Pepper
A highly extensible plattform for conversion and manipulation of linguistic data between an unbound set of formats. Pepper can be used stand-alone as a command line interface, or be integrated as an API into other software products.
If you need to convert corpora from one linguistic format into another, Pepper is your swiss-army knife.
When your annotation tool produces a different data format from the one your analysis tool can read, Pepper is there to the rescue.
- Pepper can convert documents in a variety of linguistic formats, such as: EXMARaLDA, Tiger XML, MMAX2, RST, TCF, TreeTagger format, TEI (subset), ANNIS format, PAULA and many many more.
- Pepper comes with a plug-in mechanism which makes it easy to extend it for further formats and data manipulations.
- Pepper is module-based, each mapping is done by a separate module. This enables each module to be combined with every other module in one single workflow.
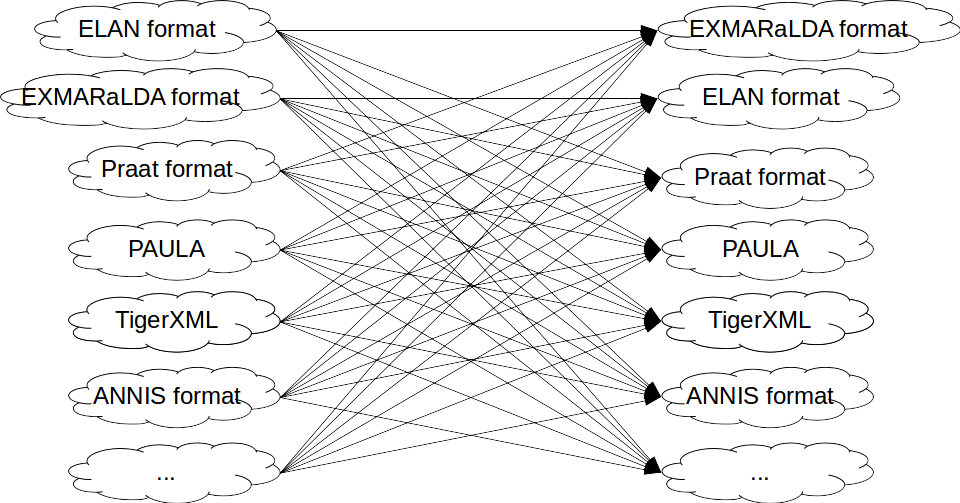
- Pepper uses the intermediate model Salt which reduces the number of mappings to convert n into m formats.
- Pepper modules, such as the MergingModule, allow to merge the data from different annotation tools together and create multi-layer corpora.
- Pepper can be used as an interactive command line tool, as a command to be included in scripts, or as an API to be integrated in other software products.
- Pepper is written in Java and can be run on all operation systems which are ready to run Java (Windows, Mac, Linux, Unix, …).
- Pepper is free and open source software. It is distributed under the Apache License, Version 2.0.
To decrease the number of conceptual mappings, Pepper uses an intermediate model, which means that a conversion consists of two mappings. First, the data coming
from format X will be mapped to the intermediate model Salt and second, the data will be
mapped from Salt to format Y. If you imagine a set of n source and target formats, this
approach will decrease the number of mappings from n²-n mappings in case of a direct
mapping approach, to 2n mappings.
Pepper itself is a platform controlling the workflow of a conversion
process. The mapping itself is done by a set of Pepper modules. Pepper is a highly pluggable
platform which offers the possibility to plug-in new modules in order to incorporate
further formats. The flexible architecture of Pepper allows to combine all existing modules
and to easily plug in new ones.

Here you will find the current stable release and also
older versions of Pepper, including a set of Pepper modules.
Pepper is system-independent and comes as a ready-to-run zip archive, so you do
not need any installation. But since Pepper is Java-based, you need to have Java
installed on your system. On most systems, Java is installed by default, but in case it
is not, please download it from www.oracle.com/technetwork/java/javase/ or
http://openjdk.java.net/. To check if Java (or more precisly a Java Runtime Environment)
is running, open a command line and run:
java -version
You need at least version 1.8, also called “Java 8”.
If you use Pepper in your scientific work, please cite it as follows.
F. Zipser & L. Romary (2010). A model oriented approach to the mapping of annotation formats using
standards. In: Proceedings of the Workshop on Language
Resource and Language Technology Standards, LREC 2010. Malta. URL: http://hal.archives-ouvertes.fr/inria-00527799/en/
User documentation
Users new to Pepper should begin by reading the User Guide
f there is no existing module which fulfills your needs, you are free to
implement your own module. With Pepper’s plug-in mechanism your module can
easily be integrated into the Pepper plattform. The possibility of combining
your new module with already existing ones lets you create completely new workflows.
Please read the Module Developer’s Guide to get a detailed documentation of how to implement a Pepper module.
Using Pepper as a library
With the Pepper library, we provide a programmatic access to the Pepper framework,
including the configuration of a conversion workflow, the start of a conversion
and getting information about the registered Pepper modules. Since Pepper is based
on a plugin structure called OSGi (see: http://www.osgi.org/), each Pepper module is plugged into the framework
separately, whether running Pepper as CLI, or running it as a
library.
To learn more about integrating Pepper as a library in other software products go to Pepper as a library.
Pepper is published under the Open Source license Apache License, Version 2.0. We want to enable everyone to use the software without restrictions, and also enable the community to take part in its developement.
Found a bug or have any feature request?
Please let us know what you have found, or which ideas for enhancements you have. Please leave us an issue on
GitHub at Pepper
or write us an e-mail: saltnpepper@lists.hu-berlin.de.
Want to contribute to the project?
For both Salt and Pepper, we have published the source code at the GitHub platform at Pepper.
If you are interested in contributing
to the project, please feel free to fork or clone it. We are happy about any
suggestions, bug reports, bug fixes, and so on. It would be nice if you keep us
informed about your ideas and enhancements: Please write us an e-mail: saltnpepper@lists.hu-berlin.de.
- F. Zipser, A. Röhrig, A. Lüdeling, M. Klotz,T. Krause, S. Druskat & V.
Voigt (2015).
SaltNPepper, ANNIS & Atomic: Eine Infrastruktur für
Mehrebenenkorpora.
Digital Humanities“-Tag 2015 – Digitale Ressourcen an der Philosophischen
Fakultät II. Berlin, 21. Mai 2015. [poster].
- F. Zipser, T. Krause, A. Lüdeling, A. Neumann, M. Stede, A. Zeldes (2015).
ANNIS, SaltNPepper & PAULA: A multilayer corpus
infrastructure.
Final Conference of the SFB 632 Information Structure: Advances in
Information Structure Research 2003 - 2015. Berlin, 08. - 09. Mai 2015.
[poster].
- F. Zipser, M. Klotz & A. Röhrig (2015).
From TEI to linguistic corpora using Pepper.
37. Jahrestagung der Deutschen Gesellschaft für Sprachwissenschaft.
Leipzig, 04.- 06. März 2015. [poster].
- Zipser, F. (2014).
SaltNPepper und das Formatpluriversum.
LAUDATIO Workshop 2014. Berlin, 07.- 08.10.2014.[slides].
- F. Zipser, M. Frank & J. Schmolling (2014).
Merging data, the essence of creation of multi-layer corpora.
36. Jahrestagung der Deutschen Gesellschaft für Sprachwissenschaft.
Marburg, 05.- 07. März 2014. [ poster].
- C. Odebrecht & F. Zipser (2013).
LAUDATIO - Eine Infrastruktur zur linguistischen Analyse historischer
Korpora.
DTA-/CLARIN-D Konferenz und -Workshops: Historische
Textkorpora für die Geistes- und Sozialwissenschaften. Fragestellungen und
Nutzungsperspektiven, Berlin 2013.
- F. Zipser, A. Zeldes, J. Ritz, L. Romary & U. Leser (2011).
Pepper: Handling a multiverse of formats.
33. Jahrestagung der Deutschen Gesellschaft für Sprachwissenschaft.
Göttingen, 23.- 25. Februar 2011. [ poster].
- F. Zipser & L. Romary (2010).
A model oriented approach to the mapping of annotation formats using
standards.
In: Proceedings of the Workshop on Language
Resource and Language Technology Standards, LREC 2010. Malta. URL: http://hal.archives-ouvertes.fr/inria-00527799/en/
- F. Zipser (2009).
Entwicklung eines Konverterframeworks für linguistisch annotierte Daten
auf Basis eines gemeinsamen (Meta-)modells.
Diplomarbeit,
Humboldt-Universität zu Berlin, Institut für Informatik. URL: http://hal.archives-ouvertes.fr/docs/00/60/61/02/PDF/Diplomarbeit_FZ_final.pdf