| title | shortTitle | category | tag | description | head | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
深入解读String类源码及其应用技巧 |
解读String类源码 |
|
|
本文将对Java String类的源码进行深入分析,帮助你理解字符串在Java中的实现原理、操作方式和性能优化策略。通过详细解读String源码,我们将揭示字符串类的内部机制,掌握如何高效地进行字符串操作,以及在实际编程中如何应用这些知识来提高代码质量和性能。 |
|
我正坐在沙发上津津有味地读刘欣大佬的《码农翻身》——Java 帝国这一章,门铃响了。起身打开门一看,是三妹,她从学校回来了。
“三妹,你回来的真及时,今天我们打算讲 Java 中的字符串呢。”等三妹换鞋的时候我说。
“哦,可以呀,哥。听说字符串的细节特别多,什么字符串常量池了、字符串不可变性了、字符串拼接了、字符串长度限制了等等,你最好慢慢讲,否则我可能一时半会消化不了。”三妹的态度显得很诚恳。
“嗯,我已经想好了,今天就只带你大概认识一下字符串,主要读一读它的源码,其他的细节咱们后面再慢慢讲,保证你能及时消化。”
“好,那就开始吧。”三妹已经准备好坐在了电脑桌的边上。
我应了一声后走到电脑桌前坐下来,顺手打开 Intellij IDEA,并找到了 String 的源码(Java 8)。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
}“第一,String 类是 final 的,意味着它不能被子类继承。”
“第二,String 类实现了 Serializable 接口,意味着它可以序列化。”
“第三,String 类实现了 Comparable 接口,意味着最好不要用‘==’来比较两个字符串是否相等,而应该用 compareTo() 方法去比较。”
因为 == 是用来比较两个对象的地址,这个在讲字符串比较的时候会详细讲。如果只是说比较字符串内容的话,可以使用 String 类的 equals 方法:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String) anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}“第四,StringBuffer、StringBuilder 和 String 一样,都实现了 CharSequence 接口,所以它们仨 8000 属于近亲。由于 String 是不可变的,所以遇到字符串拼接的时候就可以考虑一下 String 的另外两个好兄弟,StringBuffer 和 StringBuilder,它俩是可变的。”
private final char value[];“第五,Java 9 以前,String 是用 char 型数组实现的,之后改成了 byte 型数组实现,并增加了 coder 来表示编码。这样做的好处是在 Latin1 字符为主的程序里,可以把 String 占用的内存减少一半。当然,天下没有免费的午餐,这个改进在节省内存的同时引入了编码检测的开销。”
Latin1(Latin-1)是一种单字节字符集(即每个字符只使用一个字节的编码方式),也称为ISO-8859-1(国际标准化组织8859-1),它包含了西欧语言中使用的所有字符,包括英语、法语、德语、西班牙语、葡萄牙语、意大利语等等。在Latin1编码中,每个字符使用一个8位(即一个字节)的编码,可以表示256种不同的字符,其中包括ASCII字符集中的所有字符,即0x00到0x7F,以及其他西欧语言中的特殊字符,例如é、ü、ñ等等。由于Latin1只使用一个字节表示一个字符,因此在存储和传输文本时具有较小的存储空间和较快的速度
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
@Stable
private final byte[] value;
private final byte coder;
private int hash;
}接下来,我们来详细地说一下。
从 char[] 到 byte[],最主要的目的是节省字符串占用的内存空间。内存占用减少带来的另外一个好处,就是 GC 次数也会减少。
我们使用 jmap -histo:live pid | head -n 10 命令就可以查看到堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
以我正在运行着的编程喵项目实例(基于 Java 8)来说,结果是这样的。
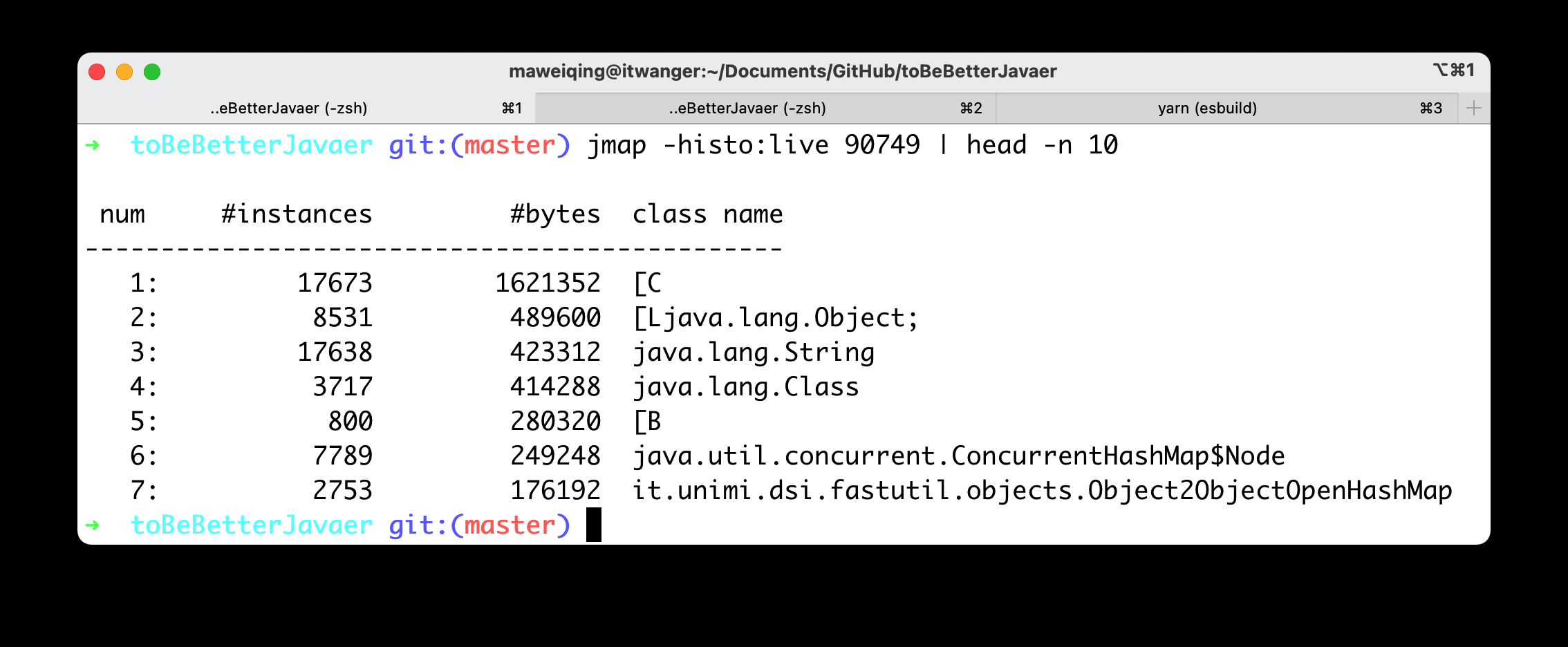
其中 String 对象有 17638 个,占用了 423312 个字节的内存,排在第三位。
由于 Java 8 的 String 内部实现仍然是 char[],所以我们可以看到内存占用排在第 1 位的就是 char 数组。
char[] 对象有 17673 个,占用了 1621352 个字节的内存,排在第一位。
那也就是说优化 String 节省内存空间是非常有必要的,如果是去优化一个使用频率没有 String 这么高的类,就没什么必要,对吧?
众所周知,char 类型的数据在 JVM 中是占用两个字节的,并且使用的是 UTF-8 编码,其值范围在 '\u0000'(0)和 '\uffff'(65,535)(包含)之间。
也就是说,使用 char[] 来表示 String 就会导致,即使 String 中的字符只用一个字节就能表示,也得占用两个字节。
PS:在计算机中,单字节字符通常指的是一个字节(8位)可以表示的字符,而双字节字符则指需要两个字节(16位)才能表示的字符。单字节字符和双字节字符的定义是相对的,不同的编码方式对应的单字节和双字节字符集也不同。常见的单字节字符集有ASCII(美国信息交换标准代码)、ISO-8859(国际标准化组织标准编号8859)、GBK(汉字内码扩展规范)、GB2312(中国国家标准,现在已经被GBK取代),像拉丁字母、数字、标点符号、控制字符都是单字节字符。双字节字符集包括 Unicode、UTF-8、GB18030(中国国家标准),中文、日文、韩文、拉丁文扩展字符属于双字节字符。
当然了,仅仅将 char[] 优化为 byte[] 是不够的,还要配合 Latin-1 的编码方式,该编码方式是用单个字节来表示字符的,这样就比 UTF-8 编码节省了更多的空间。
换句话说,对于:
String name = "jack";这样的,使用 Latin-1 编码,占用 4 个字节就够了。
但对于:
String name = "小二";这种,木的办法,只能使用 UTF16 来编码。
针对 JDK 9 的 String 源码里,为了区别编码方式,追加了一个 coder 字段来区分。
/**
* The identifier of the encoding used to encode the bytes in
* {@code value}. The supported values in this implementation are
*
* LATIN1
* UTF16
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*/
private final byte coder;Java 会根据字符串的内容自动设置为相应的编码,要么 Latin-1 要么 UTF16。
也就是说,从 char[] 到 byte[],中文是两个字节,纯英文是一个字节,在此之前呢,中文是两个字节,英文也是两个字节。
在 UTF-8 中,0-127 号的字符用 1 个字节来表示,使用和 ASCII 相同的编码。只有 128 号及以上的字符才用 2 个、3 个或者 4 个字节来表示。
- 如果只有一个字节,那么最高的比特位为 0;
- 如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
- 0xxxxxxx:一个字节;
- 110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1);
- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1);
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
也就是说,UTF-8 是变长的,那对于 String 这种有随机访问方法的类来说,就很不方便。所谓的随机访问,就是charAt、subString这种方法,随便指定一个数字,String要能给出结果。如果字符串中的每个字符占用的内存是不定长的,那么进行随机访问的时候,就需要从头开始数每个字符的长度,才能找到你想要的字符。
那你可能会问,UTF-16也是变长的呢?一个字符还可能占用 4 个字节呢?
的确,UTF-16 使用 2 个或者 4 个字节来存储字符。
- 对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储。
- 对于 Unicode 编号范围在 10000 ~ 10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800
DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00DFFF 之间的双字节存储。
但是在 Java 中,一个字符(char)就是 2 个字节,占 4 个字节的字符,在 Java 里也是用两个 char 来存储的,而String的各种操作,都是以Java的字符(char)为单位的,charAt是取得第几个char,subString取的也是第几个到第几个char组成的子串,甚至length返回的都是char的个数。
所以UTF-16在Java的世界里,就可以视为一个定长的编码。
“第六,每一个字符串都会有一个 hash 值,这个哈希值在很大概率是不会重复的,因此 String 很适合来作为 HashMap 的键值。”
来看 String 类的 hashCode 方法。
private int hash; // Cache the hash code for the string
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}hashCode 方法首先检查是否已经计算过哈希码,如果已经计算过,则直接返回缓存的哈希码。否则,方法将使用一个循环遍历字符串的所有字符,并使用一个乘法和加法的组合计算哈希码。这种计算方法被称为“31 倍哈希法”。计算完成后,将得到的哈希值存储在 hash 成员变量中,以便下次调用 hashCode 方法时直接返回该值,而不需要重新计算。这是一种缓存优化,称为“惰性计算”。
31倍哈希法(31-Hash)是一种简单有效的字符串哈希算法,常用于对字符串进行哈希处理。该算法的基本思想是将字符串中的每个字符乘以一个固定的质数31的幂次方,并将它们相加得到哈希值。具体地,假设字符串为s,长度为n,则31倍哈希值计算公式如下:
H(s) = (s[0] * 31^(n-1)) + (s[1] * 31^(n-2)) + ... + (s[n-1] * 31^0)
其中,s[i]表示字符串s中第i个字符的ASCII码值,^表示幂运算。
31倍哈希法的优点在于简单易实现,计算速度快,同时也比较均匀地分布在哈希表中。
hashCode 方法,我们会在另外一个章节里详细讲,戳前面的链接了解。
我们可以通过以下方法模拟 String 的 hashCode 方法:
public class HashCodeExample {
public static void main(String[] args) {
String text = "沉默王二";
int hashCode = computeHashCode(text);
System.out.println("字符串 \"" + text + "\" 的哈希码是: " + hashCode);
System.out.println("String 的 hashCode " + text.hashCode());
}
public static int computeHashCode(String text) {
int h = 0;
for (int i = 0; i < text.length(); i++) {
h = 31 * h + text.charAt(i);
}
return h;
}
}看一下结果:
字符串 "沉默王二" 的哈希码是: 867758096
String 的 hashCode 867758096
结果是一样的,又学到了吧?
String 类中还有一个方法比较常用 substring,用来截取字符串的,来看源码。
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}substring 方法首先检查参数的有效性,如果参数无效,则抛出 StringIndexOutOfBoundsException 异常。接下来,方法根据参数计算子字符串的长度。如果子字符串长度小于零,抛出StringIndexOutOfBoundsException异常。
如果 beginIndex 为 0,且 endIndex 等于字符串的长度,说明子串与原字符串相同,因此直接返回原字符串。否则,使用 value 数组(原字符串的字符数组)的一部分创建一个新的 String 对象并返回。
下面是几个使用 substring 方法的示例:
①、提取字符串中的一段子串:
String str = "Hello, world!";
String subStr = str.substring(7, 12); // 从第7个字符(包括)提取到第12个字符(不包括)
System.out.println(subStr); // 输出 "world"②、提取字符串中的前缀或后缀:
String str = "Hello, world!";
String prefix = str.substring(0, 5); // 提取前5个字符,即 "Hello,"
String suffix = str.substring(7); // 提取从第7个字符开始的所有字符,即 "world!"③、处理字符串中的空格和分隔符:
String str = " Hello, world! ";
String trimmed = str.trim(); // 去除字符串开头和结尾的空格
String[] words = trimmed.split("\\s+"); // 将字符串按照空格分隔成单词数组
String firstWord = words[0].substring(0, 1); // 提取第一个单词的首字母
System.out.println(firstWord); // 输出 "H"④、处理字符串中的数字和符号:
String str = "1234-5678-9012-3456";
String[] parts = str.split("-"); // 将字符串按照连字符分隔成四个部分
String last4Digits = parts[3].substring(1); // 提取最后一个部分的后三位数字
System.out.println(last4Digits); // 输出 "456"总之,substring 方法可以根据需求灵活地提取字符串中的子串,为字符串处理提供了便利。
indexOf 方法用于查找一个子字符串在原字符串中第一次出现的位置,并返回该位置的索引。来看该方法的源码:
/*
* 查找字符数组 target 在字符数组 source 中第一次出现的位置。
* sourceOffset 和 sourceCount 参数指定 source 数组中要搜索的范围,
* targetOffset 和 targetCount 参数指定 target 数组中要搜索的范围,
* fromIndex 参数指定开始搜索的位置。
* 如果找到了 target 数组,则返回它在 source 数组中的位置索引(从0开始),
* 否则返回-1。
*/
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
// 如果开始搜索的位置已经超出 source 数组的范围,则直接返回-1(如果 target 数组为空,则返回 sourceCount)
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
// 如果开始搜索的位置小于0,则从0开始搜索
if (fromIndex < 0) {
fromIndex = 0;
}
// 如果 target 数组为空,则直接返回开始搜索的位置
if (targetCount == 0) {
return fromIndex;
}
// 查找 target 数组的第一个字符在 source 数组中的位置
char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount);
// 循环查找 target 数组在 source 数组中的位置
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
// 如果 source 数组中当前位置的字符不是 target 数组的第一个字符,则在 source 数组中继续查找 target 数组的第一个字符
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
// 如果在 source 数组中找到了 target 数组的第一个字符,则继续查找 target 数组的剩余部分是否匹配
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
// 如果 target 数组全部匹配,则返回在 source 数组中的位置索引
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
// 没有找到 target 数组,则返回-1
return -1;
}来看示例。
①、示例1:查找子字符串的位置
String str = "Hello, world!";
int index = str.indexOf("world"); // 查找 "world" 子字符串在 str 中第一次出现的位置
System.out.println(index); // 输出 7②、示例2:查找字符串中某个字符的位置
String str = "Hello, world!";
int index = str.indexOf(","); // 查找逗号在 str 中第一次出现的位置
System.out.println(index); // 输出 5③、示例3:查找子字符串的位置(从指定位置开始查找)
String str = "Hello, world!";
int index = str.indexOf("l", 3); // 从索引为3的位置开始查找 "l" 子字符串在 str 中第一次出现的位置
System.out.println(index); // 输出 3④、示例4:查找多个子字符串
String str = "Hello, world!";
int index1 = str.indexOf("o"); // 查找 "o" 子字符串在 str 中第一次出现的位置
int index2 = str.indexOf("o", 5); // 从索引为5的位置开始查找 "o" 子字符串在 str 中第一次出现的位置
System.out.println(index1); // 输出 4
System.out.println(index2); // 输出 8比如说 length() 用于返回字符串长度。
比如说 isEmpty() 用于判断字符串是否为空。
比如说 charAt() 用于返回指定索引处的字符。
比如说 getBytes() 用于返回字符串的字节数组,可以指定编码方式,比如说:
String text = "沉默王二";
System.out.println(Arrays.toString(text.getBytes(StandardCharsets.UTF_8)));比如说 trim() 用于去除字符串两侧的空白字符,来看源码:
public String trim() {
int len = value.length;
int st = 0;
char[] val = value; /* avoid getfield opcode */
while ((st < len) && (val[st] <= ' ')) {
st++;
}
while ((st < len) && (val[len - 1] <= ' ')) {
len--;
}
return ((st > 0) || (len < value.length)) ? substring(st, len) : this;
}举例:" 沉默王二 ".trim() 会返回"沉默王二"
除此之外,还有 split、equals、join 等这些方法,我们后面会一一来细讲。
GitHub 上标星 7600+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 7600+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
