|
3 | 3 | { |
4 | 4 | "title": "Collaborative Filtering: Alternating Least Squares Matrix Factorization", |
5 | 5 | "text": "%md 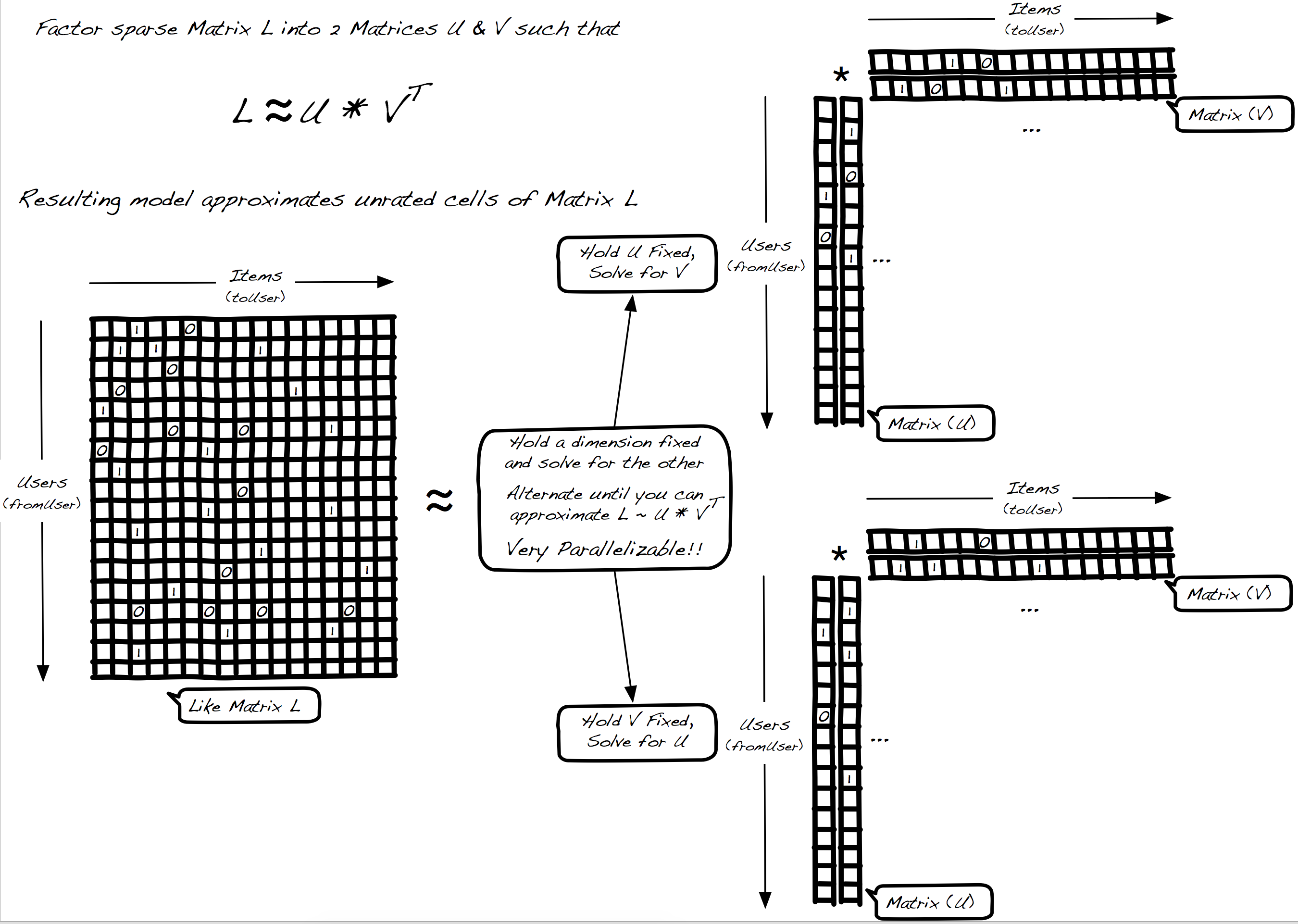", |
6 | | - "dateUpdated": "Feb 4, 2016 3:14:56 AM", |
| 6 | + "dateUpdated": "Feb 12, 2016 4:38:33 AM", |
7 | 7 | "config": { |
8 | 8 | "colWidth": 12.0, |
9 | 9 | "graph": { |
|
32 | 32 | "msg": "\u003cp\u003e\u003cimg src\u003d\"https://raw.githubusercontent.com/cfregly/spark-after-dark/master/img/ALS.png\" alt\u003d\"Alternating Least Squares - Matrix Factorization\" /\u003e\u003c/p\u003e\n" |
33 | 33 | }, |
34 | 34 | "dateCreated": "Jul 4, 2015 2:49:13 AM", |
35 | | - "dateStarted": "Jan 16, 2016 4:40:54 PM", |
36 | | - "dateFinished": "Jan 16, 2016 4:40:54 PM", |
| 35 | + "dateStarted": "Feb 12, 2016 4:38:33 AM", |
| 36 | + "dateFinished": "Feb 12, 2016 4:38:33 AM", |
37 | 37 | "status": "FINISHED", |
38 | 38 | "progressUpdateIntervalMs": 500 |
39 | 39 | }, |
40 | 40 | { |
41 | 41 | "text": "%md ", |
42 | | - "dateUpdated": "Feb 4, 2016 3:15:46 AM", |
| 42 | + "dateUpdated": "Feb 12, 2016 4:38:33 AM", |
43 | 43 | "config": { |
44 | 44 | "colWidth": 12.0, |
45 | 45 | "graph": { |
|
66 | 66 | "msg": "\u003cp\u003e\u003cimg src\u003d\"http://fluxcapacitor.com/img/netflix-facebook-integration.png\" alt\u003d\"User-to-Item Similarity with Facebook\" /\u003e\u003c/p\u003e\n" |
67 | 67 | }, |
68 | 68 | "dateCreated": "Feb 4, 2016 3:14:53 AM", |
69 | | - "dateStarted": "Feb 4, 2016 3:15:46 AM", |
70 | | - "dateFinished": "Feb 4, 2016 3:15:46 AM", |
| 69 | + "dateStarted": "Feb 12, 2016 4:38:33 AM", |
| 70 | + "dateFinished": "Feb 12, 2016 4:38:33 AM", |
71 | 71 | "status": "FINISHED", |
72 | 72 | "progressUpdateIntervalMs": 500 |
73 | 73 | }, |
74 | 74 | { |
75 | 75 | "title": "Train The Model Using The Historical Training Split Of The Historical Data", |
76 | 76 | "text": "import org.apache.spark.ml.recommendation.ALS\n\nval rank \u003d 10\nval maxIterations \u003d 20\nval convergenceThreshold \u003d 0.01\n\nval als \u003d new ALS()\n .setRank(rank)\n .setRegParam(convergenceThreshold)\n .setUserCol(\"userId\")\n .setItemCol(\"itemId\")\n .setRatingCol(\"rating\")\n\nval model \u003d als.fit(itemRatingsDF)\n\nmodel.setPredictionCol(\"confidence\")", |
77 | | - "dateUpdated": "Jan 16, 2016 4:40:54 PM", |
| 77 | + "dateUpdated": "Feb 12, 2016 4:38:33 AM", |
78 | 78 | "config": { |
79 | 79 | "colWidth": 12.0, |
80 | 80 | "graph": { |
|
98 | 98 | "jobName": "paragraph_1435978256373_-160526409", |
99 | 99 | "id": "20150704-025056_169923529", |
100 | 100 | "result": { |
101 | | - "code": "SUCCESS", |
| 101 | + "code": "ERROR", |
102 | 102 | "type": "TEXT", |
103 | | - "msg": "import org.apache.spark.ml.recommendation.ALS\nrank: Int \u003d 10\nmaxIterations: Int \u003d 20\nconvergenceThreshold: Double \u003d 0.01\nals: org.apache.spark.ml.recommendation.ALS \u003d als_9a2aa41f1d28\nmodel: org.apache.spark.ml.recommendation.ALSModel \u003d als_9a2aa41f1d28\nres29: model.type \u003d als_9a2aa41f1d28\n" |
| 103 | + "msg": "import org.apache.spark.ml.recommendation.ALS\nrank: Int \u003d 10\nmaxIterations: Int \u003d 20\nconvergenceThreshold: Double \u003d 0.01\nals: org.apache.spark.ml.recommendation.ALS \u003d als_0713aff1e6f6\n\u003cconsole\u003e:35: error: not found: value itemRatingsDF\n val model \u003d als.fit(itemRatingsDF)\n ^\n" |
104 | 104 | }, |
105 | 105 | "dateCreated": "Jul 4, 2015 2:50:56 AM", |
106 | | - "dateStarted": "Jan 16, 2016 4:40:54 PM", |
107 | | - "dateFinished": "Jan 16, 2016 4:40:58 PM", |
108 | | - "status": "FINISHED", |
| 106 | + "dateStarted": "Feb 12, 2016 4:38:33 AM", |
| 107 | + "dateFinished": "Feb 12, 2016 4:38:33 AM", |
| 108 | + "status": "ERROR", |
109 | 109 | "progressUpdateIntervalMs": 500 |
110 | 110 | }, |
111 | 111 | { |
112 | 112 | "title": "Generate Personalized Recommendations For Each Distinct User", |
113 | 113 | "text": "val recommendationsDF \u003d model.transform(itemRatingsDF.select($\"userId\", $\"itemId\"))\n\nval enrichedRecommendationsDF \u003d \n recommendationsDF.join(itemsDF, $\"itemId\" \u003d\u003d\u003d $\"id\")\n .select($\"userId\", $\"itemId\", $\"title\", $\"description\", $\"tags\", $\"img\", $\"confidence\")\n .sort($\"userId\", $\"confidence\" desc)", |
114 | | - "dateUpdated": "Jan 16, 2016 4:40:54 PM", |
| 114 | + "dateUpdated": "Feb 12, 2016 4:38:33 AM", |
115 | 115 | "config": { |
116 | 116 | "colWidth": 12.0, |
117 | 117 | "graph": { |
|
161 | 161 | "result": { |
162 | 162 | "code": "ERROR", |
163 | 163 | "type": "TEXT", |
164 | | - "msg": "java.lang.IllegalArgumentException: Field \"lyrics\" does not exist.\n\tat org.apache.spark.sql.types.StructType$$anonfun$apply$1.apply(StructType.scala:212)\n\tat org.apache.spark.sql.types.StructType$$anonfun$apply$1.apply(StructType.scala:212)\n\tat scala.collection.MapLike$class.getOrElse(MapLike.scala:128)\n\tat scala.collection.AbstractMap.getOrElse(Map.scala:58)\n\tat org.apache.spark.sql.types.StructType.apply(StructType.scala:211)\n\tat org.apache.spark.ml.UnaryTransformer.transformSchema(Transformer.scala:106)\n\tat org.apache.spark.ml.PipelineModel$$anonfun$transformSchema$5.apply(Pipeline.scala:301)\n\tat org.apache.spark.ml.PipelineModel$$anonfun$transformSchema$5.apply(Pipeline.scala:301)\n\tat scala.collection.IndexedSeqOptimized$class.foldl(IndexedSeqOptimized.scala:51)\n\tat scala.collection.IndexedSeqOptimized$class.foldLeft(IndexedSeqOptimized.scala:60)\n\tat scala.collection.mutable.ArrayOps$ofRef.foldLeft(ArrayOps.scala:108)\n\tat org.apache.spark.ml.PipelineModel.transformSchema(Pipeline.scala:301)\n\tat org.apache.spark.ml.PipelineStage.transformSchema(Pipeline.scala:68)\n\tat org.apache.spark.ml.PipelineModel.transform(Pipeline.scala:296)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:71)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:76)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:78)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:80)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:82)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:84)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:86)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:88)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:90)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:92)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:94)\n\tat $iwC$$iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:96)\n\tat $iwC$$iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:98)\n\tat $iwC$$iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:100)\n\tat $iwC$$iwC.\u003cinit\u003e(\u003cconsole\u003e:102)\n\tat $iwC.\u003cinit\u003e(\u003cconsole\u003e:104)\n\tat \u003cinit\u003e(\u003cconsole\u003e:106)\n\tat .\u003cinit\u003e(\u003cconsole\u003e:110)\n\tat .\u003cclinit\u003e(\u003cconsole\u003e)\n\tat .\u003cinit\u003e(\u003cconsole\u003e:7)\n\tat .\u003cclinit\u003e(\u003cconsole\u003e)\n\tat $print(\u003cconsole\u003e)\n\tat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\n\tat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\n\tat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\tat java.lang.reflect.Method.invoke(Method.java:497)\n\tat org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:1065)\n\tat org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:1346)\n\tat org.apache.spark.repl.SparkIMain.loadAndRunReq$1(SparkIMain.scala:840)\n\tat org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:871)\n\tat org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:819)\n\tat org.apache.zeppelin.spark.SparkInterpreter.interpretInput(SparkInterpreter.java:709)\n\tat org.apache.zeppelin.spark.SparkInterpreter.interpret(SparkInterpreter.java:674)\n\tat org.apache.zeppelin.spark.SparkInterpreter.interpret(SparkInterpreter.java:667)\n\tat org.apache.zeppelin.interpreter.ClassloaderInterpreter.interpret(ClassloaderInterpreter.java:57)\n\tat org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:93)\n\tat org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:300)\n\tat org.apache.zeppelin.scheduler.Job.run(Job.java:169)\n\tat org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:134)\n\tat java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)\n\tat java.util.concurrent.FutureTask.run(FutureTask.java:266)\n\tat java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)\n\tat java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)\n\tat java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)\n\tat java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)\n\tat java.lang.Thread.run(Thread.java:745)\n\n" |
| 164 | + "msg": "\u003cconsole\u003e:28: error: not found: value model\n val recommendationsDF \u003d model.transform(itemRatingsDF.select($\"userId\", $\"itemId\"))\n ^\n" |
165 | 165 | }, |
166 | 166 | "dateCreated": "Jul 4, 2015 2:51:32 AM", |
167 | | - "dateStarted": "Jan 16, 2016 4:40:54 PM", |
168 | | - "dateFinished": "Jan 16, 2016 4:40:59 PM", |
169 | | - "status": "FINISHED", |
| 167 | + "dateStarted": "Feb 12, 2016 4:38:33 AM", |
| 168 | + "dateFinished": "Feb 12, 2016 4:38:33 AM", |
| 169 | + "status": "ERROR", |
170 | 170 | "progressUpdateIntervalMs": 500 |
171 | 171 | }, |
172 | 172 | { |
173 | 173 | "text": "z.show(enrichedRecommendationsDF.select($\"userId\", $\"itemId\", $\"confidence\", $\"title\", $\"img\").limit(10))", |
174 | | - "dateUpdated": "Jan 16, 2016 4:40:54 PM", |
| 174 | + "dateUpdated": "Feb 12, 2016 4:38:33 AM", |
175 | 175 | "config": { |
176 | 176 | "colWidth": 12.0, |
177 | 177 | "graph": { |
|
216 | 216 | "jobName": "paragraph_1443377582412_2075344434", |
217 | 217 | "id": "20150927-181302_1140885708", |
218 | 218 | "result": { |
219 | | - "code": "SUCCESS", |
220 | | - "type": "TABLE", |
221 | | - "msg": "userId\titemId\tconfidence\ttitle\timg\n22\t43\t0.9967797\tJava\timg/software/java.png\n22\t66\t0.99488777\tRedshift\timg/software/redshift.png\n22\t49\t0.99466026\tAmazon Web Services\timg/software/aws.png\n22\t77\t0.9943304\tS3\timg/software/s3.png\n22\t52\t0.9943008\tJSON\timg/software/json.png\n22\t21\t0.99397665\tElasticSearch\timg/software/elasticsearch.png\n22\t64\t0.9937968\tCSV\timg/software/csv.png\n22\t39\t0.99280584\tTableau\timg/software/tableau.png\n22\t68\t0.9927822\tDynamoDB\timg/software/dynamodb.png\n22\t60\t0.9926167\tMySQL\timg/software/mysql.png\n" |
| 219 | + "code": "ERROR", |
| 220 | + "type": "TEXT", |
| 221 | + "msg": "\u003cconsole\u003e:31: error: not found: value enrichedRecommendationsDF\n z.show(enrichedRecommendationsDF.select($\"userId\", $\"itemId\", $\"confidence\", $\"title\", $\"img\").limit(10))\n ^\n" |
222 | 222 | }, |
223 | 223 | "dateCreated": "Sep 27, 2015 6:13:02 PM", |
224 | | - "dateStarted": "Jan 16, 2016 4:40:59 PM", |
225 | | - "dateFinished": "Jan 16, 2016 4:41:04 PM", |
226 | | - "status": "FINISHED", |
| 224 | + "dateStarted": "Feb 12, 2016 4:38:33 AM", |
| 225 | + "dateFinished": "Feb 12, 2016 4:38:33 AM", |
| 226 | + "status": "ERROR", |
227 | 227 | "progressUpdateIntervalMs": 500 |
228 | 228 | }, |
229 | 229 | { |
230 | 230 | "text": "import org.elasticsearch.spark.sql._ \nimport org.apache.spark.sql.SaveMode\n\nval esConfig \u003d Map(\"pushdown\" -\u003e \"true\", \"es.nodes\" -\u003e \"127.0.0.1\", \"es.port\" -\u003e \"9200\")\nenrichedRecommendationsDF.write.format(\"org.elasticsearch.spark.sql\").mode(SaveMode.Overwrite).options(esConfig)\n .save(\"advancedspark/personalized-als\")", |
231 | | - "dateUpdated": "Jan 16, 2016 4:40:54 PM", |
| 231 | + "dateUpdated": "Feb 12, 2016 4:38:33 AM", |
232 | 232 | "config": { |
233 | 233 | "colWidth": 12.0, |
234 | 234 | "graph": { |
|
251 | 251 | "jobName": "paragraph_1438113388648_-491234562", |
252 | 252 | "id": "20150728-195628_1365871289", |
253 | 253 | "result": { |
254 | | - "code": "SUCCESS", |
| 254 | + "code": "ERROR", |
255 | 255 | "type": "TEXT", |
256 | | - "msg": "import org.elasticsearch.spark.sql._\nimport org.apache.spark.sql.SaveMode\nesConfig: scala.collection.immutable.Map[String,String] \u003d Map(pushdown -\u003e true, es.nodes -\u003e 127.0.0.1, es.port -\u003e 9200)\n" |
| 256 | + "msg": "import org.elasticsearch.spark.sql._\nimport org.apache.spark.sql.SaveMode\nesConfig: scala.collection.immutable.Map[String,String] \u003d Map(pushdown -\u003e true, es.nodes -\u003e 127.0.0.1, es.port -\u003e 9200)\n\u003cconsole\u003e:35: error: not found: value enrichedRecommendationsDF\n enrichedRecommendationsDF.write.format(\"org.elasticsearch.spark.sql\").mode(SaveMode.Overwrite).options(esConfig)\n ^\n" |
257 | 257 | }, |
258 | 258 | "dateCreated": "Jul 28, 2015 7:56:28 PM", |
259 | | - "dateStarted": "Jan 16, 2016 4:40:59 PM", |
260 | | - "dateFinished": "Jan 16, 2016 4:41:27 PM", |
261 | | - "status": "FINISHED", |
| 259 | + "dateStarted": "Feb 12, 2016 4:38:33 AM", |
| 260 | + "dateFinished": "Feb 12, 2016 4:38:34 AM", |
| 261 | + "status": "ERROR", |
262 | 262 | "progressUpdateIntervalMs": 500 |
263 | 263 | }, |
264 | 264 | { |
265 | | - "dateUpdated": "Jan 16, 2016 4:40:54 PM", |
| 265 | + "dateUpdated": "Feb 12, 2016 4:38:33 AM", |
266 | 266 | "config": { |
267 | 267 | "colWidth": 12.0, |
268 | 268 | "graph": { |
|
288 | 288 | "type": "TEXT" |
289 | 289 | }, |
290 | 290 | "dateCreated": "Dec 25, 2015 7:08:18 PM", |
291 | | - "dateStarted": "Jan 16, 2016 4:41:04 PM", |
292 | | - "dateFinished": "Jan 16, 2016 4:41:27 PM", |
| 291 | + "dateStarted": "Feb 12, 2016 4:38:34 AM", |
| 292 | + "dateFinished": "Feb 12, 2016 4:38:34 AM", |
293 | 293 | "status": "FINISHED", |
294 | 294 | "progressUpdateIntervalMs": 500 |
295 | 295 | } |
|
0 commit comments