Usage
ArchiveBox API Reference:

- CLI Usage: Docs and examples for the ArchiveBox command line interface.
- Admin UI Usage: Docs and screenshots for the outputted HTML archive interface.
- Browser Extension Usage: Docs and screenshots for the outputted HTML archive interface.
- Disk Layout: Description of the archive folder structure and contents.
Related:
- Docker: Learn about ArchiveBox usage with Docker and Docker Compose
- Configuration: Learn about the various archive method options
- Scheduled Archiving: Learn how to set up automatic daily archiving
- Publishing Your Archive: Learn how to host your archive for others to access
- Troubleshooting: Resources if you encounter any problems
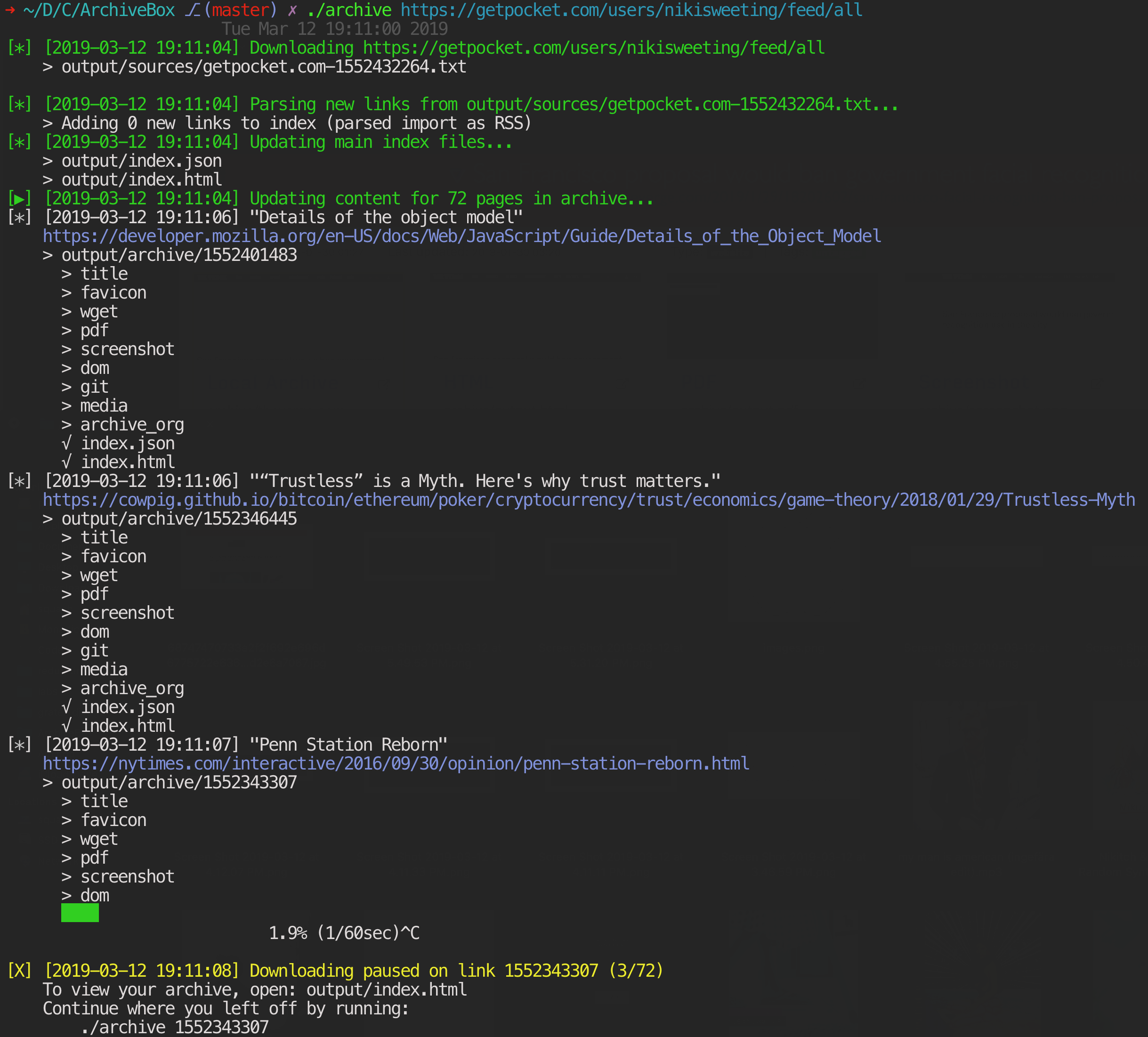
All three of these ways of running ArchiveBox are equivalent and interchangeable:
-
archivebox [subcommand] [...args]
Using the PyPI package viapip install archivebox -
docker run ... archivebox/archivebox [subcommand] [...args]
Using the official Docker image -
docker-compose run archivebox [subcommand] [...args]
Using the official Docker image w/ Docker Compose
You can share a single archivebox data directory between Docker and non-Docker instances as well, allowing you to run the server in a container but still execute CLI commands on the host for example.
For more examples see README: Usage and Docker pages.
- Run ArchiveBox with configuration options
- Import a single URL
- Import a list of URLs from a text file
- Import list of links from browser history
You can set environment variables in your shell profile, a config file, or by using the env command.
# set config via the CLI
archivebox config --set MEDIA_MAX_SIZE=750mb
# OR modify the config file directly
echo 'MEDIA_MAX_SIZE=750mb' >> ArchiveBox.conf
# OR use environment variables
env MEDIA_MAX_SIZE=750mb archivebox add 'https://example.com'See Configuration page for more details about the available options and ways to pass config.
If you're using Docker, also make sure to read the Configuration section on the Docker page.
Tip
You can run ArchiveBox commands from anywhere (without having to cd into a data directory first):
/usr/bin/env --chdir=/path/to/archivebox/data archivebox update
archivebox add 'https://example.com'
# OR
echo 'https://example.com' | archivebox addYou can also add --depth=1 to any of these commands if you want to recursively archive the URLs and all URLs one hop away. (e.g. all the outlinks on a page + the page).
cat urls_to_archive.txt | archivebox add
# OR
archivebox add < urls_to_archive.txt
# OR
curl 'https://example.com/some/rss/feed.xml' | archivebox add
# OR
archivebox add --depth=1 'https://example.com/some/rss/feed.xml'You can also pipe in RSS, XML, Netscape, or any of the other supported import formats via stdin.
archivebox add < ~/Downloads/browser_bookmarks_export.html
# OR
archivebox add < ~/Downloads/pinboard_bookmarks.json
# OR
archivebox add < ~/Downloads/any_text_containing_urls.txtLook in the bin/ folder of this repo to find a script to parse your browser's SQLite history database for URLs.
Specify the type of the browser as the first argument, and optionally the path to the SQLite history file as the second argument.
./bin/export-browser-history --chrome
archivebox add < output/sources/chrome_history.json
# or
./bin/export-browser-history --firefox
archivebox add < output/sources/firefox_history.json
# or
./bin/export-browser-history --safari
archivebox add < output/sources/safari_history.json# configure which areas you want to require login to use vs make publicly available
archivebox config --set PUBLIC_INDEX=False
archivebox config --set PUBLIC_SNAPSHOTS=False
archivebox config --set PUBLIC_ADD_VIEW=False
archivebox manage createsuperuser # set an admin password to use for any areas requiring login
archivebox server 0.0.0.0:8000 # start the archivebox web server
open http://127.0.0.1:8000 # open the admin UI in a browser to view your archiveSee the Configuration Wiki and Security Wiki for more info...
Or if you prefer to generate a static HTML index instead of using the built-in web server, you can run archivebox list --html --with-headers > ./index.html and then open ./index.html in a browser. You should see something like this.
You can sort by column, search using the box in the upper right, and see the total number of links at the bottom.
Click the Favicon under the "Files" column to go to the details page for each link.

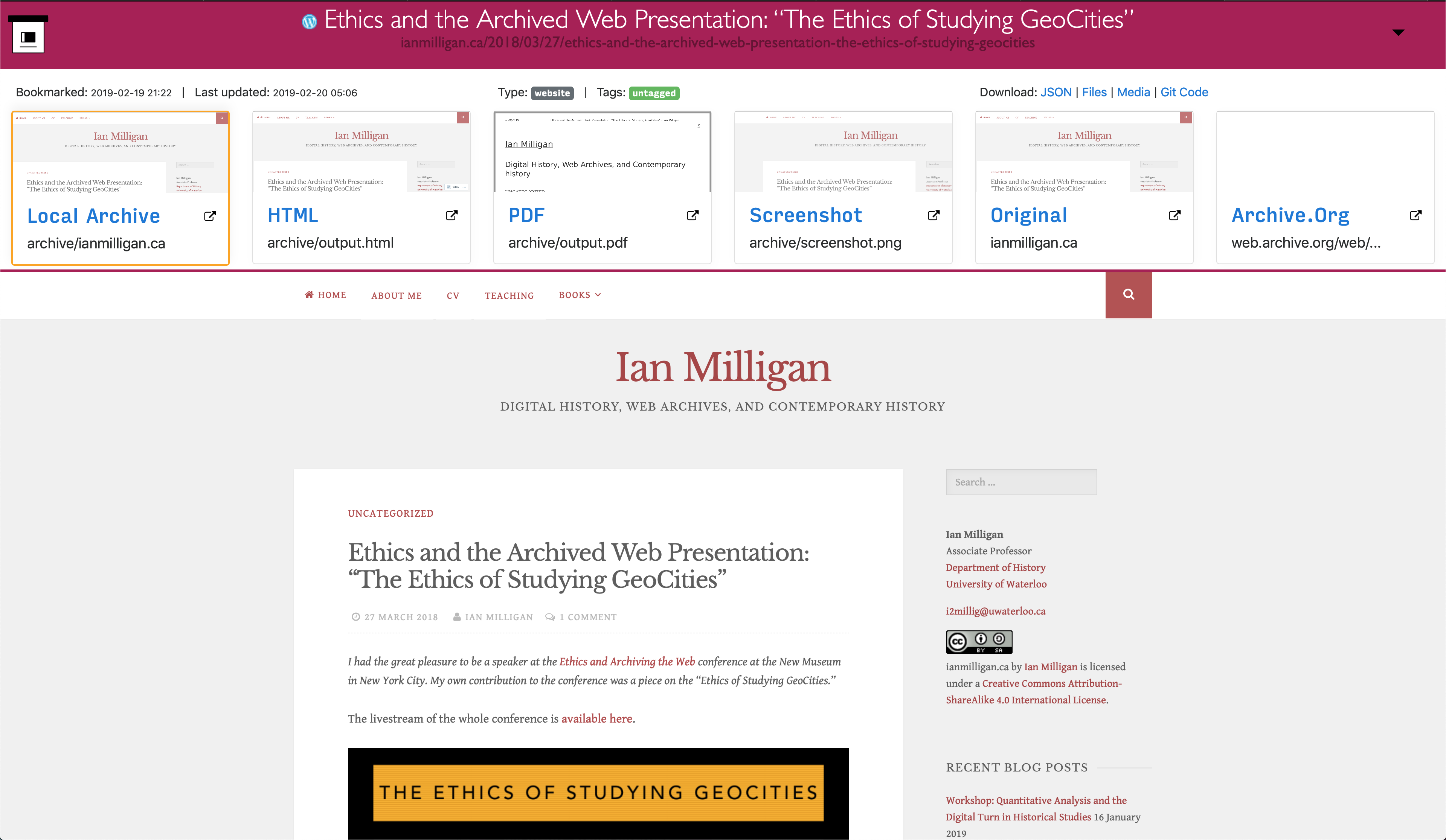

A logged-in admin user may select ☑️ one or more snapshots from the list and perform Snapshot actions:
-
Search Search text in the Snapshot title, URL, tags, or archived content (supports regex with the default ripgrep search backend, or enable the Sonic full-text search backend in
docker-compose.ymland setSEARCH_BACKEND_ENGINE=sonic,SEARCH_BACKEND_HOST,SEARCH_BACKEND_PASSWORDfor full-text fuzzy searching) https://github.com/ArchiveBox/ArchiveBox/issues/956 -
Tags Start typing in the field to select some tags, then click
+to add them or-remove them from the checked snapshots (Tagscan be created/edited from the/admin/core/tag/page) -
Title Pull the latest title and favicon without doing a full snapshot. (helpful to quickly ping any URLs that are stuck showing up as
Pending...or are missing a title) - Pull Finish downloading the Snapshot, pulls any missing/failed outputs/extractors methods (pdf, wget... etc). Resumes running the same archiving steps as when you add new URL. Useful to finish pulling when previous import was paused or interrupted by a reboot or something. https://github.com/ArchiveBox/ArchiveBox#output-formats
- Re-Snapshot Re-archive the original URL from scratch as a new separate snapshot. Differs from pulling in that it doesn't resume/update existing snapshot, it creates a new separate entry and re-snapshots the URL at the current point in time. (useful for saving multiple Snapshots of a single URL over time) https://github.com/ArchiveBox/ArchiveBox#saving-multiple-snapshots-of-a-single-url
- Reset Keep the Snapshot entry, but delete all its archive results and redownload them from scratch immediately. Useful for re-trying a bad Snapshot and overwriting its previous results, e.g. if it initially archived a temporary error page or hit a transient rate-limit/CAPTCHA/login page.
-
Delete Delete a snapshot and all its archive results entirely. This action cannot be undone. (Note: to thoroughly remove every trace of a URL ever being added, you should also manually scrub log output found in
sources/andlogs/)
Set up the official ArchiveBox Browser Extension to submit URLs directly from your browser to ArchiveBox.
-
Install the extension in your browser:
-
Log into your ArchiveBox server's admin UI in the same browser where you installed the extension, e.g.
http://localhost:8000/admin/orhttps://demo.archivebox.io/admin/
The extension will re-use your admin UI login session to submit URLs to your server, so make sure to log in!
. . .
Alternatively: You can configure Archivebox to allow submitting URLs without requiring log-in
archivebox config --set PUBLIC_ADD_VIEW=True -
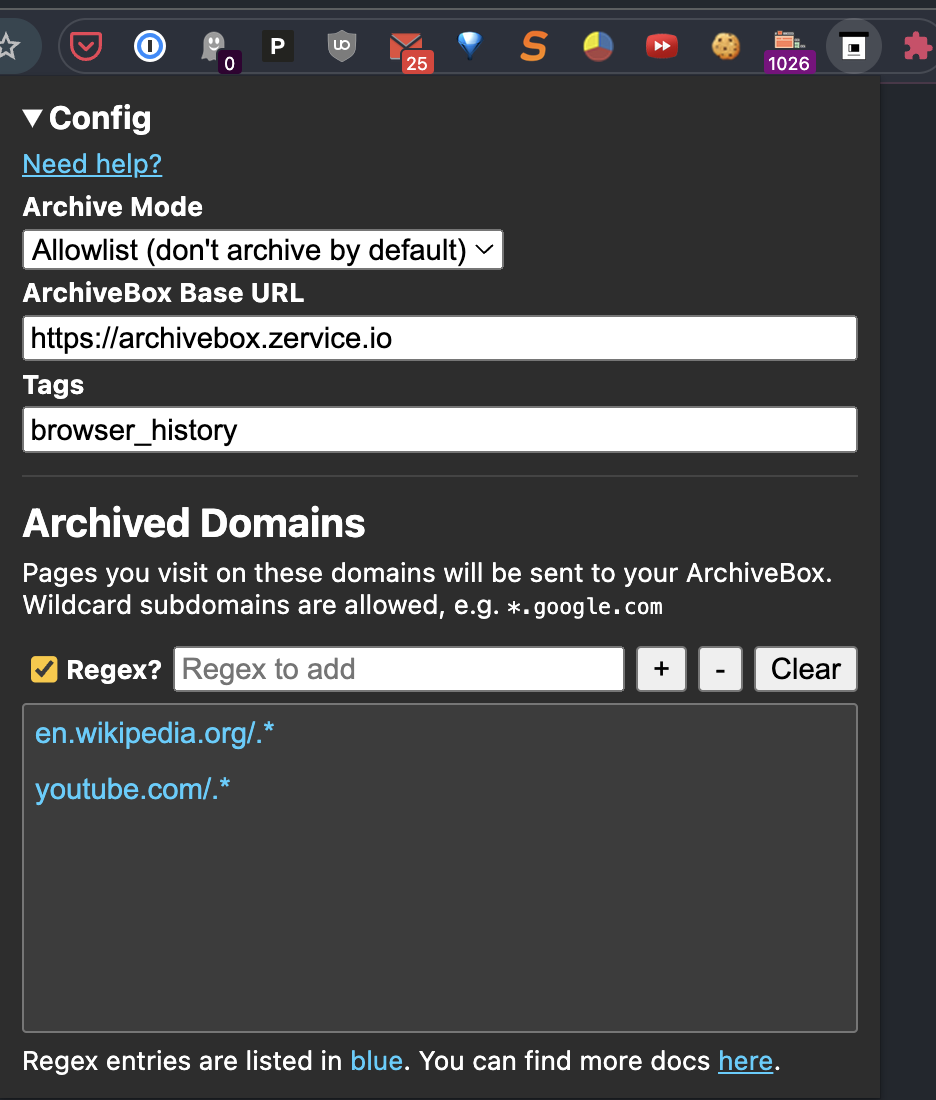
Click the ArchiveBox extension in your browser and set
Config > ArchiveBox Base URLto your server's URL, e.g.
http://localhost:8000orhttps://demo.archivebox.io -
✅ Done! Test it out:
Right-click on any page > ArchiveBox Exporter > Archive Current Page
Then check your ArchiveBox instance to confirm the URL was added.

- https://github.com/ArchiveBox/archivebox-browser-extension
- https://github.com/ArchiveBox/archivebox-browser-extension#setup
- https://github.com/ArchiveBox/archivebox-browser-extension#features
- https://github.com/ArchiveBox/archivebox-browser-extension#alternative-extensions-for-archiving
- https://github.com/ArchiveBox/ArchiveBox/issues/577
The OUTPUT_DIR folder (usually whatever folder you run the archivebox command in), contains the UI HTML and archived data with the structure outlined below.
Simply back up the entire data/ folder to back up your archive, e.g. zip -r data.backup.zip data.
- data/
- index.sqlite3 # Main index of all archived URLs
- ArchiveBox.conf # Main config file in ini format
- archive/
- 155243135/ # Archived links are stored in folders by timestamp
- index.json # Index/details page for individual archived link
- index.html
# Archive method outputs:
- warc/
- media/
- git/
...
- sources/ # Each imported URL list is saved as a copy here
- getpocket.com-1552432264.txt
- stdin-1552291774.txt
...For more info about ArchiveBox's database/filesystem layout and troubleshooting steps:
- https://github.com/ArchiveBox/ArchiveBox/wiki/Security-Overview#output-folder
- https://github.com/ArchiveBox/ArchiveBox/wiki/Upgrading-or-Merging-Archives
- https://github.com/ArchiveBox/ArchiveBox/wiki/Upgrading-or-Merging-Archives#modify-the-archivebox-sqlite3-db-directly
- https://github.com/ArchiveBox/ArchiveBox/wiki/Upgrading-or-Merging-Archives#database-troubleshooting
I've found it takes about an hour to download 1000 articles, and they'll take up roughly 1GB.
Those numbers are from running it single-threaded on my i5 machine with 50mbps down. YMMV.
Storage requirements go up immensely if you're using FETCH_MEDIA=True and are archiving many pages with audio & video.
You can try to run it in parallel by manually splitting your URLs into separate chunks (though this may not work with database locked errors on slower filesystems):
archivebox add < urls_chunk_1.txt &
archivebox add < urls_chunk_2.txt &
archivebox add < urls_chunk_3.txt &(though this may not be faster if you have a very large collection/main index)
Users have reported running it with 50k+ bookmarks with success (though it will take more RAM while running).
If you already imported a huge list of bookmarks and want to import only new
bookmarks, you can use the ONLY_NEW environment variable. This is useful if
you want to import a bookmark dump periodically and want to skip broken links
which are already in the index.
For more info about troubleshooting filesystem permissions, performance, or issues when running on a NAS:
- https://github.com/ArchiveBox/ArchiveBox/wiki/Security-Overview#output-folder
- https://github.com/ArchiveBox/ArchiveBox/wiki/Upgrading-or-Merging-Archives#database-troubleshooting
Explore the SQLite3 DB a bit to see whats available using the SQLite3 shell:
cd ~/archivebox/data
sqlite3 index.sqlite3
# example usage:
SELECT * FROM core_snapshot;
UPDATE auth_user SET email = 'someNewEmail@example.com' WHERE username = 'someUsernameHere';
...More info:
- https://github.com/ArchiveBox/ArchiveBox#-sqlpythonfilesystem-usage
- https://github.com/ArchiveBox/ArchiveBox/wiki/Upgrading-or-Merging-Archives#modify-the-archivebox-sqlite3-db-directly
- https://github.com/ArchiveBox/ArchiveBox/wiki/Upgrading-or-Merging-Archives#database-troubleshooting
- https://stackoverflow.com/questions/1074212/how-can-i-see-the-raw-sql-queries-django-is-running
- https://adamobeng.com/wddbfs-mount-a-sqlite-database-as-a-filesystem/
Explore the Python API a bit to see whats available using the archivebox shell:
Python API Documentation: https://docs.archivebox.io/dev/apidocs/index.html
$ archivebox shell
[i] [2020-09-17 16:57:07] ArchiveBox v0.4.21: archivebox shell
> /Users/squash/Documents/opt/ArchiveBox/data
# Shell Plus Model Imports
from core.models import Snapshot
from django.contrib.admin.models import LogEntry
from django.contrib.auth.models import Group, Permission, User
from django.contrib.contenttypes.models import ContentType
from django.contrib.sessions.models import Session
# Shell Plus Django Imports
from django.core.cache import cache
from django.conf import settings
from django.contrib.auth import get_user_model
from django.db import transaction
from django.db.models import Avg, Case, Count, F, Max, Min, Prefetch, Q, Sum, When
from django.utils import timezone
from django.urls import reverse
from django.db.models import Exists, OuterRef, Subquery
# ArchiveBox Imports
from archivebox.core.models import Snapshot, User
from archivebox import *
help
version
init
config
add
remove
update
list
shell
server
status
manage
oneshot
schedule
[i] Welcome to the ArchiveBox Shell!
https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#Shell-Usage
https://docs.archivebox.io/dev/apidocs/index.html
Hint: Example use:
print(Snapshot.objects.filter(is_archived=True).count())
Snapshot.objects.get(url="https://example.com").as_json()
add("https://example.com/some/new/url")
# run Python API queries/function calls directly
>>> print(Snapshot.objects.filter(is_archived=True).count())
24
# get help info on an object or function
>>> help(Snapshot)
...
# show raw SQL queries run
>>> from django.db import connection
>>> print(connection.queries)For more info and example usage:
- https://github.com/ArchiveBox/ArchiveBox/wiki/Upgrading-or-Merging-Archives#example-adding-a-new-user-with-a-hashed-password
- https://github.com/ArchiveBox/ArchiveBox/blob/dev/archivebox/main.py
- https://github.com/ArchiveBox/ArchiveBox/blob/dev/archivebox/config.py
- https://github.com/ArchiveBox/ArchiveBox/blob/dev/archivebox/core/models.py
- https://stackoverflow.com/questions/1074212/how-can-i-see-the-raw-sql-queries-django-is-running
You can interact with ArchiveBox as a Python library from external scripts or programs.
This API is a local API, designed to be used on the same machine as the ArchiveBox collection.
For example you could creat a script add_archivebox_url.py like so:
import os
DATA_DIR = '~/archivebox/data'
os.chdir(DATA_DIR)
# you must import and setup django first to establish a DB connection
from archivebox.config.legacy import setup_django
setup_django()
# then you can import all the main functions
from archivebox.main import add, remove, server
add('https://example.com', index_only=True, out_dir=DATA_DIR)
remove(...)
server(...)
...For more information see:


- 🔢 Quickstart
- 🖥️ Install
- 🐳 Docker
- ➡️ Supported Sources
- ⬅️ Supported Outputs
- ﹩Command Line
- 🌐 Web UI
- 🧩 Browser Extension
- 👾 REST API / Webhooks
- 📜 Python API / REPL / SQL API
- Upgrading
- Setting up Storage (NFS/SMB/S3/etc)
- Setting up Authentication (SSO/LDAP/etc)
- Setting up Search (rg/sonic/etc)
- Scheduled Archiving
- Publishing Your Archive
- Chromium Install
- Cookies & Sessions Setup
- Merging Collections
- Troubleshooting
- ⭐️ Web Archiving Community
- Background & Motivation
- Comparison to Other Tools
- Architecture Diagram
- Changelog & Roadmap

