SQL is here and it comes with 100+ functions from JSON processing to kNN and HLL so you can do even more with your favorite NoSQL database.

Bigtable
Scale your latency-sensitive applications with the NoSQL pioneer
Enterprise-grade, low-latency NoSQL database service for machine learning, operational analytics, and user-facing applications at scale.
New customers get $300 in free credits to spend on Bigtable.
Product highlights
Support multi-tenant, mixed operational, and real-time analytical workloads in a single platform with ease
High-performance reads and writes even in globally distributed deployments
Build multicloud and hybrid cloud architectures with the open-source Apache HBase API and bi-directional sync

Features
Low latency and high throughput
Bigtable is a key-value and wide-column store, ideal for fast access to structured, semi-structured, or unstructured data. This makes latency-sensitive workloads like personalization a perfect fit for Bigtable. However its distributed counters, high read and write throughput per dollar makes it also a great fit for clickstream and IoT use cases, and even batch analytics for high-performance computing (HPC) applications, including training ML models.
Write and read scalability with no limits
Bigtable decouples compute resources from data storage, which makes it possible to transparently adjust processing resources. Each additional node can process reads and writes equally well, providing effortless horizontal scalability. Bigtable optimizes performance by automatically scaling resources to adapt to server traffic, handling the sharding, replication, and query processing.
Data model flexibility
Bigtable lets your data model evolve organically. Store anything from scalars, JSON, Protocol Buffers, Avro, Arrow to embeddings, images, and dynamically add/remove new columns as needed. Deliver low-latency serving or high-performance batch analytics over raw, unstructured data in a single database.
From a single zone up to eight regions at once
Apps backed by Bigtable can deliver low-latency reads and writes with globally distributed multi-primary configurations, no matter where your users may be. Zonal instances are great for cost savings and can be seamlessly scaled up to multi-region deployments with automatic replication. When running a multi-region instance, your database is protected against a regional failure and offers industry-leading 99.999% availability.
Easy migration from NoSQL databases
Live migrations enable faster and simpler onboarding by ensuring accurate data migration with reduced effort. HBase Bigtable replication library allows for no-downtime live migrations with import and validation tools to easily load HBase snapshots into Bigtable while Dataflow templates simplify migrations from Cassandra to Bigtable.

High-performance, workload-isolated data processing
Bigtable Data Boost enables users to run analytical queries, batch ETL processes, train ML models or export data faster without affecting transactional workloads. Data Boost does not require capacity planning or management. It allows directly querying data stored in Google’s distributed storage system, Colossus using on-demand capacity letting users easily handle mixed workloads and share data worry-free.
Rich application and tool support
Easily connect to the open source ecosystem with the Apache HBase API. Build data-driven applications faster with seamless integrations with Apache Spark, Hadoop, GKE, Dataflow, Dataproc, Vertex AI Vector Search, and BigQuery. Meet development teams where they are with SQL and client libraries for Java, Go, Python, C#, Node.js, PHP, Ruby, C++, HBase and integration with LangChain.
No IOPS charges, no cost for taking or restoring backups, no disproportionate read/write pricing to impact your budget as your workloads evolve.
Automated maintenance
Reduce operational costs and improve reliability for any database size. Replication and maintenance are automatic and built-in with zero downtime.
Real-time change data capture and eventing
Use Bigtable change streams to capture change data from Bigtable databases and integrate it with other systems for analytics, event triggering, and compliance.
Enterprise-grade security and controls
Customer-managed encryption keys (CMEK) with Cloud External Key Manager support, IAM integration for access and controls, support for VPC-SC, Access Transparency, Access Approval and comprehensive audit logging help ensure your data is protected and complies with regulations. Fine-grained access control lets you authorize access at table, column, or row level.

Observability
Monitor performance of Bigtable databases with server-side metrics. Analyze usage patterns with Key Visualizer interactive monitoring tool. Use query stats, table stats, and the hot tablets tool for troubleshooting query performance issues and quickly diagnose latency issues with client-side monitoring.
Disaster recovery
Take instant, incremental backups of your database cost-effectively and restore on demand. Store backups in different regions for additional resilience, easily restore between instances, or projects for test versus production scenarios.
Vertex AI Vector Search integration
Use the Bigtable to Vertex AI Vector Search template to index data in your Bigtable database with Vertex AI to perform a similarity search over vector embeddings with Vertex AI Vector Search.
LangChain integration
Easily build generative AI applications that are more accurate, transparent, and reliable with built-in kNN nearest neighbor vector search (in preview) and LangChain integration. Visit the GitHub repository to learn more.
How It Works
Bigtable instances provide compute and storage in one or more regions. Each Bigtable cluster can receive both reads and writes. Data is automatically "split" for scalability and replicated between clusters asynchronously. A distributed clock called TrueTime guarantees transactions are correctly ordered.
Bigtable instances provide compute and storage in one or more regions. Each Bigtable cluster can receive both reads and writes. Data is automatically "split" for scalability and replicated between clusters asynchronously. A distributed clock called TrueTime guarantees transactions are correctly ordered.

Common Uses
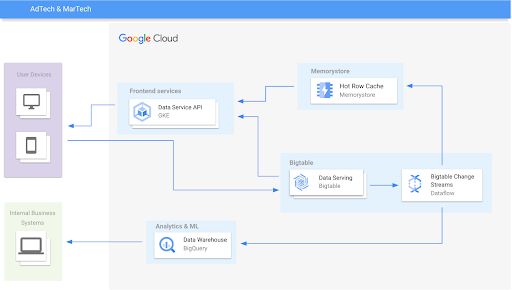
AdTech and retail
Personalize experiences in real time
Learning resources
Personalize experiences in real time
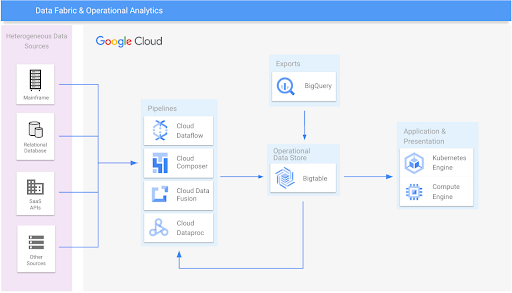
Data fabric and operational analytics
Consolidate data silos and scale out legacy systems
Learning resources
Consolidate data silos and scale out legacy systems
Cybersecurity
Detect malware, payment fraud, stop spam and scams
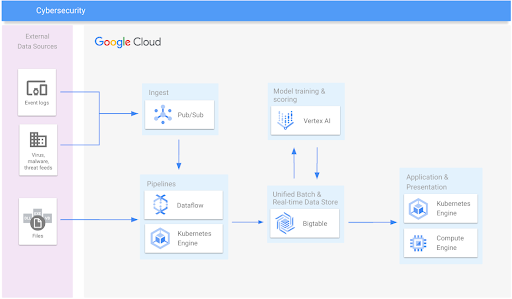
Learning resources
Detect malware, payment fraud, stop spam and scams
Media
Deliver media content and engagement analytics
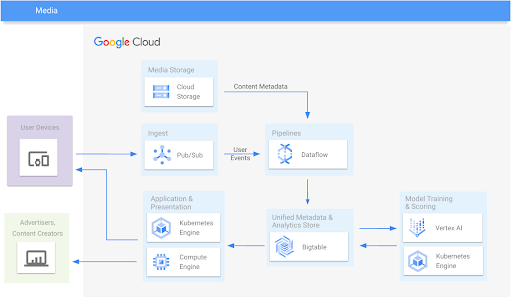
Learning resources
Deliver media content and engagement analytics
Time series and IoT
Manage time series data at any scale
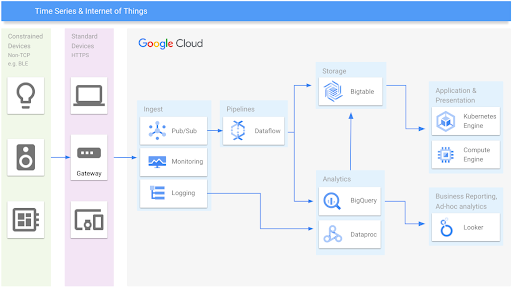
Learning resources
Manage time series data at any scale
Machine learning infrastructure
Scale model training and serving
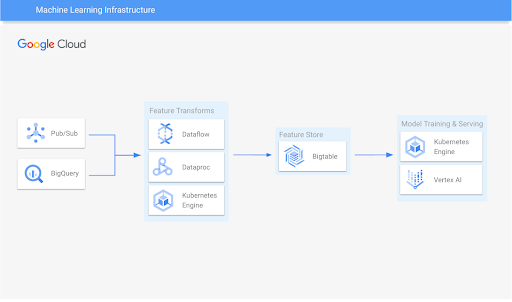
Learn how to use Bigtable with popular open-source feature stores.
Learning resources
Scale model training and serving
Learn how to use Bigtable with popular open-source feature stores.
Pricing
| How Bigtable pricing works | Bigtable pricing is based on compute capacity, database storage, backup storage, and network usage. Committed use discounts reduce the price further. | |
|---|---|---|
| Service | Description | Price |
Compute capacity | Compute capacity is provisioned as nodes. | Starting at $0.65 per node per hour |
Data storage | SSD Pricing is based on the physical size of tables. Each replica is billed separately. Recommended for low-latency serving. | Starting at $0.17 per GB per month |
HDD Pricing is based on the physical size of tables. Each replica is billed separately. | Starting at $0.026 per GB per month | |
Backups | Pricing is based on the physical size of backups. Bigtable backups are incremental. | Starting at $0.026 per GB per month |
Network | Ingress | Free |
Egress within same region | Free | |
Egress between regions | Starting at $0.10 per GB | |
Replication | Within same region | Free |
Between regions | Starting at $0.01 per GB | |
Learn more about Bigtable pricing and committed use discounts.
How Bigtable pricing works
Bigtable pricing is based on compute capacity, database storage, backup storage, and network usage. Committed use discounts reduce the price further.
Compute capacity
Compute capacity is provisioned as nodes.
Starting at
$0.65
per node per hour
Data storage
SSD
Pricing is based on the physical size of tables. Each replica is billed separately. Recommended for low-latency serving.
Starting at
$0.17
per GB per month
HDD
Pricing is based on the physical size of tables. Each replica is billed separately.
Starting at
$0.026
per GB per month
Backups
Pricing is based on the physical size of backups. Bigtable backups are incremental.
Starting at
$0.026
per GB per month
Network
Ingress
Free
Egress within same region
Free
Egress between regions
Starting at
$0.10
per GB
Replication
Within same region
Free
Between regions
Starting at
$0.01
per GB
Learn more about Bigtable pricing and committed use discounts.
PRICING CALCULATOR
CUSTOM QUOTE
Start your Bigtable proof of concept
User you $300 credit (new users)
Learn how to use Bigtable
Federate queries from BigQuery into Bigtable
Migrate from HBase, Cassandra, Aerospike, or DynamoDB to Bigtable
Dive into coding with examples
Business Case
Explore how other businesses built innovative apps to deliver great customer experiences, cut costs, and increase ROI with Bigtable
Explore how Box modernized their NoSQL databases with Bigtable
Box enhanced scalability and availability while reducing cost to manage, through a seamless migration.
Watch the video


Benefits and customers
Grow your business with innovative applications that scale limitlessly to meet any demand.
Get best-in-class price-performance and pay for what you use.
Migrate easily from other NoSQL databases and run hybrid or multicloud deployments with open source APIs and migration tools.















Partners & Integration
Take advantage of partners with Bigtable expertise to help you at every step of the journey, from assessments and business cases to migrations and building new apps on Bigtable.




































System integrators
Want to get more details about which partner or third-party integration is best for your business? Go to the partner directory.
FAQ
What type of database is Bigtable?
Bigtable is a NoSQL database service, specifically a key-value store that allows for very wide tables with tens of thousands of columns, hence also referred to as a wide-column database or a distributed multi-dimensional map. It is a NoSQL database in the "Not only SQL" sense, rather than "zero SQL".
Bigtable is most similar to popular open source projects it inspired, such as Apache HBase and Cassandra, and hence is the most common destination for customers that deal with large data volumes looking for a high-performance, cost-effective, fully managed NoSQL database solution on Google Cloud.
Does Bigtable support SQL?
In addition to its Key-Value APIs, Bigtable also supports SQL queries in three different ways:
- For low-latency application development, Bigtable offers a SQL query API that builds upon GoogleSQL with extensions for the wide-column data model resembling Cassandra Query Language (CQL).
- For data science use cases or other kinds of batch processing and ETL, Bigtable supports SparkSQL using its Spark client.
- For users who want to do post-hoc exploratory analysis or blend data from multiple sources for batch analytics, Bigtable data can also be accessed from BigQuery. Simply register your Bigtable tables in BigQuery and query like any other BigQuery table without any ETL or data duplication.
How do I migrate databases to Bigtable?
Bigtable offers migration tooling that enables faster and simpler onboarding by ensuring accurate data migration with reduced effort. HBase Bigtable replication library allows for no-downtime live migrations with import and validation tools to easily load HBase snapshots into Bigtable while Dataflow templates simplify migrations from Cassandra to Bigtable.
Is Bigtable serverless?
Bigtable storage is billed per GB used similar to a serverless model. Bigtable also offers linear horizontal scaling and can automatically scale up and down compute resources in response to demand fluctuations. Hence it doesn’t require a long term capacity commitment for storage or compute. However, pricing for low-latency compute is capacity-based and billed per node, not per request where each node can serve up to 17K requests per second. This makes Bigtable price more favorable for larger workloads but less ideal for small applications, which may be more suitable for Google Cloud databases such as Firestore.
For batch data processing Bigtable offers Data Boost, which bills in Serverless Processing Units (SPU).





















