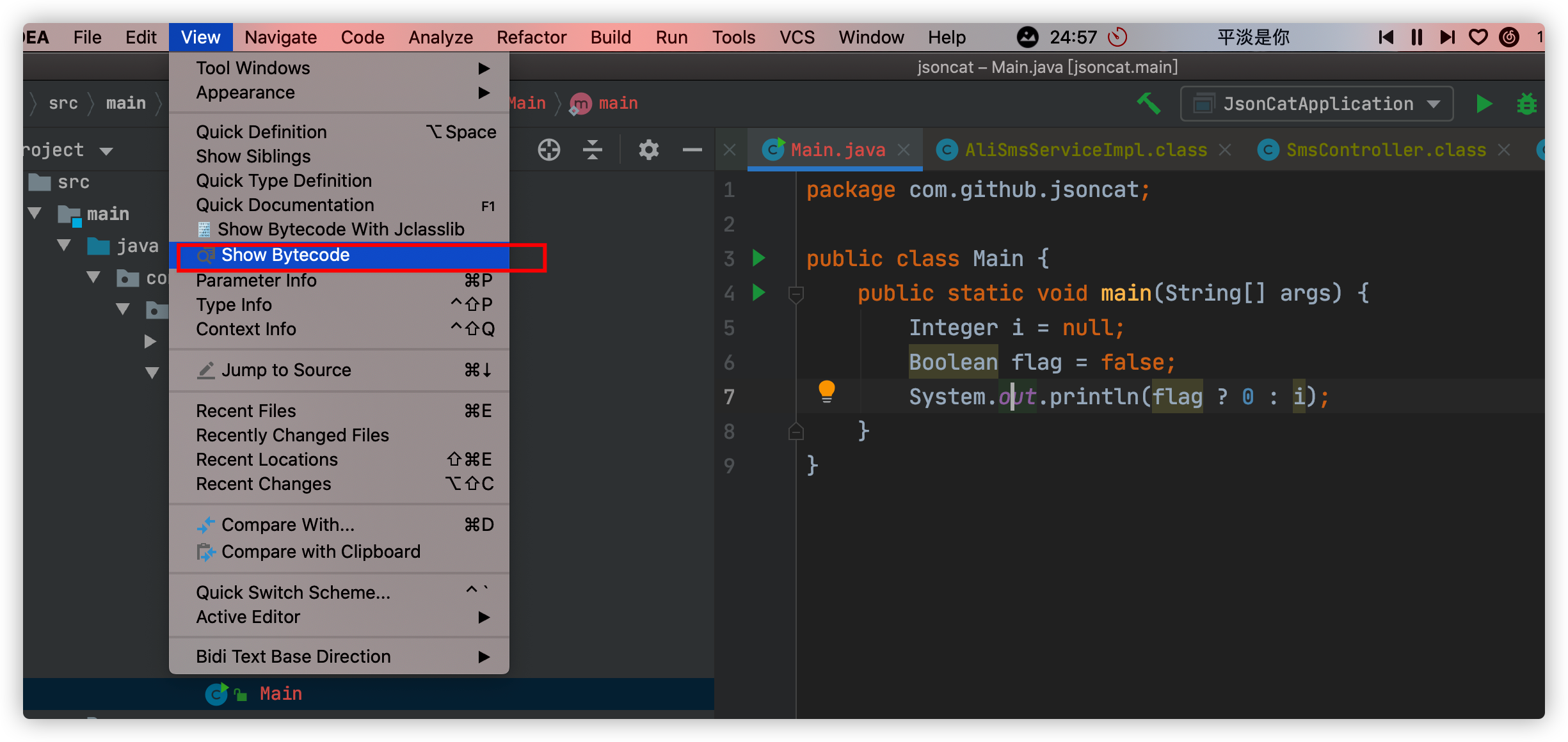
+
+稍等几秒钟之后,你就可以直观到看到对应的类的字节码内容了。
+
+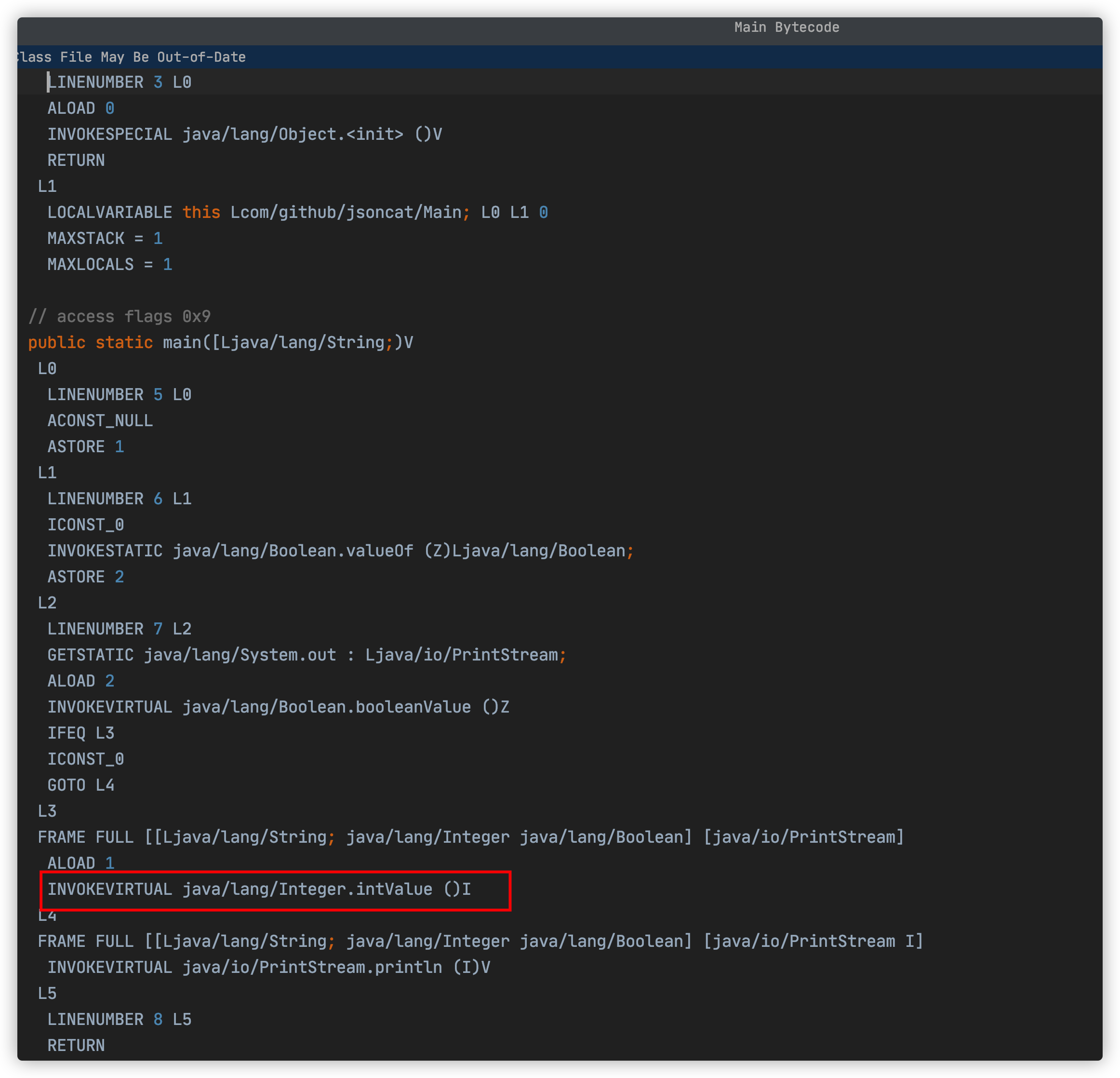
+
+从字节码中可以看出,我圈出来的位置发生了 **拆箱操作** 。
+
+> - **装箱**:将基本类型用它们对应的引用类型包装起来;
+> - **拆箱**:将包装类型转换为基本数据类型;
+
+详细解释下就是:`flag ? 0 : i` 这行代码中,0 是基本数据类型 int,返回数据的时候 i 会被强制拆箱成 int 类型,由于 i 的值是 null,因此就抛出了 NPE 异常。
+
+```java
+Integer i = null;
+Boolean flag = false;
+System.out.println(flag ? 0 : i);
+```
+
+如果,我们把代码中 `flag` 变量的值修改为 true 的话,就不会存在 NPE 问题了,因为会直接返回 0,不会进行拆箱操作。
+
+### 使用 IDEA 插件 jclasslib(推荐)
+
+相比于 IDEA 自带的查看类字节的功能,我更推荐 `jclasslib` 这个插件,非常棒!
+
+**使用 `jclasslib` 不光可以直观地查看某个类对应的字节码文件,还可以查看类的基本信息、常量池、接口、属性、函数等信息。**
+
+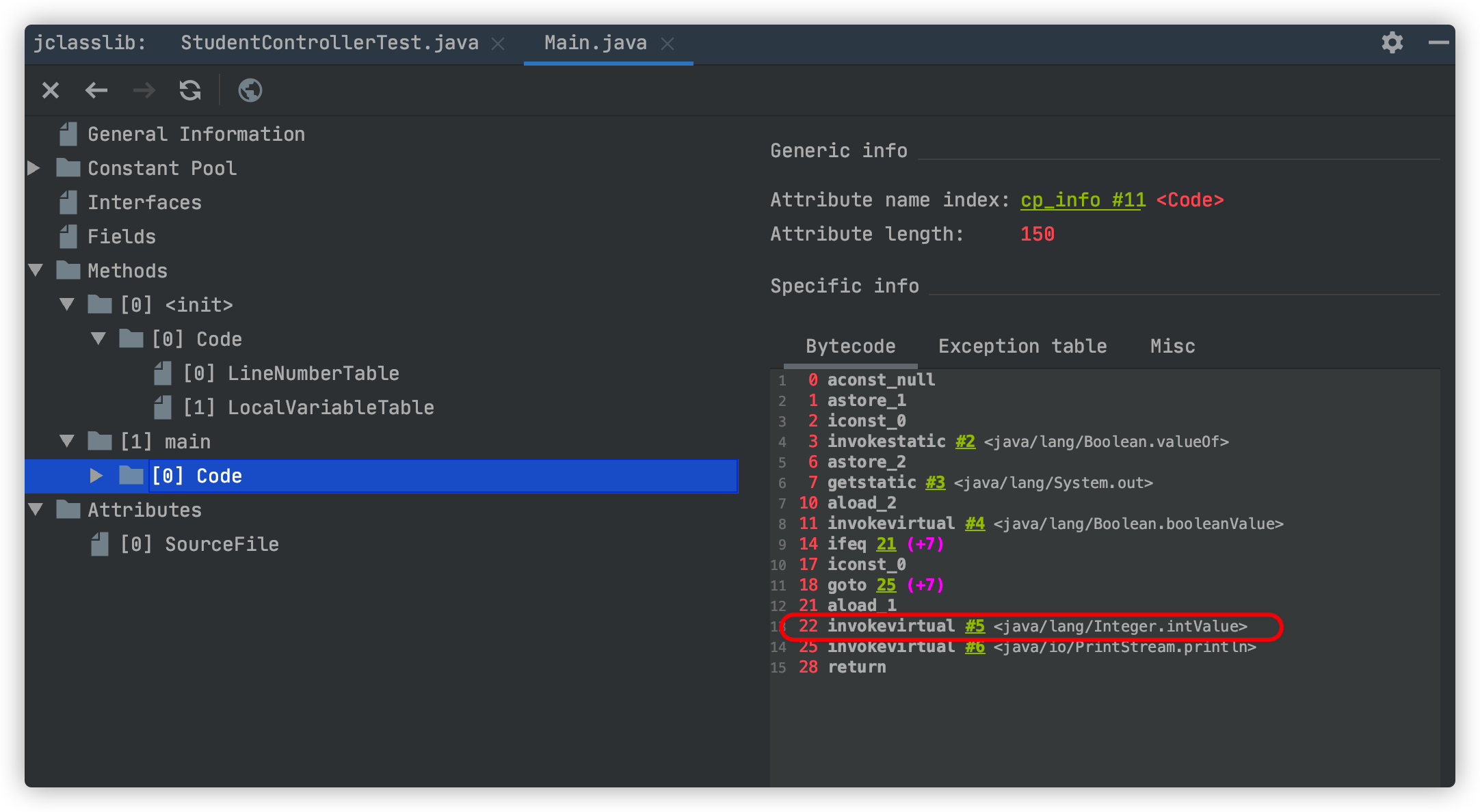
+
+我们直接在 IDEA 的插件市场即可找到这个插件。我这里已经安装好了。
+
+
+
+安装完成之后,重启 IDEA。点击`View -> Show Bytecode With jclasslib` 即可通过`jclasslib` 查看某个类对应的字节码文件。
+
+
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/maven-helper.md b/docs/idea-tutorial/idea-plugins/maven-helper.md
new file mode 100644
index 00000000000..d2b064a9934
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/maven-helper.md
@@ -0,0 +1,19 @@
+---
+title: Maven Helper:解决 Maven 依赖冲突问题
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+ - Maven
+---
+
+
+**Maven Helper** 主要用来分析 Maven 项目的相关依赖,可以帮助我们解决 Maven 依赖冲突问题。
+
+
+
+**何为依赖冲突?**
+
+说白了就是你的项目使用的 2 个 jar 包引用了同一个依赖 h,并且 h 的版本还不一样,这个时候你的项目就存在两个不同版本的 h。这时 Maven 会依据依赖路径最短优先原则,来决定使用哪个版本的 Jar 包,而另一个无用的 Jar 包则未被使用,这就是所谓的依赖冲突。
+
+大部分情况下,依赖冲突可能并不会对系统造成什么异常,因为 Maven 始终选择了一个 Jar 包来使用。但是,不排除在某些特定条件下,会出现类似找不到类的异常,所以,只要存在依赖冲突,在我看来,最好还是解决掉,不要给系统留下隐患。
diff --git a/docs/idea-tutorial/idea-plugins/others.md b/docs/idea-tutorial/idea-plugins/others.md
new file mode 100644
index 00000000000..da505ff8dfe
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/others.md
@@ -0,0 +1,21 @@
+---
+title: 其他
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+
+1. **leetcode editor** :提供在线 Leetcode 刷题功能,比较方便我们刷题,不过我试用之后发现有一些小 bug,个人感觉还是直接在网站找题目刷来的痛快一些。
+2. **A Search with Github** :直接通过 Github搜索相关代码。
+3. **stackoverflow** : 选中相关内容后单击右键即可快速跳转到 stackoverflow 。
+4. **CodeStream** :让code review变得更加容易。
+5. **Code screenshots** :代码片段保存为图片。
+6. **GitToolBox** :Git工具箱
+7. **OK, Gradle!** :搜索Java库用于Gradle项目
+8. **Java Stream Debugger** : Java8 Stream调试器
+9. **EasyCode** : Easycode 可以直接对数据的表生成entity、controller、service、dao、mapper无需任何编码,简单而强大。更多内容可以查看这篇文章:[《懒人 IDEA 插件插件:EasyCode 一键帮你生成所需代码~》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486205&idx=1&sn=0ff2f87f0d82a1bd9c0c44328ef69435&chksm=cea24536f9d5cc20c6cc7669f0d4167d747fe8b8c05a64546c0162d694aa96044a2862e24b57&token=1862674725&lang=zh_CN#rd)
+10. **JFormDesigner** :Swing GUI 在线编辑器。
+11. **VisualVM Launcher** : Java性能分析神器。
+12. ......
diff --git a/docs/idea-tutorial/idea-plugins/pictures/Codota1.gif b/docs/idea-tutorial/idea-plugins/pictures/Codota1.gif
new file mode 100644
index 00000000000..7b2947fe3a0
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/Codota1.gif differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/Codota2.png b/docs/idea-tutorial/idea-plugins/pictures/Codota2.png
new file mode 100644
index 00000000000..0fe37e36047
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/Codota2.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/Codota3.png b/docs/idea-tutorial/idea-plugins/pictures/Codota3.png
new file mode 100644
index 00000000000..44d1093e492
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/Codota3.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/Codota4.gif b/docs/idea-tutorial/idea-plugins/pictures/Codota4.gif
new file mode 100644
index 00000000000..1322b60f5e0
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/Codota4.gif differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/GsonFormat1.png b/docs/idea-tutorial/idea-plugins/pictures/GsonFormat1.png
new file mode 100644
index 00000000000..c8e678acb68
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/GsonFormat1.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/GsonFormat2.gif b/docs/idea-tutorial/idea-plugins/pictures/GsonFormat2.gif
new file mode 100644
index 00000000000..7c371162d9e
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/GsonFormat2.gif differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/IDE-Features-Trainer1.png b/docs/idea-tutorial/idea-plugins/pictures/IDE-Features-Trainer1.png
new file mode 100644
index 00000000000..27f888a9499
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/IDE-Features-Trainer1.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/IDE-Features-Trainer2.png b/docs/idea-tutorial/idea-plugins/pictures/IDE-Features-Trainer2.png
new file mode 100644
index 00000000000..6d59082c281
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/IDE-Features-Trainer2.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/JavaStreamDebugger.gif b/docs/idea-tutorial/idea-plugins/pictures/JavaStreamDebugger.gif
new file mode 100644
index 00000000000..6e910e72ed5
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/JavaStreamDebugger.gif differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/Presentation-Assistant.gif b/docs/idea-tutorial/idea-plugins/pictures/Presentation-Assistant.gif
new file mode 100644
index 00000000000..335523ea5f9
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/Presentation-Assistant.gif differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit1.png b/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit1.png
new file mode 100644
index 00000000000..5a69bc0595a
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit1.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit2.png b/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit2.png
new file mode 100644
index 00000000000..6c8aefd7638
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit2.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit3.png b/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit3.png
new file mode 100644
index 00000000000..b6cf628e76a
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit3.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit4.png b/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit4.png
new file mode 100644
index 00000000000..be15f46bdd2
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/RestfulToolkit4.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/RoboPOJOGenerator1.png b/docs/idea-tutorial/idea-plugins/pictures/RoboPOJOGenerator1.png
new file mode 100644
index 00000000000..c2d7704766b
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/RoboPOJOGenerator1.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/RoboPOJOGenerator2.png b/docs/idea-tutorial/idea-plugins/pictures/RoboPOJOGenerator2.png
new file mode 100644
index 00000000000..4334b3db390
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/RoboPOJOGenerator2.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/Statistic1.png b/docs/idea-tutorial/idea-plugins/pictures/Statistic1.png
new file mode 100644
index 00000000000..47521ee25dd
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/Statistic1.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/Statistic2.png b/docs/idea-tutorial/idea-plugins/pictures/Statistic2.png
new file mode 100644
index 00000000000..f815aa1c722
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/Statistic2.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/camel-case/camel-case1.png b/docs/idea-tutorial/idea-plugins/pictures/camel-case/camel-case1.png
new file mode 100644
index 00000000000..7fbbbba97e5
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/camel-case/camel-case1.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/camel-case/camel-case2.gif b/docs/idea-tutorial/idea-plugins/pictures/camel-case/camel-case2.gif
new file mode 100644
index 00000000000..9565231e9d7
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/camel-case/camel-case2.gif differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/camel-case/camel-case3.png b/docs/idea-tutorial/idea-plugins/pictures/camel-case/camel-case3.png
new file mode 100644
index 00000000000..d4b2fd27ab3
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/camel-case/camel-case3.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/check-style.png b/docs/idea-tutorial/idea-plugins/pictures/check-style.png
new file mode 100644
index 00000000000..e0c17b64096
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/check-style.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/code-glance.png b/docs/idea-tutorial/idea-plugins/pictures/code-glance.png
new file mode 100644
index 00000000000..afdf1a1bca0
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/code-glance.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/git-commit-template/Git-Commit-Template1.png b/docs/idea-tutorial/idea-plugins/pictures/git-commit-template/Git-Commit-Template1.png
new file mode 100644
index 00000000000..26da6cd1b06
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/git-commit-template/Git-Commit-Template1.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/git-commit-template/Git-Commit-Template2.png b/docs/idea-tutorial/idea-plugins/pictures/git-commit-template/Git-Commit-Template2.png
new file mode 100644
index 00000000000..c0e436432a5
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/git-commit-template/Git-Commit-Template2.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/git-commit-template/Git-Commit-Template3.png b/docs/idea-tutorial/idea-plugins/pictures/git-commit-template/Git-Commit-Template3.png
new file mode 100644
index 00000000000..17f81a23469
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/git-commit-template/Git-Commit-Template3.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/grep-console/grep-console.gif b/docs/idea-tutorial/idea-plugins/pictures/grep-console/grep-console.gif
new file mode 100644
index 00000000000..293c134207f
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/grep-console/grep-console.gif differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/grep-console/grep-console2.png b/docs/idea-tutorial/idea-plugins/pictures/grep-console/grep-console2.png
new file mode 100644
index 00000000000..aa338d615ee
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/grep-console/grep-console2.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/grep-console/grep-console3.png b/docs/idea-tutorial/idea-plugins/pictures/grep-console/grep-console3.png
new file mode 100644
index 00000000000..411128ed121
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/grep-console/grep-console3.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/maver-helper.png b/docs/idea-tutorial/idea-plugins/pictures/maver-helper.png
new file mode 100644
index 00000000000..35a3f6e083f
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/maver-helper.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/p3c/Alibaba-Java-Code-Guidelines1.png b/docs/idea-tutorial/idea-plugins/pictures/p3c/Alibaba-Java-Code-Guidelines1.png
new file mode 100644
index 00000000000..67c3571d836
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/p3c/Alibaba-Java-Code-Guidelines1.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/p3c/Alibaba-Java-Code-Guidelines2.png b/docs/idea-tutorial/idea-plugins/pictures/p3c/Alibaba-Java-Code-Guidelines2.png
new file mode 100644
index 00000000000..e4b1dc8c9a8
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/p3c/Alibaba-Java-Code-Guidelines2.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/p3c/Alibaba-Java-Code-Guidelines3.png b/docs/idea-tutorial/idea-plugins/pictures/p3c/Alibaba-Java-Code-Guidelines3.png
new file mode 100644
index 00000000000..5213aff02ca
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/p3c/Alibaba-Java-Code-Guidelines3.png differ
diff --git "a/docs/idea-tutorial/idea-plugins/pictures/p3c/\351\230\277\351\207\214\345\267\264\345\267\264\345\274\200\345\217\221\346\211\213\345\206\214-\347\272\277\347\250\213\346\261\240\345\210\233\345\273\272.png" "b/docs/idea-tutorial/idea-plugins/pictures/p3c/\351\230\277\351\207\214\345\267\264\345\267\264\345\274\200\345\217\221\346\211\213\345\206\214-\347\272\277\347\250\213\346\261\240\345\210\233\345\273\272.png"
new file mode 100644
index 00000000000..4d18c60b055
Binary files /dev/null and "b/docs/idea-tutorial/idea-plugins/pictures/p3c/\351\230\277\351\207\214\345\267\264\345\267\264\345\274\200\345\217\221\346\211\213\345\206\214-\347\272\277\347\250\213\346\261\240\345\210\233\345\273\272.png" differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/power-mode/Power-Mode-II.gif b/docs/idea-tutorial/idea-plugins/pictures/power-mode/Power-Mode-II.gif
new file mode 100644
index 00000000000..026c32e947e
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/power-mode/Power-Mode-II.gif differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/rainbow-brackets.png b/docs/idea-tutorial/idea-plugins/pictures/rainbow-brackets.png
new file mode 100644
index 00000000000..6529899a3ed
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/rainbow-brackets.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/save-actions/save-actions.png b/docs/idea-tutorial/idea-plugins/pictures/save-actions/save-actions.png
new file mode 100644
index 00000000000..cf765cb6d0e
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/save-actions/save-actions.png differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/save-actions/save-actions2.gif b/docs/idea-tutorial/idea-plugins/pictures/save-actions/save-actions2.gif
new file mode 100644
index 00000000000..93ae62cf6c2
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/save-actions/save-actions2.gif differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/translation/translation1.jpg b/docs/idea-tutorial/idea-plugins/pictures/translation/translation1.jpg
new file mode 100644
index 00000000000..7b512c115b1
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/translation/translation1.jpg differ
diff --git a/docs/idea-tutorial/idea-plugins/pictures/translation/translation2.png b/docs/idea-tutorial/idea-plugins/pictures/translation/translation2.png
new file mode 100644
index 00000000000..c92664718dd
Binary files /dev/null and b/docs/idea-tutorial/idea-plugins/pictures/translation/translation2.png differ
diff --git a/docs/idea-tutorial/idea-plugins/rest-devlop.md b/docs/idea-tutorial/idea-plugins/rest-devlop.md
new file mode 100644
index 00000000000..329552b33b2
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/rest-devlop.md
@@ -0,0 +1,96 @@
+---
+title: RestfulToolkit:RESTful Web 服务辅助开发工具
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+
+开始推荐这个 IDEA 插件之前,我觉得有必要花一小会时间简单聊聊 **REST** 这个我们经常打交道的概念。
+
+## REST 相关概念解读
+
+### 何为 REST?
+
+REST 即 **REpresentational State Transfer** 的缩写。这个词组的翻译过来就是"**表现层状态转化**"。
+
+这样理解起来甚是晦涩,实际上 REST 的全称是 **Resource Representational State Transfer** ,直白地翻译过来就是 **“资源”在网络传输中以某种“表现形式”进行“状态转移”** 。
+
+**有没有感觉很难理解?**
+
+没关系,看了我对 REST 涉及到的一些概念的解读之后你没准就能理解了!
+
+- **资源(Resource)** :我们可以把真实的对象数据称为资源。一个资源既可以是一个集合,也可以是单个个体。比如我们的班级 classes 是代表一个集合形式的资源,而特定的 class 代表单个个体资源。每一种资源都有特定的 URI(统一资源定位符)与之对应,如果我们需要获取这个资源,访问这个 URI 就可以了,比如获取特定的班级:`/class/12`。另外,资源也可以包含子资源,比如 `/classes/classId/teachers`:列出某个指定班级的所有老师的信息
+- **表现形式(Representational)**:"资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式比如 json,xml,image,txt 等等叫做它的"表现层/表现形式"。
+- **状态转移(State Transfer)** :大家第一眼看到这个词语一定会很懵逼?内心 BB:这尼玛是啥啊? **大白话来说 REST 中的状态转移更多地描述的服务器端资源的状态,比如你通过增删改查(通过 HTTP 动词实现)引起资源状态的改变。** (HTTP 协议是一个无状态的,所有的资源状态都保存在服务器端)
+
+### 何为 RESTful 架构?
+
+满足 REST 风格的架构设计就可以称为 RESTful 架构:
+
+1. 每一个 URI 代表一种资源;
+2. 客户端和服务器之间,传递这种资源的某种表现形式比如 json,xml,image,txt 等等;
+3. 客户端通过特定的 HTTP 动词,对服务器端资源进行操作,实现"表现层状态转化"。
+
+### 何为 RESTful Web 服务?
+
+基于 REST 架构的 Web 服务就被称为 RESTful Web 服务。
+
+## RESTful Web 服务辅助开发工具
+
+### 安装
+
+这个插件的名字叫做 “**RestfulToolkit**” 。我们直接在 IDEA 的插件市场即可找到这个插件。如下图所示。
+
+> 如果你因为网络问题没办法使用 IDEA 自带的插件市场的话,也可以通过[IDEA 插件市场的官网](https://plugins.jetbrains.com/idea)手动下载安装。
+
+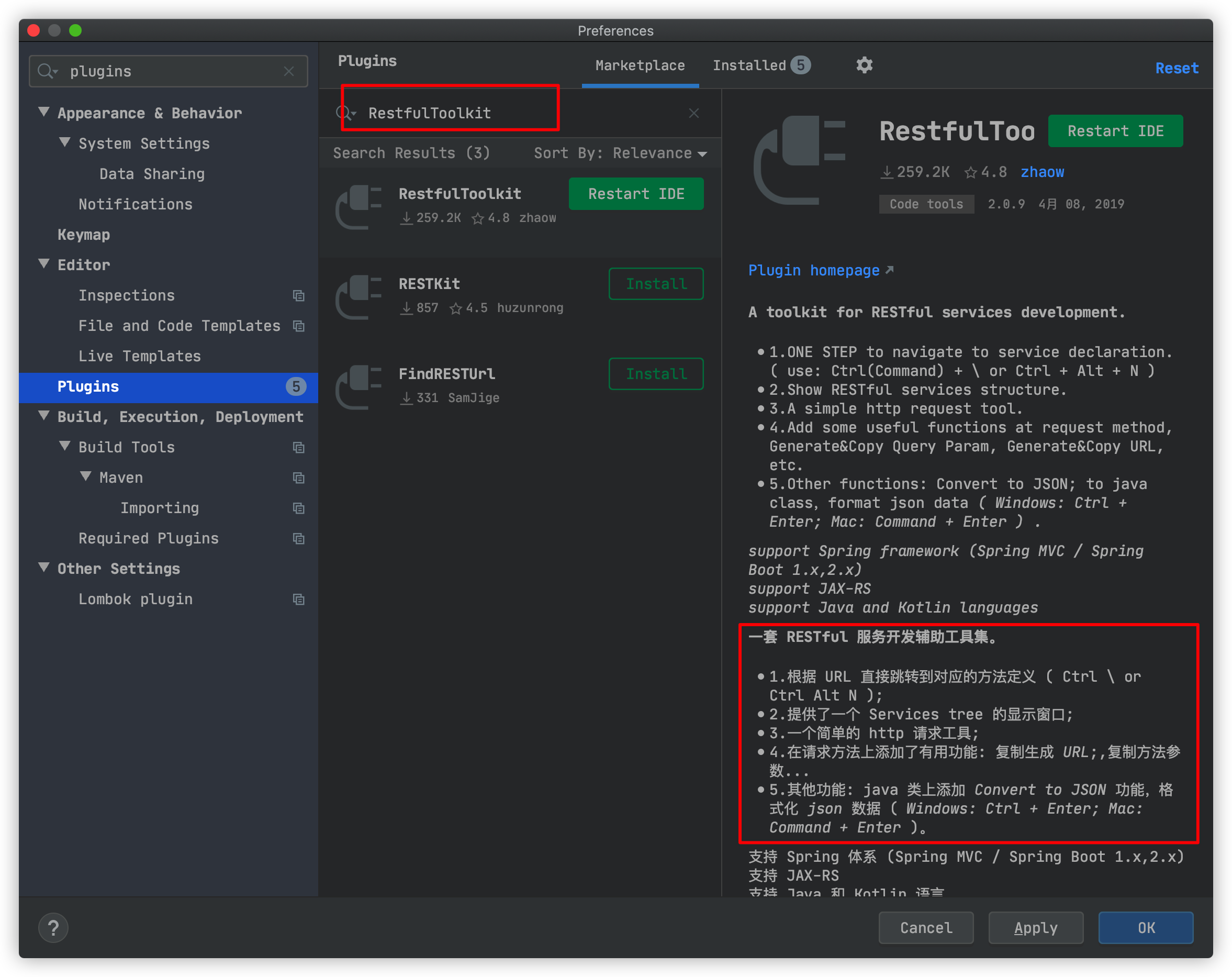
+
+### 简单使用
+
+#### URL 跳转到对应方法
+
+根据 URL 直接跳转到对应的方法定义 (Windows: `ctrl+\` or `ctrl+alt+n` Mac:`command+\` or `command+alt+n` )并且提供了一个服务的树形可视化显示窗口。 如下图所示。
+
+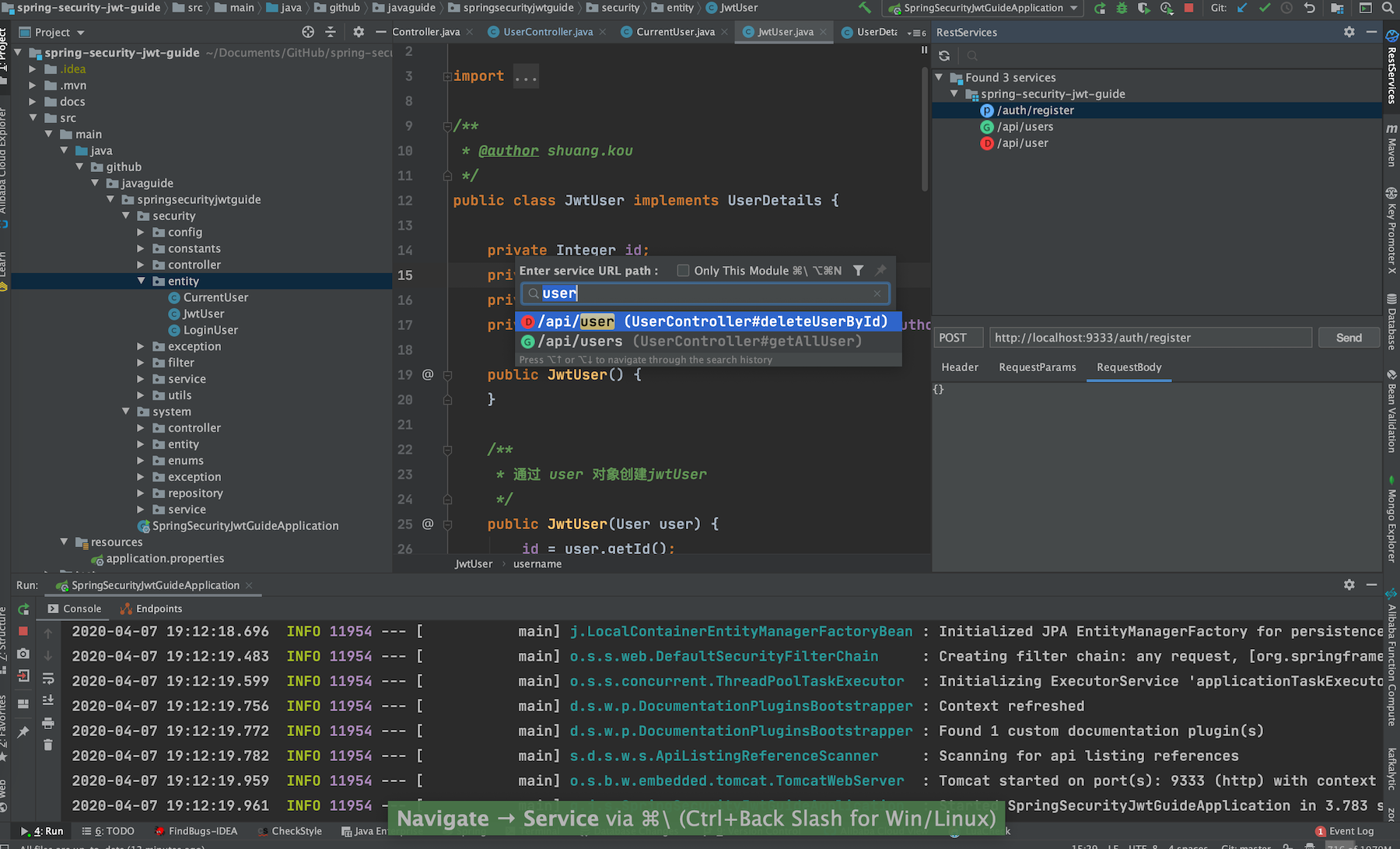
+
+#### 作为 HTTP 请求工具
+
+这个插件还可以作为一个简单的 http 请求工具来使用。如下图所示。
+
+
+
+#### 复制生成 URL、复制方法参数...
+
+这个插件还提供了生成 URL、查询参数、请求体(RequestBody)等功能。
+
+举个例子。我们选中 `Controller` 中的某个请求对应的方法右击,你会发现多了几个可选项。当你选择`Generate & Copy Full URL`的话,就可以把整个请求的路径直接复制下来。eg:`http://localhost:9333/api/users?pageNum=1&pageSize=1` 。
+
+
+
+#### 将 Java 类转换为对应的 JSON 格式
+
+这个插件还为 Java 类上添加了 **Convert to JSON** 功能 。
+
+我们选中的某个类对应的方法然后右击,你会发现多了几个可选项。
+
+
+
+当我们选择`Convert to JSON`的话,你会得到如下 json 类型的数据:
+
+```json
+{
+ "username": "demoData",
+ "password": "demoData",
+ "rememberMe": true
+}
+```
+
+## 后记
+
+RESTFulToolkit 原作者不更新了,IDEA.201 及以上版本不再适配。
+
+因此,国内就有一个大佬参考 RESTFulToolkit 开发了一款类似的插件——RestfulTool(功能较少一些,不过够用了)。
+
+
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/save-actions.md b/docs/idea-tutorial/idea-plugins/save-actions.md
new file mode 100644
index 00000000000..fc149ad301b
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/save-actions.md
@@ -0,0 +1,23 @@
+---
+title: Save Actions:优化文件保存
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+
+真必备插件!可以帮助我们在保存文件的时候:
+
+1. 优化导入;
+2. 格式化代码;
+3. 执行一些quick fix
+4. ......
+
+这个插件是支持可配置的,我的配置如下:
+
+
+
+实际使用效果如下:
+
+
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/sequence-diagram.md b/docs/idea-tutorial/idea-plugins/sequence-diagram.md
new file mode 100644
index 00000000000..050d6161163
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/sequence-diagram.md
@@ -0,0 +1,91 @@
+---
+title: SequenceDiagram:一键可以生成时序图
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+
+
+在平时的学习/工作中,我们会经常面临如下场景:
+
+1. 阅读别人的代码
+2. 阅读框架源码
+3. 阅读自己很久之前写的代码。
+
+千万不要觉得工作就是单纯写代码,实际工作中,你会发现你的大部分时间实际都花在了阅读和理解已有代码上。
+
+为了能够更快更清晰地搞清对象之间的调用关系,我经常需要用到序列图。手动画序列图还是很麻烦费时间的,不过 IDEA 提供了一个叫做**SequenceDiagram** 的插件帮助我们解决这个问题。通过 SequenceDiagram 这个插件,我们一键可以生成时序图。
+
+## 何为序列图?
+
+网上对于序列图的定义有很多,我觉得都不太好理解,太抽象了。最神奇的是,大部分文章对于序列图的定义竟然都是一模一样,看来大家是充分发挥了写代码的“精髓”啊!
+
+我还是简单说一说我的理解吧!不过,说实话,我自己对于 Sequence Diagram 也不是很明朗。下面的描述如有问题和需要完善的地方,还请指出。
+
+> **序列图**(Sequence Diagram),亦称为**循序图**,是一种[UML](https://zh.m.wikipedia.org/wiki/UML)行为图。表示系统执行某个方法/操作(如登录操作)时,对象之间的顺序调用关系。
+>
+> 这个顺序调用关系可以这样理解:你需要执行系统中某个对象 a 提供的方法/操作 login(登录),但是这个对象又依赖了对象 b 提供的方法 getUser(获取用户)。因此,这里就有了 a -> b 调用关系之说。
+
+再举两个例子来说一下!
+
+下图是微信支付的业务流程时序图。这个图描述了微信支付相关角色(顾客,商家...)在微信支付场景下,基础支付和支付的的顺序调用关系。
+
+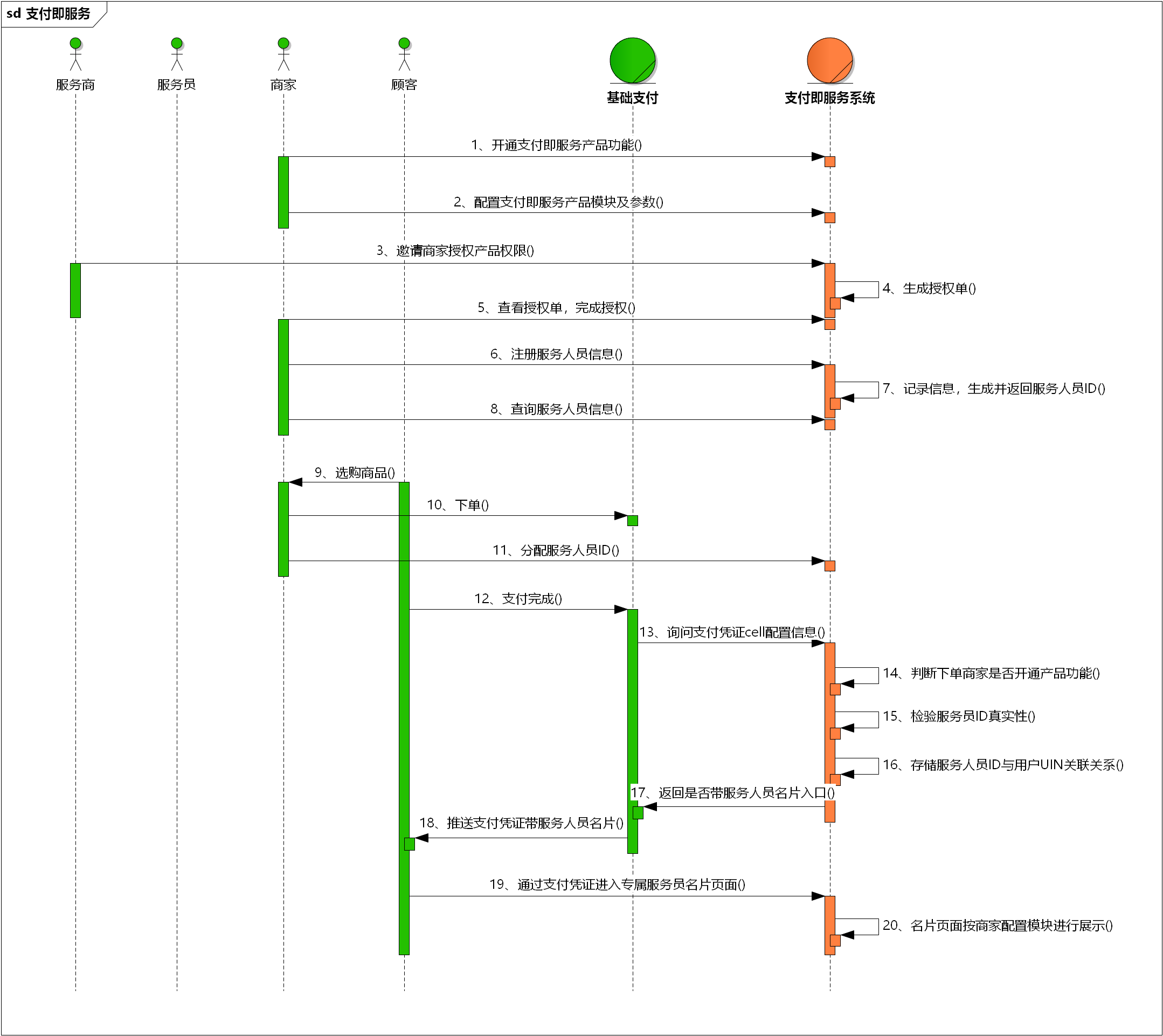
+
+下图是我写的一个 HTTP 框架中的执行某个方法的序列图。这个图描述了我们在调用 `InterceptorFactory`类的 `loadInterceptors()` 方法的时候,所涉及到的类之间的调用关系。
+
+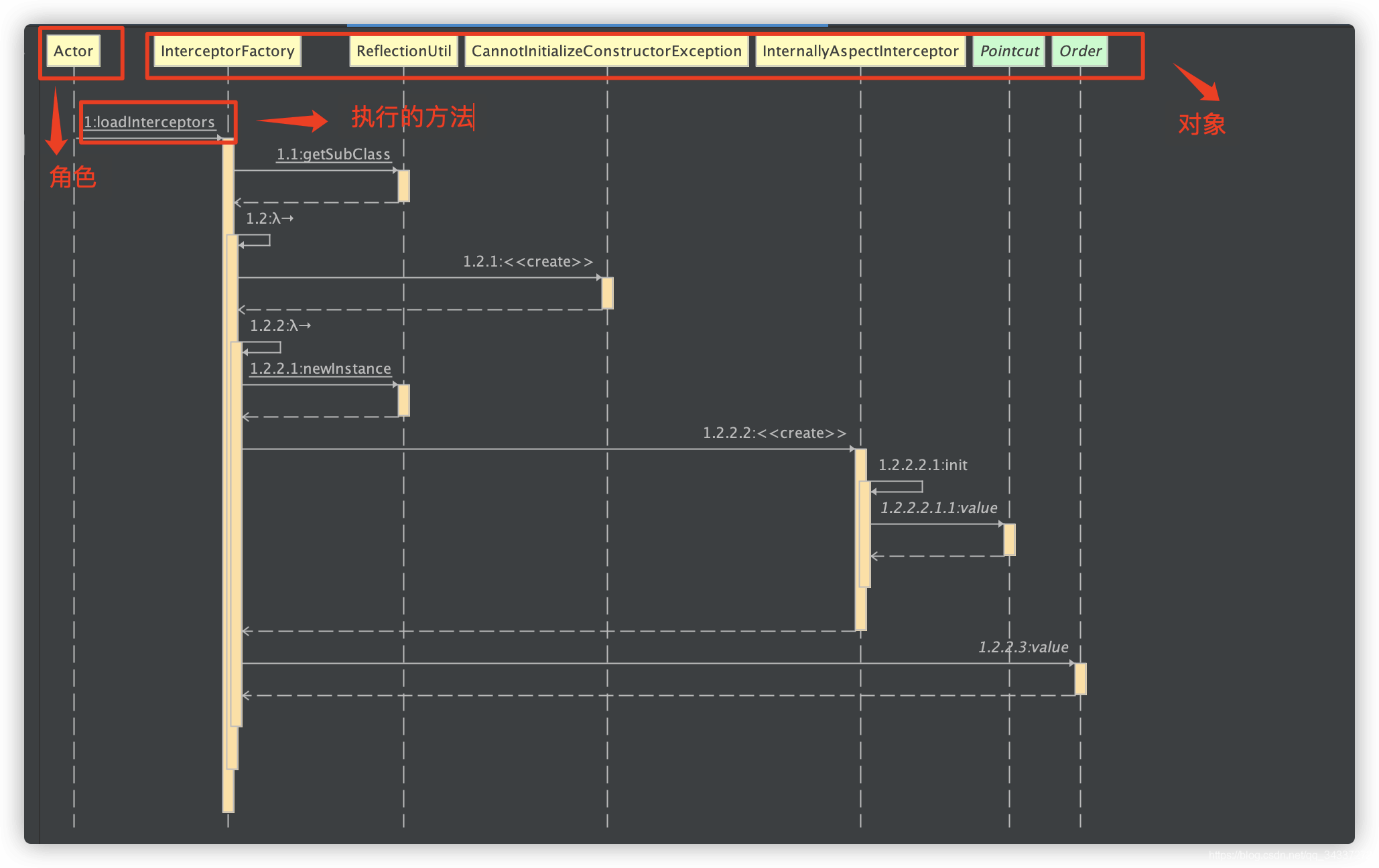
+
+另外,国内一般更喜欢称呼序列图为"时序图"。
+
+- 如果你按照纯翻译的角度来说, sequence 这个单词并无"时间"的意思,只有序列,顺序等意思,因此也有人说“时序图”的说法是不准确的。
+- 如果从定义角度来说,时序图这个描述是没问题的。因为 Sequence Diagram 中每条消息的触发时机确实是按照时间顺序执行的。
+
+我觉得称呼 Sequence Diagram 为时序图或者序列图都是没问题的,不用太纠结。
+
+## 哪些场景下需要查看类的时序图?
+
+我们在很多场景下都需要时序图,比如说:
+
+1. **阅读源码** :阅读源码的时候,你可能需要查看调用目标方法涉及的相关类的调用关系。特别是在代码的调用层级比较多的时候,对于我们理解源码非常有用。(_题外话:实际工作中,大部分时间实际我们都花在了阅读理解已有代码上。_)
+2. **技术文档编写** :我们在写项目介绍文档的时候,为了让别人更容易理解你的代码,你需要根据核心方法为相关的类生成时序图来展示他们之间的调用关系。
+3. **梳理业务流程** :当我们的系统业务流程比较复杂的时候,我们可以通过序列图将系统中涉及的重要的角色和对象的之间关系可视化出来。
+4. ......
+
+## 如何使用 IDEA 根据类中方法生成时序图?
+
+**通过 SequenceDiagram 这个插件,我们一键可以生成时序图。**
+
+并且,你还可以:
+
+1. 点击时序图中的类/方法即可跳转到对应的地方。
+2. 从时序图中删除对应的类或者方法。
+3. 将生成的时序图导出为 PNG 图片格式。
+
+### 安装
+
+我们直接在 IDEA 的插件市场即可找到这个插件。我这里已经安装好了。
+
+> 如果你因为网络问题没办法使用 IDEA 自带的插件市场的话,也可以通过[IDEA 插件市场的官网](https://plugins.jetbrains.com/idea)手动下载安装。
+
+
+
+### 简单使用
+
+1. 选中方法名(注意不要选类名),然后点击鼠标右键,选择 **Sequence Diagram** 选项即可!
+
+
+
+2. 配置生成的序列图的一些基本的参数比如调用深度之后,我们点击 ok 即可!
+
+
+
+你还可以通过生成的时序图来定位到相关的代码,这对于我们阅读源码的时候尤其有帮助!
+
+
+
+时序图生成完成之后,你还可以选择将其导出为图片。
+
+
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/shortcut-key.md b/docs/idea-tutorial/idea-plugins/shortcut-key.md
new file mode 100644
index 00000000000..c7e585290e7
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/shortcut-key.md
@@ -0,0 +1,56 @@
+---
+title: IDEA 快捷键相关插件
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+
+相信我!下面这两个一定是IDEA必备的插件。
+
+## Key Promoter X:快捷键提示
+
+这个插件的功能主要是**在你本可以使用快捷键操作的地方提醒你用快捷键操作。**
+
+举个例子。我直接点击tab栏下的菜单打开 Version Control(版本控制) 的话,这个插件就会提示你可以用快捷键 `command+9`或者`shift+command+9`打开。如下图所示。
+
+
+
+除了这个很棒的功能之外,这个插件还有一个功能我觉得非常棒。
+
+它可以展示出哪些快捷键你忘记使用的次数最多!这样的话,你可以给予你忘记次数最多的那些快捷键更多的关注。
+
+我忘记最多的快捷键是debug的时候经常使用的 F8(Step Over)。如下图所示。
+
+
+
+关于快捷键,很多人不愿意去记,觉得单纯靠鼠标就完全够了。
+
+让我来说的话!我觉得如果你偶尔使用一两次 IDEA 的话,你完全没有必要纠结快捷键。
+
+但是,如果 IDEA 是你开发的主力,你经常需要使用的话,相信我,掌握常用的一些快捷键真的很重要!
+
+不说多的,**熟练掌握IDEA的一些最常见的快捷键,你的工作效率至少提升 30 %。**
+
+**除了工作效率的提升之外,使用快捷键会让我们显得更加专业。**
+
+你在使用快捷键进行操作的时候,是很帅,很酷啊!但是,当你用 IDEA 给别人演示一些操作的时候,你使用了快捷键的话,别人可能根本不知道你进行了什么快捷键操作。
+
+**怎么解决这个问题呢?**
+
+很简单!这个时候就轮到 **Presentation Assistant** 这个插件上场了!
+
+## Presentation Assistant:快捷键展示
+
+安装这个插件之后,你使用的快捷键操作都会被可视化地展示出来,非常适合自己在录制视频或者给别人展示代码的时候使用。
+
+举个例子。我使用快捷键 `command+9`打开 Version Control ,使用了这个插件之后的效果如下图所示。
+
+
+
+从上图可以很清晰地看到,IDEA 的底部中间的位置将我刚刚所使用的快捷键给展示了出来。
+
+并且,**这个插件会展示出 Mac 和 Win/Linux 两种不同的版本的快捷键。**
+
+因此,不论你的操作系统是 Mac 还是 Win/Linux ,这款插件都能满足你的需求。
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-plugins/translation.md b/docs/idea-tutorial/idea-plugins/translation.md
new file mode 100644
index 00000000000..7de2619a3b5
--- /dev/null
+++ b/docs/idea-tutorial/idea-plugins/translation.md
@@ -0,0 +1,28 @@
+---
+title: Translation:翻译
+category: IDEA指南
+tag:
+ - IDEA
+ - IDEA插件
+---
+
+
+有了这个插件之后,你再也不用在编码的时候打开浏览器查找某个单词怎么拼写、某句英文注释什么意思了。
+
+并且,这个插件支持多种翻译源:
+
+1. Google 翻译
+2. Youdao 翻译
+3. Baidu 翻译
+
+除了翻译功能之外还提供了语音朗读、单词本等实用功能。这个插件的Github地址是:[https://github.com/YiiGuxing/TranslationPlugin](https://github.com/YiiGuxing/TranslationPlugin) (貌似是国人开发的,很赞)。
+
+**使用方法很简单!选中你要翻译的单词或者句子,使用快捷键 `command+ctrl+u(mac)` / `shift+ctrl+y(win/linux)`** (如果你忘记了快捷的话,鼠标右键操作即可!)
+
+
+
+**如果需要快速打开翻译框,使用快捷键`command+ctrl+i(mac)`/`ctrl + shift + o(win/linux)`**
+
+
+
+如果你需要将某个重要的单词添加到生词本的话,只需要点击单词旁边的收藏按钮即可!
\ No newline at end of file
diff --git a/docs/idea-tutorial/idea-tips/idea-plug-in-development-intro.md b/docs/idea-tutorial/idea-tips/idea-plug-in-development-intro.md
new file mode 100644
index 00000000000..8f8822c5946
--- /dev/null
+++ b/docs/idea-tutorial/idea-tips/idea-plug-in-development-intro.md
@@ -0,0 +1,213 @@
+# IDEA 插件开发入门
+
+我这个人没事就喜欢推荐一些好用的 [IDEA 插件](https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&album_id=1319419426898329600&__biz=Mzg2OTA0Njk0OA==#wechat_redirect)给大家。这些插件极大程度上提高了我们的生产效率以及编码舒适度。
+
+**不知道大家有没有想过自己开发一款 IDEA 插件呢?**
+
+我自己想过,但是没去尝试过。刚好有一位读者想让我写一篇入门 IDEA 开发的文章,所以,我在周末就花了一会时间简单了解一下。
+
+
+
+不过,**这篇文章只是简单带各位小伙伴入门一下 IDEA 插件开发**,个人精力有限,暂时不会深入探讨太多。如果你已经有 IDEA 插件开发的相关经验的话,这篇文章就可以不用看了,因为会浪费你 3 分钟的时间。
+
+好的废话不多说!咱们直接开始!
+
+## 01 新建一个基于 Gradle 的插件项目
+
+这里我们基于 Gradle 进行插件开发,这也是 IntelliJ 官方的推荐的插件开发解决方案。
+
+**第一步,选择 Gradle 项目类型并勾选上相应的依赖。**
+
+
+
+**第二步,填写项目相关的属性比如 GroupId、ArtifactId。**
+
+
+
+**第三步,静静等待项目下载相关依赖。**
+
+第一次创建 IDEA 插件项目的话,这一步会比较慢。因为要下载 IDEA 插件开发所需的 SDK 。
+
+## 02 插件项目结构概览
+
+新建完成的项目结构如下图所示。
+
+
+
+这里需要额外注意的是下面这两个配置文件。
+
+**`plugin.xml` :插件的核心配置文件。通过它可以配置插件名称、插件介绍、插件作者信息、Action 等信息。**
+
+```xml
+<idea-plugin>
+ <id>github.javaguide.my-first-idea-plugin</id>
+ <!--插件的名称-->
+ <name>Beauty</name>
+ <!--插件的作者相关信息-->
+ <vendor email="koushuangbwcx@163.com" url="https://github.com/Snailclimb">JavaGuide</vendor>
+ <!--插件的介绍-->
+ <description><![CDATA[
+ Guide哥代码开发的第一款IDEA插件<br>
+ <em>这尼玛是什么垃圾插件!!!</em>
+ ]]></description>
+
+ <!-- please see https://www.jetbrains.org/intellij/sdk/docs/basics/getting_started/plugin_compatibility.html
+ on how to target different products -->
+ <depends>com.intellij.modules.platform</depends>
+
+ <extensions defaultExtensionNs="com.intellij">
+ <!-- Add your extensions here -->
+ </extensions>
+
+ <actions>
+ <!-- Add your actions here -->
+ </actions>
+</idea-plugin>
+```
+
+**`build.gradle` :项目依赖配置文件。通过它可以配置项目第三方依赖、插件版本、插件版本更新记录等信息。**
+
+```groovy
+plugins {
+ id 'java'
+ id 'org.jetbrains.intellij' version '0.6.3'
+}
+
+group 'github.javaguide'
+// 当前插件版本
+version '1.0-SNAPSHOT'
+
+repositories {
+ mavenCentral()
+}
+
+// 项目依赖
+dependencies {
+ testCompile group: 'junit', name: 'junit', version: '4.12'
+}
+
+// See https://github.com/JetBrains/gradle-intellij-plugin/
+// 当前开发该插件的 IDEA 版本
+intellij {
+ version '2020.1.2'
+}
+patchPluginXml {
+ // 版本更新记录
+ changeNotes """
+ Add change notes here.<br>
+ <em>most HTML tags may be used</em>"""
+}
+```
+
+没有开发过 IDEA 插件的小伙伴直接看这两个配置文件内容可能会有点蒙。所以,我专门找了一个 IDEA 插件市场提供的现成插件来说明一下。小伙伴们对照下面这张图来看下面的配置文件内容就非常非常清晰了。
+
+
+
+这就非常贴心了!如果这都不能让你点赞,我要这文章有何用!
+
+
+
+## 03 手动创建 Action
+
+我们可以把 Action 看作是 IDEA 提高的事件响应处理器,通过 Action 我们可以自定义一些事件处理逻辑/动作。比如说你点击某个菜单的时候,我们进行一个展示对话框的操作。
+
+**第一步,右键`java`目录并选择 new 一个 Action**
+
+.png>)
+
+**第二步,配置 Action 相关信息比如展示名称。**
+
+.png>)
+
+创建完成之后,我们的 `plugin.xml` 的 `<actions>`节点下会自动生成我们刚刚创建的 Action 信息:
+
+```xml
+<actions>
+ <!-- Add your actions here -->
+ <action id="test.hello" class="HelloAction" text="Hello" description="IDEA插件入门">
+ <add-to-group group-id="ToolsMenu" anchor="first"/>
+ </action>
+</actions>
+```
+
+并且 `java` 目录下为生成一个叫做 `HelloAction` 的类。并且,这个类继承了 `AnAction` ,并覆盖了 `actionPerformed()` 方法。这个 `actionPerformed` 方法就好比 JS 中的 `onClick` 方法,会在你点击的时候被触发对应的动作。
+
+我简单对`actionPerformed` 方法进行了修改,添加了一行代码。这行代码很简单,就是显示 1 个对话框并展示一些信息。
+
+```java
+public class HelloAction extends AnAction {
+
+ @Override
+ public void actionPerformed(AnActionEvent e) {
+ //显示对话框并展示对应的信息
+ Messages.showInfoMessage("素材不够,插件来凑!", "Hello");
+ }
+}
+
+```
+
+另外,我们上面也说了,每个动作都会归属到一个 Group 中,这个 Group 可以简单看作 IDEA 中已经存在的菜单。
+
+举个例子。我上面创建的 Action 的所属 Group 是 **ToolsMenu(Tools)** 。这样的话,我们创建的 Action 所在的位置就在 Tools 这个菜单下。
+
+
+
+再举个例子。加入我上面创建的 Action 所属的 Group 是**MainMenu** (IDEA 最上方的主菜单栏)下的 **FileMenu(File)** 的话。
+
+```xml
+<actions>
+ <!-- Add your actions here -->
+ <action id="test.hello" class="HelloAction" text="Hello" description="IDEA插件入门">
+ <add-to-group group-id="FileMenu" anchor="first"/>
+ </action>
+</actions>
+```
+
+我们创建的 Action 所在的位置就在 File 这个菜单下。
+
+
+
+## 04 验收成果
+
+点击 `Gradle -> runIde` 就会启动一个默认了这个插件的 IDEA。然后,你可以在这个 IDEA 上实际使用这个插件了。
+
+
+
+效果如下:
+
+
+
+我们点击自定义的 Hello Action 的话就会弹出一个对话框并展示出我们自定义的信息。
+
+
+
+## 05 完善一下
+
+想要弄点界面花里胡哨一下, 我们还可以通过 Swing 来写一个界面。
+
+这里我们简单实现一个聊天机器人。代码的话,我是直接参考的我大二刚学 Java 那会写的一个小项目(_当时写的代码实在太烂了!就很菜!_)。
+
+
+
+首先,你需要在[图灵机器人官网](http://www.tuling123.com/ "图灵机器人官网")申请一个机器人。(_其他机器人也一样,感觉这个图灵机器人没有原来好用了,并且免费调用次数也不多_)
+
+
+
+然后,简单写一个方法来请求调用机器人。由于代码比较简单,我这里就不放出来了,大家简单看一下效果就好。
+
+
+
+## 06 深入学习
+
+如果你想要深入学习的 IDEA 插件的话,可以看一下官网文档:[https://jetbrains.org/intellij/sdk/docs/basics/basics.html ](https://jetbrains.org/intellij/sdk/docs/basics/basics.html "https://jetbrains.org/intellij/sdk/docs/basics/basics.html ") 。
+
+这方面的资料还是比较少的。除了官方文档的话,你还可以简单看看下面这几篇文章:
+
+- [8 条经验轻松上手 IDEA 插件开发](https://developer.aliyun.com/article/777850?spm=a2c6h.12873581.0.dArticle777850.118d6446r096V4&groupCode=alitech "8 条经验轻松上手 IDEA 插件开发")
+- [IDEA 插件开发入门教程](https://blog.xiaohansong.com/idea-plugin-development.html "IDEA 插件开发入门教程")
+
+## 07 后记
+
+我们开发 IDEA 插件主要是为了让 IDEA 更加好用,比如有些框架使用之后可以减少重复代码的编写、有些主题类型的插件可以让你的 IDEA 更好看。
+
+我这篇文章的这个案例说实话只是为了让大家简单入门一下 IDEA 开发,没有任何实际应用意义。**如果你想要开发一个不错的 IDEA 插件的话,还要充分发挥想象,利用 IDEA 插件平台的能力。**
diff --git a/docs/idea-tutorial/idea-tips/idea-refractor-intro.md b/docs/idea-tutorial/idea-tips/idea-refractor-intro.md
new file mode 100644
index 00000000000..7c3d4a66590
--- /dev/null
+++ b/docs/idea-tutorial/idea-tips/idea-refractor-intro.md
@@ -0,0 +1,75 @@
+# IDEA 重构入门
+
+我们在使用 IDEA 进行重构之前,先介绍一个方便我们进行重构的快捷键:`ctrl+t(mac)/ctrl+shift+alt+t`(如果忘记快捷键的话,鼠标右键也能找到重构选项),使用这个快捷键可以快速调出常用重构的选项,如下图所示:
+
+
+
+### 重命名(rename)
+
+快捷键:**Shift + F6(mac) / Shift + F6(windows/Linux):** 对类、变量或者方法名重命名。
+
+
+
+### 提取相关重构手段
+
+这部分的快捷键实际很好记忆,我是这样记忆的:
+
+前面两个键位是 `command + option(mac) / ctrl + alt (Windows/Linux)` 是固定的,只有后面一个键位会变比如Extract constant (提取变量)就是 c(constant)、Extract variable (提取变量)就是 v(variable)。
+
+#### 提取常量(extract constant)
+
+1. **使用场景** :提取未经过定义就直接出现的常量。提取常量使得你的编码更易读,避免硬编码。
+2. **快捷键:** `command + option+ c(mac)/ ctrl + alt + c(Windows/Linux)`
+
+**示例:**
+
+
+
+#### 提取参数(exact parameter)
+
+1. **使用场景** :提取参数到方法中。
+2. **快捷键:** `command + option+ p(mac)/ ctrl + alt + p(Windows/Linux)`
+
+
+
+#### 提取变量(exact variable)
+
+1. **使用场景** :提取多次出现的表达式。
+2. **快捷键:** `command + option+ v(mac) / ctrl + alt + v(Windows/Linux) `
+
+**示例:**
+
+
+
+#### 提取属性(exact field)
+
+1. **使用场景** :把当前表达式提取成为类的一个属性。
+2. **快捷键:** `command + option+ f(mac) / ctrl + alt + f(Windows/Linux) `
+
+**示例:**
+
+
+
+
+**示例:**
+
+
+
+#### 提取方法(exact method)
+
+1. **使用场景** :1个或者多个表达式可以提取为一个方法。 提取方法也能使得你的编码更易读,更加语义化。
+2. **快捷键:** `command + option+ m(mac)/ ctrl + alt + m(Windows/Linux)`
+
+**示例:**
+
+
+
+#### 提取接口(exact interface)
+
+1. **使用场景** :想要把一个类中的1个或多个方法提取到一个接口中的时候。
+2. **快捷键:** `command + option+ m(mac)/ ctrl + alt + m(Windows/Linux)`
+
+**示例:**
+
+
+
diff --git a/docs/idea-tutorial/idea-tips/idea-source-code-reading-skills.md b/docs/idea-tutorial/idea-tips/idea-source-code-reading-skills.md
new file mode 100644
index 00000000000..0064598c423
--- /dev/null
+++ b/docs/idea-tutorial/idea-tips/idea-source-code-reading-skills.md
@@ -0,0 +1,189 @@
+# IDEA源码阅读技巧
+
+项目有个新来了一个小伙伴,他看我查看项目源代码的时候,各种骚操作“花里胡哨”的。于是他向我请教,想让我分享一下我平时使用 IDEA 看源码的小技巧。
+
+## 基本操作
+
+这一部分的内容主要是一些我平时看源码的时候常用的快捷键/小技巧!非常好用!
+
+掌握这些快捷键/小技巧,看源码的效率提升一个等级!
+
+### 查看当前类的层次结构
+
+| 使用频率 | 相关快捷键 |
+| -------- | ---------- |
+| ⭐⭐⭐⭐⭐ | `Ctrl + H` |
+
+平时,我们阅读源码的时候,经常需要查看类的层次结构。就比如我们遇到抽象类或者接口的时候,经常需要查看其被哪些类实现。
+
+拿 Spring 源码为例,`BeanDefinition` 是一个关于 Bean 属性/定义的接口。
+
+```java
+public interface BeanDefinition extends AttributeAccessor, BeanMetadataElement {
+ ......
+}
+```
+
+如果我们需要查看 `BeanDefinition` 被哪些类实现的话,只需要把鼠标移动到 `BeanDefinition` 类名上,然后使用快捷键 `Ctrl + H` 即可。
+
+
+
+同理,如果你想查看接口 `BeanDefinition` 继承的接口 `AttributeAccessor` 被哪些类实现的话,只需要把鼠标移动到 `AttributeAccessor` 类名上,然后使用快捷键 `Ctrl + H` 即可。
+
+### 查看类结构
+
+| 使用频率 | 相关快捷键 |
+| -------- | ------------------------------------- |
+| ⭐⭐⭐⭐ | `Alt + 7`(Win) / `Command +7` (Mac) |
+
+类结构可以让我们快速了解到当前类的方法、变量/常量,非常使用!
+
+我们在对应的类的任意位置使用快捷键 `Alt + 7`(Win) / `Command +7` (Mac)即可。
+
+
+
+### 快速检索类
+
+| 使用频率 | 相关快捷键 |
+| -------- | ---------------------------------------- |
+| ⭐⭐⭐⭐⭐ | `Ctrl + N` (Win) / `Command + O` (Mac) |
+
+使用快捷键 `Ctrl + N` (Win) / `Command + O` (Mac)可以快速检索类/文件。
+
+
+
+### 关键字检索
+
+| 使用频率 | 相关快捷键 |
+| -------- | ---------- |
+| ⭐⭐⭐⭐⭐ | 见下文 |
+
+- 当前文件下检索 : `Ctrl + F` (Win) / `Command + F` (Mac)
+- 全局的文本检索 : `Ctrl + Shift + F` (Win) / `Command + Shift + F` (Mac)
+
+### 查看方法/类的实现类
+
+| 使用频率 | 相关快捷键 |
+| -------- | -------------------------------------------------- |
+| ⭐⭐⭐⭐ | `Ctrl + Alt + B` (Win) / `Command + Alt + B` (Mac) |
+
+如果我们想直接跳转到某个方法/类的实现类,直接在方法名或者类名上使用快捷键 `Ctrl + Alt + B/鼠标左键` (Win) / `Command + Alt + B/鼠标左键` (Mac) 即可。
+
+如果对应的方法/类只有一个实现类的话,会直接跳转到对应的实现类。
+
+比如 `BeanDefinition` 接口的 `getBeanClassName()` 方法只被 `AbstractBeanDefinition` 抽象类实现,我们对这个方法使用快捷键就可以直接跳转到 `AbstractBeanDefinition` 抽象类中对应的实现方法。
+
+```java
+public interface BeanDefinition extends AttributeAccessor, BeanMetadataElement {
+ @Nullable
+ String getBeanClassName();
+ ......
+}
+```
+
+如果对应的方法/类有多个实现类的话,IDEA 会弹出一个选择框让你选择。
+
+比如 `BeanDefinition` 接口的 `getParentName()` 方法就有多个不同的实现。
+
+
+
+### 查看方法被使用的情况
+
+| 使用频率 | 相关快捷键 |
+| -------- | ---------- |
+| ⭐⭐⭐⭐ | `Alt + F7` |
+
+我们可以通过直接在方法名上使用快捷键 `Alt + F7` 来查看这个方法在哪些地方被调用过。
+
+
+
+### 查看最近使用的文件
+
+| 使用频率 | 相关快捷键 |
+| -------- | -------------------------------------- |
+| ⭐⭐⭐⭐⭐ | `Ctrl + E`(Win) / `Command +E` (Mac) |
+
+你可以通过快捷键 `Ctrl + E`(Win) / `Command +E` (Mac)来显示 IDEA 最近使用的一些文件。
+
+
+
+### 查看图表形式的类继承链
+
+| 使用频率 | 相关快捷键 |
+| -------- | ------------------------ |
+| ⭐⭐⭐⭐ | 相关快捷键较多,不建议记 |
+
+点击类名 **右键** ,选择 **Shw Diagrams** 即可查看图表形式的类继承链。
+
+
+
+你还可以对图表进行一些操作。比如,你可以点击图表中具体的类 **右键**,然后选择显示它的实现类或者父类。
+
+
+
+再比如你还可以选择是否显示类中的属性、方法、内部类等等信息。
+
+
+
+如果你想跳转到对应类的源码的话,直接点击图表中具体的类 **右键** ,然后选择 **Jump to Source** 。
+
+
+
+## 插件推荐
+
+### 一键生成方法的序列图
+
+**序列图**(Sequence Diagram),亦称为**循序图**,是一种 UML 行为图。表示系统执行某个方法/操作(如登录操作)时,对象之间的顺序调用关系。
+
+这个顺序调用关系可以这样理解:你需要执行系统中某个对象 a 提供的方法/操作 login(登录),但是这个对象又依赖了对象 b 提供的方法 getUser(获取用户)。因此,这里就有了 a -> b 调用关系之说。
+
+我们可以通过 **SequenceDiagram** 这个插件一键生成方法的序列图。
+
+> 如果你因为网络问题没办法使用 IDEA 自带的插件市场的话,也可以通过 IDEA 插件市场的官网手动下载安装。
+
+
+
+**如何使用呢?**
+
+1、选中方法名(注意不要选类名),然后点击鼠标右键,选择 **Sequence Diagram** 选项即可!
+
+
+
+2、配置生成的序列图的一些基本的参数比如调用深度之后,我们点击 ok 即可!
+
+
+
+3、你还可以通过生成的时序图来定位到相关的代码,这对于我们阅读源码的时候尤其有帮助!
+
+
+
+4、时序图生成完成之后,你还可以选择将其导出为图片。
+
+
+
+相关阅读:[《安利一个 IDEA 骚操作:一键生成方法的序列图》](https://mp.weixin.qq.com/s/SG1twZczqdup_EQAOmNERg) 。
+
+### 项目代码统计
+
+为了快速分析项目情况,我们可以对项目的 **代码的总行数、单个文件的代码行数、注释行数等信息进行统计。**
+
+**Statistic** 这个插件来帮助我们实现这一需求。
+
+
+
+有了这个插件之后你可以非常直观地看到你的项目中所有类型的文件的信息比如数量、大小等等,可以帮助你更好地了解你们的项目。
+
+
+
+你还可以使用它看所有类的总行数、有效代码行数、注释行数、以及有效代码比重等等这些东西。
+
+
+
+如果,你担心插件过多影响 IDEA 速度的话,可以只在有代码统计需求的时候开启这个插件,其他时间禁用它就完事了!
+
+相关阅读:[快速识别烂项目!试试这款项目代码统计 IDEA 插件](https://mp.weixin.qq.com/s/fVEeMW6elhu79I-rTZB40A)
+
+
+
+
+
diff --git a/docs/idea-tutorial/idea-tips/pictures/exact/exact-field.gif b/docs/idea-tutorial/idea-tips/pictures/exact/exact-field.gif
new file mode 100644
index 00000000000..770df36522d
Binary files /dev/null and b/docs/idea-tutorial/idea-tips/pictures/exact/exact-field.gif differ
diff --git a/docs/idea-tutorial/idea-tips/pictures/exact/exact-interface.gif b/docs/idea-tutorial/idea-tips/pictures/exact/exact-interface.gif
new file mode 100644
index 00000000000..678b93de0a8
Binary files /dev/null and b/docs/idea-tutorial/idea-tips/pictures/exact/exact-interface.gif differ
diff --git a/docs/idea-tutorial/idea-tips/pictures/exact/exact-method.gif b/docs/idea-tutorial/idea-tips/pictures/exact/exact-method.gif
new file mode 100644
index 00000000000..3748903e21d
Binary files /dev/null and b/docs/idea-tutorial/idea-tips/pictures/exact/exact-method.gif differ
diff --git a/docs/idea-tutorial/idea-tips/pictures/exact/exact-parameter.gif b/docs/idea-tutorial/idea-tips/pictures/exact/exact-parameter.gif
new file mode 100644
index 00000000000..578b5ccca83
Binary files /dev/null and b/docs/idea-tutorial/idea-tips/pictures/exact/exact-parameter.gif differ
diff --git a/docs/idea-tutorial/idea-tips/pictures/exact/exact-variable.gif b/docs/idea-tutorial/idea-tips/pictures/exact/exact-variable.gif
new file mode 100644
index 00000000000..7326761ef55
Binary files /dev/null and b/docs/idea-tutorial/idea-tips/pictures/exact/exact-variable.gif differ
diff --git a/docs/idea-tutorial/idea-tips/pictures/exact/extract-constant.gif b/docs/idea-tutorial/idea-tips/pictures/exact/extract-constant.gif
new file mode 100644
index 00000000000..6752a385e74
Binary files /dev/null and b/docs/idea-tutorial/idea-tips/pictures/exact/extract-constant.gif differ
diff --git a/docs/idea-tutorial/idea-tips/pictures/refractor-help.png b/docs/idea-tutorial/idea-tips/pictures/refractor-help.png
new file mode 100644
index 00000000000..032319487ae
Binary files /dev/null and b/docs/idea-tutorial/idea-tips/pictures/refractor-help.png differ
diff --git a/docs/idea-tutorial/idea-tips/pictures/rename.gif b/docs/idea-tutorial/idea-tips/pictures/rename.gif
new file mode 100644
index 00000000000..c8a61b12863
Binary files /dev/null and b/docs/idea-tutorial/idea-tips/pictures/rename.gif differ
diff --git a/docs/idea-tutorial/readme.md b/docs/idea-tutorial/readme.md
new file mode 100644
index 00000000000..a5297b6bbed
--- /dev/null
+++ b/docs/idea-tutorial/readme.md
@@ -0,0 +1,11 @@
+---
+icon: creative
+category: IDEA指南
+---
+
+# IntelliJ IDEA 使用指南 | 必备插件推荐 | 插件开发入门 | 重构小技巧 | 源码阅读技巧
+
+分享一下自己使用 IDEA 的一些经验,希望对大家有帮助!
+
+- Github 地址:https://github.com/CodingDocs/awesome-idea-tutorial
+- 码云地址:https://gitee.com/SnailClimb/awesome-idea-tutorial (Github 无法访问或者访问速度比较慢的小伙伴可以看码云上的对应内容)
diff --git "a/docs/java/basis/BigDecimal\350\247\243\345\206\263\346\265\256\347\202\271\346\225\260\350\277\220\347\256\227\347\262\276\345\272\246\344\270\242\345\244\261\351\227\256\351\242\230.md" "b/docs/java/basis/BigDecimal\350\247\243\345\206\263\346\265\256\347\202\271\346\225\260\350\277\220\347\256\227\347\262\276\345\272\246\344\270\242\345\244\261\351\227\256\351\242\230.md"
new file mode 100644
index 00000000000..5f788f087e8
--- /dev/null
+++ "b/docs/java/basis/BigDecimal\350\247\243\345\206\263\346\265\256\347\202\271\346\225\260\350\277\220\347\256\227\347\262\276\345\272\246\344\270\242\345\244\261\351\227\256\351\242\230.md"
@@ -0,0 +1,69 @@
+## BigDecimal 介绍
+
+`BigDecimal` 可以实现对浮点数的运算,不会造成精度丢失。
+
+那为什么浮点数 `float` 或 `double` 运算的时候会有精度丢失的风险呢?
+
+这是因为计算机是二进制的,浮点数没有办法用二进制精确表示。
+
+## BigDecimal 的用处
+
+《阿里巴巴Java开发手册》中提到:**浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用 equals 来判断。** 具体原理和浮点数的编码方式有关,这里就不多提了,我们下面直接上实例:
+
+```java
+float a = 1.0f - 0.9f;
+float b = 0.9f - 0.8f;
+System.out.println(a);// 0.100000024
+System.out.println(b);// 0.099999964
+System.out.println(a == b);// false
+```
+具有基本数学知识的我们很清楚的知道输出并不是我们想要的结果(**精度丢失**),我们如何解决这个问题呢?一种很常用的方法是:**使用 BigDecimal 来定义浮点数的值,再进行浮点数的运算操作。**
+
+```java
+BigDecimal a = new BigDecimal("1.0");
+BigDecimal b = new BigDecimal("0.9");
+BigDecimal c = new BigDecimal("0.8");
+
+BigDecimal x = a.subtract(b);
+BigDecimal y = b.subtract(c);
+
+System.out.println(x); /* 0.1 */
+System.out.println(y); /* 0.1 */
+System.out.println(Objects.equals(x, y)); /* true */
+```
+
+## BigDecimal 常见方法
+
+## 大小比较
+
+`a.compareTo(b)` : 返回 -1 表示 `a` 小于 `b`,0 表示 `a` 等于 `b` , 1表示 `a` 大于 `b`。
+
+```java
+BigDecimal a = new BigDecimal("1.0");
+BigDecimal b = new BigDecimal("0.9");
+System.out.println(a.compareTo(b));// 1
+```
+### 保留几位小数
+
+通过 `setScale`方法设置保留几位小数以及保留规则。保留规则有挺多种,不需要记,IDEA会提示。
+
+```java
+BigDecimal m = new BigDecimal("1.255433");
+BigDecimal n = m.setScale(3,BigDecimal.ROUND_HALF_DOWN);
+System.out.println(n);// 1.255
+```
+
+## BigDecimal 的使用注意事项
+
+注意:我们在使用BigDecimal时,为了防止精度丢失,推荐使用它的 **BigDecimal(String)** 构造方法来创建对象。《阿里巴巴Java开发手册》对这部分内容也有提到如下图所示。
+
+
+
+## 总结
+
+BigDecimal 主要用来操作(大)浮点数,BigInteger 主要用来操作大整数(超过 long 类型)。
+
+BigDecimal 的实现利用到了 BigInteger, 所不同的是 BigDecimal 加入了小数位的概念
+
+
+
diff --git "a/docs/java/basis/io\346\250\241\345\236\213\350\257\246\350\247\243.md" "b/docs/java/basis/io\346\250\241\345\236\213\350\257\246\350\247\243.md"
new file mode 100644
index 00000000000..231da542c35
--- /dev/null
+++ "b/docs/java/basis/io\346\250\241\345\236\213\350\257\246\350\247\243.md"
@@ -0,0 +1,131 @@
+---
+title: IO模型详解
+category: Java
+tag:
+ - Java基础
+---
+
+
+IO 模型这块确实挺难理解的,需要太多计算机底层知识。写这篇文章用了挺久,就非常希望能把我所知道的讲出来吧!希望朋友们能有收获!为了写这篇文章,还翻看了一下《UNIX 网络编程》这本书,太难了,我滴乖乖!心痛~
+
+_个人能力有限。如果文章有任何需要补充/完善/修改的地方,欢迎在评论区指出,共同进步!_
+
+## 前言
+
+I/O 一直是很多小伙伴难以理解的一个知识点,这篇文章我会将我所理解的 I/O 讲给你听,希望可以对你有所帮助。
+
+## I/O
+
+### 何为 I/O?
+
+I/O(**I**nput/**O**utpu) 即**输入/输出** 。
+
+**我们先从计算机结构的角度来解读一下 I/O。**
+
+根据冯.诺依曼结构,计算机结构分为 5 大部分:运算器、控制器、存储器、输入设备、输出设备。
+
+
+
+输入设备(比如键盘)和输出设备(比如显示器)都属于外部设备。网卡、硬盘这种既可以属于输入设备,也可以属于输出设备。
+
+输入设备向计算机输入数据,输出设备接收计算机输出的数据。
+
+**从计算机结构的视角来看的话, I/O 描述了计算机系统与外部设备之间通信的过程。**
+
+**我们再先从应用程序的角度来解读一下 I/O。**
+
+根据大学里学到的操作系统相关的知识:为了保证操作系统的稳定性和安全性,一个进程的地址空间划分为 **用户空间(User space)** 和 **内核空间(Kernel space )** 。
+
+像我们平常运行的应用程序都是运行在用户空间,只有内核空间才能进行系统态级别的资源有关的操作,比如文件管理、进程通信、内存管理等等。也就是说,我们想要进行 IO 操作,一定是要依赖内核空间的能力。
+
+并且,用户空间的程序不能直接访问内核空间。
+
+当想要执行 IO 操作时,由于没有执行这些操作的权限,只能发起系统调用请求操作系统帮忙完成。
+
+因此,用户进程想要执行 IO 操作的话,必须通过 **系统调用** 来间接访问内核空间
+
+我们在平常开发过程中接触最多的就是 **磁盘 IO(读写文件)** 和 **网络 IO(网络请求和响应)**。
+
+**从应用程序的视角来看的话,我们的应用程序对操作系统的内核发起 IO 调用(系统调用),操作系统负责的内核执行具体的 IO 操作。也就是说,我们的应用程序实际上只是发起了 IO 操作的调用而已,具体 IO 的执行是由操作系统的内核来完成的。**
+
+当应用程序发起 I/O 调用后,会经历两个步骤:
+
+1. 内核等待 I/O 设备准备好数据
+2. 内核将数据从内核空间拷贝到用户空间。
+
+### 有哪些常见的 IO 模型?
+
+UNIX 系统下, IO 模型一共有 5 种: **同步阻塞 I/O**、**同步非阻塞 I/O**、**I/O 多路复用**、**信号驱动 I/O** 和**异步 I/O**。
+
+这也是我们经常提到的 5 种 IO 模型。
+
+## Java 中 3 种常见 IO 模型
+
+### BIO (Blocking I/O)
+
+**BIO 属于同步阻塞 IO 模型** 。
+
+同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
+
+
+
+在客户端连接数量不高的情况下,是没问题的。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
+
+### NIO (Non-blocking/New I/O)
+
+Java 中的 NIO 于 Java 1.4 中引入,对应 `java.nio` 包,提供了 `Channel` , `Selector`,`Buffer` 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它支持面向缓冲的,基于通道的 I/O 操作方法。 对于高负载、高并发的(网络)应用,应使用 NIO 。
+
+Java 中的 NIO 可以看作是 **I/O 多路复用模型**。也有很多人认为,Java 中的 NIO 属于同步非阻塞 IO 模型。
+
+跟着我的思路往下看看,相信你会得到答案!
+
+我们先来看看 **同步非阻塞 IO 模型**。
+
+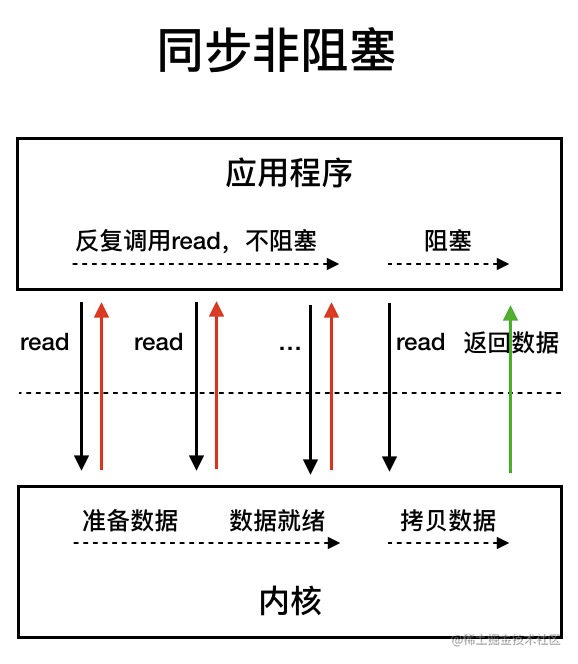
+
+同步非阻塞 IO 模型中,应用程序会一直发起 read 调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。
+
+相比于同步阻塞 IO 模型,同步非阻塞 IO 模型确实有了很大改进。通过轮询操作,避免了一直阻塞。
+
+但是,这种 IO 模型同样存在问题:**应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的。**
+
+这个时候,**I/O 多路复用模型** 就上场了。
+
+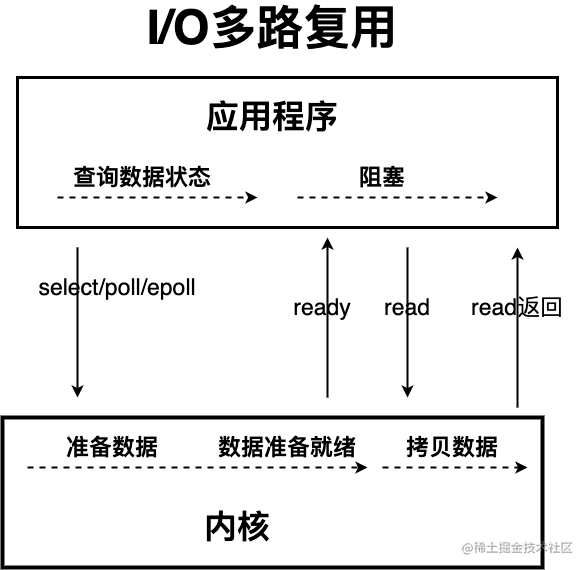
+
+IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间->用户空间)还是阻塞的。
+
+> 目前支持 IO 多路复用的系统调用,有 select,epoll 等等。select 系统调用,是目前几乎在所有的操作系统上都有支持
+>
+> - **select 调用** :内核提供的系统调用,它支持一次查询多个系统调用的可用状态。几乎所有的操作系统都支持。
+> - **epoll 调用** :linux 2.6 内核,属于 select 调用的增强版本,优化了 IO 的执行效率。
+
+**IO 多路复用模型,通过减少无效的系统调用,减少了对 CPU 资源的消耗。**
+
+Java 中的 NIO ,有一个非常重要的**选择器 ( Selector )** 的概念,也可以被称为 **多路复用器**。通过它,只需要一个线程便可以管理多个客户端连接。当客户端数据到了之后,才会为其服务。
+
+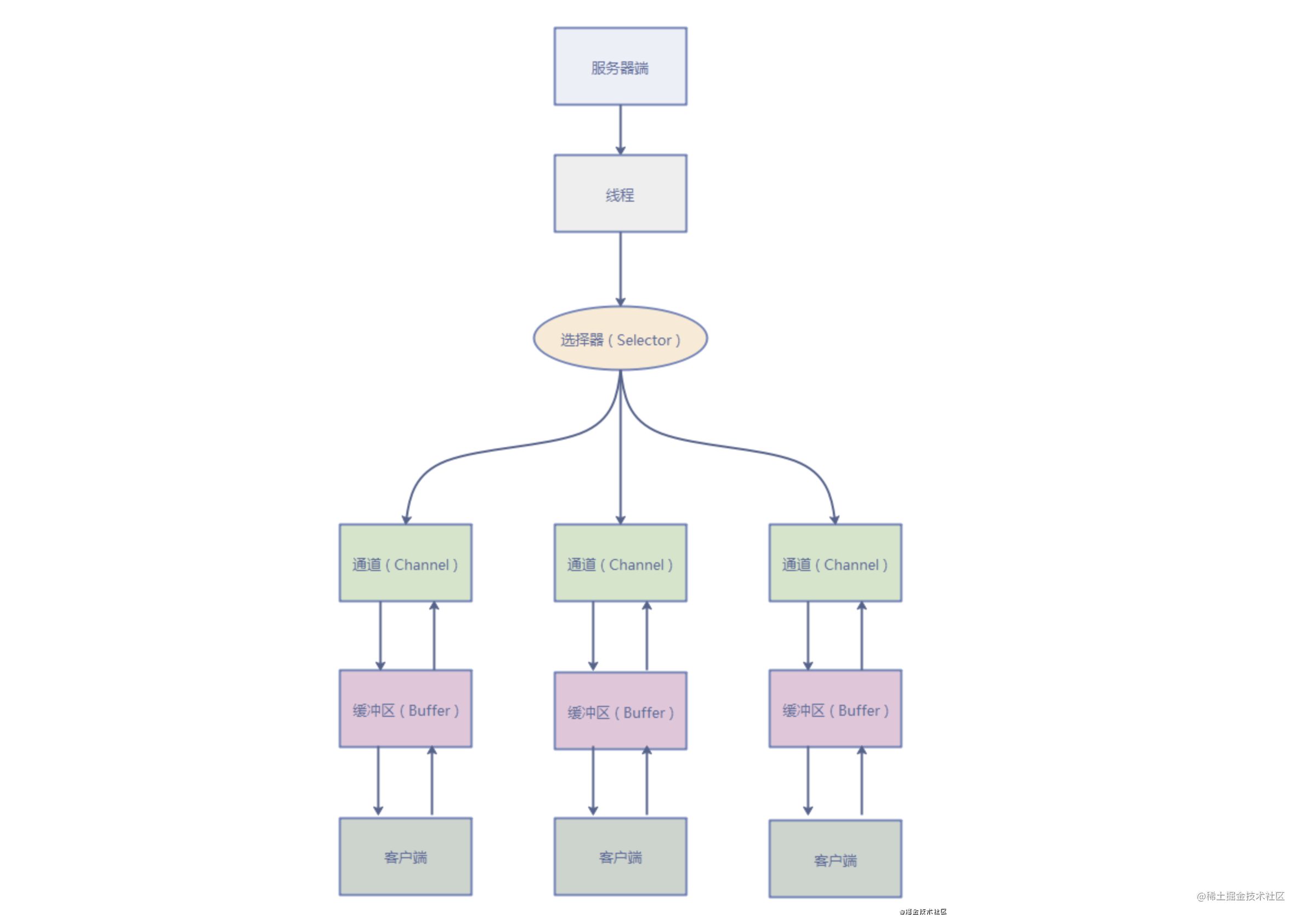
+
+### AIO (Asynchronous I/O)
+
+AIO 也就是 NIO 2。Java 7 中引入了 NIO 的改进版 NIO 2,它是异步 IO 模型。
+
+异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
+
+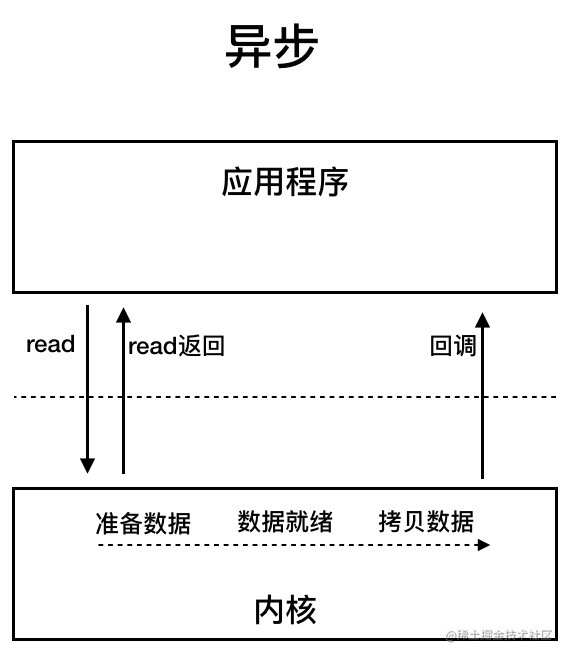
+
+目前来说 AIO 的应用还不是很广泛。Netty 之前也尝试使用过 AIO,不过又放弃了。这是因为,Netty 使用了 AIO 之后,在 Linux 系统上的性能并没有多少提升。
+
+最后,来一张图,简单总结一下 Java 中的 BIO、NIO、AIO。
+
+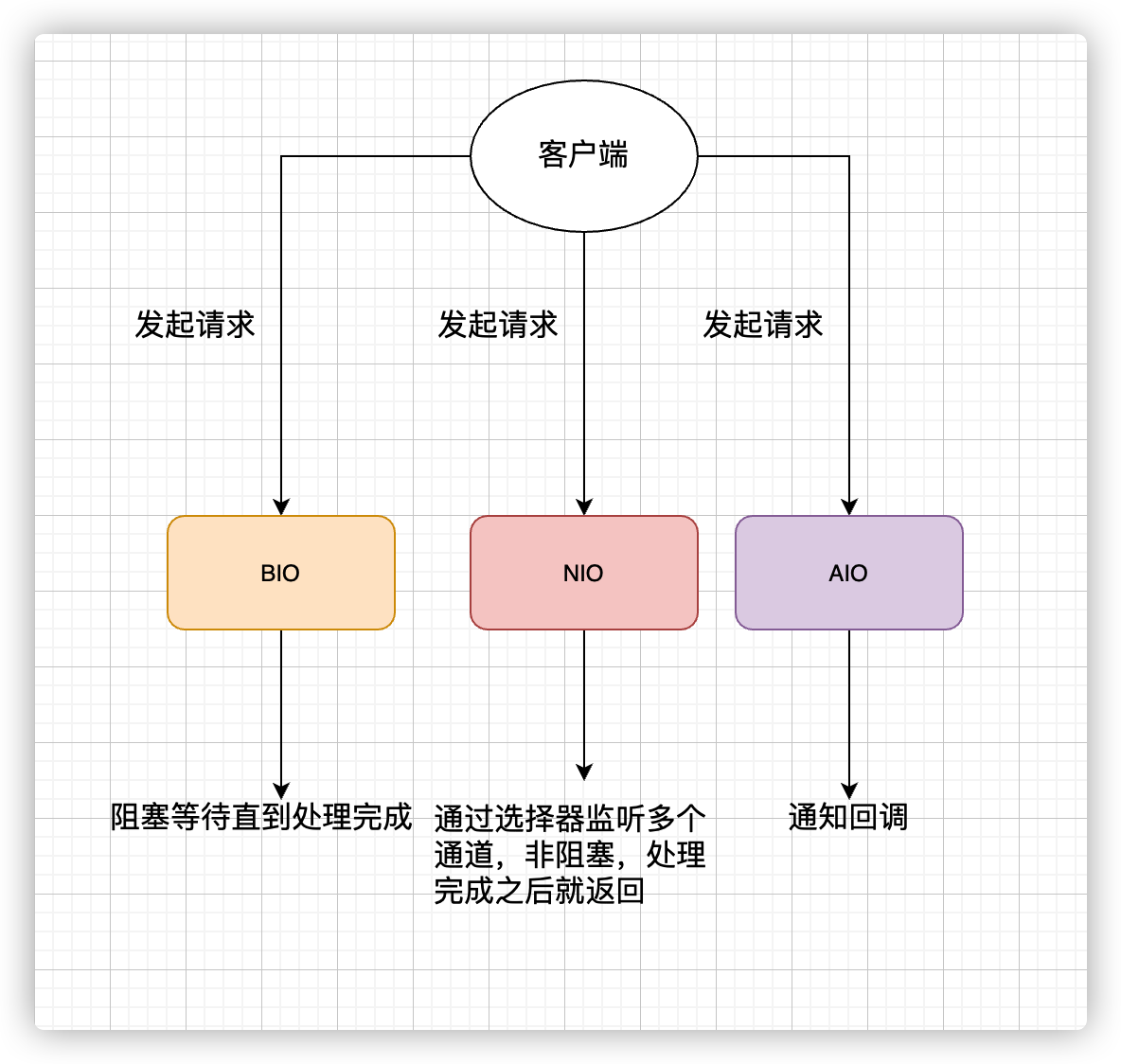
+
+## 参考
+
+- 《深入拆解 Tomcat & Jetty》
+- 如何完成一次 IO:[https://llc687.top/post/如何完成一次-io/](https://llc687.top/post/如何完成一次-io/)
+- 程序员应该这样理解 IO:[https://www.jianshu.com/p/fa7bdc4f3de7](https://www.jianshu.com/p/fa7bdc4f3de7)
+- 10 分钟看懂, Java NIO 底层原理:https://www.cnblogs.com/crazymakercircle/p/10225159.html
+- IO 模型知多少 | 理论篇:https://www.cnblogs.com/sheng-jie/p/how-much-you-know-about-io-models.html
+- 《UNIX 网络编程 卷 1;套接字联网 API 》6.2 节 IO 模型
+
diff --git "a/docs/java/basis/java\345\237\272\347\241\200\347\237\245\350\257\206\346\200\273\347\273\223.md" "b/docs/java/basis/java\345\237\272\347\241\200\347\237\245\350\257\206\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..867bfb63867
--- /dev/null
+++ "b/docs/java/basis/java\345\237\272\347\241\200\347\237\245\350\257\206\346\200\273\347\273\223.md"
@@ -0,0 +1,1374 @@
+---
+title: Java基础知识&面试题总结
+category: Java
+tag:
+ - Java基础
+---
+
+## 基础概念与常识
+
+### Java 语言有哪些特点?
+
+1. 简单易学;
+2. 面向对象(封装,继承,多态);
+3. 平台无关性( Java 虚拟机实现平台无关性);
+4. 支持多线程( C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持);
+5. 可靠性;
+6. 安全性;
+7. 支持网络编程并且很方便( Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便);
+8. 编译与解释并存;
+
+> **🐛 修正(参见: [issue#544](https://github.com/Snailclimb/JavaGuide/issues/544))** :C++11 开始(2011 年的时候),C++就引入了多线程库,在 windows、linux、macos 都可以使用`std::thread`和`std::async`来创建线程。参考链接:http://www.cplusplus.com/reference/thread/thread/?kw=thread
+
+### JVM vs JDK vs JRE
+
+#### JVM
+
+Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
+
+**什么是字节码?采用字节码的好处是什么?**
+
+> 在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
+
+**Java 程序从源代码到运行一般有下面 3 步:**
+
+
+
+我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。
+
+> HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了 JIT 预热等各方面的开销。JDK 支持分层编译和 AOT 协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。
+
+**总结:**
+
+Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
+
+#### JDK 和 JRE
+
+JDK 是 Java Development Kit 缩写,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
+
+JRE 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
+
+如果你只是为了运行一下 Java 程序的话,那么你只需要安装 JRE 就可以了。如果你需要进行一些 Java 编程方面的工作,那么你就需要安装 JDK 了。但是,这不是绝对的。有时,即使您不打算在计算机上进行任何 Java 开发,仍然需要安装 JDK。例如,如果要使用 JSP 部署 Web 应用程序,那么从技术上讲,您只是在应用程序服务器中运行 Java 程序。那你为什么需要 JDK 呢?因为应用程序服务器会将 JSP 转换为 Java servlet,并且需要使用 JDK 来编译 servlet。
+
+### 为什么说 Java 语言“编译与解释并存”?
+
+高级编程语言按照程序的执行方式分为编译型和解释型两种。简单来说,编译型语言是指编译器针对特定的操作系统将源代码一次性翻译成可被该平台执行的机器码;解释型语言是指解释器对源程序逐行解释成特定平台的机器码并立即执行。比如,你想阅读一本英文名著,你可以找一个英文翻译人员帮助你阅读,
+有两种选择方式,你可以先等翻译人员将全本的英文名著(也就是源码)都翻译成汉语,再去阅读,也可以让翻译人员翻译一段,你在旁边阅读一段,慢慢把书读完。
+
+Java 语言既具有编译型语言的特征,也具有解释型语言的特征,因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(`*.class` 文件),这种字节码必须由 Java 解释器来解释执行。因此,我们可以认为 Java 语言编译与解释并存。
+
+### Oracle JDK 和 OpenJDK 的对比
+
+可能在看这个问题之前很多人和我一样并没有接触和使用过 OpenJDK 。那么 Oracle JDK 和 OpenJDK 之间是否存在重大差异?下面我通过收集到的一些资料,为你解答这个被很多人忽视的问题。
+
+对于 Java 7,没什么关键的地方。OpenJDK 项目主要基于 Sun 捐赠的 HotSpot 源代码。此外,OpenJDK 被选为 Java 7 的参考实现,由 Oracle 工程师维护。关于 JVM,JDK,JRE 和 OpenJDK 之间的区别,Oracle 博客帖子在 2012 年有一个更详细的答案:
+
+> 问:OpenJDK 存储库中的源代码与用于构建 Oracle JDK 的代码之间有什么区别?
+>
+> 答:非常接近 - 我们的 Oracle JDK 版本构建过程基于 OpenJDK 7 构建,只添加了几个部分,例如部署代码,其中包括 Oracle 的 Java 插件和 Java WebStart 的实现,以及一些闭源的第三方组件,如图形光栅化器,一些开源的第三方组件,如 Rhino,以及一些零碎的东西,如附加文档或第三方字体。展望未来,我们的目的是开源 Oracle JDK 的所有部分,除了我们考虑商业功能的部分。
+
+**总结:**
+
+1. Oracle JDK 大概每 6 个月发一次主要版本,而 OpenJDK 版本大概每三个月发布一次。但这不是固定的,我觉得了解这个没啥用处。详情参见:[https://blogs.oracle.com/java-platform-group/update-and-faq-on-the-java-se-release-cadence](https://blogs.oracle.com/java-platform-group/update-and-faq-on-the-java-se-release-cadence) 。
+2. OpenJDK 是一个参考模型并且是完全开源的,而 Oracle JDK 是 OpenJDK 的一个实现,并不是完全开源的;
+3. Oracle JDK 比 OpenJDK 更稳定。OpenJDK 和 Oracle JDK 的代码几乎相同,但 Oracle JDK 有更多的类和一些错误修复。因此,如果您想开发企业/商业软件,我建议您选择 Oracle JDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用 OpenJDK 可能会遇到了许多应用程序崩溃的问题,但是,只需切换到 Oracle JDK 就可以解决问题;
+4. 在响应性和 JVM 性能方面,Oracle JDK 与 OpenJDK 相比提供了更好的性能;
+5. Oracle JDK 不会为即将发布的版本提供长期支持,用户每次都必须通过更新到最新版本获得支持来获取最新版本;
+6. Oracle JDK 使用 BCL/OTN 协议获得许可,而 OpenJDK 根据 GPL v2 许可获得许可。
+
+🌈 拓展一下:
+
+- BCL 协议(Oracle Binary Code License Agreement): 可以使用JDK(支持商用),但是不能进行修改。
+- OTN 协议(Oracle Technology Network License Agreement): 11 及之后新发布的JDK用的都是这个协议,可以自己私下用,但是商用需要付费。
+
+
+
+相关阅读👍:[《Differences Between Oracle JDK and OpenJDK》](https://www.baeldung.com/oracle-jdk-vs-openjdk)
+
+### Java 和 C++的区别?
+
+我知道很多人没学过 C++,但是面试官就是没事喜欢拿咱们 Java 和 C++ 比呀!没办法!!!就算没学过 C++,也要记下来!
+
+- 都是面向对象的语言,都支持封装、继承和多态
+- Java 不提供指针来直接访问内存,程序内存更加安全
+- Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
+- Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。
+- C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载(操作符重载增加了复杂性,这与 Java 最初的设计思想不符)。
+- ......
+
+### import java 和 javax 有什么区别?
+
+刚开始的时候 JavaAPI 所必需的包是 java 开头的包,javax 当时只是扩展 API 包来使用。然而随着时间的推移,javax 逐渐地扩展成为 Java API 的组成部分。但是,将扩展从 javax 包移动到 java 包确实太麻烦了,最终会破坏一堆现有的代码。因此,最终决定 javax 包将成为标准 API 的一部分。
+
+所以,实际上 java 和 javax 没有区别。这都是一个名字。
+
+## 基本语法
+
+### 字符型常量和字符串常量的区别?
+
+1. **形式** : 字符常量是单引号引起的一个字符,字符串常量是双引号引起的 0 个或若干个字符
+2. **含义** : 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)
+3. **占内存大小** : 字符常量只占 2 个字节; 字符串常量占若干个字节 (**注意: char 在 Java 中占两个字节**),
+
+ > 字符封装类 `Character` 有一个成员常量 `Character.SIZE` 值为 16,单位是`bits`,该值除以 8(`1byte=8bits`)后就可以得到 2 个字节
+
+> java 编程思想第四版:2.2.2 节
+> 
+
+### 注释
+
+Java 中的注释有三种:
+
+1. 单行注释
+
+2. 多行注释
+
+3. 文档注释。
+
+在我们编写代码的时候,如果代码量比较少,我们自己或者团队其他成员还可以很轻易地看懂代码,但是当项目结构一旦复杂起来,我们就需要用到注释了。注释并不会执行(编译器在编译代码之前会把代码中的所有注释抹掉,字节码中不保留注释),是我们程序员写给自己看的,注释是你的代码说明书,能够帮助看代码的人快速地理清代码之间的逻辑关系。因此,在写程序的时候随手加上注释是一个非常好的习惯。
+
+《Clean Code》这本书明确指出:
+
+> **代码的注释不是越详细越好。实际上好的代码本身就是注释,我们要尽量规范和美化自己的代码来减少不必要的注释。**
+>
+> **若编程语言足够有表达力,就不需要注释,尽量通过代码来阐述。**
+>
+> 举个例子:
+>
+> 去掉下面复杂的注释,只需要创建一个与注释所言同一事物的函数即可
+>
+> ```java
+> // check to see if the employee is eligible for full benefits
+> if ((employee.flags & HOURLY_FLAG) && (employee.age > 65))
+> ```
+>
+> 应替换为
+>
+> ```java
+> if (employee.isEligibleForFullBenefits())
+> ```
+
+### 标识符和关键字的区别是什么?
+
+在我们编写程序的时候,需要大量地为程序、类、变量、方法等取名字,于是就有了标识符,简单来说,标识符就是一个名字。但是有一些标识符,Java 语言已经赋予了其特殊的含义,只能用于特定的地方,这种特殊的标识符就是关键字。因此,关键字是被赋予特殊含义的标识符。比如,在我们的日常生活中 ,“警察局”这个名字已经被赋予了特殊的含义,所以如果你开一家店,店的名字不能叫“警察局”,“警察局”就是我们日常生活中的关键字。
+
+### Java 中有哪些常见的关键字?
+
+| 分类 | 关键字 | | | | | | |
+| :-------------------- | -------- | ---------- | -------- | ------------ | ---------- | --------- | ------ |
+| 访问控制 | private | protected | public | | | | |
+| 类,方法和变量修饰符 | abstract | class | extends | final | implements | interface | native |
+| | new | static | strictfp | synchronized | transient | volatile | |
+| 程序控制 | break | continue | return | do | while | if | else |
+| | for | instanceof | switch | case | default | | |
+| 错误处理 | try | catch | throw | throws | finally | | |
+| 包相关 | import | package | | | | | |
+| 基本类型 | boolean | byte | char | double | float | int | long |
+| | short | null | true | false | | | |
+| 变量引用 | super | this | void | | | | |
+| 保留字 | goto | const | | | | | |
+
+### 自增自减运算符
+
+在写代码的过程中,常见的一种情况是需要某个整数类型变量增加 1 或减少 1,Java 提供了一种特殊的运算符,用于这种表达式,叫做自增运算符(++)和自减运算符(--)。
+
+++和--运算符可以放在变量之前,也可以放在变量之后,当运算符放在变量之前时(前缀),先自增/减,再赋值;当运算符放在变量之后时(后缀),先赋值,再自增/减。例如,当 `b = ++a` 时,先自增(自己增加 1),再赋值(赋值给 b);当 `b = a++` 时,先赋值(赋值给 b),再自增(自己增加 1)。也就是,++a 输出的是 a+1 的值,a++输出的是 a 值。用一句口诀就是:“符号在前就先加/减,符号在后就后加/减”。
+
+### continue、break、和 return 的区别是什么?
+
+在循环结构中,当循环条件不满足或者循环次数达到要求时,循环会正常结束。但是,有时候可能需要在循环的过程中,当发生了某种条件之后 ,提前终止循环,这就需要用到下面几个关键词:
+
+1. continue :指跳出当前的这一次循环,继续下一次循环。
+2. break :指跳出整个循环体,继续执行循环下面的语句。
+
+return 用于跳出所在方法,结束该方法的运行。return 一般有两种用法:
+
+1. `return;` :直接使用 return 结束方法执行,用于没有返回值函数的方法
+2. `return value;` :return 一个特定值,用于有返回值函数的方法
+
+### Java 泛型了解么?什么是类型擦除?介绍一下常用的通配符?
+
+Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
+
+Java 的泛型是伪泛型,这是因为 Java 在运行期间,所有的泛型信息都会被擦掉,这也就是通常所说类型擦除 。
+
+```java
+List<Integer> list = new ArrayList<>();
+
+list.add(12);
+//这里直接添加会报错
+list.add("a");
+Class<? extends List> clazz = list.getClass();
+Method add = clazz.getDeclaredMethod("add", Object.class);
+//但是通过反射添加,是可以的
+add.invoke(list, "kl");
+
+System.out.println(list);
+```
+
+泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
+
+**1.泛型类**:
+
+```java
+//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
+//在实例化泛型类时,必须指定T的具体类型
+public class Generic<T> {
+
+ private T key;
+
+ public Generic(T key) {
+ this.key = key;
+ }
+
+ public T getKey() {
+ return key;
+ }
+}
+```
+
+如何实例化泛型类:
+
+```java
+Generic<Integer> genericInteger = new Generic<Integer>(123456);
+```
+
+**2.泛型接口** :
+
+```java
+public interface Generator<T> {
+ public T method();
+}
+```
+
+实现泛型接口,不指定类型:
+
+```java
+class GeneratorImpl<T> implements Generator<T>{
+ @Override
+ public T method() {
+ return null;
+ }
+}
+```
+
+实现泛型接口,指定类型:
+
+```java
+class GeneratorImpl implements Generator<String>{
+ @Override
+ public String method() {
+ return "hello";
+ }
+}
+```
+
+**3.泛型方法** :
+
+```java
+public static <E> void printArray(E[] inputArray) {
+ for (E element : inputArray) {
+ System.out.printf("%s ", element);
+ }
+ System.out.println();
+}
+```
+
+使用:
+
+```java
+// 创建不同类型数组: Integer, Double 和 Character
+Integer[] intArray = { 1, 2, 3 };
+String[] stringArray = { "Hello", "World" };
+printArray(intArray);
+printArray(stringArray);
+```
+
+**常用的通配符为: T,E,K,V,?**
+
+- ? 表示不确定的 java 类型
+- T (type) 表示具体的一个 java 类型
+- K V (key value) 分别代表 java 键值中的 Key Value
+- E (element) 代表 Element
+
+### ==和 equals 的区别
+
+对于基本数据类型来说,==比较的是值。对于引用数据类型来说,==比较的是对象的内存地址。
+
+> 因为 Java 只有值传递,所以,对于 == 来说,不管是比较基本数据类型,还是引用数据类型的变量,其本质比较的都是值,只是引用类型变量存的值是对象的地址。
+
+**`equals()`** 作用不能用于判断基本数据类型的变量,只能用来判断两个对象是否相等。`equals()`方法存在于`Object`类中,而`Object`类是所有类的直接或间接父类。
+
+`Object` 类 `equals()` 方法:
+
+```java
+public boolean equals(Object obj) {
+ return (this == obj);
+}
+```
+
+`equals()` 方法存在两种使用情况:
+
+- **类没有覆盖 `equals()`方法** :通过`equals()`比较该类的两个对象时,等价于通过“==”比较这两个对象,使用的默认是 `Object`类`equals()`方法。
+- **类覆盖了 `equals()`方法** :一般我们都覆盖 `equals()`方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。
+
+**举个例子:**
+
+```java
+public class test1 {
+ public static void main(String[] args) {
+ String a = new String("ab"); // a 为一个引用
+ String b = new String("ab"); // b为另一个引用,对象的内容一样
+ String aa = "ab"; // 放在常量池中
+ String bb = "ab"; // 从常量池中查找
+ if (aa == bb) // true
+ System.out.println("aa==bb");
+ if (a == b) // false,非同一对象
+ System.out.println("a==b");
+ if (a.equals(b)) // true
+ System.out.println("aEQb");
+ if (42 == 42.0) { // true
+ System.out.println("true");
+ }
+ }
+}
+```
+
+**说明:**
+
+- `String` 中的 `equals` 方法是被重写过的,因为 `Object` 的 `equals` 方法是比较的对象的内存地址,而 `String` 的 `equals` 方法比较的是对象的值。
+- 当创建 `String` 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 `String` 对象。
+
+`String`类`equals()`方法:
+
+```java
+public boolean equals(Object anObject) {
+ if (this == anObject) {
+ return true;
+ }
+ if (anObject instanceof String) {
+ String anotherString = (String)anObject;
+ int n = value.length;
+ if (n == anotherString.value.length) {
+ char v1[] = value;
+ char v2[] = anotherString.value;
+ int i = 0;
+ while (n-- != 0) {
+ if (v1[i] != v2[i])
+ return false;
+ i++;
+ }
+ return true;
+ }
+ }
+ return false;
+}
+```
+
+### hashCode()与 equals()
+
+面试官可能会问你:“你重写过 `hashcode` 和 `equals`么,为什么重写 `equals` 时必须重写 `hashCode` 方法?”
+
+**1)hashCode()介绍:**
+
+`hashCode()` 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。`hashCode()`定义在 JDK 的 `Object` 类中,这就意味着 Java 中的任何类都包含有 `hashCode()` 函数。另外需要注意的是: `Object` 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
+
+```java
+public native int hashCode();
+```
+
+散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
+
+**2)为什么要有 hashCode?**
+
+我们以“`HashSet` 如何检查重复”为例子来说明为什么要有 hashCode?
+
+当你把对象加入 `HashSet` 时,`HashSet` 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,`HashSet` 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 `equals()` 方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,`HashSet` 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head First Java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
+
+**3)为什么重写 `equals` 时必须重写 `hashCode` 方法?**
+
+如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。**因此,equals 方法被覆盖过,则 `hashCode` 方法也必须被覆盖。**
+
+> `hashCode()`的默认行为是对堆上的对象产生独特值。如果没有重写 `hashCode()`,则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
+
+**4)为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?**
+
+在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
+
+因为 `hashCode()` 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 `hashCode` )。
+
+我们刚刚也提到了 `HashSet`,如果 `HashSet` 在对比的时候,同样的 hashcode 有多个对象,它会使用 `equals()` 来判断是否真的相同。也就是说 `hashcode` 只是用来缩小查找成本。
+
+更多关于 `hashcode()` 和 `equals()` 的内容可以查看:[Java hashCode() 和 equals()的若干问题解答](https://www.cnblogs.com/skywang12345/p/3324958.html)
+
+## 基本数据类型
+
+### Java 中的几种基本数据类型是什么?对应的包装类型是什么?各自占用多少字节呢?
+
+Java 中有 8 种基本数据类型,分别为:
+
+1. 6 种数字类型 :`byte`、`short`、`int`、`long`、`float`、`double`
+2. 1 种字符类型:`char`
+3. 1 种布尔型:`boolean`。
+
+这 8 种基本数据类型的默认值以及所占空间的大小如下:
+
+| 基本类型 | 位数 | 字节 | 默认值 |
+| :-------- | :--- | :--- | :------ |
+| `int` | 32 | 4 | 0 |
+| `short` | 16 | 2 | 0 |
+| `long` | 64 | 8 | 0L |
+| `byte` | 8 | 1 | 0 |
+| `char` | 16 | 2 | 'u0000' |
+| `float` | 32 | 4 | 0f |
+| `double` | 64 | 8 | 0d |
+| `boolean` | 1 | | false |
+
+另外,对于 `boolean`,官方文档未明确定义,它依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1 位,但是实际中会考虑计算机高效存储因素。
+
+**注意:**
+
+1. Java 里使用 `long` 类型的数据一定要在数值后面加上 **L**,否则将作为整型解析。
+2. `char a = 'h'`char :单引号,`String a = "hello"` :双引号。
+
+这八种基本类型都有对应的包装类分别为:`Byte`、`Short`、`Integer`、`Long`、`Float`、`Double`、`Character`、`Boolean` 。
+
+包装类型不赋值就是 `Null` ,而基本类型有默认值且不是 `Null`。
+
+另外,这个问题建议还可以先从 JVM 层面来分析。
+
+基本数据类型直接存放在 Java 虚拟机栈中的局部变量表中,而包装类型属于对象类型,我们知道对象实例都存在于堆中。相比于对象类型, 基本数据类型占用的空间非常小。
+
+> 《深入理解 Java 虚拟机》 :局部变量表主要存放了编译期可知的基本数据类型 **(boolean、byte、char、short、int、float、long、double)**、**对象引用**(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
+
+### 自动装箱与拆箱
+
+- **装箱**:将基本类型用它们对应的引用类型包装起来;
+- **拆箱**:将包装类型转换为基本数据类型;
+
+举例:
+
+```java
+Integer i = 10; //装箱
+int n = i; //拆箱
+```
+
+上面这两行代码对应的字节码为:
+
+```java
+ L1
+
+ LINENUMBER 8 L1
+
+ ALOAD 0
+
+ BIPUSH 10
+
+ INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer;
+
+ PUTFIELD AutoBoxTest.i : Ljava/lang/Integer;
+
+ L2
+
+ LINENUMBER 9 L2
+
+ ALOAD 0
+
+ ALOAD 0
+
+ GETFIELD AutoBoxTest.i : Ljava/lang/Integer;
+
+ INVOKEVIRTUAL java/lang/Integer.intValue ()I
+
+ PUTFIELD AutoBoxTest.n : I
+
+ RETURN
+```
+
+从字节码中,我们发现装箱其实就是调用了 包装类的`valueOf()`方法,拆箱其实就是调用了 `xxxValue()`方法。
+
+因此,
+
+- `Integer i = 10` 等价于 `Integer i = Integer.valueOf(10)`
+- `int n = i` 等价于 `int n = i.intValue()`;
+
+### 8 种基本类型的包装类和常量池
+
+Java 基本类型的包装类的大部分都实现了常量池技术。`Byte`,`Short`,`Integer`,`Long` 这 4 种包装类默认创建了数值 **[-128,127]** 的相应类型的缓存数据,`Character` 创建了数值在[0,127]范围的缓存数据,`Boolean` 直接返回 `True` Or `False`。
+
+**Integer 缓存源码:**
+
+```java
+/**
+
+*此方法将始终缓存-128 到 127(包括端点)范围内的值,并可以缓存此范围之外的其他值。
+
+*/
+
+public static Integer valueOf(int i) {
+
+ if (i >= IntegerCache.low && i <= IntegerCache.high)
+
+ return IntegerCache.cache[i + (-IntegerCache.low)];
+
+ return new Integer(i);
+
+}
+
+private static class IntegerCache {
+
+ static final int low = -128;
+
+ static final int high;
+
+ static final Integer cache[];
+
+}
+```
+
+**`Character` 缓存源码:**
+
+```java
+public static Character valueOf(char c) {
+
+ if (c <= 127) { // must cache
+
+ return CharacterCache.cache[(int)c];
+
+ }
+
+ return new Character(c);
+
+}
+
+
+
+private static class CharacterCache {
+
+ private CharacterCache(){}
+
+
+
+ static final Character cache[] = new Character[127 + 1];
+
+ static {
+
+ for (int i = 0; i < cache.length; i++)
+
+ cache[i] = new Character((char)i);
+
+ }
+
+}
+```
+
+**`Boolean` 缓存源码:**
+
+```java
+public static Boolean valueOf(boolean b) {
+
+ return (b ? TRUE : FALSE);
+
+}
+```
+
+如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。
+
+两种浮点数类型的包装类 `Float`,`Double` 并没有实现常量池技术。
+
+```java
+Integer i1 = 33;
+
+Integer i2 = 33;
+
+System.out.println(i1 == i2);// 输出 true
+
+Float i11 = 333f;
+
+Float i22 = 333f;
+
+System.out.println(i11 == i22);// 输出 false
+
+Double i3 = 1.2;
+
+Double i4 = 1.2;
+
+System.out.println(i3 == i4);// 输出 false
+```
+
+下面我们来看一下问题。下面的代码的输出结果是 `true` 还是 `flase` 呢?
+
+```java
+Integer i1 = 40;
+
+Integer i2 = new Integer(40);
+
+System.out.println(i1==i2);
+```
+
+`Integer i1=40` 这一行代码会发生装箱,也就是说这行代码等价于 `Integer i1=Integer.valueOf(40)` 。因此,`i1` 直接使用的是常量池中的对象。而`Integer i1 = new Integer(40)` 会直接创建新的对象。
+
+因此,答案是 `false` 。你答对了吗?
+
+记住:**所有整型包装类对象之间值的比较,全部使用 equals 方法比较**。
+
+
+
+## 方法(函数)
+
+### 什么是方法的返回值?
+
+方法的返回值是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用是接收出结果,使得它可以用于其他的操作!
+
+### 方法有哪几种类型?
+
+**1.无参数无返回值的方法**
+
+```java
+// 无参数无返回值的方法(如果方法没有返回值,不能不写,必须写void,表示没有返回值)
+public void f1() {
+ System.out.println("无参数无返回值的方法");
+}
+```
+
+**2.有参数无返回值的方法**
+
+```java
+/**
+* 有参数无返回值的方法
+* 参数列表由零组到多组“参数类型+形参名”组合而成,多组参数之间以英文逗号(,)隔开,形参类型和形参名之间以英文空格隔开
+*/
+public void f2(int a, String b, int c) {
+ System.out.println(a + "-->" + b + "-->" + c);
+}
+```
+
+**3.有返回值无参数的方法**
+
+```java
+// 有返回值无参数的方法(返回值可以是任意的类型,在函数里面必须有return关键字返回对应的类型)
+public int f3() {
+ System.out.println("有返回值无参数的方法");
+ return 2;
+}
+```
+
+**4.有返回值有参数的方法**
+
+```java
+// 有返回值有参数的方法
+public int f4(int a, int b) {
+ return a * b;
+}
+```
+
+**5.return 在无返回值方法的特殊使用**
+
+```java
+// return在无返回值方法的特殊使用
+public void f5(int a) {
+ if (a > 10) {
+ return;//表示结束所在方法 (f5方法)的执行,下方的输出语句不会执行
+ }
+ System.out.println(a);
+}
+```
+
+### 在一个静态方法内调用一个非静态成员为什么是非法的?
+
+这个需要结合 JVM 的相关知识,静态方法是属于类的,在类加载的时候就会分配内存,可以通过类名直接访问。而非静态成员属于实例对象,只有在对象实例化之后才存在,然后通过类的实例对象去访问。在类的非静态成员不存在的时候静态成员就已经存在了,此时调用在内存中还不存在的非静态成员,属于非法操作。
+
+### 静态方法和实例方法有何不同?
+
+**1、调用方式**
+
+在外部调用静态方法时,可以使用 `类名.方法名` 的方式,也可以使用 `对象.方法名` 的方式,而实例方法只有后面这种方式。也就是说,**调用静态方法可以无需创建对象** 。
+
+不过,需要注意的是一般不建议使用 `对象.方法名` 的方式来调用静态方法。这种方式非常容易造成混淆,静态方法不属于类的某个对象而是属于这个类。
+
+因此,一般建议使用 `类名.方法名` 的方式来调用静态方法。
+
+```java
+
+public class Person {
+ public void method() {
+ //......
+ }
+
+ public static void staicMethod(){
+ //......
+ }
+ public static void main(String[] args) {
+ Person person = new Person();
+ // 调用实例方法
+ person.method();
+ // 调用静态方法
+ Person.staicMethod()
+ }
+}
+```
+
+**2、访问类成员是否存在限制**
+
+静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),不允许访问实例成员(即实例成员变量和实例方法),而实例方法不存在这个限制。
+
+### 为什么 Java 中只有值传递?
+
+首先,我们回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。
+
+**按值调用(call by value)** 表示方法接收的是调用者提供的值,**按引用调用(call by reference)** 表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。它用来描述各种程序设计语言(不只是 Java)中方法参数传递方式。
+
+**Java 程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。**
+
+**下面通过 3 个例子来给大家说明**
+
+> **example 1**
+
+```java
+public static void main(String[] args) {
+ int num1 = 10;
+ int num2 = 20;
+
+ swap(num1, num2);
+
+ System.out.println("num1 = " + num1);
+ System.out.println("num2 = " + num2);
+}
+
+public static void swap(int a, int b) {
+ int temp = a;
+ a = b;
+ b = temp;
+
+ System.out.println("a = " + a);
+ System.out.println("b = " + b);
+}
+```
+
+**结果:**
+
+```
+a = 20
+b = 10
+num1 = 10
+num2 = 20
+```
+
+**解析:**
+
+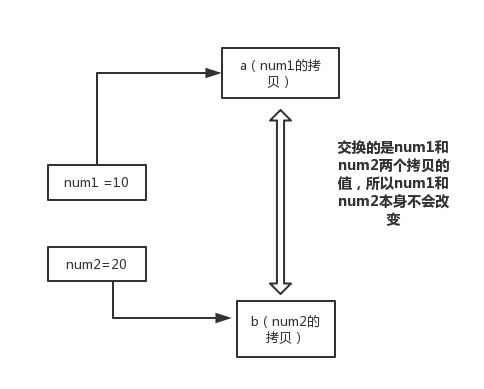
+
+在 swap 方法中,a、b 的值进行交换,并不会影响到 num1、num2。因为,a、b 中的值,只是从 num1、num2 的复制过来的。也就是说,a、b 相当于 num1、num2 的副本,副本的内容无论怎么修改,都不会影响到原件本身。
+
+**通过上面例子,我们已经知道了一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不一样,请看 example2.**
+
+> **example 2**
+
+```java
+ public static void main(String[] args) {
+ int[] arr = { 1, 2, 3, 4, 5 };
+ System.out.println(arr[0]);
+ change(arr);
+ System.out.println(arr[0]);
+ }
+
+ public static void change(int[] array) {
+ // 将数组的第一个元素变为0
+ array[0] = 0;
+ }
+```
+
+**结果:**
+
+```
+1
+0
+```
+
+**解析:**
+
+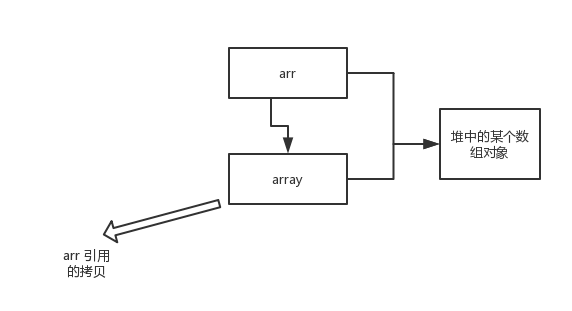
+
+array 被初始化 arr 的拷贝也就是一个对象的引用,也就是说 array 和 arr 指向的是同一个数组对象。 因此,外部对引用对象的改变会反映到所对应的对象上。
+
+**通过 example2 我们已经看到,实现一个改变对象参数状态的方法并不是一件难事。理由很简单,方法得到的是对象引用的拷贝,对象引用及其他的拷贝同时引用同一个对象。**
+
+**很多程序设计语言(特别是,C++和 Pascal)提供了两种参数传递的方式:值调用和引用调用。有些程序员(甚至本书的作者)认为 Java 程序设计语言对对象采用的是引用调用,实际上,这种理解是不对的。由于这种误解具有一定的普遍性,所以下面给出一个反例来详细地阐述一下这个问题。**
+
+> **example 3**
+
+```java
+public class Test {
+
+ public static void main(String[] args) {
+ // TODO Auto-generated method stub
+ Student s1 = new Student("小张");
+ Student s2 = new Student("小李");
+ Test.swap(s1, s2);
+ System.out.println("s1:" + s1.getName());
+ System.out.println("s2:" + s2.getName());
+ }
+
+ public static void swap(Student x, Student y) {
+ Student temp = x;
+ x = y;
+ y = temp;
+ System.out.println("x:" + x.getName());
+ System.out.println("y:" + y.getName());
+ }
+}
+```
+
+**结果:**
+
+```
+x:小李
+y:小张
+s1:小张
+s2:小李
+```
+
+**解析:**
+
+交换之前:
+
+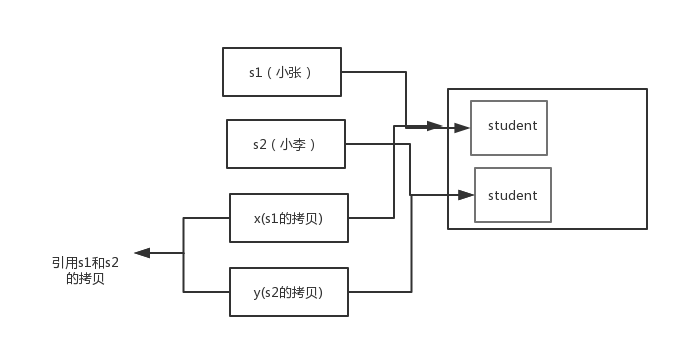
+
+交换之后:
+
+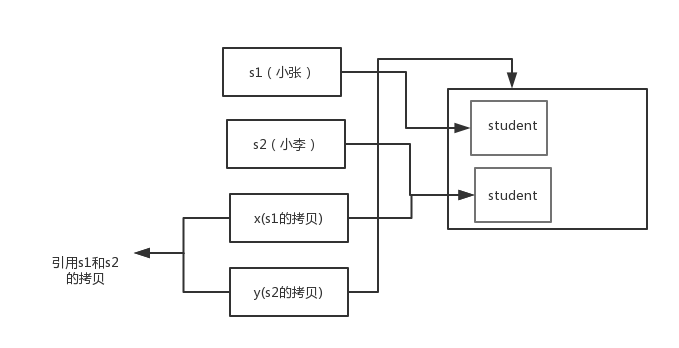
+
+通过上面两张图可以很清晰的看出: **方法并没有改变存储在变量 s1 和 s2 中的对象引用。swap 方法的参数 x 和 y 被初始化为两个对象引用的拷贝,这个方法交换的是这两个拷贝**
+
+> **总结**
+
+Java 程序设计语言对对象采用的不是引用调用,实际上,对象引用是按
+值传递的。
+
+下面再总结一下 Java 中方法参数的使用情况:
+
+- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)。
+- 一个方法可以改变一个对象参数的状态。
+- 一个方法不能让对象参数引用一个新的对象。
+
+**参考:**
+
+《Java 核心技术卷 Ⅰ》基础知识第十版第四章 4.5 小节
+
+### 重载和重写的区别
+
+> 重载就是同样的一个方法能够根据输入数据的不同,做出不同的处理
+>
+> 重写就是当子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,你就要覆盖父类方法
+
+#### 重载
+
+发生在同一个类中(或者父类和子类之间),方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
+
+下面是《Java 核心技术》对重载这个概念的介绍:
+
+
+
+综上:重载就是同一个类中多个同名方法根据不同的传参来执行不同的逻辑处理。
+
+#### 重写
+
+重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写。
+
+1. 返回值类型、方法名、参数列表必须相同,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。
+2. 如果父类方法访问修饰符为 `private/final/static` 则子类就不能重写该方法,但是被 static 修饰的方法能够被再次声明。
+3. 构造方法无法被重写
+
+综上:重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变
+
+暖心的 Guide 哥最后再来个图表总结一下!
+
+| 区别点 | 重载方法 | 重写方法 |
+| :--------- | :------- | :----------------------------------------------------------- |
+| 发生范围 | 同一个类 | 子类 |
+| 参数列表 | 必须修改 | 一定不能修改 |
+| 返回类型 | 可修改 | 子类方法返回值类型应比父类方法返回值类型更小或相等 |
+| 异常 | 可修改 | 子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等; |
+| 访问修饰符 | 可修改 | 一定不能做更严格的限制(可以降低限制) |
+| 发生阶段 | 编译期 | 运行期 |
+
+**方法的重写要遵循“两同两小一大”**(以下内容摘录自《疯狂 Java 讲义》,[issue#892](https://github.com/Snailclimb/JavaGuide/issues/892) ):
+
+- “两同”即方法名相同、形参列表相同;
+- “两小”指的是子类方法返回值类型应比父类方法返回值类型更小或相等,子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;
+- “一大”指的是子类方法的访问权限应比父类方法的访问权限更大或相等。
+
+⭐️ 关于 **重写的返回值类型** 这里需要额外多说明一下,上面的表述不太清晰准确:如果方法的返回类型是 void 和基本数据类型,则返回值重写时不可修改。但是如果方法的返回值是引用类型,重写时是可以返回该引用类型的子类的。
+
+```java
+public class Hero {
+ public String name() {
+ return "超级英雄";
+ }
+}
+public class SuperMan extends Hero{
+ @Override
+ public String name() {
+ return "超人";
+ }
+ public Hero hero() {
+ return new Hero();
+ }
+}
+
+public class SuperSuperMan extends SuperMan {
+ public String name() {
+ return "超级超级英雄";
+ }
+
+ @Override
+ public SuperMan hero() {
+ return new SuperMan();
+ }
+}
+```
+
+### 深拷贝 vs 浅拷贝
+
+1. **浅拷贝**:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
+2. **深拷贝**:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
+
+
+
+## Java 面向对象
+
+### 面向对象和面向过程的区别
+
+- **面向过程** :**面向过程性能比面向对象高。** 因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素的时候,比如单片机、嵌入式开发、Linux/Unix 等一般采用面向过程开发。但是,**面向过程没有面向对象易维护、易复用、易扩展。**
+- **面向对象** :**面向对象易维护、易复用、易扩展。** 因为面向对象有封装、继承、多态性的特性,所以可以设计出低耦合的系统,使系统更加灵活、更加易于维护。但是,**面向对象性能比面向过程低**。
+
+参见 issue : [面向过程 :面向过程性能比面向对象高??](https://github.com/Snailclimb/JavaGuide/issues/431)
+
+> 这个并不是根本原因,面向过程也需要分配内存,计算内存偏移量,Java 性能差的主要原因并不是因为它是面向对象语言,而是 Java 是半编译语言,最终的执行代码并不是可以直接被 CPU 执行的二进制机械码。
+>
+> 而面向过程语言大多都是直接编译成机械码在电脑上执行,并且其它一些面向过程的脚本语言性能也并不一定比 Java 好。
+
+### 成员变量与局部变量的区别有哪些?
+
+1. 从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被 `public`,`private`,`static` 等修饰符所修饰,而局部变量不能被访问控制修饰符及 `static` 所修饰;但是,成员变量和局部变量都能被 `final` 所修饰。
+2. 从变量在内存中的存储方式来看,如果成员变量是使用 `static` 修饰的,那么这个成员变量是属于类的,如果没有使用 `static` 修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
+3. 从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
+4. 从变量是否有默认值来看,成员变量如果没有被赋初,则会自动以类型的默认值而赋值(一种情况例外:被 `final` 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
+
+### 创建一个对象用什么运算符?对象实体与对象引用有何不同?
+
+new 运算符,new 创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。
+
+一个对象引用可以指向 0 个或 1 个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有 n 个引用指向它(可以用 n 条绳子系住一个气球)。
+
+### 对象的相等与指向他们的引用相等,两者有什么不同?
+
+对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
+
+### 一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗? 为什么?
+
+构造方法主要作用是完成对类对象的初始化工作。
+
+如果一个类没有声明构造方法,也可以执行!因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。如果我们自己添加了类的构造方法(无论是否有参),Java 就不会再添加默认的无参数的构造方法了,这时候,就不能直接 new 一个对象而不传递参数了,所以我们一直在不知不觉地使用构造方法,这也是为什么我们在创建对象的时候后面要加一个括号(因为要调用无参的构造方法)。如果我们重载了有参的构造方法,记得都要把无参的构造方法也写出来(无论是否用到),因为这可以帮助我们在创建对象的时候少踩坑。
+
+### 构造方法有哪些特点?是否可被 override?
+
+特点:
+
+1. 名字与类名相同。
+2. 没有返回值,但不能用 void 声明构造函数。
+3. 生成类的对象时自动执行,无需调用。
+
+构造方法不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况。
+
+### 面向对象三大特征
+
+#### 封装
+
+封装是指把一个对象的状态信息(也就是属性)隐藏在对象内部,不允许外部对象直接访问对象的内部信息。但是可以提供一些可以被外界访问的方法来操作属性。就好像我们看不到挂在墙上的空调的内部的零件信息(也就是属性),但是可以通过遥控器(方法)来控制空调。如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。就好像如果没有空调遥控器,那么我们就无法操控空凋制冷,空调本身就没有意义了(当然现在还有很多其他方法 ,这里只是为了举例子)。
+
+```java
+public class Student {
+ private int id;//id属性私有化
+ private String name;//name属性私有化
+
+ //获取id的方法
+ public int getId() {
+ return id;
+ }
+
+ //设置id的方法
+ public void setId(int id) {
+ this.id = id;
+ }
+
+ //获取name的方法
+ public String getName() {
+ return name;
+ }
+
+ //设置name的方法
+ public void setName(String name) {
+ this.name = name;
+ }
+}
+```
+
+#### 继承
+
+不同类型的对象,相互之间经常有一定数量的共同点。例如,小明同学、小红同学、小李同学,都共享学生的特性(班级、学号等)。同时,每一个对象还定义了额外的特性使得他们与众不同。例如小明的数学比较好,小红的性格惹人喜爱;小李的力气比较大。继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承,可以快速地创建新的类,可以提高代码的重用,程序的可维护性,节省大量创建新类的时间 ,提高我们的开发效率。
+
+**关于继承如下 3 点请记住:**
+
+1. 子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,**只是拥有**。
+2. 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
+3. 子类可以用自己的方式实现父类的方法。(以后介绍)。
+
+#### 多态
+
+多态,顾名思义,表示一个对象具有多种的状态。具体表现为父类的引用指向子类的实例。
+
+**多态的特点:**
+
+- 对象类型和引用类型之间具有继承(类)/实现(接口)的关系;
+- 引用类型变量发出的方法调用的到底是哪个类中的方法,必须在程序运行期间才能确定;
+- 多态不能调用“只在子类存在但在父类不存在”的方法;
+- 如果子类重写了父类的方法,真正执行的是子类覆盖的方法,如果子类没有覆盖父类的方法,执行的是父类的方法。
+
+### String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
+
+**可变性**
+
+简单的来说:`String` 类中使用 final 关键字修饰字符数组来保存字符串,`private final char value[]`,所以`String` 对象是不可变的。
+
+> 补充(来自[issue 675](https://github.com/Snailclimb/JavaGuide/issues/675)):在 Java 9 之后,String 、`StringBuilder` 与 `StringBuffer` 的实现改用 byte 数组存储字符串 `private final byte[] value`
+
+而 `StringBuilder` 与 `StringBuffer` 都继承自 `AbstractStringBuilder` 类,在 `AbstractStringBuilder` 中也是使用字符数组保存字符串`char[]value` 但是没有用 `final` 关键字修饰,所以这两种对象都是可变的。
+
+`StringBuilder` 与 `StringBuffer` 的构造方法都是调用父类构造方法也就是`AbstractStringBuilder` 实现的,大家可以自行查阅源码。
+
+`AbstractStringBuilder.java`
+
+```java
+abstract class AbstractStringBuilder implements Appendable, CharSequence {
+ /**
+ * The value is used for character storage.
+ */
+ char[] value;
+
+ /**
+ * The count is the number of characters used.
+ */
+ int count;
+
+ AbstractStringBuilder(int capacity) {
+ value = new char[capacity];
+ }}
+```
+
+**线程安全性**
+
+`String` 中的对象是不可变的,也就可以理解为常量,线程安全。`AbstractStringBuilder` 是 `StringBuilder` 与 `StringBuffer` 的公共父类,定义了一些字符串的基本操作,如 `expandCapacity`、`append`、`insert`、`indexOf` 等公共方法。`StringBuffer` 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。`StringBuilder` 并没有对方法进行加同步锁,所以是非线程安全的。
+
+**性能**
+
+每次对 `String` 类型进行改变的时候,都会生成一个新的 `String` 对象,然后将指针指向新的 `String` 对象。`StringBuffer` 每次都会对 `StringBuffer` 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 `StringBuilder` 相比使用 `StringBuffer` 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
+
+**对于三者使用的总结:**
+
+1. 操作少量的数据: 适用 `String`
+2. 单线程操作字符串缓冲区下操作大量数据: 适用 `StringBuilder`
+3. 多线程操作字符串缓冲区下操作大量数据: 适用 `StringBuffer`
+
+### Object 类的常见方法总结
+
+Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:
+
+```java
+public final native Class<?> getClass()//native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。
+
+public native int hashCode() //native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的HashMap。
+public boolean equals(Object obj)//用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户比较字符串的值是否相等。
+
+protected native Object clone() throws CloneNotSupportedException//naitive方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass() == x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生CloneNotSupportedException异常。
+
+public String toString()//返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方法。
+
+public final native void notify()//native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
+
+public final native void notifyAll()//native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
+
+public final native void wait(long timeout) throws InterruptedException//native方法,并且不能重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。
+
+public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。
+
+public final void wait() throws InterruptedException//跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
+
+protected void finalize() throws Throwable { }//实例被垃圾回收器回收的时候触发的操作
+```
+
+
+## 反射
+
+### 何为反射?
+
+如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。
+
+反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。
+
+通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
+
+### 反射机制优缺点
+
+- **优点** : 可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利
+- **缺点** :让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。[Java Reflection: Why is it so slow?](https://stackoverflow.com/questions/1392351/java-reflection-why-is-it-so-slow)
+
+### 反射的应用场景
+
+像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。
+
+但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
+
+**这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。**
+
+比如下面是通过 JDK 实现动态代理的示例代码,其中就使用了反射类 `Method` 来调用指定的方法。
+
+```java
+public class DebugInvocationHandler implements InvocationHandler {
+ /**
+ * 代理类中的真实对象
+ */
+ private final Object target;
+
+ public DebugInvocationHandler(Object target) {
+ this.target = target;
+ }
+
+
+ public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
+ System.out.println("before method " + method.getName());
+ Object result = method.invoke(target, args);
+ System.out.println("after method " + method.getName());
+ return result;
+ }
+}
+
+```
+
+另外,像 Java 中的一大利器 **注解** 的实现也用到了反射。
+
+为什么你使用 Spring 的时候 ,一个`@Component`注解就声明了一个类为 Spring Bean 呢?为什么你通过一个 `@Value`注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
+
+这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
+
+## 异常
+
+### Java 异常类层次结构图
+
+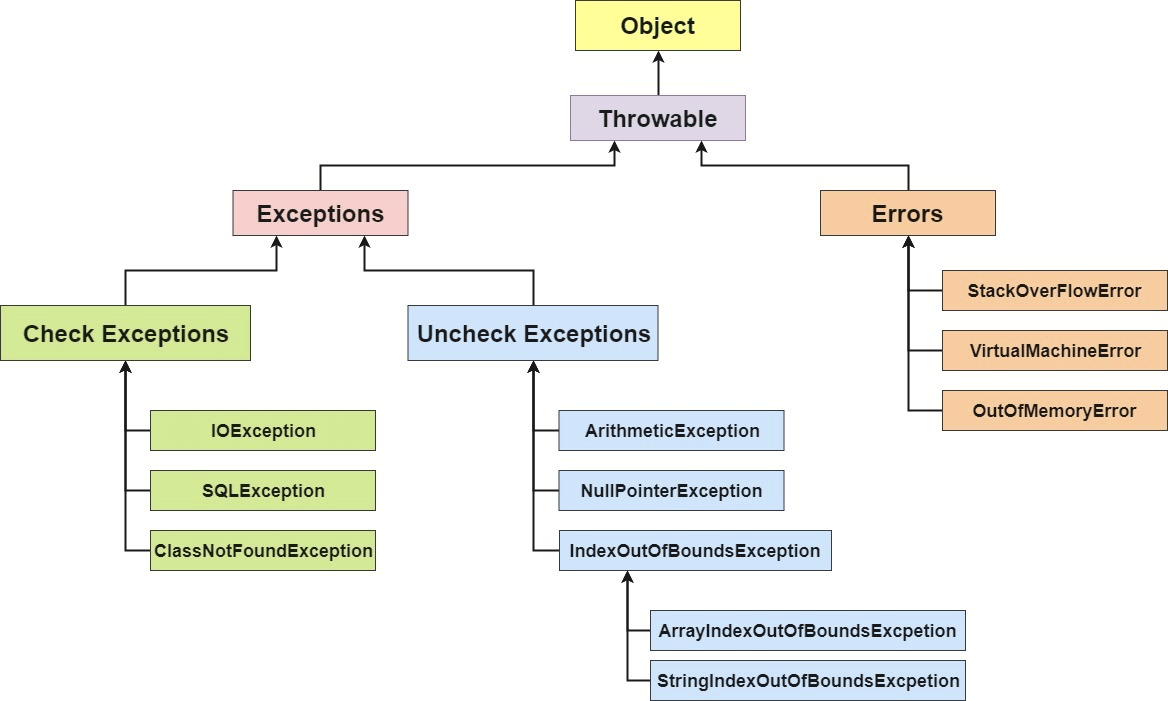
+
+<p style="font-size:13px;text-align:right">图片来自:https://simplesnippets.tech/exception-handling-in-java-part-1/</p>
+
+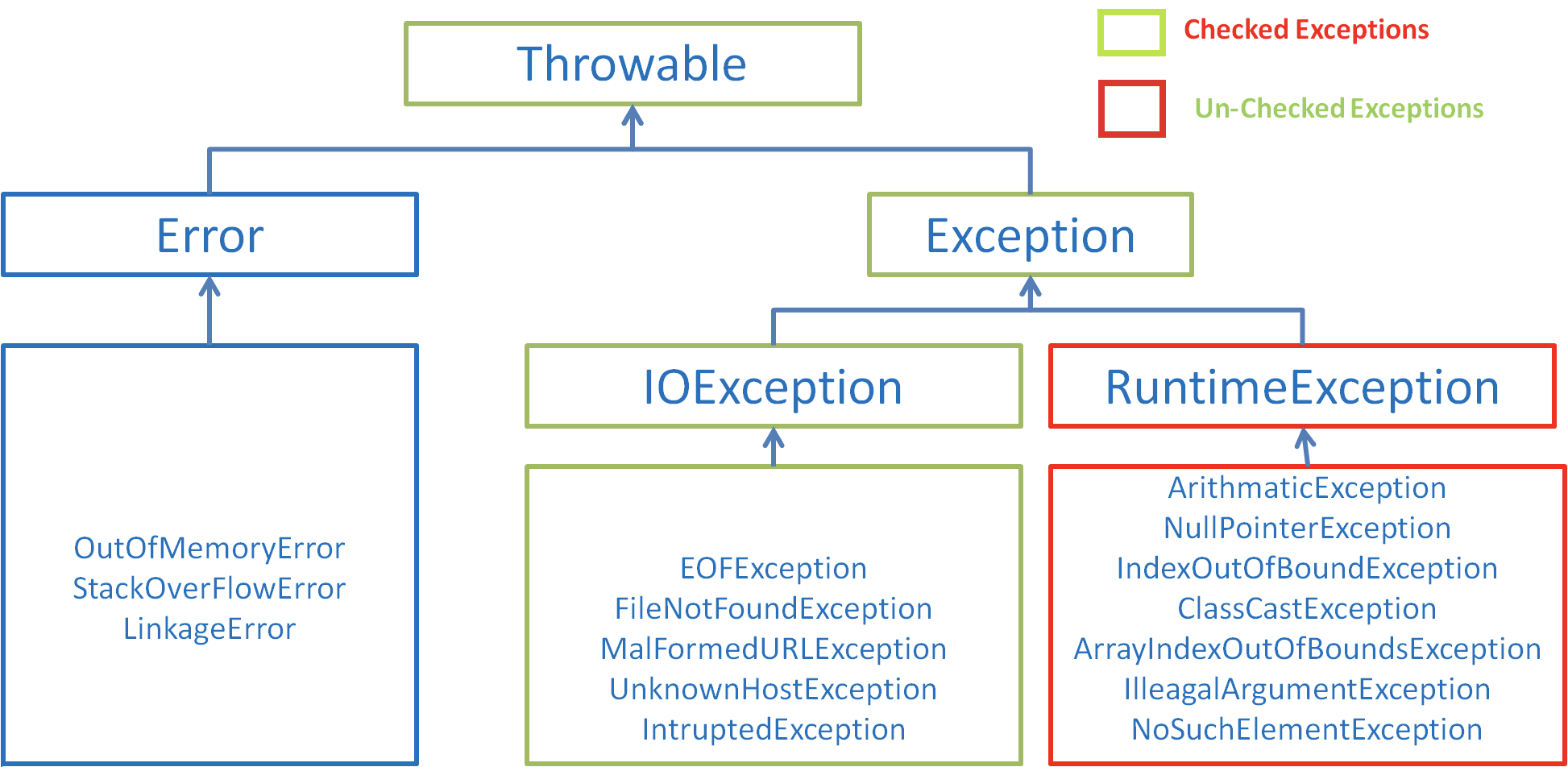
+
+<p style="font-size:13px;text-align:right">图片来自:https://chercher.tech/java-programming/exceptions-java</p>
+
+在 Java 中,所有的异常都有一个共同的祖先 `java.lang` 包中的 `Throwable` 类。`Throwable` 类有两个重要的子类 `Exception`(异常)和 `Error`(错误)。`Exception` 能被程序本身处理(`try-catch`), `Error` 是无法处理的(只能尽量避免)。
+
+`Exception` 和 `Error` 二者都是 Java 异常处理的重要子类,各自都包含大量子类。
+
+- **`Exception`** :程序本身可以处理的异常,可以通过 `catch` 来进行捕获。`Exception` 又可以分为 受检查异常(必须处理) 和 不受检查异常(可以不处理)。
+- **`Error`** :`Error` 属于程序无法处理的错误 ,我们没办法通过 `catch` 来进行捕获 。例如,Java 虚拟机运行错误(`Virtual MachineError`)、虚拟机内存不够错误(`OutOfMemoryError`)、类定义错误(`NoClassDefFoundError`)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
+
+**受检查异常**
+
+Java 代码在编译过程中,如果受检查异常没有被 `catch`/`throw` 处理的话,就没办法通过编译 。比如下面这段 IO 操作的代码。
+
+
+
+除了`RuntimeException`及其子类以外,其他的`Exception`类及其子类都属于受检查异常 。常见的受检查异常有: IO 相关的异常、`ClassNotFoundException` 、`SQLException`...。
+
+**不受检查异常**
+
+Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。
+
+`RuntimeException` 及其子类都统称为非受检查异常,例如:`NullPointerException`、`NumberFormatException`(字符串转换为数字)、`ArrayIndexOutOfBoundsException`(数组越界)、`ClassCastException`(类型转换错误)、`ArithmeticException`(算术错误)等。
+
+### Throwable 类常用方法
+
+- **`public String getMessage()`**:返回异常发生时的简要描述
+- **`public String toString()`**:返回异常发生时的详细信息
+- **`public String getLocalizedMessage()`**:返回异常对象的本地化信息。使用 `Throwable` 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 `getMessage()`返回的结果相同
+- **`public void printStackTrace()`**:在控制台上打印 `Throwable` 对象封装的异常信息
+
+### try-catch-finally
+
+- **`try`块:** 用于捕获异常。其后可接零个或多个 `catch` 块,如果没有 `catch` 块,则必须跟一个 `finally` 块。
+- **`catch`块:** 用于处理 try 捕获到的异常。
+- **`finally` 块:** 无论是否捕获或处理异常,`finally` 块里的语句都会被执行。当在 `try` 块或 `catch` 块中遇到 `return` 语句时,`finally` 语句块将在方法返回之前被执行。
+
+**在以下 3 种特殊情况下,`finally` 块不会被执行:**
+
+1. 在 `try` 或 `finally`块中用了 `System.exit(int)`退出程序。但是,如果 `System.exit(int)` 在异常语句之后,`finally` 还是会被执行
+2. 程序所在的线程死亡。
+3. 关闭 CPU。
+
+下面这部分内容来自 issue:<https://github.com/Snailclimb/JavaGuide/issues/190>。
+
+**注意:** 当 try 语句和 finally 语句中都有 return 语句时,在方法返回之前,finally 语句的内容将被执行,并且 finally 语句的返回值将会覆盖原始的返回值。如下:
+
+```java
+public class Test {
+ public static int f(int value) {
+ try {
+ return value * value;
+ } finally {
+ if (value == 2) {
+ return 0;
+ }
+ }
+ }
+}
+```
+
+如果调用 `f(2)`,返回值将是 0,因为 finally 语句的返回值覆盖了 try 语句块的返回值。
+
+### 使用 `try-with-resources` 来代替`try-catch-finally`
+
+1. **适用范围(资源的定义):** 任何实现 `java.lang.AutoCloseable`或者 `java.io.Closeable` 的对象
+2. **关闭资源和 finally 块的执行顺序:** 在 `try-with-resources` 语句中,任何 catch 或 finally 块在声明的资源关闭后运行
+
+《Effecitve Java》中明确指出:
+
+> 面对必须要关闭的资源,我们总是应该优先使用 `try-with-resources` 而不是`try-finally`。随之产生的代码更简短,更清晰,产生的异常对我们也更有用。`try-with-resources`语句让我们更容易编写必须要关闭的资源的代码,若采用`try-finally`则几乎做不到这点。
+
+Java 中类似于`InputStream`、`OutputStream` 、`Scanner` 、`PrintWriter`等的资源都需要我们调用`close()`方法来手动关闭,一般情况下我们都是通过`try-catch-finally`语句来实现这个需求,如下:
+
+```java
+ //读取文本文件的内容
+ Scanner scanner = null;
+ try {
+ scanner = new Scanner(new File("D://read.txt"));
+ while (scanner.hasNext()) {
+ System.out.println(scanner.nextLine());
+ }
+ } catch (FileNotFoundException e) {
+ e.printStackTrace();
+ } finally {
+ if (scanner != null) {
+ scanner.close();
+ }
+ }
+```
+
+使用 Java 7 之后的 `try-with-resources` 语句改造上面的代码:
+
+```java
+try (Scanner scanner = new Scanner(new File("test.txt"))) {
+ while (scanner.hasNext()) {
+ System.out.println(scanner.nextLine());
+ }
+} catch (FileNotFoundException fnfe) {
+ fnfe.printStackTrace();
+}
+```
+
+当然多个资源需要关闭的时候,使用 `try-with-resources` 实现起来也非常简单,如果你还是用`try-catch-finally`可能会带来很多问题。
+
+通过使用分号分隔,可以在`try-with-resources`块中声明多个资源。
+
+```java
+try (BufferedInputStream bin = new BufferedInputStream(new FileInputStream(new File("test.txt")));
+ BufferedOutputStream bout = new BufferedOutputStream(new FileOutputStream(new File("out.txt")))) {
+ int b;
+ while ((b = bin.read()) != -1) {
+ bout.write(b);
+ }
+ }
+ catch (IOException e) {
+ e.printStackTrace();
+ }
+```
+
+## I/O 流
+
+### 什么是序列化?什么是反序列化?
+
+如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。
+
+简单来说:
+
+- **序列化**: 将数据结构或对象转换成二进制字节流的过程
+- **反序列化**:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
+
+对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。
+
+维基百科是如是介绍序列化的:
+
+> **序列化**(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。对于许多对象,像是使用大量引用的复杂对象,这种序列化重建的过程并不容易。面向对象中的对象序列化,并不概括之前原始对象所关系的函数。这种过程也称为对象编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组、deserialization、unmarshalling)。
+
+综上:**序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。**
+
+
+
+<p style="text-align:right;font-size:13px;color:gray">https://www.corejavaguru.com/java/serialization/interview-questions-1</p>
+
+### Java 序列化中如果有些字段不想进行序列化,怎么办?
+
+对于不想进行序列化的变量,使用 `transient` 关键字修饰。
+
+`transient` 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 `transient` 修饰的变量值不会被持久化和恢复。
+
+关于 `transient` 还有几点注意:
+- `transient` 只能修饰变量,不能修饰类和方法。
+- `transient` 修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰 `int` 类型,那么反序列后结果就是 `0`。
+- `static` 变量因为不属于任何对象(Object),所以无论有没有 `transient` 关键字修饰,均不会被序列化。
+
+### 获取用键盘输入常用的两种方法
+
+方法 1:通过 `Scanner`
+
+```java
+Scanner input = new Scanner(System.in);
+String s = input.nextLine();
+input.close();
+```
+
+方法 2:通过 `BufferedReader`
+
+```java
+BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
+String s = input.readLine();
+```
+
+### Java 中 IO 流分为几种?
+
+- 按照流的流向分,可以分为输入流和输出流;
+- 按照操作单元划分,可以划分为字节流和字符流;
+- 按照流的角色划分为节点流和处理流。
+
+Java IO 流共涉及 40 多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
+
+- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
+- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
+
+按操作方式分类结构图:
+
+
+
+按操作对象分类结构图:
+
+
+
+### 既然有了字节流,为什么还要有字符流?
+
+问题本质想问:**不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?**
+
+回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
+
+## 参考
+
+- https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jre
+- https://www.educba.com/oracle-vs-openjdk/
+- https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk 基础概念与常识
+
diff --git "a/docs/java/basis/\344\273\243\347\220\206\346\250\241\345\274\217\350\257\246\350\247\243.md" "b/docs/java/basis/\344\273\243\347\220\206\346\250\241\345\274\217\350\257\246\350\247\243.md"
new file mode 100644
index 00000000000..0006caed0aa
--- /dev/null
+++ "b/docs/java/basis/\344\273\243\347\220\206\346\250\241\345\274\217\350\257\246\350\247\243.md"
@@ -0,0 +1,404 @@
+---
+title: 代理详解!静态代理+JDK/CGLIB 动态代理实战
+category: Java
+tag:
+ - Java基础
+---
+
+## 1. 代理模式
+
+代理模式是一种比较好理解的设计模式。简单来说就是 **我们使用代理对象来代替对真实对象(real object)的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。**
+
+**代理模式的主要作用是扩展目标对象的功能,比如说在目标对象的某个方法执行前后你可以增加一些自定义的操作。**
+
+举个例子:你找了小红来帮你问话,小红就可以看作是代理你的代理对象,代理的行为(方法)是问话。
+
+
+
+<p style="text-align:right;font-size:13px;color:gray">https://medium.com/@mithunsasidharan/understanding-the-proxy-design-pattern-5e63fe38052a</p>
+
+代理模式有静态代理和动态代理两种实现方式,我们 先来看一下静态代理模式的实现。
+
+## 2. 静态代理
+
+**静态代理中,我们对目标对象的每个方法的增强都是手动完成的(_后面会具体演示代码_),非常不灵活(_比如接口一旦新增加方法,目标对象和代理对象都要进行修改_)且麻烦(_需要对每个目标类都单独写一个代理类_)。** 实际应用场景非常非常少,日常开发几乎看不到使用静态代理的场景。
+
+上面我们是从实现和应用角度来说的静态代理,从 JVM 层面来说, **静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。**
+
+静态代理实现步骤:
+
+1. 定义一个接口及其实现类;
+2. 创建一个代理类同样实现这个接口
+3. 将目标对象注入进代理类,然后在代理类的对应方法调用目标类中的对应方法。这样的话,我们就可以通过代理类屏蔽对目标对象的访问,并且可以在目标方法执行前后做一些自己想做的事情。
+
+下面通过代码展示!
+
+**1.定义发送短信的接口**
+
+```java
+public interface SmsService {
+ String send(String message);
+}
+```
+
+**2.实现发送短信的接口**
+
+```java
+public class SmsServiceImpl implements SmsService {
+ public String send(String message) {
+ System.out.println("send message:" + message);
+ return message;
+ }
+}
+```
+
+**3.创建代理类并同样实现发送短信的接口**
+
+```java
+public class SmsProxy implements SmsService {
+
+ private final SmsService smsService;
+
+ public SmsProxy(SmsService smsService) {
+ this.smsService = smsService;
+ }
+
+ @Override
+ public String send(String message) {
+ //调用方法之前,我们可以添加自己的操作
+ System.out.println("before method send()");
+ smsService.send(message);
+ //调用方法之后,我们同样可以添加自己的操作
+ System.out.println("after method send()");
+ return null;
+ }
+}
+```
+
+**4.实际使用**
+
+```java
+public class Main {
+ public static void main(String[] args) {
+ SmsService smsService = new SmsServiceImpl();
+ SmsProxy smsProxy = new SmsProxy(smsService);
+ smsProxy.send("java");
+ }
+}
+```
+
+运行上述代码之后,控制台打印出:
+
+```bash
+before method send()
+send message:java
+after method send()
+```
+
+可以输出结果看出,我们已经增加了 `SmsServiceImpl` 的`send()`方法。
+
+## 3. 动态代理
+
+相比于静态代理来说,动态代理更加灵活。我们不需要针对每个目标类都单独创建一个代理类,并且也不需要我们必须实现接口,我们可以直接代理实现类( _CGLIB 动态代理机制_)。
+
+**从 JVM 角度来说,动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。**
+
+说到动态代理,Spring AOP、RPC 框架应该是两个不得不提的,它们的实现都依赖了动态代理。
+
+**动态代理在我们日常开发中使用的相对较少,但是在框架中的几乎是必用的一门技术。学会了动态代理之后,对于我们理解和学习各种框架的原理也非常有帮助。**
+
+就 Java 来说,动态代理的实现方式有很多种,比如 **JDK 动态代理**、**CGLIB 动态代理**等等。
+
+[guide-rpc-framework](https://github.com/Snailclimb/guide-rpc-framework) 使用的是 JDK 动态代理,我们先来看看 JDK 动态代理的使用。
+
+另外,虽然 [guide-rpc-framework](https://github.com/Snailclimb/guide-rpc-framework) 没有用到 **CGLIB 动态代理** ,我们这里还是简单介绍一下其使用以及和**JDK 动态代理**的对比。
+
+### 3.1. JDK 动态代理机制
+
+#### 3.1.1. 介绍
+
+**在 Java 动态代理机制中 `InvocationHandler` 接口和 `Proxy` 类是核心。**
+
+`Proxy` 类中使用频率最高的方法是:`newProxyInstance()` ,这个方法主要用来生成一个代理对象。
+
+```java
+ public static Object newProxyInstance(ClassLoader loader,
+ Class<?>[] interfaces,
+ InvocationHandler h)
+ throws IllegalArgumentException
+ {
+ ......
+ }
+```
+
+这个方法一共有 3 个参数:
+
+1. **loader** :类加载器,用于加载代理对象。
+2. **interfaces** : 被代理类实现的一些接口;
+3. **h** : 实现了 `InvocationHandler` 接口的对象;
+
+要实现动态代理的话,还必须需要实现`InvocationHandler` 来自定义处理逻辑。 当我们的动态代理对象调用一个方法时,这个方法的调用就会被转发到实现`InvocationHandler` 接口类的 `invoke` 方法来调用。
+
+```java
+public interface InvocationHandler {
+
+ /**
+ * 当你使用代理对象调用方法的时候实际会调用到这个方法
+ */
+ public Object invoke(Object proxy, Method method, Object[] args)
+ throws Throwable;
+}
+```
+
+`invoke()` 方法有下面三个参数:
+
+1. **proxy** :动态生成的代理类
+2. **method** : 与代理类对象调用的方法相对应
+3. **args** : 当前 method 方法的参数
+
+也就是说:**你通过`Proxy` 类的 `newProxyInstance()` 创建的代理对象在调用方法的时候,实际会调用到实现`InvocationHandler` 接口的类的 `invoke()`方法。** 你可以在 `invoke()` 方法中自定义处理逻辑,比如在方法执行前后做什么事情。
+
+#### 3.1.2. JDK 动态代理类使用步骤
+
+1. 定义一个接口及其实现类;
+2. 自定义 `InvocationHandler` 并重写`invoke`方法,在 `invoke` 方法中我们会调用原生方法(被代理类的方法)并自定义一些处理逻辑;
+3. 通过 `Proxy.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h)` 方法创建代理对象;
+
+#### 3.1.3. 代码示例
+
+这样说可能会有点空洞和难以理解,我上个例子,大家感受一下吧!
+
+**1.定义发送短信的接口**
+
+```java
+public interface SmsService {
+ String send(String message);
+}
+```
+
+**2.实现发送短信的接口**
+
+```java
+public class SmsServiceImpl implements SmsService {
+ public String send(String message) {
+ System.out.println("send message:" + message);
+ return message;
+ }
+}
+```
+
+**3.定义一个 JDK 动态代理类**
+
+```java
+import java.lang.reflect.InvocationHandler;
+import java.lang.reflect.InvocationTargetException;
+import java.lang.reflect.Method;
+
+/**
+ * @author shuang.kou
+ * @createTime 2020年05月11日 11:23:00
+ */
+public class DebugInvocationHandler implements InvocationHandler {
+ /**
+ * 代理类中的真实对象
+ */
+ private final Object target;
+
+ public DebugInvocationHandler(Object target) {
+ this.target = target;
+ }
+
+
+ public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
+ //调用方法之前,我们可以添加自己的操作
+ System.out.println("before method " + method.getName());
+ Object result = method.invoke(target, args);
+ //调用方法之后,我们同样可以添加自己的操作
+ System.out.println("after method " + method.getName());
+ return result;
+ }
+}
+
+```
+
+`invoke()` 方法: 当我们的动态代理对象调用原生方法的时候,最终实际上调用到的是 `invoke()` 方法,然后 `invoke()` 方法代替我们去调用了被代理对象的原生方法。
+
+**4.获取代理对象的工厂类**
+
+```java
+public class JdkProxyFactory {
+ public static Object getProxy(Object target) {
+ return Proxy.newProxyInstance(
+ target.getClass().getClassLoader(), // 目标类的类加载
+ target.getClass().getInterfaces(), // 代理需要实现的接口,可指定多个
+ new DebugInvocationHandler(target) // 代理对象对应的自定义 InvocationHandler
+ );
+ }
+}
+```
+
+`getProxy()` :主要通过`Proxy.newProxyInstance()`方法获取某个类的代理对象
+
+**5.实际使用**
+
+```java
+SmsService smsService = (SmsService) JdkProxyFactory.getProxy(new SmsServiceImpl());
+smsService.send("java");
+```
+
+运行上述代码之后,控制台打印出:
+
+```
+before method send
+send message:java
+after method send
+```
+
+### 3.2. CGLIB 动态代理机制
+
+#### 3.2.1. 介绍
+
+**JDK 动态代理有一个最致命的问题是其只能代理实现了接口的类。**
+
+**为了解决这个问题,我们可以用 CGLIB 动态代理机制来避免。**
+
+[CGLIB](https://github.com/cglib/cglib)(_Code Generation Library_)是一个基于[ASM](http://www.baeldung.com/java-asm)的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。CGLIB 通过继承方式实现代理。很多知名的开源框架都使用到了[CGLIB](https://github.com/cglib/cglib), 例如 Spring 中的 AOP 模块中:如果目标对象实现了接口,则默认采用 JDK 动态代理,否则采用 CGLIB 动态代理。
+
+**在 CGLIB 动态代理机制中 `MethodInterceptor` 接口和 `Enhancer` 类是核心。**
+
+你需要自定义 `MethodInterceptor` 并重写 `intercept` 方法,`intercept` 用于拦截增强被代理类的方法。
+
+```java
+public interface MethodInterceptor
+extends Callback{
+ // 拦截被代理类中的方法
+ public Object intercept(Object obj, java.lang.reflect.Method method, Object[] args,
+ MethodProxy proxy) throws Throwable;
+}
+
+```
+
+1. **obj** :被代理的对象(需要增强的对象)
+2. **method** :被拦截的方法(需要增强的方法)
+3. **args** :方法入参
+4. **proxy** :用于调用原始方法
+
+你可以通过 `Enhancer`类来动态获取被代理类,当代理类调用方法的时候,实际调用的是 `MethodInterceptor` 中的 `intercept` 方法。
+
+#### 3.2.2. CGLIB 动态代理类使用步骤
+
+1. 定义一个类;
+2. 自定义 `MethodInterceptor` 并重写 `intercept` 方法,`intercept` 用于拦截增强被代理类的方法,和 JDK 动态代理中的 `invoke` 方法类似;
+3. 通过 `Enhancer` 类的 `create()`创建代理类;
+
+#### 3.2.3. 代码示例
+
+不同于 JDK 动态代理不需要额外的依赖。[CGLIB](https://github.com/cglib/cglib)(_Code Generation Library_) 实际是属于一个开源项目,如果你要使用它的话,需要手动添加相关依赖。
+
+```xml
+<dependency>
+ <groupId>cglib</groupId>
+ <artifactId>cglib</artifactId>
+ <version>3.3.0</version>
+</dependency>
+```
+
+**1.实现一个使用阿里云发送短信的类**
+
+```java
+package github.javaguide.dynamicProxy.cglibDynamicProxy;
+
+public class AliSmsService {
+ public String send(String message) {
+ System.out.println("send message:" + message);
+ return message;
+ }
+}
+```
+
+**2.自定义 `MethodInterceptor`(方法拦截器)**
+
+```java
+import net.sf.cglib.proxy.MethodInterceptor;
+import net.sf.cglib.proxy.MethodProxy;
+
+import java.lang.reflect.Method;
+
+/**
+ * 自定义MethodInterceptor
+ */
+public class DebugMethodInterceptor implements MethodInterceptor {
+
+
+ /**
+ * @param o 代理对象(增强的对象)
+ * @param method 被拦截的方法(需要增强的方法)
+ * @param args 方法入参
+ * @param methodProxy 用于调用原始方法
+ */
+ @Override
+ public Object intercept(Object o, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
+ //调用方法之前,我们可以添加自己的操作
+ System.out.println("before method " + method.getName());
+ Object object = methodProxy.invokeSuper(o, args);
+ //调用方法之后,我们同样可以添加自己的操作
+ System.out.println("after method " + method.getName());
+ return object;
+ }
+
+}
+```
+
+**3.获取代理类**
+
+```java
+import net.sf.cglib.proxy.Enhancer;
+
+public class CglibProxyFactory {
+
+ public static Object getProxy(Class<?> clazz) {
+ // 创建动态代理增强类
+ Enhancer enhancer = new Enhancer();
+ // 设置类加载器
+ enhancer.setClassLoader(clazz.getClassLoader());
+ // 设置被代理类
+ enhancer.setSuperclass(clazz);
+ // 设置方法拦截器
+ enhancer.setCallback(new DebugMethodInterceptor());
+ // 创建代理类
+ return enhancer.create();
+ }
+}
+```
+
+**4.实际使用**
+
+```java
+AliSmsService aliSmsService = (AliSmsService) CglibProxyFactory.getProxy(AliSmsService.class);
+aliSmsService.send("java");
+```
+
+运行上述代码之后,控制台打印出:
+
+```bash
+before method send
+send message:java
+after method send
+```
+
+### 3.3. JDK 动态代理和 CGLIB 动态代理对比
+
+1. **JDK 动态代理只能代理实现了接口的类或者直接代理接口,而 CGLIB 可以代理未实现任何接口的类。** 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
+2. 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显。
+
+## 4. 静态代理和动态代理的对比
+
+1. **灵活性** :动态代理更加灵活,不需要必须实现接口,可以直接代理实现类,并且可以不需要针对每个目标类都创建一个代理类。另外,静态代理中,接口一旦新增加方法,目标对象和代理对象都要进行修改,这是非常麻烦的!
+2. **JVM 层面** :静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。而动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。
+
+## 5. 总结
+
+这篇文章中主要介绍了代理模式的两种实现:静态代理以及动态代理。涵盖了静态代理和动态代理实战、静态代理和动态代理的区别、JDK 动态代理和 Cglib 动态代理区别等内容。
+
+文中涉及到的所有源码,你可以在这里找到:[https://github.com/Snailclimb/guide-rpc-framework-learning/tree/master/src/main/java/github/javaguide/proxy](https://github.com/Snailclimb/guide-rpc-framework-learning/tree/master/src/main/java/github/javaguide/proxy) 。
+
diff --git "a/docs/java/basis/\345\217\215\345\260\204\346\234\272\345\210\266\350\257\246\350\247\243.md" "b/docs/java/basis/\345\217\215\345\260\204\346\234\272\345\210\266\350\257\246\350\247\243.md"
new file mode 100644
index 00000000000..cac029638e4
--- /dev/null
+++ "b/docs/java/basis/\345\217\215\345\260\204\346\234\272\345\210\266\350\257\246\350\247\243.md"
@@ -0,0 +1,182 @@
+---
+title: 反射机制详解!
+category: Java
+tag:
+ - Java基础
+---
+
+## 何为反射?
+
+如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。
+
+反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。
+
+通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
+
+## 反射的应用场景了解么?
+
+像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。
+
+但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
+
+**这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。**
+
+比如下面是通过 JDK 实现动态代理的示例代码,其中就使用了反射类 `Method` 来调用指定的方法。
+
+```java
+public class DebugInvocationHandler implements InvocationHandler {
+ /**
+ * 代理类中的真实对象
+ */
+ private final Object target;
+
+ public DebugInvocationHandler(Object target) {
+ this.target = target;
+ }
+
+
+ public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
+ System.out.println("before method " + method.getName());
+ Object result = method.invoke(target, args);
+ System.out.println("after method " + method.getName());
+ return result;
+ }
+}
+
+```
+
+另外,像 Java 中的一大利器 **注解** 的实现也用到了反射。
+
+为什么你使用 Spring 的时候 ,一个`@Component`注解就声明了一个类为 Spring Bean 呢?为什么你通过一个 `@Value`注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
+
+这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
+
+## 谈谈反射机制的优缺点
+
+**优点** : 可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利
+
+**缺点** :让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。相关阅读:[Java Reflection: Why is it so slow?](https://stackoverflow.com/questions/1392351/java-reflection-why-is-it-so-slow)
+
+## 反射实战
+
+### 获取 Class 对象的四种方式
+
+如果我们动态获取到这些信息,我们需要依靠 Class 对象。Class 类对象将一个类的方法、变量等信息告诉运行的程序。Java 提供了四种方式获取 Class 对象:
+
+**1.知道具体类的情况下可以使用:**
+
+```java
+Class alunbarClass = TargetObject.class;
+```
+
+但是我们一般是不知道具体类的,基本都是通过遍历包下面的类来获取 Class 对象,通过此方式获取 Class 对象不会进行初始化
+
+**2.通过 `Class.forName()`传入类的路径获取:**
+
+```java
+Class alunbarClass1 = Class.forName("cn.javaguide.TargetObject");
+```
+
+**3.通过对象实例`instance.getClass()`获取:**
+
+```java
+TargetObject o = new TargetObject();
+Class alunbarClass2 = o.getClass();
+```
+
+**4.通过类加载器`xxxClassLoader.loadClass()`传入类路径获取:**
+
+```java
+Class clazz = ClassLoader.loadClass("cn.javaguide.TargetObject");
+```
+
+通过类加载器获取 Class 对象不会进行初始化,意味着不进行包括初始化等一些列步骤,静态块和静态对象不会得到执行
+
+### 反射的一些基本操作
+
+1.创建一个我们要使用反射操作的类 `TargetObject`。
+
+```java
+package cn.javaguide;
+
+public class TargetObject {
+ private String value;
+
+ public TargetObject() {
+ value = "JavaGuide";
+ }
+
+ public void publicMethod(String s) {
+ System.out.println("I love " + s);
+ }
+
+ private void privateMethod() {
+ System.out.println("value is " + value);
+ }
+}
+```
+
+2.使用反射操作这个类的方法以及参数
+
+```java
+package cn.javaguide;
+
+import java.lang.reflect.Field;
+import java.lang.reflect.InvocationTargetException;
+import java.lang.reflect.Method;
+
+public class Main {
+ public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InstantiationException, InvocationTargetException, NoSuchFieldException {
+ /**
+ * 获取TargetObject类的Class对象并且创建TargetObject类实例
+ */
+ Class<?> tagetClass = Class.forName("cn.javaguide.TargetObject");
+ TargetObject targetObject = (TargetObject) tagetClass.newInstance();
+ /**
+ * 获取所有类中所有定义的方法
+ */
+ Method[] methods = tagetClass.getDeclaredMethods();
+ for (Method method : methods) {
+ System.out.println(method.getName());
+ }
+ /**
+ * 获取指定方法并调用
+ */
+ Method publicMethod = tagetClass.getDeclaredMethod("publicMethod",
+ String.class);
+
+ publicMethod.invoke(targetObject, "JavaGuide");
+ /**
+ * 获取指定参数并对参数进行修改
+ */
+ Field field = tagetClass.getDeclaredField("value");
+ //为了对类中的参数进行修改我们取消安全检查
+ field.setAccessible(true);
+ field.set(targetObject, "JavaGuide");
+ /**
+ * 调用 private 方法
+ */
+ Method privateMethod = tagetClass.getDeclaredMethod("privateMethod");
+ //为了调用private方法我们取消安全检查
+ privateMethod.setAccessible(true);
+ privateMethod.invoke(targetObject);
+ }
+}
+
+```
+
+输出内容:
+
+```
+publicMethod
+privateMethod
+I love JavaGuide
+value is JavaGuide
+```
+
+**注意** : 有读者提到上面代码运行会抛出 `ClassNotFoundException` 异常,具体原因是你没有下面把这段代码的包名替换成自己创建的 `TargetObject` 所在的包 。
+
+```java
+Class<?> tagetClass = Class.forName("cn.javaguide.TargetObject");
+```
+
diff --git "a/Java\347\233\270\345\205\263/ArrayList.md" b/docs/java/collection/arraylist-source-code.md
similarity index 53%
rename from "Java\347\233\270\345\205\263/ArrayList.md"
rename to docs/java/collection/arraylist-source-code.md
index d6792edb241..36dfcbdbfc8 100644
--- "a/Java\347\233\270\345\205\263/ArrayList.md"
+++ b/docs/java/collection/arraylist-source-code.md
@@ -1,35 +1,43 @@
+---
+title: ArrayList 源码+扩容机制分析
+category: Java
+tag:
+ - Java集合
+---
-<!-- MarkdownTOC -->
-
-- [ArrayList简介](#arraylist简介)
-- [ArrayList核心源码](#arraylist核心源码)
-- [ArrayList源码分析](#arraylist源码分析)
- - [System.arraycopy\(\)和Arrays.copyOf\(\)方法](#systemarraycopy和arrayscopyof方法)
- - [两者联系与区别](#两者联系与区别)
- - [ArrayList核心扩容技术](#arraylist核心扩容技术)
- - [内部类](#内部类)
-- [ArrayList经典Demo](#arraylist经典demo)
-
-<!-- /MarkdownTOC -->
-
-
-### ArrayList简介
- ArrayList 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用`ensureCapacity`操作来增加 ArrayList 实例的容量。这可以减少递增式再分配的数量。
-
- 它继承于 **AbstractList**,实现了 **List**, **RandomAccess**, **Cloneable**, **java.io.Serializable** 这些接口。
-
- 在我们学数据结构的时候就知道了线性表的顺序存储,插入删除元素的时间复杂度为**O(n)**,求表长以及增加元素,取第 i 元素的时间复杂度为**O(1)**
-
- ArrayList 继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
-
- ArrayList 实现了**RandomAccess 接口**,即提供了随机访问功能。RandomAccess 是 Java 中用来被 List 实现,为 List 提供**快速访问功能**的。在 ArrayList 中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。
-
- ArrayList 实现了**Cloneable 接口**,即覆盖了函数 clone(),**能被克隆**。
-
- ArrayList 实现**java.io.Serializable 接口**,这意味着ArrayList**支持序列化**,**能通过序列化去传输**。
-
- 和 Vector 不同,**ArrayList 中的操作不是线程安全的**!所以,建议在单线程中才使用 ArrayList,而在多线程中可以选择 Vector 或者 CopyOnWriteArrayList。
-### ArrayList核心源码
+
+## 1. ArrayList 简介
+
+`ArrayList` 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用`ensureCapacity`操作来增加 `ArrayList` 实例的容量。这可以减少递增式再分配的数量。
+
+`ArrayList`继承于 **`AbstractList`** ,实现了 **`List`**, **`RandomAccess`**, **`Cloneable`**, **`java.io.Serializable`** 这些接口。
+
+```java
+
+public class ArrayList<E> extends AbstractList<E>
+ implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
+
+ }
+```
+
+- `RandomAccess` 是一个标志接口,表明实现这个这个接口的 List 集合是支持**快速随机访问**的。在 `ArrayList` 中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。
+- `ArrayList` 实现了 **`Cloneable` 接口** ,即覆盖了函数`clone()`,能被克隆。
+- `ArrayList` 实现了 `java.io.Serializable`接口,这意味着`ArrayList`支持序列化,能通过序列化去传输。
+
+### 1.1. Arraylist 和 Vector 的区别?
+
+1. `ArrayList` 是 `List` 的主要实现类,底层使用 `Object[ ]`存储,适用于频繁的查找工作,线程不安全 ;
+2. `Vector` 是 `List` 的古老实现类,底层使用 `Object[ ]`存储,线程安全的。
+
+### 1.2. Arraylist 与 LinkedList 区别?
+
+1. **是否保证线程安全:** `ArrayList` 和 `LinkedList` 都是不同步的,也就是不保证线程安全;
+2. **底层数据结构:** `Arraylist` 底层使用的是 **`Object` 数组**;`LinkedList` 底层使用的是 **双向链表** 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
+3. **插入和删除是否受元素位置的影响:** ① **`ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e)`方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **`LinkedList` 采用链表存储,所以对于`add(E e)`方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置`i`插入和删除元素的话(`(add(int index, E element)`) 时间复杂度近似为`o(n))`因为需要先移动到指定位置再插入。**
+4. **是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList` 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
+5. **内存空间占用:** `ArrayList` 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 `LinkedList` 的空间花费则体现在它的每一个元素都需要消耗比 `ArrayList` 更多的空间(因为要存放直接后继和直接前驱以及数据)。
+
+## 2. ArrayList 核心源码解读
```java
package java.util;
@@ -69,23 +77,25 @@ public class ArrayList<E> extends AbstractList<E>
private int size;
/**
- * 带初始容量参数的构造函数。(用户自己指定容量)
+ * 带初始容量参数的构造函数(用户可以在创建ArrayList对象时自己指定集合的初始大小)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
- //创建initialCapacity大小的数组
+ //如果传入的参数大于0,创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
- //创建空数组
+ //如果传入的参数等于0,创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
+ //其他情况,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
- *默认构造函数,其默认初始容量为10
+ *默认无参构造函数
+ *DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
@@ -95,22 +105,22 @@ public class ArrayList<E> extends AbstractList<E>
* 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
*/
public ArrayList(Collection<? extends E> c) {
- //
+ //将指定集合转换为数组
elementData = c.toArray();
- //如果指定集合元素个数不为0
+ //如果elementData数组的长度不为0
if ((size = elementData.length) != 0) {
- // c.toArray 可能返回的不是Object类型的数组所以加上下面的语句用于判断,
- //这里用到了反射里面的getClass()方法
+ // 如果elementData不是Object类型数据(c.toArray可能返回的不是Object类型的数组所以加上下面的语句用于判断)
if (elementData.getClass() != Object[].class)
+ //将原来不是Object类型的elementData数组的内容,赋值给新的Object类型的elementData数组
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
- // 用空数组代替
+ // 其他情况,用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}
}
/**
- * 修改这个ArrayList实例的容量是列表的当前大小。 应用程序可以使用此操作来最小化ArrayList实例的存储。
+ * 修改这个ArrayList实例的容量是列表的当前大小。 应用程序可以使用此操作来最小化ArrayList实例的存储。
*/
public void trimToSize() {
modCount++;
@@ -128,13 +138,14 @@ public class ArrayList<E> extends AbstractList<E>
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
+ //如果是true,minExpand的值为0,如果是false,minExpand的值为10
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
-
+ //如果最小容量大于已有的最大容量
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
@@ -142,7 +153,7 @@ public class ArrayList<E> extends AbstractList<E>
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
- // 获取默认的容量和传入参数的较大值
+ // 获取“默认的容量”和“传入参数”两者之间的最大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
@@ -177,7 +188,7 @@ public class ArrayList<E> extends AbstractList<E>
newCapacity = minCapacity;
//再检查新容量是否超出了ArrayList所定义的最大容量,
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
- //如果minCapacity大于最大容量,则新容量则为ArrayList定义的最大容量,否则,新容量大小则为 minCapacity。
+ //如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
@@ -193,7 +204,7 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- *返回此列表中的元素数。
+ *返回此列表中的元素数。
*/
public int size() {
return size;
@@ -211,12 +222,12 @@ public class ArrayList<E> extends AbstractList<E>
* 如果此列表包含指定的元素,则返回true 。
*/
public boolean contains(Object o) {
- //indexOf()方法:返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
+ //indexOf()方法:返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
return indexOf(o) >= 0;
}
/**
- *返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
+ *返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
*/
public int indexOf(Object o) {
if (o == null) {
@@ -249,7 +260,7 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- * 返回此ArrayList实例的浅拷贝。 (元素本身不被复制。)
+ * 返回此ArrayList实例的浅拷贝。 (元素本身不被复制。)
*/
public Object clone() {
try {
@@ -265,7 +276,7 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- *以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
+ *以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
*返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
*因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
*/
@@ -274,11 +285,11 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- * 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素);
- *返回的数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。
- *否则,将为指定数组的运行时类型和此列表的大小分配一个新数组。
+ * 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素);
+ *返回的数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。
+ *否则,将为指定数组的运行时类型和此列表的大小分配一个新数组。
*如果列表适用于指定的数组,其余空间(即数组的列表数量多于此元素),则紧跟在集合结束后的数组中的元素设置为null 。
- *(这仅在调用者知道列表不包含任何空元素的情况下才能确定列表的长度。)
+ *(这仅在调用者知道列表不包含任何空元素的情况下才能确定列表的长度。)
*/
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
@@ -309,7 +320,7 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- * 用指定的元素替换此列表中指定位置的元素。
+ * 用指定的元素替换此列表中指定位置的元素。
*/
public E set(int index, E element) {
//对index进行界限检查
@@ -322,7 +333,7 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- * 将指定的元素追加到此列表的末尾。
+ * 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
@@ -332,7 +343,7 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- * 在此列表中的指定位置插入指定的元素。
+ * 在此列表中的指定位置插入指定的元素。
*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
*/
@@ -348,7 +359,7 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- * 删除该列表中指定位置的元素。 将任何后续元素移动到左侧(从其索引中减去一个元素)。
+ * 删除该列表中指定位置的元素。 将任何后续元素移动到左侧(从其索引中减去一个元素)。
*/
public E remove(int index) {
rangeCheck(index);
@@ -361,7 +372,7 @@ public class ArrayList<E> extends AbstractList<E>
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
- //从列表中删除的元素
+ //从列表中删除的元素
return oldValue;
}
@@ -400,7 +411,7 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- * 从列表中删除所有元素。
+ * 从列表中删除所有元素。
*/
public void clear() {
modCount++;
@@ -486,7 +497,7 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- * 从此列表中删除指定集合中包含的所有元素。
+ * 从此列表中删除指定集合中包含的所有元素。
*/
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
@@ -496,7 +507,7 @@ public class ArrayList<E> extends AbstractList<E>
/**
* 仅保留此列表中包含在指定集合中的元素。
- *换句话说,从此列表中删除其中不包含在指定集合中的所有元素。
+ *换句话说,从此列表中删除其中不包含在指定集合中的所有元素。
*/
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
@@ -506,8 +517,8 @@ public class ArrayList<E> extends AbstractList<E>
/**
* 从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。
- *指定的索引表示初始调用将返回的第一个元素为next 。 初始调用previous将返回指定索引减1的元素。
- *返回的列表迭代器是fail-fast 。
+ *指定的索引表示初始调用将返回的第一个元素为next 。 初始调用previous将返回指定索引减1的元素。
+ *返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
@@ -516,7 +527,7 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- *返回列表中的列表迭代器(按适当的顺序)。
+ *返回列表中的列表迭代器(按适当的顺序)。
*返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator() {
@@ -524,75 +535,103 @@ public class ArrayList<E> extends AbstractList<E>
}
/**
- *以正确的顺序返回该列表中的元素的迭代器。
- *返回的迭代器是fail-fast 。
+ *以正确的顺序返回该列表中的元素的迭代器。
+ *返回的迭代器是fail-fast 。
*/
public Iterator<E> iterator() {
return new Itr();
}
-
+
```
-### <font face="楷体" id="1" id="5">ArrayList源码分析</font>
-#### System.arraycopy()和Arrays.copyOf()方法
- 通过上面源码我们发现这两个实现数组复制的方法被广泛使用而且很多地方都特别巧妙。比如下面<font color="red">add(int index, E element)</font>方法就很巧妙的用到了<font color="red">arraycopy()方法</font>让数组自己复制自己实现让index开始之后的所有成员后移一个位置:
-```java
- /**
- * 在此列表中的指定位置插入指定的元素。
- *先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
- *再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
+
+## 3. ArrayList 扩容机制分析
+
+### 3.1. 先从 ArrayList 的构造函数说起
+
+**(JDK8)ArrayList 有三种方式来初始化,构造方法源码如下:**
+
+```java
+ /**
+ * 默认初始容量大小
*/
- public void add(int index, E element) {
- rangeCheckForAdd(index);
+ private static final int DEFAULT_CAPACITY = 10;
- ensureCapacityInternal(size + 1); // Increments modCount!!
- //arraycopy()方法实现数组自己复制自己
- //elementData:源数组;index:源数组中的起始位置;elementData:目标数组;index + 1:目标数组中的起始位置; size - index:要复制的数组元素的数量;
- System.arraycopy(elementData, index, elementData, index + 1, size - index);
- elementData[index] = element;
- size++;
+
+ private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
+
+ /**
+ *默认构造函数,使用初始容量10构造一个空列表(无参数构造)
+ */
+ public ArrayList() {
+ this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
-```
-又如toArray()方法中用到了copyOf()方法
-```java
/**
- *以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
- *返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
- *因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
+ * 带初始容量参数的构造函数。(用户自己指定容量)
*/
- public Object[] toArray() {
- //elementData:要复制的数组;size:要复制的长度
- return Arrays.copyOf(elementData, size);
+ public ArrayList(int initialCapacity) {
+ if (initialCapacity > 0) {//初始容量大于0
+ //创建initialCapacity大小的数组
+ this.elementData = new Object[initialCapacity];
+ } else if (initialCapacity == 0) {//初始容量等于0
+ //创建空数组
+ this.elementData = EMPTY_ELEMENTDATA;
+ } else {//初始容量小于0,抛出异常
+ throw new IllegalArgumentException("Illegal Capacity: "+
+ initialCapacity);
+ }
+ }
+
+
+ /**
+ *构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回
+ *如果指定的集合为null,throws NullPointerException。
+ */
+ public ArrayList(Collection<? extends E> c) {
+ elementData = c.toArray();
+ if ((size = elementData.length) != 0) {
+ // c.toArray might (incorrectly) not return Object[] (see 6260652)
+ if (elementData.getClass() != Object[].class)
+ elementData = Arrays.copyOf(elementData, size, Object[].class);
+ } else {
+ // replace with empty array.
+ this.elementData = EMPTY_ELEMENTDATA;
+ }
}
+
```
-##### 两者联系与区别
-**联系:**
-看两者源代码可以发现`copyOf()`内部调用了`System.arraycopy()`方法
-**区别:**
-1. arraycopy()需要目标数组,将原数组拷贝到你自己定义的数组里,而且可以选择拷贝的起点和长度以及放入新数组中的位置
-2. copyOf()是系统自动在内部新建一个数组,并返回该数组。
-#### ArrayList 核心扩容技术
+
+细心的同学一定会发现 :**以无参数构造方法创建 `ArrayList` 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。** 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
+
+> 补充:JDK6 new 无参构造的 `ArrayList` 对象时,直接创建了长度是 10 的 `Object[]` 数组 elementData 。
+
+### 3.2. 一步一步分析 ArrayList 扩容机制
+
+这里以无参构造函数创建的 ArrayList 为例分析
+
+#### 3.2.1. 先来看 `add` 方法
+
```java
-//下面是ArrayList的扩容机制
-//ArrayList的扩容机制提高了性能,如果每次只扩充一个,
-//那么频繁的插入会导致频繁的拷贝,降低性能,而ArrayList的扩容机制避免了这种情况。
/**
- * 如有必要,增加此ArrayList实例的容量,以确保它至少能容纳元素的数量
- * @param minCapacity 所需的最小容量
+ * 将指定的元素追加到此列表的末尾。
*/
- public void ensureCapacity(int minCapacity) {
- int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
- // any size if not default element table
- ? 0
- // larger than default for default empty table. It's already
- // supposed to be at default size.
- : DEFAULT_CAPACITY;
-
- if (minCapacity > minExpand) {
- ensureExplicitCapacity(minCapacity);
- }
+ public boolean add(E e) {
+ //添加元素之前,先调用ensureCapacityInternal方法
+ ensureCapacityInternal(size + 1); // Increments modCount!!
+ //这里看到ArrayList添加元素的实质就相当于为数组赋值
+ elementData[size++] = e;
+ return true;
}
+```
+
+> **注意** :JDK11 移除了 `ensureCapacityInternal()` 和 `ensureExplicitCapacity()` 方法
+
+#### 3.2.2. 再来看看 `ensureCapacityInternal()` 方法
+
+(JDK7)可以看到 `add` 方法 首先调用了`ensureCapacityInternal(size + 1)`
+
+```java
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
@@ -602,25 +641,49 @@ public class ArrayList<E> extends AbstractList<E>
ensureExplicitCapacity(minCapacity);
}
- //判断是否需要扩容,上面两个方法都要调用
+```
+
+**当 要 add 进第 1 个元素时,minCapacity 为 1,在 Math.max()方法比较后,minCapacity 为 10。**
+
+> 此处和后续 JDK8 代码格式化略有不同,核心代码基本一样。
+
+#### 3.2.3. `ensureExplicitCapacity()` 方法
+
+如果调用 `ensureCapacityInternal()` 方法就一定会进入(执行)这个方法,下面我们来研究一下这个方法的源码!
+
+```java
+ //判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
- // 如果说minCapacity也就是所需的最小容量大于保存ArrayList数据的数组的长度的话,就需要调用grow(minCapacity)方法扩容。
- //这个minCapacity到底为多少呢?举个例子在添加元素(add)方法中这个minCapacity的大小就为现在数组的长度加1
+ // overflow-conscious code
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
```
+
+我们来仔细分析一下:
+
+- 当我们要 add 进第 1 个元素到 ArrayList 时,elementData.length 为 0 (因为还是一个空的 list),因为执行了 `ensureCapacityInternal()` 方法 ,所以 minCapacity 此时为 10。此时,`minCapacity - elementData.length > 0`成立,所以会进入 `grow(minCapacity)` 方法。
+- 当 add 第 2 个元素时,minCapacity 为 2,此时 e lementData.length(容量)在添加第一个元素后扩容成 10 了。此时,`minCapacity - elementData.length > 0` 不成立,所以不会进入 (执行)`grow(minCapacity)` 方法。
+- 添加第 3、4···到第 10 个元素时,依然不会执行 grow 方法,数组容量都为 10。
+
+直到添加第 11 个元素,minCapacity(为 11)比 elementData.length(为 10)要大。进入 grow 方法进行扩容。
+
+#### 3.2.4. `grow()` 方法
+
```java
+ /**
+ * 要分配的最大数组大小
+ */
+ private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
+
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
- //elementData为保存ArrayList数据的数组
- ///elementData.length求数组长度elementData.size是求数组中的元素个数
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
@@ -629,110 +692,251 @@ public class ArrayList<E> extends AbstractList<E>
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
- //再检查新容量是否超出了ArrayList所定义的最大容量,
- //若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
- //如果minCapacity大于最大容量,则新容量则为ArrayList定义的最大容量,否则,新容量大小则为 minCapacity。
+ // 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,
+ //如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
-
```
- 扩容机制代码已经做了详细的解释。另外值得注意的是大家很容易忽略的一个运算符:**移位运算符**
- **简介**:移位运算符就是在二进制的基础上对数字进行平移。按照平移的方向和填充数字的规则分为三种:<font color="red"><<(左移)</font>、<font color="red">>>(带符号右移)</font>和<font color="red">>>>(无符号右移)</font>。
- **作用**:**对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源**
- 比如这里:int newCapacity = oldCapacity + (oldCapacity >> 1);
-右移一位相当于除2,右移n位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了1位所以相当于oldCapacity /2。
-**另外需要注意的是:**
+**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)!** 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
+
+> ">>"(移位运算符):>>1 右移一位相当于除 2,右移 n 位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了 1 位所以相当于 oldCapacity /2。对于大数据的 2 进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
+
+**我们再来通过例子探究一下`grow()` 方法 :**
+
+- 当 add 第 1 个元素时,oldCapacity 为 0,经比较后第一个 if 判断成立,newCapacity = minCapacity(为 10)。但是第二个 if 判断不会成立,即 newCapacity 不比 MAX_ARRAY_SIZE 大,则不会进入 `hugeCapacity` 方法。数组容量为 10,add 方法中 return true,size 增为 1。
+- 当 add 第 11 个元素进入 grow 方法时,newCapacity 为 15,比 minCapacity(为 11)大,第一个 if 判断不成立。新容量没有大于数组最大 size,不会进入 hugeCapacity 方法。数组容量扩为 15,add 方法中 return true,size 增为 11。
+- 以此类推······
+
+**这里补充一点比较重要,但是容易被忽视掉的知识点:**
+
+- java 中的 `length`属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
+- java 中的 `length()` 方法是针对字符串说的,如果想看这个字符串的长度则用到 `length()` 这个方法.
+- java 中的 `size()` 方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
+
+#### 3.2.5. `hugeCapacity()` 方法。
+
+从上面 `grow()` 方法源码我们知道: 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果 minCapacity 大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
+
+```java
+ private static int hugeCapacity(int minCapacity) {
+ if (minCapacity < 0) // overflow
+ throw new OutOfMemoryError();
+ //对minCapacity和MAX_ARRAY_SIZE进行比较
+ //若minCapacity大,将Integer.MAX_VALUE作为新数组的大小
+ //若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小
+ //MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
+ return (minCapacity > MAX_ARRAY_SIZE) ?
+ Integer.MAX_VALUE :
+ MAX_ARRAY_SIZE;
+ }
+```
+
+### 3.3. `System.arraycopy()` 和 `Arrays.copyOf()`方法
+
+阅读源码的话,我们就会发现 ArrayList 中大量调用了这两个方法。比如:我们上面讲的扩容操作以及`add(int index, E element)`、`toArray()` 等方法中都用到了该方法!
+
+#### 3.3.1. `System.arraycopy()` 方法
+
+源码:
+
+```java
+ // 我们发现 arraycopy 是一个 native 方法,接下来我们解释一下各个参数的具体意义
+ /**
+ * 复制数组
+ * @param src 源数组
+ * @param srcPos 源数组中的起始位置
+ * @param dest 目标数组
+ * @param destPos 目标数组中的起始位置
+ * @param length 要复制的数组元素的数量
+ */
+ public static native void arraycopy(Object src, int srcPos,
+ Object dest, int destPos,
+ int length);
+```
+
+场景:
+
+```java
+ /**
+ * 在此列表中的指定位置插入指定的元素。
+ *先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
+ *再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
+ */
+ public void add(int index, E element) {
+ rangeCheckForAdd(index);
+
+ ensureCapacityInternal(size + 1); // Increments modCount!!
+ //arraycopy()方法实现数组自己复制自己
+ //elementData:源数组;index:源数组中的起始位置;elementData:目标数组;index + 1:目标数组中的起始位置; size - index:要复制的数组元素的数量;
+ System.arraycopy(elementData, index, elementData, index + 1, size - index);
+ elementData[index] = element;
+ size++;
+ }
+```
+
+我们写一个简单的方法测试以下:
+
+```java
+public class ArraycopyTest {
+
+ public static void main(String[] args) {
+ // TODO Auto-generated method stub
+ int[] a = new int[10];
+ a[0] = 0;
+ a[1] = 1;
+ a[2] = 2;
+ a[3] = 3;
+ System.arraycopy(a, 2, a, 3, 3);
+ a[2]=99;
+ for (int i = 0; i < a.length; i++) {
+ System.out.print(a[i] + " ");
+ }
+ }
+
+}
+```
+
+结果:
+
+```
+0 1 99 2 3 0 0 0 0 0
+```
+
+#### 3.3.2. `Arrays.copyOf()`方法
+
+源码:
+
+```java
+ public static int[] copyOf(int[] original, int newLength) {
+ // 申请一个新的数组
+ int[] copy = new int[newLength];
+ // 调用System.arraycopy,将源数组中的数据进行拷贝,并返回新的数组
+ System.arraycopy(original, 0, copy, 0,
+ Math.min(original.length, newLength));
+ return copy;
+ }
+```
+
+场景:
-1. java 中的**length 属性**是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
+```java
+ /**
+ 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。
+ */
+ public Object[] toArray() {
+ //elementData:要复制的数组;size:要复制的长度
+ return Arrays.copyOf(elementData, size);
+ }
+```
-2. java 中的**length()方法**是针对字 符串String说的,如果想看这个字符串的长度则用到 length()这个方法.
+个人觉得使用 `Arrays.copyOf()`方法主要是为了给原有数组扩容,测试代码如下:
-3. .java 中的**size()方法**是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
+```java
+public class ArrayscopyOfTest {
+
+ public static void main(String[] args) {
+ int[] a = new int[3];
+ a[0] = 0;
+ a[1] = 1;
+ a[2] = 2;
+ int[] b = Arrays.copyOf(a, 10);
+ System.out.println("b.length"+b.length);
+ }
+}
+```
+
+结果:
+
+```
+10
+```
+
+#### 3.3.3. 两者联系和区别
+
+**联系:**
+
+看两者源代码可以发现 `copyOf()`内部实际调用了 `System.arraycopy()` 方法
+
+**区别:**
+
+`arraycopy()` 需要目标数组,将原数组拷贝到你自己定义的数组里或者原数组,而且可以选择拷贝的起点和长度以及放入新数组中的位置 `copyOf()` 是系统自动在内部新建一个数组,并返回该数组。
+
+### 3.4. `ensureCapacity`方法
+
+ArrayList 源码中有一个 `ensureCapacity` 方法不知道大家注意到没有,这个方法 ArrayList 内部没有被调用过,所以很显然是提供给用户调用的,那么这个方法有什么作用呢?
-
-#### 内部类
```java
- (1)private class Itr implements Iterator<E>
- (2)private class ListItr extends Itr implements ListIterator<E>
- (3)private class SubList extends AbstractList<E> implements RandomAccess
- (4)static final class ArrayListSpliterator<E> implements Spliterator<E>
-```
- ArrayList有四个内部类,其中的**Itr是实现了Iterator接口**,同时重写了里面的**hasNext()**,**next()**,**remove()**等方法;其中的**ListItr**继承**Itr**,实现了**ListIterator接口**,同时重写了**hasPrevious()**,**nextIndex()**,**previousIndex()**,**previous()**,**set(E e)**,**add(E e)**等方法,所以这也可以看出了**Iterator和ListIterator的区别:**ListIterator在Iterator的基础上增加了添加对象,修改对象,逆向遍历等方法,这些是Iterator不能实现的。
-### <font face="楷体" id="6"> ArrayList经典Demo</font>
+ /**
+ 如有必要,增加此 ArrayList 实例的容量,以确保它至少可以容纳由minimum capacity参数指定的元素数。
+ *
+ * @param minCapacity 所需的最小容量
+ */
+ public void ensureCapacity(int minCapacity) {
+ int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
+ // any size if not default element table
+ ? 0
+ // larger than default for default empty table. It's already
+ // supposed to be at default size.
+ : DEFAULT_CAPACITY;
+
+ if (minCapacity > minExpand) {
+ ensureExplicitCapacity(minCapacity);
+ }
+ }
+
+```
+
+**最好在 add 大量元素之前用 `ensureCapacity` 方法,以减少增量重新分配的次数**
+
+我们通过下面的代码实际测试以下这个方法的效果:
```java
-package list;
-import java.util.ArrayList;
-import java.util.Iterator;
-
-public class ArrayListDemo {
-
- public static void main(String[] srgs){
- ArrayList<Integer> arrayList = new ArrayList<Integer>();
-
- System.out.printf("Before add:arrayList.size() = %d\n",arrayList.size());
-
- arrayList.add(1);
- arrayList.add(3);
- arrayList.add(5);
- arrayList.add(7);
- arrayList.add(9);
- System.out.printf("After add:arrayList.size() = %d\n",arrayList.size());
-
- System.out.println("Printing elements of arrayList");
- // 三种遍历方式打印元素
- // 第一种:通过迭代器遍历
- System.out.print("通过迭代器遍历:");
- Iterator<Integer> it = arrayList.iterator();
- while(it.hasNext()){
- System.out.print(it.next() + " ");
- }
- System.out.println();
-
- // 第二种:通过索引值遍历
- System.out.print("通过索引值遍历:");
- for(int i = 0; i < arrayList.size(); i++){
- System.out.print(arrayList.get(i) + " ");
- }
- System.out.println();
-
- // 第三种:for循环遍历
- System.out.print("for循环遍历:");
- for(Integer number : arrayList){
- System.out.print(number + " ");
- }
-
- // toArray用法
- // 第一种方式(最常用)
- Integer[] integer = arrayList.toArray(new Integer[0]);
-
- // 第二种方式(容易理解)
- Integer[] integer1 = new Integer[arrayList.size()];
- arrayList.toArray(integer1);
-
- // 抛出异常,java不支持向下转型
- //Integer[] integer2 = new Integer[arrayList.size()];
- //integer2 = arrayList.toArray();
- System.out.println();
-
- // 在指定位置添加元素
- arrayList.add(2,2);
- // 删除指定位置上的元素
- arrayList.remove(2);
- // 删除指定元素
- arrayList.remove((Object)3);
- // 判断arrayList是否包含5
- System.out.println("ArrayList contains 5 is: " + arrayList.contains(5));
-
- // 清空ArrayList
- arrayList.clear();
- // 判断ArrayList是否为空
- System.out.println("ArrayList is empty: " + arrayList.isEmpty());
+public class EnsureCapacityTest {
+ public static void main(String[] args) {
+ ArrayList<Object> list = new ArrayList<Object>();
+ final int N = 10000000;
+ long startTime = System.currentTimeMillis();
+ for (int i = 0; i < N; i++) {
+ list.add(i);
+ }
+ long endTime = System.currentTimeMillis();
+ System.out.println("使用ensureCapacity方法前:"+(endTime - startTime));
+
+ }
+}
+```
+
+运行结果:
+
+```
+使用ensureCapacity方法前:2158
+```
+
+```java
+public class EnsureCapacityTest {
+ public static void main(String[] args) {
+ ArrayList<Object> list = new ArrayList<Object>();
+ final int N = 10000000;
+ list = new ArrayList<Object>();
+ long startTime1 = System.currentTimeMillis();
+ list.ensureCapacity(N);
+ for (int i = 0; i < N; i++) {
+ list.add(i);
+ }
+ long endTime1 = System.currentTimeMillis();
+ System.out.println("使用ensureCapacity方法后:"+(endTime1 - startTime1));
}
}
```
+运行结果:
+
+```
+使用ensureCapacity方法后:1773
+```
+
+通过运行结果,我们可以看出向 ArrayList 添加大量元素之前最好先使用`ensureCapacity` 方法,以减少增量重新分配的次数。
diff --git a/docs/java/collection/concurrent-hash-map-source-code.md b/docs/java/collection/concurrent-hash-map-source-code.md
new file mode 100644
index 00000000000..6d765697df9
--- /dev/null
+++ b/docs/java/collection/concurrent-hash-map-source-code.md
@@ -0,0 +1,594 @@
+---
+title: ConcurrentHashMap源码+底层数据结构分析
+category: Java
+tag:
+ - Java集合
+---
+
+
+> 本文来自公众号:末读代码的投稿,原文地址:https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw 。
+
+上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 `ConcurrentHashMap ` 了,作为线程安全的HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢?
+
+## 1. ConcurrentHashMap 1.7
+
+### 1. 存储结构
+
+> 下图存在一个笔误 Segmeng -> Segment
+
+
+
+Java 7 中 `ConcurrentHashMap` 的存储结构如上图,`ConcurrnetHashMap` 由很多个 `Segment` 组合,而每一个 `Segment` 是一个类似于 HashMap 的结构,所以每一个 `HashMap` 的内部可以进行扩容。但是 `Segment` 的个数一旦**初始化就不能改变**,默认 `Segment` 的个数是 16 个,你也可以认为 `ConcurrentHashMap` 默认支持最多 16 个线程并发。
+
+### 2. 初始化
+
+通过 ConcurrentHashMap 的无参构造探寻 ConcurrentHashMap 的初始化流程。
+
+```java
+ /**
+ * Creates a new, empty map with a default initial capacity (16),
+ * load factor (0.75) and concurrencyLevel (16).
+ */
+ public ConcurrentHashMap() {
+ this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
+ }
+```
+
+无参构造中调用了有参构造,传入了三个参数的默认值,他们的值是。
+
+```java
+ /**
+ * 默认初始化容量
+ */
+ static final int DEFAULT_INITIAL_CAPACITY = 16;
+
+ /**
+ * 默认负载因子
+ */
+ static final float DEFAULT_LOAD_FACTOR = 0.75f;
+
+ /**
+ * 默认并发级别
+ */
+ static final int DEFAULT_CONCURRENCY_LEVEL = 16;
+```
+
+接着看下这个有参构造函数的内部实现逻辑。
+
+```java
+@SuppressWarnings("unchecked")
+public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
+ // 参数校验
+ if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
+ throw new IllegalArgumentException();
+ // 校验并发级别大小,大于 1<<16,重置为 65536
+ if (concurrencyLevel > MAX_SEGMENTS)
+ concurrencyLevel = MAX_SEGMENTS;
+ // Find power-of-two sizes best matching arguments
+ // 2的多少次方
+ int sshift = 0;
+ int ssize = 1;
+ // 这个循环可以找到 concurrencyLevel 之上最近的 2的次方值
+ while (ssize < concurrencyLevel) {
+ ++sshift;
+ ssize <<= 1;
+ }
+ // 记录段偏移量
+ this.segmentShift = 32 - sshift;
+ // 记录段掩码
+ this.segmentMask = ssize - 1;
+ // 设置容量
+ if (initialCapacity > MAXIMUM_CAPACITY)
+ initialCapacity = MAXIMUM_CAPACITY;
+ // c = 容量 / ssize ,默认 16 / 16 = 1,这里是计算每个 Segment 中的类似于 HashMap 的容量
+ int c = initialCapacity / ssize;
+ if (c * ssize < initialCapacity)
+ ++c;
+ int cap = MIN_SEGMENT_TABLE_CAPACITY;
+ //Segment 中的类似于 HashMap 的容量至少是2或者2的倍数
+ while (cap < c)
+ cap <<= 1;
+ // create segments and segments[0]
+ // 创建 Segment 数组,设置 segments[0]
+ Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
+ (HashEntry<K,V>[])new HashEntry[cap]);
+ Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
+ UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
+ this.segments = ss;
+}
+```
+
+总结一下在 Java 7 中 ConcurrnetHashMap 的初始化逻辑。
+
+1. 必要参数校验。
+2. 校验并发级别 concurrencyLevel 大小,如果大于最大值,重置为最大值。无参构造**默认值是 16.**
+3. 寻找并发级别 concurrencyLevel 之上最近的 **2 的幂次方**值,作为初始化容量大小,**默认是 16**。
+4. 记录 segmentShift 偏移量,这个值为【容量 = 2 的N次方】中的 N,在后面 Put 时计算位置时会用到。**默认是 32 - sshift = 28**.
+5. 记录 segmentMask,默认是 ssize - 1 = 16 -1 = 15.
+6. **初始化 segments[0]**,**默认大小为 2**,**负载因子 0.75**,**扩容阀值是 2*0.75=1.5**,插入第二个值时才会进行扩容。
+
+### 3. put
+
+接着上面的初始化参数继续查看 put 方法源码。
+
+```java
+/**
+ * Maps the specified key to the specified value in this table.
+ * Neither the key nor the value can be null.
+ *
+ * <p> The value can be retrieved by calling the <tt>get</tt> method
+ * with a key that is equal to the original key.
+ *
+ * @param key key with which the specified value is to be associated
+ * @param value value to be associated with the specified key
+ * @return the previous value associated with <tt>key</tt>, or
+ * <tt>null</tt> if there was no mapping for <tt>key</tt>
+ * @throws NullPointerException if the specified key or value is null
+ */
+public V put(K key, V value) {
+ Segment<K,V> s;
+ if (value == null)
+ throw new NullPointerException();
+ int hash = hash(key);
+ // hash 值无符号右移 28位(初始化时获得),然后与 segmentMask=15 做与运算
+ // 其实也就是把高4位与segmentMask(1111)做与运算
+ int j = (hash >>> segmentShift) & segmentMask;
+ if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
+ (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
+ // 如果查找到的 Segment 为空,初始化
+ s = ensureSegment(j);
+ return s.put(key, hash, value, false);
+}
+
+/**
+ * Returns the segment for the given index, creating it and
+ * recording in segment table (via CAS) if not already present.
+ *
+ * @param k the index
+ * @return the segment
+ */
+@SuppressWarnings("unchecked")
+private Segment<K,V> ensureSegment(int k) {
+ final Segment<K,V>[] ss = this.segments;
+ long u = (k << SSHIFT) + SBASE; // raw offset
+ Segment<K,V> seg;
+ // 判断 u 位置的 Segment 是否为null
+ if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
+ Segment<K,V> proto = ss[0]; // use segment 0 as prototype
+ // 获取0号 segment 里的 HashEntry<K,V> 初始化长度
+ int cap = proto.table.length;
+ // 获取0号 segment 里的 hash 表里的扩容负载因子,所有的 segment 的 loadFactor 是相同的
+ float lf = proto.loadFactor;
+ // 计算扩容阀值
+ int threshold = (int)(cap * lf);
+ // 创建一个 cap 容量的 HashEntry 数组
+ HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
+ if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck
+ // 再次检查 u 位置的 Segment 是否为null,因为这时可能有其他线程进行了操作
+ Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
+ // 自旋检查 u 位置的 Segment 是否为null
+ while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
+ == null) {
+ // 使用CAS 赋值,只会成功一次
+ if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
+ break;
+ }
+ }
+ }
+ return seg;
+}
+```
+
+上面的源码分析了 ConcurrentHashMap 在 put 一个数据时的处理流程,下面梳理下具体流程。
+
+1. 计算要 put 的 key 的位置,获取指定位置的 Segment。
+
+2. 如果指定位置的 Segment 为空,则初始化这个 Segment.
+
+ **初始化 Segment 流程:**
+
+ 1. 检查计算得到的位置的 Segment 是否为null.
+ 2. 为 null 继续初始化,使用 Segment[0] 的容量和负载因子创建一个 HashEntry 数组。
+ 3. 再次检查计算得到的指定位置的 Segment 是否为null.
+ 4. 使用创建的 HashEntry 数组初始化这个 Segment.
+ 5. 自旋判断计算得到的指定位置的 Segment 是否为null,使用 CAS 在这个位置赋值为 Segment.
+
+3. Segment.put 插入 key,value 值。
+
+上面探究了获取 Segment 段和初始化 Segment 段的操作。最后一行的 Segment 的 put 方法还没有查看,继续分析。
+
+```java
+final V put(K key, int hash, V value, boolean onlyIfAbsent) {
+ // 获取 ReentrantLock 独占锁,获取不到,scanAndLockForPut 获取。
+ HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
+ V oldValue;
+ try {
+ HashEntry<K,V>[] tab = table;
+ // 计算要put的数据位置
+ int index = (tab.length - 1) & hash;
+ // CAS 获取 index 坐标的值
+ HashEntry<K,V> first = entryAt(tab, index);
+ for (HashEntry<K,V> e = first;;) {
+ if (e != null) {
+ // 检查是否 key 已经存在,如果存在,则遍历链表寻找位置,找到后替换 value
+ K k;
+ if ((k = e.key) == key ||
+ (e.hash == hash && key.equals(k))) {
+ oldValue = e.value;
+ if (!onlyIfAbsent) {
+ e.value = value;
+ ++modCount;
+ }
+ break;
+ }
+ e = e.next;
+ }
+ else {
+ // first 有值没说明 index 位置已经有值了,有冲突,链表头插法。
+ if (node != null)
+ node.setNext(first);
+ else
+ node = new HashEntry<K,V>(hash, key, value, first);
+ int c = count + 1;
+ // 容量大于扩容阀值,小于最大容量,进行扩容
+ if (c > threshold && tab.length < MAXIMUM_CAPACITY)
+ rehash(node);
+ else
+ // index 位置赋值 node,node 可能是一个元素,也可能是一个链表的表头
+ setEntryAt(tab, index, node);
+ ++modCount;
+ count = c;
+ oldValue = null;
+ break;
+ }
+ }
+ } finally {
+ unlock();
+ }
+ return oldValue;
+}
+```
+
+由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。
+
+1. tryLock() 获取锁,获取不到使用 **`scanAndLockForPut`** 方法继续获取。
+
+2. 计算 put 的数据要放入的 index 位置,然后获取这个位置上的 HashEntry 。
+
+3. 遍历 put 新元素,为什么要遍历?因为这里获取的 HashEntry 可能是一个空元素,也可能是链表已存在,所以要区别对待。
+
+ 如果这个位置上的 **HashEntry 不存在**:
+
+ 1. 如果当前容量大于扩容阀值,小于最大容量,**进行扩容**。
+ 2. 直接头插法插入。
+
+ 如果这个位置上的 **HashEntry 存在**:
+
+ 1. 判断链表当前元素 Key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值
+ 2. 不一致,获取链表下一个节点,直到发现相同进行值替换,或者链表表里完毕没有相同的。
+ 1. 如果当前容量大于扩容阀值,小于最大容量,**进行扩容**。
+ 2. 直接链表头插法插入。
+
+4. 如果要插入的位置之前已经存在,替换后返回旧值,否则返回 null.
+
+这里面的第一步中的 scanAndLockForPut 操作这里没有介绍,这个方法做的操作就是不断的自旋 `tryLock()` 获取锁。当自旋次数大于指定次数时,使用 `lock()` 阻塞获取锁。在自旋时顺表获取下 hash 位置的 HashEntry。
+
+```java
+private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
+ HashEntry<K,V> first = entryForHash(this, hash);
+ HashEntry<K,V> e = first;
+ HashEntry<K,V> node = null;
+ int retries = -1; // negative while locating node
+ // 自旋获取锁
+ while (!tryLock()) {
+ HashEntry<K,V> f; // to recheck first below
+ if (retries < 0) {
+ if (e == null) {
+ if (node == null) // speculatively create node
+ node = new HashEntry<K,V>(hash, key, value, null);
+ retries = 0;
+ }
+ else if (key.equals(e.key))
+ retries = 0;
+ else
+ e = e.next;
+ }
+ else if (++retries > MAX_SCAN_RETRIES) {
+ // 自旋达到指定次数后,阻塞等到只到获取到锁
+ lock();
+ break;
+ }
+ else if ((retries & 1) == 0 &&
+ (f = entryForHash(this, hash)) != first) {
+ e = first = f; // re-traverse if entry changed
+ retries = -1;
+ }
+ }
+ return node;
+}
+
+```
+
+### 4. 扩容 rehash
+
+ConcurrentHashMap 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 index+ oldSize,参数里的 node 会在扩容之后使用链表**头插法**插入到指定位置。
+
+```java
+private void rehash(HashEntry<K,V> node) {
+ HashEntry<K,V>[] oldTable = table;
+ // 老容量
+ int oldCapacity = oldTable.length;
+ // 新容量,扩大两倍
+ int newCapacity = oldCapacity << 1;
+ // 新的扩容阀值
+ threshold = (int)(newCapacity * loadFactor);
+ // 创建新的数组
+ HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
+ // 新的掩码,默认2扩容后是4,-1是3,二进制就是11。
+ int sizeMask = newCapacity - 1;
+ for (int i = 0; i < oldCapacity ; i++) {
+ // 遍历老数组
+ HashEntry<K,V> e = oldTable[i];
+ if (e != null) {
+ HashEntry<K,V> next = e.next;
+ // 计算新的位置,新的位置只可能是不便或者是老的位置+老的容量。
+ int idx = e.hash & sizeMask;
+ if (next == null) // Single node on list
+ // 如果当前位置还不是链表,只是一个元素,直接赋值
+ newTable[idx] = e;
+ else { // Reuse consecutive sequence at same slot
+ // 如果是链表了
+ HashEntry<K,V> lastRun = e;
+ int lastIdx = idx;
+ // 新的位置只可能是不便或者是老的位置+老的容量。
+ // 遍历结束后,lastRun 后面的元素位置都是相同的
+ for (HashEntry<K,V> last = next; last != null; last = last.next) {
+ int k = last.hash & sizeMask;
+ if (k != lastIdx) {
+ lastIdx = k;
+ lastRun = last;
+ }
+ }
+ // ,lastRun 后面的元素位置都是相同的,直接作为链表赋值到新位置。
+ newTable[lastIdx] = lastRun;
+ // Clone remaining nodes
+ for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
+ // 遍历剩余元素,头插法到指定 k 位置。
+ V v = p.value;
+ int h = p.hash;
+ int k = h & sizeMask;
+ HashEntry<K,V> n = newTable[k];
+ newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
+ }
+ }
+ }
+ }
+ // 头插法插入新的节点
+ int nodeIndex = node.hash & sizeMask; // add the new node
+ node.setNext(newTable[nodeIndex]);
+ newTable[nodeIndex] = node;
+ table = newTable;
+}
+```
+
+有些同学可能会对最后的两个 for 循环有疑惑,这里第一个 for 是为了寻找这样一个节点,这个节点后面的所有 next 节点的新位置都是相同的。然后把这个作为一个链表赋值到新位置。第二个 for 循环是为了把剩余的元素通过头插法插入到指定位置链表。这样实现的原因可能是基于概率统计,有深入研究的同学可以发表下意见。
+
+### 5. get
+
+到这里就很简单了,get 方法只需要两步即可。
+
+1. 计算得到 key 的存放位置。
+2. 遍历指定位置查找相同 key 的 value 值。
+
+```java
+public V get(Object key) {
+ Segment<K,V> s; // manually integrate access methods to reduce overhead
+ HashEntry<K,V>[] tab;
+ int h = hash(key);
+ long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
+ // 计算得到 key 的存放位置
+ if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
+ (tab = s.table) != null) {
+ for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
+ (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
+ e != null; e = e.next) {
+ // 如果是链表,遍历查找到相同 key 的 value。
+ K k;
+ if ((k = e.key) == key || (e.hash == h && key.equals(k)))
+ return e.value;
+ }
+ }
+ return null;
+}
+```
+
+## 2. ConcurrentHashMap 1.8
+
+### 1. 存储结构
+
+
+
+可以发现 Java8 的 ConcurrentHashMap 相对于 Java7 来说变化比较大,不再是之前的 **Segment 数组 + HashEntry 数组 + 链表**,而是 **Node 数组 + 链表 / 红黑树**。当冲突链表达到一定长度时,链表会转换成红黑树。
+
+### 2. 初始化 initTable
+
+```java
+/**
+ * Initializes table, using the size recorded in sizeCtl.
+ */
+private final Node<K,V>[] initTable() {
+ Node<K,V>[] tab; int sc;
+ while ((tab = table) == null || tab.length == 0) {
+ // 如果 sizeCtl < 0 ,说明另外的线程执行CAS 成功,正在进行初始化。
+ if ((sc = sizeCtl) < 0)
+ // 让出 CPU 使用权
+ Thread.yield(); // lost initialization race; just spin
+ else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
+ try {
+ if ((tab = table) == null || tab.length == 0) {
+ int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
+ @SuppressWarnings("unchecked")
+ Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
+ table = tab = nt;
+ sc = n - (n >>> 2);
+ }
+ } finally {
+ sizeCtl = sc;
+ }
+ break;
+ }
+ }
+ return tab;
+}
+```
+
+从源码中可以发现 ConcurrentHashMap 的初始化是通过**自旋和 CAS** 操作完成的。里面需要注意的是变量 `sizeCtl` ,它的值决定着当前的初始化状态。
+
+1. -1 说明正在初始化
+2. -N 说明有N-1个线程正在进行扩容
+3. 表示 table 初始化大小,如果 table 没有初始化
+4. 表示 table 容量,如果 table 已经初始化。
+
+### 3. put
+
+直接过一遍 put 源码。
+
+```java
+public V put(K key, V value) {
+ return putVal(key, value, false);
+}
+
+/** Implementation for put and putIfAbsent */
+final V putVal(K key, V value, boolean onlyIfAbsent) {
+ // key 和 value 不能为空
+ if (key == null || value == null) throw new NullPointerException();
+ int hash = spread(key.hashCode());
+ int binCount = 0;
+ for (Node<K,V>[] tab = table;;) {
+ // f = 目标位置元素
+ Node<K,V> f; int n, i, fh;// fh 后面存放目标位置的元素 hash 值
+ if (tab == null || (n = tab.length) == 0)
+ // 数组桶为空,初始化数组桶(自旋+CAS)
+ tab = initTable();
+ else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
+ // 桶内为空,CAS 放入,不加锁,成功了就直接 break 跳出
+ if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
+ break; // no lock when adding to empty bin
+ }
+ else if ((fh = f.hash) == MOVED)
+ tab = helpTransfer(tab, f);
+ else {
+ V oldVal = null;
+ // 使用 synchronized 加锁加入节点
+ synchronized (f) {
+ if (tabAt(tab, i) == f) {
+ // 说明是链表
+ if (fh >= 0) {
+ binCount = 1;
+ // 循环加入新的或者覆盖节点
+ for (Node<K,V> e = f;; ++binCount) {
+ K ek;
+ if (e.hash == hash &&
+ ((ek = e.key) == key ||
+ (ek != null && key.equals(ek)))) {
+ oldVal = e.val;
+ if (!onlyIfAbsent)
+ e.val = value;
+ break;
+ }
+ Node<K,V> pred = e;
+ if ((e = e.next) == null) {
+ pred.next = new Node<K,V>(hash, key,
+ value, null);
+ break;
+ }
+ }
+ }
+ else if (f instanceof TreeBin) {
+ // 红黑树
+ Node<K,V> p;
+ binCount = 2;
+ if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
+ value)) != null) {
+ oldVal = p.val;
+ if (!onlyIfAbsent)
+ p.val = value;
+ }
+ }
+ }
+ }
+ if (binCount != 0) {
+ if (binCount >= TREEIFY_THRESHOLD)
+ treeifyBin(tab, i);
+ if (oldVal != null)
+ return oldVal;
+ break;
+ }
+ }
+ }
+ addCount(1L, binCount);
+ return null;
+}
+```
+
+1. 根据 key 计算出 hashcode 。
+
+2. 判断是否需要进行初始化。
+
+3. 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
+
+4. 如果当前位置的 `hashcode == MOVED == -1`,则需要进行扩容。
+
+5. 如果都不满足,则利用 synchronized 锁写入数据。
+
+6. 如果数量大于 `TREEIFY_THRESHOLD` 则要转换为红黑树。
+
+### 4. get
+
+get 流程比较简单,直接过一遍源码。
+
+```java
+public V get(Object key) {
+ Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
+ // key 所在的 hash 位置
+ int h = spread(key.hashCode());
+ if ((tab = table) != null && (n = tab.length) > 0 &&
+ (e = tabAt(tab, (n - 1) & h)) != null) {
+ // 如果指定位置元素存在,头结点hash值相同
+ if ((eh = e.hash) == h) {
+ if ((ek = e.key) == key || (ek != null && key.equals(ek)))
+ // key hash 值相等,key值相同,直接返回元素 value
+ return e.val;
+ }
+ else if (eh < 0)
+ // 头结点hash值小于0,说明正在扩容或者是红黑树,find查找
+ return (p = e.find(h, key)) != null ? p.val : null;
+ while ((e = e.next) != null) {
+ // 是链表,遍历查找
+ if (e.hash == h &&
+ ((ek = e.key) == key || (ek != null && key.equals(ek))))
+ return e.val;
+ }
+ }
+ return null;
+}
+```
+
+总结一下 get 过程:
+
+1. 根据 hash 值计算位置。
+2. 查找到指定位置,如果头节点就是要找的,直接返回它的 value.
+3. 如果头节点 hash 值小于 0 ,说明正在扩容或者是红黑树,查找之。
+4. 如果是链表,遍历查找之。
+
+总结:
+
+总的来说 ConcurrentHashMap 在 Java8 中相对于 Java7 来说变化还是挺大的,
+
+## 3. 总结
+
+Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
+
+Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 **Segment 数组 + HashEntry 数组 + 链表** 进化成了 **Node 数组 + 链表 / 红黑树**,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
+
+有些同学可能对 Synchronized 的性能存在疑问,其实 Synchronized 锁自从引入锁升级策略后,性能不再是问题,有兴趣的同学可以自己了解下 Synchronized 的**锁升级**。
diff --git "a/Java\347\233\270\345\205\263/HashMap.md" b/docs/java/collection/hashmap-source-code.md
similarity index 70%
rename from "Java\347\233\270\345\205\263/HashMap.md"
rename to docs/java/collection/hashmap-source-code.md
index 3fb4093c68d..7996b2766d1 100644
--- "a/Java\347\233\270\345\205\263/HashMap.md"
+++ b/docs/java/collection/hashmap-source-code.md
@@ -1,45 +1,48 @@
-<!-- MarkdownTOC -->
+---
+title: HashMap源码+底层数据结构分析
+category: Java
+tag:
+ - Java集合
+---
-- [HashMap 简介](#hashmap-简介)
-- [底层数据结构分析](#底层数据结构分析)
- - [JDK1.8之前](#jdk18之前)
- - [JDK1.8之后](#jdk18之后)
-- [HashMap源码分析](#hashmap源码分析)
- - [构造方法](#构造方法)
- - [put方法](#put方法)
- - [get方法](#get方法)
- - [resize方法](#resize方法)
-- [HashMap常用方法测试](#hashmap常用方法测试)
-
-<!-- /MarkdownTOC -->
> 感谢 [changfubai](https://github.com/changfubai) 对本文的改进做出的贡献!
## HashMap 简介
-HashMap 主要用来存放键值对,它基于哈希表的Map接口实现</font>,是常用的Java集合之一。
-JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。
+HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现,是常用的 Java 集合之一,是非线程安全的。
+
+ `HashMap` 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个
+
+JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。 JDK1.8 以后的 `HashMap` 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
+
+`HashMap` 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。并且, `HashMap` 总是使用 2 的幂作为哈希表的大小。
## 底层数据结构分析
-### JDK1.8之前
-JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
-**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
+### JDK1.8 之前
+
+JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。
+
+HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
+
+所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
**JDK 1.8 HashMap 的 hash 方法源码:**
-JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
+JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
- ```java
- static final int hash(Object key) {
- int h;
- // key.hashCode():返回散列值也就是hashcode
- // ^ :按位异或
- // >>>:无符号右移,忽略符号位,空位都以0补齐
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- }
- ```
-对比一下 JDK1.7的 HashMap 的 hash 方法源码.
+```java
+ static final int hash(Object key) {
+ int h;
+ // key.hashCode():返回散列值也就是hashcode
+ // ^ :按位异或
+ // >>>:无符号右移,忽略符号位,空位都以0补齐
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+ }
+```
+
+对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
```java
static int hash(int h) {
@@ -56,55 +59,62 @@ static int hash(int h) {
所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
-
+
+
+### JDK1.8 之后
+
+相比于之前的版本,JDK1.8 以后在解决哈希冲突时有了较大的变化。
-### JDK1.8之后
-相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
+当链表长度大于阈值(默认为 8)时,会首先调用 `treeifyBin()`方法。这个方法会根据 HashMap 数组来决定是否转换为红黑树。只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是执行 `resize()` 方法对数组扩容。相关源码这里就不贴了,重点关注 `treeifyBin()`方法即可!
-
+
**类的属性:**
+
```java
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
- private static final long serialVersionUID = 362498820763181265L;
+ private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
- static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
+ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
- static final int MAXIMUM_CAPACITY = 1 << 30;
+ static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
- static final int TREEIFY_THRESHOLD = 8;
+ static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小大小
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍
- transient Node<k,v>[] table;
+ transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
- transient int modCount;
+ transient int modCount;
// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容
int threshold;
- // 填充因子
+ // 加载因子
final float loadFactor;
}
```
-- **loadFactor加载因子**
- loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,load Factor越小,也就是趋近于0,
+- **loadFactor 加载因子**
+
+ loadFactor 加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据(entry)也就越少,也就越稀疏。
- **loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值**。
+ **loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值**。
+
+ 给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 \* 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
- **threshold**
- **threshold = capacity * loadFactor**,**当Size>=threshold**的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 **衡量数组是否需要扩增的一个标准**。
+ **threshold = capacity \* loadFactor**,**当 Size>=threshold**的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 **衡量数组是否需要扩增的一个标准**。
-**Node节点类源码:**
+**Node 节点类源码:**
```java
// 继承自 Map.Entry<K,V>
@@ -147,7 +157,9 @@ static class Node<K,V> implements Map.Entry<K,V> {
}
}
```
+
**树节点类源码:**
+
```java
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父
@@ -166,28 +178,32 @@ static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
r = p;
}
```
-## HashMap源码分析
+
+## HashMap 源码分析
+
### 构造方法
-
+
+HashMap 中有四个构造方法,它们分别如下:
+
```java
// 默认构造函数。
- public More ...HashMap() {
+ public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
-
+
// 包含另一个“Map”的构造函数
- public More ...HashMap(Map<? extends K, ? extends V> m) {
+ public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);//下面会分析到这个方法
}
-
+
// 指定“容量大小”的构造函数
- public More ...HashMap(int initialCapacity) {
+ public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
-
+
// 指定“容量大小”和“加载因子”的构造函数
- public More ...HashMap(int initialCapacity, float loadFactor) {
+ public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
@@ -199,7 +215,7 @@ static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
}
```
-**putMapEntries方法:**
+**putMapEntries 方法:**
```java
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
@@ -227,17 +243,22 @@ final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
}
}
```
-### put方法
-HashMap只提供了put用于添加元素,putVal方法只是给put方法调用的一个方法,并没有提供给用户使用。
-**对putVal方法添加元素的分析如下:**
+### put 方法
-- ①如果定位到的数组位置没有元素 就直接插入。
-- ②如果定位到的数组位置有元素就和要插入的key比较,如果key相同就直接覆盖,如果key不相同,就判断p是否是一个树节点,如果是就调用`e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)`将元素添加进入。如果不是就遍历链表插入。
+HashMap 只提供了 put 用于添加元素,putVal 方法只是给 put 方法调用的一个方法,并没有提供给用户使用。
+**对 putVal 方法添加元素的分析如下:**
+1. 如果定位到的数组位置没有元素 就直接插入。
+2. 如果定位到的数组位置有元素就和要插入的 key 比较,如果 key 相同就直接覆盖,如果 key 不相同,就判断 p 是否是一个树节点,如果是就调用`e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)`将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
-
+
+
+说明:上图有两个小问题:
+
+- 直接覆盖之后应该就会 return,不会有后续操作。参考 JDK8 HashMap.java 658 行([issue#608](https://github.com/Snailclimb/JavaGuide/issues/608))。
+- 当链表长度大于阈值(默认为 8)并且 HashMap 数组长度超过 64 的时候才会执行链表转红黑树的操作,否则就只是对数组扩容。参考 HashMap 的 `treeifyBin()` 方法([issue#1087](https://github.com/Snailclimb/JavaGuide/issues/1087))。
```java
public V put(K key, V value) {
@@ -273,7 +294,9 @@ final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
- // 结点数量达到阈值,转化为红黑树
+ // 结点数量达到阈值(默认为 8 ),执行 treeifyBin 方法
+ // 这个方法会根据 HashMap 数组来决定是否转换为红黑树。
+ // 只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是对数组扩容。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
@@ -289,7 +312,7 @@ final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
- if (e != null) {
+ if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
@@ -310,21 +333,21 @@ final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
// 插入后回调
afterNodeInsertion(evict);
return null;
-}
+}
```
-**我们再来对比一下 JDK1.7 put方法的代码**
+**我们再来对比一下 JDK1.7 put 方法的代码**
-**对于put方法的分析如下:**
+**对于 put 方法的分析如下:**
-- ①如果定位到的数组位置没有元素 就直接插入。
-- ②如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的key比较,如果key相同就直接覆盖,不同就采用头插法插入元素。
+- ① 如果定位到的数组位置没有元素 就直接插入。
+- ② 如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的 key 比较,如果 key 相同就直接覆盖,不同就采用头插法插入元素。
```java
public V put(K key, V value)
- if (table == EMPTY_TABLE) {
- inflateTable(threshold);
-}
+ if (table == EMPTY_TABLE) {
+ inflateTable(threshold);
+}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
@@ -335,7 +358,7 @@ public V put(K key, V value)
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
- return oldValue;
+ return oldValue;
}
}
@@ -345,9 +368,8 @@ public V put(K key, V value)
}
```
+### get 方法
-
-### get方法
```java
public V get(Object key) {
Node<K,V> e;
@@ -378,8 +400,11 @@ final Node<K,V> getNode(int hash, Object key) {
return null;
}
```
-### resize方法
-进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
+
+### resize 方法
+
+进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的。在编写程序中,要尽量避免 resize。
+
```java
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
@@ -398,8 +423,8 @@ final Node<K,V>[] resize() {
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
- else {
- signifies using defaults
+ else {
+ // signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
@@ -422,7 +447,7 @@ final Node<K,V>[] resize() {
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
- else {
+ else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
@@ -462,7 +487,9 @@ final Node<K,V>[] resize() {
return newTab;
}
```
-## HashMap常用方法测试
+
+## HashMap 常用方法测试
+
```java
package map;
@@ -508,7 +535,8 @@ public class HashMapDemo {
}
/**
- * 另外一种不常用的遍历方式
+ * 如果既要遍历key又要value,那么建议这种方式,因为如果先获取keySet然后再执行map.get(key),map内部会执行两次遍历。
+ * 一次是在获取keySet的时候,一次是在遍历所有key的时候。
*/
// 当我调用put(key,value)方法的时候,首先会把key和value封装到
// Entry这个静态内部类对象中,把Entry对象再添加到数组中,所以我们想获取
@@ -518,7 +546,7 @@ public class HashMapDemo {
for (java.util.Map.Entry<String, String> entry : entrys) {
System.out.println(entry.getKey() + "--" + entry.getValue());
}
-
+
/**
* HashMap其他常用方法
*/
@@ -534,5 +562,4 @@ public class HashMapDemo {
}
}
-
-```
+```
\ No newline at end of file
diff --git a/docs/java/collection/images/77c95eb733284dbd8ce4e85c9cb6b042.png b/docs/java/collection/images/77c95eb733284dbd8ce4e85c9cb6b042.png
new file mode 100644
index 00000000000..54180092b12
Binary files /dev/null and b/docs/java/collection/images/77c95eb733284dbd8ce4e85c9cb6b042.png differ
diff --git a/docs/java/collection/images/Java-Collections.jpeg b/docs/java/collection/images/Java-Collections.jpeg
new file mode 100644
index 00000000000..cf9071ff6a2
Binary files /dev/null and b/docs/java/collection/images/Java-Collections.jpeg differ
diff --git "a/docs/java/collection/images/TreeMap\347\273\247\346\211\277\347\273\223\346\236\204.png" "b/docs/java/collection/images/TreeMap\347\273\247\346\211\277\347\273\223\346\236\204.png"
new file mode 100644
index 00000000000..553e41b84ac
Binary files /dev/null and "b/docs/java/collection/images/TreeMap\347\273\247\346\211\277\347\273\223\346\236\204.png" differ
diff --git a/docs/java/collection/images/ad28e3ba-e419-4724-869c-73879e604da1.png b/docs/java/collection/images/ad28e3ba-e419-4724-869c-73879e604da1.png
new file mode 100644
index 00000000000..1c05ebaad67
Binary files /dev/null and b/docs/java/collection/images/ad28e3ba-e419-4724-869c-73879e604da1.png differ
diff --git a/docs/java/collection/images/image-20200405151029416.png b/docs/java/collection/images/image-20200405151029416.png
new file mode 100644
index 00000000000..26ea14ca479
Binary files /dev/null and b/docs/java/collection/images/image-20200405151029416.png differ
diff --git a/docs/java/collection/images/java-collection-hierarchy.png b/docs/java/collection/images/java-collection-hierarchy.png
new file mode 100644
index 00000000000..78daf980845
Binary files /dev/null and b/docs/java/collection/images/java-collection-hierarchy.png differ
diff --git a/docs/java/collection/images/java8_concurrenthashmap.png b/docs/java/collection/images/java8_concurrenthashmap.png
new file mode 100644
index 00000000000..a090c7cc25e
Binary files /dev/null and b/docs/java/collection/images/java8_concurrenthashmap.png differ
diff --git "a/docs/java/collection/images/jdk1.8\344\271\213\345\211\215\347\232\204\345\206\205\351\203\250\347\273\223\346\236\204-HashMap.png" "b/docs/java/collection/images/jdk1.8\344\271\213\345\211\215\347\232\204\345\206\205\351\203\250\347\273\223\346\236\204-HashMap.png"
new file mode 100644
index 00000000000..54180092b12
Binary files /dev/null and "b/docs/java/collection/images/jdk1.8\344\271\213\345\211\215\347\232\204\345\206\205\351\203\250\347\273\223\346\236\204-HashMap.png" differ
diff --git "a/docs/java/collection/images/jdk1.8\344\271\213\345\220\216\347\232\204\345\206\205\351\203\250\347\273\223\346\236\204-HashMap.png" "b/docs/java/collection/images/jdk1.8\344\271\213\345\220\216\347\232\204\345\206\205\351\203\250\347\273\223\346\236\204-HashMap.png"
new file mode 100644
index 00000000000..7c95e73847e
Binary files /dev/null and "b/docs/java/collection/images/jdk1.8\344\271\213\345\220\216\347\232\204\345\206\205\351\203\250\347\273\223\346\236\204-HashMap.png" differ
diff --git "a/docs/java/collection/images/linkedlist/LinkedList\345\206\205\351\203\250\347\273\223\346\236\204.png" "b/docs/java/collection/images/linkedlist/LinkedList\345\206\205\351\203\250\347\273\223\346\236\204.png"
new file mode 100644
index 00000000000..b70a93721e1
Binary files /dev/null and "b/docs/java/collection/images/linkedlist/LinkedList\345\206\205\351\203\250\347\273\223\346\236\204.png" differ
diff --git "a/docs/java/collection/java\351\233\206\345\220\210\344\275\277\347\224\250\346\263\250\346\204\217\344\272\213\351\241\271.md" "b/docs/java/collection/java\351\233\206\345\220\210\344\275\277\347\224\250\346\263\250\346\204\217\344\272\213\351\241\271.md"
new file mode 100644
index 00000000000..6a65c33a264
--- /dev/null
+++ "b/docs/java/collection/java\351\233\206\345\220\210\344\275\277\347\224\250\346\263\250\346\204\217\344\272\213\351\241\271.md"
@@ -0,0 +1,439 @@
+---
+title: Java集合使用注意事项总结
+category: Java
+tag:
+ - Java集合
+---
+
+这篇文章我根据《阿里巴巴 Java 开发手册》总结了关于集合使用常见的注意事项以及其具体原理。
+
+强烈建议小伙伴们多多阅读几遍,避免自己写代码的时候出现这些低级的问题。
+
+## 集合判空
+
+《阿里巴巴 Java 开发手册》的描述如下:
+
+> **判断所有集合内部的元素是否为空,使用 `isEmpty()` 方法,而不是 `size()==0` 的方式。**
+
+这是因为 `isEmpty()` 方法的可读性更好,并且时间复杂度为 O(1)。
+
+绝大部分我们使用的集合的 `size()` 方法的时间复杂度也是 O(1),不过,也有很多复杂度不是 O(1) 的,比如 `java.util.concurrent` 包下的某些集合(`ConcurrentLinkedQueue` 、`ConcurrentHashMap`...)。
+
+下面是 `ConcurrentHashMap` 的 `size()` 方法和 `isEmpty()` 方法的源码。
+
+```java
+public int size() {
+ long n = sumCount();
+ return ((n < 0L) ? 0 :
+ (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
+ (int)n);
+}
+final long sumCount() {
+ CounterCell[] as = counterCells; CounterCell a;
+ long sum = baseCount;
+ if (as != null) {
+ for (int i = 0; i < as.length; ++i) {
+ if ((a = as[i]) != null)
+ sum += a.value;
+ }
+ }
+ return sum;
+}
+public boolean isEmpty() {
+ return sumCount() <= 0L; // ignore transient negative values
+}
+```
+
+## 集合转 Map
+
+《阿里巴巴 Java 开发手册》的描述如下:
+
+> **在使用 `java.util.stream.Collectors` 类的 `toMap()` 方法转为 `Map` 集合时,一定要注意当 value 为 null 时会抛 NPE 异常。**
+
+```java
+class Person {
+ private String name;
+ private String phoneNumber;
+ // getters and setters
+}
+
+List<Person> bookList = new ArrayList<>();
+bookList.add(new Person("jack","18163138123"));
+bookList.add(new Person("martin",null));
+// 空指针异常
+bookList.stream().collect(Collectors.toMap(Person::getName, Person::getPhoneNumber));
+```
+
+下面我们来解释一下原因。
+
+首先,我们来看 `java.util.stream.Collectors` 类的 `toMap()` 方法 ,可以看到其内部调用了 `Map` 接口的 `merge()` 方法。
+
+```java
+public static <T, K, U, M extends Map<K, U>>
+Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
+ Function<? super T, ? extends U> valueMapper,
+ BinaryOperator<U> mergeFunction,
+ Supplier<M> mapSupplier) {
+ BiConsumer<M, T> accumulator
+ = (map, element) -> map.merge(keyMapper.apply(element),
+ valueMapper.apply(element), mergeFunction);
+ return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
+}
+```
+
+`Map` 接口的 `merge()` 方法如下,这个方法是接口中的默认实现。
+
+> 如果你还不了解 Java 8 新特性的话,请看这篇文章:[《Java8 新特性总结》](https://mp.weixin.qq.com/s/ojyl7B6PiHaTWADqmUq2rw) 。
+
+```java
+default V merge(K key, V value,
+ BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
+ Objects.requireNonNull(remappingFunction);
+ Objects.requireNonNull(value);
+ V oldValue = get(key);
+ V newValue = (oldValue == null) ? value :
+ remappingFunction.apply(oldValue, value);
+ if(newValue == null) {
+ remove(key);
+ } else {
+ put(key, newValue);
+ }
+ return newValue;
+}
+```
+
+`merge()` 方法会先调用 `Objects.requireNonNull()` 方法判断 value 是否为空。
+
+```java
+public static <T> T requireNonNull(T obj) {
+ if (obj == null)
+ throw new NullPointerException();
+ return obj;
+}
+```
+
+## 集合遍历
+
+《阿里巴巴 Java 开发手册》的描述如下:
+
+> **不要在 foreach 循环里进行元素的 `remove/add` 操作。remove 元素请使用 `Iterator` 方式,如果并发操作,需要对 `Iterator` 对象加锁。**
+
+通过反编译你会发现 foreach 语法糖底层其实还是依赖 `Iterator` 。不过, `remove/add` 操作直接调用的是集合自己的方法,而不是 `Iterator` 的 `remove/add`方法
+
+这就导致 `Iterator` 莫名其妙地发现自己有元素被 `remove/add` ,然后,它就会抛出一个 `ConcurrentModificationException` 来提示用户发生了并发修改异常。这就是单线程状态下产生的 **fail-fast 机制**。
+
+> **fail-fast 机制** :多个线程对 fail-fast 集合进行修改的时候,可能会抛出`ConcurrentModificationException`。 即使是单线程下也有可能会出现这种情况,上面已经提到过。
+
+Java8 开始,可以使用 `Collection#removeIf()`方法删除满足特定条件的元素,如
+
+```java
+List<Integer> list = new ArrayList<>();
+for (int i = 1; i <= 10; ++i) {
+ list.add(i);
+}
+list.removeIf(filter -> filter % 2 == 0); /* 删除list中的所有偶数 */
+System.out.println(list); /* [1, 3, 5, 7, 9] */
+```
+
+除了上面介绍的直接使用 `Iterator` 进行遍历操作之外,你还可以:
+
+- 使用普通的 for 循环
+- 使用 fail-safe 的集合类。`java.util`包下面的所有的集合类都是 fail-fast 的,而`java.util.concurrent`包下面的所有的类都是 fail-safe 的。
+- ......
+
+## 集合去重
+
+《阿里巴巴 Java 开发手册》的描述如下:
+
+> **可以利用 `Set` 元素唯一的特性,可以快速对一个集合进行去重操作,避免使用 `List` 的 `contains()` 进行遍历去重或者判断包含操作。**
+
+这里我们以 `HashSet` 和 `ArrayList` 为例说明。
+
+```java
+// Set 去重代码示例
+public static <T> Set<T> removeDuplicateBySet(List<T> data) {
+
+ if (CollectionUtils.isEmpty(data)) {
+ return new HashSet<>();
+ }
+ return new HashSet<>(data);
+}
+
+// List 去重代码示例
+public static <T> List<T> removeDuplicateByList(List<T> data) {
+
+ if (CollectionUtils.isEmpty(data)) {
+ return new ArrayList<>();
+
+ }
+ List<T> result = new ArrayList<>(data.size());
+ for (T current : data) {
+ if (!result.contains(current)) {
+ result.add(current);
+ }
+ }
+ return result;
+}
+
+```
+
+两者的核心差别在于 `contains()` 方法的实现。
+
+`HashSet` 的 `contains()` 方法底部依赖的 `HashMap` 的 `containsKey()` 方法,时间复杂度接近于 O(1)(没有出现哈希冲突的时候为 O(1))。
+
+```java
+private transient HashMap<E,Object> map;
+public boolean contains(Object o) {
+ return map.containsKey(o);
+}
+```
+
+我们有 N 个元素插入进 Set 中,那时间复杂度就接近是 O (n)。
+
+`ArrayList` 的 `contains()` 方法是通过遍历所有元素的方法来做的,时间复杂度接近是 O(n)。
+
+```java
+public boolean contains(Object o) {
+ return indexOf(o) >= 0;
+}
+public int indexOf(Object o) {
+ if (o == null) {
+ for (int i = 0; i < size; i++)
+ if (elementData[i]==null)
+ return i;
+ } else {
+ for (int i = 0; i < size; i++)
+ if (o.equals(elementData[i]))
+ return i;
+ }
+ return -1;
+}
+
+```
+
+我们的 `List` 有 N 个元素,那时间复杂度就接近是 O (n^2)。
+
+## 集合转数组
+
+《阿里巴巴 Java 开发手册》的描述如下:
+
+> **使用集合转数组的方法,必须使用集合的 `toArray(T[] array)`,传入的是类型完全一致、长度为 0 的空数组。**
+
+`toArray(T[] array)` 方法的参数是一个泛型数组,如果 `toArray` 方法中没有传递任何参数的话返回的是 `Object`类 型数组。
+
+```java
+String [] s= new String[]{
+ "dog", "lazy", "a", "over", "jumps", "fox", "brown", "quick", "A"
+};
+List<String> list = Arrays.asList(s);
+Collections.reverse(list);
+//没有指定类型的话会报错
+s=list.toArray(new String[0]);
+```
+
+由于 JVM 优化,`new String[0]`作为`Collection.toArray()`方法的参数现在使用更好,`new String[0]`就是起一个模板的作用,指定了返回数组的类型,0 是为了节省空间,因为它只是为了说明返回的类型。详见:<https://shipilev.net/blog/2016/arrays-wisdom-ancients/>
+
+## 数组转集合
+
+《阿里巴巴 Java 开发手册》的描述如下:
+
+> **使用工具类 `Arrays.asList()` 把数组转换成集合时,不能使用其修改集合相关的方法, 它的 `add/remove/clear` 方法会抛出 `UnsupportedOperationException` 异常。**
+
+我在之前的一个项目中就遇到一个类似的坑。
+
+`Arrays.asList()`在平时开发中还是比较常见的,我们可以使用它将一个数组转换为一个 `List` 集合。
+
+```java
+String[] myArray = {"Apple", "Banana", "Orange"};
+List<String> myList = Arrays.asList(myArray);
+//上面两个语句等价于下面一条语句
+List<String> myList = Arrays.asList("Apple","Banana", "Orange");
+```
+
+JDK 源码对于这个方法的说明:
+
+```java
+/**
+ *返回由指定数组支持的固定大小的列表。此方法作为基于数组和基于集合的API之间的桥梁,
+ * 与 Collection.toArray()结合使用。返回的List是可序列化并实现RandomAccess接口。
+ */
+public static <T> List<T> asList(T... a) {
+ return new ArrayList<>(a);
+}
+```
+
+下面我们来总结一下使用注意事项。
+
+**1、`Arrays.asList()`是泛型方法,传递的数组必须是对象数组,而不是基本类型。**
+
+```java
+int[] myArray = {1, 2, 3};
+List myList = Arrays.asList(myArray);
+System.out.println(myList.size());//1
+System.out.println(myList.get(0));//数组地址值
+System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException
+int[] array = (int[]) myList.get(0);
+System.out.println(array[0]);//1
+```
+
+当传入一个原生数据类型数组时,`Arrays.asList()` 的真正得到的参数就不是数组中的元素,而是数组对象本身!此时 `List` 的唯一元素就是这个数组,这也就解释了上面的代码。
+
+我们使用包装类型数组就可以解决这个问题。
+
+```java
+Integer[] myArray = {1, 2, 3};
+```
+
+**2、使用集合的修改方法: `add()`、`remove()`、`clear()`会抛出异常。**
+
+```java
+List myList = Arrays.asList(1, 2, 3);
+myList.add(4);//运行时报错:UnsupportedOperationException
+myList.remove(1);//运行时报错:UnsupportedOperationException
+myList.clear();//运行时报错:UnsupportedOperationException
+```
+
+`Arrays.asList()` 方法返回的并不是 `java.util.ArrayList` ,而是 `java.util.Arrays` 的一个内部类,这个内部类并没有实现集合的修改方法或者说并没有重写这些方法。
+
+```java
+List myList = Arrays.asList(1, 2, 3);
+System.out.println(myList.getClass());//class java.util.Arrays$ArrayList
+```
+
+下图是 `java.util.Arrays$ArrayList` 的简易源码,我们可以看到这个类重写的方法有哪些。
+
+```java
+ private static class ArrayList<E> extends AbstractList<E>
+ implements RandomAccess, java.io.Serializable
+ {
+ ...
+
+ @Override
+ public E get(int index) {
+ ...
+ }
+
+ @Override
+ public E set(int index, E element) {
+ ...
+ }
+
+ @Override
+ public int indexOf(Object o) {
+ ...
+ }
+
+ @Override
+ public boolean contains(Object o) {
+ ...
+ }
+
+ @Override
+ public void forEach(Consumer<? super E> action) {
+ ...
+ }
+
+ @Override
+ public void replaceAll(UnaryOperator<E> operator) {
+ ...
+ }
+
+ @Override
+ public void sort(Comparator<? super E> c) {
+ ...
+ }
+ }
+```
+
+我们再看一下`java.util.AbstractList`的 `add/remove/clear` 方法就知道为什么会抛出 `UnsupportedOperationException` 了。
+
+```java
+public E remove(int index) {
+ throw new UnsupportedOperationException();
+}
+public boolean add(E e) {
+ add(size(), e);
+ return true;
+}
+public void add(int index, E element) {
+ throw new UnsupportedOperationException();
+}
+
+public void clear() {
+ removeRange(0, size());
+}
+protected void removeRange(int fromIndex, int toIndex) {
+ ListIterator<E> it = listIterator(fromIndex);
+ for (int i=0, n=toIndex-fromIndex; i<n; i++) {
+ it.next();
+ it.remove();
+ }
+}
+```
+
+**那我们如何正确的将数组转换为 `ArrayList` ?**
+
+1、手动实现工具类
+
+```java
+//JDK1.5+
+static <T> List<T> arrayToList(final T[] array) {
+ final List<T> l = new ArrayList<T>(array.length);
+
+ for (final T s : array) {
+ l.add(s);
+ }
+ return l;
+}
+
+
+Integer [] myArray = { 1, 2, 3 };
+System.out.println(arrayToList(myArray).getClass());//class java.util.ArrayList
+```
+
+2、最简便的方法
+
+```java
+List list = new ArrayList<>(Arrays.asList("a", "b", "c"))
+```
+
+3、使用 Java8 的 `Stream`(推荐)
+
+```java
+Integer [] myArray = { 1, 2, 3 };
+List myList = Arrays.stream(myArray).collect(Collectors.toList());
+//基本类型也可以实现转换(依赖boxed的装箱操作)
+int [] myArray2 = { 1, 2, 3 };
+List myList = Arrays.stream(myArray2).boxed().collect(Collectors.toList());
+```
+
+4、使用 Guava
+
+对于不可变集合,你可以使用[`ImmutableList`](https://github.com/google/guava/blob/master/guava/src/com/google/common/collect/ImmutableList.java)类及其[`of()`](https://github.com/google/guava/blob/master/guava/src/com/google/common/collect/ImmutableList.java#L101)与[`copyOf()`](https://github.com/google/guava/blob/master/guava/src/com/google/common/collect/ImmutableList.java#L225)工厂方法:(参数不能为空)
+
+```java
+List<String> il = ImmutableList.of("string", "elements"); // from varargs
+List<String> il = ImmutableList.copyOf(aStringArray); // from array
+```
+
+对于可变集合,你可以使用[`Lists`](https://github.com/google/guava/blob/master/guava/src/com/google/common/collect/Lists.java)类及其[`newArrayList()`](https://github.com/google/guava/blob/master/guava/src/com/google/common/collect/Lists.java#L87)工厂方法:
+
+```java
+List<String> l1 = Lists.newArrayList(anotherListOrCollection); // from collection
+List<String> l2 = Lists.newArrayList(aStringArray); // from array
+List<String> l3 = Lists.newArrayList("or", "string", "elements"); // from varargs
+```
+
+5、使用 Apache Commons Collections
+
+```java
+List<String> list = new ArrayList<String>();
+CollectionUtils.addAll(list, str);
+```
+
+6、 使用 Java9 的 `List.of()`方法
+
+```java
+Integer[] array = {1, 2, 3};
+List<Integer> list = List.of(array);
+```
\ No newline at end of file
diff --git "a/docs/java/collection/java\351\233\206\345\220\210\346\241\206\346\236\266\345\237\272\347\241\200\347\237\245\350\257\206&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/collection/java\351\233\206\345\220\210\346\241\206\346\236\266\345\237\272\347\241\200\347\237\245\350\257\206&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..1f901750654
--- /dev/null
+++ "b/docs/java/collection/java\351\233\206\345\220\210\346\241\206\346\236\266\345\237\272\347\241\200\347\237\245\350\257\206&\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -0,0 +1,660 @@
+---
+category: Java
+tag:
+ - Java集合
+---
+
+# Java集合框架基础知识&面试题总结
+
+## 集合概述
+
+### Java 集合概览
+
+Java 集合, 也叫作容器,主要是由两大接口派生而来:一个是 `Collecton`接口,主要用于存放单一元素;另一个是 `Map` 接口,主要用于存放键值对。对于`Collection` 接口,下面又有三个主要的子接口:`List`、`Set` 和 `Queue`。
+
+Java 集合框架如下图所示:
+
+
+
+
+注:图中只列举了主要的继承派生关系,并没有列举所有关系。比方省略了`AbstractList`, `NavigableSet`等抽象类以及其他的一些辅助类,如想深入了解,可自行查看源码。
+
+### 说说 List, Set, Queue, Map 四者的区别?
+
+- `List`(对付顺序的好帮手): 存储的元素是有序的、可重复的。
+- `Set`(注重独一无二的性质): 存储的元素是无序的、不可重复的。
+- `Queue`(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。
+- `Map`(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),"x" 代表 key,"y" 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
+
+### 集合框架底层数据结构总结
+
+先来看一下 `Collection` 接口下面的集合。
+
+#### List
+
+- `Arraylist`: `Object[]` 数组
+- `Vector`:`Object[]` 数组
+- `LinkedList`: 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
+
+#### Set
+
+- `HashSet`(无序,唯一): 基于 `HashMap` 实现的,底层采用 `HashMap` 来保存元素
+- `LinkedHashSet`: `LinkedHashSet` 是 `HashSet` 的子类,并且其内部是通过 `LinkedHashMap` 来实现的。有点类似于我们之前说的 `LinkedHashMap` 其内部是基于 `HashMap` 实现一样,不过还是有一点点区别的
+- `TreeSet`(有序,唯一): 红黑树(自平衡的排序二叉树)
+
+#### Queue
+- `PriorityQueue`: `Object[]` 数组来实现二叉堆
+- `ArrayQueue`: `Object[]` 数组 + 双指针
+
+再来看看 `Map` 接口下面的集合。
+
+#### Map
+
+- `HashMap`: JDK1.8 之前 `HashMap` 由数组+链表组成的,数组是 `HashMap` 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间
+- `LinkedHashMap`: `LinkedHashMap` 继承自 `HashMap`,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,`LinkedHashMap` 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:[《LinkedHashMap 源码详细分析(JDK1.8)》](https://www.imooc.com/article/22931)
+- `Hashtable`: 数组+链表组成的,数组是 `Hashtable` 的主体,链表则是主要为了解决哈希冲突而存在的
+- `TreeMap`: 红黑树(自平衡的排序二叉树)
+
+### 如何选用集合?
+
+主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用 `Map` 接口下的集合,需要排序时选择 `TreeMap`,不需要排序时就选择 `HashMap`,需要保证线程安全就选用 `ConcurrentHashMap`。
+
+当我们只需要存放元素值时,就选择实现`Collection` 接口的集合,需要保证元素唯一时选择实现 `Set` 接口的集合比如 `TreeSet` 或 `HashSet`,不需要就选择实现 `List` 接口的比如 `ArrayList` 或 `LinkedList`,然后再根据实现这些接口的集合的特点来选用。
+
+### 为什么要使用集合?
+
+当我们需要保存一组类型相同的数据的时候,我们应该是用一个容器来保存,这个容器就是数组,但是,使用数组存储对象具有一定的弊端,
+因为我们在实际开发中,存储的数据的类型是多种多样的,于是,就出现了“集合”,集合同样也是用来存储多个数据的。
+
+数组的缺点是一旦声明之后,长度就不可变了;同时,声明数组时的数据类型也决定了该数组存储的数据的类型;而且,数组存储的数据是有序的、可重复的,特点单一。
+但是集合提高了数据存储的灵活性,Java 集合不仅可以用来存储不同类型不同数量的对象,还可以保存具有映射关系的数据。
+
+## Collection 子接口之 List
+
+### Arraylist 和 Vector 的区别?
+
+- `ArrayList` 是 `List` 的主要实现类,底层使用 `Object[ ]`存储,适用于频繁的查找工作,线程不安全 ;
+- `Vector` 是 `List` 的古老实现类,底层使用`Object[ ]` 存储,线程安全的。
+
+### Arraylist 与 LinkedList 区别?
+
+1. **是否保证线程安全:** `ArrayList` 和 `LinkedList` 都是不同步的,也就是不保证线程安全;
+2. **底层数据结构:** `Arraylist` 底层使用的是 **`Object` 数组**;`LinkedList` 底层使用的是 **双向链表** 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
+3. **插入和删除是否受元素位置的影响:**
+ - `ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行`add(E e)`方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。
+ - `LinkedList` 采用链表存储,所以,如果是在头尾插入或者删除元素不受元素位置的影响(`add(E e)`、`addFirst(E e)`、`addLast(E e)`、`removeFirst()` 、 `removeLast()`),近似 O(1),如果是要在指定位置 `i` 插入和删除元素的话(`add(int index, E element)`,`remove(Object o)`) 时间复杂度近似为 O(n) ,因为需要先移动到指定位置再插入。
+4. **是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList` 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
+5. **内存空间占用:** ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
+
+#### 补充内容:双向链表和双向循环链表
+
+**双向链表:** 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
+
+> 另外推荐一篇把双向链表讲清楚的文章:[https://juejin.cn/post/6844903648154271757](https://juejin.cn/post/6844903648154271757)
+
+
+
+**双向循环链表:** 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
+
+
+
+#### 补充内容:RandomAccess 接口
+
+```java
+public interface RandomAccess {
+}
+```
+
+查看源码我们发现实际上 `RandomAccess` 接口中什么都没有定义。所以,在我看来 `RandomAccess` 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
+
+在 `binarySearch()` 方法中,它要判断传入的 list 是否 `RamdomAccess` 的实例,如果是,调用`indexedBinarySearch()`方法,如果不是,那么调用`iteratorBinarySearch()`方法
+
+```java
+ public static <T>
+ int binarySearch(List<? extends Comparable<? super T>> list, T key) {
+ if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
+ return Collections.indexedBinarySearch(list, key);
+ else
+ return Collections.iteratorBinarySearch(list, key);
+ }
+```
+
+`ArrayList` 实现了 `RandomAccess` 接口, 而 `LinkedList` 没有实现。为什么呢?我觉得还是和底层数据结构有关!`ArrayList` 底层是数组,而 `LinkedList` 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,`ArrayList` 实现了 `RandomAccess` 接口,就表明了他具有快速随机访问功能。 `RandomAccess` 接口只是标识,并不是说 `ArrayList` 实现 `RandomAccess` 接口才具有快速随机访问功能的!
+
+### 说一说 ArrayList 的扩容机制吧
+
+详见笔主的这篇文章:[通过源码一步一步分析 ArrayList 扩容机制](https://snailclimb.gitee.io/javaguide/#/docs/java/collection/ArrayList%E6%BA%90%E7%A0%81+%E6%89%A9%E5%AE%B9%E6%9C%BA%E5%88%B6%E5%88%86%E6%9E%90)
+
+## Collection 子接口之 Set
+
+### comparable 和 Comparator 的区别
+
+- `comparable` 接口实际上是出自`java.lang`包 它有一个 `compareTo(Object obj)`方法用来排序
+- `comparator`接口实际上是出自 java.util 包它有一个`compare(Object obj1, Object obj2)`方法用来排序
+
+一般我们需要对一个集合使用自定义排序时,我们就要重写`compareTo()`方法或`compare()`方法,当我们需要对某一个集合实现两种排序方式,比如一个 song 对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写`compareTo()`方法和使用自制的`Comparator`方法或者以两个 Comparator 来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 `Collections.sort()`.
+
+#### Comparator 定制排序
+
+```java
+ ArrayList<Integer> arrayList = new ArrayList<Integer>();
+ arrayList.add(-1);
+ arrayList.add(3);
+ arrayList.add(3);
+ arrayList.add(-5);
+ arrayList.add(7);
+ arrayList.add(4);
+ arrayList.add(-9);
+ arrayList.add(-7);
+ System.out.println("原始数组:");
+ System.out.println(arrayList);
+ // void reverse(List list):反转
+ Collections.reverse(arrayList);
+ System.out.println("Collections.reverse(arrayList):");
+ System.out.println(arrayList);
+
+ // void sort(List list),按自然排序的升序排序
+ Collections.sort(arrayList);
+ System.out.println("Collections.sort(arrayList):");
+ System.out.println(arrayList);
+ // 定制排序的用法
+ Collections.sort(arrayList, new Comparator<Integer>() {
+
+ @Override
+ public int compare(Integer o1, Integer o2) {
+ return o2.compareTo(o1);
+ }
+ });
+ System.out.println("定制排序后:");
+ System.out.println(arrayList);
+```
+
+Output:
+
+```
+原始数组:
+[-1, 3, 3, -5, 7, 4, -9, -7]
+Collections.reverse(arrayList):
+[-7, -9, 4, 7, -5, 3, 3, -1]
+Collections.sort(arrayList):
+[-9, -7, -5, -1, 3, 3, 4, 7]
+定制排序后:
+[7, 4, 3, 3, -1, -5, -7, -9]
+```
+
+#### 重写 compareTo 方法实现按年龄来排序
+
+```java
+// person对象没有实现Comparable接口,所以必须实现,这样才不会出错,才可以使treemap中的数据按顺序排列
+// 前面一个例子的String类已经默认实现了Comparable接口,详细可以查看String类的API文档,另外其他
+// 像Integer类等都已经实现了Comparable接口,所以不需要另外实现了
+public class Person implements Comparable<Person> {
+ private String name;
+ private int age;
+
+ public Person(String name, int age) {
+ super();
+ this.name = name;
+ this.age = age;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+
+ public int getAge() {
+ return age;
+ }
+
+ public void setAge(int age) {
+ this.age = age;
+ }
+
+ /**
+ * T重写compareTo方法实现按年龄来排序
+ */
+ @Override
+ public int compareTo(Person o) {
+ if (this.age > o.getAge()) {
+ return 1;
+ }
+ if (this.age < o.getAge()) {
+ return -1;
+ }
+ return 0;
+ }
+}
+
+```
+
+```java
+ public static void main(String[] args) {
+ TreeMap<Person, String> pdata = new TreeMap<Person, String>();
+ pdata.put(new Person("张三", 30), "zhangsan");
+ pdata.put(new Person("李四", 20), "lisi");
+ pdata.put(new Person("王五", 10), "wangwu");
+ pdata.put(new Person("小红", 5), "xiaohong");
+ // 得到key的值的同时得到key所对应的值
+ Set<Person> keys = pdata.keySet();
+ for (Person key : keys) {
+ System.out.println(key.getAge() + "-" + key.getName());
+
+ }
+ }
+```
+
+Output:
+
+```
+5-小红
+10-王五
+20-李四
+30-张三
+```
+
+### 无序性和不可重复性的含义是什么
+
+1、什么是无序性?无序性不等于随机性 ,无序性是指存储的数据在底层数组中并非按照数组索引的顺序添加 ,而是根据数据的哈希值决定的。
+
+2、什么是不可重复性?不可重复性是指添加的元素按照 equals()判断时 ,返回 false,需要同时重写 equals()方法和 HashCode()方法。
+
+### 比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
+
+- `HashSet`、`LinkedHashSet` 和 `TreeSet` 都是 `Set` 接口的实现类,都能保证元素唯一,并且都不是线程安全的。
+- `HashSet`、`LinkedHashSet` 和 `TreeSet` 的主要区别在于底层数据结构不同。`HashSet` 的底层数据结构是哈希表(基于 `HashMap` 实现)。`LinkedHashSet` 的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。`TreeSet` 底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。
+- 底层数据结构不同又导致这三者的应用场景不同。`HashSet` 用于不需要保证元素插入和取出顺序的场景,`LinkHashSet` 用于保证元素的插入和取出顺序满足 FIFO 的场景,`TreeSet` 用于支持对元素自定义排序规则的场景。
+
+## Collection 子接口之 Queue
+
+### Queue 与 Deque 的区别
+
+`Queue` 是单端队列,只能从一端插入元素,另一端删除元素,实现上一般遵循 **先进先出(FIFO)** 规则。
+
+`Queue` 扩展了 `Collection` 的接口,根据 **因为容量问题而导致操作失败后处理方式的不同** 可以分为两类方法: 一种在操作失败后会抛出异常,另一种则会返回特殊值。
+
+| `Queue` 接口| 抛出异常 | 返回特殊值 |
+| ------------ | --------- | ---------- |
+| 插入队尾 | add(E e) | offer(E e) |
+| 删除队首 | remove() | poll() |
+| 查询队首元素 | element() | peek() |
+
+`Deque` 是双端队列,在队列的两端均可以插入或删除元素。
+
+`Deque` 扩展了 `Queue` 的接口, 增加了在队首和队尾进行插入和删除的方法,同样根据失败后处理方式的不同分为两类:
+
+| `Deque` 接口 | 抛出异常 | 返回特殊值 |
+| ------------ | ------------- | --------------- |
+| 插入队首 | addFirst(E e) | offerFirst(E e) |
+| 插入队尾 | addLast(E e) | offerLast(E e) |
+| 删除队首 | removeFirst() | pollFirst() |
+| 删除队尾 | removeLast() | pollLast() |
+| 查询队首元素 | getFirst() | peekFirst() |
+| 查询队尾元素 | getLast() | peekLast() |
+
+事实上,`Deque` 还提供有 `push()` 和 `pop()` 等其他方法,可用于模拟栈。
+
+
+### ArrayDeque 与 LinkedList 的区别
+
+`ArrayDeque` 和 `LinkedList` 都实现了 `Deque` 接口,两者都具有队列的功能,但两者有什么区别呢?
+
+- `ArrayDeque` 是基于可变长的数组和双指针来实现,而 `LinkedList` 则通过链表来实现。
+
+- `ArrayDeque` 不支持存储 `NULL` 数据,但 `LinkedList` 支持。
+
+- `ArrayDeque` 是在 JDK1.6 才被引入的,而`LinkedList` 早在 JDK1.2 时就已经存在。
+
+- `ArrayDeque` 插入时可能存在扩容过程, 不过均摊后的插入操作依然为 O(1)。虽然 `LinkedList` 不需要扩容,但是每次插入数据时均需要申请新的堆空间,均摊性能相比更慢。
+
+从性能的角度上,选用 `ArrayDeque` 来实现队列要比 `LinkedList` 更好。此外,`ArrayDeque` 也可以用于实现栈。
+
+### 说一说 PriorityQueue
+
+`PriorityQueue` 是在 JDK1.5 中被引入的, 其与 `Queue` 的区别在于元素出队顺序是与优先级相关的,即总是优先级最高的元素先出队。
+
+这里列举其相关的一些要点:
+
+- `PriorityQueue` 利用了二叉堆的数据结构来实现的,底层使用可变长的数组来存储数据
+- `PriorityQueue` 通过堆元素的上浮和下沉,实现了在 O(logn) 的时间复杂度内插入元素和删除堆顶元素。
+- `PriorityQueue` 是非线程安全的,且不支持存储 `NULL` 和 `non-comparable` 的对象。
+- `PriorityQueue` 默认是小顶堆,但可以接收一个 `Comparator` 作为构造参数,从而来自定义元素优先级的先后。
+
+`PriorityQueue` 在面试中可能更多的会出现在手撕算法的时候,典型例题包括堆排序、求第K大的数、带权图的遍历等,所以需要会熟练使用才行。
+
+## Map 接口
+
+### HashMap 和 Hashtable 的区别
+
+1. **线程是否安全:** `HashMap` 是非线程安全的,`Hashtable` 是线程安全的,因为 `Hashtable` 内部的方法基本都经过`synchronized` 修饰。(如果你要保证线程安全的话就使用 `ConcurrentHashMap` 吧!);
+2. **效率:** 因为线程安全的问题,`HashMap` 要比 `Hashtable` 效率高一点。另外,`Hashtable` 基本被淘汰,不要在代码中使用它;
+3. **对 Null key 和 Null value 的支持:** `HashMap` 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出 `NullPointerException`。
+4. **初始容量大小和每次扩充容量大小的不同 :** ① 创建时如果不指定容量初始值,`Hashtable` 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。`HashMap` 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 `HashMap` 会将其扩充为 2 的幂次方大小(`HashMap` 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 `HashMap` 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
+5. **底层数据结构:** JDK1.8 以后的 `HashMap` 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
+
+**`HashMap` 中带有初始容量的构造函数:**
+
+```java
+ public HashMap(int initialCapacity, float loadFactor) {
+ if (initialCapacity < 0)
+ throw new IllegalArgumentException("Illegal initial capacity: " +
+ initialCapacity);
+ if (initialCapacity > MAXIMUM_CAPACITY)
+ initialCapacity = MAXIMUM_CAPACITY;
+ if (loadFactor <= 0 || Float.isNaN(loadFactor))
+ throw new IllegalArgumentException("Illegal load factor: " +
+ loadFactor);
+ this.loadFactor = loadFactor;
+ this.threshold = tableSizeFor(initialCapacity);
+ }
+ public HashMap(int initialCapacity) {
+ this(initialCapacity, DEFAULT_LOAD_FACTOR);
+ }
+```
+
+下面这个方法保证了 `HashMap` 总是使用 2 的幂作为哈希表的大小。
+
+```java
+ /**
+ * Returns a power of two size for the given target capacity.
+ */
+ static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ n |= n >>> 2;
+ n |= n >>> 4;
+ n |= n >>> 8;
+ n |= n >>> 16;
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }
+```
+
+### HashMap 和 HashSet 区别
+
+如果你看过 `HashSet` 源码的话就应该知道:`HashSet` 底层就是基于 `HashMap` 实现的。(`HashSet` 的源码非常非常少,因为除了 `clone()`、`writeObject()`、`readObject()`是 `HashSet` 自己不得不实现之外,其他方法都是直接调用 `HashMap` 中的方法。
+
+| `HashMap` | `HashSet` |
+| :------------------------------------: | :----------------------------------------------------------: |
+| 实现了 `Map` 接口 | 实现 `Set` 接口 |
+| 存储键值对 | 仅存储对象 |
+| 调用 `put()`向 map 中添加元素 | 调用 `add()`方法向 `Set` 中添加元素 |
+| `HashMap` 使用键(Key)计算 `hashcode` | `HashSet` 使用成员对象来计算 `hashcode` 值,对于两个对象来说 `hashcode` 可能相同,所以`equals()`方法用来判断对象的相等性 |
+
+### HashMap 和 TreeMap 区别
+
+`TreeMap` 和`HashMap` 都继承自`AbstractMap` ,但是需要注意的是`TreeMap`它还实现了`NavigableMap`接口和`SortedMap` 接口。
+
+
+
+实现 `NavigableMap` 接口让 `TreeMap` 有了对集合内元素的搜索的能力。
+
+实现`SortedMap`接口让 `TreeMap` 有了对集合中的元素根据键排序的能力。默认是按 key 的升序排序,不过我们也可以指定排序的比较器。示例代码如下:
+
+```java
+/**
+ * @author shuang.kou
+ * @createTime 2020年06月15日 17:02:00
+ */
+public class Person {
+ private Integer age;
+
+ public Person(Integer age) {
+ this.age = age;
+ }
+
+ public Integer getAge() {
+ return age;
+ }
+
+
+ public static void main(String[] args) {
+ TreeMap<Person, String> treeMap = new TreeMap<>(new Comparator<Person>() {
+ @Override
+ public int compare(Person person1, Person person2) {
+ int num = person1.getAge() - person2.getAge();
+ return Integer.compare(num, 0);
+ }
+ });
+ treeMap.put(new Person(3), "person1");
+ treeMap.put(new Person(18), "person2");
+ treeMap.put(new Person(35), "person3");
+ treeMap.put(new Person(16), "person4");
+ treeMap.entrySet().stream().forEach(personStringEntry -> {
+ System.out.println(personStringEntry.getValue());
+ });
+ }
+}
+```
+
+输出:
+
+```
+person1
+person4
+person2
+person3
+```
+
+可以看出,`TreeMap` 中的元素已经是按照 `Person` 的 age 字段的升序来排列了。
+
+上面,我们是通过传入匿名内部类的方式实现的,你可以将代码替换成 Lambda 表达式实现的方式:
+
+```java
+TreeMap<Person, String> treeMap = new TreeMap<>((person1, person2) -> {
+ int num = person1.getAge() - person2.getAge();
+ return Integer.compare(num, 0);
+});
+```
+
+**综上,相比于`HashMap`来说 `TreeMap` 主要多了对集合中的元素根据键排序的能力以及对集合内元素的搜索的能力。**
+
+### HashSet 如何检查重复
+
+以下内容摘自我的 Java 启蒙书《Head first java》第二版:
+
+当你把对象加入`HashSet`时,`HashSet` 会先计算对象的`hashcode`值来判断对象加入的位置,同时也会与其他加入的对象的 `hashcode` 值作比较,如果没有相符的 `hashcode`,`HashSet` 会假设对象没有重复出现。但是如果发现有相同 `hashcode` 值的对象,这时会调用`equals()`方法来检查 `hashcode` 相等的对象是否真的相同。如果两者相同,`HashSet` 就不会让加入操作成功。
+
+在openjdk8中,`HashSet`的`add()`方法只是简单的调用了`HashMap`的`put()`方法,并且判断了一下返回值以确保是否有重复元素。直接看一下`HashSet`中的源码:
+```java
+// Returns: true if this set did not already contain the specified element
+// 返回值:当set中没有包含add的元素时返回真
+public boolean add(E e) {
+ return map.put(e, PRESENT)==null;
+}
+```
+
+而在`HashMap`的`putVal()`方法中也能看到如下说明:
+```java
+// Returns : previous value, or null if none
+// 返回值:如果插入位置没有元素返回null,否则返回上一个元素
+final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
+ boolean evict) {
+...
+}
+```
+
+也就是说,在openjdk8中,实际上无论`HashSet`中是否已经存在了某元素,`HashSet`都会直接插入,只是会在`add()`方法的返回值处告诉我们插入前是否存在相同元素。
+
+**`hashCode()`与 `equals()` 的相关规定:**
+
+1. 如果两个对象相等,则 `hashcode` 一定也是相同的
+2. 两个对象相等,对两个 `equals()` 方法返回 true
+3. 两个对象有相同的 `hashcode` 值,它们也不一定是相等的
+4. 综上,`equals()` 方法被覆盖过,则 `hashCode()` 方法也必须被覆盖
+5. `hashCode()`的默认行为是对堆上的对象产生独特值。如果没有重写 `hashCode()`,则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
+
+**==与 equals 的区别**
+
+对于基本类型来说,== 比较的是值是否相等;
+
+对于引用类型来说,== 比较的是两个引用是否指向同一个对象地址(两者在内存中存放的地址(堆内存地址)是否指向同一个地方);
+
+对于引用类型(包括包装类型)来说,equals 如果没有被重写,对比它们的地址是否相等;如果 equals()方法被重写(例如 String),则比较的是地址里的内容。
+
+### HashMap 的底层实现
+
+#### JDK1.8 之前
+
+JDK1.8 之前 `HashMap` 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
+
+**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
+
+**JDK 1.8 HashMap 的 hash 方法源码:**
+
+JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
+
+```java
+ static final int hash(Object key) {
+ int h;
+ // key.hashCode():返回散列值也就是hashcode
+ // ^ :按位异或
+ // >>>:无符号右移,忽略符号位,空位都以0补齐
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+ }
+```
+
+对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
+
+```java
+static int hash(int h) {
+ // This function ensures that hashCodes that differ only by
+ // constant multiples at each bit position have a bounded
+ // number of collisions (approximately 8 at default load factor).
+
+ h ^= (h >>> 20) ^ (h >>> 12);
+ return h ^ (h >>> 7) ^ (h >>> 4);
+}
+```
+
+相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
+
+所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
+
+
+
+#### JDK1.8 之后
+
+相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
+
+
+
+> TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
+
+### HashMap 的长度为什么是 2 的幂次方
+
+为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash`”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
+
+**这个算法应该如何设计呢?**
+
+我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。**
+
+### HashMap 多线程操作导致死循环问题
+
+主要原因在于并发下的 Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
+
+详情请查看:<https://coolshell.cn/articles/9606.html>
+
+### HashMap 有哪几种常见的遍历方式?
+
+[HashMap 的 7 种遍历方式与性能分析!](https://mp.weixin.qq.com/s/zQBN3UvJDhRTKP6SzcZFKw)
+
+### ConcurrentHashMap 和 Hashtable 的区别
+
+`ConcurrentHashMap` 和 `Hashtable` 的区别主要体现在实现线程安全的方式上不同。
+
+- **底层数据结构:** JDK1.7 的 `ConcurrentHashMap` 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟 `HashMap1.8` 的结构一样,数组+链表/红黑二叉树。`Hashtable` 和 JDK1.8 之前的 `HashMap` 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
+- **实现线程安全的方式(重要):** ① **在 JDK1.7 的时候,`ConcurrentHashMap`(分段锁)** 对整个桶数组进行了分割分段(`Segment`),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 **到了 JDK1.8 的时候已经摒弃了 `Segment` 的概念,而是直接用 `Node` 数组+链表+红黑树的数据结构来实现,并发控制使用 `synchronized` 和 CAS 来操作。(JDK1.6 以后 对 `synchronized` 锁做了很多优化)** 整个看起来就像是优化过且线程安全的 `HashMap`,虽然在 JDK1.8 中还能看到 `Segment` 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **`Hashtable`(同一把锁)** :使用 `synchronized` 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
+
+**两者的对比图:**
+
+**Hashtable:**
+
+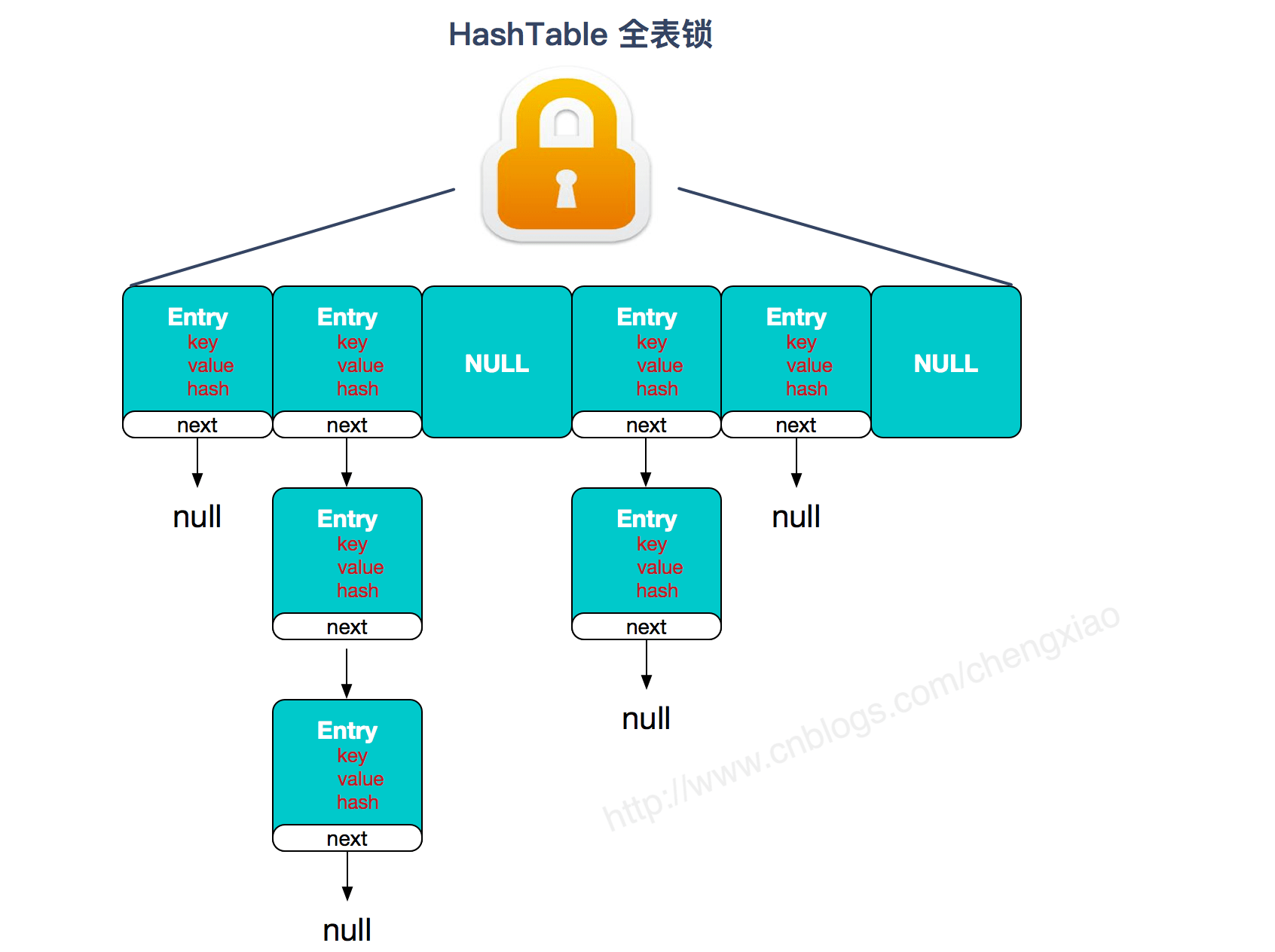
+
+<p style="text-align:right;font-size:13px;color:gray">https://www.cnblogs.com/chengxiao/p/6842045.html></p>
+
+**JDK1.7 的 ConcurrentHashMap:**
+
+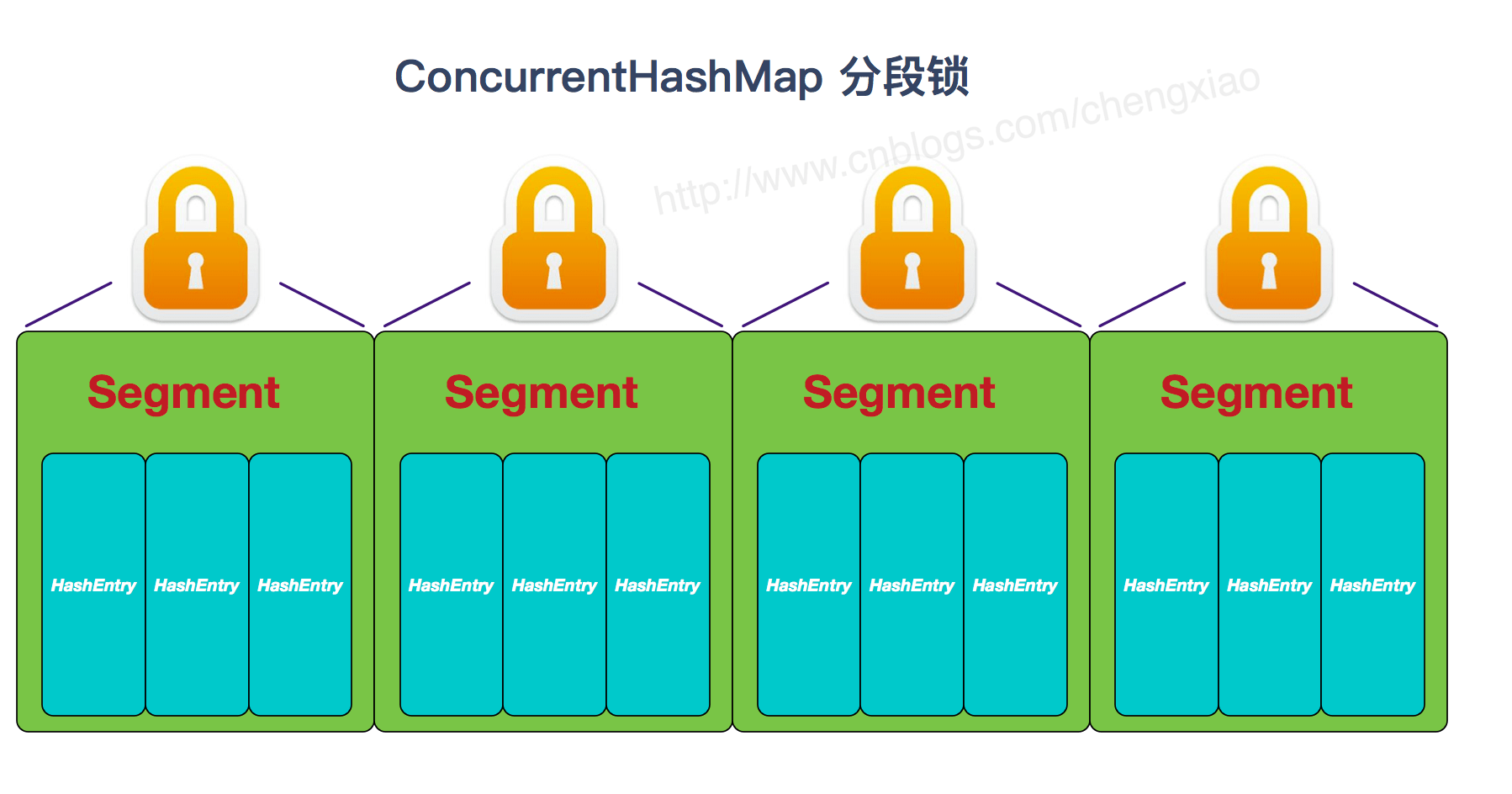
+
+<p style="text-align:right;font-size:13px;color:gray">https://www.cnblogs.com/chengxiao/p/6842045.html></p>
+
+**JDK1.8 的 ConcurrentHashMap:**
+
+
+
+JDK1.8 的 `ConcurrentHashMap` 不再是 **Segment 数组 + HashEntry 数组 + 链表**,而是 **Node 数组 + 链表 / 红黑树**。不过,Node 只能用于链表的情况,红黑树的情况需要使用 **`TreeNode`**。当冲突链表达到一定长度时,链表会转换成红黑树。
+
+### ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
+
+#### JDK1.7(上面有示意图)
+
+首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
+
+**`ConcurrentHashMap` 是由 `Segment` 数组结构和 `HashEntry` 数组结构组成**。
+
+Segment 实现了 `ReentrantLock`,所以 `Segment` 是一种可重入锁,扮演锁的角色。`HashEntry` 用于存储键值对数据。
+
+```java
+static class Segment<K,V> extends ReentrantLock implements Serializable {
+}
+```
+
+一个 `ConcurrentHashMap` 里包含一个 `Segment` 数组。`Segment` 的结构和 `HashMap` 类似,是一种数组和链表结构,一个 `Segment` 包含一个 `HashEntry` 数组,每个 `HashEntry` 是一个链表结构的元素,每个 `Segment` 守护着一个 `HashEntry` 数组里的元素,当对 `HashEntry` 数组的数据进行修改时,必须首先获得对应的 `Segment` 的锁。
+
+#### JDK1.8 (上面有示意图)
+
+`ConcurrentHashMap` 取消了 `Segment` 分段锁,采用 CAS 和 `synchronized` 来保证并发安全。数据结构跟 HashMap1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))
+
+`synchronized` 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。
+
+## Collections 工具类
+
+Collections 工具类常用方法:
+
+1. 排序
+2. 查找,替换操作
+3. 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合)
+
+### 排序操作
+
+```java
+void reverse(List list)//反转
+void shuffle(List list)//随机排序
+void sort(List list)//按自然排序的升序排序
+void sort(List list, Comparator c)//定制排序,由Comparator控制排序逻辑
+void swap(List list, int i , int j)//交换两个索引位置的元素
+void rotate(List list, int distance)//旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面
+```
+
+### 查找,替换操作
+
+```java
+int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的
+int max(Collection coll)//根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
+int max(Collection coll, Comparator c)//根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
+void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素
+int frequency(Collection c, Object o)//统计元素出现次数
+int indexOfSubList(List list, List target)//统计target在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target)
+boolean replaceAll(List list, Object oldVal, Object newVal)//用新元素替换旧元素
+```
+
+### 同步控制
+
+`Collections` 提供了多个`synchronizedXxx()`方法·,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。
+
+我们知道 `HashSet`,`TreeSet`,`ArrayList`,`LinkedList`,`HashMap`,`TreeMap` 都是线程不安全的。`Collections` 提供了多个静态方法可以把他们包装成线程同步的集合。
+
+**最好不要用下面这些方法,效率非常低,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合。**
+
+方法如下:
+
+```java
+synchronizedCollection(Collection<T> c) //返回指定 collection 支持的同步(线程安全的)collection。
+synchronizedList(List<T> list)//返回指定列表支持的同步(线程安全的)List。
+synchronizedMap(Map<K,V> m) //返回由指定映射支持的同步(线程安全的)Map。
+synchronizedSet(Set<T> s) //返回指定 set 支持的同步(线程安全的)set。
+```
diff --git "a/docs/java/concurrent/aqs\345\216\237\347\220\206\344\273\245\345\217\212aqs\345\220\214\346\255\245\347\273\204\344\273\266\346\200\273\347\273\223.md" "b/docs/java/concurrent/aqs\345\216\237\347\220\206\344\273\245\345\217\212aqs\345\220\214\346\255\245\347\273\204\344\273\266\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..43e59b4abb9
--- /dev/null
+++ "b/docs/java/concurrent/aqs\345\216\237\347\220\206\344\273\245\345\217\212aqs\345\220\214\346\255\245\347\273\204\344\273\266\346\200\273\347\273\223.md"
@@ -0,0 +1,708 @@
+---
+title: AQS 原理以及 AQS 同步组件总结
+category: Java
+tag:
+ - Java并发
+---
+
+
+开始之前,先来看几道常见的面试题!建议你带着这些问题来看这篇文章:
+
+- 何为 AQS?AQS 原理了解吗?
+- `CountDownLatch` 和 `CyclicBarrier` 了解吗?两者的区别是什么?
+- 用过 `Semaphore` 吗?应用场景了解吗?
+- ......
+
+## AQS 简单介绍
+
+AQS 的全称为 `AbstractQueuedSynchronizer` ,翻译过来的意思就是抽象队列同步器。这个类在 `java.util.concurrent.locks` 包下面。
+
+
+
+AQS 就是一个抽象类,主要用来构建锁和同步器。
+
+```java
+public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable {
+}
+```
+
+AQS 为构建锁和同步器提供了一些通用功能的是实现,因此,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的 `ReentrantLock`,`Semaphore`,其他的诸如 `ReentrantReadWriteLock`,`SynchronousQueue`,`FutureTask`(jdk1.7) 等等皆是基于 AQS 的。
+
+## AQS 原理
+
+> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于 AQS 原理的理解”。下面给大家一个示例供大家参考,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
+
+下面大部分内容其实在 AQS 类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
+
+### AQS 原理概览
+
+AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 **CLH 队列锁**实现的,即将暂时获取不到锁的线程加入到队列中。
+
+> CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。
+
+看个 AQS(`AbstractQueuedSynchronizer`)原理图:
+
+
+
+AQS 使用一个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。AQS 使用 CAS 对该同步状态进行原子操作实现对其值的修改。
+
+```java
+private volatile int state;//共享变量,使用volatile修饰保证线程可见性
+```
+
+状态信息通过 `protected` 类型的`getState()`,`setState()`,`compareAndSetState()` 进行操作
+
+```java
+//返回同步状态的当前值
+protected final int getState() {
+ return state;
+}
+ // 设置同步状态的值
+protected final void setState(int newState) {
+ state = newState;
+}
+//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
+protected final boolean compareAndSetState(int expect, int update) {
+ return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
+}
+```
+
+### AQS 对资源的共享方式
+
+AQS 定义两种资源共享方式
+
+**1)Exclusive**(独占)
+
+只有一个线程能执行,如 `ReentrantLock`。又可分为公平锁和非公平锁,`ReentrantLock` 同时支持两种锁,下面以 `ReentrantLock` 对这两种锁的定义做介绍:
+
+- **公平锁** :按照线程在队列中的排队顺序,先到者先拿到锁
+- **非公平锁** :当线程要获取锁时,先通过两次 CAS 操作去抢锁,如果没抢到,当前线程再加入到队列中等待唤醒。
+
+> 说明:下面这部分关于 `ReentrantLock` 源代码内容节选自:https://www.javadoop.com/post/AbstractQueuedSynchronizer-2 ,这是一篇很不错文章,推荐阅读。
+
+**下面来看 `ReentrantLock` 中相关的源代码:**
+
+`ReentrantLock` 默认采用非公平锁,因为考虑获得更好的性能,通过 `boolean` 来决定是否用公平锁(传入 true 用公平锁)。
+
+```java
+/** Synchronizer providing all implementation mechanics */
+private final Sync sync;
+public ReentrantLock() {
+ // 默认非公平锁
+ sync = new NonfairSync();
+}
+public ReentrantLock(boolean fair) {
+ sync = fair ? new FairSync() : new NonfairSync();
+}
+```
+
+`ReentrantLock` 中公平锁的 `lock` 方法
+
+```java
+static final class FairSync extends Sync {
+ final void lock() {
+ acquire(1);
+ }
+ // AbstractQueuedSynchronizer.acquire(int arg)
+ public final void acquire(int arg) {
+ if (!tryAcquire(arg) &&
+ acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
+ selfInterrupt();
+ }
+ protected final boolean tryAcquire(int acquires) {
+ final Thread current = Thread.currentThread();
+ int c = getState();
+ if (c == 0) {
+ // 1. 和非公平锁相比,这里多了一个判断:是否有线程在等待
+ if (!hasQueuedPredecessors() &&
+ compareAndSetState(0, acquires)) {
+ setExclusiveOwnerThread(current);
+ return true;
+ }
+ }
+ else if (current == getExclusiveOwnerThread()) {
+ int nextc = c + acquires;
+ if (nextc < 0)
+ throw new Error("Maximum lock count exceeded");
+ setState(nextc);
+ return true;
+ }
+ return false;
+ }
+}
+```
+
+非公平锁的 `lock` 方法:
+
+```java
+static final class NonfairSync extends Sync {
+ final void lock() {
+ // 2. 和公平锁相比,这里会直接先进行一次CAS,成功就返回了
+ if (compareAndSetState(0, 1))
+ setExclusiveOwnerThread(Thread.currentThread());
+ else
+ acquire(1);
+ }
+ // AbstractQueuedSynchronizer.acquire(int arg)
+ public final void acquire(int arg) {
+ if (!tryAcquire(arg) &&
+ acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
+ selfInterrupt();
+ }
+ protected final boolean tryAcquire(int acquires) {
+ return nonfairTryAcquire(acquires);
+ }
+}
+/**
+ * Performs non-fair tryLock. tryAcquire is implemented in
+ * subclasses, but both need nonfair try for trylock method.
+ */
+final boolean nonfairTryAcquire(int acquires) {
+ final Thread current = Thread.currentThread();
+ int c = getState();
+ if (c == 0) {
+ // 这里没有对阻塞队列进行判断
+ if (compareAndSetState(0, acquires)) {
+ setExclusiveOwnerThread(current);
+ return true;
+ }
+ }
+ else if (current == getExclusiveOwnerThread()) {
+ int nextc = c + acquires;
+ if (nextc < 0) // overflow
+ throw new Error("Maximum lock count exceeded");
+ setState(nextc);
+ return true;
+ }
+ return false;
+}
+```
+
+总结:公平锁和非公平锁只有两处不同:
+
+1. 非公平锁在调用 lock 后,首先就会调用 CAS 进行一次抢锁,如果这个时候恰巧锁没有被占用,那么直接就获取到锁返回了。
+2. 非公平锁在 CAS 失败后,和公平锁一样都会进入到 `tryAcquire` 方法,在 `tryAcquire` 方法中,如果发现锁这个时候被释放了(state == 0),非公平锁会直接 CAS 抢锁,但是公平锁会判断等待队列是否有线程处于等待状态,如果有则不去抢锁,乖乖排到后面。
+
+公平锁和非公平锁就这两点区别,如果这两次 CAS 都不成功,那么后面非公平锁和公平锁是一样的,都要进入到阻塞队列等待唤醒。
+
+相对来说,非公平锁会有更好的性能,因为它的吞吐量比较大。当然,非公平锁让获取锁的时间变得更加不确定,可能会导致在阻塞队列中的线程长期处于饥饿状态。
+
+**2)Share**(共享)
+
+多个线程可同时执行,如 `Semaphore/CountDownLatch`。`Semaphore`、`CountDownLatCh`、 `CyclicBarrier`、`ReadWriteLock` 我们都会在后面讲到。
+
+`ReentrantReadWriteLock` 可以看成是组合式,因为 `ReentrantReadWriteLock` 也就是读写锁允许多个线程同时对某一资源进行读。
+
+不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS 已经在上层已经帮我们实现好了。
+
+### AQS 底层使用了模板方法模式
+
+同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
+
+1. 使用者继承 `AbstractQueuedSynchronizer` 并重写指定的方法。(这些重写方法很简单,无非是对于共享资源 state 的获取和释放)
+2. 将 AQS 组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
+
+这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用,下面简单的给大家介绍一下模板方法模式,模板方法模式是一个很容易理解的设计模式之一。
+
+> 模板方法模式是基于”继承“的,主要是为了在不改变模板结构的前提下在子类中重新定义模板中的内容以实现复用代码。
+>
+> 举个很简单的例子假如我们要去一个地方的步骤是:购票 `buyTicket()`->安检 `securityCheck()`->乘坐某某工具回家 `ride()` ->到达目的地 `arrive()`。我们可能乘坐不同的交通工具回家比如飞机或者火车,所以除了`ride()`方法,其他方法的实现几乎相同。我们可以定义一个包含了这些方法的抽象类,然后用户根据自己的需要继承该抽象类然后修改 `ride()`方法。
+
+**AQS 使用了模板方法模式,自定义同步器时需要重写下面几个 AQS 提供的模板方法:**
+
+```java
+isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
+tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
+tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
+tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
+tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
+```
+
+默认情况下,每个方法都抛出 `UnsupportedOperationException`。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS 类中的其他方法都是 final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
+
+以 `ReentrantLock` 为例,state 初始化为 0,表示未锁定状态。A 线程 `lock()` 时,会调用 `tryAcquire()`独占该锁并将 state+1。此后,其他线程再 `tryAcquire()` 时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
+
+再以 `CountDownLatch` 以例,任务分为 N 个子线程去执行,state 也初始化为 N(也可以不初始化为 N,不初始化为 N,state 减到 0 也会从 await()返回)。这 N 个子线程是并行执行的,每个子线程执行完后 `countDown()` 一次,state 会 CAS(Compare and Swap)减 1。等到 `state=0`,会 `unpark()` 主调用线程,然后主调用线程就会从 `await()` 函数返回,继续后余动作。
+
+所以 `CountDownLatch` 可以做倒计数器,减到 0 后唤醒的线程可以对线程池进行处理,比如关闭线程池。
+
+一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但 AQS 也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
+
+推荐两篇 AQS 原理和相关源码分析的文章:
+
+- [Java 并发之 AQS 详解](https://www.cnblogs.com/waterystone/p/4920797.html)
+- [Java 并发包基石-AQS 详解](https://www.cnblogs.com/chengxiao/p/7141160.html)
+
+## Semaphore(信号量)
+
+`synchronized` 和 `ReentrantLock` 都是一次只允许一个线程访问某个资源,`Semaphore`(信号量)可以指定多个线程同时访问某个资源。
+
+示例代码如下:
+
+```java
+/**
+ *
+ * @author Snailclimb
+ * @date 2018年9月30日
+ * @Description: 需要一次性拿一个许可的情况
+ */
+public class SemaphoreExample1 {
+ // 请求的数量
+ private static final int threadCount = 550;
+
+ public static void main(String[] args) throws InterruptedException {
+ // 创建一个具有固定线程数量的线程池对象(如果这里线程池的线程数量给太少的话你会发现执行的很慢)
+ ExecutorService threadPool = Executors.newFixedThreadPool(300);
+ // 一次只能允许执行的线程数量。
+ final Semaphore semaphore = new Semaphore(20);
+
+ for (int i = 0; i < threadCount; i++) {
+ final int threadnum = i;
+ threadPool.execute(() -> {// Lambda 表达式的运用
+ try {
+ semaphore.acquire();// 获取一个许可,所以可运行线程数量为20/1=20
+ test(threadnum);
+ semaphore.release();// 释放一个许可
+ } catch (InterruptedException e) {
+ // TODO Auto-generated catch block
+ e.printStackTrace();
+ }
+
+ });
+ }
+ threadPool.shutdown();
+ System.out.println("finish");
+ }
+
+ public static void test(int threadnum) throws InterruptedException {
+ Thread.sleep(1000);// 模拟请求的耗时操作
+ System.out.println("threadnum:" + threadnum);
+ Thread.sleep(1000);// 模拟请求的耗时操作
+ }
+}
+```
+
+执行 `acquire()` 方法阻塞,直到有一个许可证可以获得然后拿走一个许可证;每个 `release` 方法增加一个许可证,这可能会释放一个阻塞的 `acquire()` 方法。然而,其实并没有实际的许可证这个对象,`Semaphore` 只是维持了一个可获得许可证的数量。 `Semaphore` 经常用于限制获取某种资源的线程数量。
+
+当然一次也可以一次拿取和释放多个许可,不过一般没有必要这样做:
+
+```java
+semaphore.acquire(5);// 获取5个许可,所以可运行线程数量为20/5=4
+test(threadnum);
+semaphore.release(5);// 释放5个许可
+```
+
+除了 `acquire()` 方法之外,另一个比较常用的与之对应的方法是 `tryAcquire()` 方法,该方法如果获取不到许可就立即返回 false。
+
+`Semaphore` 有两种模式,公平模式和非公平模式。
+
+- **公平模式:** 调用 `acquire()` 方法的顺序就是获取许可证的顺序,遵循 FIFO;
+- **非公平模式:** 抢占式的。
+
+`Semaphore` 对应的两个构造方法如下:
+
+```java
+ public Semaphore(int permits) {
+ sync = new NonfairSync(permits);
+ }
+
+ public Semaphore(int permits, boolean fair) {
+ sync = fair ? new FairSync(permits) : new NonfairSync(permits);
+ }
+```
+
+**这两个构造方法,都必须提供许可的数量,第二个构造方法可以指定是公平模式还是非公平模式,默认非公平模式。**
+
+[issue645 补充内容](https://github.com/Snailclimb/JavaGuide/issues/645) :`Semaphore` 与 `CountDownLatch` 一样,也是共享锁的一种实现。它默认构造 AQS 的 state 为 `permits`。当执行任务的线程数量超出 `permits`,那么多余的线程将会被放入阻塞队列 Park,并自旋判断 state 是否大于 0。只有当 state 大于 0 的时候,阻塞的线程才能继续执行,此时先前执行任务的线程继续执行 `release()` 方法,`release()` 方法使得 state 的变量会加 1,那么自旋的线程便会判断成功。
+如此,每次只有最多不超过 `permits` 数量的线程能自旋成功,便限制了执行任务线程的数量。
+
+## CountDownLatch (倒计时器)
+
+`CountDownLatch` 允许 `count` 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。
+
+`CountDownLatch` 是共享锁的一种实现,它默认构造 AQS 的 `state` 值为 `count`。当线程使用 `countDown()` 方法时,其实使用了`tryReleaseShared`方法以 CAS 的操作来减少 `state`,直至 `state` 为 0 。当调用 `await()` 方法的时候,如果 `state` 不为 0,那就证明任务还没有执行完毕,`await()` 方法就会一直阻塞,也就是说 `await()` 方法之后的语句不会被执行。然后,`CountDownLatch` 会自旋 CAS 判断 `state == 0`,如果 `state == 0` 的话,就会释放所有等待的线程,`await()` 方法之后的语句得到执行。
+
+### CountDownLatch 的两种典型用法
+
+**1、某一线程在开始运行前等待 n 个线程执行完毕。**
+
+将 `CountDownLatch` 的计数器初始化为 n (`new CountDownLatch(n)`),每当一个任务线程执行完毕,就将计数器减 1 (`countdownlatch.countDown()`),当计数器的值变为 0 时,在 `CountDownLatch 上 await()` 的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。
+
+**2、实现多个线程开始执行任务的最大并行性。**
+
+注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的 `CountDownLatch` 对象,将其计数器初始化为 1 (`new CountDownLatch(1)`),多个线程在开始执行任务前首先 `coundownlatch.await()`,当主线程调用 `countDown()` 时,计数器变为 0,多个线程同时被唤醒。
+
+### CountDownLatch 的使用示例
+
+```java
+/**
+ *
+ * @author SnailClimb
+ * @date 2018年10月1日
+ * @Description: CountDownLatch 使用方法示例
+ */
+public class CountDownLatchExample1 {
+ // 请求的数量
+ private static final int threadCount = 550;
+
+ public static void main(String[] args) throws InterruptedException {
+ // 创建一个具有固定线程数量的线程池对象(如果这里线程池的线程数量给太少的话你会发现执行的很慢)
+ ExecutorService threadPool = Executors.newFixedThreadPool(300);
+ final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
+ for (int i = 0; i < threadCount; i++) {
+ final int threadnum = i;
+ threadPool.execute(() -> {// Lambda 表达式的运用
+ try {
+ test(threadnum);
+ } catch (InterruptedException e) {
+ // TODO Auto-generated catch block
+ e.printStackTrace();
+ } finally {
+ countDownLatch.countDown();// 表示一个请求已经被完成
+ }
+
+ });
+ }
+ countDownLatch.await();
+ threadPool.shutdown();
+ System.out.println("finish");
+ }
+
+ public static void test(int threadnum) throws InterruptedException {
+ Thread.sleep(1000);// 模拟请求的耗时操作
+ System.out.println("threadnum:" + threadnum);
+ Thread.sleep(1000);// 模拟请求的耗时操作
+ }
+}
+
+```
+
+上面的代码中,我们定义了请求的数量为 550,当这 550 个请求被处理完成之后,才会执行`System.out.println("finish");`。
+
+与 `CountDownLatch` 的第一次交互是主线程等待其他线程。主线程必须在启动其他线程后立即调用 `CountDownLatch.await()` 方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
+
+其他 N 个线程必须引用闭锁对象,因为他们需要通知 `CountDownLatch` 对象,他们已经完成了各自的任务。这种通知机制是通过 `CountDownLatch.countDown()`方法来完成的;每调用一次这个方法,在构造函数中初始化的 count 值就减 1。所以当 N 个线程都调 用了这个方法,count 的值等于 0,然后主线程就能通过 `await()`方法,恢复执行自己的任务。
+
+再插一嘴:`CountDownLatch` 的 `await()` 方法使用不当很容易产生死锁,比如我们上面代码中的 for 循环改为:
+
+```java
+for (int i = 0; i < threadCount-1; i++) {
+.......
+}
+```
+
+这样就导致 `count` 的值没办法等于 0,然后就会导致一直等待。
+
+### CountDownLatch 的不足
+
+`CountDownLatch` 是一次性的,计数器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当 `CountDownLatch` 使用完毕后,它不能再次被使用。
+
+### CountDownLatch 相常见面试题
+
+- `CountDownLatch` 怎么用?应用场景是什么?
+- `CountDownLatch` 和 `CyclicBarrier` 的不同之处?
+- `CountDownLatch` 类中主要的方法?
+
+## CyclicBarrier(循环栅栏)
+
+`CyclicBarrier` 和 `CountDownLatch` 非常类似,它也可以实现线程间的技术等待,但是它的功能比 `CountDownLatch` 更加复杂和强大。主要应用场景和 `CountDownLatch` 类似。
+
+> `CountDownLatch` 的实现是基于 AQS 的,而 `CycliBarrier` 是基于 `ReentrantLock`(`ReentrantLock` 也属于 AQS 同步器)和 `Condition` 的。
+
+`CyclicBarrier` 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是:让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。
+
+`CyclicBarrier` 默认的构造方法是 `CyclicBarrier(int parties)`,其参数表示屏障拦截的线程数量,每个线程调用 `await()` 方法告诉 `CyclicBarrier` 我已经到达了屏障,然后当前线程被阻塞。
+
+再来看一下它的构造函数:
+
+```java
+public CyclicBarrier(int parties) {
+ this(parties, null);
+}
+
+public CyclicBarrier(int parties, Runnable barrierAction) {
+ if (parties <= 0) throw new IllegalArgumentException();
+ this.parties = parties;
+ this.count = parties;
+ this.barrierCommand = barrierAction;
+}
+```
+
+其中,parties 就代表了有拦截的线程的数量,当拦截的线程数量达到这个值的时候就打开栅栏,让所有线程通过。
+
+### CyclicBarrier 的应用场景
+
+`CyclicBarrier` 可以用于多线程计算数据,最后合并计算结果的应用场景。比如我们用一个 Excel 保存了用户所有银行流水,每个 Sheet 保存一个帐户近一年的每笔银行流水,现在需要统计用户的日均银行流水,先用多线程处理每个 sheet 里的银行流水,都执行完之后,得到每个 sheet 的日均银行流水,最后,再用 barrierAction 用这些线程的计算结果,计算出整个 Excel 的日均银行流水。
+
+### CyclicBarrier 的使用示例
+
+示例 1:
+
+```java
+/**
+ *
+ * @author Snailclimb
+ * @date 2018年10月1日
+ * @Description: 测试 CyclicBarrier 类中带参数的 await() 方法
+ */
+public class CyclicBarrierExample2 {
+ // 请求的数量
+ private static final int threadCount = 550;
+ // 需要同步的线程数量
+ private static final CyclicBarrier cyclicBarrier = new CyclicBarrier(5);
+
+ public static void main(String[] args) throws InterruptedException {
+ // 创建线程池
+ ExecutorService threadPool = Executors.newFixedThreadPool(10);
+
+ for (int i = 0; i < threadCount; i++) {
+ final int threadNum = i;
+ Thread.sleep(1000);
+ threadPool.execute(() -> {
+ try {
+ test(threadNum);
+ } catch (InterruptedException e) {
+ // TODO Auto-generated catch block
+ e.printStackTrace();
+ } catch (BrokenBarrierException e) {
+ // TODO Auto-generated catch block
+ e.printStackTrace();
+ }
+ });
+ }
+ threadPool.shutdown();
+ }
+
+ public static void test(int threadnum) throws InterruptedException, BrokenBarrierException {
+ System.out.println("threadnum:" + threadnum + "is ready");
+ try {
+ /**等待60秒,保证子线程完全执行结束*/
+ cyclicBarrier.await(60, TimeUnit.SECONDS);
+ } catch (Exception e) {
+ System.out.println("-----CyclicBarrierException------");
+ }
+ System.out.println("threadnum:" + threadnum + "is finish");
+ }
+
+}
+```
+
+运行结果,如下:
+
+```
+threadnum:0is ready
+threadnum:1is ready
+threadnum:2is ready
+threadnum:3is ready
+threadnum:4is ready
+threadnum:4is finish
+threadnum:0is finish
+threadnum:1is finish
+threadnum:2is finish
+threadnum:3is finish
+threadnum:5is ready
+threadnum:6is ready
+threadnum:7is ready
+threadnum:8is ready
+threadnum:9is ready
+threadnum:9is finish
+threadnum:5is finish
+threadnum:8is finish
+threadnum:7is finish
+threadnum:6is finish
+......
+```
+
+可以看到当线程数量也就是请求数量达到我们定义的 5 个的时候, `await()` 方法之后的方法才被执行。
+
+另外,`CyclicBarrier` 还提供一个更高级的构造函数 `CyclicBarrier(int parties, Runnable barrierAction)`,用于在线程到达屏障时,优先执行 `barrierAction`,方便处理更复杂的业务场景。示例代码如下:
+
+```java
+/**
+ *
+ * @author SnailClimb
+ * @date 2018年10月1日
+ * @Description: 新建 CyclicBarrier 的时候指定一个 Runnable
+ */
+public class CyclicBarrierExample3 {
+ // 请求的数量
+ private static final int threadCount = 550;
+ // 需要同步的线程数量
+ private static final CyclicBarrier cyclicBarrier = new CyclicBarrier(5, () -> {
+ System.out.println("------当线程数达到之后,优先执行------");
+ });
+
+ public static void main(String[] args) throws InterruptedException {
+ // 创建线程池
+ ExecutorService threadPool = Executors.newFixedThreadPool(10);
+
+ for (int i = 0; i < threadCount; i++) {
+ final int threadNum = i;
+ Thread.sleep(1000);
+ threadPool.execute(() -> {
+ try {
+ test(threadNum);
+ } catch (InterruptedException e) {
+ // TODO Auto-generated catch block
+ e.printStackTrace();
+ } catch (BrokenBarrierException e) {
+ // TODO Auto-generated catch block
+ e.printStackTrace();
+ }
+ });
+ }
+ threadPool.shutdown();
+ }
+
+ public static void test(int threadnum) throws InterruptedException, BrokenBarrierException {
+ System.out.println("threadnum:" + threadnum + "is ready");
+ cyclicBarrier.await();
+ System.out.println("threadnum:" + threadnum + "is finish");
+ }
+
+}
+```
+
+运行结果,如下:
+
+```
+threadnum:0is ready
+threadnum:1is ready
+threadnum:2is ready
+threadnum:3is ready
+threadnum:4is ready
+------当线程数达到之后,优先执行------
+threadnum:4is finish
+threadnum:0is finish
+threadnum:2is finish
+threadnum:1is finish
+threadnum:3is finish
+threadnum:5is ready
+threadnum:6is ready
+threadnum:7is ready
+threadnum:8is ready
+threadnum:9is ready
+------当线程数达到之后,优先执行------
+threadnum:9is finish
+threadnum:5is finish
+threadnum:6is finish
+threadnum:8is finish
+threadnum:7is finish
+......
+```
+
+### CyclicBarrier 源码分析
+
+当调用 `CyclicBarrier` 对象调用 `await()` 方法时,实际上调用的是 `dowait(false, 0L)`方法。 `await()` 方法就像树立起一个栅栏的行为一样,将线程挡住了,当拦住的线程数量达到 `parties` 的值时,栅栏才会打开,线程才得以通过执行。
+
+```java
+public int await() throws InterruptedException, BrokenBarrierException {
+ try {
+ return dowait(false, 0L);
+ } catch (TimeoutException toe) {
+ throw new Error(toe); // cannot happen
+ }
+}
+```
+
+`dowait(false, 0L)`:
+
+```java
+ // 当线程数量或者请求数量达到 count 时 await 之后的方法才会被执行。上面的示例中 count 的值就为 5。
+ private int count;
+ /**
+ * Main barrier code, covering the various policies.
+ */
+ private int dowait(boolean timed, long nanos)
+ throws InterruptedException, BrokenBarrierException,
+ TimeoutException {
+ final ReentrantLock lock = this.lock;
+ // 锁住
+ lock.lock();
+ try {
+ final Generation g = generation;
+
+ if (g.broken)
+ throw new BrokenBarrierException();
+
+ // 如果线程中断了,抛出异常
+ if (Thread.interrupted()) {
+ breakBarrier();
+ throw new InterruptedException();
+ }
+ // cout减1
+ int index = --count;
+ // 当 count 数量减为 0 之后说明最后一个线程已经到达栅栏了,也就是达到了可以执行await 方法之后的条件
+ if (index == 0) { // tripped
+ boolean ranAction = false;
+ try {
+ final Runnable command = barrierCommand;
+ if (command != null)
+ command.run();
+ ranAction = true;
+ // 将 count 重置为 parties 属性的初始化值
+ // 唤醒之前等待的线程
+ // 下一波执行开始
+ nextGeneration();
+ return 0;
+ } finally {
+ if (!ranAction)
+ breakBarrier();
+ }
+ }
+
+ // loop until tripped, broken, interrupted, or timed out
+ for (;;) {
+ try {
+ if (!timed)
+ trip.await();
+ else if (nanos > 0L)
+ nanos = trip.awaitNanos(nanos);
+ } catch (InterruptedException ie) {
+ if (g == generation && ! g.broken) {
+ breakBarrier();
+ throw ie;
+ } else {
+ // We're about to finish waiting even if we had not
+ // been interrupted, so this interrupt is deemed to
+ // "belong" to subsequent execution.
+ Thread.currentThread().interrupt();
+ }
+ }
+
+ if (g.broken)
+ throw new BrokenBarrierException();
+
+ if (g != generation)
+ return index;
+
+ if (timed && nanos <= 0L) {
+ breakBarrier();
+ throw new TimeoutException();
+ }
+ }
+ } finally {
+ lock.unlock();
+ }
+ }
+
+```
+
+总结:`CyclicBarrier` 内部通过一个 count 变量作为计数器,count 的初始值为 parties 属性的初始化值,每当一个线程到了栅栏这里了,那么就将计数器减一。如果 count 值为 0 了,表示这是这一代最后一个线程到达栅栏,就尝试执行我们构造方法中输入的任务。
+
+### CyclicBarrier 和 CountDownLatch 的区别
+
+下面这个是国外一个大佬的回答:
+
+`CountDownLatch` 是计数器,只能使用一次,而 `CyclicBarrier` 的计数器提供 `reset` 功能,可以多次使用。但是我不那么认为它们之间的区别仅仅就是这么简单的一点。我们来从 jdk 作者设计的目的来看,javadoc 是这么描述它们的:
+
+> CountDownLatch: A synchronization aid that allows one or more threads to wait until a set of operations being performed in other threads completes.(CountDownLatch: 一个或者多个线程,等待其他多个线程完成某件事情之后才能执行;)
+> CyclicBarrier : A synchronization aid that allows a set of threads to all wait for each other to reach a common barrier point.(CyclicBarrier : 多个线程互相等待,直到到达同一个同步点,再继续一起执行。)
+
+对于 `CountDownLatch` 来说,重点是“一个线程(多个线程)等待”,而其他的 N 个线程在完成“某件事情”之后,可以终止,也可以等待。而对于 `CyclicBarrier`,重点是多个线程,在任意一个线程没有完成,所有的线程都必须等待。
+
+`CountDownLatch` 是计数器,线程完成一个记录一个,只不过计数不是递增而是递减,而 `CyclicBarrier` 更像是一个阀门,需要所有线程都到达,阀门才能打开,然后继续执行。
+
+### ReentrantLock 和 ReentrantReadWriteLock
+
+`ReentrantLock` 和 `synchronized` 的区别在上面已经讲过了这里就不多做讲解。另外,需要注意的是:读写锁 `ReentrantReadWriteLock` 可以保证多个线程可以同时读,所以在读操作远大于写操作的时候,读写锁就非常有用了。
diff --git "a/docs/java/concurrent/atomic\345\216\237\345\255\220\347\261\273\346\200\273\347\273\223.md" "b/docs/java/concurrent/atomic\345\216\237\345\255\220\347\261\273\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..7628e1fe7d2
--- /dev/null
+++ "b/docs/java/concurrent/atomic\345\216\237\345\255\220\347\261\273\346\200\273\347\273\223.md"
@@ -0,0 +1,583 @@
+---
+title: Atomic 原子类总结
+category: Java
+tag:
+ - Java并发
+---
+
+
+## Atomic 原子类介绍
+
+Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的。在我们这里 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
+
+所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
+
+并发包 `java.util.concurrent` 的原子类都存放在`java.util.concurrent.atomic`下,如下图所示。
+
+
+
+根据操作的数据类型,可以将 JUC 包中的原子类分为 4 类
+
+**基本类型**
+
+使用原子的方式更新基本类型
+
+- AtomicInteger:整型原子类
+- AtomicLong:长整型原子类
+- AtomicBoolean :布尔型原子类
+
+**数组类型**
+
+使用原子的方式更新数组里的某个元素
+
+- AtomicIntegerArray:整型数组原子类
+- AtomicLongArray:长整型数组原子类
+- AtomicReferenceArray :引用类型数组原子类
+
+**引用类型**
+
+- AtomicReference:引用类型原子类
+- AtomicMarkableReference:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,~~也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。~~
+- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
+
+**对象的属性修改类型**
+
+- AtomicIntegerFieldUpdater:原子更新整型字段的更新器
+- AtomicLongFieldUpdater:原子更新长整型字段的更新器
+- AtomicReferenceFieldUpdater:原子更新引用类型里的字段
+
+> **🐛 修正(参见:[issue#626](https://github.com/Snailclimb/JavaGuide/issues/626))** : `AtomicMarkableReference` 不能解决 ABA 问题。
+
+```java
+ /**
+
+AtomicMarkableReference是将一个boolean值作是否有更改的标记,本质就是它的版本号只有两个,true和false,
+
+修改的时候在这两个版本号之间来回切换,这样做并不能解决ABA的问题,只是会降低ABA问题发生的几率而已
+
+@author : mazh
+
+@Date : 2020/1/17 14:41
+*/
+
+public class SolveABAByAtomicMarkableReference {
+
+ private static AtomicMarkableReference atomicMarkableReference = new AtomicMarkableReference(100, false);
+
+ public static void main(String[] args) {
+
+ Thread refT1 = new Thread(() -> {
+ try {
+ TimeUnit.SECONDS.sleep(1);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ atomicMarkableReference.compareAndSet(100, 101, atomicMarkableReference.isMarked(), !atomicMarkableReference.isMarked());
+ atomicMarkableReference.compareAndSet(101, 100, atomicMarkableReference.isMarked(), !atomicMarkableReference.isMarked());
+ });
+
+ Thread refT2 = new Thread(() -> {
+ boolean marked = atomicMarkableReference.isMarked();
+ try {
+ TimeUnit.SECONDS.sleep(2);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ boolean c3 = atomicMarkableReference.compareAndSet(100, 101, marked, !marked);
+ System.out.println(c3); // 返回true,实际应该返回false
+ });
+
+ refT1.start();
+ refT2.start();
+ }
+ }
+```
+
+**CAS ABA 问题**
+
+- 描述: 第一个线程取到了变量 x 的值 A,然后巴拉巴拉干别的事,总之就是只拿到了变量 x 的值 A。这段时间内第二个线程也取到了变量 x 的值 A,然后把变量 x 的值改为 B,然后巴拉巴拉干别的事,最后又把变量 x 的值变为 A (相当于还原了)。在这之后第一个线程终于进行了变量 x 的操作,但是此时变量 x 的值还是 A,所以 compareAndSet 操作是成功。
+- 例子描述(可能不太合适,但好理解): 年初,现金为零,然后通过正常劳动赚了三百万,之后正常消费了(比如买房子)三百万。年末,虽然现金零收入(可能变成其他形式了),但是赚了钱是事实,还是得交税的!
+- 代码例子(以`AtomicInteger`为例)
+
+```java
+import java.util.concurrent.atomic.AtomicInteger;
+
+public class AtomicIntegerDefectDemo {
+ public static void main(String[] args) {
+ defectOfABA();
+ }
+
+ static void defectOfABA() {
+ final AtomicInteger atomicInteger = new AtomicInteger(1);
+
+ Thread coreThread = new Thread(
+ () -> {
+ final int currentValue = atomicInteger.get();
+ System.out.println(Thread.currentThread().getName() + " ------ currentValue=" + currentValue);
+
+ // 这段目的:模拟处理其他业务花费的时间
+ try {
+ Thread.sleep(300);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+
+ boolean casResult = atomicInteger.compareAndSet(1, 2);
+ System.out.println(Thread.currentThread().getName()
+ + " ------ currentValue=" + currentValue
+ + ", finalValue=" + atomicInteger.get()
+ + ", compareAndSet Result=" + casResult);
+ }
+ );
+ coreThread.start();
+
+ // 这段目的:为了让 coreThread 线程先跑起来
+ try {
+ Thread.sleep(100);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+
+ Thread amateurThread = new Thread(
+ () -> {
+ int currentValue = atomicInteger.get();
+ boolean casResult = atomicInteger.compareAndSet(1, 2);
+ System.out.println(Thread.currentThread().getName()
+ + " ------ currentValue=" + currentValue
+ + ", finalValue=" + atomicInteger.get()
+ + ", compareAndSet Result=" + casResult);
+
+ currentValue = atomicInteger.get();
+ casResult = atomicInteger.compareAndSet(2, 1);
+ System.out.println(Thread.currentThread().getName()
+ + " ------ currentValue=" + currentValue
+ + ", finalValue=" + atomicInteger.get()
+ + ", compareAndSet Result=" + casResult);
+ }
+ );
+ amateurThread.start();
+ }
+}
+```
+
+输出内容如下:
+
+```
+Thread-0 ------ currentValue=1
+Thread-1 ------ currentValue=1, finalValue=2, compareAndSet Result=true
+Thread-1 ------ currentValue=2, finalValue=1, compareAndSet Result=true
+Thread-0 ------ currentValue=1, finalValue=2, compareAndSet Result=true
+```
+
+下面我们来详细介绍一下这些原子类。
+
+## 基本类型原子类
+
+### 基本类型原子类介绍
+
+使用原子的方式更新基本类型
+
+- AtomicInteger:整型原子类
+- AtomicLong:长整型原子类
+- AtomicBoolean :布尔型原子类
+
+上面三个类提供的方法几乎相同,所以我们这里以 AtomicInteger 为例子来介绍。
+
+**AtomicInteger 类常用方法**
+
+```java
+public final int get() //获取当前的值
+public final int getAndSet(int newValue)//获取当前的值,并设置新的值
+public final int getAndIncrement()//获取当前的值,并自增
+public final int getAndDecrement() //获取当前的值,并自减
+public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
+boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
+public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
+```
+
+### AtomicInteger 常见方法使用
+
+```java
+import java.util.concurrent.atomic.AtomicInteger;
+
+public class AtomicIntegerTest {
+
+ public static void main(String[] args) {
+ // TODO Auto-generated method stub
+ int temvalue = 0;
+ AtomicInteger i = new AtomicInteger(0);
+ temvalue = i.getAndSet(3);
+ System.out.println("temvalue:" + temvalue + "; i:" + i);//temvalue:0; i:3
+ temvalue = i.getAndIncrement();
+ System.out.println("temvalue:" + temvalue + "; i:" + i);//temvalue:3; i:4
+ temvalue = i.getAndAdd(5);
+ System.out.println("temvalue:" + temvalue + "; i:" + i);//temvalue:4; i:9
+ }
+
+}
+```
+
+### 基本数据类型原子类的优势
+
+通过一个简单例子带大家看一下基本数据类型原子类的优势
+
+**① 多线程环境不使用原子类保证线程安全(基本数据类型)**
+
+```java
+class Test {
+ private volatile int count = 0;
+ //若要线程安全执行执行count++,需要加锁
+ public synchronized void increment() {
+ count++;
+ }
+
+ public int getCount() {
+ return count;
+ }
+}
+```
+
+**② 多线程环境使用原子类保证线程安全(基本数据类型)**
+
+```java
+class Test2 {
+ private AtomicInteger count = new AtomicInteger();
+
+ public void increment() {
+ count.incrementAndGet();
+ }
+ //使用AtomicInteger之后,不需要加锁,也可以实现线程安全。
+ public int getCount() {
+ return count.get();
+ }
+}
+
+```
+
+### AtomicInteger 线程安全原理简单分析
+
+AtomicInteger 类的部分源码:
+
+```java
+ // setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
+ private static final Unsafe unsafe = Unsafe.getUnsafe();
+ private static final long valueOffset;
+
+ static {
+ try {
+ valueOffset = unsafe.objectFieldOffset
+ (AtomicInteger.class.getDeclaredField("value"));
+ } catch (Exception ex) { throw new Error(ex); }
+ }
+
+ private volatile int value;
+```
+
+AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
+
+CAS 的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址。另外 value 是一个 volatile 变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
+
+## 数组类型原子类
+
+### 数组类型原子类介绍
+
+使用原子的方式更新数组里的某个元素
+
+- AtomicIntegerArray:整形数组原子类
+- AtomicLongArray:长整形数组原子类
+- AtomicReferenceArray :引用类型数组原子类
+
+上面三个类提供的方法几乎相同,所以我们这里以 AtomicIntegerArray 为例子来介绍。
+
+**AtomicIntegerArray 类常用方法**
+
+```java
+public final int get(int i) //获取 index=i 位置元素的值
+public final int getAndSet(int i, int newValue)//返回 index=i 位置的当前的值,并将其设置为新值:newValue
+public final int getAndIncrement(int i)//获取 index=i 位置元素的值,并让该位置的元素自增
+public final int getAndDecrement(int i) //获取 index=i 位置元素的值,并让该位置的元素自减
+public final int getAndAdd(int i, int delta) //获取 index=i 位置元素的值,并加上预期的值
+boolean compareAndSet(int i, int expect, int update) //如果输入的数值等于预期值,则以原子方式将 index=i 位置的元素值设置为输入值(update)
+public final void lazySet(int i, int newValue)//最终 将index=i 位置的元素设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
+```
+
+### AtomicIntegerArray 常见方法使用
+
+```java
+
+import java.util.concurrent.atomic.AtomicIntegerArray;
+
+public class AtomicIntegerArrayTest {
+
+ public static void main(String[] args) {
+ // TODO Auto-generated method stub
+ int temvalue = 0;
+ int[] nums = { 1, 2, 3, 4, 5, 6 };
+ AtomicIntegerArray i = new AtomicIntegerArray(nums);
+ for (int j = 0; j < nums.length; j++) {
+ System.out.println(i.get(j));
+ }
+ temvalue = i.getAndSet(0, 2);
+ System.out.println("temvalue:" + temvalue + "; i:" + i);
+ temvalue = i.getAndIncrement(0);
+ System.out.println("temvalue:" + temvalue + "; i:" + i);
+ temvalue = i.getAndAdd(0, 5);
+ System.out.println("temvalue:" + temvalue + "; i:" + i);
+ }
+
+}
+```
+
+## 引用类型原子类
+
+### 引用类型原子类介绍
+
+基本类型原子类只能更新一个变量,如果需要原子更新多个变量,需要使用 引用类型原子类。
+
+- AtomicReference:引用类型原子类
+- AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
+- AtomicMarkableReference :原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,~~也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。~~
+
+上面三个类提供的方法几乎相同,所以我们这里以 AtomicReference 为例子来介绍。
+
+### AtomicReference 类使用示例
+
+```java
+import java.util.concurrent.atomic.AtomicReference;
+
+public class AtomicReferenceTest {
+
+ public static void main(String[] args) {
+ AtomicReference<Person> ar = new AtomicReference<Person>();
+ Person person = new Person("SnailClimb", 22);
+ ar.set(person);
+ Person updatePerson = new Person("Daisy", 20);
+ ar.compareAndSet(person, updatePerson);
+
+ System.out.println(ar.get().getName());
+ System.out.println(ar.get().getAge());
+ }
+}
+
+class Person {
+ private String name;
+ private int age;
+
+ public Person(String name, int age) {
+ super();
+ this.name = name;
+ this.age = age;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+
+ public int getAge() {
+ return age;
+ }
+
+ public void setAge(int age) {
+ this.age = age;
+ }
+
+}
+```
+
+上述代码首先创建了一个 Person 对象,然后把 Person 对象设置进 AtomicReference 对象中,然后调用 compareAndSet 方法,该方法就是通过 CAS 操作设置 ar。如果 ar 的值为 person 的话,则将其设置为 updatePerson。实现原理与 AtomicInteger 类中的 compareAndSet 方法相同。运行上面的代码后的输出结果如下:
+
+```
+Daisy
+20
+```
+
+### AtomicStampedReference 类使用示例
+
+```java
+import java.util.concurrent.atomic.AtomicStampedReference;
+
+public class AtomicStampedReferenceDemo {
+ public static void main(String[] args) {
+ // 实例化、取当前值和 stamp 值
+ final Integer initialRef = 0, initialStamp = 0;
+ final AtomicStampedReference<Integer> asr = new AtomicStampedReference<>(initialRef, initialStamp);
+ System.out.println("currentValue=" + asr.getReference() + ", currentStamp=" + asr.getStamp());
+
+ // compare and set
+ final Integer newReference = 666, newStamp = 999;
+ final boolean casResult = asr.compareAndSet(initialRef, newReference, initialStamp, newStamp);
+ System.out.println("currentValue=" + asr.getReference()
+ + ", currentStamp=" + asr.getStamp()
+ + ", casResult=" + casResult);
+
+ // 获取当前的值和当前的 stamp 值
+ int[] arr = new int[1];
+ final Integer currentValue = asr.get(arr);
+ final int currentStamp = arr[0];
+ System.out.println("currentValue=" + currentValue + ", currentStamp=" + currentStamp);
+
+ // 单独设置 stamp 值
+ final boolean attemptStampResult = asr.attemptStamp(newReference, 88);
+ System.out.println("currentValue=" + asr.getReference()
+ + ", currentStamp=" + asr.getStamp()
+ + ", attemptStampResult=" + attemptStampResult);
+
+ // 重新设置当前值和 stamp 值
+ asr.set(initialRef, initialStamp);
+ System.out.println("currentValue=" + asr.getReference() + ", currentStamp=" + asr.getStamp());
+
+ // [不推荐使用,除非搞清楚注释的意思了] weak compare and set
+ // 困惑!weakCompareAndSet 这个方法最终还是调用 compareAndSet 方法。[版本: jdk-8u191]
+ // 但是注释上写着 "May fail spuriously and does not provide ordering guarantees,
+ // so is only rarely an appropriate alternative to compareAndSet."
+ // todo 感觉有可能是 jvm 通过方法名在 native 方法里面做了转发
+ final boolean wCasResult = asr.weakCompareAndSet(initialRef, newReference, initialStamp, newStamp);
+ System.out.println("currentValue=" + asr.getReference()
+ + ", currentStamp=" + asr.getStamp()
+ + ", wCasResult=" + wCasResult);
+ }
+}
+```
+
+输出结果如下:
+
+```
+currentValue=0, currentStamp=0
+currentValue=666, currentStamp=999, casResult=true
+currentValue=666, currentStamp=999
+currentValue=666, currentStamp=88, attemptStampResult=true
+currentValue=0, currentStamp=0
+currentValue=666, currentStamp=999, wCasResult=true
+```
+
+### AtomicMarkableReference 类使用示例
+
+```java
+import java.util.concurrent.atomic.AtomicMarkableReference;
+
+public class AtomicMarkableReferenceDemo {
+ public static void main(String[] args) {
+ // 实例化、取当前值和 mark 值
+ final Boolean initialRef = null, initialMark = false;
+ final AtomicMarkableReference<Boolean> amr = new AtomicMarkableReference<>(initialRef, initialMark);
+ System.out.println("currentValue=" + amr.getReference() + ", currentMark=" + amr.isMarked());
+
+ // compare and set
+ final Boolean newReference1 = true, newMark1 = true;
+ final boolean casResult = amr.compareAndSet(initialRef, newReference1, initialMark, newMark1);
+ System.out.println("currentValue=" + amr.getReference()
+ + ", currentMark=" + amr.isMarked()
+ + ", casResult=" + casResult);
+
+ // 获取当前的值和当前的 mark 值
+ boolean[] arr = new boolean[1];
+ final Boolean currentValue = amr.get(arr);
+ final boolean currentMark = arr[0];
+ System.out.println("currentValue=" + currentValue + ", currentMark=" + currentMark);
+
+ // 单独设置 mark 值
+ final boolean attemptMarkResult = amr.attemptMark(newReference1, false);
+ System.out.println("currentValue=" + amr.getReference()
+ + ", currentMark=" + amr.isMarked()
+ + ", attemptMarkResult=" + attemptMarkResult);
+
+ // 重新设置当前值和 mark 值
+ amr.set(initialRef, initialMark);
+ System.out.println("currentValue=" + amr.getReference() + ", currentMark=" + amr.isMarked());
+
+ // [不推荐使用,除非搞清楚注释的意思了] weak compare and set
+ // 困惑!weakCompareAndSet 这个方法最终还是调用 compareAndSet 方法。[版本: jdk-8u191]
+ // 但是注释上写着 "May fail spuriously and does not provide ordering guarantees,
+ // so is only rarely an appropriate alternative to compareAndSet."
+ // todo 感觉有可能是 jvm 通过方法名在 native 方法里面做了转发
+ final boolean wCasResult = amr.weakCompareAndSet(initialRef, newReference1, initialMark, newMark1);
+ System.out.println("currentValue=" + amr.getReference()
+ + ", currentMark=" + amr.isMarked()
+ + ", wCasResult=" + wCasResult);
+ }
+}
+```
+
+输出结果如下:
+
+```
+currentValue=null, currentMark=false
+currentValue=true, currentMark=true, casResult=true
+currentValue=true, currentMark=true
+currentValue=true, currentMark=false, attemptMarkResult=true
+currentValue=null, currentMark=false
+currentValue=true, currentMark=true, wCasResult=true
+```
+
+## 对象的属性修改类型原子类
+
+### 对象的属性修改类型原子类介绍
+
+如果需要原子更新某个类里的某个字段时,需要用到对象的属性修改类型原子类。
+
+- AtomicIntegerFieldUpdater:原子更新整形字段的更新器
+- AtomicLongFieldUpdater:原子更新长整形字段的更新器
+- AtomicReferenceFieldUpdater :原子更新引用类型里的字段的更新器
+
+要想原子地更新对象的属性需要两步。第一步,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新的对象属性必须使用 public volatile 修饰符。
+
+上面三个类提供的方法几乎相同,所以我们这里以 `AtomicIntegerFieldUpdater`为例子来介绍。
+
+### AtomicIntegerFieldUpdater 类使用示例
+
+```java
+import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;
+
+public class AtomicIntegerFieldUpdaterTest {
+ public static void main(String[] args) {
+ AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
+
+ User user = new User("Java", 22);
+ System.out.println(a.getAndIncrement(user));// 22
+ System.out.println(a.get(user));// 23
+ }
+}
+
+class User {
+ private String name;
+ public volatile int age;
+
+ public User(String name, int age) {
+ super();
+ this.name = name;
+ this.age = age;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+
+ public int getAge() {
+ return age;
+ }
+
+ public void setAge(int age) {
+ this.age = age;
+ }
+
+}
+```
+
+输出结果:
+
+```
+22
+23
+```
+
+## Reference
+
+- 《Java 并发编程的艺术》
diff --git a/docs/java/concurrent/completablefuture-intro.md b/docs/java/concurrent/completablefuture-intro.md
new file mode 100644
index 00000000000..810d5a61708
--- /dev/null
+++ b/docs/java/concurrent/completablefuture-intro.md
@@ -0,0 +1,526 @@
+---
+title: CompletableFuture入门
+category: Java
+tag:
+ - Java并发
+---
+
+
+自己在项目中使用 `CompletableFuture` 比较多,看到很多开源框架中也大量使用到了 `CompletableFuture` 。
+
+因此,专门写一篇文章来介绍这个 Java 8 才被引入的一个非常有用的用于异步编程的类。
+
+## 简单介绍
+
+`CompletableFuture` 同时实现了 `Future` 和 `CompletionStage` 接口。
+
+```java
+public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {
+}
+```
+
+`CompletableFuture` 除了提供了更为好用和强大的 `Future` 特性之外,还提供了函数式编程的能力。
+
+
+
+`Future` 接口有 5 个方法:
+
+- `boolean cancel(boolean mayInterruptIfRunning)` :尝试取消执行任务。
+- `boolean isCancelled()` :判断任务是否被取消。
+- `boolean isDone()` : 判断任务是否已经被执行完成。
+- `get()` :等待任务执行完成并获取运算结果。
+- `get(long timeout, TimeUnit unit)` :多了一个超时时间。
+
+
+
+`CompletionStage<T>` 接口中的方法比较多,`CompletableFuture` 的函数式能力就是这个接口赋予的。从这个接口的方法参数你就可以发现其大量使用了 Java8 引入的函数式编程。
+
+由于方法众多,所以这里不能一一讲解,下文中我会介绍大部分常见方法的使用。
+
+## 常见操作
+
+### 创建 CompletableFuture
+
+常见的创建 `CompletableFuture` 对象的方法如下:
+
+1. 通过 new 关键字。
+2. 基于 `CompletableFuture` 自带的静态工厂方法:`runAsync()` 、`supplyAsync()` 。
+
+#### new 关键字
+
+通过 new 关键字创建 `CompletableFuture` 对象这种使用方式可以看作是将 `CompletableFuture` 当做 `Future` 来使用。
+
+我在我的开源项目 [guide-rpc-framework](https://github.com/Snailclimb/guide-rpc-framework) 中就是这种方式创建的 `CompletableFuture` 对象。
+
+下面咱们来看一个简单的案例。
+
+我们通过创建了一个结果值类型为 `RpcResponse<Object>` 的 `CompletableFuture`,你可以把 `resultFuture` 看作是异步运算结果的载体。
+
+```java
+CompletableFuture<RpcResponse<Object>> resultFuture = new CompletableFuture<>();
+```
+
+假设在未来的某个时刻,我们得到了最终的结果。这时,我们可以调用 `complete()` 方法为其传入结果,这表示 `resultFuture` 已经被完成了。
+
+```java
+// complete() 方法只能调用一次,后续调用将被忽略。
+resultFuture.complete(rpcResponse);
+```
+
+你可以通过 `isDone()` 方法来检查是否已经完成。
+
+```java
+public boolean isDone() {
+ return result != null;
+}
+```
+
+获取异步计算的结果也非常简单,直接调用 `get()` 方法即可!
+
+```java
+rpcResponse = completableFuture.get();
+```
+
+注意 : `get()` 方法并不会阻塞,因为我们已经知道异步运算的结果了。
+
+如果你已经知道计算的结果的话,可以使用静态方法 `completedFuture()` 来创建 `CompletableFuture` 。
+
+```java
+CompletableFuture<String> future = CompletableFuture.completedFuture("hello!");
+assertEquals("hello!", future.get());
+```
+
+`completedFuture()` 方法底层调用的是带参数的 new 方法,只不过,这个方法不对外暴露。
+
+```java
+public static <U> CompletableFuture<U> completedFuture(U value) {
+ return new CompletableFuture<U>((value == null) ? NIL : value);
+}
+```
+
+#### 静态工厂方法
+
+这两个方法可以帮助我们封装计算逻辑。
+
+```java
+static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier);
+// 使用自定义线程池(推荐)
+static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor);
+static CompletableFuture<Void> runAsync(Runnable runnable);
+// 使用自定义线程池(推荐)
+static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor);
+```
+
+`runAsync()` 方法接受的参数是 `Runnable` ,这是一个函数式接口,不允许返回值。当你需要异步操作且不关心返回结果的时候可以使用 `runAsync()` 方法。
+
+```java
+@FunctionalInterface
+public interface Runnable {
+ public abstract void run();
+}
+```
+
+`supplyAsync()` 方法接受的参数是 `Supplier<U>` ,这也是一个函数式接口,`U` 是返回结果值的类型。
+
+```java
+@FunctionalInterface
+public interface Supplier<T> {
+
+ /**
+ * Gets a result.
+ *
+ * @return a result
+ */
+ T get();
+}
+```
+
+当你需要异步操作且关心返回结果的时候,可以使用 `supplyAsync()` 方法。
+
+```java
+CompletableFuture<Void> future = CompletableFuture.runAsync(() -> System.out.println("hello!"));
+future.get();// 输出 "hello!"
+CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> "hello!");
+assertEquals("hello!", future2.get());
+```
+
+### 处理异步结算的结果
+
+当我们获取到异步计算的结果之后,还可以对其进行进一步的处理,比较常用的方法有下面几个:
+
+- `thenApply()`
+- `thenAccept()`
+- `thenRun()`
+- `whenComplete()`
+
+`thenApply()` 方法接受一个 `Function` 实例,用它来处理结果。
+
+```java
+// 沿用上一个任务的线程池
+public <U> CompletableFuture<U> thenApply(
+ Function<? super T,? extends U> fn) {
+ return uniApplyStage(null, fn);
+}
+
+//使用默认的 ForkJoinPool 线程池(不推荐)
+public <U> CompletableFuture<U> thenApplyAsync(
+ Function<? super T,? extends U> fn) {
+ return uniApplyStage(defaultExecutor(), fn);
+}
+// 使用自定义线程池(推荐)
+public <U> CompletableFuture<U> thenApplyAsync(
+ Function<? super T,? extends U> fn, Executor executor) {
+ return uniApplyStage(screenExecutor(executor), fn);
+}
+```
+
+`thenApply()` 方法使用示例如下:
+
+```java
+CompletableFuture<String> future = CompletableFuture.completedFuture("hello!")
+ .thenApply(s -> s + "world!");
+assertEquals("hello!world!", future.get());
+// 这次调用将被忽略。
+future.thenApply(s -> s + "nice!");
+assertEquals("hello!world!", future.get());
+```
+
+你还可以进行 **流式调用**:
+
+```java
+CompletableFuture<String> future = CompletableFuture.completedFuture("hello!")
+ .thenApply(s -> s + "world!").thenApply(s -> s + "nice!");
+assertEquals("hello!world!nice!", future.get());
+```
+
+**如果你不需要从回调函数中获取返回结果,可以使用 `thenAccept()` 或者 `thenRun()`。这两个方法的区别在于 `thenRun()` 不能访问异步计算的结果。**
+
+`thenAccept()` 方法的参数是 `Consumer<? super T>` 。
+
+```java
+public CompletableFuture<Void> thenAccept(Consumer<? super T> action) {
+ return uniAcceptStage(null, action);
+}
+
+public CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action) {
+ return uniAcceptStage(defaultExecutor(), action);
+}
+
+public CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action,
+ Executor executor) {
+ return uniAcceptStage(screenExecutor(executor), action);
+}
+```
+
+顾名思义,`Consumer` 属于消费型接口,它可以接收 1 个输入对象然后进行“消费”。
+
+```java
+@FunctionalInterface
+public interface Consumer<T> {
+
+ void accept(T t);
+
+ default Consumer<T> andThen(Consumer<? super T> after) {
+ Objects.requireNonNull(after);
+ return (T t) -> { accept(t); after.accept(t); };
+ }
+}
+```
+
+`thenRun()` 的方法是的参数是 `Runnable` 。
+
+```java
+public CompletableFuture<Void> thenRun(Runnable action) {
+ return uniRunStage(null, action);
+}
+
+public CompletableFuture<Void> thenRunAsync(Runnable action) {
+ return uniRunStage(defaultExecutor(), action);
+}
+
+public CompletableFuture<Void> thenRunAsync(Runnable action,
+ Executor executor) {
+ return uniRunStage(screenExecutor(executor), action);
+}
+```
+
+`thenAccept()` 和 `thenRun()` 使用示例如下:
+
+```java
+CompletableFuture.completedFuture("hello!")
+ .thenApply(s -> s + "world!").thenApply(s -> s + "nice!").thenAccept(System.out::println);//hello!world!nice!
+
+CompletableFuture.completedFuture("hello!")
+ .thenApply(s -> s + "world!").thenApply(s -> s + "nice!").thenRun(() -> System.out.println("hello!"));//hello!
+```
+
+`whenComplete()` 的方法的参数是 `BiConsumer<? super T, ? super Throwable>` 。
+
+```java
+public CompletableFuture<T> whenComplete(
+ BiConsumer<? super T, ? super Throwable> action) {
+ return uniWhenCompleteStage(null, action);
+}
+
+
+public CompletableFuture<T> whenCompleteAsync(
+ BiConsumer<? super T, ? super Throwable> action) {
+ return uniWhenCompleteStage(defaultExecutor(), action);
+}
+// 使用自定义线程池(推荐)
+public CompletableFuture<T> whenCompleteAsync(
+ BiConsumer<? super T, ? super Throwable> action, Executor executor) {
+ return uniWhenCompleteStage(screenExecutor(executor), action);
+}
+```
+
+相对于 `Consumer` , `BiConsumer` 可以接收 2 个输入对象然后进行“消费”。
+
+```java
+@FunctionalInterface
+public interface BiConsumer<T, U> {
+ void accept(T t, U u);
+
+ default BiConsumer<T, U> andThen(BiConsumer<? super T, ? super U> after) {
+ Objects.requireNonNull(after);
+
+ return (l, r) -> {
+ accept(l, r);
+ after.accept(l, r);
+ };
+ }
+}
+```
+
+`whenComplete()` 使用示例如下:
+
+```java
+CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "hello!")
+ .whenComplete((res, ex) -> {
+ // res 代表返回的结果
+ // ex 的类型为 Throwable ,代表抛出的异常
+ System.out.println(res);
+ // 这里没有抛出异常所有为 null
+ assertNull(ex);
+ });
+assertEquals("hello!", future.get());
+```
+
+### 异常处理
+
+你可以通过 `handle()` 方法来处理任务执行过程中可能出现的抛出异常的情况。
+
+```java
+public <U> CompletableFuture<U> handle(
+ BiFunction<? super T, Throwable, ? extends U> fn) {
+ return uniHandleStage(null, fn);
+}
+
+public <U> CompletableFuture<U> handleAsync(
+ BiFunction<? super T, Throwable, ? extends U> fn) {
+ return uniHandleStage(defaultExecutor(), fn);
+}
+
+public <U> CompletableFuture<U> handleAsync(
+ BiFunction<? super T, Throwable, ? extends U> fn, Executor executor) {
+ return uniHandleStage(screenExecutor(executor), fn);
+}
+```
+
+示例代码如下:
+
+```java
+CompletableFuture<String> future
+ = CompletableFuture.supplyAsync(() -> {
+ if (true) {
+ throw new RuntimeException("Computation error!");
+ }
+ return "hello!";
+}).handle((res, ex) -> {
+ // res 代表返回的结果
+ // ex 的类型为 Throwable ,代表抛出的异常
+ return res != null ? res : "world!";
+});
+assertEquals("world!", future.get());
+```
+
+你还可以通过 `exceptionally()` 方法来处理异常情况。
+
+```java
+CompletableFuture<String> future
+ = CompletableFuture.supplyAsync(() -> {
+ if (true) {
+ throw new RuntimeException("Computation error!");
+ }
+ return "hello!";
+}).exceptionally(ex -> {
+ System.out.println(ex.toString());// CompletionException
+ return "world!";
+});
+assertEquals("world!", future.get());
+```
+
+如果你想让 `CompletableFuture` 的结果就是异常的话,可以使用 `completeExceptionally()` 方法为其赋值。
+
+```java
+CompletableFuture<String> completableFuture = new CompletableFuture<>();
+// ...
+completableFuture.completeExceptionally(
+ new RuntimeException("Calculation failed!"));
+// ...
+completableFuture.get(); // ExecutionException
+```
+
+### 组合 CompletableFuture
+
+你可以使用 `thenCompose()` 按顺序链接两个 `CompletableFuture` 对象。
+
+```java
+public <U> CompletableFuture<U> thenCompose(
+ Function<? super T, ? extends CompletionStage<U>> fn) {
+ return uniComposeStage(null, fn);
+}
+
+public <U> CompletableFuture<U> thenComposeAsync(
+ Function<? super T, ? extends CompletionStage<U>> fn) {
+ return uniComposeStage(defaultExecutor(), fn);
+}
+
+public <U> CompletableFuture<U> thenComposeAsync(
+ Function<? super T, ? extends CompletionStage<U>> fn,
+ Executor executor) {
+ return uniComposeStage(screenExecutor(executor), fn);
+}
+```
+
+`thenCompose()` 方法会使用示例如下:
+
+```java
+CompletableFuture<String> future
+ = CompletableFuture.supplyAsync(() -> "hello!")
+ .thenCompose(s -> CompletableFuture.supplyAsync(() -> s + "world!"));
+assertEquals("hello!world!", future.get());
+```
+
+在实际开发中,这个方法还是非常有用的。比如说,我们先要获取用户信息然后再用用户信息去做其他事情。
+
+和 `thenCompose()` 方法类似的还有 `thenCombine()` 方法, `thenCombine()` 同样可以组合两个 `CompletableFuture` 对象。
+
+```java
+CompletableFuture<String> completableFuture
+ = CompletableFuture.supplyAsync(() -> "hello!")
+ .thenCombine(CompletableFuture.supplyAsync(
+ () -> "world!"), (s1, s2) -> s1 + s2)
+ .thenCompose(s -> CompletableFuture.supplyAsync(() -> s + "nice!"));
+assertEquals("hello!world!nice!", completableFuture.get());
+```
+
+**那 `thenCompose()` 和 `thenCombine()` 有什么区别呢?**
+
+- `thenCompose()` 可以两个 `CompletableFuture` 对象,并将前一个任务的返回结果作为下一个任务的参数,它们之间存在着先后顺序。
+- `thenCombine()` 会在两个任务都执行完成后,把两个任务的结果合并。两个任务是并行执行的,它们之间并没有先后依赖顺序。
+
+### 并行运行多个 CompletableFuture
+
+你可以通过 `CompletableFuture` 的 `allOf()`这个静态方法来并行运行多个 `CompletableFuture` 。
+
+实际项目中,我们经常需要并行运行多个互不相关的任务,这些任务之间没有依赖关系,可以互相独立地运行。
+
+比说我们要读取处理 6 个文件,这 6 个任务都是没有执行顺序依赖的任务,但是我们需要返回给用户的时候将这几个文件的处理的结果进行统计整理。像这种情况我们就可以使用并行运行多个 `CompletableFuture` 来处理。
+
+示例代码如下:
+
+```java
+CompletableFuture<Void> task1 =
+ CompletableFuture.supplyAsync(()->{
+ //自定义业务操作
+ });
+......
+CompletableFuture<Void> task6 =
+ CompletableFuture.supplyAsync(()->{
+ //自定义业务操作
+ });
+......
+ CompletableFuture<Void> headerFuture=CompletableFuture.allOf(task1,.....,task6);
+
+ try {
+ headerFuture.join();
+ } catch (Exception ex) {
+ ......
+ }
+System.out.println("all done. ");
+```
+
+经常和 `allOf()` 方法拿来对比的是 `anyOf()` 方法。
+
+**`allOf()` 方法会等到所有的 `CompletableFuture` 都运行完成之后再返回**
+
+```java
+Random rand = new Random();
+CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> {
+ try {
+ Thread.sleep(1000 + rand.nextInt(1000));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ } finally {
+ System.out.println("future1 done...");
+ }
+ return "abc";
+});
+CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
+ try {
+ Thread.sleep(1000 + rand.nextInt(1000));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ } finally {
+ System.out.println("future2 done...");
+ }
+ return "efg";
+});
+```
+
+调用 `join()` 可以让程序等`future1` 和 `future2` 都运行完了之后再继续执行。
+
+```java
+CompletableFuture<Void> completableFuture = CompletableFuture.allOf(future1, future2);
+completableFuture.join();
+assertTrue(completableFuture.isDone());
+System.out.println("all futures done...");
+```
+
+输出:
+
+```java
+future1 done...
+future2 done...
+all futures done...
+```
+
+**`anyOf()` 方法不会等待所有的 `CompletableFuture` 都运行完成之后再返回,只要有一个执行完成即可!**
+
+```java
+CompletableFuture<Object> f = CompletableFuture.anyOf(future1, future2);
+System.out.println(f.get());
+```
+
+输出结果可能是:
+
+```java
+future2 done...
+efg
+```
+
+也可能是:
+
+```
+future1 done...
+abc
+```
+
+## 后记
+
+这篇文章只是简单介绍了 `CompletableFuture` 比较常用的一些 API 。
+
+如果想要深入学习的话,可以多找一些书籍和博客看。
+
+另外,建议G友们可以看看京东的 [asyncTool](https://gitee.com/jd-platform-opensource/asyncTool) 这个并发框架,里面大量使用到了 `CompletableFuture` 。
diff --git "a/docs/java/concurrent/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png" "b/docs/java/concurrent/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png"
new file mode 100644
index 00000000000..6997f5cacfc
Binary files /dev/null and "b/docs/java/concurrent/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png" differ
diff --git "a/docs/java/concurrent/images/interview-questions/synchronized\345\205\263\351\224\256\345\255\227.png" "b/docs/java/concurrent/images/interview-questions/synchronized\345\205\263\351\224\256\345\255\227.png"
new file mode 100644
index 00000000000..24ac1a8cc26
Binary files /dev/null and "b/docs/java/concurrent/images/interview-questions/synchronized\345\205\263\351\224\256\345\255\227.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/CachedThreadPool-execute.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/CachedThreadPool-execute.png"
new file mode 100644
index 00000000000..8b2ede8ab54
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/CachedThreadPool-execute.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executors\345\267\245\345\205\267\347\261\273.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executors\345\267\245\345\205\267\347\261\273.png"
new file mode 100644
index 00000000000..87658aa3f09
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executors\345\267\245\345\205\267\347\261\273.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executor\346\241\206\346\236\266\347\232\204\344\275\277\347\224\250\347\244\272\346\204\217\345\233\276.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executor\346\241\206\346\236\266\347\232\204\344\275\277\347\224\250\347\244\272\346\204\217\345\233\276.png"
new file mode 100644
index 00000000000..5cc148dd79a
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executor\346\241\206\346\236\266\347\232\204\344\275\277\347\224\250\347\244\272\346\204\217\345\233\276.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/FixedThreadPool.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/FixedThreadPool.png"
new file mode 100644
index 00000000000..fc1c7034fdf
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/FixedThreadPool.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\211\247\350\241\214\345\221\250\346\234\237\344\273\273\345\212\241\346\255\245\351\252\244.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\211\247\350\241\214\345\221\250\346\234\237\344\273\273\345\212\241\346\255\245\351\252\244.png"
new file mode 100644
index 00000000000..c56521d283e
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\211\247\350\241\214\345\221\250\346\234\237\344\273\273\345\212\241\346\255\245\351\252\244.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\234\272\345\210\266.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\234\272\345\210\266.png"
new file mode 100644
index 00000000000..bae0dc5b2dc
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\234\272\345\210\266.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/SingleThreadExecutor.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/SingleThreadExecutor.png"
new file mode 100644
index 00000000000..c933674fad4
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/SingleThreadExecutor.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/threadpoolexecutor\346\236\204\351\200\240\345\207\275\346\225\260.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/threadpoolexecutor\346\236\204\351\200\240\345\207\275\346\225\260.png"
new file mode 100644
index 00000000000..30c298591bc
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/threadpoolexecutor\346\236\204\351\200\240\345\207\275\346\225\260.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\344\273\273\345\212\241\347\232\204\346\211\247\350\241\214\347\233\270\345\205\263\346\216\245\345\217\243.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\344\273\273\345\212\241\347\232\204\346\211\247\350\241\214\347\233\270\345\205\263\346\216\245\345\217\243.png"
new file mode 100644
index 00000000000..6aebd60b591
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\344\273\273\345\212\241\347\232\204\346\211\247\350\241\214\347\233\270\345\205\263\346\216\245\345\217\243.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\345\233\276\350\247\243\347\272\277\347\250\213\346\261\240\345\256\236\347\216\260\345\216\237\347\220\206.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\345\233\276\350\247\243\347\272\277\347\250\213\346\261\240\345\256\236\347\216\260\345\216\237\347\220\206.png"
new file mode 100644
index 00000000000..bc661944a0a
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\345\233\276\350\247\243\347\272\277\347\250\213\346\261\240\345\256\236\347\216\260\345\216\237\347\220\206.png" differ
diff --git "a/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\347\272\277\347\250\213\346\261\240\345\220\204\344\270\252\345\217\202\346\225\260\344\271\213\351\227\264\347\232\204\345\205\263\347\263\273.png" "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\347\272\277\347\250\213\346\261\240\345\220\204\344\270\252\345\217\202\346\225\260\344\271\213\351\227\264\347\232\204\345\205\263\347\263\273.png"
new file mode 100644
index 00000000000..d609943bafe
Binary files /dev/null and "b/docs/java/concurrent/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\347\272\277\347\250\213\346\261\240\345\220\204\344\270\252\345\217\202\346\225\260\344\271\213\351\227\264\347\232\204\345\205\263\347\263\273.png" differ
diff --git a/docs/java/concurrent/images/thread-local/1.png b/docs/java/concurrent/images/thread-local/1.png
new file mode 100644
index 00000000000..b394e304a75
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/1.png differ
diff --git a/docs/java/concurrent/images/thread-local/10.png b/docs/java/concurrent/images/thread-local/10.png
new file mode 100644
index 00000000000..c9edb13f4f1
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/10.png differ
diff --git a/docs/java/concurrent/images/thread-local/11.png b/docs/java/concurrent/images/thread-local/11.png
new file mode 100644
index 00000000000..06d30638805
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/11.png differ
diff --git a/docs/java/concurrent/images/thread-local/12.png b/docs/java/concurrent/images/thread-local/12.png
new file mode 100644
index 00000000000..bd765217654
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/12.png differ
diff --git a/docs/java/concurrent/images/thread-local/13.png b/docs/java/concurrent/images/thread-local/13.png
new file mode 100644
index 00000000000..34c8d8c8ebe
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/13.png differ
diff --git a/docs/java/concurrent/images/thread-local/14.png b/docs/java/concurrent/images/thread-local/14.png
new file mode 100644
index 00000000000..b1b3abd63e3
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/14.png differ
diff --git a/docs/java/concurrent/images/thread-local/15.png b/docs/java/concurrent/images/thread-local/15.png
new file mode 100644
index 00000000000..25f5cb2b9ce
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/15.png differ
diff --git a/docs/java/concurrent/images/thread-local/16.png b/docs/java/concurrent/images/thread-local/16.png
new file mode 100644
index 00000000000..45d0424fe60
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/16.png differ
diff --git a/docs/java/concurrent/images/thread-local/17.png b/docs/java/concurrent/images/thread-local/17.png
new file mode 100644
index 00000000000..3194e4a3e25
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/17.png differ
diff --git a/docs/java/concurrent/images/thread-local/18.png b/docs/java/concurrent/images/thread-local/18.png
new file mode 100644
index 00000000000..2b340b0b565
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/18.png differ
diff --git a/docs/java/concurrent/images/thread-local/19.png b/docs/java/concurrent/images/thread-local/19.png
new file mode 100644
index 00000000000..4c9062794f7
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/19.png differ
diff --git a/docs/java/concurrent/images/thread-local/2.png b/docs/java/concurrent/images/thread-local/2.png
new file mode 100644
index 00000000000..c9af80e1e42
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/2.png differ
diff --git a/docs/java/concurrent/images/thread-local/20.png b/docs/java/concurrent/images/thread-local/20.png
new file mode 100644
index 00000000000..234c32a66ad
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/20.png differ
diff --git a/docs/java/concurrent/images/thread-local/21.png b/docs/java/concurrent/images/thread-local/21.png
new file mode 100644
index 00000000000..1b5a02b91c9
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/21.png differ
diff --git a/docs/java/concurrent/images/thread-local/22.png b/docs/java/concurrent/images/thread-local/22.png
new file mode 100644
index 00000000000..62eeff1215e
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/22.png differ
diff --git a/docs/java/concurrent/images/thread-local/23.png b/docs/java/concurrent/images/thread-local/23.png
new file mode 100644
index 00000000000..0b4a0409664
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/23.png differ
diff --git a/docs/java/concurrent/images/thread-local/24.png b/docs/java/concurrent/images/thread-local/24.png
new file mode 100644
index 00000000000..ae2fe0df682
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/24.png differ
diff --git a/docs/java/concurrent/images/thread-local/25.png b/docs/java/concurrent/images/thread-local/25.png
new file mode 100644
index 00000000000..9c66e254ec4
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/25.png differ
diff --git a/docs/java/concurrent/images/thread-local/26.png b/docs/java/concurrent/images/thread-local/26.png
new file mode 100644
index 00000000000..ef53f0a9bf7
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/26.png differ
diff --git a/docs/java/concurrent/images/thread-local/27.png b/docs/java/concurrent/images/thread-local/27.png
new file mode 100644
index 00000000000..617100507bf
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/27.png differ
diff --git a/docs/java/concurrent/images/thread-local/28.png b/docs/java/concurrent/images/thread-local/28.png
new file mode 100644
index 00000000000..68f67602412
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/28.png differ
diff --git a/docs/java/concurrent/images/thread-local/29.png b/docs/java/concurrent/images/thread-local/29.png
new file mode 100644
index 00000000000..d662f80b527
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/29.png differ
diff --git a/docs/java/concurrent/images/thread-local/3.png b/docs/java/concurrent/images/thread-local/3.png
new file mode 100644
index 00000000000..a0b418c0fc0
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/3.png differ
diff --git a/docs/java/concurrent/images/thread-local/30.png b/docs/java/concurrent/images/thread-local/30.png
new file mode 100644
index 00000000000..27ec27f74e6
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/30.png differ
diff --git a/docs/java/concurrent/images/thread-local/31.png b/docs/java/concurrent/images/thread-local/31.png
new file mode 100644
index 00000000000..96b83ca1c0a
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/31.png differ
diff --git a/docs/java/concurrent/images/thread-local/4.png b/docs/java/concurrent/images/thread-local/4.png
new file mode 100644
index 00000000000..b0278b70188
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/4.png differ
diff --git a/docs/java/concurrent/images/thread-local/5.png b/docs/java/concurrent/images/thread-local/5.png
new file mode 100644
index 00000000000..81f24a08b70
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/5.png differ
diff --git a/docs/java/concurrent/images/thread-local/6.png b/docs/java/concurrent/images/thread-local/6.png
new file mode 100644
index 00000000000..66dc77c110b
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/6.png differ
diff --git a/docs/java/concurrent/images/thread-local/7.png b/docs/java/concurrent/images/thread-local/7.png
new file mode 100644
index 00000000000..d13653a05c9
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/7.png differ
diff --git a/docs/java/concurrent/images/thread-local/8.png b/docs/java/concurrent/images/thread-local/8.png
new file mode 100644
index 00000000000..b7e466d838a
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/8.png differ
diff --git a/docs/java/concurrent/images/thread-local/9.png b/docs/java/concurrent/images/thread-local/9.png
new file mode 100644
index 00000000000..5964fb0c4d1
Binary files /dev/null and b/docs/java/concurrent/images/thread-local/9.png differ
diff --git a/docs/java/concurrent/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png b/docs/java/concurrent/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
new file mode 100644
index 00000000000..62f2c3e3733
Binary files /dev/null and b/docs/java/concurrent/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png differ
diff --git a/docs/java/concurrent/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png b/docs/java/concurrent/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
new file mode 100644
index 00000000000..1dc7e4b6d7e
Binary files /dev/null and b/docs/java/concurrent/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png differ
diff --git a/docs/java/concurrent/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png b/docs/java/concurrent/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
new file mode 100644
index 00000000000..7dc9b398c90
Binary files /dev/null and b/docs/java/concurrent/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png differ
diff --git a/docs/java/concurrent/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png b/docs/java/concurrent/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
new file mode 100644
index 00000000000..27cdbee3ead
Binary files /dev/null and b/docs/java/concurrent/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png differ
diff --git a/docs/java/concurrent/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png b/docs/java/concurrent/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
new file mode 100644
index 00000000000..f0a781d62cd
Binary files /dev/null and b/docs/java/concurrent/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png differ
diff --git "a/docs/java/concurrent/images/thread-pool/\347\272\277\347\250\213\346\261\240\344\275\277\347\224\250\344\270\215\345\275\223\345\257\274\350\207\264\346\255\273\351\224\201.drawio" "b/docs/java/concurrent/images/thread-pool/\347\272\277\347\250\213\346\261\240\344\275\277\347\224\250\344\270\215\345\275\223\345\257\274\350\207\264\346\255\273\351\224\201.drawio"
new file mode 100644
index 00000000000..3a2c775adc7
--- /dev/null
+++ "b/docs/java/concurrent/images/thread-pool/\347\272\277\347\250\213\346\261\240\344\275\277\347\224\250\344\270\215\345\275\223\345\257\274\350\207\264\346\255\273\351\224\201.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-09-13T02:23:43.163Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="ZquFXXcWCCCaLHGcsSdS" version="13.4.5" type="device"><diagram id="2QZ9v8tFcnqdJ94wR8Zd" name="Page-1">7Vpbj5s4GP01fkwFBgw8QkLaSl2p0qzU3acVA+ayJTglziTpr18bTLg5WaYThrQdaTRjf75gn/Md+7M9QFtuju8Lf5v8QUKcAaiER6CtAISqqiD2h1tOlcWyYWWIizQUlRrDQ/odC6MirPs0xLtORUpIRtNt1xiQPMcB7dj8oiCHbrWIZN2vbv0YDwwPgZ8NrV/SkCZiFtBs7B9wGif1l1VkVyUbv64sZrJL/JAcWibNA9qyIIRWqc1xiTMOXo1L1W59ofQ8sALndEyDKF4s0OLpz4do5cF/PirF8tNuoVW9PPnZXkxYDJaeagQKss9DzDtRgeYekpTih60f8NID45zZErrJRHGUZtmSZKQo22qhj60oYPYdLchX3CpBgYUfI1YynIaY2RMuKD62TGJa7zHZYFqcWBVRaguEhYsZInto+FJrEpIWV0jYfOEi8bnjBkWWEEA+A1R9WlCjCKNACmpo2o+KMgmoqj43qsaNUb09RlCbGyM0xMgzgGsClyXYbxdYa+BZwPK4kRWxrI24xWVpHXgIuA5g02KVbae06LwV++GVHeCoA9AZVrSLbNcvc5LjnhMLk5+lcc6yAWMAM7vLkU/Z2uuIgk0ahvwzUiobsrnHRySnYvdQ0W3YPe9Bgl5Twq4pYRdOxa45il0ELBs4JieVsWUteR3HKxNvpA5IVdHcrFoSVhGwl8Bx3qT6g6xKY4BXZdWW7FYo4+jvtn7eoQV92/MYsMRlsSuBcVgFBsmxKWSpuPzLhe4Ad80TDnMPt/QEFTiKzDfWwF0Cy+IWVsG1ygVjDSxN3o/NSpXSkVhXTl63t+uxMyiq4YvB9B2MAcMC80tu0A5pej7QjxsNbIW6LMSx4KOGbuQ1RtdpdDh0GmgZQ6dR7am8RhLT4JCdR0SWFDQhMcn9zGusPXU1dT4RshVw/4spPQm8/T0lXTIYgsXpL9G+zPzNM++MOrs6tgtXp+cKeUf2RYCvzFutj3Z+EWN6raKgg6NyleICZz5Nn7qnuNvzpb3xdZ0vdFd81ePubLYmXyBdNNw/hxvoxGfhCXZGo78zyuKdVz2jQP031QwcqxnrrjQDjTn4mgN3+65wr8f9ghBSRZdCyAsrHhwb6N3/pWB/4dNnvxaE6Ddd+LSRAqzZuBMB1nf8b3xdAki9K75U2WPGxAtm/usumGj2SFEd8ZCC89Dhz3zgfFUV+rvkDHQLVG7/7FOKi7y0QEU7Q1o/7cGukKBxDdr/dfsWcIYEt9o2Wh3iC59JykbS8Ibsd0aXuf6tViV50a4hZdiV2XUBQ+91VC0Jg45Kds8TfwHhsjeeSl+clVEK1pmCS+kORGwAZ1Veig3OeQu1JePqSxPIeMS7XXsR128ja1PpHQCV2WUteaV67jqty9fpKxRPE9pOQJCmzk6Q5EliaoJgR4OTbaWv83bep1SfX3Mvf4/4AUp/Gs0Zs2uu/thrEpT/yppD81MquWyentKfRnOm5LntVgSxbPOPdVV02vx7oub9Bw==</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/java/concurrent/images/thread-pool/\347\272\277\347\250\213\346\261\240\344\275\277\347\224\250\344\270\215\345\275\223\345\257\274\350\207\264\346\255\273\351\224\201.png" "b/docs/java/concurrent/images/thread-pool/\347\272\277\347\250\213\346\261\240\344\275\277\347\224\250\344\270\215\345\275\223\345\257\274\350\207\264\346\255\273\351\224\201.png"
new file mode 100644
index 00000000000..1ad4f811ac8
Binary files /dev/null and "b/docs/java/concurrent/images/thread-pool/\347\272\277\347\250\213\346\261\240\344\275\277\347\224\250\344\270\215\345\275\223\345\257\274\350\207\264\346\255\273\351\224\201.png" differ
diff --git "a/docs/java/concurrent/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png" "b/docs/java/concurrent/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png"
new file mode 100644
index 00000000000..a5791ce5af6
Binary files /dev/null and "b/docs/java/concurrent/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png" differ
diff --git "a/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png" "b/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png"
new file mode 100644
index 00000000000..ff907c9caa9
Binary files /dev/null and "b/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png" differ
diff --git "a/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png" "b/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png"
new file mode 100644
index 00000000000..862f282f6f9
Binary files /dev/null and "b/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png" differ
diff --git "a/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png" "b/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png"
new file mode 100644
index 00000000000..05e3bff506c
Binary files /dev/null and "b/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png" differ
diff --git "a/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png" "b/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png"
new file mode 100644
index 00000000000..ab61bff85dc
Binary files /dev/null and "b/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png" differ
diff --git "a/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png" "b/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png"
new file mode 100644
index 00000000000..14d1ea85d24
Binary files /dev/null and "b/docs/java/concurrent/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png" differ
diff --git "a/docs/java/concurrent/java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/concurrent/java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..2cf5c7cf22e
--- /dev/null
+++ "b/docs/java/concurrent/java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -0,0 +1,282 @@
+---
+title: Java 并发常见知识点&面试题总结(基础篇)
+category: Java
+tag:
+ - Java并发
+---
+
+## 什么是线程和进程?
+
+### 何为进程?
+
+进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。
+
+在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。
+
+如下图所示,在 windows 中通过查看任务管理器的方式,我们就可以清楚看到 window 当前运行的进程(.exe 文件的运行)。
+
+
+
+### 何为线程?
+
+线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的**堆**和**方法区**资源,但每个线程有自己的**程序计数器**、**虚拟机栈**和**本地方法栈**,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
+
+Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。
+
+```java
+public class MultiThread {
+ public static void main(String[] args) {
+ // 获取 Java 线程管理 MXBean
+ ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
+ // 不需要获取同步的 monitor 和 synchronizer 信息,仅获取线程和线程堆栈信息
+ ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false);
+ // 遍历线程信息,仅打印线程 ID 和线程名称信息
+ for (ThreadInfo threadInfo : threadInfos) {
+ System.out.println("[" + threadInfo.getThreadId() + "] " + threadInfo.getThreadName());
+ }
+ }
+}
+```
+
+上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可):
+
+```
+[5] Attach Listener //添加事件
+[4] Signal Dispatcher // 分发处理给 JVM 信号的线程
+[3] Finalizer //调用对象 finalize 方法的线程
+[2] Reference Handler //清除 reference 线程
+[1] main //main 线程,程序入口
+```
+
+从上面的输出内容可以看出:**一个 Java 程序的运行是 main 线程和多个其他线程同时运行**。
+
+## 请简要描述线程与进程的关系,区别及优缺点?
+
+**从 JVM 角度说进程和线程之间的关系**
+
+### 图解进程和线程的关系
+
+下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。
+
+
+
+从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
+
+**总结:** **线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。**
+
+下面是该知识点的扩展内容!
+
+下面来思考这样一个问题:为什么**程序计数器**、**虚拟机栈**和**本地方法栈**是线程私有的呢?为什么堆和方法区是线程共享的呢?
+
+### 程序计数器为什么是私有的?
+
+程序计数器主要有下面两个作用:
+
+1. 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
+2. 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
+
+需要注意的是,如果执行的是 native 方法,那么程序计数器记录的是 undefined 地址,只有执行的是 Java 代码时程序计数器记录的才是下一条指令的地址。
+
+所以,程序计数器私有主要是为了**线程切换后能恢复到正确的执行位置**。
+
+### 虚拟机栈和本地方法栈为什么是私有的?
+
+- **虚拟机栈:** 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
+- **本地方法栈:** 和虚拟机栈所发挥的作用非常相似,区别是: **虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。** 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
+
+所以,为了**保证线程中的局部变量不被别的线程访问到**,虚拟机栈和本地方法栈是线程私有的。
+
+### 一句话简单了解堆和方法区
+
+堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (几乎所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
+
+## 说说并发与并行的区别?
+
+- **并发:** 同一时间段,多个任务都在执行 (单位时间内不一定同时执行);
+- **并行:** 单位时间内,多个任务同时执行。
+
+## 为什么要使用多线程呢?
+
+先从总体上来说:
+
+- **从计算机底层来说:** 线程可以比作是轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
+- **从当代互联网发展趋势来说:** 现在的系统动不动就要求百万级甚至千万级的并发量,而多线程并发编程正是开发高并发系统的基础,利用好多线程机制可以大大提高系统整体的并发能力以及性能。
+
+再深入到计算机底层来探讨:
+
+- **单核时代**: 在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
+- **多核时代**: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
+
+## 使用多线程可能带来什么问题?
+
+并发编程的目的就是为了能提高程序的执行效率提高程序运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、死锁、线程不安全等等。
+
+## 说说线程的生命周期和状态?
+
+Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态(图源《Java 并发编程艺术》4.1.4 节)。
+
+
+
+线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。Java 线程状态变迁如下图所示(图源《Java 并发编程艺术》4.1.4 节):
+
+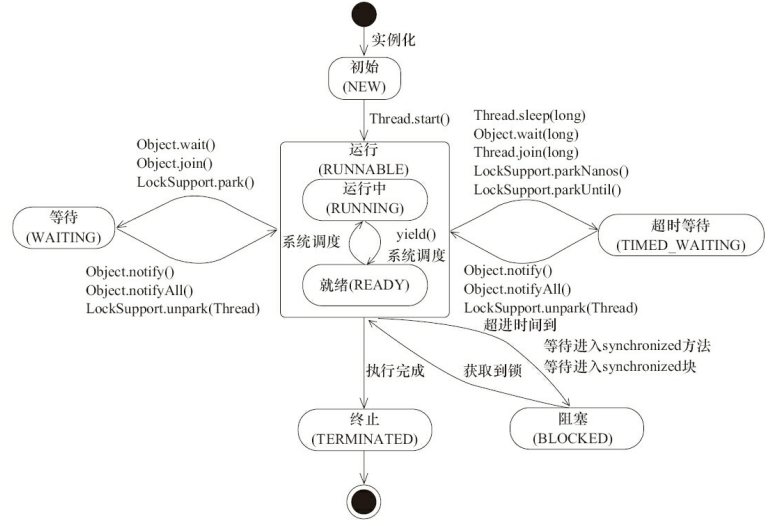
+
+> 订正(来自[issue736](https://github.com/Snailclimb/JavaGuide/issues/736)):原图中 wait 到 runnable 状态的转换中,`join`实际上是`Thread`类的方法,但这里写成了`Object`。
+
+由上图可以看出:线程创建之后它将处于 **NEW(新建)** 状态,调用 `start()` 方法后开始运行,线程这时候处于 **READY(可运行)** 状态。可运行状态的线程获得了 CPU 时间片(timeslice)后就处于 **RUNNING(运行)** 状态。
+
+> 在操作系统中层面线程有 READY 和 RUNNING 状态,而在 JVM 层面只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinJava.com/ "HowToDoInJava"):[Java Thread Life Cycle and Thread States](https://howtodoinJava.com/Java/multi-threading/Java-thread-life-cycle-and-thread-states/ "Java Thread Life Cycle and Thread States")),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。
+>
+> **为什么 JVM 没有区分这两种状态呢?** (摘自:[java线程运行怎么有第六种状态? - Dawell的回答](https://www.zhihu.com/question/56494969/answer/154053599) ) 现在的<b>时分</b>(time-sharing)<b>多任务</b>(multi-task)操作系统架构通常都是用所谓的“<b>时间分片</b>(time quantum or time slice)”方式进行<b>抢占式</b>(preemptive)轮转调度(round-robin式)。这个时间分片通常是很小的,一个线程一次最多只能在 CPU 上运行比如 10-20ms 的时间(此时处于 running 状态),也即大概只有 0.01 秒这一量级,时间片用后就要被切换下来放入调度队列的末尾等待再次调度。(也即回到 ready 状态)。线程切换的如此之快,区分这两种状态就没什么意义了。
+
+
+
+当线程执行 `wait()`方法之后,线程进入 **WAITING(等待)** 状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 **TIMED_WAITING(超时等待)** 状态相当于在等待状态的基础上增加了超时限制,比如通过 `sleep(long millis)`方法或 `wait(long millis)`方法可以将 Java 线程置于 TIMED_WAITING 状态。当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 **BLOCKED(阻塞)** 状态。线程在执行 Runnable 的`run()`方法之后将会进入到 **TERMINATED(终止)** 状态。
+
+相关阅读:[挑错 |《Java 并发编程的艺术》中关于线程状态的三处错误](https://mp.weixin.qq.com/s/UOrXql_LhOD8dhTq_EPI0w) 。
+
+## 什么是上下文切换?
+
+线程在执行过程中会有自己的运行条件和状态(也称上下文),比如上文所说到过的程序计数器,栈信息等。当出现如下情况的时候,线程会从占用 CPU 状态中退出。
+- 主动让出 CPU,比如调用了 `sleep()`, `wait()` 等。
+- 时间片用完,因为操作系统要防止一个线程或者进程长时间占用CPU导致其他线程或者进程饿死。
+- 调用了阻塞类型的系统中断,比如请求 IO,线程被阻塞。
+- 被终止或结束运行
+
+这其中前三种都会发生线程切换,线程切换意味着需要保存当前线程的上下文,留待线程下次占用 CPU 的时候恢复现场。并加载下一个将要占用 CPU 的线程上下文。这就是所谓的 **上下文切换**。
+
+上下文切换是现代操作系统的基本功能,因其每次需要保存信息恢复信息,这将会占用 CPU,内存等系统资源进行处理,也就意味着效率会有一定损耗,如果频繁切换就会造成整体效率低下。
+
+## 什么是线程死锁?如何避免死锁?
+
+### 认识线程死锁
+
+线程死锁描述的是这样一种情况:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
+
+如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
+
+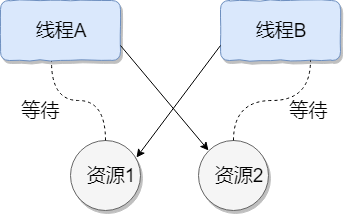
+
+下面通过一个例子来说明线程死锁,代码模拟了上图的死锁的情况 (代码来源于《并发编程之美》):
+
+```java
+public class DeadLockDemo {
+ private static Object resource1 = new Object();//资源 1
+ private static Object resource2 = new Object();//资源 2
+
+ public static void main(String[] args) {
+ new Thread(() -> {
+ synchronized (resource1) {
+ System.out.println(Thread.currentThread() + "get resource1");
+ try {
+ Thread.sleep(1000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println(Thread.currentThread() + "waiting get resource2");
+ synchronized (resource2) {
+ System.out.println(Thread.currentThread() + "get resource2");
+ }
+ }
+ }, "线程 1").start();
+
+ new Thread(() -> {
+ synchronized (resource2) {
+ System.out.println(Thread.currentThread() + "get resource2");
+ try {
+ Thread.sleep(1000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println(Thread.currentThread() + "waiting get resource1");
+ synchronized (resource1) {
+ System.out.println(Thread.currentThread() + "get resource1");
+ }
+ }
+ }, "线程 2").start();
+ }
+}
+```
+
+Output
+
+```
+Thread[线程 1,5,main]get resource1
+Thread[线程 2,5,main]get resource2
+Thread[线程 1,5,main]waiting get resource2
+Thread[线程 2,5,main]waiting get resource1
+```
+
+线程 A 通过 `synchronized (resource1)` 获得 `resource1` 的监视器锁,然后通过`Thread.sleep(1000);`让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。上面的例子符合产生死锁的四个必要条件。
+
+学过操作系统的朋友都知道产生死锁必须具备以下四个条件:
+
+1. 互斥条件:该资源任意一个时刻只由一个线程占用。
+2. 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
+3. 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
+4. 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
+
+### 如何预防和避免线程死锁?
+
+**如何预防死锁?** 破坏死锁的产生的必要条件即可:
+
+1. **破坏请求与保持条件** :一次性申请所有的资源。
+2. **破坏不剥夺条件** :占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
+3. **破坏循环等待条件** :靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
+
+**如何避免死锁?**
+
+避免死锁就是在资源分配时,借助于算法(比如银行家算法)对资源分配进行计算评估,使其进入安全状态。
+
+**安全状态** 指的是系统能够按照某种进程推进顺序(P1、P2、P3.....Pn)来为每个进程分配所需资源,直到满足每个进程对资源的最大需求,使每个进程都可顺利完成。称<P1、P2、P3.....Pn>序列为安全序列。
+
+我们对线程 2 的代码修改成下面这样就不会产生死锁了。
+
+```java
+ new Thread(() -> {
+ synchronized (resource1) {
+ System.out.println(Thread.currentThread() + "get resource1");
+ try {
+ Thread.sleep(1000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println(Thread.currentThread() + "waiting get resource2");
+ synchronized (resource2) {
+ System.out.println(Thread.currentThread() + "get resource2");
+ }
+ }
+ }, "线程 2").start();
+```
+
+Output
+
+```
+Thread[线程 1,5,main]get resource1
+Thread[线程 1,5,main]waiting get resource2
+Thread[线程 1,5,main]get resource2
+Thread[线程 2,5,main]get resource1
+Thread[线程 2,5,main]waiting get resource2
+Thread[线程 2,5,main]get resource2
+
+Process finished with exit code 0
+```
+
+我们分析一下上面的代码为什么避免了死锁的发生?
+
+线程 1 首先获得到 resource1 的监视器锁,这时候线程 2 就获取不到了。然后线程 1 再去获取 resource2 的监视器锁,可以获取到。然后线程 1 释放了对 resource1、resource2 的监视器锁的占用,线程 2 获取到就可以执行了。这样就破坏了破坏循环等待条件,因此避免了死锁。
+
+## 说说 sleep() 方法和 wait() 方法区别和共同点?
+
+- 两者最主要的区别在于:**`sleep()` 方法没有释放锁,而 `wait()` 方法释放了锁** 。
+- 两者都可以暂停线程的执行。
+- `wait()` 通常被用于线程间交互/通信,`sleep() `通常被用于暂停执行。
+- `wait()` 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 `notify() `或者 `notifyAll()` 方法。`sleep() `方法执行完成后,线程会自动苏醒。或者可以使用 `wait(long timeout)` 超时后线程会自动苏醒。
+
+## 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
+
+这是另一个非常经典的 Java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
+
+new 一个 Thread,线程进入了新建状态。调用 `start()`方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 `start()` 会执行线程的相应准备工作,然后自动执行 `run()` 方法的内容,这是真正的多线程工作。 但是,直接执行 `run()` 方法,会把 `run()` 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
+
+**总结: 调用 `start()` 方法方可启动线程并使线程进入就绪状态,直接执行 `run()` 方法的话不会以多线程的方式执行。**
diff --git "a/docs/java/concurrent/java\345\271\266\345\217\221\350\277\233\351\230\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/concurrent/java\345\271\266\345\217\221\350\277\233\351\230\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..2278eaf1b08
--- /dev/null
+++ "b/docs/java/concurrent/java\345\271\266\345\217\221\350\277\233\351\230\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -0,0 +1,1052 @@
+---
+title: Java 并发常见知识点&面试题总结(进阶篇)
+category: Java
+tag:
+ - Java并发
+---
+
+## 1.synchronized 关键字
+
+
+
+### 1.1.说一说自己对于 synchronized 关键字的了解
+
+**`synchronized` 关键字解决的是多个线程之间访问资源的同步性,`synchronized`关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。**
+
+另外,在 Java 早期版本中,`synchronized` 属于 **重量级锁**,效率低下。
+
+**为什么呢?**
+
+因为监视器锁(monitor)是依赖于底层的操作系统的 `Mutex Lock` 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
+
+庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 `synchronized` 较大优化,所以现在的 `synchronized` 锁效率也优化得很不错了。JDK1.6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
+
+所以,你会发现目前的话,不论是各种开源框架还是 JDK 源码都大量使用了 `synchronized` 关键字。
+
+### 1.2. 说说自己是怎么使用 synchronized 关键字
+
+**synchronized 关键字最主要的三种使用方式:**
+
+**1.修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得 **当前对象实例的锁**
+
+```java
+synchronized void method() {
+ //业务代码
+}
+```
+
+**2.修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 **当前 class 的锁**。因为静态成员不属于任何一个实例对象,是类成员( _static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份_)。所以,如果一个线程 A 调用一个实例对象的非静态 `synchronized` 方法,而线程 B 需要调用这个实例对象所属类的静态 `synchronized` 方法,是允许的,不会发生互斥现象,**因为访问静态 `synchronized` 方法占用的锁是当前类的锁,而访问非静态 `synchronized` 方法占用的锁是当前实例对象锁**。
+
+```java
+synchronized static void method() {
+ //业务代码
+}
+```
+
+**3.修饰代码块** :指定加锁对象,对给定对象/类加锁。`synchronized(this|object)` 表示进入同步代码库前要获得**给定对象的锁**。`synchronized(类.class)` 表示进入同步代码前要获得 **当前 class 的锁**
+
+```java
+synchronized(this) {
+ //业务代码
+}
+```
+
+**总结:**
+
+- `synchronized` 关键字加到 `static` 静态方法和 `synchronized(class)` 代码块上都是是给 Class 类上锁。
+- `synchronized` 关键字加到实例方法上是给对象实例上锁。
+- 尽量不要使用 `synchronized(String a)` 因为 JVM 中,字符串常量池具有缓存功能!
+
+下面我以一个常见的面试题为例讲解一下 `synchronized` 关键字的具体使用。
+
+面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
+
+**双重校验锁实现对象单例(线程安全)**
+
+```java
+public class Singleton {
+
+ private volatile static Singleton uniqueInstance;
+
+ private Singleton() {
+ }
+
+ public static Singleton getUniqueInstance() {
+ //先判断对象是否已经实例过,没有实例化过才进入加锁代码
+ if (uniqueInstance == null) {
+ //类对象加锁
+ synchronized (Singleton.class) {
+ if (uniqueInstance == null) {
+ uniqueInstance = new Singleton();
+ }
+ }
+ }
+ return uniqueInstance;
+ }
+}
+```
+
+另外,需要注意 `uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要。
+
+`uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
+
+1. 为 `uniqueInstance` 分配内存空间
+2. 初始化 `uniqueInstance`
+3. 将 `uniqueInstance` 指向分配的内存地址
+
+但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 `getUniqueInstance`() 后发现 `uniqueInstance` 不为空,因此返回 `uniqueInstance`,但此时 `uniqueInstance` 还未被初始化。
+
+使用 `volatile` 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
+
+### 1.3. 构造方法可以使用 synchronized 关键字修饰么?
+
+先说结论:**构造方法不能使用 synchronized 关键字修饰。**
+
+构造方法本身就属于线程安全的,不存在同步的构造方法一说。
+
+### 1.3. 讲一下 synchronized 关键字的底层原理
+
+**synchronized 关键字底层原理属于 JVM 层面。**
+
+#### 1.3.1. synchronized 同步语句块的情况
+
+```java
+public class SynchronizedDemo {
+ public void method() {
+ synchronized (this) {
+ System.out.println("synchronized 代码块");
+ }
+ }
+}
+
+```
+
+通过 JDK 自带的 `javap` 命令查看 `SynchronizedDemo` 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
+
+
+
+从上面我们可以看出:
+
+**`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。**
+
+当执行 `monitorenter` 指令时,线程试图获取锁也就是获取 **对象监视器 `monitor`** 的持有权。
+
+> 在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由[ObjectMonitor](https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/runtime/objectMonitor.cpp)实现的。每个对象中都内置了一个 `ObjectMonitor`对象。
+>
+> 另外,`wait/notify`等方法也依赖于`monitor`对象,这就是为什么只有在同步的块或者方法中才能调用`wait/notify`等方法,否则会抛出`java.lang.IllegalMonitorStateException`的异常的原因。
+
+在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
+
+在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
+
+#### 1.3.2. synchronized 修饰方法的的情况
+
+```java
+public class SynchronizedDemo2 {
+ public synchronized void method() {
+ System.out.println("synchronized 方法");
+ }
+}
+
+```
+
+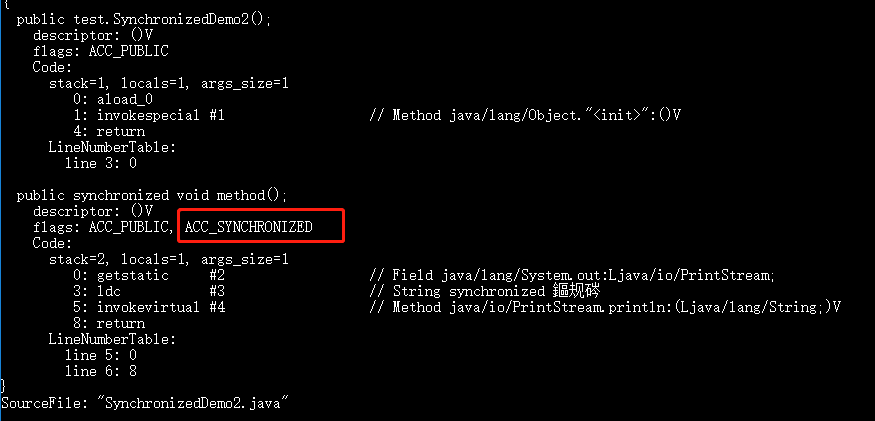
+
+`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。JVM 通过该 `ACC_SYNCHRONIZED` 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
+
+#### 1.3.3.总结
+
+`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。
+
+`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。
+
+**不过两者的本质都是对对象监视器 monitor 的获取。**
+
+### 1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗
+
+JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
+
+锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
+
+关于这几种优化的详细信息可以查看下面这篇文章:[Java6 及以上版本对 synchronized 的优化](https://www.cnblogs.com/wuqinglong/p/9945618.html)
+
+### 1.5. 谈谈 synchronized 和 ReentrantLock 的区别
+
+#### 1.5.1. 两者都是可重入锁
+
+**“可重入锁”** 指的是自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
+
+#### 1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
+
+`synchronized` 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 `synchronized` 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。`ReentrantLock` 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
+
+#### 1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能
+
+相比`synchronized`,`ReentrantLock`增加了一些高级功能。主要来说主要有三点:
+
+- **等待可中断** : `ReentrantLock`提供了一种能够中断等待锁的线程的机制,通过 `lock.lockInterruptibly()` 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
+- **可实现公平锁** : `ReentrantLock`可以指定是公平锁还是非公平锁。而`synchronized`只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。`ReentrantLock`默认情况是非公平的,可以通过 `ReentrantLock`类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
+- **可实现选择性通知(锁可以绑定多个条件)**: `synchronized`关键字与`wait()`和`notify()`/`notifyAll()`方法相结合可以实现等待/通知机制。`ReentrantLock`类当然也可以实现,但是需要借助于`Condition`接口与`newCondition()`方法。
+
+> `Condition`是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个`Lock`对象中可以创建多个`Condition`实例(即对象监视器),**线程对象可以注册在指定的`Condition`中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用`notify()/notifyAll()`方法进行通知时,被通知的线程是由 JVM 选择的,用`ReentrantLock`类结合`Condition`实例可以实现“选择性通知”** ,这个功能非常重要,而且是 Condition 接口默认提供的。而`synchronized`关键字就相当于整个 Lock 对象中只有一个`Condition`实例,所有的线程都注册在它一个身上。如果执行`notifyAll()`方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而`Condition`实例的`signalAll()`方法 只会唤醒注册在该`Condition`实例中的所有等待线程。
+
+**如果你想使用上述功能,那么选择 ReentrantLock 是一个不错的选择。性能已不是选择标准**
+
+## 2. volatile 关键字
+
+我们先要从 **CPU 缓存模型** 说起!
+
+### 2.1. CPU 缓存模型
+
+**为什么要弄一个 CPU 高速缓存呢?**
+
+类比我们开发网站后台系统使用的缓存(比如 Redis)是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。 **CPU 缓存则是为了解决 CPU 处理速度和内存处理速度不对等的问题。**
+
+我们甚至可以把 **内存可以看作外存的高速缓存**,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。
+
+总结:**CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。**
+
+为了更好地理解,我画了一个简单的 CPU Cache 示意图如下(实际上,现代的 CPU Cache 通常分为三层,分别叫 L1,L2,L3 Cache):
+
+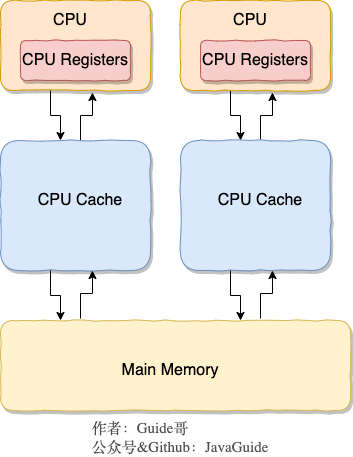
+
+**CPU Cache 的工作方式:**
+
+先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。但是,这样存在 **内存缓存不一致性的问题** !比如我执行一个 i++操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 1++运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
+
+**CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议或者其他手段来解决。**
+
+### 2.2. 讲一下 JMM(Java 内存模型)
+
+在 JDK1.2 之前,Java 的内存模型实现总是从**主存**(即共享内存)读取变量,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存**本地内存**(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成**数据的不一致**。
+
+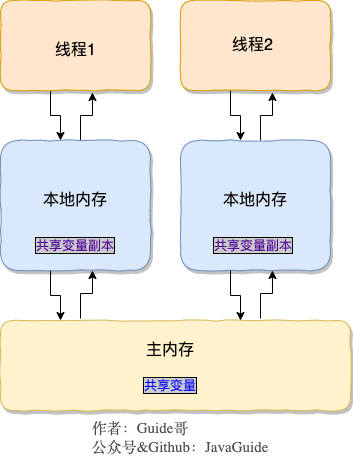
+
+要解决这个问题,就需要把变量声明为 **`volatile`** ,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
+
+所以,**`volatile` 关键字 除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。**
+
+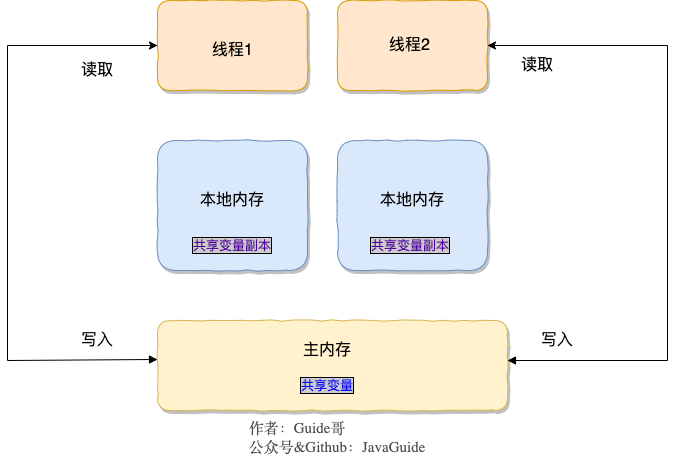
+
+### 2.3. 并发编程的三个重要特性
+
+1. **原子性** : 一个的操作或者多次操作,要么所有的操作全部都得到执行并且不会收到任何因素的干扰而中断,要么所有的操作都执行,要么都不执行。`synchronized` 可以保证代码片段的原子性。
+2. **可见性** :当一个线程对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。`volatile` 关键字可以保证共享变量的可见性。
+3. **有序性** :代码在执行的过程中的先后顺序,Java 在编译器以及运行期间的优化,代码的执行顺序未必就是编写代码时候的顺序。`volatile` 关键字可以禁止指令进行重排序优化。
+
+### 2.4. 说说 synchronized 关键字和 volatile 关键字的区别
+
+`synchronized` 关键字和 `volatile` 关键字是两个互补的存在,而不是对立的存在!
+
+- **`volatile` 关键字**是线程同步的**轻量级实现**,所以 **`volatile `性能肯定比` synchronized `关键字要好** 。但是 **`volatile` 关键字只能用于变量而 `synchronized` 关键字可以修饰方法以及代码块** 。
+- **`volatile` 关键字能保证数据的可见性,但不能保证数据的原子性。`synchronized` 关键字两者都能保证。**
+- **`volatile`关键字主要用于解决变量在多个线程之间的可见性,而 `synchronized` 关键字解决的是多个线程之间访问资源的同步性。**
+
+## 3. ThreadLocal
+
+### 3.1. ThreadLocal 简介
+
+通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK 中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
+
+**如果你创建了一个`ThreadLocal`变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是`ThreadLocal`变量名的由来。他们可以使用 `get()` 和 `set()` 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。**
+
+再举个简单的例子:
+
+比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么 ThreadLocal 就是用来避免这两个线程竞争的。
+
+### 3.2. ThreadLocal 示例
+
+相信看了上面的解释,大家已经搞懂 ThreadLocal 类是个什么东西了。
+
+```java
+import java.text.SimpleDateFormat;
+import java.util.Random;
+
+public class ThreadLocalExample implements Runnable{
+
+ // SimpleDateFormat 不是线程安全的,所以每个线程都要有自己独立的副本
+ private static final ThreadLocal<SimpleDateFormat> formatter = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
+
+ public static void main(String[] args) throws InterruptedException {
+ ThreadLocalExample obj = new ThreadLocalExample();
+ for(int i=0 ; i<10; i++){
+ Thread t = new Thread(obj, ""+i);
+ Thread.sleep(new Random().nextInt(1000));
+ t.start();
+ }
+ }
+
+ @Override
+ public void run() {
+ System.out.println("Thread Name= "+Thread.currentThread().getName()+" default Formatter = "+formatter.get().toPattern());
+ try {
+ Thread.sleep(new Random().nextInt(1000));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ //formatter pattern is changed here by thread, but it won't reflect to other threads
+ formatter.set(new SimpleDateFormat());
+
+ System.out.println("Thread Name= "+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern());
+ }
+
+}
+
+```
+
+Output:
+
+```
+Thread Name= 0 default Formatter = yyyyMMdd HHmm
+Thread Name= 0 formatter = yy-M-d ah:mm
+Thread Name= 1 default Formatter = yyyyMMdd HHmm
+Thread Name= 2 default Formatter = yyyyMMdd HHmm
+Thread Name= 1 formatter = yy-M-d ah:mm
+Thread Name= 3 default Formatter = yyyyMMdd HHmm
+Thread Name= 2 formatter = yy-M-d ah:mm
+Thread Name= 4 default Formatter = yyyyMMdd HHmm
+Thread Name= 3 formatter = yy-M-d ah:mm
+Thread Name= 4 formatter = yy-M-d ah:mm
+Thread Name= 5 default Formatter = yyyyMMdd HHmm
+Thread Name= 5 formatter = yy-M-d ah:mm
+Thread Name= 6 default Formatter = yyyyMMdd HHmm
+Thread Name= 6 formatter = yy-M-d ah:mm
+Thread Name= 7 default Formatter = yyyyMMdd HHmm
+Thread Name= 7 formatter = yy-M-d ah:mm
+Thread Name= 8 default Formatter = yyyyMMdd HHmm
+Thread Name= 9 default Formatter = yyyyMMdd HHmm
+Thread Name= 8 formatter = yy-M-d ah:mm
+Thread Name= 9 formatter = yy-M-d ah:mm
+```
+
+从输出中可以看出,Thread-0 已经改变了 formatter 的值,但仍然是 thread-2 默认格式化程序与初始化值相同,其他线程也一样。
+
+上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA 会提示你转换为 Java8 的格式(IDEA 真的不错!)。因为 ThreadLocal 类在 Java 8 中扩展,使用一个新的方法`withInitial()`,将 Supplier 功能接口作为参数。
+
+```java
+private static final ThreadLocal<SimpleDateFormat> formatter = new ThreadLocal<SimpleDateFormat>(){
+ @Override
+ protected SimpleDateFormat initialValue(){
+ return new SimpleDateFormat("yyyyMMdd HHmm");
+ }
+};
+```
+
+### 3.3. ThreadLocal 原理
+
+从 `Thread`类源代码入手。
+
+```java
+public class Thread implements Runnable {
+ //......
+ //与此线程有关的ThreadLocal值。由ThreadLocal类维护
+ ThreadLocal.ThreadLocalMap threadLocals = null;
+
+ //与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
+ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
+ //......
+}
+```
+
+从上面`Thread`类 源代码可以看出`Thread` 类中有一个 `threadLocals` 和 一个 `inheritableThreadLocals` 变量,它们都是 `ThreadLocalMap` 类型的变量,我们可以把 `ThreadLocalMap` 理解为`ThreadLocal` 类实现的定制化的 `HashMap`。默认情况下这两个变量都是 null,只有当前线程调用 `ThreadLocal` 类的 `set`或`get`方法时才创建它们,实际上调用这两个方法的时候,我们调用的是`ThreadLocalMap`类对应的 `get()`、`set()`方法。
+
+`ThreadLocal`类的`set()`方法
+
+```java
+public void set(T value) {
+ Thread t = Thread.currentThread();
+ ThreadLocalMap map = getMap(t);
+ if (map != null)
+ map.set(this, value);
+ else
+ createMap(t, value);
+}
+ThreadLocalMap getMap(Thread t) {
+ return t.threadLocals;
+}
+```
+
+通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,`ThreadLocal` 可以理解为只是`ThreadLocalMap`的封装,传递了变量值。** `ThrealLocal` 类中可以通过`Thread.currentThread()`获取到当前线程对象后,直接通过`getMap(Thread t)`可以访问到该线程的`ThreadLocalMap`对象。
+
+**每个`Thread`中都具备一个`ThreadLocalMap`,而`ThreadLocalMap`可以存储以`ThreadLocal`为 key ,Object 对象为 value 的键值对。**
+
+```java
+ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
+ //......
+}
+```
+
+比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。
+
+
+
+`ThreadLocalMap`是`ThreadLocal`的静态内部类。
+
+
+
+### 3.4. ThreadLocal 内存泄露问题
+
+`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
+
+```java
+static class Entry extends WeakReference<ThreadLocal<?>> {
+ /** The value associated with this ThreadLocal. */
+ Object value;
+
+ Entry(ThreadLocal<?> k, Object v) {
+ super(k);
+ value = v;
+ }
+}
+```
+
+**弱引用介绍:**
+
+> 如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
+>
+> 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
+
+## 4. 线程池
+
+### 4.1. 为什么要用线程池?
+
+> **池化技术想必大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。**
+
+**线程池**提供了一种限制和管理资源(包括执行一个任务)。 每个**线程池**还维护一些基本统计信息,例如已完成任务的数量。
+
+这里借用《Java 并发编程的艺术》提到的来说一下**使用线程池的好处**:
+
+- **降低资源消耗**。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
+- **提高响应速度**。当任务到达时,任务可以不需要等到线程创建就能立即执行。
+- **提高线程的可管理性**。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
+
+### 4.2. 实现 Runnable 接口和 Callable 接口的区别
+
+`Runnable`自 Java 1.0 以来一直存在,但`Callable`仅在 Java 1.5 中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口** 不会返回结果或抛出检查异常,但是 **`Callable` 接口** 可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口** ,这样代码看起来会更加简洁。
+
+工具类 `Executors` 可以实现将 `Runnable` 对象转换成 `Callable` 对象。(`Executors.callable(Runnable task)` 或 `Executors.callable(Runnable task, Object result)`)。
+
+`Runnable.java`
+
+```java
+@FunctionalInterface
+public interface Runnable {
+ /**
+ * 被线程执行,没有返回值也无法抛出异常
+ */
+ public abstract void run();
+}
+```
+
+`Callable.java`
+
+```java
+@FunctionalInterface
+public interface Callable<V> {
+ /**
+ * 计算结果,或在无法这样做时抛出异常。
+ * @return 计算得出的结果
+ * @throws 如果无法计算结果,则抛出异常
+ */
+ V call() throws Exception;
+}
+```
+
+### 4.3. 执行 execute()方法和 submit()方法的区别是什么呢?
+
+1. **`execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;**
+2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功**,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
+
+我们以 **`AbstractExecutorService` 接口** 中的一个 `submit` 方法为例子来看看源代码:
+
+```java
+public Future<?> submit(Runnable task) {
+ if (task == null) throw new NullPointerException();
+ RunnableFuture<Void> ftask = newTaskFor(task, null);
+ execute(ftask);
+ return ftask;
+}
+```
+
+上面方法调用的 `newTaskFor` 方法返回了一个 `FutureTask` 对象。
+
+```java
+protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
+ return new FutureTask<T>(runnable, value);
+}
+```
+
+我们再来看看`execute()`方法:
+
+```java
+public void execute(Runnable command) {
+ ...
+}
+```
+
+### 4.4. 如何创建线程池
+
+《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
+
+> Executors 返回线程池对象的弊端如下:
+>
+> - **FixedThreadPool 和 SingleThreadExecutor** : 允许请求的队列长度为 Integer.MAX_VALUE ,可能堆积大量的请求,从而导致 OOM。
+> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
+
+**方式一:通过构造方法实现**
+
+
+
+**方式二:通过 Executor 框架的工具类 Executors 来实现**
+
+我们可以创建三种类型的 ThreadPoolExecutor:
+
+- **FixedThreadPool** : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
+- **SingleThreadExecutor:** 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
+- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
+
+对应 Executors 工具类中的方法如图所示:
+
+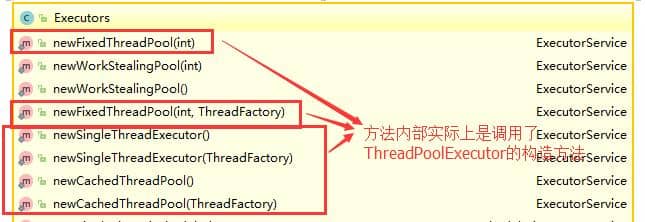
+
+### 4.5 ThreadPoolExecutor 类分析
+
+`ThreadPoolExecutor` 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生(其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么),这里就不贴代码讲了,比较简单。
+
+```java
+/**
+ * 用给定的初始参数创建一个新的ThreadPoolExecutor。
+ */
+public ThreadPoolExecutor(int corePoolSize,
+ int maximumPoolSize,
+ long keepAliveTime,
+ TimeUnit unit,
+ BlockingQueue<Runnable> workQueue,
+ ThreadFactory threadFactory,
+ RejectedExecutionHandler handler) {
+ if (corePoolSize < 0 ||
+ maximumPoolSize <= 0 ||
+ maximumPoolSize < corePoolSize ||
+ keepAliveTime < 0)
+ throw new IllegalArgumentException();
+ if (workQueue == null || threadFactory == null || handler == null)
+ throw new NullPointerException();
+ this.corePoolSize = corePoolSize;
+ this.maximumPoolSize = maximumPoolSize;
+ this.workQueue = workQueue;
+ this.keepAliveTime = unit.toNanos(keepAliveTime);
+ this.threadFactory = threadFactory;
+ this.handler = handler;
+}
+```
+
+**下面这些对创建 非常重要,在后面使用线程池的过程中你一定会用到!所以,务必拿着小本本记清楚。**
+
+#### 4.5.1 `ThreadPoolExecutor`构造函数重要参数分析
+
+**`ThreadPoolExecutor` 3 个最重要的参数:**
+
+- **`corePoolSize` :** 核心线程数定义了最小可以同时运行的线程数量。
+- **`maximumPoolSize` :** 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
+- **`workQueue`:** 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
+
+`ThreadPoolExecutor`其他常见参数:
+
+1. **`keepAliveTime`**:当线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`才会被回收销毁;
+2. **`unit`** : `keepAliveTime` 参数的时间单位。
+3. **`threadFactory`** :executor 创建新线程的时候会用到。
+4. **`handler`** :饱和策略。关于饱和策略下面单独介绍一下。
+
+#### 4.5.2 `ThreadPoolExecutor` 饱和策略
+
+**`ThreadPoolExecutor` 饱和策略定义:**
+
+如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolTaskExecutor` 定义一些策略:
+
+- **`ThreadPoolExecutor.AbortPolicy`:** 抛出 `RejectedExecutionException`来拒绝新任务的处理。
+- **`ThreadPoolExecutor.CallerRunsPolicy`:** 调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
+- **`ThreadPoolExecutor.DiscardPolicy`:** 不处理新任务,直接丢弃掉。
+- **`ThreadPoolExecutor.DiscardOldestPolicy`:** 此策略将丢弃最早的未处理的任务请求。
+
+举个例子: Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecutor` 的构造函数创建线程池的时候,当我们不指定 `RejectedExecutionHandler` 饱和策略的话来配置线程池的时候默认使用的是 `ThreadPoolExecutor.AbortPolicy`。在默认情况下,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。 对于可伸缩的应用程序,建议使用 `ThreadPoolExecutor.CallerRunsPolicy`。当最大池被填满时,此策略为我们提供可伸缩队列。(这个直接查看 `ThreadPoolExecutor` 的构造函数源码就可以看出,比较简单的原因,这里就不贴代码了)
+
+### 4.6 一个简单的线程池 Demo
+
+为了让大家更清楚上面的面试题中的一些概念,我写了一个简单的线程池 Demo。
+
+首先创建一个 `Runnable` 接口的实现类(当然也可以是 `Callable` 接口,我们上面也说了两者的区别。)
+
+`MyRunnable.java`
+
+```java
+import java.util.Date;
+
+/**
+ * 这是一个简单的Runnable类,需要大约5秒钟来执行其任务。
+ * @author shuang.kou
+ */
+public class MyRunnable implements Runnable {
+
+ private String command;
+
+ public MyRunnable(String s) {
+ this.command = s;
+ }
+
+ @Override
+ public void run() {
+ System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
+ processCommand();
+ System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
+ }
+
+ private void processCommand() {
+ try {
+ Thread.sleep(5000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+
+ @Override
+ public String toString() {
+ return this.command;
+ }
+}
+
+```
+
+编写测试程序,我们这里以阿里巴巴推荐的使用 `ThreadPoolExecutor` 构造函数自定义参数的方式来创建线程池。
+
+`ThreadPoolExecutorDemo.java`
+
+```java
+import java.util.concurrent.ArrayBlockingQueue;
+import java.util.concurrent.ThreadPoolExecutor;
+import java.util.concurrent.TimeUnit;
+
+public class ThreadPoolExecutorDemo {
+
+ private static final int CORE_POOL_SIZE = 5;
+ private static final int MAX_POOL_SIZE = 10;
+ private static final int QUEUE_CAPACITY = 100;
+ private static final Long KEEP_ALIVE_TIME = 1L;
+ public static void main(String[] args) {
+
+ //使用阿里巴巴推荐的创建线程池的方式
+ //通过ThreadPoolExecutor构造函数自定义参数创建
+ ThreadPoolExecutor executor = new ThreadPoolExecutor(
+ CORE_POOL_SIZE,
+ MAX_POOL_SIZE,
+ KEEP_ALIVE_TIME,
+ TimeUnit.SECONDS,
+ new ArrayBlockingQueue<>(QUEUE_CAPACITY),
+ new ThreadPoolExecutor.CallerRunsPolicy());
+
+ for (int i = 0; i < 10; i++) {
+ //创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
+ Runnable worker = new MyRunnable("" + i);
+ //执行Runnable
+ executor.execute(worker);
+ }
+ //终止线程池
+ executor.shutdown();
+ while (!executor.isTerminated()) {
+ }
+ System.out.println("Finished all threads");
+ }
+}
+```
+
+可以看到我们上面的代码指定了:
+
+1. `corePoolSize`: 核心线程数为 5。
+2. `maximumPoolSize` :最大线程数 10
+3. `keepAliveTime` : 等待时间为 1L。
+4. `unit`: 等待时间的单位为 TimeUnit.SECONDS。
+5. `workQueue`:任务队列为 `ArrayBlockingQueue`,并且容量为 100;
+6. `handler`:饱和策略为 `CallerRunsPolicy`。
+
+**Output:**
+
+```
+pool-1-thread-3 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-5 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-2 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-1 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-4 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-3 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-4 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-1 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-5 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-1 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-2 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-5 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-4 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-3 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-2 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-1 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-4 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-5 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-3 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
+
+```
+
+### 4.7 线程池原理分析
+
+承接 4.6 节,我们通过代码输出结果可以看出:**线程池首先会先执行 5 个任务,然后这些任务有任务被执行完的话,就会去拿新的任务执行。** 大家可以先通过上面讲解的内容,分析一下到底是咋回事?(自己独立思考一会)
+
+现在,我们就分析上面的输出内容来简单分析一下线程池原理。
+
+**为了搞懂线程池的原理,我们需要首先分析一下 `execute`方法。** 在 4.6 节中的 Demo 中我们使用 `executor.execute(worker)`来提交一个任务到线程池中去,这个方法非常重要,下面我们来看看它的源码:
+
+```java
+// 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
+private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
+
+private static int workerCountOf(int c) {
+ return c & CAPACITY;
+}
+
+private final BlockingQueue<Runnable> workQueue;
+
+public void execute(Runnable command) {
+ // 如果任务为null,则抛出异常。
+ if (command == null)
+ throw new NullPointerException();
+ // ctl 中保存的线程池当前的一些状态信息
+ int c = ctl.get();
+
+ // 下面会涉及到 3 步 操作
+ // 1.首先判断当前线程池中执行的任务数量是否小于 corePoolSize
+ // 如果小于的话,通过addWorker(command, true)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
+ if (workerCountOf(c) < corePoolSize) {
+ if (addWorker(command, true))
+ return;
+ c = ctl.get();
+ }
+ // 2.如果当前执行的任务数量大于等于 corePoolSize 的时候就会走到这里
+ // 通过 isRunning 方法判断线程池状态,线程池处于 RUNNING 状态才会被并且队列可以加入任务,该任务才会被加入进去
+ if (isRunning(c) && workQueue.offer(command)) {
+ int recheck = ctl.get();
+ // 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
+ if (!isRunning(recheck) && remove(command))
+ reject(command);
+ // 如果当前线程池为空就新创建一个线程并执行。
+ else if (workerCountOf(recheck) == 0)
+ addWorker(null, false);
+ }
+ //3. 通过addWorker(command, false)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
+ //如果addWorker(command, false)执行失败,则通过reject()执行相应的拒绝策略的内容。
+ else if (!addWorker(command, false))
+ reject(command);
+}
+```
+
+通过下图可以更好的对上面这 3 步做一个展示,下图是我为了省事直接从网上找到,原地址不明。
+
+
+
+现在,让我们在回到 4.6 节我们写的 Demo, 现在是不是很容易就可以搞懂它的原理了呢?
+
+没搞懂的话,也没关系,可以看看我的分析:
+
+> 我们在代码中模拟了 10 个任务,我们配置的核心线程数为 5 、等待队列容量为 100 ,所以每次只可能存在 5 个任务同时执行,剩下的 5 个任务会被放到等待队列中去。当前的5个任务中如果有任务被执行完了,线程池就会去拿新的任务执行。
+
+## 5. Atomic 原子类
+
+### 5.1. 介绍一下 Atomic 原子类
+
+`Atomic` 翻译成中文是原子的意思。在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的。在我们这里 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
+
+所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
+
+并发包 `java.util.concurrent` 的原子类都存放在`java.util.concurrent.atomic`下,如下图所示。
+
+
+
+### 5.2. JUC 包中的原子类是哪 4 类?
+
+**基本类型**
+
+使用原子的方式更新基本类型
+
+- `AtomicInteger`:整形原子类
+- `AtomicLong`:长整型原子类
+- `AtomicBoolean`:布尔型原子类
+
+**数组类型**
+
+使用原子的方式更新数组里的某个元素
+
+- `AtomicIntegerArray`:整形数组原子类
+- `AtomicLongArray`:长整形数组原子类
+- `AtomicReferenceArray`:引用类型数组原子类
+
+**引用类型**
+
+- `AtomicReference`:引用类型原子类
+- `AtomicStampedReference`:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
+- `AtomicMarkableReference` :原子更新带有标记位的引用类型
+
+**对象的属性修改类型**
+
+- `AtomicIntegerFieldUpdater`:原子更新整形字段的更新器
+- `AtomicLongFieldUpdater`:原子更新长整形字段的更新器
+- `AtomicReferenceFieldUpdater`:原子更新引用类型字段的更新器
+
+### 5.3. 讲讲 AtomicInteger 的使用
+
+**AtomicInteger 类常用方法**
+
+```java
+public final int get() //获取当前的值
+public final int getAndSet(int newValue)//获取当前的值,并设置新的值
+public final int getAndIncrement()//获取当前的值,并自增
+public final int getAndDecrement() //获取当前的值,并自减
+public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
+boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
+public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
+```
+
+**AtomicInteger 类的使用示例**
+
+使用 AtomicInteger 之后,不用对 increment() 方法加锁也可以保证线程安全。
+
+```java
+class AtomicIntegerTest {
+ private AtomicInteger count = new AtomicInteger();
+ //使用AtomicInteger之后,不需要对该方法加锁,也可以实现线程安全。
+ public void increment() {
+ count.incrementAndGet();
+ }
+
+ public int getCount() {
+ return count.get();
+ }
+}
+
+```
+
+### 5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理
+
+AtomicInteger 线程安全原理简单分析
+
+AtomicInteger 类的部分源码:
+
+```java
+// setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
+private static final Unsafe unsafe = Unsafe.getUnsafe();
+private static final long valueOffset;
+
+static {
+ try {
+ valueOffset = unsafe.objectFieldOffset
+ (AtomicInteger.class.getDeclaredField("value"));
+ } catch (Exception ex) { throw new Error(ex); }
+}
+
+private volatile int value;
+```
+
+AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
+
+CAS 的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个 volatile 变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
+
+关于 Atomic 原子类这部分更多内容可以查看我的这篇文章:并发编程面试必备:[JUC 中的 Atomic 原子类总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484834&idx=1&sn=7d3835091af8125c13fc6db765f4c5bd&source=41#wechat_redirect)
+
+## 6. AQS
+
+### 6.1. AQS 介绍
+
+AQS 的全称为(`AbstractQueuedSynchronizer`),这个类在` java.util.concurrent.locks `包下面。
+
+
+
+AQS 是一个用来构建锁和同步器的框架,使用 AQS 能简单且高效地构造出大量应用广泛的同步器,比如我们提到的 `ReentrantLock`,`Semaphore`,其他的诸如 `ReentrantReadWriteLock`,`SynchronousQueue`,`FutureTask` 等等皆是基于 AQS 的。当然,我们自己也能利用 AQS 非常轻松容易地构造出符合我们自己需求的同步器。
+
+### 6.2. AQS 原理分析
+
+AQS 原理这部分参考了部分博客,在 5.2 节末尾放了链接。
+
+> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于 AQS 原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
+
+下面大部分内容其实在 AQS 类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
+
+#### 6.2.1. AQS 原理概览
+
+**AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁实现的,即将暂时获取不到锁的线程加入到队列中。**
+
+> CLH(Craig,Landin and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。
+
+看个 AQS(AbstractQueuedSynchronizer)原理图:
+
+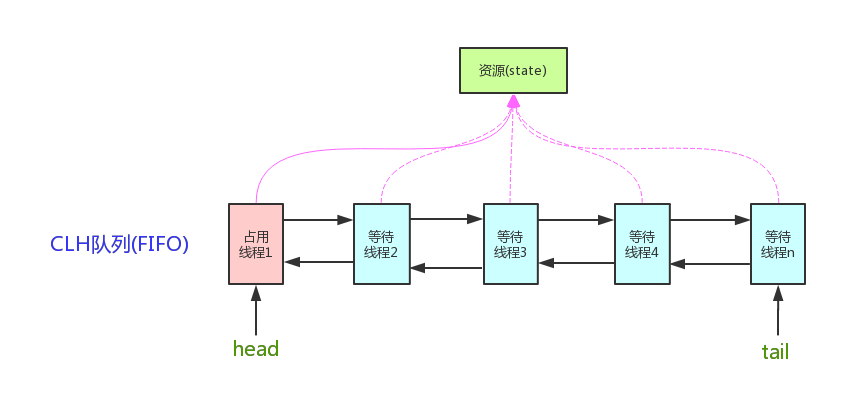
+
+AQS 使用一个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。AQS 使用 CAS 对该同步状态进行原子操作实现对其值的修改。
+
+```java
+private volatile int state;//共享变量,使用volatile修饰保证线程可见性
+```
+
+状态信息通过 protected 类型的 getState,setState,compareAndSetState 进行操作
+
+```java
+
+//返回同步状态的当前值
+protected final int getState() {
+ return state;
+}
+//设置同步状态的值
+protected final void setState(int newState) {
+ state = newState;
+}
+//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
+protected final boolean compareAndSetState(int expect, int update) {
+ return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
+}
+```
+
+#### 6.2.2. AQS 对资源的共享方式
+
+**AQS 定义两种资源共享方式**
+
+- **Exclusive**(独占):只有一个线程能执行,如 `ReentrantLock`。又可分为公平锁和非公平锁:
+ - 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
+ - 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
+- **Share**(共享):多个线程可同时执行,如` CountDownLatch`、`Semaphore`、 `CyclicBarrier`、`ReadWriteLock` 我们都会在后面讲到。
+
+`ReentrantReadWriteLock` 可以看成是组合式,因为 `ReentrantReadWriteLock` 也就是读写锁允许多个线程同时对某一资源进行读。
+
+不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS 已经在顶层实现好了。
+
+#### 6.2.3. AQS 底层使用了模板方法模式
+
+同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
+
+1. 使用者继承 `AbstractQueuedSynchronizer` 并重写指定的方法。(这些重写方法很简单,无非是对于共享资源 state 的获取和释放)
+2. 将 AQS 组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
+
+这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
+
+**AQS 使用了模板方法模式,自定义同步器时需要重写下面几个 AQS 提供的模板方法:**
+
+```java
+isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
+tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
+tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
+tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
+tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
+
+```
+
+默认情况下,每个方法都抛出 `UnsupportedOperationException`。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS 类中的其他方法都是 final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
+
+以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多少次,这样才能保证 state 是能回到零态的。
+
+再以 `CountDownLatch` 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后` countDown()` 一次,state 会 CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然后主调用线程就会从 `await()` 函数返回,继续后余动作。
+
+一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但 AQS 也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
+
+推荐两篇 AQS 原理和相关源码分析的文章:
+
+- https://www.cnblogs.com/waterystone/p/4920797.html
+- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
+
+### 6.3. AQS 组件总结
+
+- **`Semaphore`(信号量)-允许多个线程同时访问:** `synchronized` 和 `ReentrantLock` 都是一次只允许一个线程访问某个资源,`Semaphore`(信号量)可以指定多个线程同时访问某个资源。
+- **`CountDownLatch `(倒计时器):** `CountDownLatch` 是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
+- **`CyclicBarrier`(循环栅栏):** `CyclicBarrier` 和 `CountDownLatch` 非常类似,它也可以实现线程间的技术等待,但是它的功能比 `CountDownLatch` 更加复杂和强大。主要应用场景和 `CountDownLatch` 类似。`CyclicBarrier` 的字面意思是可循环使用(`Cyclic`)的屏障(`Barrier`)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。`CyclicBarrier` 默认的构造方法是 `CyclicBarrier(int parties)`,其参数表示屏障拦截的线程数量,每个线程调用 `await()` 方法告诉 `CyclicBarrier` 我已经到达了屏障,然后当前线程被阻塞。
+
+### 6.4. 用过 CountDownLatch 么?什么场景下用的?
+
+`CountDownLatch` 的作用就是 允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。之前在项目中,有一个使用多线程读取多个文件处理的场景,我用到了 `CountDownLatch` 。具体场景是下面这样的:
+
+我们要读取处理 6 个文件,这 6 个任务都是没有执行顺序依赖的任务,但是我们需要返回给用户的时候将这几个文件的处理的结果进行统计整理。
+
+为此我们定义了一个线程池和 count 为 6 的`CountDownLatch`对象 。使用线程池处理读取任务,每一个线程处理完之后就将 count-1,调用`CountDownLatch`对象的 `await()`方法,直到所有文件读取完之后,才会接着执行后面的逻辑。
+
+伪代码是下面这样的:
+
+```java
+public class CountDownLatchExample1 {
+ // 处理文件的数量
+ private static final int threadCount = 6;
+
+ public static void main(String[] args) throws InterruptedException {
+ // 创建一个具有固定线程数量的线程池对象(推荐使用构造方法创建)
+ ExecutorService threadPool = Executors.newFixedThreadPool(10);
+ final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
+ for (int i = 0; i < threadCount; i++) {
+ final int threadnum = i;
+ threadPool.execute(() -> {
+ try {
+ //处理文件的业务操作
+ //......
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ } finally {
+ //表示一个文件已经被完成
+ countDownLatch.countDown();
+ }
+
+ });
+ }
+ countDownLatch.await();
+ threadPool.shutdown();
+ System.out.println("finish");
+ }
+}
+```
+
+**有没有可以改进的地方呢?**
+
+可以使用 `CompletableFuture` 类来改进!Java8 的 `CompletableFuture` 提供了很多对多线程友好的方法,使用它可以很方便地为我们编写多线程程序,什么异步、串行、并行或者等待所有线程执行完任务什么的都非常方便。
+
+```java
+CompletableFuture<Void> task1 =
+ CompletableFuture.supplyAsync(()->{
+ //自定义业务操作
+ });
+......
+CompletableFuture<Void> task6 =
+ CompletableFuture.supplyAsync(()->{
+ //自定义业务操作
+ });
+......
+CompletableFuture<Void> headerFuture=CompletableFuture.allOf(task1,.....,task6);
+
+try {
+ headerFuture.join();
+} catch (Exception ex) {
+ //......
+}
+System.out.println("all done. ");
+```
+
+上面的代码还可以接续优化,当任务过多的时候,把每一个 task 都列出来不太现实,可以考虑通过循环来添加任务。
+
+```java
+//文件夹位置
+List<String> filePaths = Arrays.asList(...)
+// 异步处理所有文件
+List<CompletableFuture<String>> fileFutures = filePaths.stream()
+ .map(filePath -> doSomeThing(filePath))
+ .collect(Collectors.toList());
+// 将他们合并起来
+CompletableFuture<Void> allFutures = CompletableFuture.allOf(
+ fileFutures.toArray(new CompletableFuture[fileFutures.size()])
+);
+
+```
+
+## 7 Reference
+
+- 《深入理解 Java 虚拟机》
+- 《实战 Java 高并发程序设计》
+- 《Java 并发编程的艺术》
+- https://www.cnblogs.com/waterystone/p/4920797.html
+- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
+- <https://www.journaldev.com/1076/java-threadlocal-example>
diff --git "a/docs/java/concurrent/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md" "b/docs/java/concurrent/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..1140df91c48
--- /dev/null
+++ "b/docs/java/concurrent/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
@@ -0,0 +1,856 @@
+---
+title: Java线程池学习总结
+category: Java
+tag:
+ - Java并发
+---
+
+
+
+## 一 使用线程池的好处
+
+> **池化技术想必大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。**
+
+**线程池**提供了一种限制和管理资源(包括执行一个任务)。 每个**线程池**还维护一些基本统计信息,例如已完成任务的数量。
+
+这里借用《Java 并发编程的艺术》提到的来说一下**使用线程池的好处**:
+
+- **降低资源消耗**。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
+- **提高响应速度**。当任务到达时,任务可以不需要等到线程创建就能立即执行。
+- **提高线程的可管理性**。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
+
+## 二 Executor 框架
+
+### 2.1 简介
+
+`Executor` 框架是 Java5 之后引进的,在 Java 5 之后,通过 `Executor` 来启动线程比使用 `Thread` 的 `start` 方法更好,除了更易管理,效率更好(用线程池实现,节约开销)外,还有关键的一点:有助于避免 this 逃逸问题。
+
+> 补充:this 逃逸是指在构造函数返回之前其他线程就持有该对象的引用. 调用尚未构造完全的对象的方法可能引发令人疑惑的错误。
+
+`Executor` 框架不仅包括了线程池的管理,还提供了线程工厂、队列以及拒绝策略等,`Executor` 框架让并发编程变得更加简单。
+
+### 2.2 Executor 框架结构(主要由三大部分组成)
+
+#### 1) 任务(`Runnable` /`Callable`)
+
+执行任务需要实现的 **`Runnable` 接口** 或 **`Callable`接口**。**`Runnable` 接口**或 **`Callable` 接口** 实现类都可以被 **`ThreadPoolExecutor`** 或 **`ScheduledThreadPoolExecutor`** 执行。
+
+#### 2) 任务的执行(`Executor`)
+
+如下图所示,包括任务执行机制的核心接口 **`Executor`** ,以及继承自 `Executor` 接口的 **`ExecutorService` 接口。`ThreadPoolExecutor`** 和 **`ScheduledThreadPoolExecutor`** 这两个关键类实现了 **ExecutorService 接口**。
+
+**这里提了很多底层的类关系,但是,实际上我们需要更多关注的是 `ThreadPoolExecutor` 这个类,这个类在我们实际使用线程池的过程中,使用频率还是非常高的。**
+
+> **注意:** 通过查看 `ScheduledThreadPoolExecutor` 源代码我们发现 `ScheduledThreadPoolExecutor` 实际上是继承了 `ThreadPoolExecutor` 并实现了 ScheduledExecutorService ,而 `ScheduledExecutorService` 又实现了 `ExecutorService`,正如我们下面给出的类关系图显示的一样。
+
+**`ThreadPoolExecutor` 类描述:**
+
+```java
+//AbstractExecutorService实现了ExecutorService接口
+public class ThreadPoolExecutor extends AbstractExecutorService
+```
+
+**`ScheduledThreadPoolExecutor` 类描述:**
+
+```java
+//ScheduledExecutorService继承ExecutorService接口
+public class ScheduledThreadPoolExecutor
+ extends ThreadPoolExecutor
+ implements ScheduledExecutorService
+```
+
+
+
+#### 3) 异步计算的结果(`Future`)
+
+**`Future`** 接口以及 `Future` 接口的实现类 **`FutureTask`** 类都可以代表异步计算的结果。
+
+当我们把 **`Runnable`接口** 或 **`Callable` 接口** 的实现类提交给 **`ThreadPoolExecutor`** 或 **`ScheduledThreadPoolExecutor`** 执行。(调用 `submit()` 方法时会返回一个 **`FutureTask`** 对象)
+
+### 2.3 Executor 框架的使用示意图
+
+
+
+1. **主线程首先要创建实现 `Runnable` 或者 `Callable` 接口的任务对象。**
+2. **把创建完成的实现 `Runnable`/`Callable`接口的 对象直接交给 `ExecutorService` 执行**: `ExecutorService.execute(Runnable command)`)或者也可以把 `Runnable` 对象或`Callable` 对象提交给 `ExecutorService` 执行(`ExecutorService.submit(Runnable task)`或 `ExecutorService.submit(Callable <T> task)`)。
+3. **如果执行 `ExecutorService.submit(…)`,`ExecutorService` 将返回一个实现`Future`接口的对象**(我们刚刚也提到过了执行 `execute()`方法和 `submit()`方法的区别,`submit()`会返回一个 `FutureTask 对象)。由于 FutureTask` 实现了 `Runnable`,我们也可以创建 `FutureTask`,然后直接交给 `ExecutorService` 执行。
+4. **最后,主线程可以执行 `FutureTask.get()`方法来等待任务执行完成。主线程也可以执行 `FutureTask.cancel(boolean mayInterruptIfRunning)`来取消此任务的执行。**
+
+## 三 (重要)ThreadPoolExecutor 类简单介绍
+
+**线程池实现类 `ThreadPoolExecutor` 是 `Executor` 框架最核心的类。**
+
+### 3.1 ThreadPoolExecutor 类分析
+
+`ThreadPoolExecutor` 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生(其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么)。
+
+```java
+ /**
+ * 用给定的初始参数创建一个新的ThreadPoolExecutor。
+ */
+ public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
+ int maximumPoolSize,//线程池的最大线程数
+ long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
+ TimeUnit unit,//时间单位
+ BlockingQueue<Runnable> workQueue,//任务队列,用来储存等待执行任务的队列
+ ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
+ RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
+ ) {
+ if (corePoolSize < 0 ||
+ maximumPoolSize <= 0 ||
+ maximumPoolSize < corePoolSize ||
+ keepAliveTime < 0)
+ throw new IllegalArgumentException();
+ if (workQueue == null || threadFactory == null || handler == null)
+ throw new NullPointerException();
+ this.corePoolSize = corePoolSize;
+ this.maximumPoolSize = maximumPoolSize;
+ this.workQueue = workQueue;
+ this.keepAliveTime = unit.toNanos(keepAliveTime);
+ this.threadFactory = threadFactory;
+ this.handler = handler;
+ }
+```
+
+下面这些对创建非常重要,在后面使用线程池的过程中你一定会用到!所以,务必拿着小本本记清楚。
+
+**`ThreadPoolExecutor` 3 个最重要的参数:**
+
+- **`corePoolSize` :** 核心线程数线程数定义了最小可以同时运行的线程数量。
+- **`maximumPoolSize` :** 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
+- **`workQueue`:** 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
+
+`ThreadPoolExecutor`其他常见参数 :
+
+1. **`keepAliveTime`**:当线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`才会被回收销毁;
+2. **`unit`** : `keepAliveTime` 参数的时间单位。
+3. **`threadFactory`** :executor 创建新线程的时候会用到。
+4. **`handler`** :饱和策略。关于饱和策略下面单独介绍一下。
+
+下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
+
+
+
+**`ThreadPoolExecutor` 饱和策略定义:**
+
+如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolTaskExecutor` 定义一些策略:
+
+- **`ThreadPoolExecutor.AbortPolicy`** :抛出 `RejectedExecutionException`来拒绝新任务的处理。
+- **`ThreadPoolExecutor.CallerRunsPolicy`** :调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
+- **`ThreadPoolExecutor.DiscardPolicy`** :不处理新任务,直接丢弃掉。
+- **`ThreadPoolExecutor.DiscardOldestPolicy`** : 此策略将丢弃最早的未处理的任务请求。
+
+举个例子:
+
+> Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecutor` 的构造函数创建线程池的时候,当我们不指定 `RejectedExecutionHandler` 饱和策略的话来配置线程池的时候默认使用的是 `ThreadPoolExecutor.AbortPolicy`。在默认情况下,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。 对于可伸缩的应用程序,建议使用 `ThreadPoolExecutor.CallerRunsPolicy`。当最大池被填满时,此策略为我们提供可伸缩队列。(这个直接查看 `ThreadPoolExecutor` 的构造函数源码就可以看出,比较简单的原因,这里就不贴代码了。)
+
+### 3.2 推荐使用 `ThreadPoolExecutor` 构造函数创建线程池
+
+在《阿里巴巴 Java 开发手册》“并发处理”这一章节,明确指出线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
+
+**为什么呢?**
+
+> 使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源开销,解决资源不足的问题。如果不使用线程池,有可能会造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
+
+另外,《阿里巴巴 Java 开发手册》中强制线程池不允许使用 `Executors` 去创建,而是通过 `ThreadPoolExecutor` 构造函数的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
+
+> `Executors` 返回线程池对象的弊端如下(后文会详细介绍到):
+>
+> - **`FixedThreadPool` 和 `SingleThreadExecutor`** : 允许请求的队列长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
+> - **`CachedThreadPool` 和 `ScheduledThreadPool`** : 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
+
+**方式一:通过`ThreadPoolExecutor`构造函数实现(推荐)**
+
+
+**方式二:通过 `Executor` 框架的工具类 `Executors` 来实现**
+我们可以创建三种类型的 `ThreadPoolExecutor`:
+
+- `FixedThreadPool`
+- `SingleThreadExecutor`
+- CachedThreadPool
+
+对应 Executors 工具类中的方法如图所示:
+
+
+
+## 四 ThreadPoolExecutor 使用+原理分析
+
+我们上面讲解了 `Executor`框架以及 `ThreadPoolExecutor` 类,下面让我们实战一下,来通过写一个 `ThreadPoolExecutor` 的小 Demo 来回顾上面的内容。
+
+### 4.1 示例代码:`Runnable`+`ThreadPoolExecutor`
+
+首先创建一个 `Runnable` 接口的实现类(当然也可以是 `Callable` 接口,我们上面也说了两者的区别。)
+
+`MyRunnable.java`
+
+```java
+import java.util.Date;
+
+/**
+ * 这是一个简单的Runnable类,需要大约5秒钟来执行其任务。
+ * @author shuang.kou
+ */
+public class MyRunnable implements Runnable {
+
+ private String command;
+
+ public MyRunnable(String s) {
+ this.command = s;
+ }
+
+ @Override
+ public void run() {
+ System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
+ processCommand();
+ System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
+ }
+
+ private void processCommand() {
+ try {
+ Thread.sleep(5000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+
+ @Override
+ public String toString() {
+ return this.command;
+ }
+}
+
+```
+
+编写测试程序,我们这里以阿里巴巴推荐的使用 `ThreadPoolExecutor` 构造函数自定义参数的方式来创建线程池。
+
+`ThreadPoolExecutorDemo.java`
+
+```java
+import java.util.concurrent.ArrayBlockingQueue;
+import java.util.concurrent.ThreadPoolExecutor;
+import java.util.concurrent.TimeUnit;
+
+public class ThreadPoolExecutorDemo {
+
+ private static final int CORE_POOL_SIZE = 5;
+ private static final int MAX_POOL_SIZE = 10;
+ private static final int QUEUE_CAPACITY = 100;
+ private static final Long KEEP_ALIVE_TIME = 1L;
+ public static void main(String[] args) {
+
+ //使用阿里巴巴推荐的创建线程池的方式
+ //通过ThreadPoolExecutor构造函数自定义参数创建
+ ThreadPoolExecutor executor = new ThreadPoolExecutor(
+ CORE_POOL_SIZE,
+ MAX_POOL_SIZE,
+ KEEP_ALIVE_TIME,
+ TimeUnit.SECONDS,
+ new ArrayBlockingQueue<>(QUEUE_CAPACITY),
+ new ThreadPoolExecutor.CallerRunsPolicy());
+
+ for (int i = 0; i < 10; i++) {
+ //创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
+ Runnable worker = new MyRunnable("" + i);
+ //执行Runnable
+ executor.execute(worker);
+ }
+ //终止线程池
+ executor.shutdown();
+ while (!executor.isTerminated()) {
+ }
+ System.out.println("Finished all threads");
+ }
+}
+
+```
+
+可以看到我们上面的代码指定了:
+
+1. `corePoolSize`: 核心线程数为 5。
+2. `maximumPoolSize` :最大线程数 10
+3. `keepAliveTime` : 等待时间为 1L。
+4. `unit`: 等待时间的单位为 TimeUnit.SECONDS。
+5. `workQueue`:任务队列为 `ArrayBlockingQueue`,并且容量为 100;
+6. `handler`:饱和策略为 `CallerRunsPolicy`。
+
+**Output:**
+
+```
+pool-1-thread-3 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-5 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-2 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-1 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-4 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-3 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-4 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-1 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-5 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-1 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-2 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-5 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-4 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-3 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-2 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-1 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-4 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-5 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-3 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
+
+```
+
+### 4.2 线程池原理分析
+
+承接 4.1 节,我们通过代码输出结果可以看出:**线程池首先会先执行 5 个任务,然后这些任务有任务被执行完的话,就会去拿新的任务执行。** 大家可以先通过上面讲解的内容,分析一下到底是咋回事?(自己独立思考一会)
+
+现在,我们就分析上面的输出内容来简单分析一下线程池原理。
+
+**为了搞懂线程池的原理,我们需要首先分析一下 `execute`方法。** 在 4.1 节中的 Demo 中我们使用 `executor.execute(worker)`来提交一个任务到线程池中去,这个方法非常重要,下面我们来看看它的源码:
+
+```java
+ // 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
+ private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
+
+ private static int workerCountOf(int c) {
+ return c & CAPACITY;
+ }
+ //任务队列
+ private final BlockingQueue<Runnable> workQueue;
+
+ public void execute(Runnable command) {
+ // 如果任务为null,则抛出异常。
+ if (command == null)
+ throw new NullPointerException();
+ // ctl 中保存的线程池当前的一些状态信息
+ int c = ctl.get();
+
+ // 下面会涉及到 3 步 操作
+ // 1.首先判断当前线程池中之行的任务数量是否小于 corePoolSize
+ // 如果小于的话,通过addWorker(command, true)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
+ if (workerCountOf(c) < corePoolSize) {
+ if (addWorker(command, true))
+ return;
+ c = ctl.get();
+ }
+ // 2.如果当前之行的任务数量大于等于 corePoolSize 的时候就会走到这里
+ // 通过 isRunning 方法判断线程池状态,线程池处于 RUNNING 状态才会被并且队列可以加入任务,该任务才会被加入进去
+ if (isRunning(c) && workQueue.offer(command)) {
+ int recheck = ctl.get();
+ // 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
+ if (!isRunning(recheck) && remove(command))
+ reject(command);
+ // 如果当前线程池为空就新创建一个线程并执行。
+ else if (workerCountOf(recheck) == 0)
+ addWorker(null, false);
+ }
+ //3. 通过addWorker(command, false)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
+ //如果addWorker(command, false)执行失败,则通过reject()执行相应的拒绝策略的内容。
+ else if (!addWorker(command, false))
+ reject(command);
+ }
+```
+
+通过下图可以更好的对上面这 3 步做一个展示,下图是我为了省事直接从网上找到,原地址不明。
+
+
+
+**`addWorker` 这个方法主要用来创建新的工作线程,如果返回 true 说明创建和启动工作线程成功,否则的话返回的就是 false。**
+
+```java
+ // 全局锁,并发操作必备
+ private final ReentrantLock mainLock = new ReentrantLock();
+ // 跟踪线程池的最大大小,只有在持有全局锁mainLock的前提下才能访问此集合
+ private int largestPoolSize;
+ // 工作线程集合,存放线程池中所有的(活跃的)工作线程,只有在持有全局锁mainLock的前提下才能访问此集合
+ private final HashSet<Worker> workers = new HashSet<>();
+ //获取线程池状态
+ private static int runStateOf(int c) { return c & ~CAPACITY; }
+ //判断线程池的状态是否为 Running
+ private static boolean isRunning(int c) {
+ return c < SHUTDOWN;
+ }
+
+
+ /**
+ * 添加新的工作线程到线程池
+ * @param firstTask 要执行
+ * @param core参数为true的话表示使用线程池的基本大小,为false使用线程池最大大小
+ * @return 添加成功就返回true否则返回false
+ */
+ private boolean addWorker(Runnable firstTask, boolean core) {
+ retry:
+ for (;;) {
+ //这两句用来获取线程池的状态
+ int c = ctl.get();
+ int rs = runStateOf(c);
+
+ // Check if queue empty only if necessary.
+ if (rs >= SHUTDOWN &&
+ ! (rs == SHUTDOWN &&
+ firstTask == null &&
+ ! workQueue.isEmpty()))
+ return false;
+
+ for (;;) {
+ //获取线程池中线程的数量
+ int wc = workerCountOf(c);
+ // core参数为true的话表明队列也满了,线程池大小变为 maximumPoolSize
+ if (wc >= CAPACITY ||
+ wc >= (core ? corePoolSize : maximumPoolSize))
+ return false;
+ //原子操作将workcount的数量加1
+ if (compareAndIncrementWorkerCount(c))
+ break retry;
+ // 如果线程的状态改变了就再次执行上述操作
+ c = ctl.get();
+ if (runStateOf(c) != rs)
+ continue retry;
+ // else CAS failed due to workerCount change; retry inner loop
+ }
+ }
+ // 标记工作线程是否启动成功
+ boolean workerStarted = false;
+ // 标记工作线程是否创建成功
+ boolean workerAdded = false;
+ Worker w = null;
+ try {
+
+ w = new Worker(firstTask);
+ final Thread t = w.thread;
+ if (t != null) {
+ // 加锁
+ final ReentrantLock mainLock = this.mainLock;
+ mainLock.lock();
+ try {
+ //获取线程池状态
+ int rs = runStateOf(ctl.get());
+ //rs < SHUTDOWN 如果线程池状态依然为RUNNING,并且线程的状态是存活的话,就会将工作线程添加到工作线程集合中
+ //(rs=SHUTDOWN && firstTask == null)如果线程池状态小于STOP,也就是RUNNING或者SHUTDOWN状态下,同时传入的任务实例firstTask为null,则需要添加到工作线程集合和启动新的Worker
+ // firstTask == null证明只新建线程而不执行任务
+ if (rs < SHUTDOWN ||
+ (rs == SHUTDOWN && firstTask == null)) {
+ if (t.isAlive()) // precheck that t is startable
+ throw new IllegalThreadStateException();
+ workers.add(w);
+ //更新当前工作线程的最大容量
+ int s = workers.size();
+ if (s > largestPoolSize)
+ largestPoolSize = s;
+ // 工作线程是否启动成功
+ workerAdded = true;
+ }
+ } finally {
+ // 释放锁
+ mainLock.unlock();
+ }
+ //// 如果成功添加工作线程,则调用Worker内部的线程实例t的Thread#start()方法启动真实的线程实例
+ if (workerAdded) {
+ t.start();
+ /// 标记线程启动成功
+ workerStarted = true;
+ }
+ }
+ } finally {
+ // 线程启动失败,需要从工作线程中移除对应的Worker
+ if (! workerStarted)
+ addWorkerFailed(w);
+ }
+ return workerStarted;
+ }
+```
+
+更多关于线程池源码分析的内容推荐这篇文章:《[JUC 线程池 ThreadPoolExecutor 源码分析](http://www.throwable.club/2019/07/15/java-concurrency-thread-pool-executor/)》
+
+现在,让我们在回到 4.1 节我们写的 Demo, 现在应该是不是很容易就可以搞懂它的原理了呢?
+
+没搞懂的话,也没关系,可以看看我的分析:
+
+> 我们在代码中模拟了 10 个任务,我们配置的核心线程数为 5 、等待队列容量为 100 ,所以每次只可能存在 5 个任务同时执行,剩下的 5 个任务会被放到等待队列中去。当前的 5 个任务中如果有任务被执行完了,线程池就会去拿新的任务执行。
+
+### 4.3 几个常见的对比
+
+#### 4.3.1 `Runnable` vs `Callable`
+
+`Runnable`自 Java 1.0 以来一直存在,但`Callable`仅在 Java 1.5 中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口**不会返回结果或抛出检查异常,但是 **`Callable` 接口**可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口**,这样代码看起来会更加简洁。
+
+工具类 `Executors` 可以实现将 `Runnable` 对象转换成 `Callable` 对象。(`Executors.callable(Runnable task)` 或 `Executors.callable(Runnable task, Object result)`)。
+
+`Runnable.java`
+
+```java
+@FunctionalInterface
+public interface Runnable {
+ /**
+ * 被线程执行,没有返回值也无法抛出异常
+ */
+ public abstract void run();
+}
+```
+
+`Callable.java`
+
+```java
+@FunctionalInterface
+public interface Callable<V> {
+ /**
+ * 计算结果,或在无法这样做时抛出异常。
+ * @return 计算得出的结果
+ * @throws 如果无法计算结果,则抛出异常
+ */
+ V call() throws Exception;
+}
+
+```
+
+#### 4.3.2 `execute()` vs `submit()`
+
+- `execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;
+- `submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
+
+我们以 `AbstractExecutorService` 接口中的一个 `submit()` 方法为例子来看看源代码:
+
+```java
+ public Future<?> submit(Runnable task) {
+ if (task == null) throw new NullPointerException();
+ RunnableFuture<Void> ftask = newTaskFor(task, null);
+ execute(ftask);
+ return ftask;
+ }
+```
+
+上面方法调用的 `newTaskFor` 方法返回了一个 `FutureTask` 对象。
+
+```java
+ protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
+ return new FutureTask<T>(runnable, value);
+ }
+```
+
+我们再来看看`execute()`方法:
+
+```java
+ public void execute(Runnable command) {
+ ...
+ }
+```
+
+#### 4.3.3 `shutdown()`VS`shutdownNow()`
+
+- **`shutdown()`** :关闭线程池,线程池的状态变为 `SHUTDOWN`。线程池不再接受新任务了,但是队列里的任务得执行完毕。
+- **`shutdownNow()`** :关闭线程池,线程的状态变为 `STOP`。线程池会终止当前正在运行的任务,并停止处理排队的任务并返回正在等待执行的 List。
+
+#### 4.3.2 `isTerminated()` VS `isShutdown()`
+
+- **`isShutDown`** 当调用 `shutdown()` 方法后返回为 true。
+- **`isTerminated`** 当调用 `shutdown()` 方法后,并且所有提交的任务完成后返回为 true
+
+### 4.4 加餐:`Callable`+`ThreadPoolExecutor`示例代码
+
+`MyCallable.java`
+
+```java
+
+import java.util.concurrent.Callable;
+
+public class MyCallable implements Callable<String> {
+ @Override
+ public String call() throws Exception {
+ Thread.sleep(1000);
+ //返回执行当前 Callable 的线程名字
+ return Thread.currentThread().getName();
+ }
+}
+```
+
+`CallableDemo.java`
+
+```java
+
+import java.util.ArrayList;
+import java.util.Date;
+import java.util.List;
+import java.util.concurrent.ArrayBlockingQueue;
+import java.util.concurrent.Callable;
+import java.util.concurrent.ExecutionException;
+import java.util.concurrent.Future;
+import java.util.concurrent.ThreadPoolExecutor;
+import java.util.concurrent.TimeUnit;
+
+public class CallableDemo {
+
+ private static final int CORE_POOL_SIZE = 5;
+ private static final int MAX_POOL_SIZE = 10;
+ private static final int QUEUE_CAPACITY = 100;
+ private static final Long KEEP_ALIVE_TIME = 1L;
+
+ public static void main(String[] args) {
+
+ //使用阿里巴巴推荐的创建线程池的方式
+ //通过ThreadPoolExecutor构造函数自定义参数创建
+ ThreadPoolExecutor executor = new ThreadPoolExecutor(
+ CORE_POOL_SIZE,
+ MAX_POOL_SIZE,
+ KEEP_ALIVE_TIME,
+ TimeUnit.SECONDS,
+ new ArrayBlockingQueue<>(QUEUE_CAPACITY),
+ new ThreadPoolExecutor.CallerRunsPolicy());
+
+ List<Future<String>> futureList = new ArrayList<>();
+ Callable<String> callable = new MyCallable();
+ for (int i = 0; i < 10; i++) {
+ //提交任务到线程池
+ Future<String> future = executor.submit(callable);
+ //将返回值 future 添加到 list,我们可以通过 future 获得 执行 Callable 得到的返回值
+ futureList.add(future);
+ }
+ for (Future<String> fut : futureList) {
+ try {
+ System.out.println(new Date() + "::" + fut.get());
+ } catch (InterruptedException | ExecutionException e) {
+ e.printStackTrace();
+ }
+ }
+ //关闭线程池
+ executor.shutdown();
+ }
+}
+```
+
+Output:
+
+```
+Wed Nov 13 13:40:41 CST 2019::pool-1-thread-1
+Wed Nov 13 13:40:42 CST 2019::pool-1-thread-2
+Wed Nov 13 13:40:42 CST 2019::pool-1-thread-3
+Wed Nov 13 13:40:42 CST 2019::pool-1-thread-4
+Wed Nov 13 13:40:42 CST 2019::pool-1-thread-5
+Wed Nov 13 13:40:42 CST 2019::pool-1-thread-3
+Wed Nov 13 13:40:43 CST 2019::pool-1-thread-2
+Wed Nov 13 13:40:43 CST 2019::pool-1-thread-1
+Wed Nov 13 13:40:43 CST 2019::pool-1-thread-4
+Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
+```
+
+## 五 几种常见的线程池详解
+
+### 5.1 FixedThreadPool
+
+#### 5.1.1 介绍
+
+`FixedThreadPool` 被称为可重用固定线程数的线程池。通过 Executors 类中的相关源代码来看一下相关实现:
+
+```java
+ /**
+ * 创建一个可重用固定数量线程的线程池
+ */
+ public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
+ return new ThreadPoolExecutor(nThreads, nThreads,
+ 0L, TimeUnit.MILLISECONDS,
+ new LinkedBlockingQueue<Runnable>(),
+ threadFactory);
+ }
+```
+
+另外还有一个 `FixedThreadPool` 的实现方法,和上面的类似,所以这里不多做阐述:
+
+```java
+ public static ExecutorService newFixedThreadPool(int nThreads) {
+ return new ThreadPoolExecutor(nThreads, nThreads,
+ 0L, TimeUnit.MILLISECONDS,
+ new LinkedBlockingQueue<Runnable>());
+ }
+```
+
+**从上面源代码可以看出新创建的 `FixedThreadPool` 的 `corePoolSize` 和 `maximumPoolSize` 都被设置为 nThreads,这个 nThreads 参数是我们使用的时候自己传递的。**
+
+#### 5.1.2 执行任务过程介绍
+
+`FixedThreadPool` 的 `execute()` 方法运行示意图(该图片来源:《Java 并发编程的艺术》):
+
+
+
+**上图说明:**
+
+1. 如果当前运行的线程数小于 corePoolSize, 如果再来新任务的话,就创建新的线程来执行任务;
+2. 当前运行的线程数等于 corePoolSize 后, 如果再来新任务的话,会将任务加入 `LinkedBlockingQueue`;
+3. 线程池中的线程执行完 手头的任务后,会在循环中反复从 `LinkedBlockingQueue` 中获取任务来执行;
+
+#### 5.1.3 为什么不推荐使用`FixedThreadPool`?
+
+**`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`(队列的容量为 Integer.MAX_VALUE)作为线程池的工作队列会对线程池带来如下影响 :**
+
+1. 当线程池中的线程数达到 `corePoolSize` 后,新任务将在无界队列中等待,因此线程池中的线程数不会超过 corePoolSize;
+2. 由于使用无界队列时 `maximumPoolSize` 将是一个无效参数,因为不可能存在任务队列满的情况。所以,通过创建 `FixedThreadPool`的源码可以看出创建的 `FixedThreadPool` 的 `corePoolSize` 和 `maximumPoolSize` 被设置为同一个值。
+3. 由于 1 和 2,使用无界队列时 `keepAliveTime` 将是一个无效参数;
+4. 运行中的 `FixedThreadPool`(未执行 `shutdown()`或 `shutdownNow()`)不会拒绝任务,在任务比较多的时候会导致 OOM(内存溢出)。
+
+### 5.2 SingleThreadExecutor 详解
+
+#### 5.2.1 介绍
+
+`SingleThreadExecutor` 是只有一个线程的线程池。下面看看**SingleThreadExecutor 的实现:**
+
+```java
+ /**
+ *返回只有一个线程的线程池
+ */
+ public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
+ return new FinalizableDelegatedExecutorService
+ (new ThreadPoolExecutor(1, 1,
+ 0L, TimeUnit.MILLISECONDS,
+ new LinkedBlockingQueue<Runnable>(),
+ threadFactory));
+ }
+```
+
+```java
+ public static ExecutorService newSingleThreadExecutor() {
+ return new FinalizableDelegatedExecutorService
+ (new ThreadPoolExecutor(1, 1,
+ 0L, TimeUnit.MILLISECONDS,
+ new LinkedBlockingQueue<Runnable>()));
+ }
+```
+
+从上面源代码可以看出新创建的 `SingleThreadExecutor` 的 `corePoolSize` 和 `maximumPoolSize` 都被设置为 1.其他参数和 `FixedThreadPool` 相同。
+
+#### 5.2.2 执行任务过程介绍
+
+`SingleThreadExecutor` 的运行示意图(该图片来源:《Java 并发编程的艺术》):
+
+
+**上图说明** :
+
+1. 如果当前运行的线程数少于 `corePoolSize`,则创建一个新的线程执行任务;
+2. 当前线程池中有一个运行的线程后,将任务加入 `LinkedBlockingQueue`
+3. 线程执行完当前的任务后,会在循环中反复从`LinkedBlockingQueue` 中获取任务来执行;
+
+#### 5.2.3 为什么不推荐使用`SingleThreadExecutor`?
+
+`SingleThreadExecutor` 使用无界队列 `LinkedBlockingQueue` 作为线程池的工作队列(队列的容量为 Intger.MAX_VALUE)。`SingleThreadExecutor` 使用无界队列作为线程池的工作队列会对线程池带来的影响与 `FixedThreadPool` 相同。说简单点就是可能会导致 OOM,
+
+### 5.3 CachedThreadPool 详解
+
+#### 5.3.1 介绍
+
+`CachedThreadPool` 是一个会根据需要创建新线程的线程池。下面通过源码来看看 `CachedThreadPool` 的实现:
+
+```java
+ /**
+ * 创建一个线程池,根据需要创建新线程,但会在先前构建的线程可用时重用它。
+ */
+ public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
+ return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
+ 60L, TimeUnit.SECONDS,
+ new SynchronousQueue<Runnable>(),
+ threadFactory);
+ }
+
+```
+
+```java
+ public static ExecutorService newCachedThreadPool() {
+ return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
+ 60L, TimeUnit.SECONDS,
+ new SynchronousQueue<Runnable>());
+ }
+```
+
+`CachedThreadPool` 的`corePoolSize` 被设置为空(0),`maximumPoolSize`被设置为 `Integer.MAX.VALUE`,即它是无界的,这也就意味着如果主线程提交任务的速度高于 `maximumPool` 中线程处理任务的速度时,`CachedThreadPool` 会不断创建新的线程。极端情况下,这样会导致耗尽 cpu 和内存资源。
+
+#### 5.3.2 执行任务过程介绍
+
+`CachedThreadPool` 的 `execute()` 方法的执行示意图(该图片来源:《Java 并发编程的艺术》):
+
+
+**上图说明:**
+
+1. 首先执行 `SynchronousQueue.offer(Runnable task)` 提交任务到任务队列。如果当前 `maximumPool` 中有闲线程正在执行 `SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS)`,那么主线程执行 offer 操作与空闲线程执行的 `poll` 操作配对成功,主线程把任务交给空闲线程执行,`execute()`方法执行完成,否则执行下面的步骤 2;
+2. 当初始 `maximumPool` 为空,或者 `maximumPool` 中没有空闲线程时,将没有线程执行 `SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS)`。这种情况下,步骤 1 将失败,此时 `CachedThreadPool` 会创建新线程执行任务,execute 方法执行完成;
+
+#### 5.3.3 为什么不推荐使用`CachedThreadPool`?
+
+`CachedThreadPool`允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
+
+## 六 ScheduledThreadPoolExecutor 详解
+
+**`ScheduledThreadPoolExecutor` 主要用来在给定的延迟后运行任务,或者定期执行任务。** 这个在实际项目中基本不会被用到,也不推荐使用,大家只需要简单了解一下它的思想即可。
+
+### 6.1 简介
+
+`ScheduledThreadPoolExecutor` 使用的任务队列 `DelayQueue` 封装了一个 `PriorityQueue`,`PriorityQueue` 会对队列中的任务进行排序,执行所需时间短的放在前面先被执行(`ScheduledFutureTask` 的 `time` 变量小的先执行),如果执行所需时间相同则先提交的任务将被先执行(`ScheduledFutureTask` 的 `squenceNumber` 变量小的先执行)。
+
+**`ScheduledThreadPoolExecutor` 和 `Timer` 的比较:**
+
+- `Timer` 对系统时钟的变化敏感,`ScheduledThreadPoolExecutor`不是;
+- `Timer` 只有一个执行线程,因此长时间运行的任务可以延迟其他任务。 `ScheduledThreadPoolExecutor` 可以配置任意数量的线程。 此外,如果你想(通过提供 ThreadFactory),你可以完全控制创建的线程;
+- 在`TimerTask` 中抛出的运行时异常会杀死一个线程,从而导致 `Timer` 死机:-( ...即计划任务将不再运行。`ScheduledThreadExecutor` 不仅捕获运行时异常,还允许您在需要时处理它们(通过重写 `afterExecute` 方法`ThreadPoolExecutor`)。抛出异常的任务将被取消,但其他任务将继续运行。
+
+**综上,在 JDK1.5 之后,你没有理由再使用 Timer 进行任务调度了。**
+
+> 关于定时任务的详细介绍,小伙伴们可以在 JavaGuide 的项目首页搜索“定时任务”找到对应的原创内容。
+
+### 6.2 运行机制
+
+
+
+**`ScheduledThreadPoolExecutor` 的执行主要分为两大部分:**
+
+1. 当调用 `ScheduledThreadPoolExecutor` 的 **`scheduleAtFixedRate()`** 方法或者 **`scheduleWithFixedDelay()`** 方法时,会向 `ScheduledThreadPoolExecutor` 的 **`DelayQueue`** 添加一个实现了 **`RunnableScheduledFuture`** 接口的 **`ScheduledFutureTask`** 。
+2. 线程池中的线程从 `DelayQueue` 中获取 `ScheduledFutureTask`,然后执行任务。
+
+**`ScheduledThreadPoolExecutor` 为了实现周期性的执行任务,对 `ThreadPoolExecutor`做了如下修改:**
+
+- 使用 **`DelayQueue`** 作为任务队列;
+- 获取任务的方不同
+- 执行周期任务后,增加了额外的处理
+
+### 6.3 ScheduledThreadPoolExecutor 执行周期任务的步骤
+
+
+
+1. 线程 1 从 `DelayQueue` 中获取已到期的 `ScheduledFutureTask(DelayQueue.take())`。到期任务是指 `ScheduledFutureTask`的 time 大于等于当前系统的时间;
+2. 线程 1 执行这个 `ScheduledFutureTask`;
+3. 线程 1 修改 `ScheduledFutureTask` 的 time 变量为下次将要被执行的时间;
+4. 线程 1 把这个修改 time 之后的 `ScheduledFutureTask` 放回 `DelayQueue` 中(`DelayQueue.add()`)。
+
+## 七 线程池大小确定
+
+**线程池数量的确定一直是困扰着程序员的一个难题,大部分程序员在设定线程池大小的时候就是随心而定。**
+
+很多人甚至可能都会觉得把线程池配置过大一点比较好!我觉得这明显是有问题的。就拿我们生活中非常常见的一例子来说:**并不是人多就能把事情做好,增加了沟通交流成本。你本来一件事情只需要 3 个人做,你硬是拉来了 6 个人,会提升做事效率嘛?我想并不会。** 线程数量过多的影响也是和我们分配多少人做事情一样,对于多线程这个场景来说主要是增加了**上下文切换**成本。不清楚什么是上下文切换的话,可以看我下面的介绍。
+
+> 上下文切换:
+>
+> 多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。**任务从保存到再加载的过程就是一次上下文切换**。
+>
+> 上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
+>
+> Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
+
+**类比于实现世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。**
+
+**如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的! CPU 根本没有得到充分利用。**
+
+**但是,如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。**
+
+有一个简单并且适用面比较广的公式:
+
+- **CPU 密集型任务(N+1):** 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
+- **I/O 密集型任务(2N):** 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
+
+**如何判断是 CPU 密集任务还是 IO 密集任务?**
+
+CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
+
+## 八 参考
+
+- 《Java 并发编程的艺术》
+- [Java Scheduler ScheduledExecutorService ScheduledThreadPoolExecutor Example](https://www.journaldev.com/2340/java-scheduler-scheduledexecutorservice-scheduledthreadpoolexecutor-example "Java Scheduler ScheduledExecutorService ScheduledThreadPoolExecutor Example")
+- [java.util.concurrent.ScheduledThreadPoolExecutor Example](https://examples.javacodegeeks.com/core-java/util/concurrent/scheduledthreadpoolexecutor/java-util-concurrent-scheduledthreadpoolexecutor-example/ "java.util.concurrent.ScheduledThreadPoolExecutor Example")
+- [ThreadPoolExecutor – Java Thread Pool Example](https://www.journaldev.com/1069/threadpoolexecutor-java-thread-pool-example-executorservice "ThreadPoolExecutor – Java Thread Pool Example")
+
+## 九 其他推荐阅读
+
+- [Java 并发(三)线程池原理](https://www.cnblogs.com/warehouse/p/10720781.html "Java并发(三)线程池原理")
+- [如何优雅的使用和理解线程池](https://github.com/crossoverJie/JCSprout/blob/master/MD/ThreadPoolExecutor.md "如何优雅的使用和理解线程池")
diff --git a/docs/java/concurrent/reentrantlock.md b/docs/java/concurrent/reentrantlock.md
new file mode 100644
index 00000000000..fad97ff4dc7
--- /dev/null
+++ b/docs/java/concurrent/reentrantlock.md
@@ -0,0 +1,994 @@
+---
+title: 从ReentrantLock的实现看AQS的原理及应用
+category: Java
+tag:
+ - Java并发
+---
+
+> 本文转载自:https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html
+>
+> 作者:美团技术团队
+
+## 前言
+
+Java中的大部分同步类(Lock、Semaphore、ReentrantLock等)都是基于AbstractQueuedSynchronizer(简称为AQS)实现的。AQS是一种提供了原子式管理同步状态、阻塞和唤醒线程功能以及队列模型的简单框架。本文会从应用层逐渐深入到原理层,并通过ReentrantLock的基本特性和ReentrantLock与AQS的关联,来深入解读AQS相关独占锁的知识点,同时采取问答的模式来帮助大家理解AQS。由于篇幅原因,本篇文章主要阐述AQS中独占锁的逻辑和Sync Queue,不讲述包含共享锁和Condition Queue的部分(本篇文章核心为AQS原理剖析,只是简单介绍了ReentrantLock,感兴趣同学可以阅读一下ReentrantLock的源码)。
+
+## 1 ReentrantLock
+
+### 1.1 ReentrantLock特性概览
+
+ReentrantLock意思为可重入锁,指的是一个线程能够对一个临界资源重复加锁。为了帮助大家更好地理解ReentrantLock的特性,我们先将ReentrantLock跟常用的Synchronized进行比较,其特性如下(蓝色部分为本篇文章主要剖析的点):
+
+
+
+下面通过伪代码,进行更加直观的比较:
+
+```java
+// **************************Synchronized的使用方式**************************
+// 1.用于代码块
+synchronized (this) {}
+// 2.用于对象
+synchronized (object) {}
+// 3.用于方法
+public synchronized void test () {}
+// 4.可重入
+for (int i = 0; i < 100; i++) {
+ synchronized (this) {}
+}
+// **************************ReentrantLock的使用方式**************************
+public void test () throw Exception {
+ // 1.初始化选择公平锁、非公平锁
+ ReentrantLock lock = new ReentrantLock(true);
+ // 2.可用于代码块
+ lock.lock();
+ try {
+ try {
+ // 3.支持多种加锁方式,比较灵活; 具有可重入特性
+ if(lock.tryLock(100, TimeUnit.MILLISECONDS)){ }
+ } finally {
+ // 4.手动释放锁
+ lock.unlock()
+ }
+ } finally {
+ lock.unlock();
+ }
+}
+```
+
+### 1.2 ReentrantLock与AQS的关联
+
+通过上文我们已经了解,ReentrantLock支持公平锁和非公平锁(关于公平锁和非公平锁的原理分析,可参考《[不可不说的Java“锁”事](https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749434&idx=3&sn=5ffa63ad47fe166f2f1a9f604ed10091&chksm=bd12a5778a652c61509d9e718ab086ff27ad8768586ea9b38c3dcf9e017a8e49bcae3df9bcc8&scene=38#wechat_redirect)》),并且ReentrantLock的底层就是由AQS来实现的。那么ReentrantLock是如何通过公平锁和非公平锁与AQS关联起来呢? 我们着重从这两者的加锁过程来理解一下它们与AQS之间的关系(加锁过程中与AQS的关联比较明显,解锁流程后续会介绍)。
+
+非公平锁源码中的加锁流程如下:
+
+```java
+// java.util.concurrent.locks.ReentrantLock#NonfairSync
+
+// 非公平锁
+static final class NonfairSync extends Sync {
+ ...
+ final void lock() {
+ if (compareAndSetState(0, 1))
+ setExclusiveOwnerThread(Thread.currentThread());
+ else
+ acquire(1);
+ }
+ ...
+}
+```
+
+这块代码的含义为:
+
+- 若通过CAS设置变量State(同步状态)成功,也就是获取锁成功,则将当前线程设置为独占线程。
+- 若通过CAS设置变量State(同步状态)失败,也就是获取锁失败,则进入Acquire方法进行后续处理。
+
+第一步很好理解,但第二步获取锁失败后,后续的处理策略是怎么样的呢?这块可能会有以下思考:
+
+- 某个线程获取锁失败的后续流程是什么呢?有以下两种可能:
+
+(1) 将当前线程获锁结果设置为失败,获取锁流程结束。这种设计会极大降低系统的并发度,并不满足我们实际的需求。所以就需要下面这种流程,也就是AQS框架的处理流程。
+
+(2) 存在某种排队等候机制,线程继续等待,仍然保留获取锁的可能,获取锁流程仍在继续。
+
+- 对于问题1的第二种情况,既然说到了排队等候机制,那么就一定会有某种队列形成,这样的队列是什么数据结构呢?
+- 处于排队等候机制中的线程,什么时候可以有机会获取锁呢?
+- 如果处于排队等候机制中的线程一直无法获取锁,还是需要一直等待吗,还是有别的策略来解决这一问题?
+
+带着非公平锁的这些问题,再看下公平锁源码中获锁的方式:
+
+```
+// java.util.concurrent.locks.ReentrantLock#FairSync
+
+static final class FairSync extends Sync {
+ ...
+ final void lock() {
+ acquire(1);
+ }
+ ...
+}
+```
+
+看到这块代码,我们可能会存在这种疑问:Lock函数通过Acquire方法进行加锁,但是具体是如何加锁的呢?
+
+结合公平锁和非公平锁的加锁流程,虽然流程上有一定的不同,但是都调用了Acquire方法,而Acquire方法是FairSync和UnfairSync的父类AQS中的核心方法。
+
+对于上边提到的问题,其实在ReentrantLock类源码中都无法解答,而这些问题的答案,都是位于Acquire方法所在的类AbstractQueuedSynchronizer中,也就是本文的核心——AQS。下面我们会对AQS以及ReentrantLock和AQS的关联做详细介绍(相关问题答案会在2.3.5小节中解答)。
+
+## 2 AQS
+
+首先,我们通过下面的架构图来整体了解一下AQS框架:
+
+
+
+- 上图中有颜色的为Method,无颜色的为Attribution。
+- 总的来说,AQS框架共分为五层,自上而下由浅入深,从AQS对外暴露的API到底层基础数据。
+- 当有自定义同步器接入时,只需重写第一层所需要的部分方法即可,不需要关注底层具体的实现流程。当自定义同步器进行加锁或者解锁操作时,先经过第一层的API进入AQS内部方法,然后经过第二层进行锁的获取,接着对于获取锁失败的流程,进入第三层和第四层的等待队列处理,而这些处理方式均依赖于第五层的基础数据提供层。
+
+下面我们会从整体到细节,从流程到方法逐一剖析AQS框架,主要分析过程如下:
+
+
+
+### 2.1 原理概览
+
+AQS核心思想是,如果被请求的共享资源空闲,那么就将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中。
+
+CLH:Craig、Landin and Hagersten队列,是单向链表,AQS中的队列是CLH变体的虚拟双向队列(FIFO),AQS是通过将每条请求共享资源的线程封装成一个节点来实现锁的分配。
+
+主要原理图如下:
+
+
+
+AQS使用一个Volatile的int类型的成员变量来表示同步状态,通过内置的FIFO队列来完成资源获取的排队工作,通过CAS完成对State值的修改。
+
+#### 2.1.1 AQS数据结构
+
+先来看下AQS中最基本的数据结构——Node,Node即为上面CLH变体队列中的节点。
+
+
+
+解释一下几个方法和属性值的含义:
+
+| 方法和属性值 | 含义 |
+| :----------- | :----------------------------------------------------------- |
+| waitStatus | 当前节点在队列中的状态 |
+| thread | 表示处于该节点的线程 |
+| prev | 前驱指针 |
+| predecessor | 返回前驱节点,没有的话抛出npe |
+| nextWaiter | 指向下一个处于CONDITION状态的节点(由于本篇文章不讲述Condition Queue队列,这个指针不多介绍) |
+| next | 后继指针 |
+
+线程两种锁的模式:
+
+| 模式 | 含义 |
+| :-------- | :----------------------------- |
+| SHARED | 表示线程以共享的模式等待锁 |
+| EXCLUSIVE | 表示线程正在以独占的方式等待锁 |
+
+waitStatus有下面几个枚举值:
+
+| 枚举 | 含义 |
+| :-------- | :--------------------------------------------- |
+| 0 | 当一个Node被初始化的时候的默认值 |
+| CANCELLED | 为1,表示线程获取锁的请求已经取消了 |
+| CONDITION | 为-2,表示节点在等待队列中,节点线程等待唤醒 |
+| PROPAGATE | 为-3,当前线程处在SHARED情况下,该字段才会使用 |
+| SIGNAL | 为-1,表示线程已经准备好了,就等资源释放了 |
+
+#### 2.1.2 同步状态State
+
+在了解数据结构后,接下来了解一下AQS的同步状态——State。AQS中维护了一个名为state的字段,意为同步状态,是由Volatile修饰的,用于展示当前临界资源的获锁情况。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+private volatile int state;
+```
+
+下面提供了几个访问这个字段的方法:
+
+| 方法名 | 描述 |
+| :----------------------------------------------------------- | :------------------- |
+| protected final int getState() | 获取State的值 |
+| protected final void setState(int newState) | 设置State的值 |
+| protected final boolean compareAndSetState(int expect, int update) | 使用CAS方式更新State |
+
+这几个方法都是Final修饰的,说明子类中无法重写它们。我们可以通过修改State字段表示的同步状态来实现多线程的独占模式和共享模式(加锁过程)。
+
+
+
+
+
+对于我们自定义的同步工具,需要自定义获取同步状态和释放状态的方式,也就是AQS架构图中的第一层:API层。
+
+## 2.2 AQS重要方法与ReentrantLock的关联
+
+从架构图中可以得知,AQS提供了大量用于自定义同步器实现的Protected方法。自定义同步器实现的相关方法也只是为了通过修改State字段来实现多线程的独占模式或者共享模式。自定义同步器需要实现以下方法(ReentrantLock需要实现的方法如下,并不是全部):
+
+| 方法名 | 描述 |
+| :------------------------------------------ | :----------------------------------------------------------- |
+| protected boolean isHeldExclusively() | 该线程是否正在独占资源。只有用到Condition才需要去实现它。 |
+| protected boolean tryAcquire(int arg) | 独占方式。arg为获取锁的次数,尝试获取资源,成功则返回True,失败则返回False。 |
+| protected boolean tryRelease(int arg) | 独占方式。arg为释放锁的次数,尝试释放资源,成功则返回True,失败则返回False。 |
+| protected int tryAcquireShared(int arg) | 共享方式。arg为获取锁的次数,尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。 |
+| protected boolean tryReleaseShared(int arg) | 共享方式。arg为释放锁的次数,尝试释放资源,如果释放后允许唤醒后续等待结点返回True,否则返回False。 |
+
+一般来说,自定义同步器要么是独占方式,要么是共享方式,它们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。ReentrantLock是独占锁,所以实现了tryAcquire-tryRelease。
+
+以非公平锁为例,这里主要阐述一下非公平锁与AQS之间方法的关联之处,具体每一处核心方法的作用会在文章后面详细进行阐述。
+
+
+
+为了帮助大家理解ReentrantLock和AQS之间方法的交互过程,以非公平锁为例,我们将加锁和解锁的交互流程单独拎出来强调一下,以便于对后续内容的理解。
+
+
+
+加锁:
+
+- 通过ReentrantLock的加锁方法Lock进行加锁操作。
+- 会调用到内部类Sync的Lock方法,由于Sync#lock是抽象方法,根据ReentrantLock初始化选择的公平锁和非公平锁,执行相关内部类的Lock方法,本质上都会执行AQS的Acquire方法。
+- AQS的Acquire方法会执行tryAcquire方法,但是由于tryAcquire需要自定义同步器实现,因此执行了ReentrantLock中的tryAcquire方法,由于ReentrantLock是通过公平锁和非公平锁内部类实现的tryAcquire方法,因此会根据锁类型不同,执行不同的tryAcquire。
+- tryAcquire是获取锁逻辑,获取失败后,会执行框架AQS的后续逻辑,跟ReentrantLock自定义同步器无关。
+
+解锁:
+
+- 通过ReentrantLock的解锁方法Unlock进行解锁。
+- Unlock会调用内部类Sync的Release方法,该方法继承于AQS。
+- Release中会调用tryRelease方法,tryRelease需要自定义同步器实现,tryRelease只在ReentrantLock中的Sync实现,因此可以看出,释放锁的过程,并不区分是否为公平锁。
+- 释放成功后,所有处理由AQS框架完成,与自定义同步器无关。
+
+通过上面的描述,大概可以总结出ReentrantLock加锁解锁时API层核心方法的映射关系。
+
+
+
+## 2.3 通过ReentrantLock理解AQS
+
+ReentrantLock中公平锁和非公平锁在底层是相同的,这里以非公平锁为例进行分析。
+
+在非公平锁中,有一段这样的代码:
+
+```java
+// java.util.concurrent.locks.ReentrantLock
+
+static final class NonfairSync extends Sync {
+ ...
+ final void lock() {
+ if (compareAndSetState(0, 1))
+ setExclusiveOwnerThread(Thread.currentThread());
+ else
+ acquire(1);
+ }
+ ...
+}
+```
+
+看一下这个Acquire是怎么写的:
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+public final void acquire(int arg) {
+ if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
+ selfInterrupt();
+}
+```
+
+再看一下tryAcquire方法:
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+protected boolean tryAcquire(int arg) {
+ throw new UnsupportedOperationException();
+}
+```
+
+可以看出,这里只是AQS的简单实现,具体获取锁的实现方法是由各自的公平锁和非公平锁单独实现的(以ReentrantLock为例)。如果该方法返回了True,则说明当前线程获取锁成功,就不用往后执行了;如果获取失败,就需要加入到等待队列中。下面会详细解释线程是何时以及怎样被加入进等待队列中的。
+
+### 2.3.1 线程加入等待队列
+
+#### 2.3.1.1 加入队列的时机
+
+当执行Acquire(1)时,会通过tryAcquire获取锁。在这种情况下,如果获取锁失败,就会调用addWaiter加入到等待队列中去。
+
+#### 2.3.1.2 如何加入队列
+
+获取锁失败后,会执行addWaiter(Node.EXCLUSIVE)加入等待队列,具体实现方法如下:
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+private Node addWaiter(Node mode) {
+ Node node = new Node(Thread.currentThread(), mode);
+ // Try the fast path of enq; backup to full enq on failure
+ Node pred = tail;
+ if (pred != null) {
+ node.prev = pred;
+ if (compareAndSetTail(pred, node)) {
+ pred.next = node;
+ return node;
+ }
+ }
+ enq(node);
+ return node;
+}
+private final boolean compareAndSetTail(Node expect, Node update) {
+ return unsafe.compareAndSwapObject(this, tailOffset, expect, update);
+}
+```
+
+主要的流程如下:
+
+- 通过当前的线程和锁模式新建一个节点。
+- Pred指针指向尾节点Tail。
+- 将New中Node的Prev指针指向Pred。
+- 通过compareAndSetTail方法,完成尾节点的设置。这个方法主要是对tailOffset和Expect进行比较,如果tailOffset的Node和Expect的Node地址是相同的,那么设置Tail的值为Update的值。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+static {
+ try {
+ stateOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("state"));
+ headOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("head"));
+ tailOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("tail"));
+ waitStatusOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField("waitStatus"));
+ nextOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField("next"));
+ } catch (Exception ex) {
+ throw new Error(ex);
+ }
+}
+```
+
+从AQS的静态代码块可以看出,都是获取一个对象的属性相对于该对象在内存当中的偏移量,这样我们就可以根据这个偏移量在对象内存当中找到这个属性。tailOffset指的是tail对应的偏移量,所以这个时候会将new出来的Node置为当前队列的尾节点。同时,由于是双向链表,也需要将前一个节点指向尾节点。
+
+- 如果Pred指针是Null(说明等待队列中没有元素),或者当前Pred指针和Tail指向的位置不同(说明被别的线程已经修改),就需要看一下Enq的方法。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+private Node enq(final Node node) {
+ for (;;) {
+ Node t = tail;
+ if (t == null) { // Must initialize
+ if (compareAndSetHead(new Node()))
+ tail = head;
+ } else {
+ node.prev = t;
+ if (compareAndSetTail(t, node)) {
+ t.next = node;
+ return t;
+ }
+ }
+ }
+}
+```
+
+如果没有被初始化,需要进行初始化一个头结点出来。但请注意,初始化的头结点并不是当前线程节点,而是调用了无参构造函数的节点。如果经历了初始化或者并发导致队列中有元素,则与之前的方法相同。其实,addWaiter就是一个在双端链表添加尾节点的操作,需要注意的是,双端链表的头结点是一个无参构造函数的头结点。
+
+总结一下,线程获取锁的时候,过程大体如下:
+
+1. 当没有线程获取到锁时,线程1获取锁成功。
+2. 线程2申请锁,但是锁被线程1占有。
+
+
+
+1. 如果再有线程要获取锁,依次在队列中往后排队即可。
+
+回到上边的代码,hasQueuedPredecessors是公平锁加锁时判断等待队列中是否存在有效节点的方法。如果返回False,说明当前线程可以争取共享资源;如果返回True,说明队列中存在有效节点,当前线程必须加入到等待队列中。
+
+```java
+// java.util.concurrent.locks.ReentrantLock
+
+public final boolean hasQueuedPredecessors() {
+ // The correctness of this depends on head being initialized
+ // before tail and on head.next being accurate if the current
+ // thread is first in queue.
+ Node t = tail; // Read fields in reverse initialization order
+ Node h = head;
+ Node s;
+ return h != t && ((s = h.next) == null || s.thread != Thread.currentThread());
+}
+```
+
+看到这里,我们理解一下h != t && ((s = h.next) == null || s.thread != Thread.currentThread());为什么要判断的头结点的下一个节点?第一个节点储存的数据是什么?
+
+> 双向链表中,第一个节点为虚节点,其实并不存储任何信息,只是占位。真正的第一个有数据的节点,是在第二个节点开始的。当h != t时: 如果(s = h.next) == null,等待队列正在有线程进行初始化,但只是进行到了Tail指向Head,没有将Head指向Tail,此时队列中有元素,需要返回True(这块具体见下边代码分析)。 如果(s = h.next) != null,说明此时队列中至少有一个有效节点。如果此时s.thread == Thread.currentThread(),说明等待队列的第一个有效节点中的线程与当前线程相同,那么当前线程是可以获取资源的;如果s.thread != Thread.currentThread(),说明等待队列的第一个有效节点线程与当前线程不同,当前线程必须加入进等待队列。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer#enq
+
+if (t == null) { // Must initialize
+ if (compareAndSetHead(new Node()))
+ tail = head;
+} else {
+ node.prev = t;
+ if (compareAndSetTail(t, node)) {
+ t.next = node;
+ return t;
+ }
+}
+```
+
+节点入队不是原子操作,所以会出现短暂的head != tail,此时Tail指向最后一个节点,而且Tail指向Head。如果Head没有指向Tail(可见5、6、7行),这种情况下也需要将相关线程加入队列中。所以这块代码是为了解决极端情况下的并发问题。
+
+#### 2.3.1.3 等待队列中线程出队列时机
+
+回到最初的源码:
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+public final void acquire(int arg) {
+ if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
+ selfInterrupt();
+}
+```
+
+上文解释了addWaiter方法,这个方法其实就是把对应的线程以Node的数据结构形式加入到双端队列里,返回的是一个包含该线程的Node。而这个Node会作为参数,进入到acquireQueued方法中。acquireQueued方法可以对排队中的线程进行“获锁”操作。
+
+总的来说,一个线程获取锁失败了,被放入等待队列,acquireQueued会把放入队列中的线程不断去获取锁,直到获取成功或者不再需要获取(中断)。
+
+下面我们从“何时出队列?”和“如何出队列?”两个方向来分析一下acquireQueued源码:
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+final boolean acquireQueued(final Node node, int arg) {
+ // 标记是否成功拿到资源
+ boolean failed = true;
+ try {
+ // 标记等待过程中是否中断过
+ boolean interrupted = false;
+ // 开始自旋,要么获取锁,要么中断
+ for (;;) {
+ // 获取当前节点的前驱节点
+ final Node p = node.predecessor();
+ // 如果p是头结点,说明当前节点在真实数据队列的首部,就尝试获取锁(别忘了头结点是虚节点)
+ if (p == head && tryAcquire(arg)) {
+ // 获取锁成功,头指针移动到当前node
+ setHead(node);
+ p.next = null; // help GC
+ failed = false;
+ return interrupted;
+ }
+ // 说明p为头节点且当前没有获取到锁(可能是非公平锁被抢占了)或者是p不为头结点,这个时候就要判断当前node是否要被阻塞(被阻塞条件:前驱节点的waitStatus为-1),防止无限循环浪费资源。具体两个方法下面细细分析
+ if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
+ interrupted = true;
+ }
+ } finally {
+ if (failed)
+ cancelAcquire(node);
+ }
+}
+```
+
+注:setHead方法是把当前节点置为虚节点,但并没有修改waitStatus,因为它是一直需要用的数据。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+private void setHead(Node node) {
+ head = node;
+ node.thread = null;
+ node.prev = null;
+}
+
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+// 靠前驱节点判断当前线程是否应该被阻塞
+private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
+ // 获取头结点的节点状态
+ int ws = pred.waitStatus;
+ // 说明头结点处于唤醒状态
+ if (ws == Node.SIGNAL)
+ return true;
+ // 通过枚举值我们知道waitStatus>0是取消状态
+ if (ws > 0) {
+ do {
+ // 循环向前查找取消节点,把取消节点从队列中剔除
+ node.prev = pred = pred.prev;
+ } while (pred.waitStatus > 0);
+ pred.next = node;
+ } else {
+ // 设置前任节点等待状态为SIGNAL
+ compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
+ }
+ return false;
+}
+```
+
+parkAndCheckInterrupt主要用于挂起当前线程,阻塞调用栈,返回当前线程的中断状态。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+private final boolean parkAndCheckInterrupt() {
+ LockSupport.park(this);
+ return Thread.interrupted();
+}
+```
+
+上述方法的流程图如下:
+
+
+
+从上图可以看出,跳出当前循环的条件是当“前置节点是头结点,且当前线程获取锁成功”。为了防止因死循环导致CPU资源被浪费,我们会判断前置节点的状态来决定是否要将当前线程挂起,具体挂起流程用流程图表示如下(shouldParkAfterFailedAcquire流程):
+
+
+
+从队列中释放节点的疑虑打消了,那么又有新问题了:
+
+- shouldParkAfterFailedAcquire中取消节点是怎么生成的呢?什么时候会把一个节点的waitStatus设置为-1?
+- 是在什么时间释放节点通知到被挂起的线程呢?
+
+### 2.3.2 CANCELLED状态节点生成
+
+acquireQueued方法中的Finally代码:
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+final boolean acquireQueued(final Node node, int arg) {
+ boolean failed = true;
+ try {
+ ...
+ for (;;) {
+ final Node p = node.predecessor();
+ if (p == head && tryAcquire(arg)) {
+ ...
+ failed = false;
+ ...
+ }
+ ...
+ } finally {
+ if (failed)
+ cancelAcquire(node);
+ }
+}
+```
+
+通过cancelAcquire方法,将Node的状态标记为CANCELLED。接下来,我们逐行来分析这个方法的原理:
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+private void cancelAcquire(Node node) {
+ // 将无效节点过滤
+ if (node == null)
+ return;
+ // 设置该节点不关联任何线程,也就是虚节点
+ node.thread = null;
+ Node pred = node.prev;
+ // 通过前驱节点,跳过取消状态的node
+ while (pred.waitStatus > 0)
+ node.prev = pred = pred.prev;
+ // 获取过滤后的前驱节点的后继节点
+ Node predNext = pred.next;
+ // 把当前node的状态设置为CANCELLED
+ node.waitStatus = Node.CANCELLED;
+ // 如果当前节点是尾节点,将从后往前的第一个非取消状态的节点设置为尾节点
+ // 更新失败的话,则进入else,如果更新成功,将tail的后继节点设置为null
+ if (node == tail && compareAndSetTail(node, pred)) {
+ compareAndSetNext(pred, predNext, null);
+ } else {
+ int ws;
+ // 如果当前节点不是head的后继节点,1:判断当前节点前驱节点的是否为SIGNAL,2:如果不是,则把前驱节点设置为SINGAL看是否成功
+ // 如果1和2中有一个为true,再判断当前节点的线程是否为null
+ // 如果上述条件都满足,把当前节点的前驱节点的后继指针指向当前节点的后继节点
+ if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) {
+ Node next = node.next;
+ if (next != null && next.waitStatus <= 0)
+ compareAndSetNext(pred, predNext, next);
+ } else {
+ // 如果当前节点是head的后继节点,或者上述条件不满足,那就唤醒当前节点的后继节点
+ unparkSuccessor(node);
+ }
+ node.next = node; // help GC
+ }
+}
+```
+
+当前的流程:
+
+- 获取当前节点的前驱节点,如果前驱节点的状态是CANCELLED,那就一直往前遍历,找到第一个waitStatus <= 0的节点,将找到的Pred节点和当前Node关联,将当前Node设置为CANCELLED。
+- 根据当前节点的位置,考虑以下三种情况:
+
+(1) 当前节点是尾节点。
+
+(2) 当前节点是Head的后继节点。
+
+(3) 当前节点不是Head的后继节点,也不是尾节点。
+
+根据上述第二条,我们来分析每一种情况的流程。
+
+当前节点是尾节点。
+
+
+
+当前节点是Head的后继节点。
+
+
+
+当前节点不是Head的后继节点,也不是尾节点。
+
+
+
+通过上面的流程,我们对于CANCELLED节点状态的产生和变化已经有了大致的了解,但是为什么所有的变化都是对Next指针进行了操作,而没有对Prev指针进行操作呢?什么情况下会对Prev指针进行操作?
+
+> 执行cancelAcquire的时候,当前节点的前置节点可能已经从队列中出去了(已经执行过Try代码块中的shouldParkAfterFailedAcquire方法了),如果此时修改Prev指针,有可能会导致Prev指向另一个已经移除队列的Node,因此这块变化Prev指针不安全。 shouldParkAfterFailedAcquire方法中,会执行下面的代码,其实就是在处理Prev指针。shouldParkAfterFailedAcquire是获取锁失败的情况下才会执行,进入该方法后,说明共享资源已被获取,当前节点之前的节点都不会出现变化,因此这个时候变更Prev指针比较安全。
+>
+> ```java
+> do {
+> node.prev = pred = pred.prev;
+> } while (pred.waitStatus > 0);
+> ```
+
+### 2.3.3 如何解锁
+
+我们已经剖析了加锁过程中的基本流程,接下来再对解锁的基本流程进行分析。由于ReentrantLock在解锁的时候,并不区分公平锁和非公平锁,所以我们直接看解锁的源码:
+
+```java
+// java.util.concurrent.locks.ReentrantLock
+
+public void unlock() {
+ sync.release(1);
+}
+```
+
+可以看到,本质释放锁的地方,是通过框架来完成的。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+public final boolean release(int arg) {
+ if (tryRelease(arg)) {
+ Node h = head;
+ if (h != null && h.waitStatus != 0)
+ unparkSuccessor(h);
+ return true;
+ }
+ return false;
+}
+```
+
+在ReentrantLock里面的公平锁和非公平锁的父类Sync定义了可重入锁的释放锁机制。
+
+```java
+// java.util.concurrent.locks.ReentrantLock.Sync
+
+// 方法返回当前锁是不是没有被线程持有
+protected final boolean tryRelease(int releases) {
+ // 减少可重入次数
+ int c = getState() - releases;
+ // 当前线程不是持有锁的线程,抛出异常
+ if (Thread.currentThread() != getExclusiveOwnerThread())
+ throw new IllegalMonitorStateException();
+ boolean free = false;
+ // 如果持有线程全部释放,将当前独占锁所有线程设置为null,并更新state
+ if (c == 0) {
+ free = true;
+ setExclusiveOwnerThread(null);
+ }
+ setState(c);
+ return free;
+}
+```
+
+我们来解释下述源码:
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+public final boolean release(int arg) {
+ // 上边自定义的tryRelease如果返回true,说明该锁没有被任何线程持有
+ if (tryRelease(arg)) {
+ // 获取头结点
+ Node h = head;
+ // 头结点不为空并且头结点的waitStatus不是初始化节点情况,解除线程挂起状态
+ if (h != null && h.waitStatus != 0)
+ unparkSuccessor(h);
+ return true;
+ }
+ return false;
+}
+```
+
+这里的判断条件为什么是h != null && h.waitStatus != 0?
+
+> h == null Head还没初始化。初始情况下,head == null,第一个节点入队,Head会被初始化一个虚拟节点。所以说,这里如果还没来得及入队,就会出现head == null 的情况。
+>
+> h != null && waitStatus == 0 表明后继节点对应的线程仍在运行中,不需要唤醒。
+>
+> h != null && waitStatus < 0 表明后继节点可能被阻塞了,需要唤醒。
+
+再看一下unparkSuccessor方法:
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+private void unparkSuccessor(Node node) {
+ // 获取头结点waitStatus
+ int ws = node.waitStatus;
+ if (ws < 0)
+ compareAndSetWaitStatus(node, ws, 0);
+ // 获取当前节点的下一个节点
+ Node s = node.next;
+ // 如果下个节点是null或者下个节点被cancelled,就找到队列最开始的非cancelled的节点
+ if (s == null || s.waitStatus > 0) {
+ s = null;
+ // 就从尾部节点开始找,到队首,找到队列第一个waitStatus<0的节点。
+ for (Node t = tail; t != null && t != node; t = t.prev)
+ if (t.waitStatus <= 0)
+ s = t;
+ }
+ // 如果当前节点的下个节点不为空,而且状态<=0,就把当前节点unpark
+ if (s != null)
+ LockSupport.unpark(s.thread);
+}
+```
+
+为什么要从后往前找第一个非Cancelled的节点呢?原因如下。
+
+之前的addWaiter方法:
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+private Node addWaiter(Node mode) {
+ Node node = new Node(Thread.currentThread(), mode);
+ // Try the fast path of enq; backup to full enq on failure
+ Node pred = tail;
+ if (pred != null) {
+ node.prev = pred;
+ if (compareAndSetTail(pred, node)) {
+ pred.next = node;
+ return node;
+ }
+ }
+ enq(node);
+ return node;
+}
+```
+
+我们从这里可以看到,节点入队并不是原子操作,也就是说,node.prev = pred; compareAndSetTail(pred, node) 这两个地方可以看作Tail入队的原子操作,但是此时pred.next = node;还没执行,如果这个时候执行了unparkSuccessor方法,就没办法从前往后找了,所以需要从后往前找。还有一点原因,在产生CANCELLED状态节点的时候,先断开的是Next指针,Prev指针并未断开,因此也是必须要从后往前遍历才能够遍历完全部的Node。
+
+综上所述,如果是从前往后找,由于极端情况下入队的非原子操作和CANCELLED节点产生过程中断开Next指针的操作,可能会导致无法遍历所有的节点。所以,唤醒对应的线程后,对应的线程就会继续往下执行。继续执行acquireQueued方法以后,中断如何处理?
+
+### 2.3.4 中断恢复后的执行流程
+
+唤醒后,会执行return Thread.interrupted();,这个函数返回的是当前执行线程的中断状态,并清除。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+private final boolean parkAndCheckInterrupt() {
+ LockSupport.park(this);
+ return Thread.interrupted();
+}
+```
+
+再回到acquireQueued代码,当parkAndCheckInterrupt返回True或者False的时候,interrupted的值不同,但都会执行下次循环。如果这个时候获取锁成功,就会把当前interrupted返回。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+final boolean acquireQueued(final Node node, int arg) {
+ boolean failed = true;
+ try {
+ boolean interrupted = false;
+ for (;;) {
+ final Node p = node.predecessor();
+ if (p == head && tryAcquire(arg)) {
+ setHead(node);
+ p.next = null; // help GC
+ failed = false;
+ return interrupted;
+ }
+ if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
+ interrupted = true;
+ }
+ } finally {
+ if (failed)
+ cancelAcquire(node);
+ }
+}
+```
+
+如果acquireQueued为True,就会执行selfInterrupt方法。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+static void selfInterrupt() {
+ Thread.currentThread().interrupt();
+}
+```
+
+该方法其实是为了中断线程。但为什么获取了锁以后还要中断线程呢?这部分属于Java提供的协作式中断知识内容,感兴趣同学可以查阅一下。这里简单介绍一下:
+
+1. 当中断线程被唤醒时,并不知道被唤醒的原因,可能是当前线程在等待中被中断,也可能是释放了锁以后被唤醒。因此我们通过Thread.interrupted()方法检查中断标记(该方法返回了当前线程的中断状态,并将当前线程的中断标识设置为False),并记录下来,如果发现该线程被中断过,就再中断一次。
+2. 线程在等待资源的过程中被唤醒,唤醒后还是会不断地去尝试获取锁,直到抢到锁为止。也就是说,在整个流程中,并不响应中断,只是记录中断记录。最后抢到锁返回了,那么如果被中断过的话,就需要补充一次中断。
+
+这里的处理方式主要是运用线程池中基本运作单元Worder中的runWorker,通过Thread.interrupted()进行额外的判断处理,感兴趣的同学可以看下ThreadPoolExecutor源码。
+
+### 2.3.5 小结
+
+我们在1.3小节中提出了一些问题,现在来回答一下。
+
+> Q:某个线程获取锁失败的后续流程是什么呢?
+>
+> A:存在某种排队等候机制,线程继续等待,仍然保留获取锁的可能,获取锁流程仍在继续。
+>
+> Q:既然说到了排队等候机制,那么就一定会有某种队列形成,这样的队列是什么数据结构呢?
+>
+> A:是CLH变体的FIFO双端队列。
+>
+> Q:处于排队等候机制中的线程,什么时候可以有机会获取锁呢?
+>
+> A:可以详细看下2.3.1.3小节。
+>
+> Q:如果处于排队等候机制中的线程一直无法获取锁,需要一直等待么?还是有别的策略来解决这一问题?
+>
+> A:线程所在节点的状态会变成取消状态,取消状态的节点会从队列中释放,具体可见2.3.2小节。
+>
+> Q:Lock函数通过Acquire方法进行加锁,但是具体是如何加锁的呢?
+>
+> A:AQS的Acquire会调用tryAcquire方法,tryAcquire由各个自定义同步器实现,通过tryAcquire完成加锁过程。
+
+## 3 AQS应用
+
+### 3.1 ReentrantLock的可重入应用
+
+ReentrantLock的可重入性是AQS很好的应用之一,在了解完上述知识点以后,我们很容易得知ReentrantLock实现可重入的方法。在ReentrantLock里面,不管是公平锁还是非公平锁,都有一段逻辑。
+
+公平锁:
+
+```java
+// java.util.concurrent.locks.ReentrantLock.FairSync#tryAcquire
+
+if (c == 0) {
+ if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) {
+ setExclusiveOwnerThread(current);
+ return true;
+ }
+}
+else if (current == getExclusiveOwnerThread()) {
+ int nextc = c + acquires;
+ if (nextc < 0)
+ throw new Error("Maximum lock count exceeded");
+ setState(nextc);
+ return true;
+}
+```
+
+非公平锁:
+
+```java
+// java.util.concurrent.locks.ReentrantLock.Sync#nonfairTryAcquire
+
+if (c == 0) {
+ if (compareAndSetState(0, acquires)){
+ setExclusiveOwnerThread(current);
+ return true;
+ }
+}
+else if (current == getExclusiveOwnerThread()) {
+ int nextc = c + acquires;
+ if (nextc < 0) // overflow
+ throw new Error("Maximum lock count exceeded");
+ setState(nextc);
+ return true;
+}
+```
+
+从上面这两段都可以看到,有一个同步状态State来控制整体可重入的情况。State是Volatile修饰的,用于保证一定的可见性和有序性。
+
+```java
+// java.util.concurrent.locks.AbstractQueuedSynchronizer
+
+private volatile int state;
+```
+
+接下来看State这个字段主要的过程:
+
+1. State初始化的时候为0,表示没有任何线程持有锁。
+2. 当有线程持有该锁时,值就会在原来的基础上+1,同一个线程多次获得锁是,就会多次+1,这里就是可重入的概念。
+3. 解锁也是对这个字段-1,一直到0,此线程对锁释放。
+
+### 3.2 JUC中的应用场景
+
+除了上边ReentrantLock的可重入性的应用,AQS作为并发编程的框架,为很多其他同步工具提供了良好的解决方案。下面列出了JUC中的几种同步工具,大体介绍一下AQS的应用场景:
+
+| 同步工具 | 同步工具与AQS的关联 |
+| :--------------------- | :----------------------------------------------------------- |
+| ReentrantLock | 使用AQS保存锁重复持有的次数。当一个线程获取锁时,ReentrantLock记录当前获得锁的线程标识,用于检测是否重复获取,以及错误线程试图解锁操作时异常情况的处理。 |
+| Semaphore | 使用AQS同步状态来保存信号量的当前计数。tryRelease会增加计数,acquireShared会减少计数。 |
+| CountDownLatch | 使用AQS同步状态来表示计数。计数为0时,所有的Acquire操作(CountDownLatch的await方法)才可以通过。 |
+| ReentrantReadWriteLock | 使用AQS同步状态中的16位保存写锁持有的次数,剩下的16位用于保存读锁的持有次数。 |
+| ThreadPoolExecutor | Worker利用AQS同步状态实现对独占线程变量的设置(tryAcquire和tryRelease)。 |
+
+### 3.3 自定义同步工具
+
+了解AQS基本原理以后,按照上面所说的AQS知识点,自己实现一个同步工具。
+
+```java
+public class LeeLock {
+
+ private static class Sync extends AbstractQueuedSynchronizer {
+ @Override
+ protected boolean tryAcquire (int arg) {
+ return compareAndSetState(0, 1);
+ }
+
+ @Override
+ protected boolean tryRelease (int arg) {
+ setState(0);
+ return true;
+ }
+
+ @Override
+ protected boolean isHeldExclusively () {
+ return getState() == 1;
+ }
+ }
+
+ private Sync sync = new Sync();
+
+ public void lock () {
+ sync.acquire(1);
+ }
+
+ public void unlock () {
+ sync.release(1);
+ }
+}
+```
+
+通过我们自己定义的Lock完成一定的同步功能。
+
+```java
+public class LeeMain {
+
+ static int count = 0;
+ static LeeLock leeLock = new LeeLock();
+
+ public static void main (String[] args) throws InterruptedException {
+
+ Runnable runnable = new Runnable() {
+ @Override
+ public void run () {
+ try {
+ leeLock.lock();
+ for (int i = 0; i < 10000; i++) {
+ count++;
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ leeLock.unlock();
+ }
+
+ }
+ };
+ Thread thread1 = new Thread(runnable);
+ Thread thread2 = new Thread(runnable);
+ thread1.start();
+ thread2.start();
+ thread1.join();
+ thread2.join();
+ System.out.println(count);
+ }
+}
+```
+
+上述代码每次运行结果都会是20000。通过简单的几行代码就能实现同步功能,这就是AQS的强大之处。
+
+## 总结
+
+我们日常开发中使用并发的场景太多,但是对并发内部的基本框架原理了解的人却不多。由于篇幅原因,本文仅介绍了可重入锁ReentrantLock的原理和AQS原理,希望能够成为大家了解AQS和ReentrantLock等同步器的“敲门砖”。
+
+## 参考资料
+
+- Lea D. The java. util. concurrent synchronizer framework[J]. Science of Computer Programming, 2005, 58(3): 293-309.
+- 《Java并发编程实战》
+- [不可不说的Java“锁”事](https://tech.meituan.com/2018/11/15/java-lock.html)
\ No newline at end of file
diff --git a/docs/java/concurrent/threadlocal.md b/docs/java/concurrent/threadlocal.md
new file mode 100644
index 00000000000..a4aff50f23a
--- /dev/null
+++ b/docs/java/concurrent/threadlocal.md
@@ -0,0 +1,914 @@
+---
+title: 万字解析 ThreadLocal 关键字
+category: Java
+tag:
+ - Java并发
+---
+
+
+
+> 本文来自一枝花算不算浪漫投稿, 原文地址:[https://juejin.im/post/5eacc1c75188256d976df748](https://juejin.im/post/5eacc1c75188256d976df748)。
+
+### 前言
+
+
+
+**全文共 10000+字,31 张图,这篇文章同样耗费了不少的时间和精力才创作完成,原创不易,请大家点点关注+在看,感谢。**
+
+对于`ThreadLocal`,大家的第一反应可能是很简单呀,线程的变量副本,每个线程隔离。那这里有几个问题大家可以思考一下:
+
+- `ThreadLocal`的 key 是**弱引用**,那么在 `ThreadLocal.get()`的时候,发生**GC**之后,key 是否为**null**?
+- `ThreadLocal`中`ThreadLocalMap`的**数据结构**?
+- `ThreadLocalMap`的**Hash 算法**?
+- `ThreadLocalMap`中**Hash 冲突**如何解决?
+- `ThreadLocalMap`的**扩容机制**?
+- `ThreadLocalMap`中**过期 key 的清理机制**?**探测式清理**和**启发式清理**流程?
+- `ThreadLocalMap.set()`方法实现原理?
+- `ThreadLocalMap.get()`方法实现原理?
+- 项目中`ThreadLocal`使用情况?遇到的坑?
+- ......
+
+上述的一些问题你是否都已经掌握的很清楚了呢?本文将围绕这些问题使用图文方式来剖析`ThreadLocal`的**点点滴滴**。
+
+### 目录
+
+**注明:** 本文源码基于`JDK 1.8`
+
+### `ThreadLocal`代码演示
+
+我们先看下`ThreadLocal`使用示例:
+
+```java
+public class ThreadLocalTest {
+ private List<String> messages = Lists.newArrayList();
+
+ public static final ThreadLocal<ThreadLocalTest> holder = ThreadLocal.withInitial(ThreadLocalTest::new);
+
+ public static void add(String message) {
+ holder.get().messages.add(message);
+ }
+
+ public static List<String> clear() {
+ List<String> messages = holder.get().messages;
+ holder.remove();
+
+ System.out.println("size: " + holder.get().messages.size());
+ return messages;
+ }
+
+ public static void main(String[] args) {
+ ThreadLocalTest.add("一枝花算不算浪漫");
+ System.out.println(holder.get().messages);
+ ThreadLocalTest.clear();
+ }
+}
+```
+
+打印结果:
+
+```java
+[一枝花算不算浪漫]
+size: 0
+```
+
+`ThreadLocal`对象可以提供线程局部变量,每个线程`Thread`拥有一份自己的**副本变量**,多个线程互不干扰。
+
+### `ThreadLocal`的数据结构
+
+
+
+`Thread`类有一个类型为`ThreadLocal.ThreadLocalMap`的实例变量`threadLocals`,也就是说每个线程有一个自己的`ThreadLocalMap`。
+
+`ThreadLocalMap`有自己的独立实现,可以简单地将它的`key`视作`ThreadLocal`,`value`为代码中放入的值(实际上`key`并不是`ThreadLocal`本身,而是它的一个**弱引用**)。
+
+每个线程在往`ThreadLocal`里放值的时候,都会往自己的`ThreadLocalMap`里存,读也是以`ThreadLocal`作为引用,在自己的`map`里找对应的`key`,从而实现了**线程隔离**。
+
+`ThreadLocalMap`有点类似`HashMap`的结构,只是`HashMap`是由**数组+链表**实现的,而`ThreadLocalMap`中并没有**链表**结构。
+
+我们还要注意`Entry`, 它的`key`是`ThreadLocal<?> k` ,继承自`WeakReference`, 也就是我们常说的弱引用类型。
+
+### GC 之后 key 是否为 null?
+
+回应开头的那个问题, `ThreadLocal` 的`key`是弱引用,那么在`ThreadLocal.get()`的时候,发生`GC`之后,`key`是否是`null`?
+
+为了搞清楚这个问题,我们需要搞清楚`Java`的**四种引用类型**:
+
+- **强引用**:我们常常 new 出来的对象就是强引用类型,只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足的时候
+- **软引用**:使用 SoftReference 修饰的对象被称为软引用,软引用指向的对象在内存要溢出的时候被回收
+- **弱引用**:使用 WeakReference 修饰的对象被称为弱引用,只要发生垃圾回收,若这个对象只被弱引用指向,那么就会被回收
+- **虚引用**:虚引用是最弱的引用,在 Java 中使用 PhantomReference 进行定义。虚引用中唯一的作用就是用队列接收对象即将死亡的通知
+
+接着再来看下代码,我们使用反射的方式来看看`GC`后`ThreadLocal`中的数据情况:(下面代码来源自:https://blog.csdn.net/thewindkee/article/details/103726942 本地运行演示 GC 回收场景)
+
+```java
+public class ThreadLocalDemo {
+
+ public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, InterruptedException {
+ Thread t = new Thread(()->test("abc",false));
+ t.start();
+ t.join();
+ System.out.println("--gc后--");
+ Thread t2 = new Thread(() -> test("def", true));
+ t2.start();
+ t2.join();
+ }
+
+ private static void test(String s,boolean isGC) {
+ try {
+ new ThreadLocal<>().set(s);
+ if (isGC) {
+ System.gc();
+ }
+ Thread t = Thread.currentThread();
+ Class<? extends Thread> clz = t.getClass();
+ Field field = clz.getDeclaredField("threadLocals");
+ field.setAccessible(true);
+ Object ThreadLocalMap = field.get(t);
+ Class<?> tlmClass = ThreadLocalMap.getClass();
+ Field tableField = tlmClass.getDeclaredField("table");
+ tableField.setAccessible(true);
+ Object[] arr = (Object[]) tableField.get(ThreadLocalMap);
+ for (Object o : arr) {
+ if (o != null) {
+ Class<?> entryClass = o.getClass();
+ Field valueField = entryClass.getDeclaredField("value");
+ Field referenceField = entryClass.getSuperclass().getSuperclass().getDeclaredField("referent");
+ valueField.setAccessible(true);
+ referenceField.setAccessible(true);
+ System.out.println(String.format("弱引用key:%s,值:%s", referenceField.get(o), valueField.get(o)));
+ }
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
+
+结果如下:
+
+```java
+弱引用key:java.lang.ThreadLocal@433619b6,值:abc
+弱引用key:java.lang.ThreadLocal@418a15e3,值:java.lang.ref.SoftReference@bf97a12
+--gc后--
+弱引用key:null,值:def
+```
+
+
+
+如图所示,因为这里创建的`ThreadLocal`并没有指向任何值,也就是没有任何引用:
+
+```java
+new ThreadLocal<>().set(s);
+```
+
+所以这里在`GC`之后,`key`就会被回收,我们看到上面`debug`中的`referent=null`, 如果**改动一下代码:**
+
+
+
+这个问题刚开始看,如果没有过多思考,**弱引用**,还有**垃圾回收**,那么肯定会觉得是`null`。
+
+其实是不对的,因为题目说的是在做 `ThreadLocal.get()` 操作,证明其实还是有**强引用**存在的,所以 `key` 并不为 `null`,如下图所示,`ThreadLocal`的**强引用**仍然是存在的。
+
+
+
+如果我们的**强引用**不存在的话,那么 `key` 就会被回收,也就是会出现我们 `value` 没被回收,`key` 被回收,导致 `value` 永远存在,出现内存泄漏。
+
+### `ThreadLocal.set()`方法源码详解
+
+
+
+`ThreadLocal`中的`set`方法原理如上图所示,很简单,主要是判断`ThreadLocalMap`是否存在,然后使用`ThreadLocal`中的`set`方法进行数据处理。
+
+代码如下:
+
+```java
+public void set(T value) {
+ Thread t = Thread.currentThread();
+ ThreadLocalMap map = getMap(t);
+ if (map != null)
+ map.set(this, value);
+ else
+ createMap(t, value);
+}
+
+void createMap(Thread t, T firstValue) {
+ t.threadLocals = new ThreadLocalMap(this, firstValue);
+}
+```
+
+主要的核心逻辑还是在`ThreadLocalMap`中的,一步步往下看,后面还有更详细的剖析。
+
+### `ThreadLocalMap` Hash 算法
+
+既然是`Map`结构,那么`ThreadLocalMap`当然也要实现自己的`hash`算法来解决散列表数组冲突问题。
+
+```java
+int i = key.threadLocalHashCode & (len-1);
+```
+
+`ThreadLocalMap`中`hash`算法很简单,这里`i`就是当前 key 在散列表中对应的数组下标位置。
+
+这里最关键的就是`threadLocalHashCode`值的计算,`ThreadLocal`中有一个属性为`HASH_INCREMENT = 0x61c88647`
+
+```java
+public class ThreadLocal<T> {
+ private final int threadLocalHashCode = nextHashCode();
+
+ private static AtomicInteger nextHashCode = new AtomicInteger();
+
+ private static final int HASH_INCREMENT = 0x61c88647;
+
+ private static int nextHashCode() {
+ return nextHashCode.getAndAdd(HASH_INCREMENT);
+ }
+
+ static class ThreadLocalMap {
+ ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
+ table = new Entry[INITIAL_CAPACITY];
+ int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
+
+ table[i] = new Entry(firstKey, firstValue);
+ size = 1;
+ setThreshold(INITIAL_CAPACITY);
+ }
+ }
+}
+```
+
+每当创建一个`ThreadLocal`对象,这个`ThreadLocal.nextHashCode` 这个值就会增长 `0x61c88647` 。
+
+这个值很特殊,它是**斐波那契数** 也叫 **黄金分割数**。`hash`增量为 这个数字,带来的好处就是 `hash` **分布非常均匀**。
+
+我们自己可以尝试下:
+
+
+
+可以看到产生的哈希码分布很均匀,这里不去细纠**斐波那契**具体算法,感兴趣的可以自行查阅相关资料。
+
+### `ThreadLocalMap` Hash 冲突
+
+> **注明:** 下面所有示例图中,**绿色块**`Entry`代表**正常数据**,**灰色块**代表`Entry`的`key`值为`null`,**已被垃圾回收**。**白色块**表示`Entry`为`null`。
+
+虽然`ThreadLocalMap`中使用了**黄金分割数**来作为`hash`计算因子,大大减少了`Hash`冲突的概率,但是仍然会存在冲突。
+
+`HashMap`中解决冲突的方法是在数组上构造一个**链表**结构,冲突的数据挂载到链表上,如果链表长度超过一定数量则会转化成**红黑树**。
+
+而 `ThreadLocalMap` 中并没有链表结构,所以这里不能使用 `HashMap` 解决冲突的方式了。
+
+
+
+如上图所示,如果我们插入一个`value=27`的数据,通过 `hash` 计算后应该落入槽位 4 中,而槽位 4 已经有了 `Entry` 数据。
+
+此时就会线性向后查找,一直找到 `Entry` 为 `null` 的槽位才会停止查找,将当前元素放入此槽位中。当然迭代过程中还有其他的情况,比如遇到了 `Entry` 不为 `null` 且 `key` 值相等的情况,还有 `Entry` 中的 `key` 值为 `null` 的情况等等都会有不同的处理,后面会一一详细讲解。
+
+这里还画了一个`Entry`中的`key`为`null`的数据(**Entry=2 的灰色块数据**),因为`key`值是**弱引用**类型,所以会有这种数据存在。在`set`过程中,如果遇到了`key`过期的`Entry`数据,实际上是会进行一轮**探测式清理**操作的,具体操作方式后面会讲到。
+
+### `ThreadLocalMap.set()`详解
+
+#### `ThreadLocalMap.set()`原理图解
+
+看完了`ThreadLocal` **hash 算法**后,我们再来看`set`是如何实现的。
+
+往`ThreadLocalMap`中`set`数据(**新增**或者**更新**数据)分为好几种情况,针对不同的情况我们画图来说明。
+
+**第一种情况:** 通过`hash`计算后的槽位对应的`Entry`数据为空:
+
+
+
+这里直接将数据放到该槽位即可。
+
+**第二种情况:** 槽位数据不为空,`key`值与当前`ThreadLocal`通过`hash`计算获取的`key`值一致:
+
+
+
+这里直接更新该槽位的数据。
+
+**第三种情况:** 槽位数据不为空,往后遍历过程中,在找到`Entry`为`null`的槽位之前,没有遇到`key`过期的`Entry`:
+
+
+
+遍历散列数组,线性往后查找,如果找到`Entry`为`null`的槽位,则将数据放入该槽位中,或者往后遍历过程中,遇到了**key 值相等**的数据,直接更新即可。
+
+**第四种情况:** 槽位数据不为空,往后遍历过程中,在找到`Entry`为`null`的槽位之前,遇到`key`过期的`Entry`,如下图,往后遍历过程中,遇到了`index=7`的槽位数据`Entry`的`key=null`:
+
+
+
+散列数组下标为 7 位置对应的`Entry`数据`key`为`null`,表明此数据`key`值已经被垃圾回收掉了,此时就会执行`replaceStaleEntry()`方法,该方法含义是**替换过期数据的逻辑**,以**index=7**位起点开始遍历,进行探测式数据清理工作。
+
+初始化探测式清理过期数据扫描的开始位置:`slotToExpunge = staleSlot = 7`
+
+以当前`staleSlot`开始 向前迭代查找,找其他过期的数据,然后更新过期数据起始扫描下标`slotToExpunge`。`for`循环迭代,直到碰到`Entry`为`null`结束。
+
+如果找到了过期的数据,继续向前迭代,直到遇到`Entry=null`的槽位才停止迭代,如下图所示,**slotToExpunge 被更新为 0**:
+
+
+
+以当前节点(`index=7`)向前迭代,检测是否有过期的`Entry`数据,如果有则更新`slotToExpunge`值。碰到`null`则结束探测。以上图为例`slotToExpunge`被更新为 0。
+
+上面向前迭代的操作是为了更新探测清理过期数据的起始下标`slotToExpunge`的值,这个值在后面会讲解,它是用来判断当前过期槽位`staleSlot`之前是否还有过期元素。
+
+接着开始以`staleSlot`位置(`index=7`)向后迭代,**如果找到了相同 key 值的 Entry 数据:**
+
+
+
+从当前节点`staleSlot`向后查找`key`值相等的`Entry`元素,找到后更新`Entry`的值并交换`staleSlot`元素的位置(`staleSlot`位置为过期元素),更新`Entry`数据,然后开始进行过期`Entry`的清理工作,如下图所示:
+
+向后遍历过程中,如果没有找到相同 key 值的 Entry 数据:
+
+
+
+从当前节点`staleSlot`向后查找`key`值相等的`Entry`元素,直到`Entry`为`null`则停止寻找。通过上图可知,此时`table`中没有`key`值相同的`Entry`。
+
+创建新的`Entry`,替换`table[stableSlot]`位置:
+
+
+
+替换完成后也是进行过期元素清理工作,清理工作主要是有两个方法:`expungeStaleEntry()`和`cleanSomeSlots()`,具体细节后面会讲到,请继续往后看。
+
+#### `ThreadLocalMap.set()`源码详解
+
+上面已经用图的方式解析了`set()`实现的原理,其实已经很清晰了,我们接着再看下源码:
+
+`java.lang.ThreadLocal`.`ThreadLocalMap.set()`:
+
+```java
+private void set(ThreadLocal<?> key, Object value) {
+ Entry[] tab = table;
+ int len = tab.length;
+ int i = key.threadLocalHashCode & (len-1);
+
+ for (Entry e = tab[i];
+ e != null;
+ e = tab[i = nextIndex(i, len)]) {
+ ThreadLocal<?> k = e.get();
+
+ if (k == key) {
+ e.value = value;
+ return;
+ }
+
+ if (k == null) {
+ replaceStaleEntry(key, value, i);
+ return;
+ }
+ }
+
+ tab[i] = new Entry(key, value);
+ int sz = ++size;
+ if (!cleanSomeSlots(i, sz) && sz >= threshold)
+ rehash();
+}
+```
+
+这里会通过`key`来计算在散列表中的对应位置,然后以当前`key`对应的桶的位置向后查找,找到可以使用的桶。
+
+```java
+Entry[] tab = table;
+int len = tab.length;
+int i = key.threadLocalHashCode & (len-1);
+```
+
+什么情况下桶才是可以使用的呢?
+
+1. `k = key` 说明是替换操作,可以使用
+2. 碰到一个过期的桶,执行替换逻辑,占用过期桶
+3. 查找过程中,碰到桶中`Entry=null`的情况,直接使用
+
+接着就是执行`for`循环遍历,向后查找,我们先看下`nextIndex()`、`prevIndex()`方法实现:
+
+
+
+```java
+private static int nextIndex(int i, int len) {
+ return ((i + 1 < len) ? i + 1 : 0);
+}
+
+private static int prevIndex(int i, int len) {
+ return ((i - 1 >= 0) ? i - 1 : len - 1);
+}
+```
+
+接着看剩下`for`循环中的逻辑:
+
+1. 遍历当前`key`值对应的桶中`Entry`数据为空,这说明散列数组这里没有数据冲突,跳出`for`循环,直接`set`数据到对应的桶中
+2. 如果`key`值对应的桶中`Entry`数据不为空
+ 2.1 如果`k = key`,说明当前`set`操作是一个替换操作,做替换逻辑,直接返回
+ 2.2 如果`key = null`,说明当前桶位置的`Entry`是过期数据,执行`replaceStaleEntry()`方法(核心方法),然后返回
+3. `for`循环执行完毕,继续往下执行说明向后迭代的过程中遇到了`entry`为`null`的情况
+ 3.1 在`Entry`为`null`的桶中创建一个新的`Entry`对象
+ 3.2 执行`++size`操作
+4. 调用`cleanSomeSlots()`做一次启发式清理工作,清理散列数组中`Entry`的`key`过期的数据
+ 4.1 如果清理工作完成后,未清理到任何数据,且`size`超过了阈值(数组长度的 2/3),进行`rehash()`操作
+ 4.2 `rehash()`中会先进行一轮探测式清理,清理过期`key`,清理完成后如果**size >= threshold - threshold / 4**,就会执行真正的扩容逻辑(扩容逻辑往后看)
+
+接着重点看下`replaceStaleEntry()`方法,`replaceStaleEntry()`方法提供替换过期数据的功能,我们可以对应上面**第四种情况**的原理图来再回顾下,具体代码如下:
+
+`java.lang.ThreadLocal.ThreadLocalMap.replaceStaleEntry()`:
+
+```java
+private void replaceStaleEntry(ThreadLocal<?> key, Object value,
+ int staleSlot) {
+ Entry[] tab = table;
+ int len = tab.length;
+ Entry e;
+
+ int slotToExpunge = staleSlot;
+ for (int i = prevIndex(staleSlot, len);
+ (e = tab[i]) != null;
+ i = prevIndex(i, len))
+
+ if (e.get() == null)
+ slotToExpunge = i;
+
+ for (int i = nextIndex(staleSlot, len);
+ (e = tab[i]) != null;
+ i = nextIndex(i, len)) {
+
+ ThreadLocal<?> k = e.get();
+
+ if (k == key) {
+ e.value = value;
+
+ tab[i] = tab[staleSlot];
+ tab[staleSlot] = e;
+
+ if (slotToExpunge == staleSlot)
+ slotToExpunge = i;
+ cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
+ return;
+ }
+
+ if (k == null && slotToExpunge == staleSlot)
+ slotToExpunge = i;
+ }
+
+ tab[staleSlot].value = null;
+ tab[staleSlot] = new Entry(key, value);
+
+ if (slotToExpunge != staleSlot)
+ cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
+}
+```
+
+`slotToExpunge`表示开始探测式清理过期数据的开始下标,默认从当前的`staleSlot`开始。以当前的`staleSlot`开始,向前迭代查找,找到没有过期的数据,`for`循环一直碰到`Entry`为`null`才会结束。如果向前找到了过期数据,更新探测清理过期数据的开始下标为 i,即`slotToExpunge=i`
+
+```java
+for (int i = prevIndex(staleSlot, len);
+ (e = tab[i]) != null;
+ i = prevIndex(i, len)){
+
+ if (e.get() == null){
+ slotToExpunge = i;
+ }
+}
+```
+
+接着开始从`staleSlot`向后查找,也是碰到`Entry`为`null`的桶结束。
+如果迭代过程中,**碰到 k == key**,这说明这里是替换逻辑,替换新数据并且交换当前`staleSlot`位置。如果`slotToExpunge == staleSlot`,这说明`replaceStaleEntry()`一开始向前查找过期数据时并未找到过期的`Entry`数据,接着向后查找过程中也未发现过期数据,修改开始探测式清理过期数据的下标为当前循环的 index,即`slotToExpunge = i`。最后调用`cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);`进行启发式过期数据清理。
+
+```java
+if (k == key) {
+ e.value = value;
+
+ tab[i] = tab[staleSlot];
+ tab[staleSlot] = e;
+
+ if (slotToExpunge == staleSlot)
+ slotToExpunge = i;
+
+ cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
+ return;
+}
+```
+
+`cleanSomeSlots()`和`expungeStaleEntry()`方法后面都会细讲,这两个是和清理相关的方法,一个是过期`key`相关`Entry`的启发式清理(`Heuristically scan`),另一个是过期`key`相关`Entry`的探测式清理。
+
+**如果 k != key**则会接着往下走,`k == null`说明当前遍历的`Entry`是一个过期数据,`slotToExpunge == staleSlot`说明,一开始的向前查找数据并未找到过期的`Entry`。如果条件成立,则更新`slotToExpunge` 为当前位置,这个前提是前驱节点扫描时未发现过期数据。
+
+```java
+if (k == null && slotToExpunge == staleSlot)
+ slotToExpunge = i;
+```
+
+往后迭代的过程中如果没有找到`k == key`的数据,且碰到`Entry`为`null`的数据,则结束当前的迭代操作。此时说明这里是一个添加的逻辑,将新的数据添加到`table[staleSlot]` 对应的`slot`中。
+
+```java
+tab[staleSlot].value = null;
+tab[staleSlot] = new Entry(key, value);
+```
+
+最后判断除了`staleSlot`以外,还发现了其他过期的`slot`数据,就要开启清理数据的逻辑:
+
+```java
+if (slotToExpunge != staleSlot)
+ cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
+```
+
+### `ThreadLocalMap`过期 key 的探测式清理流程
+
+上面我们有提及`ThreadLocalMap`的两种过期`key`数据清理方式:**探测式清理**和**启发式清理**。
+
+我们先讲下探测式清理,也就是`expungeStaleEntry`方法,遍历散列数组,从开始位置向后探测清理过期数据,将过期数据的`Entry`设置为`null`,沿途中碰到未过期的数据则将此数据`rehash`后重新在`table`数组中定位,如果定位的位置已经有了数据,则会将未过期的数据放到最靠近此位置的`Entry=null`的桶中,使`rehash`后的`Entry`数据距离正确的桶的位置更近一些。操作逻辑如下:
+
+
+
+如上图,`set(27)` 经过 hash 计算后应该落到`index=4`的桶中,由于`index=4`桶已经有了数据,所以往后迭代最终数据放入到`index=7`的桶中,放入后一段时间后`index=5`中的`Entry`数据`key`变为了`null`
+
+
+
+如果再有其他数据`set`到`map`中,就会触发**探测式清理**操作。
+
+如上图,执行**探测式清理**后,`index=5`的数据被清理掉,继续往后迭代,到`index=7`的元素时,经过`rehash`后发现该元素正确的`index=4`,而此位置已经有了数据,往后查找离`index=4`最近的`Entry=null`的节点(刚被探测式清理掉的数据:`index=5`),找到后移动`index= 7`的数据到`index=5`中,此时桶的位置离正确的位置`index=4`更近了。
+
+经过一轮探测式清理后,`key`过期的数据会被清理掉,没过期的数据经过`rehash`重定位后所处的桶位置理论上更接近`i= key.hashCode & (tab.len - 1)`的位置。这种优化会提高整个散列表查询性能。
+
+接着看下`expungeStaleEntry()`具体流程,我们还是以先原理图后源码讲解的方式来一步步梳理:
+
+
+
+我们假设`expungeStaleEntry(3)` 来调用此方法,如上图所示,我们可以看到`ThreadLocalMap`中`table`的数据情况,接着执行清理操作:
+
+
+
+第一步是清空当前`staleSlot`位置的数据,`index=3`位置的`Entry`变成了`null`。然后接着往后探测:
+
+
+
+执行完第二步后,index=4 的元素挪到 index=3 的槽位中。
+
+继续往后迭代检查,碰到正常数据,计算该数据位置是否偏移,如果被偏移,则重新计算`slot`位置,目的是让正常数据尽可能存放在正确位置或离正确位置更近的位置
+
+
+
+在往后迭代的过程中碰到空的槽位,终止探测,这样一轮探测式清理工作就完成了,接着我们继续看看具体**实现源代码**:
+
+```java
+private int expungeStaleEntry(int staleSlot) {
+ Entry[] tab = table;
+ int len = tab.length;
+
+ tab[staleSlot].value = null;
+ tab[staleSlot] = null;
+ size--;
+
+ Entry e;
+ int i;
+ for (i = nextIndex(staleSlot, len);
+ (e = tab[i]) != null;
+ i = nextIndex(i, len)) {
+ ThreadLocal<?> k = e.get();
+ if (k == null) {
+ e.value = null;
+ tab[i] = null;
+ size--;
+ } else {
+ int h = k.threadLocalHashCode & (len - 1);
+ if (h != i) {
+ tab[i] = null;
+
+ while (tab[h] != null)
+ h = nextIndex(h, len);
+ tab[h] = e;
+ }
+ }
+ }
+ return i;
+}
+```
+
+这里我们还是以`staleSlot=3` 来做示例说明,首先是将`tab[staleSlot]`槽位的数据清空,然后设置`size--`
+接着以`staleSlot`位置往后迭代,如果遇到`k==null`的过期数据,也是清空该槽位数据,然后`size--`
+
+```java
+ThreadLocal<?> k = e.get();
+
+if (k == null) {
+ e.value = null;
+ tab[i] = null;
+ size--;
+}
+```
+
+如果`key`没有过期,重新计算当前`key`的下标位置是不是当前槽位下标位置,如果不是,那么说明产生了`hash`冲突,此时以新计算出来正确的槽位位置往后迭代,找到最近一个可以存放`entry`的位置。
+
+```java
+int h = k.threadLocalHashCode & (len - 1);
+if (h != i) {
+ tab[i] = null;
+
+ while (tab[h] != null)
+ h = nextIndex(h, len);
+
+ tab[h] = e;
+}
+```
+
+这里是处理正常的产生`Hash`冲突的数据,经过迭代后,有过`Hash`冲突数据的`Entry`位置会更靠近正确位置,这样的话,查询的时候 效率才会更高。
+
+### `ThreadLocalMap`扩容机制
+
+在`ThreadLocalMap.set()`方法的最后,如果执行完启发式清理工作后,未清理到任何数据,且当前散列数组中`Entry`的数量已经达到了列表的扩容阈值`(len*2/3)`,就开始执行`rehash()`逻辑:
+
+```java
+if (!cleanSomeSlots(i, sz) && sz >= threshold)
+ rehash();
+```
+
+接着看下`rehash()`具体实现:
+
+```java
+private void rehash() {
+ expungeStaleEntries();
+
+ if (size >= threshold - threshold / 4)
+ resize();
+}
+
+private void expungeStaleEntries() {
+ Entry[] tab = table;
+ int len = tab.length;
+ for (int j = 0; j < len; j++) {
+ Entry e = tab[j];
+ if (e != null && e.get() == null)
+ expungeStaleEntry(j);
+ }
+}
+```
+
+这里首先是会进行探测式清理工作,从`table`的起始位置往后清理,上面有分析清理的详细流程。清理完成之后,`table`中可能有一些`key`为`null`的`Entry`数据被清理掉,所以此时通过判断`size >= threshold - threshold / 4` 也就是`size >= threshold * 3/4` 来决定是否扩容。
+
+我们还记得上面进行`rehash()`的阈值是`size >= threshold`,所以当面试官套路我们`ThreadLocalMap`扩容机制的时候 我们一定要说清楚这两个步骤:
+
+
+
+接着看看具体的`resize()`方法,为了方便演示,我们以`oldTab.len=8`来举例:
+
+
+
+扩容后的`tab`的大小为`oldLen * 2`,然后遍历老的散列表,重新计算`hash`位置,然后放到新的`tab`数组中,如果出现`hash`冲突则往后寻找最近的`entry`为`null`的槽位,遍历完成之后,`oldTab`中所有的`entry`数据都已经放入到新的`tab`中了。重新计算`tab`下次扩容的**阈值**,具体代码如下:
+
+```java
+private void resize() {
+ Entry[] oldTab = table;
+ int oldLen = oldTab.length;
+ int newLen = oldLen * 2;
+ Entry[] newTab = new Entry[newLen];
+ int count = 0;
+
+ for (int j = 0; j < oldLen; ++j) {
+ Entry e = oldTab[j];
+ if (e != null) {
+ ThreadLocal<?> k = e.get();
+ if (k == null) {
+ e.value = null;
+ } else {
+ int h = k.threadLocalHashCode & (newLen - 1);
+ while (newTab[h] != null)
+ h = nextIndex(h, newLen);
+ newTab[h] = e;
+ count++;
+ }
+ }
+ }
+
+ setThreshold(newLen);
+ size = count;
+ table = newTab;
+}
+```
+
+### `ThreadLocalMap.get()`详解
+
+上面已经看完了`set()`方法的源码,其中包括`set`数据、清理数据、优化数据桶的位置等操作,接着看看`get()`操作的原理。
+
+#### `ThreadLocalMap.get()`图解
+
+**第一种情况:** 通过查找`key`值计算出散列表中`slot`位置,然后该`slot`位置中的`Entry.key`和查找的`key`一致,则直接返回:
+
+
+
+**第二种情况:** `slot`位置中的`Entry.key`和要查找的`key`不一致:
+
+
+
+我们以`get(ThreadLocal1)`为例,通过`hash`计算后,正确的`slot`位置应该是 4,而`index=4`的槽位已经有了数据,且`key`值不等于`ThreadLocal1`,所以需要继续往后迭代查找。
+
+迭代到`index=5`的数据时,此时`Entry.key=null`,触发一次探测式数据回收操作,执行`expungeStaleEntry()`方法,执行完后,`index 5,8`的数据都会被回收,而`index 6,7`的数据都会前移,此时继续往后迭代,到`index = 6`的时候即找到了`key`值相等的`Entry`数据,如下图所示:
+
+
+
+#### `ThreadLocalMap.get()`源码详解
+
+`java.lang.ThreadLocal.ThreadLocalMap.getEntry()`:
+
+```java
+private Entry getEntry(ThreadLocal<?> key) {
+ int i = key.threadLocalHashCode & (table.length - 1);
+ Entry e = table[i];
+ if (e != null && e.get() == key)
+ return e;
+ else
+ return getEntryAfterMiss(key, i, e);
+}
+
+private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
+ Entry[] tab = table;
+ int len = tab.length;
+
+ while (e != null) {
+ ThreadLocal<?> k = e.get();
+ if (k == key)
+ return e;
+ if (k == null)
+ expungeStaleEntry(i);
+ else
+ i = nextIndex(i, len);
+ e = tab[i];
+ }
+ return null;
+}
+```
+
+### `ThreadLocalMap`过期 key 的启发式清理流程
+
+上面多次提及到`ThreadLocalMap`过期key的两种清理方式:**探测式清理(expungeStaleEntry())**、**启发式清理(cleanSomeSlots())**
+
+探测式清理是以当前`Entry` 往后清理,遇到值为`null`则结束清理,属于**线性探测清理**。
+
+而启发式清理被作者定义为:**Heuristically scan some cells looking for stale entries**.
+
+
+
+具体代码如下:
+
+```java
+private boolean cleanSomeSlots(int i, int n) {
+ boolean removed = false;
+ Entry[] tab = table;
+ int len = tab.length;
+ do {
+ i = nextIndex(i, len);
+ Entry e = tab[i];
+ if (e != null && e.get() == null) {
+ n = len;
+ removed = true;
+ i = expungeStaleEntry(i);
+ }
+ } while ( (n >>>= 1) != 0);
+ return removed;
+}
+```
+
+### `InheritableThreadLocal`
+
+我们使用`ThreadLocal`的时候,在异步场景下是无法给子线程共享父线程中创建的线程副本数据的。
+
+为了解决这个问题,JDK 中还有一个`InheritableThreadLocal`类,我们来看一个例子:
+
+```java
+public class InheritableThreadLocalDemo {
+ public static void main(String[] args) {
+ ThreadLocal<String> ThreadLocal = new ThreadLocal<>();
+ ThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>();
+ ThreadLocal.set("父类数据:threadLocal");
+ inheritableThreadLocal.set("父类数据:inheritableThreadLocal");
+
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ System.out.println("子线程获取父类ThreadLocal数据:" + ThreadLocal.get());
+ System.out.println("子线程获取父类inheritableThreadLocal数据:" + inheritableThreadLocal.get());
+ }
+ }).start();
+ }
+}
+```
+
+打印结果:
+
+```java
+子线程获取父类ThreadLocal数据:null
+子线程获取父类inheritableThreadLocal数据:父类数据:inheritableThreadLocal
+```
+
+实现原理是子线程是通过在父线程中通过调用`new Thread()`方法来创建子线程,`Thread#init`方法在`Thread`的构造方法中被调用。在`init`方法中拷贝父线程数据到子线程中:
+
+```java
+private void init(ThreadGroup g, Runnable target, String name,
+ long stackSize, AccessControlContext acc,
+ boolean inheritThreadLocals) {
+ if (name == null) {
+ throw new NullPointerException("name cannot be null");
+ }
+
+ if (inheritThreadLocals && parent.inheritableThreadLocals != null)
+ this.inheritableThreadLocals =
+ ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
+ this.stackSize = stackSize;
+ tid = nextThreadID();
+}
+```
+
+但`InheritableThreadLocal`仍然有缺陷,一般我们做异步化处理都是使用的线程池,而`InheritableThreadLocal`是在`new Thread`中的`init()`方法给赋值的,而线程池是线程复用的逻辑,所以这里会存在问题。
+
+当然,有问题出现就会有解决问题的方案,阿里巴巴开源了一个`TransmittableThreadLocal`组件就可以解决这个问题,这里就不再延伸,感兴趣的可自行查阅资料。
+
+### `ThreadLocal`项目中使用实战
+
+#### `ThreadLocal`使用场景
+
+我们现在项目中日志记录用的是`ELK+Logstash`,最后在`Kibana`中进行展示和检索。
+
+现在都是分布式系统统一对外提供服务,项目间调用的关系可以通过 `traceId` 来关联,但是不同项目之间如何传递 `traceId` 呢?
+
+这里我们使用 `org.slf4j.MDC` 来实现此功能,内部就是通过 `ThreadLocal` 来实现的,具体实现如下:
+
+当前端发送请求到**服务 A**时,**服务 A**会生成一个类似`UUID`的`traceId`字符串,将此字符串放入当前线程的`ThreadLocal`中,在调用**服务 B**的时候,将`traceId`写入到请求的`Header`中,**服务 B**在接收请求时会先判断请求的`Header`中是否有`traceId`,如果存在则写入自己线程的`ThreadLocal`中。
+
+
+
+图中的`requestId`即为我们各个系统链路关联的`traceId`,系统间互相调用,通过这个`requestId`即可找到对应链路,这里还有会有一些其他场景:
+
+
+
+针对于这些场景,我们都可以有相应的解决方案,如下所示
+
+#### Feign 远程调用解决方案
+
+**服务发送请求:**
+
+```java
+@Component
+@Slf4j
+public class FeignInvokeInterceptor implements RequestInterceptor {
+
+ @Override
+ public void apply(RequestTemplate template) {
+ String requestId = MDC.get("requestId");
+ if (StringUtils.isNotBlank(requestId)) {
+ template.header("requestId", requestId);
+ }
+ }
+}
+```
+
+**服务接收请求:**
+
+```java
+@Slf4j
+@Component
+public class LogInterceptor extends HandlerInterceptorAdapter {
+
+ @Override
+ public void afterCompletion(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, Exception arg3) {
+ MDC.remove("requestId");
+ }
+
+ @Override
+ public void postHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, ModelAndView arg3) {
+ }
+
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
+
+ String requestId = request.getHeader(BaseConstant.REQUEST_ID_KEY);
+ if (StringUtils.isBlank(requestId)) {
+ requestId = UUID.randomUUID().toString().replace("-", "");
+ }
+ MDC.put("requestId", requestId);
+ return true;
+ }
+}
+```
+
+#### 线程池异步调用,requestId 传递
+
+因为`MDC`是基于`ThreadLocal`去实现的,异步过程中,子线程并没有办法获取到父线程`ThreadLocal`存储的数据,所以这里可以自定义线程池执行器,修改其中的`run()`方法:
+
+```java
+public class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {
+
+ @Override
+ public void execute(Runnable runnable) {
+ Map<String, String> context = MDC.getCopyOfContextMap();
+ super.execute(() -> run(runnable, context));
+ }
+
+ @Override
+ private void run(Runnable runnable, Map<String, String> context) {
+ if (context != null) {
+ MDC.setContextMap(context);
+ }
+ try {
+ runnable.run();
+ } finally {
+ MDC.remove();
+ }
+ }
+}
+```
+
+#### 使用 MQ 发送消息给第三方系统
+
+在 MQ 发送的消息体中自定义属性`requestId`,接收方消费消息后,自己解析`requestId`使用即可。
diff --git "a/docs/java/concurrent/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md" "b/docs/java/concurrent/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..d6f3691bfad
--- /dev/null
+++ "b/docs/java/concurrent/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md"
@@ -0,0 +1,202 @@
+---
+title: JDK 提供的并发容器总结
+category: Java
+tag:
+ - Java并发
+---
+
+JDK 提供的这些容器大部分在 `java.util.concurrent` 包中。
+
+- **`ConcurrentHashMap`** : 线程安全的 `HashMap`
+- **`CopyOnWriteArrayList`** : 线程安全的 `List`,在读多写少的场合性能非常好,远远好于 `Vector`。
+- **`ConcurrentLinkedQueue`** : 高效的并发队列,使用链表实现。可以看做一个线程安全的 `LinkedList`,这是一个非阻塞队列。
+- **`BlockingQueue`** : 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
+- **`ConcurrentSkipListMap`** : 跳表的实现。这是一个 Map,使用跳表的数据结构进行快速查找。
+
+## ConcurrentHashMap
+
+我们知道 `HashMap` 不是线程安全的,在并发场景下如果要保证一种可行的方式是使用 `Collections.synchronizedMap()` 方法来包装我们的 `HashMap`。但这是通过使用一个全局的锁来同步不同线程间的并发访问,因此会带来不可忽视的性能问题。
+
+所以就有了 `HashMap` 的线程安全版本—— `ConcurrentHashMap` 的诞生。
+
+在 `ConcurrentHashMap` 中,无论是读操作还是写操作都能保证很高的性能:在进行读操作时(几乎)不需要加锁,而在写操作时通过锁分段技术只对所操作的段加锁而不影响客户端对其它段的访问。
+
+## CopyOnWriteArrayList
+
+### CopyOnWriteArrayList 简介
+
+```java
+public class CopyOnWriteArrayList<E>
+extends Object
+implements List<E>, RandomAccess, Cloneable, Serializable
+```
+
+在很多应用场景中,读操作可能会远远大于写操作。由于读操作根本不会修改原有的数据,因此对于每次读取都进行加锁其实是一种资源浪费。我们应该允许多个线程同时访问 `List` 的内部数据,毕竟读取操作是安全的。
+
+这和我们之前在多线程章节讲过 `ReentrantReadWriteLock` 读写锁的思想非常类似,也就是读读共享、写写互斥、读写互斥、写读互斥。JDK 中提供了 `CopyOnWriteArrayList` 类比相比于在读写锁的思想又更进一步。为了将读取的性能发挥到极致,`CopyOnWriteArrayList` 读取是完全不用加锁的,并且更厉害的是:写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。这样一来,读操作的性能就会大幅度提升。**那它是怎么做的呢?**
+
+### CopyOnWriteArrayList 是如何做到的?
+
+`CopyOnWriteArrayList` 类的所有可变操作(add,set 等等)都是通过创建底层数组的新副本来实现的。当 List 需要被修改的时候,我并不修改原有内容,而是对原有数据进行一次复制,将修改的内容写入副本。写完之后,再将修改完的副本替换原来的数据,这样就可以保证写操作不会影响读操作了。
+
+从 `CopyOnWriteArrayList` 的名字就能看出 `CopyOnWriteArrayList` 是满足 `CopyOnWrite` 的。所谓 `CopyOnWrite` 也就是说:在计算机,如果你想要对一块内存进行修改时,我们不在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后呢,就将指向原来内存指针指向新的内存,原来的内存就可以被回收掉了。
+
+### CopyOnWriteArrayList 读取和写入源码简单分析
+
+#### CopyOnWriteArrayList 读取操作的实现
+
+读取操作没有任何同步控制和锁操作,理由就是内部数组 `array` 不会发生修改,只会被另外一个 `array` 替换,因此可以保证数据安全。
+
+```java
+ /** The array, accessed only via getArray/setArray. */
+ private transient volatile Object[] array;
+ public E get(int index) {
+ return get(getArray(), index);
+ }
+ @SuppressWarnings("unchecked")
+ private E get(Object[] a, int index) {
+ return (E) a[index];
+ }
+ final Object[] getArray() {
+ return array;
+ }
+
+```
+
+#### 3.3.2 CopyOnWriteArrayList 写入操作的实现
+
+`CopyOnWriteArrayList` 写入操作 `add()`方法在添加集合的时候加了锁,保证了同步,避免了多线程写的时候会 copy 出多个副本出来。
+
+```java
+ /**
+ * Appends the specified element to the end of this list.
+ *
+ * @param e element to be appended to this list
+ * @return {@code true} (as specified by {@link Collection#add})
+ */
+ public boolean add(E e) {
+ final ReentrantLock lock = this.lock;
+ lock.lock();//加锁
+ try {
+ Object[] elements = getArray();
+ int len = elements.length;
+ Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝新数组
+ newElements[len] = e;
+ setArray(newElements);
+ return true;
+ } finally {
+ lock.unlock();//释放锁
+ }
+ }
+```
+
+## ConcurrentLinkedQueue
+
+Java 提供的线程安全的 `Queue` 可以分为**阻塞队列**和**非阻塞队列**,其中阻塞队列的典型例子是 `BlockingQueue`,非阻塞队列的典型例子是 `ConcurrentLinkedQueue`,在实际应用中要根据实际需要选用阻塞队列或者非阻塞队列。 **阻塞队列可以通过加锁来实现,非阻塞队列可以通过 CAS 操作实现。**
+
+从名字可以看出,`ConcurrentLinkedQueue`这个队列使用链表作为其数据结构.`ConcurrentLinkedQueue` 应该算是在高并发环境中性能最好的队列了。它之所有能有很好的性能,是因为其内部复杂的实现。
+
+`ConcurrentLinkedQueue` 内部代码我们就不分析了,大家知道 `ConcurrentLinkedQueue` 主要使用 CAS 非阻塞算法来实现线程安全就好了。
+
+`ConcurrentLinkedQueue` 适合在对性能要求相对较高,同时对队列的读写存在多个线程同时进行的场景,即如果对队列加锁的成本较高则适合使用无锁的 `ConcurrentLinkedQueue` 来替代。
+
+## BlockingQueue
+
+### BlockingQueue 简介
+
+上面我们己经提到了 `ConcurrentLinkedQueue` 作为高性能的非阻塞队列。下面我们要讲到的是阻塞队列——`BlockingQueue`。阻塞队列(`BlockingQueue`)被广泛使用在“生产者-消费者”问题中,其原因是 `BlockingQueue` 提供了可阻塞的插入和移除的方法。当队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。
+
+`BlockingQueue` 是一个接口,继承自 `Queue`,所以其实现类也可以作为 `Queue` 的实现来使用,而 `Queue` 又继承自 `Collection` 接口。下面是 `BlockingQueue` 的相关实现类:
+
+
+
+下面主要介绍一下 3 个常见的 `BlockingQueue` 的实现类:`ArrayBlockingQueue`、`LinkedBlockingQueue` 、`PriorityBlockingQueue` 。
+
+### ArrayBlockingQueue
+
+`ArrayBlockingQueue` 是 `BlockingQueue` 接口的有界队列实现类,底层采用数组来实现。
+
+```java
+public class ArrayBlockingQueue<E>
+extends AbstractQueue<E>
+implements BlockingQueue<E>, Serializable{}
+```
+
+`ArrayBlockingQueue` 一旦创建,容量不能改变。其并发控制采用可重入锁 `ReentrantLock` ,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。当队列容量满时,尝试将元素放入队列将导致操作阻塞;尝试从一个空队列中取一个元素也会同样阻塞。
+
+`ArrayBlockingQueue` 默认情况下不能保证线程访问队列的公平性,所谓公平性是指严格按照线程等待的绝对时间顺序,即最先等待的线程能够最先访问到 `ArrayBlockingQueue`。而非公平性则是指访问 `ArrayBlockingQueue` 的顺序不是遵守严格的时间顺序,有可能存在,当 `ArrayBlockingQueue` 可以被访问时,长时间阻塞的线程依然无法访问到 `ArrayBlockingQueue`。如果保证公平性,通常会降低吞吐量。如果需要获得公平性的 `ArrayBlockingQueue`,可采用如下代码:
+
+```java
+private static ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(10,true);
+```
+
+### LinkedBlockingQueue
+
+`LinkedBlockingQueue` 底层基于**单向链表**实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用,同样满足 FIFO 的特性,与 `ArrayBlockingQueue` 相比起来具有更高的吞吐量,为了防止 `LinkedBlockingQueue` 容量迅速增,损耗大量内存。通常在创建 `LinkedBlockingQueue` 对象时,会指定其大小,如果未指定,容量等于 `Integer.MAX_VALUE` 。
+
+**相关构造方法:**
+
+```java
+ /**
+ *某种意义上的无界队列
+ * Creates a {@code LinkedBlockingQueue} with a capacity of
+ * {@link Integer#MAX_VALUE}.
+ */
+ public LinkedBlockingQueue() {
+ this(Integer.MAX_VALUE);
+ }
+
+ /**
+ *有界队列
+ * Creates a {@code LinkedBlockingQueue} with the given (fixed) capacity.
+ *
+ * @param capacity the capacity of this queue
+ * @throws IllegalArgumentException if {@code capacity} is not greater
+ * than zero
+ */
+ public LinkedBlockingQueue(int capacity) {
+ if (capacity <= 0) throw new IllegalArgumentException();
+ this.capacity = capacity;
+ last = head = new Node<E>(null);
+ }
+```
+
+### PriorityBlockingQueue
+
+`PriorityBlockingQueue` 是一个支持优先级的无界阻塞队列。默认情况下元素采用自然顺序进行排序,也可以通过自定义类实现 `compareTo()` 方法来指定元素排序规则,或者初始化时通过构造器参数 `Comparator` 来指定排序规则。
+
+`PriorityBlockingQueue` 并发控制采用的是可重入锁 `ReentrantLock`,队列为无界队列(`ArrayBlockingQueue` 是有界队列,`LinkedBlockingQueue` 也可以通过在构造函数中传入 `capacity` 指定队列最大的容量,但是 `PriorityBlockingQueue` 只能指定初始的队列大小,后面插入元素的时候,**如果空间不够的话会自动扩容**)。
+
+简单地说,它就是 `PriorityQueue` 的线程安全版本。不可以插入 null 值,同时,插入队列的对象必须是可比较大小的(comparable),否则报 `ClassCastException` 异常。它的插入操作 put 方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
+
+**推荐文章:** [《解读 Java 并发队列 BlockingQueue》](https://javadoop.com/post/java-concurrent-queue)
+
+## ConcurrentSkipListMap
+
+下面这部分内容参考了极客时间专栏[《数据结构与算法之美》](https://time.geekbang.org/column/intro/126?code=zl3GYeAsRI4rEJIBNu5B/km7LSZsPDlGWQEpAYw5Vu0=&utm_term=SPoster "《数据结构与算法之美》")以及《实战 Java 高并发程序设计》。
+
+为了引出 `ConcurrentSkipListMap`,先带着大家简单理解一下跳表。
+
+对于一个单链表,即使链表是有序的,如果我们想要在其中查找某个数据,也只能从头到尾遍历链表,这样效率自然就会很低,跳表就不一样了。跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。它们都可以对元素进行快速的查找。但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整。而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。这样带来的好处是:在高并发的情况下,你会需要一个全局锁来保证整个平衡树的线程安全。而对于跳表,你只需要部分锁即可。这样,在高并发环境下,你就可以拥有更好的性能。而就查询的性能而言,跳表的时间复杂度也是 **O(logn)** 所以在并发数据结构中,JDK 使用跳表来实现一个 Map。
+
+跳表的本质是同时维护了多个链表,并且链表是分层的,
+
+
+
+最低层的链表维护了跳表内所有的元素,每上面一层链表都是下面一层的子集。
+
+跳表内的所有链表的元素都是排序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续找。这也就是说在查找过程中,搜索是跳跃式的。如上图所示,在跳表中查找元素 18。
+
+
+
+查找 18 的时候原来需要遍历 18 次,现在只需要 7 次即可。针对链表长度比较大的时候,构建索引查找效率的提升就会非常明显。
+
+从上面很容易看出,**跳表是一种利用空间换时间的算法。**
+
+使用跳表实现 `Map` 和使用哈希算法实现 `Map` 的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,你会得到一个有序的结果。所以,如果你的应用需要有序性,那么跳表就是你不二的选择。JDK 中实现这一数据结构的类是 `ConcurrentSkipListMap`。
+
+## 参考
+
+- 《实战 Java 高并发程序设计》
+- https://javadoop.com/post/java-concurrent-queue
+- https://juejin.im/post/5aeebd02518825672f19c546
diff --git "a/docs/java/concurrent/\346\213\277\346\235\245\345\215\263\347\224\250\347\232\204java\347\272\277\347\250\213\346\261\240\346\234\200\344\275\263\345\256\236\350\267\265.md" "b/docs/java/concurrent/\346\213\277\346\235\245\345\215\263\347\224\250\347\232\204java\347\272\277\347\250\213\346\261\240\346\234\200\344\275\263\345\256\236\350\267\265.md"
new file mode 100644
index 00000000000..45034bf3392
--- /dev/null
+++ "b/docs/java/concurrent/\346\213\277\346\235\245\345\215\263\347\224\250\347\232\204java\347\272\277\347\250\213\346\261\240\346\234\200\344\275\263\345\256\236\350\267\265.md"
@@ -0,0 +1,308 @@
+---
+title: 拿来即用的Java线程池最佳实践
+category: Java
+tag:
+ - Java并发
+---
+
+这篇文章篇幅虽短,但是绝对是干货。标题稍微有点夸张,嘿嘿,实际都是自己使用线程池的时候总结的一些个人感觉比较重要的点。
+
+## 线程池知识回顾
+
+开始这篇文章之前还是简单介绍一嘴线程池,之前写的[《新手也能看懂的线程池学习总结》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485808&idx=1&sn=1013253533d73450cef673aee13267ab&chksm=cea246bbf9d5cfad1c21316340a0ef1609a7457fea4113a1f8d69e8c91e7d9cd6285f5ee1490&token=510053261&lang=zh_CN&scene=21#wechat_redirect)这篇文章介绍的很详细了。
+
+### 为什么要使用线程池?
+
+> **池化技术想必大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。**
+
+**线程池**提供了一种限制和管理资源(包括执行一个任务)。 每个**线程池**还维护一些基本统计信息,例如已完成任务的数量。
+
+这里借用《Java 并发编程的艺术》提到的来说一下**使用线程池的好处**:
+
+- **降低资源消耗**。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
+- **提高响应速度**。当任务到达时,任务可以不需要等到线程创建就能立即执行。
+- **提高线程的可管理性**。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
+
+### 线程池在实际项目的使用场景
+
+**线程池一般用于执行多个不相关联的耗时任务,没有多线程的情况下,任务顺序执行,使用了线程池的话可让多个不相关联的任务同时执行。**
+
+假设我们要执行三个不相关的耗时任务,Guide 画图给大家展示了使用线程池前后的区别。
+
+注意:**下面三个任务可能做的是同一件事情,也可能是不一样的事情。**
+
+
+
+### 如何使用线程池?
+
+一般是通过 `ThreadPoolExecutor` 的构造函数来创建线程池,然后提交任务给线程池执行就可以了。
+
+ `ThreadPoolExecutor`构造函数如下:
+
+```java
+ /**
+ * 用给定的初始参数创建一个新的ThreadPoolExecutor。
+ */
+ public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
+ int maximumPoolSize,//线程池的最大线程数
+ long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
+ TimeUnit unit,//时间单位
+ BlockingQueue<Runnable> workQueue,//任务队列,用来储存等待执行任务的队列
+ ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
+ RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
+ ) {
+ if (corePoolSize < 0 ||
+ maximumPoolSize <= 0 ||
+ maximumPoolSize < corePoolSize ||
+ keepAliveTime < 0)
+ throw new IllegalArgumentException();
+ if (workQueue == null || threadFactory == null || handler == null)
+ throw new NullPointerException();
+ this.corePoolSize = corePoolSize;
+ this.maximumPoolSize = maximumPoolSize;
+ this.workQueue = workQueue;
+ this.keepAliveTime = unit.toNanos(keepAliveTime);
+ this.threadFactory = threadFactory;
+ this.handler = handler;
+ }
+```
+
+简单演示一下如何使用线程池,更详细的介绍,请看:[《新手也能看懂的线程池学习总结》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485808&idx=1&sn=1013253533d73450cef673aee13267ab&chksm=cea246bbf9d5cfad1c21316340a0ef1609a7457fea4113a1f8d69e8c91e7d9cd6285f5ee1490&token=510053261&lang=zh_CN&scene=21#wechat_redirect) 。
+
+```java
+ private static final int CORE_POOL_SIZE = 5;
+ private static final int MAX_POOL_SIZE = 10;
+ private static final int QUEUE_CAPACITY = 100;
+ private static final Long KEEP_ALIVE_TIME = 1L;
+
+ public static void main(String[] args) {
+
+ //使用阿里巴巴推荐的创建线程池的方式
+ //通过ThreadPoolExecutor构造函数自定义参数创建
+ ThreadPoolExecutor executor = new ThreadPoolExecutor(
+ CORE_POOL_SIZE,
+ MAX_POOL_SIZE,
+ KEEP_ALIVE_TIME,
+ TimeUnit.SECONDS,
+ new ArrayBlockingQueue<>(QUEUE_CAPACITY),
+ new ThreadPoolExecutor.CallerRunsPolicy());
+
+ for (int i = 0; i < 10; i++) {
+ executor.execute(() -> {
+ try {
+ Thread.sleep(2000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println("CurrentThread name:" + Thread.currentThread().getName() + "date:" + Instant.now());
+ });
+ }
+ //终止线程池
+ executor.shutdown();
+ try {
+ executor.awaitTermination(5, TimeUnit.SECONDS);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println("Finished all threads");
+ }
+```
+
+控制台输出:
+
+```java
+CurrentThread name:pool-1-thread-5date:2020-06-06T11:45:31.639Z
+CurrentThread name:pool-1-thread-3date:2020-06-06T11:45:31.639Z
+CurrentThread name:pool-1-thread-1date:2020-06-06T11:45:31.636Z
+CurrentThread name:pool-1-thread-4date:2020-06-06T11:45:31.639Z
+CurrentThread name:pool-1-thread-2date:2020-06-06T11:45:31.639Z
+CurrentThread name:pool-1-thread-2date:2020-06-06T11:45:33.656Z
+CurrentThread name:pool-1-thread-4date:2020-06-06T11:45:33.656Z
+CurrentThread name:pool-1-thread-1date:2020-06-06T11:45:33.656Z
+CurrentThread name:pool-1-thread-3date:2020-06-06T11:45:33.656Z
+CurrentThread name:pool-1-thread-5date:2020-06-06T11:45:33.656Z
+Finished all threads
+```
+
+## 线程池最佳实践
+
+简单总结一下我了解的使用线程池的时候应该注意的东西,网上似乎还没有专门写这方面的文章。
+
+因为Guide还比较菜,有补充和完善的地方,可以在评论区告知或者在微信上与我交流。
+
+### 1. 使用 `ThreadPoolExecutor ` 的构造函数声明线程池
+
+**1. 线程池必须手动通过 `ThreadPoolExecutor ` 的构造函数来声明,避免使用`Executors ` 类的 `newFixedThreadPool` 和 `newCachedThreadPool` ,因为可能会有 OOM 的风险。**
+
+> Executors 返回线程池对象的弊端如下:
+>
+> - **`FixedThreadPool` 和 `SingleThreadExecutor`** : 允许请求的队列长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
+> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
+
+说白了就是:**使用有界队列,控制线程创建数量。**
+
+除了避免 OOM 的原因之外,不推荐使用 `Executors `提供的两种快捷的线程池的原因还有:
+
+1. 实际使用中需要根据自己机器的性能、业务场景来手动配置线程池的参数比如核心线程数、使用的任务队列、饱和策略等等。
+2. 我们应该显示地给我们的线程池命名,这样有助于我们定位问题。
+
+### 2.监测线程池运行状态
+
+你可以通过一些手段来检测线程池的运行状态比如 SpringBoot 中的 Actuator 组件。
+
+除此之外,我们还可以利用 `ThreadPoolExecutor` 的相关 API做一个简陋的监控。从下图可以看出, `ThreadPoolExecutor`提供了获取线程池当前的线程数和活跃线程数、已经执行完成的任务数、正在排队中的任务数等等。
+
+
+
+下面是一个简单的 Demo。`printThreadPoolStatus()`会每隔一秒打印出线程池的线程数、活跃线程数、完成的任务数、以及队列中的任务数。
+
+```java
+ /**
+ * 打印线程池的状态
+ *
+ * @param threadPool 线程池对象
+ */
+ public static void printThreadPoolStatus(ThreadPoolExecutor threadPool) {
+ ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1, createThreadFactory("print-images/thread-pool-status", false));
+ scheduledExecutorService.scheduleAtFixedRate(() -> {
+ log.info("=========================");
+ log.info("ThreadPool Size: [{}]", threadPool.getPoolSize());
+ log.info("Active Threads: {}", threadPool.getActiveCount());
+ log.info("Number of Tasks : {}", threadPool.getCompletedTaskCount());
+ log.info("Number of Tasks in Queue: {}", threadPool.getQueue().size());
+ log.info("=========================");
+ }, 0, 1, TimeUnit.SECONDS);
+ }
+```
+
+### 3.建议不同类别的业务用不同的线程池
+
+很多人在实际项目中都会有类似这样的问题:**我的项目中多个业务需要用到线程池,是为每个线程池都定义一个还是说定义一个公共的线程池呢?**
+
+一般建议是不同的业务使用不同的线程池,配置线程池的时候根据当前业务的情况对当前线程池进行配置,因为不同的业务的并发以及对资源的使用情况都不同,重心优化系统性能瓶颈相关的业务。
+
+**我们再来看一个真实的事故案例!** (本案例来源自:[《线程池运用不当的一次线上事故》](https://club.perfma.com/article/646639) ,很精彩的一个案例)
+
+
+
+上面的代码可能会存在死锁的情况,为什么呢?画个图给大家捋一捋。
+
+试想这样一种极端情况:假如我们线程池的核心线程数为 **n**,父任务(扣费任务)数量为 **n**,父任务下面有两个子任务(扣费任务下的子任务),其中一个已经执行完成,另外一个被放在了任务队列中。由于父任务把线程池核心线程资源用完,所以子任务因为无法获取到线程资源无法正常执行,一直被阻塞在队列中。父任务等待子任务执行完成,而子任务等待父任务释放线程池资源,这也就造成了 **"死锁"**。
+
+
+
+解决方法也很简单,就是新增加一个用于执行子任务的线程池专门为其服务。
+
+### 4.别忘记给线程池命名
+
+初始化线程池的时候需要显示命名(设置线程池名称前缀),有利于定位问题。
+
+默认情况下创建的线程名字类似 pool-1-thread-n 这样的,没有业务含义,不利于我们定位问题。
+
+给线程池里的线程命名通常有下面两种方式:
+
+**1.利用 guava 的 `ThreadFactoryBuilder` **
+
+```java
+ThreadFactory threadFactory = new ThreadFactoryBuilder()
+ .setNameFormat(threadNamePrefix + "-%d")
+ .setDaemon(true).build();
+ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory)
+```
+
+**2.自己实现 `ThreadFactor`。**
+
+```java
+import java.util.concurrent.Executors;
+import java.util.concurrent.ThreadFactory;
+import java.util.concurrent.atomic.AtomicInteger;
+/**
+ * 线程工厂,它设置线程名称,有利于我们定位问题。
+ */
+public final class NamingThreadFactory implements ThreadFactory {
+
+ private final AtomicInteger threadNum = new AtomicInteger();
+ private final ThreadFactory delegate;
+ private final String name;
+
+ /**
+ * 创建一个带名字的线程池生产工厂
+ */
+ public NamingThreadFactory(ThreadFactory delegate, String name) {
+ this.delegate = delegate;
+ this.name = name; // TODO consider uniquifying this
+ }
+
+ @Override
+ public Thread newThread(Runnable r) {
+ Thread t = delegate.newThread(r);
+ t.setName(name + " [#" + threadNum.incrementAndGet() + "]");
+ return t;
+ }
+
+}
+```
+
+### 5.正确配置线程池参数
+
+说到如何给线程池配置参数,美团的骚操作至今让我难忘(后面会提到)!
+
+我们先来看一下各种书籍和博客上一般推荐的配置线程池参数的方式,可以作为参考!
+
+#### 常规操作
+
+很多人甚至可能都会觉得把线程池配置过大一点比较好!我觉得这明显是有问题的。就拿我们生活中非常常见的一例子来说:**并不是人多就能把事情做好,增加了沟通交流成本。你本来一件事情只需要 3 个人做,你硬是拉来了 6 个人,会提升做事效率嘛?我想并不会。** 线程数量过多的影响也是和我们分配多少人做事情一样,对于多线程这个场景来说主要是增加了**上下文切换**成本。不清楚什么是上下文切换的话,可以看我下面的介绍。
+
+> 上下文切换:
+>
+> 多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。**任务从保存到再加载的过程就是一次上下文切换**。
+>
+> 上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
+>
+> Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
+
+**类比于实现世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。**
+
+**如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的! CPU 根本没有得到充分利用。**
+
+**但是,如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。**
+
+有一个简单并且适用面比较广的公式:
+
+- **CPU 密集型任务(N+1):** 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
+- **I/O 密集型任务(2N):** 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
+
+**如何判断是 CPU 密集任务还是 IO 密集任务?**
+
+CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
+
+#### 美团的骚操作
+
+美团技术团队在[《Java线程池实现原理及其在美团业务中的实践》](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)这篇文章中介绍到对线程池参数实现可自定义配置的思路和方法。
+
+美团技术团队的思路是主要对线程池的核心参数实现自定义可配置。这三个核心参数是:
+
+- **`corePoolSize` :** 核心线程数线程数定义了最小可以同时运行的线程数量。
+- **`maximumPoolSize` :** 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
+- **`workQueue`:** 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
+
+**为什么是这三个参数?**
+
+我在这篇[《新手也能看懂的线程池学习总结》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485808&idx=1&sn=1013253533d73450cef673aee13267ab&chksm=cea246bbf9d5cfad1c21316340a0ef1609a7457fea4113a1f8d69e8c91e7d9cd6285f5ee1490&token=510053261&lang=zh_CN&scene=21#wechat_redirect) 中就说过这三个参数是 `ThreadPoolExecutor` 最重要的参数,它们基本决定了线程池对于任务的处理策略。
+
+**如何支持参数动态配置?** 且看 `ThreadPoolExecutor` 提供的下面这些方法。
+
+
+
+格外需要注意的是`corePoolSize`, 程序运行期间的时候,我们调用 `setCorePoolSize() `这个方法的话,线程池会首先判断当前工作线程数是否大于`corePoolSize`,如果大于的话就会回收工作线程。
+
+另外,你也看到了上面并没有动态指定队列长度的方法,美团的方式是自定义了一个叫做 `ResizableCapacityLinkedBlockIngQueue` 的队列(主要就是把`LinkedBlockingQueue`的capacity 字段的final关键字修饰给去掉了,让它变为可变的)。
+
+最终实现的可动态修改线程池参数效果如下。👏👏👏
+
+
+
+还没看够?推荐 why神的[《如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。》](https://mp.weixin.qq.com/s/9HLuPcoWmTqAeFKa1kj-_A)这篇文章,深度剖析,很不错哦!
+
+
+
diff --git a/docs/java/jvm/class-file-structure.md b/docs/java/jvm/class-file-structure.md
new file mode 100644
index 00000000000..b5a2611397e
--- /dev/null
+++ b/docs/java/jvm/class-file-structure.md
@@ -0,0 +1,211 @@
+---
+category: Java
+tag:
+ - JVM
+---
+
+# 类文件结构详解
+
+## 一 概述
+
+在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
+
+Clojure(Lisp 语言的一种方言)、Groovy、Scala 等语言都是运行在 Java 虚拟机之上。下图展示了不同的语言被不同的编译器编译成`.class`文件最终运行在 Java 虚拟机之上。`.class`文件的二进制格式可以使用 [WinHex](https://www.x-ways.net/winhex/) 查看。
+
+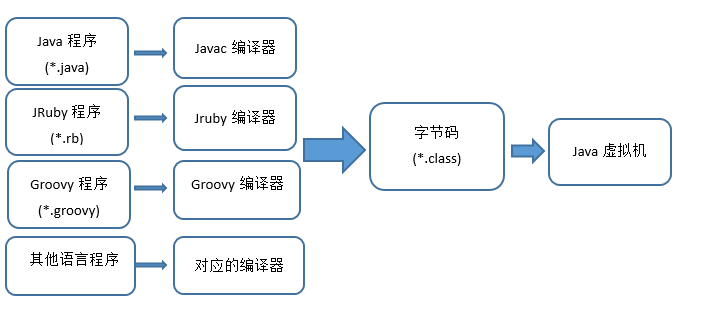
+
+可以说`.class`文件是不同的语言在 Java 虚拟机之间的重要桥梁,同时也是支持 Java 跨平台很重要的一个原因。
+
+## 二 Class 文件结构总结
+
+根据 Java 虚拟机规范,Class 文件通过 `ClassFile` 定义,有点类似 C 语言的结构体。
+
+`ClassFile` 的结构如下:
+
+```java
+ClassFile {
+ u4 magic; //Class 文件的标志
+ u2 minor_version;//Class 的小版本号
+ u2 major_version;//Class 的大版本号
+ u2 constant_pool_count;//常量池的数量
+ cp_info constant_pool[constant_pool_count-1];//常量池
+ u2 access_flags;//Class 的访问标记
+ u2 this_class;//当前类
+ u2 super_class;//父类
+ u2 interfaces_count;//接口
+ u2 interfaces[interfaces_count];//一个类可以实现多个接口
+ u2 fields_count;//Class 文件的字段属性
+ field_info fields[fields_count];//一个类会可以有多个字段
+ u2 methods_count;//Class 文件的方法数量
+ method_info methods[methods_count];//一个类可以有个多个方法
+ u2 attributes_count;//此类的属性表中的属性数
+ attribute_info attributes[attributes_count];//属性表集合
+}
+```
+
+通过分析 `ClassFile` 的内容,我们便可以知道 class 文件的组成。
+
+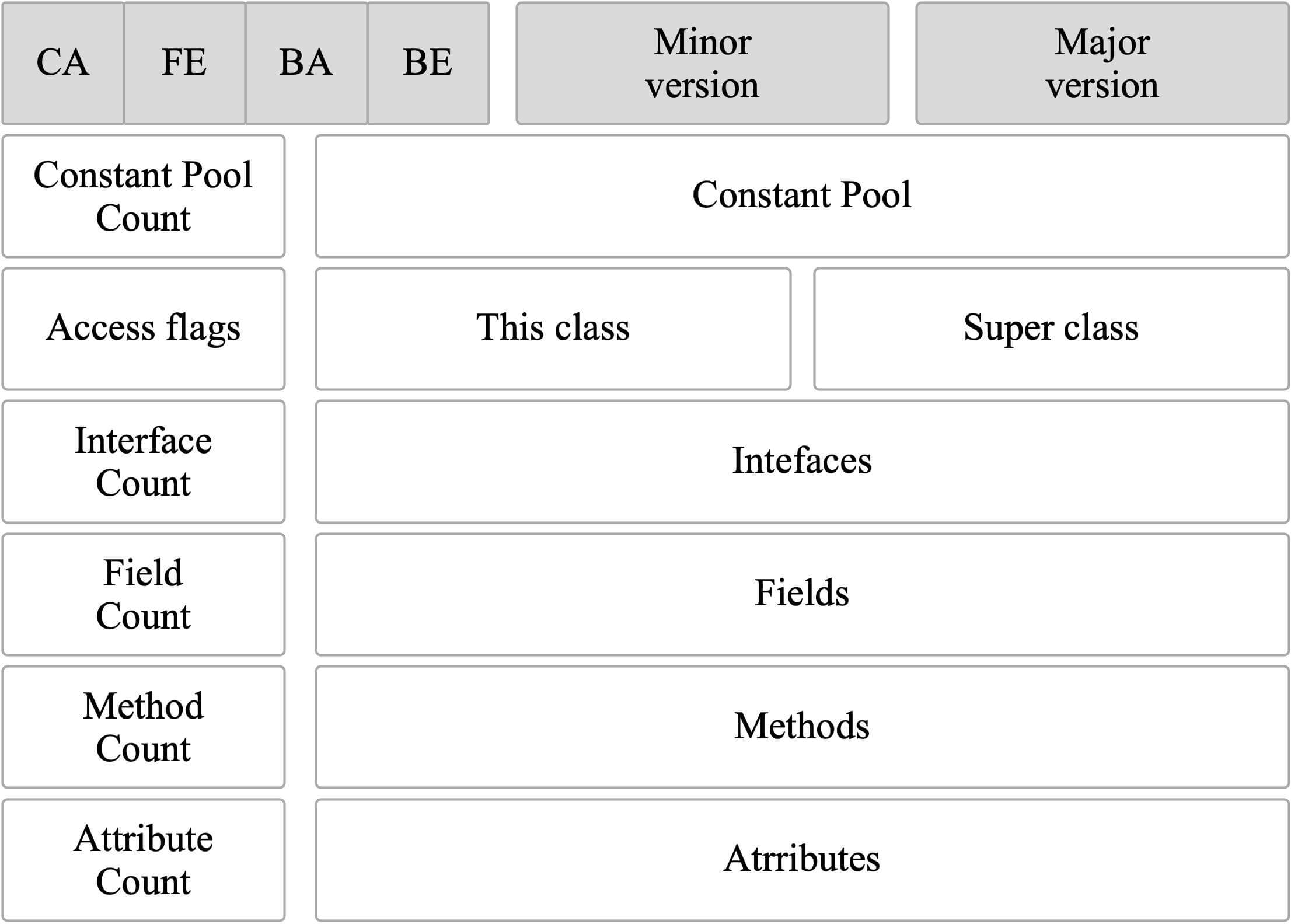
+
+下面这张图是通过 IDEA 插件 `jclasslib` 查看的,你可以更直观看到 Class 文件结构。
+
+
+
+使用 `jclasslib` 不光可以直观地查看某个类对应的字节码文件,还可以查看类的基本信息、常量池、接口、属性、函数等信息。
+
+下面详细介绍一下 Class 文件结构涉及到的一些组件。
+
+### 2.1 魔数(Magic Number)
+
+```java
+ u4 magic; //Class 文件的标志
+```
+
+每个 Class 文件的头 4 个字节称为魔数(Magic Number),它的唯一作用是**确定这个文件是否为一个能被虚拟机接收的 Class 文件**。
+
+程序设计者很多时候都喜欢用一些特殊的数字表示固定的文件类型或者其它特殊的含义。
+
+### 2.2 Class 文件版本号(Minor&Major Version)
+
+```java
+ u2 minor_version;//Class 的小版本号
+ u2 major_version;//Class 的大版本号
+```
+
+紧接着魔数的四个字节存储的是 Class 文件的版本号:第 5 和第 6 位是**次版本号**,第 7 和第 8 位是**主版本号**。
+
+每当 Java 发布大版本(比如 Java 8,Java9)的时候,主版本号都会加 1。你可以使用 `javap -v` 命令来快速查看 Class 文件的版本号信息。
+
+高版本的 Java 虚拟机可以执行低版本编译器生成的 Class 文件,但是低版本的 Java 虚拟机不能执行高版本编译器生成的 Class 文件。所以,我们在实际开发的时候要确保开发的的 JDK 版本和生产环境的 JDK 版本保持一致。
+
+### 2.3 常量池(Constant Pool)
+
+```java
+ u2 constant_pool_count;//常量池的数量
+ cp_info constant_pool[constant_pool_count-1];//常量池
+```
+
+紧接着主次版本号之后的是常量池,常量池的数量是 `constant_pool_count-1`(**常量池计数器是从 1 开始计数的,将第 0 项常量空出来是有特殊考虑的,索引值为 0 代表“不引用任何一个常量池项”**)。
+
+常量池主要存放两大常量:字面量和符号引用。字面量比较接近于 Java 语言层面的的常量概念,如文本字符串、声明为 final 的常量值等。而符号引用则属于编译原理方面的概念。包括下面三类常量:
+
+- 类和接口的全限定名
+- 字段的名称和描述符
+- 方法的名称和描述符
+
+常量池中每一项常量都是一个表,这 14 种表有一个共同的特点:**开始的第一位是一个 u1 类型的标志位 -tag 来标识常量的类型,代表当前这个常量属于哪种常量类型.**
+
+| 类型 | 标志(tag) | 描述 |
+| :------------------------------: | :---------: | :--------------------: |
+| CONSTANT_utf8_info | 1 | UTF-8 编码的字符串 |
+| CONSTANT_Integer_info | 3 | 整形字面量 |
+| CONSTANT_Float_info | 4 | 浮点型字面量 |
+| CONSTANT_Long_info | 5 | 长整型字面量 |
+| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
+| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
+| CONSTANT_String_info | 8 | 字符串类型字面量 |
+| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
+| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
+| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
+| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
+| CONSTANT_MothodType_info | 16 | 标志方法类型 |
+| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
+| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
+
+`.class` 文件可以通过`javap -v class类名` 指令来看一下其常量池中的信息(`javap -v class类名-> temp.txt` :将结果输出到 temp.txt 文件)。
+
+### 2.4 访问标志(Access Flags)
+
+在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口,是否为 `public` 或者 `abstract` 类型,如果是类的话是否声明为 `final` 等等。
+
+类访问和属性修饰符:
+
+
+
+我们定义了一个 Employee 类
+
+```java
+package top.snailclimb.bean;
+public class Employee {
+ ...
+}
+```
+
+通过`javap -v class类名` 指令来看一下类的访问标志。
+
+
+
+### 2.5 当前类(This Class)、父类(Super Class)、接口(Interfaces)索引集合
+
+```java
+ u2 this_class;//当前类
+ u2 super_class;//父类
+ u2 interfaces_count;//接口
+ u2 interfaces[interfaces_count];//一个类可以实现多个接口
+```
+
+类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。
+
+接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按 `implements` (如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。
+
+### 2.6 字段表集合(Fields)
+
+```java
+ u2 fields_count;//Class 文件的字段的个数
+ field_info fields[fields_count];//一个类会可以有个字段
+```
+
+字段表(field info)用于描述接口或类中声明的变量。字段包括类级变量以及实例变量,但不包括在方法内部声明的局部变量。
+
+**field info(字段表) 的结构:**
+
+
+
+- **access_flags:** 字段的作用域(`public` ,`private`,`protected`修饰符),是实例变量还是类变量(`static`修饰符),可否被序列化(transient 修饰符),可变性(final),可见性(volatile 修饰符,是否强制从主内存读写)。
+- **name_index:** 对常量池的引用,表示的字段的名称;
+- **descriptor_index:** 对常量池的引用,表示字段和方法的描述符;
+- **attributes_count:** 一个字段还会拥有一些额外的属性,attributes_count 存放属性的个数;
+- **attributes[attributes_count]:** 存放具体属性具体内容。
+
+上述这些信息中,各个修饰符都是布尔值,要么有某个修饰符,要么没有,很适合使用标志位来表示。而字段叫什么名字、字段被定义为什么数据类型这些都是无法固定的,只能引用常量池中常量来描述。
+
+**字段的 access_flag 的取值:**
+
+
+
+### 2.7 方法表集合(Methods)
+
+```java
+ u2 methods_count;//Class 文件的方法的数量
+ method_info methods[methods_count];//一个类可以有个多个方法
+```
+
+methods_count 表示方法的数量,而 method_info 表示方法表。
+
+Class 文件存储格式中对方法的描述与对字段的描述几乎采用了完全一致的方式。方法表的结构如同字段表一样,依次包括了访问标志、名称索引、描述符索引、属性表集合几项。
+
+**method_info(方法表的) 结构:**
+
+
+
+**方法表的 access_flag 取值:**
+
+
+
+注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
+
+### 2.8 属性表集合(Attributes)
+
+```java
+ u2 attributes_count;//此类的属性表中的属性数
+ attribute_info attributes[attributes_count];//属性表集合
+```
+
+在 Class 文件,字段表,方法表中都可以携带自己的属性表集合,以用于描述某些场景专有的信息。与 Class 文件中其它的数据项目要求的顺序、长度和内容不同,属性表集合的限制稍微宽松一些,不再要求各个属性表具有严格的顺序,并且只要不与已有的属性名重复,任何人实现的编译器都可以向属性表中写 入自己定义的属性信息,Java 虚拟机运行时会忽略掉它不认识的属性。
+
+## 参考
+
+- <https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html>
+- <https://coolshell.cn/articles/9229.html>
+- <https://blog.csdn.net/luanlouis/article/details/39960815>
+- 《实战 Java 虚拟机》
\ No newline at end of file
diff --git a/docs/java/jvm/class-loading-process.md b/docs/java/jvm/class-loading-process.md
new file mode 100644
index 00000000000..fbe1b161d68
--- /dev/null
+++ b/docs/java/jvm/class-loading-process.md
@@ -0,0 +1,112 @@
+---
+category: Java
+tag:
+ - JVM
+---
+
+
+# 类加载过程详解
+
+## 类的生命周期
+
+一个类的完整生命周期如下:
+
+
+
+## 类加载过程
+
+Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
+
+系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
+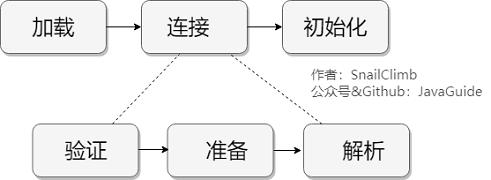
+
+详见:[jvm规范5.4](https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-5.html#jvms-5.4) 。
+
+
+
+### 加载
+
+类加载过程的第一步,主要完成下面 3 件事情:
+
+1. 通过全类名获取定义此类的二进制字节流
+2. 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
+3. 在内存中生成一个代表该类的 `Class` 对象,作为方法区这些数据的访问入口
+
+虚拟机规范上面这 3 点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 `ZIP` 包中读取(日后出现的 `JAR`、`EAR`、`WAR` 格式的基础)、其他文件生成(典型应用就是 `JSP`)等等。
+
+**一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。**
+
+类加载器、双亲委派模型也是非常重要的知识点,这部分内容会在后面的文章中单独介绍到。
+
+加载阶段和连接阶段的部分内容是交叉进行的,加载阶段尚未结束,连接阶段可能就已经开始了。
+
+### 验证
+
+
+
+### 准备
+
+**准备阶段是正式为类变量分配内存并设置类变量初始值的阶段**,这些内存都将在方法区中分配。对于该阶段有以下几点需要注意:
+
+1. 这时候进行内存分配的仅包括类变量( Class Variables ,即静态变量,被 `static` 关键字修饰的变量,只与类相关,因此被称为类变量),而不包括实例变量。实例变量会在对象实例化时随着对象一块分配在 Java 堆中。
+2. 从概念上讲,类变量所使用的内存都应当在 **方法区** 中进行分配。不过有一点需要注意的是:JDK 7 之前,HotSpot 使用永久代来实现方法区的时候,实现是完全符合这种逻辑概念的。 而在 JDK 7 及之后,HotSpot 已经把原本放在永久代的字符串常量池、静态变量等移动到堆中,这个时候类变量则会随着 Class 对象一起存放在 Java 堆中。相关阅读:[《深入理解Java虚拟机(第3版)》勘误#75](https://github.com/fenixsoft/jvm_book/issues/75)
+3. 这里所设置的初始值"通常情况"下是数据类型默认的零值(如 0、0L、null、false 等),比如我们定义了`public static int value=111` ,那么 value 变量在准备阶段的初始值就是 0 而不是 111(初始化阶段才会赋值)。特殊情况:比如给 value 变量加上了 final 关键字`public static final int value=111` ,那么准备阶段 value 的值就被赋值为 111。
+
+**基本数据类型的零值** : (图片来自《深入理解 Java 虚拟机》第 3 版 7.33 )
+
+
+
+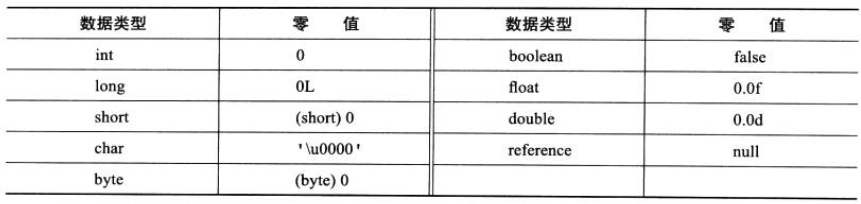
+
+### 解析
+
+解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符 7 类符号引用进行。
+
+符号引用就是一组符号来描述目标,可以是任何字面量。**直接引用**就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。在程序实际运行时,只有符号引用是不够的,举个例子:在程序执行方法时,系统需要明确知道这个方法所在的位置。Java 虚拟机为每个类都准备了一张方法表来存放类中所有的方法。当需要调用一个类的方法的时候,只要知道这个方法在方法表中的偏移量就可以直接调用该方法了。通过解析操作符号引用就可以直接转变为目标方法在类中方法表的位置,从而使得方法可以被调用。
+
+综上,解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程,也就是得到类或者字段、方法在内存中的指针或者偏移量。
+
+### 初始化
+
+初始化阶段是执行初始化方法 `<clinit> ()`方法的过程,是类加载的最后一步,这一步 JVM 才开始真正执行类中定义的 Java 程序代码(字节码)。
+
+> 说明: `<clinit> ()`方法是编译之后自动生成的。
+
+对于`<clinit> ()` 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 `<clinit> ()` 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起多个进程阻塞,并且这种阻塞很难被发现。
+
+对于初始化阶段,虚拟机严格规范了有且只有 5 种情况下,必须对类进行初始化(只有主动去使用类才会初始化类):
+
+1. 当遇到 `new` 、 `getstatic`、`putstatic` 或 `invokestatic` 这 4 条直接码指令时,比如 `new` 一个类,读取一个静态字段(未被 final 修饰)、或调用一个类的静态方法时。
+ - 当 jvm 执行 `new` 指令时会初始化类。即当程序创建一个类的实例对象。
+ - 当 jvm 执行 `getstatic` 指令时会初始化类。即程序访问类的静态变量(不是静态常量,常量会被加载到运行时常量池)。
+ - 当 jvm 执行 `putstatic` 指令时会初始化类。即程序给类的静态变量赋值。
+ - 当 jvm 执行 `invokestatic` 指令时会初始化类。即程序调用类的静态方法。
+2. 使用 `java.lang.reflect` 包的方法对类进行反射调用时如 `Class.forname("...")`, `newInstance()` 等等。如果类没初始化,需要触发其初始化。
+3. 初始化一个类,如果其父类还未初始化,则先触发该父类的初始化。
+4. 当虚拟机启动时,用户需要定义一个要执行的主类 (包含 `main` 方法的那个类),虚拟机会先初始化这个类。
+5. `MethodHandle` 和 `VarHandle` 可以看作是轻量级的反射调用机制,而要想使用这 2 个调用,
+ 就必须先使用 `findStaticVarHandle` 来初始化要调用的类。
+6. **「补充,来自[issue745](https://github.com/Snailclimb/JavaGuide/issues/745)」** 当一个接口中定义了 JDK8 新加入的默认方法(被 default 关键字修饰的接口方法)时,如果有这个接口的实现类发生了初始化,那该接口要在其之前被初始化。
+
+## 卸载
+
+> 卸载这部分内容来自 [issue#662](https://github.com/Snailclimb/JavaGuide/issues/662)由 **[guang19](https://github.com/guang19)** 补充完善。
+
+卸载类即该类的 Class 对象被 GC。
+
+卸载类需要满足 3 个要求:
+
+1. 该类的所有的实例对象都已被 GC,也就是说堆不存在该类的实例对象。
+2. 该类没有在其他任何地方被引用
+3. 该类的类加载器的实例已被 GC
+
+所以,在 JVM 生命周期内,由 jvm 自带的类加载器加载的类是不会被卸载的。但是由我们自定义的类加载器加载的类是可能被卸载的。
+
+只要想通一点就好了,jdk 自带的 `BootstrapClassLoader`, `ExtClassLoader`, `AppClassLoader` 负责加载 jdk 提供的类,所以它们(类加载器的实例)肯定不会被回收。而我们自定义的类加载器的实例是可以被回收的,所以使用我们自定义加载器加载的类是可以被卸载掉的。
+
+**参考**
+
+- 《深入理解 Java 虚拟机》
+- 《实战 Java 虚拟机》
+- <https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-5.html>
diff --git a/docs/java/jvm/classloader.md b/docs/java/jvm/classloader.md
new file mode 100644
index 00000000000..93cd907e45a
--- /dev/null
+++ b/docs/java/jvm/classloader.md
@@ -0,0 +1,123 @@
+---
+category: Java
+tag:
+ - JVM
+---
+
+# 类加载器详解
+
+## 回顾一下类加载过程
+
+类加载过程:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
+
+
+一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。
+
+所有的类都由类加载器加载,加载的作用就是将 `.class`文件加载到内存。
+
+## 类加载器总结
+
+JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`:
+
+1. **BootstrapClassLoader(启动类加载器)** :最顶层的加载类,由 C++实现,负责加载 `%JAVA_HOME%/lib`目录下的 jar 包和类或者被 `-Xbootclasspath`参数指定的路径中的所有类。
+2. **ExtensionClassLoader(扩展类加载器)** :主要负责加载 `%JRE_HOME%/lib/ext` 目录下的 jar 包和类,或被 `java.ext.dirs` 系统变量所指定的路径下的 jar 包。
+3. **AppClassLoader(应用程序类加载器)** :面向我们用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类。
+
+## 双亲委派模型
+
+### 双亲委派模型介绍
+
+每一个类都有一个对应它的类加载器。系统中的 ClassLoader 在协同工作的时候会默认使用 **双亲委派模型** 。即在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。加载的时候,首先会把该请求委派给父类加载器的 `loadClass()` 处理,因此所有的请求最终都应该传送到顶层的启动类加载器 `BootstrapClassLoader` 中。当父类加载器无法处理时,才由自己来处理。当父类加载器为 null 时,会使用启动类加载器 `BootstrapClassLoader` 作为父类加载器。
+
+
+
+每个类加载都有一个父类加载器,我们通过下面的程序来验证。
+
+```java
+public class ClassLoaderDemo {
+ public static void main(String[] args) {
+ System.out.println("ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader());
+ System.out.println("The Parent of ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader().getParent());
+ System.out.println("The GrandParent of ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader().getParent().getParent());
+ }
+}
+```
+
+Output
+
+```
+ClassLodarDemo's ClassLoader is sun.misc.Launcher$AppClassLoader@18b4aac2
+The Parent of ClassLodarDemo's ClassLoader is sun.misc.Launcher$ExtClassLoader@1b6d3586
+The GrandParent of ClassLodarDemo's ClassLoader is null
+```
+
+`AppClassLoader`的父类加载器为`ExtClassLoader`,
+`ExtClassLoader`的父类加载器为 null,**null 并不代表`ExtClassLoader`没有父类加载器,而是 `BootstrapClassLoader`** 。
+
+其实这个双亲翻译的容易让别人误解,我们一般理解的双亲都是父母,这里的双亲更多地表达的是“父母这一辈”的人而已,并不是说真的有一个 Mother ClassLoader 和一个 Father ClassLoader 。另外,类加载器之间的“父子”关系也不是通过继承来体现的,是由“优先级”来决定。官方 API 文档对这部分的描述如下:
+
+> The Java platform uses a delegation model for loading classes. **The basic idea is that every class loader has a "parent" class loader.** When loading a class, a class loader first "delegates" the search for the class to its parent class loader before attempting to find the class itself.
+
+### 双亲委派模型实现源码分析
+
+双亲委派模型的实现代码非常简单,逻辑非常清晰,都集中在 `java.lang.ClassLoader` 的 `loadClass()` 中,相关代码如下所示。
+
+```java
+private final ClassLoader parent;
+protected Class<?> loadClass(String name, boolean resolve)
+ throws ClassNotFoundException
+ {
+ synchronized (getClassLoadingLock(name)) {
+ // 首先,检查请求的类是否已经被加载过
+ Class<?> c = findLoadedClass(name);
+ if (c == null) {
+ long t0 = System.nanoTime();
+ try {
+ if (parent != null) {//父加载器不为空,调用父加载器loadClass()方法处理
+ c = parent.loadClass(name, false);
+ } else {//父加载器为空,使用启动类加载器 BootstrapClassLoader 加载
+ c = findBootstrapClassOrNull(name);
+ }
+ } catch (ClassNotFoundException e) {
+ //抛出异常说明父类加载器无法完成加载请求
+ }
+
+ if (c == null) {
+ long t1 = System.nanoTime();
+ //自己尝试加载
+ c = findClass(name);
+
+ // this is the defining class loader; record the stats
+ sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
+ sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
+ sun.misc.PerfCounter.getFindClasses().increment();
+ }
+ }
+ if (resolve) {
+ resolveClass(c);
+ }
+ return c;
+ }
+ }
+```
+
+### 双亲委派模型的好处
+
+双亲委派模型保证了 Java 程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 `java.lang.Object` 类的话,那么程序运行的时候,系统就会出现多个不同的 `Object` 类。
+
+### 如果我们不想用双亲委派模型怎么办?
+
+~~为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重写 `loadClass()` 即可。~~
+
+**🐛 修正(参见:[issue871](https://github.com/Snailclimb/JavaGuide/issues/871) )** :自定义加载器的话,需要继承 `ClassLoader` 。如果我们不想打破双亲委派模型,就重写 `ClassLoader` 类中的 `findClass()` 方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。但是,如果想打破双亲委派模型则需要重写 `loadClass()` 方法
+
+## 自定义类加载器
+
+除了 `BootstrapClassLoader` 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`。如果我们要自定义自己的类加载器,很明显需要继承 `ClassLoader`。
+
+## 推荐阅读
+
+- <https://blog.csdn.net/xyang81/article/details/7292380>
+- <https://juejin.im/post/5c04892351882516e70dcc9b>
+- <http://gityuan.com/2016/01/24/java-classloader/>
diff --git a/docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md b/docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md
new file mode 100644
index 00000000000..37e2c0d320e
--- /dev/null
+++ b/docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md
@@ -0,0 +1,311 @@
+---
+category: Java
+tag:
+ - JVM
+---
+
+# JDK 监控和故障处理工具总结
+
+## JDK 命令行工具
+
+这些命令在 JDK 安装目录下的 bin 目录下:
+
+- **`jps`** (JVM Process Status): 类似 UNIX 的 `ps` 命令。用于查看所有 Java 进程的启动类、传入参数和 Java 虚拟机参数等信息;
+- **`jstat`**(JVM Statistics Monitoring Tool): 用于收集 HotSpot 虚拟机各方面的运行数据;
+- **`jinfo`** (Configuration Info for Java) : Configuration Info for Java,显示虚拟机配置信息;
+- **`jmap`** (Memory Map for Java) : 生成堆转储快照;
+- **`jhat`** (JVM Heap Dump Browser) : 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果;
+- **`jstack`** (Stack Trace for Java) : 生成虚拟机当前时刻的线程快照,线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。
+
+### `jps`:查看所有 Java 进程
+
+`jps`(JVM Process Status) 命令类似 UNIX 的 `ps` 命令。
+
+`jps`:显示虚拟机执行主类名称以及这些进程的本地虚拟机唯一 ID(Local Virtual Machine Identifier,LVMID)。`jps -q` :只输出进程的本地虚拟机唯一 ID。
+
+```powershell
+C:\Users\SnailClimb>jps
+7360 NettyClient2
+17396
+7972 Launcher
+16504 Jps
+17340 NettyServer
+```
+
+`jps -l`:输出主类的全名,如果进程执行的是 Jar 包,输出 Jar 路径。
+
+```powershell
+C:\Users\SnailClimb>jps -l
+7360 firstNettyDemo.NettyClient2
+17396
+7972 org.jetbrains.jps.cmdline.Launcher
+16492 sun.tools.jps.Jps
+17340 firstNettyDemo.NettyServer
+```
+
+`jps -v`:输出虚拟机进程启动时 JVM 参数。
+
+`jps -m`:输出传递给 Java 进程 main() 函数的参数。
+
+### `jstat`: 监视虚拟机各种运行状态信息
+
+jstat(JVM Statistics Monitoring Tool) 使用于监视虚拟机各种运行状态信息的命令行工具。 它可以显示本地或者远程(需要远程主机提供 RMI 支持)虚拟机进程中的类信息、内存、垃圾收集、JIT 编译等运行数据,在没有 GUI,只提供了纯文本控制台环境的服务器上,它将是运行期间定位虚拟机性能问题的首选工具。
+
+**`jstat` 命令使用格式:**
+
+```powershell
+jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]
+```
+
+比如 `jstat -gc -h3 31736 1000 10`表示分析进程 id 为 31736 的 gc 情况,每隔 1000ms 打印一次记录,打印 10 次停止,每 3 行后打印指标头部。
+
+**常见的 option 如下:**
+
+- `jstat -class vmid` :显示 ClassLoader 的相关信息;
+- `jstat -compiler vmid` :显示 JIT 编译的相关信息;
+- `jstat -gc vmid` :显示与 GC 相关的堆信息;
+- `jstat -gccapacity vmid` :显示各个代的容量及使用情况;
+- `jstat -gcnew vmid` :显示新生代信息;
+- `jstat -gcnewcapcacity vmid` :显示新生代大小与使用情况;
+- `jstat -gcold vmid` :显示老年代和永久代的行为统计,从jdk1.8开始,该选项仅表示老年代,因为永久代被移除了;
+- `jstat -gcoldcapacity vmid` :显示老年代的大小;
+- `jstat -gcpermcapacity vmid` :显示永久代大小,从jdk1.8开始,该选项不存在了,因为永久代被移除了;
+- `jstat -gcutil vmid` :显示垃圾收集信息;
+
+另外,加上 `-t`参数可以在输出信息上加一个 Timestamp 列,显示程序的运行时间。
+
+### `jinfo`: 实时地查看和调整虚拟机各项参数
+
+`jinfo vmid` :输出当前 jvm 进程的全部参数和系统属性 (第一部分是系统的属性,第二部分是 JVM 的参数)。
+
+`jinfo -flag name vmid` :输出对应名称的参数的具体值。比如输出 MaxHeapSize、查看当前 jvm 进程是否开启打印 GC 日志 ( `-XX:PrintGCDetails` :详细 GC 日志模式,这两个都是默认关闭的)。
+
+```powershell
+C:\Users\SnailClimb>jinfo -flag MaxHeapSize 17340
+-XX:MaxHeapSize=2124414976
+C:\Users\SnailClimb>jinfo -flag PrintGC 17340
+-XX:-PrintGC
+```
+
+使用 jinfo 可以在不重启虚拟机的情况下,可以动态的修改 jvm 的参数。尤其在线上的环境特别有用,请看下面的例子:
+
+`jinfo -flag [+|-]name vmid` 开启或者关闭对应名称的参数。
+
+```powershell
+C:\Users\SnailClimb>jinfo -flag PrintGC 17340
+-XX:-PrintGC
+
+C:\Users\SnailClimb>jinfo -flag +PrintGC 17340
+
+C:\Users\SnailClimb>jinfo -flag PrintGC 17340
+-XX:+PrintGC
+```
+
+### `jmap`:生成堆转储快照
+
+`jmap`(Memory Map for Java)命令用于生成堆转储快照。 如果不使用 `jmap` 命令,要想获取 Java 堆转储,可以使用 `“-XX:+HeapDumpOnOutOfMemoryError”` 参数,可以让虚拟机在 OOM 异常出现之后自动生成 dump 文件,Linux 命令下可以通过 `kill -3` 发送进程退出信号也能拿到 dump 文件。
+
+`jmap` 的作用并不仅仅是为了获取 dump 文件,它还可以查询 finalizer 执行队列、Java 堆和永久代的详细信息,如空间使用率、当前使用的是哪种收集器等。和`jinfo`一样,`jmap`有不少功能在 Windows 平台下也是受限制的。
+
+示例:将指定应用程序的堆快照输出到桌面。后面,可以通过 jhat、Visual VM 等工具分析该堆文件。
+
+```powershell
+C:\Users\SnailClimb>jmap -dump:format=b,file=C:\Users\SnailClimb\Desktop\heap.hprof 17340
+Dumping heap to C:\Users\SnailClimb\Desktop\heap.hprof ...
+Heap dump file created
+```
+
+### **`jhat`**: 分析 heapdump 文件
+
+ **`jhat`** 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果。
+
+```powershell
+C:\Users\SnailClimb>jhat C:\Users\SnailClimb\Desktop\heap.hprof
+Reading from C:\Users\SnailClimb\Desktop\heap.hprof...
+Dump file created Sat May 04 12:30:31 CST 2019
+Snapshot read, resolving...
+Resolving 131419 objects...
+Chasing references, expect 26 dots..........................
+Eliminating duplicate references..........................
+Snapshot resolved.
+Started HTTP server on port 7000
+Server is ready.
+```
+
+访问 <http://localhost:7000/>
+
+### **`jstack`** :生成虚拟机当前时刻的线程快照
+
+`jstack`(Stack Trace for Java)命令用于生成虚拟机当前时刻的线程快照。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合.
+
+生成线程快照的目的主要是定位线程长时间出现停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等都是导致线程长时间停顿的原因。线程出现停顿的时候通过`jstack`来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做些什么事情,或者在等待些什么资源。
+
+**下面是一个线程死锁的代码。我们下面会通过 `jstack` 命令进行死锁检查,输出死锁信息,找到发生死锁的线程。**
+
+```java
+public class DeadLockDemo {
+ private static Object resource1 = new Object();//资源 1
+ private static Object resource2 = new Object();//资源 2
+
+ public static void main(String[] args) {
+ new Thread(() -> {
+ synchronized (resource1) {
+ System.out.println(Thread.currentThread() + "get resource1");
+ try {
+ Thread.sleep(1000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println(Thread.currentThread() + "waiting get resource2");
+ synchronized (resource2) {
+ System.out.println(Thread.currentThread() + "get resource2");
+ }
+ }
+ }, "线程 1").start();
+
+ new Thread(() -> {
+ synchronized (resource2) {
+ System.out.println(Thread.currentThread() + "get resource2");
+ try {
+ Thread.sleep(1000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println(Thread.currentThread() + "waiting get resource1");
+ synchronized (resource1) {
+ System.out.println(Thread.currentThread() + "get resource1");
+ }
+ }
+ }, "线程 2").start();
+ }
+}
+```
+
+Output
+
+```
+Thread[线程 1,5,main]get resource1
+Thread[线程 2,5,main]get resource2
+Thread[线程 1,5,main]waiting get resource2
+Thread[线程 2,5,main]waiting get resource1
+```
+
+线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过` Thread.sleep(1000);`让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
+
+**通过 `jstack` 命令分析:**
+
+```powershell
+C:\Users\SnailClimb>jps
+13792 KotlinCompileDaemon
+7360 NettyClient2
+17396
+7972 Launcher
+8932 Launcher
+9256 DeadLockDemo
+10764 Jps
+17340 NettyServer
+
+C:\Users\SnailClimb>jstack 9256
+```
+
+输出的部分内容如下:
+
+```powershell
+Found one Java-level deadlock:
+=============================
+"线程 2":
+ waiting to lock monitor 0x000000000333e668 (object 0x00000000d5efe1c0, a java.lang.Object),
+ which is held by "线程 1"
+"线程 1":
+ waiting to lock monitor 0x000000000333be88 (object 0x00000000d5efe1d0, a java.lang.Object),
+ which is held by "线程 2"
+
+Java stack information for the threads listed above:
+===================================================
+"线程 2":
+ at DeadLockDemo.lambda$main$1(DeadLockDemo.java:31)
+ - waiting to lock <0x00000000d5efe1c0> (a java.lang.Object)
+ - locked <0x00000000d5efe1d0> (a java.lang.Object)
+ at DeadLockDemo$$Lambda$2/1078694789.run(Unknown Source)
+ at java.lang.Thread.run(Thread.java:748)
+"线程 1":
+ at DeadLockDemo.lambda$main$0(DeadLockDemo.java:16)
+ - waiting to lock <0x00000000d5efe1d0> (a java.lang.Object)
+ - locked <0x00000000d5efe1c0> (a java.lang.Object)
+ at DeadLockDemo$$Lambda$1/1324119927.run(Unknown Source)
+ at java.lang.Thread.run(Thread.java:748)
+
+Found 1 deadlock.
+```
+
+可以看到 `jstack` 命令已经帮我们找到发生死锁的线程的具体信息。
+
+## JDK 可视化分析工具
+
+### JConsole:Java 监视与管理控制台
+
+JConsole 是基于 JMX 的可视化监视、管理工具。可以很方便的监视本地及远程服务器的 java 进程的内存使用情况。你可以在控制台输出`console`命令启动或者在 JDK 目录下的 bin 目录找到`jconsole.exe`然后双击启动。
+
+#### 连接 Jconsole
+
+
+
+如果需要使用 JConsole 连接远程进程,可以在远程 Java 程序启动时加上下面这些参数:
+
+```properties
+-Djava.rmi.server.hostname=外网访问 ip 地址
+-Dcom.sun.management.jmxremote.port=60001 //监控的端口号
+-Dcom.sun.management.jmxremote.authenticate=false //关闭认证
+-Dcom.sun.management.jmxremote.ssl=false
+```
+
+在使用 JConsole 连接时,远程进程地址如下:
+
+```
+外网访问 ip 地址:60001
+```
+
+#### 查看 Java 程序概况
+
+
+
+#### 内存监控
+
+JConsole 可以显示当前内存的详细信息。不仅包括堆内存/非堆内存的整体信息,还可以细化到 eden 区、survivor 区等的使用情况,如下图所示。
+
+点击右边的“执行 GC(G)”按钮可以强制应用程序执行一个 Full GC。
+
+> - **新生代 GC(Minor GC)**:指发生新生代的的垃圾收集动作,Minor GC 非常频繁,回收速度一般也比较快。
+> - **老年代 GC(Major GC/Full GC)**:指发生在老年代的 GC,出现了 Major GC 经常会伴随至少一次的 Minor GC(并非绝对),Major GC 的速度一般会比 Minor GC 的慢 10 倍以上。
+
+
+
+#### 线程监控
+
+类似我们前面讲的 `jstack` 命令,不过这个是可视化的。
+
+最下面有一个"检测死锁 (D)"按钮,点击这个按钮可以自动为你找到发生死锁的线程以及它们的详细信息 。
+
+
+
+### Visual VM:多合一故障处理工具
+
+VisualVM 提供在 Java 虚拟机 (Java Virutal Machine, JVM) 上运行的 Java 应用程序的详细信息。在 VisualVM 的图形用户界面中,您可以方便、快捷地查看多个 Java 应用程序的相关信息。Visual VM 官网:<https://visualvm.github.io/> 。Visual VM 中文文档:<https://visualvm.github.io/documentation.html>。
+
+下面这段话摘自《深入理解 Java 虚拟机》。
+
+> VisualVM(All-in-One Java Troubleshooting Tool)是到目前为止随 JDK 发布的功能最强大的运行监视和故障处理程序,官方在 VisualVM 的软件说明中写上了“All-in-One”的描述字样,预示着他除了运行监视、故障处理外,还提供了很多其他方面的功能,如性能分析(Profiling)。VisualVM 的性能分析功能甚至比起 JProfiler、YourKit 等专业且收费的 Profiling 工具都不会逊色多少,而且 VisualVM 还有一个很大的优点:不需要被监视的程序基于特殊 Agent 运行,因此他对应用程序的实际性能的影响很小,使得他可以直接应用在生产环境中。这个优点是 JProfiler、YourKit 等工具无法与之媲美的。
+
+ VisualVM 基于 NetBeans 平台开发,因此他一开始就具备了插件扩展功能的特性,通过插件扩展支持,VisualVM 可以做到:
+
+- **显示虚拟机进程以及进程的配置、环境信息(jps、jinfo)。**
+- **监视应用程序的 CPU、GC、堆、方法区以及线程的信息(jstat、jstack)。**
+- **dump 以及分析堆转储快照(jmap、jhat)。**
+- **方法级的程序运行性能分析,找到被调用最多、运行时间最长的方法。**
+- **离线程序快照:收集程序的运行时配置、线程 dump、内存 dump 等信息建立一个快照,可以将快照发送开发者处进行 Bug 反馈。**
+- **其他 plugins 的无限的可能性......**
+
+这里就不具体介绍 VisualVM 的使用,如果想了解的话可以看:
+
+- <https://visualvm.github.io/documentation.html>
+- <https://www.ibm.com/developerworks/cn/java/j-lo-visualvm/index.html>
diff --git a/docs/java/jvm/jvm-garbage-collection.md b/docs/java/jvm/jvm-garbage-collection.md
new file mode 100644
index 00000000000..058b2794f2c
--- /dev/null
+++ b/docs/java/jvm/jvm-garbage-collection.md
@@ -0,0 +1,565 @@
+---
+category: Java
+tag:
+ - JVM
+---
+
+# JVM 垃圾回收详解
+
+## 写在前面
+
+### 本节常见面试题
+
+问题答案在文中都有提到
+
+- 如何判断对象是否死亡(两种方法)。
+- 简单的介绍一下强引用、软引用、弱引用、虚引用(虚引用与软引用和弱引用的区别、使用软引用能带来的好处)。
+- 如何判断一个常量是废弃常量
+- 如何判断一个类是无用的类
+- 垃圾收集有哪些算法,各自的特点?
+- HotSpot 为什么要分为新生代和老年代?
+- 常见的垃圾回收器有哪些?
+- 介绍一下 CMS,G1 收集器。
+- Minor Gc 和 Full GC 有什么不同呢?
+
+### 本文导火索
+
+
+
+当需要排查各种内存溢出问题、当垃圾收集成为系统达到更高并发的瓶颈时,我们就需要对这些“自动化”的技术实施必要的监控和调节。
+
+## 1 揭开 JVM 内存分配与回收的神秘面纱
+
+Java 的自动内存管理主要是针对对象内存的回收和对象内存的分配。同时,Java 自动内存管理最核心的功能是 **堆** 内存中对象的分配与回收。
+
+Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(Garbage Collected Heap)**.从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代:再细致一点有:Eden 空间、From Survivor、To Survivor 空间等。**进一步划分的目的是更好地回收内存,或者更快地分配内存。**
+
+**堆空间的基本结构:**
+
+
+
+上图所示的 Eden 区、From Survivor0("From") 区、To Survivor1("To") 区都属于新生代,Old Memory 区属于老年代。
+
+大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为大于 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置默认值,这个值会在虚拟机运行过程中进行调整,可以通过`-XX:+PrintTenuringDistribution`来打印出当次GC后的Threshold。
+
+> **🐛 修正(参见:[issue552](https://github.com/Snailclimb/JavaGuide/issues/552))**:“Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了 survivor 区的一半时,取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值”。
+>
+> **动态年龄计算的代码如下**
+>
+> ```c++
+> uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
+> //survivor_capacity是survivor空间的大小
+> size_t desired_survivor_size = (size_t)((((double)survivor_capacity)*TargetSurvivorRatio)/100);
+> size_t total = 0;
+> uint age = 1;
+> while (age < table_size) {
+> //sizes数组是每个年龄段对象大小
+> total += sizes[age];
+> if (total > desired_survivor_size) {
+> break;
+> }
+> age++;
+> }
+> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
+> ...
+> }
+>
+> ```
+
+经过这次 GC 后,Eden 区和"From"区已经被清空。这个时候,"From"和"To"会交换他们的角色,也就是新的"To"就是上次 GC 前的“From”,新的"From"就是上次 GC 前的"To"。不管怎样,都会保证名为 To 的 Survivor 区域是空的。Minor GC 会一直重复这样的过程,在这个过程中,有可能当次Minor GC后,Survivor 的"From"区域空间不够用,有一些还达不到进入老年代条件的实例放不下,则放不下的部分会提前进入老年代。
+
+接下来我们提供一个调试脚本来测试这个过程。
+
+**调试代码参数如下**
+```
+-verbose:gc
+-Xmx200M
+-Xms200M
+-Xmn50M
+-XX:+PrintGCDetails
+-XX:TargetSurvivorRatio=60
+-XX:+PrintTenuringDistribution
+-XX:+PrintGCDetails
+-XX:+PrintGCDateStamps
+-XX:MaxTenuringThreshold=3
+-XX:+UseConcMarkSweepGC
+-XX:+UseParNewGC
+```
+**示例代码如下:**
+```java
+/*
+* 本实例用于java GC以后,新生代survivor区域的变化,以及晋升到老年代的时间和方式的测试代码。需要自行分步注释不需要的代码进行反复测试对比
+*
+* 由于java的main函数以及其他基础服务也会占用一些eden空间,所以要提前空跑一次main函数,来看看这部分占用。
+*
+* 自定义的代码中,我们使用堆内分配数组和栈内分配数组的方式来分别模拟不可被GC的和可被GC的资源。
+*
+*
+* */
+
+public class JavaGcTest {
+
+ public static void main(String[] args) throws InterruptedException {
+ //空跑一次main函数来查看java服务本身占用的空间大小,我这里是占用了3M。所以40-3=37,下面分配三个1M的数组和一个34M的垃圾数组。
+
+
+ // 为了达到TargetSurvivorRatio(期望占用的Survivor区域的大小)这个比例指定的值, 即5M*60%=3M(Desired survivor size),
+ // 这里用1M的数组的分配来达到Desired survivor size
+ //说明: 5M为S区的From或To的大小,60%为TargetSurvivorRatio参数指定,可以更改参数获取不同的效果。
+ byte[] byte1m_1 = new byte[1 * 1024 * 1024];
+ byte[] byte1m_2 = new byte[1 * 1024 * 1024];
+ byte[] byte1m_3 = new byte[1 * 1024 * 1024];
+
+ //使用函数方式来申请空间,函数运行完毕以后,就会变成垃圾等待回收。此时应保证eden的区域占用达到100%。可以通过调整传入值来达到效果。
+ makeGarbage(34);
+
+ //再次申请一个数组,因为eden已经满了,所以这里会触发Minor GC
+ byte[] byteArr = new byte[10*1024*1024];
+ // 这次Minor Gc时, 三个1M的数组因为尚有引用,所以进入From区域(因为是第一次GC)age为1
+ // 且由于From区已经占用达到了60%(-XX:TargetSurvivorRatio=60), 所以会重新计算对象晋升的age。
+ // 计算方法见上文,计算出age:min(age, MaxTenuringThreshold) = 1,输出中会有Desired survivor size 3145728 bytes, new threshold 1 (max 3)字样
+ //新的数组byteArr进入eden区域。
+
+
+ //再次触发垃圾回收,证明三个1M的数组会因为其第二次回收后age为2,大于上一次计算出的new threshold 1,所以进入老年代。
+ //而byteArr因为超过survivor的单个区域,直接进入了老年代。
+ makeGarbage(34);
+ }
+ private static void makeGarbage(int size){
+ byte[] byteArrTemp = new byte[size * 1024 * 1024];
+ }
+}
+
+```
+
+注意:如下输出结果中老年代的信息为 `concurrent mark-sweep generation` 和以前版本略有不同。另外,还列出了某次GC后是否重新生成了threshold,以及各个年龄占用空间的大小。
+```bash
+2021-07-01T10:41:32.257+0800: [GC (Allocation Failure) 2021-07-01T10:41:32.257+0800: [ParNew
+Desired survivor size 3145728 bytes, new threshold 1 (max 3)
+- age 1: 3739264 bytes, 3739264 total
+: 40345K->3674K(46080K), 0.0014584 secs] 40345K->3674K(199680K), 0.0015063 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
+2021-07-01T10:41:32.259+0800: [GC (Allocation Failure) 2021-07-01T10:41:32.259+0800: [ParNew
+Desired survivor size 3145728 bytes, new threshold 3 (max 3)
+: 13914K->0K(46080K), 0.0046596 secs] 13914K->13895K(199680K), 0.0046873 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
+Heap
+ par new generation total 46080K, used 35225K [0x05000000, 0x08200000, 0x08200000)
+ eden space 40960K, 86% used [0x05000000, 0x072667f0, 0x07800000)
+ from space 5120K, 0% used [0x07800000, 0x07800000, 0x07d00000)
+ to space 5120K, 0% used [0x07d00000, 0x07d00000, 0x08200000)
+ concurrent mark-sweep generation total 153600K, used 13895K [0x08200000, 0x11800000, 0x11800000)
+ Metaspace used 153K, capacity 2280K, committed 2368K, reserved 4480K
+
+```
+
+
+### 1.1 对象优先在 eden 区分配
+
+目前主流的垃圾收集器都会采用分代回收算法,因此需要将堆内存分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
+
+大多数情况下,对象在新生代中 eden 区分配。当 eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC.下面我们来进行实际测试以下。
+
+**测试:**
+
+```java
+public class GCTest {
+
+ public static void main(String[] args) {
+ byte[] allocation1, allocation2;
+ allocation1 = new byte[30900*1024];
+ //allocation2 = new byte[900*1024];
+ }
+}
+```
+
+通过以下方式运行:
+
+
+添加的参数:`-XX:+PrintGCDetails`
+
+
+运行结果 (红色字体描述有误,应该是对应于 JDK1.7 的永久代):
+
+
+
+从上图我们可以看出 eden 区内存几乎已经被分配完全(即使程序什么也不做,新生代也会使用 2000 多 k 内存)。假如我们再为 allocation2 分配内存会出现什么情况呢?
+
+```java
+allocation2 = new byte[900*1024];
+```
+
+
+
+**简单解释一下为什么会出现这种情况:** 因为给 allocation2 分配内存的时候 eden 区内存几乎已经被分配完了,我们刚刚讲了当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC.GC 期间虚拟机又发现 allocation1 无法存入 Survivor 空间,所以只好通过 **分配担保机制** 把新生代的对象提前转移到老年代中去,老年代上的空间足够存放 allocation1,所以不会出现 Full GC。执行 Minor GC 后,后面分配的对象如果能够存在 eden 区的话,还是会在 eden 区分配内存。可以执行如下代码验证:
+
+```java
+public class GCTest {
+
+ public static void main(String[] args) {
+ byte[] allocation1, allocation2,allocation3,allocation4,allocation5;
+ allocation1 = new byte[32000*1024];
+ allocation2 = new byte[1000*1024];
+ allocation3 = new byte[1000*1024];
+ allocation4 = new byte[1000*1024];
+ allocation5 = new byte[1000*1024];
+ }
+}
+
+```
+
+### 1.2 大对象直接进入老年代
+
+大对象就是需要大量连续内存空间的对象(比如:字符串、数组)。
+
+**为什么要这样呢?**
+
+为了避免为大对象分配内存时由于分配担保机制带来的复制而降低效率。
+
+### 1.3 长期存活的对象将进入老年代
+
+既然虚拟机采用了分代收集的思想来管理内存,那么内存回收时就必须能识别哪些对象应放在新生代,哪些对象应放在老年代中。为了做到这一点,虚拟机给每个对象一个对象年龄(Age)计数器。
+
+如果对象在 Eden 出生并经过第一次 Minor GC 后仍然能够存活,并且能被 Survivor 容纳的话,将被移动到 Survivor 空间中,并将对象年龄设为 1.对象在 Survivor 中每熬过一次 MinorGC,年龄就增加 1 岁,当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
+
+### 1.4 动态对象年龄判定
+
+大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
+
+> 修正([issue552](https://github.com/Snailclimb/JavaGuide/issues/552)):“Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了 survivor 区的 50% 时(默认值是 50%,可以通过 `-XX:TargetSurvivorRatio=percent` 来设置,参见 [issue1199](https://github.com/Snailclimb/JavaGuide/issues/1199) ),取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值”。
+>
+> jdk8官方文档引用 :https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html 。
+>
+> 
+>
+> **动态年龄计算的代码如下:**
+>
+> ```c++
+> uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
+> //survivor_capacity是survivor空间的大小
+> size_t desired_survivor_size = (size_t)((((double)survivor_capacity)*TargetSurvivorRatio)/100);
+> size_t total = 0;
+> uint age = 1;
+> while (age < table_size) {
+> //sizes数组是每个年龄段对象大小
+> total += sizes[age];
+> if (total > desired_survivor_size) {
+> break;
+> }
+> age++;
+> }
+> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
+> ...
+> }
+>
+> ```
+>
+> 额外补充说明([issue672](https://github.com/Snailclimb/JavaGuide/issues/672)):**关于默认的晋升年龄是 15,这个说法的来源大部分都是《深入理解 Java 虚拟机》这本书。**
+> 如果你去 Oracle 的官网阅读[相关的虚拟机参数](https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html),你会发现`-XX:MaxTenuringThreshold=threshold`这里有个说明
+>
+> **Sets the maximum tenuring threshold for use in adaptive GC sizing. The largest value is 15. The default value is 15 for the parallel (throughput) collector, and 6 for the CMS collector.默认晋升年龄并不都是 15,这个是要区分垃圾收集器的,CMS 就是 6.**
+
+### 1.5 主要进行 gc 的区域
+
+周志明先生在《深入理解 Java 虚拟机》第二版中 P92 如是写道:
+
+> ~~_“老年代 GC(Major GC/Full GC),指发生在老年代的 GC……”_~~
+
+上面的说法已经在《深入理解 Java 虚拟机》第三版中被改正过来了。感谢 R 大的回答:
+
+
+
+**总结:**
+
+针对 HotSpot VM 的实现,它里面的 GC 其实准确分类只有两大种:
+
+部分收集 (Partial GC):
+
+- 新生代收集(Minor GC / Young GC):只对新生代进行垃圾收集;
+- 老年代收集(Major GC / Old GC):只对老年代进行垃圾收集。需要注意的是 Major GC 在有的语境中也用于指代整堆收集;
+- 混合收集(Mixed GC):对整个新生代和部分老年代进行垃圾收集。
+
+整堆收集 (Full GC):收集整个 Java 堆和方法区。
+
+### 1.6 空间分配担保
+
+空间分配担保是为了确保在 Minor GC 之前老年代本身还有容纳新生代所有对象的剩余空间。
+
+《深入理解Java虚拟机》第三章对于空间分配担保的描述如下:
+
+> JDK 6 Update 24 之前,在发生 Minor GC 之前,虚拟机必须先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果这个条件成立,那这一次 Minor GC 可以确保是安全的。如果不成立,则虚拟机会先查看 `-XX:HandlePromotionFailure` 参数的设置值是否允许担保失败(Handle Promotion Failure);如果允许,那会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试进行一次 Minor GC,尽管这次 Minor GC 是有风险的;如果小于,或者 `-XX: HandlePromotionFailure` 设置不允许冒险,那这时就要改为进行一次 Full GC。
+>
+> JDK 6 Update 24之后的规则变为只要老年代的连续空间大于新生代对象总大小或者历次晋升的平均大小,就会进行 Minor GC,否则将进行 Full GC。
+
+## 2 对象已经死亡?
+
+堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断哪些对象已经死亡(即不能再被任何途径使用的对象)。
+
+
+
+### 2.1 引用计数法
+
+给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加 1;当引用失效,计数器就减 1;任何时候计数器为 0 的对象就是不可能再被使用的。
+
+**这个方法实现简单,效率高,但是目前主流的虚拟机中并没有选择这个算法来管理内存,其最主要的原因是它很难解决对象之间相互循环引用的问题。** 所谓对象之间的相互引用问题,如下面代码所示:除了对象 objA 和 objB 相互引用着对方之外,这两个对象之间再无任何引用。但是他们因为互相引用对方,导致它们的引用计数器都不为 0,于是引用计数算法无法通知 GC 回收器回收他们。
+
+```java
+public class ReferenceCountingGc {
+ Object instance = null;
+ public static void main(String[] args) {
+ ReferenceCountingGc objA = new ReferenceCountingGc();
+ ReferenceCountingGc objB = new ReferenceCountingGc();
+ objA.instance = objB;
+ objB.instance = objA;
+ objA = null;
+ objB = null;
+
+ }
+}
+```
+
+### 2.2 可达性分析算法
+
+这个算法的基本思想就是通过一系列的称为 **“GC Roots”** 的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的。
+
+
+
+可作为 GC Roots 的对象包括下面几种:
+
+- 虚拟机栈(栈帧中的本地变量表)中引用的对象
+- 本地方法栈(Native 方法)中引用的对象
+- 方法区中类静态属性引用的对象
+- 方法区中常量引用的对象
+- 所有被同步锁持有的对象
+
+### 2.3 再谈引用
+
+无论是通过引用计数法判断对象引用数量,还是通过可达性分析法判断对象的引用链是否可达,判定对象的存活都与“引用”有关。
+
+JDK1.2 之前,Java 中引用的定义很传统:如果 reference 类型的数据存储的数值代表的是另一块内存的起始地址,就称这块内存代表一个引用。
+
+JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱)
+
+**1.强引用(StrongReference)**
+
+以前我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于**必不可少的生活用品**,垃圾回收器绝不会回收它。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
+
+**2.软引用(SoftReference)**
+
+如果一个对象只具有软引用,那就类似于**可有可无的生活用品**。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
+
+软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,JAVA 虚拟机就会把这个软引用加入到与之关联的引用队列中。
+
+**3.弱引用(WeakReference)**
+
+如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
+
+弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
+
+**4.虚引用(PhantomReference)**
+
+"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
+
+**虚引用主要用来跟踪对象被垃圾回收的活动**。
+
+**虚引用与软引用和弱引用的一个区别在于:** 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
+
+特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为**软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生**。
+
+### 2.4 不可达的对象并非“非死不可”
+
+即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或 finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。
+
+被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。
+
+### 2.5 如何判断一个常量是废弃常量?
+
+运行时常量池主要回收的是废弃的常量。那么,我们如何判断一个常量是废弃常量呢?
+
+~~**JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。**~~
+
+> **🐛 修正(参见:[issue747](https://github.com/Snailclimb/JavaGuide/issues/747),[reference](https://blog.csdn.net/q5706503/article/details/84640762))** :
+>
+> 1. **JDK1.7 之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时 hotspot 虚拟机对方法区的实现为永久代**
+> 2. **JDK1.7 字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是 hotspot 中的永久代** 。
+> 3. **JDK1.8 hotspot 移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)**
+
+假如在字符串常量池中存在字符串 "abc",如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 "abc" 就是废弃常量,如果这时发生内存回收的话而且有必要的话,"abc" 就会被系统清理出常量池了。
+
+### 2.6 如何判断一个类是无用的类
+
+方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
+
+判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 **“无用的类”** :
+
+- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
+- 加载该类的 `ClassLoader` 已经被回收。
+- 该类对应的 `java.lang.Class` 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
+
+虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
+
+## 3 垃圾收集算法
+
+
+
+### 3.1 标记-清除算法
+
+该算法分为“标记”和“清除”阶段:首先标记出所有不需要回收的对象,在标记完成后统一回收掉所有没有被标记的对象。它是最基础的收集算法,后续的算法都是对其不足进行改进得到。这种垃圾收集算法会带来两个明显的问题:
+
+1. **效率问题**
+2. **空间问题(标记清除后会产生大量不连续的碎片)**
+
+
+
+### 3.2 标记-复制算法
+
+为了解决效率问题,“标记-复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
+
+
+
+### 3.3 标记-整理算法
+
+根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
+
+
+
+### 3.4 分代收集算法
+
+当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
+
+**比如在新生代中,每次收集都会有大量对象死去,所以可以选择”标记-复制“算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。**
+
+**延伸面试问题:** HotSpot 为什么要分为新生代和老年代?
+
+根据上面的对分代收集算法的介绍回答。
+
+## 4 垃圾收集器
+
+
+
+**如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。**
+
+虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为直到现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了。
+
+### 4.1 Serial 收集器
+
+Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
+
+**新生代采用标记-复制算法,老年代采用标记-整理算法。**
+
+
+
+虚拟机的设计者们当然知道 Stop The World 带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
+
+但是 Serial 收集器有没有优于其他垃圾收集器的地方呢?当然有,它**简单而高效(与其他收集器的单线程相比)**。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择。
+
+### 4.2 ParNew 收集器
+
+**ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。**
+
+**新生代采用标记-复制算法,老年代采用标记-整理算法。**
+
+
+
+它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
+
+**并行和并发概念补充:**
+
+- **并行(Parallel)** :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
+
+- **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
+
+### 4.3 Parallel Scavenge 收集器
+
+Parallel Scavenge 收集器也是使用标记-复制算法的多线程收集器,它看上去几乎和 ParNew 都一样。 **那么它有什么特别之处呢?**
+
+```
+-XX:+UseParallelGC
+
+ 使用 Parallel 收集器+ 老年代串行
+
+-XX:+UseParallelOldGC
+
+ 使用 Parallel 收集器+ 老年代并行
+
+```
+
+**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用 Parallel Scavenge 收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
+
+**新生代采用标记-复制算法,老年代采用标记-整理算法。**
+
+
+
+**这是 JDK1.8 默认收集器**
+
+使用 java -XX:+PrintCommandLineFlags -version 命令查看
+
+```
+-XX:InitialHeapSize=262921408 -XX:MaxHeapSize=4206742528 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
+java version "1.8.0_211"
+Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
+Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
+```
+
+JDK1.8 默认使用的是 Parallel Scavenge + Parallel Old,如果指定了-XX:+UseParallelGC 参数,则默认指定了-XX:+UseParallelOldGC,可以使用-XX:-UseParallelOldGC 来禁用该功能
+
+### 4.4.Serial Old 收集器
+
+**Serial 收集器的老年代版本**,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
+
+### 4.5 Parallel Old 收集器
+
+**Parallel Scavenge 收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
+
+### 4.6 CMS 收集器
+
+**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。**
+
+**CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。**
+
+从名字中的**Mark Sweep**这两个词可以看出,CMS 收集器是一种 **“标记-清除”算法**实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
+
+- **初始标记:** 暂停所有的其他线程,并记录下直接与 root 相连的对象,速度很快 ;
+- **并发标记:** 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
+- **重新标记:** 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
+- **并发清除:** 开启用户线程,同时 GC 线程开始对未标记的区域做清扫。
+
+
+
+从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:**并发收集、低停顿**。但是它有下面三个明显的缺点:
+
+- **对 CPU 资源敏感;**
+- **无法处理浮动垃圾;**
+- **它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。**
+
+### 4.7 G1 收集器
+
+**G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.**
+
+被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备一下特点:
+
+- **并行与并发**:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
+- **分代收集**:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
+- **空间整合**:与 CMS 的“标记-清理”算法不同,G1 从整体来看是基于“标记-整理”算法实现的收集器;从局部上来看是基于“标记-复制”算法实现的。
+- **可预测的停顿**:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
+
+G1 收集器的运作大致分为以下几个步骤:
+
+- **初始标记**
+- **并发标记**
+- **最终标记**
+- **筛选回收**
+
+**G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)** 。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 G1 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
+
+### 4.8 ZGC 收集器
+
+与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
+
+在 ZGC 中出现 Stop The World 的情况会更少!
+
+详情可以看 : [《新一代垃圾回收器 ZGC 的探索与实践》](https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html)
+
+## 参考
+
+- 《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第二版》
+- https://my.oschina.net/hosee/blog/644618
+- <https://docs.oracle.com/javase/specs/jvms/se8/html/index.html>
diff --git a/docs/java/jvm/jvm-intro.md b/docs/java/jvm/jvm-intro.md
new file mode 100644
index 00000000000..87cd046a0f8
--- /dev/null
+++ b/docs/java/jvm/jvm-intro.md
@@ -0,0 +1,517 @@
+---
+category: Java
+tag:
+ - JVM
+---
+
+# 大白话带你认识JVM
+
+> 来自掘金用户:[说出你的愿望吧丷](https://juejin.im/user/5c2400afe51d45451758aa96)投稿,原文地址:https://juejin.im/post/5e1505d0f265da5d5d744050#heading-28
+
+## 前言
+
+如果在文中用词或者理解方面出现问题,欢迎指出。此文旨在提及而不深究,但会尽量效率地把知识点都抛出来
+
+## 一、JVM的基本介绍
+
+JVM 是 Java Virtual Machine 的缩写,它是一个虚构出来的计算机,一种规范。通过在实际的计算机上仿真模拟各类计算机功能实现···
+
+好,其实抛开这么专业的句子不说,就知道JVM其实就类似于一台小电脑运行在windows或者linux这些操作系统环境下即可。它直接和操作系统进行交互,与硬件不直接交互,而操作系统可以帮我们完成和硬件进行交互的工作。
+
+
+
+### 1.1 Java文件是如何被运行的
+
+比如我们现在写了一个 HelloWorld.java 好了,那这个 HelloWorld.java 抛开所有东西不谈,那是不是就类似于一个文本文件,只是这个文本文件它写的都是英文,而且有一定的缩进而已。
+
+那我们的 **JVM** 是不认识文本文件的,所以它需要一个 **编译** ,让其成为一个它会读二进制文件的 **HelloWorld.class**
+
+#### ① 类加载器
+
+如果 **JVM** 想要执行这个 **.class** 文件,我们需要将其装进一个 **类加载器** 中,它就像一个搬运工一样,会把所有的 **.class** 文件全部搬进JVM里面来。
+
+
+
+#### ② 方法区
+
+**方法区** 是用于存放类似于元数据信息方面的数据的,比如类信息,常量,静态变量,编译后代码···等
+
+类加载器将 .class 文件搬过来就是先丢到这一块上
+
+#### ③ 堆
+
+**堆** 主要放了一些存储的数据,比如对象实例,数组···等,它和方法区都同属于 **线程共享区域** 。也就是说它们都是 **线程不安全** 的
+
+#### ④ 栈
+
+**栈** 这是我们的代码运行空间。我们编写的每一个方法都会放到 **栈** 里面运行。
+
+我们会听说过 本地方法栈 或者 本地方法接口 这两个名词,不过我们基本不会涉及这两块的内容,它俩底层是使用C来进行工作的,和Java没有太大的关系。
+
+#### ⑤ 程序计数器
+
+主要就是完成一个加载工作,类似于一个指针一样的,指向下一行我们需要执行的代码。和栈一样,都是 **线程独享** 的,就是说每一个线程都会有自己对应的一块区域而不会存在并发和多线程的问题。
+
+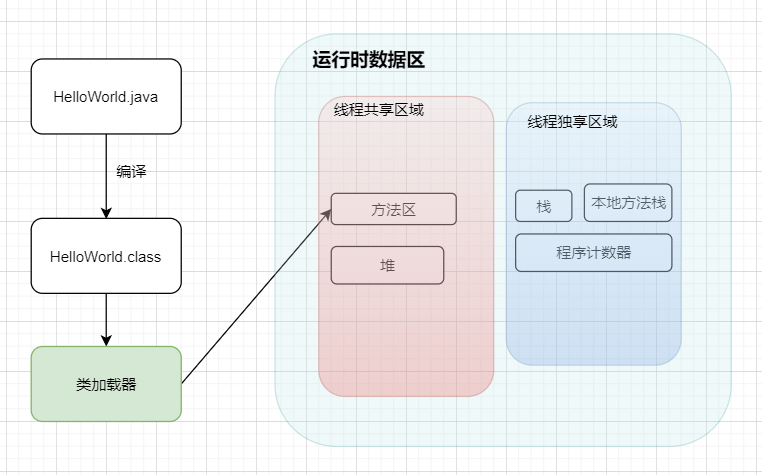
+
+#### 小总结
+
+1. Java文件经过编译后变成 .class 字节码文件
+2. 字节码文件通过类加载器被搬运到 JVM 虚拟机中
+3. 虚拟机主要的5大块:方法区,堆都为线程共享区域,有线程安全问题,栈和本地方法栈和计数器都是独享区域,不存在线程安全问题,而 JVM 的调优主要就是围绕堆,栈两大块进行
+
+### 1.2 简单的代码例子
+
+一个简单的学生类
+
+
+
+一个main方法
+
+
+
+执行main方法的步骤如下:
+
+1. 编译好 App.java 后得到 App.class 后,执行 App.class,系统会启动一个 JVM 进程,从 classpath 路径中找到一个名为 App.class 的二进制文件,将 App 的类信息加载到运行时数据区的方法区内,这个过程叫做 App 类的加载
+2. JVM 找到 App 的主程序入口,执行main方法
+3. 这个main中的第一条语句为 Student student = new Student("tellUrDream") ,就是让 JVM 创建一个Student对象,但是这个时候方法区中是没有 Student 类的信息的,所以 JVM 马上加载 Student 类,把 Student 类的信息放到方法区中
+4. 加载完 Student 类后,JVM 在堆中为一个新的 Student 实例分配内存,然后调用构造函数初始化 Student 实例,这个 Student 实例持有 **指向方法区中的 Student 类的类型信息** 的引用
+5. 执行student.sayName();时,JVM 根据 student 的引用找到 student 对象,然后根据 student 对象持有的引用定位到方法区中 student 类的类型信息的方法表,获得 sayName() 的字节码地址。
+6. 执行sayName()
+
+其实也不用管太多,只需要知道对象实例初始化时会去方法区中找类信息,完成后再到栈那里去运行方法。找方法就在方法表中找。
+
+## 二、类加载器的介绍
+
+之前也提到了它是负责加载.class文件的,它们在文件开头会有特定的文件标示,将class文件字节码内容加载到内存中,并将这些内容转换成方法区中的运行时数据结构,并且ClassLoader只负责class文件的加载,而是否能够运行则由 Execution Engine 来决定
+
+### 2.1 类加载器的流程
+
+从类被加载到虚拟机内存中开始,到释放内存总共有7个步骤:加载,验证,准备,解析,初始化,使用,卸载。其中**验证,准备,解析三个部分统称为连接**
+
+#### 2.1.1 加载
+
+1. 将class文件加载到内存
+2. 将静态数据结构转化成方法区中运行时的数据结构
+3. 在堆中生成一个代表这个类的 java.lang.Class对象作为数据访问的入口
+
+#### 2.1.2 链接
+
+1. 验证:确保加载的类符合 JVM 规范和安全,保证被校验类的方法在运行时不会做出危害虚拟机的事件,其实就是一个安全检查
+2. 准备:为static变量在方法区中分配内存空间,设置变量的初始值,例如 static int a = 3 (注意:准备阶段只设置类中的静态变量(方法区中),不包括实例变量(堆内存中),实例变量是对象初始化时赋值的)
+3. 解析:虚拟机将常量池内的符号引用替换为直接引用的过程(符号引用比如我现在import java.util.ArrayList这就算符号引用,直接引用就是指针或者对象地址,注意引用对象一定是在内存进行)
+
+#### 2.1.3 初始化
+
+初始化其实就是执行类构造器方法的`<clinit>()`的过程,而且要保证执行前父类的`<clinit>()`方法执行完毕。这个方法由编译器收集,顺序执行所有类变量(static修饰的成员变量)显式初始化和静态代码块中语句。此时准备阶段时的那个 `static int a` 由默认初始化的0变成了显式初始化的3。 由于执行顺序缘故,初始化阶段类变量如果在静态代码块中又进行了更改,会覆盖类变量的显式初始化,最终值会为静态代码块中的赋值。
+>注意:字节码文件中初始化方法有两种,非静态资源初始化的`<init>`和静态资源初始化的`<clinit>`,类构造器方法`<clinit>()`不同于类的构造器,这些方法都是字节码文件中只能给JVM识别的特殊方法。
+
+#### 2.1.4 卸载
+
+GC将无用对象从内存中卸载
+
+### 2.2 类加载器的加载顺序
+
+加载一个Class类的顺序也是有优先级的,类加载器从最底层开始往上的顺序是这样的
+
+1. BootStrap ClassLoader:rt.jar
+2. Extension ClassLoader: 加载扩展的jar包
+3. App ClassLoader:指定的classpath下面的jar包
+4. Custom ClassLoader:自定义的类加载器
+
+### 2.3 双亲委派机制
+
+当一个类收到了加载请求时,它是不会先自己去尝试加载的,而是委派给父类去完成,比如我现在要 new 一个 Person,这个 Person 是我们自定义的类,如果我们要加载它,就会先委派 App ClassLoader ,只有当父类加载器都反馈自己无法完成这个请求(也就是父类加载器都没有找到加载所需的 Class)时,子类加载器才会自行尝试加载。
+
+这样做的好处是,加载位于 rt.jar 包中的类时不管是哪个加载器加载,最终都会委托到 BootStrap ClassLoader 进行加载,这样保证了使用不同的类加载器得到的都是同一个结果。
+
+其实这个也是一个隔离的作用,避免了我们的代码影响了 JDK 的代码,比如我现在自己定义一个 `java.lang.String` :
+
+```java
+package java.lang;
+public class String {
+ public static void main(String[] args) {
+ System.out.println();
+ }
+}
+```
+
+尝试运行当前类的 `main` 函数的时候,我们的代码肯定会报错。这是因为在加载的时候其实是找到了 rt.jar 中的`java.lang.String`,然而发现这个里面并没有 `main` 方法。
+
+## 三、运行时数据区
+
+### 3.1 本地方法栈和程序计数器
+
+比如说我们现在点开Thread类的源码,会看到它的start0方法带有一个native关键字修饰,而且不存在方法体,这种用native修饰的方法就是本地方法,这是使用C来实现的,然后一般这些方法都会放到一个叫做本地方法栈的区域。
+
+程序计数器其实就是一个指针,它指向了我们程序中下一句需要执行的指令,它也是内存区域中唯一一个不会出现OutOfMemoryError的区域,而且占用内存空间小到基本可以忽略不计。这个内存仅代表当前线程所执行的字节码的行号指示器,字节码解析器通过改变这个计数器的值选取下一条需要执行的字节码指令。
+
+如果执行的是native方法,那这个指针就不工作了。
+
+### 3.2 方法区
+
+方法区主要的作用是存放类的元数据信息,常量和静态变量···等。当它存储的信息过大时,会在无法满足内存分配时报错。
+
+
+### 3.3 虚拟机栈和虚拟机堆
+
+一句话便是:栈管运行,堆管存储。则虚拟机栈负责运行代码,而虚拟机堆负责存储数据。
+
+#### 3.3.1 虚拟机栈的概念
+
+它是Java方法执行的内存模型。里面会对局部变量,动态链表,方法出口,栈的操作(入栈和出栈)进行存储,且线程独享。同时如果我们听到局部变量表,那也是在说虚拟机栈
+
+```java
+public class Person{
+ int a = 1;
+
+ public void doSomething(){
+ int b = 2;
+ }
+}
+```
+
+
+#### 3.3.2 虚拟机栈存在的异常
+
+如果线程请求的栈的深度大于虚拟机栈的最大深度,就会报 **StackOverflowError** (这种错误经常出现在递归中)。Java虚拟机也可以动态扩展,但随着扩展会不断地申请内存,当无法申请足够内存时就会报错 **OutOfMemoryError**。
+
+#### 3.3.3 虚拟机栈的生命周期
+
+对于栈来说,不存在垃圾回收。只要程序运行结束,栈的空间自然就会释放了。栈的生命周期和所处的线程是一致的。
+
+这里补充一句:8种基本类型的变量+对象的引用变量+实例方法都是在栈里面分配内存。
+
+#### 3.3.4 虚拟机栈的执行
+
+我们经常说的栈帧数据,说白了在JVM中叫栈帧,放到Java中其实就是方法,它也是存放在栈中的。
+
+栈中的数据都是以栈帧的格式存在,它是一个关于方法和运行期数据的数据集。比如我们执行一个方法a,就会对应产生一个栈帧A1,然后A1会被压入栈中。同理方法b会有一个B1,方法c会有一个C1,等到这个线程执行完毕后,栈会先弹出C1,后B1,A1。它是一个先进后出,后进先出原则。
+
+#### 3.3.5 局部变量的复用
+
+局部变量表用于存放方法参数和方法内部所定义的局部变量。它的容量是以Slot为最小单位,一个slot可以存放32位以内的数据类型。
+
+虚拟机通过索引定位的方式使用局部变量表,范围为[0,局部变量表的slot的数量]。方法中的参数就会按一定顺序排列在这个局部变量表中,至于怎么排的我们可以先不关心。而为了节省栈帧空间,这些slot是可以复用的,当方法执行位置超过了某个变量,那么这个变量的slot可以被其它变量复用。当然如果需要复用,那我们的垃圾回收自然就不会去动这些内存。
+
+#### 3.3.6 虚拟机堆的概念
+
+JVM内存会划分为堆内存和非堆内存,堆内存中也会划分为**年轻代**和**老年代**,而非堆内存则为**永久代**。年轻代又会分为**Eden**和**Survivor**区。Survivor也会分为**FromPlace**和**ToPlace**,toPlace的survivor区域是空的。Eden,FromPlace和ToPlace的默认占比为 **8:1:1**。当然这个东西其实也可以通过一个 -XX:+UsePSAdaptiveSurvivorSizePolicy 参数来根据生成对象的速率动态调整
+
+堆内存中存放的是对象,垃圾收集就是收集这些对象然后交给GC算法进行回收。非堆内存其实我们已经说过了,就是方法区。在1.8中已经移除永久代,替代品是一个元空间(MetaSpace),最大区别是metaSpace是不存在于JVM中的,它使用的是本地内存。并有两个参数
+
+ MetaspaceSize:初始化元空间大小,控制发生GC
+ MaxMetaspaceSize:限制元空间大小上限,防止占用过多物理内存。
+
+移除的原因可以大致了解一下:融合HotSpot JVM和JRockit VM而做出的改变,因为JRockit是没有永久代的,不过这也间接性地解决了永久代的OOM问题。
+
+#### 3.3.7 Eden年轻代的介绍
+
+当我们new一个对象后,会先放到Eden划分出来的一块作为存储空间的内存,但是我们知道对堆内存是线程共享的,所以有可能会出现两个对象共用一个内存的情况。这里JVM的处理是每个线程都会预先申请好一块连续的内存空间并规定了对象存放的位置,而如果空间不足会再申请多块内存空间。这个操作我们会称作TLAB,有兴趣可以了解一下。
+
+当Eden空间满了之后,会触发一个叫做Minor GC(就是一个发生在年轻代的GC)的操作,存活下来的对象移动到Survivor0区。Survivor0区满后触发 Minor GC,就会将存活对象移动到Survivor1区,此时还会把from和to两个指针交换,这样保证了一段时间内总有一个survivor区为空且to所指向的survivor区为空。经过多次的 Minor GC后仍然存活的对象(**这里的存活判断是15次,对应到虚拟机参数为 -XX:MaxTenuringThreshold 。为什么是15,因为HotSpot会在对象投中的标记字段里记录年龄,分配到的空间仅有4位,所以最多只能记录到15**)会移动到老年代。老年代是存储长期存活的对象的,占满时就会触发我们最常听说的Full GC,期间会停止所有线程等待GC的完成。所以对于响应要求高的应用应该尽量去减少发生Full GC从而避免响应超时的问题。
+
+而且当老年区执行了full gc之后仍然无法进行对象保存的操作,就会产生OOM,这时候就是虚拟机中的堆内存不足,原因可能会是堆内存设置的大小过小,这个可以通过参数-Xms、-Xmx来调整。也可能是代码中创建的对象大且多,而且它们一直在被引用从而长时间垃圾收集无法收集它们。
+
+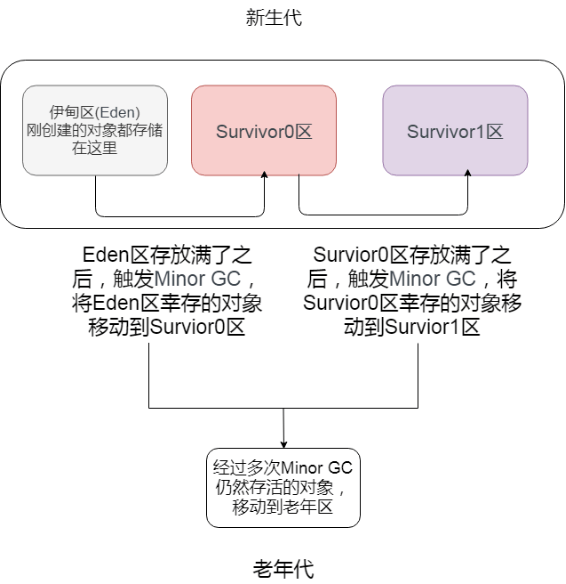
+
+补充说明:关于-XX:TargetSurvivorRatio参数的问题。其实也不一定是要满足-XX:MaxTenuringThreshold才移动到老年代。可以举个例子:如对象年龄5的占30%,年龄6的占36%,年龄7的占34%,加入某个年龄段(如例子中的年龄6)后,总占用超过Survivor空间*TargetSurvivorRatio的时候,从该年龄段开始及大于的年龄对象就要进入老年代(即例子中的年龄6对象,就是年龄6和年龄7晋升到老年代),这时候无需等到MaxTenuringThreshold中要求的15
+
+#### 3.3.8 如何判断一个对象需要被干掉
+
+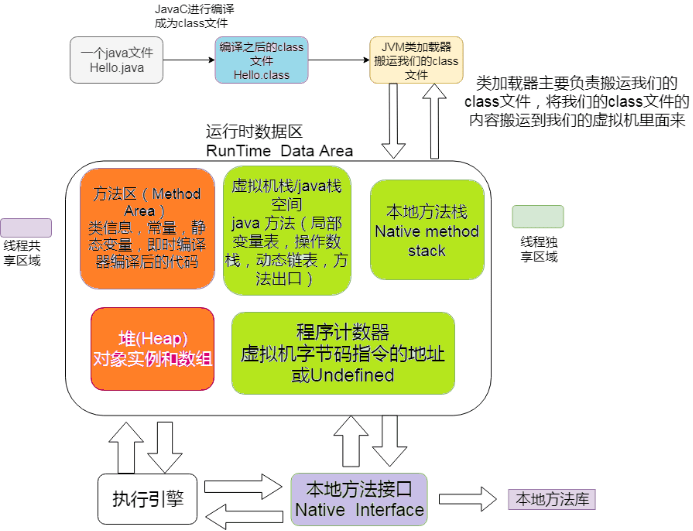
+
+图中程序计数器、虚拟机栈、本地方法栈,3个区域随着线程的生存而生存的。内存分配和回收都是确定的。随着线程的结束内存自然就被回收了,因此不需要考虑垃圾回收的问题。而Java堆和方法区则不一样,各线程共享,内存的分配和回收都是动态的。因此垃圾收集器所关注的都是堆和方法这部分内存。
+
+在进行回收前就要判断哪些对象还存活,哪些已经死去。下面介绍两个基础的计算方法
+
+1.引用计数器计算:给对象添加一个引用计数器,每次引用这个对象时计数器加一,引用失效时减一,计数器等于0时就是不会再次使用的。不过这个方法有一种情况就是出现对象的循环引用时GC没法回收。
+
+2.可达性分析计算:这是一种类似于二叉树的实现,将一系列的GC ROOTS作为起始的存活对象集,从这个节点往下搜索,搜索所走过的路径成为引用链,把能被该集合引用到的对象加入到集合中。搜索当一个对象到GC Roots没有使用任何引用链时,则说明该对象是不可用的。主流的商用程序语言,例如Java,C#等都是靠这招去判定对象是否存活的。
+
+(了解一下即可)在Java语言汇总能作为GC Roots的对象分为以下几种:
+
+1. 虚拟机栈(栈帧中的本地方法表)中引用的对象(局部变量)
+2. 方法区中静态变量所引用的对象(静态变量)
+3. 方法区中常量引用的对象
+4. 本地方法栈(即native修饰的方法)中JNI引用的对象(JNI是Java虚拟机调用对应的C函数的方式,通过JNI函数也可以创建新的Java对象。且JNI对于对象的局部引用或者全局引用都会把它们指向的对象都标记为不可回收)
+5. 已启动的且未终止的Java线程
+
+
+这种方法的优点是能够解决循环引用的问题,可它的实现需要耗费大量资源和时间,也需要GC(它的分析过程引用关系不能发生变化,所以需要停止所有进程)
+
+#### 3.3.9 如何宣告一个对象的真正死亡
+
+首先必须要提到的是一个名叫 **finalize()** 的方法
+
+finalize()是Object类的一个方法、一个对象的finalize()方法只会被系统自动调用一次,经过finalize()方法逃脱死亡的对象,第二次不会再调用。
+
+补充一句:并不提倡在程序中调用finalize()来进行自救。建议忘掉Java程序中该方法的存在。因为它执行的时间不确定,甚至是否被执行也不确定(Java程序的不正常退出),而且运行代价高昂,无法保证各个对象的调用顺序(甚至有不同线程中调用)。在Java9中已经被标记为 **deprecated** ,且java.lang.ref.Cleaner(也就是强、软、弱、幻象引用的那一套)中已经逐步替换掉它,会比finalize来的更加的轻量及可靠。
+
+
+
+判断一个对象的死亡至少需要两次标记
+
+1. 如果对象进行可达性分析之后没发现与GC Roots相连的引用链,那它将会第一次标记并且进行一次筛选。判断的条件是决定这个对象是否有必要执行finalize()方法。如果对象有必要执行finalize()方法,则被放入F-Queue队列中。
+2. GC对F-Queue队列中的对象进行二次标记。如果对象在finalize()方法中重新与引用链上的任何一个对象建立了关联,那么二次标记时则会将它移出“即将回收”集合。如果此时对象还没成功逃脱,那么只能被回收了。
+
+如果确定对象已经死亡,我们又该如何回收这些垃圾呢
+
+### 3.4 垃圾回收算法
+
+不会非常详细的展开,常用的有标记清除,复制,标记整理和分代收集算法
+
+#### 3.4.1 标记清除算法
+
+标记清除算法就是分为“标记”和“清除”两个阶段。标记出所有需要回收的对象,标记结束后统一回收。这个套路很简单,也存在不足,后续的算法都是根据这个基础来加以改进的。
+
+其实它就是把已死亡的对象标记为空闲内存,然后记录在一个空闲列表中,当我们需要new一个对象时,内存管理模块会从空闲列表中寻找空闲的内存来分给新的对象。
+
+不足的方面就是标记和清除的效率比较低下。且这种做法会让内存中的碎片非常多。这个导致了如果我们需要使用到较大的内存块时,无法分配到足够的连续内存。比如下图
+
+
+
+此时可使用的内存块都是零零散散的,导致了刚刚提到的大内存对象问题
+
+#### 3.4.2 复制算法
+
+为了解决效率问题,复制算法就出现了。它将可用内存按容量划分成两等分,每次只使用其中的一块。和survivor一样也是用from和to两个指针这样的玩法。fromPlace存满了,就把存活的对象copy到另一块toPlace上,然后交换指针的内容。这样就解决了碎片的问题。
+
+这个算法的代价就是把内存缩水了,这样堆内存的使用效率就会变得十分低下了
+
+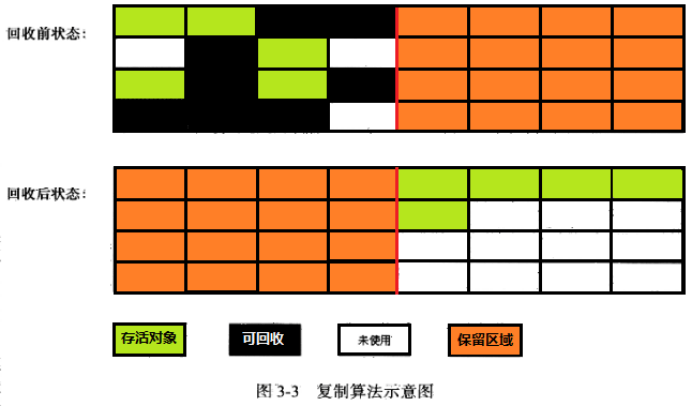
+
+不过它们分配的时候也不是按照1:1这样进行分配的,就类似于Eden和Survivor也不是等价分配是一个道理。
+
+#### 3.4.3 标记整理算法
+
+复制算法在对象存活率高的时候会有一定的效率问题,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉边界以外的内存
+
+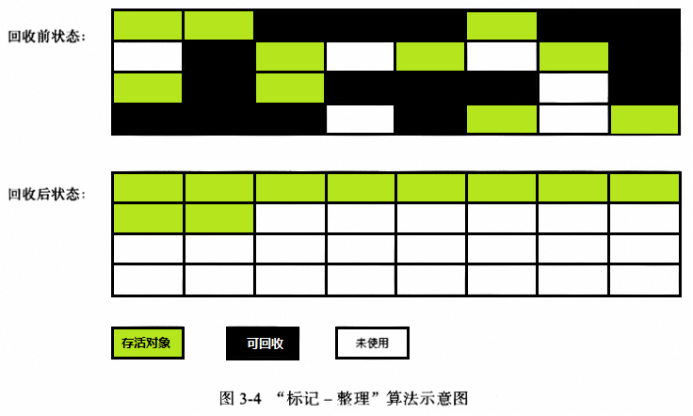
+
+#### 3.4.4 分代收集算法
+
+这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或者“标记-整理”算法来进行回收。
+
+说白了就是八仙过海各显神通,具体问题具体分析了而已。
+
+### 3.5 (了解)各种各样的垃圾回收器
+
+HotSpot VM中的垃圾回收器,以及适用场景
+
+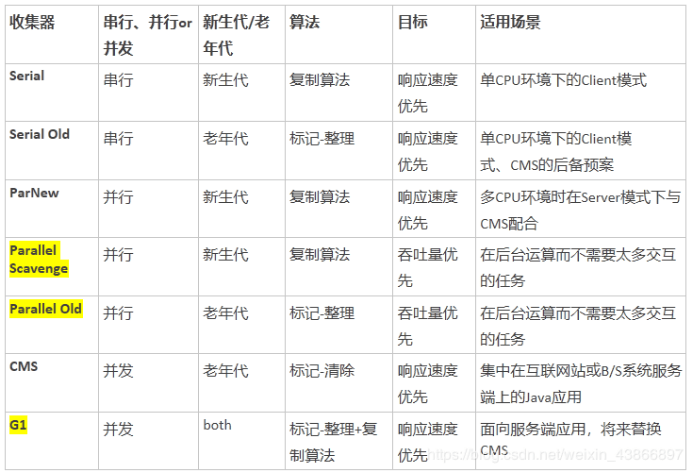
+
+到jdk8为止,默认的垃圾收集器是Parallel Scavenge 和 Parallel Old
+
+从jdk9开始,G1收集器成为默认的垃圾收集器
+目前来看,G1回收器停顿时间最短而且没有明显缺点,非常适合Web应用。在jdk8中测试Web应用,堆内存6G,新生代4.5G的情况下,Parallel Scavenge 回收新生代停顿长达1.5秒。G1回收器回收同样大小的新生代只停顿0.2秒。
+
+### 3.6 (了解)JVM的常用参数
+
+JVM的参数非常之多,这里只列举比较重要的几个,通过各种各样的搜索引擎也可以得知这些信息。
+
+| 参数名称 | 含义 | 默认值 | 说明 |
+|------|------------|------------|------|
+| -Xms | 初始堆大小 | 物理内存的1/64(<1GB) |默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制.
+| -Xmx | 最大堆大小 | 物理内存的1/4(<1GB) | 默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制
+| -Xmn | 年轻代大小(1.4or lator) | |注意:此处的大小是(eden+ 2 survivor space).与jmap -heap中显示的New gen是不同的。整个堆大小=年轻代大小 + 老年代大小 + 持久代(永久代)大小.增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8
+| -XX:NewSize | 设置年轻代大小(for 1.3/1.4) | |
+| -XX:MaxNewSize | 年轻代最大值(for 1.3/1.4) | |
+| -XX:PermSize | 设置持久代(perm gen)初始值 | 物理内存的1/64 |
+| -XX:MaxPermSize | 设置持久代最大值 | 物理内存的1/4 |
+| -Xss | 每个线程的堆栈大小 | | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.根据应用的线程所需内存大小进行 调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。(校长)和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:-Xss is translated in a VM flag named ThreadStackSize”一般设置这个值就可以了
+| -XX:NewRatio | 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) | |-XX:NewRatio=4表示年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。
+| -XX:SurvivorRatio | Eden区与Survivor区的大小比值 | |设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10
+| -XX:+DisableExplicitGC | 关闭System.gc() | |这个参数需要严格的测试
+| -XX:PretenureSizeThreshold | 对象超过多大是直接在旧生代分配 | 0 |单位字节 新生代采用Parallel ScavengeGC时无效另一种直接在旧生代分配的情况是大的数组对象,且数组中无外部引用对象.
+| -XX:ParallelGCThreads | 并行收集器的线程数 | |此值最好配置与处理器数目相等 同样适用于CMS
+| -XX:MaxGCPauseMillis | 每次年轻代垃圾回收的最长时间(最大暂停时间) | |如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值.
+
+其实还有一些打印及CMS方面的参数,这里就不以一一列举了
+
+## 四、关于JVM调优的一些方面
+
+根据刚刚涉及的jvm的知识点,我们可以尝试对JVM进行调优,主要就是堆内存那块
+
+所有线程共享数据区大小=新生代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m。所以java堆中增大年轻代后,将会减小年老代大小(因为老年代的清理是使用fullgc,所以老年代过小的话反而是会增多fullgc的)。此值对系统性能影响较大,Sun官方推荐配置为java堆的3/8。
+
+### 4.1 调整最大堆内存和最小堆内存
+
+-Xmx –Xms:指定java堆最大值(默认值是物理内存的1/4(<1GB))和初始java堆最小值(默认值是物理内存的1/64(<1GB))
+
+默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制.,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制。简单点来说,你不停地往堆内存里面丢数据,等它剩余大小小于40%了,JVM就会动态申请内存空间不过会小于-Xmx,如果剩余大小大于70%,又会动态缩小不过不会小于–Xms。就这么简单
+
+开发过程中,通常会将 -Xms 与 -Xmx两个参数配置成相同的值,其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源。
+
+我们执行下面的代码
+
+```java
+System.out.println("Xmx=" + Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); //系统的最大空间
+System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); //系统的空闲空间
+System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M"); //当前可用的总空间
+```
+
+注意:此处设置的是Java堆大小,也就是新生代大小 + 老年代大小
+
+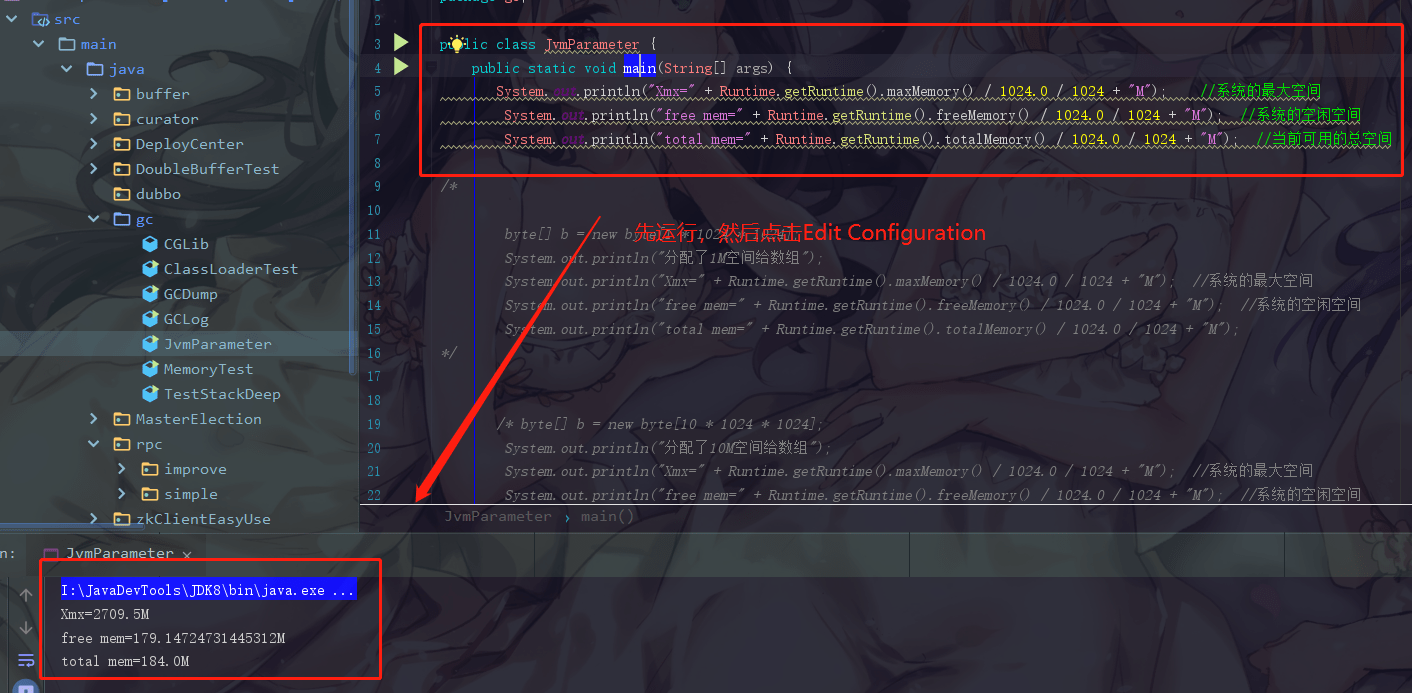
+
+设置一个VM options的参数
+
+ -Xmx20m -Xms5m -XX:+PrintGCDetails
+
+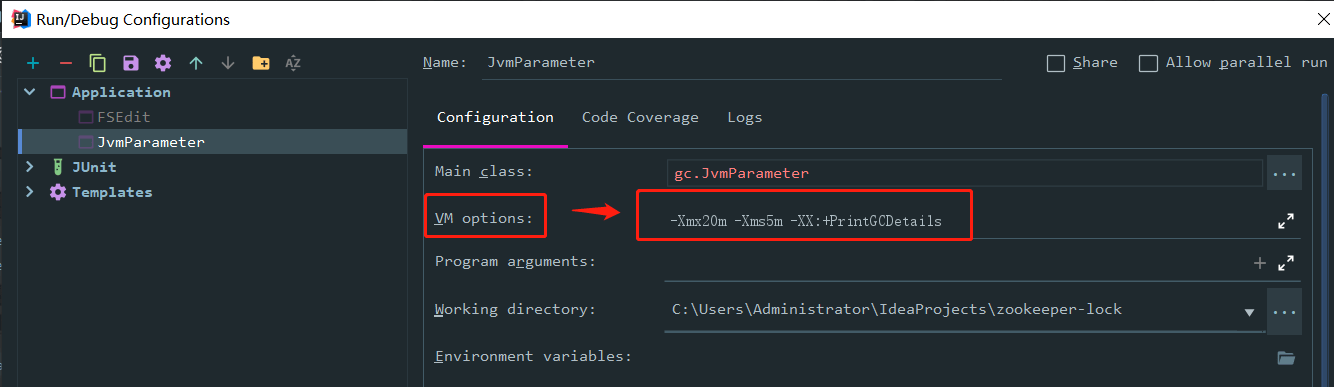
+
+再次启动main方法
+
+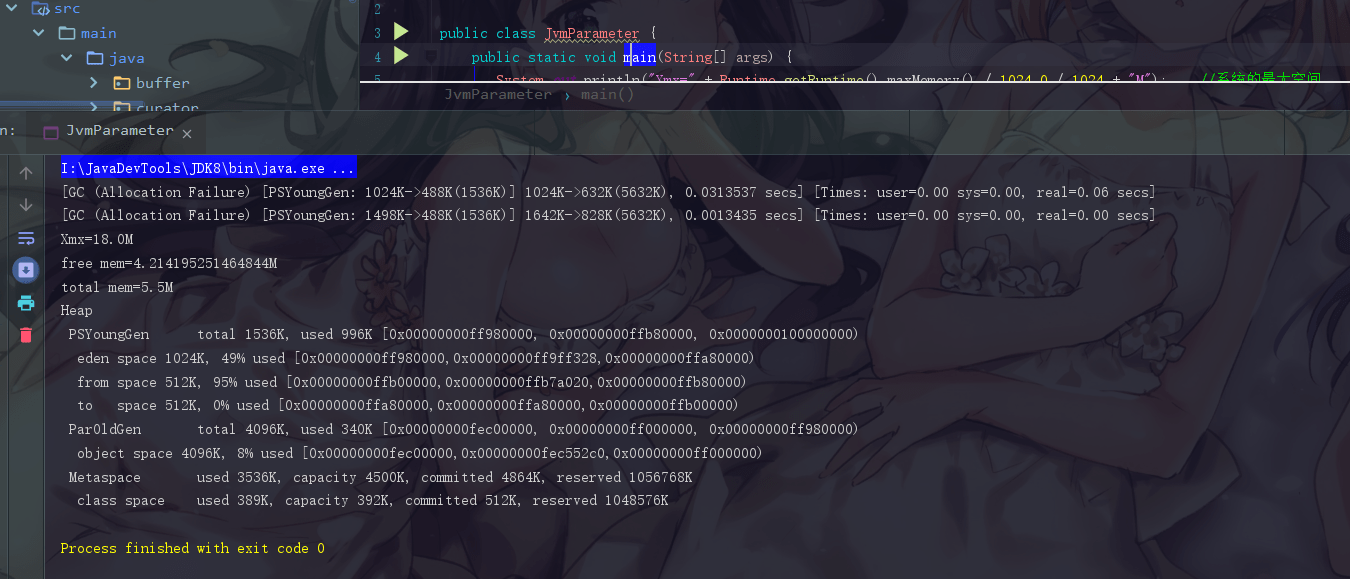
+
+这里GC弹出了一个Allocation Failure分配失败,这个事情发生在PSYoungGen,也就是年轻代中
+
+这时候申请到的内存为18M,空闲内存为4.214195251464844M
+
+我们此时创建一个字节数组看看,执行下面的代码
+
+```java
+byte[] b = new byte[1 * 1024 * 1024];
+System.out.println("分配了1M空间给数组");
+System.out.println("Xmx=" + Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); //系统的最大空间
+System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); //系统的空闲空间
+System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M");
+```
+
+
+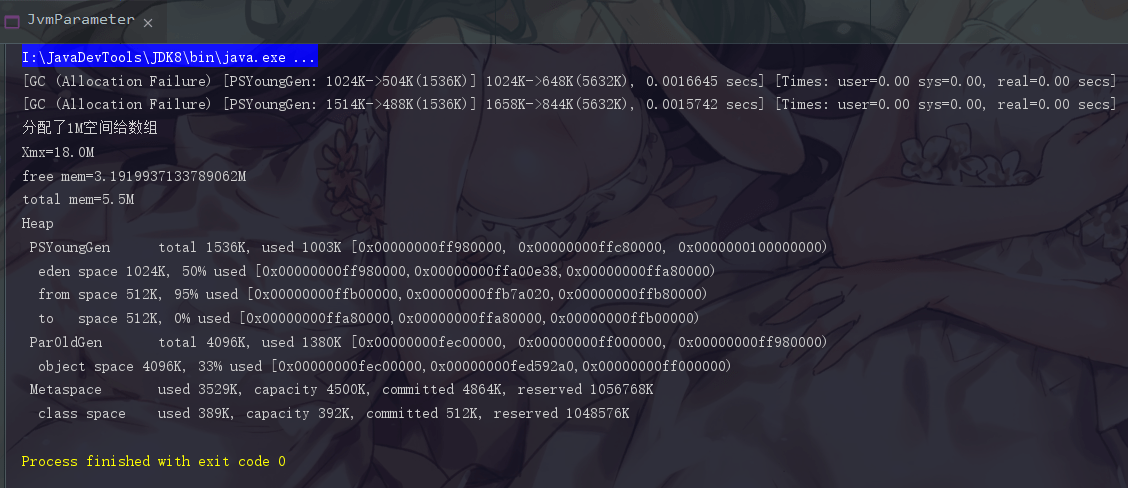
+
+此时free memory就又缩水了,不过total memory是没有变化的。Java会尽可能将total mem的值维持在最小堆内存大小
+
+
+ byte[] b = new byte[10 * 1024 * 1024];
+ System.out.println("分配了10M空间给数组");
+ System.out.println("Xmx=" + Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); //系统的最大空间
+ System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); //系统的空闲空间
+ System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M"); //当前可用的总空间
+
+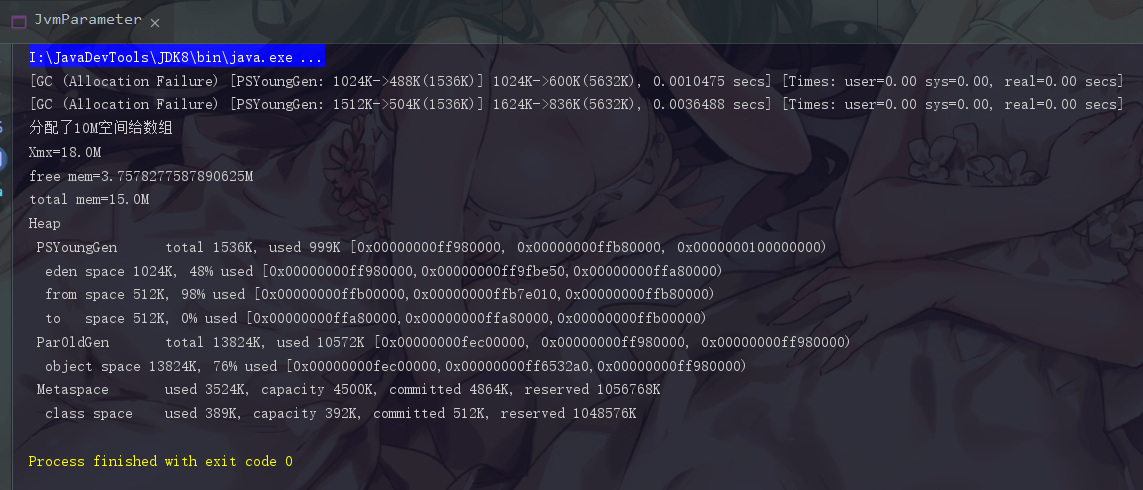
+
+这时候我们创建了一个10M的字节数据,这时候最小堆内存是顶不住的。我们会发现现在的total memory已经变成了15M,这就是已经申请了一次内存的结果。
+
+此时我们再跑一下这个代码
+
+```java
+System.gc();
+System.out.println("Xmx=" + Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); //系统的最大空间
+System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); //系统的空闲空间
+System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M"); //当前可用的总空间
+```
+
+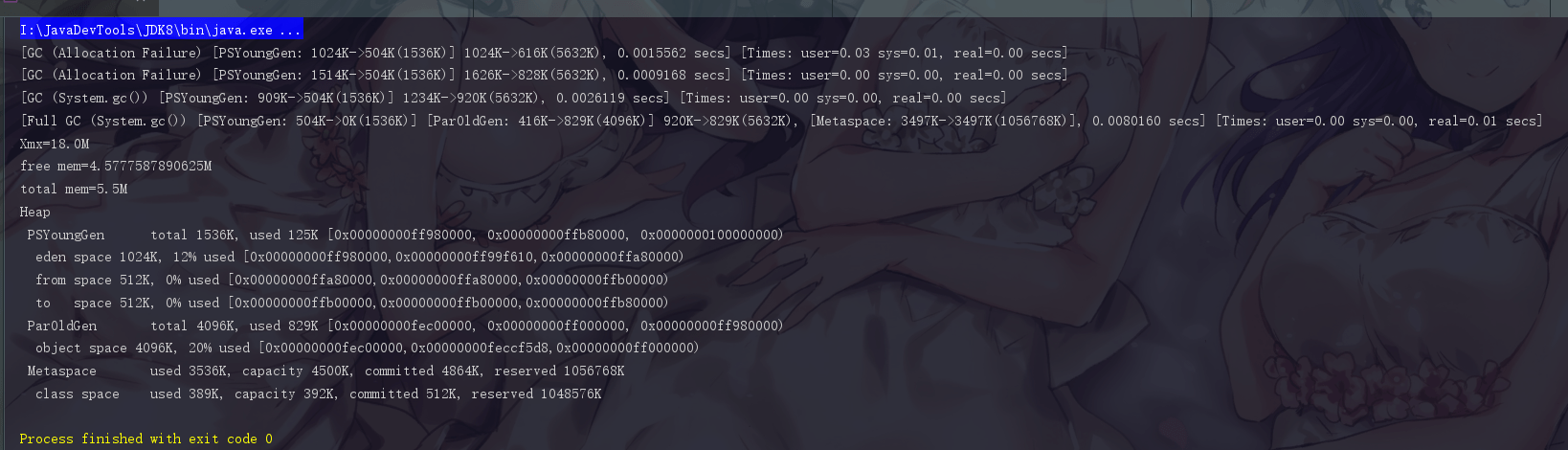
+
+此时我们手动执行了一次fullgc,此时total memory的内存空间又变回5.5M了,此时又是把申请的内存释放掉的结果。
+
+### 4.2 调整新生代和老年代的比值
+
+-XX:NewRatio --- 新生代(eden+2*Survivor)和老年代(不包含永久区)的比值
+
+例如:-XX:NewRatio=4,表示新生代:老年代=1:4,即新生代占整个堆的1/5。在Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。
+
+### 4.3 调整Survivor区和Eden区的比值
+
+-XX:SurvivorRatio(幸存代)--- 设置两个Survivor区和eden的比值
+
+例如:8,表示两个Survivor:eden=2:8,即一个Survivor占年轻代的1/10
+
+### 4.4 设置年轻代和老年代的大小
+
+-XX:NewSize --- 设置年轻代大小
+
+-XX:MaxNewSize --- 设置年轻代最大值
+
+可以通过设置不同参数来测试不同的情况,反正最优解当然就是官方的Eden和Survivor的占比为8:1:1,然后在刚刚介绍这些参数的时候都已经附带了一些说明,感兴趣的也可以看看。反正最大堆内存和最小堆内存如果数值不同会导致多次的gc,需要注意。
+
+### 4.5 小总结
+
+根据实际事情调整新生代和幸存代的大小,官方推荐新生代占java堆的3/8,幸存代占新生代的1/10
+
+在OOM时,记得Dump出堆,确保可以排查现场问题,通过下面命令你可以输出一个.dump文件,这个文件可以使用VisualVM或者Java自带的Java VisualVM工具。
+
+ -Xmx20m -Xms5m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=你要输出的日志路径
+
+一般我们也可以通过编写脚本的方式来让OOM出现时给我们报个信,可以通过发送邮件或者重启程序等来解决。
+
+### 4.6 永久区的设置
+
+ -XX:PermSize -XX:MaxPermSize
+
+初始空间(默认为物理内存的1/64)和最大空间(默认为物理内存的1/4)。也就是说,jvm启动时,永久区一开始就占用了PermSize大小的空间,如果空间还不够,可以继续扩展,但是不能超过MaxPermSize,否则会OOM。
+
+tips:如果堆空间没有用完也抛出了OOM,有可能是永久区导致的。堆空间实际占用非常少,但是永久区溢出 一样抛出OOM。
+
+### 4.7 JVM的栈参数调优
+
+#### 4.7.1 调整每个线程栈空间的大小
+
+可以通过-Xss:调整每个线程栈空间的大小
+
+JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右
+
+#### 4.7.2 设置线程栈的大小
+ -XXThreadStackSize:
+ 设置线程栈的大小(0 means use default stack size)
+
+这些参数都是可以通过自己编写程序去简单测试的,这里碍于篇幅问题就不再提供demo了
+
+### 4.8 (可以直接跳过了)JVM其他参数介绍
+
+形形色色的参数很多,就不会说把所有都扯个遍了,因为大家其实也不会说一定要去深究到底。
+
+#### 4.8.1 设置内存页的大小
+
+ -XXThreadStackSize:
+ 设置内存页的大小,不可设置过大,会影响Perm的大小
+
+#### 4.8.2 设置原始类型的快速优化
+
+ -XX:+UseFastAccessorMethods:
+ 设置原始类型的快速优化
+
+#### 4.8.3 设置关闭手动GC
+ -XX:+DisableExplicitGC:
+ 设置关闭System.gc()(这个参数需要严格的测试)
+
+#### 4.8.4 设置垃圾最大年龄
+ -XX:MaxTenuringThreshold
+ 设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代.
+ 对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,
+ 则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,
+ 增加在年轻代即被回收的概率。该参数只有在串行GC时才有效.
+
+#### 4.8.5 加快编译速度
+ -XX:+AggressiveOpts
+加快编译速度
+
+#### 4.8.6 改善锁机制性能
+ -XX:+UseBiasedLocking
+
+#### 4.8.7 禁用垃圾回收
+ -Xnoclassgc
+
+#### 4.8.8 设置堆空间存活时间
+ -XX:SoftRefLRUPolicyMSPerMB
+ 设置每兆堆空闲空间中SoftReference的存活时间,默认值是1s。
+
+#### 4.8.9 设置对象直接分配在老年代
+ -XX:PretenureSizeThreshold
+ 设置对象超过多大时直接在老年代分配,默认值是0。
+
+#### 4.8.10 设置TLAB占eden区的比例
+ -XX:TLABWasteTargetPercent
+ 设置TLAB占eden区的百分比,默认值是1% 。
+
+#### 4.8.11设置是否优先YGC
+ -XX:+CollectGen0First
+ 设置FullGC时是否先YGC,默认值是false。
+
+
+## finally
+
+真的扯了很久这东西,参考了多方的资料,有极客时间的《深入拆解虚拟机》和《Java核心技术面试精讲》,也有百度,也有自己在学习的一些线上课程的总结。希望对你有所帮助,谢谢。
diff --git a/docs/java/jvm/jvm-parameters-intro.md b/docs/java/jvm/jvm-parameters-intro.md
new file mode 100644
index 00000000000..4b9bf19670d
--- /dev/null
+++ b/docs/java/jvm/jvm-parameters-intro.md
@@ -0,0 +1,143 @@
+---
+category: Java
+tag:
+ - JVM
+---
+
+
+# 最重要的 JVM 参数总结
+
+本文由 JavaGuide 翻译自 [https://www.baeldung.com/jvm-parameters](https://www.baeldung.com/jvm-parameters),并对文章进行了大量的完善补充。翻译不易,如需转载请注明出处,作者:[baeldung](https://www.baeldung.com/author/baeldung/) 。
+
+## 1.概述
+
+在本篇文章中,你将掌握最常用的 JVM 参数配置。如果对于下面提到了一些概念比如堆、
+
+## 2.堆内存相关
+
+>Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。**此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。**
+
+### 2.1.显式指定堆内存`–Xms`和`-Xmx`
+
+与性能有关的最常见实践之一是根据应用程序要求初始化堆内存。如果我们需要指定最小和最大堆大小(推荐显示指定大小),以下参数可以帮助你实现:
+
+```
+-Xms<heap size>[unit]
+-Xmx<heap size>[unit]
+```
+
+- **heap size** 表示要初始化内存的具体大小。
+- **unit** 表示要初始化内存的单位。单位为***“ g”*** (GB) 、***“ m”***(MB)、***“ k”***(KB)。
+
+举个栗子🌰,如果我们要为JVM分配最小2 GB和最大5 GB的堆内存大小,我们的参数应该这样来写:
+
+```
+-Xms2G -Xmx5G
+```
+
+### 2.2.显式新生代内存(Young Generation)
+
+根据[Oracle官方文档](https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/sizing.html),在堆总可用内存配置完成之后,第二大影响因素是为 `Young Generation` 在堆内存所占的比例。默认情况下,YG 的最小大小为 1310 *MB*,最大大小为*无限制*。
+
+一共有两种指定 新生代内存(Young Ceneration)大小的方法:
+
+**1.通过`-XX:NewSize`和`-XX:MaxNewSize`指定**
+
+```
+-XX:NewSize=<young size>[unit]
+-XX:MaxNewSize=<young size>[unit]
+```
+
+举个栗子🌰,如果我们要为 新生代分配 最小256m 的内存,最大 1024m的内存我们的参数应该这样来写:
+
+```
+-XX:NewSize=256m
+-XX:MaxNewSize=1024m
+```
+
+**2.通过`-Xmn<young size>[unit] `指定**
+
+举个栗子🌰,如果我们要为 新生代分配256m的内存(NewSize与MaxNewSize设为一致),我们的参数应该这样来写:
+
+```
+-Xmn256m
+```
+
+GC 调优策略中很重要的一条经验总结是这样说的:
+
+> 将新对象预留在新生代,由于 Full GC 的成本远高于 Minor GC,因此尽可能将对象分配在新生代是明智的做法,实际项目中根据 GC 日志分析新生代空间大小分配是否合理,适当通过“-Xmn”命令调节新生代大小,最大限度降低新对象直接进入老年代的情况。
+
+另外,你还可以通过**`-XX:NewRatio=<int>`**来设置新生代和老年代内存的比值。
+
+比如下面的参数就是设置新生代(包括Eden和两个Survivor区)与老年代的比值为1。也就是说:新生代与老年代所占比值为1:1,新生代占整个堆栈的 1/2。
+
+```
+-XX:NewRatio=1
+```
+
+### 2.3.显式指定永久代/元空间的大小
+
+**从Java 8开始,如果我们没有指定 Metaspace 的大小,随着更多类的创建,虚拟机会耗尽所有可用的系统内存(永久代并不会出现这种情况)。**
+
+JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参数来调节方法区大小
+
+```java
+-XX:PermSize=N //方法区 (永久代) 初始大小
+-XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen
+```
+
+相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
+
+**JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是本地内存。**
+
+下面是一些常用参数:
+
+```java
+-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
+-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存。
+```
+
+## 3.垃圾收集相关
+
+### 3.1.垃圾回收器
+
+为了提高应用程序的稳定性,选择正确的[垃圾收集](http://www.oracle.com/webfolder/technetwork/tutorials/obe/java/gc01/index.html)算法至关重要。
+
+JVM具有四种类型的*GC*实现:
+
+- 串行垃圾收集器
+- 并行垃圾收集器
+- CMS垃圾收集器
+- G1垃圾收集器
+
+可以使用以下参数声明这些实现:
+
+```
+-XX:+UseSerialGC
+-XX:+UseParallelGC
+-XX:+UseParNewGC
+-XX:+UseG1GC
+```
+
+有关*垃圾回收*实施的更多详细信息,请参见[此处](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/jvm/JVM%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6.md)。
+
+### 3.2.GC记录
+
+为了严格监控应用程序的运行状况,我们应该始终检查JVM的*垃圾回收*性能。最简单的方法是以人类可读的格式记录*GC*活动。
+
+使用以下参数,我们可以记录*GC*活动:
+
+```
+-XX:+UseGCLogFileRotation
+-XX:NumberOfGCLogFiles=< number of log files >
+-XX:GCLogFileSize=< file size >[ unit ]
+-Xloggc:/path/to/gc.log
+```
+
+## 推荐阅读
+
+- [CMS GC 默认新生代是多大?](https://www.jianshu.com/p/832fc4d4cb53)
+- [CMS GC启动参数优化配置](https://www.cnblogs.com/hongdada/p/10277782.html)
+- [从实际案例聊聊Java应用的GC优化-美团技术团队](https://tech.meituan.com/2017/12/29/jvm-optimize.html)
+- [JVM性能调优详解](https://www.choupangxia.com/2019/11/11/interview-jvm-gc-08/) (2019-11-11)
+- [JVM参数使用手册](https://segmentfault.com/a/1190000010603813)
diff --git a/docs/java/jvm/memory-area.md b/docs/java/jvm/memory-area.md
new file mode 100644
index 00000000000..68d98002c47
--- /dev/null
+++ b/docs/java/jvm/memory-area.md
@@ -0,0 +1,604 @@
+---
+category: Java
+tag:
+ - JVM
+---
+
+# Java 内存区域详解
+
+如果没有特殊说明,都是针对的是 HotSpot 虚拟机。
+
+## 写在前面 (常见面试题)
+
+### 基本问题
+
+- **介绍下 Java 内存区域(运行时数据区)**
+- **Java 对象的创建过程(五步,建议能默写出来并且要知道每一步虚拟机做了什么)**
+- **对象的访问定位的两种方式(句柄和直接指针两种方式)**
+
+### 拓展问题
+
+- **String 类和常量池**
+- **8 种基本类型的包装类和常量池**
+
+## 一 概述
+
+对于 Java 程序员来说,在虚拟机自动内存管理机制下,不再需要像 C/C++程序开发程序员这样为每一个 new 操作去写对应的 delete/free 操作,不容易出现内存泄漏和内存溢出问题。正是因为 Java 程序员把内存控制权利交给 Java 虚拟机,一旦出现内存泄漏和溢出方面的问题,如果不了解虚拟机是怎样使用内存的,那么排查错误将会是一个非常艰巨的任务。
+
+## 二 运行时数据区域
+
+Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域。JDK 1.8 和之前的版本略有不同,下面会介绍到。
+
+**JDK 1.8 之前:**
+
+
+
+**JDK 1.8 :**
+
+
+
+**线程私有的:**
+
+- 程序计数器
+- 虚拟机栈
+- 本地方法栈
+
+**线程共享的:**
+
+- 堆
+- 方法区
+- 直接内存 (非运行时数据区的一部分)
+
+### 2.1 程序计数器
+
+程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。**字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。**
+
+另外,**为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。**
+
+**从上面的介绍中我们知道程序计数器主要有两个作用:**
+
+1. 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
+2. 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
+
+**注意:程序计数器是唯一一个不会出现 `OutOfMemoryError` 的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡。**
+
+### 2.2 Java 虚拟机栈
+
+**与程序计数器一样,Java 虚拟机栈也是线程私有的,它的生命周期和线程相同,描述的是 Java 方法执行的内存模型,每次方法调用的数据都是通过栈传递的。**
+
+**Java 内存可以粗糙的区分为堆内存(Heap)和栈内存 (Stack),其中栈就是现在说的虚拟机栈,或者说是虚拟机栈中局部变量表部分。** (实际上,Java 虚拟机栈是由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法出口信息。)
+
+**局部变量表主要存放了编译期可知的各种数据类型**(boolean、byte、char、short、int、float、long、double)、**对象引用**(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
+
+**Java 虚拟机栈会出现两种错误:`StackOverFlowError` 和 `OutOfMemoryError`。**
+
+- **`StackOverFlowError`:** 若 Java 虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 错误。
+- **`OutOfMemoryError`:** Java 虚拟机栈的内存大小可以动态扩展, 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出`OutOfMemoryError`异常。
+
+
+
+Java 虚拟机栈也是线程私有的,每个线程都有各自的 Java 虚拟机栈,而且随着线程的创建而创建,随着线程的死亡而死亡。
+
+**扩展:那么方法/函数如何调用?**
+
+Java 栈可以类比数据结构中栈,Java 栈中保存的主要内容是栈帧,每一次函数调用都会有一个对应的栈帧被压入 Java 栈,每一个函数调用结束后,都会有一个栈帧被弹出。
+
+Java 方法有两种返回方式:
+
+1. return 语句。
+2. 抛出异常。
+
+不管哪种返回方式都会导致栈帧被弹出。
+
+### 2.3 本地方法栈
+
+和虚拟机栈所发挥的作用非常相似,区别是: **虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。** 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
+
+本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。
+
+方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 `StackOverFlowError` 和 `OutOfMemoryError` 两种错误。
+
+### 2.4 堆
+
+Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。**此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。**
+
+Java 世界中“几乎”所有的对象都在堆中分配,但是,随着 JIT 编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。从 JDK 1.7 开始已经默认开启逃逸分析,如果某些方法中的对象引用没有被返回或者未被外面使用(也就是未逃逸出去),那么对象可以直接在栈上分配内存。
+
+Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(Garbage Collected Heap)**。从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代;再细致一点有:Eden 空间、From Survivor、To Survivor 空间等。**进一步划分的目的是更好地回收内存,或者更快地分配内存。**
+
+在 JDK 7 版本及 JDK 7 版本之前,堆内存被通常分为下面三部分:
+
+1. 新生代内存(Young Generation)
+2. 老生代(Old Generation)
+3. 永生代(Permanent Generation)
+
+
+
+JDK 8 版本之后方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。
+
+
+
+**上图所示的 Eden 区、两个 Survivor 区都属于新生代(为了区分,这两个 Survivor 区域按照顺序被命名为 from 和 to),中间一层属于老年代。**
+
+大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
+
+> **🐛 修正(参见:[issue552](https://github.com/Snailclimb/JavaGuide/issues/552))** :“Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了 survivor 区的一半时,取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值”。
+>
+> **动态年龄计算的代码如下**
+>
+> ```c++
+> uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
+> //survivor_capacity是survivor空间的大小
+> size_t desired_survivor_size = (size_t)((((double) survivor_capacity)*TargetSurvivorRatio)/100);
+> size_t total = 0;
+> uint age = 1;
+> while (age < table_size) {
+> total += sizes[age];//sizes数组是每个年龄段对象大小
+> if (total > desired_survivor_size) break;
+> age++;
+> }
+> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
+> ...
+> }
+> ```
+
+堆这里最容易出现的就是 OutOfMemoryError 错误,并且出现这种错误之后的表现形式还会有几种,比如:
+
+1. **`java.lang.OutOfMemoryError: GC Overhead Limit Exceeded`** : 当 JVM 花太多时间执行垃圾回收并且只能回收很少的堆空间时,就会发生此错误。
+2. **`java.lang.OutOfMemoryError: Java heap space`** :假如在创建新的对象时, 堆内存中的空间不足以存放新创建的对象, 就会引发此错误。(和配置的最大堆内存有关,且受制于物理内存大小。最大堆内存可通过`-Xmx`参数配置,若没有特别配置,将会使用默认值,详见:[Default Java 8 max heap size](https://stackoverflow.com/questions/28272923/default-xmxsize-in-java-8-max-heap-size))
+3. ......
+
+### 2.5 方法区
+
+方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 **Java 虚拟机规范把方法区描述为堆的一个逻辑部分**,但是它却有一个别名叫做 **Non-Heap(非堆)**,目的应该是与 Java 堆区分开来。
+
+方法区也被称为永久代。很多人都会分不清方法区和永久代的关系,为此我也查阅了文献。
+
+#### 2.5.1 方法区和永久代的关系
+
+> 《Java 虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。那么,在不同的 JVM 上方法区的实现肯定是不同的了。 **方法区和永久代的关系很像 Java 中接口和类的关系,类实现了接口,而永久代就是 HotSpot 虚拟机对虚拟机规范中方法区的一种实现方式。** 也就是说,永久代是 HotSpot 的概念,方法区是 Java 虚拟机规范中的定义,是一种规范,而永久代是一种实现,一个是标准一个是实现,其他的虚拟机实现并没有永久代这一说法。
+
+#### 2.5.2 常用参数
+
+JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参数来调节方法区大小
+
+```java
+-XX:PermSize=N //方法区 (永久代) 初始大小
+-XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen
+```
+
+相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
+
+JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。
+
+下面是一些常用参数:
+
+```java
+-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
+-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小
+```
+
+与永久代很大的不同就是,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存。
+
+#### 2.5.3 为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢?
+
+下图来自《深入理解 Java 虚拟机》第 3 版 2.2.5
+
+
+
+1. 整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
+
+ > 当元空间溢出时会得到如下错误: `java.lang.OutOfMemoryError: MetaSpace`
+
+你可以使用 `-XX:MaxMetaspaceSize` 标志设置最大元空间大小,默认值为 unlimited,这意味着它只受系统内存的限制。`-XX:MetaspaceSize` 调整标志定义元空间的初始大小如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
+
+2. 元空间里面存放的是类的元数据,这样加载多少类的元数据就不由 `MaxPermSize` 控制了, 而由系统的实际可用空间来控制,这样能加载的类就更多了。
+
+3. 在 JDK8,合并 HotSpot 和 JRockit 的代码时, JRockit 从来没有一个叫永久代的东西, 合并之后就没有必要额外的设置这么一个永久代的地方了。
+
+### 2.6 运行时常量池
+
+运行时常量池是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池表(用于存放编译期生成的各种字面量和符号引用)
+
+既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 错误。
+
+~~**JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。**~~
+
+> **🐛 修正(参见:[issue747](https://github.com/Snailclimb/JavaGuide/issues/747),[reference](https://blog.csdn.net/q5706503/article/details/84640762))** :
+>
+> 1. **JDK1.7 之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时 hotspot 虚拟机对方法区的实现为永久代**
+> 2. **JDK1.7 字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是 hotspot 中的永久代** 。
+> 3. **JDK1.8 hotspot 移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)**
+
+相关问题:JVM 常量池中存储的是对象还是引用呢?: https://www.zhihu.com/question/57109429/answer/151717241 by RednaxelaFX
+
+### 2.7 直接内存
+
+**直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。**
+
+JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**通道(Channel)**与**缓存区(Buffer)**的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为**避免了在 Java 堆和 Native 堆之间来回复制数据**。
+
+本机直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
+
+## 三 HotSpot 虚拟机对象探秘
+
+通过上面的介绍我们大概知道了虚拟机的内存情况,下面我们来详细的了解一下 HotSpot 虚拟机在 Java 堆中对象分配、布局和访问的全过程。
+
+### 3.1 对象的创建
+
+下图便是 Java 对象的创建过程,我建议最好是能默写出来,并且要掌握每一步在做什么。
+
+
+#### Step1:类加载检查
+
+虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
+
+#### Step2:分配内存
+
+在**类加载检查**通过后,接下来虚拟机将为新生对象**分配内存**。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。**分配方式**有 **“指针碰撞”** 和 **“空闲列表”** 两种,**选择哪种分配方式由 Java 堆是否规整决定,而 Java 堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定**。
+
+**内存分配的两种方式:(补充内容,需要掌握)**
+
+选择以上两种方式中的哪一种,取决于 Java 堆内存是否规整。而 Java 堆内存是否规整,取决于 GC 收集器的算法是"标记-清除",还是"标记-整理"(也称作"标记-压缩"),值得注意的是,复制算法内存也是规整的
+
+
+
+**内存分配并发问题(补充内容,需要掌握)**
+
+在创建对象的时候有一个很重要的问题,就是线程安全,因为在实际开发过程中,创建对象是很频繁的事情,作为虚拟机来说,必须要保证线程是安全的,通常来讲,虚拟机采用两种方式来保证线程安全:
+
+- **CAS+失败重试:** CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。**虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。**
+- **TLAB:** 为每一个线程预先在 Eden 区分配一块儿内存,JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,再采用上述的 CAS 进行内存分配
+
+#### Step3:初始化零值
+
+内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
+
+#### Step4:设置对象头
+
+初始化零值完成之后,**虚拟机要对对象进行必要的设置**,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 **这些信息存放在对象头中。** 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
+
+#### Step5:执行 init 方法
+
+在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,`<init>` 方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行 `<init>` 方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
+
+### 3.2 对象的内存布局
+
+在 Hotspot 虚拟机中,对象在内存中的布局可以分为 3 块区域:**对象头**、**实例数据**和**对齐填充**。
+
+**Hotspot 虚拟机的对象头包括两部分信息**,**第一部分用于存储对象自身的运行时数据**(哈希码、GC 分代年龄、锁状态标志等等),**另一部分是类型指针**,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是那个类的实例。
+
+**实例数据部分是对象真正存储的有效信息**,也是在程序中所定义的各种类型的字段内容。
+
+**对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。** 因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
+
+### 3.3 对象的访问定位
+
+建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有**① 使用句柄**和**② 直接指针**两种:
+
+1. **句柄:** 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
+
+ 
+
+2. **直接指针:** 如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象的地址。
+
+
+
+**这两种对象访问方式各有优势。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。**
+
+## 四 重点补充内容
+
+### 4.1 字符串常量池常见问题
+
+我们先来看一个非常常见的面试题:**String 类型的变量和常量做“+”运算时发生了什么?** 。
+
+先来看字符串不加 `final` 关键字拼接的情况(JDK1.8):
+
+```java
+String str1 = "str";
+String str2 = "ing";
+String str3 = "str" + "ing";//常量池中的对象
+String str4 = str1 + str2; //在堆上创建的新的对象
+String str5 = "string";//常量池中的对象
+System.out.println(str3 == str4);//false
+System.out.println(str3 == str5);//true
+System.out.println(str4 == str5);//false
+```
+
+> **注意** :比较 String 字符串的值是否相等,可以使用 `equals()` 方法。 `String` 中的 `equals` 方法是被重写过的。 `Object` 的 `equals` 方法是比较的对象的内存地址,而 `String` 的 `equals` 方法比较的是字符串的值是否相等。如果你使用 `==` 比较两个字符串是否相等的话,IDEA 还是提示你使用 `equals()` 方法替换。
+
+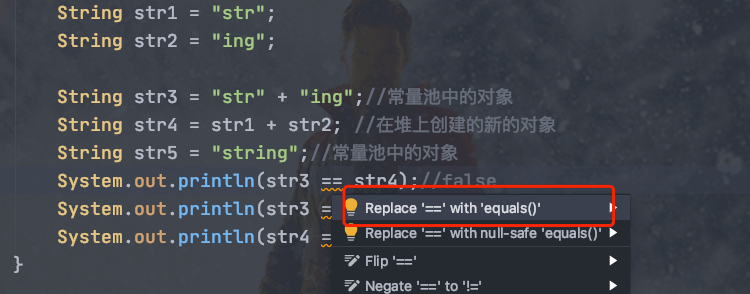
+
+> 对于基本数据类型来说,== 比较的是值。对于引用数据类型来说,==比较的是对象的内存地址。
+
+对于编译期可以确定值的字符串,也就是常量字符串 ,jvm 会将其存入字符串常量池。
+
+> **字符串常量池** 是 JVM 为了提升性能和减少内存消耗针为字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
+>
+> ```java
+> String aa = "ab"; // 放在常量池中
+> String bb = "ab"; // 从常量池中查找
+> System.out.println("aa==bb");// true
+> ```
+>
+> JDK1.7 之前运行时常量池逻辑包含字符串常量池存放在方法区。JDK1.7 的时候,字符串常量池被从方法区拿到了堆中。
+
+并且,字符串常量拼接得到的字符串常量在编译阶段就已经被存放字符串常量池,这个得益于编译器的优化。
+
+> 在编译过程中,Javac 编译器(下文中统称为编译器)会进行一个叫做 **常量折叠(Constant Folding)** 的代码优化。《深入理解 Java 虚拟机》中是也有介绍到:
+>
+> 
+>
+> 常量折叠会把常量表达式的值求出来作为常量嵌在最终生成的代码中,这是 Javac 编译器会对源代码做的极少量优化措施之一(代码优化几乎都在即时编译器中进行)。
+>
+> 对于 `String str3 = "str" + "ing";` 编译器会给你优化成 `String str3 = "string";` 。
+>
+> 并不是所有的常量都会进行折叠,只有编译器在程序编译期就可以确定值的常量才可以:
+>
+> 1. 基本数据类型(byte、boolean、short、char、int、float、long、double)以及字符串常量
+> 2. `final` 修饰的基本数据类型和字符串变量
+> 3. 字符串通过 “+”拼接得到的字符串、基本数据类型之间算数运算(加减乘除)、基本数据类型的位运算(<<、\>>、\>>> )
+
+因此,`str1` 、 `str2` 、 `str3` 都属于字符串常量池中的对象。
+
+引用的值在程序编译期是无法确定的,编译器无法对其进行优化。
+
+对象引用和“+”的字符串拼接方式,实际上是通过 `StringBuilder` 调用 `append()` 方法实现的,拼接完成之后调用 `toString()` 得到一个 `String` 对象 。
+
+```java
+String str4 = new StringBuilder().append(str1).append(str2).toString();
+```
+
+因此,`str4` 并不是字符串常量池中存在的对象,属于堆上的新对象。
+
+我画了一个图帮助理解:
+
+
+
+我们在平时写代码的时候,尽量避免多个字符串对象拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用 `StringBuilder` 或者 `StringBuffer`。
+
+不过,字符串使用 `final` 关键字声明之后,可以让编译器当做常量来处理。
+
+```java
+final String str1 = "str";
+final String str2 = "ing";
+// 下面两个表达式其实是等价的
+String c = "str" + "str2";// 常量池中的对象
+String d = str1 + str2; // 常量池中的对象
+System.out.println(c == d);// true
+```
+
+被 `final` 关键字修改之后的 `String` 会被编译器当做常量来处理,编译器在程序编译期就可以确定它的值,其效果就想到于访问常量。
+
+如果 ,编译器在运行时才能知道其确切值的话,就无法对其优化。
+
+示例代码如下(`str2` 在运行时才能确定其值):
+
+```java
+final String str1 = "str";
+final String str2 = getStr();
+String c = "str" + "str2";// 常量池中的对象
+String d = str1 + str2; // 常量池中的对象
+System.out.println(c == d);// false
+public static String getStr() {
+ return "ing";
+}
+```
+
+**我们再来看一个类似的问题!**
+
+```java
+String str1 = "abcd";
+String str2 = new String("abcd");
+String str3 = new String("abcd");
+System.out.println(str1==str2);
+System.out.println(str2==str3);
+```
+
+上面的代码运行之后会输出什么呢?
+
+答案是:
+
+```
+false
+false
+```
+
+**这是为什么呢?**
+
+我们先来看下面这种创建字符串对象的方式:
+
+```java
+// 从字符串常量池中拿对象
+String str1 = "abcd";
+```
+
+这种情况下,jvm 会先检查字符串常量池中有没有"abcd",如果字符串常量池中没有,则创建一个,然后 str1 指向字符串常量池中的对象,如果有,则直接将 str1 指向"abcd"";
+
+因此,`str1` 指向的是字符串常量池的对象。
+
+我们再来看下面这种创建字符串对象的方式:
+
+```java
+// 直接在堆内存空间创建一个新的对象。
+String str2 = new String("abcd");
+String str3 = new String("abcd");
+```
+
+**只要使用 new 的方式创建对象,便需要创建新的对象** 。
+
+使用 new 的方式创建对象的方式如下,可以简单概括为 3 步:
+
+1. 在堆中创建一个字符串对象
+2. 检查字符串常量池中是否有和 new 的字符串值相等的字符串常量
+3. 如果没有的话需要在字符串常量池中也创建一个值相等的字符串常量,如果有的话,就直接返回堆中的字符串实例对象地址。
+
+因此,`str2` 和 `str3` 都是在堆中新创建的对象。
+
+**字符串常量池比较特殊,它的主要使用方法有两种:**
+
+1. 直接使用双引号声明出来的 `String` 对象会直接存储在常量池中。
+2. 如果不是用双引号声明的 `String` 对象,使用 `String` 提供的 `intern()` 方法也有同样的效果。`String.intern()` 是一个 Native 方法,它的作用是:如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,JDK1.7 之前(不包含 1.7)的处理方式是在常量池中创建与此 `String` 内容相同的字符串,并返回常量池中创建的字符串的引用,JDK1.7 以及之后,字符串常量池被从方法区拿到了堆中,jvm 不会在常量池中创建该对象,而是将堆中这个对象的引用直接放到常量池中,减少不必要的内存开销。
+
+示例代码如下(JDK 1.8) :
+
+```java
+String s1 = "Javatpoint";
+String s2 = s1.intern();
+String s3 = new String("Javatpoint");
+String s4 = s3.intern();
+System.out.println(s1==s2); // True
+System.out.println(s1==s3); // False
+System.out.println(s1==s4); // True
+System.out.println(s2==s3); // False
+System.out.println(s2==s4); // True
+System.out.println(s3==s4); // False
+```
+
+**总结** :
+
+1. 对于基本数据类型来说,==比较的是值。对于引用数据类型来说,==比较的是对象的内存地址。
+2. 在编译过程中,Javac 编译器(下文中统称为编译器)会进行一个叫做 **常量折叠(Constant Folding)** 的代码优化。常量折叠会把常量表达式的值求出来作为常量嵌在最终生成的代码中,这是 Javac 编译器会对源代码做的极少量优化措施之一(代码优化几乎都在即时编译器中进行)。
+3. 一般来说,我们要尽量避免通过 new 的方式创建字符串。使用双引号声明的 `String` 对象( `String s1 = "java"` )更利于让编译器有机会优化我们的代码,同时也更易于阅读。
+4. 被 `final` 关键字修改之后的 `String` 会被编译器当做常量来处理,编译器程序编译期就可以确定它的值,其效果就想到于访问常量。
+
+### 4.2 String s1 = new String("abc");这句话创建了几个字符串对象?
+
+会创建 1 或 2 个字符串:
+
+- 如果字符串常量池中已存在字符串常量“abc”,则只会在堆空间创建一个字符串常量“abc”。
+- 如果字符串常量池中没有字符串常量“abc”,那么它将首先在字符串常量池中创建,然后在堆空间中创建,因此将创建总共 2 个字符串对象。
+
+**验证:**
+
+```java
+String s1 = new String("abc");// 堆内存的地址值
+String s2 = "abc";
+System.out.println(s1 == s2);// 输出 false,因为一个是堆内存,一个是常量池的内存,故两者是不同的。
+System.out.println(s1.equals(s2));// 输出 true
+```
+
+**结果:**
+
+```
+false
+true
+```
+
+### 4.3 8 种基本类型的包装类和常量池
+
+ Java 基本类型的包装类的大部分都实现了常量池技术。
+
+`Byte`,`Short`,`Integer`,`Long` 这 4 种包装类默认创建了数值 **[-128,127]** 的相应类型的缓存数据,`Character` 创建了数值在 **[0,127]** 范围的缓存数据,`Boolean` 直接返回 `True` Or `False`。
+
+两种浮点数类型的包装类 `Float`,`Double` 并没有实现常量池技术。
+
+```java
+Integer i1 = 33;
+Integer i2 = 33;
+System.out.println(i1 == i2);// 输出 true
+Integer i11 = 333;
+Integer i22 = 333;
+System.out.println(i11 == i22);// 输出 false
+Double i3 = 1.2;
+Double i4 = 1.2;
+System.out.println(i3 == i4);// 输出 false
+```
+
+**Integer 缓存源代码:**
+
+```java
+/**
+*此方法将始终缓存-128 到 127(包括端点)范围内的值,并可以缓存此范围之外的其他值。
+*/
+public static Integer valueOf(int i) {
+ if (i >= IntegerCache.low && i <= IntegerCache.high)
+ return IntegerCache.cache[i + (-IntegerCache.low)];
+ return new Integer(i);
+}
+private static class IntegerCache {
+ static final int low = -128;
+ static final int high;
+ static final Integer cache[];
+}
+```
+
+**`Character` 缓存源码:**
+
+```java
+public static Character valueOf(char c) {
+ if (c <= 127) { // must cache
+ return CharacterCache.cache[(int)c];
+ }
+ return new Character(c);
+}
+
+private static class CharacterCache {
+ private CharacterCache(){}
+
+ static final Character cache[] = new Character[127 + 1];
+ static {
+ for (int i = 0; i < cache.length; i++)
+ cache[i] = new Character((char)i);
+ }
+}
+```
+
+**`Boolean` 缓存源码:**
+
+```java
+public static Boolean valueOf(boolean b) {
+ return (b ? TRUE : FALSE);
+}
+```
+
+如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。
+
+下面我们来看一下问题。下面的代码的输出结果是 `true` 还是 `flase` 呢?
+
+```java
+Integer i1 = 40;
+Integer i2 = new Integer(40);
+System.out.println(i1==i2);
+```
+
+`Integer i1=40` 这一行代码会发生装箱,也就是说这行代码等价于 `Integer i1=Integer.valueOf(40)` 。因此,`i1` 直接使用的是常量池中的对象。而`Integer i1 = new Integer(40)` 会直接创建新的对象。
+
+因此,答案是 `false` 。你答对了吗?
+
+记住:**所有整型包装类对象之间值的比较,全部使用 equals 方法比较**。
+
+
+
+**Integer 比较更丰富的一个例子:**
+
+```java
+Integer i1 = 40;
+Integer i2 = 40;
+Integer i3 = 0;
+Integer i4 = new Integer(40);
+Integer i5 = new Integer(40);
+Integer i6 = new Integer(0);
+
+System.out.println(i1 == i2);// true
+System.out.println(i1 == i2 + i3);//true
+System.out.println(i1 == i4);// false
+System.out.println(i4 == i5);// false
+System.out.println(i4 == i5 + i6);// true
+System.out.println(40 == i5 + i6);// true
+```
+
+`i1` , `i2 ` , `i3` 都是常量池中的对象,`i4` , `i5` , `i6` 是堆中的对象。
+
+ `i4 == i5 + i6` 为什么是 true 呢?因为, `i5` 和 `i6` 会进行自动拆箱操作,进行数值相加,即 `i4 == 40` 。 `Integer` 对象无法与数值进行直接比较,所以 `i4` 自动拆箱转为 int 值 40,最终这条语句转为 `40 == 40` 进行数值比较。
+
+## 参考
+
+- 《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第二版》
+- 《实战 java 虚拟机》
+- <https://docs.oracle.com/javase/specs/index.html>
+- <http://www.pointsoftware.ch/en/under-the-hood-runtime-data-areas-javas-memory-model/>
+- <https://dzone.com/articles/jvm-permgen-%E2%80%93-where-art-thou>
+- <https://stackoverflow.com/questions/9095748/method-area-and-permgen>
+- 深入解析 String#intern<https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html>
+- R 大(RednaxelaFX)关于常量折叠的回答:https://www.zhihu.com/question/55976094/answer/147302764
diff --git a/docs/java/jvm/pictures/HsJXU8S4oVtCTM7.png b/docs/java/jvm/pictures/HsJXU8S4oVtCTM7.png
new file mode 100644
index 00000000000..52f4b008c8c
Binary files /dev/null and b/docs/java/jvm/pictures/HsJXU8S4oVtCTM7.png differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/2019-3String-Pool-Java1-450x249.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/2019-3String-Pool-Java1-450x249.png"
new file mode 100644
index 00000000000..b6e24178cbd
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/2019-3String-Pool-Java1-450x249.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/JVM\345\240\206\345\206\205\345\255\230\347\273\223\346\236\204-JDK7.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/JVM\345\240\206\345\206\205\345\255\230\347\273\223\346\236\204-JDK7.png"
new file mode 100644
index 00000000000..3e90da89577
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/JVM\345\240\206\345\206\205\345\255\230\347\273\223\346\236\204-JDK7.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/JVM\345\240\206\345\206\205\345\255\230\347\273\223\346\236\204-jdk8.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/JVM\345\240\206\345\206\205\345\255\230\347\273\223\346\236\204-jdk8.png"
new file mode 100644
index 00000000000..829aede4426
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/JVM\345\240\206\345\206\205\345\255\230\347\273\223\346\236\204-jdk8.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/JVM\350\277\220\350\241\214\346\227\266\346\225\260\346\215\256\345\214\272\345\237\237.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/JVM\350\277\220\350\241\214\346\227\266\346\225\260\346\215\256\345\214\272\345\237\237.png"
new file mode 100644
index 00000000000..bf52c66e1db
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/JVM\350\277\220\350\241\214\346\227\266\346\225\260\346\215\256\345\214\272\345\237\237.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/Java\345\210\233\345\273\272\345\257\271\350\261\241\347\232\204\350\277\207\347\250\213.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/Java\345\210\233\345\273\272\345\257\271\350\261\241\347\232\204\350\277\207\347\250\213.png"
new file mode 100644
index 00000000000..7c4a79f1f01
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/Java\345\210\233\345\273\272\345\257\271\350\261\241\347\232\204\350\277\207\347\250\213.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/Java\350\277\220\350\241\214\346\227\266\346\225\260\346\215\256\345\214\272\345\237\237JDK1.8.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/Java\350\277\220\350\241\214\346\227\266\346\225\260\346\215\256\345\214\272\345\237\237JDK1.8.png"
new file mode 100644
index 00000000000..5c599ba8116
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/Java\350\277\220\350\241\214\346\227\266\346\225\260\346\215\256\345\214\272\345\237\237JDK1.8.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\343\200\212\346\267\261\345\205\245\347\220\206\350\247\243\350\231\232\346\213\237\346\234\272\343\200\213\347\254\254\344\270\211\347\211\210\347\232\204\347\254\2542\347\253\240-\350\231\232\346\213\237\346\234\272\346\240\210.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\343\200\212\346\267\261\345\205\245\347\220\206\350\247\243\350\231\232\346\213\237\346\234\272\343\200\213\347\254\254\344\270\211\347\211\210\347\232\204\347\254\2542\347\253\240-\350\231\232\346\213\237\346\234\272\346\240\210.png"
new file mode 100644
index 00000000000..f769ad33b42
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\343\200\212\346\267\261\345\205\245\347\220\206\350\247\243\350\231\232\346\213\237\346\234\272\343\200\213\347\254\254\344\270\211\347\211\210\347\232\204\347\254\2542\347\253\240-\350\231\232\346\213\237\346\234\272\346\240\210.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\206\205\345\255\230\345\210\206\351\205\215\347\232\204\344\270\244\347\247\215\346\226\271\345\274\217.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\206\205\345\255\230\345\210\206\351\205\215\347\232\204\344\270\244\347\247\215\346\226\271\345\274\217.png"
new file mode 100644
index 00000000000..1d0081b14e5
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\206\205\345\255\230\345\210\206\351\205\215\347\232\204\344\270\244\347\247\215\346\226\271\345\274\217.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\255\227\347\254\246\344\270\262\346\213\274\346\216\245-\345\270\270\351\207\217\346\261\240.drawio" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\255\227\347\254\246\344\270\262\346\213\274\346\216\245-\345\270\270\351\207\217\346\261\240.drawio"
new file mode 100644
index 00000000000..764cc0be828
--- /dev/null
+++ "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\255\227\347\254\246\344\270\262\346\213\274\346\216\245-\345\270\270\351\207\217\346\261\240.drawio"
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-08-17T04:11:31.953Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="e0WDqV46oSxYOHa3xZl5" version="13.4.5" type="device"><diagram id="_ekre9nY7dw9-rCbcCB4" name="Page-1">7Vpdb6M4FP011j61AoMNPCZpZkYrrbRStZqZRxccsOLgDDhNMr9+bTAhfKSTtqG0melL8L3mYp9zbny5DXBmq93njKyTf0REOYBWtAPOHYDQti2sPrRlX1r8AJaGOGORmVQb7tlPaoyWsW5YRPPGRCkEl2zdNIYiTWkoGzaSZWLbnLYQvPnUNYlpx3AfEt61fmWRTMwuoFfbv1AWJ9WTbRyUnhWpJpud5AmJxPbI5MyBM8uEkOXVajejXINX4VLe9+mE97CwjKbynBuW6c/Zcu/fPOZp8vjfarvJ/57cmCiPhG/MhgHEXMWbLoQKq1Yt9wYK/GMjKsdNXhA1UROgs97VTnUV689cZnYVSS2pDFa6DBqHuDATmzSiepW2cm8TJun9moTau1WiUrZErrhxx5zkubk+IFoMllSGiRmYXdFM0t1JuOwDCUq9VKyozPZqirnBN7QZ3TqeGW9rFdiWsSVHCkDGRozw4kPkmht1Yeh5BlVwOKrQVVGF0dhUOcNR5V4VVcgfmyp3OKqc66LKHpsqNBxV8Kqoct2xqcI9VH0IJCFCTSitLpSOi7pQOtZQWHonZZ+vSfpy2dcWlQANd5UJZfwPlQmHMq3izxk7FfzB6WNpfLX0jV4fBAMdOo3sO8XgBzyK2gyi0ROwqlueOoxUGLbO6a9xFMrDpN6bOmMV1YzzmeAiK8I4EaH+Iiw5FUt65MGhTx8Wg59ePr6FrQOsp2yD2LvtOcKgjYaioKfNMEdgYgEfd7hQ25dN0JtopiKlLeiNiXAWp2oYKriosk81mCwkfGIcKxZF/BTLdT5ZPUSrTDTNKTu4DFlu0HptrcqKI6bcnkSBgyVKT4dBs3QHAg/MPTCZgQkGcxdMfTAtXPrCB/MA+B7wP4E5BlNbs/q7UuqgTv6hoMuqDfvzbzBi+/oR7W/ANJrodqnGWp8VLGwS1kaL7pj8Znz6+rsGWe2qHN3tDObFYG8G5UNp1Om4tvBVCxObLKRPbamcJ0kWU/mr4rnL1xEZ6ImzKKOcSPbYXG4fPeYJ/wpW1ASVfk69l1Uhym2au2qSO4Gg0wzkBK1AJQ6dQIVaDtt+hYD6uiSDCMh7MwWhMxXkj6qgdjVlv1RBsCVF/MYK6mvevFJBFxSDe6YYgnclBv9CYjjU6G8lhm576K8zaoaMqpcq8lBM0F8Ga72+YsVoCtDds6oFTh4on5JwGRc1wlGlvij+nlMfmH89mpWBA7rHQnwiKU5WE9ati3CDqOrYe6mQqiliscjpMNSe7lb9eV/uLRmx26AYj967tfs6Vh+7WnTO/Hq331W5iC9VLqK3Lhf7mmavVVCq1vSt0okeHGlID2sRFaPnq+idH/5tcXjoMuLAGF1IHGpY/5qlnF7/JsiZ/w8=</diagram></mxfile>
\ No newline at end of file
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\255\227\347\254\246\344\270\262\346\213\274\346\216\245-\345\270\270\351\207\217\346\261\240.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\255\227\347\254\246\344\270\262\346\213\274\346\216\245-\345\270\270\351\207\217\346\261\240.png"
new file mode 100644
index 00000000000..4c6f20e9508
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\255\227\347\254\246\344\270\262\346\213\274\346\216\245-\345\270\270\351\207\217\346\261\240.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\344\275\277\347\224\250\345\217\245\346\237\204.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\344\275\277\347\224\250\345\217\245\346\237\204.png"
new file mode 100644
index 00000000000..88b494732af
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\344\275\277\347\224\250\345\217\245\346\237\204.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png"
new file mode 100644
index 00000000000..f954d8a7375
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png" differ
diff --git "a/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/1JConsole\350\277\236\346\216\245.png" "b/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/1JConsole\350\277\236\346\216\245.png"
new file mode 100644
index 00000000000..ae1e61060d8
Binary files /dev/null and "b/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/1JConsole\350\277\236\346\216\245.png" differ
diff --git "a/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/2\346\237\245\347\234\213Java\347\250\213\345\272\217\346\246\202\345\206\265.png" "b/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/2\346\237\245\347\234\213Java\347\250\213\345\272\217\346\246\202\345\206\265.png"
new file mode 100644
index 00000000000..3a997022c01
Binary files /dev/null and "b/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/2\346\237\245\347\234\213Java\347\250\213\345\272\217\346\246\202\345\206\265.png" differ
diff --git "a/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/3\345\206\205\345\255\230\347\233\221\346\216\247.png" "b/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/3\345\206\205\345\255\230\347\233\221\346\216\247.png"
new file mode 100644
index 00000000000..56d98052850
Binary files /dev/null and "b/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/3\345\206\205\345\255\230\347\233\221\346\216\247.png" differ
diff --git "a/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/4\347\272\277\347\250\213\347\233\221\346\216\247.png" "b/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/4\347\272\277\347\250\213\347\233\221\346\216\247.png"
new file mode 100644
index 00000000000..2ad324bd991
Binary files /dev/null and "b/docs/java/jvm/pictures/jdk\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223/4\347\272\277\347\250\213\347\233\221\346\216\247.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/01d330d8-2710-4fad-a91c-7bbbfaaefc0e.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/01d330d8-2710-4fad-a91c-7bbbfaaefc0e.png"
new file mode 100644
index 00000000000..7934357e0eb
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/01d330d8-2710-4fad-a91c-7bbbfaaefc0e.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/10317146.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/10317146.png"
new file mode 100644
index 00000000000..a77222ba04a
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/10317146.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/11034259.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/11034259.png"
new file mode 100644
index 00000000000..092dc12ef7b
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/11034259.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/22018368.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/22018368.png"
new file mode 100644
index 00000000000..c79c76f3868
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/22018368.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/22018368213213.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/22018368213213.png"
new file mode 100644
index 00000000000..c79c76f3868
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/22018368213213.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/25178350.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/25178350.png"
new file mode 100644
index 00000000000..cc307027f70
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/25178350.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/29176325.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/29176325.png"
new file mode 100644
index 00000000000..a6d2199ed46
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/29176325.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/46873026.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/46873026.png"
new file mode 100644
index 00000000000..2145dce9375
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/46873026.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/72762049.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/72762049.png"
new file mode 100644
index 00000000000..f326103f964
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/72762049.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/82825079.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/82825079.png"
new file mode 100644
index 00000000000..3ed3bd82543
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/82825079.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/90984624.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/90984624.png"
new file mode 100644
index 00000000000..6909a605925
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/90984624.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/94057049.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/94057049.png"
new file mode 100644
index 00000000000..86d43ee6f48
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/94057049.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/CMS\346\224\266\351\233\206\345\231\250.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/CMS\346\224\266\351\233\206\345\231\250.png"
new file mode 100644
index 00000000000..3ed3bd82543
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/CMS\346\224\266\351\233\206\345\231\250.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/parllel-scavenge\346\224\266\351\233\206\345\231\250.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/parllel-scavenge\346\224\266\351\233\206\345\231\250.png"
new file mode 100644
index 00000000000..c79c76f3868
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/parllel-scavenge\346\224\266\351\233\206\345\231\250.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\345\236\203\345\234\276\346\224\266\351\233\206\345\231\250.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\345\236\203\345\234\276\346\224\266\351\233\206\345\231\250.png"
new file mode 100644
index 00000000000..888f879d882
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\345\236\203\345\234\276\346\224\266\351\233\206\345\231\250.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\345\236\203\345\234\276\346\224\266\351\233\206\347\256\227\346\263\225.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\345\236\203\345\234\276\346\224\266\351\233\206\347\256\227\346\263\225.png"
new file mode 100644
index 00000000000..0a4973bd15a
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\345\236\203\345\234\276\346\224\266\351\233\206\347\256\227\346\263\225.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\345\240\206\345\206\205\345\255\230.png" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\345\240\206\345\206\205\345\255\230.png"
new file mode 100644
index 00000000000..14815710289
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\345\240\206\345\206\205\345\255\230.png" differ
diff --git "a/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\346\240\207\350\256\260-\346\270\205\351\231\244\347\256\227\346\263\225.jpeg" "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\346\240\207\350\256\260-\346\270\205\351\231\244\347\256\227\346\263\225.jpeg"
new file mode 100644
index 00000000000..c4cdc75009f
Binary files /dev/null and "b/docs/java/jvm/pictures/jvm\345\236\203\345\234\276\345\233\236\346\224\266/\346\240\207\350\256\260-\346\270\205\351\231\244\347\256\227\346\263\225.jpeg" differ
diff --git "a/docs/java/jvm/pictures/\345\206\205\345\255\230\345\214\272\345\237\237\345\270\270\350\247\201\351\205\215\347\275\256\345\217\202\346\225\260.png" "b/docs/java/jvm/pictures/\345\206\205\345\255\230\345\214\272\345\237\237\345\270\270\350\247\201\351\205\215\347\275\256\345\217\202\346\225\260.png"
new file mode 100644
index 00000000000..7199d806882
Binary files /dev/null and "b/docs/java/jvm/pictures/\345\206\205\345\255\230\345\214\272\345\237\237\345\270\270\350\247\201\351\205\215\347\275\256\345\217\202\346\225\260.png" differ
diff --git a/docs/java/new-features/java8-common-new-features.md b/docs/java/new-features/java8-common-new-features.md
new file mode 100644
index 00000000000..1e9d8cd974a
--- /dev/null
+++ b/docs/java/new-features/java8-common-new-features.md
@@ -0,0 +1,1020 @@
+# Java8新特性实战
+
+> 本文来自[cowbi](https://github.com/cowbi)的投稿~
+
+Oracle 于 2014 发布了 Java8(jdk1.8),诸多原因使它成为目前市场上使用最多的 jdk 版本。虽然发布距今已将近 7 年,但很多程序员对其新特性还是不够了解,尤其是用惯了 java8 之前版本的老程序员,比如我。
+
+为了不脱离队伍太远,还是有必要对这些新特性做一些总结梳理。它较 jdk.7 有很多变化或者说是优化,比如 interface 里可以有静态方法,并且可以有方法体,这一点就颠覆了之前的认知;`java.util.HashMap` 数据结构里增加了红黑树;还有众所周知的 Lambda 表达式等等。本文不能把所有的新特性都给大家一一分享,只列出比较常用的新特性给大家做详细讲解。更多相关内容请看[官网关于 Java8 的新特性的介绍](https://www.oracle.com/java/technologies/javase/8-whats-new.html)。
+
+## Interface
+
+interface 的设计初衷是面向抽象,提高扩展性。这也留有一点遗憾,Interface 修改的时候,实现它的类也必须跟着改。
+
+为了解决接口的修改与现有的实现不兼容的问题。新 interface 的方法可以用`default` 或 `static`修饰,这样就可以有方法体,实现类也不必重写此方法。
+
+一个 interface 中可以有多个方法被它们修饰,这 2 个修饰符的区别主要也是普通方法和静态方法的区别。
+
+1. `default`修饰的方法,是普通实例方法,可以用`this`调用,可以被子类继承、重写。
+2. `static`修饰的方法,使用上和一般类静态方法一样。但它不能被子类继承,只能用`Interface`调用。
+
+我们来看一个实际的例子。
+
+```java
+public interface InterfaceNew {
+ static void sm() {
+ System.out.println("interface提供的方式实现");
+ }
+ static void sm2() {
+ System.out.println("interface提供的方式实现");
+ }
+
+ default void def() {
+ System.out.println("interface default方法");
+ }
+ default void def2() {
+ System.out.println("interface default2方法");
+ }
+ //须要实现类重写
+ void f();
+}
+
+public interface InterfaceNew1 {
+ default void def() {
+ System.out.println("InterfaceNew1 default方法");
+ }
+}
+```
+
+如果有一个类既实现了 `InterfaceNew` 接口又实现了 `InterfaceNew1`接口,它们都有`def()`,并且 `InterfaceNew` 接口和 `InterfaceNew1`接口没有继承关系的话,这时就必须重写`def()`。不然的话,编译的时候就会报错。
+
+```java
+public class InterfaceNewImpl implements InterfaceNew , InterfaceNew1{
+ public static void main(String[] args) {
+ InterfaceNewImpl interfaceNew = new InterfaceNewImpl();
+ interfaceNew.def();
+ }
+
+ @Override
+ public void def() {
+ InterfaceNew1.super.def();
+ }
+
+ @Override
+ public void f() {
+ }
+}
+```
+
+**在 Java 8 ,接口和抽象类有什么区别的?**
+
+很多小伙伴认为:“既然 interface 也可以有自己的方法实现,似乎和 abstract class 没多大区别了。”
+
+其实它们还是有区别的
+
+1. interface 和 class 的区别,好像是废话,主要有:
+
+ - 接口多实现,类单继承
+ - 接口的方法是 public abstract 修饰,变量是 public static final 修饰。 abstract class 可以用其他修饰符
+
+2. interface 的方法是更像是一个扩展插件。而 abstract class 的方法是要继承的。
+
+开始我们也提到,interface 新增`default`和`static`修饰的方法,为了解决接口的修改与现有的实现不兼容的问题,并不是为了要替代`abstract class`。在使用上,该用 abstract class 的地方还是要用 abstract class,不要因为 interface 的新特性而将之替换。
+
+**记住接口永远和类不一样。**
+
+## functional interface 函数式接口
+
+**定义**:也称 SAM 接口,即 Single Abstract Method interfaces,有且只有一个抽象方法,但可以有多个非抽象方法的接口。
+
+在 java 8 中专门有一个包放函数式接口`java.util.function`,该包下的所有接口都有 `@FunctionalInterface` 注解,提供函数式编程。
+
+在其他包中也有函数式接口,其中一些没有`@FunctionalInterface` 注解,但是只要符合函数式接口的定义就是函数式接口,与是否有
+
+`@FunctionalInterface`注解无关,注解只是在编译时起到强制规范定义的作用。其在 Lambda 表达式中有广泛的应用。
+
+## Lambda 表达式
+
+接下来谈众所周知的 Lambda 表达式。它是推动 Java 8 发布的最重要新特性。是继泛型(`Generics`)和注解(`Annotation`)以来最大的变化。
+
+使用 Lambda 表达式可以使代码变的更加简洁紧凑。让 java 也能支持简单的*函数式编程*。
+
+> Lambda 表达式是一个匿名函数,java 8 允许把函数作为参数传递进方法中。
+
+### 语法格式
+
+```java
+(parameters) -> expression 或
+(parameters) ->{ statements; }
+```
+
+### Lambda 实战
+
+我们用常用的实例来感受 Lambda 带来的便利
+
+#### 替代匿名内部类
+
+过去给方法传动态参数的唯一方法是使用内部类。比如
+
+**1.`Runnable` 接口**
+
+```java
+new Thread(new Runnable() {
+ @Override
+ public void run() {
+ System.out.println("The runable now is using!");
+ }
+}).start();
+//用lambda
+new Thread(() -> System.out.println("It's a lambda function!")).start();
+```
+
+**2.`Comperator` 接口**
+
+```java
+List<Integer> strings = Arrays.asList(1, 2, 3);
+
+Collections.sort(strings, new Comparator<Integer>() {
+@Override
+public int compare(Integer o1, Integer o2) {
+ return o1 - o2;}
+});
+
+//Lambda
+Collections.sort(strings, (Integer o1, Integer o2) -> o1 - o2);
+//分解开
+Comparator<Integer> comperator = (Integer o1, Integer o2) -> o1 - o2;
+Collections.sort(strings, comperator);
+```
+
+**3.`Listener` 接口**
+
+```java
+JButton button = new JButton();
+button.addItemListener(new ItemListener() {
+@Override
+public void itemStateChanged(ItemEvent e) {
+ e.getItem();
+}
+});
+//lambda
+button.addItemListener(e -> e.getItem());
+```
+
+**4.自定义接口**
+
+上面的 3 个例子是我们在开发过程中最常见的,从中也能体会到 Lambda 带来的便捷与清爽。它只保留实际用到的代码,把无用代码全部省略。那它对接口有没有要求呢?我们发现这些匿名内部类只重写了接口的一个方法,当然也只有一个方法须要重写。这就是我们上文提到的**函数式接口**,也就是说只要方法的参数是函数式接口都可以用 Lambda 表达式。
+
+```java
+@FunctionalInterface
+public interface Comparator<T>{}
+
+@FunctionalInterface
+public interface Runnable{}
+```
+
+我们自定义一个函数式接口
+
+```java
+@FunctionalInterface
+public interface LambdaInterface {
+ void f();
+}
+//使用
+public class LambdaClass {
+ public static void forEg() {
+ lambdaInterfaceDemo(()-> System.out.println("自定义函数式接口"));
+ }
+ //函数式接口参数
+ static void lambdaInterfaceDemo(LambdaInterface i){
+ System.out.println(i);
+ }
+}
+```
+
+#### 集合迭代
+
+```java
+void lamndaFor() {
+ List<String> strings = Arrays.asList("1", "2", "3");
+ //传统foreach
+ for (String s : strings) {
+ System.out.println(s);
+ }
+ //Lambda foreach
+ strings.forEach((s) -> System.out.println(s));
+ //or
+ strings.forEach(System.out::println);
+ //map
+ Map<Integer, String> map = new HashMap<>();
+ map.forEach((k,v)->System.out.println(v));
+}
+```
+
+#### 方法的引用
+
+Java 8 允许使用 `::` 关键字来传递方法或者构造函数引用,无论如何,表达式返回的类型必须是 functional-interface。
+
+```java
+public class LambdaClassSuper {
+ LambdaInterface sf(){
+ return null;
+ }
+}
+
+public class LambdaClass extends LambdaClassSuper {
+ public static LambdaInterface staticF() {
+ return null;
+ }
+
+ public LambdaInterface f() {
+ return null;
+ }
+
+ void show() {
+ //1.调用静态函数,返回类型必须是functional-interface
+ LambdaInterface t = LambdaClass::staticF;
+
+ //2.实例方法调用
+ LambdaClass lambdaClass = new LambdaClass();
+ LambdaInterface lambdaInterface = lambdaClass::f;
+
+ //3.超类上的方法调用
+ LambdaInterface superf = super::sf;
+
+ //4. 构造方法调用
+ LambdaInterface tt = LambdaClassSuper::new;
+ }
+}
+```
+
+#### 访问变量
+
+```java
+int i = 0;
+Collections.sort(strings, (Integer o1, Integer o2) -> o1 - i);
+//i =3;
+```
+
+lambda 表达式可以引用外边变量,但是该变量默认拥有 final 属性,不能被修改,如果修改,编译时就报错。
+
+## Stream
+
+java 新增了 `java.util.stream` 包,它和之前的流大同小异。之前接触最多的是资源流,比如`java.io.FileInputStream`,通过流把文件从一个地方输入到另一个地方,它只是内容搬运工,对文件内容不做任何*CRUD*。
+
+`Stream`依然不存储数据,不同的是它可以检索(Retrieve)和逻辑处理集合数据、包括筛选、排序、统计、计数等。可以想象成是 Sql 语句。
+
+它的源数据可以是 `Collection`、`Array` 等。由于它的方法参数都是函数式接口类型,所以一般和 Lambda 配合使用。
+
+### 流类型
+
+1. stream 串行流
+2. parallelStream 并行流,可多线程执行
+
+### 常用方法
+
+接下来我们看`java.util.stream.Stream`常用方法
+
+```java
+/**
+* 返回一个串行流
+*/
+default Stream<E> stream()
+
+/**
+* 返回一个并行流
+*/
+default Stream<E> parallelStream()
+
+/**
+* 返回T的流
+*/
+public static<T> Stream<T> of(T t)
+
+/**
+* 返回其元素是指定值的顺序流。
+*/
+public static<T> Stream<T> of(T... values) {
+ return Arrays.stream(values);
+}
+
+
+/**
+* 过滤,返回由与给定predicate匹配的该流的元素组成的流
+*/
+Stream<T> filter(Predicate<? super T> predicate);
+
+/**
+* 此流的所有元素是否与提供的predicate匹配。
+*/
+boolean allMatch(Predicate<? super T> predicate)
+
+/**
+* 此流任意元素是否有与提供的predicate匹配。
+*/
+boolean anyMatch(Predicate<? super T> predicate);
+
+/**
+* 返回一个 Stream的构建器。
+*/
+public static<T> Builder<T> builder();
+
+/**
+* 使用 Collector对此流的元素进行归纳
+*/
+<R, A> R collect(Collector<? super T, A, R> collector);
+
+/**
+ * 返回此流中的元素数。
+*/
+long count();
+
+/**
+* 返回由该流的不同元素(根据 Object.equals(Object) )组成的流。
+*/
+Stream<T> distinct();
+
+/**
+ * 遍历
+*/
+void forEach(Consumer<? super T> action);
+
+/**
+* 用于获取指定数量的流,截短长度不能超过 maxSize 。
+*/
+Stream<T> limit(long maxSize);
+
+/**
+* 用于映射每个元素到对应的结果
+*/
+<R> Stream<R> map(Function<? super T, ? extends R> mapper);
+
+/**
+* 根据提供的 Comparator进行排序。
+*/
+Stream<T> sorted(Comparator<? super T> comparator);
+
+/**
+* 在丢弃流的第一个 n元素后,返回由该流的 n元素组成的流。
+*/
+Stream<T> skip(long n);
+
+/**
+* 返回一个包含此流的元素的数组。
+*/
+Object[] toArray();
+
+/**
+* 使用提供的 generator函数返回一个包含此流的元素的数组,以分配返回的数组,以及分区执行或调整大小可能需要的任何其他数组。
+*/
+<A> A[] toArray(IntFunction<A[]> generator);
+
+/**
+* 合并流
+*/
+public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
+```
+
+### 实战
+
+本文列出 `Stream` 具有代表性的方法之使用,更多的使用方法还是要看 Api。
+
+```java
+@Test
+public void test() {
+ List<String> strings = Arrays.asList("abc", "def", "gkh", "abc");
+ //返回符合条件的stream
+ Stream<String> stringStream = strings.stream().filter(s -> "abc".equals(s));
+ //计算流符合条件的流的数量
+ long count = stringStream.count();
+
+ //forEach遍历->打印元素
+ strings.stream().forEach(System.out::println);
+
+ //limit 获取到1个元素的stream
+ Stream<String> limit = strings.stream().limit(1);
+ //toArray 比如我们想看这个limitStream里面是什么,比如转换成String[],比如循环
+ String[] array = limit.toArray(String[]::new);
+
+ //map 对每个元素进行操作返回新流
+ Stream<String> map = strings.stream().map(s -> s + "22");
+
+ //sorted 排序并打印
+ strings.stream().sorted().forEach(System.out::println);
+
+ //Collectors collect 把abc放入容器中
+ List<String> collect = strings.stream().filter(string -> "abc".equals(string)).collect(Collectors.toList());
+ //把list转为string,各元素用,号隔开
+ String mergedString = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.joining(","));
+
+ //对数组的统计,比如用
+ List<Integer> number = Arrays.asList(1, 2, 5, 4);
+
+ IntSummaryStatistics statistics = number.stream().mapToInt((x) -> x).summaryStatistics();
+ System.out.println("列表中最大的数 : "+statistics.getMax());
+ System.out.println("列表中最小的数 : "+statistics.getMin());
+ System.out.println("平均数 : "+statistics.getAverage());
+ System.out.println("所有数之和 : "+statistics.getSum());
+
+ //concat 合并流
+ List<String> strings2 = Arrays.asList("xyz", "jqx");
+ Stream.concat(strings2.stream(),strings.stream()).count();
+
+ //注意 一个Stream只能操作一次,不能断开,否则会报错。
+ Stream stream = strings.stream();
+ //第一次使用
+ stream.limit(2);
+ //第二次使用
+ stream.forEach(System.out::println);
+ //报错 java.lang.IllegalStateException: stream has already been operated upon or closed
+
+ //但是可以这样, 连续使用
+ stream.limit(2).forEach(System.out::println);
+}
+```
+
+### 延迟执行
+
+在执行返回 `Stream` 的方法时,并不立刻执行,而是等返回一个非 `Stream` 的方法后才执行。因为拿到 `Stream` 并不能直接用,而是需要处理成一个常规类型。这里的 `Stream` 可以想象成是二进制流(2 个完全不一样的东东),拿到也看不懂。
+
+我们下面分解一下 `filter` 方法。
+
+```java
+@Test
+public void laziness(){
+ List<String> strings = Arrays.asList("abc", "def", "gkh", "abc");
+ Stream<Integer> stream = strings.stream().filter(new Predicate() {
+ @Override
+ public boolean test(Object o) {
+ System.out.println("Predicate.test 执行");
+ return true;
+ }
+ });
+
+ System.out.println("count 执行");
+ stream.count();
+}
+/*-------执行结果--------*/
+count 执行
+Predicate.test 执行
+Predicate.test 执行
+Predicate.test 执行
+Predicate.test 执行
+```
+
+按执行顺序应该是先打印 4 次「`Predicate.test` 执行」,再打印「`count` 执行」。实际结果恰恰相反。说明 filter 中的方法并没有立刻执行,而是等调用`count()`方法后才执行。
+
+上面都是串行 `Stream` 的实例。并行 `parallelStream` 在使用方法上和串行一样。主要区别是 `parallelStream` 可多线程执行,是基于 ForkJoin 框架实现的,有时间大家可以了解一下 `ForkJoin` 框架和 `ForkJoinPool`。这里可以简单的理解它是通过线程池来实现的,这样就会涉及到线程安全,线程消耗等问题。下面我们通过代码来体验一下并行流的多线程执行。
+
+```java
+@Test
+public void parallelStreamTest(){
+ List<Integer> numbers = Arrays.asList(1, 2, 5, 4);
+ numbers.parallelStream() .forEach(num->System.out.println(Thread.currentThread().getName()+">>"+num));
+}
+//执行结果
+main>>5
+ForkJoinPool.commonPool-worker-2>>4
+ForkJoinPool.commonPool-worker-11>>1
+ForkJoinPool.commonPool-worker-9>>2
+```
+
+从结果中我们看到,for-each 用到的是多线程。
+
+### 小结
+
+从源码和实例中我们可以总结出一些 stream 的特点
+
+1. 通过简单的链式编程,使得它可以方便地对遍历处理后的数据进行再处理。
+2. 方法参数都是函数式接口类型
+3. 一个 Stream 只能操作一次,操作完就关闭了,继续使用这个 stream 会报错。
+4. Stream 不保存数据,不改变数据源
+
+## Optional
+
+在[阿里巴巴开发手册关于 Optional 的介绍](https://share.weiyun.com/ThuqEbD5)中这样写到:
+
+> 防止 NPE,是程序员的基本修养,注意 NPE 产生的场景:
+>
+> 1) 返回类型为基本数据类型,return 包装数据类型的对象时,自动拆箱有可能产生 NPE。
+>
+> 反例:public int f() { return Integer 对象}, 如果为 null,自动解箱抛 NPE。
+>
+> 2) 数据库的查询结果可能为 null。
+>
+> 3) 集合里的元素即使 isNotEmpty,取出的数据元素也可能为 null。
+>
+> 4) 远程调用返回对象时,一律要求进行空指针判断,防止 NPE。
+>
+> 5) 对于 Session 中获取的数据,建议进行 NPE 检查,避免空指针。
+>
+> 6) 级联调用 obj.getA().getB().getC();一连串调用,易产生 NPE。
+>
+> 正例:使用 JDK8 的 Optional 类来防止 NPE 问题。
+
+他建议使用 `Optional` 解决 NPE(`java.lang.NullPointerException`)问题,它就是为 NPE 而生的,其中可以包含空值或非空值。下面我们通过源码逐步揭开 `Optional` 的红盖头。
+
+假设有一个 `Zoo` 类,里面有个属性 `Dog`,需求要获取 `Dog` 的 `age`。
+
+```java
+class Zoo {
+ private Dog dog;
+}
+
+class Dog {
+ private int age;
+}
+```
+
+传统解决 NPE 的办法如下:
+
+```java
+Zoo zoo = getZoo();
+if(zoo != null){
+ Dog dog = zoo.getDog();
+ if(dog != null){
+ int age = dog.getAge();
+ System.out.println(age);
+ }
+}
+```
+
+层层判断对象非空,有人说这种方式很丑陋不优雅,我并不这么认为。反而觉得很整洁,易读,易懂。你们觉得呢?
+
+`Optional` 是这样的实现的:
+
+```java
+Optional.ofNullable(zoo).map(o -> o.getDog()).map(d -> d.getAge()).ifPresent(age ->
+ System.out.println(age)
+);
+```
+
+是不是简洁了很多呢?
+
+### 如何创建一个 Optional
+
+上例中`Optional.ofNullable`是其中一种创建 Optional 的方式。我们先看一下它的含义和其他创建 Optional 的源码方法。
+
+```java
+/**
+* Common instance for {@code empty()}. 全局EMPTY对象
+*/
+private static final Optional<?> EMPTY = new Optional<>();
+
+/**
+* Optional维护的值
+*/
+private final T value;
+
+/**
+* 如果value是null就返回EMPTY,否则就返回of(T)
+*/
+public static <T> Optional<T> ofNullable(T value) {
+ return value == null ? empty() : of(value);
+}
+/**
+* 返回 EMPTY 对象
+*/
+public static<T> Optional<T> empty() {
+ Optional<T> t = (Optional<T>) EMPTY;
+ return t;
+}
+/**
+* 返回Optional对象
+*/
+public static <T> Optional<T> of(T value) {
+ return new Optional<>(value);
+}
+/**
+* 私有构造方法,给value赋值
+*/
+private Optional(T value) {
+ this.value = Objects.requireNonNull(value);
+}
+/**
+* 所以如果of(T value) 的value是null,会抛出NullPointerException异常,这样貌似就没处理NPE问题
+*/
+public static <T> T requireNonNull(T obj) {
+ if (obj == null)
+ throw new NullPointerException();
+ return obj;
+}
+```
+
+`ofNullable` 方法和`of`方法唯一区别就是当 value 为 null 时,`ofNullable` 返回的是`EMPTY`,of 会抛出 `NullPointerException` 异常。如果需要把 `NullPointerException` 暴漏出来就用 `of`,否则就用 `ofNullable`。
+
+### `map()`相关方法。
+
+```java
+/**
+* 如果value为null,返回EMPTY,否则返回Optional封装的参数值
+*/
+public<U> Optional<U> map(Function<? super T, ? extends U> mapper) {
+ Objects.requireNonNull(mapper);
+ if (!isPresent())
+ return empty();
+ else {
+ return Optional.ofNullable(mapper.apply(value));
+ }
+}
+/**
+* 如果value为null,返回EMPTY,否则返回Optional封装的参数值,如果参数值返回null会抛 NullPointerException
+*/
+public<U> Optional<U> flatMap(Function<? super T, Optional<U>> mapper) {
+ Objects.requireNonNull(mapper);
+ if (!isPresent())
+ return empty();
+ else {
+ return Objects.requireNonNull(mapper.apply(value));
+ }
+}
+```
+
+**`map()` 和 `flatMap()` 有什么区别的?**
+
+**1.参数不一样,`map` 的参数上面看到过,`flatMap` 的参数是这样**
+
+```java
+class ZooFlat {
+ private DogFlat dog = new DogFlat();
+
+ public DogFlat getDog() {
+ return dog;
+ }
+ }
+
+class DogFlat {
+ private int age = 1;
+ public Optional<Integer> getAge() {
+ return Optional.ofNullable(age);
+ }
+}
+
+ZooFlat zooFlat = new ZooFlat();
+Optional.ofNullable(zooFlat).map(o -> o.getDog()).flatMap(d -> d.getAge()).ifPresent(age ->
+ System.out.println(age)
+);
+```
+
+**2.`flatMap()` 参数返回值如果是 null 会抛 `NullPointerException`,而 `map()` 返回`EMPTY`。**
+
+### 判断 value 是否为 null
+
+```java
+/**
+* value是否为null
+*/
+public boolean isPresent() {
+ return value != null;
+}
+/**
+* 如果value不为null执行consumer.accept
+*/
+public void ifPresent(Consumer<? super T> consumer) {
+ if (value != null)
+ consumer.accept(value);
+}
+```
+
+### 获取 value
+
+```java
+/**
+* Return the value if present, otherwise invoke {@code other} and return
+* the result of that invocation.
+* 如果value != null 返回value,否则返回other的执行结果
+*/
+public T orElseGet(Supplier<? extends T> other) {
+ return value != null ? value : other.get();
+}
+
+/**
+* 如果value != null 返回value,否则返回T
+*/
+public T orElse(T other) {
+ return value != null ? value : other;
+}
+
+/**
+* 如果value != null 返回value,否则抛出参数返回的异常
+*/
+public <X extends Throwable> T orElseThrow(Supplier<? extends X> exceptionSupplier) throws X {
+ if (value != null) {
+ return value;
+ } else {
+ throw exceptionSupplier.get();
+ }
+}
+/**
+* value为null抛出NoSuchElementException,不为空返回value。
+*/
+public T get() {
+ if (value == null) {
+ throw new NoSuchElementException("No value present");
+ }
+ return value;
+}
+```
+
+### 过滤值
+
+```java
+/**
+* 1. 如果是empty返回empty
+* 2. predicate.test(value)==true 返回this,否则返回empty
+*/
+public Optional<T> filter(Predicate<? super T> predicate) {
+ Objects.requireNonNull(predicate);
+ if (!isPresent())
+ return this;
+ else
+ return predicate.test(value) ? this : empty();
+}
+```
+
+### 小结
+
+看完 `Optional` 源码,`Optional` 的方法真的非常简单,值得注意的是如果坚决不想看见 `NPE`,就不要用 `of() `、 `get()` 、`flatMap(..)`。最后再综合用一下 `Optional` 的高频方法。
+
+```java
+Optional.ofNullable(zoo).map(o -> o.getDog()).map(d -> d.getAge()).filter(v->v==1).orElse(3);
+```
+
+## Date-Time API
+
+这是对`java.util.Date`强有力的补充,解决了 Date 类的大部分痛点:
+
+1. 非线程安全
+2. 时区处理麻烦
+3. 各种格式化、和时间计算繁琐
+4. 设计有缺陷,Date 类同时包含日期和时间;还有一个 java.sql.Date,容易混淆。
+
+我们从常用的时间实例来对比 java.util.Date 和新 Date 有什么区别。用`java.util.Date`的代码该改改了。
+
+### java.time 主要类
+
+`java.util.Date` 既包含日期又包含时间,而 `java.time` 把它们进行了分离
+
+```java
+LocalDateTime.class //日期+时间 format: yyyy-MM-ddTHH:mm:ss.SSS
+LocalDate.class //日期 format: yyyy-MM-dd
+LocalTime.class //时间 format: HH:mm:ss
+```
+
+### 格式化
+
+**Java 8 之前:**
+
+```java
+public void oldFormat(){
+ Date now = new Date();
+ //format yyyy-MM-dd HH:mm:ss
+ SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
+ String date = sdf.format(now);
+ System.out.println(String.format("date format : %s", date));
+
+ //format HH:mm:ss
+ SimpleDateFormat sdft = new SimpleDateFormat("HH:mm:ss");
+ String time = sdft.format(now);
+ System.out.println(String.format("time format : %s", time));
+
+ //format yyyy-MM-dd HH:mm:ss
+ SimpleDateFormat sdfdt = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
+ String datetime = sdfdt.format(now);
+ System.out.println(String.format("dateTime format : %s", datetime));
+}
+```
+
+**Java 8 之后:**
+
+```java
+public void newFormat(){
+ //format yyyy-MM-dd
+ LocalDate date = LocalDate.now();
+ System.out.println(String.format("date format : %s", date));
+
+ //format HH:mm:ss
+ LocalTime time = LocalTime.now().withNano(0);
+ System.out.println(String.format("time format : %s", time));
+
+ //format yyyy-MM-dd HH:mm:ss
+ LocalDateTime dateTime = LocalDateTime.now();
+ DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
+ String dateTimeStr = dateTime.format(dateTimeFormatter);
+ System.out.println(String.format("dateTime format : %s", dateTimeStr));
+}
+```
+
+### 字符串转日期格式
+
+**Java 8 之前:**
+
+```java
+//已弃用
+Date date = new Date("2021-01-26");
+//替换为
+SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
+Date date1 = sdf.parse("2021-01-26");
+```
+
+**Java 8 之后:**
+
+```java
+LocalDate date = LocalDate.of(2021, 1, 26);
+LocalDate.parse("2021-01-26");
+
+LocalDateTime dateTime = LocalDateTime.of(2021, 1, 26, 12, 12, 22);
+LocalDateTime.parse("2021-01-26 12:12:22");
+
+LocalTime time = LocalTime.of(12, 12, 22);
+LocalTime.parse("12:12:22");
+```
+
+**Java 8 之前** 转换都需要借助 `SimpleDateFormat` 类,而**Java 8 之后**只需要 `LocalDate`、`LocalTime`、`LocalDateTime`的 `of` 或 `parse` 方法。
+
+### 日期计算
+
+下面仅以**一周后日期**为例,其他单位(年、月、日、1/2 日、时等等)大同小异。另外,这些单位都在 _java.time.temporal.ChronoUnit_ 枚举中定义。
+
+**Java 8 之前:**
+
+```java
+public void afterDay(){
+ //一周后的日期
+ SimpleDateFormat formatDate = new SimpleDateFormat("yyyy-MM-dd");
+ Calendar ca = Calendar.getInstance();
+ ca.add(Calendar.DATE, 7);
+ Date d = ca.getTime();
+ String after = formatDate.format(d);
+ System.out.println("一周后日期:" + after);
+
+ //算两个日期间隔多少天,计算间隔多少年,多少月方法类似
+ String dates1 = "2021-12-23";
+ String dates2 = "2021-02-26";
+ SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
+ Date date1 = format.parse(dates1);
+ Date date2 = format.parse(dates2);
+ int day = (int) ((date1.getTime() - date2.getTime()) / (1000 * 3600 * 24));
+ System.out.println(dates2 + "和" + dates2 + "相差" + day + "天");
+ //结果:2021-12-23和2021-12-23相差300天
+}
+```
+
+**Java 8 之后:**
+
+```java
+public void pushWeek(){
+ //一周后的日期
+ LocalDate localDate = LocalDate.now();
+ //方法1
+ LocalDate after = localDate.plus(1, ChronoUnit.WEEKS);
+ //方法2
+ LocalDate after2 = localDate.plusWeeks(1);
+ System.out.println("一周后日期:" + after);
+
+ //算两个日期间隔多少天,计算间隔多少年,多少月
+ LocalDate date1 = LocalDate.parse("2021-02-26");
+ LocalDate date2 = LocalDate.parse("2021-12-23");
+ Period period = Period.between(date1, date2);
+ System.out.println("date1 到 date2 相隔:"
+ + period.getYears() + "年"
+ + period.getMonths() + "月"
+ + period.getDays() + "天");
+ //打印结果是 “date1 到 date2 相隔:0年9月27天”
+ //这里period.getDays()得到的天是抛去年月以外的天数,并不是总天数
+ //如果要获取纯粹的总天数应该用下面的方法
+ long day = date2.toEpochDay() - date1.toEpochDay();
+ System.out.println(date2 + "和" + date2 + "相差" + day + "天");
+ //打印结果:2021-12-23和2021-12-23相差300天
+}
+```
+
+### 获取指定日期
+
+除了日期计算繁琐,获取特定一个日期也很麻烦,比如获取本月最后一天,第一天。
+
+**Java 8 之前:**
+
+```java
+public void getDay() {
+
+ SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
+ //获取当前月第一天:
+ Calendar c = Calendar.getInstance();
+ c.set(Calendar.DAY_OF_MONTH, 1);
+ String first = format.format(c.getTime());
+ System.out.println("first day:" + first);
+
+ //获取当前月最后一天
+ Calendar ca = Calendar.getInstance();
+ ca.set(Calendar.DAY_OF_MONTH, ca.getActualMaximum(Calendar.DAY_OF_MONTH));
+ String last = format.format(ca.getTime());
+ System.out.println("last day:" + last);
+
+ //当年最后一天
+ Calendar currCal = Calendar.getInstance();
+ Calendar calendar = Calendar.getInstance();
+ calendar.clear();
+ calendar.set(Calendar.YEAR, currCal.get(Calendar.YEAR));
+ calendar.roll(Calendar.DAY_OF_YEAR, -1);
+ Date time = calendar.getTime();
+ System.out.println("last day:" + format.format(time));
+}
+```
+
+**Java 8 之后:**
+
+```java
+public void getDayNew() {
+ LocalDate today = LocalDate.now();
+ //获取当前月第一天:
+ LocalDate firstDayOfThisMonth = today.with(TemporalAdjusters.firstDayOfMonth());
+ // 取本月最后一天
+ LocalDate lastDayOfThisMonth = today.with(TemporalAdjusters.lastDayOfMonth());
+ //取下一天:
+ LocalDate nextDay = lastDayOfThisMonth.plusDays(1);
+ //当年最后一天
+ LocalDate lastday = today.with(TemporalAdjusters.lastDayOfYear());
+ //2021年最后一个周日,如果用Calendar是不得烦死。
+ LocalDate lastMondayOf2021 = LocalDate.parse("2021-12-31").with(TemporalAdjusters.lastInMonth(DayOfWeek.SUNDAY));
+}
+```
+
+`java.time.temporal.TemporalAdjusters` 里面还有很多便捷的算法,这里就不带大家看 Api 了,都很简单,看了秒懂。
+
+### JDBC 和 java8
+
+现在 jdbc 时间类型和 java8 时间类型对应关系是
+
+1. `Date` ---> `LocalDate`
+2. `Time` ---> `LocalTime`
+3. `Timestamp` ---> `LocalDateTime`
+
+而之前统统对应 `Date`,也只有 `Date`。
+
+### 时区
+
+> 时区:正式的时区划分为每隔经度 15° 划分一个时区,全球共 24 个时区,每个时区相差 1 小时。但为了行政上的方便,常将 1 个国家或 1 个省份划在一起,比如我国幅员宽广,大概横跨 5 个时区,实际上只用东八时区的标准时即北京时间为准。
+
+`java.util.Date` 对象实质上存的是 1970 年 1 月 1 日 0 点( GMT)至 Date 对象所表示时刻所经过的毫秒数。也就是说不管在哪个时区 new Date,它记录的毫秒数都一样,和时区无关。但在使用上应该把它转换成当地时间,这就涉及到了时间的国际化。`java.util.Date` 本身并不支持国际化,需要借助 `TimeZone`。
+
+```java
+//北京时间:Wed Jan 27 14:05:29 CST 2021
+Date date = new Date();
+
+SimpleDateFormat bjSdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
+//北京时区
+bjSdf.setTimeZone(TimeZone.getTimeZone("Asia/Shanghai"));
+System.out.println("毫秒数:" + date.getTime() + ", 北京时间:" + bjSdf.format(date));
+
+//东京时区
+SimpleDateFormat tokyoSdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
+tokyoSdf.setTimeZone(TimeZone.getTimeZone("Asia/Tokyo")); // 设置东京时区
+System.out.println("毫秒数:" + date.getTime() + ", 东京时间:" + tokyoSdf.format(date));
+
+//如果直接print会自动转成当前时区的时间
+System.out.println(date);
+//Wed Jan 27 14:05:29 CST 2021
+```
+
+在新特性中引入了 `java.time.ZonedDateTime ` 来表示带时区的时间。它可以看成是 `LocalDateTime + ZoneId`。
+
+```java
+//当前时区时间
+ZonedDateTime zonedDateTime = ZonedDateTime.now();
+System.out.println("当前时区时间: " + zonedDateTime);
+
+//东京时间
+ZoneId zoneId = ZoneId.of(ZoneId.SHORT_IDS.get("JST"));
+ZonedDateTime tokyoTime = zonedDateTime.withZoneSameInstant(zoneId);
+System.out.println("东京时间: " + tokyoTime);
+
+// ZonedDateTime 转 LocalDateTime
+LocalDateTime localDateTime = tokyoTime.toLocalDateTime();
+System.out.println("东京时间转当地时间: " + localDateTime);
+
+//LocalDateTime 转 ZonedDateTime
+ZonedDateTime localZoned = localDateTime.atZone(ZoneId.systemDefault());
+System.out.println("本地时区时间: " + localZoned);
+
+//打印结果
+当前时区时间: 2021-01-27T14:43:58.735+08:00[Asia/Shanghai]
+东京时间: 2021-01-27T15:43:58.735+09:00[Asia/Tokyo]
+东京时间转当地时间: 2021-01-27T15:43:58.735
+当地时区时间: 2021-01-27T15:53:35.618+08:00[Asia/Shanghai]
+```
+
+### 小结
+
+通过上面比较新老 `Date` 的不同,当然只列出部分功能上的区别,更多功能还得自己去挖掘。总之 date-time-api 给日期操作带来了福利。在日常工作中遇到 date 类型的操作,第一考虑的是 date-time-api,实在解决不了再考虑老的 Date。
+
+## 总结
+
+我们梳理总结的 java 8 新特性有
+
+- Interface & functional Interface
+- Lambda
+- Stream
+- Optional
+- Date time-api
+
+这些都是开发当中比较常用的特性。梳理下来发现它们真香,而我却没有更早的应用。总觉得学习 java 8 新特性比较麻烦,一直使用老的实现方式。其实这些新特性几天就可以掌握,一但掌握,效率会有很大的提高。其实我们涨工资也是涨的学习的钱,不学习终究会被淘汰,35 岁危机会提前来临。
diff --git a/docs/java/new-features/java8-tutorial-translate.md b/docs/java/new-features/java8-tutorial-translate.md
new file mode 100644
index 00000000000..97bb45cf94e
--- /dev/null
+++ b/docs/java/new-features/java8-tutorial-translate.md
@@ -0,0 +1,905 @@
+# 《Java8指南》中文翻译
+
+随着 Java 8 的普及度越来越高,很多人都提到面试中关于Java 8 也是非常常问的知识点。应各位要求和需要,我打算对这部分知识做一个总结。本来准备自己总结的,后面看到Github 上有一个相关的仓库,地址:
+[https://github.com/winterbe/java8-tutorial](https://github.com/winterbe/java8-tutorial)。这个仓库是英文的,我对其进行了翻译并添加和修改了部分内容,下面是正文。
+
+------
+
+欢迎阅读我对Java 8的介绍。本教程将逐步指导您完成所有新语言功能。 在简短的代码示例的基础上,您将学习如何使用默认接口方法,lambda表达式,方法引用和可重复注释。 在本文的最后,您将熟悉最新的 API 更改,如流,函数式接口(Functional Interfaces),Map 类的扩展和新的 Date API。 没有大段枯燥的文字,只有一堆注释的代码片段。
+
+
+### 接口的默认方法(Default Methods for Interfaces)
+
+Java 8使我们能够通过使用 `default` 关键字向接口添加非抽象方法实现。 此功能也称为[虚拟扩展方法](http://stackoverflow.com/a/24102730)。
+
+第一个例子:
+
+```java
+interface Formula{
+
+ double calculate(int a);
+
+ default double sqrt(int a) {
+ return Math.sqrt(a);
+ }
+
+}
+```
+
+Formula 接口中除了抽象方法计算接口公式还定义了默认方法 `sqrt`。 实现该接口的类只需要实现抽象方法 `calculate`。 默认方法`sqrt` 可以直接使用。当然你也可以直接通过接口创建对象,然后实现接口中的默认方法就可以了,我们通过代码演示一下这种方式。
+
+```java
+public class Main {
+
+ public static void main(String[] args) {
+ // 通过匿名内部类方式访问接口
+ Formula formula = new Formula() {
+ @Override
+ public double calculate(int a) {
+ return sqrt(a * 100);
+ }
+ };
+
+ System.out.println(formula.calculate(100)); // 100.0
+ System.out.println(formula.sqrt(16)); // 4.0
+
+ }
+
+}
+```
+
+ formula 是作为匿名对象实现的。该代码非常容易理解,6行代码实现了计算 `sqrt(a * 100)`。在下一节中,我们将会看到在 Java 8 中实现单个方法对象有一种更好更方便的方法。
+
+**译者注:** 不管是抽象类还是接口,都可以通过匿名内部类的方式访问。不能通过抽象类或者接口直接创建对象。对于上面通过匿名内部类方式访问接口,我们可以这样理解:一个内部类实现了接口里的抽象方法并且返回一个内部类对象,之后我们让接口的引用来指向这个对象。
+
+### Lambda表达式(Lambda expressions)
+
+首先看看在老版本的Java中是如何排列字符串的:
+
+```java
+List<String> names = Arrays.asList("peter", "anna", "mike", "xenia");
+
+Collections.sort(names, new Comparator<String>() {
+ @Override
+ public int compare(String a, String b) {
+ return b.compareTo(a);
+ }
+});
+```
+
+只需要给静态方法` Collections.sort` 传入一个 List 对象以及一个比较器来按指定顺序排列。通常做法都是创建一个匿名的比较器对象然后将其传递给 `sort` 方法。
+
+在Java 8 中你就没必要使用这种传统的匿名对象的方式了,Java 8提供了更简洁的语法,lambda表达式:
+
+```java
+Collections.sort(names, (String a, String b) -> {
+ return b.compareTo(a);
+});
+```
+
+可以看出,代码变得更短且更具有可读性,但是实际上还可以写得更短:
+
+```java
+Collections.sort(names, (String a, String b) -> b.compareTo(a));
+```
+
+对于函数体只有一行代码的,你可以去掉大括号{}以及return关键字,但是你还可以写得更短点:
+
+```java
+names.sort((a, b) -> b.compareTo(a));
+```
+
+List 类本身就有一个 `sort` 方法。并且Java编译器可以自动推导出参数类型,所以你可以不用再写一次类型。接下来我们看看lambda表达式还有什么其他用法。
+
+### 函数式接口(Functional Interfaces)
+
+**译者注:** 原文对这部分解释不太清楚,故做了修改!
+
+Java 语言设计者们投入了大量精力来思考如何使现有的函数友好地支持Lambda。最终采取的方法是:增加函数式接口的概念。**“函数式接口”是指仅仅只包含一个抽象方法,但是可以有多个非抽象方法(也就是上面提到的默认方法)的接口。** 像这样的接口,可以被隐式转换为lambda表达式。`java.lang.Runnable` 与 `java.util.concurrent.Callable` 是函数式接口最典型的两个例子。Java 8增加了一种特殊的注解`@FunctionalInterface`,但是这个注解通常不是必须的(某些情况建议使用),只要接口只包含一个抽象方法,虚拟机会自动判断该接口为函数式接口。一般建议在接口上使用`@FunctionalInterface` 注解进行声明,这样的话,编译器如果发现你标注了这个注解的接口有多于一个抽象方法的时候会报错的,如下图所示
+
+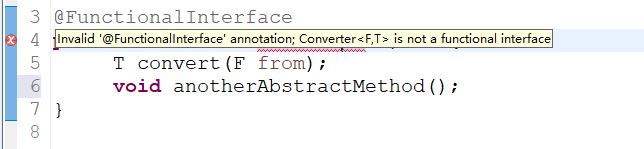
+
+示例:
+
+```java
+@FunctionalInterface
+public interface Converter<F, T> {
+ T convert(F from);
+}
+```
+
+```java
+ // TODO 将数字字符串转换为整数类型
+ Converter<String, Integer> converter = (from) -> Integer.valueOf(from);
+ Integer converted = converter.convert("123");
+ System.out.println(converted.getClass()); //class java.lang.Integer
+```
+
+**译者注:** 大部分函数式接口都不用我们自己写,Java8都给我们实现好了,这些接口都在java.util.function包里。
+
+### 方法和构造函数引用(Method and Constructor References)
+
+前一节中的代码还可以通过静态方法引用来表示:
+
+```java
+ Converter<String, Integer> converter = Integer::valueOf;
+ Integer converted = converter.convert("123");
+ System.out.println(converted.getClass()); //class java.lang.Integer
+```
+Java 8允许您通过`::`关键字传递方法或构造函数的引用。 上面的示例显示了如何引用静态方法。 但我们也可以引用对象方法:
+
+```java
+class Something {
+ String startsWith(String s) {
+ return String.valueOf(s.charAt(0));
+ }
+}
+```
+
+```java
+Something something = new Something();
+Converter<String, String> converter = something::startsWith;
+String converted = converter.convert("Java");
+System.out.println(converted); // "J"
+```
+
+接下来看看构造函数是如何使用`::`关键字来引用的,首先我们定义一个包含多个构造函数的简单类:
+
+```java
+class Person {
+ String firstName;
+ String lastName;
+
+ Person() {}
+
+ Person(String firstName, String lastName) {
+ this.firstName = firstName;
+ this.lastName = lastName;
+ }
+}
+```
+接下来我们指定一个用来创建Person对象的对象工厂接口:
+
+```java
+interface PersonFactory<P extends Person> {
+ P create(String firstName, String lastName);
+}
+```
+
+这里我们使用构造函数引用来将他们关联起来,而不是手动实现一个完整的工厂:
+
+```java
+PersonFactory<Person> personFactory = Person::new;
+Person person = personFactory.create("Peter", "Parker");
+```
+我们只需要使用 `Person::new` 来获取Person类构造函数的引用,Java编译器会自动根据`PersonFactory.create`方法的参数类型来选择合适的构造函数。
+
+### Lambda 表达式作用域(Lambda Scopes)
+
+#### 访问局部变量
+
+我们可以直接在 lambda 表达式中访问外部的局部变量:
+
+```java
+final int num = 1;
+Converter<Integer, String> stringConverter =
+ (from) -> String.valueOf(from + num);
+
+stringConverter.convert(2); // 3
+```
+
+但是和匿名对象不同的是,这里的变量num可以不用声明为final,该代码同样正确:
+
+```java
+int num = 1;
+Converter<Integer, String> stringConverter =
+ (from) -> String.valueOf(from + num);
+
+stringConverter.convert(2); // 3
+```
+
+不过这里的 num 必须不可被后面的代码修改(即隐性的具有final的语义),例如下面的就无法编译:
+
+```java
+int num = 1;
+Converter<Integer, String> stringConverter =
+ (from) -> String.valueOf(from + num);
+num = 3;//在lambda表达式中试图修改num同样是不允许的。
+```
+
+#### 访问字段和静态变量
+
+与局部变量相比,我们对lambda表达式中的实例字段和静态变量都有读写访问权限。 该行为和匿名对象是一致的。
+
+```java
+class Lambda4 {
+ static int outerStaticNum;
+ int outerNum;
+
+ void testScopes() {
+ Converter<Integer, String> stringConverter1 = (from) -> {
+ outerNum = 23;
+ return String.valueOf(from);
+ };
+
+ Converter<Integer, String> stringConverter2 = (from) -> {
+ outerStaticNum = 72;
+ return String.valueOf(from);
+ };
+ }
+}
+```
+
+#### 访问默认接口方法
+
+还记得第一节中的 formula 示例吗? `Formula` 接口定义了一个默认方法`sqrt`,可以从包含匿名对象的每个 formula 实例访问该方法。 这不适用于lambda表达式。
+
+无法从 lambda 表达式中访问默认方法,故以下代码无法编译:
+
+```java
+Formula formula = (a) -> sqrt(a * 100);
+```
+
+### 内置函数式接口(Built-in Functional Interfaces)
+
+JDK 1.8 API包含许多内置函数式接口。 其中一些接口在老版本的 Java 中是比较常见的比如: `Comparator` 或`Runnable`,这些接口都增加了`@FunctionalInterface`注解以便能用在 lambda 表达式上。
+
+但是 Java 8 API 同样还提供了很多全新的函数式接口来让你的编程工作更加方便,有一些接口是来自 [Google Guava](https://code.google.com/p/guava-libraries/) 库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
+
+#### Predicate
+
+Predicate 接口是只有一个参数的返回布尔类型值的 **断言型** 接口。该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非):
+
+**译者注:** Predicate 接口源码如下
+
+```java
+package java.util.function;
+import java.util.Objects;
+
+@FunctionalInterface
+public interface Predicate<T> {
+
+ // 该方法是接受一个传入类型,返回一个布尔值.此方法应用于判断.
+ boolean test(T t);
+
+ //and方法与关系型运算符"&&"相似,两边都成立才返回true
+ default Predicate<T> and(Predicate<? super T> other) {
+ Objects.requireNonNull(other);
+ return (t) -> test(t) && other.test(t);
+ }
+ // 与关系运算符"!"相似,对判断进行取反
+ default Predicate<T> negate() {
+ return (t) -> !test(t);
+ }
+ //or方法与关系型运算符"||"相似,两边只要有一个成立就返回true
+ default Predicate<T> or(Predicate<? super T> other) {
+ Objects.requireNonNull(other);
+ return (t) -> test(t) || other.test(t);
+ }
+ // 该方法接收一个Object对象,返回一个Predicate类型.此方法用于判断第一个test的方法与第二个test方法相同(equal).
+ static <T> Predicate<T> isEqual(Object targetRef) {
+ return (null == targetRef)
+ ? Objects::isNull
+ : object -> targetRef.equals(object);
+ }
+```
+
+示例:
+
+```java
+Predicate<String> predicate = (s) -> s.length() > 0;
+
+predicate.test("foo"); // true
+predicate.negate().test("foo"); // false
+
+Predicate<Boolean> nonNull = Objects::nonNull;
+Predicate<Boolean> isNull = Objects::isNull;
+
+Predicate<String> isEmpty = String::isEmpty;
+Predicate<String> isNotEmpty = isEmpty.negate();
+```
+
+#### Function
+
+Function 接口接受一个参数并生成结果。默认方法可用于将多个函数链接在一起(compose, andThen):
+
+**译者注:** Function 接口源码如下
+
+```java
+
+package java.util.function;
+
+import java.util.Objects;
+
+@FunctionalInterface
+public interface Function<T, R> {
+
+ //将Function对象应用到输入的参数上,然后返回计算结果。
+ R apply(T t);
+ //将两个Function整合,并返回一个能够执行两个Function对象功能的Function对象。
+ default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
+ Objects.requireNonNull(before);
+ return (V v) -> apply(before.apply(v));
+ }
+ //
+ default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
+ Objects.requireNonNull(after);
+ return (T t) -> after.apply(apply(t));
+ }
+
+ static <T> Function<T, T> identity() {
+ return t -> t;
+ }
+}
+```
+
+
+
+```java
+Function<String, Integer> toInteger = Integer::valueOf;
+Function<String, String> backToString = toInteger.andThen(String::valueOf);
+backToString.apply("123"); // "123"
+```
+
+#### Supplier
+
+Supplier 接口产生给定泛型类型的结果。 与 Function 接口不同,Supplier 接口不接受参数。
+
+```java
+Supplier<Person> personSupplier = Person::new;
+personSupplier.get(); // new Person
+```
+
+#### Consumer
+
+Consumer 接口表示要对单个输入参数执行的操作。
+
+```java
+Consumer<Person> greeter = (p) -> System.out.println("Hello, " + p.firstName);
+greeter.accept(new Person("Luke", "Skywalker"));
+```
+
+#### Comparator
+
+Comparator 是老Java中的经典接口, Java 8在此之上添加了多种默认方法:
+
+```java
+Comparator<Person> comparator = (p1, p2) -> p1.firstName.compareTo(p2.firstName);
+
+Person p1 = new Person("John", "Doe");
+Person p2 = new Person("Alice", "Wonderland");
+
+comparator.compare(p1, p2); // > 0
+comparator.reversed().compare(p1, p2); // < 0
+```
+
+## Optional
+
+Optional不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optional的工作原理。
+
+Optional 是一个简单的容器,其值可能是null或者不是null。在Java 8之前一般某个函数应该返回非空对象但是有时却什么也没有返回,而在Java 8中,你应该返回 Optional 而不是 null。
+
+译者注:示例中每个方法的作用已经添加。
+
+```java
+//of():为非null的值创建一个Optional
+Optional<String> optional = Optional.of("bam");
+// isPresent(): 如果值存在返回true,否则返回false
+optional.isPresent(); // true
+//get():如果Optional有值则将其返回,否则抛出NoSuchElementException
+optional.get(); // "bam"
+//orElse():如果有值则将其返回,否则返回指定的其它值
+optional.orElse("fallback"); // "bam"
+//ifPresent():如果Optional实例有值则为其调用consumer,否则不做处理
+optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b"
+```
+
+推荐阅读:[[Java8]如何正确使用Optional](https://blog.kaaass.net/archives/764)
+
+## Streams(流)
+
+`java.util.Stream` 表示能应用在一组元素上一次执行的操作序列。Stream 操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,这样你就可以将多个操作依次串起来。Stream 的创建需要指定一个数据源,比如` java.util.Collection` 的子类,List 或者 Set, Map 不支持。Stream 的操作可以串行执行或者并行执行。
+
+首先看看Stream是怎么用,首先创建实例代码需要用到的数据List:
+
+```java
+List<String> stringList = new ArrayList<>();
+stringList.add("ddd2");
+stringList.add("aaa2");
+stringList.add("bbb1");
+stringList.add("aaa1");
+stringList.add("bbb3");
+stringList.add("ccc");
+stringList.add("bbb2");
+stringList.add("ddd1");
+```
+
+Java 8扩展了集合类,可以通过 Collection.stream() 或者 Collection.parallelStream() 来创建一个Stream。下面几节将详细解释常用的Stream操作:
+
+### Filter(过滤)
+
+过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于**中间操作**,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。
+
+```java
+ // 测试 Filter(过滤)
+ stringList
+ .stream()
+ .filter((s) -> s.startsWith("a"))
+ .forEach(System.out::println);//aaa2 aaa1
+```
+
+forEach 是为 Lambda 而设计的,保持了最紧凑的风格。而且 Lambda 表达式本身是可以重用的,非常方便。
+
+### Sorted(排序)
+
+排序是一个 **中间操作**,返回的是排序好后的 Stream。**如果你不指定一个自定义的 Comparator 则会使用默认排序。**
+
+```java
+ // 测试 Sort (排序)
+ stringList
+ .stream()
+ .sorted()
+ .filter((s) -> s.startsWith("a"))
+ .forEach(System.out::println);// aaa1 aaa2
+```
+
+需要注意的是,排序只创建了一个排列好后的Stream,而不会影响原有的数据源,排序之后原数据stringList是不会被修改的:
+
+```java
+ System.out.println(stringList);// ddd2, aaa2, bbb1, aaa1, bbb3, ccc, bbb2, ddd1
+```
+
+### Map(映射)
+
+中间操作 map 会将元素根据指定的 Function 接口来依次将元素转成另外的对象。
+
+下面的示例展示了将字符串转换为大写字符串。你也可以通过map来将对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
+
+```java
+ // 测试 Map 操作
+ stringList
+ .stream()
+ .map(String::toUpperCase)
+ .sorted((a, b) -> b.compareTo(a))
+ .forEach(System.out::println);// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "BBB1", "AAA2", "AAA1"
+```
+
+
+
+### Match(匹配)
+
+Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配整个Stream。所有的匹配操作都是 **最终操作** ,并返回一个 boolean 类型的值。
+
+```java
+ // 测试 Match (匹配)操作
+ boolean anyStartsWithA =
+ stringList
+ .stream()
+ .anyMatch((s) -> s.startsWith("a"));
+ System.out.println(anyStartsWithA); // true
+
+ boolean allStartsWithA =
+ stringList
+ .stream()
+ .allMatch((s) -> s.startsWith("a"));
+
+ System.out.println(allStartsWithA); // false
+
+ boolean noneStartsWithZ =
+ stringList
+ .stream()
+ .noneMatch((s) -> s.startsWith("z"));
+
+ System.out.println(noneStartsWithZ); // true
+```
+
+
+
+### Count(计数)
+
+计数是一个 **最终操作**,返回Stream中元素的个数,**返回值类型是 long**。
+
+```java
+ //测试 Count (计数)操作
+ long startsWithB =
+ stringList
+ .stream()
+ .filter((s) -> s.startsWith("b"))
+ .count();
+ System.out.println(startsWithB); // 3
+```
+
+### Reduce(规约)
+
+这是一个 **最终操作** ,允许通过指定的函数来将stream中的多个元素规约为一个元素,规约后的结果是通过Optional 接口表示的:
+
+```java
+ //测试 Reduce (规约)操作
+ Optional<String> reduced =
+ stringList
+ .stream()
+ .sorted()
+ .reduce((s1, s2) -> s1 + "#" + s2);
+
+ reduced.ifPresent(System.out::println);//aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2
+```
+
+
+
+**译者注:** 这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于`Integer sum = integers.reduce(0, (a, b) -> a+b);`也有没有起始值的情况,这时会把 Stream 的前面两个元素组合起来,返回的是 Optional。
+
+```java
+// 字符串连接,concat = "ABCD"
+String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
+// 求最小值,minValue = -3.0
+double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
+// 求和,sumValue = 10, 有起始值
+int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
+// 求和,sumValue = 10, 无起始值
+sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
+// 过滤,字符串连接,concat = "ace"
+concat = Stream.of("a", "B", "c", "D", "e", "F").
+ filter(x -> x.compareTo("Z") > 0).
+ reduce("", String::concat);
+```
+
+上面代码例如第一个示例的 reduce(),第一个参数(空白字符)即为起始值,第二个参数(String::concat)为 BinaryOperator。这类有起始值的 reduce() 都返回具体的对象。而对于第四个示例没有起始值的 reduce(),由于可能没有足够的元素,返回的是 Optional,请留意这个区别。更多内容查看: [IBM:Java 8 中的 Streams API 详解](https://www.ibm.com/developerworks/cn/java/j-lo-java8streamapi/index.html)
+
+## Parallel Streams(并行流)
+
+前面提到过Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
+
+下面的例子展示了是如何通过并行Stream来提升性能:
+
+首先我们创建一个没有重复元素的大表:
+
+```java
+int max = 1000000;
+List<String> values = new ArrayList<>(max);
+for (int i = 0; i < max; i++) {
+ UUID uuid = UUID.randomUUID();
+ values.add(uuid.toString());
+}
+```
+
+我们分别用串行和并行两种方式对其进行排序,最后看看所用时间的对比。
+
+### Sequential Sort(串行排序)
+
+```java
+//串行排序
+long t0 = System.nanoTime();
+long count = values.stream().sorted().count();
+System.out.println(count);
+
+long t1 = System.nanoTime();
+
+long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
+System.out.println(String.format("sequential sort took: %d ms", millis));
+```
+
+```
+1000000
+sequential sort took: 709 ms//串行排序所用的时间
+```
+
+### Parallel Sort(并行排序)
+
+```java
+//并行排序
+long t0 = System.nanoTime();
+
+long count = values.parallelStream().sorted().count();
+System.out.println(count);
+
+long t1 = System.nanoTime();
+
+long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
+System.out.println(String.format("parallel sort took: %d ms", millis));
+
+```
+
+```java
+1000000
+parallel sort took: 475 ms//串行排序所用的时间
+```
+
+上面两个代码几乎是一样的,但是并行版的快了 50% 左右,唯一需要做的改动就是将 `stream()` 改为`parallelStream()`。
+
+## Maps
+
+前面提到过,Map 类型不支持 streams,不过Map提供了一些新的有用的方法来处理一些日常任务。Map接口本身没有可用的 `stream()`方法,但是你可以在键,值上创建专门的流或者通过 `map.keySet().stream()`,`map.values().stream()`和`map.entrySet().stream()`。
+
+此外,Maps 支持各种新的和有用的方法来执行常见任务。
+
+```java
+Map<Integer, String> map = new HashMap<>();
+
+for (int i = 0; i < 10; i++) {
+ map.putIfAbsent(i, "val" + i);
+}
+
+map.forEach((id, val) -> System.out.println(val));//val0 val1 val2 val3 val4 val5 val6 val7 val8 val9
+```
+
+`putIfAbsent` 阻止我们在null检查时写入额外的代码;`forEach`接受一个 consumer 来对 map 中的每个元素操作。
+
+此示例显示如何使用函数在 map 上计算代码:
+
+```java
+map.computeIfPresent(3, (num, val) -> val + num);
+map.get(3); // val33
+
+map.computeIfPresent(9, (num, val) -> null);
+map.containsKey(9); // false
+
+map.computeIfAbsent(23, num -> "val" + num);
+map.containsKey(23); // true
+
+map.computeIfAbsent(3, num -> "bam");
+map.get(3); // val33
+```
+
+接下来展示如何在Map里删除一个键值全都匹配的项:
+
+```java
+map.remove(3, "val3");
+map.get(3); // val33
+map.remove(3, "val33");
+map.get(3); // null
+```
+
+另外一个有用的方法:
+
+```java
+map.getOrDefault(42, "not found"); // not found
+```
+
+对Map的元素做合并也变得很容易了:
+
+```java
+map.merge(9, "val9", (value, newValue) -> value.concat(newValue));
+map.get(9); // val9
+map.merge(9, "concat", (value, newValue) -> value.concat(newValue));
+map.get(9); // val9concat
+```
+
+Merge 做的事情是如果键名不存在则插入,否则对原键对应的值做合并操作并重新插入到map中。
+
+## Date API(日期相关API)
+
+Java 8在 `java.time` 包下包含一个全新的日期和时间API。新的Date API与Joda-Time库相似,但它们不一样。以下示例涵盖了此新 API 的最重要部分。译者对这部分内容参考相关书籍做了大部分修改。
+
+**译者注(总结):**
+
+- Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代 `System.currentTimeMillis()` 来获取当前的微秒数。某一个特定的时间点也可以使用 `Instant` 类来表示,`Instant` 类也可以用来创建旧版本的`java.util.Date` 对象。
+
+- 在新API中时区使用 ZoneId 来表示。时区可以很方便的使用静态方法of来获取到。 抽象类`ZoneId`(在`java.time`包中)表示一个区域标识符。 它有一个名为`getAvailableZoneIds`的静态方法,它返回所有区域标识符。
+
+- jdk1.8中新增了 LocalDate 与 LocalDateTime等类来解决日期处理方法,同时引入了一个新的类DateTimeFormatter 来解决日期格式化问题。可以使用Instant代替 Date,LocalDateTime代替 Calendar,DateTimeFormatter 代替 SimpleDateFormat。
+
+
+
+### Clock
+
+Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代 `System.currentTimeMillis()` 来获取当前的微秒数。某一个特定的时间点也可以使用 `Instant` 类来表示,`Instant` 类也可以用来创建旧版本的`java.util.Date` 对象。
+
+```java
+Clock clock = Clock.systemDefaultZone();
+long millis = clock.millis();
+System.out.println(millis);//1552379579043
+Instant instant = clock.instant();
+System.out.println(instant);
+Date legacyDate = Date.from(instant); //2019-03-12T08:46:42.588Z
+System.out.println(legacyDate);//Tue Mar 12 16:32:59 CST 2019
+```
+
+### Timezones(时区)
+
+在新API中时区使用 ZoneId 来表示。时区可以很方便的使用静态方法of来获取到。 抽象类`ZoneId`(在`java.time`包中)表示一个区域标识符。 它有一个名为`getAvailableZoneIds`的静态方法,它返回所有区域标识符。
+
+```java
+//输出所有区域标识符
+System.out.println(ZoneId.getAvailableZoneIds());
+
+ZoneId zone1 = ZoneId.of("Europe/Berlin");
+ZoneId zone2 = ZoneId.of("Brazil/East");
+System.out.println(zone1.getRules());// ZoneRules[currentStandardOffset=+01:00]
+System.out.println(zone2.getRules());// ZoneRules[currentStandardOffset=-03:00]
+```
+
+### LocalTime(本地时间)
+
+LocalTime 定义了一个没有时区信息的时间,例如 晚上10点或者 17:30:15。下面的例子使用前面代码创建的时区创建了两个本地时间。之后比较时间并以小时和分钟为单位计算两个时间的时间差:
+
+```java
+LocalTime now1 = LocalTime.now(zone1);
+LocalTime now2 = LocalTime.now(zone2);
+System.out.println(now1.isBefore(now2)); // false
+
+long hoursBetween = ChronoUnit.HOURS.between(now1, now2);
+long minutesBetween = ChronoUnit.MINUTES.between(now1, now2);
+
+System.out.println(hoursBetween); // -3
+System.out.println(minutesBetween); // -239
+```
+
+LocalTime 提供了多种工厂方法来简化对象的创建,包括解析时间字符串.
+
+```java
+LocalTime late = LocalTime.of(23, 59, 59);
+System.out.println(late); // 23:59:59
+DateTimeFormatter germanFormatter =
+ DateTimeFormatter
+ .ofLocalizedTime(FormatStyle.SHORT)
+ .withLocale(Locale.GERMAN);
+
+LocalTime leetTime = LocalTime.parse("13:37", germanFormatter);
+System.out.println(leetTime); // 13:37
+```
+
+### LocalDate(本地日期)
+
+LocalDate 表示了一个确切的日期,比如 2014-03-11。该对象值是不可变的,用起来和LocalTime基本一致。下面的例子展示了如何给Date对象加减天/月/年。另外要注意的是这些对象是不可变的,操作返回的总是一个新实例。
+
+```java
+LocalDate today = LocalDate.now();//获取现在的日期
+System.out.println("今天的日期: "+today);//2019-03-12
+LocalDate tomorrow = today.plus(1, ChronoUnit.DAYS);
+System.out.println("明天的日期: "+tomorrow);//2019-03-13
+LocalDate yesterday = tomorrow.minusDays(2);
+System.out.println("昨天的日期: "+yesterday);//2019-03-11
+LocalDate independenceDay = LocalDate.of(2019, Month.MARCH, 12);
+DayOfWeek dayOfWeek = independenceDay.getDayOfWeek();
+System.out.println("今天是周几:"+dayOfWeek);//TUESDAY
+```
+
+从字符串解析一个 LocalDate 类型和解析 LocalTime 一样简单,下面是使用 `DateTimeFormatter` 解析字符串的例子:
+
+```java
+ String str1 = "2014==04==12 01时06分09秒";
+ // 根据需要解析的日期、时间字符串定义解析所用的格式器
+ DateTimeFormatter fomatter1 = DateTimeFormatter
+ .ofPattern("yyyy==MM==dd HH时mm分ss秒");
+
+ LocalDateTime dt1 = LocalDateTime.parse(str1, fomatter1);
+ System.out.println(dt1); // 输出 2014-04-12T01:06:09
+
+ String str2 = "2014$$$四月$$$13 20小时";
+ DateTimeFormatter fomatter2 = DateTimeFormatter
+ .ofPattern("yyy$$$MMM$$$dd HH小时");
+ LocalDateTime dt2 = LocalDateTime.parse(str2, fomatter2);
+ System.out.println(dt2); // 输出 2014-04-13T20:00
+
+```
+
+再来看一个使用 `DateTimeFormatter` 格式化日期的示例
+
+```java
+LocalDateTime rightNow=LocalDateTime.now();
+String date=DateTimeFormatter.ISO_LOCAL_DATE_TIME.format(rightNow);
+System.out.println(date);//2019-03-12T16:26:48.29
+DateTimeFormatter formatter=DateTimeFormatter.ofPattern("YYYY-MM-dd HH:mm:ss");
+System.out.println(formatter.format(rightNow));//2019-03-12 16:26:48
+```
+
+**🐛 修正(参见: [issue#1157](https://github.com/Snailclimb/JavaGuide/issues/1157))**:使用 `YYYY` 显示年份时,会显示当前时间所在周的年份,在跨年周会有问题。一般情况下都使用 `yyyy`,来显示准确的年份。
+
+跨年导致日期显示错误示例:
+
+```java
+LocalDateTime rightNow = LocalDateTime.of(2020, 12, 31, 12, 0, 0);
+String date= DateTimeFormatter.ISO_LOCAL_DATE_TIME.format(rightNow);
+// 2020-12-31T12:00:00
+System.out.println(date);
+DateTimeFormatter formatterOfYYYY = DateTimeFormatter.ofPattern("YYYY-MM-dd HH:mm:ss");
+// 2021-12-31 12:00:00
+System.out.println(formatterOfYYYY.format(rightNow));
+
+DateTimeFormatter formatterOfYyyy = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
+// 2020-12-31 12:00:00
+System.out.println(formatterOfYyyy.format(rightNow));
+```
+
+从下图可以更清晰的看到具体的错误,并且 IDEA 已经智能地提示更倾向于使用 `yyyy` 而不是 `YYYY` 。
+
+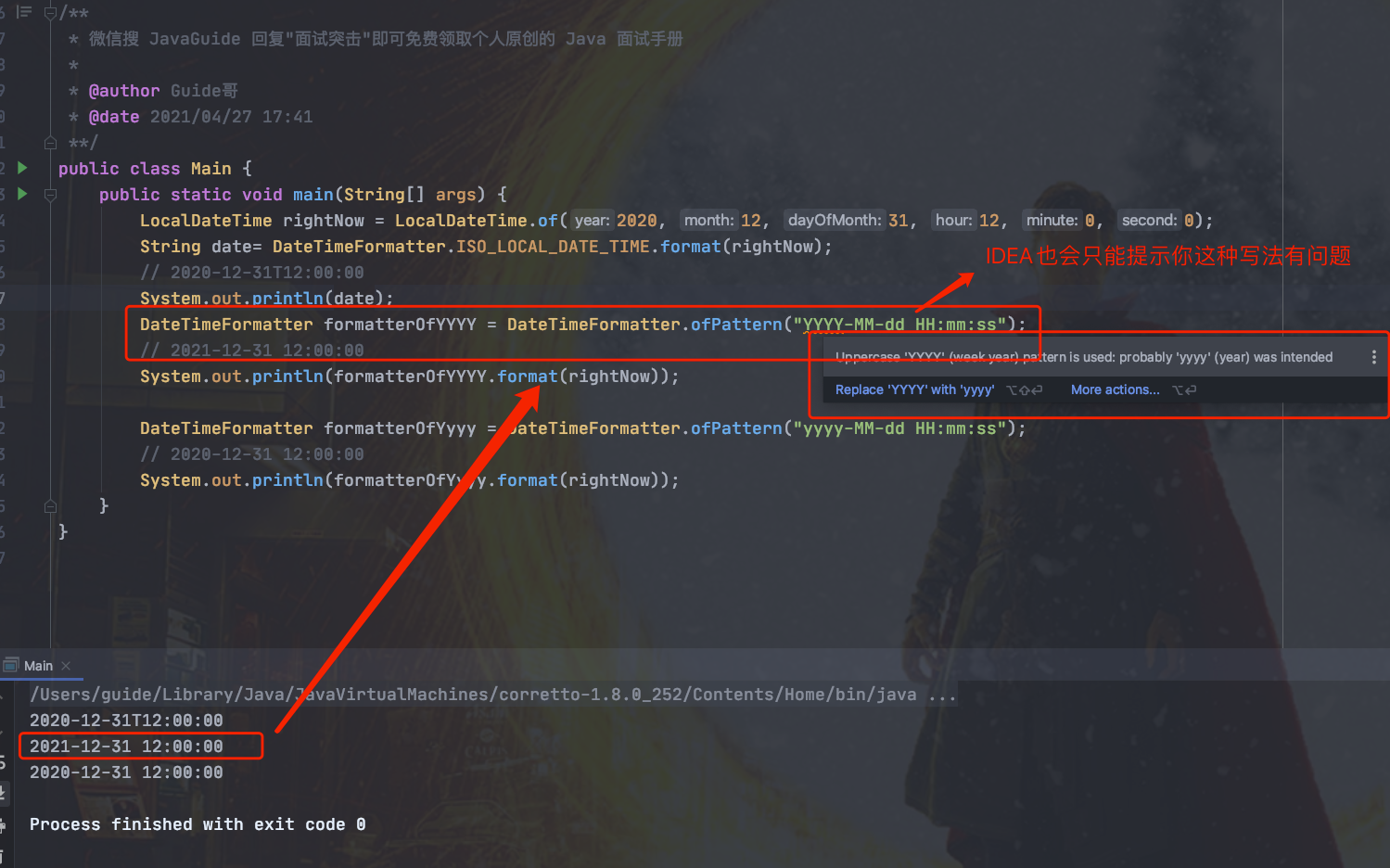
+
+### LocalDateTime(本地日期时间)
+
+LocalDateTime 同时表示了时间和日期,相当于前两节内容合并到一个对象上了。LocalDateTime 和 LocalTime还有 LocalDate 一样,都是不可变的。LocalDateTime 提供了一些能访问具体字段的方法。
+
+```java
+LocalDateTime sylvester = LocalDateTime.of(2014, Month.DECEMBER, 31, 23, 59, 59);
+
+DayOfWeek dayOfWeek = sylvester.getDayOfWeek();
+System.out.println(dayOfWeek); // WEDNESDAY
+
+Month month = sylvester.getMonth();
+System.out.println(month); // DECEMBER
+
+long minuteOfDay = sylvester.getLong(ChronoField.MINUTE_OF_DAY);
+System.out.println(minuteOfDay); // 1439
+```
+
+只要附加上时区信息,就可以将其转换为一个时间点Instant对象,Instant时间点对象可以很容易的转换为老式的`java.util.Date`。
+
+```java
+Instant instant = sylvester
+ .atZone(ZoneId.systemDefault())
+ .toInstant();
+
+Date legacyDate = Date.from(instant);
+System.out.println(legacyDate); // Wed Dec 31 23:59:59 CET 2014
+```
+
+格式化LocalDateTime和格式化时间和日期一样的,除了使用预定义好的格式外,我们也可以自己定义格式:
+
+```java
+DateTimeFormatter formatter =
+ DateTimeFormatter
+ .ofPattern("MMM dd, yyyy - HH:mm");
+LocalDateTime parsed = LocalDateTime.parse("Nov 03, 2014 - 07:13", formatter);
+String string = formatter.format(parsed);
+System.out.println(string); // Nov 03, 2014 - 07:13
+```
+
+和java.text.NumberFormat不一样的是新版的DateTimeFormatter是不可变的,所以它是线程安全的。
+关于时间日期格式的详细信息在[这里](https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html)。
+
+## Annotations(注解)
+
+在Java 8中支持多重注解了,先看个例子来理解一下是什么意思。
+首先定义一个包装类Hints注解用来放置一组具体的Hint注解:
+
+```java
+@Retention(RetentionPolicy.RUNTIME)
+@interface Hints {
+ Hint[] value();
+}
+@Repeatable(Hints.class)
+@interface Hint {
+ String value();
+}
+```
+
+Java 8允许我们把同一个类型的注解使用多次,只需要给该注解标注一下`@Repeatable`即可。
+
+例 1: 使用包装类当容器来存多个注解(老方法)
+
+```java
+@Hints({@Hint("hint1"), @Hint("hint2")})
+class Person {}
+```
+
+例 2:使用多重注解(新方法)
+
+```java
+@Hint("hint1")
+@Hint("hint2")
+class Person {}
+```
+
+第二个例子里java编译器会隐性的帮你定义好@Hints注解,了解这一点有助于你用反射来获取这些信息:
+
+```java
+Hint hint = Person.class.getAnnotation(Hint.class);
+System.out.println(hint); // null
+Hints hints1 = Person.class.getAnnotation(Hints.class);
+System.out.println(hints1.value().length); // 2
+
+Hint[] hints2 = Person.class.getAnnotationsByType(Hint.class);
+System.out.println(hints2.length); // 2
+```
+
+即便我们没有在 `Person`类上定义 `@Hints`注解,我们还是可以通过 `getAnnotation(Hints.class) `来获取 `@Hints`注解,更加方便的方法是使用 `getAnnotationsByType` 可以直接获取到所有的`@Hint`注解。
+另外Java 8的注解还增加到两种新的target上了:
+
+```java
+@Target({ElementType.TYPE_PARAMETER, ElementType.TYPE_USE})
+@interface MyAnnotation {}
+```
+
+## Where to go from here?
+
+关于Java 8的新特性就写到这了,肯定还有更多的特性等待发掘。JDK 1.8里还有很多很有用的东西,比如`Arrays.parallelSort`, `StampedLock`和`CompletableFuture`等等。
diff --git "a/docs/java/new-features/java\346\226\260\347\211\271\346\200\247\346\200\273\347\273\223.md" "b/docs/java/new-features/java\346\226\260\347\211\271\346\200\247\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..a2714b49d51
--- /dev/null
+++ "b/docs/java/new-features/java\346\226\260\347\211\271\346\200\247\346\200\273\347\273\223.md"
@@ -0,0 +1,944 @@
+# 一文带你看遍 JDK9~15 的重要新特性!
+
+Java 8 新特性见这里:[Java8 新特性最佳指南](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484744&idx=1&sn=9db31dca13d327678845054af75efb74&chksm=cea24a83f9d5c3956f4feb9956b068624ab2fdd6c4a75fe52d5df5dca356a016577301399548&token=1082669959&lang=zh_CN&scene=21#wechat_redirect) 。
+
+你可以在 [Archived OpenJDK General-Availability Releases](http://jdk.java.net/archive/) 上下载自己需要的 JDK 版本!
+
+官方的新特性说明文档地址: https://openjdk.java.net/projects/jdk/ 。
+
+_Guide :别人家的特性都用了几年了,我 Java 才出来,哈哈!真实!_
+
+## Java9
+
+发布于 2017 年 9 月 21 日 。作为 Java8 之后 3 年半才发布的新版本,Java 9 带 来了很多重大的变化其中最重要的改动是 Java 平台模块系统的引入,其他还有诸如集合、Stream 流
+
+### Java 平台模块系统
+
+Java 平台模块系统是[Jigsaw Project](https://openjdk.java.net/projects/jigsaw/)的一部分,把模块化开发实践引入到了 Java 平台中,可以让我们的代码可重用性更好!
+
+什么是模块系统?官方的定义是:A uniquely named, reusable group of related packages, as well as resources (such as images and XML files) and a module descriptor.
+
+简单来说,你可以将一个模块看作是一组唯一命名、可重用的包、资源和模块描述文件(module-info.java)。
+
+任意一个 jar 文件,只要加上一个 模块描述文件(module-info.java),就可以升级为一个模块。
+
+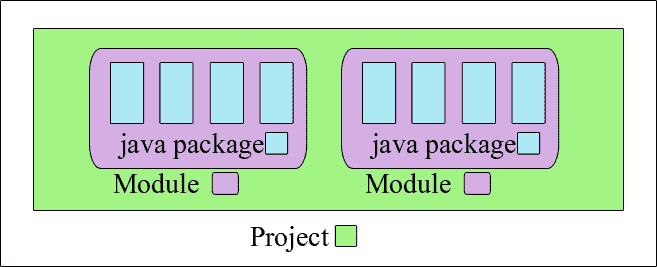
+
+在引入了模块系统之后,JDK 被重新组织成 94 个模块。Java 应用可以通过新增的 jlink 工具,创建出只包含所依赖的 JDK 模块的自定义运行时镜像。这样可以极大的减少 Java 运行时环境的大小。
+
+我们可以通过 exports 关键词精准控制哪些类可以对外开放使用,哪些类只能内部使用。
+
+```java
+module my.module {
+ //exports 公开指定包的所有公共成员
+ exports com.my.package.name;
+}
+
+module my.module {
+ //exports…to 限制访问的成员范围
+ export com.my.package.name to com.specific.package;
+}
+```
+
+Java 9 模块的重要特征是在其工件(artifact)的根目录中包含了一个描述模块的 `module-info.java` 文 件。 工件的格式可以是传统的 JAR 文件或是 Java 9 新增的 JMOD 文件。
+
+想要深入了解 Java 9 的模块化,参见:
+
+- [《Project Jigsaw: Module System Quick-Start Guide》](https://openjdk.java.net/projects/jigsaw/quick-start)
+- [《Java 9 Modules: part 1》](https://stacktraceguru.com/java9/module-introduction)
+
+### Jshell
+
+jshell 是 Java 9 新增的一个实用工具。为 Java 提供了类似于 Python 的实时命令行交互工具。
+
+在 Jshell 中可以直接输入表达式并查看其执行结果。
+
+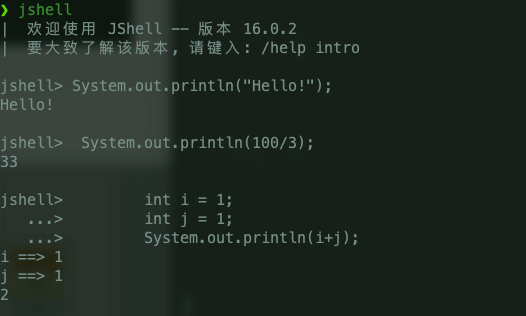
+
+### 集合增强
+
+增加 了 `List.of()`、`Set.of()`、`Map.of()` 和 `Map.ofEntries()`等工厂方法来创建不可变集合(这部分内容有点参考 Guava 的味道)
+
+```java
+List.of("Java", "C++");
+Set.of("Java", "C++");
+Map.of("Java", 1, "C++", 2);
+```
+
+使用 `of()` 创建的集合为不可变集合,不能进行添加、删除、替换、 排序等操作,不然会报 `java.lang.UnsupportedOperationException` 异常。
+
+`Collectors` 中增加了新的方法 `filtering()` 和 `flatMapping()`。
+
+`Collectors` 的 `filtering()` 方法类似于 `Stream` 类的 `filter()` 方法,都是用于过滤元素。
+
+> Java 8 为 `Collectors` 类引入了 `groupingBy` 操作,用于根据特定的属性将对象分组。
+
+```java
+List<String> list = List.of("x","www", "yy", "zz");
+Map<Integer, List<String>> result = list.stream()
+ .collect(Collectors.groupingBy(String::length,
+ Collectors.filtering(s -> !s.contains("z"),
+ Collectors.toList())));
+
+System.out.println(result); // {1=[x], 2=[yy], 3=[www]}
+```
+
+### Stream & Optional 增强
+
+`Stream` 中增加了新的方法 `ofNullable()`、`dropWhile()`、`takeWhile()` 以及 `iterate()` 方法的重载方法。
+
+Java 9 中的 `ofNullable()` 方 法允许我们创建一个单元素的 `Stream`,可以包含一个非空元素,也可以创建一个空 `Stream`。 而在 Java 8 中则不可以创建空的 `Stream` 。
+
+```java
+Stream<String> stringStream = Stream.ofNullable("Java");
+System.out.println(stringStream.count());// 1
+Stream<String> nullStream = Stream.ofNullable(null);
+System.out.println(nullStream.count());//0
+```
+
+`takeWhile()` 方法可以从 `Stream` 中依次获取满足条件的元素,直到不满足条件为止结束获取。
+
+```java
+List<Integer> integerList = List.of(11, 33, 66, 8, 9, 13);
+integerList.stream().takeWhile(x -> x < 50).forEach(System.out::println);// 11 33
+```
+
+`dropWhile()` 方法的效果和 `takeWhile()` 相反。
+
+```java
+List<Integer> integerList2 = List.of(11, 33, 66, 8, 9, 13);
+integerList2.stream().dropWhile(x -> x < 50).forEach(System.out::println);// 66 8 9 13
+```
+
+`iterate()` 方法的新重载方法提供了一个 `Predicate` 参数 (判断条件)来决定什么时候结束迭代
+
+```java
+public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f) {
+}
+// 新增加的重载方法
+public static<T> Stream<T> iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> next) {
+
+}
+```
+
+两者的使用对比如下,新的 `iterate()` 重载方法更加灵活一些。
+
+```java
+// 使用原始 iterate() 方法输出数字 1~10
+Stream.iterate(1, i -> i + 1).limit(10).forEach(System.out::println);
+// 使用新的 iterate() 重载方法输出数字 1~10
+Stream.iterate(1, i -> i <= 10, i -> i + 1).forEach(System.out::println);
+```
+
+`Optional` 类中新增了 `ifPresentOrElse()`、`or()` 和 `stream()` 等方法
+
+`ifPresentOrElse()` 方法接受两个参数 `Consumer` 和 `Runnable` ,如果 `Optional` 不为空调用 `Consumer` 参数,为空则调用 `Runnable` 参数。
+
+```java
+public void ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction)
+
+Optional<Object> objectOptional = Optional.empty();
+objectOptional.ifPresentOrElse(System.out::println, () -> System.out.println("Empty!!!"));// Empty!!!
+```
+
+`or()` 方法接受一个 `Supplier` 参数 ,如果 `Optional` 为空则返回 `Supplier` 参数指定的 `Optional` 值。
+
+```java
+public Optional<T> or(Supplier<? extends Optional<? extends T>> supplier)
+
+Optional<Object> objectOptional = Optional.empty();
+objectOptional.or(() -> Optional.of("java")).ifPresent(System.out::println);//java
+```
+
+### String 存储结构变更
+
+JDK 8 及之前的版本,`String` 一直是用 `char[]` 存储。在 Java 9 之后,`String` 的实现改用 `byte[]` 数组存储字符串。
+
+### 进程 API
+
+Java 9 增加了 `ProcessHandle` 接口,可以对原生进程进行管理,尤其适合于管理长时间运行的进程。
+
+```java
+System.out.println(ProcessHandle.current().pid());
+System.out.println(ProcessHandle.current().info());
+```
+
+
+
+### 平台日志 API 和服务
+
+Java 9 允许为 JDK 和应用配置同样的日志实现。新增了 `System.LoggerFinder` 用来管理 JDK 使 用的日志记录器实现。JVM 在运行时只有一个系统范围的 `LoggerFinder` 实例。
+
+我们可以通过添加自己的 `System.LoggerFinder` 实现来让 JDK 和应用使用 SLF4J 等其他日志记录框架。
+
+### 反应式流 ( Reactive Streams )
+
+在 Java9 中的 `java.util.concurrent.Flow` 类中新增了反应式流规范的核心接口 。
+
+`Flow` 中包含了 `Flow.Publisher`、`Flow.Subscriber`、`Flow.Subscription` 和 `Flow.Processor` 等 4 个核心接口。Java 9 还提供了`SubmissionPublisher` 作为`Flow.Publisher` 的一个实现。
+
+### 变量句柄
+
+变量句柄是一个变量或一组变量的引用,包括静态域,非静态域,数组元素和堆外数据结构中的组成部分等
+
+变量句柄的含义类似于已有的方法句柄 `MethodHandle` ,由 Java 类 `java.lang.invoke.VarHandle` 来表示,可以使用类 `java.lang.invoke.MethodHandles.Lookup` 中的静态工厂方法来创建 `VarHandle` 对象。
+
+`VarHandle` 的出现替代了 `java.util.concurrent.atomic` 和 `sun.misc.Unsafe` 的部分操作。并且提供了一系列标准的内存屏障操作,用于更加细粒度的控制内存排序。在安全性、可用性、性能上都要优于现有的 API。
+
+### 改进方法句柄(Method Handle)
+
+方法句柄从 Java7 开始引入,Java9 在类`java.lang.invoke.MethodHandles` 中新增了更多的静态方法来创建不同类型的方法句柄。
+
+### 接口私有方法
+
+Java 9 允许在接口中使用私有方法。
+
+```java
+public interface MyInterface {
+ private void methodPrivate(){
+
+ }
+}
+```
+
+### Java9 其它新特性
+
+- **try-with-resources 增强** :在 try-with-resources 语句中可以使用 effectively-final 变量(什么是 effectively-final 变量,见这篇文章:[《Effectively Final Variables in Java》](https://ilkinulas.github.io/programming/java/2016/03/27/effectively-final-java.html)
+- 类 `CompletableFuture` 中增加了几个新的方法(`completeAsync` ,`orTimeout` 等)
+- **Nashorn 引擎的增强** :Nashorn 从 Java8 开始引入的 JavaScript 引擎,Java9 对 Nashorn 做了些增强,实现了一些 ES6 的新特性(Java 11 中已经被弃用)。
+- **I/O 流的新特性** :增加了新的方法来读取和复制 `InputStream` 中包含的数据
+- **改进应用的安全性能** :Java 9 新增了 4 个 SHA- 3 哈希算法,SHA3-224、SHA3-256、SHA3-384 和 SHA3-512
+- ......
+
+## Java10
+
+发布于 2018 年 3 月 20 日,最知名的特性应该是 var 关键字(局部变量类型推断)的引入了,其他还有垃圾收集器改善、GC 改进、性能提升、线程管控等一批新特性
+
+### var(局部变量推断)
+
+由于太多 Java 开发者希望 Java 中引入局部变量推断,于是 Java 10 的时候它来了,也算是众望所归了!
+
+Java 10 提供了 var 关键字声明局部变量。
+
+> Scala 和 Kotlin 中有 val 关键字 ( `final var` 组合关键字),Java10 中并没有引入。
+
+Java 10 只引入了 var,而
+
+```java
+var id = 0;
+var codefx = new URL("https://mp.weixin.qq.com/");
+var list = new ArrayList<>();
+var list = List.of(1, 2, 3);
+var map = new HashMap<String, String>();
+var p = Paths.of("src/test/java/Java9FeaturesTest.java");
+var numbers = List.of("a", "b", "c");
+for (var n : list)
+ System.out.print(n+ " ");
+```
+
+var 关键字只能用于带有构造器的局部变量和 for 循环中。
+
+```java
+var count=null; //❌编译不通过,不能声明为 null
+var r = () -> Math.random();//❌编译不通过,不能声明为 Lambda表达式
+var array = {1,2,3};//❌编译不通过,不能声明数组
+```
+
+var 并不会改变 Java 是一门静态类型语言的事实,编译器负责推断出类型。
+
+相关阅读:[《Java 10 新特性之局部变量类型推断》](https://zhuanlan.zhihu.com/p/34911982)。
+
+### 集合增强
+
+`list`,`set`,`map` 提供了静态方法`copyOf()`返回入参集合的一个不可变拷贝。
+
+以下为 JDK 的源码:
+
+```java
+static <E> List<E> copyOf(Collection<? extends E> coll) {
+ return ImmutableCollections.listCopy(coll);
+}
+```
+
+使用 `copyOf()` 创建的集合为不可变集合,不能进行添加、删除、替换、 排序等操作,不然会报 `java.lang.UnsupportedOperationException` 异常。 IDEA 也会有相应的提示。
+
+
+
+`java.util.stream.Collectors` 中新增了静态方法,用于将流中的元素收集为不可变的集合。
+
+```java
+var list = new ArrayList<>();
+list.stream().collect(Collectors.toUnmodifiableList());
+list.stream().collect(Collectors.toUnmodifiableSet());
+```
+
+### Optional
+
+新增了`orElseThrow()`方法来在没有值时抛出指定的异常。
+
+```java
+Optional.ofNullable(cache.getIfPresent(key))
+ .orElseThrow(() -> new PrestoException(NOT_FOUND, "Missing entry found for key: " + key));
+```
+
+### 并行全垃圾回收器 G1
+
+从 Java9 开始 G1 就了默认的垃圾回收器,G1 是以一种低延时的垃圾回收器来设计的,旨在避免进行 Full GC,但是 Java9 的 G1 的 FullGC 依然是使用单线程去完成标记清除算法,这可能会导致垃圾回收期在无法回收内存的时候触发 Full GC。
+
+为了最大限度地减少 Full GC 造成的应用停顿的影响,从 Java10 开始,G1 的 FullGC 改为并行的标记清除算法,同时会使用与年轻代回收和混合回收相同的并行工作线程数量,从而减少了 Full GC 的发生,以带来更好的性能提升、更大的吞吐量。
+
+### 应用程序类数据共享(扩展 CDS 功能)
+
+在 Java 5 中就已经引入了类数据共享机制 (Class Data Sharing,简称 CDS),允许将一组类预处理为共享归档文件,以便在运行时能够进行内存映射以减少 Java 程序的启动时间,当多个 Java 虚拟机(JVM)共享相同的归档文件时,还可以减少动态内存的占用量,同时减少多个虚拟机在同一个物理或虚拟的机器上运行时的资源占用。CDS 在当时还是 Oracle JDK 的商业特性。
+
+Java 10 在现有的 CDS 功能基础上再次拓展,以允许应用类放置在共享存档中。CDS 特性在原来的 bootstrap 类基础之上,扩展加入了应用类的 CDS 为 (Application Class-Data Sharing,AppCDS) 支持,大大加大了 CDS 的适用范围。其原理为:在启动时记录加载类的过程,写入到文本文件中,再次启动时直接读取此启动文本并加载。设想如果应用环境没有大的变化,启动速度就会得到提升。
+
+### Java10 其他新特性
+
+- **线程-局部管控**:Java 10 中线程管控引入 JVM 安全点的概念,将允许在不运行全局 JVM 安全点的情况下实现线程回调,由线程本身或者 JVM 线程来执行,同时保持线程处于阻塞状态,这种方式使得停止单个线程变成可能,而不是只能启用或停止所有线程
+- **备用存储装置上的堆分配**:Java 10 中将使得 JVM 能够使用适用于不同类型的存储机制的堆,在可选内存设备上进行堆内存分配
+- **统一的垃圾回收接口**:Java 10 中,hotspot/gc 代码实现方面,引入一个干净的 GC 接口,改进不同 GC 源代码的隔离性,多个 GC 之间共享的实现细节代码应该存在于辅助类中。统一垃圾回收接口的主要原因是:让垃圾回收器(GC)这部分代码更加整洁,便于新人上手开发,便于后续排查相关问题。
+- ......
+
+## Java11
+
+Java11 于 2018 年 9 月 25 日正式发布,这是很重要的一个版本!Java 11 和 2017 年 9 月份发布的 Java 9 以及 2018 年 3 月份发布的 Java 10 相比,其最大的区别就是:在长期支持(Long-Term-Support)方面,**Oracle 表示会对 Java 11 提供大力支持,这一支持将会持续至 2026 年 9 月。这是据 Java 8 以后支持的首个长期版本。**
+
+
+
+### String
+
+Java 11 增加了一系列的字符串处理方法,如以下所示。
+
+_Guide:说白点就是多了层封装,JDK 开发组的人没少看市面上常见的工具类框架啊!_
+
+```java
+//判断字符串是否为空
+" ".isBlank();//true
+//去除字符串首尾空格
+" Java ".strip();// "Java"
+//去除字符串首部空格
+" Java ".stripLeading(); // "Java "
+//去除字符串尾部空格
+" Java ".stripTrailing(); // " Java"
+//重复字符串多少次
+"Java".repeat(3); // "JavaJavaJava"
+
+//返回由行终止符分隔的字符串集合。
+"A\nB\nC".lines().count(); // 3
+"A\nB\nC".lines().collect(Collectors.toList());
+```
+
+### Optional
+
+新增了`empty()`方法来判断指定的 `Optional` 对象是否为空。
+
+```java
+var op = Optional.empty();
+System.out.println(op.isEmpty());//判断指定的 Optional 对象是否为空
+```
+
+### ZGC(可伸缩低延迟垃圾收集器)
+
+**ZGC 即 Z Garbage Collector**,是一个可伸缩的、低延迟的垃圾收集器。
+
+ZGC 主要为了满足如下目标进行设计:
+
+- GC 停顿时间不超过 10ms
+- 即能处理几百 MB 的小堆,也能处理几个 TB 的大堆
+- 应用吞吐能力不会下降超过 15%(与 G1 回收算法相比)
+- 方便在此基础上引入新的 GC 特性和利用 colored 针以及 Load barriers 优化奠定基础
+- 当前只支持 Linux/x64 位平台
+
+ZGC 目前 **处在实验阶段**,只支持 Linux/x64 平台。
+
+与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
+
+在 ZGC 中出现 Stop The World 的情况会更少!
+
+详情可以看 : [《新一代垃圾回收器 ZGC 的探索与实践》](https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html)
+
+### 标准 HTTP Client 升级
+
+Java 11 对 Java 9 中引入并在 Java 10 中进行了更新的 Http Client API 进行了标准化,在前两个版本中进行孵化的同时,Http Client 几乎被完全重写,并且现在完全支持异步非阻塞。
+
+并且,Java11 中,Http Client 的包名由 `jdk.incubator.http` 改为`java.net.http`,该 API 通过 `CompleteableFuture` 提供非阻塞请求和响应语义。使用起来也很简单,如下:
+
+```java
+var request = HttpRequest.newBuilder()
+ .uri(URI.create("https://javastack.cn"))
+ .GET()
+ .build();
+var client = HttpClient.newHttpClient();
+
+// 同步
+HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
+System.out.println(response.body());
+
+// 异步
+client.sendAsync(request, HttpResponse.BodyHandlers.ofString())
+ .thenApply(HttpResponse::body)
+ .thenAccept(System.out::println);
+```
+
+### var(Lambda 参数的局部变量语法)
+
+从 Java 10 开始,便引入了局部变量类型推断这一关键特性。类型推断允许使用关键字 var 作为局部变量的类型而不是实际类型,编译器根据分配给变量的值推断出类型。
+
+Java 10 中对 var 关键字存在几个限制
+
+- 只能用于局部变量上
+- 声明时必须初始化
+- 不能用作方法参数
+- 不能在 Lambda 表达式中使用
+
+Java11 开始允许开发者在 Lambda 表达式中使用 var 进行参数声明。
+
+```java
+// 下面两者是等价的
+Consumer<String> consumer = (var i) -> System.out.println(i);
+Consumer<String> consumer = (String i) -> System.out.println(i);
+```
+
+### 启动单文件源代码程序
+
+[JEP 330:启动单文件源代码程序(aunch Single-File Source-Code Programs)](https://openjdk.java.net/jeps/330) 可以让我们运行单一文件的 Java 源代码。此功能允许使用 Java 解释器直接执行 Java 源代码。源代码在内存中编译,然后由解释器执行,不需要在磁盘上生成 `.class` 文件了。
+
+唯一的约束在于所有相关的类必须定义在同一个 Java 文件中。
+
+对于 Java 初学者并希望尝试简单程序的人特别有用,并且能和 jshell 一起使用
+
+一定能程度上增强了使用 Java 来写脚本程序的能力。
+
+### Java11 其他新特性
+
+- **新的垃圾回收器 Epsilon** :一个完全消极的 GC 实现,分配有限的内存资源,最大限度的降低内存占用和内存吞吐延迟时间
+- **低开销的 Heap Profiling** :Java 11 中提供一种低开销的 Java 堆分配采样方法,能够得到堆分配的 Java 对象信息,并且能够通过 JVMTI 访问堆信息
+- **TLS1.3 协议** :Java 11 中包含了传输层安全性(TLS)1.3 规范(RFC 8446)的实现,替换了之前版本中包含的 TLS,包括 TLS 1.2,同时还改进了其他 TLS 功能,例如 OCSP 装订扩展(RFC 6066,RFC 6961),以及会话散列和扩展主密钥扩展(RFC 7627),在安全性和性能方面也做了很多提升
+- **飞行记录器(Java Flight Recorder)** :飞行记录器之前是商业版 JDK 的一项分析工具,但在 Java 11 中,其代码被包含到公开代码库中,这样所有人都能使用该功能了。
+- ......
+
+## Java12
+
+### String
+
+Java 11 增加了两个的字符串处理方法,如以下所示。
+
+`indent()` 方法可以实现字符串缩进。
+
+```java
+String text = "Java";
+// 缩进 4 格
+text = text.indent(4);
+System.out.println(text);
+text = text.indent(-10);
+System.out.println(text);
+```
+
+输出:
+
+```
+ Java
+Java
+```
+
+`transform()` 方法可以用来转变指定字符串。
+
+```java
+String result = "foo".transform(input -> input + " bar");
+System.out.println(result); // foo bar
+```
+
+### 文件比较
+
+Java 12 添加了以下方法来比较两个文件:
+
+```java
+public static long mismatch(Path path, Path path2) throws IOException
+```
+
+`mismatch()` 方法用于比较两个文件,并返回第一个不匹配字符的位置,如果文件相同则返回 -1L。
+
+代码示例(两个文件内容相同的情况):
+
+```java
+Path filePath1 = Files.createTempFile("file1", ".txt");
+Path filePath2 = Files.createTempFile("file2", ".txt");
+Files.writeString(filePath1, "Java 12 Article");
+Files.writeString(filePath2, "Java 12 Article");
+
+long mismatch = Files.mismatch(filePath1, filePath2);
+assertEquals(-1, mismatch);
+```
+
+代码示例(两个文件内容不相同的情况):
+
+```java
+Path filePath3 = Files.createTempFile("file3", ".txt");
+Path filePath4 = Files.createTempFile("file4", ".txt");
+Files.writeString(filePath3, "Java 12 Article");
+Files.writeString(filePath4, "Java 12 Tutorial");
+
+long mismatch = Files.mismatch(filePath3, filePath4);
+assertEquals(8, mismatch);
+```
+
+### 数字格式化工具类
+
+`NumberFormat` 新增了对复杂的数字进行格式化的支持
+
+```java
+NumberFormat fmt = NumberFormat.getCompactNumberInstance(Locale.US, NumberFormat.Style.SHORT);
+String result = fmt.format(1000);
+ System.out.println(result); // 输出为 1K,计算工资是多少K更方便了。。。
+```
+
+### Shenandoah GC
+
+Redhat 主导开发的 Pauseless GC 实现,主要目标是 99.9% 的暂停小于 10ms,暂停与堆大小无关等
+
+和 Java11 开源的 ZGC 相比(需要升级到 JDK11 才能使用),Shenandoah GC 有稳定的 JDK8u 版本,在 Java8 占据主要市场份额的今天有更大的可落地性。
+
+### G1 收集器提升
+
+Java12 为默认的垃圾收集器 G1 带来了两项更新:
+
+- **可中止的混合收集集合** :JEP344 的实现,为了达到用户提供的停顿时间目标,JEP 344 通过把要被回收的区域集(混合收集集合)拆分为强制和可选部分,使 G1 垃圾回收器能中止垃圾回收过程。 G1 可以中止可选部分的回收以达到停顿时间目标
+- **及时返回未使用的已分配内存** :JEP346 的实现,增强 G1 GC,以便在空闲时自动将 Java 堆内存返回给操作系统
+
+### 预览新特性
+
+作为预览特性加入,需要在`javac`编译和`java`运行时增加参数`--enable-preview` 。
+
+#### 增强 Switch
+
+传统的 `switch` 语法存在容易漏写 `break` 的问题,而且从代码整洁性层面来看,多个 break 本质也是一种重复
+
+Java12 增强了 `swtich` 表达式,使用类似 lambda 语法条件匹配成功后的执行块,不需要多写 break 。
+
+```java
+switch (day) {
+ case MONDAY, FRIDAY, SUNDAY -> System.out.println(6);
+ case TUESDAY -> System.out.println(7);
+ case THURSDAY, SATURDAY -> System.out.println(8);
+ case WEDNESDAY -> System.out.println(9);
+}
+```
+
+#### instanceof 模式匹配
+
+`instanceof` 主要在**类型强转前探测对象的具体类型**。
+
+之前的版本中,我们需要显示地对对象进行类型转换。
+
+```java
+Object obj = "我是字符串";
+if(obj instanceof String){
+ String str = (String) obj;
+ System.out.println(str);
+}
+```
+
+新版的 `instanceof` 可以在判断是否属于具体的类型同时完成转换。
+
+```java
+Object obj = "我是字符串";
+if(obj instanceof String str){
+ System.out.println(str);
+}
+```
+
+## Java13
+
+### 增强 ZGC(释放未使用内存)
+
+在 Java 11 中是实验性的引入的 ZGC 在实际的使用中存在未能主动将未使用的内存释放给操作系统的问题。
+
+ZGC 堆由一组称为 ZPages 的堆区域组成。在 GC 周期中清空 ZPages 区域时,它们将被释放并返回到页面缓存 **ZPageCache** 中,此缓存中的 ZPages 按最近最少使用(LRU)的顺序,并按照大小进行组织。
+
+在 Java 13 中,ZGC 将向操作系统返回被标识为长时间未使用的页面,这样它们将可以被其他进程重用。
+
+### SocketAPI 重构
+
+Java Socket API 终于迎来了重大更新!
+
+Java 13 将 Socket API 的底层进行了重写, `NioSocketImpl` 是对 `PlainSocketImpl` 的直接替代,它使用 `java.util.concurrent` 包下的锁而不是同步方法。如果要使用旧实现,请使用 `-Djdk.net.usePlainSocketImpl=true`。
+
+并且,在 Java 13 中是默认使用新的 Socket 实现。
+
+```java
+public final class NioSocketImpl extends SocketImpl implements PlatformSocketImpl {
+}
+```
+
+### FileSystems
+
+`FileSystems` 类中添加了以下三种新方法,以便更容易地使用将文件内容视为文件系统的文件系统提供程序:
+
+- `newFileSystem(Path)`
+- `newFileSystem(Path, Map<String, ?>)`
+- `newFileSystem(Path, Map<String, ?>, ClassLoader)`
+
+### 动态 CDS 存档
+
+Java 13 中对 Java 10 中引入的应用程序类数据共享(AppCDS)进行了进一步的简化、改进和扩展,即:**允许在 Java 应用程序执行结束时动态进行类归档**,具体能够被归档的类包括所有已被加载,但不属于默认基层 CDS 的应用程序类和引用类库中的类。
+
+这提高了应用程序类数据共享([AppCDS](https://openjdk.java.net/jeps/310))的可用性。无需用户进行试运行来为每个应用程序创建类列表。
+
+```bash
+$ java -XX:ArchiveClassesAtExit=my_app_cds.jsa -cp my_app.jar
+$ java -XX:SharedArchiveFile=my_app_cds.jsa -cp my_app.jar
+```
+
+### 预览新特性
+
+#### 文本块
+
+解决 Java 定义多行字符串时只能通过换行转义或者换行连接符来变通支持的问题,引入**三重双引号**来定义多行文本。
+
+Java 13 支持两个 `"""` 符号中间的任何内容都会被解释为字符串的一部分,包括换行符。
+
+未支持文本块之前的 HTML 写法:
+
+```java
+String json ="{\n" +
+ " \"name\":\"mkyong\",\n" +
+ " \"age\":38\n" +
+ "}\n";
+```
+
+支持文本块之后的 HTML 写法:
+
+```java
+ String json = """
+ {
+ "name":"mkyong",
+ "age":38
+ }
+ """;
+```
+
+未支持文本块之前的 SQL 写法:
+
+```sql
+String query = "SELECT `EMP_ID`, `LAST_NAME` FROM `EMPLOYEE_TB`\n" +
+ "WHERE `CITY` = 'INDIANAPOLIS'\n" +
+ "ORDER BY `EMP_ID`, `LAST_NAME`;\n";
+```
+
+支持文本块之后的 SQL 写法:
+
+```sql
+String query = """
+ SELECT `EMP_ID`, `LAST_NAME` FROM `EMPLOYEE_TB`
+ WHERE `CITY` = 'INDIANAPOLIS'
+ ORDER BY `EMP_ID`, `LAST_NAME`;
+ """;
+```
+
+另外,`String` 类新增加了 3 个新的方法来操作文本块:
+
+- `formatted(Object... args)` :它类似于 `String` 的`format()`方法。添加它是为了支持文本块的格式设置。
+- `stripIndent()` :用于去除文本块中每一行开头和结尾的空格。
+- `translateEscapes()` :转义序列如 _“\\\t”_ 转换为 _“\t”_
+
+由于文本块是一项预览功能,可以在未来版本中删除,因此这些新方法被标记为弃用。
+
+```java
+@Deprecated(forRemoval=true, since="13")
+public String stripIndent() {
+}
+@Deprecated(forRemoval=true, since="13")
+public String formatted(Object... args) {
+
+}
+@Deprecated(forRemoval=true, since="13")
+public String translateEscapes() {
+}
+```
+
+#### 增强 Switch(引入 yield 关键字到 Switch 中)
+
+`Switch` 表达式中就多了一个关键字用于跳出 `Switch` 块的关键字 `yield`,主要用于返回一个值
+
+`yield`和 `return` 的区别在于:`return` 会直接跳出当前循环或者方法,而 `yield` 只会跳出当前 `Switch` 块,同时在使用 `yield` 时,需要有 `default` 条件
+
+```java
+ private static String descLanguage(String name) {
+ return switch (name) {
+ case "Java": yield "object-oriented, platform independent and secured";
+ case "Ruby": yield "a programmer's best friend";
+ default: yield name +" is a good language";
+ };
+ }
+```
+
+## Java14
+
+### 空指针异常精准提示
+
+通过 JVM 参数中添加`-XX:+ShowCodeDetailsInExceptionMessages`,可以在空指针异常中获取更为详细的调用信息,更快的定位和解决问题。
+
+```java
+a.b.c.i = 99; // 假设这段代码会发生空指针
+```
+
+Java 14 之前:
+
+```java
+Exception in thread "main" java.lang.NullPointerException
+ at NullPointerExample.main(NullPointerExample.java:5)
+```
+
+Java 14 之后:
+
+```java
+ // 增加参数后提示的异常中很明确的告知了哪里为空导致
+Exception in thread "main" java.lang.NullPointerException:
+ Cannot read field 'c' because 'a.b' is null.
+ at Prog.main(Prog.java:5)
+```
+
+### switch 的增强(转正)
+
+Java12 引入的 switch(预览特性)在 Java14 变为正式版本,不需要增加参数来启用,直接在 JDK14 中就能使用。
+
+Java12 为 switch 表达式引入了类似 lambda 语法条件匹配成功后的执行块,不需要多写 break ,Java13 提供了 `yield` 来在 block 中返回值。
+
+```java
+String result = switch (day) {
+ case "M", "W", "F" -> "MWF";
+ case "T", "TH", "S" -> "TTS";
+ default -> {
+ if(day.isEmpty())
+ yield "Please insert a valid day.";
+ else
+ yield "Looks like a Sunday.";
+ }
+
+ };
+System.out.println(result);
+```
+
+### 预览新特性
+
+#### record 关键字
+
+简化数据类的定义方式,使用 `record` 代替 `class` 定义的类,只需要声明属性,就可以在获得属性的访问方法,以及 `toString()`,`hashCode()`, `equals()`方法
+
+类似于使用 `class` 定义类,同时使用了 lombok 插件,并打上了`@Getter,@ToString,@EqualsAndHashCode`注解
+
+```java
+/**
+ * 这个类具有两个特征
+ * 1. 所有成员属性都是final
+ * 2. 全部方法由构造方法,和两个成员属性访问器组成(共三个)
+ * 那么这种类就很适合使用record来声明
+ */
+final class Rectangle implements Shape {
+ final double length;
+ final double width;
+
+ public Rectangle(double length, double width) {
+ this.length = length;
+ this.width = width;
+ }
+
+ double length() { return length; }
+ double width() { return width; }
+}
+/**
+ * 1. 使用record声明的类会自动拥有上面类中的三个方法
+ * 2. 在这基础上还附赠了equals(),hashCode()方法以及toString()方法
+ * 3. toString方法中包括所有成员属性的字符串表示形式及其名称
+ */
+record Rectangle(float length, float width) { }
+```
+
+#### 文本块
+
+Java14 中,文本块依然是预览特性,不过,其引入了两个新的转义字符:
+
+- `\` : 表示行尾,不引入换行符
+- `\s` :表示单个空格
+
+```java
+String str = "凡心所向,素履所往,生如逆旅,一苇以航。";
+
+String str2 = """
+ 凡心所向,素履所往, \
+ 生如逆旅,一苇以航。""";
+System.out.println(str2);// 凡心所向,素履所往, 生如逆旅,一苇以航。
+String text = """
+ java
+ c++\sphp
+ """;
+System.out.println(text);
+//输出:
+java
+c++ php
+```
+
+#### instanceof 增强
+
+依然是**预览特性** ,Java 12 新特性中介绍过。
+
+### Java14 其他特性
+
+- 从 Java11 引入的 ZGC 作为继 G1 过后的下一代 GC 算法,从支持 Linux 平台到 Java14 开始支持 MacOS 和 Window(个人感觉是终于可以在日常开发工具中先体验下 ZGC 的效果了,虽然其实 G1 也够用)
+- 移除了 CMS(Concurrent Mark Sweep) 垃圾收集器(功成而退)
+- 新增了 jpackage 工具,标配将应用打成 jar 包外,还支持不同平台的特性包,比如 linux 下的`deb`和`rpm`,window 平台下的`msi`和`exe`
+
+## Java15
+
+### CharSequence
+
+`CharSequence` 接口添加了一个默认方法 `isEmpty()` 来判断字符序列为空,如果是则返回 true。
+
+```java
+public interface CharSequence {
+ default boolean isEmpty() {
+ return this.length() == 0;
+ }
+}
+```
+
+### TreeMap
+
+`TreeMap` 新引入了下面这些方法:
+
+- `putIfAbsent()`
+- `computeIfAbsent()`
+- `computeIfPresent()`
+- `compute()`
+- `merge()`
+
+### ZGC(转正)
+
+Java11 的时候 ,ZGC 还在试验阶段。
+
+当时,ZGC 的出现让众多 Java 开发者看到了垃圾回收器的另外一种可能,因此备受关注。
+
+经过多个版本的迭代,不断的完善和修复问题,ZGC 在 Java 15 已经可以正式使用了!
+
+不过,默认的垃圾回收器依然是 G1。你可以通过下面的参数启动 ZGC:
+
+```bash
+$ java -XX:+UseZGC className
+```
+
+### EdDSA(数字签名算法)
+
+新加入了一个安全性和性能都更强的基于 Edwards-Curve Digital Signature Algorithm (EdDSA)实现的数字签名算法。
+
+虽然其性能优于现有的 ECDSA 实现,不过,它并不会完全取代 JDK 中现有的椭圆曲线数字签名算法( ECDSA)。
+
+```java
+KeyPairGenerator kpg = KeyPairGenerator.getInstance("Ed25519");
+KeyPair kp = kpg.generateKeyPair();
+
+byte[] msg = "test_string".getBytes(StandardCharsets.UTF_8);
+
+Signature sig = Signature.getInstance("Ed25519");
+sig.initSign(kp.getPrivate());
+sig.update(msg);
+byte[] s = sig.sign();
+
+String encodedString = Base64.getEncoder().encodeToString(s);
+System.out.println(encodedString);
+```
+
+输出:
+
+```
+0Hc0lxxASZNvS52WsvnncJOH/mlFhnA8Tc6D/k5DtAX5BSsNVjtPF4R4+yMWXVjrvB2mxVXmChIbki6goFBgAg==
+```
+
+### 文本块(转正)
+
+在 Java 15 ,文本块是正式的功能特性了。
+
+### 隐藏类(Hidden Classes)
+
+隐藏类是为框架(frameworks)所设计的,隐藏类不能直接被其他类的字节码使用,只能在运行时生成类并通过反射间接使用它们。
+
+### 预览新特性
+
+#### 密封类
+
+Java 15 对 Java 14 中引入的预览新特性进行了增强,主要是引入了一个新的概念 **密封类(Sealed Classes)。**
+
+密封类可以对继承或者实现它们的类进行限制。
+
+比如抽象类 `Person` 只允许 `Employee` 和 `Manager` 继承。
+
+```java
+public abstract sealed class Person
+ permits Employee, Manager {
+
+ //...
+}
+```
+
+另外,任何扩展密封类的类本身都必须声明为 `sealed`、`non-sealed` 或 `final`。
+
+```java
+public final class Employee extends Person {
+}
+
+public non-sealed class Manager extends Person {
+}
+```
+
+
+
+#### instanceof 模式匹配
+
+Java 15 并没有对此特性进行调整,继续预览特性,主要用于接受更多的使用反馈。
+
+在未来的 Java 版本中,Java 的目标是继续完善 `instanceof` 模式匹配新特性。
+
+### Java15 其他新特性
+
+- **Nashorn JavaScript 引擎彻底移除** :Nashorn 从 Java8 开始引入的 JavaScript 引擎,Java9 对 Nashorn 做了些增强,实现了一些 ES6 的新特性。在 Java 11 中就已经被弃用,到了 Java 15 就彻底被删除了。
+- **DatagramSocket API 重构**
+- **禁用和废弃偏向锁(Biased Locking)** : 偏向锁的引入增加了 JVM 的复杂性大于其带来的性能提升。不过,你仍然可以使用 `-XX:+UseBiasedLocking` 启用偏向锁定,但它会提示 这是一个已弃用的 API。
+- ......
+
+## 总结
+
+### 关于预览特性
+
+先贴一段 oracle 官网原文:`This is a preview feature, which is a feature whose design, specification, and implementation are complete, but is not permanent, which means that the feature may exist in a different form or not at all in future JDK releases. To compile and run code that contains preview features, you must specify additional command-line options.`
+
+这是一个预览功能,该功能的设计,规格和实现是完整的,但不是永久性的,这意味着该功能可能以其他形式存在或在将来的 JDK 版本中根本不存在。 要编译和运行包含预览功能的代码,必须指定其他命令行选项。
+
+就以`switch`的增强为例子,从 Java12 中推出,到 Java13 中将继续增强,直到 Java14 才正式转正进入 JDK 可以放心使用,不用考虑后续 JDK 版本对其的改动或修改
+
+一方面可以看出 JDK 作为标准平台在增加新特性的严谨态度,另一方面个人认为是对于预览特性应该采取审慎使用的态度。特性的设计和实现容易,但是其实际价值依然需要在使用中去验证
+
+### JVM 虚拟机优化
+
+每次 Java 版本的发布都伴随着对 JVM 虚拟机的优化,包括对现有垃圾回收算法的改进,引入新的垃圾回收算法,移除老旧的不再适用于今天的垃圾回收算法等
+
+整体优化的方向是**高效,低时延的垃圾回收表现**
+
+对于日常的应用开发者可能比较关注新的语法特性,但是从一个公司角度来说,在考虑是否升级 Java 平台时更加考虑的是**JVM 运行时的提升**
+
+## 参考资料
+
+- JDK Project Overview : <https://openjdk.java.net/projects/jdk/ >
+- IBM Developer Java9 <https://www.ibm.com/developerworks/cn/java/the-new-features-of-Java-9/>
+- Guide to Java10 <https://www.baeldung.com/java-10-overview>
+- Java 10 新特性介绍<https://www.ibm.com/developerworks/cn/java/the-new-features-of-Java-10/index.html>
+- IBM Devloper Java11 <https://www.ibm.com/developerworks/cn/java/the-new-features-of-Java-11/index.html>
+- Java 11 – Features and Comparison: <https://www.geeksforgeeks.org/java-11-features-and-comparison/>
+- Oracle Java12 ReleaseNote <https://www.oracle.com/technetwork/java/javase/12all-relnotes-5211423.html#NewFeature>
+- Oracle Java13 ReleaseNote <https://www.oracle.com/technetwork/java/javase/13all-relnotes-5461743.html#NewFeature>
+- New Features in Java 12 <https://www.baeldung.com/java-12-new-features>
+- New Java13 Features <https://www.baeldung.com/java-13-new-features>
+- Java13 新特性概述 <https://www.ibm.com/developerworks/cn/java/the-new-features-of-Java-13/index.html>
+- Oracle Java14 record <https://docs.oracle.com/en/java/javase/14/language/records.html>
+- java14-features <https://www.techgeeknext.com/java/java14-features>
+- Java 14 Features : <https://www.journaldev.com/37273/java-14-features>
+- What is new in Java 15: https://mkyong.com/java/what-is-new-in-java-15/
diff --git a/docs/java/tips/jad.md b/docs/java/tips/jad.md
new file mode 100644
index 00000000000..47d25a4ed53
--- /dev/null
+++ b/docs/java/tips/jad.md
@@ -0,0 +1,371 @@
+# JAD 反编译
+
+[jad](https://varaneckas.com/jad/)反编译工具,已经不再更新,且只支持 JDK1.4,但并不影响其强大的功能。
+
+基本用法:`jad xxx.class`,会生成直接可读的 `xxx.jad` 文件。
+
+## 自动拆装箱
+
+对于基本类型和包装类型之间的转换,通过 xxxValue()和 valueOf()两个方法完成自动拆装箱,使用 jad 进行反编译可以看到该过程:
+
+```java
+public class Demo {
+ public static void main(String[] args) {
+ int x = new Integer(10); // 自动拆箱
+ Integer y = x; // 自动装箱
+ }
+}
+```
+
+反编译后结果:
+
+```java
+public class Demo
+{
+ public Demo(){}
+
+ public static void main(String args[])
+ {
+ int i = (new Integer(10)).intValue(); // intValue()拆箱
+ Integer integer = Integer.valueOf(i); // valueOf()装箱
+ }
+}
+```
+
+## foreach 语法糖
+
+在遍历迭代时可以 foreach 语法糖,对于数组类型直接转换成 for 循环:
+
+```java
+// 原始代码
+int[] arr = {1, 2, 3, 4, 5};
+ for(int item: arr) {
+ System.out.println(item);
+ }
+}
+
+// 反编译后代码
+int ai[] = {
+ 1, 2, 3, 4, 5
+};
+int ai1[] = ai;
+int i = ai1.length;
+// 转换成for循环
+for(int j = 0; j < i; j++)
+{
+ int k = ai1[j];
+ System.out.println(k);
+}
+```
+
+对于容器类的遍历会使用 iterator 进行迭代:
+
+```java
+import java.io.PrintStream;
+import java.util.*;
+
+public class Demo
+{
+ public Demo() {}
+ public static void main(String args[])
+ {
+ ArrayList arraylist = new ArrayList();
+ arraylist.add(Integer.valueOf(1));
+ arraylist.add(Integer.valueOf(2));
+ arraylist.add(Integer.valueOf(3));
+ Integer integer;
+ // 使用的for循环+Iterator,类似于链表迭代:
+ // for (ListNode cur = head; cur != null; System.out.println(cur.val)){
+ // cur = cur.next;
+ // }
+ for(Iterator iterator = arraylist.iterator(); iterator.hasNext(); System.out.println(integer))
+ integer = (Integer)iterator.next();
+ }
+}
+```
+
+## Arrays.asList(T...)
+
+熟悉 Arrays.asList(T...)用法的小伙伴都应该知道,asList()方法传入的参数不能是基本类型的数组,必须包装成包装类型再使用,否则对应生成的列表的大小永远是 1:
+
+```java
+import java.util.*;
+public class Demo {
+ public static void main(String[] args) {
+ int[] arr1 = {1, 2, 3};
+ Integer[] arr2 = {1, 2, 3};
+ List lists1 = Arrays.asList(arr1);
+ List lists2 = Arrays.asList(arr2);
+ System.out.println(lists1.size()); // 1
+ System.out.println(lists2.size()); // 3
+ }
+}
+```
+
+从反编译结果来解释,为什么传入基本类型的数组后,返回的 List 大小是 1:
+
+```java
+// 反编译后文件
+import java.io.PrintStream;
+import java.util.Arrays;
+import java.util.List;
+
+public class Demo
+{
+ public Demo() {}
+
+ public static void main(String args[])
+ {
+ int ai[] = {
+ 1, 2, 3
+ };
+ // 使用包装类型,全部元素由int包装为Integer
+ Integer ainteger[] = {
+ Integer.valueOf(1), Integer.valueOf(2), Integer.valueOf(3)
+ };
+
+ // 注意这里被反编译成二维数组,而且是一个1行三列的二维数组
+ // list.size()当然返回1
+ List list = Arrays.asList(new int[][] { ai });
+ List list1 = Arrays.asList(ainteger);
+ System.out.println(list.size());
+ System.out.println(list1.size());
+ }
+}
+```
+
+从上面结果可以看到,传入基本类型的数组后,会被转换成一个二维数组,而且是**new int\[1]\[arr.length]**这样的数组,调用 list.size()当然返回 1。
+
+## 注解
+
+Java 中的类、接口、枚举、注解都可以看做是类类型。使用 jad 来看一下@interface 被转换成什么:
+
+```java
+import java.lang.annotation.Retention;
+import java.lang.annotation.RetentionPolicy;
+
+@Retention(RetentionPolicy.RUNTIME)
+public @interface Foo{
+ String[] value();
+ boolean bar();
+}
+```
+
+查看反编译代码可以看出:
+
+- 自定义的注解类 Foo 被转换成接口 Foo,并且继承 Annotation 接口
+- 原来自定义接口中的 value()和 bar()被转换成抽象方法
+
+```java
+import java.lang.annotation.Annotation;
+
+public interface Foo
+ extends Annotation
+{
+ public abstract String[] value();
+
+ public abstract boolean bar();
+}
+```
+
+注解通常和反射配合使用,而且既然自定义的注解最终被转换成接口,注解中的属性被转换成接口中的抽象方法,那么通过反射之后拿到接口实例,在通过接口实例自然能够调用对应的抽象方法:
+
+```java
+import java.util.Arrays;
+
+@Foo(value={"sherman", "decompiler"}, bar=true)
+public class Demo{
+ public static void main(String[] args) {
+ Foo foo = Demo.class.getAnnotation(Foo.class);
+ System.out.println(Arrays.toString(foo.value())); // [sherman, decompiler]
+ System.out.println(foo.bar()); // true
+ }
+}
+```
+
+## 枚举
+
+通过 jad 反编译可以很好地理解枚举类。
+
+### 空枚举
+
+先定义一个空的枚举类:
+
+```java
+public enum DummyEnum {
+}
+```
+
+使用 jad 反编译查看结果:
+
+- 自定义枚举类被转换成 final 类,并且继承 Enum
+- 提供了两个参数(name,odinal)的私有构造器,并且调用了父类的构造器。注意即使没有提供任何参数,也会有该构造器,其中 name 就是枚举实例的名称,odinal 是枚举实例的索引号
+- 初始化了一个 private static final 自定义类型的空数组 **\$VALUES**
+- 提供了两个 public static 方法:
+ - values()方法通过 clone()方法返回内部\$VALUES 的浅拷贝。这个方法结合私有构造器可以完美实现单例模式,想一想 values()方法是不是和单例模式中 getInstance()方法功能类似
+ - valueOf(String s):调用父类 Enum 的 valueOf 方法并强转返回
+
+```java
+public final class DummyEnum extends Enum
+{
+ // 功能和单例模式的getInstance()方法相同
+ public static DummyEnum[] values()
+ {
+ return (DummyEnum[])$VALUES.clone();
+ }
+ // 调用父类的valueOf方法,并强转返回
+ public static DummyEnum valueOf(String s)
+ {
+ return (DummyEnum)Enum.valueOf(DummyEnum, s);
+ }
+ // 默认提供一个私有的两个参数的构造器,并调用父类Enum的构造器
+ private DummyEnum(String s, int i)
+ {
+ super(s, i);
+ }
+ // 初始化一个private static final的本类空数组
+ private static final DummyEnum $VALUES[] = new DummyEnum[0];
+
+}
+
+```
+
+### 包含抽象方法的枚举
+
+枚举类中也可以包含抽象方法,但是必须定义枚举实例并且立即重写抽象方法,就像下面这样:
+
+```java
+public enum DummyEnum {
+ DUMMY1 {
+ public void dummyMethod() {
+ System.out.println("[1]: implements abstract method in enum class");
+ }
+ },
+
+ DUMMY2 {
+ public void dummyMethod() {
+ System.out.println("[2]: implements abstract method in enum class");
+ }
+ };
+
+ abstract void dummyMethod();
+
+}
+```
+
+再来反编译看看有哪些变化:
+
+- 原来 final class 变成了 abstract class:这很好理解,有抽象方法的类自然是抽象类
+- 多了两个 public static final 的成员 DUMMY1、DUMMY2,这两个实例的初始化过程被放到了 static 代码块中,并且实例过程中直接重写了抽象方法,类似于匿名内部类的形式。
+- 数组 **\$VALUES[]** 初始化时放入枚举实例
+
+还有其它变化么?
+
+在反编译后的 DummyEnum 类中,是存在抽象方法的,而枚举实例在静态代码块中初始化过程中重写了抽象方法。在 Java 中,抽象方法和抽象方法重写同时放在一个类中,只能通过内部类形式完成。因此上面第二点应该说成就是以内部类形式初始化。
+
+可以看一下 DummyEnum.class 存放的位置,应该多了两个文件:
+
+- DummyEnum\$1.class
+- DummyEnum\$2.class
+
+Java 中.class 文件出现 $ 符号表示有内部类存在,就像OutClass$InnerClass,这两个文件出现也应证了上面的匿名内部类初始化的说法。
+
+```java
+import java.io.PrintStream;
+
+public abstract class DummyEnum extends Enum
+{
+ public static DummyEnum[] values()
+ {
+ return (DummyEnum[])$VALUES.clone();
+ }
+
+ public static DummyEnum valueOf(String s)
+ {
+ return (DummyEnum)Enum.valueOf(DummyEnum, s);
+ }
+
+ private DummyEnum(String s, int i)
+ {
+ super(s, i);
+ }
+
+ // 抽象方法
+ abstract void dummyMethod();
+
+ // 两个pubic static final实例
+ public static final DummyEnum DUMMY1;
+ public static final DummyEnum DUMMY2;
+ private static final DummyEnum $VALUES[];
+
+ // static代码块进行初始化
+ static
+ {
+ DUMMY1 = new DummyEnum("DUMMY1", 0) {
+ public void dummyMethod()
+ {
+ System.out.println("[1]: implements abstract method in enum class");
+ }
+ }
+;
+ DUMMY2 = new DummyEnum("DUMMY2", 1) {
+ public void dummyMethod()
+ {
+ System.out.println("[2]: implements abstract method in enum class");
+ }
+ }
+;
+ // 对本类数组进行初始化
+ $VALUES = (new DummyEnum[] {
+ DUMMY1, DUMMY2
+ });
+ }
+}
+```
+
+### 正常的枚举类
+
+实际开发中,枚举类通常的形式是有两个参数(int code,Sring msg)的构造器,可以作为状态码进行返回。Enum 类实际上也是提供了包含两个参数且是 protected 的构造器,这里为了避免歧义,将枚举类的构造器设置为三个,使用 jad 反编译:
+
+最大的变化是:现在的 private 构造器从 2 个参数变成 5 个,而且在内部仍然将前两个参数通过 super 传递给父类,剩余的三个参数才是真正自己提供的参数。可以想象,如果自定义的枚举类只提供了一个参数,最终生成底层代码中 private 构造器应该有三个参数,前两个依然通过 super 传递给父类。
+
+```java
+public final class CustomEnum extends Enum
+{
+ public static CustomEnum[] values()
+ {
+ return (CustomEnum[])$VALUES.clone();
+ }
+
+ public static CustomEnum valueOf(String s)
+ {
+ return (CustomEnum)Enum.valueOf(CustomEnum, s);
+ }
+
+ private CustomEnum(String s, int i, int j, String s1, Object obj)
+ {
+ super(s, i);
+ code = j;
+ msg = s1;
+ data = obj;
+ }
+
+ public static final CustomEnum FIRST;
+ public static final CustomEnum SECOND;
+ public static final CustomEnum THIRD;
+ private int code;
+ private String msg;
+ private Object data;
+ private static final CustomEnum $VALUES[];
+
+ static
+ {
+ FIRST = new CustomEnum("FIRST", 0, 10010, "first", Long.valueOf(100L));
+ SECOND = new CustomEnum("SECOND", 1, 10020, "second", "Foo");
+ THIRD = new CustomEnum("THIRD", 2, 10030, "third", new Object());
+ $VALUES = (new CustomEnum[] {
+ FIRST, SECOND, THIRD
+ });
+ }
+}
+```
diff --git a/docs/java/tips/locate-performance-problems/images/0605fbf554814a23b80f6351408598be-1.png b/docs/java/tips/locate-performance-problems/images/0605fbf554814a23b80f6351408598be-1.png
new file mode 100644
index 00000000000..4a2f13c6ffa
Binary files /dev/null and b/docs/java/tips/locate-performance-problems/images/0605fbf554814a23b80f6351408598be-1.png differ
diff --git a/docs/java/tips/locate-performance-problems/images/1fb751b0d78b4a3b8d0f528598ae885d-1.png b/docs/java/tips/locate-performance-problems/images/1fb751b0d78b4a3b8d0f528598ae885d-1.png
new file mode 100644
index 00000000000..37581b61c66
Binary files /dev/null and b/docs/java/tips/locate-performance-problems/images/1fb751b0d78b4a3b8d0f528598ae885d-1.png differ
diff --git a/docs/java/tips/locate-performance-problems/images/392e4090c0094657ae29af030d3646e3-1.png b/docs/java/tips/locate-performance-problems/images/392e4090c0094657ae29af030d3646e3-1.png
new file mode 100644
index 00000000000..7ac1b402e48
Binary files /dev/null and b/docs/java/tips/locate-performance-problems/images/392e4090c0094657ae29af030d3646e3-1.png differ
diff --git a/docs/java/tips/locate-performance-problems/images/3be5a280b0f5499a80c706c8e5da2a4f-1.png b/docs/java/tips/locate-performance-problems/images/3be5a280b0f5499a80c706c8e5da2a4f-1.png
new file mode 100644
index 00000000000..68c0b685ac4
Binary files /dev/null and b/docs/java/tips/locate-performance-problems/images/3be5a280b0f5499a80c706c8e5da2a4f-1.png differ
diff --git a/docs/java/tips/locate-performance-problems/images/3d8d5ffd3ada43fb86ef54b05408c656-1.png b/docs/java/tips/locate-performance-problems/images/3d8d5ffd3ada43fb86ef54b05408c656-1.png
new file mode 100644
index 00000000000..8c50d818e64
Binary files /dev/null and b/docs/java/tips/locate-performance-problems/images/3d8d5ffd3ada43fb86ef54b05408c656-1.png differ
diff --git a/docs/java/tips/locate-performance-problems/images/53fd3ee9a1a0448ca1878e865f4e5f96-1.png b/docs/java/tips/locate-performance-problems/images/53fd3ee9a1a0448ca1878e865f4e5f96-1.png
new file mode 100644
index 00000000000..03907f53af2
Binary files /dev/null and b/docs/java/tips/locate-performance-problems/images/53fd3ee9a1a0448ca1878e865f4e5f96-1.png differ
diff --git a/docs/java/tips/locate-performance-problems/images/ba07b0fee1754ffc943e546a18a3907e-1.png b/docs/java/tips/locate-performance-problems/images/ba07b0fee1754ffc943e546a18a3907e-1.png
new file mode 100644
index 00000000000..8e8648df554
Binary files /dev/null and b/docs/java/tips/locate-performance-problems/images/ba07b0fee1754ffc943e546a18a3907e-1.png differ
diff --git a/docs/java/tips/locate-performance-problems/images/e9bf831860f442a3a992eef64ebb6a50-1.png b/docs/java/tips/locate-performance-problems/images/e9bf831860f442a3a992eef64ebb6a50-1.png
new file mode 100644
index 00000000000..e204e10c235
Binary files /dev/null and b/docs/java/tips/locate-performance-problems/images/e9bf831860f442a3a992eef64ebb6a50-1.png differ
diff --git "a/docs/java/tips/locate-performance-problems/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\345\256\232\344\275\215\345\270\270\350\247\201Java\346\200\247\350\203\275\351\227\256\351\242\230.md" "b/docs/java/tips/locate-performance-problems/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\345\256\232\344\275\215\345\270\270\350\247\201Java\346\200\247\350\203\275\351\227\256\351\242\230.md"
new file mode 100644
index 00000000000..7856d542333
--- /dev/null
+++ "b/docs/java/tips/locate-performance-problems/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\345\256\232\344\275\215\345\270\270\350\247\201Java\346\200\247\350\203\275\351\227\256\351\242\230.md"
@@ -0,0 +1,402 @@
+# 手把手教你定位常见 Java 性能问题
+
+> 本文来自木木匠投稿。
+
+## 概述
+
+性能优化一向是后端服务优化的重点,但是线上性能故障问题不是经常出现,或者受限于业务产品,根本就没办法出现性能问题,包括笔者自己遇到的性能问题也不多,所以为了提前储备知识,当出现问题的时候不会手忙脚乱,我们本篇文章来模拟下常见的几个 Java 性能故障,来学习怎么去分析和定位。
+
+## 预备知识
+
+既然是定位问题,肯定是需要借助工具,我们先了解下需要哪些工具可以帮忙定位问题。
+
+**top 命令**
+
+`top`命令使我们最常用的 Linux 命令之一,它可以实时的显示当前正在执行的进程的 CPU 使用率,内存使用率等系统信息。`top -Hp pid` 可以查看线程的系统资源使用情况。
+
+**vmstat 命令**
+
+vmstat 是一个指定周期和采集次数的虚拟内存检测工具,可以统计内存,CPU,swap 的使用情况,它还有一个重要的常用功能,用来观察进程的上下文切换。字段说明如下:
+
+- r: 运行队列中进程数量(当数量大于 CPU 核数表示有阻塞的线程)
+- b: 等待 IO 的进程数量
+- swpd: 使用虚拟内存大小
+- free: 空闲物理内存大小
+- buff: 用作缓冲的内存大小(内存和硬盘的缓冲区)
+- cache: 用作缓存的内存大小(CPU 和内存之间的缓冲区)
+- si: 每秒从交换区写到内存的大小,由磁盘调入内存
+- so: 每秒写入交换区的内存大小,由内存调入磁盘
+- bi: 每秒读取的块数
+- bo: 每秒写入的块数
+- in: 每秒中断数,包括时钟中断。
+- cs: 每秒上下文切换数。
+- us: 用户进程执行时间百分比(user time)
+- sy: 内核系统进程执行时间百分比(system time)
+- wa: IO 等待时间百分比
+- id: 空闲时间百分比
+
+ **pidstat 命令**
+
+pidstat 是 Sysstat 中的一个组件,也是一款功能强大的性能监测工具,`top` 和 `vmstat` 两个命令都是监测进程的内存、CPU 以及 I/O 使用情况,而 pidstat 命令可以检测到线程级别的。`pidstat`命令线程切换字段说明如下:
+
+- UID :被监控任务的真实用户 ID。
+
+- TGID :线程组 ID。
+
+- TID:线程 ID。
+
+- cswch/s:主动切换上下文次数,这里是因为资源阻塞而切换线程,比如锁等待等情况。
+
+- nvcswch/s:被动切换上下文次数,这里指 CPU 调度切换了线程。
+
+ **jstack 命令**
+
+jstack 是 JDK 工具命令,它是一种线程堆栈分析工具,最常用的功能就是使用 `jstack pid` 命令查看线程的堆栈信息,也经常用来排除死锁情况。
+
+**jstat 命令**
+
+它可以检测 Java 程序运行的实时情况,包括堆内存信息和垃圾回收信息,我们常常用来查看程序垃圾回收情况。常用的命令是`jstat -gc pid`。信息字段说明如下:
+
+- S0C:年轻代中 To Survivor 的容量(单位 KB);
+
+- S1C:年轻代中 From Survivor 的容量(单位 KB);
+
+- S0U:年轻代中 To Survivor 目前已使用空间(单位 KB);
+
+- S1U:年轻代中 From Survivor 目前已使用空间(单位 KB);
+
+- EC:年轻代中 Eden 的容量(单位 KB);
+
+- EU:年轻代中 Eden 目前已使用空间(单位 KB);
+
+- OC:老年代的容量(单位 KB);
+
+- OU:老年代目前已使用空间(单位 KB);
+
+- MC:元空间的容量(单位 KB);
+
+- MU:元空间目前已使用空间(单位 KB);
+
+- YGC:从应用程序启动到采样时年轻代中 gc 次数;
+
+- YGCT:从应用程序启动到采样时年轻代中 gc 所用时间 (s);
+
+- FGC:从应用程序启动到采样时 老年代(Full Gc)gc 次数;
+
+- FGCT:从应用程序启动到采样时 老年代代(Full Gc)gc 所用时间 (s);
+
+- GCT:从应用程序启动到采样时 gc 用的总时间 (s)。
+
+ **jmap 命令**
+
+jmap 也是 JDK 工具命令,他可以查看堆内存的初始化信息以及堆内存的使用情况,还可以生成 dump 文件来进行详细分析。查看堆内存情况命令`jmap -heap pid`。
+
+**mat 内存工具**
+
+MAT(Memory Analyzer Tool)工具是 eclipse 的一个插件(MAT 也可以单独使用),它分析大内存的 dump 文件时,可以非常直观的看到各个对象在堆空间中所占用的内存大小、类实例数量、对象引用关系、利用 OQL 对象查询,以及可以很方便的找出对象 GC Roots 的相关信息。
+
+**idea 中也有这么一个插件,就是 JProfiler**。
+
+相关阅读:[《性能诊断利器 JProfiler 快速入门和最佳实践》](https://segmentfault.com/a/1190000017795841)
+
+## 模拟环境准备
+
+基础环境 jdk1.8,采用 SpringBoot 框架来写几个接口来触发模拟场景,首先是模拟 CPU 占满情况
+
+### CPU 占满
+
+模拟 CPU 占满还是比较简单,直接写一个死循环计算消耗 CPU 即可。
+
+```java
+ /**
+ * 模拟CPU占满
+ */
+ @GetMapping("/cpu/loop")
+ public void testCPULoop() throws InterruptedException {
+ System.out.println("请求cpu死循环");
+ Thread.currentThread().setName("loop-thread-cpu");
+ int num = 0;
+ while (true) {
+ num++;
+ if (num == Integer.MAX_VALUE) {
+ System.out.println("reset");
+ }
+ num = 0;
+ }
+
+ }
+```
+
+请求接口地址测试`curl localhost:8080/cpu/loop`,发现 CPU 立马飙升到 100%
+
+
+
+通过执行`top -Hp 32805` 查看 Java 线程情况
+
+
+
+执行 `printf '%x' 32826` 获取 16 进制的线程 id,用于`dump`信息查询,结果为 `803a`。最后我们执行`jstack 32805 |grep -A 20 803a`来查看下详细的`dump`信息。
+
+
+
+这里`dump`信息直接定位出了问题方法以及代码行,这就定位出了 CPU 占满的问题。
+
+### 内存泄露
+
+模拟内存泄漏借助了 ThreadLocal 对象来完成,ThreadLocal 是一个线程私有变量,可以绑定到线程上,在整个线程的生命周期都会存在,但是由于 ThreadLocal 的特殊性,ThreadLocal 是基于 ThreadLocalMap 实现的,ThreadLocalMap 的 Entry 继承 WeakReference,而 Entry 的 Key 是 WeakReference 的封装,换句话说 Key 就是弱引用,弱引用在下次 GC 之后就会被回收,如果 ThreadLocal 在 set 之后不进行后续的操作,因为 GC 会把 Key 清除掉,但是 Value 由于线程还在存活,所以 Value 一直不会被回收,最后就会发生内存泄漏。
+
+```Java
+/**
+ * 模拟内存泄漏
+ */
+ @GetMapping(value = "/memory/leak")
+ public String leak() {
+ System.out.println("模拟内存泄漏");
+ ThreadLocal<Byte[]> localVariable = new ThreadLocal<Byte[]>();
+ localVariable.set(new Byte[4096 * 1024]);// 为线程添加变量
+ return "ok";
+ }
+```
+
+我们给启动加上堆内存大小限制,同时设置内存溢出的时候输出堆栈快照并输出日志。
+
+```bash
+java -jar -Xms500m -Xmx500m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/tmp/heaplog.log analysis-demo-0.0.1-SNAPSHOT.jar
+```
+
+启动成功后我们循环执行 100 次,`for i in {1..500}; do curl localhost:8080/memory/leak;done`,还没执行完毕,系统已经返回 500 错误了。查看系统日志出现了如下异常:
+
+```
+java.lang.OutOfMemoryError: Java heap space
+```
+
+我们用`jstat -gc pid` 命令来看看程序的 GC 情况。
+
+
+
+很明显,内存溢出了,堆内存经过 45 次 Full Gc 之后都没释放出可用内存,这说明当前堆内存中的对象都是存活的,有 GC Roots 引用,无法回收。那是什么原因导致内存溢出呢?是不是我只要加大内存就行了呢?如果是普通的内存溢出也许扩大内存就行了,但是如果是内存泄漏的话,扩大的内存不一会就会被占满,所以我们还需要确定是不是内存泄漏。我们之前保存了堆 Dump 文件,这个时候借助我们的 MAT 工具来分析下。导入工具选择`Leak Suspects Report`,工具直接就会给你列出问题报告。
+
+
+
+这里已经列出了可疑的 4 个内存泄漏问题,我们点击其中一个查看详情。
+
+
+
+这里已经指出了内存被线程占用了接近 50M 的内存,占用的对象就是 ThreadLocal。如果想详细的通过手动去分析的话,可以点击`Histogram`,查看最大的对象占用是谁,然后再分析它的引用关系,即可确定是谁导致的内存溢出。
+
+
+
+上图发现占用内存最大的对象是一个 Byte 数组,我们看看它到底被那个 GC Root 引用导致没有被回收。按照上图红框操作指引,结果如下图:
+
+
+
+我们发现 Byte 数组是被线程对象引用的,图中也标明,Byte 数组对像的 GC Root 是线程,所以它是不会被回收的,展开详细信息查看,我们发现最终的内存占用对象是被 ThreadLocal 对象占据了。这也和 MAT 工具自动帮我们分析的结果一致。
+
+### 死锁
+
+死锁会导致耗尽线程资源,占用内存,表现就是内存占用升高,CPU 不一定会飙升(看场景决定),如果是直接 new 线程,会导致 JVM 内存被耗尽,报无法创建线程的错误,这也是体现了使用线程池的好处。
+
+```java
+ ExecutorService service = new ThreadPoolExecutor(4, 10,
+ 0, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(1024),
+ Executors.defaultThreadFactory(),
+ new ThreadPoolExecutor.AbortPolicy());
+ /**
+ * 模拟死锁
+ */
+ @GetMapping("/cpu/test")
+ public String testCPU() throws InterruptedException {
+ System.out.println("请求cpu");
+ Object lock1 = new Object();
+ Object lock2 = new Object();
+ service.submit(new DeadLockThread(lock1, lock2), "deadLookThread-" + new Random().nextInt());
+ service.submit(new DeadLockThread(lock2, lock1), "deadLookThread-" + new Random().nextInt());
+ return "ok";
+ }
+
+public class DeadLockThread implements Runnable {
+ private Object lock1;
+ private Object lock2;
+
+ public DeadLockThread1(Object lock1, Object lock2) {
+ this.lock1 = lock1;
+ this.lock2 = lock2;
+ }
+
+ @Override
+ public void run() {
+ synchronized (lock2) {
+ System.out.println(Thread.currentThread().getName()+"get lock2 and wait lock1");
+ try {
+ TimeUnit.MILLISECONDS.sleep(2000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ synchronized (lock1) {
+ System.out.println(Thread.currentThread().getName()+"get lock1 and lock2 ");
+ }
+ }
+ }
+}
+```
+
+我们循环请求接口 2000 次,发现不一会系统就出现了日志错误,线程池和队列都满了,由于我选择的当队列满了就拒绝的策略,所以系统直接抛出异常。
+
+```
+java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@2760298 rejected from java.util.concurrent.ThreadPoolExecutor@7ea7cd51[Running, pool size = 10, active threads = 10, queued tasks = 1024, completed tasks = 846]
+```
+
+通过`ps -ef|grep java`命令找出 Java 进程 pid,执行`jstack pid` 即可出现 java 线程堆栈信息,这里发现了 5 个死锁,我们只列出其中一个,很明显线程`pool-1-thread-2`锁住了`0x00000000f8387d88`等待`0x00000000f8387d98`锁,线程`pool-1-thread-1`锁住了`0x00000000f8387d98`等待锁`0x00000000f8387d88`,这就产生了死锁。
+
+```JAVA
+Java stack information for the threads listed above:
+===================================================
+"pool-1-thread-2":
+ at top.luozhou.analysisdemo.controller.DeadLockThread2.run(DeadLockThread.java:30)
+ - waiting to lock <0x00000000f8387d98> (a java.lang.Object)
+ - locked <0x00000000f8387d88> (a java.lang.Object)
+ at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
+ at java.util.concurrent.FutureTask.run(FutureTask.java:266)
+ at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
+ at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
+ at java.lang.Thread.run(Thread.java:748)
+"pool-1-thread-1":
+ at top.luozhou.analysisdemo.controller.DeadLockThread1.run(DeadLockThread.java:30)
+ - waiting to lock <0x00000000f8387d88> (a java.lang.Object)
+ - locked <0x00000000f8387d98> (a java.lang.Object)
+ at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
+ at java.util.concurrent.FutureTask.run(FutureTask.java:266)
+ at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
+ at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
+ at java.lang.Thread.run(Thread.java:748)
+
+ Found 5 deadlocks.
+```
+
+### 线程频繁切换
+
+上下文切换会导致将大量 CPU 时间浪费在寄存器、内核栈以及虚拟内存的保存和恢复上,导致系统整体性能下降。当你发现系统的性能出现明显的下降时候,需要考虑是否发生了大量的线程上下文切换。
+
+```java
+ @GetMapping(value = "/thread/swap")
+ public String theadSwap(int num) {
+ System.out.println("模拟线程切换");
+ for (int i = 0; i < num; i++) {
+ new Thread(new ThreadSwap1(new AtomicInteger(0)),"thread-swap"+i).start();
+ }
+ return "ok";
+ }
+public class ThreadSwap1 implements Runnable {
+ private AtomicInteger integer;
+
+ public ThreadSwap1(AtomicInteger integer) {
+ this.integer = integer;
+ }
+
+ @Override
+ public void run() {
+ while (true) {
+ integer.addAndGet(1);
+ Thread.yield(); //让出CPU资源
+ }
+ }
+}
+```
+
+这里我创建多个线程去执行基础的原子+1 操作,然后让出 CPU 资源,理论上 CPU 就会去调度别的线程,我们请求接口创建 100 个线程看看效果如何,`curl localhost:8080/thread/swap?num=100`。接口请求成功后,我们执行 `vmstat 1 10`,表示每 1 秒打印一次,打印 10 次,线程切换采集结果如下:
+
+```
+procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
+ r b swpd free buff cache si so bi bo in cs us sy id wa st
+101 0 128000 878384 908 468684 0 0 0 0 4071 8110498 14 86 0 0 0
+100 0 128000 878384 908 468684 0 0 0 0 4065 8312463 15 85 0 0 0
+100 0 128000 878384 908 468684 0 0 0 0 4107 8207718 14 87 0 0 0
+100 0 128000 878384 908 468684 0 0 0 0 4083 8410174 14 86 0 0 0
+100 0 128000 878384 908 468684 0 0 0 0 4083 8264377 14 86 0 0 0
+100 0 128000 878384 908 468688 0 0 0 108 4182 8346826 14 86 0 0 0
+```
+
+这里我们关注 4 个指标,`r`,`cs`,`us`,`sy`。
+
+**r=100**,说明等待的进程数量是 100,线程有阻塞。
+
+**cs=800 多万**,说明每秒上下文切换了 800 多万次,这个数字相当大了。
+
+**us=14**,说明用户态占用了 14%的 CPU 时间片去处理逻辑。
+
+**sy=86**,说明内核态占用了 86%的 CPU,这里明显就是做上下文切换工作了。
+
+我们通过`top`命令以及`top -Hp pid`查看进程和线程 CPU 情况,发现 Java 进程 CPU 占满了,但是线程 CPU 使用情况很平均,没有某一个线程把 CPU 吃满的情况。
+
+```
+PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
+ 87093 root 20 0 4194788 299056 13252 S 399.7 16.1 65:34.67 java
+```
+
+```
+ PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
+ 87189 root 20 0 4194788 299056 13252 R 4.7 16.1 0:41.11 java
+ 87129 root 20 0 4194788 299056 13252 R 4.3 16.1 0:41.14 java
+ 87130 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.51 java
+ 87133 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.59 java
+ 87134 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.95 java
+```
+
+结合上面用户态 CPU 只使用了 14%,内核态 CPU 占用了 86%,可以基本判断是 Java 程序线程上下文切换导致性能问题。
+
+我们使用`pidstat`命令来看看 Java 进程内部的线程切换数据,执行`pidstat -p 87093 -w 1 10`,采集数据如下:
+
+```
+11:04:30 PM UID TGID TID cswch/s nvcswch/s Command
+11:04:30 PM 0 - 87128 0.00 16.07 |__java
+11:04:30 PM 0 - 87129 0.00 15.60 |__java
+11:04:30 PM 0 - 87130 0.00 15.54 |__java
+11:04:30 PM 0 - 87131 0.00 15.60 |__java
+11:04:30 PM 0 - 87132 0.00 15.43 |__java
+11:04:30 PM 0 - 87133 0.00 16.02 |__java
+11:04:30 PM 0 - 87134 0.00 15.66 |__java
+11:04:30 PM 0 - 87135 0.00 15.23 |__java
+11:04:30 PM 0 - 87136 0.00 15.33 |__java
+11:04:30 PM 0 - 87137 0.00 16.04 |__java
+```
+
+根据上面采集的信息,我们知道 Java 的线程每秒切换 15 次左右,正常情况下,应该是个位数或者小数。结合这些信息我们可以断定 Java 线程开启过多,导致频繁上下文切换,从而影响了整体性能。
+
+**为什么系统的上下文切换是每秒 800 多万,而 Java 进程中的某一个线程切换才 15 次左右?**
+
+系统上下文切换分为三种情况:
+
+1、多任务:在多任务环境中,一个进程被切换出 CPU,运行另外一个进程,这里会发生上下文切换。
+
+2、中断处理:发生中断时,硬件会切换上下文。在 vmstat 命令中是`in`
+
+3、用户和内核模式切换:当操作系统中需要在用户模式和内核模式之间进行转换时,需要进行上下文切换,比如进行系统函数调用。
+
+Linux 为每个 CPU 维护了一个就绪队列,将活跃进程按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。也就是 vmstat 命令中的`r`。
+
+那么,进程在什么时候才会被调度到 CPU 上运行呢?
+
+- 进程执行完终止了,它之前使用的 CPU 会释放出来,这时再从就绪队列中拿一个新的进程来运行
+- 为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片被轮流分配给各个进程。当某个进程时间片耗尽了就会被系统挂起,切换到其它等待 CPU 的进程运行。
+- 进程在系统资源不足时,要等待资源满足后才可以运行,这时进程也会被挂起,并由系统调度其它进程运行。
+- 当进程通过睡眠函数 sleep 主动挂起时,也会重新调度。
+- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
+- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
+
+结合我们之前的内容分析,阻塞的就绪队列是 100 左右,而我们的 CPU 只有 4 核,这部分原因造成的上下文切换就可能会相当高,再加上中断次数是 4000 左右和系统的函数调用等,整个系统的上下文切换到 800 万也不足为奇了。Java 内部的线程切换才 15 次,是因为线程使用`Thread.yield()`来让出 CPU 资源,但是 CPU 有可能继续调度该线程,这个时候线程之间并没有切换,这也是为什么内部的某个线程切换次数并不是非常大的原因。
+
+## 总结
+
+本文模拟了常见的性能问题场景,分析了如何定位 CPU100%、内存泄漏、死锁、线程频繁切换问题。分析问题我们需要做好两件事,第一,掌握基本的原理,第二,借助好工具。本文也列举了分析问题的常用工具和命令,希望对你解决问题有所帮助。当然真正的线上环境可能十分复杂,并没有模拟的环境那么简单,但是原理是一样的,问题的表现也是类似的,我们重点抓住原理,活学活用,相信复杂的线上问题也可以顺利解决。
+
+## 参考
+
+1、https://linux.die.net/man/1/pidstat
+
+2、https://linux.die.net/man/8/vmstat
+
+3、https://help.eclipse.org/2020-03/index.jsp?topic=/org.eclipse.mat.ui.help/welcome.html
+
+4、https://www.linuxblogs.cn/articles/18120200.html
+
+5、https://www.tutorialspoint.com/what-is-context-switching-in-operating-system
\ No newline at end of file
diff --git a/docs/readme.md b/docs/readme.md
new file mode 100644
index 00000000000..814f5e936a5
--- /dev/null
+++ b/docs/readme.md
@@ -0,0 +1,70 @@
+---
+icon: creative
+title: JavaGuide(Java学习&&面试指南)
+---
+
+> 1. **贡献指南** :欢迎参与 [JavaGuide 的维护工作](https://github.com/Snailclimb/JavaGuide/issues/1235),这是一件非常有意义的事情。
+> 2. **知识星球** : 简历指导/Java 学习/面试指导/面试小册。欢迎加入[我的知识星球](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=100015911&idx=1&sn=2e8a0f5acb749ecbcbb417aa8a4e18cc&chksm=4ea1b0ec79d639fae37df1b86f196e8ce397accfd1dd2004bcadb66b4df5f582d90ae0d62448#rd) 。
+> 3. **面试专版** :准备面试的小伙伴可以考虑面试专版:[《Java 面试进阶指北 》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7) (质量很高,专为面试打造)
+> 4. **转载须知** :以下所有文章如非文首说明为转载皆为我(Guide 哥)的原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!⛽️
+
+在大三准备面试的时候,我开源了 JavaGuide 。我把自己准备面试过程中的一些总结都毫不保留地通过 JavaGuide 分享了出来。
+
+开源 JavaGuide 初始想法源于自己的个人那一段比较迷茫的学习经历。主要目的是为了通过这个开源平台来帮助一些在学习 Java 或者面试过程中遇到问题的小伙伴。
+
+- **对于 Java 初学者来说:** 本文档倾向于给你提供一个比较详细的学习路径,让你对于 Java 整体的知识体系有一个初步认识。另外,本文的一些文章也是你学习和复习 Java 知识不错的实践;
+- **对于非 Java 初学者来说:** 本文档更适合回顾知识,准备面试,搞清面试应该把重心放在那些问题上。要搞清楚这个道理:提前知道那些面试常见,不是为了背下来应付面试,而是为了让你可以更有针对的学习重点。
+
+相比于其他通过 JavaGuide 学到东西或者说助力获得 offer 的朋友来说 , JavaGuide 对我的意义更加重大。不夸张的说,有时候真的感觉像是自己的孩子一点一点长大一样,我一直用心呵护着它。
+
+虽然,我花了很长时间来维护它,但是,我觉得非常值得!非常有有益!
+
+另外,[JavaGuide](https://github.com/Snailclimb/JavaGuide) 的 Star 数量虽然比较多,但是它的价值和含金量一定是不能和 Dubbo、Nacos 、SkyWalking 这些优秀的国产开源项目比的。希望国内可以出更多优秀的开源项目!
+
+希望大家对面试不要抱有侥幸的心理,打铁还需自身硬! 我希望这个文档是为你学习 Java 指明方向,而不是用来应付面试用的。加油!奥利给!
+
+## 项目说明
+
+1. 项目的 Markdown 格式参考:[Github Markdown 格式](https://guides.github.com/features/mastering-markdown/),表情素材来自:[EMOJI CHEAT SHEET](https://www.webpagefx.com/tools/emoji-cheat-sheet/)。
+2. Logo 下的小图标是使用[Shields.IO](https://shields.io/) 生成的。
+
+## 如何对该开源文档进行贡献
+
+- 笔记内容大多是手敲,所以难免会有笔误,你可以帮我找错别字。
+- 很多知识点我可能没有涉及到,所以你可以对其他知识点进行补充。
+- 现有的知识点难免存在不完善或者错误,所以你可以对已有知识点进行修改/补充。
+
+如果要提 issue/question 的话,强烈推荐阅读 [《提问的智慧》](https://github.com/ryanhanwu/How-To-Ask-Questions-The-Smart-Way)、[《如何向开源社区提问题》](https://github.com/seajs/seajs/issues/545) 和 [《如何有效地报告 Bug》](http://www.chiark.greenend.org.uk/~sgtatham/bugs-cn.html)、[《如何向开源项目提交无法解答的问题》](https://zhuanlan.zhihu.com/p/25795393)。
+
+## 贡献者
+
+[你可以点此链接查看 JavaGuide 的所有贡献者。](https://github.com/Snailclimb/JavaGuide/graphs/contributors) 感谢你们让 JavaGuide 变得更好!如果你们来到武汉一定要找我,我请你们吃饭玩耍。
+
+_悄悄话:JavaGuide 会不定时为贡献者们送福利。_
+
+## 待办
+
+- [ ] 计算机网络知识点完善
+- [ ] 分布式常见理论和算法总结完善
+
+## 捐赠支持
+
+项目的发展离不开你的支持,如果 JavaGuide 帮助到了你找到自己满意的 offer,请作者喝杯咖啡吧 ☕ 后续会继续完善更新!加油!
+
+[点击捐赠支持作者](https://www.yuque.com/snailclimb/dr6cvl/mr44yt#vu3ok)
+
+## 联系我
+
+
+
+整理了一份各个技术的学习路线,需要的小伙伴加我微信:“**JavaGuide1996**”备注“**Github-学习路线**”即可!
+
+
+
+## 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号“**JavaGuide**”。
+
+**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V4.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可领取!
+
+
diff --git "a/Java\347\233\270\345\205\263/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/system-design/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
similarity index 70%
rename from "Java\347\233\270\345\205\263/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
rename to "docs/system-design/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
index f673332a1ce..22ce6911669 100644
--- "a/Java\347\233\270\345\205\263/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/system-design/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -1,3 +1,5 @@
+点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
+
<!-- MarkdownTOC -->
- [Servlet总结](#servlet总结)
@@ -26,7 +28,7 @@
## Servlet总结
-在Java Web程序中,**Servlet**主要负责接收用户请求**HttpServletRequest**,在**doGet()**,**doPost()**中做相应的处理,并将回应**HttpServletResponse**反馈给用户。Servlet可以设置初始化参数,供Servlet内部使用。一个Servlet类只会有一个实例,在它初始化时调用**init()方法**,销毁时调用**destroy()方法**。**Servlet需要在web.xml中配置**(MyEclipse中创建Servlet会自动配置),**一个Servlet可以设置多个URL访问**。**Servlet不是线程安全**,因此要谨慎使用类变量。
+在Java Web程序中,**Servlet**主要负责接收用户请求 `HttpServletRequest`,在`doGet()`,`doPost()`中做相应的处理,并将回应`HttpServletResponse`反馈给用户。**Servlet** 可以设置初始化参数,供Servlet内部使用。一个Servlet类只会有一个实例,在它初始化时调用`init()`方法,销毁时调用`destroy()`方法**。**Servlet需要在web.xml中配置(MyEclipse中创建Servlet会自动配置),**一个Servlet可以设置多个URL访问**。**Servlet不是线程安全**,因此要谨慎使用类变量。
## 阐述Servlet和CGI的区别?
@@ -55,33 +57,23 @@
## Servlet接口中有哪些方法及Servlet生命周期探秘
Servlet接口定义了5个方法,其中**前三个方法与Servlet生命周期相关**:
-- **void init(ServletConfig config) throws ServletException**
-- **void service(ServletRequest req, ServletResponse resp) throws ServletException, java.io.IOException**
-- **void destory()**
-- java.lang.String getServletInfo()
-- ServletConfig getServletConfig()
+- `void init(ServletConfig config) throws ServletException`
+- `void service(ServletRequest req, ServletResponse resp) throws ServletException, java.io.IOException`
+- `void destroy()`
+- `java.lang.String getServletInfo()`
+- `ServletConfig getServletConfig()`
-**生命周期:** **Web容器加载Servlet并将其实例化后,Servlet生命周期开始**,容器运行其**init()方法**进行Servlet的初始化;请求到达时调用Servlet的**service()方法**,service()方法会根据需要调用与请求对应的**doGet或doPost**等方法;当服务器关闭或项目被卸载时服务器会将Servlet实例销毁,此时会调用Servlet的**destroy()方法**。**init方法和destory方法只会执行一次,service方法客户端每次请求Servlet都会执行**。Servlet中有时会用到一些需要初始化与销毁的资源,因此可以把初始化资源的代码放入init方法中,销毁资源的代码放入destroy方法中,这样就不需要每次处理客户端的请求都要初始化与销毁资源。
+**生命周期:** **Web容器加载Servlet并将其实例化后,Servlet生命周期开始**,容器运行其**init()方法**进行Servlet的初始化;请求到达时调用Servlet的**service()方法**,service()方法会根据需要调用与请求对应的**doGet或doPost**等方法;当服务器关闭或项目被卸载时服务器会将Servlet实例销毁,此时会调用Servlet的**destroy()方法**。**init方法和destroy方法只会执行一次,service方法客户端每次请求Servlet都会执行**。Servlet中有时会用到一些需要初始化与销毁的资源,因此可以把初始化资源的代码放入init方法中,销毁资源的代码放入destroy方法中,这样就不需要每次处理客户端的请求都要初始化与销毁资源。
参考:《javaweb整合开发王者归来》P81
## get和post请求的区别
-> 网上也有文章说:get和post请求实际上是没有区别,大家可以自行查询相关文章!我下面给出的只是一种常见的答案。
-
-①get请求用来从服务器上获得资源,而post是用来向服务器提交数据;
-
-②get将表单中数据按照name=value的形式,添加到action 所指向的URL 后面,并且两者使用"?"连接,而各个变量之间使用"&"连接;post是将表单中的数据放在HTTP协议的请求头或消息体中,传递到action所指向URL;
-
-③get传输的数据要受到URL长度限制(1024字节即256个字符);而post可以传输大量的数据,上传文件通常要使用post方式;
+get和post请求实际上是没有区别,大家可以自行查询相关文章(参考文章:[https://www.cnblogs.com/logsharing/p/8448446.html](https://www.cnblogs.com/logsharing/p/8448446.html),知乎对应的问题链接:[get和post区别?](https://www.zhihu.com/question/28586791))!
-④使用get时参数会显示在地址栏上,如果这些数据不是敏感数据,那么可以使用get;对于敏感数据还是应用使用post;
+可以把 get 和 post 当作两个不同的行为,两者并没有什么本质区别,底层都是 TCP 连接。 get请求用来从服务器上获得资源,而post是用来向服务器提交数据。比如你要获取人员列表可以用 get 请求,你需要创建一个人员可以用 post 。这也是 Restful API 最基本的一个要求。
-⑤get使用MIME类型application/x-www-form-urlencoded的URL编码(也叫百分号编码)文本的格式传递参数,保证被传送的参数由遵循规范的文本组成,例如一个空格的编码是"%20"。
-
-补充:GET方式提交表单的典型应用是搜索引擎。GET方式就是被设计为查询用的。
-
-还有另外一种回答。推荐大家看一下:
+推荐阅读:
- https://www.zhihu.com/question/28586791
- https://mp.weixin.qq.com/s?__biz=MzI3NzIzMzg3Mw==&mid=100000054&idx=1&sn=71f6c214f3833d9ca20b9f7dcd9d33e4#rd
@@ -93,12 +85,12 @@ Form标签里的method的属性为get时调用doGet(),为post时调用doPost()
**转发是服务器行为,重定向是客户端行为。**
-**转发(Forword)**
+**转发(Forward)**
通过RequestDispatcher对象的forward(HttpServletRequest request,HttpServletResponse response)方法实现的。RequestDispatcher可以通过HttpServletRequest 的getRequestDispatcher()方法获得。例如下面的代码就是跳转到login_success.jsp页面。
```java
request.getRequestDispatcher("login_success.jsp").forward(request, response);
```
-**重定向(Redirect)** 是利用服务器返回的状态吗来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过HttpServletRequestResponse的setStatus(int status)方法设置状态码。如果服务器返回301或者302,则浏览器会到新的网址重新请求该资源。
+**重定向(Redirect)** 是利用服务器返回的状态码来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过 `HttpServletResponse` 的 `setStatus(int status)` 方法设置状态码。如果服务器返回301或者302,则浏览器会到新的网址重新请求该资源。
1. **从地址栏显示来说**
@@ -123,9 +115,9 @@ redirect:低.
## 自动刷新(Refresh)
自动刷新不仅可以实现一段时间之后自动跳转到另一个页面,还可以实现一段时间之后自动刷新本页面。Servlet中通过HttpServletResponse对象设置Header属性实现自动刷新例如:
```java
-Response.setHeader("Refresh","1000;URL=http://localhost:8080/servlet/example.htm");
+Response.setHeader("Refresh","5;URL=http://localhost:8080/servlet/example.htm");
```
-其中1000为时间,单位为毫秒。URL指定就是要跳转的页面(如果设置自己的路径,就会实现没过一秒自动刷新本页面一次)
+其中5为时间,单位为秒。URL指定就是要跳转的页面(如果设置自己的路径,就会实现每过5秒自动刷新本页面一次)
## Servlet与线程安全
@@ -143,13 +135,11 @@ Response.setHeader("Refresh","1000;URL=http://localhost:8080/servlet/example.htm
JSP是一种Servlet,但是与HttpServlet的工作方式不太一样。HttpServlet是先由源代码编译为class文件后部署到服务器下,为先编译后部署。而JSP则是先部署后编译。JSP会在客户端第一次请求JSP文件时被编译为HttpJspPage类(接口Servlet的一个子类)。该类会被服务器临时存放在服务器工作目录里面。下面通过实例给大家介绍。
工程JspLoginDemo下有一个名为login.jsp的Jsp文件,把工程第一次部署到服务器上后访问这个Jsp文件,我们发现这个目录下多了下图这两个东东。
.class文件便是JSP对应的Servlet。编译完毕后再运行class文件来响应客户端请求。以后客户端访问login.jsp的时候,Tomcat将不再重新编译JSP文件,而是直接调用class文件来响应客户端请求。
-
+
由于JSP只会在客户端第一次请求的时候被编译 ,因此第一次请求JSP时会感觉比较慢,之后就会感觉快很多。如果把服务器保存的class文件删除,服务器也会重新编译JSP。
开发Web程序时经常需要修改JSP。Tomcat能够自动检测到JSP程序的改动。如果检测到JSP源代码发生了改动。Tomcat会在下次客户端请求JSP时重新编译JSP,而不需要重启Tomcat。这种自动检测功能是默认开启的,检测改动会消耗少量的时间,在部署Web应用的时候可以在web.xml中将它关掉。
-
-
参考:《javaweb整合开发王者归来》P97
## JSP有哪些内置对象、作用分别是什么
@@ -195,31 +185,31 @@ JSP有9个内置对象:
## request.getAttribute()和 request.getParameter()有何区别
**从获取方向来看:**
-getParameter()是获取 POST/GET 传递的参数值;
+`getParameter()`是获取 POST/GET 传递的参数值;
-getAttribute()是获取对象容器中的数据值;
+`getAttribute()`是获取对象容器中的数据值;
**从用途来看:**
-getParameter用于客户端重定向时,即点击了链接或提交按扭时传值用,即用于在用表单或url重定向传值时接收数据用。
+`getParameter()`用于客户端重定向时,即点击了链接或提交按扭时传值用,即用于在用表单或url重定向传值时接收数据用。
-getAttribute用于服务器端重定向时,即在 sevlet 中使用了 forward 函数,或 struts 中使用了
+`getAttribute()` 用于服务器端重定向时,即在 sevlet 中使用了 forward 函数,或 struts 中使用了
mapping.findForward。 getAttribute 只能收到程序用 setAttribute 传过来的值。
-另外,可以用 setAttribute,getAttribute 发送接收对象.而 getParameter 显然只能传字符串。
-setAttribute 是应用服务器把这个对象放在该页面所对应的一块内存中去,当你的页面服务器重定向到另一个页面时,应用服务器会把这块内存拷贝另一个页面所对应的内存中。这样getAttribute就能取得你所设下的值,当然这种方法可以传对象。session也一样,只是对象在内存中的生命周期不一样而已。getParameter只是应用服务器在分析你送上来的 request页面的文本时,取得你设在表单或 url 重定向时的值。
+另外,可以用 `setAttribute()`,`getAttribute()` 发送接收对象.而 `getParameter()` 显然只能传字符串。
+`setAttribute()` 是应用服务器把这个对象放在该页面所对应的一块内存中去,当你的页面服务器重定向到另一个页面时,应用服务器会把这块内存拷贝另一个页面所对应的内存中。这样`getAttribute()`就能取得你所设下的值,当然这种方法可以传对象。session也一样,只是对象在内存中的生命周期不一样而已。`getParameter()`只是应用服务器在分析你送上来的 request页面的文本时,取得你设在表单或 url 重定向时的值。
**总结:**
-getParameter 返回的是String,用于读取提交的表单中的值;(获取之后会根据实际需要转换为自己需要的相应类型,比如整型,日期类型啊等等)
+`getParameter()`返回的是String,用于读取提交的表单中的值;(获取之后会根据实际需要转换为自己需要的相应类型,比如整型,日期类型啊等等)
-getAttribute 返回的是Object,需进行转换,可用setAttribute 设置成任意对象,使用很灵活,可随时用
+`getAttribute()`返回的是Object,需进行转换,可用`setAttribute()`设置成任意对象,使用很灵活,可随时用
## include指令include的行为的区别
**include指令:** JSP可以通过include指令来包含其他文件。被包含的文件可以是JSP文件、HTML文件或文本文件。包含的文件就好像是该JSP文件的一部分,会被同时编译执行。 语法格式如下:
<%@ include file="文件相对 url 地址" %>
-i**nclude动作:** <jsp:include>动作元素用来包含静态和动态的文件。该动作把指定文件插入正在生成的页面。语法格式如下:
+i**nclude动作:** `<jsp:include>`动作元素用来包含静态和动态的文件。该动作把指定文件插入正在生成的页面。语法格式如下:
<jsp:include page="相对 URL 地址" flush="true" />
## JSP九大内置对象,七大动作,三大指令
@@ -232,11 +222,9 @@ JSP中的四种作用域包括page、request、session和application,具体来
- **session**代表与某个用户与服务器建立的一次会话相关的对象和属性。跟某个用户相关的数据应该放在用户自己的session中。
- **application**代表与整个Web应用程序相关的对象和属性,它实质上是跨越整个Web应用程序,包括多个页面、请求和会话的一个全局作用域。
-
-
## 如何实现JSP或Servlet的单线程模式
对于JSP页面,可以通过page指令进行设置。
-<%@page isThreadSafe=”false”%>
+`<%@page isThreadSafe="false"%>`
对于Servlet,可以让自定义的Servlet实现SingleThreadModel标识接口。
@@ -294,12 +282,20 @@ if(cookies !=null){
在所有会话跟踪技术中,HttpSession对象是最强大也是功能最多的。当一个用户第一次访问某个网站时会自动创建 HttpSession,每个用户可以访问他自己的HttpSession。可以通过HttpServletRequest对象的getSession方 法获得HttpSession,通过HttpSession的setAttribute方法可以将一个值放在HttpSession中,通过调用 HttpSession对象的getAttribute方法,同时传入属性名就可以获取保存在HttpSession中的对象。与上面三种方式不同的 是,HttpSession放在服务器的内存中,因此不要将过大的对象放在里面,即使目前的Servlet容器可以在内存将满时将HttpSession 中的对象移到其他存储设备中,但是这样势必影响性能。添加到HttpSession中的值可以是任意Java对象,这个对象最好实现了 Serializable接口,这样Servlet容器在必要的时候可以将其序列化到文件中,否则在序列化时就会出现异常。
## Cookie和Session的的区别
-1. 由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
-2. 思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
-3. Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。所以,总结一下:Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
+Cookie 和 Session都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
+
+ **Cookie 一般用来保存用户信息** 比如①我们在 Cookie 中保存已经登录过得用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了;②一般的网站都会有保持登录也就是说下次你再访问网站的时候就不需要重新登录了,这是因为用户登录的时候我们可以存放了一个 Token 在 Cookie 中,下次登录的时候只需要根据 Token 值来查找用户即可(为了安全考虑,重新登录一般要将 Token 重写);③登录一次网站后访问网站其他页面不需要重新登录。**Session 的主要作用就是通过服务端记录用户的状态。** 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
+
+Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。
+
+Cookie 存储在客户端中,而Session存储在服务器上,相对来说 Session 安全性更高。如果使用 Cookie 的一些敏感信息不要写入 Cookie 中,最好能将 Cookie 信息加密然后使用到的时候再去服务器端解密。
+
+## 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-参考:
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-https://www.zhihu.com/question/19786827/answer/28752144
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-《javaweb整合开发王者归来》P158 Cookie和Session的比较
+
diff --git a/docs/system-design/basis/RESTfulAPI.md b/docs/system-design/basis/RESTfulAPI.md
new file mode 100644
index 00000000000..142c0f735f7
--- /dev/null
+++ b/docs/system-design/basis/RESTfulAPI.md
@@ -0,0 +1,178 @@
+
+# RestFul API 简明教程
+
+
+
+
+大家好,我是 Guide哥!
+
+这篇文章简单聊聊后端程序员必备的 RESTful API 相关的知识。
+
+开始正式介绍 RESTful API 之前,我们需要首先搞清 :**API 到底是什么?**
+
+## 何为 API?
+
+
+
+**API(Application Programming Interface)** 翻译过来是应用程序编程接口的意思。
+
+我们在进行后端开发的时候,主要的工作就是为前端或者其他后端服务提供 API 比如查询用户数据的 API 。
+
+
+
+但是, API 不仅仅代表后端系统暴露的接口,像框架中提供的方法也属于 API 的范畴。
+
+为了方便大家理解,我再列举几个例子 🌰:
+
+1. 你通过某电商网站搜索某某商品,电商网站的前端就调用了后端提供了搜索商品相关的 API。
+2. 你使用 JDK 开发 Java 程序,想要读取用户的输入的话,你就需要使用 JDK 提供的 IO 相关的 API。
+3. ......
+
+你可以把 API 理解为程序与程序之间通信的桥梁,其本质就是一个函数而已。另外,API 的使用也不是没有章法的,它的规则由(比如数据输入和输出的格式)API 提供方制定。
+
+## 何为 RESTful API?
+
+**RESTful API** 经常也被叫做 **REST API**,它是基于 REST 构建的 API。这个 REST 到底是什么,我们后文在讲,涉及到的概念比较多。
+
+如果你看 RESTful API 相关的文章的话一般都比较晦涩难懂,主要是因为 REST 涉及到的一些概念比较难以理解。但是,实际上,我们平时开发用到的 RESTful API 的知识非常简单也很容易概括!
+
+举个例子,如果我给你下面两个 API 你是不是立马能知道它们是干什么用的!这就是 RESTful API 的强大之处!
+
+```
+GET /classes:列出所有班级
+POST /classes:新建一个班级
+```
+
+**RESTful API 可以让你看到 URL+Http Method 就知道这个 URL 是干什么的,让你看到了 HTTP 状态码(status code)就知道请求结果如何。**
+
+像咱们在开发过程中设计 API 的时候也应该至少要满足 RESTful API 的最基本的要求(比如接口中尽量使用名词,使用 `POST` 请求创建资源,`DELETE` 请求删除资源等等,示例:`GET /notes/id`:获取某个指定 id 的笔记的信息)。
+
+## 解读 REST
+
+**REST** 是 `REpresentational State Transfer` 的缩写。这个词组的翻译过来就是“**表现层状态转化**”。
+
+这样理解起来甚是晦涩,实际上 REST 的全称是 **Resource Representational State Transfer** ,直白地翻译过来就是 **“资源”在网络传输中以某种“表现形式”进行“状态转移”** 。如果还是不能继续理解,请继续往下看,相信下面的讲解一定能让你理解到底啥是 REST 。
+
+我们分别对上面涉及到的概念进行解读,以便加深理解,实际上你不需要搞懂下面这些概念,也能看懂我下一部分要介绍到的内容。不过,为了更好地能跟别人扯扯 “RESTful API”我建议你还是要好好理解一下!
+
+- **资源(Resource)** :我们可以把真实的对象数据称为资源。一个资源既可以是一个集合,也可以是单个个体。比如我们的班级 classes 是代表一个集合形式的资源,而特定的 class 代表单个个体资源。每一种资源都有特定的 URI(统一资源标识符)与之对应,如果我们需要获取这个资源,访问这个 URI 就可以了,比如获取特定的班级:`/class/12`。另外,资源也可以包含子资源,比如 `/classes/classId/teachers`:列出某个指定班级的所有老师的信息
+- **表现形式(Representational)**:"资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式比如 `json`,`xml`,`image`,`txt` 等等叫做它的"表现层/表现形式"。
+- **状态转移(State Transfer)** :大家第一眼看到这个词语一定会很懵逼?内心 BB:这尼玛是啥啊? 大白话来说 REST 中的状态转移更多地描述的服务器端资源的状态,比如你通过增删改查(通过 HTTP 动词实现)引起资源状态的改变。ps:互联网通信协议 HTTP 协议,是一个无状态协议,所有的资源状态都保存在服务器端。
+
+综合上面的解释,我们总结一下什么是 RESTful 架构:
+
+1. 每一个 URI 代表一种资源;
+2. 客户端和服务器之间,传递这种资源的某种表现形式比如 `json`,`xml`,`image`,`txt` 等等;
+3. 客户端通过特定的 HTTP 动词,对服务器端资源进行操作,实现"表现层状态转化"。
+
+## RESTful API 规范
+
+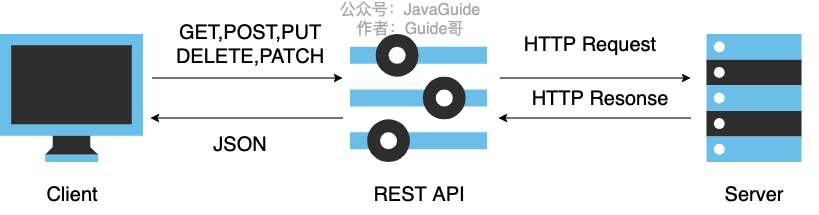
+
+### 动作
+
+- `GET`:请求从服务器获取特定资源。举个例子:`GET /classes`(获取所有班级)
+- `POST` :在服务器上创建一个新的资源。举个例子:`POST /classes`(创建班级)
+- `PUT` :更新服务器上的资源(客户端提供更新后的整个资源)。举个例子:`PUT /classes/12`(更新编号为 12 的班级)
+- `DELETE` :从服务器删除特定的资源。举个例子:`DELETE /classes/12`(删除编号为 12 的班级)
+- `PATCH` :更新服务器上的资源(客户端提供更改的属性,可以看做作是部分更新),使用的比较少,这里就不举例子了。
+
+### 路径(接口命名)
+
+路径又称"终点"(endpoint),表示 API 的具体网址。实际开发中常见的规范如下:
+
+1. **网址中不能有动词,只能有名词,API 中的名词也应该使用复数。** 因为 REST 中的资源往往和数据库中的表对应,而数据库中的表都是同种记录的"集合"(collection)。如果 API 调用并不涉及资源(如计算,翻译等操作)的话,可以用动词。比如:`GET /calculate?param1=11¶m2=33` 。
+2. **不用大写字母,建议用中杠 - 不用下杠 \_** 。比如邀请码写成 `invitation-code`而不是 ~~invitation_code~~ 。
+3. **善用版本化 API**。当我们的 API 发生了重大改变而不兼容前期版本的时候,我们可以通过 URL 来实现版本化,比如 `http://api.example.com/v1`、`http://apiv1.example.com` 。版本不必非要是数字,只是数字用的最多,日期、季节都可以作为版本标识符,项目团队达成共识就可。
+4. **接口尽量使用名词,避免使用动词。** RESTful API 操作(HTTP Method)的是资源(名词)而不是动作(动词)。
+
+Talk is cheap!来举个实际的例子来说明一下吧!现在有这样一个 API 提供班级(class)的信息,还包括班级中的学生和教师的信息,则它的路径应该设计成下面这样。
+
+```
+GET /classes:列出所有班级
+POST /classes:新建一个班级
+GET /classes/{classId}:获取某个指定班级的信息
+PUT /classes/{classId}:更新某个指定班级的信息(一般倾向整体更新)
+PATCH /classes/{classId}:更新某个指定班级的信息(一般倾向部分更新)
+DELETE /classes/{classId}:删除某个班级
+GET /classes/{classId}/teachers:列出某个指定班级的所有老师的信息
+GET /classes/{classId}/students:列出某个指定班级的所有学生的信息
+DELETE /classes/{classId}/teachers/{ID}:删除某个指定班级下的指定的老师的信息
+```
+
+反例:
+
+```
+/getAllclasses
+/createNewclass
+/deleteAllActiveclasses
+```
+
+理清资源的层次结构,比如业务针对的范围是学校,那么学校会是一级资源:`/schools`,老师: `/schools/teachers`,学生: `/schools/students` 就是二级资源。
+
+### 过滤信息(Filtering)
+
+如果我们在查询的时候需要添加特定条件的话,建议使用 url 参数的形式。比如我们要查询 state 状态为 active 并且 name 为 guidegege 的班级:
+
+```
+GET /classes?state=active&name=guidegege
+```
+
+比如我们要实现分页查询:
+
+```
+GET /classes?page=1&size=10 //指定第1页,每页10个数据
+```
+
+### 状态码(Status Codes)
+
+**状态码范围:**
+
+| 2xx:成功 | 3xx:重定向 | 4xx:客户端错误 | 5xx:服务器错误 |
+| --------- | -------------- | ---------------- | --------------- |
+| 200 成功 | 301 永久重定向 | 400 错误请求 | 500 服务器错误 |
+| 201 创建 | 304 资源未修改 | 401 未授权 | 502 网关错误 |
+| | | 403 禁止访问 | 504 网关超时 |
+| | | 404 未找到 | |
+| | | 405 请求方法不对 | |
+
+## RESTful 的极致 HATEOAS
+
+> **RESTful 的极致是 hateoas ,但是这个基本不会在实际项目中用到。**
+
+上面是 RESTful API 最基本的东西,也是我们平时开发过程中最容易实践到的。实际上,RESTful API 最好做到 Hypermedia,即返回结果中提供链接,连向其他 API 方法,使得用户不查文档,也知道下一步应该做什么。
+
+比如,当用户向 `api.example.com` 的根目录发出请求,会得到这样一个返回结果
+
+```javascript
+{"link": {
+ "rel": "collection https://www.example.com/classes",
+ "href": "https://api.example.com/classes",
+ "title": "List of classes",
+ "type": "application/vnd.yourformat+json"
+}}
+```
+
+上面代码表示,文档中有一个 `link` 属性,用户读取这个属性就知道下一步该调用什么 API 了。`rel` 表示这个 API 与当前网址的关系(collection 关系,并给出该 collection 的网址),`href` 表示 API 的路径,title 表示 API 的标题,`type` 表示返回类型 `Hypermedia API` 的设计被称为[HATEOAS](http://en.wikipedia.org/wiki/HATEOAS)。
+
+在 Spring 中有一个叫做 HATEOAS 的 API 库,通过它我们可以更轻松的创建出符合 HATEOAS 设计的 API。相关文章:
+
+- [在 Spring Boot 中使用 HATEOAS](https://blog.aisensiy.me/2017/06/04/spring-boot-and-hateoas/)
+- [Building REST services with Spring](https://spring.io/guides/tutorials/rest/) (Spring 官网 )
+- [An Intro to Spring HATEOAS](https://www.baeldung.com/spring-hateoas-tutorial)
+- [spring-hateoas-examples](https://github.com/spring-projects/spring-hateoas-examples/tree/master/hypermedia)
+- [Spring HATEOAS](https://spring.io/projects/spring-hateoas#learn) (Spring 官网 )
+
+## 参考
+
+- https://RESTfulapi.net/
+
+- https://www.ruanyifeng.com/blog/2014/05/restful_api.html
+
+- https://juejin.im/entry/59e460c951882542f578f2f0
+
+- https://phauer.com/2016/testing-RESTful-services-java-best-practices/
+
+- https://www.seobility.net/en/wiki/REST_API
+
+- https://dev.to/duomly/rest-api-vs-graphql-comparison-3j6g
diff --git a/docs/system-design/basis/naming.md b/docs/system-design/basis/naming.md
new file mode 100644
index 00000000000..66f333458a3
--- /dev/null
+++ b/docs/system-design/basis/naming.md
@@ -0,0 +1,249 @@
+
+
+# Java 命名之道
+
+我还记得我刚工作那一段时间, 项目 Code Review 的时候,我经常因为变量命名不规范而被 “diss”!
+
+究其原因还是自己那会经验不足,而且,大学那会写项目的时候不太注意这些问题,想着只要把功能实现出来就行了。
+
+但是,工作中就不一样,为了代码的可读性、可维护性,项目组对于代码质量的要求还是很高的!
+
+前段时间,项目组新来的一个实习生也经常在 Code Review 因为变量命名不规范而被 “diss”,这让我想到自己刚到公司写代码那会的日子。
+
+于是,我就简单写了这篇关于变量命名规范的文章,希望能对同样有此困扰的小伙伴提供一些帮助。
+
+确实,编程过程中,有太多太多让我们头疼的事情了,比如命名、维护其他人的代码、写测试、与其他人沟通交流等等。
+
+据说之前在 Quora 网站,由接近 5000 名程序员票选出来的最难的事情就是“命名”。
+
+大名鼎鼎的《重构》的作者老马(Martin Fowler)曾经在[TwoHardThings](https://martinfowler.com/bliki/TwoHardThings.html)这篇文章中提到过CS 领域有两大最难的事情:一是 **缓存失效** ,一是 **程序命名** 。
+
+
+
+这个句话实际上也是老马引用别人的,类似的表达还有很多。比如分布式系统领域有两大最难的事情:一是 **保证消息顺序** ,一是 **严格一次传递** 。
+
+
+
+今天咱们就单独拎出 “**命名**” 来聊聊!
+
+这篇文章配合我之前发的 [《编码 5 分钟,命名 2 小时?史上最全的 Java 命名规范参考!》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486449&idx=1&sn=c3b502529ff991c7180281bcc22877af&chksm=cea2443af9d5cd2c1c87049ed15ccf6f88275419c7dbe542406166a703b27d0f3ecf2af901f8&token=999884676&lang=zh_CN#rd) 这篇文章阅读效果更佳哦!
+
+## 为什么需要重视命名?
+
+咱们需要先搞懂为什么要重视编程中的命名这一行为,它对于我们的编码工作有着什么意义。
+
+**为什么命名很重要呢?** 这是因为 **好的命名即是注释,别人一看到你的命名就知道你的变量、方法或者类是做什么的!**
+
+简单来说就是 **别人根据你的命名就能知道你的代码要表达的意思** (不过,前提这个人也要有基本的英语知识,对于一些编程中常见的单词比较熟悉)。
+
+简单举个例子说明一下命名的重要性。
+
+《Clean Code》这本书明确指出:
+
+> **好的代码本身就是注释,我们要尽量规范和美化自己的代码来减少不必要的注释。**
+>
+> **若编程语言足够有表达力,就不需要注释,尽量通过代码来阐述。**
+>
+> 举个例子:
+>
+> 去掉下面复杂的注释,只需要创建一个与注释所言同一事物的函数即可
+>
+> ```java
+> // check to see if the employee is eligible for full benefits
+> if ((employee.flags & HOURLY_FLAG) && (employee.age > 65))
+> ```
+>
+> 应替换为
+>
+> ```java
+> if (employee.isEligibleForFullBenefits())
+> ```
+
+## 常见命名规则以及适用场景
+
+这里只介绍 3 种最常见的命名规范。
+
+### 驼峰命名法(CamelCase)
+
+驼峰命名法应该我们最常见的一个,这种命名方式使用大小写混合的格式来区别各个单词,并且单词之间不使用空格隔开或者连接字符连接的命名方式
+
+#### 大驼峰命名法(UpperCamelCase)
+
+**类名需要使用大驼峰命名法(UpperCamelCase)**
+
+正例:
+
+```java
+ServiceDiscovery、ServiceInstance、LruCacheFactory
+```
+
+反例:
+
+```java
+serviceDiscovery、Serviceinstance、LRUCacheFactory
+```
+
+#### 小驼峰命名法(lowerCamelCase)
+
+**方法名、参数名、成员变量、局部变量需要使用小驼峰命名法(lowerCamelCase)。**
+
+正例:
+
+```java
+getUserInfo()
+createCustomThreadPool()
+setNameFormat(String nameFormat)
+Uservice userService;
+```
+
+反例:
+
+```java
+GetUserInfo()、CreateCustomThreadPool()、setNameFormat(String NameFormat)
+Uservice user_service
+```
+
+### 蛇形命名法(snake_case)
+
+**测试方法名、常量、枚举名称需要使用蛇形命名法(snake_case)**
+
+在蛇形命名法中,各个单词之间通过下划线“\_”连接,比如`should_get_200_status_code_when_request_is_valid`、`CLIENT_CONNECT_SERVER_FAILURE`。
+
+蛇形命名法的优势是命名所需要的单词比较多的时候,比如我把上面的命名通过小驼峰命名法给大家看一下:“shouldGet200StatusCodeWhenRequestIsValid”。
+
+感觉如何? 相比于使用蛇形命名法(snake_case)来说是不是不那么易读?
+
+正例:
+
+```java
+@Test
+void should_get_200_status_code_when_request_is_valid() {
+ ......
+}
+```
+
+反例:
+
+```java
+@Test
+void shouldGet200StatusCodeWhenRequestIsValid() {
+ ......
+}
+```
+
+### 串式命名法(kebab-case)
+
+在串式命名法中,各个单词之间通过连接符“-”连接,比如`dubbo-registry`。
+
+建议项目文件夹名称使用串式命名法(kebab-case),比如 dubbo 项目的各个模块的命名是下面这样的。
+
+
+
+## 常见命名规范
+
+### Java 语言基本命名规范
+
+**1、类名需要使用大驼峰命名法(UpperCamelCase)风格。方法名、参数名、成员变量、局部变量需要使用小驼峰命名法(lowerCamelCase)。**
+
+**2、测试方法名、常量、枚举名称需要使用蛇形命名法(snake_case)**,比如`should_get_200_status_code_when_request_is_valid`、`CLIENT_CONNECT_SERVER_FAILURE`。并且,**测试方法名称要求全部小写,常量以及枚举名称需要全部大写。**
+
+**3、项目文件夹名称使用串式命名法(kebab-case),比如`dubbo-registry`。**
+
+**4、包名统一使用小写,尽量使用单个名词作为包名,各个单词通过 "." 分隔符连接,并且各个单词必须为单数。**
+
+正例: `org.apache.dubbo.common.threadlocal`
+
+反例: ~~`org.apache_dubbo.Common.threadLocals`~~
+
+**5、抽象类命名使用 Abstract 开头**。
+
+```java
+//为远程传输部分抽象出来的一个抽象类(出处:Dubbo源码)
+public abstract class AbstractClient extends AbstractEndpoint implements Client {
+
+}
+```
+
+**6、异常类命名使用 Exception 结尾。**
+
+```java
+//自定义的 NoSuchMethodException(出处:Dubbo源码)
+public class NoSuchMethodException extends RuntimeException {
+ private static final long serialVersionUID = -2725364246023268766L;
+
+ public NoSuchMethodException() {
+ super();
+ }
+
+ public NoSuchMethodException(String msg) {
+ super(msg);
+ }
+}
+```
+
+**7、测试类命名以它要测试的类的名称开始,以 Test 结尾。**
+
+```java
+//为 AnnotationUtils 类写的测试类(出处:Dubbo源码)
+public class AnnotationUtilsTest {
+ ......
+}
+```
+
+POJO 类中布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误。
+
+如果模块、接口、类、方法使用了设计模式,在命名时需体现出具体模式。
+
+### 命名易读性规范
+
+**1、为了能让命名更加易懂和易读,尽量不要缩写/简写单词,除非这些单词已经被公认可以被这样缩写/简写。比如 `CustomThreadFactory` 不可以被写成 ~~`CustomTF` 。**
+
+**2、命名不像函数一样要尽量追求短,可读性强的名字优先于简短的名字,虽然可读性强的名字会比较长一点。** 这个对应我们上面说的第 1 点。
+
+**3、避免无意义的命名,你起的每一个名字都要能表明意思。**
+
+正例:`UserService userService;` `int userCount`;
+
+反例: ~~`UserService service`~~ ~~`int count`~~
+
+**4、避免命名过长(50 个字符以内最好),过长的命名难以阅读并且丑陋。**
+
+**5、不要使用拼音,更不要使用中文。** 不过像 alibaba 、wuhan、taobao 这种国际通用名词可以当做英文来看待。
+
+正例:discount
+
+反例:~~dazhe~~
+
+## Codelf:变量命名神器?
+
+这是一个由国人开发的网站,网上有很多人称其为变量命名神器, 我在实际使用了几天之后感觉没那么好用。小伙伴们可以自行体验一下,然后再给出自己的判断。
+
+Codelf 提供了在线网站版本,网址:[https://unbug.github.io/codelf/](https://unbug.github.io/codelf/),具体使用情况如下:
+
+我选择了 Java 编程语言,然后搜索了“序列化”这个关键词,然后它就返回了很多关于序列化的命名。
+
+
+
+并且,Codelf 还提供了 VS code 插件,看这个评价,看来大家还是很喜欢这款命名工具的。
+
+
+
+## 相关阅读推荐
+
+1. 《阿里巴巴 Java 开发手册》
+2. 《Clean Code》
+3. Google Java 代码指南:https://google.github.io/styleguide/javaguide.html#s5.1-identifier-name
+4. 告别编码5分钟,命名2小时!史上最全的Java命名规范参考:https://www.cnblogs.com/liqiangchn/p/12000361.html
+
+## 总结
+
+作为一个合格的程序员,小伙伴们应该都知道代码表义的重要性。想要写出高质量代码,好的命名就是第一步!
+
+好的命名对于其他人(包括你自己)理解你的代码有着很大的帮助!你的代码越容易被理解,可维护性就越强,侧面也就说明你的代码设计的也就越好!
+
+在日常编码过程中,我们需要谨记常见命名规范比如类名需要使用大驼峰命名法、不要使用拼音,更不要使用中文......。
+
+另外,国人开发的一个叫做 Codelf 的网站被很多人称为“变量命名神器”,当你为命名而头疼的时候,你可以去参考一下上面提供的一些命名示例。
+
+最后,祝愿大家都不用再为命名而困扰!
+
diff --git a/docs/system-design/basis/pictures/Codelf.png b/docs/system-design/basis/pictures/Codelf.png
new file mode 100644
index 00000000000..2f030785c9f
Binary files /dev/null and b/docs/system-design/basis/pictures/Codelf.png differ
diff --git a/docs/system-design/basis/pictures/dubbo-naming.png b/docs/system-design/basis/pictures/dubbo-naming.png
new file mode 100644
index 00000000000..2081bb88280
Binary files /dev/null and b/docs/system-design/basis/pictures/dubbo-naming.png differ
diff --git a/docs/system-design/basis/pictures/marting-naming.png b/docs/system-design/basis/pictures/marting-naming.png
new file mode 100644
index 00000000000..5a797c431ee
Binary files /dev/null and b/docs/system-design/basis/pictures/marting-naming.png differ
diff --git a/docs/system-design/basis/pictures/naming-mindmap.png b/docs/system-design/basis/pictures/naming-mindmap.png
new file mode 100644
index 00000000000..131f7888a67
Binary files /dev/null and b/docs/system-design/basis/pictures/naming-mindmap.png differ
diff --git a/docs/system-design/basis/pictures/vscode-codelf.png b/docs/system-design/basis/pictures/vscode-codelf.png
new file mode 100644
index 00000000000..96b64502265
Binary files /dev/null and b/docs/system-design/basis/pictures/vscode-codelf.png differ
diff --git a/docs/system-design/framework/mybatis/mybatis-interview.md b/docs/system-design/framework/mybatis/mybatis-interview.md
new file mode 100644
index 00000000000..8f982e328cf
--- /dev/null
+++ b/docs/system-design/framework/mybatis/mybatis-interview.md
@@ -0,0 +1,281 @@
+# MyBatis 常见面试总结
+
+> 本篇文章是 JavaGuide 收集自网络,原出处不明。
+
+MyBatis 技术内幕系列博客,从原理和源码角度,介绍了其内部实现细节,无论是写的好与不好,我确实是用心写了,由于并不是介绍如何使用 MyBatis 的文章,所以,一些参数使用细节略掉了,我们的目标是介绍 MyBatis 的技术架构和重要组成部分,以及基本运行原理。
+
+博客写的很辛苦,但是写出来却不一定好看,所谓开始很兴奋,过程很痛苦,结束很遗憾。要求不高,只要读者能从系列博客中,学习到一点其他博客所没有的技术点,作为作者,我就很欣慰了,我也读别人写的博客,通常对自己当前研究的技术,是很有帮助的。
+
+尽管还有很多可写的内容,但是,我认为再写下去已经没有意义,任何其他小的功能点,都是在已经介绍的基本框架和基本原理下运行的,只有结束,才能有新的开始。写博客也积攒了一些经验,源码多了感觉就是复制黏贴,源码少了又觉得是空谈原理,将来再写博客,我希望是“精炼博文”,好读好懂美观读起来又不累,希望自己能再写一部开源分布式框架原理系列博客。
+
+有胆就来,我出几道 MyBatis 面试题,看你能回答上来几道(都是我出的,可不是网上找的)。
+
+#### 1、#{}和\${}的区别是什么?
+
+注:这道题是面试官面试我同事的。
+
+答:
+
+- `${}`是 Properties 文件中的变量占位符,它可以用于标签属性值和 sql 内部,属于静态文本替换,比如\${driver}会被静态替换为`com.mysql.jdbc. Driver`。
+- `#{}`是 sql 的参数占位符,MyBatis 会将 sql 中的`#{}`替换为? 号,在 sql 执行前会使用 PreparedStatement 的参数设置方法,按序给 sql 的? 号占位符设置参数值,比如 ps.setInt(0, parameterValue),`#{item.name}` 的取值方式为使用反射从参数对象中获取 item 对象的 name 属性值,相当于 `param.getItem().getName()`。
+
+#### 2、Xml 映射文件中,除了常见的 select|insert|update|delete 标签之外,还有哪些标签?
+
+注:这道题是京东面试官面试我时问的。
+
+答:还有很多其他的标签, `<resultMap>` 、 `<parameterMap>` 、 `<sql>` 、 `<include>` 、 `<selectKey>` ,加上动态 sql 的 9 个标签, `trim|where|set|foreach|if|choose|when|otherwise|bind` 等,其中 `<sql>` 为 sql 片段标签,通过 `<include>` 标签引入 sql 片段, `<selectKey>` 为不支持自增的主键生成策略标签。
+
+#### 3、最佳实践中,通常一个 Xml 映射文件,都会写一个 Dao 接口与之对应,请问,这个 Dao 接口的工作原理是什么?Dao 接口里的方法,参数不同时,方法能重载吗?
+
+注:这道题也是京东面试官面试我被问的。
+
+答:Dao 接口,就是人们常说的 `Mapper` 接口,接口的全限名,就是映射文件中的 namespace 的值,接口的方法名,就是映射文件中 `MappedStatement` 的 id 值,接口方法内的参数,就是传递给 sql 的参数。 `Mapper` 接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为 key 值,可唯一定位一个 `MappedStatement` ,举例: `com.mybatis3.mappers. StudentDao.findStudentById` ,可以唯一找到 namespace 为 `com.mybatis3.mappers. StudentDao` 下面 `id = findStudentById` 的 `MappedStatement` 。在 MyBatis 中,每一个 `<select>` 、 `<insert>` 、 `<update>` 、 `<delete>` 标签,都会被解析为一个 `MappedStatement` 对象。
+
+~~Dao 接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。~~
+
+Dao 接口里的方法可以重载,但是 Mybatis 的 XML 里面的 ID 不允许重复。
+
+Mybatis 版本 3.3.0,亲测如下:
+
+```java
+/**
+ * Mapper接口里面方法重载
+ */
+public interface StuMapper {
+
+ List<Student> getAllStu();
+
+ List<Student> getAllStu(@Param("id") Integer id);
+}
+```
+
+然后在 `StuMapper.xml` 中利用 Mybatis 的动态 sql 就可以实现。
+
+```java
+ <select id="getAllStu" resultType="com.pojo.Student">
+ select * from student
+ <where>
+ <if test="id != null">
+ id = #{id}
+ </if>
+ </where>
+ </select>
+```
+
+能正常运行,并能得到相应的结果,这样就实现了在 Dao 接口中写重载方法。
+
+**Mybatis 的 Dao 接口可以有多个重载方法,但是多个接口对应的映射必须只有一个,否则启动会报错。**
+
+相关 issue :[更正:Dao 接口里的方法可以重载,但是 Mybatis 的 XML 里面的 ID 不允许重复!](https://github.com/Snailclimb/JavaGuide/issues/1122)。
+
+Dao 接口的工作原理是 JDK 动态代理,MyBatis 运行时会使用 JDK 动态代理为 Dao 接口生成代理 proxy 对象,代理对象 proxy 会拦截接口方法,转而执行 `MappedStatement` 所代表的 sql,然后将 sql 执行结果返回。
+
+##### ==补充:==
+
+Dao 接口方法可以重载,但是需要满足以下条件:
+
+1. 仅有一个无参方法和一个有参方法
+2. 多个有参方法时,参数数量必须一致。且使用相同的 `@Param` ,或者使用 `param1` 这种
+
+测试如下:
+
+`PersonDao.java`
+
+```java
+Person queryById();
+
+Person queryById(@Param("id") Long id);
+
+Person queryById(@Param("id") Long id, @Param("name") String name);
+```
+
+`PersonMapper.xml`
+
+```xml
+<select id="queryById" resultMap="PersonMap">
+ select
+ id, name, age, address
+ from person
+ <where>
+ <if test="id != null">
+ id = #{id}
+ </if>
+ <if test="name != null and name != ''">
+ name = #{name}
+ </if>
+ </where>
+ limit 1
+</select>
+```
+
+`org.apache.ibatis.scripting.xmltags. DynamicContext. ContextAccessor#getProperty` 方法用于获取 `<if>` 标签中的条件值
+
+```java
+public Object getProperty(Map context, Object target, Object name) {
+ Map map = (Map) target;
+
+ Object result = map.get(name);
+ if (map.containsKey(name) || result != null) {
+ return result;
+ }
+
+ Object parameterObject = map.get(PARAMETER_OBJECT_KEY);
+ if (parameterObject instanceof Map) {
+ return ((Map)parameterObject).get(name);
+ }
+
+ return null;
+}
+```
+
+`parameterObject` 为 map,存放的是 Dao 接口中参数相关信息。
+
+`((Map)parameterObject).get(name)` 方法如下
+
+```java
+public V get(Object key) {
+ if (!super.containsKey(key)) {
+ throw new BindingException("Parameter '" + key + "' not found. Available parameters are " + keySet());
+ }
+ return super.get(key);
+}
+```
+
+1. `queryById()`方法执行时,`parameterObject`为 null,`getProperty`方法返回 null 值,`<if>`标签获取的所有条件值都为 null,所有条件不成立,动态 sql 可以正常执行。
+2. `queryById(1L)`方法执行时,`parameterObject`为 map,包含了`id`和`param1`两个 key 值。当获取`<if>`标签中`name`的属性值时,进入`((Map)parameterObject).get(name)`方法中,map 中 key 不包含`name`,所以抛出异常。
+3. `queryById(1L,"1")`方法执行时,`parameterObject`中包含`id`,`param1`,`name`,`param2`四个 key 值,`id`和`name`属性都可以获取到,动态 sql 正常执行。
+
+#### 4、MyBatis 是如何进行分页的?分页插件的原理是什么?
+
+注:我出的。
+
+答:**(1)** MyBatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非物理分页;**(2)** 可以在 sql 内直接书写带有物理分页的参数来完成物理分页功能,**(3)** 也可以使用分页插件来完成物理分页。
+
+分页插件的基本原理是使用 MyBatis 提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的 sql,然后重写 sql,根据 dialect 方言,添加对应的物理分页语句和物理分页参数。
+
+举例: `select _ from student` ,拦截 sql 后重写为: `select t._ from (select \* from student)t limit 0,10`
+
+#### 5、简述 MyBatis 的插件运行原理,以及如何编写一个插件。
+
+注:我出的。
+
+答:MyBatis 仅可以编写针对 `ParameterHandler` 、 `ResultSetHandler` 、 `StatementHandler` 、 `Executor` 这 4 种接口的插件,MyBatis 使用 JDK 的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是 `InvocationHandler` 的 `invoke()` 方法,当然,只会拦截那些你指定需要拦截的方法。
+
+实现 MyBatis 的 Interceptor 接口并复写 `intercept()` 方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
+
+#### 6、MyBatis 执行批量插入,能返回数据库主键列表吗?
+
+注:我出的。
+
+答:能,JDBC 都能,MyBatis 当然也能。
+
+#### 7、MyBatis 动态 sql 是做什么的?都有哪些动态 sql?能简述一下动态 sql 的执行原理不?
+
+注:我出的。
+
+答:MyBatis 动态 sql 可以让我们在 Xml 映射文件内,以标签的形式编写动态 sql,完成逻辑判断和动态拼接 sql 的功能,MyBatis 提供了 9 种动态 sql 标签 `trim|where|set|foreach|if|choose|when|otherwise|bind` 。
+
+其执行原理为,使用 OGNL 从 sql 参数对象中计算表达式的值,根据表达式的值动态拼接 sql,以此来完成动态 sql 的功能。
+
+#### 8、MyBatis 是如何将 sql 执行结果封装为目标对象并返回的?都有哪些映射形式?
+
+注:我出的。
+
+答:第一种是使用 `<resultMap>` 标签,逐一定义列名和对象属性名之间的映射关系。第二种是使用 sql 列的别名功能,将列别名书写为对象属性名,比如 T_NAME AS NAME,对象属性名一般是 name,小写,但是列名不区分大小写,MyBatis 会忽略列名大小写,智能找到与之对应对象属性名,你甚至可以写成 T_NAME AS NaMe,MyBatis 一样可以正常工作。
+
+有了列名与属性名的映射关系后,MyBatis 通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
+
+#### 9、MyBatis 能执行一对一、一对多的关联查询吗?都有哪些实现方式,以及它们之间的区别。
+
+注:我出的。
+
+<!-- 答:能,MyBatis 不仅可以执行一对一、一对多的关联查询,还可以执行多对一,多对多的关联查询,多对一查询,其实就是一对一查询,只需要把 `selectOne()` 修改为 `selectList()` 即可;多对多查询,其实就是一对多查询,只需要把 `selectOne()` 修改为 `selectList()` 即可。 -->
+
+关联对象查询,有两种实现方式,一种是单独发送一个 sql 去查询关联对象,赋给主对象,然后返回主对象。另一种是使用嵌套查询,嵌套查询的含义为使用 join 查询,一部分列是 A 对象的属性值,另外一部分列是关联对象 B 的属性值,好处是只发一个 sql 查询,就可以把主对象和其关联对象查出来。
+
+那么问题来了,join 查询出来 100 条记录,如何确定主对象是 5 个,而不是 100 个?其去重复的原理是 `<resultMap>` 标签内的 `<id>` 子标签,指定了唯一确定一条记录的 id 列,MyBatis 根据 `<id>` 列值来完成 100 条记录的去重复功能, `<id>` 可以有多个,代表了联合主键的语意。
+
+同样主对象的关联对象,也是根据这个原理去重复的,尽管一般情况下,只有主对象会有重复记录,关联对象一般不会重复。
+
+举例:下面 join 查询出来 6 条记录,一、二列是 Teacher 对象列,第三列为 Student 对象列,MyBatis 去重复处理后,结果为 1 个老师 6 个学生,而不是 6 个老师 6 个学生。
+
+| t_id | t_name | s_id |
+| ---- | ------- | ---- |
+| 1 | teacher | 38 |
+| 1 | teacher | 39 |
+| 1 | teacher | 40 |
+| 1 | teacher | 41 |
+| 1 | teacher | 42 |
+| 1 | teacher | 43 |
+
+#### 10、MyBatis 是否支持延迟加载?如果支持,它的实现原理是什么?
+
+注:我出的。
+
+答:MyBatis 仅支持 association 关联对象和 collection 关联集合对象的延迟加载,association 指的就是一对一,collection 指的就是一对多查询。在 MyBatis 配置文件中,可以配置是否启用延迟加载 `lazyLoadingEnabled=true|false。`
+
+它的原理是,使用 `CGLIB` 创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用 `a.getB().getName()` ,拦截器 `invoke()` 方法发现 `a.getB()` 是 null 值,那么就会单独发送事先保存好的查询关联 B 对象的 sql,把 B 查询上来,然后调用 a.setB(b),于是 a 的对象 b 属性就有值了,接着完成 `a.getB().getName()` 方法的调用。这就是延迟加载的基本原理。
+
+当然了,不光是 MyBatis,几乎所有的包括 Hibernate,支持延迟加载的原理都是一样的。
+
+#### 11、MyBatis 的 Xml 映射文件中,不同的 Xml 映射文件,id 是否可以重复?
+
+注:我出的。
+
+答:不同的 Xml 映射文件,如果配置了 namespace,那么 id 可以重复;如果没有配置 namespace,那么 id 不能重复;毕竟 namespace 不是必须的,只是最佳实践而已。
+
+原因就是 namespace+id 是作为 `Map<String, MappedStatement>` 的 key 使用的,如果没有 namespace,就剩下 id,那么,id 重复会导致数据互相覆盖。有了 namespace,自然 id 就可以重复,namespace 不同,namespace+id 自然也就不同。
+
+#### 12、MyBatis 中如何执行批处理?
+
+注:我出的。
+
+答:使用 BatchExecutor 完成批处理。
+
+#### 13、MyBatis 都有哪些 Executor 执行器?它们之间的区别是什么?
+
+注:我出的
+
+答:MyBatis 有三种基本的 Executor 执行器,** `SimpleExecutor` 、 `ReuseExecutor` 、 `BatchExecutor` 。**
+
+** `SimpleExecutor` :**每执行一次 update 或 select,就开启一个 Statement 对象,用完立刻关闭 Statement 对象。
+
+** `ReuseExecutor` :**执行 update 或 select,以 sql 作为 key 查找 Statement 对象,存在就使用,不存在就创建,用完后,不关闭 Statement 对象,而是放置于 Map<String, Statement>内,供下一次使用。简言之,就是重复使用 Statement 对象。
+
+** `BatchExecutor` :**执行 update(没有 select,JDBC 批处理不支持 select),将所有 sql 都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个 Statement 对象,每个 Statement 对象都是 addBatch()完毕后,等待逐一执行 executeBatch()批处理。与 JDBC 批处理相同。
+
+作用范围:Executor 的这些特点,都严格限制在 SqlSession 生命周期范围内。
+
+#### 14、MyBatis 中如何指定使用哪一种 Executor 执行器?
+
+注:我出的
+
+答:在 MyBatis 配置文件中,可以指定默认的 ExecutorType 执行器类型,也可以手动给 `DefaultSqlSessionFactory` 的创建 SqlSession 的方法传递 ExecutorType 类型参数。
+
+#### 15、MyBatis 是否可以映射 Enum 枚举类?
+
+注:我出的
+
+答:MyBatis 可以映射枚举类,不单可以映射枚举类,MyBatis 可以映射任何对象到表的一列上。映射方式为自定义一个 `TypeHandler` ,实现 `TypeHandler` 的 `setParameter()` 和 `getResult()` 接口方法。 `TypeHandler` 有两个作用,一是完成从 javaType 至 jdbcType 的转换,二是完成 jdbcType 至 javaType 的转换,体现为 `setParameter()` 和 `getResult()` 两个方法,分别代表设置 sql 问号占位符参数和获取列查询结果。
+
+#### 16、MyBatis 映射文件中,如果 A 标签通过 include 引用了 B 标签的内容,请问,B 标签能否定义在 A 标签的后面,还是说必须定义在 A 标签的前面?
+
+注:我出的
+
+答:虽然 MyBatis 解析 Xml 映射文件是按照顺序解析的,但是,被引用的 B 标签依然可以定义在任何地方,MyBatis 都可以正确识别。
+
+原理是,MyBatis 解析 A 标签,发现 A 标签引用了 B 标签,但是 B 标签尚未解析到,尚不存在,此时,MyBatis 会将 A 标签标记为未解析状态,然后继续解析余下的标签,包含 B 标签,待所有标签解析完毕,MyBatis 会重新解析那些被标记为未解析的标签,此时再解析 A 标签时,B 标签已经存在,A 标签也就可以正常解析完成了。
+
+#### 17、简述 MyBatis 的 Xml 映射文件和 MyBatis 内部数据结构之间的映射关系?
+
+注:我出的
+
+答:MyBatis 将所有 Xml 配置信息都封装到 All-In-One 重量级对象 Configuration 内部。在 Xml 映射文件中, `<parameterMap>` 标签会被解析为 `ParameterMap` 对象,其每个子元素会被解析为 ParameterMapping 对象。 `<resultMap>` 标签会被解析为 `ResultMap` 对象,其每个子元素会被解析为 `ResultMapping` 对象。每一个 `<select>、<insert>、<update>、<delete>` 标签均会被解析为 `MappedStatement` 对象,标签内的 sql 会被解析为 BoundSql 对象。
+
+#### 18、为什么说 MyBatis 是半自动 ORM 映射工具?它与全自动的区别在哪里?
+
+注:我出的
+
+答:Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。而 MyBatis 在查询关联对象或关联集合对象时,需要手动编写 sql 来完成,所以,称之为半自动 ORM 映射工具。
+
+面试题看似都很简单,但是想要能正确回答上来,必定是研究过源码且深入的人,而不是仅会使用的人或者用的很熟的人,以上所有面试题及其答案所涉及的内容,在我的 MyBatis 系列博客中都有详细讲解和原理分析。
diff --git a/docs/system-design/framework/netty.md b/docs/system-design/framework/netty.md
new file mode 100644
index 00000000000..75f3efc3afb
--- /dev/null
+++ b/docs/system-design/framework/netty.md
@@ -0,0 +1,7 @@
+# Netty 知识点&面试题总结
+
+这部分内容为我的星球专属,已经整理到了[《Java面试进阶指北 打造个人的技术竞争力》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7?# )中。
+
+欢迎加入我的星球,[一个纯 Java 面试交流圈子 !Ready!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=100015911&idx=1&sn=2e8a0f5acb749ecbcbb417aa8a4e18cc&chksm=4ea1b0ec79d639fae37df1b86f196e8ce397accfd1dd2004bcadb66b4df5f582d90ae0d62448#rd) (点击链接了解星球详细信息,还有专属优惠款可以领取)。
+
+
\ No newline at end of file
diff --git "a/docs/system-design/framework/spring/Spring&SpringBoot\345\270\270\347\224\250\346\263\250\350\247\243\346\200\273\347\273\223.md" "b/docs/system-design/framework/spring/Spring&SpringBoot\345\270\270\347\224\250\346\263\250\350\247\243\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..ad5f0e8ed7b
--- /dev/null
+++ "b/docs/system-design/framework/spring/Spring&SpringBoot\345\270\270\347\224\250\346\263\250\350\247\243\346\200\273\347\273\223.md"
@@ -0,0 +1,962 @@
+
+# Spring/Spring Boot 常用注解总结!安排!
+
+### 0.前言
+
+_大家好,我是 Guide 哥!这是我的 221 篇优质原创文章。如需转载,请在文首注明地址,蟹蟹!_
+
+本文已经收录进我的 75K Star 的 Java 开源项目 JavaGuide:[https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)。
+
+可以毫不夸张地说,这篇文章介绍的 Spring/SpringBoot 常用注解基本已经涵盖你工作中遇到的大部分常用的场景。对于每一个注解我都说了具体用法,掌握搞懂,使用 SpringBoot 来开发项目基本没啥大问题了!
+
+**为什么要写这篇文章?**
+
+最近看到网上有一篇关于 SpringBoot 常用注解的文章被转载的比较多,我看了文章内容之后属实觉得质量有点低,并且有点会误导没有太多实际使用经验的人(这些人又占据了大多数)。所以,自己索性花了大概 两天时间简单总结一下了。
+
+**因为我个人的能力和精力有限,如果有任何不对或者需要完善的地方,请帮忙指出!Guide 哥感激不尽!**
+
+### 1. `@SpringBootApplication`
+
+这里先单独拎出`@SpringBootApplication` 注解说一下,虽然我们一般不会主动去使用它。
+
+_Guide 哥:这个注解是 Spring Boot 项目的基石,创建 SpringBoot 项目之后会默认在主类加上。_
+
+```java
+@SpringBootApplication
+public class SpringSecurityJwtGuideApplication {
+ public static void main(java.lang.String[] args) {
+ SpringApplication.run(SpringSecurityJwtGuideApplication.class, args);
+ }
+}
+```
+
+我们可以把 `@SpringBootApplication`看作是 `@Configuration`、`@EnableAutoConfiguration`、`@ComponentScan` 注解的集合。
+
+```java
+package org.springframework.boot.autoconfigure;
+@Target(ElementType.TYPE)
+@Retention(RetentionPolicy.RUNTIME)
+@Documented
+@Inherited
+@SpringBootConfiguration
+@EnableAutoConfiguration
+@ComponentScan(excludeFilters = {
+ @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
+ @Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
+public @interface SpringBootApplication {
+ ......
+}
+
+package org.springframework.boot;
+@Target(ElementType.TYPE)
+@Retention(RetentionPolicy.RUNTIME)
+@Documented
+@Configuration
+public @interface SpringBootConfiguration {
+
+}
+```
+
+根据 SpringBoot 官网,这三个注解的作用分别是:
+
+- `@EnableAutoConfiguration`:启用 SpringBoot 的自动配置机制
+- `@ComponentScan`: 扫描被`@Component` (`@Service`,`@Controller`)注解的 bean,注解默认会扫描该类所在的包下所有的类。
+- `@Configuration`:允许在 Spring 上下文中注册额外的 bean 或导入其他配置类
+
+### 2. Spring Bean 相关
+
+#### 2.1. `@Autowired`
+
+自动导入对象到类中,被注入进的类同样要被 Spring 容器管理比如:Service 类注入到 Controller 类中。
+
+```java
+@Service
+public class UserService {
+ ......
+}
+
+@RestController
+@RequestMapping("/users")
+public class UserController {
+ @Autowired
+ private UserService userService;
+ ......
+}
+```
+
+#### 2.2. `@Component`,`@Repository`,`@Service`, `@Controller`
+
+我们一般使用 `@Autowired` 注解让 Spring 容器帮我们自动装配 bean。要想把类标识成可用于 `@Autowired` 注解自动装配的 bean 的类,可以采用以下注解实现:
+
+- `@Component` :通用的注解,可标注任意类为 `Spring` 组件。如果一个 Bean 不知道属于哪个层,可以使用`@Component` 注解标注。
+- `@Repository` : 对应持久层即 Dao 层,主要用于数据库相关操作。
+- `@Service` : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。
+- `@Controller` : 对应 Spring MVC 控制层,主要用于接受用户请求并调用 Service 层返回数据给前端页面。
+
+#### 2.3. `@RestController`
+
+`@RestController`注解是`@Controller`和`@ResponseBody`的合集,表示这是个控制器 bean,并且是将函数的返回值直接填入 HTTP 响应体中,是 REST 风格的控制器。
+
+_Guide 哥:现在都是前后端分离,说实话我已经很久没有用过`@Controller`。如果你的项目太老了的话,就当我没说。_
+
+单独使用 `@Controller` 不加 `@ResponseBody`的话一般是用在要返回一个视图的情况,这种情况属于比较传统的 Spring MVC 的应用,对应于前后端不分离的情况。`@Controller` +`@ResponseBody` 返回 JSON 或 XML 形式数据
+
+关于`@RestController` 和 `@Controller`的对比,请看这篇文章:[@RestController vs @Controller](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485544&idx=1&sn=3cc95b88979e28fe3bfe539eb421c6d8&chksm=cea247a3f9d5ceb5e324ff4b8697adc3e828ecf71a3468445e70221cce768d1e722085359907&token=1725092312&lang=zh_CN#rd)。
+
+#### 2.4. `@Scope`
+
+声明 Spring Bean 的作用域,使用方法:
+
+```java
+@Bean
+@Scope("singleton")
+public Person personSingleton() {
+ return new Person();
+}
+```
+
+**四种常见的 Spring Bean 的作用域:**
+
+- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的。
+- prototype : 每次请求都会创建一个新的 bean 实例。
+- request : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
+- session : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
+
+#### 2.5. `@Configuration`
+
+一般用来声明配置类,可以使用 `@Component`注解替代,不过使用`@Configuration`注解声明配置类更加语义化。
+
+```java
+@Configuration
+public class AppConfig {
+ @Bean
+ public TransferService transferService() {
+ return new TransferServiceImpl();
+ }
+
+}
+```
+
+### 3. 处理常见的 HTTP 请求类型
+
+**5 种常见的请求类型:**
+
+- **GET** :请求从服务器获取特定资源。举个例子:`GET /users`(获取所有学生)
+- **POST** :在服务器上创建一个新的资源。举个例子:`POST /users`(创建学生)
+- **PUT** :更新服务器上的资源(客户端提供更新后的整个资源)。举个例子:`PUT /users/12`(更新编号为 12 的学生)
+- **DELETE** :从服务器删除特定的资源。举个例子:`DELETE /users/12`(删除编号为 12 的学生)
+- **PATCH** :更新服务器上的资源(客户端提供更改的属性,可以看做作是部分更新),使用的比较少,这里就不举例子了。
+
+#### 3.1. GET 请求
+
+`@GetMapping("users")` 等价于`@RequestMapping(value="/users",method=RequestMethod.GET)`
+
+```java
+@GetMapping("/users")
+public ResponseEntity<List<User>> getAllUsers() {
+ return userRepository.findAll();
+}
+```
+
+#### 3.2. POST 请求
+
+`@PostMapping("users")` 等价于`@RequestMapping(value="/users",method=RequestMethod.POST)`
+
+关于`@RequestBody`注解的使用,在下面的“前后端传值”这块会讲到。
+
+```java
+@PostMapping("/users")
+public ResponseEntity<User> createUser(@Valid @RequestBody UserCreateRequest userCreateRequest) {
+ return userRespository.save(userCreateRequest);
+}
+```
+
+#### 3.3. PUT 请求
+
+`@PutMapping("/users/{userId}")` 等价于`@RequestMapping(value="/users/{userId}",method=RequestMethod.PUT)`
+
+```java
+@PutMapping("/users/{userId}")
+public ResponseEntity<User> updateUser(@PathVariable(value = "userId") Long userId,
+ @Valid @RequestBody UserUpdateRequest userUpdateRequest) {
+ ......
+}
+```
+
+#### 3.4. **DELETE 请求**
+
+`@DeleteMapping("/users/{userId}")`等价于`@RequestMapping(value="/users/{userId}",method=RequestMethod.DELETE)`
+
+```java
+@DeleteMapping("/users/{userId}")
+public ResponseEntity deleteUser(@PathVariable(value = "userId") Long userId){
+ ......
+}
+```
+
+#### 3.5. **PATCH 请求**
+
+一般实际项目中,我们都是 PUT 不够用了之后才用 PATCH 请求去更新数据。
+
+```java
+ @PatchMapping("/profile")
+ public ResponseEntity updateStudent(@RequestBody StudentUpdateRequest studentUpdateRequest) {
+ studentRepository.updateDetail(studentUpdateRequest);
+ return ResponseEntity.ok().build();
+ }
+```
+
+### 4. 前后端传值
+
+**掌握前后端传值的正确姿势,是你开始 CRUD 的第一步!**
+
+#### 4.1. `@PathVariable` 和 `@RequestParam`
+
+`@PathVariable`用于获取路径参数,`@RequestParam`用于获取查询参数。
+
+举个简单的例子:
+
+```java
+@GetMapping("/klasses/{klassId}/teachers")
+public List<Teacher> getKlassRelatedTeachers(
+ @PathVariable("klassId") Long klassId,
+ @RequestParam(value = "type", required = false) String type ) {
+...
+}
+```
+
+如果我们请求的 url 是:`/klasses/123456/teachers?type=web`
+
+那么我们服务获取到的数据就是:`klassId=123456,type=web`。
+
+#### 4.2. `@RequestBody`
+
+用于读取 Request 请求(可能是 POST,PUT,DELETE,GET 请求)的 body 部分并且**Content-Type 为 application/json** 格式的数据,接收到数据之后会自动将数据绑定到 Java 对象上去。系统会使用`HttpMessageConverter`或者自定义的`HttpMessageConverter`将请求的 body 中的 json 字符串转换为 java 对象。
+
+我用一个简单的例子来给演示一下基本使用!
+
+我们有一个注册的接口:
+
+```java
+@PostMapping("/sign-up")
+public ResponseEntity signUp(@RequestBody @Valid UserRegisterRequest userRegisterRequest) {
+ userService.save(userRegisterRequest);
+ return ResponseEntity.ok().build();
+}
+```
+
+`UserRegisterRequest`对象:
+
+```java
+@Data
+@AllArgsConstructor
+@NoArgsConstructor
+public class UserRegisterRequest {
+ @NotBlank
+ private String userName;
+ @NotBlank
+ private String password;
+ @NotBlank
+ private String fullName;
+}
+```
+
+我们发送 post 请求到这个接口,并且 body 携带 JSON 数据:
+
+```json
+{"userName":"coder","fullName":"shuangkou","password":"123456"}
+```
+
+这样我们的后端就可以直接把 json 格式的数据映射到我们的 `UserRegisterRequest` 类上。
+
+
+
+👉 需要注意的是:**一个请求方法只可以有一个`@RequestBody`,但是可以有多个`@RequestParam`和`@PathVariable`**。 如果你的方法必须要用两个 `@RequestBody`来接受数据的话,大概率是你的数据库设计或者系统设计出问题了!
+
+### 5. 读取配置信息
+
+**很多时候我们需要将一些常用的配置信息比如阿里云 oss、发送短信、微信认证的相关配置信息等等放到配置文件中。**
+
+**下面我们来看一下 Spring 为我们提供了哪些方式帮助我们从配置文件中读取这些配置信息。**
+
+我们的数据源`application.yml`内容如下:
+
+```yaml
+wuhan2020: 2020年初武汉爆发了新型冠状病毒,疫情严重,但是,我相信一切都会过去!武汉加油!中国加油!
+
+my-profile:
+ name: Guide哥
+ email: koushuangbwcx@163.com
+
+library:
+ location: 湖北武汉加油中国加油
+ books:
+ - name: 天才基本法
+ description: 二十二岁的林朝夕在父亲确诊阿尔茨海默病这天,得知自己暗恋多年的校园男神裴之即将出国深造的消息——对方考取的学校,恰是父亲当年为她放弃的那所。
+ - name: 时间的秩序
+ description: 为什么我们记得过去,而非未来?时间“流逝”意味着什么?是我们存在于时间之内,还是时间存在于我们之中?卡洛·罗韦利用诗意的文字,邀请我们思考这一亘古难题——时间的本质。
+ - name: 了不起的我
+ description: 如何养成一个新习惯?如何让心智变得更成熟?如何拥有高质量的关系? 如何走出人生的艰难时刻?
+```
+
+#### 5.1. `@Value`(常用)
+
+使用 `@Value("${property}")` 读取比较简单的配置信息:
+
+```java
+@Value("${wuhan2020}")
+String wuhan2020;
+```
+
+#### 5.2. `@ConfigurationProperties`(常用)
+
+通过`@ConfigurationProperties`读取配置信息并与 bean 绑定。
+
+```java
+@Component
+@ConfigurationProperties(prefix = "library")
+class LibraryProperties {
+ @NotEmpty
+ private String location;
+ private List<Book> books;
+
+ @Setter
+ @Getter
+ @ToString
+ static class Book {
+ String name;
+ String description;
+ }
+ 省略getter/setter
+ ......
+}
+```
+
+你可以像使用普通的 Spring bean 一样,将其注入到类中使用。
+
+#### 5.3. `@PropertySource`(不常用)
+
+`@PropertySource`读取指定 properties 文件
+
+```java
+@Component
+@PropertySource("classpath:website.properties")
+
+class WebSite {
+ @Value("${url}")
+ private String url;
+
+ 省略getter/setter
+ ......
+}
+```
+
+更多内容请查看我的这篇文章:《[10 分钟搞定 SpringBoot 如何优雅读取配置文件?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486181&idx=2&sn=10db0ae64ef501f96a5b0dbc4bd78786&chksm=cea2452ef9d5cc384678e456427328600971180a77e40c13936b19369672ca3e342c26e92b50&token=816772476&lang=zh_CN#rd)》 。
+
+### 6. 参数校验
+
+**数据的校验的重要性就不用说了,即使在前端对数据进行校验的情况下,我们还是要对传入后端的数据再进行一遍校验,避免用户绕过浏览器直接通过一些 HTTP 工具直接向后端请求一些违法数据。**
+
+**JSR(Java Specification Requests)** 是一套 JavaBean 参数校验的标准,它定义了很多常用的校验注解,我们可以直接将这些注解加在我们 JavaBean 的属性上面,这样就可以在需要校验的时候进行校验了,非常方便!
+
+校验的时候我们实际用的是 **Hibernate Validator** 框架。Hibernate Validator 是 Hibernate 团队最初的数据校验框架,Hibernate Validator 4.x 是 Bean Validation 1.0(JSR 303)的参考实现,Hibernate Validator 5.x 是 Bean Validation 1.1(JSR 349)的参考实现,目前最新版的 Hibernate Validator 6.x 是 Bean Validation 2.0(JSR 380)的参考实现。
+
+SpringBoot 项目的 spring-boot-starter-web 依赖中已经有 hibernate-validator 包,不需要引用相关依赖。如下图所示(通过 idea 插件—Maven Helper 生成):
+
+**注**:更新版本的 spring-boot-starter-web 依赖中不再有 hibernate-validator 包(如2.3.11.RELEASE),需要自己引入 `spring-boot-starter-validation` 依赖。
+
+
+
+非 SpringBoot 项目需要自行引入相关依赖包,这里不多做讲解,具体可以查看我的这篇文章:《[如何在 Spring/Spring Boot 中做参数校验?你需要了解的都在这里!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485783&idx=1&sn=a407f3b75efa17c643407daa7fb2acd6&chksm=cea2469cf9d5cf8afbcd0a8a1c9cc4294d6805b8e01bee6f76bb2884c5bc15478e91459def49&token=292197051&lang=zh_CN#rd)》。
+
+👉 需要注意的是: **所有的注解,推荐使用 JSR 注解,即`javax.validation.constraints`,而不是`org.hibernate.validator.constraints`**
+
+#### 6.1. 一些常用的字段验证的注解
+
+- `@NotEmpty` 被注释的字符串的不能为 null 也不能为空
+- `@NotBlank` 被注释的字符串非 null,并且必须包含一个非空白字符
+- `@Null` 被注释的元素必须为 null
+- `@NotNull` 被注释的元素必须不为 null
+- `@AssertTrue` 被注释的元素必须为 true
+- `@AssertFalse` 被注释的元素必须为 false
+- `@Pattern(regex=,flag=)`被注释的元素必须符合指定的正则表达式
+- `@Email` 被注释的元素必须是 Email 格式。
+- `@Min(value)`被注释的元素必须是一个数字,其值必须大于等于指定的最小值
+- `@Max(value)`被注释的元素必须是一个数字,其值必须小于等于指定的最大值
+- `@DecimalMin(value)`被注释的元素必须是一个数字,其值必须大于等于指定的最小值
+- `@DecimalMax(value)` 被注释的元素必须是一个数字,其值必须小于等于指定的最大值
+- `@Size(max=, min=)`被注释的元素的大小必须在指定的范围内
+- `@Digits(integer, fraction)`被注释的元素必须是一个数字,其值必须在可接受的范围内
+- `@Past`被注释的元素必须是一个过去的日期
+- `@Future` 被注释的元素必须是一个将来的日期
+- ......
+
+#### 6.2. 验证请求体(RequestBody)
+
+```java
+@Data
+@AllArgsConstructor
+@NoArgsConstructor
+public class Person {
+
+ @NotNull(message = "classId 不能为空")
+ private String classId;
+
+ @Size(max = 33)
+ @NotNull(message = "name 不能为空")
+ private String name;
+
+ @Pattern(regexp = "((^Man$|^Woman$|^UGM$))", message = "sex 值不在可选范围")
+ @NotNull(message = "sex 不能为空")
+ private String sex;
+
+ @Email(message = "email 格式不正确")
+ @NotNull(message = "email 不能为空")
+ private String email;
+
+}
+```
+
+我们在需要验证的参数上加上了`@Valid`注解,如果验证失败,它将抛出`MethodArgumentNotValidException`。
+
+```java
+@RestController
+@RequestMapping("/api")
+public class PersonController {
+
+ @PostMapping("/person")
+ public ResponseEntity<Person> getPerson(@RequestBody @Valid Person person) {
+ return ResponseEntity.ok().body(person);
+ }
+}
+```
+
+#### 6.3. 验证请求参数(Path Variables 和 Request Parameters)
+
+**一定一定不要忘记在类上加上 `@Validated` 注解了,这个参数可以告诉 Spring 去校验方法参数。**
+
+```java
+@RestController
+@RequestMapping("/api")
+@Validated
+public class PersonController {
+
+ @GetMapping("/person/{id}")
+ public ResponseEntity<Integer> getPersonByID(@Valid @PathVariable("id") @Max(value = 5,message = "超过 id 的范围了") Integer id) {
+ return ResponseEntity.ok().body(id);
+ }
+}
+```
+
+更多关于如何在 Spring 项目中进行参数校验的内容,请看《[如何在 Spring/Spring Boot 中做参数校验?你需要了解的都在这里!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485783&idx=1&sn=a407f3b75efa17c643407daa7fb2acd6&chksm=cea2469cf9d5cf8afbcd0a8a1c9cc4294d6805b8e01bee6f76bb2884c5bc15478e91459def49&token=292197051&lang=zh_CN#rd)》这篇文章。
+
+### 7. 全局处理 Controller 层异常
+
+介绍一下我们 Spring 项目必备的全局处理 Controller 层异常。
+
+**相关注解:**
+
+1. `@ControllerAdvice` :注解定义全局异常处理类
+2. `@ExceptionHandler` :注解声明异常处理方法
+
+如何使用呢?拿我们在第 5 节参数校验这块来举例子。如果方法参数不对的话就会抛出`MethodArgumentNotValidException`,我们来处理这个异常。
+
+```java
+@ControllerAdvice
+@ResponseBody
+public class GlobalExceptionHandler {
+
+ /**
+ * 请求参数异常处理
+ */
+ @ExceptionHandler(MethodArgumentNotValidException.class)
+ public ResponseEntity<?> handleMethodArgumentNotValidException(MethodArgumentNotValidException ex, HttpServletRequest request) {
+ ......
+ }
+}
+```
+
+更多关于 Spring Boot 异常处理的内容,请看我的这两篇文章:
+
+1. [SpringBoot 处理异常的几种常见姿势](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485568&idx=2&sn=c5ba880fd0c5d82e39531fa42cb036ac&chksm=cea2474bf9d5ce5dcbc6a5f6580198fdce4bc92ef577579183a729cb5d1430e4994720d59b34&token=2133161636&lang=zh_CN#rd)
+2. [使用枚举简单封装一个优雅的 Spring Boot 全局异常处理!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486379&idx=2&sn=48c29ae65b3ed874749f0803f0e4d90e&chksm=cea24460f9d5cd769ed53ad7e17c97a7963a89f5350e370be633db0ae8d783c3a3dbd58c70f8&token=1054498516&lang=zh_CN#rd)
+
+### 8. JPA 相关
+
+#### 8.1. 创建表
+
+`@Entity`声明一个类对应一个数据库实体。
+
+`@Table` 设置表名
+
+```java
+@Entity
+@Table(name = "role")
+public class Role {
+ @Id
+ @GeneratedValue(strategy = GenerationType.IDENTITY)
+ private Long id;
+ private String name;
+ private String description;
+ 省略getter/setter......
+}
+```
+
+#### 8.2. 创建主键
+
+`@Id` :声明一个字段为主键。
+
+使用`@Id`声明之后,我们还需要定义主键的生成策略。我们可以使用 `@GeneratedValue` 指定主键生成策略。
+
+**1.通过 `@GeneratedValue`直接使用 JPA 内置提供的四种主键生成策略来指定主键生成策略。**
+
+```java
+@Id
+@GeneratedValue(strategy = GenerationType.IDENTITY)
+private Long id;
+```
+
+JPA 使用枚举定义了 4 种常见的主键生成策略,如下:
+
+_Guide 哥:枚举替代常量的一种用法_
+
+```java
+public enum GenerationType {
+
+ /**
+ * 使用一个特定的数据库表格来保存主键
+ * 持久化引擎通过关系数据库的一张特定的表格来生成主键,
+ */
+ TABLE,
+
+ /**
+ *在某些数据库中,不支持主键自增长,比如Oracle、PostgreSQL其提供了一种叫做"序列(sequence)"的机制生成主键
+ */
+ SEQUENCE,
+
+ /**
+ * 主键自增长
+ */
+ IDENTITY,
+
+ /**
+ *把主键生成策略交给持久化引擎(persistence engine),
+ *持久化引擎会根据数据库在以上三种主键生成 策略中选择其中一种
+ */
+ AUTO
+}
+
+```
+
+`@GeneratedValue`注解默认使用的策略是`GenerationType.AUTO`
+
+```java
+public @interface GeneratedValue {
+
+ GenerationType strategy() default AUTO;
+ String generator() default "";
+}
+```
+
+一般使用 MySQL 数据库的话,使用`GenerationType.IDENTITY`策略比较普遍一点(分布式系统的话需要另外考虑使用分布式 ID)。
+
+**2.通过 `@GenericGenerator`声明一个主键策略,然后 `@GeneratedValue`使用这个策略**
+
+```java
+@Id
+@GeneratedValue(generator = "IdentityIdGenerator")
+@GenericGenerator(name = "IdentityIdGenerator", strategy = "identity")
+private Long id;
+```
+
+等价于:
+
+```java
+@Id
+@GeneratedValue(strategy = GenerationType.IDENTITY)
+private Long id;
+```
+
+jpa 提供的主键生成策略有如下几种:
+
+```java
+public class DefaultIdentifierGeneratorFactory
+ implements MutableIdentifierGeneratorFactory, Serializable, ServiceRegistryAwareService {
+
+ @SuppressWarnings("deprecation")
+ public DefaultIdentifierGeneratorFactory() {
+ register( "uuid2", UUIDGenerator.class );
+ register( "guid", GUIDGenerator.class ); // can be done with UUIDGenerator + strategy
+ register( "uuid", UUIDHexGenerator.class ); // "deprecated" for new use
+ register( "uuid.hex", UUIDHexGenerator.class ); // uuid.hex is deprecated
+ register( "assigned", Assigned.class );
+ register( "identity", IdentityGenerator.class );
+ register( "select", SelectGenerator.class );
+ register( "sequence", SequenceStyleGenerator.class );
+ register( "seqhilo", SequenceHiLoGenerator.class );
+ register( "increment", IncrementGenerator.class );
+ register( "foreign", ForeignGenerator.class );
+ register( "sequence-identity", SequenceIdentityGenerator.class );
+ register( "enhanced-sequence", SequenceStyleGenerator.class );
+ register( "enhanced-table", TableGenerator.class );
+ }
+
+ public void register(String strategy, Class generatorClass) {
+ LOG.debugf( "Registering IdentifierGenerator strategy [%s] -> [%s]", strategy, generatorClass.getName() );
+ final Class previous = generatorStrategyToClassNameMap.put( strategy, generatorClass );
+ if ( previous != null ) {
+ LOG.debugf( " - overriding [%s]", previous.getName() );
+ }
+ }
+
+}
+```
+
+#### 8.3. 设置字段类型
+
+`@Column` 声明字段。
+
+**示例:**
+
+设置属性 userName 对应的数据库字段名为 user_name,长度为 32,非空
+
+```java
+@Column(name = "user_name", nullable = false, length=32)
+private String userName;
+```
+
+设置字段类型并且加默认值,这个还是挺常用的。
+
+```java
+@Column(columnDefinition = "tinyint(1) default 1")
+private Boolean enabled;
+```
+
+#### 8.4. 指定不持久化特定字段
+
+`@Transient` :声明不需要与数据库映射的字段,在保存的时候不需要保存进数据库 。
+
+如果我们想让`secrect` 这个字段不被持久化,可以使用 `@Transient`关键字声明。
+
+```java
+@Entity(name="USER")
+public class User {
+
+ ......
+ @Transient
+ private String secrect; // not persistent because of @Transient
+
+}
+```
+
+除了 `@Transient`关键字声明, 还可以采用下面几种方法:
+
+```java
+static String secrect; // not persistent because of static
+final String secrect = "Satish"; // not persistent because of final
+transient String secrect; // not persistent because of transient
+```
+
+一般使用注解的方式比较多。
+
+#### 8.5. 声明大字段
+
+`@Lob`:声明某个字段为大字段。
+
+```java
+@Lob
+private String content;
+```
+
+更详细的声明:
+
+```java
+@Lob
+//指定 Lob 类型数据的获取策略, FetchType.EAGER 表示非延迟加载,而 FetchType.LAZY 表示延迟加载 ;
+@Basic(fetch = FetchType.EAGER)
+//columnDefinition 属性指定数据表对应的 Lob 字段类型
+@Column(name = "content", columnDefinition = "LONGTEXT NOT NULL")
+private String content;
+```
+
+#### 8.6. 创建枚举类型的字段
+
+可以使用枚举类型的字段,不过枚举字段要用`@Enumerated`注解修饰。
+
+```java
+public enum Gender {
+ MALE("男性"),
+ FEMALE("女性");
+
+ private String value;
+ Gender(String str){
+ value=str;
+ }
+}
+```
+
+```java
+@Entity
+@Table(name = "role")
+public class Role {
+ @Id
+ @GeneratedValue(strategy = GenerationType.IDENTITY)
+ private Long id;
+ private String name;
+ private String description;
+ @Enumerated(EnumType.STRING)
+ private Gender gender;
+ 省略getter/setter......
+}
+```
+
+数据库里面对应存储的是 MALE/FEMALE。
+
+#### 8.7. 增加审计功能
+
+只要继承了 `AbstractAuditBase`的类都会默认加上下面四个字段。
+
+```java
+@Data
+@AllArgsConstructor
+@NoArgsConstructor
+@MappedSuperclass
+@EntityListeners(value = AuditingEntityListener.class)
+public abstract class AbstractAuditBase {
+
+ @CreatedDate
+ @Column(updatable = false)
+ @JsonIgnore
+ private Instant createdAt;
+
+ @LastModifiedDate
+ @JsonIgnore
+ private Instant updatedAt;
+
+ @CreatedBy
+ @Column(updatable = false)
+ @JsonIgnore
+ private String createdBy;
+
+ @LastModifiedBy
+ @JsonIgnore
+ private String updatedBy;
+}
+
+```
+
+我们对应的审计功能对应地配置类可能是下面这样的(Spring Security 项目):
+
+```java
+
+@Configuration
+@EnableJpaAuditing
+public class AuditSecurityConfiguration {
+ @Bean
+ AuditorAware<String> auditorAware() {
+ return () -> Optional.ofNullable(SecurityContextHolder.getContext())
+ .map(SecurityContext::getAuthentication)
+ .filter(Authentication::isAuthenticated)
+ .map(Authentication::getName);
+ }
+}
+```
+
+简单介绍一下上面涉及到的一些注解:
+
+1. `@CreatedDate`: 表示该字段为创建时间字段,在这个实体被 insert 的时候,会设置值
+2. `@CreatedBy` :表示该字段为创建人,在这个实体被 insert 的时候,会设置值
+
+ `@LastModifiedDate`、`@LastModifiedBy`同理。
+
+`@EnableJpaAuditing`:开启 JPA 审计功能。
+
+#### 8.8. 删除/修改数据
+
+`@Modifying` 注解提示 JPA 该操作是修改操作,注意还要配合`@Transactional`注解使用。
+
+```java
+@Repository
+public interface UserRepository extends JpaRepository<User, Integer> {
+
+ @Modifying
+ @Transactional(rollbackFor = Exception.class)
+ void deleteByUserName(String userName);
+}
+```
+
+#### 8.9. 关联关系
+
+- `@OneToOne` 声明一对一关系
+- `@OneToMany` 声明一对多关系
+- `@ManyToOne` 声明多对一关系
+- `@MangToMang` 声明多对多关系
+
+更多关于 Spring Boot JPA 的文章请看我的这篇文章:[一文搞懂如何在 Spring Boot 正确中使用 JPA](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485689&idx=1&sn=061b32c2222869932be5631fb0bb5260&chksm=cea24732f9d5ce24a356fb3675170e7843addbfcc79ee267cfdb45c83fc7e90babf0f20d22e1&token=292197051&lang=zh_CN#rd) 。
+
+### 9. 事务 `@Transactional`
+
+在要开启事务的方法上使用`@Transactional`注解即可!
+
+```java
+@Transactional(rollbackFor = Exception.class)
+public void save() {
+ ......
+}
+
+```
+
+我们知道 Exception 分为运行时异常 RuntimeException 和非运行时异常。在`@Transactional`注解中如果不配置`rollbackFor`属性,那么事务只会在遇到`RuntimeException`的时候才会回滚,加上`rollbackFor=Exception.class`,可以让事务在遇到非运行时异常时也回滚。
+
+`@Transactional` 注解一般可以作用在`类`或者`方法`上。
+
+- **作用于类**:当把`@Transactional` 注解放在类上时,表示所有该类的 public 方法都配置相同的事务属性信息。
+- **作用于方法**:当类配置了`@Transactional`,方法也配置了`@Transactional`,方法的事务会覆盖类的事务配置信息。
+
+更多关于 Spring 事务的内容请查看:
+
+1. [可能是最漂亮的 Spring 事务管理详解](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484943&idx=1&sn=46b9082af4ec223137df7d1c8303ca24&chksm=cea249c4f9d5c0d2b8212a17252cbfb74e5fbe5488b76d829827421c53332326d1ec360f5d63&token=1082669959&lang=zh_CN#rd)
+2. [一口气说出 6 种 @Transactional 注解失效场景](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486483&idx=2&sn=77be488e206186803531ea5d7164ec53&chksm=cea243d8f9d5cacecaa5c5daae4cde4c697b9b5b21f96dfc6cce428cfcb62b88b3970c26b9c2&token=816772476&lang=zh_CN#rd)
+
+### 10. json 数据处理
+
+#### 10.1. 过滤 json 数据
+
+**`@JsonIgnoreProperties` 作用在类上用于过滤掉特定字段不返回或者不解析。**
+
+```java
+//生成json时将userRoles属性过滤
+@JsonIgnoreProperties({"userRoles"})
+public class User {
+
+ private String userName;
+ private String fullName;
+ private String password;
+ private List<UserRole> userRoles = new ArrayList<>();
+}
+```
+
+**`@JsonIgnore`一般用于类的属性上,作用和上面的`@JsonIgnoreProperties` 一样。**
+
+```java
+
+public class User {
+
+ private String userName;
+ private String fullName;
+ private String password;
+ //生成json时将userRoles属性过滤
+ @JsonIgnore
+ private List<UserRole> userRoles = new ArrayList<>();
+}
+```
+
+#### 10.2. 格式化 json 数据
+
+`@JsonFormat`一般用来格式化 json 数据。
+
+比如:
+
+```java
+@JsonFormat(shape=JsonFormat.Shape.STRING, pattern="yyyy-MM-dd'T'HH:mm:ss.SSS'Z'", timezone="GMT")
+private Date date;
+```
+
+#### 10.3. 扁平化对象
+
+```java
+@Getter
+@Setter
+@ToString
+public class Account {
+ private Location location;
+ private PersonInfo personInfo;
+
+ @Getter
+ @Setter
+ @ToString
+ public static class Location {
+ private String provinceName;
+ private String countyName;
+ }
+ @Getter
+ @Setter
+ @ToString
+ public static class PersonInfo {
+ private String userName;
+ private String fullName;
+ }
+}
+
+```
+
+未扁平化之前:
+
+```json
+{
+ "location": {
+ "provinceName":"湖北",
+ "countyName":"武汉"
+ },
+ "personInfo": {
+ "userName": "coder1234",
+ "fullName": "shaungkou"
+ }
+}
+```
+
+使用`@JsonUnwrapped` 扁平对象之后:
+
+```java
+@Getter
+@Setter
+@ToString
+public class Account {
+ @JsonUnwrapped
+ private Location location;
+ @JsonUnwrapped
+ private PersonInfo personInfo;
+ ......
+}
+```
+
+```json
+{
+ "provinceName":"湖北",
+ "countyName":"武汉",
+ "userName": "coder1234",
+ "fullName": "shaungkou"
+}
+```
+
+### 11. 测试相关
+
+**`@ActiveProfiles`一般作用于测试类上, 用于声明生效的 Spring 配置文件。**
+
+```java
+@SpringBootTest(webEnvironment = RANDOM_PORT)
+@ActiveProfiles("test")
+@Slf4j
+public abstract class TestBase {
+ ......
+}
+```
+
+**`@Test`声明一个方法为测试方法**
+
+**`@Transactional`被声明的测试方法的数据会回滚,避免污染测试数据。**
+
+**`@WithMockUser` Spring Security 提供的,用来模拟一个真实用户,并且可以赋予权限。**
+
+```java
+ @Test
+ @Transactional
+ @WithMockUser(username = "user-id-18163138155", authorities = "ROLE_TEACHER")
+ void should_import_student_success() throws Exception {
+ ......
+ }
+```
+
+_暂时总结到这里吧!虽然花了挺长时间才写完,不过可能还是会一些常用的注解的被漏掉,所以,我将文章也同步到了 Github 上去,Github 地址: 欢迎完善!_
+
+本文已经收录进我的 75K Star 的 Java 开源项目 JavaGuide:[https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)。
diff --git "a/docs/system-design/framework/spring/SpringBoot\350\207\252\345\212\250\350\243\205\351\205\215\345\216\237\347\220\206.md" "b/docs/system-design/framework/spring/SpringBoot\350\207\252\345\212\250\350\243\205\351\205\215\345\216\237\347\220\206.md"
new file mode 100644
index 00000000000..e8a8e58c53c
--- /dev/null
+++ "b/docs/system-design/framework/spring/SpringBoot\350\207\252\345\212\250\350\243\205\351\205\215\345\216\237\347\220\206.md"
@@ -0,0 +1,320 @@
+
+# Spring Boot 自动装配原理
+
+> 本文已经收录进 Github 95k+ Star 的Java项目JavaGuide 。JavaGuide项目地址 : https://github.com/Snailclimb/JavaGuide 。
+>
+> 作者:[Miki-byte-1024](https://github.com/Miki-byte-1024) & [Snailclimb](https://github.com/Snailclimb)
+
+每次问到 Spring Boot, 面试官非常喜欢问这个问题:“讲述一下 SpringBoot 自动装配原理?”。
+
+我觉得我们可以从以下几个方面回答:
+
+1. 什么是 SpringBoot 自动装配?
+2. SpringBoot 是如何实现自动装配的?如何实现按需加载?
+3. 如何实现一个 Starter?
+
+篇幅问题,这篇文章并没有深入,小伙伴们也可以直接使用 debug 的方式去看看 SpringBoot 自动装配部分的源代码。
+
+## 前言
+
+使用过 Spring 的小伙伴,一定有被 XML 配置统治的恐惧。即使 Spring 后面引入了基于注解的配置,我们在开启某些 Spring 特性或者引入第三方依赖的时候,还是需要用 XML 或 Java 进行显式配置。
+
+举个例子。没有 Spring Boot 的时候,我们写一个 RestFul Web 服务,还首先需要进行如下配置。
+
+```java
+@Configuration
+public class RESTConfiguration
+{
+ @Bean
+ public View jsonTemplate() {
+ MappingJackson2JsonView view = new MappingJackson2JsonView();
+ view.setPrettyPrint(true);
+ return view;
+ }
+
+ @Bean
+ public ViewResolver viewResolver() {
+ return new BeanNameViewResolver();
+ }
+}
+```
+
+`spring-servlet.xml`
+
+```xml
+<beans xmlns="http://www.springframework.org/schema/beans"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
+ xmlns:mvc="http://www.springframework.org/schema/mvc"
+ xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
+ http://www.springframework.org/schema/context/ http://www.springframework.org/schema/context/spring-context.xsd
+ http://www.springframework.org/schema/mvc/ http://www.springframework.org/schema/mvc/spring-mvc.xsd">
+
+ <context:component-scan base-package="com.howtodoinjava.demo" />
+ <mvc:annotation-driven />
+
+ <!-- JSON Support -->
+ <bean name="viewResolver" class="org.springframework.web.servlet.view.BeanNameViewResolver"/>
+ <bean name="jsonTemplate" class="org.springframework.web.servlet.view.json.MappingJackson2JsonView"/>
+
+</beans>
+```
+
+但是,Spring Boot 项目,我们只需要添加相关依赖,无需配置,通过启动下面的 `main` 方法即可。
+
+```java
+@SpringBootApplication
+public class DemoApplication {
+ public static void main(String[] args) {
+ SpringApplication.run(DemoApplication.class, args);
+ }
+}
+```
+
+并且,我们通过 Spring Boot 的全局配置文件 `application.properties`或`application.yml`即可对项目进行设置比如更换端口号,配置 JPA 属性等等。
+
+**为什么 Spring Boot 使用起来这么酸爽呢?** 这得益于其自动装配。**自动装配可以说是 Spring Boot 的核心,那究竟什么是自动装配呢?**
+
+## 什么是 SpringBoot 自动装配?
+
+我们现在提到自动装配的时候,一般会和 Spring Boot 联系在一起。但是,实际上 Spring Framework 早就实现了这个功能。Spring Boot 只是在其基础上,通过 SPI 的方式,做了进一步优化。
+
+> SpringBoot 定义了一套接口规范,这套规范规定:SpringBoot 在启动时会扫描外部引用 jar 包中的`META-INF/spring.factories`文件,将文件中配置的类型信息加载到 Spring 容器(此处涉及到 JVM 类加载机制与 Spring 的容器知识),并执行类中定义的各种操作。对于外部 jar 来说,只需要按照 SpringBoot 定义的标准,就能将自己的功能装置进 SpringBoot。
+
+没有 Spring Boot 的情况下,如果我们需要引入第三方依赖,需要手动配置,非常麻烦。但是,Spring Boot 中,我们直接引入一个 starter 即可。比如你想要在项目中使用 redis 的话,直接在项目中引入对应的 starter 即可。
+
+```xml
+<dependency>
+ <groupId>org.springframework.boot</groupId>
+ <artifactId>spring-boot-starter-data-redis</artifactId>
+</dependency>
+```
+
+引入 starter 之后,我们通过少量注解和一些简单的配置就能使用第三方组件提供的功能了。
+
+在我看来,自动装配可以简单理解为:**通过注解或者一些简单的配置就能在 Spring Boot 的帮助下实现某块功能。**
+
+## SpringBoot 是如何实现自动装配的?
+
+我们先看一下 SpringBoot 的核心注解 `SpringBootApplication` 。
+
+```java
+@Target({ElementType.TYPE})
+@Retention(RetentionPolicy.RUNTIME)
+@Documented
+@Inherited
+<1.>@SpringBootConfiguration
+<2.>@ComponentScan
+<3.>@EnableAutoConfiguration
+public @interface SpringBootApplication {
+
+}
+
+@Target({ElementType.TYPE})
+@Retention(RetentionPolicy.RUNTIME)
+@Documented
+@Configuration //实际上它也是一个配置类
+public @interface SpringBootConfiguration {
+}
+```
+
+大概可以把 `@SpringBootApplication`看作是 `@Configuration`、`@EnableAutoConfiguration`、`@ComponentScan` 注解的集合。根据 SpringBoot 官网,这三个注解的作用分别是:
+
+- `@EnableAutoConfiguration`:启用 SpringBoot 的自动配置机制
+- `@Configuration`:允许在上下文中注册额外的 bean 或导入其他配置类
+- `@ComponentScan`: 扫描被`@Component` (`@Service`,`@Controller`)注解的 bean,注解默认会扫描启动类所在的包下所有的类 ,可以自定义不扫描某些 bean。如下图所示,容器中将排除`TypeExcludeFilter`和`AutoConfigurationExcludeFilter`。
+
+ 
+
+`@EnableAutoConfiguration` 是实现自动装配的重要注解,我们以这个注解入手。
+
+### @EnableAutoConfiguration:实现自动装配的核心注解
+
+`EnableAutoConfiguration` 只是一个简单地注解,自动装配核心功能的实现实际是通过 `AutoConfigurationImportSelector`类。
+
+```java
+@Target({ElementType.TYPE})
+@Retention(RetentionPolicy.RUNTIME)
+@Documented
+@Inherited
+@AutoConfigurationPackage //作用:将main包下的所有组件注册到容器中
+@Import({AutoConfigurationImportSelector.class}) //加载自动装配类 xxxAutoconfiguration
+public @interface EnableAutoConfiguration {
+ String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
+
+ Class<?>[] exclude() default {};
+
+ String[] excludeName() default {};
+}
+```
+
+我们现在重点分析下`AutoConfigurationImportSelector` 类到底做了什么?
+
+### AutoConfigurationImportSelector:加载自动装配类
+
+`AutoConfigurationImportSelector`类的继承体系如下:
+
+```java
+public class AutoConfigurationImportSelector implements DeferredImportSelector, BeanClassLoaderAware, ResourceLoaderAware, BeanFactoryAware, EnvironmentAware, Ordered {
+
+}
+
+public interface DeferredImportSelector extends ImportSelector {
+
+}
+
+public interface ImportSelector {
+ String[] selectImports(AnnotationMetadata var1);
+}
+```
+
+可以看出,`AutoConfigurationImportSelector` 类实现了 `ImportSelector`接口,也就实现了这个接口中的 `selectImports`方法,该方法主要用于**获取所有符合条件的类的全限定类名,这些类需要被加载到 IoC 容器中**。
+
+```java
+private static final String[] NO_IMPORTS = new String[0];
+
+public String[] selectImports(AnnotationMetadata annotationMetadata) {
+ // <1>.判断自动装配开关是否打开
+ if (!this.isEnabled(annotationMetadata)) {
+ return NO_IMPORTS;
+ } else {
+ //<2>.获取所有需要装配的bean
+ AutoConfigurationMetadata autoConfigurationMetadata = AutoConfigurationMetadataLoader.loadMetadata(this.beanClassLoader);
+ AutoConfigurationImportSelector.AutoConfigurationEntry autoConfigurationEntry = this.getAutoConfigurationEntry(autoConfigurationMetadata, annotationMetadata);
+ return StringUtils.toStringArray(autoConfigurationEntry.getConfigurations());
+ }
+ }
+```
+
+这里我们需要重点关注一下`getAutoConfigurationEntry()`方法,这个方法主要负责加载自动配置类的。
+
+该方法调用链如下:
+
+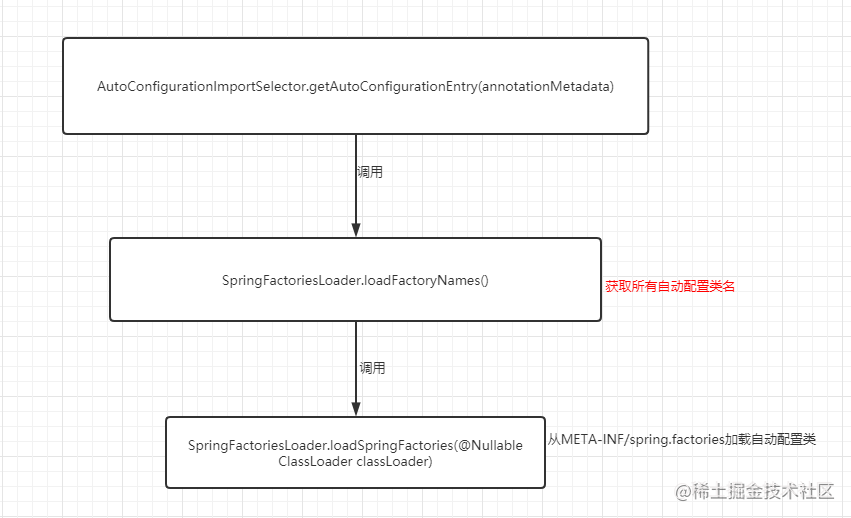
+
+现在我们结合`getAutoConfigurationEntry()`的源码来详细分析一下:
+
+```java
+private static final AutoConfigurationEntry EMPTY_ENTRY = new AutoConfigurationEntry();
+
+AutoConfigurationEntry getAutoConfigurationEntry(AutoConfigurationMetadata autoConfigurationMetadata, AnnotationMetadata annotationMetadata) {
+ //<1>.
+ if (!this.isEnabled(annotationMetadata)) {
+ return EMPTY_ENTRY;
+ } else {
+ //<2>.
+ AnnotationAttributes attributes = this.getAttributes(annotationMetadata);
+ //<3>.
+ List<String> configurations = this.getCandidateConfigurations(annotationMetadata, attributes);
+ //<4>.
+ configurations = this.removeDuplicates(configurations);
+ Set<String> exclusions = this.getExclusions(annotationMetadata, attributes);
+ this.checkExcludedClasses(configurations, exclusions);
+ configurations.removeAll(exclusions);
+ configurations = this.filter(configurations, autoConfigurationMetadata);
+ this.fireAutoConfigurationImportEvents(configurations, exclusions);
+ return new AutoConfigurationImportSelector.AutoConfigurationEntry(configurations, exclusions);
+ }
+ }
+```
+
+**第 1 步**:
+
+判断自动装配开关是否打开。默认`spring.boot.enableautoconfiguration=true`,可在 `application.properties` 或 `application.yml` 中设置
+
+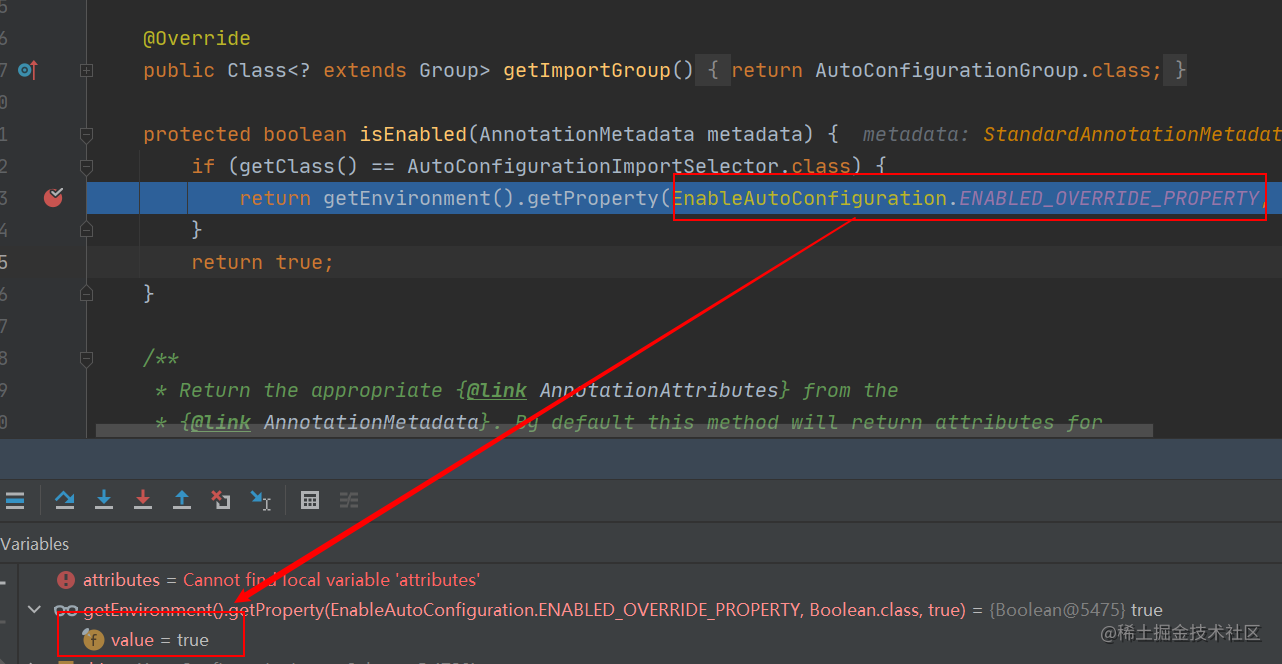
+
+**第 2 步** :
+
+用于获取`EnableAutoConfiguration`注解中的 `exclude` 和 `excludeName`。
+
+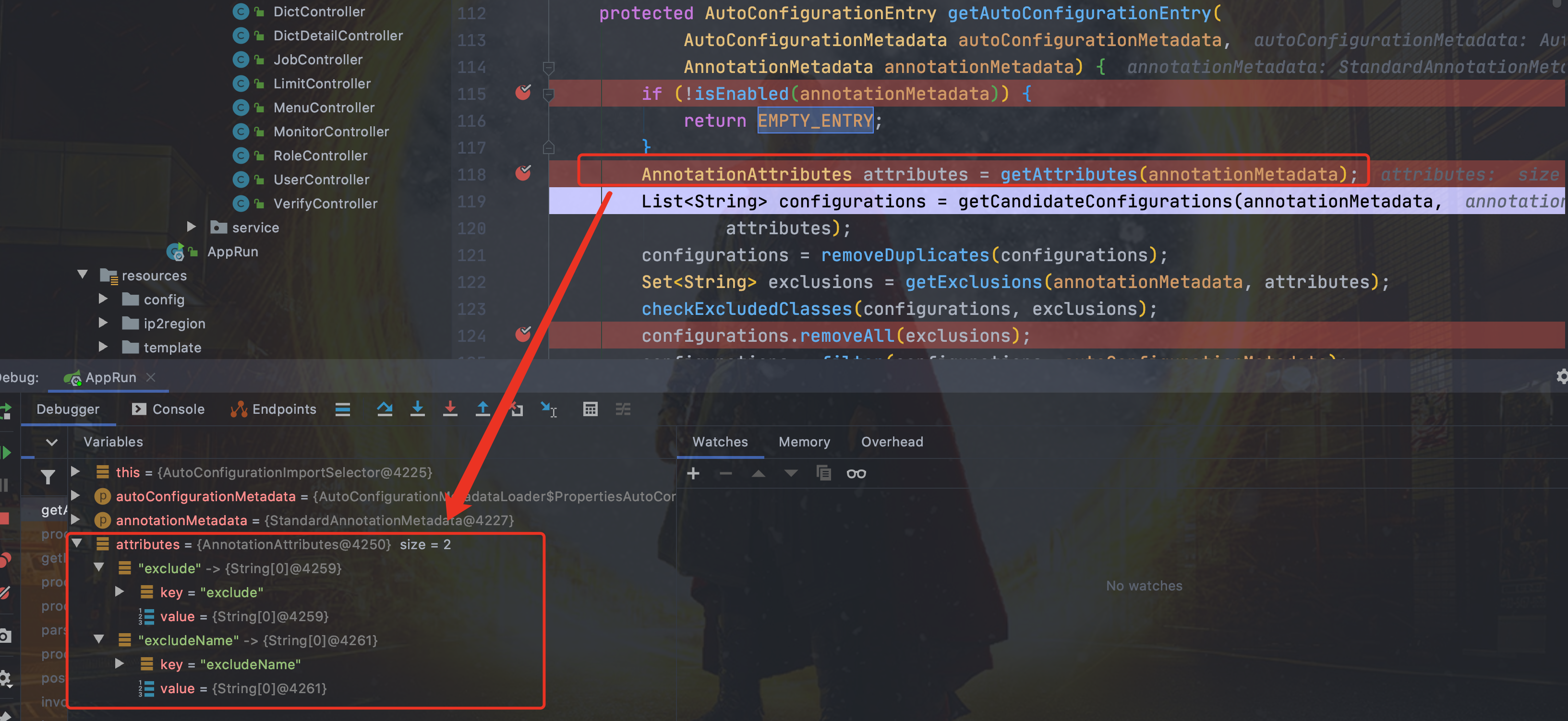
+
+**第 3 步**
+
+获取需要自动装配的所有配置类,读取`META-INF/spring.factories`
+
+```
+spring-boot/spring-boot-project/spring-boot-autoconfigure/src/main/resources/META-INF/spring.factories
+```
+
+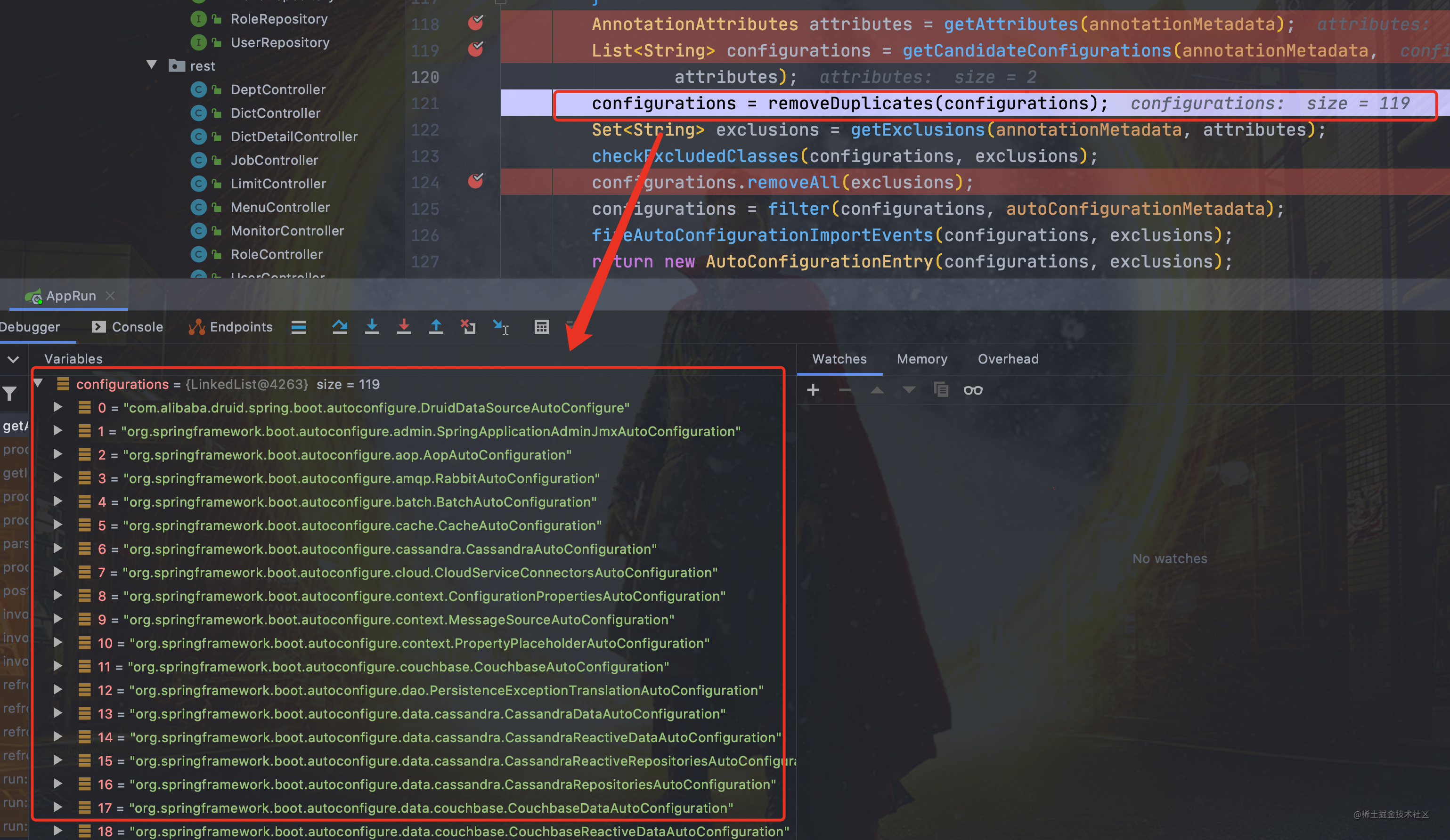
+
+从下图可以看到这个文件的配置内容都被我们读取到了。`XXXAutoConfiguration`的作用就是按需加载组件。
+
+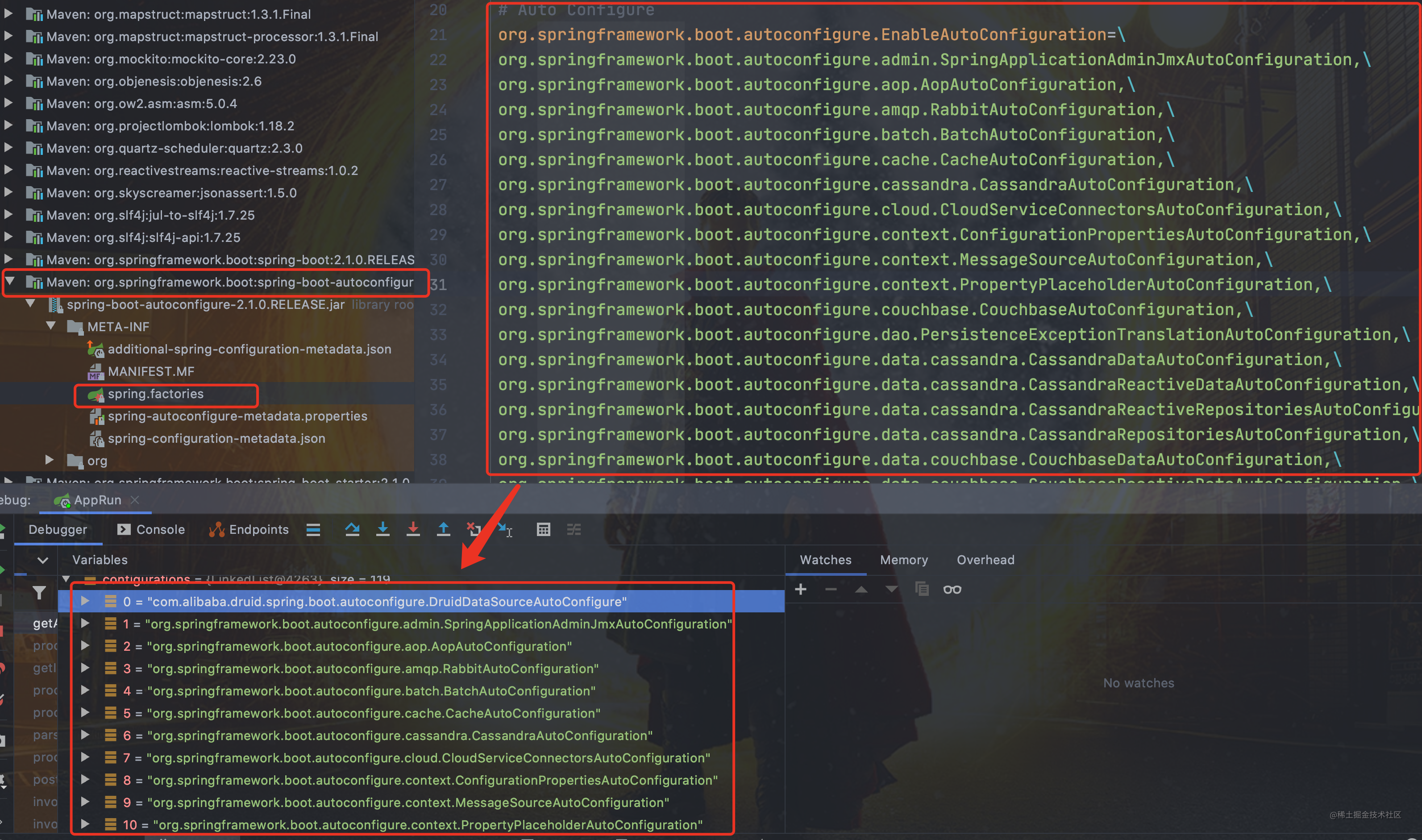
+
+不光是这个依赖下的`META-INF/spring.factories`被读取到,所有 Spring Boot Starter 下的`META-INF/spring.factories`都会被读取到。
+
+所以,你可以清楚滴看到, druid 数据库连接池的 Spring Boot Starter 就创建了`META-INF/spring.factories`文件。
+
+如果,我们自己要创建一个 Spring Boot Starter,这一步是必不可少的。
+
+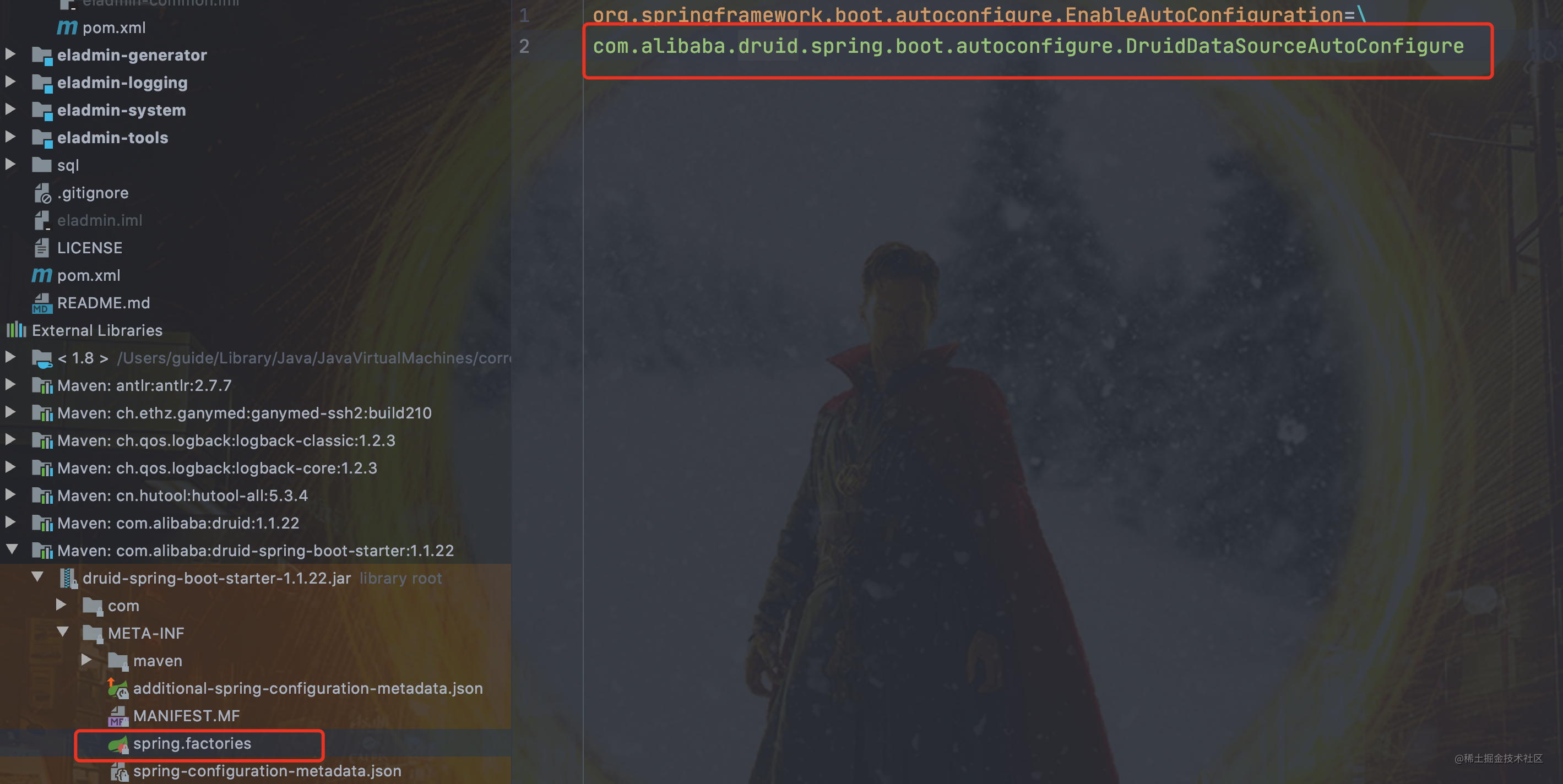
+
+**第 4 步** :
+
+到这里可能面试官会问你:“`spring.factories`中这么多配置,每次启动都要全部加载么?”。
+
+很明显,这是不现实的。我们 debug 到后面你会发现,`configurations` 的值变小了。
+
+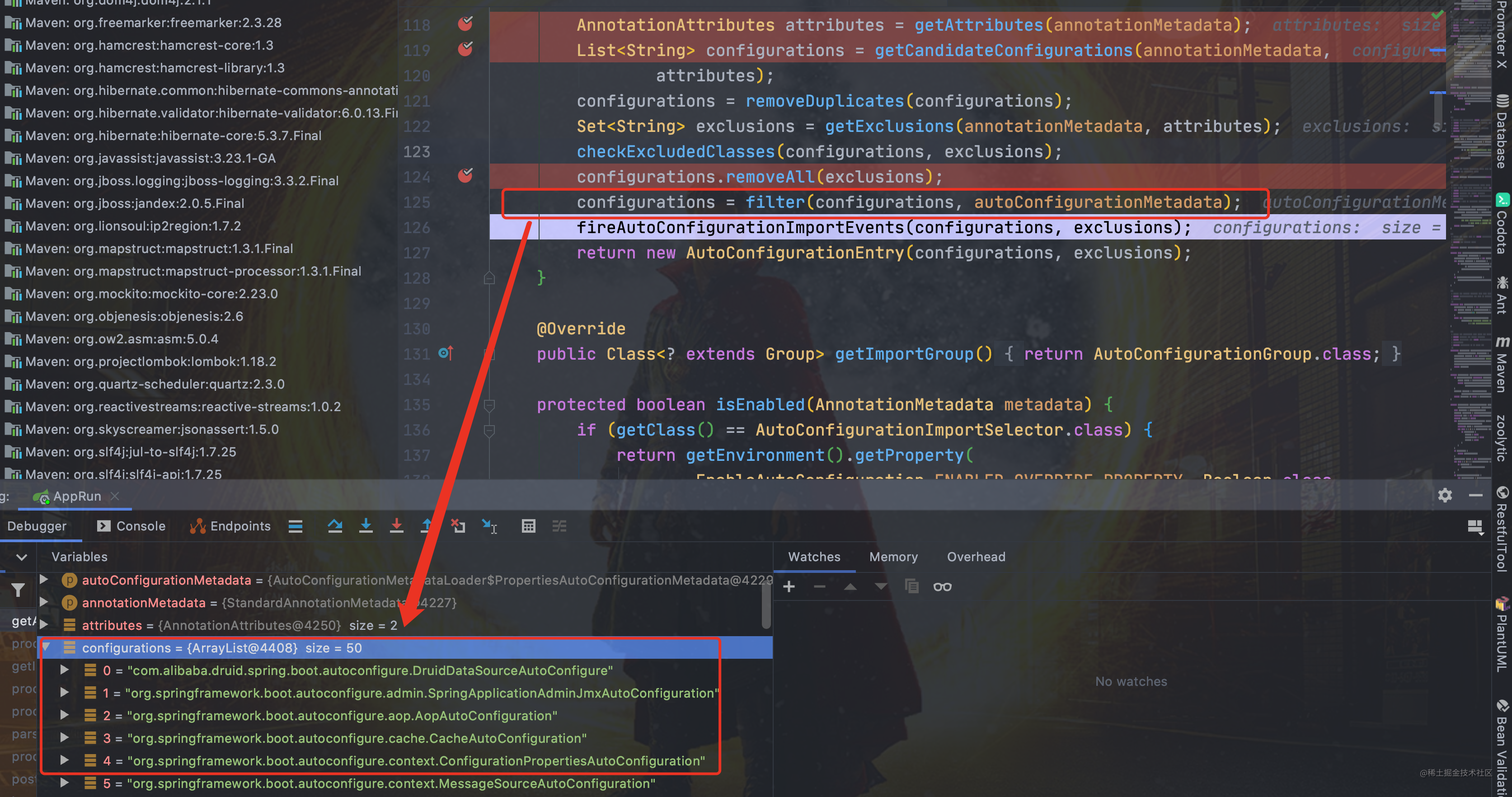
+
+因为,这一步有经历了一遍筛选,`@ConditionalOnXXX` 中的所有条件都满足,该类才会生效。
+
+```java
+@Configuration
+// 检查相关的类:RabbitTemplate 和 Channel是否存在
+// 存在才会加载
+@ConditionalOnClass({ RabbitTemplate.class, Channel.class })
+@EnableConfigurationProperties(RabbitProperties.class)
+@Import(RabbitAnnotationDrivenConfiguration.class)
+public class RabbitAutoConfiguration {
+}
+```
+
+有兴趣的童鞋可以详细了解下 Spring Boot 提供的条件注解
+
+- `@ConditionalOnBean`:当容器里有指定 Bean 的条件下
+- `@ConditionalOnMissingBean`:当容器里没有指定 Bean 的情况下
+- `@ConditionalOnSingleCandidate`:当指定 Bean 在容器中只有一个,或者虽然有多个但是指定首选 Bean
+- `@ConditionalOnClass`:当类路径下有指定类的条件下
+- `@ConditionalOnMissingClass`:当类路径下没有指定类的条件下
+- `@ConditionalOnProperty`:指定的属性是否有指定的值
+- `@ConditionalOnResource`:类路径是否有指定的值
+- `@ConditionalOnExpression`:基于 SpEL 表达式作为判断条件
+- `@ConditionalOnJava`:基于 Java 版本作为判断条件
+- `@ConditionalOnJndi`:在 JNDI 存在的条件下差在指定的位置
+- `@ConditionalOnNotWebApplication`:当前项目不是 Web 项目的条件下
+- `@ConditionalOnWebApplication`:当前项目是 Web 项 目的条件下
+
+## 如何实现一个 Starter
+
+光说不练假把式,现在就来撸一个 starter,实现自定义线程池
+
+第一步,创建`threadpool-spring-boot-starter`工程
+
+
+
+第二步,引入 Spring Boot 相关依赖
+
+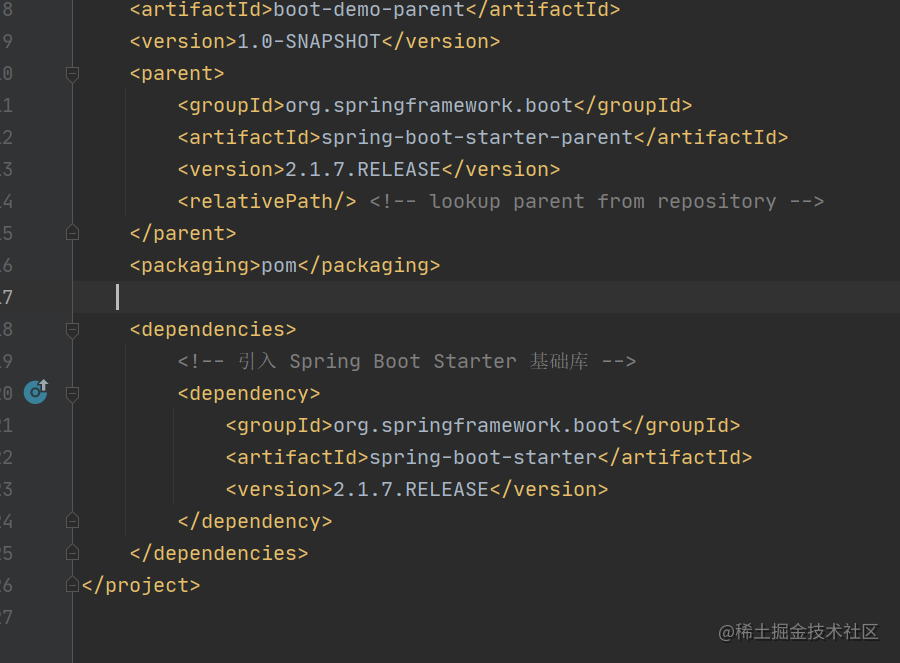
+
+第三步,创建`ThreadPoolAutoConfiguration`
+
+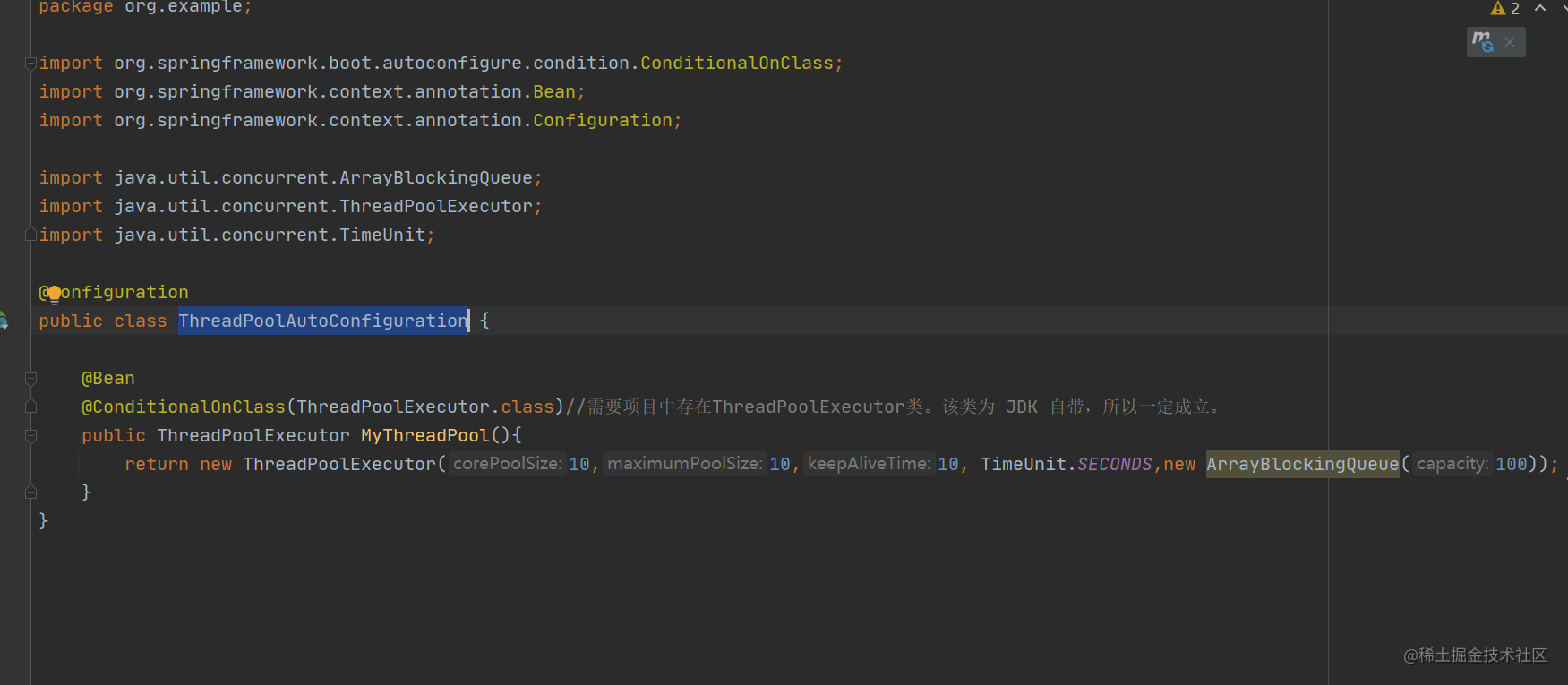
+
+第四步,在`threadpool-spring-boot-starter`工程的 resources 包下创建`META-INF/spring.factories`文件
+
+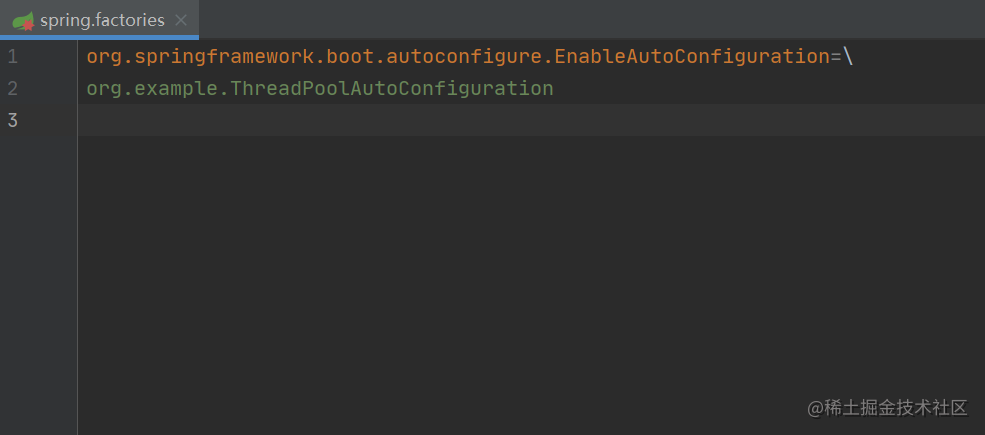
+
+最后新建工程引入`threadpool-spring-boot-starter`
+
+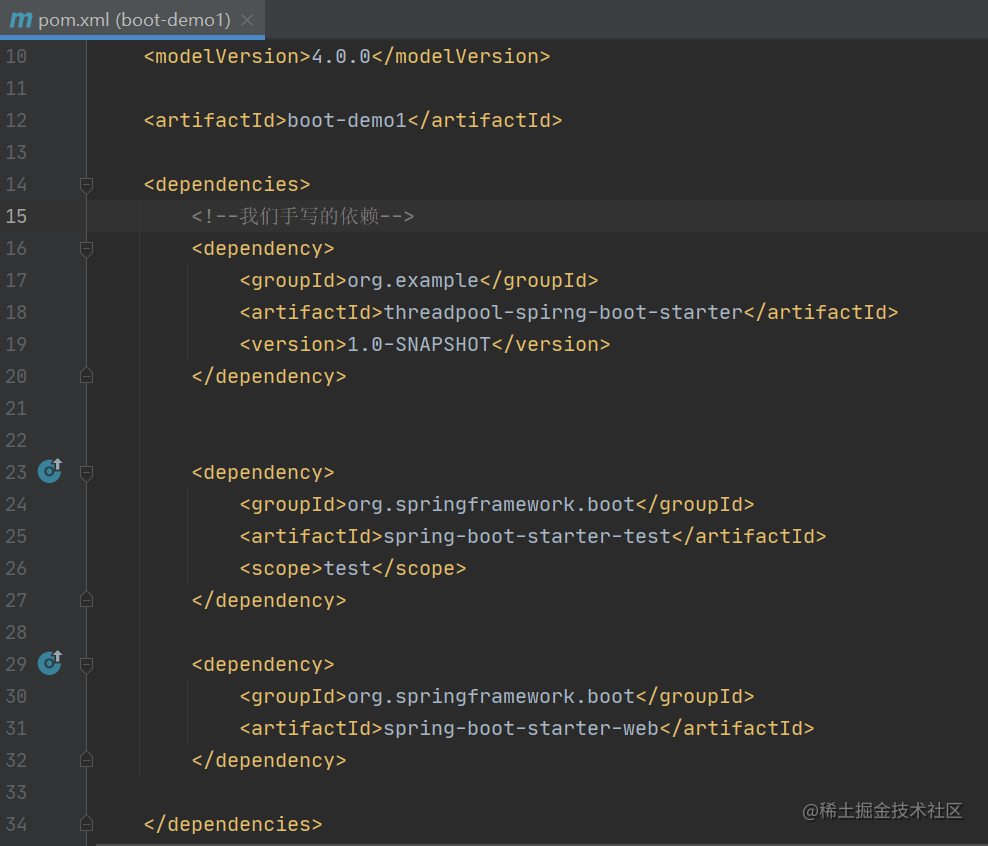
+
+测试通过!!!
+
+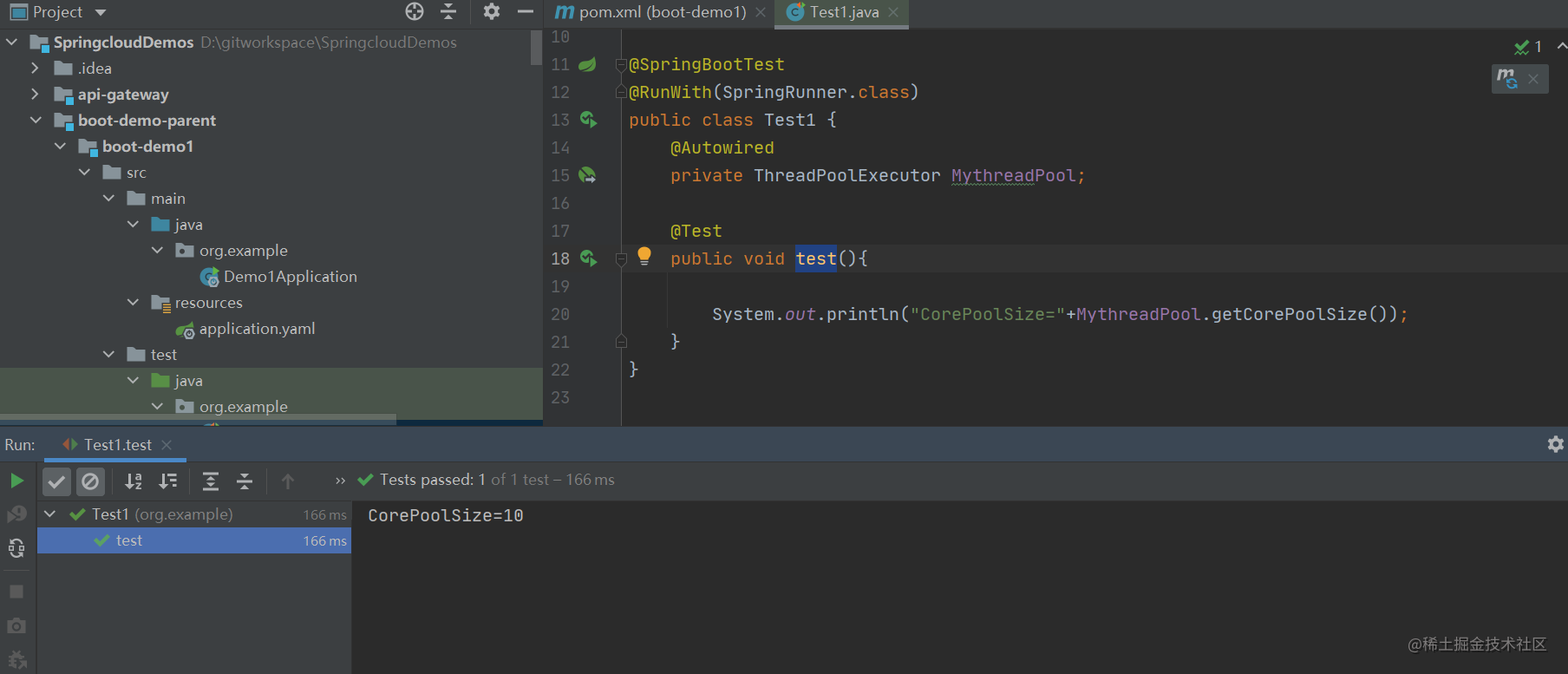
+
+## 总结
+
+Spring Boot 通过`@EnableAutoConfiguration`开启自动装配,通过 SpringFactoriesLoader 最终加载`META-INF/spring.factories`中的自动配置类实现自动装配,自动配置类其实就是通过`@Conditional`按需加载的配置类,想要其生效必须引入`spring-boot-starter-xxx`包实现起步依赖
diff --git "a/docs/system-design/framework/spring/Spring\344\272\213\345\212\241\346\200\273\347\273\223.md" "b/docs/system-design/framework/spring/Spring\344\272\213\345\212\241\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..dfe98c1eeca
--- /dev/null
+++ "b/docs/system-design/framework/spring/Spring\344\272\213\345\212\241\346\200\273\347\273\223.md"
@@ -0,0 +1,700 @@
+
+# Spring 事务总结
+
+大家好,我是 Guide 哥,前段时间答应读者的 **Spring 事务**分析总结终于来了。这部分内容比较重要,不论是对于工作还是面试,但是网上比较好的参考资料比较少。
+
+如果本文有任何不对或者需要完善的地方,请帮忙指出!Guide 哥感激不尽!
+
+## 1. 什么是事务?
+
+**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
+
+_Guide 哥:大家应该都能背上面这句话了,下面我结合我们日常的真实开发来谈一谈。_
+
+我们系统的每个业务方法可能包括了多个原子性的数据库操作,比如下面的 `savePerson()` 方法中就有两个原子性的数据库操作。这些原子性的数据库操作是有依赖的,它们要么都执行,要不就都不执行。
+
+```java
+ public void savePerson() {
+ personDao.save(person);
+ personDetailDao.save(personDetail);
+ }
+```
+
+另外,需要格外注意的是:**事务能否生效数据库引擎是否支持事务是关键。比如常用的 MySQL 数据库默认使用支持事务的`innodb`引擎。但是,如果把数据库引擎变为 `myisam`,那么程序也就不再支持事务了!**
+
+事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作就是:
+
+1. 将小明的余额减少 1000 元
+
+2. 将小红的余额增加 1000 元。
+
+万一在这两个操作之间突然出现错误比如银行系统崩溃或者网络故障,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
+
+```java
+public class OrdersService {
+ private AccountDao accountDao;
+
+ public void setOrdersDao(AccountDao accountDao) {
+ this.accountDao = accountDao;
+ }
+
+ @Transactional(propagation = Propagation.REQUIRED,
+ isolation = Isolation.DEFAULT, readOnly = false, timeout = -1)
+ public void accountMoney() {
+ //小红账户多1000
+ accountDao.addMoney(1000,xiaohong);
+ //模拟突然出现的异常,比如银行中可能为突然停电等等
+ //如果没有配置事务管理的话会造成,小红账户多了1000而小明账户没有少钱
+ int i = 10 / 0;
+ //小王账户少1000
+ accountDao.reduceMoney(1000,xiaoming);
+ }
+}
+```
+
+另外,数据库事务的 ACID 四大特性是事务的基础,下面简单来了解一下。
+
+## 2. 事务的特性(ACID)了解么?
+
+
+
+- **原子性(Atomicity):** 一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。
+- **一致性(Consistency):** 在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。
+- **隔离性(Isolation):** 数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。
+- **持久性(Durability):** 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
+
+参考 :[https://zh.wikipedia.org/wiki/ACID](https://zh.wikipedia.org/wiki/ACID) 。
+
+## 3. 详谈 Spring 对事务的支持
+
+**再提醒一次:你的程序是否支持事务首先取决于数据库 ,比如使用 MySQL 的话,如果你选择的是 innodb 引擎,那么恭喜你,是可以支持事务的。但是,如果你的 MySQL 数据库使用的是 myisam 引擎的话,那不好意思,从根上就是不支持事务的。**
+
+这里再多提一下一个非常重要的知识点: **MySQL 怎么保证原子性的?**
+
+我们知道如果想要保证事务的原子性,就需要在异常发生时,对已经执行的操作进行**回滚**,在 MySQL 中,恢复机制是通过 **回滚日志(undo log)** 实现的,所有事务进行的修改都会先先记录到这个回滚日志中,然后再执行相关的操作。如果执行过程中遇到异常的话,我们直接利用 **回滚日志** 中的信息将数据回滚到修改之前的样子即可!并且,回滚日志会先于数据持久化到磁盘上。这样就保证了即使遇到数据库突然宕机等情况,当用户再次启动数据库的时候,数据库还能够通过查询回滚日志来回滚将之前未完成的事务。
+
+### 3.1. Spring 支持两种方式的事务管理
+
+#### 1).编程式事务管理
+
+通过 `TransactionTemplate`或者`TransactionManager`手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。
+
+使用`TransactionTemplate` 进行编程式事务管理的示例代码如下:
+
+```java
+@Autowired
+private TransactionTemplate transactionTemplate;
+public void testTransaction() {
+
+ transactionTemplate.execute(new TransactionCallbackWithoutResult() {
+ @Override
+ protected void doInTransactionWithoutResult(TransactionStatus transactionStatus) {
+
+ try {
+
+ // .... 业务代码
+ } catch (Exception e){
+ //回滚
+ transactionStatus.setRollbackOnly();
+ }
+
+ }
+ });
+}
+```
+
+使用 `TransactionManager` 进行编程式事务管理的示例代码如下:
+
+```java
+@Autowired
+private PlatformTransactionManager transactionManager;
+
+public void testTransaction() {
+
+ TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
+ try {
+ // .... 业务代码
+ transactionManager.commit(status);
+ } catch (Exception e) {
+ transactionManager.rollback(status);
+ }
+}
+```
+
+#### 2)声明式事务管理
+
+推荐使用(代码侵入性最小),实际是通过 AOP 实现(基于`@Transactional` 的全注解方式使用最多)。
+
+使用 `@Transactional`注解进行事务管理的示例代码如下:
+
+```java
+@Transactional(propagation=propagation.PROPAGATION_REQUIRED)
+public void aMethod {
+ //do something
+ B b = new B();
+ C c = new C();
+ b.bMethod();
+ c.cMethod();
+}
+```
+
+### 3.2. Spring 事务管理接口介绍
+
+Spring 框架中,事务管理相关最重要的 3 个接口如下:
+
+- **`PlatformTransactionManager`**: (平台)事务管理器,Spring 事务策略的核心。
+- **`TransactionDefinition`**: 事务定义信息(事务隔离级别、传播行为、超时、只读、回滚规则)。
+- **`TransactionStatus`**: 事务运行状态。
+
+我们可以把 **`PlatformTransactionManager`** 接口可以被看作是事务上层的管理者,而 **`TransactionDefinition`** 和 **`TransactionStatus`** 这两个接口可以看作是事务的描述。
+
+**`PlatformTransactionManager`** 会根据 **`TransactionDefinition`** 的定义比如事务超时时间、隔离级别、传播行为等来进行事务管理 ,而 **`TransactionStatus`** 接口则提供了一些方法来获取事务相应的状态比如是否新事务、是否可以回滚等等。
+
+#### 3.2.1. PlatformTransactionManager:事务管理接口
+
+**Spring 并不直接管理事务,而是提供了多种事务管理器** 。Spring 事务管理器的接口是: **`PlatformTransactionManager`** 。
+
+通过这个接口,Spring 为各个平台如 JDBC(`DataSourceTransactionManager`)、Hibernate(`HibernateTransactionManager`)、JPA(`JpaTransactionManager`)等都提供了对应的事务管理器,但是具体的实现就是各个平台自己的事情了。
+
+**`PlatformTransactionManager` 接口的具体实现如下:**
+
+
+
+`PlatformTransactionManager`接口中定义了三个方法:
+
+```java
+package org.springframework.transaction;
+
+import org.springframework.lang.Nullable;
+
+public interface PlatformTransactionManager {
+ //获得事务
+ TransactionStatus getTransaction(@Nullable TransactionDefinition var1) throws TransactionException;
+ //提交事务
+ void commit(TransactionStatus var1) throws TransactionException;
+ //回滚事务
+ void rollback(TransactionStatus var1) throws TransactionException;
+}
+
+```
+
+**这里多插一嘴。为什么要定义或者说抽象出来`PlatformTransactionManager`这个接口呢?**
+
+主要是因为要将事务管理行为抽象出来,然后不同的平台去实现它,这样我们可以保证提供给外部的行为不变,方便我们扩展。我前段时间分享过:**“为什么我们要用接口?”**
+
+
+
+#### 3.2.2. TransactionDefinition:事务属性
+
+事务管理器接口 **`PlatformTransactionManager`** 通过 **`getTransaction(TransactionDefinition definition)`** 方法来得到一个事务,这个方法里面的参数是 **`TransactionDefinition`** 类 ,这个类就定义了一些基本的事务属性。
+
+那么什么是 **事务属性** 呢?
+
+事务属性可以理解成事务的一些基本配置,描述了事务策略如何应用到方法上。
+
+事务属性包含了 5 个方面:
+
+
+
+`TransactionDefinition` 接口中定义了 5 个方法以及一些表示事务属性的常量比如隔离级别、传播行为等等。
+
+```java
+package org.springframework.transaction;
+
+import org.springframework.lang.Nullable;
+
+public interface TransactionDefinition {
+ int PROPAGATION_REQUIRED = 0;
+ int PROPAGATION_SUPPORTS = 1;
+ int PROPAGATION_MANDATORY = 2;
+ int PROPAGATION_REQUIRES_NEW = 3;
+ int PROPAGATION_NOT_SUPPORTED = 4;
+ int PROPAGATION_NEVER = 5;
+ int PROPAGATION_NESTED = 6;
+ int ISOLATION_DEFAULT = -1;
+ int ISOLATION_READ_UNCOMMITTED = 1;
+ int ISOLATION_READ_COMMITTED = 2;
+ int ISOLATION_REPEATABLE_READ = 4;
+ int ISOLATION_SERIALIZABLE = 8;
+ int TIMEOUT_DEFAULT = -1;
+ // 返回事务的传播行为,默认值为 REQUIRED。
+ int getPropagationBehavior();
+ //返回事务的隔离级别,默认值是 DEFAULT
+ int getIsolationLevel();
+ // 返回事务的超时时间,默认值为-1。如果超过该时间限制但事务还没有完成,则自动回滚事务。
+ int getTimeout();
+ // 返回是否为只读事务,默认值为 false
+ boolean isReadOnly();
+
+ @Nullable
+ String getName();
+}
+```
+
+#### 3.2.3. TransactionStatus:事务状态
+
+`TransactionStatus`接口用来记录事务的状态 该接口定义了一组方法,用来获取或判断事务的相应状态信息。
+
+`PlatformTransactionManager.getTransaction(…)`方法返回一个 `TransactionStatus` 对象。
+
+**TransactionStatus 接口接口内容如下:**
+
+```java
+public interface TransactionStatus{
+ boolean isNewTransaction(); // 是否是新的事务
+ boolean hasSavepoint(); // 是否有恢复点
+ void setRollbackOnly(); // 设置为只回滚
+ boolean isRollbackOnly(); // 是否为只回滚
+ boolean isCompleted; // 是否已完成
+}
+```
+
+### 3.3. 事务属性详解
+
+_实际业务开发中,大家一般都是使用 `@Transactional` 注解来开启事务,很多人并不清楚这个参数里面的参数是什么意思,有什么用。为了更好的在项目中使用事务管理,强烈推荐好好阅读一下下面的内容。_
+
+#### 3.3.1. 事务传播行为
+
+**事务传播行为是为了解决业务层方法之间互相调用的事务问题**。
+
+当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
+
+**举个例子!**
+
+我们在 A 类的`aMethod()`方法中调用了 B 类的 `bMethod()` 方法。这个时候就涉及到业务层方法之间互相调用的事务问题。如果我们的 `bMethod()`如果发生异常需要回滚,如何配置事务传播行为才能让 `aMethod()`也跟着回滚呢?这个时候就需要事务传播行为的知识了,如果你不知道的话一定要好好看一下。
+
+```java
+Class A {
+ @Transactional(propagation=propagation.xxx)
+ public void aMethod {
+ //do something
+ B b = new B();
+ b.bMethod();
+ }
+}
+
+Class B {
+ @Transactional(propagation=propagation.xxx)
+ public void bMethod {
+ //do something
+ }
+}
+```
+
+在`TransactionDefinition`定义中包括了如下几个表示传播行为的常量:
+
+```java
+public interface TransactionDefinition {
+ int PROPAGATION_REQUIRED = 0;
+ int PROPAGATION_SUPPORTS = 1;
+ int PROPAGATION_MANDATORY = 2;
+ int PROPAGATION_REQUIRES_NEW = 3;
+ int PROPAGATION_NOT_SUPPORTED = 4;
+ int PROPAGATION_NEVER = 5;
+ int PROPAGATION_NESTED = 6;
+ ......
+}
+```
+
+不过如此,为了方便使用,Spring 会相应地定义了一个枚举类:`Propagation`
+
+```java
+package org.springframework.transaction.annotation;
+
+import org.springframework.transaction.TransactionDefinition;
+
+public enum Propagation {
+
+ REQUIRED(TransactionDefinition.PROPAGATION_REQUIRED),
+
+ SUPPORTS(TransactionDefinition.PROPAGATION_SUPPORTS),
+
+ MANDATORY(TransactionDefinition.PROPAGATION_MANDATORY),
+
+ REQUIRES_NEW(TransactionDefinition.PROPAGATION_REQUIRES_NEW),
+
+ NOT_SUPPORTED(TransactionDefinition.PROPAGATION_NOT_SUPPORTED),
+
+ NEVER(TransactionDefinition.PROPAGATION_NEVER),
+
+ NESTED(TransactionDefinition.PROPAGATION_NESTED);
+
+
+ private final int value;
+
+ Propagation(int value) {
+ this.value = value;
+ }
+
+ public int value() {
+ return this.value;
+ }
+
+}
+
+```
+
+**正确的事务传播行为可能的值如下** :
+
+**1.`TransactionDefinition.PROPAGATION_REQUIRED`**
+
+使用的最多的一个事务传播行为,我们平时经常使用的`@Transactional`注解默认使用就是这个事务传播行为。如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。也就是说:
+
+1. 如果外部方法没有开启事务的话,`Propagation.REQUIRED`修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
+2. 如果外部方法开启事务并且被`Propagation.REQUIRED`的话,所有`Propagation.REQUIRED`修饰的内部方法和外部方法均属于同一事务 ,只要一个方法回滚,整个事务均回滚。
+
+举个例子:如果我们上面的`aMethod()`和`bMethod()`使用的都是`PROPAGATION_REQUIRED`传播行为的话,两者使用的就是同一个事务,只要其中一个方法回滚,整个事务均回滚。
+
+```java
+Class A {
+ @Transactional(propagation=propagation.PROPAGATION_REQUIRED)
+ public void aMethod {
+ //do something
+ B b = new B();
+ b.bMethod();
+ }
+}
+
+Class B {
+ @Transactional(propagation=propagation.PROPAGATION_REQUIRED)
+ public void bMethod {
+ //do something
+ }
+}
+```
+
+**`2.TransactionDefinition.PROPAGATION_REQUIRES_NEW`**
+
+创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,`Propagation.REQUIRES_NEW`修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
+
+举个例子:如果我们上面的`bMethod()`使用`PROPAGATION_REQUIRES_NEW`事务传播行为修饰,`aMethod`还是用`PROPAGATION_REQUIRED`修饰的话。如果`aMethod()`发生异常回滚,`bMethod()`不会跟着回滚,因为 `bMethod()`开启了独立的事务。但是,如果 `bMethod()`抛出了未被捕获的异常并且这个异常满足事务回滚规则的话,`aMethod()`同样也会回滚,因为这个异常被 `aMethod()`的事务管理机制检测到了。
+
+```java
+Class A {
+ @Transactional(propagation=propagation.PROPAGATION_REQUIRED)
+ public void aMethod {
+ //do something
+ B b = new B();
+ b.bMethod();
+ }
+}
+
+Class B {
+ @Transactional(propagation=propagation.REQUIRES_NEW)
+ public void bMethod {
+ //do something
+ }
+}
+```
+
+**3.`TransactionDefinition.PROPAGATION_NESTED`**:
+
+如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于`TransactionDefinition.PROPAGATION_REQUIRED`。也就是说:
+
+1. 在外部方法未开启事务的情况下`Propagation.NESTED`和`Propagation.REQUIRED`作用相同,修饰的内部方法都会新开启自己的事务,且开启的事务相互独立,互不干扰。
+2. 如果外部方法开启事务的话,`Propagation.NESTED`修饰的内部方法属于外部事务的子事务,外部主事务回滚的话,子事务也会回滚,而内部子事务可以单独回滚而不影响外部主事务和其他子事务。
+
+这里还是简单举个例子:
+
+如果 `aMethod()` 回滚的话,`bMethod()`和`bMethod2()`都要回滚,而`bMethod()`回滚的话,并不会造成 `aMethod()` 和`bMethod()2`回滚。
+
+```java
+Class A {
+ @Transactional(propagation=propagation.PROPAGATION_REQUIRED)
+ public void aMethod {
+ //do something
+ B b = new B();
+ b.bMethod();
+ b.bMethod2();
+ }
+}
+
+Class B {
+ @Transactional(propagation=propagation.PROPAGATION_NESTED)
+ public void bMethod {
+ //do something
+ }
+ @Transactional(propagation=propagation.PROPAGATION_NESTED)
+ public void bMethod2 {
+ //do something
+ }
+}
+```
+
+**4.`TransactionDefinition.PROPAGATION_MANDATORY`**
+
+如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
+
+这个使用的很少,就不举例子来说了。
+
+**若是错误的配置以下 3 种事务传播行为,事务将不会发生回滚,这里不对照案例讲解了,使用的很少。**
+
+- **`TransactionDefinition.PROPAGATION_SUPPORTS`**: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
+- **`TransactionDefinition.PROPAGATION_NOT_SUPPORTED`**: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
+- **`TransactionDefinition.PROPAGATION_NEVER`**: 以非事务方式运行,如果当前存在事务,则抛出异常。
+
+更多关于事务传播行为的内容请看这篇文章:[《太难了~面试官让我结合案例讲讲自己对 Spring 事务传播行为的理解。》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486668&idx=2&sn=0381e8c836442f46bdc5367170234abb&chksm=cea24307f9d5ca11c96943b3ccfa1fc70dc97dd87d9c540388581f8fe6d805ff548dff5f6b5b&token=1776990505&lang=zh_CN#rd)
+
+#### 3.3.2 事务隔离级别
+
+`TransactionDefinition` 接口中定义了五个表示隔离级别的常量:
+
+```java
+public interface TransactionDefinition {
+ ......
+ int ISOLATION_DEFAULT = -1;
+ int ISOLATION_READ_UNCOMMITTED = 1;
+ int ISOLATION_READ_COMMITTED = 2;
+ int ISOLATION_REPEATABLE_READ = 4;
+ int ISOLATION_SERIALIZABLE = 8;
+ ......
+}
+```
+
+和事务传播行为这块一样,为了方便使用,Spring 也相应地定义了一个枚举类:`Isolation`
+
+```java
+public enum Isolation {
+
+ DEFAULT(TransactionDefinition.ISOLATION_DEFAULT),
+
+ READ_UNCOMMITTED(TransactionDefinition.ISOLATION_READ_UNCOMMITTED),
+
+ READ_COMMITTED(TransactionDefinition.ISOLATION_READ_COMMITTED),
+
+ REPEATABLE_READ(TransactionDefinition.ISOLATION_REPEATABLE_READ),
+
+ SERIALIZABLE(TransactionDefinition.ISOLATION_SERIALIZABLE);
+
+ private final int value;
+
+ Isolation(int value) {
+ this.value = value;
+ }
+
+ public int value() {
+ return this.value;
+ }
+
+}
+```
+
+下面我依次对每一种事务隔离级别进行介绍:
+
+- **`TransactionDefinition.ISOLATION_DEFAULT`** :使用后端数据库默认的隔离级别,MySQL 默认采用的 `REPEATABLE_READ` 隔离级别 Oracle 默认采用的 `READ_COMMITTED` 隔离级别.
+- **`TransactionDefinition.ISOLATION_READ_UNCOMMITTED`** :最低的隔离级别,使用这个隔离级别很少,因为它允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**
+- **`TransactionDefinition.ISOLATION_READ_COMMITTED`** : 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**
+- **`TransactionDefinition.ISOLATION_REPEATABLE_READ`** : 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生。**
+- **`TransactionDefinition.ISOLATION_SERIALIZABLE`** : 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
+
+因为平时使用 MySQL 数据库比较多,这里再多提一嘴!
+
+MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+
+```sql
+mysql> SELECT @@tx_isolation;
++-----------------+
+| @@tx_isolation |
++-----------------+
+| REPEATABLE-READ |
++-----------------+
+```
+
+~~这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)** 事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了 SQL标准的 **SERIALIZABLE(可串行化)** 隔离级别。~~
+
+🐛问题更正:**MySQL InnoDB的REPEATABLE-READ(可重读)并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁度使用到的机制就是 Next-Key Locks。**
+
+因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是InnoDB 存储引擎默认使用 **REPEAaTABLE-READ(可重读)** 并不会有任何性能损失。
+
+InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALIZABLE(可串行化)** 隔离级别。
+
+🌈拓展一下(以下内容摘自《MySQL技术内幕:InnoDB存储引擎(第2版)》7.7章):
+
+> InnoDB存储引擎提供了对XA事务的支持,并通过XA事务来支持分布式事务的实现。分布式事务指的是允许多个独立的事务资源(transactional resources)参与到一个全局的事务中。事务资源通常是关系型数据库系统,但也可以是其他类型的资源。全局事务要求在其中的所有参与的事务要么都提交,要么都回滚,这对于事务原有的ACID要求又有了提高。另外,在使用分布式事务时,InnoDB存储引擎的事务隔离级别必须设置为SERIALIZABLE。
+
+#### 3.3.3. 事务超时属性
+
+所谓事务超时,就是指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。在 `TransactionDefinition` 中以 int 的值来表示超时时间,其单位是秒,默认值为-1。
+
+#### 3.3.4. 事务只读属性
+
+```java
+package org.springframework.transaction;
+
+import org.springframework.lang.Nullable;
+
+public interface TransactionDefinition {
+ ......
+ // 返回是否为只读事务,默认值为 false
+ boolean isReadOnly();
+
+}
+```
+
+对于只有读取数据查询的事务,可以指定事务类型为 readonly,即只读事务。只读事务不涉及数据的修改,数据库会提供一些优化手段,适合用在有多条数据库查询操作的方法中。
+
+很多人就会疑问了,为什么我一个数据查询操作还要启用事务支持呢?
+
+拿 MySQL 的 innodb 举例子,根据官网 [https://dev.mysql.com/doc/refman/5.7/en/innodb-autocommit-commit-rollback.html](https://dev.mysql.com/doc/refman/5.7/en/innodb-autocommit-commit-rollback.html) 描述:
+
+> MySQL 默认对每一个新建立的连接都启用了`autocommit`模式。在该模式下,每一个发送到 MySQL 服务器的`sql`语句都会在一个单独的事务中进行处理,执行结束后会自动提交事务,并开启一个新的事务。
+
+但是,如果你给方法加上了`Transactional`注解的话,这个方法执行的所有`sql`会被放在一个事务中。如果声明了只读事务的话,数据库就会去优化它的执行,并不会带来其他的什么收益。
+
+如果不加`Transactional`,每条`sql`会开启一个单独的事务,中间被其它事务改了数据,都会实时读取到最新值。
+
+分享一下关于事务只读属性,其他人的解答:
+
+1. 如果你一次执行单条查询语句,则没有必要启用事务支持,数据库默认支持 SQL 执行期间的读一致性;
+2. 如果你一次执行多条查询语句,例如统计查询,报表查询,在这种场景下,多条查询 SQL 必须保证整体的读一致性,否则,在前条 SQL 查询之后,后条 SQL 查询之前,数据被其他用户改变,则该次整体的统计查询将会出现读数据不一致的状态,此时,应该启用事务支持
+
+#### 3.3.5. 事务回滚规则
+
+这些规则定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行期异常(RuntimeException 的子类)时才会回滚,Error 也会导致事务回滚,但是,在遇到检查型(Checked)异常时不会回滚。
+
+
+
+如果你想要回滚你定义的特定的异常类型的话,可以这样:
+
+```java
+@Transactional(rollbackFor= MyException.class)
+```
+
+### 3.4. @Transactional 注解使用详解
+
+#### 1) `@Transactional` 的作用范围
+
+1. **方法** :推荐将注解使用于方法上,不过需要注意的是:**该注解只能应用到 public 方法上,否则不生效。**
+2. **类** :如果这个注解使用在类上的话,表明该注解对该类中所有的 public 方法都生效。
+3. **接口** :不推荐在接口上使用。
+
+#### 2) `@Transactional` 的常用配置参数
+
+`@Transactional`注解源码如下,里面包含了基本事务属性的配置:
+
+```java
+@Target({ElementType.TYPE, ElementType.METHOD})
+@Retention(RetentionPolicy.RUNTIME)
+@Inherited
+@Documented
+public @interface Transactional {
+
+ @AliasFor("transactionManager")
+ String value() default "";
+
+ @AliasFor("value")
+ String transactionManager() default "";
+
+ Propagation propagation() default Propagation.REQUIRED;
+
+ Isolation isolation() default Isolation.DEFAULT;
+
+ int timeout() default TransactionDefinition.TIMEOUT_DEFAULT;
+
+ boolean readOnly() default false;
+
+ Class<? extends Throwable>[] rollbackFor() default {};
+
+ String[] rollbackForClassName() default {};
+
+ Class<? extends Throwable>[] noRollbackFor() default {};
+
+ String[] noRollbackForClassName() default {};
+
+}
+```
+
+**`@Transactional` 的常用配置参数总结(只列出了 5 个我平时比较常用的):**
+
+| 属性名 | 说明 |
+| :---------- | :------------------------------------------------------------------------------------------- |
+| propagation | 事务的传播行为,默认值为 REQUIRED,可选的值在上面介绍过 |
+| isolation | 事务的隔离级别,默认值采用 DEFAULT,可选的值在上面介绍过 |
+| timeout | 事务的超时时间,默认值为-1(不会超时)。如果超过该时间限制但事务还没有完成,则自动回滚事务。 |
+| readOnly | 指定事务是否为只读事务,默认值为 false。 |
+| rollbackFor | 用于指定能够触发事务回滚的异常类型,并且可以指定多个异常类型。 |
+
+#### 3)`@Transactional` 事务注解原理
+
+面试中在问 AOP 的时候可能会被问到的一个问题。简单说下吧!
+
+我们知道,**`@Transactional` 的工作机制是基于 AOP 实现的,AOP 又是使用动态代理实现的。如果目标对象实现了接口,默认情况下会采用 JDK 的动态代理,如果目标对象没有实现了接口,会使用 CGLIB 动态代理。**
+
+多提一嘴:`createAopProxy()` 方法 决定了是使用 JDK 还是 Cglib 来做动态代理,源码如下:
+
+```java
+public class DefaultAopProxyFactory implements AopProxyFactory, Serializable {
+
+ @Override
+ public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException {
+ if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) {
+ Class<?> targetClass = config.getTargetClass();
+ if (targetClass == null) {
+ throw new AopConfigException("TargetSource cannot determine target class: " +
+ "Either an interface or a target is required for proxy creation.");
+ }
+ if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) {
+ return new JdkDynamicAopProxy(config);
+ }
+ return new ObjenesisCglibAopProxy(config);
+ }
+ else {
+ return new JdkDynamicAopProxy(config);
+ }
+ }
+ .......
+}
+```
+
+如果一个类或者一个类中的 public 方法上被标注`@Transactional` 注解的话,Spring 容器就会在启动的时候为其创建一个代理类,在调用被`@Transactional` 注解的 public 方法的时候,实际调用的是,`TransactionInterceptor` 类中的 `invoke()`方法。这个方法的作用就是在目标方法之前开启事务,方法执行过程中如果遇到异常的时候回滚事务,方法调用完成之后提交事务。
+
+> `TransactionInterceptor` 类中的 `invoke()`方法内部实际调用的是 `TransactionAspectSupport` 类的 `invokeWithinTransaction()`方法。由于新版本的 Spring 对这部分重写很大,而且用到了很多响应式编程的知识,这里就不列源码了。
+
+#### 4)Spring AOP 自调用问题
+
+若同一类中的其他没有 `@Transactional` 注解的方法内部调用有 `@Transactional` 注解的方法,有`@Transactional` 注解的方法的事务会失效。
+
+这是由于`Spring AOP`代理的原因造成的,因为只有当 `@Transactional` 注解的方法在类以外被调用的时候,Spring 事务管理才生效。
+
+`MyService` 类中的`method1()`调用`method2()`就会导致`method2()`的事务失效。
+
+```java
+@Service
+public class MyService {
+
+private void method1() {
+ method2();
+ //......
+}
+@Transactional
+ public void method2() {
+ //......
+ }
+}
+```
+
+解决办法就是避免同一类中自调用或者使用 AspectJ 取代 Spring AOP 代理。
+
+#### 5) `@Transactional` 的使用注意事项总结
+
+1. `@Transactional` 注解只有作用到 public 方法上事务才生效,不推荐在接口上使用;
+2. 避免同一个类中调用 `@Transactional` 注解的方法,这样会导致事务失效;
+3. 正确的设置 `@Transactional` 的 rollbackFor 和 propagation 属性,否则事务可能会回滚失败
+4. ......
+
+## 4. Reference
+
+1. [总结]Spring 事务管理中@Transactional 的参数:[http://www.mobabel.net/spring 事务管理中 transactional 的参数/](http://www.mobabel.net/spring事务管理中transactional的参数/)
+
+2. Spring 官方文档:[https://docs.spring.io/spring/docs/4.2.x/spring-framework-reference/html/transaction.html](https://docs.spring.io/spring/docs/4.2.x/spring-framework-reference/html/transaction.html)
+
+3. 《Spring5 高级编程》
+
+4. 透彻的掌握 Spring 中@transactional 的使用: [https://www.ibm.com/developerworks/cn/java/j-master-spring-transactional-use/index.html](https://www.ibm.com/developerworks/cn/java/j-master-spring-transactional-use/index.html)
+
+5. Spring 事务的传播特性:[https://github.com/love-somnus/Spring/wiki/Spring 事务的传播特性](https://github.com/love-somnus/Spring/wiki/Spring事务的传播特性)
+
+6. [Spring 事务传播行为详解](https://segmentfault.com/a/1190000013341344) :[https://segmentfault.com/a/1190000013341344](https://segmentfault.com/a/1190000013341344)
+
+7. 全面分析 Spring 的编程式事务管理及声明式事务管理:[https://www.ibm.com/developerworks/cn/education/opensource/os-cn-spring-trans/index.html](https://www.ibm.com/developerworks/cn/education/opensource/os-cn-spring-trans/index.html)
+
diff --git "a/docs/system-design/framework/spring/Spring\345\270\270\350\247\201\351\227\256\351\242\230\346\200\273\347\273\223.md" "b/docs/system-design/framework/spring/Spring\345\270\270\350\247\201\351\227\256\351\242\230\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..56ceeb19fd9
--- /dev/null
+++ "b/docs/system-design/framework/spring/Spring\345\270\270\350\247\201\351\227\256\351\242\230\346\200\273\347\273\223.md"
@@ -0,0 +1,461 @@
+# Spring常见问题总结
+
+这篇文章主要是想通过一些问题,加深大家对于 Spring 的理解,所以不会涉及太多的代码!
+
+下面的很多问题我自己在使用 Spring 的过程中也并没有注意,自己也是临时查阅了很多资料和书籍补上的。网上也有一些很多关于 Spring 常见问题/面试题整理的文章,我感觉大部分都是互相 copy,而且很多问题也不是很好,有些回答也存在问题。所以,自己花了一周的业余时间整理了一下,希望对大家有帮助。
+
+## 什么是 Spring 框架?
+
+Spring 是一款开源的轻量级 Java 开发框架,旨在提高开发人员的开发效率以及系统的可维护性。
+
+Spring 翻译过来就是春天的意思,可见其目标和使命就是为 Java 程序员带来春天啊!感动!
+
+> 题外话 : 语言的流行通常需要一个杀手级的应用,Spring 就是 Java 生态的一个杀手级的应用框架。
+
+我们一般说 Spring 框架指的都是 Spring Framework,它是很多模块的集合,使用这些模块可以很方便地协助我们进行开发。
+
+比如说 Spring 自带 IoC(Inverse of Control:控制反转) 和 AOP(Aspect-Oriented Programming:面向切面编程)、可以很方便地对数据库进行访问、可以很方便地集成第三方组件(电子邮件,任务,调度,缓存等等)、对单元测试支持比较好、支持 RESTful Java 应用程序的开发。
+
+
+
+Spring 最核心的思想就是不重新造轮子,开箱即用!
+
+Spring 提供的核心功能主要是 IoC 和 AOP。学习 Spring ,一定要把 IoC 和 AOP 的核心思想搞懂!
+
+- Spring 官网:<https://spring.io/>
+- Github 地址: https://github.com/spring-projects/spring-framework
+
+## 列举一些重要的 Spring 模块?
+
+下图对应的是 Spring4.x 版本。目前最新的 5.x 版本中 Web 模块的 Portlet 组件已经被废弃掉,同时增加了用于异步响应式处理的 WebFlux 组件。
+
+
+
+**Spring Core**
+
+核心模块, Spring 其他所有的功能基本都需要依赖于该类库,主要提供 IoC 依赖注入功能的支持。
+
+**Spring Aspects**
+
+该模块为与 AspectJ 的集成提供支持。
+
+**Spring AOP**
+
+提供了面向切面的编程实现。
+
+**Spring Data Access/Integration :**
+
+Spring Data Access/Integration 由 5 个模块组成:
+
+- spring-jdbc : 提供了对数据库访问的抽象 JDBC。不同的数据库都有自己独立的 API 用于操作数据库,而 Java 程序只需要和 JDBC API 交互,这样就屏蔽了数据库的影响。
+- spring-tx : 提供对事务的支持。
+- spring-orm : 提供对 Hibernate 等 ORM 框架的支持。
+- spring-oxm : 提供对 Castor 等 OXM 框架的支持。
+- spring-jms : Java 消息服务。
+
+**Spring Web**
+
+Spring Web 由 4 个模块组成:
+
+- spring-web :对 Web 功能的实现提供一些最基础的支持。
+- spring-webmvc : 提供对 Spring MVC 的实现。
+- spring-websocket : 提供了对 WebSocket 的支持,WebSocket 可以让客户端和服务端进行双向通信。
+- spring-webflux :提供对 WebFlux 的支持。WebFlux 是 Spring Framework 5.0 中引入的新的响应式框架。与 Spring MVC 不同,它不需要 Servlet API,是完全异步.
+
+**Spring Test**
+
+Spring 团队提倡测试驱动开发(TDD)。有了控制反转 (IoC)的帮助,单元测试和集成测试变得更简单。
+
+Spring 的测试模块对 JUnit(单元测试框架)、TestNG(类似 JUnit)、Mockito(主要用来 Mock 对象)、PowerMock(解决 Mockito 的问题比如无法模拟 final, static, private 方法)等等常用的测试框架支持的都比较好。
+
+## Spring IOC & AOP
+
+### 谈谈自己对于 Spring IoC 的了解
+
+**IoC(Inverse of Control:控制反转)** 是一种设计思想,而不是一个具体的技术实现。IoC 的思想就是将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理。不过, IoC 并非 Spirng 特有,在其他语言中也有应用。
+
+**为什么叫控制反转?**
+
+- **控制** :指的是对象创建(实例化、管理)的权力
+- **反转** :控制权交给外部环境(Spring 框架、IoC 容器)
+
+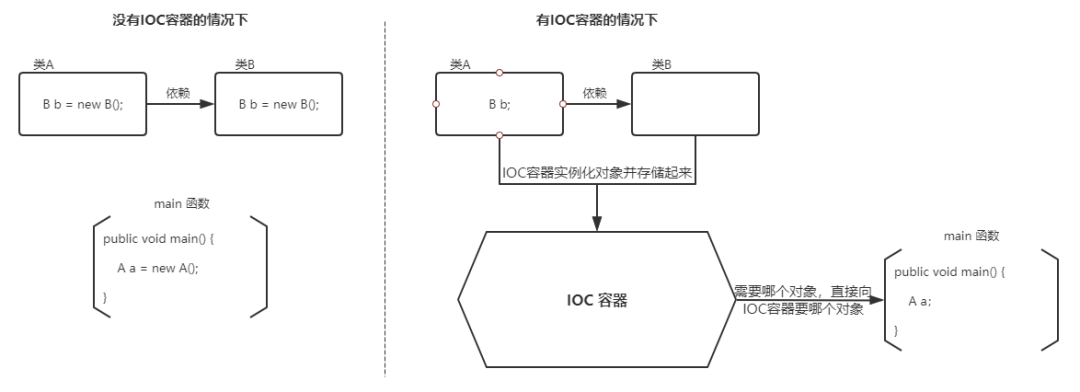
+
+将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。
+
+在实际项目中一个 Service 类可能依赖了很多其他的类,假如我们需要实例化这个 Service,你可能要每次都要搞清这个 Service 所有底层类的构造函数,这可能会把人逼疯。如果利用 IoC 的话,你只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。
+
+在 Spring 中, IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个 Map(key,value),Map 中存放的是各种对象。
+
+Spring 时代我们一般通过 XML 文件来配置 Bean,后来开发人员觉得 XML 文件来配置不太好,于是 SpringBoot 注解配置就慢慢开始流行起来。
+
+相关阅读:
+
+- [IoC 源码阅读](https://javadoop.com/post/spring-ioc)
+- [面试被问了几百遍的 IoC 和 AOP ,还在傻傻搞不清楚?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486938&idx=1&sn=c99ef0233f39a5ffc1b98c81e02dfcd4&chksm=cea24211f9d5cb07fa901183ba4d96187820713a72387788408040822ffb2ed575d28e953ce7&token=1736772241&lang=zh_CN#rd)
+
+### 谈谈自己对于 AOP 的了解
+
+AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
+
+Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 **JDK Proxy**,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 **Cglib** 生成一个被代理对象的子类来作为代理,如下图所示:
+
+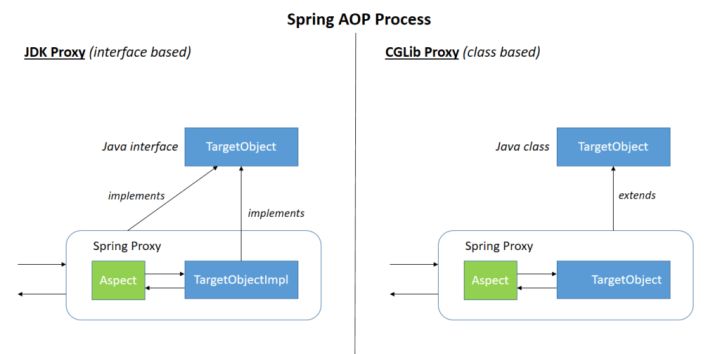
+
+当然你也可以使用 **AspectJ** !Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
+
+### Spring AOP 和 AspectJ AOP 有什么区别?
+
+**Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。** Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
+
+Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单,
+
+如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比 Spring AOP 快很多。
+
+## Spring bean
+
+### 什么是 bean?
+
+简单来说,bean 代指的就是那些被 IoC 容器所管理的对象。
+
+我们需要告诉 IoC 容器帮助我们管理哪些对象,这个是通过配置元数据来定义的。配置元数据可以是 XML 文件、注解或者 Java 配置类。
+
+```xml
+<!-- Constructor-arg with 'value' attribute -->
+<bean id="..." class="...">
+ <constructor-arg value="..."/>
+</bean>
+```
+
+下图简单地展示了 IoC 容器如何使用配置元数据来管理对象。
+
+
+
+`org.springframework.beans`和 `org.springframework.context` 这两个包是 IoC 实现的基础,如果想要研究 IoC 相关的源码的话,可以去看看
+
+### bean 的作用域有哪些?
+
+Spring 中 Bean 的作用域通常有下面几种:
+
+- **singleton** : 唯一 bean 实例,Spring 中的 bean 默认都是单例的,对单例设计模式的应用。
+- **prototype** : 每次请求都会创建一个新的 bean 实例。
+- **request** : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
+- **session** : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
+- **global-session** : 全局 session 作用域,仅仅在基于 portlet 的 web 应用中才有意义,Spring5 已经没有了。Portlet 是能够生成语义代码(例如:HTML)片段的小型 Java Web 插件。它们基于 portlet 容器,可以像 servlet 一样处理 HTTP 请求。但是,与 servlet 不同,每个 portlet 都有不同的会话。
+
+**如何配置 bean 的作用域呢?**
+
+xml 方式:
+
+```xml
+<bean id="..." class="..." scope="singleton"></bean>
+```
+
+注解方式:
+
+```java
+@Bean
+@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
+public Person personPrototype() {
+ return new Person();
+}
+```
+
+### 单例 bean 的线程安全问题了解吗?
+
+大部分时候我们并没有在项目中使用多线程,所以很少有人会关注这个问题。单例 bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候是存在资源竞争的。
+
+常见的有两种解决办法:
+
+1. 在 bean 中尽量避免定义可变的成员变量。
+2. 在类中定义一个 `ThreadLocal` 成员变量,将需要的可变成员变量保存在 `ThreadLocal` 中(推荐的一种方式)。
+
+不过,大部分 bean 实际都是无状态(没有实例变量)的(比如 Dao、Service),这种情况下, bean 是线程安全的。
+
+### @Component 和 @Bean 的区别是什么?
+
+1. `@Component` 注解作用于类,而`@Bean`注解作用于方法。
+2. `@Component`通常是通过类路径扫描来自动侦测以及自动装配到 Spring 容器中(我们可以使用 `@ComponentScan` 注解定义要扫描的路径从中找出标识了需要装配的类自动装配到 Spring 的 bean 容器中)。`@Bean` 注解通常是我们在标有该注解的方法中定义产生这个 bean,`@Bean`告诉了 Spring 这是某个类的实例,当我需要用它的时候还给我。
+3. `@Bean` 注解比 `@Component` 注解的自定义性更强,而且很多地方我们只能通过 `@Bean` 注解来注册 bean。比如当我们引用第三方库中的类需要装配到 `Spring`容器时,则只能通过 `@Bean`来实现。
+
+`@Bean`注解使用示例:
+
+```java
+@Configuration
+public class AppConfig {
+ @Bean
+ public TransferService transferService() {
+ return new TransferServiceImpl();
+ }
+
+}
+```
+
+上面的代码相当于下面的 xml 配置
+
+```xml
+<beans>
+ <bean id="transferService" class="com.acme.TransferServiceImpl"/>
+</beans>
+```
+
+下面这个例子是通过 `@Component` 无法实现的。
+
+```java
+@Bean
+public OneService getService(status) {
+ case (status) {
+ when 1:
+ return new serviceImpl1();
+ when 2:
+ return new serviceImpl2();
+ when 3:
+ return new serviceImpl3();
+ }
+}
+```
+
+### 将一个类声明为 bean 的注解有哪些?
+
+我们一般使用 `@Autowired` 注解自动装配 bean,要想把类标识成可用于 `@Autowired` 注解自动装配的 bean 的类,采用以下注解可实现:
+
+- `@Component` :通用的注解,可标注任意类为 `Spring` 组件。如果一个 Bean 不知道属于哪个层,可以使用`@Component` 注解标注。
+- `@Repository` : 对应持久层即 Dao 层,主要用于数据库相关操作。
+- `@Service` : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。
+- `@Controller` : 对应 Spring MVC 控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面。
+
+### bean 的生命周期?
+
+> 下面的内容整理自:<https://yemengying.com/2016/07/14/spring-bean-life-cycle/> ,除了这篇文章,再推荐一篇很不错的文章 :<https://www.cnblogs.com/zrtqsk/p/3735273.html> 。
+
+- Bean 容器找到配置文件中 Spring Bean 的定义。
+- Bean 容器利用 Java Reflection API 创建一个 Bean 的实例。
+- 如果涉及到一些属性值 利用 `set()`方法设置一些属性值。
+- 如果 Bean 实现了 `BeanNameAware` 接口,调用 `setBeanName()`方法,传入 Bean 的名字。
+- 如果 Bean 实现了 `BeanClassLoaderAware` 接口,调用 `setBeanClassLoader()`方法,传入 `ClassLoader`对象的实例。
+- 如果 Bean 实现了 `BeanFactoryAware` 接口,调用 `setBeanFactory()`方法,传入 `BeanFactory`对象的实例。
+- 与上面的类似,如果实现了其他 `*.Aware`接口,就调用相应的方法。
+- 如果有和加载这个 Bean 的 Spring 容器相关的 `BeanPostProcessor` 对象,执行`postProcessBeforeInitialization()` 方法
+- 如果 Bean 实现了`InitializingBean`接口,执行`afterPropertiesSet()`方法。
+- 如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法。
+- 如果有和加载这个 Bean 的 Spring 容器相关的 `BeanPostProcessor` 对象,执行`postProcessAfterInitialization()` 方法
+- 当要销毁 Bean 的时候,如果 Bean 实现了 `DisposableBean` 接口,执行 `destroy()` 方法。
+- 当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法。
+
+图示:
+
+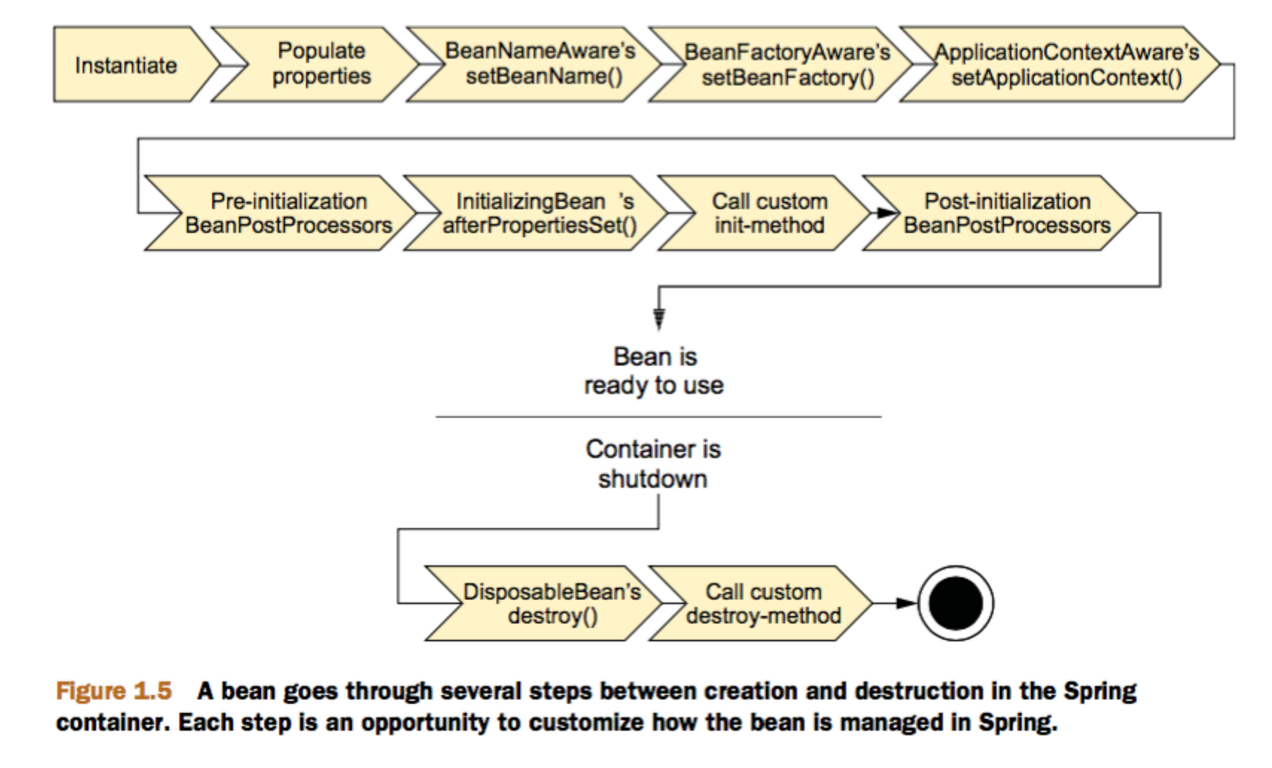
+
+与之比较类似的中文版本:
+
+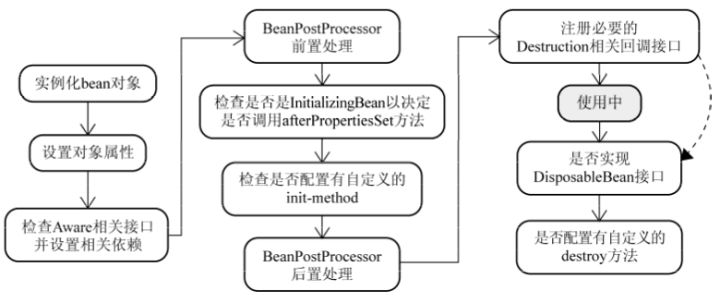
+
+## Spring MVC
+
+### 说说自己对于 Spring MVC 了解?
+
+MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。
+
+
+
+网上有很多人说 MVC 不是设计模式,只是软件设计规范,我个人更倾向于 MVC 同样是众多设计模式中的一种。**[java-design-patterns](https://github.com/iluwatar/java-design-patterns)** 项目中就有关于 MVC 的相关介绍。
+
+
+
+想要真正理解 Spring MVC,我们先来看看 Model 1 和 Model 2 这两个没有 Spring MVC 的时代。
+
+**Model 1 时代**
+
+很多学 Java 后端比较晚的朋友可能并没有接触过 Model 1 时代下的 JavaWeb 应用开发。在 Model1 模式下,整个 Web 应用几乎全部用 JSP 页面组成,只用少量的 JavaBean 来处理数据库连接、访问等操作。
+
+这个模式下 JSP 即是控制层(Controller)又是表现层(View)。显而易见,这种模式存在很多问题。比如控制逻辑和表现逻辑混杂在一起,导致代码重用率极低;再比如前端和后端相互依赖,难以进行测试维护并且开发效率极低。
+
+
+
+**Model 2 时代**
+
+学过 Servlet 并做过相关 Demo 的朋友应该了解“Java Bean(Model)+ JSP(View)+Servlet(Controller) ”这种开发模式,这就是早期的 JavaWeb MVC 开发模式。
+
+- Model:系统涉及的数据,也就是 dao 和 bean。
+- View:展示模型中的数据,只是用来展示。
+- Controller:处理用户请求都发送给 ,返回数据给 JSP 并展示给用户。
+
+
+
+Model2 模式下还存在很多问题,Model2 的抽象和封装程度还远远不够,使用 Model2 进行开发时不可避免地会重复造轮子,这就大大降低了程序的可维护性和复用性。
+
+于是,很多 JavaWeb 开发相关的 MVC 框架应运而生比如 Struts2,但是 Struts2 比较笨重。
+
+**Spring MVC 时代**
+
+随着 Spring 轻量级开发框架的流行,Spring 生态圈出现了 Spring MVC 框架, Spring MVC 是当前最优秀的 MVC 框架。相比于 Struts2 , Spring MVC 使用更加简单和方便,开发效率更高,并且 Spring MVC 运行速度更快。
+
+MVC 是一种设计模式,Spring MVC 是一款很优秀的 MVC 框架。Spring MVC 可以帮助我们进行更简洁的 Web 层的开发,并且它天生与 Spring 框架集成。Spring MVC 下我们一般把后端项目分为 Service 层(处理业务)、Dao 层(数据库操作)、Entity 层(实体类)、Controller 层(控制层,返回数据给前台页面)。
+
+### SpringMVC 工作原理了解吗?
+
+**Spring MVC 原理如下图所示:**
+
+> SpringMVC 工作原理的图解我没有自己画,直接图省事在网上找了一个非常清晰直观的,原出处不明。
+
+
+
+**流程说明(重要):**
+
+1. 客户端(浏览器)发送请求,直接请求到 `DispatcherServlet`。
+2. `DispatcherServlet` 根据请求信息调用 `HandlerMapping`,解析请求对应的 `Handler`。
+3. 解析到对应的 `Handler`(也就是我们平常说的 `Controller` 控制器)后,开始由 `HandlerAdapter` 适配器处理。
+4. `HandlerAdapter` 会根据 `Handler`来调用真正的处理器开处理请求,并处理相应的业务逻辑。
+5. 处理器处理完业务后,会返回一个 `ModelAndView` 对象,`Model` 是返回的数据对象,`View` 是个逻辑上的 `View`。
+6. `ViewResolver` 会根据逻辑 `View` 查找实际的 `View`。
+7. `DispaterServlet` 把返回的 `Model` 传给 `View`(视图渲染)。
+8. 把 `View` 返回给请求者(浏览器)
+
+## Spring 框架中用到了哪些设计模式?
+
+关于下面一些设计模式的详细介绍,可以看笔主前段时间的原创文章[《面试官:“谈谈 Spring 中都用到了那些设计模式?”。》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485303&idx=1&sn=9e4626a1e3f001f9b0d84a6fa0cff04a&chksm=cea248bcf9d5c1aaf48b67cc52bac74eb29d6037848d6cf213b0e5466f2d1fda970db700ba41&token=255050878&lang=zh_CN#rd) 。
+
+- **工厂设计模式** : Spring 使用工厂模式通过 `BeanFactory`、`ApplicationContext` 创建 bean 对象。
+- **代理设计模式** : Spring AOP 功能的实现。
+- **单例设计模式** : Spring 中的 Bean 默认都是单例的。
+- **模板方法模式** : Spring 中 `jdbcTemplate`、`hibernateTemplate` 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
+- **包装器设计模式** : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
+- **观察者模式:** Spring 事件驱动模型就是观察者模式很经典的一个应用。
+- **适配器模式** : Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配`Controller`。
+- ......
+
+## Spring 事务
+
+Spring/SpringBoot 模块下专门有一篇是讲 Spring 事务的,总结的非常详细,通俗易懂。
+
+### Spring 管理事务的方式有几种?
+
+- **编程式事务** : 在代码中硬编码(不推荐使用) : 通过 `TransactionTemplate`或者 `TransactionManager` 手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。
+- **声明式事务** : 在 XML 配置文件中配置或者直接基于注解(推荐使用) : 实际是通过 AOP 实现(基于`@Transactional` 的全注解方式使用最多)
+
+### Spring 事务中哪几种事务传播行为?
+
+**事务传播行为是为了解决业务层方法之间互相调用的事务问题**。
+
+当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
+
+正确的事务传播行为可能的值如下:
+
+**1.`TransactionDefinition.PROPAGATION_REQUIRED`**
+
+使用的最多的一个事务传播行为,我们平时经常使用的`@Transactional`注解默认使用就是这个事务传播行为。如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
+
+**`2.TransactionDefinition.PROPAGATION_REQUIRES_NEW`**
+
+创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,`Propagation.REQUIRES_NEW`修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
+
+**3.`TransactionDefinition.PROPAGATION_NESTED`**
+
+如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于`TransactionDefinition.PROPAGATION_REQUIRED`。
+
+**4.`TransactionDefinition.PROPAGATION_MANDATORY`**
+
+如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
+
+这个使用的很少。
+
+若是错误的配置以下 3 种事务传播行为,事务将不会发生回滚:
+
+- **`TransactionDefinition.PROPAGATION_SUPPORTS`**: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
+- **`TransactionDefinition.PROPAGATION_NOT_SUPPORTED`**: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
+- **`TransactionDefinition.PROPAGATION_NEVER`**: 以非事务方式运行,如果当前存在事务,则抛出异常。
+
+### Spring 事务中的隔离级别有哪几种?
+
+和事务传播行为这块一样,为了方便使用,Spring 也相应地定义了一个枚举类:`Isolation`
+
+```java
+public enum Isolation {
+
+ DEFAULT(TransactionDefinition.ISOLATION_DEFAULT),
+
+ READ_UNCOMMITTED(TransactionDefinition.ISOLATION_READ_UNCOMMITTED),
+
+ READ_COMMITTED(TransactionDefinition.ISOLATION_READ_COMMITTED),
+
+ REPEATABLE_READ(TransactionDefinition.ISOLATION_REPEATABLE_READ),
+
+ SERIALIZABLE(TransactionDefinition.ISOLATION_SERIALIZABLE);
+
+ private final int value;
+
+ Isolation(int value) {
+ this.value = value;
+ }
+
+ public int value() {
+ return this.value;
+ }
+
+}
+```
+
+下面我依次对每一种事务隔离级别进行介绍:
+
+- **`TransactionDefinition.ISOLATION_DEFAULT`** :使用后端数据库默认的隔离级别,MySQL 默认采用的 `REPEATABLE_READ` 隔离级别 Oracle 默认采用的 `READ_COMMITTED` 隔离级别.
+- **`TransactionDefinition.ISOLATION_READ_UNCOMMITTED`** :最低的隔离级别,使用这个隔离级别很少,因为它允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**
+- **`TransactionDefinition.ISOLATION_READ_COMMITTED`** : 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**
+- **`TransactionDefinition.ISOLATION_REPEATABLE_READ`** : 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生。**
+- **`TransactionDefinition.ISOLATION_SERIALIZABLE`** : 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
+
+### @Transactional(rollbackFor = Exception.class)注解了解吗?
+
+`Exception` 分为运行时异常 `RuntimeException` 和非运行时异常。事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性。
+
+当 `@Transactional` 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。如果类或者方法加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。
+
+在 `@Transactional` 注解中如果不配置`rollbackFor`属性,那么事务只会在遇到`RuntimeException`的时候才会回滚,加上 `rollbackFor=Exception.class`,可以让事务在遇到非运行时异常时也回滚。
+
+## JPA
+
+### 如何使用 JPA 在数据库中非持久化一个字段?
+
+假如我们有下面一个类:
+
+```java
+@Entity(name="USER")
+public class User {
+
+ @Id
+ @GeneratedValue(strategy = GenerationType.AUTO)
+ @Column(name = "ID")
+ private Long id;
+
+ @Column(name="USER_NAME")
+ private String userName;
+
+ @Column(name="PASSWORD")
+ private String password;
+
+ private String secrect;
+
+}
+```
+
+如果我们想让`secrect` 这个字段不被持久化,也就是不被数据库存储怎么办?我们可以采用下面几种方法:
+
+```java
+static String transient1; // not persistent because of static
+final String transient2 = "Satish"; // not persistent because of final
+transient String transient3; // not persistent because of transient
+@Transient
+String transient4; // not persistent because of @Transient
+```
+
+一般使用后面两种方式比较多,我个人使用注解的方式比较多。
+
+## 参考
+
+- 《Spring 技术内幕》
+- <http://www.cnblogs.com/wmyskxz/p/8820371.html>
+- <https://www.journaldev.com/2696/spring-interview-questions-and-answers>
+- <https://www.edureka.co/blog/interview-questions/spring-interview-questions/>
+- https://www.cnblogs.com/clwydjgs/p/9317849.html
+- <https://howtodoinjava.com/interview-questions/top-spring-interview-questions-with-answers/>
+- <http://www.tomaszezula.com/2014/02/09/spring-series-part-5-component-vs-bean/>
+- <https://stackoverflow.com/questions/34172888/difference-between-bean-and-autowired>
diff --git "a/docs/system-design/framework/spring/Spring\350\256\276\350\256\241\346\250\241\345\274\217\346\200\273\347\273\223.md" "b/docs/system-design/framework/spring/Spring\350\256\276\350\256\241\346\250\241\345\274\217\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..d883c194ce9
--- /dev/null
+++ "b/docs/system-design/framework/spring/Spring\350\256\276\350\256\241\346\250\241\345\274\217\346\200\273\347\273\223.md"
@@ -0,0 +1,337 @@
+# Spring设计模式总结
+
+JDK 中用到了那些设计模式?Spring 中用到了那些设计模式?这两个问题,在面试中比较常见。我在网上搜索了一下关于 Spring 中设计模式的讲解几乎都是千篇一律,而且大部分都年代久远。所以,花了几天时间自己总结了一下,由于我的个人能力有限,文中如有任何错误各位都可以指出。另外,文章篇幅有限,对于设计模式以及一些源码的解读我只是一笔带过,这篇文章的主要目的是回顾一下 Spring 中的设计模式。
+
+Design Patterns(设计模式) 表示面向对象软件开发中最好的计算机编程实践。 Spring 框架中广泛使用了不同类型的设计模式,下面我们来看看到底有哪些设计模式?
+
+## 控制反转(IoC)和依赖注入(DI)
+
+**IoC(Inversion of Control,控制反转)** 是Spring 中一个非常非常重要的概念,它不是什么技术,而是一种解耦的设计思想。它的主要目的是借助于“第三方”(Spring 中的 IOC 容器) 实现具有依赖关系的对象之间的解耦(IOC容器管理对象,你只管使用即可),从而降低代码之间的耦合度。**IOC 是一个原则,而不是一个模式,以下模式(但不限于)实现了IoC原则。**
+
+
+
+**Spring IOC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。** IOC 容器负责创建对象,将对象连接在一起,配置这些对象,并从创建中处理这些对象的整个生命周期,直到它们被完全销毁。
+
+在实际项目中一个 Service 类如果有几百甚至上千个类作为它的底层,我们需要实例化这个 Service,你可能要每次都要搞清这个 Service 所有底层类的构造函数,这可能会把人逼疯。如果利用 IOC 的话,你只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。关于Spring IOC 的理解,推荐看这一下知乎的一个回答:<https://www.zhihu.com/question/23277575/answer/169698662> ,非常不错。
+
+**控制反转怎么理解呢?** 举个例子:"对象a 依赖了对象 b,当对象 a 需要使用 对象 b的时候必须自己去创建。但是当系统引入了 IOC 容器后, 对象a 和对象 b 之前就失去了直接的联系。这个时候,当对象 a 需要使用 对象 b的时候, 我们可以指定 IOC 容器去创建一个对象b注入到对象 a 中"。 对象 a 获得依赖对象 b 的过程,由主动行为变为了被动行为,控制权反转,这就是控制反转名字的由来。
+
+**DI(Dependecy Inject,依赖注入)是实现控制反转的一种设计模式,依赖注入就是将实例变量传入到一个对象中去。**
+
+## 工厂设计模式
+
+Spring使用工厂模式可以通过 `BeanFactory` 或 `ApplicationContext` 创建 bean 对象。
+
+**两者对比:**
+
+- `BeanFactory` :延迟注入(使用到某个 bean 的时候才会注入),相比于`ApplicationContext` 来说会占用更少的内存,程序启动速度更快。
+- `ApplicationContext` :容器启动的时候,不管你用没用到,一次性创建所有 bean 。`BeanFactory` 仅提供了最基本的依赖注入支持,` ApplicationContext` 扩展了 `BeanFactory` ,除了有`BeanFactory`的功能还有额外更多功能,所以一般开发人员使用` ApplicationContext`会更多。
+
+ApplicationContext的三个实现类:
+
+1. `ClassPathXmlApplication`:把上下文文件当成类路径资源。
+2. `FileSystemXmlApplication`:从文件系统中的 XML 文件载入上下文定义信息。
+3. `XmlWebApplicationContext`:从Web系统中的XML文件载入上下文定义信息。
+
+Example:
+
+```java
+import org.springframework.context.ApplicationContext;
+import org.springframework.context.support.FileSystemXmlApplicationContext;
+
+public class App {
+ public static void main(String[] args) {
+ ApplicationContext context = new FileSystemXmlApplicationContext(
+ "C:/work/IOC Containers/springframework.applicationcontext/src/main/resources/bean-factory-config.xml");
+
+ HelloApplicationContext obj = (HelloApplicationContext) context.getBean("helloApplicationContext");
+ obj.getMsg();
+ }
+}
+```
+
+## 单例设计模式
+
+在我们的系统中,有一些对象其实我们只需要一个,比如说:线程池、缓存、对话框、注册表、日志对象、充当打印机、显卡等设备驱动程序的对象。事实上,这一类对象只能有一个实例,如果制造出多个实例就可能会导致一些问题的产生,比如:程序的行为异常、资源使用过量、或者不一致性的结果。
+
+**使用单例模式的好处:**
+
+- 对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
+- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间。
+
+**Spring 中 bean 的默认作用域就是 singleton(单例)的。** 除了 singleton 作用域,Spring 中 bean 还有下面几种作用域:
+
+- prototype : 每次请求都会创建一个新的 bean 实例。
+- request : 每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
+- session : 每一次HTTP请求都会产生一个新的 bean,该bean仅在当前 HTTP session 内有效。
+- global-session: 全局session作用域,仅仅在基于portlet的web应用中才有意义,Spring5已经没有了。Portlet是能够生成语义代码(例如:HTML)片段的小型Java Web插件。它们基于portlet容器,可以像servlet一样处理HTTP请求。但是,与 servlet 不同,每个 portlet 都有不同的会话
+
+**Spring 实现单例的方式:**
+
+- xml : `<bean id="userService" class="top.snailclimb.UserService" scope="singleton"/>`
+- 注解:`@Scope(value = "singleton")`
+
+**Spring 通过 `ConcurrentHashMap` 实现单例注册表的特殊方式实现单例模式。Spring 实现单例的核心代码如下**
+
+```java
+// 通过 ConcurrentHashMap(线程安全) 实现单例注册表
+private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(64);
+
+public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
+ Assert.notNull(beanName, "'beanName' must not be null");
+ synchronized (this.singletonObjects) {
+ // 检查缓存中是否存在实例
+ Object singletonObject = this.singletonObjects.get(beanName);
+ if (singletonObject == null) {
+ //...省略了很多代码
+ try {
+ singletonObject = singletonFactory.getObject();
+ }
+ //...省略了很多代码
+ // 如果实例对象在不存在,我们注册到单例注册表中。
+ addSingleton(beanName, singletonObject);
+ }
+ return (singletonObject != NULL_OBJECT ? singletonObject : null);
+ }
+ }
+ //将对象添加到单例注册表
+ protected void addSingleton(String beanName, Object singletonObject) {
+ synchronized (this.singletonObjects) {
+ this.singletonObjects.put(beanName, (singletonObject != null ? singletonObject : NULL_OBJECT));
+
+ }
+ }
+}
+```
+
+## 代理设计模式
+
+### 代理模式在 AOP 中的应用
+
+AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,**却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来**,便于**减少系统的重复代码**,**降低模块间的耦合度**,并**有利于未来的可拓展性和可维护性**。
+
+**Spring AOP 就是基于动态代理的**,如果要代理的对象,实现了某个接口,那么Spring AOP会使用**JDK Proxy**,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用**Cglib** ,这时候Spring AOP会使用 **Cglib** 生成一个被代理对象的子类来作为代理,如下图所示:
+
+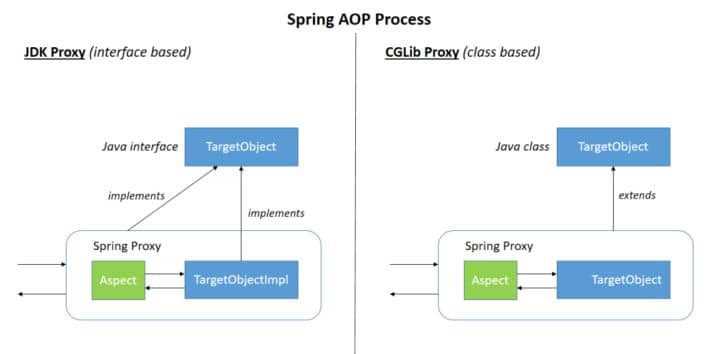
+
+当然你也可以使用 AspectJ ,Spring AOP 已经集成了AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
+
+使用 AOP 之后我们可以把一些通用功能抽象出来,在需要用到的地方直接使用即可,这样大大简化了代码量。我们需要增加新功能时也方便,这样也提高了系统扩展性。日志功能、事务管理等等场景都用到了 AOP 。
+
+### Spring AOP 和 AspectJ AOP 有什么区别?
+
+**Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。** Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
+
+ Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单,
+
+如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比Spring AOP 快很多。
+
+## 模板方法
+
+模板方法模式是一种行为设计模式,它定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。 模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤的实现方式。
+
+```java
+public abstract class Template {
+ //这是我们的模板方法
+ public final void TemplateMethod(){
+ PrimitiveOperation1();
+ PrimitiveOperation2();
+ PrimitiveOperation3();
+ }
+
+ protected void PrimitiveOperation1(){
+ //当前类实现
+ }
+
+ //被子类实现的方法
+ protected abstract void PrimitiveOperation2();
+ protected abstract void PrimitiveOperation3();
+
+}
+public class TemplateImpl extends Template {
+
+ @Override
+ public void PrimitiveOperation2() {
+ //当前类实现
+ }
+
+ @Override
+ public void PrimitiveOperation3() {
+ //当前类实现
+ }
+}
+
+```
+
+Spring 中 `jdbcTemplate`、`hibernateTemplate` 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。一般情况下,我们都是使用继承的方式来实现模板模式,但是 Spring 并没有使用这种方式,而是使用Callback 模式与模板方法模式配合,既达到了代码复用的效果,同时增加了灵活性。
+
+## 观察者模式
+
+观察者模式是一种对象行为型模式。它表示的是一种对象与对象之间具有依赖关系,当一个对象发生改变的时候,这个对象所依赖的对象也会做出反应。Spring 事件驱动模型就是观察者模式很经典的一个应用。Spring 事件驱动模型非常有用,在很多场景都可以解耦我们的代码。比如我们每次添加商品的时候都需要重新更新商品索引,这个时候就可以利用观察者模式来解决这个问题。
+
+### Spring 事件驱动模型中的三种角色
+
+#### 事件角色
+
+ `ApplicationEvent` (`org.springframework.context`包下)充当事件的角色,这是一个抽象类,它继承了`java.util.EventObject`并实现了 `java.io.Serializable`接口。
+
+Spring 中默认存在以下事件,他们都是对 `ApplicationContextEvent` 的实现(继承自`ApplicationContextEvent`):
+
+- `ContextStartedEvent`:`ApplicationContext` 启动后触发的事件;
+- `ContextStoppedEvent`:`ApplicationContext` 停止后触发的事件;
+- `ContextRefreshedEvent`:`ApplicationContext` 初始化或刷新完成后触发的事件;
+- `ContextClosedEvent`:`ApplicationContext` 关闭后触发的事件。
+
+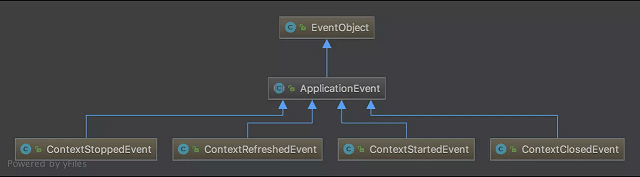
+
+#### 事件监听者角色
+
+`ApplicationListener` 充当了事件监听者角色,它是一个接口,里面只定义了一个 `onApplicationEvent()`方法来处理`ApplicationEvent`。`ApplicationListener`接口类源码如下,可以看出接口定义看出接口中的事件只要实现了 `ApplicationEvent`就可以了。所以,在 Spring中我们只要实现 `ApplicationListener` 接口的 `onApplicationEvent()` 方法即可完成监听事件
+
+```java
+package org.springframework.context;
+import java.util.EventListener;
+@FunctionalInterface
+public interface ApplicationListener<E extends ApplicationEvent> extends EventListener {
+ void onApplicationEvent(E var1);
+}
+```
+
+#### 事件发布者角色
+
+`ApplicationEventPublisher` 充当了事件的发布者,它也是一个接口。
+
+```java
+@FunctionalInterface
+public interface ApplicationEventPublisher {
+ default void publishEvent(ApplicationEvent event) {
+ this.publishEvent((Object)event);
+ }
+
+ void publishEvent(Object var1);
+}
+
+```
+
+`ApplicationEventPublisher` 接口的`publishEvent()`这个方法在`AbstractApplicationContext`类中被实现,阅读这个方法的实现,你会发现实际上事件真正是通过`ApplicationEventMulticaster`来广播出去的。具体内容过多,就不在这里分析了,后面可能会单独写一篇文章提到。
+
+### Spring 的事件流程总结
+
+1. 定义一个事件: 实现一个继承自 `ApplicationEvent`,并且写相应的构造函数;
+2. 定义一个事件监听者:实现 `ApplicationListener` 接口,重写 `onApplicationEvent()` 方法;
+3. 使用事件发布者发布消息: 可以通过 `ApplicationEventPublisher ` 的 `publishEvent()` 方法发布消息。
+
+Example:
+
+```java
+// 定义一个事件,继承自ApplicationEvent并且写相应的构造函数
+public class DemoEvent extends ApplicationEvent{
+ private static final long serialVersionUID = 1L;
+
+ private String message;
+
+ public DemoEvent(Object source,String message){
+ super(source);
+ this.message = message;
+ }
+
+ public String getMessage() {
+ return message;
+ }
+
+
+// 定义一个事件监听者,实现ApplicationListener接口,重写 onApplicationEvent() 方法;
+@Component
+public class DemoListener implements ApplicationListener<DemoEvent>{
+
+ //使用onApplicationEvent接收消息
+ @Override
+ public void onApplicationEvent(DemoEvent event) {
+ String msg = event.getMessage();
+ System.out.println("接收到的信息是:"+msg);
+ }
+
+}
+// 发布事件,可以通过ApplicationEventPublisher 的 publishEvent() 方法发布消息。
+@Component
+public class DemoPublisher {
+
+ @Autowired
+ ApplicationContext applicationContext;
+
+ public void publish(String message){
+ //发布事件
+ applicationContext.publishEvent(new DemoEvent(this, message));
+ }
+}
+
+```
+
+当调用 `DemoPublisher ` 的 `publish()` 方法的时候,比如 `demoPublisher.publish("你好")` ,控制台就会打印出:`接收到的信息是:你好` 。
+
+## 适配器模式
+
+适配器模式(Adapter Pattern) 将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper)。
+
+### spring AOP中的适配器模式
+
+我们知道 Spring AOP 的实现是基于代理模式,但是 Spring AOP 的增强或通知(Advice)使用到了适配器模式,与之相关的接口是`AdvisorAdapter ` 。Advice 常用的类型有:`BeforeAdvice`(目标方法调用前,前置通知)、`AfterAdvice`(目标方法调用后,后置通知)、`AfterReturningAdvice`(目标方法执行结束后,return之前)等等。每个类型Advice(通知)都有对应的拦截器:`MethodBeforeAdviceInterceptor`、`AfterReturningAdviceAdapter`、`AfterReturningAdviceInterceptor`。Spring预定义的通知要通过对应的适配器,适配成 `MethodInterceptor`接口(方法拦截器)类型的对象(如:`MethodBeforeAdviceInterceptor` 负责适配 `MethodBeforeAdvice`)。
+
+### spring MVC中的适配器模式
+
+在Spring MVC中,`DispatcherServlet` 根据请求信息调用 `HandlerMapping`,解析请求对应的 `Handler`。解析到对应的 `Handler`(也就是我们平常说的 `Controller` 控制器)后,开始由`HandlerAdapter` 适配器处理。`HandlerAdapter` 作为期望接口,具体的适配器实现类用于对目标类进行适配,`Controller` 作为需要适配的类。
+
+**为什么要在 Spring MVC 中使用适配器模式?** Spring MVC 中的 `Controller` 种类众多,不同类型的 `Controller` 通过不同的方法来对请求进行处理。如果不利用适配器模式的话,`DispatcherServlet` 直接获取对应类型的 `Controller`,需要的自行来判断,像下面这段代码一样:
+
+```java
+if(mappedHandler.getHandler() instanceof MultiActionController){
+ ((MultiActionController)mappedHandler.getHandler()).xxx
+}else if(mappedHandler.getHandler() instanceof XXX){
+ ...
+}else if(...){
+ ...
+}
+```
+
+假如我们再增加一个 `Controller`类型就要在上面代码中再加入一行 判断语句,这种形式就使得程序难以维护,也违反了设计模式中的开闭原则 – 对扩展开放,对修改关闭。
+
+## 装饰者模式
+
+装饰者模式可以动态地给对象添加一些额外的属性或行为。相比于使用继承,装饰者模式更加灵活。简单点儿说就是当我们需要修改原有的功能,但我们又不愿直接去修改原有的代码时,设计一个Decorator套在原有代码外面。其实在 JDK 中就有很多地方用到了装饰者模式,比如 `InputStream`家族,`InputStream` 类下有 `FileInputStream` (读取文件)、`BufferedInputStream` (增加缓存,使读取文件速度大大提升)等子类都在不修改`InputStream` 代码的情况下扩展了它的功能。
+
+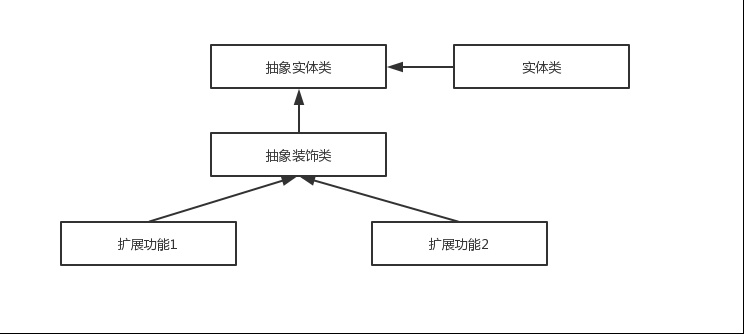
+
+Spring 中配置 DataSource 的时候,DataSource 可能是不同的数据库和数据源。我们能否根据客户的需求在少修改原有类的代码下动态切换不同的数据源?这个时候就要用到装饰者模式(这一点我自己还没太理解具体原理)。Spring 中用到的包装器模式在类名上含有 `Wrapper`或者 `Decorator`。这些类基本上都是动态地给一个对象添加一些额外的职责
+
+## 总结
+
+Spring 框架中用到了哪些设计模式?
+
+- **工厂设计模式** : Spring使用工厂模式通过 `BeanFactory`、`ApplicationContext` 创建 bean 对象。
+- **代理设计模式** : Spring AOP 功能的实现。
+- **单例设计模式** : Spring 中的 Bean 默认都是单例的。
+- **模板方法模式** : Spring 中 `jdbcTemplate`、`hibernateTemplate` 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
+- **包装器设计模式** : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
+- **观察者模式:** Spring 事件驱动模型就是观察者模式很经典的一个应用。
+- **适配器模式** :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配`Controller`。
+- ......
+
+## 参考
+
+- 《Spring技术内幕》
+- <https://blog.eduonix.com/java-programming-2/learn-design-patterns-used-spring-framework/>
+- <http://blog.yeamin.top/2018/03/27/单例模式-Spring单例实现原理分析/>
+- <https://www.tutorialsteacher.com/ioc/inversion-of-control>
+- <https://design-patterns.readthedocs.io/zh_CN/latest/behavioral_patterns/observer.html>
+- <https://juejin.im/post/5a8eb261f265da4e9e307230>
+- <https://juejin.im/post/5ba28986f265da0abc2b6084>
+
+## 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+
diff --git a/docs/system-design/framework/spring/images/spring-annotations/@RequestBody.png b/docs/system-design/framework/spring/images/spring-annotations/@RequestBody.png
new file mode 100644
index 00000000000..75d43a72be2
Binary files /dev/null and b/docs/system-design/framework/spring/images/spring-annotations/@RequestBody.png differ
diff --git a/docs/system-design/framework/spring/images/spring-transaction/a616b84d-9eea-4ad1-b4fc-461ff05e951d.png b/docs/system-design/framework/spring/images/spring-transaction/a616b84d-9eea-4ad1-b4fc-461ff05e951d.png
new file mode 100644
index 00000000000..f99c106a65e
Binary files /dev/null and b/docs/system-design/framework/spring/images/spring-transaction/a616b84d-9eea-4ad1-b4fc-461ff05e951d.png differ
diff --git a/docs/system-design/framework/spring/images/spring-transaction/ae964c2c-7289-441c-bddd-511161f51ee1.png b/docs/system-design/framework/spring/images/spring-transaction/ae964c2c-7289-441c-bddd-511161f51ee1.png
new file mode 100644
index 00000000000..c50b87485ba
Binary files /dev/null and b/docs/system-design/framework/spring/images/spring-transaction/ae964c2c-7289-441c-bddd-511161f51ee1.png differ
diff --git a/docs/system-design/framework/spring/images/spring-transaction/bda7231b-ab05-4e23-95ee-89ac90ac7fcf.png b/docs/system-design/framework/spring/images/spring-transaction/bda7231b-ab05-4e23-95ee-89ac90ac7fcf.png
new file mode 100644
index 00000000000..4232f8b9855
Binary files /dev/null and b/docs/system-design/framework/spring/images/spring-transaction/bda7231b-ab05-4e23-95ee-89ac90ac7fcf.png differ
diff --git a/docs/system-design/framework/spring/images/spring-transaction/f6c6f0aa-0f26-49e1-84b3-7f838c7379d1.png b/docs/system-design/framework/spring/images/spring-transaction/f6c6f0aa-0f26-49e1-84b3-7f838c7379d1.png
new file mode 100644
index 00000000000..d6b83731c70
Binary files /dev/null and b/docs/system-design/framework/spring/images/spring-transaction/f6c6f0aa-0f26-49e1-84b3-7f838c7379d1.png differ
diff --git "a/docs/system-design/framework/spring/images/spring-transaction/\346\216\245\345\217\243\344\275\277\347\224\250\345\216\237\345\233\240.png" "b/docs/system-design/framework/spring/images/spring-transaction/\346\216\245\345\217\243\344\275\277\347\224\250\345\216\237\345\233\240.png"
new file mode 100644
index 00000000000..eb7e6748411
Binary files /dev/null and "b/docs/system-design/framework/spring/images/spring-transaction/\346\216\245\345\217\243\344\275\277\347\224\250\345\216\237\345\233\240.png" differ
diff --git a/docs/system-design/framework/springcloud/springcloud-intro.md b/docs/system-design/framework/springcloud/springcloud-intro.md
new file mode 100644
index 00000000000..37a10dad8c1
--- /dev/null
+++ b/docs/system-design/framework/springcloud/springcloud-intro.md
@@ -0,0 +1,624 @@
+# Spring Cloud 入门
+
+> 本文基于 Spring Cloud Netflix 。Spring Cloud Alibaba 也是非常不错的选择哦!
+>
+> 授权转载自:https://juejin.im/post/5de2553e5188256e885f4fa3
+
+
+
+首先我给大家看一张图,如果大家对这张图有些地方不太理解的话,我希望你们看完我这篇文章会恍然大悟。
+
+
+
+## 什么是Spring Cloud
+
+> 构建分布式系统不需要复杂和容易出错。Spring Cloud 为最常见的分布式系统模式提供了一种简单且易于接受的编程模型,帮助开发人员构建有弹性的、可靠的、协调的应用程序。Spring Cloud 构建于 Spring Boot 之上,使得开发者很容易入手并快速应用于生产中。
+
+官方果然官方,介绍都这么有板有眼的。
+
+我所理解的 `Spring Cloud` 就是微服务系统架构的一站式解决方案,在平时我们构建微服务的过程中需要做如 **服务发现注册** 、**配置中心** 、**消息总线** 、**负载均衡** 、**断路器** 、**数据监控** 等操作,而 Spring Cloud 为我们提供了一套简易的编程模型,使我们能在 Spring Boot 的基础上轻松地实现微服务项目的构建。
+
+## Spring Cloud 的版本
+
+当然这个只是个题外话。
+
+`Spring Cloud` 的版本号并不是我们通常见的数字版本号,而是一些很奇怪的单词。这些单词均为英国伦敦地铁站的站名。同时根据字母表的顺序来对应版本时间顺序,比如:最早 的 `Release` 版本 `Angel`,第二个 `Release` 版本 `Brixton`(英国地名),然后是 `Camden`、 `Dalston`、`Edgware`、`Finchley`、`Greenwich`、`Hoxton`。
+
+## Spring Cloud 的服务发现框架——Eureka
+
+> `Eureka`是基于`REST`(代表性状态转移)的服务,主要在 `AWS` 云中用于定位服务,以实现负载均衡和中间层服务器的故障转移。我们称此服务为`Eureka`服务器。Eureka还带有一个基于 `Java` 的客户端组件 `Eureka Client`,它使与服务的交互变得更加容易。客户端还具有一个内置的负载平衡器,可以执行基本的循环负载平衡。在 `Netflix`,更复杂的负载均衡器将 `Eureka` 包装起来,以基于流量,资源使用,错误条件等多种因素提供加权负载均衡,以提供出色的弹性。
+
+总的来说,`Eureka` 就是一个服务发现框架。何为服务,何又为发现呢?
+
+举一个生活中的例子,就比如我们平时租房子找中介的事情。
+
+在没有中介的时候我们需要一个一个去寻找是否有房屋要出租的房东,这显然会非常的费力,一你找凭一个人的能力是找不到很多房源供你选择,再者你也懒得这么找下去(找了这么久,没有合适的只能将就)。**这里的我们就相当于微服务中的 `Consumer` ,而那些房东就相当于微服务中的 `Provider` 。消费者 `Consumer` 需要调用提供者 `Provider` 提供的一些服务,就像我们现在需要租他们的房子一样。**
+
+但是如果只是租客和房东之间进行寻找的话,他们的效率是很低的,房东找不到租客赚不到钱,租客找不到房东住不了房。所以,后来房东肯定就想到了广播自己的房源信息(比如在街边贴贴小广告),这样对于房东来说已经完成他的任务(将房源公布出去),但是有两个问题就出现了。第一、其他不是租客的都能收到这种租房消息,这在现实世界没什么,但是在计算机的世界中就会出现 **资源消耗** 的问题了。第二、租客这样还是很难找到你,试想一下我需要租房,我还需要东一个西一个地去找街边小广告,麻不麻烦?
+
+那怎么办呢?我们当然不会那么傻乎乎的,第一时间就是去找 **中介** 呀,它为我们提供了统一房源的地方,我们消费者只需要跑到它那里去找就行了。而对于房东来说,他们也只需要把房源在中介那里发布就行了。
+
+
+
+那么现在,我们的模式就是这样的了。
+
+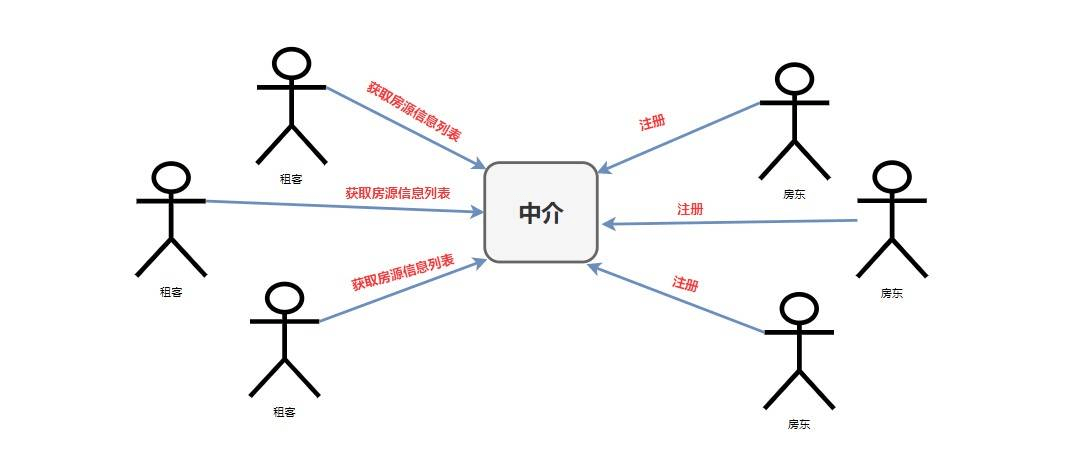
+
+但是,这个时候还会出现一些问题。
+
+1. 房东注册之后如果不想卖房子了怎么办?我们是不是需要让房东 **定期续约** ?如果房东不进行续约是不是要将他们从中介那里的注册列表中 **移除** 。
+2. 租客是不是也要进行 **注册** 呢?不然合同乙方怎么来呢?
+3. 中介可不可以做 **连锁店** 呢?如果这一个店因为某些不可抗力因素而无法使用,那么我们是否可以换一个连锁店呢?
+
+针对上面的问题我们来重新构建一下上面的模式图
+
+
+
+好了,举完这个:chestnut:我们就可以来看关于 `Eureka` 的一些基础概念了,你会发现这东西理解起来怎么这么简单。:punch::punch::punch:
+
+**服务发现**:其实就是一个“中介”,整个过程中有三个角色:**服务提供者(出租房子的)、服务消费者(租客)、服务中介(房屋中介)**。
+
+**服务提供者**: 就是提供一些自己能够执行的一些服务给外界。
+
+**服务消费者**: 就是需要使用一些服务的“用户”。
+
+**服务中介**: 其实就是服务提供者和服务消费者之间的“桥梁”,服务提供者可以把自己注册到服务中介那里,而服务消费者如需要消费一些服务(使用一些功能)就可以在服务中介中寻找注册在服务中介的服务提供者。
+
+**服务注册 Register**:
+
+官方解释:当 `Eureka` 客户端向 `Eureka Server` 注册时,它提供自身的**元数据**,比如IP地址、端口,运行状况指示符URL,主页等。
+
+结合中介理解:房东 (提供者 `Eureka Client Provider`)在中介 (服务器 `Eureka Server`) 那里登记房屋的信息,比如面积,价格,地段等等(元数据 `metaData`)。
+
+**服务续约 Renew**:
+
+官方解释:**`Eureka` 客户会每隔30秒(默认情况下)发送一次心跳来续约**。 通过续约来告知 `Eureka Server` 该 `Eureka` 客户仍然存在,没有出现问题。 正常情况下,如果 `Eureka Server` 在90秒没有收到 `Eureka` 客户的续约,它会将实例从其注册表中删除。
+
+结合中介理解:房东 (提供者 `Eureka Client Provider`) 定期告诉中介 (服务器 `Eureka Server`) 我的房子还租(续约) ,中介 (服务器`Eureka Server`) 收到之后继续保留房屋的信息。
+
+**获取注册列表信息 Fetch Registries**:
+
+官方解释:`Eureka` 客户端从服务器获取注册表信息,并将其缓存在本地。客户端会使用该信息查找其他服务,从而进行远程调用。该注册列表信息定期(每30秒钟)更新一次。每次返回注册列表信息可能与 `Eureka` 客户端的缓存信息不同, `Eureka` 客户端自动处理。如果由于某种原因导致注册列表信息不能及时匹配,`Eureka` 客户端则会重新获取整个注册表信息。 `Eureka` 服务器缓存注册列表信息,整个注册表以及每个应用程序的信息进行了压缩,压缩内容和没有压缩的内容完全相同。`Eureka` 客户端和 `Eureka` 服务器可以使用JSON / XML格式进行通讯。在默认的情况下 `Eureka` 客户端使用压缩 `JSON` 格式来获取注册列表的信息。
+
+结合中介理解:租客(消费者 `Eureka Client Consumer`) 去中介 (服务器 `Eureka Server`) 那里获取所有的房屋信息列表 (客户端列表 `Eureka Client List`) ,而且租客为了获取最新的信息会定期向中介 (服务器 `Eureka Server`) 那里获取并更新本地列表。
+
+**服务下线 Cancel**:
+
+官方解释:Eureka客户端在程序关闭时向Eureka服务器发送取消请求。 发送请求后,该客户端实例信息将从服务器的实例注册表中删除。该下线请求不会自动完成,它需要调用以下内容:`DiscoveryManager.getInstance().shutdownComponent();`
+
+结合中介理解:房东 (提供者 `Eureka Client Provider`) 告诉中介 (服务器 `Eureka Server`) 我的房子不租了,中介之后就将注册的房屋信息从列表中剔除。
+
+**服务剔除 Eviction**:
+
+官方解释:在默认的情况下,**当Eureka客户端连续90秒(3个续约周期)没有向Eureka服务器发送服务续约,即心跳,Eureka服务器会将该服务实例从服务注册列表删除**,即服务剔除。
+
+结合中介理解:房东(提供者 `Eureka Client Provider`) 会定期联系 中介 (服务器 `Eureka Server`) 告诉他我的房子还租(续约),如果中介 (服务器 `Eureka Server`) 长时间没收到提供者的信息,那么中介会将他的房屋信息给下架(服务剔除)。
+
+下面就是 `Netflix` 官方给出的 `Eureka` 架构图,你会发现和我们前面画的中介图别无二致。
+
+
+
+当然,可以充当服务发现的组件有很多:`Zookeeper` ,`Consul` , `Eureka` 等。
+
+更多关于 `Eureka` 的知识(自我保护,初始注册策略等等)可以自己去官网查看,或者查看我的另一篇文章 [深入理解 Eureka](<https://juejin.im/post/5dd497e3f265da0ba7718018>)。
+
+## 负载均衡之 Ribbon
+
+### 什么是 `RestTemplate`?
+
+不是讲 `Ribbon` 么?怎么扯到了 `RestTemplate` 了?你先别急,听我慢慢道来。
+
+我不听我不听我不听:hear_no_evil::hear_no_evil::hear_no_evil:。
+
+我就说一句!**`RestTemplate`是`Spring`提供的一个访问Http服务的客户端类**,怎么说呢?就是微服务之间的调用是使用的 `RestTemplate` 。比如这个时候我们 消费者B 需要调用 提供者A 所提供的服务我们就需要这么写。如我下面的伪代码。
+
+```java
+@Autowired
+private RestTemplate restTemplate;
+// 这里是提供者A的ip地址,但是如果使用了 Eureka 那么就应该是提供者A的名称
+private static final String SERVICE_PROVIDER_A = "http://localhost:8081";
+
+@PostMapping("/judge")
+public boolean judge(@RequestBody Request request) {
+ String url = SERVICE_PROVIDER_A + "/service1";
+ return restTemplate.postForObject(url, request, Boolean.class);
+}
+```
+ 如果你对源码感兴趣的话,你会发现上面我们所讲的 `Eureka` 框架中的 **注册**、**续约** 等,底层都是使用的 `RestTemplate` 。
+
+### 为什么需要 Ribbon?
+
+`Ribbon` 是 `Netflix` 公司的一个开源的负载均衡 项目,是一个客户端/进程内负载均衡器,**运行在消费者端**。
+
+我们再举个:chestnut:,比如我们设计了一个秒杀系统,但是为了整个系统的 **高可用** ,我们需要将这个系统做一个集群,而这个时候我们消费者就可以拥有多个秒杀系统的调用途径了,如下图。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/秒杀系统-ribbon.jpg" style="zoom:50%;" />
+
+如果这个时候我们没有进行一些 **均衡操作** ,如果我们对 `秒杀系统1` 进行大量的调用,而另外两个基本不请求,就会导致 `秒杀系统1` 崩溃,而另外两个就变成了傀儡,那么我们为什么还要做集群,我们高可用体现的意义又在哪呢?
+
+所以 `Ribbon` 出现了,注意我们上面加粗的几个字——**运行在消费者端**。指的是,`Ribbon` 是运行在消费者端的负载均衡器,如下图。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/秒杀系统-ribbon2.jpg" style="zoom:50%;" />
+
+其工作原理就是 `Consumer` 端获取到了所有的服务列表之后,在其**内部**使用**负载均衡算法**,进行对多个系统的调用。
+
+### Nginx 和 Ribbon 的对比
+
+提到 **负载均衡** 就不得不提到大名鼎鼎的 `Nignx` 了,而和 `Ribbon` 不同的是,它是一种**集中式**的负载均衡器。
+
+何为集中式呢?简单理解就是 **将所有请求都集中起来,然后再进行负载均衡**。如下图。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/nginx-vs-ribbon1.jpg" style="zoom:50%;" />
+
+我们可以看到 `Nginx` 是接收了所有的请求进行负载均衡的,而对于 `Ribbon` 来说它是在消费者端进行的负载均衡。如下图。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/nginx-vs-ribbon2.jpg" style="zoom:50%;" />
+
+> 请注意 `Request` 的位置,在 `Nginx` 中请求是先进入负载均衡器,而在 `Ribbon` 中是先在客户端进行负载均衡才进行请求的。
+
+### Ribbon 的几种负载均衡算法
+
+负载均衡,不管 `Nginx` 还是 `Ribbon` 都需要其算法的支持,如果我没记错的话 `Nginx` 使用的是 轮询和加权轮询算法。而在 `Ribbon` 中有更多的负载均衡调度算法,其默认是使用的 `RoundRobinRule` 轮询策略。
+
+* **`RoundRobinRule`**:轮询策略。`Ribbon` 默认采用的策略。若经过一轮轮询没有找到可用的 `provider`,其最多轮询 10 轮。若最终还没有找到,则返回 `null`。
+* **`RandomRule`**: 随机策略,从所有可用的 `provider` 中随机选择一个。
+* **`RetryRule`**: 重试策略。先按照 `RoundRobinRule` 策略获取 `provider`,若获取失败,则在指定的时限内重试。默认的时限为 500 毫秒。
+
+🐦🐦🐦 还有很多,这里不一一举:chestnut:了,你最需要知道的是默认轮询算法,并且可以更换默认的负载均衡算法,只需要在配置文件中做出修改就行。
+
+```yaml
+providerName:
+ ribbon:
+ NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
+```
+
+当然,在 `Ribbon` 中你还可以**自定义负载均衡算法**,你只需要实现 `IRule` 接口,然后修改配置文件或者自定义 `Java Config` 类。
+
+## 什么是 Open Feign
+
+有了 `Eureka` ,`RestTemplate` ,`Ribbon`, 我们就可以愉快地进行服务间的调用了,但是使用 `RestTemplate` 还是不方便,我们每次都要进行这样的调用。
+
+```java
+@Autowired
+private RestTemplate restTemplate;
+// 这里是提供者A的ip地址,但是如果使用了 Eureka 那么就应该是提供者A的名称
+private static final String SERVICE_PROVIDER_A = "http://localhost:8081";
+
+@PostMapping("/judge")
+public boolean judge(@RequestBody Request request) {
+ String url = SERVICE_PROVIDER_A + "/service1";
+ // 是不是太麻烦了???每次都要 url、请求、返回类型的
+ return restTemplate.postForObject(url, request, Boolean.class);
+}
+```
+
+这样每次都调用 `RestRemplate` 的 `API` 是否太麻烦,我能不能像**调用原来代码一样进行各个服务间的调用呢?**
+
+:bulb::bulb::bulb:聪明的小朋友肯定想到了,那就用 **映射** 呀,就像域名和IP地址的映射。我们可以将被调用的服务代码映射到消费者端,这样我们就可以 **“无缝开发” **啦。
+
+> `OpenFeign` 也是运行在消费者端的,使用 `Ribbon` 进行负载均衡,所以 `OpenFeign` 直接内置了 `Ribbon`。
+
+在导入了 `Open Feign` 之后我们就可以进行愉快编写 `Consumer` 端代码了。
+
+```java
+// 使用 @FeignClient 注解来指定提供者的名字
+@FeignClient(value = "eureka-client-provider")
+public interface TestClient {
+ // 这里一定要注意需要使用的是提供者那端的请求相对路径,这里就相当于映射了
+ @RequestMapping(value = "/provider/xxx",
+ method = RequestMethod.POST)
+ CommonResponse<List<Plan>> getPlans(@RequestBody planGetRequest request);
+}
+```
+
+然后我们在 `Controller` 就可以像原来调用 `Service` 层代码一样调用它了。
+
+```java
+@RestController
+public class TestController {
+ // 这里就相当于原来自动注入的 Service
+ @Autowired
+ private TestClient testClient;
+ // controller 调用 service 层代码
+ @RequestMapping(value = "/test", method = RequestMethod.POST)
+ public CommonResponse<List<Plan>> get(@RequestBody planGetRequest request) {
+ return testClient.getPlans(request);
+ }
+}
+```
+
+## 必不可少的 Hystrix
+
+### 什么是 Hystrix之熔断和降级
+
+> 在分布式环境中,不可避免地会有许多服务依赖项中的某些失败。Hystrix是一个库,可通过添加等待时间容限和容错逻辑来帮助您控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点,停止服务之间的级联故障并提供后备选项来实现此目的,所有这些都可以提高系统的整体弹性。
+
+总体来说 `Hystrix` 就是一个能进行 **熔断** 和 **降级** 的库,通过使用它能提高整个系统的弹性。
+
+那么什么是 熔断和降级 呢?再举个:chestnut:,此时我们整个微服务系统是这样的。服务A调用了服务B,服务B再调用了服务C,但是因为某些原因,服务C顶不住了,这个时候大量请求会在服务C阻塞。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/Hystrix1.jpg" style="zoom:50%;" />
+
+服务C阻塞了还好,毕竟只是一个系统崩溃了。但是请注意这个时候因为服务C不能返回响应,那么服务B调用服务C的的请求就会阻塞,同理服务B阻塞了,那么服务A也会阻塞崩溃。
+
+> 请注意,为什么阻塞会崩溃。因为这些请求会消耗占用系统的线程、IO 等资源,消耗完你这个系统服务器不就崩了么。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/Hystrix2.jpg" style="zoom:50%;" />
+
+这就叫 **服务雪崩**。妈耶,上面两个 **熔断** 和 **降级** 你都没给我解释清楚,你现在又给我扯什么 **服务雪崩** ?:tired_face::tired_face::tired_face:
+
+别急,听我慢慢道来。
+
+
+
+不听我也得讲下去!
+
+所谓 **熔断** 就是服务雪崩的一种有效解决方案。当指定时间窗内的请求失败率达到设定阈值时,系统将通过 **断路器** 直接将此请求链路断开。
+
+也就是我们上面服务B调用服务C在指定时间窗内,调用的失败率到达了一定的值,那么 `Hystrix` 则会自动将 服务B与C 之间的请求都断了,以免导致服务雪崩现象。
+
+其实这里所讲的 **熔断** 就是指的 `Hystrix` 中的 **断路器模式** ,你可以使用简单的 `@HystrixCommand` 注解来标注某个方法,这样 `Hystrix` 就会使用 **断路器** 来“包装”这个方法,每当调用时间超过指定时间时(默认为1000ms),断路器将会中断对这个方法的调用。
+
+当然你可以对这个注解的很多属性进行设置,比如设置超时时间,像这样。
+
+```java
+@HystrixCommand(
+ commandProperties = {@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "1200")}
+)
+public List<Xxx> getXxxx() {
+ // ...省略代码逻辑
+}
+```
+
+但是,我查阅了一些博客,发现他们都将 **熔断** 和 **降级** 的概念混淆了,以我的理解,**降级是为了更好的用户体验,当一个方法调用异常时,通过执行另一种代码逻辑来给用户友好的回复**。这也就对应着 `Hystrix` 的 **后备处理** 模式。你可以通过设置 `fallbackMethod` 来给一个方法设置备用的代码逻辑。比如这个时候有一个热点新闻出现了,我们会推荐给用户查看详情,然后用户会通过id去查询新闻的详情,但是因为这条新闻太火了(比如最近什么*易对吧),大量用户同时访问可能会导致系统崩溃,那么我们就进行 **服务降级** ,一些请求会做一些降级处理比如当前人数太多请稍后查看等等。
+
+```java
+// 指定了后备方法调用
+@HystrixCommand(fallbackMethod = "getHystrixNews")
+@GetMapping("/get/news")
+public News getNews(@PathVariable("id") int id) {
+ // 调用新闻系统的获取新闻api 代码逻辑省略
+}
+//
+public News getHystrixNews(@PathVariable("id") int id) {
+ // 做服务降级
+ // 返回当前人数太多,请稍后查看
+}
+```
+
+### 什么是Hystrix之其他
+
+我在阅读 《Spring微服务实战》这本书的时候还接触到了一个 **舱壁模式** 的概念。在不使用舱壁模式的情况下,服务A调用服务B,这种调用默认的是 **使用同一批线程来执行** 的,而在一个服务出现性能问题的时候,就会出现所有线程被刷爆并等待处理工作,同时阻塞新请求,最终导致程序崩溃。而舱壁模式会将远程资源调用隔离在他们自己的线程池中,以便可以控制单个表现不佳的服务,而不会使该程序崩溃。
+
+具体其原理我推荐大家自己去了解一下,本篇文章中对 **舱壁模式** 不做过多解释。当然还有 **`Hystrix` 仪表盘**,它是**用来实时监控 `Hystrix` 的各项指标信息的**,这里我将这个问题也抛出去,希望有不了解的可以自己去搜索一下。
+
+## 微服务网关——Zuul
+
+> ZUUL 是从设备和 web 站点到 Netflix 流应用后端的所有请求的前门。作为边界服务应用,ZUUL 是为了实现动态路由、监视、弹性和安全性而构建的。它还具有根据情况将请求路由到多个 Amazon Auto Scaling Groups(亚马逊自动缩放组,亚马逊的一种云计算方式) 的能力
+
+在上面我们学习了 `Eureka` 之后我们知道了 *服务提供者* 是 *消费者* 通过 `Eureka Server` 进行访问的,即 `Eureka Server` 是 *服务提供者* 的统一入口。那么整个应用中存在那么多 *消费者* 需要用户进行调用,这个时候用户该怎样访问这些 *消费者工程* 呢?当然可以像之前那样直接访问这些工程。但这种方式没有统一的消费者工程调用入口,不便于访问与管理,而 Zuul 就是这样的一个对于 *消费者* 的统一入口。
+
+> 如果学过前端的肯定都知道 Router 吧,比如 Flutter 中的路由,Vue,React中的路由,用了 Zuul 你会发现在路由功能方面和前端配置路由基本是一个理。:smile: 我偶尔撸撸 Flutter。
+
+大家对网关应该很熟吧,简单来讲网关是系统唯一对外的入口,介于客户端与服务器端之间,用于对请求进行**鉴权**、**限流**、 **路由**、**监控**等功能。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/zuul-sj22o93nfdsjkdsf.jpg" style="zoom:50%;" />
+
+没错,网关有的功能,`Zuul` 基本都有。而 `Zuul` 中最关键的就是 **路由和过滤器** 了,在官方文档中 `Zuul` 的标题就是
+
+> Router and Filter : Zuul
+
+### Zuul 的路由功能
+
+#### 简单配置
+
+本来想给你们复制一些代码,但是想了想,因为各个代码配置比较零散,看起来也比较零散,我决定还是给你们画个图来解释吧。
+
+> 请不要因为我这么好就给我点赞 :thumbsup: 。 疯狂暗示。
+
+比如这个时候我们已经向 `Eureka Server` 注册了两个 `Consumer` 、三个 `Provicer` ,这个时候我们再加个 `Zuul` 网关应该变成这样子了。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/zuul-sj22o93nfdsjkdsf2312.jpg" style="zoom:50%;" />
+
+emmm,信息量有点大,我来解释一下。关于前面的知识我就不解释了:neutral_face:。
+
+首先,`Zuul` 需要向 `Eureka` 进行注册,注册有啥好处呢?
+
+你傻呀,`Consumer` 都向 `Eureka Server` 进行注册了,我网关是不是只要注册就能拿到所有 `Consumer` 的信息了?
+
+拿到信息有什么好处呢?
+
+我拿到信息我是不是可以获取所有的 `Consumer` 的元数据(名称,ip,端口)?
+
+拿到这些元数据有什么好处呢?拿到了我们是不是直接可以做**路由映射**?比如原来用户调用 `Consumer1` 的接口 `localhost:8001/studentInfo/update` 这个请求,我们是不是可以这样进行调用了呢?`localhost:9000/consumer1/studentInfo/update` 呢?你这样是不是恍然大悟了?
+
+> 这里的url为了让更多人看懂所以没有使用 restful 风格。
+
+上面的你理解了,那么就能理解关于 `Zuul` 最基本的配置了,看下面。
+
+```yaml
+server:
+ port: 9000
+eureka:
+ client:
+ service-url:
+ # 这里只要注册 Eureka 就行了
+ defaultZone: http://localhost:9997/eureka
+```
+
+然后在启动类上加入 `@EnableZuulProxy` 注解就行了。没错,就是那么简单:smiley:。
+
+#### 统一前缀
+
+这个很简单,就是我们可以在前面加一个统一的前缀,比如我们刚刚调用的是 `localhost:9000/consumer1/studentInfo/update`,这个时候我们在 `yaml` 配置文件中添加如下。
+
+```yaml
+zuul:
+ prefix: /zuul
+```
+
+这样我们就需要通过 `localhost:9000/zuul/consumer1/studentInfo/update` 来进行访问了。
+
+#### 路由策略配置
+
+你会发现前面的访问方式(直接使用服务名),需要将微服务名称暴露给用户,会存在安全性问题。所以,可以自定义路径来替代微服务名称,即自定义路由策略。
+
+```yaml
+zuul:
+ routes:
+ consumer1: /FrancisQ1/**
+ consumer2: /FrancisQ2/**
+```
+
+这个时候你就可以使用 ` `localhost:9000/zuul/FrancisQ1/studentInfo/update` 进行访问了。
+
+#### 服务名屏蔽
+
+这个时候你别以为你好了,你可以试试,在你配置完路由策略之后使用微服务名称还是可以访问的,这个时候你需要将服务名屏蔽。
+
+```yaml
+zuul:
+ ignore-services: "*"
+```
+
+#### 路径屏蔽
+
+`Zuul` 还可以指定屏蔽掉的路径 URI,即只要用户请求中包含指定的 URI 路径,那么该请求将无法访问到指定的服务。通过该方式可以限制用户的权限。
+
+```yaml
+zuul:
+ ignore-patterns: **/auto/**
+```
+
+这样关于 auto 的请求我们就可以过滤掉了。
+
+> ** 代表匹配多级任意路径
+>
+> *代表匹配一级任意路径
+
+#### 敏感请求头屏蔽
+
+默认情况下,像 `Cookie`、`Set-Cookie` 等敏感请求头信息会被 `zuul` 屏蔽掉,我们可以将这些默认屏蔽去掉,当然,也可以添加要屏蔽的请求头。
+
+### Zuul 的过滤功能
+
+如果说,路由功能是 `Zuul` 的基操的话,那么**过滤器**就是 `Zuul`的利器了。毕竟所有请求都经过网关(Zuul),那么我们可以进行各种过滤,这样我们就能实现 **限流**,**灰度发布**,**权限控制** 等等。
+
+#### 简单实现一个请求时间日志打印
+
+要实现自己定义的 `Filter` 我们只需要继承 `ZuulFilter` 然后将这个过滤器类以 `@Component` 注解加入 Spring 容器中就行了。
+
+在给你们看代码之前我先给你们解释一下关于过滤器的一些注意点。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/zuul-sj22o93nfdsjkdsf2312244.jpg" style="zoom:50%;" />
+
+过滤器类型:`Pre`、`Routing`、`Post`。前置`Pre`就是在请求之前进行过滤,`Routing`路由过滤器就是我们上面所讲的路由策略,而`Post`后置过滤器就是在 `Response` 之前进行过滤的过滤器。你可以观察上图结合着理解,并且下面我会给出相应的注释。
+
+```java
+// 加入Spring容器
+@Component
+public class PreRequestFilter extends ZuulFilter {
+ // 返回过滤器类型 这里是前置过滤器
+ @Override
+ public String filterType() {
+ return FilterConstants.PRE_TYPE;
+ }
+ // 指定过滤顺序 越小越先执行,这里第一个执行
+ // 当然不是只真正第一个 在Zuul内置中有其他过滤器会先执行
+ // 那是写死的 比如 SERVLET_DETECTION_FILTER_ORDER = -3
+ @Override
+ public int filterOrder() {
+ return 0;
+ }
+ // 什么时候该进行过滤
+ // 这里我们可以进行一些判断,这样我们就可以过滤掉一些不符合规定的请求等等
+ @Override
+ public boolean shouldFilter() {
+ return true;
+ }
+ // 如果过滤器允许通过则怎么进行处理
+ @Override
+ public Object run() throws ZuulException {
+ // 这里我设置了全局的RequestContext并记录了请求开始时间
+ RequestContext ctx = RequestContext.getCurrentContext();
+ ctx.set("startTime", System.currentTimeMillis());
+ return null;
+ }
+}
+```
+
+
+
+```java
+// lombok的日志
+@Slf4j
+// 加入 Spring 容器
+@Component
+public class AccessLogFilter extends ZuulFilter {
+ // 指定该过滤器的过滤类型
+ // 此时是后置过滤器
+ @Override
+ public String filterType() {
+ return FilterConstants.POST_TYPE;
+ }
+ // SEND_RESPONSE_FILTER_ORDER 是最后一个过滤器
+ // 我们此过滤器在它之前执行
+ @Override
+ public int filterOrder() {
+ return FilterConstants.SEND_RESPONSE_FILTER_ORDER - 1;
+ }
+ @Override
+ public boolean shouldFilter() {
+ return true;
+ }
+ // 过滤时执行的策略
+ @Override
+ public Object run() throws ZuulException {
+ RequestContext context = RequestContext.getCurrentContext();
+ HttpServletRequest request = context.getRequest();
+ // 从RequestContext获取原先的开始时间 并通过它计算整个时间间隔
+ Long startTime = (Long) context.get("startTime");
+ // 这里我可以获取HttpServletRequest来获取URI并且打印出来
+ String uri = request.getRequestURI();
+ long duration = System.currentTimeMillis() - startTime;
+ log.info("uri: " + uri + ", duration: " + duration / 100 + "ms");
+ return null;
+ }
+}
+```
+
+上面就简单实现了请求时间日志打印功能,你有没有感受到 `Zuul` 过滤功能的强大了呢?
+
+没有?好的、那我们再来。
+
+#### 令牌桶限流
+
+当然不仅仅是令牌桶限流方式,`Zuul` 只要是限流的活它都能干,这里我只是简单举个:chestnut:。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/zuui-令牌桶限流.jpg" alt="令牌桶限流" style="zoom:50%;" />
+
+我先来解释一下什么是 **令牌桶限流** 吧。
+
+首先我们会有个桶,如果里面没有满那么就会以一定 **固定的速率** 会往里面放令牌,一个请求过来首先要从桶中获取令牌,如果没有获取到,那么这个请求就拒绝,如果获取到那么就放行。很简单吧,啊哈哈、
+
+下面我们就通过 `Zuul` 的前置过滤器来实现一下令牌桶限流。
+
+```java
+package com.lgq.zuul.filter;
+
+import com.google.common.util.concurrent.RateLimiter;
+import com.netflix.zuul.ZuulFilter;
+import com.netflix.zuul.context.RequestContext;
+import com.netflix.zuul.exception.ZuulException;
+import lombok.extern.slf4j.Slf4j;
+import org.springframework.cloud.netflix.zuul.filters.support.FilterConstants;
+import org.springframework.stereotype.Component;
+
+@Component
+@Slf4j
+public class RouteFilter extends ZuulFilter {
+ // 定义一个令牌桶,每秒产生2个令牌,即每秒最多处理2个请求
+ private static final RateLimiter RATE_LIMITER = RateLimiter.create(2);
+ @Override
+ public String filterType() {
+ return FilterConstants.PRE_TYPE;
+ }
+
+ @Override
+ public int filterOrder() {
+ return -5;
+ }
+
+ @Override
+ public Object run() throws ZuulException {
+ log.info("放行");
+ return null;
+ }
+
+ @Override
+ public boolean shouldFilter() {
+ RequestContext context = RequestContext.getCurrentContext();
+ if(!RATE_LIMITER.tryAcquire()) {
+ log.warn("访问量超载");
+ // 指定当前请求未通过过滤
+ context.setSendZuulResponse(false);
+ // 向客户端返回响应码429,请求数量过多
+ context.setResponseStatusCode(429);
+ return false;
+ }
+ return true;
+ }
+}
+```
+
+这样我们就能将请求数量控制在一秒两个,有没有觉得很酷?
+
+### 关于 Zuul 的其他
+
+`Zuul` 的过滤器的功能肯定不止上面我所实现的两种,它还可以实现 **权限校验**,包括我上面提到的 **灰度发布** 等等。
+
+当然,`Zuul` 作为网关肯定也存在 **单点问题** ,如果我们要保证 `Zuul` 的高可用,我们就需要进行 `Zuul` 的集群配置,这个时候可以借助额外的一些负载均衡器比如 `Nginx` 。
+
+##Spring Cloud配置管理——Config
+
+### 为什么要使用进行配置管理?
+
+当我们的微服务系统开始慢慢地庞大起来,那么多 `Consumer` 、`Provider` 、`Eureka Server` 、`Zuul` 系统都会持有自己的配置,这个时候我们在项目运行的时候可能需要更改某些应用的配置,如果我们不进行配置的统一管理,我们只能**去每个应用下一个一个寻找配置文件然后修改配置文件再重启应用**。
+
+首先对于分布式系统而言我们就不应该去每个应用下去分别修改配置文件,再者对于重启应用来说,服务无法访问所以直接抛弃了可用性,这是我们更不愿见到的。
+
+那么有没有一种方法**既能对配置文件统一地进行管理,又能在项目运行时动态修改配置文件呢?**
+
+那就是我今天所要介绍的 `Spring Cloud Config` 。
+
+> 能进行配置管理的框架不止 `Spring Cloud Config` 一种,大家可以根据需求自己选择(`disconf`,阿波罗等等)。而且对于 `Config` 来说有些地方实现的不是那么尽人意。
+
+### Config 是什么
+
+> `Spring Cloud Config` 为分布式系统中的外部化配置提供服务器和客户端支持。使用 `Config` 服务器,可以在中心位置管理所有环境中应用程序的外部属性。
+
+简单来说,`Spring Cloud Config` 就是能将各个 应用/系统/模块 的配置文件存放到 **统一的地方然后进行管理**(Git 或者 SVN)。
+
+你想一下,我们的应用是不是只有启动的时候才会进行配置文件的加载,那么我们的 `Spring Cloud Config` 就暴露出一个接口给启动应用来获取它所想要的配置文件,应用获取到配置文件然后再进行它的初始化工作。就如下图。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/config-ksksks.jpg" style="zoom:50%;" />
+
+当然这里你肯定还会有一个疑问,如果我在应用运行时去更改远程配置仓库(Git)中的对应配置文件,那么依赖于这个配置文件的已启动的应用会不会进行其相应配置的更改呢?
+
+答案是不会的。
+
+什么?那怎么进行动态修改配置文件呢?这不是出现了 **配置漂移** 吗?你个渣男:rage:,你又骗我!
+
+别急嘛,你可以使用 `Webhooks` ,这是 `github` 提供的功能,它能确保远程库的配置文件更新后客户端中的配置信息也得到更新。
+
+噢噢,这还差不多。我去查查怎么用。
+
+慢着,听我说完,`Webhooks` 虽然能解决,但是你了解一下会发现它根本不适合用于生产环境,所以基本不会使用它的。
+
+
+
+而一般我们会使用 `Bus` 消息总线 + `Spring Cloud Config` 进行配置的动态刷新。
+
+## 引出 Spring Cloud Bus
+
+> 用于将服务和服务实例与分布式消息系统链接在一起的事件总线。在集群中传播状态更改很有用(例如配置更改事件)。
+
+你可以简单理解为 `Spring Cloud Bus` 的作用就是**管理和广播分布式系统中的消息**,也就是消息引擎系统中的广播模式。当然作为 **消息总线** 的 `Spring Cloud Bus` 可以做很多事而不仅仅是客户端的配置刷新功能。
+
+而拥有了 `Spring Cloud Bus` 之后,我们只需要创建一个简单的请求,并且加上 `@ResfreshScope` 注解就能进行配置的动态修改了,下面我画了张图供你理解。
+
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/springcloud-bus-s213dsfsd.jpg" style="zoom:50%;" />
+
+## 总结
+
+这篇文章中我带大家初步了解了 `Spring Cloud` 的各个组件,他们有
+
+* `Eureka` 服务发现框架
+* `Ribbon` 进程内负载均衡器
+* `Open Feign` 服务调用映射
+* `Hystrix` 服务降级熔断器
+* `Zuul` 微服务网关
+* `Config` 微服务统一配置中心
+* `Bus` 消息总线
+
+如果你能这个时候能看懂文首那张图,也就说明了你已经对 `Spring Cloud` 微服务有了一定的架构认识。
\ No newline at end of file
diff --git a/docs/system-design/security/basis-of-authority-certification.md b/docs/system-design/security/basis-of-authority-certification.md
new file mode 100644
index 00000000000..ce624842036
--- /dev/null
+++ b/docs/system-design/security/basis-of-authority-certification.md
@@ -0,0 +1,259 @@
+# 认证授权基础
+
+## 认证 (Authentication) 和授权 (Authorization)的区别是什么?
+
+这是一个绝大多数人都会混淆的问题。首先先从读音上来认识这两个名词,很多人都会把它俩的读音搞混,所以我建议你先先去查一查这两个单词到底该怎么读,他们的具体含义是什么。
+
+说简单点就是:
+
+- **认证 (Authentication):** 你是谁。
+- **授权 (Authorization):** 你有权限干什么。
+
+稍微正式点(啰嗦点)的说法就是 :
+
+- **Authentication(认证)** 是验证您的身份的凭据(例如用户名/用户 ID 和密码),通过这个凭据,系统得以知道你就是你,也就是说系统存在你这个用户。所以,Authentication 被称为身份/用户验证。
+- **Authorization(授权)** 发生在 **Authentication(认证)** 之后。授权嘛,光看意思大家应该就明白,它主要掌管我们访问系统的权限。比如有些特定资源只能具有特定权限的人才能访问比如 admin,有些对系统资源操作比如删除、添加、更新只能特定人才具有。
+
+认证 :
+
+
+
+授权:
+
+
+
+这两个一般在我们的系统中被结合在一起使用,目的就是为了保护我们系统的安全性。
+
+## RBAC 模型了解吗?
+
+系统权限控制最常采用的访问控制模型就是 **RBAC 模型** 。
+
+**什么是 RBAC 呢?**
+
+RBAC 即基于角色的权限访问控制(Role-Based Access Control)。这是一种通过角色关联权限,角色同时又关联用户的授权的方式。
+
+简单地说:一个用户可以拥有若干角色,每一个角色又可以被分配若干权限,这样就构造成“用户-角色-权限” 的授权模型。在这种模型中,用户与角色、角色与权限之间构成了多对多的关系,如下图
+
+
+
+**在 RBAC 中,权限与角色相关联,用户通过成为适当角色的成员而得到这些角色的权限。这就极大地简化了权限的管理。**
+
+本系统的权限设计相关的表如下(一共 5 张表,2 张用户建立表之间的联系):
+
+
+
+通过这个权限模型,我们可以创建不同的角色并为不同的角色分配不同的权限范围(菜单)。
+
+
+
+通常来说,如果系统对于权限控制要求比较严格的话,一般都会选择使用 RBAC 模型来做权限控制。
+
+## 什么是 Cookie ? Cookie 的作用是什么?
+
+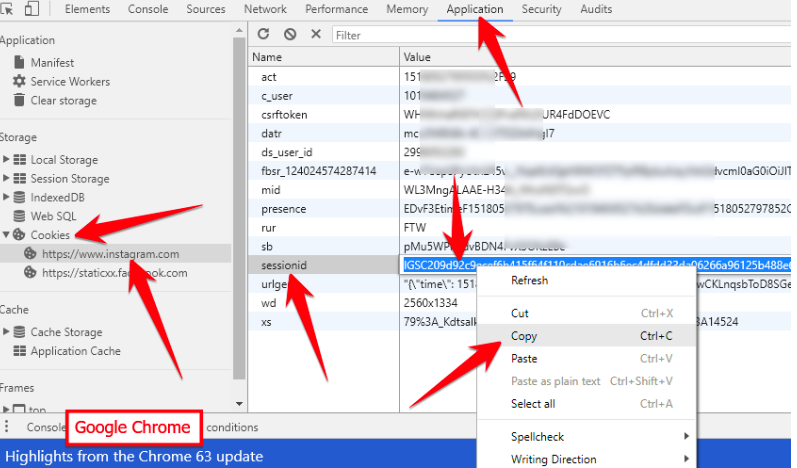
+
+`Cookie` 和 `Session` 都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
+
+维基百科是这样定义 `Cookie` 的:
+
+> `Cookies` 是某些网站为了辨别用户身份而储存在用户本地终端上的数据(通常经过加密)。
+
+简单来说: **`Cookie` 存放在客户端,一般用来保存用户信息**。
+
+下面是 `Cookie` 的一些应用案例:
+
+1. 我们在 `Cookie` 中保存已经登录过的用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了。除此之外,`Cookie` 还能保存用户首选项,主题和其他设置信息。
+2. 使用 `Cookie` 保存 `Session` 或者 `Token` ,向后端发送请求的时候带上 `Cookie`,这样后端就能取到 `Session` 或者 `Token` 了。这样就能记录用户当前的状态了,因为 HTTP 协议是无状态的。
+3. `Cookie` 还可以用来记录和分析用户行为。举个简单的例子你在网上购物的时候,因为 HTTP 协议是没有状态的,如果服务器想要获取你在某个页面的停留状态或者看了哪些商品,一种常用的实现方式就是将这些信息存放在 `Cookie`
+4. ......
+
+## 如何在项目中使用 Cookie 呢?
+
+我这里以 Spring Boot 项目为例。
+
+**1)设置 `Cookie` 返回给客户端**
+
+```java
+@GetMapping("/change-username")
+public String setCookie(HttpServletResponse response) {
+ // 创建一个 cookie
+ Cookie cookie = new Cookie("username", "Jovan");
+ //设置 cookie过期时间
+ cookie.setMaxAge(7 * 24 * 60 * 60); // expires in 7 days
+ //添加到 response 中
+ response.addCookie(cookie);
+
+ return "Username is changed!";
+}
+```
+
+**2) 使用 Spring 框架提供的 `@CookieValue` 注解获取特定的 cookie 的值**
+
+```java
+@GetMapping("/")
+public String readCookie(@CookieValue(value = "username", defaultValue = "Atta") String username) {
+ return "Hey! My username is " + username;
+}
+```
+
+**3) 读取所有的 `Cookie` 值**
+
+```java
+@GetMapping("/all-cookies")
+public String readAllCookies(HttpServletRequest request) {
+
+ Cookie[] cookies = request.getCookies();
+ if (cookies != null) {
+ return Arrays.stream(cookies)
+ .map(c -> c.getName() + "=" + c.getValue()).collect(Collectors.joining(", "));
+ }
+
+ return "No cookies";
+}
+```
+
+更多关于如何在 Spring Boot 中使用 `Cookie` 的内容可以查看这篇文章:[How to use cookies in Spring Boot](https://attacomsian.com/blog/cookies-spring-boot。) 。
+
+## Cookie 和 Session 有什么区别?
+
+**`Session` 的主要作用就是通过服务端记录用户的状态。** 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 `Session` 之后就可以标识这个用户并且跟踪这个用户了。
+
+`Cookie` 数据保存在客户端(浏览器端),`Session` 数据保存在服务器端。相对来说 `Session` 安全性更高。如果使用 `Cookie` 的一些敏感信息不要写入 `Cookie` 中,最好能将 `Cookie` 信息加密然后使用到的时候再去服务器端解密。
+
+**那么,如何使用 `Session` 进行身份验证?**
+
+## 如何使用 Session-Cookie 方案进行身份验证?
+
+很多时候我们都是通过 `SessionID` 来实现特定的用户,`SessionID` 一般会选择存放在 Redis 中。举个例子:
+
+1. 用户成功登陆系统,然后返回给客户端具有 `SessionID` 的 `Cookie`
+2. 当用户向后端发起请求的时候会把 `SessionID` 带上,这样后端就知道你的身份状态了。
+
+关于这种认证方式更详细的过程如下:
+
+
+
+1. 用户向服务器发送用户名、密码、验证码用于登陆系统。
+2. 服务器验证通过后,服务器为用户创建一个 `Session`,并将 `Session` 信息存储起来。
+3. 服务器向用户返回一个 `SessionID`,写入用户的 `Cookie`。
+4. 当用户保持登录状态时,`Cookie` 将与每个后续请求一起被发送出去。
+5. 服务器可以将存储在 `Cookie` 上的 `SessionID` 与存储在内存中或者数据库中的 `Session` 信息进行比较,以验证用户的身份,返回给用户客户端响应信息的时候会附带用户当前的状态。
+
+使用 `Session` 的时候需要注意下面几个点:
+
+1. 依赖 `Session` 的关键业务一定要确保客户端开启了 `Cookie`。
+2. 注意 `Session` 的过期时间。
+
+另外,Spring Session 提供了一种跨多个应用程序或实例管理用户会话信息的机制。如果想详细了解可以查看下面几篇很不错的文章:
+
+- [Getting Started with Spring Session](https://codeboje.de/spring-Session-tutorial/)
+- [Guide to Spring Session](https://www.baeldung.com/spring-Session)
+- [Sticky Sessions with Spring Session & Redis](https://medium.com/@gvnix/sticky-Sessions-with-spring-Session-redis-bdc6f7438cc3)
+
+## 多服务器节点下 Session-Cookie 方案如何做?
+
+Session-Cookie 方案在单体环境是一个非常好的身份认证方案。但是,当服务器水平拓展成多节点时,Session-Cookie 方案就要面临挑战了。
+
+举个例子:假如我们部署了两份相同的服务 A,B,用户第一次登陆的时候 ,Nginx 通过负载均衡机制将用户请求转发到 A 服务器,此时用户的 Session 信息保存在 A 服务器。结果,用户第二次访问的时候 Nginx 将请求路由到 B 服务器,由于 B 服务器没有保存 用户的 Session 信息,导致用户需要重新进行登陆。
+
+**我们应该如何避免上面这种情况的出现呢?**
+
+有几个方案可供大家参考:
+
+1. 某个用户的所有请求都通过特性的哈希策略分配给同一个服务器处理。这样的话,每个服务器都保存了一部分用户的 Session 信息。服务器宕机,其保存的所有 Session 信息就完全丢失了。
+2. 每一个服务器保存的 Session 信息都是互相同步的,也就是说每一个服务器都保存了全量的 Session 信息。每当一个服务器的 Session 信息发生变化,我们就将其同步到其他服务器。这种方案成本太大,并且,节点越多时,同步成本也越高。
+3. 单独使用一个所有服务器都能访问到的数据节点(比如缓存)来存放 Session 信息。为了保证高可用,数据节点尽量要避免是单点。
+
+## 如果没有 Cookie 的话 Session 还能用吗?
+
+这是一道经典的面试题!
+
+一般是通过 `Cookie` 来保存 `SessionID` ,假如你使用了 `Cookie` 保存 `SessionID` 的方案的话, 如果客户端禁用了 `Cookie`,那么 `Session` 就无法正常工作。
+
+但是,并不是没有 `Cookie` 之后就不能用 `Session` 了,比如你可以将 `SessionID` 放在请求的 `url` 里面`https://javaguide.cn/?Session_id=xxx` 。这种方案的话可行,但是安全性和用户体验感降低。当然,为了你也可以对 `SessionID` 进行一次加密之后再传入后端。
+
+## 为什么 Cookie 无法防止 CSRF 攻击,而 Token 可以?
+
+**CSRF(Cross Site Request Forgery)**一般被翻译为 **跨站请求伪造** 。那么什么是 **跨站请求伪造** 呢?说简单用你的身份去发送一些对你不友好的请求。举个简单的例子:
+
+小壮登录了某网上银行,他来到了网上银行的帖子区,看到一个帖子下面有一个链接写着“科学理财,年盈利率过万”,小壮好奇的点开了这个链接,结果发现自己的账户少了 10000 元。这是这么回事呢?原来黑客在链接中藏了一个请求,这个请求直接利用小壮的身份给银行发送了一个转账请求,也就是通过你的 Cookie 向银行发出请求。
+
+```html
+<a src=http://www.mybank.com/Transfer?bankId=11&money=10000>科学理财,年盈利率过万</>
+```
+
+上面也提到过,进行 `Session` 认证的时候,我们一般使用 `Cookie` 来存储 `SessionId`,当我们登陆后后端生成一个 `SessionId` 放在 Cookie 中返回给客户端,服务端通过 Redis 或者其他存储工具记录保存着这个 `SessionId`,客户端登录以后每次请求都会带上这个 `SessionId`,服务端通过这个 `SessionId` 来标示你这个人。如果别人通过 `Cookie` 拿到了 `SessionId` 后就可以代替你的身份访问系统了。
+
+`Session` 认证中 `Cookie` 中的 `SessionId` 是由浏览器发送到服务端的,借助这个特性,攻击者就可以通过让用户误点攻击链接,达到攻击效果。
+
+但是,我们使用 `Token` 的话就不会存在这个问题,在我们登录成功获得 `Token` 之后,一般会选择存放在 `localStorage` (浏览器本地存储)中。然后我们在前端通过某些方式会给每个发到后端的请求加上这个 `Token`,这样就不会出现 CSRF 漏洞的问题。因为,即使有个你点击了非法链接发送了请求到服务端,这个非法请求是不会携带 `Token` 的,所以这个请求将是非法的。
+
+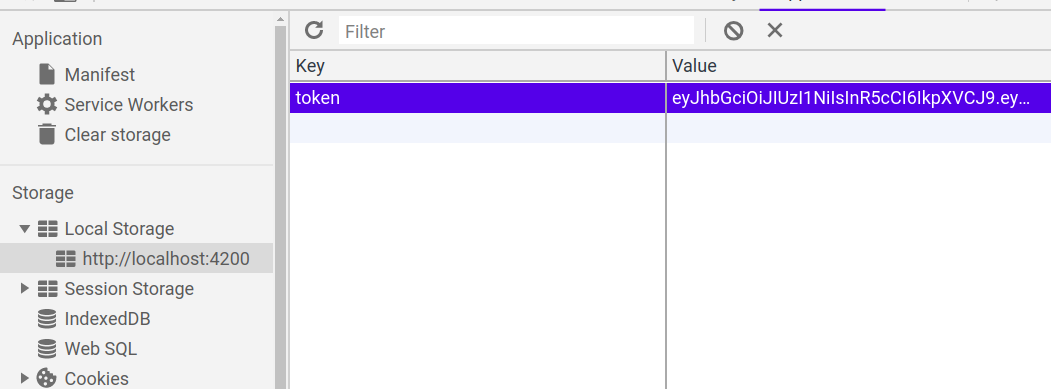
+
+需要注意的是不论是 `Cookie` 还是 `Token` 都无法避免 **跨站脚本攻击(Cross Site Scripting)XSS** 。
+
+> 跨站脚本攻击(Cross Site Scripting)缩写为 CSS 但这会与层叠样式表(Cascading Style Sheets,CSS)的缩写混淆。因此,有人将跨站脚本攻击缩写为 XSS。
+
+XSS 中攻击者会用各种方式将恶意代码注入到其他用户的页面中。就可以通过脚本盗用信息比如 `Cookie` 。
+
+推荐阅读:[如何防止 CSRF 攻击?—美团技术团队](https://tech.meituan.com/2018/10/11/fe-security-csrf.html)
+
+## 什么是 Token?什么是 JWT?
+
+我们在前面的问题中探讨了使用 `Session` 来鉴别用户的身份,并且给出了几个 Spring Session 的案例分享。 我们知道 `Session` 信息需要保存一份在服务器端。这种方式会带来一些麻烦,比如需要我们保证保存 `Session` 信息服务器的可用性、不适合移动端(依赖 `Cookie`)等等。
+
+有没有一种不需要自己存放 `Session` 信息就能实现身份验证的方式呢?使用 `Token` 即可!**JWT** (JSON Web Token) 就是这种方式的实现,通过这种方式服务器端就不需要保存 `Session` 数据了,只用在客户端保存服务端返回给客户的 `Token` 就可以了,扩展性得到提升。
+
+**JWT 本质上就一段签名的 JSON 格式的数据。由于它是带有签名的,因此接收者便可以验证它的真实性。**
+
+下面是 [RFC 7519](https://tools.ietf.org/html/rfc7519) 对 JWT 做的较为正式的定义。
+
+> JSON Web Token (JWT) is a compact, URL-safe means of representing claims to be transferred between two parties. The claims in a JWT are encoded as a JSON object that is used as the payload of a JSON Web Signature (JWS) structure or as the plaintext of a JSON Web Encryption (JWE) structure, enabling the claims to be digitally signed or integrity protected with a Message Authentication Code (MAC) and/or encrypted. ——[JSON Web Token (JWT)](https://tools.ietf.org/html/rfc7519)
+
+JWT 由 3 部分构成:
+
+1. **Header** : 描述 JWT 的元数据,定义了生成签名的算法以及 `Token` 的类型。
+2. **Payload** : 用来存放实际需要传递的数据
+3. **Signature(签名)** :服务器通过`Payload`、`Header`和一个密钥(`secret`)使用 `Header` 里面指定的签名算法(默认是 HMAC SHA256)生成。
+
+## 如何基于 Token 进行身份验证?
+
+在基于 Token 进行身份验证的的应用程序中,服务器通过`Payload`、`Header`和一个密钥(`secret`)创建令牌(`Token`)并将 `Token` 发送给客户端,客户端将 `Token` 保存在 Cookie 或者 localStorage 里面,以后客户端发出的所有请求都会携带这个令牌。你可以把它放在 Cookie 里面自动发送,但是这样不能跨域,所以更好的做法是放在 HTTP Header 的 Authorization 字段中:`Authorization: Bearer Token`。
+
+
+
+1. 用户向服务器发送用户名和密码用于登陆系统。
+2. 身份验证服务响应并返回了签名的 JWT,上面包含了用户是谁的内容。
+3. 用户以后每次向后端发请求都在 `Header` 中带上 JWT。
+4. 服务端检查 JWT 并从中获取用户相关信息。
+
+## 什么是 SSO?
+
+SSO(Single Sign On)即单点登录说的是用户登陆多个子系统的其中一个就有权访问与其相关的其他系统。举个例子我们在登陆了京东金融之后,我们同时也成功登陆京东的京东超市、京东国际、京东生鲜等子系统。
+
+
+
+## 什么是 OAuth 2.0?
+
+OAuth 是一个行业的标准授权协议,主要用来授权第三方应用获取有限的权限。而 OAuth 2.0 是对 OAuth 1.0 的完全重新设计,OAuth 2.0 更快,更容易实现,OAuth 1.0 已经被废弃。详情请见:[rfc6749](https://tools.ietf.org/html/rfc6749)。
+
+实际上它就是一种授权机制,它的最终目的是为第三方应用颁发一个有时效性的令牌 Token,使得第三方应用能够通过该令牌获取相关的资源。
+
+OAuth 2.0 比较常用的场景就是第三方登录,当你的网站接入了第三方登录的时候一般就是使用的 OAuth 2.0 协议。
+
+另外,现在 OAuth 2.0 也常见于支付场景(微信支付、支付宝支付)和开发平台(微信开放平台、阿里开放平台等等)。
+
+微信支付账户相关参数:
+
+
+
+下图是 [Slack OAuth 2.0 第三方登录](https://api.slack.com/legacy/oauth)的示意图:
+
+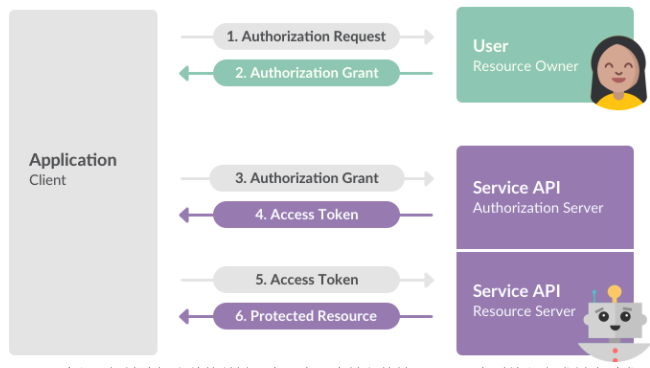
+
+**推荐阅读:**
+
+- [OAuth 2.0 的一个简单解释](http://www.ruanyifeng.com/blog/2019/04/oauth_design.html)
+- [10 分钟理解什么是 OAuth 2.0 协议](https://deepzz.com/post/what-is-oauth2-protocol.html)
+- [OAuth 2.0 的四种方式](http://www.ruanyifeng.com/blog/2019/04/oauth-grant-types.html)
+- [GitHub OAuth 第三方登录示例教程](http://www.ruanyifeng.com/blog/2019/04/github-oauth.html)
diff --git a/docs/system-design/security/images/basis-of-authority-certification/Session-Based-Authentication-flow.png b/docs/system-design/security/images/basis-of-authority-certification/Session-Based-Authentication-flow.png
new file mode 100644
index 00000000000..4a21c3d45dd
Binary files /dev/null and b/docs/system-design/security/images/basis-of-authority-certification/Session-Based-Authentication-flow.png differ
diff --git a/docs/system-design/security/images/basis-of-authority-certification/cookie-sessionId.png b/docs/system-design/security/images/basis-of-authority-certification/cookie-sessionId.png
new file mode 100644
index 00000000000..f3940106437
Binary files /dev/null and b/docs/system-design/security/images/basis-of-authority-certification/cookie-sessionId.png differ
diff --git a/docs/system-design/security/images/basis-of-authority-certification/jwt.drawio b/docs/system-design/security/images/basis-of-authority-certification/jwt.drawio
new file mode 100644
index 00000000000..9ed78b84869
--- /dev/null
+++ b/docs/system-design/security/images/basis-of-authority-certification/jwt.drawio
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-06-15T07:51:52.006Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="BlT26OI0w3JnmsRQ2GOB" version="13.4.5" type="device"><diagram id="Gv1XkoxmDoOVkgf1aGpN" name="Page-1">7XvZlqNIsu3X5OOpxTw8OvMgEKNAvCFAzIOYxddfJzMyszKz+vY551Z19+rbilgKMHDD3Wy72TbH4xPOt7s8xkNh9GnWfMKQdP+EC58wDEURCv45Je8vEpalvwjysUw/bvoucMsj+xAiH9KlTLPphxvnvm/mcvhRmPRdlyXzD7J4HPvtx9ueffPjU4c4z34RuEnc/CoNynQuvkgZjP4uV7IyL74+GaXYL1fa+OvNHyOZijjtt9+JcPETzo99P385anc+a07jfbXLl3bS37j6rWNj1s3/nQZOLGiFUNQCaVOYqPtBohD/hWJf1Kxxs3yM+KO38/urCcZ+6dLs1IJ+wrmtKOfMHeLkvLpBp0NZMbfNx+Vn2TR83/Tj57Z4GmfMM4HyaR77OvvdFSphssfzvFJnc1J8NP/oTTbO2f43x4l+sx6EXda32Ty+4S0fDUgc+Y0mv7T6AB3Kfvhg++5C9Ktfit+5Dyc+hPEHbPJv6r9bFh58GPd/Ymj8rzX085lRyR8aOqXZB4L8BYbGqd/+9cxM/H0zw4k4nIdl+3nuc6cRSjjjL/Eja6x+Kuey7+D1Rz/PfQtvaM4LXJzU+WcP/WD18/M7HaAp87Pt3J/uiqfhS0x6lvvpV+7zI8FXKfJVAo/TeI4/4eDLKSYNXf4J48sbd3U2RJfzHsCP6fqF6OfwSGXgFw9/7qf8bXqDDP+KjNiI9s0hwgVLrgjr+44r0ViQm/tYCW/ejyuxbufKDojLG1Db5OlH/9L3ib2x6gj/Pg1PjcldnDzRkd+TkTv5Q8cto+dd0b7SI61Y+LJmlRooVyzI0tmjMfzuaaS+rixiydJG+ulbqDfJSs3wnlxtwOSS8AAZPzwc5JHbiRxXE7AuwXx/W9smcjNH8N3c3SaOI+6vKwIY08WqHgdgu6JKnMsH+/CatO+mm8Ll3ptmMm4PYuVGmA0zDWpKL5R/SQjKsJPluCGKMioGbuSSUqUOBWpOGXED53P5n3S+F8HzrSyxMNKbebM/Ydwl6QeTyET2uN54X0IkSx+1a8rNPHQ5Z13sRJORHii1eSwoHUsc2XYtXYHjSI/5iaSvx2ZY13s0p1SScYNlaymIT5nV540kX5+8n9xrNDqGnM+Zw6OzAZDkQmIzdUVNolUaY8IW9mrxiNLLC5A+y5DNLStFqfTFcGNWYWfjaSLtMXpHbjCbYvF58HoW02jAfgAEQ+R4hjC9shdJIqk2LRlHJjRZfcep6uP5vVUwWamXm+5tzNxeJPJiXBmrMhxfvTFiJZLStda9w7AEUqioUP88yibfoQXiTYDSo74ByeLUU+I4wzmSioFPtO9U/S7uWaShkWEtE6gYNtEkm6sQx7DqIN4myyAOCwn0wSACpS2dwDuOERCHEfK3EKi77Hmk3DKCcEDdYGObcvAyrSDvU1hPG71BqbFLdhFuruHVPmUPlrExVn21hqT3lTbOAkEhR2AwVnd1fODDASmkJNe6cFytg+Wql6dLBVl3t/pURm28daAbHJBsOeIpcaKR3+CADDgg5/6qDzigWJMiy7pOQmXsiXZLQCVGplV/8SwhCFigN589BUOJewirQBzijZee0ERXxxv4minoCbISCSPSYyyYcBWOfk6t5tjX1Yfy55WyXsT8RqcuG9hSyaJ4eY9FcoVxY72PMalZwh12znxdXpPglWQxX/KaMUca68txY3mtbZGJrwhsXeNcty6YimWxu8lWFcPAzb1A/UVPZBQhzBxS+sRYZxnOS9ZBTiFWteSp3x5vn6M8nAoS1UzY5a1QzvWZ4NZx6hFF82Dtejc9FzOc1xUPPfWRcXrDe2+tksm3oGFdGa43dtbI19rcsiNIBzpCKe/hZqlGeueXEMAvxfHuVMEczj6yQ3atGXTFXuuwWv5c0qlTDdb1dQZbS22ZYTVqYxw1I3QzbSFvGLuQ0EOJMLBNEMZdm+PYCzHUA0u7iHyG6PyAncU0+BWQvXPdMuPWXY2eOSBkJcMzjol+w5Aq0t7jjQ24LXeLtC1a1GCRPoc3+bWS76wbKXp+hKiOvFCpnxFQEEWiUtWzMu6CFmMznVjBdJqFSZU3A0o+2Z2YlyXW4PKpquNqTe7D3DhALshbItKGzbE8r64V8yxoF/akxq/N/datEOxSom8bsdsSy3eXKW8ATvQBTPapGNEMO2LKiBCPNss8B5GD7kkvx1M42OvOPpUUtrY46D7JT0UaiWvVwx/Iuiz2xc2jMPZQJMYvSdOpfESJQNglXY9IJaxgFzhpJ/gB6xBdJWBW53ImCfcp6EOYojzOtdbB0mTjwg8C+W7euoGPqUYgVpFl/Vycj8w1mhPLwljNKLHPhMdpjk+KY63leX4m4vP3z+eRyA/kBsfx33DmF37D4r/SGwb/DSP+KoJD/v9BcMDvCI4gWK1ygQfGtf5GcNLnffNZp1PWMy1Mipu6YeE8uODtx0LTpNjdMqygwXTOvHE9OsQFDGzSiwMO1qDXah4G+Qz/xiOg3luCDcfcvEanuZrmTR7vfYmtw34/6CXtvBNO3KzF/OHH87UawGM9TMVYMzFEniN8etRGMCqkTA3dJ81Vxz5Xhm1IfG94XpxeCG0AxCDyvq0NDySb4FunBYjI9hbUEyuyJQtExGo6V+x90qj7nHLCGclvryf9Yhv75l4iq9epnesUjb0KI6EQwhusDXVZNcWww9LeoskVquihZC1+8gii8AF/PUMU/H00ZbWGcMq4xGl7yldwBBX2NpWHOMsnsseXnusvnMoX2y0LxKf4Np/Vy9mTmr8QQm1st8t8vaOvkbudcQSCW3INyAiZKR2dlMLSOtwU26AR3Ai68JzybV6OAbwNrO/tEd9PGRVcHpsAI87MKfPB+cia8wWYrhC9XH1Gp6riN45C59HYrs2pRHfKkh9BxzYtPG05hzoj4fHaX+CmxxtX2/hNWlRmSMMcFI+y6ypN6azjwF4wUpLLyN8V5dW3ue4/SF83dGy/nl1Hw5dJcJOgSjWJ2goUoW1TnckprsH4cEwoCe+r6CFcfaGYFImbIJ2M3rxd/CWs1k01rDGthwK2uFXZpuWSiy2AzinM9Z6Rz4J0ijITt1rLj0tG8XjPu8BAIY2Ens5G9/Yf/t6DOxIUaNCWFxu07/fjceCE116miNIJ5JqiD5M5SIcMd3W5wQfh+hgOVTSQYZ0fwNgEZr8p7HRkYqd5JrOqhI0AvZkS1wLXqK57DNFegCfWNo9NvDWR+9nd1+3YQcWvAOcnFvaIJjjYo4N87s12AfEZlIzUHQg55kVP05y5ZKjmrkjPR8qetmdOADlrdon8Ec+tlqcR7D3x77rtEjXrV84H6JkADzGQvMngCOfiHte0jlvDNIpsWi5cvjG+p5s0sVJuLuck9Q5bRS5jC8AsGsGHhPDqC/NYon0/D865au8L7ooz9XLdeBjPrHt/3q+inxbA1MesTW+mjD1cU3DM/MjC6uIZsHUjYHlEoVdueOhxLYtkEjCI25XatgN9nmkp5mdp66izsxEyt/irYlYahOMZF3LRO9zHVtq7Ufckh4qhOL+MpiuPtJ63gXbgPW8bW1s060z0Yt820SX9pXAw1rOkp+wAg6O4CfB1LNAP9bT8ObIn+qYcBvDuqnPohUx6ISdSxSqP5WrfoeEckziI5zb7iCNo3ehqcoHtLna4YlTONclHVpSvj0Fks1q5Oh2cYBztUA8iS6FbuGvY4ZBuScjz/SxVrB1zGh3OmVM1Z3/x1+ZiwWWHyCnabe7Xidtyvk7m+zKZ71epSWoz7XWHHPsr2lFtL8O3VajYlZzk9OliHXpQG0TXS34Mox7wDNiN3rcJ23WyrZWAXLKs1WqHY7R0pA7QAvTc1hAV1yqijqN9corssFHwfiT+1D9uzEgVQft8N7mV05z6gjA9RhGn+pMkkq4h5pekAsqom10wJOx1eMgia4vi89I9oqFT9MC4+DBJcym1r/0g4jDmkVZf34EN1JNakzovLrCPK8T77K1uzNhpLnnBRlCtp2pFwIqpBqCCAuCi5q9naAQlF66cYljbLO4JvCY4LWGK0JWsGQZid7dpXYyZAMWsEXndjYIRHOYBzDHOqNjXiSYEyYHcEsnZooK4u+3zWenniERFrOAEHbtCiD6zX2kb3rzImdJKX86wpg4C7HlsSrYgiFZxVlfXohgOD7T+S6oK2LZ6DWgSCoRXhOBwEJQ4ajcuiuKxRIgPCViAd6yTNTedqQg0533xSRUopYNSQMS788iBmocWKhwUAXgFEQknhrm2gLEZMsJD3zgolAnOt4Nc4ZqaaZfpvqP65SH6xTNQlSpTaRisYrkftMviIwAOyrhLAOhAU2gjtdteEkk/WIAzYNNdYnQgyoU83wwAOUW9h5O7ibkuuVVb1kDugnfeIQMArhQ3NkwIfOU18XbZAtBLvBkXdwwoi5GigAytR1eoCFVlIy2vLOKWpGrZ/HZGmjIMTUWHBuyBrpnUQwA3UF0lGxgOzFOcTI98DqTc7MVdazlMJ7hYBxHWMVYxRgdoy9Pvhql1cfvshUtz1kq8iEdKq5F3qGli+cWaVByJQqU7Z9NeEV5nPx2OoIERrV6p73eiX7ed0bYSbVhYEkirtdhMVsP6VC4+52DJLpGVP1CbP4oyiq0nBA5DXXGtz01wpXB8xeFcbonoXVZpr77MnCcwfMexc4i1X5FvbbsHKxfV/MxW+xaDnCRh7j1xfnIFM90gSrPnlrH8l+IqoMBJngGRKRuXtWrQzoQJ88X2XLmVtfBDovdakieIXllf622d5g6sGDu2Y2o5TD3kB5HEinQhX4DZEn1E/LMMEZQnd98CQ4AWhRUj0CdbAY8H27wPqT9T3OqrxEM5Y+hlPuPT/saMJ0Hz+wW7kJkgG1LOr5SdMFlFRSfJlG6351kuIgmkRVwZyzjtbK6q2NxCwIpNUamgoQYiZ/v+aT3OBF6l2EHgS7w1FX8H9MrIF9thr7L1rqYyhqQQXM8q27s2CkGIW1Y/s1VTHzDCmoa9vXYJOPzpyS6wg02yOVjWTZst2Vr1QhFpgTksFXjFEEv1kltDUZ4M4f62mEW9OiN4UuhYaqTfQ6BpJBLvecf5glCZ2kPdevCge7TSEr6XJZmKEYe7Axx3Rtk9GZJuIWif85s2L0J2bWDMvPvhMDpAyb1HJjM3FZjG1q9eUAKLbwPGJAqbALA660uzVUdiOwtO9AUI2dIhdLRMu1EZ1vqQ7zDls00CW8kninN4KgGlOYpPnQxBxh9wZl6GjVexyWHGKiuBWs3F8zXd4qrwX8slIq5pEfDxGQ65GkhITufS4LH5g00yRnolgNGHRHiiLuRvGRC+YKwcPByLo72PMlcCXHbTl8I7tHBR33e6yEfNMdZLFnrrjl8e5zyzJJt/l3No41MeeJ0GwlgdzKegNcPJ+NzUy85w8daL252da3R8RTlM08ihVxPrFBcuQ2+boOpcwD/c4ZEBPleQtqbHyCQ2W8toX645eURHSBQs38iB/84C3BOVnkCRwniQEwiX9fGmLO+FD93Nc0xmlmJWL2Zqeeo8DMcY5gVLv4DyDek3e8eq1KhpQaKjrBmD1+U93TeL0PahxbDHvqqOOioosiSdCTksd9csX9aBDpMwWu1NLjlwot0uMSEswlhYcx62LD7oTDAXDObJAWQgfKIu7w5xFMyBs2/K3tCQVSImTbQw/P0qPQASMTDbZWgizw9Wo68XU6mTDGGdI72JVQx4W1ugbbObqD1u6LYfA7fHzTT5ycZNUjLmFkp3irkGF0eG2v2i5dlJNcWpptTczMnMPyyPNSrSmTUsnV06yC+r/JoR7rLUR5Wey5LRM206Knuj1QTWqg1W5lzIKioAwi7CgEUJj/jMa0bz4KonR+pNwhRRTsvPiicYQtMFxTGqZV3RYh6ZZuojFMz7BgmQkR73Tj/wCT+sRjVVZgNGY9xd38HdPoYPUQw6aNuzlFnw93NWjkR5BrVeJgOhdEC2wUNoc6Wx3ROUYdqshzgSZHsSxX1w37bLkG0v3Pc119BQTvcb1Ra0W8WKATh5qARPDYeLmctAwHCPsbKh2ind5wnlVoN7boipbUPFyqqaQ+lQx1lu9mScV+hAgBqo4QiksRtthMKOB7rTOKm/zugnaYDf5Hw9FP+VcfVZlIUZsTjIRhdYzsRrZlyYJvWJ4nWNbqEI9FxXTBvShE3oVqJTIuBiM9kJaobRzfJgeCQHd317zV5xJWn0rOtCDUtm0E2BygVAVy7m6uMvYunWC9KrAAeMNMDw6HaBHC5xAilfgmqjzqxBoWRRFi3I6Lrr7SQjWDvdz6p0Y0B0LtKsCiwObx3NE1werkLnYJlTOsrieKYFwHvhwovkBGdxeRVUCsXlgrNs3wvMReZvFNcCO6+PnSv4lY+tzZlmrRJDSViuTrCmt5PjwKabiYP3jpBxFxy+P4VkOsuLHmY4rDTbHhSlRIgLOJ5xP8ytgrHLWaHNV/yM7pGKPxu7a94MeBkol/rWnWSw28kH39drcnI5SUT6SmbAYrZuEEwDiFC+jUJH2p3ebexr/Wh9isjENVc3XlTk4KU6zymEwZ/RKxEx+oagR3qCqvR4HQiI/McaKue6d2q6pD2+iYJobY1LYRboMfyFEvOJV8wPeQCq3ca4SUlg0Y3eVOWQ3qCg6cvhEHNqR5kq8hOnqkk9un36IpOB54qopMRTuSqoU9UtdKtaIuf6B+Ymx/XCTpAbgXOtI2jh3D42g+C1YZBPcE46cgjIkxqeVXo7FCsLMjtCFzp9l8+dUJnirNrydGC79RFZ95DI/3HLaAT68+tYHEV/XUdjfl1H+yr78xfRqF8W0bix37Lxl6U0OO75x/euP75f7fou++ll7Ico/lgoS6CdoOJfV9DaMk3Px/zhi97vr4LPNbRn380fWyNQ5uv5RyfRv8BnNP2Dv75tYfidv4g/eK2L/WVvdelf/OVm4/off32dY/QvWx6+baD5p/mM+fsL1VmXgnOPzmn2Jp6mMvlpj8NPdsx2SB3Pk98QjP04v582/w0l6I9zYf9wwueT9+9OrGws4dhO5wp/Yz9Elv6yG+gnH8D+98uYZH93q8evzvqdJ8g/8MRX2Zg18VyuP/bjj9zz8QSrL2EPv+/K+Om9BfbzXosv/f9o9fv9Qj8pIvG/o2iOxzybf1H0GS3fhv3/ACD23xJA/yxcoBSMETjy/YP94F0C+d/D5OfYA3X99lX9PwgsX8PYnwqWDvYp/IwOlqW+Cr7ABUe+Cb7j5fPZ+/dnPyPmK/7+Cxroi4ZvAMRR7N8bgCdQSPRHoNDYbwjOfv9Q/zsMouTPW9EI+h8brL6a4z/4+5fGH/Ij/nDsT8PfT3r/wej7dRevdXW9T2c3pGU6ebLU9HnZfcKo5uTHDyih8vmb1/7lGfSfzZh/3t2BIb/SZZShfgXjX8aXsV83CGuB92sQaZpymP6WEf8v0eSn/cLZ588f7RfGKZzF07/C5sxPNif/wOboHwQA6i+z+a8U08mmoe+ggf8zLz7nUeKfPS/wX5ndv/m8+Bs7zf6sqXG+o/v2TydfMtD3f93Bxf8D</diagram></mxfile>
\ No newline at end of file
diff --git a/docs/system-design/security/images/basis-of-authority-certification/jwt.png b/docs/system-design/security/images/basis-of-authority-certification/jwt.png
new file mode 100644
index 00000000000..53a6a98f336
Binary files /dev/null and b/docs/system-design/security/images/basis-of-authority-certification/jwt.png differ
diff --git a/docs/system-design/security/images/basis-of-authority-certification/session-cookie.drawio b/docs/system-design/security/images/basis-of-authority-certification/session-cookie.drawio
new file mode 100644
index 00000000000..c5d46f5767f
--- /dev/null
+++ b/docs/system-design/security/images/basis-of-authority-certification/session-cookie.drawio
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-08-09T08:51:58.985Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="8V5xbVs_TM5qi22DgBJ3" version="13.4.5" type="device"><diagram id="Fq0hJoVpaqgBU1I4s99t" name="Page-1">7XtXt6O6lu6vqceuQQ6PIgeDiQb7DQMmB5PNr7+ialVc1ffs7t619+k+x2sN20yhKWnGbwr5A843mzxEfW50SVp/wJBk+4ALHzAMRREKfhyU12cKw2KfCdlQJG83fSO4xZ6+EZE36lwk6fjDjVPX1VPR/0iMu7ZN4+kHWjQM3frjbY+u/nHUPsrSdwQ3jur31KBIpvxtFRj9ja6kRZZ/GRml2M8tTfTl5reVjHmUdOt3JFz8gPND102fvzUbn9aH8L7I5XM/6T9p/TqxIW2nP9IBGborH18rN0xtQ72fpUJy/uNNO0tUz28Lfpvs9PoigaGb2yQ9mKAfcG7Niyl1+yg+Wleoc0jLp6Z+a34Udc13dTd86osnUco8Ykgfp6Gr0u9aqJhJ74+jpUqnOH/r/n5Nb8tc0mFKt+9Ib2uU065Jp+EFb3lrJXHkI01+7vVmcyj7poL1mwbRL2rJv9MeTrwRozeryb6y/yZY+OVNtv8FOaO/V86PR0rFv5RzQrN3BPkNcsapj/90Usb+sZShF/bH16L55PjcseACuvspuqe11Y3FVHQtbL9309Q18Ib6aOCiuMo+KegHoR+v73iAusiOvlN3aCsa+88B6VFsh1q5T0OCL1TkCwV+T6Ip+oCDz5eY1LfZB4wvLtzZWRFdzjoAX6br56KfwW8qA994+Hc96C/T62X4KTJiLdoXhwhnLD4jrO87rkRjQWZuQym8eD8qxaqZSjsgTi9AraOn791T30b2wqoD/HwYnhqRmzh6oiO/RiNzsruOW0bHu6J9pgdasfB5SUs1UM5YkCaTR2P41dNIfVlYxJKllfSTl1CtkpWY4TU+24DJJOEOUr6/O8g9s2M5KkdgnYLp+rLWVeQmjuDbqb2MHEdcn2cEMKaLlR0OwHpGlSiTd/bu1UnXjheFy7wXzaTcFkTKhTBrZuzVhJ4p/xQTlGHH835BFGVQDNzIJKVMHApUnDLgBs5n8t90veXB46XMkTDQq3mxP2DcKe56k0hFdj9feF9CJEsftHPCTTxUOWed7FiTkQ4olbnPKB1JHNm0DV2CfU/26YEkz/tqWOfrbUqoOOV6y9YSEB00q8tqST4/eB86BXrb+4zPmN2j0x6Q5ExiE3VGTaJRamPEZvZs8YjSyTOQPtGQ1S1KRSn12XAjVmEn42EizT54e2Ywq2LxWfB85ONgwHkABEPkaIJmemZPkkRSTVIwjkxosvqKEtXHs2ujYLJSzRfdW5mpOUnkyTgzVmk4vnphxFIkpXOle7thCaRQUqH+aZV1tkEJRKsAqXt1AZLFqQfFcfpjJSUDR7SvVPXKr+lNQ2+GNY+gZNhYk2yuRBzDqoJoHS2D2C0k0HuDCJSmcAJv3wdA7EbIX0KgbrLnkXLDCMIOeYOVrYveS7WcvI5hNa70CqnGJtl5uLqGV/mU3VvGyljV2erjzleaKA0EhRyAwVjt2fGBDxekkJJc6cJ+tnaWK5+eLuVk1V6qgxm18taOrnBBsuWIB8W5DfwKF2TABTnXZ7XDBUWadLOs8yiUxhZrlxiU4s20qs+aJQQBC/T6k6ZgKHF3YRGIXbzw0gOK6Ox4PV8xOT1CSCJhRLIPORMuwt5NiVXv27L4kP44U9aTmF7o2KY9WyjpLZpfQx6fYdxYrkNEapZwhZMzn6fnKHgFmU+nrGLMgca6YlhZXmsaZORLAluWKNOtE6ZiaeSuslVGMG5zT1B95nMz8hAmDil5YKwz90eTtZNjiJUNefC3h8unIA9dQaLqETu9FMo5P2Lc2g8+omjurF1tpudihvM846Gn3lNOr3nvpZUy+RI0rC3C5cJOGvlc6ku6B0lP31DKu7tpopHe8SYE8E1xvCuVM7uzDWyfnisGXbDn0i+WPxV04pS9dX4ewdZSG6ZfjMoYBs0I3VSbyQvGziTUUCz0bB2EUdtkOPZEDHXHkvZGPkJ0usPJYhp8C8jOOa+pcWnPRsfs0GQlwzP2kX7BkCrS3v2F9bgtt7O0ztqtxm76FF7k50K+0nag6OkeojryRKVuQkBO5LFKlY/SuApahE10bAXjIRYmUV4MKPh4cyJelliDy8ayisolvvZT7QA5Jy+xSBs2x/K8upTMI6ddOJMKP9fXS7tAY5difV2JzZZYvj2NWQ1wogtg+k/EG82wA6YMCHFv0tRzEDloH/S8P4SdPW/sQ0lgb4uD6pP8RKSRqFI9/I4s82yf3OwWRh6KRPgprluVv1EiEDZJ12+kEpZwCpy0EXyPtYiuEjCpcxkTh9sYdCFMUR7nWktvabJx4nuBfNUv3cCHRCMQK0/TbsqPITON5sQiNxbzFttHwuM0xyfFodKyLDsS8fH/56NI5Adsg+P4R5x5B29Y/D26YfCPGPGb8A3xr4FvwHf4RhCsRjnBL8a5+opvksd19VmnVZYjK4yKm7hh7ty54OVHQl0n2NUyrKDGdM68cB3aRzmMa9KTAw5Wo+dy6nv5iP7GPaBea4z1+1Q/B6c+m+ZFHq5dgS39dt3pOWm9w5q4SYv43Y+mc9mD+7KbirGkYog8Bjj6rbnBoJAwFdSeNJUt+1gYtibxreZ5cXwitAEQg8i6pjI8EK+Cbx0SIG62N6OeWJINmSMiVtGZYm+jRl2nhBOOQH55PugnW9sX93SzOp3auFbR2LMwEAohvMBSU6dFUww7LOz1NrpCebsraYMfMILIfcCfjwgF/+91US4h9BiXOGRP+QqOoMLWJHIfpdlIdvjccd2JU/l8vaSB+BBf5qN8Oltc8SdCqIz1cprOV/Q5cJcjjEAblFwDAkJmTAYnobCkClfFNmgEN4I2PDy+yYohgLeB5bXeo+tBo4LTfRVgwJk4Zdo5H1kyPgfjGVovVx3BqSz5laPQaTDWc30w0Z2i4AfQsnUDLxvOoY5AuD+3J7jo0cpVNn6RZpXpkzAD+b1o21JTWmvfsScMlOQ88FdFeXZNpvt30tcNHdvOx9TR8GkS3CioUkWitgJJaFOXR26KKjDcHRNSwusieghXnSgmQaI6SEajMy8nfw7LZVUNa0iqPoc9LmW6apnkYjOgMwpzvcfNZ0Ey3lITtxrLjwpG8XjPO8E4IQ2EnkxG+/Lv/taBKxLkaNAUJxs0r9f9vuOE15zGG6UTyDlB7yazkw4Zbup8gQPh+hD25a0nwyrbgbEKzHZR2HFPxVbzTGZRCRsBej3GrgXOt6rqMER7Ap5Ymiwy8cZErsd0n5d9AyW/AJwfWTgjmuDgjHbysdXrCURHTDIStyfkiBc9TXOmgqHqqyI97gl7yJ45DMhZ0tPNH/DMangawV4j/6qaNlbTbuF8gB75bxcDyRsNjnBO7n5OqqgxTCNPx/nEZSvje7pJEwvlZnJGUq+wUeQisgBMojc4SAhbn5jHEs3rsXPOWXudcFecqKfrRv1wJN3r43oW/SQHpj6kTXIxZezumoJjZnsalifPgL1rActuFHrm+rseVbJIxgGDuG2hrRvQp4mWIn6S1pY6JntDpgZ/lsxCg3A44kImert7Xwt7M6qO5FAxFKenUbfFnlTT2tMOvOdlY0uDpq2JnuzLKrqkP+cOxnqW9JAdYHAUNwK+igT6rh6SP1b2QF+UwwDeXXQOPZFxJ2REoljFPp/tKxScYxI78VgnH3EErR1cTc6xzcV2V7wVU0XyN+uWLfdeZNNKOTstdDCOdqg7kSZQLdw5bHGItiTk8XoUKtYMGY32h+eU9TFf/Lm6WHDaoOXkzTp1y8itGV/F03Uezdez0CS1HreqRfbtedtQbSvCl5Wr2Jkc5eThYi26Uyu0rqd87wc94BmwGZ1vE7brpGsjAblgWavRdsdo6JvaQwnQU1NBqziXN2rfmwenyA57C1732B+7+4UZqDxoHq86szKaU5/QTPdBxKnuwIika4jZKS6BMuhmG/Qxe+7vssjaovg4tfdb3yp6YJx8mKO5hNqWrhdxGPNIq6uuwAbqgaxJnRdnOMcF2vvkLW7E2EkmecFKUI2nannAiokGIIMc4KLmL0doBAUXLpxiWOskbjFsE5yGMEWoStYMA7G92rQuRkyAYtaAPK9GzggOcwfmEKVU5OtEHYJ4Ry6x5Ky3nLi6zeNR6seKREUsoYMObS7cPoFfae1fvMiZ0kKfjrCm9gKceWRKtiCIVn4UV+c873cPNP5TKnPYt3z2aBwKhJeHYHcQlNgrN8rz/D7fEB/irwBvWSetLzpTEmjG++KDylFKB4WAiFfnngE1Cy1U2CkC8AoiEk4Ec20OYzMEhLu+cpAoE5xvB5nC1RXTzON1Q/XTXfTzR6AqZarSMFhFctdrp9lHAFyUcZUA0IGm0EZiN50kkn4wA6fHxqvE6ECUc3m6GABiimoLR3cVM11yy6aogNwGr6xFegBcKaptmBD40quj9bQGoJN4M8qvGFBmI0EBGVr3NlcRqkwHWl5YxC1I1bL59Yg0RRiaig4F2AFdM6m7AC6gPEs2MByYpziZHvgMSJnZiZvWcJhOcJEObljLWPlw20FTHHo3TK2NmkcnnOqjVOJF/KY0GnmFnEaWn61RxZFbqLSHN20l4bX2w+EIGhi3xSv07Up0y7ox2lqgNQsrAmmxZptJK1ieyvmnHCzZBbLwO2rze17cIusBDYehzrjWZSY4Uzi+4NCXG+L2KsqkU59mxhMYvuHYscTKL8mXtl6DhbtV/MSW2xqBjCRh7j3s/MAKZrJCK00fa8ryn2urgAIHdgZEqqxc2qhBMxEmzBfrY+EW1sJ3id4qSR6h9cr6Uq3LOLVgwdihGRLLYao+24k4UqQT+QTMGusD4h9ViKA8uOsaGAKUKCwYgT7aCrjf2fq1S92R4hZfJe7KEUNP0xGfthdmPAia307YiUwF2ZAyfqHsmElL6naATOlyeRzVIhJDWMQVkYzTzuqqis3NBCzYFJUKaqonMrbrHtb9SOBlgu0EPkdrXfJXQC+MfLId9ixbr3IsIggKwfkosr1zrRCEuKbVI1009Q4jrGnY63OTgMMfmmwDO1glm4NV3bjakq2VTxSRZpjDEoFXDLFQT5nV58WBEK4vi5nVszOAB4UOhUb6HTQ0jUSiLWs5XxBKU7urawfudIeWWsx3siRTEeJwV4DjziC7B0LSLQTtMn7VpllIzzWMmVc/7AcHKJl3T2XmogLTWLvFCwpg8U3AmERuEwAWZ11hNupArEe9iT4BIVs6NB0t1S5UijU+xDtM8WjiwFaykeIcnopBYQ7iQydDkPI79MxTv/IqNjrMUKYFUMspfzzHS1Tm/nM+3Yhzkgd8dIRDrgISktGZ1HtsdmfjlJGeMWD0PhYeqAvxWwqEzzZW9B6ORbetu6WuBLj0os+5t2vhrL6udJ4NmmMspzT0lg0/3Q8/sySbfxVTaONjFnitBsJI7c2HoNX9gfjcxEuPcPHS88uVnSp0eN4ymKaRXS9H1slPXIpeVkHVuYC/u/09BXymIE1FDzeTWG0tpX254uQBHSBQsHwjA/4rDXBPVDoCRXLjTo4gnJf7i7K8J963F88xmUmKWD2fqPmh8zAcY5gXzN0MiheE3+wVKxOjogWJvqX1EDxPr/G6WoS29Q2G3bdFddRBQZE5bk2IYbmrZvmyDnSYhNFyqzPJgY52OUWEMAtDbk1Z2LB4rzPBlDOYJwcQgfCxOr9axFEwB3rfmL6gIMtYjOvbzPDXs3QHyI2B2S5FY3m6sxp9PplKFacI6+zJRSwjwNvaDGWbXkTtfkHXbe+5LarH0Y9XbpTiIbNQulXMJTg5MuTu5w3PjqopjhWlZmZGpv5ueaxRks6kYcnk0kF2WuTnhHCnudrL5NiVvD2SuqXSF1qOYCmbYGGOfay8BCBsbxiwKOEeHXnNqO9c+eBIvY6Z/JbR8qPkCYbQdEFxjHJeFjSfBqYeuxsKpm2FAMhI9mur7/iI71atmiqzAqM2rq7v4G4XwUEUgw6a5ihlZvz1mJQ9Vh5BpRdxTygtkG1wF5pMqW33MMowqZddHAiyOYDi1rsv22XIphOu25JpaCgn24VqctotI8UAnNyXgqeG/cnMZCBguMdYaV9ulO7zhHKpwDUzxMS2IWNlUc2+cKj9KDc7MspKtCdABdRwANLQDjZCYfsd3Wic1J9H9JM0wK9ytuyK/0y56ijKwpSYHWSlcyxjoiU1Tkyd+ET+PN8uoQj0TFdMG8KEVWgXolVuwMUmshXUFKPr+c7wSAau+vqcvPxM0uhR14UaFk+gHQOVC4CunMzFx5/E3C4npFMBDhiph+HRbQM5nKMYQr4Y1QadWYJcSW/pbUYG110uBxjBmvF6VKUrA27HHs2iwOLw0tI8wWXhIrQOljqFo8yOZ1oAvGYuPElOcBSXZ0GlUFzOOcv2vcCcZf5CcQ2ws2rfuJxf+MhanXHSSjGUhPnsBEtyOTAO7LqaOHhtCBm1we77Y0gmkzzrYYrDSrPpQF5IhDiD/RF1/dQoGDsfFdp0xo/oflPxR2239YsBTwPlEt+6kgx2OfDg63yODywniUhXygyYzcYNgrEHN5RvbqEjbU7n1va5ujc+RaTikqkrLypy8FSdxxjC4M/opYgYXU3QAz1CVnq09AS0/PsSKse2d2K6pD28iJxobI1LYBboMPyJEtNhr5gf8gCUm41xoxLDohu9qMouvUBO06fdIabEvqWqyI+cqsbV4HbJk4x7nstvBSUezFVBHct2phvVEjnX3zE33s8ndoTYCBx7HUEDfXtfDYLX+l4+jHPUkV1AHlT/KJPLrlhpkNo3dKaTV/HYCJXJj6otS3q2Xe436xoS2V+3i0agPz+LxVH0/TYa834b7QvtT99Do9/toXFDt6bDu500uMbpx4euPz5cbbs2/elJ7Bspetsni6HkIOP3G2hNkSTHML98yvvtOfCxhfbo2untVATKfLl+myT6G1RG0z+o6+vphe/URfzimS72ux7pMu/U5abD8m91ffEw+t1ph69HZ/4ulbH/eJc6bRNwHM45pF5H41jEPx1v+EmM6QZx43HxEcHYt+vrIfKPKEG/XQvbmw4+Xby+u7DSoYBLO3Qr/PGjEGM3D3H6j890pMkPJ4jeq+o7PZC/0MMX2pDW0VQsP547+pVy3kawugLO+Nt5jJ8eWWA/n7L4vJ63Xt+fE/qJEYn/A0ZTNGTp9I7RJ1v5uuz/wVGZP3BW5n+D/fyT2AVKwQiBI99e2A/aJZD/vpn8HHkgr49f2P9VxoL/BmNp4ZzCT9bBstQXwmdzwZGvhG/28unq9f3Vzxbzxf7+AwroM4evBoij2P9tAzwMhUR/NBQa+4jg7LcX9d+zQZSkPhLfsWHpn4b5iyPXH3g++29j/NuNEfnRGHHsTzPGn/j+xdZHvrM+6+x6H45pSPN4QGap7rKi/YBR9QGV75BCZdNXrf3Tg+k/Gzz/fMoDQ94jZ5Sh3hvjb4PO6B84jw3ZFP34n0nw/xNKfjoznH56/erMME7hLJ78DoEzPwmc/IXA0V94P/XbBP5+O4DvuqpI/0VdAkd/Kiapv7mYRN9vAIwpTJtdqyb/C3RE/hU6Yv5uHf2Riv//TtTC8b87an3R5L+j1q894usvTP4uj8De72H8O2r9pKO/O7Ng71O/k459147/qm70Mx4mfuFGfxYePk6LfP3p4+cS6NsPSHHx/wE=</diagram></mxfile>
\ No newline at end of file
diff --git a/docs/system-design/security/images/basis-of-authority-certification/session-cookie.png b/docs/system-design/security/images/basis-of-authority-certification/session-cookie.png
new file mode 100644
index 00000000000..b3724f5284a
Binary files /dev/null and b/docs/system-design/security/images/basis-of-authority-certification/session-cookie.png differ
diff --git a/docs/system-design/security/images/basis-of-authority-certification/sso.drawio b/docs/system-design/security/images/basis-of-authority-certification/sso.drawio
new file mode 100644
index 00000000000..226a76052d0
--- /dev/null
+++ b/docs/system-design/security/images/basis-of-authority-certification/sso.drawio
@@ -0,0 +1 @@
+<mxfile host="Electron" modified="2021-06-15T08:09:27.916Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="WkS12LLgR0uFu5QGbf4c" version="13.4.5" type="device"><diagram id="SeqBh6is4YTJ0tLNeMIa" name="Page-1">7XzZlqPIku3X5GPXYh4enXkQiFEgXu5CAjEPYhZf305G5Fx9TnX3qVN1e0VkLAVu4I67mbnZth2R/gnnm00e4j43uiStP2FIsn3ChU8YhqIIBX8cktebhGXpN0E2FMn7Q98EbrGn70LkXToXSTr+8ODUdfVU9D8K713bpvfpB1k8DN3642OPrv7xrX2cpb8I3Htc/yoNimTK36QMRn+TK2mR5V/ejFLs250m/vLw+0rGPE669TsRLn7C+aHrprerZuPT+lDeF7289ZP+i7tfJzak7fRHOkh2+h+YL4mv/ye9pIKLaslZ/uPdOuP0+rLgNIHrf292w5R3WdfGtfhNyg3d3CbpMSoCW9+eOXVdD4UoFJbpNL3ejRnPUwdF+dTU73cfXTu930QZ2B6rdLrn7zffJnTM4r9c57to7Obhnv6DxX3xl3jI0ukfPId/tQZ047Rr0ml4wX5DWsdTsfw4j/jdn7Kvz31TObx41/p/wwLv4y5xPb+/6ReTQM/pj8ui+eys3JIOUwFd9BTf0trqxmIquhbev3XT1DXfPQDqIjtuTIdhuHjs33bIo9gO83GfxwNfpMgXCbxO4in+hIO3Jib1bfYJ44sLd3ZWRJezDsAv0/Vz0c/glcrADx7+ux7yl+n1MvwpMmIt2heHCGfsfkZY33dcicaCzNyGUnjxflyKVTOVdkCcXoBaR0/fu6e+jeyFVQf482F4akxu4uiJjvwajczJbjpuGR3vivaZHmjFwuclLdVAOWNBmkwejeFXTyP1ZWERS5ZW0k9eQrVKVmKG1/vZBkwmCTeQ8v3NQW6ZfZfjcgTWKZiuL2tdRW7iCL6d2svIccT1eUYAY7pY2eEArGdUiTN5Z29enXTteFG4zHvRTMptQaxcCLNmxl5N6JnyT3eCMuz7vF8QRRkUAzcySSkThwIVpwy4gfOZ/Be1tzx4vJQ5FgZ6NS/2J4w73bveJFKR3c8X3pcQydIH7ZxwEw9Nzlkn+67JSAeUytxnlI4ljmzahi7Bvif79ECS5201rPM1mhLqnnK9ZWsJiA+Z1WW1JJ8fvH+/Vmi09xmfMbtHpz0gyZnEJuqMmkSj1MaIzezZ4hGlk2cgfZYhq1uUilLqs+HGrMJOxsNEmn3w9sxgVsXis+D5yMfBgPMACIbI8QTd9MyeJImkmqRgHJnQZPUVJ6qPZ9dGwWSlmi+6tzJTc5LIk3FmrNJwfPXCiKVISudK93bDEkihpEL98yrrbIMaiFcBSvfqAiSLUw+J4/THSkoGvtG+UtUrv6aRhkaGNY+gZNi7JtlciTiGVQXxOloGsVtIoPcGEShN4QTevg+A2I2Qv4RA3WTPI+WGEYQdjg1Wti56L9Vy8jqG1bjSK5Qam2Tn4eoaXuVTdm8ZK2NVZ6u/d77SxGkgKOQADMZqz44PfLgghZTkShf2s7WzXPn0dCknq/ZSHYNRK2/t6AoXJFuOeEicaOBXuCADLsi5PqsdLijWpMiyzqNQGttdu9xBKUamVb1ZlhAELNDrz5aCocTdhUUgdvHCSw+oorPj9XzF5PQIc6SEEck+5Ey4CHs3JVa9b8viQ/njTFlPYnqhY5v2bKGkUTy/hvx+hnFjuQ4xqVnCFU7OfJ6eo+AVZD6dsooxBxrrimFlea1pkJEvCWxZ4ky3TpiKpbG7ylYZw6DMPUH1Nk5k5CGMsVLywFhn7o9b1k6OIVY25DG+PVw+R3C4FSSqHrHTS6Gc8+OOW/sxjiiaO2tXm+m5mOE8z3joqbeU02vee2mlTL4EDWuLcLmwk0Y+l/qS7kHS0xFKeTc3TTTSOz6EAH4ojnelcmZ3toHt03PFoAv2XPrF8qeCTpyyt87PI9haasP0i1EZw6AZoZtqM3nB2JmEFroLPVsHYdw2GY49EUPdsaSNyEeITjc4WUyDHwHZOec1NS7t2eiYHbqsZHjGPtIvGFJF2ru9sB635XaW1lmLaizSp/AiPxfylbYDRU+3ENWRJyp1EwJyIr+rVPkojaugxdhE361gPNTCJMqLAQV/35yYlyXW4LKxrOJyuV/7qXaAnJOXu0gbNsfyvLqUzCOnXTiTCj/X10u7QGeX7vq6EpstsXx7GrMa4EQXwByfiBHNsAOmDAhxa9LUcxA5aB/0vD+EnT1v7ENJYG+Lg+aT/ESkkbhSPfyGLPNsn9wsCmMPRWL8dK9blY8oEQibpOsRqYQlnAInbQTfYy2iqwTM2FzG3MNtDLoQpiiPc62ltzTZOPG9QL7ql27gQ6IRiJWnaTflxyszjebEIjcWM7rbR8LjNMcnxaHSsiw7Evbx/SOm+YaYviGcI0en2z/GOL9ikvcOOEX/Rr51esfVJPI+yPoNpbL4myj/DqAy+G8Y8SdBGfwXKOO6518BZg1D3HjgmC+45l5384FH1ryYUrePP4O6FdYT/w3Y+K9XMUL8oGD8S0XynYK/Yvv8hxIA+ZP0S/9zqPhPVPjnqgzFkR9Uhv6OylDi91RG/lkqY/4PoGvwHboWBKtRTvDCOFdf0XXyuK4+67TKcmCSUXETN8ydGxe8/Fio6wS7WoYV1JjOmReuQ/s4h1lVenLAwWr0XE59Lx/Yw7gF1Gu9Y/0+1c/Bqc+meZGHa1dgS79dd3pOWu/wE27SYn734+lc9uC27KZiLKkYIo8Bvj1qIpiSEqaCppGmsmUfC8PWJL7VPC+OT4Q2AGIQWddUhgfuq+BbhwaIyPZm1BNLsiFzRMQqOlPsbdSo65RwwgEjLs8H/WRr++KeIqvTqY1rFY09CwOhEMILLDV1WjTFsMPCXqPRFcropqQNfoBYIvcBfz7yI/y+1UW5hDBeu8She8pXcAQVtiaR+zjNRrLD547rTpzK5+slDcSH+DIf5dPZ7hV/IoTKWC+n6XxFnwN3OZIYDBKSa8ByhBmTwUkoLKnCVbENGsGNoA2PfNNkxRDAx8DyWm/x9ZBRwem2CjDdTZwy7ZyPLBmfg/EMXZOrjtRYlvzKUeg0GOu5PgbRnaLgB9CydQObDedQRxren9sTXPR45Sobv0izyvRJmIH8VrRtqSmtte/YE6Zpch74q6I8uybT/Rvp64aObedj6mj4NAluFFSpIlFbgSK0qcsDGcUVGG6OCSXhdRE9hKtOFJMgcR0ko9GZl5M/h+WyqoY1JFWfwx6XMl21THKxGdAZhbneI/JZkIxRauJWY/lxwSge73knmCikgdCTyWhf/s3fOnBFghwNmuJkg+b1ut12nPCa0xhROoGcE/RmMjvpkOGmzhf4Ilwfwr6MejKssh0Yq8BsF4Ud91RsNc9kFpWwEaDX4921wDmqqg5DtCfgiaXJYhNvTOR6TPd52TdQ8gvA+ZGFM6IJDs5oJx9bvZ5AfAQcI3F7Qo550dM0ZyoYqr4q0uOWsIfumcOBnCU9Rf6AZ1bD0wj2GvlX1bR3Ne0Wzgfogb52MZC80eAI5+Tu56SKG8M08nScT1y2Mr6nmzSxUG4mZyT1ChtFLmILQAgXwZeE8O4T81iieT12zjlrrxPuihP1dN24Hw7Id31cz6Kf5MDUh7RJLqaM3VxTcMxsT8Py5Bmwdy1gWUShZ66/6XEli+Q9YBC3LbR1A/o00VLMT9LaUsdkI2Rq8GfJLDQIhyMuZKK3u7e1sDej6kgOFUNxehp1W+xJNa097cBnXja2NGjamujJvqyiS/pz7mCsZ0kP2QEGR3Ej4KtYoG/qofljZQ/0RTkM4N1F59ATee+EjEgUq9jns32FinNMYice6+QjjqC1g6vJOba52O6KUTFVJB9ZUbbcepFNK+XstHCDcbRD3Yg0gWbhzmGLQ6wvIY/Xo1CxZshotD92Tlkf88Wfq4sFpw16Tt6sU7eM3Jrx1X26zqP5ehaapNbjVrXIvj2jDdW2InxZuYqdyVFOHi7Woju1Qu96yrd+0AOeAZvR+TZhu066NhKQC5a1Gm13jIaO1B5qgJ6aCnrFuYyofW8enCI7bBS8bnd/7G4XZqDyoHm86szKaE59QjfdBxGnuqNCIV1DzE73EiiDbrZBf2fP/U0WWVsUH6f2FvWtogfGyYc5lEuobel6EYcxj7S66gpsoB51Hanz4gznuEB/n7zFjRk7ySQvWAmq8VQtD1gx0QAcIAe4qPnLERpBwYULpxjWOonbHd4TnIYwRWhK1gwDsb3atC7GTIBi1oA8r0bOCA5zA+YQp1Ts60QdgvuOXO6Ss0Y5cXWbx6PUjxWJiljCDTq0uRB9Lr2ktX/xImdKC306wpraC3DmsSnZgiBa+VHan/O83z3Q+E+pzGHf8tmj91AgvDwEu4OgxF65cZ7ntzlCfIj+A7xlnbS+6ExJoBnviw8qRykdFAIiXp1bBtQstFBhpwjAK4hIODHMtTmMzbAc2fWVg0KZ4Hw7yBSurphmHq8bqp9uop8/AlUpU5WGwSqWu147zT4C4KKMqwSADjSFNhK76SSR9IMZOD02XiVGB6Kcy9PFAAnfVVs4uquY6ZJbNkUF5DZ4ZS3SA+BKcW3DhMCXXh2vpzUAncSbcX7FgDIbCQrI0Lq1uYpQZTrQ8sIibkGqls2vR6QpwtBUdKjADuiaSd0EcAHlWbKB4cA8xcn0wGdAysxO3LSGw3SCi3UQYS1j5UO0g6Y47G6YWhs3j0441Uehzot4pDQaeYUjjSw/W6OKI1GotMdu2krCa+2HwxE0MKLFK/TtSnTLujHaWqA1C+tRabFmm0mreYRF4eccLNkFsvA7avN7XkSx9YCOw1BnXOsyE5wpHF9wuJcbInoVZdKpTzPjCQzfcOxYYuWX5Etbr8HCRRU/seW2xiAjSZh7Dz8/sIKZrNBL08easvxbZR9Q4KjcAJEqK5c2atBMhAnzxfpYuIW18F2it0qSR+i9sr5U6zJOLVgwdmiGxHKYqs924h4r0ol8Ama96wPiHzWwoDy46xoYAtSoZglAH20F3G5s/dql7khxi68SN+WIoafpiE/bCzMeBM1vJ+xEpoJsSBm/UPadSUsqOsCodLk8Dq4CuUNYxBWxjNPO6qqKzc0Egy6KSgU11RMZ23UP63Yk8DLBdgKf47Uu+SugF0Y+2Q57lq1XORYxBIXgfFA83rlWCEJc0+qRLpp6gxHWNOz1uUnA4Q9LtoEdrJLNIYY6rrZka+UTRaQZ5rBE4BVDLNRTZvV5cSCE68tiZvXsDOBBoUOhkX4HHU0jkXjLWs4XhNLUburagRvdoaV25ztZkqkYcbgrwHFnkN0DIekWgnYZv2rTLKTnGsbMqx/2gwOUzLulMnNRgWms3eIFBbD4JmBMIrcJwLBDV5iNOhDrwXagT0DIlg5dR0u1C5VijQ/xDlM8mntgK9lIcQ5P3UFhDuJDJ0OQ8jvcmad+5VVsdJihTAugllP+eI6XuMz953yKiHOSB3x8hEOuAhKS0ZnUe2x2Y+8pIz3vgNH7u/BAXYjfUiC8+VjRezgWR1sXpa4EuPSiz7m3a+Gsvq50ng2aYyynNPSWDT/djn1mSTb/KqbQxscs8FoNhLHamw9Bq/sD8bmJlx7h4qXnlys7VejwjDKYppFdL0fWyU9cil5WQdW5gL+5/S0FfKYgTUUPkUmstpbSvlxx8oDCInCwfCMD/isNcE9UOgJFcuNGjiCcl9uLsrwn3rcXzzGZSYpZPZ+o+aHzMBxjmBfM3QyKF4Tf7BUrE6OiBYmO0noInqfXeF0tQtv6BsNu26I66qCgyHxvTYhhuatm+bIOdJiE0XKrM8mBG+1yiglhFobcmrKwYfFeZ4IpZzBPDiAC4e/q/GoRR8EcuPvG9AUVWd7Fex3NDH89SzeARAzMdil6l6cbq9Hnk6lU9xRhnT25iGUMeFuboW7Ti6jdLui67T23xfU4+veVG6X7kFko3SrmEpwcGY7u5w3PjqopjhWlZmZGpv5ueaxRks6kYcnk0kF2WuTnhHCnudrL5ODEo0dSt1T6QssRLGUTLMzBouYlAGEbYcCihFt85DWjvnHlgyP1+s7kUUbLj5InGELTBcUxynlZ0HwamHrsIhRM2woBkJHs11bf8RHfrVo1VWYFRm1cXd/B3S6GL1EMOmiao5SZ8ddjUva78ggqvbj3hNIC2QY3ocmU2nYPpwyTetnFgSCbAyhuvfuyXYZsOuG6LZmGhnKyXagmp90yVgzAyX0peGrYn8xMBgKGe4yV9uVG6T5PKJcKXDNDTGwbDqwsqtkXDrUf5WZHxlmJ9gSogBoOQBrawUYobL+hG42T+vOIfpIG+FXOll3xnylXHUVZmBKzg6x0jmVMvKTGiakTn8if5+gSikDPdMW0IUxYhXYhWiUCLjaRraCmGF3PN4ZHMnDV1+fk5WeSRo+6LtSw+wTaMVC5AOjKyVx8/EnM7XJCOhXggJF6GB7dNpDDOb5DyHdHtUFnliBX0iiNZmRw3eVygBGsGa9HVboyIDoYwkWBxeGlpXmCy8JFaB0sdQpHmR3PtAB4zVx4kpzgKC7PgkqhuJxzlu17gTnL/IXiGmBn1b5xOb/wsbU646SVYigJ89kJluRyYBzYdTVx8NoQMm6D3ffHkEwmedbDFIeVZtOBvJAIcQb7I+76qVEwdj4qtOmMH9E9UvFHbbf1iwFPA+US37qSDHY58ODrfL4fWE4Ska6UGTCbjRsEYw8ilG+i0JE2p3Nr+1zdGp8iUnHJ1JUXFTl4qs5jDGHwZ/RSRIyuJuiBHuFQerz0BPT82xIqxy9dEtMl7eFF5ERja1wCs0CH4U+UmA5/xfyQB6DcbIwblTssutGLquzSC+Q0fdodYkrsKFVFfuRU9V4Nbpc8yXvPc3lUUOIxuCqoY9nOdKNaIuf6O+be9/OJHSE2AgfXETRwb++rQfBa38uHc446sgvIg+ofZXLZFSsNUjtCZzp5FY+NUJn8qNqypGfb5RZZ15DI/iIOFyXRH9ky8ncYXOZXsuyL7F/OlbG/cmUi8YkDnwD/+YL5BPGUyHziqE8M+UkkDwkDe1A1nBl3g0GGyqavuvmOYYM6mn7iIaehq1K+q7sBStquPYi3R1HXP4nid4rtDnWaDr/DvTVFknz+o4TfIz5/Jow/t9+n9W9gQ8kfGXoU+5UNZX+HDMX+LC70Cxv7t+WPcfJvxx+j/xf+POODQP4gkD8I5A8C+YNA/iCQPwjkDwL5g0D+IJA/COQPAvmDQP4gkD8I5A8C+YNA/v+SQMbpvxmBjGJ/iEEmP7HcJ074JLKfWPagkj/44jdz/t344l//nvvvxRdTf0O+mPjgiz/44g+++IMv/uCLP/jiD774gy/+4Is/+OIPvviDL/7giz/44g+++IMv/uCLP/jiv4Yvpv52fDH5h/hi+hNLfGKlgy/msEPywRe/mfPvxhdT/5z7TNsEHKfyfTNBEo/5V7V8Z8JDbsUTNEv7WYIh+FfDfjmJD/tXHSb3q5K/UyL5O0r8IvvDZ8S9v8HqCvjirzYk0Z8YbPon47ydcffe65t9fhmI+mcDvR2C98tAnw39ddn/C9v/gbNJfrX9PzjcJd0gUj1o7N8Q+r15/dwk3lvC9k5yf268vmtY6VDA9Rz7+U3WwrWF3zofzWMs9DcExb8Ivg33ufX6vvXzgH/WeYXvv2/5p+cV0n+ly6LMj56G/3zczR91Weyn02Iw6t/ssn/gbJj/ocsSDPaDzyIs+n/ca/+yAErgvxHIt68fEQ5OYr8h5P/MPQn0F/f8Dfn+i/r3euvv/O+sf5G3MswPzoqR/xtfRWj07++tfyDGon+tW2NQkz+dP4ZD0U8D/VFfJrGffPlfhg4O0vHrCcZvj387BxoX/xM=</diagram></mxfile>
\ No newline at end of file
diff --git a/docs/system-design/security/images/basis-of-authority-certification/sso.png b/docs/system-design/security/images/basis-of-authority-certification/sso.png
new file mode 100644
index 00000000000..8a87978a2f8
Binary files /dev/null and b/docs/system-design/security/images/basis-of-authority-certification/sso.png differ
diff --git "a/docs/system-design/security/images/basis-of-authority-certification/\345\276\256\344\277\241\346\224\257\344\273\230-fnglfdlgdfj.png" "b/docs/system-design/security/images/basis-of-authority-certification/\345\276\256\344\277\241\346\224\257\344\273\230-fnglfdlgdfj.png"
new file mode 100644
index 00000000000..b3c75a97289
Binary files /dev/null and "b/docs/system-design/security/images/basis-of-authority-certification/\345\276\256\344\277\241\346\224\257\344\273\230-fnglfdlgdfj.png" differ
diff --git "a/docs/system-design/security/jwt\344\274\230\347\274\272\347\202\271\345\210\206\346\236\220\344\273\245\345\217\212\345\270\270\350\247\201\351\227\256\351\242\230\350\247\243\345\206\263\346\226\271\346\241\210.md" "b/docs/system-design/security/jwt\344\274\230\347\274\272\347\202\271\345\210\206\346\236\220\344\273\245\345\217\212\345\270\270\350\247\201\351\227\256\351\242\230\350\247\243\345\206\263\346\226\271\346\241\210.md"
new file mode 100644
index 00000000000..9e209c226fe
--- /dev/null
+++ "b/docs/system-design/security/jwt\344\274\230\347\274\272\347\202\271\345\210\206\346\236\220\344\273\245\345\217\212\345\270\270\350\247\201\351\227\256\351\242\230\350\247\243\345\206\263\346\226\271\346\241\210.md"
@@ -0,0 +1,93 @@
+# JWT 身份认证优缺点分析以及常见问题解决方案
+
+之前分享了一个使用 Spring Security 实现 JWT 身份认证的 Demo,文章地址:[适合初学者入门 Spring Security With JWT 的 Demo](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485622&idx=1&sn=e9750ed63c47457ba1896db8dfceac6a&chksm=cea2477df9d5ce6b7af20e582c6c60b7408a6459b05b849394c45f04664d1651510bdee029f7&token=684071313&lang=zh_CN&scene=21#wechat_redirect)。 Demo 非常简单,没有介绍到 JWT 存在的一些问题。所以,单独抽了一篇文章出来介绍。为了完成这篇文章,我查阅了很多资料和文献,我觉得应该对大家有帮助。
+
+相关阅读:
+
+- [《一问带你区分清楚Authentication,Authorization以及Cookie、Session、Token》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485626&idx=1&sn=3247aa9000693dd692de8a04ccffeec1&chksm=cea24771f9d5ce675ea0203633a95b68bfe412dc6a9d05f22d221161147b76161d1b470d54b3&token=684071313&lang=zh_CN&scene=21#wechat_redirect)
+- [适合初学者入门 Spring Security With JWT 的 Demo](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485622&idx=1&sn=e9750ed63c47457ba1896db8dfceac6a&chksm=cea2477df9d5ce6b7af20e582c6c60b7408a6459b05b849394c45f04664d1651510bdee029f7&token=684071313&lang=zh_CN&scene=21#wechat_redirect)
+- [Spring Boot 使用 JWT 进行身份和权限验证](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485640&idx=1&sn=0ff147808318d53b371f16bb730c96ef&chksm=cea24703f9d5ce156ba67662f6f3f482330e8e6ebd9d44c61bf623083e9b941d8a180db6b0ea&token=1533246333&lang=zh_CN#rd)
+
+## Token 认证的优势
+
+ 相比于 Session 认证的方式来说,使用 token 进行身份认证主要有下面四个优势:
+
+### 1.无状态
+
+token 自身包含了身份验证所需要的所有信息,使得我们的服务器不需要存储 Session 信息,这显然增加了系统的可用性和伸缩性,大大减轻了服务端的压力。但是,也正是由于 token 的无状态,也导致了它最大的缺点:当后端在token 有效期内废弃一个 token 或者更改它的权限的话,不会立即生效,一般需要等到有效期过后才可以。另外,当用户 Logout 的话,token 也还有效。除非,我们在后端增加额外的处理逻辑。
+
+### 2.有效避免了CSRF 攻击
+
+**CSRF(Cross Site Request Forgery)** 一般被翻译为 **跨站请求伪造**,属于网络攻击领域范围。相比于 SQL 脚本注入、XSS等安全攻击方式,CSRF 的知名度并没有它们高。但是,它的确是每个系统都要考虑的安全隐患,就连技术帝国 Google 的 Gmail 在早些年也被曝出过存在 CSRF 漏洞,这给 Gmail 的用户造成了很大的损失。
+
+那么究竟什么是 **跨站请求伪造** 呢?说简单用你的身份去发送一些对你不友好的请求。举个简单的例子:
+
+小壮登录了某网上银行,他来到了网上银行的帖子区,看到一个帖子下面有一个链接写着“科学理财,年盈利率过万”,小壮好奇的点开了这个链接,结果发现自己的账户少了10000元。这是这么回事呢?原来黑客在链接中藏了一个请求,这个请求直接利用小壮的身份给银行发送了一个转账请求,也就是通过你的 Cookie 向银行发出请求。
+
+```html
+<a src="http://www.mybank.com/Transfer?bankId=11&money=10000">科学理财,年盈利率过万</a>
+```
+
+导致这个问题很大的原因就是: Session 认证中 Cookie 中的 session_id 是由浏览器发送到服务端的,借助这个特性,攻击者就可以通过让用户误点攻击链接,达到攻击效果。
+
+**那为什么 token 不会存在这种问题呢?**
+
+我是这样理解的:一般情况下我们使用 JWT 的话,在我们登录成功获得 token 之后,一般会选择存放在 local storage 中。然后我们在前端通过某些方式会给每个发到后端的请求加上这个 token,这样就不会出现 CSRF 漏洞的问题。因为,即使你点击了非法链接发送了请求到服务端,这个非法请求是不会携带 token 的,所以这个请求将是非法的。
+
+但是这样会存在 XSS 攻击中被盗的风险,为了避免 XSS 攻击,你可以选择将 token 存储在标记为`httpOnly` 的cookie 中。但是,这样又导致了你必须自己提供CSRF保护。
+
+具体采用上面哪种方式存储 token 呢,大部分情况下存放在 local storage 下都是最好的选择,某些情况下可能需要存放在标记为`httpOnly` 的cookie 中会更好。
+
+### 3.适合移动端应用
+
+使用 Session 进行身份认证的话,需要保存一份信息在服务器端,而且这种方式会依赖到 Cookie(需要 Cookie 保存 SessionId),所以不适合移动端。
+
+但是,使用 token 进行身份认证就不会存在这种问题,因为只要 token 可以被客户端存储就能够使用,而且 token 还可以跨语言使用。
+
+### 4.单点登录友好
+
+使用 Session 进行身份认证的话,实现单点登录,需要我们把用户的 Session 信息保存在一台电脑上,并且还会遇到常见的 Cookie 跨域的问题。但是,使用 token 进行认证的话, token 被保存在客户端,不会存在这些问题。
+
+## Token 认证常见问题以及解决办法
+
+### 1.注销登录等场景下 token 还有效
+
+与之类似的具体相关场景有:
+
+1. 退出登录;
+2. 修改密码;
+3. 服务端修改了某个用户具有的权限或者角色;
+4. 用户的帐户被删除/暂停。
+5. 用户由管理员注销;
+
+这个问题不存在于 Session 认证方式中,因为在 Session 认证方式中,遇到这种情况的话服务端删除对应的 Session 记录即可。但是,使用 token 认证的方式就不好解决了。我们也说过了,token 一旦派发出去,如果后端不增加其他逻辑的话,它在失效之前都是有效的。那么,我们如何解决这个问题呢?查阅了很多资料,总结了下面几种方案:
+
+- **将 token 存入内存数据库**:将 token 存入 DB 中,redis 内存数据库在这里是不错的选择。如果需要让某个 token 失效就直接从 redis 中删除这个 token 即可。但是,这样会导致每次使用 token 发送请求都要先从 DB 中查询 token 是否存在的步骤,而且违背了 JWT 的无状态原则。
+- **黑名单机制**:和上面的方式类似,使用内存数据库比如 redis 维护一个黑名单,如果想让某个 token 失效的话就直接将这个 token 加入到 **黑名单** 即可。然后,每次使用 token 进行请求的话都会先判断这个 token 是否存在于黑名单中。
+- **修改密钥 (Secret)** : 我们为每个用户都创建一个专属密钥,如果我们想让某个 token 失效,我们直接修改对应用户的密钥即可。但是,这样相比于前两种引入内存数据库带来了危害更大,比如:1) 如果服务是分布式的,则每次发出新的 token 时都必须在多台机器同步密钥。为此,你需要将密钥存储在数据库或其他外部服务中,这样和 Session 认证就没太大区别了。 2) 如果用户同时在两个浏览器打开系统,或者在手机端也打开了系统,如果它从一个地方将账号退出,那么其他地方都要重新进行登录,这是不可取的。
+- **保持令牌的有效期限短并经常轮换** :很简单的一种方式。但是,会导致用户登录状态不会被持久记录,而且需要用户经常登录。
+
+对于修改密码后 token 还有效问题的解决还是比较容易的,说一种我觉得比较好的方式:**使用用户的密码的哈希值对 token 进行签名。因此,如果密码更改,则任何先前的令牌将自动无法验证。**
+
+### 2.token 的续签问题
+
+token 有效期一般都建议设置的不太长,那么 token 过期后如何认证,如何实现动态刷新 token,避免用户经常需要重新登录?
+
+我们先来看看在 Session 认证中一般的做法:**假如 session 的有效期30分钟,如果 30 分钟内用户有访问,就把 session 有效期延长30分钟。**
+
+1. **类似于 Session 认证中的做法**:这种方案满足于大部分场景。假设服务端给的 token 有效期设置为30分钟,服务端每次进行校验时,如果发现 token 的有效期马上快过期了,服务端就重新生成 token 给客户端。客户端每次请求都检查新旧token,如果不一致,则更新本地的token。这种做法的问题是仅仅在快过期的时候请求才会更新 token ,对客户端不是很友好。
+2. **每次请求都返回新 token** :这种方案的的思路很简单,但是,很明显,开销会比较大。
+3. **token 有效期设置到半夜** :这种方案是一种折衷的方案,保证了大部分用户白天可以正常登录,适用于对安全性要求不高的系统。
+4. **用户登录返回两个 token** :第一个是 accessToken ,它的过期时间 token 本身的过期时间比如半个小时,另外一个是 refreshToken 它的过期时间更长一点比如为1天。客户端登录后,将 accessToken和refreshToken 保存在本地,每次访问将 accessToken 传给服务端。服务端校验 accessToken 的有效性,如果过期的话,就将 refreshToken 传给服务端。如果有效,服务端就生成新的 accessToken 给客户端。否则,客户端就重新登录即可。该方案的不足是:1) 需要客户端来配合;2) 用户注销的时候需要同时保证两个 token 都无效;3) 重新请求获取 token 的过程中会有短暂 token 不可用的情况(可以通过在客户端设置定时器,当accessToken 快过期的时候,提前去通过 refreshToken 获取新的accessToken)。
+
+## 总结
+
+JWT 最适合的场景是不需要服务端保存用户状态的场景,如果考虑到 token 注销和 token 续签的场景话,没有特别好的解决方案,大部分解决方案都给 token 加上了状态,这就有点类似 Session 认证了。
+
+## Reference
+
+- [JWT 超详细分析](https://learnku.com/articles/17883?order_by=vote_count&)
+- https://medium.com/devgorilla/how-to-log-out-when-using-jwt-a8c7823e8a6
+- https://medium.com/@agungsantoso/csrf-protection-with-json-web-tokens-83e0f2fcbcc
+- [Invalidating JSON Web Tokens](https://stackoverflow.com/questions/21978658/invalidating-json-web-tokens)
+
diff --git a/docs/system-design/security/readme.md b/docs/system-design/security/readme.md
new file mode 100644
index 00000000000..7fb81f18cb7
--- /dev/null
+++ b/docs/system-design/security/readme.md
@@ -0,0 +1,7 @@
+**[《认证授权基础》](https://snailclimb.gitee.io/javaguide/#/docs/system-design/authority-certification/basis-of-authority-certification)** 这篇文章中我会介绍认证授权常见概念: **Authentication**,**Authorization** 以及 **Cookie**、**Session**、Token、**OAuth 2**、**SSO** 。如果你不清楚这些概念的话,建议好好阅读一下这篇文章。
+
+- **JWT** :JWT(JSON Web Token)是一种身份认证的方式,JWT 本质上就一段签名的 JSON 格式的数据。由于它是带有签名的,因此接收者便可以验证它的真实性。相关阅读:
+
+
+
+- **SSO(单点登录)** :**SSO(Single Sign On)** 即单点登录说的是用户登陆多个子系统的其中一个就有权访问与其相关的其他系统。举个例子我们在登陆了京东金融之后,我们同时也成功登陆京东的京东超市、京东家电等子系统。相关阅读:[**SSO 单点登录看这篇就够了!**](https://snailclimb.gitee.io/javaguide/#/docs/system-design/authority-certification/SSO单点登录看这一篇就够了)
\ No newline at end of file
diff --git a/docs/system-design/security/sso-intro.md b/docs/system-design/security/sso-intro.md
new file mode 100644
index 00000000000..65fea52e1fc
--- /dev/null
+++ b/docs/system-design/security/sso-intro.md
@@ -0,0 +1,125 @@
+# SSO 单点登录
+
+> 本文授权转载自 : https://ken.io/note/sso-design-implement 作者:ken.io
+>
+> 相关推荐阅读:**[系统的讲解 - SSO单点登录](https://www.imooc.com/article/286710)**
+
+## 一、前言
+
+### 1、SSO说明
+
+SSO英文全称Single Sign On,单点登录。SSO是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。https://baike.baidu.com/item/SSO/3451380
+
+例如访问在网易账号中心(https://reg.163.com/ )登录之后
+访问以下站点都是登录状态
+
+- 网易直播 [https://v.163.com](https://v.163.com/)
+- 网易博客 [https://blog.163.com](https://blog.163.com/)
+- 网易花田 [https://love.163.com](https://love.163.com/)
+- 网易考拉 [https://www.kaola.com](https://www.kaola.com/)
+- 网易Lofter [http://www.lofter.com](http://www.lofter.com/)
+
+### 2、单点登录系统的好处
+
+1. **用户角度** :用户能够做到一次登录多次使用,无需记录多套用户名和密码,省心。
+2. **系统管理员角度** : 管理员只需维护好一个统一的账号中心就可以了,方便。
+3. **新系统开发角度:** 新系统开发时只需直接对接统一的账号中心即可,简化开发流程,省时。
+
+### 3、设计目标
+
+本篇文章也主要是为了探讨如何设计&实现一个SSO系统
+
+以下为需要实现的核心功能:
+
+- 单点登录
+- 单点登出
+- 支持跨域单点登录
+- 支持跨域单点登出
+
+## 二、SSO设计与实现
+
+### 1、核心应用与依赖
+
+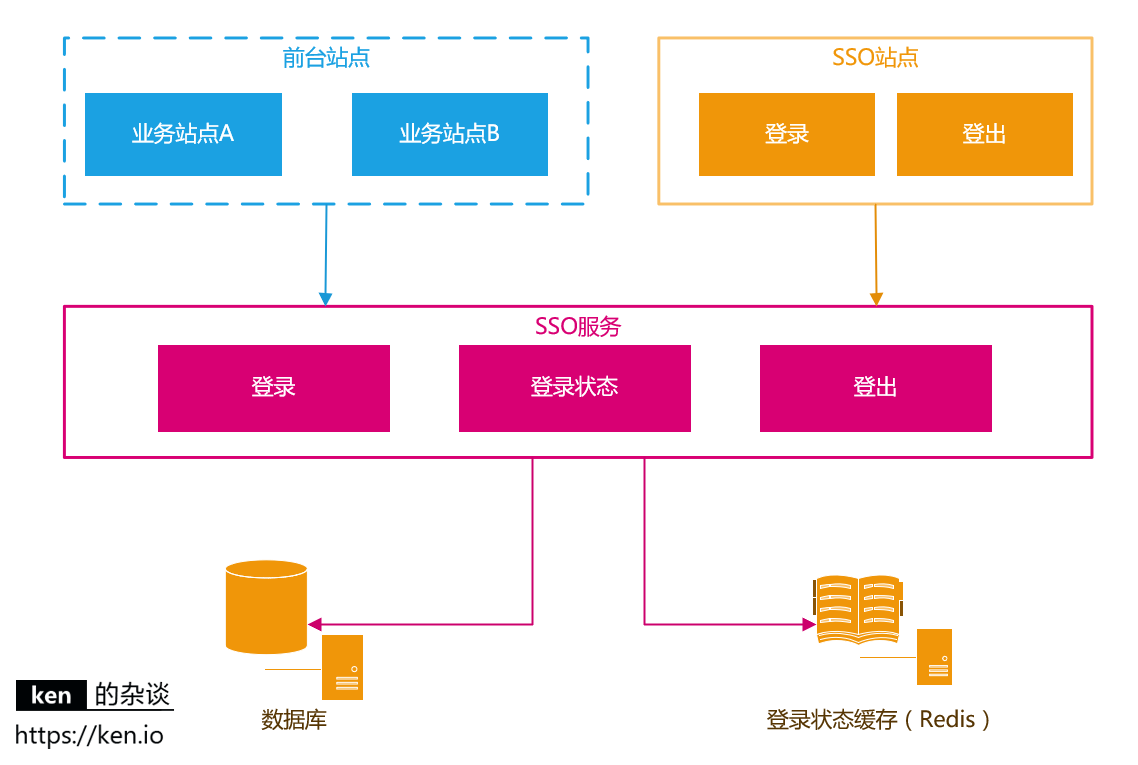
+
+| 应用/模块/对象 | 说明 |
+| ---------------- | ----------------------------------- |
+| 前台站点 | 需要登录的站点 |
+| SSO站点-登录 | 提供登录的页面 |
+| SSO站点-登出 | 提供注销登录的入口 |
+| SSO服务-登录 | 提供登录服务 |
+| SSO服务-登录状态 | 提供登录状态校验/登录信息查询的服务 |
+| SSO服务-登出 | 提供用户注销登录的服务 |
+| 数据库 | 存储用户账户信息 |
+| 缓存 | 存储用户的登录信息,通常使用Redis |
+
+### 2、用户登录状态的存储与校验
+
+常见的Web框架对于[Session](https://ken.io/note/session-principle-skill)的实现都是生成一个SessionId存储在浏览器Cookie中。然后将Session内容存储在服务器端内存中,这个 ken.io 在之前[Session工作原理](https://ken.io/note/session-principle-skill)中也提到过。整体也是借鉴这个思路。
+用户登录成功之后,生成AuthToken交给客户端保存。如果是浏览器,就保存在Cookie中。如果是手机App就保存在App本地缓存中。本篇主要探讨基于Web站点的SSO。
+用户在浏览需要登录的页面时,客户端将AuthToken提交给SSO服务校验登录状态/获取用户登录信息
+
+对于登录信息的存储,建议采用Redis,使用Redis集群来存储登录信息,既可以保证高可用,又可以线性扩充。同时也可以让SSO服务满足负载均衡/可伸缩的需求。
+
+| 对象 | 说明 |
+| --------- | ------------------------------------------------------------ |
+| AuthToken | 直接使用UUID/GUID即可,如果有验证AuthToken合法性需求,可以将UserName+时间戳加密生成,服务端解密之后验证合法性 |
+| 登录信息 | 通常是将UserId,UserName缓存起来 |
+
+### 3、用户登录/登录校验
+
+- 登录时序图
+
+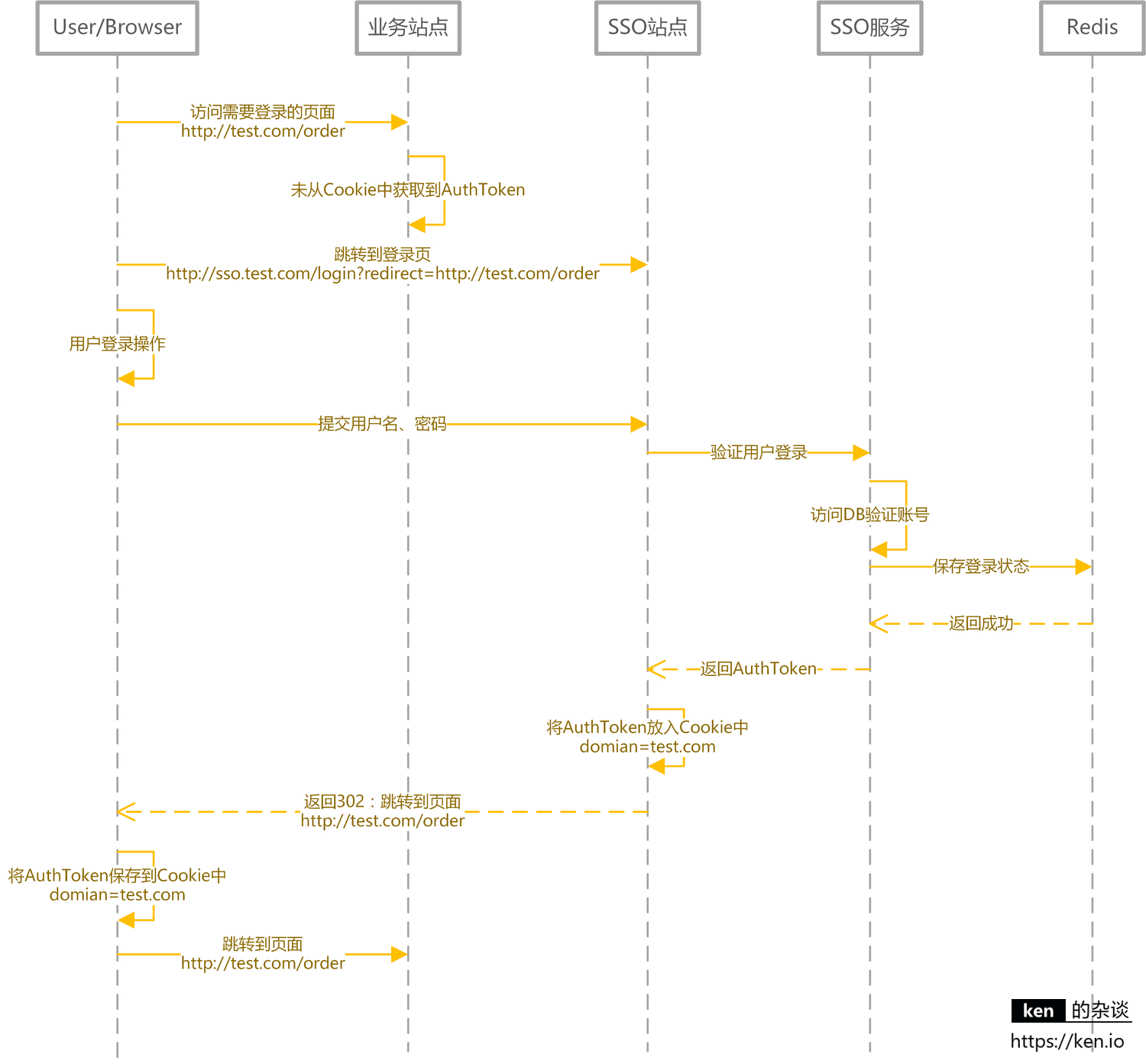
+
+按照上图,用户登录后AuthToken保存在Cookie中。 domain=test.com
+浏览器会将domain设置成 .test.com,
+这样访问所有*.test.com的web站点,都会将AuthToken携带到服务器端。
+然后通过SSO服务,完成对用户状态的校验/用户登录信息的获取
+
+- 登录信息获取/登录状态校验
+
+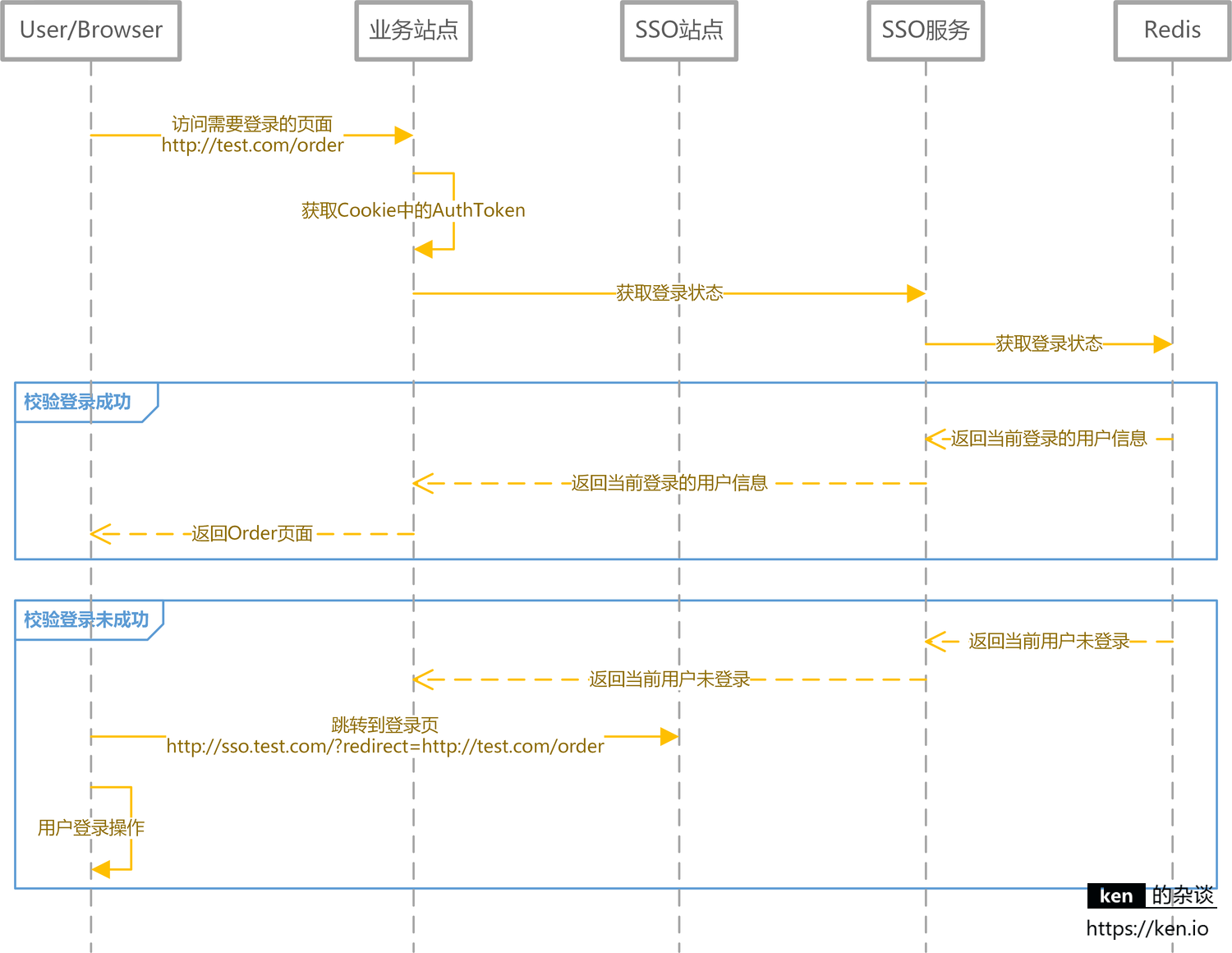
+
+### 4、用户登出
+
+用户登出时要做的事情很简单:
+
+1. 服务端清除缓存(Redis)中的登录状态
+2. 客户端清除存储的AuthToken
+
+- 登出时序图
+
+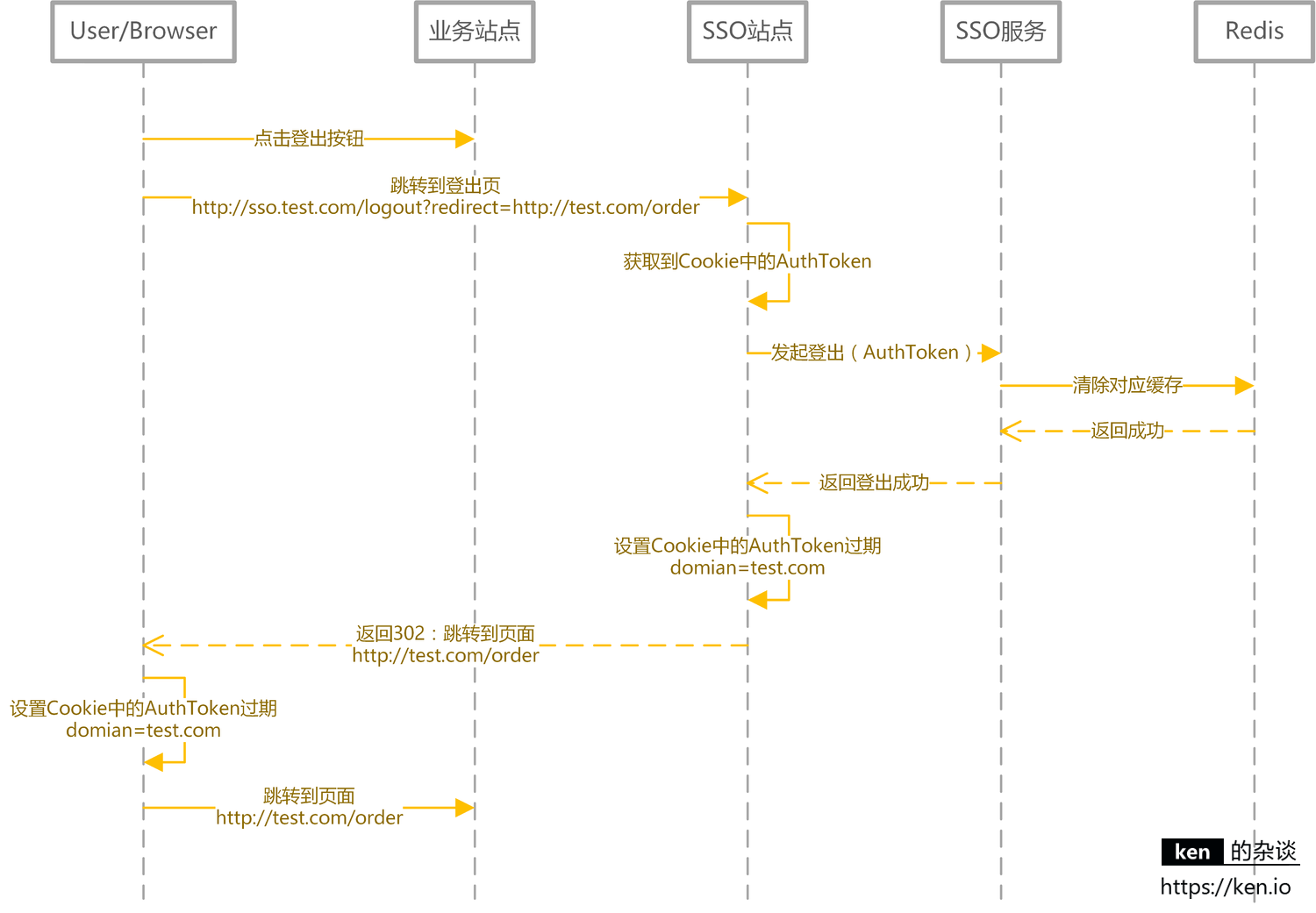
+
+### 5、跨域登录、登出
+
+前面提到过,核心思路是客户端存储AuthToken,服务器端通过Redis存储登录信息。由于客户端是将AuthToken存储在Cookie中的。所以跨域要解决的问题,就是如何解决Cookie的跨域读写问题。
+
+> **Cookie是不能跨域的** ,比如我一个
+
+解决跨域的核心思路就是:
+
+- 登录完成之后通过回调的方式,将AuthToken传递给主域名之外的站点,该站点自行将AuthToken保存在当前域下的Cookie中。
+- 登出完成之后通过回调的方式,调用非主域名站点的登出页面,完成设置Cookie中的AuthToken过期的操作。
+- 跨域登录(主域名已登录)
+
+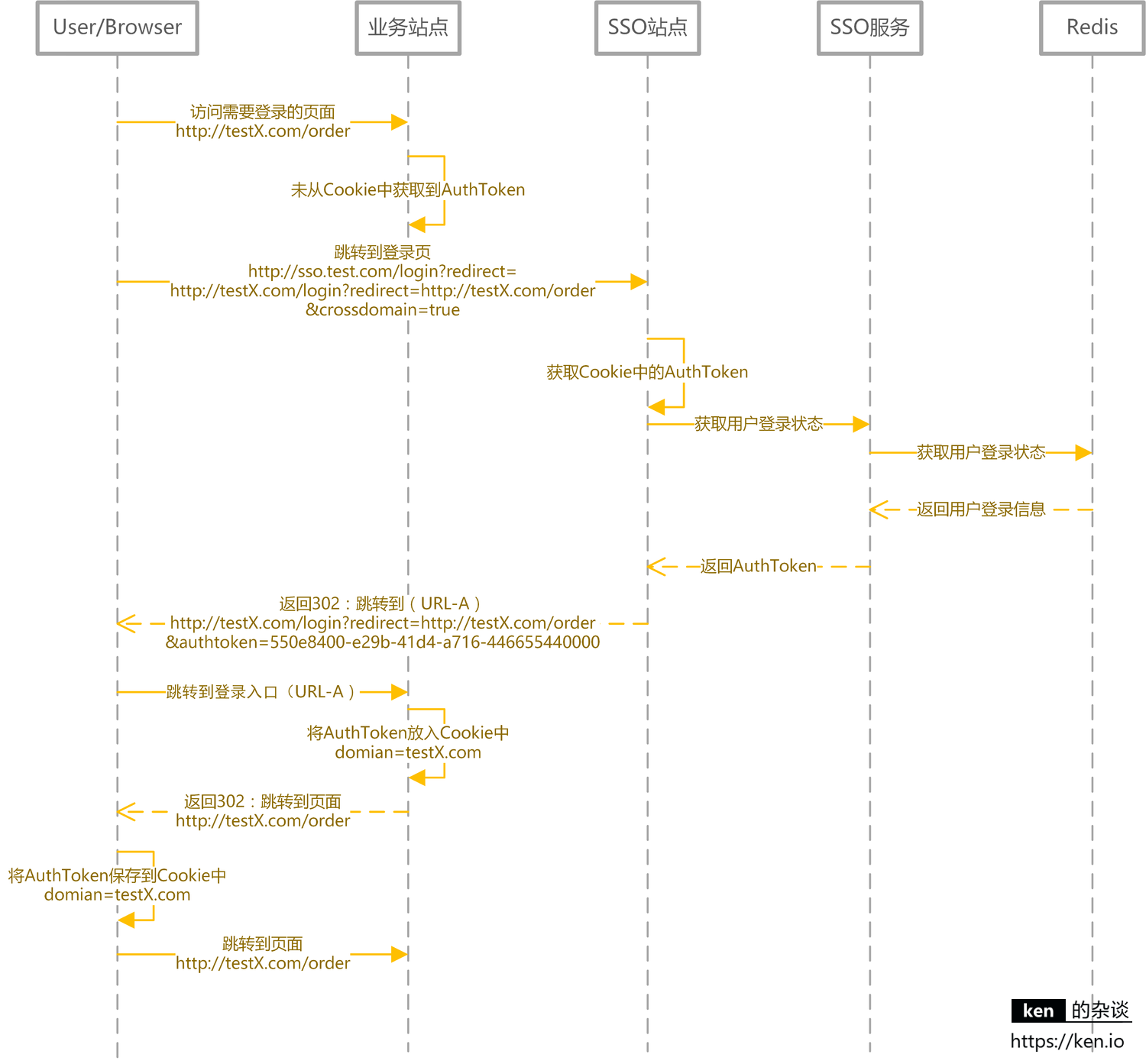
+
+- 跨域登录(主域名未登录)
+
+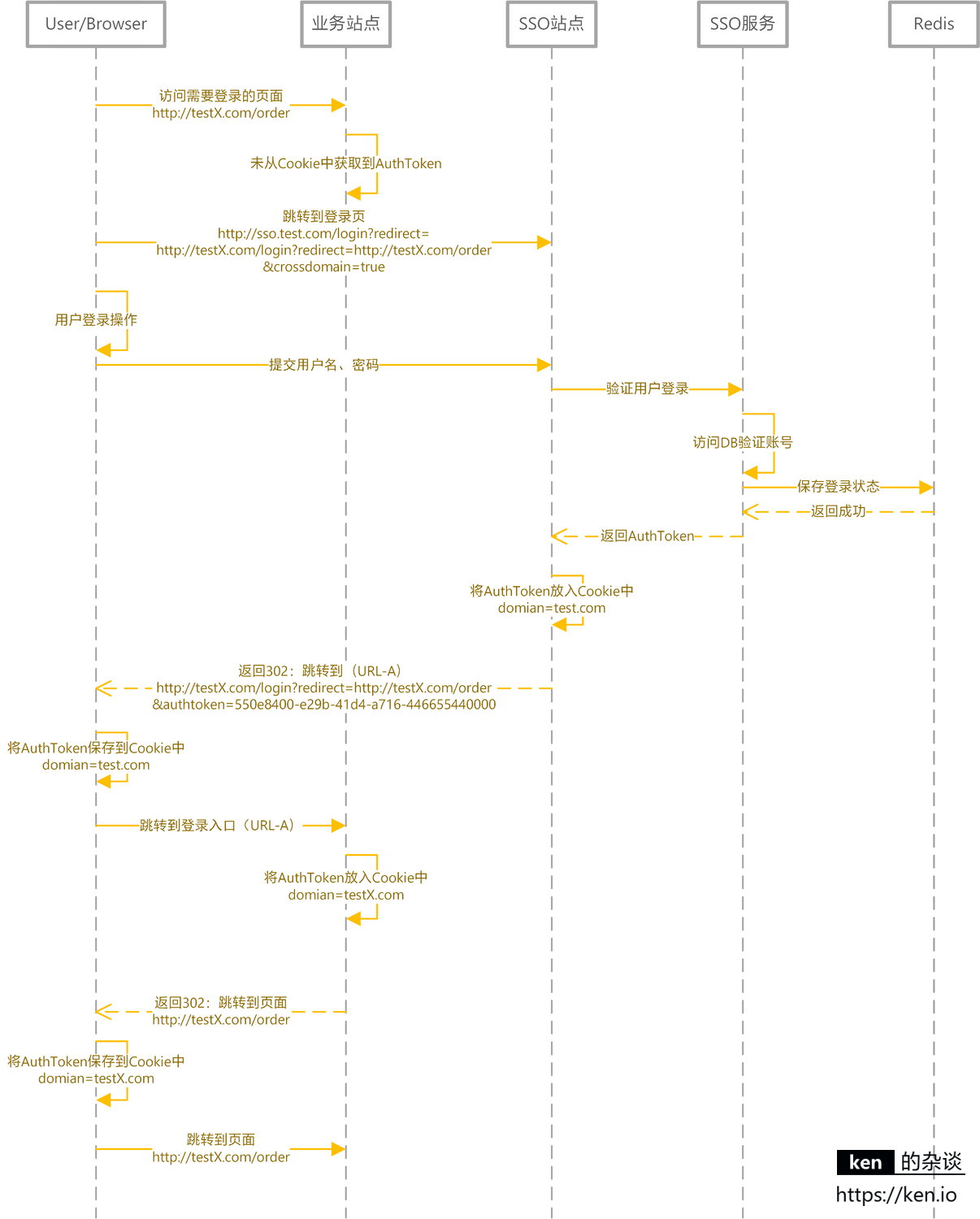
+
+- 跨域登出
+
+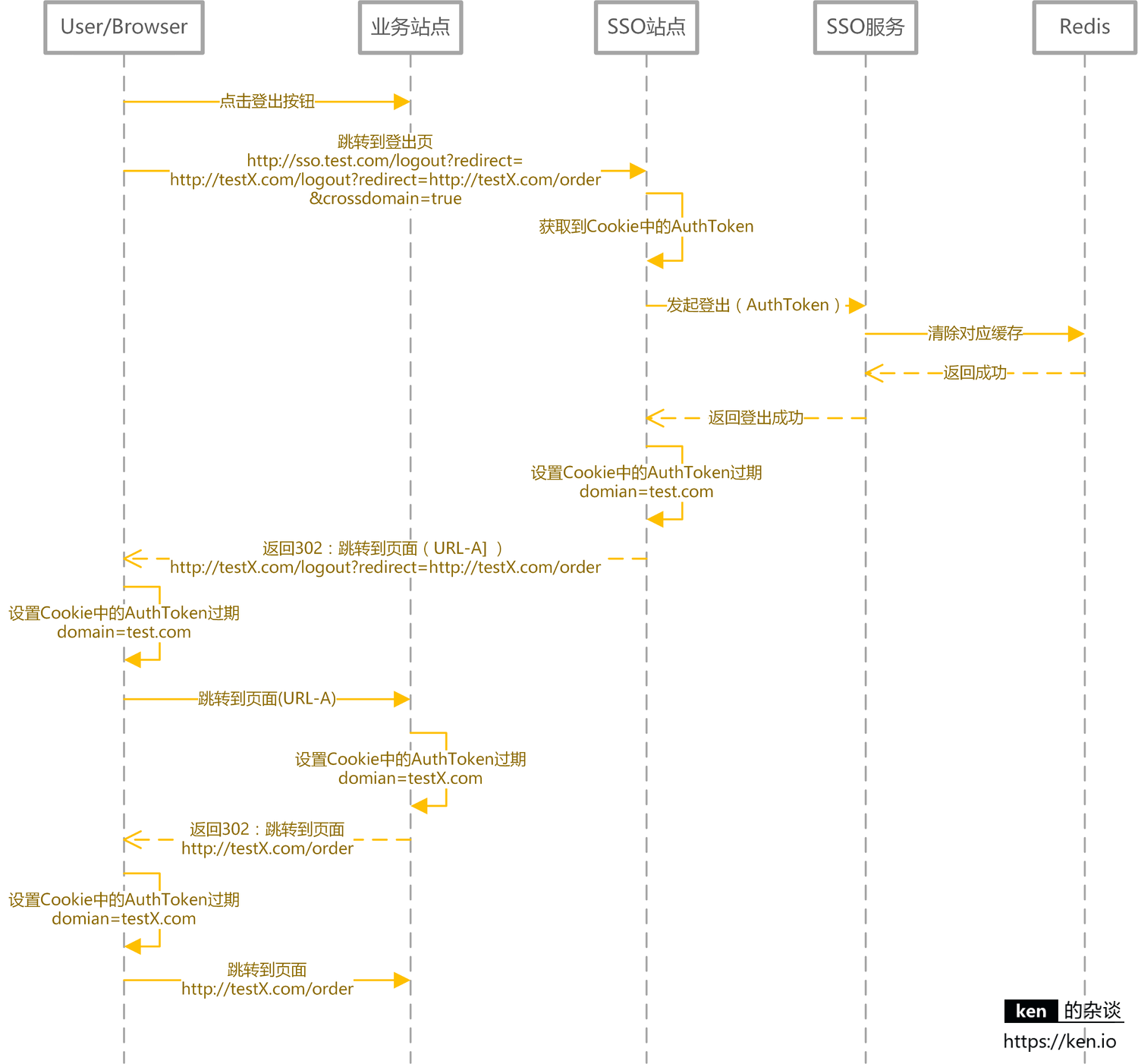
+
+## 三、备注
+
+- 关于方案
+
+这次设计方案更多是提供实现思路。如果涉及到APP用户登录等情况,在访问SSO服务时,增加对APP的签名验证就好了。当然,如果有无线网关,验证签名不是问题。
+
+- 关于时序图
+
+时序图中并没有包含所有场景,ken.io只列举了核心/主要场景,另外对于一些不影响理解思路的消息能省就省了。
diff --git "a/docs/system-design/security/\346\225\260\346\215\256\350\204\261\346\225\217.md" "b/docs/system-design/security/\346\225\260\346\215\256\350\204\261\346\225\217.md"
new file mode 100644
index 00000000000..58da1b305a3
--- /dev/null
+++ "b/docs/system-design/security/\346\225\260\346\215\256\350\204\261\346\225\217.md"
@@ -0,0 +1,3 @@
+# 数据脱敏
+
+数据脱敏说的就是我们根据特定的规则对敏感信息数据进行变形,比如我们把手机号、身份证号某些位数使用 * 来代替。
\ No newline at end of file
diff --git "a/docs/system-design/\345\256\232\346\227\266\344\273\273\345\212\241.md" "b/docs/system-design/\345\256\232\346\227\266\344\273\273\345\212\241.md"
new file mode 100644
index 00000000000..026bfa075db
--- /dev/null
+++ "b/docs/system-design/\345\256\232\346\227\266\344\273\273\345\212\241.md"
@@ -0,0 +1,319 @@
+# Java定时任务大揭秘
+
+## 为什么需要定时任务?
+
+我们来看一下几个非常常见的业务场景:
+
+1. 某系统凌晨要进行数据备份。
+2. 某电商平台,用户下单半个小时未支付的情况下需要自动取消订单。
+3. 某媒体聚合平台,每 10 分钟动态抓取某某网站的数据为自己所用。
+4. 某博客平台,支持定时发送文章。
+5. 某基金平台,每晚定时计算用户当日收益情况并推送给用户最新的数据。
+6. ......
+
+这些场景往往都要求我们在某个特定的时间去做某个事情。
+
+## 单机定时任务技术选型
+
+### Timer
+
+`java.util.Timer`是 JDK 1.3 开始就已经支持的一种定时任务的实现方式。
+
+`Timer` 内部使用一个叫做 `TaskQueue` 的类存放定时任务,它是一个基于最小堆实现的优先级队列。`TaskQueue` 会按照任务距离下一次执行时间的大小将任务排序,保证在堆顶的任务最先执行。这样在需要执行任务时,每次只需要取出堆顶的任务运行即可!
+
+`Timer` 使用起来比较简单,通过下面的方式我们就能创建一个 1s 之后执行的定时任务。
+
+```java
+// 示例代码:
+TimerTask task = new TimerTask() {
+ public void run() {
+ System.out.println("当前时间: " + new Date() + "n" +
+ "线程名称: " + Thread.currentThread().getName());
+ }
+};
+System.out.println("当前时间: " + new Date() + "n" +
+ "线程名称: " + Thread.currentThread().getName());
+Timer timer = new Timer("Timer");
+long delay = 1000L;
+timer.schedule(task, delay);
+
+
+//输出:
+当前时间: Fri May 28 15:18:47 CST 2021n线程名称: main
+当前时间: Fri May 28 15:18:48 CST 2021n线程名称: Timer
+```
+
+不过其缺陷较多,比如一个 `Timer` 一个线程,这就导致 `Timer` 的任务的执行只能串行执行,一个任务执行时间过长的话会影响其他任务(性能非常差),再比如发生异常时任务直接停止(`Timer` 只捕获了 `InterruptedException` )。
+
+`Timer` 类上的有一段注释是这样写的:
+
+```JAVA
+ * This class does not offer real-time guarantees: it schedules
+ * tasks using the <tt>Object.wait(long)</tt> method.
+ *Java 5.0 introduced the {@code java.util.concurrent} package and
+ * one of the concurrency utilities therein is the {@link
+ * java.util.concurrent.ScheduledThreadPoolExecutor
+ * ScheduledThreadPoolExecutor} which is a thread pool for repeatedly
+ * executing tasks at a given rate or delay. It is effectively a more
+ * versatile replacement for the {@code Timer}/{@code TimerTask}
+ * combination, as it allows multiple service threads, accepts various
+ * time units, and doesn't require subclassing {@code TimerTask} (just
+ * implement {@code Runnable}). Configuring {@code
+ * ScheduledThreadPoolExecutor} with one thread makes it equivalent to
+ * {@code Timer}.
+```
+
+大概的意思就是: `ScheduledThreadPoolExecutor` 支持多线程执行定时任务并且功能更强大,是 `Timer` 的替代品。
+
+### ScheduledExecutorService
+
+`ScheduledExecutorService` 是一个接口,有多个实现类,比较常用的是 `ScheduledThreadPoolExecutor` 。
+
+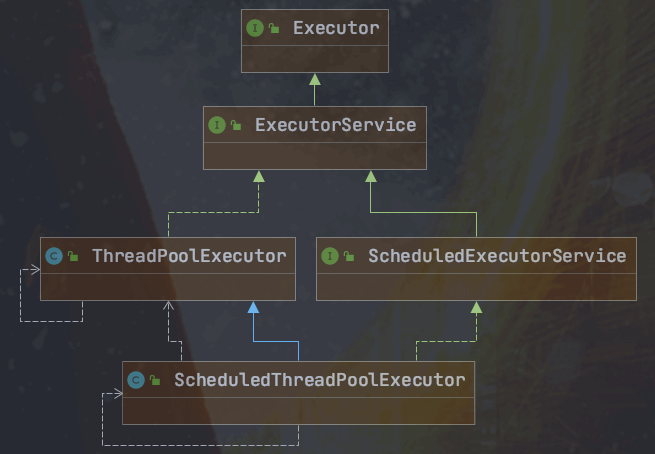
+
+`ScheduledThreadPoolExecutor` 本身就是一个线程池,支持任务并发执行。并且,其内部使用 `DelayQueue` 作为任务队列。
+
+```java
+// 示例代码:
+TimerTask repeatedTask = new TimerTask() {
+ @SneakyThrows
+ public void run() {
+ System.out.println("当前时间: " + new Date() + "n" +
+ "线程名称: " + Thread.currentThread().getName());
+ }
+};
+System.out.println("当前时间: " + new Date() + "n" +
+ "线程名称: " + Thread.currentThread().getName());
+ScheduledExecutorService executor = Executors.newScheduledThreadPool(3);
+long delay = 1000L;
+long period = 1000L;
+executor.scheduleAtFixedRate(repeatedTask, delay, period, TimeUnit.MILLISECONDS);
+Thread.sleep(delay + period * 5);
+executor.shutdown();
+//输出:
+当前时间: Fri May 28 15:40:46 CST 2021n线程名称: main
+当前时间: Fri May 28 15:40:47 CST 2021n线程名称: pool-1-thread-1
+当前时间: Fri May 28 15:40:48 CST 2021n线程名称: pool-1-thread-1
+当前时间: Fri May 28 15:40:49 CST 2021n线程名称: pool-1-thread-2
+当前时间: Fri May 28 15:40:50 CST 2021n线程名称: pool-1-thread-2
+当前时间: Fri May 28 15:40:51 CST 2021n线程名称: pool-1-thread-2
+当前时间: Fri May 28 15:40:52 CST 2021n线程名称: pool-1-thread-2
+```
+
+不论是使用 `Timer` 还是 `ScheduledExecutorService` 都无法使用 Cron 表达式指定任务执行的具体时间。
+
+### Spring Task
+
+
+
+我们直接通过 Spring 提供的 `@Scheduled` 注解即可定义定时任务,非常方便!
+
+```java
+/**
+ * cron:使用Cron表达式。 每分钟的1,2秒运行
+ */
+@Scheduled(cron = "1-2 * * * * ? ")
+public void reportCurrentTimeWithCronExpression() {
+ log.info("Cron Expression: The time is now {}", dateFormat.format(new Date()));
+}
+
+```
+
+我在大学那会做的一个 SSM 的企业级项目,就是用的 Spring Task 来做的定时任务。
+
+并且,Spring Task 还是支持 **Cron 表达式** 的。Cron 表达式主要用于定时作业(定时任务)系统定义执行时间或执行频率的表达式,非常厉害,你可以通过 Cron 表达式进行设置定时任务每天或者每个月什么时候执行等等操作。咱们要学习定时任务的话,Cron 表达式是一定是要重点关注的。推荐一个在线 Cron 表达式生成器:[http://cron.qqe2.com/](http://cron.qqe2.com/) 。
+
+但是,Spring 自带的定时调度只支持单机,并且提供的功能比较单一。之前写过一篇文章:[《5 分钟搞懂如何在 Spring Boot 中 Schedule Tasks》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485563&idx=1&sn=7419341f04036a10b141b74624a3f8c9&chksm=cea247b0f9d5cea6440759e6d49b4e77d06f4c99470243a10c1463834e873ca90266413fbc92&token=2133161636&lang=zh_CN#rd) ,不了解的小伙伴可以参考一下。
+
+Spring Task 底层是基于 JDK 的 `ScheduledThreadPoolExecutor` 线程池来实现的。
+
+**优缺点总结:**
+
+- 优点: 简单,轻量,支持 Cron 表达式
+- 缺点 :功能单一
+
+### 时间轮
+
+Kafka、Dubbo、ZooKeeper、Netty 、Caffeine 、Akka 中都有对时间轮的实现。
+
+时间轮简单来说就是一个环形的队列(底层一般基于数组实现),队列中的每一个元素(时间格)都可以存放一个定时任务列表。
+
+时间轮中的每个时间格代表了时间轮的基本时间跨度或者说时间精度,加入时间一秒走一个时间格的话,那么这个时间轮的最高精度就是 1 秒(也就是说 3 s 和 3.9s 会在同一个时间格中)。
+
+下图是一个有 12 个时间格的时间轮,转完一圈需要 12 s。当我们需要新建一个 3s 后执行的定时任务,只需要将定时任务放在下标为 3 的时间格中即可。当我们需要新建一个 9s 后执行的定时任务,只需要将定时任务放在下标为 9 的时间格中即可。
+
+
+
+那当我们需要创建一个 13s 后执行的定时任务怎么办呢?这个时候可以引入一叫做 **圈数/轮数** 的概念,也就是说这个任务还是放在下标为 3 的时间格中, 不过它的圈数为 2 。
+
+除了增加圈数这种方法之外,还有一种 **多层次时间轮** (类似手表),Kafka 采用的就是这种方案。
+
+针对下图的时间轮,我来举一个例子便于大家理解。
+
+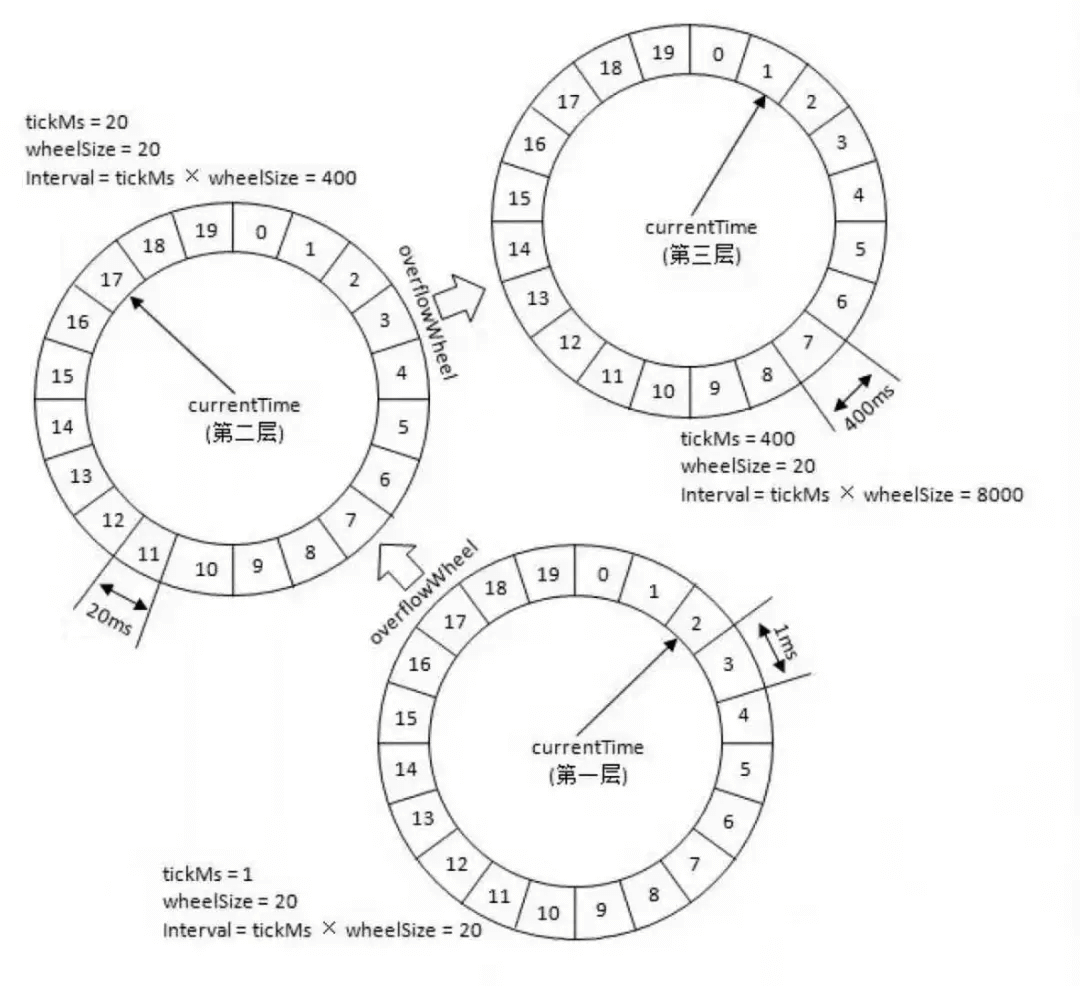
+
+上图的时间轮,第 1 层的时间精度为 1 ,第 2 层的时间精度为 20 ,第 3 层的时间精度为 400。假如我们需要添加一个 350s 后执行的任务 A 的话(当前时间是 0s),这个任务会被放在第 2 层(因为第二层的时间跨度为 20\*20=400>350)的第 350/20=17 个时间格子。
+
+当第一层转了 17 圈之后,时间过去了 340s ,第 2 层的指针此时来到第 17 个时间格子。此时,第 2 层第 17 个格子的任务会被移动到第 1 层。
+
+任务 A 当前是 10s 之后执行,因此它会被移动到第 1 层的第 10 个时间格子。
+
+这里在层与层之间的移动也叫做时间轮的升降级。参考手表来理解就好!
+
+
+
+**时间轮比较适合任务数量比较多的定时任务场景,它的任务写入和执行的时间复杂度都是 0(1)。**
+
+## 分布式定时任务技术选型
+
+上面提到的一些定时任务的解决方案都是在单机下执行的,适用于比较简单的定时任务场景比如每天凌晨备份一次数据。
+
+如果我们需要一些高级特性比如支持任务在分布式场景下的分片和高可用的话,我们就需要用到分布式任务调度框架了。
+
+通常情况下,一个定时任务的执行往往涉及到下面这些角色:
+
+- **任务** : 首先肯定是要执行的任务,这个任务就是具体的业务逻辑比如定时发送文章。
+- **调度器** :其次是调度中心,调度中心主要负责任务管理,会分配任务给执行器。
+- **执行器** : 最后就是执行器,执行器接收调度器分派的任务并执行。
+
+### Quartz
+
+
+
+一个很火的开源任务调度框架,完全由`Java`写成。`Quartz` 可以说是 Java 定时任务领域的老大哥或者说参考标准,其他的任务调度框架基本都是基于 `Quartz` 开发的,比如当当网的`elastic-job`就是基于`quartz`二次开发之后的分布式调度解决方案。
+
+使用 `Quartz` 可以很方便地与 `Spring` 集成,并且支持动态添加任务和集群。但是,`Quartz` 使用起来也比较麻烦,API 繁琐。
+
+并且,`Quzrtz` 并没有内置 UI 管理控制台,不过你可以使用 [quartzui](https://github.com/zhaopeiym/quartzui) 这个开源项目来解决这个问题。
+
+另外,`Quartz` 虽然也支持分布式任务。但是,它是在数据库层面,通过数据库的锁机制做的,有非常多的弊端比如系统侵入性严重、节点负载不均衡。有点伪分布式的味道。
+
+**优缺点总结:**
+
+- 优点: 可以与 `Spring` 集成,并且支持动态添加任务和集群。
+- 缺点 :分布式支持不友好,没有内置 UI 管理控制台、使用麻烦(相比于其他同类型框架来说)
+
+### Elastic-Job
+
+
+
+`Elastic-Job` 是当当网开源的一个基于`Quartz`和`ZooKeeper`的分布式调度解决方案,由两个相互独立的子项目 `Elastic-Job-Lite` 和 `Elastic-Job-Cloud` 组成,一般我们只要使用 `Elastic-Job-Lite` 就好。
+
+`ElasticJob` 支持任务在分布式场景下的分片和高可用、任务可视化管理等功能。
+
+
+
+ElasticJob-Lite 的架构设计如下图所示:
+
+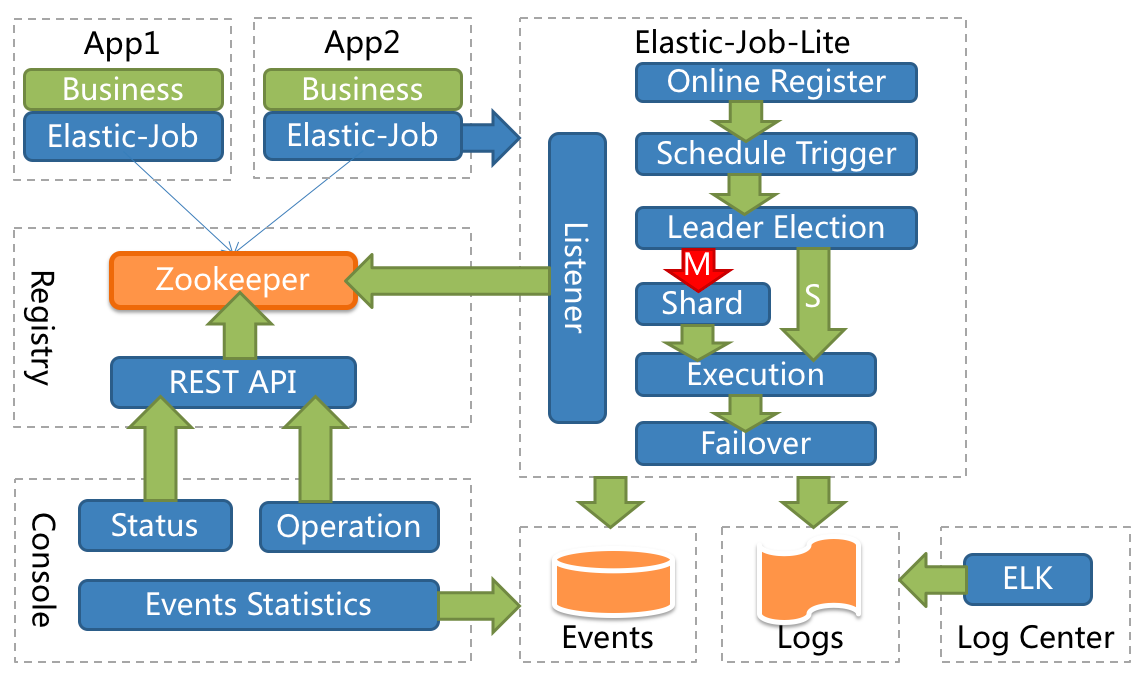
+
+从上图可以看出,`Elastic-Job` 没有调度中心这一概念,而是使用 `ZooKeeper` 作为注册中心,注册中心负责协调分配任务到不同的节点上。
+
+Elastic-Job 中的定时调度都是由执行器自行触发,这种设计也被称为去中心化设计(调度和处理都是执行器单独完成)。
+
+```java
+@Component
+@ElasticJobConf(name = "dayJob", cron = "0/10 * * * * ?", shardingTotalCount = 2,
+ shardingItemParameters = "0=AAAA,1=BBBB", description = "简单任务", failover = true)
+public class TestJob implements SimpleJob {
+ @Override
+ public void execute(ShardingContext shardingContext) {
+ log.info("TestJob任务名:【{}】, 片数:【{}】, param=【{}】", shardingContext.getJobName(), shardingContext.getShardingTotalCount(),
+ shardingContext.getShardingParameter());
+ }
+}
+```
+
+**相关地址:**
+
+- Github 地址:https://github.com/apache/shardingsphere-elasticjob。
+- 官方网站:https://shardingsphere.apache.org/elasticjob/index_zh.html 。
+
+**优缺点总结:**
+
+- 优点 :可以与 `Spring` 集成、支持分布式、支持集群、性能不错
+- 缺点 :依赖了额外的中间件比如 Zookeeper(复杂度增加,可靠性降低、维护成本变高)
+
+### XXL-JOB
+
+
+
+`XXL-JOB` 于 2015 年开源,是一款优秀的轻量级分布式任务调度框架,支持任务可视化管理、弹性扩容缩容、任务失败重试和告警、任务分片等功能,
+
+
+
+根据 `XXL-JOB` 官网介绍,其解决了很多 `Quartz` 的不足。
+
+
+
+`XXL-JOB` 的架构设计如下图所示:
+
+
+
+从上图可以看出,`XXL-JOB` 由 **调度中心** 和 **执行器** 两大部分组成。调度中心主要负责任务管理、执行器管理以及日志管理。执行器主要是接收调度信号并处理。另外,调度中心进行任务调度时,是通过自研 RPC 来实现的。
+
+不同于 `Elastic-Job` 的去中心化设计, `XXL-JOB` 的这种设计也被称为中心化设计(调度中心调度多个执行器执行任务)。
+
+和 `Quzrtz` 类似 `XXL-JOB` 也是基于数据库锁调度任务,存在性能瓶颈。不过,一般在任务量不是特别大的情况下,没有什么影响的,可以满足绝大部分公司的要求。
+
+不要被 `XXL-JOB` 的架构图给吓着了,实际上,我们要用 `XXL-JOB` 的话,只需要重写 `IJobHandler` 自定义任务执行逻辑就可以了,非常易用!
+
+```java
+@JobHandler(value="myApiJobHandler")
+@Component
+public class MyApiJobHandler extends IJobHandler {
+
+ @Override
+ public ReturnT<String> execute(String param) throws Exception {
+ //......
+ return ReturnT.SUCCESS;
+ }
+}
+```
+
+还可以直接基于注解定义任务。
+
+```java
+@XxlJob("myAnnotationJobHandler")
+public ReturnT<String> myAnnotationJobHandler(String param) throws Exception {
+ //......
+ return ReturnT.SUCCESS;
+}
+```
+
+
+
+**相关地址:**
+
+- Github 地址:https://github.com/xuxueli/xxl-job/。
+- 官方介绍:https://www.xuxueli.com/xxl-job/ 。
+
+**优缺点总结:**
+
+- 优点:开箱即用(学习成本比较低)、与 Spring 集成、支持分布式、支持集群、内置了 UI 管理控制台。
+- 缺点:不支持动态添加任务(如果一定想要动态创建任务也是支持的,参见:[xxl-job issue277](https://github.com/xuxueli/xxl-job/issues/277))。
+
+### PowerJob
+
+
+
+非常值得关注的一个分布式任务调度框架,分布式任务调度领域的新星。目前,已经有很多公司接入比如 OPPO、京东、中通、思科。
+
+这个框架的诞生也挺有意思的,PowerJob 的作者当时在阿里巴巴实习过,阿里巴巴那会使用的是内部自研的 SchedulerX(阿里云付费产品)。实习期满之后,PowerJob 的作者离开了阿里巴巴。想着说自研一个 SchedulerX,防止哪天 SchedulerX 满足不了需求,于是 PowerJob 就诞生了。
+
+更多关于 PowerJob 的故事,小伙伴们可以去看看 PowerJob 作者的视频 [《我和我的任务调度中间件》](https://www.bilibili.com/video/BV1SK411A7F3/)。简单点概括就是:“游戏没啥意思了,我要扛起了新一代分布式任务调度与计算框架的大旗!”。
+
+由于 SchedulerX 属于人民币产品,我这里就不过多介绍。PowerJob 官方也对比过其和 QuartZ、XXL-JOB 以及 SchedulerX。
+
+
+
+## 总结
+
+这篇文章中,我主要介绍了:
+
+- **定时任务的相关概念** :为什么需要定时任务、定时任务中的核心角色、分布式定时任务。
+- **定时任务的技术选型** : XXL-JOB 2015 年推出,已经经过了很多年的考验。XXL-JOB 轻量级,并且使用起来非常简单。虽然存在性能瓶颈,但是,在绝大多数情况下,对于企业的基本需求来说是没有影响的。PowerJob 属于分布式任务调度领域里的新星,其稳定性还有待继续考察。ElasticJob 由于在架构设计上是基于 Zookeeper ,而 XXL-JOB 是基于数据库,性能方面的话,ElasticJob 略胜一筹。
+
+这篇文章并没有介绍到实际使用,但是,并不代表实际使用不重要。我在写这篇文章之前,已经动手写过相应的 Demo。像 Quartz,我在大学那会就用过。不过,当时用的是 Spring 。为了能够更好地体验,我自己又在 Spring Boot 上实际体验了一下。如果你并没有实际使用某个框架,就直接说它并不好用的话,是站不住脚的。
+
+最后,这篇文章要感谢艿艿的帮助,写这篇文章的时候向艿艿询问过一些问题。推荐一篇艿艿写的偏实战类型的硬核文章:[《Spring Job?Quartz?XXL-Job?年轻人才做选择,艿艿全莽~》](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247490679&idx=1&sn=25374dbdcca95311d41be5d7b7db454d&chksm=fa4963c6cd3eead055bb9cd10cca13224bb35d0f7373a27aa22a55495f71e24b8273a7603314&scene=27#wechat_redirect) 。
\ No newline at end of file
diff --git a/docs/tools/database/CHINER.md b/docs/tools/database/CHINER.md
new file mode 100644
index 00000000000..a9543afad2a
--- /dev/null
+++ b/docs/tools/database/CHINER.md
@@ -0,0 +1,100 @@
+# CHINER: 干掉 PowerDesigner,这个国产数据库建模工具很强!
+
+大家好,我是 Guide!
+
+今天给小伙伴们分享一个我平时经常使用的国产数据库建模工具,非常好用!
+
+这个数据库建模工具的名字叫做 **CHINER** [kaɪˈnər] 。可能大部分小伙伴都没有听过这个工具,不过,相信大部分小伙伴应该都听说过 CHINER 的前身 **PDMan**。
+
+CHINER 是 CHINESE Entity Relation 的缩写,翻译过来就是国产实体关系图工具,中文名称为:**元数建模**,也作:"**CHINER[元数建模]**"公开使用。
+
+CHINER 对 PDMan 的架构设计进行了大幅改善,并对 PDMan 做到高度兼容。
+
+CHINER 的界面简单,功能简洁,非常容易上手。并且,可以直接导入 PowerDesigner 文件、PDMan 文件,还可以直接从数据库或者 DDL 语句直接导入。
+
+
+
+CHINER 的技术栈:React+Electron+Java 。
+
+* Gitee 地址:https://gitee.com/robergroup/chiner 。
+* 操作手册: https://www.yuque.com/chiner/docs/manual 。
+
+## 快速体验
+
+### 下载安装
+
+CHINER 提供了 **Windows** 、**Mac** 、**Linux** 下的一键安装包,我们直接下载即可。
+
+> 下载地址:https://gitee.com/robergroup/chiner/releases
+
+需要注意的是:如果你当前使用的 Chrome 浏览器的话,无法直接点击链接下载。你可以更换浏览器下载或者右键链接选择链接存储为...。
+
+
+
+打开软件之后,界面如下图所示。
+
+
+
+我这里以电商项目参考模板来演示 CHINER 的基本操作。
+
+### 模块化管理
+
+电商项目比较复杂,我们可以将其拆分为一个一个独立的模块(表分组),每个模块下有数据表,视图,关系图,数据字典。
+
+像这个电商项目就创建了 3 个模块:消费端、商家端、平台端。
+
+
+
+不过,对于一些比较简单的项目比如博客系统、企业管理系统直接使用简单模式即可。
+
+### 数据库表管理
+
+右键数据表即可创建新的数据库表,点击指定的数据库表即可对指定的数据库表进行设计。
+
+
+
+并且,数据表字段可以直接关联数据字典。
+
+
+
+如果需要创建视图的话,直接右键视图即可。视图是从一个或多个表导出的虚拟的表,其内容由查询定义。具有普通表的结构,但是不实现数据存储。
+
+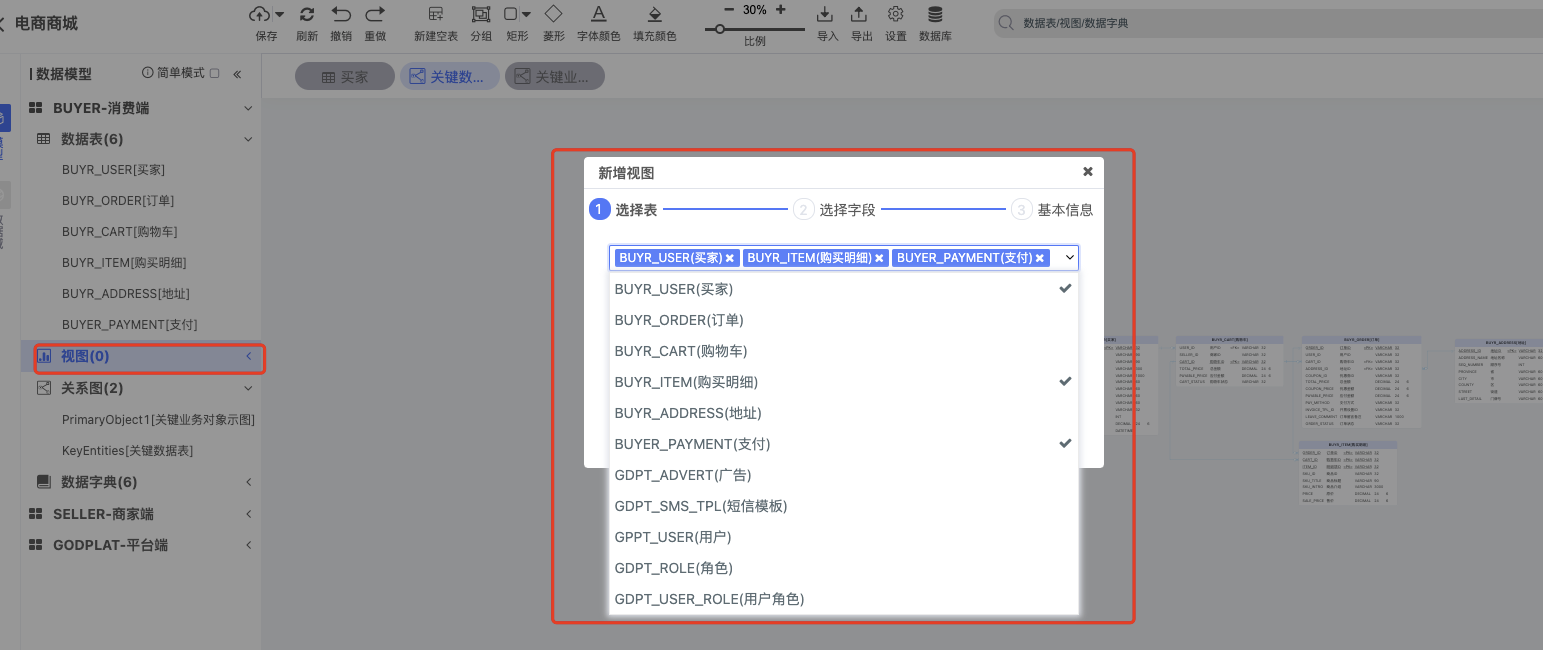
+
+数据库视图可以方便我们进行查询。不过,数据库视图会影响数据库性能,通常不建议使用。
+
+### 关系图
+
+我平时在项目中比较常见的 **ER 关联关系图** ,可以使用 CHINER 进行手动维护。
+
+如果你需要添加新的数据库表到关系图的话,直接拖拽指定的数据库表到右边的关系图展示界面即可。另外,表与表之间的关联也需要你手动对相关联的字段进行连接。
+
+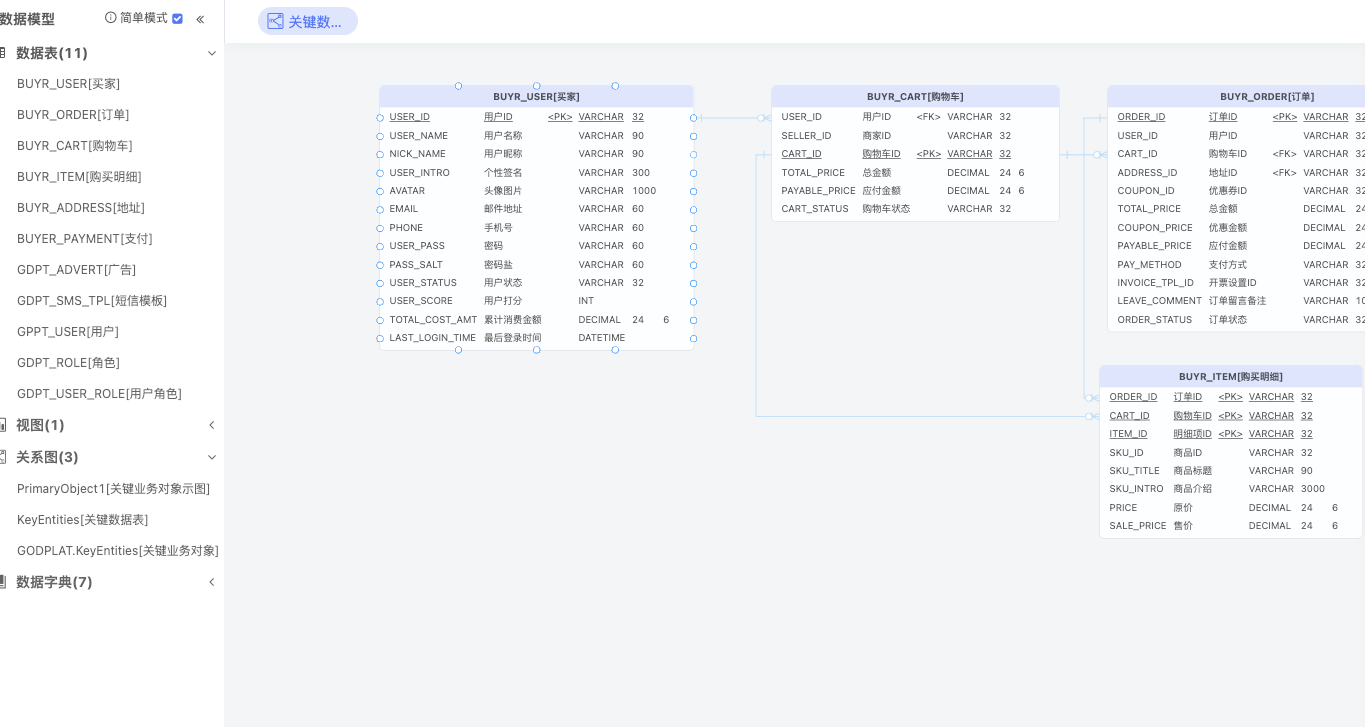
+
+手动进行维护,说实话还是比较麻烦的,也比较容易出错。
+
+像 [Navicat Data Modeler](https://www.navicat.com.cn/products/navicat-data-modeler) 在这方面就强多了,它可以自动生成 ER 图。
+
+
+
+### 数据库表代码模板
+
+支持直接生成对应表的 SQL 代码(支持 MySQL、Oracle、SQL Server、PostgreSQL 等数据库)并且还提供了 Java 和 C# 的 JavaBean。
+
+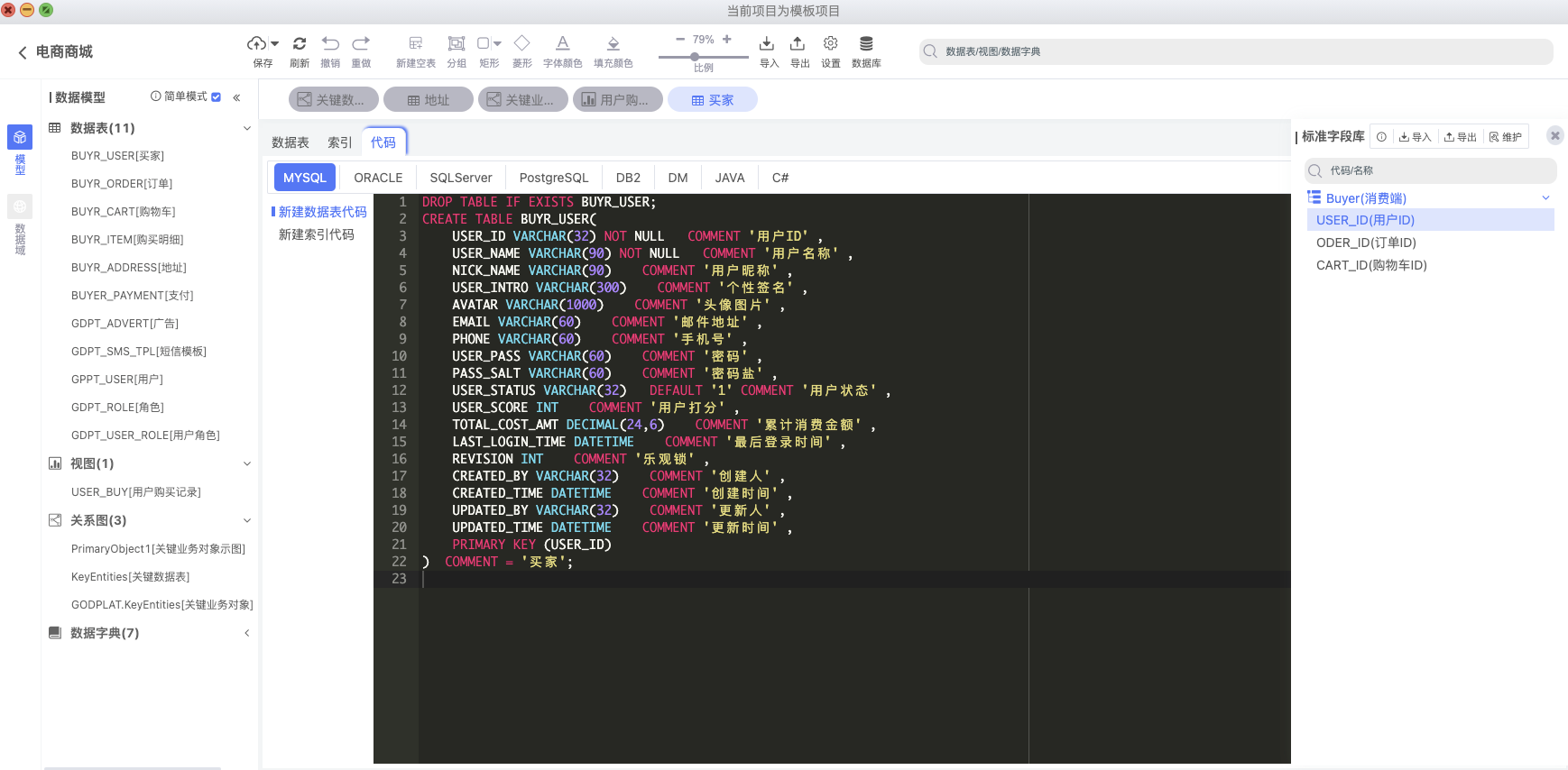
+
+### 导出数据库表
+
+你可以选择导出 DDL、Word 文档、数据字典 SQL、当前关系图的图片。
+
+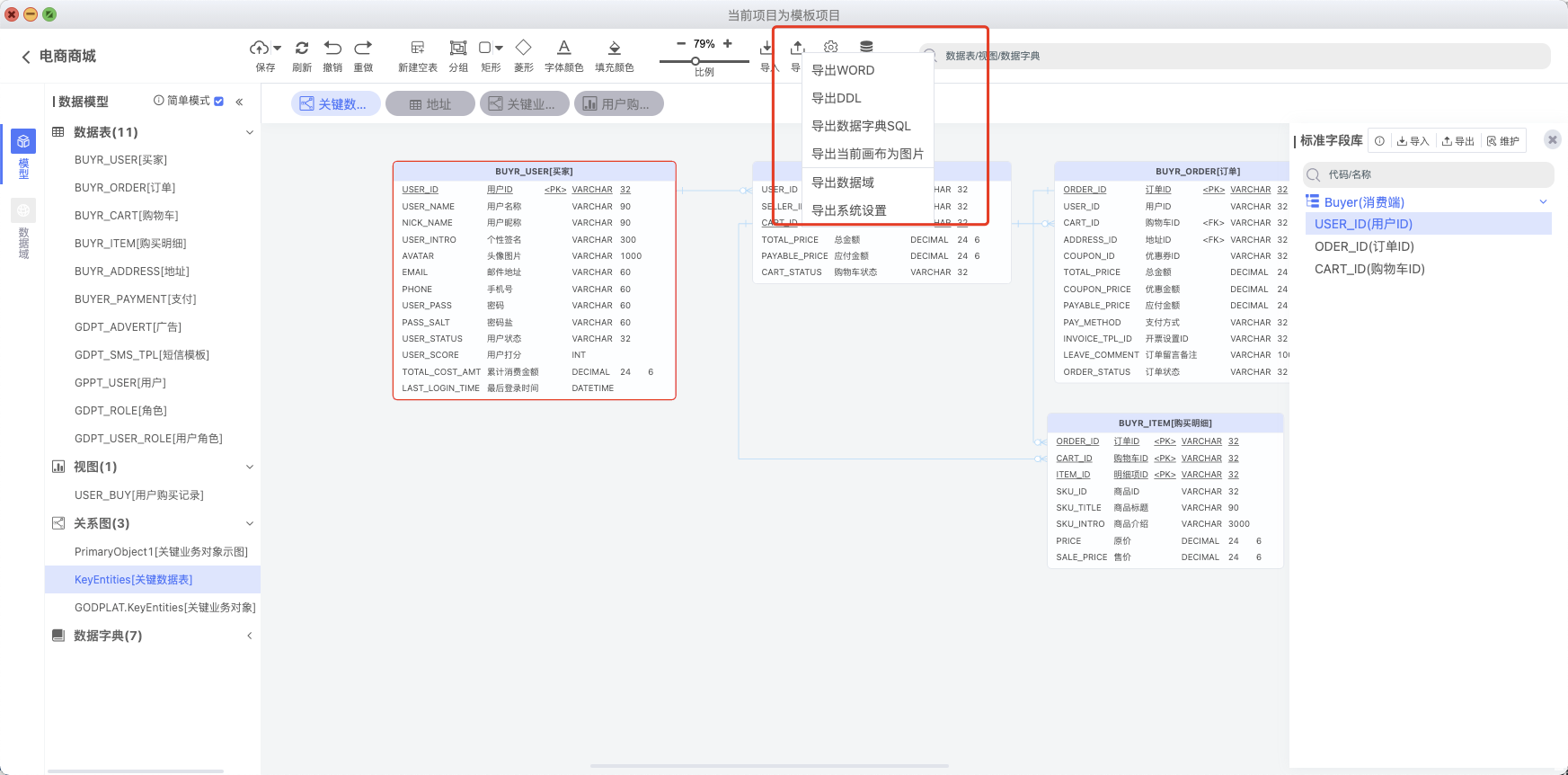
+
+### 数据库逆向
+
+你还可以连接数据库,逆向解析数据库。
+
+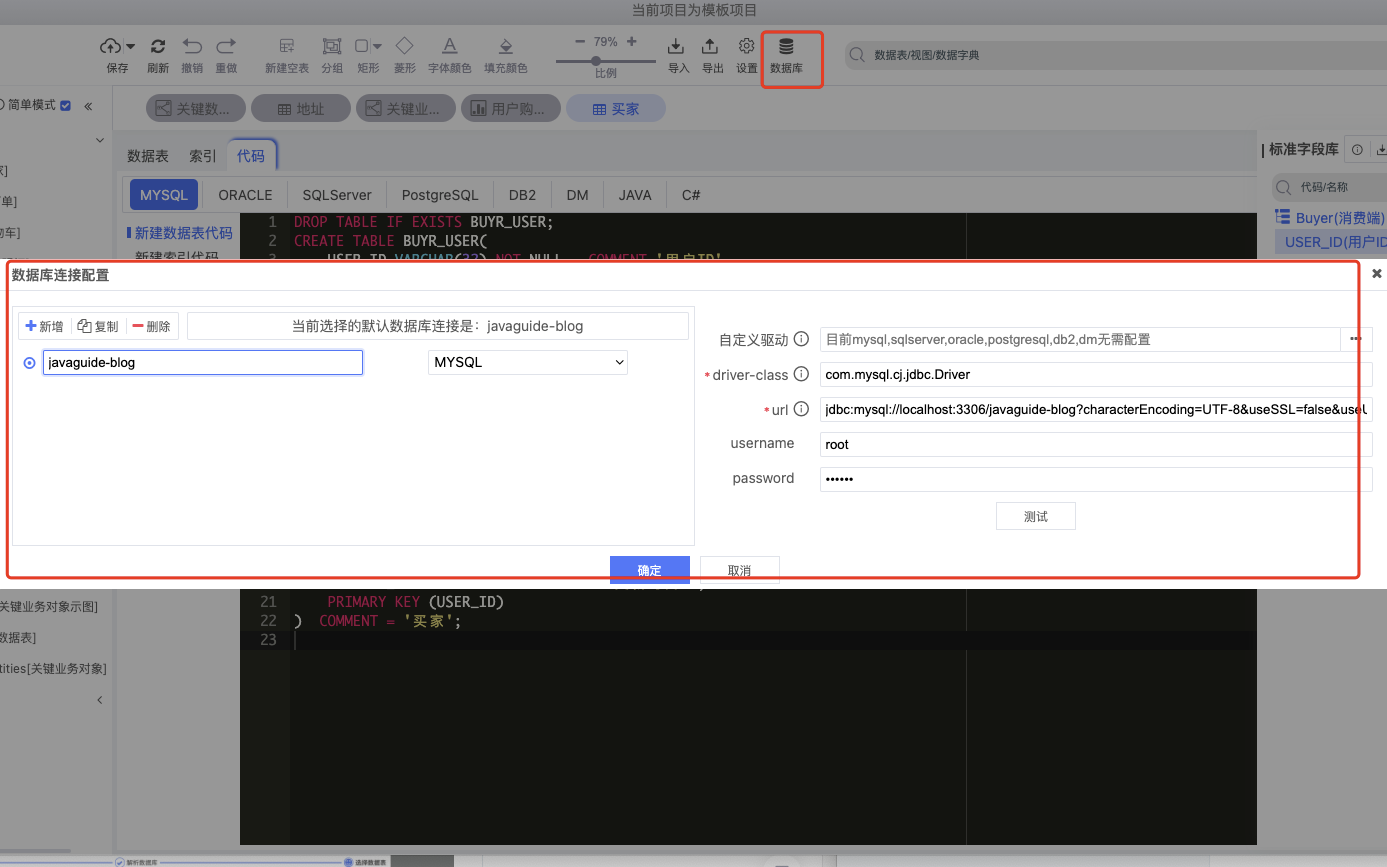
+
+数据库连接成功之后,我们点击右上角的菜单 `导入—> 从数据库导入` 即可。
+
+
diff --git a/docs/tools/database/DBeaver.md b/docs/tools/database/DBeaver.md
new file mode 100644
index 00000000000..f57f9450b8b
--- /dev/null
+++ b/docs/tools/database/DBeaver.md
@@ -0,0 +1,85 @@
+# DBeaver:开源数据库管理工具。
+
+[《再见,Navicat!同事安利的这个IDEA的兄弟,真香!》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247489523&idx=1&sn=4e96972842bdcea2e05cb267d17c5e8e&chksm=cea25838f9d5d12e45a9939370eccf2bff7177038e70437ea0e01d64030118852ee66ae72284&token=2000865596&lang=zh_CN#rd) 这篇文章发了之后很多人抱怨Datagrip 的占用内存太大,很多人推荐了 DBeaver 这款开源免费的数据库管理工具。于是,我昨夜简单体验了一下 DBeaver ,然后写了这篇文章。
+
+## DBeaver 概览
+
+DBeaver 是一个基于 Java 开发 ,并且支持几乎所有的数据库产品的开源数据库管理工具。
+
+DBeaver 社区版不光支持关系型数据库比如MySQL、PostgreSQL、MariaDB、SQLite、Oracle、Db2、SQL Server,还比如 SQLite、H2这些内嵌数据库。还支持常见的全文搜索引擎比如 Elasticsearch 和 Solr、大数据相关的工具比如Hive和 Spark。
+
+
+
+甚至说,DBeaver 的商业版本还支持各种 NoSQL 数据库。
+
+
+
+## 使用
+
+**DBeaver 虽然小巧,但是功能还是十分强大的。基本的表设计、SQL执行、ER图、数据导入导出等等常用功能都不在话下。**
+
+**我下面只简单演示一下基本的数据库的创建以及表的创建。**
+
+### 下载安装
+
+官方网提供的下载地址:https://dbeaver.io/download/ ,你可以根据自己的操作系统选择合适的版本进行下载安装。
+
+比较简单,这里就不演示了。
+
+### 连接数据库
+
+**1.选择自己想要的连接的数据库,然后点击下一步即可(第一次连接可能需要下载相关驱动)。**
+
+我这里以MySQL为例。
+
+
+
+**2.输入数据库的地址、用户名和密码等信息,然后点击完成即可连接**
+
+点击完成之前,你可以先通过左下方的测试连接来看一下数据库是否可以被成功连接上。
+
+
+
+### 新建数据库
+
+右键-> 新建数据库(MySQL 用户记得使用 utf8mb4而不是 utf8)
+
+
+
+### 数据库表相关操作
+
+#### 新建表
+
+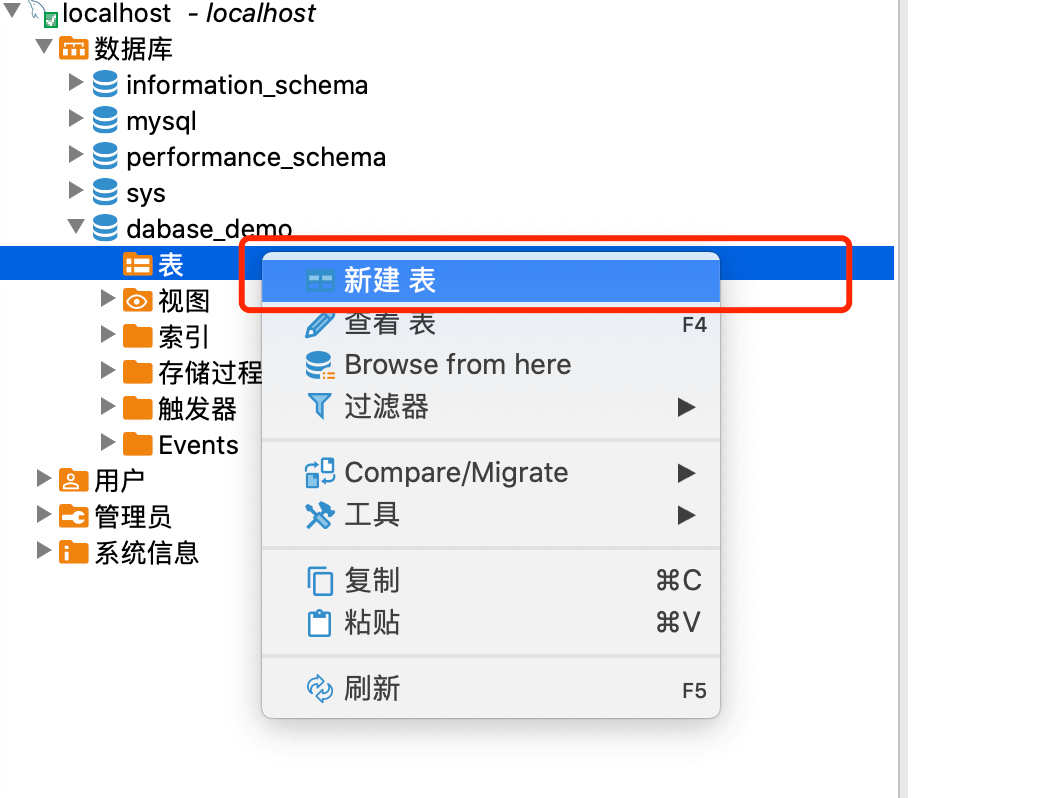
+
+#### 新建列
+
+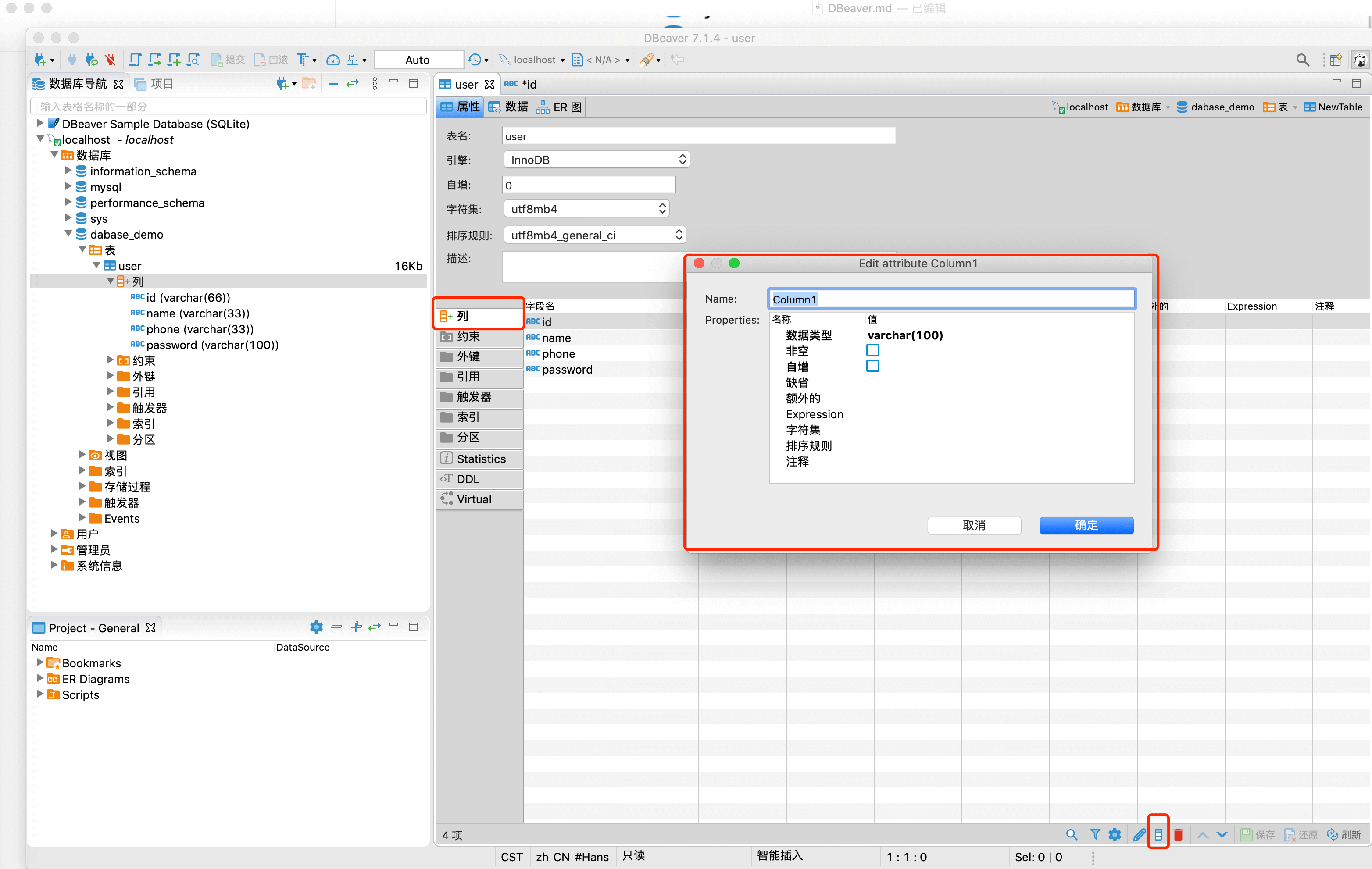
+
+#### 创建约束(主键、唯一键)
+
+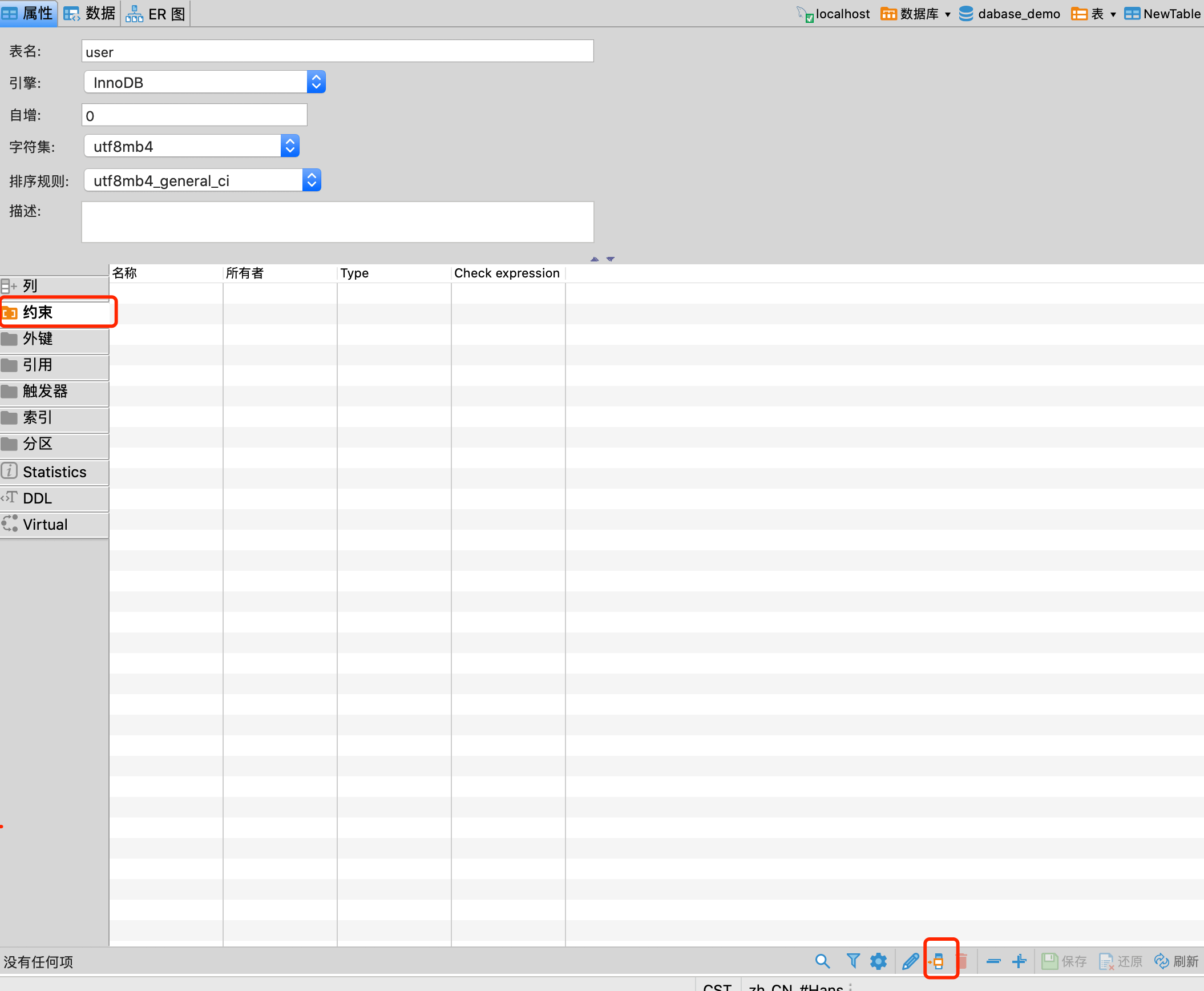
+
+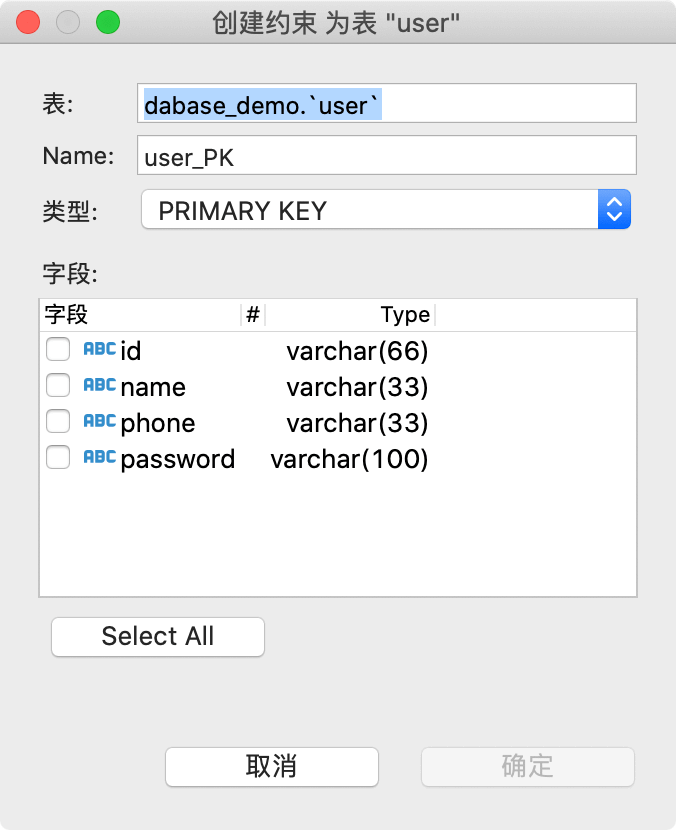
+
+#### 插入数据
+
+我们通过 SQL 编辑器插入数据:
+
+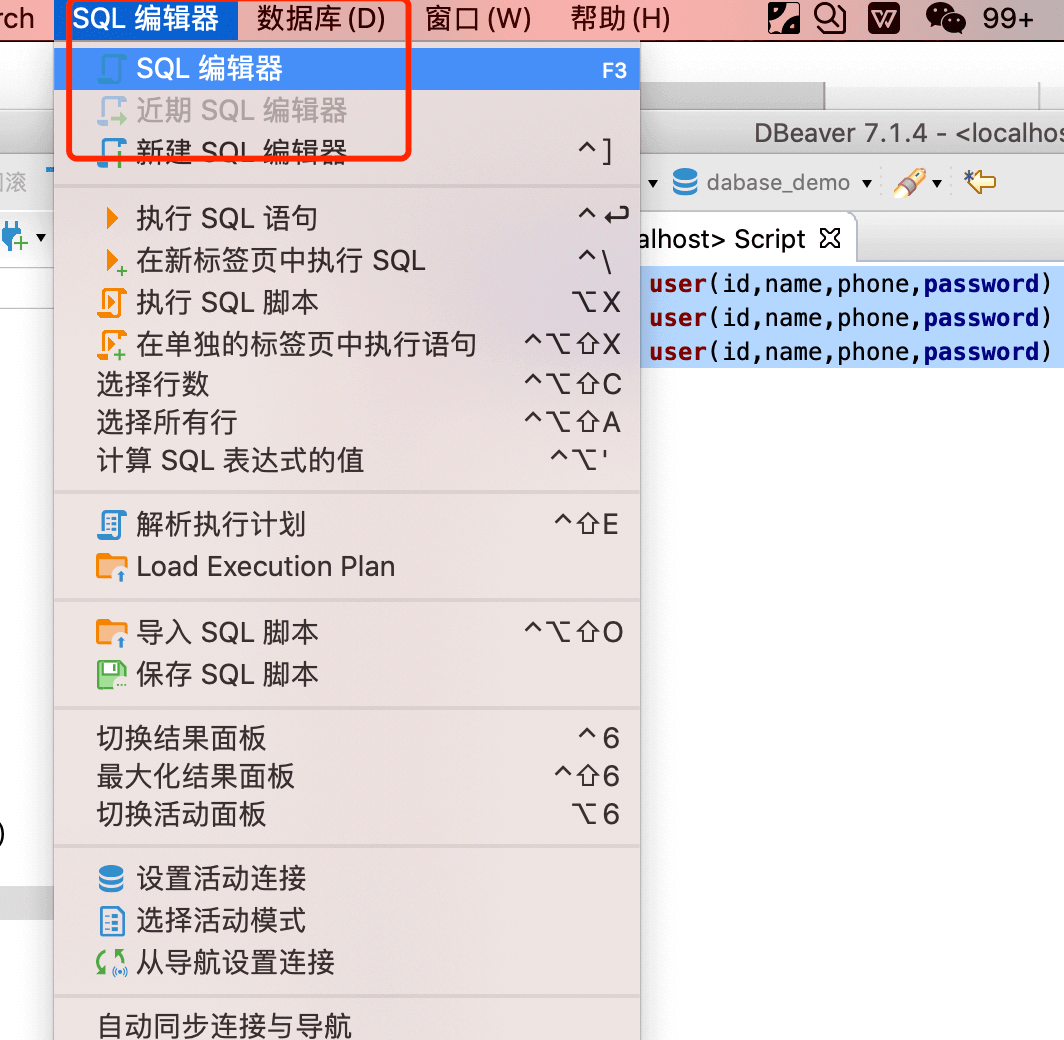
+
+```java
+INSERT into user(id,name,phone,password) values ('A00001','guide哥','181631312315','123456');
+INSERT into user(id,name,phone,password) values ('A00002','guide哥2','181631312313','123456');
+INSERT into user(id,name,phone,password) values ('A00003','guide哥3','181631312312','123456');
+```
+
+## 总结
+
+总的来说,简单体验之后感觉还是很不错的,占用内存也确实比 DataGrip 确实要小很多。
+
+各位小伙伴可以自行体验一下。毕竟免费并且开源,还是很香的!
+
+
+
+
diff --git a/docs/tools/database/screw.md b/docs/tools/database/screw.md
new file mode 100644
index 00000000000..30542e17efe
--- /dev/null
+++ b/docs/tools/database/screw.md
@@ -0,0 +1,296 @@
+# screw:一键生成数据库文档,堪称数据库界的Swagger
+
+在项目中,我们经常需要整理数据库表结构文档。
+
+一般情况下,我们都是手动整理数据库表结构文档,当表结构有变动的时候,自己手动进行维护。
+
+数据库表少的时候还好,数据库表多了之后,手动整理和维护数据库表结构文档简直不要太麻烦,而且,还非常容易出错!
+
+**有没有什么好用的工具帮助我们自动生成数据库表结构文档呢?**
+
+当然有!Github 上就有一位朋友开源了一款数据库表结构文档自动生成工具—— **screw** 。
+
+项目地址: https://github.com/pingfangushi/screw 。
+
+
+
+screw 翻译过来的意思就是螺丝钉,作者希望这个工具能够像螺丝钉一样切实地帮助到我们的开发工作。
+
+目前的话,screw 已经支持市面上大部分常见的数据库比如 MySQL、MariaDB、Oracle、SqlServer、PostgreSQL、TiDB。
+
+另外,screw 使用起来也非常简单,根据官网提示,不用 10 分钟就能成功在本地使用起来!
+
+## 快速入门
+
+为了验证 screw 自动生成数据库表结构文档的效果,我们首先创建一个简单的存放博客数据的数据库表。
+
+```sql
+CREATE TABLE `blog` (
+ `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
+ `title` varchar(255) NOT NULL COMMENT '博客标题',
+ `content` longtext NOT NULL COMMENT '博客内容',
+ `description` varchar(255) DEFAULT NULL COMMENT '博客简介',
+ `cover` varchar(255) DEFAULT NULL COMMENT '博客封面图片地址',
+ `views` int(11) NOT NULL DEFAULT '0' COMMENT '博客阅读次数',
+ `user_id` bigint(20) DEFAULT '0' COMMENT '发表博客的用户ID',
+ `channel_id` bigint(20) NOT NULL COMMENT '博客分类ID',
+ `recommend` bit(1) NOT NULL DEFAULT b'0' COMMENT '是否推荐',
+ `top` bit(1) NOT NULL DEFAULT b'0' COMMENT '是否置顶',
+ `comment` bit(1) NOT NULL DEFAULT b'1' COMMENT '是否开启评论',
+ `created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
+ `updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8mb4 COMMENT='博客';
+```
+
+### 基于 Java 代码
+
+#### 引入依赖
+
+创建一个普通的 Maven 项目即可!然后引入 screw、HikariCP、MySQL 这 3 个依赖。
+
+```xml
+<!--screw-->
+<dependency>
+ <groupId>cn.smallbun.screw</groupId>
+ <artifactId>screw-core</artifactId>
+ <version>1.0.5</version>
+</dependency>
+<!-- HikariCP -->
+<dependency>
+ <groupId>com.zaxxer</groupId>
+ <artifactId>HikariCP</artifactId>
+ <version>3.4.5</version>
+</dependency>
+<!--MySQL-->
+<dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.20</version>
+</dependency>
+```
+
+你可以通过下面的地址在 mvnrepository 获取最新版本的 screw。
+
+> https://mvnrepository.com/artifact/cn.smallbun.screw/screw-core
+
+#### 编写代码
+
+生成数据库文档的代码的整个代码逻辑还是比较简单的,我们只需要经过下面 5 步即可:
+
+```java
+// 1.获取数据源
+DataSource dataSource = getDataSource();
+// 2.获取数据库文档生成配置(文件路径、文件类型)
+EngineConfig engineConfig = getEngineConfig();
+// 3.获取数据库表的处理配置,可忽略
+ProcessConfig processConfig = getProcessConfig();
+// 4.Screw 完整配置
+Configuration config = getScrewConfig(dataSource, engineConfig, processConfig);
+// 5.执行生成数据库文档
+new DocumentationExecute(config).execute();
+```
+
+**1、获取数据库源**
+
+对数据库以及数据库连接池进行相关配置。务必将数据库相关的配置修改成你自己的。
+
+```java
+/**
+ * 获取数据库源
+ */
+private static DataSource getDataSource() {
+ //数据源
+ HikariConfig hikariConfig = new HikariConfig();
+ hikariConfig.setDriverClassName("com.mysql.cj.jdbc.Driver");
+ hikariConfig.setJdbcUrl("jdbc:mysql://127.0.0.1:3306/javaguide-blog");
+ hikariConfig.setUsername("root");
+ hikariConfig.setPassword("123456");
+ //设置可以获取tables remarks信息
+ hikariConfig.addDataSourceProperty("useInformationSchema", "true");
+ hikariConfig.setMinimumIdle(2);
+ hikariConfig.setMaximumPoolSize(5);
+ return new HikariDataSource(hikariConfig);
+}
+```
+
+**2、获取文件生成配置**
+
+这一步会指定数据库文档生成的位置、文件类型以及文件名称。
+
+```java
+/**
+ * 获取文件生成配置
+ */
+private static EngineConfig getEngineConfig() {
+ //生成配置
+ return EngineConfig.builder()
+ //生成文件路径
+ .fileOutputDir("/Users/guide/Documents/代码示例/screw-demo/doc")
+ //打开目录
+ .openOutputDir(true)
+ //文件类型
+ .fileType(EngineFileType.HTML)
+ //生成模板实现
+ .produceType(EngineTemplateType.freemarker)
+ //自定义文件名称
+ .fileName("数据库结构文档").build();
+}
+```
+
+如果不配置生成文件路径的话,默认也会存放在项目的 `doc` 目录下。
+
+另外,我们这里指定生成的文件格式为 HTML。除了 HTML 之外,screw 还支持 Word 、Markdown 这两种文件格式。
+
+不太建议生成 Word 格式,比较推荐 Markdown 格式。
+
+**3、获取数据库表的处理配置**
+
+这一步你可以指定只生成哪些表:
+
+```java
+/**
+ * 获取数据库表的处理配置,可忽略
+ */
+private static ProcessConfig getProcessConfig() {
+ return ProcessConfig.builder()
+ // 指定只生成 blog 表
+ .designatedTableName(new ArrayList<>(Collections.singletonList("blog")))
+ .build();
+}
+```
+
+还可以指定忽略生成哪些表:
+
+```java
+private static ProcessConfig getProcessConfig() {
+ ArrayList<String> ignoreTableName = new ArrayList<>();
+ ignoreTableName.add("test_user");
+ ignoreTableName.add("test_group");
+ ArrayList<String> ignorePrefix = new ArrayList<>();
+ ignorePrefix.add("test_");
+ ArrayList<String> ignoreSuffix = new ArrayList<>();
+ ignoreSuffix.add("_test");
+ return ProcessConfig.builder()
+ //忽略表名
+ .ignoreTableName(ignoreTableName)
+ //忽略表前缀
+ .ignoreTablePrefix(ignorePrefix)
+ //忽略表后缀
+ .ignoreTableSuffix(ignoreSuffix)
+ .build();
+}
+```
+
+这一步也可以省略。如果不指定 `ProcessConfig` 的话,就会按照默认配置来!
+
+**4、生成 screw 完整配置**
+
+根据前面 3 步,生成 screw 完整配置。
+
+```java
+private static Configuration getScrewConfig(DataSource dataSource, EngineConfig engineConfig, ProcessConfig processConfig) {
+ return Configuration.builder()
+ //版本
+ .version("1.0.0")
+ //描述
+ .description("数据库设计文档生成")
+ //数据源
+ .dataSource(dataSource)
+ //生成配置
+ .engineConfig(engineConfig)
+ //生成配置
+ .produceConfig(processConfig)
+ .build();
+}
+```
+
+**5、执行生成数据库文档**
+
+
+
+下图就是生成的 HTML 格式的数据库设计文档。
+
+
+
+### 基于 Maven 插件
+
+除了基于 Java 代码这种方式之外,你还可以通过 screw 提供的 Maven 插件来生成数据库文档。方法也非常简单!
+
+**1、配置 Maven 插件**
+
+务必将数据库相关的配置修改成你自己的。
+
+```xml
+<build>
+ <plugins>
+ <plugin>
+ <groupId>cn.smallbun.screw</groupId>
+ <artifactId>screw-maven-plugin</artifactId>
+ <version>1.0.5</version>
+ <dependencies>
+ <!-- HikariCP -->
+ <dependency>
+ <groupId>com.zaxxer</groupId>
+ <artifactId>HikariCP</artifactId>
+ <version>3.4.5</version>
+ </dependency>
+ <!--mysql driver-->
+ <dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.20</version>
+ </dependency>
+ </dependencies>
+ <configuration>
+ <!--username-->
+ <username>root</username>
+ <!--password-->
+ <password>123456</password>
+ <!--driver-->
+ <driverClassName>com.mysql.cj.jdbc.Driver</driverClassName>
+ <!--jdbc url-->
+ <jdbcUrl>jdbc:mysql://127.0.0.1:3306/javaguide-blog</jdbcUrl>
+ <!--生成文件类型-->
+ <fileType>MD</fileType>
+ <!--打开文件输出目录-->
+ <openOutputDir>true</openOutputDir>
+ <!--生成模板-->
+ <produceType>freemarker</produceType>
+ <!--文档名称 为空时:将采用[数据库名称-描述-版本号]作为文档名称-->
+ <fileName>数据库结构文档</fileName>
+ <!--描述-->
+ <description>数据库设计文档生成</description>
+ <!--版本-->
+ <version>${project.version}</version>
+ <!--标题-->
+ <title>数据库文档</title>
+ </configuration>
+ <executions>
+ <execution>
+ <phase>compile</phase>
+ <goals>
+ <goal>run</goal>
+ </goals>
+ </execution>
+ </executions>
+ </plugin>
+ </plugins>
+</build>
+```
+
+**2、手动执行生成数据库文档**
+
+
+
+我们这里指定生成的是 Markdown 格式。
+
+
+
+下图就是生成的 Markdown 格式的数据库设计文档,效果还是非常不错的!
+
+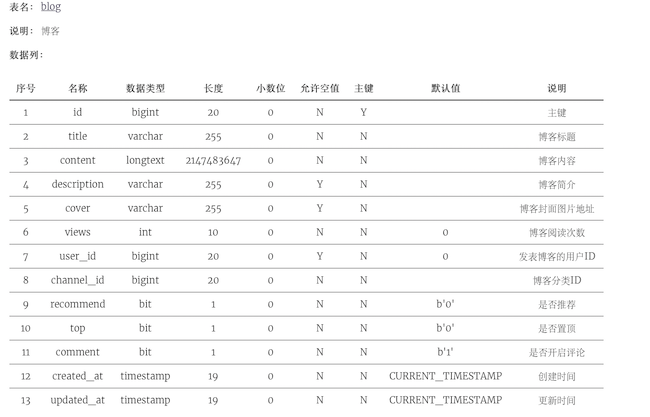
+
+
+
+
diff --git a/docs/tools/docker/docker.md b/docs/tools/docker/docker.md
new file mode 100644
index 00000000000..26e0c636274
--- /dev/null
+++ b/docs/tools/docker/docker.md
@@ -0,0 +1,296 @@
+# Docker 基本概念解读
+
+**本文只是对 Docker 的概念做了较为详细的介绍,并不涉及一些像 Docker 环境的安装以及 Docker 的一些常见操作和命令。**
+
+## 一 认识容器
+
+**Docker 是世界领先的软件容器平台**,所以想要搞懂 Docker 的概念我们必须先从容器开始说起。
+
+### 1.1 什么是容器?
+
+#### 先来看看容器较为官方的解释
+
+**一句话概括容器:容器就是将软件打包成标准化单元,以用于开发、交付和部署。**
+
+- **容器镜像是轻量的、可执行的独立软件包** ,包含软件运行所需的所有内容:代码、运行时环境、系统工具、系统库和设置。
+- **容器化软件适用于基于 Linux 和 Windows 的应用,在任何环境中都能够始终如一地运行。**
+- **容器赋予了软件独立性**,使其免受外在环境差异(例如,开发和预演环境的差异)的影响,从而有助于减少团队间在相同基础设施上运行不同软件时的冲突。
+
+#### 再来看看容器较为通俗的解释
+
+**如果需要通俗地描述容器的话,我觉得容器就是一个存放东西的地方,就像书包可以装各种文具、衣柜可以放各种衣服、鞋架可以放各种鞋子一样。我们现在所说的容器存放的东西可能更偏向于应用比如网站、程序甚至是系统环境。**
+
+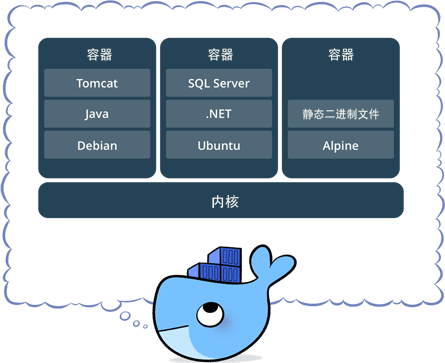
+
+
+
+### 1.2 图解物理机,虚拟机与容器
+
+关于虚拟机与容器的对比在后面会详细介绍到,这里只是通过网上的图片加深大家对于物理机、虚拟机与容器这三者的理解(下面的图片来源于网络)。
+
+**物理机:**
+
+
+
+**虚拟机:**
+
+
+
+**容器:**
+
+
+
+通过上面这三张抽象图,我们可以大概通过类比概括出: **容器虚拟化的是操作系统而不是硬件,容器之间是共享同一套操作系统资源的。虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统。因此容器的隔离级别会稍低一些。**
+
+---
+
+**相信通过上面的解释大家对于容器这个既陌生又熟悉的概念有了一个初步的认识,下面我们就来谈谈 Docker 的一些概念。**
+
+## 二 再来谈谈 Docker 的一些概念
+
+### 2.1 什么是 Docker?
+
+说实话关于 Docker 是什么并太好说,下面我通过四点向你说明 Docker 到底是个什么东西。
+
+- **Docker 是世界领先的软件容器平台。**
+- **Docker** 使用 Google 公司推出的 **Go 语言** 进行开发实现,基于 **Linux 内核** 提供的 CGroup 功能和 namespace 来实现的,以及 AUFS 类的 **UnionFS** 等技术,**对进程进行封装隔离,属于操作系统层面的虚拟化技术。** 由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
+- **Docker 能够自动执行重复性任务,例如搭建和配置开发环境,从而解放了开发人员以便他们专注在真正重要的事情上:构建杰出的软件。**
+- **用户可以方便地创建和使用容器,把自己的应用放入容器。容器还可以进行版本管理、复制、分享、修改,就像管理普通的代码一样。**
+
+### 2.2 Docker 思想
+
+- **集装箱**
+- **标准化:** ① 运输方式 ② 存储方式 ③ API 接口
+- **隔离**
+
+### 2.3 Docker 容器的特点
+
+- **轻量** : 在一台机器上运行的多个 Docker 容器可以共享这台机器的操作系统内核;它们能够迅速启动,只需占用很少的计算和内存资源。镜像是通过文件系统层进行构造的,并共享一些公共文件。这样就能尽量降低磁盘用量,并能更快地下载镜像。
+- **标准** : Docker 容器基于开放式标准,能够在所有主流 Linux 版本、Microsoft Windows 以及包括 VM、裸机服务器和云在内的任何基础设施上运行。
+- **安全** : Docker 赋予应用的隔离性不仅限于彼此隔离,还独立于底层的基础设施。Docker 默认提供最强的隔离,因此应用出现问题,也只是单个容器的问题,而不会波及到整台机器。
+
+### 2.4 为什么要用 Docker ?
+
+- **Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 “这段代码在我机器上没问题啊” 这类问题;——一致的运行环境**
+- **可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。——更快速的启动时间**
+- **避免公用的服务器,资源会容易受到其他用户的影响。——隔离性**
+- **善于处理集中爆发的服务器使用压力;——弹性伸缩,快速扩展**
+- **可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。——迁移方便**
+- **使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付、部署。——持续交付和部署**
+
+---
+
+## 三 容器 VS 虚拟机
+
+**每当说起容器,我们不得不将其与虚拟机做一个比较。就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。**
+
+简单来说: **容器和虚拟机具有相似的资源隔离和分配优势,但功能有所不同,因为容器虚拟化的是操作系统,而不是硬件,因此容器更容易移植,效率也更高。**
+
+### 3.1 两者对比图
+
+传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
+
+
+
+### 3.2 容器与虚拟机总结
+
+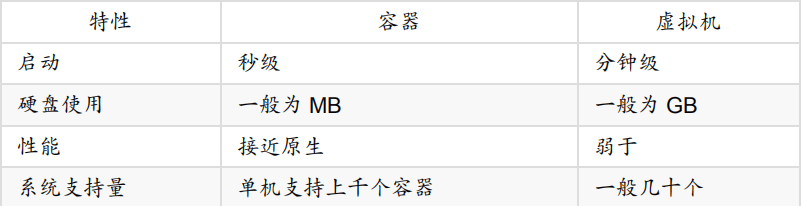
+
+- **容器是一个应用层抽象,用于将代码和依赖资源打包在一起。** **多个容器可以在同一台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行** 。与虚拟机相比, **容器占用的空间较少**(容器镜像大小通常只有几十兆),**瞬间就能完成启动** 。
+
+- **虚拟机 (VM) 是一个物理硬件层抽象,用于将一台服务器变成多台服务器。** 管理程序允许多个 VM 在一台机器上运行。每个 VM 都包含一整套操作系统、一个或多个应用、必要的二进制文件和库资源,因此 **占用大量空间** 。而且 VM **启动也十分缓慢** 。
+
+通过 Docker 官网,我们知道了这么多 Docker 的优势,但是大家也没有必要完全否定虚拟机技术,因为两者有不同的使用场景。**虚拟机更擅长于彻底隔离整个运行环境**。例如,云服务提供商通常采用虚拟机技术隔离不同的用户。而 **Docker 通常用于隔离不同的应用** ,例如前端,后端以及数据库。
+
+### 3.3 容器与虚拟机两者是可以共存的
+
+就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。
+
+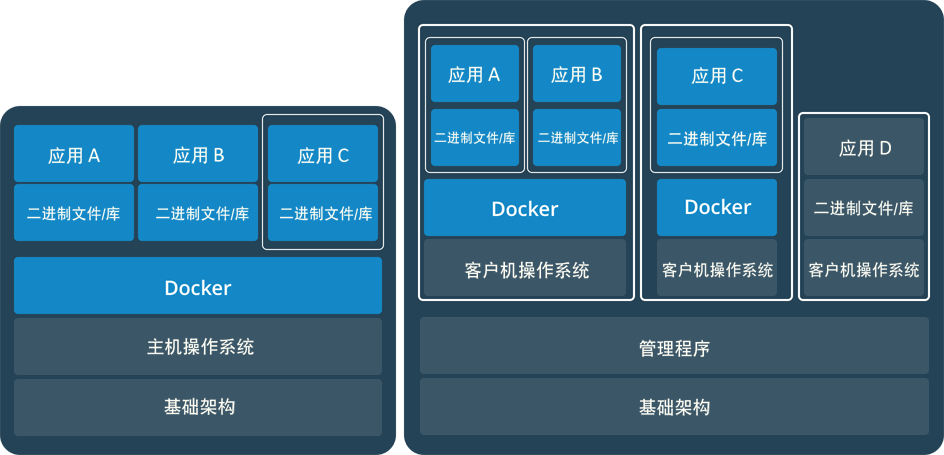
+
+---
+
+## 四 Docker 基本概念
+
+**Docker 中有非常重要的三个基本概念,理解了这三个概念,就理解了 Docker 的整个生命周期。**
+
+- **镜像(Image)**
+- **容器(Container)**
+- **仓库(Repository)**
+
+理解了这三个概念,就理解了 Docker 的整个生命周期
+
+
+
+### 4.1 镜像(Image):一个特殊的文件系统
+
+**操作系统分为内核和用户空间**。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而 Docker 镜像(Image),就相当于是一个 root 文件系统。
+
+**Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。** 镜像不包含任何动态数据,其内容在构建之后也不会被改变。
+
+Docker 设计时,就充分利用 **Union FS** 的技术,将其设计为**分层存储的架构** 。镜像实际是由多层文件系统联合组成。
+
+**镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。** 比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
+
+分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
+
+### 4.2 容器(Container):镜像运行时的实体
+
+镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,**容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等** 。
+
+**容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 命名空间。前面讲过镜像使用的是分层存储,容器也是如此。**
+
+**容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。**
+
+按照 Docker 最佳实践的要求,**容器不应该向其存储层内写入任何数据** ,容器存储层要保持无状态化。**所有的文件写入操作,都应该使用数据卷(Volume)、或者绑定宿主目录**,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此, **使用数据卷后,容器可以随意删除、重新 run ,数据却不会丢失。**
+
+### 4.3 仓库(Repository):集中存放镜像文件的地方
+
+镜像构建完成后,可以很容易的在当前宿主上运行,但是, **如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。**
+
+一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。所以说:**镜像仓库是 Docker 用来集中存放镜像文件的地方类似于我们之前常用的代码仓库。**
+
+通常,**一个仓库会包含同一个软件不同版本的镜像**,而**标签就常用于对应该软件的各个版本** 。我们可以通过`<仓库名>:<标签>`的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签.。
+
+**这里补充一下 Docker Registry 公开服务和私有 Docker Registry 的概念:**
+
+**Docker Registry 公开服务** 是开放给用户使用、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
+
+最常使用的 Registry 公开服务是官方的 **Docker Hub** ,这也是默认的 Registry,并拥有大量的高质量的官方镜像,网址为:[https://hub.docker.com/](https://hub.docker.com/ "https://hub.docker.com/") 。官方是这样介绍 Docker Hub 的:
+
+> Docker Hub 是 Docker 官方提供的一项服务,用于与您的团队查找和共享容器镜像。
+
+比如我们想要搜索自己想要的镜像:
+
+
+
+在 Docker Hub 的搜索结果中,有几项关键的信息有助于我们选择合适的镜像:
+
+- **OFFICIAL Image** :代表镜像为 Docker 官方提供和维护,相对来说稳定性和安全性较高。
+- **Stars** :和点赞差不多的意思,类似 GitHub 的 Star。
+- **Dowloads** :代表镜像被拉取的次数,基本上能够表示镜像被使用的频度。
+
+当然,除了直接通过 Docker Hub 网站搜索镜像这种方式外,我们还可以通过 `docker search` 这个命令搜索 Docker Hub 中的镜像,搜索的结果是一致的。
+
+```bash
+➜ ~ docker search mysql
+NAME DESCRIPTION STARS OFFICIAL AUTOMATED
+mysql MySQL is a widely used, open-source relation… 8763 [OK]
+mariadb MariaDB is a community-developed fork of MyS… 3073 [OK]
+mysql/mysql-server Optimized MySQL Server Docker images. Create… 650 [OK]
+```
+
+在国内访问**Docker Hub** 可能会比较慢国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 [时速云镜像库](https://www.tenxcloud.com/ "时速云镜像库")、[网易云镜像服务](https://www.163yun.com/product/repo "网易云镜像服务")、[DaoCloud 镜像市场](https://www.daocloud.io/ "DaoCloud 镜像市场")、[阿里云镜像库](https://www.aliyun.com/product/containerservice?utm_content=se_1292836 "阿里云镜像库")等。
+
+除了使用公开服务外,用户还可以在 **本地搭建私有 Docker Registry** 。Docker 官方提供了 Docker Registry 镜像,可以直接使用做为私有 Registry 服务。开源的 Docker Registry 镜像只提供了 Docker Registry API 的服务端实现,足以支持 docker 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
+
+---
+
+## 五 常见命令
+
+### 5.1 基本命令
+
+```bash
+docker version # 查看docker版本
+docker images # 查看所有已下载镜像,等价于:docker image ls 命令
+docker container ls # 查看所有容器
+docker ps #查看正在运行的容器
+docker image prune # 清理临时的、没有被使用的镜像文件。-a, --all: 删除所有没有用的镜像,而不仅仅是临时文件;
+```
+
+### 5.2 拉取镜像
+
+```bash
+docker search mysql # 查看mysql相关镜像
+docker pull mysql:5.7 # 拉取mysql镜像
+docker image ls # 查看所有已下载镜像
+```
+
+### 5.3 删除镜像
+
+比如我们要删除我们下载的 mysql 镜像。
+
+通过 `docker rmi [image]` (等价于`docker image rm [image]`)删除镜像之前首先要确保这个镜像没有被容器引用(可以通过标签名称或者镜像 ID删除)。通过我们前面讲的` docker ps`命令即可查看。
+
+```shell
+➜ ~ docker ps
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+c4cd691d9f80 mysql:5.7 "docker-entrypoint.s…" 7 weeks ago Up 12 days 0.0.0.0:3306->3306/tcp, 33060/tcp mysql
+```
+
+可以看到 mysql 正在被 id 为 c4cd691d9f80 的容器引用,我们需要首先通过 `docker stop c4cd691d9f80` 或者 `docker stop mysql`暂停这个容器。
+
+然后查看 mysql 镜像的 id
+
+```shell
+➜ ~ docker images
+REPOSITORY TAG IMAGE ID CREATED SIZE
+mysql 5.7 f6509bac4980 3 months ago 373MB
+```
+
+通过 IMAGE ID 或者 REPOSITORY 名字即可删除
+
+```shell
+docker rmi f6509bac4980 # 或者 docker rmi mysql
+```
+
+## 六 Build Ship and Run
+
+**Docker 的概念以及常见命令基本上已经讲完,我们再来谈谈:Build, Ship, and Run。**
+
+如果你搜索 Docker 官网,会发现如下的字样:**“Docker - Build, Ship, and Run Any App, Anywhere”**。那么 Build, Ship, and Run 到底是在干什么呢?
+
+
+
+- **Build(构建镜像)** : 镜像就像是集装箱包括文件以及运行环境等等资源。
+- **Ship(运输镜像)** :主机和仓库间运输,这里的仓库就像是超级码头一样。
+- **Run (运行镜像)** :运行的镜像就是一个容器,容器就是运行程序的地方。
+
+**Docker 运行过程也就是去仓库把镜像拉到本地,然后用一条命令把镜像运行起来变成容器。所以,我们也常常将 Docker 称为码头工人或码头装卸工,这和 Docker 的中文翻译搬运工人如出一辙。**
+
+## 七 简单了解一下 Docker 底层原理
+
+### 7.1 虚拟化技术
+
+首先,Docker **容器虚拟化**技术为基础的软件,那么什么是虚拟化技术呢?
+
+简单点来说,虚拟化技术可以这样定义:
+
+> 虚拟化技术是一种资源管理技术,是将计算机的各种[实体资源](https://zh.wikipedia.org/wiki/資源_(計算機科學 "实体资源"))([CPU](https://zh.wikipedia.org/wiki/CPU "CPU")、[内存](https://zh.wikipedia.org/wiki/内存 "内存")、[磁盘空间](https://zh.wikipedia.org/wiki/磁盘空间 "磁盘空间")、[网络适配器](https://zh.wikipedia.org/wiki/網路適配器 "网络适配器")等),予以抽象、转换后呈现出来并可供分割、组合为一个或多个电脑配置环境。由此,打破实体结构间的不可切割的障碍,使用户可以比原本的配置更好的方式来应用这些电脑硬件资源。这些资源的新虚拟部分是不受现有资源的架设方式,地域或物理配置所限制。一般所指的虚拟化资源包括计算能力和数据存储。
+
+### 7.2 Docker 基于 LXC 虚拟容器技术
+
+Docker 技术是基于 LXC(Linux container- Linux 容器)虚拟容器技术的。
+
+> LXC,其名称来自 Linux 软件容器(Linux Containers)的缩写,一种操作系统层虚拟化(Operating system–level virtualization)技术,为 Linux 内核容器功能的一个用户空间接口。它将应用软件系统打包成一个软件容器(Container),内含应用软件本身的代码,以及所需要的操作系统核心和库。通过统一的名字空间和共用 API 来分配不同软件容器的可用硬件资源,创造出应用程序的独立沙箱运行环境,使得 Linux 用户可以容易的创建和管理系统或应用容器。
+
+LXC 技术主要是借助 Linux 内核中提供的 CGroup 功能和 namespace 来实现的,通过 LXC 可以为软件提供一个独立的操作系统运行环境。
+
+**cgroup 和 namespace 介绍:**
+
+- **namespace 是 Linux 内核用来隔离内核资源的方式。** 通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
+
+ (以上关于 namespace 介绍内容来自https://www.cnblogs.com/sparkdev/p/9365405.html ,更多关于 namespace 的呢内容可以查看这篇文章 )。
+
+- **CGroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物力资源 (如 cpu memory i/o 等等) 的机制。**
+
+ (以上关于 CGroup 介绍内容来自 https://www.ibm.com/developerworks/cn/linux/1506_cgroup/index.html ,更多关于 CGroup 的内容可以查看这篇文章 )。
+
+**cgroup 和 namespace 两者对比:**
+
+两者都是将进程进行分组,但是两者的作用还是有本质区别。namespace 是为了隔离进程组之间的资源,而 cgroup 是为了对一组进程进行统一的资源监控和限制。
+
+## 八 总结
+
+本文主要把 Docker 中的一些常见概念做了详细的阐述,但是并不涉及 Docker 的安装、镜像的使用、容器的操作等内容。这部分东西,希望读者自己可以通过阅读书籍与官方文档的形式掌握。如果觉得官方文档阅读起来很费力的话,这里推荐一本书籍《Docker 技术入门与实战第二版》。
+
+## 九 推荐阅读
+
+- [10 分钟看懂 Docker 和 K8S](https://zhuanlan.zhihu.com/p/53260098 "10分钟看懂Docker和K8S")
+- [从零开始入门 K8s:详解 K8s 容器基本概念](https://www.infoq.cn/article/te70FlSyxhltL1Cr7gzM "从零开始入门 K8s:详解 K8s 容器基本概念")
+
+## 十 参考
+
+- [Linux Namespace 和 Cgroup](https://segmentfault.com/a/1190000009732550 "Linux Namespace和Cgroup")
+- [LXC vs Docker: Why Docker is Better](https://www.upguard.com/articles/docker-vs-lxc "LXC vs Docker: Why Docker is Better")
+- [CGroup 介绍、应用实例及原理描述](https://www.ibm.com/developerworks/cn/linux/1506_cgroup/index.html "CGroup 介绍、应用实例及原理描述")
diff --git "a/docs/tools/docker/docker\344\273\216\345\205\245\351\227\250\345\210\260\345\256\236\346\210\230.md" "b/docs/tools/docker/docker\344\273\216\345\205\245\351\227\250\345\210\260\345\256\236\346\210\230.md"
new file mode 100644
index 00000000000..5348b4a510f
--- /dev/null
+++ "b/docs/tools/docker/docker\344\273\216\345\205\245\351\227\250\345\210\260\345\256\236\346\210\230.md"
@@ -0,0 +1,637 @@
+# Docker从入门到上手干事
+
+## Docker介绍
+
+### 什么是 Docker?
+
+说实话关于 Docker 是什么并不太好说,下面我通过四点向你说明 Docker 到底是个什么东西。
+
+- Docker 是世界领先的软件容器平台,基于 **Go 语言** 进行开发实现。
+- Docker 能够自动执行重复性任务,例如搭建和配置开发环境,从而解放开发人员。
+- 用户可以方便地创建和使用容器,把自己的应用放入容器。容器还可以进行版本管理、复制、分享、修改,就像管理普通的代码一样。
+- Docker 可以**对进程进行封装隔离,属于操作系统层面的虚拟化技术。** 由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
+
+官网地址:https://www.docker.com/ 。
+
+
+
+### 为什么要用 Docker?
+
+Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。
+
+容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销极低。
+
+传统的开发流程中,我们的项目通常需要使用 MySQL、Redis、FastDFS 等等环境,这些环境都是需要我们手动去进行下载并配置的,安装配置流程极其复杂,而且不同系统下的操作也不一样。
+
+Docker 的出现完美地解决了这一问题,我们可以在容器中安装 MySQL、Redis 等软件环境,使得应用和环境架构分开,它的优势在于:
+
+1. 一致的运行环境,能够更轻松地迁移
+2. 对进程进行封装隔离,容器与容器之间互不影响,更高效地利用系统资源
+3. 可以通过镜像复制多个一致的容器
+
+另外,[《Docker 从入门到实践》](https://yeasy.gitbook.io/docker_practice/introduction/why) 这本开源书籍中也已经给出了使用 Docker 的原因。
+
+
+
+## Docker 的安装
+
+### Windows
+
+接下来对 Docker 进行安装,以 Windows 系统为例,访问 Docker 的官网:
+
+
+
+然后点击`Get Started`:
+
+
+
+在此处点击`Download for Windows`即可进行下载。
+
+如果你的电脑是`Windows 10 64位专业版`的操作系统,则在安装 Docker 之前需要开启一下`Hyper-V`,开启方式如下。打开控制面板,选择程序:
+
+
+
+点击`启用或关闭Windows功能`:
+
+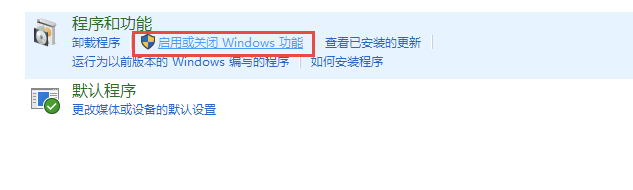
+
+勾选上`Hyper-V`,点击确定即可:
+
+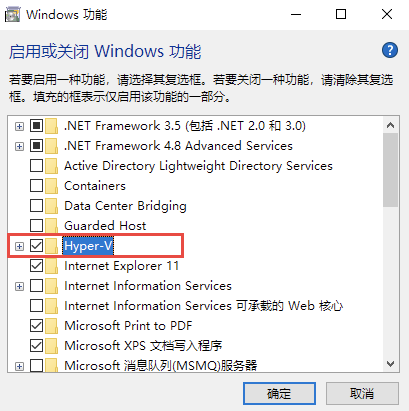
+
+完成更改后需要重启一下计算机。
+
+开启了`Hyper-V`后,我们就可以对 Docker 进行安装了,打开安装程序后,等待片刻点击`Ok`即可:
+
+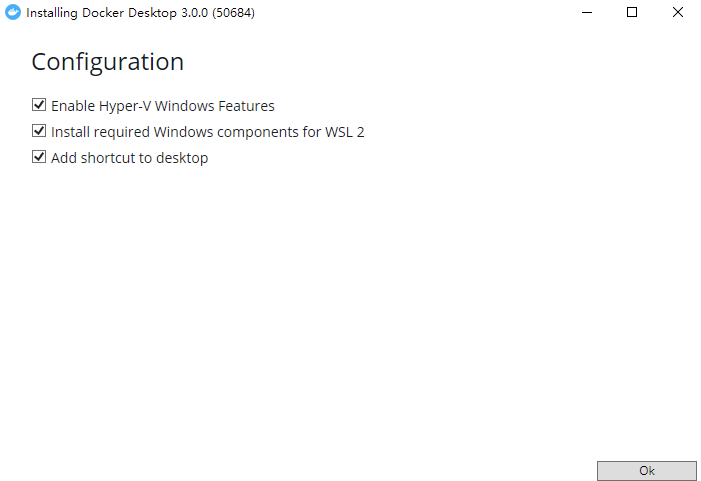
+
+安装完成后,我们仍然需要重启计算机,重启后,若提示如下内容:
+
+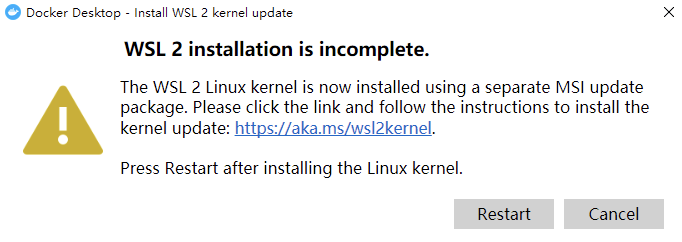
+
+它的意思是询问我们是否使用 WSL2,这是基于 Windows 的一个 Linux 子系统,这里我们取消即可,它就会使用我们之前勾选的`Hyper-V`虚拟机。
+
+因为是图形界面的操作,这里就不介绍 Docker Desktop 的具体用法了。
+
+### Mac
+
+直接使用 Homebrew 安装即可
+
+```shell
+brew install --cask docker
+```
+
+### Linux
+
+下面来看看 Linux 中如何安装 Docker,这里以 CentOS7 为例。
+
+在测试或开发环境中,Docker 官方为了简化安装流程,提供了一套便捷的安装脚本,执行这个脚本后就会自动地将一切准备工作做好,并且把 Docker 的稳定版本安装在系统中。
+
+```shell
+curl -fsSL get.docker.com -o get-docker.sh
+```
+
+```shell
+sh get-docker.sh --mirror Aliyun
+```
+
+安装完成后直接启动服务:
+
+```shell
+systemctl start docker
+```
+
+推荐设置开机自启,执行指令:
+
+```shell
+systemctl enable docker
+```
+
+## Docker 中的几个概念
+
+在正式学习 Docker 之前,我们需要了解 Docker 中的几个核心概念:
+
+### 镜像
+
+镜像就是一个只读的模板,镜像可以用来创建 Docker 容器,一个镜像可以创建多个容器
+
+### 容器
+
+容器是用镜像创建的运行实例,Docker 利用容器独立运行一个或一组应用。它可以被启动、开始、停止、删除,每个容器都是相互隔离的、保证安全的平台。 可以把容器看作是一个简易的 Linux 环境和运行在其中的应用程序。容器的定义和镜像几乎一模一样,也是一堆层的统一视角,唯一区别在于容器的最上面那一层是可读可写的
+
+### 仓库
+
+仓库是集中存放镜像文件的场所。仓库和仓库注册服务器是有区别的,仓库注册服务器上往往存放着多个仓库,每个仓库中又包含了多个镜像,每个镜像有不同的标签。 仓库分为公开仓库和私有仓库两种形式,最大的公开仓库是 DockerHub,存放了数量庞大的镜像供用户下载,国内的公开仓库有阿里云、网易云等
+
+### 总结
+
+通俗点说,一个镜像就代表一个软件;而基于某个镜像运行就是生成一个程序实例,这个程序实例就是容器;而仓库是用来存储 Docker 中所有镜像的。
+
+其中仓库又分为远程仓库和本地仓库,和 Maven 类似,倘若每次都从远程下载依赖,则会大大降低效率,为此,Maven 的策略是第一次访问依赖时,将其下载到本地仓库,第二次、第三次使用时直接用本地仓库的依赖即可,Docker 的远程仓库和本地仓库的作用也是类似的。
+
+## Docker 初体验
+
+下面我们来对 Docker 进行一个初步的使用,这里以下载一个 MySQL 的镜像为例`(在CentOS7下进行)`。
+
+和 GitHub 一样,Docker 也提供了一个 DockerHub 用于查询各种镜像的地址和安装教程,为此,我们先访问 DockerHub:[https://hub.docker.com/](https://hub.docker.com/)
+
+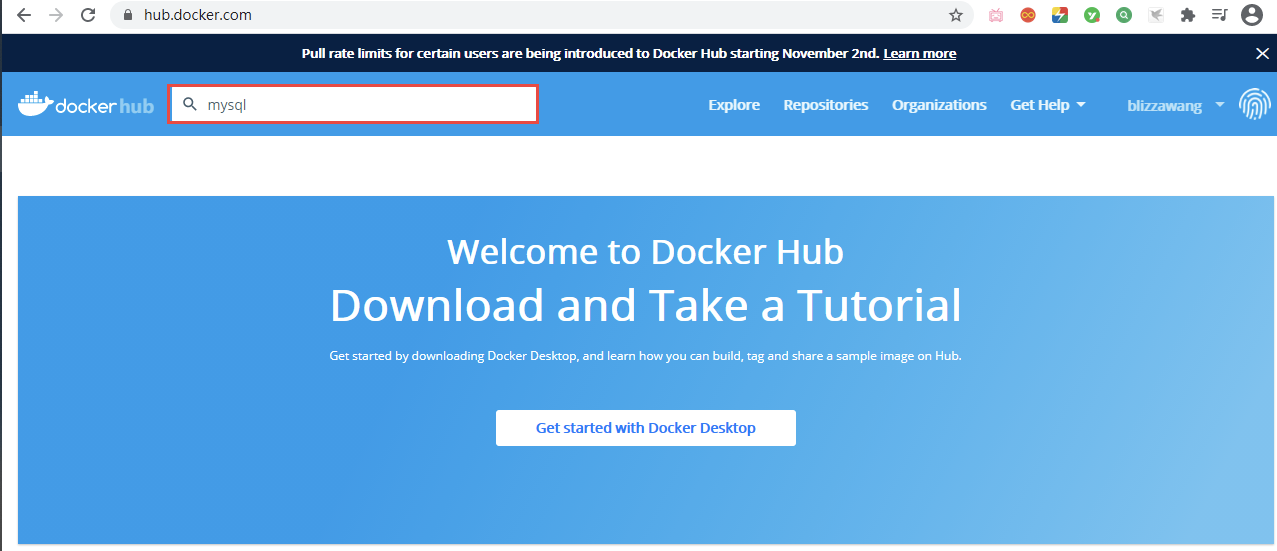
+
+在左上角的搜索框中输入`MySQL`并回车:
+
+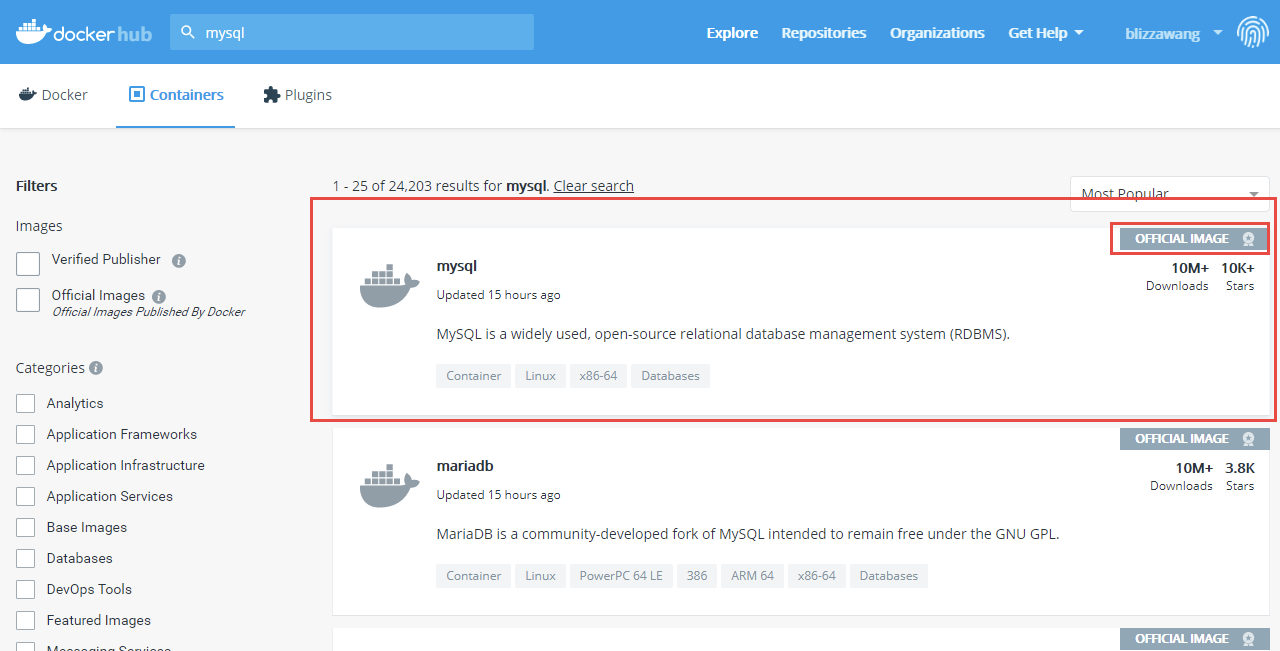
+
+可以看到相关 MySQL 的镜像非常多,若右上角有`OFFICIAL IMAGE`标识,则说明是官方镜像,所以我们点击第一个 MySQL 镜像:
+
+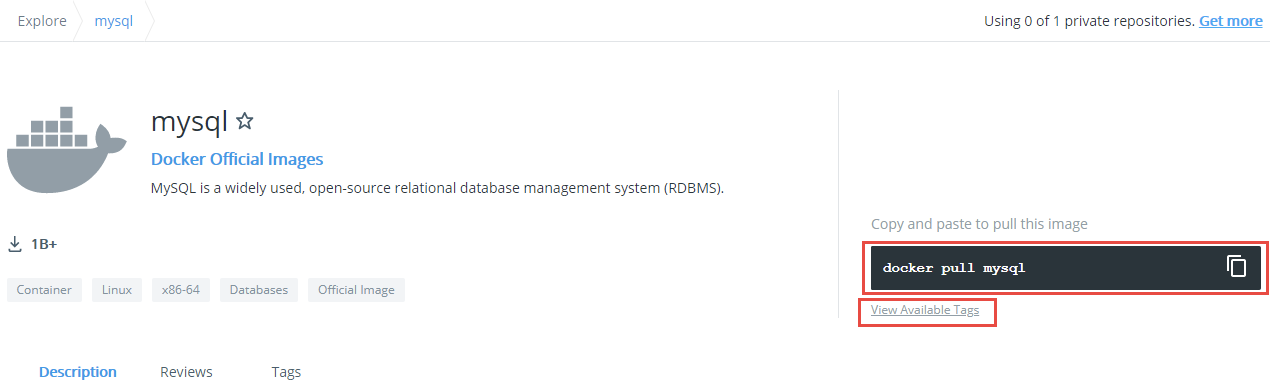
+
+右边提供了下载 MySQL 镜像的指令为`docker pull MySQL`,但该指令始终会下载 MySQL 镜像的最新版本。
+
+若是想下载指定版本的镜像,则点击下面的`View Available Tags`:
+
+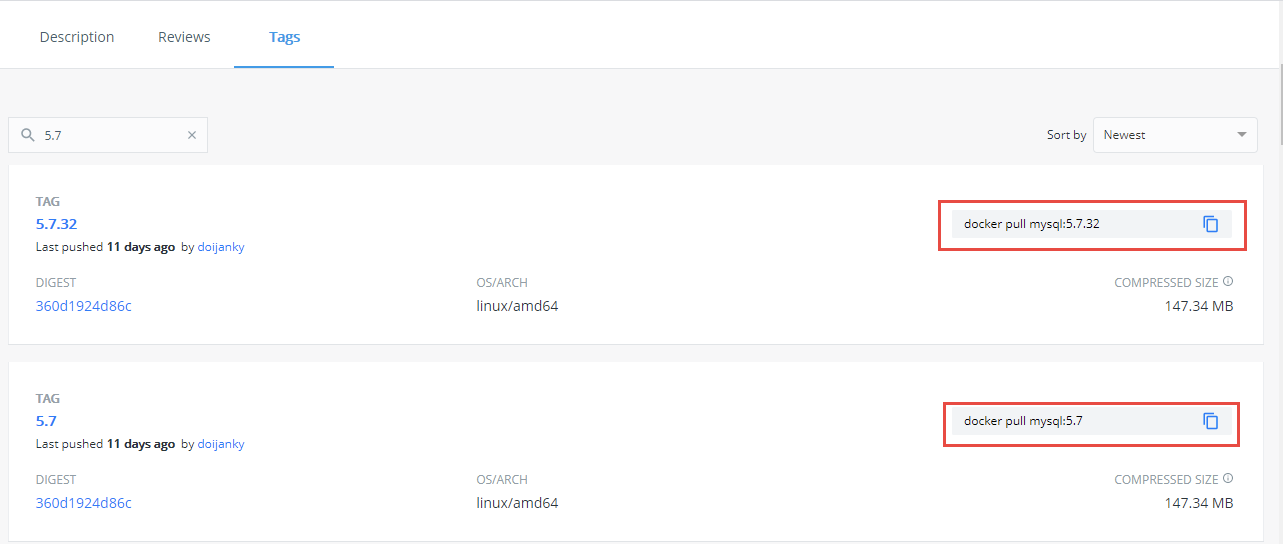
+
+这里就可以看到各种版本的镜像,右边有下载的指令,所以若是想下载 5.7.32 版本的 MySQL 镜像,则执行:
+
+```shell
+docker pull MySQL:5.7.32
+```
+
+然而下载镜像的过程是非常慢的,所以我们需要配置一下镜像源加速下载,访问`阿里云`官网:
+
+
+
+点击控制台:
+
+
+
+然后点击左上角的菜单,在弹窗的窗口中,将鼠标悬停在产品与服务上,并在右侧搜索容器镜像服务,最后点击容器镜像服务:
+
+
+
+点击左侧的镜像加速器,并依次执行右侧的配置指令即可。
+
+```shell
+sudo mkdir -p /etc/docker
+sudo tee /etc/docker/daemon.json <<-'EOF'
+{
+ "registry-mirrors": ["https://679xpnpz.mirror.aliyuncs.com"]
+}
+EOF
+sudo systemctl daemon-reload
+sudo systemctl restart docker
+```
+
+## Docker 镜像指令
+
+Docker 需要频繁地操作相关的镜像,所以我们先来了解一下 Docker 中的镜像指令。
+
+若想查看 Docker 中当前拥有哪些镜像,则可以使用 `docker images` 命令。
+
+```shell
+[root@izrcf5u3j3q8xaz ~]# docker images
+REPOSITORY TAG IMAGE ID CREATED SIZE
+MySQL 5.7.32 f07dfa83b528 11 days ago 448MB
+tomcat latest feba8d001e3f 2 weeks ago 649MB
+nginx latest ae2feff98a0c 2 weeks ago 133MB
+hello-world latest bf756fb1ae65 12 months ago 13.3kB
+```
+
+其中`REPOSITORY`为镜像名,`TAG`为版本标志,`IMAGE ID`为镜像 id(唯一的),`CREATED`为创建时间,注意这个时间并不是我们将镜像下载到 Docker 中的时间,而是镜像创建者创建的时间,`SIZE`为镜像大小。
+
+该指令能够查询指定镜像名:
+
+```shell
+docker image MySQL
+```
+
+若如此做,则会查询出 Docker 中的所有 MySQL 镜像:
+
+```shell
+[root@izrcf5u3j3q8xaz ~]# docker images MySQL
+REPOSITORY TAG IMAGE ID CREATED SIZE
+MySQL 5.6 0ebb5600241d 11 days ago 302MB
+MySQL 5.7.32 f07dfa83b528 11 days ago 448MB
+MySQL 5.5 d404d78aa797 20 months ago 205MB
+```
+
+该指令还能够携带`-q`参数:`docker images -q` , `-q`表示仅显示镜像的 id:
+
+```shell
+[root@izrcf5u3j3q8xaz ~]# docker images -q
+0ebb5600241d
+f07dfa83b528
+feba8d001e3f
+d404d78aa797
+```
+
+若是要下载镜像,则使用:
+
+```shell
+docker pull MySQL:5.7
+```
+
+`docker pull`是固定的,后面写上需要下载的镜像名及版本标志;若是不写版本标志,而是直接执行`docker pull MySQL`,则会下载镜像的最新版本。
+
+一般在下载镜像前我们需要搜索一下镜像有哪些版本才能对指定版本进行下载,使用指令:
+
+```shell
+docker search MySQL
+```
+
+
+
+不过该指令只能查看 MySQL 相关的镜像信息,而不能知道有哪些版本,若想知道版本,则只能这样查询:
+
+```shell
+docker search MySQL:5.5
+```
+
+
+
+若是查询的版本不存在,则结果为空:
+
+
+
+删除镜像使用指令:
+
+```shell
+docker image rm MySQL:5.5
+```
+
+若是不指定版本,则默认删除的也是最新版本。
+
+还可以通过指定镜像 id 进行删除:
+
+```shell
+docker image rm bf756fb1ae65
+```
+
+然而此时报错了:
+
+```shell
+[root@izrcf5u3j3q8xaz ~]# docker image rm bf756fb1ae65
+Error response from daemon: conflict: unable to delete bf756fb1ae65 (must be forced) - image is being used by stopped container d5b6c177c151
+```
+
+这是因为要删除的`hello-world`镜像正在运行中,所以无法删除镜像,此时需要强制执行删除:
+
+```shell
+docker image rm -f bf756fb1ae65
+```
+
+该指令会将镜像和通过该镜像执行的容器全部删除,谨慎使用。
+
+Docker 还提供了删除镜像的简化版本:`docker rmi 镜像名:版本标志` 。
+
+此时我们即可借助`rmi`和`-q`进行一些联合操作,比如现在想删除所有的 MySQL 镜像,那么你需要查询出 MySQL 镜像的 id,并根据这些 id 一个一个地执行`docker rmi`进行删除,但是现在,我们可以这样:
+
+```shell
+docker rmi -f $(docker images MySQL -q)
+```
+
+首先通过`docker images MySQL -q`查询出 MySQL 的所有镜像 id,`-q`表示仅查询 id,并将这些 id 作为参数传递给`docker rmi -f`指令,这样所有的 MySQL 镜像就都被删除了。
+
+## Docker 容器指令
+
+掌握了镜像的相关指令之后,我们需要了解一下容器的指令,容器是基于镜像的。
+
+若需要通过镜像运行一个容器,则使用:
+
+```shell
+docker run tomcat:8.0-jre8
+```
+
+当然了,运行的前提是你拥有这个镜像,所以先下载镜像:
+
+```shell
+docker pull tomcat:8.0-jre8
+```
+
+下载完成后就可以运行了,运行后查看一下当前运行的容器:`docker ps` 。
+
+
+
+其中`CONTAINER_ID`为容器的 id,`IMAGE`为镜像名,`COMMAND`为容器内执行的命令,`CREATED`为容器的创建时间,`STATUS`为容器的状态,`PORTS`为容器内服务监听的端口,`NAMES`为容器的名称。
+
+通过该方式运行的 tomcat 是不能直接被外部访问的,因为容器具有隔离性,若是想直接通过 8080 端口访问容器内部的 tomcat,则需要对宿主机端口与容器内的端口进行映射:
+
+```shell
+docker run -p 8080:8080 tomcat:8.0-jre8
+```
+
+解释一下这两个端口的作用(`8080:8080`),第一个 8080 为宿主机端口,第二个 8080 为容器内的端口,外部访问 8080 端口就会通过映射访问容器内的 8080 端口。
+
+此时外部就可以访问 Tomcat 了:
+
+
+
+若是这样进行映射:
+
+```shell
+docker run -p 8088:8080 tomcat:8.0-jre8
+```
+
+则外部需访问 8088 端口才能访问 tomcat,需要注意的是,每次运行的容器都是相互独立的,所以同时运行多个 tomcat 容器并不会产生端口的冲突。
+
+容器还能够以后台的方式运行,这样就不会占用终端:
+
+```shell
+docker run -d -p 8080:8080 tomcat:8.0-jre8
+```
+
+启动容器时默认会给容器一个名称,但这个名称其实是可以设置的,使用指令:
+
+```shell
+docker run -d -p 8080:8080 --name tomcat01 tomcat:8.0-jre8
+```
+
+此时的容器名称即为 tomcat01,容器名称必须是唯一的。
+
+再来引申一下`docker ps`中的几个指令参数,比如`-a`:
+
+```shell
+docker ps -a
+```
+
+该参数会将运行和非运行的容器全部列举出来:
+
+
+
+`-q`参数将只查询正在运行的容器 id:`docker ps -q` 。
+
+```shell
+[root@izrcf5u3j3q8xaz ~]# docker ps -q
+f3aac8ee94a3
+074bf575249b
+1d557472a708
+4421848ba294
+```
+
+若是组合使用,则查询运行和非运行的所有容器 id:`docker ps -qa` 。
+
+```shell
+[root@izrcf5u3j3q8xaz ~]# docker ps -aq
+f3aac8ee94a3
+7f7b0e80c841
+074bf575249b
+a1e830bddc4c
+1d557472a708
+4421848ba294
+b0440c0a219a
+c2f5d78c5d1a
+5831d1bab2a6
+d5b6c177c151
+```
+
+接下来是容器的停止、重启指令,因为非常简单,就不过多介绍了。
+
+```shell
+docker start c2f5d78c5d1a
+```
+
+通过该指令能够将已经停止运行的容器运行起来,可以通过容器的 id 启动,也可以通过容器的名称启动。
+
+```shell
+docker restart c2f5d78c5d1a
+```
+
+该指令能够重启指定的容器。
+
+```shell
+docker stop c2f5d78c5d1a
+```
+
+该指令能够停止指定的容器。
+
+```shell
+docker kill c2f5d78c5d1a
+```
+
+该指令能够直接杀死指定的容器。
+
+以上指令都能够通过容器的 id 和容器名称两种方式配合使用。
+
+---
+
+当容器被停止之后,容器虽然不再运行了,但仍然是存在的,若是想删除它,则使用指令:
+
+```shell
+docker rm d5b6c177c151
+```
+
+需要注意的是容器的 id 无需全部写出来,只需唯一标识即可。
+
+若是想删除正在运行的容器,则需要添加`-f`参数强制删除:
+
+```shell
+docker rm -f d5b6c177c151
+```
+
+若是想删除所有容器,则可以使用组合指令:
+
+```shell
+docker rm -f $(docker ps -qa)
+```
+
+先通过`docker ps -qa`查询出所有容器的 id,然后通过`docker rm -f`进行删除。
+
+---
+
+当容器以后台的方式运行时,我们无法知晓容器的运行状态,若此时需要查看容器的运行日志,则使用指令:
+
+```shell
+docker logs 289cc00dc5ed
+```
+
+这样的方式显示的日志并不是实时的,若是想实时显示,需要使用`-f`参数:
+
+```shell
+docker logs -f 289cc00dc5ed
+```
+
+通过`-t`参数还能够显示日志的时间戳,通常与`-f`参数联合使用:
+
+```shell
+docker logs -ft 289cc00dc5ed
+```
+
+---
+
+查看容器内运行了哪些进程,可以使用指令:
+
+```shell
+docker top 289cc00dc5ed
+```
+
+
+
+若是想与容器进行交互,则使用指令:
+
+```shell
+docker exec -it 289cc00dc5ed bash
+```
+
+
+
+此时终端将会进入容器内部,执行的指令都将在容器中生效,在容器内只能执行一些比较简单的指令,如:ls、cd 等,若是想退出容器终端,重新回到 CentOS 中,则执行`exit`即可。
+
+现在我们已经能够进入容器终端执行相关操作了,那么该如何向 tomcat 容器中部署一个项目呢?
+
+```shell
+docker cp ./test.html 289cc00dc5ed:/usr/local/tomcat/webapps
+```
+
+通过`docker cp`指令能够将文件从 CentOS 复制到容器中,`./test.html`为 CentOS 中的资源路径,`289cc00dc5ed`为容器 id,`/usr/local/tomcat/webapps`为容器的资源路径,此时`test.html`文件将会被复制到该路径下。
+
+```shell
+[root@izrcf5u3j3q8xaz ~]# docker exec -it 289cc00dc5ed bash
+root@289cc00dc5ed:/usr/local/tomcat# cd webapps
+root@289cc00dc5ed:/usr/local/tomcat/webapps# ls
+test.html
+root@289cc00dc5ed:/usr/local/tomcat/webapps#
+```
+
+若是想将容器内的文件复制到 CentOS 中,则反过来写即可:
+
+```shell
+docker cp 289cc00dc5ed:/usr/local/tomcat/webapps/test.html ./
+```
+
+所以现在若是想要部署项目,则先将项目上传到 CentOS,然后将项目从 CentOS 复制到容器内,此时启动容器即可。
+
+---
+
+虽然使用 Docker 启动软件环境非常简单,但同时也面临着一个问题,我们无法知晓容器内部具体的细节,比如监听的端口、绑定的 ip 地址等等,好在这些 Docker 都帮我们想到了,只需使用指令:
+
+```shell
+docker inspect 923c969b0d91
+```
+
+
+
+## Docker 数据卷
+
+学习了容器的相关指令之后,我们来了解一下 Docker 中的数据卷,它能够实现宿主机与容器之间的文件共享,它的好处在于我们对宿主机的文件进行修改将直接影响容器,而无需再将宿主机的文件再复制到容器中。
+
+现在若是想将宿主机中`/opt/apps`目录与容器中`webapps`目录做一个数据卷,则应该这样编写指令:
+
+```shell
+docker run -d -p 8080:8080 --name tomcat01 -v /opt/apps:/usr/local/tomcat/webapps tomcat:8.0-jre8
+```
+
+然而此时访问 tomcat 会发现无法访问:
+
+
+
+这就说明我们的数据卷设置成功了,Docker 会将容器内的`webapps`目录与`/opt/apps`目录进行同步,而此时`/opt/apps`目录是空的,导致`webapps`目录也会变成空目录,所以就访问不到了。
+
+此时我们只需向`/opt/apps`目录下添加文件,就会使得`webapps`目录也会拥有相同的文件,达到文件共享,测试一下:
+
+```shell
+[root@centos-7 opt]# cd apps/
+[root@centos-7 apps]# vim test.html
+[root@centos-7 apps]# ls
+test.html
+[root@centos-7 apps]# cat test.html
+<h1>This is a test html!</h1>
+```
+
+在`/opt/apps`目录下创建了一个 `test.html` 文件,那么容器内的`webapps`目录是否会有该文件呢?进入容器的终端:
+
+```shell
+[root@centos-7 apps]# docker exec -it tomcat01 bash
+root@115155c08687:/usr/local/tomcat# cd webapps/
+root@115155c08687:/usr/local/tomcat/webapps# ls
+test.html
+```
+
+容器内确实已经有了该文件,那接下来我们编写一个简单的 Web 应用:
+
+```java
+public class HelloServlet extends HttpServlet {
+
+ @Override
+ protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ resp.getWriter().println("Hello World!");
+ }
+
+ @Override
+ protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ doGet(req,resp);
+ }
+}
+```
+
+这是一个非常简单的 Servlet,我们将其打包上传到`/opt/apps`中,那么容器内肯定就会同步到该文件,此时进行访问:
+
+
+
+这种方式设置的数据卷称为自定义数据卷,因为数据卷的目录是由我们自己设置的,Docker 还为我们提供了另外一种设置数据卷的方式:
+
+```shell
+docker run -d -p 8080:8080 --name tomcat01 -v aa:/usr/local/tomcat/webapps tomcat:8.0-jre8
+```
+
+此时的`aa`并不是数据卷的目录,而是数据卷的别名,Docker 会为我们自动创建一个名为`aa`的数据卷,并且会将容器内`webapps`目录下的所有内容复制到数据卷中,该数据卷的位置在`/var/lib/docker/volumes`目录下:
+
+```shell
+[root@centos-7 volumes]# pwd
+/var/lib/docker/volumes
+[root@centos-7 volumes]# cd aa/
+[root@centos-7 aa]# ls
+_data
+[root@centos-7 aa]# cd _data/
+[root@centos-7 _data]# ls
+docs examples host-manager manager ROOT
+```
+
+此时我们只需修改该目录的内容就能能够影响到容器。
+
+---
+
+最后再介绍几个容器和镜像相关的指令:
+
+```shell
+docker commit -m "描述信息" -a "镜像作者" tomcat01 my_tomcat:1.0
+```
+
+该指令能够将容器打包成一个镜像,此时查询镜像:
+
+```shell
+[root@centos-7 _data]# docker images
+REPOSITORY TAG IMAGE ID CREATED SIZE
+my_tomcat 1.0 79ab047fade5 2 seconds ago 463MB
+tomcat 8 a041be4a5ba5 2 weeks ago 533MB
+MySQL latest db2b37ec6181 2 months ago 545MB
+```
+
+若是想将镜像备份出来,则可以使用指令:
+
+```shell
+docker save my_tomcat:1.0 -o my-tomcat-1.0.tar
+```
+
+```shell
+[root@centos-7 ~]# docker save my_tomcat:1.0 -o my-tomcat-1.0.tar
+[root@centos-7 ~]# ls
+anaconda-ks.cfg initial-setup-ks.cfg 公共 视频 文档 音乐
+get-docker.sh my-tomcat-1.0.tar 模板 图片 下载 桌面
+```
+
+若是拥有`.tar`格式的镜像,该如何将其加载到 Docker 中呢?执行指令:
+
+```shell
+docker load -i my-tomcat-1.0.tar
+```
+
+```shell
+root@centos-7 ~]# docker load -i my-tomcat-1.0.tar
+b28ef0b6fef8: Loading layer [==================================================>] 105.5MB/105.5MB
+0b703c74a09c: Loading layer [==================================================>] 23.99MB/23.99MB
+......
+Loaded image: my_tomcat:1.0
+[root@centos-7 ~]# docker images
+REPOSITORY TAG IMAGE ID CREATED SIZE
+my_tomcat 1.0 79ab047fade5 7 minutes ago 463MB
+```
diff --git a/docs/tools/git/git-intro.md b/docs/tools/git/git-intro.md
new file mode 100644
index 00000000000..2cfb2e95ef8
--- /dev/null
+++ b/docs/tools/git/git-intro.md
@@ -0,0 +1,252 @@
+# Git 入门
+
+## 版本控制
+
+### 什么是版本控制
+
+版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。 除了项目源代码,你可以对任何类型的文件进行版本控制。
+
+### 为什么要版本控制
+
+有了它你就可以将某个文件回溯到之前的状态,甚至将整个项目都回退到过去某个时间点的状态,你可以比较文件的变化细节,查出最后是谁修改了哪个地方,从而找出导致怪异问题出现的原因,又是谁在何时报告了某个功能缺陷等等。
+
+### 本地版本控制系统
+
+许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别。 这么做唯一的好处就是简单,但是特别容易犯错。 有时候会混淆所在的工作目录,一不小心会写错文件或者覆盖意想外的文件。
+
+为了解决这个问题,人们很久以前就开发了许多种本地版本控制系统,大多都是采用某种简单的数据库来记录文件的历次更新差异。
+
+
+
+### 集中化的版本控制系统
+
+接下来人们又遇到一个问题,如何让在不同系统上的开发者协同工作? 于是,集中化的版本控制系统(Centralized Version Control Systems,简称 CVCS)应运而生。
+
+集中化的版本控制系统都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。
+
+
+
+这么做虽然解决了本地版本控制系统无法让在不同系统上的开发者协同工作的诟病,但也还是存在下面的问题:
+
+- **单点故障:** 中央服务器宕机,则其他人无法使用;如果中心数据库磁盘损坏又没有进行备份,你将丢失所有数据。本地版本控制系统也存在类似问题,只要整个项目的历史记录被保存在单一位置,就有丢失所有历史更新记录的风险。
+- **必须联网才能工作:** 受网络状况、带宽影响。
+
+### 分布式版本控制系统
+
+于是分布式版本控制系统(Distributed Version Control System,简称 DVCS)面世了。 Git 就是一个典型的分布式版本控制系统。
+
+这类系统,客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。
+
+
+
+分布式版本控制系统可以不用联网就可以工作,因为每个人的电脑上都是完整的版本库,当你修改了某个文件后,你只需要将自己的修改推送给别人就可以了。但是,在实际使用分布式版本控制系统的时候,很少会直接进行推送修改,而是使用一台充当“中央服务器”的东西。这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
+
+分布式版本控制系统的优势不单是不必联网这么简单,后面我们还会看到 Git 极其强大的分支管理等功能。
+
+## 认识 Git
+
+### Git 简史
+
+Linux 内核项目组当时使用分布式版本控制系统 BitKeeper 来管理和维护代码。但是,后来开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了 Linux 内核社区免费使用 BitKeeper 的权力。 Linux 开源社区(特别是 Linux 的缔造者 Linus Torvalds)基于使用 BitKeeper 时的经验教训,开发出自己的版本系统,而且对新的版本控制系统做了很多改进。
+
+### Git 与其他版本管理系统的主要区别
+
+ Git 在保存和对待各种信息的时候与其它版本控制系统有很大差异,尽管操作起来的命令形式非常相近,理解这些差异将有助于防止你使用中的困惑。
+
+下面我们主要说一个关于 Git 与其他版本管理系统的主要差别:**对待数据的方式**。
+
+**Git采用的是直接记录快照的方式,而非差异比较。我后面会详细介绍这两种方式的差别。**
+
+大部分版本控制系统(CVS、Subversion、Perforce、Bazaar 等等)都是以文件变更列表的方式存储信息,这类系统**将它们保存的信息看作是一组基本文件和每个文件随时间逐步累积的差异。**
+
+具体原理如下图所示,理解起来其实很简单,每当我们提交更新一个文件之后,系统都会记录这个文件做了哪些更新,以增量符号Δ(Delta)表示。
+
+<div align="center">
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3deltas.png" width="500px"/>
+</br>
+</div>
+
+**我们怎样才能得到一个文件的最终版本呢?**
+
+很简单,高中数学的基本知识,我们只需要将这些原文件和这些增加进行相加就行了。
+
+**这种方式有什么问题呢?**
+
+比如我们的增量特别特别多的话,如果我们要得到最终的文件是不是会耗费时间和性能。
+
+Git 不按照以上方式对待或保存数据。 反之,Git 更像是把数据看作是对小型文件系统的一组快照。 每次你提交更新,或在 Git 中保存项目状态时,它主要对当时的全部文件制作一个快照并保存这个快照的索引。 为了高效,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件。 Git 对待数据更像是一个 **快照流**。
+
+<div align="center">
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3snapshots.png" width="500px"/>
+</br>
+</div>
+
+
+### Git 的三种状态
+
+Git 有三种状态,你的文件可能处于其中之一:
+
+1. **已提交(committed)**:数据已经安全的保存在本地数据库中。
+2. **已修改(modified)**:已修改表示修改了文件,但还没保存到数据库中。
+3. **已暂存(staged)**:表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
+
+由此引入 Git 项目的三个工作区域的概念:**Git 仓库(.git directory)**、**工作目录(Working Directory)** 以及 **暂存区域(Staging Area)** 。
+
+<div align="center">
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3areas.png" width="500px"/>
+</div>
+
+**基本的 Git 工作流程如下:**
+
+1. 在工作目录中修改文件。
+2. 暂存文件,将文件的快照放入暂存区域。
+3. 提交更新,找到暂存区域的文件,将快照永久性存储到 Git 仓库目录。
+
+## Git 使用快速入门
+
+### 获取 Git 仓库
+
+有两种取得 Git 项目仓库的方法。
+
+1. 在现有目录中初始化仓库: 进入项目目录运行 `git init` 命令,该命令将创建一个名为 `.git` 的子目录。
+2. 从一个服务器克隆一个现有的 Git 仓库: `git clone [url]` 自定义本地仓库的名字: `git clone [url] directoryname`
+
+### 记录每次更新到仓库
+
+1. **检测当前文件状态** : `git status`
+2. **提出更改(把它们添加到暂存区**):`git add filename ` (针对特定文件)、`git add *`(所有文件)、`git add *.txt`(支持通配符,所有 .txt 文件)
+3. **忽略文件**:`.gitignore` 文件
+4. **提交更新:** `git commit -m "代码提交信息"` (每次准备提交前,先用 `git status` 看下,是不是都已暂存起来了, 然后再运行提交命令 `git commit`)
+5. **跳过使用暂存区域更新的方式** : `git commit -a -m "代码提交信息"`。 `git commit` 加上 `-a` 选项,Git 就会自动把所有已经跟踪过的文件暂存起来一并提交,从而跳过 `git add` 步骤。
+6. **移除文件** :`git rm filename` (从暂存区域移除,然后提交。)
+7. **对文件重命名** :`git mv README.md README`(这个命令相当于`mv README.md README`、`git rm README.md`、`git add README` 这三条命令的集合)
+
+### 一个好的 Git 提交消息
+一个好的 Git 提交消息如下:
+
+ 标题行:用这一行来描述和解释你的这次提交
+
+ 主体部分可以是很少的几行,来加入更多的细节来解释提交,最好是能给出一些相关的背景或者解释这个提交能修复和解决什么问题。
+
+ 主体部分当然也可以有几段,但是一定要注意换行和句子不要太长。因为这样在使用 "git log" 的时候会有缩进比较好看。
+
+提交的标题行描述应该尽量的清晰和尽量的一句话概括。这样就方便相关的 Git 日志查看工具显示和其他人的阅读。
+
+### 推送改动到远程仓库
+
+- 如果你还没有克隆现有仓库,并欲将你的仓库连接到某个远程服务器,你可以使用如下命令添加:`git remote add origin <server>` ,比如我们要让本地的一个仓库和 Github 上创建的一个仓库关联可以这样`git remote add origin https://github.com/Snailclimb/test.git`
+- 将这些改动提交到远端仓库:`git push origin master` (可以把 *master* 换成你想要推送的任何分支)
+
+ 如此你就能够将你的改动推送到所添加的服务器上去了。
+
+### 远程仓库的移除与重命名
+
+- 将 test 重命名为 test1:`git remote rename test test1`
+- 移除远程仓库 test1:`git remote rm test1`
+
+### 查看提交历史
+
+在提交了若干更新,又或者克隆了某个项目之后,你也许想回顾下提交历史。 完成这个任务最简单而又有效的工具是 `git log` 命令。`git log` 会按提交时间列出所有的更新,最近的更新排在最上面。
+
+**可以添加一些参数来查看自己希望看到的内容:**
+
+只看某个人的提交记录:
+
+```shell
+git log --author=bob
+```
+
+### 撤销操作
+
+有时候我们提交完了才发现漏掉了几个文件没有添加,或者提交信息写错了。 此时,可以运行带有 `--amend` 选项的提交命令尝试重新提交:
+
+```shell
+git commit --amend
+```
+
+取消暂存的文件
+
+```shell
+git reset filename
+```
+
+撤消对文件的修改:
+
+```shell
+git checkout -- filename
+```
+
+假如你想丢弃你在本地的所有改动与提交,可以到服务器上获取最新的版本历史,并将你本地主分支指向它:
+
+```shell
+git fetch origin
+git reset --hard origin/master
+```
+
+
+### 分支
+
+分支是用来将特性开发绝缘开来的。在你创建仓库的时候,*master* 是“默认”的分支。在其他分支上进行开发,完成后再将它们合并到主分支上。
+
+我们通常在开发新功能、修复一个紧急 bug 等等时候会选择创建分支。单分支开发好还是多分支开发好,还是要看具体场景来说。
+
+创建一个名字叫做 test 的分支
+
+```shell
+git branch test
+```
+
+切换当前分支到 test(当你切换分支的时候,Git 会重置你的工作目录,使其看起来像回到了你在那个分支上最后一次提交的样子。 Git 会自动添加、删除、修改文件以确保此时你的工作目录和这个分支最后一次提交时的样子一模一样)
+
+```shell
+git checkout test
+```
+
+<div align="center">
+<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3切换分支.png" width="500px"/>
+</div>
+
+你也可以直接这样创建分支并切换过去(上面两条命令的合写)
+
+```shell
+git checkout -b feature_x
+```
+
+切换到主分支
+
+```shell
+git checkout master
+```
+
+合并分支(可能会有冲突)
+
+```shell
+ git merge test
+```
+
+把新建的分支删掉
+
+```shell
+git branch -d feature_x
+```
+
+将分支推送到远端仓库(推送成功后其他人可见):
+
+```shell
+git push origin
+```
+
+## 推荐
+
+**在线演示学习工具:**
+
+「补充,来自[issue729](https://github.com/Snailclimb/JavaGuide/issues/729)」Learn Git Branching https://oschina.gitee.io/learn-git-branching/ 。该网站可以方便的演示基本的git操作,讲解得明明白白。每一个基本命令的作用和结果。
+
+**推荐阅读:**
+
+- [Git - 简明指南](https://rogerdudler.github.io/git-guide/index.zh.html)
+- [图解Git](https://marklodato.github.io/visual-git-guide/index-zh-cn.html)
+- [猴子都能懂得Git入门](https://backlog.com/git-tutorial/cn/intro/intro1_1.html)
+- https://git-scm.com/book/en/v2
+- [Generating a new SSH key and adding it to the ssh-agent](https://help.github.com/en/articles/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent)
+- [一个好的 Git 提交消息,出自 Linus 之手](https://github.com/torvalds/subsurface-for-dirk/blob/a48494d2fbed58c751e9b7e8fbff88582f9b2d02/README#L88)
diff --git "a/docs/tools/git/github\346\212\200\345\267\247.md" "b/docs/tools/git/github\346\212\200\345\267\247.md"
new file mode 100644
index 00000000000..1142b3e38e1
--- /dev/null
+++ "b/docs/tools/git/github\346\212\200\345\267\247.md"
@@ -0,0 +1,117 @@
+# Github小技巧
+
+我使用 Github 已经有 5 年多了,今天毫无保留地把自己觉得比较有用的 Github 小技巧送给关注 JavaGuide 的各位小伙伴。
+
+这篇文章肝了很久,就挺用心的,大家看内容就知道了。
+
+如果觉得有收获的话,不要白嫖!点个赞/在看就是对我最大的鼓励。你要是可以三连(点赞+在看+转发)的话,我就更爽了(_我在想屁吃?_)。
+
+## 1. 一键生成 Github 简历
+
+通过 [https://resume.github.io/](https://resume.github.io/) 这个网站你可以一键生成一个在线的 Github 简历。
+
+当时我参加的校招的时候,个人信息那里就放了一个在线的 Github 简历。我觉得这样会让面试官感觉你是一个内行,会提高一些印象分。
+
+但是,如果你的 Github 没有什么项目的话还是不要放在简历里面了。生成后的效果如下图所示。
+
+
+
+## 2. 个性化 Github 首页
+
+Github 目前支持在个人主页自定义展示一些内容。展示效果如下图所示。
+
+
+
+想要做到这样非常简单,你只需要创建一个和你的 Github 账户同名的仓库,然后自定义`README.md`的内容即可。
+
+展示在你主页的自定义内容就是`README.md`的内容(_不会 Markdown 语法的小伙伴自行面壁 5 分钟_)。
+
+
+
+这个也是可以玩出花来的!比如说:通过 [github-readme-stats](https://hellogithub.com/periodical/statistics/click/?target=https://github.com/anuraghazra/github-readme-stats) 这个开源项目,你可以 README 中展示动态生成的 GitHub 统计信息。展示效果如下图所示。
+
+
+
+关于个性化首页这个就不多提了,感兴趣的小伙伴自行研究一下。
+
+## 3. 自定义项目徽章
+
+你在 Github 上看到的项目徽章都是通过 [https://shields.io/](https://shields.io/) 这个网站生成的。我的 JavaGuide 这个项目的徽章如下图所示。
+
+
+
+并且,你不光可以生成静态徽章,shield.io 还可以动态读取你项目的状态并生成对应的徽章。
+
+
+
+生成的描述项目状态的徽章效果如下图所示。
+
+
+
+## 4. Github 表情
+
+
+
+如果你想要在 Github 使用表情的话,可以在这里找找 :[www.webfx.com/tools/emoji-cheat-sheet/ ](www.webfx.com/tools/emoji-cheat-sheet/)。
+
+
+
+## 5. 高效阅读 Github 项目的源代码
+
+Github 前段时间推出的 Codespaces 可以提供类似 VS Code 的在线 IDE,不过目前还没有完全开发使用。
+
+简单介绍几种我最常用的阅读 Github 项目源代码的方式。
+
+### 5.1. Chrome 插件 Octotree
+
+这个已经老生常谈了,是我最喜欢的一种方式。使用了 Octotree 之后网页侧边栏会按照树形结构展示项目,为我们带来 IDE 般的阅读源代码的感受。
+
+
+
+### 5.2. Chrome 插件 SourceGraph
+
+我不想将项目 clone 到本地的时候一般就会使用这种方式来阅读项目源代码。SourceGraph 不仅可以让我们在 Github 优雅的查看代码,它还支持一些骚操作,比如:类之间的跳转、代码搜索等功能。
+
+当你下载了这个插件之后,你的项目主页会多出一个小图标如下图所示。点击这个小图标即可在线阅读项目源代码。
+
+
+
+使用 SourceGraph 阅读代码的就像下面这样,同样是树形结构展示代码,但是我个人感觉没有 Octotree 的手感舒服。不过,SourceGraph 内置了很多插件,而且还支持类之间的跳转!
+
+
+
+### 5.3. 克隆项目到本地
+
+先把项目克隆到本地,然后使用自己喜欢的 IDE 来阅读。可以说是最酸爽的方式了!
+
+如果你想要深入了解某个项目的话,首选这种方式。一个`git clone` 就完事了。
+
+### 5.4. 其他
+
+如果你要看的是前端项目的话,还可以考虑使用 [https://stackblitz.com/](https://stackblitz.com/) 这个网站。
+
+这个网站会提供一个类似 VS Code 的在线 IDE。
+
+## 6. 扩展 Github 的功能
+
+**Enhanced GitHub** 可以让你的 Github 更好用。这个 Chrome 插件可以可视化你的 Github 仓库大小,每个文件的大小并且可以让你快速下载单个文件。
+
+
+
+## 7. 自动为 Markdown 文件生成目录
+
+如果你想为 Github 上的 Markdown 文件生成目录的话,通过 VS Code 的 **Markdown Preview Enhanced** 这个插件就可以了。
+
+生成的目录效果如下图所示。你直接点击目录中的链接即可跳转到文章对应的位置,可以优化阅读体验。
+
+.png>)
+
+## 8. 后记
+
+这篇文章是我上周六的时候坐在窗台写的,花了一下午时间。
+
+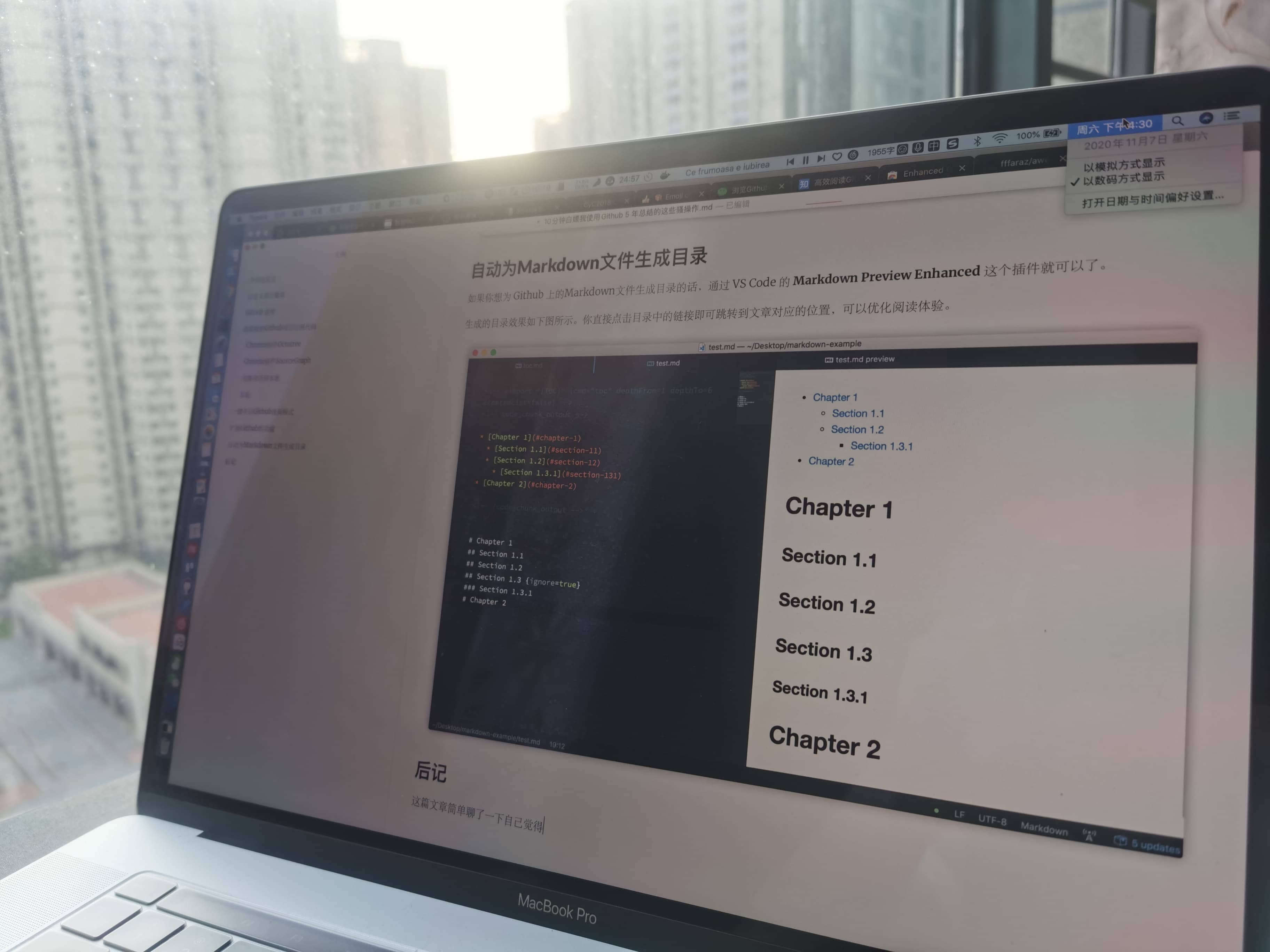
+
+除了我提到的这些技巧之外,像 Github 搜索技巧、GitHub Actions 等内容的话,我这里没有提,感兴趣的小伙伴自行研究一下。
+
+这里多说一句心里话: **Github 搜索技巧不必要记网上那些文章说的各种命令啥的,真没啥卵用。你会发现你用的最多的还是关键字搜索以及 Github 自带的筛选功能。**
diff --git a/docs/tools/readme.md b/docs/tools/readme.md
new file mode 100644
index 00000000000..258557b4412
--- /dev/null
+++ b/docs/tools/readme.md
@@ -0,0 +1,19 @@
+---
+icon: tool
+---
+
+# 常用开发工具总结
+
+## 数据库
+
+- [CHINER: 干掉 PowerDesigner,这个国产数据库建模工具很强!](./database/CHINER.md)
+- [DBeaver:开源数据库管理工具。](./database/DBeaver.md)
+- [screw:一键生成数据库文档,堪称数据库界的Swagger](./database/screw.md)
+
+## Git
+
+- [Git 入门](./git/git-intro.md)
+- [Github 小技巧](./git/git-intro.md)
+
+## Docker
+
diff --git a/index.html b/index.html
new file mode 100755
index 00000000000..8f2161cb0cb
--- /dev/null
+++ b/index.html
@@ -0,0 +1,92 @@
+<!DOCTYPE html>
+<html lang="en">
+ <head>
+ <meta charset="UTF-8" />
+ <title>JavaGuide</title>
+ <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" />
+ <meta name="description" content="Description" />
+ <meta
+ name="viewport"
+ content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0"
+ />
+ <link rel="stylesheet" href="//unpkg.com/docsify/lib/themes/prism.css" />
+ <!--主题-->
+ <link rel="stylesheet" href="//unpkg.com/docsify/lib/themes/vue.css" />
+ </head>
+
+ <body>
+ <nav>
+ <a href="https://cowtransfer.com/s/fbed14f0c22a4d">图解计算机基础</a>
+ <a href="https://wx.zsxq.com/dweb2/index/group/48418884588288"
+ >知识星球</a
+ >
+ </nav>
+ <div id="app"></div>
+ <!-- docsify-edit-on-github -->
+ <script src="//unpkg.com/docsify-edit-on-github/index.js"></script>
+ <script>
+ // 离线支持
+ if (typeof navigator.serviceWorker !== "undefined") {
+ navigator.serviceWorker.register("sw.js");
+ }
+ window.$docsify = {
+ name: "JavaGuide",
+ repo: "https://github.com/Snailclimb/JavaGuide",
+ maxLevel: 4, //最大支持渲染的标题层级
+ //封面,_coverpage.md
+ //coverpage: true,
+ auto2top: true, //切换页面后是否自动跳转到页面顶部
+ //ga: 'UA-138586553-1',
+ //logo: 'https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3logo-透明.png' ,
+ search: {
+ //maxAge: 86400000, // 过期时间,单位毫秒,默认一天
+ paths: "auto",
+ placeholder: "搜索",
+ noData: "找不到结果",
+ // 搜索标题的最大程级, 1 - 6
+ depth: 3,
+ },
+ // 备案
+ beian: {
+ ICP: "鄂ICP备2020015769号",
+ NISMSP: {
+ number: "",
+ url: "",
+ id: "",
+ },
+ },
+ // 字数统计
+ count: {
+ countable: true,
+ fontsize: "0.9em",
+ color: "rgb(90,90,90)",
+ language: "chinese",
+ },
+ plugins: [
+ EditOnGithubPlugin.create(
+ "https://github.com/Snailclimb/JavaGuide/blob/master/"
+ ),
+ ],
+ };
+ </script>
+ <script src="//unpkg.com/docsify/lib/docsify.min.js"></script>
+ <!--Java代码高亮-->
+ <script src="//unpkg.com/prismjs/components/prism-java.js"></script>
+ <!--全文搜索,直接用官方提供的无法生效-->
+ <script src="https://cdn.bootcss.com/docsify/4.5.9/plugins/search.min.js"></script>
+ <!--谷歌统计
+ <script src="//unpkg.com/docsify" data-ga="UA-138586553-1"></script>
+ <script src="//unpkg.com/docsify/lib/plugins/ga.js"></script>
+ -->
+ <!-- 复制到剪贴板 -->
+ <script src="//unpkg.com/docsify-copy-code"></script>
+ <!-- 图片缩放 -->
+ <script src="//unpkg.com/docsify/lib/plugins/zoom-image.js"></script>
+ <!-- 表情 -->
+ <script src="//unpkg.com/docsify/lib/plugins/emoji.js"></script>
+ <!-- 字数统计 -->
+ <script src="//unpkg.com/docsify-count/dist/countable.js"></script>
+ <!-- 备案 -->
+ <script src="https://cdn.jsdelivr.net/npm/docsify-beian@latest/dist/beian.min.js"></script>
+ </body>
+</html>
diff --git a/media/pictures/logo.png b/media/pictures/logo.png
new file mode 100644
index 00000000000..239f9a89d13
Binary files /dev/null and b/media/pictures/logo.png differ
diff --git "a/media/sponsor/\347\237\245\350\257\206\346\230\237\347\220\203.png" "b/media/sponsor/\347\237\245\350\257\206\346\230\237\347\220\203.png"
new file mode 100644
index 00000000000..565a8406507
Binary files /dev/null and "b/media/sponsor/\347\237\245\350\257\206\346\230\237\347\220\203.png" differ
diff --git a/package.json b/package.json
new file mode 100644
index 00000000000..066b4c57fb2
--- /dev/null
+++ b/package.json
@@ -0,0 +1,16 @@
+{
+ "name": "javaguide-blog",
+ "version": "1.0.0",
+ "description": "A project of vuepress-theme-hope",
+ "license": "MIT",
+ "scripts": {
+ "build": "vuepress build docs",
+ "clean-dev": "vuepress dev docs --no-cache",
+ "dev": "vuepress dev docs",
+ "eject-theme": "vuepress eject-hope docs"
+ },
+ "devDependencies": {
+ "vuepress": "^1.8.2",
+ "vuepress-theme-hope": "^1.20.5"
+ }
+}
diff --git a/sw.js b/sw.js
new file mode 100644
index 00000000000..cf6295c494b
--- /dev/null
+++ b/sw.js
@@ -0,0 +1,83 @@
+/* ===========================================================
+ * docsify sw.js
+ * ===========================================================
+ * Copyright 2016 @huxpro
+ * Licensed under Apache 2.0
+ * Register service worker.
+ * ========================================================== */
+
+const RUNTIME = 'docsify'
+const HOSTNAME_WHITELIST = [
+ self.location.hostname,
+ 'fonts.gstatic.com',
+ 'fonts.googleapis.com',
+ 'unpkg.com'
+]
+
+// The Util Function to hack URLs of intercepted requests
+const getFixedUrl = (req) => {
+ var now = Date.now()
+ var url = new URL(req.url)
+
+ // 1. fixed http URL
+ // Just keep syncing with location.protocol
+ // fetch(httpURL) belongs to active mixed content.
+ // And fetch(httpRequest) is not supported yet.
+ url.protocol = self.location.protocol
+
+ // 2. add query for caching-busting.
+ // Github Pages served with Cache-Control: max-age=600
+ // max-age on mutable content is error-prone, with SW life of bugs can even extend.
+ // Until cache mode of Fetch API landed, we have to workaround cache-busting with query string.
+ // Cache-Control-Bug: https://bugs.chromium.org/p/chromium/issues/detail?id=453190
+ if (url.hostname === self.location.hostname) {
+ url.search += (url.search ? '&' : '?') + 'cache-bust=' + now
+ }
+ return url.href
+}
+
+/**
+ * @Lifecycle Activate
+ * New one activated when old isnt being used.
+ *
+ * waitUntil(): activating ====> activated
+ */
+self.addEventListener('activate', event => {
+ event.waitUntil(self.clients.claim())
+})
+
+/**
+ * @Functional Fetch
+ * All network requests are being intercepted here.
+ *
+ * void respondWith(Promise<Response> r)
+ */
+self.addEventListener('fetch', event => {
+ // Skip some of cross-origin requests, like those for Google Analytics.
+ if (HOSTNAME_WHITELIST.indexOf(new URL(event.request.url).hostname) > -1) {
+ // Stale-while-revalidate
+ // similar to HTTP's stale-while-revalidate: https://www.mnot.net/blog/2007/12/12/stale
+ // Upgrade from Jake's to Surma's: https://gist.github.com/surma/eb441223daaedf880801ad80006389f1
+ const cached = caches.match(event.request)
+ const fixedUrl = getFixedUrl(event.request)
+ const fetched = fetch(fixedUrl, { cache: 'no-store' })
+ const fetchedCopy = fetched.then(resp => resp.clone())
+
+ // Call respondWith() with whatever we get first.
+ // If the fetch fails (e.g disconnected), wait for the cache.
+ // If there’s nothing in cache, wait for the fetch.
+ // If neither yields a response, return offline pages.
+ event.respondWith(
+ Promise.race([fetched.catch(_ => cached), cached])
+ .then(resp => resp || fetched)
+ .catch(_ => { /* eat any errors */ })
+ )
+
+ // Update the cache with the version we fetched (only for ok status)
+ event.waitUntil(
+ Promise.all([fetchedCopy, caches.open(RUNTIME)])
+ .then(([response, cache]) => response.ok && cache.put(event.request, response))
+ .catch(_ => { /* eat any errors */ })
+ )
+ }
+})
\ No newline at end of file
diff --git "a/\344\270\273\346\265\201\346\241\206\346\236\266/SpringBean.md" "b/\344\270\273\346\265\201\346\241\206\346\236\266/SpringBean.md"
deleted file mode 100644
index 09e3b5d261b..00000000000
--- "a/\344\270\273\346\265\201\346\241\206\346\236\266/SpringBean.md"
+++ /dev/null
@@ -1,449 +0,0 @@
-<!-- MarkdownTOC -->
-
-- [前言](#前言)
-- [一 bean的作用域](#一-bean的作用域)
- - [1. singleton——唯一 bean 实例](#1-singleton——唯一-bean-实例)
- - [2. prototype——每次请求都会创建一个新的 bean 实例](#2-prototype——每次请求都会创建一个新的-bean-实例)
- - [3. request——每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效](#3-request——每一次http请求都会产生一个新的bean,该bean仅在当前http-request内有效)
- - [4. session——每一次HTTP请求都会产生一个新的 bean,该bean仅在当前 HTTP session 内有效](#4-session——每一次http请求都会产生一个新的-bean,该bean仅在当前-http-session-内有效)
- - [5. globalSession](#5-globalsession)
-- [二 bean的生命周期](#二-bean的生命周期)
- - [initialization 和 destroy](#initialization-和-destroy)
- - [实现*Aware接口 在Bean中使用Spring框架的一些对象](#实现aware接口-在bean中使用spring框架的一些对象)
- - [BeanPostProcessor](#beanpostprocessor)
- - [总结](#总结)
- - [单例管理的对象](#单例管理的对象)
- - [非单例管理的对象](#非单例管理的对象)
-- [三 说明](#三-说明)
-
-<!-- /MarkdownTOC -->
-
-# 前言
-在 Spring 中,那些组成应用程序的主体及由 Spring IOC 容器所管理的对象,被称之为 bean。简单地讲,bean 就是由 IOC 容器初始化、装配及管理的对象,除此之外,bean 就与应用程序中的其他对象没有什么区别了。而 bean 的定义以及 bean 相互间的依赖关系将通过配置元数据来描述。
-
-**Spring中的bean默认都是单例的,这些单例Bean在多线程程序下如何保证线程安全呢?** 例如对于Web应用来说,Web容器对于每个用户请求都创建一个单独的Sevlet线程来处理请求,引入Spring框架之后,每个Action都是单例的,那么对于Spring托管的单例Service Bean,如何保证其安全呢? **Spring的单例是基于BeanFactory也就是Spring容器的,单例Bean在此容器内只有一个,Java的单例是基于 JVM,每个 JVM 内只有一个实例。**
-
-# 一 bean的作用域
-
-创建一个bean定义,其实质是用该bean定义对应的类来创建真正实例的“配方”。把bean定义看成一个配方很有意义,它与class很类似,只根据一张“处方”就可以创建多个实例。不仅可以控制注入到对象中的各种依赖和配置值,还可以控制该对象的作用域。这样可以灵活选择所建对象的作用域,而不必在Java Class级定义作用域。Spring Framework支持五种作用域,分别阐述如下表。
-
-
-
-
-五种作用域中,**request、session** 和 **global session** 三种作用域仅在基于web的应用中使用(不必关心你所采用的是什么web应用框架),只能用在基于 web 的 Spring ApplicationContext 环境。
-
-
-
-### 1. singleton——唯一 bean 实例
-
-**当一个 bean 的作用域为 singleton,那么Spring IoC容器中只会存在一个共享的 bean 实例,并且所有对 bean 的请求,只要 id 与该 bean 定义相匹配,则只会返回bean的同一实例。** singleton 是单例类型(对应于单例模式),就是在创建起容器时就同时自动创建了一个bean的对象,不管你是否使用,但我们可以指定Bean节点的 `lazy-init=”true”` 来延迟初始化bean,这时候,只有在第一次获取bean时才会初始化bean,即第一次请求该bean时才初始化。 每次获取到的对象都是同一个对象。注意,singleton 作用域是Spring中的缺省作用域。要在XML中将 bean 定义成 singleton ,可以这样配置:
-
-```xml
-<bean id="ServiceImpl" class="cn.csdn.service.ServiceImpl" scope="singleton">
-```
-
-也可以通过 `@Scope` 注解(它可以显示指定bean的作用范围。)的方式
-
-```java
-@Service
-@Scope("singleton")
-public class ServiceImpl{
-
-}
-```
-
-### 2. prototype——每次请求都会创建一个新的 bean 实例
-
-**当一个bean的作用域为 prototype,表示一个 bean 定义对应多个对象实例。** **prototype 作用域的 bean 会导致在每次对该 bean 请求**(将其注入到另一个 bean 中,或者以程序的方式调用容器的 getBean() 方法**)时都会创建一个新的 bean 实例。prototype 是原型类型,它在我们创建容器的时候并没有实例化,而是当我们获取bean的时候才会去创建一个对象,而且我们每次获取到的对象都不是同一个对象。根据经验,对有状态的 bean 应该使用 prototype 作用域,而对无状态的 bean 则应该使用 singleton 作用域。** 在 XML 中将 bean 定义成 prototype ,可以这样配置:
-
-```java
-<bean id="account" class="com.foo.DefaultAccount" scope="prototype"/>
- 或者
-<bean id="account" class="com.foo.DefaultAccount" singleton="false"/>
-```
-通过 `@Scope` 注解的方式实现就不做演示了。
-
-### 3. request——每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效
-
-**request只适用于Web程序,每一次 HTTP 请求都会产生一个新的bean,同时该bean仅在当前HTTP request内有效,当请求结束后,该对象的生命周期即告结束。** 在 XML 中将 bean 定义成 prototype ,可以这样配置:
-
-```java
-<bean id="loginAction" class=cn.csdn.LoginAction" scope="request"/>
-```
-
-### 4. session——每一次HTTP请求都会产生一个新的 bean,该bean仅在当前 HTTP session 内有效
-
-**session只适用于Web程序,session 作用域表示该针对每一次 HTTP 请求都会产生一个新的 bean,同时该 bean 仅在当前 HTTP session 内有效.与request作用域一样,可以根据需要放心的更改所创建实例的内部状态,而别的 HTTP session 中根据 userPreferences 创建的实例,将不会看到这些特定于某个 HTTP session 的状态变化。当HTTP session最终被废弃的时候,在该HTTP session作用域内的bean也会被废弃掉。**
-
-```xml
-<bean id="userPreferences" class="com.foo.UserPreferences" scope="session"/>
-```
-
-### 5. globalSession
-
-global session 作用域类似于标准的 HTTP session 作用域,不过仅仅在基于 portlet 的 web 应用中才有意义。Portlet 规范定义了全局 Session 的概念,它被所有构成某个 portlet web 应用的各种不同的 portle t所共享。在global session 作用域中定义的 bean 被限定于全局portlet Session的生命周期范围内。
-
-```xml
-<bean id="user" class="com.foo.Preferences "scope="globalSession"/>
-```
-
-# 二 bean的生命周期
-
-Spring Bean是Spring应用中最最重要的部分了。所以来看看Spring容器在初始化一个bean的时候会做那些事情,顺序是怎样的,在容器关闭的时候,又会做哪些事情。
-
-> spring版本:4.2.3.RELEASE
-鉴于Spring源码是用gradle构建的,我也决定舍弃我大maven,尝试下洪菊推荐过的gradle。运行beanLifeCycle模块下的junit test即可在控制台看到如下输出,可以清楚了解Spring容器在创建,初始化和销毁Bean的时候依次做了那些事情。
-
-```
-Spring容器初始化
-=====================================
-调用GiraffeService无参构造函数
-GiraffeService中利用set方法设置属性值
-调用setBeanName:: Bean Name defined in context=giraffeService
-调用setBeanClassLoader,ClassLoader Name = sun.misc.Launcher$AppClassLoader
-调用setBeanFactory,setBeanFactory:: giraffe bean singleton=true
-调用setEnvironment
-调用setResourceLoader:: Resource File Name=spring-beans.xml
-调用setApplicationEventPublisher
-调用setApplicationContext:: Bean Definition Names=[giraffeService, org.springframework.context.annotation.CommonAnnotationBeanPostProcessor#0, com.giraffe.spring.service.GiraffeServicePostProcessor#0]
-执行BeanPostProcessor的postProcessBeforeInitialization方法,beanName=giraffeService
-调用PostConstruct注解标注的方法
-执行InitializingBean接口的afterPropertiesSet方法
-执行配置的init-method
-执行BeanPostProcessor的postProcessAfterInitialization方法,beanName=giraffeService
-Spring容器初始化完毕
-=====================================
-从容器中获取Bean
-giraffe Name=李光洙
-=====================================
-调用preDestroy注解标注的方法
-执行DisposableBean接口的destroy方法
-执行配置的destroy-method
-Spring容器关闭
-```
-
-先来看看,Spring在Bean从创建到销毁的生命周期中可能做得事情。
-
-
-### initialization 和 destroy
-
-有时我们需要在Bean属性值set好之后和Bean销毁之前做一些事情,比如检查Bean中某个属性是否被正常的设置好值了。Spring框架提供了多种方法让我们可以在Spring Bean的生命周期中执行initialization和pre-destroy方法。
-
-**1.实现InitializingBean和DisposableBean接口**
-
-这两个接口都只包含一个方法。通过实现InitializingBean接口的afterPropertiesSet()方法可以在Bean属性值设置好之后做一些操作,实现DisposableBean接口的destroy()方法可以在销毁Bean之前做一些操作。
-
-例子如下:
-
-```java
-public class GiraffeService implements InitializingBean,DisposableBean {
- @Override
- public void afterPropertiesSet() throws Exception {
- System.out.println("执行InitializingBean接口的afterPropertiesSet方法");
- }
- @Override
- public void destroy() throws Exception {
- System.out.println("执行DisposableBean接口的destroy方法");
- }
-}
-```
-这种方法比较简单,但是不建议使用。因为这样会将Bean的实现和Spring框架耦合在一起。
-
-**2.在bean的配置文件中指定init-method和destroy-method方法**
-
-Spring允许我们创建自己的 init 方法和 destroy 方法,只要在 Bean 的配置文件中指定 init-method 和 destroy-method 的值就可以在 Bean 初始化时和销毁之前执行一些操作。
-
-例子如下:
-
-```java
-public class GiraffeService {
- //通过<bean>的destroy-method属性指定的销毁方法
- public void destroyMethod() throws Exception {
- System.out.println("执行配置的destroy-method");
- }
- //通过<bean>的init-method属性指定的初始化方法
- public void initMethod() throws Exception {
- System.out.println("执行配置的init-method");
- }
-}
-```
-
-配置文件中的配置:
-
-```
-<bean name="giraffeService" class="com.giraffe.spring.service.GiraffeService" init-method="initMethod" destroy-method="destroyMethod">
-</bean>
-```
-
-需要注意的是自定义的init-method和post-method方法可以抛异常但是不能有参数。
-
-这种方式比较推荐,因为可以自己创建方法,无需将Bean的实现直接依赖于spring的框架。
-
-**3.使用@PostConstruct和@PreDestroy注解**
-
-除了xml配置的方式,Spring 也支持用 `@PostConstruct`和 `@PreDestroy`注解来指定 `init` 和 `destroy` 方法。这两个注解均在`javax.annotation` 包中。为了注解可以生效,需要在配置文件中定义org.springframework.context.annotation.CommonAnnotationBeanPostProcessor或context:annotation-config
-
-例子如下:
-
-```java
-public class GiraffeService {
- @PostConstruct
- public void initPostConstruct(){
- System.out.println("执行PostConstruct注解标注的方法");
- }
- @PreDestroy
- public void preDestroy(){
- System.out.println("执行preDestroy注解标注的方法");
- }
-}
-```
-
-配置文件:
-
-```xml
-
-<bean class="org.springframework.context.annotation.CommonAnnotationBeanPostProcessor" />
-
-```
-
-### 实现*Aware接口 在Bean中使用Spring框架的一些对象
-
-有些时候我们需要在 Bean 的初始化中使用 Spring 框架自身的一些对象来执行一些操作,比如获取 ServletContext 的一些参数,获取 ApplicaitionContext 中的 BeanDefinition 的名字,获取 Bean 在容器中的名字等等。为了让 Bean 可以获取到框架自身的一些对象,Spring 提供了一组名为*Aware的接口。
-
-这些接口均继承于`org.springframework.beans.factory.Aware`标记接口,并提供一个将由 Bean 实现的set*方法,Spring通过基于setter的依赖注入方式使相应的对象可以被Bean使用。
-网上说,这些接口是利用观察者模式实现的,类似于servlet listeners,目前还不明白,不过这也不在本文的讨论范围内。
-介绍一些重要的Aware接口:
-
-- **ApplicationContextAware**: 获得ApplicationContext对象,可以用来获取所有Bean definition的名字。
-- **BeanFactoryAware**:获得BeanFactory对象,可以用来检测Bean的作用域。
-- **BeanNameAware**:获得Bean在配置文件中定义的名字。
-- **ResourceLoaderAware**:获得ResourceLoader对象,可以获得classpath中某个文件。
-- **ServletContextAware**:在一个MVC应用中可以获取ServletContext对象,可以读取context中的参数。
-- **ServletConfigAware**: 在一个MVC应用中可以获取ServletConfig对象,可以读取config中的参数。
-
-```java
-public class GiraffeService implements ApplicationContextAware,
- ApplicationEventPublisherAware, BeanClassLoaderAware, BeanFactoryAware,
- BeanNameAware, EnvironmentAware, ImportAware, ResourceLoaderAware{
- @Override
- public void setBeanClassLoader(ClassLoader classLoader) {
- System.out.println("执行setBeanClassLoader,ClassLoader Name = " + classLoader.getClass().getName());
- }
- @Override
- public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
- System.out.println("执行setBeanFactory,setBeanFactory:: giraffe bean singleton=" + beanFactory.isSingleton("giraffeService"));
- }
- @Override
- public void setBeanName(String s) {
- System.out.println("执行setBeanName:: Bean Name defined in context="
- + s);
- }
- @Override
- public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
- System.out.println("执行setApplicationContext:: Bean Definition Names="
- + Arrays.toString(applicationContext.getBeanDefinitionNames()));
- }
- @Override
- public void setApplicationEventPublisher(ApplicationEventPublisher applicationEventPublisher) {
- System.out.println("执行setApplicationEventPublisher");
- }
- @Override
- public void setEnvironment(Environment environment) {
- System.out.println("执行setEnvironment");
- }
- @Override
- public void setResourceLoader(ResourceLoader resourceLoader) {
- Resource resource = resourceLoader.getResource("classpath:spring-beans.xml");
- System.out.println("执行setResourceLoader:: Resource File Name="
- + resource.getFilename());
- }
- @Override
- public void setImportMetadata(AnnotationMetadata annotationMetadata) {
- System.out.println("执行setImportMetadata");
- }
-}
-```
-
-### BeanPostProcessor
-
-上面的*Aware接口是针对某个实现这些接口的Bean定制初始化的过程,
-Spring同样可以针对容器中的所有Bean,或者某些Bean定制初始化过程,只需提供一个实现BeanPostProcessor接口的类即可。 该接口中包含两个方法,postProcessBeforeInitialization和postProcessAfterInitialization。 postProcessBeforeInitialization方法会在容器中的Bean初始化之前执行, postProcessAfterInitialization方法在容器中的Bean初始化之后执行。
-
-例子如下:
-
-```java
-public class CustomerBeanPostProcessor implements BeanPostProcessor {
- @Override
- public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
- System.out.println("执行BeanPostProcessor的postProcessBeforeInitialization方法,beanName=" + beanName);
- return bean;
- }
- @Override
- public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
- System.out.println("执行BeanPostProcessor的postProcessAfterInitialization方法,beanName=" + beanName);
- return bean;
- }
-}
-```
-
-要将BeanPostProcessor的Bean像其他Bean一样定义在配置文件中
-
-```xml
-<bean class="com.giraffe.spring.service.CustomerBeanPostProcessor"/>
-```
-
-### 总结
-
-所以。。。结合第一节控制台输出的内容,Spring Bean的生命周期是这样纸的:
-
-- Bean容器找到配置文件中 Spring Bean 的定义。
-- Bean容器利用Java Reflection API创建一个Bean的实例。
-- 如果涉及到一些属性值 利用set方法设置一些属性值。
-- 如果Bean实现了BeanNameAware接口,调用setBeanName()方法,传入Bean的名字。
-- 如果Bean实现了BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
-- 如果Bean实现了BeanFactoryAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
-- 与上面的类似,如果实现了其他*Aware接口,就调用相应的方法。
-- 如果有和加载这个Bean的Spring容器相关的BeanPostProcessor对象,执行postProcessBeforeInitialization()方法
-- 如果Bean实现了InitializingBean接口,执行afterPropertiesSet()方法。
-- 如果Bean在配置文件中的定义包含init-method属性,执行指定的方法。
-- 如果有和加载这个Bean的Spring容器相关的BeanPostProcessor对象,执行postProcessAfterInitialization()方法
-- 当要销毁Bean的时候,如果Bean实现了DisposableBean接口,执行destroy()方法。
-- 当要销毁Bean的时候,如果Bean在配置文件中的定义包含destroy-method属性,执行指定的方法。
-
-用图表示一下(图来源:http://www.jianshu.com/p/d00539babca5):
-
-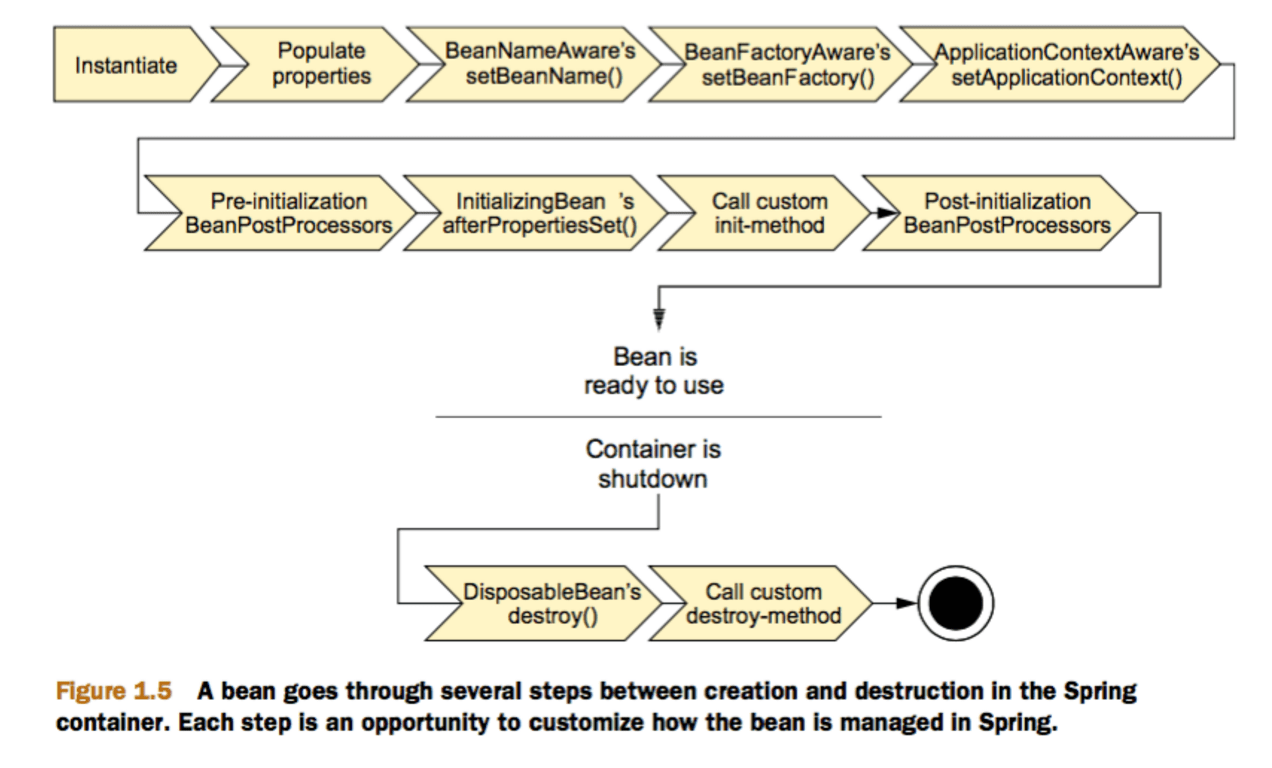
-
-与之比较类似的中文版本:
-
-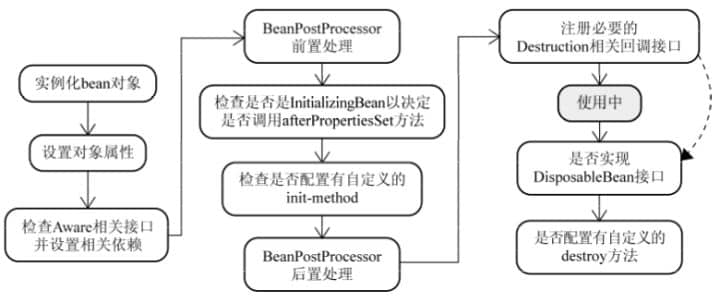
-
-
-**其实很多时候我们并不会真的去实现上面说描述的那些接口,那么下面我们就除去那些接口,针对bean的单例和非单例来描述下bean的生命周期:**
-
-### 单例管理的对象
-
-当scope=”singleton”,即默认情况下,会在启动容器时(即实例化容器时)时实例化。但我们可以指定Bean节点的lazy-init=”true”来延迟初始化bean,这时候,只有在第一次获取bean时才会初始化bean,即第一次请求该bean时才初始化。如下配置:
-
-```xml
-<bean id="ServiceImpl" class="cn.csdn.service.ServiceImpl" lazy-init="true"/>
-```
-
-如果想对所有的默认单例bean都应用延迟初始化,可以在根节点beans设置default-lazy-init属性为true,如下所示:
-
-```xml
-<beans default-lazy-init="true" …>
-```
-
-默认情况下,Spring 在读取 xml 文件的时候,就会创建对象。在创建对象的时候先调用构造器,然后调用 init-method 属性值中所指定的方法。对象在被销毁的时候,会调用 destroy-method 属性值中所指定的方法(例如调用Container.destroy()方法的时候)。写一个测试类,代码如下:
-
-```java
-public class LifeBean {
- private String name;
-
- public LifeBean(){
- System.out.println("LifeBean()构造函数");
- }
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- System.out.println("setName()");
- this.name = name;
- }
-
- public void init(){
- System.out.println("this is init of lifeBean");
- }
-
- public void destory(){
- System.out.println("this is destory of lifeBean " + this);
- }
-}
-```
- life.xml配置如下:
-
-```xml
-<bean id="life_singleton" class="com.bean.LifeBean" scope="singleton"
- init-method="init" destroy-method="destory" lazy-init="true"/>
-```
-
-测试代码:
-
-```java
-public class LifeTest {
- @Test
- public void test() {
- AbstractApplicationContext container =
- new ClassPathXmlApplicationContext("life.xml");
- LifeBean life1 = (LifeBean)container.getBean("life");
- System.out.println(life1);
- container.close();
- }
-}
-```
-
-运行结果:
-
-```
-LifeBean()构造函数
-this is init of lifeBean
-com.bean.LifeBean@573f2bb1
-……
-this is destory of lifeBean com.bean.LifeBean@573f2bb1
-```
-
-### 非单例管理的对象
-
-当`scope=”prototype”`时,容器也会延迟初始化 bean,Spring 读取xml 文件的时候,并不会立刻创建对象,而是在第一次请求该 bean 时才初始化(如调用getBean方法时)。在第一次请求每一个 prototype 的bean 时,Spring容器都会调用其构造器创建这个对象,然后调用`init-method`属性值中所指定的方法。对象销毁的时候,Spring 容器不会帮我们调用任何方法,因为是非单例,这个类型的对象有很多个,Spring容器一旦把这个对象交给你之后,就不再管理这个对象了。
-
-为了测试prototype bean的生命周期life.xml配置如下:
-
-```xml
-<bean id="life_prototype" class="com.bean.LifeBean" scope="prototype" init-method="init" destroy-method="destory"/>
-```
-
-测试程序:
-
-```java
-public class LifeTest {
- @Test
- public void test() {
- AbstractApplicationContext container = new ClassPathXmlApplicationContext("life.xml");
- LifeBean life1 = (LifeBean)container.getBean("life_singleton");
- System.out.println(life1);
-
- LifeBean life3 = (LifeBean)container.getBean("life_prototype");
- System.out.println(life3);
- container.close();
- }
-}
-```
-
-运行结果:
-
-```
-LifeBean()构造函数
-this is init of lifeBean
-com.bean.LifeBean@573f2bb1
-LifeBean()构造函数
-this is init of lifeBean
-com.bean.LifeBean@5ae9a829
-……
-this is destory of lifeBean com.bean.LifeBean@573f2bb1
-```
-
-可以发现,对于作用域为 prototype 的 bean ,其`destroy`方法并没有被调用。**如果 bean 的 scope 设为prototype时,当容器关闭时,`destroy` 方法不会被调用。对于 prototype 作用域的 bean,有一点非常重要,那就是 Spring不能对一个 prototype bean 的整个生命周期负责:容器在初始化、配置、装饰或者是装配完一个prototype实例后,将它交给客户端,随后就对该prototype实例不闻不问了。** 不管何种作用域,容器都会调用所有对象的初始化生命周期回调方法。但对prototype而言,任何配置好的析构生命周期回调方法都将不会被调用。**清除prototype作用域的对象并释放任何prototype bean所持有的昂贵资源,都是客户端代码的职责**(让Spring容器释放被prototype作用域bean占用资源的一种可行方式是,通过使用bean的后置处理器,该处理器持有要被清除的bean的引用)。谈及prototype作用域的bean时,在某些方面你可以将Spring容器的角色看作是Java new操作的替代者,任何迟于该时间点的生命周期事宜都得交由客户端来处理。
-
-**Spring 容器可以管理 singleton 作用域下 bean 的生命周期,在此作用域下,Spring 能够精确地知道bean何时被创建,何时初始化完成,以及何时被销毁。而对于 prototype 作用域的bean,Spring只负责创建,当容器创建了 bean 的实例后,bean 的实例就交给了客户端的代码管理,Spring容器将不再跟踪其生命周期,并且不会管理那些被配置成prototype作用域的bean的生命周期。**
-
-
-# 三 说明
-
-本文的完成结合了下面两篇文章,并做了相应修改:
-
-- https://blog.csdn.net/fuzhongmin05/article/details/73389779
-- https://yemengying.com/2016/07/14/spring-bean-life-cycle/
-
-由于本文非本人独立原创,所以未声明为原创!在此说明!
diff --git "a/\344\270\273\346\265\201\346\241\206\346\236\266/SpringMVC \345\267\245\344\275\234\345\216\237\347\220\206\350\257\246\350\247\243.md" "b/\344\270\273\346\265\201\346\241\206\346\236\266/SpringMVC \345\267\245\344\275\234\345\216\237\347\220\206\350\257\246\350\247\243.md"
deleted file mode 100644
index 0efcd3f9534..00000000000
--- "a/\344\270\273\346\265\201\346\241\206\346\236\266/SpringMVC \345\267\245\344\275\234\345\216\237\347\220\206\350\257\246\350\247\243.md"
+++ /dev/null
@@ -1,269 +0,0 @@
-> 本文整理自网络,原文出处暂不知,对原文做了较大的改动,在此说明!
-
-### 先来看一下什么是 MVC 模式
-
-MVC 是一种设计模式.
-
-**MVC 的原理图如下:**
-
-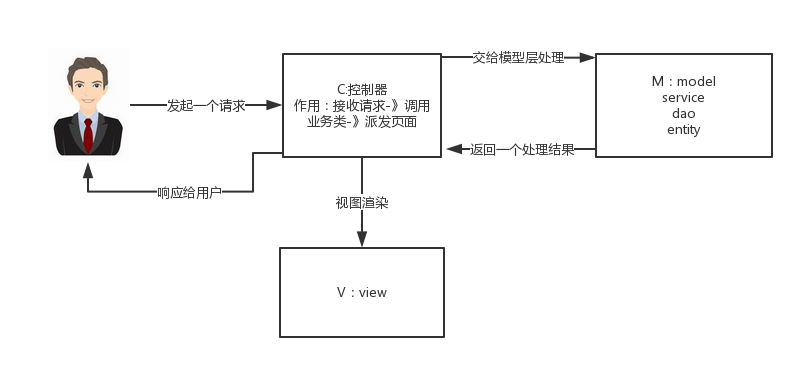
-
-
-
-### SpringMVC 简单介绍
-
-SpringMVC 框架是以请求为驱动,围绕 Servlet 设计,将请求发给控制器,然后通过模型对象,分派器来展示请求结果视图。其中核心类是 DispatcherServlet,它是一个 Servlet,顶层是实现的Servlet接口。
-
-### SpringMVC 使用
-
-需要在 web.xml 中配置 DispatcherServlet 。并且需要配置 Spring 监听器ContextLoaderListener
-
-```xml
-
-<listener>
- <listener-class>org.springframework.web.context.ContextLoaderListener
- </listener-class>
-</listener>
-<servlet>
- <servlet-name>springmvc</servlet-name>
- <servlet-class>org.springframework.web.servlet.DispatcherServlet
- </servlet-class>
- <!-- 如果不设置init-param标签,则必须在/WEB-INF/下创建xxx-servlet.xml文件,其中xxx是servlet-name中配置的名称。 -->
- <init-param>
- <param-name>contextConfigLocation</param-name>
- <param-value>classpath:spring/springmvc-servlet.xml</param-value>
- </init-param>
- <load-on-startup>1</load-on-startup>
-</servlet>
-<servlet-mapping>
- <servlet-name>springmvc</servlet-name>
- <url-pattern>/</url-pattern>
-</servlet-mapping>
-
-```
-
-### SpringMVC 工作原理(重要)
-
-**简单来说:**
-
-客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器开处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Moder)->将得到视图对象返回给用户
-
-
-
-**如下图所示:**
-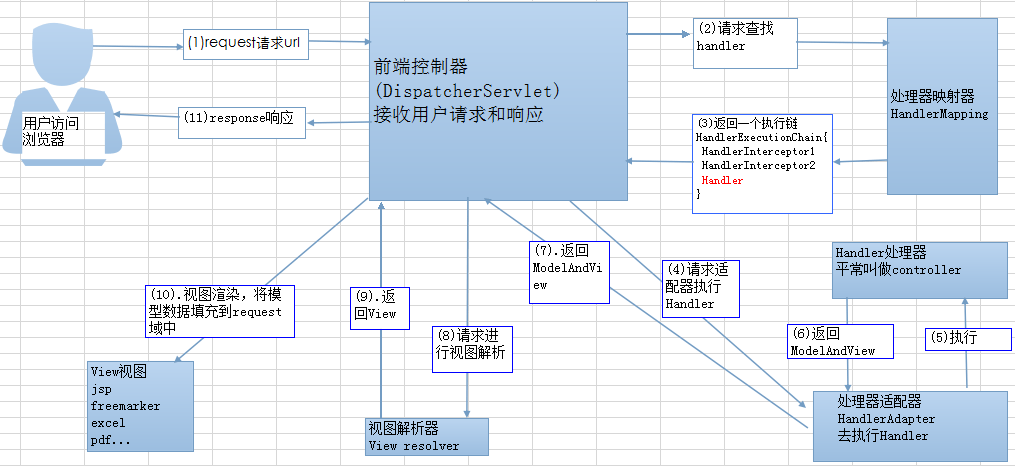
-
-上图的一个笔误的小问题:Spring MVC 的入口函数也就是前端控制器 DispatcherServlet 的作用是接收请求,响应结果。
-
-**流程说明(重要):**
-
-(1)客户端(浏览器)发送请求,直接请求到 DispatcherServlet。
-
-(2)DispatcherServlet 根据请求信息调用 HandlerMapping,解析请求对应的 Handler。
-
-(3)解析到对应的 Handler(也就是我们平常说的 Controller 控制器)后,开始由 HandlerAdapter 适配器处理。
-
-(4)HandlerAdapter 会根据 Handler 来调用真正的处理器开处理请求,并处理相应的业务逻辑。
-
-(5)处理器处理完业务后,会返回一个 ModelAndView 对象,Model 是返回的数据对象,View 是个逻辑上的 View。
-
-(6)ViewResolver 会根据逻辑 View 查找实际的 View。
-
-(7)DispaterServlet 把返回的 Model 传给 View(视图渲染)。
-
-(8)把 View 返回给请求者(浏览器)
-
-
-
-### SpringMVC 重要组件说明
-
-
-**1、前端控制器DispatcherServlet(不需要工程师开发),由框架提供(重要)**
-
-作用:**Spring MVC 的入口函数。接收请求,响应结果,相当于转发器,中央处理器。有了 DispatcherServlet 减少了其它组件之间的耦合度。用户请求到达前端控制器,它就相当于mvc模式中的c,DispatcherServlet是整个流程控制的中心,由它调用其它组件处理用户的请求,DispatcherServlet的存在降低了组件之间的耦合性。**
-
-**2、处理器映射器HandlerMapping(不需要工程师开发),由框架提供**
-
-作用:根据请求的url查找Handler。HandlerMapping负责根据用户请求找到Handler即处理器(Controller),SpringMVC提供了不同的映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
-
-**3、处理器适配器HandlerAdapter**
-
-作用:按照特定规则(HandlerAdapter要求的规则)去执行Handler
-通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。
-
-**4、处理器Handler(需要工程师开发)**
-
-注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执行Handler
-Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。
-由于Handler涉及到具体的用户业务请求,所以一般情况需要工程师根据业务需求开发Handler。
-
-**5、视图解析器View resolver(不需要工程师开发),由框架提供**
-
-作用:进行视图解析,根据逻辑视图名解析成真正的视图(view)
-View Resolver负责将处理结果生成View视图,View Resolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。 springmvc框架提供了很多的View视图类型,包括:jstlView、freemarkerView、pdfView等。
-一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由工程师根据业务需求开发具体的页面。
-
-**6、视图View(需要工程师开发)**
-
-View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf...)
-
-**注意:处理器Handler(也就是我们平常说的Controller控制器)以及视图层view都是需要我们自己手动开发的。其他的一些组件比如:前端控制器DispatcherServlet、处理器映射器HandlerMapping、处理器适配器HandlerAdapter等等都是框架提供给我们的,不需要自己手动开发。**
-
-### DispatcherServlet详细解析
-
-首先看下源码:
-
-```java
-package org.springframework.web.servlet;
-
-@SuppressWarnings("serial")
-public class DispatcherServlet extends FrameworkServlet {
-
- public static final String MULTIPART_RESOLVER_BEAN_NAME = "multipartResolver";
- public static final String LOCALE_RESOLVER_BEAN_NAME = "localeResolver";
- public static final String THEME_RESOLVER_BEAN_NAME = "themeResolver";
- public static final String HANDLER_MAPPING_BEAN_NAME = "handlerMapping";
- public static final String HANDLER_ADAPTER_BEAN_NAME = "handlerAdapter";
- public static final String HANDLER_EXCEPTION_RESOLVER_BEAN_NAME = "handlerExceptionResolver";
- public static final String REQUEST_TO_VIEW_NAME_TRANSLATOR_BEAN_NAME = "viewNameTranslator";
- public static final String VIEW_RESOLVER_BEAN_NAME = "viewResolver";
- public static final String FLASH_MAP_MANAGER_BEAN_NAME = "flashMapManager";
- public static final String WEB_APPLICATION_CONTEXT_ATTRIBUTE = DispatcherServlet.class.getName() + ".CONTEXT";
- public static final String LOCALE_RESOLVER_ATTRIBUTE = DispatcherServlet.class.getName() + ".LOCALE_RESOLVER";
- public static final String THEME_RESOLVER_ATTRIBUTE = DispatcherServlet.class.getName() + ".THEME_RESOLVER";
- public static final String THEME_SOURCE_ATTRIBUTE = DispatcherServlet.class.getName() + ".THEME_SOURCE";
- public static final String INPUT_FLASH_MAP_ATTRIBUTE = DispatcherServlet.class.getName() + ".INPUT_FLASH_MAP";
- public static final String OUTPUT_FLASH_MAP_ATTRIBUTE = DispatcherServlet.class.getName() + ".OUTPUT_FLASH_MAP";
- public static final String FLASH_MAP_MANAGER_ATTRIBUTE = DispatcherServlet.class.getName() + ".FLASH_MAP_MANAGER";
- public static final String EXCEPTION_ATTRIBUTE = DispatcherServlet.class.getName() + ".EXCEPTION";
- public static final String PAGE_NOT_FOUND_LOG_CATEGORY = "org.springframework.web.servlet.PageNotFound";
- private static final String DEFAULT_STRATEGIES_PATH = "DispatcherServlet.properties";
- protected static final Log pageNotFoundLogger = LogFactory.getLog(PAGE_NOT_FOUND_LOG_CATEGORY);
- private static final Properties defaultStrategies;
- static {
- try {
- ClassPathResource resource = new ClassPathResource(DEFAULT_STRATEGIES_PATH, DispatcherServlet.class);
- defaultStrategies = PropertiesLoaderUtils.loadProperties(resource);
- }
- catch (IOException ex) {
- throw new IllegalStateException("Could not load 'DispatcherServlet.properties': " + ex.getMessage());
- }
- }
-
- /** Detect all HandlerMappings or just expect "handlerMapping" bean? */
- private boolean detectAllHandlerMappings = true;
-
- /** Detect all HandlerAdapters or just expect "handlerAdapter" bean? */
- private boolean detectAllHandlerAdapters = true;
-
- /** Detect all HandlerExceptionResolvers or just expect "handlerExceptionResolver" bean? */
- private boolean detectAllHandlerExceptionResolvers = true;
-
- /** Detect all ViewResolvers or just expect "viewResolver" bean? */
- private boolean detectAllViewResolvers = true;
-
- /** Throw a NoHandlerFoundException if no Handler was found to process this request? **/
- private boolean throwExceptionIfNoHandlerFound = false;
-
- /** Perform cleanup of request attributes after include request? */
- private boolean cleanupAfterInclude = true;
-
- /** MultipartResolver used by this servlet */
- private MultipartResolver multipartResolver;
-
- /** LocaleResolver used by this servlet */
- private LocaleResolver localeResolver;
-
- /** ThemeResolver used by this servlet */
- private ThemeResolver themeResolver;
-
- /** List of HandlerMappings used by this servlet */
- private List<HandlerMapping> handlerMappings;
-
- /** List of HandlerAdapters used by this servlet */
- private List<HandlerAdapter> handlerAdapters;
-
- /** List of HandlerExceptionResolvers used by this servlet */
- private List<HandlerExceptionResolver> handlerExceptionResolvers;
-
- /** RequestToViewNameTranslator used by this servlet */
- private RequestToViewNameTranslator viewNameTranslator;
-
- private FlashMapManager flashMapManager;
-
- /** List of ViewResolvers used by this servlet */
- private List<ViewResolver> viewResolvers;
-
- public DispatcherServlet() {
- super();
- }
-
- public DispatcherServlet(WebApplicationContext webApplicationContext) {
- super(webApplicationContext);
- }
- @Override
- protected void onRefresh(ApplicationContext context) {
- initStrategies(context);
- }
-
- protected void initStrategies(ApplicationContext context) {
- initMultipartResolver(context);
- initLocaleResolver(context);
- initThemeResolver(context);
- initHandlerMappings(context);
- initHandlerAdapters(context);
- initHandlerExceptionResolvers(context);
- initRequestToViewNameTranslator(context);
- initViewResolvers(context);
- initFlashMapManager(context);
- }
-}
-
-```
-
-DispatcherServlet类中的属性beans:
-
-- HandlerMapping:用于handlers映射请求和一系列的对于拦截器的前处理和后处理,大部分用@Controller注解。
-- HandlerAdapter:帮助DispatcherServlet处理映射请求处理程序的适配器,而不用考虑实际调用的是 哪个处理程序。- - -
-- ViewResolver:根据实际配置解析实际的View类型。
-- ThemeResolver:解决Web应用程序可以使用的主题,例如提供个性化布局。
-- MultipartResolver:解析多部分请求,以支持从HTML表单上传文件。-
-- FlashMapManager:存储并检索可用于将一个请求属性传递到另一个请求的input和output的FlashMap,通常用于重定向。
-
-在Web MVC框架中,每个DispatcherServlet都拥自己的WebApplicationContext,它继承了ApplicationContext。WebApplicationContext包含了其上下文和Servlet实例之间共享的所有的基础框架beans。
-
-**HandlerMapping**
-
-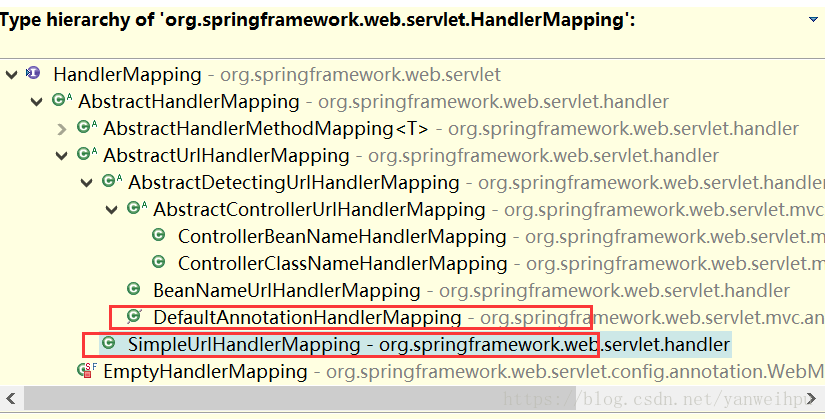
-
-HandlerMapping接口处理请求的映射HandlerMapping接口的实现类:
-
-- SimpleUrlHandlerMapping类通过配置文件把URL映射到Controller类。
-- DefaultAnnotationHandlerMapping类通过注解把URL映射到Controller类。
-
-**HandlerAdapter**
-
-
-
-
-HandlerAdapter接口-处理请求映射
-
-AnnotationMethodHandlerAdapter:通过注解,把请求URL映射到Controller类的方法上。
-
-**HandlerExceptionResolver**
-
-
-
-
-HandlerExceptionResolver接口-异常处理接口
-
-- SimpleMappingExceptionResolver通过配置文件进行异常处理。
-- AnnotationMethodHandlerExceptionResolver:通过注解进行异常处理。
-
-**ViewResolver**
-
-
-
-ViewResolver接口解析View视图。
-
-UrlBasedViewResolver类 通过配置文件,把一个视图名交给到一个View来处理。
diff --git "a/\344\270\273\346\265\201\346\241\206\346\236\266/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md" "b/\344\270\273\346\265\201\346\241\206\346\236\266/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md"
deleted file mode 100644
index 732717aa3a6..00000000000
--- "a/\344\270\273\346\265\201\346\241\206\346\236\266/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md"
+++ /dev/null
@@ -1,128 +0,0 @@
-
-
-# Spring相关教程/资料:
-
-> ## 官网相关
-
- [Spring官网](https://spring.io/)
-
-[Spring系列主要项目](https://spring.io/projects)
-
-从配置到安全性,Web应用到大数据 - 无论您的应用程序的基础架构需求如何,都有一个Spring Project来帮助您构建它。 从小处着手,根据需要使用 - Spring是通过设计模块化的。
-
- [Spring官网指南](https://spring.io/guides)
-
-无论您在构建什么,这些指南都旨在尽可能快地提高您的工作效率 - 使用Spring团队推荐的最新Spring项目发布和技术。
-
- [Spring官方文档翻译(1~6章)](https://blog.csdn.net/tangtong1/article/details/51326887)
-
-> ## 系统学习教程:
-
-### 文档:
-
- [极客学院Spring Wiki](http://wiki.jikexueyuan.com/project/spring/transaction-management.html)
-
- [Spring W3Cschool教程 ](https://www.w3cschool.cn/wkspring/f6pk1ic8.html)
-
-### 视频:
-
-[网易云课堂——58集精通java教程Spring框架开发](http://study.163.com/course/courseMain.htm?courseId=1004475015#/courseDetail?tab=1&35)
-
- [慕课网相关视频](https://www.imooc.com/)
-
-**黑马视频(非常推荐):**
-微信公众号:“**Java面试通关手册**”后台回复“**资源分享第一波**”免费领取。
-
-> ## 一些常用的东西
-
-[Spring Framework 4.3.17.RELEASE API](https://docs.spring.io/spring/docs/4.3.17.RELEASE/javadoc-api/)
-
-默认浏览器打开,当需要查某个类的作用的时候,可以在浏览器通过ctrl+f搜索。
-
-
-# 面试必备知识点
-
-
-> ## SpringAOP,IOC实现原理
-
-AOP实现原理、动态代理和静态代理、Spring IOC的初始化过程、IOC原理、自己实现怎么实现一个IOC容器?这些东西都是经常会被问到的。
-
-[自己动手实现的 Spring IOC 和 AOP - 上篇](http://www.coolblog.xyz/2018/01/18/自己动手实现的-Spring-IOC-和-AOP-上篇/)
-
-[自己动手实现的 Spring IOC 和 AOP - 下篇](http://www.coolblog.xyz/2018/01/18/自己动手实现的-Spring-IOC-和-AOP-下篇/)
-
-### AOP:
-
-AOP思想的实现一般都是基于 **代理模式** ,在JAVA中一般采用JDK动态代理模式,但是我们都知道,**JDK动态代理模式只能代理接口而不能代理类**。因此,Spring AOP 会这样子来进行切换,因为Spring AOP 同时支持 CGLIB、ASPECTJ、JDK动态代理。
-
-- 如果目标对象的实现类实现了接口,Spring AOP 将会采用 JDK 动态代理来生成 AOP 代理类;
-- 如果目标对象的实现类没有实现接口,Spring AOP 将会采用 CGLIB 来生成 AOP 代理类——不过这个选择过程对开发者完全透明、开发者也无需关心。
-
-
-
-[※静态代理、JDK动态代理、CGLIB动态代理讲解](http://www.cnblogs.com/puyangsky/p/6218925.html)
-
-我们知道AOP思想的实现一般都是基于 **代理模式** ,所以在看下面的文章之前建议先了解一下静态代理以及JDK动态代理、CGLIB动态代理的实现方式。
-
-[Spring AOP 入门](https://juejin.im/post/5aa7818af265da23844040c6)
-
-带你入门的一篇文章。这篇文章主要介绍了AOP中的基本概念:5种类型的通知(Before,After,After-returning,After-throwing,Around);Spring中对AOP的支持:AOP思想的实现一般都是基于代理模式,在JAVA中一般采用JDK动态代理模式,Spring AOP 同时支持 CGLIB、ASPECTJ、JDK动态代理,
-
-[※Spring AOP 基于AspectJ注解如何实现AOP](https://juejin.im/post/5a55af9e518825734d14813f)
-
-
-**AspectJ是一个AOP框架,它能够对java代码进行AOP编译(一般在编译期进行),让java代码具有AspectJ的AOP功能(当然需要特殊的编译器)**,可以这样说AspectJ是目前实现AOP框架中最成熟,功能最丰富的语言,更幸运的是,AspectJ与java程序完全兼容,几乎是无缝关联,因此对于有java编程基础的工程师,上手和使用都非常容易
-
-Spring注意到AspectJ在AOP的实现方式上依赖于特殊编译器(ajc编译器),因此Spring很机智回避了这点,转向采用动态代理技术的实现原理来构建Spring AOP的内部机制(动态织入),这是与AspectJ(静态织入)最根本的区别。
-
-
-[※探秘Spring AOP(慕课网视频,很不错)](https://www.imooc.com/learn/869)
-
-慕课网视频,讲解的很不错,详细且深入
-
-
-[spring源码剖析(六)AOP实现原理剖析](https://blog.csdn.net/fighterandknight/article/details/51209822)
-
-通过源码分析Spring AOP的原理
-
-### IOC:
-
-Spring IOC的初始化过程:
-
-
-[[Spring框架]Spring IOC的原理及详解。](https://www.cnblogs.com/wang-meng/p/5597490.html)
-
-[Spring IOC核心源码学习](https://yikun.github.io/2015/05/29/Spring-IOC核心源码学习/)
-
-比较简短,推荐阅读。
-
-[Spring IOC 容器源码分析](https://javadoop.com/post/spring-ioc)
-
-强烈推荐,内容详尽,而且便于阅读。
-
-> ## Spring事务管理
-
-[可能是最漂亮的Spring事务管理详解](https://juejin.im/post/5b00c52ef265da0b95276091)
-
-[Spring编程式和声明式事务实例讲解](https://juejin.im/post/5b010f27518825426539ba38)
-
-> ## 其他
-
-**Spring单例与线程安全:**
-
-[Spring框架中的单例模式(源码解读)](http://www.cnblogs.com/chengxuyuanzhilu/p/6404991.html)
-
-单例模式是一种常用的软件设计模式。通过单例模式可以保证系统中一个类只有一个实例。spring依赖注入时,使用了 多重判断加锁 的单例模式。
-
-> ## Spring源码阅读
-
-阅读源码不仅可以加深我们对Spring设计思想的理解,提高自己的编码水品,还可以让自己字面试中如鱼得水。下面的是Github上的一个开源的Spring源码阅读,大家有时间可以看一下,当然你如果有时间也可以自己慢慢研究源码。
-
-### [Spring源码阅读](https://github.com/seaswalker/Spring)
- - [spring-core](https://github.com/seaswalker/Spring/blob/master/note/Spring.md)
-- [spring-aop](https://github.com/seaswalker/Spring/blob/master/note/spring-aop.md)
-- [spring-context](https://github.com/seaswalker/Spring/blob/master/note/spring-context.md)
-- [spring-task](https://github.com/seaswalker/Spring/blob/master/note/spring-task.md)
-- [spring-transaction](https://github.com/seaswalker/Spring/blob/master/note/spring-transaction.md)
-- [spring-mvc](https://github.com/seaswalker/Spring/blob/master/note/spring-mvc.md)
-- [guava-cache](https://github.com/seaswalker/Spring/blob/master/note/guava-cache.md)
diff --git "a/\344\270\273\346\265\201\346\241\206\346\236\266/ZooKeeper.md" "b/\344\270\273\346\265\201\346\241\206\346\236\266/ZooKeeper.md"
deleted file mode 100644
index 0fc0abe3895..00000000000
--- "a/\344\270\273\346\265\201\346\241\206\346\236\266/ZooKeeper.md"
+++ /dev/null
@@ -1,187 +0,0 @@
-
-## 前言
-
-相信大家对 ZooKeeper 应该不算陌生。但是你真的了解 ZooKeeper 是个什么东西吗?如果别人/面试官让你给他讲讲 ZooKeeper 是个什么东西,你能回答到什么地步呢?
-
-我本人曾经使用过 ZooKeeper 作为 Dubbo 的注册中心,另外在搭建 solr 集群的时候,我使用到了 ZooKeeper 作为 solr 集群的管理工具。前几天,总结项目经验的时候,我突然问自己 ZooKeeper 到底是个什么东西?想了半天,脑海中只是简单的能浮现出几句话:“①Zookeeper 可以被用作注册中心。 ②Zookeeper 是 Hadoop 生态系统的一员;③构建 Zookeeper 集群的时候,使用的服务器最好是奇数台。” 可见,我对于 Zookeeper 的理解仅仅是停留在了表面。
-
-所以,**通过本文,希望带大家稍微详细的了解一下 ZooKeeper 。如果没有学过 ZooKeeper ,那么本文将会是你进入 ZooKeeper 大门的垫脚砖。如果你已经接触过 ZooKeeper ,那么本文将带你回顾一下 ZooKeeper 的一些基础概念。**
-
-最后,**本文只涉及 ZooKeeper 的一些概念,并不涉及 ZooKeeper 的使用以及 ZooKeeper 集群的搭建。** 网上有介绍 ZooKeeper 的使用以及搭建 ZooKeeper 集群的文章,大家有需要可以自行查阅。
-
-## 一 什么是 ZooKeeper
-
-### ZooKeeper 的由来
-
-**下面这段内容摘自《从Paxos到Zookeeper 》第四章第一节的某段内容,推荐大家阅读以下:**
-
-> Zookeeper最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,**雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。**
->
->关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家RaghuRamakrishnan开玩笑地说:“在这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧一一一因为各个以动物命名的分布式组件放在一起,**雅虎的整个分布式系统看上去就像一个大型的动物园了,而Zookeeper正好要用来进行分布式环境的协调一一于是,Zookeeper的名字也就由此诞生了。**
-
-
-### 1.1 ZooKeeper 概览
-
-ZooKeeper 是一个开源的分布式协调服务,ZooKeeper框架最初是在“Yahoo!"上构建的,用于以简单而稳健的方式访问他们的应用程序。 后来,Apache ZooKeeper成为Hadoop,HBase和其他分布式框架使用的有组织服务的标准。 例如,Apache HBase使用ZooKeeper跟踪分布式数据的状态。**ZooKeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。**
-
-> **原语:** 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性·即原语的执行必须是连续的,在执行过程中不允许被中断。
-
-**ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。**
-
-**Zookeeper 一个最常用的使用场景就是用于担任服务生产者和服务消费者的注册中心。** 服务生产者将自己提供的服务注册到Zookeeper中心,服务的消费者在进行服务调用的时候先到Zookeeper中查找服务,获取到服务生产者的详细信息之后,再去调用服务生产者的内容与数据。如下图所示,在 Dubbo架构中 Zookeeper 就担任了注册中心这一角色。
-
-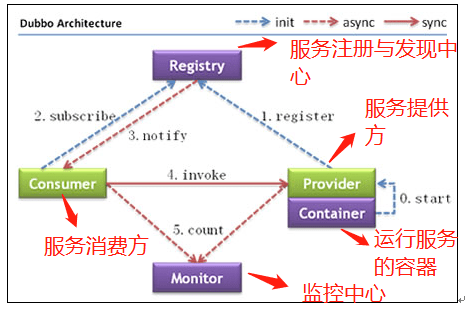
-
-### 1.2 结合个人使用情况的讲一下 ZooKeeper
-
-在我自己做过的项目中,主要使用到了 ZooKeeper 作为 Dubbo 的注册中心(Dubbo 官方推荐使用 ZooKeeper注册中心)。另外在搭建 solr 集群的时候,我使用 ZooKeeper 作为 solr 集群的管理工具。这时,ZooKeeper 主要提供下面几个功能:1、集群管理:容错、负载均衡。2、配置文件的集中管理3、集群的入口。
-
-
-我个人觉得在使用 ZooKeeper 的时候,最好是使用 集群版的 ZooKeeper 而不是单机版的。官网给出的架构图就描述的是一个集群版的 ZooKeeper 。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。
-
-**为什么最好使用奇数台服务器构成 ZooKeeper 集群?**
-
-所谓的zookeeper容错是指,当宕掉几个zookeeper服务器之后,剩下的个数必须大于宕掉的个数的话整个zookeeper才依然可用。假如我们的集群中有n台zookeeper服务器,那么也就是剩下的服务数必须大于n/2。先说一下结论,2n和2n-1的容忍度是一样的,都是n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
-比如假如我们有3台,那么最大允许宕掉1台zookeeper服务器,如果我们有4台的的时候也同样只允许宕掉1台。
-假如我们有5台,那么最大允许宕掉2台zookeeper服务器,如果我们有6台的的时候也同样只允许宕掉2台。
-
-综上,何必增加那一个不必要的zookeeper呢?
-
-
-
-## 二 关于 ZooKeeper 的一些重要概念
-
-### 2.1 重要概念总结
-
-- **ZooKeeper 本身就是一个分布式程序(只要半数以上节点存活,ZooKeeper 就能正常服务)。**
-- **为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。**
-- **ZooKeeper 将数据保存在内存中,这也就保证了 高吞吐量和低延迟**(但是内存限制了能够存储的容量不太大,此限制也是保持znode中存储的数据量较小的进一步原因)。
-- **ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。**(“读”多于“写”是协调服务的典型场景。)
-- **ZooKeeper有临时节点的概念。 当创建临时节点的客户端会话一直保持活动,瞬时节点就一直存在。而当会话终结时,瞬时节点被删除。持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上。**
-- ZooKeeper 底层其实只提供了两个功能:①管理(存储、读取)用户程序提交的数据;②为用户程序提交数据节点监听服务。
-
-**下面关于会话(Session)、 Znode、版本、Watcher、ACL概念的总结都在《从Paxos到Zookeeper 》第四章第一节以及第七章第八节有提到,感兴趣的可以看看!**
-
-### 2.2 会话(Session)
-
-Session 指的是 ZooKeeper 服务器与客户端会话。**在 ZooKeeper 中,一个客户端连接是指客户端和服务器之间的一个 TCP 长连接**。客户端启动的时候,首先会与服务器建立一个 TCP 连接,从第一次连接建立开始,客户端会话的生命周期也开始了。**通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向Zookeeper服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的Watch事件通知。** Session的`sessionTimeout`值用来设置一个客户端会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,**只要在`sessionTimeout`规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。**
-
-**在为客户端创建会话之前,服务端首先会为每个客户端都分配一个sessionID。由于 sessionID 是 Zookeeper 会话的一个重要标识,许多与会话相关的运行机制都是基于这个 sessionID 的,因此,无论是哪台服务器为客户端分配的 sessionID,都务必保证全局唯一。**
-
-### 2.3 Znode
-
-**在谈到分布式的时候,我们通常说的“节点"是指组成集群的每一台机器。然而,在Zookeeper中,“节点"分为两类,第一类同样是指构成集群的机器,我们称之为机器节点;第二类则是指数据模型中的数据单元,我们称之为数据节点一一ZNode。**
-
-Zookeeper将所有数据存储在内存中,数据模型是一棵树(Znode Tree),由斜杠(/)的进行分割的路径,就是一个Znode,例如/foo/path1。每个上都会保存自己的数据内容,同时还会保存一系列属性信息。
-
-**在Zookeeper中,node可以分为持久节点和临时节点两类。所谓持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上。而临时节点就不一样了,它的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。**另外,ZooKeeper还允许用户为每个节点添加一个特殊的属性:**SEQUENTIAL**.一旦节点被标记上这个属性,那么在这个节点被创建的时候,Zookeeper会自动在其节点名后面追加上一个整型数字,这个整型数字是一个由父节点维护的自增数字。
-
-### 2.4 版本
-
-在前面我们已经提到,Zookeeper 的每个 ZNode 上都会存储数据,对应于每个ZNode,Zookeeper 都会为其维护一个叫作 **Stat** 的数据结构,Stat中记录了这个 ZNode 的三个数据版本,分别是version(当前ZNode的版本)、cversion(当前ZNode子节点的版本)和 cversion(当前ZNode的ACL版本)。
-
-
-### 2.5 Watcher
-
-**Watcher(事件监听器),是Zookeeper中的一个很重要的特性。Zookeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper服务端会将事件通知到感兴趣的客户端上去,该机制是Zookeeper实现分布式协调服务的重要特性。**
-
-### 2.6 ACL
-
-Zookeeper采用ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。Zookeeper 定义了如下5种权限。
-
-
-
-其中尤其需要注意的是,CREATE和DELETE这两种权限都是针对子节点的权限控制。
-
-## 三 ZooKeeper 特点
-
-- **顺序一致性:** 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
-- **原子性:** 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
-- **单一系统映像 :** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
-- **可靠性:** 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
-
-## 四 ZooKeeper 设计目标
-
-### 4.1 简单的数据模型
-
-ZooKeeper 允许分布式进程通过共享的层次结构命名空间进行相互协调,这与标准文件系统类似。 名称空间由 ZooKeeper 中的数据寄存器组成 - 称为znode,这些类似于文件和目录。 与为存储设计的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟。
-
-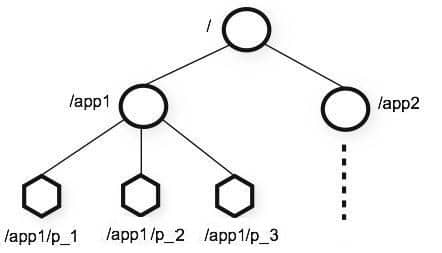
-
-### 4.2 可构建集群
-
-**为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么zookeeper本身仍然是可用的。** 客户端在使用 ZooKeeper 时,需要知道集群机器列表,通过与集群中的某一台机器建立 TCP 连接来使用服务,客户端使用这个TCP链接来发送请求、获取结果、获取监听事件以及发送心跳包。如果这个连接异常断开了,客户端可以连接到另外的机器上。
-
-**ZooKeeper 官方提供的架构图:**
-
-
-
-上图中每一个Server代表一个安装Zookeeper服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 Zab 协议(Zookeeper Atomic Broadcast)来保持数据的一致性。
-
-### 4.3 顺序访问
-
-**对于来自客户端的每个更新请求,ZooKeeper 都会分配一个全局唯一的递增编号,这个编号反应了所有事务操作的先后顺序,应用程序可以使用 ZooKeeper 这个特性来实现更高层次的同步原语。** **这个编号也叫做时间戳——zxid(Zookeeper Transaction Id)**
-
-### 4.4 高性能
-
-**ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)**
-
-## 五 ZooKeeper 集群角色介绍
-
-**最典型集群模式: Master/Slave 模式(主备模式)**。在这种模式中,通常 Master服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
-
-但是,**在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三种角色**。如下图所示
-
-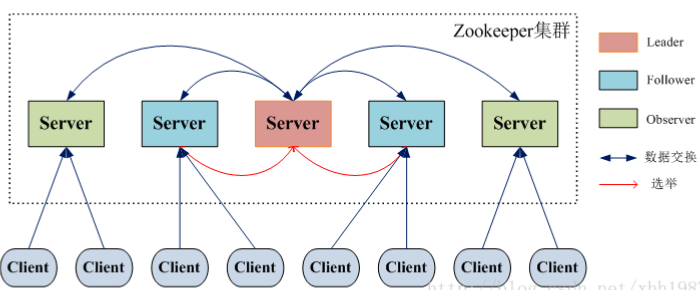
-
- **ZooKeeper 集群中的所有机器通过一个 Leader 选举过程来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。**
-
-
-
-**当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进人恢复模式并选举产生新的Leader服务器。这个过程大致是这样的:**
-
-1. Leader election(选举阶段):节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
-2. Discovery(发现阶段):在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
-3. Synchronization(同步阶段):同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后
-准 leader 才会成为真正的 leader。
-4. Broadcast(广播阶段)
-到了这个阶段,Zookeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
-
-## 六 ZooKeeper &ZAB 协议&Paxos算法
-
-### 6.1 ZAB 协议&Paxos算法
-
-Paxos 算法应该可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并没有完全采用 Paxos算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。另外,在ZooKeeper的官方文档中也指出,ZAB协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为Zookeeper设计的崩溃可恢复的原子消息广播算法。
-
-### 6.2 ZAB 协议介绍
-
-**ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。**
-
-### 6.3 ZAB 协议两种基本的模式:崩溃恢复和消息广播
-
-ZAB协议包括两种基本的模式,分别是 **崩溃恢复和消息广播**。当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进人恢复模式并选举产生新的Leader服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该Leader服务器完成了状态同步之后,ZAB协议就会退出恢复模式。其中,**所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和Leader服务器的数据状态保持一致**。
-
-**当集群中已经有过半的Follower服务器完成了和Leader服务器的状态同步,那么整个服务框架就可以进人消息广播模式了。** 当一台同样遵守ZAB协议的服务器启动后加人到集群中时,如果此时集群中已经存在一个Leader服务器在负责进行消息广播,那么新加人的服务器就会自觉地进人数据恢复模式:找到Leader所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。正如上文介绍中所说的,ZooKeeper设计成只允许唯一的一个Leader服务器来进行事务请求的处理。Leader服务器在接收到客户端的事务请求后,会生成对应的事务提案并发起一轮广播协议;而如果集群中的其他机器接收到客户端的事务请求,那么这些非Leader服务器会首先将这个事务请求转发给Leader服务器。
-
-关于 **ZAB 协议&Paxos算法** 需要讲和理解的东西太多了,说实话,笔主到现在不太清楚这俩兄弟的具体原理和实现过程。推荐阅读下面两篇文章:
-
-- [图解 Paxos 一致性协议](http://blog.xiaohansong.com/2016/09/30/Paxos/)
-- [Zookeeper ZAB 协议分析](http://blog.xiaohansong.com/2016/08/25/zab/)
-
-关于如何使用 zookeeper 实现分布式锁,可以查看下面这篇文章:
-
--
-[10分钟看懂!基于Zookeeper的分布式锁](https://blog.csdn.net/qiangcuo6087/article/details/79067136)
-
-## 六 总结
-
-通过阅读本文,想必大家已从 **①ZooKeeper的由来。** -> **②ZooKeeper 到底是什么 。**-> **③ ZooKeeper 的一些重要概念**(会话(Session)、 Znode、版本、Watcher、ACL)-> **④ZooKeeper 的特点。** -> **⑤ZooKeeper 的设计目标。**-> **⑥ ZooKeeper 集群角色介绍** (Leader、Follower 和 Observer 三种角色)-> **⑦ZooKeeper &ZAB 协议&Paxos算法。** 这七点了解了 ZooKeeper 。
-
-## 参考
-
-- 《从Paxos到Zookeeper 》
-- https://cwiki.apache.org/confluence/display/ZOOKEEPER/ProjectDescription
-- https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index
-- https://www.cnblogs.com/raphael5200/p/5285583.html
-- https://zhuanlan.zhihu.com/p/30024403
-
diff --git "a/\345\205\266\344\273\226/2018 \347\247\213\346\213\233.md" "b/\345\205\266\344\273\226/2018 \347\247\213\346\213\233.md"
deleted file mode 100644
index a2b47de8eee..00000000000
--- "a/\345\205\266\344\273\226/2018 \347\247\213\346\213\233.md"
+++ /dev/null
@@ -1,93 +0,0 @@
-
-
-# 秋招历程流水账总结
-
-笔主大四准毕业生,在秋招末流比较幸运地进入了一家自己非常喜欢一家公司——ThoughtWorks.
-
-
-
-从9-6号投递出去第一份简历,到10-18号左右拿到第一份 offer ,中间差不多有 1 个半月的时间了。可能自己比较随缘,而且自己所在的大学所处的位置并不是互联网比较发达的城市的原因。所以,很少会有公司愿意跑到我们学校那边来宣讲,来的公司也大多是一些自己没听过或者不太喜欢的公司。所以,在前期,我仅仅能够通过网上投递简历的方式来找工作。
-
-零零总总算了一下,自己在网上投了大概有 10 份左右的简历,都是些自己还算喜欢的公司。简单说一下自己投递的一些公司:网上投递的公司有:ThoughtWorks、网易、小米、携程、爱奇艺、知乎、小红书、搜狐、欢聚时代、京东;直接邮箱投递的有:烽火、中电数据、蚂蚁金服花呗部门、今日头条;线下宣讲会投递的有:玄武科技。
-
-网上投递的大部分简历都是在做完笔试之后就没有了下文了,即使有几场笔试自我感觉做的很不错的情况下,还是没有收到后续的面试邀请。还有些邮箱投递的简历,后面也都没了回应。所以,我总共也只参加了3个公司的面试,ThoughtWorks、玄武科技和中电数据,都算是拿到了 offer。拿到 ThoughtWorks 的 offer之后,后面的一些笔试和少部分面试都拒了。决定去 ThoughtWorks 了,春招的大部队会没有我的存在。
-
-
-我个人对 ThoughtWorks 最有好感,ThoughtWorks 也是我自己之前很想去的一家公司。不光是因为我投递简历的时候可以不用重新填一遍表格可以直接发送我已经编辑好的PDF格式简历的友好,这个公司的文化也让我很喜欢。每次投递一家公司几乎都要重新填写一遍简历真的很让人头疼,即使是用牛客网的简历助手也还是有很多东西需要自己重新填写。
-
-说句实话,自己在拿到第一份 offer 之前心里还是比较空的,虽然说对自己还是比较自信。包括自己当时来到武汉的原因,也是因为自己没有 offer ,就感觉心里空空的,我相信很多人在这个时候与我也有一样的感觉。然后,我就想到武汉参加一下别的学校宣讲会。现在看来,这个决定也是不必要的,因为我最后去的公司 ThoughtWorks,虽然就在我租的房子的附近,但之前投递的时候,选择的还是远程面试。来到武汉,简单的修整了一下之后,我就去参加了玄武科技在武理工的宣讲会,顺便做了笔试,然后接着就是技术面、HR面、高管面。总体来说,玄武科技的 HR 真的很热情,为他们点个赞,虽然自己最后没能去玄武科技,然后就是技术面非常简单,HR面和高管面也都还好,不会有压抑的感觉,总体聊得很愉快。需要注意的是 玄武科技和很多公司一样都有笔试中有逻辑题,我之前没有做过类似的题,所以当时第一次做有点懵逼。高管面的时候,高管还专门在我做的逻辑题上聊了一会,让我重新做了一些做错的题,并且给他讲一些题的思路,可以看出高层对于应聘者的这项能力还是比较看重的。
-
-
-
-中电数据的技术面试是电话进行的,花了1个多小时一点,个人感觉问的还是比较深的,感觉自己总体回答的还是比较不错的。
-
-这里我着重说一下 ThoughtWorks,也算是给想去 ThoughtWorks 的同学一点小小的提示。我是 9.11 号在官网:https://join.thoughtworks.cn/ 投递的简历,9.20 日邮件通知官网下载作业,作业总体来说不难,9.21 号花了半天多的时间做完,然后就直接在9.21 号下午提交了。然后等了挺长时间的,可能是因为 ThoughtWorks 在管理方面比较扁平化的原因,所以总体来说效率可能不算高。因为我选的是远程面试,所以直接下载好 zoom 之后,等HR打电话过来告诉你一个房间号,你就可以直接进去面试就好,一般技术面试有几个人看着你。技术面试的内容,首先就是在面试官让你在你之前做的作业的基础上新增加一个或者两个功能(20分钟)。所以,你在技术面试之前一定要保证你的程序的扩展性是不错的,另外就是你在技术面试之前最好能重构一下自己写的程序。重构本身就是你自己对你写的程序的理解加强很好的一种方式,另外重构也能让你发现你的程序的一些小问题。然后,这一步完成之后,面试官可能会问你一些基础问题,比较简单,所以我觉得 ThoughtWorks 可能更看重你的代码质量。ThoughtWorks 的 HR 面和其他公司的唯一不同可能在于,他会让你用英语介绍一下自己或者说自己的技术栈啊这些。
-
-
-
-
-# 关于面试一些重要的问题总结
-另外,再给大家总结一些我个人想到一些关于面试非常重要的一些问题。
-
-### 面试前
-
-**如何准备**
-
-
-运筹帷幄之后,决胜千里之外!不打毫无准备的仗,我觉得大家可以先从下面几个方面来准备面试:
-
-1. 自我介绍。(你可千万这样介绍:“我叫某某,性别,来自哪里,学校是那个,自己爱干什么”,记住:多说点简历上没有的,多说点自己哪里比别人强!)
-2. 自己面试中可能涉及哪些知识点、那些知识点是重点。
-3. 面试中哪些问题会被经常问到、面试中自己改如何回答。(强烈不推荐背题,第一:通过背这种方式你能记住多少?能记住多久?第二:背题的方式的学习很难坚持下去!)
-4. 自己的简历该如何写。
-
-
-
-另外,如果你想去类似阿里巴巴、腾讯这种比较大的互联网公司的话,一定要尽早做打算。像阿里巴巴在7月份左右就开始了提前批招聘,到了9月份差不多就已经招聘完毕了。所以,秋招没有参加到阿里的面试还是很遗憾的,毕竟面试即使失败了,也能从阿里难度Max的面试中学到很多东西。
-
-**关于着装**
-
-穿西装、打领带、小皮鞋?NO!NO!NO!这是互联网公司面试又不是去走红毯,所以你只需要穿的简单大方就好,不需要太正式。
-
-**关于自我介绍**
-
-如果你简历上写的基本信息就不要说了,比如性别、年龄、学校。另外,你也不要一上来就说自己爱好什么这方面内容。因为,面试官根本不关心这些东西。你直接挑和你岗位相关的重要经历和自己最突出的特点讲就好了。
-
-
-
-**提前准备**
-
-面试之前可以在网上找找有没有你要面试的公司的面经。在我面试 ThoughtWorks 的前几天我就在网上找了一些关于 ThoughtWorks 的技术面的一些文章。然后知道了 ThoughtWorks 的技术面会让我们在之前做的作业的基础上增加一个或两个功能,所以我提前一天就把我之前做的程序重新重构了一下。然后在技术面的时候,简单的改了几行代码之后写个测试就完事了。如果没有提前准备,我觉得 20 分钟我很大几率会完不成这项任务。
-
-
-### 面试中
-
-面试的时候一定要自信,千万不要怕自己哪里会答不出来,或者说某个问题自己忘记怎么回答了。面试过程中,很多问题可能是你之前没有碰到过的,这个时候你就要通过自己构建的知识体系来思考这些问题。如果某些问题你回答不上来,你也可以让面试官给你简单的提示一下。总之,你要自信,你自信的前提是自己要做好充分的准备。下面给大家总结一些面试非常常见的问题:
-
-- SpringMVC 工作原理
-- 说一下自己对 IOC 、AOP 的理解
-- Spring 中用到了那些设计模式,讲一下自己对于这些设计模式的理解
-- Spring Bean 的作用域和生命周期了解吗
-- Spring 事务中的隔离级别
-- Spring 事务中的事务传播行为
-- 手写一个 LRU 算法
-- 知道那些排序算法,简单介绍一下快排的原理,能不能手写一下快排
-- String 为什么是不可变的?String为啥要设计为不可变的?
-- Arraylist 与 LinkedList 异同
-- HashMap的底层实现
-- HashMap 的长度为什么是2的幂次方
-- ConcurrentHashMap 和 Hashtable 的区别
-- ConcurrentHashMap线程安全的具体实现方式/底层具体实现
-- 如果你的简历写了redis 、dubbo、zookeeper、docker的话,面试官还会问一下这些东西。比如redis可能会问你:为什么要用 redis、为什么要用 redis 而不用 map/guava 做缓存、redis 常见数据结构以及使用场景分析、 redis 设置过期时间、redis 内存淘汰机制、 redis 持久化机制、 缓存雪崩和缓存穿透问题、如何解决 Redis 的并发竞争 Key 问题、如何保证缓存与数据库双写时的数据一致性。
-- 一些简单的 Linux 命令。
-- 为什么要用 消息队列
-- 关于 Java多线程,在面试的时候,问的比较多的就是①悲观锁和乐观锁②synchronized 和 ReenTrantLock 区别以及 volatile 和 synchronized 的区别,③可重入锁与非可重入锁的区别、④多线程是解决什么问题的、⑤线程池解决什么问题,为什么要用线程池 ⑥Synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 ReenTrantLock 对比;⑦线程池使用时的注意事项、⑧AQS 原理以及 AQS 同步组件:Semaphore、CountDownLatCh、 CyclicBarrier、ReadWriteLock、⑨ReentranLock源码,设计原理,整体过程 等等问题。
-- 关于 Java 虚拟机问的比较多的是:①Java内存区域、②虚拟机垃圾算法、③虚拟机垃圾收集器、④JVM内存管理、⑤JVM调优这些问题。
-
-
-### 面试后
-
-如果失败,不要灰心;如果通过,切勿狂喜。面试和工作实际上是两回事,可能很多面试未通过的人,工作能力比你强的多,反之亦然。我个人觉得面试也像是一场全新的征程,失败和胜利都是平常之事。所以,劝各位不要因为面试失败而灰心、丧失斗志。也不要因为面试通过而沾沾自喜,等待你的将是更美好的未来,继续加油!
-
-
-
diff --git "a/\345\205\266\344\273\226/\344\270\252\344\272\272\351\230\205\350\257\273\344\271\246\347\261\215\346\270\205\345\215\225.md" "b/\345\205\266\344\273\226/\344\270\252\344\272\272\351\230\205\350\257\273\344\271\246\347\261\215\346\270\205\345\215\225.md"
deleted file mode 100644
index fb53c0ff164..00000000000
--- "a/\345\205\266\344\273\226/\344\270\252\344\272\272\351\230\205\350\257\273\344\271\246\347\261\215\346\270\205\345\215\225.md"
+++ /dev/null
@@ -1,86 +0,0 @@
-下面是个人阅读书籍的部分清单,我比较建议阅读的书籍前都加上了:thumbsup: 表情。
-> ### 核心基础知识
-
-- :thumbsup: [《图解HTTP》](https://book.douban.com/subject/25863515/)
-
- 讲漫画一样的讲HTTP,很有意思,不会觉得枯燥,大概也涵盖也HTTP常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究HTTP相关知识的话,读这本书的话应该来说就差不多了。
-
-> ### Java相关
-
-- :thumbsup: [《Head First Java.第二版》](https://book.douban.com/subject/2000732/)
-
- 可以说是我的Java启蒙书籍了,特别适合新手读当然也适合我们用来温故Java知识点。
-
-- [《Java多线程编程核心技术》](https://book.douban.com/subject/26555197/)
-
- Java多线程入门级书籍还不错,但是说实话,质量不是很高,很快就可以阅读完。
-
-- [《JAVA网络编程 第4版》](https://book.douban.com/subject/26259017/)
-
- 可以系统的学习一下网络的一些概念以及网络编程在Java中的使用。
-
-- :thumbsup: [《Java核心技术卷1+卷2》](https://book.douban.com/subject/25762168/)
-
- 很棒的两本书,建议有点Java基础之后再读,介绍的还是比较深入的,非常推荐。这两本书我一般也会用来巩固知识点,是两本适合放在自己身边的好书。
-
-- :thumbsup: [《Java编程思想(第4版)》](https://book.douban.com/subject/2130190/)
-
- 这本书要常读,初学者可以快速概览,中等程序员可以深入看看java,老鸟还可以用之回顾java的体系。这本书之所以厉害,因为它在无形中整合了设计模式,这本书之所以难读,也恰恰在于他对设计模式的整合是无形的。
-
-- :thumbsup: [《Java并发编程的艺术》](https://book.douban.com/subject/26591326/)
-
- 这本书不是很适合作为Java并发入门书籍,需要具备一定的JVM基础。我感觉有些东西讲的还是挺深入的,推荐阅读。
-- :thumbsup: [《实战Java高并发程序设计》](https://book.douban.com/subject/26663605/)
-
- 豆瓣评分 8.3 ,书的质量没的说,推荐大家好好看一下。
-
-- [《Java程序员修炼之道》](https://book.douban.com/subject/24841235/)
-
- 很杂,我只看了前面几章,不太推荐阅读。
-
-- :thumbsup: [《深入理解Java虚拟机(第2版)周志明》](https://book.douban.com/subject/24722612/)
-
- 神书!神书!神书!建议多刷几遍,书中的所有知识点可以通过JAVA运行时区域和JAVA的内存模型与线程两个大模块罗列完全。
-
-> ### JavaWeb相关
-
-- :thumbsup: [《深入分析Java Web技术内幕》](https://book.douban.com/subject/25953851/)
-
- 感觉还行,涉及的东西也蛮多,推荐阅读。
-
-- :thumbsup: [《Spring实战(第4版)》](https://book.douban.com/subject/26767354/)
-
- 不建议当做入门书籍读,入门的话可以找点国人的书或者视频看。这本定位就相当于是关于Spring的新华字典,只有一些基本概念的介绍和示例,涵盖了Spring的各个方面,但都不够深入。就像作者在最后一页写的那样:“学习Spring,这才刚刚开始”。
-
-- [《Java Web整合开发王者归来》](https://book.douban.com/subject/4189495/)
-
- 当时刚开始学的时候就是开的这本书,基本上是完完整整的看完了。不过,我不是很推荐大家看。这本书比较老了,里面很多东西都已经算是过时了。不过,这本书的一个很大优点是:基础知识点概括全面。
-
-- :thumbsup: [《Redis实战》](https://book.douban.com/subject/26612779/)
-
- 如果你想了解Redis的一些概念性知识的话,这本书真的非常不错。
-
-> ### 架构相关
-
-- :thumbsup: [《大型网站技术架构:核心原理与案例分析+李智慧》](https://book.douban.com/subject/25723064/)
-
- 这本书我读过,基本不需要你有什么基础啊~读起来特别轻松,但是却可以学到很多东西,非常推荐了。另外我写过这本书的思维导图,关注我的微信公众号:“Java面试通关手册”回复“大型网站技术架构”即可领取思维导图。
-
-- [《架构解密从分布式到微服务(Leaderus著)》](https://book.douban.com/subject/27081188/)
-
- 很一般的书籍,我就是当做课后图书来阅读的。
-
-> ### 代码优化
-
-- :thumbsup: [《重构_改善既有代码的设计》](https://book.douban.com/subject/4262627/)
-
- 豆瓣 9.1 分,重构书籍的开山鼻祖。
-
-> ### 课外书籍
-
-《技术奇点》 :thumbsup:《追风筝的人》 :thumbsup:《穆斯林的葬礼》 :thumbsup:《三体》 《人工智能——李开复》
-:thumbsup:《活着——余华》
-
-
-
-
diff --git "a/\345\205\266\344\273\226/\351\200\211\346\213\251\346\212\200\346\234\257\346\226\271\345\220\221\351\203\275\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\233\240\347\264\240.md" "b/\345\205\266\344\273\226/\351\200\211\346\213\251\346\212\200\346\234\257\346\226\271\345\220\221\351\203\275\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\233\240\347\264\240.md"
deleted file mode 100644
index fa39c7c1150..00000000000
--- "a/\345\205\266\344\273\226/\351\200\211\346\213\251\346\212\200\346\234\257\346\226\271\345\220\221\351\203\275\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\233\240\347\264\240.md"
+++ /dev/null
@@ -1,63 +0,0 @@
-本文主要是作者读安晓辉老师的《程序员程序员职场进阶 32 讲 》中关于“选择技术方向都要考虑哪些因素”这部分做的一些笔记和自己的思考。在这里分享给各位!
-
-### 选择一种技术可能会考虑到的决定因素
-
-1. 就业机会
-
- 选择一门就业面广的技术还是比较重要的。我的很多学PHP的同学现在都在培训班学Java,真的!!!
-2. 难易程度
-
- 我当时是在C/C++语言与Java中选择了Java,因为我感觉Java学起来确实要比C++简单一些。
-3. 个人兴趣
-
- 兴趣是你能坚持下来的一个很重要的条件。
-4. 薪资水平
-
- 薪资虽然不是人的唯一追求,但是一定是必备的追求。
-5. 发展前景
-
- 你肯定不愿意看到这种情况发生:选择了一门技术,结果一年后它就没人用、没市场了。所以我们在选择时就要考虑这一点,做一些预判。
-
- 选择技术时存在两种考虑:一种是选择稳定的、经典的技术;一种是卡位将来的市场缺口,选择将来可能需要用到的技术。
-6. 他人推荐
-
- 我们在懵懵懂懂的时候,往往最容易听从别人的推荐,然后选择某种技术。
-7. 相近原则
-
- 当我们已经掌握了一些技术,要学习新技术时,就可以根据一种新技术是否和自己已经掌握的技术比较接近来判断选择。相近的技术,学起来会更容易上手。
-8. 互补原则
-
- 和相近性类似,互补性也常用在拓展我们技术能力的情景下。它指的是,有一些技术可以和你已经掌握的技术互相补充,组合在一起,形成更完整、更系统的技术图谱,给你带来更大的竞争力。关于相近原则与互补原则,我们也会在后面的文章里具体解读。
-9. 团队技术图谱
-
- 我觉得这个可能就是团队开发过程中的需要。比如在做一个项目的时候,这个项目需要你去学习一下某个你没有接触过的新技术。
-
-### 入行时如何选择技术方向
-
- 为了明确自己的求职目标,可以问问自己下面的问题:
-- 我想在哪个城市工作?
-- 我想在哪些行业、领域发展?
-- 我想去什么样的公司?
-- 我想做什么样的产品?
-
-另外你要知道的是热门技术会有更多机会,相应竞争压力也会更大,并不能保证你找到合适的工作。
-冷门技术,机会相对较少,而且机会相对确定 。
-
-### 构建技能树时如何选择技术方向
-
-当我们过了专项能力提升的初级阶段之后,就应该开始构建自己的技能体系了。在为搭建技能树而选择技术时,通常考虑下面两个原则:
-- 相近原则
-- 互补原则
-
-“学习技术时一定要学对自己以后发展有用的技术”是我经常对自己强调的,另外我觉得很误导人同时也很错误的一个思想是:“只要是技术学了就会有用的”,这句话在我刚学编程时经常听到有人对我说。希望大家不要被误导,很多技术过时了就是过时了,没有必要再去花时间学。
-
-我觉得相近原则和互补原则互补原则就是你主精和自己技术方向相同的的东西或者对自己技术领域有提升的东西。比如我目前暂时选择了Java为我的主要发展语言,所以我就要求自己大部分时间还是搞和Java相关的东西比如:Spring、SpingBoot、Dubbo、Mybatis等等。但是千万不要被语言所束缚,在业余时间我学的比较多的就是Python以及JS、C/C++/C#也会偶尔接触。因为我经常会接触前端另外我自己偶尔有爬虫需求或者需要用Python的一些第三库解决一些问题,所以我业余学Pyton以及JS就比较多一点,我觉得这两门技术也是对我现有技术的一个补充了。
-
-
-### 技术转型时的方向选择
-
-我觉得对于技术转型主要有一下几点建议
-
-- 与自己当前技术栈跨度不太大的领域,比如你做安卓的话转型可以选择做Java后端。
-- 真正适合自己去做的,并不是一味看着这个领域火了(比如人工智能),然后自己就不考虑实际的去转型到这个领域里去。
-- 技术转型方向尽量对自己以后的发展需要有帮助。
diff --git "a/\346\223\215\344\275\234\347\263\273\347\273\237/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/\346\223\215\344\275\234\347\263\273\347\273\237/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md"
deleted file mode 100644
index 35edec3742e..00000000000
--- "a/\346\223\215\344\275\234\347\263\273\347\273\237/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ /dev/null
@@ -1,327 +0,0 @@
-
-> 学习Linux之前,我们先来简单的认识一下操作系统。
-
-## 一 从认识操作系统开始
-### 1.1 操作系统简介
-
-我通过以下四点介绍什么操作系统:
-
-- **操作系统(Operation System,简称OS)是管理计算机硬件与软件资源的程序,是计算机系统的内核与基石;**
-- **操作系统本质上是运行在计算机上的软件程序 ;**
-- **为用户提供一个与系统交互的操作界面 ;**
-- **操作系统分内核与外壳(我们可以把外壳理解成围绕着内核的应用程序,而内核就是能操作硬件的程序)。**
-
-
-### 1.2 操作系统简单分类
-
-1. **Windows:** 目前最流行的个人桌面操作系统 ,不做多的介绍,大家都清楚。
-2. **Unix:** 最早的多用户、多任务操作系统 .按照操作系统的分类,属于分时操作系统。Unix 大多被用在服务器、工作站,现在也有用在个人计算机上。它在创建互联网、计算机网络或客户端/服务器模型方面发挥着非常重要的作用。
-
-3. **Linux:** Linux是一套免费使用和自由传播的类Unix操作系统.Linux存在着许多不同的Linux版本,但它们都使用了 **Linux内核** 。Linux可安装在各种计算机硬件设备中,比如手机、平板电脑、路由器、视频游戏控制台、台式计算机、大型机和超级计算机。严格来讲,Linux这个词本身只表示Linux内核,但实际上人们已经习惯了用Linux来形容整个基于Linux内核,并且使用GNU 工程各种工具和数据库的操作系统。
-
-
-
-
-## 二 初探Linux
-
-### 2.1 Linux简介
-
-我们上面已经介绍到了Linux,我们这里只强调三点。
-- **类Unix系统:** Linux是一种自由、开放源码的类似Unix的操作系统
-- **Linux内核:** 严格来说,Linux这个词本身只表示Linux内核
-- **Linux之父:** 一个编程领域的传奇式人物。他是Linux内核的最早作者,随后发起了这个开源项目,担任Linux内核的首要架构师与项目协调者,是当今世界最著名的电脑程序员、黑客之一。他还发起了Git这个开源项目,并为主要的开发者。
-
-
-
-### 2.2 Linux诞生简介
-
-- 1991年,芬兰的业余计算机爱好者Linus Torvalds编写了一款类似Minix的系统(基于微内核架构的类Unix操作系统)被ftp管理员命名为Linux 加入到自由软件基金的GNU计划中;
-- Linux以一只可爱的企鹅作为标志,象征着敢作敢为、热爱生活。
-
-
-### 2.3 Linux的分类
-
-**Linux根据原生程度,分为两种:**
-
-1. **内核版本:** Linux不是一个操作系统,严格来讲,Linux只是一个操作系统中的内核。内核是什么?内核建立了计算机软件与硬件之间通讯的平台,内核提供系统服务,比如文件管理、虚拟内存、设备I/O等;
-2. **发行版本:** 一些组织或公司在内核版基础上进行二次开发而重新发行的版本。Linux发行版本有很多种(ubuntu和CentOS用的都很多,初学建议选择CentOS),如下图所示:
-
-
-
-## 三 Linux文件系统概览
-
-### 3.1 Linux文件系统简介
-
-**在Linux操作系统中,所有被操作系统管理的资源,例如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或是目录都被看作是一个文件。**
-
-也就是说在LINUX系统中有一个重要的概念:**一切都是文件**。其实这是UNIX哲学的一个体现,而Linux是重写UNIX而来,所以这个概念也就传承了下来。在UNIX系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。
-
-
-### 3.2 文件类型与目录结构
-
-**Linux支持5种文件类型 :**
-
-
-**Linux的目录结构如下:**
-
-Linux文件系统的结构层次鲜明,就像一棵倒立的树,最顶层是其根目录:
-
-
-**常见目录说明:**
-
-- **/bin:** 存放二进制可执行文件(ls,cat,mkdir等),常用命令一般都在这里;
-- **/etc:** 存放系统管理和配置文件;
-- **/home:** 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示;
-- **/usr :** 用于存放系统应用程序;
-- **/opt:** 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里;
-- **/proc:** 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
-- **/root:** 超级用户(系统管理员)的主目录(特权阶级^o^);
-- **/sbin:** 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等;
-- **/dev:** 用于存放设备文件;
-- **/mnt:** 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
-- **/boot:** 存放用于系统引导时使用的各种文件;
-- **/lib :** 存放着和系统运行相关的库文件 ;
-- **/tmp:** 用于存放各种临时文件,是公用的临时文件存储点;
-- **/var:** 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
-- **/lost+found:** 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里。
-
-
-## 四 Linux基本命令
-
-下面只是给出了一些比较常用的命令。推荐一个Linux命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。
-
-Linux命令大全:[http://man.linuxde.net/](http://man.linuxde.net/)
-### 4.1 目录切换命令
-
-- **`cd usr`:** 切换到该目录下usr目录
-- **`cd ..(或cd../)`:** 切换到上一层目录
-- **`cd /`:** 切换到系统根目录
-- **`cd ~`:** 切换到用户主目录
-- **`cd -`:** 切换到上一个所在目录
-
-### 4.2 目录的操作命令(增删改查)
-
-1. **`mkdir 目录名称`:** 增加目录
-2. **`ls或者ll`**(ll是ls -l的缩写,ll命令以看到该目录下的所有目录和文件的详细信息):查看目录信息
-3. **`find 目录 参数`:** 寻找目录(查)
-
- 示例:
-
- - 列出当前目录及子目录下所有文件和文件夹: `find .`
- - 在`/home`目录下查找以.txt结尾的文件名:`find /home -name "*.txt"`
- - 同上,但忽略大小写: `find /home -iname "*.txt"`
- - 当前目录及子目录下查找所有以.txt和.pdf结尾的文件:`find . \( -name "*.txt" -o -name "*.pdf" \)`或`find . -name "*.txt" -o -name "*.pdf" `
-
-4. **`mv 目录名称 新目录名称`:** 修改目录的名称(改)
-
- 注意:mv的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩包等进行 重命名的操作。mv命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。后面会介绍到mv命令的另一个用法。
-5. **`mv 目录名称 目录的新位置`:** 移动目录的位置---剪切(改)
-
- 注意:mv语法不仅可以对目录进行剪切操作,对文件和压缩包等都可执行剪切操作。另外mv与cp的结果不同,mv好像文件“搬家”,文件个数并未增加。而cp对文件进行复制,文件个数增加了。
-6. **`cp -r 目录名称 目录拷贝的目标位置`:** 拷贝目录(改),-r代表递归拷贝
-
- 注意:cp命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r递归
-7. **`rm [-rf] 目录`:** 删除目录(删)
-
- 注意:rm不仅可以删除目录,也可以删除其他文件或压缩包,为了增强大家的记忆, 无论删除任何目录或文件,都直接使用`rm -rf` 目录/文件/压缩包
-
-
-### 4.3 文件的操作命令(增删改查)
-
-1. **`touch 文件名称`:** 文件的创建(增)
-2. **`cat/more/less/tail 文件名称`** 文件的查看(查)
- - **`cat`:** 只能显示最后一屏内容
- - **`more`:** 可以显示百分比,回车可以向下一行, 空格可以向下一页,q可以退出查看
- - **`less`:** 可以使用键盘上的PgUp和PgDn向上 和向下翻页,q结束查看
- - **`tail-10` :** 查看文件的后10行,Ctrl+C结束
-
- 注意:命令 tail -f 文件 可以对某个文件进行动态监控,例如tomcat的日志文件, 会随着程序的运行,日志会变化,可以使用tail -f catalina-2016-11-11.log 监控 文 件的变化
-3. **`vim 文件`:** 修改文件的内容(改)
-
- vim编辑器是Linux中的强大组件,是vi编辑器的加强版,vim编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用vim编辑修改文件的方式基本会使用就可以了。
-
- **在实际开发中,使用vim编辑器主要作用就是修改配置文件,下面是一般步骤:**
-
- vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q! (输入wq代表写入内容并退出,即保存;输入q!代表强制退出不保存。)
-4. **`rm -rf 文件`:** 删除文件(删)
-
- 同目录删除:熟记 `rm -rf` 文件 即可
-
-### 4.4 压缩文件的操作命令
-
-**1)打包并压缩文件:**
-
-Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.gz结尾的。
-
-而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般.tar.gz。
-命令:**`tar -zcvf 打包压缩后的文件名 要打包压缩的文件`**
-其中:
-
- z:调用gzip压缩命令进行压缩
-
- c:打包文件
-
- v:显示运行过程
-
- f:指定文件名
-
-比如:加入test目录下有三个文件分别是 :aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz可以使用命令:**`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt`或:`tar -zcvf test.tar.gz /test/`**
-
-
-**2)解压压缩包:**
-
-命令:tar [-xvf] 压缩文件
-
-其中:x:代表解压
-
-示例:
-
-1 将/test下的test.tar.gz解压到当前目录下可以使用命令:**`tar -xvf test.tar.gz`**
-
-2 将/test下的test.tar.gz解压到根目录/usr下:**`tar -xvf xxx.tar.gz -C /usr`**(- C代表指定解压的位置)
-
-
-### 4.5 Linux的权限命令
-
- 操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在Linux中权限一般分为读(readable)、写(writable)和执行(excutable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
-
-示例:在随意某个目录下`ls -l`
-
-
-
-第一列的内容的信息解释如下:
-
-
-
-> 下面将详细讲解文件的类型、Linux中权限以及文件有所有者、所在组、其它组具体是什么?
-
-
-**文件的类型:**
-
-- d: 代表目录
-- -: 代表文件
-- l: 代表链接(可以认为是window中的快捷方式)
-
-
-**Linux中权限分为以下几种:**
-
-- r:代表权限是可读,r也可以用数字4表示
-- w:代表权限是可写,w也可以用数字2表示
-- x:代表权限是可执行,x也可以用数字1表示
-
-**文件和目录权限的区别:**
-
- 对文件和目录而言,读写执行表示不同的意义。
-
- 对于文件:
-
-| 权限名称 | 可执行操作 |
-| :-------- | --------:|
-| r | 可以使用cat查看文件的内容 |
-|w | 可以修改文件的内容 |
-| x | 可以将其运行为二进制文件 |
-
- 对于目录:
-
-| 权限名称 | 可执行操作 |
-| :-------- | --------:|
-| r | 可以查看目录下列表 |
-|w | 可以创建和删除目录下文件 |
-| x | 可以使用cd进入目录 |
-
-
-
-**在linux中的每个用户必须属于一个组,不能独立于组外。在linux中每个文件有所有者、所在组、其它组的概念。**
-
-- **所有者**
-
- 一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用ls ‐ahl命令可以看到文件的所有者 也可以使用chown 用户名 文件名来修改文件的所有者 。
-- **文件所在组**
-
- 当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组 用ls ‐ahl命令可以看到文件的所有组 也可以使用chgrp 组名 文件名来修改文件所在的组。
-- **其它组**
-
- 除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组
-
-> 我们再来看看如何修改文件/目录的权限。
-
-**修改文件/目录的权限的命令:`chmod`**
-
-示例:修改/test下的aaa.txt的权限为属主有全部权限,属主所在的组有读写权限,
-其他用户只有读的权限
-
-**`chmod u=rwx,g=rw,o=r aaa.txt`**
-
-
-
-上述示例还可以使用数字表示:
-
-chmod 764 aaa.txt
-
-
-**补充一个比较常用的东西:**
-
-假如我们装了一个zookeeper,我们每次开机到要求其自动启动该怎么办?
-
-1. 新建一个脚本zookeeper
-2. 为新建的脚本zookeeper添加可执行权限,命令是:`chmod +x zookeeper`
-3. 把zookeeper这个脚本添加到开机启动项里面,命令是:` chkconfig --add zookeeper`
-4. 如果想看看是否添加成功,命令是:`chkconfig --list`
-
-
-### 4.6 Linux 用户管理
-
-Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
-
-用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
-
-**Linux用户管理相关命令:**
-- `useradd 选项 用户名`:添加用户账号
-- `userdel 选项 用户名`:删除用户帐号
-- `usermod 选项 用户名`:修改帐号
-- `passwd 用户名`:更改或创建用户的密码
-- `passwd -S 用户名` :显示用户账号密码信息
-- `passwd -d 用户名`: 清除用户密码
-
-useradd命令用于Linux中创建的新的系统用户。useradd可用来建立用户帐号。帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号。使用useradd指令所建立的帐号,实际上是保存在/etc/passwd文本文件中。
-
-passwd命令用于设置用户的认证信息,包括用户密码、密码过期时间等。系统管理者则能用它管理系统用户的密码。只有管理者可以指定用户名称,一般用户只能变更自己的密码。
-
-
-### 4.7 Linux系统用户组的管理
-
-每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
-
-用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
-
-**Linux系统用户组的管理相关命令:**
-- `groupadd 选项 用户组` :增加一个新的用户组
-- `groupdel 用户组`:要删除一个已有的用户组
-- `groupmod 选项 用户组` : 修改用户组的属性
-
-
-### 4.8 其他常用命令
-
-- **`pwd`:** 显示当前所在位置
-- **`grep 要搜索的字符串 要搜索的文件 --color`:** 搜索命令,--color代表高亮显示
-- **`ps -ef`/`ps aux`:** 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:**`ps aux|grep redis`** (查看包括redis字符串的进程)
-
- 注意:如果直接用ps((Process Status))命令,会显示所有进程的状态,通常结合grep命令查看某进程的状态。
-- **`kill -9 进程的pid`:** 杀死进程(-9 表示强制终止。)
-
- 先用ps查找进程,然后用kill杀掉
-- **网络通信命令:**
- - 查看当前系统的网卡信息:ifconfig
- - 查看与某台机器的连接情况:ping
- - 查看当前系统的端口使用:netstat -an
-- **`shutdown`:** `shutdown -h now`: 指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定5分钟后关机,同时送出警告信息给登入用户。
-- **`reboot`:** **`reboot`:** 重开机。**`reboot -w`:** 做个重开机的模拟(只有纪录并不会真的重开机)。
-
-
-
-
-
-
-
-
-
diff --git "a/\346\225\260\346\215\256\345\255\230\345\202\250/MySQL Index.md" "b/\346\225\260\346\215\256\345\255\230\345\202\250/MySQL Index.md"
deleted file mode 100644
index 27b82c8bc70..00000000000
--- "a/\346\225\260\346\215\256\345\255\230\345\202\250/MySQL Index.md"
+++ /dev/null
@@ -1,112 +0,0 @@
-
-# 思维导图-索引篇
-
-> 系列思维导图源文件(数据库+架构)以及思维导图制作软件—XMind8 破解安装,公众号后台回复:**“思维导图”** 免费领取!(下面的图片不是很清楚,原图非常清晰,另外提供给大家源文件也是为了大家根据自己需要进行修改)
-
-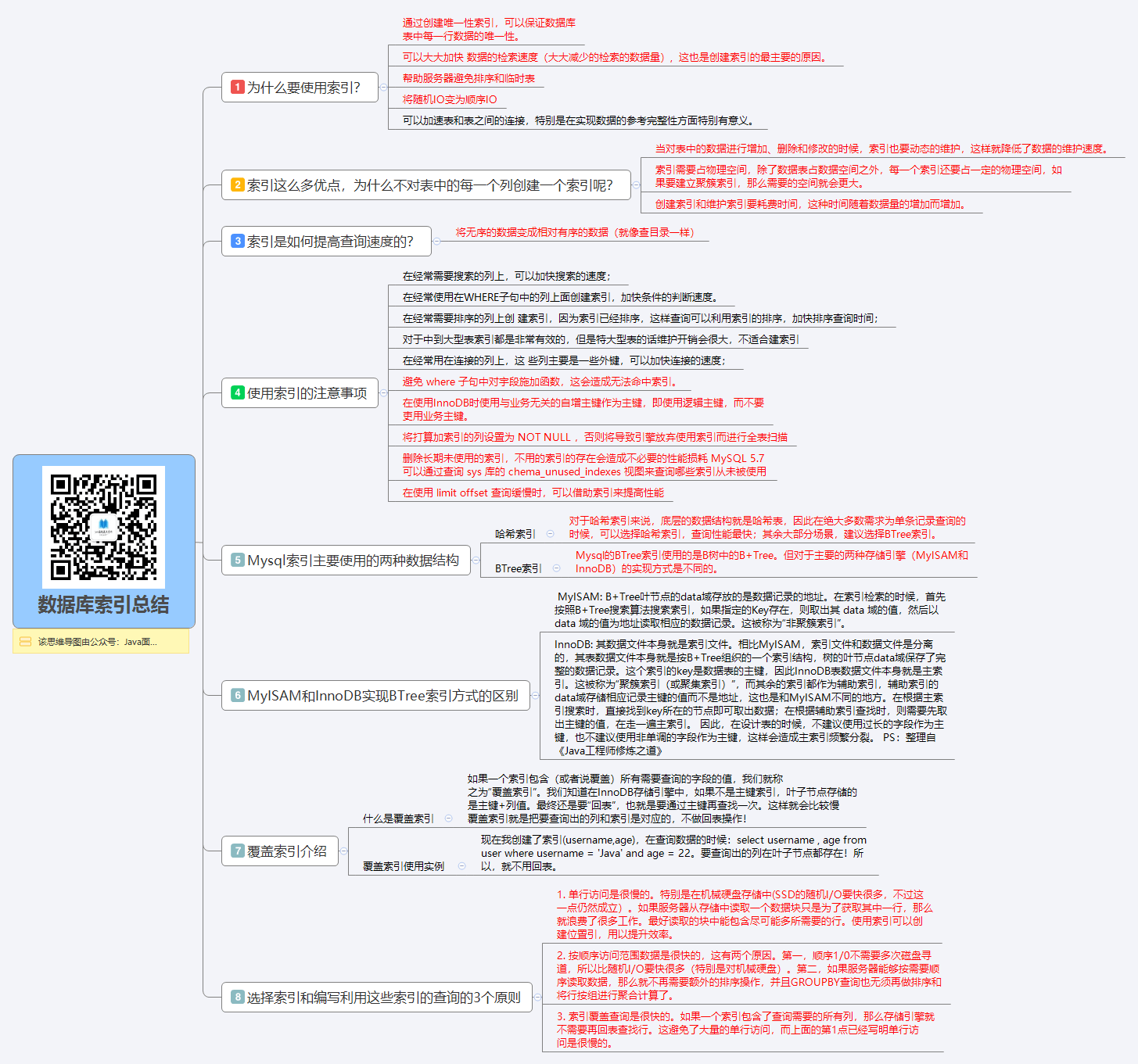
-
-> **下面是我补充的一些内容**
-
-# 为什么索引能提高查询速度
-
-> 以下内容整理自:
-> 地址: https://juejin.im/post/5b55b842f265da0f9e589e79
-> 作者 :Java3y
-
-### 先从 MySQL 的基本存储结构说起
-
-MySQL的基本存储结构是页(记录都存在页里边):
-
-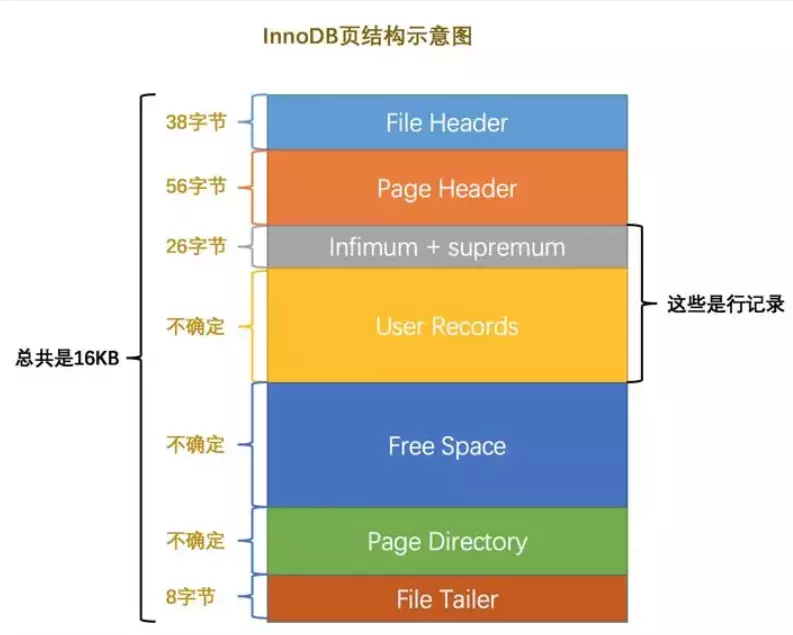
-
-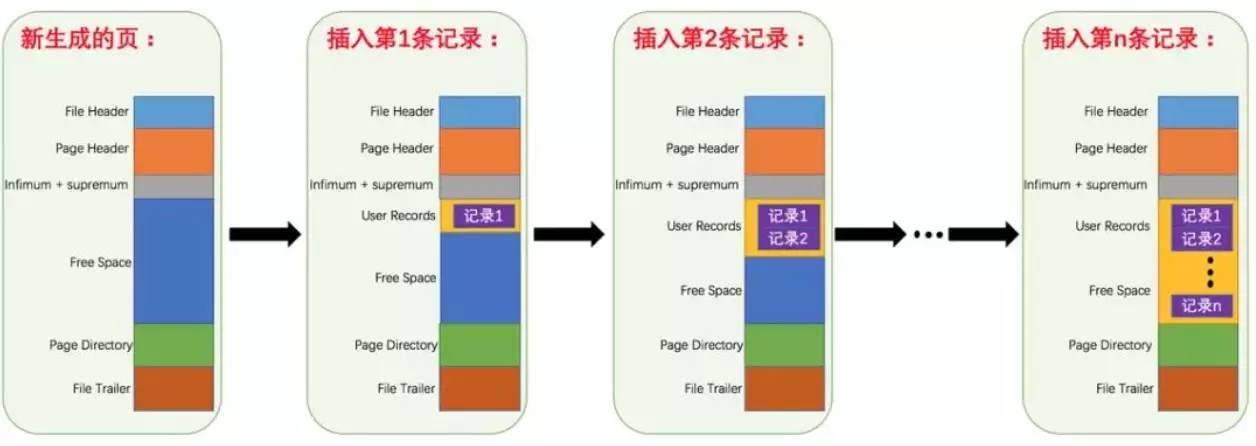
-
- - **各个数据页可以组成一个双向链表**
- - **每个数据页中的记录又可以组成一个单向链表**
- - 每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
- - 以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。
-
-所以说,如果我们写select * from user where indexname = 'xxx'这样没有进行任何优化的sql语句,默认会这样做:
-
-1. **定位到记录所在的页:需要遍历双向链表,找到所在的页**
-2. **从所在的页内中查找相应的记录:由于不是根据主键查询,只能遍历所在页的单链表了**
-
-很明显,在数据量很大的情况下这样查找会很慢!这样的时间复杂度为O(n)。
-
-
-### 使用索引之后
-
-索引做了些什么可以让我们查询加快速度呢?其实就是将无序的数据变成有序(相对):
-
-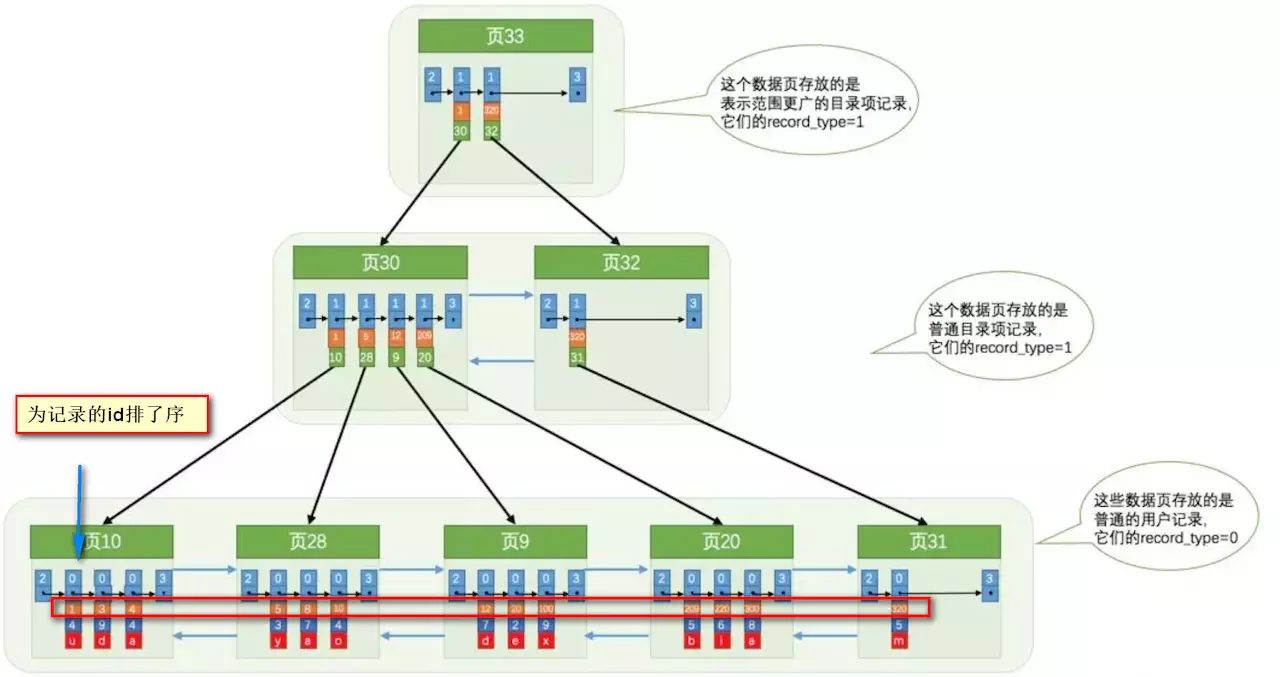
-
-要找到id为8的记录简要步骤:
-
-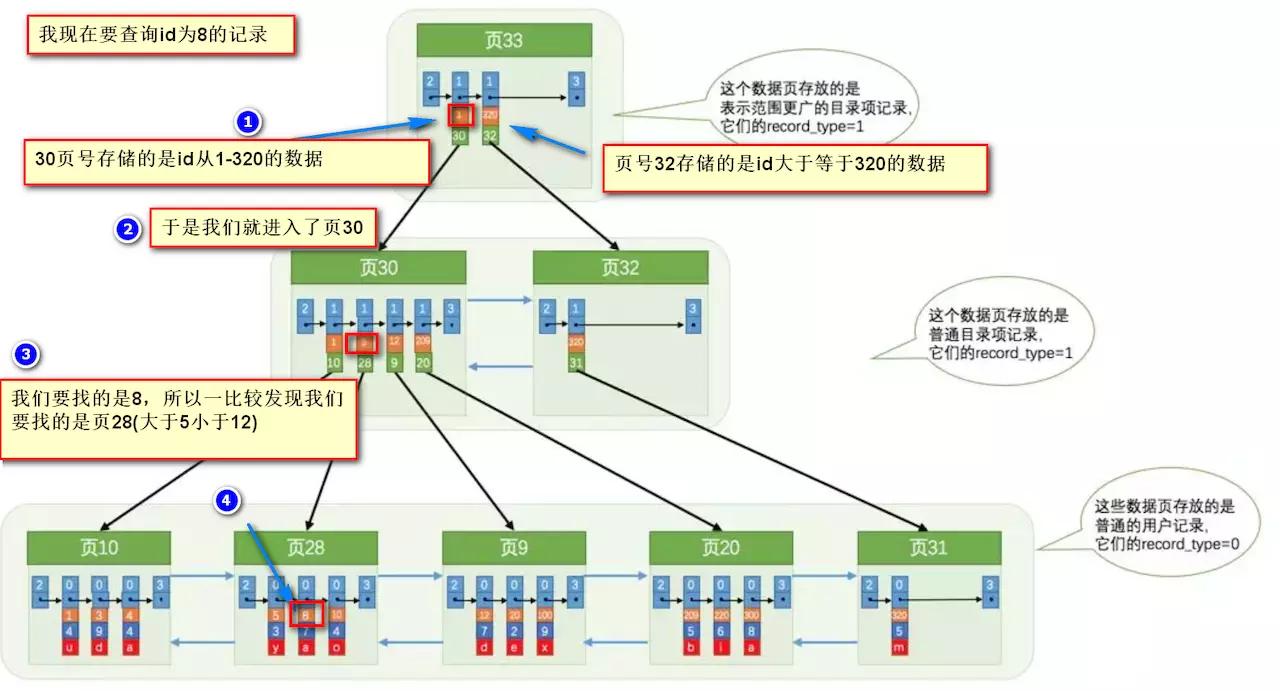
-
-很明显的是:没有用索引我们是需要遍历双向链表来定位对应的页,现在通过 **“目录”** 就可以很快地定位到对应的页上了!(二分查找,时间复杂度近似为O(logn))
-
-其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
-
-# 关于索引其他重要的内容补充
-
-> 以下内容整理自:《Java工程师修炼之道》
-
-
-### 最左前缀原则
-
-MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索引。如User表的name和city加联合索引就是(name,city)o而最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。如下:
-
-```
-select * from user where name=xx and city=xx ; //可以命中索引
-select * from user where name=xx ; // 可以命中索引
-select * from user where city=xx; // 无法命中索引
-```
-这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如 `city= xx and name =xx`,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的.
-
-由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDERBY子句也遵循此规则。
-
-### 注意避免冗余索引
-
-冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
-
-MySQLS.7 版本后,可以通过查询 sys 库的 `schemal_r dundant_indexes` 表来查看冗余索引
-
-### Mysql如何为表字段添加索引???
-
-1.添加PRIMARY KEY(主键索引)
-
-```
-ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
-```
-2.添加UNIQUE(唯一索引)
-
-```
-ALTER TABLE `table_name` ADD UNIQUE ( `column` )
-```
-
-3.添加INDEX(普通索引)
-
-```
-ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
-```
-
-4.添加FULLTEXT(全文索引)
-
-```
-ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
-```
-
-5.添加多列索引
-
-```
-ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
-```
-
-
-# 参考
-
-- 《Java工程师修炼之道》
-- 《MySQL高性能书籍_第3版》
-- https://juejin.im/post/5b55b842f265da0f9e589e79
-
diff --git "a/\346\225\260\346\215\256\345\255\230\345\202\250/MySQL.md" "b/\346\225\260\346\215\256\345\255\230\345\202\250/MySQL.md"
deleted file mode 100644
index 6d7a484d658..00000000000
--- "a/\346\225\260\346\215\256\345\255\230\345\202\250/MySQL.md"
+++ /dev/null
@@ -1,172 +0,0 @@
-
-
-Java面试通关手册(Java学习指南,欢迎Star,会一直完善下去,欢迎建议和指导):[https://github.com/Snailclimb/Java_Guide](https://github.com/Snailclimb/Java_Guide)
-
-> ## 书籍推荐
-
-**《高性能MySQL : 第3版》**
-
-> ## 文字教程推荐
-
-[MySQL 教程(菜鸟教程)](http://www.runoob.com/mysql/mysql-tutorial.html)
-
-[MySQL教程(易百教程)](https://www.yiibai.com/mysql/)
-
-> ## 视频教程推荐
-
-
-**基础入门:** [与MySQL的零距离接触-慕课网](https://www.imooc.com/learn/122)
-
-**Mysql开发技巧:** [MySQL开发技巧(一)](https://www.imooc.com/learn/398) [MySQL开发技巧(二)](https://www.imooc.com/learn/427) [MySQL开发技巧(三)](https://www.imooc.com/learn/449)
-
-**Mysql5.7新特性及相关优化技巧:** [MySQL5.7版本新特性](https://www.imooc.com/learn/533) [性能优化之MySQL优化](https://www.imooc.com/learn/194)
-
-[MySQL集群(PXC)入门](https://www.imooc.com/learn/993) [MyCAT入门及应用](https://www.imooc.com/learn/951)
-
-
-
-> ## 常见问题总结
-
-- ### ①存储引擎
-
- [MySQL常见的两种存储引擎:MyISAM与InnoDB的爱恨情仇](https://juejin.im/post/5b1685bef265da6e5c3c1c34)
-
-- ### ②字符集及校对规则
-
- 字符集指的是一种从二进制编码到某类字符符号的映射。校对规则则是指某种字符集下的排序规则。Mysql中每一种字符集都会对应一系列的校对规则。
-
- Mysql采用的是类似继承的方式指定字符集的默认值,每个数据库以及每张数据表都有自己的默认值,他们逐层继承。比如:某个库中所有表的默认字符集将是该数据库所指定的字符集(这些表在没有指定字符集的情况下,才会采用默认字符集) PS:整理自《Java工程师修炼之道》
-
- 详细内容可以参考: [MySQL字符集及校对规则的理解](https://www.cnblogs.com/geaozhang/p/6724393.html#mysqlyuzifuji)
-
-- ### ③索引相关的内容(数据库使用中非常关键的技术,合理正确的使用索引可以大大提高数据库的查询性能)
-
- Mysql索引使用的数据结构主要有**BTree索引** 和 **哈希索引** 。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
-
- Mysql的BTree索引使用的是B数中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
-
- **MyISAM:** B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
-
- **InnoDB:** 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。**在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。** **因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。** PS:整理自《Java工程师修炼之道》
-
- 详细内容可以参考:
-
- [干货:mysql索引的数据结构](https://www.jianshu.com/p/1775b4ff123a)
-
- [MySQL优化系列(三)--索引的使用、原理和设计优化](https://blog.csdn.net/Jack__Frost/article/details/72571540)
-
- [数据库两大神器【索引和锁】](https://juejin.im/post/5b55b842f265da0f9e589e79#comment)
-
-- ### ④查询缓存的使用
-
- my.cnf加入以下配置,重启Mysql开启查询缓存
- ```
- query_cache_type=1
- query_cache_size=600000
- ```
-
- Mysql执行以下命令也可以开启查询缓存
-
- ```
- set global query_cache_type=1;
- set global query_cache_size=600000;
- ```
- 如上,**开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果**。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。因此任何两个查询在任何字符上的不同都会导致缓存不命中。此外,如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、Mysql库中的系统表,其查询结果也不会被缓存。
-
- 缓存建立之后,Mysql的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
-
- **缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
- ```
- select sql_no_cache count(*) from usr;
- ```
-
-- ### ⑤事务机制
-
- **关系性数据库需要遵循ACID规则,具体内容如下:**
-
-
-
- 1. **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 2. **一致性:** 执行事务前后,数据保持一致;
- 3. **隔离性:** 并发访问数据库时,一个用户的事物不被其他事物所干扰,各并发事务之间数据库是独立的;
- 4. **持久性:** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库 发生故障也不应该对其有任何影响。
-
- **为了达到上述事务特性,数据库定义了几种不同的事务隔离级别:**
-
-- **READ_UNCOMMITTED(未授权读取):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**
-- **READ_COMMITTED(授权读取):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**
-- **REPEATABLE_READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生。**
-- **SERIALIZABLE(串行):** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
-
- 这里需要注意的是:**Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.**
-
- 事务隔离机制的实现基于锁机制和并发调度。其中并发调度使用的是MVVC(多版本并发控制),通过保存修改的旧版本信息来支持并发一致性读和回滚等特性。
-
- 详细内容可以参考: [可能是最漂亮的Spring事务管理详解](https://blog.csdn.net/qq_34337272/article/details/80394121)
-
-- ### ⑥锁机制与InnoDB锁算法
- **MyISAM和InnoDB存储引擎使用的锁:**
-
- - MyISAM采用表级锁(table-level locking)。
- - InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
-
- **表级锁和行级锁对比:**
-
- - **表级锁:** Mysql中锁定 **粒度最大** 的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM和 InnoDB引擎都支持表级锁。
- - **行级锁:** Mysql中锁定 **粒度最小** 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
-
- 详细内容可以参考:
- [Mysql锁机制简单了解一下](https://blog.csdn.net/qq_34337272/article/details/80611486)
-
- **InnoDB存储引擎的锁的算法有三种:**
- - Record lock:单个行记录上的锁
- - Gap lock:间隙锁,锁定一个范围,不包括记录本身
- - Next-key lock:record+gap 锁定一个范围,包含记录本身
-
- **相关知识点:**
- 1. innodb对于行的查询使用next-key lock
- 2. Next-locking keying为了解决Phantom Problem幻读问题
- 3. 当查询的索引含有唯一属性时,将next-key lock降级为record key
- 4. Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
- 5. 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
-
-- ### ⑦大表优化
-
- 当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
-
- 1. **限定数据的范围:** 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内。;
- 2. **读/写分离:** 经典的数据库拆分方案,主库负责写,从库负责读;
- 3. **缓存:** 使用MySQL的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存;
- 4. **垂直分区:**
-
- **根据数据库里面数据表的相关性进行拆分。** 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
-
- **简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。** 如下图所示,这样来说大家应该就更容易理解了。
- 
-
- **垂直拆分的优点:** 可以使得行数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
-
- **垂直拆分的缺点:** 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
-
- 5. **水平分区:**
-
-
- **保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。**
-
- 水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
-
- 
-
- 水品拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 **水品拆分最好分库** 。
-
- 水平拆分能够 **支持非常大的数据量存储,应用端改造也少**,但 **分片事务难以解决** ,跨界点Join性能较差,逻辑复杂。《Java工程师修炼之道》的作者推荐 **尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度** ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
-
- **下面补充一下数据库分片的两种常见方案:**
- - **客户端代理:** **分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。** 当当网的 **Sharding-JDBC** 、阿里的TDDL是两种比较常用的实现。
- - **中间件代理:** **在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。** 我们现在谈的 **Mycat** 、360的Atlas、网易的DDB等等都是这种架构的实现。
-
-
- 详细内容可以参考:
- [MySQL大表优化方案](https://segmentfault.com/a/1190000006158186)
-
-
diff --git "a/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/Redis.md" "b/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/Redis.md"
deleted file mode 100644
index 41234cf55ac..00000000000
--- "a/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/Redis.md"
+++ /dev/null
@@ -1,300 +0,0 @@
-<!-- MarkdownTOC -->
-
-- [redis 简介](#redis-简介)
-- [为什么要用 redis /为什么要用缓存](#为什么要用-redis-为什么要用缓存)
-- [为什么要用 redis 而不用 map/guava 做缓存?](#为什么要用-redis-而不用-mapguava-做缓存)
-- [redis 和 memcached 的区别](#redis-和-memcached-的区别)
-- [redis 常见数据结构以及使用场景分析](#redis-常见数据结构以及使用场景分析)
- - [1. String](#1-string)
- - [2.Hash](#2hash)
- - [3.List](#3list)
- - [4.Set](#4set)
- - [5.Sorted Set](#5sorted-set)
-- [redis 设置过期时间](#redis-设置过期时间)
-- [redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)](#redis-内存淘汰机制(mysql里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据?))
-- [redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)](#redis-持久化机制(怎么保证-redis-挂掉之后再重启数据可以进行恢复))
-- [redis 事务](#redis-事务)
-- [缓存雪崩和缓存穿透问题解决方案](#缓存雪崩和缓存穿透问题解决方案)
-- [如何解决 Redis 的并发竞争 Key 问题](#如何解决-redis-的并发竞争-key-问题)
-- [如何保证缓存与数据库双写时的数据一致性?](#如何保证缓存与数据库双写时的数据一致性?)
-- [参考:](#参考:)
-
-<!-- /MarkdownTOC -->
-
-
-### redis 简介
-
-简单来说 redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以存写速度非常快,因此 redis 被广泛应用于缓存方向。另外,redis 也经常用来做分布式锁。redis 提供了多种数据类型来支持不同的业务场景。除此之外,redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
-
-### 为什么要用 redis /为什么要用缓存
-
-主要从“高性能”和“高并发”这两点来看待这个问题。
-
-**高性能:**
-
-假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
-
-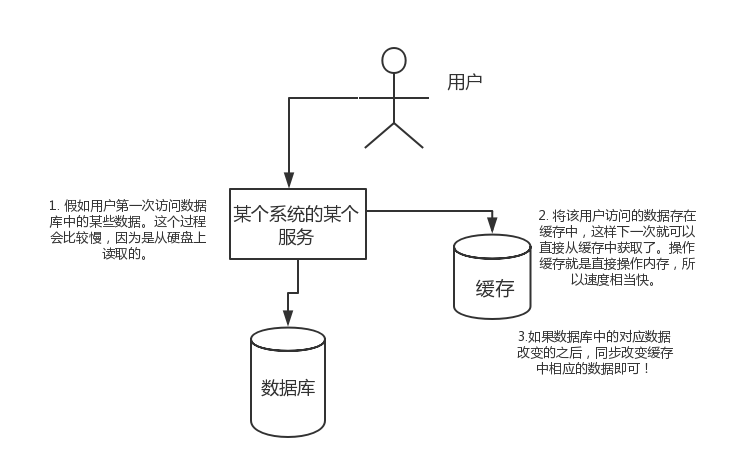
-
-
-**高并发:**
-
-直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
-
-
-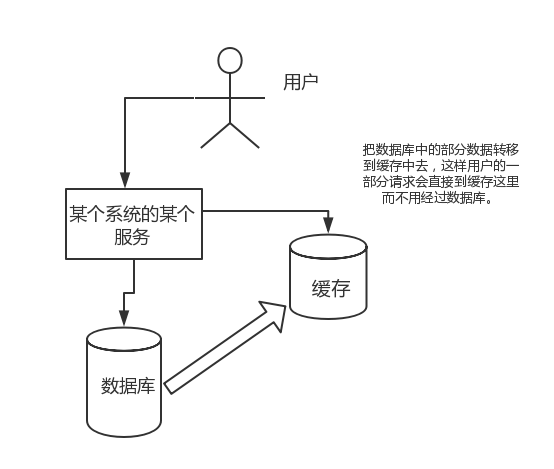
-
-
-### 为什么要用 redis 而不用 map/guava 做缓存?
-
-
->下面的内容来自 segmentfault 一位网友的提问,地址:https://segmentfault.com/q/1010000009106416
-
-缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
-
-使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
-
-
-### redis 和 memcached 的区别
-
-对于 redis 和 memcached 我总结了下面四点。现在公司一般都是用 redis 来实现缓存,而且 redis 自身也越来越强大了!
-
-1. **redis支持更丰富的数据类型(支持更复杂的应用场景)**:Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
-2. **Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中。**
-3. **集群模式**:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 redis 目前是原生支持 cluster 模式的.
-4. **Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路 IO 复用模型。**
-
-
-> 来自网络上的一张图,这里分享给大家!
-
-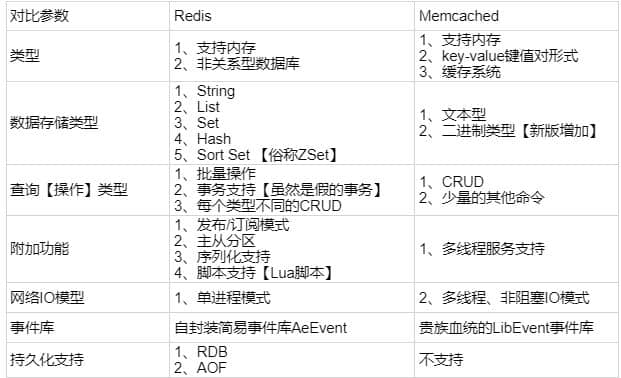
-
-
-### redis 常见数据结构以及使用场景分析
-
-#### 1. String
-
-> **常用命令:** set,get,decr,incr,mget 等。
-
-
-String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。
-常规key-value缓存应用;
-常规计数:微博数,粉丝数等。
-
-#### 2.Hash
-> **常用命令:** hget,hset,hgetall 等。
-
-Hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以Hash数据结构来存储用户信息,商品信息等等。比如下面我就用 hash 类型存放了我本人的一些信息:
-
-```
-key=JavaUser293847
-value={
- “id”: 1,
- “name”: “SnailClimb”,
- “age”: 22,
- “location”: “Wuhan, Hubei”
-}
-
-```
-
-
-#### 3.List
-> **常用命令:** lpush,rpush,lpop,rpop,lrange等
-
-list 就是链表,Redis list 的应用场景非常多,也是Redis最重要的数据结构之一,比如微博的关注列表,粉丝列表,消息列表等功能都可以用Redis的 list 结构来实现。
-
-Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
-
-另外可以通过 lrange 命令,就是从某个元素开始读取多少个元素,可以基于 list 实现分页查询,这个很棒的一个功能,基于 redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西(一页一页的往下走),性能高。
-
-#### 4.Set
-
-> **常用命令:**
-sadd,spop,smembers,sunion 等
-
-set 对外提供的功能与list类似是一个列表的功能,特殊之处在于 set 是可以自动排重的。
-
-当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。
-
-比如:在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程,具体命令如下:
-
-```
-sinterstore key1 key2 key3 将交集存在key1内
-```
-
-#### 5.Sorted Set
-> **常用命令:** zadd,zrange,zrem,zcard等
-
-
-和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列。
-
-**举例:** 在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息,适合使用 Redis 中的 SortedSet 结构进行存储。
-
-
-### redis 设置过期时间
-
-Redis中有个设置时间过期的功能,即对存储在 redis 数据库中的值可以设置一个过期时间。作为一个缓存数据库,这是非常实用的。如我们一般项目中的 token 或者一些登录信息,尤其是短信验证码都是有时间限制的,按照传统的数据库处理方式,一般都是自己判断过期,这样无疑会严重影响项目性能。
-
-我们 set key 的时候,都可以给一个 expire time,就是过期时间,通过过期时间我们可以指定这个 key 可以存活的时间。
-
-如果假设你设置了一批 key 只能存活1个小时,那么接下来1小时后,redis是怎么对这批key进行删除的?
-
-**定期删除+惰性删除。**
-
-通过名字大概就能猜出这两个删除方式的意思了。
-
-- **定期删除**:redis默认是每隔 100ms 就**随机抽取**一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载!
-- **惰性删除** :定期删除可能会导致很多过期 key 到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,也是够懒的哈!
-
-
-但是仅仅通过设置过期时间还是有问题的。我们想一下:如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期key堆积在内存里,导致redis内存块耗尽了。怎么解决这个问题呢?
-
-**redis 内存淘汰机制。**
-
-### redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)
-
-redis 配置文件 redis.conf 中有相关注释,我这里就不贴了,大家可以自行查阅或者通过这个网址查看: [http://download.redis.io/redis-stable/redis.conf](http://download.redis.io/redis-stable/redis.conf)
-
-**redis 提供 6种数据淘汰策略:**
-
-1. **volatile-lru**:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
-2. **volatile-ttl**:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
-3. **volatile-random**:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
-4. **allkeys-lru**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的).
-5. **allkeys-random**:从数据集(server.db[i].dict)中任意选择数据淘汰
-6. **no-enviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
-
-
-**备注: 关于 redis 设置过期时间以及内存淘汰机制,我这里只是简单的总结一下,后面会专门写一篇文章来总结!**
-
-
-### redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)
-
-很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后回复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
-
-Redis不同于Memcached的很重一点就是,Redis支持持久化,而且支持两种不同的持久化操作。**Redis的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file,AOF)**.这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
-
-**快照(snapshotting)持久化(RDB)**
-
-Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
-
-快照持久化是Redis默认采用的持久化方式,在redis.conf配置文件中默认有此下配置:
-
-```conf
-
-save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-
-save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-
-save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-```
-
-
-**AOF(append-only file)持久化**
-
-与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
-
-```conf
-appendonly yes
-```
-
-开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof。
-
-在Redis的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
-
-```conf
-appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
-appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
-appendfsync no #让操作系统决定何时进行同步
-```
-
-为了兼顾数据和写入性能,用户可以考虑 appendfsync everysec选项 ,让Redis每秒同步一次AOF文件,Redis性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
-
-
-**Redis 4.0 对于持久化机制的优化**
-
-Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
-
-如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
-
-
-
-**补充内容:AOF 重写**
-
-AOF重写可以产生一个新的AOF文件,这个新的AOF文件和原有的AOF文件所保存的数据库状态一样,但体积更小。
-
-AOF重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有AOF文件进行任伺读入、分析或者写入操作。
-
-在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新AOF文件期间,记录服务器执行的所有写命令。当子进程完成创建新AOF文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新AOF文件的末尾,使得新旧两个AOF文件所保存的数据库状态一致。最后,服务器用新的AOF文件替换旧的AOF文件,以此来完成AOF文件重写操作
-
-
-**更多内容可以查看我的这篇文章:**
-
-- [https://github.com/Snailclimb/JavaGuide/blob/master/数据存储/Redis/Redis持久化.md](https://github.com/Snailclimb/JavaGuide/blob/master/数据存储/Redis/Redis持久化.md)
-
-
-### redis 事务
-
-Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。
-
-在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性。在 Redis 中,事务总是具有原子性(Atomicity)、一致性(Consistency)和隔离性(Isolation),并且当 Redis 运行在某种特定的持久化模式下时,事务也具有持久性(Durability)。
-
-### 缓存雪崩和缓存穿透问题解决方案
-
-**缓存雪崩**
-
-简介:缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
-
-解决办法(中华石杉老师在他的视频中提到过,视频地址在最后一个问题中有提到):
-
-- 事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
-- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
-- 事后:利用 redis 持久化机制保存的数据尽快恢复缓存
-
-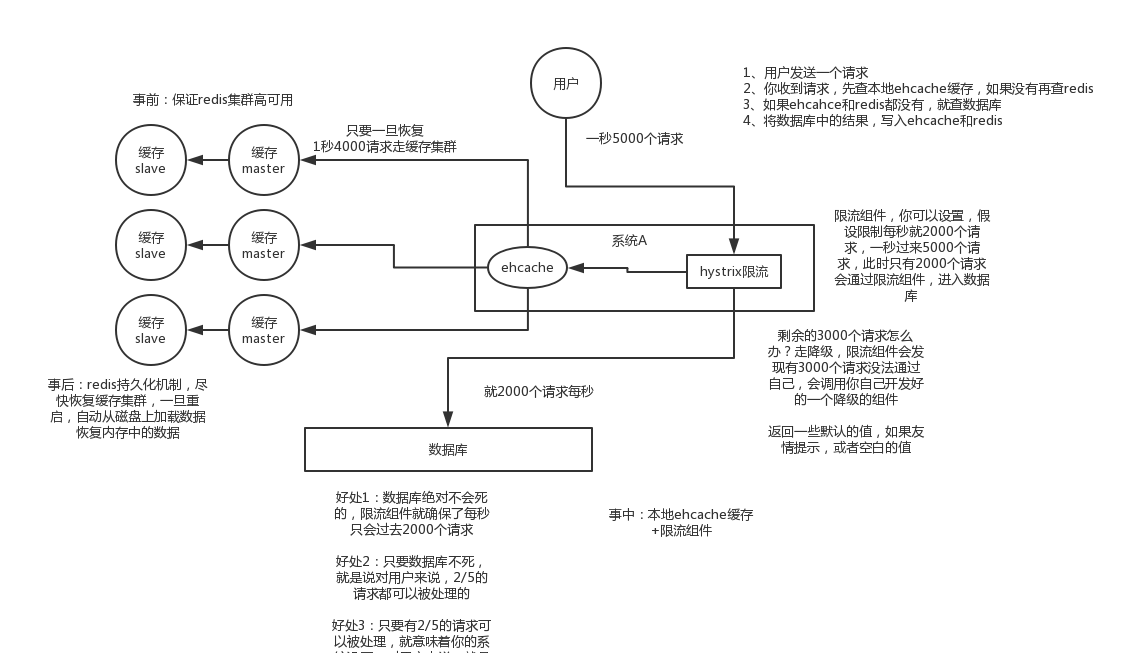
-
-
-**缓存穿透**
-
-简介:一般是黑客故意去请求缓存中不存在的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
-
-解决办法: 有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
-
-参考:
-
-- https://blog.csdn.net/zeb_perfect/article/details/54135506[enter link description here](https://blog.csdn.net/zeb_perfect/article/details/54135506)
-
-### 如何解决 Redis 的并发竞争 Key 问题
-
-所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同!
-
-推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
-
-基于zookeeper临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
-
-在实践中,当然是从以可靠性为主。所以首推Zookeeper。
-
-参考:
-
-- https://www.jianshu.com/p/8bddd381de06
-
-
-### 如何保证缓存与数据库双写时的数据一致性?
-
-
-你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
-
-一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,最好不要做这个方案,读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况
-
-串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
-
-**参考:**
-
-- Java工程师面试突击第1季(可能是史上最好的Java面试突击课程)-中华石杉老师。视频地址见下面!
- - 链接: https://pan.baidu.com/s/18pp6g1xKVGCfUATf_nMrOA
- - 密码:5i58
-
-### 参考:
-
-- redis设计与实现(第二版)
-
diff --git "a/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/Redis\346\214\201\344\271\205\345\214\226.md" "b/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/Redis\346\214\201\344\271\205\345\214\226.md"
deleted file mode 100644
index fbad95556a0..00000000000
--- "a/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/Redis\346\214\201\344\271\205\345\214\226.md"
+++ /dev/null
@@ -1,118 +0,0 @@
-
-
-非常感谢《redis实战》真本书,本文大多内容也参考了书中的内容。非常推荐大家看一下《redis实战》这本书,感觉书中的很多理论性东西还是很不错的。
-
-为什么本文的名字要加上春夏秋冬又一春,哈哈 ,这是一部韩国的电影,我感觉电影不错,所以就用在文章名字上了,没有什么特别的含义,然后下面的有些配图也是电影相关镜头。
-
-
-
-**很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后回复数据),或者是为了防止系统故障而将数据备份到一个远程位置。**
-
-Redis不同于Memcached的很重一点就是,**Redis支持持久化**,而且支持两种不同的持久化操作。Redis的一种持久化方式叫**快照(snapshotting,RDB)**,另一种方式是**只追加文件(append-only file,AOF)**.这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
-
-
-## 快照(snapshotting)持久化
-
-Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
-
-
-
-
-**快照持久化是Redis默认采用的持久化方式**,在redis.conf配置文件中默认有此下配置:
-```
-
-save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-
-save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-
-save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-```
-
-根据配置,快照将被写入dbfilename选项指定的文件里面,并存储在dir选项指定的路径上面。如果在新的快照文件创建完毕之前,Redis、系统或者硬件这三者中的任意一个崩溃了,那么Redis将丢失最近一次创建快照写入的所有数据。
-
-举个例子:假设Redis的上一个快照是2:35开始创建的,并且已经创建成功。下午3:06时,Redis又开始创建新的快照,并且在下午3:08快照创建完毕之前,有35个键进行了更新。如果在下午3:06到3:08期间,系统发生了崩溃,导致Redis无法完成新快照的创建工作,那么Redis将丢失下午2:35之后写入的所有数据。另一方面,如果系统恰好在新的快照文件创建完毕之后崩溃,那么Redis将丢失35个键的更新数据。
-
-**创建快照的办法有如下几种:**
-
-- **BGSAVE命令:** 客户端向Redis发送 **BGSAVE命令** 来创建一个快照。对于支持BGSAVE命令的平台来说(基本上所有平台支持,除了Windows平台),Redis会调用fork来创建一个子进程,然后子进程负责将快照写入硬盘,而父进程则继续处理命令请求。
-- **SAVE命令:** 客户端还可以向Redis发送 **SAVE命令** 来创建一个快照,接到SAVE命令的Redis服务器在快照创建完毕之前不会再响应任何其他命令。SAVE命令不常用,我们通常只会在没有足够内存去执行BGSAVE命令的情况下,又或者即使等待持久化操作执行完毕也无所谓的情况下,才会使用这个命令。
-- **save选项:** 如果用户设置了save选项(一般会默认设置),比如 **save 60 10000**,那么从Redis最近一次创建快照之后开始算起,当“60秒之内有10000次写入”这个条件被满足时,Redis就会自动触发BGSAVE命令。
-- **SHUTDOWN命令:** 当Redis通过SHUTDOWN命令接收到关闭服务器的请求时,或者接收到标准TERM信号时,会执行一个SAVE命令,阻塞所有客户端,不再执行客户端发送的任何命令,并在SAVE命令执行完毕之后关闭服务器。
-- **一个Redis服务器连接到另一个Redis服务器:** 当一个Redis服务器连接到另一个Redis服务器,并向对方发送SYNC命令来开始一次复制操作的时候,如果主服务器目前没有执行BGSAVE操作,或者主服务器并非刚刚执行完BGSAVE操作,那么主服务器就会执行BGSAVE命令
-
-如果系统真的发生崩溃,用户将丢失最近一次生成快照之后更改的所有数据。因此,快照持久化只适用于即使丢失一部分数据也不会造成一些大问题的应用程序。不能接受这个缺点的话,可以考虑AOF持久化。
-
-
-
-## **AOF(append-only file)持久化**
-与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
-```
-appendonly yes
-```
-
-开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof。
-
-
-
-**在Redis的配置文件中存在三种同步方式,它们分别是:**
-
-```
-
-appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
-appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
-appendfsync no #让操作系统决定何时进行同步
-```
-
-**appendfsync always** 可以实现将数据丢失减到最少,不过这种方式需要对硬盘进行大量的写入而且每次只写入一个命令,十分影响Redis的速度。另外使用固态硬盘的用户谨慎使用appendfsync always选项,因为这会明显降低固态硬盘的使用寿命。
-
-为了兼顾数据和写入性能,用户可以考虑 **appendfsync everysec选项** ,让Redis每秒同步一次AOF文件,Redis性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
-
-
-**appendfsync no** 选项一般不推荐,这种方案会使Redis丢失不定量的数据而且如果用户的硬盘处理写入操作的速度不够的话,那么当缓冲区被等待写入的数据填满时,Redis的写入操作将被阻塞,这会导致Redis的请求速度变慢。
-
-**虽然AOF持久化非常灵活地提供了多种不同的选项来满足不同应用程序对数据安全的不同要求,但AOF持久化也有缺陷——AOF文件的体积太大。**
-
-## 重写/压缩AOF
-
-AOF虽然在某个角度可以将数据丢失降低到最小而且对性能影响也很小,但是极端的情况下,体积不断增大的AOF文件很可能会用完硬盘空间。另外,如果AOF体积过大,那么还原操作执行时间就可能会非常长。
-
-为了解决AOF体积过大的问题,用户可以向Redis发送 **BGREWRITEAOF命令** ,这个命令会通过移除AOF文件中的冗余命令来重写(rewrite)AOF文件来减小AOF文件的体积。BGREWRITEAOF命令和BGSAVE创建快照原理十分相似,所以AOF文件重写也需要用到子进程,这样会导致性能问题和内存占用问题,和快照持久化一样。更糟糕的是,如果不加以控制的话,AOF文件的体积可能会比快照文件大好几倍。
-
-**文件重写流程:**
-
-
-和快照持久化可以通过设置save选项来自动执行BGSAVE一样,AOF持久化也可以通过设置
-
-```
-auto-aof-rewrite-percentage
-```
-
-选项和
-
-```
-auto-aof-rewrite-min-size
-```
-
-选项自动执行BGREWRITEAOF命令。举例:假设用户对Redis设置了如下配置选项并且启用了AOF持久化。那么当AOF文件体积大于64mb,并且AOF的体积比上一次重写之后的体积大了至少一倍(100%)的时候,Redis将执行BGREWRITEAOF命令。
-
-```
-auto-aof-rewrite-percentage 100
-auto-aof-rewrite-min-size 64mb
-```
-
-无论是AOF持久化还是快照持久化,将数据持久化到硬盘上都是非常有必要的,但除了进行持久化外,用户还必须对持久化得到的文件进行备份(最好是备份到不同的地方),这样才能尽量避免数据丢失事故发生。如果条件允许的话,最好能将快照文件和重新重写的AOF文件备份到不同的服务器上面。
-
-随着负载量的上升,或者数据的完整性变得 越来越重要时,用户可能需要使用到复制特性。
-
-## Redis 4.0 对于持久化机制的优化
-Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
-
-如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分就是压缩格式不再是 AOF 格式,可读性较差。
-
-参考:
-
-《Redis实战》
-
-[深入学习Redis(2):持久化](https://www.cnblogs.com/kismetv/p/9137897.html)
-
-
diff --git "a/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/Redlock\345\210\206\345\270\203\345\274\217\351\224\201.md" "b/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/Redlock\345\210\206\345\270\203\345\274\217\351\224\201.md"
deleted file mode 100644
index b1742f2fbf9..00000000000
--- "a/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/Redlock\345\210\206\345\270\203\345\274\217\351\224\201.md"
+++ /dev/null
@@ -1,47 +0,0 @@
-这篇文章主要是对 Redis 官方网站刊登的 [Distributed locks with Redis](https://redis.io/topics/distlock) 部分内容的总结和翻译。
-
-## 什么是 RedLock
-
-Redis 官方站这篇文章提出了一种权威的基于 Redis 实现分布式锁的方式名叫 *Redlock*,此种方式比原先的单节点的方法更安全。它可以保证以下特性:
-
-1. 安全特性:互斥访问,即永远只有一个 client 能拿到锁
-2. 避免死锁:最终 client 都可能拿到锁,不会出现死锁的情况,即使原本锁住某资源的 client crash 了或者出现了网络分区
-3. 容错性:只要大部分 Redis 节点存活就可以正常提供服务
-
-## 怎么在单节点上实现分布式锁
-
-> SET resource_name my_random_value NX PX 30000
-
-主要依靠上述命令,该命令仅当 Key 不存在时(NX保证)set 值,并且设置过期时间 3000ms (PX保证),值 my_random_value 必须是所有 client 和所有锁请求发生期间唯一的,释放锁的逻辑是:
-
-```lua
-if redis.call("get",KEYS[1]) == ARGV[1] then
- return redis.call("del",KEYS[1])
-else
- return 0
-end
-```
-
-上述实现可以避免释放另一个client创建的锁,如果只有 del 命令的话,那么如果 client1 拿到 lock1 之后因为某些操作阻塞了很长时间,此时 Redis 端 lock1 已经过期了并且已经被重新分配给了 client2,那么 client1 此时再去释放这把锁就会造成 client2 原本获取到的锁被 client1 无故释放了,但现在为每个 client 分配一个 unique 的 string 值可以避免这个问题。至于如何去生成这个 unique string,方法很多随意选择一种就行了。
-
-## Redlock 算法
-
-算法很易懂,起 5 个 master 节点,分布在不同的机房尽量保证可用性。为了获得锁,client 会进行如下操作:
-
-1. 得到当前的时间,微妙单位
-2. 尝试顺序地在 5 个实例上申请锁,当然需要使用相同的 key 和 random value,这里一个 client 需要合理设置与 master 节点沟通的 timeout 大小,避免长时间和一个 fail 了的节点浪费时间
-3. 当 client 在大于等于 3 个 master 上成功申请到锁的时候,且它会计算申请锁消耗了多少时间,这部分消耗的时间采用获得锁的当下时间减去第一步获得的时间戳得到,如果锁的持续时长(lock validity time)比流逝的时间多的话,那么锁就真正获取到了。
-4. 如果锁申请到了,那么锁真正的 lock validity time 应该是 origin(lock validity time) - 申请锁期间流逝的时间
-5. 如果 client 申请锁失败了,那么它就会在少部分申请成功锁的 master 节点上执行释放锁的操作,重置状态
-
-## 失败重试
-
-如果一个 client 申请锁失败了,那么它需要稍等一会在重试避免多个 client 同时申请锁的情况,最好的情况是一个 client 需要几乎同时向 5 个 master 发起锁申请。另外就是如果 client 申请锁失败了它需要尽快在它曾经申请到锁的 master 上执行 unlock 操作,便于其他 client 获得这把锁,避免这些锁过期造成的时间浪费,当然如果这时候网络分区使得 client 无法联系上这些 master,那么这种浪费就是不得不付出的代价了。
-
-## 放锁
-
-放锁操作很简单,就是依次释放所有节点上的锁就行了
-
-## 性能、崩溃恢复和 fsync
-
-如果我们的节点没有持久化机制,client 从 5 个 master 中的 3 个处获得了锁,然后其中一个重启了,这是注意 **整个环境中又出现了 3 个 master 可供另一个 client 申请同一把锁!** 违反了互斥性。如果我们开启了 AOF 持久化那么情况会稍微好转一些,因为 Redis 的过期机制是语义层面实现的,所以在 server 挂了的时候时间依旧在流逝,重启之后锁状态不会受到污染。但是考虑断电之后呢,AOF部分命令没来得及刷回磁盘直接丢失了,除非我们配置刷回策略为 fsnyc = always,但这会损伤性能。解决这个问题的方法是,当一个节点重启之后,我们规定在 max TTL 期间它是不可用的,这样它就不会干扰原本已经申请到的锁,等到它 crash 前的那部分锁都过期了,环境不存在历史锁了,那么再把这个节点加进来正常工作。
diff --git "a/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/\345\246\202\344\275\225\345\201\232\345\217\257\351\235\240\347\232\204\345\210\206\345\270\203\345\274\217\351\224\201\357\274\214Redlock\347\234\237\347\232\204\345\217\257\350\241\214\344\271\210.md" "b/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/\345\246\202\344\275\225\345\201\232\345\217\257\351\235\240\347\232\204\345\210\206\345\270\203\345\274\217\351\224\201\357\274\214Redlock\347\234\237\347\232\204\345\217\257\350\241\214\344\271\210.md"
deleted file mode 100644
index 043df96566d..00000000000
--- "a/\346\225\260\346\215\256\345\255\230\345\202\250/Redis/\345\246\202\344\275\225\345\201\232\345\217\257\351\235\240\347\232\204\345\210\206\345\270\203\345\274\217\351\224\201\357\274\214Redlock\347\234\237\347\232\204\345\217\257\350\241\214\344\271\210.md"
+++ /dev/null
@@ -1,91 +0,0 @@
-本文是对 [Martin Kleppmann](https://martin.kleppmann.com/) 的文章 [How to do distributed locking](https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html) 部分内容的翻译和总结,上次写 Redlock 的原因就是看到了 Martin 的这篇文章,写得很好,特此翻译和总结。感兴趣的同学可以翻看原文,相信会收获良多。
-
-开篇作者认为现在 Redis 逐渐被使用到数据管理领域,这个领域需要更强的数据一致性和耐久性,这使得他感到担心,因为这不是 Redis 最初设计的初衷(事实上这也是很多业界程序员的误区,越来越把 Redis 当成数据库在使用),其中基于 Redis 的分布式锁就是令人担心的其一。
-
-Martin 指出首先你要明确你为什么使用分布式锁,为了性能还是正确性?为了帮你区分这二者,在这把锁 fail 了的时候你可以询问自己以下问题:
-1. **要性能的:** 拥有这把锁使得你不会重复劳动(例如一个 job 做了两次),如果这把锁 fail 了,两个节点同时做了这个 Job,那么这个 Job 增加了你的成本。
-2. **要正确性的:** 拥有锁可以防止并发操作污染你的系统或者数据,如果这把锁 fail 了两个节点同时操作了一份数据,结果可能是数据不一致、数据丢失、file 冲突等,会导致严重的后果。
-
-上述二者都是需求锁的正确场景,但是你必须清楚自己是因为什么原因需要分布式锁。
-
-如果你只是为了性能,那没必要用 Redlock,它成本高且复杂,你只用一个 Redis 实例也够了,最多加个从防止主挂了。当然,你使用单节点的 Redis 那么断电或者一些情况下,你会丢失锁,但是你的目的只是加速性能且断电这种事情不会经常发生,这并不是什么大问题。并且如果你使用了单节点 Redis,那么很显然你这个应用需要的锁粒度是很模糊粗糙的,也不会是什么重要的服务。
-
-那么是否 Redlock 对于要求正确性的场景就合适呢?Martin 列举了若干场景证明 Redlock 这种算法是不可靠的。
-
-## 用锁保护资源
-这节里 Martin 先将 Redlock 放在了一边而是仅讨论总体上一个分布式锁是怎么工作的。在分布式环境下,锁比 mutex 这类复杂,因为涉及到不同节点、网络通信并且他们随时可能无征兆的 fail 。
-Martin 假设了一个场景,一个 client 要修改一个文件,它先申请得到锁,然后修改文件写回,放锁。另一个 client 再申请锁 ... 代码流程如下:
-
-```java
-// THIS CODE IS BROKEN
-function writeData(filename, data) {
- var lock = lockService.acquireLock(filename);
- if (!lock) {
- throw 'Failed to acquire lock';
- }
-
- try {
- var file = storage.readFile(filename);
- var updated = updateContents(file, data);
- storage.writeFile(filename, updated);
- } finally {
- lock.release();
- }
-}
-```
-
-可惜即使你的锁服务非常完美,上述代码还是可能跪,下面的流程图会告诉你为什么:
-
-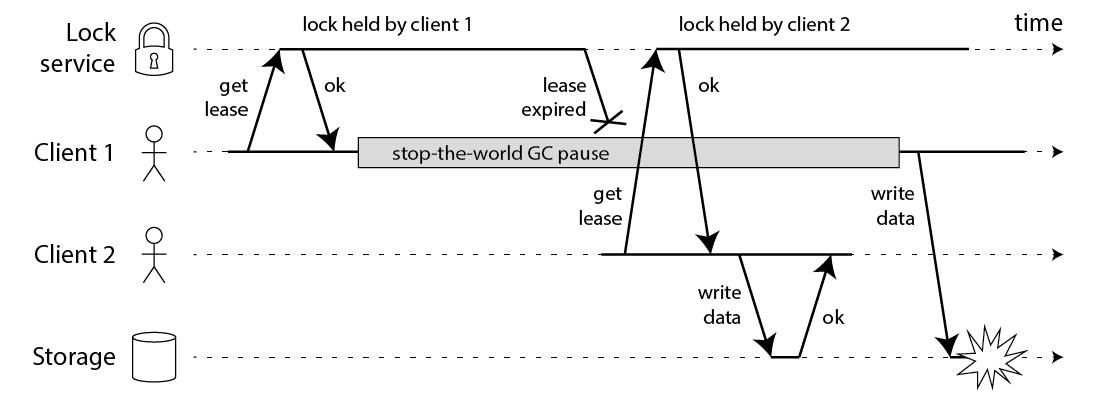
-
-上述图中,得到锁的 client1 在持有锁的期间 pause 了一段时间,例如 GC 停顿。锁有过期时间(一般叫租约,为了防止某个 client 崩溃之后一直占有锁),但是如果 GC 停顿太长超过了锁租约时间,此时锁已经被另一个 client2 所得到,原先的 client1 还没有感知到锁过期,那么奇怪的结果就会发生,曾经 HBase 就发生过这种 Bug。即使你在 client1 写回之前检查一下锁是否过期也无助于解决这个问题,因为 GC 可能在任何时候发生,即使是你非常不便的时候(在最后的检查与写操作期间)。
-如果你认为自己的程序不会有长时间的 GC 停顿,还有其他原因会导致你的进程 pause。例如进程可能读取尚未进入内存的数据,所以它得到一个 page fault 并且等待 page 被加载进缓存;还有可能你依赖于网络服务;或者其他进程占用 CPU;或者其他人意外发生 SIGSTOP 等。
-
-... .... 这里 Martin 又增加了一节列举各种进程 pause 的例子,为了证明上面的代码是不安全的,无论你的锁服务多完美。
-
-## 使用 Fencing (栅栏)使得锁变安全
-修复问题的方法也很简单:你需要在每次写操作时加入一个 fencing token。这个场景下,fencing token 可以是一个递增的数字(lock service 可以做到),每次有 client 申请锁就递增一次:
-
-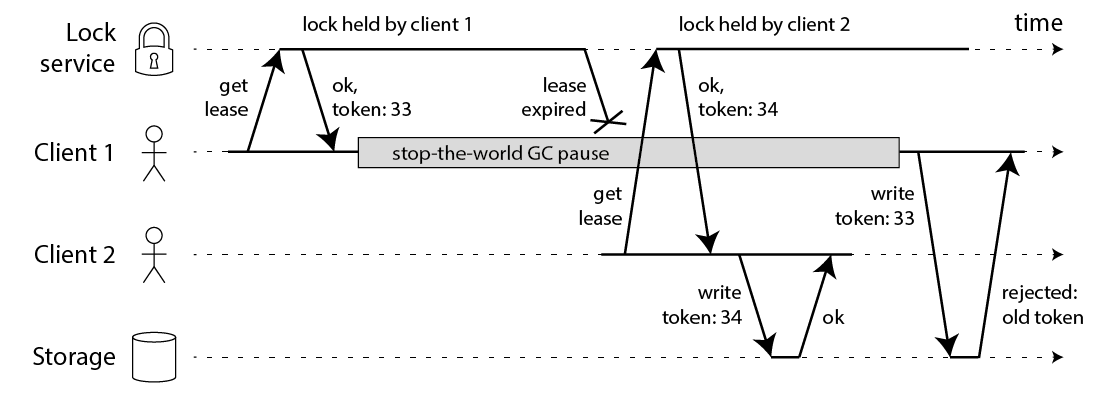
-
-client1 申请锁同时拿到 token33,然后它进入长时间的停顿锁也过期了。client2 得到锁和 token34 写入数据,紧接着 client1 活过来之后尝试写入数据,自身 token33 比 34 小因此写入操作被拒绝。注意这需要存储层来检查 token,但这并不难实现。如果你使用 Zookeeper 作为 lock service 的话那么你可以使用 zxid 作为递增数字。
-但是对于 Redlock 你要知道,没什么生成 fencing token 的方式,并且怎么修改 Redlock 算法使其能产生 fencing token 呢?好像并不那么显而易见。因为产生 token 需要单调递增,除非在单节点 Redis 上完成但是这又没有高可靠性,你好像需要引进一致性协议来让 Redlock 产生可靠的 fencing token。
-
-## 使用时间来解决一致性
-Redlock 无法产生 fencing token 早该成为在需求正确性的场景下弃用它的理由,但还有一些值得讨论的地方。
-
-学术界有个说法,算法对时间不做假设:因为进程可能pause一段时间、数据包可能因为网络延迟延后到达、时钟可能根本就是错的。而可靠的算法依旧要在上述假设下做正确的事情。
-
-对于 failure detector 来说,timeout 只能作为猜测某个节点 fail 的依据,因为网络延迟、本地时钟不正确等其他原因的限制。考虑到 Redis 使用 gettimeofday,而不是单调的时钟,会受到系统时间的影响,可能会突然前进或者后退一段时间,这会导致一个 key 更快或更慢地过期。
-
-可见,Redlock 依赖于许多时间假设,它假设所有 Redis 节点都能对同一个 Key 在其过期前持有差不多的时间、跟过期时间相比网络延迟很小、跟过期时间相比进程 pause 很短。
-
-## 用不可靠的时间打破 Redlock
-这节 Martin 举了个因为时间问题,Redlock 不可靠的例子。
-
-1. client1 从 ABC 三个节点处申请到锁,DE由于网络原因请求没有到达
-2. C节点的时钟往前推了,导致 lock 过期
-3. client2 在CDE处获得了锁,AB由于网络原因请求未到达
-4. 此时 client1 和 client2 都获得了锁
-
-**在 Redlock 官方文档中也提到了这个情况,不过是C崩溃的时候,Redlock 官方本身也是知道 Redlock 算法不是完全可靠的,官方为了解决这种问题建议使用延时启动,相关内容可以看之前的[这篇文章](https://zhuanlan.zhihu.com/p/40915772)。但是 Martin 这里分析得更加全面,指出延时启动不也是依赖于时钟的正确性的么?**
-
-接下来 Martin 又列举了进程 Pause 时而不是时钟不可靠时会发生的问题:
-
-1. client1 从 ABCDE 处获得了锁
-2. 当获得锁的 response 还没到达 client1 时 client1 进入 GC 停顿
-3. 停顿期间锁已经过期了
-4. client2 在 ABCDE 处获得了锁
-5. client1 GC 完成收到了获得锁的 response,此时两个 client 又拿到了同一把锁
-
-**同时长时间的网络延迟也有可能导致同样的问题。**
-
-## Redlock 的同步性假设
-这些例子说明了,仅有在你假设了一个同步性系统模型的基础上,Redlock 才能正常工作,也就是系统能满足以下属性:
-
-1. 网络延时边界,即假设数据包一定能在某个最大延时之内到达
-2. 进程停顿边界,即进程停顿一定在某个最大时间之内
-3. 时钟错误边界,即不会从一个坏的 NTP 服务器处取得时间
-
-## 结论
-Martin 认为 Redlock 实在不是一个好的选择,对于需求性能的分布式锁应用它太重了且成本高;对于需求正确性的应用来说它不够安全。因为它对高危的时钟或者说其他上述列举的情况进行了不可靠的假设,如果你的应用只需要高性能的分布式锁不要求多高的正确性,那么单节点 Redis 够了;如果你的应用想要保住正确性,那么不建议 Redlock,建议使用一个合适的一致性协调系统,例如 Zookeeper,且保证存在 fencing token。
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.classpath" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.classpath"
deleted file mode 100644
index 0a1daddd3e8..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.classpath"
+++ /dev/null
@@ -1,26 +0,0 @@
-<?xml version="1.0" encoding="UTF-8"?>
-<classpath>
- <classpathentry kind="src" output="target/classes" path="src/main/java">
- <attributes>
- <attribute name="optional" value="true"/>
- <attribute name="maven.pomderived" value="true"/>
- </attributes>
- </classpathentry>
- <classpathentry kind="src" output="target/test-classes" path="src/test/java">
- <attributes>
- <attribute name="optional" value="true"/>
- <attribute name="maven.pomderived" value="true"/>
- </attributes>
- </classpathentry>
- <classpathentry kind="con" path="org.eclipse.jdt.launching.JRE_CONTAINER/org.eclipse.jdt.internal.debug.ui.launcher.StandardVMType/J2SE-1.5">
- <attributes>
- <attribute name="maven.pomderived" value="true"/>
- </attributes>
- </classpathentry>
- <classpathentry kind="con" path="org.eclipse.m2e.MAVEN2_CLASSPATH_CONTAINER">
- <attributes>
- <attribute name="maven.pomderived" value="true"/>
- </attributes>
- </classpathentry>
- <classpathentry kind="output" path="target/classes"/>
-</classpath>
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.gitignore" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.gitignore"
deleted file mode 100644
index b83d22266ac..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.gitignore"
+++ /dev/null
@@ -1 +0,0 @@
-/target/
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.project" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.project"
deleted file mode 100644
index 7b9c539d09c..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.project"
+++ /dev/null
@@ -1,23 +0,0 @@
-<?xml version="1.0" encoding="UTF-8"?>
-<projectDescription>
- <name>securityAlgorithm</name>
- <comment></comment>
- <projects>
- </projects>
- <buildSpec>
- <buildCommand>
- <name>org.eclipse.jdt.core.javabuilder</name>
- <arguments>
- </arguments>
- </buildCommand>
- <buildCommand>
- <name>org.eclipse.m2e.core.maven2Builder</name>
- <arguments>
- </arguments>
- </buildCommand>
- </buildSpec>
- <natures>
- <nature>org.eclipse.jdt.core.javanature</nature>
- <nature>org.eclipse.m2e.core.maven2Nature</nature>
- </natures>
-</projectDescription>
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.settings/org.eclipse.core.resources.prefs" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.settings/org.eclipse.core.resources.prefs"
deleted file mode 100644
index f9fe34593fc..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.settings/org.eclipse.core.resources.prefs"
+++ /dev/null
@@ -1,4 +0,0 @@
-eclipse.preferences.version=1
-encoding//src/main/java=UTF-8
-encoding//src/test/java=UTF-8
-encoding/<project>=UTF-8
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.settings/org.eclipse.jdt.core.prefs" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.settings/org.eclipse.jdt.core.prefs"
deleted file mode 100644
index abec6ca389a..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.settings/org.eclipse.jdt.core.prefs"
+++ /dev/null
@@ -1,5 +0,0 @@
-eclipse.preferences.version=1
-org.eclipse.jdt.core.compiler.codegen.targetPlatform=1.5
-org.eclipse.jdt.core.compiler.compliance=1.5
-org.eclipse.jdt.core.compiler.problem.forbiddenReference=warning
-org.eclipse.jdt.core.compiler.source=1.5
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.settings/org.eclipse.m2e.core.prefs" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.settings/org.eclipse.m2e.core.prefs"
deleted file mode 100644
index f897a7f1cb2..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/.settings/org.eclipse.m2e.core.prefs"
+++ /dev/null
@@ -1,4 +0,0 @@
-activeProfiles=
-eclipse.preferences.version=1
-resolveWorkspaceProjects=true
-version=1
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/pom.xml" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/pom.xml"
deleted file mode 100644
index 39d693b84b0..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/pom.xml"
+++ /dev/null
@@ -1,37 +0,0 @@
-<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
-
- <groupId>com.snailclimb.ks</groupId>
- <artifactId>securityAlgorithm</artifactId>
- <version>0.0.1-SNAPSHOT</version>
- <packaging>jar</packaging>
-
- <name>securityAlgorithm</name>
- <url>http://maven.apache.org</url>
-
- <properties>
- <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
- </properties>
-
- <dependencies>
- <dependency>
- <groupId>junit</groupId>
- <artifactId>junit</artifactId>
- <version>4.12</version>
- <scope>test</scope>
- </dependency>
- <!-- Base64 -->
- <dependency>
- <groupId>commons-codec</groupId>
- <artifactId>commons-codec</artifactId>
- <version>1.8</version>
- </dependency>
- <dependency>
- <groupId>org.bouncycastle</groupId>
- <artifactId>bcprov-jdk15on</artifactId>
- <version>1.56</version>
- </dependency>
-
- </dependencies>
-</project>
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/Base64Demo.java" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/Base64Demo.java"
deleted file mode 100644
index 1c6fd6df0ea..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/Base64Demo.java"
+++ /dev/null
@@ -1,49 +0,0 @@
-package com.snailclimb.ks.securityAlgorithm;
-
-import java.io.UnsupportedEncodingException;
-import java.util.Base64;
-
-public class Base64Demo {
-
- public static void main(String[] args) throws UnsupportedEncodingException {
- // TODO Auto-generated method stub
- CommonsCodecDemo();
- bouncyCastleDemo();
- jdkDemo();
- }
-
- static String str = "你若安好,便是晴天";
-
- /**
- * commons codec实现Base64加密解密
- */
- public static void CommonsCodecDemo() {
- // 加密:
- byte[] encodeBytes = org.apache.commons.codec.binary.Base64.encodeBase64(str.getBytes());
- System.out.println("commons codec实现base64加密: " + new String(encodeBytes));
- // 解密:
- byte[] decodeBytes = org.apache.commons.codec.binary.Base64.decodeBase64(encodeBytes);
- System.out.println("commons codec实现base64解密: " + new String(decodeBytes));
- }
-
- /**
- * bouncy castle实现Base64加密解密
- */
- public static void bouncyCastleDemo() {
- // 加密
- byte[] encodeBytes = org.bouncycastle.util.encoders.Base64.encode(str.getBytes());
- System.out.println("bouncy castle实现base64加密: " + new String(encodeBytes));
- // 解密
- byte[] decodeBytes = org.bouncycastle.util.encoders.Base64.decode(encodeBytes);
- System.out.println("bouncy castle实现base64解密:" + new String(decodeBytes));
- }
-
- public static void jdkDemo() throws UnsupportedEncodingException {
- // 加密
- String encodeBytes = Base64.getEncoder().encodeToString(str.getBytes("UTF-8"));
- System.out.println("JDK实现的base64加密: " + encodeBytes);
- //解密
- byte[] decodeBytes = Base64.getDecoder().decode(encodeBytes.getBytes("UTF-8"));
- System.out.println("JDK实现的base64解密: "+new String(decodeBytes));
- }
-}
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/DesDemo.java" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/DesDemo.java"
deleted file mode 100644
index ce8b09ee1da..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/DesDemo.java"
+++ /dev/null
@@ -1,100 +0,0 @@
-package com.snailclimb.ks.securityAlgorithm;
-
-import java.io.UnsupportedEncodingException;
-import java.security.SecureRandom;
-import javax.crypto.spec.DESKeySpec;
-import javax.crypto.SecretKeyFactory;
-import javax.crypto.SecretKey;
-import javax.crypto.Cipher;
-
-/**
- * DES加密介绍 DES是一种对称加密算法,所谓对称加密算法即:加密和解密使用相同密钥的算法。DES加密算法出自IBM的研究,
- * 后来被美国政府正式采用,之后开始广泛流传,但是近些年使用越来越少,因为DES使用56位密钥,以现代计算能力,
- * 24小时内即可被破解。虽然如此,在某些简单应用中,我们还是可以使用DES加密算法,本文简单讲解DES的JAVA实现 。
- * 注意:DES加密和解密过程中,密钥长度都必须是8的倍数
- */
-public class DesDemo {
- public DesDemo() {
- }
-
- // 测试
- public static void main(String args[]) {
- // 待加密内容
- String str = "cryptology";
- // 密码,长度要是8的倍数
- String password = "95880288";
-
- byte[] result;
- try {
- result = DesDemo.encrypt(str.getBytes(), password);
- System.out.println("加密后:" + result);
- byte[] decryResult = DesDemo.decrypt(result, password);
- System.out.println("解密后:" + decryResult);
- } catch (UnsupportedEncodingException e2) {
- // TODO Auto-generated catch block
- e2.printStackTrace();
- } catch (Exception e1) {
- e1.printStackTrace();
- }
- }
-
- // 直接将如上内容解密
-
- /**
- * 加密
- *
- * @param datasource
- * byte[]
- * @param password
- * String
- * @return byte[]
- */
- public static byte[] encrypt(byte[] datasource, String password) {
- try {
- SecureRandom random = new SecureRandom();
- DESKeySpec desKey = new DESKeySpec(password.getBytes());
- // 创建一个密匙工厂,然后用它把DESKeySpec转换成
- SecretKeyFactory keyFactory = SecretKeyFactory.getInstance("DES");
- SecretKey securekey = keyFactory.generateSecret(desKey);
- // Cipher对象实际完成加密操作
- Cipher cipher = Cipher.getInstance("DES");
- // 用密匙初始化Cipher对象,ENCRYPT_MODE用于将 Cipher 初始化为加密模式的常量
- cipher.init(Cipher.ENCRYPT_MODE, securekey, random);
- // 现在,获取数据并加密
- // 正式执行加密操作
- return cipher.doFinal(datasource); // 按单部分操作加密或解密数据,或者结束一个多部分操作
- } catch (Throwable e) {
- e.printStackTrace();
- }
- return null;
- }
-
- /**
- * 解密
- *
- * @param src
- * byte[]
- * @param password
- * String
- * @return byte[]
- * @throws Exception
- */
- public static byte[] decrypt(byte[] src, String password) throws Exception {
- // DES算法要求有一个可信任的随机数源
- SecureRandom random = new SecureRandom();
- // 创建一个DESKeySpec对象
- DESKeySpec desKey = new DESKeySpec(password.getBytes());
- // 创建一个密匙工厂
- SecretKeyFactory keyFactory = SecretKeyFactory.getInstance("DES");// 返回实现指定转换的
- // Cipher
- // 对象
- // 将DESKeySpec对象转换成SecretKey对象
- SecretKey securekey = keyFactory.generateSecret(desKey);
- // Cipher对象实际完成解密操作
- Cipher cipher = Cipher.getInstance("DES");
- // 用密匙初始化Cipher对象
- cipher.init(Cipher.DECRYPT_MODE, securekey, random);
- // 真正开始解密操作
- return cipher.doFinal(src);
- }
-}
\ No newline at end of file
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/IDEADemo.java" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/IDEADemo.java"
deleted file mode 100644
index 5ce251df0fa..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/IDEADemo.java"
+++ /dev/null
@@ -1,46 +0,0 @@
-package com.snailclimb.ks.securityAlgorithm;
-
-import java.security.Key;
-import java.security.Security;
-
-import javax.crypto.Cipher;
-import javax.crypto.KeyGenerator;
-import javax.crypto.SecretKey;
-import javax.crypto.spec.SecretKeySpec;
-
-import org.apache.commons.codec.binary.Base64;
-import org.bouncycastle.jce.provider.BouncyCastleProvider;
-
-public class IDEADemo {
- public static void main(String args[]) {
- bcIDEA();
- }
- public static void bcIDEA() {
- String src = "www.xttblog.com security idea";
- try {
- Security.addProvider(new BouncyCastleProvider());
-
- //生成key
- KeyGenerator keyGenerator = KeyGenerator.getInstance("IDEA");
- keyGenerator.init(128);
- SecretKey secretKey = keyGenerator.generateKey();
- byte[] keyBytes = secretKey.getEncoded();
-
- //转换密钥
- Key key = new SecretKeySpec(keyBytes, "IDEA");
-
- //加密
- Cipher cipher = Cipher.getInstance("IDEA/ECB/ISO10126Padding");
- cipher.init(Cipher.ENCRYPT_MODE, key);
- byte[] result = cipher.doFinal(src.getBytes());
- System.out.println("bc idea encrypt : " + Base64.encodeBase64String(result));
-
- //解密
- cipher.init(Cipher.DECRYPT_MODE, key);
- result = cipher.doFinal(result);
- System.out.println("bc idea decrypt : " + new String(result));
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
-}
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/MD5.java" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/MD5.java"
deleted file mode 100644
index 2b8e31f83f5..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/MD5.java"
+++ /dev/null
@@ -1,160 +0,0 @@
-package com.snailclimb.ks.securityAlgorithm;
-
-public class MD5{
- /*
- *四个链接变量
- */
- private final int A=0x67452301;
- private final int B=0xefcdab89;
- private final int C=0x98badcfe;
- private final int D=0x10325476;
- /*
- *ABCD的临时变量
- */
- private int Atemp,Btemp,Ctemp,Dtemp;
-
- /*
- *常量ti
- *公式:floor(abs(sin(i+1))×(2pow32)
- */
- private final int K[]={
- 0xd76aa478,0xe8c7b756,0x242070db,0xc1bdceee,
- 0xf57c0faf,0x4787c62a,0xa8304613,0xfd469501,0x698098d8,
- 0x8b44f7af,0xffff5bb1,0x895cd7be,0x6b901122,0xfd987193,
- 0xa679438e,0x49b40821,0xf61e2562,0xc040b340,0x265e5a51,
- 0xe9b6c7aa,0xd62f105d,0x02441453,0xd8a1e681,0xe7d3fbc8,
- 0x21e1cde6,0xc33707d6,0xf4d50d87,0x455a14ed,0xa9e3e905,
- 0xfcefa3f8,0x676f02d9,0x8d2a4c8a,0xfffa3942,0x8771f681,
- 0x6d9d6122,0xfde5380c,0xa4beea44,0x4bdecfa9,0xf6bb4b60,
- 0xbebfbc70,0x289b7ec6,0xeaa127fa,0xd4ef3085,0x04881d05,
- 0xd9d4d039,0xe6db99e5,0x1fa27cf8,0xc4ac5665,0xf4292244,
- 0x432aff97,0xab9423a7,0xfc93a039,0x655b59c3,0x8f0ccc92,
- 0xffeff47d,0x85845dd1,0x6fa87e4f,0xfe2ce6e0,0xa3014314,
- 0x4e0811a1,0xf7537e82,0xbd3af235,0x2ad7d2bb,0xeb86d391};
- /*
- *向左位移数,计算方法未知
- */
- private final int s[]={7,12,17,22,7,12,17,22,7,12,17,22,7,
- 12,17,22,5,9,14,20,5,9,14,20,5,9,14,20,5,9,14,20,
- 4,11,16,23,4,11,16,23,4,11,16,23,4,11,16,23,6,10,
- 15,21,6,10,15,21,6,10,15,21,6,10,15,21};
-
-
- /*
- *初始化函数
- */
- private void init(){
- Atemp=A;
- Btemp=B;
- Ctemp=C;
- Dtemp=D;
- }
- /*
- *移动一定位数
- */
- private int shift(int a,int s){
- return(a<<s)|(a>>>(32-s));//右移的时候,高位一定要补零,而不是补充符号位
- }
- /*
- *主循环
- */
- private void MainLoop(int M[]){
- int F,g;
- int a=Atemp;
- int b=Btemp;
- int c=Ctemp;
- int d=Dtemp;
- for(int i = 0; i < 64; i ++){
- if(i<16){
- F=(b&c)|((~b)&d);
- g=i;
- }else if(i<32){
- F=(d&b)|((~d)&c);
- g=(5*i+1)%16;
- }else if(i<48){
- F=b^c^d;
- g=(3*i+5)%16;
- }else{
- F=c^(b|(~d));
- g=(7*i)%16;
- }
- int tmp=d;
- d=c;
- c=b;
- b=b+shift(a+F+K[i]+M[g],s[i]);
- a=tmp;
- }
- Atemp=a+Atemp;
- Btemp=b+Btemp;
- Ctemp=c+Ctemp;
- Dtemp=d+Dtemp;
-
- }
- /*
- *填充函数
- *处理后应满足bits≡448(mod512),字节就是bytes≡56(mode64)
- *填充方式为先加一个0,其它位补零
- *最后加上64位的原来长度
- */
- private int[] add(String str){
- int num=((str.length()+8)/64)+1;//以512位,64个字节为一组
- int strByte[]=new int[num*16];//64/4=16,所以有16个整数
- for(int i=0;i<num*16;i++){//全部初始化0
- strByte[i]=0;
- }
- int i;
- for(i=0;i<str.length();i++){
- strByte[i>>2]|=str.charAt(i)<<((i%4)*8);//一个整数存储四个字节,小端序
- }
- strByte[i>>2]|=0x80<<((i%4)*8);//尾部添加1
- /*
- *添加原长度,长度指位的长度,所以要乘8,然后是小端序,所以放在倒数第二个,这里长度只用了32位
- */
- strByte[num*16-2]=str.length()*8;
- return strByte;
- }
- /*
- *调用函数
- */
- public String getMD5(String source){
- init();
- int strByte[]=add(source);
- for(int i=0;i<strByte.length/16;i++){
- int num[]=new int[16];
- for(int j=0;j<16;j++){
- num[j]=strByte[i*16+j];
- }
- MainLoop(num);
- }
- return changeHex(Atemp)+changeHex(Btemp)+changeHex(Ctemp)+changeHex(Dtemp);
-
- }
- /*
- *整数变成16进制字符串
- */
- private String changeHex(int a){
- String str="";
- for(int i=0;i<4;i++){
- str+=String.format("%2s", Integer.toHexString(((a>>i*8)%(1<<8))&0xff)).replace(' ', '0');
-
- }
- return str;
- }
- /*
- *单例
- */
- private static MD5 instance;
- public static MD5 getInstance(){
- if(instance==null){
- instance=new MD5();
- }
- return instance;
- }
-
- private MD5(){};
-
- public static void main(String[] args){
- String str=MD5.getInstance().getMD5("你若安好,便是晴天");
- System.out.println(str);
- }
-}
\ No newline at end of file
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/MD5Demo.java" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/MD5Demo.java"
deleted file mode 100644
index 3a8635d1e69..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/MD5Demo.java"
+++ /dev/null
@@ -1,50 +0,0 @@
-package com.snailclimb.ks.securityAlgorithm;
-
-import java.security.MessageDigest;
-
-public class MD5Demo {
-
- // test
- public static void main(String[] args) {
- System.out.println(getMD5Code("你若安好,便是晴天"));
- }
-
- private MD5Demo() {
- }
-
- // md5加密
- public static String getMD5Code(String message) {
- String md5Str = "";
- try {
- //创建MD5算法消息摘要
- MessageDigest md = MessageDigest.getInstance("MD5");
- //生成的哈希值的字节数组
- byte[] md5Bytes = md.digest(message.getBytes());
- md5Str = bytes2Hex(md5Bytes);
- }catch(Exception e) {
- e.printStackTrace();
- }
- return md5Str;
- }
-
- // 2进制转16进制
- public static String bytes2Hex(byte[] bytes) {
- StringBuffer result = new StringBuffer();
- int temp;
- try {
- for (int i = 0; i < bytes.length; i++) {
- temp = bytes[i];
- if(temp < 0) {
- temp += 256;
- }
- if (temp < 16) {
- result.append("0");
- }
- result.append(Integer.toHexString(temp));
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- return result.toString();
- }
-}
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/RSADemo.java" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/RSADemo.java"
deleted file mode 100644
index 5234028ece4..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/RSADemo.java"
+++ /dev/null
@@ -1,249 +0,0 @@
-package com.snailclimb.ks.securityAlgorithm;
-
-import org.apache.commons.codec.binary.Base64;
-
-import java.security.*;
-import java.security.spec.PKCS8EncodedKeySpec;
-import java.security.spec.X509EncodedKeySpec;
-import java.util.HashMap;
-import java.util.Map;
-
-import javax.crypto.Cipher;
-
-/**
- * Created by humf.需要依赖 commons-codec 包
- */
-public class RSADemo {
-
- public static void main(String[] args) throws Exception {
- Map<String, Key> keyMap = initKey();
- String publicKey = getPublicKey(keyMap);
- String privateKey = getPrivateKey(keyMap);
-
- System.out.println(keyMap);
- System.out.println("-----------------------------------");
- System.out.println(publicKey);
- System.out.println("-----------------------------------");
- System.out.println(privateKey);
- System.out.println("-----------------------------------");
- byte[] encryptByPrivateKey = encryptByPrivateKey("123456".getBytes(), privateKey);
- byte[] encryptByPublicKey = encryptByPublicKey("123456", publicKey);
- System.out.println(encryptByPrivateKey);
- System.out.println("-----------------------------------");
- System.out.println(encryptByPublicKey);
- System.out.println("-----------------------------------");
- String sign = sign(encryptByPrivateKey, privateKey);
- System.out.println(sign);
- System.out.println("-----------------------------------");
- boolean verify = verify(encryptByPrivateKey, publicKey, sign);
- System.out.println(verify);
- System.out.println("-----------------------------------");
- byte[] decryptByPublicKey = decryptByPublicKey(encryptByPrivateKey, publicKey);
- byte[] decryptByPrivateKey = decryptByPrivateKey(encryptByPublicKey, privateKey);
- System.out.println(decryptByPublicKey);
- System.out.println("-----------------------------------");
- System.out.println(decryptByPrivateKey);
-
- }
-
- public static final String KEY_ALGORITHM = "RSA";
- public static final String SIGNATURE_ALGORITHM = "MD5withRSA";
-
- private static final String PUBLIC_KEY = "RSAPublicKey";
- private static final String PRIVATE_KEY = "RSAPrivateKey";
-
- public static byte[] decryptBASE64(String key) {
- return Base64.decodeBase64(key);
- }
-
- public static String encryptBASE64(byte[] bytes) {
- return Base64.encodeBase64String(bytes);
- }
-
- /**
- * 用私钥对信息生成数字签名
- *
- * @param data
- * 加密数据
- * @param privateKey
- * 私钥
- * @return
- * @throws Exception
- */
- public static String sign(byte[] data, String privateKey) throws Exception {
- // 解密由base64编码的私钥
- byte[] keyBytes = decryptBASE64(privateKey);
- // 构造PKCS8EncodedKeySpec对象
- PKCS8EncodedKeySpec pkcs8KeySpec = new PKCS8EncodedKeySpec(keyBytes);
- // KEY_ALGORITHM 指定的加密算法
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- // 取私钥匙对象
- PrivateKey priKey = keyFactory.generatePrivate(pkcs8KeySpec);
- // 用私钥对信息生成数字签名
- Signature signature = Signature.getInstance(SIGNATURE_ALGORITHM);
- signature.initSign(priKey);
- signature.update(data);
- return encryptBASE64(signature.sign());
- }
-
- /**
- * 校验数字签名
- *
- * @param data
- * 加密数据
- * @param publicKey
- * 公钥
- * @param sign
- * 数字签名
- * @return 校验成功返回true 失败返回false
- * @throws Exception
- */
- public static boolean verify(byte[] data, String publicKey, String sign) throws Exception {
- // 解密由base64编码的公钥
- byte[] keyBytes = decryptBASE64(publicKey);
- // 构造X509EncodedKeySpec对象
- X509EncodedKeySpec keySpec = new X509EncodedKeySpec(keyBytes);
- // KEY_ALGORITHM 指定的加密算法
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- // 取公钥匙对象
- PublicKey pubKey = keyFactory.generatePublic(keySpec);
- Signature signature = Signature.getInstance(SIGNATURE_ALGORITHM);
- signature.initVerify(pubKey);
- signature.update(data);
- // 验证签名是否正常
- return signature.verify(decryptBASE64(sign));
- }
-
- public static byte[] decryptByPrivateKey(byte[] data, String key) throws Exception {
- // 对密钥解密
- byte[] keyBytes = decryptBASE64(key);
- // 取得私钥
- PKCS8EncodedKeySpec pkcs8KeySpec = new PKCS8EncodedKeySpec(keyBytes);
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- Key privateKey = keyFactory.generatePrivate(pkcs8KeySpec);
- // 对数据解密
- Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
- cipher.init(Cipher.DECRYPT_MODE, privateKey);
- return cipher.doFinal(data);
- }
-
- /**
- * 解密<br>
- * 用私钥解密
- *
- * @param data
- * @param key
- * @return
- * @throws Exception
- */
- public static byte[] decryptByPrivateKey(String data, String key) throws Exception {
- return decryptByPrivateKey(decryptBASE64(data), key);
- }
-
- /**
- * 解密<br>
- * 用公钥解密
- *
- * @param data
- * @param key
- * @return
- * @throws Exception
- */
- public static byte[] decryptByPublicKey(byte[] data, String key) throws Exception {
- // 对密钥解密
- byte[] keyBytes = decryptBASE64(key);
- // 取得公钥
- X509EncodedKeySpec x509KeySpec = new X509EncodedKeySpec(keyBytes);
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- Key publicKey = keyFactory.generatePublic(x509KeySpec);
- // 对数据解密
- Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
- cipher.init(Cipher.DECRYPT_MODE, publicKey);
- return cipher.doFinal(data);
- }
-
- /**
- * 加密<br>
- * 用公钥加密
- *
- * @param data
- * @param key
- * @return
- * @throws Exception
- */
- public static byte[] encryptByPublicKey(String data, String key) throws Exception {
- // 对公钥解密
- byte[] keyBytes = decryptBASE64(key);
- // 取得公钥
- X509EncodedKeySpec x509KeySpec = new X509EncodedKeySpec(keyBytes);
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- Key publicKey = keyFactory.generatePublic(x509KeySpec);
- // 对数据加密
- Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
- cipher.init(Cipher.ENCRYPT_MODE, publicKey);
- return cipher.doFinal(data.getBytes());
- }
-
- /**
- * 加密<br>
- * 用私钥加密
- *
- * @param data
- * @param key
- * @return
- * @throws Exception
- */
- public static byte[] encryptByPrivateKey(byte[] data, String key) throws Exception {
- // 对密钥解密
- byte[] keyBytes = decryptBASE64(key);
- // 取得私钥
- PKCS8EncodedKeySpec pkcs8KeySpec = new PKCS8EncodedKeySpec(keyBytes);
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- Key privateKey = keyFactory.generatePrivate(pkcs8KeySpec);
- // 对数据加密
- Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
- cipher.init(Cipher.ENCRYPT_MODE, privateKey);
- return cipher.doFinal(data);
- }
-
- /**
- * 取得私钥
- *
- * @param keyMap
- * @return
- * @throws Exception
- */
- public static String getPrivateKey(Map<String, Key> keyMap) throws Exception {
- Key key = (Key) keyMap.get(PRIVATE_KEY);
- return encryptBASE64(key.getEncoded());
- }
-
- /**
- * 取得公钥
- *
- * @param keyMap
- * @return
- * @throws Exception
- */
- public static String getPublicKey(Map<String, Key> keyMap) throws Exception {
- Key key = keyMap.get(PUBLIC_KEY);
- return encryptBASE64(key.getEncoded());
- }
-
- /**
- * 初始化密钥
- *
- * @return
- * @throws Exception
- */
- public static Map<String, Key> initKey() throws Exception {
- KeyPairGenerator keyPairGen = KeyPairGenerator.getInstance(KEY_ALGORITHM);
- keyPairGen.initialize(1024);
- KeyPair keyPair = keyPairGen.generateKeyPair();
- Map<String, Key> keyMap = new HashMap(2);
- keyMap.put(PUBLIC_KEY, keyPair.getPublic());// 公钥
- keyMap.put(PRIVATE_KEY, keyPair.getPrivate());// 私钥
- return keyMap;
- }
-
-}
\ No newline at end of file
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/SHA1Demo.java" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/SHA1Demo.java"
deleted file mode 100644
index ab19e3d0cf9..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/SHA1Demo.java"
+++ /dev/null
@@ -1,45 +0,0 @@
-package com.snailclimb.ks.securityAlgorithm;
-
-import java.io.UnsupportedEncodingException;
-import java.security.MessageDigest;
-import java.security.NoSuchAlgorithmException;
-
-public class SHA1Demo {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- System.out.println(getSha1("你若安好,便是晴天"));
-
- }
-
- public static String getSha1(String str) {
- if (null == str || 0 == str.length()) {
- return null;
- }
- char[] hexDigits = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f' };
- try {
- //创建SHA1算法消息摘要对象
- MessageDigest mdTemp = MessageDigest.getInstance("SHA1");
- //使用指定的字节数组更新摘要。
- mdTemp.update(str.getBytes("UTF-8"));
- //生成的哈希值的字节数组
- byte[] md = mdTemp.digest();
- //SHA1算法生成信息摘要关键过程
- int j = md.length;
- char[] buf = new char[j * 2];
- int k = 0;
- for (int i = 0; i < j; i++) {
- byte byte0 = md[i];
- buf[k++] = hexDigits[byte0 >>> 4 & 0xf];
- buf[k++] = hexDigits[byte0 & 0xf];
- }
- return new String(buf);
- } catch (NoSuchAlgorithmException e) {
- e.printStackTrace();
- } catch (UnsupportedEncodingException e) {
- e.printStackTrace();
- }
- return "0";
-
- }
-}
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/readme" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/readme"
deleted file mode 100644
index 5c2d452dd23..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/main/java/com/snailclimb/ks/securityAlgorithm/readme"
+++ /dev/null
@@ -1,3 +0,0 @@
-Des算法参考:http://blog.csdn.net/super_cui/article/details/70820983
-IDEA算法参考:https://www.xttblog.com/?p=1121
-RSA算法实现参考:https://www.cnblogs.com/xlhan/p/7120488.html
\ No newline at end of file
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/test/java/com/snailclimb/ks/securityAlgorithm/AppTest.java" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/test/java/com/snailclimb/ks/securityAlgorithm/AppTest.java"
deleted file mode 100644
index 932254515a0..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/source code/securityAlgorithm/src/test/java/com/snailclimb/ks/securityAlgorithm/AppTest.java"
+++ /dev/null
@@ -1,38 +0,0 @@
-package com.snailclimb.ks.securityAlgorithm;
-
-import junit.framework.Test;
-import junit.framework.TestCase;
-import junit.framework.TestSuite;
-
-/**
- * Unit test for simple App.
- */
-public class AppTest
- extends TestCase
-{
- /**
- * Create the test case
- *
- * @param testName name of the test case
- */
- public AppTest( String testName )
- {
- super( testName );
- }
-
- /**
- * @return the suite of tests being tested
- */
- public static Test suite()
- {
- return new TestSuite( AppTest.class );
- }
-
- /**
- * Rigourous Test :-)
- */
- public void testApp()
- {
- assertTrue( true );
- }
-}
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\345\270\270\350\247\201\345\256\211\345\205\250\347\256\227\346\263\225\357\274\210MD5\343\200\201SHA1\343\200\201Base64\347\255\211\347\255\211\357\274\211\346\200\273\347\273\223.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\345\270\270\350\247\201\345\256\211\345\205\250\347\256\227\346\263\225\357\274\210MD5\343\200\201SHA1\343\200\201Base64\347\255\211\347\255\211\357\274\211\346\200\273\347\273\223.md"
deleted file mode 100644
index 79a03d391d8..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\345\270\270\350\247\201\345\256\211\345\205\250\347\256\227\346\263\225\357\274\210MD5\343\200\201SHA1\343\200\201Base64\347\255\211\347\255\211\357\274\211\346\200\273\347\273\223.md"
+++ /dev/null
@@ -1,849 +0,0 @@
-本文主要对消息摘要算法和加密算法做了整理,包括MD5、SHA、DES、AES、RSA等,并且提供了相应算法的Java实现和测试。
-
-# 一 消息摘要算法
-
-## **1. 简介:**
-
-- **消息摘要算法的主要特征是加密过程不需要密钥,并且经过加密的数据无法被解密**
-- **只有输入相同的明文数据经过相同的消息摘要算法才能得到相同的密文。**
-- **消息摘要算法主要应用在“数字签名”领域,作为对明文的摘要算法。**
-- **著名的摘要算法有RSA公司的MD5算法和SHA-1算法及其大量的变体**。
-
-## **2. 特点:**
-
-1. **无论输入的消息有多长,计算出来的消息摘要的长度总是固定的。**
-2. **消息摘要看起来是“伪随机的”。也就是说对相同的信息求摘要结果相同。**
-3. **消息轻微改变生成的摘要变化会很大**
-4. **只能进行正向的信息摘要,而无法从摘要中恢复出任何的消息,甚至根本就找不到任何与原信息相关的信息**
-
-## **3. 应用:**
-
-消息摘要算法最常用的场景就是数字签名以及数据(密码)加密了。(一般平时做项目用的比较多的就是使用MD5对用户密码进行加密)
-
-## **4. 何谓数字签名:**
-
-数字签名主要用到了非对称密钥加密技术与数字摘要技术。数字签名技术是将摘要信息用发送者的私钥加密,与原文一起传送给接收者。接收者只有用发送者的公钥才能解密被加密的摘要信息,然后用HASH函数对收到的原文产生一个摘要信息,与解密的摘要信息对比。
-如果相同,则说明收到的信息是完整的,在传输过程中没有被修改,否则说明信息被修改过.
-
-因此数字签名能够验证信息的完整性。
-数字签名是个加密的过程,数字签名验证是个解密的过程。
-
-## **5. 常见消息/数字摘要算法:**
-
-### [**MD5:**](https://baike.baidu.com/item/MD5/212708?fr=aladdin)
-
-#### 简介:
-
-MD5的作用是让大容量信息在用数字签名软件签署私人密钥前被"压缩"成一种保密的格式
- (也就是把一个任意长度的字节串变换成一定长的十六进制数字串)。
-
-#### 特点:
-
-1. **压缩性:** 任意长度的数据,算出的MD5值长度都是固定的。
-2. **容易计算:** 从原数据计算出MD5值很容易。
-3. **抗修改性:** 对原数据进行任何改动,哪怕只修改1个字节,所得到的MD5值都有很大区别。
-4. **强抗碰撞:** 已知原数据和其MD5值,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
-
-#### 代码实现:
-
-**利用JDK提供java.security.MessageDigest类实现MD5算法:**
-
-```java
-package com.snailclimb.ks.securityAlgorithm;
-
-import java.security.MessageDigest;
-
-public class MD5Demo {
-
- // test
- public static void main(String[] args) {
- System.out.println(getMD5Code("你若安好,便是晴天"));
- }
-
- private MD5Demo() {
- }
-
- // md5加密
- public static String getMD5Code(String message) {
- String md5Str = "";
- try {
- //创建MD5算法消息摘要
- MessageDigest md = MessageDigest.getInstance("MD5");
- //生成的哈希值的字节数组
- byte[] md5Bytes = md.digest(message.getBytes());
- md5Str = bytes2Hex(md5Bytes);
- }catch(Exception e) {
- e.printStackTrace();
- }
- return md5Str;
- }
-
- // 2进制转16进制
- public static String bytes2Hex(byte[] bytes) {
- StringBuffer result = new StringBuffer();
- int temp;
- try {
- for (int i = 0; i < bytes.length; i++) {
- temp = bytes[i];
- if(temp < 0) {
- temp += 256;
- }
- if (temp < 16) {
- result.append("0");
- }
- result.append(Integer.toHexString(temp));
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- return result.toString();
- }
-}
-
-```
-
-**结果:**
-```
-6bab82679914f7cb480a120b532ffa80
-
-```
-
-**注意MessageDigest类的几个方法:**
-
-```java
-static MessageDigest getInstance(String algorithm)//返回实现指定摘要算法的MessageDigest对象
-```
-```java
-byte[] digest(byte[] input)//使用指定的字节数组对摘要执行最终更新,然后完成摘要计算。
-```
-
-#### 不利用Java提供的java.security.MessageDigest类实现MD5算法:
-
-```java
-package com.snailclimb.ks.securityAlgorithm;
-
-public class MD5{
- /*
- *四个链接变量
- */
- private final int A=0x67452301;
- private final int B=0xefcdab89;
- private final int C=0x98badcfe;
- private final int D=0x10325476;
- /*
- *ABCD的临时变量
- */
- private int Atemp,Btemp,Ctemp,Dtemp;
-
- /*
- *常量ti
- *公式:floor(abs(sin(i+1))×(2pow32)
- */
- private final int K[]={
- 0xd76aa478,0xe8c7b756,0x242070db,0xc1bdceee,
- 0xf57c0faf,0x4787c62a,0xa8304613,0xfd469501,0x698098d8,
- 0x8b44f7af,0xffff5bb1,0x895cd7be,0x6b901122,0xfd987193,
- 0xa679438e,0x49b40821,0xf61e2562,0xc040b340,0x265e5a51,
- 0xe9b6c7aa,0xd62f105d,0x02441453,0xd8a1e681,0xe7d3fbc8,
- 0x21e1cde6,0xc33707d6,0xf4d50d87,0x455a14ed,0xa9e3e905,
- 0xfcefa3f8,0x676f02d9,0x8d2a4c8a,0xfffa3942,0x8771f681,
- 0x6d9d6122,0xfde5380c,0xa4beea44,0x4bdecfa9,0xf6bb4b60,
- 0xbebfbc70,0x289b7ec6,0xeaa127fa,0xd4ef3085,0x04881d05,
- 0xd9d4d039,0xe6db99e5,0x1fa27cf8,0xc4ac5665,0xf4292244,
- 0x432aff97,0xab9423a7,0xfc93a039,0x655b59c3,0x8f0ccc92,
- 0xffeff47d,0x85845dd1,0x6fa87e4f,0xfe2ce6e0,0xa3014314,
- 0x4e0811a1,0xf7537e82,0xbd3af235,0x2ad7d2bb,0xeb86d391};
- /*
- *向左位移数,计算方法未知
- */
- private final int s[]={7,12,17,22,7,12,17,22,7,12,17,22,7,
- 12,17,22,5,9,14,20,5,9,14,20,5,9,14,20,5,9,14,20,
- 4,11,16,23,4,11,16,23,4,11,16,23,4,11,16,23,6,10,
- 15,21,6,10,15,21,6,10,15,21,6,10,15,21};
-
-
- /*
- *初始化函数
- */
- private void init(){
- Atemp=A;
- Btemp=B;
- Ctemp=C;
- Dtemp=D;
- }
- /*
- *移动一定位数
- */
- private int shift(int a,int s){
- return(a<<s)|(a>>>(32-s));//右移的时候,高位一定要补零,而不是补充符号位
- }
- /*
- *主循环
- */
- private void MainLoop(int M[]){
- int F,g;
- int a=Atemp;
- int b=Btemp;
- int c=Ctemp;
- int d=Dtemp;
- for(int i = 0; i < 64; i ++){
- if(i<16){
- F=(b&c)|((~b)&d);
- g=i;
- }else if(i<32){
- F=(d&b)|((~d)&c);
- g=(5*i+1)%16;
- }else if(i<48){
- F=b^c^d;
- g=(3*i+5)%16;
- }else{
- F=c^(b|(~d));
- g=(7*i)%16;
- }
- int tmp=d;
- d=c;
- c=b;
- b=b+shift(a+F+K[i]+M[g],s[i]);
- a=tmp;
- }
- Atemp=a+Atemp;
- Btemp=b+Btemp;
- Ctemp=c+Ctemp;
- Dtemp=d+Dtemp;
-
- }
- /*
- *填充函数
- *处理后应满足bits≡448(mod512),字节就是bytes≡56(mode64)
- *填充方式为先加一个0,其它位补零
- *最后加上64位的原来长度
- */
- private int[] add(String str){
- int num=((str.length()+8)/64)+1;//以512位,64个字节为一组
- int strByte[]=new int[num*16];//64/4=16,所以有16个整数
- for(int i=0;i<num*16;i++){//全部初始化0
- strByte[i]=0;
- }
- int i;
- for(i=0;i<str.length();i++){
- strByte[i>>2]|=str.charAt(i)<<((i%4)*8);//一个整数存储四个字节,小端序
- }
- strByte[i>>2]|=0x80<<((i%4)*8);//尾部添加1
- /*
- *添加原长度,长度指位的长度,所以要乘8,然后是小端序,所以放在倒数第二个,这里长度只用了32位
- */
- strByte[num*16-2]=str.length()*8;
- return strByte;
- }
- /*
- *调用函数
- */
- public String getMD5(String source){
- init();
- int strByte[]=add(source);
- for(int i=0;i<strByte.length/16;i++){
- int num[]=new int[16];
- for(int j=0;j<16;j++){
- num[j]=strByte[i*16+j];
- }
- MainLoop(num);
- }
- return changeHex(Atemp)+changeHex(Btemp)+changeHex(Ctemp)+changeHex(Dtemp);
-
- }
- /*
- *整数变成16进制字符串
- */
- private String changeHex(int a){
- String str="";
- for(int i=0;i<4;i++){
- str+=String.format("%2s", Integer.toHexString(((a>>i*8)%(1<<8))&0xff)).replace(' ', '0');
-
- }
- return str;
- }
- /*
- *单例
- */
- private static MD5 instance;
- public static MD5 getInstance(){
- if(instance==null){
- instance=new MD5();
- }
- return instance;
- }
-
- private MD5(){};
-
- public static void main(String[] args){
- String str=MD5.getInstance().getMD5("你若安好,便是晴天");
- System.out.println(str);
- }
-}
-```
-
-### [**SHA1:**](https://baike.baidu.com/item/MD5/212708?fr=aladdin)
-对于长度小于2^64位的消息,SHA1会产生一个160位(40个字符)的消息摘要。当接收到消息的时候,这个消息摘要可以用来验证数据的完整性。在传输的过程中,数据很可能会发生变化,那么这时候就会产生不同的消息摘要。
-
-SHA1有如下特性:
-
-- 不可以从消息摘要中复原信息;
-- 两个不同的消息不会产生同样的消息摘要,(但会有1x10 ^ 48分之一的机率出现相同的消息摘要,一般使用时忽略)。
-
-#### 代码实现:
-
-**利用JDK提供java.security.MessageDigest类实现SHA1算法:*
-
-```java
-package com.snailclimb.ks.securityAlgorithm;
-
-import java.io.UnsupportedEncodingException;
-import java.security.MessageDigest;
-import java.security.NoSuchAlgorithmException;
-
-public class SHA1Demo {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- System.out.println(getSha1("你若安好,便是晴天"));
-
- }
-
- public static String getSha1(String str) {
- if (null == str || 0 == str.length()) {
- return null;
- }
- char[] hexDigits = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f' };
- try {
- //创建SHA1算法消息摘要对象
- MessageDigest mdTemp = MessageDigest.getInstance("SHA1");
- //使用指定的字节数组更新摘要。
- mdTemp.update(str.getBytes("UTF-8"));
- //生成的哈希值的字节数组
- byte[] md = mdTemp.digest();
- //SHA1算法生成信息摘要关键过程
- int j = md.length;
- char[] buf = new char[j * 2];
- int k = 0;
- for (int i = 0; i < j; i++) {
- byte byte0 = md[i];
- buf[k++] = hexDigits[byte0 >>> 4 & 0xf];
- buf[k++] = hexDigits[byte0 & 0xf];
- }
- return new String(buf);
- } catch (NoSuchAlgorithmException e) {
- e.printStackTrace();
- } catch (UnsupportedEncodingException e) {
- e.printStackTrace();
- }
- return "0";
-
- }
-}
-
-```
-
-**结果:**
-
-```
-8ce764110a42da9b08504b20e26b19c9e3382414
-```
-
-
-
-# 二 加密算法
-
-## **1. 简介:**
-
-- **加密技术包括两个元素:加密算法和密钥。**
-- **加密算法是将普通的文本(或者可以理解的信息)与一串数字(密钥)的结合,产生不可理解的密文的步骤。**
-- **密钥是用来对数据进行编码和解码的一种算法。**
-- **在安全保密中,可通过适当的密钥加密技术和管理机制来保证网络的信息通讯安全。**
-
-## **2. 分类:**
-
-**密钥加密技术的密码体制分为对称密钥体制和非对称密钥体制两种。相应地,对数据加密的技术分为两类,即对称加密(私人密钥加密)和非对称加密(公开密钥加密)。**
-
-**对称加密以数据加密标准(DES,Data Encryption Standard)算法为典型代表,非对称加密通常以RSA(Rivest Shamir Adleman)算法为代表。**
-
-**对称加密的加密密钥和解密密钥相同。非对称加密的加密密钥和解密密钥不同,加密密钥可以公开而解密密钥需要保密**
-## **3. 应用:**
-
-常被用在电子商务或者其他需要保证网络传输安全的范围。
-
-## **4. 对称加密:**
-
-加密密钥和解密密钥相同的加密算法。
-
-对称加密算法使用起来简单快捷,密钥较短,且破译困难,除了数据加密标准(DES),
-另一个对称密钥加密系统是国际数据加密算法(IDEA),它比DES的加密性好,而且对计算机功能要求也没有那么高。IDEA加密标准由PGP(Pretty Good Privacy)系统使用。
-### [**DES:**](https://baike.baidu.com/item/DES)
-
-DES全称为Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法,现在已经过时。
-
-#### 代码实现:
-
-DES算法实现 :
-
-```java
-package com.snailclimb.ks.securityAlgorithm;
-
-import java.io.UnsupportedEncodingException;
-import java.security.SecureRandom;
-import javax.crypto.spec.DESKeySpec;
-import javax.crypto.SecretKeyFactory;
-import javax.crypto.SecretKey;
-import javax.crypto.Cipher;
-
-/**
- * DES加密介绍 DES是一种对称加密算法,所谓对称加密算法即:加密和解密使用相同密钥的算法。DES加密算法出自IBM的研究,
- * 后来被美国政府正式采用,之后开始广泛流传,但是近些年使用越来越少,因为DES使用56位密钥,以现代计算能力,
- * 24小时内即可被破解。虽然如此,在某些简单应用中,我们还是可以使用DES加密算法,本文简单讲解DES的JAVA实现 。
- * 注意:DES加密和解密过程中,密钥长度都必须是8的倍数
- */
-public class DesDemo {
- public DesDemo() {
- }
-
- // 测试
- public static void main(String args[]) {
- // 待加密内容
- String str = "cryptology";
- // 密码,长度要是8的倍数
- String password = "95880288";
-
- byte[] result;
- try {
- result = DesDemo.encrypt(str.getBytes(), password);
- System.out.println("加密后:" + result);
- byte[] decryResult = DesDemo.decrypt(result, password);
- System.out.println("解密后:" + new String(decryResult));
- } catch (UnsupportedEncodingException e2) {
- // TODO Auto-generated catch block
- e2.printStackTrace();
- } catch (Exception e1) {
- e1.printStackTrace();
- }
- }
-
- // 直接将如上内容解密
-
- /**
- * 加密
- *
- * @param datasource
- * byte[]
- * @param password
- * String
- * @return byte[]
- */
- public static byte[] encrypt(byte[] datasource, String password) {
- try {
- SecureRandom random = new SecureRandom();
- DESKeySpec desKey = new DESKeySpec(password.getBytes());
- // 创建一个密匙工厂,然后用它把DESKeySpec转换成
- SecretKeyFactory keyFactory = SecretKeyFactory.getInstance("DES");
- SecretKey securekey = keyFactory.generateSecret(desKey);
- // Cipher对象实际完成加密操作
- Cipher cipher = Cipher.getInstance("DES");
- // 用密匙初始化Cipher对象,ENCRYPT_MODE用于将 Cipher 初始化为加密模式的常量
- cipher.init(Cipher.ENCRYPT_MODE, securekey, random);
- // 现在,获取数据并加密
- // 正式执行加密操作
- return cipher.doFinal(datasource); // 按单部分操作加密或解密数据,或者结束一个多部分操作
- } catch (Throwable e) {
- e.printStackTrace();
- }
- return null;
- }
-
- /**
- * 解密
- *
- * @param src
- * byte[]
- * @param password
- * String
- * @return byte[]
- * @throws Exception
- */
- public static byte[] decrypt(byte[] src, String password) throws Exception {
- // DES算法要求有一个可信任的随机数源
- SecureRandom random = new SecureRandom();
- // 创建一个DESKeySpec对象
- DESKeySpec desKey = new DESKeySpec(password.getBytes());
- // 创建一个密匙工厂
- SecretKeyFactory keyFactory = SecretKeyFactory.getInstance("DES");// 返回实现指定转换的
- // Cipher
- // 对象
- // 将DESKeySpec对象转换成SecretKey对象
- SecretKey securekey = keyFactory.generateSecret(desKey);
- // Cipher对象实际完成解密操作
- Cipher cipher = Cipher.getInstance("DES");
- // 用密匙初始化Cipher对象
- cipher.init(Cipher.DECRYPT_MODE, securekey, random);
- // 真正开始解密操作
- return cipher.doFinal(src);
- }
-}
-```
-
-结果:
-
-```
-加密后:[B@50cbc42f
-解密后:cryptology
-```
-
-### [**IDEA:**](https://baike.baidu.com/item/%E5%9B%BD%E9%99%85%E6%95%B0%E6%8D%AE%E5%8A%A0%E5%AF%86%E7%AE%97%E6%B3%95/11048972?fr=aladdin)
-
-- **这种算法是在DES算法的基础上发展出来的,类似于三重DES。**
-- **发展IDEA也是因为感到DES具有密钥太短等缺点。**
-- **DEA的密钥为128位,这么长的密钥在今后若干年内应该是安全的。**
-- **在实际项目中用到的很少了解即可。**
-
-#### 代码实现:
-
-IDEA算法实现
-
-```java
-package com.snailclimb.ks.securityAlgorithm;
-
-import java.security.Key;
-import java.security.Security;
-
-import javax.crypto.Cipher;
-import javax.crypto.KeyGenerator;
-import javax.crypto.SecretKey;
-import javax.crypto.spec.SecretKeySpec;
-
-import org.apache.commons.codec.binary.Base64;
-import org.bouncycastle.jce.provider.BouncyCastleProvider;
-
-public class IDEADemo {
- public static void main(String args[]) {
- bcIDEA();
- }
- public static void bcIDEA() {
- String src = "www.xttblog.com security idea";
- try {
- Security.addProvider(new BouncyCastleProvider());
-
- //生成key
- KeyGenerator keyGenerator = KeyGenerator.getInstance("IDEA");
- keyGenerator.init(128);
- SecretKey secretKey = keyGenerator.generateKey();
- byte[] keyBytes = secretKey.getEncoded();
-
- //转换密钥
- Key key = new SecretKeySpec(keyBytes, "IDEA");
-
- //加密
- Cipher cipher = Cipher.getInstance("IDEA/ECB/ISO10126Padding");
- cipher.init(Cipher.ENCRYPT_MODE, key);
- byte[] result = cipher.doFinal(src.getBytes());
- System.out.println("bc idea encrypt : " + Base64.encodeBase64String(result));
-
- //解密
- cipher.init(Cipher.DECRYPT_MODE, key);
- result = cipher.doFinal(result);
- System.out.println("bc idea decrypt : " + new String(result));
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
-}
-
-```
-
-## **5. 非对称加密:**
-
-- 与对称加密算法不同,非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥 (privatekey)。
-- 公开密钥与私有密钥是一对,如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密;
-- 如果用私有密钥对数据进行加密,那么只有用对应的公开密钥才能解密。
-- 因为加密和解密使用的是两个不同的密钥,所以这种算法叫作非对称加密算法。
-### [**RAS:**](https://baike.baidu.com/item/DES)
-
-RSA是目前最有影响力和最常用的公钥加密算法。它能够抵抗到目前为止已知的绝大多数密码攻击,已被ISO推荐为公钥数据加密标准。
-
-#### 代码实现:
-
-RAS算法实现:
-
-```java
-package com.snailclimb.ks.securityAlgorithm;
-
-import org.apache.commons.codec.binary.Base64;
-
-import java.security.*;
-import java.security.spec.PKCS8EncodedKeySpec;
-import java.security.spec.X509EncodedKeySpec;
-import java.util.HashMap;
-import java.util.Map;
-
-import javax.crypto.Cipher;
-
-/**
- * Created by humf.需要依赖 commons-codec 包
- */
-public class RSADemo {
-
- public static void main(String[] args) throws Exception {
- Map<String, Key> keyMap = initKey();
- String publicKey = getPublicKey(keyMap);
- String privateKey = getPrivateKey(keyMap);
-
- System.out.println(keyMap);
- System.out.println("-----------------------------------");
- System.out.println(publicKey);
- System.out.println("-----------------------------------");
- System.out.println(privateKey);
- System.out.println("-----------------------------------");
- byte[] encryptByPrivateKey = encryptByPrivateKey("123456".getBytes(), privateKey);
- byte[] encryptByPublicKey = encryptByPublicKey("123456", publicKey);
- System.out.println(encryptByPrivateKey);
- System.out.println("-----------------------------------");
- System.out.println(encryptByPublicKey);
- System.out.println("-----------------------------------");
- String sign = sign(encryptByPrivateKey, privateKey);
- System.out.println(sign);
- System.out.println("-----------------------------------");
- boolean verify = verify(encryptByPrivateKey, publicKey, sign);
- System.out.println(verify);
- System.out.println("-----------------------------------");
- byte[] decryptByPublicKey = decryptByPublicKey(encryptByPrivateKey, publicKey);
- byte[] decryptByPrivateKey = decryptByPrivateKey(encryptByPublicKey, privateKey);
- System.out.println(decryptByPublicKey);
- System.out.println("-----------------------------------");
- System.out.println(decryptByPrivateKey);
-
- }
-
- public static final String KEY_ALGORITHM = "RSA";
- public static final String SIGNATURE_ALGORITHM = "MD5withRSA";
-
- private static final String PUBLIC_KEY = "RSAPublicKey";
- private static final String PRIVATE_KEY = "RSAPrivateKey";
-
- public static byte[] decryptBASE64(String key) {
- return Base64.decodeBase64(key);
- }
-
- public static String encryptBASE64(byte[] bytes) {
- return Base64.encodeBase64String(bytes);
- }
-
- /**
- * 用私钥对信息生成数字签名
- *
- * @param data
- * 加密数据
- * @param privateKey
- * 私钥
- * @return
- * @throws Exception
- */
- public static String sign(byte[] data, String privateKey) throws Exception {
- // 解密由base64编码的私钥
- byte[] keyBytes = decryptBASE64(privateKey);
- // 构造PKCS8EncodedKeySpec对象
- PKCS8EncodedKeySpec pkcs8KeySpec = new PKCS8EncodedKeySpec(keyBytes);
- // KEY_ALGORITHM 指定的加密算法
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- // 取私钥匙对象
- PrivateKey priKey = keyFactory.generatePrivate(pkcs8KeySpec);
- // 用私钥对信息生成数字签名
- Signature signature = Signature.getInstance(SIGNATURE_ALGORITHM);
- signature.initSign(priKey);
- signature.update(data);
- return encryptBASE64(signature.sign());
- }
-
- /**
- * 校验数字签名
- *
- * @param data
- * 加密数据
- * @param publicKey
- * 公钥
- * @param sign
- * 数字签名
- * @return 校验成功返回true 失败返回false
- * @throws Exception
- */
- public static boolean verify(byte[] data, String publicKey, String sign) throws Exception {
- // 解密由base64编码的公钥
- byte[] keyBytes = decryptBASE64(publicKey);
- // 构造X509EncodedKeySpec对象
- X509EncodedKeySpec keySpec = new X509EncodedKeySpec(keyBytes);
- // KEY_ALGORITHM 指定的加密算法
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- // 取公钥匙对象
- PublicKey pubKey = keyFactory.generatePublic(keySpec);
- Signature signature = Signature.getInstance(SIGNATURE_ALGORITHM);
- signature.initVerify(pubKey);
- signature.update(data);
- // 验证签名是否正常
- return signature.verify(decryptBASE64(sign));
- }
-
- public static byte[] decryptByPrivateKey(byte[] data, String key) throws Exception {
- // 对密钥解密
- byte[] keyBytes = decryptBASE64(key);
- // 取得私钥
- PKCS8EncodedKeySpec pkcs8KeySpec = new PKCS8EncodedKeySpec(keyBytes);
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- Key privateKey = keyFactory.generatePrivate(pkcs8KeySpec);
- // 对数据解密
- Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
- cipher.init(Cipher.DECRYPT_MODE, privateKey);
- return cipher.doFinal(data);
- }
-
- /**
- * 解密<br>
- * 用私钥解密
- *
- * @param data
- * @param key
- * @return
- * @throws Exception
- */
- public static byte[] decryptByPrivateKey(String data, String key) throws Exception {
- return decryptByPrivateKey(decryptBASE64(data), key);
- }
-
- /**
- * 解密<br>
- * 用公钥解密
- *
- * @param data
- * @param key
- * @return
- * @throws Exception
- */
- public static byte[] decryptByPublicKey(byte[] data, String key) throws Exception {
- // 对密钥解密
- byte[] keyBytes = decryptBASE64(key);
- // 取得公钥
- X509EncodedKeySpec x509KeySpec = new X509EncodedKeySpec(keyBytes);
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- Key publicKey = keyFactory.generatePublic(x509KeySpec);
- // 对数据解密
- Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
- cipher.init(Cipher.DECRYPT_MODE, publicKey);
- return cipher.doFinal(data);
- }
-
- /**
- * 加密<br>
- * 用公钥加密
- *
- * @param data
- * @param key
- * @return
- * @throws Exception
- */
- public static byte[] encryptByPublicKey(String data, String key) throws Exception {
- // 对公钥解密
- byte[] keyBytes = decryptBASE64(key);
- // 取得公钥
- X509EncodedKeySpec x509KeySpec = new X509EncodedKeySpec(keyBytes);
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- Key publicKey = keyFactory.generatePublic(x509KeySpec);
- // 对数据加密
- Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
- cipher.init(Cipher.ENCRYPT_MODE, publicKey);
- return cipher.doFinal(data.getBytes());
- }
-
- /**
- * 加密<br>
- * 用私钥加密
- *
- * @param data
- * @param key
- * @return
- * @throws Exception
- */
- public static byte[] encryptByPrivateKey(byte[] data, String key) throws Exception {
- // 对密钥解密
- byte[] keyBytes = decryptBASE64(key);
- // 取得私钥
- PKCS8EncodedKeySpec pkcs8KeySpec = new PKCS8EncodedKeySpec(keyBytes);
- KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
- Key privateKey = keyFactory.generatePrivate(pkcs8KeySpec);
- // 对数据加密
- Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
- cipher.init(Cipher.ENCRYPT_MODE, privateKey);
- return cipher.doFinal(data);
- }
-
- /**
- * 取得私钥
- *
- * @param keyMap
- * @return
- * @throws Exception
- */
- public static String getPrivateKey(Map<String, Key> keyMap) throws Exception {
- Key key = (Key) keyMap.get(PRIVATE_KEY);
- return encryptBASE64(key.getEncoded());
- }
-
- /**
- * 取得公钥
- *
- * @param keyMap
- * @return
- * @throws Exception
- */
- public static String getPublicKey(Map<String, Key> keyMap) throws Exception {
- Key key = keyMap.get(PUBLIC_KEY);
- return encryptBASE64(key.getEncoded());
- }
-
- /**
- * 初始化密钥
- *
- * @return
- * @throws Exception
- */
- public static Map<String, Key> initKey() throws Exception {
- KeyPairGenerator keyPairGen = KeyPairGenerator.getInstance(KEY_ALGORITHM);
- keyPairGen.initialize(1024);
- KeyPair keyPair = keyPairGen.generateKeyPair();
- Map<String, Key> keyMap = new HashMap(2);
- keyMap.put(PUBLIC_KEY, keyPair.getPublic());// 公钥
- keyMap.put(PRIVATE_KEY, keyPair.getPrivate());// 私钥
- return keyMap;
- }
-
-}
-```
-
-结果:
-
-```
-{RSAPublicKey=Sun RSA public key, 1024 bits
- modulus: 115328826086047873902606456571034976538836553998745367981848911677968062571831626674499650854318207280419960767020601253071739555161388135589487284843845439403614883967713749605268831336418001722701924537624573180276356615050309809260289965219855862692230362893996010057188170525719351126759886050891484226169
- public exponent: 65537, RSAPrivateKey=sun.security.rsa.RSAPrivateCrtKeyImpl@93479}
------------------------------------
-MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCkO9PBTOFJQTkzznALN62PU7ixd9YFjXrt2dPOGj3wwhymbOU8HLoCztjwpLXHgbpBUJlGmbURV955M1BkZ1kr5dkZYR5x1gO4xOnu8rEipy4AAMcpFttfiarIZrtzL9pKEvEOxABltVN4yzFDr3IjBqY46aHna7YjwhXI0xHieQIDAQAB
------------------------------------
-MIICdQIBADANBgkqhkiG9w0BAQEFAASCAl8wggJbAgEAAoGBAKQ708FM4UlBOTPOcAs3rY9TuLF31gWNeu3Z084aPfDCHKZs5TwcugLO2PCktceBukFQmUaZtRFX3nkzUGRnWSvl2RlhHnHWA7jE6e7ysSKnLgAAxykW21+Jqshmu3Mv2koS8Q7EAGW1U3jLMUOvciMGpjjpoedrtiPCFcjTEeJ5AgMBAAECgYAK4sxOa8IjEOexv2U92Rrv/SSo3sCY7Z/QVDft2V9xrewoO9+V9HF/7iYDDWffKYInAiimvVl7JM/iSLxza0ZFv29VMpyDcr4TigYmWwBlk7ZbxSTkqLdNwxxldMmEoTn1py53MUm+1V1K3rzNvJjuZaZFAevU7vUnwQwD+JGQYQJBAM9HBaC+dF3PJ2mkXekHpDS1ZPaSFdrdzd/GvHFi/cJAMM+Uz6PmpkosNXRtOpSYWwlOMRamLZtrHhfQoqSk3S8CQQDK1qL1jGvVdqw5OjqxktR7MmOsWUVZdWiBN+6ojxBgA0yVn0n7vkdAAgEZBj89WG0VHPEu3hd4AgXFZHDfXeDXAkBvSn7nE9t/Et7ihfI2UHgGJO8UxNMfNMB5Skebyb7eMYEDs67ZHdpjMOFypcMyTatzj5wjwQ3zyMvblZX+ONbZAkAX4ysRy9WvL+icXLUo0Gfhkk+WrnSyUldaUGH0y9Rb2kecn0OxN/lgGlxSvB+ac910zRHCOTl+Uo6nbmq0g3PFAkAyqA4eT7G9GXfncakgW1Kdkn72w/ODpozgfhTLNX0SGw1ITML3c4THTtH5h3zLi3AF9zJO2O+K6ajRbV0szHHI
------------------------------------
-[B@387c703b
------------------------------------
-[B@224aed64
------------------------------------
-la4Hc4n/UbeBu0z9iLRuwKVv014SiOJMXkO5qdJvKBsw0MlnsrM+89a3p73yMrb1dAnCU/2kgO0PtFpvmG8pzxTe1u/5nX/25iIyUXALlwVRptJyjzFE83g2IX0XEv/Dxqr1RCRcrMHOLQM0oBoxZCaChmyw1Ub4wsSs6Ndxb9M=
------------------------------------
-true
------------------------------------
-[B@c39f790
------------------------------------
-[B@71e7a66b
-
-```
-
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\346\225\260\346\215\256\347\273\223\346\236\204.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\346\225\260\346\215\256\347\273\223\346\236\204.md"
deleted file mode 100644
index 8b8207f7f82..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\346\225\260\346\215\256\347\273\223\346\236\204.md"
+++ /dev/null
@@ -1,182 +0,0 @@
-<!-- MarkdownTOC -->
-
-- [Queue](#queue)
- - [什么是队列](#什么是队列)
- - [队列的种类](#队列的种类)
- - [Java 集合框架中的队列 Queue](#java-集合框架中的队列-queue)
- - [推荐文章](#推荐文章)
-- [Set](#set)
- - [什么是 Set](#什么是-set)
- - [补充:有序集合与无序集合说明](#补充:有序集合与无序集合说明)
- - [HashSet 和 TreeSet 底层数据结构](#hashset-和-treeset-底层数据结构)
- - [推荐文章](#推荐文章-1)
-- [List](#list)
- - [什么是List](#什么是list)
- - [List的常见实现类](#list的常见实现类)
- - [ArrayList 和 LinkedList 源码学习](#arraylist-和-linkedlist-源码学习)
- - [推荐阅读](#推荐阅读)
-- [Map](#map)
-- [树](#树)
-
-<!-- /MarkdownTOC -->
-
-
-## Queue
-
-### 什么是队列
-队列是数据结构中比较重要的一种类型,它支持 FIFO,尾部添加、头部删除(先进队列的元素先出队列),跟我们生活中的排队类似。
-
-### 队列的种类
-
-- **单队列**(单队列就是常见的队列, 每次添加元素时,都是添加到队尾,存在“假溢出”的问题也就是明明有位置却不能添加的情况)
-- **循环队列**(避免了“假溢出”的问题)
-
-### Java 集合框架中的队列 Queue
-
-Java 集合中的 Queue 继承自 Collection 接口 ,Deque, LinkedList, PriorityQueue, BlockingQueue 等类都实现了它。
-Queue 用来存放 等待处理元素 的集合,这种场景一般用于缓冲、并发访问。
-除了继承 Collection 接口的一些方法,Queue 还添加了额外的 添加、删除、查询操作。
-
-### 推荐文章
-
-- [Java 集合深入理解(9):Queue 队列](https://blog.csdn.net/u011240877/article/details/52860924)
-
-## Set
-
-### 什么是 Set
-Set 继承于 Collection 接口,是一个不允许出现重复元素,并且无序的集合,主要 HashSet 和 TreeSet 两大实现类。
-
-在判断重复元素的时候,Set 集合会调用 hashCode()和 equal()方法来实现。
-
-### 补充:有序集合与无序集合说明
-- 有序集合:集合里的元素可以根据 key 或 index 访问 (List、Map)
-- 无序集合:集合里的元素只能遍历。(Set)
-
-
-### HashSet 和 TreeSet 底层数据结构
-
-**HashSet** 是哈希表结构,主要利用 HashMap 的 key 来存储元素,计算插入元素的 hashCode 来获取元素在集合中的位置;
-
-**TreeSet** 是红黑树结构,每一个元素都是树中的一个节点,插入的元素都会进行排序;
-
-
-### 推荐文章
-
-- [Java集合--Set(基础)](https://www.jianshu.com/p/b48c47a42916)
-
-## List
-
-### 什么是List
-
-在 List 中,用户可以精确控制列表中每个元素的插入位置,另外用户可以通过整数索引(列表中的位置)访问元素,并搜索列表中的元素。 与 Set 不同,List 通常允许重复的元素。 另外 List 是有序集合而 Set 是无序集合。
-
-### List的常见实现类
-
-**ArrayList** 是一个数组队列,相当于动态数组。它由数组实现,随机访问效率高,随机插入、随机删除效率低。
-
-**LinkedList** 是一个双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList随机访问效率低,但随机插入、随机删除效率高。
-
-**Vector** 是矢量队列,和ArrayList一样,它也是一个动态数组,由数组实现。但是ArrayList是非线程安全的,而Vector是线程安全的。
-
-**Stack** 是栈,它继承于Vector。它的特性是:先进后出(FILO, First In Last Out)。相关阅读:[java数据结构与算法之栈(Stack)设计与实现](https://blog.csdn.net/javazejian/article/details/53362993)
-
-### ArrayList 和 LinkedList 源码学习
-- [ArrayList 源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/ArrayList.md)
-- [LinkedList 源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/LinkedList.md)
-
-### 推荐阅读
-
-- [java 数据结构与算法之顺序表与链表深入分析](https://blog.csdn.net/javazejian/article/details/52953190)
-
-
-## Map
-
-
-- [集合框架源码学习之 HashMap(JDK1.8)](https://juejin.im/post/5ab0568b5188255580020e56)
-- [ConcurrentHashMap 实现原理及源码分析](https://link.juejin.im/?target=http%3A%2F%2Fwww.cnblogs.com%2Fchengxiao%2Fp%2F6842045.html)
-
-## 树
- * ### 1 二叉树
-
- [二叉树](https://baike.baidu.com/item/%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
-
- (1)[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
-
- (2)[满二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
-
- (3)[平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91/10421057)——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
-
- * ### 2 完全二叉树
-
- [完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
-
- 完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树
- * ### 3 满二叉树
-
- [满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,国内外的定义不同)
-
- 国内教程定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
- * ### 堆
-
- [数据结构之堆的定义](https://blog.csdn.net/qq_33186366/article/details/51876191)
-
- 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
- * ### 4 二叉查找树(BST)
-
- [浅谈算法和数据结构: 七 二叉查找树](http://www.cnblogs.com/yangecnu/p/Introduce-Binary-Search-Tree.html)
-
- 二叉查找树的特点:
-
- 1. 若任意节点的左子树不空,则左子树上所有结点的 值均小于它的根结点的值;
- 2. 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 3. 任意节点的左、右子树也分别为二叉查找树。
- 4. 没有键值相等的节点(no duplicate nodes)。
-
- * ### 5 平衡二叉树(Self-balancing binary search tree)
-
- [ 平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等)
- * ### 6 红黑树
-
- - 红黑树特点:
- 1. 每个节点非红即黑;
- 2. 根节点总是黑色的;
- 3. 每个叶子节点都是黑色的空节点(NIL节点);
- 4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
- 5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
-
- - 红黑树的应用:
-
- TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。
-
- - 为什么要用红黑树
-
- 简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
-
- - 推荐文章:
- - [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
- - [寻找红黑树的操作手册](http://dandanlove.com/2018/03/18/red-black-tree/)(文章排版以及思路真的不错)
- - [红黑树深入剖析及Java实现](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
- * ### 7 B-,B+,B*树
-
- [二叉树学习笔记之B树、B+树、B*树 ](https://yq.aliyun.com/articles/38345)
-
- [《B-树,B+树,B*树详解》](https://blog.csdn.net/aqzwss/article/details/53074186)
-
- [《B-树,B+树与B*树的优缺点比较》](https://blog.csdn.net/bigtree_3721/article/details/73632405)
-
- B-树(或B树)是一种平衡的多路查找(又称排序)树,在文件系统中有所应用。主要用作文件的索引。其中的B就表示平衡(Balance)
- 1. B+ 树的叶子节点链表结构相比于 B- 树便于扫库,和范围检索。
- 2. B+树支持range-query(区间查询)非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
- 3. B*树 是B+树的变体,B*树分配新结点的概率比B+树要低,空间使用率更高;
- * ### 8 LSM 树
-
- [[HBase] LSM树 VS B+树](https://blog.csdn.net/dbanote/article/details/8897599)
-
- B+树最大的性能问题是会产生大量的随机IO
-
- 为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
-
- [LSM树由来、设计思想以及应用到HBase的索引](http://www.cnblogs.com/yanghuahui/p/3483754.html)
-
-
-
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225.md"
deleted file mode 100644
index ec53e7002f9..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225.md"
+++ /dev/null
@@ -1,90 +0,0 @@
-
-## LeetCode
-[LeetCode(中国)官网](https://leetcode-cn.com/)
-
-[如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
-
-
-## 牛客网:
-
-[牛客网首页](https://www.nowcoder.com)
-
-
-> ### **[剑指offer编程题](https://www.nowcoder.com/ta/coding-interviews)**
-
-**分类解析:**
-- [(1)斐波那契数列问题和跳台阶问题](https://github.com/Snailclimb/Java-Guide/tree/master/数据结构与算法/算法题解析/剑指offer/(1)斐波那契数列问题和跳台阶问题.md)
-- [(2)二维数组查找和替换空格问题](https://github.com/Snailclimb/Java-Guide/tree/master/数据结构与算法/算法题解析/剑指offer/(2)二维数组查找和替换空格问题.md)
-- [(3)数值的整数次方和调整数组元素顺序](https://github.com/Snailclimb/Java-Guide/tree/master/数据结构与算法/算法题解析/剑指offer/(3)数值的整数次方和调整数组元素顺序.md)
-- [(4)链表相关编程题](https://github.com/Snailclimb/Java-Guide/tree/master/数据结构与算法/算法题解析/剑指offer/(4)链表相关编程题.md)
-- [(5)栈变队列和栈的压入、弹出序列](https://github.com/Snailclimb/Java-Guide/tree/master/数据结构与算法/算法题解析/剑指offer/(5)栈变队列和栈的压入、弹出序列.md)
-
-> ### [2017校招真题](https://www.nowcoder.com/ta/2017test)
-
-> ### [华为机试题](https://www.nowcoder.com/ta/huawei)
-
-
-## 公司真题
-
-> [ 网易2018校园招聘编程题真题集合](https://www.nowcoder.com/test/6910869/summary)
-
-**解析:**
-- [ 网易2018校招编程题1-3](https://github.com/Snailclimb/Java-Guide/tree/master/数据结构与算法/算法题解析/公司真题/网易2018校招编程题1-3.md)
-
-> [ 网易2018校招内推编程题集合](https://www.nowcoder.com/test/6291726/summary)
-
-> [2017年校招全国统一模拟笔试(第五场)编程题集合](https://www.nowcoder.com/test/5986669/summary)
-
- > [2017年校招全国统一模拟笔试(第四场)编程题集合](https://www.nowcoder.com/test/5507925/summary)
-
-> [2017年校招全国统一模拟笔试(第三场)编程题集合](https://www.nowcoder.com/test/5217106/summary)
-
-> [2017年校招全国统一模拟笔试(第二场)编程题集合](https://www.nowcoder.com/test/4546329/summary)
-
-> [ 2017年校招全国统一模拟笔试(第一场)编程题集合](https://www.nowcoder.com/test/4236887/summary)
-
-
-> [百度2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4998655/summary)
-
-> [网易2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4575457/summary)
-
- > [网易2017秋招编程题集合](https://www.nowcoder.com/test/2811407/summary)
-
- > [网易有道2017内推编程题](https://www.nowcoder.com/test/2385858/summary)
-
- > [ 滴滴出行2017秋招笔试真题-编程题汇总](https://www.nowcoder.com/test/3701760/summary)
-
-> [腾讯2017暑期实习生编程题](https://www.nowcoder.com/test/1725829/summary)
-
- > [今日头条2017客户端工程师实习生笔试题](https://www.nowcoder.com/test/1649301/summary)
-
- > [今日头条2017后端工程师实习生笔试题](https://www.nowcoder.com/test/1649268/summary)
-
-
-
-## 排序算法:
-[图解排序算法(一)之3种简单排序(选择,冒泡,直接插入)](http://www.cnblogs.com/chengxiao/p/6103002.html)
-
-[图解排序算法(二)之希尔排序](https://www.cnblogs.com/chengxiao/p/6104371.html)
-
-[图解排序算法(三)之堆排序](http://www.cnblogs.com/chengxiao/p/6129630.html)
-
-[图解排序算法(四)之归并排序](http://www.cnblogs.com/chengxiao/p/6194356.html)
-
-[图解排序算法(五)之快速排序——三数取中法](http://www.cnblogs.com/chengxiao/p/6262208.html)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\205\254\345\217\270\347\234\237\351\242\230/\347\275\221\346\230\2232018\346\240\241\346\213\233\347\274\226\347\250\213\351\242\2301-3.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\205\254\345\217\270\347\234\237\351\242\230/\347\275\221\346\230\2232018\346\240\241\346\213\233\347\274\226\347\250\213\351\242\2301-3.md"
deleted file mode 100644
index d929d20046c..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\205\254\345\217\270\347\234\237\351\242\230/\347\275\221\346\230\2232018\346\240\241\346\213\233\347\274\226\347\250\213\351\242\2301-3.md"
+++ /dev/null
@@ -1,256 +0,0 @@
-下面三道编程题来自网易2018校招编程题,这三道应该来说是非常简单的编程题了,这些题目大家稍微有点编程和数学基础的话应该没什么问题。看答案之前一定要自己先想一下如果是自己做的话会怎么去做,然后再对照这我的答案看看,和你自己想的有什么区别?那一种方法更好?
-
-
-> # 问题
-
-## 一 获得特定数量硬币问题
-
-小易准备去魔法王国采购魔法神器,购买魔法神器需要使用魔法币,但是小易现在一枚魔法币都没有,但是小易有两台魔法机器可以通过投入x(x可以为0)个魔法币产生更多的魔法币。
-
-魔法机器1:如果投入x个魔法币,魔法机器会将其变为2x+1个魔法币
-
-魔法机器2:如果投入x个魔法币,魔法机器会将其变为2x+2个魔法币
-
-小易采购魔法神器总共需要n个魔法币,所以小易只能通过两台魔法机器产生恰好n个魔法币,小易需要你帮他设计一个投入方案使他最后恰好拥有n个魔法币。
-
-**输入描述:** 输入包括一行,包括一个正整数n(1 ≤ n ≤ 10^9),表示小易需要的魔法币数量。
-
-
-**输出描述:** 输出一个字符串,每个字符表示该次小易选取投入的魔法机器。其中只包含字符'1'和'2'。
-
-**输入例子1:** 10
-
-**输出例子1:** 122
-
-## 二 求“相反数”问题
-
-为了得到一个数的"相反数",我们将这个数的数字顺序颠倒,然后再加上原先的数得到"相反数"。例如,为了得到1325的"相反数",首先我们将该数的数字顺序颠倒,我们得到5231,之后再加上原先的数,我们得到5231+1325=6556.如果颠倒之后的数字有前缀零,前缀零将会被忽略。例如n = 100, 颠倒之后是1.
-
-**输入描述:** 输入包括一个整数n,(1 ≤ n ≤ 10^5)
-
-
-**输出描述:** 输出一个整数,表示n的相反数
-
-**输入例子1:** 1325
-
-**输出例子1:** 6556
-
-## 三 字符串碎片的平均长度
-
-一个由小写字母组成的字符串可以看成一些同一字母的最大碎片组成的。例如,"aaabbaaac"是由下面碎片组成的:'aaa','bb','c'。牛牛现在给定一个字符串,请你帮助计算这个字符串的所有碎片的平均长度是多少。
-
-**输入描述:** 输入包括一个字符串s,字符串s的长度length(1 ≤ length ≤ 50),s只含小写字母('a'-'z')
-
-
-**输出描述:** 输出一个整数,表示所有碎片的平均长度,四舍五入保留两位小数。
-
-**如样例所示:** s = "aaabbaaac"
-所有碎片的平均长度 = (3 + 2 + 3 + 1) / 4 = 2.25
-
-**输入例子1:** aaabbaaac
-
-**输出例子1:** 2.25
-
-
-
-> # 答案
-
-## 一 获得特定数量硬币问题
-
-### 分析:
-
-作为该试卷的第一题,这道题应该只要思路正确就很简单了。
-
-解题关键:明确魔法机器1只能产生奇数,魔法机器2只能产生偶数即可。我们从后往前一步一步推回去即可。
-
-### 示例代码
-注意:由于用户的输入不确定性,一般是为了程序高可用性使需要将捕获用户输入异常然后友好提示用户输入类型错误并重新输入的。所以下面我给了两个版本,这两个版本都是正确的。这里只是给大家演示如何捕获输入类型异常,后面的题目中我给的代码没有异常处理的部分,参照下面两个示例代码,应该很容易添加。(PS:企业面试中没有明确就不用添加异常处理,当然你有的话也更好)
-
-**不带输入异常处理判断的版本:**
-
-```java
-import java.util.Scanner;
-
-public class Main2 {
- // 解题关键:明确魔法机器1只能产生奇数,魔法机器2只能产生偶数即可。我们从后往前一步一步推回去即可。
-
- public static void main(String[] args) {
- System.out.println("请输入要获得的硬币数量:");
- Scanner scanner = new Scanner(System.in);
- int coincount = scanner.nextInt();
- StringBuilder sb = new StringBuilder();
- while (coincount >= 1) {
- // 偶数的情况
- if (coincount % 2 == 0) {
- coincount = (coincount - 2) / 2;
- sb.append("2");
- // 奇数的情况
- } else {
- coincount = (coincount - 1) / 2;
- sb.append("1");
- }
- }
- // 输出反转后的字符串
- System.out.println(sb.reverse());
-
- }
-}
-```
-
-**带输入异常处理判断的版本(当输入的不是整数的时候会提示重新输入):**
-
-```java
-import java.util.InputMismatchException;
-import java.util.Scanner;
-
-
-public class Main {
- // 解题关键:明确魔法机器1只能产生奇数,魔法机器2只能产生偶数即可。我们从后往前一步一步推回去即可。
-
- public static void main(String[] args) {
- System.out.println("请输入要获得的硬币数量:");
- Scanner scanner = new Scanner(System.in);
- boolean flag = true;
- while (flag) {
- try {
- int coincount = scanner.nextInt();
- StringBuilder sb = new StringBuilder();
- while (coincount >= 1) {
- // 偶数的情况
- if (coincount % 2 == 0) {
- coincount = (coincount - 2) / 2;
- sb.append("2");
- // 奇数的情况
- } else {
- coincount = (coincount - 1) / 2;
- sb.append("1");
- }
- }
- // 输出反转后的字符串
- System.out.println(sb.reverse());
- flag=false;//程序结束
- } catch (InputMismatchException e) {
- System.out.println("输入数据类型不匹配,请您重新输入:");
- scanner.nextLine();
- continue;
- }
- }
-
- }
-}
-
-```
-
-
-## 二 求“相反数”问题
-
-### 分析:
-
-解决本道题有几种不同的方法,但是最快速的方法就是利用reverse()方法反转字符串然后再将字符串转换成int类型的整数,这个方法是快速解决本题关键。我们先来回顾一下下面两个知识点:
-
-**1)String转int;**
-
-在 Java 中要将 String 类型转化为 int 类型时,需要使用 Integer 类中的 parseInt() 方法或者 valueOf() 方法进行转换.
-```java
- String str = "123";
- int a = Integer.parseInt(str);
-```
- 或
-```java
- String str = "123";
- int a = Integer.valueOf(str).intValue();
-```
-
-
-**2)next()和nextLine()的区别**
-
-在Java中输入字符串有两种方法,就是next()和nextLine().两者的区别就是:nextLine()的输入是碰到回车就终止输入,而next()方法是碰到空格,回车,Tab键都会被视为终止符。所以next()不会得到带空格的字符串,而nextLine()可以得到带空格的字符串。
-
-### 示例代码:
-
-```java
-import java.util.Scanner;
-
-/**
- * 本题关键:①String转int;②next()和nextLine()的区别
- */
-public class Main {
-
- public static void main(String[] args) {
-
- System.out.println("请输入一个整数:");
- Scanner scanner = new Scanner(System.in);
- String s=scanner.next();
- //将字符串转换成数字
- int number1=Integer.parseInt(s);
- //将字符串倒序后转换成数字
- //因为Integer.parseInt()的参数类型必须是字符串所以必须加上toString()
- int number2=Integer.parseInt(new StringBuilder(s).reverse().toString());
- System.out.println(number1+number2);
-
- }
-}
-```
-
-## 三 字符串碎片的平均长度
-
-### 分析:
-
-这道题的意思也就是要求:(字符串的总长度)/(相同字母团构成的字符串的个数)。
-
-这样就很简单了,就变成了字符串的字符之间的比较。如果需要比较字符串的字符的话,我们可以利用charAt(i)方法:取出特定位置的字符与后一个字符比较,或者利用toCharArray()方法将字符串转换成字符数组采用同样的方法做比较。
-
-### 示例代码
-
-**利用charAt(i)方法:**
-
-```java
-import java.util.Scanner;
-
-public class Main {
-
- public static void main(String[] args) {
-
- Scanner sc = new Scanner(System.in);
- while (sc.hasNext()) {
- String s = sc.next();
- //个数至少为一个
- float count = 1;
- for (int i = 0; i < s.length() - 1; i++) {
- if (s.charAt(i) != s.charAt(i + 1)) {
- count++;
- }
- }
- System.out.println(s.length() / count);
- }
- }
-
-}
-```
-
-**利用toCharArray()方法:**
-
-```java
-import java.util.Scanner;
-
-public class Main2 {
-
- public static void main(String[] args) {
-
- Scanner sc = new Scanner(System.in);
- while (sc.hasNext()) {
- String s = sc.next();
- //个数至少为一个
- float count = 1;
- char [] stringArr = s.toCharArray();
- for (int i = 0; i < stringArr.length - 1; i++) {
- if (stringArr[i] != stringArr[i + 1]) {
- count++;
- }
- }
- System.out.println(s.length() / count);
- }
- }
-
-}
-```
\ No newline at end of file
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2101\357\274\211\346\226\220\346\263\242\351\202\243\345\245\221\346\225\260\345\210\227\351\227\256\351\242\230\345\222\214\350\267\263\345\217\260\351\230\266\351\227\256\351\242\230.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2101\357\274\211\346\226\220\346\263\242\351\202\243\345\245\221\346\225\260\345\210\227\351\227\256\351\242\230\345\222\214\350\267\263\345\217\260\351\230\266\351\227\256\351\242\230.md"
deleted file mode 100644
index 87a51d9083e..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2101\357\274\211\346\226\220\346\263\242\351\202\243\345\245\221\346\225\260\345\210\227\351\227\256\351\242\230\345\222\214\350\267\263\345\217\260\351\230\266\351\227\256\351\242\230.md"
+++ /dev/null
@@ -1,127 +0,0 @@
-### 一 斐波那契数列
-#### **题目描述:**
-大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项。
-n<=39
-
-#### **问题分析:**
-可以肯定的是这一题通过递归的方式是肯定能做出来,但是这样会有一个很大的问题,那就是递归大量的重复计算会导致内存溢出。另外可以使用迭代法,用fn1和fn2保存计算过程中的结果,并复用起来。下面我会把两个方法示例代码都给出来并给出两个方法的运行时间对比。
-
-#### **示例代码:**
-**采用迭代法:**
-
-```java
-
- int Fibonacci(int number) {
- if (number <= 0) {
- return 0;
- }
- if (number == 1 || number == 2) {
- return 1;
- }
- int first = 1, second = 1, third = 0;
- for (int i = 3; i <= number; i++) {
- third = first + second;
- first = second;
- second = third;
- }
- return third;
- }
-```
-**采用递归:**
-```java
- public int Fibonacci(int n) {
-
- if (n <= 0) {
- return 0;
- }
- if (n == 1||n==2) {
- return 1;
- }
-
- return Fibonacci(n - 2) + Fibonacci(n - 1);
-
- }
-```
-
-#### **运行时间对比:**
-假设n为40我们分别使用迭代法和递归法计算,计算结果如下:
-1. 迭代法
-
-2. 递归法
- 
-
-
-### 二 跳台阶问题
-#### **题目描述:**
-一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
-#### **问题分析:**
-**正常分析法:**
-a.如果两种跳法,1阶或者2阶,那么假定第一次跳的是一阶,那么剩下的是n-1个台阶,跳法是f(n-1);
-b.假定第一次跳的是2阶,那么剩下的是n-2个台阶,跳法是f(n-2)
-c.由a,b假设可以得出总跳法为: f(n) = f(n-1) + f(n-2)
-d.然后通过实际的情况可以得出:只有一阶的时候 f(1) = 1 ,只有两阶的时候可以有 f(2) = 2
-**找规律分析法:**
-f(1) = 1, f(2) = 2, f(3) = 3, f(4) = 5, 可以总结出f(n) = f(n-1) + f(n-2)的规律。
-但是为什么会出现这样的规律呢?假设现在6个台阶,我们可以从第5跳一步到6,这样的话有多少种方案跳到5就有多少种方案跳到6,另外我们也可以从4跳两步跳到6,跳到4有多少种方案的话,就有多少种方案跳到6,其他的不能从3跳到6什么的啦,所以最后就是f(6) = f(5) + f(4);这样子也很好理解变态跳台阶的问题了。
-
-**所以这道题其实就是斐波那契数列的问题。**
-代码只需要在上一题的代码稍做修改即可。和上一题唯一不同的就是这一题的初始元素变为 1 2 3 5 8.....而上一题为1 1 2 3 5 .......。另外这一题也可以用递归做,但是递归效率太低,所以我这里只给出了迭代方式的代码。
-#### **示例代码:**
-```java
-
- int jumpFloor(int number) {
- if (number <= 0) {
- return 0;
- }
- if (number == 1) {
- return 1;
- }
- if (number == 2) {
- return 2;
- }
- int first = 1, second = 2, third = 0;
- for (int i = 3; i <= number; i++) {
- third = first + second;
- first = second;
- second = third;
- }
- return third;
- }
-```
-
-
-### 三 变态跳台阶问题
-#### **题目描述:**
-一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
-
-#### **问题分析:**
-假设n>=2,第一步有n种跳法:跳1级、跳2级、到跳n级
-跳1级,剩下n-1级,则剩下跳法是f(n-1)
-跳2级,剩下n-2级,则剩下跳法是f(n-2)
-......
-跳n-1级,剩下1级,则剩下跳法是f(1)
-跳n级,剩下0级,则剩下跳法是f(0)
-所以在n>=2的情况下:
-f(n)=f(n-1)+f(n-2)+...+f(1)
-因为f(n-1)=f(n-2)+f(n-3)+...+f(1)
-所以f(n)=2*f(n-1) 又f(1)=1,所以可得**f(n)=2^(number-1)**
-
-#### **示例代码:**
-
-```java
- int JumpFloorII(int number) {
- return 1 << --number;//2^(number-1)用位移操作进行,更快
- }
-```
-#### **补充:**
-**java中有三种移位运算符:**
-
-1. “<<” : **左移运算符**,等同于乘2的n次方
-2. “>>”: **右移运算符**,等同于除2的n次方
-3. “>>>” **无符号右移运算符**,不管移动前最高位是0还是1,右移后左侧产生的空位部分都以0来填充。与>>类似。
-例:
- int a = 16;
- int b = a << 2;//左移2,等同于16 * 2的2次方,也就是16 * 4
- int c = a >> 2;//右移2,等同于16 / 2的2次方,也就是16 / 4
-
-
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2102\357\274\211\344\272\214\347\273\264\346\225\260\347\273\204\346\237\245\346\211\276\345\222\214\346\233\277\346\215\242\347\251\272\346\240\274\351\227\256\351\242\230.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2102\357\274\211\344\272\214\347\273\264\346\225\260\347\273\204\346\237\245\346\211\276\345\222\214\346\233\277\346\215\242\347\251\272\346\240\274\351\227\256\351\242\230.md"
deleted file mode 100644
index 964ed6c9892..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2102\357\274\211\344\272\214\347\273\264\346\225\260\347\273\204\346\237\245\346\211\276\345\222\214\346\233\277\346\215\242\347\251\272\346\240\274\351\227\256\351\242\230.md"
+++ /dev/null
@@ -1,64 +0,0 @@
-### 一 二维数组查找
-#### **题目描述:**
-在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
-#### **问题解析:**
-这一道题还是比较简单的,我们需要考虑的是如何做,效率最快。这里有一种很好理解的思路:
-
-> 矩阵是有序的,从左下角来看,向上数字递减,向右数字递增,
- 因此从左下角开始查找,当要查找数字比左下角数字大时。右移
- 要查找数字比左下角数字小时,上移。这样找的速度最快。
-
-#### **示例代码:**
-```java
- public boolean Find(int target, int [][] array) {
- //基本思路从左下角开始找,这样速度最快
- int row = array.length-1;//行
- int column = 0;//列
- //当行数大于0,当前列数小于总列数时循环条件成立
- while((row >= 0)&& (column< array[0].length)){
- if(array[row][column] > target){
- row--;
- }else if(array[row][column] < target){
- column++;
- }else{
- return true;
- }
- }
- return false;
- }
-```
-### 二 替换空格
-#### **题目描述:**
-请实现一个函数,将一个字符串中的空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
-#### **问题分析:**
-这道题不难,我们可以通过循环判断字符串的字符是否为空格,是的话就利用append()方法添加追加“%20”,否则还是追加原字符。
-
-或者最简单的方法就是利用: replaceAll(String regex,String replacement)方法了,一行代码就可以解决。
-
-#### **示例代码:**
-**常规做法:**
-```java
- public String replaceSpace(StringBuffer str) {
- StringBuffer out=new StringBuffer();
- for (int i = 0; i < str.toString().length(); i++) {
- char b=str.charAt(i);
- if(String.valueOf(b).equals(" ")){
- out.append("%20");
- }else{
- out.append(b);
- }
- }
- return out.toString();
- }
-```
-**一行代码解决:**
-```java
- public String replaceSpace(StringBuffer str) {
- //return str.toString().replaceAll(" ", "%20");
- //public String replaceAll(String regex,String replacement)
- //用给定的替换替换与给定的regular expression匹配的此字符串的每个子字符串。
- //\ 转义字符. 如果你要使用 "\" 本身, 则应该使用 "\\". String类型中的空格用“\s”表示,所以我这里猜测"\\s"就是代表空格的意思
- return str.toString().replaceAll("\\s", "%20");
- }
-
-```
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2103\357\274\211\346\225\260\345\200\274\347\232\204\346\225\264\346\225\260\346\254\241\346\226\271\345\222\214\350\260\203\346\225\264\346\225\260\347\273\204\345\205\203\347\264\240\351\241\272\345\272\217.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2103\357\274\211\346\225\260\345\200\274\347\232\204\346\225\264\346\225\260\346\254\241\346\226\271\345\222\214\350\260\203\346\225\264\346\225\260\347\273\204\345\205\203\347\264\240\351\241\272\345\272\217.md"
deleted file mode 100644
index 291569c0375..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2103\357\274\211\346\225\260\345\200\274\347\232\204\346\225\264\346\225\260\346\254\241\346\226\271\345\222\214\350\260\203\346\225\264\346\225\260\347\273\204\345\205\203\347\264\240\351\241\272\345\272\217.md"
+++ /dev/null
@@ -1,113 +0,0 @@
-### 一 数值的整数次方
-#### **题目描述:**
-给定一个double类型的浮点数base和int类型的整数exponent。求base的exponent次方。
-#### **问题解析:**
-这道题算是比较麻烦和难一点的一个了。我这里采用的是**二分幂**思想,当然也可以采用**快速幂**。
-更具剑指offer书中细节,该题的解题思路如下:
-1.当底数为0且指数<0时,会出现对0求倒数的情况,需进行错误处理,设置一个全局变量;
-2.判断底数是否等于0,由于base为double型,所以不能直接用==判断
-3.优化求幂函数(二分幂)。
-当n为偶数,a^n =(a^n/2)*(a^n/2);
-当n为奇数,a^n = a^[(n-1)/2] * a^[(n-1)/2] * a。时间复杂度O(logn)
-
-**时间复杂度**:O(logn)
-#### **示例代码:**
-```java
-public class Solution {
- boolean invalidInput=false;
- public double Power(double base, int exponent) {
- //如果底数等于0并且指数小于0
- //由于base为double型,不能直接用==判断
- if(equal(base,0.0)&&exponent<0){
- invalidInput=true;
- return 0.0;
- }
- int absexponent=exponent;
- //如果指数小于0,将指数转正
- if(exponent<0)
- absexponent=-exponent;
- //getPower方法求出base的exponent次方。
- double res=getPower(base,absexponent);
- //如果指数小于0,所得结果为上面求的结果的倒数
- if(exponent<0)
- res=1.0/res;
- return res;
- }
- //比较两个double型变量是否相等的方法
- boolean equal(double num1,double num2){
- if(num1-num2>-0.000001&&num1-num2<0.000001)
- return true;
- else
- return false;
- }
- //求出b的e次方的方法
- double getPower(double b,int e){
- //如果指数为0,返回1
- if(e==0)
- return 1.0;
- //如果指数为1,返回b
- if(e==1)
- return b;
- //e>>1相等于e/2,这里就是求a^n =(a^n/2)*(a^n/2)
- double result=getPower(b,e>>1);
- result*=result;
- //如果指数n为奇数,则要再乘一次底数base
- if((e&1)==1)
- result*=b;
- return result;
- }
-}
-```
-
-当然这一题也可以采用笨方法:累乘。不过这种方法的时间复杂度为O(n),这样没有前一种方法效率高。
-```java
- // 使用累乘
- public double powerAnother(double base, int exponent) {
- double result = 1.0;
- for (int i = 0; i < Math.abs(exponent); i++) {
- result *= base;
- }
- if (exponent >= 0)
- return result;
- else
- return 1 / result;
- }
-```
-### 二 调整数组顺序使奇数位于偶数前面
-#### **题目描述:**
-输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
-
-#### **问题解析:**
-这道题有挺多种解法的,给大家介绍一种我觉得挺好理解的方法:
-我们首先统计奇数的个数假设为n,然后新建一个等长数组,然后通过循环判断原数组中的元素为偶数还是奇数。如果是则从数组下标0的元素开始,把该奇数添加到新数组;如果是偶数则从数组下标为n的元素开始把该偶数添加到新数组中。
-
-#### **示例代码:**
-时间复杂度为O(n),空间复杂度为O(n)的算法
-```java
-public class Solution {
- public void reOrderArray(int [] array) {
- //如果数组长度等于0或者等于1,什么都不做直接返回
- if(array.length==0||array.length==1)
- return;
- //oddCount:保存奇数个数
- //oddBegin:奇数从数组头部开始添加
- int oddCount=0,oddBegin=0;
- //新建一个数组
- int[] newArray=new int[array.length];
- //计算出(数组中的奇数个数)开始添加元素
- for(int i=0;i<array.length;i++){
- if((array[i]&1)==1) oddCount++;
- }
- for(int i=0;i<array.length;i++){
- //如果数为基数新数组从头开始添加元素
- //如果为偶数就从oddCount(数组中的奇数个数)开始添加元素
- if((array[i]&1)==1)
- newArray[oddBegin++]=array[i];
- else newArray[oddCount++]=array[i];
- }
- for(int i=0;i<array.length;i++){
- array[i]=newArray[i];
- }
- }
-}
-```
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2104\357\274\211\351\223\276\350\241\250\347\233\270\345\205\263\347\274\226\347\250\213\351\242\230.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2104\357\274\211\351\223\276\350\241\250\347\233\270\345\205\263\347\274\226\347\250\213\351\242\230.md"
deleted file mode 100644
index f241e781ccb..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2104\357\274\211\351\223\276\350\241\250\347\233\270\345\205\263\347\274\226\347\250\213\351\242\230.md"
+++ /dev/null
@@ -1,189 +0,0 @@
-### 一 链表中倒数第k个节点
-#### **题目描述:**
-输入一个链表,输出该链表中倒数第k个结点
-#### **问题分析:**
-**一句话概括:**
-两个指针一个指针p1先开始跑,指针p1跑到k-1个节点后,另一个节点p2开始跑,当p1跑到最后时,p2所指的指针就是倒数第k个节点。
-
-**思想的简单理解:**
-前提假设:链表的结点个数(长度)为n。
-规律一:要找到倒数第k个结点,需要向前走多少步呢?比如倒数第一个结点,需要走n步,那倒数第二个结点呢?很明显是向前走了n-1步,所以可以找到规律是找到倒数第k个结点,需要向前走n-k+1步。
-**算法开始:**
-1. 设两个都指向head的指针p1和p2,当p1走了k-1步的时候,停下来。p2之前一直不动。
-2. p1的下一步是走第k步,这个时候,p2开始一起动了。至于为什么p2这个时候动呢?看下面的分析。
-3. 当p1走到链表的尾部时,即p1走了n步。由于我们知道p2是在p1走了k-1步才开始动的,也就是说p1和p2永远差k-1步。所以当p1走了n步时,p2走的应该是在n-(k-1)步。即p2走了n-k+1步,此时巧妙的是p2正好指向的是规律一的倒数第k个结点处。
-这样是不是很好理解了呢?
-#### **考察内容:**
-链表+代码的鲁棒性
-#### **示例代码:**
-```java
-/*
-//链表类
-public class ListNode {
- int val;
- ListNode next = null;
-
- ListNode(int val) {
- this.val = val;
- }
-}*/
-
-//时间复杂度O(n),一次遍历即可
-public class Solution {
- public ListNode FindKthToTail(ListNode head,int k) {
- ListNode pre=null,p=null;
- //两个指针都指向头结点
- p=head;
- pre=head;
- //记录k值
- int a=k;
- //记录节点的个数
- int count=0;
- //p指针先跑,并且记录节点数,当p指针跑了k-1个节点后,pre指针开始跑,
- //当p指针跑到最后时,pre所指指针就是倒数第k个节点
- while(p!=null){
- p=p.next;
- count++;
- if(k<1){
- pre=pre.next;
- }
- k--;
- }
- //如果节点个数小于所求的倒数第k个节点,则返回空
- if(count<a) return null;
- return pre;
-
- }
-}
-```
-
-### 二 反转链表
-#### **题目描述:**
-输入一个链表,反转链表后,输出链表的所有元素。
-#### **问题分析:**
-链表的很常规的一道题,这一道题思路不算难,但自己实现起来真的可能会感觉无从下手,我是参考了别人的代码。
-思路就是我们根据链表的特点,前一个节点指向下一个节点的特点,把后面的节点移到前面来。
-就比如下图:我们把1节点和2节点互换位置,然后再将3节点指向2节点,4节点指向3节点,这样以来下面的链表就被反转了。
-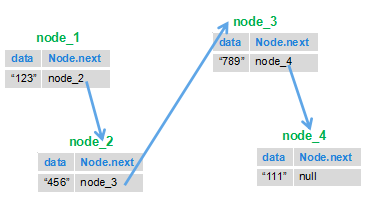
-#### **考察内容:**
-链表+代码的鲁棒性
-#### **示例代码:**
-```java
-/*
-public class ListNode {
- int val;
- ListNode next = null;
-
- ListNode(int val) {
- this.val = val;
- }
-}*/
-public class Solution {
-public ListNode ReverseList(ListNode head) {
- ListNode next = null;
- ListNode pre = null;
- while (head != null) {
- //保存要反转到头来的那个节点
- next = head.next;
- //要反转的那个节点指向已经反转的上一个节点
- head.next = pre;
- //上一个已经反转到头部的节点
- pre = head;
- //一直向链表尾走
- head = next;
- }
- return pre;
-}
-
-}
-```
-
-### 三 合并两个排序的链表
-#### **题目描述:**
-输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
-#### **问题分析:**
-我们可以这样分析:
-1. 假设我们有两个链表 A,B;
-2. A的头节点A1的值与B的头结点B1的值比较,假设A1小,则A1为头节点;
-3. A2再和B1比较,假设B1小,则,A1指向B1;
-4. A2再和B2比较。。。。。。。
-就这样循环往复就行了,应该还算好理解。
-#### **考察内容:**
-链表+代码的鲁棒性
-#### **示例代码:**
-
-**非递归版本:**
-```java
-/*
-public class ListNode {
- int val;
- ListNode next = null;
-
- ListNode(int val) {
- this.val = val;
- }
-}*/
-public class Solution {
- public ListNode Merge(ListNode list1,ListNode list2) {
- //list1为空,直接返回list2
- if(list1 == null){
- return list2;
- }
- //list2为空,直接返回list1
- if(list2 == null){
- return list1;
- }
- ListNode mergeHead = null;
- ListNode current = null;
- //当list1和list2不为空时
- while(list1!=null && list2!=null){
- //取较小值作头结点
- if(list1.val <= list2.val){
- if(mergeHead == null){
- mergeHead = current = list1;
- }else{
- current.next = list1;
- //current节点保存list1节点的值因为下一次还要用
- current = list1;
- }
- //list1指向下一个节点
- list1 = list1.next;
- }else{
- if(mergeHead == null){
- mergeHead = current = list2;
- }else{
- current.next = list2;
- //current节点保存list2节点的值因为下一次还要用
- current = list2;
- }
- //list2指向下一个节点
- list2 = list2.next;
- }
- }
- if(list1 == null){
- current.next = list2;
- }else{
- current.next = list1;
- }
- return mergeHead;
- }
-}
-```
-**递归版本:**
-```java
-public ListNode Merge(ListNode list1,ListNode list2) {
- if(list1 == null){
- return list2;
- }
- if(list2 == null){
- return list1;
- }
- if(list1.val <= list2.val){
- list1.next = Merge(list1.next, list2);
- return list1;
- }else{
- list2.next = Merge(list1, list2.next);
- return list2;
- }
- }
-```
\ No newline at end of file
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2105\357\274\211\346\240\210\345\217\230\351\230\237\345\210\227\345\222\214\346\240\210\347\232\204\345\216\213\345\205\245\343\200\201\345\274\271\345\207\272\345\272\217\345\210\227.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2105\357\274\211\346\240\210\345\217\230\351\230\237\345\210\227\345\222\214\346\240\210\347\232\204\345\216\213\345\205\245\343\200\201\345\274\271\345\207\272\345\272\217\345\210\227.md"
deleted file mode 100644
index 55869d7036e..00000000000
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225/\347\256\227\346\263\225\351\242\230\350\247\243\346\236\220/\345\211\221\346\214\207offer/\357\274\2105\357\274\211\346\240\210\345\217\230\351\230\237\345\210\227\345\222\214\346\240\210\347\232\204\345\216\213\345\205\245\343\200\201\345\274\271\345\207\272\345\272\217\345\210\227.md"
+++ /dev/null
@@ -1,111 +0,0 @@
-### 一 用两个栈实现队列
-#### **题目描述:**
-用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
-
-#### 问题分析:
-先来回顾一下栈和队列的基本特点:
-**栈:**后进先出(LIFO)
-**队列:** 先进先出
-很明显我们需要根据JDK给我们提供的栈的一些基本方法来实现。先来看一下Stack类的一些基本方法:
-
-
-既然题目给了我们两个栈,我们可以这样考虑当push的时候将元素push进stack1,pop的时候我们先把stack1的元素pop到stack2,然后再对stack2执行pop操作,这样就可以保证是先进先出的。(负[pop]负[pop]得正[先进先出])
-
-#### 考察内容:
-
-队列+栈
-
-#### 示例代码:
-```java
-//左程云的《程序员代码面试指南》的答案
-import java.util.Stack;
-
-public class Solution {
- Stack<Integer> stack1 = new Stack<Integer>();
- Stack<Integer> stack2 = new Stack<Integer>();
-
- //当执行push操作时,将元素添加到stack1
- public void push(int node) {
- stack1.push(node);
- }
-
- public int pop() {
- //如果两个队列都为空则抛出异常,说明用户没有push进任何元素
- if(stack1.empty()&&stack2.empty()){
- throw new RuntimeException("Queue is empty!");
- }
- //如果stack2不为空直接对stack2执行pop操作,
- if(stack2.empty()){
- while(!stack1.empty()){
- //将stack1的元素按后进先出push进stack2里面
- stack2.push(stack1.pop());
- }
- }
- return stack2.pop();
- }
-}
-```
-
-### 二 栈的压入、弹出序列
-#### **题目描述:**
-输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
-#### **题目分析:**
-这道题想了半天没有思路,参考了Alias的答案,他的思路写的也很详细应该很容易看懂。
-作者:Alias
-https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106
-来源:牛客网
-
-【思路】借用一个辅助的栈,遍历压栈顺序,先讲第一个放入栈中,这里是1,然后判断栈顶元素是不是出栈顺序的第一个元素,这里是4,很显然1≠4,所以我们继续压栈,直到相等以后开始出栈,出栈一个元素,则将出栈顺序向后移动一位,直到不相等,这样循环等压栈顺序遍历完成,如果辅助栈还不为空,说明弹出序列不是该栈的弹出顺序。
-
-举例:
-
-入栈1,2,3,4,5
-
-出栈4,5,3,2,1
-
-首先1入辅助栈,此时栈顶1≠4,继续入栈2
-
-此时栈顶2≠4,继续入栈3
-
-此时栈顶3≠4,继续入栈4
-
-此时栈顶4=4,出栈4,弹出序列向后一位,此时为5,,辅助栈里面是1,2,3
-
-此时栈顶3≠5,继续入栈5
-
-此时栈顶5=5,出栈5,弹出序列向后一位,此时为3,,辅助栈里面是1,2,3
-
-….
-依次执行,最后辅助栈为空。如果不为空说明弹出序列不是该栈的弹出顺序。
-
-
-
-#### **考察内容:**
-栈
-
-#### **示例代码:**
-```java
-import java.util.ArrayList;
-import java.util.Stack;
-//这道题没想出来,参考了Alias同学的答案:https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106
-public class Solution {
- public boolean IsPopOrder(int [] pushA,int [] popA) {
- if(pushA.length == 0 || popA.length == 0)
- return false;
- Stack<Integer> s = new Stack<Integer>();
- //用于标识弹出序列的位置
- int popIndex = 0;
- for(int i = 0; i< pushA.length;i++){
- s.push(pushA[i]);
- //如果栈不为空,且栈顶元素等于弹出序列
- while(!s.empty() &&s.peek() == popA[popIndex]){
- //出栈
- s.pop();
- //弹出序列向后一位
- popIndex++;
- }
- }
- return s.empty();
- }
-}
-```
\ No newline at end of file
diff --git "a/\346\236\266\346\236\204/\345\210\206\345\270\203\345\274\217.md" "b/\346\236\266\346\236\204/\345\210\206\345\270\203\345\274\217.md"
deleted file mode 100644
index f9d9f76737c..00000000000
--- "a/\346\236\266\346\236\204/\345\210\206\345\270\203\345\274\217.md"
+++ /dev/null
@@ -1,37 +0,0 @@
- - ### 一 分布式系统的经典基础理论
-
- [分布式系统的经典基础理论](https://blog.csdn.net/qq_34337272/article/details/80444032)
-
- 本文主要是简单的介绍了三个常见的概念: **分布式系统设计理念** 、 **CAP定理** 、 **BASE理论** ,关于分布式系统的还有很多很多东西。
- 
-
- - ### 二 分布式事务
- 分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。以上是百度百科的解释,简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
- * [深入理解分布式事务](http://www.codeceo.com/article/distributed-transaction.html)
- * [分布式事务?No, 最终一致性](https://zhuanlan.zhihu.com/p/25933039)
- * [聊聊分布式事务,再说说解决方案](https://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html)
-
-
- - ### 三 分布式系统一致性
- [分布式服务化系统一致性的“最佳实干”](https://www.jianshu.com/p/1156151e20c8)
-
- - ### 四 一致性协议/算法
- 早在1898年就诞生了著名的 **Paxos经典算法** (**Zookeeper就采用了Paxos算法的近亲兄弟Zab算法**),但由于Paxos算法非常难以理解、实现、排错。所以不断有人尝试简化这一算法,直到2013年才有了重大突破:斯坦福的Diego Ongaro、John Ousterhout以易懂性为目标设计了新的一致性算法—— **Raft算法** ,并发布了对应的论文《In Search of an Understandable Consensus Algorithm》,到现在有十多种语言实现的Raft算法框架,较为出名的有以Go语言实现的Etcd,它的功能类似于Zookeeper,但采用了更为主流的Rest接口。
- * [图解 Paxos 一致性协议](http://blog.xiaohansong.com/2016/09/30/Paxos/)
- * [图解分布式协议-RAFT](http://ifeve.com/raft/)
- * [Zookeeper ZAB 协议分析](http://blog.xiaohansong.com/2016/08/25/zab/)
-
-- ### 五 分布式存储
-
- **分布式存储系统将数据分散存储在多台独立的设备上**。传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
-
- * [分布式存储系统概要](http://witchiman.top/2017/05/05/distributed-system/)
-
-- ### 六 分布式计算
-
- **所谓分布式计算是一门计算机科学,它研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终的结果。**
- 分布式网络存储技术是将数据分散的存储于多台独立的机器设备上。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,不但解决了传统集中式存储系统中单存储服务器的瓶颈问题,还提高了系统的可靠性、可用性和扩展性。
-
- * [关于分布式计算的一些概念](https://blog.csdn.net/qq_34337272/article/details/80549020)
-
-
\ No newline at end of file
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\344\270\216\346\225\260\346\215\256\351\200\232\344\277\241/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\344\270\216\346\225\260\346\215\256\351\200\232\344\277\241/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
deleted file mode 100644
index a5a50f10cea..00000000000
--- "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\344\270\216\346\225\260\346\215\256\351\200\232\344\277\241/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
+++ /dev/null
@@ -1,421 +0,0 @@
-> # 目录结构
-### 1. [计算机概述 ](#一计算机概述)
-### 2. [物理层 ](#二物理层)
-### 3. [数据链路层 ](#三数据链路层 )
-### 4. [网络层 ](#四网络层 )
-### 5. [运输层 ](#五运输层 )
-### 6. [应用层](#六应用层)
-
-
-## 一计算机概述
-### <font color="#003333">(1),基本术语<font>
-
-#### <font color="#99CC33"> 结点 (node):<font>
-
- 网络中的结点可以是计算机,集线器,交换机或路由器等。
-#### <font color="#99CC33"> 链路(link ):
-
- 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
-#### <font color="#99CC33"> 主机(host):
- 连接在因特网上的计算机.
-#### <font color="#99CC33"> ISP(Internet Service Provider):
- 因特网服务提供者(提供商).
-#### <font color="#99CC33"> IXP(Internet eXchange Point):
- 互联网交换点IXP的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。.
-#### <font color="#99CC33"> RFC(Request For Comments)
- 意思是“请求评议”,包含了关于Internet几乎所有的重要的文字资料。
-#### <font color="#99CC33"> 广域网WAN(Wide Area Network)
- 任务是通过长距离运送主机发送的数据
-#### <font color="#99CC33"> 城域网MAN(Metropolitan Area Network)
- 用来讲多个局域网进行互连
-
-#### <font color="#99CC33"> 局域网LAN(Local Area Network)
- 学校或企业大多拥有多个互连的局域网
-#### <font color="#99CC33"> 个人区域网PAN(Personal Area Network)
- 在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络
-#### <font color="#99CC33"> 端系统(end system):
- 处在因特网边缘的部分即是连接在因特网上的所有的主机.
-#### <font color="#99CC33"> 分组(packet ):
- 因特网中传送的数据单元。由首部header和数据段组成。分组又称为包,首部可称为包头。
-#### <font color="#99CC33"> 存储转发(store and forward ):
- 路由器收到一个分组,先存储下来,再检查气首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
-#### <font color="#99CC33"> 带宽(bandwidth):
- 在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为b/s。
-#### <font color="#99CC33"> 吞吐量(throughput ):
- 表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
-
-### <font color="#003333">(2),重要知识点总结<font>
-
- <font color="#999999">1,计算机网络(简称网络)把许多计算机连接在一起,而互联网把许多网络连接在一起,是网络的网络。
-
- <font color="#999999">2,小写字母i开头的internet(互联网)是通用名词,它泛指由多个计算机网络相互连接而成的网络。在这些网络之间的通信协议(即通信规则)可以是任意的。
-
- <font color="#999999">大写字母I开头的Internet(互联网)是专用名词,它指全球最大的,开放的,由众多网络相互连接而成的特定的互联网,并采用TCP/IP协议作为通信规则,其前身为ARPANET。Internet的推荐译名为因特网,现在一般流行称为互联网。
-
- <font color="#999999">3,路由器是实现分组交换的关键构件,其任务是转发受到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后在进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据端的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组有称为包。分组是在互联网中传送的数据单元,正式由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
-
-<font color="#999999">4,互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由西组成边缘部分,其作用是提供连通性和交换。
-
- <font color="#999999">5,计算机通信是计算机中进程(即运行着的程序)之间的通信。计算机网络采用的通信方式是客户-服务器方式(C/S方式)和对等连接方式(P2P方式)。
-
- <font color="#999999">6,客户和服务器都是指通信中所涉及的应用进程。客户是服务请求方,服务器是服务提供方。
-
-<font color="#999999">7,按照作用范围的不同,计算机网络分为广域网WAN,城域网MAN,局域网LAN,个人区域网PAN。
-
- <font color="#999999">8,计算机网络最常用的性能指标是:速率,带宽,吞吐量,时延(发送时延,处理时延,排队时延),时延带宽积,往返时间和信道利用率。
-
- <font color="#999999">9,网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
-
- <font color="#999999">10,五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是TCP和UDP协议,网络层最重要的协议是IP协议。
-
-## 二物理层
-### <font color="#003333">(1),基本术语<font>
-#### <font color="#99CC33">数据(data):<font>
- 运送消息的实体。
-#### <font color="#99CC33">信号(signal):<font>
- 数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
-#### <font color="#99CC33">码元( code): <font>
- 在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
-#### <font color="#99CC33">单工(simplex ):<font>
- 只能有一个方向的通信而没有反方向的交互。
-#### <font color="#99CC33">半双工(half duplex ):<font>
- 通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
-#### <font color="#99CC33">全双工(full duplex): <font>
- 通信的双方可以同时发送和接收信息。
-#### <font color="#99CC33">奈氏准则:<font>
- 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
-#### <font color="#99CC33">基带信号(baseband signal):<font>
- 来自信源的信号。指没有经过调制的数字信号或模拟信号。
-#### <font color="#99CC33"> 带通(频带)信号(bandpass signal):<font>
- 把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
-#### <font color="#99CC33"> 调制(modulation ):<font>
- 对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
-#### <font color="#99CC33">信噪比(signal-to-noise ratio ):<font>
- 指信号的平均功率和噪声的平均功率之比,记为S/N。信噪比(dB)=10*log10(S/N)
-#### <font color="#99CC33">信道复用(channel multiplexing ):<font>
- 指多个用户共享同一个信道。(并不一定是同时)
-#### <font color="#99CC33">比特率(bit rate ):<font>
- 单位时间(每秒)内传送的比特数。
-#### <font color="#99CC33">波特率(baud rate):<font>
- 单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
-#### <font color="#99CC33">复用(multiplexing):<font>
- 共享信道的方法
-#### <font color="#99CC33">ADSL(Asymmetric Digital Subscriber Line ): <font>
- 非对称数字用户线。
-#### <font color="#99CC33">光纤同轴混合网(HFC网):<font>
- 在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
-
-### <font color="#003333">(2),重要知识点总结<font>
-
- <font color="#999999">1,物理层的主要任务就是确定与传输媒体接口有关的一些特性,如机械特性,电气特性,功能特性,过程特性。</font>
-
- <font color="#999999">2,一个数据通信系统可划分为三大部分,即源系统,传输系统,目的系统。源系统包括源点(或源站,信源)和发送器,目的系统包括接收器和终点。</font>
-
- <font color="#999999">3,通信的目的是传送消息。如话音,文字,图像等都是消息,数据是运送消息的实体。信号则是数据的电器或电磁的表现。</font>
-
- <font color="#999999">4,根据信号中代表消息的参数的取值方式不同,信号可分为模拟信号(或连续信号)和数字信号(或离散信号)。在使用时间域(简称时域)的波形表示数字信号时,代表不同离散数值的基本波形称为码元。</font>
-
- <font color="#999999">5,根据双方信息交互的方式,通信可划分为单向通信(或单工通信),双向交替通信(或半双工通信),双向同时通信(全双工通信)。</font>
-
- <font color="#999999">6,来自信源的信号称为基带信号。信号要在信道上传输就要经过调制。调制有基带调制和带通调制之分。最基本的带通调制方法有调幅,调频和调相。还有更复杂的调制方法,如正交振幅调制。</font>
-
- <font color="#999999">7,要提高数据在信道上的传递速率,可以使用更好的传输媒体,或使用先进的调制技术。但数据传输速率不可能任意被提高。</font>
-
- <font color="#999999">8,传输媒体可分为两大类,即导引型传输媒体(双绞线,同轴电缆,光纤)和非导引型传输媒体(无线,红外,大气激光)。</font>
-
- <font color="#999999">9,为了有效利用光纤资源,在光纤干线和用户之间广泛使用无源光网络PON。无源光网络无需配备电源,其长期运营成本和管理成本都很低。最流行的无源光网络是以太网无源光网络EPON和吉比特无源光网络GPON。</font>
-
-### <font color="#003333">(3),最重要的知识点<font>
-#### <font color="#003333">**①,物理层的任务**<font>
- <font color="#999999">透明地传送比特流。也可以将物理层的主要任务描述为确定与传输媒体的接口的一些特性,即:机械特性(接口所用接线器的一些物理属性如形状尺寸),电气特性(接口电缆的各条线上出现的电压的范围),功能特性(某条线上出现的某一电平的电压的意义),过程特性(对于不同功能能的各种可能事件的出现顺序)。</font>
-
-#### 拓展:
- <font color="#999999">物理层考虑的是怎样才能在连接各种计算机的传输媒体上传输数据比特流,而不是指具体的传输媒体。现有的计算机网络中的硬件设备和传输媒体的种类非常繁多,而且通信手段也有许多不同的方式。物理层的作用正是尽可能地屏蔽掉这些传输媒体和通信手段的差异,使物理层上面的数据链路层感觉不到这些差异,这样就可以使数据链路层只考虑完成本层的协议和服务,而不必考虑网络的具体传输媒体和通信手段是什么。</font>
-
-#### <font color="#003333">**②,几种常用的信道复用技术**<font>
-
-
-### <font color="#003333">**③,几种常用的宽带接入技术,主要是ADSL和FTTx**<font>
- <font color="#999999">用户到互联网的宽带接入方法有非对称数字用户线ADSL(用数字技术对现有的模拟电话线进行改造,而不需要重新布线。ASDL的快速版本是甚高速数字用户线VDSL。),光纤同轴混合网HFC(是在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网)和FTTx(即光纤到······)。</font>
-
-## 三数据链路层
-### <font color="#003333">(1),基本术语<font>
-
-#### <font color="#99CC33"> 链路(link):<font>
- 一个结点到相邻结点的一段物理链路
-#### <font color="#99CC33"> 数据链路(data link):<font>
- 把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路
-#### <font color="#99CC33"> 循环冗余检验CRC(Cyclic Redundancy Check):<font>
- 为了保证数据传输的可靠性,CRC是数据链路层广泛使用的一种检错技术
-#### <font color="#99CC33"> 帧(frame):<font>
- 一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
-#### <font color="#99CC33"> MTU(Maximum Transfer Uint ):<font>
- 最大传送单元。帧的数据部分的的长度上限。
-#### <font color="#99CC33"> 误码率BER(Bit Error Rate ):<font>
- 在一段时间内,传输错误的比特占所传输比特总数的比率。
-#### <font color="#99CC33"> PPP(Point-to-Point Protocol ):<font>
- 点对点协议。即用户计算机和ISP进行通信时所使用的数据链路层协议。以下是PPP帧的示意图:
-
-#### <font color="#99CC33"> MAC地址(Media Access Control或者Medium Access Control):<font>
- 意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。
- 在OSI模型中,第三层网络层负责 IP地址,第二层数据链路层则负责 MAC地址。
- 因此一个主机会有一个MAC地址,而每个网络位置会有一个专属于它的IP地址 。
- 地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处”
-#### <font color="#99CC33"> 网桥(bridge):<font>
- 一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
-#### <font color="#99CC33"> 交换机(switch ):<font>
- 广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
-
-
-### <font color="#003333">(2),重要知识点总结<font>
-
-<font color="#999999">1,链路是从一个结点到相邻节点的一段物理链路,数据链路则在链路的基础上增加了一些必要的硬件(如网络适配器)和软件(如协议的实现)</font>
-
-<font color="#999999">2,数据链路层使用的主要是**点对点信道**和**广播信道**两种。</font>
-
-<font color="#999999">3,数据链路层传输的协议数据单元是帧。数据链路层的三个基本问题是:**封装成帧**,**透明传输**和**差错检测**</font>
-
-<font color="#999999">4,**循环冗余检验CRC**是一种检错方法,而帧检验序列FCS是添加在数据后面的冗余码</font>
-
-<font color="#999999">5,**点对点协议PPP**是数据链路层使用最多的一种协议,它的特点是:简单,只检测差错而不去纠正差错,不使用序号,也不进行流量控制,可同时支持多种网络层协议</font>
-
-<font color="#999999"> 6,PPPoE是为宽带上网的主机使用的链路层协议</font>
-
-<font color="#999999">7,局域网的优点是:具有广播功能,从一个站点可方便地访问全网;便于系统的扩展和逐渐演变;提高了系统的可靠性,可用性和生存性。</font>
-
-<font color="#999999">8,共向媒体通信资源的方法有二:一是静态划分信道(各种复用技术),而是动态媒体接入控制,又称为多点接入(随即接入或受控接入)</font>
-
-<font color="#999999">9,计算机与外接局域网通信需要通过通信适配器(或网络适配器),它又称为网络接口卡或网卡。**计算器的硬件地址就在适配器的ROM中**。</font>
-
-<font color="#999999">10,以太网采用的无连接的工作方式,对发送的数据帧不进行编号,也不要求对方发回确认。目的站收到有差错帧就把它丢掉,其他什么也不做</font>
-
-<font color="#999999">11,以太网采用的协议是具有冲突检测的**载波监听多点接入CSMA/CD**。协议的特点是:**发送前先监听,边发送边监听,一旦发现总线上出现了碰撞,就立即停止发送。然后按照退避算法等待一段随机时间后再次发送。** 因此,每一个站点在自己发送数据之后的一小段时间内,存在这遭遇碰撞的可能性。以太网上的各站点平等的争用以太网信道</font>
-
-<font color="#999999">12,以太网的适配器具有过滤功能,它只接收单播帧,广播帧和多播帧。</font>
-
-<font color="#999999">13,使用集线器可以在物理层扩展以太网(扩展后的以太网任然是一个网络)</font>
-### <font color="#003333">(3),最重要的知识点<font>
-#### ① <font color="#999999">数据链路层的点对点信道和广播信道的特点,以及这两种信道所使用的协议(PPP协议以及CSMA/CD协议)的特点<font>
-#### ② <font color="#999999">数据链路层的三个基本问题:**封装成帧**,**透明传输**,**差错检测**<font>
-#### ③ <font color="#999999">以太网的MAC层硬件地址<font>
-#### ④ <font color="#999999">适配器,转发器,集线器,网桥,以太网交换机的作用以及适用场合<font>
-
-## <font color="#003333" id="4">四网络层<font>
-### <font color="#003333">(1),基本术语<font>
-
-#### <font color="#99CC33">虚电路(Virtual Circuit):<font>
- 在两个终端设备的逻辑或物理端口之间,通过建立的双向的透明传输通道。虚电路表示这只是一条逻辑上的连接,分组都沿着这条逻辑连接按照存储转发方式传送,而并不是真正建立了一条物理连接。
-#### <font color="#99CC33">IP(Internet Protocol ):<font>
- 网际协议 IP 是 TCP/IP体系中两个最主要的协议之一,是TCP/IP体系结构网际层的核心。配套的有ARP,RARP,ICMP,IGMP。
- 
-#### <font color="#99CC33">ARP(Address Resolution Protocol):<font>
- 地址解析协议
-#### <font color="#99CC33">ICMP(Internet Control Message Protocol ):<font>
- 网际控制报文协议 (ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告。)
-#### <font color="#99CC33">子网掩码(subnet mask ):<font>
- 它是一种用来指明一个IP地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合IP地址一起使用。
-#### <font color="#99CC33"> CIDR( Classless Inter-Domain Routing ):<font>
- 无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)
-#### <font color="#99CC33">默认路由(default route):<font>
- 当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
-#### <font color="#99CC33">路由选择算法(Virtual Circuit):<font>
- 路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
-
-### <font color="#003333">(2),重要知识点总结<font>
-<font color="#999999">1,TCP/IP协议中的网络层向上只提供简单灵活的,无连接的,尽最大努力交付的数据报服务。网络层不提供服务质量的承诺,不保证分组交付的时限所传送的分组可能出错,丢失,重复和失序。进程之间通信的可靠性由运输层负责</font>
-
-<font color="#999999">2,在互联网的交付有两种,一是在本网络直接交付不用经过路由器,另一种是和其他网络的间接交付,至少经过一个路由器,但最后一次一定是直接交付</font>
-
-<font color="#999999">3,分类的IP地址由网络号字段(指明网络)和主机号字段(指明主机)组成。网络号字段最前面的类别指明IP地址的类别。IP地址市一中分等级的地址结构。IP地址管理机构分配IP地址时只分配网络号,主机号由得到该网络号的单位自行分配。路由器根据目的主机所连接的网络号来转发分组。一个路由器至少连接到两个网络,所以一个路由器至少应当有两个不同的IP地址</font>
-
-<font color="#999999">4,IP数据报分为首部和数据两部分。首部的前一部分是固定长度,共20字节,是所有IP数据包必须具有的(源地址,目的地址,总长度等重要地段都固定在首部)。一些长度可变的可选字段固定在首部的后面。IP首部中的生存时间给出了IP数据报在互联网中所能经过的最大路由器数。可防止IP数据报在互联网中无限制的兜圈子。</font>
-
-<font color="#999999">5,地址解析协议ARP把IP地址解析为硬件地址。ARP的高速缓存可以大大减少网络上的通信量。因为这样可以使主机下次再与同样地址的主机通信时,可以直接从高速缓存中找到所需要的硬件地址而不需要再去广播方式发送ARP请求分组</font>
-
-<font color="#999999">6,无分类域间路由选择CIDR是解决目前IP地址紧缺的一个好办法。CIDR记法把IP地址后面加上斜线“/”,然后写上前缀所所占的位数。前缀(或网络前缀用来指明网络),前缀后面的部分是后缀,用来指明主机。CIDR把前缀都相同的连续的IP地址组成一个“CIDR地址块”,IP地址分配都以CIDR地址块为单位。</font>
-
-<font color="#999999">7, 网际控制报文协议是IP层的协议.ICMP报文作为IP数据报的数据,加上首部后组成IP数据报发送出去。使用ICMP数据报并不是为了实现可靠传输。ICMP允许主机或路由器报告差错情况和提供有关异常情况的报告。ICMP报文的种类有两种 ICMP差错报告报文和ICMP询问报文。</font>
-
-<font color="#999999">8,要解决IP地址耗尽的问题,最根本的办法是采用具有更大地址弓箭的新版本IP协议-IPv6。IPv6所带来的变化有①更大的地址空间(采用128位地址)②灵活的首部格式③改进的选项④支持即插即用⑤支持资源的预分配⑥IPv6的首部改为8字节对齐。另外IP数据报的目的地址可以是以下三种基本类型地址之一:单播,多播和任播</font>
-
-<font color="#999999">9,虚拟专用网络VPN利用公用的互联网作为本机构专用网之间的通信载体。VPN内使用互联网的专用地址。一个VPN至少要有一个路由器具有合法的全球IP地址,这样才能和本系统的另一个VPN通过互联网进行通信。所有通过互联网传送的数据都需要加密</font>
-
-<font color="#999999">10, MPLS的特点是:①支持面向连接的服务质量②支持流量工程,平衡网络负载③有效的支持虚拟专用网VPN。MPLS在入口节点给每一个IP数据报打上固定长度的“标记”,然后根据标记在第二层(链路层)用硬件进行转发(在标记交换路由器中进行标记交换),因而转发速率大大加快。</font>
-
-### <font color="#003333">(3),最重要知识点<font>
-#### ① <font color="#999999">虚拟互联网络的概念
-#### ② <font color="#999999">IP地址和物理地址的关系
-#### ③ <font color="#999999"> 传统的分类的IP地址(包括子网掩码)和误分类域间路由选择CIDR
-#### ④ <font color="#999999"> 路由选择协议的工作原理
-
-## <font color="#003333" id="5">五运输层<font>
-
-### <font color="#003333">(1),基本术语<font>
-
-#### <font color="#99CC33">进程(process):<font>
- 指计算机中正在运行的程序实体
-#### <font color="#99CC33">应用进程互相通信:<font>
- 一台主机的进程和另一台主机中的一个进程交换数据的过程(另外注意通信真正的端点不是主机而是主机中的进程,也就是说端到端的通信是应用进程之间的通信)
-#### <font color="#99CC33">传输层的复用与分用:<font>
- 复用指发送方不同的进程都可以通过统一个运输层协议传送数据。分用指接收方的运输层在剥去报文的首部后能把这些数据正确的交付到目的应用进程。
-#### <font color="#99CC33">TCP(Transmission Control Protocol):<font>
- 传输控制协议
-#### <font color="#99CC33">UDP(User Datagram Protocol):<font>
- 用户数据报协议
-#### <font color="#99CC33">端口(port)(link):<font>
- 端口的目的是为了确认对方机器是那个进程在于自己进行交互,比如MSN和QQ的端口不同,如果没有端口就可能出现QQ进程和MSN交互错误。端口又称协议端口号。
-#### <font color="#99CC33">停止等待协议(link):<font>
- 指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
-#### <font color="#99CC33">流量控制(link):<font>
- 就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。
-#### <font color="#99CC33">拥塞控制(link):<font>
- 防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
-
-
-### <font color="#003333">(2),重要知识点总结<font>
-
-<font color="#999999">1,运输层提供应用进程之间的逻辑通信,也就是说,运输层之间的通信并不是真正在两个运输层之间直接传输数据。运输层向应用层屏蔽了下面网络的细节(如网络拓补,所采用的路由选择协议等),它使应用进程之间看起来好像两个运输层实体之间有一条端到端的逻辑通信信道。
-
-2,网络层为主机提供逻辑通信,而运输层为应用进程之间提供端到端的逻辑通信。
-
-3,运输层的两个重要协议是用户数据报协议UDP和传输控制协议TCP。按照OSI的术语,两个对等运输实体在通信时传送的数据单位叫做运输协议数据单元TPDU(Transport Protocol Data Unit)。但在TCP/IP体系中,则根据所使用的协议是TCP或UDP,分别称之为TCP报文段或UDP用户数据报。
-
-4,UDP在传送数据之前不需要先建立连接,远地主机在收到UDP报文后,不需要给出任何确认。虽然UDP不提供可靠交付,但在某些情况下UDP确是一种最有效的工作方式。 TCP提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。TCP不提供广播或多播服务。由于TCP要提供可靠的,面向连接的运输服务,这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。
-
-5,硬件端口是不同硬件设备进行交互的接口,而软件端口是应用层各种协议进程与运输实体进行层间交互的一种地址。UDP和TCP的首部格式中都有源端口和目的端口这两个重要字段。当运输层收到IP层交上来的运输层报文时,就能够 根据其首部中的目的端口号把数据交付应用层的目的应用层。(两个进程之间进行通信不光要知道对方IP地址而且要知道对方的端口号(为了找到对方计算机中的应用进程))
-
-6,运输层用一个16位端口号标志一个端口。端口号只有本地意义,它只是为了标志计算机应用层中的各个进程在和运输层交互时的层间接口。在互联网的不同计算机中,相同的端口号是没有关联的。协议端口号简称端口。虽然通信的终点是应用进程,但只要把所发送的报文交到目的主机的某个合适端口,剩下的工作(最后交付目的进程)就由TCP和UDP来完成。
-
-7,运输层的端口号分为服务器端使用的端口号(0~1023指派给熟知端口,1024~49151是登记端口号)和客户端暂时使用的端口号(49152~65535)
-
-8,UDP的主要特点是①无连接②尽最大努力交付③面向报文④无拥塞控制⑤支持一对一,一对多,多对一和多对多的交互通信⑥首部开销小(只有四个字段:源端口,目的端口,长度和检验和)
-
-9,TCP的主要特点是①面向连接②每一条TCP连接只能是一对一的③提供可靠交付④提供全双工通信⑤面向字节流
-
-10,TCP用主机的IP地址加上主机上的端口号作为TCP连接的端点。这样的端点就叫做套接字(socket)或插口。套接字用(IP地址:端口号)来表示。每一条TCP连接唯一被通信两端的两个端点所确定。
-
- 11,停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
-
-12,为了提高传输效率,发送方可以不使用低效率的停止等待协议,而是采用流水线传输。流水线传输就是发送方可连续发送多个分组,不必每发完一个分组就停下来等待对方确认。这样可使信道上一直有数据不间断的在传送。这种传输方式可以明显提高信道利用率。
-
-13,停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重转时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求ARQ。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。连续ARQ协议可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
-
-14,TCP报文段的前20个字节是固定的,后面有4n字节是根据需要增加的选项。因此,TCP首部的最小长度是20字节。
-
-15,TCP使用滑动窗口机制。发送窗口里面的序号表示允许发送的序号。发送窗口后沿的后面部分表示已发送且已收到确认,而发送窗口前沿的前面部分表示不晕与发送。发送窗口后沿的变化情况有两种可能,即不动(没有收到新的确认)和前移(收到了新的确认)。发送窗口的前沿通常是不断向前移动的。一般来说,我们总是希望数据传输更快一些。但如果发送方把数据发送的过快,接收方就可能来不及接收,这就会造成数据的丢失。所谓流量控制就是让发送方的发送速率不要太快,要让接收方来得及接收。
-
-16,在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
-
-17,为了进行拥塞控制,TCP发送方要维持一个拥塞窗口cwnd的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
-
-18,TCP的拥塞控制采用了四种算法,即慢开始,拥塞避免,快重传和快恢复。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理AQM),以减少网络拥塞的发生。
-
-19,运输连接的三个阶段,即:连接建立,数据传送和连接释放。
-
-20,主动发起TCP连接建立的应用进程叫做客户,而被动等待连接建立的应用进程叫做服务器。TCP连接采用三报文握手机制。服务器要确认用户的连接请求,然后客户要对服务器的确认进行确认。
-
-21,TCP的连接释放采用四报文握手机制。任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送时,则发送连接释放通知,对方确认后就完全关闭了TCP连接
-### <font color="#003333">(3),最重要的知识点<font>
-#### ① <font color="#999999">端口和套接字的意义<font>
-
-#### ② <font color="#999999">无连接UDP的特点<font>
-
-#### ③ <font color="#999999">面向连接TCP的特点<font>
-
-#### ④ <font color="#999999">在不可靠的网络上实现可靠传输的工作原理,停止等待协议和ARQ协议<font>
-
-#### ① <font color="#999999">TCP的滑动窗口,流量控制,拥塞控制和连接管理<font>
-
-## <font color="#003333" id="6">六应用层<font>
-### <font color="#003333">(1),基本术语<font>
-#### <font color="#99CC33"> 域名系统(DNS):<font>
- DNS(Domain Name System,域名系统),万维网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。
- 通过域名,最终得到该域名对应的IP地址的过程叫做域名解析(或主机名解析)。DNS协议运行在UDP协议之上,使用端口号53。在RFC文档中RFC 2181对DNS有规范说明,RFC 2136对DNS的动态更新进行说明,RFC 2308对DNS查询的反向缓存进行说明。
-#### <font color="#99CC33"> 文件传输协议(FTP):<font>
- FTP 是File TransferProtocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于Internet上的控制文件的双向传输。同时,它也是一个应用程序(Application)。
- 基于不同的操作系统有不同的FTP应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在FTP的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。
- "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用Internet语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
-
-#### <font color="#99CC33"> 简单文件传输协议(TFTP):<font>
- TFTP(Trivial File Transfer Protocol,简单文件传输协议)是TCP/IP协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为69。
-
-#### <font color="#99CC33"> 远程终端协议(TELENET):<font>
- Telnet协议是TCP/IP协议族中的一员,是Internet远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。
- 在终端使用者的电脑上使用telnet程序,用它连接到服务器。终端使用者可以在telnet程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。
- 可以在本地就能控制服务器。要开始一个telnet会话,必须输入用户名和密码来登录服务器。Telnet是常用的远程控制Web服务器的方法。
-
-
-#### <font color="#99CC33"> 万维网(WWW):<font>
- WWW是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为Web。分为Web客户端和Web服务器程序。
- WWW可以让Web客户端(常用浏览器)访问浏览Web服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。
- 万维网联盟(英语:World Wide Web Consortium,简称W3C),又称W3C理事会。1994年10月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。
- 万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
-#### <font color="#99CC33"> 万维网的大致工作工程:<font>
-
-
-#### <font color="#99CC33"> 统一资源定位符(URL):<font>
- 统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
-
-#### <font color="#99CC33"> 超文本传输协议(HTTP):<font>
- 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。
- 设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。1960年美国人Ted Nelson构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了HTTP超文本传输协议标准架构的发展根基。
-
-#### <font color="#99CC33"> 代理服务器(Proxy Server):<font>
- 代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。
- 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按URL的地址再次去互联网访问该资源。
- 代理服务器可在客户端或服务器工作,也可以在中间系统工作。
-
-#### <font color="#99CC33"> http请求头:<font>
- http请求头,HTTP客户程序(例如浏览器),向服务器发送请求的时候必须指明请求类型(一般是GET或者POST)。如有必要,客户程序还可以选择发送其他的请求头。
- - Accept:浏览器可接受的MIME类型。
- - Accept-Charset:浏览器可接受的字符集。
- - Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。Servlet能够向支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间。
- - Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。
- - Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中。
- - Connection:表示是否需要持久连接。如果Servlet看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点,Servlet需要在应答中发送一个Content-Length头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然后在正式写出内容之前计算它的大小。
- - Content-Length:表示请求消息正文的长度。
- - Cookie:这是最重要的请求头信息之一
- - From:请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它。
- - Host:初始URL中的主机和端口。
- - If-Modified-Since:只有当所请求的内容在指定的日期之后又经过修改才返回它,否则返回304“Not Modified”应答。
- - Pragma:指定“no-cache”值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝。
- - Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。
- - User-Agent:浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用。
-#### <font color="#99CC33">简单邮件传输协议(SMTP):<font>
- SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。
- SMTP协议属于TCP/IP协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。
- 通过SMTP协议所指定的服务器,就可以把E-mail寄到收信人的服务器上了,整个过程只要几分钟。SMTP服务器则是遵循SMTP协议的发送邮件服务器,用来发送或中转发出的电子邮件。
-
-#### <font color="#99CC33">搜索引擎:<font>
- 搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。
- 搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
-#### <font color="#99CC33">全文索引:<font>
- 全文索引技术是目前搜索引擎的关键技术。
- 试想在1M大小的文件中搜索一个词,可能需要几秒,在100M的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。
- 所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
-#### <font color="#99CC33">目录索引:<font>
- 目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
-
-
-#### <font color="#99CC33">垂直搜索引擎:<font>
- 垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。
- 垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。
- 其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
-
-### <font color="#003333">(2),重要知识点总结<font>
-<font color="#999999">1,文件传输协议(FTP)使用TCP可靠的运输服务。FTP使用客户服务器方式。一个FTP服务器进程可以同时为多个用户提供服务。在进进行文件传输时,FTP的客户和服务器之间要先建立两个并行的TCP连接:控制连接和数据连接。实际用于传输文件的是数据连接。
-
-<font color="#999999">2,万维网客户程序与服务器之间进行交互使用的协议时超文本传输协议HTTP。HTTP使用TCP连接进行可靠传输。但HTTP本身是无连接、无状态的。HTTP/1.1协议使用了持续连接(分为非流水线方式和流水线方式)
-
-<font color="#999999">3,电子邮件把邮件发送到收件人使用的邮件服务器,并放在其中的收件人邮箱中,收件人可随时上网到自己使用的邮件服务器读取,相当于电子邮箱。
-
-<font color="#999999">4,一个电子邮件系统有三个重要组成构件:用户代理、邮件服务器、邮件协议(包括邮件发送协议,如SMTP,和邮件读取协议,如POP3和IMAP)。用户代理和邮件服务器都要运行这些协议。
-
-
-
-### <font color="#003333">(3),最重要知识点总结<font>
-
-#### ① <font color="#999999">域名系统-从域名解析出IP地址<font>
-#### ② <font color="#999999">访问一个网站大致的过程<font>
-#### ③ <font color="#999999">系统调用和应用编程接口概念<font>
-
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\344\270\216\346\225\260\346\215\256\351\200\232\344\277\241/\346\225\260\346\215\256\351\200\232\344\277\241(RESTful\343\200\201RPC\343\200\201\346\266\210\346\201\257\351\230\237\345\210\227).md" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\344\270\216\346\225\260\346\215\256\351\200\232\344\277\241/\346\225\260\346\215\256\351\200\232\344\277\241(RESTful\343\200\201RPC\343\200\201\346\266\210\346\201\257\351\230\237\345\210\227).md"
deleted file mode 100644
index 2df02d0312c..00000000000
--- "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\344\270\216\346\225\260\346\215\256\351\200\232\344\277\241/\346\225\260\346\215\256\351\200\232\344\277\241(RESTful\343\200\201RPC\343\200\201\346\266\210\346\201\257\351\230\237\345\210\227).md"
+++ /dev/null
@@ -1,100 +0,0 @@
-> ## RPC
-
-**RPC(Remote Procedure Call)—远程过程调用** ,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发分布式程序就像开发本地程序一样简单。
-
-**RPC采用客户端(服务调用方)/服务器端(服务提供方)模式,** 都运行在自己的JVM中。客户端只需要引入要使用的接口,接口的实现和运行都在服务器端。RPC主要依赖的技术包括序列化、反序列化和数据传输协议,这是一种定义与实现相分离的设计。
-
-**目前Java使用比较多的RPC方案主要有RMI(JDK自带)、Hessian、Dubbo以及Thrift等。**
-
-**注意: RPC主要指内部服务之间的调用,RESTful也可以用于内部服务之间的调用,但其主要用途还在于外部系统提供服务,因此没有将其包含在本知识点内。**
-
-### 常见RPC框架:
-
-- **RMI(JDK自带):** JDK自带的RPC
-
- 详细内容可以参考:[从懵逼到恍然大悟之Java中RMI的使用](https://blog.csdn.net/lmy86263/article/details/72594760)
-
-- **Dubbo:** Dubbo是 阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。
-
- 详细内容可以参考:
-
- - [ 高性能优秀的服务框架-dubbo介绍](https://blog.csdn.net/qq_34337272/article/details/79862899)
-
- - [Dubbo是什么?能做什么?](https://blog.csdn.net/houshaolin/article/details/76408399)
-
-
-- **Hessian:** Hessian是一个轻量级的remotingonhttp工具,使用简单的方法提供了RMI的功能。 相比WebService,Hessian更简单、快捷。采用的是二进制RPC协议,因为采用的是二进制协议,所以它很适合于发送二进制数据。
-
- 详细内容可以参考: [Hessian的使用以及理解](https://blog.csdn.net/sunwei_pyw/article/details/74002351)
-
-- **Thrift:** Apache Thrift是Facebook开源的跨语言的RPC通信框架,目前已经捐献给Apache基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用,有能力的公司甚至会基于thrift研发一套分布式服务框架,增加诸如服务注册、服务发现等功能。
-
-
- 详细内容可以参考: [【Java】分布式RPC通信框架Apache Thrift 使用总结](https://www.cnblogs.com/zeze/p/8628585.html)
-
-### 如何进行选择:
-
-- **是否允许代码侵入:** 即需要依赖相应的代码生成器生成代码,比如Thrift。
-- **是否需要长连接获取高性能:** 如果对于性能需求较高的haul,那么可以果断选择基于TCP的Thrift、Dubbo。
-- **是否需要跨越网段、跨越防火墙:** 这种情况一般选择基于HTTP协议的Hessian和Thrift的HTTP Transport。
-
-此外,Google推出的基于HTTP2.0的gRPC框架也开始得到应用,其序列化协议基于Protobuf,网络框架使用的是Netty4,但是其需要生成代码,可扩展性也比较差。
-
-> ## 消息中间件
-
-**消息中间件,也可以叫做中央消息队列或者是消息队列(区别于本地消息队列,本地消息队列指的是JVM内的队列实现)**,是一种独立的队列系统,消息中间件经常用来解决内部服务之间的 **异步调用问题** 。请求服务方把请求队列放到队列中即可返回,然后等待服务提供方去队列中获取请求进行处理,之后通过回调等机制把结果返回给请求服务方。
-
-异步调用只是消息中间件一个非常常见的应用场景。此外,常用的消息队列应用场景还偷如下几个:
-- **解耦 :** 一个业务的非核心流程需要依赖其他系统,但结果并不重要,有通知即可。
-- **最终一致性 :** 指的是两个系统的状态保持一致,可以有一定的延迟,只要最终达到一致性即可。经常用在解决分布式事务上。
-- **广播 :** 消息队列最基本的功能。生产者只负责生产消息,订阅者接收消息。
-- **错峰和流控**
-
-
-具体可以参考:
-
-[《消息队列深入解析》](https://blog.csdn.net/qq_34337272/article/details/80029918)
-
-当前使用较多的消息队列有ActiveMQ(性能差,不推荐使用)、RabbitMQ、RocketMQ、Kafka等等,我们之前提高的redis数据库也可以实现消息队列,不过不推荐,redis本身设计就不是用来做消息队列的。
-
-- **ActiveMQ:** ActiveMQ是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ是一个完全支持JMS1.1和J2EE 1.4规范的JMSProvider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位。
-
- 具体可以参考:
-
- [《消息队列ActiveMQ的使用详解》](https://blog.csdn.net/qq_34337272/article/details/80031702)
-
-- **RabbitMQ:** RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗
- > AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
-
-
- 具体可以参考:
-
- [《消息队列之 RabbitMQ》](https://www.jianshu.com/p/79ca08116d57)
-
-- **RocketMQ:**
-
- 具体可以参考:
-
- [《RocketMQ 实战之快速入门》](https://www.jianshu.com/p/824066d70da8)
-
- [《十分钟入门RocketMQ》](http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/) (阿里中间件团队博客)
-
-
-- **Kafka**:Kafka是一个分布式的、可分区的、可复制的、基于发布/订阅的消息系统,Kafka主要用于大数据领域,当然在分布式系统中也有应用。目前市面上流行的消息队列RocketMQ就是阿里借鉴Kafka的原理、用Java开发而得。
-
- 具体可以参考:
-
- [《Kafka应用场景》](http://book.51cto.com/art/201801/565244.htm)
-
- [《初谈Kafka》](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484106&idx=1&sn=aa1999895d009d91eb3692a3e6429d18&chksm=fd9854abcaefddbd1101ca5dc2c7c783d7171320d6300d9b2d8e68b7ef8abd2b02ea03e03600#rd)
-
-**推荐阅读:**
-
-[《Kafka、RabbitMQ、RocketMQ等消息中间件的对比 —— 消息发送性能和区别》](https://mp.weixin.qq.com/s?__biz=MzU5OTMyODAyNg==&mid=2247484721&idx=1&sn=11e4e29886e581dd328311d308ccc068&chksm=feb7d144c9c058529465b02a4e26a25ef76b60be8984ace9e4a0f5d3d98ca52e014ecb73b061&scene=21#wechat_redirect)
-
-
-
-
-
-
-
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\344\270\216\346\225\260\346\215\256\351\200\232\344\277\241/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\344\270\216\346\225\260\346\215\256\351\200\232\344\277\241/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
deleted file mode 100644
index ba5fb91ecc9..00000000000
--- "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\344\270\216\346\225\260\346\215\256\351\200\232\344\277\241/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
+++ /dev/null
@@ -1,344 +0,0 @@
-
-<!-- MarkdownTOC -->
-
-- [一 OSI与TCP/IP各层的结构与功能,都有哪些协议](#一-osi与tcpip各层的结构与功能都有哪些协议)
- - [五层协议的体系结构](#五层协议的体系结构)
- - [1 应用层](#1-应用层)
- - [域名系统](#域名系统)
- - [HTTP协议](#http协议)
- - [2 运输层](#2-运输层)
- - [运输层主要使用以下两种协议](#运输层主要使用以下两种协议)
- - [UDP 的主要特点](#udp-的主要特点)
- - [TCP 的主要特点](#tcp-的主要特点)
- - [3 网络层](#3-网络层)
- - [4 数据链路层](#4-数据链路层)
- - [5 物理层](#5-物理层)
- - [总结一下](#总结一下)
-- [二 TCP 三次握手和四次挥手\(面试常客\)](#二-tcp-三次握手和四次挥手面试常客)
- - [为什么要三次握手](#为什么要三次握手)
- - [为什么要传回 SYN](#为什么要传回-syn)
- - [传了 SYN,为啥还要传 ACK](#传了-syn为啥还要传-ack)
- - [为什么要四次挥手](#为什么要四次挥手)
-- [三 TCP、UDP 协议的区别](#三-tcp、udp-协议的区别)
-- [四 TCP 协议如何保证可靠传输](#四-tcp-协议如何保证可靠传输)
- - [停止等待协议](#停止等待协议)
- - [自动重传请求 ARQ 协议](#自动重传请求-arq-协议)
- - [连续ARQ协议](#连续arq协议)
- - [滑动窗口](#滑动窗口)
- - [流量控制](#流量控制)
- - [拥塞控制](#拥塞控制)
-- [五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)](#五-在浏览器中输入url地址---显示主页的过程(面试常客))
-- [六 状态码](#六-状态码)
-- [七 各种协议与HTTP协议之间的关系](#七-各种协议与http协议之间的关系)
-- [八 HTTP长连接、短连接](#八-http长连接、短连接)
-- [写在最后](#写在最后)
- - [计算机网络常见问题回顾](#计算机网络常见问题回顾)
- - [建议](#建议)
-
-<!-- /MarkdownTOC -->
-
-
-相对与上一个版本的计算机网路面试知识总结,这个版本增加了 “TCP协议如何保证可靠传输”包括超时重传、停止等待协议、滑动窗口、流量控制、拥塞控制等内容并且对一些已有内容做了补充。
-
-
-## 一 OSI与TCP/IP各层的结构与功能,都有哪些协议
-
-
-### 五层协议的体系结构
-
-学习计算机网络时我们一般采用折中的办法,也就是中和 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚。
-
-
-
-结合互联网的情况,自上而下地,非常简要的介绍一下各层的作用。
-
-### 1 应用层
-
-**应用层(application-layer)的任务是通过应用进程间的交互来完成特定网络应用。**应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和交互的规则。对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如**域名系统DNS**,支持万维网应用的 **HTTP协议**,支持电子邮件的 **SMTP协议**等等。我们把应用层交互的数据单元称为报文。
-
-#### 域名系统
-
-> 域名系统(Domain Name System缩写 DNS,Domain Name被译为域名)是因特网的一项核心服务,它作为可以将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。(百度百科)例如:一个公司的 Web 网站可看作是它在网上的门户,而域名就相当于其门牌地址,通常域名都使用该公司的名称或简称。例如上面提到的微软公司的域名,类似的还有:IBM 公司的域名是 www.ibm.com、Oracle 公司的域名是 www.oracle.com、Cisco公司的域名是 www.cisco.com 等。
-
-#### HTTP协议
-> 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW(万维网) 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。(百度百科)
-
-### 2 运输层
-
-**运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务**。应用进程利用该服务传送应用层报文。“通用的”是指并不针对某一个特定的网络应用,而是多种应用可以使用同一个运输层服务。由于一台主机可同时运行多个线程,因此运输层有复用和分用的功能。所谓复用就是指多个应用层进程可同时使用下面运输层的服务,分用和复用相反,是运输层把收到的信息分别交付上面应用层中的相应进程。
-
-#### 运输层主要使用以下两种协议
-
-1. **传输控制协议 TCP**(Transmisson Control Protocol)--提供**面向连接**的,**可靠的**数据传输服务。
-2. **用户数据协议 UDP**(User Datagram Protocol)--提供**无连接**的,尽最大努力的数据传输服务(**不保证数据传输的可靠性**)。
-
-#### UDP 的主要特点
-1. UDP 是无连接的;
-2. UDP 使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态(这里面有许多参数);
-3. UDP 是面向报文的;
-4. UDP 没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如 直播,实时视频会议等);
-5. UDP 支持一对一、一对多、多对一和多对多的交互通信;
-6. UDP 的首部开销小,只有8个字节,比TCP的20个字节的首部要短。
-
-#### TCP 的主要特点
-1. TCP 是面向连接的。(就好像打电话一样,通话前需要先拨号建立连接,通话结束后要挂机释放连接);
-2. 每一条 TCP 连接只能有两个端点,每一条TCP连接只能是点对点的(一对一);
-3. TCP 提供可靠交付的服务。通过TCP连接传送的数据,无差错、不丢失、不重复、并且按序到达;
-4. TCP 提供全双工通信。TCP 允许通信双方的应用进程在任何时候都能发送数据。TCP 连接的两端都设有发送缓存和接收缓存,用来临时存放双方通信的数据;
-5. 面向字节流。TCP 中的“流”(Stream)指的是流入进程或从进程流出的字节序列。“面向字节流”的含义是:虽然应用程序和 TCP 的交互是一次一个数据块(大小不等),但 TCP 把应用程序交下来的数据仅仅看成是一连串的无结构的字节流。
-
-
-### 3 网络层
-
-**在 计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。** 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 **IP 协议**,因此分组也叫 **IP 数据报** ,简称 **数据报**。
-
-这里要注意:**不要把运输层的“用户数据报 UDP ”和网络层的“ IP 数据报”弄混**。另外,无论是哪一层的数据单元,都可笼统地用“分组”来表示。
-
-
-这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称.
-
-互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Prococol)和许多路由选择协议,因此互联网的网络层也叫做**网际层**或**IP层**。
-
-### 4 数据链路层
-**数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。** 在两个相邻节点之间传送数据时,**数据链路层将网络层交下来的 IP 数据报组装程帧**,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
-
-在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结束。这样,数据链路层在收到一个帧后,就可从中提出数据部分,上交给网络层。
-控制信息还使接收端能够检测到所收到的帧中有误差错。如果发现差错,数据链路层就简单地丢弃这个出了差错的帧,以避免继续在网络中传送下去白白浪费网络资源。如果需要改正数据在链路层传输时出现差错(这就是说,数据链路层不仅要检错,而且还要纠错),那么就要采用可靠性传输协议来纠正出现的差错。这种方法会使链路层的协议复杂些。
-
-### 5 物理层
-在物理层上所传送的数据单位是比特。
- **物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。** 使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
-
-在互联网使用的各种协中最重要和最著名的就是 TCP/IP 两个协议。现在人们经常提到的TCP/IP并不一定单指TCP和IP这两个具体的协议,而往往表示互联网所使用的整个TCP/IP协议族。
-
-### 总结一下
-
-上面我们对计算机网络的五层体系结构有了初步的了解,下面附送一张七层体系结构图总结一下。图片来源:https://blog.csdn.net/yaopeng_2005/article/details/7064869
-
-
-## 二 TCP 三次握手和四次挥手(面试常客)
-
-为了准确无误地把数据送达目标处,TCP协议采用了三次握手策略。
-
-**漫画图解:**
-
-图片来源:《图解HTTP》
-
-
-**简单示意图:**
-
-
-- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
-- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
-- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
-
-### 为什么要三次握手
-
-**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
-
-第一次握手:Client 什么都不能确认;Server 确认了对方发送正常
-
-第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常
-
-第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送接收正常
-
-所以三次握手就能确认双发收发功能都正常,缺一不可。
-
-### 为什么要传回 SYN
-接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
-
-> SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的TCP连接,数据才可以在客户机和服务器之间传递。
-
-
-### 传了 SYN,为啥还要传 ACK
-
-双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
-
-
-
-断开一个 TCP 连接则需要“四次挥手”:
-
-- 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
-- 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加1 。和 SYN 一样,一个 FIN 将占用一个序号
-- 服务器-关闭与客户端的连接,发送一个FIN给客户端
-- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
-
-
-### 为什么要四次挥手
-
-任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
-
-举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
-
-上面讲的比较概括,推荐一篇讲的比较细致的文章:[https://blog.csdn.net/qzcsu/article/details/72861891](https://blog.csdn.net/qzcsu/article/details/72861891)
-
-## 三 TCP、UDP 协议的区别
-
-
-UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
-
-TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的运输服务(TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
-
-## 四 TCP 协议如何保证可靠传输
-
-1. 应用数据被分割成 TCP 认为最适合发送的数据块。
-2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
-3. **校验和:** TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
-4. TCP 的接收端会丢弃重复的数据。
-5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
-6. **拥塞控制:** 当网络拥塞时,减少数据的发送。
-7. **停止等待协议** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。 **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
-
-
-
-### 停止等待协议
-- 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组;
-- 在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认;
-
-
-**1) 无差错情况:**
-
-
-
-发送方发送分组,接收方在规定时间内收到,并且回复确认.发送方再次发送。
-
-**2) 出现差错情况(超时重传):**
-
-停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重转时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为 **自动重传请求 ARQ** 。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。**连续 ARQ 协议** 可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
-
-**3) 确认丢失和确认迟到**
-
-- **确认丢失**:确认消息在传输过程丢失
- 
- 当A发送M1消息,B收到后,B向A发送了一个M1确认消息,但却在传输过程中丢失。而A并不知道,在超时计时过后,A重传M1消息,B再次收到该消息后采取以下两点措施:
-
- 1. 丢弃这个重复的M1消息,不向上层交付。
- 2. 向A发送确认消息。(不会认为已经发送过了,就不再发送。A能重传,就证明B的确认消息丢失)。
-- **确认迟到** :确认消息在传输过程中迟到
- 
- A发送M1消息,B收到并发送确认。在超时时间内没有收到确认消息,A重传M1消息,B仍然收到并继续发送确认消息(B收到了2份M1)。此时A收到了B第二次发送的确认消息。接着发送其他数据。过了一会,A收到了B第一次发送的对M1的确认消息(A也收到了2份确认消息)。处理如下:
- 1. A收到重复的确认后,直接丢弃。
- 2. B收到重复的M1后,也直接丢弃重复的M1。
-
-### 自动重传请求 ARQ 协议
-停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重转时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求ARQ。
-
-**优点:** 简单
-
-**缺点:** 信道利用率低
-
-### 连续ARQ协议
-
-连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
-
-**优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
-
-**缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5条 消息,中间第三条丢失(3号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
-
-### 滑动窗口
-
-- TCP 利用滑动窗口实现流量控制的机制。
-- 滑动窗口(Sliding window)是一种流量控制技术。早期的网络通信中,通信双方不会考虑网络的拥挤情况直接发送数据。由于大家不知道网络拥塞状况,同时发送数据,导致中间节点阻塞掉包,谁也发不了数据,所以就有了滑动窗口机制来解决此问题。
-- TCP 中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为 0 时,发送方一般不能再发送数据报,但有两种情况除外,一种情况是可以发送紧急数据,例如,允许用户终止在远端机上的运行进程。另一种情况是发送方可以发送一个 1 字节的数据报来通知接收方重新声明它希望接收的下一字节及发送方的滑动窗口大小。
-
-### 流量控制
-
-- TCP 利用滑动窗口实现流量控制。
-- 流量控制是为了控制发送方发送速率,保证接收方来得及接收。
-- 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
-
-### 拥塞控制
-
-在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
-
-为了进行拥塞控制,TCP 发送方要维持一个 **拥塞窗口(cwnd)** 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
-
-TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免** 、**快重传** 和 **快恢复**。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
-
-- **慢开始:** 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd初始值为1,每经过一个传播轮次,cwnd加倍。
- 
-- **拥塞避免:** 拥塞避免算法的思路是让拥塞窗口cwnd缓慢增大,即每经过一个往返时间RTT就把发送放的cwnd加1.
-- **快重传与快恢复:**
- 在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。 当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
- 
-
-
-
-## 五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)
-百度好像最喜欢问这个问题。
-> 打开一个网页,整个过程会使用哪些协议
-
-图解(图片来源:《图解HTTP》):
-
-
-
-总体来说分为以下几个过程:
-
-1. DNS解析
-2. TCP连接
-3. 发送HTTP请求
-4. 服务器处理请求并返回HTTP报文
-5. 浏览器解析渲染页面
-6. 连接结束
-
-具体可以参考下面这篇文章:
-
-- [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700)
-
-
-
-
-## 六 状态码
-
-
-
-
-## 七 各种协议与HTTP协议之间的关系
-一般面试官会通过这样的问题来考察你对计算机网络知识体系的理解。
-
-图片来源:《图解HTTP》
-
-
-
-## 八 HTTP长连接、短连接
-
-在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
-
-而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
-
-```
-Connection:keep-alive
-```
-
-在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
-
-**HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。**
-
-—— [《HTTP长连接、短连接究竟是什么?》](https://www.cnblogs.com/gotodsp/p/6366163.html)
-
-
-## 写在最后
-### 计算机网络常见问题回顾
-
-- ①TCP三次握手和四次挥手、
-- ②在浏览器中输入url地址->>显示主页的过程
-- ③HTTP和HTTPS的区别
-- ④TCP、UDP协议的区别
-- ⑤常见的状态码。
-
-### 建议
-非常推荐大家看一下 《图解HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
-
-
-
-### 参考
-
-- [https://blog.csdn.net/qq_16209077/article/details/52718250](https://blog.csdn.net/qq_16209077/article/details/52718250)
-- [https://blog.csdn.net/zixiaomuwu/article/details/60965466](https://blog.csdn.net/zixiaomuwu/article/details/60965466)
-- [https://blog.csdn.net/turn__back/article/details/73743641](https://blog.csdn.net/turn__back/article/details/73743641)
-
-
-
-
-
-
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/books.md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/books.md"
deleted file mode 100644
index 34f495fd798..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/books.md"
+++ /dev/null
@@ -1,66 +0,0 @@
-
-### 核心基础知识
-
-- [《图解HTTP》](https://book.douban.com/subject/25863515/)(推荐,豆瓣评分 8.1 , 1.6K+人评价): 讲漫画一样的讲HTTP,很有意思,不会觉得枯燥,大概也涵盖也HTTP常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究HTTP相关知识的话,读这本书的话应该来说就差不多了。
-- [《大话数据结构》](https://book.douban.com/subject/6424904/)(推荐,豆瓣评分 7.9 , 1K+人评价):入门类型的书籍,读起来比较浅显易懂,适合没有数据结构基础或者说数据结构没学好的小伙伴用来入门数据结构。
-- [《数据结构与算法分析:C语言描述》](https://book.douban.com/subject/1139426/)(推荐,豆瓣评分 8.9,1.6K+人评价):本书是《Data Structures and Algorithm Analysis in C》一书第2版的简体中译本。原书曾被评为20世纪顶尖的30部计算机著作之一,作者Mark Allen Weiss在数据结构和算法分析方面卓有建树,他的数据结构和算法分析的著作尤其畅销,并受到广泛好评.已被世界500余所大学用作教材。
-- [《算法图解》](https://book.douban.com/subject/26979890/)(推荐,豆瓣评分 8.4,0.6K+人评价):入门类型的书籍,读起来比较浅显易懂,适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
-- [《算法 第四版》](https://book.douban.com/subject/10432347/)(推荐,豆瓣评分 9.3,0.4K+人评价):Java语言描述,算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。书的内容非常多,可以说是Java程序员的必备书籍之一了。
-
-
-
-
-### Java相关
-
-- [《Effective java 》](https://book.douban.com/subject/3360807/)(推荐,豆瓣评分 9.0,1.4K+人评价):本书介绍了在Java编程中78条极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案。通过对Java平台设计专家所使用的技术的全面描述,揭示了应该做什么,不应该做什么才能产生清晰、健壮和高效的代码。本书中的每条规则都以简短、独立的小文章形式出现,并通过例子代码加以进一步说明。本书内容全面,结构清晰,讲解详细。可作为技术人员的参考用书。
-- [《Head First Java.第二版》](https://book.douban.com/subject/2000732/)(推荐,豆瓣评分 8.7,1.0K+人评价): 可以说是我的Java启蒙书籍了,特别适合新手读当然也适合我们用来温故Java知识点。
-- [《Java多线程编程核心技术》](https://book.douban.com/subject/26555197/): Java多线程入门级书籍还不错,但是说实话,质量不是很高,很快就可以阅读完。
-- [《JAVA网络编程 第4版》](https://book.douban.com/subject/26259017/): 可以系统的学习一下网络的一些概念以及网络编程在Java中的使用。
-- [《Java核心技术卷1+卷2》](https://book.douban.com/subject/25762168/)(推荐): 很棒的两本书,建议有点Java基础之后再读,介绍的还是比较深入的,非常推荐。这两本书我一般也会用来巩固知识点,是两本适合放在自己身边的好书。
-- [《Java编程思想(第4版)》](https://book.douban.com/subject/2130190/)(推荐,豆瓣评分 9.1,3.2K+人评价):这本书要常读,初学者可以快速概览,中等程序员可以深入看看java,老鸟还可以用之回顾java的体系。这本书之所以厉害,因为它在无形中整合了设计模式,这本书之所以难读,也恰恰在于他对设计模式的整合是无形的。
-- [《Java并发编程的艺术》](https://book.douban.com/subject/26591326/)(推荐,豆瓣评分 7.2,0.2K+人评价): 这本书不是很适合作为Java并发入门书籍,需要具备一定的JVM基础。我感觉有些东西讲的还是挺深入的,推荐阅读。
-- [《实战Java高并发程序设计》](https://book.douban.com/subject/26663605/)(推荐):豆瓣评分 8.3 ,书的质量没的说,推荐大家好好看一下。
-- [《Java程序员修炼之道》](https://book.douban.com/subject/24841235/): 很杂,我只看了前面几章,不太推荐阅读。
-- [《深入理解Java虚拟机(第2版)周志明》](https://book.douban.com/subject/24722612/)(推荐,豆瓣评分 8.9,1.0K+人评价):建议多刷几遍,书中的所有知识点可以通过JAVA运行时区域和JAVA的内存模型与线程两个大模块罗列完全。
-- [《Netty实战》](https://book.douban.com/subject/27038538/)(推荐,豆瓣评分 7.8,92人评价):内容很细,如果想学Netty的话,推荐阅读这本书!
-- [《从Paxos到Zookeeper》](https://book.douban.com/subject/26292004/)(推荐,豆瓣评分 7.8,0.3K人评价):简要介绍几种典型的分布式一致性协议,以及解决分布式一致性问题的思路,其中重点讲解了Paxos和ZAB协议。同时,本书深入介绍了分布式一致性问题的工业解决方案——ZooKeeper,并着重向读者展示这一分布式协调框架的使用方法、内部实现及运维技巧,旨在帮助读者全面了解ZooKeeper,并更好地使用和运维ZooKeeper。
-
-### JavaWeb相关
-
-- [《深入分析Java Web技术内幕》](https://book.douban.com/subject/25953851/): 感觉还行,涉及的东西也蛮多。
-- [《Spring实战(第4版)》](https://book.douban.com/subject/26767354/)(推荐,豆瓣评分 8.3
-,0.3K+人评价):不建议当做入门书籍读,入门的话可以找点国人的书或者视频看。这本定位就相当于是关于Spring的新华字典,只有一些基本概念的介绍和示例,涵盖了Spring的各个方面,但都不够深入。就像作者在最后一页写的那样:“学习Spring,这才刚刚开始”。
-- [《Java Web整合开发王者归来》](https://book.douban.com/subject/4189495/)(已过时):当时刚开始学的时候就是开的这本书,基本上是完完整整的看完了。不过,我不是很推荐大家看。这本书比较老了,里面很多东西都已经算是过时了。不过,这本书的一个很大优点是:基础知识点概括全面。
-- [《Redis实战》](https://book.douban.com/subject/26612779/):如果你想了解Redis的一些概念性知识的话,这本书真的非常不错。
-- [《Redis设计与实现》](https://book.douban.com/subject/25900156/)(推荐,豆瓣评分 8.5,0.5K+人评价)
-- [《深入剖析Tomcat》](https://book.douban.com/subject/10426640/)(推荐,豆瓣评分 8.4,0.2K+人评价):本书深入剖析Tomcat 4和Tomcat 5中的每个组件,并揭示其内部工作原理。通过学习本书,你将可以自行开发Tomcat组件,或者扩展已有的组件。 读完这本书,基本可以摆脱背诵面试题的尴尬。
-- [《高性能MySQL》](https://book.douban.com/subject/23008813/)(推荐,豆瓣评分 9.3,0.4K+人评价):mysql 领域的经典之作,拥有广泛的影响力。不但适合数据库管理员(dba)阅读,也适合开发人员参考学习。不管是数据库新手还是专家,相信都能从本书有所收获。
-- [深入理解Nginx(第2版)](https://book.douban.com/subject/26745255/):作者讲的非常细致,注释都写的都很工整,对于 Nginx 的开发人员非常有帮助。优点是细致,缺点是过于细致,到处都是代码片段,缺少一些抽象。
-- [《RabbitMQ实战指南》](https://book.douban.com/subject/27591386/):《RabbitMQ实战指南》从消息中间件的概念和RabbitMQ的历史切入,主要阐述RabbitMQ的安装、使用、配置、管理、运维、原理、扩展等方面的细节。如果你想浅尝RabbitMQ的使用,这本书是你最好的选择;如果你想深入RabbitMQ的原理,这本书也是你最好的选择;总之,如果你想玩转RabbitMQ,这本书一定是最值得看的书之一
-- [《Spring Cloud微服务实战》](https://book.douban.com/subject/27025912/):从时下流行的微服务架构概念出发,详细介绍了Spring Cloud针对微服务架构中几大核心要素的解决方案和基础组件。对于各个组件的介绍,《Spring Cloud微服务实战》主要以示例与源码结合的方式来帮助读者更好地理解这些组件的使用方法以及运行原理。同时,在介绍的过程中,还包含了作者在实践中所遇到的一些问题和解决思路,可供读者在实践中作为参考。
-- [《第一本Docker书》](https://book.douban.com/subject/26780404/):Docker入门书籍!
-
-### 操作系统
-
-- [《鸟哥的Linux私房菜》](https://book.douban.com/subject/4889838/)(推荐,,豆瓣评分 9.1,0.3K+人评价):本书是最具知名度的Linux入门书《鸟哥的Linux私房菜基础学习篇》的最新版,全面而详细地介绍了Linux操作系统。全书分为5个部分:第一部分着重说明Linux的起源及功能,如何规划和安装Linux主机;第二部分介绍Linux的文件系统、文件、目录与磁盘的管理;第三部分介绍文字模式接口 shell和管理系统的好帮手shell脚本,另外还介绍了文字编辑器vi和vim的使用方法;第四部分介绍了对于系统安全非常重要的Linux账号的管理,以及主机系统与程序的管理,如查看进程、任务分配和作业管理;第五部分介绍了系统管理员(root)的管理事项,如了解系统运行状况、系统服务,针对登录文件进行解析,对系统进行备份以及核心的管理等。
-
-### 架构相关
-
-- [《大型网站技术架构:核心原理与案例分析+李智慧》](https://book.douban.com/subject/25723064/)(推荐):这本书我读过,基本不需要你有什么基础啊~读起来特别轻松,但是却可以学到很多东西,非常推荐了。另外我写过这本书的思维导图,关注我的微信公众号:“Java面试通关手册”回复“大型网站技术架构”即可领取思维导图。
-- [《亿级流量网站架构核心技术》](https://book.douban.com/subject/26999243/)(推荐):一书总结并梳理了亿级流量网站高可用和高并发原则,通过实例详细介绍了如何落地这些原则。本书分为四部分:概述、高可用原则、高并发原则、案例实战。从负载均衡、限流、降级、隔离、超时与重试、回滚机制、压测与预案、缓存、池化、异步化、扩容、队列等多方面详细介绍了亿级流量网站的架构核心技术,让读者看后能快速运用到实践项目中。
-- [《架构解密从分布式到微服务(Leaderus著)》](https://book.douban.com/subject/27081188/):很一般的书籍,我就是当做课后图书来阅读的。
-
-### 代码优化
-
-- [《重构_改善既有代码的设计》](https://book.douban.com/subject/4262627/)(推荐):豆瓣 9.1 分,重构书籍的开山鼻祖。
-
-### 课外书籍
-
-- 《追风筝的人》(推荐)
-- 《穆斯林的葬礼》 (推荐)
-- 《三体》 (推荐)
-- 《活着——余华》 (推荐)
-
-
-
-
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/interviewPrepare.md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/interviewPrepare.md"
deleted file mode 100644
index c99ca1c156e..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/interviewPrepare.md"
+++ /dev/null
@@ -1,74 +0,0 @@
-这是【备战春招/秋招系列】的第二篇文章,主要是简单地介绍如何去准备面试。
-
-不论是校招还是社招都避免不了各种面试、笔试,如何去准备这些东西就显得格外重要。不论是笔试还是面试都是有章可循的,我这个“有章可循”说的意思只是说应对技术面试是可以提前准备。 我其实特别不喜欢那种临近考试就提前背啊记啊各种题的行为,非常反对!我觉得这种方法特别极端,而且在稍有一点经验的面试官面前是根本没有用的。建议大家还是一步一个脚印踏踏实实地走。
-
-### 1 如何获取大厂面试机会?
-
-**在讲如何获取大厂面试机会之前,先来给大家科普/对比一下两个校招非常常见的概念——春招和秋招。**
-
-1. **招聘人数** :秋招多于春招 ;
-2. **招聘时间** : 秋招一般7月左右开始,大概一直持续到10月底。<font color="red">但是大厂(如BAT)都会早开始早结束,所以一定要把握好时间。</font>春招最佳时间为3月,次佳时间为4月,进入5月基本就不会再有春招了(金三银四)。
-3. **应聘难度** :秋招略大于春招;
-4. **招聘公司:** 秋招数量多,而春招数量较少,一般为秋招的补充。
-
-**综上,一般来说,秋招的含金量明显是高于春招的。**
-
-**下面我就说一下我自己知道的一些方法,不过应该也涵盖了大部分获取面试机会的方法。**
-
-1. **关注大厂官网,随时投递简历(走流程的网申);**
-2. **线下参加宣讲会,直接投递简历;**
-3. **找到师兄师姐/认识的人,帮忙内推(能够让你避开网申简历筛选,笔试筛选,还是挺不错的,不过也还是需要你的简历够棒);**
-4. **博客发文被看中/Github优秀开源项目作者,大厂内部人员邀请你面试;**
-5. **求职类网站投递简历(不是太推荐,适合海投);**
-
-
-除了这些方法,我也遇到过这样的经历:有些大公司的一些部门可能暂时没招够人,然后如果你的亲戚或者朋友刚好在这个公司,而你正好又在寻求offer,那么面试机会基本上是有了,而且这种面试的难度好像一般还普遍比其他正规面试低很多。
-
-### 2 面试前的准备
-
-### 2.1 准备自己的自我介绍
-
-从HR面、技术面到高管面/部门主管面,面试官一般会让你先自我介绍一下,所以好好准备自己的自我介绍真的非常重要。网上一般建议的是准备好两份自我介绍:一份对hr说的,主要讲能突出自己的经历,会的编程技术一语带过;另一份对技术面试官说的,主要讲自己会的技术细节,项目经验,经历那些就一语带过。
-
-我这里简单分享一下我自己的自我介绍的一个简单的模板吧:
-
-> 面试官,您好!我叫某某。大学时间我主要利用课外时间学习某某。在校期间参与过一个某某系统的开发,另外,自己学习过程中也写过很多系统比如某某系统。在学习之余,我比较喜欢通过博客整理分享自己所学知识。我现在是某某社区的认证作者,写过某某很不错的文章。另外,我获得过某某奖,我的Github上开源的某个项目已经有多少Star了。
-
-### 2.2 关于着装
-
-穿西装、打领带、小皮鞋?NO!NO!NO!这是互联网公司面试又不是去走红毯,所以你只需要穿的简单大方就好,不需要太正式。
-
-### 2.3 随身带上自己的成绩单和简历
-
-有的公司在面试前都会让你交一份成绩单和简历当做面试中的参考。
-
-### 2.4 如果需要笔试就提前刷一些笔试题
-
-平时空闲时间多的可以刷一下笔试题目(牛客网上有很多)。但是不要只刷面试题,不动手code,程序员不是为了考试而存在的。
-
-### 2.5 花时间一些逻辑题
-
-面试中发现有些公司都有逻辑题测试环节,并且都把逻辑笔试成绩作为很重要的一个参考。
-
-### 2.6 准备好自己的项目介绍
-
-如果有项目的话,技术面试第一步,面试官一般都是让你自己介绍一下你的项目。你可以从下面几个方向来考虑:
-
-1. 对项目整体设计的一个感受(面试官可能会让你画系统的架构图)
-2. 在这个项目中你负责了什么、做了什么、担任了什么角色
-3. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
-4. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用redis做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
-
-### 2.7 提前准备技术面试
-
-搞清楚自己面试中可能涉及哪些知识点、那些知识点是重点。面试中哪些问题会被经常问到、自己改如何回答。(强烈不推荐背题,第一:通过背这种方式你能记住多少?能记住多久?第二:背题的方式的学习很难坚持下去!)
-
-### 2.7 面试之前做好定向复习
-
-所谓定向复习就是专门针对你要面试的公司来复习。比如你在面试之前可以在网上找找有没有你要面试的公司的面经。
-
-举个栗子:在我面试 ThoughtWorks 的前几天我就在网上找了一些关于 ThoughtWorks 的技术面的一些文章。然后知道了 ThoughtWorks 的技术面会让我们在之前做的作业的基础上增加一个或两个功能,所以我提前一天就把我之前做的程序重新重构了一下。然后在技术面的时候,简单的改了几行代码之后写个测试就完事了。如果没有提前准备,我觉得 20 分钟我很大几率会完不成这项任务。
-
-# 3 面试之后复盘
-
-如果失败,不要灰心;如果通过,切勿狂喜。面试和工作实际上是两回事,可能很多面试未通过的人,工作能力比你强的多,反之亦然。我个人觉得面试也像是一场全新的征程,失败和胜利都是平常之事。所以,劝各位不要因为面试失败而灰心、丧失斗志。也不要因为面试通过而沾沾自喜,等待你的将是更美好的未来,继续加油!
\ No newline at end of file
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
deleted file mode 100644
index 9cb2811b75f..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
+++ /dev/null
@@ -1,93 +0,0 @@
-## Markdown 简历模板样式一览
-
-**可以看到我把联系方式放在第一位,因为公司一般会与你联系,所以把联系方式放在第一位也是为了方便联系考虑。**
-
-## 为什么要用 Markdown 写简历?
-
-Markdown 语法简单,易于上手。使用正确的 Markdown 语言写出来的简历不论是在排版还是格式上都比较干净,易于阅读。另外,使用 Markdown 写简历也会给面试官一种你比较专业的感觉。
-
-除了这些,我觉得使用 Markdown 写简历可以很方便将其与PDF、HTML、PNG格式之间转换。后面我会介绍到转换方法,只需要一条命令你就可以实现 Markdown 到 PDF、HTML 与 PNG之间的无缝切换。
-
-> 下面的一些内容我在之前的一篇文章中已经提到过,这里再说一遍,最后会分享如何实现Markdown 到 PDF、HTML、PNG格式之间转换。
-
-## 为什么说简历很重要?
-
-假如你是网申,你的简历必然会经过HR的筛选,一张简历HR可能也就花费10秒钟看一下,然后HR就会决定你这一关是Fail还是Pass。
-
-假如你是内推,如果你的简历没有什么优势的话,就算是内推你的人再用心,也无能为力。
-
-另外,就算你通过了筛选,后面的面试中,面试官也会根据你的简历来判断你究竟是否值得他花费很多时间去面试。
-
-## 写简历的两大法则
-
-目前写简历的方式有两种普遍被认可,一种是 STAR, 一种是 FAB。
-
-**STAR法则(Situation Task Action Result):**
-
-- **Situation:** 事情是在什么情况下发生;
-- **Task::** 你是如何明确你的任务的;
-- **Action:** 针对这样的情况分析,你采用了什么行动方式;
-- **Result:** 结果怎样,在这样的情况下你学习到了什么。
-
-**FAB 法则(Feature Advantage Benefit):**
-
-- **Feature:** 是什么;
-- **Advantage:** 比别人好在哪些地方;
-- **Benefit:** 如果雇佣你,招聘方会得到什么好处。
-
-## 项目经历怎么写?
-简历上有一两个项目经历很正常,但是真正能把项目经历很好的展示给面试官的非常少。对于项目经历大家可以考虑从如下几点来写:
-
-1. 对项目整体设计的一个感受
-2. 在这个项目中你负责了什么、做了什么、担任了什么角色
-3. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
-4. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的。
-
-## 专业技能该怎么写?
-先问一下你自己会什么,然后看看你意向的公司需要什么。一般HR可能并不太懂技术,所以他在筛选简历的时候可能就盯着你专业技能的关键词来看。对于公司有要求而你不会的技能,你可以花几天时间学习一下,然后在简历上可以写上自己了解这个技能。比如你可以这样写:
-
-- Dubbo:精通
-- Spring:精通
-- Docker:掌握
-- SOA分布式开发 :掌握
-- Spring Cloud:了解
-
-## 简历模板分享
-
-**开源程序员简历模板**: [https://github.com/geekcompany/ResumeSample](https://github.com/geekcompany/ResumeSample)(包括PHP程序员简历模板、iOS程序员简历模板、Android程序员简历模板、Web前端程序员简历模板、Java程序员简历模板、C/C++程序员简历模板、NodeJS程序员简历模板、架构师简历模板以及通用程序员简历模板)
-
-**上述简历模板的改进版本:** [https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/简历模板.md](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/简历模板.md)
-
-## 其他的一些小tips
-
-1. 尽量避免主观表述,少一点语义模糊的形容词,尽量要简洁明了,逻辑结构清晰。
-2. 注意排版(不需要花花绿绿的),尽量使用Markdown语法。
-3. 如果自己有博客或者个人技术栈点的话,写上去会为你加分很多。
-4. 如果自己的Github比较活跃的话,写上去也会为你加分很多。
-5. 注意简历真实性,一定不要写自己不会的东西,或者带有欺骗性的内容
-6. 项目经历建议以时间倒序排序,另外项目经历不在于多,而在于有亮点。
-7. 如果内容过多的话,不需要非把内容压缩到一页,保持排版干净整洁就可以了。
-8. 简历最后最好能加上:“感谢您花时间阅读我的简历,期待能有机会和您共事。”这句话,显的你会很有礼貌。
-
-
-> 我们刚刚讲了很多关于如何写简历的内容并且分享了一份 Markdown 格式的简历文档。下面我们来看看如何实现 Markdown 到 HTML格式、PNG格式之间转换。
-## Markdown 到 HTML格式、PNG格式之间转换
-
-网上很难找到一个比较方便并且效果好的转换方法,最后我是通过 Visual Studio Code 的 Markdown PDF 插件完美解决了这个问题!
-
-### 安装 Markdown PDF 插件
-
-**① 打开Visual Studio Code ,按快捷键 F1,选择安装扩展选项**
-
-
-
-**② 搜索 “Markdown PDF” 插件并安装 ,然后重启**
-
-
-
-### 使用方法
-
-随便打开一份 Markdown 文件 点击F1,然后输入export即可!
-
-
-
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\346\234\200\346\234\200\346\234\200\345\270\270\350\247\201\347\232\204Java\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223/\347\254\254\344\270\200\345\221\250\357\274\2102018-8-7\357\274\211.md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/\346\234\200\346\234\200\346\234\200\345\270\270\350\247\201\347\232\204Java\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223/\347\254\254\344\270\200\345\221\250\357\274\2102018-8-7\357\274\211.md"
deleted file mode 100644
index 4ca58dbfff6..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\346\234\200\346\234\200\346\234\200\345\270\270\350\247\201\347\232\204Java\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223/\347\254\254\344\270\200\345\221\250\357\274\2102018-8-7\357\274\211.md"
+++ /dev/null
@@ -1,253 +0,0 @@
-
-
-## 一 为什么 Java 中只有值传递?
-
-
-首先回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。**按值调用(call by value)表示方法接收的是调用者提供的值,而按引用调用(call by reference)表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。** 它用来描述各种程序设计语言(不只是Java)中方法参数传递方式。
-
-**Java程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。**
-
-**下面通过 3 个例子来给大家说明**
-
-### example 1
-
-
-```java
-public static void main(String[] args) {
- int num1 = 10;
- int num2 = 20;
-
- swap(num1, num2);
-
- System.out.println("num1 = " + num1);
- System.out.println("num2 = " + num2);
-}
-
-public static void swap(int a, int b) {
- int temp = a;
- a = b;
- b = temp;
-
- System.out.println("a = " + a);
- System.out.println("b = " + b);
-}
-```
-
-**结果:**
-
-```
-a = 20
-b = 10
-num1 = 10
-num2 = 20
-```
-
-**解析:**
-
-
-
-在swap方法中,a、b的值进行交换,并不会影响到 num1、num2。因为,a、b中的值,只是从 num1、num2 的复制过来的。也就是说,a、b相当于num1、num2 的副本,副本的内容无论怎么修改,都不会影响到原件本身。
-
-**通过上面例子,我们已经知道了一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不一样,请看 example2.**
-
-
-### example 2
-
-```java
- public static void main(String[] args) {
- int[] arr = { 1, 2, 3, 4, 5 };
- System.out.println(arr[0]);
- change(arr);
- System.out.println(arr[0]);
- }
-
- public static void change(int[] array) {
- // 将数组的第一个元素变为0
- array[0] = 0;
- }
-```
-
-**结果:**
-
-```
-1
-0
-```
-
-**解析:**
-
-
-
-array 被初始化 arr 的拷贝也就是一个对象的引用,也就是说 array 和 arr 指向的时同一个数组对象。 因此,外部对引用对象的改变会反映到所对应的对象上。
-
-
-**通过 example2 我们已经看到,实现一个改变对象参数状态的方法并不是一件难事。理由很简单,方法得到的是对象引用的拷贝,对象引用及其他的拷贝同时引用同一个对象。**
-
-**很多程序设计语言(特别是,C++和Pascal)提供了两种参数传递的方式:值调用和引用调用。有些程序员(甚至本书的作者)认为Java程序设计语言对对象采用的是引用调用,实际上,这种理解是不对的。由于这种误解具有一定的普遍性,所以下面给出一个反例来详细地阐述一下这个问题。**
-
-
-### example 3
-
-```java
-public class Test {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- Student s1 = new Student("小张");
- Student s2 = new Student("小李");
- Test.swap(s1, s2);
- System.out.println("s1:" + s1.getName());
- System.out.println("s2:" + s2.getName());
- }
-
- public static void swap(Student x, Student y) {
- Student temp = x;
- x = y;
- y = temp;
- System.out.println("x:" + x.getName());
- System.out.println("y:" + y.getName());
- }
-}
-```
-
-**结果:**
-
-```
-x:小李
-y:小张
-s1:小张
-s2:小李
-```
-
-**解析:**
-
-交换之前:
-
-
-
-交换之后:
-
-
-
-
-通过上面两张图可以很清晰的看出: **方法并没有改变存储在变量 s1 和 s2 中的对象引用。swap方法的参数x和y被初始化为两个对象引用的拷贝,这个方法交换的是这两个拷贝**
-
-### 总结
-
-Java程序设计语言对对象采用的不是引用调用,实际上,对象引用是按
-值传递的。
-
-下面再总结一下Java中方法参数的使用情况:
-
-- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型》
-- 一个方法可以改变一个对象参数的状态。
-- 一个方法不能让对象参数引用一个新的对象。
-
-
-### 参考:
-
-《Java核心技术卷Ⅰ》基础知识第十版第四章4.5小节
-
-## 二 ==与equals(重要)
-
-**==** : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
-
-**equals()** : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
-
-- 情况1:类没有覆盖equals()方法。则通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。
-- 情况2:类覆盖了equals()方法。一般,我们都覆盖equals()方法来两个对象的内容相等;若它们的内容相等,则返回true(即,认为这两个对象相等)。
-
-
-**举个例子:**
-
-```java
-public class test1 {
- public static void main(String[] args) {
- String a = new String("ab"); // a 为一个引用
- String b = new String("ab"); // b为另一个引用,对象的内容一样
- String aa = "ab"; // 放在常量池中
- String bb = "ab"; // 从常量池中查找
- if (aa == bb) // true
- System.out.println("aa==bb");
- if (a == b) // false,非同一对象
- System.out.println("a==b");
- if (a.equals(b)) // true
- System.out.println("aEQb");
- if (42 == 42.0) { // true
- System.out.println("true");
- }
- }
-}
-```
-
-**说明:**
-
-- String中的equals方法是被重写过的,因为object的equals方法是比较的对象的内存地址,而String的equals方法比较的是对象的值。
-- 当创建String类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个String对象。
-
-
-
-## 三 hashCode与equals(重要)
-
-面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写equals时必须重写hashCode方法?”
-
-### hashCode()介绍
-hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
-
-```java
- /**
- * Returns a hash code value for the object. This method is
- * supported for the benefit of hash tables such as those provided by
- * {@link java.util.HashMap}.
- * <p>
- * As much as is reasonably practical, the hashCode method defined by
- * class {@code Object} does return distinct integers for distinct
- * objects. (This is typically implemented by converting the internal
- * address of the object into an integer, but this implementation
- * technique is not required by the
- * Java™ programming language.)
- *
- * @return a hash code value for this object.
- * @see java.lang.Object#equals(java.lang.Object)
- * @see java.lang.System#identityHashCode
- */
- public native int hashCode();
-```
-
-散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
-
-### 为什么要有hashCode
-
-
-**我们以“HashSet如何检查重复”为例子来说明为什么要有hashCode:**
-
-当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他已经加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head fist java》第二版)。这样我们就大大减少了equals的次数,相应就大大提高了执行速度。
-
-
-
-### hashCode()与equals()的相关规定
-
-1. 如果两个对象相等,则hashcode一定也是相同的
-2. 两个对象相等,对两个对象分别调用equals方法都返回true
-3. 两个对象有相同的hashcode值,它们也不一定是相等的
-4. **因此,equals方法被覆盖过,则hashCode方法也必须被覆盖**
-5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
-
-### 为什么两个对象有相同的hashcode值,它们也不一定是相等的?
-
-在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
-
-因为hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode)。
-
-我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
-
-参考:
-
-[https://blog.csdn.net/zhzhao999/article/details/53449504](https://blog.csdn.net/zhzhao999/article/details/53449504)
-
-[https://www.cnblogs.com/skywang12345/p/3324958.html](https://www.cnblogs.com/skywang12345/p/3324958.html)
-
-[https://www.cnblogs.com/skywang12345/p/3324958.html](https://www.cnblogs.com/skywang12345/p/3324958.html)
-
-[https://www.cnblogs.com/Eason-S/p/5524837.html](https://www.cnblogs.com/Eason-S/p/5524837.html)
-
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\346\234\200\346\234\200\346\234\200\345\270\270\350\247\201\347\232\204Java\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223/\347\254\254\344\272\214\345\221\250(2018-8-13).md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/\346\234\200\346\234\200\346\234\200\345\270\270\350\247\201\347\232\204Java\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223/\347\254\254\344\272\214\345\221\250(2018-8-13).md"
deleted file mode 100644
index 88aa2a6ec4a..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\346\234\200\346\234\200\346\234\200\345\270\270\350\247\201\347\232\204Java\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223/\347\254\254\344\272\214\345\221\250(2018-8-13).md"
+++ /dev/null
@@ -1,198 +0,0 @@
-
-### String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?
-
-#### String和StringBuffer、StringBuilder的区别
-
-**可变性**
-
-
-简单的来说:String 类中使用 final 关键字字符数组保存字符串,`private final char value[]`,所以 String 对象是不可变的。而StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串`char[]value` 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
-
-StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。
-
-AbstractStringBuilder.java
-
-```java
-abstract class AbstractStringBuilder implements Appendable, CharSequence {
- char[] value;
- int count;
- AbstractStringBuilder() {
- }
- AbstractStringBuilder(int capacity) {
- value = new char[capacity];
- }
-```
-
-
-**线程安全性**
-
-String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
-
-
-**性能**
-
-每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StirngBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
-
-**对于三者使用的总结:**
-1. 操作少量的数据 = String
-2. 单线程操作字符串缓冲区下操作大量数据 = StringBuilder
-3. 多线程操作字符串缓冲区下操作大量数据 = StringBuffer
-
-#### String为什么是不可变的吗?
-简单来说就是String类利用了final修饰的char类型数组存储字符,源码如下图所以:
-
-```java
- /** The value is used for character storage. */
- private final char value[];
-```
-
-#### String真的是不可变的吗?
-我觉得如果别人问这个问题的话,回答不可变就可以了。
-下面只是给大家看两个有代表性的例子:
-
-**1) String不可变但不代表引用不可以变**
-```java
- String str = "Hello";
- str = str + " World";
- System.out.println("str=" + str);
-```
-结果:
-```
-str=Hello World
-```
-解析:
-
-实际上,原来String的内容是不变的,只是str由原来指向"Hello"的内存地址转为指向"Hello World"的内存地址而已,也就是说多开辟了一块内存区域给"Hello World"字符串。
-
-**2) 通过反射是可以修改所谓的“不可变”对象**
-
-```java
- // 创建字符串"Hello World", 并赋给引用s
- String s = "Hello World";
-
- System.out.println("s = " + s); // Hello World
-
- // 获取String类中的value字段
- Field valueFieldOfString = String.class.getDeclaredField("value");
-
- // 改变value属性的访问权限
- valueFieldOfString.setAccessible(true);
-
- // 获取s对象上的value属性的值
- char[] value = (char[]) valueFieldOfString.get(s);
-
- // 改变value所引用的数组中的第5个字符
- value[5] = '_';
-
- System.out.println("s = " + s); // Hello_World
-```
-
-结果:
-
-```
-s = Hello World
-s = Hello_World
-```
-
-解析:
-
-用反射可以访问私有成员, 然后反射出String对象中的value属性, 进而改变通过获得的value引用改变数组的结构。但是一般我们不会这么做,这里只是简单提一下有这个东西。
-
-### 什么是反射机制?反射机制的应用场景有哪些?
-
-#### 反射机制介绍
-
-JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
-
-#### 静态编译和动态编译
-
-- **静态编译:**在编译时确定类型,绑定对象
-- **动态编译:**运行时确定类型,绑定对象
-
-#### 反射机制优缺点
-
-- **优点:** 运行期类型的判断,动态加载类,提高代码灵活度。
-- **缺点:** 性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的java代码要慢很多。
-
-#### 反射的应用场景
-
-反射是框架设计的灵魂。
-
-在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
-
-举例:①我们在使用JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序;②Spring框架也用到很多反射机制,最经典的就是xml的配置模式。Spring 通过 XML 配置模式装载 Bean 的过程:1) 将程序内所有 XML 或 Properties 配置文件加载入内存中;
- 2)Java类里面解析xml或properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息; 3)使用反射机制,根据这个字符串获得某个类的Class实例; 4)动态配置实例的属性
-
-**推荐阅读:**
-
-- [Reflection:Java反射机制的应用场景](https://segmentfault.com/a/1190000010162647?utm_source=tuicool&utm_medium=referral)
-- [Java基础之—反射(非常重要)](https://blog.csdn.net/sinat_38259539/article/details/71799078)
-### 什么是JDK?什么是JRE?什么是JVM?三者之间的联系与区别
-
-这几个是Java中很基本很基本的东西,但是我相信一定还有很多人搞不清楚!为什么呢?因为我们大多数时候在使用现成的编译工具以及环境的时候,并没有去考虑这些东西。
-
-**JDK:** 顾名思义它是给开发者提供的开发工具箱,是给程序开发者用的。它除了包括完整的JRE(Java Runtime Environment),Java运行环境,还包含了其他供开发者使用的工具包。
-
-**JRE:** 普通用户而只需要安装JRE(Java Runtime Environment)来运行Java程序。而程序开发者必须安装JDK来编译、调试程序。
-
-**JVM:** 当我们运行一个程序时,JVM负责将字节码转换为特定机器代码,JVM提供了内存管理/垃圾回收和安全机制等。这种独立于硬件和操作系统,正是java程序可以一次编写多处执行的原因。
-
-**区别与联系:**
-
- 1. JDK用于开发,JRE用于运行java程序 ;
- 2. JDK和JRE中都包含JVM ;
- 3. JVM是java编程语言的核心并且具有平台独立性。
-
-### 什么是字节码?采用字节码的最大好处是什么?
-
-**先看下java中的编译器和解释器:**
-
-Java中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在Java中,这种供虚拟机理解的代码叫做`字节码`(即扩展名为`.class`的文件),它不面向任何特定的处理器,只面向虚拟机。每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行。这也就是解释了Java的编译与解释并存的特点。
-
- Java源代码---->编译器---->jvm可执行的Java字节码(即虚拟指令)---->jvm---->jvm中解释器----->机器可执行的二进制机器码---->程序运行。
-
-**采用字节码的好处:**
-
-Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。
-
-### Java和C++的区别
-
-我知道很多人没学过C++,但是面试官就是没事喜欢拿咱们Java和C++比呀!没办法!!!就算没学过C++,也要记下来!
-
-- 都是面向对象的语言,都支持封装、继承和多态
-- Java不提供指针来直接访问内存,程序内存更加安全
-- Java的类是单继承的,C++支持多重继承;虽然Java的类不可以多继承,但是接口可以多继承。
-- Java有自动内存管理机制,不需要程序员手动释放无用内存
-
-
-### 接口和抽象类的区别是什么?
-
-1. 接口的方法默认是public,所有方法在接口中不能有实现,抽象类可以有非抽象的方法
-2. 接口中的实例变量默认是final类型的,而抽象类中则不一定
-3. 一个类可以实现多个接口,但最多只能实现一个抽象类
-4. 一个类实现接口的话要实现接口的所有方法,而抽象类不一定
-5. 接口不能用new实例化,但可以声明,但是必须引用一个实现该接口的对象 从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
-
-### 成员变量与局部变量的区别有那些?
-
-1. 从语法形式上,看成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被public,private,static等修饰符所修饰,而局部变量不能被访问控制修饰符及static所修饰;但是,成员变量和局部变量都能被final所修饰;
-2. 从变量在内存中的存储方式来看,成员变量是对象的一部分,而对象存在于堆内存,局部变量存在于栈内存
-3. 从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
-4. 成员变量如果没有被赋初值,则会自动以类型的默认值而赋值(一种情况例外被final修饰但没有被static修饰的成员变量必须显示地赋值);而局部变量则不会自动赋值。
-
-### 重载和重写的区别
-
-**重载:** 发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
-
-**重写:** 发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为private则子类就不能重写该方法。
-
-### 字符型常量和字符串常量的区别
-1) 形式上:
-字符常量是单引号引起的一个字符
-字符串常量是双引号引起的若干个字符
-2) 含义上:
-字符常量相当于一个整形值(ASCII值),可以参加表达式运算
-字符串常量代表一个地址值(该字符串在内存中存放位置)
-3) 占内存大小
-字符常量只占一个字节
-字符串常量占若干个字节(至少一个字符结束标志)
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\346\234\200\346\234\200\346\234\200\345\270\270\350\247\201\347\232\204Java\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223/\347\254\254\345\233\233\345\221\250(2018-8-30).md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/\346\234\200\346\234\200\346\234\200\345\270\270\350\247\201\347\232\204Java\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223/\347\254\254\345\233\233\345\221\250(2018-8-30).md"
deleted file mode 100644
index 3cb02d73d5b..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\346\234\200\346\234\200\346\234\200\345\270\270\350\247\201\347\232\204Java\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223/\347\254\254\345\233\233\345\221\250(2018-8-30).md"
+++ /dev/null
@@ -1,195 +0,0 @@
-
-## 1. 简述线程,程序、进程的基本概念。以及他们之间关系是什么?
-
-**线程**与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
-
-**程序**是含有指令和数据的文件,被存储在磁盘或其他的数据存储设备中,也就是说程序是静态的代码。
-
-**进程**是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。简单来说,一个进程就是一个执行中的程序,它在计算机中一个指令接着一个指令地执行着,同时,每个进程还占有某些系统资源如CPU时间,内存空间,文件,文件,输入输出设备的使用权等等。换句话说,当程序在执行时,将会被操作系统载入内存中。
-
-**线程** 是 **进程** 划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。从另一角度来说,进程属于操作系统的范畴,主要是同一段时间内,可以同时执行一个以上的程序,而线程则是在同一程序内几乎同时执行一个以上的程序段。
-
-**线程上下文的切换比进程上下文切换要快很多**
-
-- 进程切换时,涉及到当前进程的CPU环境的保存和新被调度运行进程的CPU环境的设置。
-- 线程切换仅需要保存和设置少量的寄存器内容,不涉及存储管理方面的操作。
-
-## 2. 线程有哪些基本状态?这些状态是如何定义的?
-
-1. **新建(new)**:新创建了一个线程对象。
-2. **可运行(runnable)**:线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获 取cpu的使用权。
-3. **运行(running)**:可运行状态(runnable)的线程获得了cpu时间片(timeslice),执行程序代码。
-4. **阻塞(block)**:阻塞状态是指线程因为某种原因放弃了cpu使用权,也即让出了cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有 机会再次获得cpu timeslice转到运行(running)状态。阻塞的情况分三种:
- - **(一). 等待阻塞**:运行(running)的线程执行o.wait()方法,JVM会把该线程放 入等待队列(waiting queue)中。
- - **(二). 同步阻塞**:运行(running)的线程在获取对象的同步锁时,若该同步 锁 被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
- - **(三). 其他阻塞**: 运行(running)的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
-5. **死亡(dead)**:线程run()、main()方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
-
-
-
-备注: 可以用早起坐地铁来比喻这个过程(下面参考自牛客网某位同学的回答):
-
-1. 还没起床:sleeping
-2. 起床收拾好了,随时可以坐地铁出发:Runnable
-3. 等地铁来:Waiting
-4. 地铁来了,但要排队上地铁:I/O阻塞
-5. 上了地铁,发现暂时没座位:synchronized阻塞
-6. 地铁上找到座位:Running
-7. 到达目的地:Dead
-
-
-## 3. 何为多线程?
-
-多线程就是多个线程同时运行或交替运行。单核CPU的话是顺序执行,也就是交替运行。多核CPU的话,因为每个CPU有自己的运算器,所以在多个CPU中可以同时运行。
-
-
-## 4. 为什么多线程是必要的?
-
-1. 使用线程可以把占据长时间的程序中的任务放到后台去处理。
-2. 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
-3. 程序的运行速度可能加快。
-
-## 5 使用多线程常见的三种方式
-
-### ①继承Thread类
-
-MyThread.java
-
-```java
-public class MyThread extends Thread {
- @Override
- public void run() {
- super.run();
- System.out.println("MyThread");
- }
-}
-```
-Run.java
-
-```java
-public class Run {
-
- public static void main(String[] args) {
- MyThread mythread = new MyThread();
- mythread.start();
- System.out.println("运行结束");
- }
-
-}
-
-```
-运行结果:
-
-从上面的运行结果可以看出:线程是一个子任务,CPU以不确定的方式,或者说是以随机的时间来调用线程中的run方法。
-
-### ②实现Runnable接口
-推荐实现Runnable接口方式开发多线程,因为Java单继承但是可以实现多个接口。
-
-MyRunnable.java
-
-```java
-public class MyRunnable implements Runnable {
- @Override
- public void run() {
- System.out.println("MyRunnable");
- }
-}
-```
-
-Run.java
-
-```java
-public class Run {
-
- public static void main(String[] args) {
- Runnable runnable=new MyRunnable();
- Thread thread=new Thread(runnable);
- thread.start();
- System.out.println("运行结束!");
- }
-
-}
-```
-运行结果:
-
-
-### ③使用线程池
-
-**在《阿里巴巴Java开发手册》“并发处理”这一章节,明确指出线程资源必须通过线程池提供,不允许在应用中自行显示创建线程。**
-
-**为什么呢?**
-
-> **使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源开销,解决资源不足的问题。如果不使用线程池,有可能会造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。**
-
-**另外《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险**
-
-> Executors 返回线程池对象的弊端如下:
->
-> - **FixedThreadPool 和 SingleThreadExecutor** : 允许请求的队列长度为 Integer.MAX_VALUE,可能堆积大量的请求,从而导致OOM。
-> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致OOM。
-
-对于线程池感兴趣的可以查看我的这篇文章:[《Java多线程学习(八)线程池与Executor 框架》](http://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484042&idx=1&sn=541dbf2cb969a151d79f4a4f837ee1bd&chksm=fd9854ebcaefddfd1876bb96ab218be3ae7b12546695a403075d4ed22e5e17ff30ebdabc8bbf#rd) 点击阅读原文即可查看到该文章的最新版。
-
-
-## 6 线程的优先级
-
-每个线程都具有各自的优先级,**线程的优先级可以在程序中表明该线程的重要性,如果有很多线程处于就绪状态,系统会根据优先级来决定首先使哪个线程进入运行状态**。但这个并不意味着低
-优先级的线程得不到运行,而只是它运行的几率比较小,如垃圾回收机制线程的优先级就比较低。所以很多垃圾得不到及时的回收处理。
-
-**线程优先级具有继承特性。** 比如A线程启动B线程,则B线程的优先级和A是一样的。
-
-**线程优先级具有随机性。** 也就是说线程优先级高的不一定每一次都先执行完。
-
-Thread类中包含的成员变量代表了线程的某些优先级。如**Thread.MIN_PRIORITY(常数1)**,**Thread.NORM_PRIORITY(常数5)**,
-**Thread.MAX_PRIORITY(常数10)**。其中每个线程的优先级都在**Thread.MIN_PRIORITY(常数1)** 到**Thread.MAX_PRIORITY(常数10)** 之间,在默认情况下优先级都是**Thread.NORM_PRIORITY(常数5)**。
-
-学过操作系统这门课程的话,我们可以发现多线程优先级或多或少借鉴了操作系统对进程的管理。
-
-
-## 7 Java多线程分类
-
-### 用户线程
-
-运行在前台,执行具体的任务,如程序的主线程、连接网络的子线程等都是用户线程
-
-### 守护线程
-
-运行在后台,为其他前台线程服务.也可以说守护线程是JVM中非守护线程的 **“佣人”**。
-
-
-- **特点:** 一旦所有用户线程都结束运行,守护线程会随JVM一起结束工作
-- **应用:** 数据库连接池中的检测线程,JVM虚拟机启动后的检测线程
-- **最常见的守护线程:** 垃圾回收线程
-
-
-**如何设置守护线程?**
-
-可以通过调用 Thead 类的 `setDaemon(true)` 方法设置当前的线程为守护线程。
-
-注意事项:
-
- 1. setDaemon(true)必须在start()方法前执行,否则会抛出IllegalThreadStateException异常
- 2. 在守护线程中产生的新线程也是守护线程
- 3. 不是所有的任务都可以分配给守护线程来执行,比如读写操作或者计算逻辑
-
-
-## 8 sleep()方法和wait()方法简单对比
-
-- 两者最主要的区别在于:**sleep方法没有释放锁,而wait方法释放了锁** 。
-- 两者都可以暂停线程的执行。
-- Wait通常被用于线程间交互/通信,sleep通常被用于暂停执行。
-- wait()方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的notify()或者notifyAll()方法。sleep()方法执行完成后,线程会自动苏醒。
-
-
-## 9 为什么我们调用start()方法时会执行run()方法,为什么我们不能直接调用run()方法?
-
-这是另一个非常经典的java多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
-
-new一个Thread,线程进入了新建状态;调用start()方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。
-start()会执行线程的相应准备工作,然后自动执行run()方法的内容,这是真正的多线程工作。 而直接执行run()方法,会把run方法当成一个mian线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
-
-**总结: 调用start方法方可启动线程并使线程进入就绪状态,而run方法只是thread的一个普通方法调用,还是在主线程里执行。**
-
-
-
-
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\250\213\345\272\217\345\221\230\347\232\204\347\256\200\345\216\206\344\271\213\351\201\223.md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/\347\250\213\345\272\217\345\221\230\347\232\204\347\256\200\345\216\206\344\271\213\351\201\223.md"
deleted file mode 100644
index d07fa52a7e7..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\250\213\345\272\217\345\221\230\347\232\204\347\256\200\345\216\206\344\271\213\351\201\223.md"
+++ /dev/null
@@ -1,106 +0,0 @@
-# 程序员的简历就该这样写
-
-### 1 前言
-<font color="red">一份好的简历可以在整个申请面试以及面试过程中起到非常好的作用。</font> 在不夸大自己能力的情况下,写出一份好的简历也是一项很棒的能力。
-
-### 2 为什么说简历很重要?
-
-#### 2.1 先从面试前来说
-
-假如你是网申,你的简历必然会经过HR的筛选,一张简历HR可能也就花费10秒钟看一下,然后HR就会决定你这一关是Fail还是Pass。
-
-假如你是内推,如果你的简历没有什么优势的话,就算是内推你的人再用心,也无能为力。
-
-另外,就算你通过了筛选,后面的面试中,面试官也会根据你的简历来判断你究竟是否值得他花费很多时间去面试。
-
-所以,简历就像是我们的一个门面一样,它在很大程度上决定了你能否进入到下一轮的面试中。
-
-#### 2.2 再从面试中来说
-
-我发现大家比较喜欢看面经 ,这点无可厚非,但是大部分面经都没告诉你很多问题都是在特定条件下才问的。举个简单的例子:一般情况下你的简历上注明你会的东西才会被问到(Java、数据结构、网络、算法这些基础是每个人必问的),比如写了你会 redis,那面试官就很大概率会问你 redis 的一些问题。比如:redis的常见数据类型及应用场景、redis是单线程为什么还这么快、 redis 和 memcached 的区别、redis 内存淘汰机制等等。
-
-所以,首先,你要明确的一点是:**你不会的东西就不要写在简历上**。另外,**你要考虑你该如何才能让你的亮点在简历中凸显出来**,比如:你在某某项目做了什么事情解决了什么问题(只要有项目就一定有要解决的问题)、你的某一个项目里使用了什么技术后整体性能和并发量提升了很多等等。
-
-面试和工作是两回事,聪明的人会把面试官往自己擅长的领域领,其他人则被面试官牵着鼻子走。虽说面试和工作是两回事,但是你要想要获得自己满意的 offer ,你自身的实力必须要强。
-
-### 3 下面这几点你必须知道
-
-1. 大部分公司的HR都说我们不看重学历(骗你的!),但是如果你的学校不出众的话,很难在一堆简历中脱颖而出,除非你的简历上有特别的亮点,比如:某某大厂的实习经历、获得了某某大赛的奖等等。
-2. **大部分应届生找工作的硬伤是没有工作经验或实习经历,所以如果你是应届生就不要错过秋招和春招。一旦错过,你后面就极大可能会面临社招,这个时候没有工作经验的你可能就会面临各种碰壁,导致找不到一个好的工作**
-3. **写在简历上的东西一定要慎重,这是面试官大量提问的地方;**
-4. **将自己的项目经历完美的展示出来非常重要。**
-
-### 4 必须了解的两大法则
-
-
-**①STAR法则(Situation Task Action Result):**
-
-- **Situation:** 事情是在什么情况下发生;
-- **Task::** 你是如何明确你的任务的;
-- **Action:** 针对这样的情况分析,你采用了什么行动方式;
-- **Result:** 结果怎样,在这样的情况下你学习到了什么。
-
-简而言之,STAR法则,就是一种讲述自己故事的方式,或者说,是一个清晰、条理的作文模板。不管是什么,合理熟练运用此法则,可以轻松的对面试官描述事物的逻辑方式,表现出自己分析阐述问题的清晰性、条理性和逻辑性。
-
-下面这段内容摘自百度百科,我觉得写的非常不错:
-
-> STAR法则,500强面试题回答时的技巧法则,备受面试者成功者和500强HR的推崇。
-由于这个法则被广泛应用于面试问题的回答,尽管我们还在写简历阶段,但是,写简历时能把面试的问题就想好,会使自己更加主动和自信,做到简历,面试关联性,逻辑性强,不至于在一个月后去面试,却把简历里的东西都忘掉了(更何况有些朋友会稍微夸大简历内容)
-在我们写简历时,每个人都要写上自己的工作经历,活动经历,想必每一个同学,都会起码花上半天甚至更长的时间去搜寻脑海里所有有关的经历,争取找出最好的东西写在简历上。
-但是此时,我们要注意了,简历上的任何一个信息点都有可能成为日后面试时的重点提问对象,所以说,不能只管写上让自己感觉最牛的经历就完事了,要想到今后,在面试中,你所写的经历万一被面试官问到,你真的能回答得流利,顺畅,且能通过这段经历,证明自己正是适合这个职位的人吗?
-
-**②FAB 法则(Feature Advantage Benefit):**
-
-- **Feature:** 是什么;
-- **Advantage:** 比别人好在哪些地方;
-- **Benefit:** 如果雇佣你,招聘方会得到什么好处。
-
-简单来说,这个法则主要是让你的面试官知道你的优势、招了你之后对公司有什么帮助。
-
-### 5 项目经历怎么写?
-
-简历上有一两个项目经历很正常,但是真正能把项目经历很好的展示给面试官的非常少。对于项目经历大家可以考虑从如下几点来写:
-
-1. 对项目整体设计的一个感受
-2. 在这个项目中你负责了什么、做了什么、担任了什么角色
-3. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
-4. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用redis做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
-
-### 6 专业技能该怎么写?
-先问一下你自己会什么,然后看看你意向的公司需要什么。一般HR可能并不太懂技术,所以他在筛选简历的时候可能就盯着你专业技能的关键词来看。对于公司有要求而你不会的技能,你可以花几天时间学习一下,然后在简历上可以写上自己了解这个技能。比如你可以这样写(下面这部分内容摘自我的简历,大家可以根据自己的情况做一些修改和完善):
-
-- 计算机网络、数据结构、算法、操作系统等课内基础知识:掌握
-- Java 基础知识:掌握
-- JVM 虚拟机(Java内存区域、虚拟机垃圾算法、虚拟垃圾收集器、JVM内存管理):掌握
-- 高并发、高可用、高性能系统开发:掌握
-- Struts2、Spring、Hibernate、Ajax、Mybatis、JQuery :掌握
-- SSH 整合、SSM 整合、 SOA 架构:掌握
-- Dubbo: 掌握
-- Zookeeper: 掌握
-- 常见消息队列: 掌握
-- Linux:掌握
-- MySQL常见优化手段:掌握
-- Spring Boot +Spring Cloud +Docker:了解
-- Hadoop 生态相关技术中的 HDFS、Storm、MapReduce、Hive、Hbase :了解
-- Python 基础、一些常见第三方库比如OpenCV、wxpy、wordcloud、matplotlib:熟悉
-
-### 7 开源程序员Markdown格式简历模板分享
-
-分享一个Github上开源的程序员简历模板。包括PHP程序员简历模板、iOS程序员简历模板、Android程序员简历模板、Web前端程序员简历模板、Java程序员简历模板、C/C++程序员简历模板、NodeJS程序员简历模板、架构师简历模板以及通用程序员简历模板 。
-Github地址:[https://github.com/geekcompany/ResumeSample](https://github.com/geekcompany/ResumeSample)
-
-
-我的下面这篇文章讲了如何写一份Markdown格式的简历,另外,文中还提到了一种实现 Markdown 格式到PDF、HTML、JPEG这几种格式的转换方法。
-
-[手把手教你用Markdown写一份高质量的简历](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484347&idx=1&sn=a986ea7e199871999a5257bd3ed78be1&chksm=fd9855dacaefdccc2c5d5f8f79c4aa1b608ad5b42936bccaefb99a850a2e6e8e2e910e1b3153&token=719595858&lang=zh_CN#rd)
-
-### 8 其他的一些小tips
-
-1. 尽量避免主观表述,少一点语义模糊的形容词,尽量要简洁明了,逻辑结构清晰。
-2. 注意排版(不需要花花绿绿的),尽量使用Markdown语法。
-3. 如果自己有博客或者个人技术栈点的话,写上去会为你加分很多。
-4. 如果自己的Github比较活跃的话,写上去也会为你加分很多。
-5. 注意简历真实性,一定不要写自己不会的东西,或者带有欺骗性的内容
-6. 项目经历建议以时间倒序排序,另外项目经历不在于多,而在于有亮点。
-7. 如果内容过多的话,不需要非把内容压缩到一页,保持排版干净整洁就可以了。
-8. 简历最后最好能加上:“感谢您花时间阅读我的简历,期待能有机会和您共事。”这句话,显的你会很有礼貌。
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\256\200\345\216\206\346\250\241\346\235\277.md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/\347\256\200\345\216\206\346\250\241\346\235\277.md"
deleted file mode 100644
index 2a7a0431f35..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\256\200\345\216\206\346\250\241\346\235\277.md"
+++ /dev/null
@@ -1,79 +0,0 @@
-# 联系方式
-
-- 手机:
-- Email:
-- 微信:
-
-# 个人信息
-
- - 姓名/性别/出生日期
- - 本科/xxx计算机系xxx专业/英语六级
- - 技术博客:[http://snailclimb.top/](http://snailclimb.top/)
- - 荣誉奖励:获得了什么奖(获奖时间)
- - Github:[https://github.com/Snailclimb ](https://github.com/Snailclimb)
- - Github Resume: [http://resume.github.io/?Snailclimb](http://resume.github.io/?Snailclimb)
- - 期望职位:Java 研发程序员/大数据工程师(Java后台开发为首选)
- - 期望城市:xxx城市
-
-
-# 项目经历
-
-## xxx项目
-
-### 项目描述
-
-介绍该项目是做什么的、使用到了什么技术以及你对项目整体设计的一个感受
-
-### 责任描述
-
-主要可以从下面三点来写:
-
-1. 在这个项目中你负责了什么、做了什么、担任了什么角色
-2. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
-3. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的。
-
-# 开源项目和技术文章
-
-## 开源项目
-
-- [Java-Guide](https://github.com/Snailclimb/Java-Guide) :一份涵盖大部分Java程序员所需要掌握的核心知识。Star:3.9K; Fork:0.9k。
-
-
-## 技术文章推荐
-
-- [可能是把Java内存区域讲的最清楚的一篇文章](https://juejin.im/post/5b7d69e4e51d4538ca5730cb)
-- [搞定JVM垃圾回收就是这么简单](https://juejin.im/post/5b85ea54e51d4538dd08f601)
-- [前端&后端程序员必备的Linux基础知识](https://juejin.im/post/5b3b19856fb9a04fa42f8c71)
-- [可能是把Docker的概念讲的最清楚的一篇文章](https://juejin.im/post/5b260ec26fb9a00e8e4b031a)
-
-
-# 校园经历(可选)
-
-## 2016-2017
-
-担任学校社团-致深社副会长,主要负责团队每周活动的组建以及每周例会的主持。
-
-## 2017-2018
- 担任学校传媒组织:“长江大学在线信息传媒”的副站长以及安卓组成员。主要负责每周例会主持、活动策划以及学校校园通APP的研发工作。
-
-
-# 技能清单
-
-以下均为我熟练使用的技能
-
-- Web开发:PHP/Hack/Node
-- Web框架:ThinkPHP/Yaf/Yii/Lavarel/LazyPHP
-- 前端框架:Bootstrap/AngularJS/EmberJS/HTML5/Cocos2dJS/ionic
-- 前端工具:Bower/Gulp/SaSS/LeSS/PhoneGap
-- 数据库相关:MySQL/PgSQL/PDO/SQLite
-- 版本管理、文档和自动化部署工具:Svn/Git/PHPDoc/Phing/Composer
-- 单元测试:PHPUnit/SimpleTest/Qunit
-- 云和开放平台:SAE/BAE/AWS/微博开放平台/微信应用开发
-
-# 自我评价(可选)
-
-自我发挥。切记不要过度自夸!!!
-
-
-### 感谢您花时间阅读我的简历,期待能有机会和您共事。
-
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\276\216\345\233\242-\345\237\272\347\241\200\347\257\207.md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/\347\276\216\345\233\242-\345\237\272\347\241\200\347\257\207.md"
deleted file mode 100644
index 53e45d1e70a..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\276\216\345\233\242-\345\237\272\347\241\200\347\257\207.md"
+++ /dev/null
@@ -1,357 +0,0 @@
-
-<!-- MarkdownTOC -->
-
-- [1. `System.out.println(3 | 9);`输出什么?](#1-systemoutprintln3-|-9输出什么)
-- [2. 说一下转发\(Forward\)和重定向\(Redirect\)的区别](#2-说一下转发forward和重定向redirect的区别)
-- [3. 在浏览器中输入url地址到显示主页的过程,整个过程会使用哪些协议](#3-在浏览器中输入url地址到显示主页的过程整个过程会使用哪些协议)
-- [4. TCP 三次握手和四次挥手](#4-tcp-三次握手和四次挥手)
- - [为什么要三次握手](#为什么要三次握手)
- - [为什么要传回 SYN](#为什么要传回-syn)
- - [传了 SYN,为啥还要传 ACK](#传了-syn为啥还要传-ack)
- - [为什么要四次挥手](#为什么要四次挥手)
-- [5. IP地址与MAC地址的区别](#5-ip地址与mac地址的区别)
-- [6. HTTP请求、响应报文格式](#6-http请求响应报文格式)
-- [7. 为什么要使用索引?索引这么多优点,为什么不对表中的每一个列创建一个索引呢?索引是如何提高查询速度的?说一下使用索引的注意事项?Mysql索引主要使用的两种数据结构?什么是覆盖索引?](#7-为什么要使用索引索引这么多优点为什么不对表中的每一个列创建一个索引呢索引是如何提高查询速度的说一下使用索引的注意事项mysql索引主要使用的两种数据结构什么是覆盖索引)
-- [8. 进程与线程的区别是什么?进程间的几种通信方式说一下?线程间的几种通信方式知道不?](#8-进程与线程的区别是什么进程间的几种通信方式说一下线程间的几种通信方式知道不)
-- [9. 为什么要用单例模式?手写几种线程安全的单例模式?](#9-为什么要用单例模式手写几种线程安全的单例模式)
-- [10. 简单介绍一下bean。知道Spring的bean的作用域与生命周期吗?](#10-简单介绍一下bean知道spring的bean的作用域与生命周期吗)
-- [11. Spring 中的事务传播行为了解吗?TransactionDefinition 接口中哪五个表示隔离级别的常量?](#11-spring-中的事务传播行为了解吗transactiondefinition-接口中哪五个表示隔离级别的常量)
- - [事务传播行为](#事务传播行为)
- - [隔离级别](#隔离级别)
-- [12. SpringMVC 原理了解吗?](#12-springmvc-原理了解吗)
-- [13. Spring AOP IOC 实现原理](#13-spring-aop-ioc-实现原理)
-
-<!-- /MarkdownTOC -->
-
-
-
-
-**系列文章:**
-
-- [【备战春招/秋招系列1】程序员的简历就该这样写](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484573&idx=1&sn=8c5965d4a3710d405d8e8cc10c7b0ce5&chksm=fd9852fccaefdbea8dfe0bc40188b7579f1cddb1e8905dc981669a3f21d2a04cadceafa9023f&token=1990180468&lang=zh_CN#rd)
-- [【备战春招/秋招系列2】初出茅庐的程序员该如何准备面试?](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484578&idx=1&sn=eea72d80a2325257f00aaed21d5b226f&chksm=fd9852c3caefdbd52dd8a537cc723ed1509314401b3a669a253ef5bc0360b6fddef48b9c2e94&token=1990180468&lang=zh_CN#rd)
-- [【备战春招/秋招系列3】Java程序员必备书单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484592&idx=1&sn=6d9731ce7401be49e97c1af6ed384ecc&chksm=fd9852d1caefdbc720a361ae65a8ad9d53cfb4800b15a7c68cbdc630b313215c6c52e0934ec2&token=1990180468&lang=zh_CN#rd)
-
-这是我总结的美团面经的基础篇,后面还有进阶和终结篇哦!下面只是我从很多份美团面经中总结的在面试中一些常见的问题。不同于个人面经,这份面经具有普适性。每次面试必备的自我介绍、项目介绍这些东西,大家可以自己私下好好思考。我在前面的文章中也提到了应该怎么做自我介绍与项目介绍,详情可以查看这篇文章:[【备战春招/秋招系列2】初出茅庐的程序员该如何准备面试?](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484578&idx=1&sn=eea72d80a2325257f00aaed21d5b226f&chksm=fd9852c3caefdbd52dd8a537cc723ed1509314401b3a669a253ef5bc0360b6fddef48b9c2e94&token=1990180468&lang=zh_CN#rd)。
-
-
-### 1. `System.out.println(3 | 9);`输出什么?
-
-正确答案:11.
-
-**考察知识点:&和&&;|和||**
-
-**&和&&:**
-
-共同点:两者都可做逻辑运算符。它们都表示运算符的两边都是true时,结果为true;
-
-不同点: &也是位运算符。& 表示在运算时两边都会计算,然后再判断;&&表示先运算符号左边的东西,然后判断是否为true,是true就继续运算右边的然后判断并输出,是false就停下来直接输出不会再运行后面的东西。
-
-**|和||:**
-
-共同点:两者都可做逻辑运算符。它们都表示运算符的两边任意一边为true,结果为true,两边都不是true,结果就为false;
-
-不同点:|也是位运算符。| 表示两边都会运算,然后再判断结果;|| 表示先运算符号左边的东西,然后判断是否为true,是true就停下来直接输出不会再运行后面的东西,是false就继续运算右边的然后判断并输出。
-
-**回到本题:**
-
-3 | 9=0011(二进制) | 1001(二进制)=1011(二进制)=11(十进制)
-
-### 2. 说一下转发(Forward)和重定向(Redirect)的区别
-
-**转发是服务器行为,重定向是客户端行为。**
-
-**转发(Forword)** 通过RequestDispatcher对象的`forward(HttpServletRequest request,HttpServletResponse response)`方法实现的。`RequestDispatcher` 可以通过`HttpServletRequest` 的 `getRequestDispatcher()`方法获得。例如下面的代码就是跳转到 login_success.jsp 页面。
-
-```java
-request.getRequestDispatcher("login_success.jsp").forward(request, response);
-```
-
-**重定向(Redirect)** 是利用服务器返回的状态吗来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过HttpServletRequestResponse的setStatus(int status)方法设置状态码。如果服务器返回301或者302,则浏览器会到新的网址重新请求该资源。
-
-1. **从地址栏显示来说:** forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器.浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址. redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址.所以地址栏显示的是新的URL.
-2. **从数据共享来说:** forward:转发页面和转发到的页面可以共享request里面的数据. redirect:不能共享数据.
-3. **从运用地方来说:** forward:一般用于用户登陆的时候,根据角色转发到相应的模块. redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等
-4. **从效率来说:** forward:高. redirect:低.
-
-
-### 3. 在浏览器中输入url地址到显示主页的过程,整个过程会使用哪些协议
-
-图解(图片来源:《图解HTTP》):
-
-
-
-总体来说分为以下几个过程:
-
-1. DNS解析
-2. TCP连接
-3. 发送HTTP请求
-4. 服务器处理请求并返回HTTP报文
-5. 浏览器解析渲染页面
-6. 连接结束
-
-具体可以参考下面这篇文章:
-
-- [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700)
-
-### 4. TCP 三次握手和四次挥手
-
-为了准确无误地把数据送达目标处,TCP协议采用了三次握手策略。
-
-**漫画图解:**
-
-图片来源:《图解HTTP》
-
-
-**简单示意图:**
-
-
-- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
-- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
-- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
-
-#### 为什么要三次握手
-
-**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
-
-第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常。
-
-第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常
-
-第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送接收正常
-
-所以三次握手就能确认双发收发功能都正常,缺一不可。
-
-#### 为什么要传回 SYN
-接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
-
-> SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的TCP连接,数据才可以在客户机和服务器之间传递。
-
-
-#### 传了 SYN,为啥还要传 ACK
-
-双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方(主动关闭方)到接收方(被动关闭方)的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
-
-
-
-断开一个 TCP 连接则需要“四次挥手”:
-
-- 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
-- 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加1 。和 SYN 一样,一个 FIN 将占用一个序号
-- 服务器-关闭与客户端的连接,发送一个FIN给客户端
-- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
-
-
-#### 为什么要四次挥手
-
-任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
-
-举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
-
-上面讲的比较概括,推荐一篇讲的比较细致的文章:[https://blog.csdn.net/qzcsu/article/details/72861891](https://blog.csdn.net/qzcsu/article/details/72861891)
-
-
-
-### 5. IP地址与MAC地址的区别
-
-参考:[https://blog.csdn.net/guoweimelon/article/details/50858597](https://blog.csdn.net/guoweimelon/article/details/50858597)
-
-IP地址是指互联网协议地址(Internet Protocol Address)IP Address的缩写。IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
-
-
-
-MAC 地址又称为物理地址、硬件地址,用来定义网络设备的位置。网卡的物理地址通常是由网卡生产厂家写入网卡的,具有全球唯一性。MAC地址用于在网络中唯一标示一个网卡,一台电脑会有一或多个网卡,每个网卡都需要有一个唯一的MAC地址。
-
-### 6. HTTP请求,响应报文格式
-
-
-
-HTTP请求报文主要由请求行、请求头部、请求正文3部分组成
-
-HTTP响应报文主要由状态行、响应头部、响应正文3部分组成
-
-详细内容可以参考:[https://blog.csdn.net/a19881029/article/details/14002273](https://blog.csdn.net/a19881029/article/details/14002273)
-
-### 7. 为什么要使用索引?索引这么多优点,为什么不对表中的每一个列创建一个索引呢?索引是如何提高查询速度的?说一下使用索引的注意事项?Mysql索引主要使用的两种数据结构?什么是覆盖索引?
-
-**为什么要使用索引?**
-
-1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
-2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
-3. 帮助服务器避免排序和临时表
-4. 将随机IO变为顺序IO
-5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
-
-**索引这么多优点,为什么不对表中的每一个列创建一个索引呢?**
-
-1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
-2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
-3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
-
-**索引是如何提高查询速度的?**
-
-将无序的数据变成相对有序的数据(就像查目录一样)
-
-**说一下使用索引的注意事项**
-
-1. 避免 where 子句中对宇段施加函数,这会造成无法命中索引。
-2. 在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
-3. 将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描
-4. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用
-5. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
-
-**Mysql索引主要使用的哪两种数据结构?**
-
-- 哈希索引:对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
-- BTree索引:Mysql的BTree索引使用的是B树中的B+Tree。但对于主要的两种存储引擎(MyISAM和InnoDB)的实现方式是不同的。
-
-更多关于索引的内容可以查看我的这篇文章:[【思维导图-索引篇】搞定数据库索引就是这么简单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484486&idx=1&sn=215450f11e042bca8a58eac9f4a97686&chksm=fd985227caefdb3117b8375f150676f5824aa20d1ebfdbcfb93ff06e23e26efbafae6cf6b48e&token=1990180468&lang=zh_CN#rd)
-
-**什么是覆盖索引?**
-
-如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称
-之为“覆盖索引”。我们知道在InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次,这样就会比较慢。覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
-
-
-### 8. 进程与线程的区别是什么?进程间的几种通信方式说一下?线程间的几种通信方式知道不?
- **进程与线程的区别是什么?**
-
-线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。另外,也正是因为共享资源,所以线程中执行时一般都要进行同步和互斥。总的来说,进程和线程的主要差别在于它们是不同的操作系统资源管理方式。
-
-**进程间的几种通信方式说一下?**
-
-
-1. **管道(pipe)**:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有血缘关系的进程间使用。进程的血缘关系通常指父子进程关系。管道分为pipe(无名管道)和fifo(命名管道)两种,有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间通信。
-2. **信号量(semophore)**:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它通常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
-4. **消息队列(message queue)**:消息队列是由消息组成的链表,存放在内核中 并由消息队列标识符标识。消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。消息队列与管道通信相比,其优势是对每个消息指定特定的消息类型,接收的时候不需要按照队列次序,而是可以根据自定义条件接收特定类型的消息。
-5. **信号(signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某一事件已经发生。
-6. **共享内存(shared memory)**:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问,共享内存是最快的IPC方式,它是针对其他进程间的通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间的同步和通信。
-7. **套接字(socket)**:套接口也是一种进程间的通信机制,与其他通信机制不同的是它可以用于不同及其间的进程通信。
-
-**线程间的几种通信方式知道不?**
-
-1、锁机制
-
-- 互斥锁:提供了以排它方式阻止数据结构被并发修改的方法。
-- 读写锁:允许多个线程同时读共享数据,而对写操作互斥。
-- 条件变量:可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
-
-2、信号量机制:包括无名线程信号量与有名线程信号量
-
-3、信号机制:类似于进程间的信号处理。
-
-线程间通信的主要目的是用于线程同步,所以线程没有象进程通信中用于数据交换的通信机制。
-
-### 9. 为什么要用单例模式?手写几种线程安全的单例模式?
-
-**简单来说使用单例模式可以带来下面几个好处:**
-
-- 对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
-- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间。
-
-**懒汉式(双重检查加锁版本)**
-
-```java
-public class Singleton {
-
- //volatile保证,当uniqueInstance变量被初始化成Singleton实例时,多个线程可以正确处理uniqueInstance变量
- private volatile static Singleton uniqueInstance;
- private Singleton() {
- }
- public static Singleton getInstance() {
- //检查实例,如果不存在,就进入同步代码块
- if (uniqueInstance == null) {
- //只有第一次才彻底执行这里的代码
- synchronized(Singleton.class) {
- //进入同步代码块后,再检查一次,如果仍是null,才创建实例
- if (uniqueInstance == null) {
- uniqueInstance = new Singleton();
- }
- }
- }
- return uniqueInstance;
- }
-}
-```
-
-**静态内部类方式**
-
-静态内部实现的单例是懒加载的且线程安全。
-
-只有通过显式调用 getInstance 方法时,才会显式装载 SingletonHolder 类,从而实例化 instance(只有第一次使用这个单例的实例的时候才加载,同时不会有线程安全问题)。
-
-```java
-public class Singleton {
- private static class SingletonHolder {
- private static final Singleton INSTANCE = new Singleton();
- }
- private Singleton (){}
- public static final Singleton getInstance() {
- return SingletonHolder.INSTANCE;
- }
-}
-```
-
-### 10. 简单介绍一下bean。知道Spring的bean的作用域与生命周期吗?
-
-在 Spring 中,那些组成应用程序的主体及由 Spring IOC 容器所管理的对象,被称之为 bean。简单地讲,bean 就是由 IOC 容器初始化、装配及管理的对象,除此之外,bean 就与应用程序中的其他对象没有什么区别了。而 bean 的定义以及 bean 相互间的依赖关系将通过配置元数据来描述。
-
-Spring中的bean默认都是单例的,这些单例Bean在多线程程序下如何保证线程安全呢? 例如对于Web应用来说,Web容器对于每个用户请求都创建一个单独的Sevlet线程来处理请求,引入Spring框架之后,每个Action都是单例的,那么对于Spring托管的单例Service Bean,如何保证其安全呢? Spring的单例是基于BeanFactory也就是Spring容器的,单例Bean在此容器内只有一个,Java的单例是基于 JVM,每个 JVM 内只有一个实例。
-
-
-
-Spring的bean的生命周期以及更多内容可以查看:[一文轻松搞懂Spring中bean的作用域与生命周期](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484400&idx=2&sn=7201eb365102fce017f89cb3527fb0bc&chksm=fd985591caefdc872a2fac897288119f94c345e4e12150774f960bf5f816b79e4b9b46be3d7f&token=1990180468&lang=zh_CN#rd)
-
-
-### 11. Spring 中的事务传播行为了解吗?TransactionDefinition 接口中哪五个表示隔离级别的常量?
-
-#### 事务传播行为
-
-事务传播行为(为了解决业务层方法之间互相调用的事务问题):
-当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。在TransactionDefinition定义中包括了如下几个表示传播行为的常量:
-
-**支持当前事务的情况:**
-
-- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
-- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
-- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
-
-**不支持当前事务的情况:**
-
-- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
-- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
-- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
-
-**其他情况:**
-
-- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
-
-
-#### 隔离级别
-
-TransactionDefinition 接口中定义了五个表示隔离级别的常量:
-
-- **TransactionDefinition.ISOLATION_DEFAULT:** 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.
-- **TransactionDefinition.ISOLATION_READ_UNCOMMITTED:** 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
-- **TransactionDefinition.ISOLATION_READ_COMMITTED:** 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
-- **TransactionDefinition.ISOLATION_REPEATABLE_READ:** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-- **TransactionDefinition.ISOLATION_SERIALIZABLE:** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
-
-### 12. SpringMVC 原理了解吗?
-
-
-
-客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器开处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Moder)->将得到视图对象返回给用户
-
-关于 SpringMVC 原理更多内容可以查看我的这篇文章:[SpringMVC 工作原理详解](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484496&idx=1&sn=5472ffa687fe4a05f8900d8ee6726de4&chksm=fd985231caefdb27fc75b44ecf76b6f43e4617e0b01b3c040f8b8fab32e51dfa5118eed1d6ad&token=1990180468&lang=zh_CN#rd)
-
-### 13. Spring AOP IOC 实现原理
-
-过了秋招挺长一段时间了,说实话我自己也忘了如何简要概括 Spring AOP IOC 实现原理,就在网上找了一个较为简洁的答案,下面分享给各位。
-
-**IOC:** 控制反转也叫依赖注入。IOC利用java反射机制,AOP利用代理模式。IOC 概念看似很抽象,但是很容易理解。说简单点就是将对象交给容器管理,你只需要在spring配置文件中配置对应的bean以及设置相关的属性,让spring容器来生成类的实例对象以及管理对象。在spring容器启动的时候,spring会把你在配置文件中配置的bean都初始化好,然后在你需要调用的时候,就把它已经初始化好的那些bean分配给你需要调用这些bean的类。
-
-**AOP:** 面向切面编程。(Aspect-Oriented Programming) 。AOP可以说是对OOP的补充和完善。OOP引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码,属于静态代理。
-
-
-
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\276\216\345\233\242-\347\273\210\347\273\223\347\257\207.md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/\347\276\216\345\233\242-\347\273\210\347\273\223\347\257\207.md"
deleted file mode 100644
index 5d08de551ac..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\276\216\345\233\242-\347\273\210\347\273\223\347\257\207.md"
+++ /dev/null
@@ -1,353 +0,0 @@
-
-<!-- MarkdownTOC -->
-
-- [一. Object类有哪些方法?](#一-object类有哪些方法)
- - [1.1 Object类的常见方法总结](#11-object类的常见方法总结)
- - [1.2 hashCode与equals](#12-hashcode与equals)
- - [1.2.1 hashCode()介绍](#121-hashcode()介绍)
- - [1.2.2 为什么要有hashCode](#122-为什么要有hashcode)
- - [1.2.3 hashCode()与equals()的相关规定](#123-hashcode()与equals()的相关规定)
- - [1.2.4 为什么两个对象有相同的hashcode值,它们也不一定是相等的?](#124-为什么两个对象有相同的hashcode值,它们也不一定是相等的?)
- - [1.3 ==与equals](#13-与equals)
-- [二 ConcurrentHashMap 相关问题](#二-concurrenthashmap-相关问题)
- - [2.1 ConcurrentHashMap 和 Hashtable 的区别](#21-concurrenthashmap-和-hashtable-的区别)
- - [2.2 ConcurrentHashMap线程安全的具体实现方式/底层具体实现](#22-concurrenthashmap线程安全的具体实现方式底层具体实现)
- - [JDK1.7(上面有示意图)](#jdk17(上面有示意图))
- - [JDK1.8 (上面有示意图)](#jdk18-(上面有示意图))
-- [三 谈谈 synchronized 和 ReenTrantLock 的区别](#三-谈谈-synchronized-和-reentrantlock-的区别)
-- [四 线程池了解吗?](#四-线程池了解吗?)
- - [4.1 为什么要用线程池?](#41-为什么要用线程池?)
- - [4.2 Java 提供了哪几种线程池?他们各自的使用场景是什么?](#42-java-提供了哪几种线程池?他们各自的使用场景是什么?)
- - [Java 主要提供了下面4种线程池](#java-主要提供了下面4种线程池)
- - [各种线程池的适用场景介绍](#各种线程池的适用场景介绍)
- - [4.3 创建的线程池的方式](#43-创建的线程池的方式)
-- [五 Nginx](#五-nginx)
- - [5.1 简单介绍一下Nginx](#51-简单介绍一下nginx)
- - [反向代理](#反向代理)
- - [负载均衡](#负载均衡)
- - [动静分离](#动静分离)
- - [5.2 为什么要用 Nginx ?](#52-为什么要用-nginx-?)
- - [5.3 Nginx 的四个主要组成部分了解吗?](#53-nginx-的四个主要组成部分了解吗?)
-
-<!-- /MarkdownTOC -->
-
-
-> 下面这个问题,面试中经常出现。我觉得不论是出于应付面试还是说更好地掌握Java这门编程语言,大家都要掌握!
-
-# 一. Object类有哪些方法?
-
-### 1.1 Object类的常见方法总结
-
-Object类是一个特殊的类,是所有类的父类。它主要提供了以下11个方法:
-
-```java
-
-public final native Class<?> getClass()//native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。
-
-public native int hashCode() //native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的HashMap。
-public boolean equals(Object obj)//用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户比较字符串的值是否相等。
-
-protected native Object clone() throws CloneNotSupportedException//naitive方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass() == x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生CloneNotSupportedException异常。
-
-public String toString()//返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方法。
-
-public final native void notify()//native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
-
-public final native void notifyAll()//native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
-
-public final native void wait(long timeout) throws InterruptedException//native方法,并且不能重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。
-
-public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。
-
-public final void wait() throws InterruptedException//跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
-
-protected void finalize() throws Throwable { }//实例被垃圾回收器回收的时候触发的操作
-
-```
-
-> 问完上面这个问题之后,面试官很可能紧接着就会问你“hashCode与equals”相关的问题。
-
-### 1.2 hashCode与equals
-
-面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写equals时必须重写hashCode方法?”
-
-#### 1.2.1 hashCode()介绍
-hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
-
-```java
- public native int hashCode();
-```
-
-散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
-
-#### 1.2.2 为什么要有hashCode
-
-
-**我们以“HashSet如何检查重复”为例子来说明为什么要有hashCode:**
-
-当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他已经加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head fist java》第二版)。这样我们就大大减少了equals的次数,相应就大大提高了执行速度。
-
-
-#### 1.2.3 hashCode()与equals()的相关规定
-
-1. 如果两个对象相等,则hashcode一定也是相同的
-2. 两个对象相等,对两个对象分别调用equals方法都返回true
-3. 两个对象有相同的hashcode值,它们也不一定是相等的
-4. **因此,equals方法被覆盖过,则hashCode方法也必须被覆盖**
-5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
-
-#### 1.2.4 为什么两个对象有相同的hashcode值,它们也不一定是相等的?
-
-在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
-
-因为hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode)。
-
-我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
-
-> ==与equals 的对比也是比较常问的基础问题之一!
-
-### 1.3 ==与equals
-
-**==** : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
-
-**equals()** : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
-
-- 情况1:类没有覆盖equals()方法。则通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。
-- 情况2:类覆盖了equals()方法。一般,我们都覆盖equals()方法来两个对象的内容相等;若它们的内容相等,则返回true(即,认为这两个对象相等)。
-
-
-**举个例子:**
-
-```java
-public class test1 {
- public static void main(String[] args) {
- String a = new String("ab"); // a 为一个引用
- String b = new String("ab"); // b为另一个引用,对象的内容一样
- String aa = "ab"; // 放在常量池中
- String bb = "ab"; // 从常量池中查找
- if (aa == bb) // true
- System.out.println("aa==bb");
- if (a == b) // false,非同一对象
- System.out.println("a==b");
- if (a.equals(b)) // true
- System.out.println("aEQb");
- if (42 == 42.0) { // true
- System.out.println("true");
- }
- }
-}
-```
-
-**说明:**
-
-- String中的equals方法是被重写过的,因为object的equals方法是比较的对象的内存地址,而String的equals方法比较的是对象的值。
-- 当创建String类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个String对象。
-
-> 在[【备战春招/秋招系列5】美团面经总结进阶篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484625&idx=1&sn=9c4fa1f7d4291a5fbd7daa44bac2b012&chksm=fd9852b0caefdba6edcf9a827aa4a17ddc97bf6ad2e5ee6f7e1aa1b443b54444d05d2b76732b&token=723699735&lang=zh_CN#rd) 这篇文章中,我们已经提到了一下关于 HashMap 在面试中常见的问题:HashMap 的底层实现、简单讲一下自己对于红黑树的理解、红黑树这么优秀,为何不直接使用红黑树得了、HashMap 和 Hashtable 的区别/HashSet 和 HashMap 区别。HashMap 和 ConcurrentHashMap 这俩兄弟在一般只要面试中问到集合相关的问题就一定会被问到,所以各位务必引起重视!
-
-# 二 ConcurrentHashMap 相关问题
-
-### 2.1 ConcurrentHashMap 和 Hashtable 的区别
-
-ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
-
-- **底层数据结构:** JDK1.7的 ConcurrentHashMap 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
-- **实现线程安全的方式(重要):** ① **在JDK1.7的时候,ConcurrentHashMap(分段锁)** 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。) **到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化)** 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **Hashtable(同一把锁)** :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
-
-**两者的对比图:**
-
-图片来源:http://www.cnblogs.com/chengxiao/p/6842045.html
-
-HashTable:
-
-
-JDK1.7的ConcurrentHashMap:
-
-JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点
-Node: 链表节点):
-
-
-### 2.2 ConcurrentHashMap线程安全的具体实现方式/底层具体实现
-
-#### JDK1.7(上面有示意图)
-
-首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
-
-**ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成**。
-
-Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
-
-```java
-static class Segment<K,V> extends ReentrantLock implements Serializable {
-}
-```
-
-一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
-
-#### JDK1.8 (上面有示意图)
-
-ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构类似,数组+链表/红黑二叉树。
-
-synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
-
-# 三 谈谈 synchronized 和 ReenTrantLock 的区别
-
-**① 两者都是可重入锁**
-
-两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
-
-**② synchronized 依赖于 JVM 而 ReenTrantLock 依赖于 API**
-
-synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReenTrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
-
-**③ ReenTrantLock 比 synchronized 增加了一些高级功能**
-
-相比synchronized,ReenTrantLock增加了一些高级功能。主要来说主要有三点:**①等待可中断;②可实现公平锁;③可实现选择性通知(锁可以绑定多个条件)**
-
-- **ReenTrantLock提供了一种能够中断等待锁的线程的机制**,通过lock.lockInterruptibly()来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
-- **ReenTrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。** ReenTrantLock默认情况是非公平的,可以通过 ReenTrantLock类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
-- synchronized关键字与wait()和notify/notifyAll()方法相结合可以实现等待/通知机制,ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition() 方法。Condition是JDK1.5之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个Lock对象中可以创建多个Condition实例(即对象监视器),**线程对象可以注册在指定的Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用notify/notifyAll()方法进行通知时,被通知的线程是由 JVM 选择的,用ReentrantLock类结合Condition实例可以实现“选择性通知”** ,这个功能非常重要,而且是Condition接口默认提供的。而synchronized关键字就相当于整个Lock对象中只有一个Condition实例,所有的线程都注册在它一个身上。如果执行notifyAll()方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而Condition实例的signalAll()方法 只会唤醒注册在该Condition实例中的所有等待线程。
-
-如果你想使用上述功能,那么选择ReenTrantLock是一个不错的选择。
-
-**④ 两者的性能已经相差无几**
-
-在JDK1.6之前,synchronized 的性能是比 ReenTrantLock 差很多。具体表示为:synchronized 关键字吞吐量岁线程数的增加,下降得非常严重。而ReenTrantLock 基本保持一个比较稳定的水平。我觉得这也侧面反映了, synchronized 关键字还有非常大的优化余地。后续的技术发展也证明了这一点,我们上面也讲了在 JDK1.6 之后 JVM 团队对 synchronized 关键字做了很多优化。JDK1.6 之后,synchronized 和 ReenTrantLock 的性能基本是持平了。所以网上那些说因为性能才选择 ReenTrantLock 的文章都是错的!JDK1.6之后,性能已经不是选择synchronized和ReenTrantLock的影响因素了!而且虚拟机在未来的性能改进中会更偏向于原生的synchronized,所以还是提倡在synchronized能满足你的需求的情况下,优先考虑使用synchronized关键字来进行同步!优化后的synchronized和ReenTrantLock一样,在很多地方都是用到了CAS操作。
-
-
-# 四 线程池了解吗?
-
-
-### 4.1 为什么要用线程池?
-
-线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
-
-这里借用《Java并发编程的艺术》提到的来说一下使用线程池的好处:
-
-- **降低资源消耗。** 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
-- **提高响应速度。** 当任务到达时,任务可以不需要的等到线程创建就能立即执行。
-- **提高线程的可管理性。** 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
-
-### 4.2 Java 提供了哪几种线程池?他们各自的使用场景是什么?
-
-#### Java 主要提供了下面4种线程池
-
-- **FixedThreadPool** : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
-- **SingleThreadExecutor:** 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
-- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
-- **ScheduledThreadPoolExecutor:**主要用来在给定的延迟后运行任务,或者定期执行任务。ScheduledThreadPoolExecutor又分为:ScheduledThreadPoolExecutor(包含多个线程)和SingleThreadScheduledExecutor (只包含一个线程)两种。
-
-#### 各种线程池的适用场景介绍
-
-- **FixedThreadPool:** 适用于为了满足资源管理需求,而需要限制当前线程数量的应用场景。它适用于负载比较重的服务器;
-- **SingleThreadExecutor:** 适用于需要保证顺序地执行各个任务并且在任意时间点,不会有多个线程是活动的应用场景。
-- **CachedThreadPool:** 适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器;
-- **ScheduledThreadPoolExecutor:** 适用于需要多个后台执行周期任务,同时为了满足资源管理需求而需要限制后台线程的数量的应用场景,
-- **SingleThreadScheduledExecutor:** 适用于需要单个后台线程执行周期任务,同时保证顺序地执行各个任务的应用场景。
-
-### 4.3 创建的线程池的方式
-
-**(1) 使用 Executors 创建**
-
-我们上面刚刚提到了 Java 提供的几种线程池,通过 Executors 工具类我们可以很轻松的创建我们上面说的几种线程池。但是实际上我们一般都不是直接使用Java提供好的线程池,另外在《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 构造函数 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
-
-```java
-Executors 返回线程池对象的弊端如下:
-
-FixedThreadPool 和 SingleThreadExecutor : 允许请求的队列长度为 Integer.MAX_VALUE,可能堆积大量的请求,从而导致OOM。
-CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致OOM。
-
-```
-**(2) ThreadPoolExecutor的构造函数创建**
-
-
-我们可以自己直接调用 ThreadPoolExecutor 的构造函数来自己创建线程池。在创建的同时,给 BlockQueue 指定容量就可以了。示例如下:
-
-```java
-private static ExecutorService executor = new ThreadPoolExecutor(13, 13,
- 60L, TimeUnit.SECONDS,
- new ArrayBlockingQueue(13));
-```
-
-这种情况下,一旦提交的线程数超过当前可用线程数时,就会抛出java.util.concurrent.RejectedExecutionException,这是因为当前线程池使用的队列是有边界队列,队列已经满了便无法继续处理新的请求。但是异常(Exception)总比发生错误(Error)要好。
-
-**(3) 使用开源类库**
-
-Hollis 大佬之前在他的文章中也提到了:“除了自己定义ThreadPoolExecutor外。还有其他方法。这个时候第一时间就应该想到开源类库,如apache和guava等。”他推荐使用guava提供的ThreadFactoryBuilder来创建线程池。下面是参考他的代码示例:
-
-```java
-public class ExecutorsDemo {
-
- private static ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
- .setNameFormat("demo-pool-%d").build();
-
- private static ExecutorService pool = new ThreadPoolExecutor(5, 200,
- 0L, TimeUnit.MILLISECONDS,
- new LinkedBlockingQueue<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
-
- public static void main(String[] args) {
-
- for (int i = 0; i < Integer.MAX_VALUE; i++) {
- pool.execute(new SubThread());
- }
- }
-}
-```
-
-通过上述方式创建线程时,不仅可以避免OOM的问题,还可以自定义线程名称,更加方便的出错的时候溯源。
-
-# 五 Nginx
-
-### 5.1 简单介绍一下Nginx
-
-Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。 Nginx 主要提供反向代理、负载均衡、动静分离(静态资源服务)等服务。下面我简单地介绍一下这些名词。
-
-#### 反向代理
-
-谈到反向代理,就不得不提一下正向代理。无论是正向代理,还是反向代理,说到底,就是代理模式的衍生版本罢了
-
-- **正向代理:**某些情况下,代理我们用户去访问服务器,需要用户手动的设置代理服务器的ip和端口号。正向代理比较常见的一个例子就是 VPN了。
-- **反向代理:** 是用来代理服务器的,代理我们要访问的目标服务器。代理服务器接受请求,然后将请求转发给内部网络的服务器,并将从服务器上得到的结果返回给客户端,此时代理服务器对外就表现为一个服务器。
-
-通过下面两幅图,大家应该更好理解(图源:http://blog.720ui.com/2016/nginx_action_05_proxy/):
-
-
-
-
-
-所以,简单的理解,就是正向代理是为客户端做代理,代替客户端去访问服务器,而反向代理是为服务器做代理,代替服务器接受客户端请求。
-
-#### 负载均衡
-
-在高并发情况下需要使用,其原理就是将并发请求分摊到多个服务器执行,减轻每台服务器的压力,多台服务器(集群)共同完成工作任务,从而提高了数据的吞吐量。
-
-Nginx支持的weight轮询(默认)、ip_hash、fair、url_hash这四种负载均衡调度算法,感兴趣的可以自行查阅。
-
-负载均衡相比于反向代理更侧重的时将请求分担到多台服务器上去,所以谈论负载均衡只有在提供某服务的服务器大于两台时才有意义。
-
-#### 动静分离
-
-动静分离是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们就可以根据静态资源的特点将其做缓存操作,这就是网站静态化处理的核心思路。
-
-### 5.2 为什么要用 Nginx ?
-
-> 这部分内容参考极客时间—[Nginx核心知识100讲的内容](https://time.geekbang.org/course/intro/138?code=AycjiiQk6uQRxnVJzBupFkrGkvZlmYELPRsZbWzaAHE=)。
-
-如果面试官问你这个问题,就一定想看你知道 Nginx 服务器的一些优点吗。
-
-Nginx 有以下5个优点:
-
-1. 高并发、高性能(这是其他web服务器不具有的)
-2. 可扩展性好(模块化设计,第三方插件生态圈丰富)
-3. 高可靠性(可以在服务器行持续不间断的运行数年)
-4. 热部署(这个功能对于 Nginx 来说特别重要,热部署指可以在不停止 Nginx服务的情况下升级 Nginx)
-5. BSD许可证(意味着我们可以将源代码下载下来进行修改然后使用自己的版本)
-
-### 5.3 Nginx 的四个主要组成部分了解吗?
-
-> 这部分内容参考极客时间—[Nginx核心知识100讲的内容](https://time.geekbang.org/course/intro/138?code=AycjiiQk6uQRxnVJzBupFkrGkvZlmYELPRsZbWzaAHE=)。
-
-- Nginx 二进制可执行文件:由各模块源码编译出一个文件
-- Nginx.conf 配置文件:控制Nginx 行为
-- acess.log 访问日志: 记录每一条HTTP请求信息
-- error.log 错误日志:定位问题
\ No newline at end of file
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\276\216\345\233\242-\350\277\233\351\230\266\347\257\207.md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/\347\276\216\345\233\242-\350\277\233\351\230\266\347\257\207.md"
deleted file mode 100644
index fc47a12d642..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\276\216\345\233\242-\350\277\233\351\230\266\347\257\207.md"
+++ /dev/null
@@ -1,271 +0,0 @@
-
-<!-- MarkdownTOC -->
-
-- [一 消息队列MQ的套路](#一-消息队列mq的套路)
- - [1.1 介绍一下消息队列MQ的应用场景/使用消息队列的好处](#11-介绍一下消息队列mq的应用场景使用消息队列的好处)
- - [①.通过异步处理提高系统性能](#①通过异步处理提高系统性能)
- - [②.降低系统耦合性](#②降低系统耦合性)
- - [1.2 那么使用消息队列会带来什么问题?考虑过这个问题吗?](#12-那么使用消息队列会带来什么问题考虑过这个问题吗)
- - [1.3 介绍一下你知道哪几种消息队列,该如何选择呢?](#13-介绍一下你知道哪几种消息队列该如何选择呢)
- - [1.4 关于消息队列其他一些常见的问题展望](#14-关于消息队列其他一些常见的问题展望)
-- [二 谈谈 InnoDB 和 MyIsam 两者的区别](#二-谈谈-innodb-和-myisam-两者的区别)
- - [2.1 两者的对比](#21-两者的对比)
- - [2.2 关于两者的总结](#22-关于两者的总结)
-- [三 聊聊 Java 中的集合吧!](#三-聊聊-java-中的集合吧!)
- - [3.1 Arraylist 与 LinkedList 有什么不同?(注意加上从数据结构分析的内容)](#31-arraylist-与-linkedlist-有什么不同?(注意加上从数据结构分析的内容))
- - [3.2 HashMap的底层实现](#32-hashmap的底层实现)
- - [① JDK1.8之前](#①-jdk18之前)
- - [② JDK1.8之后](#②-jdk18之后)
- - [3.3 既然谈到了红黑树,你给我手绘一个出来吧,然后简单讲一下自己对于红黑树的理解](#33-既然谈到了红黑树,你给我手绘一个出来吧,然后简单讲一下自己对于红黑树的理解)
- - [3.4 红黑树这么优秀,为何不直接使用红黑树得了?](#34-红黑树这么优秀为何不直接使用红黑树得了)
- - [3.5 HashMap 和 Hashtable 的区别/HashSet 和 HashMap 区别](#35-hashmap-和-hashtable-的区别hashset-和-hashmap-区别)
-
-<!-- /MarkdownTOC -->
-
-
-> 该文已加入开源文档:JavaGuide(一份涵盖大部分Java程序员所需要掌握的核心知识)。地址:https://github.com/Snailclimb/JavaGuide.
-
-
-**系列文章:**
-
-- [【备战春招/秋招系列1】程序员的简历就该这样写](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484573&idx=1&sn=8c5965d4a3710d405d8e8cc10c7b0ce5&chksm=fd9852fccaefdbea8dfe0bc40188b7579f1cddb1e8905dc981669a3f21d2a04cadceafa9023f&token=1990180468&lang=zh_CN#rd)
-- [【备战春招/秋招系列2】初出茅庐的程序员该如何准备面试?](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484578&idx=1&sn=eea72d80a2325257f00aaed21d5b226f&chksm=fd9852c3caefdbd52dd8a537cc723ed1509314401b3a669a253ef5bc0360b6fddef48b9c2e94&token=1990180468&lang=zh_CN#rd)
-- [【备战春招/秋招系列3】Java程序员必备书单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484592&idx=1&sn=6d9731ce7401be49e97c1af6ed384ecc&chksm=fd9852d1caefdbc720a361ae65a8ad9d53cfb4800b15a7c68cbdc630b313215c6c52e0934ec2&token=1990180468&lang=zh_CN#rd)
-- [【备战春招/秋招系列4】美团面经总结基础篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484601&idx=1&sn=4907b7fef0856791c565d49d788ba8cc&chksm=fd9852d8caefdbce88e51c0a10a4ec77c97f382fd2af4a840ea47cffc828bfd0f993f50d5f0d&token=2045370425&lang=zh_CN#rd)
-
-这是我总结的美团面经的进阶篇,后面还有终结篇哦!下面只是我从很多份美团面经中总结的在美团面试中一些常见的问题。不同于个人面经,这份面经具有普适性。每次面试必备的自我介绍、项目介绍这些东西,大家可以自己私下好好思考。我在前面的文章中也提到了应该怎么做自我介绍与项目介绍,详情可以查看这篇文章:[【备战春招/秋招系列2】初出茅庐的程序员该如何准备面试?](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484578&idx=1&sn=eea72d80a2325257f00aaed21d5b226f&chksm=fd9852c3caefdbd52dd8a537cc723ed1509314401b3a669a253ef5bc0360b6fddef48b9c2e94&token=1990180468&lang=zh_CN#rd)。
-
-有人私信我让我对美团面试难度做一个评级,我觉得如果有10级的话,美团面试的难度大概在6级左右吧!部分情况可能因人而异了。
-
-> 消息队列/消息中间件应该是Java程序员必备的一个技能了,如果你之前没接触过消息队列的话,建议先去百度一下某某消息队列入门,然后花2个小时就差不多可以学会任何一种消息队列的使用了。如果说仅仅学会使用是万万不够的,在实际生产环境还要考虑消息丢失等等情况。关于消息队列面试相关的问题,推荐大家也可以看一下视频《Java工程师面试突击第1季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java面试通关手册”后台回复关键字“1”即可!
-
-# 一 消息队列MQ的套路
-
-> 面试官一般会先问你这个问题,预热一下,看你知道消息队列不,一般在第一面的时候面试官可能只会问消息队列MQ的应用场景/使用消息队列的好处、使用消息队列会带来什么问题、消息队列的技术选型这几个问题,不会太深究下去,在后面的第二轮/第三轮技术面试中可能会深入问一下。
-
-### 1.1 介绍一下消息队列MQ的应用场景/使用消息队列的好处
-
-**《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。**
-
-#### ①.通过异步处理提高系统性能
-
-如上图,**在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。**
-
-通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
-
-因为**用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败**。因此使用消息队列进行异步处理之后,需要**适当修改业务流程进行配合**,比如**用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
-
-### ②.降低系统耦合性
-我们知道模块分布式部署以后聚合方式通常有两种:1.**分布式消息队列**和2.**分布式服务**。
-
-> **先来简单说一下分布式服务:**
-
-目前使用比较多的用来构建**SOA(Service Oriented Architecture面向服务体系结构)**的**分布式服务框架**是阿里巴巴开源的**Dubbo**.如果想深入了解Dubbo的可以看我写的关于Dubbo的这一篇文章:**《高性能优秀的服务框架-dubbo介绍》**:[https://juejin.im/post/5acadeb1f265da2375072f9c](https://juejin.im/post/5acadeb1f265da2375072f9c)
-
-> **再来谈我们的分布式消息队列:**
-
-我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
-
-我们最常见的**事件驱动架构**类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构。如下图所示:
-
-**消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
-
-消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
-
-**另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。**
-
-**备注:** 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的,**比如在我们的ActiveMQ消息队列中还有点对点工作模式**,具体的会在后面的文章给大家详细介绍,这一篇文章主要还是让大家对消息队列有一个更透彻的了解。
-
-> 这个问题一般会在上一个问题问完之后,紧接着被问到。“使用消息队列会带来什么问题?”这个问题要引起重视,一般我们都会考虑使用消息队列会带来的好处而忽略它带来的问题!
-
-### 1.2 那么使用消息队列会带来什么问题?考虑过这个问题吗?
-
-- **系统可用性降低:**系统可用性在某种程度上降低,为什么这样说呢?在加入MQ之前,你不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后你就需要去考虑了!
-- **系统复杂性提高:** 加入MQ之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
-- **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
-
-> 了解下面这个问题是为了我们更好的进行技术选型!该部分摘自:《Java工程师面试突击第1季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java面试通关手册”后台回复关键字“1”即可!
-
-### 1.3 介绍一下你知道哪几种消息队列,该如何选择呢?
-
-
-|特性 | ActiveMQ| RabbitMQ| RocketMQ| Kafaka|
-| :-------- | ----------:|--------:|--------:|--------:|
-| 单机吞吐量 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 |10万级,RocketMQ也是可以支撑高吞吐的一种MQ |10万级别,这是kafka最大的优点,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
-| topic数量对吞吐量的影响 | | | topic可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic |topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源|
-|可用性 |高,基于主从架构实现高可用性|高,基于主从架构实现高可用性 | 非常高,分布式架构|非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用|
-|消息可靠性 | 有较低的概率丢失数据 | | 经过参数优化配置,可以做到0丢失|经过参数优化配置,消息可以做到0丢失 |
-|时效性 |ms级| 微秒级,这是rabbitmq的一大特点,延迟是最低的 | ms级 |延迟在ms级以内 |
-|功能支持| MQ领域的功能极其完备 |基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 |功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
-|优劣势总结| 非常成熟,功能强大,在业内大量的公司以及项目中都有应用。偶尔会有较低概率丢失消息,而且现在社区以及国内应用都越来越少,官方社区现在对ActiveMQ 5.x维护越来越少,几个月才发布一个版本而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 | erlang语言开发,性能极其好,延时很低;吞吐量到万级,MQ功能比较完备而且开源提供的管理界面非常棒,用起来很好用。社区相对比较活跃,几乎每个月都发布几个版本分在国内一些互联网公司近几年用rabbitmq也比较多一些但是问题也是显而易见的,RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。而且erlang开发,国内有几个公司有实力做erlang源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复bug。而且rabbitmq集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是erlang语言本身带来的问题。很难读源码,很难定制和掌控。| 接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障。日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是ok的,还可以支撑大规模的topic数量,支持复杂MQ业务场景。而且一个很大的优势在于,阿里出品都是java系的,我们可以自己阅读源码,定制自己公司的MQ,可以掌控。社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准JMS规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ挺好的|kafka的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时kafka最好是支撑较少的topic数量即可,保证其超高吞吐量。而且kafka唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。|
-
-> 这部分内容,我这里不给出答案,大家可以自行根据自己学习的消息队列查阅相关内容,我可能会在后面的文章中介绍到这部分内容。另外,下面这些问题在视频《Java工程师面试突击第1季-中华石杉老师》中都有提到,如果大家没有资源的话,可以在我的公众号“Java面试通关手册”后台回复关键字“1”即可!
-
-### 1.4 关于消息队列其他一些常见的问题展望
-
-1. 引入消息队列之后如何保证高可用性
-2. 如何保证消息不被重复消费呢?
-3. 如何保证消息的可靠性传输(如何处理消息丢失的问题)?
-4. 我该怎么保证从消息队列里拿到的数据按顺序执行?
-5. 如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
-6. 如果让你来开发一个消息队列中间件,你会怎么设计架构?
-
-
-
-# 二 谈谈 InnoDB 和 MyIsam 两者的区别
-
-### 2.1 两者的对比
-
-1) **count运算上的区别:** 因为MyISAM缓存有表meta-data(行数等),因此在做COUNT(*)时对于一个结构很好的查询是不需要消耗多少资源的。而对于InnoDB来说,则没有这种缓存。
-
-2) **是否支持事务和崩溃后的安全恢复:** MyISAM 强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。但是InnoDB 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
-
-3)**是否支持外键:** MyISAM不支持,而InnoDB支持。
-
-
-
-### 2.2 关于两者的总结
-
-MyISAM更适合读密集的表,而InnoDB更适合写密集的的表。 在数据库做主从分离的情况下,经常选择MyISAM作为主库的存储引擎。
-
-一般来说,如果需要事务支持,并且有较高的并发读取频率(MyISAM的表锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了),InnoDB是不错的选择。如果你的数据量很大(MyISAM支持压缩特性可以减少磁盘的空间占用),而且不需要支持事务时,MyISAM是最好的选择。
-
-
-# 三 聊聊 Java 中的集合吧!
-
-
-### 3.1 Arraylist 与 LinkedList 有什么不同?(注意加上从数据结构分析的内容)
-
-- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-- **2. 底层数据结构:** Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别:);
-- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。**
-- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
-- **5. 内存空间占用:** ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
-
-**补充内容:RandomAccess接口**
-
-```java
-public interface RandomAccess {
-}
-```
-
-查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
-
-在binarySearch()方法中,它要判断传入的list 是否RamdomAccess的实例,如果是,调用indexedBinarySearch()方法,如果不是,那么调用iteratorBinarySearch()方法
-
-```java
- public static <T>
- int binarySearch(List<? extends Comparable<? super T>> list, T key) {
- if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
- return Collections.indexedBinarySearch(list, key);
- else
- return Collections.iteratorBinarySearch(list, key);
- }
-
-```
-ArraysList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArraysList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,ArraysList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArraysList 实现 RandomAccess 接口才具有快速随机访问功能的!
-
-
-
-**下面再总结一下 list 的遍历方式选择:**
-
-- 实现了RadmoAcces接口的list,优先选择普通for循环 ,其次foreach,
-- 未实现RadmoAcces接口的ist, 优先选择iterator遍历(foreach遍历底层也是通过iterator实现的),大size的数据,千万不要使用普通for循环
-
-> Java 中的集合这类问题几乎是面试必问的,问到这类问题的时候,HashMap 又是几乎必问的问题,所以大家一定要引起重视!
-
-### 3.2 HashMap的底层实现
-
-####① JDK1.8之前
-
-JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的时数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
-
-**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
-
-**JDK 1.8 HashMap 的 hash 方法源码:**
-
-JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
-
-```java
- static final int hash(Object key) {
- int h;
- // key.hashCode():返回散列值也就是hashcode
- // ^ :按位异或
- // >>>:无符号右移,忽略符号位,空位都以0补齐
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- }
-```
-对比一下 JDK1.7的 HashMap 的 hash 方法源码.
-
-```java
-static int hash(int h) {
- // This function ensures that hashCodes that differ only by
- // constant multiples at each bit position have a bounded
- // number of collisions (approximately 8 at default load factor).
-
- h ^= (h >>> 20) ^ (h >>> 12);
- return h ^ (h >>> 7) ^ (h >>> 4);
-}
-```
-
-相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
-
-所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
-
-
-
-
-
-
-###② JDK1.8之后
-
-相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
-
-
-
-TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
-
-> 问完 HashMap 的底层原理之后,面试官可能就会紧接着问你 HashMap 底层数据结构相关的问题!
-
-### 3.3 既然谈到了红黑树,你给我手绘一个出来吧,然后简单讲一下自己对于红黑树的理解
-
-
-
-**红黑树特点:**
-
-1. 每个节点非红即黑;
-2. 根节点总是黑色的;
-3. 每个叶子节点都是黑色的空节点(NIL节点);
-4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
-5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
-
-**红黑树的应用:**
-
-TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。
-
-**为什么要用红黑树**
-
-简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
-
-
-### 3.4 红黑树这么优秀,为何不直接使用红黑树得了?
-
-说一下自己对于这个问题的看法:我们知道红黑树属于(自)平衡二叉树,但是为了保持“平衡”是需要付出代价的,红黑树在插入新数据后可能需要通过左旋,右旋、变色这些操作来保持平衡,这费事啊。你说说我们引入红黑树就是为了查找数据快,如果链表长度很短的话,根本不需要引入红黑树的,你引入之后还要付出代价维持它的平衡。但是链表过长就不一样了。至于为什么选 8 这个值呢?通过概率统计所得,这个值是综合查询成本和新增元素成本得出的最好的一个值。
-
-### 3.5 HashMap 和 Hashtable 的区别/HashSet 和 HashMap 区别
-
-**HashMap 和 Hashtable 的区别**
-
-1. **线程是否安全:** HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过 `synchronized` 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
-2. **效率:** 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
-3. **对Null key 和Null value的支持:** HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
-4. **初始容量大小和每次扩充容量大小的不同 :** ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
-5. **底层数据结构:** JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
-
-**HashSet 和 HashMap 区别**
-
-如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone() 方法、writeObject()方法、readObject()方法是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。)
-
-
-
-
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md" "b/\351\235\242\350\257\225\345\277\205\345\244\207/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
deleted file mode 100644
index b6f40fbc31b..00000000000
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
+++ /dev/null
@@ -1,91 +0,0 @@
-### 何谓悲观锁与乐观锁
-
-> 乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。这两种人各有优缺点,不能不以场景而定说一种人好于另外一种人。
-
-#### 悲观锁
-
-总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中`synchronized`和`ReentrantLock`等独占锁就是悲观锁思想的实现。
-
-
-#### 乐观锁
-
-总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。**乐观锁适用于多读的应用类型,这样可以提高吞吐量**,像数据库提供的类似于**write_condition机制**,其实都是提供的乐观锁。在Java中`java.util.concurrent.atomic`包下面的原子变量类就是使用了乐观锁的一种实现方式**CAS**实现的。
-
-#### 两种锁的使用场景
-
-从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像**乐观锁适用于写比较少的情况下(多读场景)**,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以**一般多写的场景下用悲观锁就比较合适。**
-
-
-### 乐观锁常见的两种实现方式
-
-> **乐观锁一般会使用版本号机制或CAS算法实现。**
-
-#### 1. 版本号机制
-
-一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
-
-**举一个简单的例子:**
-假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
-
-1. 操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。
-2. 在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。
-3. 操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
-4. 操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
-
-这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
-
-#### 2. CAS算法
-
-即**compare and swap(比较与交换)**,是一种有名的**无锁算法**。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。**CAS算法**涉及到三个操作数
-
-- 需要读写的内存值 V
-- 进行比较的值 A
-- 拟写入的新值 B
-
-当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个**自旋操作**,即**不断的重试**。
-
-关于自旋锁,大家可以看一下这篇文章,非常不错:[《
-面试必备之深入理解自旋锁》](https://blog.csdn.net/qq_34337272/article/details/81252853)
-
-### 乐观锁的缺点
-
-> ABA 问题是乐观锁一个常见的问题
-
-#### 1 ABA 问题
-
-如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然是A值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回A,那CAS操作就会误认为它从来没有被修改过。这个问题被称为CAS操作的 **"ABA"问题。**
-
-JDK 1.5 以后的 `AtomicStampedReference 类`就提供了此种能力,其中的 `compareAndSet 方法`就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
-
-#### 2 循环时间长开销大
-**自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销。** 如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
-
-#### 3 只能保证一个共享变量的原子操作
-
-CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了`AtomicReference类`来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference类`把多个共享变量合并成一个共享变量来操作。
-
-
-
-### CAS与synchronized的使用情景
-
-> **简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)**
-
-1. 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
-2. 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
-
-
-补充: Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
-
-
-
-
-
-
-
-
-
-
-
-
-
-