⭐️ About
| 🚀 Quick start
| 📚 Pipeline
| 🧑💻 Training
| 📊 Evaluation
|

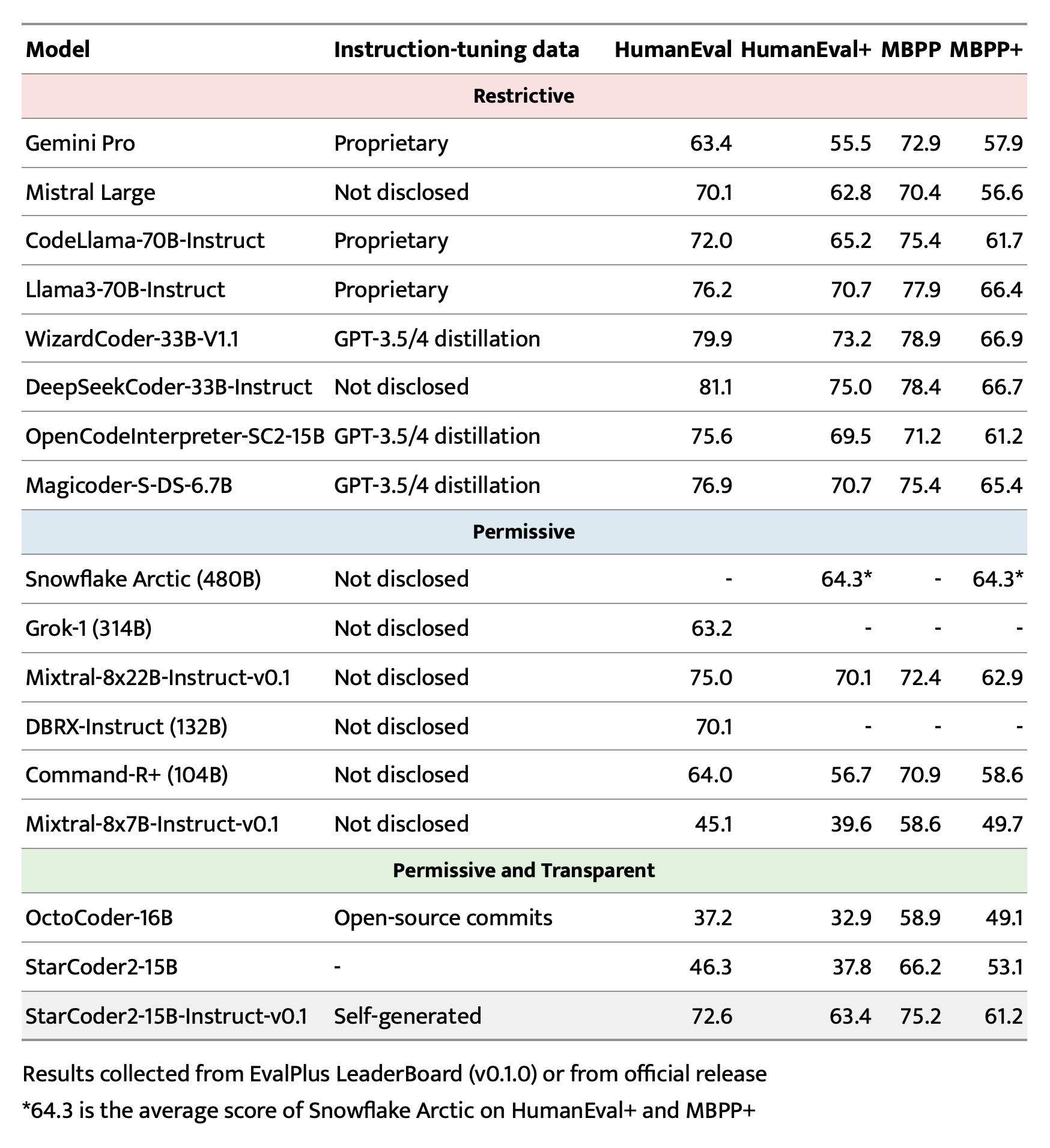
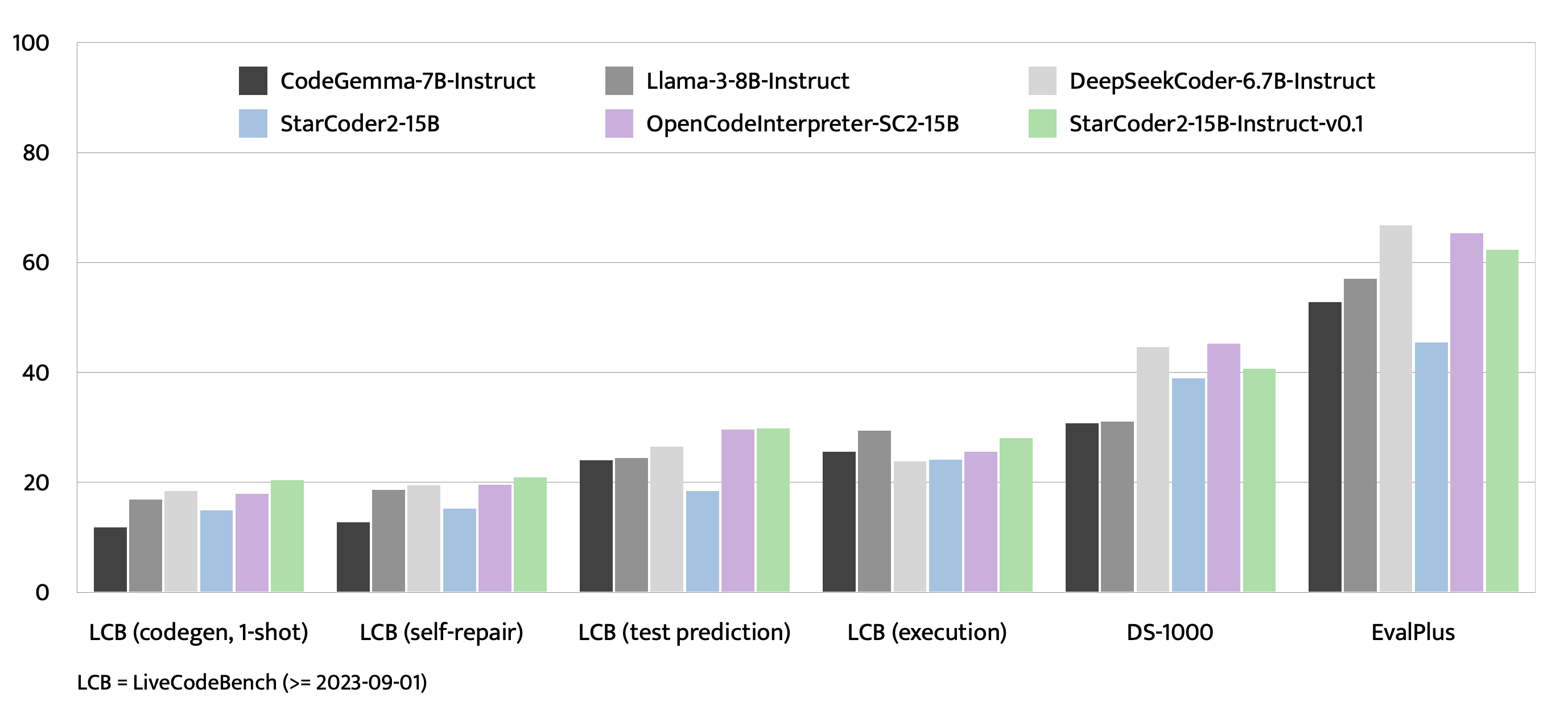
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
- Model: bigcode/starcoder2-15b-instruct-v0.1
- Code: bigcode-project/starcoder2-self-align
- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k
- Authors: Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Harm de Vries, Leandro von Werra, Arjun Guha, Lingming Zhang.

Here is an example to get started with StarCoder2-15B-Instruct-v0.1 using the transformers library:
import transformers
import torch
pipeline = transformers.pipeline(
model="bigcode/starcoder2-15b-instruct-v0.1",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
def respond(instruction: str, response_prefix: str) -> str:
messages = [{"role": "user", "content": instruction}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
prompt += response_prefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
response_prefix = ""
print(respond(instruction, response_prefix))We used vLLM's OpenAI compatible server for data generation. So, before running the following commands, make sure the vLLM server is running, and the associated openai environment variables are set.
For example, you can start an vLLM server with docker:
docker run --gpus '"device=0"' \
-v $HF_HOME:/root/.cache/huggingface \
-p 10000:8000 \
--ipc=host \
vllm/vllm-openai:v0.3.3 \
--model bigcode/starcoder2-15b \
--tensor-parallel-size 1 --dtype bfloat16And then set the environment variables as follows:
export OPENAI_API_KEY="EMPTY"
export OPENAI_BASE_URL="http://localhost:10000/v1/"Snippet to concepts generation
python src/star_align/self_ossinstruct.py \
--instruct_mode "S->C" \
--seed_data_files /path/to/seeds.jsonl \
--max_new_data 50000 \
--tag concept_gen \
--temperature 0.7 \
--seed_code_start_index 0 \
--model bigcode/starcoder2-15b \
--num_fewshots 8 \
--num_batched_requests 32 \
--num_sample_per_request 1Concepts to instruction generation
python src/star_align/self_ossinstruct.py \
--instruct_mode "C->I" \
--seed_data_files /path/to/concepts.jsonl \
--max_new_data 50000 \
--tag instruction_gen \
--temperature 0.7 \
--seed_code_start_index 0 \
--model bigcode/starcoder2-15b \
--num_fewshots 8 \
--num_sample_per_request 1 \
--num_batched_request 32Instruction to response (with self-validation code) generation
python src/star_align/self_ossinstruct.py \
--instruct_mode "I->R" \
--seed_data_files path/to/instructions.jsonl \
--max_new_data 50000 \
--tag response_gen \
--seed_code_start_index 0 \
--model bigcode/starcoder2-15b \
--num_fewshots 1 \
--num_batched_request 8 \
--num_sample_per_request 10 \
--temperature 0.7Execution filter
[!WARNING] Though we implemented reliability guards, it is highly recommended to run execution in a sandbox environment. The command below doesn't provide sandboxing by default.
python src/star_align/execution_filter.py --response_path /path/to/response.jsonl --result_path /path/to/filtered.jsonl
# The current implementation may cause deadlock.
# If you encounter deadlock, manually do `ps -ef | grep execution_filter` and kill the stuck process.
# Note that filtered.jsonl may contain multiple passing samples for the same instruction which needs further selection.Data sanitization and selection
RAW=1 python src/star_align/sanitize_data.py /path/to/filtered.jsonl /path/to/sanitized.jsonl
python src/star_align/clean_data.py --data_files /path/to/sanitized.jsonl --output_file /path/to/sanitized.jsonl --diversify_func_names
SMART=1 python src/star_align/sanitize_data.py /path/to/sanitized.jsonl /path/to/sanitized.jsonl- Optimizer: Adafactor
- Learning rate: 1e-5
- Epoch: 4
- Batch size: 64
- Warmup ratio: 0.05
- Scheduler: Linear
- Sequence length: 1280
- Dropout: Not applied
1 x NVIDIA A100 80GB
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a response prefix or a one-shot example to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the StarCoder2-15B model card.